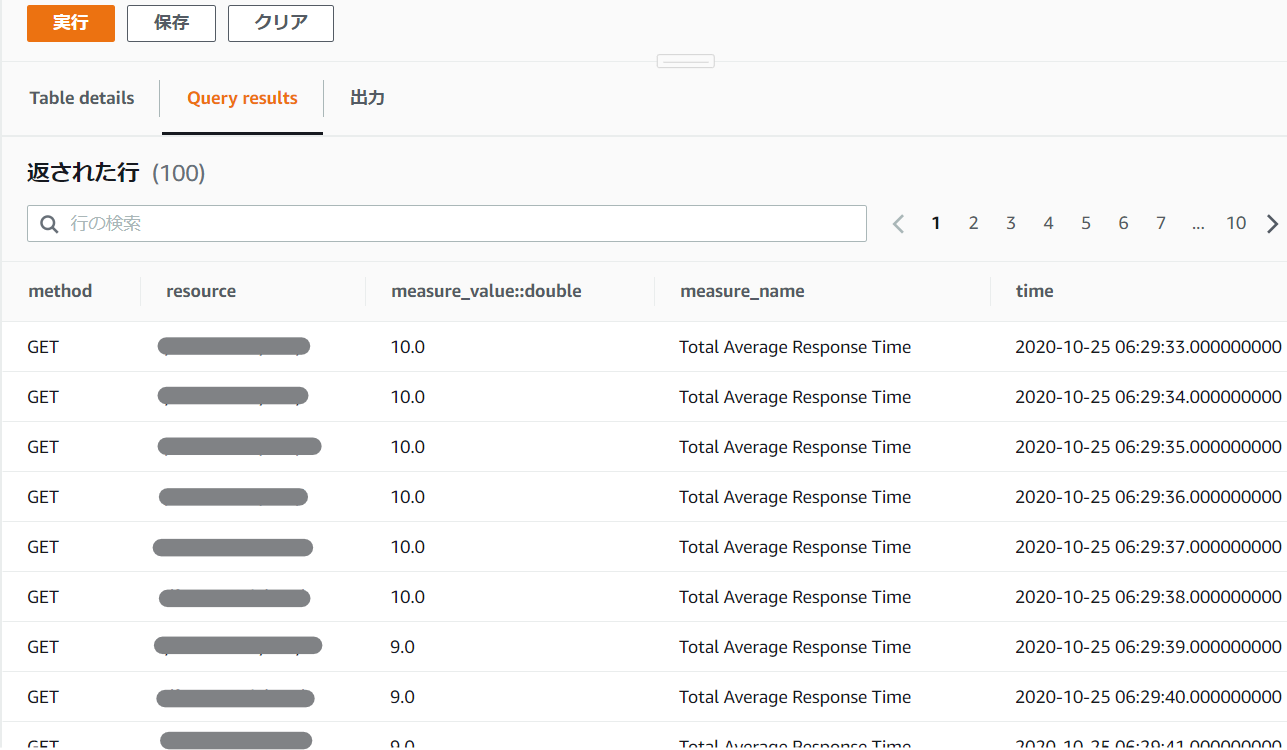
- 投稿日:2020-10-25T23:58:14+09:00
Django APIドキュメントの設定をする
APIドキュメント
APIがたくさん増えてどんなAPIがあるかわからない!!
的なことが起きたのでDjangoでAPIドキュメントの設定をしていきます?そこで今回は、
Swaggerを導入していきたいと思います?設定方法
インストール
terminalpip install drf_yasg
drf_yasgは、djangorestframeworkのバージョンによっては、エラーが発生するようなので注意です???
私がそれ⇦
(djangorestframeworkのバージョンが3.12だと出るかも?)
その場合は、drf_yasg2をインストールterminalpip install drf_yasg2settingのINSTALLED_APPSに追加
drf_yasgの方はdrf_yasg2を適時読み変えてください。
setting.pyINSTALLED_APPS = [ ... 'rest_framework', 'django_filters', 'drf_yasg2', # <- or drf_yasg ]プロジェクトのurls.pyに追加
urls.pyfrom drf_yasg2 import openapi # <- or from drf_yasg from drf_yasg2.views import get_schema_view # <- or from drf_yasg schema_view = get_schema_view( openapi.Info( title="Snippets API", default_version='v1', ), public=True, permission_classes=(permissions.AllowAny,), ) urlpatterns += [ re_path('^swagger(?P<format>\.json|\.yaml)$', schema_view.without_ui(cache_timeout=0), name='schema-json'), path('swagger/', schema_view.with_ui('swagger', cache_timeout=0), name='schema-swagger-ui'), path('redoc/', schema_view.with_ui('redoc', cache_timeout=0), name='schema-redoc'), ]完成
ブラウザでアクセスすると
http://localhost:8000/redoc/
や
http://localhost:8000/swagger/こんな感じで確認することができます??????
以上!!
お疲れ様です☺️☺️☺️☺️☺️
- 投稿日:2020-10-25T23:57:29+09:00
pythondict辞書キーを正規表現で検索する
dictキーを正規表現で検索したい
dict辞書は高速で非常に使い勝手が良い。
キーを正規表現で検索したい場合普通はこうすると思うが、多用する場合は面倒だ。a = dict(abc=1, def=2) #-> {"abc": 1, "def": 2} s = re.compile(".bc") ret = [] for k in a: if s.search(k): ret.append(a[k]) print(ret) #-> [1] # 内包表記で短くなってもせいぜいこんな感じだが、可読性が悪く、忘れたころにソースを読むと何をやりたかったのかよくわからん。 s = re.compile(".bc") [a[k] for k in a if s.search(k)] #-> [1]これが面倒なので標準のdictを拡張してこんな感じで使えるようにしてみた。
a = rdict(abc=1, def=2) #-> {"abc": 1, "def": 2} a.search(".bc") #-> [1]ソースはこう。
import re from functools import lru_cache @lru_cache(16) # re.compileは結構重めな処理なので、同じ正規表現パターンはキャッシュし、性能稼ぐ def re_call(pattern, flags=0, call_re_func="search"): return re.compile(pattern, flags=flags).__getattribute__(call_re_func) class rdict(dict): def _filter(self, _callable): return (k for k in self if _callable(k)) def isin(self, key_or_function): if callable(key_or_function): return any(True for _ in self._filter(key_or_function)) return dict.__contains__(self, key_or_function) def findall(self, key_or_function): if callable(key_or_function): return [dict.__getitem__(self, key) for key in self._filter(key_or_function)] return dict.__getitem__(self, key_or_function) def search(self, pattern, flags=0): return [dict.__getitem__(self,key) for key in self if re_call(pattern, flags, "search")(key)] def fullmatch(self, pattern, flags=0): return [dict.__getitem__(self,key) for key in self if re_call(pattern, flags, "fullmatch")(key)] def __setitem__(self, key_or_function, value): if callable(key_or_function): for key in self._filter(key_or_function): dict.__setitem__(self, key, value) else: return dict.__setitem__(self, key_or_function, value) def __delitem__(self, key_or_function): if callable(key_or_function): for key in list(self._filter(key_or_function)): dict.__delitem__(self, key) else: return dict.__delitem__(self, key_or_function)その他にもいくつか関数を追加してるが使い方のイメージはこう。
正規表現パターンで一致するキーがあるかどうかを調べる
>>> a.isin(re.compile(".b.*").search) True >>> a.isin(re.compile(".z.*").search) Falseその他1、条件が真になる場合のキーを持つ場合の値を返す
>>> a.findall(lambda x: len(x) == 3) [1, 2]その他2、キーを範囲で検索し、値を返す
findallの引数はcallableなら、何でも動くので以下のような応用も可>>> from datetime import datetime >>> b = funcdict() >>> b[datetime(2020,1,1)] = "2020/01/01" >>> b[datetime(2020,2,1)] = "2020/02/01" >>> b[datetime(2020,3,1)] = "2020/03/01" >>> def between_0131_0202(x): ... return datetime(2020,1,31) < x and x < datetime(2020,2,2) >>> b.findall(between_0131_0202) ['2020/02/01'] >>> def less_0401(x): ... return x < datetime(2020, 4, 1) >>> b.isin(less_0401) True >>> def grater_0401(x): ... return x > datetime(2020, 4, 1) >>> b.isin(grater_0401) False >>> b.findall(less_0401) ['2020/01/01', '2020/02/01', '2020/03/01']あとは、条件にマッチするキーの値を一括で変更する機能
>>> b[less_0401] = "test" >>> b {datetime.datetime(2020, 1, 1, 0, 0): 'test', datetime.datetime(2020, 2, 1, 0, 0): 'test', datetime.datetime(2020, 3, 1, 0, 0): 'test'}ついでに、条件にマッチするキーを一括で削除する機能
>>> del b[between_0131_0202] >>> b {datetime.datetime(2020, 1, 1, 0, 0): 'test', datetime.datetime(2020, 3, 1, 0, 0): 'test'}
- 投稿日:2020-10-25T23:35:52+09:00
進捗管理に使える確率・統計を python プログラムで理解する
問1
サイコロを100回振ったとき出目の合計はいくつになる?
平均・期待値
小学校で習う平均は統計量の筆頭です。まずは平均を用いてはじめの問の答えを導き、シミュレーション結果と照らし合わせてみます。
プログラム
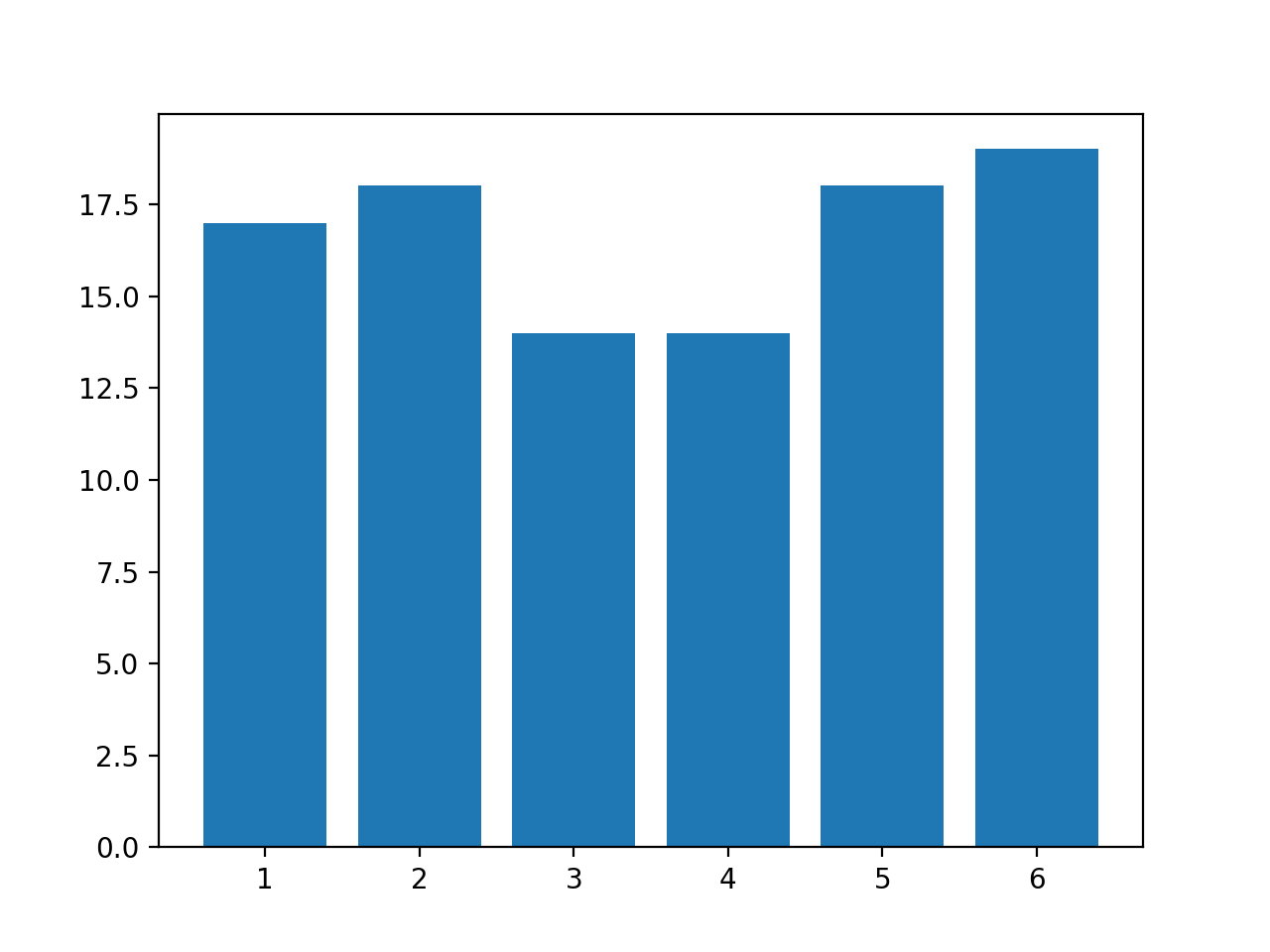
import numpy as np import numpy.random as rd import matplotlib.pyplot as plt # サイコロを定義する # 平均が分かる dice = [1, 2, 3, 4, 5, 6] print("平均:", np.mean(dice)) # 試行回数を定義する # 平均と組み合わせて合計の期待値が分かる trialsNum = 100 print("合計の期待値:", np.mean(dice) * trialsNum) input("続行するにはEnterキーを押してください . . .") # 実際に試行する # ヒストグラムを描画して出目の分布を確認する resultList = [rd.choice(dice) for i in range(trialsNum)] plt.hist(resultList, bins=6, rwidth=0.8, range=(0.5, 6.5)) plt.show() print("合計:", np.sum(resultList))実行結果(例)
乱数を使うので結果は一定ではありません。
標本平均: 3.5 合計の期待値: 350.0 続行するにはEnterキーを押してください . . .
合計: 355解説
サイコロを1回振ったとき出うる目の平均は 3.5 ですから、100回振った合計は平均の100倍の 350 くらい...とはじめの問に答えられます。平均・期待値を使うと下記のような進捗管理ができます。
- リソース単位(人日など)あたりに消化したタスク量の平均(=進捗ペース)を過去の実績から求める
- 期日までに使える残りのリソース量と進捗ペースを掛け算して、消化できるタスク量の期待値を求める
- 期待値と期日までに消化しなければならない残りのタスク量を比較して進捗の良し悪しを判断する
しかし比較して判断するのは人間の経験と勘に任せて良いんでしょうか?バーンダウンチャートを使うと時系列の傾向を見て判断できますが経験と勘に頼ることに変わりはありません。
分散・標準偏差
350 くらい...とはじめの問に答えられます。
350 くらい...というのはどのくらい”350 くらい”なのでしょうか?それを表すのが分散・標準偏差です。まずは標本から標準偏差を求め、次にシミュレーション結果から標準偏差を求めて照らし合わせてみます。
プログラム
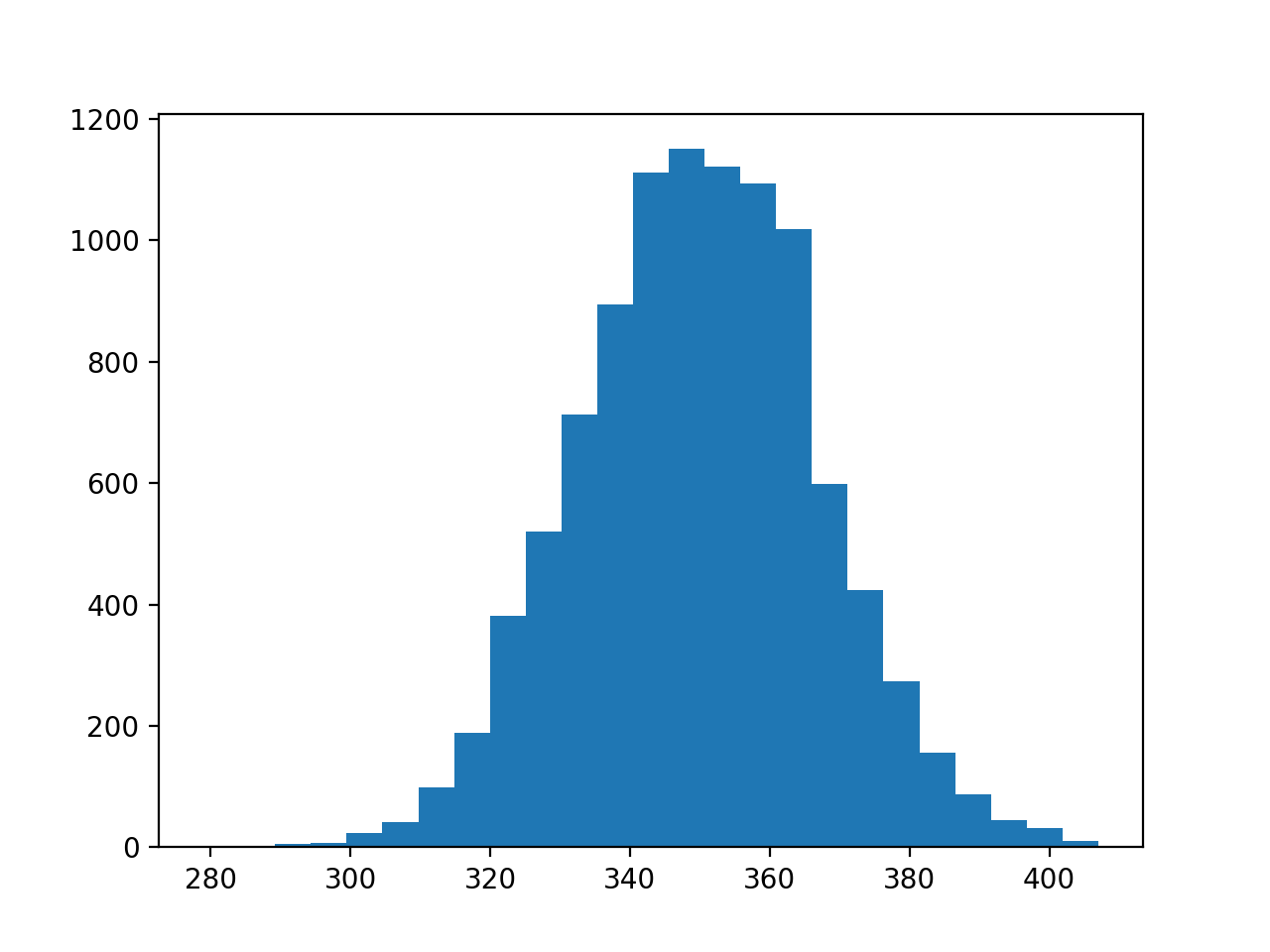
import numpy as np import numpy.random as rd import matplotlib.pyplot as plt # サイコロを定義する # 平均と分散が分かる dice = [1, 2, 3, 4, 5, 6] print("標本平均:", np.mean(dice)) print("標本分散:", np.var(dice)) # 試行回数を定義する # 標本平均と組み合わせて合計の期待値が分かる # 標本分散と組み合わせて合計の標準偏差を予想できる trialsNum = 100 print("合計の期待値 :", np.mean(dice) * trialsNum) print("合計の標準偏差(予想):", np.sqrt(np.var(dice) * trialsNum)) input("続行するにはEnterキーを押してください . . .") # 実際に試行する...を試行する metaTrialsNum = 10000 resultList = [np.sum([rd.choice(dice) for i in range(trialsNum)]) for i in range(metaTrialsNum)] myMean = np.mean(resultList) myStd = np.std(resultList) print("合計の平均 :", myMean) print("合計の標準偏差(実際):", myStd) # 68–95–99.7則に当てはまるか確認する win = [len([n for n in resultList if myMean - r * myStd <= n and n <= myMean + r * myStd]) / metaTrialsNum for r in range(1, 4)] print( f'μ±σ : {myMean - 1 * myStd :.1f} ~ {myMean + 1 * myStd:.1f}: {win[0]:.2%}') print( f'μ±2σ: {myMean - 2 * myStd :.1f} ~ {myMean + 2 * myStd:.1f}: {win[1]:.2%}') print( f'μ±3σ: {myMean - 3 * myStd :.1f} ~ {myMean + 3 * myStd:.1f}: {win[2]:.2%}') # ヒストグラムを描画して合計の分布を確認する plt.hist(resultList, bins=25) plt.show()実行結果(例)
やはり乱数を使うので結果は一定ではありません。
標本平均: 3.5 標本分散: 2.9166666666666665 合計の期待値 : 350.0 合計の標準偏差(予想): 17.078251276599328 続行するにはEnterキーを押してください . . .
合計の平均 : 349.9814 合計の標準偏差(実際): 17.034108548438923 μ±σ : 332.9 ~ 367.0: 69.69% μ±2σ: 315.9 ~ 384.0: 95.77% μ±3σ: 298.9 ~ 401.1: 99.76%解説
合計の分布は 68–95–99.7則 へ綺麗に当てはまる正規分布となりました。約17となった標準偏差によって、どのくらい”350 くらい”なのかが表された訳です。そして標準偏差はシミュレーションせずとも標本から求めることができます。
誤差関数 erf
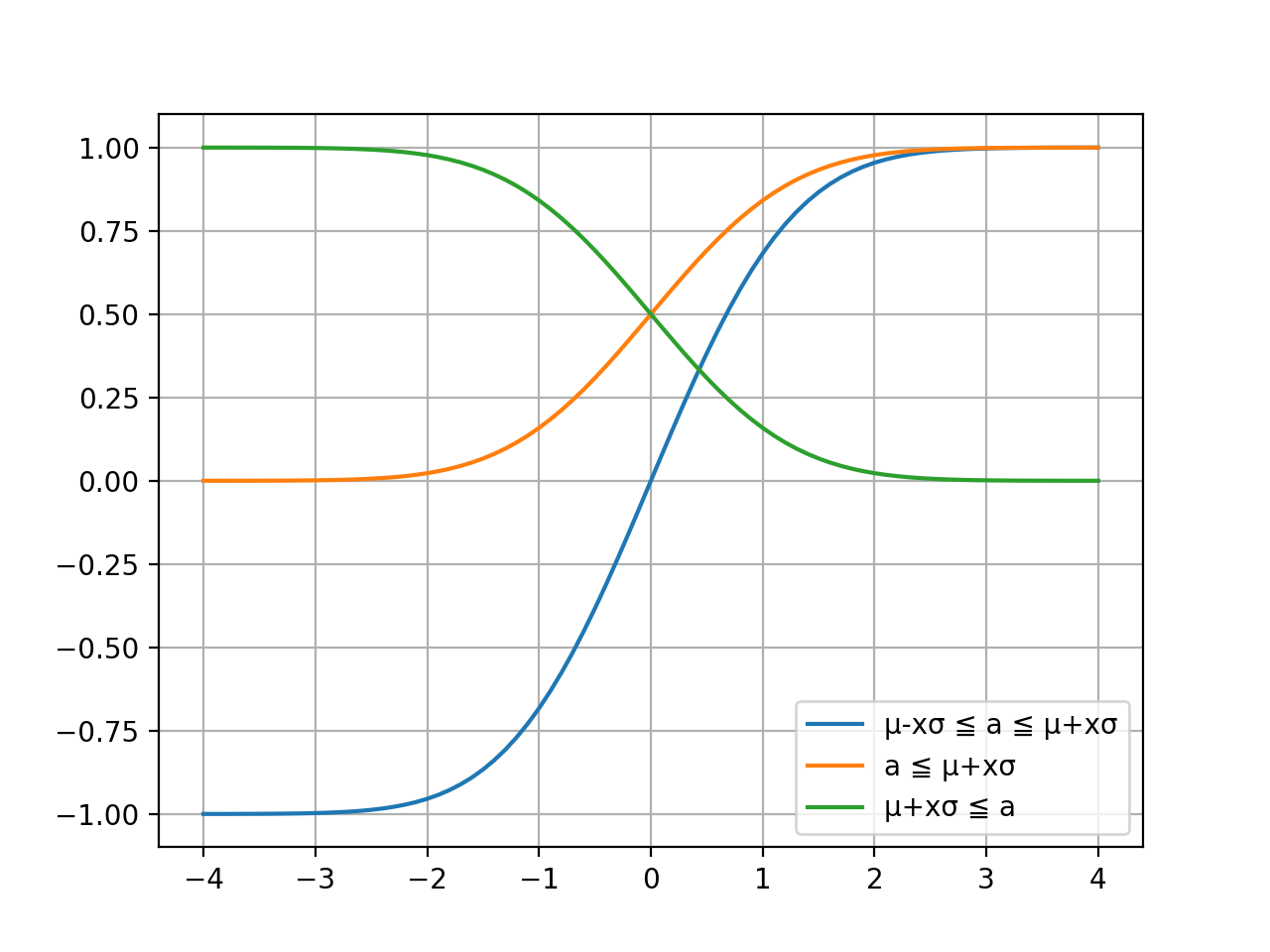
68–95–99.7則から μ±xσ の x が 1,2,3 の場合に試行結果がその範囲内である確率が分かりました。では x が 1.5 のときの確率などは分からないのでしょうか?あるいは出目の合計が 370 以上となる確率などは分らないのでしょうか?そこで誤差関数 erf の出番です。下記の python プログラムでこの関数の働きを図示してみます。
プログラム
import math import numpy as np import matplotlib.pyplot as plt x = np.arange(-4.0, 4.1, 0.1) leg1 = "μ-xσ ≦ a ≦ μ+xσ" y1 = [math.erf(i/math.sqrt(2)) for i in x] p1 = plt.plot(x, y1) leg2 = "a ≦ μ+xσ" y2 = [0.5 + 0.5 * math.erf(i/math.sqrt(2)) for i in x] p2 = plt.plot(x, y2) leg3 = "μ+xσ ≦ a" y3 = [0.5 - 0.5 * math.erf(i/math.sqrt(2)) for i in x] p3 = plt.plot(x, y3) plt.legend((p1[0], p2[0], p3[0]), (leg1, leg2, leg3), loc=0) plt.grid(True) plt.show()実行結果
解説
- 青色の線:試行結果 a が μ±xσ の範囲である確率を表します
- 橙色の線:試行結果 a が μ+xσ 以下である確率を表します
- 緑色の線:試行結果 a が μ+xσ 以上である確率を表します
誤差関数 erf により、任意の x について試行結果が μ±xσ 内である確率と μ+xσ 以下、あるいは以上である確率を計算できます。
あるいは出目の合計が 370 以上となる確率などは分らないのでしょうか?
誤差関数 erf を使い求めることができます
まずは次の式の μ と σ に値を当てはめて x の値を求めます。μ+xσ = 370
合計の期待値 : 350.0
合計の標準偏差(予想): 17.078251276599328350+17x = 370
17x = 20
x = 1.18そしてプログラムで使用した式の x に値を当てはめると確率が計算できます。
0.5 - 0.5 * math.erf(i/math.sqrt(2)0.5 - 0.5 * erf(1.18/√2) = 0.12 = 12%
サイコロを100回振ったとき出目の合計が 370 以上になる確率は約 12% です。平均、標準偏差、誤差関数により、はじめの問に対していろいろなことが答えられるようになりました。
問2
下表のペースで進んだチームはイテレーション20の完了時点でどこまで進む?
イテレーション ベロシティ 累積 1 7 7 2 3 10 3 3 13 4 6 19 5 6 25 平均・期待値
μ = 200 ですね。
分散・標準偏差
イテレーション5までの分散は 3.5 であることからイテレーション20までの標準偏差は σ = √(3.5*20) ≒ 8.4 と予想できます。μ±3σの範囲はおよそ 175 ~ 225 となります。
誤差関数 erf
80% くらいの確度で答えるなら μ-1σ で 191 とでも言っときましょう(端数切り捨て)。イテレーション20までの進捗目標がそれより大きいなら目標を 191 まで下げるよう交渉すべきです。
99% の確度で答えるなら μ-3σ で 175 と言いましょう。目標が 225 だったら間に合う確率は 1% もありません。目標が 200 でも間に合う確率は 50% で五分五分の博打になります。「このまま平均通りのペースで進めば間に合うから順調だ!」なんて判断していると痛い目を見がちです。
進捗の実績が貯まるごとに μ も σ も変動するので目標以上に進める確率を随時、誤差関数 erf で計算しましょう。サイコロと違って完璧な標本はないのですから。
なおリソース量の単位はイテレーション数とすると簡単ですが、より細かくしたい場合は日数や人日で計算することもできます。

- 投稿日:2020-10-25T23:25:42+09:00
Django ModelViewSetの使い方
ModelViewSetとは
モデルに対する、
一覧取得、詳細取得、新規作成、更新、削除を
一括で作成してくれます?
ReadOnlyModelViewSetを継承すれば、一覧取得と詳細取得だけにできる??基本的な使い方
書き方
使い方の注意は、
urls.pyにパス追加する方法が、APIViewなどとは少し違うということ!book/views.pyfrom rest_framework import generics, viewsets class BookViewSet(viewsets.ModelViewSet): serializer_class = BookSerializer queryset = Book.objects.all()book/urls.pyfrom rest_framework import routers router = routers.DefaultRouter() router.register('books', BookViewSet)確認する
terminalcurl http://127.0.0.1:8000/api/v1/book/books/ [{"id":"a088ae31-dbe4-4435-8dc9-356378b6def9","is_deleted":"0","created_at: ...."}] curl http://127.0.0.1:8000/api/v1/book/books/<pkをいれる>/ {"id":"a088ae31-dbe4-4435-8dc9-356378b6def9","is_deleted":"0"," ....."} curl -XPOST http://127.0.0.1:8000/api/v1/book/books/ -d "title=test&sub_titl..." {"id":"fc21044e-7388-4391-b498-8b472350282f","is_deleted":"0"...} curl -XPATCH http://127.0.0.1:8000/api/v1/book/books/<pk>/ -d 'is_deleted=1' {"id":"a088ae31-dbe4-4435-8dc9-356378b6def9","is_deleted":"1"," ....."} curl -XDELETE http://127.0.0.1:8000/api/v1/book/books/<pk>/無事にできました?
カスタマイズする
actionデコレータ
これは絶対に覚えておきたいと思うので最初に書きます!
urlに追加してくれて、機能を追加してくれます☺️例:
views.pyclass BookViewSet(viewsets.ModelViewSet): serializer_class = BookSerializer queryset = Book.objects.all() @action(detail=True, methods=['get']) def authors(self, request, pk=None): author = Author.objects.all() serializer = AuthorSerializer(author, many=True) return Response(serializer.data)このように書きます!
もちろん、こんな感じの機能は追加することはないでしょうが笑
ということでAPIを確認します!?terminalcurl http://127.0.0.1:8000/api/v1/book/books/1/authors/ [{"id":"a739d3f5-a170-4472-a7af-33a44f8f5512","is_deleted":"0"...}]
detailとは、一覧APIなのか詳細APIなのかを判断しています。(Trueだと詳細)
一覧APIの場合は、引数のpkは入りません。!
methodsとは、HTTPメソッドを定義しています。(get,post,put,patch,delete)
※複数も可能methods=['get', 'patch']認証の設定
APIViewなどのように認証の設定も可能ですviews.pyclass BookViewSet(viewsets.ModelViewSet): serializer_class = BookSerializer queryset = Book.objects.all() authentication_classes = [IsAccountAdminOrReadOnly]actionデコレータでも可能!
views.py@action(detail=True, methods=['post'], permission_classes=[IsAccountAdminOrReadOnly])フィルターの設定
rest_frameworkのfiltersを使ってみる?
views.pyfrom rest_framework import filters class BookViewSet(viewsets.ModelViewSet): serializer_class = BookSerializer queryset = Book.objects.all() filter_backends = [filters.SearchFilter] search_fields = ['sub_title','title']確認する!
?serach=検索文字列で検索できる☺️terminalcurl http://127.0.0.1:8000/api/v1/book/books/?search=設計・運用計画の鉄則 [{"id":"a088ae31-dbe4-4435-8dc9-356378b6def9","is_deleted":"0" ... ,"sub_title":"設計・運用計画の鉄則" ...}]無事に取得できました???
使わないHTTPメソッドを省く
ViewSetを使うと、DELETEとか使わないのにあるからデータ消されちゃう????
その対策は、継承を変更すれば大丈夫!!!views.pyfrom rest_framework import mixins class AuthorViewSet(mixins.CreateModelMixin, mixins.ListModelMixin, viewsets.GenericViewSet):この場合は作成と一覧のみ!!
mixins.CreateModelMixin
mixins.RetrieveModelMixin
mixins.UpdateModelMixin
mixins.DestroyModelMixin
mixins.ListModelMixin使うものを継承する??????
以上!!!
お疲れ様です!!??
- 投稿日:2020-10-25T23:24:07+09:00
Python + OpenCVで顔検出 〜リアルタイムカメラから検出〜
目次
1.仮想環境の準備
2.openCVのインストール
3.顔検出のプログラム準備
4.分類器のファイルを取得
5.実行
6.ソースコード仮想環境の準備
opencvEnvの環境をvenvで作成
$ python3 -m venv opencvEnv # activate しておく $ source opencvEnv/bin/activate (opencvEnv)$ ...openCVのインストール
pipでopenCVをイントール
(opencvEnv)$ pip install opencv-python Collecting opencv-python Downloading https://files.pythonhosted.org/packages/e2/a9/cd3912ca0576ea6588095dce55e54c5f0efeb3d63fb88f16f4c06c0fac8d/opencv_python-4.1.2.30-cp36-cp36m-macosx_10_9_x86_64.whl (45.2MB) 100% |████████████████████████████████| 45.2MB 721kB/s Collecting numpy>=1.11.3 (from opencv-python) Using cached https://files.pythonhosted.org/packages/22/99/36e3408ae2cb8b72260de4e538196d17736d7fb82a1086cb2c21ee156ddc/numpy-1.17.4-cp36-cp36m-macosx_10_9_x86_64.whl Installing collected packages: numpy, opencv-python Successfully installed numpy-1.17.4 opencv-python-4.1.2.30 import cv2顔検出のプログラム準備
face_detect.pyを作成する
face_detect.pyimport cv2 if __name__ == '__main__': # 定数定義 ESC_KEY = 27 # Escキー INTERVAL= 33 # 待ち時間 FRAME_RATE = 30 # fps ORG_WINDOW_NAME = "org" GAUSSIAN_WINDOW_NAME = "gaussian" DEVICE_ID = 0 # 分類器の指定 cascade_file = "../xml/haarcascade_frontalface_alt2.xml" cascade = cv2.CascadeClassifier(cascade_file) # カメラ映像取得 cap = cv2.VideoCapture(DEVICE_ID) # 初期フレームの読込 end_flag, c_frame = cap.read() height, width, channels = c_frame.shape # ウィンドウの準備 cv2.namedWindow(ORG_WINDOW_NAME) cv2.namedWindow(GAUSSIAN_WINDOW_NAME) # 変換処理ループ while end_flag == True: # 画像の取得と顔の検出 img = c_frame img_gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY) face_list = cascade.detectMultiScale(img_gray, minSize=(100, 100)) # 検出した顔に印を付ける for (x, y, w, h) in face_list: color = (0, 0, 225) pen_w = 3 cv2.rectangle(img_gray, (x, y), (x+w, y+h), color, thickness = pen_w) # フレーム表示 cv2.imshow(ORG_WINDOW_NAME, c_frame) cv2.imshow(GAUSSIAN_WINDOW_NAME, img_gray) # Escキーで終了 key = cv2.waitKey(INTERVAL) if key == ESC_KEY: break # 次のフレーム読み込み end_flag, c_frame = cap.read() # 終了処理 cv2.destroyAllWindows() cap.release()分類器のファイルを取得
顔検出に使用する
haarcascade_frontalface_alt2.xmlを以下のサイトから取得し、任意の場所にファイルをダウンロードする。実行
face_ detect.pyを実行する。ターミナルからカメラのアクセス許可を求めらるので許可する。
(opencvEnv)$ python face_ detect.pyカメラで取得できる映像から顔検出することができる。カメラは[Esc]で強制終了できる。
ソースコード
今回のソースコードは以下のリポジトリの
face_detect.pyから転載。https://github.com/kawakeee/openCV_practice/blob/master/detection/face_detect.py
参考記事
個人ブログもやっています。長野エンジニアライフ

- 投稿日:2020-10-25T23:24:07+09:00
サクッとPython + OpenCVで顔検出した時のメモ
目次
1.仮想環境の準備
2.openCVのインストール
3.顔検出のプログラム準備
4.分類器のファイルを取得
5.実行
6.ソースコード仮想環境の準備
opencvEnvの環境をvenvで作成
$ python3 -m venv opencvEnv # activate しておく $ source opencvEnv/bin/activate (opencvEnv)$ ...openCVのインストール
pipでopenCVをイントール
(opencvEnv)$ pip install opencv-python Collecting opencv-python Downloading https://files.pythonhosted.org/packages/e2/a9/cd3912ca0576ea6588095dce55e54c5f0efeb3d63fb88f16f4c06c0fac8d/opencv_python-4.1.2.30-cp36-cp36m-macosx_10_9_x86_64.whl (45.2MB) 100% |████████████████████████████████| 45.2MB 721kB/s Collecting numpy>=1.11.3 (from opencv-python) Using cached https://files.pythonhosted.org/packages/22/99/36e3408ae2cb8b72260de4e538196d17736d7fb82a1086cb2c21ee156ddc/numpy-1.17.4-cp36-cp36m-macosx_10_9_x86_64.whl Installing collected packages: numpy, opencv-python Successfully installed numpy-1.17.4 opencv-python-4.1.2.30 import cv2顔検出のプログラム準備
face_detect.pyを作成する
face_detect.pyimport cv2 if __name__ == '__main__': # 定数定義 ESC_KEY = 27 # Escキー INTERVAL= 33 # 待ち時間 FRAME_RATE = 30 # fps ORG_WINDOW_NAME = "org" GAUSSIAN_WINDOW_NAME = "gaussian" DEVICE_ID = 0 # 分類器の指定 cascade_file = "../xml/haarcascade_frontalface_alt2.xml" cascade = cv2.CascadeClassifier(cascade_file) # カメラ映像取得 cap = cv2.VideoCapture(DEVICE_ID) # 初期フレームの読込 end_flag, c_frame = cap.read() height, width, channels = c_frame.shape # ウィンドウの準備 cv2.namedWindow(ORG_WINDOW_NAME) cv2.namedWindow(GAUSSIAN_WINDOW_NAME) # 変換処理ループ while end_flag == True: # 画像の取得と顔の検出 img = c_frame img_gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY) face_list = cascade.detectMultiScale(img_gray, minSize=(100, 100)) # 検出した顔に印を付ける for (x, y, w, h) in face_list: color = (0, 0, 225) pen_w = 3 cv2.rectangle(img_gray, (x, y), (x+w, y+h), color, thickness = pen_w) # フレーム表示 cv2.imshow(ORG_WINDOW_NAME, c_frame) cv2.imshow(GAUSSIAN_WINDOW_NAME, img_gray) # Escキーで終了 key = cv2.waitKey(INTERVAL) if key == ESC_KEY: break # 次のフレーム読み込み end_flag, c_frame = cap.read() # 終了処理 cv2.destroyAllWindows() cap.release()分類器のファイルを取得
顔検出に使用する
haarcascade_frontalface_alt2.xmlを以下のサイトから取得し、任意の場所にファイルをダウンロードする。実行
face_ detect.pyを実行する。ターミナルからカメラのアクセス許可を求めらるので許可する。
(opencvEnv)$ python face_ detect.pyカメラで取得できる映像から顔検出することができる。カメラは[Esc]で強制終了できる。
ソースコード
今回のソースコードは以下のリポジトリの
face_detect.pyから転載。https://github.com/kawakeee/openCV_practice/blob/master/detection/face_detect.py
参考記事
個人ブログもやっています。長野エンジニアライフ
- 投稿日:2020-10-25T22:48:16+09:00
EC2でJupyterLabやJupyter Notebookを使う
データ分析ではJupyterLabやJupyterNotebookを使うことも多いかと思います。
ちょっとした処理ならローカルで動作させてもいいですが、重い計算を回すときはローカルではなくクラウド上の計算機を使いたい場合も多いと思います。
今回はAWS EC2上でJupyterLabを動かす方法についてメモしていきます(Jupyter Notebookも同じ手順で起動できます)。
EC2インスタンスを起動してssh接続する
AWSコンソールにログインしてインスタンスを起動します。OSはpythonが入っているubuntuが良いかと思います。
自分のIPからの接続しか許可しないようにセキュリティグループを設定します。
インスタンス概要の「パブリックIPv4アドレス」に書かれているIPに対してssh接続してサーバーにログインします。
JupyterLabをインストールする
OSをubuntuにしている場合、pythonはすでに入っています。
$ python3 --version Python 3.8.2pipとライブラリ類を入れていきます。
sudo apt update sudo apt install -y python3-pip公式ドキュメントを参考に、現バージョンで推奨されるインストール方法に従ってインストールしていきます。
pip3 install jupyterlabPATHにないところにインストールされたようなWARNINGが出ていたので、PATHに追加しておきます。
WARNING: The scripts jupyter, jupyter-migrate and jupyter-troubleshoot are installed in '/home/ubuntu/.local/bin' which is not on PATH.export PATH="$HOME/.local/bin:$PATH"JupyterLabを起動する
起動時には、jupyter-server側ではすべてのipを許可するように指定して起動します。
jupyter-lab --ip='0.0.0.0'ローカルPCからブラウザで
http://<EC2インスタンスのパブリックIPv4>:8888のアドレスに接続するとtokenの入力画面が出てきて、入力すればログインできます。
あるいは
http://<EC2インスタンスのパブリックIPv4>:8888/?token=<token>のようにリクエストパラメータにtokenを含めると直接ログインできます。ログインするといつものJupyterLabの画面になり、分析を開始できます。
昔ながらのjupyter notebookも同様にipを指定して起動して使うことができます。
jupyter notebook --ip='0.0.0.0'TIPS:パスワードでログインしたい場合
tokenの入力が面倒な場合はパスワードを設定できます。
$ jupyter notebook password Enter password: **** Verify password: ****の1コマンドで設定できます(参考:Running a notebook server — Jupyter Notebook 6.1.4 documentation)。
- 投稿日:2020-10-25T22:45:15+09:00
BeautifulSoupのインスタンス生成を高速化する方法
BeautifulSoupを使った画像検索botの、実行速度を改善した時の知見です。
スクレイピングの実行速度が遅くて困っている方の参考になれば幸いです。さっそく方法
環境
- python 3.7.9
- BeautifulSoup 4.9.3
スクリプト
BeautifulSoupの引数:from_encodingに、適切な文字コードを指定してあげる事で高速化することができます。
from urllib import request import bs4 page = request.urlopen("https://news.yahoo.co.jp/") html = page.read() # from_encodingにスクレイピングするサイトの文字コードを代入(今回のYahooニュースさんの場合utf-8) soup = bs4.BeautifulSoup(html, "html.parser", from_encoding="utf-8")文字コードの調べ方
基本的にmetaタグのcharset=以降に書いてあります。
<!-- Yahooニュースさんの場合 --> <meta http-equiv="Content-Type" content="text/html; charset=UTF-8">実行時間の比較
以下のスクリプトで検証しました。インスタンスを生成する前後で計測しています
verification_bs4.pyfrom urllib import request as req from urllib import parse import bs4 import time import copy url = "https://news.yahoo.co.jp/" page = req.urlopen(url) html = page.read() page.close() start = time.time() soup = bs4.BeautifulSoup(html, "html.parser") print('{:.5f}'.format(time.time() - start) + "[s] html.parser, None") start = time.time() soup = bs4.BeautifulSoup(html, "lxml") print('{:.5f}'.format(time.time() - start) + "[s] lxml, None") start = time.time() hoge = copy.copy(soup) print('{:.5f}'.format(time.time() - start) + "[s] copy(lxml, None)") start = time.time() soup = bs4.BeautifulSoup(html, "html.parser", from_encoding="utf-8") print('{:.5f}'.format(time.time() - start) + "[s] html.parser, utf-8") start = time.time() soup = bs4.BeautifulSoup(html, "lxml", from_encoding="utf-8") print('{:.5f}'.format(time.time() - start) + "[s] lxml, utf-8") start = time.time() hoge = copy.copy(soup) print('{:.5f}'.format(time.time() - start) + "[s] copy(lxml, utf-8)") start = time.time() soup = bs4.BeautifulSoup(html, "lxml", from_encoding="utf-16") # 文字コードが違うため戻り値は空 print('{:.5f}'.format(time.time() - start) + "[s] lxml, utf-16")出力結果はこちらです。
% python verification_bs4.py 2.10937[s] html.parser, None 2.00081[s] lxml, None 0.04704[s] copy(lxml, None) 0.03124[s] html.parser, utf-8 0.03115[s] lxml, utf-8 0.04188[s] copy(lxml, utf-8) 0.01651[s] lxml, utf-16まとめ
from_encodingに文字コードを指定することによってインスタンスの生成を高速化できました。
BeautifulSoupが遅いと言っている方のコードを見ると、from_encodingに代入していなかったので、それが原因だと思います。時間がある方向け
何故このような仕様になってるか気になったので、ソースコードを確認してみました。
ただ、普段あまりPythonは触らないので検討はずれなことを書いてる可能性があります
ソースコードはこちら遅い理由
おそらくbs4/dammit.py内に定義されているEncodingDetectorクラスが原因だと思います。
以下一部コードを抜粋します。class EncodingDetector: """Suggests a number of possible encodings for a bytestring. Order of precedence: 1. Encodings you specifically tell EncodingDetector to try first (the override_encodings argument to the constructor). 2. An encoding declared within the bytestring itself, either in an XML declaration (if the bytestring is to be interpreted as an XML document), or in a <meta> tag (if the bytestring is to be interpreted as an HTML document.) 3. An encoding detected through textual analysis by chardet, cchardet, or a similar external library. 4. UTF-8. 5. Windows-1252. """ @property def encodings(self): """Yield a number of encodings that might work for this markup. :yield: A sequence of strings. """ tried = set() for e in self.override_encodings: if self._usable(e, tried): yield e # Did the document originally start with a byte-order mark # that indicated its encoding? if self._usable(self.sniffed_encoding, tried): yield self.sniffed_encoding # Look within the document for an XML or HTML encoding # declaration. if self.declared_encoding is None: self.declared_encoding = self.find_declared_encoding( self.markup, self.is_html) if self._usable(self.declared_encoding, tried): yield self.declared_encoding # Use third-party character set detection to guess at the # encoding. if self.chardet_encoding is None: self.chardet_encoding = chardet_dammit(self.markup) if self._usable(self.chardet_encoding, tried): yield self.chardet_encoding # As a last-ditch effort, try utf-8 and windows-1252. for e in ('utf-8', 'windows-1252'): if self._usable(e, tried): yield eクラスの最初に書いてあるコメントを翻訳するとこうなります(DeepL翻訳)
""""バイト文字列のためのいくつかの可能なエンコーディングを提案します。 優先順位は以下の通りです。 1. EncodingDetector に最初に試すように指示したエンコーディング コンストラクタの引数 override_encodings)を使用します。 2. bytestring 自体の中で宣言されたエンコーディング。 XML 宣言 (バイト文字列が XML として解釈される場合) ドキュメント)、または<meta>タグ内(バイト文字列が HTML ドキュメントとして解釈されます)。 3. シャルデによるテキスト解析によって検出されたエンコーディング。 cchardet、または同様の外部ライブラリを使用します。 4. 4.UTF-8。 5. Windows-1252。 """コメントと処理から推測すると、上の1~5のリストを順に成功するまで、処理しているため遅くなっているのだと思います。
2を見ると、先ほどのmetaタグからの文字コード推測も自動でやってくれるため、webサイトのソースを見て文字コードを指定しなくても使えるようにするための配慮だと思います。
ただ、スクレイピングする際は大体ソースコードを確認すると思うので、ここまで遅くなるならいらない気がします。
(どの処理がネックになってるかの検証はしてないので、誰かよろしくお願いします。)Copyが早い理由
先ほどの実行時間測定スクリプトで、copy.copy()メソッドでインスタンスの複製を行っていますが、これが早い理由はbs4/init.pyの__copy__にあります。
以下一部コードを抜粋します。__init__.pyclass BeautifulSoup(Tag): def __copy__(self): """Copy a BeautifulSoup object by converting the document to a string and parsing it again.""" copy = type(self)( self.encode('utf-8'), builder=self.builder, from_encoding='utf-8' ) # Although we encoded the tree to UTF-8, that may not have # been the encoding of the original markup. Set the copy's # .original_encoding to reflect the original object's # .original_encoding. copy.original_encoding = self.original_encoding return copyここでutf-8に決め打ちしているため、早くなっています。
ただ逆に、スクレイピングするサイトの文字コードがutf-8以外だった場合、遅くなります。
以下の測定スクリプトでは、文字コードがshift-jisの価格comさんで測定しています。verification_bs4_2.pyfrom urllib import request as req from urllib import parse import bs4 import time import copy url = "https://kakaku.com/" page = req.urlopen(url) html = page.read() page.close() start = time.time() soup = bs4.BeautifulSoup(html, "html.parser") print('{:.5f}'.format(time.time() - start) + "[s] html.parser, None") start = time.time() soup = bs4.BeautifulSoup(html, "lxml") print('{:.5f}'.format(time.time() - start) + "[s] lxml, None") start = time.time() soup = bs4.BeautifulSoup(html, "lxml", from_encoding="shift_jis") print('{:.5f}'.format(time.time() - start) + "[s] lxml, shift_jis") start = time.time() hoge = copy.copy(soup) print('{:.5f}'.format(time.time() - start) + "[s] copy(lxml, shift_jis)")出力結果はこちらです。
% python verification_bs4_2.py 0.11084[s] html.parser, None 0.08563[s] lxml, None 0.08643[s] lxml, shift_jis 0.13631[s] copy(lxml, shift_jis)上記のようにcopyがutf-8に比べて遅くなっています。ただ、shift-jisの場合from_encodingに何も指定しなくても、ほとんど実行速度が変わってないです。
これもうわかんねぇな最後に
ここまで読んでいただきありがとうございました!最後、雑になってしまい申し訳ないです。
全世界のWebサイトの90%以上がutf-8なのに遅いのはどうなの?とは思います。BeautifulSoupで検索して上位にヒットするサイトが、この事に言及していないのが問題に感じ記事を作成しました。
もし、役に立ちましたら「LGTM」していただけると励みになります。
- 投稿日:2020-10-25T22:24:57+09:00
OpenCVでスプライトを回転させる #3 ~人任せにせず自分で計算せよ~
はじめに
今回は以前のプログラムを改変していますが、その際変数名なども細かく変えています。
- OpenCVで日本語フォントを描写する を関数化する
- OpenCVで日本語フォントを描写する を関数化する を汎用的にする
- OpenCVで透過画像を扱う ~スプライトを舞わせる~
- OpenCVでスプライトを回転させる
- OpenCVでスプライトを回転させる #2 ~cv2.warpAffine()を使いこなす~
- OpenCVでスプライトを回転させる #3 ~人任せにせず自分で計算せよ~ ←今ここ
目指す姿
往年のホビーパソコンのスプライト的な重ね合わせ関数について、
putSprite(back, front4, pos, angle=0, home=(0,0))
とする。表現はこれまでの記事とほとんど変わらないが、引数の意味するところを変更する。
- back 背景画像。RGB3チャンネル。
- front4 重ねたい前景画像。RGBAの4チャンネル。半透明は未対応。半透明って、あんま関心がわかないのよね。
- pos 前景画像の左上ではなく、homeで指定した原点の座標とする。
- angle 回転角度。単位は度でデフォ値は
0。- home スプライトの表示および回転の原点。デフォ値は左上すなわち
(0,0)。こっちのほうが使いやすいんじゃないかな、と。
基本プログラム
毎度毎度アニメーションさせるのも面倒なので、こんなのを作った。
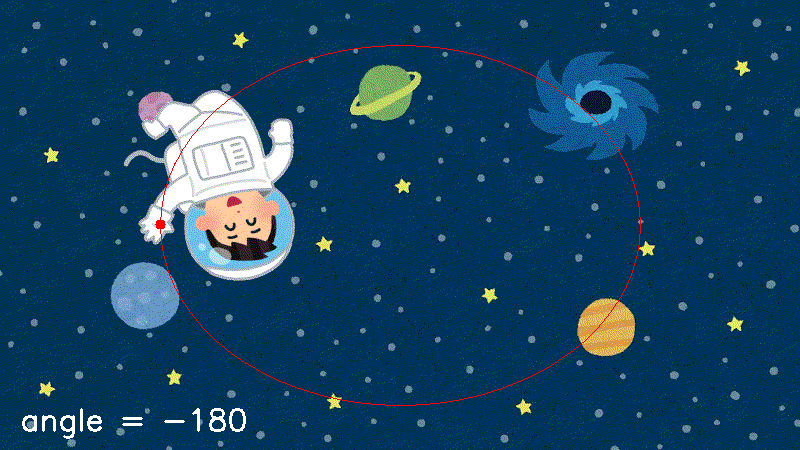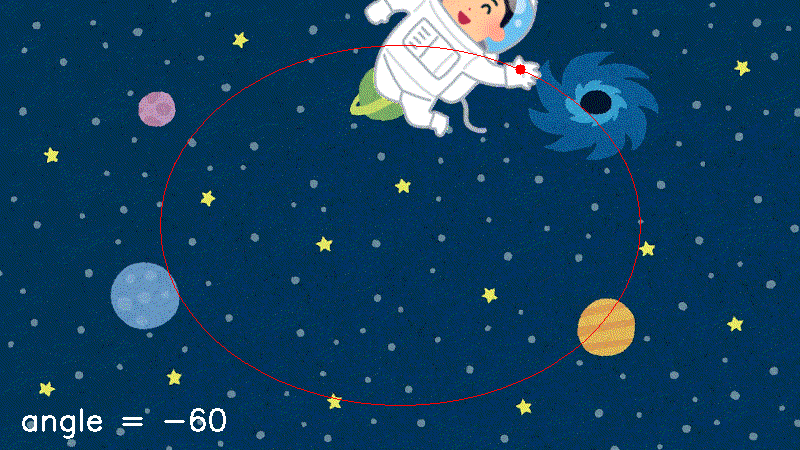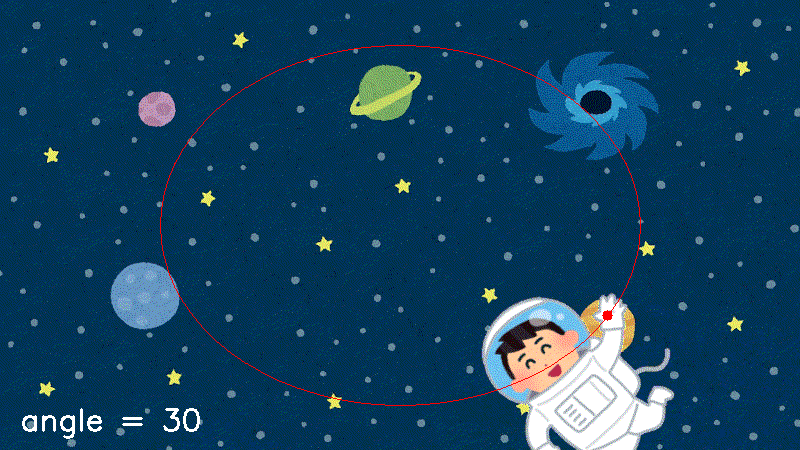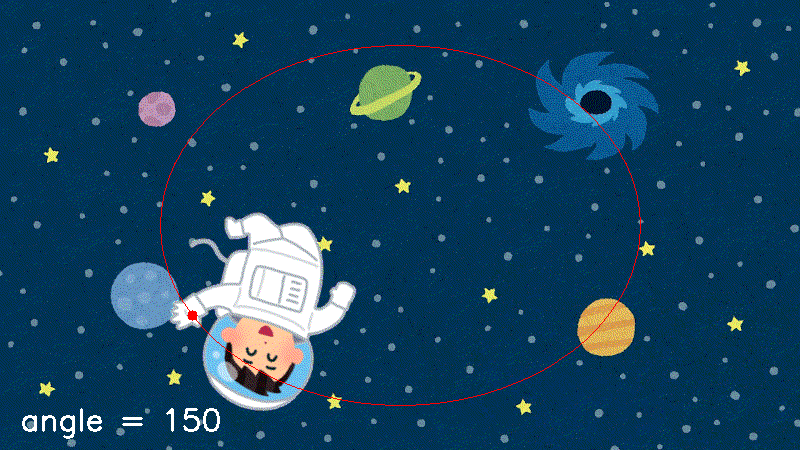
sample.pyimport cv2 import numpy as np def makeSampleImg(img4): h, w = img4.shape[:2] cv2.rectangle(img4, (0,0), (w-1,h-1), (0,0,255,255), 1) return img4 def putSprite(img_back, img_front, pos, angle=0, home=(0,0)): # さまざまな手法で実装し、最適なものを選ぶ。 pass def main(): img_front = cv2.imread("uchuhikoushi.png", -1) img_front = makeSampleImg(img_front) img_back = cv2.imread("space.jpg", -1) pos = (100,80) home = (140,60) angle = 30 # ここがメイン。必要に応じて関数名を変える img = putSprite(img_back.copy(), img_front, pos, angle, home) cv2.circle(img, pos, 5, (0,0,255), -1) # 同じ座標(pos)に丸を描く cv2.imshow("rotation", img) cv2.waitKey(0) cv2.destroyAllWindows() if __name__ == "__main__": main()結果はこうなる。はず。
結果 最小外接四角形を求める
「OpenCVでスプライトを回転させる」では回転した画像の左上座標を求めることができなかったが、その後なんとか算出することができた。わかっていたことだが、高校レベルの数学だった。
putSprite_calcdef putSprite_calc(back, front4, pos, angle=0, home=(0,0)): fh, fw = front4.shape[:2] bh, bw = back.shape[:2] x, y = pos xc, yc = home[0] - fw/2, home[1] - fh/2 # homeを左上基準から画像中央基準にする a = np.radians(angle) cos , sin = np.cos(a), np.sin(a) # この三角関数は何度も出るので変数にする w_rot = int(fw * abs(cos) + fh * abs(sin)) h_rot = int(fw * abs(sin) + fh * abs(cos)) M = cv2.getRotationMatrix2D((fw/2,fh/2), angle, 1) # 画像中央で回転 M[0][2] += w_rot/2 - fw/2 M[1][2] += h_rot/2 - fh/2 imgRot = cv2.warpAffine(front4, M, (w_rot,h_rot)) # 回転画像を含む外接四角形 # 外接四角形の全体が背景画像外なら何もしない xc_rot = xc * cos + yc * sin # 画像中央で回転した際の移動量 yc_rot = -xc * sin + yc * cos x0 = int(x - xc_rot - w_rot / 2) # 外接四角形の左上座標 y0 = int(y - yc_rot - h_rot / 2) if not ((-w_rot < x0 < bw) and (-h_rot < y0 < bh)) : return back # 外接四角形のうち、背景画像内のみを取得する x1, y1 = max(x0, 0), max(y0, 0) x2, y2 = min(x0 + w_rot, bw), min(y0 + h_rot, bh) imgRot = imgRot[y1-y0:y2-y0, x1-x0:x2-x0] # マスク手法で外接四角形と背景を合成する result = back.copy() front = imgRot[:, :, :3] mask1 = imgRot[:, :, 3] mask = 255 - cv2.merge((mask1, mask1, mask1)) roi = result[y1:y2, x1:x2] tmp = cv2.bitwise_and(roi, mask) tmp = cv2.bitwise_or(tmp, front) result[y1:y2, x1:x2] = tmp return result
imgRot 正方形ROIの改変
「OpenCVでスプライトを回転させる」では結局既知の寸法関係を使った無駄に大きな正方形を使った。
このときの関数を、今回の仕様に改変する。putSprite_mask2改def putSprite_mask2(back, front4, pos, angle=0, home=(0,0)): fh, fw = front4.shape[:2] bh, bw = back.shape[:2] x, y = pos xc, yc = home # 回転中心と四隅の距離の最大値を求める pts = np.array([(0,0), (fw,0), (fw,fh), (0,fh)]) ctr = np.array([(xc,yc)]) r = int(np.sqrt(max(np.sum((pts-ctr)**2, axis=1)))) # 回転画像を含む正方形 M = cv2.getRotationMatrix2D((xc,yc), angle, 1) # homeで回転 M[0][2] += r - xc M[1][2] += r - yc imgRot = cv2.warpAffine(front4, M, (2*r,2*r)) # 回転画像を含む正方形 # 四角形の全体が背景画像外なら何もしない x0, y0 = x-r, y-r if not ((-2*r < x0 < bw) and (-2*r < y0 < bh)) : return back # 四角形のうち、背景画像内のみを取得する x1, y1 = max(x0, 0), max(y0, 0) x2, y2 = min(x0+2*r, bw), min(y0+2*r, bh) imgRot = imgRot[y1-y0:y2-y0, x1-x0:x2-x0] # マスク手法で外接四角形と背景を合成する result = back.copy() front = imgRot[:, :, :3] mask1 = imgRot[:, :, 3] mask = 255 - cv2.merge((mask1, mask1, mask1)) roi = result[y1:y2, x1:x2] tmp = cv2.bitwise_and(roi, mask) tmp = cv2.bitwise_or(tmp, front) result[y1:y2, x1:x2] = tmp return result
imgRot 正方形ROIの最小化
この無駄に大きな正方形から最小の外接四角形を得るのに数学的にではなくプログラム的に対策できないかといろいろググっていたら、まさしく求めている記事を見つけた。
numpyの2次元配列の非ゼロ領域を囲む四角形の情報を取得する方法について理解する(Kei Minagawa's Blog)
図形の問題が最後まで解けなかったらこちらのお世話になるつもりだった。
imgRot 最小化 cv2.warpAffine()によるスプライト関数の改変
「OpenCVでスプライトを回転させる #2 ~cv2.warpAffine()を使いこなす~」のプログラムも修正しておこう。
回転途中の画像サイズは背景画像のそれに等しいので大きな背景画像の上に小さいスプライトを多数置こうとするととたんに実行スピードが落ちるであろう。
imgRot 実行速度比較
OpenCVで透過画像を扱う ~スプライトを舞わせる~で作った比較プログラムに回転要素を追加して実行してみる。
rot_test.pyimport cv2 import numpy as np import time # def makeSampleImg(img4)は不要 def putSprite_calc(back, front4, pos, angle=0, home=(0,0)): # 上で挙げたやつ def putSprite_mask2(back, front4, pos, angle=0, home=(0,0)): # 上で挙げたやつ def putSprite_Affine2(back, front4, pos, angle=0, home=(0,0)): # 上で挙げたやつ def main(func): filename_back = "space.jpg" filename_front = "uchuhikoushi.png" img_back = cv2.imread(filename_back) img_front = cv2.imread(filename_front, -1) bh, bw = img_back.shape[:2] xc, yc = bw//2, bh//2 rx, ry = bw*0.3, bh*0.4 home = (140,60) cv2.putText(img_back, func, (20,bh-20), cv2.FONT_HERSHEY_SIMPLEX, 1, (255,255,255)) ### 時間を計るのはここから start_time = time.time() for angle in range(-180, 180, 10): back = img_back.copy() x = int(xc + rx * np.cos(np.radians(angle))) y = int(yc + ry * np.sin(np.radians(angle))) img = eval(func)(img_back, img_front, (x,y), angle=angle, home=home) #ここは必要に応じて有効にしたり無効にしたりする #cv2.imshow(func, img) #cv2.waitKey(1) elasped_time = time.time() - start_time ### ここまで print (f"{func} : {elasped_time} sec") cv2.destroyAllWindows() if __name__ == "__main__": funcs = ["putSprite_calc", "putSprite_mask2", "putSprite_Affine2" ] for func in funcs: for i in range(10): main(func)作られるアニメーションは、わかりやすくするためいろいろ要素追加しているがおおよそ下のようになる。
結果 その処理にかかる時間は私の環境ではこう。
putSprite_calc : 0.12500691413879395 sec putSprite_mask2 : 0.27501583099365234 sec putSprite_Affine2 : 0.5620322227478027 secわかっていたことだが、ROIの面積が小さいほど実行速度が速い。
ROIの大きさは縦×横×RGB3チャンネルの計算量に直結しているので、OpenCVがうまいことやってくれるからといって無駄に大きなROIを使うとたちまち遅くなってしまうわけだ。終わりに
せっかくここまで作ったのだからゲームを作りたくなったぞ。いいかげんディープラーニングの勉強もしなくてはいけないのだが。
無理矢理ディープラーニングに関連付けるのなら、ディープラーニングをぶん回す際もサイズをいい具合に小さくすることで計算量を少なくすることができるであろう。




- 投稿日:2020-10-25T22:03:02+09:00
Vue.jsとDjangoでWebアプリケーションを作ってみる (Mac編) - (1) 環境構築、アプリケーション作成
はじめに
サーバーサイドをPythonのDjango、クライアントサイトをVue.jsで組んでみます。
Djangoアプリケーションは、cookiecutterで作成します。
環境構築
Python
pyenvインストール
- Mac : ローカルPCにPython環境をインストールする(pyenv, venv on Mac)
- WSL : すみません、まだ作成していません。作成したらリンクを貼ります。
Python3.9.0インストール
pyenv versionsでインストール済みのバージョン一覧を表示し、
3.9.0がない場合はインストールします。pyenv install 3.9.0cookiecutter実行用仮想環境作成
pyenv shell 3.9.0 python -m venv ~/.venv/3.9.0/cookiecutter-3.9 pyenv shell --unset # pyenvのshellを終了する。Djangoアプリケーション実行用仮想環境作成
pyenv shell 3.9.0 python -m venv ~/.venv/3.9.0/django-sample-3.9 pyenv shell --unset # pyenvのshellを終了する。nodenv
nodenvインストール
node.js 13.11.0インストール
nodenv versionsでインストール済みのバージョン一覧を表示し、
13.11.0がない場合はインストールします。nodenv install 13.11.0バージョン確認
nodenv versionscookiecutterアプリケーション作成、実行
cookiecutterの環境を作成
mkdir cookiecutter cd cookiecutter/ source ~/.venv/3.9.0/cookiecutter-3.9/bin/activate pip install --upgrade pip pip install cookiecuttercookiecutter実行
cookiecutter https://github.com/pydanny/cookiecutter-django対話式で色々聞かれるので、答えながら先へ進みます。
【注意】
Select cloud_providerで「3」(None)を選択し、use_whitenoiseで「n」とすると、下記のようなエラーになるので、Select cloud_providerで「1」か「2」を選択するか、あるいは、use_whitenoiseで「y」と答えます。You should either use Whitenoise or select a Cloud Provider to serve static files ERROR: Stopping generation because pre_gen_project hook script didn't exit successfully Hook script failed (exit status: 1)project_name [My Awesome Project]: django-sample project_slug [django_sample]: app description [Behold My Awesome Project!]: Django Sample Application author_name [Daniel Roy Greenfeld]: ***** domain_name [example.com]: email [daniel-roy-greenfeld@example.com]: *****@*****.*** version [0.1.0]: Select open_source_license: 1 - MIT 2 - BSD 3 - GPLv3 4 - Apache Software License 2.0 5 - Not open source Choose from 1, 2, 3, 4, 5 [1]: 5 timezone [UTC]: Asia/Tokyo windows [n]: use_pycharm [n]: use_docker [n]: Select postgresql_version: 1 - 12.3 2 - 11.8 3 - 10.8 4 - 9.6 5 - 9.5 Choose from 1, 2, 3, 4, 5 [1]: Select js_task_runner: 1 - None 2 - Gulp Choose from 1, 2 [1]: Select cloud_provider: 1 - AWS 2 - GCP 3 - None Choose from 1, 2, 3 [1]: 3 Select mail_service: 1 - Mailgun 2 - Amazon SES 3 - Mailjet 4 - Mandrill 5 - Postmark 6 - Sendgrid 7 - SendinBlue 8 - SparkPost 9 - Other SMTP Choose from 1, 2, 3, 4, 5, 6, 7, 8, 9 [1]: 9 use_async [n]: use_drf [n]: custom_bootstrap_compilation [n]: use_compressor [n]: use_celery [n]: use_mailhog [n]: use_sentry [n]: use_whitenoise [n]: y use_heroku [n]: Select ci_tool: 1 - None 2 - Travis 3 - Gitlab 4 - Github Choose from 1, 2, 3, 4 [1]: keep_local_envs_in_vcs [y]: debug [n]: [INFO]: .env(s) are only utilized when Docker Compose and/or Heroku support is enabled so keeping them does not make sense given your current setup. [WARNING]: You chose not to use a cloud provider, media files won't be served in production. [SUCCESS]: Project initialized, keep up the good work!
質問 デフォルト 設定 備考 project_name My Awesome Project django-sample project_slug django_sample app description Behold My Awesome Project! Django Sample Application そのままでも問題ないです author_name Daniel Roy Greenfeld ***** 自分の名前を入れます domain_name example.com (デフォルト) 後から変えることになると思いますが、 とりあえずそのままで大丈夫です daniel-roy-greenfeld@example.com 自分のメールアドレスを入れます ~ version 0.1.0 (デフォルト) Select open_source_license
1 - MIT
2 - BSD
3 - GPLv3
4 - Apache Software License 2.0
5 - Not open source
Choose from 1, 2, 3, 4, 51 5 オープンソースにする場合はライセンスを選択します timezone UTC Asia/Tokyo windows n (デフォルト) use_pycharm n (デフォルト) PyCharmを使う場合はyにしてもいいと思います use_docker n (デフォルト) Select postgresql_version:
1 - 12.3
2 - 11.8
3 - 10.8
4 - 9.6
5 - 9.5
Choose from 1, 2, 3, 4, 51 (デフォルト) 私の場合、MySQLやMariaDBを使う事が多いので、後で変更することになるため、ここでは適当にデフォルトで先へ進めます Select js_task_runner:
1 - None
2 - Gulp
Choose from 1, 21 (デフォルト) Select cloud_provider:
1 - AWS
2 - GCP
3 - None
Choose from 1, 2, 31 3 クラウドプロバイダが決まっていないので3にします。すでに決まっている場合は1〜2でも大丈夫だと思います。 Select mail_service:
1 - Mailgun
2 - Amazon SES
3 - Mailjet
4 - Mandrill
5 - Postmark
6 - Sendgrid
7 - SendinBlue
8 - SparkPost
9 - Other SMTP
Choose from 1, 2, 3, 4, 5, 6, 7, 8, 91 9 メール送信のサービスで使うものが決まっている場合は選択します。 use_async n (デフォルト) use_drf n (デフォルト) custom_bootstrap_compilation n (デフォルト) use_compressor n (デフォルト) use_celery n (デフォルト) use_mailhog n (デフォルト) use_sentry n (デフォルト) use_whitenoise n y クラウドプロバイダでNoneを指定した場合、ここでyを選ぶ必要があるようです use_heroku n (デフォルト) Select ci_tool:
1 - None
2 - Travis
3 - Gitlab
4 - Github
Choose from 1, 2, 3, 41 (デフォルト) keep_local_envs_in_vcs y (デフォルト) debug n (デフォルト) cookiecutterの実行が完了すると、
project_slugで回答したスラグ名のディレクトリが作成されます。
そのディレクトリを、ホームディレクトリ直下にdjango-sampleとして移動します。/bin/cp -Ra app ~/django-sampleVue.jsアプリケーション作成
mkdir ~/vue-sample/ cd ~/vue-sample/ nodenv local 13.11.0 node -v # nodeのバージョンがv13.11.0であることを確認 npm init --yes npm install npm # npmを最新化 npm install @vue/cli npm install @vue/cli-init次に、Pathを通すため、以下を実行します。
npm binMacの場合、
/Users/*****/vue-sample/node_modules/.binのように表示されるので、そのパスをPATHに追加します。
export PATH="/Users/*****/vue-sample/node_modules/.bin:$PATH"プロジェクトを作成します。
vue init webpack vue-sample? Project name vue-sample ? Project description A Vue.js project ? Author ? Vue build standalone ? Install vue-router? No ? Use ESLint to lint your code? No ? Set up unit tests No ? Setup e2e tests with Nightwatch? No ? Should we run `npm install` for you after the project has been created? (recommended) npmアプリケーションの作成に成功すると、
# Project initialization finished! # ======================== To get started: cd vue-sample npm run devのように表示されるので、以下のコマンドを実行し、アプリケーションを実行します。
cd vue-sample npm run devYour application is running here: http://localhost:8080と表示されるので、http://localhost:8080へアクセスします。

- 投稿日:2020-10-25T21:52:09+09:00
【祝】強化学習ライブラリTF2RL v1.0到達 ~CIやドキュメントサイトなど開発・利用環境の整備~
1. はじめに
以前紹介した友人が開発しているTensorFlow 2.x 向け強化学習ライブラリTF2RLが、諸々整備してバージョン1.0に到達しました?
(いつの間にかスターも300超えていてすごい!)バージョン1.0到達以降も、まだまだ様々な強化学習アルゴリズムを追加しようと開発が進んでいます。(この記事を準備している間にも、v1.1.0が公開されてます。)
インストール方法や基本となる使い方は、公式ReadMeや、前の記事を読んでいただければと思うので、この記事では割愛します。
この記事では、私もお手伝いさせてもらって整備したアルゴリズム以外の部分について紹介します。
2. マルチプラットフォームテスト (PR 97)
GitHub Actions によって、Windows/macOS/Ubuntu のマルチプラットフォームで、push や pull requestの度にユニットテストを自動で走らせれるようになりました。
特に、Windowsの開発機を友人も私も持っておらず、なかなかサポートできていなかったのですが、このActionsによってWindows上での問題があぶり出されWindowsでも無事動作できるようになりました。
(Windowsでは、multiprocessing.Poolなどを利用する際に渡すことができるのは、ネストしていないモジュール直下で定義されたクラス・関数だけみたいですね。なんでもfork()システムコールの代わりに利用している pickleのシリアライズが原因みたいですが、なんでそこに制約があるのかまでは理解できていません。)同じコードを複数のTFとPythonのバージョンの関係もあって、下のように綺麗なマトリックス戦略になっていないのですが、もうちょっとうまく記述する方法はありませんかね。
.github/workflows/test.yml(抜粋)strategy: matrix: os: [ubuntu-latest, macos-latest, windows-latest] python: ['3.7', '3.8'] TF: ['2.2', '2.3'] include: - os: ubuntu-latest python: '3.7' TF: '2.0' - os: ubuntu-latest python: '3.7' TF: '2.1' - os: macos-latest python: '3.7' TF: '2.0' - os: macos-latest python: '3.7' TF: '2.1' - os: windows-latest python: '3.7' TF: '2.0' - os: windows-latest python: '3.7' TF: '2.1'3. Super-Linterでコードの自動チェック (PR 102)
GitHub Super-Linterを利用し、元々手作業で行っていたLinterでのコードのルールチェックが自動化されました。
Super-Linterで躓いたのは、カスタム設定のファイルを
.github/linters/ディレクトリに置かないといけないことでした。 カスタム設定のファイル名自体は、Super-Linterの起動時のオプションで指定できますが、あくまで上記のディレクトリにおいていないと見つからずデフォルトの設定が使用されてしまいます。(最終的にわからなくて質問しました。)4. Sphinx を利用したドキュメントサイト構築 (PR 107)
GitHub Actionsの中で、Sphinxを利用してドキュメントを自動生成しています。
docstring から自動でクラスリファレンスを生成する autodoc とMarkdown形式文書を取り込む recommonmark を有効にしています。(テーマはRead The Docsテーマとしました。)
conf.pyfrom recommonmark.transform import AutoStructify extensions = ["sphinx.ext.autodoc", "recommonmark"] html_theme = "sphinx_rtd_theme" def setup(app): app.add_transform(AutoStructify)ちょっとだけつまづいたのは、
sphinx-apidocコマンドで autodocの雛形となる一式をソースコードから生成するのですが、自動生成されるindex.rstが 手作りのindex.mdより優先されてしまって、うまく表示ができなかったので(しばらく悩んだあとに)index.rstを削除するコードを追加しすることで表示できるようになりました。GitHub Pagesへの公開は、MasterブランチかつFork先ではない時に、peaceiris/actions-gh-pagesを利用して公開しています。
(どうも、gh-pagesというブランチを作ってそこに生成物をpushする仕組みみたいです。なのでよくあるmasterブランチの doc以下を公開という設定とは異なります。).github/workflows/doc.yml(抜粋)- uses: peaceiris/actions-gh-pages@v3 with: github_token: ${{ secrets.GITHUB_TOKEN }} publish_dir: ./public if: (github.ref == 'refs/heads/master') && (github.repository == 'keiohta/tf2rl')Sphinxによって自動的に書き出されたクラスレファレンスはこちら
(クラスリファレンス以外のチュートリアルも自分で書きたいと聞いていたので、Markdownで書けるように環境は整備しましたが、まだ無いようです。。。乞うご期待。)5. Docker と GitHub Container Registry を利用した構築済みコンテナ環境の提供 (PR 111)
ログインせずともコンテナイメージをダウンロードできるGitHub Container Registryがベータ公開されたのに併せて、構築済みコンテナ環境を利用できるようにしました。(それ以前のGitHub Packagesはログインしないとpublicなイメージもダウンロードできないという謎仕様で、フォーラムでも何人もの人がおかしいって言い続けていました。)
docker run -it ghcr.io/keiohta/tf2rl/cpu:v1.1.0 bashまた、Linuxオンリーかつマルチプロセスでの学習(ApeX)でうまく行かない例が散見されるのでexperimentalという扱いですが、NVIDIAのGPUを利用できるGPUコンテナバージョンも準備しています。
(私がMacBook Proしかなく、NVIDIA GPUの刺さったマシンを手元に持っていないためデバッグが難しく、環境をもった有識者が支援してくれると助かります。)docker run --gpus all -it ghcr.io/keiohta/tf2rl/nvidia:v1.1.0 bashGPUコンテナについては、こちらの記事が非常に詳しくてためになりました。
コンテナイメージのビルドは以下のように設定してあり、tagつきでpushされたら、ビルドしてそのtag名をもったコンテナイメージをGitHub Container Registryに格納する仕組みになっています。
.github/workflows/docker.ymlname: docker on: push: tags: - '**' jobs: build: runs-on: ubuntu-latest env: DOCKER_BUILDKIT: 1 steps: - uses: actions/checkout@v2 - uses: docker/build-push-action@v1 with: registry: ghcr.io repository: ${{ github.repository_owner }}/tf2rl/cpu tag_with_ref: true username: ${{ github.repository_owner }} password: ${{ secrets.GHCR_TOKEN }} dockerfile: Dockerfile always_pull: true - uses: docker/build-push-action@v1 with: registry: ghcr.io repository: ${{ github.repository_owner }}/tf2rl/nvidia tag_with_ref: true username: ${{ github.repository_owner }} password: ${{ secrets.GHCR_TOKEN }} dockerfile: Dockerfile.nvidia always_pull: truedocker/build-push-actionは v2 があるのですが、ログインが分離されて二度手間で、tagを手動で切り出さなければならず、使い勝手が悪かったので、あえて v1 で固定しています。
また、ベータ版だからなのか、GitHub Container Registryは、GitHub Actionsの自動生成されるシークレットでは認証が通らないので、Personal Access Tokenを作って設定する必要があります。
もうひとつ、忘れがちなのはGitHub Container Registry にpushされたイメージは初めはプライベートになっています。皆が使えるようにするには、
https://github.com/<ユーザー名>?tab=packagesから指定のイメージを選んで、ポチポチ公開設定する必要があります。6.
Trainerをコマンドラインプログラム以外 (Jupyter Notebook等) からも実行可能に (PR 105)TF2RLは元々コマンドラインからのスクリプト実行を前提とした作りになっており、構築したモデルを学習させる
Trainerクラスはargparseと強く結合してしまっており、Jupyter Notebook上で利用するには(できなくはないが)ちょっと面倒であった。後方互換性を維持するかつ元のコードへの変更点を最小限にするために、
argparseではなくdictが渡されたときには空のNamespaceを構築してその中にdict指定のデータを詰め込むことにした。こうすることで、わざわざコマンドラインパラメータを模擬した文字列のリストを経由しないで、パラメータを設定できる。tf2rl/experiments/trainer.py(抜粋)if isinstance(args, dict): _args = args args = policy.__class__.get_argument(Trainer.get_argument()) args = args.parse_args([]) for k, v in _args.items(): if hasattr(args, k): setattr(args, k, v) else: raise ValueError(f"{k} is invalid parameter.")7. TensorFlow Probability のバージョンの自動指定 (PR 113)
最近TF2RLがTensorFlow Probability (TFP) を利用するようになったのですが、TFPは動作するTensorFlow (TF)のバージョンが決まっている割にはインストール時にいい感じにしてくれなくて、何も考えずにインストールするとバージョン非互換でエラーが発生することがありました。
そこで、TF2RLの setup.py に以下のコードブロックを追加し、ユーザーがインストール済みのTFのバージョンに応じて、インストールすべきTFPのバージョンを切り替える方式を導入しました。
setup.py(抜粋)tf_version = "2.3" # Default Version compatible_tfp = {"2.3": ["tensorflow~=2.3.0", "tensorflow-probability~=0.11.0"], "2.2": ["tensorflow-probability~=0.10.0"], "2.1": ["tensorflow-probability~=0.8.0"], "2.0": ["tensorflow-probability~=0.8.0"]} try: import tensorflow as tf tf_version = tf.version.VERSION.rsplit('.', 1)[0] except ImportError: pass install_requires = [ "cpprb>=8.1.1", "setuptools>=41.0.0", "numpy>=1.16.0", "joblib", "scipy", *compatible_tfp[tf_version] ]
~=は、バージョンの最後の数字はアップデートを許容するシンタックスで、この場合はメジャーバージョンやマイナーバージョンの更新は許可しないが、バグフィックス(だと思われる)更新は許可するためにこうしてあります。TF2.4 が出たらエラーになりますが、それは他のTF2.4変更対応とともに対処することになるでしょう。
8. 最後に
TensorFlow は書きにくいから PyTorch って思っている方も結構いるようですが、TF 2.0 以降非常に書きやすくなっていると個人的には思います。
TF2RLのユーザーがもっと増えたらいいなと思っています。
TF2RLでも利用している経験再生(Experience Replay)用のライブラリ cpprb (GitHubミラー) を開発しています。
こちらもぜひ興味を持ってもらえると嬉しいです。


- 投稿日:2020-10-25T21:13:36+09:00
【AWSハンズオン】サーバレスアーキテクチャで、有名人識別サービスを作ろう!
本記事について
- 会社の同僚向けに、業務外にて実施をした「AWS ハンズオン」の資料を、一般公開したものです。
- サーバレスアーキテクチャを用いて、有名人の画像解析 API サービスを、約1時間で作成するという内容になっています。
- 言語は Python を用いますが、基礎知識が無くても楽しめる構成にしています。
- ハンズオンの実施にあたっては、以下のリソースが必要です。
- インターネットに接続できるPC( Windows, Mac 問わない)
- AWS IAM ユーザーアカウント
- 本資料の作成には細心の注意を払っておりますが、その正確性を担保するものではありません。また、本資料が起因して生じた損害について、作成者は一切の責任を負いません。
追記:スライド版を公開
- Speaker Deck にて、本ハンズオンのスライド版資料を公開しています。
- スライド版の方が、デザインが整っていて見やすいかと思います。
- 対して、Qiitaの本記事の方には、ソースコードをコピペできるメリットがあります。
- スライド版、Qiita版、両方を併用して実施されると良いと思います。
- https://speakerdeck.com/hayate_h/awshanzuon-sabaresuakitekutiyade-you-ming-ren-shi-bie-sabisuwozuo-rou
はじめに(概要説明)
つくるもの
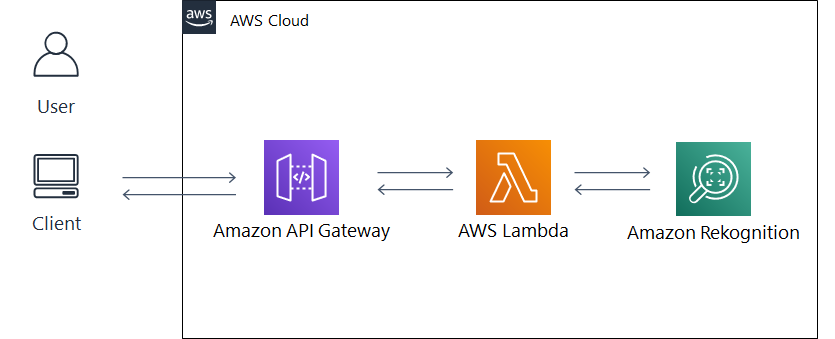
- Amazon Rekognition(画像解析AI) を用いて、有名人識別APIを作成します。
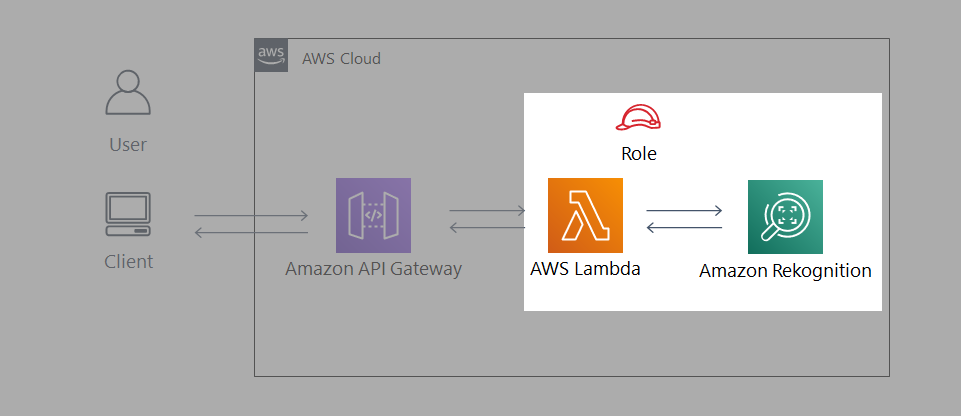
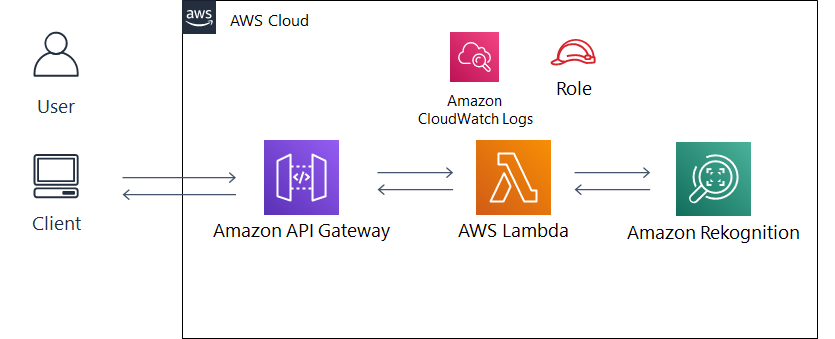
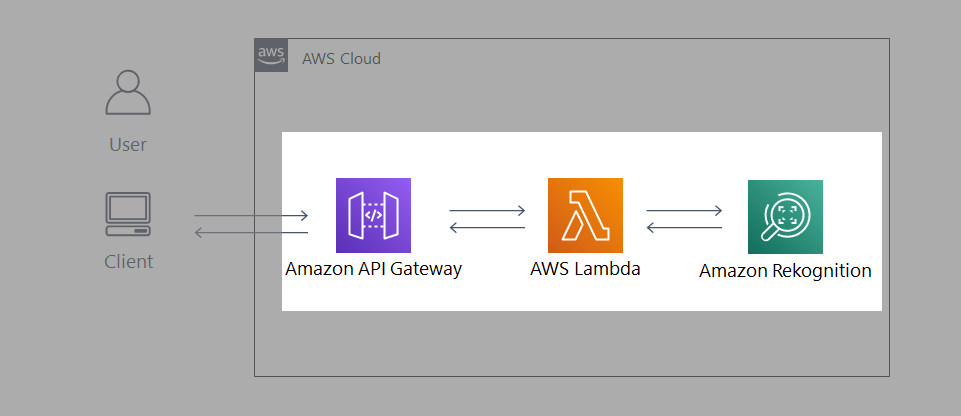
- システム構成図は以下のようになります。
- 明示的なサーバが存在しない「サーバレスアーキテクチャ」のため構築が簡単です。
- また運用管理の手間やコストも軽減します。
動作イメージ
- 例えば、日本が世界に誇る有名俳優「渡辺謙」さんの写真を用意し、今回作成するAIに読み込ませてみます。
- ※ 以下のスクリーンショットでは、知財権保護のため画像をぼかしています。
- 「ファイルを選択」ボタンから「渡辺謙」さんの画像を選択します。
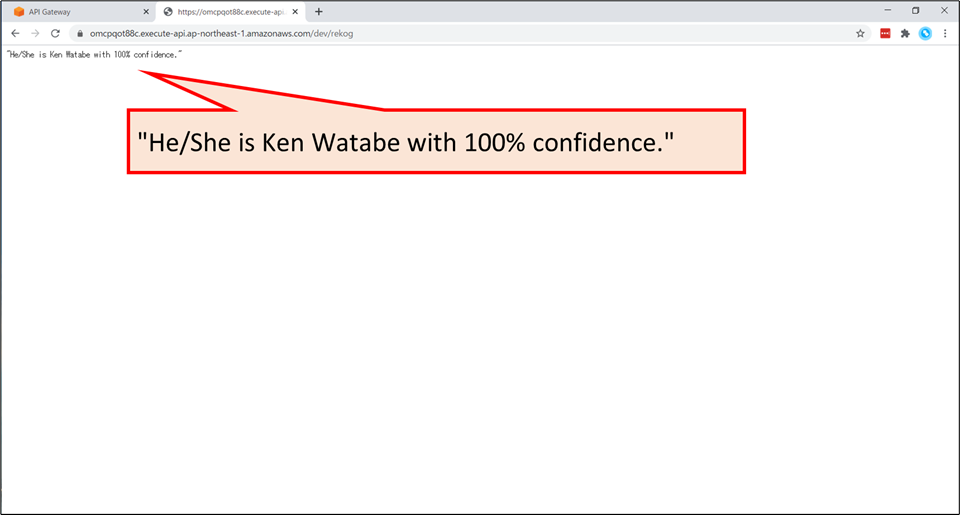
- ファイルを選択後、「送信」ボタンを押すと…
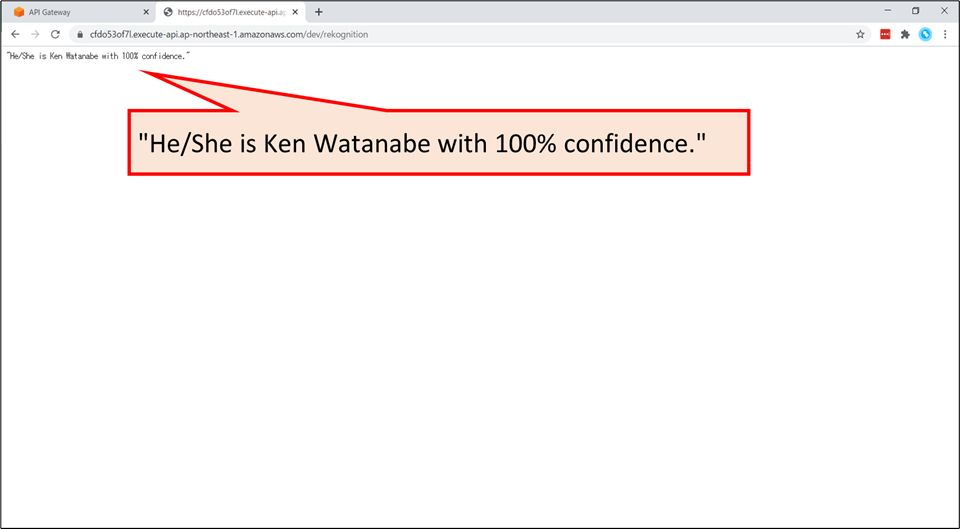
“He/She is Ken Watanabe with 100% confidence.”と表示されます。- 今回のハンズオンでは、このサービスのバックエンドを作成していきます。
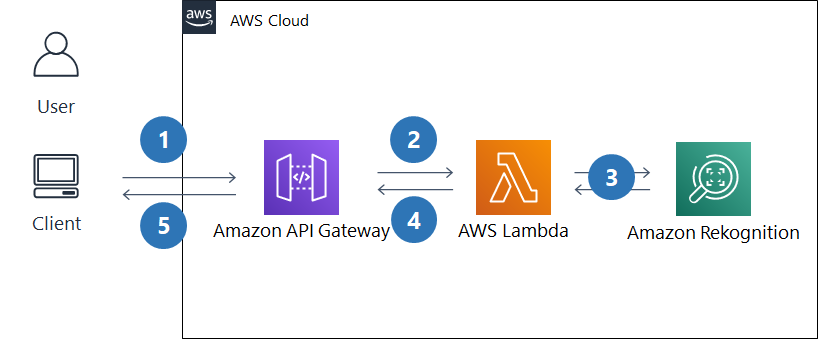
アーキテクチャ説明
- クライアントPCから API Gateway 経由で有名人の画像をアップロードします。
- 画像ファイルを受信すると、Lambda 関数が起動します。
- Lambda 関数内で Amazon Rekognition の recognize_celebrities 機能に画像ファイルを送り、画像内の有名人を識別します。
- 取得した有名人の情報を出力用に整形して、API Gateway を通して返します。
- 呼び出し元のブラウザ上で、識別結果が表示されます。
AWS サービスについて
使用する AWS サービスの紹介
- 今回使用する3つのサービスを簡単に紹介します。
- 「習うより慣れよ」の考えで、ハンズオンを進めていきましょう。
AWS 用語解説:「サーバレス」とは
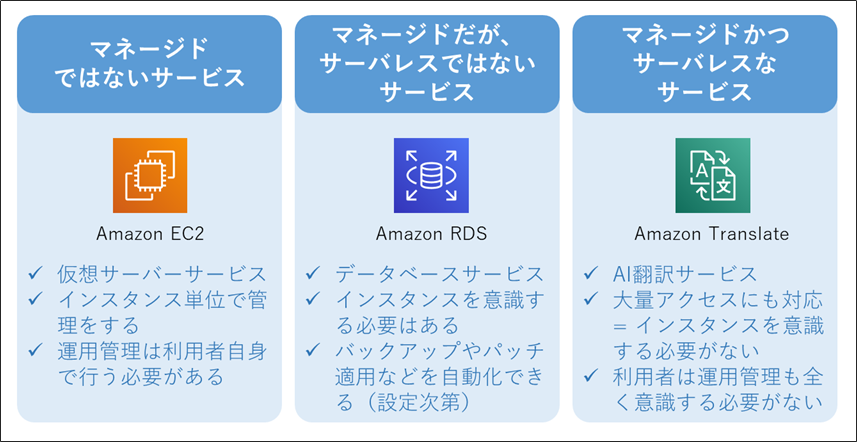
- 利用者がサーバを意識する必要のないサービスやアーキテクチャのことです。
- 注意:サーバが全く存在しないわけではありません。サーバはAWSが管理しています。
- プログラムコードを「置くだけ」で動作します。そのため運用管理が楽になります。
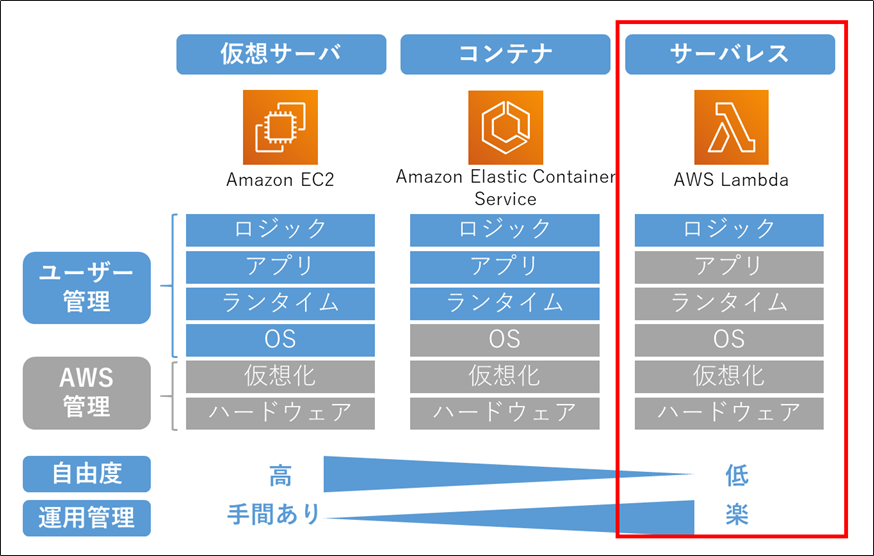
AWS 用語解説:「マネージドサービス」とは
- AWSが運用管理(の一部)を担ってくれるサービスのことです。
- 担ってくれる運用管理の内容や範囲はサービスによって多様ですが、「バックアップを定期的にとる」などだけではなく、「アクセスが増えたら自動でスケールする」なども提供していることが多いです。
- 運用管理の範囲が広く、利用者の手間がほとんどかからない場合は、「フルマネージドサービス」と言われることが多いです。
- 「マネージド」であっても、常に「サーバレス」とは限りません。
開発手順
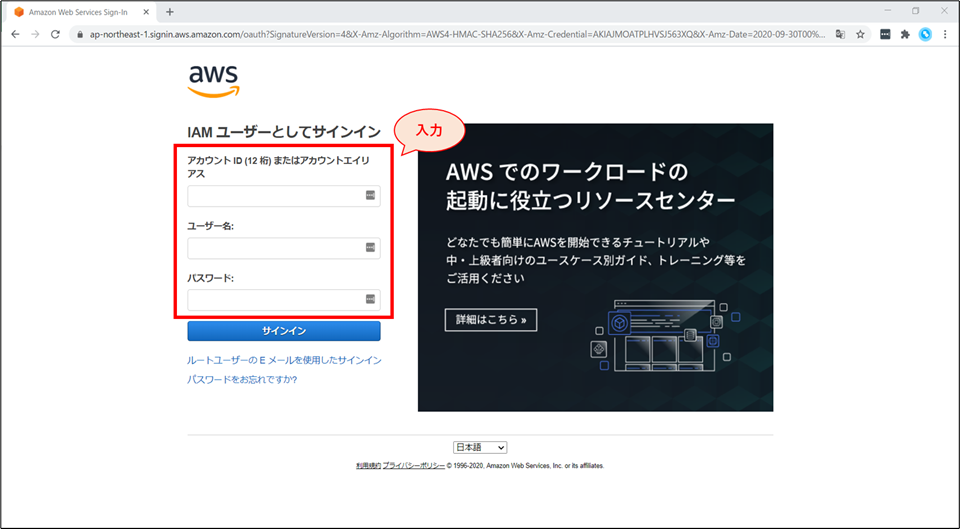
サインイン
- AWSマネジメントコンソールへアクセスし、IAM ユーザー情報でサインインをしてください。
サインイン補足情報
- 今回のハンズオンでは、ハンズオンを実施するIAMユーザーに”AdministratorAccess”のIAMポリシーが付与されていることを前提にして進めています。
- “AdministratorAccess” の権限が付与されていなかった場合、以下の手順の中でリソースが作れない等のエラーが発生する可能性があります。
- その場合は、適切なポリシーをアタッチした上で再度実行をしてください。
- なお、以下のサイトに記載されていたIAMの設定内容は大変参考になりました。
- ハンズオンの手順が全て実行できることを確認済みです。
- 社外の開発メンバーをAWSアカウントに入れるときのIAM設定を考えている - kmiya_bbmのブログ
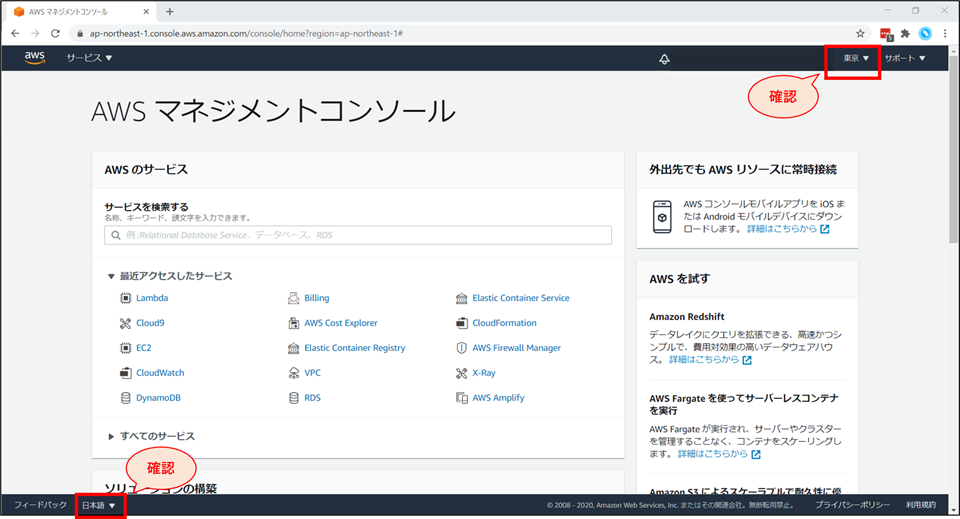
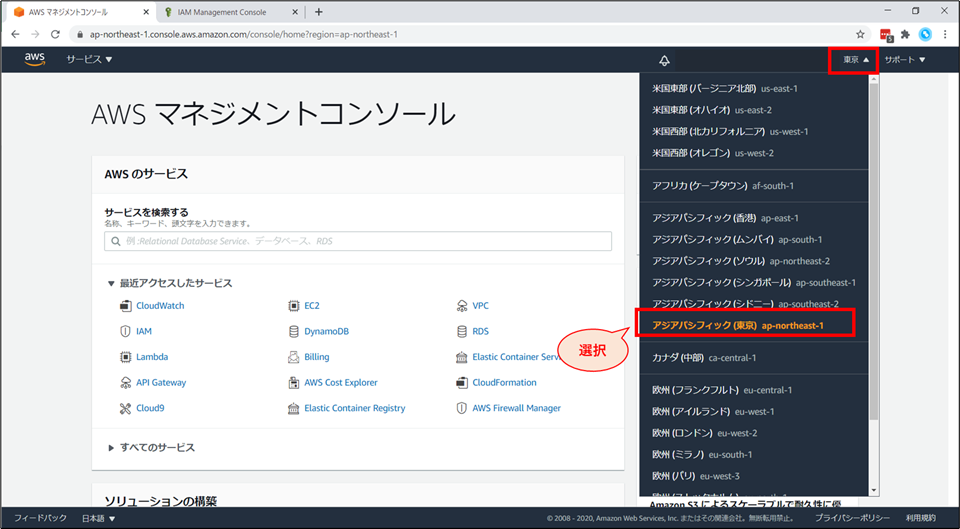
リージョンと言語の確認
- 画面右上が「東京(リージョン)」 画面左下が「日本語」になっていることを確認します。
- 変更が必要な場合は、次のページを参考に切り替え作業を行ってください。
[補足] リージョンの変更方法
- 画面右上の地名を押下し、「アジアパシフィック(東京)ap-northeast-1」を選択します。
[補足] 言語の変更方法
- 画面左下の言語を押下し、「日本語」を選択します。
Lambda 関数の作成
Lambda 関数の新規作成
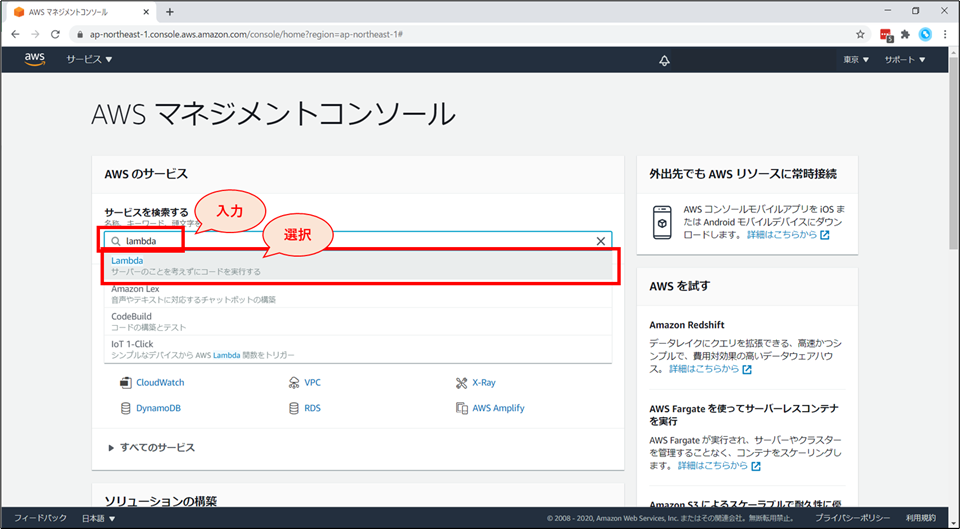
最初にLambda 関数を作成し、基本的な使い方を学習しましょう。
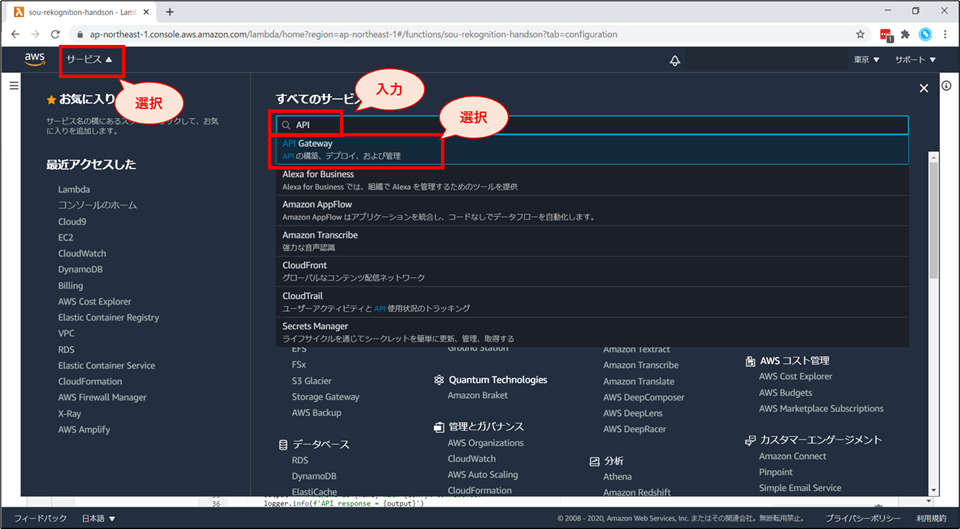
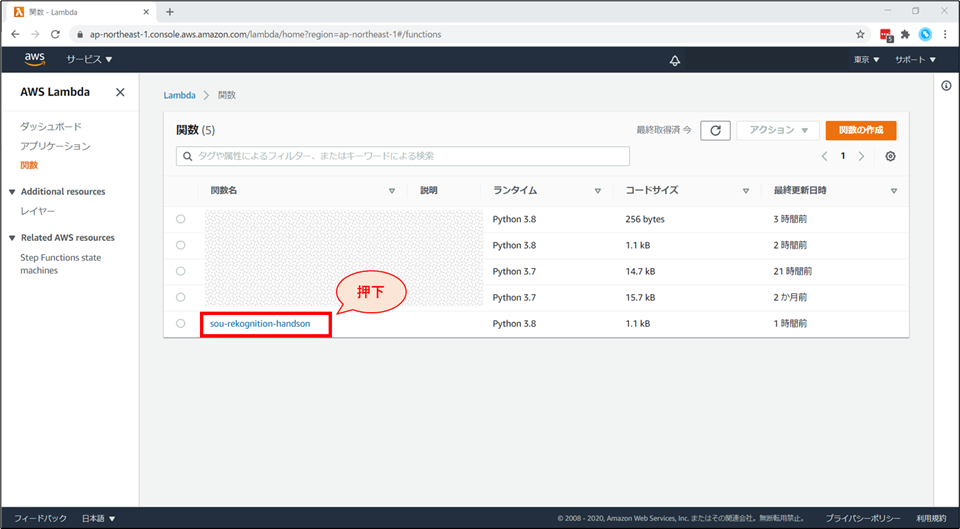
マネジメントコンソールの画面にて、検索窓に「Lambda」と入力し、表示された「Lambda」を選択してください。
Lambdaの画面が開きましたら、「関数の作成」ボタンを押してください。
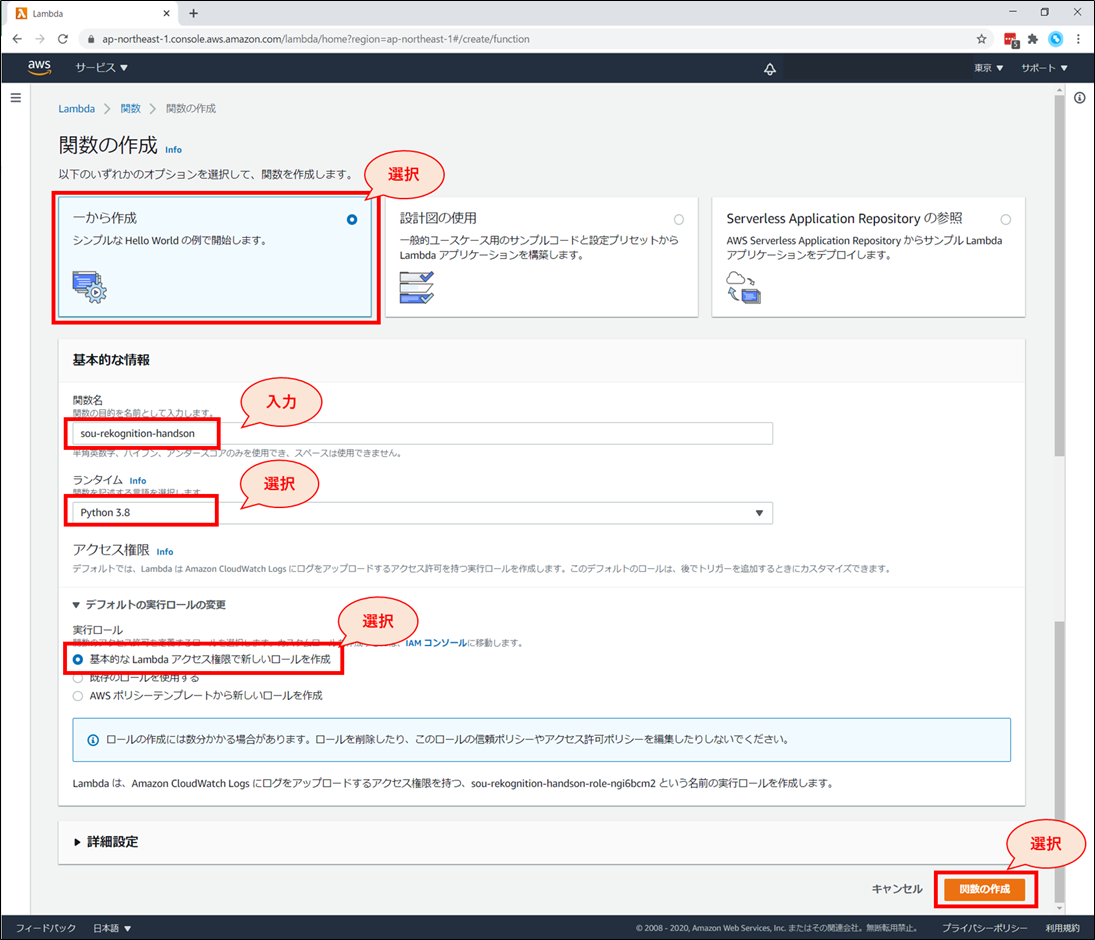
関数の作成画面にて、以下を選択、入力していきます。
- 「一から作成」を選択
- 「関数名」に「《お名前》-rekognition-handson」と入力
- 例:higuchi-rekognition-handson
- 「ランタイム」に「Python3.8」を選択
- 「アクセス権限」-「デフォルトの実行ロールの変更」 を開き、「基本的なLambdaアクセス権限で新しいロールを作成」を選択
上記設定が終わったら、画面右下「関数の作成」ボタンを押下します。
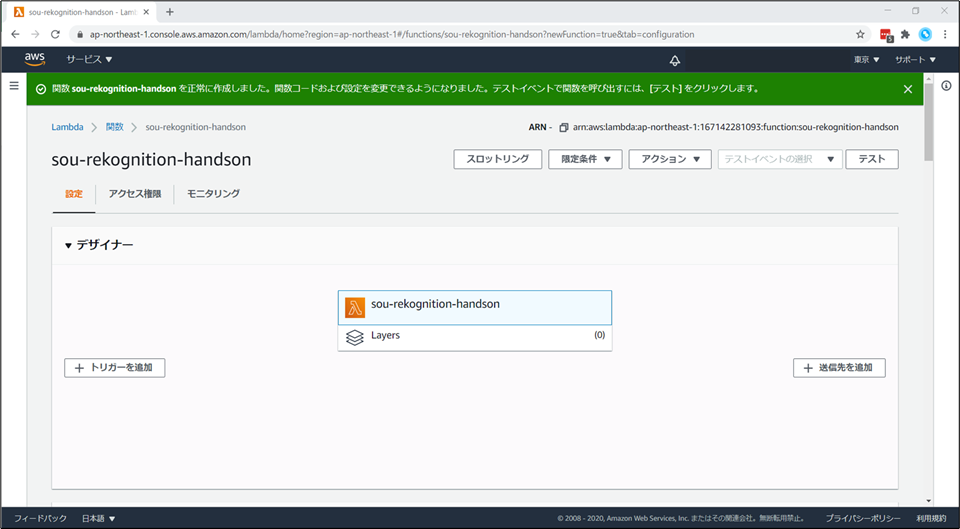
Lambda関数が作成されます。
今から動くコードを記述していきます。
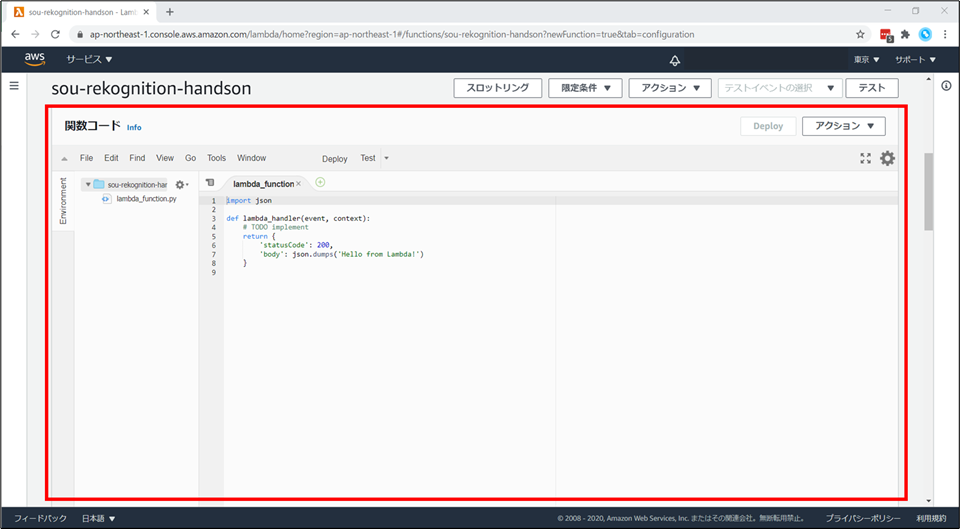
「関数コード」のところまで下にスクロールします。ここがロジックを記述するエディタとなります。
Lambda 関数の使い方説明
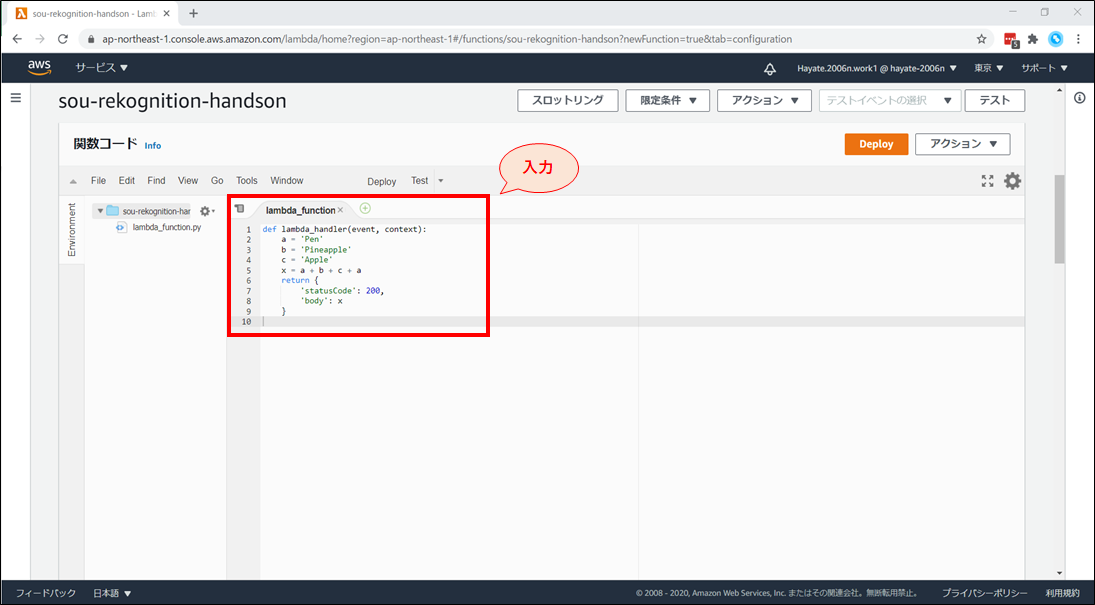
まずは、シンプルなPythonコードを書いて Lambda の動きを学習しましょう。
例えば、文字列を結合して出力する、以下のコードを記述します。
- 変数に文字列を設定し、結合をしたものを return する内容となっています。
- 具体的には、’Pen’ + ’Pineapple’ + ’Apple’ + ’Pen’ → ‘PenPineappleApplePen’ になります。
lambda_function.pydef lambda_handler(event, context): a = 'Pen' b = 'Pineapple' c = 'Apple' x = a + b + c + a return { 'statusCode': 200, 'body': x }
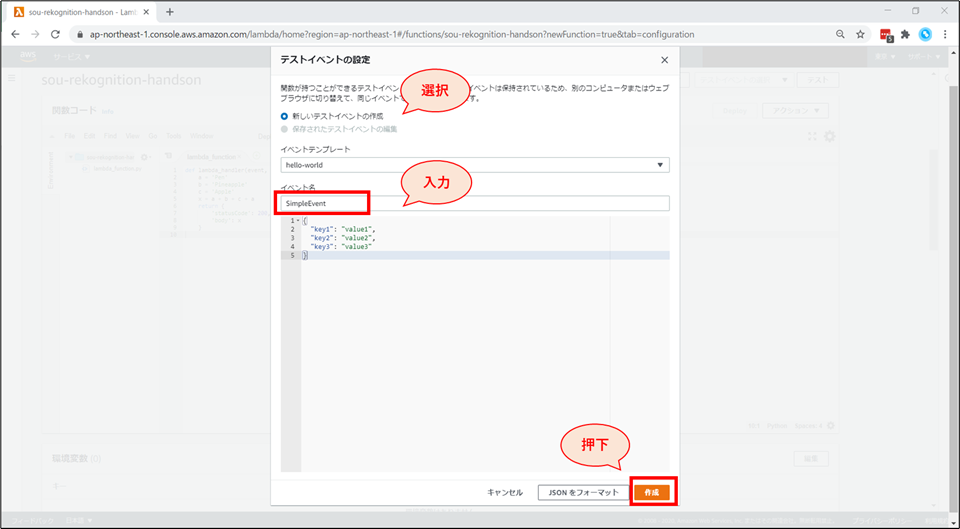
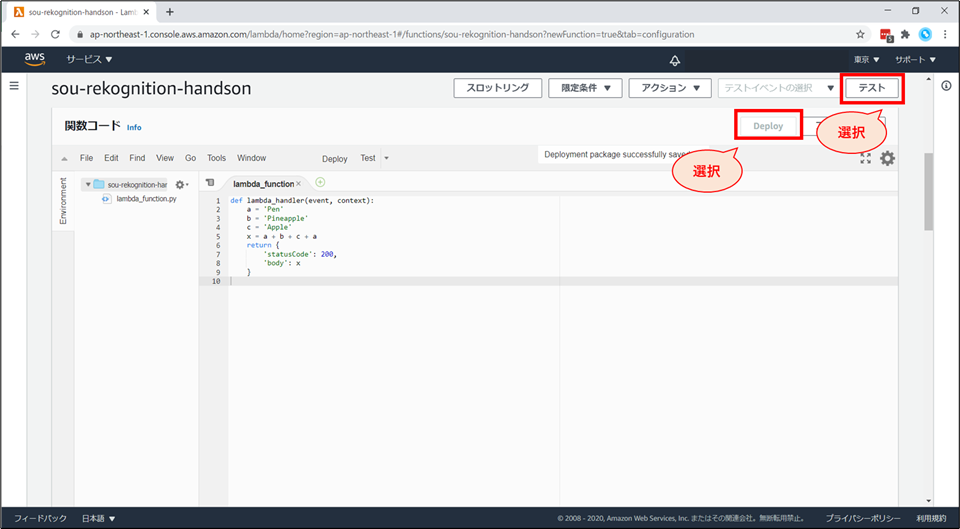
記述後、「Deploy」 ボタンを押したのち、右上の「テスト」を押下します。
「テストイベントの設定」画面が表示されます。以下の設定をした後、「作成」ボタンを押下します。
- 「新しいテストイベントの作成」を選択します。
- イベント名に「SimpleEvent」と入力します
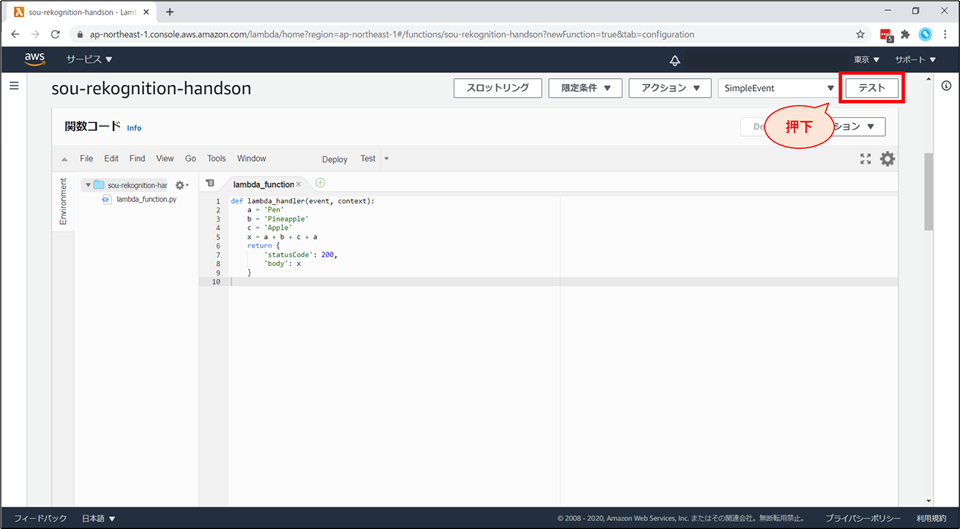
右上の「テスト」を押下します。
- 先ほど作成したテストイベントで、テストが実行されます。
Lambda がテスト実行されました。
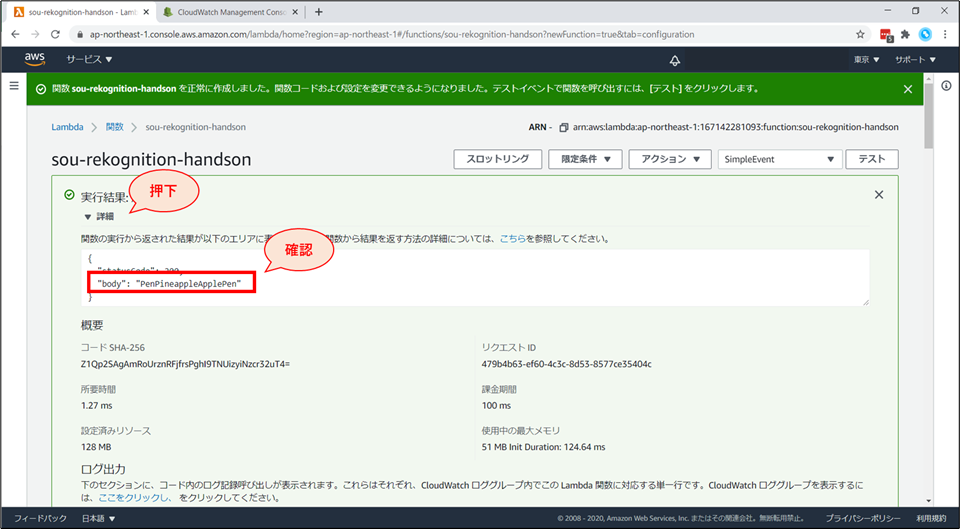
- 画面上部に「成功」と表示が出れば、コードは正常に動いた証拠です。
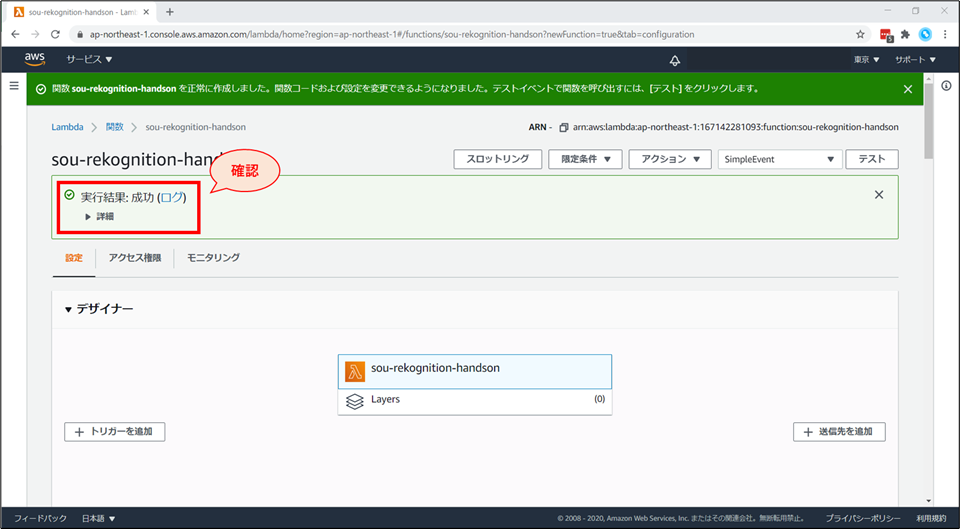
詳細をクリックすると、関数の実行結果が展開されます。
- ここでは、“body” が “PenPineappleApplePen”となっており、期待した通りの output になっています。
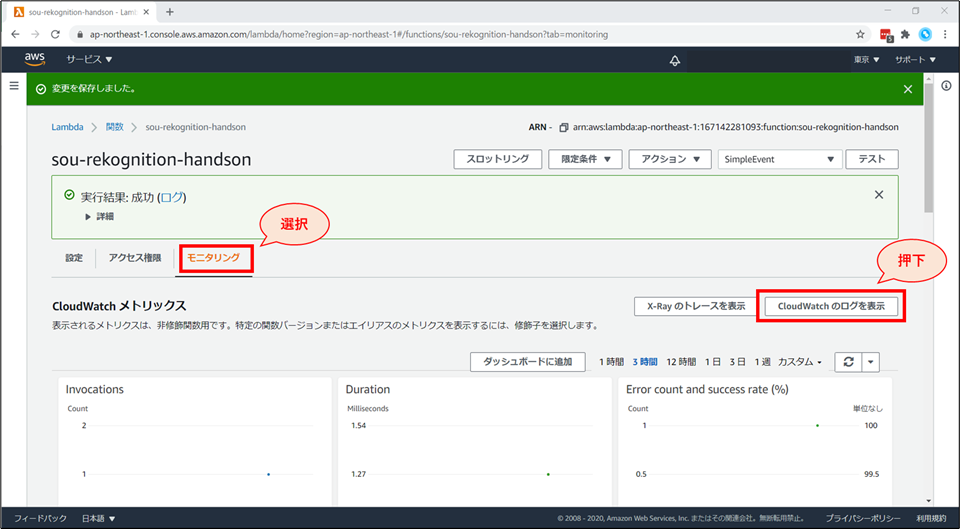
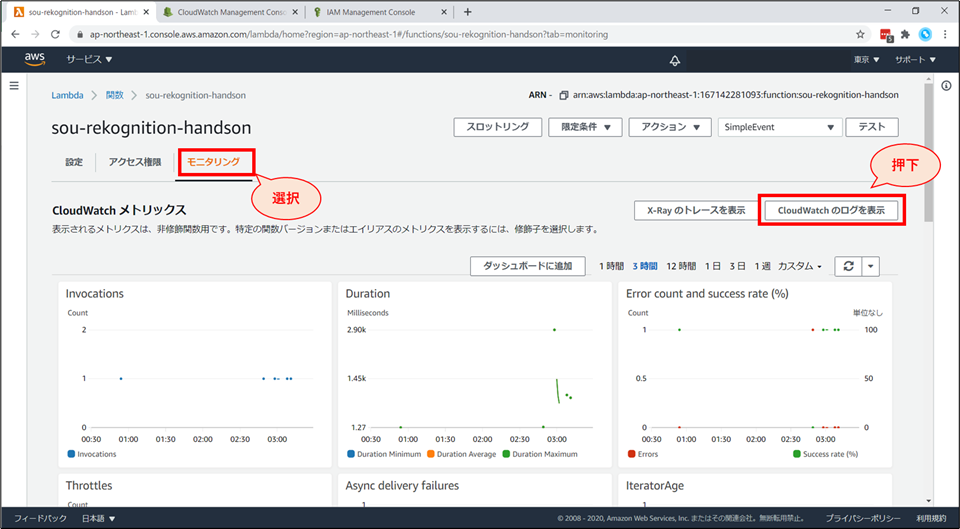
Lambda 実行時の詳細なログは、"CloudWatch Logs" で確認できます。
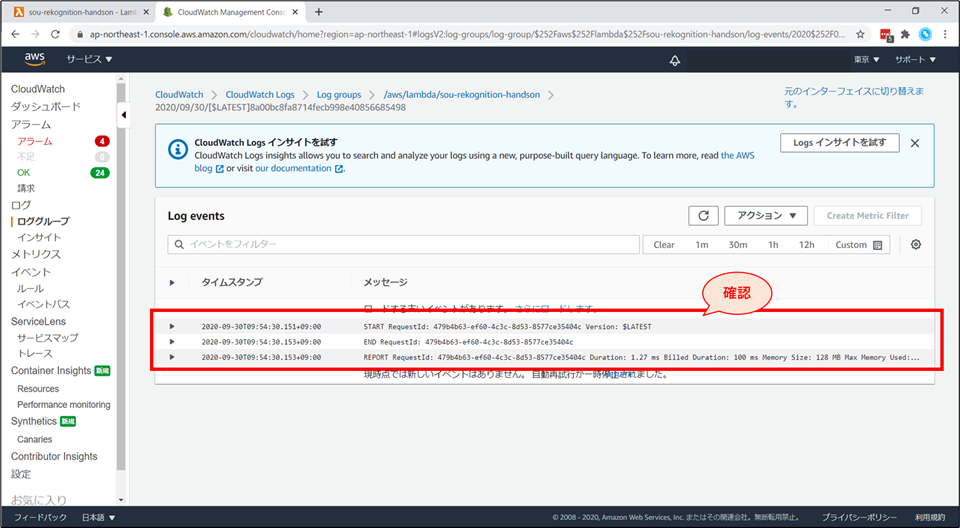
- 「モニタリング」→「CloudWatchのログを表示」をクリックすると、“CloudWatch Logs” のページに遷移します。
「ログストリーム」画面にて「20xx/xx/xx[$LATEST]xxxxxx」を選択するとログが確認できます。デバック時にご活用ください。
- Logger などを設定すると、ここにログが出力されるようになります。
Lambda 関数の編集
- ここから、Lambda関数を、画像解析AI (Rekognition)と紐づける作業をしていきます。
- Lambda関数から、Rekognitionを呼び出すには、適切な権限が必要です。
- 具体的には、Lambdaに付与されているIAMロールに、Rekognitionへのアクセスを許可するIAMポリシーをアタッチする必要があります。
- まずは、権限付与から行っていきましょう。
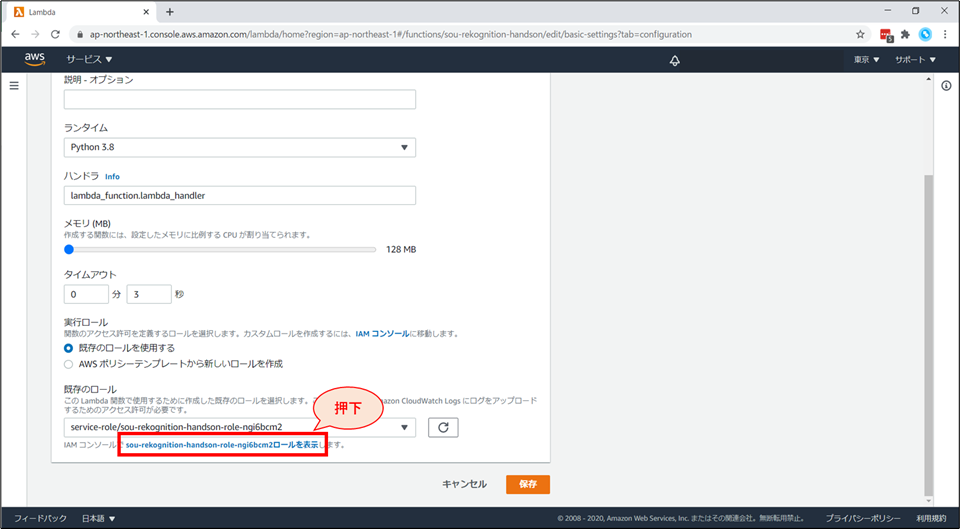
IAM ロール(権限)の変更
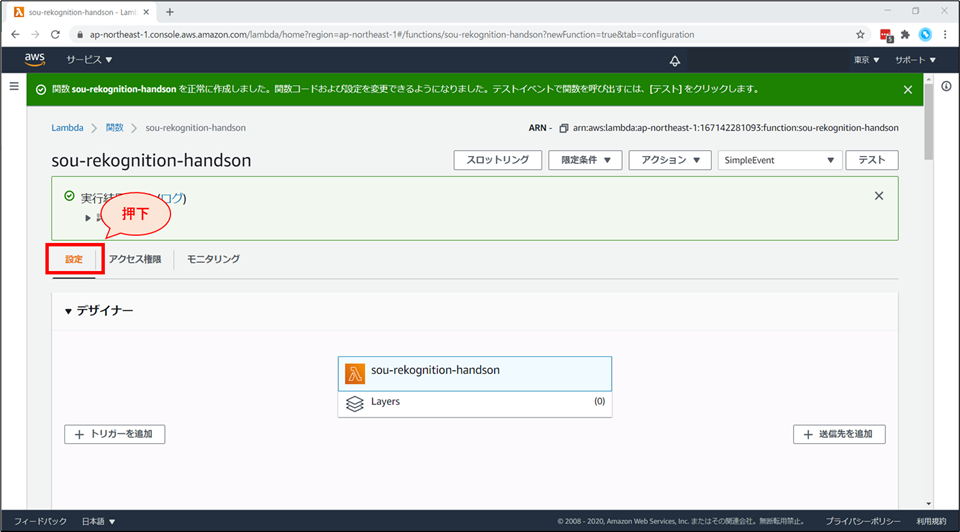
Lambda画面の上部で「設定」を選びます
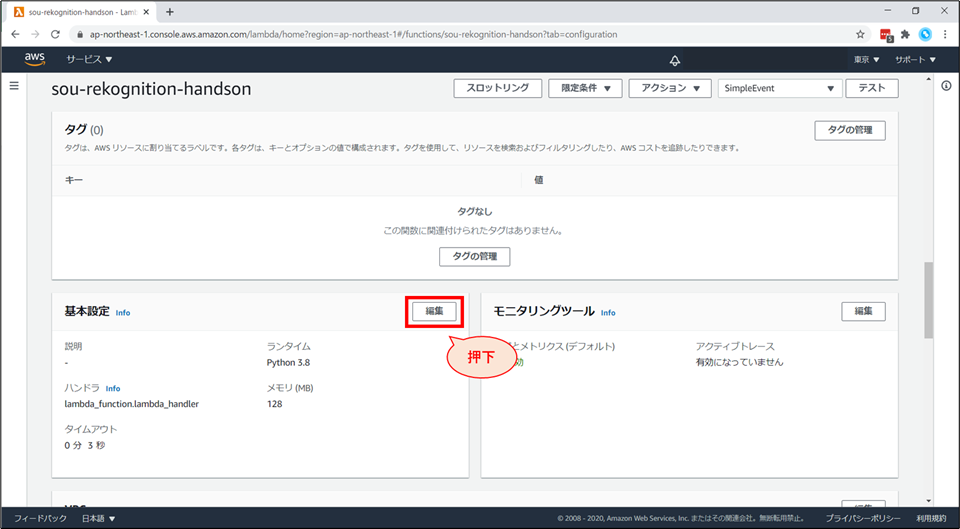
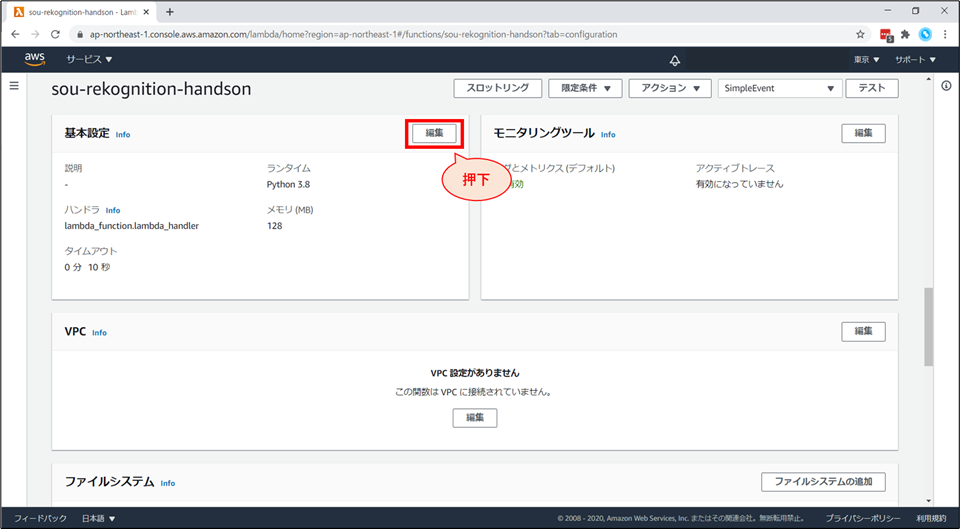
「設定」画面の下部「基本設定」の「編集」を選択します。
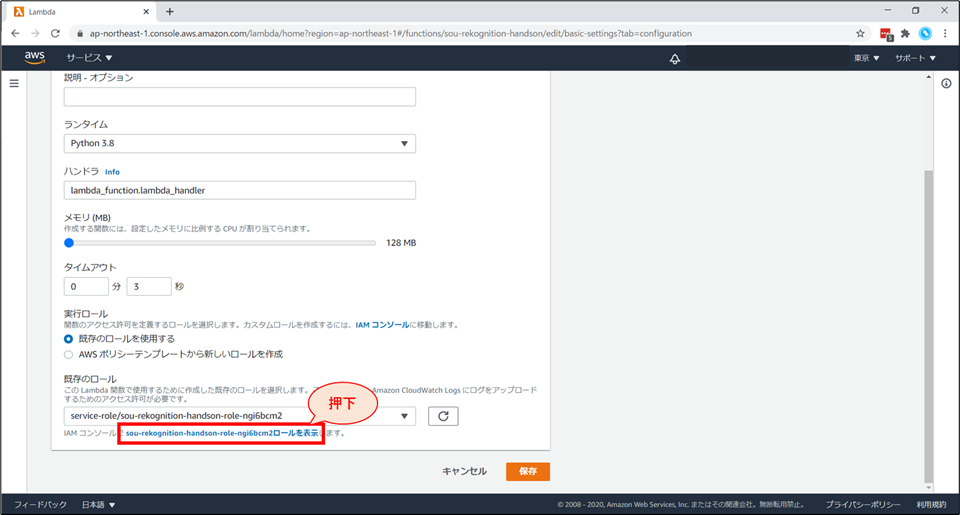
「基本設定を編集」画面の下部まで行き、「IAMコンソールでxxxロールを表示します。」をクリックします。
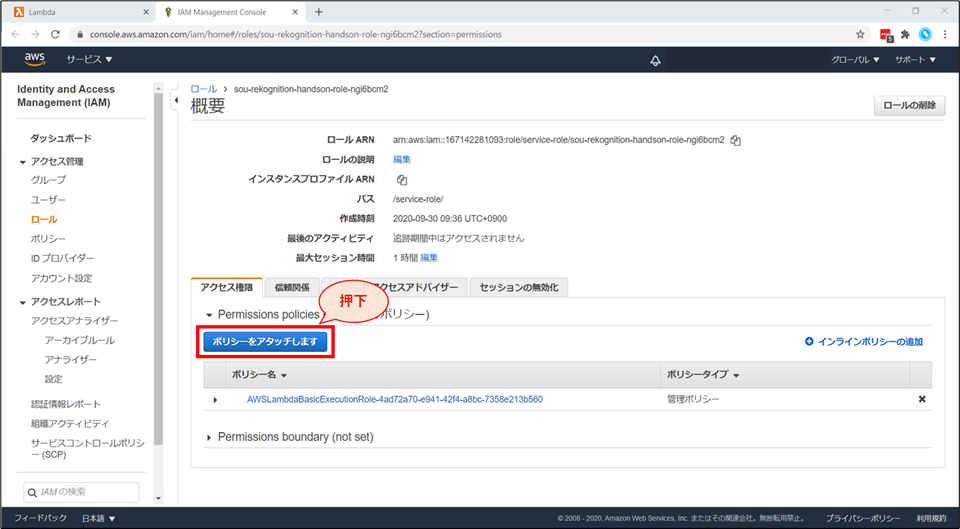
別タブで、IAMロールの画面が開きます。
「ポリシーをアタッチします」ボタンを押下します。
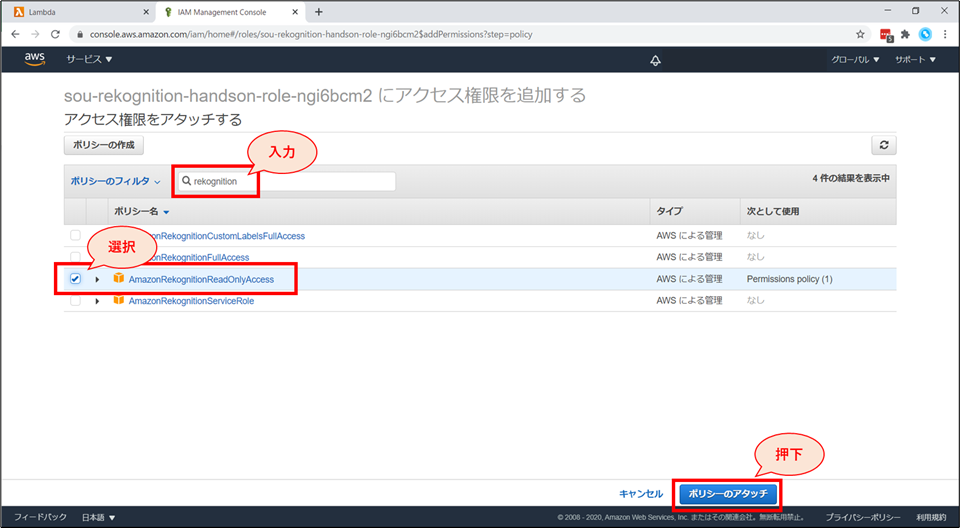
検索窓に「Rekognition」と入力し、「AmazonRekognitionReadOnlyAccess」ポリシーにチェックを入れて、「ポリシーのアタッチ」ボタンを押下します。
IAMのコンソール画面で、「AmazonRekognitionReadOnlyAccess」がアタッチされていることを確認します。
これで、Lambda に Rekognition を呼び出せる権限を付与できました。
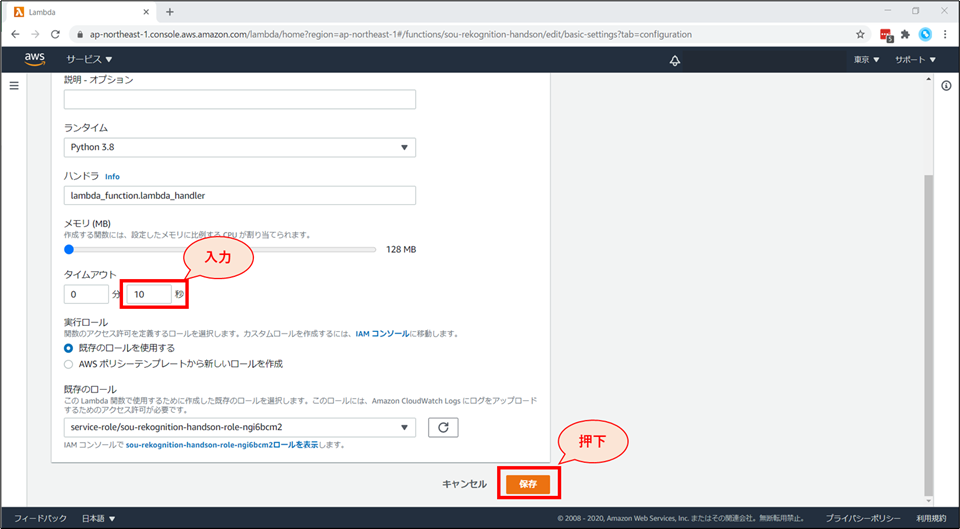
Lambda の「基本設定を編集」画面に戻ります。
- タイムアウトを「10秒」に変更します。
上記設定後、「保存」ボタンを押下します。
Lambda 関数の更新
- Lambda 関数を、有名人識別のコードに書き換えます。
- 「関数コード」を以下の内容で上書きし、「Deploy」ボタンを押下します。
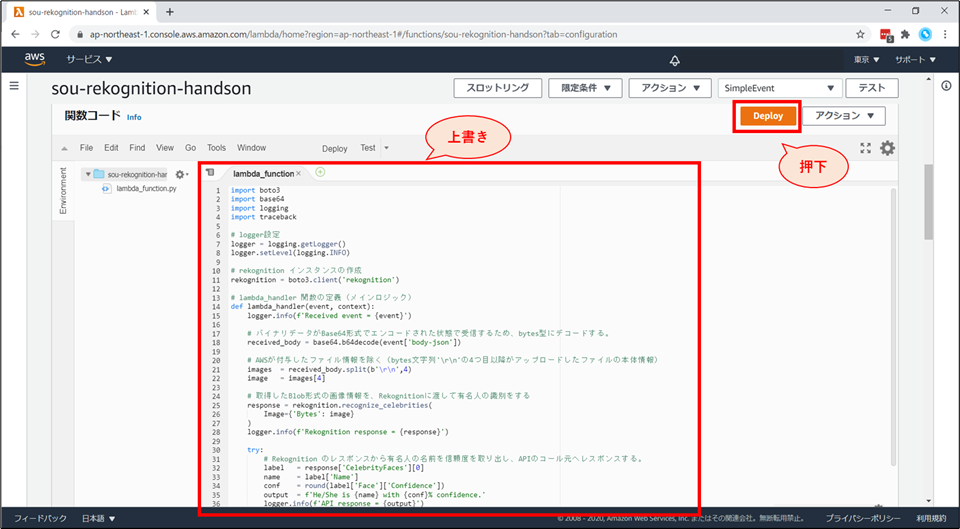
貼り付けるコード
lambda_function.pyimport boto3 import base64 import logging import traceback # logger設定 logger = logging.getLogger() logger.setLevel(logging.INFO) # rekognition インスタンスの作成 rekognition = boto3.client('rekognition') # lambda_handler 関数の定義(メインロジック) def lambda_handler(event, context): logger.info(f'Received event = {event}') # バイナリデータがBase64形式でエンコードされた状態で受信するため、bytes型にデコードする。 received_body = base64.b64decode(event['body-json']) # AWSが付与したファイル情報を除く(bytes文字列'\r\n'の4つ目以降がアップロードしたファイルの本体情報) images = received_body.split(b'\r\n',4) image = images[4] # 取得したBlob形式の画像情報を、Rekognitionに渡して有名人の識別をする response = rekognition.recognize_celebrities( Image={'Bytes': image} ) logger.info(f'Rekognition response = {response}') try: # Rekognition のレスポンスから有名人の名前を信頼度を取り出し、APIのコール元へレスポンスする。 label = response['CelebrityFaces'][0] name = label['Name'] conf = round(label['Face']['Confidence']) output = f'He/She is {name} with {conf}% confidence.' logger.info(f'API response = {output}') return output except IndexError as e: # Rekognition のレスポンスから有名人情報を取得出来なかった場合、他の写真にするように伝える。 logger.info(f"Coudn't detect celebrities in the Photo. Exception = {e}") logger.info(traceback.format_exc()) return "Couldn't detect celebrities in the uploaded photo. Please upload another photo."コードの説明( #コメントに書ききれなかった部分)
- 1行目
import boto3
- AWS サービスを扱う上で必要なモジュールのインポートをしています。
- boto3はPythonでAWSリソースを操作する際に用いるSDKです。
- https://boto3.amazonaws.com/v1/documentation/api/latest/reference/services/index.html
- 25~27行目
response = rekognition.recognize_celebrities(Image={'Bytes': image})
- rekognitionの使い方は、boto3のドキュメントに記載されています。
- https://boto3.amazonaws.com/v1/documentation/api/latest/reference/services/rekognition.html#Rekognition.Client.recognize_celebrities
- 37行目
return文
- これは、実はアンチパターンの return 文です。
- 実際には、Lambdaのプロキシ統合のフォーマットに合わせたレスポンス形式にすると良いでしょう。
- 今回は、ブラウザ上での動作確認を行うため、明示的にプロキシ統合を使わず、また出力のフォーマットも意図的に無視をした記載にしています。
- 詳しくは「API Gateway 統合レスポンス」で検索してください。
- https://docs.aws.amazon.com/ja_jp/apigateway/latest/developerguide/api-gateway-integration-settings-integration-response.html
API Gateway の追加
ここから、API Gateway と Lambda を紐づけていきます。
画面上部「サービス」から検索窓に"API"と入力し、候補にあがる「API Gateway」 を選択します。
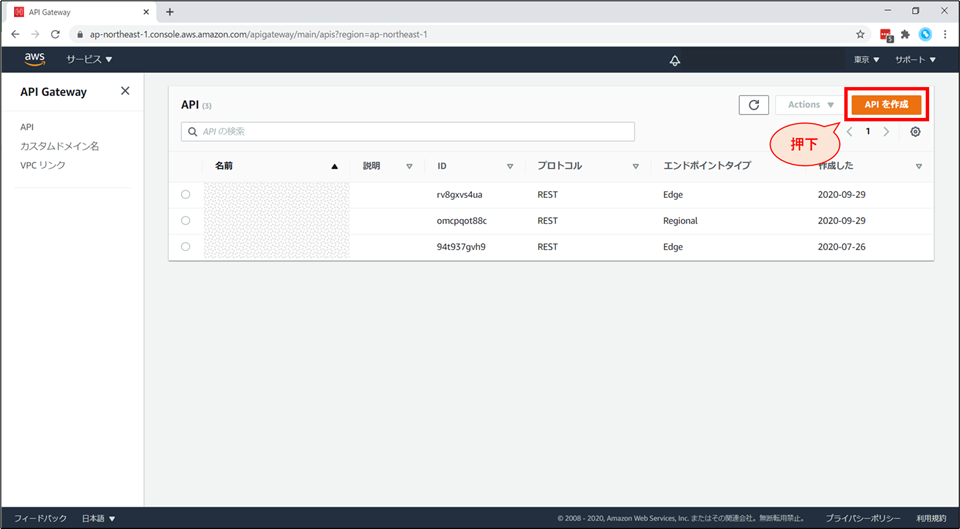
画面右上「APIを作成」を押下します。
REST API の「構築」ボタンを押下します。
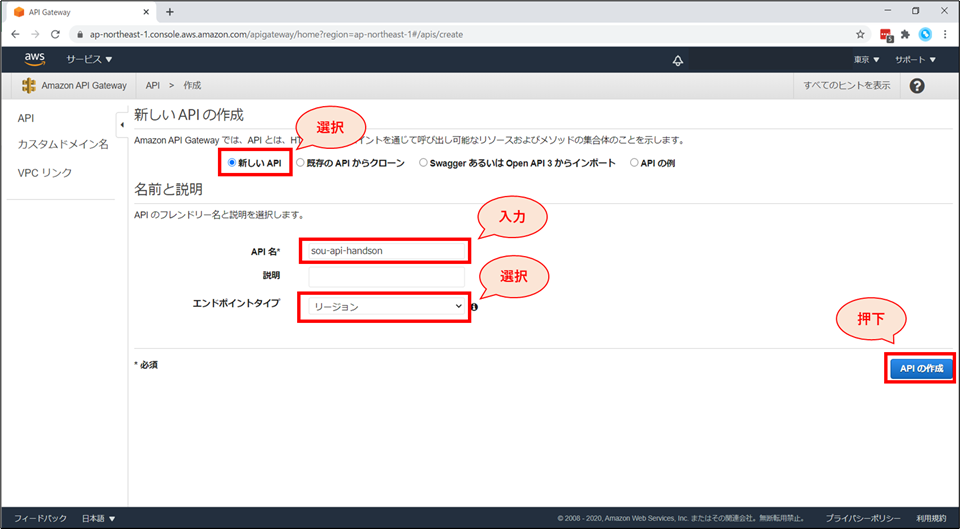
「新しいAPIの作成」画面にて以下の設定を行い、「APIの作成」ボタンを押下します。
- 「新しいAPI」を選択
- API名:「《お名前》-api-handson」と入力(例:higuchi-api-handson)
- エンドポイントタイプ:「リージョン」を選択
API は「リソース」×「メソッド」で開発をしていきます。
- 例えば「/users に GET」や「/users/12345 にPOST」などです。

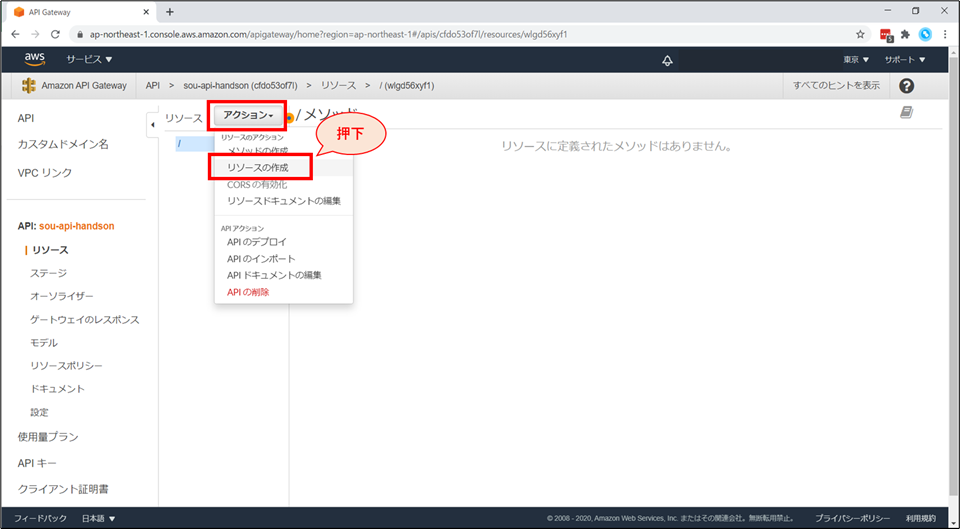
まず、リソースを作成します。「アクション」から「リソースの作成」を選択します。
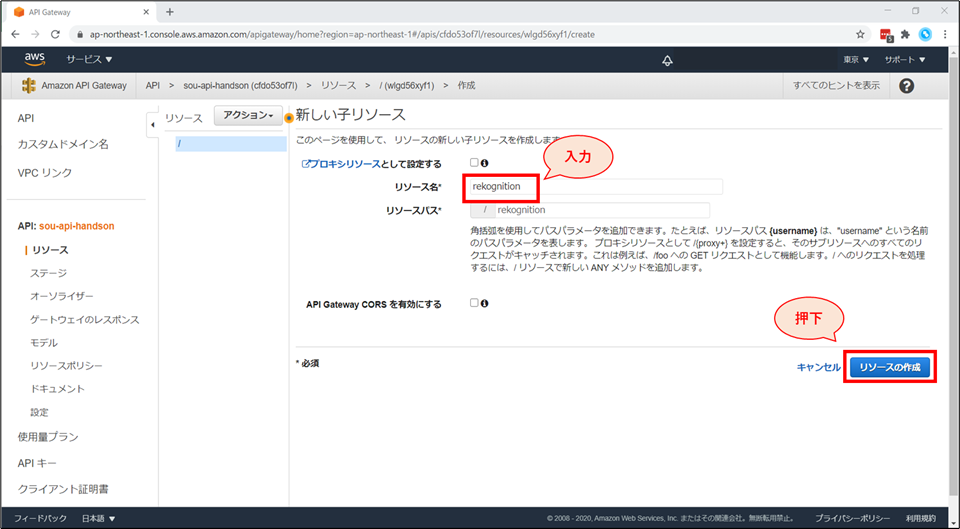
リソース名に「Rekognition」と入力し「リソースの作成」ボタンを押下します。
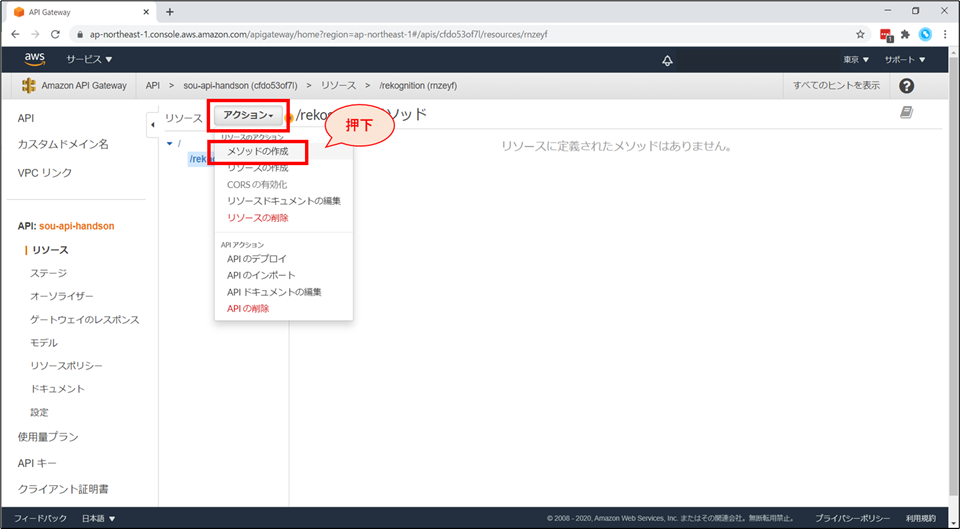
次にメソッドの作成をします。リソースを選択した上で、「アクション」→「メソッドの作成」を選択します。
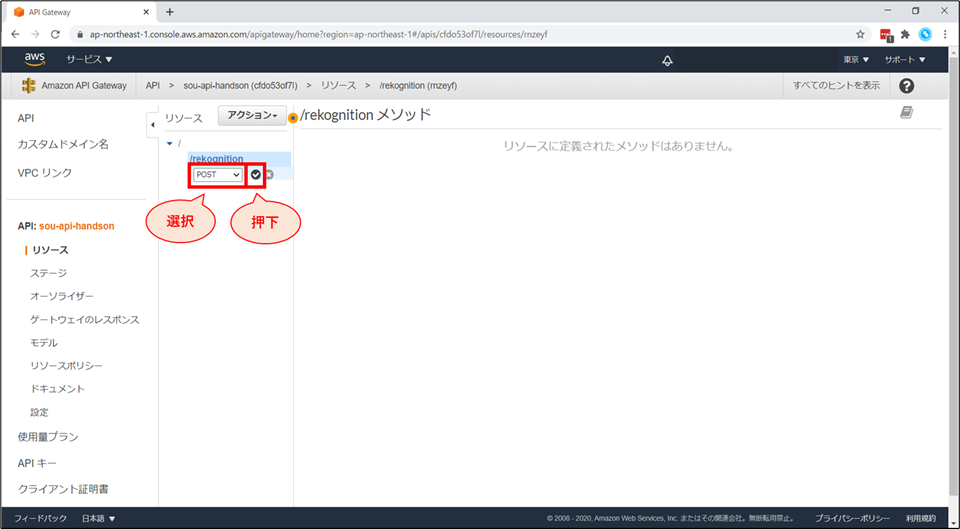
プルダウンから「POST」を選んで、「チェックボタン」を押下します。
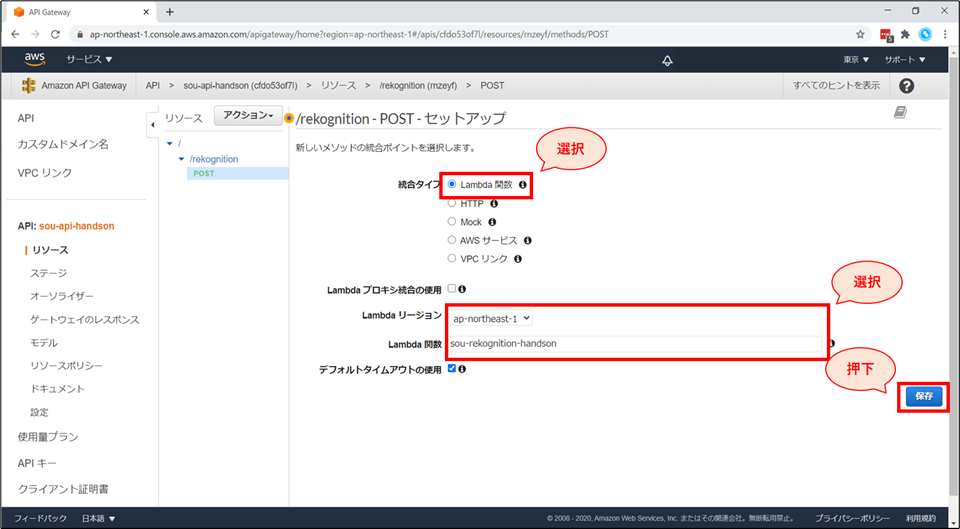
統合タイプにて「Lambda関数」を選択し、Lambda関数にて先ほど作成した「《お名前》-rekognition-handson」を選択後、「保存」ボタンを押下します。
「Lambda 関数に権限を追加する」の確認画面が表示されるので、「OK」ボタンを押下します。
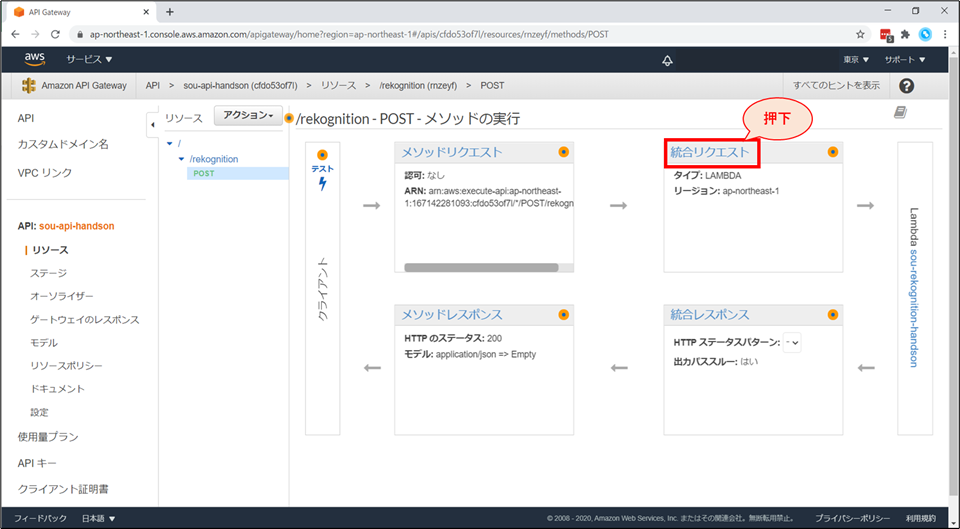
「統合リクエスト」を選択します。
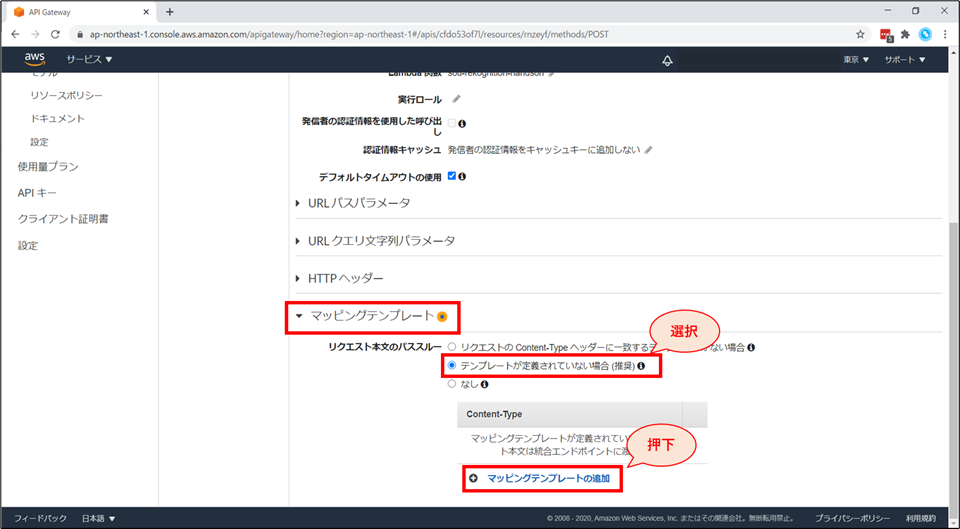
画面下部「マッピングテンプレート」を展開し、「リクエスト本文のパススルー」の項目で「テンプレートが定義されていない場合(推奨)」を選択します。
「Content-Type」の項目にて、「マッピングテンプレートの追加」を押下します。
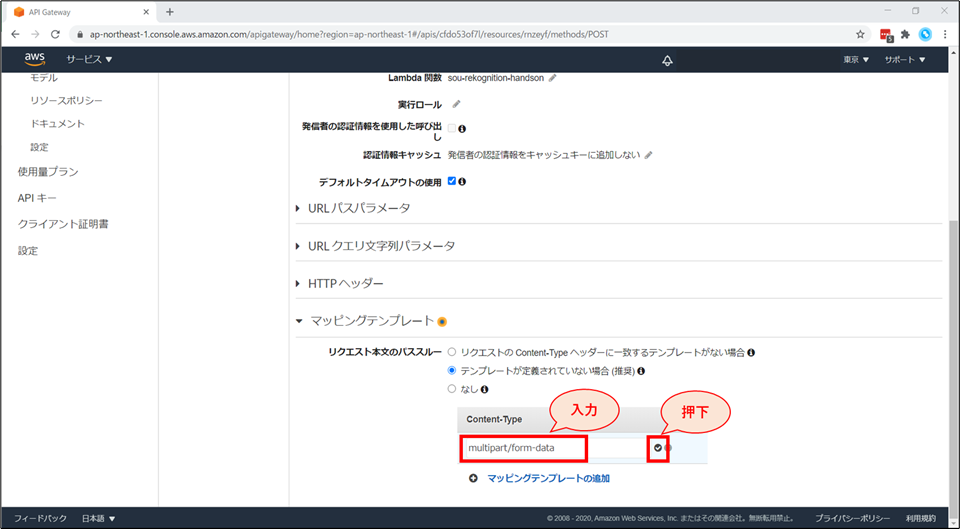
「Content-Type」の項目にて、
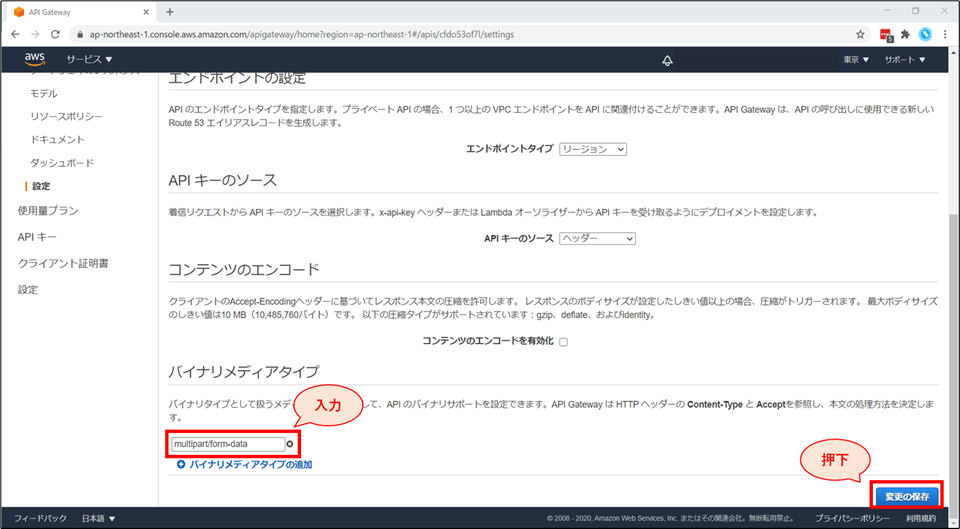
multipart/form-dataと入力し、チェックボタンを押します。
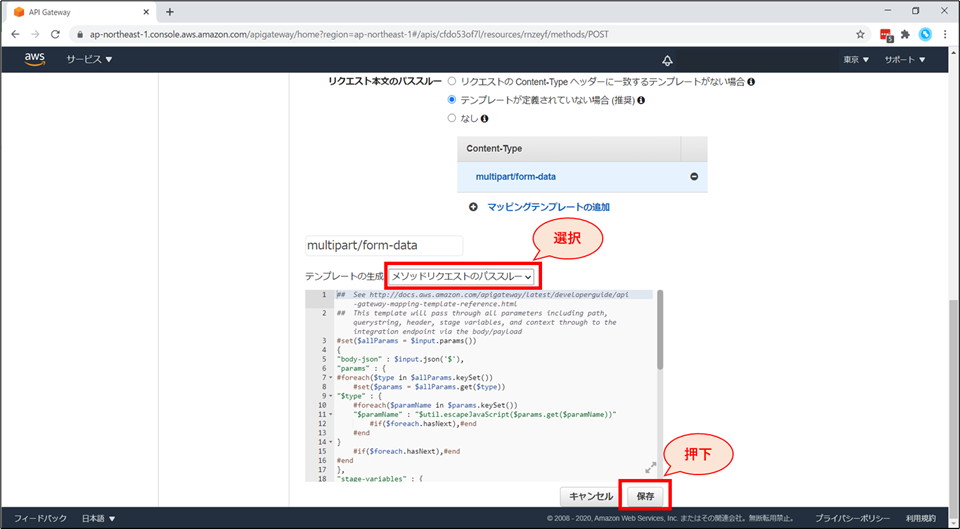
画面下部にテンプレートの生成画面が追加されます。
テンプレートの生成のプルダウンにて、「メソッドリクエストのパススルー」を選択し「保存」ボタンを押します。
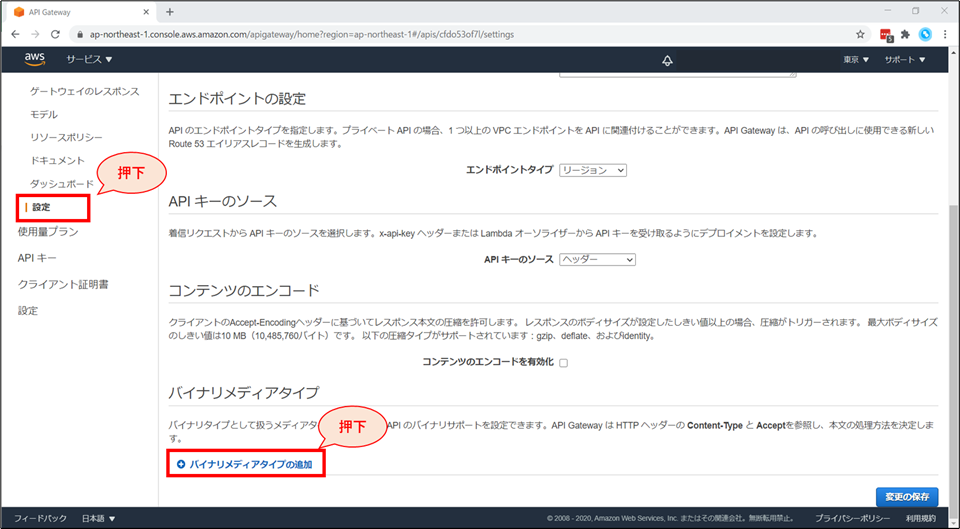
画面左「設定」を選択し、「設定」画面の下部「バイナリメディアタイプ」の項目にて「バイナリメディアタイプの追加」を押下します。
multipart/form-dataと入力し、「変更の保存」ボタンを押下します。
画面左ペイン「リソース」を選択後、画面上部「アクション」より「APIのデプロイ」を選択します。
APIのデプロイ画面にて、以下の設定をし、「デプロイ」ボタンを押下します。
- デプロイされるステージ:「新しいステージ」を選択
- ステージ名:「dev」を入力
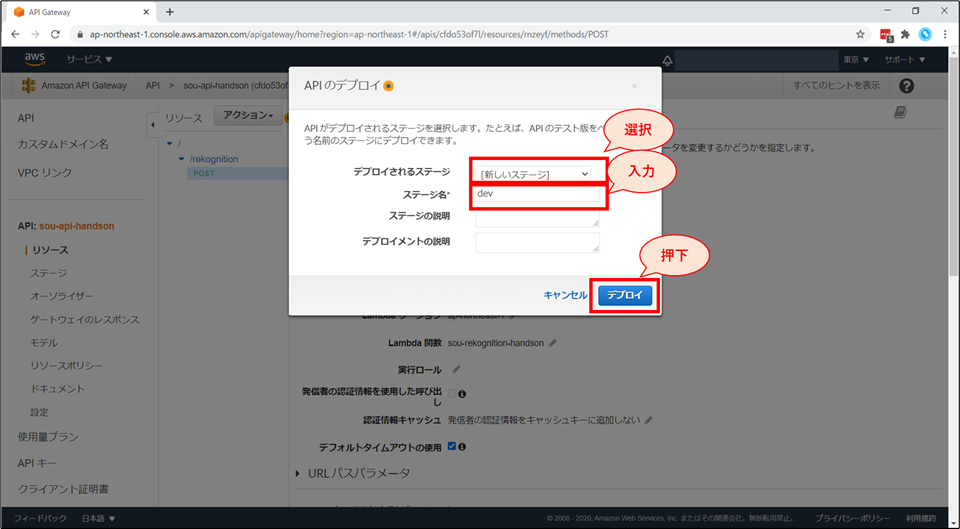
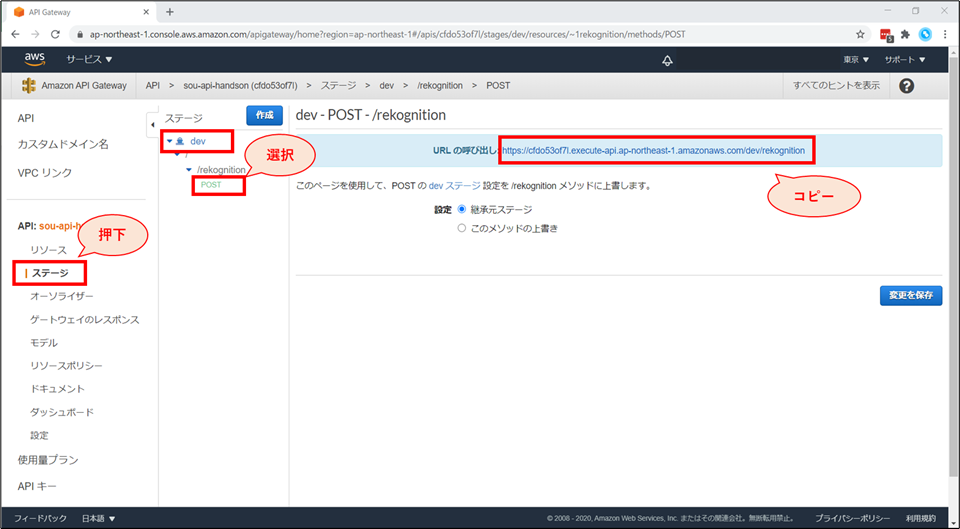
画面左ペインから、「ステージ」を選択し、「dev」-「rekognition」-「POST」を選択します。
画面右に、「URLの呼び出し」として作成された API の URL が表示されるので、これをコピーします。
HTML ファイルの作成
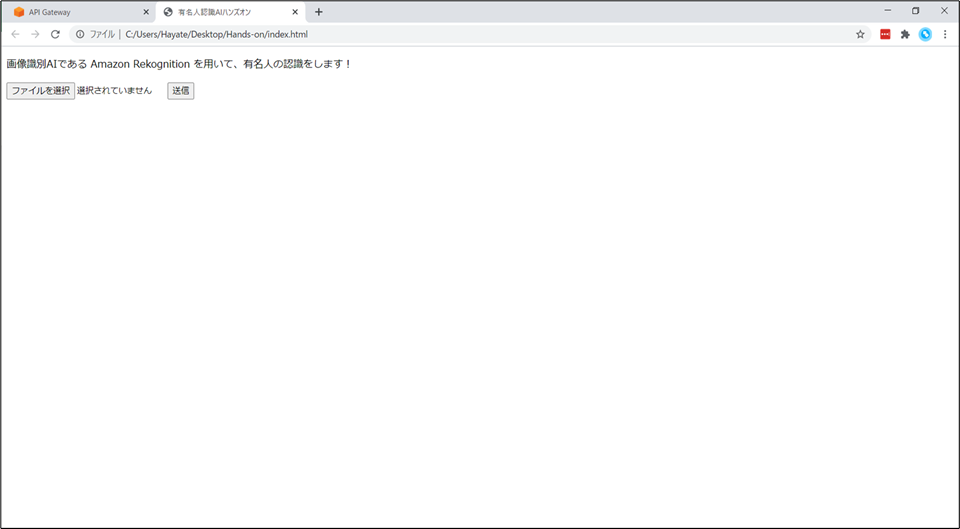
- 以下のHTMLの
****API Gateway URL 貼り付け****の部分に、先ほど作成した API Gateway の URL を貼り付け、"index.html"のファイル名で保存します。
- フォームを用いて、選択されたファイルを送信するだけの、単純な HTML ファイルです。
index.html<!DOCTYPE html> <html lang="ja"> <head> <meta charset="UTF-8"> <title>有名人認識AIハンズオン</title> </head> <body> <p>画像識別AIである Amazon Rekognition を用いて、有名人の認識をします!</p> <form action="****API Gateway URL 貼り付け****" enctype="multipart/form-data" method="POST"> <input type="file" name="写真ファイルを選択" /> <input type="submit" name="アップロード"/> </form> </body> </html>
- 作成したIndex.html をブラウザで開きます。(ファイルを選択しブラウザ上までドラッグ&ドロップすれば開けます)
動作確認
例えば、日本が世界に誇るお笑い芸人(?)「世界のワタベ」で試してみましょう。
- ※以下のスクリーンショットでは、知財権保護のため画像をぼかしています。

ファイルを選択し、「送信」ボタンを押すと…
"He/She is Ken Watabe with 100% confidence."と表示されました!有名人識別サービスの完成です!
- さすが「世界のワタベ」ですね。
お片付け
- 以下のリソースを削除していきます。
- API Gateway
- Lambda
- CloudWatch ロググループ(Lambdaの実行ログ)
- Lambda用 IAMロール
API Gateway の削除
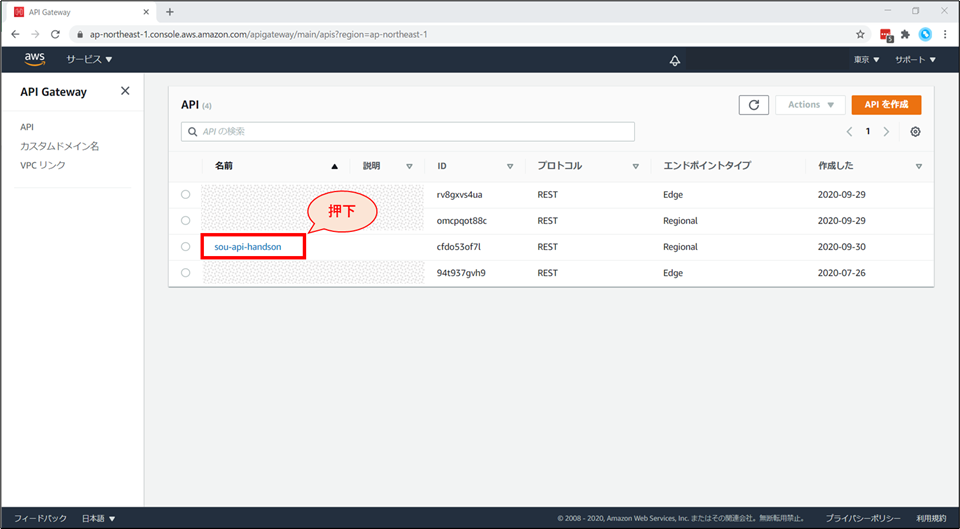
API Gateway の画面から、作成した「《お名前》-api-handson」を選択します。
API Gateway の画面から、作成した「《お名前》-api-handson」を選択します。
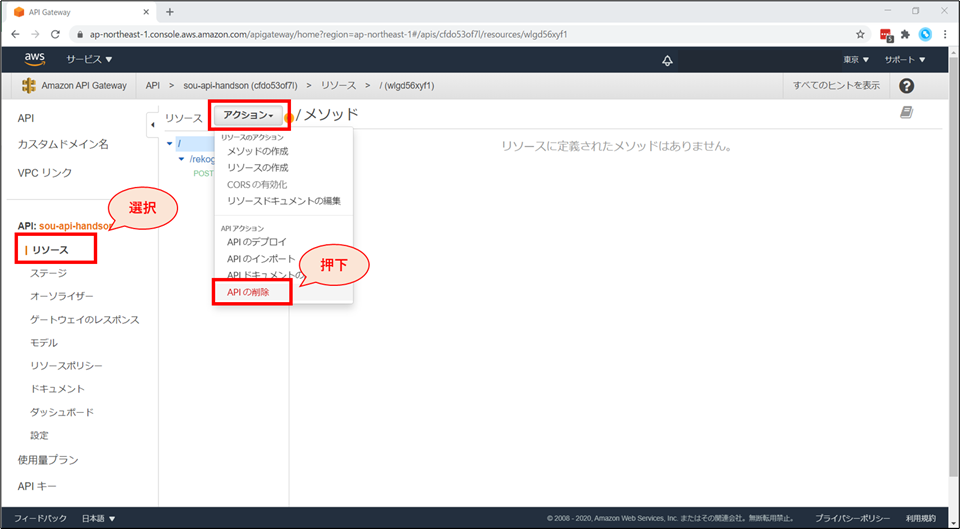
画面左ペインで「リソース」が選択されている状態で、アクションから「APIの削除」を選択します。
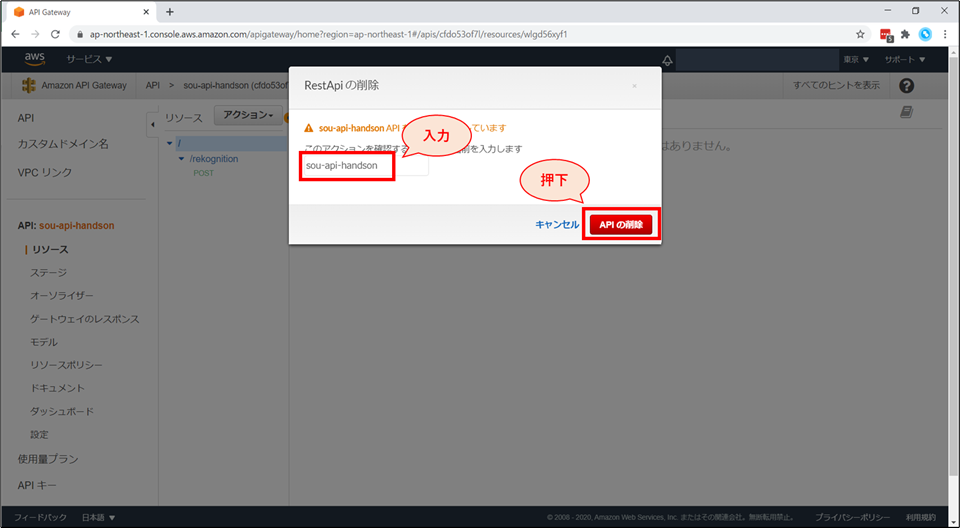
削除前の確認画面が表示されるので、API名を入力後、「APIの削除」を押下します。
CloudWatch ログの削除
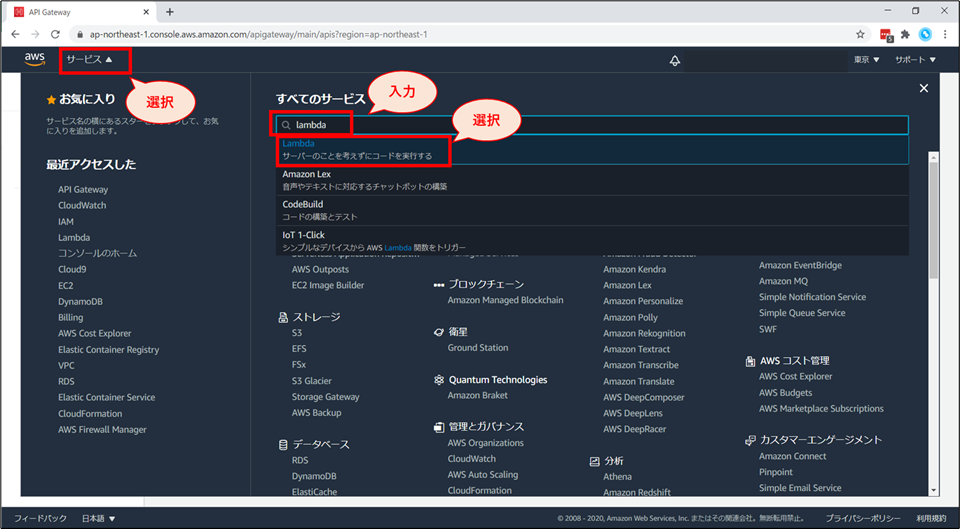
Lambda のコンソール画面へ遷移するために、画面上部の「サービス」から「Lambda」を検索し選択します。
一覧画面にて、「《お名前》-rekognition-handson」を選択します。
画面上部「モニタリング」を選択し、「CloudWatchのログを表示」ボタンを押下します。
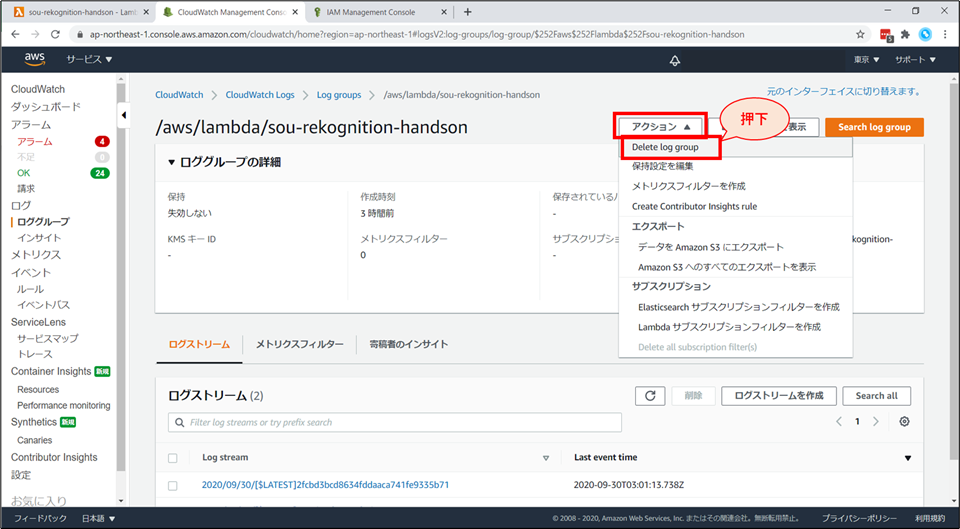
CloudWatch Logs の画面に遷移します。「アクション」から「Delete log group」を選択します。
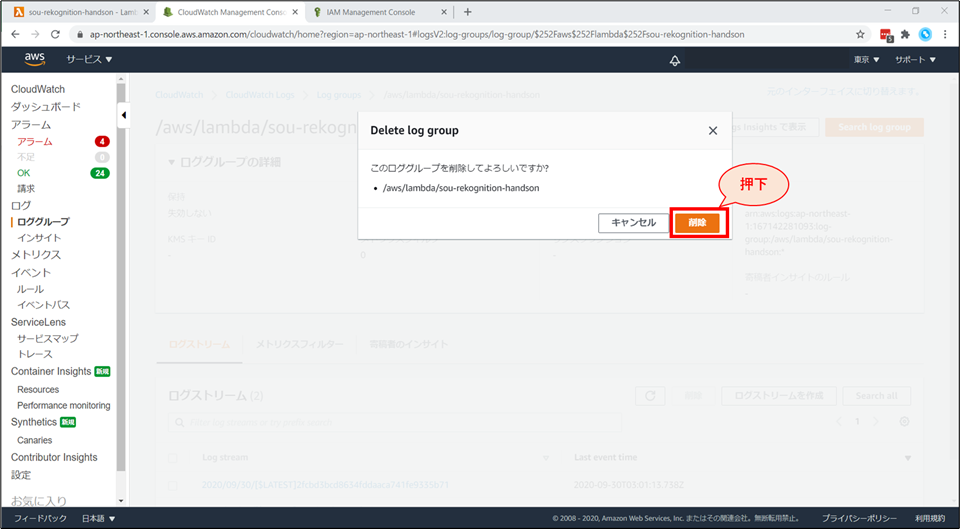
確認画面が表示されるので、「削除」ボタンを押します。
IAM ロールの削除
Lambda の画面に戻り、「設定」を開きます。
Lambdaの画面下部、「基本設定」の「編集」を押します。
「基本設定を編集」画面の下部まで行き、「IAMコンソールでxxxロールを表示します。」を選択します。
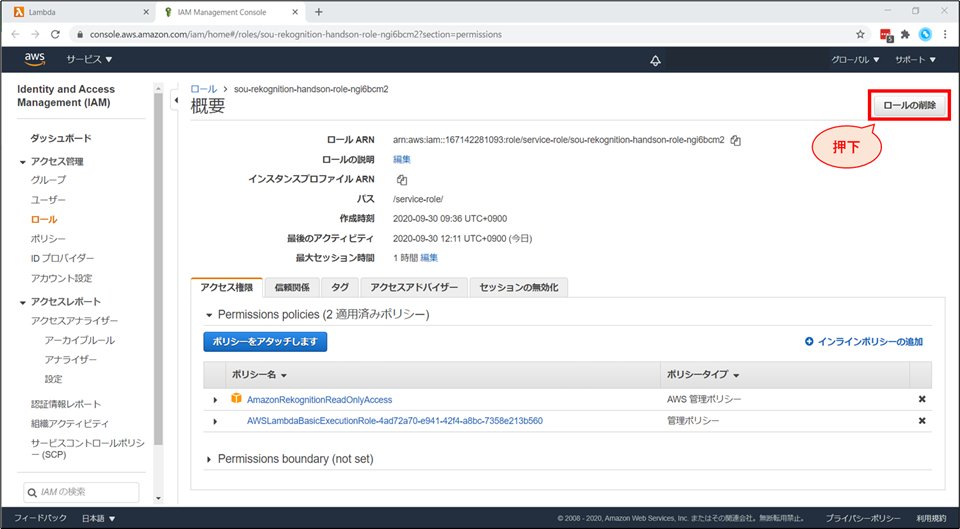
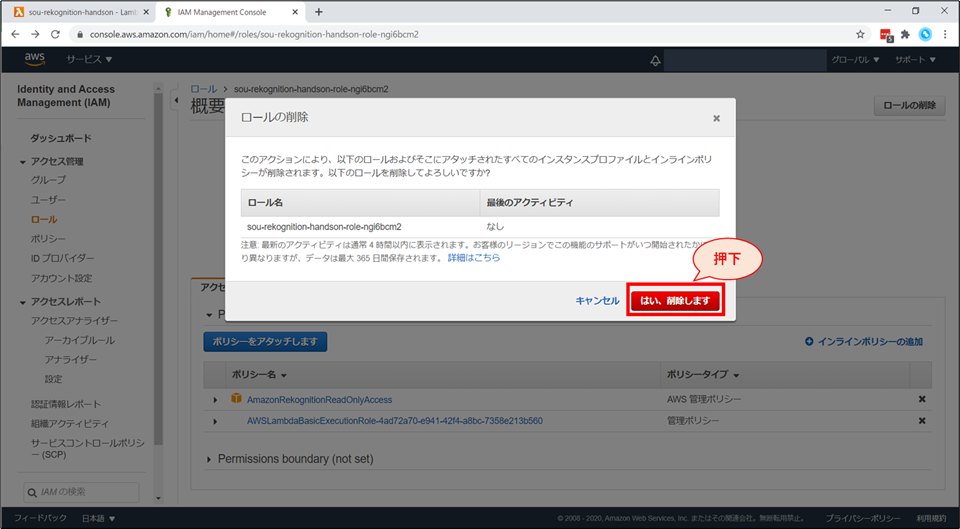
IAMロールの画面に遷移します。画面右上「ロールの削除」を選択します。
確認画面が出るので、「はい、削除します」を押下します。
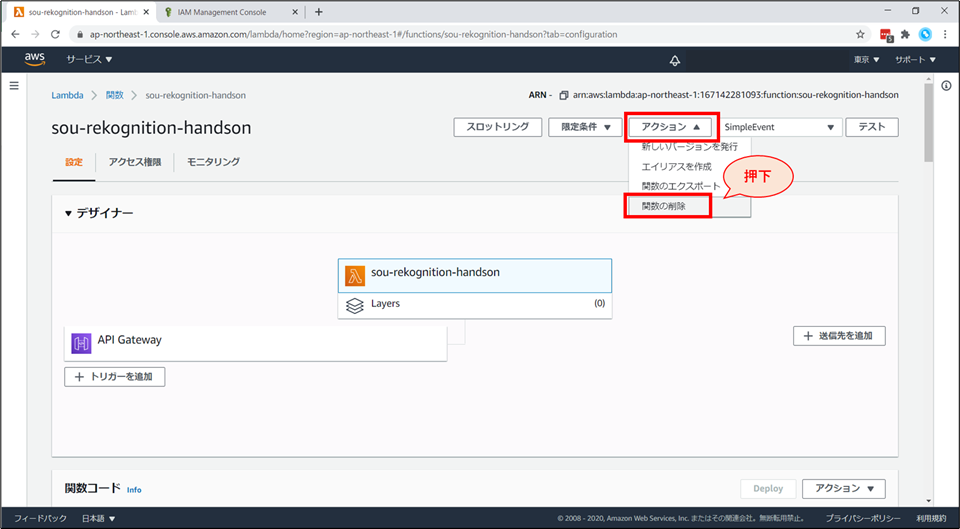
Lambda 関数の削除
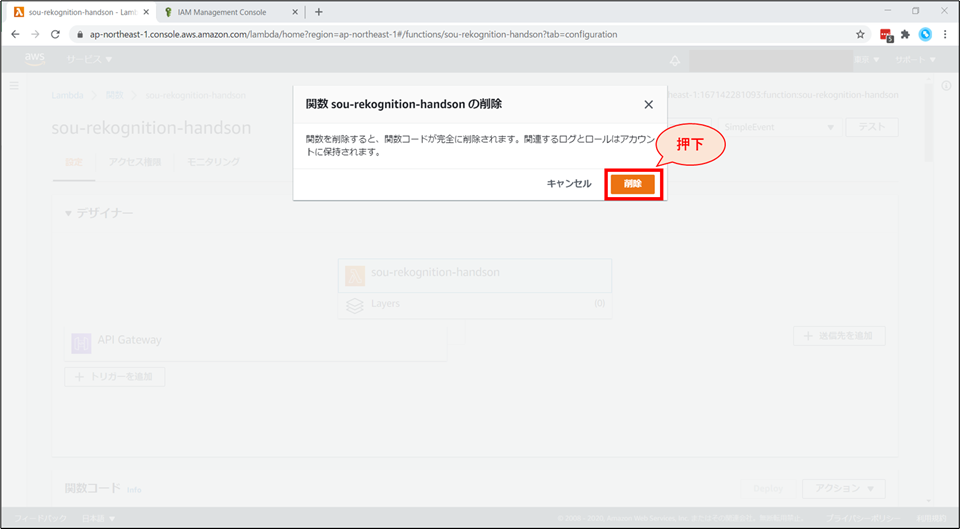
Lambda の画面に戻り、画面上部「アクション」から「関数の削除」を選択します。
確認画面が表示されるので、「削除」を選択します。
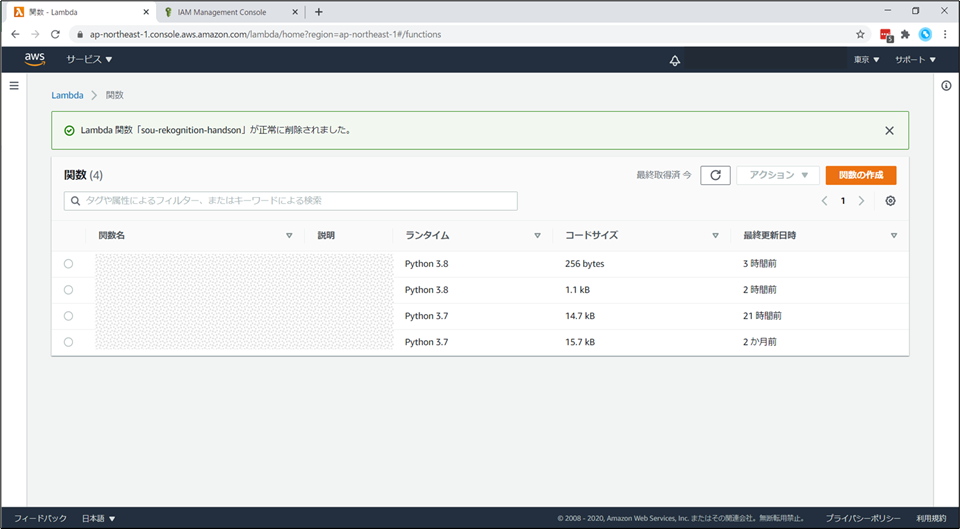
「正常に削除されました。」と表示がでます。
お片付けは以上で終了です。お疲れ様でした。
補足事項
料金
- AWSの各種サービスには、一定の無料利用枠があります。
- 今回の構成は、APIを大量にコールしない限り、全てAWSの無料利用枠に収まる想定です。
- 参考までに、無料枠を超えた際に発生する料金の目安を記載しておきます。
- (2020年10月13日時点 東京リージョン 月単位)
サービス分類 区分 料金 補足 データ通信料 AWSへのイン 0.000USD/GB 〃 AWSからのアウト 0.114USD/GB 最初の1GB~10TB CloudWatch ログ収集 0.760USD/GB 〃 ログ保存 0.033USD/GB Lambda リクエスト課金 0.20USD/100万件 〃 実行時間課金 0.0000002083USD
/128MB,100ミリ秒API Gateway REST API 4.25USD/100万件 最初の3 億3,300万コール受信数 Rekognition Image 0.0013USD/1画像 最初の100万枚 参考資料・ドキュメント






- 投稿日:2020-10-25T21:03:00+09:00
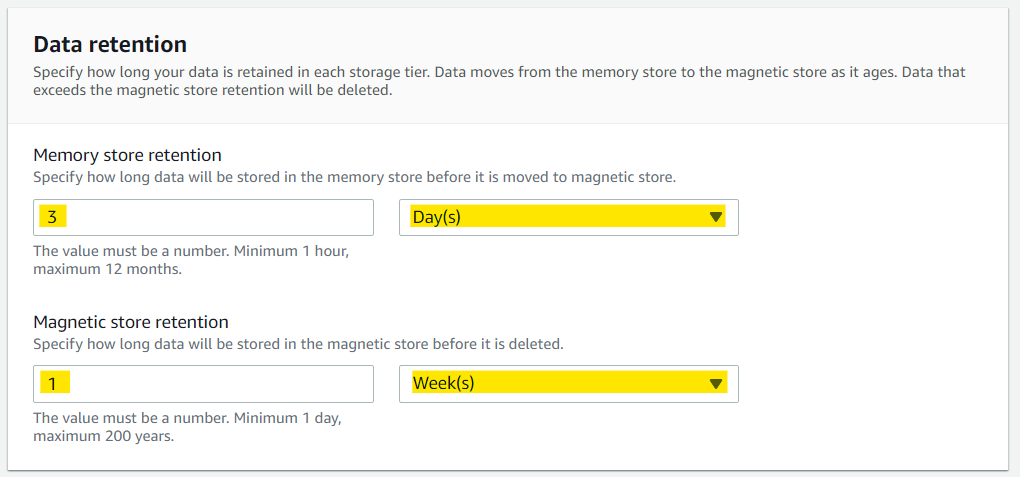
PySimpleGUI + OpenCVで動画プレイヤーを作る3 マスク機能の追加
はじめに
前回の記事に加えて、操作の対象として選ぶ領域ROI (Region of Interest)と特定の部分のみを処理対象とする処理(マスク)を付け加えます。
PySimpleGUI + OpenCVで動画プレイヤーを作る2 ROI設定と保存機能の追加(DIVX, MJPG, GIF)
この記事でできること
ROI内の特定の部分(マスク)に処理を掛けることが出来ます。
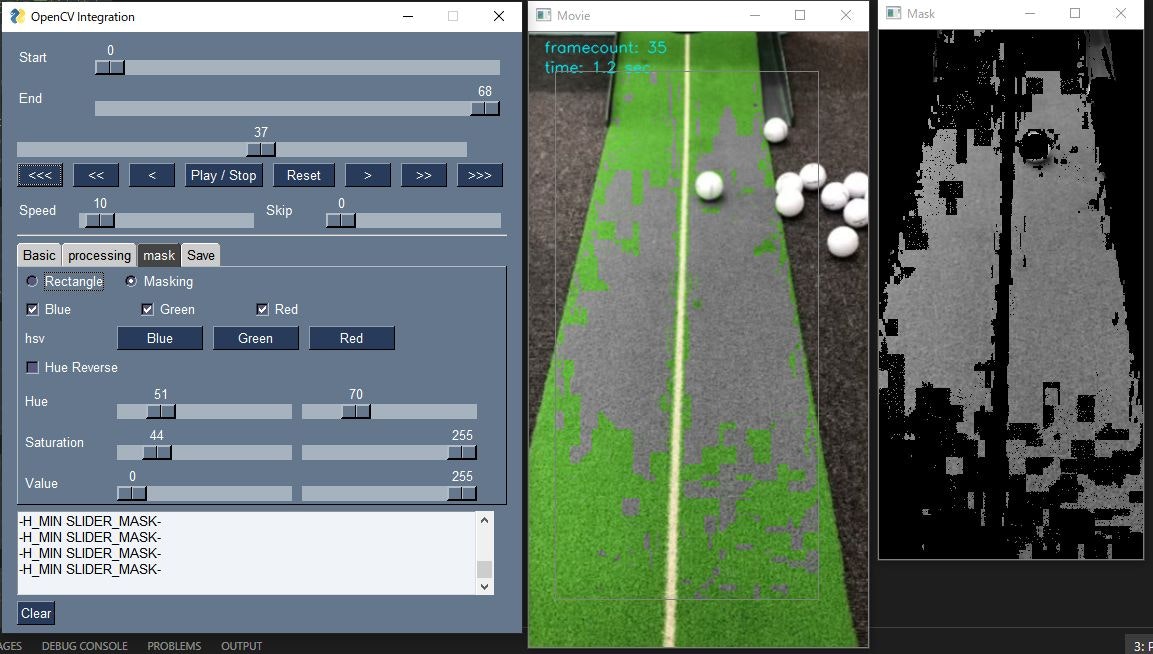
マスクの選択は画像をHSVに変換し、それぞれスライダで数値を選択できるようにしています。マスク部分は別ウィンドウで表示して確認できるようにしています。
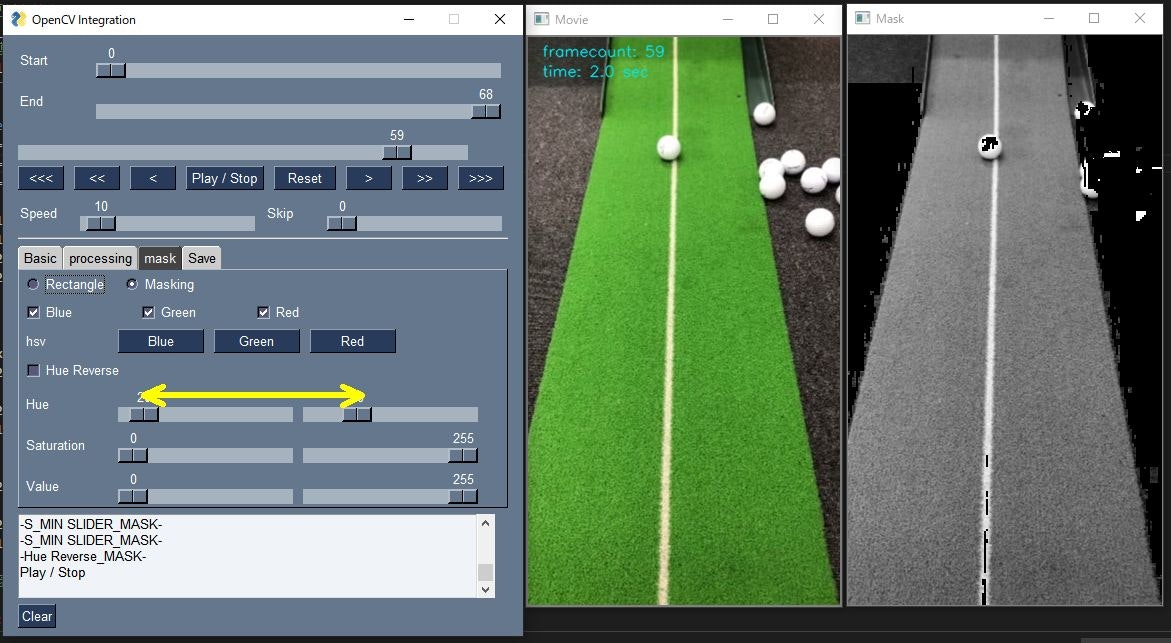
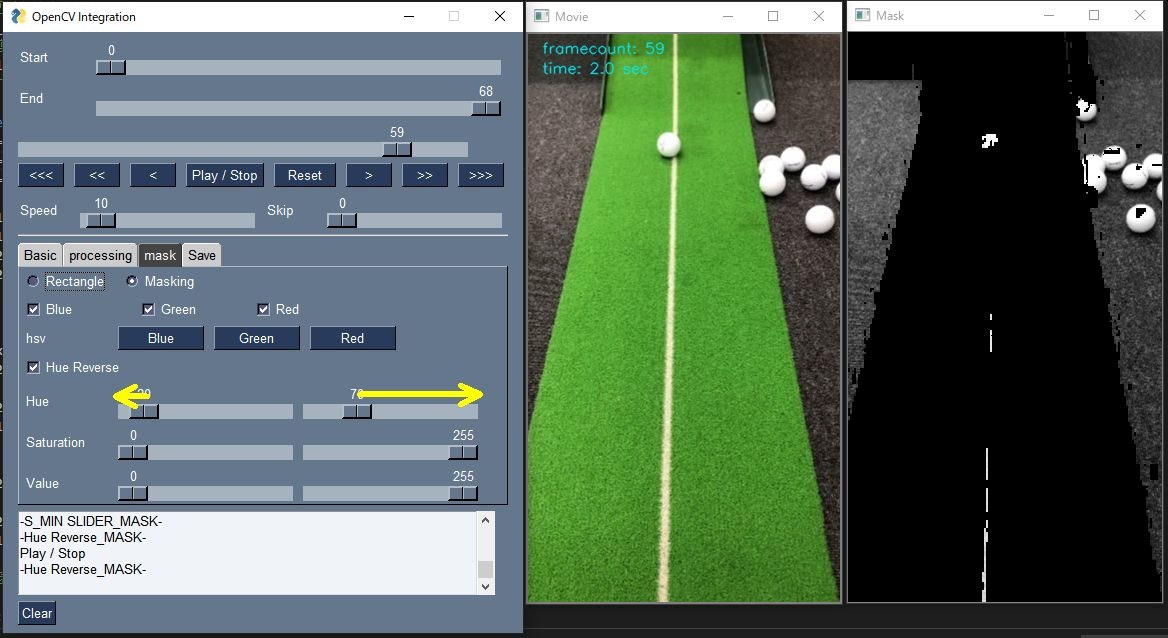
赤色を選択する場合は、Hueの値を0-20と110-255程度の二つの範囲を選択する必要があるため、Hue Reverseというチェックボックスを作成し、チェックボックスが選択されている場合は、2つのスライダの外側の値をマスク範囲とするようにしています。
Hue Reverse 【オフ】
Hueの左右のスライダの間の範囲がマスク範囲となります。
Hue Reverse 【オン】
Hueの左右のスライダの外側がマスク範囲となります。マスク範囲を反転することが出来ます。
指定範囲の動画をDIVX, MJEG, GIFで保存することが出来ます。
ファイルの読込
GUIを利用して読み込むファイルを選択します。
```python
import PySimpleGUI as sg
import cv2
import numpy as np
from PIL import Image
from pathlib import Pathdef file_read():
'''
ファイルを選択して読み込む
'''
fp = ""
# GUIのレイアウト
layout = [
[
sg.FileBrowse(key="file"),
sg.Text("ファイル"),
sg.InputText()
],
[sg.Submit(key="submit"), sg.Cancel("Exit")]
]
# WINDOWの生成
window = sg.Window("ファイル選択", layout)# イベントループ while True: event, values = window.read(timeout=100) if event == 'Exit' or event == sg.WIN_CLOSED: break elif event == 'submit': if values[0] == "": sg.popup("ファイルが入力されていません。") event = "" else: fp = values[0] break window.close() return Path(fp)## HSVによる色検出 HSV変換 → マスク処理を関数化しています。GUIから受け取ったH, S, Vそれぞれのmin, maxの値からmaskを作成し、cv2.bitwize_and()でマスク画像を作成します。 ```python def hsv(frame, H_max, H_min, S_max, S_min, V_max, V_min, reverse=False): frame_hsv = cv2.cvtColor(frame, cv2.COLOR_BGR2HSV) if reverse: lower1 = np.array([0, int(S_min), int(V_min)]) upper1 = np.array([int(H_min), int(S_max), int(V_max)]) mask1 = cv2.inRange(frame_hsv, lower1, upper1) lower2 = np.array([int(H_max), int(S_min), int(V_min)]) upper2 = np.array([255, int(S_max), int(V_max)]) mask2 = cv2.inRange(frame_hsv, lower2, upper2) mask = mask1 + mask2 frame = cv2.bitwise_and(frame, frame, mask=mask) # mask = cv2.bitwise_and(frame, mask, mask=mask) else: lower = np.array([int(H_min), int(S_min), int(V_min)]) upper = np.array([int(H_max), int(S_max), int(V_max)]) mask = cv2.inRange(frame_hsv, lower, upper) frame = cv2.bitwise_and(frame, frame, mask=mask) return frame class Main: def __init__(self): self.fp = file_read() self.cap = cv2.VideoCapture(str(self.fp)) # 動画の保存フラグ self.rec_flg = False # 1フレーム目の取得 # 取得可能かの確認 self.ret, self.f_frame = self.cap.read() self.cap.set(cv2.CAP_PROP_POS_FRAMES, 0) # フレームが取得できた場合、各種パラメータを取得 if self.ret: self.cap.set(cv2.CAP_PROP_POS_FRAMES, 0) # 動画情報の取得 self.fps = self.cap.get(cv2.CAP_PROP_FPS) self.width = int(self.cap.get(cv2.CAP_PROP_FRAME_WIDTH)) self.height = int(self.cap.get(cv2.CAP_PROP_FRAME_HEIGHT)) self.total_count = self.cap.get(cv2.CAP_PROP_FRAME_COUNT) # ROI self.frames_roi = np.zeros((5, self.height, self.width))マスク画像として、ROIと同サイズのグレースケールのマスク画像を用意しておきます。
# マスク画像の定義 self.mask = np.zeros_like(self.f_frame[:, :, 0]) # オリジナルサイズの保存 self.org_width = self.width self.org_height = self.height # フレーム関係 self.frame_count = 0 self.s_frame = 0 self.e_frame = self.total_count # 画像きり抜き位置 self.x1 = 0 self.y1 = 0 self.x2 = self.width self.y2 = self.height # 再生の一時停止フラグ self.stop_flg = False # マウスの動きの制御 # マウスのボタンが押されているかどうか self.mouse_flg = False self.event = "" # ROIへの演算を適応するかどうか self.roi_flg = True cv2.namedWindow("Movie") # マウスイベントのコールバック登録 cv2.setMouseCallback("Movie", self.onMouse) # フレームを取得出来なかった場合に終了する else: sg.Popup("ファイルの読込に失敗しました。") return # マウスイベント def onMouse(self, event, x, y, flags, param): # 左クリック if event == cv2.EVENT_LBUTTONDOWN: self.x1 = self.x2 = x self.y1 = self.y2 = y # 長方形の描写開始。マウスを一回押すと長方形描写を開始する。 self.mouse_flg = True # ROI部分の演算を一時停止 self.roi_flg = False return elif event == cv2.EVENT_LBUTTONUP: # 長方形の更新を停止 self.mouse_flg = False # ROIへの演算を開始する self.roi_flg = True # ROIの選択で0の場合はリセットし、ROIの演算をストップ if ( x == self.x1 or y == self.y1 or x <= 0 or y <= 0 ): self.x1 = 0 self.y1 = 0 self.x2 = self.width self.y2 = self.height return # x1 < x2になるようにする elif self.x1 < x: self.x2 = x else: self.x2 = self.x1 self.x1 = x if self.y1 < y: self.y2 = y else: self.y2 = self.y1 self.y1 = y # ROI範囲を表示 print( "ROI x:{0}:{1} y:{2}:{3}".format( str(self.x1), str(self.x2), str(self.y1), str(self.y2) ) ) return # マウスが押下されている場合、長方形を表示し続ける if self.mouse_flg: self.x2 = x self.y2 = y return def run(self): # GUI ####################################################### # GUIのレイアウト # タブ1 T1 = sg.Tab("Basic", [ [ sg.Text("Resize ", size=(13, 1)), sg.Slider( (0.1, 4), 1, 0.01, orientation='h', size=(40, 15), key='-RESIZE SLIDER-', enable_events=True ) ], [ sg.Checkbox( 'blur', size=(10, 1), key='-BLUR-', enable_events=True ), sg.Slider( (1, 10), 1, 1, orientation='h', size=(40, 15), key='-BLUR SLIDER-', enable_events=True ) ], ]) T2 = sg.Tab("processing", [ [ sg.Checkbox( 'gray', size=(10, 1), key='-GRAY-', enable_events=True ) ], ])マスク設定用GUI
マスク処理用のタブを用意します。
ラジオボタンでMaskingを選択した場合マスク処理を行います。T3 = sg.Tab("mask", [ [ sg.Radio( 'Rectangle', "RADIO2", key='-RECTANGLE_MASK-', default=True, size=(8, 1) ), sg.Radio( 'Masking', "RADIO2", key='-MASKING-', size=(8, 1) ) ], [ sg.Checkbox( "Blue", size=(10, 1), default=True, key='-BLUE_MASK-', enable_events=True ), sg.Checkbox( "Green", size=(10, 1), default=True, key='-GREEN_MASK-', enable_events=True ), sg.Checkbox( "Red", size=(10, 1), default=True, key='-RED_MASK-', enable_events=True ) ], [ sg.Text( 'hsv', size=(10, 1), key='-HSV_MASK-', enable_events=True ), sg.Button('Blue', size=(10, 1)), sg.Button('Green', size=(10, 1)), sg.Button('Red', size=(10, 1)) ], [ sg.Checkbox( 'Hue Reverse', size=(10, 1), key='-Hue Reverse_MASK-', enable_events=True ) ], [ sg.Text('Hue', size=(10, 1), key='-Hue_MASK-'), sg.Slider( (0, 255), 0, 1, orientation='h', size=(19.4, 15), key='-H_MIN SLIDER_MASK-', enable_events=True ), sg.Slider( (1, 255), 125, 1, orientation='h', size=(19.4, 15), key='-H_MAX SLIDER_MASK-', enable_events=True ) ], [ sg.Text('Saturation', size=(10, 1), key='-Saturation_MASK-'), sg.Slider( (0, 255), 50, 1, orientation='h', size=(19.4, 15), key='-S_MIN SLIDER_MASK-', enable_events=True ), sg.Slider( (1, 255), 255, 1, orientation='h', size=(19.4, 15), key='-S_MAX SLIDER_MASK-', enable_events=True ) ], [ sg.Text('Value', size=(10, 1), key='-Value_MASK-'), sg.Slider( (0, 255), 50, 1, orientation='h', size=(19.4, 15), key='-V_MIN SLIDER_MASK-', enable_events=True ), sg.Slider( (1, 255), 255, 1, orientation='h', size=(19.4, 15), key='-V_MAX SLIDER_MASK-', enable_events=True ) ] ]) T4 = sg.Tab("Save", [ [ sg.Button('Write', size=(10, 1)), sg.Radio( 'DIVX', "RADIO1", key='-DIVX-', default=True, size=(8, 1) ), sg.Radio('MJPG', "RADIO1", key='-MJPG-', size=(8, 1)), sg.Radio('GIF', "RADIO1", key='-GIF-', size=(8, 1)) ], [ sg.Text('Caption', size=(10, 1)), sg.InputText( size=(32, 50), key='-CAPTION-', enable_events=True ) ] ]) layout = [ [ sg.Text("Start", size=(8, 1)), sg.Slider( (0, self.total_count - 1), 0, 1, orientation='h', size=(45, 15), key='-START FRAME SLIDER-', enable_events=True ) ], [ sg.Text("End ", size=(8, 1)), sg.Slider( (0, self.total_count - 1), self.total_count - 1, 1, orientation='h', size=(45, 15), key='-END FRAME SLIDER-', enable_events=True ) ], [sg.Slider( (0, self.total_count - 1), 0, 1, orientation='h', size=(50, 15), key='-PROGRESS SLIDER-', enable_events=True )], [ sg.Button('<<<', size=(5, 1)), sg.Button('<<', size=(5, 1)), sg.Button('<', size=(5, 1)), sg.Button('Play / Stop', size=(9, 1)), sg.Button('Reset', size=(7, 1)), sg.Button('>', size=(5, 1)), sg.Button('>>', size=(5, 1)), sg.Button('>>>', size=(5, 1)) ], [ sg.Text("Speed", size=(6, 1)), sg.Slider( (0, 240), 10, 10, orientation='h', size=(19.4, 15), key='-SPEED SLIDER-', enable_events=True ), sg.Text("Skip", size=(6, 1)), sg.Slider( (0, 300), 0, 1, orientation='h', size=(19.4, 15), key='-SKIP SLIDER-', enable_events=True ) ], [sg.HorizontalSeparator()], [ sg.TabGroup( [[T1, T2, T3, T4]], tab_background_color="#ccc", selected_title_color="#fff", selected_background_color="#444", tab_location="topleft" ) ], [sg.Output(size=(65, 5), key='-OUTPUT-')], [sg.Button('Clear')] ] # Windowを生成 window = sg.Window('OpenCV Integration', layout, location=(0, 0)) # 動画情報の表示 self.event, values = window.read(timeout=0) print("ファイルが読み込まれました。") print("File Path: " + str(self.fp)) print("fps: " + str(int(self.fps))) print("width: " + str(self.width)) print("height: " + str(self.height)) print("frame count: " + str(int(self.total_count))) # メインループ ######################################################### try: while True: # GUIイベントの読込 self.event, values = window.read( timeout=values["-SPEED SLIDER-"] ) # イベントをウィンドウに表示 if self.event != "__TIMEOUT__": print(self.event) # Exitボタンが押されたら、またはウィンドウの閉じるボタンが押されたら終了 if self.event in ('Exit', sg.WIN_CLOSED, None): break # 動画の再読み込み # スタートフレームを設定していると動く if self.event == 'Reset': self.cap.set(cv2.CAP_PROP_POS_FRAMES, self.s_frame) self.frame_count = self.s_frame window['-PROGRESS SLIDER-'].update(self.frame_count) self.video_stabilization_flg = False self.stab_prepare_flg = False # Progress sliderへの変更を反映させるためにcontinue continue # 動画の書き出し if self.event == 'Write': self.rec_flg = True self.cap.set(cv2.CAP_PROP_POS_FRAMES, self.s_frame) self.frame_count = self.s_frame window['-PROGRESS SLIDER-'].update(self.frame_count) if values["-GIF-"]: images = [] else: # 動画として保存 # コーデックの選択 # DIVXは圧縮率高い # MJEGはImageJで解析可能 if values["-DIVX-"]: codec = "DIVX" elif values["-MJPG-"]: codec = "MJPG" fourcc = cv2.VideoWriter_fourcc(*codec) out = cv2.VideoWriter( str(( self.fp.parent / (self.fp.stem + '_' + codec + '.avi') )), fourcc, self.fps, (int(self.x2 - self.x1), int(self.y2 - self.y1)) ) continue if self.event == 'Stabilization': self.cap.set(cv2.CAP_PROP_POS_FRAMES, self.s_frame) self.frame_count = self.s_frame window['-PROGRESS SLIDER-'].update(self.frame_count) self.play_count = int(self.e_frame - self.s_frame) self.video_stabilization_flg = True continue # フレーム操作 ################################################ # スライダを直接変更した場合は優先する if self.event == '-PROGRESS SLIDER-': # フレームカウントをプログレスバーに合わせる self.frame_count = int(values['-PROGRESS SLIDER-']) self.cap.set(cv2.CAP_PROP_POS_FRAMES, self.frame_count) if values['-PROGRESS SLIDER-'] > values['-END FRAME SLIDER-']: window['-END FRAME SLIDER-'].update( values['-PROGRESS SLIDER-']) # スタートフレームを変更した場合 if self.event == '-START FRAME SLIDER-': self.s_frame = int(values['-START FRAME SLIDER-']) self.cap.set(cv2.CAP_PROP_POS_FRAMES, self.s_frame) self.frame_count = self.s_frame window['-PROGRESS SLIDER-'].update(self.frame_count) if values['-START FRAME SLIDER-'] > values['-END FRAME SLIDER-']: window['-END FRAME SLIDER-'].update( values['-START FRAME SLIDER-']) self.e_frame = self.s_frame # エンドフレームを変更した場合 if self.event == '-END FRAME SLIDER-': if values['-END FRAME SLIDER-'] < values['-START FRAME SLIDER-']: window['-START FRAME SLIDER-'].update( values['-END FRAME SLIDER-']) self.s_frame = self.e_frame # エンドフレームの設定 self.e_frame = int(values['-END FRAME SLIDER-']) if self.event == '<<<': self.frame_count = np.maximum(0, self.frame_count - 150) window['-PROGRESS SLIDER-'].update(self.frame_count) self.cap.set(cv2.CAP_PROP_POS_FRAMES, self.frame_count) if self.event == '<<': self.frame_count = np.maximum(0, self.frame_count - 30) window['-PROGRESS SLIDER-'].update(self.frame_count) self.cap.set(cv2.CAP_PROP_POS_FRAMES, self.frame_count) if self.event == '<': self.frame_count = np.maximum(0, self.frame_count - 1) window['-PROGRESS SLIDER-'].update(self.frame_count) self.cap.set(cv2.CAP_PROP_POS_FRAMES, self.frame_count) if self.event == '>': self.frame_count = self.frame_count + 1 window['-PROGRESS SLIDER-'].update(self.frame_count) self.cap.set(cv2.CAP_PROP_POS_FRAMES, self.frame_count) if self.event == '>>': self.frame_count = self.frame_count + 30 window['-PROGRESS SLIDER-'].update(self.frame_count) self.cap.set(cv2.CAP_PROP_POS_FRAMES, self.frame_count) if self.event == '>>>': self.frame_count = self.frame_count + 150 window['-PROGRESS SLIDER-'].update(self.frame_count) self.cap.set(cv2.CAP_PROP_POS_FRAMES, self.frame_count) # カウンタがエンドフレーム以上になった場合、スタートフレームから再開 if self.frame_count >= self.e_frame: self.cap.set(cv2.CAP_PROP_POS_FRAMES, self.s_frame) self.frame_count = self.s_frame window['-PROGRESS SLIDER-'].update(self.frame_count) continue # ストップボタンで動画の読込を一時停止 if self.event == 'Play / Stop': self.stop_flg = not self.stop_flg # ストップフラグが立っており、eventが発生した場合以外はcountinueで # 操作を停止しておく # ストップボタンが押された場合は動画の処理を止めるが、何らかの # eventが発生した場合は画像の更新のみ行う # mouse操作を行っている場合も同様 if( ( self.stop_flg and self.event == "__TIMEOUT__" and self.mouse_flg is False ) ): window['-PROGRESS SLIDER-'].update(self.frame_count) continue # スキップフレーム分とばす if not self.stop_flg and values['-SKIP SLIDER-'] != 0: self.frame_count += values["-SKIP SLIDER-"] self.cap.set(cv2.CAP_PROP_POS_FRAMES, self.frame_count) # フレームの読込 ############################################## self.ret, self.frame = self.cap.read() self.valid_frame = int(self.frame_count - self.s_frame) # 最後のフレームが終わった場合self.s_frameから再開 if not self.ret: self.cap.set(cv2.CAP_PROP_POS_FRAMES, self.s_frame) self.frame_count = self.s_frame continue # 以降にフレームに対する処理を記述 ################################## # frame全体に対する処理をはじめに実施 ############################## # リサイズ self.width = int(self.org_width * values['-RESIZE SLIDER-']) self.height = int(self.org_height * values['-RESIZE SLIDER-']) self.frame = cv2.resize(self.frame, (self.width, self.height)) if self.event == '-RESIZE SLIDER-': self.x1 = self.y1 = 0 self.x2 = self.width self.y2 = self.height # ROIに対して処理を実施 ########################################## if self.roi_flg: self.frame_roi = self.frame[ self.y1:self.y2, self.x1:self.x2, : ]RGBマスク処理
マスク処理を記述します。
HSVではなく、RGBでの色指定を入れています。RGBで色を指定した後、HSVのV(明度)でマスク範囲を指定することが出来ます。この場合は、Hueは0-255の全範囲を指定して、Vのみ変更したほうが良いです。# MASK画像への処理 ################################################################## if values['-MASKING-']: # RGB分離 self.mask = np.copy(self.frame_roi) if not values['-BLUE_MASK-']: self.mask[:, :, 0] = 0 if not values['-GREEN_MASK-']: self.mask[:, :, 1] = 0 if not values['-RED_MASK-']: self.mask[:, :, 2] = 0HSVマスク処理
HSVでのマスク処理を記述します。
Red, Green, Blueボタンで各色をある程度適当な範囲で選択できるようにしています。元動画とマスク動画を見ながら、閾値を調整して対象物をマスクすることが出来ます。if self.event == 'Blue': window['-H_MIN SLIDER_MASK-'].update(70) window['-H_MAX SLIDER_MASK-'].update(110) window['-S_MIN SLIDER_MASK-'].update(70) window['-S_MAX SLIDER_MASK-'].update(255) window['-V_MIN SLIDER_MASK-'].update(0) window['-V_MAX SLIDER_MASK-'].update(255) window['-Hue Reverse_MASK-'].update(False) if self.event == 'Green': window['-H_MIN SLIDER_MASK-'].update(20) window['-H_MAX SLIDER_MASK-'].update(70) window['-S_MIN SLIDER_MASK-'].update(70) window['-S_MAX SLIDER_MASK-'].update(255) window['-V_MIN SLIDER_MASK-'].update(0) window['-V_MAX SLIDER_MASK-'].update(255) window['-Hue Reverse_MASK-'].update(False) if self.event == 'Red': window['-H_MIN SLIDER_MASK-'].update(20) window['-H_MAX SLIDER_MASK-'].update(110) window['-S_MIN SLIDER_MASK-'].update(70) window['-S_MAX SLIDER_MASK-'].update(255) window['-V_MIN SLIDER_MASK-'].update(0) window['-V_MAX SLIDER_MASK-'].update(255) window['-Hue Reverse_MASK-'].update(True) self.mask = hsv( self.mask, values['-H_MAX SLIDER_MASK-'], values['-H_MIN SLIDER_MASK-'], values['-S_MAX SLIDER_MASK-'], values['-S_MIN SLIDER_MASK-'], values['-V_MAX SLIDER_MASK-'], values['-V_MIN SLIDER_MASK-'], values['-Hue Reverse_MASK-'] ) # グレイスケール self.mask = cv2.cvtColor( self.mask, cv2.COLOR_BGR2GRAY ) # ぼかし if values['-BLUR-']: self.frame_roi = cv2.GaussianBlur( self.frame_roi, (21, 21), values['-BLUR SLIDER-'] ) if values['-GRAY-']: self.frame_roi = cv2.cvtColor( self.frame_roi, cv2.COLOR_BGR2GRAY ) self.frame_roi = cv2.cvtColor( self.frame_roi, cv2.COLOR_GRAY2BGR )ROI内のマスク範囲のみ処理を適用します。
cv2.bitwise_notを入れ子で使用して実施していますが、より適切な実現方法あるかもしれません。if values['-MASKING-']: # frame_roi内にマスクを適用 # マスク処理部のみをframe_roiに変える self.frame_roi = cv2.bitwise_not( cv2.bitwise_not(self.frame_roi), self.frame[self.y1:self.y2, self.x1:self.x2, :], mask=self.mask ) # 処理したROIをframeに戻す self.frame[self.y1:self.y2, self.x1:self.x2, :] = self.frame_roi # 動画の保存 if self.rec_flg: # 手振れ補正後再度roiを切り抜き self.frame_roi = self.frame[ self.y1:self.y2, self.x1:self.x2, : ] if values["-GIF-"]: images.append( Image.fromarray( cv2.cvtColor( self.frame_roi, cv2.COLOR_BGR2RGB ) ) ) else: out.write(self.frame_roi) # 保存中の表示 cv2.putText( self.frame, str("Now Recording"), (20, 60), cv2.FONT_HERSHEY_SIMPLEX, 0.5, (10, 10, 255), 1, cv2.LINE_AA ) # e_frameになったら終了 if self.frame_count >= self.e_frame - values["-SKIP SLIDER-"] - 1: if values["-GIF-"]: images[0].save( str((self.fp.parent / (self.fp.stem + '.gif'))), save_all=True, append_images=images[1:], optimize=False, duration=1000 // self.fps, loop=0 ) else: out.release() self.rec_flg = False # フレーム数と経過秒数の表示 cv2.putText( self.frame, str("framecount: {0:.0f}".format(self.frame_count)), ( 15, 20), cv2.FONT_HERSHEY_SIMPLEX, 0.5, (240, 230, 0), 1, cv2.LINE_AA ) cv2.putText( self.frame, str("time: {0:.1f} sec".format( self.frame_count / self.fps)), (15, 40), cv2.FONT_HERSHEY_SIMPLEX, 0.5, (240, 230, 0), 1, cv2.LINE_AA ) # ROIへの演算を実施している場合 or マウス左ボタンを押している最中 # 長方形を描写する if self.roi_flg or self.mouse_flg: cv2.rectangle( self.frame, (self.x1, self.y1), (self.x2 - 1, self.y2 - 1), (128, 128, 128) )Maskingを選択している場合のみ、マスク画像を表示するようにしています。
# 画像を表示 cv2.imshow("Movie", self.frame) if values['-MASKING-']: cv2.imshow("Mask", cv2.cvtColor(self.mask, cv2.COLOR_GRAY2BGR)) cv2.setWindowProperty("Mask", cv2.WND_PROP_VISIBLE, 0) elif not values['-MASKING-'] and cv2.getWindowProperty("Mask", cv2.WND_PROP_VISIBLE): cv2.destroyWindow("Mask") if self.stop_flg: self.cap.set(cv2.CAP_PROP_POS_FRAMES, self.frame_count) else: self.frame_count += 1 window['-PROGRESS SLIDER-'].update(self.frame_count + 1) # その他の処理 ############################################### # ログウィンドウのクリア if self.event == 'Clear': window['-OUTPUT-'].update('') finally: cv2.destroyWindow("Movie") cv2.destroyWindow("Mask") self.cap.release() window.close() if __name__ == '__main__': Main().run()参考リンク
pythonで赤い物体を認識しよう
Wikipedia: HSV色空間
Python, OpenCV, NumPyで画像のアルファブレンドとマスク処理

- 投稿日:2020-10-25T20:39:03+09:00
AI学習のためのPython学習計画 進展管理
背景と目的
ChainerによるPythonの学習がひと段落しそうなので
計画の見直しをします結論
下記で紹介する専門書を学習し、機械学習を使ったアプリケーションをアウトプットする。
頑張ります!!!内容
とりあえずさらっと学習済み
- 機械学習に必要な数学
- Python
- 機械学習に関する知識
- 微分(偏微分まで)
- 線形代数
- 基礎統計(平均、分散、標準偏差など)
- 単回帰分析の数学
- 重回帰分析の数学
- Python(Chainer)
- ニューラルネットワークの計算(順伝播), 線形変換, 非線形変換 ,ニューラルネットワークの計算(逆伝播) 誤差逆伝播法, 勾配降下法, ミニバッチ学習
次に勉強予定(基本的に専門書で触る程度のことはできそう)
この本で勉強します
ニューラルネットワークの実装(TensorFlow もしくは PyTorch)
教師あり学習の代表的なアルゴリズム(書店をあさった結果、「機械学習」の専門書の勉強が必要そう)
重回帰分析, リッジ回帰, ラッソ回帰, ロジスティク回帰, k 近傍法, サポートベクトルマシン, 決定木, ランダムフォレスト, 教師なし学習の代表的なアルゴリズム, k 平均法, 主成分分析, ハイパーパラメータの代表的な調整方法, グリッドサーチ, ランダムサーチ, ベイズ最適化, 分類の代表的な評価指標, 正解率, 適合率, 再現率, F 値
さらに次のステップ
下記は、作りたいプログラムに応じて適宜勉強したら良さそうなので、学ぶ順番としては今ではなくて後半になりそう
画像データ, 畳み込みニューラルネットワーク (CNN), 物体検出のアルゴリズム (R-CNN 、YOLO 、SSD など), セマンティックセグメンテーションのアルゴリズム, 文章データ, 文章データの特徴抽出方法(Bag of words 、Word2Vec など), 機械翻訳のアルゴリズム (Seq2Seq 、Attention など)
時系列データ(1/1 の来店者数は 100 人のデータに前後関係が存在するデータ)
再帰型ニューラルネットワーク (RNN 、LSTM 、GRU など)
畳み込みニューラルネットワーク (CNN)
表データ(Excel のシートに記載されるようなデータ)
特徴量エンジニアリング
発展的な機械学習アルゴリズム (XGBoost 、LightGBM など)

- 投稿日:2020-10-25T20:30:21+09:00
【internal_math編②】AtCoder Library 解読 〜Pythonでの実装まで〜
0. はじめに
2020年9月7日にAtCoder公式のアルゴリズム集 AtCoder Library (ACL)が公開されました。
自分はACLに収録されているアルゴリズムのほとんどが初見だったのでいい機会だと思い、アルゴリズムの勉強からPythonでの実装までを行いました。この記事ではinternal_mathをみていきます。
internal_mathはACLの内部で使われる数論的アルゴリズムの詰め合わせで内容は以下の通りです。
名称 概要 safe_mod 整数 $x$ の正整数 $m$ による剰余($x \% m$)。ただし $0 \leq x \% m < m $ を満たす。 barrett 高速な剰余演算。 pow_mod $x^n \pmod{m}$ の計算。 is_prime 高速な素数判定。 inv_gcd 整数 $a$ と正整数 $b$ の最大公約数 $g$ および $xa \equiv g \pmod{b}$ となる $x$ の計算。ただし $0 \leq x < \frac{b}{g} $ を満たす。 primitive_root 素数 $m$ の原始根。 本記事ではこれらの内、
- is_prime
- primitive_root
を扱います。なお、constexpr(定数式)自体については触れません。
本記事で扱わない
- safe_mod
- pow_mod
- inv_gcd
- barrett
については以下の記事で扱っています。よろしければそちらもご覧ください。
【internal_math編①】AtCoder Library 解読 〜Pythonでの実装まで〜対象としている読者
- ACLのコードを見てみたけど何をしているのかわからない方。
- C++はわからないのでPythonで読み進めたい方。
対象としていない読者
- ACLのPythonに最適化されたコードが欲しい方。 →極力ACLと同じになるように実装したのでPythonでの実行速度等は全く考慮していません。Cythonから直接使えるようにするという動きがあるようなのでそちらを追ってみるといいかもしれません。
参考にしたもの
is_primeに関連するwikipediaのページです。
強い擬素数についての論文です。
ミラー-ラビン素数判定法について書かれている@srtk86さんの記事です。わかりやすいです。
原始根について説明されています。
1. is_prime
正整数 $n$ が素数であるか判定することを考えます。
1.1. 決定的素数判定法
素数の定義は、「正の約数が1と自分自身のみである、1より大きい自然数」ですから、2から $n - 1$ までの自然数で $n$ を割って、割り切れなかったら $n$ は素数だといえます。いわゆる試し割りという方法です。Pythonで実装すると以下のようになります。
def deterministicPT(n): if n <= 1: return False if n == 2: return True for i in range(2, n): if n % i == 0: return False return Trueこれを使って素数判定を行うと以下のようになります。
for n in range(1, 10): if deterministicPT(n): print(f'{n}は素数である') else: print(f'{n}は素数でない') # 1は素数でない # 2は素数である # 3は素数である # 4は素数でない # 5は素数である # 6は素数でない # 7は素数である # 8は素数でない # 9は素数でないこの方法では定義に忠実に確かめたので、$n$ が素数であるか否かを確実に判定することができます。このような方法を決定的素数判定法といいます。
決定的素数判定法は言い換えれば次のような性質を持つテストを行うことです。
- 素数ならば必ず合格になる
- 素数でないならば必ず不合格になる
1.2. 確率的素数判定法
「素数である」「素数でない」のどちらかを判定する決定的素数判定法に対して、「素数かもしれない」「素数でない」のどちらかを判定するアルゴリズムを確率的素数判定法と言います。
確率的素数判定法に用いられるテストは次の性質を持っています。
- 素数ならば必ず合格する
- 素数でないならば合格不合格のどちらにもなりうる
- 自然数 $a$ が組み込まれている
そして、このようなテストに合格する自然数を「底 $a$ の確率的素数」と言います。
具体例を見てみましょう。判定したい自然数 $n$ に対して次のようなテストを考えます。
- $n=1$ ならば不合格
- $2 \leq n \leq a$ ならば合格
- $n > a$ ならば $a$ で割り切れなければ合格、割り切れたら不合格
このテストは上で挙げた3つの性質を満たしているので確率的素数判定法に用いることができます。Pythonで実装すると次のようになるでしょう。
class ProbabilisticPT: def __init__(self, a=2): self._a = a def change_base(self, a): self._a = a def test(self, n): if n == 1: return False if n <= self._a: return True if n % self._a != 0: return True else: return False$a = 2$ の場合に素数判定をしてみましょう。
a = 2 ppt = ProbabilisticPT(a) for n in range(10): if ppt.test(n): print(f'{n}は底{a}の確率的素数') else: print(f'{n}は素数でない') # 1は素数でない # 2は底2の確率的素数 # 3は底2の確率的素数 # 4は素数でない # 5は底2の確率的素数 # 6は素数でない # 7は底2の確率的素数 # 8は素数でない # 9は底2の確率的素数確率的素数判定において「素数でない」という判定は信用できます。なぜならテストの持つ性質の一つ、「素数ならば必ず合格になる」の対偶は「不合格ならば必ず素数でない」だからです。よって4, 6, 8は素数でないことが確定しました。しかし、「確率的素数」と判定された場合、そこからはあまり情報が得られませんので注意が必要です。
確率的素数判定のメリットはやはりその計算速度でしょう。今回の例で言えばたった1回の割り算で「確率的素数」か「素数でない」かが判定できます。しかしあくまでも得られる結果は「素数の可能性あり」であり、本当に素数かはわかりません。実際、合成数である9も確率的素数と判定されています。
1.3. 精度を向上させるために
確率的素数判定法では判定の精度を向上するために複数の底でテストを行います。もしある一つの底で「素数でない」と判定されたならその自然数は素数でないことが確定するので判定精度の向上が期待できます。
実際に底が2, 3, 5の場合に30未満の自然数についてテストを行ってみます。ppt = ProbabilisticPT() p = {} for a in [2, 3, 5]: p[a] = set() ppt.change_base(a) # 底をaに設定 for n in range(30): if ppt.test(n): p[a].add(n) for k, v in p.items(): print(f'底{k}の確率的素数 : {v}') # 各底の確率的素数の集合の共通部分を求める print('全ての底での確率的素数 :', p[2] & p[3] & p[5]) # 底2の確率的素数 : {2, 3, 5, 7, 9, 11, 13, 15, 17, 19, 21, 23, 25, 27, 29} # 底3の確率的素数 : {2, 3, 4, 5, 7, 8, 10, 11, 13, 14, 16, 17, 19, 20, 22, 23, 25, 26, 28, 29} # 底5の確率的素数 : {2, 3, 4, 5, 6, 7, 8, 9, 11, 12, 13, 14, 16, 17, 18, 19, 21, 22, 23, 24, 26, 27, 28, 29} # 全ての底での確率的素数 : {2, 3, 5, 7, 11, 13, 17, 19, 23, 29}底が2の場合に確率的素数と判定された9は底が3のテストで合成数であることが確定しました。
このように、複数の底を組み合わせることで全ての底での確率的素数が素数である確率を十分な精度まで向上させるのが確率的素数判定法の考え方です。今回用いたテストでは3つの底(2, 3, 5)を組み合わせることで30未満の自然数を100%の精度で素数判定することができました。1.4. フェルマーテスト
フェルマーの小定理をテストに用いるものをフェルマーテストと言います。
フェルマーの小定理とは次のものです。
$p$ を素数とし、$a$ を $p$ の倍数でない整数($a$ と $p$ は互いに素)とするときに、
a^{p-1} \equiv 1 \pmod{p}が成り立つ。
つまり、フェルマーテストとは
- $n$ と互いに素な自然数 $a$ に対し $a^{n-1} \equiv 1 \pmod{n}$ を満たせば合格
- 満たさなければ不合格
というものです。
フェルマーテストは先ほど用いたテストに比べて非常に強力で、$25\times 10^9$ までの奇数の合成数11,408,012,595個の内、底が2のフェルマーテストに合格できるのは21,853個しかないそうです。(「日本語版Wikipedia-確率的素数」より)しかし、フェルマーテストにも欠点があります。カーマイケル数と呼ばれる合成数は任意の底のフェルマーテストに合格します。よって、いくらたくさんの底を組み合わせてもフェルマーテストでは誤判定の可能性が無視できない大きさで残ります。
1.5. modの世界における1の平方根
フェルマーテストを改良する準備としてまず、modの世界における1の平方根について考えます。
modの世界における1の平方根とは2以上の自然数 $n$ に対して次の合同式を満たす $x$ のことです。x^2 \equiv 1 \pmod{n}明らかに $x = 1, n-1$ はこの式を満たすので、これらを自明な平方根と言い、これら以外を非自明な平方根と言います。
非自明な平方根について考えてみましょう。つまり $x$ は $1$ でも $n-1$ でもない場合を考えます。例えば $n=15$ のとき、$x = 4, 11$ は非自明な平方根となります。
\begin{aligned} (4)^2 &= 16 \equiv 1 \pmod{15}\\ (11)^2 &= 121 \equiv 1 \pmod{15} \end{aligned}では $n$ が素数の場合はどうでしょうか。実はこのとき非自明な平方根は存在しません。これを背理法で示しましょう。
いま素数 $p$ を法とする非自明な平方根が存在し、これを $x$ とします。つまり、$x$ は $1$ でも $p-1$ でもなく、x^2 \equiv 1 \pmod{p}を満たします。このとき、
\begin{aligned} x^2 &\equiv 1 \pmod{p}\\ x^2 - 1 &\equiv 0 \pmod{p}\\ (x + 1) (x - 1) &\equiv 0 \pmod{p} \end{aligned}となり、$p$ は素数なので $(x + 1)$ と $(x - 1)$ の少なくとも一方は $p$ で割り切れます。しかし、$x$ は $1$ でも $p-1$ でもないので
\begin{aligned} (x + 1) \not \equiv 0 \pmod{p}\\ (x - 1) \not \equiv 0 \pmod{p} \end{aligned}となります。つまり $(x + 1)$ と $(x - 1)$ は共に $p$ で割り切れません。よって矛盾が生じたので素数 $p$ を法とする非自明な平方根は存在しないことが示されました。
1.6. 奇素数に対するフェルマーの小定理
判定したい自然数が2の場合は素数であることが自明なので、事前に処理したとします。このとき、素数は必ず奇数になるので、奇素数 $p$ に対するフェルマーの小定理を考えます。いま、$p-1$ は偶数なので自然数 $s$ と奇数 $d$ を用いて
p - 1 = 2^s \cdot dと表せます。よってフェルマーの小定理は
a^{2^s \cdot d} \equiv 1 \pmod{p}となり、これは
(a^{2^{s-1} \cdot d})^2 \equiv 1 \pmod{p}と見ることもできます。前節で示した通り、素数 $p$ を法とする $1$ の非自明な平方根は存在しないので、
\begin{aligned} a^{2^{s-1} \cdot d} &\equiv \;\;\:1 \pmod{p}\\ a^{2^{s-1} \cdot d} &\equiv -1 \pmod{p} \end{aligned}のどちらかになります。1つ目であった場合は $s - 1 > 0$ であればさらに
(a^{2^{s-2} \cdot d})^2 \equiv 1 \pmod{p}と見ることができ、これもやはり
\begin{aligned} a^{2^{s-2} \cdot d} &\equiv \;\;\:1 \pmod{p}\\ a^{2^{s-2} \cdot d} &\equiv -1 \pmod{p} \end{aligned}のどちらかとなります。これを繰り返していくといつかは
\begin{aligned} a^{d} &\equiv \;\;\:1 \pmod{p}\\ a^{d} &\equiv -1 \pmod{p} \end{aligned}となります。
ここまでをまとめると次のようになります。
$p$ が奇素数のとき、自然数 $s$ と奇数 $d$ を用いて
p - 1 = 2^s \cdot dと書くことができ、以下の $p$ を法とした合同式のうち必ずどれか一つを満たす。
\begin{aligned} a^{2^{s-1} \cdot d} &\equiv -1\\ a^{2^{s-2} \cdot d} &\equiv -1\\ \cdots\\ a^{2 \cdot d} &\equiv -1\\ a^{d} &\equiv -1\\ a^d &\equiv \;\;\:1 \end{aligned}
この合同式は高々 $\log_2{p}$ 個程度ですので全てチェックしてしまいましょう。
以上より判定したい自然数 $n$ に対するテストはこのようになります。
- $n=1$ ならば不合格
- $n=2$ ならば合格
- $n \geq 3$ が偶数ならば不合格
$n \geq 3$ が奇数ならば $n - 1 = 2^s \cdot d$ とし、$n$ と互いに素な自然数 $a$ に対し $n$ を法として
\begin{aligned} a^{2^{s-1} \cdot d} &\equiv -1\\ a^{2^{s-2} \cdot d} &\equiv -1\\ \cdots\\ a^{2 \cdot d} &\equiv -1\\ a^{d} &\equiv -1\\ a^d &\equiv \;\;\:1 \end{aligned}のうち一つでも満たせば合格、一つも満たさなければ不合格
このテストを用いた確率的素数判定法はミラー-ラビン素数判定法と呼ばれています。
1.7. テストの実装法
3以上の奇数 $n$ に対する判定を整理します。
確率的素数判定法は複数の底でテストを行い全てに合格した場合のみ素数であると判定するので、テストの過程では不合格の場合のみを検出すれば良いです。
いま $n - 1 = 2^s \cdot d$ とし、テストの底を $a$ とします。このとき $0 \leq r < s$ となる $r$ について $a^{2^rd}$ を計算します。まず、$r=0$ のときa^d \equiv 1\; or\; -1 \pmod{n}であれば底 $a$ のテストは終了です。
そうでない場合、$r=1, 2, \cdots, s-1$ についてa^{2^rd} \not \equiv 1\; or\; -1 \pmod{n}である限り計算します。また、$r$ についての終了条件 $r < s$ は $2^rd < n - 1$ に対応します。
もし $a^{2^rd} \equiv -1 \pmod{n}$ となった場合は底 $a$ のテストは終了です。
しかし、 $a^{2^rd} \equiv 1 \pmod{n}$ となった場合はどうでしょうか。このとき、$a^{2^{r-1}d}$ は $1$ でも $-1$ でもないことはすでに確認されているので $a^{2^{r-1}d}$ は $1$ の非自明な平方根です。よって $n$ は素数でないので不合格となります。
また、最後まで $a^{2^rd} \not \equiv 1\; or\; -1 \pmod{n}$ であった場合も不合格となります。
以上をまとめると下図のようになります。
1.8. 底の選び方
ミラー-ラビン素数判定法では一般的には底の数を自分で決めて $a < n$ となる自然数 $a$ をランダムに選び底とします。計算速度と判定の精度はトレードオフの関係にあるので必要な精度を確保できる中でできるだけ少ない数の底が望ましいです。そのため効率的に精度を上げることができる底の組み合わせが研究されてきました。
ACLでは底として $a = {2, 7, 61}$ を採用しています。Jaeschke(1993)によると、この底のテストを全て通過する最小の合成数は $4759123141\;(=48781 \cdot 97561 > 2^{32})$ です。よって $n < 2^{32}$ の範囲(符号なし4バイト整数の範囲)では $100\%$ の精度で判定できます。1.9. 実装
それでは実装します。なおACLにおいてpow_modを用いている部分は、同等の機能であるPythonの組み込み関数powで代用しています
def is_prime(n): # 自明な部分 if (n <= 1): return False if (n == 2 or n == 7 or n == 61): return True if (n % 2 == 0): return False d = n - 1 # nは奇数 while (d % 2 == 0): d //= 2 # 奇数dを求める for a in (2, 7, 61): t = d # dは他の底でも使うので保持 y = pow(a, t, n) # a^d = 1, -1ならこのループは入らない # a^t = 1, -1となるまで繰り返す while (t != n - 1 and y != 1 and y != n - 1): y = y * y % n t <<= 1 # a^d = 1, -1は通過 (t%2 == 0) # a^t = -1は通過 (y != n - 1) if (y != n - 1 and t % 2 == 0): return False return True print(is_prime(17)) # True print(is_prime(1000000007)) # True print(is_prime(121)) # False print(is_prime(561)) # False (561はカーマイケル数のひとつ) # 底{2, 7, 61}のテストを通過する最小の合成数 print(is_prime(4759123141)) # True1.10. 計算速度の比較
時間計算量 $O(\sqrt{n})$ の決定的素数判定法と比較してみます。
比較に使用したコードは以下のものです。import random # ミラー-ラビン素数判定法(確率的素数判定法) def pro_is_prime(n): if (n <= 1): return False if (n == 2 or n == 7 or n == 61): return True if (n % 2 == 0): return False d = n - 1 while (d % 2 == 0): d //= 2 for a in (2, 7, 61): t = d y = pow(a, t, n) while (t != n - 1 and y != 1 and y != n - 1): y = y * y % n t <<= 1 if (y != n - 1 and t % 2 == 0): return False return True # 決定的素数判定法 def det_is_prime(n): if n < 2: return False if n == 2: return True if n % 2 == 0: return False for i in range(3, int(n ** 0.5) + 1): if n % i == 0: return False return True def random_1(): l1, r1 = [3, 1 << 16] return random.randrange(l1, r1, 2) def random_2(): l2, r2 = [(1 << 16) + 1, 1 << 32] return random.randrange(l2, r2, 2) def random_3(): l3, r3 = [3, 1 << 32] return random.randrange(l3, r3, 2) def main(): """ seed_list = [111, 222, 333, 444, 555, \ 666, 777, 888, 999, 101010] """ random.seed(111) # 乱数固定 loop = 10000 # ループ回数 10^4 or 10^6 for _ in range(loop): n = random_1() #n = random_2() #n = random_3() pro_is_prime(n) # 確率的 #det_is_prime(n) # 決定的 if __name__ == "__main__": main()計測方法
AtCoderのコードテスト(Python 3.8.2)を使用しました。
10種類のシード値で3種類の範囲から乱数を生成し、素数判定10000回あたりの実行時間を調べました。
偶数の場合はどちらも最初に処理されるので奇数のみとしました。
- random_1
- 乱数の範囲 : $[3, 2^{16}]$ の奇数
- ループ回数 : $10^4, 10^6$ ($10^4$ ではimportなどのオーバーヘッドがメインになる可能性があるため)
- random_2
- 乱数の範囲 : $[2^{16}, 2^{32}]$ の奇数
- ループ回数 : $10^4$
- random_3
- 乱数の範囲 : $[3, 2^{32}]$ の奇数
- ループ回数 : $10^4$
測定結果
結果は下図のようになりました。数値は素数判定10000回あたりの時間で単位はmsです。
ミラー-ラビン 決定的素数判定法 random_1(10^4) 63 59 random_1(10^6) 34 30 random_2 100 4060 random_3 99 4113 判定したい数が $10^5$ 程度の小さな数であれば決定的素数判定法の方がわずかに速いようです。
しかし、数が大きくなるとミラー-ラビン素数判定法の優位性が顕著になります。2. primitive_root
素数 $m$ を法とする原始根のうち最小のものを求めます。
2.1. 位数
最初に、原始根を説明する上で重要な用語である「位数」についてみていきます。定義はこうです。
2以上の自然数 $m$ および $m$ と互いに素な整数 $a$ に対して
a^{n} \equiv 1 \pmod{m}となる最小の自然数 $n$ を $m$ を法とする $a$ の位数という。
具体例をみてみましょう。
$m = 5, a = 3$ のとき、\begin{aligned} 3^1 &= 3 & \not \equiv 1 \pmod{5}\\ 3^2 &= 9 & \not \equiv 1 \pmod{5}\\ 3^3 &= 27 & \not \equiv 1 \pmod{5}\\ 3^4 &= 81 & \equiv 1 \pmod{5} \end{aligned}なので $5$ を法とする $3$ の位数は $4$ です。
また、$m = 12, a = 5$ のとき、\begin{aligned} 5^1 &= 2 & \not \equiv 1 \pmod{12}\\ 5^2 &= 25 & \equiv 1 \pmod{12} \end{aligned}なので $12$ を法とする $5$ の位数は $2$ です。
位数の性質
$m$ を法として $m$ と互いに素な整数 $a$ の位数 $e$ は正整数 $n$ に対して次の性質を持ちます。
a^n \equiv 1 \pmod{m} \Leftrightarrow e\; は \;n\; の約数
(証明)
$\Leftarrow:$
$e$ は $n$ の約数なので自然数 $k$ を用いて $n = ke$ とかける。よって $m$ を法として\begin{aligned} a^n &=a^{ke}\\ &= (a^e)^k\\ &\equiv 1 \end{aligned}となり、成立。
$\Rightarrow:$
$n$ を非負整数 $q, r$ を用いて $n=qe + r \;(0 \leq r < e)$ と表す。このとき $m$ を法として\begin{aligned} a^r &\equiv (a^{e})^qa^r\\ &\equiv a^{qe+r}\\ &\equiv 1 \end{aligned}となる。もし $0 < r < e$ だとすると、$e$ が位数であることと矛盾する(位数は $a^e\equiv 1 \pmod{m}$ を満たす最小の整数)。よって $r = 0$ であり、すなわち $e$ は $n$ の約数となる。
(証明終)
特に $m$ が素数の場合、フェルマーの小定理より位数は $m - 1$ の約数となります。
2.2. 原始根
$m$ が素数の場合を考えます。フェルマーの小定理から $m$ を法として $m$ と互いに素な整数 $a$ の位数は必ず $m - 1$ 以下になります。そこで、位数がちょうど $m - 1$ となる $a$ を特別視し、これを $m$ を法とする原始根と呼びます。
例えば、$m = 7$, $a = 3$ のとき
\begin{aligned} 3^1 &= 3 &\not \equiv 1 \pmod{7}\\ 3^2 &= 9 &\not \equiv 1 \pmod{7}\\ 3^3 &= 27 &\not \equiv 1 \pmod{7}\\ 3^4 &= 81 &\not \equiv 1 \pmod{7}\\ 3^5 &= 243 &\not \equiv 1 \pmod{7}\\ 3^6 &= 729 &\equiv 1 \pmod{7}\\ \end{aligned}なので $7$ を法とする $3$ の位数は $6$ です。よって $3$ は $7$ を法とする原始根です。
原始根は1つとは限りません。位数のところで示した例の1つ目から、$3$ は $5$ を法とする原始根であることがわかります。一方、$a = 2$ のとき\begin{aligned} 2^1 &= 2 & \not \equiv 1 \pmod{5}\\ 2^2 &= 4 & \not \equiv 1 \pmod{5}\\ 2^3 &= 8 & \not \equiv 1 \pmod{5}\\ 2^4 &= 16 & \equiv 1 \pmod{5} \end{aligned}となるので $2$ もまた $5$ を法とする原始根です。
なお、$m$ が素数のとき原始根は必ず存在します。
証明は「原始根定理」で調べてみてください。原始根の性質
素数 $m$ を法とする原始根 $g$ は次の性質を持ちます.
$m$ を法とした $g$ のべき乗の集合
\{g\pmod{m}, g^2\pmod{m}, \cdots , g^{m - 1}\pmod{m}\}と整数を $m$ で割ったあまりの集合から $0$ を除いた集合
\{1, 2, \cdots , m - 1\}は一致する。
これは次のように言い換えられます。
$1 \leq k \leq m-1$ の自然数 $k$ について
- $g^k \not \equiv 0$
- $g^k$ はすべて異なる。
1つ目は $g$ と $m$ が互いに素であることから明らかです。
よって2つ目を証明します。(証明)
いま、$k < l \leq m - 1$ なる自然数 $k, l$ が存在し、$g^k \equiv g^l\pmod{m}$ であったとします。このとき\begin{aligned} g^l - g^k &\equiv 0 \pmod{m}\\ g^k(g^{l-k} - 1) &\equiv 0 \pmod{m}\\ g^{l-k} - 1 &\equiv 0 \pmod{m}\\ g^{l-k} &\equiv 1 \pmod{m} \end{aligned}となります。$l - k < m - 1$ なので原始根である $g$ の位数は $m-1$ であることと矛盾します。
したがって、$1 \leq k \leq m-1$ に対し、$g^k$ はすべて異なります。
(証明終)2.3. 原始根であるかの確認方法1
ある2以上の自然数 $g$ が $m$ を法とする原始根であるかどうかを判定するためには、原始根の定義から $m$ を法として $g, g^2, \cdots, g^{m - 2}$ がすべて $1$ と合同でないことを確かめれば良いです。したがって、最小の原始根を求めるアルゴリズムの実装は以下のようになります。
def naive_primitive_root(m): g = 2 while True: for i in range(1, m - 1): if pow(g, i, m) == 1: g += 1 break else: return g print(naive_primitive_root(7)) # 3 print(naive_primitive_root(23)) # 5 #print(naive_primitive_root(1000000007)) # 非常に時間がかかりますこの方法では $g$ の $m - 2$ までのべき乗をすべて調べるので $m$ が大きくなると非常に時間がかかります。
2.4. 原始根であるかの確認方法2
実は原始根の性質を用いることでより簡単に原始根であるかの確認をすることができます。用いる性質は次のものです。
素数 $p_i$ および自然数 $e_i$ を用いて $3$ 以上の素数 $m$ に対して $m-1$ が
m-1 = \prod_{i = 1}^n{p_i^{e_i}}と素因数分解されたとき、$2$ 以上の自然数 $g$ について次のことが成り立つ。
g\;が\;m\;を法とする原始根 \Leftrightarrow 1 \leq i \leq n\;に対し\; g^{\frac{m-1}{p_i}}\not\equiv 1 \pmod{m}
(証明)
$\Rightarrow:$
$p_i$ は $m-1$ の素因数なので $\frac{m-1}{p_i}$ は整数であり、$1 \leq \frac{m-1}{p_i} < p - 1$ を満たす。$g$ が原始根のとき $g^{p-1}$ が初めて $1$ と合同になるべき乗なので $1 \leq i \leq n\;に対し\; g^{\frac{m-1}{p_i}}\not\equiv 1 \pmod{m}$ となる。$\Leftarrow:$
この主張の対偶はgは原始根でない \Rightarrow g^{\frac{m-1}{p_i}}\equiv 1 \pmod{m}となるiが存在するなのでこれを示す。
いま $g$ は原始根でないので位数 $e$ は $m-1$ 未満である。位数の性質で示した通り、$e$ は $m-1$ の約数なので $m-1$ の素因数と同じ $p_i$ を用いてe = \prod_{j = 1}^n{p_j^{e_j^{\prime}}}\;\;\;(e_j^{\prime} \leq e_j)と素因数分解でき、とくに $e_j^{\prime} < e_j$ となる $j$ が少なくとも1つ存在する。このような $j$ のうち1つを $i$ とする。このとき
\begin{aligned} \frac{m-1}{p_i} &= \frac{1}{p_i}\prod_{j}{p_j^{e_j}}\\ &= \frac{1}{p_i}\left(\prod_{j}{p_j^{e_j - e_j^{\prime}}}\right)\left(\prod_j{p_j^{e_j^{\prime}}}\right)\\ &= p_i^{e_i - e_i^{\prime} - 1}\left(\prod_{j \ne i}{p_j^{e_j - e_j^{\prime}}}\right)\left(\prod_j{p_j^{e_j^{\prime}}}\right) \end{aligned}ここで、$e_i - e_i^{\prime} - 1 \geq 0$ かつ $e_j - e_j^{\prime} \geq 0$ なので
\frac{m-1}{p_i} = (自然数) \times eとなる。
したがって、$g$ が原始根でないならばg^{\frac{m-1}{p_i}} \equiv \left(g^e\right)^{自然数} \equiv 1 \pmod{m}となる $i$ が存在する。
(証明終)
以上より
- $m-1$ の素因数を求める。
- 各素因数 $p_i$ について $g^{\frac{m-1}{p_i}}\not\equiv 1 \pmod{m}$ となるか調べる。
という手順で $g$ が原始根であるかを判定できます。
2.5. 実装
それでは実装します。is_primeと同様にpow_modは組み込み関数powで代用します。
# @param m must be prime def primitive_root(m): if m == 2: return 1 if m == 167772161: return 3 if m == 469762049: return 3 if m == 754974721: return 11 if m == 998244353: return 3 # m-1の素因数抽出 divs = [2] x = (m - 1) // 2 while x % 2 == 0: x //= 2 i = 3 while i * i <= x: if x % i == 0: divs.append(i) while x % i == 0: x //= i i += 2 if x > 1: divs.append(x) # 全ての素因数で1と合同でない最小のgを探す g = 2 while True: if all(pow(g, (m - 1) // div, m) != 1 for div in divs): return g g += 1 print(primitive_root(7)) # 3 print(primitive_root(23)) # 5 print(primitive_root(1000000007)) # 5最初に判定しているいくつかの $m$ はconvolutionで使われるmodのようです。
3. おわりに
今回は素数判定法と原始根について見てきました。とくに確率的素数判定法の考え方が面白いと感じました。
internal_mathのなかで今回触れなかったものについてはinternal_math編①で書いていますので、よろしければそちらもご覧ください。
説明の間違いやバグ、アドバイス等ありましたらお知らせください。
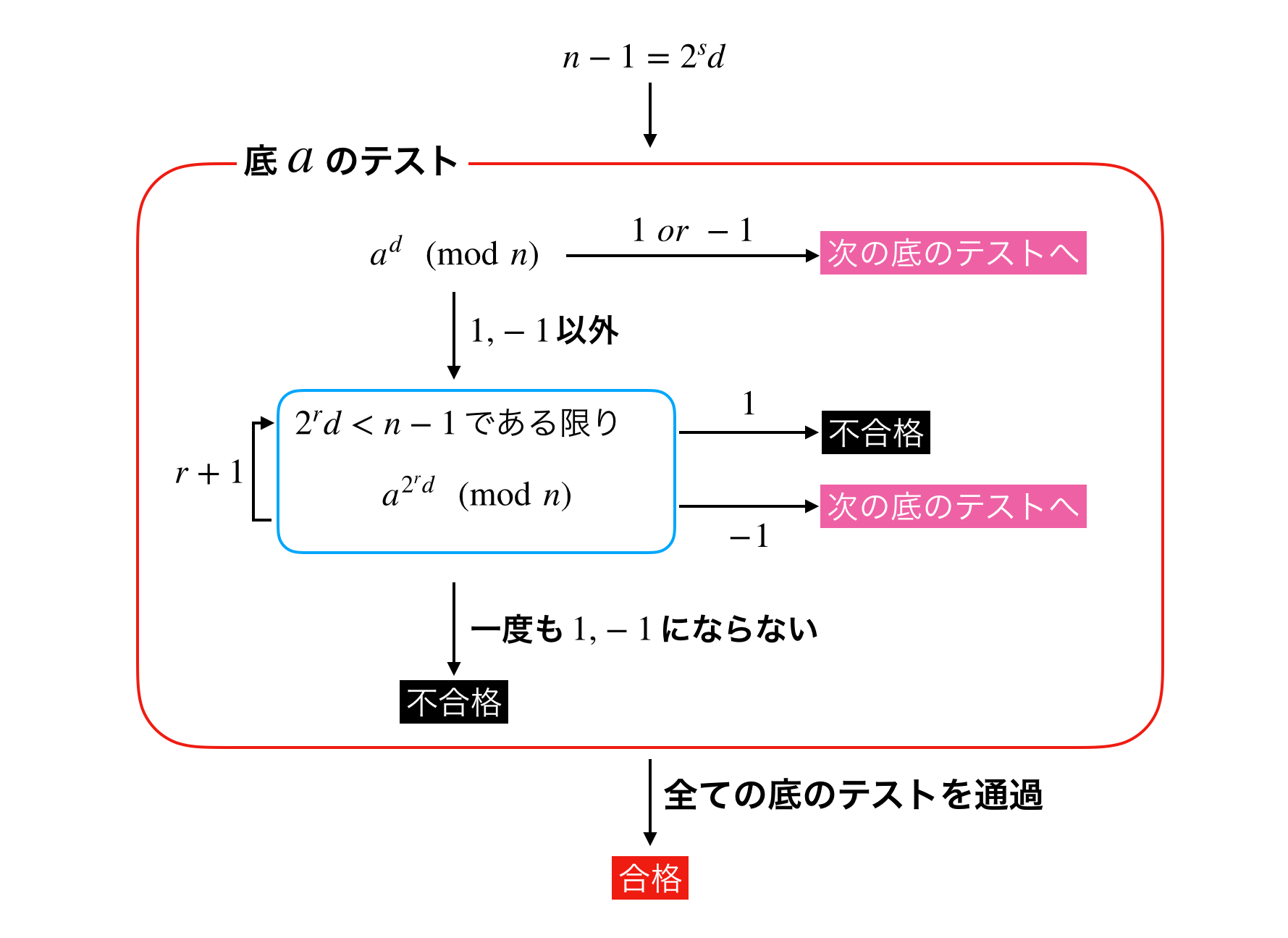
- 投稿日:2020-10-25T20:28:44+09:00
Chainerによる機械学習のためのPython学習メモ 13章 ニューラルネットワークの訓練 〜Chainer完了
What
Chainerを利用して機械学習を学ぶにあたり、私自身が、気がついた点、リサーチした内容をまとめる記事になります。今回は、ニューラルネットワークの訓練について勉強します。
私の理解に基づいて記述しているため、間違っている場合があります。間違いは都度修正するつもりです、ご容赦ください。
Content
ニューラルネットワークの訓練
端的に言えばモデルの精度をあげること、ユーザーからしたら賢くすること
目的関数
ニューラルネットワークも一段掘り下げれば、つまり目的関数を最適化することになる。下記、代表的な2種類の目的関数が紹介されている。
- 回帰問題でよく用いられる平均二乗誤差 (mean squared error)
- 分類問題でよく用いられる交差エントロピー (cross entropy)
平均二乗誤差はモデルのパラメータの最適解を求める時に、バチっと一つの解がもとまる手法であるのに対して、
確率的にこっちの方がありえるかなぁ〜を予測する方法が交差エントロピーという理解をしてます。目的関数の最適化
勾配降下法・・・名前の通り勾配からパラメータを更新していく方法
ミニバッチ学習法・・・データセットを複数の組みにしてそれぞれの目的関数を導出。そして、目的関数の平均値をとることでパラメータを更新していく方法(正直よくわからない)活性化関数
活性化関数の勾配の値が小さいと各層のパラメータも小さくなってしまう。これを勾配消失という。
活性化関数って何か制約があるのでしょうか?(発散しないとか、収束するとか・・・)
確率として出力するから1以下になるようにしないといけない???
そこでReLU関数が紹介されているけど、誰がどうやって見つけたんでしょうか・・・?
また詳細がわかったら更新します。勾配消失の問題が解決されたことによってディープラーニングが可能になったのかな
Comment
とりあえず、機械学習の概要は掴めてきました。
次は、具体的にプログラムを何か作ってみたいと思います。
というわけで、この本を購入しました。正直、知識が浅すぎて何買えばいいのかわからなかったのですが、目次を索引を見ると、
Chainerで学習したライブラリを使っているので実戦向き
Webアプリケーション作成について紹介があり、プログラムを一般公開するのに役立ちそう
だったので購入を決めました。なので、この本勉強して
STEP.1 機械学習の実戦
STEP.2 Pyhtonをアプリ公開レベルまで使いこなすを次の目標に頑張ります。

- 投稿日:2020-10-25T20:24:31+09:00
Django Customコマンドの中に潜ってみる [1]
はじめに
初記事投稿になります。
勉強した事を何か形に残る形で残したいと思い始める事にしました。djangoを深く使いこなす事をモットーに最近は勉強しております。
本記事は、djangoのカスタムコマンドについての勉強の足跡です。目次
- djangoカスタムコマンドとは
- カスタムコマンド利用の前準備
- カスタムコマンドの作り方
- カスタムコマンドの流れ
- カスタムコマンドのカスタマイズ
- まとめ
1. djangoカスタムコマンドとは
CUIで、pythonスクリプトを実行できる仕組みであり、
・djangoの各種機能(db ORM等)が使える
・コマンドの管理がラクといった利点があります。後者は、
-利用できるコマンドを一覧表示-
python manage.py --help[shop] customcommand cusyomcommand2 ...-カスタムコマンドの説明を表示-
python manage.py customcommand --helpusage: manage.py customcommand2 [-h] [--version] [-v {0,1,2,3}] [--settings SETTINGS] [--pythonpath PYTHONPATH] [--traceback] [--no-color] [--force-color] [--skip-checks] データを格納する関数このような事が可能です。
2. カスタムコマンド利用の前準備
(1) アプリケーションを作成(今回はscriptという名前で作成)
python manage.py startapp script(2) management/commandsの階層構造を作成
script/ ├── management/ ├── commands/ ├── admin.py ├── apps.py ├── models.py ├── tests.py └── views.py(3) スクリプトファイルをcommands以下に入れる
ここでは、customcommand.pyという名前で作成します3. カスタムコマンドの作り方
基となるBaseCommandクラスのコメントを読むと、"コマンド実行のフローを変えない場合は、BaseCommandクラスを継承したCommandという名の子クラスを利用すれば良い"という旨が書かれているので、基本的には以下の構成で大丈夫だと思います。
customcommand.pyclass Command(BaseCommand): # オーバーライドしたhandle関数にスクリプトで処理したい内容を記述 def handle(self, *args, **options): pass4. カスタムコマンドの流れ
本題のカスタムコマンドがどのように呼ばれ、どのような関数を経由して処理を行うかのお話です。
処理の流れは以下になります。
python manage.py customcommandの実行Commandクラスの呼び出し
run_from_argvメソッド
create_parserメソッド
add_argumentsメソッド
parse_argsメソッド
executeメソッド
handleメソッド
run_from_argvという関数が全体の処理の流れを表して、その他の関数内で細かい処理をしているようなイメージを受けました。よって、4以降の細かい処理の概念を以下に記します。
4. create_parserメソッド
引数は[コマンドライン引数[0], コマンドライン引数[1]]の形式
->今回の例なら、['manage.py', 'customcommand']まずmanage.pyのファイル名の切り出しを行います。
->manage.pyをフルパスで記載した場合はここでmanage.pyのみ取り出される。次にParserオブジェクトを作成します。
Parserオブジェクトは以下のような属性を持ちます。
-prog: "manage.py customcommand" (命令をスペースで区切ったもの)
-description: help文 (self.helpで取得)
-formatter_class: (--versionといったあらかじめ決められたDjangoのhelpオプション)
など※parserオブジェクト自体は予期される引数を持つイメージです。
5. add_argumentsメソッド
parserオブジェクトに処理で用いたい引数を追加します。例えば、
parser.add_argument('parameters', nargs='+', type=int)
とすれば、int型の1つ以上の引数を強制する事ができます。
->python manage.py customcommand 3 5など6. parse_argsメソッド
ここで実際に入力した命令群のフォーマットの確認を行います。
・--version等、Djangoのhelpオプションが来た場合はここで処理を終える
・入力フォーマットが違う場合は、予期される引数(parserの中身)を標準出力する7,8. executeメソッド, handleメソッド
6の処理でフォーマットチェックを通過した場合のみexcuteメソッドに渡され、handleメソッドに渡されます。
※5の処理で、引数を追加した場合はhandleメソッドのoptions引数から参照する事ができます。5. カスタムコマンドのカスタマイズ
コマンドのヘルプ文の追加
help = '~する関数'help引数を定義しておけばOK
引数の追加
ArgumentParserの使い方を簡単にまとめた
こちらの記事で詳しく解説されていました。6. まとめ
色々と調べましたが、よっぽどhandle関数とadd_arguments関数、後はhelpの追加くらいを押さえて置いたら大丈夫そうな印象を受けました。
parseオブジェクトの概念に関しては、可変な引数の扱いなどで広く使われていそうなので、勉強になりました。
- 投稿日:2020-10-25T19:37:32+09:00
ANACONDA仮想環境をPycharmで使用時のPATH(2020/10/03)
結論
Mac環境で、Anaconda(Django/Python) + PyCharmでの開発環境を作成した時、PycharmでAnaconda仮想環境を紐づけるためののPathが変わっていました(2020/10/03時点)。
/opt/anaconda3/envs/(ANACONDAで作成した環境名)/bin/python[Python Django 3 RestFramework + Angular 9]でWebフルスタック完全攻略
こちらを学習時、PATHでつまづいたのですが、2020/10/03時点で変更されたようです。詳細
- Mac環境(MacBook Pro 13inch 2020 / MacOS Catalina)
ANACONDAでDjango/Pythonの仮想環境を作成(ANACONDA NAVIGATOR 4.8.3)
- ANACONDA NAVIGATOR → Environments → Create →
- popupmenuでるので仮想環境名とpythonのバージョンはそのままにしてcreate押下で抜けると設定した仮想環境ができる
- 上で指定した仮想環境名の横の▶︎を押下し、Open terminalでターミナルが使える
- ターミナルから以下をpip innstall
- django 3.0.4 djangorstframework 3.11.0
PyCharmでANACONDAの仮想環境をコーディングできるようセットアップ(PyCharm 2020.2.3 (Community Edition))
- 任意の場所(私はユーザーホーム直下)にPyCharmプロジェクト用のフォルダを任意名で作成
- PyCharmから上で作ったフォルダを作成
- Pycharm → Preferences → Project:PyCharmプロジェクト名/Project Interpreter → ⚙ → Add...
これで以下の状態になり、Existing environment を選択し、Interpreter:のパスを選ぶと、PyCharmのプロジェクトにANACONDAの仮想環境が紐づく。
- Pathは以下のキャプチャにあるように
/opt/anaconda3/envs/(ANACONDAで作成した環境名)/bin/python
つまづいたのは、PyCharmからANACONDA仮想環境にひもづけるためのPATHが変更されていたことです。
このPATHを見つけるのに一苦労しました…。(2020/10/03時点)
- 投稿日:2020-10-25T19:37:32+09:00
ANACONDA仮想環境をPycharmで使用時のPATH(2020/10/03時点)
結論
Mac環境で、Anaconda(Django/Python) + PyCharmでの開発環境を作成した時、PycharmでAnaconda仮想環境を紐づけるためののPathが変わっていました(2020/10/03時点)。
/opt/anaconda3/envs/(ANACONDAで作成した環境名)/bin/python[Python Django 3 RestFramework + Angular 9]でWebフルスタック完全攻略
こちらを学習時、PATHでつまづいたのですが、2020/10/03時点で変更されたようです。詳細
- Mac環境(MacBook Pro 13inch 2020 / MacOS Catalina)
ANACONDAでDjango/Pythonの仮想環境を作成(ANACONDA NAVIGATOR 4.8.3)
- ANACONDA NAVIGATOR → Environments → Create →
- popupmenuでるので仮想環境名とpythonのバージョンはそのままにしてcreate押下で抜けると設定した仮想環境ができる
- 上で指定した仮想環境名の横の▶︎を押下し、Open terminalでターミナルが使える
- ターミナルから以下をpip innstall
- django 3.0.4 djangorstframework 3.11.0
PyCharmでANACONDAの仮想環境をコーディングできるようセットアップ(PyCharm 2020.2.3 (Community Edition))
- 任意の場所(私はユーザーホーム直下)にPyCharmプロジェクト用のフォルダを任意名で作成
- PyCharmから上で作ったフォルダを作成
- Pycharm → Preferences → Project:PyCharmプロジェクト名/Project Interpreter → ⚙ → Add...
これで以下の状態になり、Existing environment を選択し、Interpreter:のパスを選ぶと、PyCharmのプロジェクトにANACONDAの仮想環境が紐づく。
- Pathは以下のキャプチャにあるように
/opt/anaconda3/envs/(ANACONDAで作成した環境名)/bin/python
つまづいたのは、PyCharmからANACONDA仮想環境にひもづけるためのPATHが変更されていたことです。
このPATHを見つけるのに一苦労しました…。(2020/10/03時点)
- 投稿日:2020-10-25T19:37:32+09:00
ANACONDA仮想環境をPycharmで使用時のPATH(Mac 2020/10/03時点)
結論
Mac環境で、Anaconda(Django/Python) + PyCharmでの開発環境を作成した時、PycharmでAnaconda仮想環境を紐づけるためののPathが変わっていました(2020/10/03時点)。
/opt/anaconda3/envs/(ANACONDAで作成した環境名)/bin/python[Python Django 3 RestFramework + Angular 9]でWebフルスタック完全攻略
こちらを学習時つまづいたPATHは、2020/10/03時点で変更されたようです。詳細
- Mac環境(MacBook Pro 13inch 2020 / MacOS Catalina)
ANACONDAでDjango/Pythonの仮想環境を作成(ANACONDA NAVIGATOR 4.8.3)
- ANACONDA NAVIGATOR → Environments → Create →
- popupmenuでるので仮想環境名とpythonのバージョンはそのままにしてcreate押下で抜けると設定した仮想環境ができる
- 上で指定した仮想環境名の横の▶︎を押下し、Open terminalでターミナルが使える
- ターミナルから以下をpip innstall
- django 3.0.4 djangorstframework 3.11.0
PyCharmでANACONDAの仮想環境をコーディングできるようセットアップ(PyCharm 2020.2.3 (Community Edition))
- 任意の場所(私はユーザーホーム直下)にPyCharmプロジェクト用のフォルダを任意名で作成
- PyCharmから上で作ったフォルダを作成
- Pycharm → Preferences → Project:PyCharmプロジェクト名/Project Interpreter → ⚙ → Add...
これで以下の状態になり、Existing environment を選択し、Interpreter:のパスを選ぶと、PyCharmのプロジェクトにANACONDAの仮想環境が紐づく。
- Pathは以下のキャプチャにあるように
/opt/anaconda3/envs/(ANACONDAで作成した環境名)/bin/python
つまづいたのは、PyCharmからANACONDA仮想環境にひもづけるためのPATHが変更されていたことです。
このPATHを見つけるのに一苦労しました…。(2020/10/03時点)
- 投稿日:2020-10-25T19:10:54+09:00
Python学習4日目
Pythonでcsvの中身を集計
目的:今後スクレイピングで取得したデータをcsvにし、データの整形、分析を行いた為
今回行うこと:csvに記入されている会議室と記入数を表示する
初学者です、Markdownの書き方すら調べながら行っているレベルです。
アウトプットは必須だと思ったので自分用に残そうと思っています。環境
pc:Macbook pro
python3 ver3.8.6
pyqファイルの作成
ターミナルを使用してファイルを作成します。
~$cd Documents ~Documents$mkdir study ~Documents$cd study ~Documents/study$touch room.csv ~Documents/study$touch study.py ~Documents/study$ls room.csv test.py --実行-- ~Documents/study$python3 study.pyroom.csv会議室A,一条 会議室B,七草 会議室C,十文字 会議室A,八代 会議室A,四葉 会議室A,三矢 会議室B,一条 会議室B,二木 会議室C,六塚 会議室A,十文字 会議室B,二階堂 会議室C,七瀬 会議室A,一色stury.py#リスト初期化 book = {} #csv読み込み with open ('room.csv', encoding='utf-8') as f: #会議室A,山田 for row in f: #空白を削除しリスト化 columns = row.rstrip().split(',') room = columns [0] #2回め以降・・・ if room in book: book[room] += 1 #1回目{'会議室A': 1, '会議室B': 1, '会議室C': 1} else: book[room] = 1 #keys values items itemsは両方を持つから引数を2つ #print(book) → {'会議室A': 6, '会議室B': 4, '会議室C': 3} for room_name, count in book.items(): print(room_name + ':' + str(count)) -----------result----------- 会議室A:6 会議室B:4 会議室C:3
- 投稿日:2020-10-25T18:10:31+09:00
NetworkXのgraph generator一覧
NetworkXで作成できるグラフのリストです。
前情報
NetworkXのバージョンは2.4です。
公式ドキュメントを和訳したものです。全ては網羅できていません。訳語が間違っている場合はお知らせください。下記のコードを実行するにはあらかじめ
networkxとmatplotlib.pyplotをインポートしておいてください。import networkx as nx import matplotlib.pyplot as pltClassic(古典的グラフ)
balanced tree(平衡木)
balanced_tree(r, h, create_using=None)高さが
hである完全平衡r分木を返します。
パラメータ 型 説明 r int 木の枝分かれ数。各ノードはr個の子ノードを持ちます。 h int 木の高さ create_using NetworkX graph constructor, optional (default=nx.Graph) 作成したいグラフの型 例
#balanced_tree G=nx.balanced_tree(3,2) plt.cla() nx.draw_networkx(G) plt.show()
Barbell graph(バーベルグラフ)
barbell_graph(m1, m2, create_using=None)バーベルグラフ(
m1個のノードで構成された2つの完全グラフがm2個のノードからなる1本の道によってつながれたグラフ)を返します。
パラメータ 型 説明 m1 int 左右の完全グラフ(bell)の個数。m1>1 m2 int 左右の完全グラフをつなぐ経路のノード数。m2>=0 create_using NetworkX graph constructor, optional (default=nx.Graph) 作成したいグラフの型 ノードのナンバリング方法
左の完全グラフ:0,1,...,m1-1
経路:m1,m1+1,...,m1+m2-1
右の完全グラフ:m1+m2,m1+m2+1,...,2*m1+m2-1例1
#barbell_graph G=nx.barbell_graph(5,2) plt.cla() nx.draw_networkx(G) plt.show()
例2(m2=0のとき)
G=nx.barbell_graph(5,0) plt.cla() nx.draw_networkx(G) plt.show()
binomial_tree(二項木)
binomial_tree(n)次数が
nである二項木を返します。ノード数は$2^n$個、エッジ数は$2^n-1$個です。
パラメータ 型 説明 n int 木の次数 例
G=nx.binomial_tree(3) plt.cla() nx.draw_networkx(G) plt.show()
complete_graph(完全グラフ)
complete_graph(n, create_using=None)あるノードが他のすべてのノードと連結しているグラフを返します。
パラメータ 型 説明 n int または iterable container of nodes nが整数型のとき、ノードはrange(n)から作成されます。nがノードのイテラブルコンテナであるとき、それらノードによるグラフが作成されます create_using NetworkX graph constructor, optional (default=nx.Graph) 作成したいグラフの型 例1(nが整数型のとき)
G=nx.complete_graph(6) plt.cla() nx.draw_networkx(G) plt.show()
例2(nがノードのコンテナであるとき)
G=nx.complete_graph(range(12,18)) plt.cla() nx.draw_networkx(G) plt.show()
complete_multipartite_graph(完全多部グラフ)
complete_multipartite_graph(*subset_sizes)
パラメータ 型 説明 subset_sizes taple of integers または tuple of node iterables nが整数型のとき、多部グラフの各サブセットはn個の頂点をもちます。nがイテラブルであるときは、それらノードによるグラフが作成されます create_using NetworkX graph constructor, optional (default=nx.Graph) 作成したいグラフの型 例
それぞれ2,3,3個のノードをもつ3つのサブセットからなる完全多部グラフを作成します。G=nx.complete_multipartite_graph(2,3,3) plt.cla() nx.draw_networkx(G) plt.show()
circular_ladder_graph(環状ラダーグラフ)
circular_ladder_graph(n, create_using=None)
長さnの環状ラダーグラフを返します。
パラメータ 型 説明 n int 1周の長さ create_using NetworkX graph constructor, optional (default=nx.Graph) 作成したいグラフの型 例
G=nx.circular_ladder_graph(10) plt.cla() nx.draw_networkx(G) plt.show()
circulant_graph(循環グラフ)
circulant_graph(n, offsets, create_using=None)
n個のノードからなる、循環グラフを返します。あるノードが他のどのノードとつながるかはoffsetsで指定されます。
パラメータ 型 説明 n int ノードの個数 offsets lists of integers ノードオフセットのリスト create_using NetworkX graph constructor, optional (default=nx.Graph) 作成したいグラフの型 例
G=nx.circulant_graph(10,[1,2]) plt.cla() nx.draw_networkx(G) plt.show()
offsets=[1,2]であることから、頂点iは頂点i+1,i+2とそれぞれつながっています。頂点0は頂点1,2に、頂点1は頂点2,3に,...,頂点9は頂点0,1につながっています。
cycle_graph(閉路グラフ)
cycle_graph(n, create_using=None)
パラメータ 型 説明 n int またはiterble container of nodes nが整数型のとき、ノードはrange(n)から作成されます。nがノードのイテラブルコンテナであるとき、それらノードによるグラフが作成されます create_using NetworkX graph constructor, optional (default=nx.Graph) 作成したいグラフの型 例
G=nx.cycle_graph(10) plt.cla() nx.draw_networkx(G) plt.show()
dorogovtsev_goltsev_mendes_graph(Dorogovstev-Goltsev-Mendesグラフ)
dorogovtsev_goltsev_mendes_graph(n, create_using=None)Dorogovstev-Goltsev-Mendesアルゴリズムによって作成されたグラフを返します。
元論文
https://arxiv.org/abs/cond-mat/0112143
パラメータ 型 説明 n int 世代数 create_using NetworkX graph constructor, optional (default=nx.Graph) 作成したいグラフの型 G=nx.dorogovtsev_goltsev_mendes_graph(3) plt.cla() nx.draw_networkx(G) plt.show()
empty_graph(ノードをもつ空グラフ)
empty_graph(n=0, create_using=None, default=<class 'networkx.classes.graph.Graph'>)エッジを持たない
n個のノードからなるグラフを返します。
パラメータ 型 説明 n int ノード数 create_using Graph Instance, Constructor or None 作成したいグラフの型。Noneが指定されたときは defaultコンストラクタを使います。default Graph constructor (optional, default = nx.Graph) create_using=Noneのときに使用されるコンストラクタ。例
G=nx.empty_graph(10) plt.cla() nx.draw_networkx(G,pos) plt.show()
create_usingの使い方
変数 create_using は Graph コンストラクタまたは "graph" ライクなオブジェクトでなければなりません。
create_usingの主な用途は3つあります。
1. 空グラフの性質を指定する。
2. 既存のグラフを空グラフにする
3. 自作のグラフ作成関数を作るとき、create_usingに好きなグラフコンストラクタを渡せるようにする。1の例
空の有向グラフ(DiGraph)を作成します。
n = 10 G = nx.empty_graph(n, create_using=nx.DiGraph)2の例
完全グラフG1からエッジを取り除いた空グラフG2を作成します。
n=5 G1=nx.complete_graph(n) G1.number_of_edges() #10 G2=nx.empty_graph(n,create_using=G1) G2.number_of_edges() #03の例
自作のグラフ作成関数
mygraphについて、create_usingの指定がないときはデフォルトコンストラクタnx.MultiGraphを使い、そうでないときは指定されたコンストラクタを使うように設定します。def mygraph(n, create_using=None): G = nx.empty_graph(n, create_using, default=nx.MultiGraph) G.add_edges_from([(0, 1), (0, 1)]) return G G = mygraph(3) G.is_multigraph() #True G = mygraph(3, nx.Graph) G.is_multigraph() #Falsefull_rary_tree(全r分木)
full_rary_tree(r, n, create_using=None)
n個のノードから構成された全r分木を作成します。すべてのノードが葉であるかr個の子ノードを持っています。
パラメータ 型 説明 r int 木の枝分かれ数 n int ノード数 create_using NetworkX graph constructor, optional (default=nx.Graph) 作成したいグラフの型 例
G=nx.full_rary_tree(3,16) pos=nx.spring_layout(G,iterations=1000) plt.cla() nx.draw_networkx(G,pos) plt.show()
ladder_graph(ラダーグラフ)
ladder_graph(n, create_using=None)ラダーグラフを返します。
パラメータ 型 説明 n int ラダーの長さ create_using NetworkX graph constructor, optional (default=nx.Graph) 作成したいグラフの型 例
G=nx.ladder_graph(7) plt.cla() nx.draw_networkx(G) plt.show()
lollipop_graph(ロリポップグラフ)
lollipop_graph(m, n, create_using=None)ロリポップグラフ(
m個のノードからなる完全グラフとそれにつながるn個のノードからなる経路)を返します。
パラメータ 型 説明 m int or iterable container of nodes (default = 0) 完全グラフを構成するノード数 n int or iterable container of nodes (default = 0)) 経路を構成するノード数 create_using NetworkX graph constructor, optional (default=nx.Graph) 作成したいグラフの型 例
G=nx.lollipop_graph(6,3) plt.cla() nx.draw_networkx(G) plt.show()
null_graph(空グラフ)
null_graph(create_using=None)ノードもエッジも持たないグラフを返します。
create_usingの使い方についてはempty_graphを参照してください。
パラメータ 型 説明 create_using NetworkX graph constructor, optional (default=nx.Graph) 作成したいグラフの型 例
G=nx.null_graph() plt.cla() nx.draw_networkx(G) plt.show()
path_graph(道グラフ)
path_graph(n, create_using=None)
n個のノードからなる、同じノードを2度通らないグラフを返します。
パラメータ 型 説明 n int or iterable ノードの個数 create_using NetworkX graph constructor, optional (default=nx.Graph) 作成したいグラフの型 G=nx.path_graph(5) plt.cla() nx.draw_networkx(G) plt.show()
star_graph(星グラフ)
star_graph(n, create_using=None)1つの中心ノードに対し
n個の外周ノードが連結されたグラフを返します。
パラメータ 型 説明 n int or iterable 外周ノードの個数 create_using NetworkX graph constructor, optional (default=nx.Graph) 作成したいグラフの型 G=nx.star_graph(5) plt.cla() nx.draw_networkx(G) plt.show()
trivial_graph(トリビアルグラフ)
trivial_graph(create_using=None)1個のノードのみからなる最も単純なグラフを返します。
パラメータ 型 説明 create_using NetworkX graph constructor, optional (default=nx.Graph) 作成したいグラフの型 G=nx.trivial_graph() plt.cla() nx.draw_networkx(G) plt.show()
turan_graph(トゥラーングラフ)
turan_graph(n, r)
n個のノードをr個の非連結部分に分けた完全多部グラフを返します。
エッジの数はn**2*(r-1)/(2*r)の端数を切り捨てた数になります。
パラメータ 型 説明 n int ノードの個数。 r int 非連結部分の個数。1<=r<=nである必要があります。 create_using NetworkX graph constructor, optional (default=nx.Graph) 作成したいグラフの型 G=nx.turan_graph(6,3) plt.cla() nx.draw_networkx(G) plt.show()
ノードは(0,1),(2,3),(4,5)の3部分に分かれています。同じ部分に属しているノードは連結していません。
例で挙げたグラフは「3組のカップルがカクテルパーティーへ出かけた。会場では、全員が自身とその配偶者を除くすべての参加者とそれぞれ握手をする。そのときの関係性を参加者をノード、握手をエッジとして表現するとどのようなグラフになるか?」という問いに対する解答となっています。そのため「カクテルパーティーグラフ」と呼ばれます。
wheel_graph(ホイールグラフ)
wheel_graph(n, create_using=None)1つのハブノードに対し、n-1個の外周ノードが連結されたグラフを返します。
パラメータ 型 説明 n int or iterable ノードの個数。 create_using NetworkX graph constructor, optional (default=nx.Graph) 作成したいグラフの型 Example
G=nx.wheel_graph(10) plt.cla() nx.draw_networkx(G) plt.show()
Expander graph(拡張グラフ)
強連結成分をもつ疎グラフです。
margulis_gabber_galil_graph(Margulis-Gabber-Galilグラフ)
margulis_gabber_galil_graph(n, create_using=None)Margulis-Gabber-Galilグラフを返します。無向多重グラフであり、ノードの次数は8です。このグラフの隣接行列の2番目に大きな固有値は$5\sqrt{2}$です。
グラフが有向または多重グラフでないときはエラーが返されます。
パラメータ 型 説明 n int or iterable ノードの個数を定義します。ノードの個数は$n^2$です。 create_using NetworkX graph constructor, optional (default MultiGraph) 作成したいグラフの型 G=nx.margulis_gabber_galil_graph(3) pos=nx.circular_layout(G) plt.cla() nx.draw_networkx(G) plt.show()
chordal_cycle_graph(弦を持つ閉路グラフ)
chordal_cycle_graph(p, create_using=None)弦(chord, 閉路の一部ではないが閉路グラフ上の2つのノード間を連結するエッジ)をもつ閉路グラフを返します。ノードxはx*y=1(mod p)を満たすノードyに対し弦を持ちます。
グラフが有向または多重グラフでないときはエラーが返されます。
パラメータ 型 説明 p prime number ノードの個数を定義します。素数である必要があります。 create_using NetworkX graph constructor, optional (default MultiGraph) 作成したいグラフの型 G=nx.chordal_cycle_graph(7) pos=nx.circular_layout(G) plt.cla() nx.draw_networkx(G,pos) plt.show()
Social Networks
有名なソーシャルネットワークグラフです。
karate_club_graph(Zacharyの空手クラブ)
karate_club_graph()アメリカの社会心理学者Zacharyが調査した空手クラブのメンバー間のネットワークです。ノード0とノード32,33を中心とする2つの派閥に分かれていることがわかります。
Zachary, Wayne W. “An Information Flow Model for Conflict and Fission in Small Groups.” Journal of Anthropological Research, 33, 452–473, (1977).
G=nx.karate_club_graph() plt.figure(figsize=(8,6)) nx.draw_networkx(G) plt.show()
davis_southern_women_graph(Davisらの南部女性グラフ)
davis_southern_women_graph()1930年代にDavisらによって調査されたアメリカ南部の女性18人のネットワークです。18個の女性を表すノードと14個の参加したイベントをノードから構成される2部グラフです。
A. Davis, Gardner, B. B., Gardner, M. R., 1941. Deep South. University of Chicago Press, Chicago, IL.
florentine_families_graph(フィレンツェの家族)
florentine_families_graph()ルネサンス期フィレンツェにおけるメディチ家などの有力家の婚姻関係です。
Ronald L. Breiger and Philippa E. Pattison Cumulated social roles: The duality of persons and their algebras,1 Social Networks, Volume 8, Issue 3, September 1986, Pages 215-256
les_miserables_graph()
les_miserables_graph()小説「レ・ミゼラブル」の登場人物のグラフです。
D. E. Knuth, 1993. The Stanford GraphBase: a platform for combinatorial computing, pp. 74-87. New York: AcM Press.
参照



- 投稿日:2020-10-25T17:54:03+09:00
Djangoでbase.htmlが呼び出せないとき
Djangoで共通テンプレートを作成してTemplateDoesNotExistと怒られたときの対応
自分がすぐ忘れるので、自分用メモです。
状況
- プロジェクトディレクトリ直下にtemplatesディレクトリを作成し、その中にbase.htmlを作成
- 各アプリディレクトリ中のtemplatesディレクトリ直下のhtmlから、base.htnlを呼び出すと[TemplateDoesNotExist]エラーが発生
下の図だと、list.htmlからbase.htmlを呼び出したい
Djangoのバージョン
3.1.1
解決策
プロジェクトディレクトリ直下のsettings.pyに
import os
'DIRS': [os.path.join(BASE_DIR, 'templates')]
を追加
あとは、base.htmlを読み込みたいhtmlファイルで
でOK!
[import os]を忘れていると
[name 'os' is not defined]
と怒られます。
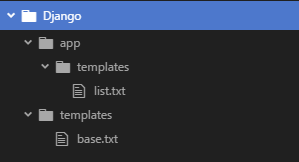
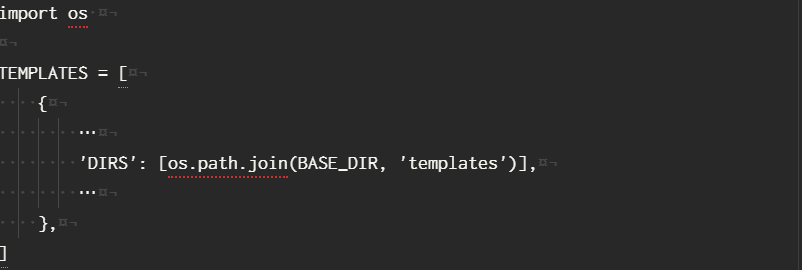

- 投稿日:2020-10-25T17:47:22+09:00
CPythonに機能追加してみた(三項演算子)
はじめに
ここでは、CPythonに三項演算子を追加する手順ついて説明します。
本記事ではPython3.10を使用しています。CPythonのビルド、ファイル構造の説明はこちらでしているので併せてご参照ください。
* この記事はEEIC(東京大学工学部 電気電子工学科/電子情報工学科)3年の後期実験「大規模ソフトウェアを手探る」のレポートとして書きました。
* 以下の記事はチームメンバーが書いたものです。
CPythonに機能追加してみた(ビルド&構造把握)
pythonに2種類のswitch文を追加する
前置インクリメント2. 三項演算子の追加
2.1 Pythonの三項演算子
Pythonの三項演算子は以下です。Pythonでは(条件がTrueのときの値)が先に来て、(条件)がその次、最後に(条件がFalseのときの値)が来ます。三項演算子の文法で(条件)が真ん中に来るのは一般的ではありません。
(条件がTrueのときの値) if (条件) else (条件がFalseのときの値)2.2 変更後の三項演算子
変更後の三項演算子は以下です。(条件)が先に来て、その後に、(条件がTrueのときの値)、最後に、(条件がFalseの値)が来るようにしました。C言語などはこの順番で三項演算子を記述します。
if (条件) then (条件がTrueのときの値) else (条件がFalseのときの値)2.3 コード変更
それでは、Pythonの三項演算子を2.2で示したものに変更していきます。Pythonには既に三項演算子が存在します。なので、これを流用して、if then elseが来た時に同じ処理を呼ぶようにすれば良いです。ここで、変更するのはpython.gramだけです。Grammer/python.gramのL341に以下の記述があります。
Grammer/python.grama = disjunction 'if' b=disjunction 'else' c=expression { _Py_IfExp(b, a, c, EXTRA) }これは、元のPythonの三項演算子の記述です。これを真似して、下の行に変更後の三項演算子を記述します。
Grammer/python.gram'if' a = disjunction 'then' b=disjunction 'else' c=expression { _Py_IfExp(a, b, c, EXTRA) }ここで、_Py_IfExpを呼ぶときの変数の順番に注意します。以上の変更で
$ make regen-pegenを実行し、再ビルドを行えば、三項演算子の追加ができます。もちろん、元の三項演算子の文法を使うこともできます。
3. デモ
以上の変更で実装された三項演算子は以下のように動作します。
参考資料
大規模ソフトウェアを手探る
実験のサイトですCPython
CPythonのリポジトリです24. Changing CPython’s Grammar
CPythonに機能追加を行う時のチェックリストが載っていてCPythonの構造理解に役立ちました
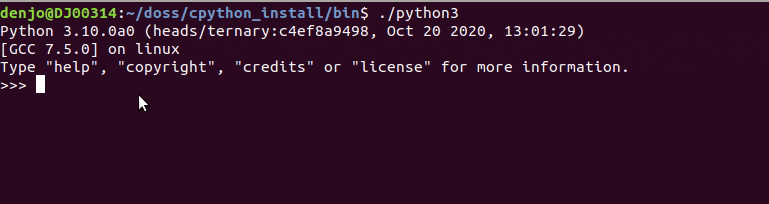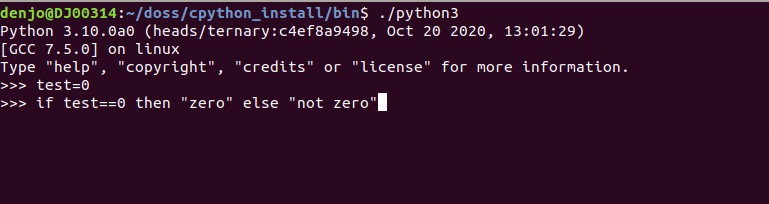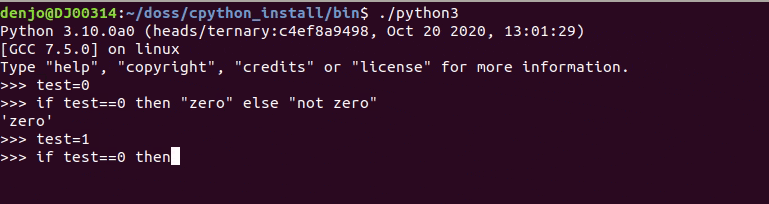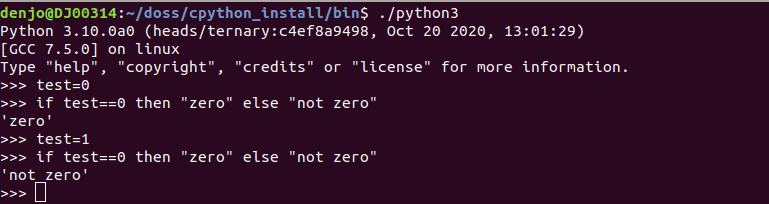
- 投稿日:2020-10-25T17:46:47+09:00
CPythonに機能追加してみた(ビルド&構造把握)
1. はじめに
ここでは、CPythonに機能追加する上で必要となるCPythonのビルドとCPythonのファイル構造について説明します。
本記事ではPython3.10を使用しています。
* この記事はEEIC(東京大学工学部 電気電子工学科/電子情報工学科)3年の後期実験「大規模ソフトウェアを手探る」のレポートとして書きました。
* 以下の記事はチームメンバーが書いたものです。CPythonに機能追加してみた(三項演算子)
pythonに2種類のswitch文を追加する
前置インクリメント2. CPythonとは
CPythonとは、C言語で書かれたPythonのことで、一般的にPythonと呼ぶ時、このPythonのことを指してることが多いです。コードはGitHub上で管理されておりPRを出すこともできます。
3. CPythonのビルド
CPythonのビルドについては公式の記事が非常に参考になります。まず、CPython3.10のリポジトリからコードをcloneします。
$ git clone https://github.com/python/cpython次に、ディレクトリを移動し、configureスクリプトを実行します。ここでは、-gで実行可能ファイルに「デバッグシンボル」を含め、-O0で最適化を最低レベルにしています。また、--prefixをつけることでインストールするフォルダを指定しています。
$ cd cpython $ CFLAGS="-O0 -g" ./configure --with-pydebug --prefix=(インストールするディレクトリ)続いて、コンパイル&インストールを行います。
$ make -s -j2 $ make install以上で、CPythonが無事インストールできます。インストールしたPythonを実行するには以下のようにします。
$ cd (インストールしたディレクトリ)/bin $ ./python34. CPythonに機能追加
CPythonに機能追加する時のチェックリストが公式によりまとめられています。以下では、こちらを参考にして説明していきます。
4.1 CPythonのファイル構成
CPythonに機能追加を行う際に主に変更を加えるファイルで重要なのはこの4つとなります。順に見ていきます。
4.1.1 python.gram
まず、python.gramについて説明します。
CPythonのGrammer/python.gramにあるファイルです。python.gramではPythonの文法を規定しています。追加する文法をこのファイルに記述します。$ make regen-pegenよりParserを自動生成してくれます。
4.1.2 python.asdl
続いて、python.asdlについて説明します。
抽象構文木(AST)を作成するためのファイルです。python.gramで新たな関数を定義したなら、このファイルにも関数定義を記述する必要があります。$ make regen-astよりASTが自動生成されます。
4.1.3 compile.c
続いて、compile.cについて説明します。
ASTをバイトコードに変換するファイルです。構文ごとの処理をバイトコードで記述します。文法追加の際、その文法の処理をバイトコードでこちらに記述します。4.1.4 ceval.c
続いて、ceval.cについて説明します。
バイトコードを実行します。既存のバイトコードで実装不可能な場合、こちらに新しいバイトコードを追加します。5. まとめ
以上では、CPythonのビルドと構造把握について説明しました。CPythonはコード量こそ膨大ですが、公式のチェックリストで文法変更の手順がまとまっていたので、注目する必要のあるコード量については少なく感じました。
参考資料
大規模ソフトウェアを手探る
実験のサイトですCPython
CPythonのリポジトリです24. Changing CPython’s Grammar
CPythonに機能追加を行う時のチェックリストが載っていてCPythonの構造理解に役立ちました1. Getting Started
CPythonのビルドに関して参考になりました

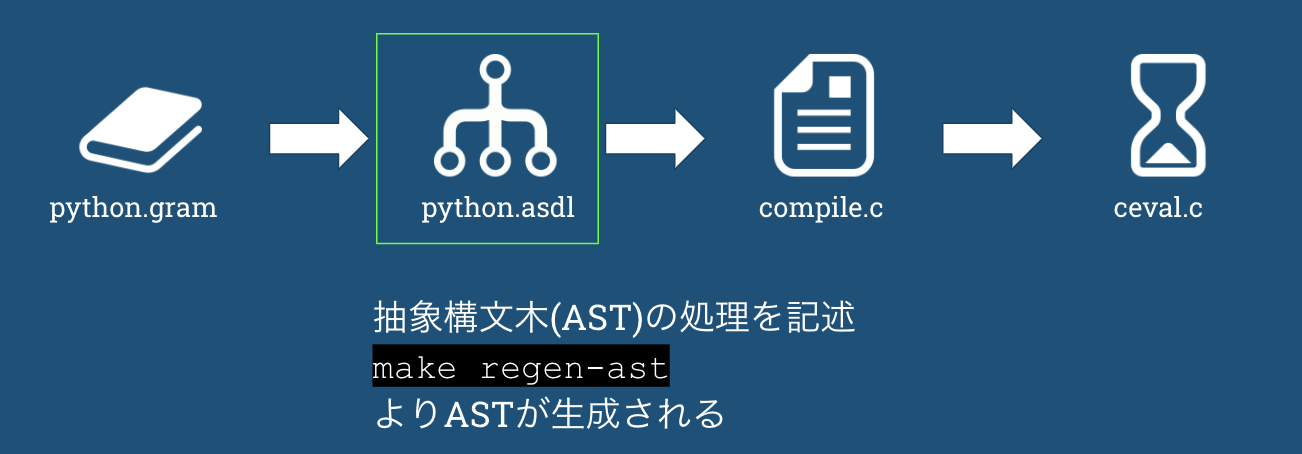
- 投稿日:2020-10-25T17:33:48+09:00
Pydriveの認証ファイルを,スクリプトと別ディレクトリに保存する
結論
Pydriveの認証ファイルをスクリプトと別ディレクトリに保存したい場合は,以下のように書けばOK.
from pydrive.auth import GoogleAuth from pydrive.drive import GoogleDrive from oauth2client.file import Storage gauth = GoogleAuth(settings_file=f"{保存したいディレクトリの絶対Path}/settings.yaml") gauth.credentials = Storage(f"{保存したいディレクトリの絶対Path}/credentials.json").get() gauth.CommandLineAuth() drive = GoogleDrive(gauth)依存環境
python==3.7.6 pydrive==1.3.1背景
はじめに
Pydriveの基本的な使用方法や設定方法は,以下のサイトが丁寧に解説しているため割愛.
参考サイト:
Python, PyDriveでGoogle Driveのダウンロード、アップロード、削除など - note.nkmk.meデフォルトだと,認証ファイルを別ディレクトリに保存できない.
Pydriveの認証ファイルは,(デフォルトだと)スクリプトが保存されているディレクトリと同じディレクトリに保存されていないと認証NGとなる.
例えば以下のように,スクリプト
main.pyと同じディレクトリに,認証ファイルclient_secrets.json,credentials.json,settings.yamlを保存することがMust./home/hogehoge/ └ hoge_project/ └ src/ ├ client_secrets.json ├ credentials.json ├ settings.yaml └ main.pymain.pyfrom pydrive.auth import GoogleAuth from pydrive.drive import GoogleDrive gauth = GoogleAuth() gauth.CommandLineAuth() drive = GoogleDrive(gauth)でも別ディレクトリに保存したい.
でも,
srcディレクトリの中にスクリプトと認証ファイルとが混在しているのはなんか気持ちが悪い.
そこでなんとかして,以下のように認証ファイルをcreds/ディレクトリ下に移動させたい./home/hogehoge/ └ hoge_project/ ├ creds/ │ ├ client_secrets.json │ ├ credentials.json │ └ settings.yaml │ └ src/ └ main.py引数を指定することで,別ディレクトリの認証ファイルを読み込むことが可能.
以下のように書けば,
creds/以下の認証ファイルを,main.pyが認識することが可能となる.main.pyfrom pydrive.auth import GoogleAuth from pydrive.drive import GoogleDrive from oauth2client.file import Storage gauth = GoogleAuth(settings_file=f"/home/hogehoge/creds/settings.yaml") gauth.credentials = Storage(f"/home/hogehoge/creds/credentials.json").get() gauth.CommandLineAuth() drive = GoogleDrive(gauth)参考サイト:pythonのスクレイピングで躓いたところをメモ - Qiita
さいごに
なかなか情報が見つからなくて苦労した.
他に何かあれば教えて下さい.
- 投稿日:2020-10-25T17:21:57+09:00
Houdini(Python 3)でBlender Python API
Houdini 18.5でPython 3がProduction Buildsに
Production Buildsの項目にHoudini 18.5 - Python 3が追加されました。
Python3が使えるようになったのでPython3系にしかないライブラリが使えるようになったはず!
なので今回はPython3.7で使用できるbpy(Blender Python)をHoudiniに入れてみます。使用したのは以下のWindows版のHoudiniです。
houdini-py3-18.5.351-win64-vc141.exebpyをビルド
Python Moduleとしてのbpyは現状配布されていないので以下を参考にソースコードからビルドする必要があります。
Building Blender as a Python Moduleビルド環境を整備
Blenderをソースコードからビルドする日本語記事は検索すればすぐ見つかると思いますのでより詳しい情報が必要な場合はそちらを探してみてください。
- Visual Studio 2019
- CMake
- Git
- Subversion
あたりがインストールされていれば多分大丈夫なはず・・・?
ソースコードを落としてくる
https://developer.blender.org/diffusion/B/ を参考にソースコードを落としてきます。
githubのミラーからだとzipで落とせると思います。ビルドする
ソースコードを展開すると以下の用のディレクトリ構成になっていると思います。
このディレクトリ(make.batがある)でコマンドプロンプトを開いて
make bpyを実行するとビルドに必要な他のライブラリをSubversionで落としてきてビルドされます
(開始してすぐに必要な他のライブラリを落として良いか聞かれるので y を押して進めます)。
初回はすごく時間がかかります。ビルド成果物をHoudiniで読めるように配置
ビルド成果物は
(blenderのソースコードのディレクトリ)..\build_windows_Bpy_x64_vc16_Release\bin\Release
にあります。bpy.pyd, libfftw3-3.dll
この2つはHoudiniのpythonが読めるディレクトリに配置します。
必要なdllはblenderのバージョンが変わると増減するかもしれないです。
ここでは以下に配置しました。
C:\Users\(ユーザー名)\Documents\houdini18.5\python3.7libs
2.90(ビルドしたblenderのバージョン)フォルダ
このフォルダはインストールしたHoudiniのexeがあるディレクトリに配置します。
環境変数を設定すると別の場所でも良くなるかもしれません(未検証)。
ここでは以下に配置しました。
C:\Program Files\Side Effects Software\Houdini 18.5.351\bin
Blender Python API を使う
import bpyの確認
やっと使用準備が整いました。Python ShellやPython(SOP)などで
import bpyがエラーなく実行できることを確認します。ビルド成果物や配置場所に問題があるとエラーを出したりHoudiniが落ちたりします。
.blendファイルを読み込む
Python(SOP)で.blendファイルを読み込む処理を作成します。
テストデータの用意
キューブとスザンヌを配置した.blendを用意しました。
スザンヌは半分に切ってMirror, Subdivisionモディファイアを設定しています。
Python(SOP)でPythonコードを書く
Primitiveアトリビュートでname
Vertexアトリビュートで N, uv
を読み込むコードを書きました。パラメータは以下の通りです。
Label Name 説明 Blender File blend_file 読み込む.blendの指定 Object Name objects 読み込むオブジェクトの指定 Apply Modifier apply_modifier モディファイアを適用するかの指定
import os import bpy from bpy_extras.io_utils import axis_conversion node = hou.pwd() geo = node.geometry() # 設定するアトリビュートを準備 name_attrib = geo.addAttrib(hou.attribType.Prim, 'name', '') normal_attrib = geo.addAttrib(hou.attribType.Vertex, 'N', (0.0, 0.0, 0.0)) uv_attrib = geo.addAttrib(hou.attribType.Vertex, 'uv', (0.0, 0.0, 0.0)) # パラメータの読み取り blend_file = node.parm('blend_file').evalAsString() apply_modifier = node.parm('apply_modifier').evalAsInt() object_names = [ s.strip() for s in node.parm('objects').evalAsString().split() ] if len(blend_file)>0: # .blendを開く bpy.ops.wm.open_mainfile(filepath=blend_file) # 名前が設定されてなければすべてのオブジェクトを読む if len(object_names)==0: object_names = bpy.data.objects.keys() else: # blenderの初期ファイルを開いてスザンヌを出す bpy.ops.wm.read_homefile(app_template='') bpy.ops.mesh.primitive_monkey_add() object_names = ['Suzanne'] depsgraph = bpy.context.evaluated_depsgraph_get() # blenderの軸の向きをHoudiniの軸の向きに変換する行列 axis_conv_mat = axis_conversion( from_forward='-Y', from_up='Z', to_forward='Z', to_up='Y' ).to_4x4() # 指定された名前のオブジェクトを開く for obj_name in object_names: obj = bpy.data.objects[obj_name] if obj.type!='MESH': continue # モディファイアを必要なら適用 ob_for_convert = obj.evaluated_get(depsgraph) if apply_modifier else obj.original # オブジェクトからメッシュを取り出す try: me = ob_for_convert.to_mesh() except: me = None if me is None: continue # 軸変換とオブジェクトのトランスフォームをメッシュに適用 me.transform( axis_conv_mat @ obj.matrix_world ) # マイナスのスケールがかかっている場合の対応 if obj.matrix_world.determinant() < 0.0: me.flip_normals() # Vertex Normalを計算する me.calc_normals_split() # UVのデータを取得 uv_layer = me.uv_layers.active.data[:] if len(me.uv_layers) > 0 else None # ポイントを作成 points = [ hou.Vector3(v.co) for v in me.vertices ] pt_list = geo.createPoints(points) # blenderとhoudiniでポリゴンの頂点順が異なるので変換する loop_indices_list = list() for mpoly in me.polygons: count = len(mpoly.loop_indices) loop_indices_list.append( [ mpoly.loop_indices[(count-i)%count] for i in range(0, count) ] ) for loop_indices in loop_indices_list: poly = geo.createPolygon() poly.setAttribValue(name_attrib, obj_name) for i in loop_indices: # ポリゴンを作る v = poly.addVertex( pt_list[ me.loops[i].vertex_index ] ) # N attribute v.setAttribValue(normal_attrib, me.loops[i].normal) # uv attribute if uv_layer: uv = uv_layer[i].uv v.setAttribValue(uv_attrib, (uv[0], uv[1], 0.0))Object Nameのパラメータは以下のようにMenu Scriptで▽から選べるようにしました。
import os import bpy name_list = list() node = hou.pwd() blend_file = node.parm('blend_file').evalAsString() # ファイルの存在チェック if not os.path.exists(blend_file): return name_list # Meshのオブジェクトの名前を列挙 objects = bpy.data.objects for obj in objects: if obj.type == 'MESH': name_list.extend( [obj.name]*2 ) return name_listコードにコメントを書いているので詳細な説明は省略します。
Blender Python APIでメッシュ情報を取得するコードは
(Blenderインストールディレクトリ)\(Blenderバージョン)\scripts\addons
以下でio_で始まるものがImporter/Exporterのアドオンなのでそちらが参考になります。
↑のコードはio_scene_objを参考に書きました。その他
bpyで.blendファイルを読み込んだ際に以下のようなログが出力されます。
これを外から止める方法は分かりませんでした。
どうしても邪魔だという時はbpyをビルドする際にこのログ出力コードをコメントアウトすれば出力されなくなります。
source\blender\blenkernel\intern\blendfile.cint BKE_blendfile_read(bContext *C, const char *filepath, const struct BlendFileReadParams *params, ReportList *reports) { BlendFileData *bfd; bool success = false; /* Don't print startup file loading. */ if (params->is_startup == false) { printf("Read blend: %s\n", filepath); } ... }
- 投稿日:2020-10-25T16:34:23+09:00
生産計画の最適化(OR-Tools)
はじめに
- Googleの数理最適化ツール(OR-Tools)を使用して、生産計画を最適化するプログラムを作成してみた。
- https://developers.google.com/optimization
生産計画の仕様
- 複数の作業ロット(lot)があり、各ロットは連続するジョブ(job)で構成される。
- 各ジョブには、生産に必要な時間(size)が指定される。
- 各ジョブは、複数の設備のいずれかに割付ける必要がある。
- 同一の設備に割付けられたジョブは、互いに重なってはいけない。
- 同一のロットを構成するジョブは順番に生産する必要がある。
- 全てのジョブが終了するまでの時間を最小化する。
変数の定義方法
- ジョブ毎に、開始時刻(start_var)と終了時刻(end_var)を表す変数を定義する。
- ジョブ・設備毎に割付けるか否かを表すブール変数(bool_var)を定義して、インターバル変数(interval_var)を定義する。
- ジョブ毎にブール変数の合計が1となる制約を定義する。
- 設備毎にインターバル変数が互いに重ならない制約を定義する。
- 同じロットを構成するジョブに前後の順序制約を定義する。
データの生成
from ortools.sat.python import cp_model from collections import defaultdict from dataclasses import dataclass import pandas as pd import matplotlib import matplotlib.pyplot as plt import random num_machines = 3 num_lots = 5 num_jobs_per_lot = 3 num_jobs = num_lots * num_jobs_per_lot @dataclass class job_type: id: int lot_id: int size: int random.seed(1) jobs_list = [job_type(j, j//num_jobs_per_lot, random.randint(1, 10)) for j in range(num_jobs)] horizon = sum([job.size for job in jobs_list])変数と制約条件の定義
model = cp_model.CpModel() machine_to_intervals = defaultdict(list) for job in jobs_list: start_var = model.NewIntVar(0, horizon, 'start_' + str(job.id)) end_var = model.NewIntVar(0, horizon, 'end_' + str(job.id)) job.start_var = start_var job.end_var = end_var bool_var_list = [] for m in range(num_machines): suffix = str(m) + '_' + str(job.id) bool_var = model.NewBoolVar('bool_' + suffix) bool_var_list.append(bool_var) interval_var = model.NewOptionalIntervalVar(start_var, job.size, end_var, bool_var, 'interval_' + suffix) interval_var.job = job interval_var.bool_var = bool_var machine_to_intervals[m].append(interval_var) model.Add(sum(bool_var_list) == 1) for m in machine_to_intervals: model.AddNoOverlap(machine_to_intervals[m]) for j in range(num_jobs-1): if jobs_list[j].lot_id != jobs_list[j+1].lot_id: continue model.Add(jobs_list[j].end_var <= jobs_list[j+1].start_var)最適化
span_var = model.NewIntVar(0, horizon, 'span_var') model.AddMaxEquality(span_var, [j.end_var for j in jobs_list]) model.Minimize(span_var) solver = cp_model.CpSolver() solver.Solve(model) print(solver.StatusName(), solver.ObjectiveValue())手元の環境では、およそ230msで最適値28が得られた。
結果出力
result = [] for m in machine_to_intervals: for i in machine_to_intervals[m]: if solver.Value(i.bool_var) == 0: continue result.append([m, i.job.lot_id, i.job.id, solver.Value(i.job.start_var), solver.Value(i.job.end_var), i.job.size]) result = pd.DataFrame(result, columns=['machine', 'lot', 'job', 'start', 'end', 'size']).sort_values(['machine', 'start'], ignore_index=True) print(result)
machine lot job start end size 0 0 4 12 0 1 1 1 0 2 6 1 9 8 2 0 0 1 9 19 10 3 0 1 5 19 27 8 4 1 3 9 0 4 4 5 1 3 10 4 6 2 6 1 0 0 6 9 3 7 1 1 4 9 11 2 8 1 2 7 11 19 8 9 1 0 2 19 21 2 10 1 4 14 21 28 7 11 2 1 3 0 5 5 12 2 3 11 6 14 8 13 2 4 13 14 21 7 14 2 2 8 21 28 7 ガントチャートの表示
span_max = solver.Value(span_var) cmap = plt.cm.get_cmap('hsv', num_lots+1) fig = plt.figure(figsize=(12, 8)) for m in machine_to_intervals: ax = fig.add_subplot(num_machines, 1, m+1, yticks=[], ylabel=m) ax.set_xlim(-1, span_max+1) ax.set_ylim(-0.1, 1.1) for i in machine_to_intervals[m]: if solver.Value(i.bool_var) == 0: continue start = solver.Value(i.job.start_var) rectangle = matplotlib.patches.Rectangle((start, 0), i.job.size, 1, fill=False, color=cmap(i.job.lot_id), hatch='/') ax.add_patch(rectangle) rx, ry = rectangle.get_xy() cx = rx + rectangle.get_width()/2 cy = ry + rectangle.get_height()/2 lab = str(i.job.lot_id) + '-' + str(i.job.id) ax.annotate(lab, (cx, cy), ha='center', va='center') plt.show()
ロット毎に色を変えている。ジョブの処理順序を満たしながら、きっちり詰まっている。
おわりに
- 問題の規模が小さければ、OR-Toolsを使用して生産計画の最適化問題を解くことが可能。
- 但し、現実の問題では変数の数が数万となることもある。見極めが必要。
- 投稿日:2020-10-25T16:27:26+09:00
Pythonを改造して機能を追加した話
※このブログはeeicの実験「大規模ソフトウェアを手探る」のレポートとして書かれたものです。
東京大学工学部電子情報工学科/電気電子工学科(eeic)の選択できる実験として「大規模ソフトウェアを手探る」があります。これは、OSS(オープンソースソフトウェア)として公開されている大規模なプログラムを改良/機能拡張することで、普段授業で扱うような小規模なプログラムでは触れられない、全容を把握することが困難なプログラムを扱う方法を身につけるというものです。
自分たちは授業でも使い馴染みのあるPythonを手探ることにしました。リンク
- 概要(Pythonを改造して機能を追加した話) ←イマここ
- PythonにC言語っぽい文法を追加する
・論理演算子として&&や||や!を追加する
・論理値のTrue,Falseをtrue,falseにも対応させる
・elifだけでなくelse ifにも対応させる- Pythonにオートインデント機能をつける
- (おまけ)Pythonにunless文を追加する
環境
- OS
Ubuntu20.04 / Ubuntu18.04- 改造対象
Python3.10(cpython)- 使ったツール
Emacs, gdb準備
まず作業用のディレクトリを作成します(ここでは
~/cpython)。
Github上のPython3.10(cpython)からgit cloneを用いてリポジトリを複製します。terminal$ mkdir cpython $ cd cpython $ git clone https://github.com/python/cpythonビルド
configureでMakefileを作成します。このとき--prefixオプションをもちいて最終的にプログラムをどこに配置するかを決定します(ここでは~/python-install)。また環境変数CFLAGSに-O0を付けることで最適化レベルを落とし、さらに-gを付けることで実行可能ファイルに「デバッグシンボル」を含めます。こうすることで、gdbを使ってプログラムの挙動を1行ずつ追うことができます。
configureでMakefileが作成できたら、makeとmake installでコンパイルとインストールを行います。terminal$ CFLAGS="-g -O0" ./configure --prefix=/home/[username]/python-install/ $ make $ make installこれでビルドが完了し、
~/python-install/bin/python3を実行することで、pythonが起動できます。
コードを変更したときは、make cleanをしてからmakeをする必要があります。デバッガで追跡
Emacsを起動し、
M-x shellコマンドで~/python-install/bin/に移動します。
移動できたらM-x gud-gdbとgdb --fullname python3を叩いてgdbを起動、これを用いてプログラムの追跡を行いました。参考資料
- 実験のホームページです。
CPythonの公式ドキュメント(Changing CPython’s Grammar)
CPythonの公式ドキュメント(Design of CPython’s Compiler)
- pythonに文法を追加する際にどのファイルを変更すればよいかが記載されています。
- Pythonにオートインデント機能をつけるで参考にしたドキュメントです。
- unless文をPythonに追加したEEICの先輩の記事です。Pythonを改造するにあたって、何から始めればいいかを参考にしました。
- 投稿日:2020-10-25T16:19:19+09:00
Amazon Timestreamを動かしてみる
はじめに
フルマネージドな時系列データベースのAmazon Timestreamが9/30に一般公開されたので触ってみる。
時系列データベースは存在自体は以前から知っていたものの、使ったことはないので楽しみ。新しすぎてまだCloudFormationもTerraformも対応していないので、今回はコンソールからポチポチやってみる。ちなみに東京リージョンではまだ使えないので、コンソールを利用可能なリージョンに向けておこう。
データベースを作ってみる
さて、自分で作ってみようとしたらよく分からなかったので、こういう時はチュートリアルを見ながらやるのが定石だろう。
Timestreamの以下の画面で「Create database」のボタンを押す。
で、開いたデータベース作成の画面で、データベース名を設定する。
※お手軽設定もあるが、今回はStandard databaseを選択する。
KMSの設定は、空白にしておくと勝手にキーを作成してくれた。
タグを好きに設定して「Create database」ボタンを押す。
作成完了!
テーブルを作ってみる
さて、↑で作ったテーブル名のリンクを押してみよう。
データベースの詳細画面に「Create table」のボタンがあるので押す。で、開いたテーブル作成の画面で、テーブル名を設定する。
データ保存の設定は、今回はお試しなのでテキトーに。
タグをお好みで設定して「Create table」のボタンを押す。
テーブルの作成も完了!
データを登録する
チュートリアルと同じように作るのは面白みがないので、Locustの出力するデータを登録してみることにしよう。
登録対象のデータは以下のようなイメージだ。
Timestamp,User Count,Type,Name,Requests/s,Failures/s,50%,66%,75%,80%,90%,95%,98%,99%,99.9%,99.99%,100%,Total Request Count,Total Failure Count,Total Median Response Time,Total Average Response Time,Total Min Response Time,Total Max Response Time,Total Average Content Size 1603535373,20,GET,/xxxxx/,1.000000,0.000000,5,6,6,6,8,9,9,9,9,9,9,16,0,4.11685699998543,5.413748562499876,4.11685699998543,9.385663000045952,14265.0これを、以下のPythonでコマンドを作ってロードする。
ディメンションというのがよく分からないかもしれないが、要するに分類するための属性情報だと思えば良い。
今回は、HTTPのリソースとメソッドを属性として定義した。import sys import csv import time import boto3 import psutil from botocore.config import Config FILENAME = sys.argv[1] DATABASE_NAME = "xxxxx-test-timestream" TABLE_NAME = "xxxxx-test-table" def write_records(records): try: result = write_client.write_records(DatabaseName=DATABASE_NAME, TableName=TABLE_NAME, Records=records, CommonAttributes={}) status = result['ResponseMetadata']['HTTPStatusCode'] print("Processed %d records.WriteRecords Status: %s" % (len(records), status)) except Exception as err: print("Error:", err) if __name__ == '__main__': session = boto3.Session() write_client = session.client('timestream-write', config=Config( read_timeout=20, max_pool_connections=5000, retries={'max_attempts': 10})) query_client = session.client('timestream-query') with open(FILENAME) as f: reader = csv.reader(f, quoting=csv.QUOTE_NONE) for csv_record in reader: if csv_record[0] == 'Timestamp' or csv_record[3] == 'Aggregated': continue ts_records = [] ts_columns = [ { 'MeasureName': 'Requests/s', 'MeasureValue': csv_record[4] }, { 'MeasureName': '95Percentile Response Time', 'MeasureValue': csv_record[10] }, { 'MeasureName': 'Total Median Response Time', 'MeasureValue': csv_record[18] }, { 'MeasureName': 'Total Average Response Time', 'MeasureValue': csv_record[19] }, ] for ts_column in ts_columns: ts_records.append ({ 'Time': str(int(csv_record[0]) * 1000), 'Dimensions': [ {'Name': 'resource', 'Value': csv_record[3]}, {'Name': 'method', 'Value': csv_record[2]} ], 'MeasureName': ts_column['MeasureName'], 'MeasureValue': ts_column['MeasureValue'], 'MeasureValueType': 'DOUBLE' }) write_records(ts_records)だが、一般公開されたばかりの機能なので、boto3のバージョンが古い人がいるだろう。
$ pip list -oで、boto3がLatestになっているか確認しよう。
Package Version Latest Type --------------------- -------- ---------- ----- boto3 1.13.26 1.16.4 wheelpipでのアップデートは
-Uで行う。$ pip install -U boto3また、
aws configureでデフォルトリージョンを、↑でデータベースを作ったリージョンに向けておこう。psutilが入っていない場合は以下でインストールする。
$ yum install python3-devel $ pip3 install psutilいずれ修正されると思うが、2020/10/25時点では↑の公式のブログではコマンド名が間違っているので、ブログを信じてpip3するとインストールできなくて悲しい気持ちになる。
さて、無事データロードできただろうか。
クエリを発行する
左のメニューから「Query Editor」を選択すると以下のような画面が表示されるので、テキトーに属性を絞りながらSQLを実行してみよう。/xxxxx/ の GET リクエストの平均レスポンス時間を知りたい!
実行したら、バッチリ欲しい情報だけが抽出された!
これを生データで取得するには、またCLIなりboto3なりで取得する。
ページネーターが必要だったりで結構面倒。
そもそもちょっとした分量なら、pandasを使うのが楽なのだけど、実際の利用シーンでは、何千台もあるサーバ等から定感覚で収集した情報を素早く取り出すので、ローカルでpandasで整形できるような情報量ではないはずだ。
Grafanaと組み合わせてリアルタイムにモニタリングしたりできるという点が真骨頂なんだろうな……。