- 投稿日:2020-10-25T23:53:09+09:00
【AWS】Athena+QuickSightでCloudTrailログを可視化してみた。
0.初めに
CloudTrailログを可視化したい!ってことありませんか?(ないですよね泣)
AWSコンソールでCloudTrailのイベント履歴が見れますので不要だとは思いますが、確認できる項目は4個と少ないです。。(全43項目あります)
さらにリッチに表示させたいとなるとQuickSightとの連携も必要となります。1.概要
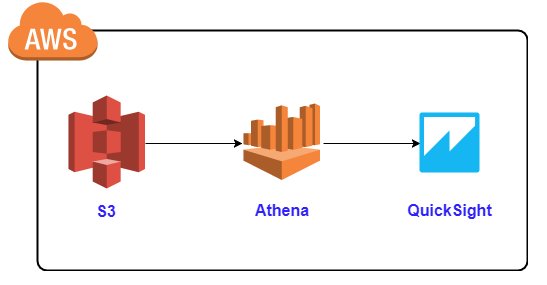
構成は以下の通りです。CloudTrailログをS3に保存していることが前提です。CloudTrailの証跡設定で保存できます
「QuickSightとAthenaを活用!データ分析入門」より引用①CloudTrailログのスキーマ定義設定
Athenaのクエリに以下をコピペし実行することでCloudTrailのスキーマを定義できます。
「AWS公式ページ」より引用◆以下に注意してください
【LOCATION句】
CloudTrailログが保存されているS3バケットのパスを指定してください。【PARTITIONED句】
PARTITIONED BY(region string, year string, month string)と書いている箇所です。
これは、ログに対してクエリ実行する範囲を指定するために追記しています。
書かなくても実行できますが、Athenaはクエリ実行する範囲が多くなると料金が高くなりますので、
指定することをお勧めします。CloudTrailのスキーマ定義.txCREATE EXTERNAL TABLE cloudtrail_logs_table ( eventVersion STRING, userIdentity STRUCT< type: STRING, principalId: STRING, arn: STRING, accountId: STRING, invokedBy: STRING, accessKeyId: STRING, userName: STRING, sessionContext: STRUCT< attributes: STRUCT< mfaAuthenticated: STRING, creationDate: STRING>, sessionIssuer: STRUCT< type: STRING, principalId: STRING, arn: STRING, accountId: STRING, userName: STRING>>>, eventTime STRING, eventSource STRING, eventName STRING, awsRegion STRING, sourceIpAddress STRING, userAgent STRING, errorCode STRING, errorMessage STRING, requestParameters STRING, responseElements STRING, additionalEventData STRING, requestId STRING, eventId STRING, resources ARRAY<STRUCT< arn: STRING, accountId: STRING, type: STRING>>, eventType STRING, apiVersion STRING, readOnly STRING, recipientAccountId STRING, serviceEventDetails STRING, sharedEventID STRING, vpcEndpointId STRING ) COMMENT 'CloudTrail table for cloudtrail-bucket bucket' PARTITIONED BY(region string, year string, month string) ROW FORMAT SERDE 'com.amazon.emr.hive.serde.CloudTrailSerde' STORED AS INPUTFORMAT 'com.amazon.emr.cloudtrail.CloudTrailInputFormat' OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat' LOCATION 's3://◆◆◆バケット名◆◆◆/AWSLogs/◆◆◆AWSアカウント番号◆◆◆/CloudTrail/' TBLPROPERTIES ('classification'='cloudtrail')[Run query]を実行してください。
②CloudTrailログのテーブル作成
①ではスキーマ定義しかしておりませんので、データ読込するクエリを実行する必要があります。
例↓:2020年10月をクエリ実行範囲に指定しています。①【PARTITIONED句】を指定している場合.txtALTER TABLE cloudtrail_logs_table ADD PARTITION (region='ap-northeast-1',year='2020',month='10') location 's3://◆◆◆バケット名◆◆◆/AWSLogs/◆◆◆AWSアカウント番号◆◆◆/CloudTrail/ap-northeast-1/2020/10'例↓:クエリ範囲を指定しない場合
②【PARTITIONED句】を追記していない場合.txtMSCK REPAIR TABLE cloudtrail_logs_table;どちらかで[Run query]を実行してください。
【PARTITIONED句ありの場合】翌月にデータ読込クエリを実行する必要があります。
【PARTITIONED句なしの場合】「MSCK REPAIR TABLE」1回実行するだけでよいです。#①スキーマ定義で「CREATE EXTERNAL TABLE」でスキーマ定義しているのでS3バケットにCloudTrailログが保存されるたびに自動でテーブル更新されます。
筆者は定期的に「MSCK REPAIR TABLE」を実行しないと最新のログか表示されないと勘違いしておりました。。。
③QuickSight表示する項目だけ抽出したテーブル作成
②まで作業完了している場合は作成したテーブルをQuickSightで指定するだけで可視化されますが、
あまりにも項目が多いので項目を選別したいと思います。
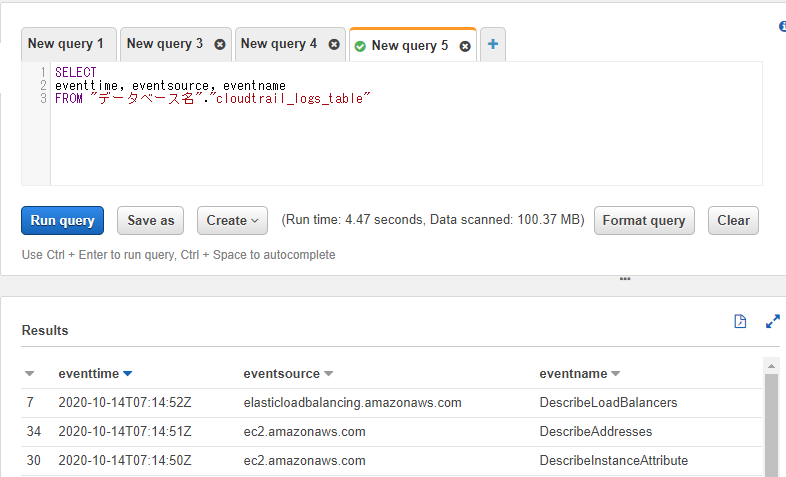
CloudTrailログの「eventtime」「eventsource」「eventname」を表示させたい場合は以下を実行します。
これらはstring型のデータなので項目指定するだけでQuickSightで読み込ませることができます。SELECT eventtime, eventsource, eventname FROM "データベース名"."cloudtrail_logs_table"
注意が必要なのは「userIdentity」、「resources」項目です。
これらはstruct型、Array型の項目なのでQuickSightで表示できません。(表示させる型をサポートしていません)
ですので、以下のように必要な項目を抽出する必要があります。useridentityをQuickSightで表示させる場合.SELECT useridentity.arn ← useridentityのarn項目だけ表示させている FROM "データベース名"."cloudtrail_logs_table"「resources」はArray型なのでさらにややこしいです
resourcesをQuickSightで表示させる場合.SELECT resource.arn FROM "データベース名"."cloudtrail_logs_table" CROSS JOIN UNNEST(resources) AS t (resource)④QuickSightでテーブル読込設定
私がまとめるよりこちらのほうが参考になります
「サッと始める QuickSight の使い方」以下のように必要項目だけ抽出したテーブルを作成してQuickSightで指定し可視化します。
resourcesをQuickSightで表示させる場合.CREATE TABLE データベース名.QuickSight用テーブル名 WITH ( format='PARQUET' ) AS SELECT resource.arn FROM "データベース名"."cloudtrail_logs_table" CROSS JOIN UNNEST(resources) AS t (resource)終わりに
以上の作業を実施することでCloudTrailの全項目(resources項目、userIdentity項目を除く)は可視化できますが、③で作成したようなオリジナルのテーブルは毎度、手動で作成しないとQuickSightで可視化できません。
次回は「CloudWatch」と「Lambda」を用いてオリジナルテーブルを自動更新する方法を掲載します。
「Amazon Athenaのパーティション設定を定期更新する」より引用

- 投稿日:2020-10-25T23:16:06+09:00
AWS lambdaでPOST+JSONをテストイベント、Webアプリからのイベントに対応する
やりたい事
lambdaにPost+JSONが来た時に、bodyからデータを取り出し変数に格納したいが、
テストイベントとWebアプリからのイベントで別のコードに分けていたので、同じにしたいテストイベント用のコード
まずテストイベントでは以下のようなJsonを使っていた
{ "body": {"name":"test","score":0} }受け取りの処理は以下のように取得できる
exports.handler = async (event, context) => { let bodyMessage = event.body; let name = bodyMessage.name; let score = bodyMessage.score; }しかし、Webアプリケーション側でbodyにJSONを付与した場合はJSON.Parseをしないとデータが取得できず、nameとscoreの変数に格納される値は空欄となってしまっていた
Webアプリ用のコード
Jsonの形式は同じなので省略
以下のように取得するexports.handler = async (event, context) => { let bodyMessage = JSON.parse(event.body); let name = bodyMessage.name; let score = bodyMessage.score; }JSON.parseをする事でJSONに変換し、変数に値を格納していた。
先ほど作ったテストイベントを使うと以下のようにエラーが起こるERROR Invoke Error {"errorType":"SyntaxError","errorMessage":"Unexpected token o in JSON at position 1","stack":["SyntaxError: Unexpected token o in JSON at position 1"," at JSON.parse (<anonymous>)"," at Runtime.exports.handler (/var/task/index.js:10:28)"," at Runtime.handleOnce (/var/runtime/Runtime.js:66:25)"]} END RequestId: 554eb535-495a-423c-9c7f-47419d0e8dae解決策
以下のコードで分岐させる事で解決したが、コードがテスト専用のコードになっているため、良くない。
let bodyMessage = event.body; //Webアプリケーションからの場合、parseをしないとundefineになる if(bodyMessage.name===undefined){ bodyMessage = JSON.parse(event.body); }一旦はこの状態で利用しているが、より良い方法が見つかれば追記する。
- 投稿日:2020-10-25T22:35:55+09:00
S3からバケット指定でファイルダウンロード、削除するpythonのクライアントアプリ
概要
特定のバケットからファイルをすべて取得したいときにコンソールからだと面倒だったので、
バケットを指定することでファイルを一括で取得できるツールを作ってみました。
(たぶん既にありそうですが・・・)
取得だけでなく削除処理もつけてみました。
(こちらを使用して何か起こっても自己責任でお願いします。)使用ライブラリ
- boto3を使っています。
- exeに固めるため PyInstaller を使用しています。
ツールの説明
ソース自体はこちらで公開しています。
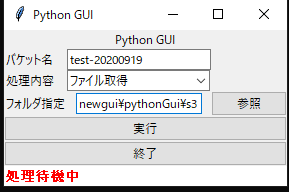
ツールを起動すると以下のようになります
- こちらはtkinterを使用して作成しています。
- バケット名はプロパティに設定しているので適宜設定できます。
- 処理内容はファイル取得か削除かを選択できます。
- フォルダ指定はファイル取得するときにどこに格納するかを選択します。
プロパティファイルにaccess keyとsecret access keyを設定する形になっていますが、 aws configure でアカウントの設定していればこちらの設定は不要です
ソースのS3に関する部分は以下になります。
if aws_access_key_id =='': s3 = boto3.resource('s3') s3client=boto3.client('s3') else: s3 = boto3.resource('s3', aws_access_key_id=aws_access_key_id, aws_secret_access_key=aws_secret_access_key_id) s3client=boto3.client('s3', aws_access_key_id=aws_access_key_id, aws_secret_access_key=aws_secret_access_key_id) bucketName=self.inputFileName.get() resultFolder=self.outputFolder.get() dataBaseDir=os.path.join(resultFolder,bucketName) executeType=EXECUTE_LIST.index(self.combo.get()) s3bucket=s3.Bucket(bucketName) objs = s3bucket.meta.client.list_objects_v2(Bucket=s3bucket.name) for o in objs.get('Contents'): key = o.get('Key') s3Paths=os.path.splitext(key) if len(s3Paths[1]) !=0: keys=key.split('/') filename=keys[len(keys)-1] if executeType==0: outputDataDir=key.split(filename)[0] outputDataDir=os.path.join(dataBaseDir,outputDataDir) os.makedirs(outputDataDir,exist_ok=True) outputDataFile=os.path.join(outputDataDir,filename) s3bucket.download_file(key,outputDataFile) else: s3client.delete_object(Bucket=s3bucket.name, Key=key)
- ツールの方から入力されたバケット名、処理内容をもとに度の処理を動かすかを判定しています。
- 対象のバケットの中は
objs = s3bucket.meta.client.list_objects_v2(Bucket=s3bucket.name)の部分で取得できるのであとはfor文で処理をしています。
引数にPrefixを追加することで特定のフォルダ、ファイルのみを指定することも可能です。
- ソースを実行しても確認ができますが、クライアントアプリとして使う場合は以下のコマンドでexeを作成します。 ソースのファイル名を
pythonGui.pyとした場合以下のようになります。
- pyinstaller pythonGui.py --onefile
- 投稿日:2020-10-25T21:13:36+09:00
【AWSハンズオン】サーバレスアーキテクチャで、有名人識別サービスを作ろう!
本記事について
- 会社の同僚向けに、業務外にて実施をした「AWS ハンズオン」の資料を、一般公開したものです。
- サーバレスアーキテクチャを用いて、有名人の画像解析 API サービスを、約1時間で作成するという内容になっています。
- 言語は Python を用いますが、基礎知識が無くても楽しめる構成にしています。
- ハンズオンの実施にあたっては、以下のリソースが必要です。
- インターネットに接続できるPC( Windows, Mac 問わない)
- AWS IAM ユーザーアカウント
- 本資料の作成には細心の注意を払っておりますが、その正確性を担保するものではありません。また、本資料が起因して生じた損害について、作成者は一切の責任を負いません。
追記:スライド版を公開
- Speaker Deck にて、本ハンズオンのスライド版資料を公開しています。
- スライド版の方が、デザインが整っていて見やすいかと思います。
- 対して、Qiitaの本記事の方には、ソースコードをコピペできるメリットがあります。
- スライド版、Qiita版、両方を併用して実施されると良いと思います。
- https://speakerdeck.com/hayate_h/awshanzuon-sabaresuakitekutiyade-you-ming-ren-shi-bie-sabisuwozuo-rou
はじめに(概要説明)
つくるもの
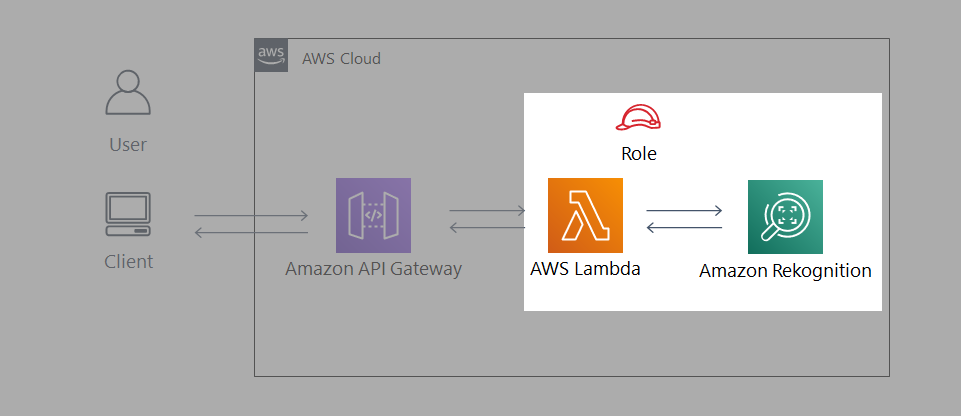
- Amazon Rekognition(画像解析AI) を用いて、有名人識別APIを作成します。
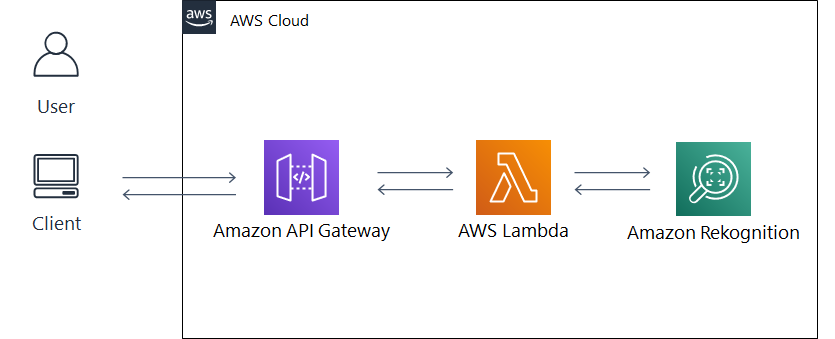
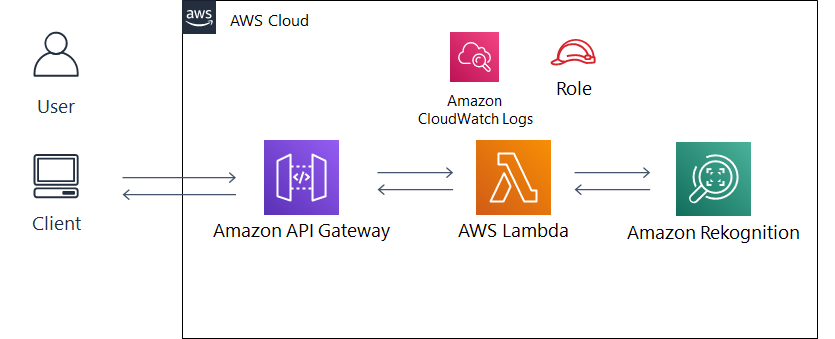
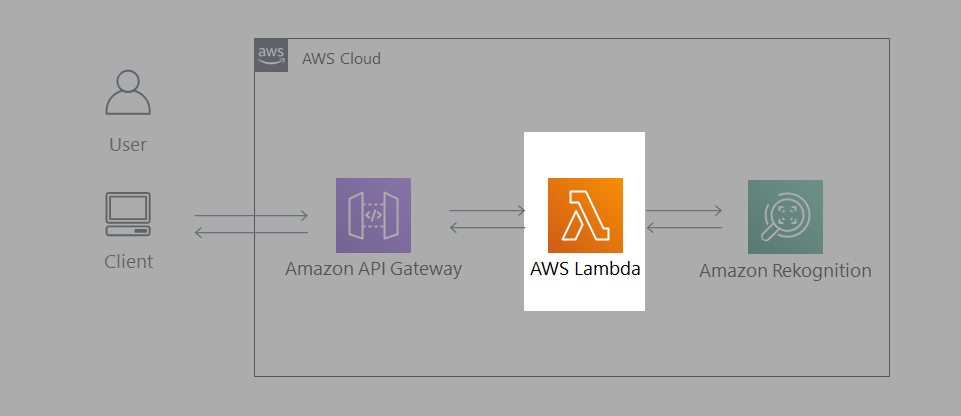
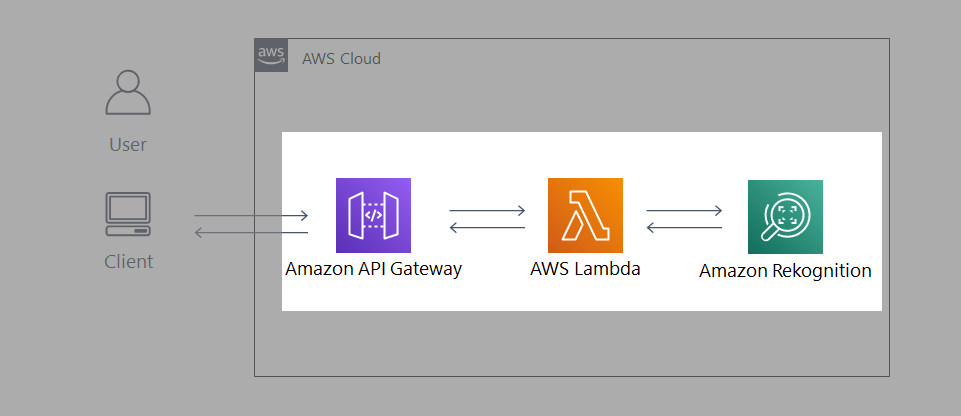
- システム構成図は以下のようになります。
- 明示的なサーバが存在しない「サーバレスアーキテクチャ」のため構築が簡単です。
- また運用管理の手間やコストも軽減します。
動作イメージ
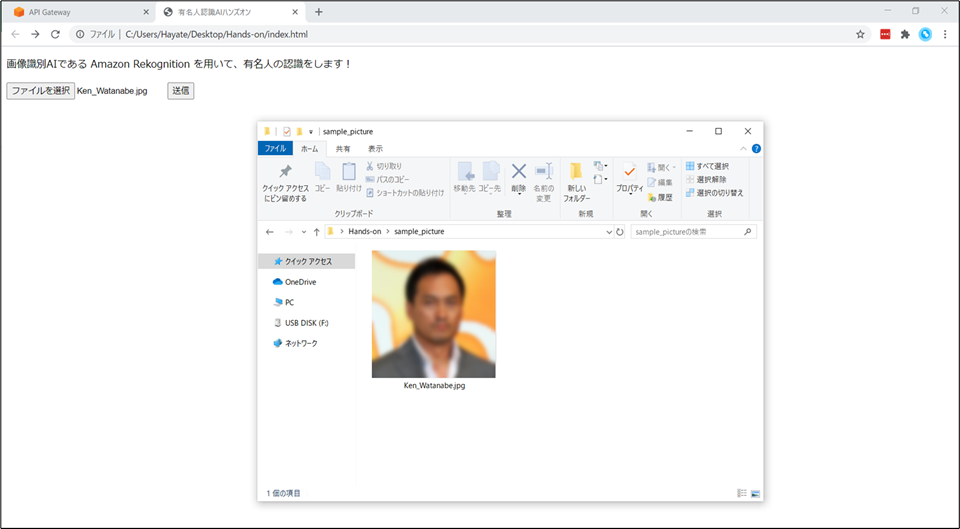
- 例えば、日本が世界に誇る有名俳優「渡辺謙」さんの写真を用意し、今回作成するAIに読み込ませてみます。
- ※ 以下のスクリーンショットでは、知財権保護のため画像をぼかしています。
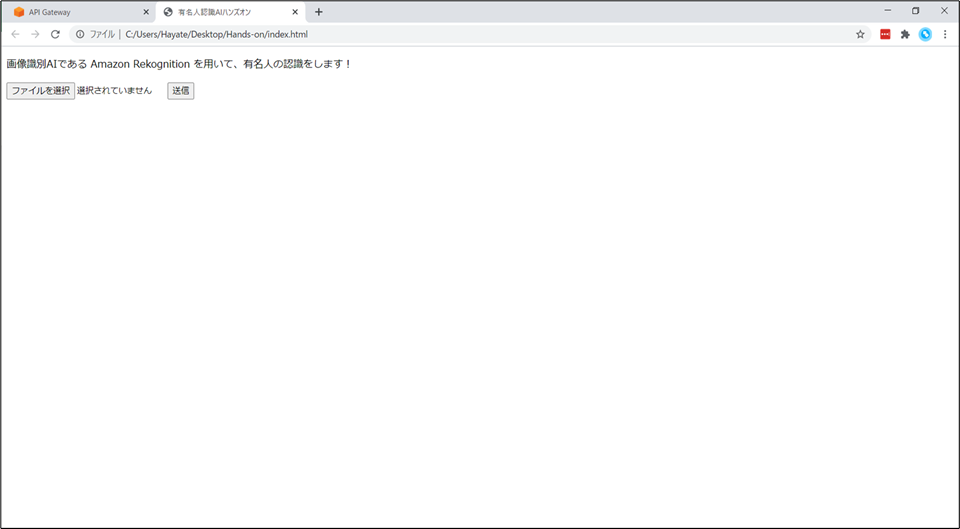
- 「ファイルを選択」ボタンから「渡辺謙」さんの画像を選択します。
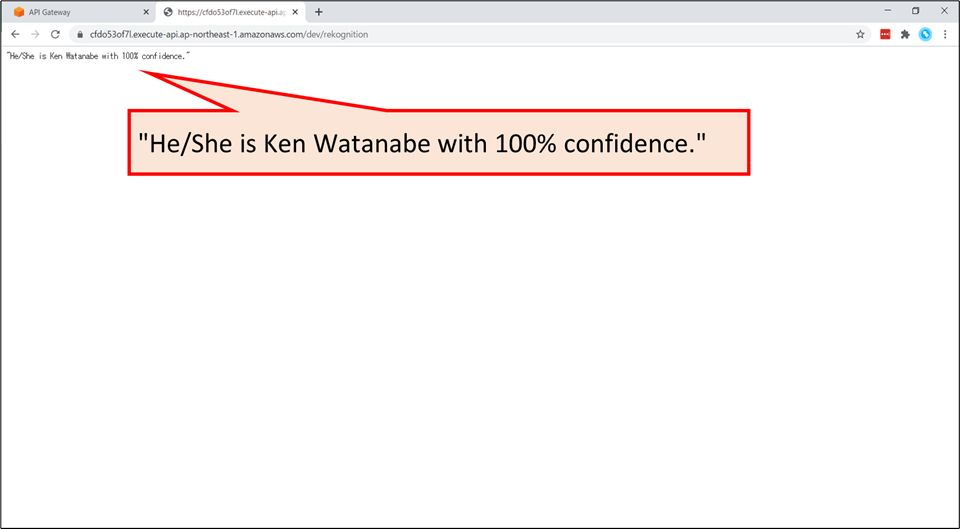
- ファイルを選択後、「送信」ボタンを押すと…
“He/She is Ken Watanabe with 100% confidence.”と表示されます。- 今回のハンズオンでは、このサービスのバックエンドを作成していきます。
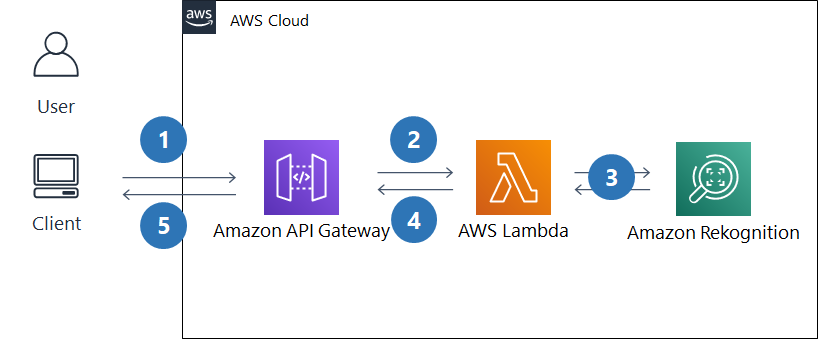
アーキテクチャ説明
- クライアントPCから API Gateway 経由で有名人の画像をアップロードします。
- 画像ファイルを受信すると、Lambda 関数が起動します。
- Lambda 関数内で Amazon Rekognition の recognize_celebrities 機能に画像ファイルを送り、画像内の有名人を識別します。
- 取得した有名人の情報を出力用に整形して、API Gateway を通して返します。
- 呼び出し元のブラウザ上で、識別結果が表示されます。
AWS サービスについて
使用する AWS サービスの紹介
- 今回使用する3つのサービスを簡単に紹介します。
- 「習うより慣れよ」の考えで、ハンズオンを進めていきましょう。
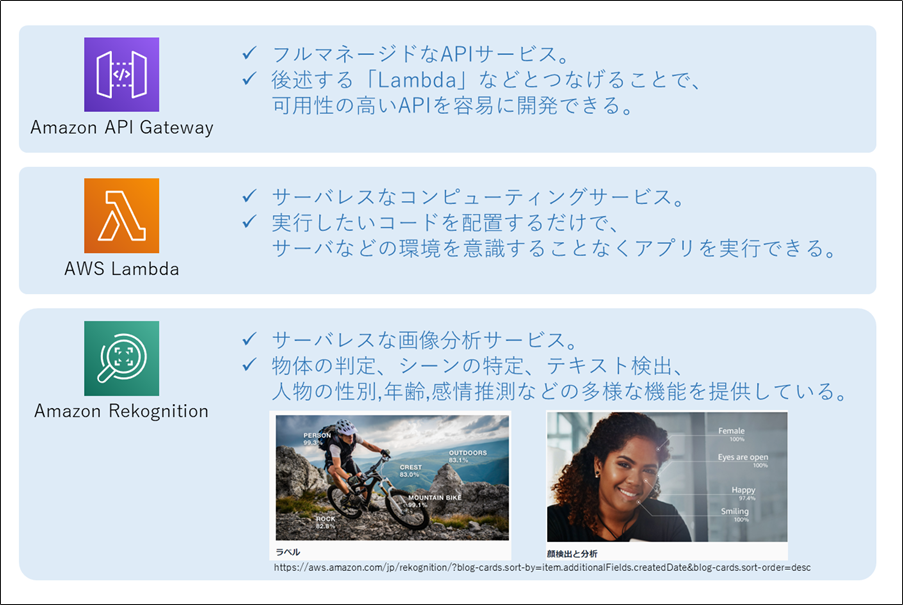
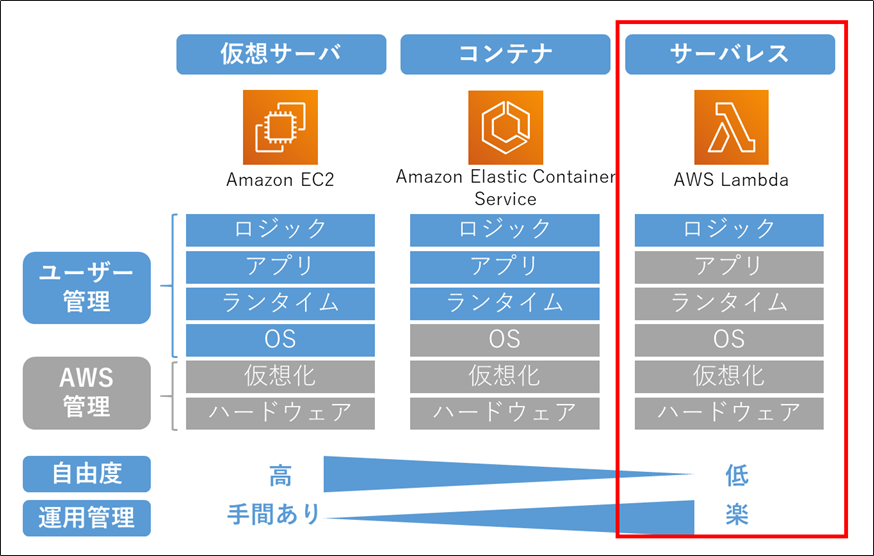
AWS 用語解説:「サーバレス」とは
- 利用者がサーバを意識する必要のないサービスやアーキテクチャのことです。
- 注意:サーバが全く存在しないわけではありません。サーバはAWSが管理しています。
- プログラムコードを「置くだけ」で動作します。そのため運用管理が楽になります。
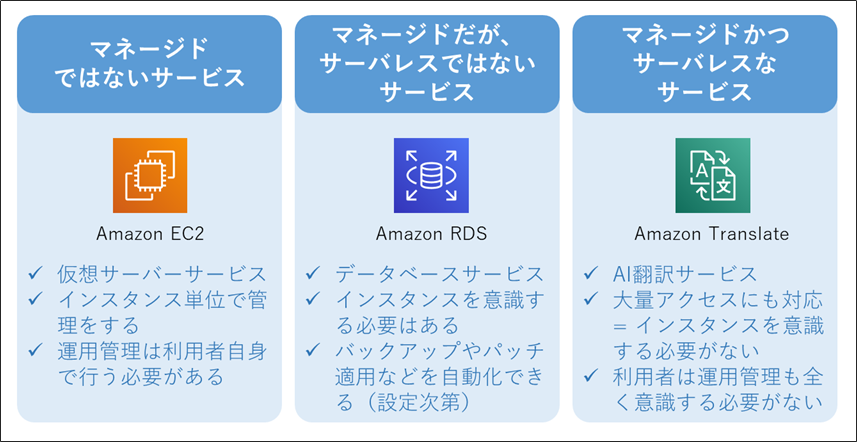
AWS 用語解説:「マネージドサービス」とは
- AWSが運用管理(の一部)を担ってくれるサービスのことです。
- 担ってくれる運用管理の内容や範囲はサービスによって多様ですが、「バックアップを定期的にとる」などだけではなく、「アクセスが増えたら自動でスケールする」なども提供していることが多いです。
- 運用管理の範囲が広く、利用者の手間がほとんどかからない場合は、「フルマネージドサービス」と言われることが多いです。
- 「マネージド」であっても、常に「サーバレス」とは限りません。
開発手順
サインイン
- AWSマネジメントコンソールへアクセスし、IAM ユーザー情報でサインインをしてください。
サインイン補足情報
- 今回のハンズオンでは、ハンズオンを実施するIAMユーザーに”AdministratorAccess”のIAMポリシーが付与されていることを前提にして進めています。
- “AdministratorAccess” の権限が付与されていなかった場合、以下の手順の中でリソースが作れない等のエラーが発生する可能性があります。
- その場合は、適切なポリシーをアタッチした上で再度実行をしてください。
- なお、以下のサイトに記載されていたIAMの設定内容は大変参考になりました。
- ハンズオンの手順が全て実行できることを確認済みです。
- 社外の開発メンバーをAWSアカウントに入れるときのIAM設定を考えている - kmiya_bbmのブログ
リージョンと言語の確認
- 画面右上が「東京(リージョン)」 画面左下が「日本語」になっていることを確認します。
- 変更が必要な場合は、次のページを参考に切り替え作業を行ってください。
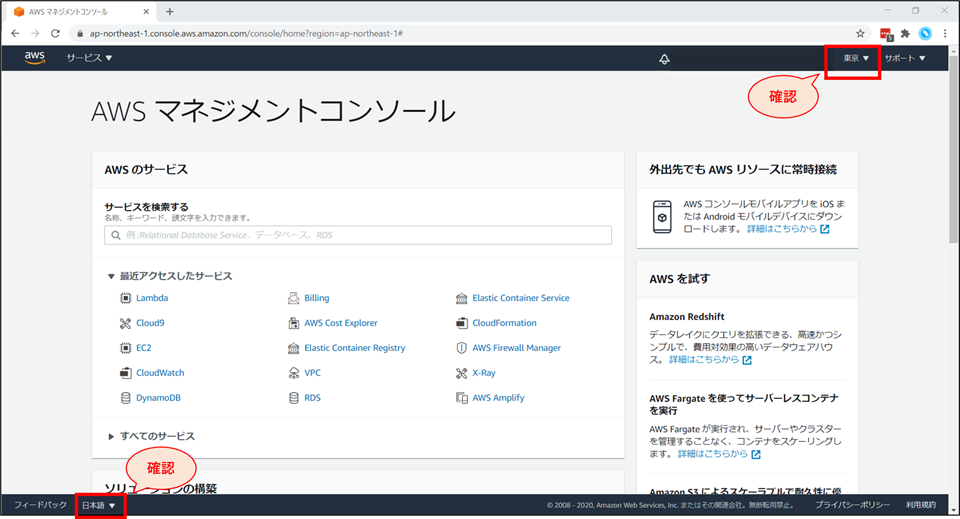
[補足] リージョンの変更方法
- 画面右上の地名を押下し、「アジアパシフィック(東京)ap-northeast-1」を選択します。
[補足] 言語の変更方法
- 画面左下の言語を押下し、「日本語」を選択します。
Lambda 関数の作成
Lambda 関数の新規作成
最初にLambda 関数を作成し、基本的な使い方を学習しましょう。
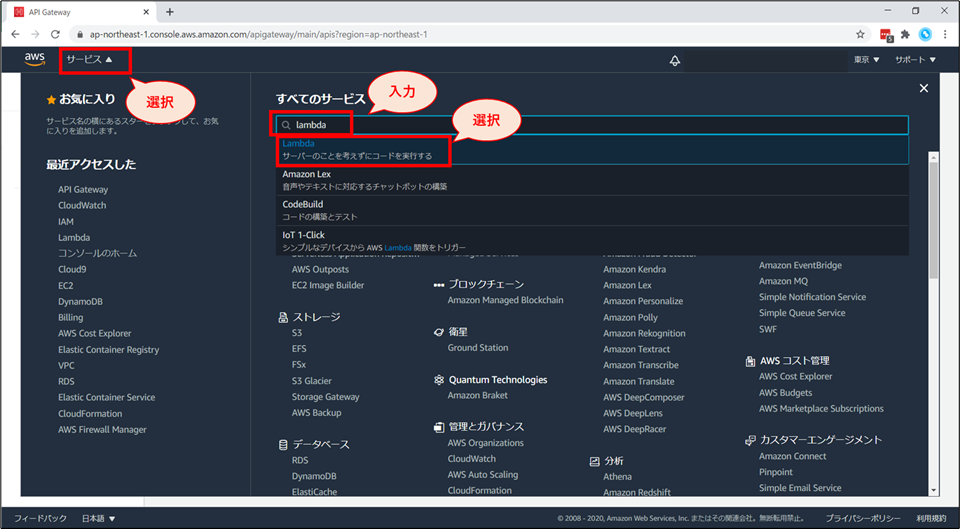
マネジメントコンソールの画面にて、検索窓に「Lambda」と入力し、表示された「Lambda」を選択してください。
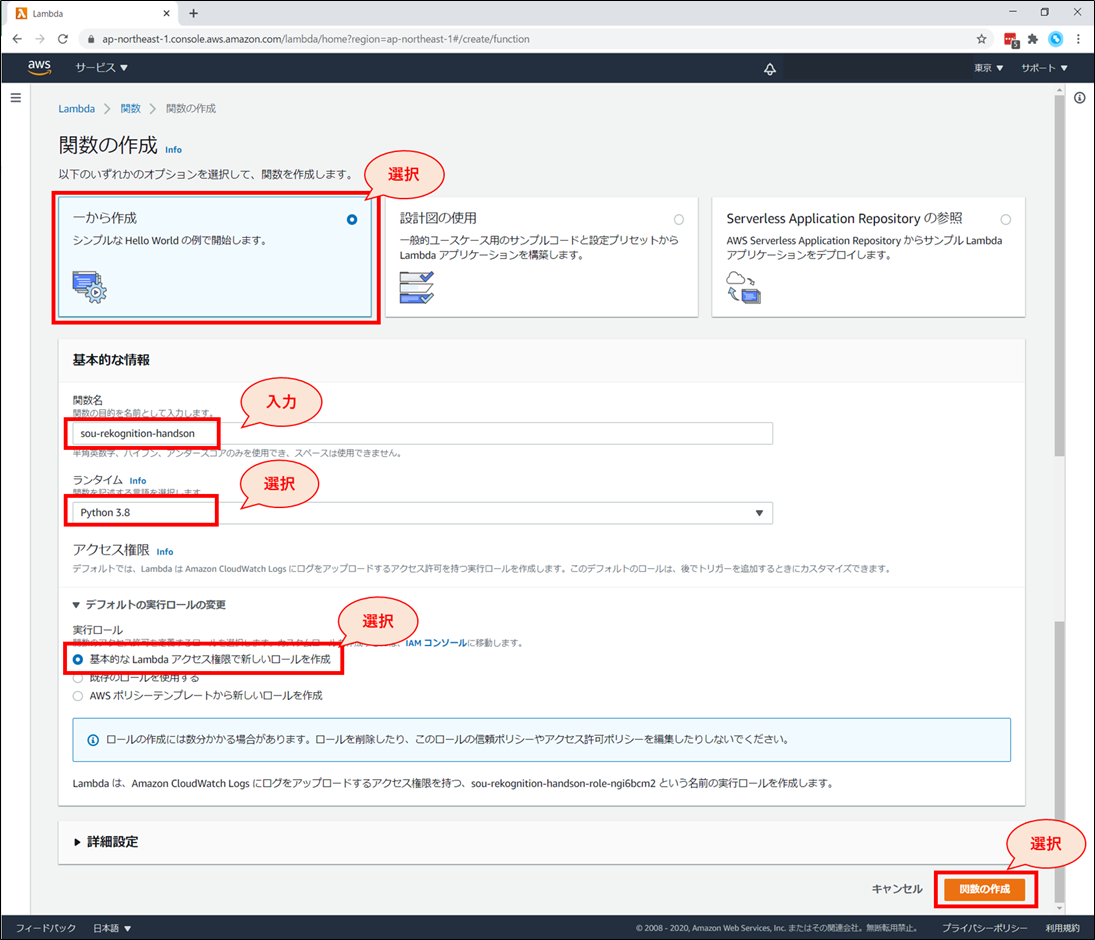
Lambdaの画面が開きましたら、「関数の作成」ボタンを押してください。
関数の作成画面にて、以下を選択、入力していきます。
- 「一から作成」を選択
- 「関数名」に「《お名前》-rekognition-handson」と入力
- 例:higuchi-rekognition-handson
- 「ランタイム」に「Python3.8」を選択
- 「アクセス権限」-「デフォルトの実行ロールの変更」 を開き、「基本的なLambdaアクセス権限で新しいロールを作成」を選択
上記設定が終わったら、画面右下「関数の作成」ボタンを押下します。
Lambda関数が作成されます。
今から動くコードを記述していきます。
「関数コード」のところまで下にスクロールします。ここがロジックを記述するエディタとなります。
Lambda 関数の使い方説明
まずは、シンプルなPythonコードを書いて Lambda の動きを学習しましょう。
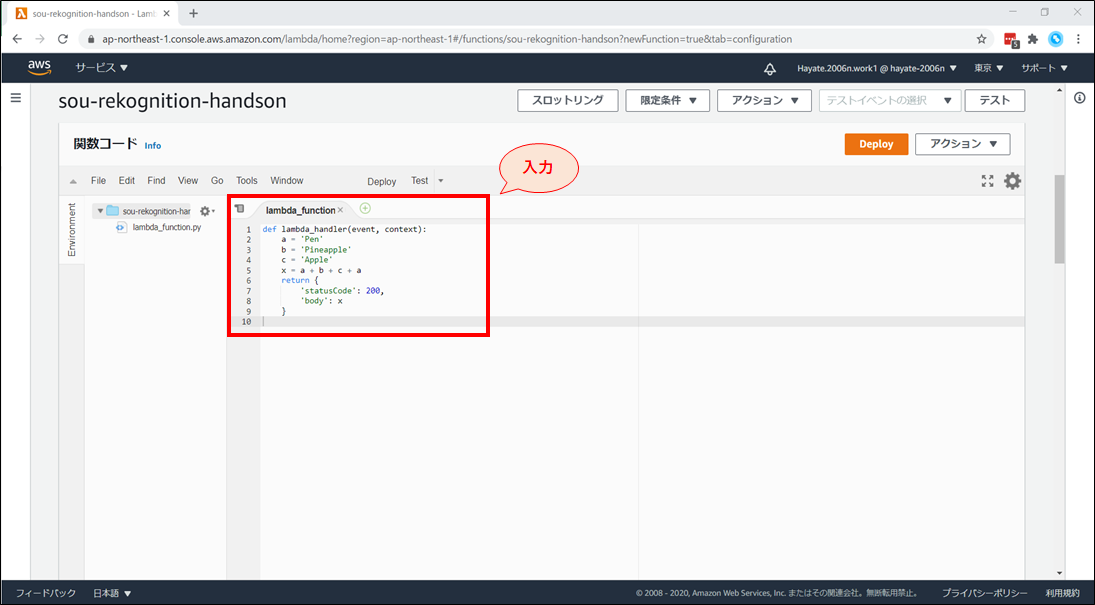
例えば、文字列を結合して出力する、以下のコードを記述します。
- 変数に文字列を設定し、結合をしたものを return する内容となっています。
- 具体的には、’Pen’ + ’Pineapple’ + ’Apple’ + ’Pen’ → ‘PenPineappleApplePen’ になります。
lambda_function.pydef lambda_handler(event, context): a = 'Pen' b = 'Pineapple' c = 'Apple' x = a + b + c + a return { 'statusCode': 200, 'body': x }
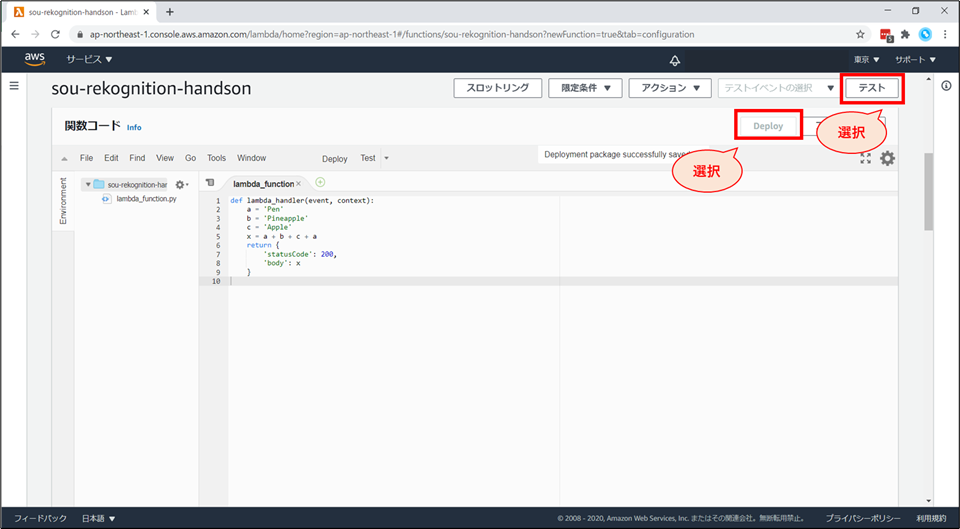
記述後、「Deploy」 ボタンを押したのち、右上の「テスト」を押下します。
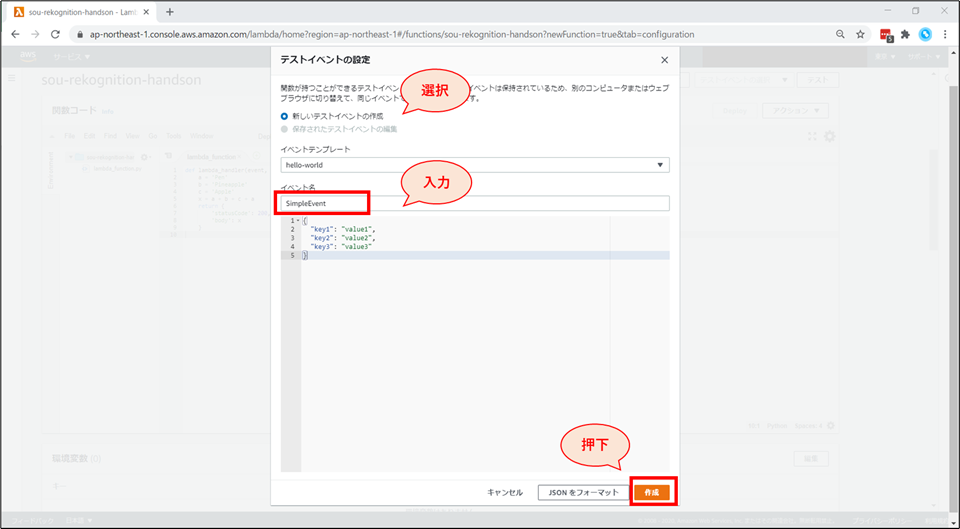
「テストイベントの設定」画面が表示されます。以下の設定をした後、「作成」ボタンを押下します。
- 「新しいテストイベントの作成」を選択します。
- イベント名に「SimpleEvent」と入力します
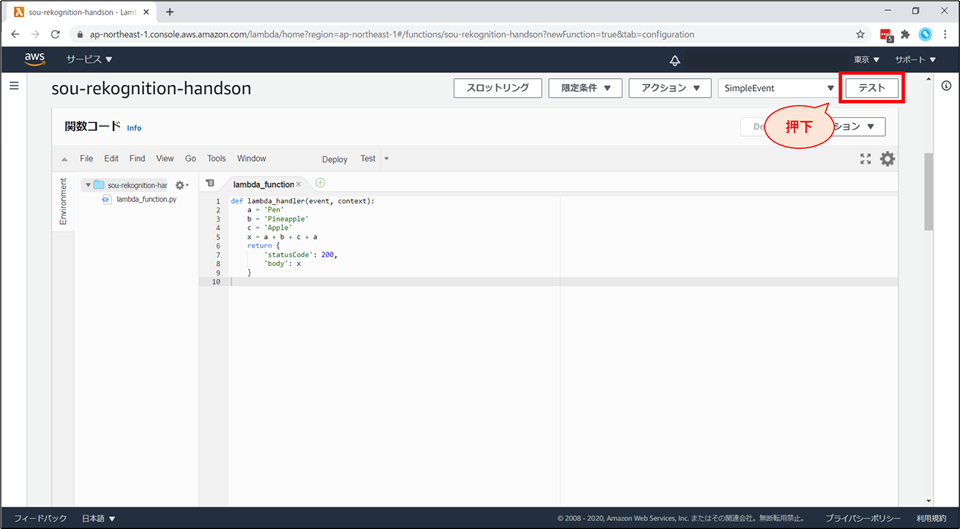
右上の「テスト」を押下します。
- 先ほど作成したテストイベントで、テストが実行されます。
Lambda がテスト実行されました。
- 画面上部に「成功」と表示が出れば、コードは正常に動いた証拠です。
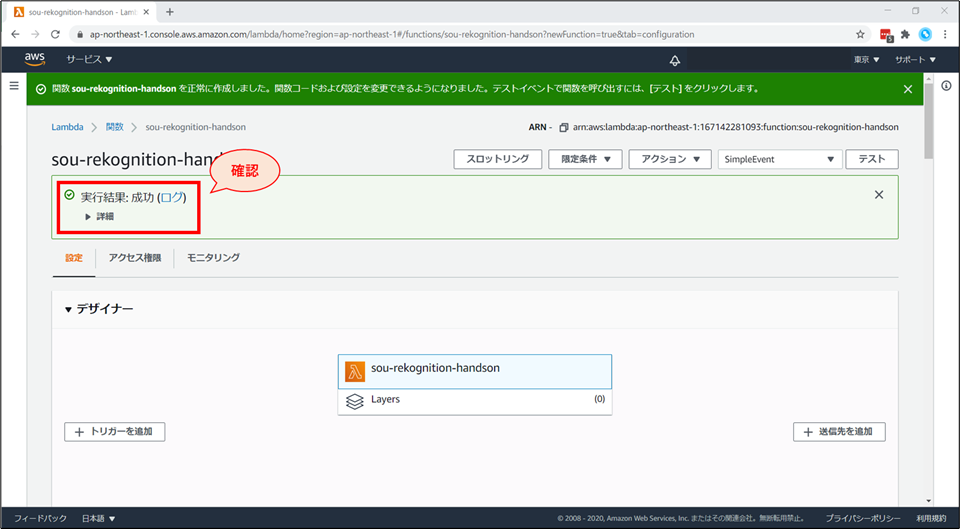
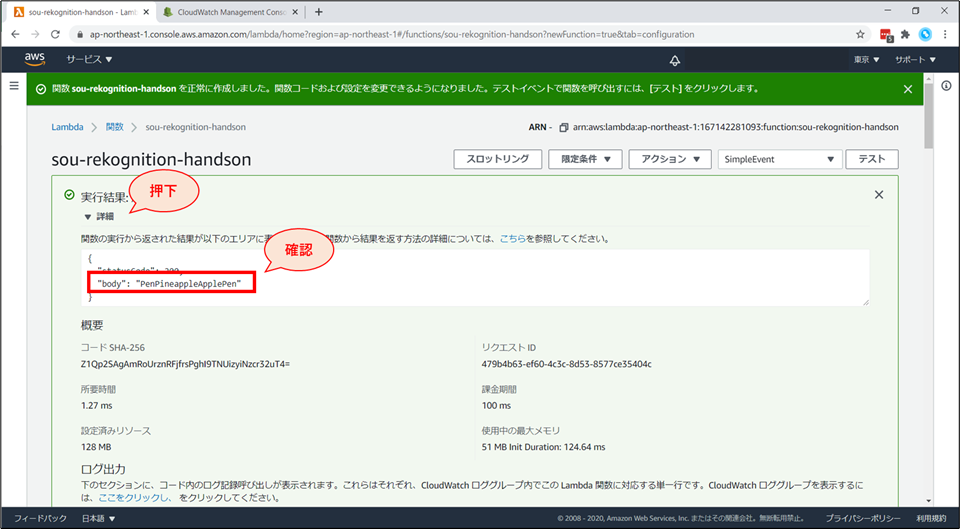
詳細をクリックすると、関数の実行結果が展開されます。
- ここでは、“body” が “PenPineappleApplePen”となっており、期待した通りの output になっています。
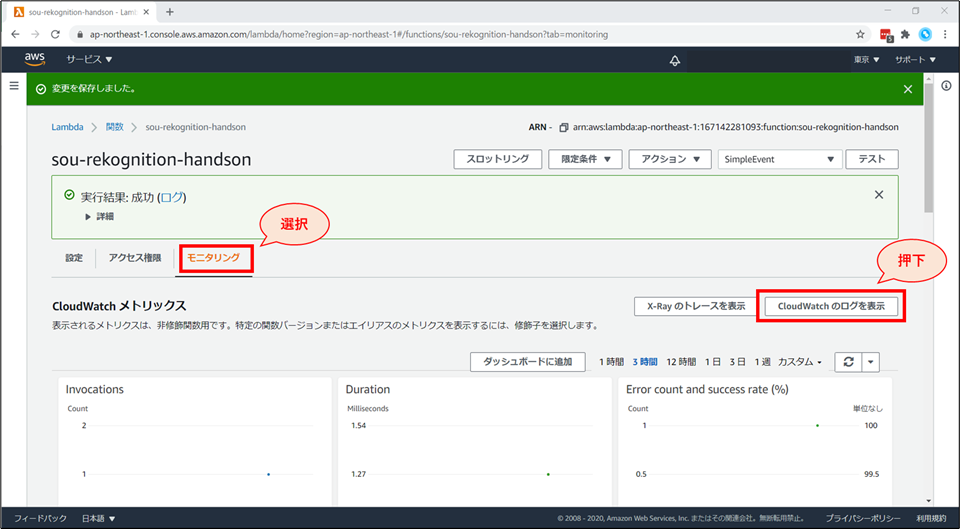
Lambda 実行時の詳細なログは、"CloudWatch Logs" で確認できます。
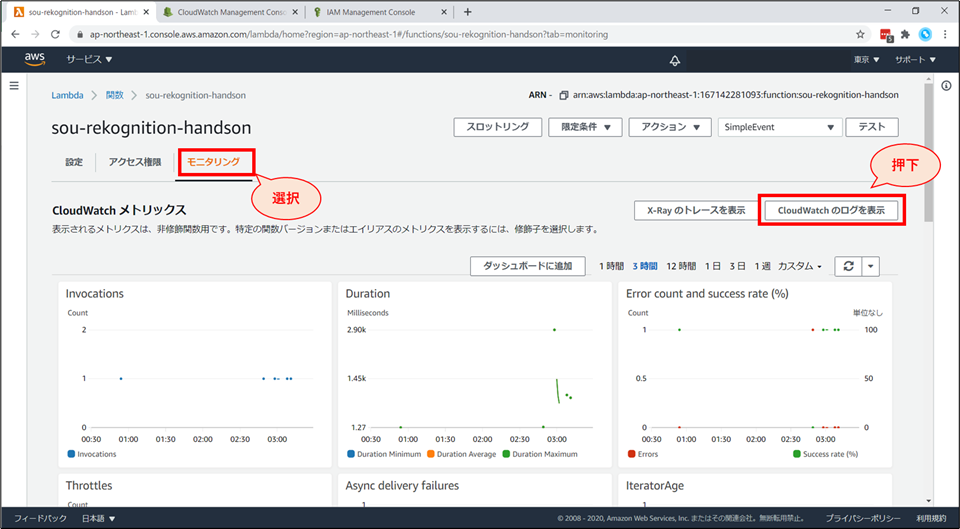
- 「モニタリング」→「CloudWatchのログを表示」をクリックすると、“CloudWatch Logs” のページに遷移します。
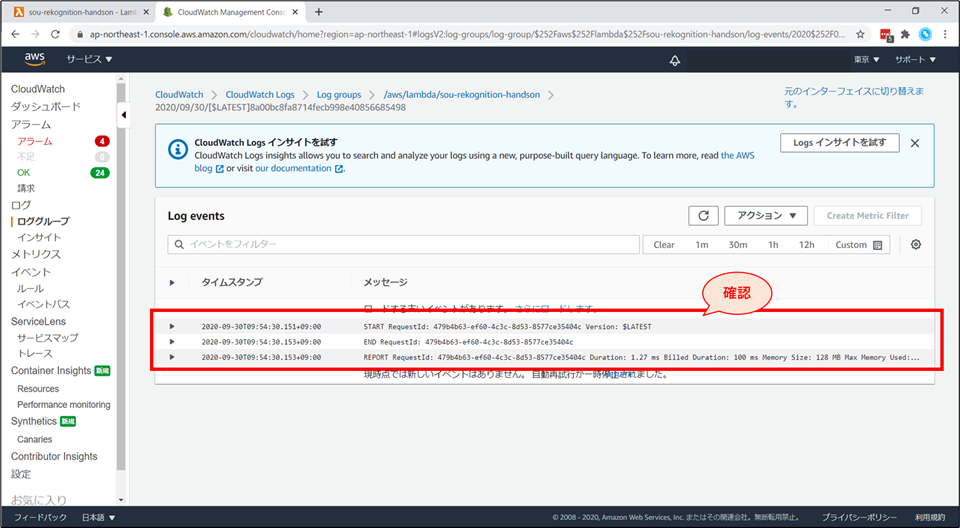
「ログストリーム」画面にて「20xx/xx/xx[$LATEST]xxxxxx」を選択するとログが確認できます。デバック時にご活用ください。
- Logger などを設定すると、ここにログが出力されるようになります。
Lambda 関数の編集
- ここから、Lambda関数を、画像解析AI (Rekognition)と紐づける作業をしていきます。
- Lambda関数から、Rekognitionを呼び出すには、適切な権限が必要です。
- 具体的には、Lambdaに付与されているIAMロールに、Rekognitionへのアクセスを許可するIAMポリシーをアタッチする必要があります。
- まずは、権限付与から行っていきましょう。
IAM ロール(権限)の変更
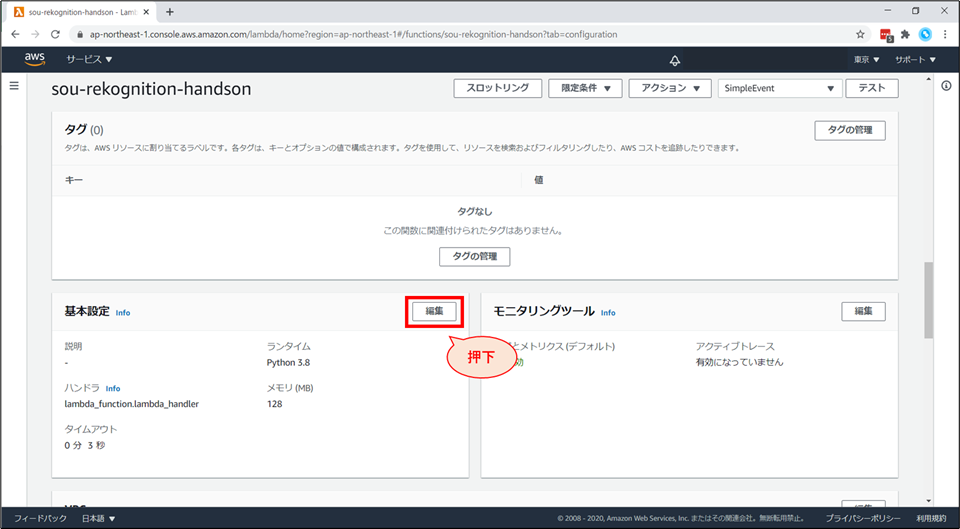
Lambda画面の上部で「設定」を選びます
「設定」画面の下部「基本設定」の「編集」を選択します。
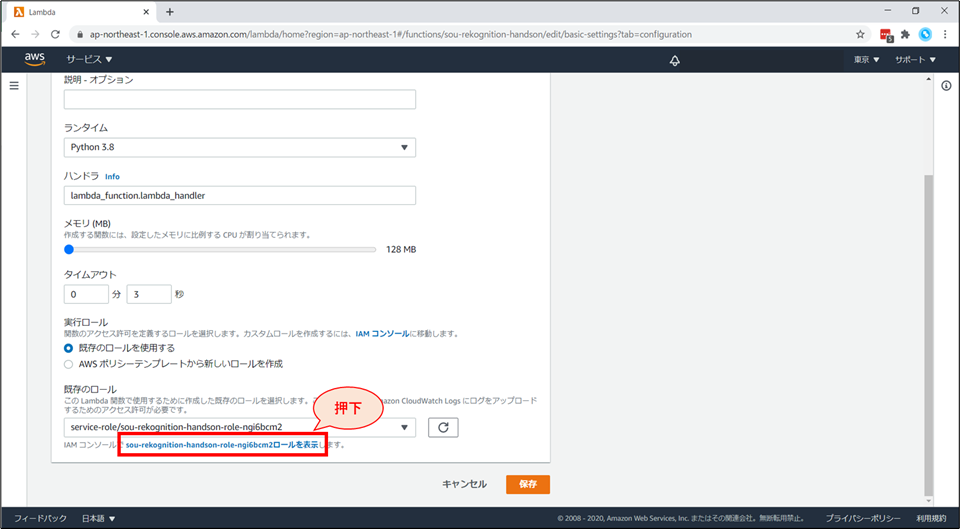
「基本設定を編集」画面の下部まで行き、「IAMコンソールでxxxロールを表示します。」をクリックします。
別タブで、IAMロールの画面が開きます。
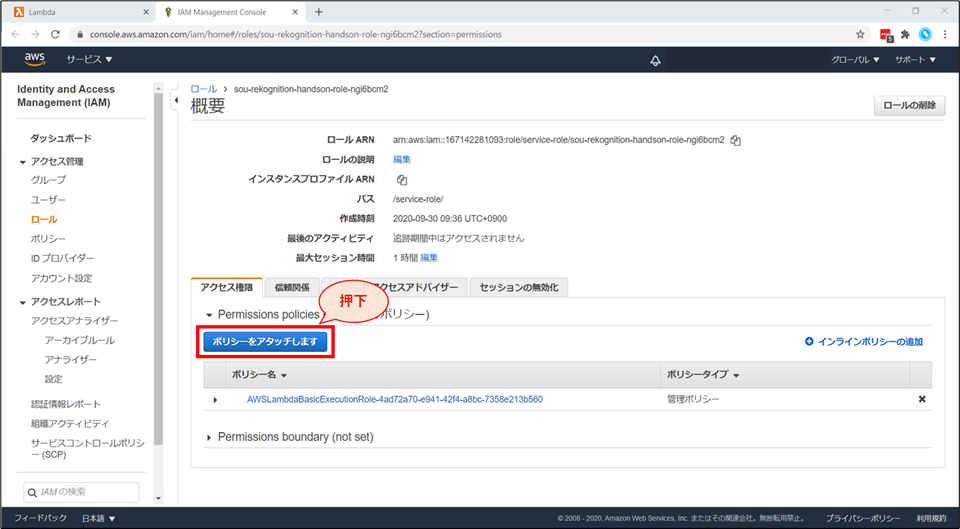
「ポリシーをアタッチします」ボタンを押下します。
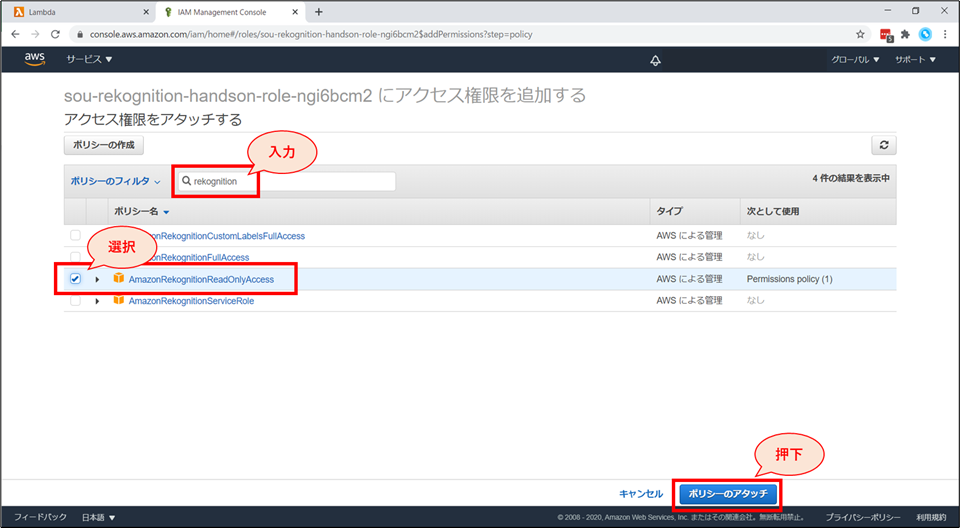
検索窓に「Rekognition」と入力し、「AmazonRekognitionReadOnlyAccess」ポリシーにチェックを入れて、「ポリシーのアタッチ」ボタンを押下します。
IAMのコンソール画面で、「AmazonRekognitionReadOnlyAccess」がアタッチされていることを確認します。
これで、Lambda に Rekognition を呼び出せる権限を付与できました。
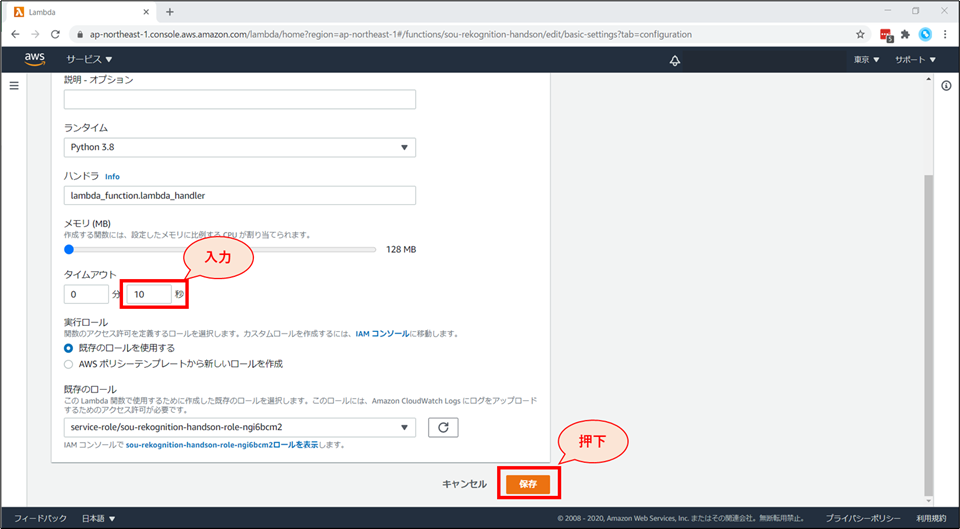
Lambda の「基本設定を編集」画面に戻ります。
- タイムアウトを「10秒」に変更します。
上記設定後、「保存」ボタンを押下します。
Lambda 関数の更新
- Lambda 関数を、有名人識別のコードに書き換えます。
- 「関数コード」を以下の内容で上書きし、「Deploy」ボタンを押下します。
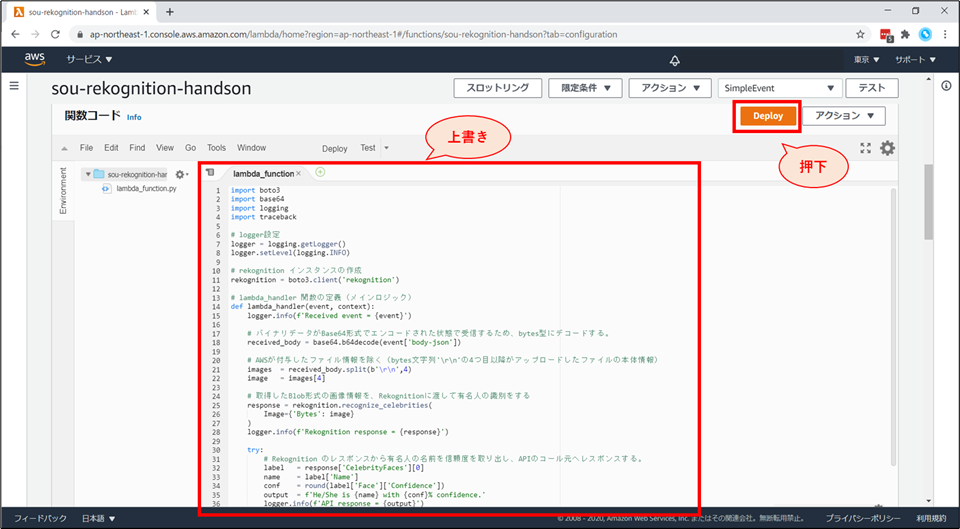
貼り付けるコード
lambda_function.pyimport boto3 import base64 import logging import traceback # logger設定 logger = logging.getLogger() logger.setLevel(logging.INFO) # rekognition インスタンスの作成 rekognition = boto3.client('rekognition') # lambda_handler 関数の定義(メインロジック) def lambda_handler(event, context): logger.info(f'Received event = {event}') # バイナリデータがBase64形式でエンコードされた状態で受信するため、bytes型にデコードする。 received_body = base64.b64decode(event['body-json']) # AWSが付与したファイル情報を除く(bytes文字列'\r\n'の4つ目以降がアップロードしたファイルの本体情報) images = received_body.split(b'\r\n',4) image = images[4] # 取得したBlob形式の画像情報を、Rekognitionに渡して有名人の識別をする response = rekognition.recognize_celebrities( Image={'Bytes': image} ) logger.info(f'Rekognition response = {response}') try: # Rekognition のレスポンスから有名人の名前を信頼度を取り出し、APIのコール元へレスポンスする。 label = response['CelebrityFaces'][0] name = label['Name'] conf = round(label['Face']['Confidence']) output = f'He/She is {name} with {conf}% confidence.' logger.info(f'API response = {output}') return output except IndexError as e: # Rekognition のレスポンスから有名人情報を取得出来なかった場合、他の写真にするように伝える。 logger.info(f"Coudn't detect celebrities in the Photo. Exception = {e}") logger.info(traceback.format_exc()) return "Couldn't detect celebrities in the uploaded photo. Please upload another photo."コードの説明( #コメントに書ききれなかった部分)
- 1行目
import boto3
- AWS サービスを扱う上で必要なモジュールのインポートをしています。
- boto3はPythonでAWSリソースを操作する際に用いるSDKです。
- https://boto3.amazonaws.com/v1/documentation/api/latest/reference/services/index.html
- 25~27行目
response = rekognition.recognize_celebrities(Image={'Bytes': image})
- rekognitionの使い方は、boto3のドキュメントに記載されています。
- https://boto3.amazonaws.com/v1/documentation/api/latest/reference/services/rekognition.html#Rekognition.Client.recognize_celebrities
- 37行目
return文
- これは、実はアンチパターンの return 文です。
- 実際には、Lambdaのプロキシ統合のフォーマットに合わせたレスポンス形式にすると良いでしょう。
- 今回は、ブラウザ上での動作確認を行うため、明示的にプロキシ統合を使わず、また出力のフォーマットも意図的に無視をした記載にしています。
- 詳しくは「API Gateway 統合レスポンス」で検索してください。
- https://docs.aws.amazon.com/ja_jp/apigateway/latest/developerguide/api-gateway-integration-settings-integration-response.html
API Gateway の追加
ここから、API Gateway と Lambda を紐づけていきます。
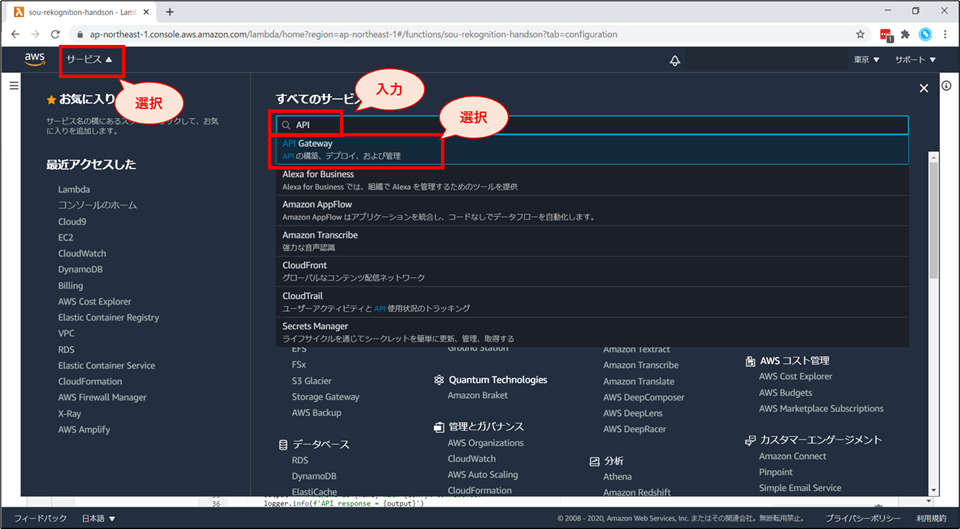
画面上部「サービス」から検索窓に"API"と入力し、候補にあがる「API Gateway」 を選択します。
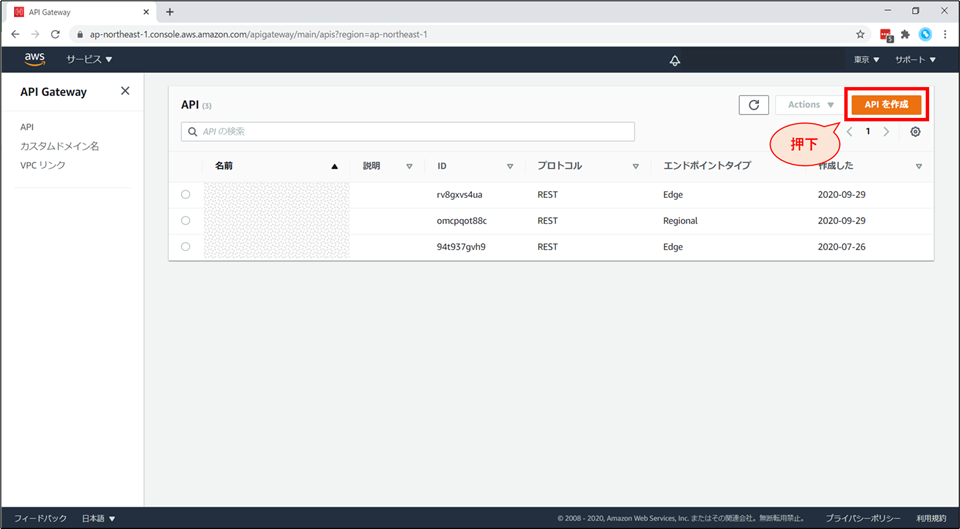
画面右上「APIを作成」を押下します。
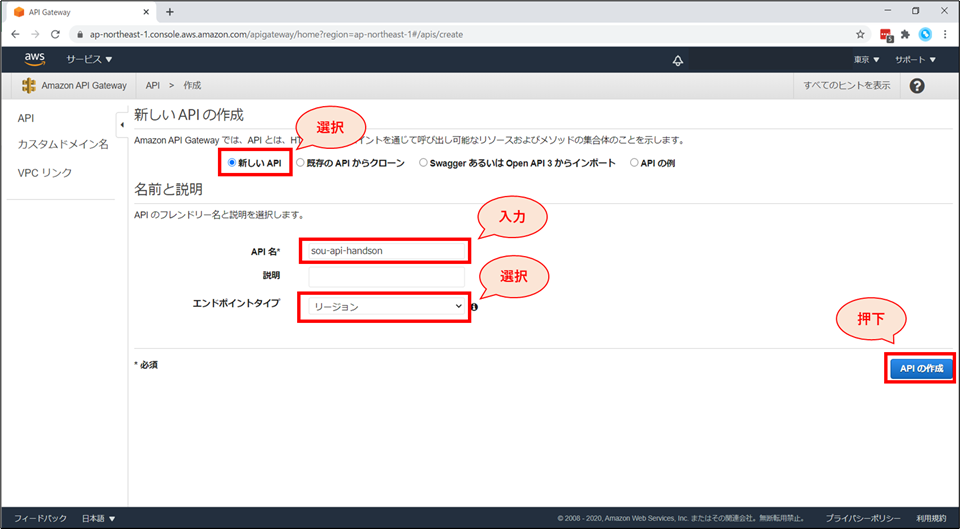
REST API の「構築」ボタンを押下します。
「新しいAPIの作成」画面にて以下の設定を行い、「APIの作成」ボタンを押下します。
- 「新しいAPI」を選択
- API名:「《お名前》-api-handson」と入力(例:higuchi-api-handson)
- エンドポイントタイプ:「リージョン」を選択
API は「リソース」×「メソッド」で開発をしていきます。
- 例えば「/users に GET」や「/users/12345 にPOST」などです。

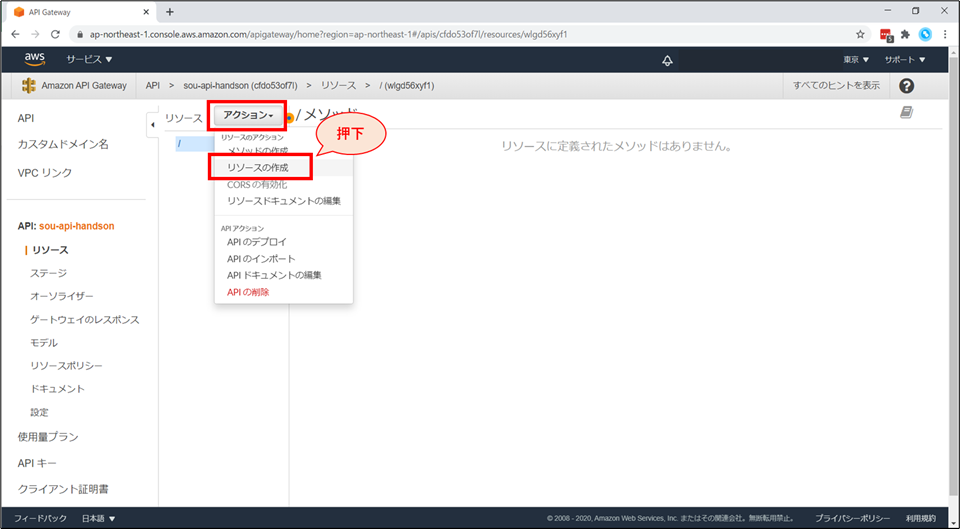
まず、リソースを作成します。「アクション」から「リソースの作成」を選択します。
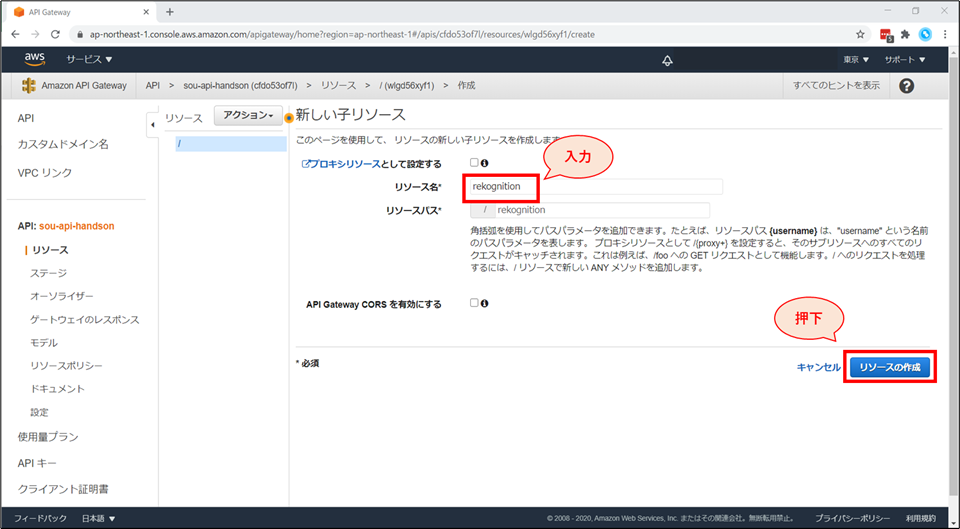
リソース名に「Rekognition」と入力し「リソースの作成」ボタンを押下します。
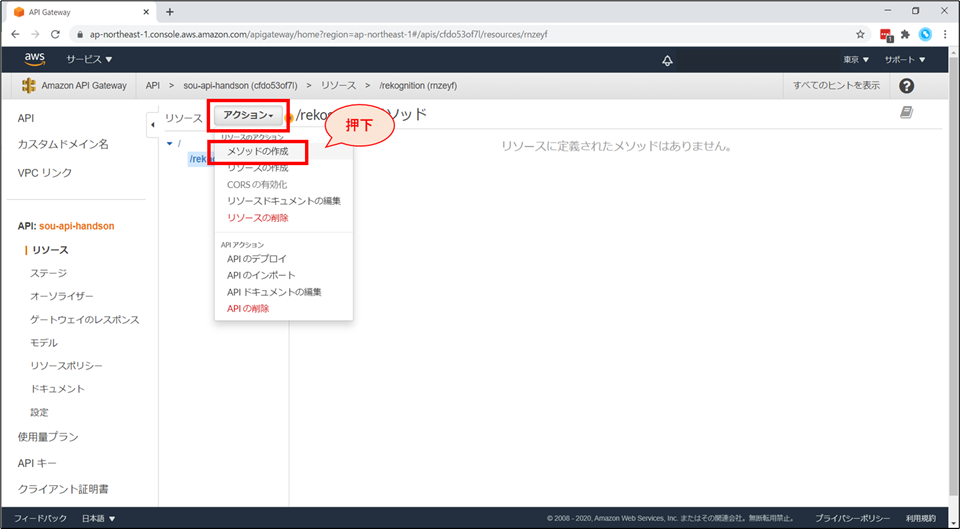
次にメソッドの作成をします。リソースを選択した上で、「アクション」→「メソッドの作成」を選択します。
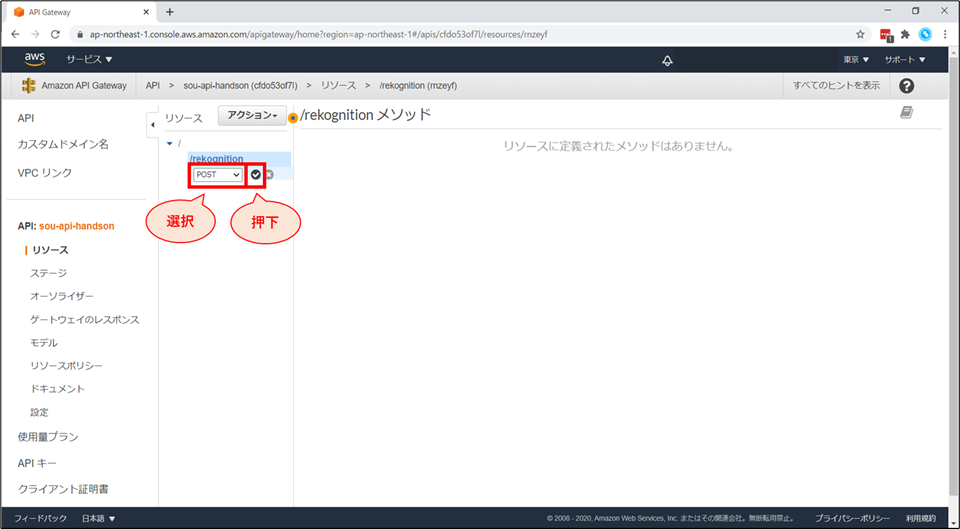
プルダウンから「POST」を選んで、「チェックボタン」を押下します。
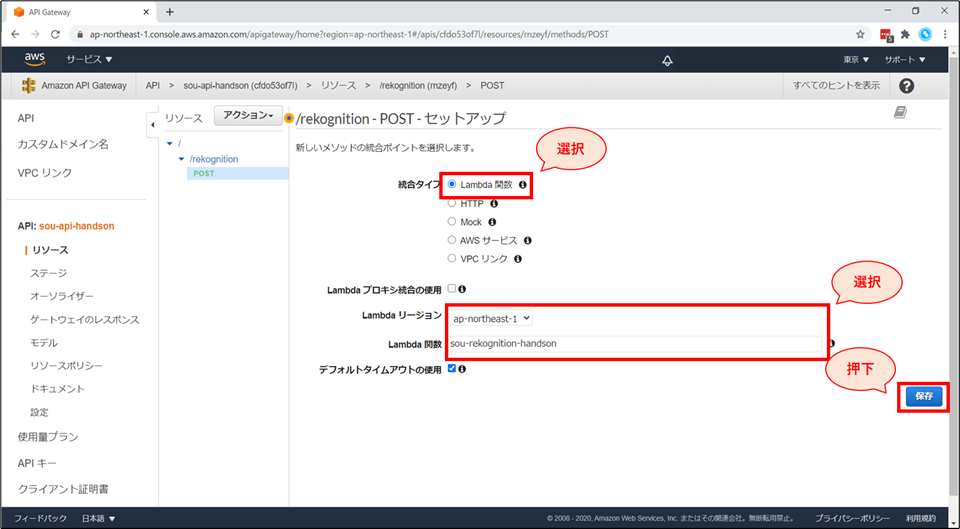
統合タイプにて「Lambda関数」を選択し、Lambda関数にて先ほど作成した「《お名前》-rekognition-handson」を選択後、「保存」ボタンを押下します。
「Lambda 関数に権限を追加する」の確認画面が表示されるので、「OK」ボタンを押下します。
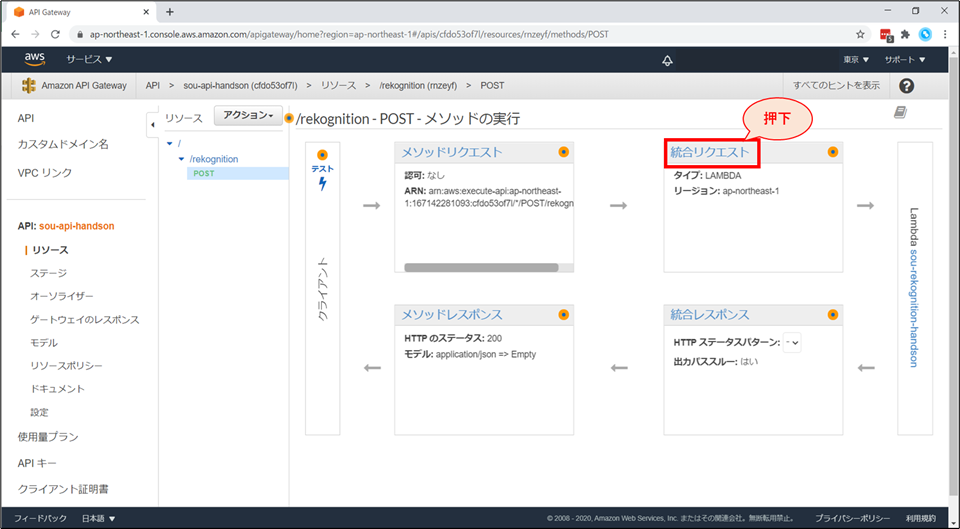
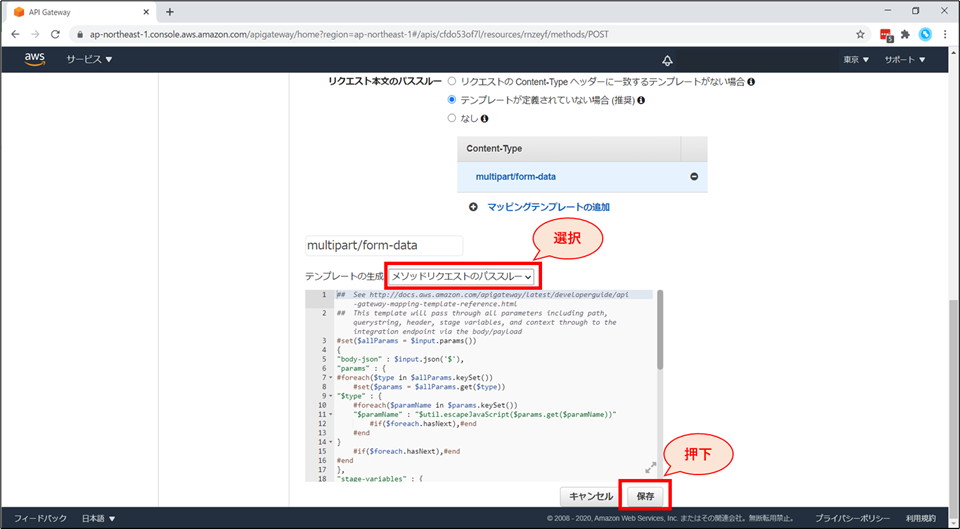
「統合リクエスト」を選択します。
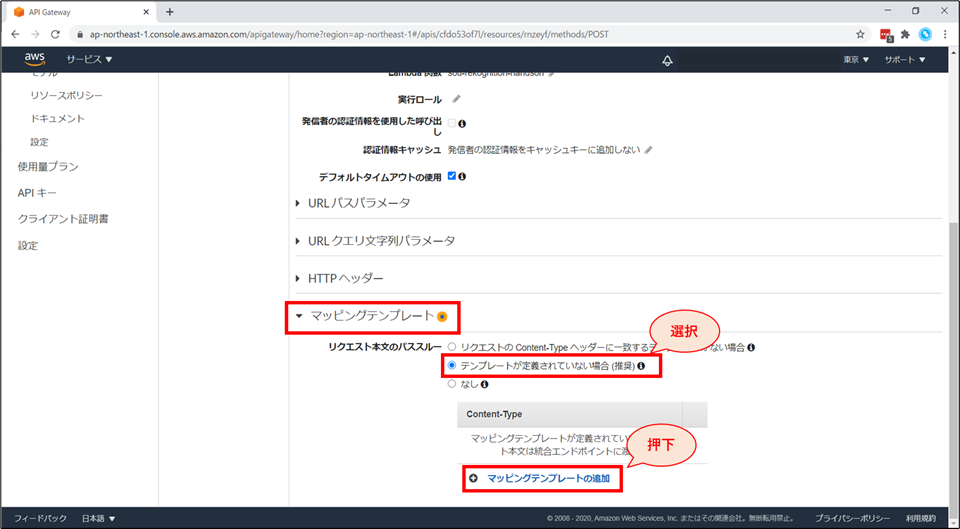
画面下部「マッピングテンプレート」を展開し、「リクエスト本文のパススルー」の項目で「テンプレートが定義されていない場合(推奨)」を選択します。
「Content-Type」の項目にて、「マッピングテンプレートの追加」を押下します。
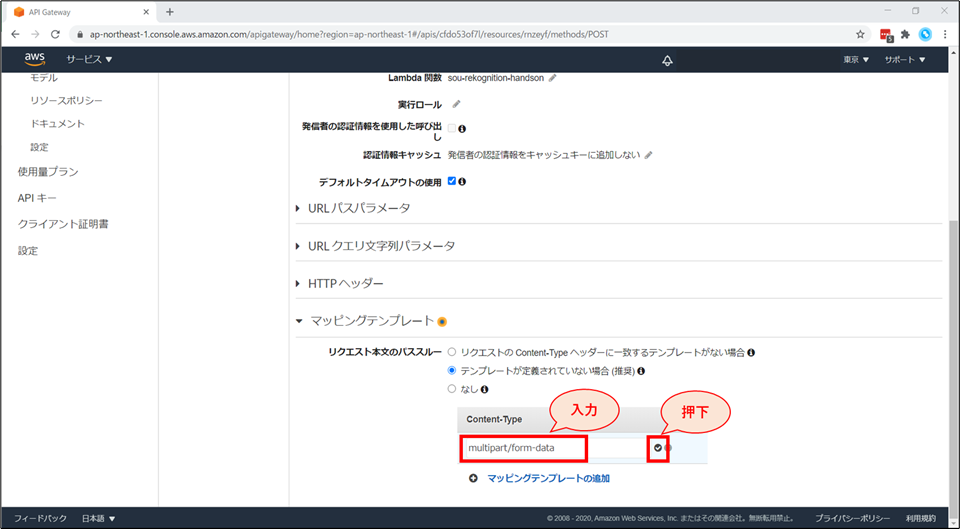
「Content-Type」の項目にて、
multipart/form-dataと入力し、チェックボタンを押します。
画面下部にテンプレートの生成画面が追加されます。
テンプレートの生成のプルダウンにて、「メソッドリクエストのパススルー」を選択し「保存」ボタンを押します。
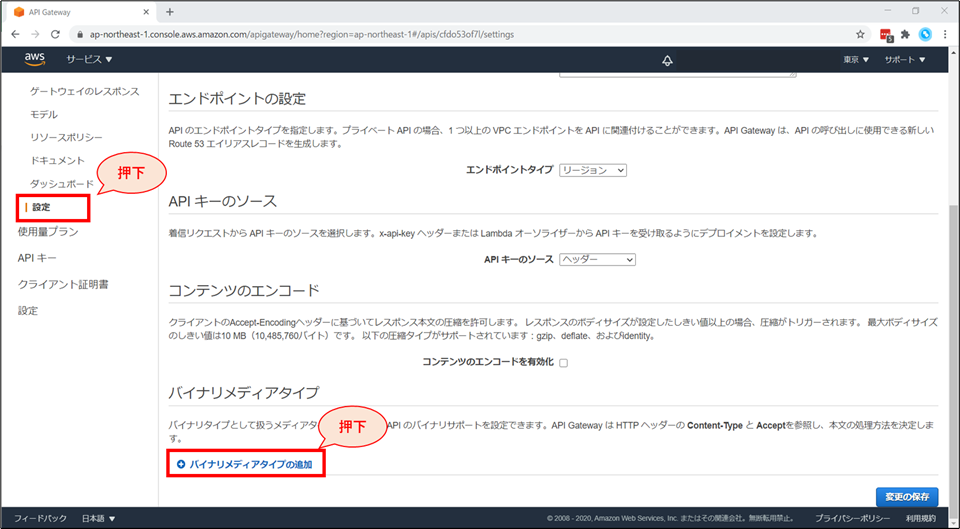
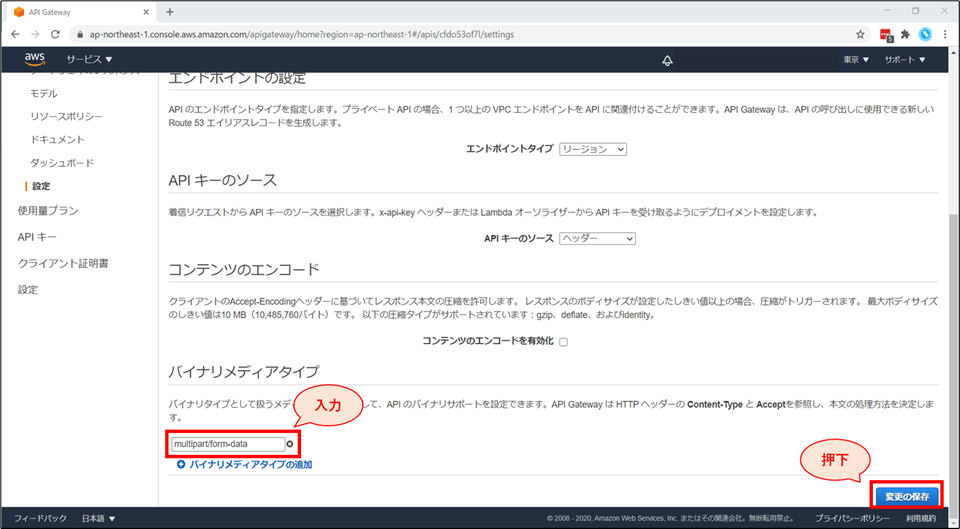
画面左「設定」を選択し、「設定」画面の下部「バイナリメディアタイプ」の項目にて「バイナリメディアタイプの追加」を押下します。
multipart/form-dataと入力し、「変更の保存」ボタンを押下します。
画面左ペイン「リソース」を選択後、画面上部「アクション」より「APIのデプロイ」を選択します。
APIのデプロイ画面にて、以下の設定をし、「デプロイ」ボタンを押下します。
- デプロイされるステージ:「新しいステージ」を選択
- ステージ名:「dev」を入力
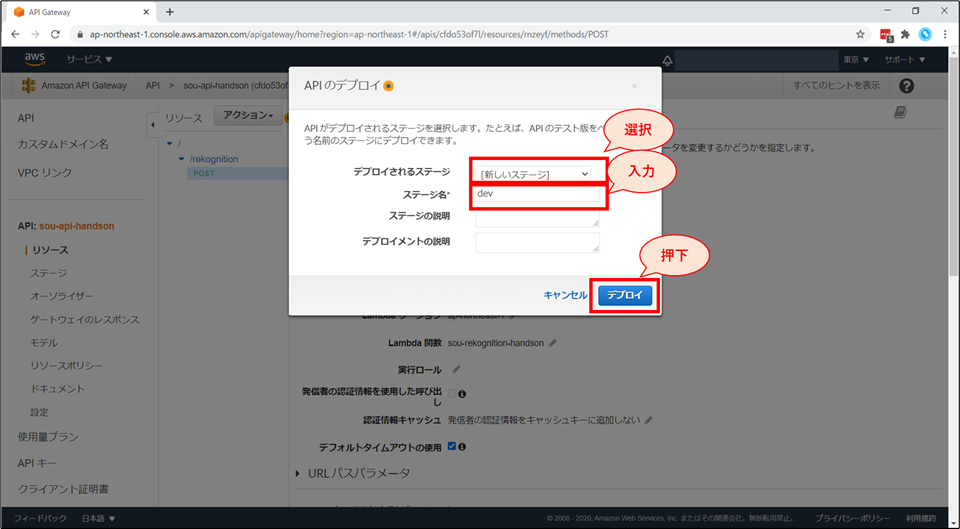
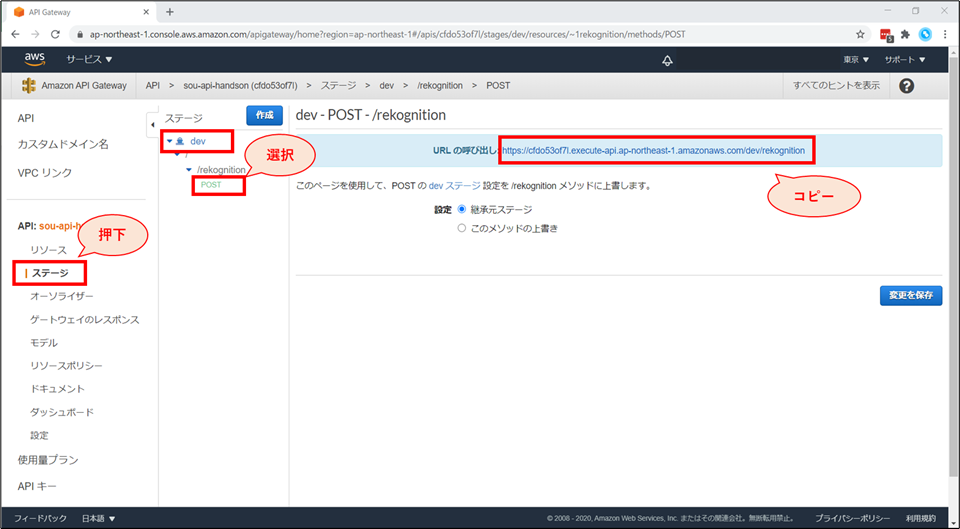
画面左ペインから、「ステージ」を選択し、「dev」-「rekognition」-「POST」を選択します。
画面右に、「URLの呼び出し」として作成された API の URL が表示されるので、これをコピーします。
HTML ファイルの作成
- 以下のHTMLの
****API Gateway URL 貼り付け****の部分に、先ほど作成した API Gateway の URL を貼り付け、"index.html"のファイル名で保存します。
- フォームを用いて、選択されたファイルを送信するだけの、単純な HTML ファイルです。
index.html<!DOCTYPE html> <html lang="ja"> <head> <meta charset="UTF-8"> <title>有名人認識AIハンズオン</title> </head> <body> <p>画像識別AIである Amazon Rekognition を用いて、有名人の認識をします!</p> <form action="****API Gateway URL 貼り付け****" enctype="multipart/form-data" method="POST"> <input type="file" name="写真ファイルを選択" /> <input type="submit" name="アップロード"/> </form> </body> </html>
- 作成したIndex.html をブラウザで開きます。(ファイルを選択しブラウザ上までドラッグ&ドロップすれば開けます)
動作確認
例えば、日本が世界に誇るお笑い芸人(?)「世界のワタベ」で試してみましょう。
- ※以下のスクリーンショットでは、知財権保護のため画像をぼかしています。

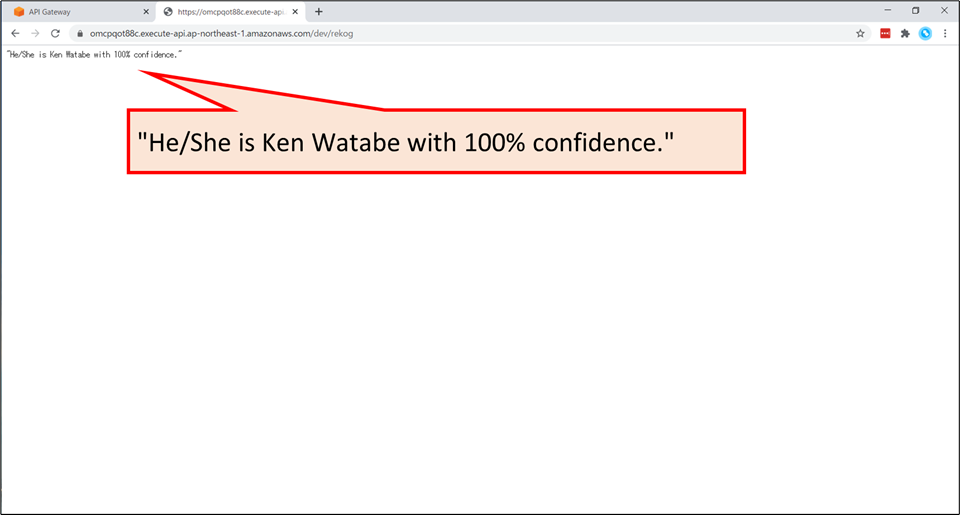
ファイルを選択し、「送信」ボタンを押すと…
"He/She is Ken Watabe with 100% confidence."と表示されました!有名人識別サービスの完成です!
- さすが「世界のワタベ」ですね。
お片付け
- 以下のリソースを削除していきます。
- API Gateway
- Lambda
- CloudWatch ロググループ(Lambdaの実行ログ)
- Lambda用 IAMロール
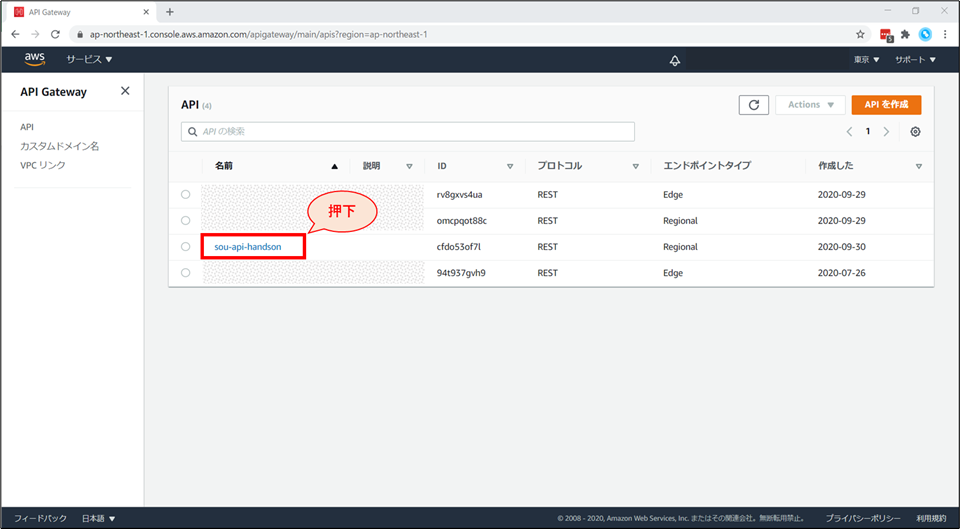
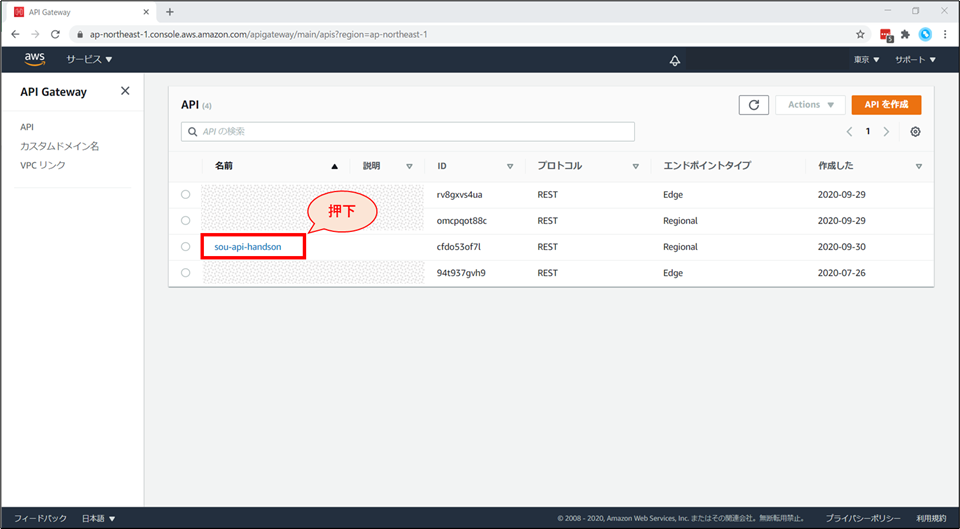
API Gateway の削除
API Gateway の画面から、作成した「《お名前》-api-handson」を選択します。
API Gateway の画面から、作成した「《お名前》-api-handson」を選択します。
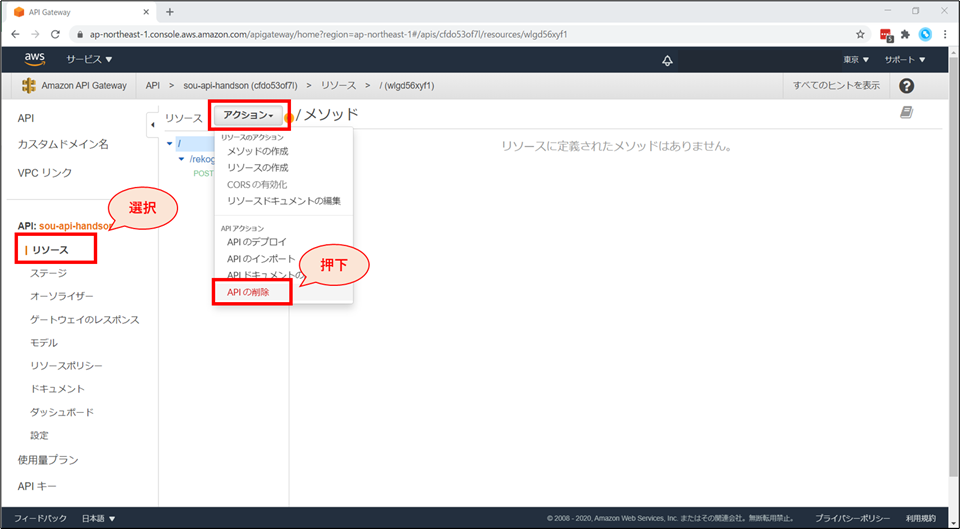
画面左ペインで「リソース」が選択されている状態で、アクションから「APIの削除」を選択します。
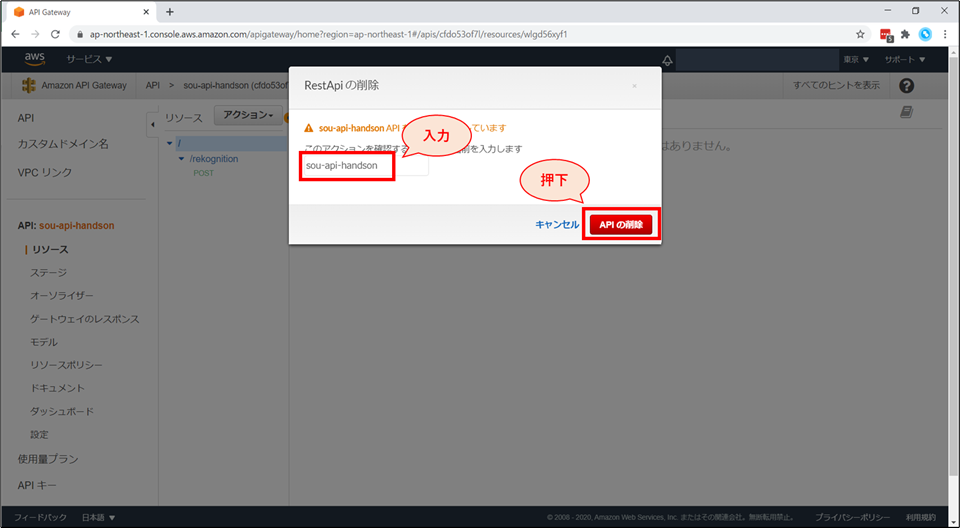
削除前の確認画面が表示されるので、API名を入力後、「APIの削除」を押下します。
CloudWatch ログの削除
Lambda のコンソール画面へ遷移するために、画面上部の「サービス」から「Lambda」を検索し選択します。
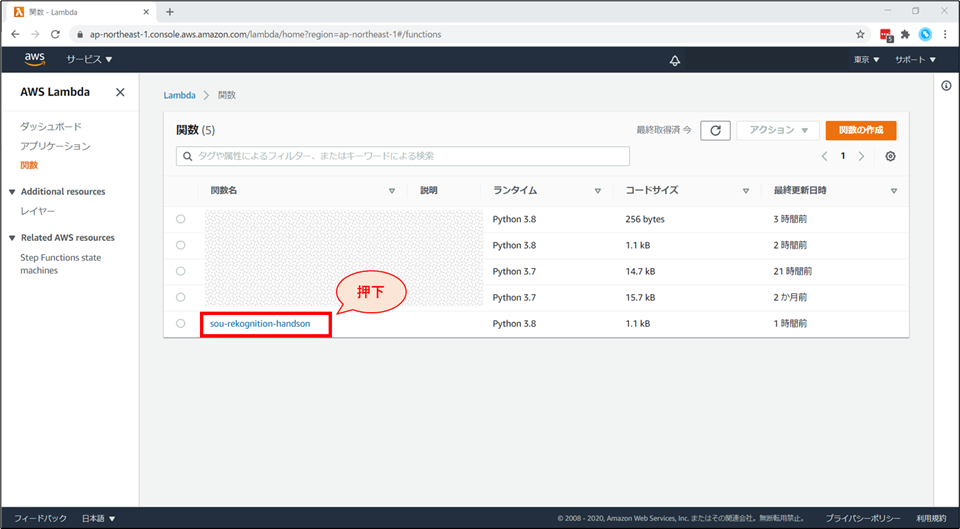
一覧画面にて、「《お名前》-rekognition-handson」を選択します。
画面上部「モニタリング」を選択し、「CloudWatchのログを表示」ボタンを押下します。
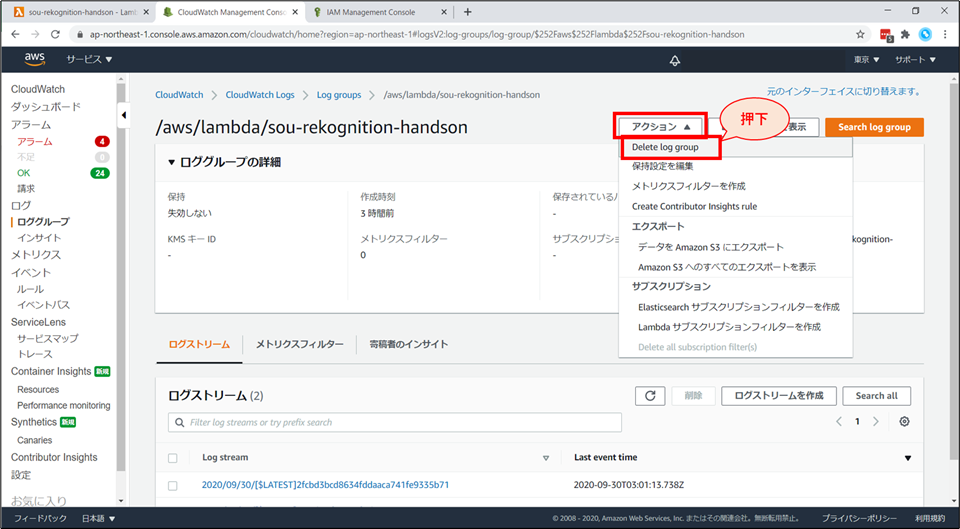
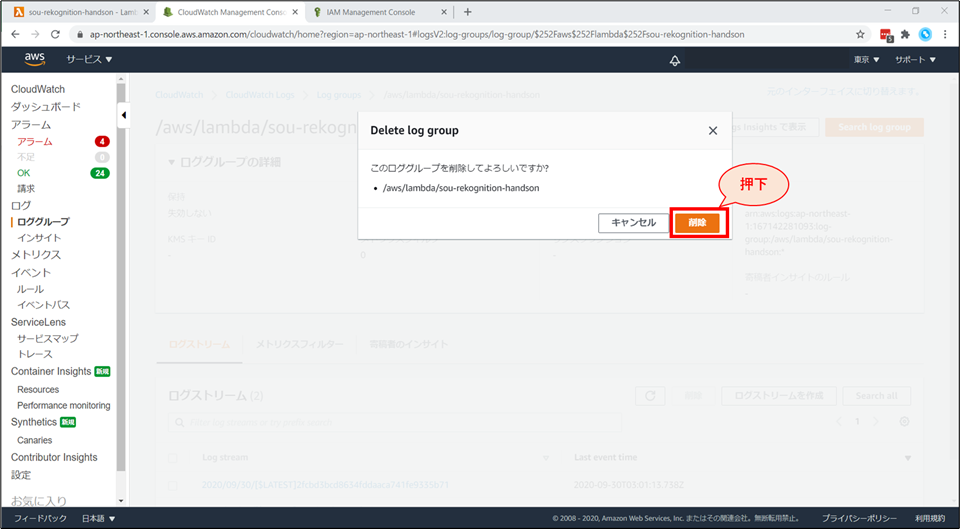
CloudWatch Logs の画面に遷移します。「アクション」から「Delete log group」を選択します。
確認画面が表示されるので、「削除」ボタンを押します。
IAM ロールの削除
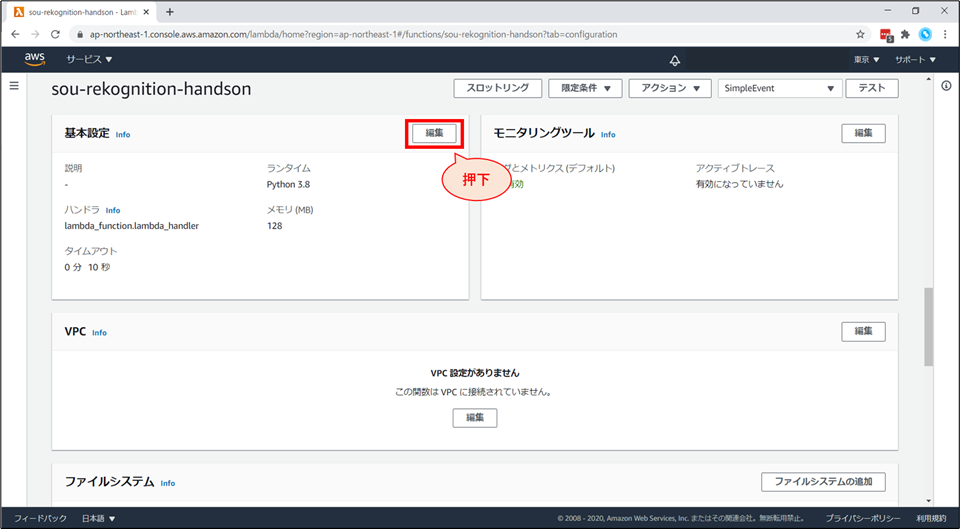
Lambda の画面に戻り、「設定」を開きます。
Lambdaの画面下部、「基本設定」の「編集」を押します。
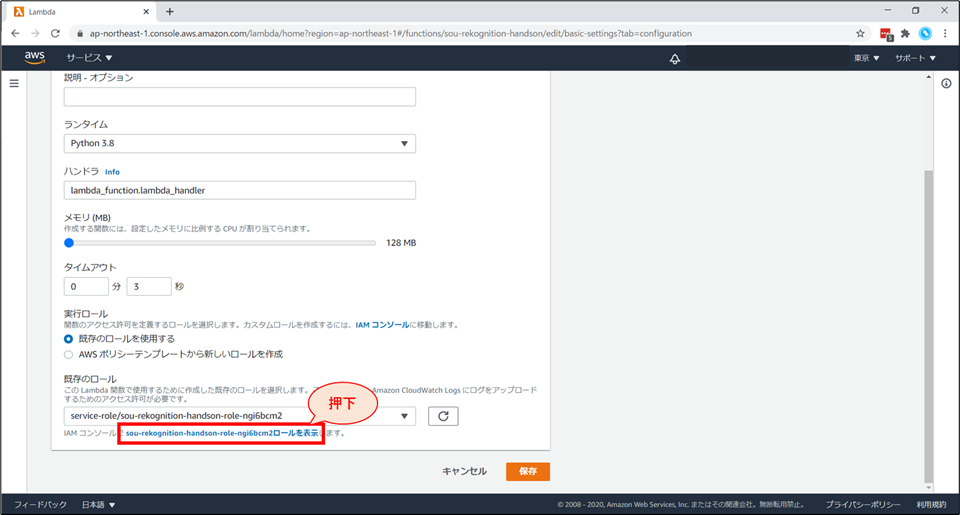
「基本設定を編集」画面の下部まで行き、「IAMコンソールでxxxロールを表示します。」を選択します。
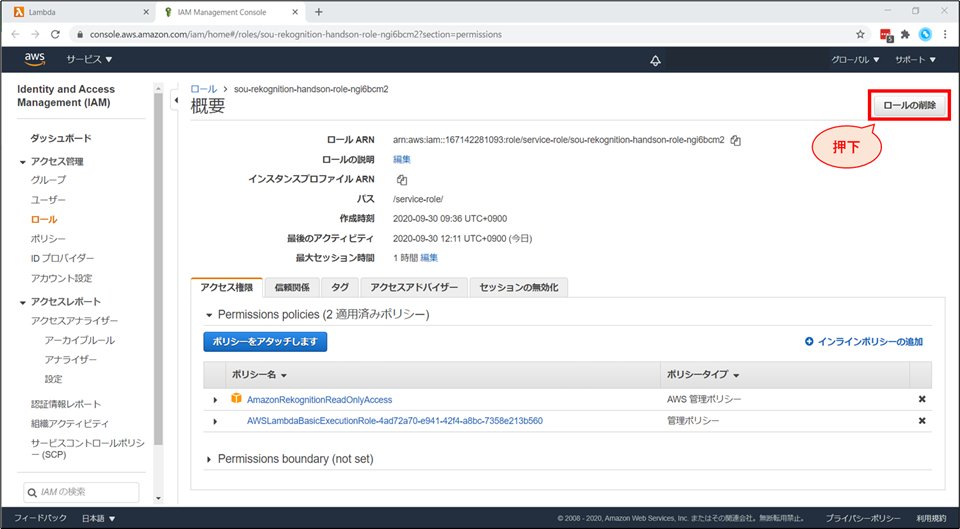
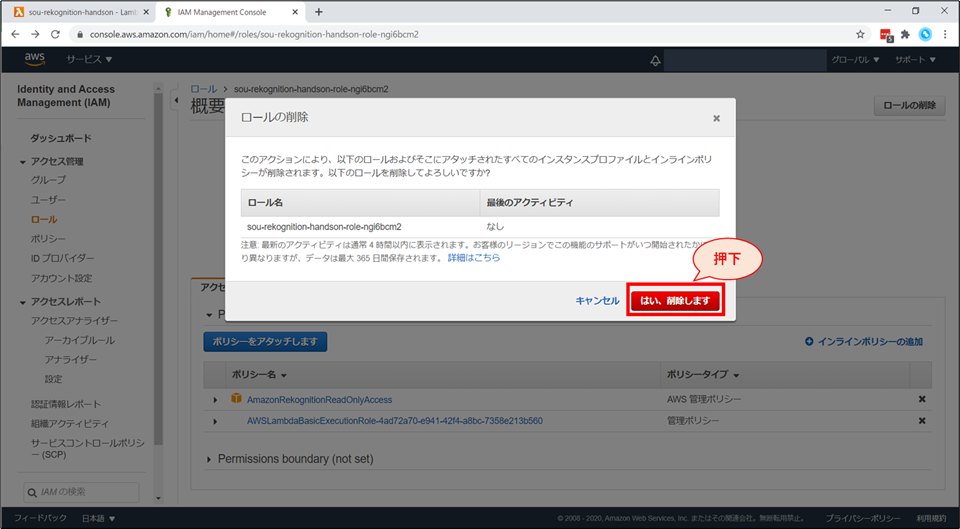
IAMロールの画面に遷移します。画面右上「ロールの削除」を選択します。
確認画面が出るので、「はい、削除します」を押下します。
Lambda 関数の削除
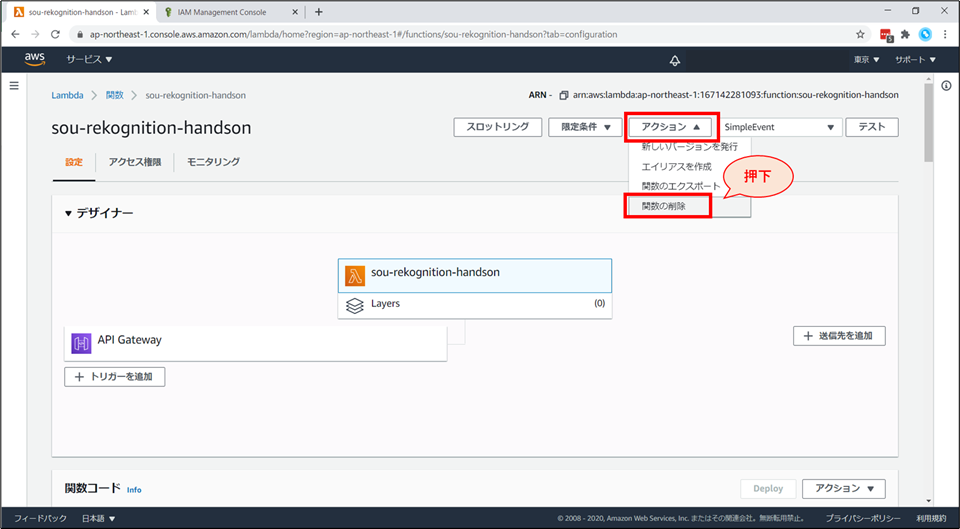
Lambda の画面に戻り、画面上部「アクション」から「関数の削除」を選択します。
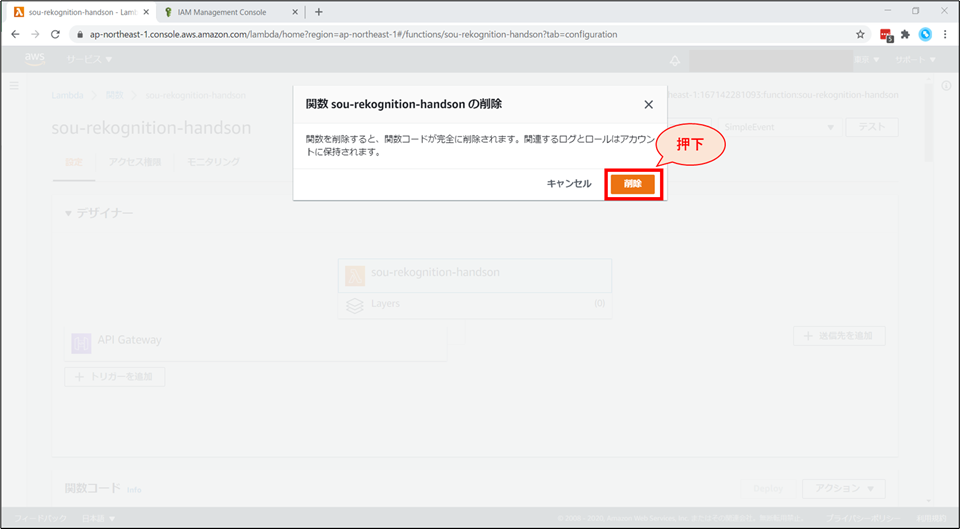
確認画面が表示されるので、「削除」を選択します。
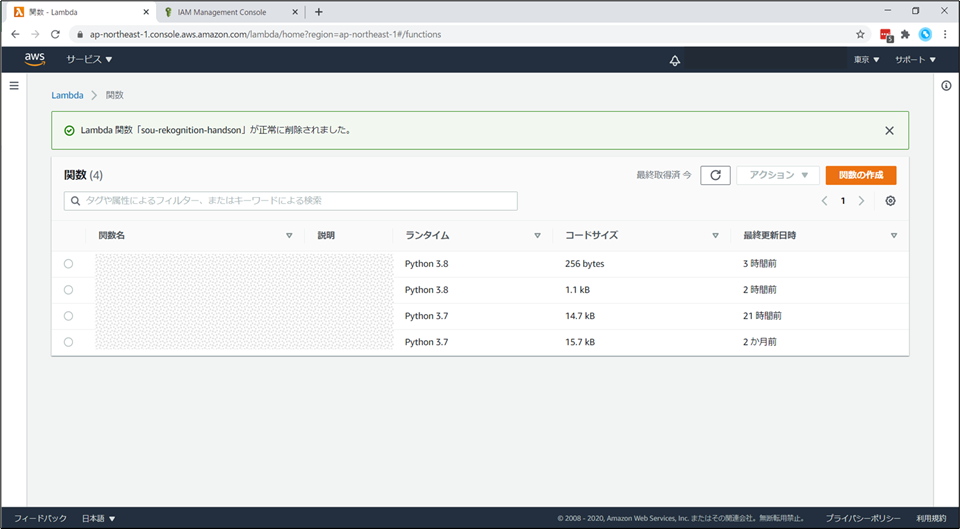
「正常に削除されました。」と表示がでます。
お片付けは以上で終了です。お疲れ様でした。
補足事項
料金
- AWSの各種サービスには、一定の無料利用枠があります。
- 今回の構成は、APIを大量にコールしない限り、全てAWSの無料利用枠に収まる想定です。
- 参考までに、無料枠を超えた際に発生する料金の目安を記載しておきます。
- (2020年10月13日時点 東京リージョン 月単位)
サービス分類 区分 料金 補足 データ通信料 AWSへのイン 0.000USD/GB 〃 AWSからのアウト 0.114USD/GB 最初の1GB~10TB CloudWatch ログ収集 0.760USD/GB 〃 ログ保存 0.033USD/GB Lambda リクエスト課金 0.20USD/100万件 〃 実行時間課金 0.0000002083USD
/128MB,100ミリ秒API Gateway REST API 4.25USD/100万件 最初の3 億3,300万コール受信数 Rekognition Image 0.0013USD/1画像 最初の100万枚 参考資料・ドキュメント






- 投稿日:2020-10-25T21:02:50+09:00
オンプレミスのサーバを Systems Manager で管理する
これはメモです。その通りやってできなくても責任を持てませんし、固有名詞等は適当に直してみてください。
https://dev.classmethod.jp/cloud/aws/ec2-systems-manager-on-premises/
Systems manager -> マネージドインスタンス ->
まずは、これを見て、アクティべーションを行う必要がある。
https://docs.aws.amazon.com/ja_jp/systems-manager/latest/userguide/sysman-managed-instance-activation.html
「アクティべーションの作成」をクリックする。
リージョンを選択する。(オプション) [Activation description] フィールドに、このアクティベーションの説明を入力します。説明は省略可能です。多数のサーバーや VM を有効化する場合は、説明を入力することをお勧めします。
ーーーーーーーーーーー
「VirtualBox CentOS7-home」と説明に入力する。
[インスタンス制限] に 1 (デフォルト)を入力する。
ーーーーーーーーーーー[IAM ロール名] セクションで、サーバーや VM とクラウド内の AWS Systems Manager との通信を可能にするサービスロールオプションを選択します。
[Use the system created default command execution role] を選択し、AWS で作成されたロールとマネージドポリシーを使用します。 [必要な権限を備えた既存のカスタム IAM ロールを選択] を選択し、前に作成したオプションのカスタムロールを使用します。ーーーーーーーーーーーー
IAM ロール
マネージドインスタンスの SSM エージェントと AWS の間で通信を有効にするには、IAM ロールを指定します。
必要な権限を備えたシステムのデフォルトコマンド実行ロールを作成
このオプションを選択した場合、AmazonEC2RunCommandRoleForManagedInstances という名前の新しいロールが作成されます。このロールでは、既存の AmazonSSMManagedInstanceCore & AmazonSSMDirectoryServiceAccess パブリック管理ポリシーが使用され、SSM サービスに AssumeRole 権限が与えられます。
ーーーーーーーーーーーー
選択されているところのままにしておく。なお、オンプレミスの場合は、オンプレミス用のユーザを作成してポリシをアタッチする必要がある。
たとえば、onpremise というユーザを作成して、以下のポリシを割り当てる。CloudWatchAgentAdminPolicy(これは外した方がよいだろう:いや、これ外したら、ssmのメトリクスに報告しなくなったからいるみたい) CloudWatchAgentServerPolicy AmazonSSMManagedInstanceCore getWidgetMetricImageできるポリシも追加すること。そして、credential.csv をダウンロードして、それを、オンプレミスマシンの /root/.aws/credentials に記述する。
[Activation expiry date] フィールドで、アクティベーションの有効期限日を指定します。
ーーーー
「アクティべーションの作成」をクリックする。
コードと id が返ったのを確認する。
新しいアクティベーションは正常に作成されました。 アクティベーションコードを以下に示します。このコードに再びアクセスすることはできないため、これをコピーし、安全な場所に保存してください。
次は、ここを見る。
https://docs.aws.amazon.com/ja_jp/systems-manager/latest/userguide/sysman-install-managed-linux.htmlCentOS7 上で、以下のコマンドを実行して、SSM パッケージをインストールする。
# curl -OL https://s3.ap-northeast-1.amazonaws.com/amazon-ssm-ap-northeast-1/latest/linux_amd64/amazon-ssm-agent.rpm インストールする # rpm -ivh amazon-ssm-agent.rpm 一度停止する。 # systemctl stop amazon-ssm-agent.service # systemctl status amazon-ssm-agent.service 再起動後に有効にする。 # systemctl enable amazon-ssm-agent.service 登録する # amazon-ssm-agent -register -code "<Activation-code>" -id "<ID>" -region "ap-northeast-1" (表示) INFO Successfully registered the instance with AWS SSM using Managed instance-id: <INSTANCE-ID> もし、invalid activation のようになったら、もう一度アクティベーションを最初から作成してみる。「マネージドインスタンス」をクリックするとサーバが登録されているのが確認できる。
サービスを立ち上げる。
# systemctl start amazon-ssm-agent.serviceちなみに、ICMP の IPV4 と IPV6 を開けておく。
AWS Systems Manager の画面で、「マネージドインスタンス」を確認すると、オンラインになっているのが確認できる。次に、collectd パッケージをインストールする。
# yum install collectd # systemctl enable collectd # systemctl start collectd # systemctl status collectd次に、以下のページを参考にする。
https://docs.aws.amazon.com/ja_jp/AmazonCloudWatch/latest/monitoring/install-CloudWatch-Agent-on-premise.html
Systems Manager Run Command またはコマンドラインを使用して CloudWatch エージェントを開始できます。
SSM Agent を使用してオンプレミスサーバーで CloudWatch エージェントを開始するには
Open the Systems Manager console at https://console.aws.amazon.com/systems-manager/
.
In the navigation pane, choose Run Command.
-or-
If the AWS Systems Manager home page opens, scroll down and choose Explore Run Command.
[Run command (コマンドの実行)] を選択します。
[Command document] リストで、[AmazonCloudWatch-ManageAgent] の横のボタンを選択します。
[Targets] 領域で、エージェントをインストールしたインスタンスを選択します。
[Action] リストで、[configure] を選択します。
[Mode] リストで、[onPremise] を選択します。
[Optional Configuration Location (オプションの設定場所)] ボックスで、ウィザードで作成して Parameter Store に保存したエージェント設定ファイルの名前を入力します。
[Run] を選択します。
エージェントが、設定ファイルで指定した設定で開始されます。aws ssm send-command --document-name "AmazonCloudWatch-ManageAgent" --document-version "4" --targets '[{"Key":"InstanceIds","Values":["i-03ab9086afe41e441"]}]' --parameters '{"action":["configure"],"mode":["ec2"],"optionalConfigurationSource":["ssm"],"optionalConfigurationLocation":[""],"optionalRestart":["yes"]}' --timeout-seconds 600 --max-concurrency "50" --max-errors "0" --region ap-northeast-1 aws ssm send-command --document-name "AmazonCloudWatch-ManageAgent" --document-version "4" --targets '[{"Key":"InstanceIds","Values":["i-03ab9086afe41e441"]}]' --parameters '{"action":["configure"],"mode":["ec2"],"optionalConfigurationSource":["ssm"],"optionalConfigurationLocation":[""],"optionalRestart":["yes"]}' --timeout-seconds 600 --max-concurrency "50" --max-errors "0" --region ap-northeast-1 aws ssm send-command --document-name "AmazonCloudWatch-ManageAgent" --document-version "4" --targets '[{"Key":"InstanceIds","Values":["i-03ab9086afe41e441"]}]' --parameters '{"action":["configure"],"mode":["ec2"],"optionalConfigurationSource":["ssm"],"optionalConfigurationLocation":[""],"optionalRestart":["yes"]}' --timeout-seconds 600 --max-concurrency "50" --max-errors "0" --region ap-northeast-1
要すれば、これで、先程の端末に、CloudWatch がインストールできるということ。
コマンド xxxxx が正常に送信されました、と出力されているのが確認できる。
「コマンドのステータス」が「進行中」になっている事が確認できる。
Run コマンドのコマンド履歴で、インストールが成功しているのがわかる。なお、オンプレミスのマシンからコマンドによりインストールするには、以下のページから curl -OL <パッケージ名> でダウンロード後、rpm -ivh <パッケージ名> でインストールすべし。
https://docs.aws.amazon.com/ja_jp/AmazonCloudWatch/latest/monitoring/download-cloudwatch-agent-commandline.html# cd /opt/aws/amazon-cloudwatch-agent # ls (表示) LICENSE NOTICE RELEASE_NOTES THIRD-PARTY-LICENSES bin doc etc logs varちなみに、IAM でオンプレミス用のユーザを作成しておく必要がある。
次に、一度、手動で初期化しておくのがよい。
なお、config-wizard を起動しても、以下のポリシが設定されていないとエラーになるので、テンポラリに設定をしていなければいけない。config-wizard が終了したら、設定を外すこと。
CloudWatchAgentAdminPolicy# /opt/aws/amazon-cloudwatch-agent/bin/amazon-cloudwatch-agent-config-wizard以下のリンクに書いてある通りにやればよいと思われる。
http://blog.serverworks.co.jp/tech/2020/01/28/cloudwtach-agent-ssm-centos/ところで、オンプレミスのマシンの場合には、aws-cli コマンドがない。要すれば、aws のパッケージをインストールしなければいけない。
オンプレミスのマシンに aws-cli をインストールするには、以下を参考にする。
https://docs.aws.amazon.com/ja_jp/cli/latest/userguide/install-cliv2-linux.htmlちなみに、この過程で、credentials を聞かれるはず。
適当に other にして、id も key も空欄でとりあえず進めて構わない。
次に、以下のファイルを編集する。
/etc/.aws/credentials
このファイルは、デフォルトの credentials ファイル。
ここに、IAM で作成してダウンロードしておいた csv ファイルの中身を記述する。ちなみに、オンプレミスマシンの場合は、既に [default] が入っているようである。
以下のように、cloudwatch専用であることを明言して、csv ファイルの中身を記述する。[AmazonCloudWatchAgent] aws_access_key_id = xxxxxxxx aws_secret_access_key = xxxxxxxx region = ap-northeast-1インスタンスに、このロールを与える。
https://docs.aws.amazon.com/ja_jp/AmazonCloudWatch/latest/monitoring/install-CloudWatch-Agent-on-EC2-Instance-fleet.html#install-CloudWatch-Agent-iam_permissions-fleetこれで手動でやってみる。
https://qiita.com/t_okkan/items/9bec49fa5be76de4e5ef
/var/log/messages や、httpd の error log を S3 に転送もしてみるのは、以下でできそう。
https://dev.classmethod.jp/cloud/aws/cloudwatchagent-nocli-install/実際に書き出してみると、こんな感じ。
{ "agent": { "metrics_collection_interval": 60, "run_as_user": "root" }, "logs": { "logs_collected": { "files": { "collect_list": [ { "file_path": "/var/log/messages", "log_group_name": "messages", "log_stream_name": "{hostname}" }, { "file_path": "/var/log/secure", "log_group_name": "secure", "log_stream_name": "{hostname}" }, { "file_path": "/var/log/httpd/ssl_error_log", "log_group_name": "ssl_error_log", "log_stream_name": "{hostname}" } ] } } }, "metrics": { "metrics_collected": { "collectd": { "metrics_aggregation_interval": 60 }, "cpu": { "measurement": [ "cpu_usage_idle" ], "metrics_collection_interval": 60, "resources": [ "*" ], "totalcpu": true }, "disk": { "measurement": [ "used_percent" ], "metrics_collection_interval": 60, "resources": [ "*" ] }, "diskio": { "measurement": [ "write_bytes", "read_bytes", "writes", "reads" ], "metrics_collection_interval": 60, "resources": [ "*" ] }, "mem": { "measurement": [ "mem_used_percent" ], "metrics_collection_interval": 60 }, "net": { "measurement": [ "bytes_sent", "bytes_recv", "packets_sent", "packets_recv" ], "metrics_collection_interval": 60, "resources": [ "*" ] }, "statsd": { "metrics_aggregation_interval": 60, "metrics_collection_interval": 10, "service_address": ":8125" }, "swap": { "measurement": [ "swap_used_percent" ], "metrics_collection_interval": 60 } } } }
設定ファイルをSystem Managerで作成し終えると、あとはエージェントをインストールしたインスタンスで設定ファイルを指定してAgentを実行するのみです。
以下のコマンドの意味だけど、最新の ssm のパラメーターを取得する、という意味。
これをやらないといけなくて、ssm の設定がこのコマンドにより、/etc/aws/amazon-cloudwatch-agent/etc/amazon-cloudwatch-agent.d/ 配下に実行権限付きのファイルとして保存される。たまにやるとよいかも。
CloudWatch Agentの起動は以下のコマンドで行います。
$ /opt/aws/amazon-cloudwatch-agent/bin/amazon-cloudwatch-agent-ctl -a fetch-config -m <ec2|onPremise> -c ssm:CloudWatchAgentParemeter(AWS Systems Manager-パラメータの名前)-s-a fetch-configオプションでSystem Managerのパラメーターストアから設定ファイルを読み込むように指定し、-cオプションで設定ファイルを指定しています。指定方法は、ssm:"パラメーター名"となります。
(参考)
https://docs.aws.amazon.com/AmazonCloudWatch/latest/monitoring/install-CloudWatch-Agent-commandline-fleet.html今回、パラメーター名は、moodle35-template-test-1 とした。
うまくいった。
Valid Json input schema. I! Detecting runasuser... No csm configuration found. Configuration validation first phase succeeded /opt/aws/amazon-cloudwatch-agent/bin/amazon-cloudwatch-agent -schematest -config /opt/aws/amazon-cloudwatch-agent/etc/amazon-cloudwatch-agent.toml Configuration validation second phase succeeded Configuration validation succeeded起動したようなら、以下のコマンドによりログを確認する。
# tail -f /opt/aws/amazon-cloudwatch-agent/logs/amazon-cloudwatch-agent.log次のようになっていれば、大丈夫。
...(snip)... I! Agent Config: Interval:1m0s, Quiet:false, Hostname:"<マシン名>", Flush Interval:1sそれでは、cloudwatch のページに行き、メトリクスに書き込んでいるかを確認する。
cloudwatch が立ち上がる時、以下の表示が出て、実はうまくいっていないということがある。
なぜ?/opt/aws/amazon-cloudwatch-agent/etc/amazon-cloudwatch-agent.json does not exist or cannot read. Skipping it.出来た。問題は、時間が UTC になっているところ。
オンプレには、証明書をインストールしなければいけないっぽい。
cloudwatch の時刻表示が utc になっているのは、これで直る?
https://docs.aws.amazon.com/ja_jp/AmazonCloudWatch/latest/monitoring/change_dashboard_time_format.htmlここを見てみる。
https://dev.classmethod.jp/articles/cloudwatch-agent-on-premise-windows/
https://qiita.com/murata-tomohide/items/3e66d63b21c08d6481a2
this plugin should be used on EC2 only cloudwatch
アマゾンの説明ページ
https://docs.aws.amazon.com/ja_jp/AmazonCloudWatch/latest/monitoring/Install-CloudWatch-Agent.html
IAMユーザの作り方
https://docs.aws.amazon.com/AmazonCloudWatch/latest/monitoring/create-iam-roles-for-cloudwatch-agent.html
[小ネタ] CloudWatch メトリクスのグラフをローカルに保存しちゃうぞ!
https://dev.classmethod.jp/articles/clw_metrics_graph_export/現在のAWSだと、「発信元」-「イメージAPI」をクリックして、コピペして、json ファイルを作成する。それをサーバに上げる。そして、このコマンドを定期的に実行すれば画像をダウンロードできる(タイムスタンプとか適当につければよい)webページを作成して、この png を貼っておき、定期的にリフレッシュすればよいでしょう。
# aws cloudwatch get-metric-widget-image --metric-widget file://metrics_moodle-workplace2_12h.json --output-format "png" --output text --query MetricWidgetImage | base64 --decode > metrics_moodle-workplace_12h.pngところで、これをスクリプトで回すことも考えられるが、他人のサーバ上で、やっている事がわかるのは気持ち悪い。
なので、Lambda でできることに越したことはない。以下を参考にしてみよう。
https://aws.amazon.com/jp/blogs/devops/building-an-amazon-cloudwatch-dashboard-outside-of-the-aws-management-console/日本語のサイトがあるが、これが使えないか。
http://blog.serverworks.co.jp/tech/2017/02/16/apigateway-lambda-cloudwatch-alarm/いや、もっとよい方法があった。Lambda から boto3 を使えるし、これがいいかな。
https://hacknote.jp/archives/51333/いやいや、ssm の run command の方が柔軟性がありそうだ。
https://hacknote.jp/archives/37181/そして、run command では、bash で直接書くのではなく、yaml で書いた方がよいだろう。
https://qiita.com/myoshioka/items/c9294fc8f02d8578dff4うーん、この荒らしい方法がハマっているのかもしれない。
https://dev.classmethod.jp/articles/systems-manager-change-calendar-release/なんか、aws コマンドがない言われる。
https://qiita.com/debari/items/1030c214d0e4e86b2fceいろいろやってみたけど、ssm のメンテナンスウィンドウを活用するのが一番良い、というか、他のやり方が上手くいかない。
定期的に実行するには、以下の設定にすればよい。Cron/Rate 式 cron(*/5 * * * ? *)そして、ターゲットを目的の一つのインスタンスにして、ドキュメントは、ドキュメント:AWS-RunShellScript にする。
かんじんのスクリプトをどこに記述するのか、なかなか分からなかったが、以下のところに書けばよい。その他は、よしなに設定すること。
この json ファイルの元ををどうやって作ったかというと、グラフを作って、そこのソース(グラフ用だったか)をコピーすれば、それ自体が、json ファイルとなっている。パラメーター
Commands
(Required) Specify a shell script or a command to run.#!/bin/bash cat << 'EOF' > /tmp/tmp.json { "view": "timeSeries", "stacked": false, "metrics": [ [ "CustmeMetrics Sample", "disk_used_percent", "path", "/", "InstanceId", "i-xxxxxx", "ImageId", "ami-xxxxxx", "InstanceType", "t2.small", "device", "xvda1", "fstype", "xfs" ], [ ".", "cpu_usage_idle", "InstanceId", "i-xxxxxx", "ImageId", "ami-xxxxxx", "cpu", "cpu0", ".", "." ], [ ".", "cpu_usage_iowait", ".", ".", ".", ".", ".", ".", ".", "." ], [ ".", "cpu_usage_user", ".", ".", ".", ".", ".", ".", ".", "." ], [ ".", "cpu_usage_system", ".", ".", ".", ".", ".", ".", ".", "." ], [ ".", "mem_used_percent", ".", ".", ".", ".", "InstanceType", "t2.small" ], [ ".", "swap_used_percent", ".", ".", ".", ".", ".", "." ] ], "width": 1514, "height": 250, "start": "-PT12H", "end": "P0D", "timezone": "+0900" } EOF aws cloudwatch get-metric-widget-image --metric-widget file:///tmp/tmp.json --output-format "png" --output text --query MetricWidgetImage | base64 --decode > /tmp/metrics_moodle-workplace_12h.png rm -f /tmp/tmp.json得られた画像が、5分毎に、/tmp に上書きされていく。それを、どう見せるかという話だが、document root のあるディレクトリにおいて、digest 認証で守ればよいのではないか。
digest 認証について
https://qiita.com/miyazawa214/items/45c5e6a5109dc9e12e65最初に IAM ユーザを作成した時にダウンロードした csv ファイルで確認できたIDとSECRET_KEY を /root/.aws/credentials に設定するのを忘れずに。
ちなみに、以下のようなポリシを IAMユーザ- onmise に与えている。
{ "Version": "2012-10-17", "Statement": [ { "Sid": "VisualEditor0", "Effect": "Allow", "Action": [ "cloudwatch:DescribeAlarmHistory", "cloudwatch:GetDashboard", "cloudwatch:GetMetricWidgetImage", "cloudwatch:GetInsightRuleReport", "cloudwatch:DescribeAlarms" ], "Resource": "arn:aws:cloudwatch::*:dashboard/*" }, { "Sid": "VisualEditor1", "Effect": "Allow", "Action": [ "cloudwatch:DescribeInsightRules", "cloudwatch:GetMetricData", "cloudwatch:DescribeAlarmsForMetric", "cloudwatch:GetMetricStatistics", "cloudwatch:GetMetricWidgetImage", "cloudwatch:DescribeAnomalyDetectors" ], "Resource": "*" } ] }ちなみに、この一連の動作を再起動後も実行させるには、systemd のサービス化しておきたいところ。
以下のようなサービスを考えてみる。#/etc/systemd/system/amazon-cloudwatch-agent-ctl.service [Unit] Description=Amazon CloudWatch Agent Ctl After=network.target [Service] Type=simple ## ssm のパラメータから取ってくるところを見せないほうがいいとすれば、下の方がいいでしょう。 #ExecStart=/opt/aws/amazon-cloudwatch-agent/bin/amazon-cloudwatch-agent-ctl -a fetch-config -m <ec2|onPremise> -c ssm:<ssm のパラメータストアにある名前> ExecStart=/opt/aws/amazon-cloudwatch-agent/bin/amazon-cloudwatch-agent -config /opt/aws/amazon-cloudwatch-agent/etc/amazon-cloudwatch-agent.toml -pidfile /opt/aws/amazon-cloudwatch-agent/var/amazon-cloudwatch-agent.pid KillMode=process Restart=on-failure RestartSec=60s [Install] WantedBy=multi-user.target# systemctl list-unit-files --type=service | grep amazon-cloudwatch-agent-ctl amazon-cloudwatch-agent-ctl.service disabledでは、有効化して立ち上げておく。
# systemctl enable amazon-cloudwatch-agent-ctl # systemctl start amazon-cloudwatch-agent-ctl # systemctl status amazon-cloudwatch-agent-ctlもし、ssm のパラメータストアでメトリクスを追加したり変更したならば、以下のコマンドで上記サービスを再起動すれば、新しいパラメータを引っ張ってくるはず。
# systemctl restart amazon-cloudwatch-agent-ctlstatus でもわかりますが、コマンドは ssm からメトリクスパラメータを次のファイルにダウンロードするので、開いて内容を確認してみるとよい。というか、他人のサーバで実行する場合は、ssm のパラメータをダウンロードするのではなく、toml ファイルを直接編集した方がよい。
# less /opt/aws/amazon-cloudwatch-agent/etc/amazon-cloudwatch-agent.tomlいやいや、そんなことをしなくてもよかった。
実は、一回、AWS から設定をダウンロードしてきたら、以下のコマンドを実行しなければいけなかった。
このコマンドを実行すると、必要な設定が変わる、というか、このコマンドを実行しなければ変わらないようだ。/opt/aws/amazon-cloudwatch-agent/bin/amazon-cloudwatch-agent-ctl -a fetch-config -m ec2 -c file:/opt/aws/amazon-cloudwatch-agent/bin/config.json -s(引用:https://go-journey.club/archives/12931)
一度「/opt/aws/amazon-cloudwatch-agent/bin/amazon-cloudwatch-agent-ctl -a fetch-config -m ec2 -c file:/opt/aws/amazon-cloudwatch-agent/bin/config.json -s 」コマンドで設定を読み込む必要があります。 このコマンドで「/opt/aws/amazon-cloudwatch-agent/etc/amazon-cloudwatch-agent.toml」と「/opt/aws/amazon-cloudwatch-agent/etc/amazon-cloudwatch-agent.d/file_config.json」が更新されます。なお、config.json が鍵であることがわかった。これを使う、という config.json を取っておいて、それを指定して上記コマンドを実行すると、簡単になると考えられます。
また、collectd を起動すると、不要なログが大量に messages に出る件であるが、以下のハックがあり、それを実行したら止んだ。
https://github.com/scylladb/scylla/commit/740d98901fd6aa79102a1aca4a7d11d188be8d14/etc/collectd.conf を編集した。
+ # dummy write_graphite to silent noisy warning + LoadPlugin network + <Plugin "network"> + Server "127.0.0.1 65534" + </Plugin>ーーーーーーーー
ここから調べて
https://docs.aws.amazon.com/AmazonCloudWatch/latest/monitoring/download-CloudWatch-Agent-on-EC2-Instance-SSM-first.html
ここを見て
https://docs.aws.amazon.com/systems-manager/latest/userguide/systems-manager-setting-up.html#systems-manager-prereqs
ここに辿り着き(step3)
https://docs.aws.amazon.com/systems-manager/latest/userguide/systems-manager-managedinstances.html
証明書がいる?
https://docs.aws.amazon.com/systems-manager/latest/userguide/hybrid-tls-certificate.html
ここからダウンロード?
https://www.amazontrust.com/repository/コマンドで、値を取ってきたりしたい。できれば画像を取ってきて、たとえば、60秒ごとに置き換えたい。
https://htnosm.hatenablog.com/entry/2015/09/23/090000
- 投稿日:2020-10-25T20:40:08+09:00
CloudFormationでS3とDynamDBを作成する
S3のテンプレートは以下になります。
create_s3.yamlAWSTemplateFormatVersion: 2010-09-09 Resources: S3Bucket: Type: AWS::S3::BucketDynamoDBのテンプレートは以下になります。
create_ddb.yamlResources: DDBTable: Type: AWS::DynamoDB::Table Properties: AttributeDefinitions: - AttributeName: "ArtistId" AttributeType: "S" KeySchema: - AttributeName: "ArtistId" KeyType: "HASH" ProvisionedThroughput: ReadCapacityUnits: 5 WriteCapacityUnits: 5スタックの作成と削除は以下のコマンドでおこないます。
create-s3aws cloudformation deploy --template-file create_s3.yml --stack-name my-s3create-ddbaws cloudformation deploy --template-file create_ddb.yml --stack-name my-ddbdelete-s3aws cloudformation delete-stack --stack-name my-s3delete-ddbaws cloudformation delete-stack --stack-name my-ddb最後まで読んでいただきありがとうございました。
- 投稿日:2020-10-25T20:32:08+09:00
AWS SAMでLambdaとAPI Gatewayをデプロイする
SAMアプリケーションの作成
sam init
SAMアプリケーションのビルド
sam build
SAMアプリケーションのパッケージ化
sam package --s3-bucket test --output-template-file out.yaml
SAMアプリケーションのビルド
sam deploy --template-file out.yaml --stack-name test --capabilities CAPABILITY_IAM最後まで読んでいただきありがとうございました。
- 投稿日:2020-10-25T19:20:14+09:00
AWSアカウントでセキュリティチェックをし、採点してみた
はじめに
AWSは俊敏にリソースを調達できたりし、AWS社がある程度のセキュリティも担保してくれる一方でたとえばIaaSであれば、責任共有モデル的に、ユーザデータなどOS以上のレイヤーはユーザ自身の責任でセキュリティを担保しなければなりません。
設定ミス一つでデータのリークなど大事件につながることもありえます。
今回は、普段使用しているAWSアカウントにConformityというツールを導入して採点してみようと思います。導入方法
以下のサイトのFree Trialでアカウントを作成します。作成すると14日間無料で使用できます。
https://www.cloudconformity.com/help/
次に登録時に入力したメールアドレスおよびパスワードを使用し、「Sign in」します。
サインインして、次にAWSアカウントをConformityに登録し、アカウント連携をします。
連携方法は非常に簡単で、画面左ペインの「Add an account」を選択し、「AWS Account」を選択します。
ちなみに、AzureのSubscriptionも追加できるようですが、今回はAWSアカウントを追加します。
初期のセットアップには、自動セットアップ(Automated setup)と手動セットアップ(Manual setup)がありますが、自動セットアップでは用意されたCloudFormationで数分でセットアップできます。
CloudFormationだと何を設定されているかわからないという不安な方は手動セットアップで手順を見ながら、設定内容をよく確認して、設定を行えばよいでしょう。
以上、初期設定が完了となります。
特に管理サーバを用意する必要もないため、サインインから導入までたぶん5分もあればできてしまうかもです。AWSアカウントをチェックする
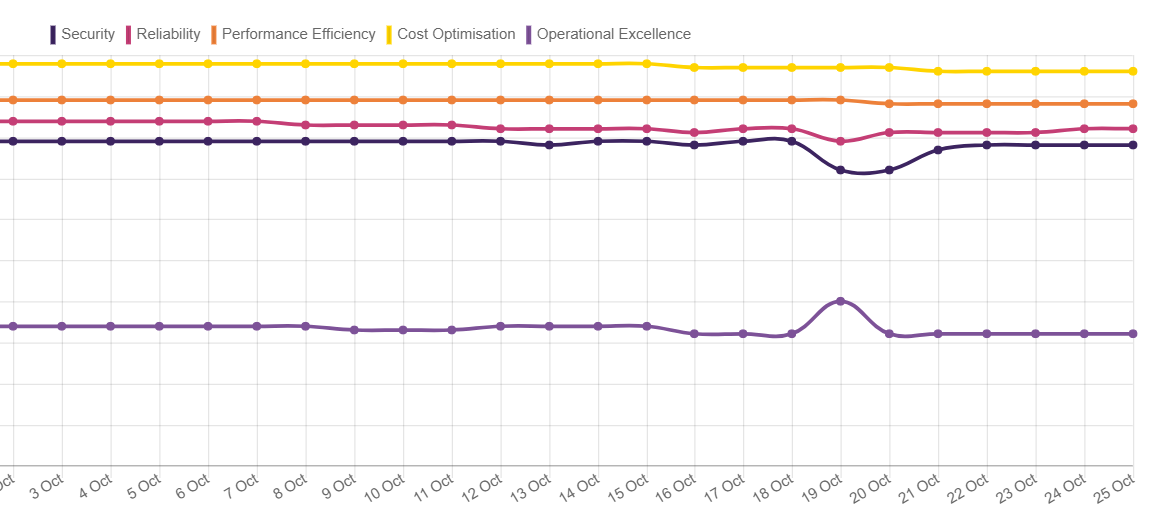
Conformityを導入し、しばらくすると以下のような結果が表示されます。
AWS Well-Architectedフレームワークを意識し、AWS Well-Architectureの5本柱に沿って結果表示されています。
パーセンテージが低いほど結果が良くないということになりますが、Operation Excellenceが明らかに低かったです。でも検証で使ったりしている環境なのでこの環境においては運用上の優秀性(Operational Excenllence)は二の次かもしれません。(笑)次にセキュリティにフォーカスし、見てみましょう。「Improve...」を押すと検知した結果の一覧を確認することができます。EC2からCloudWatchの設定までいろいろと指摘されてしまいました。以下のスクリーンショットは検知内容の一部にすぎません。
この中で「EC2 Instance Not in Public Subnet」というルールにひっかかりましたが、Public SubnetにEc2に配置してはいけなかったのですか?なぜでしょう?早速「Resolve...」を押して理由を確認してみましょう。そうすると以下の内容が表示されます。
英語か。。。。Google翻訳を使いましょう(笑)
なるほど。。。要するに閉鎖されたネットワークにEC2を配置し、パブリックネットワークの後ろにプライベートネットワークを用意し、EC2はそのプライベートネットワークに展開すべきということですね。さあ、いかがでしょうか。特にAWSへ移行中のユーザであれば、こういったツールがあると非常に便利かもしれません。特にテスト段階で展開してみて、設定不備やベストプラクティスに沿ってない構成を早期に見つけることが大事ですね、商用環境に展開してしまうとなかなか構成が変えられませんので、早めに設定不備を見つけることが非常に重要だと私は思います。
ちなみに、複数のAWSアカウントを登録できるようなので、たぶん想定されるユースケースは社内のセキュリティチームか何かで一元管理して、全社のAWSアカウントを管理したりとか、他社向けに監視サービスを提供したりとかでしょうか。
また、検知した内容を指定のユーザにメールで検知した内容と解決策をメールなどで送ることができますので、これで監視センターの気分を味わうことができますね(笑)
また、全リージョンのステータスの可視化機能もありどこのリージョンが危険なことになっているかが一目瞭然です。
さらに過去の状況を可視化できます。改善状況や、改悪状況(笑)も確認できます。
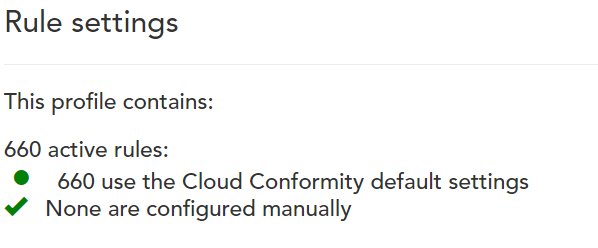
チェックに使われているルールはなんと!600個以上も存在しています。
コンプライアンス準拠確認
個人のテストでは使うことはあまりないかもしれませんが、商用環境でAWS環境を使用する際に、コンプライアンス準拠か否かが気になることも多いと思います。
Conformityを使用すれば、コンプライアンス違反になりうる設定不備をレポート化できます。
対応するコンプライアンスは以下のものがあります。
HIPAA
NIST Cybersecurity Framework
PCIDSS
GDPR
などなど定期的に通知を受信する
Conformityでは定期的に外部のアプリケーションに通知を送ることもできるようです。
これでいちいちログインをしなくても検知状況を受け取ることができます。
試しにSlackに連携してみると、以下の画面のように検知内容を受信することができます。
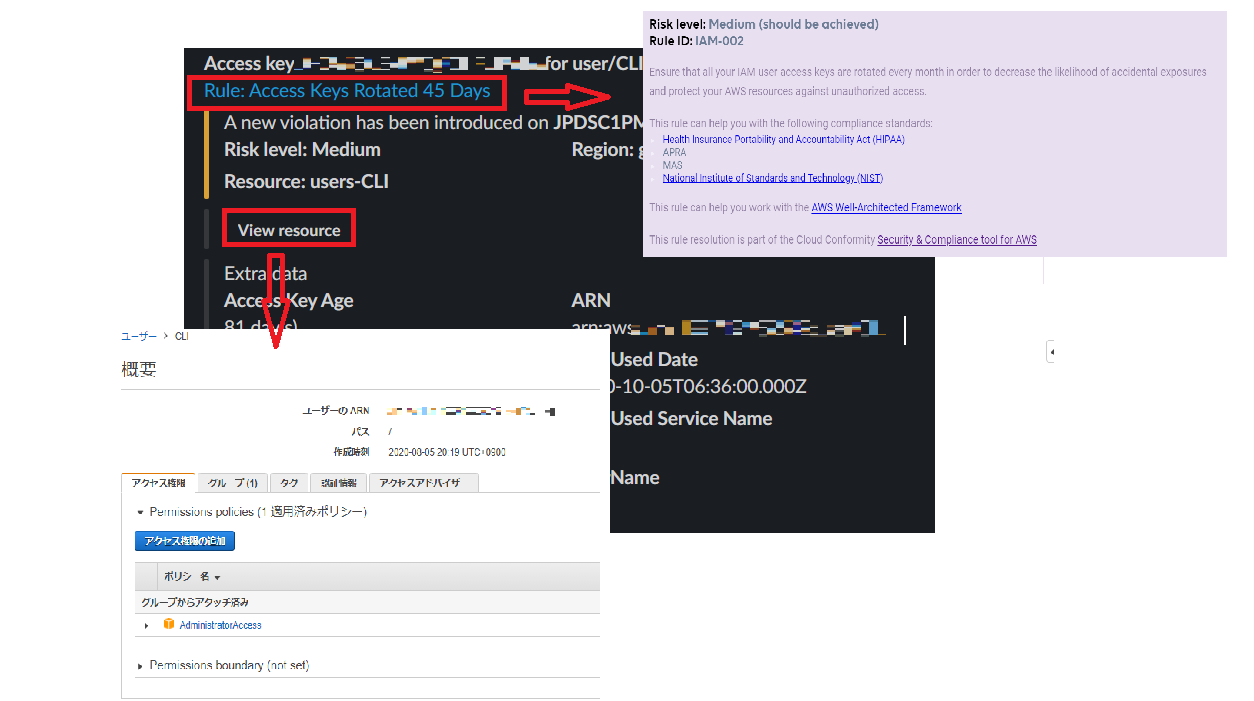
さらに、Rule:XXXXXをクリックするとKBに飛ぶので、検知理由を確認することができます。
View resourceをクリックすればAWSコンソールに入り、検知された対象が表示されます。この例の場合は、アクセスキーが45日以上そのまま放置されていたため、アクセスキーのローテーションを行うことで対処できます。
ここまで読んでいただいて、Conformityを使ってみたくなったのではないでしょうか?でも、Conformityを使うと余分なお金がかかるのではないかと心配されるかもしれませんが、Conformityを導入しても余分な費用はかからないそうです。
https://www.cloudconformity.com/frequently-asked-questions.html
まとめ
さて、いかがでしたでしょうか?
AWS勉強中の私でも、このツールを使いながら、設定不備を見つけられそうです。これを使ってみて、感じたことですが、
1.Conformityの導入が簡単で、特に管理サーバを用意したりするといった手間もかかりません。
2.複数のアカウントを一元管理できます。
3.検知した内容はすべてKBでその理由などの説明があり、どう対処すべきかが分かりやすいです。
4.チェックに使われるルール数が非常に多いです。(言い換えるとチェックが厳しいということになります。)
5.DevOpsを意識した設計で、通知やレポート機能が充実しています。









- 投稿日:2020-10-25T19:20:14+09:00
AWSアカウントのセキュリティチェックをし、採点してみた
はじめに
AWSは俊敏にリソースを調達できたりし、AWS社がある程度のセキュリティも担保してくれる一方でたとえばIaaSであれば、責任共有モデル的に、ユーザデータなどOS以上のレイヤーはユーザ自身の責任でセキュリティを担保しなければなりません。
設定ミス一つでデータのリークなど大事件につながることもありえます。
今回は、普段使用しているAWSアカウントにConformityというツールを導入して採点してみようと思います。導入方法
以下のサイトのFree Trialでアカウントを作成します。作成すると14日間無料で使用できます。
https://www.cloudconformity.com/help/
次に登録時に入力したメールアドレスおよびパスワードを使用し、「Sign in」します。
サインインして、次にAWSアカウントをConformityに登録し、アカウント連携をします。
連携方法は非常に簡単で、画面左ペインの「Add an account」を選択し、「AWS Account」を選択します。
ちなみに、AzureのSubscriptionも追加できるようですが、今回はAWSアカウントを追加します。
初期のセットアップには、自動セットアップ(Automated setup)と手動セットアップ(Manual setup)がありますが、自動セットアップでは用意されたCloudFormationで数分でセットアップできます。
CloudFormationだと何を設定されているかわからないという不安な方は手動セットアップで手順を見ながら、設定内容をよく確認して、設定を行えばよいでしょう。
以上、初期設定が完了となります。
特に管理サーバを用意する必要もないため、サインインから導入までたぶん5分もあればできてしまうかもです。AWSアカウントをチェックする
Conformityを導入し、しばらくすると以下のような結果が表示されます。
AWS Well-Architectedフレームワークを意識し、AWS Well-Architectureの5本柱に沿って結果表示されています。
パーセンテージが低いほど結果が良くないということになりますが、Operation Excellenceが明らかに低かったです。でも検証で使ったりしている環境なのでこの環境においては運用上の優秀性(Operational Excenllence)は二の次かもしれません。(笑)次にセキュリティにフォーカスし、見てみましょう。「Improve...」を押すと検知した結果の一覧を確認することができます。EC2からCloudWatchの設定までいろいろと指摘されてしまいました。以下のスクリーンショットは検知内容の一部にすぎません。
この中で「EC2 Instance Not in Public Subnet」というルールにひっかかりましたが、Public SubnetにEc2に配置してはいけなかったのですか?なぜでしょう?早速「Resolve...」を押して理由を確認してみましょう。そうすると以下の内容が表示されます。
英語か。。。。Google翻訳を使いましょう(笑)
なるほど。。。要するに閉鎖されたネットワークにEC2を配置し、パブリックネットワークの後ろにプライベートネットワークを用意し、EC2はそのプライベートネットワークに展開すべきということですね。さあ、いかがでしょうか。特にAWSへ移行中のユーザであれば、こういったツールがあると非常に便利かもしれません。特にテスト段階で展開してみて、設定不備やベストプラクティスに沿ってない構成を早期に見つけることが大事ですね、商用環境に展開してしまうとなかなか構成が変えられませんので、早めに設定不備を見つけることが非常に重要だと私は思います。
ちなみに、複数のAWSアカウントを登録できるようなので、たぶん想定されるユースケースは社内のセキュリティチームか何かで一元管理して、全社のAWSアカウントを管理したりとか、他社向けに監視サービスを提供したりとかでしょうか。
また、検知した内容を指定のユーザにメールで検知した内容と解決策をメールなどで送ることができますので、これで監視センターの気分を味わうことができますね(笑)
また、全リージョンのステータスの可視化機能もありどこのリージョンが危険なことになっているかが一目瞭然です。
さらに過去の状況を可視化できます。改善状況や、改悪状況(笑)も確認できます。
チェックに使われているルールはなんと!600個以上も存在しています。
コンプライアンス準拠確認
個人のテストでは使うことはあまりないかもしれませんが、商用環境でAWS環境を使用する際に、コンプライアンス準拠か否かが気になることも多いと思います。
Conformityを使用すれば、コンプライアンス違反になりうる設定不備をレポート化できます。
対応するコンプライアンスは以下のものがあります。
HIPAA
NIST Cybersecurity Framework
PCIDSS
GDPR
などなど定期的に通知を受信する
Conformityでは定期的に外部のアプリケーションに通知を送ることもできるようです。
これでいちいちログインをしなくても検知状況を受け取ることができます。
試しにSlackに連携してみると、以下の画面のように検知内容を受信することができます。
さらに、Rule:XXXXXをクリックするとKBに飛ぶので、検知理由を確認することができます。
View resourceをクリックすればAWSコンソールに入り、検知された対象が表示されます。この例の場合は、アクセスキーが45日以上そのまま放置されていたため、アクセスキーのローテーションを行うことで対処できます。
ここまで読んでいただいて、Conformityを使ってみたくなったのではないでしょうか?でも、Conformityを使うと余分なお金がかかるのではないかと心配されるかもしれませんが、Conformityを導入しても余分な費用はかからないそうです。
https://www.cloudconformity.com/frequently-asked-questions.html
まとめ
さて、いかがでしたでしょうか?
AWS勉強中の私でも、このツールを使いながら、設定不備を見つけられそうです。これを使ってみて、感じたことですが、
1.Conformityの導入が簡単で、特に管理サーバを用意したりするといった手間もかかりません。
2.複数のアカウントを一元管理できます。
3.検知した内容はすべてKBでその理由などの説明があり、どう対処すべきかが分かりやすいです。
4.チェックに使われるルール数が非常に多いです。(言い換えるとチェックが厳しいということになります。)
5.DevOpsを意識した設計で、通知やレポート機能が充実しています。
- 投稿日:2020-10-25T19:18:34+09:00
AWS初心者がTerraformでECSクラスタを構築してみた
先日、Terraformを使って、ECSのクラスタを構築する機会がありましたので、やったことをメモとして残したいと思います。開始当初の知識レベルは「EC2完全に理解した(※)」「VPC?なにそれおいしいの」という状態です。Terraformは存在自体知りませんでした。従って、間違ってること言ってたらご指摘頂けるとありがたいです。
tl;dr
https://github.com/foo-543674/terraform-aws-ecr-with-ec2
書かないこと
ECSやTerraform自体の説明や導入手順については参考にしたサイトを貼るだけに留めて割愛します。
- https://docs.aws.amazon.com/AmazonECS/latest/developerguide/Welcome.html
- https://registry.terraform.io/providers/hashicorp/aws/latest/docs
- https://qiita.com/NewGyu/items/9597ed2eda763bd504d7
- https://buildersbox.corp-sansan.com/entry/2020/01/28/110000
- https://hub.docker.com/r/zenika/terraform-aws-cli
Terraform準備
TerraformはCLIコマンドを実行したディレクトリの.tfファイルを参照してそこに書いてあるリソースを作成します。自動的に参照されるのはコマンドを実行したディレクトリの.tfファイルのみで、上位はもちろん、サブディレクトリも明示的に呼ばない限りは読み込まれません。今回は小難しい設定はなしにして最低限の初期設定だけ行います。
provider.tfprovider "aws" { region = "ap-northeast-1" }まずはプロバイダです。これでAWS用のプラグインが読み込まれ、AWSのリソースを作成できるようになります。
versions.tfterraform { required_version = ">= 0.12" }こちらは実行するバージョンを限定できます。上記で"0.12より上のバージョンでのみ動作する"ということを明示します。
作り込むと実行結果(作成されたリソースのARNとか)をS3に保存してリモートステータスとして参照とかできますが、割愛します。
2つのファイルを作成したらterraform initを実行してみましょう。実行するために必要なファイルが色々作成されます。ECRリポジトリ
Terraformの準備が整ったところで、作成するリソースをゴリゴリ書いていきます。まずはECRのリポジトリから作ります。ECRは、DockerHubのようにAWSが提供しているコンテナイメージのレジストリです。DockerHubのイメージそのまま使ってもいいのですが、せっかくなのでこちらにイメージを作ってそこからpullしたいと思います。
リポジトリ作成
早速、コンテナイメージを格納するリポジトリをECRにを作成します。
ecr.tfresource "aws_ecr_repository" "nginx" { name = "nginx" image_tag_mutability = "IMMUTABLE" image_scanning_configuration { scan_on_push = true } }
image_tag_mutabilityは一度作成したTagの上書きの可否です。
image_scanning_configuration.scan_on_pushはイメージをプッシュした際に、脆弱性を診断してくれます。
リポジトリを作成したらイメージをプッシュします。AWS CLIを使うとECRへのログインコマンドを作ってくれますので、以下でECRにログインします。aws ecr get-login --region ap-northeast-1 --no-include-email | bashあとはDockerイメージをビルドしてプッシュするだけです。イメージ名は作成したECRリポジトリのURIにしてください。
URI="************.dkr.ecr.[region].amazonaws.com/[image]" docker build -t $URI . docker push $URI:latestVPCエンドポイント作成
次に、VPCエンドポイントを作成します。これがないと、VPCの中からAWSのサービスを参照できませんので、ECRからイメージをpullできません。
vpc.tf... resource "aws_vpc_endpoint" "ecr" { vpc_id = aws_vpc.main.id subnet_ids = [aws_subnet.main.id] service_name = "com.amazonaws.ap-northeast-1.ecr.dkr" vpc_endpoint_type = "Interface" security_group_ids = [ aws_security_group.allows_tls.id ] policy = <<EOF { "Statement": [ { "Action": "*", "Effect": "Allow", "Resource": "*", "Principal": "*" } ] } EOF } ...更に、ECRはイメージの実体をS3に保存してますので、イメージをダウンロードするためにS3のVPCエンドポイントも必要です。
vpc.tf... resource "aws_vpc_endpoint" "s3" { vpc_id = aws_vpc.main.id service_name = "com.amazonaws.ap-northeast-1.s3" vpc_endpoint_type = "Gateway" policy = <<EOF { "Statement": [ { "Action": [ "s3:GetObject" ], "Effect": "Allow", "Resource": [ "arn:aws:s3:::prod-region-starport-layer-bucket/*" ], "Principal": "*" } ] } EOF } ...この時、リソース名を制限する場合は
arn:aws:s3:::prod-region-starport-layer-bucket/*を許可するようにしてください。ECSタスク定義
タスク定義は、ECS上でどんなコンテナを動かすのかを決めるところです。docker-compose.yamlを作るイメージに近いと思います。
タスク定義
task_definition.tfresource "aws_ecs_task_definition" "nginx" { family = "nginx" container_definitions = templatefile("container_definition.json", { repository_url = aws_ecr_repository.nginx.repository_url log_group_name = aws_cloudwatch_log_group.nginx_log.name }) task_role_arn = aws_iam_role.task.arn execution_role_arn = aws_iam_role.task_execution.arn requires_compatibilities = ["EC2"] network_mode = "awsvpc" }
familyがタスク定義の名前です。container_definitionはどんなコンテナを動かすのかをJSONで書きます(後述)。分かりづらいところで、ロールの割り当てが
task_role_arnとexecution_role_arnの2つがあります。execution_role_arnはタスクを実行するプロセスに割り当てられるロールで、ECRにあるイメージを使う場合はECRへの参照権限が必要です。基本的にはデフォルトで用意されているAmazonECSTaskExecutionRolePolicyがアタッチされてるロールであれば問題ないと思います。task_role_arnは実行されたタスクに割り当てられるロールです。例えば、起動したコンテナの中で稼働するアプリが、S3にファイルを書き込んだりしてる場合は、S3への書き込み権限を持ったロールを割り当てる必要があります。
requires_compatibilitiesでこのタスク定義がどの起動タイプで起動できるかを設定します。今回はEC2でのみ起動可能なタスクとして設定してます。
network_modeはタスクのネットワークドライバを指定します。docker-compose.yamlによく書かれてるのはbridgeですが、今回はawsvpcを使います。awsvpcにすると、タスクに直接ENIがアタッチされ、タスクにサブネットのIPアドレスが振られます。注意点として、EC2を使う場合、インスタンスタイプ毎のENI上限に引っかからないようにする必要があります。具体例として、t2.smallのインスタンスタイプを使ってるEC2インスタンス上の場合、上限は2なので、3つ目のタスクを起動しようとするとコンテナの起動に失敗します。この上限はECSのアカウント設定で緩和できるので忘れずにしておきましょう。以下のコマンドで設定できます。aws ecs put-account-setting --name awsvpcTrunking --value enabled --region a-^northeast-1緩和後の上限などについては以下がわかりやすいです。
https://dev.classmethod.jp/articles/ecs-eni-limit-add/コンテナ定義
container_definition.json[ { "name": "nginx", "image": "${repository_url}", "portMappings": [ { "containerPort": 80, "protocol": "tcp" } ], "memoryReservation": 512, "logConfiguration": { "logDriver": "awslogs", "secretOptions": null, "options": { "awslogs-group": "${log_group_name}", "awslogs-region": "ap-northeast-1", "awslogs-stream-prefix": "ecs" } }, "essential": true } ]
imageは使用するイメージです。今回はECRのリポジトリなので、ECRのURLを書きます。DockerHubからpullする場合はイメージの名前だけで大丈夫です。
logConfigurationを設定するとdocker logsで出力される内容が、設定した場所に送信されるようになります。今回はCloudwatchのロググループに書き込むようにしてます。
portMappingsは基本的にはコンテナのポートだけ記載すれば問題ありません。awsvpcを使う時はホストのポートが使われることはありません。bridge等を使う場合も動的ポートマッピングを使ったほうがいいと思われますので、ホストのポートを指定しなくていいです。また、コンテナの定義が配列なのでお察しかと思いますが、複数のコンテナを定義できます。同一タスク上のコンテナ同士は
localhostで通信可能です。もっと詳しく設定内容について知りたい方は以下のリンクをご参照ください。
https://docs.aws.amazon.com/AmazonECS/latest/developerguide/task_definition_parameters.html
https://registry.terraform.io/providers/hashicorp/aws/latest/docs/resources/ecs_task_definitionECSクラスタ
次にクラスタを作成していきます。クラスタ自体の設定内容はほぼないのですが、EC2を使う場合EC2インスタンス関連の設定が必要になります。Faegate使う場合途中から読み飛ばしても問題ないです。
クラスタ
cluster.tflocals { cluster_name = "test-cluster" } resource "aws_ecs_cluster" "test" { name = local.cluster_name capacity_providers = [aws_ecs_capacity_provider.test.name] default_capacity_provider_strategy { capacity_provider = aws_ecs_capacity_provider.test.name weight = 1 base = 0 } }
capacity_providersでこのクラスター内で使用できるキャパシティープロバイダーを指定します。キャパシティープロバイダーについての説明は後述します。
default_capacity_provider_strategyでスケールイン・アウト時のタスクの配分を決められます。この数字が変わるとどうなるのかは、以下の記事の"Capacity Provider strategyによるタスク配分戦略"の項がわかりやすかったです。
https://dev.classmethod.jp/articles/regrwoth-capacity-provider/
ちなみにFargate使う場合こちらで用意する必要ありません。これだけでいいです。cluster.tflocals { cluster_name = "test-cluster" } resource "aws_ecs_cluster" "test" { name = local.cluster_name capacity_providers = ["FARGATE", "FARGATE_SPOT"] default_capacity_provider_strategy { capacity_provider = "FARGATE" weight = 1 base = 0 } }キャパシティープロバイダー
起動タイプにEC2を使う場合、どんなEC2インスタンスをどのように起動して、どれくらい使うかという
面倒な設定が必要になります。それがこのキャパシティープロバイダーです。cluster.tfresource "aws_ecs_capacity_provider" "test" { name = "ec2" auto_scaling_group_provider { auto_scaling_group_arn = aws_autoscaling_group.test.arn managed_termination_protection = "ENABLED" managed_scaling { maximum_scaling_step_size = 1 minimum_scaling_step_size = 1 status = "ENABLED" target_capacity = 100 } } }EC2インスタンス自体の設定やスケールイン・アウトの設定はEC2のオートスケーリンググループを使います。
managed_termination_protectionはコンテナがまだ起動してるのに、オートスケーリンググループによってEC2インスタンスを停止させられてしまうことをECSの方で防いでくれるようになります。
managed_scaling.target_capacityはこのオートスケーリンググループによって起動されたEC2インスタンスのリソースを、どれくらいECSのタスクに割くかを設定します。上記だと100%ECSが専有します。
maximum|minimum_scaling_step_sizeというのは一度のスケールイン・アウトでいくつコンテナを起動・終了させるかです。オートスケーリンググループ
こちらはECSの機能ではないので、詳しい説明は省いて、ECSに関わる部分の注意点のみ説明します。
ec2.tfresource "aws_autoscaling_group" "test" { name = "test" launch_template { id = aws_launch_template.test.id version = "$Latest" } protect_from_scale_in = true max_size = 1 min_size = 1 }ポイントは2つです。
-protect_from_scale_inをtrueにすること。
-launch_configurationではなくlaunch_templateを使うこと。
protect_from_scale_inはキャパシティープロバイダーのmanaged_termination_protectionを有効にする場合はtrueにする必要があります。launch_templateについてはこの後説明します。起動テンプレート
これもECSの機能ではないので、詳しい説明は省きます。
ec2.tfresource "aws_launch_template" "test" { name = "test" image_id = data.aws_ssm_parameter.amzn2_for_ecs_ami.value instance_type = "t2.micro" ebs_optimized = true user_data = base64encode(templatefile("./userdata.sh", { cluster_name = local.cluster_name })) block_device_mappings { device_name = "/dev/sda1" ebs { volume_size = 40 volume_type = "gp2" } } } data "aws_ssm_parameter" "amzn2_for_ecs_ami" { name = "/aws/service/ecs/optimized-ami/amazon-linux-2/recommended/image_id" }こちらもポイントは2つです。
- AMIにECSに最適化されたイメージを使う。
-user_dataでECSの設定を行う。AMIにはECSに最適化されたイメージを使います。以下のページでどんなイメージがあるか確認できます。
https://docs.aws.amazon.com/ja_jp/AmazonECS/latest/developerguide/ecs-ami-versions.html
user_dataの方ですが、まずテンプレートで読み込んでるファイルは以下の通りです。userdata.sh#!/bin/bash echo 'ECS_CLUSTER=${cluster_name}' >> /etc/ecs/ecs.config何をやってるかというと、ECSのエージェントに自分が所属すべきクラスターの名前を教えています。これがないと、ECSのエージェントは所属するクラスター名を
defaultと判断します。作成したクラスター名はdefaultではないので、これを設定しないと、起動したEC2インスタンスがクラスターに登録されず、コンテナを起動できません。オートスケーリンググループの作成時にlaunch_configurationではなくlaunch_templateを使ったのはこのuser_dataを設定する必要があるためです。ECSサービス
ようやくクラスター内で稼働するサービスを作成します。
サービス
resource "aws_ecs_service" "nginx" { name = "nginx" cluster = aws_ecs_cluster.test.id task_definition = aws_ecs_task_definition.nginx.arn desired_count = 1 deployment_minimum_healthy_percent = 100 load_balancer { target_group_arn = aws_lb_target_group.test.arn container_name = "nginx" container_port = 80 } network_configuration { subnets = [aws_subnet.main.id] security_groups = [aws_security_group.allows_http] } }
desired_countで稼働を維持させるタスクの数を指定します。
deployment_minimum_healthy_percentは、サービスを更新してタスクをアップグレードする際、維持させるタスクの数をdesired_countに対するパーセンテージで指定します。上記だと100%なので、1個はタスクを維持したまま新しいタスクを起動します。
WEBサービスの場合はロードバランサを指定します。同時に、ロードバランサと繋がるコンテナと、コンテナの通信を受け付けるポートを指定します。
タスク定義で設定したnetwork_modeがawsvpcの場合は、network_configurationでタスクが所属するサブネットや適用するセキュリティグループ、パブリックIPをタスクに割り当てるかどうかを指定します。オートスケーリンググループ
「オートスケーリンググループはさっき作ったじゃん。ボケた?」と思った方、安心してください。まだボケてません。
さっき作成したのはEC2インスタンスのオートスケーリンググループで、こちらはECSのサービスによって稼働するタスクのオートスケーリンググループです。resource "aws_appautoscaling_target" "ecs_service" { max_capacity = 2 min_capacity = 1 resource_id = "service/${aws_ecs_cluster.test.name}/${aws_ecs_service.nginx.name}" scalable_dimension = "ecs:service:DesiredCount" service_namespace = "ecs" }そのままなので大体わかるかと思いますが、
max|min_capacityで稼働を維持するタスクの最低数と、スケールアウトする最大数を指定します。コンピューティングリソースではなく、別のメトリクスでスケールイン・アウトする場合はその設定も必要になります。終わり
以上です。WEBサービスの場合は、この後ロードバランサーの設定やらRoute53やらCertificateやら色々やってインターネットからアクセスできるようにする必要が出てきます。AWSやインフラの知識がなかったので結構色んな罠にハマりました。ただ、ハマったおかげで色々知識として吸収できたのでそこは良かったです。次はEKSにチャレンジしたい。
- 投稿日:2020-10-25T18:24:18+09:00
1分で学習手順OK! AWS認定クラウドプラクティショナー 合格へ
【1分で学習手順OK! AWS認定クラウドプラクティショナー 合格へ】
10/24に受験して、1回で合格しました!
(隠した方が良さそうなところは隠しました。スコアは700点台でした。)
私が実践した学習手順は合格の再現性が高いと思ったので簡単な記事にまとめてみました。はじめに
これだけでAWS認定試験クラウドプラクティショナーに合格することが可能だと思います。
私の保有IT資格(一応記載)
ITパスポート のみ。
(今年度秋期の基本情報技術者試験を受験予定でしたが中止になりました。。)
AWS認定試験クラウドプラクティショナーの概要など。
700/1000 点 なので、約7割解けたら合格です。
制限時間100分。65問です。
分野 1: クラウドの概念
1.1 AWS クラウドの概念とその価値提案について説明する
1.2 AWS クラウドエコノミクスの特徴を説明する
1.3 多種多様なクラウドアーキテクチャの設計原理を定義する分野 2: セキュリティおよびコンプライアンス
2.1 AWS の責任共有モデルについて理解する
2.2 AWS クラウドのセキュリティとコンプライアンスに関するコンセプトを理解する
2.3 AWS のアクセス管理機能を特定する
2.4 セキュリティサポートのリソースを特定する分野 3: テクノロジー
3.1 AWS クラウドにおけるデプロイと運用の方法を理解する
3.2 AWS のグローバルインフラストラクチャについて理解する
3.3 AWS の主要なサービスを識別する
3.4 テクノロジーサポートのリソースを特定する分野 4: 請求と料金
4.1 AWS のさまざまな料金モデルを比較対照する
4.2 AWS 請求と料金に関連した多様なアカウント構造を認識する
4.3 請求サポートに利用できるリソースを特定する試験の質問には以下の 2 種類があります。
• 択一選択問題: 選択肢には 1 つの正解と 3 つの不正解 (誤答) があります。
• 複数選択問題: 5 つの選択肢のうち、2 つが正解です。(AWS認定公式サイトから引用)
詳しい内容は、こちらからご確認頂くと良いと思います。
→AWS 認定 クラウドプラクティショナー学習教材
使用した学習教材は2つのみです。
AWS公式のデジタルコースなどの利用はしていません。・一夜漬け AWS認定クラウドプラクティショナー 直前対策テキスト
・この問題だけで合格可能!AWS 認定クラウドプラクティショナー 模擬試験問題集(7回分455問)
※Udemyの教材は、セール時の購入が良いと思います。
学習順序
1、テキストを1周流し読み
2、テキストに演習問題が65問あるのでとりあえず解いてみる。
3、Udemyの模擬試験を解く。
(基礎①、基礎②、応用①、応用②だけで大丈夫です。)4、Udemyの模擬試験の間違えた箇所をテキストで復習する。
1、2を終えたら、3、4をひたすら繰り返すのみです。
わからない用語が出てきたら、その都度調べるようにしました。とりあえず量をこなせば、大丈夫だと思います。
+α を求めるなら
Qiita @sew_sou19さんの記事を参考にすれば、合格に必要なレベルがわかると思います。
・AWS クラウドプラクティショナー 勉強〜合格までのメモ学習当初、不安で色んな方のブログやQiitaを見ていました。
ただ、ほとんど意味のないことだったと後からわかりました。
他の教材や他人の体験談が気になってしまっても見る意味はさほどないと思います。やるべきことは、ひたすら問題を解くだけです。
通勤電車や昼休憩にUdemyの模擬試験を解くだけで合格は目指せます。おわりに (ここを読むと1分超えると思います)
この記事の最後で「【今年、残り3ヶ月の目標】 AWS認定クラウドプラクティショナー、LPIC1の資格を取得する!!」と目標を立てていました。
まず、1つ目標達成出来てよかったです。
今回は基礎レベルの試験に合格しただけで慢心せずに今後もAWSに触れていき、実践的な知識を身につけていこうと思います。今後のキャリアアップのためにモチベーション上げて、自己研鑽に努めていきます。
次は、LPIC level 1 を取得します!余談ですが、この資格試験は会社が受験料を負担してくれました。
それに加えて一時金ではありますが資格奨励金が頂けます。
有り難く受け取って、自分へのご褒美に大好きな鰻を食べに行こうと思います笑・おまけ Udemyの模擬試験の点数推移を参考に。
このような感じでした。
1度目は、全問回答しないで問題文と解答を照らし合わせました。基礎① 0%正解→66%正解→73%正解→76%正解→96%正解→100%正解
基礎② 0%正解→52%正解→69%正解→83%正解→92%正解→98%正解
応用① 0%正解→56%正解→70%正解→90%正解→96%正解→96%正解
応用② 0%正解→64%正解→72%正解→89%正解→95%正解→92%正解
応用② 0%正解→33%正解(1回のみ。不要という記事をQiitaで何度か見たため。)


- 投稿日:2020-10-25T18:08:12+09:00
IPアドレスの基礎学習
はじめに
AWSはAmazon Web Servisesの略で、Amazonが提供しているクラウドサーバーのサービスです。
AWSへの理解度を高めるために、学んだことをアウトプットします。
今回はIPアドレスのことを説明します。IPアドレス
インターネットで使われるTCP/IPというプロトコルでは、通信先を特定するのに、IPアドレスを用います。
IPアドレスは、ネットワーク上での住所のようなもので、ネットワーク上が重複しないようになっています。
IPv4とIPv6が存在しますが、今回はIPv4を説明すると、4つに区切られた最大12桁の数字になります。例)192.168.1.2
ピリオドで区切られた数字は0~255までの数字が入ります。(0.0.0.0 ~ 255.255.255.255)
IPアドレスは32ビットで構成されます。
ピリオドで区切られた数字はそれぞれ8ビットずつとなります。(255は8桁の2進数の最大値)
簡単なイメージでいうと、1ビットの中には0か1の数字が入り、それが8個連なって8ビットが構成されているということです。パブリックIPアドレスとプライベートIPアドレス
パブリックIPアドレス
インターネットで使われるIPアドレスのこと。
IPアドレスが重複すると正しく通信できないため、ICANNという機関がパブリックIPアドレスを管理しています。プライベートIPアドレス
インターネットで使われないIPアドレスのこと。
10.0.0.0 ~ 10.255.255.255
172.16.0.0 ~ 172.31.255.255
192.168.0.0 ~ 192.168.255.255上記の範囲のIPアドレスはプライベートIPであり、どこかに申請する必要がなく、自由に使えます。
IPアドレス範囲と表記方法
VPCで指定したIPアドレスはネットワーク部とホスト部に分けられます。
ネットワーク部は同じネットワークに属する限り、同じ値となる部分です。
ホスト部は割り当てたいサーバーやクライアント、ネットワーク機器に対しての値となる部分です。例)192.168.1.0 ~ 192.168.1.255
192.168.1までは変わらないため、ネットワーク部です。
0や255は変わるため、ホスト部です。(数字を割り当てるために、変化させる)IPアドレスの範囲を表す際に、192.168.1.0 ~ 192.168.1.255のような表現は長いため、通常しません。
CIDR表記、もしくは、サブネットマスク表記を使うことが一般的です。CIDR表記
例)192.168.1.0 ~ 192.168.1.255
CIDR表記 192.168.1.0/2424という数字はネットワーク部のビット長を表します。
192.168.1までがネットワーク部となるため、24ビットとなります。(1つの数字ごとに8ビット)
ちなみに、この24ビットはプレフィックス(prefix)と呼ばれます。サブネットマスク表記
例)192.168.1.0 ~ 192.168.1.255
サブネットマスク表記 192.168.1.0/255.255.255.0プレフィックスのビット数だけ2進数の1を並べ、残りは0を記述した表記になります。
8ビットに全て1を入れた時が255なので、プレフィックスが24ビットの時は255.255.255.0となります。参考
「Amazon Web Services 基礎からのネットワーク&サーバー構築」
著者:大澤文孝、玉川憲、片山暁雄、今井雄太最後に
本投稿が初学者の復習の一助となればと幸いです。
- 投稿日:2020-10-25T16:20:15+09:00
AWS CDK コマンドチートシート
インストール
npm install -g aws-cdkLinuxの場合は、
sudoが必要です。プロジェクトの作成
mkdir my-first-cdk cdk init app --language typescriptモジュールの追加
たとえばec2のモジュールを追加するには、
npm install @aws-cdk/aws-ec2or
yarn add @aws-cdk/aws-ec2こんなかんじ。
bootstrap
CDKを実行するために必要なAWS内の環境を初期化。
AWS_PROFILE=your_profile cdk boostrapビルド
npm run builddeploy
AWS_PROFILE=your_profile cdk deploy変更差分の確認
AWS_PROFILE=your_profile cdk diff変更適用
AWS_PROFILE=your_profile cdk deploy
- 投稿日:2020-10-25T16:19:19+09:00
Amazon Timestreamを動かしてみる
はじめに
フルマネージドな時系列データベースのAmazon Timestreamが9/30に一般公開されたので触ってみる。
時系列データベースは存在自体は以前から知っていたものの、使ったことはないので楽しみ。新しすぎてまだCloudFormationもTerraformも対応していないので、今回はコンソールからポチポチやってみる。ちなみに東京リージョンではまだ使えないので、コンソールを利用可能なリージョンに向けておこう。
データベースを作ってみる
さて、自分で作ってみようとしたらよく分からなかったので、こういう時はチュートリアルを見ながらやるのが定石だろう。
Timestreamの以下の画面で「Create database」のボタンを押す。
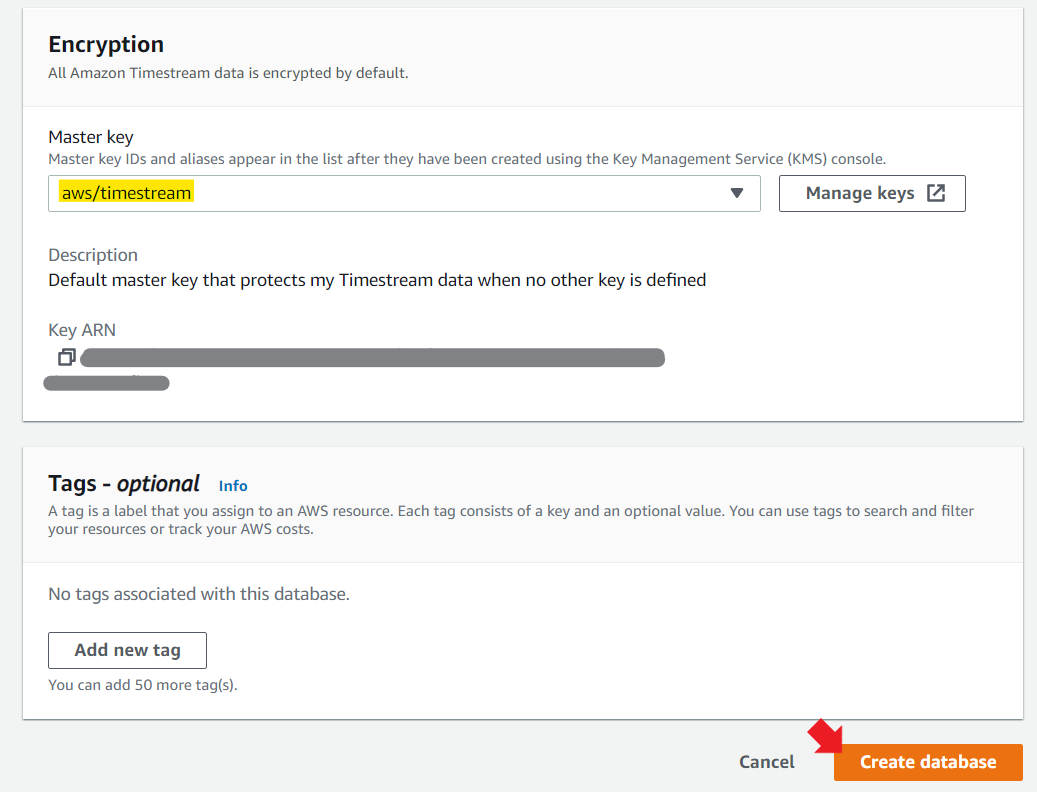
で、開いたデータベース作成の画面で、データベース名を設定する。
※お手軽設定もあるが、今回はStandard databaseを選択する。
KMSの設定は、空白にしておくと勝手にキーを作成してくれた。
タグを好きに設定して「Create database」ボタンを押す。
作成完了!
テーブルを作ってみる
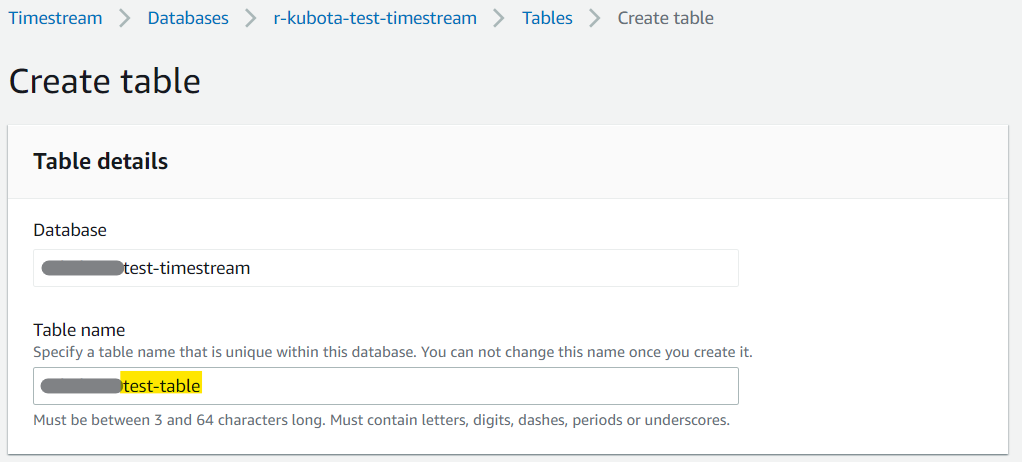
さて、↑で作ったテーブル名のリンクを押してみよう。
データベースの詳細画面に「Create table」のボタンがあるので押す。で、開いたテーブル作成の画面で、テーブル名を設定する。
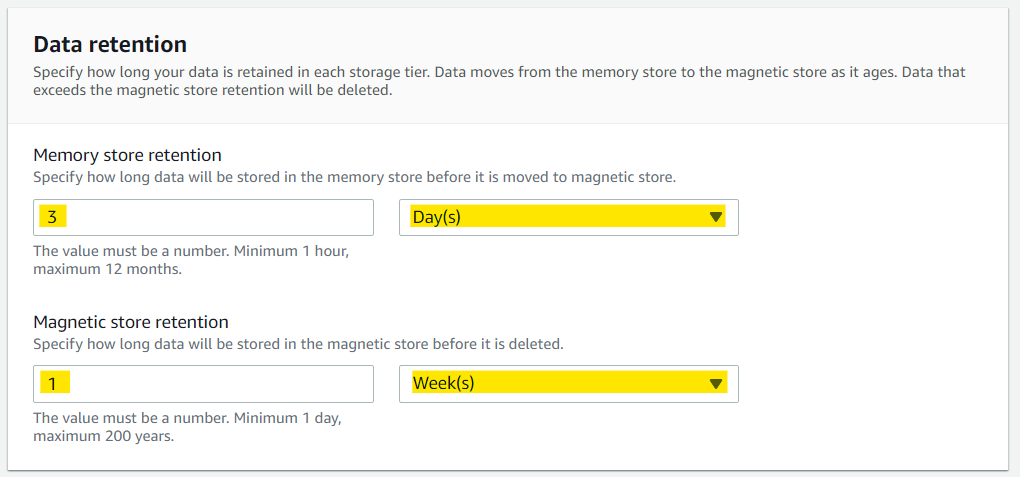
データ保存の設定は、今回はお試しなのでテキトーに。
タグをお好みで設定して「Create table」のボタンを押す。
テーブルの作成も完了!
データを登録する
チュートリアルと同じように作るのは面白みがないので、Locustの出力するデータを登録してみることにしよう。
登録対象のデータは以下のようなイメージだ。
Timestamp,User Count,Type,Name,Requests/s,Failures/s,50%,66%,75%,80%,90%,95%,98%,99%,99.9%,99.99%,100%,Total Request Count,Total Failure Count,Total Median Response Time,Total Average Response Time,Total Min Response Time,Total Max Response Time,Total Average Content Size 1603535373,20,GET,/xxxxx/,1.000000,0.000000,5,6,6,6,8,9,9,9,9,9,9,16,0,4.11685699998543,5.413748562499876,4.11685699998543,9.385663000045952,14265.0これを、以下のPythonでコマンドを作ってロードする。
ディメンションというのがよく分からないかもしれないが、要するに分類するための属性情報だと思えば良い。
今回は、HTTPのリソースとメソッドを属性として定義した。import sys import csv import time import boto3 import psutil from botocore.config import Config FILENAME = sys.argv[1] DATABASE_NAME = "xxxxx-test-timestream" TABLE_NAME = "xxxxx-test-table" def write_records(records): try: result = write_client.write_records(DatabaseName=DATABASE_NAME, TableName=TABLE_NAME, Records=records, CommonAttributes={}) status = result['ResponseMetadata']['HTTPStatusCode'] print("Processed %d records.WriteRecords Status: %s" % (len(records), status)) except Exception as err: print("Error:", err) if __name__ == '__main__': session = boto3.Session() write_client = session.client('timestream-write', config=Config( read_timeout=20, max_pool_connections=5000, retries={'max_attempts': 10})) query_client = session.client('timestream-query') with open(FILENAME) as f: reader = csv.reader(f, quoting=csv.QUOTE_NONE) for csv_record in reader: if csv_record[0] == 'Timestamp' or csv_record[3] == 'Aggregated': continue ts_records = [] ts_columns = [ { 'MeasureName': 'Requests/s', 'MeasureValue': csv_record[4] }, { 'MeasureName': '95Percentile Response Time', 'MeasureValue': csv_record[10] }, { 'MeasureName': 'Total Median Response Time', 'MeasureValue': csv_record[18] }, { 'MeasureName': 'Total Average Response Time', 'MeasureValue': csv_record[19] }, ] for ts_column in ts_columns: ts_records.append ({ 'Time': str(int(csv_record[0]) * 1000), 'Dimensions': [ {'Name': 'resource', 'Value': csv_record[3]}, {'Name': 'method', 'Value': csv_record[2]} ], 'MeasureName': ts_column['MeasureName'], 'MeasureValue': ts_column['MeasureValue'], 'MeasureValueType': 'DOUBLE' }) write_records(ts_records)だが、一般公開されたばかりの機能なので、boto3のバージョンが古い人がいるだろう。
$ pip list -oで、boto3がLatestになっているか確認しよう。
Package Version Latest Type --------------------- -------- ---------- ----- boto3 1.13.26 1.16.4 wheelpipでのアップデートは
-Uで行う。$ pip install -U boto3また、
aws configureでデフォルトリージョンを、↑でデータベースを作ったリージョンに向けておこう。psutilが入っていない場合は以下でインストールする。
$ yum install python3-devel $ pip3 install psutilいずれ修正されると思うが、2020/10/25時点では↑の公式のブログではコマンド名が間違っているので、ブログを信じてpip3するとインストールできなくて悲しい気持ちになる。
さて、無事データロードできただろうか。
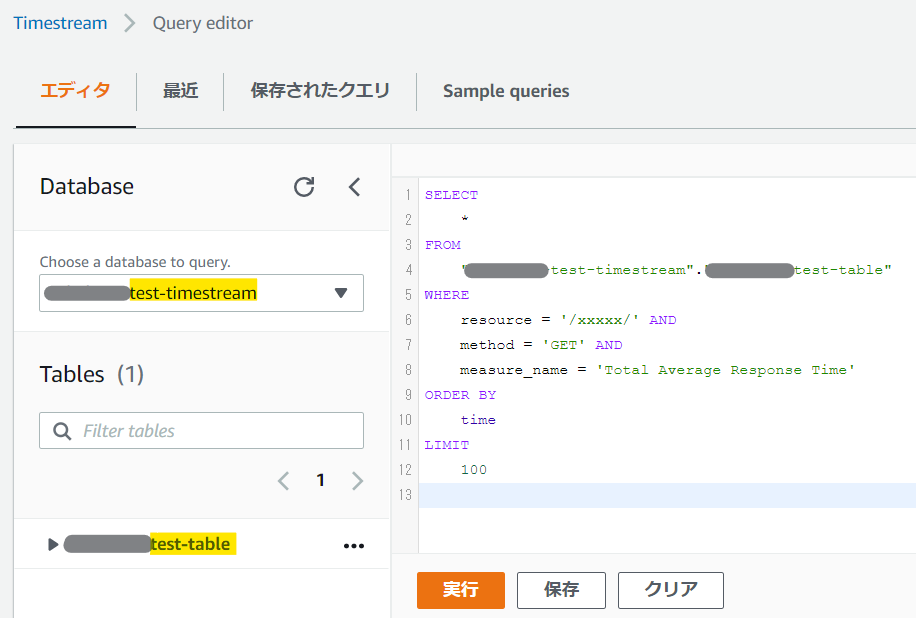
クエリを発行する
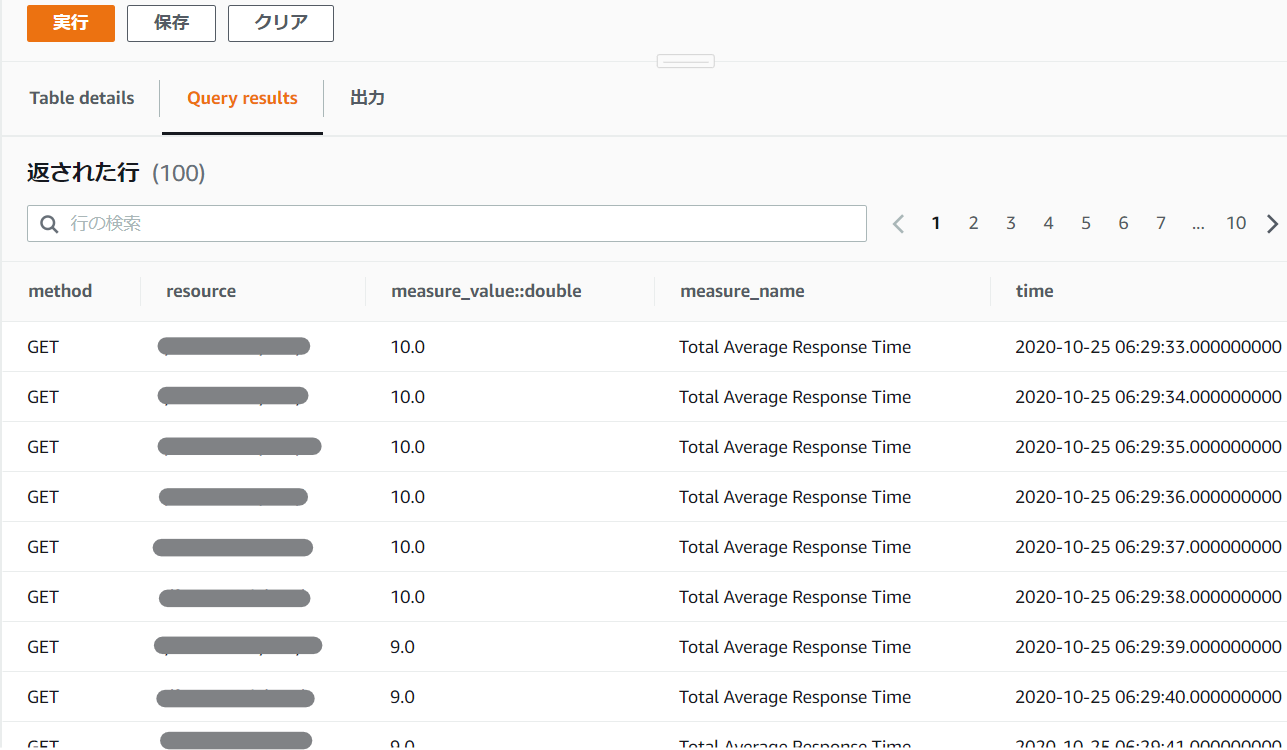
左のメニューから「Query Editor」を選択すると以下のような画面が表示されるので、テキトーに属性を絞りながらSQLを実行してみよう。/xxxxx/ の GET リクエストの平均レスポンス時間を知りたい!
実行したら、バッチリ欲しい情報だけが抽出された!
これを生データで取得するには、またCLIなりboto3なりで取得する。
ページネーターが必要だったりで結構面倒。
そもそもちょっとした分量なら、pandasを使うのが楽なのだけど、実際の利用シーンでは、何千台もあるサーバ等から定感覚で収集した情報を素早く取り出すので、ローカルでpandasで整形できるような情報量ではないはずだ。
Grafanaと組み合わせてリアルタイムにモニタリングしたりできるという点が真骨頂なんだろうな……。

- 投稿日:2020-10-25T15:42:37+09:00
AWS CDKでNAT GatewayにEIPを割り当てる方法
2020年10月時点ではきれいにやる方法を公式が提供していないので、EIPを取得して作成したNAT Gatewayの既存のEIPを削除して付け直すみたいな無理やり的な方法でできる。しかたないね。
export class VpcStack extends cdk.Stack { private vpc: ec2.Vpc; constructor(scope: cdk.Construct, id: string, props?: cdk.StackProps) { super(scope, id, props); const allocationIds: string[] = []; const eips: string[] = []; const numberOfAz = 2; this.vpc = new ec2.Vpc(this, 'MyVpc', { cidr: '172.16.0.0/16', maxAzs: numberOfAz, subnetConfiguration: [ { name: 'ingress', subnetType: ec2.SubnetType.PUBLIC, cidrMask: 24, }, { name: 'application_1', subnetType: ec2.SubnetType.PRIVATE, cidrMask: 24, }, { name: 'application_2', subnetType: ec2.SubnetType.PRIVATE, cidrMask: 24, reserved: true, }, { name: 'database', subnetType: ec2.SubnetType.ISOLATED, cidrMask: 24, }, ], }); // Create as many EIP as there are AZ/Subnets and store their allocIds & refs. for (let i = 0; i < numberOfAz; i++) { var eip = new ec2.CfnEIP(this, `VPCPublicSubnet${i+1}NATGatewayEIP${i}`, { domain: 'vpc', tags: [ { key: 'Name', value: `MyApp/VPC/PublicSubnet${i+1}`, }, ] }) allocationIds.push(eip.attrAllocationId) // Do whatever you need with your EIPs here, ie. store their ref for later use eips.push(eip.ref) // Add a dependency on the VPC to encure allocation happens before the VPC is created this.vpc.node.addDependency(eip) } this.vpc.publicSubnets.forEach((subnet, index) => { // Find the NAT Gateway var natGateway = subnet.node.children.find(child => child.node.id == 'NATGateway') as ec2.CfnNatGateway // Delete the default EIP created by CDK subnet.node.tryRemoveChild('EIP') // Override the allocationId on the NATGateway natGateway.allocationId = allocationIds[index] }) } getVpc(): ec2.Vpc { return this.vpc; } }refs
- 投稿日:2020-10-25T15:08:15+09:00
クラウドサービスを使うときは、チームメンバー全員、クラウド利用費を意識しようという話
私は、普段の業務でAWSの各サービスを利用しています。
AWS,Azure,GCPと、使ってる基盤は違えど、パブリッククラウドを使用している企業さんは今時多いんじゃないかと思います。身の丈に合ったリソースを柔軟・簡単・迅速に構築でき、使った分だけ請求される。非常に便利なパブリッククラウドの各サービス達ですが、気づいた時には、
社長「あれ?思ったより高額じゃね?」「もっとコスト下げんかい!」って話になってしまうリスクもあります。このあたりのクラウド利用コストは、エンジニアがきちんとコスト感を持っていれば防げるものも多いと思います。
トップダウンでコスト削減の話が降ってきたときにはもう手遅れ、「やっちまった」と思いたいものです。
私が過去、痛い目を見た経験も踏まえ、クラウドを利用する際のコスト意識について書いてみようと思います。
※AWSを例に挙げて話していこうと思います。1.まずは現実を受け止めよう
https://aws.amazon.com/jp/aws-cost-management/aws-cost-and-usage-reporting/
AWSは毎月コストレポートを出してくれます。
どのリソースにいくら使ってるのか?まずは現実を知る所からです。2.直ぐに削れるところはないか?確認しよう
まずはEC2,RDSといった、予めインスタンスを確保しておき、確保した分に対して料金を払うサービスを見直してみましょう。
①POCや技術検証の為に作ったけど、今は利用していないもの。
②例えば負荷試験の為に一時的にスケールアップしているが、試験は終了していて今は最低限のリソースで十分なもの。
③開発の計画が変更になり、元々必要で立てたものの、不要になったもの。上記のようなリソースは無いでしょうか。意外と残ってたりするんじゃないでしょうか。
この辺の管理はしっかり行いましょう。私の居たチームでは過去、この辺りの管理が雑になっており、毎月ウン万単位の無駄なコストが発生していました。~対策~
①エクセルでも何でも良いので、まずは管理しましょう。自分たちが使っているサービスのインスタンスタイプは?ストレージは?(分散基盤の場合)ノード数は?
②その上で、不要なものは直ぐに削除、下げられるリソースは徹底的に下げましょう。クラウドサービスの多くは従量課金になっており、下げた・消したその瞬間から料金は下がります。早いに越したことはありません。3.使った分だけしか請求されない=使った分だけ請求される
次にAthena,Lambdaや、RDSからのデータ抽出など、「使った分だけ課金される」部分の見直しです。
タイトルの通り、
使った分だけしか請求されない=使った分だけ請求される
ということです。
無駄なクエリは打っていないでしょうか。無駄なデータ抽出を行っていないでしょうか。
この辺のサービスは、処理1つ1つがコストです。、
開発中だから色々試しちゃえーー!と、ジャブジャブ処理を動かしていると、その分お金も溶けていきます。~対策~
私は、この辺はもう意識の問題かと思っています。
自分の打つクエリ1つ1つがコストです。本当にこのクエリで思った通りのデータが取ってこれるか?思った通りの処理を実現できるか?しっかり確認しましょう。4.まとめ
ここまで読んでいただきありがとうございます。
「なんだ、当たり前の事しか書いてないじゃん」と思われた方も多いと思いますが、
特に小数のチームだと、この辺りの管理って雑になりがちだと思っています。
また、当たり前のことほど難しいものです。しっかり意識するために、チーム単位でPL表などを作成してみるのも良いと思います。
私のチームはPL表を作成し、マネージャではなくエンジニアが管理することで、
全員がコスト意識を持ち、煩雑だったあの当時に比べ、AWSコストは本当に必要な部分のみに徹底的に抑えられています。(自分へのメッセージでもありますが、)
エンジニアとして、本当に必要な部分でコストかけて勝負できるように、
日々コスト意識をもって、無駄なコストは徹底的に、管理&削減していきましょう。
- 投稿日:2020-10-25T14:57:08+09:00
AWS CDKで現在のアカウントIDを取得する方法
const accountId = cdk.Stack.of(this).account;
- 投稿日:2020-10-25T14:47:35+09:00
aws cliで自分のアカウントが保有しているAMIの一覧を取得する
aws ec2 describe-images \ --owners $(aws sts get-caller-identity | jq .Account | sed -e 's/\"//g') \ | jq .Images
- 投稿日:2020-10-25T14:43:56+09:00
aws cliで自分のアカウントIDを取得する
aws sts get-caller-identity | jq .Account | sed -e 's/\"//g'
- 投稿日:2020-10-25T13:18:22+09:00
AWS S3 download, upload
- 投稿日:2020-10-25T12:31:31+09:00
AWS認定資格クラウドプラクティショナーをPSIオンライン受験した話~身分証明でつまずきました~
はじめに
AWS認定資格「クラウドプラクティショナー」をPSIでオンライン受験して、無事合格したので勉強方法とオンライン受験の体験記です。
私のスペック
基本情報、応用情報は取得済み。
令和2年度秋のネットワークスペシャリストを受験予定でした。(コロナの影響で中止)
よって、ネットワークなどの技術については、あらかじめ分かっている状態です。事前準備
勉強方法
とりあえず、
AWS認定資格試験テキスト AWS認定 クラウドプラクティショナーを書店で購入し、ひととおり読みました。
しかし、awsの取説をそのままコピーしたような印象があり、あまり役には立ちませんでした。つづいて、
UdemyでAWS:ゼロから実践するAmazon Web Services。手を動かしながらインフラの基礎を習得を受講しました。
やはり実際に手を動かすと理解が早いです。
なお、本講習は高額請求されないように対策する方法も講じているので、初心者に超おすすめです。仕上げに、
AWS認定資格 無料WEB問題集&徹底解説で過去問を解きました。トータルの所要時間としては、事前勉強に1週間、過去問に1週間、計2週間程度でした。
費用は書籍とUdemyの講習代で計5,000円程度です。だいたいの技術は分かってたので、AWSの用語を覚える暗記作業でした。
オンライン受験登録
AWS認定資格を受験する場合、「PSI」か「ピアソンVUE」のどちらかで受験することになります。
他の方の意見を聞くと、日本語で対応できる「ピアソンVUE」がおすすめされているのですが、
あまりに人気のため、予約が埋まっていました。
そこで、リスクはありますが、「PSI」で受験することにしました。とりあえず、試験前のプリチェックを行います。
事前の準備では、通信環境、カメラ、マイクの動作チェックを行います。
カメラ、マイクは事前に購入しておきましょう。
ちなみに、マイクは周辺で変な音を出していないか確認するためのもので、
試験官とのコミュニケーションはチャットを通じて行います。
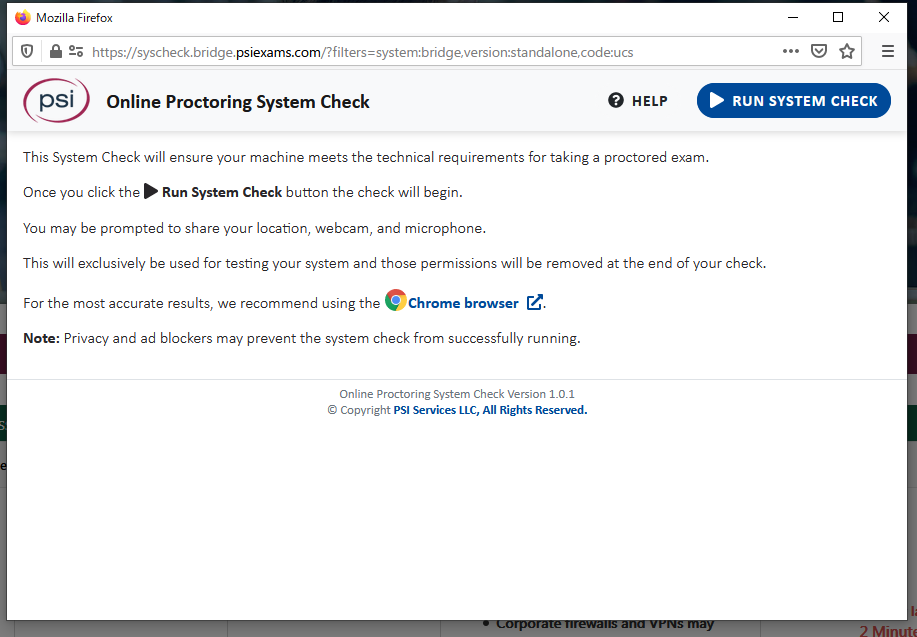
GoogleChrome推奨と記載されていますが、Firefoxでもできました。
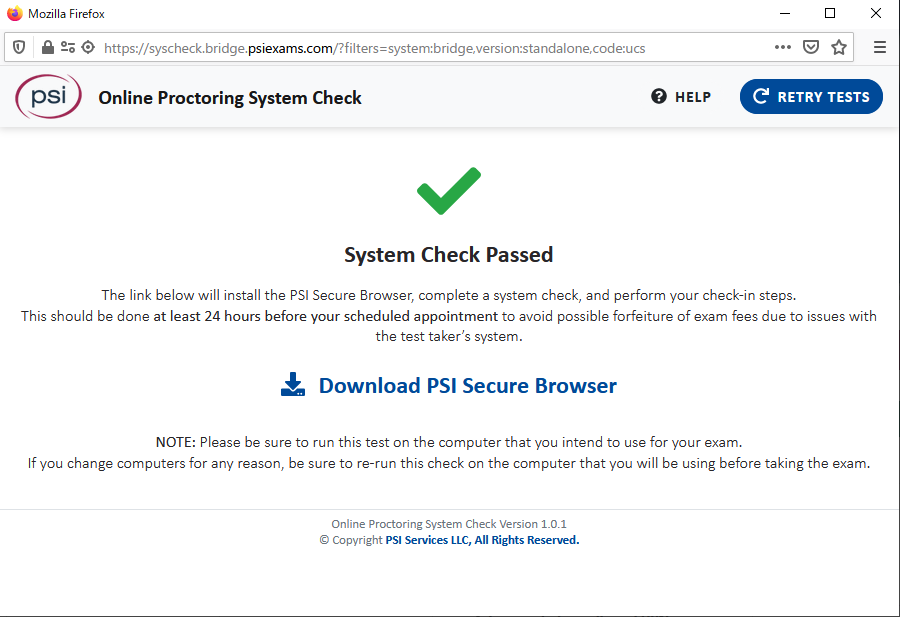
位置情報はとりあえず共有しておきました。
画面共有設定は、とりあえず「全画面」にしました。
無事、チェックが終わりました。
最後にOSI Secure Browserをダウンロードして、実行したら終わりです。
オンライン試験当日
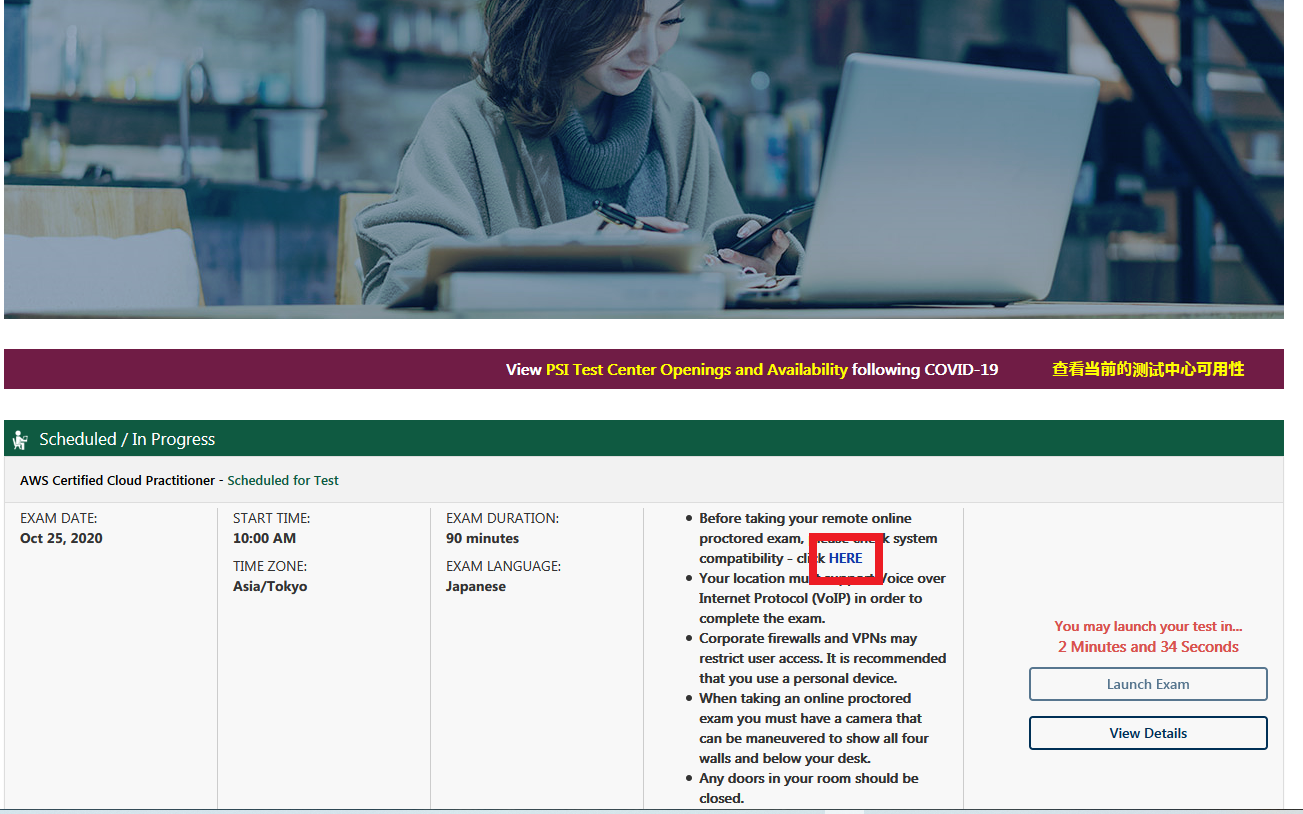
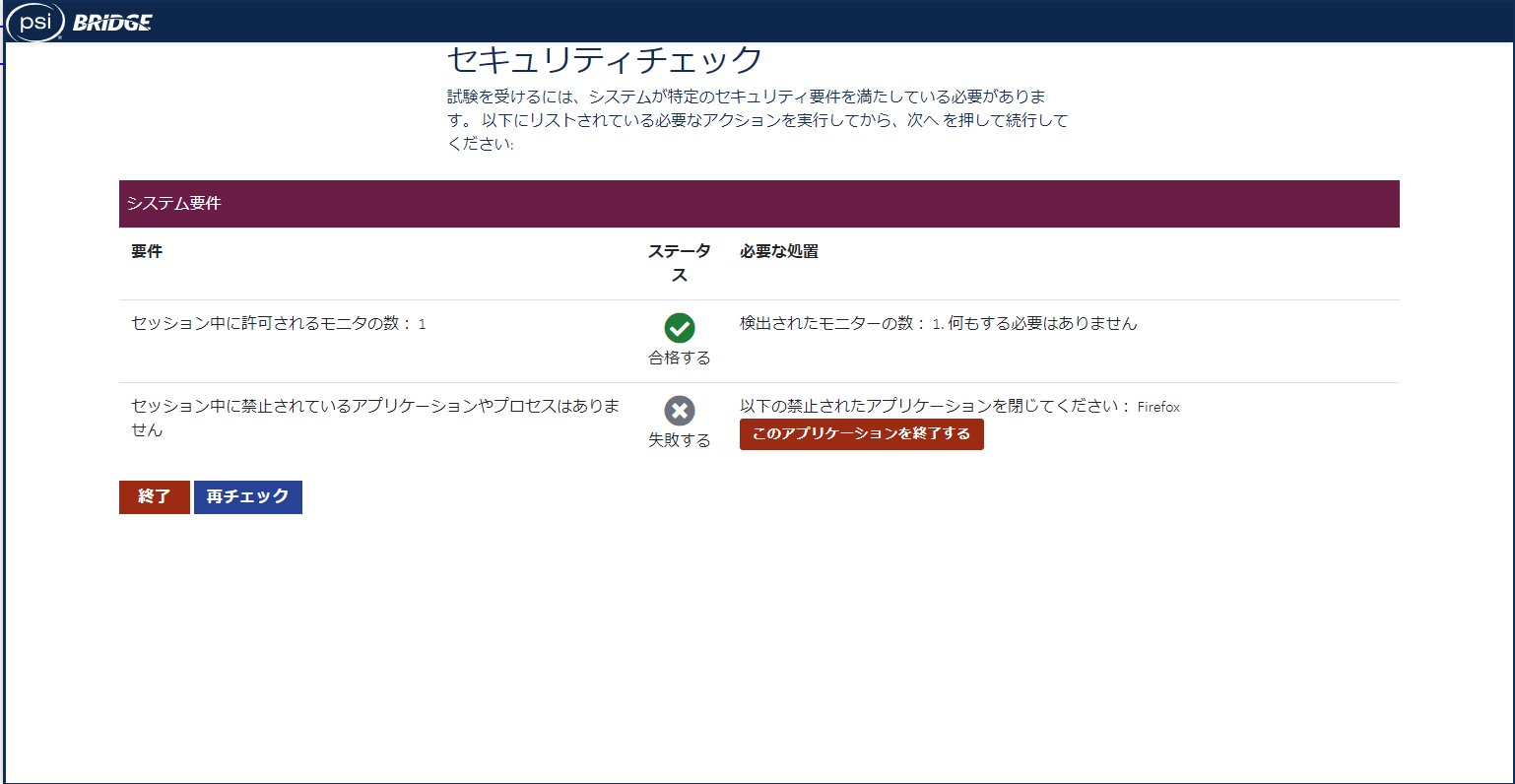
試験開始予定の30分前から受付が始まります。
最初にセキュリティチェックが行われます。
Firefoxを終了しろと言われたので終了しました。
(Google翻訳使うために残しておきたかった)
続いて本人認証です。
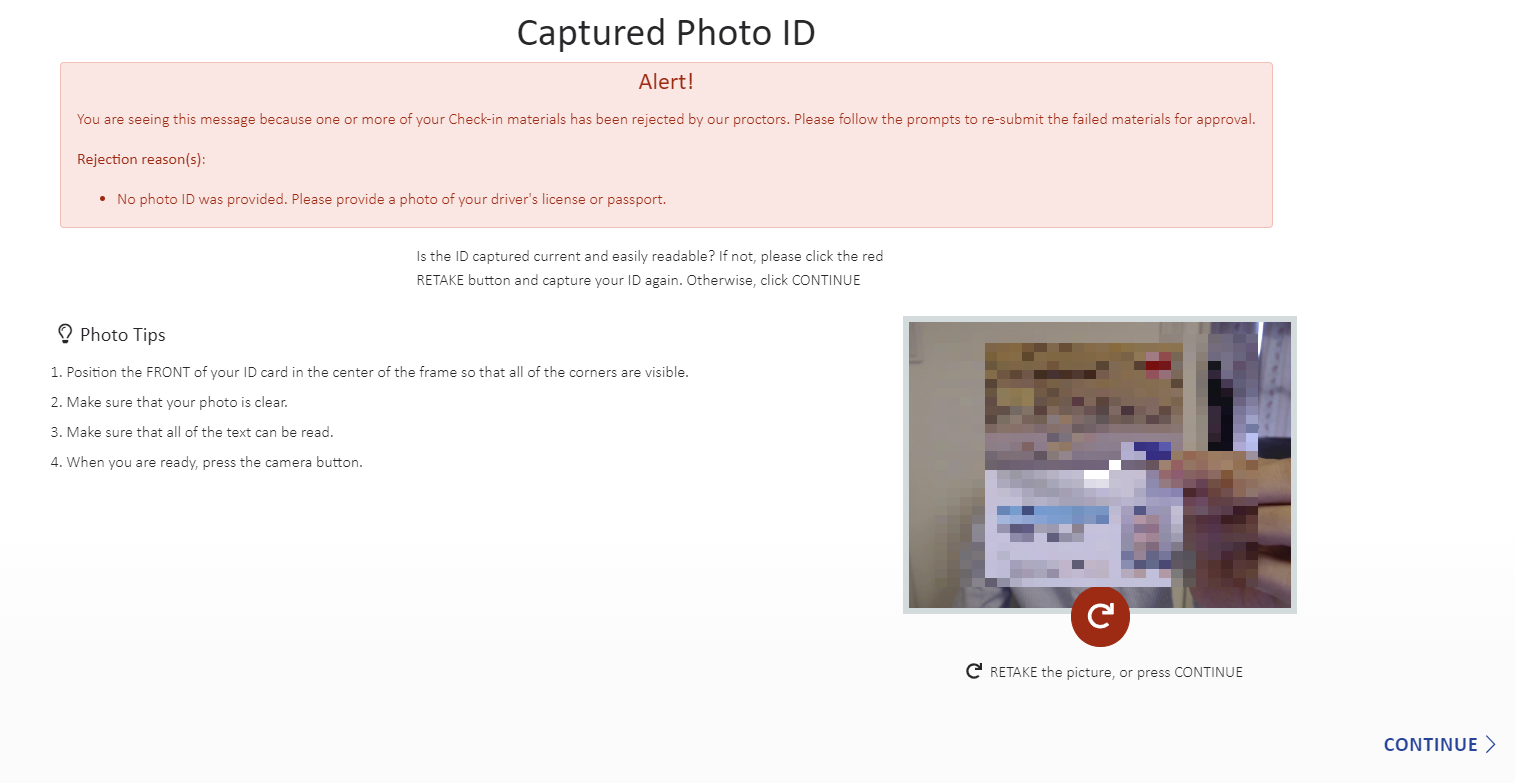
身分証明書、次に自分の顔を撮影します。
私の場合、身分証明書を撮るべきタイミングで間違えて顔を撮ってしまったので、再撮影となりました。
ここで1つトラブルが発生しました。
公式ページだと、以下の書類が身分証明書として使用可能です。
・Primary ID Forms (valid and current)
Government-issued Driver's license
U.S. Department of State Driver's License
National/State/Country Identification Card
Passport
Passport cards
Military ID→現在は使用不能と試験中に言われました。
・Secondary ID Forms (valid and current)
Debit/ATM Card
Credit Card
Any form of ID on the primary list.そこで私は、運転免許証とクレジットカードを提示したのですが、試験官に、
「英語で名前が記載された証明書を提示してください。」
とチャットで言われました。
残念ながら日本の運転免許証には英語氏名がありません。
マイナンバーカードにもありません。
たまたま家にあった船舶の運転免許証が英語氏名で記載してあったので、これを提示したところ、
「政府が発行している証明書でないとだめです。パスポートはありますか?」
と怒られました。
船舶の運転免許証は国土交通省が発行している旨、伝えたところ、なんとかなりました。
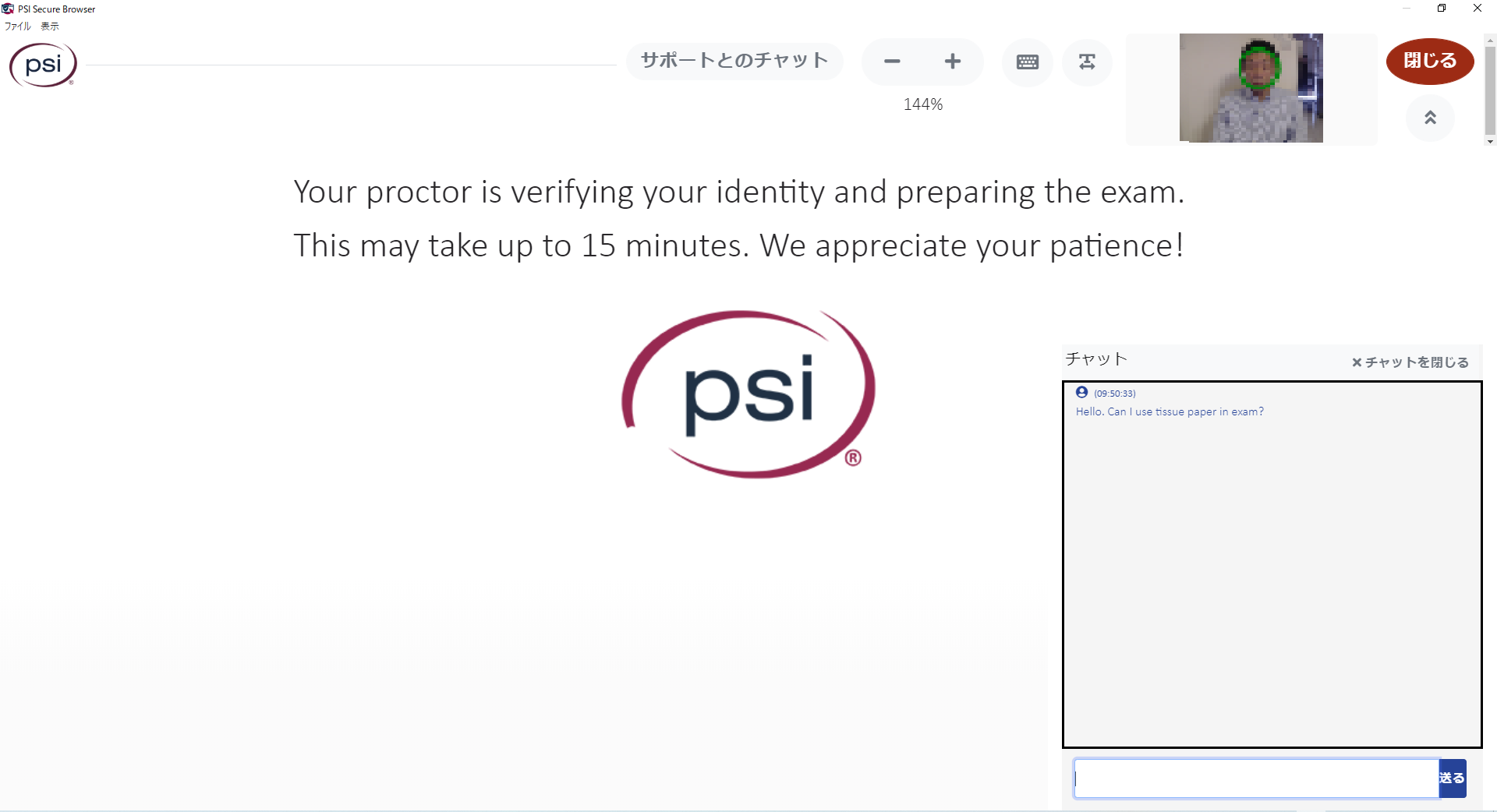
繰り返しになりますが、上記の会話は全て英語です。ちなみに、チャットでこちらからも質問できるそうです。
「ティッシュ使っていいですか?」と質問しましたが、上記の件で忙しかったのか、回答はありませんでした。
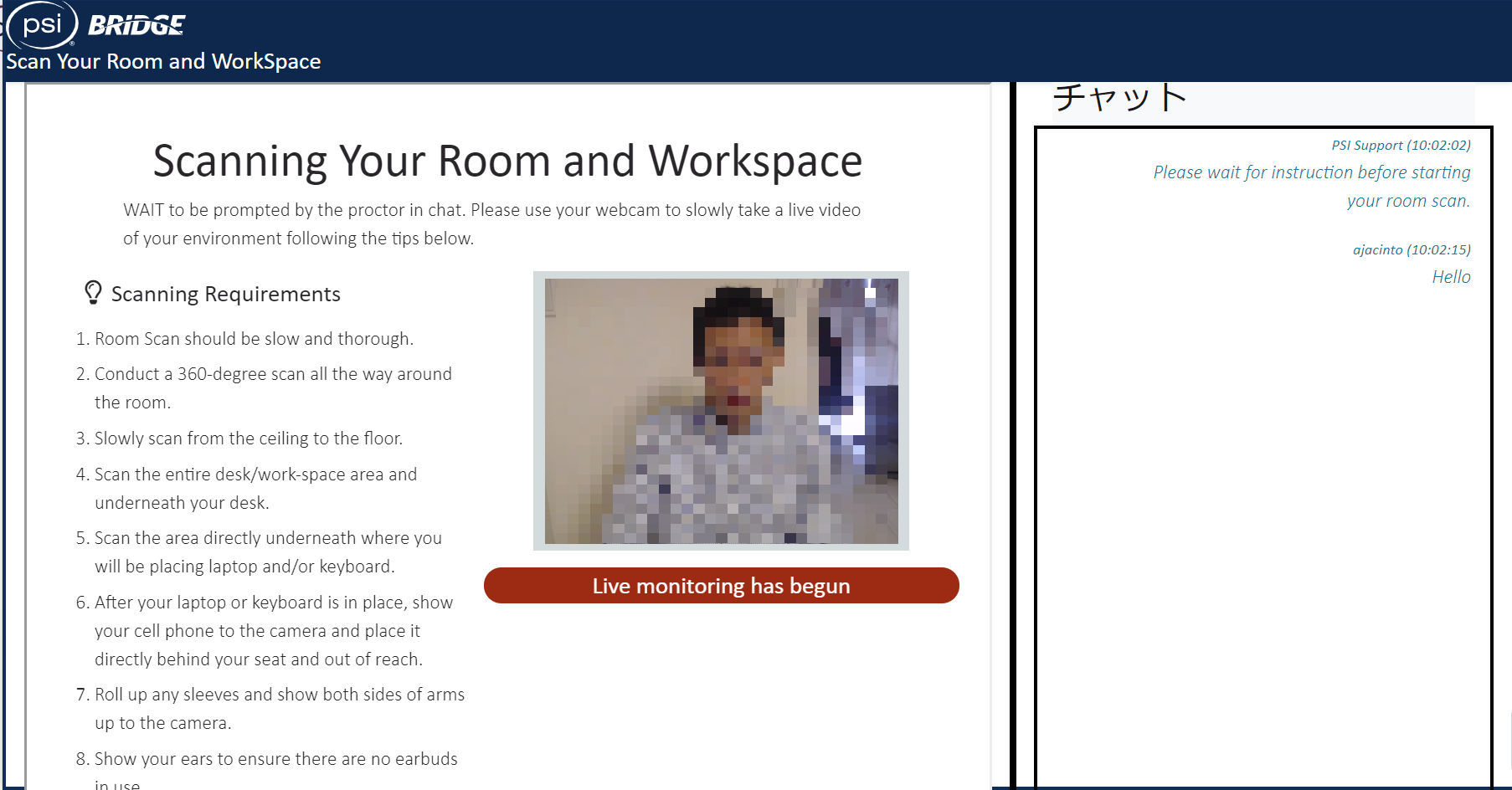
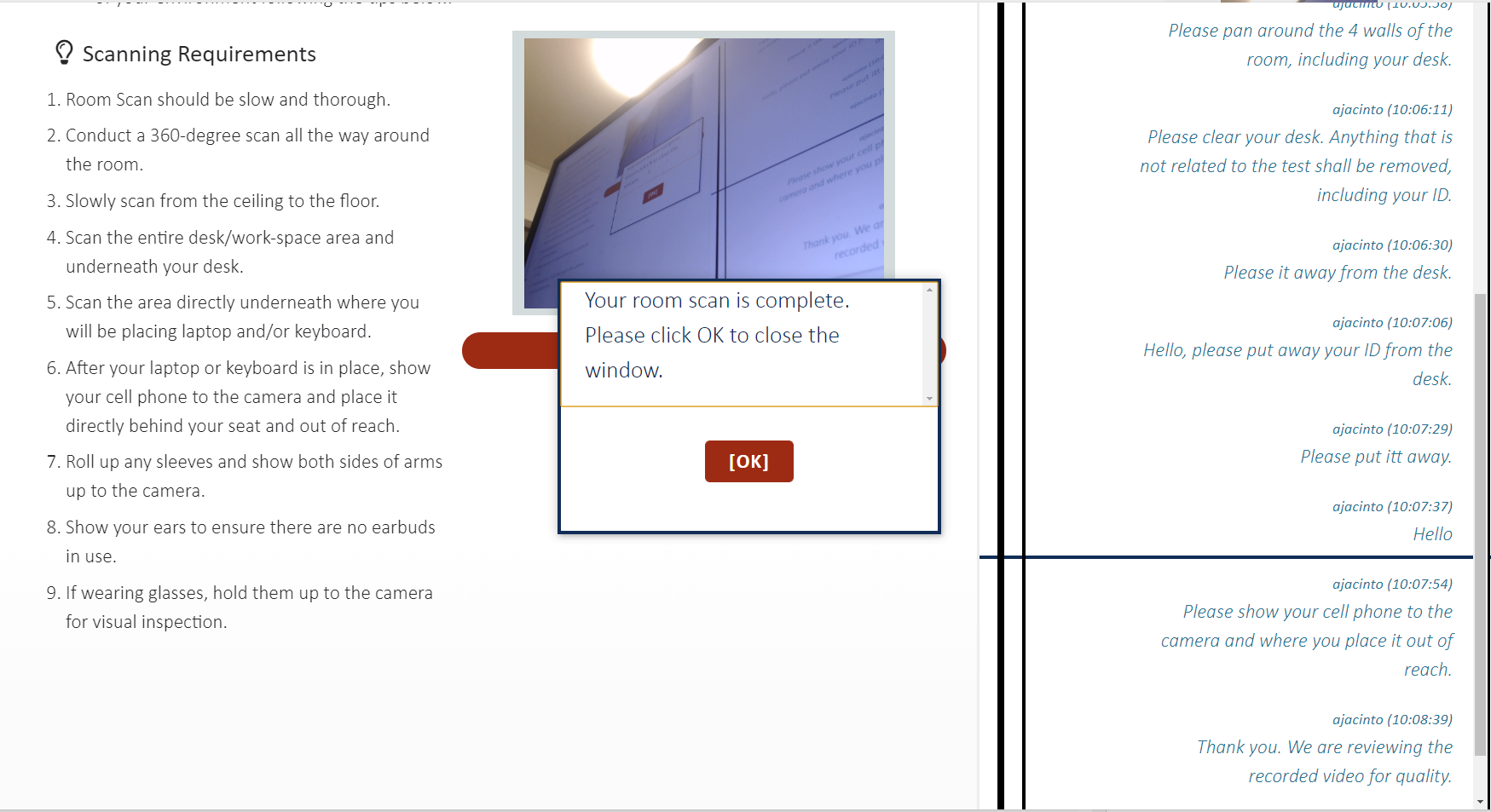
次に、カメラを使用して、部屋のチェックを行います。
撮影時になにかしらの不備があると、チャットで指示が来ます。
スクリーンショットには書いていませんが、スマホをカメラで撮影したのち、手の届かないところに置くように指示がありました。
まぁまぁ散らかっている部屋でしたが、OKでした。
やっと、試験が開始されます。
試験時の画面はこんな感じです。
問題分、選択肢にはモザイクいれています。
あとで見返したい問題は右下の「フラグ」をクリックします。
相変わらず、問題文の日本語が意味不明なときがあるので、必要に応じて言語を切り替えました。
「セクションの終了」をクリックすると、試験終了です。
試験後にはアンケートに10問程度答える必要があります。
すぐに合否判定がでます。
しばらくすると、アプリケーションが勝手に終了します。
PSIオンライン受験の注意点
試験官とのコミュニケーションは全て英語です。
今回のように色々不手際があると、その場でチャットで対応する必要があることから、なかなかの英語力が必要です。
英語力に自身の無い方は、ピアソンVUEでの受験を強くお勧めします。おわりに
事前チェックで、ばたばたしましたが、無事にクラウドプラクティショナーを取得することができました。
もう1つぐらいAWSの資格をとりたいです。


- 投稿日:2020-10-25T12:31:31+09:00
AWS認定資格クラウドプラクティショナーをPSIオンライン受験した話 ~身分証明でつまずきました~
はじめに
AWS認定資格「クラウドプラクティショナー」をPSIでオンライン受験して、無事合格したので勉強方法とオンライン受験の体験記です。
私のスペック
基本情報、応用情報は取得済み。
令和2年度秋のネットワークスペシャリストを受験予定でした。(コロナの影響で中止)
よって、ネットワークなどの技術については、あらかじめ分かっている状態です。事前準備
勉強方法
とりあえず、
AWS認定資格試験テキスト AWS認定 クラウドプラクティショナーを書店で購入し、ひととおり読みました。
しかし、awsの取説をそのままコピーしたような印象があり、あまり役には立ちませんでした。つづいて、
UdemyでAWS:ゼロから実践するAmazon Web Services。手を動かしながらインフラの基礎を習得を受講しました。
やはり実際に手を動かすと理解が早いです。
なお、本講習は高額請求されないように対策する方法も講じているので、初心者に超おすすめです。仕上げに、
AWS認定資格 無料WEB問題集&徹底解説で過去問を解きました。トータルの所要時間としては、事前勉強に1週間、過去問に1週間、計2週間程度でした。
費用は書籍とUdemyの講習代で計5,000円程度です。だいたいの技術は分かってたので、AWSの用語を覚える暗記作業でした。
オンライン受験登録
AWS認定資格を受験する場合、「PSI」か「ピアソンVUE」のどちらかで受験することになります。
他の方の意見を聞くと、日本語で対応できる「ピアソンVUE」がおすすめされているのですが、
あまりに人気のため、予約が埋まっていました。
そこで、リスクはありますが、「PSI」で受験することにしました。とりあえず、試験前のプリチェックを行います。
事前の準備では、通信環境、カメラ、マイクの動作チェックを行います。
カメラ、マイクは事前に購入しておきましょう。
ちなみに、マイクは周辺で変な音を出していないか確認するためのもので、
試験官とのコミュニケーションはチャットを通じて行います。
GoogleChrome推奨と記載されていますが、Firefoxでもできました。
位置情報はとりあえず共有しておきました。
画面共有設定は、とりあえず「全画面」にしました。
無事、チェックが終わりました。
最後にOSI Secure Browserをダウンロードして、実行したら終わりです。
オンライン試験当日
試験開始予定の30分前から受付が始まります。
最初にセキュリティチェックが行われます。
Firefoxを終了しろと言われたので終了しました。
(Google翻訳使うために残しておきたかった)
続いて本人認証です。
身分証明書、次に自分の顔を撮影します。
私の場合、身分証明書を撮るべきタイミングで間違えて顔を撮ってしまったので、再撮影となりました。
ここで1つトラブルが発生しました。
公式ページだと、以下の書類が身分証明書として使用可能です。
・Primary ID Forms (valid and current)
Government-issued Driver's license
U.S. Department of State Driver's License
National/State/Country Identification Card
Passport
Passport cards
Military ID→現在は使用不能と試験中に言われました。
・Secondary ID Forms (valid and current)
Debit/ATM Card
Credit Card
Any form of ID on the primary list.そこで私は、運転免許証とクレジットカードを提示したのですが、試験官に、
「英語で名前が記載された証明書を提示してください。」
とチャットで言われました。
残念ながら日本の運転免許証には英語氏名がありません。
マイナンバーカードにもありません。
たまたま家にあった船舶の運転免許証が英語氏名で記載してあったので、これを提示したところ、
「政府が発行している証明書でないとだめです。パスポートはありますか?」
と怒られました。
船舶の運転免許証は国土交通省が発行している旨、伝えたところ、なんとかなりました。
繰り返しになりますが、上記の会話は全て英語です。ちなみに、チャットでこちらからも質問できるそうです。
「ティッシュ使っていいですか?」と質問しましたが、上記の件で忙しかったのか、回答はありませんでした。
次に、カメラを使用して、部屋のチェックを行います。
撮影時になにかしらの不備があると、チャットで指示が来ます。
スクリーンショットには書いていませんが、スマホをカメラで撮影したのち、手の届かないところに置くように指示がありました。
まぁまぁ散らかっている部屋でしたが、OKでした。
やっと、試験が開始されます。
試験時の画面はこんな感じです。
問題分、選択肢にはモザイクいれています。
あとで見返したい問題は右下の「フラグ」をクリックします。
相変わらず、問題文の日本語が意味不明なときがあるので、必要に応じて言語を切り替えました。
「セクションの終了」をクリックすると、試験終了です。
試験後にはアンケートに10問程度答える必要があります。
すぐに合否判定がでます。
しばらくすると、アプリケーションが勝手に終了します。
PSIオンライン受験の注意点
試験官とのコミュニケーションは全て英語です。
事前のチェックも英語でチャットのやりとりがあり、
さらに、今回のように色々不手際があると、その場でチャットで対応する必要があることから、なかなかの英語力が必要です。
英語力に自身の無い方は、ピアソンVUEでの受験を強くお勧めします。おわりに
事前チェックで、ばたばたしましたが、無事にクラウドプラクティショナーを取得することができました。
もう1つぐらいAWSの資格をとりたいです。追記
よく見たらちゃんと書いてありましたね。
みなさまはお気をつけください。

- 投稿日:2020-10-25T11:25:36+09:00
TerraformでECS環境(on EC2)を立ち上げる方法
動機
Terraformを学んだばかりで、EC2でECS環境を立ち上げたいと思って調べてみるものの、出てくる情報はFargateばかりでした。
そこで、EC2でECS環境を立ち上げるにはどうしたらいいかまとめました。環境
- Terraform 0.13.4
- AWS provider 3.12.0
前提
タスク定義やALBなどは作成済みとしています。
今回は、ECSのサービスとクラスターを作成するところをみていきます。
また、AWS公式のチュートリアルを参照して、必要なリソースを確認しながら作成しましたので、そちらも参照するといいと思います。キャパシティープロバイダーの作成
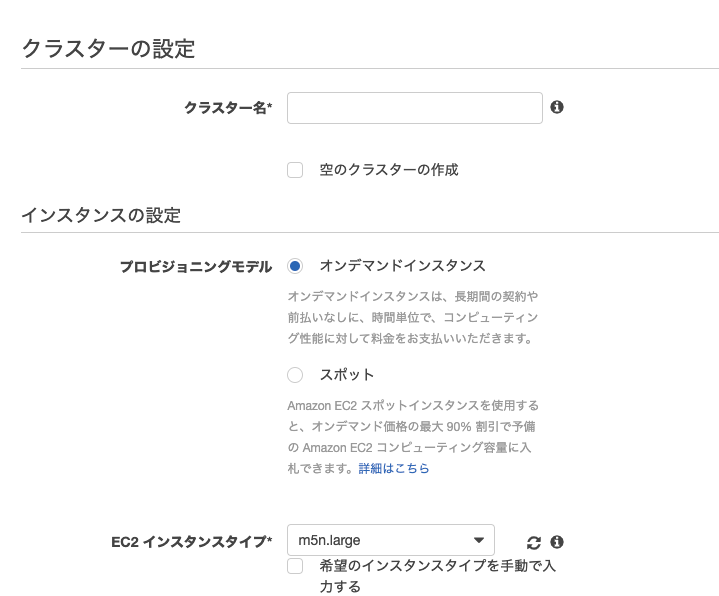
いきなりですが、ここが一番難しかったです。クラスター作成時はいつもインスタンスの設定をしていたので、Terraformで立ち上げる際は苦労しました。
通常は以下の画面で、ぽちぽち設定していくかと思うのですが、Terraformでは自分でキャパシティープロバイダーを作成する必要があります。
その過程を以下でみていきます。
IAMロールとインスタンスプロファイル
まずはEC2のIAMロールを作成し、インスタンスプロファイルのリソースを作成します。これがEC2の起動設定に必要となります。
asg.tf# EC2がECSを利用できるように data "aws_iam_policy" "ec2_container_service" { arn = "arn:aws:iam::aws:policy/service-role/AmazonEC2ContainerServiceforEC2Role" } # ポリシードキュメント data "aws_iam_policy_document" "ec2_container_service" { source_json = data.aws_iam_policy.ec2_container_service.policy } # ポリシーとロールのリソース作成 module "ec2_container_service" { source = "./iam_role" name = "ec2_container_service" policy_document = data.aws_iam_policy_document.ec2_container_service.json identifiers = ["ec2.amazonaws.com"] } # インスタンスプロファイル。これが必要。 resource "aws_iam_instance_profile" "ec2_container_service" { name = "es2_container_service" role = module.ec2_container_service.role.name }モジュールの内容は以下になります。
iam_role/iam_role.tfvariable policy_document { description = "policy document data" } variable identifiers { type = list(string) description = "identifiers for assume policy" } variable name { type = string description = "policy and role name" } # IAMポリシーの作成 resource "aws_iam_policy" "default" { name = var.name path = "/" policy = var.policy_document } # ロールの信頼ポリシー(どのリソースにアタッチするのか) data "aws_iam_policy_document" "default" { statement { actions = ["sts:AssumeRole"] principals { type = "Service" identifiers = var.identifiers } } } # ロールの設定 resource "aws_iam_role" "default" { name = var.name assume_role_policy = data.aws_iam_policy_document.default.json } # ロールにポリシーをアタッチする resource "aws_iam_role_policy_attachment" "ecs_role_attach" { role = aws_iam_role.default.name policy_arn = aws_iam_policy.default.arn } output role { value = aws_iam_role.default }AMI
EC2インスタンス用のAMIになります。ECSで使用するために最適化されているようです。詳細はAWSのドキュメントをご参照ください。
asg.tf# AMIのデータ。ECS用に最適化されたもの data "aws_ami" "ecs" { filter { name = "name" values = ["amzn2-ami-ecs-hvm-2.0.20201013-x86_64-ebs"] } owners = ["amazon"] }起動設定
ここで、先ほど作成したIAMのインスタンスプロファイルやAMIなどを指定します。
user_dataは引っ掛かりポイントかなと思います。AWSのドキュメントに書かれていますので、指定しておきます。asg.tf# launch configuration resource "aws_launch_configuration" "ecs" { name_prefix = "ecs-launch-tf-" image_id = data.aws_ami.ecs.id instance_type = "t2.micro" security_groups = [module.nginx_sg.id] enable_monitoring = true iam_instance_profile = aws_iam_instance_profile.ec2_container_service.name user_data = <<EOF #!/bin/bash echo ECS_CLUSTER=${local.app_name}-cluster >> /etc/ecs/ecs.config; EOF associate_public_ip_address = false lifecycle { create_before_destroy = true } }Auto Scalingグループ
ここで、起動設定をもとにAuto Scalingグループを作成します。
ここは、tagsに注意が必要です。Auto Scalingグループをキャパシティープロバイダーに関連づける場合は、tagsを指定する必要があります。
Terraformのドキュメントではtagとなっていますが、エラーになってしまったので今回はtagsを使用しました。また、今回は無効にしていますが、スケールイン保護を利用する場合は、
protect_from_scale_in = trueとする必要があります。asg.tf# auto scalingグループの設定 # この設定でEC2が立ち上がる。 resource "aws_autoscaling_group" "ecs" { name = "ecs-tf-asg" min_size = 1 max_size = 2 desired_capacity = 2 launch_configuration = aws_launch_configuration.ecs.name vpc_zone_identifier = [aws_subnet.private_1a.id, aws_subnet.private_1c.id] protect_from_scale_in = false lifecycle { create_before_destroy = true ignore_changes = [load_balancers, target_group_arns] } # 自動的に付与されるタグだけど、Terraformだと明記する必要あり。詳細はドキュメント参照。 tags = [ { key = "AmazonECSManaged" propagate_at_launch = true } ] }キャパシティープロバイダー
作成したAuto Scalingグループを指定して、キャパシティープロバイダーを作成します。
重要なポイントはmanaged_scalingブロックのstatus = "ENABLED"で、ECSが自動スケーリングするのを許可しています。
これをクラスターとサービスと関連づけることで、EC2インスタンスが立ち上がり、タスクが実行されます。asg.tfresource "aws_ecs_capacity_provider" "main" { name = "main" auto_scaling_group_provider { auto_scaling_group_arn = aws_autoscaling_group.ecs.arn managed_termination_protection = "DISABLED" managed_scaling { status = "ENABLED" target_capacity = 100 } } }ECSクラスター、サービスの作成
クラスター
ここで、作成したキャパシティープロバイダーを指定します。
少し引っ掛かったのが、weightとbaseで、おそらくEC2インスタンスが実行するタスクの数(?)を指定しているかと思います。
今回は、1つのインスタンスでタスクは1個だけでいいので、どちらも1にしました。ecs.tf# クラスターの定義 resource "aws_ecs_cluster" "main" { name = "${local.app_name}-cluster" capacity_providers = [aws_ecs_capacity_provider.main.name] default_capacity_provider_strategy { capacity_provider = aws_ecs_capacity_provider.main.name weight = 1 base = 1 } }サービス
サービスでも、キャパシティープロバイダーを指定します。
ecs.tfresource "aws_ecs_service" "main" { name = "${local.app_name}-service" capacity_provider_strategy { capacity_provider = aws_ecs_capacity_provider.main.name weight = 1 base = 1 } cluster = aws_ecs_cluster.main.id task_definition = aws_ecs_task_definition.main.arn health_check_grace_period_seconds = 60 desired_count = 2 deployment_maximum_percent = 100 deployment_minimum_healthy_percent = 50 network_configuration { assign_public_ip = false security_groups = [module.nginx_sg.id] subnets = [ aws_subnet.private_1a.id, aws_subnet.private_1c.id, ] } load_balancer { target_group_arn = aws_lb_target_group.alb.arn container_name = "web" container_port = 80 } }まとめ
以上で、ECS環境をTerraformで立ち上げることができました。
まだまだ理解が足りない部分が多いので、学習を進めていきたいと思います。参考
- 投稿日:2020-10-25T02:39:01+09:00
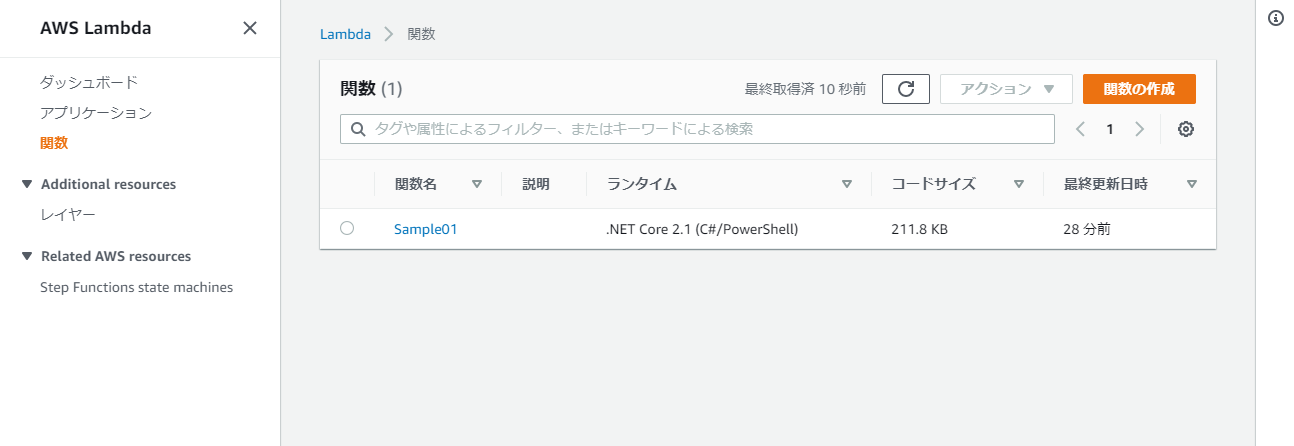
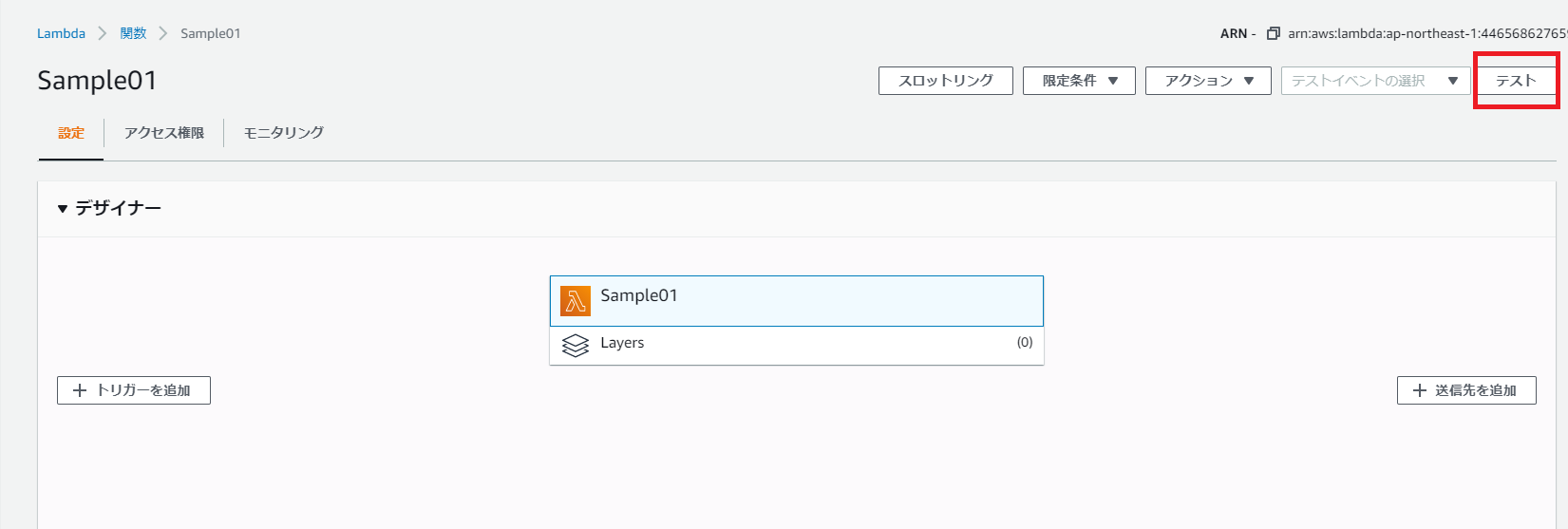
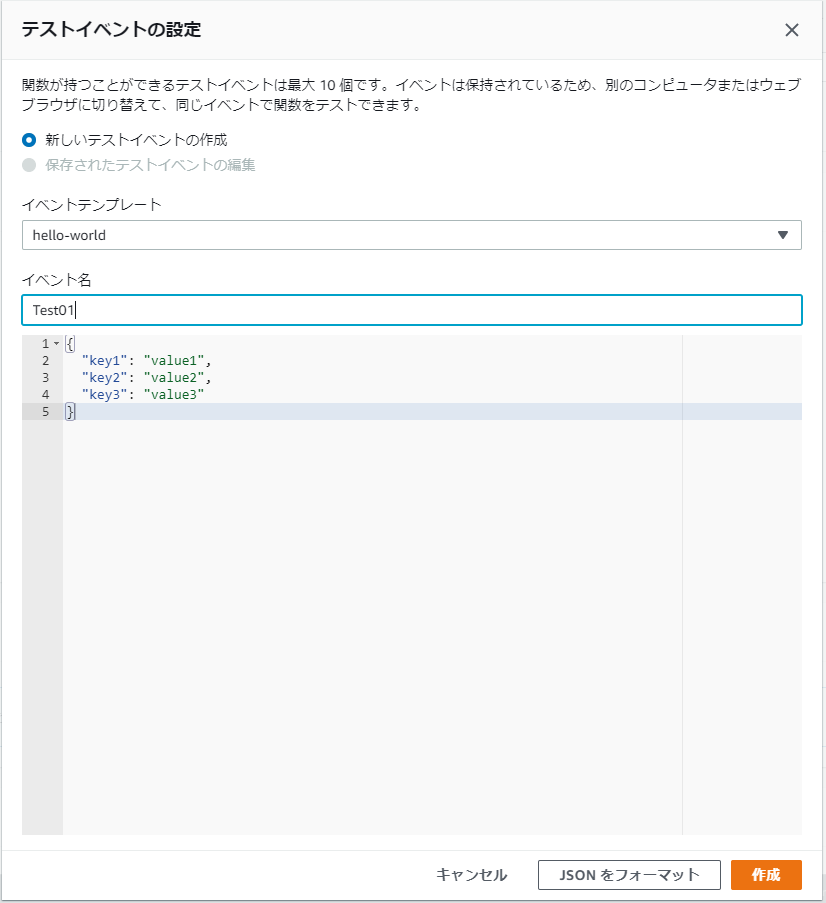
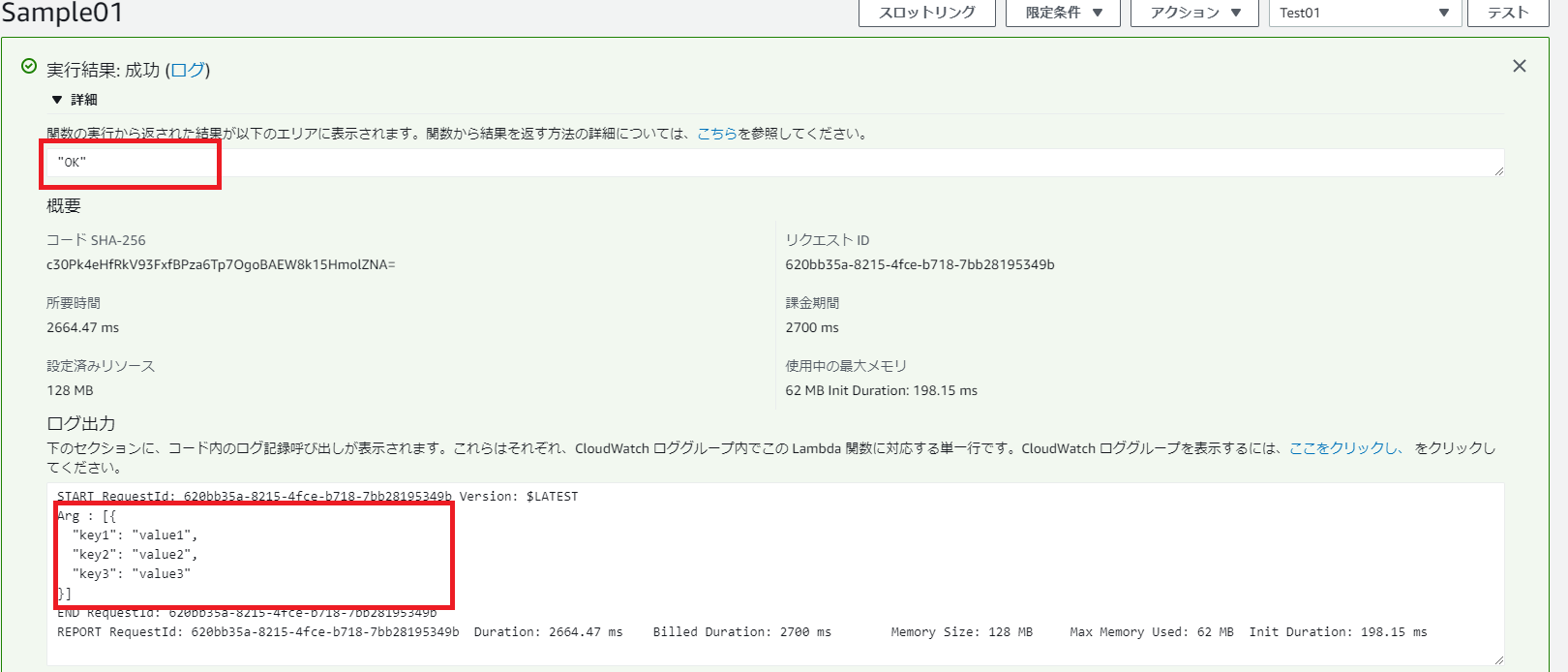
AWS Lambda を C# で書いてみる
はじめに
このドキュメントは AWS Lambda を C# で記述するための手順です。
コードエディットやパブリッシュには Visual Studio を使用します。開発・実行環境準備
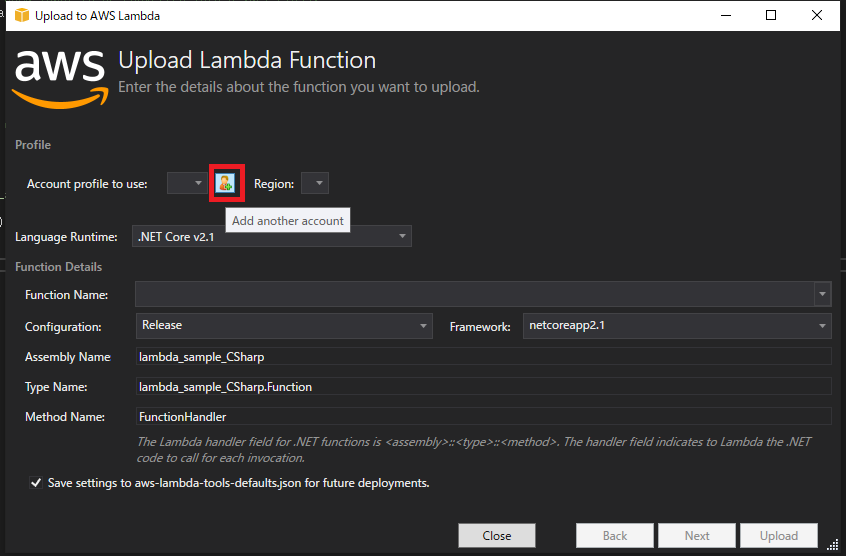
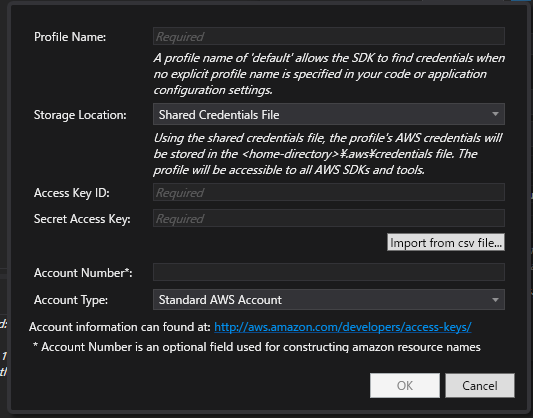
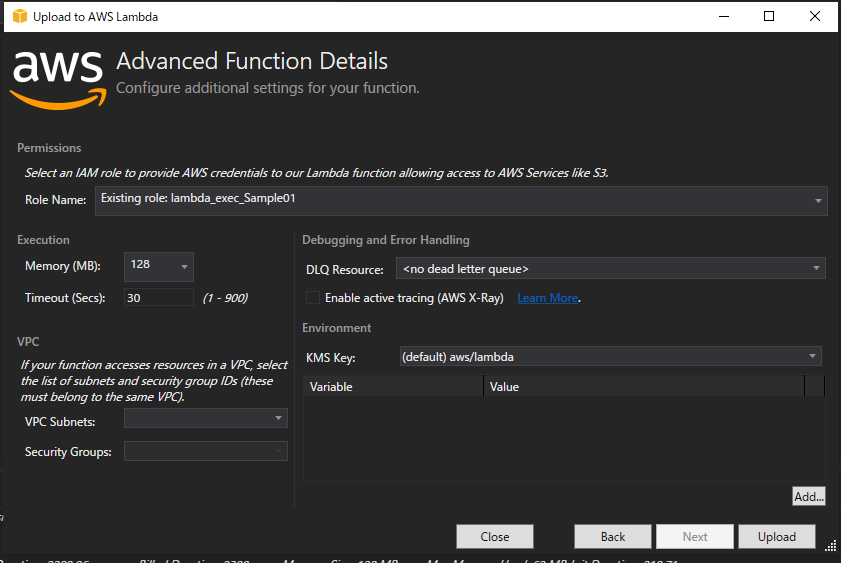
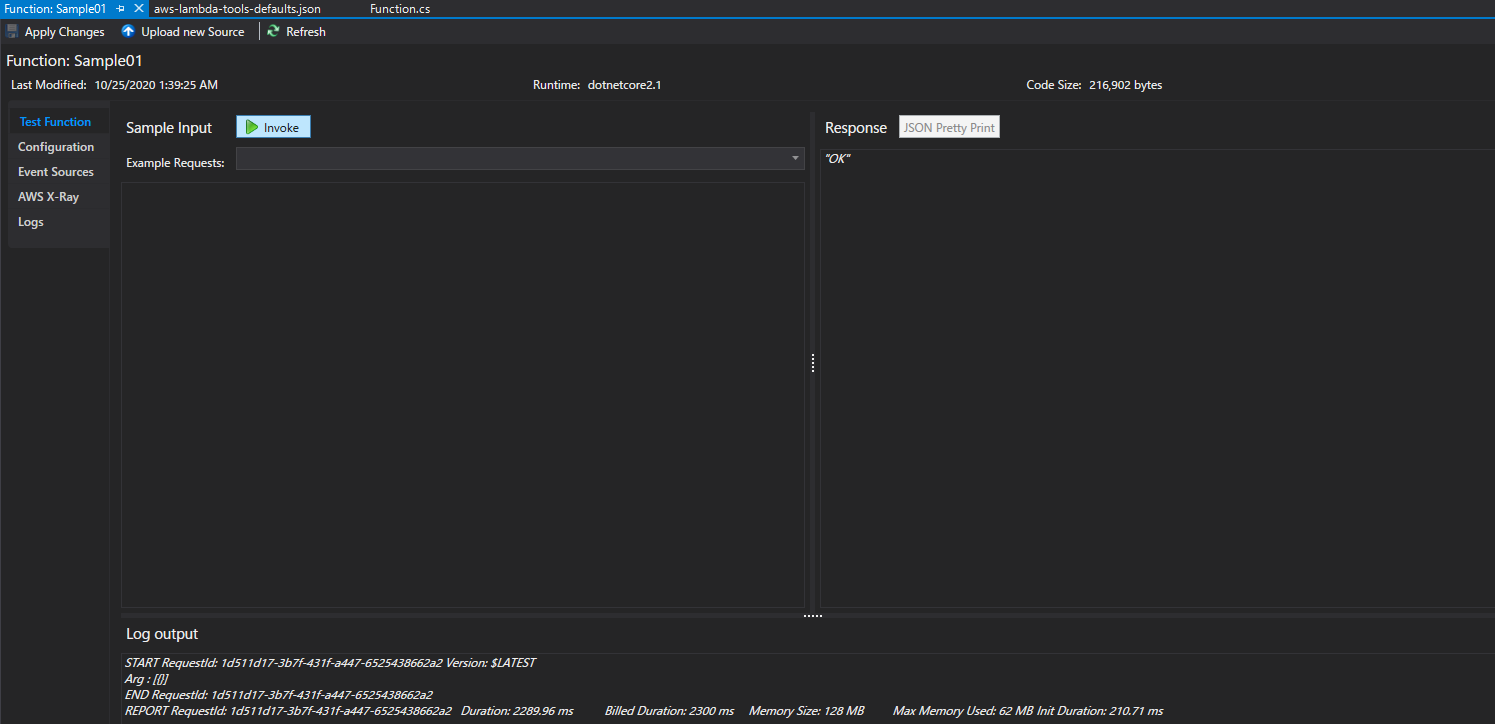
VisualStudio プラグイン
開発者ガイドのAWS Toolkit for Visual Studioを参考に、Visual Studio の拡張機能をインストールします。
プロジェクト作成
Visual Studio の「ファイル」メニューから「新規作成」を選択し、「プロジェクト」を選択します。
「新しいプロジェクト」ウインドウで [AWS Lambda] ツリーを選択し、
「AWS Lambda Project(.NET Core - C#)」を選択します。
プロジェクト名と保存場所は適宜入力します。
「New AWS Lambda C# Project」ウインドウでは、サンプルアプリケーションのコードを選択することができます。
ここでは、最低限のコードが記述されている[Empty Function]を選択し、「Finish」ボタンをクリックします。
開発とデプロイ
コード記述
このままでも動作するかと思いますが、念のため引数の型を変更します。
// // 修正前(プロジェクト作成デフォルト状態) // public string FunctionHandler(string input, ILambdaContext context) { // 引数で受け取った文字列を大文字にして返す return input?.ToUpper(); }// // 修正後 // public string FunctionHandler(object input, ILambdaContext context) { // 受け取った引数をログに出力 context.Logger.LogLine($"Arg : [{input}]"); // OK という文字列を返す return "OK"; //input?.ToUpper(); }デプロイ設定
認証情報の準備
Visual Studio から パブリッシュするための認証情報を AWS コンソールから取得します。
AWS コンソール右上のメニューから「ユーザ名▼」を選択し、「マイセキュリティ資格情報」を選択します
[IAM Management Console] (セキュリティ認証情報)画面で、「アクセスキー(アクセスキー IDとシークレットアクセスキー)」を開きます。
「新しいアクセスキーの作成」ボタンをクリックしアクセスキーIDを発行します。
[アクセスキーの作成]ダイアログが表示されたら、[アクセスキーID]と[シークレットアクセスキー]を控えておきます。
デプロイ
Visual Studio のソリューションエクスプローラで、プロジェクトを右クリックし「Publish to AWS Lambda...」を選択します。
[Upload Lambda Function]ダイアログで、「Account profile to use:」のドロップダウン右にあるアイコンをクリックします。
アップロードするためのユーザを追加する画面で以下の項目を入力します。
- Profile Name:任意
- Storage Location:Shared Credentials File
- Access Key ID:認証情報の準備で控えたアクセスキーID
- Secret Access Key:認証情報の準備で控えたシークレットアクセスキー
入力がおわったら「OK」ボタンをクリックします。
再び[Upload Lambda Function]ダイアログで、「Function Name」に作成する Lambda関数の名前を入力します。
入力したら「Next」ボタンをクリックします。
[Advanced Function Details]ダイアログでは、以下の項目を入力します。
- Role Name:「New role based on AWS managed policy: AWSLambdaExecute」
- Memory(MB):「128」
入力がおわったら「Upload」ボタンをクリックします。
これでデプロイは完了です。
テスト
Visual Studio でテスト
デプロイが完了すると、Visual Studio に、作成した Lambda 関数をテストするためのタブが表示されます。
赤い枠のテキストエリアに入力された文字が、Lambda関数の引数として渡されます。
「Example Requetes:」ドロップダウンでは、AWS で接続可能なサービスからの引数サンプルを選択することもできます。
引数の設定が完了したら「Invoke」ボタンをクリックします。
実行結果が、右側のペインに表示されます。また、タブ下部のペインには実行ログが表示されます。
AWS Console でテスト
[AWS Console]から「Lambda」を選択すると、Visual Studio でデプロイした関数が表示されます。
関数名をクリックし詳細画面を表示した後、右上の「テスト」ボタンをクリックします。
[テストイベントの設定]ダイアログが表示されるので、以下の項目を入力します。
- 新しいテストイベントの作成を選択
- イベント名:保存するテストパータンの名称
- 下部テキストボックス:関数に引き渡すテストデータ
入力が終ったら「作成」ボタンをクリックします。
再び「テスト」ボタンをクリックすると関数のテストが実行されます。
テストの実行結果が画面に表示されるので「詳細」をクリックします。
下記キャプチャの、上側の赤枠が関数の戻り値。OKを返していることがわかります。
また、下側の赤枠には関数のログが出力されますが、テストデータとして渡した引数がログに出力されていることが確認できます。