- 投稿日:2020-10-25T21:21:52+09:00
[linux]プロセスを終了するkillコマンド
killコマンドとは?
指定したプロセスIDのプロセスを終了させるコマンド。
$ kill プロセス番号(PID)使い方
1.以下のコマンドを実行してプロセスIDを調べる。
$ ps # 現在起動しているプロセスを確認する $ ps ax | grep gedit # プロセスに”gedit”の名称がついたプロセスのみを表示 16619 ? Sl 0:01 gedit2.killコマンドでプロセスIDを指定してプログラムを終了する。
$ kill 166193.強制終了したい場合は以下のコマンドを実行する。
$ kill -9 16619主なオプション
コマンド 概要 -s シグナル 指定したシグナル名またはシグナル番号を送信する -シグナル 指定したシグナル名またはシグナル番号を送信する -l [] シグナル名とシグナル番号の対応を表示する
- 投稿日:2020-10-25T21:21:39+09:00
マルチゾーンでFirewalldをらくらく設定
はじめに
先日、firewalldで特定IPアドレスのみsshを許可する という記事を書いては見たものの、-add-rich-rule というオプションを使ってゴリゴリの特別ルールでの対応がどうも引っかかった。Firewalldといえばiptablesの後継として比較的新しいライブラリであり、もっと洗練されたうまいやり方があるはずだと。
そこで色々調べた結果、あったあった。その名もマルチゾーン機能。この機能を使うことにより、かなり柔軟かつ効率的に設定できることが分かったので今回調べたことを共有したい。
環境
- CentOS 8
- firewalld 0.8.0-4
Firewalldの利点
まずはおさらいとして、Firewalldって何がいいのか見てみよう。
参考文献[1]によると、iptablesに対するFirewallの利点は以下とされている。
- 送信元IPやネットワークインターフェイスで定義されたゾーンごとに、拒否、許可等のルールを定義することができる。
- ポートやプロトコルではなく、サービスの名前を指定することができるため、構文が簡略化される
- iptablesのように、ステートメントの順序を気にする必要がない。
- リロード機能などにより、一時的に変更するなどのインタラクティブな設定変更が可能である。
なるほど、ゾーンをうまく活用することが重要そうだ。
そういえば前回の私の記事は、publicゾーンに無理やりルールを追加していた。ゾーンとは
次にゾーンについて見てみよう。
これまた参考文献[1]によると、ゾーンを理解するにあたって、IntarfaceとSourceが重要な概念であることが分かる。Interface
- Intafaceはハードウェアおよび仮想ネットワークアダプタのシステム名である。
- 全てのアクティブなIntafaceは、デフォルトゾーンまたはユーザー指定のゾーンのいずれかにゾーンに割り当てられる。
- Intafaceを複数のゾーンに割り当てることはできない。
- デフォルトの設定では、firewalldは全Interfaceをpublicゾーンに紐づけており、かつどのゾーンにもSourceを設定していない。その結果、publicゾーンが唯一のアクティブゾーンになっている。
Source
- Sourceは送信元のIPアドレス範囲のことであり、ゾーンに割り当てることもできる。
- Sourceを複数のゾーンに割り当てることはできない。これができてしまうと、そのSourceにどのルールを適用する必要があるか分からなくなるためである。
- あるSourceに一致するSourceを持つゾーンが必ずしも存在するわけではない。その場合何等かの優先順位によって処理されるが詳しくは後述する。
ゾーンそのものの説明はしていないが、何となく分かっただろうか?
で、マルチゾーンとは
マルチゾーン(Multi-Zone)とは、参考文献[1]で使われている用語であるが、要するに1つのゾーンだけではなく、複数のアクティブゾーンを使うことによって、うまいことルールを設定する方法と考えてもらえばよい。
たびたびお世話になるが、参考文献[1]によると、マルチゾーンの場合のFirewalldの適用ルールはざっくりと以下の通りとなる
(注) かなり端折って書いているため、厳密に理解されたい場合、参考文献[1]、またはFirewalldのマニュアルを見てください.
- アクティブゾーンはIntafaceが紐づけられたゾーンか、Sourceが紐づけられたゾーンかによって役割が異なる。ただし両方の役割を果たすことも可能である。
- Firewalldは、次の順序でパケットを処理する。
- パケットに対応するSourceをもつゾーンがあった場合(ない場合もある)、パケットがRich Ruleを満たしている、サービスがホワイトリストに登録されているなどの理由により、このゾーンで処理されれば終了する。 そうでない場合次に進む。
- パケットに対応するInterfaceをもつゾーンにより処理されれば終了する。そうでない場合次に進む。
- Firewalldのデフォルトアクションが適用される。すなわちicmpパケットは受け入れ、それ以外はすべて拒否される。
重要なことは、SourceゾーンがInterfaceゾーンよりも優先される、ということである。したがって、マルチゾーン構成の一般的な設計パターンとしては、Sourceゾーンにより特定のIPに対し特定のサービスへのアクセスを許可するようにし、Interfaceゾーンでは他の全てのユーザに対してアクセスを制限することになる。
疑似構成でやってみよう
では、次から実例を元にやってみよう。
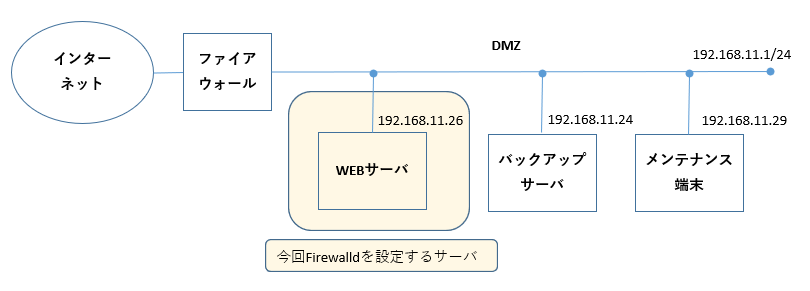
ネットワーク構成
今回はこんな構成で進めることとしたい。
概要を説明しよう。
- 色付けしたWEBサーバが今回Firwalldを設定するサーバである。
- WEBサーバはhttp/httpsにより、インターネット上にサービスを提供する。
- バックアップサーバは、WEBサーバのシステムをバックアップするサーバであり、WEBサーバ上のMySQLサーバとNFSサーバにアクセスする。
- メンテナンス端末は、WEBサーバのメンテナンスを行う端末であり、WEBサーバにsshで接続する。
- DMZにつなげるべきではないとか、グローバルIPアドレスがおかしいというツッコミはあると思うが、今回は話を単純にするためにこれでいかせてほしい。
実現したいFirewalldルール
で、文章で書くと曖昧になるため、WEBサーバでパケットを許可するルールを表にしてみる。
送信元 プロトコル ゾーン名 ゾーン役割 ANY https, http public Interfaceゾーン 192.168.11.24 mysql, nfs share Sourceゾーン 192.168.11.29 ssh mainte Sourceゾーン 上以外は全て拒否するルールとなる。
なお、すでに表に「ゾーン名」「ゾーン役割」欄があり、public、share、mainteといった名前のゾーンの記載があるが、まさにこれから、これらのマルチゾーンによって、実際に上記ルールを設定していこう。publicゾーンの設定
publicゾーンはデフォルトのものを修正する感じになる。
firewall-cmd --permanent --zone=public --remove-service=dhcpv6-client firewall-cmd --permanent --zone=public --remove-service=cockpit firewall-cmd --permanent --zone=public --remove-service=ssh firewall-cmd --permanent --zone=public --add-service=http firewall-cmd --permanent --zone=public --add-service=https firewall-cmd --permanent --zone=public --set-target=DROP firewall-cmd --reload
- まず上の3行は、最初からpublicゾーンにサービスとして入っていたため、削除している(入っていない場合は無視してほしい)。
- 4, 5行目が全てのユーザ向けにhttps, httpを許可する設定である。
- 6行目はssh対策である。内部ゾーン外のIPからサーバーにSSHで接続しようとした場合に, DENYではなく、DROPをした方が安全だからのようである。(これによってpingも通らなくなるが、回避策は参考文献[1]を参照のこと)
mainteゾーンの設定
mainteゾーンは、元々存在しないため新規に作成した上で設定する。
firewall-cmd --permanent --new-zone=mainte firewall-cmd --permanent --zone=mainte --add-service=ssh firewall-cmd --permanent --zone=mainte --add-source=192.168.11.29 firewall-cmd --reload2行目で許可するサービスとしてssh、3行目で許可する送信元IPとしてメンテナンス端末のIPを指定している。
shareゾーンの設定
shareゾーンも、元々存在しないため新規に作成した上で設定する。
firewall-cmd --permanent --new-zone=share firewall-cmd --permanent --zone=share --add-port=2049/tcp firewall-cmd --permanent --zone=share --add-port=3306/tcp firewall-cmd --permanent --zone=share --add-source=192.168.11.24 firewall-cmd --reload2, 3行目で許可するポートとしてnfs, mysqlのポートを指定し、4行目で、許可する送信元IPとしてバックアップサーバのIPを指定している
かくにん!
まずは、メンテナンス端末からnmapを実行してみよう。
[kimisyo@localhost ~]$ nmap 192.168.11.26 Starting Nmap 7.70 ( https://nmap.org ) at 2020-10-25 20:59 JST Nmap scan report for 192.168.11.26 Host is up (0.00063s latency). Not shown: 997 filtered ports PORT STATE SERVICE 22/tcp open ssh 80/tcp open http 443/tcp open https確かにhttp/httpsポートに加え、sshが見えている。(逆にnfs, mysqlは見えていない)
次に、バックアップサーバからnmapを実行してみよう。
(base) kimisyo@ubuntu20:~$ nmap 192.168.11.26 Starting Nmap 7.80 ( https://nmap.org ) at 2020-10-25 11:59 UTC Nmap scan report for 192.168.11.26 Host is up (0.0011s latency). Not shown: 996 filtered ports PORT STATE SERVICE 80/tcp open http 443/tcp open https 2049/tcp open nfs 3306/tcp open mysqlhttp/httpsポートに加え、2049/tcpと3306/tcpが見えている。(逆にsshは見えていない)
おわりに
最後に、実際にやってみて感じたマルチゾーンのメリットをまとめてみる。
- 1ゾーンだとプロトコル(サービス)と送信元IPアドレスの組み合わせが多くなった場合、サービスや送信元IPの変更による影響が大きいが、マルチゾーンだとゾーンにadd-serviceや、add-sourceだけで済む。例えば、今回の例でメンテナンス端末に別の端末を追加する場合
firewall-cmd --permanent --zone=mainte --add-source=192.168.11.19のようなルールを追加するだけで済む。- 参考文献[1]にもあるが、不正アクセスしてくる特定のIPを除外するといったことが簡単に行える。具体的には、全ての接続をDROPするDROPゾーンを作っておき、そのゾーンにadd-sourceで除外したいIPを加えるだけで済む。
- あるゾーンに含まれる送信元IP群に対して、許可するサービスを追加したり除去したりすることをまとめて行うことができる。
- まさに柔軟さは無限大である。詳しく知りたい方は是非、参考文献や、Firewalldのドキュメントを見てほしい。
参考文献
- 投稿日:2020-10-25T20:28:12+09:00
Ubuntuでよく使うディスク関係のコマンド(備忘録)
はじめに
ubuntuを使っていて、バックアップの為、外付けSSDを接続してデータをコピーしたり、データベースの保存場所をセカンダリディスクにしたりなどよくディスク関係のコマンドを使う思います。
なので今回、自分用の備忘録としてよく使うコマンドをまとめました。
皆さんの役にも立てると幸いです。ディスクの管理関係のよく使うコマンド
Linuxでディスクを利用するために、主に以下のコマンドを使っています。
- fdiskコマンド
- blkidコマンド
- dmesgコマンド
- treeコマンド
- df コマンド
- du コマンド
- mkfsコマンド
- mount/umountコマンド
- lshwコマンド
- lsblkコマンド
よく使うコマンド #パーティション一覧表示 sudo fdisk -l #ハードディスク情報取得 sudo blkid #デバイスが認識されていることを確認 dmesg | grep sd #ディレクトリのみ、2階層目まで表示 tree -d -L 2 #空き容量を確認する sudo df -h #ルートディレクトリがどのディスク上にあるか確認する df / -h #どのデバイスがどこにマウントされているのか確認 df -Th #どこのディレクトリの容量が大きいのかを表示する sudo du -sh /* #容量の多いトップ5のディレクトリを表示する sudo du -sm ./* | sort -rn | head -5 #HDDをExt4フォーマット sudo mkfs.ext4 "ディスクパス" #ディスクのマウント sudo mount "ディスクパス" "マウントするディレクトリパス" #ディスクのアンマウント umount /mnt #ハードウェアの情報を表示する sudo lshw -short -C disk #ブロックデバイスを一覧表示する(ディスク名とプラッタがあるか表示(1の場合HDD、0の場合はSSD)) lsblk -o name,rota #ディスクがHDDかSSDか確認する(返り値が1の場合HDD、0の場合はSSD) cat /sys/block/"ディスク名"/queue/rotational補足1---Linux のディスクの扱い
LinuxではWindowsと異なりドライブレターがないのでCドライブやDドライブといった表現がない。そのため、ディスク内のパーティションをマウントすると、フォルダのような扱いになり、HDDの中身にアクセスできるようになります。
ディスクが認識されている場合、各HDDは/dev/sda、/dev/sdb・・・といった感じで表現される。sdの部分が固定で、その後ろのアルファベットがaから順に続いていく感じ。(CD/DVDドライブの場合はsr)
補足2---Linux のディレクトリ構造
Linuxのディレクトリ構造は、FHS(Filesystem Hierarchy Standard)という規格にしたがってつくられている。
現在のFHS(FHS 3.0)で規定された、ルートディレクトリ直下のディレクトリで必須とされているものは、「/bin」「/boot」「/dev」「/etc」「/lib」「/media」「/mnt」「/opt」「/run」「/sbin」「/srv」「/tmp」「/usr」「/var」の14個です(「/home」「/root」についてはオプションとして規定)。
ディレクトリ 役割 / ルートディレクトリ。ここが階層の起点。 /bin シングルユーザーモードでシステムの起動や修理を行う際に必要な実行形式ファイルが含まれる。例えば、cat、cp、ls、more、tarなどの実行ファイル。 /boot Linuxのカーネルやブートマネージャーなどが含まれる。 このディレクトリにはブートプロセスの間に必要なファイルだけが置かれる。 /dev 物理デバイスを参照しているコンピューターに接続されたデバイス(マウスやキーボード、ディスク等)のスペシャルファイルやデバイスファイルの置き場所。 /etc ほとんどのシステム設定ファイルが入っているディレクトリ。また、サブディレクトリの/etc/rc.dには初期化スクリプトが入っている。 /lib システムの起動時に必要な共有ライブラリや、 ルートファイルシステムでコマンドを実行するのに必要な共有ライブラリがおかれる場所。 /media CD-ROMやフロッピーディスクなどの外付けメディア用のマウントポイント。 /mnt 一時的にマウントされるファイルシステムのマウントポイント。 /opt アドオンパッケージの静的なファイルが置かれる。 /run 実行中のプロセスに関連するデータが置かれる。 /sbin /bin と同様に、 このディレクトリにはシステムの起動に必要なコマンドが含まれる。 ただしここには、一般ユーザーは通常実行しないコマンドが置かれる。 /srv 定期的なジョブによって、またはシステム起動時に、 無条件に削除して構わない一時的なファイルが置かれる。 /tmp 定期的なジョブによって、またはシステム起動時に、 無条件に削除して構わない一時的なファイルが置かれる。 /usr ユーザが独自にインストールするファイル類がおかれる。ルート直下と同様の構造が作成されている。 /var スプールファイルやログファイルのような、 サイズが変化するファイルが置かれる。 もちろん、FHSに策定されているものはこれだけではなく、さらに下層のディレクトリ(「/usr/share」など)についても言及されています。
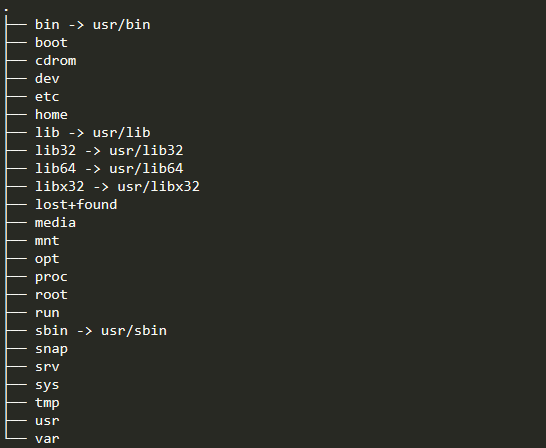
実際に以下のコマンドをUbuntuでたたいてみると下のようなディレクトリ構造が表示されました。
tree -d -L 2
参考にした、参考になるサイト
- 投稿日:2020-10-25T18:27:20+09:00
docker-compose --help 日本語訳
docker-compose --help実行時に表示されるヘルプドキュメントの日本語訳。Docker を使用してマルチコンテナーアプリケーションを定義し、実行します。
使用法:
docker-compose [-f <arg>...] [options] [--] [COMMAND] [ARGS...] docker-compose -h|--helpオプション:
- -f, --file FILE 代替の compose ファイルを指定します(デフォルト:
docker-compose.yml)- -p, --project-name NAME 代替プロジェクト名を指定します(デフォルト: ディレクトリ名)
- -c, --context NAME コンテキスト名を指定します。
- --verbose より多くの出力を表示します。
- --log-level LEVEL ログレベルを指定します。
- DEBUG
- INFO
- WARNING
- ERROR
- CRITICAL
- --no-ansi ANSI 制御文字を非表示にします。
- -v, --version バージョンを表示して終了します
- -H, --host HOST 接続するデーモンソケットを指定します。
- --tls TLS を使用します;
--tlsverifyによって暗示されます。- --tlscacert CA_PATH この CA によってのみ署名された信頼証明書
- --tlscert CLIENT_CERT_PATH TLS 証明書ファイルへのパス
- --tlskey TLS_KEY_PATH TLS キーファイルへのパス
- --tlsverify TLS を使用して接続を確認します
- --skip-hostname-check デーモンのホスト名をクライアント証明書で指定された名前と照合しないようにします
- --project-directory PATH 代替作業ディレクトリを指定します(デフォルト: compose ファイルのパス)
- --compatibility 設定されている場合 Compose は v3 ファイルのキーを Swarm 以外の同等のものに変換しようとします(非推奨)
- --env-file PATH 代替環境ファイルを指定します
Commands:
- build サービスのビルドまたは再ビルドを実行します
- config compose ファイルを検証して表示します
- create サービスを作成します
- down コンテナ、ネットワーク、イメージ、ボリュームを停止して削除します
- events コンテナからリアルタイムのイベントを受信します
- exec 実行中のコンテナでコマンドを実行します。
- help コマンドのヘルプを表示します。
- images イメージを列挙します。
- kill コンテナを停止します。
- logs コンテナからの出力を表示します。
- pause サービスを一時停止します。
- port ポートバインディングの為の公開ポートを表示します。
- ps コンテナを列挙します。
- pull サービスイメージをプルします。
- push サービスイメージをプッシュします。
- restart サービスを再起動します。
- rm 停止されたコンテナを削除します。
- run 一度限りのコマンドを実行します。
- scale サービスに使用するコンテナ数を指定します。
- start サービスを開始します。
- stop サービスを停止します。
- top 実行中のプロセスを表示します。
- unpause サービスの一時停止を解除します。
- up コンテナを作成して開始します。
- version バージョン情報を表示して終了します。
- 投稿日:2020-10-25T14:21:49+09:00
勉強メモ9_CentOS7にJenkinsのをインストール
★1 ユーザーをrootに切り替えて開始、まずはJavaのバージョン確認(Java1.7以上インストールされてないと動かないらしい)
[root@localhost ~]# java -version openjdk version "1.8.0_222-ea" OpenJDK Runtime Environment (build 1.8.0_222-ea-b03) OpenJDK 64-Bit Server VM (build 25.222-b03, mixed mode)★2 yumリポジトリの追加
[root@localhost ~]# wget -O /etc/yum.repos.d/jenkins.repo http://pkg.jenkins-ci.org/redhat-stable/jenkins.repo --2020-10-25 13:09:38-- http://pkg.jenkins-ci.org/redhat-stable/jenkins.repo pkg.jenkins-ci.org (pkg.jenkins-ci.org) をDNSに問いあわせています... 52.202.51.185 pkg.jenkins-ci.org (pkg.jenkins-ci.org)|52.202.51.185|:80 に接続しています... 接続しました。 HTTP による接続要求を送信しました、応答を待っています... 200 OK 長さ: 85 `/etc/yum.repos.d/jenkins.repo' に保存中 100%[===================================================================================================================================================>] 85 --.-K/s 時間 0s 2020-10-25 13:09:39 (5.16 MB/s) - `/etc/yum.repos.d/jenkins.repo' へ保存完了 [85/85]★3 RPM公開鍵のインストール
[root@localhost ~]# rpm --import https://jenkins-ci.org/redhat/jenkins-ci.org.key [root@localhost ~]#★4 ★3だと、下記★5のyumでのJenkinsインストールで「jenkins-2.249.2-1.1.noarch.rpm の公開鍵がインストールされていません」のエラーが出るので、以下をインポート
[root@localhost ~]# rpm --import https://pkg.jenkins.io/redhat/jenkins.io.key [root@localhost ~]#★5 Jenkinsパッケージのインストール
[root@localhost ~]# yum -y install jenkins 読み込んだプラグイン:fastestmirror, langpacks Loading mirror speeds from cached hostfile * base: ftp.riken.jp * extras: ftp.riken.jp * updates: ftp.riken.jp 依存性の解決をしています --> トランザクションの確認を実行しています。 ---> パッケージ jenkins.noarch 0:2.249.2-1.1 を インストール --> 依存性解決を終了しました。 依存性を解決しました ============================================================================================================================================================================================= Package アーキテクチャー バージョン リポジトリー 容量 ============================================================================================================================================================================================= インストール中: jenkins noarch 2.249.2-1.1 jenkins 64 M トランザクションの要約 ============================================================================================================================================================================================= インストール 1 パッケージ 合計容量: 64 M インストール容量: 64 M Downloading packages: Running transaction check Running transaction test Transaction test succeeded Running transaction インストール中 : jenkins-2.249.2-1.1.noarch 1/1 検証中 : jenkins-2.249.2-1.1.noarch 1/1 インストール: jenkins.noarch 0:2.249.2-1.1 完了しました! [root@localhost ~]#★6 待ち受けポートの設定(8080になってるので、他のサービスの衝突を考えて、8000に変更)
[root@localhost ~]# vim /etc/sysconfig/jenkins --- JENKINS_PORT="8000" ---★7 サービスの有効化と開始(enableは失敗してるように見えるが、
https://qiita.com/sawa_toru/items/d8eedef13ab66e823404
によると有効らしい[root@localhost ~]# systemctl enable jenkins jenkins.service is not a native service, redirecting to /sbin/chkconfig. Executing /sbin/chkconfig jenkins on [root@localhost ~]# systemctl start jenkins [root@localhost ~]#★8 ブラウザで「 http://localhost:8000 」でアクセス
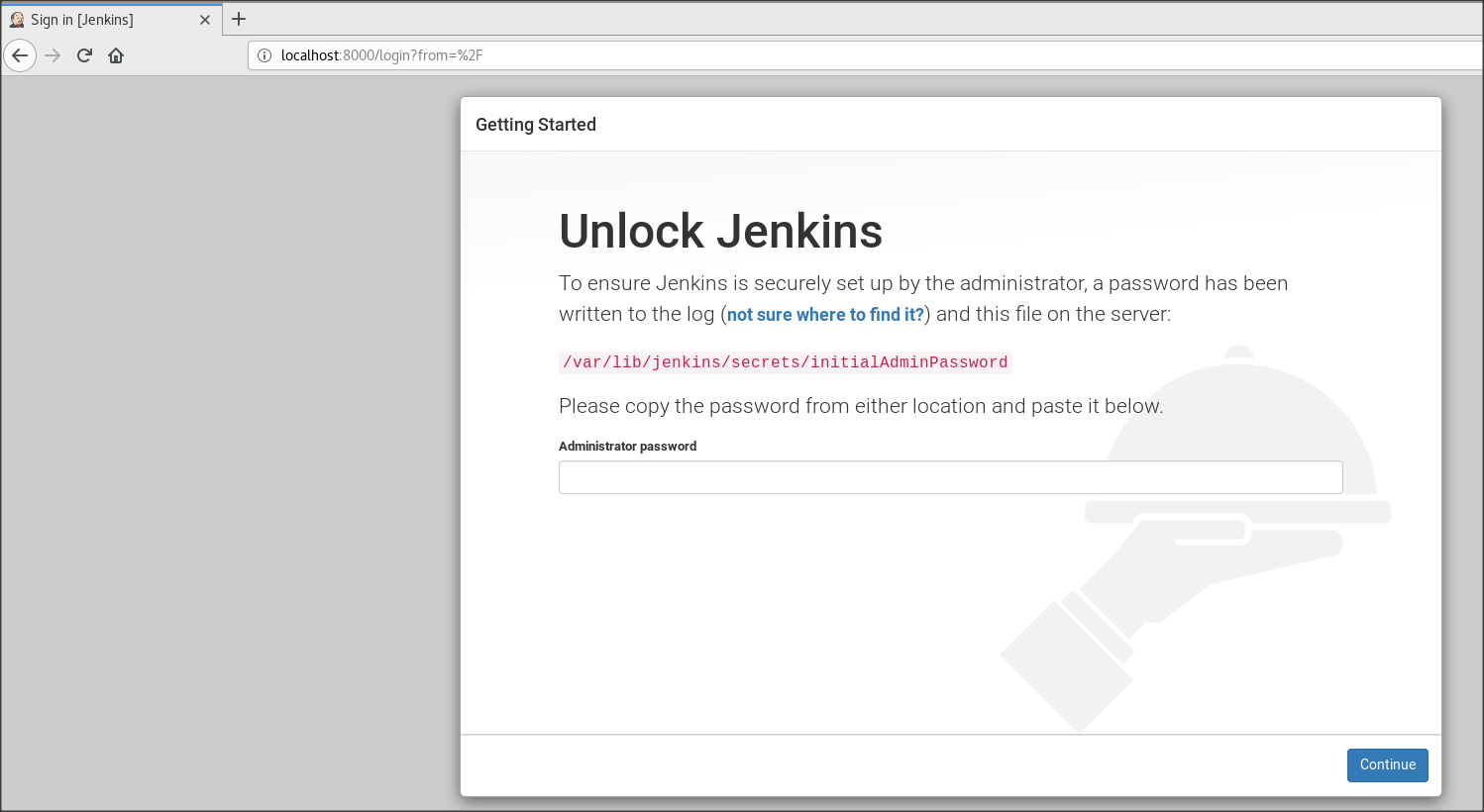
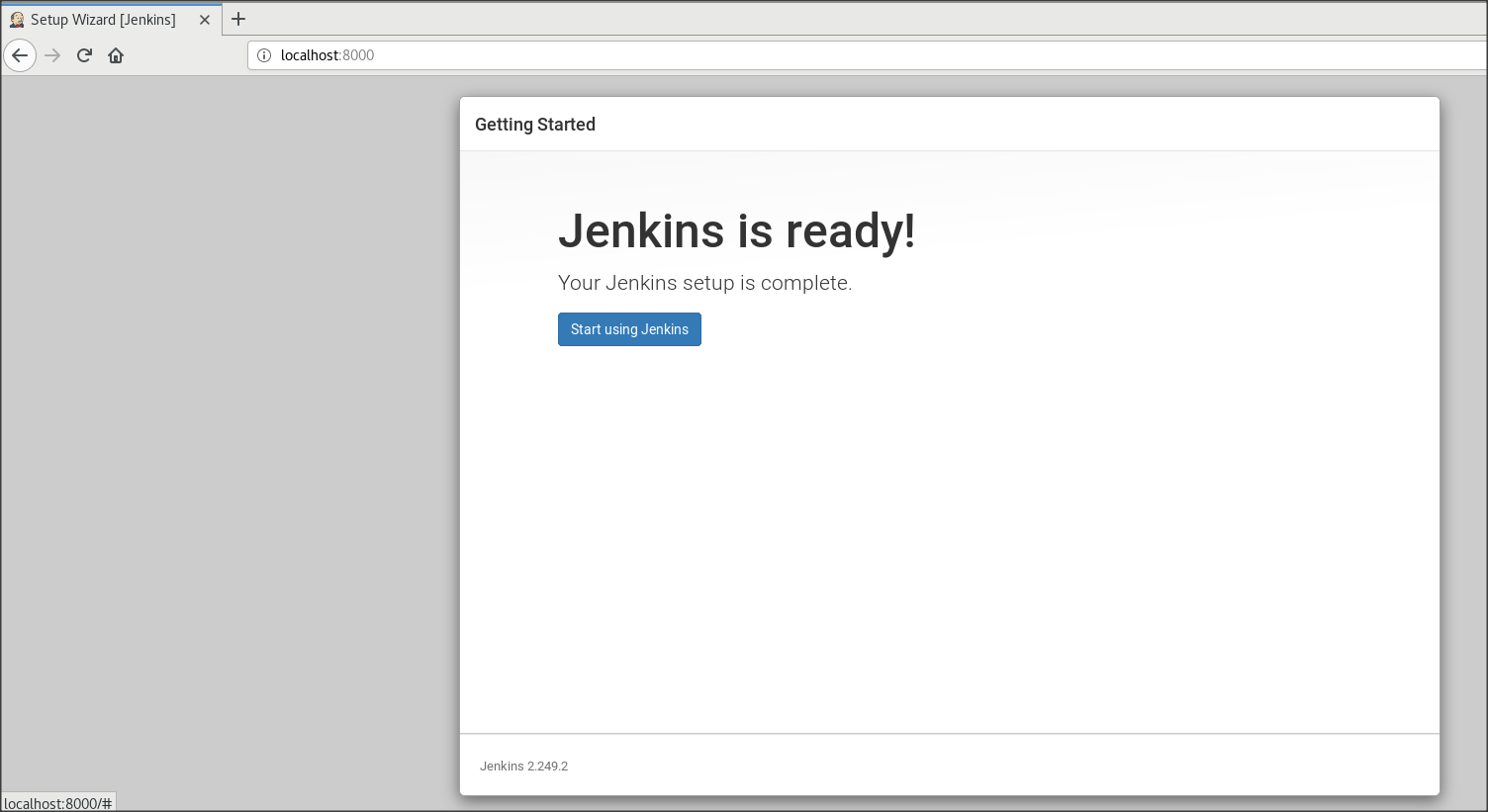
下記、Unlock Jenkinsという、管理者パスワードを入力する画面になります。
★9 初期のAdministrator Passwordは、下記で確認し、★8の画面に入力。
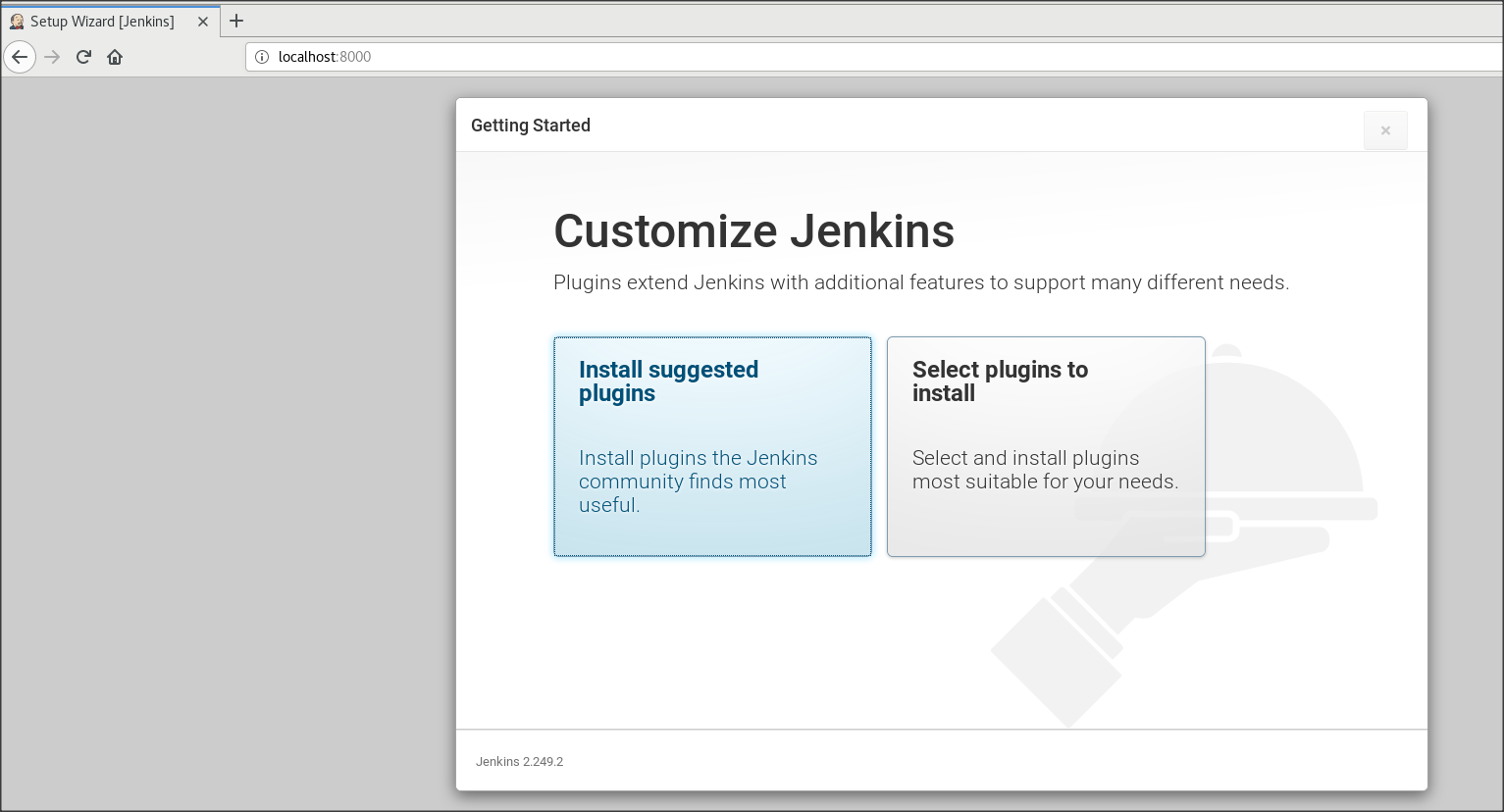
[root@localhost ~]# cat /var/lib/jenkins/secrets/initialAdminPassword★10 Customer Jenkinsの画面が出るので、「install suggensted plugins」を選択
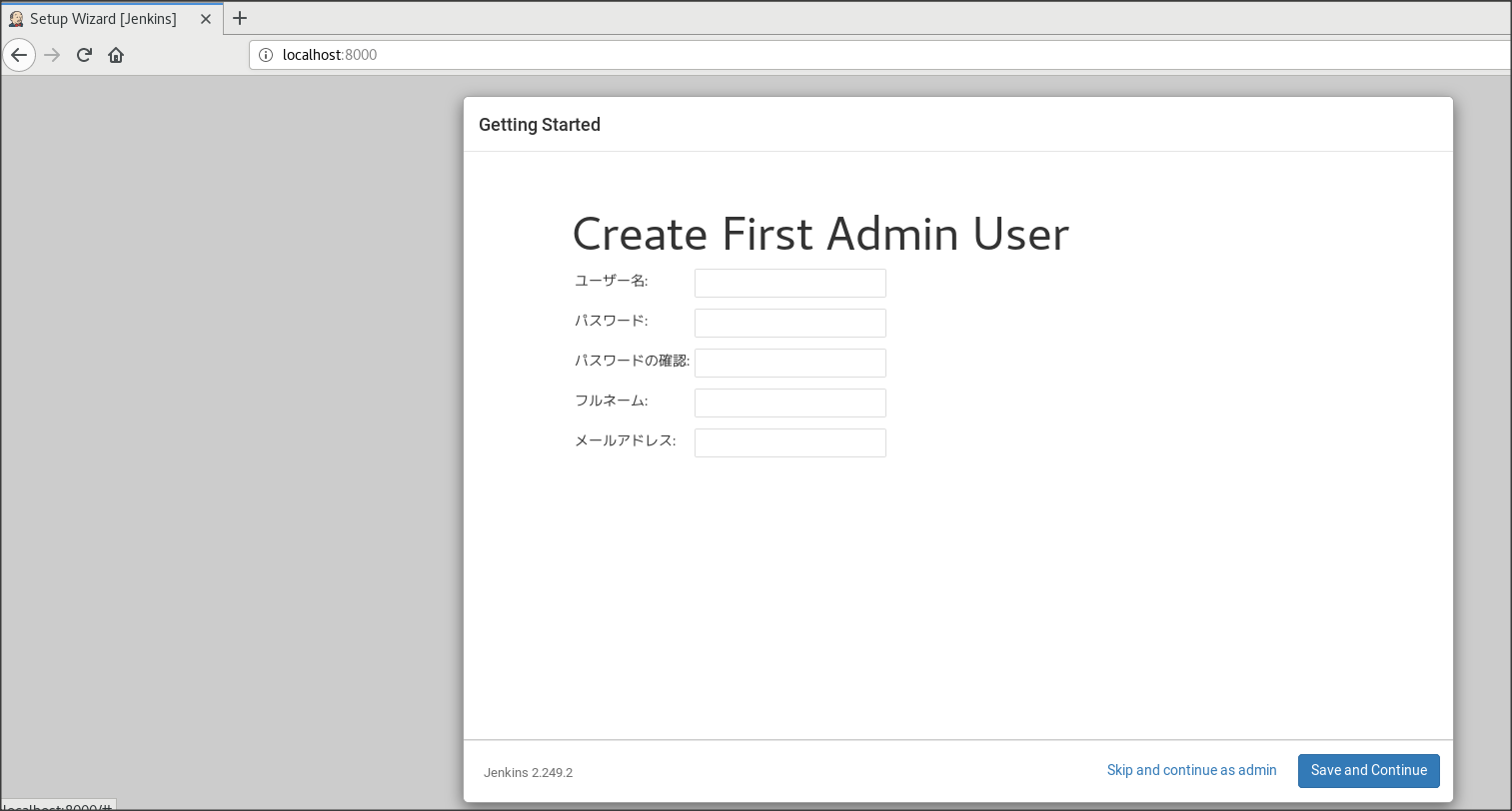
★11 Create First Admin User 画面でアドミンユーザーを作成
★12 ユーザー作成後、以下の画面がでるが、そのまま進む
★13 さらにそのまま進む
★14 ようこそ画面が出ましたので、一旦完了
★15 参考にした記事
・https://qiita.com/inakadegaebal/items/b526ffbdbe7ff2b443f1
・https://stackoverflow.com/questions/61344317/im-getting-error-public-key-for-jenkins-2-232-1-1-noarch-rpm-is-not-installed
・https://weblabo.oscasierra.net/jenkins-install-centos7/
・https://qiita.com/sawa_toru/items/d8eedef13ab66e823404
- 投稿日:2020-10-25T14:21:49+09:00
勉強メモ9_CentOS7にJenkinsをインストール
★1 ユーザーをrootに切り替えて開始、まずはJavaのバージョン確認(Java1.7以上インストールされてないと動かないらしい)
[root@localhost ~]# java -version openjdk version "1.8.0_222-ea" OpenJDK Runtime Environment (build 1.8.0_222-ea-b03) OpenJDK 64-Bit Server VM (build 25.222-b03, mixed mode)★2 yumリポジトリの追加
[root@localhost ~]# wget -O /etc/yum.repos.d/jenkins.repo http://pkg.jenkins-ci.org/redhat-stable/jenkins.repo --2020-10-25 13:09:38-- http://pkg.jenkins-ci.org/redhat-stable/jenkins.repo pkg.jenkins-ci.org (pkg.jenkins-ci.org) をDNSに問いあわせています... 52.202.51.185 pkg.jenkins-ci.org (pkg.jenkins-ci.org)|52.202.51.185|:80 に接続しています... 接続しました。 HTTP による接続要求を送信しました、応答を待っています... 200 OK 長さ: 85 `/etc/yum.repos.d/jenkins.repo' に保存中 100%[===================================================================================================================================================>] 85 --.-K/s 時間 0s 2020-10-25 13:09:39 (5.16 MB/s) - `/etc/yum.repos.d/jenkins.repo' へ保存完了 [85/85]★3 RPM公開鍵のインストール
[root@localhost ~]# rpm --import https://jenkins-ci.org/redhat/jenkins-ci.org.key [root@localhost ~]#★4 ★3だと、下記★5のyumでのJenkinsインストールで「jenkins-2.249.2-1.1.noarch.rpm の公開鍵がインストールされていません」のエラーが出るので、以下をインポート
[root@localhost ~]# rpm --import https://pkg.jenkins.io/redhat/jenkins.io.key [root@localhost ~]#★5 Jenkinsパッケージのインストール
[root@localhost ~]# yum -y install jenkins 読み込んだプラグイン:fastestmirror, langpacks Loading mirror speeds from cached hostfile * base: ftp.riken.jp * extras: ftp.riken.jp * updates: ftp.riken.jp 依存性の解決をしています --> トランザクションの確認を実行しています。 ---> パッケージ jenkins.noarch 0:2.249.2-1.1 を インストール --> 依存性解決を終了しました。 依存性を解決しました ============================================================================================================================================================================================= Package アーキテクチャー バージョン リポジトリー 容量 ============================================================================================================================================================================================= インストール中: jenkins noarch 2.249.2-1.1 jenkins 64 M トランザクションの要約 ============================================================================================================================================================================================= インストール 1 パッケージ 合計容量: 64 M インストール容量: 64 M Downloading packages: Running transaction check Running transaction test Transaction test succeeded Running transaction インストール中 : jenkins-2.249.2-1.1.noarch 1/1 検証中 : jenkins-2.249.2-1.1.noarch 1/1 インストール: jenkins.noarch 0:2.249.2-1.1 完了しました! [root@localhost ~]#★6 待ち受けポートの設定(8080になってるので、他のサービスの衝突を考えて、8000に変更)
[root@localhost ~]# vim /etc/sysconfig/jenkins --- JENKINS_PORT="8000" ---★7 サービスの有効化と開始(enableは失敗してるように見えるが、
https://qiita.com/sawa_toru/items/d8eedef13ab66e823404
によると有効らしい[root@localhost ~]# systemctl enable jenkins jenkins.service is not a native service, redirecting to /sbin/chkconfig. Executing /sbin/chkconfig jenkins on [root@localhost ~]# systemctl start jenkins [root@localhost ~]#★8 ブラウザで「 http://localhost:8000 」でアクセス
下記、Unlock Jenkinsという、管理者パスワードを入力する画面になります。
★9 初期のAdministrator Passwordは、下記で確認し、★8の画面に入力。
[root@localhost ~]# cat /var/lib/jenkins/secrets/initialAdminPassword★10 Customer Jenkinsの画面が出るので、「install suggensted plugins」を選択
★11 Create First Admin User 画面でアドミンユーザーを作成
★12 ユーザー作成後、以下の画面がでるが、そのまま進む
★13 さらにそのまま進む
★14 ようこそ画面が出ましたので、一旦完了
★15 参考にした記事
・https://qiita.com/inakadegaebal/items/b526ffbdbe7ff2b443f1
・https://stackoverflow.com/questions/61344317/im-getting-error-public-key-for-jenkins-2-232-1-1-noarch-rpm-is-not-installed
・https://weblabo.oscasierra.net/jenkins-install-centos7/
・https://qiita.com/sawa_toru/items/d8eedef13ab66e823404
- 投稿日:2020-10-25T09:08:34+09:00
お堅い企業で働く人こそ読みたい「伽藍とバザール」
「伽藍とバザール」について
ってみなさんどれくらい読んでいるんでしょう?
なんとなく、「人月の神話」や「熊とワルツを」、あるいは「エキストリームプログラミング(白本)」のような、プログラミングにおける古典読み物のひとつだと個人的には感じています。
とはいえ、上げた三冊は私も一通り読んでいるのですが、じつは伽藍とバザールは素通りしていました。
なんでかっていうと、これOSSソフトウェア、特にLinuxの開発モデルについて開発した本なんです。こういう古典読み物を読み漁っていた当時としては、あんまり興味を引く題材じゃなかったのですよね。もっぱらプロプライエタリかつオンプレミスなソフトを書き続けていた日々だったので。
安易な人員投入を批判する「人月の神話」や、リスク管理について教えてくれる「熊とワルツを」、アジャイル開発の熱い萌芽を感じる「エクストリームプログラミング」なんかとは、だいぶ違う毛色を感じたんですよね。
Amazonの書籍紹介ページにも「Linux、オープンソース(OSS)関係者必読の書」って書いてあって、もちろんそれは正しいと思うのだけれど、安易に読者を狭め過ぎじゃないのかと思うんですよね。1
特に、今あらゆるものがどんどんオープンになっているこの世の中で、どのようにソフトウェアの開発はあるべきなのか、それを示している書籍になります。
と、書籍と言いましたが、さすがOSSについて書いた本です。書籍、及び翻訳自体もクリエイティブ・コモンズのもとにOSSとなっています。
実は書籍版は、上記に加え「ノウアスフィアの開墾」と「魔法のおなべ」、あとは訳者の山形センセイによるインタビューなんかもセットになっていますが、今回取り上げるのは「伽藍とバザール」までです。そこまでで十分面白いので、未読の方は是非。PDFで40ページほどととっても読みやすい分量となっております。
「伽藍とバザール」のメタファの誤解
ちょっと伽藍とバザールのことを知っているなら、あるいはOSSと大企業(窓の会社とか青い会社とか赤い会社とか)との戦いの歴史を知っている人なら、「伽藍」とは大企業手動によるプロプライエタリでクローズドな開発のことを、そしてバザールとはOSSによる自由なソフトウェア開発のことを指している、と考えるでしょう。
そう思っている人こそ、読んでもらいたいです。なぜなら 伽藍とバザールとは、大企業とOSSのメタファではないからです。
本文より引用しましょう。伽藍とは以下のようなモデルです。
でももっと上のレベルでは何かどうしようもない複雑な部分がでてきて、もっと中央集権的で、アプリオリなアプローチが必要に なってくるものだとも思っていた。一番だいじなソフト(OS や、Emacs みたいな本当に大規模なツール)は伽藍のように組み立てられなきゃダメで、一人のウィザードか魔術師の小集団が、まったく孤立して慎重に組み立てあげるべ きもので、完成するまでベータ版も出さないようでなくちゃダメだと思っていた。
そう、伽藍とは初期の大規模設計(Big Design Upfront)を前提とするシリアルなモデル のことを指しています。
ではバザールモデルとは。
リーヌス・トーヴァルズの開発スタイル――はやめにしょっちゅうリリース、任せられるものはなんでも任して、乱交まがいになんでもオープンにする――には まったく驚かされた。
バザールとは、 頻繁なリリースサイクルを前提とした、オープンでイテレーティブな開発モデル を指しています。
つまり、いまの俗な言葉で言えば(定義としての揺れがあることは十分に承知しつつ)、
- 伽藍 = ウォーターフォール かつ 中央集権
- バザール = アジャイル かつ 自己組織化
といえるのではないでしょうか。
もちろん伽藍モデルは大企業に多く、バザールモデルはOSSに多いことは事実ですが、あくまで伽藍とバザールが指すのは開発モデルであって、プロジェクトの形態ではありません。何が言いたいかというと、 企業内のクローズドな開発であっても、ある程度のバザール的要素は適用できるのです。
「伽藍とバザール」に書いてあること
伽藍とバザールに書いてあるのは、「なぜバザールモデルが機能するのか」という分析です。そしてこの分析というのは1990年代に行われたもの、というのに価値があります。
なぜなら、その時代にはGithubどころか、Gitすら存在していないのです(LinusがGitを作るのはちょうどこの文章が日本語訳された後)。もちろんSlackもありません。あるのはメーリングリストと初期のWWWのみ。
これは現代のGithubなれしている人たちからしたらただの昔話ですが、実際の皆さんの組織はどうでしょう?社内の情報共有の仕組みって、実質1990年代で止まっているのではないですか?メールによる伝達が主で、ソースコードは結局共有ファイルサーバに上げられて、あってもSVNまでしかない、という人はまだまだいるのでは?
そう、そんな状況だって、バザールモデルが機能するのだ、ということがこの本を読むとわかるのです。これはすなわち、「納得できたなら、どんな会社でもやれる」ということになります。
バザールモデルが機能する仕組み
ではなぜ「はやめにしょっちゅうリリース、任せられるものはなんでも任して、乱交まがいになんでもオープンにする」、どう考えても秩序が取れないバザールモデルはなぜ機能するのでしょうか。
本書には多くのポイントが書いてありますが、個人的に重要だと思うのは以下の3つです。
- 開発者の個人的な情熱を原動力とする
- 逆に情熱を失ったならメインからは降りる
- ユーザーを共同開発者として扱う
- 優秀なベータテスター兼デバッガー兼修正者となる
- ユーザーの興味と情熱を惹きつけつづける
- 頻繁なリリース
- 貢献の可視化
まず重要なのは、バザールモデルとはいえどもそのバザールの長、LinuxでいうLinusでありEmacsにおけるRMSのような存在がいるということです。これは個人であったりチームであったりもしますが、どのみちバザールにはその進路をゆるく決定づけられる(そしてそうあるよう皆から信託された)人物がいます。その人物の個人的な情熱を原動力とし、プロジェクトは牽引されます。
そして、バザールにおいてはそのソフトウェアやライブラリのユーザは共同開発者として扱います。もちろんその条件としては、ユーザも情熱を持ってそのソフトウェアを利用していることが条件になるでしょう。
そして情熱を持った開発者がいて、情熱を持ったユーザがいて、あと一つ必要なのは情熱を焚き付けつづける仕組みです。これを担保するのが頻繁なリリースであり、貢献の可視化であり、もっといえばプロジェクトの透明性そのものとなります。
情熱を持った開発者が、自分のソフトウェアをオープンにし、頻繁なリリースと貢献の感謝で熱狂的なユーザを獲得し、その熱狂的なユーザの貢献によりさらにプロジェクトが発展する。
ごく単純化してしまえば、この流れがバザールモデルが機能する仕組みとなります。
企業内にバザールモデルは適用できるのか
上記のようなプロセスを考えたときに、果たして企業内にそのようなプロセスを持ち込むことができるのでしょうか。
個人的にはできる、と考えています。ある程度大きな企業においては「社内OSS」、中小規模においては「部分的OSS」というアプローチがあるのではないでしょうか。
社内OSS
文字通り、社内にむけてソースコードを公開しプロジェクトをすすめることです。公開するのは、各プロジェクトそのものでもいいですが、難しい場合はそのプロジェクトで使ったツール類、ライブラリ類、あるいはIaCコード、そういったものが考えられると思います。
重要なのは、ただ公開するだけではなく、ちゃんと自分たちのプロジェクトで使っていること、レポジトリオーナー権をもたせてある程度の所有権を与えること、だと思います。いろいろな話を伝え聞くに、Googleというのはこれを最も積極的にやっている企業なのではないでしょうか。もちろんGoogle自体がOSSにおいてかなり先駆的な役割を果たしているのですが、それ以上にGoogleでは社内のツールから新たな製品やOSSが生み出されているのです。
たとえばKubernetesはもはやコンテナオーケストレーションツールのスタンダードとなっていますが、もともとはGoogle社内で、かつクローズドなツールから派生していったものだったはずです。Kubernetesは結果的にはOSSになっていますが、それ以外にもGCPに乗っかっているようなツール群は、社内のツール群をうまく活用して製品に展開していっているように思えます。これは、社内におけるバザールモデルが機能していることの証左ではないでしょうか。
部分的OSS
これは、コアとなる部分はOSS化せずにプロプライエタリに保ちつつ、その周辺ツールをOSS化する、という方法です。
このやり方でぱっと頭にうかぶのが時雨堂です。時雨堂はコア製品である"WebRTC SFU Sora"についてはクローズドかつプロプライエタリですが、その周辺ツールはことこどくOSS化しています。2そしてOSS群に関しては、Discordサーバで活発な議論がなされつつ機能追加がなされており、開発スピードが保たれていると同時に、そのオープンさから開発者を惹きつけ、おそらくはSora自体の売上にもかなりの貢献をしているものと思われます。
このように、OSS的な側面を企業として取り入れ、バザール手法のメリットを取り入れることは可能なはずです。
企業がバザールモデルを取り入れられる条件とは
とはいえ、どんな企業でもこのプロセスが有効であるとも思いません。企業内で「透明性」と「スラック(ゆとり)」が確保されていないと、それを発展させるのは難しいでしょう。
透明性
まず必要なのは透明性です。各プロジェクトにおいて、今どのような技術で何を作っているのか、という現在の状態だけではなく、未来に向けたロードマップを提示することがまず非常に重要でしょう。
それを社内に公開するのか社外に公開するのかに関わらず、変な隠し立てをせずに技術的な透明性を常にアピールしないと、そもそも使ってもらうこと自体が難しいはずです。
スラック(ゆとり)
チャットツールじゃないですよ。こっちです。
社内にせよ社外にせよ、こういったOSS活動は稼働を100%切り詰めていては不可能です。Googleの20%ルールが有名ですが、そもそも自分の情熱を傾けてプロダクトを作る時間、というのを確保しないと、バザールモデルというのは機能しません。
終わりに
というわけでつらつらと書いてきました。個人的には、会社のソフトウェアをどう発展させていくかというのの方向性として、ひとついい視点をもらったな、と今更ながら感じたので、ざっと書いてみました。
また古典を読み直そうかな。良い本でした。


- 投稿日:2020-10-25T00:13:48+09:00
【Cyberduck】VirtualBoxで起動したLinux(CentOS7)上のファイルをGUIでmacと相互にやり取りする方法
【VirtualBoxのCentOS7にDockerコンテナでJenkinsサーバーを構築し、ローカルPCからJenkinsサーバーにアクセスする方法】
https://qiita.com/JUN_WEB_FREE/items/b1a817c03cdb19487a44上記記事で作成したLinuxのデータとmacのデータをGUIでやり取りしたかったので、本記事を作成しました。
WindowsにはFTPツールとしてWinSCPがあり、このツールを用いることでLinux上のデータとWindows上のデータをGUIでやり取りできます。
macにはそういったツールは無いのでしょうか?もちろんあります。
それがCyberduckです。
インストールはこちらから
https://cyberduck.io/
インストールしたらさっそく使い方に移ります。
VirtualBox上のLinuxを起動した状態で、cyberduckを起動します。
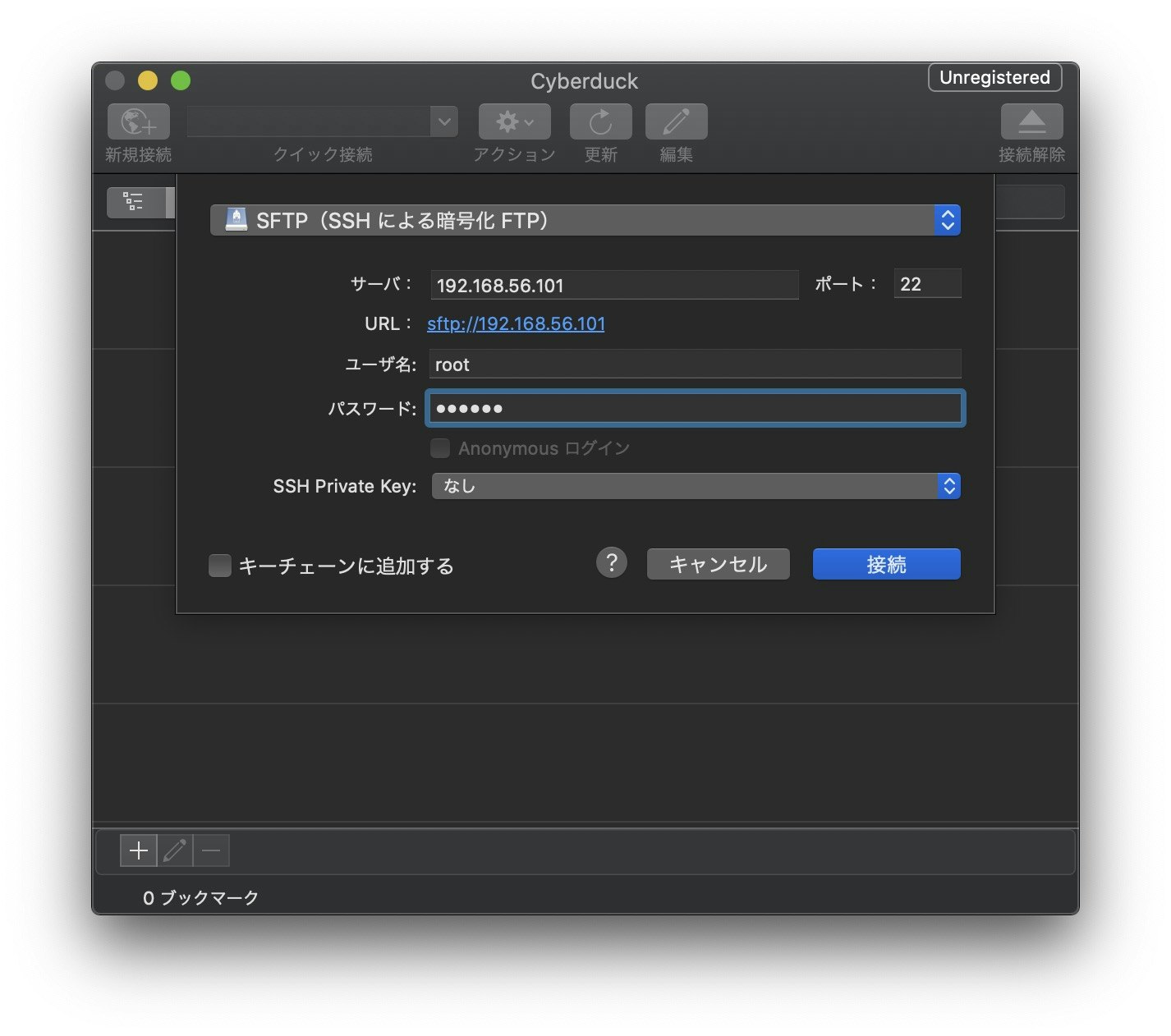
左上の新規接続をクリックし、下記の設定にします。
プロトコル:SFTP
サーバ:192.168.56.101(ここは接続するマシンのIPアドレスに合わせる)
ポート:22(SSH接続するから)
ユーザ名:root(だいたいそう)
パスワード:123456(ここは接続するマシンのパスワードに合わせる)
SSH Private Key:なし(ssh鍵を作成したかどうかによる)
キーチェーンに追加する:なし(お好みで)
接続をクリックします。
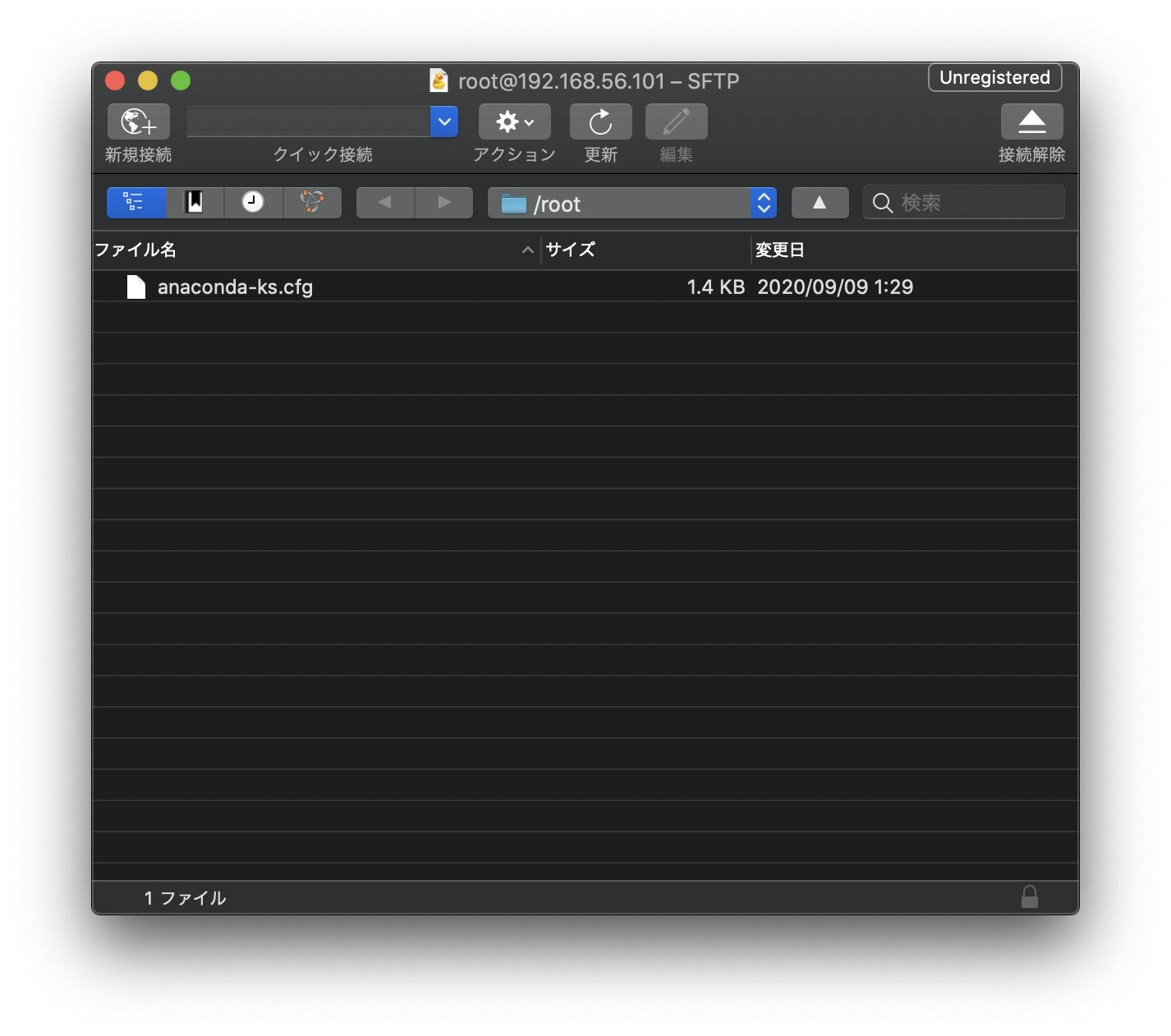
これで接続完了です。Linux上のデータをmacに移動する場合は2本指タップでダウンロードを選択します。
逆にmac上のデータをLinux上に移動する場合は2本指タップでアップロードを選択します。