- 投稿日:2020-10-19T23:45:32+09:00
deviseの導入
Railsでdeviseの導入流れ
1. Gemをインストールしてサーバーを再起動
2. コマンドを利用してdeviseの設定ファイルを作成
3. コマンドを利用してUserモデルを作成
4. 未ログイン時とログイン時でボタンの表示を変える実装
5. コントローラーにリダイレクトを設定
deviseのgemインストール
Gemfile# 中略 gem 'devise'ターミナル# サーバーを起動 % rails sコマンドを実行して設定ファイルを作成
ターミナル# deviseの設定ファイルを作成 % rails g devise:installコマンドを実行してUserモデルを作成
ターミナル# deviseコマンドでUserモデルを作成 % rails g devise userマイグレーションを実行
ターミナル# マイグレーションを実行 % rails db:migrateローカルサーバーを再起動
ターミナル# 「ctrl + C」でローカルサーバーを終了 # 再度、ローカルサーバーを起動 % rails sリダイレクト処理を用意
app/controllers/tweets_controller.rbclass TweetsController < ApplicationController before_action :set_tweet, only: [:edit, :show] before_action :move_to_index, except: [:index, :show] def index @tweets = Tweet.all end def new @tweet = Tweet.new end def create Tweet.create(tweet_params) end def destroy tweet = Tweet.find(params[:id]) tweet.destroy end def edit end def update tweet = Tweet.find(params[:id]) tweet.update(tweet_params) end def show end private def tweet_params params.require(:tweet).permit(:name, :image, :text) end def set_tweet @tweet = Tweet.find(params[:id]) end def move_to_index unless user_signed_in? redirect_to action: :index end end endコマンドを実行してdevise用のビューを作成
ターミナルrails g devise:viewsusersテーブルにnicknameカラムをstring型で追加
ターミナル# ディレクトリがpictweetであることを確認 % pwd # usersテーブルにnicknameカラムをstring型で追加するマイグレーションファイルを作成 % rails g migration AddNicknameToUsers nickname:string # 作成したマイグレーションを実行 % rails db:migrateターミナル# 「ctrl + C」でローカルサーバーを終了 # 再度、ローカルサーバーを起動 % rails sapplication_controller.rbを編集
app/controllers/application_controller.rbclass ApplicationController < ActionController::Base before_action :configure_permitted_parameters, if: :devise_controller? private def configure_permitted_parameters devise_parameter_sanitizer.permit(:sign_up, keys: [:nickname]) end end以上です!
deviseには元々デフォルトでemailとpasswordは内部で動いてくれているのでカラムを追加しない場合はパラメーターに記述不要です!
- 投稿日:2020-10-19T23:38:35+09:00
Nuxt.js × Railsでアプリ作成 CORS policy エラーの解決
やりたいこと
- Railsで作ったAPIに対してNuxt.js側から投稿する(前回の記事の続編です)
開発環境
ruby 2.6.5
Rails 6.0.3.4
node v14.7.0
yarn 1.22.4
フロント(Nuxt.js)のローカルサーバーのport番号は8000
API(Rails)のローカルサーバーのport番号は3000投稿画面のマークアップ
- sendボタンがクリックされたら、Postmanで投稿ができることを確認できたURI
http://localhost:3000/api/v1/postsにPOSTリクエストを送るような処理を実装
pages/index.vue<template> <div class="container"> <h4>新規投稿</h4> <div class="form-control"> <span>Title</span> <input type="text" v-model="title" > </div> <div class="form-control"> <span>Body</span> <input type="text" v-model="body" > </div> <div class="form-control"> <button @click="postMessage">send</button> </div> </div> </template> <script> export default { data: () => ({ title: null, body: null, }), methods: { postMessage() { const url = 'http://localhost:3000/api/v1/posts'; const post = { title: this.title, body: this.body, }; this.$axios.post(url, { post }) .then(res => console.log(res.status)) .catch(error => console.log(error)); }, } } </script> <style> .container { width: 60%; max-width: 600px; margin: 0 auto; } .form-control { margin: 20px 0; } h4 { text-align: center; } span { width: 4em; display: inline-block; } input[type="text"] { width: calc(100% - 6em); } button { margin: auto; display: block; } </style>CORSでのエラーになる時の解決方法
- 上記で実装すると、console.logに下記が出力される
Access to XMLHttpRequest at 'http://localhost:3000/' from origin 'http://localhost:8000' has been blocked by CORS policy: Response to preflight request doesn't pass access control check: No 'Access-Control-Allow-Origin' header is present on the requested resource.
なぜ正しくリクエストが送れていないのか?
結論
Nuxt側(フロント側)からそのままURIを指定してしまうと CORSの制限がかかっているため 正しくリクエストが送れていないCORSとは
オリジン間リソース共有Cross-Origin Resource Sharing (CORS) は、追加の HTTP ヘッダーを使用して、あるオリジンで動作しているウェブアプリケーションに、異なるオリジンにある選択されたリソースへのアクセス権を与えるようブラウザーに指示するための仕組みです。
ウェブアプリケーションは、自分とは異なるオリジン (ドメイン、プロトコル、ポート番号) にあるリソースをリクエストするとき、オリジン間 HTTP リクエストを実行します。MDNより抜粋
CORS (オリジン間リソース共有) の問題を解決する
Nuxt公式ページに書いてある方法をそのまま実施します
※ 公式ページではnpmでインストールしていますが、今回はyarnで開発しているので下記コマンドを使います(npmやyarnのコマンドについてはこちらも参照ください)// @nuxtjs/proxyのインストール $ yarn add @nuxtjs/proxyapp/nuxt.config.jsmodules: [ '@nuxtjs/axios', '@nuxtjs/proxy' ], proxy: { '/api': { target: 'http://localhost:3000', pathRewrite: { '^/api' : '/api/v1' } } },
pathRewriteの'^/api' : '/api/v1'の記述は、 @nuxtjs/proxyのgithubを参考にしています上記では、vue側でリクエストとして指定している
/apiがつく接頭辞を/api/v1にリライト(書き換え)て、http://localhost:3000に送ってね、と指定していますproxyやpathRewriteについての記述方法はこのサイトも参考になりました
Nuxt側の修正
上記でProxyを設定してCORSの問題を解決する設定をしたので、NuxtのファイルでリクエストをPOSTしている箇所を修正します
pages/index.vue// 上の部分は省略 methods: { postMessage() { const url = '/api/posts'; const post = { title: this.title, body: this.body, }; this.$axios.post(url, { post }) .then(res => console.log(res.status)) .catch(error => console.log(error)); }, } // 以下省略
const url = '/api/posts';と訂正する
※ Proxyの設定、pathRewriteの設定により、http://localhost:3000/api/v1/postsにリクエストして、と変換されるRails側の修正
api/app/controllers/api/v1/posts_controller.rb# 上の部分は省略 private def set_post @post = Post.find(params[:id]) end def post_params params.require(:post).permit(:title, :body) end end送られてくるパラメーターは、Nuxt側でこのようなオブジェクト型で指定しているため、
require(:post)をする必要があるpages/index.vueconst post = { title: this.title, body: this.body, };※このオブジェクト名がhogeだったら、
require(:hoge)となる

- 投稿日:2020-10-19T23:28:16+09:00
地味に大切だった命名規則。もう二度と間違えない!
はじめに
本日の学習で出会ったエラーが、今まででいちばん意外なところでのエラーだったので、忘れないために記録しておく。
命名規則
クラス名はアッパーキャメルケースで記述する。
アッパーキャメルケース:先頭の単語と、単語の区切りの頭の文字を大文字にする。
キャメルケース:先頭は小文字で、単語の区切りの頭の文字は大文字にする。
スネークケース:単語と単語の区切りをアンダースコア(_)で繋げる。クラス名→アッパーキャメルケース
変数名・メソッド名→スネークケース最後に
本日の学習では、処理の記述を何度見返しても、違いが見つからず、単語を繋げたクラス名をスネークケースで記述してしまい、クラスを読み取らないというエラーが出てしまった。
ちまみに、キャメルはラクダ。大文字のところが、コブってこと。アンダースコアは蛇に見えるか?
- 投稿日:2020-10-19T23:17:05+09:00
【Ruby】Your Ruby version is 2.6.3, but your Gemfile specified 2.5.8
はじめに
Rubyを触っていたときにタイトルのエラーが出たので記事にしました。
エラーとの遭遇
作成途中だったアプリを触っていたときに、
bundle installでエラーに遭遇。$ bundle install -> Ruby version is 2.6.3, but your Gemfile specified 2.5.8エラー文から、RubyのバージョンとGemfileが指定してるバージョンが違うんだろうなーと検討がつく。
対応したこと
まず、Rubyのバージョンを確認してみる。
$ ruby -v -> ruby 2.5.8p224 (2020-03-31 revision 67882) [x86_64-darwin19]rbenvを使用しているので、そちらでも確認
$ rbenv versions system 2.1.5 2.5.1 * 2.5.8 2.6.3 2.7.1見た感じは合ってるっぽい。
今使っているRubyのパスを参照したりできる
gem environmentで確認してみよう。$ gem environment -> RubyGems Environment: - RUBYGEMS VERSION: 2.7.6.2 - RUBY VERSION: 2.5.8 (2020-03-31 patchlevel 224) [x86_64-darwin19] - INSTALLATION DIRECTORY: /Users/username/.rbenv/gems/2.5.0 - USER INSTALLATION DIRECTORY: /Users/username/.gem/ruby/2.5.0 - RUBY EXECUTABLE: /Users/username/.rbenv/versions/2.5.8/bin/ruby - EXECUTABLE DIRECTORY: /Users/username/.rbenv/gems/2.5.0/bin - SPEC CACHE DIRECTORY: /Users/username/.gem/specs - SYSTEM CONFIGURATION DIRECTORY: /Users/username/.rbenv/versions/2.5.8/etc - RUBYGEMS PLATFORMS: - ruby - x86_64-darwin-19 - GEM PATHS: - /Users/username/.rbenv/gems/2.5.0 - GEM CONFIGURATION: ...(続く)うーん、間違ってなさそう...
解決した方法
bundle の配置場所を確認してみる
$ which bundle -> /usr/local/bin/bundle中身を見てみる
-> % cat /usr/local/bin/bundle #!/System/Library/Frameworks/Ruby.framework/Versions/2.6/usr/bin/ruby # # This file was generated by RubyGems. # # The application 'bundler' is installed as part of a gem, and # this file is here to facilitate running it. # require 'rubygems' version = ">= 0.a" str = ARGV.first if str str = str.b[/\A_(.*)_\z/, 1] if str and Gem::Version.correct?(str) version = str ARGV.shift end end ...(続く)あ、
/System/Library/Frameworks/Ruby.framework/Versions/2.6/usr/bin/rubyを参照しているぞ...$ which ruby /Users/username/.rbenv/shims/ruby参照先を
/Users/username/.rbenv/shims/rubyに変更。無事
bundle installが通りました!参考記事
https://qiita.com/h5y1m141@github/items/74029cab9706971c8dbe
- 投稿日:2020-10-19T23:03:34+09:00
pluckメソッドとは
今回、pluckメソッドについて学習したため、アウトプットいたします。
pluckメソッドとは?
その使い方とは?について記述いたします。
pluckメソッドとは?
pluckメソッドとはこう書かれています。
「引数に指定したカラムの値を配列で返すメソッド。」同様の効果のあるメソッドとしてmapメソッドが上げられますが、返り値を配列として取得する場合は、pluckメソッドを使った方がシンプルで楽です。
では実際に使ってみましょう。
使い方
usersテーブルのnameカラムに"田中", "吉田", "鈴木", "高橋"の4人が入っていたとする。
そこで、userテーブルのnameカラムだけ取得したい場合、pluckメソッドは力を発揮するUser.pluck(:name) #すると以下のような処理がされる SELECT `users`.`name` FROM `users` => ["田中", "吉田", "鈴木", "高橋"] # 返り値このようにテーブルやデータベースに登録された情報を配列としてまとめて取得したい場合にとても便利です。
- 投稿日:2020-10-19T19:38:42+09:00
Railsで開発する際の準備
はじめに
Railsで開発をする際、コードを書き始めるところまでの準備を書いていきます。
VirtualBox、Vagrantを既にインストールしている状態で話を進めます。
まだVirtualBox、Vagrantのインストールが終わってない場合は、Googleで検索してみてください。目次
- Vagrantの初期設定
- Vagrantの起動
- 仮想環境への接続
- 仮想環境の共有フォルダへ移動
- Ruby on Railsでの開発を始める
- 作業終了時
- 終わりに
1. Vagrantの初期設定
まず、ターミナルでデスクトップに移動する。
$ cd Desktopそして、「work」という名前のフォルダを作成し、そのフォルダに移動する。
$ mkdir work $ cd workその後、「work」というフォルダ内に、「vagrant」というフォルダ名を作成し、そのフォルダに移動する。
$ mkdir vagrant $ cd vagrantこの「vagrant」というフォルダ内で、Vagrantfileを作成する。
$ vagrant initこれでVagrantの初期設定は終わりになります。
下記のようになっていることを、ターミナルで確認してください。ユーザー名:vagrant ユーザー名$2. Vagrantの起動
続いて、Vagrantを起動していきます。
ここから先は、開発をしていく際に毎回行う作業になってくるかと思います。Vagrantの起動は簡単です。
以下のコマンドを打ちましょう。$ vagrant up一番初めの起動は、ものすごく時間がかかります。
ご飯を食べて、お風呂に入れるかもしれません。
もしかしたら、映画を1本見れるかもしれません。
そのくらいのことをしていたら、気づいたときには終わっていると思います最初の起動が完了すると、
下の方に、
Your now on Rails!という言葉と共に、
汽車の絵のようなものがあらわれます。
これでVagrantの起動が完了しました。
※ 2回目以降のVagrantの起動は数秒で終わります。
飲み物を飲む程度のことはできるかもしれません3. 仮想環境への接続
自分のPCと仮想環境に安全に通信するために「SSH接続」を行います。
以下のコマンドを打ちましょう。$ vagrant ssh正しく接続されると
[vagrant@localhost ~]$このように表示されます。
これで仮想環境への接続が完了しました。
4. 仮想環境の共有フォルダへ移動
仮想環境内の共有フォルダは、
/home/vagrant/workにあります。
ですので、その共有フォルダに移動します。[vagrant@localhost ~]$ cd /home/vagrant/work以下のように表示されると、移動できたことになります。
[vagrant@localhost work]$ここで、仮想環境から一旦ログアウトします。
以下のコマンドでログアウトができます。[vagrant@localhost work]$ exitこの結果、以下のように表示されれば、ログアウト完了です。
ユーザー名:vagrant ユーザー名$この状態で、次の「5. Ruby on Railsでの開発を始める」の作業に移ります。
5. Ruby on Railsでの開発を始める
Ruby on Railsで新規のアプリケーションを作成する際は
rails newコマンドを使用します。
「sample」というアプリケーションを作成する場合、以下のように打ちます。$ rails new sampleこのコマンドが正しく実行されると、sampleフォルダが共有フォルダ内に作成されます。
VScodeなどでファイルメニューの「開く」または、「Open」を選択し、
「デスクトップ」→「work」→「vagrant」→「sample」を選択して、
sampleフォルダを開きます。ここまでできたら、ターミナルでまたSSH接続をして仮想環境へ接続します。
ユーザー名:vagrant ユーザー名$ vagrant ssh以下のようになったら、仮想環境への接続が完了したことになります。
[vagrant@localhost ~]$それから、以下のコマンドを打ち、先ほど作成したsampleディレクトリに移動します。
[vagrant@localhost ~]$ cd /home/vagrant/work/sample「~」となっていた部分が「sample」となれば移動できたことになります。
[vagrant@localhost sample]$以上で、実際にコードを書き始めていくまでの準備が完了しました。
ここまで終われば、コードを書き始められます。お疲れ様でした。
6. 作業終了時
作業が終了し、パソコンを閉じる前には、毎回仮想環境からのログアウトと仮想環境のシャットダウンを行った方がよいかもしれません。
仮想環境のログアウトは「4. 仮想環境の共有フォルダへ移動」にも記載しましたが、もう一度。
[vagrant@localhost work]$ exitこのコマンドで、「SSH接続」されているところから、ログアウトすることができます。以下のようになればログアウト完了です。
ユーザー名:vagrant ユーザー名$次に、仮想環境のシャットダウンです。
以下のコマンドを打つとシャットダウンすることができます。$ vagrant halt仮想環境をシャットダウンし、また仮想環境を起動する場合は、
$ vagrant upからやり直してください。7. 終わりに
最後まで見ていただいた方、ありがとうございます。
実際には、忘れたときの未来の自分用に書きました。間違っているところがあれば、教えてくださると嬉しいです。
これからも、未来の自分のためと私の記事を偶然にも見つけてしまい、見てくれた方のために記事を書いていきたいと思います。
- 投稿日:2020-10-19T18:24:13+09:00
習得したい基本的なRailsコマンド
習得したい基本的なRailsコマンド
現場で使えるRuby on Rails 5 速習実践ガイドより 抜粋です。
コマンド名 説明 rails new app_name 新規Railsアプリ作成 rails new app_name -m
https://raw.github.com/
Atelier-Mirai/rengeso/
main/rengeso.rb雛型からRailsアプリ作成 rails -h Railsのヘルプを表示 rails -v Railsのバージョンを表示 rails s サーバー起動 rails s -p 3001 別サーバー起動 rails c コンソール起動 rails c -s コンソール起動 (サンドボックス) rails db データベースコンソール起動 show-routes --grep user (コンソール内で実行)
userに関するルーティングを表示show-model User (コンソール内で実行)
Userモデルの属性表示rails g migration
CreateBooks title:string describe:textマイグレーションファイルの雛型作成 rails g model Book title:string describe:text モデル (とマイグレーションファイル)の雛型作成 rails g controller Books index new create コントローラ (とビュー、ヘルパー
アセット、テストファイル)の雛型作成rails g scaffold Book title:string describe:text モデル、コントローラなど一式作成 rails d scaffold Book モデル、コントローラなど一式削除 rails db:create データベース作成 rails db:drop データベース削除 rails db:migrate マイグレーションファイル実行 rails db:seed db/seed.rbによりデータを投入 rails r sample.rb Rubyコードの実行。
モデル利用のバッチ処理などに活用。rails stats Railsアプリの各種統計表示 参考
- 投稿日:2020-10-19T17:53:49+09:00
Rails 新規アプリケーション作成の基本
新規アプリケーション作成の基本
今回はruby on railsで新規アプリケーションを立ち上げる際の基本をまとめておこうと思います。
前提としてrailsのバージョンは6.0.0でデータベースはMySQLというツールを用います。
新規アプリの準備
# ディレクトリの移動 % cd ~/アプリを作成したいディレクトリ名 # 新規アプリを作成(chochikuというアプリ名)、-dオプションでMySQLの使用を明示して作成 % rails _6.0.0_ new chochiku -d mysql # 作成したchochikuのディレクトリに移動 % cd chochiku以上のコードをターミナルに打つことで新規アプリケーションが立ち上がります。
データベースの作成
コマンドを利用してアプリのデータベースを作成しますが、その前にデータベースに関する設定を少しする必要があります。
データベースに関する設定はdatabase.ymlに記述します。
database.ymlのdefaultの下のencoding: utf8mb4という記述を
encoding: utf8に変更しますそして以下のコマンドを実行すればデータベースの作成を行います
※必ず自分の作るアプリのディレクトリでコマンドを実行してください!% rails db:createモデルの作成
railsのアプリケーションにはデータベースとやりとりをするモデルが必要になります。
# Expenseモデルを作成 % rails g model expenseテーブルの作成
マイグレーションファイルの編集
上記のモデルを作成した時、同時にマイグレーションファイルがdb/migrateというディレクトリに生成されます。
このマイグレーションファイルを編集してテーブルに保存する情報を決定します。class CreateExpenses < ActiveRecord::Migration[6.0] def change create_table :expenses do |t| t.string :name t.integer :shuppi t.timestamps end end end例えばt.string :nameというコードはstring型でnameというカラムをテーブルに追加しているということです。
マイグレーションの実行
マイグレーションファイルを編集しただけではテーブルについて変更を加えたことにはなりません。そこでマイグレーションの実行をする必要があります。
以下のコマンドを実行することでマイグレーションを実行することができます。% rails db:migrateまとめ
以上でアプリの一つのモデルとそのモデルに紐づくテーブルを作ることができました。
実際にはこれからこのモデルに紐づくコントローラーやルーティング、ビューを作っていくことでアプリを作ることになります。
新規アプリ作成の基本としてはとりあえずここまでですm
- 投稿日:2020-10-19T16:14:14+09:00
保存された状態で同じ画面に遷移したい
【概要】
1.結論
2.どのようにコーディングしたか
3.開発環境
補足
1.結論
redirect_to "/XXXX/#{@@@@@.XXXX.id}"とコーディングする!
2.どのようにコーディングしたか
def create @comment = Comment.new(comment_params) if @comment.valid? @comment.save redirect_to "/reports/#{@comment.report.id}" endreportという投稿に、さらにその投稿にコメントを付け加えることができるアプリです。その際に、reportの投稿にコメントを付け加え終わった後にrootで最初の画面に戻っても良いと思います。しかし、ちゃんとコメントが残っているかの確認も含めてコメントを投稿する画面に戻したいのでこのようなコーディングになりました。
3.開発環境
Mac catalina 10.15.4
Vscode
Ruby 2.6.5
Rails 6.0.3.3
補足
redirect_to report_path(id: current_user) #devise gemを使用。としても一応エラーは起きませんが、current_userなので、1番目に登録したのであれば/reports/1という風になってしまい、2番目に投稿したreportとは違う1番目のreportに戻されるので注意が必要です。
- 投稿日:2020-10-19T15:52:38+09:00
三項演算子について
アプリケーションを作成するにあたり三項演算子について学んだので備忘録として残しておきます。
三項演算子とは
「if ~ else ~」を一文で書きたいときに使う演算子
例) (結果は同じ)
①if〜elseで記述if hoge == 3 "true" else "false" end②三項演算子を利用hoge == 3 ? 'true' : 'false'
条件1 ? 条件1が正しいとき : 条件1が正しくないときで使用する便利そうではあるが式が複雑になるとわかりづらくなりそうなため、うまく使い分けることが大切ではないだろうか。
Rubyのリファレンスには条件演算子で載っておりrailsドキュメントには三項演算子で載っている。
調べてみたところ違いはなさそう。参考記事
- 投稿日:2020-10-19T15:15:33+09:00
[rails]DBのカラムの順番を変更したい時に便利なafterオプション
概要
テーブルに新たなカラムを追加して、Sequel Pro等を使って確認する時、新しく追加したカラムが一番最後に表示されて見辛いという経験があり、直す方法について調べてみました。
例
特に何も指定せずにカラムを追加すると、この図のように、新しく追加したカラム(total_price, is_cancel)がupdated_atの後ろに配置されてしまいます。
afterオプション
migration.rbclass AddColumnToOrders < ActiveRecord::Migration[6.0] def change add_column :orders, :total_price, :integer, null: false, after: :user_id add_column :orders, :is_cancel, :boolean, null: false, default: 0, after: :total_price end endこのように、afterオプションを使って、新しく追加するカラムをどのカラムの後に置きたいか指定することができます!
user_idカラムの横に新しいカラムを配置することができました。参考


- 投稿日:2020-10-19T12:17:34+09:00
rails-erd はどうやってエンティティや関連づけ情報を取得しているのか
はじめに
ERD を自動生成しようと思い rails-erd を触り始めたのですが、いい感じに関連付けなどを表現してくれるので、どのようにして関連付けを取得しているのかなー?と思い、調べてみた内容を記載しています。
と、本題に入る前に自分がすごいと思う rails-erd の特徴を述べさせてください?♂️
本題のスタートは こちら です。私の考える rails-erd のすごい特徴3つ
1. バリデーションから必須の判定を行ってくれる
ERD から素早くドメインロジックを理解するには、エンティティ間の関係性が正確に記述されている必要があります。1対1なのか、1対多なのか、多対多なのかは必須の情報ですよね。そして、そこにプラスで「必須かどうか」の情報があると私としてはすごく理解が早まります。rails-erd は必須のバリデーション(
presence: true)を設定していれば、必須と判定してくれます!ありがたい。ドキュメントにもしれっと以下のように記載されています。
properties are automatically determined based on your validators and non-nullable foreign keys.
訳)プロパティは、バリデータと NOT NULL な外部キーに基づいて自動的に決定されます。
2. 単一テーブル継承やポリモーフィックを理解できる
rails-erd では単純な関連付けだけではなく、単一テーブル継承やポリモーフィックも表現させることができます。ドメインロジックを理解する上で重要な情報なので、ERD から確認できると便利ですよね。スキーマ情報を解析して生成される ERD では表現するのが難しいですが、rails-erd はリフレクションと呼ばれるしくみを利用しているため、メタプログラミングで書かれたコードでも理解できるそうです。
Rails ERD uses reflection instead of static analysis, it even recognises meta-programmed associations.
訳)Rails ERDは静的分析の代わりにリフレクションを使用しており、メタプログラムされた関連付けも認識します。
3. カスタマイズが簡単らしい
Another goal of Rails ERD is to be so extensible that it's the last diagramming tool for Active Record models that you'll ever need. If the standard output is unsatisfying, it shouldn't be a reason to have to switch to a different tool.
訳)Rails ERDのもう一つの目標は、Active Record モデルのための最終的なダイアグラムツールとして選ばれるほど拡張性が高いことです。
Rails を使うユーザーが最終的に行き着くダイアグラムツールを目指しているということなのですが、なんと rails-erd は出力するダイアグラムツールを変更することが可能なんです。Customise ページ には、yuml というダイアグラムツールで出力する例が記載されています。もっと見やすくビジュアライズしてくれるツールがあれば、そちらに乗り換えるという選択ができるわけです。
ソースコードを読む
ここからが本題です。ソースコードを追っていきながら読み解いていきます。
代表的なクラスの紹介
最初に、rails-erd の代表的なクラスについて紹介します。
Class名 役割 RailsERD::Domain Rails のドメインモデルを表す。ここがモデル情報のスタート地点。 RailsERD::Domain::Entity エンティティ。ActiveRecord のモデルを表す。 RailsERD::Domain::Attribute エンティティの属性(カラム情報)を表す。 RailsERD::Domain::Relationship エンティティ間の関連付けを表す。 RailsERD::Domain::Specialization エンティティの特殊な関連付け(単一テーブル継承やポリモーフィックなど)を扱う。 RailsERD::Diagram 図の作成を簡単にするための抽象クラス RailsERD::Diagram::Graphviz Graphviz ベースの図を作成するためのクラス ※ RailsERD::Diagram, RailsERD::Diagram::Graphviz クラスは、 RailsERD::Domain から取得される情報を元にダイアグラムを作成するクラスになるので、この記事ではこれ以上は触れません。
RailsERD::Domain クラス
RailsERD::Domain がドメインモデルのスタートです。以下のように扱うことができます。
require "rails_erd/domain" # Rails のモデルやコントローラなどを全てロードする Rails.application.eager_load! domain = RailsERD::Domain.generate # 全てのエンティティを返す domain.entities # エンティティの属性を返却する domain.entities.first.attributes # 全ての関連づけを返す domain.relationships # 全ての特殊情報を返す domain.specializationsRailsERD::Domain.generate は何を行っているのか
class Domain class << self def generate(options = {}) new ActiveRecord::Base.descendants, options end end def initialize(models = [], options = {}) @source_models, @options = models, RailsERD.options.merge(options) end endここでは
ActiveRecord::Base.descendantsを@source_modelsに格納して、インスタンスを返しています。descendantsは全ての下位クラスを返すメソッドなので、ActiveRecord::Base.descendantsは全てのモデルを返します。実はこれがドメインモデル情報の大元になっています!entities, relationships, specializations メソッドでは何をやっているのか
def entities @entities ||= Entity.from_models(self, models) end def relationships @relationships ||= Relationship.from_associations(self, associations) end def specializations @specializations ||= Specialization.from_models(self, models) endEntity, Relationship, Specialization の各クラスからそれぞれ情報を取って来て返却しています。それぞれのクラスでどのように情報を取ってきているか見ていく必要がありますね。
引数に渡される models と associations
ここで、
modelsとassociationsが新しく出てきたので、どのような内容が入っているのか確認します。def models @models ||= @source_models.select { |model| check_model_validity(model) }.reject { |model| check_habtm_model(model) } end def associations @associations ||= models.collect(&:reflect_on_all_associations).flatten.select { |assoc| check_association_validity(assoc) } end
modelsは@source_modelsから妥当なモデルのみを抽出して返却してます。詳細は割愛しますが、モデルに名前がついているか、has_and_belongs_to_many の関連性などで選別しているようです。そして、
associationsはmodelsで取得した各モデルに対してreflect_on_all_associationsメソッドを実行した結果から、association として妥当なものを抽出しています。reflect_on_all_associationsという聴き慣れないメソッドが出て来ましたので、ドキュメント を読んでみます。Returns an array of AssociationReflection objects for all the associations in the class.
訳)クラス内のすべてのアソシエーションについて、AssociationReflectionオブジェクトの配列を返します。
出て来ました、
AssociationReflectionというワード。rails-erd は静的解析せずにこのリフレクションという機能を使っているので、動的に生成されたモデルでも検知できるとのことだったのですが、AssociationReflection とは一体何者なのでしょうか。ドキュメント の概要には以下のように記載されていました。Holds all the metadata about an association as it was specified in the Active Record class.
訳)Active Record クラスで指定されたアソシエーションに関するすべてのメタデータを保持します。
関連付けに関する情報全てを管理するクラスのようですね。どうやらこのリフレクションが関連付けの親玉のようです。
イメージがつきやすいように、実際に reflect_on_all_associations メソッドを実行してみました。User → Profile に has_one、User → Cat に has_many の関連づけを持っている時は以下のようなデータが返って来ます。
> User.reflect_on_all_associations => [ #<ActiveRecord::Reflection::HasManyReflection:0x00007f8147a6ba60 @name=:cats, @scope=nil, @options={}, @active_record=User(id: integer, name: string, email: string, created_at: datetime, updated_at: datetime), @klass=nil, @plural_name="cats", @type=nil, @foreign_type=nil, @constructable=true, @association_scope_cache=#<Concurrent::Map:0x00007f8147a6b7b8 entries=0 default_proc=nil>>, #<ActiveRecord::Reflection::HasOneReflection:0x00007f8142b01470 @name=:profile, @scope=nil, @options={}, @active_record=User(id: integer, name: string, email: string, created_at: datetime, updated_at: datetime), @klass=nil, @plural_name="profiles", @type=nil, @foreign_type=nil, @constructable=true, @association_scope_cache=#<Concurrent::Map:0x00007f8142b00f98 entries=0 default_proc=nil>> ]User クラスがどのような関連づけを持っているのか返って来ました。なるほど?
ここから ERD で表現する関連付けやカーディナリティ情報を取得して来ていたんですね。ここからは、RailsERD::Domain のサブクラスを見ていきます。
RailsERD::Domain::Entity クラス
Entity.from_models(self, models)が何をやっているのかを見ていきます。class Entity class << self def from_models(domain, models) (concrete_from_models(domain, models) + abstract_from_models(domain, models)).sort end private def concrete_from_models(domain, models) models.collect { |model| new(domain, model.name, model) } end def abstract_from_models(domain, models) models.collect(&:reflect_on_all_associations).flatten.collect { |association| association.options[:as].to_s.classify if association.options[:as] }.flatten.compact.uniq.collect { |name| new(domain, name) } end end end
from_modelsメソッドでは、concrete_from_modelsとabstract_from_modelsから取得して来たエンティティをソートしているだけですね。そして、concrete_from_modelsでは models から Entity クラスのインスタンスを作成しており、abstract_from_modelsでは models から先ほど出て来た AssociationReflection オブジェクトを取得し、options[:as]から Entity クラスのインスタンスを作成しています。options[:as]はポリモーフィック関連を定義するときなどに出てくる、あのasです。class User < ApplicationRecord has_many :posts, as: :postable # <- これ endRailsERD::Domain::Attribute クラス
次に
domain.entities.first.attributesが何をやっているかを見ていきます。Entity クラスでは以下のように
attributesメソッドを定義しています。class Entity def attributes @attributes ||= generalized? ? [] : Attribute.from_model(domain, model) end end
generalized?は抽象クラス、もしくはポリモーフィックの場合に true になるようです。つまり、抽象クラス、もしくはポリモーフィックの場合は属性はなく、それ以外の時は Attribute クラスから属性を取得してきています。Attribute クラスを見てみます。
class Attribute class << self def from_model(domain, model) attributes = model.columns.collect { |column| new(domain, model, column) } # 一部省略 attributes end end end
from_modelメソッドではカラムを取り出して、そのカラムごとに Attribute クラスのインスタンスを返しています。対象となるカラムがプライマリーキーなのか、ユニークなのか、外部キーなのかなどの情報も Attribute クラスのインスタンスメソッドとして定義されています。詳細は割愛しますが、モデルが持つプライマリーキー情報や、バリデーション情報、後ほど出てくる関連付け情報などから判定していました。
RailsERD::Domain::Relation クラス
Relationship.from_associations(self, associations)が何をやっているかを見ていきます。class Relationship class << self def from_associations(domain, associations) assoc_groups = associations.group_by { |assoc| association_identity(assoc) } assoc_groups.collect { |_, assoc_group| new(domain, assoc_group.to_a) } end private def association_identity(association) Set[association_owner(association), association_target(association)] end # association_owner, association_target は省略 end end
from_associatioonosでは、まず引数で受け取った associations をどのクラス間の関連付けなのかでグループ分けしています。例えば、User → Cat に has_many、Cat → User に belongs_to の関連付けがある場合、それらは一つのassoc_groupと見なされます。そして、そのように分けられたグループごとに、Relationship クラスのインスタンスにして返却しています。カーディナリティの判定
では、具体的にカーディナリティをどのように判定しているかを見ていきます。細かな条件等はありますが、筆者がカーディナリティの判定において重要だと思うソースコードを抜粋しました。
def association_minimum(association) minimum = association_validators(:presence, association).any? || foreign_key_required?(association) ? 1 : 0 # 一部省略 end def association_maximum(association) maximum = association.collection? ? N : 1 # 一部省略 end例えば、
association_minimumの値が 1 かつ、association_maximumの値が 1 の場合は、「必ず1つ持つ」という関係性になり、association_minimumの値が 0 かつ、association_maximumの値が N の場合は、「0以上の複数持つ」という関係性になります。
association_minimumメソッドは、presence バリデーションがある、もしくは外部キーが必須の場合 1 となり、それ以外では 0 です。一方、association_maximumメソッドはassociation.collection?の場合 N となり、それ以外は 1 となります。collection?は AssociationReflection クラスのインスタンスメソッドで、has_many もしくは has_and_belongs_to_many の場合に true を返します。こうやって判定していたんですね?RailsERD::Domain::Specialization クラス
最後に
Specialization.from_models(self, models)が何を行っているのか見ていきます。class Specialization class << self def from_models(domain, models) models = polymorphic_from_models(domain, models) + inheritance_from_models(domain, models) + abstract_from_models(domain, models) models.sort end end end
from_modelsメソッドでは単に、polymorphic_from_models,inheritance_from_models,abstract_from_modelsからモデルを取り出しているのみです。それぞれのメソッドも見ていきます。polymorphic_from_models
def polymorphic_from_models(domain, models) models.collect(&:reflect_on_all_associations).flatten.collect { |association| [association.options[:as].to_s.classify, association.active_record.name] if association.options[:as] }.compact.uniq.collect { |names| new(...省略) } end複雑なことをしているように見えますが、AssociationReflection オブジェクトから、options[:as] がある時は、そのモデルと
asで指定したモデルを抽出しているといったところでしょうか。判定材料はasですね。inheritance_from_models
def inheritance_from_models(domain, models) models.reject(&:descends_from_active_record?).collect { |model| new(...省略) } end
descends_from_active_record?は STI タイプの条件が必要でない時 true、つまり STI タイプの条件が必要な時、false となるメソッドらしいです。ですので、それを reject で集めているので、STI タイプが必要なモデルのみを抽出しているということですね。abstract_from_models
def abstract_from_models(domain, models) models.select(&:abstract_class?).collect(&:direct_descendants).flatten.collect { |model| new(...省略)} end抽象クラスを抽出し、その抽象クラス直下のクラスを取り出しています。
このようにして特殊なモデルも取り出していたんですね。
まとめ
延々とソースコードを追っていきましたが、簡単にまとめます。
- 大元は ActiveRecord::Base.descendants から得られる全モデル
- 特に、関連付けに関する情報は reflect_on_all_associations メソッドを実行して得られる AssociationReflection オブジェクト から得ている
- エンティティ、カラムの情報(カラム名、PK, UK, FKなど)、関連付け、カーディナリティは、結局のところモデルと AssociationReflection オブジェクトからうまく情報を取り出して得ている
最後に
rails-erd のソースコードを読みながらどうやってエンティティや関連付け情報を取得しているかを見ていきました。調べてみて思ったことは、Rails がすでにモデルの情報や関連付けの情報などは用意してくれていて、rails-erd ではその情報を ERD を生成しやすいように加工しているだけなんだなということです。リフレクション機能に関してはあまり詳しくありませんが、Rails はモデルを操作する仕組みがよくできているなと思いました。
各クラスの細かいインスタンスメソッドについては説明を飛ばしたため、説明不足な部分も多いかと思いますが、
ActiveRecord::Base.descendantsが大元なんだなということだけでも伝われば幸いです。ソースコードもコメント多めでわかりやすく書かれているので、興味がある方は覗いてみてください。参考
- 投稿日:2020-10-19T11:36:33+09:00
【0からAWSに挑戦】EC2とVPCを使ってRailsアプリをAWSにデプロイする part3
EC2とVPCを使ってRailsアプリをAWSにデプロイする part3
前回の続きです。
↓↓↓↓前回の記事はこちら↓↓↓↓↓
①EC2とVPCを使ってRailsアプリをAWSにデプロイする part1
②EC2とVPCを使ってRailsアプリをAWSにデプロイする part2環境
・Ruby on Rails 6.0
・Ruby 2.6.6
・dbはmysqlを使用
・アプリケーションサーバはpumaを使用
・webサーバーはnginxを使用手順
前回は④までいきました。なので今回は⑤からやります
①VPCを作成
②VPC内にサブネットを作成
③インターネットゲートウェイ・セキュリティグループ・ルートテーブルの設定
④EC2を作成
⑤EC2にrails環境を構築、gitからアプリをpullする⑤EC2にrails環境を構築、gitからアプリをpullする
ⅰ. Railsに必要なものをインストール
sshでEC2サーバーにターミナルでアクセスできたので、そこにRails環境を整えます。PCに環境構築した時と同様のことをするだけです。ただ正直プログラミングを初めてばっかりの頃は、参考書やカリキュラムの言うがままに環境構築していたため、あまりRailsの環境の構築方法を理解していません。なので今回はいい機会なので、EC2と少し関係ないですが改めてRailsの環境構築について深ぼって学んでいきたいと思います。
まずRailsを動かすために必要なものをインストールします。インストールするべきものは下記に分類できます。
※今回はgitから既存のアプリをpullして動かします。
種類 今回の例 設定関連 yum, git etc ruby関連 rbenv, ruby 2.6.6 javascript関連 yarn, node.js サーバー関連 nginx,(puma) データベース関連 mysql では上から順にみていきましょう。
設定関連
ここは主にlinux関連の機能やパッケージをインストールします。この設定関連はOSによって違うので注意してください(Macで環境構築したことある方はhomebrewを使って設定します)。ここは正直覚えるよりも、毎回ググって必要なものを都度インストールする形で問題ないと思います。
今回はlinuxなので、linux上に必要なパッケージをインストールします。下記がコマンドです。ec2$ sudo yum -y update &&sudo yum -y install git \ make gcc-c++ patch \ libyaml-devel libffi-devel libicu-devel \ zlib-devel readline-devel libxml2-devel libxslt-devel \ ImageMagick ImageMagick-devel openssl-devel libcurl libcurl-devel curl少し長いですが説明します。
- 「sudo」は一時的にルート権限で実行するという意味です
- 「-y」はyesの意味です。インストールの際「yes or no」の質問と聞かれますが、それを自動でyesと答えます。
- 「yum」はLinuxのパッケージ管理ツールです。ルビー勉強している方なら、linuxOS界のbundlerと思ってください。
- 「git」はご存知の通りバージョン管理ツールです
- 「yum」コマンドのあとupdate,installと続きます。updateによってyumのパッケージを最新版にしてから、インストールするという流れです。updateを先にしないと古いバージョンのパッケージがインストールされる可能性があります。
- 「make gcc-c++ patch」ここはコンパイラの設定です。コンパイラとはプログラミング言語を機械の言語に翻訳することです。ここでは「gcc-c++」というコンパイラパッケージについて、「patch」コマンドで基から備わっているコンパイラパッケージとの差分をとり、新しいファイルを生成するという意味です。
- 「libyaml-devel libffi-devel libicu-devel zlib-devel readline-devel libxml2-devel libxslt-devel」 は共通点が多いです。「lib-」は基本的にライブラリを差します。「devel」は開発するためのファイルの意味です。例えば「libyaml-devel」では開発に必要なyamlファイルに関するライブラリのインストール、 「libffi-devel」は外部関数インターフェースという開発に必要なライブラリをインストールします。他の説明は割愛しますが、基本的にOS付近・すなわち機械に近いところで働く必要機能をインストールしています。
- 「ImageMagick ImageMagick-devel openssl-devel libcurl libcurl-devel curl」も基本的には開発に必要なライブラリをインストールしています。「ImageMagic」関連は画像形式に関するライブラリ、「openssl」はc言語で書かれた基本的な暗号等に関するライブラリ、curlはデータ転送に関するライブラリです。
もしかしたら覚える必要も、深く理解する必要もないものかもしれませんが、1つ1つ見ていくと面白いですね。裏ではC言語が活躍してることが多いのも1つ発見です。
ruby関連
rbenvとruby(任意のバージョン)をインストールします。rbenvはrubyのバージョンを簡単に切り替えたり、管理できたりするツールです。早速インストールしましょう。下記コマンドを上から順にインストールします。
ec2$ git clone https://github.com/sstephenson/rbenv.git ~/.rbenv $ echo 'export PATH="$HOME/.rbenv/bin:$PATH"' >> ~/.bash_profile $ echo 'eval "$(rbenv init -)"' >> ~/.bash_profile $ source .bash_profile $ git clone https://github.com/sstephenson/ruby-build.git ~/.rbenv/plugins/ruby-build $ rbenv rehash $ rbenv install -v 2.6.6 $ rbenv global 2.6.6 $ rbenv rehashこちらも少し長いですが説明します。
- 1行目の「git clone ~」でrbenvをインストールします
- 2行目は、パスを通しています。パスを通すとは、簡単に言うといつどこからでもコマンドが実行できるようにメモしておくことです。「echo」コマンドは環境変数を出力,「export」は環境変数の設定、「PATH=HOME/.rbenv/bin:$PATH」は新たに,「.rbenv」を加えたパスを定義しています。つまり2行目は「bash_profileというシェルに、新たにrbenvを定義したパスを設定するという意味です」
- 3行目もパスに関する記述です。「eval」は文字列を実行するコマンドです、「rbenv init」はshimsとautocompletionの有効化です。もっと砕けていうとバージョンの切り替えや管理のために必要なコマンドです。つまり3行目は「rbenv init(バージョンの管理・切り替え)のために必要なファイルを有効化し、パスに反映させる」といった意味です。
- 4行目の「source .bash_profile」で2~3行目の変更を反映させます。
- 5行目は「ruby-build」をインストールしています。「ruby-build」とは異なるrubyのバージョンをインストールするためのプラグインです。これをインストールすることで「rbenv install」コマンドが実行できます。
- 6行目の「rbenv rehash」をすることによって、「/.rbenv/shims/」以下で各ファイルが実行できるようになります。 さきほど「shims」は先程でましたね。とバージョンの切り替えを管理してくれるファイルです。つまり「rbenv rehash」によって、いままで設定したファイルのバージョンの簡単に管理できるように設定しています。
- 7行目はrubyの2.6.6をrbenvを使ってインストールしています。
- 8行目はシステム全体に「rubyのこのバージョンを使うよ」というのを伝えています
- 最後は「rbenv rehash」です。6行目と同じです。
以上でRubyのインストール関連は終わりです。もしアプリをこれから作る場合だとここから、「bundler」や「gem rails6.0」をインストールする必要があります。
javascript関連
ここはRails6.0になって大きく変わった場所ですので気をつけましょう。下記のコマンドを打ちます。
ec2$ sudo curl -sL https://rpm.nodesource.com/setup_10.x | sudo bash - $ sudo yum -y install nodejs $ sudo yum -y install wget $ sudo wget https://dl.yarnpkg.com/rpm/yarn.repo -O /etc/yum.repos.d/yarn.repo $ sudo yum -y install yarn
- 1行目でnode.jsのデータをシェルに転送しています。「-sL」はオプションで、進捗状況を非表示にする・リダイレクトを有効化するという意味です。
- 2行目で、1行目で送られたデータをインストールしています
- 3行目は「yum」で「wget」をインストールしています。「wget」はURLからファイルを指定してダウンロードするコマンドです。※設定関連の際にまとめてダウンロードしたほうが良かったかもしれません
- 4行目はwgetを使って指定URLのyarnを取得しています。
- 5行目は4行目で取得したデータをインストールしています。
少しjavascript関連の知識を整理すると,nodejsはサーバーサイドで動くjavascriptで、yarnがnodejsのパッケージマネージャです。(※nodejsのパッケージマネージャにはnpmもあります)。また今回はgitから既存のアプリをpullするので実行していませんが、rails6.0ではwebpackerもインストールする必要があります。webpackerはモジュールパンドラーといって、javascriptや画像ファイルをまとめてくれるものです。
サーバー関連
今回はwebサーバーは「nginx」、アプリケーションサーバは「puma」を使います。「puma」はrails標準装備ですのでインストールは不要です。「puma」ではなく「unicorn」を使う場合は、別途インストールが必要です。では下記コマンドを入力します。
ec2sudo yum install nginx
- 1行だけです。こちらでnginxのインストールは完了です。
サーバー周りはインストールは簡単ですが、後ほどやる設定周りが大変なのです。
データベース関連
今回はmysqlを使用します。下記コマンドを入力してください。
ec2$ sudo yum install http://dev.mysql.com/get/mysql80-community-release-el7-11.noarch.rpm $ sudo yum install mysql-community-server $ sudo yum install mysql-devel
- 1行目でmysqlのファイルをインストールしています。「mysql80」の箇所でバージョンを指定しています。
- 2行目でmysqlのサーバに関する設定をインストールしています
- 3行目はmysqlサーバを操作するための設定のインストールです
いずれか1つでもかけると、DB設定時にエラーが起こるので気をつけましょう。自分はDB関係のエラーで死ぬほど悩まされました。
以上ですべてのインストールが完了しました。
ⅱ. gitから既存アプリをpullする
githubとEC2を連携するために、EC2で鍵を発行し、それをgithubで登録する必要があります。なので下記コマンドを入力します
EC2$ ssh-keygen -t rsa -b 4096 $ cat ~/.ssh/id_rsa.pub
- 1行目で鍵を発行します。「-t rsa」はどんなキーペアを作成するか(今回はrsaを使います)、「-b 4049」は鍵の長さをビット数で表記しています。
- 2行目で先程作成した鍵ファイルを表示しています。「cat」はファイルの中身を簡単にみれるコマンドです。
では作成した鍵をgithubに登録しましょう。以下のURLから、先程の鍵を登録します。名前をつけてコピペするだけです。
github-sshキー登録
以下のようにコマンドをうち、successfullyがでたら成功です。EC2$ ssh -T git@github.com You've successfully authenticated, but GitHub does not provide shell access.あとは「git clone」するだけです。ただホームディレクトリ上にrailsファイルを置くと少し不都合があるので、新しいディレクトリをつくります。場所は「/var/www/自分のアプリケーション名」にします。なので「www」上で「git clone」しましょう。
※ちなみにvarフォルダとはlinux上で元から用意されているフォルダです。一時的なログなどをいれるフォルダですが、tmpフォルダと異なりデータは残り続けます。EC2/var/www/ $ git clone http ・・・以上でgitから既存のアプリをプルすることに成功しました。
ⅲ. ファイルの設定
やっと最後です。データベースやweb・アプリケーションサーバが動くようにファイルを編集しましょう。ここはインストール内容やバージョンによって異なり、エラーがでやすいので注意が必要です。
データベース関連の設定
まずmysqlの設定をします
EC2$ sudo service mysqld restart $ sudo cat /var/log/mysqld.log | grep password $ mysql -u root -p (mysql内) mysql > ALTER USER root@localhost IDENTIFIED BY '{自分の設定したいパスワード}';
- mysqlにはデフォルトでパスワードがかかっていることが多いので、デフォルトのpasswordを確認します
- 先程のパスワードを使って、ルートユーザーでログインします(2行目入力語にパスワードを聞かれる)
- デフォルトのパスワードを変更します
上記の設定だけでも基本よいのですが、場合によってはroot@localhostを作り直したり,mysqlの8.0バージョンを使っている方は認証方法の変更が必要です。前者のroot@localhostを作り直しに関しては、たまにですがこのあと本番環境でアクセス拒否される場合があります。その場合はroot@localhostを作り直すか、新しいユーザーを作るなどをして対応します。後者のmysqlの8.0バージョンの場合は、本番環境アクセス時に認証エラーがでるかと思いますので、rootユーザー(もしくは使用中のユーザー)の認証方式を変更してください。参考記事を書きに添付します。
【参考】mysqlユーザーrootとしてログインできません
【参考】MySQL8.0.17の認証プラグインを変更する次にconfig/database.yamlを以下のように設定します
config/database.ymlproduction: <<: *default database: webapp_production username: root password:本番環境なので「production」以下に書きましょう。以上でDBは終わりですが、DBはエラー起きやすいので気をつけてください。ログも確認しましょう。
サーバ関連の設定
nginxとpumaの設定です。こちら以前dockerで開発環境構築した際に結構触れたので今回は簡単に説明します(前回のdockerの記事)。
では始めます。新規にファイル作成する必要がある場合もあるので気をつけてください。まず下記のファイルを作成し、編集しましょう。大部分はフォーマットがネットに転がっています。ただIPアドレスやアプリ名は自分用に変える必要があります。/etc/nginx/conf.d/{自分のアプリ名}.conf# log directory error_log /var/www/rails/webapp/log/nginx.error.log; access_log /var/www/rails/webapp/log/nginx.access.log; # max body size client_max_body_size 2G; upstream app_server { # for UNIX domain socket setups server unix:/var/www/rails/webapp/tmp/sockets/puma.sock fail_timeout=0; } server { listen 80; server_name ElasticIP; # nginx so increasing this is generally safe... keepalive_timeout 5; # path for static files root /var/www/rails/webapp/public; # page cache loading try_files $uri/index.html $uri.html $uri @app; location @app { # HTTP headers proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for; proxy_set_header Host $http_host; proxy_redirect off; proxy_pass http://app_server; } # Rails error pages error_page 500 502 503 504 /500.html; location = /500.html { root /var/www/rails/webapp/public; } }また編集後に権限の変更も必要です
EC2(/var/libに移動) $ sudo chmod -R 775 nginx (上記完了後にnginxを稼働させます) $ sudo service nginx startちなみにserviceコマンドはサイトによってsystemctlになっている場合がありますが、現状どちらかで動けば気にしなくよいです。
【参考】
Linuxのコマンド実行で使うserviceとsystemctlの違いとは何か?続いてpumaの設定です。こちらもネットにあるテンプレで基本大丈夫です。ただ「 port ENV.fetch("PORT") { 3000 }」の記述がある場合は削除するように気をつけましょう。
config/puma.rbthreads_count = ENV.fetch("RAILS_MAX_THREADS") { 5 }.to_i threads threads_count, threads_count environment "RAILS_ENV" plugin :tmp_restart app_root = File.expand_path("../..", __FILE__) bind "unix://#{app_root}/tmp/sockets/puma.sock" stdout_redirect "#{app_root}/log/puma.stdout.log", "#{app_root}/log/puma.stderr.log", true以上で設定完了です。下記コマンドを実行しましょう
EC2$ sudo service mysqld start $ rake db:create RAILS_ENV=production $ rake db:migrate RAILS_ENV=production $ rails assets:precompile RAILS_ENV=production $ RAILS_ENV=production rails s
- 1行目でデーモン環境でmysqlを動かします
- 2行目と3行目でデータベースを本番環境で作成・反映しています。
- 4行目はファイルのプリコンパイルです。本番環境で画像,cssを正しく動かすのに必要です
- 5行目でpumaを起動しています
これでElasticIPにアクセスすればアプリケーションがみれるはずです。もしこれで映らなければpuma.socketファイルを削除、各ファイルの権限を確認してみてください。だいたいこれで解決できるはずです。
まとめ
自分は細かいところまで気になって調べたくなっちゃう体質なので、徹底的に調べました。もちろんまだわからないことがたくさんありますが、今回でだいぶ力ついた気がします。記事の長さはクリストファー・ノーランばりの大作になってしまいましたが、、、、
またAmaxonRDSを使ったり、本番環境でDockerを運用してみたり、その他AWS機能も実装頑張ってみたいと思います。参考
「Amazon Web Services 基礎からのネットワーク&サーバー構築 改訂3版 著 大澤文孝,玉川憲,片山暁雄,今井雄太」
→おすすめの本です。AWSだけでなくネットワーク知識についても触れているので、初学者にとっては神技術書です。(下準備編)世界一丁寧なAWS解説。EC2を利用して、RailsアプリをAWSにあげるまで
→こちらもわかりやすくてよかったです。AWSの内容は「Amazon Web Services 基礎からのネットワーク&サーバー構築」とほとんど同じです。なのでこちらだけでAWSやってみるのもありかと思います。ただネットワーク知識が浅い人やインフラ初心者は最初に「Amazon Web Services 基礎からのネットワーク&サーバー構築」にやってネットワーク知識補充しながらやらないと苦労すると思います※本記事は上記2つを参考にさせていただきながら実装しています。
なので実装に関しては類似箇所も多いかと思いますが、WEBサーバーの種類・DBのバージョンなどの構成などはもちろん自分なりにアレンジしています。
- 投稿日:2020-10-19T11:21:17+09:00
db:maigrate:resetでエラー
rails db:maigrate:resetがエラーになったとき
環境
Rails 5.2.4.4エラー内容
rails db:migrate:resetをした時にText file busy @ apply2filesのエラーが出た。解決法
rails db:migrate:resetは$ rm db/development.sqlite3 $ bin/rails db:setup
rails db:migrate:resetは$ rm db/development.sqlite3 $ bin/rails db:create db:migrateそれぞれこちらで実行できました。
windows環境で起きることがあるみたいです。
- 投稿日:2020-10-19T10:45:52+09:00
pryでparamsの中身を確認する
背景
記事詳細を表示する際に、ユーザー名を表示したかったが、どこに格納されているのかわからず、paramsの中身を調べることにした。その過程のログを残しておく。
やり方
gemをインストール (gem 'pry-rails')
↓
bundle install
↓
調べたい該当箇所に、binding.pryを入力。
↓
rails s
↓
該当箇所をブラウザでぽちぽち。ターミナルに、入力した箇所で止まったログが表示される。
↓
そして、[1] pry(#)>
と表示されるから、そこに知りたい文字列を入力。qiita.controller.rb12: def show 13: #一つの投稿のみを取得したい。 14: @post = Post.find(params[:id]) => 15: binding.pry 16: end試しに上から順に、
id
params[:id]
@post.content
@post.user
と入力してみた![1] pry(#<PostsController>)> id NameError: undefined local variable or method `id' for #<PostsController:0x00007f9f26ea4828> from (pry):1:in `show' [2] pry(#<PostsController>)> params[:id] => "1" [3] pry(#<PostsController>)> @post.content => "Temporibus vel ratione aperiam alias aut libero reiciendis voluptatem quo autem rerum doloribus adipisci a voluptas modi illo qui ipsum aliquid voluptatum nventore at esse maiores ut omnis accusantium animi ducimus qui autem architecto excepturi itaque ex minus facere soluta inventore molestias id unde vero sunt aliquam quia dolorum quae placeat deserunt aspernatur qui suscipit quod dolorem maxime nulla id molestiae incidunt aut beatae aut voluptate aliquid dicta velit sit sint eum possimus nihil non voluptatem provident enim assumenda consequatur fugiat." [4] pry(#<PostsController>)> @post.user User Load (0.2ms) SELECT "users".* FROM "users" WHERE "users"."id" = ? LIMIT ? [["id", 1], ["LIMIT", 1]] ↳ (pry):4:in `show' => #<User:0x00007f9f26c77b68 id: 1, name: "swifty_kazu", email: "hogehogehoge", created_at: Fri, 16 Oct 2020 02:53:43 UTC +00:00, updated_at: Fri, 16 Oct 2020 02:53:43 UTC +00:00, password_digest: [FILTERED], admin: true> [5] pry(#<PostsController>)> @post.user.name => "swifty_kazu" [6] pry(#<PostsController>)>exit!で抜け出せる
参考記事
https://qiita.com/tomoharutt/items/6b12af3dc5eb8dfb9801
https://pikawaka.com/rails/params#params%E3%81%AE%E4%B8%AD%E8%BA%AB%E3%82%92%E7%A2%BA%E8%AA%8D%E3%81%97%E3%81%A6%E3%81%BF%E3%82%88%E3%81%86
https://qiita.com/k0kubun/items/b118e9ccaef8707c4d9f
- 投稿日:2020-10-19T10:40:26+09:00
Railsのサーバ処理時間をServer Timingを使って可視化する
はじめに
開発環境の Rails サーバの処理時間を手軽に可視化する方法として、ActiveSupport::Notifications を使ってサーバの処理速度を計測し、Server Timing を使って可視化するという方法を紹介します。
対象読者
- Rails を利用している
- Chrome などの検証ツールを使っている
- サーバの処理速度を手軽に計測 & 可視化したいと思っている
出来上がるもの
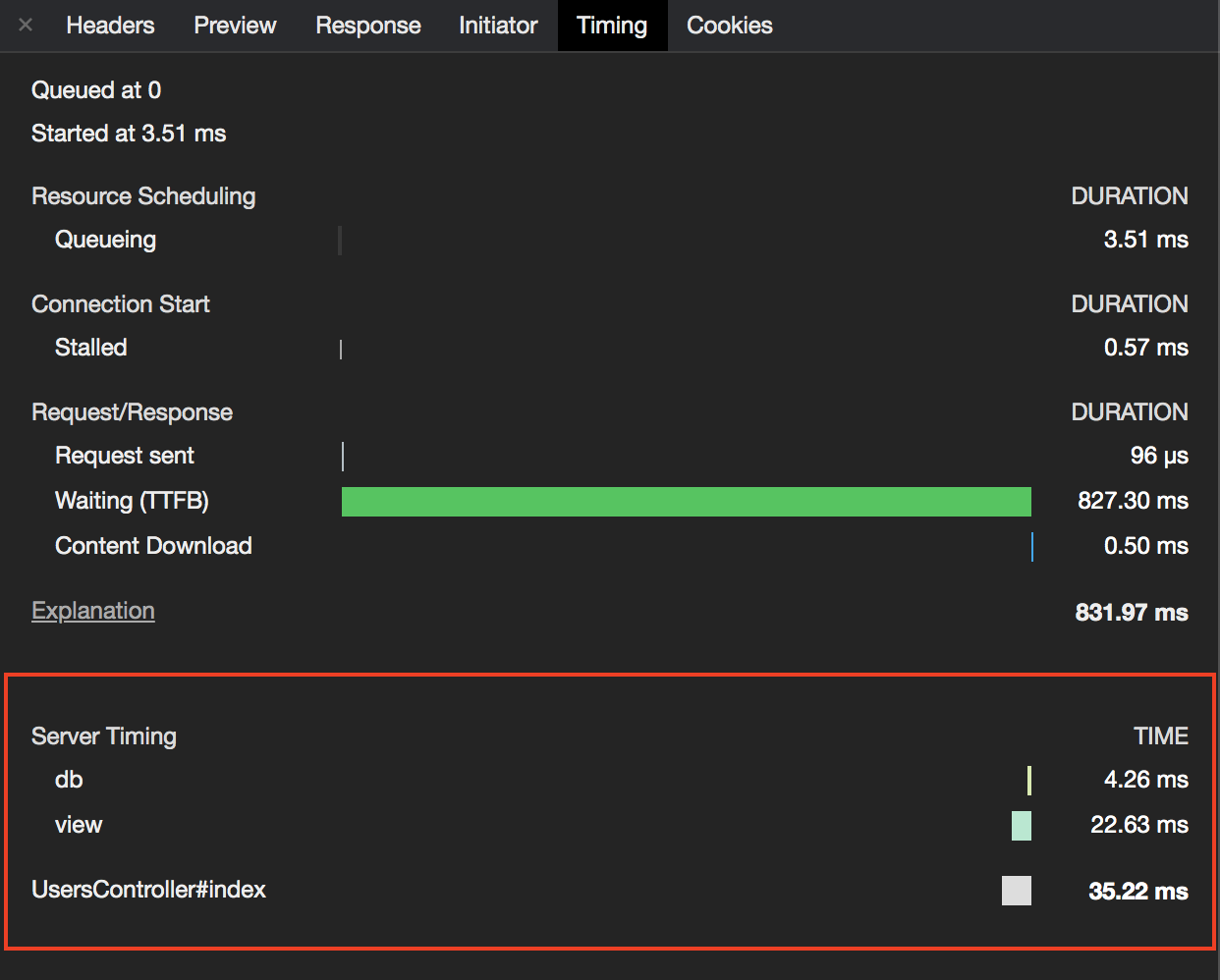
Chrome の検証ツールから対象となる通信を選択して、Timing のタブを選択すると以下の図のように Server Timing を表示できるようになります。
これは、データベースクエリの処理に 4.26ms、ビューの構築に 22.63ms、UserController#index として合計 35.22ms かかったことを表しています。ActiveSupport::Notifications とは
Ruby 用の計測 API を提供してくれるライブラリです。
イベントの計測と計測結果を購読する仕組みが用意されており、このような感じで簡単に利用することができます。# 購読 ActiveSupport::Notifications.subscribe("my.event") do |name, start, finish, id, payload| name # => イベント名: "my.event" start # => 計測開始時刻: 2020-10-18 12:34:56 +0900 finish # => 計測終了時刻: 2020-10-18 12:34:56 +0900 id # => ユニークなイベントのID: "xxxxxxxxxxxxx" payload # => ペイロード・追加情報(ハッシュ): {data: :hoge} end # 計測 ActiveSupport::Notifications.instrument("my.event", data: :hoge) do # イベントを実行 endServer Timing とは
サーバ側の処理時間をHTTPヘッダを通して通信する仕組みです。
レスポンスヘッダの Server-Timing ヘッダフィールドに計測時間などの情報を付け加えることで、検証ツールが自動的に可視化してくれます。記法
- 基本形:
名前;desc=説明文;dur=計測時間- 計測時間の総計を表すときには、名前を
totalにする- 複数ある場合は、カンマで区切る
組み合わせる
まずは、サーバの処理時間を計測する必要があるのですが、実は Rails ではすでにその計測が
process_action.action_controllerという名前で行われています。ですので、購読する部分から作成すれば良いです。config/initializer に以下のようなファイルを作成します。
config/initializers/server_timing.rbActiveSupport::Notifications.subscribe "process_action.action_controller" do |*args| # ActiveSupport::Notifications::Event は引数をそのまま受け渡すと、いい感じにデータを加工してくれます event = ActiveSupport::Notifications::Event.new(*args) duration = event.duration # 処理時間 payload = event.payload # ペイロード controller_name = payload.controller # コントローラ名 action_name = payload.action # アクション名 db_runtime = payload.db_runtime # データベースへのクエリ実行にかかった時間 view_runtime = payload.view_runtime # ビューにかかった合計時間 server_timing = "total;desc=\"#{controller_name}\##{action_name}\";dur=#{duration}, " \ "db;dur=#{db_runtime}" \ "view;dur=#{view_runtime}" end"process_action.action_controller" のペイロードの内容は以下に記載されています。
https://railsguides.jp/active_support_instrumentation.html#process-action-action-controllerこれで、サーバでの処理時間の取得が完了しました。
あとは、Server-Timingヘッダにserver_timingを登録するのみです。Rails ではあまりグローバル変数は使わないですが、他に良い方法を知らないので今回はグローバル変数を使います。コントローラから取得できる response オブジェクトをグローバル変数に格納し、先ほどの購読処理の中で response オブジェクトに
Server-Timingヘッダを付け加えます。app/controllers/application_controller.rbclass ApplicationController < ActionController::Base prepend_before_action { $response = response } endconfig/initializers/server_timing.rbActiveSupport::Notifications.subscribe "process_action.action_controller" do |*args| # ... # 省略 # ... response = $response response.headers["Server-Timing"] = server_timing end実装は以上です。
これで Server-Timing ヘッダフィールドに以下のような値が付与され、Chromeの検証ツールがいい感じに可視化してくれるようになります。
Server-Timing: total;desc="UsersController#index";dur=17.167, db;dur=0.5440000677481294, view;dur=15.272999997250736最後に
私自身、ActiveSupport::Notifications も Server Timing も初めて利用しましたが、簡単にサーバのどこで時間がかかっているのかを可視化でき、便利だなと思いました。ActiveSupport::Notifications は、他にも ActiveRecord で作成されたインスタンス数や SQL でキャッシュが利用されたかなどもわかるので、工夫次第ではより詳細な情報を知ることができます。また、機会があれば詳細情報も可視化してみたいと思います。
参考
- 投稿日:2020-10-19T09:28:07+09:00
Gem ~ active_model_serializers ~
公式
https://github.com/rails-api/active_model_serializers/tree/v0.10.6/docs
Serializer の作成
be rails g serializer api::v1::articles_preview_serializer作成されたファイル
app/serializers/api/v1/articles_preview_serializers.rb
class Api::V1::ArticlesPreviewSerializer < ActiveModel::Serializer # 出力したい値を指定 attributes :id, :title, :updated_at endid, title, updated_at を出力するよう指定。
コントローラ
app/controllers/api/v1/articles_controllers.rb
module Api::V1 class ArticlesController < BaseApiController def index articles = Article.all.order(updated_at: "DESC") # レスポンスの値が複数の場合、 each_serializer を使用する。 render json: articles, each_serializer: Api::V1::ArticlesPreviewSerializer end end endserializer と同じ階層構造にすること。
作成した article を updated_at 順に昇順にするよう指定。
同階層に base_api_controllers.rb
class Api::V1::BaseApiController < ApplicationController endRequest spec
とりあえずダミーデータを作成して参照する。
spec/requests/api/v1/article_request_spec.rb
require 'rails_helper' RSpec.describe "Api::V1::Articles", type: :request do describe " GET /api/v1/article " do subject { get(api_v1_articles_path) } before { create(:article, updated_at: 3.days.ago ) } before { create(:article) } before { create(:article, updated_at: 1.days.ago ) } it "記事の一覧が取得できる" do subject end end endRequest spec についてはまた後日。
実行結果
[1] pry(#<RSpec::ExampleGroups::ApiV1Articles::GETApiV1Article>)> res = JSON.parse(response.body) => [{"id"=>56, "title"=>"Consequuntur quia corporis perspiciatis.", "updated_at"=>"2020-10-17T22:19:32.120Z"}, {"id"=>57, "title"=>"Molestiae tempore recusandae qui.", "updated_at"=>"2020-10-16T22:19:32.122Z"}, {"id"=>55, "title"=>"Consectetur nam odio voluptatibus.", "updated_at"=>"2020-10-14T22:19:31.192Z"}]UserSerializer の追加
class Api::V1::UserSerializer < ActiveModel::Serializer # 出力したい値を指定 attributes :id, :name, :email endArticlesPreviewSerializer の修正
class Api::V1::ArticlesPreviewSerializer < ActiveModel::Serializer # 出力したい値を指定 attributes :id, :title, :updated_at belongs_to :user, serializer: Api::V1::UserSerializer end実行結果
[1] pry(#<RSpec::ExampleGroups::ApiV1Articles::GETApiV1Article>)> res = JSON.parse(response.body) => [{"id"=>59, "title"=>"Esse facere cum rerum.", "updated_at"=>"2020-10-19T00:06:27.375Z", "user"=>{"id"=>69, "name"=>"Eduardo Kohler Haley", "email"=>"2_janella@renner-dach.org"}}, {"id"=>60, "title"=>"Cumque aut repudiandae numquam.", "updated_at"=>"2020-10-18T00:06:27.377Z", "user"=>{"id"=>70, "name"=>"Collen Stark Brakus", "email"=>"3_hung@wintheiser.org"}}, {"id"=>58, "title"=>"Corporis molestiae dolor odit.", "updated_at"=>"2020-10-16T00:06:26.556Z", "user"=>{"id"=>68, "name"=>"Fr. Pauline Sporer Greenfelder", "email"=>"1_wendy@goldner.net"}}]
- 投稿日:2020-10-19T01:02:28+09:00
ゲストログイン機能の追加
はじめに
オリジナルアプリを作成するにあたって、中身を見てもらいやすくするためにボタン一つでログインできるようにゲストログイン機能を追加した時の備忘録です。
新規登録やログイン機能はdeviseを使用しています。guest user 実装
models/users.rbdef self.guest find_or_create_by!(username: 'ゲスト', email: 'guest@example.com') do |user| user.password = SecureRandom.urlsafe_base64 end endまずはルーティングの設定を行います。
routes.rbdevise_scope :user do post 'users/guest_sign_in', to: 'users/sessions#new_guest' end
new_guest,アクションをusers/sessions_controller.rbに追加します。usersディレクトリはcontrollersに追加。users/sessions_controller.rbclass Users::SessionsController < Devise::SessionsController def new_guest user = User.guest sign_in user redirect_to root_path, notice: 'ゲストユーザーとしてログインしました。' end end最後にボタンなどviewを追加すれば、実装完了。
application.html.erm<p class="control"> <%= link_to 'ゲストログイン', users_guest_sign_in_path, class: "button is-warning is-fullwidth", method: :post %> </p>最後に
ポートフォリオ(オリジナルアプリ)を見てもらうためにはとても重要な機能の追加。比較的簡単に実装が出来ました。
最後まで読んでいただきありがとうございます
- 投稿日:2020-10-19T00:19:29+09:00
初めてのwebアプリ共同制作
はじめに
初めてのwebアプリ共同制作なので、備忘録を残しておきます。
作るのはこれです。
「大学生が使いたくなる家探しサービスを作ろう」
https://techbowl.co.jp/techtrain/missions/24目的
就活の時に使えるポートフォリオになるようなものを作る。
共同開発経験が欲しい、そのために、、、、
- ちゃんとgithubの機能を使いこなす
- フロントエンドからバックエンドまで一通り触る
- デザインとかは最小限にして、とりあえず動くものを作る
最初にしたこと
使う言語とスケジュールを決めた
ちなみに、html/css/js/docker以外触れたことない。
html/css/js苦手、dockerは簡単なdockerfile書くくらいならできる。フロント -- HTML --css (Bulmaというフレームワークを使おうと思います) -- javascript (余裕があれば) バックエンド -- Rails データベース -- mysql 開発環境 -- docker デプロイ先 -- AWS CI/CD -- CircleCI(余裕があれば)スケジュールとタスクを書き出す
やったこと、役に立った記事まとめ
ruby on rails
- progate
- railsガイド https://railsguides.jp/getting_started.html
html/css
js
mysql
知らなかったワードとかメモ
webpack, yarn
rails serverサーバーをrailsで立てようとした時に必要って言われてインストールした。
- 投稿日:2020-10-19T00:19:29+09:00
初めてのwebアプリ共同制作(未完成)(12月完成予定)
はじめに
初めてのwebアプリ共同制作なので、備忘録を残しておきます。
作るのはこれです。
「大学生が使いたくなる家探しサービスを作ろう」
https://techbowl.co.jp/techtrain/missions/24目的
就活の時に使えるポートフォリオになるようなものを作る。
共同開発経験が欲しい、そのために、、、、
- ちゃんとgithubの機能を使いこなす
- フロントエンドからバックエンドまで一通り触る
- デザインとかは最小限にして、とりあえず動くものを作る
最初にしたこと
使う言語とスケジュールを決めた
ちなみに、html/css/js/docker以外触れたことない。
html/css/js苦手、dockerは簡単なdockerfile書くくらいならできる。フロント -- HTML --css (Bulmaというフレームワークを使おうと思います) -- javascript (余裕があれば) バックエンド -- Rails データベース -- mysql 開発環境 -- docker デプロイ先 -- AWS CI/CD -- CircleCI(余裕があれば)スケジュールとタスクを書き出す
やったこと、役に立った記事まとめ
ruby on rails
- progate
- railsガイド https://railsguides.jp/getting_started.html
html/css
js
mysql
知らなかったワードとかメモ
webpack, yarn
rails serverサーバーをrailsで立てようとした時に必要って言われてインストールした。
- 投稿日:2020-10-19T00:11:05+09:00
画像をぼかす方法(超簡単)

- 投稿日:2020-10-19T00:04:01+09:00
【RSpec】mailer(パスワードのリセット処理)のテストを書いたときにはまった点
最近RSpecにも割と慣れてきて油断しているところに、見たこともないエラーが出てきて少し詰まったのでここで共有したいと思います。
リクエストスペックでmailer(パスワードのリセット処理)のテストを書いたときの話です!エラー内容
Failure/Error: expect(mail.body.encoded).to match user.reset_token expected "\r\n----==_mimepart_5b18de57c36e0_75293fd69de666b8448c9\r\nContent-Type: text/plain;\r\n charset=UTF...\nL2E+CgogIDwvYm9keT4KPC9odG1sPgo=\r\n\r\n----==_mimepart_5b18de57c36e0_75293fd69de666b8448c9--\r\n" to match "HAY" Diff: @@ -1,2 +1,32 @@ -HAY + +----==_mimepart_5b18de57c36e0_75293fd69de666b8448c9 +Content-Type: text/plain; + charset=UTF-8 +Content-Transfer-Encoding: base64 + +SEFZCuOBggoK + +----==_mimepart_5b18de57c36e0_75293fd69de666b8448c9 +Content-Type: text/html; + charset=UTF-8 +Content-Transfer-Encoding: base64 + +PCFET0NUWVBFIGh0bWw+CjxodG1sPgogIDxoZWFkPgogICAgPG1ldGEgaHR0 (省略) +L2E+CgogIDwvYm9keT4KPC9odG1sPgo= + +----==_mimepart_5b18de57c36e0_75293fd69de666b8448c9--こんな感じのエラーが出てきました。
どうやらRSpecでメール本文のエンコード処理が正しくできていないせいで、期待している値と一致せずにテストに失敗しているようです。解決策
パスワードのリセットトークンを作る時、Base64を使ってエンコードしているので、それを元に戻して比較するとうまくいきました。(デコード)
password_resets_request_spec.rbRSpec.describe UserMailer, type: :mailer do let(:user) { FactoryBot.create(:user, email: 'mailer_tester@example.com') } describe "パスワードリセット処理" do let(:mail) { UserMailer.password_reset(user) } # Base64 encodeをデコードして比較できるようにする let(:mail_body) { mail.body.encoded.split(/\r\n/).map{|i| Base64.decode64(i)}.join } it "ヘッダーが正しく表示されること" do user.reset_token = User.new_token expect(mail.to).to eq ["mailer_tester@example.com"] expect(mail.from).to eq ["noreply@protuku.com"] expect(mail.subject).to eq "パスワードの再設定" end # メールプレビューのテスト it "メール文が正しく表示されること" do user.reset_token = User.new_token expect(mail_body).to match user.reset_token expect(mail_body).to match CGI.escape(user.email) end end end最後まで読んでいただきありがとうございます!
実は、この情報にたどり着くのに少し手間取ったため、記事にしました。
同じようなところで困っている方のお力になれれば幸いです!
ご指摘などあればコメントいただけますと嬉しいです。