- 投稿日:2020-10-16T23:51:47+09:00
yukicoder contest 270 (mathematics contest) 参戦記
yukicoder contest 270 (mathematics contest) 参戦記
mathematics という文字列を見ただけでやる気が無くなるのはなぜだろうか. そしてまた鯖落ち.
A 1256 連続整数列
長さ3の連続整数列を考える. 0+1+2=3 で、これに +3n できるので、3の倍数なら何でも生成できる. 同様の長さ4の整数列は4n+2、長さ5の整数列は5nが、長さ6の整数列は6n+3が生成できることが分かる. これをまとめると長さnの整数列は、nが奇数の場合にはnの倍数が、nが偶数のときにはnの倍数+(n/2)が生成できることが分かる.
つまりAが偶数の場合には長さ2Aの連続整数列で必ず生成できる. Aが奇数の場合には長さAもしくは長さ2Aの連続整数列で必ず生成できる. ところで問題の制約により長さ1, 2の連続整数列は使えないので、1だけが生成できない整数になる.
A = int(input()) if A == 1: print('NO') else: print('YES')B 1257 変わった平均値
操作1を1回だけやると整数ではなくなって絶対に一致しない. かといって2回やるともとの値に戻る. となると使える操作は実質2だけになるので、A, B, C と D, E, F の構成する整数が順序を変えただけなら、'Yes' で1回だけ操作2をしてやればよく、そうでないなら 'No' となる.
A, B, C = map(int, input().split()) D, E, F = map(int, input().split()) if sorted([A, B, C]) == sorted([D, E, F]): print('Yes') print(2) else: print('No')C 1258 コインゲーム
求めるものは X = 0 のとき NC0M0+NC2M2+... となり、X = 1 のときは NC1M1+NC3M3+... となる. ところで (M+1)N=NCNMN+NCN-1MN-1+...+NC0M0 であり (M-1)N=NCNMN-NCN-1MN-1+... なことから (M+1)N と (M-1)N から求めるものは計算できる.
from sys import stdin readline = stdin.readline m = 1000000007 S = int(readline()) div2 = pow(2, m - 2, m) for _ in range(S): N, M, X = map(int, readline().split()) a = pow(M + 1, N, m) b = pow(M - 1, N, m) if (N + X) % 2 == 0: print((a + b) * div2 % m) else: print((a - b) * div2 % m)
- 投稿日:2020-10-16T23:35:19+09:00
Chainerによる機械学習のためのPython学習メモ 8章 Numpy入門
What
Chainerを利用して機械学習を学ぶにあたり、私自身が、気がついた点、リサーチした内容をまとめる記事になります。今回は、Numpyを勉強します。
私の理解に基づいて記述しているため、間違っている場合があります。間違いは都度修正するつもりです、ご容赦ください。
Content
Numpyとは
回帰分析を取り扱うアルゴリズム、多次元配列を便利に扱えるライブラリ?
Pythonプログラムへのモジュール読み込み
import numpy as npテキスト読んでて、ライブラリとモジュールの違いが分からなくなったので調べてみました。下記参考記事
https://qiita.com/yutaro50/items/f93893a2d7b23cb05461
テンソルはarrayで扱う。テンソルの取り扱い方法
a = np.array([1, 2, 3]) #Numpy形式の行列を定義 a.shape => #形をタプルで出力 a.rank => #ランクを出力 a.size =>#サイズを出力 データ個数 a.ndim => # lenを出力 a = np.zeros((3, 3)) => #3x3の零行列 a = np.ones((2, 3)) => #2x3の要素が全て1の行列 a = np.full((3, 2), 9) => #3x2の要素が全て9の行列 a = np.eye(5) => #5x5の単位行列 a = np.random.random((4, 5)) => #4x5で要素が0~1の乱数で決定された行列 a = np.arange(3, 10, 1) => #3から10まで1ずつ増える行ベクトル a = np[0,3] => #1行4列目をの値 #↓この説明が理解できない>< # 4 x 5 行列 e の真ん中の 2 x 3 = 6 個の値を取り出す center = e[1:3, 1:4] a[[0, 2, 1], [1, 1, 0]] => # (1, 2), (3, 2), (2, 1)の要素を行ベクトルで出力そのほか四則演算もできる
行列形が違くても加減算ができる=ブロードキャスト
逆に不本意な計算が発生する可能性がある。注意行列積 ABの計算
np.dot(A,B) or A.dot(B) # とかく np.dot(X.T, X) # 行列Xの転置行列とXの積を計算 np.linalg.inv(A) # 行列Aの逆行列を計算交換法則は一般には成り立たないので順序に注意
行列の取り扱いに困ったときはここを見返そう
Comment
内容が難しくなってきたので、更新頻度が落ちてしまっているが頑張ろう
- 投稿日:2020-10-16T23:15:30+09:00
Streamlit を用いたフロントエンドアプリケーション制作
Streamlit とは
本稿では、Streamlit の使い方を説明する。
Streamlit とは、フロントエンドアプリケーションを作成できる python のフレームワークである。Pandas の DataFrame や、 plotly・altair といった描画ライブラリで作成したグラフを埋め込むことができ、工夫次第でデータサイエンスにも応用することができる。環境
- macOS Catalina (ver.10.15.6)
インストール
いくつかの方法でインストールすることできる。
1) pip でインストールする。公式HP推奨ターミナルpip install streamlit2) conda で仮想環境を構築する。公式Forum参照
ターミナルconda create -y -n streamlit python=3.7 conda activate streamlit pip install streamlitファイルの実行
Python ファイルを以下のように実行する。
ターミナルstreamlit run ファイル名.pyStreamlit の機能
公式 HP の API reference に、streamlit の機能がまとめられている。その中でデータサイエンスに活用できる機能を中心にまとめた。
タイトルの表示
st_app.pyimport streamlit as st st.title('My app')文書の表示
st_app.pyimport streamlit as st st.write("Good morning")DataFrame の表示
st_app.pyimport streamlit as st import pandas as pd st.table(pd.DataFrame({ 'first column': [1, 2, 3, 4], 'second column': [10, 20, 30, 40] }))Markdown の表示
st_app.pyimport streamlit as st st.markdown('# Markdown documents')HTML 文書の表示
st_app.pyimport streamlit as st body = ''' <body> <meta http-equiv="content-type" charset="utf-8"> 見出し(ヘッドライン)を書くときには次のようなものがある. <h1>大見出し</h1> <h2>中見出し</h2> <h3>小見出し</h3> <h4>小見出し</h4> <h5>小見出し</h5> <h6>小見出し</h6> でも,これは見出し用のタグなので勝手に改行してしまいます.<p> 見出し以外の本文中で自由に文字サイズを変えるには <font size="7">こ</font> <font size="6">ん</font> <font size="5">な</font> <font size="4">風</font> <font size="3">に</font> <font size="2">す</font> <font size="1">る</font><p> <font size="5"> また,<b>太字</b>や<i>斜体</i>,<blink>点滅</blink>も 簡単にできます. </font> </body> ''' st.markdown(body,unsafe_allow_html=True)Plotly の表示
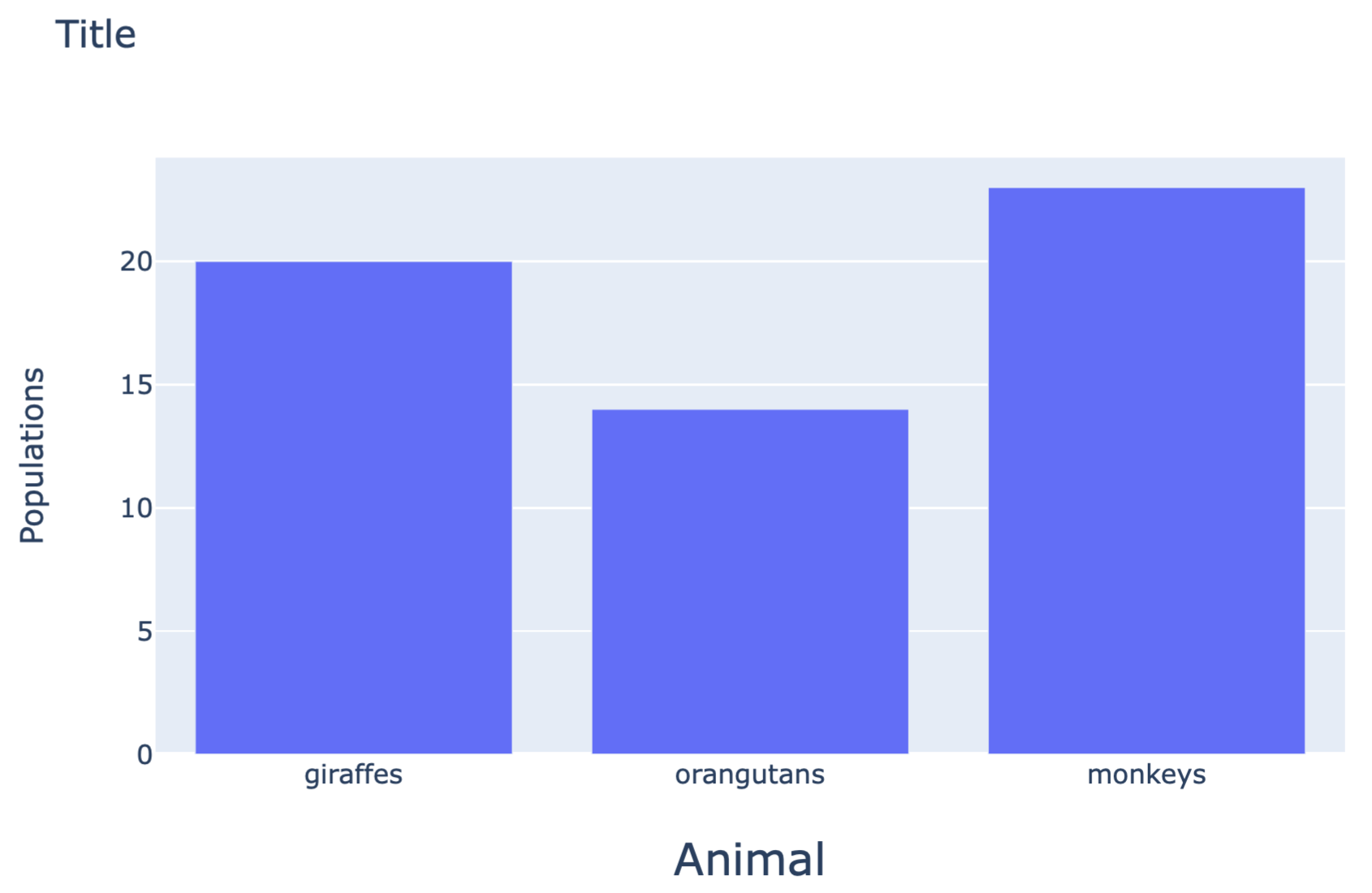
Plotlyは、python 描画ライブラリのひとつで、様々な種類のグラフを作成できる。
st_app.pyimport streamlit as st import plotly.graph_objs as go animals = ['giraffes', 'orangutans', 'monkeys'] populations = [20, 14, 23] fig = go.Figure(data=[go.Bar(x=animals, y=populations)]) fig.update_layout( xaxis = dict( tickangle = 0, title_text = "Animal", title_font = {"size": 20}, title_standoff = 25), yaxis = dict( title_text = "Populations", title_standoff = 25), title ='Title') st.plotly_chart(fig, use_container_width=True)
Altair の表示
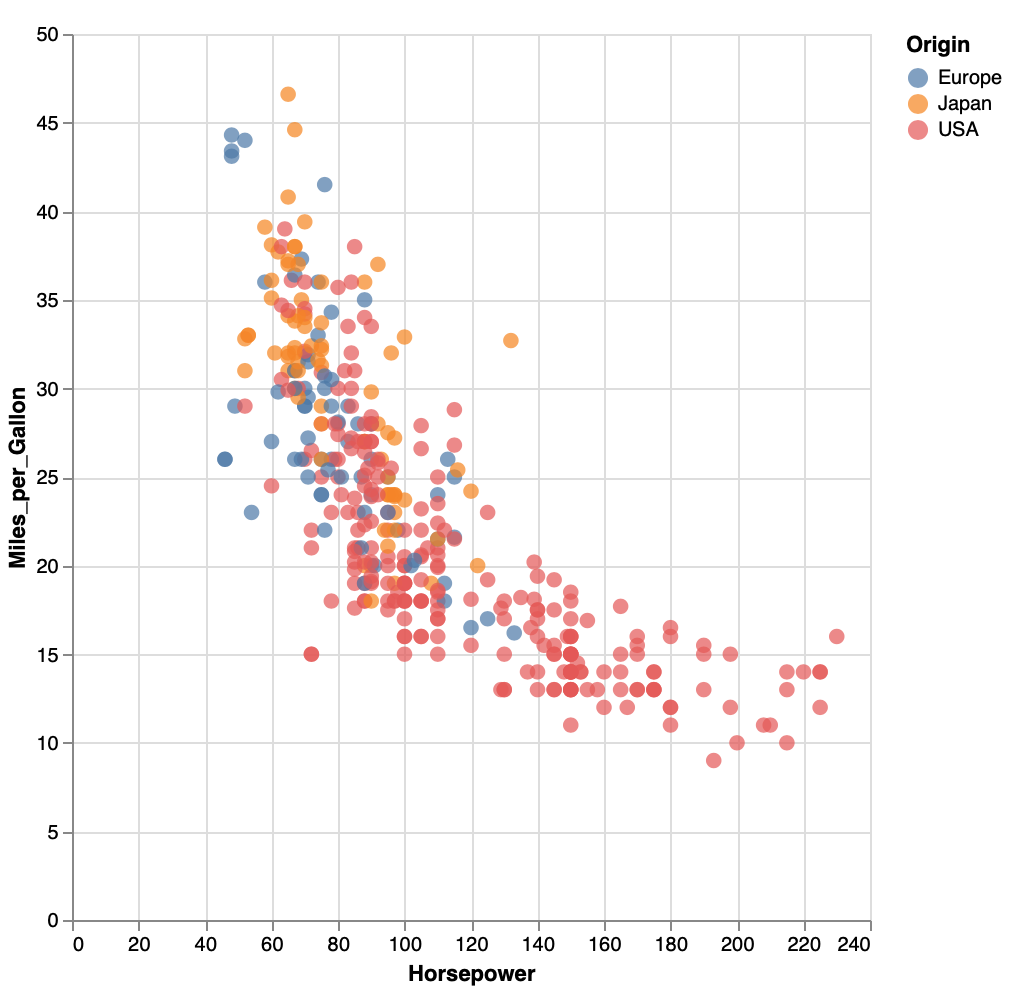
Altair は、python 描画ライブラリのひとつで、様々な種類のグラフを作成できる。Pandas の DataFrame でデータを入力するのが特徴。
st_app.pyimport streamlit as st import altair as alt from vega_datasets import data source = data.cars() fig = alt.Chart(source).mark_circle(size=60).encode( x='Horsepower', y='Miles_per_Gallon', color='Origin', tooltip=['Name', 'Origin', 'Horsepower', 'Miles_per_Gallon'] ).properties( width=500, height=500 ).interactive() st.write(fig)
ドロップダウンの表示
ドロップダウンから1つだけ選択する場合は以下のとおり。
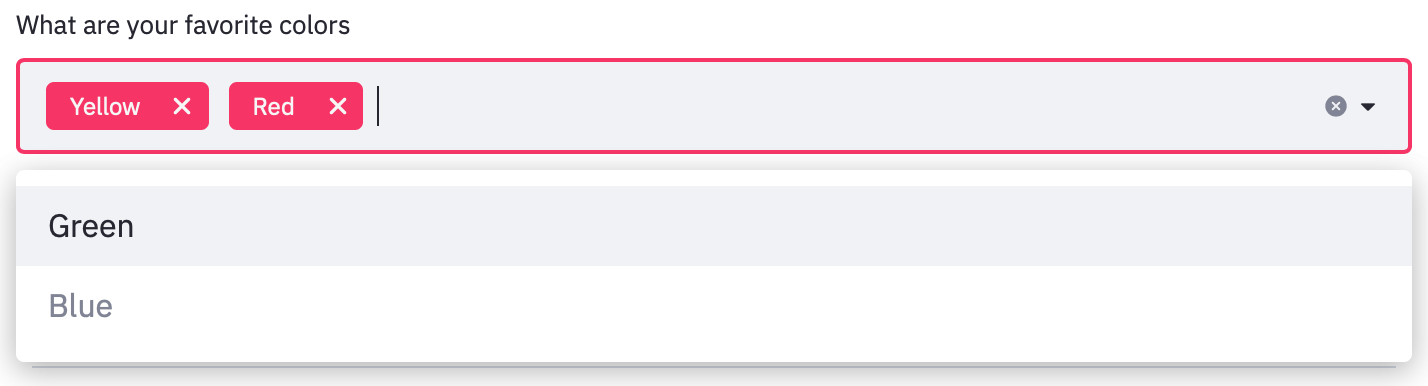
st_app.pyimport streamlit as st option = st.selectbox( 'How would you like to be contacted?', ('Email', 'Home phone', 'Mobile phone')) st.write('You selected:', option)ドロップダウンから2つ以上同時に選択する場合は以下のとおり。
st_app.pyimport streamlit as st options = st.multiselect( 'What are your favorite colors', ['Green', 'Yellow', 'Red', 'Blue'], ['Yellow', 'Red']) st.table(options)スライダーの表示
1 つの値を選択する場合は以下のとおり。
以下の例では、最小値0、最大値130、初期値25 で動くスライダーを表示させる。st_app.pyimport streamlit as st age = st.slider('How old are you?', 0, 130, 25) st.write("I'm ", age, 'years old')
2 つの値を選択する場合は以下のとおり。
以下の例では、最小値0.0、最大値100.0、初期値(25.0,75.0)で動くスライダーを表示させる。st_app.pyimport streamlit as st values = st.slider( 'Select a range of values', 0.0, 100.0, (25.0, 75.0)) st.write('Values:', values)


- 投稿日:2020-10-16T23:15:30+09:00
Streamlit を用いたデータ分析アプリケーション制作
Streamlit とは
本稿では、Streamlit の使い方を説明する。
Streamlit とは、フロントエンドアプリケーションを作成できる python のフレームワークである。Pandas の DataFrame や、 plotly・altair といった描画ライブラリで作成したグラフを埋め込むことができ、工夫次第でデータ分析にも応用することができる。環境
- macOS Catalina (ver.10.15.6)
インストール
いくつかの方法でインストールすることできる。
1) pip でインストールする。公式HP推奨ターミナルpip install streamlit2) conda で仮想環境を構築する。公式Forum参照
ターミナルconda create -y -n streamlit python=3.7 conda activate streamlit pip install streamlitファイルの実行
Python ファイルを以下のように実行する。
ターミナルstreamlit run ファイル名.pyStreamlit の機能
公式 HP の API reference に、streamlit の機能がまとめられている。その中でデータ分析に活用できる機能を中心にまとめた。
タイトルの表示
st_app.pyimport streamlit as st st.title('My app')
文書の表示
st_app.pyimport streamlit as st st.write("Good morning")
DataFrame の表示
st_app.pyimport streamlit as st import pandas as pd st.table(pd.DataFrame({ 'first column': [1, 2, 3, 4], 'second column': [10, 20, 30, 40] }))
Markdown の表示
st_app.pyimport streamlit as st st.markdown('# Markdown documents')Plotly の表示
Plotlyは、python 描画ライブラリのひとつで、様々な種類のグラフを作成できる。
st_app.pyimport streamlit as st import plotly.graph_objs as go animals = ['giraffes', 'orangutans', 'monkeys'] populations = [20, 14, 23] fig = go.Figure(data=[go.Bar(x=animals, y=populations)]) fig.update_layout( xaxis = dict( tickangle = 0, title_text = "Animal", title_font = {"size": 20}, title_standoff = 25), yaxis = dict( title_text = "Populations", title_standoff = 25), title ='Title') st.plotly_chart(fig, use_container_width=True)
Altair の表示
Altair は、python 描画ライブラリのひとつで、様々な種類のグラフを作成できる。Pandas の DataFrame でデータを入力するのが特徴。
st_app.pyimport streamlit as st import altair as alt from vega_datasets import data source = data.cars() fig = alt.Chart(source).mark_circle(size=60).encode( x='Horsepower', y='Miles_per_Gallon', color='Origin', tooltip=['Name', 'Origin', 'Horsepower', 'Miles_per_Gallon'] ).properties( width=500, height=500 ).interactive() st.write(fig)
ドロップダウンの表示
ドロップダウンから1つだけ選択する場合は以下のとおり。
st_app.pyimport streamlit as st option = st.selectbox( 'How would you like to be contacted?', ('Email', 'Home phone', 'Mobile phone')) st.write('You selected:', option)
ドロップダウンから2つ以上同時に選択する場合は以下のとおり。
st_app.pyimport streamlit as st options = st.multiselect( 'What are your favorite colors', ['Green', 'Yellow', 'Red', 'Blue'], ['Yellow', 'Red']) st.table(options)
スライダーの表示
1 つの値を選択する場合は以下のとおり。
以下の例では、最小値0、最大値130、初期値25 で動くスライダーを表示させる。st_app.pyimport streamlit as st age = st.slider('How old are you?', 0, 130, 25) st.write("I'm ", age, 'years old')
2 つの値を選択する場合は以下のとおり。
以下の例では、最小値0.0、最大値100.0、初期値(25.0,75.0)で動くスライダーを表示させる。st_app.pyimport streamlit as st values = st.slider( 'Select a range of values', 0.0, 100.0, (25.0, 75.0)) st.write('Values:', values)




- 投稿日:2020-10-16T22:53:29+09:00
GCPコンソールのpythonアップデートで詰まっている②(解決編)
前回のあらすじ
aptが動けるようにした
pipを入れた
pyenvを入れた
pythonをインストールできない!←ここ前回出ていたエラー(おさらい)
$ pyenv install 3.7.4 Downloading Python-3.7.4.tar.xz... -> https://www.python.org/ftp/python/3.7.4/Python-3.7.4.tar.xz Installing Python-3.7.4... BUILD FAILED (Ubuntu 16.04 using python-build 1.2.21) Inspect or clean up the working tree at /tmp/python-build.20201015120257.27370 Results logged to /tmp/python-build.20201015120257.27370.log Last 10 log lines: sys.exit(ensurepip._main()) File "/tmp/python-build.20201015120257.27370/Python-3.7.4/Lib/ensurepip/__init__.py", line 204, in _main default_pip=args.default_pip, File "/tmp/python-build.20201015120257.27370/Python-3.7.4/Lib/ensurepip/__init__.py", line 117, in _bootstrap return _run_pip(args + [p[0] for p in _PROJECTS], additional_paths) File "/tmp/python-build.20201015120257.27370/Python-3.7.4/Lib/ensurepip/__init__.py", line 27, in _run_pip import pip._internal zipimport.ZipImportError: can't decompress data; zlib not available Makefile:1132: recipe for target 'install' failed make: *** [install] Error 1参考にしたサイト
「Ubuntu16.04でpyenv3.7系の環境構築にひたすら躓いた話」
https://qiita.com/kenta_ojapi/items/6b19e0c05b268f3e74da「【pyenv】ubuntu16.04でのpython環境の構築」
https://qiita.com/banaoh/items/00aea13fe045fab7e8ba実際の手順
$ sudo apt-get install -y make build-essential libssl-dev zlib1g-dev libbz2-dev \ libreadline-dev libsqlite3-dev wget curl llvm libncurses5-dev libncursesw5-dev \ xz-utils tk-dev libffi-dev liblzma-dev python-openssl githttps://github.com/pyenv/pyenv/wiki/Common-build-problems を見ろとのことなので、こちらに記載のある以下のコマンドにて解決。
というコメントを信じて詠唱。
中身は全く理解していないが、必要なものをインストールしてくれるのだろう。再度Pythonインストールも、失敗。
zlibがないと言われるのでインストールsudo apt-get install zlib1g-devインストール失敗。やたら時間がかかるのに結局失敗するのが痛い。
WARNING: The Python bz2 extension was not compiled. Missing the bzip2 lib?とあったので、bzip2 libを個別にインストール。
すると、うまくいった。
Installed Python-3.7.4を見たときの達成感と言ったら無い。
今後
ゴールしたみたいなテンションでここまで作業した&書き記したが、
APIを使って何か作る、というのがゴールなので、
まだスタート時点にやっとたどり着いたぐらいである。また気合を入れて向き合う必要がある。
- 投稿日:2020-10-16T22:11:18+09:00
tkinterでコンボボックスの変化によって動きを変える
ソースコードは以下になります。
import tkinter from tkinter import ttk colors = ['Red', 'Green', 'Blue'] subcolors = ["Black", "White"] def add_combobox_subcolors(): def inner(self): cb_subcolors.config(values=subcolors) cb_subcolors.set(subcolors[0]) cb_subcolors.pack() return inner root = tkinter.Tk() root.geometry("200x200") root.title("Color Picker") cb_subcolors = ttk.Combobox(root, values=colors, width=10, state='readonly') cb_colors = ttk.Combobox(root, values=colors, width=10, state='readonly') cb_colors.set(colors[0]) cb_colors.bind('<<ComboboxSelected>>', add_combobox_subcolors()) cb_colors.pack() root.mainloop()colorsのコンボボックスの選択を変えるとサブカラーのコンボボックスが出現します。
colorsのコンボボックスの選択時にサブカラーのコンボボックスが持つリストも代入しているので、
最初のコンボボックスで選択された要素によって追加するコンボボックスの内容を変えたい場合に有効です。最後まで読んでいただきありがとうございました。
またお会いしましょう。
- 投稿日:2020-10-16T22:07:26+09:00
将棋AIで学ぶディープラーニング on Mac and Google Colab 第12章3
select_max_ucb_child()
4章に出てきた以下の式の値いわゆるUCB値が最大となる子ノードを選択するメソッド。
Stは現在のノードの状態、つまり局面のこと。
aは候補手。
Q(St,a)は期待値項。状態Stにおける行動aの行動価値を表す。本では子ノードaの合計勝率を子ノードaの訪問回数で割った値としている。
U(St,a)はボーナス項。探索回数が少ない手ほど優先して選択される。さらに方策ネットワークで得た指し手の確率P(s,a)も利用して有望な手が優先して探索されるようにする。
Cpuct : ボーナス項の重みを調整する定数。
P(s,a) : 方策ネットワークの予測した着手確率。
N(s,a) : 状態sにおける行動aの訪問回数。本では+1している。訪問回数0のときに分母が0になるのを避けるためか。
√ΣN(s,b) : 状態sにおけるすべての行動の訪問回数。実際select_max_ucb_child()でやっていることのイメージ図
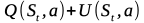
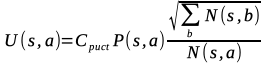
- 投稿日:2020-10-16T21:43:02+09:00
バケットソートとは?メリデメとコード実例
バケットソートとは?
各要素の数をカウントし、その要素を入れる配列番号を特定して、順に挿入していくソート方法。
用意する配列は2つ。
(1)カウンタ配列
各要素が何個あるかカウントする。(2)ソート結果を入れる配列
ソートしたい配列と同じ要素数を持った配列を用意し、(1)で特定した要素を個数分だけ挿入していく。
▼バケットソートのイメージ
[1,3,2,1,2,1]の配列の場合1,2,3の入れ物(バケツ)を用意し、そこに各要素を入れて数をカウントする。(例:1は3つ、2は2つ、3は1つ)
その要素を順に並べていく。
バケットソートのメリデメ
・メリット
直感的でわかりやすい。計算量ベースでは最速のソートアルゴリズム。
最大値が小さく、同じ数値が何度も重複する場合に効率的なソート。
・デメリット
元の配列の最大値が大きい場合、その最大値分のバケツを用意しなければいけない。
下記条件の時には使えない。
・整数以外(小数点を含む)
┗ バケットを用意できないため・最大値が大きすぎる
┗ カウンタ配列のメモリ使用量が膨大になってしまうため
▼デメリットの例(無駄なバケツが発生することを明示的に理解する)list=[1,2,1,10]を並び替える場合
3~9は存在しないが、その分のバケツも用意しなければならない。
バケツ: 1 2 3 4 5 6 7 8 9 10 要素の数: 2 1 0 0 0 0 0 0 0 1 最大値が小さければソートは早いが、最大値が大きくなればなるほど用意するバケツの数も増える。
バケットソートのコード実例
def bucket_sort(arr): arrc = [0]*(max(arr)+1) #カウンタ配列の作成。0始まり。0番目は常に0 for i in arr: arrc[i] += 1 #ソート結果を入れる配列を用意 ans=[] for j in range(1, len(arrc)): ans.extend([j]*arrc[j]) return ans配列を足し合わせるextendを使う。
※appendは1つのまとまった要素として追加されるため、ここでは使えない。確認list=[8,3,1,2,3,3,10,7,6,7] bucket_sort(list) #[1, 2, 3, 3, 3, 6, 7, 7, 8, 10]
extendを使わない方法
def bucket_sort2(arr): arrc = [0]*(max(arr)+1) #カウンタ配列の作成。0始まり。0番目は常に0 for i in arr: arrc[i] += 1 #ソート結果を入れる配列を用意 ans=[] for j in range(1, len(arrc)): ans+([j]*arrc[j]) return ans各バケットは同じ深さのため、単純に足していく。
確認list=[8,3,1,2,3,3,10,7,6,7] bucket_sort2(list) #[1, 2, 3, 3, 3, 6, 7, 7, 8, 10]
累積和から挿入位置を決めていく方法
カウンタ配列を累積和に変換し、指定の要素を挿入する場所を見つけていく。
要素が重複している場合も考慮して、右から挿入したら、その要素が挿入される場所を-1する。
def bucket_sort3(arr): #配列内の最大値の数だけ要素数がある配列を作る。 #累積和を求める時に、-1の要素を参照するため0からカウントする。 arrc = [0] *(max(arr)+1) #配列の要素の数をカウント #指定の配列番号に1を足していく for i in arr: arrc[i] += 1 #カウントを累積和に変換する。 #現在の要素に一つ前の要素を足して、置き換えていく for j in range(1, len(arrc)) : arrc[j] = arrc[j] + arrc[j-1] #ソート結果を入れる配列を作る。配列の要素数は元の配列と同じ arrs = [0]*len(arr) #元の配列の要素を一つづつ取り出して、何番目に入るか調べて挿入していく for i in arr: #iを何番目に挿入するか調べる。ソート後の配列は0が不要のため、-1した場所に挿入する #同じ数が複数ある場合は一番右側から左に向かって埋めていく arrs[arrc[i]-1] =i #同じ要素が複数ある場合を考慮し累積和から、自分iの要素の数を一つ減らす arrc[i] -= 1 return arrs確認list=[8,3,1,2,3,3,10,7,6,7] bucket_sort3(list) #[1, 2, 3, 3, 3, 6, 7, 7, 8, 10]教材で累積和を使う方法が紹介されていたので処理を紐解いてみたが、正直、直感的にわかりにくい。
- 投稿日:2020-10-16T21:30:40+09:00
Git hub でプルしようとするとPermission denied(publickey)エラーが出てしまう場合の対処法
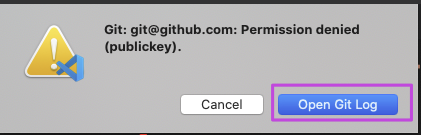
Git habでプルをしようとしてコマンド実行すると
このようなエラーが出てしまいます。
その場合は、ターミナルから
% git pullを実行しましょう。
その際、
fatal: not a git repository (or any of the parent directories): .gitのエラーが出た場合は、
% ls -aで戻って
.gitがあるところまで、戻りましょう。場合によっては2階層くらいあるかもしれません!
. .. .git mysite venvこの表示になったら、先ほどのコマンド実行してください。
- 投稿日:2020-10-16T21:00:30+09:00
【python】input()の使い方
input()とは
入力である。
input()の使い方
例として入力に1を入れたコードを書く。
a = input() print(a) #1 #1以上のように入力した数である1がinput()になっていることが分かる。
input()の型
input()に入る文字の型を見てみる。intなのかfloatなのかstringなのか。
a = input() print(type(a)) #1 #<class 'str'>以上の例から、入力した値の型はstring(文字)になっていることが分かる。
input()をintの型に変更
input()をintの型に変更するコードを以下に書く。
a = int(input()) print(type(a)) #1 <class 'int'>以上のようにinput()に入力した1がint(数字)の1になっていることが分かる。
intにしないときのエラー
input()に数字を入れてそのまま足し算をしてもエラーになる。
以下がその例。
a = input() b = a + 1 print(b) #1 Traceback (most recent call last): File "practice.py", line 3, in <module> b = a + 1 TypeError: can only concatenate str (not "int") to strこれは入力した1が数字の1ではなく文字の1だと認識されている。
そのため、入力した1を数字の1に直す必要がある。
- 投稿日:2020-10-16T20:40:33+09:00
Codeforces Round #672 (Div. 2) バチャ復習(10/16)
今回の成績
今回の感想
今回は割と問題設定を整理しながら進めたおかげで(時間はかかったものの)WAを出さずに解き進めることができた。また、D問題は座圧して高速化をするのが面倒だったのでsetのまま扱ったら危なくTLEするところだった(1996ms/2000ms)。
C2はfriendの順位表を見てupsolveしてる人が多かったが、やる気が出なかったのでしない。昨日から二日連続でupsolveをしてないので、この習慣がつかないよう明日以降はしっかりupsolveに励もうと思う。
A問題
BITで転倒数!?となったが、そんなわけがなかった。転倒数の最大値は降順に要素が並んでいる時のみで$\frac{n(n-1)}{2}$なので、その最大値になるかを判定する。また、同じ要素が複数ある時は$\frac{n(n-1)}{2}$にならないことに注意が必要だが、親切にもサンプルにその場合がある。
A.pyfor _ in range(int(input())): n=int(input()) a=list(map(int,input().split())) if a==sorted(a,reverse=True) and len(set(a))==n: print("NO") else: print("YES")B問題
初め問題を勘違いしかけて危なかった(任意のビットが同じなので同じ要素!とか考えていた)。
$a_i,a_j$の$k$ビット目をそれぞれ$a_{ik},a_{jk}$とすれば、$a_{ik}$&$a_{jk}$,$a_{ik} \oplus a_{jk}$は以下のようになります。(ビットごと!)
$a_{ik}$ $a_{jk}$ $a_{ik}$&$a_{jk}$ $a_{ik} \oplus a_{jk}$ 0 0 0 0 0 1 0 1 1 0 0 1 1 1 1 0 したがって、$a_i$&$a_j \geqq a_i \oplus a_j$が成り立つのは$(a_{ik},a_{jk})=(0,0),(1,1)$となります。よって、$a_i$の上のビットから見て初めて立つビット(MSB)があった時、$a_i$と条件を満たす数は同じMSBの数になります($\because$正の数なので必ずビットは立ちます)。
よって、それぞれの$a_{i}$をMSBによって場合分けし、そのような$a_{i}$が$x$個存在する時は$_x C_2$通りの組み合わせが存在します。これの合計を求めれば答えになります。
B.pyfrom collections import Counter for _ in range(int(input())): n=int(input()) x=[0 for i in range(30)] l=list(map(int,input().split())) for i in l: for j in range(29,-1,-1): if (i>>j)&1: x[j]+=1 break ans=0 for i in x: if i>1: ans+=(i*(i-1)//2) print(ans)C1問題
コドフォで既出です。なのに添字を間違えました。アホですか…?
部分列の(特殊な)和の最大値を求めれば良いので、-か+かは直前に選んだ要素の-か+かで決まります。よって、以下のようなDPを考えます。
$dp[i][j]:=$($i$番目の数までの中から選んだ部分列の(特殊な)和の最大値,ただし$j=0$のときは最後に選んだ数が-で$j=1$のときは最後に選んだ数が+)
遷移は以下のようになります。部分列の遷移は大体下記の三通りを考えれば良いです。-か+かの場合分けのみ注意が必要です。
(1)$i+1$番目の要素を選ばない場合
$dp[i+1][0]←dp[i][0]$
$dp[i+1][1]←dp[i][1]$(2)$i+1$番目の要素を初めてではなく選ぶ場合
$dp[i+1][0]←dp[i][1]-a[i+1]$
$dp[i+1][1]←dp[i][0]+a[i+1]$(3)$i+1$番目の要素を初めて選ぶ場合
$dp[i+1][1]←a[i+1]$
上記の最大値を順に求めていけば$max(dp[n-1])$が答えです。
C.pyinf=10**12 import sys input = sys.stdin.readline for _ in range(int(input())): n,q=map(int,input().split()) a=list(map(int,input().split())) dp=[[-inf,-inf] for i in range(n)] dp[0]=[-inf,a[0]] for i in range(n-1): dp[i+1][0]=dp[i][0] dp[i+1][1]=dp[i][1] dp[i+1][0]=max(dp[i+1][0],dp[i][1]-a[i+1]) dp[i+1][1]=max(dp[i+1][1],dp[i][0]+a[i+1]) dp[i+1][1]=max(dp[i+1][1],a[i+1]) print(max(dp[n-1])) #print(dp)C2問題
今回は飛ばします。
D問題
高速に解けるべきであった気はするので、実装力をあげていきたいです。
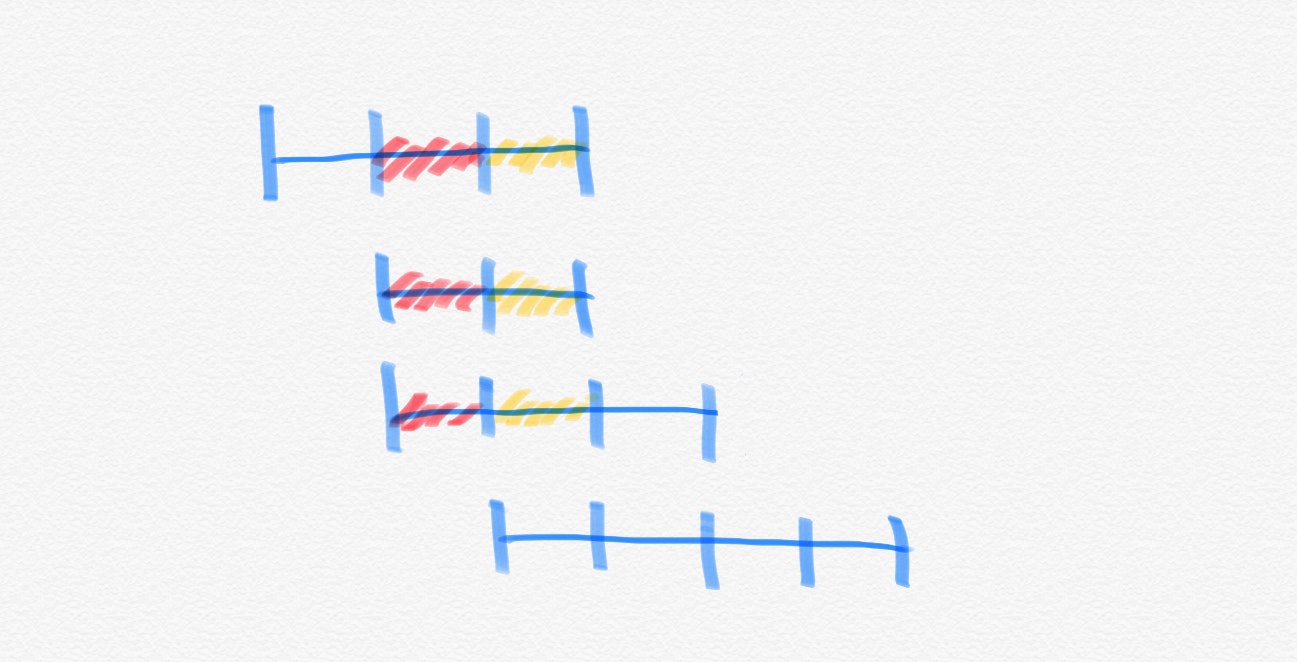
閉区間が$n$個あるそれぞれの区間の端が重なるかをチェックすれば良いです。つまり、区間の端のみへと座圧することで、高々$2n$個の座標のみを考えれば良いです。よって、少なくとも一つの座標で重なる$k$個の区間は題意の区間として選ぶことができます(題意の言い換え!)。
ここで、複数の座標で同じ区間の組み合わせを選べる時が存在する(✳︎)ので、注意を払う必要があります。例えば、下図の赤色及び黄色の部分です($k=3$です)。
また、まずは貪欲に考えたいので座標の小さい順に見ていきます。ここで、ある座標にすでに選んだ区間が$x$個,初めて選んだ区間が$y$個あったとすると、「まだ選んでない区間の選び方」は「ここで選べる区間の任意の選び方」から「すでに選んだ区間のみから選ぶ選び方」を除いたもので総数は$_{x+y}C_k-_xC_k$になります(だいぶ気づくのに時間がかかりましたが、簡単な包除原理です)。したがって、それぞれの座標を含む区間を管理しておけば、組み合わせの計算を$O(1)$で求めることができます(組み合わせの前計算は$O(n)$です)。
よって、実装としては以下のようになります(実装をまとめる!)。
nowseg:今見ている座標を含む区間の情報を(区間の右端の座標,インデックス)として持つset
nexseg:まだ見ていない区間の情報を区間の左端をkey,(区間の右端の座標,インデックス)をvalueとして持つmap
coordinates:ありうる区間の端を持つset(昇順で保持したいのと座圧の実装をサボりたかったので)このようにすればそれぞれの座標$i$において
①nowsegのサイズを$x$,nexseg[i]のサイズを$y$として組み合わせ計算により新たにできる区間の組み合わせの数を求める
②nexseg[i]の全要素をnowsegに追加する
③nowsegにある中で区間の右端の座標が$i$となるもののみ削除する(nowsegの最初の要素から順にチェックする)の順番で操作を行うことで、簡単に実装することができます。
D.cc//デバッグ用オプション:-fsanitize=undefined,address //コンパイラ最適化 #pragma GCC optimize("Ofast") //インクルードなど #include<bits/stdc++.h> using namespace std; typedef long long ll; //マクロ //forループ //引数は、(ループ内変数,動く範囲)か(ループ内変数,始めの数,終わりの数)、のどちらか //Dがついてないものはループ変数は1ずつインクリメントされ、Dがついてるものはループ変数は1ずつデクリメントされる //FORAは範囲for文(使いにくかったら消す) #define REP(i,n) for(ll i=0;i<ll(n);i++) #define REPD(i,n) for(ll i=n-1;i>=0;i--) #define FOR(i,a,b) for(ll i=a;i<=ll(b);i++) #define FORD(i,a,b) for(ll i=a;i>=ll(b);i--) #define FORA(i,I) for(const auto& i:I) //xにはvectorなどのコンテナ #define ALL(x) x.begin(),x.end() #define SIZE(x) ll(x.size()) //定数 #define INF 1000000000000 //10^12:∞ #define MOD 998244353 //10^9+7:合同式の法 #define MAXR 300002 //10^5:配列の最大のrange //略記 #define PB push_back //挿入 #define MP make_pair //pairのコンストラクタ #define F first //pairの一つ目の要素 #define S second //pairの二つ目の要素 template<ll mod> class modint{ public: ll val=0; //コンストラクタ modint(ll x=0){while(x<0)x+=mod;val=x%mod;} //コピーコンストラクタ modint(const modint &r){val=r.val;} //算術演算子 modint operator -(){return modint(-val);} //単項 modint operator +(const modint &r){return modint(*this)+=r;} modint operator -(const modint &r){return modint(*this)-=r;} modint operator *(const modint &r){return modint(*this)*=r;} modint operator /(const modint &r){return modint(*this)/=r;} //代入演算子 modint &operator +=(const modint &r){ val+=r.val; if(val>=mod)val-=mod; return *this; } modint &operator -=(const modint &r){ if(val<r.val)val+=mod; val-=r.val; return *this; } modint &operator *=(const modint &r){ val=val*r.val%mod; return *this; } modint &operator /=(const modint &r){ ll a=r.val,b=mod,u=1,v=0; while(b){ ll t=a/b; a-=t*b;swap(a,b); u-=t*v;swap(u,v); } val=val*u%mod; if(val<0)val+=mod; return *this; } //等価比較演算子 bool operator ==(const modint& r){return this->val==r.val;} bool operator <(const modint& r){return this->val<r.val;} bool operator !=(const modint& r){return this->val!=r.val;} }; using mint = modint<MOD>; //入出力ストリーム istream &operator >>(istream &is,mint& x){//xにconst付けない ll t;is >> t; x=t; return (is); } ostream &operator <<(ostream &os,const mint& x){ return os<<x.val; } //累乗 mint modpow(const mint &a,ll n){ if(n==0)return 1; mint t=modpow(a,n/2); t=t*t; if(n&1)t=t*a; return t; } //二項係数の計算 mint fac[MAXR+1],finv[MAXR+1],inv[MAXR+1]; //テーブルの作成 void COMinit() { fac[0]=fac[1]=1; finv[0]=finv[1]=1; inv[1]=1; FOR(i,2,MAXR){ fac[i]=fac[i-1]*mint(i); inv[i]=-inv[MOD%i]*mint(MOD/i); finv[i]=finv[i-1]*inv[i]; } } //演算部分 mint COM(ll n,ll k){ if(n<k)return 0; if(n<0 || k<0)return 0; return fac[n]*finv[k]*finv[n-k]; } signed main(){ //入力の高速化用のコード //ios::sync_with_stdio(false); //cin.tie(nullptr); COMinit(); ll n,k;cin>>n>>k; map<ll,vector<pair<ll,ll>>> nexseg; set<pair<ll,ll>> nowseg; set<ll> coordinates; REP(i,n){ ll l,r;cin>>l>>r; nexseg[l].PB(MP(r,i)); coordinates.insert(l); coordinates.insert(r); } //左から座標の走査 //元々と新規の追加(数のチェック)→抜けるもののチェック //その後に削除 mint ans=0; FORA(i,coordinates){ //cout<<1<<endl; ll x,y;x=SIZE(nowseg); if(nexseg.find(i)==nexseg.end()){ y=0; ans+=0; }else{ y=SIZE(nexseg[i]); FORA(j,nexseg[i]){ nowseg.insert(j); } ans+=(COM(x+y,k)-COM(x,k)); } //cout<<x<<" "<<y<<" "<<ans<<endl; auto j=nowseg.begin(); //cout<<j->F<<" "<<j->S<<endl; while(j!=nowseg.end()){ //cout<<1<<endl; if(j->F==i){ j=nowseg.erase(j); }else{ break; } } } cout<<ans<<endl; }E問題
今回は飛ばします。

- 投稿日:2020-10-16T19:46:59+09:00
Pythonで学ぶ音源分離(機械学習実践シリーズ)のソースコード
ビームフォーミングのコード自前で書いていたけど、色々な手法が記載されている。
散々探していい例がないなと思っていたけど、いいのがあったのでメモ
- 投稿日:2020-10-16T19:46:24+09:00
ルービックキューブロボットのソフトウェアをアップデートした 3. 解法探索
この記事はなに?
私は現在2x2x2ルービックキューブを解くロボットを開発中です。これはそのロボットのプログラムの解説記事集です。
かつてこちらの記事に代表される記事集を書きましたが、この時からソフトウェアが大幅にアップデートされたので新しいプログラムについて紹介しようと思います。該当するコードはこちらで公開しています。
関連する記事集
「ルービックキューブを解くロボットを作ろう!」
1. 概要編
2. アルゴリズム編
3. ソフトウェア編
4. ハードウェア編ルービックキューブロボットのソフトウェアをアップデートした
1. 基本関数
2. 事前計算
3. 解法探索(本記事)
4. 状態認識
5. 機械操作(Python)
6. 機械操作(Arduino)
7. 主要処理今回は解法探索編として、
solver.pyを紹介します。基本関数をインポートする
基本関数編で紹介した関数をインポートします
from basic_functions import *グローバル変数
グローバルに置いた変数や配列です。
''' 配列の読み込み ''' ''' Load arrays ''' with open('cp_cost.csv', mode='r') as f: cp_cost = [int(i) for i in f.readline().replace('\n', '').split(',')] with open('co_cost.csv', mode='r') as f: co_cost = [int(i) for i in f.readline().replace('\n', '').split(',')] cp_trans = [] with open('cp_trans.csv', mode='r') as f: for line in map(str.strip, f): cp_trans.append([int(i) for i in line.replace('\n', '').split(',')]) co_trans = [] with open('co_trans.csv', mode='r') as f: for line in map(str.strip, f): co_trans.append([int(i) for i in line.replace('\n', '').split(',')]) neary_solved_idx = [] with open('neary_solved_idx.csv', mode='r') as f: for line in map(str.strip, f): neary_solved_idx.append([int(i) for i in line.replace('\n', '').split(',')]) neary_solved_solution = [] with open('neary_solved_solution.csv', mode='r') as f: for line in map(str.strip, f): if line.replace('\n', '') == '': neary_solved_solution.append([]) else: neary_solved_solution.append([int(i) for i in line.replace('\n', '').split(',')]) len_neary_solved = len(neary_solved_idx) solution = [] solved_cp_idx = 0 solved_co_idx = 0枝刈りやパズルを回す操作、そしてあと少しで揃う状態をCSVファイルから読み込みます。
また、
solution配列は解法探索に用い、ここに要素を追加/削除していくことでこの配列に解法が格納されるようにします。色の状態からパズルの状態配列を作る
これは少し煩雑です。パズルの各パーツにある色とその順番(パーツを斜め上から時計回りに見ていったときの色の現れる順番)を事前に手動で列挙しておいて、それに合うパーツを1つずつ探していきます。
すべての色が4色ずつ現れていなかったり、同じパーツが複数出てきたり、どのパーツ候補にも当てはまらないパーツがあったりするとエラーです。ここのエラー処理は結構面倒でした。
''' 色の情報からパズルの状態配列を作る ''' ''' Create CO and CP arrays from the colors of stickers ''' def create_arr(colors): # すべての色が4つずつ現れているかチェック for i in j2color: cnt = 0 for j in colors: if i in j: cnt += j.count(i) if cnt != 4: return -1, -1 cp = [-1 for _ in range(8)] co = [-1 for _ in range(8)] set_parts_color = [set(i) for i in parts_color] # パーツ1つずつCPとCOを埋めていく for i in range(8): tmp = [] for j in range(3): tmp.append(colors[parts_place[i][j][0]][parts_place[i][j][1]]) tmp1 = 'w' if 'w' in tmp else 'y' co[i] = tmp.index(tmp1) if not set(tmp) in set_parts_color: return -1, -1 cp[i] = set_parts_color.index(set(tmp)) tmp2 = list(set(range(7)) - set(cp)) if tmp2: tmp2 = tmp2[0] for i in range(7): if cp[i] > tmp2: cp[i] -= 1 return cp, co意味のない変数名を多用していて申し訳ありません。変数名を考えるのは大変ですが過去の自分にきつく言っておきます。
パズルの状態から解までの距離を求める
探索の途中で枝刈りに使うため、パズルの状態から解までの距離を知る必要があります。
''' その状態から解までの距離を返す ''' ''' Returns the distance between the state and the solved state ''' def distance(cp_idx, co_idx): # CPだけ、COだけを揃えるときのそれぞれの最小コストの最大値を返す return max(cp_cost[cp_idx], co_cost[co_idx])この関数は、「CPのみを揃える際の最小コスト」と「COのみを揃える際の最小コスト」の最大値を返します。この数字は、実際にCPとCOを両方揃えるときにかかるコストと同じか、または小さくなりますよね。
distance関数が返す値を$h(cp, co)$、実際にかかるコストを$h^*(cp, co)$とすると、$h(cp, co) \leq h^*(cp, co)$
ということです。このとき許容可能であると言い、必ず最短手順が探索できます。
パズルを回す
パズルを回す行為はインデックスレベルで行います。つまり、パズルの配列を作ってそれを置換するのではなく、パズルの状態を表す数値を使って表を見るだけで行えます。前回の事前計算で作った表を使います。
''' 遷移テーブルを使ってパズルの状態を変化させる ''' ''' Change the state using transition tables ''' def move(cp_idx, co_idx, twist): return cp_trans[cp_idx][twist], co_trans[co_idx][twist]ここで、
co_transおよびcp_transが遷移を表す配列です。これについて、
遷移配列[回転前の状態番号][回転番号] == 回転後の状態番号です。CPとCOのそれぞれにおいて遷移させます。
二分探索
二分探索は、事前計算で作った「少ないコストで揃う状態とその解法」を列挙した配列を検索するのに使います。
この配列はCPとCOを合わせた値($cp\times2187+co$: ここで2187はCOの最大値+1)をキーにソートされています。ただしこのキーは連続した整数として表されているわけではなく、この中から目的の番号を探すのは大変です。
そこで二分探索を用います。二分探索は$N$個の要素で構成されたソート済み配列から目的の要素を探し出すのに$\log_2N$(ここで底の2はしばしば省略されます)の計算回数、厳密にはループ、で済みます。普通にしらみ潰しに見ていったら最大で$N$回のループが必要であることを考えれば圧倒的に速いのが想像できると思います。例として$N=100, 100000, 1000000000=10^2, 10^5, 10^9$で$\log N$の値を見てみましょう。
$N$ $\log N$ $10^2$ $6.6$ $10^5$ $16.6$ $10^9$ $29.9$ $N$が大きくなるにつれて凄まじい差が現れます。
''' 二分探索 ''' ''' Binary search ''' def bin_search(num): # 二分探索でneary_solvedの中で目的のインデックスを探す l = 0 r = len_neary_solved while r - l > 1: c = (l + r) // 2 if neary_solved_idx[c][0] == num: return c elif neary_solved_idx[c][0] > num: r = c else: l = c if r == len_neary_solved: return -1 if num == neary_solved_idx[l][0]: return l elif num == neary_solved_idx[r][0]: return r else: return -1深さ優先探索
解法探索の本丸であるIDA*探索の中身には深さ優先探索(厳密には少し違うかもしれません)が使われています。深さ優先探索は再帰で実装するとスッキリ書けるので、再帰で実装しました。基本的にはこれまで紹介した関数を使って回転させ、コストを計算して次にまた自分自身を呼びます。このとき、グローバル変数に置いた
solution配列に要素(回転番号)を追加/削除していくだけで、揃った時(Trueを返した時)のsolution配列が解法になります。これが再帰のスッキリした点です。''' 深さ優先探索 ''' ''' Depth-first search ''' def search(cp_idx, co_idx, depth, mode): global solution # 前回に回した手と直交する方向の回転を使う twist_idx_lst = [range(6, 12), range(6), range(12)] for twist in twist_idx_lst[mode]: # パズルを回転させる cost = cost_lst[twist] n_cp_idx, n_co_idx = move(cp_idx, co_idx, twist) # 残り深さを更新 n_depth = depth - cost - grip_cost # 次の再帰に使う値を計算 n_mode = twist // 6 n_dis = distance(n_cp_idx, n_co_idx) if n_dis > n_depth: continue # グローバルの手順配列に要素を追加 solution.append(twist) # 前計算した少ないコストで揃う状態のどれかになった場合 if n_dis <= neary_solved_depth <= n_depth: tmp = bin_search(n_cp_idx * 2187 + n_co_idx) if tmp >= 0 and neary_solved_solution[tmp][0] // 6 != solution[-1] // 6: solution.extend(neary_solved_solution[tmp]) return True, grip_cost + neary_solved_idx[tmp][1] # 次の深さの探索 tmp, ans_cost = search(n_cp_idx, n_co_idx, n_depth, n_mode) if tmp: return True, ans_cost # 解が見つからなかったらグローバルの手順配列から要素をpop solution.pop() return False, -1IDA*探索
やっと本丸です。とは言ってもIDA*探索は、深さ優先探索を最大深さを増やしながら何回も行うだけなので、そこまで複雑な実装ではありません。
探索する前から「もうすぐ揃う状態」になっている場合は探索しません。探索する場合は
depthを1から順番に大きくしながら深さ優先探索をします。解が見つかった時点で探索を打ち切り、その解(を次の処理がしやすいように変換したもの)を返します。''' IDA*探索 ''' ''' IDA* algorithm ''' def solver(colors): global solution # CPとCOのインデックスを求める cp, co = create_arr(colors) if cp == -1 or co == -1: return -1, -1 cp_idx = cp2idx(cp) co_idx = co2idx(co) # 探索する前にもう答えがわかってしまう場合 if distance(cp_idx, co_idx) <= neary_solved_depth: tmp = bin_search(cp_idx * 2187 + co_idx) if tmp >= 0: return [twist_lst[i] for i in neary_solved_solution[tmp]], neary_solved_idx[tmp][1] res_cost = 0 # IDA* for depth in range(1, 34): solution = [] tmp, cost = search(cp_idx, co_idx, depth, 2) if tmp: res_cost = depth + cost break if solution == []: return -1, res_cost return [twist_lst[i] for i in solution], res_costまとめ
今回はこのロボットの一番面白い(と筆者が感じている)ところである解法探索のプログラムを解説しました。ここで解説した方法は他の様々なパズルを解くのに使えると思います。パズルを解きたい方の参考になれば幸いです。

- 投稿日:2020-10-16T19:02:43+09:00
Ubuntu 20.04 に Python 3.9 をインストール(OS標準?)
はじめに
Ubuntu 20.04にPython 3.9をインストール
LOG
インストール
# cat /etc/os-release NAME="Ubuntu" VERSION="20.04.1 LTS (Focal Fossa)" ID=ubuntu ID_LIKE=debian PRETTY_NAME="Ubuntu 20.04.1 LTS" VERSION_ID="20.04" HOME_URL="https://www.ubuntu.com/" SUPPORT_URL="https://help.ubuntu.com/" BUG_REPORT_URL="https://bugs.launchpad.net/ubuntu/" PRIVACY_POLICY_URL="https://www.ubuntu.com/legal/terms-and-policies/privacy-policy" VERSION_CODENAME=focal UBUNTU_CODENAME=focal # apt update; apt install -y python3.9 ... 略各種確認
# ll /usr/bin/python* -rwxr-xr-x. 1 root root 5808064 Sep 3 19:31 /usr/bin/python3.9* # python3.9 -V Python 3.9.0rc1 # apt show python3.9 Package: python3.9 Version: 3.9.0~rc1-1~20.04 Priority: optional Section: universe/python Origin: Ubuntu Maintainer: Ubuntu Developers <ubuntu-devel-discuss@lists.ubuntu.com> Original-Maintainer: Matthias Klose <doko@debian.org> Bugs: https://bugs.launchpad.net/ubuntu/+filebug Installed-Size: 542 kB Depends: python3.9-minimal (= 3.9.0~rc1-1~20.04), libpython3.9-stdlib (= 3.9.0~rc1-1~20.04), mime-support Suggests: python3.9-venv, python3.9-doc, binutils Breaks: python3-all (<< 3.6.5~rc1-1), python3-dev (<< 3.6.5~rc1-1), python3-venv (<< 3.6.5-2) Download-Size: 406 kB APT-Manual-Installed: yes APT-Sources: http://archive.ubuntu.com/ubuntu focal-updates/universe amd64 Packages Description: Interactive high-level object-oriented language (version 3.9)python 3.8では表示される
(default python3 version)がないので標準ではないのかもしれない。
RCが取れたら標準になるのかもしれない。
未調査
- 投稿日:2020-10-16T18:22:33+09:00
将棋AIで学ぶディープラーニング on Mac and Google Colab 第12章3
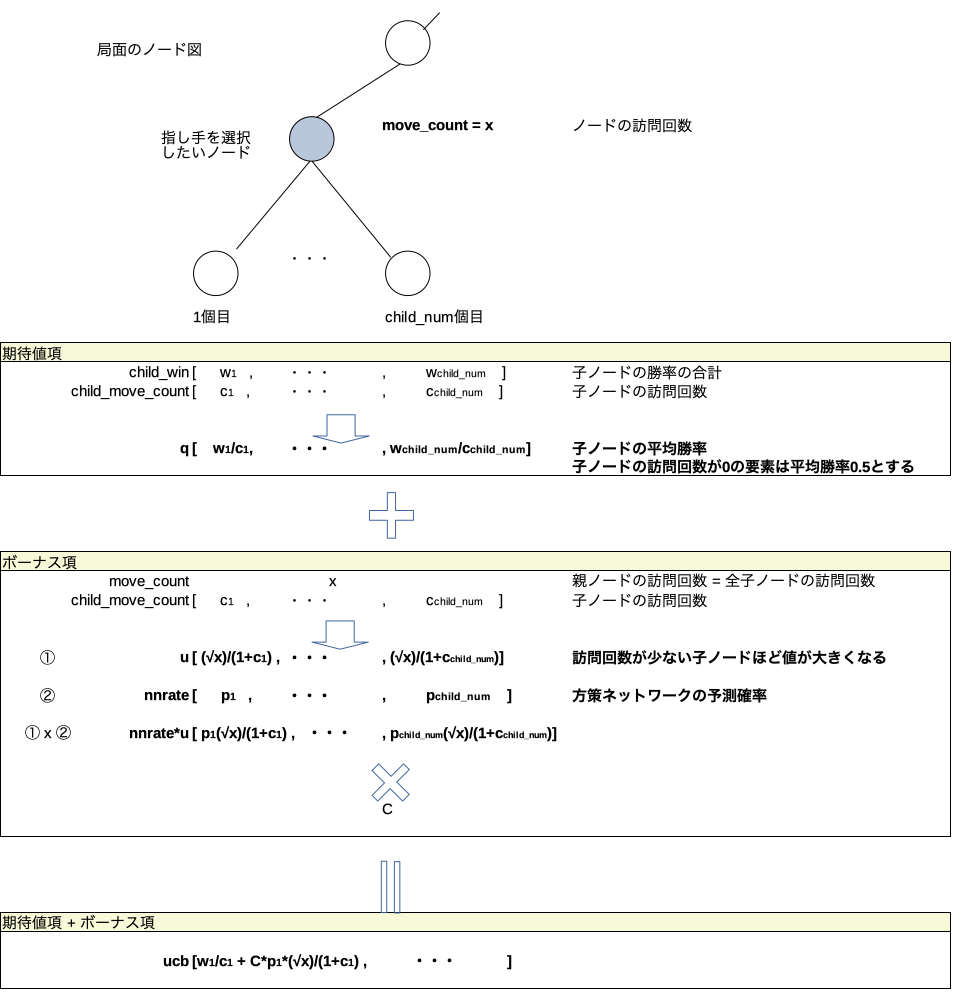
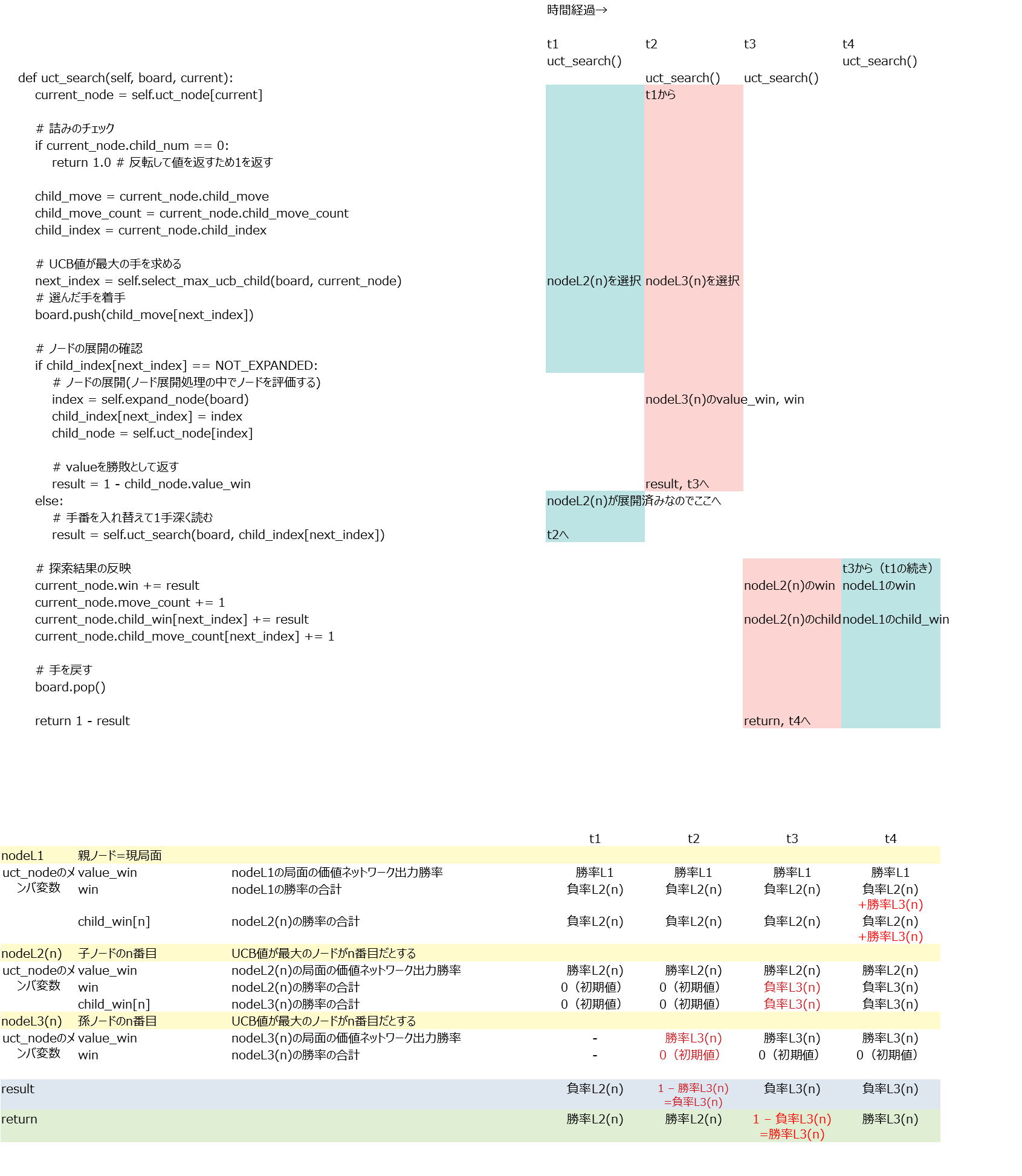
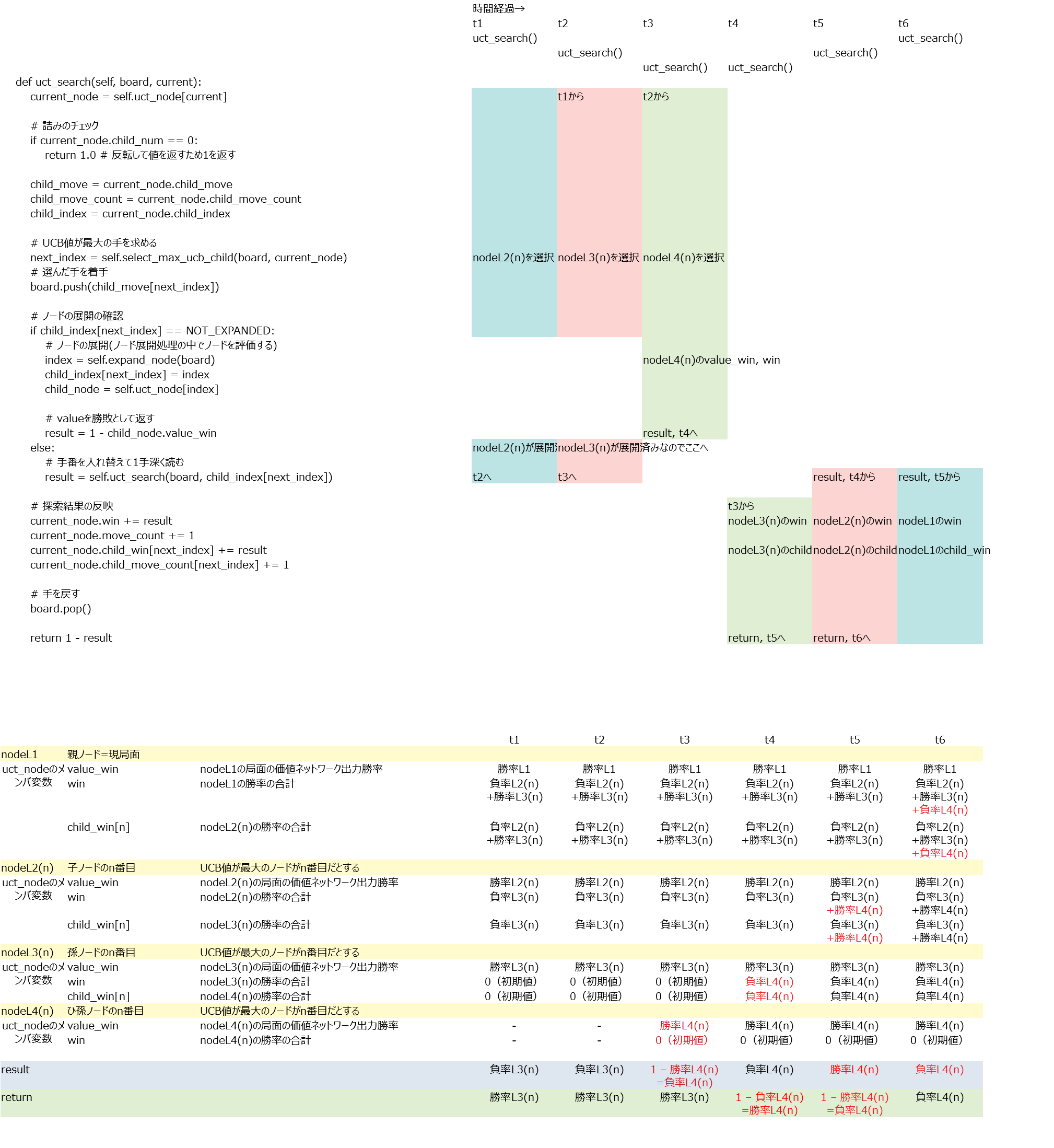
uct_search()
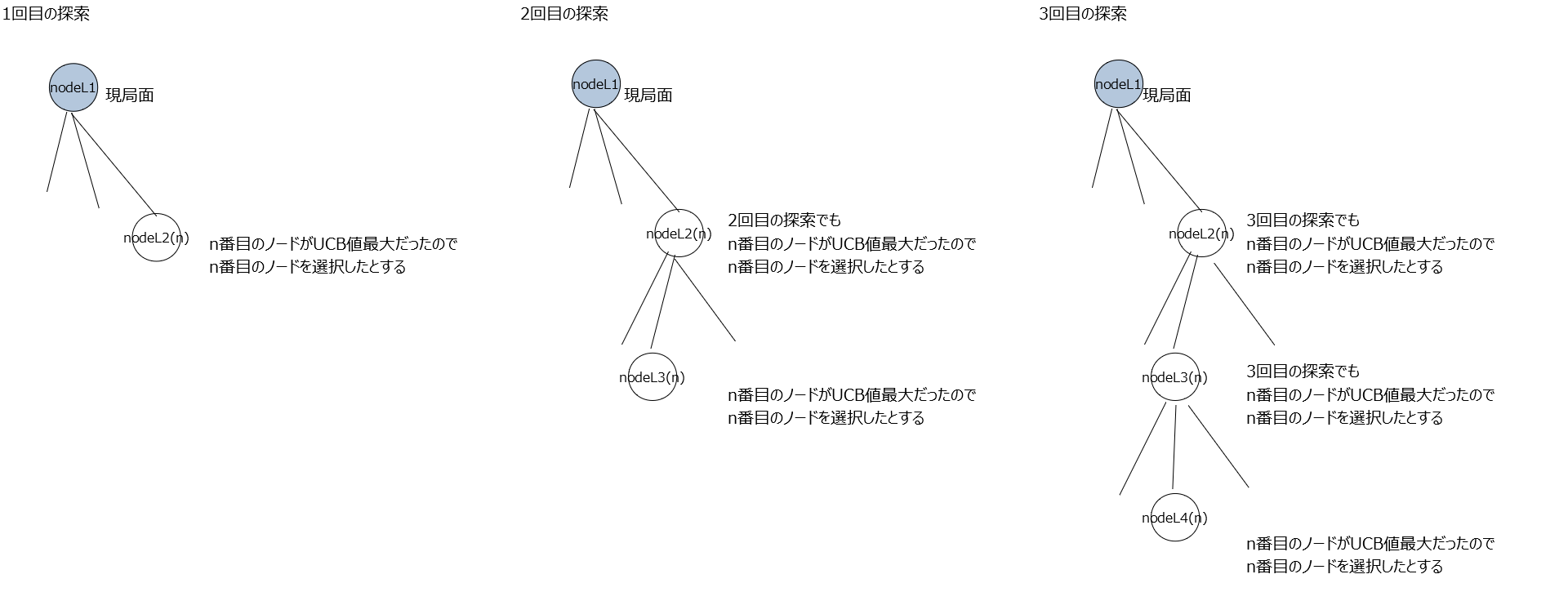
ざっくり言うとUCB値が大きいノードを選択し勝率の合計を加算していくメソッド。理解がかなり難しかったので例を作成して理解した。例えば探索開始から3回目の探索までを下記のように行ったとする。
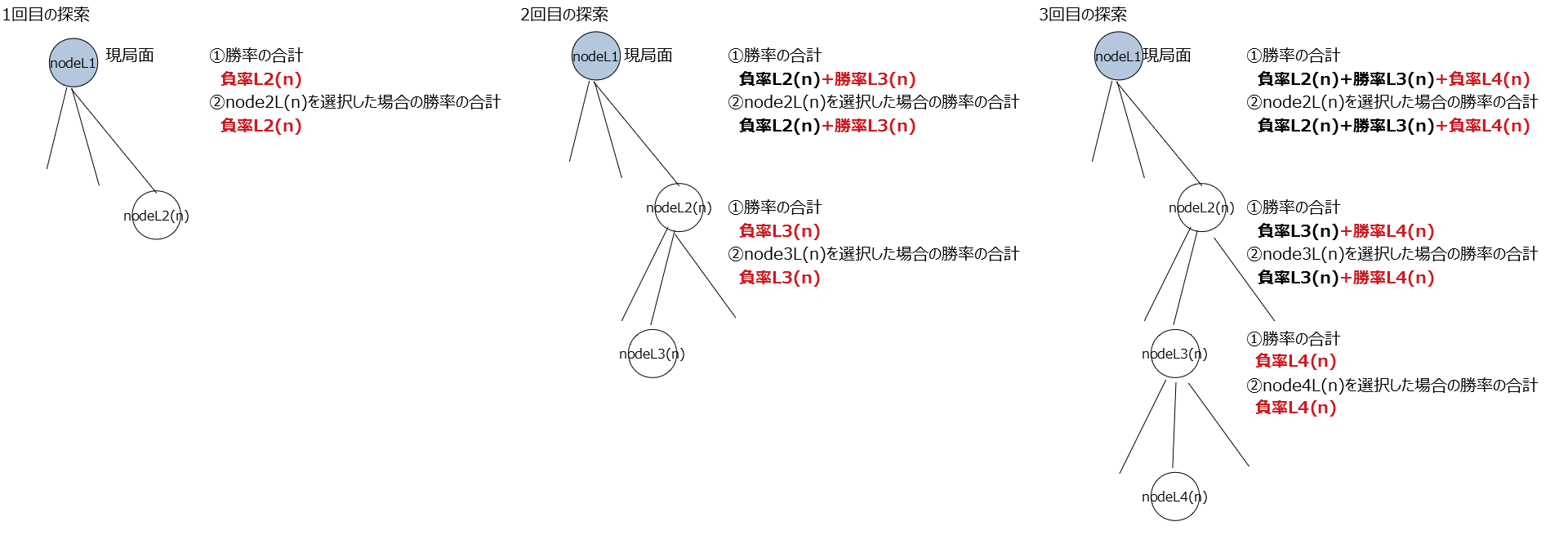
探索が行われるごとに各ノードが持つ変数にそのノード視点での勝率が加算される。
変数① 勝率の合計(変数名win):全ノード分の②の合計。(この例は①は②と同じ値になっているが各ノードがまだ1個しか探索していないから同じ値になっているだけで①と②は別の変数である。)
変数② node**を選択した場合の勝率の合計(変数名child_win)
他にも変数は有るが重要なのはこの①と②の2つ。価値ネットワークの予測勝率(変数名value_win)と①は別の変数であることに注意。
なお、この関数uct_search()では各ノードの訪問回数も記録している。この関数を抜けた後、go()関数の中では訪問回数が最大の手を最終的な指し手として選択することになる。また、②を訪問回数で割った値つまり平均勝率をその指し手の勝率として扱うことになる。それを念頭に置いておくと理解しやすくなる。
この例において変数の中身がどのように変化していくか時系列で追ってみた。
1回目の探索
2回目の探索
3回目の探索
ここまでやってやっと理解できた。単に自分の勝率と相手の負率(=自分の勝率)を積算しているだけである。

- 投稿日:2020-10-16T17:47:23+09:00
クイックソートの詳細とコード事例
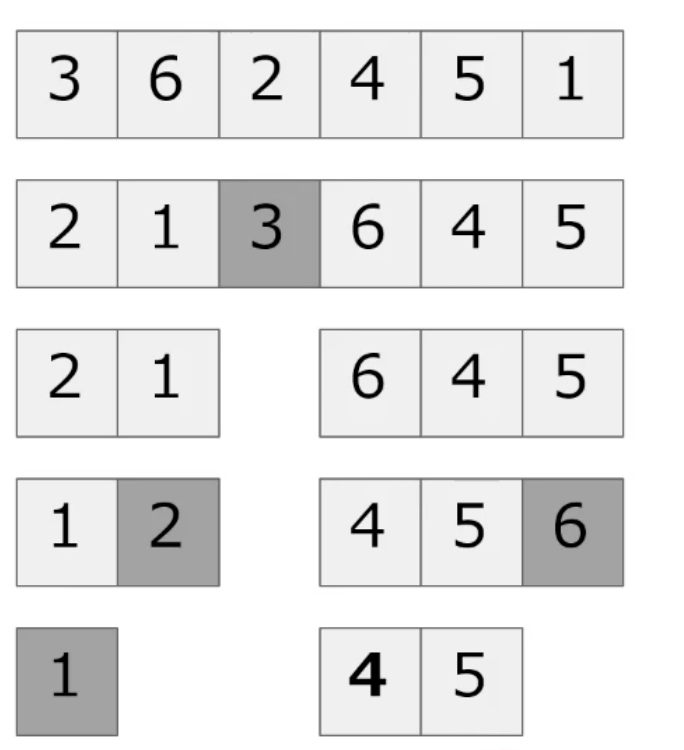
クイックソートとは?
要素をピボット(基準)を決めて、残りの要素を、ピボットより大きいいか、小さいかで前後に配置していく。
この前後に配置した要素を更に、ピボットを決め前後に配置していく作業を繰り返す。
要素が1つになったら確定する。
▼先頭の要素をpivotにする場合
クイックソートの流れ
- ピボットを決定し、その数値より大きいか小さいかで前後に振り分けていく。ピボットの値と場所は確定とする。
- 前方の配列に対し、再度1の処理を行う
- 後方の配列に対し、再度1の処理を行う
- 2、3の処理でピボットがどんどん確定していき、最終的には全ての要素が確定する。
一番左側をpivotにした場合
##pivotを指定して左側+pivot+右側で並び替えた配列を作る関数(quick_sort) def quick_sort(arr): #要素が1つになったらソート終了(要素が2つ未満の場合はソート不要) if len(arr) <= 1 : return arr #pivotの値を指定 p = arr[0] #pivotを基準に分割する処理を行う。div関数 arr1, arr2 = div(p, arr[1:]) #pivotを基準にして、分割した配列を結合する。 #分割した配列自体にもquick_sortを行う。 return quick_sort(arr1) + [p] + quick_sort(arr2) ##pivotを基準に左側と右側の配列を作成する関数 (div) def div(p, arr): #pivotの左側と右側の配列を入れる変数を定義 left, right=[], [] for i in arr: #pivotより小さければ左側に格納 if i < p: left.append(i) #pivot以上であれば右側に格納 else: right.append(i) #左側と右側の配列をそれぞれ出力 return left, rightマージソートに比べると直感的でわかりやすい。
※注意
一番左側の値をpivotにすると、既に降順に並んでいる場合などに計算量が多くなってしまう。このため、pivotはランダムに決定することが推奨される。
pivotをランダムに決定した場合のクイックソート
numpyのrandom.choice(配列)を使用する。
上記のquick_sort関数のpivotを以下のように変更する。
import numpy as np p = random.choice(arr)quick_sortimport numpy as np def quick_sort2(arr): #要素が1つになったらソート終了(要素が2つ未満の場合はソート不要) if len(arr) <= 1 : return arr #pivotの値を指定 p = random.choice(arr) #pivotを基準に分割する処理を行う。div関数 arr1, arr2 = div(p, arr[1:]) #pivotを基準にして、分割した配列を結合する。 #分割した配列自体にもquick_sortを行う。 return quick_sort(arr1) + [p] + quick_sort(arr2)
- 投稿日:2020-10-16T17:15:46+09:00
新型コロナウイルスに有効な界面活性剤が含まれている製品リストのPDFをCSVに変換
独立行政法人製品評価技術基盤機構の新型コロナウイルスに有効な界面活性剤が含まれている製品リストのPDFをCSVに変換
apt install python3-tk ghostscript pip install camelot-py[cv]スクレイピング
- 最新のPDFをスクレイピング
from urllib.parse import urljoin import requests from bs4 import BeautifulSoup url = "https://www.nite.go.jp/information/osirasedetergentlist.html" r = requests.get(url) r.raise_for_status() soup = BeautifulSoup(r.content, "html.parser") tag = soup.select_one("div.main div.cf ul > li > a") link = urljoin(url, tag.get("href"))データラングリング
import camelot import pandas as pd tables = camelot.read_pdf( link, pages="all", split_text=True, line_scale=40, copy_text=["v"] ) df_tmp = pd.concat([table.df for table in tables[:-1]]) # 住宅家具用洗剤など df1 = df_tmp.iloc[1:].set_axis(df_tmp.iloc[0].to_list(), axis=1).reset_index(drop=True) df1.index += 1 df1.to_csv("housing.csv", encoding="utf_8_sig") # 台所用合成洗剤など df2 = tables[-1].df.iloc[1:].set_axis(tables[-1].df.iloc[0].to_list(), axis=1) df2.to_csv("kitchen.csv", encoding="utf_8_sig")
- 投稿日:2020-10-16T17:11:44+09:00
kerasによる敵対的生成ネットワーク(GAN)の実装例【初学者向け】
この記事でやったこと
- GANによるminstの画像生成
- kerasを使った実装方法を紹介はじめに
敵対的生成ネットワーク、つまりGAN。なんだか凄い流行ってるって事はよく聞きますが、実際に自分で実装しようとなるとなかなか敷居高いですよね。
自分もこれまで重要そうな技術だなあ、とっておきながら外から見るだけで放置していました。意外とそういう人って結構多いんじゃないですかね。
そんなGANについて今回はmnist のデータを用いて実装した例を紹介します。
データやコードは「pythonによる教師なし学習」を参考にさせて頂いています。参考にした書籍ではオブジェクト指向を使って書かれていたので、 ちょっとレベルが高かったですがかなり勉強になりました。
同じく、初学者の参考になれば幸いです。
最初に得られた結果を示しておきます。見た目にインパクトあるので。
本物
生成
生成画像もなかには気持ち悪いくらい似ている気がしますね...
もっと長く学習ささせればもっといいものができるかもしれないです。敵対的生成ネットワーク(GAN)ってなに?
ここでは簡単に概要を述べます。詳細はコチラの記事を参考ください。
GAN:敵対的生成ネットワークとは何か ~「教師なし学習」による画像生成
https://www.imagazine.co.jp/gan%EF%BC%9A%E6%95%B5%E5%AF%BE%E7%9A%84%E7%94%9F%E6%88%90%E3%83%8D%E3%83%83%E3%83%88%E3%83%AF%E3%83%BC%E3%82%AF%E3%81%A8%E3%81%AF%E4%BD%95%E3%81%8B%E3%80%80%EF%BD%9E%E3%80%8C%E6%95%99%E5%B8%AB/GANを用いることで、データセットを学習して、まるで同じデータセットと同じようなデータを作成することができます。
参考記事の例では実際には存在しないベッドルームの写真をGAN を用いて生成しています。やーまったく見分けがつかないですね機械学習恐ろしい。今回の記事ではmnistを用いるので、 手書き文字を生成していきます。 このどうやってこの手書き文字を生成しているのでしょうか。
GANでは、データを生成するモデルとデータを識別するモデルの二つがあります。
データを生成するモデルでは、 手書き文字っぽいデータを作成していきます。 そしてその作成されたデータを識別モデルで、 偽物なのか本物なのかを判断していきます。そしてその結果をもとに生成モデルを学習させて、次はより本物に近い画像を作成していきます。簡単に言うとこれだけのモデルなんですよね。 ただ疑問に残るのは、 どうやってデータを学習させるか、どうやってデータを学習させるのか?だと思います。
データの学習
今回のモデルではデータの学習は下記のように行います。
- 生成モデルでノイズ(100*1*1)から画像(1*28*28)を生成する
- 「実際の画像」と「生成モデルで作成された画像」で識別モデルを学習させる
- 新たに生成モデルから画像を生成する。生成された画像が識別モデルで「実際の画像」と分類されるように、生成モデルと識別モデルを学習させる。このモデルを実際に実装していきます。
ライブラリのインポート
参考図書のまんまですが、google colabでも使えるようにすこし改良しています。
'''Main''' import numpy as np import pandas as pd import os, time, re import pickle, gzip, datetime '''Data Viz''' import matplotlib.pyplot as plt import seaborn as sns color = sns.color_palette() import matplotlib as mpl from mpl_toolkits.axes_grid1 import Grid %matplotlib inline '''Data Prep and Model Evaluation''' from sklearn import preprocessing as pp from sklearn.model_selection import train_test_split from sklearn.model_selection import StratifiedKFold from sklearn.metrics import log_loss, accuracy_score from sklearn.metrics import precision_recall_curve, average_precision_score from sklearn.metrics import roc_curve, auc, roc_auc_score, mean_squared_error from keras.utils import to_categorical '''Algos''' import lightgbm as lgb '''TensorFlow and Keras''' import tensorflow as tf import keras from keras import backend as K from keras.models import Sequential, Model from keras.layers import Activation, Dense, Dropout, Flatten, Conv2D, MaxPool2D from keras.layers import LeakyReLU, Reshape, UpSampling2D, Conv2DTranspose from keras.layers import BatchNormalization, Input, Lambda from keras.layers import Embedding, Flatten, dot from keras import regularizers from keras.losses import mse, binary_crossentropy from IPython.display import SVG from keras.utils.vis_utils import model_to_dot from keras.optimizers import Adam, RMSprop from keras.datasets import mnist sns.set("talk")データ読み込み
データの読み込みです。minstのデータを使用します。colaboratoryでの使用を想定しています。
x_trainしか使用しないので、reshpaeと0~1の値の正規化はx_trainにしかしていません。# 学習データとテストデータに分割したデータ (x_train, y_train), (x_test, y_test) = mnist.load_data() x_train = x_train.reshape((60000, 28, 28, 1)) # ピクセルの値を 0~1 の間に正規化 x_train= x_train / 255.0DCGANのクラス設計
超重要なDCGANのコードです。生成モデル、識別モデルをまとめたクラスで定義しています。
それぞれの関数の働きを簡単に記すとgenerator
- 100*1*1のベクトルを28*28*1の画像に変換するニューラルネットワーク
- これを学習させていくことでそれっぽい画像が生成されるようになる
discriminator
- 28*28*1の画像が本物か、偽物かを識別するニューラルネットワーク
discriminator_model
- 識別用のニューラルネットワークをコンパイルしてモデル化
adversarial?model
- generaorとdiscriminatorをつなげて作成されたモデル
- このモデルで生成ネットワークを学習させる
#DCGANのクラス class DCGAN(object): #初期化 def __init__(self, img_rows=28, img_cols=28, channel=1): self.img_rows = img_rows self.img_cols = img_cols self.channel = channel self.D = None # discriminator self.G = None # generator self.AM = None # adversarial model self.DM = None # discriminator model #生成ネットワーク #100*1*1の行列をデータセットの画像と同じ1*28*28にする def generator(self, depth=256, dim=7, dropout=0.3, momentum=0.8, \ window=5, input_dim=100, output_depth=1): if self.G: return self.G self.G = Sequential() #100*1*1 → 256*7*7 self.G.add(Dense(dim*dim*depth, input_dim=input_dim)) self.G.add(BatchNormalization(momentum=momentum)) self.G.add(Activation('relu')) self.G.add(Reshape((dim, dim, depth))) self.G.add(Dropout(dropout)) #256*7*7 → 128*14*14 self.G.add(UpSampling2D()) self.G.add(Conv2DTranspose(int(depth/2), window, padding='same')) self.G.add(BatchNormalization(momentum=momentum)) self.G.add(Activation('relu')) #128*14*14 → 64*28*28 self.G.add(UpSampling2D()) self.G.add(Conv2DTranspose(int(depth/4), window, padding='same')) self.G.add(BatchNormalization(momentum=momentum)) self.G.add(Activation('relu')) #64*28*28→32*28*28 self.G.add(Conv2DTranspose(int(depth/8), window, padding='same')) self.G.add(BatchNormalization(momentum=momentum)) self.G.add(Activation('relu')) #1*28*28 self.G.add(Conv2DTranspose(output_depth, window, padding='same')) #各ピクセルを0~1の間の値にする self.G.add(Activation('sigmoid')) self.G.summary() return self.G #識別ネットワーク #28*28*1の画像が本物かどうかを見分ける def discriminator(self, depth=64, dropout=0.3, alpha=0.3): if self.D: return self.D self.D = Sequential() input_shape = (self.img_rows, self.img_cols, self.channel) #28*28*1 → 14*14*64 self.D.add(Conv2D(depth*1, 5, strides=2, input_shape=input_shape,padding='same')) self.D.add(LeakyReLU(alpha=alpha)) self.D.add(Dropout(dropout)) #14*14*64 → 7*7*128 self.D.add(Conv2D(depth*2, 5, strides=2, padding='same')) self.D.add(LeakyReLU(alpha=alpha)) self.D.add(Dropout(dropout)) #7*7*128 → 4*4*256 self.D.add(Conv2D(depth*4, 5, strides=2, padding='same')) self.D.add(LeakyReLU(alpha=alpha)) self.D.add(Dropout(dropout)) #4*4*512 → 4*4*512 ####ただしあっているか確認### self.D.add(Conv2D(depth*8, 5, strides=1, padding='same')) self.D.add(LeakyReLU(alpha=alpha)) self.D.add(Dropout(dropout)) #フラット化してsigmoidで分類 self.D.add(Flatten()) self.D.add(Dense(1)) self.D.add(Activation('sigmoid')) self.D.summary() return self.D #識別モデル def discriminator_model(self): if self.DM: return self.DM optimizer = RMSprop(lr=0.0002, decay=6e-8) self.DM = Sequential() self.DM.add(self.discriminator()) self.DM.compile(loss='binary_crossentropy', \ optimizer=optimizer, metrics=['accuracy']) return self.DM #生成モデル def adversarial_model(self): if self.AM: return self.AM optimizer = RMSprop(lr=0.0001, decay=3e-8) self.AM = Sequential() self.AM.add(self.generator()) self.AM.add(self.discriminator()) self.AM.compile(loss='binary_crossentropy', \ optimizer=optimizer, metrics=['accuracy']) return self.AMmnist用DCGANのクラス設計
次にこれらの関数を用いてminstのデータを実際に訓練して画像を生成していきます。
train関数で画像の訓練を、plot_imagesで画像を保存していきます。train関数では下記のような流れで実行されています。
- 訓練用のデータをノイズから生成
- 生成されたデータを識別モデルにかける。このときどのくらい上手に識別できたかをD_lossに保存。
- 生成データが本物っぽくなるようadversarial_modelで学習させる。このときにどのくらい騙せたかをA_lossに保存。#MNISTのデータにDCGANを適用するクラス class MNIST_DCGAN(object): #初期化 def __init__(self, x_train): self.img_rows = 28 self.img_cols = 28 self.channel = 1 self.x_train = x_train #DCGANの識別、敵対的生成モデルの定義 self.DCGAN = DCGAN() self.discriminator = self.DCGAN.discriminator_model() self.adversarial = self.DCGAN.adversarial_model() self.generator = self.DCGAN.generator() #訓練用の関数 #train_on_batchは各batchごとに学習している。出力はlossとacc def train(self, train_steps=2000, batch_size=256, save_interval=0): noise_input = None if save_interval>0: noise_input = np.random.uniform(-1.0, 1.0, size=[16, 100]) for i in range(train_steps): #訓練用のデータをbatch_sizeだけランダムに取り出す images_train = self.x_train[np.random.randint(0,self.x_train.shape[0], size=batch_size), :, :, :] # 100*1*1のノイズをbatch sizeだけ生み出して偽画像とする noise = np.random.uniform(-1.0, 1.0, size=[batch_size, 100]) #生成画像を学習させる images_fake = self.generator.predict(noise) x = np.concatenate((images_train, images_fake)) #訓練データを1に、生成データを0にする y = np.ones([2*batch_size, 1]) y[batch_size:, :] = 0 #識別モデルを学習させる d_loss = self.discriminator.train_on_batch(x, y) y = np.ones([batch_size, 1]) noise = np.random.uniform(-1.0, 1.0, size=[batch_size, 100]) #生成&識別モデルを学習させる #生成モデルの学習はここでのみ行われる a_loss = self.adversarial.train_on_batch(noise, y) #訓練データと生成モデルのlossと精度 #D lossは生成された画像と実際の画像のときのlossとacc #A lossはadversarialで生み出された画像を1としたときのlossとacc log_mesg = "%d: [D loss: %f, acc: %f]" % (i, d_loss[0], d_loss[1]) log_mesg = "%s [A loss: %f, acc: %f]" % (log_mesg, a_loss[0], a_loss[1]) print(log_mesg) #save_intervalごとにデータを保存する if save_interval>0: if (i+1)%save_interval==0: self.plot_images(save2file=True, \ samples=noise_input.shape[0],\ noise=noise_input, step=(i+1)) #訓練結果をプロットする def plot_images(self, save2file=False, fake=True, samples=16, \ noise=None, step=0): current_path = os.getcwd() file = os.path.sep.join(["","data", 'images', 'chapter12', 'synthetic_mnist', '']) filename = 'mnist.png' if fake: if noise is None: noise = np.random.uniform(-1.0, 1.0, size=[samples, 100]) else: filename = "mnist_%d.png" % step images = self.generator.predict(noise) else: i = np.random.randint(0, self.x_train.shape[0], samples) images = self.x_train[i, :, :, :] plt.figure(figsize=(10,10)) for i in range(images.shape[0]): plt.subplot(4, 4, i+1) image = images[i, :, :, :] image = np.reshape(image, [self.img_rows, self.img_cols]) plt.imshow(image, cmap='gray') plt.axis('off') plt.tight_layout() if save2file: plt.savefig(current_path+file+filename) plt.close('all') else: plt.show()終わりに
GAN、すごいですね。なんか手書き文字っぽいものが生成されるのみると気持ち悪さすら感じます。
実際の現場だと異常検知などで使えるみたいですね。
ただ、参考図書のまとめのところに「GANを使う場合、多大なる労力がかかることを覚悟してほしい」という記載がありました。その詳しい理由については記述はありませんでしたが...
一体どれだけ苦労するんだ、GAN。
最後までお読みいただきありがとうございました。


- 投稿日:2020-10-16T17:06:30+09:00
マージソートの処理を理解する。流れを追って細かく分解。
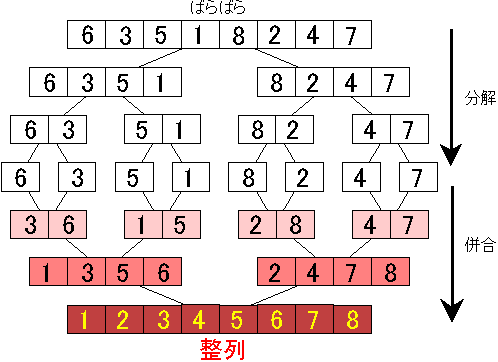
マージソートとは?
ソートの一種。安定したソート。分割統治法(divide-and-conquer)を使用している。
- ソート対象の配列を2分割する(divide)
- 分割したものをさらに2分割するのを要素が1つになるまで繰り返す(divide)
- それぞれの先頭要素同士を比較して、小さい数値を前方にしてマージ(solve, merge)
- ソート済み同士の要素の最初の数値を比較して小さい方から並べてマージ(conquer, merge)
参考:鹿児島大学HP
マージソートのコード
#最少単位に分解後にmergeを行う。この処理を繰り返す def merge_sort(arr): #要素が1つか0のときはその配列をそのまま返す。(比較対象がなくソートの必要性がないため) if len(arr) <= 1: return arr #2分割する。スライスで切り分けるため、整数部のみ抽出する mid = len(arr)//2 #元の配列を2分割 arr1 = arr[:mid] arr2 = arr[mid:] #最少単位になるまで2分割を続ける #returnになった時点で再帰が終了する arr1 = merge_sort(arr1) arr2 = merge_sort(arr2) return merge1(arr1, arr2) #2つの要素を比較して、小さい方を先頭に並べる def merge1(arr1,arr2): #マージ結果を入れる配列 merged = [] l_i, r_i =0,0 while l_i < len(arr1) and r_i < len(arr2): if arr1[l_i] <= arr2[r_i]: merged.append(arr1[l_i]) l_i += 1 else: merged.append(arr2[r_i]) r_i += 1 if l_i < len(arr1): merged.extend(arr1[l_i:]) if r_i < len(arr2): merged.extend(arr2[r_i:]) return merged確認list=[7,4,3,5,6,1,2] merge_sort(list) #[1, 2, 3, 4, 5, 6, 7]
マージソートの詳細
2つの関数が走っているためわかりにくいので分解してみる。
- 最少単位を作る関数(div_arr)
- 比較して小さい方を配列に追加していく関数(merge)
最少単位を作る関数
まずは、各要素を全て分割する関数を考える
def div_arr(arr): #要素が1つか0のときはその配列をそのまま返す。(比較対象がなくソートの必要性がないため) if len(arr) <= 1: return print(arr) #2分割する。スライスで切り分けるため、整数部のみ抽出する mid = len(arr)//2 #元の配列を2分割 arr1 = arr[:mid] arr2 = arr[mid:] #最少単位になるまで2分割を続ける #returnになった時点で再帰が終了する arr1 = div_arr(arr1) arr2 = div_arr(arr2)確認list=[7,4,3,5,6,1,2] div_arr(list) [7] [4] [3] [5] [6] [1] [2]ポイントはarr1とarr2の2つを用意していること。
関数に投入された値は2分割され、後方(arr2)は常に処理がストックされる。このため、arr1がreturnで終了したあとも、arr2がストックされた分だけ処理され続ける。
return arrで配列が出力されることを想定していたが、何も表示されたないため、return print(arr)にしている。(なぜ表示されないか不明、、)
(参考)前列だけで再帰処理した場合
def div_arr(arr): if len(arr) <= 1: return print(arr) mid = len(arr)//2 arr1 = arr[:mid] arr1 = div_arr(arr1)list=[7,4,3,5,6,1,2] div_arr(list) [7]arr1しか処理しないため、[7]だけが出力される。
※[7],[4],[3]とならない。再帰処理を繰り返す中で、[4],[3]はarr2に割り振られるため。
比較して小さい方を配列に追加していく関数
#2つの要素を比較して、小さい方を先頭に並べる def merge1(arr1,arr2): #マージ結果を入れる配列 #初期値0だが、mergeを繰り返す度に中身が増えていく merged = [] #対比する要素の配列番号初期値 l_i, r_i =0,0 #ループ終了条件。どちらかの配列を全て比較仕切ったら終了 while l_i < len(arr1) and r_i < len(arr2): #前方の要素の方が小さい場合 #同じ場合は先方を優先するためイコールをつける if arr1[l_i] <= arr2[r_i]: merged.append(arr1[l_i]) #同じ要素を再度検証しないよう配列番号に1をたす。 l_i += 1 else: merged.append(arr2[r_i]) r_i += 1 # while文が終了したら、追加されていない方を丸ごと答えに追加する。 # 各配列は既に昇順にソート済みであるため、そのまま追加している。 if l_i < len(arr1): merged.extend(arr1[l_i:]) if r_i < len(arr2): merged.extend(arr2[r_i:]) return merged確認a=[2,3] b=[1,8,9] merge1(a,b) #[1, 2, 3, 8, 9]
全体の処理の流れを可視化
上記2つの処理を踏まえて、merge_sortの処理を見てみる。
#ソートする配列 arr=[7,4,3,5,6] #1回目の処理 arr1=[7,4] arr2=[3,5,6] #arr1を再帰 arr1`=[7] arr2`=[4] ##arr1の解## merge`=[4,7] #arr2を再帰 arr1``=[3] arr2``=[5,6] #arr2``を再帰 arr1```=[5] arr2```=[6] ##arr2``の解## merge``=[5,6] ##arr2の解## merge```=[3,5,6] ##いよいよarrの解## merge=[3,4,5,6,7] ##arrの解はarr1とarr2をmergeしたもの #arr1の解 merge`=[4,7] #arr2の解 merge```=[3,5,6]、、ややこしい。最後の3行が肝心
arr1 = merge_sort(arr1) arr2 = merge_sort(arr2) return merge1(arr1, arr2)merge_sortの度にmergedした値(merge1の結果)がarr1とarr2に入る。
それがさらにmergeされていく。
これで最少単位まで分解した要素が再度組み上がる。
これ考えた人すげぇ、、そしてこれを理解している人もすげぇ
- 投稿日:2020-10-16T16:05:45+09:00
Pythonで少しでも見やすく、短くコーディングするためのコツ~選~
こんにちは、rickyです。
今回はpythonでコーディングするときに少しでもコードを少しでも見やすくする方法、短くする方法をご紹介します。
pythonの初心者さんがより良いコードを書けるようになれれば幸いです。
- 数値
num.py# before num = 10000000 # after num = 10_00_000
- 変数宣言
variable.py# before a = 1 b = 2 # after a, b = 1, 2 # supplement # 別の型同士でも可能 a, b = 3, "b"
- if文
if.pya, b = 1, 2 # before if a < b: print("A") else: print("B") # after print("A") if a < b else print("B")
- スワップ
swap.py# before a, b = 2, 3 tmp = b b = a a = tep # after a, b = 2, 3 a, b = b, aまとめ
pythonでコーディングをしている際に後から自分のコードを見直したときに可読性が悪いと感じ今回の記事を書きました。
個人的にif文の書き方はかなり参考になりました。
この記事がみなさんの役に立てば幸いです。
- 投稿日:2020-10-16T16:05:45+09:00
Pythonで少しでも見やすく、短くコーディングするためのコツ
こんにちは、rickyです。
今回はpythonでコーディングするときに少しでもコードを少しでも見やすくする方法、短くする方法をご紹介します。
pythonの初心者さんがより良いコードを書けるようになれれば幸いです。
- 数値
num.py# before num = 10000000 # after num = 10_00_000
- 変数宣言
variable.py# before a = 1 b = 2 # after a, b = 1, 2 # supplement # 別の型同士でも可能 a, b = 3, "b"
- if文
if.pya, b = 1, 2 # before if a < b: print("A") else: print("B") # after print("A") if a < b else print("B")
- スワップ
swap.py# before a, b = 2, 3 tmp = b b = a a = tep # after a, b = 2, 3 a, b = b, aまとめ
pythonでコーディングをしている際に後から自分のコードを見直したときに可読性が悪いと感じ今回の記事を書きました。
個人的にif文の書き方はかなり参考になりました。
この記事がみなさんの役に立てば幸いです。
- 投稿日:2020-10-16T15:27:30+09:00
【Python】クリップボード内の改行を削除するプログラムを作る+windowsでショートカットに登録する
経緯
- PDFファイルの論文からコピペしてgoogle翻訳に通したい時、余計な改行が入るのが邪魔。
- コピペ時の改行を削除するシンプルな方法として、以下のもの↓が既にqiitaに投稿されている。ぶっちゃけこれでいい。
- 自分の使っているマウスのマクロボタンにこの機能を登録したかったため、pythonで実装を行った。
- .pyファイルを.exe化、さらにショートカットキーに登録した。ここで多少詰まったため、以下にその手順をまとめておく。
コードを書く
import pyperclip s = pyperclip.paste() s = s.replace("\n", "") s = s.replace("\r", "") pyperclip.copy(s)
pyperclipというモジュールを導入して、クリップボードの操作を行う。pyperclip.paste()でクリップボードの取得。
replace()を用いて改行コードの削除。もし削除する文字が"\r""\n"の二種類だと不都合があるなら適宜調整する。
pyperclip.copy()でクリップボードに貼り付け。なお、
pyautoguiを用いてペーストまで自動で行うのも試してみたが、実行速度が倍以上かかって使い物にならなかったのでボツ。クリップボードの操作だけできればいいとした。exe化する
pyinstallerを用いて実行形式に変換する。コマンドプロンプトから導入する。pip install pyinstaller続けて以下のコマンドを打ち込んで実行。
pyinstaller ファイル名 --onefiledistフォルダの中にexeファイルが作られる。
ショートカットキーに登録する
参考: プログラムを素早く起動する方法(ショートカット・キーを設定する)
- 作成したexeファイルを右クリックし、ショートカットを作成する。
ショートカットファイルはデスクトップ(もしくはスタートメニューフォルダ、もしくはその下のProgramsフォルダ)に配置する。
ショートカットのプロパティを開く。ショートカットキーの項目があるので、そこに任意のキー(ctrl+alt+数字など)を入力する。
ついでに実行時にウィンドウがいちいち開くと邪魔なので「実行時の大きさ」を選んで「最小化」に設定する。
これで完了。登録したキーで動かなかったら一度再起動する。
終わり
マウスのマクロボタンに登録して目標達成。
なお、実行完了に三秒くらいかかったので実用性がそこまで高いわけではない。それなら先人の方法でいいやとも言える。後は外部のマクロ機能に依存するなら別にコマンド一つで完結させる必要はないので、ショートカットのファイル名を一文字にしてpathの通ったフォルダに置く→「win+R, ファイル名, エンターを打ち込んで実行する」マクロとして登録しちゃうってのもアリ。何ならタスクバーに配置してwin+数字のショートカットで起動するのもアリ。これらの方が実行が早い説がある。
あとはもっと普通に効率よく改行を消す手段もあるかもしれません。
- 投稿日:2020-10-16T15:17:33+09:00
Pythonでリストのコピーをする
はじめに
Python3.8.3で実行した結果を記載しています。
リストのコピー
「リストのコピーを作り、値を変えて元のものと比較したい」と思うことがある。その場合、次のようにcopyモジュールのdeepcopyメソッドを使って書く必要がある。
1次元リスト
リストが1次元のときは、
deepcopy()、スライス、list()などでコピーできる。list_copy_example_1.pyimport copy list_1 = [0,1,2] list_2 = copy.deepcopy(list_1) #deepcopy()を使う list_3 = list_1[:] #元のリストをスライスする list_4 = list(list_1) #list()を使う list_2[0] = 1000 list_3[0] = 2000 list_4[0] = 3000 print(list_1) print(list_2) print(list_3) print(list_4)出力はこのようになる。
[0, 1, 2] [1000, 1, 2] [2000, 1, 2] [3000, 1, 2]2次元リスト
リストが2次元(以上)のときは、
deepcopy()でコピーできる。スライスやlist()ではうまくいかない(後述)。list_copy_example_2.pyimport copy list_1 = [[0,1,2], [3,4,5]] list_2 = copy.deepcopy(list_1) list_2[0][0] = 1000 print(list_1) print(list_2)出力はこのようになる。
[[0, 1, 2], [3, 4, 5]] [[1000, 1, 2], [3, 4, 5]]うまくいかないパターン
=で代入
リストの参照自体をコピーしているため、元のリストの値も変更されてしまう。
anti_pattern_1.py#=で代入する list_1 = [0,1,2,3] list_2 = list_1 list_2[0] = 1000 print(list_1) print(list_2)出力
[1000, 1, 2, 3] [1000, 1, 2, 3]スライス、list( )でコピー
Pythonのリストで参照渡しでないコピーを作成する話 には、スライスでコピーするのが手軽だとあるが、これはリストが1次元のときのみうまくいく。
リストが2次元以上になると、次のようになる。途中で参照渡しが起こるのでうまくいかないようだ。
anti_pattern_2#元のリストをスライスでコピーする(2次元) list_3 = [[0,1,2], [3,4,5]] list_4 = list_3[:] list_4[0][0] = 1000 print(list_3) print(list_4)出力
[[1000, 1, 2], [3, 4, 5]] [[1000, 1, 2], [3, 4, 5]]また、スライスの代わりに
list()メソッドを使っても同じ結果になる。解説
リストを普通に複製すると、値ではなく参照自体がコピーされる。これを浅いコピーという。逆に、値のみをコピーすることを深いコピーという。Pythonでは、リストや辞書のような複合オブジェクトには、特に指定がない限り浅いコピーが適用される。多次元リストをスライスでコピーしたときに参照渡しになっていたのも、スライス内部での2次元目のコピーが浅いコピーだったからだろう。
そして、copy.deepcopy()メソッドは「深いコピーをして」という指示である。これを使うと、多次元リストのコピーでも、すべての要素に深いコピーをしてくれる。
詳しくは、公式のcopy --- 浅いコピーおよび深いコピー操作を参照。まとめ
1次元リストならスライス、
list()、copy.deepcopy()
多次元リストならcopy.deepcopy()
- 投稿日:2020-10-16T14:59:38+09:00
Your URL didn't respond with the value of the challenge parameter.
slack APIを使っていたら、flaskのエンドポイントが使えないというエラーが出ました。
これはchallenge parameterを返すようなapiになっていないとokをださないよというもの。
だから、以下のようにpostでくれたchallenge parameterをそのまま返してあげるapiを作ればok!@app.route("/slack/sample", methods=["POST"]) def slack_sample(): return request.json["challenge"]
- 投稿日:2020-10-16T14:41:55+09:00
「独学プログラマー」を読んでみてのレビュー
はじめに
筆者はシステムエンジニアとして9年近く働いてきている。
実際にコーディングをするのは3,4年まともにやっていなく、最近はもっぱらwebシステムのSE業(PJ管理、要件定義、設計)を行ってきていました。
ふとしたきっかけからデータサイエンスよりの職種にジョブチェンジしたいと思い、改めて1から「学ぶ」ということをしてみようと思い、今回その手始めに「独学プログラマー」を読んだのでそのレビューをしていきます。参考書について
タイトル:独学プログラマー Python言語の基本から仕事のやり方まで
著者 :コーリー・アルソフ
Amazon URL:
https://www.amazon.co.jp/exec/obidos/ASIN/B07BKVP9QY/ktnch-22/概要
本書はプログラマーになるための入門書という扱い。
プログラミング言語としては今流行りのPythonを用いて、基礎的な構文から学び、プログラマーとして必要な基礎知識、考え方を学べる構成になっている。
ざっくり流れは↓のような感じ。・Pythonのプログラミング入門
Python基本的な構文からオブジェクト指向プラグラミングについて学べ、まとめとして例題あり。
・Bashや正規表現、パッケージ管理などプログラミング周りの基礎知識習得
・プログラマーとしての働き方、学び方についてレビュー
※あくまで個人的な感想です。
Good
- Pythonを1から学びたい!という人に対してもおすすめできる一冊。(もちろんプログラミング自体を初めて学んでみたいという方にもおすすめ)
- 初心者がつまづきやすい専門用語や使い方についても注釈でしっかりと書いてありフォローされている。
- 例題やプラクティスに関して、GitHubから確認可能
Bad(というほどでも無いけど気になった点)
- Python以外のプログラミングをある程度行っている中級者以上にとっては物足りない内容。(実際に私はPythonの入門用としては役立ちましたが、それ以外の内容はサラッと読み進めました)
以上
- 投稿日:2020-10-16T13:44:40+09:00
回帰分析の基礎
文脈の無いデータは単なる数値の羅列にしか過ぎない。手元にあるデータをうまく活用するにはデータの背後にある現象の仕組み、歴史的背景、環境など多岐にわたる情報を収集する必要がある。そしてそのような情報をもとに自由な発想でデータをさらに集める。
データは集めただけでは意味を成さない。比較することでその特徴がみえてくる。平均とか分散を計算することを、要約統計量を得るという。また、頻度図や折れ線グラフを描いて、データの特徴をつかむデータの可視化を行う。
このような分析手法を用いて、現象の全体像が見えてきたら、いよいよ統計的手法を用いる。その際には分析の目的が明確である必要がある。大きく
1) 現象の構造の把握
2) 情報の収集
3) 予測
の3つに分類できる。このように分類するには普遍的な理由がある。統計学では得られたデータのもとになるデータがあると考え、これを母集団とか単にモデルとか呼んだりする。そして手元に得られたデータはその母集団から抽出されたと考える。抽出された、または観測されたデータを標本といい母集団と区別する。母集団が得られるということはモデルが得られたということと同等だ。真のモデルが得られたともいう。多くの場合、真のモデルがえられたということはその現象の背後にある構造をつかめたということだ。しかし、残念なことに、母集団が得られることはほとんどない。それはモデルが得られないということでもある。したがって、母集団が得られないのであれば、とりあえず分析対象となるデータの傾向をつかんだり、他のデータとの関連性をつかんだりと新たな情報を得ようということが目的となる。また、真のモデルが得られなくても予測がうまくいく場合がある。そのようなときには、予測をすることが分析の目的となる。比較についてさらに加えると、比較には何らかの基準が必要である。その際に2つの方法がある。1つはこの基準を外部に求めるものである。これは先ほどの真のモデルとの比較になる。しかし、これはほぼ不可能だ。そこで、手元にあるデータそのものと比べる。t-分布を用いたり分散分析がこれに相当する。
すでにモデルという用語が出たが、これは一言でいうと確率分布のことだ。これは確率的現象の表現方法の1つで、現象がある確率で起きる様子を表現している。しかし、実際に起きる現象がこのような確率分布にしたがうということは稀だ。実際に目にする現象は、それぞれの状況に応じて、少しずつ性格が違うからだ。また、データに観測ノイズが含まれているかもしれない。そこで、条件付分布モデルというものを考える。そして、このようなモデルの代表が回帰分析だ。statsmodelsではこのような分析に適したライブラリーが多数存在する。
statsmodelsでは線形回帰モデル
$$y=f(x_i)+e=\beta_0+\beta_1 x_1 +,\cdots,+ e $$
の切片($\beta_0$)と回帰係数($\beta_i$)を
日本語 statsmodels 最小二乗法 OLS 加重最小二乗法 WLS 一般化最小二乗法 GLS 再帰的最小二乗法 Recursive LS という4つの方法により推定する。$x$は説明変数、$e$は誤差である。$y$は被説明変数で、$x$の線形結合としてモデル化される。最小二乗法によって得られるモデルがもっともらしくあるためには、誤差には
- 偏りがない。
- 分散は既知で一定である。
- 共分散は0である。
- 正規分布にしたがう。
という前提条件が課される。GLSは誤差の分散が一定ではない分散不均一性、誤差同士が相関をもつ自己相関をもつ誤差に対処できるモデルで、WLSは分散不均一性を扱っていて、Recursive LSは自己相関をもつ誤差を扱っている。これらのモデルでは条件を満たせない誤差の問題をいろいろと調整をして、これらの条件を成り立たせることで回帰係数を推定している。
線形回帰というときには
1) パラメータに対して線形
という条件が課される。また、x(独立変数、説明変数)については
a) 確率変数ではなく確定した値
b) 確率変数
の場合に分けられ、確率変数の場合にはxは誤差項と独立である必要がある。また、$y$の分布を指数分布族として指定して、残差を任意の分布としたものとして一般化線形モデルがある。これをさらに発展させたものとして
などがある。線形回帰ではOLSを用いるが、一般化線形モデルとその発展形では最尤法、またはそれに準じた方法を用いて回帰係数の推定を行う。
- 投稿日:2020-10-16T13:36:01+09:00
python C++ メモ
python
最大公約数
Q: 51と15の最大公約数は?
1. 51÷15 = 3 あまり6
2. 15÷6 = 2あまり3
3. 6÷3 = 2あまり0
A: 3!!def GCD(m,n): if n==0: return m return GCD(n,m%n) print(GCD(51,15))#include <bits/stdc++.h> using namespace std; int GCD(int m, int n){ if (n==0) return m; return GCD(n,m%n); } int main() { cout << GCD(51,15); }フィボナッチ数列
出力
[0, 1, 1, 2, 3, 5, 8, 13, 21, 34, 55, 89, 144, 233, 377, 610, 987, 1597, 2584, 4181, 6765, 10946, 17711, 28657, 46368, 75025, 121393, 196418, 317811, 514229, 832040, 1346269, 2178309, 3524578, 5702887, 9227465, 14930352, 24157817, 39088169, 63245986, 102334155, 165580141, 267914296, 433494437, 701408733, 1134903170, 1836311903, 2971215073, 4807526976, 7778742049]fibo = [None]*50 fibo[0]=0 fibo[1]=1 for i in range(2,50): fibo[i]=fibo[i-1]+fibo[i-2] print(fibo)#include <bits/stdc++.h> using namespace std; int main() { std::vector<long long> fibo(50); fibo[0] = 0, fibo[1]=1; for (int i=2;i<50;++i){ fibo[i]=fibo[i-1]+fibo[i-2]; } for (int i=0;i<50;++i) cout << fibo[i] << "," << " "; }メモ化すると↓
memo = [-1]*50 memo[0] = 0 memo[1] = 1 def fibo(n): if n==0: return 0 elif n==1: return 1 if memo[n] != -1: return memo[n] memo[n] = fibo(n-1)+fibo(n-2) return memo[n] fibo(49) print(memo)#include <bits/stdc++.h> using namespace std; std::vector<long long> memo; long long fibo(int n){ if (n==0) return 0; else if (n==1) return 1; if (memo[n] != -1) return memo[n]; return memo[n] = fibo(n-1)+fibo(n-2); } int main() { memo.assign(50,-1); fibo(49); for (int n=2;n<50;++n){ cout << memo[n] << ","<< " "; } }
- 投稿日:2020-10-16T12:59:45+09:00
kaggleのtitanic xgboostを使った生存者予測 [80.1%]
はじめに
前回はタイタニックのtrainデータを見て、生存率に関係のある特徴量とは何かを見てみました。
前回:kaggleのtitanic 特徴量生成の前のデータ分析
(こちらの記事も合わせて見ていただけると嬉しいです)その結果を元に、今回は欠損値の補完と必要な特徴量を追加して予測モデルに与えるデータフレームを作成します。
なお、今回は予測モデルとして、kaggleのコンペでもよく使われている「GBDT(勾配ブースティング木)のxgboost」を使うのでデータをそれに適した形にしていきます。
1. データの取得と欠損値の確認
import pandas as pd import numpy as np train = pd.read_csv('/kaggle/input/titanic/train.csv') test = pd.read_csv('/kaggle/input/titanic/test.csv') #trainデータとtestデータを1つにまとめる data = pd.concat([train,test]).reset_index(drop=True) #欠損値が含まれる行数を確認 train.isnull().sum() test.isnull().sum()それぞれの欠損値の数は下のようになりました。
trainデータ testデータ PassengerId 0 0 Survived 0 Pclass 0 0 Name 0 0 Sex 0 0 Age 177 86 SibSp 0 0 Parch 0 0 Ticket 0 0 Fare 0 1 Cabin 687 327 Embarked 2 0 2. 欠損値の補完と特徴量の作成
2.1 Fareの補完と階級分け
欠損している行のPclassは3でEmbarkedはSでした。
ですのでこの2つの条件を満たす人の中での中央値で補完します。
その後、Fareの値による生存率の違いとPclassを考慮して階級分けを行います。#欠損値の補完 data['Fare'] = data['Fare'].fillna(data.query('Pclass==3 & Embarked=="S"')['Fare'].median()) #階級分けしたものを'Fare_bin'に入れる data['Fare_bin'] = 0 data.loc[(data['Fare']>=10) & (data['Fare']<50), 'Fare_bin'] = 1 data.loc[(data['Fare']>=50) & (data['Fare']<100), 'Fare_bin'] = 2 data.loc[(data['Fare']>=100), 'Fare_bin'] = 32.2 グループごとの生死の違い'Family_survival'の作成
Titanic [0.82] - [0.83]こちらのコードで紹介されていた 'Family_survival' という特徴量を作成します。
家族や友人同士だと船内で行動を共にしている可能性が高いので生存できたかどうかもグループ内で同じ結果になりやすいといえます。
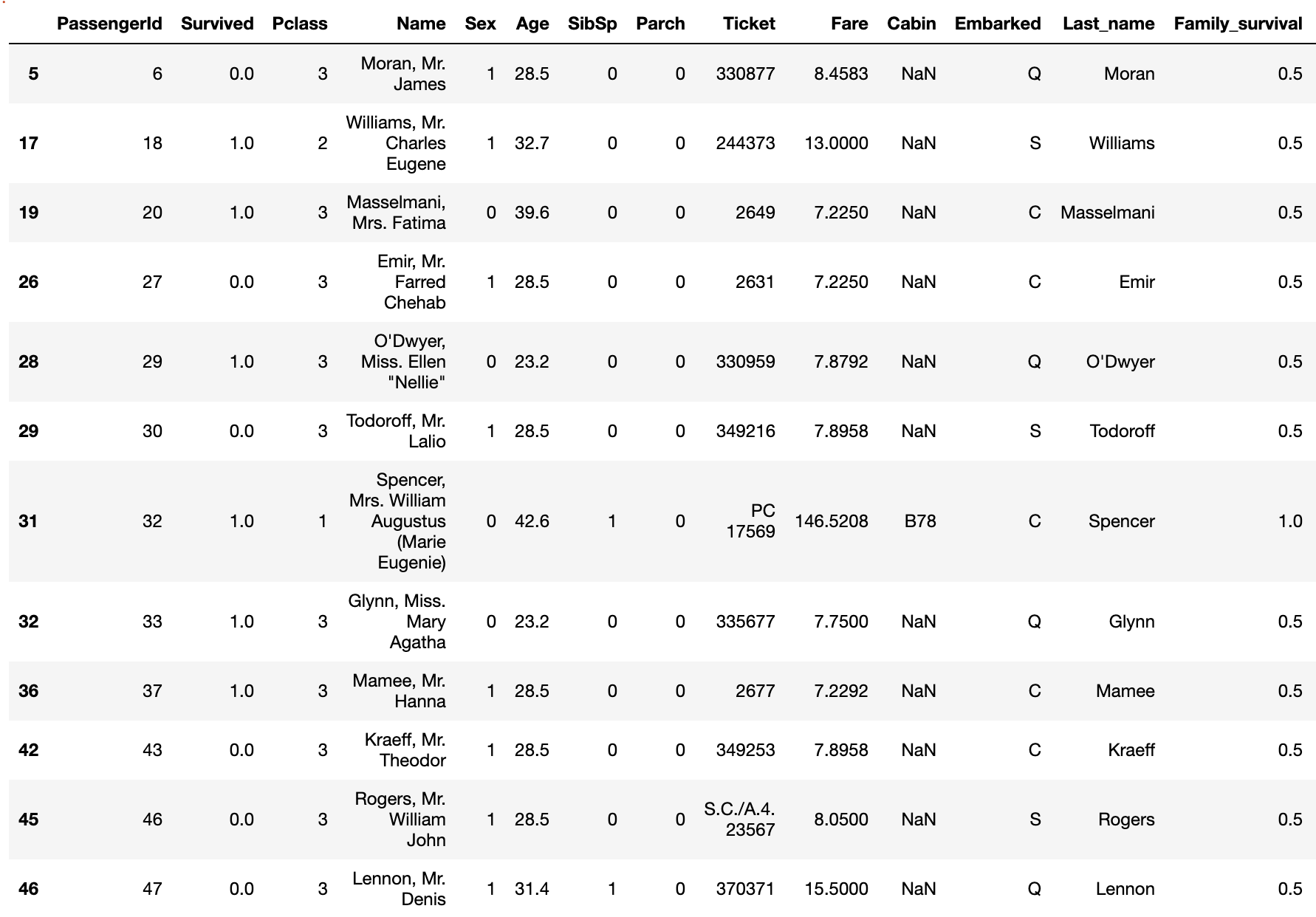
そこで名前の名字とチケット番号でグルーピングを行い、そのグループのメンバーが生存しているかどうかで値を決めます。
#名前の名字を取得して'Last_name'に入れる data['Last_name'] = data['Name'].apply(lambda x: x.split(",")[0]) data['Family_survival'] = 0.5 #デフォルトの値 #Last_nameとFareでグルーピング for grp, grp_df in data.groupby(['Last_name', 'Fare']): if (len(grp_df) != 1): #(名字が同じ)かつ(Fareが同じ)人が2人以上いる場合 for index, row in grp_df.iterrows(): smax = grp_df.drop(index)['Survived'].max() smin = grp_df.drop(index)['Survived'].min() passID = row['PassengerId'] if (smax == 1.0): data.loc[data['PassengerId'] == passID, 'Family_survival'] = 1 elif (smin == 0.0): data.loc[data['PassengerId'] == passID, 'Family_survival'] = 0 #グループ内の自身以外のメンバーについて #1人でも生存している → 1 #生存者がいない(NaNも含む) → 0 #全員NaN → 0.5 #チケット番号でグルーピング for grp, grp_df in data.groupby('Ticket'): if (len(grp_df) != 1): #チケット番号が同じ人が2人以上いる場合 #グループ内で1人でも生存者がいれば'Family_survival'を1にする for ind, row in grp_df.iterrows(): if (row['Family_survival'] == 0) | (row['Family_survival']== 0.5): smax = grp_df.drop(ind)['Survived'].max() smin = grp_df.drop(ind)['Survived'].min() passID = row['PassengerId'] if (smax == 1.0): data.loc[data['PassengerId'] == passID, 'Family_survival'] = 1 elif (smin == 0.0): data.loc[data['PassengerId'] == passID, 'Family_survival'] = 02.3 家族の人数を表す特徴量 'Family_size' の作成と階級分け
SibSpとParchの値を使って何人家族でタイタニックに乗船したかという特徴量'Family_size'をつくり、それぞれの生存率に応じた階級分けをします。
#Family_sizeの作成 data['Family_size'] = data['SibSp']+data['Parch']+1 #1, 2~4, 5~の3つに分ける data['Family_size_bin'] = 0 data.loc[(data['Family_size']>=2) & (data['Family_size']<=4),'Family_size_bin'] = 1 data.loc[(data['Family_size']>=5) & (data['Family_size']<=7),'Family_size_bin'] = 2 data.loc[(data['Family_size']>=8),'Family_size_bin'] = 32.4 名前の敬称 'Title' の作成
Nameの列から'Mr','Miss'などの敬称を取得します。
数が少ない敬称('Mme','Mlle'など)は同じ意味を表す敬称に統合します。#名前の敬称を取得して'Title'に入れる data['Title'] = data['Name'].map(lambda x: x.split(', ')[1].split('. ')[0]) #数の少ない敬称を統合 data['Title'].replace(['Capt', 'Col', 'Major', 'Dr', 'Rev'], 'Officer', inplace=True) data['Title'].replace(['Don', 'Sir', 'the Countess', 'Lady', 'Dona'], 'Royalty', inplace=True) data['Title'].replace(['Mme', 'Ms'], 'Mrs', inplace=True) data['Title'].replace(['Mlle'], 'Miss', inplace=True) data['Title'].replace(['Jonkheer'], 'Master', inplace=True)2.5 チケット番号のラベリング
チケット番号には数字のみのものと数字とアルファベットを含むものがあります。
その2つを分けてからチケット番号の種類ごとにラベリングを行います。#数字のみのチケットと数字とアルファベットを含むチケットに分ける #数字のみのチケットを取得 num_ticket = data[data['Ticket'].str.match('[0-9]+')].copy() num_ticket_index = num_ticket.index.values.tolist() #元のdataから数字のみのチケットの行を落とした残りがアルファベットを含むチケット num_alpha_ticket = data.drop(num_ticket_index).copy() #数字のみのチケットの階級分け #チケット番号は文字列になっているので数値に変換 num_ticket['Ticket'] = num_ticket['Ticket'].apply(lambda x:int(x)) num_ticket['Ticket_bin'] = 0 num_ticket.loc[(num_ticket['Ticket']>=100000) & (num_ticket['Ticket']<200000), 'Ticket_bin'] = 1 num_ticket.loc[(num_ticket['Ticket']>=200000) & (num_ticket['Ticket']<300000), 'Ticket_bin'] = 2 num_ticket.loc[(num_ticket['Ticket']>=300000),'Ticket_bin'] = 3 #数字とアルファベットを含むチケットの階級分け num_alpha_ticket['Ticket_bin'] = 4 num_alpha_ticket.loc[num_alpha_ticket['Ticket'].str.match('A.+'),'Ticket_bin'] = 5 num_alpha_ticket.loc[num_alpha_ticket['Ticket'].str.match('C.+'),'Ticket_bin'] = 6 num_alpha_ticket.loc[num_alpha_ticket['Ticket'].str.match('C\.*A\.*.+'),'Ticket_bin'] = 7 num_alpha_ticket.loc[num_alpha_ticket['Ticket'].str.match('F\.C.+'),'Ticket_bin'] = 8 num_alpha_ticket.loc[num_alpha_ticket['Ticket'].str.match('PC.+'),'Ticket_bin'] = 9 num_alpha_ticket.loc[num_alpha_ticket['Ticket'].str.match('S\.+.+'),'Ticket_bin'] = 10 num_alpha_ticket.loc[num_alpha_ticket['Ticket'].str.match('SC.+'),'Ticket_bin'] = 11 num_alpha_ticket.loc[num_alpha_ticket['Ticket'].str.match('SOTON.+'),'Ticket_bin'] = 12 num_alpha_ticket.loc[num_alpha_ticket['Ticket'].str.match('STON.+'),'Ticket_bin'] = 13 num_alpha_ticket.loc[num_alpha_ticket['Ticket'].str.match('W\.*/C.+'),'Ticket_bin'] = 14 data = pd.concat([num_ticket,num_alpha_ticket]).sort_values('PassengerId')2.6 Ageの補完と階級分け
Ageの欠損値については中央値や名前の敬称ごとに年齢の平均値を求めて補完する方法がありますが、調べてみるとランダムフォレストを使って欠損している部分の年齢を予測させる方法がありましたので今回はそちらを使ってみます。
from sklearn.preprocessing import LabelEncoder from sklearn.ensemble import RandomForestRegressor #文字列になっている特徴量をラベリング le = LabelEncoder() data['Sex'] = le.fit_transform(data['Sex']) #生存率予測に使うのでついでにラベリング data['Title'] = le.fit_transform(data['Title']) #Ageの予測に使う特徴量を'age_data'にいれる age_data = data[['Age','Pclass','Family_size', 'Fare_bin','Title']].copy() #Ageが欠損している行と欠損していない行に分ける known_age = age_data[age_data['Age'].notnull()].values unknown_age = age_data[age_data['Age'].isnull()].values x = known_age[:, 1:] y = known_age[:, 0] #ランダムフォレストで学習 rfr = RandomForestRegressor(random_state=0, n_estimators=100, n_jobs=-1) rfr.fit(x, y) #予測値を元のデータフレームに反映する age_predict = rfr.predict(unknown_age[:, 1:]) data.loc[(data['Age'].isnull()), 'Age'] = np.round(age_predict,1)これでAgeの欠損値を補完できました。
そしてAgeも階級分けしていきます。
data['Age_bin'] = 0 data.loc[(data['Age']>18) & (data['Age']<=60),'Age_bin'] = 1 data.loc[(data['Age']>60),'Age_bin'] = 2最後にいらない特徴量を落とします。
data = data.drop(['PassengerId','Name','Age','SibSp','Parch','Ticket', 'Fare','Cabin','Embarked','Last_name','Family_size'], axis=1)最終的にデータフレームはこのようになりました。
Survived Pclass Sex Fare_bin Family_survival Family_size_bin Title Ticket_bin Age_bin 0 0.0 3 1 0 0.5 1 2 5 1 1 1.0 1 0 2 0.5 1 3 9 1 2 1.0 3 0 0 0.5 0 1 13 1 3 1.0 1 0 2 0.0 1 3 1 1 4 0.0 3 1 0 0.5 0 2 3 1 ... ... ... ... ... ... ... ... ... ... 1304 NaN 3 1 0 0.5 0 2 5 1 1305 NaN 1 0 3 1.0 0 5 9 1 1306 NaN 3 1 0 0.5 0 2 12 1 1307 NaN 3 1 0 0.5 0 2 3 1 1308 NaN 3 1 1 1.0 1 0 0 0 1309 rows × 9 columns
統合させていたデータをtrainデータとtestデータに分けて特徴量の処理は終了です。
model_train = data[:891] model_test = data[891:] X = model_train.drop('Survived', axis=1) Y = pd.DataFrame(model_train['Survived']) x_test = model_test.drop('Survived', axis=1)3 xgboostでの予測
loglossとaccuracyの2つを求めてモデルの性能をみてみます。
from sklearn.metrics import log_loss from sklearn.metrics import accuracy_score from sklearn.model_selection import KFold import xgboost as xgb #パラメータを設定 params = {'objective':'binary:logistic', 'max_depth':5, 'eta': 0.1, 'min_child_weight':1.0, 'gamma':0.0, 'colsample_bytree':0.8, 'subsample':0.8} num_round = 1000 logloss = [] accuracy = [] kf = KFold(n_splits=4, shuffle=True, random_state=0) for train_index, valid_index in kf.split(X): x_train, x_valid = X.iloc[train_index], X.iloc[valid_index] y_train, y_valid = Y.iloc[train_index], Y.iloc[valid_index] #データフレームをxgboostに適した形に変換 dtrain = xgb.DMatrix(x_train, label=y_train) dvalid = xgb.DMatrix(x_valid, label=y_valid) dtest = xgb.DMatrix(x_test) #xgboostで学習 model = xgb.train(params, dtrain, num_round,evals=[(dtrain,'train'),(dvalid,'eval')], early_stopping_rounds=50) valid_pred_proba = model.predict(dvalid) #loglossを求める score = log_loss(y_valid, valid_pred_proba) logloss.append(score) #accuracyを求める #valid_pred_probaは確率値なので0と1に変換 valid_pred = np.where(valid_pred_proba >0.5,1,0) acc = accuracy_score(y_valid, valid_pred) accuracy.append(acc) print(f'log_loss:{np.mean(logloss)}') print(f'accuracy:{np.mean(accuracy)}')こちらのコードで
log_loss : 0.39114
accuracy : 0.8338
という結果になりました。モデルが出来たのでkaggleに提出する予測データを作成します。
#predictで予測 y_pred_proba = model.predict(dtest) y_pred= np.where(y_pred_proba > 0.5,1,0) #データフレームを作成 submission = pd.DataFrame({'PassengerId':test['PassengerId'], 'Survived':y_pred}) submission.to_csv('titanic_xgboost.csv', index=False)
正解率は80.1%でギリギリ8割に到達しました。まとめ
今回実際にkaggleに予測値を提出するところまでやってみました。
初めはCabinもラベリングして特徴量として使用していたのですがCabinを使わないほうが予測精度が上がりました。やはり欠損値が多すぎてxgboostにはあまり適さなかったようです。
また、FareやAgeなどの特徴量を階級分けせずに予測を行うとloglossやaccuracyの値は良くなるのですが予測値の正解率は向上しませんでした。
特徴量をそのまま使うよりも生存率の違いなどから階級分けしたほうが過学習気味にならず適正なモデル作成ができるのではないかと感じました。ご意見、ご指摘などがございましたらコメント、編集リクエストをしていただけるとありがたいです。
参考にさせていただいたサイト、書籍
KaggleチュートリアルTitanicで上位2%以内に入るノウハウ
pyhaya’s diary
Titanic [0.82] - [0.83]
Kaggleで勝つデータ分析の技術


- 投稿日:2020-10-16T12:49:34+09:00
Python基礎②
Pythonの基礎知識②です。
自分の勉強メモです。
過度な期待はしないでください。リスト
-複数のデータをまとめて管理する事
例:['orange', 'banana', 'apple']-文字列と数値の混合で作ることも可
例:['banana', 'apple', 100, 200]-リストを変数に代入
例:fruits = ['orange', 'banana', 'apple']-リストの要素には、前から順に「0, 1, 2,・・・」と数字が割り振られる
-リスト(fruits)のインデックス番号0の要素を出力する時
print(fruits[0])-リストの要素を更新
リスト[インデックス番号] = 値
例:fruits[0] = 'grape'
fruits = ['grape', 'banana', 'apple']に変更される-リストに要素を追加
リスト.append(値)
例:fruits.append('grape')
fruits = ['grape', 'banana', 'apple', 'grape']と追加される-リストの要素を全て取得
for 変数名 in リスト:と書く事でリストの要素を全て取得
for文 → 繰り返し処理をする例fruits = ['orange', 'banana', 'apple'] for fruit in fruits: #行末にコロンは必須 print('私の好きな果物は、'+ fruit + 'です。') #インデントを揃える(半角スペース4つ分)出力結果私の好きな果物は、orangeです。 私の好きな果物は、bananaです。 私の好きな果物は、appleです。
辞書
-リストと同じように複数のデータをまとめて管理するのに用いる
辞書は{キー1: 値1, キー2: 値2, …}のように作成、 辞書は{}で囲みます。
例:fruits = {'orange':'orange', 'banana':'yellow', 'apple':'red'}-辞書の値を取り出し
例fruits = {'orange':'orange', 'banana':'yellow', 'apple':'red'} print('bananaの色は、'+ fruits['banana']+ 'です。') # → bananaの色は、yellowです。-辞書の要素の更新
fruits['banana'] = black
辞書名[キー名] = 値と書くことで要素の更新になる結果fruits = {'orange':'orange', 'banana':'yellow', 'apple':'red'} fruits['banana'] = black print(fruits) # → {'orange':'orange', 'banana':'black', 'apple':'red'}-辞書に要素の追加
fruits['melon'] = green
辞書名[新しいキー名] = 値と書くことで辞書に新しい要素を追加結果fruits = {'orange':'orange', 'banana':'yellow', 'apple':'red'} fruits['melon'] = green print(fruits) # → {'orange':'orange', 'banana':'yellow', 'apple':'red', 'melon:green'}-辞書の要素を全て取得
for 変数名 in 辞書:例fruits = {'orange':'orange', 'banana':'yellow', 'apple':'red'} for fruit_key in fruits: #行末にコロンは必須 print(fruit_key+ 'の色は、'+ fruits[fruit_key] + 'です。') #インデントを揃える(半角スペース4つ分)出力結果orangeの色は、orangeです。 bananaの色は、yellowです。 appleの色は、redです。
while文
-
while 条件式:のように書きます。
条件式の結果がTrueの間、while文内の処理を繰り返す例x = 1 while x <= 10: #行末にコロンは必須 print(x) x+=1 #インデントを揃える(半角スペース4つ分)
break
-breakを用いると繰り返し処理を終了させる
例numbers = [765, 921, 777, 256] for number in numbers: #行末にコロンは必須 print(number) if number == 777: #行末にコロンは必須 break #インデントを揃える(半角スペース4つ分)
continue
-continueはその周の処理だけをスキップさせる
例.3で割り切れる数字をスキップさせるnumbers = [765, 921, 777, 256] for number in numbers: #行末にコロンは必須 if number % 3 == 0: continue print(number) #インデントを揃える(半角スペース4つ分)
- 投稿日:2020-10-16T12:24:18+09:00
もしかして「pipenv.exceptions.ResolutionFailure」で困ってる?
pipenvのエラー
存在しないパッケージを
pipenv installすると、Pipfileに書き込まれて、以降pipenv ~ するときにエラーが出る。# よくでるエラー pipenv.exceptions.ResolutionFailure解決策
Pipfileに書かれた存在しないパッケージ名を手動で消す。よく起こる原因
個人的にはタイピングのミスなどで起こる事が多い。
例
pipenv install pandsa←タイピングミスしている。- 「ああ、間違ってた」と、正しいパッケージ名で
pipenv install pandas実行。pipenv.exceptions.ResolutionFailureエラー発生。その他
もっと良い方法があれば教えていただけると幸いです。