- 投稿日:2020-10-19T23:52:32+09:00
IAM認証のAWS API GatewayにC#からIAMロールでSigV4署名してアクセスするには
IAM認証を使っているAWSのAPI Gatewayは、APIリクエスト時にSigV4署名が必要です。
前回の記事では、IAMユーザで認証するAPI Gateway呼び出しをC#で書きました。
今回は、EC2インスタンスにアタッチされているIAMロールでの認証です。
前提
IAMロールのアタッチされているEC2インスタンスでC#のコードを実行します。
~/.aws/configに以下のようにIAMロールが指定されているものとします。[profile default] role_arn = arn:aws:iam::999999999999:role/ROLENAME credential_source = Ec2InstanceMetadataAPI GatewayのリソースポリシーにはこのIAMロールからのAPIアクセスを許可してあるものとします。
動作確認した環境はUbuntu 20.04です。
C#の環境は以下の通り。
$ dotnet --version 3.1.402以下は私の記事でして、このとおりC#をほとんど始めて触っています。C#の流儀と違うところがあったらごめんなさい。
サンプルコードダウンロード
SigV4署名するC#のサンプルコードはAWS公式サイトにありますので、それをダウンロードし、必要なディレクトリのみ残します。
ここの手順の詳細は前回の記事を参照。
$ mkdir sample $ cd sample $ mkdir tmp $ cd tmp $ wget https://docs.aws.amazon.com/AmazonS3/latest/API/samples/AmazonS3SigV4_Samples_CSharp.zip $ unzip AmazonS3SigV4_Samples_CSharp.zip $ cd .. $ mv tmp/AWSSignatureV4-S3-Sample/Signers ./ $ mv tmp/AWSSignatureV4-S3-Sample/Util ./ $ rm -r tmpサンプルソースコードのnamespaceを全置換しておきます。(このコマンドの説明は sedコマンドでディレクトリ内の全ファイルをテキスト全置換するには)
$ grep -rl AWSSignatureV4_S3_Sample Signers | xargs sed -i 's/AWSSignatureV4_S3_Sample/Sample/g' $ grep -rl AWSSignatureV4_S3_Sample Util | xargs sed -i 's/AWSSignatureV4_S3_Sample/Sample/g'C#のプロジェクト作成
dotnetコマンドでプロジェクトを作成します。$ dotnet new console以下のようなディレクトリ構成になります。
$ tree . ├── obj │ ├── project.assets.json │ ├── project.nuget.cache │ ├── sample.csproj.nuget.dgspec.json │ ├── sample.csproj.nuget.g.props │ └── sample.csproj.nuget.g.targets ├── Program.cs ├── sample.csproj ├── Signers │ ├── AWS4SignerBase.cs │ ├── AWS4SignerForAuthorizationHeader.cs │ ├── AWS4SignerForChunkedUpload.cs │ ├── AWS4SignerForPOST.cs │ └── AWS4SignerForQueryParameterAuth.cs └── Util └── HttpHelpers.cs 3 directories, 13 files
sample.csprojに以下のようにRootNamespaceの項目を追加します。サンプルダウンロード後に全置換したnamespaceを指定します。<Project Sdk="Microsoft.NET.Sdk"> <PropertyGroup> <OutputType>Exe</OutputType> <TargetFramework>netcoreapp3.1</TargetFramework> <RootNamespace>Sample</RootNamespace> </PropertyGroup> </Project>必要なパッケージをダウンロードします。
$ dotnet add package AWSSDK.SecurityTokenC#のソースコード
Program.csは以下です。using System; using System.Collections.Generic; using System.Threading.Tasks; using Amazon.Runtime; using Amazon.Runtime.CredentialManagement; using Amazon.SecurityToken; using Amazon.SecurityToken.Model; using Sample.Signers; using Sample.Util; namespace Sample { class Program { private static async Task Run() { // ~/.aws/credentials からRoleArnを読み取る SharedCredentialsFile sharedFile = new SharedCredentialsFile(); sharedFile.TryGetProfile("default", out CredentialProfile credentialProfile); string roleArn = credentialProfile.Options.RoleArn; // IAMロールにassumeする InstanceProfileAWSCredentials instanceCredentials = new InstanceProfileAWSCredentials(); AmazonSecurityTokenServiceClient stsClient = new AmazonSecurityTokenServiceClient(instanceCredentials); AssumeRoleRequest assumeRoleRequest = new AssumeRoleRequest { RoleArn = roleArn, RoleSessionName = "test_session", }; var assumeRoleResponse = await stsClient.AssumeRoleAsync(assumeRoleRequest); var credentials = assumeRoleResponse.Credentials; var uri = new Uri("https://xxxxxxxxxx.execute-api.ap-northeast-1.amazonaws.com/Prod/hello"); // 署名するためのソースとなるヘッダ情報 var headers = new Dictionary<string, string> { {AWS4SignerBase.X_Amz_Content_SHA256, AWS4SignerBase.EMPTY_BODY_SHA256}, {"content-type", "text/plain"}, {"x-amz-security-token", credentials.SessionToken}, // IAMロールではこれが必要 }; // 署名を作成 var signer = new AWS4SignerForAuthorizationHeader { EndpointUri = uri, HttpMethod = "GET", Service = "execute-api", Region = "ap-northeast-1" }; var authorization = signer.ComputeSignature(headers, "", // no query parameters AWS4SignerBase.EMPTY_BODY_SHA256, credentials.AccessKeyId, credentials.SecretAccessKey); // リクエストヘッダに署名を追加 headers.Add("Authorization", authorization); // リクエスト実行 // HttpHelpers はUtilで定義 HttpHelpers.InvokeHttpRequest(uri, "GET", headers, null); } static void Main(string[] args) { Run().Wait(); } } }
uriはAPI GatewayのAPIのURLを入れます。実行
以下のコマンドで実行できます。
$ dotnet runダウンロードしたサンプルコードの
SignersとUtilにデバッグ用出力があるので、いろいろ表示されますが、最後にAPI Gatewayからのレスポンスが表示されます。情報源
C#でIAMロールにAssumeする方法がわからず、今回のテーマは難儀でした。わかってしまえば大したことないのですが。
参考にした情報は、前回の記事に加えて、AWS SDK for .NETのAPIレファレンスとPython boto3のソースコードと、参考として
awscurlというコマンドのソースコードです。AWS SDK for .NETのドキュメントは、説明が少なく、メソッドのシグニチャはわかってもどう使ったらいいのかがわかりませんでした。IAMロールでの署名をしているはずの
awscurlのソースコードを読み、awscurlが呼び出しているboto3のソースコードも読むことで、AWSのAPIをどう呼び出しているのかを把握し、同じことをC#で書くことで実装できました。
- 前回の自分の記事
- AWS SDK for .NETのAPIレファレンス
- Pythonのboto3のソース
awscurlコマンドのソースboto3はAWSのAPIを呼び出しているだけだと思っていましたが、使いやすいように多くの機能をPythonで実装していることを実感しました。boto3とは違って、AWS SDK for .NETは単にAWS API呼び出しをそのままメソッドにしているだけのように見えます。
- 投稿日:2020-10-19T23:29:36+09:00
Line Messaging APIで簡単Line Bot作成(超初心者向け)
はじめに
Line Messaging APIを使った超初心者向けLine Bot作成の手順を記載したものです。
本記事の手順を実施するには、以下のアカウントが必要になります。
- Line Developperアカウント
- AWSアカウント
Messaging APIとは
Line公式ドキュメントによると、「Messaging APIを使って、ユーザー個人に合わせた体験をLINE上で提供するボットを作成できます。作成したボットは、LINEプラットフォームのチャネルに紐づけます。チャネルを作成すると生成されるLINE公式アカウントをボットモードで運用すると、LINE公式アカウントがボットとして動作します。」とあります。
つまり、Messaging APIを使用することで、Lineのアプリ(チャネル)とサーバー(ボットサーバー)を連携でき、Line Botが作成できるというわけです。
※Line公式ドキュメントより簡単なLine Botを作成する
まずは、固定のメッセージを返答するLine Botを作成します。
Line Botは、Line Developperサイトにてチャネルという物を作成し、チャネルを作成した際に表示されるQRコードからLine公式アカウントを友達登録することで作成され、スマホなどのLineアプリからLine Botを使用する事ができるようになります。
上記の作業を行うだけで、ボット用サーバーを用意することなく、固定のメッセージを返答するLine Botを作成する事ができます。作成手順
1. Line Developperログイン
ここからLineアカウントでLine Developperへログインします。Lineアカウントのユーザ名/パスワードは、スマホなどのLineアプリで登録したメールアドレスとパスワードになります。
まだ、登録していない方は、Lineアプリでメールアドレスとパスワードを登録してください。
画面中央にある、ログインボタンを押します。
LINEアカウントでログインボタンを押します。
Lineアプリで登録したメールアドレスとパスワードを入力し、ログインします。
初回ログイン時のみ開発者登録を行う必要がありますので、名前とメールアドレスを登録します。
メールアドレスは、ログイン時に使用した物と同じでなくても問題ありません。
2. 新規プロバイダー作成
新規にプロバイダー作成します。プロバイダーとは組織名のことです。任意の名称(本手順ではSample Providerとします)を入力します。
プロバイダー作成ボタンを押します。
プロバイダー名を入力し、作成ボタンを押します。
プロバイダーを作成が完了すると以下のような画面となります。
3. チャネル作成
プロバイダー作成完了後の画面で、「MessagingAPI」を選択します。
必要事項を記入します。
- チャネル名
- 任意の名称を入力してください。
- チャネル説明
- 任意の説明文を入力してください。
- 大業種
- 選択肢の中から選んでください。
- 小業種
- 選択肢の中から選んでください。
- メールアドレス
- 自身のメールアドレスを入力してください。
利用規程に同意にチェックを入れて、作成ボタンを押します。
チャネルの作成が完了すると、以下のような画面になります。
4. LINE公式アカウントの友達登録
チャネル作成完了後の画面で、「MessagingAPI設定」を選択します。
QRコードが表示されるので、コードリーダーアプリで読み取ります。LINEアプリで読み取る必要はありません。
友達追加します。
動作確認
これで、固定メッセージを返却するLine Botが完成しました。Lineアプリを開いてメッセージを送信してみてください。
毎回同じメッセージで返答されます。
バックエンド(ボットサーバー)と連携する。
ここからは、バックエンドと連携させていきます。
バックエンドと連携させる事ができれば、AI等をバックエンドで実行させて結果をLineに返すなど、Line Botの機能の幅が格段に拡がります。本記事では、「こんにちは」というメッセージを受け取ったら「こんにちは」を返し、「おはようございます」というメッセージを受け取ったら「おはようございます」というメッセージを返すバックエンドシステムを構築します。
バックエンドシステムはAWSを利用して構築し、使用するサービスは以下です。

手順(LINE:チャネルアクセストークンの発行)
先程作成したチャネルから、チャネルアクセストークンを発行します。チャネルアクセストークンはバックエンドからメッセージを送信するために必要となります。
1-1. チャネルアクセストークンの発行
友達登録用のQRコードを確認したページを下までスクロールします。ページ最下部に、チャネルアクセストークンの発行ボタンがありますのでクリックします。
これで、チャネルアクセストークンが発行されます。発行されたチャネルアクセストークンはメモしておいてください。
手順(バックエンド構築)
AWS Lambda
2-1. Lambdaサービスの選択
AWSコンソールにログインし、Lambdaを選択します。
2-2. 関数作成
関数作成ボタンをクリックし、関数の作成を開始します。
2-3. 関数名の入力とランタイムの選択。
本記事では、関数名は「ReplayMessageFunction」としています。ランタイムはPython3.8を選択してください。
2-4. ソースコード及びライブラリの登録
ソースコード及びライブラリを登録します。アクションから.zipファイルをアップロードを選択します。
アップロードをクリックし、Lambda関数ファイルをアップロードをします
アップロードするファイルはこちらからダウンロードしてください。
用意したファイルをアップロードすることで、ソースファイル(Python)とPython用LineBotライブラリがアップロードされます。
2-6. 関数の修正
Lmabda関数の6行目にある「<channel access token>」を、手順1-1で発行したチャネルアクセストークンに書き換えてください。
2-7. 修正の反映
Deployボタンをクリックします。修正した内容が反映されます。
これで、Lambdaの設定は完了です。
Amazon API Gateway
3-1. API Gatewayサービスの選択
AWSコンソールにログインし、API Gatewayを選択します。
3-2. API作成
左のメニューからAPIを選択し、APIを作成ボタンをクリックします。
3-3. HTTP APIの構築
HTTP APIの構築ボタンをクリックします。
3-4. 統合の追加
統合を追加ボタンをクリックします。
3-5. 統合サービスの選択
統合するサービスのリストからLambdaを選択します。
3-6. 必要事項の入力
AWSリージョン・Lambda関数・API名を入力/選択して、次へボタンをクリックします。
Lambda関数は、先の手順で作成したLambda関数を選択します。
その他については、以下を設定します。
- AWSリージョン:ap-northeast-1
- API名:replayMesssage
3-7. ルートの設定
メソッドは「POST」を選択、リソースパスは「/replayMessage」を入力し、次へボタンをクリックします。
3-8. ステージの定義
ここは何も変更せず、次へボタンをクリックします。
3-9. 設定内容の確認
設定内容を確認し、作成ボタンをクリックします。
3-10. 発行されたURLの確認
次の手順でURLを使用しますので、メモしておきます。
これで、API Gatewayの設定は完了です。
手順(LINE:Webhookの設定)
4-1. Webhookの設定
バックエンドと連携する為に、Webhookを設定します。編集ボタンをクリックします。
3-10で発行されたURLと、3-7で設定したリソースパスを組み合わせたURLを入力します。
例:https://XXXXXXXXX.execute-api.ap-northeast-1.amazonaws.com/replyMessage
4-2. Webhookの有効化
Webhookの利用ボタンをクリックして有効化します。
4-3. メッセージの無効化
応答メッセージ及びあいさつメッセージを無効化します。
「簡単なLine Botを作成する」で固定メッセージを応答するLine Botを作成しましたが、この機能が有効化していたことで、自動で応答メッセージを返していました。
バックエンドから応答メッセージを返しますので、この機能は無効化しておきます。
応答メッセージ項目の右にある編集ボタンをクリックします。
あいさつメッセージ及び応答メッセージ共にオフを選択します。
これで設定はすべて完了です。Lineアプリからメッセージを送信してみてください。
まとめ
Line DeveloperとAWSでLine Botを作成してみました。
ローコーディングでサービスを構築でき、また、普段使用しているアプリを使ってUIを構築する事ができることは、ユーザーにとっては使用するさいの学習コストが少なくてすみます。さらにバックエンドとしてAWSを利用することで、開発コストも抑える事ができます。









































- 投稿日:2020-10-19T23:11:11+09:00
Djangoチュートリアル(ブログアプリ作成)⑤ - 記事作成機能編
前回、Djangoチュートリアル(ブログアプリ作成)④ - ユニットテスト編 ではユニットテストの実装方法を学んでいきました。
本来であれば、せっかくなので期待するテストを先に書くテスト駆動開発スタイルで実装していきたいところですが
このチュートリアルでは Django ではどんなことが出来るかを学びながらなので、先に実装してからユニットテストを書いていきます。これから、何回かに分けて今回は以下の機能を追加していきます。
1.記事の作成 (Create)
2.記事の詳細 (Read)
3.記事の編集 (Update)
4.記事の削除 (Delete)これら機能の頭文字をとって「CRUD」とここでは呼ぶことにします。
(厳密にいえば既に blog_list で Read は出来るので違うかもしれませんが)さて、今回はベースともいえる記事の作成機能を追加していきましょう。
これまでは管理サイトを使って superuser 権限で記事を追加していましたが、アプリ内で記事を作成出来たほうが便利ですよね。form の準備
アプリからデータを追加するときは form という仕組みを使います。
form がユーザから入力データを受け付け、view を通して model へデータを渡してデータベースへ登録することができるようになります。まずは blog アプリ配下に forms.py というファイルを作成します。
. ├── blog │ ├── __init__.py │ ├── admin.py │ ├── apps.py │ ├── forms.py # 追加 │ ├── migrations │ │ ├── 0001_initial.py │ │ └── __init__.py │ ├── models.py │ ├── tests │ │ ├── __init__.py │ │ ├── test_forms.py │ │ ├── test_models.py │ │ ├── test_urls.py │ │ └── test_views.py │ ├── urls.py │ └── views.py ├── db.sqlite3 ├── manage.py ├── mysite │ ├── __init__.py │ ├── settings.py │ ├── urls.py │ └── wsgi.py └── templates └── blog ├── index.html └── post_list.html作成した forms.py の中身はこのようになります。
forms.pyfrom django import forms from .models import Post class PostCreateForm(forms.ModelForm): # DjangoのModelFormでは強力なValidationを使える class Meta: model = Post # Post モデルと接続し、Post モデルの内容に応じてformを作ってくれる fields = ('title', 'text') # 入力するカラムを指定説明文も入れているのである程度わかるかと思います。
データを投入したい model を指定すると form が対応する入力フォームを用意してくれるようになります。なお、最終行でデータを入力するカラムをフィールドとして指定していますが、
fields = 'all' と定義することで全てのカラムを手入力するように指定することもできます。urls.py の修正
新たに view に追加するクラスは **PostCreateView と名前を予め決めておき、
urls.py では次のようにルーティングを追加しておきましょう。urls.pyfrom django.urls import path from . import views app_name = 'blog' urlpatterns = [ path('', views.IndexView.as_view(), name='index'), path('post_list', views.PostListView.as_view(), name='post_list'), path('post_create', views.PostCreateView.as_view(), name='post_create'), # 追加 ]success_url では、データベースの変更に成功した場合にリダイレクトさせるページを指定しています。
「アプリ名:逆引きURL名」の形で指定し、結果的に urls.py で指定した 'post_list' にリダイレクトされることになります。
※reverse_lazy は、view に対応した「URLの文字列」を返す。今回であれば /blog/post_list を返してくれますviews.py の修正
先ほど追加するクラス名は PostCreateView と決めましたね。
また、form で入力フォーム用のクラスも作成しました。次は views.py の中で、またまた汎用クラスビューを使ってクラスを作成します。
views.pyfrom django.views import generic from django.urls import reverse_lazy from .forms import PostCreateForm # forms.py で作ったクラスをimport from .models import Post class IndexView(generic.TemplateView): template_name = 'blog/index.html' class PostListView(generic.ListView): model = Post class PostCreateView(generic.CreateView): # 追加 model = Post # 作成したい model を指定 form_class = PostCreateForm # 作成した form クラスを指定 success_url = reverse_lazy('blog:post_list') # 記事作成に成功した時のリダイレクト先を指定Django の強力なクラスベース汎用ビューのおかげで、これだけのコードで済みます。
作成したい model、作成した form クラス、そして記事作成が成功した時のリダイレクト先を指定してあげるだけです。template の準備
まだ記事作成(投稿)用の html は作成していなかったので、templates/blog 配下に作成してあげましょう。
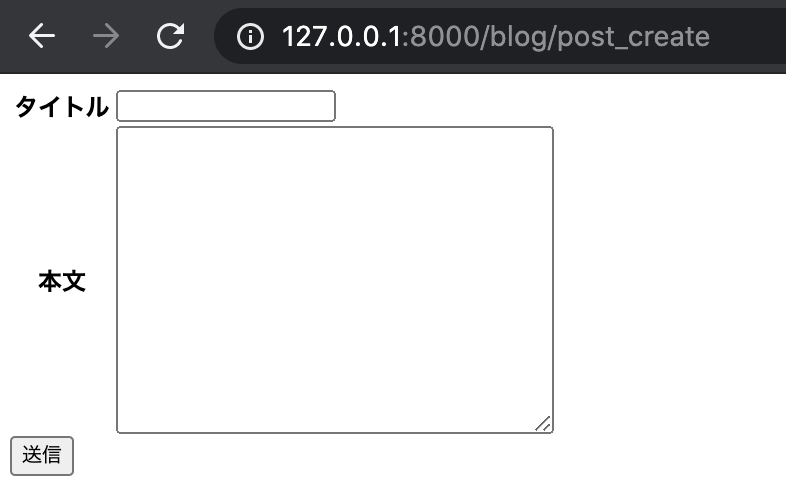
名前は post_form.html とします。
※クラスベース汎用ビューの命名規則に沿うことで template 名を指定しなくても OK になります└── templates └── blog ├── index.html ├── post_form.html # 追加 └── post_list.htmlpost_create.html<form action="" method="POST"> <table class="table"> <tr> <th>タイトル</th> <td>{{ form.title }}</td> </tr> <tr> <th>本文</th> <td>{{ form.text }}</td> </tr> </table> <button type="submit" class="btn btn-primary">送信</button> {% csrf_token %} </form>forms.py の fields で指定した入力フィールドを form という変数で受け取ることができるので、
template 側では form.title と form.text という形で取り出すことができます。また CSRF (クロスサイトリクエストフォージェリ) という、入力フォームを利用した攻撃を防ぐためのものです。
入力フォームを html に表示させる時は、必ず入れておきましょう。この状態で runserver コマンドでサーバを起動すると、見た目はひどいものですが入力フォームが表示されます。
(度々ですが、まずは Django の基本をおさえてから見た目を整えます)
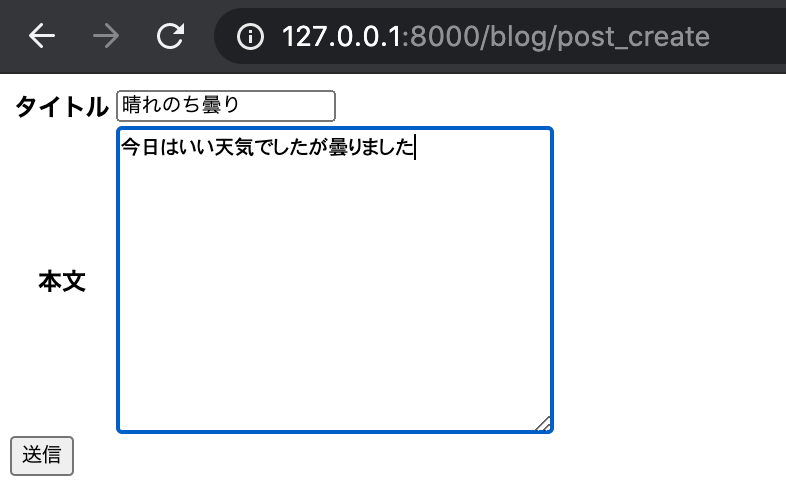
では試しに値を入力し、送信してみましょう。
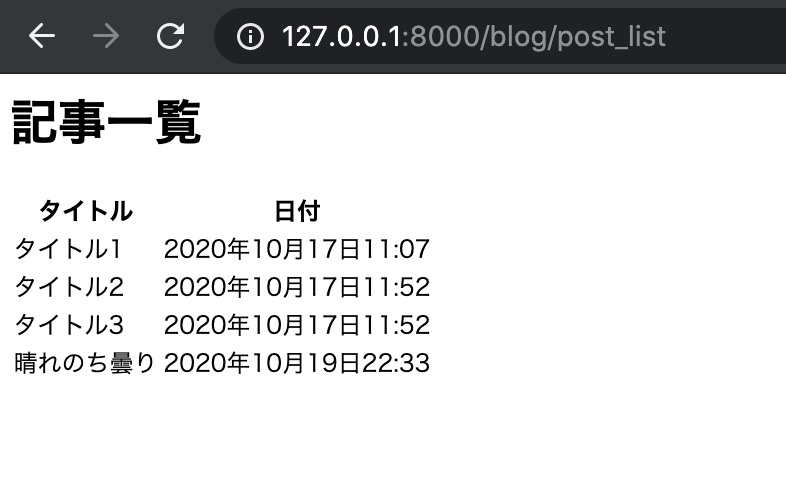
送信を押すと、post_list にリダイレクトされます。
そして、先ほど投稿した記事が追加されていることが分かるかと思います。
これで無事に記事投稿機能を追加することができました。
test_views.py の修正
最後に今回の機能のテストを実装しましょう。
test_views.py に下記のテストクラスを作成します。
test_views.py... class PostCreateTests(TestCase): """PostCreateビューのテストクラス.""" def test_get(self): """GET メソッドでアクセスしてステータスコード200を返されることを確認""" response = self.client.get(reverse('blog:post_create')) self.assertEqual(response.status_code, 200) def test_post_with_data(self): """適当なデータで POST すると、成功してリダイレクトされることを確認""" data = { 'title': 'test_title', 'text': 'test_text', } response = self.client.post(reverse('blog:post_create'), data=data) self.assertEqual(response.status_code, 302) def test_post_null(self): """空のデータで POST を行うとリダイレクトも無く 200 だけ返されることを確認""" data = {} response = self.client.post(reverse('blog:post_create'), data=data) self.assertEqual(response.status_code, 200)基本となる GET の確認、適当なデータの投入とリダイレクトの確認、そして空データ投入時のレスポンスを見ています。
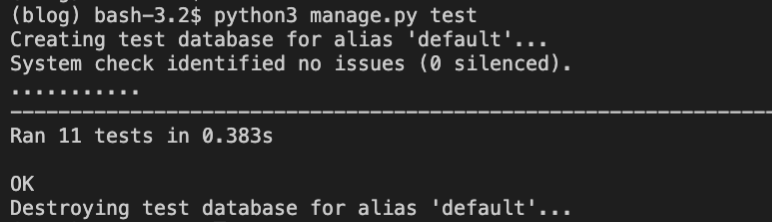
最後にテストを実行しましょう。
無事に通りましたね。
次回は一気に記事の詳細画面を作成していきます。
- 投稿日:2020-10-19T21:05:15+09:00
AWSソリューションアーキテクト - プロフェッショナル(SAP)に合格しました
これはなに
AWS認定 ソリューションアーキテクト プロフェッショナル(SAP)に合格したので
自慢します参考になれば情報を書きます。
↓試験概要
https://aws.amazon.com/jp/certification/certified-solutions-architect-professional/おまえだれ
某APN所属企業でインフラエンジニアをしています。
持っているAWS認定資格は・クラウドプラクティショナー(2019/06取得)
・ソリューションアーキテクト アソシエイト(2020/01取得)です。ちょうどエンジニアを初めて1年経ちました。(プラクティショナーは営業職の時に取りました)
なにしたの
試験対策のために行ったことです。本腰入れてやったのはだいたい3か月間。
・最近出た参考書を一通り読む
・Udemyの模擬試験をひたすらやる
・AWS Well-Architectedフレームワーク ホワイトペーパー を全部読む
・AWS Black Blet Onlice Seminarと公式ドキュメントで苦手サービスの集中学習
・公式の模擬試験を受ける最近出た参考書を一通り読む
こちら(Amazon)です。
この本は試験で頻出のサービスをカテゴリごとに解説、試験分野ごとに例題を基に解説をしてくれています。
最初のとっかかりには最適で、今まで知らなかったサービスを体系的に理解できます。巻末に75問の模擬試験も付いてます。
ただ、優しくて正しい日本語で書かれていたり文章が短かったりするので、本番の試験と比べると難易度は易しい部類です。(良いことなんですが)Udemyの模擬試験をひたすらやる
こちらです。頻繁にセールをやるので1,500円くらいになったときが買い時です。
計5回分・各回75問の模擬試験が受けられます。途中でやめたりセーブしたりも出来るので、少しずつやって理解を深めるというやり方も出来ます。
このサービスで得られる一番重要なことは問題を解く能力を身に着けられることです。
問題文は上の参考書に比べて実際の試験に近くなっています。ですのでどこを抑えれば回答を導き出せるのか、問題文の読み方が自然と身体に染み付き、実際の試験で大いに助かりました。
注意点としてはどこかの誰かさんが作った模擬問題なので(つまり公式ではない)、たまに不正確な解説があったりします。
いやいやwと思う問題があったらQ&Aからクレームフィードバックを送ります。AWS Well-Architectedフレームワーク ホワイトペーパーを全部読む
こちらです。
AWSアーキテクチャを設計する上での5つの柱を解説しているので、当然試験対策にはもってこいです。
(というかこの内容が全部頭に入ってれば当然試験には受かります)
ご覧になると分かりますが結構なボリューム量なので、重要度が高い順
(セキュリティ → 信頼性 → 運用上の優秀性 → パフォーマンス効率 → コスト最適化)の順に読むことをオススメします。AWS Black Blet Onlice Seminarと公式ドキュメントで苦手サービスの集中学習
これはやったほうがいいというか絶対にやるべきだと感じました。最悪Well-Architectedホワイトペーパーを読むのが嫌でもこちらは実践した方が良いです。
参考書やUdemyの試験問題で、ある程度自分がどのようなものが苦手かが浮かんできたと思います。
そのサービスの公式ドキュメントとサービスカットシリーズ(Black Blet)での弱点補強をオススメします。
AWSJ公式Youtubeチャンネルでもアップされています。公式の模擬試験を受ける
問題は20問90分しかありませんが、本番問題文の雰囲気を実際に体感できる貴重な機会なので、是非受けてみてください。
受験料は4,000円しますが、何かしらのAWS試験に合格していれば1回無料で受けられます。本番当日
テストセンターについて
ピアソンVUEから予約しました。多くの方は自分のAWS認定アカウントからご予約されるかと思います。
私は神奈川県民なので武蔵小杉テストセンターを利用しました。渋谷や横浜でも受験したことがありますが、テストルームには耳栓もイヤーカフもあり、とても集中できる環境です。室内は監視カメラでモニタリングされていますが、途中のトイレ離席もきちんと申告すれば許可されます。(センターによるかも)本番試験
テスト開始後「おっ、意外といけるやん」と思ったのも9問目まで、そろそろラストかなと思って問題数を見たら20問しか解き終わってなかった時には早くも絶望を感じ始めました。
途中、もうむりぽと思ったら目を瞑り5分ほど瞑想、という休憩を3回ほど取り、1度のトイレ離席を経てやっと75問解き終わりました。(残り25分)
そこからチェックを付けた問題を見直し(という名の流し読み)をし、終了ボタンを押した時には残り5分でした。
か、確実に時間が足りない・・・!というか日本語が怪しい問題がたくさんあって原文を何度も読み返したりしました。
日本語と原文で内容が全然違う、日本語にない文章が原文にはある、とかざらなので、少しでもおかしいなと思ったら原文を確認した方が良いです。自信のある回答が出来たのは正直半分くらい、半ば諦めていましたが[合格]の文字が見えたときは思わず会場で泣いてしまいました。
結果
結果は783点・・・!ギリギリでしたがなんとか合格できました。
まとめ
ソリューションアーキテクト プロフェッショナル試験は全AWS認定の中で一番範囲の広い試験かと思います。
その分普段触れたことのないサービスばかり出てきて最初は苦しかったですが、慣れてくると本当にAWSで色々なことが出来るなと学ぶのが楽しくなってきました。アソシエイト認定を持っている方には是非、チャレンジしていただきたいと思います。クラウドの活用が大幅に広がります。
- 投稿日:2020-10-19T20:15:12+09:00
EC2でnode.jsサーバーを立てる時に最低限インストールするもの。
概要
EC2立てた後に、node.jsを入れる手順
インストールするもの
・nvm(必須) これはgitが必要なのであとでやる。
・git(必須)1、yumでgitをインストールする
$ sudo yum install git2、nvmをインストールする。
// git cloneする $ git clone https://github.com/creationix/nvm.git ~/.nvm // nvmへのパスを通す。 $ source ~/.nvm/nvm.sh // ログアウト時にパスの設定が消えてしまうので.bash_profileに記述しておく $ vi .bash_profile →ファイルが開くので、下記を追加 # nvm if [[ -s ~/.nvm/nvm.sh ]] ; then source ~/.nvm/nvm.sh ; fi3,node.jsをインストールする
// インストール可能なバージョンを確認する。 nvm ls-remote //インストールして使用する nvm install v12.19.0 nvm use v12.19.0 //きちんとインストールできていることを確認する node -v
- 投稿日:2020-10-19T19:20:54+09:00
Terraformにおけるmoduleの使い所
対象読者
Terraformは触ったことがあるが、moduleがあまりわからない。または、moduleをつかったことがない人が対象になります。
またAWSをTerraform化する場合を例に出すので、AWSの知識も少し必要です。はじめに
私はTerraformを触って2年近くになりますが、moduleを使った設計は行わずに基本的に以下のフューチャーアーキテクトさんの記事で書かれている
環境毎にディレクトリで分離派に則ってTerraformを作成しておりました。
参考資料: https://future-architect.github.io/articles/20190903/ただ、やはり環境ごとで同様の設定を書くことがあり、冗長に感じたので、DRYの法則に則りmoduleを使ってみました。
moduleの使い方と設計の勘所のメモとしてこの記事を書きます。moduleとは
アプリケーションで使う場合のmoduleと同じく、terraformでも共通で使いたい部分をテンプレートとして使うためのものです。
既存のコードをmodule化する
このようなterraformのコードが存在するとします。
この場合、vpc.tfが共通化できる設定であると仮定してmodule化していきます。├── prod │ ├── main.tf │ ├── variables.tf │ └── vpc.tf └── stag ├── main.tf ├── variables.tf └── vpc.tfmodule作成
terraformではmodule化をしたものを読み込む時に
moduleを宣言して扱います。
例えば、terraformのルートディレクトリにmodulesディレクトリを掘って、その中に共通化したい resourceを定義します。
この場合は、vpc.tfを共通化したいので、vpcのresourceを定義します。modules/vpc/main.tfresource "aws_vpc" "this" { cidr_block = "192.168.0.0/20" instance_tenancy = "default" tags = { "Name" = "this" } }この
modules/vpc/main.tfを呼び出してstag環境を作ろうとするならば、
相対パスで指定してmodule化したディレクトリ指定します。stag/vpc.tfmodule "vpc" { source = "../modules/vpc" }moduleの値を参照する
moduleで定義した内容を別で定義した
resourceで参照したい場合は、outputを定義して使えるようにします。
逆にmoduleに値を渡したい時はvariableを使います。
言い換えると、moduleから出力されたものを定義するのがoutputで、moduleに入力するものを定義するのがvariableです。これを使ってmoduleを直していきます。
stag環境以外に本番環境も使えるmoduleにしたい場合はこのように修正しましょう。modules/vpc/main.tfvariable "vpc_cidr" {} resource "aws_vpc" "this" { cidr_block = "${var.vpc_cidr}/20" instance_tenancy = "default" tags = { "Name" = "this" } }
vpc_cidrが空なのはmodule参照時に定義される値を読み込むためです。
先ほど定義したstag/vpc.tfでmoduleのvariableで定義したvpc_cidrに値を渡してあげましょう。stag/vpc.tfmodule "vpc" { source = "../modules/vpc" vpc_cidr = "192.168.0.0" }このようにすると
modules/vpc/main.tfのvpc_cidrに192.168.0.0が定義されて、
variable定義前と同じ設定内容になります。prod環境でvpcを作りたい場合もmoduleを呼び出して作れます。
prod/vpc.tfmodule "vpc" { source = "../modules/vpc" vpc_cidr = "172.16.0.0" }またmoduleで定義した内容を他のresourceでも参照したい時には
outputを使います。
先ほど設定したmodules/vpc/main.tfにoutputで別のresourceに参照される値を定義します。modules/vpc/main.tf~省略~ output "this_vpc_id" { value = aws_vpc.this.id }ここでは、stag環境で新たに
igw.tfを作りインターネットゲートウェイの設定を定義します。
moduleで定義した内容を読み込む場合はmodule.<module名>.<outputの定義名>で値を参照します。stag/igw.tfresource "aws_internet_gateway" "this" { vpc_id = module.vpc.this_vpc_id tags = { "Name" = "this" } }module化したあとのコード
全体のディレクトリ構成はこのようになります。
現在はprod/stagでmoduleを読み込むtfファイルとmoduleのディレクトリ名を1対1に作ってますが、
modulesにEC2やVPCを全部いれたmoduleを作り、それをprod/stagで読むこともできます。├── modules │ └── vpc │ └── main.tf ├── prod │ ├── main.tf │ ├── variables.tf │ └── vpc.tf └── stag ├── igw.tf ├── main.tf ├── variables.tf └── vpc.tfこの記事の内容はこちらにサンプルコードとして載せて置くので、
完成したコードを読みたい方がいればご覧ください。所感
moduleは大変便利だと感じた一方、値の参照が多いネットワーク系(AWSでいうとvpcやsecurity groupなど)で使う場合は、何をどこで参照させるかを考える必要が出てくると感じました。
ただ、ECRなどの他のリソースとの依存関係がほぼなくサービス単体で成り立つものに関してはmodule化をすると見通しがよいコードになると感じます。
- 投稿日:2020-10-19T18:26:25+09:00
【初心者向け】EC2でユーザーを登録してローカルからエイリアスで接続するまで
概要
EC2でユーザーを登録する処理とローカルでsshのエイリアスを作成する方法をまとめます。
久しぶりにサーバー立てるとつい手順を忘れちゃいますね。ゴール
1,ユーザーを作成する。
2,作成したユーザーに対して、(ローカルで) ssh <<任意の名前>>
と打てばssh接続することができる。手順
1,EC2にログインする。
$ ssh -i hogehoge.pem ec2-user@52.222.222.222 // Elastic IPにssh接続2,ユーザーを作成して、コマンドの実行権限を付与(ルートユーザーの作成)
// ユーザーを作成する 今回はtaroというユーザーを作成する。 $ sudo adduser taro // ユーザーのパスワードを設定 $ sudo passwd taro →パスワードを聞かれるので入力 // すべてのコマンドの権限を付与する $ sudo visudo →開いたら、 「root ALL=(ALL) ALL」 と記載してある場所を探し、 その下に 「taro ALL=(ALL) ALL」 を追加3,ユーザーにsshの公開鍵を追加し、(ローカルで) ssh <<任意の名前>>
と打てばssh接続することができるようにする。// ユーザーを切り替える $ sudo su - taro //認証情報をユーザー配下に追加 $ mkdir .ssh $ chmod 700 .ssh $ cd .ssh $ vim authorized_keys →ファイルを開いたら公開鍵(id_rsa.pub的なやつ)の内容をペースト、作成方法は下に記載。 $ chmod 600 authorized_keys これにてサーバー側完了。 この状態でも鍵は登録してあるので該当ユーザーでSSH接続は可能だが、 コマンドを短縮化して直感で扱えるようにローカルでエイリアスを作成する。4,ユーザー側でエイリアスを作成する。
$ cd .ssh $ vim config →ファイルを開いたら以下の内容を追加 /********************* Host <<任意の名前>> Hostname 52.222.222.222 // インスタンスのElastic IP Port 22 User taro // サーバーで鍵を持つユーザー IdentityFile ~/.ssh/id_rsa // サーバーに登録した鍵とペアになる秘密鍵 *************************/これで、ローカルで ssh <<任意の名前>>と打てば、接続できるはずです。
補足
公開鍵と秘密鍵の作りかた。
$ cd ~/.ssh $ ssh-keygen -t rsaこれで作成されるもののうち、拡張子が.pubの方が公開鍵で、pubがない方が秘密鍵です。
例: id_rsa(秘密鍵) , id_rsa.pub(公開鍵)
- 投稿日:2020-10-19T17:24:57+09:00
Python で parameter store を使う
はじめに
以前、仕事で使った Parameter Store(AWS Systems Manager) をまた使うことになったので思い出しました。
今回もPoetry + Dockerを開発環境にしています。
ソースは Github にあげてあります。Parameter Store を設定する
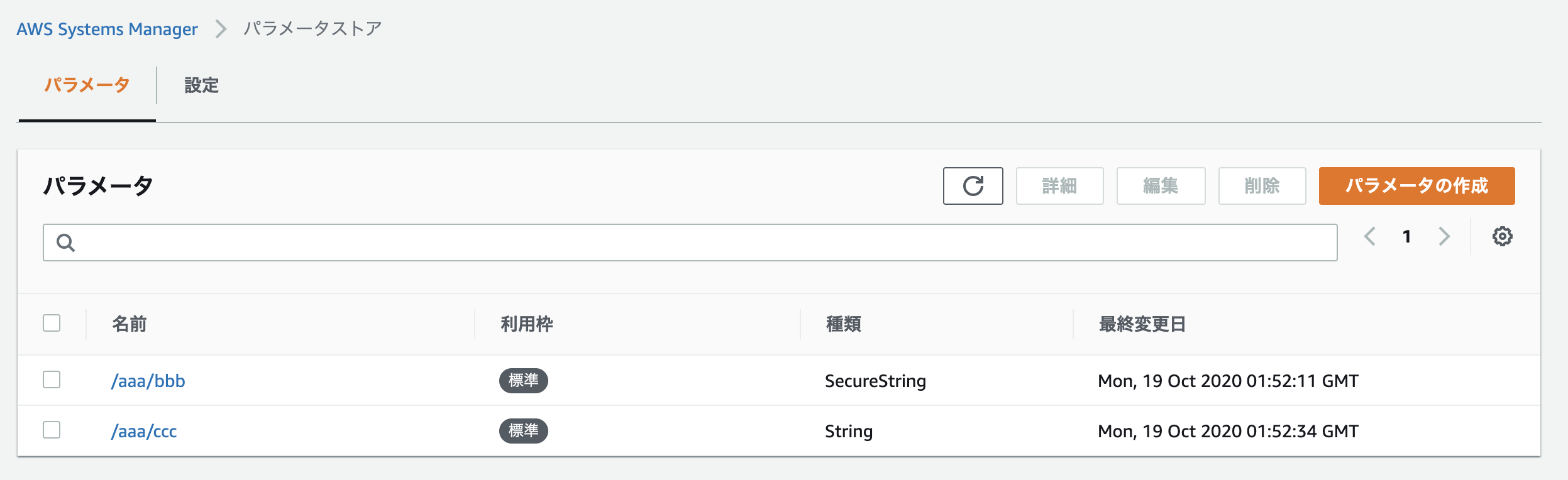
/aaaで始まるように作成
ファイル
mainとライブラリとしてファイルを分けています。
main.pyfrom src.ssm_manager import SsmManager print("start") ssm_manager = SsmManager(region_name="ap-northeast-1") ssm_manager.load_parameter(base_ssm_path="/aaa") print(ssm_manager.parameters)ssm_manager.pyfrom typing import List, Dict import boto3 class SsmManager: def __init__(self, region_name: str): self.__ssm = boto3.client('ssm', region_name=region_name) self.__parameters = [] self.__base_ssm_path = None @property def parameters(self) -> List[Dict[str, any]]: return [{ 'name': item['Name'].replace(f'{self.__base_ssm_path}/', ''), 'value': item['Value'] } for item in self.__parameters] def load_parameter(self, base_ssm_path: str) -> None: self.__base_ssm_path = base_ssm_path result = [] next_token = None while True: dict_parameter = { 'Path': base_ssm_path, 'Recursive': True, 'WithDecryption': True, } if next_token is not None: dict_parameter['NextToken'] = next_token response = self.__ssm.get_parameters_by_path(**dict_parameter) parameters = response['Parameters'] result.extend(parameters) if 'NextToken' not in response: break next_token = response['NextToken'] self.__parameters = result終わりに
これで、環境変数などに入れていたRDSのパスワードなどを保存できます。
- 投稿日:2020-10-19T15:05:47+09:00
Hinemos ver.6.2 をAWS上にインストールして監視するまで(監視設定編)
このページは、以前投稿した「Hinemos ver.6.2をAWS上にインストールして監視するまで(初期設定編)の続きになります。
(だらだら書いてたら前回から1年近く経ってしまった。。。)
そちらでは、Hinemosの初期設定方法をまとめていますので、そちらも見てみてください。
Hinemos ver.6.2 をAWS上にインストールして監視するまで(初期設定編)このページで実施すること
このページでは、主に下記の内容をまとめます。
- 監視対象マシンの登録
- リソース監視をするために必要な設定
- リソース監視とメール通知設定
前提知識として、SNMP(Simple Network Management Protocol)というプロトコルについて概要だけでも理解していた方が良いと思います。
また、メール通知をするために必要な設定は前の記事で解説しているので、そちらを参照してください。設定をする前に
今回AWS上で監視対象とするマシン(Ubuntu)のNet-SNMPの設定をします。
AWS上で監視対象のインスタンスに対して、下記のインバウンド設定がされていないと、正常に設定ができないので注意してください。
ポート番号 TCP or UDP 用途 備考 161 UDP リソース監視、プロセス監視、SNMP監視のため 監視対象マシンの登録とリソース監視のための準備
今回は、監視対象マシンとしてUbuntuのEC2インスタンスを利用します。
とはいえ、RHEL系OSでもやることはほぼ同じ(ファイルパスは微妙に違うかも)なので、参考としてもらえればと思います。Net-SNMPの設定
Hinemosは一部の監視でSNMPを利用します。
なので、監視対象のマシンにHinemosマネージャとSNMP通信ができる様に設定をあらかじめする必要があります。SNMPとは?
SNMP(Sinmple Network Management Protocol)のめちゃくちゃ大雑把に概要を説明すると、主にNW機器のステータス(CPU使用率やプロセス稼働状況)などを管理するためのプロトコルです。OID(Object ID)をリクエストで渡すことで、そのOIDに対応した値を返却するものになります。
OIDは「どの機器に対しても共通で利用できるもの(標準MIB)」と「特定のベンダーの製品だけで利用できるもの(拡張MIB)」が存在します。
※本ページではMIB(Management Information Base)についての説明は省きます。詳細はこの辺を見ると分かりやすかもしれません例えば、「CPU使用率」を求めるOID(.1.3.6.1.2.1.25.3.3.1.2)をリクエスト送信すると、リクエストを受け取ったマシンがCPU使用率をレスポンスで返してくれます。そのほかにも、起動中プロセスの一覧を取得することもできます。
Net-SNMPの設定例
SNMPでは、不特定多数のマシンからのアクセスを抑制するために、「コミュニティ名」を設定します(デフォルトは「public」)。
厳密には違いますが、コミュニティ名は相手のマシンの情報を取得するための簡易パスワードのようなものだと思えば良いかなと思います。
※SNMPv2cまでは通信時の認証機能はありませんでしたが、SNMPv3からちゃんとした認証機能が追加されています。下記はSNMPバージョン「2c」、コミュニティ名「testCom」を設定する例です。
詳しくは、別の方がとても詳しく解説されているので、 そちらをご覧ください。
net-snmpの設定/etc/snmp/snmpd.conf# コミュニティ名「testCom」、SNMPバージョン2cでSNMP通信するための設定例 # これらを任意の場所に追記する com2sec notConfigUser default testCom group testGroup v2c notConfigUser # リソース監視をするため、先頭.1.3.6.1(標準MIB)で始まるOIDのリクエストを許可 view systemview included .1.3.6.1 access testGroup "" v2c noauth exact systemview none none上記の設定を追記したら、snmpdを再起動しましょう。
service snmpd restart監視対象マシンの登録
監視対象マシンをHinemosマネージャ上に登録します。
監視対象のマシンを管理するのは、「リポジトリ」パースペクティブになるので、画面左上から「パースペクティブ」>「リポジトリ」の順番で選択しましょう。
なお、パースペクティブとは、Hinemosの機能ごとにまとめた画面を指します。
今回の場合、監視対象マシンを登録したりする「リポジトリ機能」を利用するため、「リポジトリ」パースペクティブを開きました。あとで、監視設定を行うため、「監視設定」パースペクティブを開きます。また、似た言葉で「ビュー」という言葉が出ますが、これはパースペクティブ内の小画面のことを指します。
図にすると下の様な感じです。下の図の場合、パースペクティブの中に3つのビューが同時に表示されていることがわかります。
では、「リポジトリ(ノード)」ビューの右上にある「+」のアイコンをクリックして、実際に監視対象のマシンを追加してみましょう。
すると、下の様な監視対象のマシンを追加するためのダイアログが出力されます。ここで、少し便利な「デバイスサーチ機能」(下画像の上側の赤枠)を利用して、マシンを登録しましょう。
これは、SNNPリクエストを指定したIPアドレスのマシンに送信し、応答内容から登録に必要な情報を抽出して自動入力する機能です。監視対象マシンのIPアドレスとNet-SNMPで設定したコミュニティ名とバージョンを指定してSearchを押すと、登録に必要な情報を自動入力してくれます。
マシン登録の注意点(ファシリティID)
デバイスサーチ機能を使ってマシンを登録するとき、1点だけ注意する必要があります。
デバイスサーチ機能を使った場合、ファシリティID(Hinemosマネージャ内で一意の監視対象マシンのID)は「マシンのホスト名」になります。
ホスト名が同じマシンを複数登録する場合、2つ目以降のマシンはファシリティIDが重複するので登録ができません。その時は、ホスト名を変更するか、手動でファシリティIDを変更する必要があります。スコープの設定
監視対象マシンの登録ができたら、今度はスコープの登録と割り当てを行いましょう。
スコープとは、監視を行う対象のグループのことを言います。
Hinemosではスコープは複数作成して、階層構造を持たせることができますし、監視対象のマシンも複数のスコープに所属することができます。
上記の図を例にすると、Hinemosに管理されている一番大きなスコープ「登録ノードすべて」があり、その中にHinemosが管理している「システムA(B)」スコープがあり、さらにその中にそれぞれ「Webサーバ」「APサーバ」「DBサーバ」といった感じで階層構造別にスコープを作成し、そこに該当するマシンを登録することができます。また、システムをまたいで監視やジョブを実行したい場合は、それに加えてシステムを跨ぐようなスコープ(上図だと、横に伸びている半透明緑色の四角)を定義することも可能です。
監視・ジョブはマシン単体を対象に指定することももちろんできますし、スコープを監視対象に選ぶことができます。あらかじめスコープを監視・ジョブ実行対象としておけば、同じ監視をさせたいマシンが増えた時に対象のスコープにマシンを追加するだけで、監視設定を変更することなく同じ監視を行うことができます。
スコープの設定は、リポジトリパースペクティブの(デフォルトでは)下部分に表示されている「スコープ」ビューで行います。
スコープを作成する際によく混乱するのですが、まずは左側のツリーからスコープを作成したい先の親スコープを選択しないと作成ボタン(+アイコン)が有効化しません。
スコープのファシリティIDとスコープ名を決めて「OK」を押すと、スコープを作成することができます。
スコープを作成したら、次はそのスコープにマシンを割り当てます。
(これも左側のツリーから割り当てをしたいスコープを選択してから「割当て」ボタンをクリックします。
すると、割り当て可能なマシンの一覧が表示されるので割り当てたいマシンを選択(複数選択したい場合はCtrlキーを押しながら選択)して「割当て」ボタンをクリックして完了です。
リソース監視の設定
今回は例として、5分おきにファイルシステム使用率を監視し、ファイルシステム使用率が90%超えた時に1時間おきにメールで通知する仕組みを作ります。
「1時間おきにメール通知する」という設定根拠ですが、あまりにも頻繁にメールが来ると、たとえものすごく重要なメッセージでも運用者は鬱陶しくなって通知を見なくなるからです。
メール通知するのはメール通知するに足る内容かつ適切な頻度であることが重要だと考えます。上の仕組みを作るにあたって、行う作業は下記になります。
- メールテンプレートの作成
- メール通知の作成
- リソース監視(ファイルシステム使用率)の作成
メールテンプレートの作成
まずは、メール通知をするためのテンプレートを作成します。
テンプレートは、「ファイルシステム使用率がしきい値を超えた時に利用するもの」を作成します。
「監視設定」パースペクティブの「メールテンプレート」ビューを開き、右上の「+」アイコンをクリックして、メールテンプレート作成ダイアログを開きます。
メールの本文はお試しで(1)どのマシンの(2)どのファイルシステムが(3)使用率何パーセントになっているのか、の3点がわかるような本文とします。
メール本文中には変数を使用することができ、変数は#[変数名]で呼び出すことができます。下の画像の通り本文を設定することで、メール本文中にファシリティID(Hinemosマネージャ内で一意に決まる監視対象マシンのID)、IPアドレス、実際にしきい値を超えたファイルシステムと現在のファイルシステム使用率を埋め込むことができます。
どんな変数が利用できるかは、本文のところでマウスオーバーするとポップアップで一覧が出てきます。
それぞれの変数や使い方はマニュアルを参照してください。
メール通知の設定
では次に、前節で設定したメールテンプレートを利用したメール通知の設定をします。今回は、監視結果が「危険」になった場合、メール通知するよう設定をします。
※監視の重要度については、重要度の種類と「不明」についてで解説します。
通知IDと説明は、何の通知なのかをわかりやすくしておくとあとで管理しやすいです。
ここで注目するべき内容は、「重要度変化後の初回通知」と「重要度変化後の二回目以降の通知」でしょうか。重要度変化後の初回通知
ここは記載がある通り、同じ重要度の監視結果が指定回以上連続した場合にだけ通知をする(メール通知の場合は、メール送信をする)という設定になります。
CPU使用率やメモリ使用率のように、「瞬間的に100%になったりする」ことがある監視の場合に2以上の数値を指定します。重要度変化後の二回目以降の通知
ここは、前述の初回通知の後に同じ監視結果が連続した場合にどう扱うか、という設定です。
下記の3種類が指定できます。
- 常に通知する:同じ監視結果が続く限りずっと通知し続ける
- 前回通知から●●分間は同一重要度の通知はしない:文字通り、指定した時間の間同じ監視結果が続いている限り通知しない(指定時間中に違う監視結果が発生した場合はリセットされる)
- 通知しない:前回通知した監視結果とは別の監視結果となるまで通知を一切しない
基本的には「常に通知する」でいいと思いますが、「メール通知」は頻繁にメールがきた場合、鬱陶しくて見なくなってしまいます。
なので、ある程度ここの設定でメール送信を抑制した方が良いと個人的に思います。上記の通知抑止設定まで行ったら、あとは先ほど作成したメールテンプレートを「メールテンプレートID」のプルダウンメニューから選択し、重要度別に通知する or しない設定とメール送信先のメールアドレスを指定するだけで完了です。
ステータス通知の作成
メール通知の設定だけでは、正しく動作していた場合(ファイルシステム使用率がしきい値範囲内だった場合)に何も通知されず、正しく動いているのかわからないので、確認用にステータス通知も定義します。
ステータス通知は、各監視の最新結果だけをHinemosクライアント上に表示させる通知設定です。
最新結果だけを表示するので、過去の監視結果は常に最新に更新され、履歴は残りません。先ほどメール通知の設定ダイアログを開いたのと同じ要領で、今度は「ステータス通知」を選択肢てダイアログを開きます。
ステータス通知の設定ダイアログは、上半分の部分は上記で解説した内容と全く同じになります。
下半分は、どの重要度の時に通知する(画面に表示する)かと、画面に表示し続ける時間を設定します。残りは画面に記載されている通りの設定内容なので、本記事では省略します。
リソース監視の設定
では本題のファイルシステム使用率を監視するためのリソース監視を設定します。
監視設定[一覧]ビューで作成ボタン(+アイコン)を押すと下のようなダイアログが出るので、その中から「リソース監視(数値)」を選択して「次へ」を押します。
リソース監視とは?
リソース監視は、名前の通り監視対象マシンのCPU、メモリ、ファイルシステム使用率などなどを監視することができます。
この監視はSNMPを利用するため、冒頭で行ったNet-SNMPの設定がされていないと利用できません。下のキャプチャは「test-node」スコープに対して、「全てのファイルシステムを監視する」設定を行った例になります。
赤枠の上にある「監視項目」のプルダウンメニューから、この監視設定で監視したいリソース値を選択します。今回の場合は、ひとまず全部のパーティションを監視することとします。
いくつかテクニックなどの補足説明をしたいと思います
基本、未来予測、変化量タブについて
赤枠の部分ですが、Hinemosのリソース監視を含めた「数値を監視する系」の監視は「基本」、「将来予測」、「変化量」の観点で監視をすることができます。それぞれ下記のような意味があります。
- 基本:HinemosがSNMPリクエストを投げて受け取った瞬間の結果を監視する
- 将来予測:過去の監視結果をもとに、ユーザが指定した未来時間(分単位で指定)がどうなるかを監視
- 変化量:過去の監視結果をもとに変化量の標準偏差を導き出し、それをしきい値として監視
上記説明(特に変化量のところ)は少しわかりづらいと思うので、今回のファイルシステム使用率監視の例に例えると
- 基本:Hinemosが監視対象とSNMP通信をした瞬間のファイルシステム使用率を監視
- 将来予測:過去のファイルシステム使用率の値をもとに30日後のファイルシステム使用率を推測して監視
- 変化量:過去のファイルシステム使用率の増え方(例えば毎時だいたい○MB増えてる)から大きく逸脱したもの(いきなり1時間でXGB増えた or 1バイトも増えてない)がないかを監視
といったことができます。
ファイルシステム監視だとデータの取捨選択や最悪ディスクの交換など対応に時間がかかる(言い換えれば、「いつまでに対応しなきゃいけないのか」を教えて欲しい)内容の監視なので、もしかしたら「将来予測」を利用するのが一番いいかもしれませんね。重要度の種類と「不明」について
Hinemosの数値系監視の結果の重要度は4種類あり、そのうち必ず3種類のしきい値を設定しなければいけません。
- 情報(緑背景で表示)
- 警告(黄背景で表示)
- 危険(赤背景で表示)
- 不明(青背景で表示)
ユーザが指定しなければいけないのは情報、警告、危険の3種類です。
じゃあ不明は?となりますが、なんらかの原因で監視できなかった場合に不明となります
今回の場合は、下記のような状況になった場合に不明の結果となります。
- SNMP通信に失敗した
- SNMP通信がタイムアウトした
しきい値の設定について
前節で、ユーザは3種類の重要度をしきい値で設定することを説明しました。でも往往にして、「3つも重要度いらないよ。情報と危険だけでいいよ」って思う時があるわけですよ。
実はしきい値の設定を下のようにすることでそれができます。
具体的には、情報と警告を全く同じしきい値設定をします。
そうすることで、上記の場合、ファイルシステム使用率が90%未満の場合は重要度「情報」、90%以上になったら「危険」で通知するように設定ができます。通知の設定
最後に通知IDの「選択」ボタンを押して、このリソース監視に設定する通知を選択することができます。
今回は、上記で作成した「ステータス通知」と「メール通知」を指定しました。
では、設定も終わったので、しばらく様子を見てみましょう
監視結果の確認
上記で設定したリソース監視は、30秒間隔で監視するよう設定をしたので、適当に1〜2分待っていれば通知が上がっているはずです。
ステータス通知は、「監視履歴」パースペクティブの「監視履歴[ステータス]」ビューで確認できます。
上記のように、パーティション別にファイルシステム使用率の結果が表示されます。
上の場合はすべて緑色(情報)なので、90%未満であることがわかります。
詳しく現在の使用率を知りたい場合は「メッセージ列」または気になる通知の行をダブルクリックすることで詳細ダイアログを開くことができます。
ファイルシステム90%超えた時の監視結果確認
今回は、ルート(/)パーティションのファイルシステム使用率が90%以上になるようなダミーファイルを作成して、ファイルシステム使用率が90%を超えた場合の動作も確認してみましょう。
具体的には、対象のマシンにSSHログインして下記のような操作を行います。
# 現状のファイルシステム使用率を確認 df -h Filesystem Size Used Avail Use% Mounted on udev 987M 12K 987M 1% /dev tmpfs 201M 364K 200M 1% /run /dev/xvda1 20G 12G 6.9G 64% / none 4.0K 0 4.0K 0% /sys/fs/cgroup none 5.0M 0 5.0M 0% /run/lock none 1001M 0 1001M 0% /run/shm none 100M 8.0K 100M 1% /run/user # 上記の場合、ルート(/)パーティションに7GB弱の空き容量があるのがわかるので、6GBのダミーファイルを作成します # 下記のcount=の部分は環境に合わせて変更してください dd if=/dev/zero of=6G.dummy bs=1M count=6000 6000+0 records in 6000+0 records out 6291456000 bytes (6.3 GB) copied, 92.3561 s, 68.1 MB/s上記操作を完了したらしばらく待ってみましょう。
そうすると、監視結果「危険」のステータス通知を確認できました。
また、メール通知に指定したメールアドレスにメールも届いていました。
また、リソース監視は30秒間隔で実施されていますが、メール通知の抑止制限により、60分間は同じ重要度の監視結果は通知されないため、30秒おきにメールが送られてくるということもありません。
・・・といった感じで、ファイルシステム使用率の監視設定がうまくできていることを確認できました。
まとめ
本記事では、前記事(Hinemos ver.6.2 をAWS上にインストールして監視するまで(初期設定編))で行った初期設定を元に、監視対象マシンに対して下記の監視を行うための準備および設定を行いました。
- ファイルシステム使用率を監視する
- 使用率が90%以上になった場合に限り、60分に1回メールで知らせる
- Hinemosクライアント上で監視結果を確認できるようにする
また需要がありそうなら、他のテクニック等についてもまとめてみようと思います。

























- 投稿日:2020-10-19T10:31:59+09:00
AWS EKS:アーキテクチャとモニタリング
はじめに
AWS Elastic Container Service for Kubernetes(EKS)は、重くて変動するワークロードを実行しているノードの大規模なクラスターに最適なマネージドKubernetesサービスです。 AWSでアカウントのアクセス許可が機能する方法のため、EKSのアーキテクチャは多少複雑であり、モニタリング戦略にいくつかの小さな違いが生じます。 ただし、言えることは全体的に見て、あなたが知っているKubernetesと同じものです。
Kubernetesクラスターアーキテクチャ
Kubernetesは、コントロールプレーンとデータプレーンで構成されています。コントロールプレーンには、Kubernetesがノードを管理するために必要なサービス、主にkube-apiserver(特に、kubectlによって使用される)、controller-manager、およびkube-schedulerが含まれます。これらは通常、クラスター内の1つ以上のマスターノードで実行されます。マスターノードはフォールトトレランスのために複製できますが、コントロールプレーンコンポーネントはKubernetes自体の中にポッドとしてデプロイすることもできます。これは、たとえばminikubeで開発するときに表示されます。
データプレーンは、すべてkubeletサービスとkube-proxyを実行しているサーバーノードまたはVMノードで構成されており、Kubernetes構成の変更に対応できます。 Kubeletは、コンテナの実行を駆動するポッドAPIとノードAPIも管理し、KubernetesのすべてのAPIと同様に、ツールや拡張機能の基盤として表示および利用できます。
クラスタ内のすべてのノードはetcdを実行して、クラスタの状態をクラスタ全体で調整できるようにします。クラスターの状態を変更するリクエストがkube-apiserverに対して行われると、kube-apiserverはetcd内のオブジェクトを更新し、それがクラスター全体に伝播されます。次に、Kubeletはこれらの変更を各ノードに実装します。
マスターノードがダウンすると、ノードのグループは事実上クラスターではなくなりますが、アプリケーションは通常、マスターがなくても機能し続けます。ノードを再起動すると、マスターがバックアップされるまでDNSルーティングで問題が発生する可能性がありますが、通常、短時間の停止は大きな影響はありません。
EKSのコントロールプレーン
EKSはマネージドKubernetesサービスであり、アカウントとAWSの間で2つのプレーンの責任を分担します。 これはKubernetesとすべて同じ可動部分で構成されているため、kubectlとapi-serverを介してクラスターを完全に制御できますが、マスターノードとコントロールプレーンはAWSによって独自のアカウントで管理および維持されます。 さらに、クラウドコントローラーマネージャーデーモンが実行され、AWSリソースとの相互作用を処理します。 ローカルkubectlがkube-apiserverに接続するための設定の詳細が提供され、AWSアカウントには、クラスター内のノードとして機能するアカウント上のインスタンスにアクセスするためのアクセス許可が付与されます。
これを設定するには、いくつかの要件があります。
- Kubernetesマスターノードには、各ノードのkubeletのAPIへのフルアクセスが必要です。 各kubeletは、見返りにマスターにアクセスする必要があります。
- Cloud-controller-managerはあなたのアカウントにアクセスする必要があります。
- etcdは、両方のアカウントのノード間で同期できる必要があります。 そして
- ノードとポッドは、相互に通信するために、静的なDNSで検出可能なIPアドレスを維持できる必要があります。
EKSを設定すると、AWSアカウントからノードへのアクセスを許可するために使用できるIAMロールを提供するように求められます。また、kubernetes固有のポートへのアクセスを許可するセキュリティグループも求められます。ポッドとノードがお互いを見つけるために使用できる静的(内部)アドレスを提供するために使用されるVPC(仮想プライベートクラウド)を求められます。
VPCアドレス空間のサイズにより、実行できるポッドの数が制限されるため、十分に広い範囲を選択してください。たとえば、/ 24サブネットは254個のアドレスしか提供せず、クラスター内の各ノードにもアドレスが必要です。これにより、ポッドで使用できる合計が減少します。また、ネットワークインターフェースの数と、それぞれが維持できるIPの数に基づいて、1つのノードに割り当てることができるIPの数にも制限があります。
EKSクラスターのスピンアップと管理のプロセスを簡素化するために、AWSはeksctlと呼ばれる小さなコマンドラインユーティリティを提供します。このユーティリティは、awscliによって保存された認証情報を使用して、ユーザーに代わってクラスターノードとロールを作成できます。クラスタを制御するために必要な資格情報がkubectlに自動的にエクスポートされます。
EKSのサービス
サービスを起動すると、Kubernetesのcloud-controller-managerは、サービスの種類に応じて起動する適切なAWSリソースを選択します。 EKSでは、NodePortまたはClusterIPサービスは通常のKubernetesセットアップと同じように機能しますが、LoadBalancerまたはIngressサービスタイプは両方ともAWSリソースの作成をトリガーします。
デフォルトでは、LoadBalancerサービスタイプは、AWSによって作成された元のロードバランサーであるClassic Elastic LoadBalancerを作成します。このタイプのロードバランサーは、実際には、ラウンドロビンアプローチを使用して定義されたエンドポイントにリクエストをルーティングする小さなインスタンスで構成されています。
または、プロトコル、送信元IP /ポート、宛先IP /ポート、およびTCPシーケンス番号に基づいてハッシュマップを作成することにより、要求をさまざまなエンドポイントにルーティングするネットワークロードバランサーを使用できます。 1つの- TCP接続のすべてのトラフィックは、同じエンドポイントに転送されます。サービスにアノテーションを設定することで、クラシックロードバランサーの代わりにネットワークロードバランサーを使用するようにKubernetesに指示できます:service.beta.kubernetes.io/aws-load-balancer-type:nlb
Ingressサービスタイプは、要求された宛先URL(レイヤー7ルーティング)に基づいてトラフィックを異なるポッドに分散し、複数の宛先のトラフィックを同じIPアドレスに送信できるようにします。サービスは、URLに基づいて異なるポッドセットにトラフィックを送信します。実際に使用されました。 EKSの場合、このタイプのサービスは、AWS独自のレイヤー7ルーティングLBであるApplication LoadBalancerによって処理されます。
このページでは、AWSのさまざまなロードバランサーによってトラフィックがどのようにルーティングされるかについて詳しく説明します。
EKSのボリューム
Kubernetesは多数のストレージタイプをサポートしていますが、その中で最も単純なのはemptyDirです。これは、ポッド内でのコンテナの再起動に関係なく、接続されているポッドの存続期間中持続するボリュームです。 デフォルトでは、emptyDirボリュームはノードのディスクスペースに作成されます。EKSでは、ノードはEC2インスタンスであるため、emptyDirに使用される実際のストレージタイプは(通常)Elastic BlockStorageボリュームです。 EC2は、インスタンスストアと呼ばれる一時的なローカルストレージも提供しますが、一時的な性質のため、これはデフォルトではなくなりました。
Kubernetesは、EBSボリュームをストレージとして直接使用することもサポートしているため、ポッド間で永続するボリュームを作成できます。 オプションで、ポッドがアクセスする必要のあるデータをEBSボリュームにプリロードすることもできます。 EBSボリュームは、一度に1つのEC2インスタンスにのみマウントできます。これは、ポッドがアクセスするために必要です。
EKSの監視
通常のKubernetesセットアップでは、監視する最も重要なことの1つはマスターノードです。これがないと、Kubernetesクラスターはクラスターでなくなるためです。 EKSでは、マスターノードとほとんどのコントロールプレーンはAWSによって管理されており、それらは手の届かないところにあります。クラスター全体に関するメトリックを取得できる場合がありますが、実際のマスターノードは取得できません。
Kubernetesの仕事の1つはノードとコンテナの停止に対処することであるため、独自のモニタリング設定の一部としてアクセスできるモニタリングが組み込まれています。 Kubeletは、ノード、ポッド、およびコンテナー(cAdvisorが組み込まれている)の状態に関するデータを収集して、コンテナーに問題があり、再起動が必要な場合に通知します。メトリックは、メトリックサーバーから利用できます。メトリックサーバーは、短期ストレージを備えた非常に軽量なサービスであるため、リクエストに応じてKubernetesリソースの現在の状態をキャプチャするために使用されます。メトリックを時系列としてキャプチャし、それらをグラフとして使用するには、別のツールが必要です。
AWSは、CloudWatchに保存されているEC2インスタンスのモニタリングをすでに提供しています。また、Container Insightsと呼ばれるサービスも提供します。これは、EKSクラスターでDaemonSetとして実行できるエージェントであり、ノード、ポッド、コンテナーに関するメトリクスを取得し、カスタムメトリクスとしてCloudWatchに送り返します。
ただし、CloudWatchではカスタムメトリクスのコストが比較的高くなります。アラートが追加される前のメトリクスあたり$ 0.30です。より一般的なアプローチは、Prometheusを使用してクラスターをモニタリングすることです。 KubernetesはProm形式のメトリクスをネイティブにサポートしているため、簡単に起動して実行できます。オプションで、KubernetesパッケージマネージャーであるHelmをセットアップできます。これにより、Prometheusだけでなく、Alert Manager、PushGateway、Nodeやノンエクスポーターなどのすべてのサポートサービスがインストールおよび構成されます。
AWS CloudWatchはAPIアクセスメトリクスを提供するため、CloudWatchからメトリクスを取得してPrometheusで利用できるようにするPrometheusCloudWatchエクスポーターの形で中間点があります。 Helmを使用して、またはgithubから直接インストールできます。
Prometheusでは、取得するメトリックデータをどこに保持するかを選択できます。 Prometheusポッドが意味をなす限り存続するemptyDirタイプのストレージボリューム(上記)。ただし、復元力は提供されません。個別のEBSボリュームは、ノードとコンテナーとは別に存在するため安全なオプションであり、必要に応じてサイズを増やすこともできます。ただし、最小サイズがあるため、そのすべてのストレージが必要ない場合は、無駄になる可能性があります。リモートストレージは復元力を提供し、アラートとダッシュボードをクラスターの外部でも作成できるようにする場合があります(たとえば、MetricFireのHosted Prometheusサービス)。
EKSは、大規模なクロスAZ展開に最適なサービスであり、それがKubernetesが最も得意とするサービスです。ただし、不要な高価なEC2インスタンスにお金をかけるのは非常に簡単なので、モニタリングは依然として不可欠です。クラスターの容量がリソース消費量と一致していることを確認することは非常に重要であり、適切な監視はそれを確実に達成するのに役立ちます。
ベストプラクティスの監視と発生している問題について詳しく知りたい方はPrometheusas-a-serviceとGraphiteas-a-serviceの両方を提供するMetricFireのデモを予約して、自分に合った監視ソリューションについて直接お問い合わせいただくこともできます。

- 投稿日:2020-10-19T10:08:23+09:00
サブドメイン間でセッションを維持できなくする方法
ネット上で見たらサブドメイン間でセッションを維持できる方法ばかりだったために少し困ったから自分の忘備録として記入
やること自体は非常に単純で、SameSite属性を設定する。
SameSite属性には3段階あって
None
Lax
Strict
の3つが設定できる。その内サブドメインでもセッションを維持できるというかセキュリティ的に一番甘いのがNone
激重がStrictである。
これをStrictに設定すればとりあえずサブドメイン間でのセッション維持はできなくなる形としては
cookie = "Info="+token+"&"+"何か適当にその他"+ "&"+domainName +";path=/;SameSite=Strict;Secure;HTTPOnly;expires="+exDate;StrictをNoneに変えれば逆にほかのサブドメインでもセッション維持できるのでそれで切り替えるのが一番楽(コーディングで修正しようとして困りかけた)
このような形で自分は書いた
他のやり方等の方が遥かに参考になると思うのでSametimeに関するお話は以下のURLを見るとわかりやすい
https://www.future-shop.jp/magazine/info-samesiteHTTPOnlyはcookieに格納されたIDをJSで取り出せなくするためにも大事
SecureはつけるとHTTPSでしか送信できなくなるため必須でつける
基本形はこんな形でいいんじゃないかな…?
ほぼ自分へのメモ帳なので説明する気0ですが…
- 投稿日:2020-10-19T10:05:55+09:00
AWS インフラ0startから誰かに教えられるまで
AWSの非常に便利な機能の一つに
CloudFormationという機能があります。
これを用いればコードをCloudFormation側に渡してあげるだけで
あとは自動にインフラを構築してくれるという優れものです。一方で非常に学習コストが高い。。。
それはなぜかというと
- インフラそのもの理解
- コードの理解
この2点が必須となるからです。
元々サービス側でしか携わっていなかった自分ですから
インフラ部分も把握しておかないと一人でサービス作り上げることができないんですよね。。。なのでインフラ周りを改めて勉強しようとなりました。。。
インフラ周りの知識
ここの学習になりますが上記テンプレートの中身を理解しようと考えています。
それぞれVPCやSubnetなど今までのプログラミング人生上一切学んでこなかったネットワークやセキュリティの部分の話になりますので
非常に厄介そうですが学んで色んな現場で働けるように挑戦してまいります?ざっくり自分が学んだことを説明していくので
もし参考になれば是非〜VPC
こちらは Virtual Private Cloudの略で
AWSアカウント専用の仮想ネットワークを意味しています。AWSが使える場所って感じですかね。
Type: AWS::EC2::VPC Properties: CidrBlock: !Ref VpcCIDR EnableDnsSupport: true EnableDnsHostnames: true Tags: - Key: Name Value: !Ref EnvironmentNameInternetGateWay
VPCとインターネット館の通信を可能にするVPCコンポーネント
役割としては
- インターネットでルーティング可能なトラフィックの送信先をBPCのルートテーブルに追加できる
- パブリックIPv4アドレスが割り当てられているインスタンスに対してネットワークアドレス変換を行うこと
簡略図
VPC ---- InternetGateWay ---- インターネット
↑
VPCとインターネットの仲介役って感じですね。InternetGateway: Type: AWS::EC2::InternetGateway Properties: Tags: - Key: Name Value: !Ref EnvironmentNameInternetGatewayAttachment
インターネットゲートウェイまたは仮想プライベートゲートウェイを VPC に接続し、
インターネットと VPC 間の接続を可能にします。このInternetGatewayAttachment
がVPCとインターネットの接続役って感じでしたね。Type: AWS::EC2::VPCGatewayAttachment Properties: InternetGatewayId: String VpcId: String VpnGatewayId: StringSubnet
一つのネットワークを細分化したもの
細分化したものを複数定義して別のインターネットとつなげる認識ですかね。
Type: AWS::EC2::Subnet Properties: AssignIpv6AddressOnCreation: Boolean AvailabilityZone: String CidrBlock: String Ipv6CidrBlock: String MapPublicIpOnLaunch: Boolean Tags: - Tag VpcId: StringEIP
Elastic IP (EIP) アドレスを指定し、オプションで Amazon EC2 インスタンスに関連付けることができます。
Type: AWS::EC2::EIP Properties: Domain: String InstanceId: String PublicIpv4Pool: String Tags: - TagNatGateway
ネットワークアドレス変換 (NAT) ゲートウェイを使用して、プライベートサブネットのインスタンスからはインターネットや他の AWS サービスに接続できるが、インターネットからはこれらのインスタンスとの接続を開始できないようにすることができます。
```外部のインターネットからは接続できないように対応するのがこの
NatGateWayの用途みたいですね。NatGateway1: Type: AWS::EC2::NatGateway Properties: AllocationId: !GetAtt NatGateway1EIP.AllocationId SubnetId: !Ref PublicSubnet1RouteTable
指定された VPC のルートテーブルを指定します。ルートテーブルを作成すると、ルートを追加し、テーブルをサブネットと関連付けることができます。
テーブルをサブネットと関連付けるために必要なテーブルの大元みたいな認識
Type: AWS::EC2::RouteTable Properties: Tags: - Tag VpcId: StringRoute
VPC 内のルートテーブルにルートを指定します。
VPC内のルートを指定することで接続を可能にするものですかね。。。
この辺り理解が乏しいです。Type: AWS::EC2::Route Properties: DestinationCidrBlock: String DestinationIpv6CidrBlock: String EgressOnlyInternetGatewayId: String GatewayId: String InstanceId: String NatGatewayId: String NetworkInterfaceId: String RouteTableId: String TransitGatewayId: String VpcPeeringConnectionId: StringSubnetRouteTableAssociation
サブネットをルートテーブルに関連付けます。サブネットとルートテーブルは同じ VPC にある必要があります。この関連付けにより、サブネットから発信されるトラフィックは、ルートテーブルのルートに従ってルーティングされます。
サブネットから送信するトラフィックをルートテーブルに定義されているルートに沿って送信されるというもの。
RouteTable
指定された VPC のルートテーブルを指定します。ルートテーブルを作成すると、ルートを追加し、テーブルをサブネットと関連付けることができます。
- 投稿日:2020-10-19T09:15:14+09:00
AWSのALBにAzure AD(OIDC)を使ったときに欲しい情報が取れなくてハマった話
AWSのApplication Load Balancerには、OIDCを設定して簡単に認証を組み込むことができます。
詳細は公式ドキュメントを参照ください。
https://docs.aws.amazon.com/ja_jp/elasticloadbalancing/latest/application/listener-authenticate-users.htmlそのときにAzure ADをOIDCのIDプロバイダーとして使ったのですが、Azure ADはID Tokenやアクセストークンに様々な情報を付与することができます。
詳細は公式ドキュメントを参照ください。
https://docs.microsoft.com/ja-jp/azure/active-directory/develop/active-directory-optional-claimsどうハマったのか
公式ドキュメントの引用ですが、ALBは認証した時の情報をヘッダーに付加してくれます。
ロードバランサーは以下の HTTP ヘッダーを追加します。
x-amzn-oidc-accesstoken
トークンエンドポイントからのアクセストークン (プレーンテキスト)。
x-amzn-oidc-identity
ユーザー情報エンドポイントからの件名フィールド (sub) (プレーンテキスト)。
x-amzn-oidc-data
ユーザークレーム (JSON ウェブトークン (JWT) 形式)ユーザークレームは
x-amzn-oidc-dataから取ることができるようなので、こちらから必要な情報を取るように実装しました。
ただ、x-amzn-oidc-dataのJWTをデコードしても、上記にAzureのドキュメントに書いてある様々な情報が全く設定されておらずかなりハマりました。どう解決したのか
Azureのドキュメントをよく読むと、『ID Tokenやアクセストークンに様々な情報を付与する』と書いてあります。
アクセストークンはx-amzn-oidc-accesstokenに入っています。
こちらは使わないと思い、当初は確認していなかったのですが値を見てみたらJWTが入っていました。
x-amzn-oidc-accesstokenから取得できたJWTをデコードしたらきちんとAzureが設定した様々な情報を取得することができました!!JWTの検証でもハマった
JWTが正しく生成されたものかは署名を検証することで確認することができます。
ここでも少しハマりました。
x-amzn-oidc-dataのJWTはAWSが生成したものなのでAWSが提供している公開鍵で検証することができます。
手順は最初に記載したAWSのドキュメントに記載されています。一方、
x-amzn-oidc-accesstokenに設定されているJWTはAzureが生成したものなのでAzureが提供している公開鍵を使って検証する必要があります。
Azureの方は公式ドキュメントを探しても検証の仕方が全然見つからなかったのですが、下記のページがかなり役に立ちました。
https://tsmatz.wordpress.com/2015/02/17/azure-ad-service-access-token-validation-check/
- 投稿日:2020-10-19T07:39:17+09:00
sshログインパスワードを固定にしている方へ
はじめに
私が所属するaslead DevOpsチームでは、日々変化するユーザの開発サーバ構成に対して、セキュリティを保ちつつ開発業務の効率化・自動化ができないかを検討しています。
この記事では、開発サーバなどのOSにsshでログインする際の方法についてご紹介します。そもそもセキュリティの観点では、OSに対してsshでログインせず操作できる状態が理想ではあります。しかしながら、テスト環境での利便性やレガシーシステムへの接続など、様々な事情でsshのログインを残さざるを得ないケースもあるかと思います。
そこで、Hashicorp社が提供しているVaultを利用し、sshログインするパスワードがランダムに払い出されることでセキュリティを向上させるアプローチを考えてみます。使い捨てのコードを用意する、ワンタイムパスワード(OTP)とは若干異なりますのでご注意下さい。
Vaultとは
公式サイトより、Vaultは主に以下のような機能を持っています。
- Secret Management:様々な環境のパスワードのライフサイクルを管理する
- Data Encryption:データの暗号化/複合化を行う(データ自体は保持せず、変換だけ)
- Identity-based Access:同一人物の様々な環境上のアカウントを一つに取りまとめる
本記事ではSecret Managementに分類される機能を取り扱います。
想定するパスワード運用
以下のようなセキュリティに懸念がある運用ケースを想定し、解消を試みてみます。
- パスワードでsshログインしている
- 構築したOSに共通のパスワードを設定している
- パスワード一覧表をファイルサーバなどに置いて運用している
- 定期的にパスワード変更する運用があるが、規則性のあるパスワードで変更される
- 管理者権限ユーザのパスワードは作業で必要になったメンバに徐々に渡している
Vaultによる解決策
上記の課題に対し、今回は公式チュートリアルを参考にログインするたびにランダムにパスワードが変更されるアプローチをとってみます。
これにより、以下のようなメリットがもたらされます。
- パスワードの文字列を考える必要がなく、構築したどのOSも異なるパスワードになる
- パスワード一覧はVaultが保持し、Vault自体のログインはLDAPなど既存の認証の仕組みが利用できる
- 管理者権限を渡す必要があっても、一度しか使えないためチームごとの権限分割は保たれる
以下では具体的にVaultを構築し、ランダムなパスワードが発行される仕組みについて実装していきます。
実装
実装する環境
今回は以下の環境で実装を行います。
AWSを利用していますが、ローカルでも確認可能な内容になっています。
- Vault:ver1.5.4
- OS:Amazon Linux 2
- IaaS:AWS EC2サービス
OS部分の構築
本記事の主な解説対象ではないため、割愛します。
Acrovision社の記事などが参考になるかと思います。以降は、Vaultが稼働するOSを
vault、ログイン対象OSをtargetというホスト名で作成し、
お互いに任意の通信が可能な状態で構築された前提で進みます。Vaultのインストール
2020/07/24より、Linuxレポジトリからの取得が可能になりましたので、こちらを利用して
vaultに対してインストールしていきます。$ sudo yum install -y yum-utils Loaded plugins: extras_suggestions, langpacks, priorities, update-motd amzn2-core | 3.7 kB 00:00:00 Package yum-utils-1.1.31-46.amzn2.0.1.noarch already installed and latest version Nothing to do $ sudo yum-config-manager --add-repo https://rpm.releases.hashicorp.com/AmazonLinux/hashicorp.repo Loaded plugins: extras_suggestions, langpacks, priorities, update-motd adding repo from: https://rpm.releases.hashicorp.com/AmazonLinux/hashicorp.repo grabbing file https://rpm.releases.hashicorp.com/AmazonLinux/hashicorp.repo to /etc/yum.repos.d/hashicorp.repo repo saved to /etc/yum.repos.d/hashicorp.repo $ sudo yum install -y vault ~中略~ Complete!説明の簡便のため、起動は開発者モードで行います。
-dev-listen-addressはvaultのIPアドレスを含めて下さい。EC2の場合は下記のようにメタデータから取得することができます。$ vault server -dev -dev-root-token-id="root" -dev-listen-address="$(curl -s http://169.254.169.254/latest/meta-data/local-ipv4):8200" ==> Vault server configuration: Api Address: http://172.31.39.141:8200 Cgo: disabled Cluster Address: https://172.31.39.141:8201 Go Version: go1.14.7 Listener 1: tcp (addr: "172.31.39.141:8200", cluster address: "172.31.39.141:8201", max_request_duration: "1m30s", max_request_size: "33554432", tls: "disabled") Log Level: info Mlock: supported: true, enabled: false Recovery Mode: false Storage: inmem Version: Vault v1.5.4 Version Sha: 1a730771ec70149293efe91e1d283b10d255c6d1 ~中略~ ==> Vault server started! Log data will stream in below: ~省略~ブラウザから
Api Addressに記載されたアドレス(上記ではhttp://172.31.39.141:8200)にアクセスし、下記のようにログイン画面が表示されればインストールと起動は完了です。
パスワードのランダム化
vault側の設定パスワードのランダム化にはSSH Secret Engineという機能を利用します。
利用の仕方については後述するとして、本節では設定を行います。
先ほど開いたものとは別にvaultのターミナルを開きます。$ export VAULT_ADDR="http://$(curl -s http://169.254.169.25 4/latest/meta-data/local-ipv4):8200" $ vault secrets enable ssh Success! Enabled the ssh secrets engine at: ssh/ $ vault write ssh/roles/otp_key_role key_type=otp \ > default_user=ec2-user \ > cidr_list=0.0.0.0/0 Success! Data written to: ssh/roles/otp_key_roleブラウザから
vaultに8200ポートでアクセスし、Tokenにrootを入力してログイン、Secrets>sshにアクセスし、otp_key_roleが表示されれば設定は成功です。
target側の設定Vaultにパスワードを照合する
Vault SSH Helperを配置します。
targetがインターネットにアクセスできない場合は、アクセス可能な端末で取得し転送して下さい。$ wget https://releases.hashicorp.com/vault-ssh-helper/0.1.6/vault-ssh-helper_0.1.6_linux_amd64.zip $ sudo unzip -q vault-ssh-helper_0.1.6_linux_amd64.zip -d /usr/local/bin $ sudo chmod 0755 /usr/local/bin/vault-ssh-helper $ sudo chown root:root /usr/local/bin/vault-ssh-helper
Vault SSH Helperの設定ファイルを作成します。
vault_addrのIPアドレスはvaultのものを使用します。
tls_skip_verifyでTLS証明書の検証はスキップしていますが、本格利用ではスキップしないことを推奨します。$ sudo mkdir /etc/vault-ssh-helper.d/ $ sudo tee /etc/vault-ssh-helper.d/config.hcl <<EOF vault_addr = "http://172.31.39.141:8200" tls_skip_verify = false ssh_mount_point = "ssh" allowed_roles = "*" EOFLinuxの認証モジュールであるPAMの設定ファイルを修正し、
Vault SSH Helperを利用した認証を定義します。$ sudo cp /etc/pam.d/sshd /etc/pam.d/sshd.orig $ sudo vi /etc/pam.d/sshd ## 以下をコメントアウト #auth required pam_sepermit.so #auth substack password-auth #auth include postlogin # Used with polkit to reauthorize users in remote sessions #-auth optional pam_reauthorize.so prepare ## 以下を追記 auth requisite pam_exec.so quiet expose_authtok log=/var/log/vault-ssh.log /usr/local/bin/vault-ssh-helper -dev -config=/etc/vault-ssh-helper.d/config.hcl auth optional pam_unix.so not_set_pass use_first_pass nodelaysshdの設定ファイルを修正します。
パスワードではなくチャレンジレスポンス形式で、PAMを使って認証するようにします。
EC2を利用する場合には公式チュートリアルから追加で設定が必要な項目があることに注意して下さい。$ sudo cp /etc/ssh/sshd_config /etc/ssh/sshd_config.orig $ sudo vi /etc/ssh/sshd_config ## 以下の設定項目になるように修正 ChallengeResponseAuthentication yes UsePAM yes PasswordAuthentication no ## 以下はEC2の場合に設定とコメントアウトが必要 PubkeyAuthentication no #AuthorizedKeysCommand /opt/aws/bin/eic_run_authorized_keys %u %f #AuthorizedKeysCommandUser ec2-instance-connect $ sudo systemctl restart sshd検証コマンドを実行し、以下のような出力がされていれば設定は完了です。
$ vault-ssh-helper -verify-only -dev -config /etc/vault-ssh-helper.d/config.hcl ==> WARNING: Dev mode is enabled! [INFO] using SSH mount point: ssh [INFO] using namespace: us [INFO] vault-ssh-helper verification successful!ランダムパスワードでのログイン
(画像は https://learn.hashicorp.com/vault/secrets-management/sm-ssh-otp より引用)ブラウザから
vaultに8200ポートでアクセスし、Tokenにrootを入力してログインします。
ログイン後、Secrets>sshにアクセスし、otp_key_roleの右にある三点リーダーをクリックします。
表示されたメニューから、Generate Credentialをクリックします
Usernameにはログインしたいユーザを入力します。ここではec2-userにしています。
IP AddressにはtargetのIPアドレスを入力します。ここでは172.31.32.67にしています。
ユーザとIPアドレスを入力したら、Generateボタンをクリックします。
パスワードが生成されますので控えます。
targetに対して先ほど控えたパスワードでsshログインするとログインに成功します。$ ssh ec2-user@172.31.32.67 Password:先ほどと同じパスワードでもう一度ログインしようとすると、失敗します。
$ ssh ec2-user@172.31.32.67 Password: Password:まとめ
本記事で伝えたかったことは以下の2点です。
- 固定のsshログインパスワードや一覧表などの運用はセキュリティに懸念がある
- Hashicorp Vaultによりログインごとにパスワードを払い出すことができる







- 投稿日:2020-10-19T02:08:21+09:00
転職したら(GCPエンジニアが)AWS案件メンバーだった件
GCP エンジニアが AWS 案件に参画した話
業務上で GCP の開発スキルしか持っていないエンジニアが、転職して Amazon Web Service(AWS)の開発案件に参画しました。このパターンを私はあまり聞いたことがなく(この逆パターンはよく聞きます)、折角なので、GCP エンジニア目線で AWS 案件に参画した時の両サービスの比較を書いてみました。
(巷には GCP と AWS の比較ネタはたくさんあると思います。)対象読者
- GCP しか知らない人。
- AWS 有識者で GCP エンジニアが AWS を始めてどう思ったか知りたい人。
- 同じ境遇のエンジニア
GCP と AWS の違い
ここでは、AWS で作業する上で、引っかかったり気になったことを挙げています。
GCP 案件しかやったことがなく、もしかしたらディスりっぽく感じる書き方のところもあるかもしれませんがご容赦ください。
また、特にまとまりなく書いていますがご容赦ください。アカウント
AWS の場合、アカウントは AWSの契約を指し、AWS アカウントに対してルートユーザー、IAM ユーザーが存在するイメージです。GCP というか Google の場合、アカウントというとユーザーのイメージでユーザーアカウント、特権管理者アカウントと言ったりします。以下、混乱しそうなので、GCP の場合もユーザーと記述しています。
ルートユーザー
AWS を新規で使用する場合、最初にルートユーザーが作成されます。GCP ではルートユーザーは存在しません。GCP プロジェクトではオーナーが管理者権限と言えます。また、G Suite(現 Google Workplace) や Cloud Identity を使い組織管理する場合は特権管理者というユーザーが存在しますが、ルートユーザーとは違い GCP のユーザーを管理する組織の管理者となります。
AWS のルートユーザーは全権限を持っているためそのまま使うことができますが、業務ではルートユーザーは使わず、IAM で管理者権限など必要な権限を付与したユーザーを作成して使います。(案件では通常ルートユーザーの権限を貰えることはありませんが・・・)
AWS の IAM セキュリティのベストプラクティスについて、公式ドキュメントに記載があります。ちなみに GCP も特権管理者の管理にベストプラクティスがあります。プロジェクトがない
GCP はプロジェクト単位にサービスを作成、開発、運用します。ですので、コンソールに入るとプロジェクトの画面となります(組織の時もありますけど)。プロジェクト単位に本番環境、ステージング環境、開発環境と分けることができてわかりやすいです。
AWS の場合、環境を分けるにはどうするんでしょうか。
環境はタグで分けたり、AWS アカウント自体を分けたりするそうです。リージョン
AWS にログインすると、コンソール画面はリージョン単位で表示されます。
右上のリージョンを選択してリージョンを切り替えます。
マルチリージョンの環境構築は、いちいち画面を切り替えるのがめんどくさいなあと思いましたが、そんなにマルチリージョンの環境は作らないのでしょうか。マルチAZまでですかね。一応、コンソール画面を貼っておきます。GCP コンソール画面
AWS コンソール画面
VPC
VPC は GCPと AWS は名前も同じだしあまり違いがないと思いきや、大きな違いがあります。
AWSは VPCで利用する CIDR ブロックを設定する必要があります。GCPでは VPCの CIDR なんて気にしたことはありません。
GCP でVPCを作成する時は、同時にサブネットも作成します。サブネット作成時にIPアドレス範囲を設定します。AWS の VPC 作成画面
GCP の VPC ネットワーク作成画面
サブネット
GCP は 1つの VPC 内には複数リージョンのサブネットを作成できますが、AWS は1つの VPC には1つのリージョンのみ設定が可能です、というか、そもそもリージョン毎の画面なので、他のリージョンを選べません。
VPC で設定した CIDR の範囲内でIPアドレス範囲を設定し、サブネットを作成することになります。AWS のサブネット作成画面
GCP の VPC ネットワーク画面(サブネットを確認)
インターネットゲートウェイ、ルートテーブルの作成
AWS はサブネットを作成した時点では、サブネットからインターネットに接続できません。VPC とサブネットを作成してからサブネット内にVMインスタンス(EC2)を作成しても、外(インターネット)に繋がらないのです。外部IPアドレスを割り振っても繋がりません。GCPの場合、VMインスタンス(EC2)を作成した時点で外には繋がります(Default のVPCのまま、インスタンス作成時に「http、httpsトラフィックを許可する」をチェックした場合)。GCP ではルートテーブルの作成は自動でされます。AWSは自分でインターネットゲートウェイの作成とルートテーブルの設定をする必要があります。
インターネットゲートウェイの作成
インターネットゲートウェイを作成します。
インターネットゲートウェイは、VPC にアタッチする必要があります。
アタッチして完了です。
ルートテーブルの関連付け
ルートテーブルは VPC 作成時に自動で1つ作成されてますが、サブネットに関連付けはされてません。自分で関連付けます。
ルートテーブル画面
そしてインターネットに接続したい場合は、インターネットゲートウェイにルーティングする設定を追加します。以下の設定でローカル以外はインターネットにルーティングされます。
ルートの編集画面
GCPではインターネットゲートウェイを自分で作成する必要はありませんし、ルートテーブルはプロジェクト作成時に自動でデフォルトが作成されます。自動で作成されてしまうことは意識しておくべきです。
ネットワーク ACL、セキュリティグループ
セキュリティグループはファイアウォールルールと同じと思ってましたが、どちらかと言うとネットワーク ACL が GCP のファイアウォールルールに近いとおもいました。
GCP のファイアウォールルールは VPC に対しての制御ですが、AWS のネットワーク ACL はサブネットに割り当てます。複数のサブネットに1つのネットワーク ACLを割り当てることもできます。
AWS のセキュリティグループは、インスタンスなどに割り当てるファイアウォールみたいなものでしょうか。EC2 インスタンスなどに紐付けます。VPC やサブネットレベルで制御するものではありません。
設定できるのは、インバウンドとアウトバウンドのネットワークトラフィックの許可・拒否ですので同じ感じです。
勝手なイメージ図を作ってみました。
AWS のセキュリティグループは他のセキュリティグループを設定できます。これは面白いです。
例えば、kinesis Data Analytics から Elasticache にアクセスするために、kinesis Data Analytics のセキュリティグループを Elasticache のセキュリティグループに登録し許可するといった使い方ができます。
関連付け
AWS では、サブネット、ルートテーブル、ネットワーク ACL、セキュリティグループなどサービス間の関連付けが必要なものがあります。
例えば、ネットワーク ACL を作成したら、サブネットに関連付けます。
VPC を作成した段階で、デフォルトのネットワーク ACL、セキュリティグループが作成され、サブネットを作成すると、デフォルトのネットワーク ACL が関連付けられます。追加で作成した場合は関連付けが必要のようです。GCP で関連付けするサービスは何かありましたかね。Cloud VPN と Cloud Router みたいな感じでしょうか。
VM インスタンスの鍵
AWS の VM インスタンスはみなさんご存知 EC2 です。
EC2 を作成する手順のイメージは GCP とあまり変わらないのでは?と思っていました。EC2の作成を進めていくと画面の遷移が多く、GCPには無い「セキュリティグループを新規作成、または既存のグループに割り当て」が必要です。AWS のEC2作成時のセキュリティグループの設定画面
また、EC2 の作成の最後に以下の画面が表示されます。
インスタンスにSSH接続するためのキーペアを作成、秘密鍵をダウンロードする必要があります。(キーペアのダウンロードと書いてありますけど、実際は秘密鍵だけです。)
EC2 は秘密鍵を取得し、SSH接続で使用します。ダウンロードした秘密鍵を適切な権限(400)に変更します。
GCP の場合、SSH 接続は複数の方法があります。コンソールの VM インスタンス一覧画面で、SSH ボタンをクリックすれば特に鍵を意識せずに SSH 接続が可能です。
ローカル PC のコンソールや Cloud Shell から SSH 接続する場合も通常は鍵を意識する必要はありません。しかし鍵が無い訳ではなく、"gcloud compute ssh" コマンドで初めてインスタンスに接続する際、勝手にキーペアを作成してssh接続できるようにしてくれます。~/.sshフォルダの中にキーペアが作成されます。GCP の VMインスタンス画面(Compute Engine の画面)
ローカル PC(Mac)から gcloud compute ssh 接続
EC2 の IP アドレス
GCP の Compute Engine を作成ではデフォルトでパブリックIPアドレスが割り当てられます。EC2 はデフォルトではパブリック IP アドレスが割り当てられません。EC2はデフォルトはパブリック IP 無効(厳密には「サブネット設定を使用(無効)」)です。パブリック IP アドレスは、インスタンス作成後に設定できます。また、 固定のパブリック IP アドレスを割り当てる ElasticIP も設定できます。
GCP と AWS の VM インスタンスの IP アドレス設定は、微妙に違うので対比表を作成しました。IPアドレス対比表
IP種類 GCP AWS 設定 可変外部IP エフェメラル 自動割り当てパブリック IP GCPは作成後起動中可能、AWSは不可能 固定外部IP 外部IPアドレス ElasticIP 両方作成後起動中可能 固定内部IP 静的内部 IP アドレス プライベートIP GCPは作成後起動中可能,AWSは作成時のみ指定可能(※) ※ AWSの場合、インスタンス作成後のプライベートIP指定は、セカンダリIPとなる。
ローカル PC(Mac)から AWS の SSH 接続
セキュリティグループにport:22を通す設定をしてから ssh コマンドを実行します。
クラウドストレージのバケットの作成
AWS にはクラウドストレージサービスとして有名な S3 があります。GCP は Google Cloud Storage(GCS)です。クラウドストレージとしては大差ないという印象でしたが、S3 でバケット内のファイルを更新したりした時に違いがありました。
S3 の上書きの PUT および DELETE は結果整合性
S3 の管理は結果整合性のため、バケットのファイルを上書きアップロード、削除では直後に反映されない時があります。
GCS は強整合性
GCS は裏で管理に Cloud Spanner を使用しています。
この Cloud Spanner は公式ドキュメントには水平スケーリングが可能であり、低レイテンシでのデータ配信を可能にしつつトランザクションの整合性を維持しており、可用性は業界トップクラスの 99.999% を実現します。
と記載がある通り、CAP定理を無視したデータベースです。
GCS を使っていた時は当たり前というか何も考えたこともなかったバケット内のファイル更新後すぐに反映されることは、GCP だからできていたということですね。タグ
GCP でタグというと、ファイアウォールルールをタグで適用したりというぐらいしか浮かびませんが、AWSにおいてタグは重要で、以下のようなことができます。
- リソース整理
- タグ別にリソースを設定して、検索やフィルタリングが可能。
- コスト配分
- AWS のコストをタグ別に分類できる。
- オートメーション
- 自動タスクの制御する対象リソースを特定する。
- アクセス制御
- IAM ポリシーで、タグベースの条件を設定できる。
AWS のタグは素晴らしいです。
ARN
AWS でちょくちょく出てくる ARN ってなんだろうと思っていましたが、Amazon Resource Name の略で、IAM ポリシーや API を呼ぶときに、AWS リソースを一意に識別するものです。
サービス間の連携
GCP では Compute Engine や App Engine 、Cloud Functions から他のリソースを操作したい場合、それぞれのリソースにはサービスアカウントが割り当たっていて(別途作成も可能)、サービスアカウントに権限を付与し、他の操作を可能にします。
AWS ではサービスアカウントはなく、IAM ポリシーで権限設定をします。そのIAM ポリシーをリソースにアタッチすることで、他のリソースを操作することができます。
AWS の IAM ポリシーは、細かな権限設定が可能です。最近は GCP も Cloud IAM Conditions という細かい制御が可能なサービスがありますが、設定可能なリソースが限定されています。暖機申請
AWS の運用業務では暖機申請という言葉を聞きます。暖機申請は、EC2 がスケールアウトする Load Balancer + EC2 の環境で、多量のアクセスが見込まれる場合、事前に EC2 をスケールさせておくために AWS へお願いする申請とのことです。
GCP ではこのような申請は聞いたことがありません。オートスケール
GCP のような素早いオートスケールはAWSではしないようです。Kinesis Data Analytics のオートスケールは思ってスケールと違いましたので、もし使う場合はしっかり検証すべきです。
CPUクレジット
AWS の EC2 インスタンスや EKS のノードなどのインスタンスタイプを選択する際、選択するインスタンスタイプによって、CPUクレジットというものが適用されます。CPU クレジットはパフォーマンスに影響するため、単純にt系のインスタンスタイプを選定しないようにしましょう。
終わりに
ご存知の方は多いと思いますが、GCP と AWS の似ているサービスでも詳細は違いがかなりあるということがわかりました。これは AWS と GCP の思想の違いが見えて面白いところでもあります。
また、AWS案件では、GCP 案件では聞いたことがない言葉がいくつかありました。
また、インフラ設計をするときの考慮点について、大きな違いはないと思ってましたが、サービスのリソース配置・設定など細かい点はかなり違いました。私は最初戸惑いました。
本記事ではほんの一部しか取り上げていませんし、まだたくさんのサービスがあり、また日々アップデートされていますし、新機能、新サービスも毎年のようにリリースされていますので、この仕事をしている間は戸惑いが無くなることはないのだろうと思いました。
本記事ではほんの一部のみ取り上げていますが、機会があれば他のサービスも書きたい思いです。(機会があれば)お断り
- 本記事での GCP エンジニアは、業務で Google Cloud Platform の案件に対応できるスキルを持っているエンジニアのことを指しています。
- AWS 開発案件初心者で、勘違いしている点もありえるので、もしあったらご指摘ください。

















