- 投稿日:2020-10-16T22:24:01+09:00
[初学者] AWS デプロイ時のエラー解決に役立ちそうなコマンドや知識
背景
AWSへのデプロイ時に多くのエラーに悩まされたため、記事にまとめようと思いました。
私と同じような初学者の方の役にたてば嬉しいです!
構成
私自身はRuby on Rails, VPC/EC2(Nginx,Unicorn)/RDS(PostgreSQL)/Route53/ALBを使用してデプロイしました。
デプロイ時に参考にした記事
https://qiita.com/naoki_mochizuki/items/f795fe3e661a3349a7ce
https://qiita.com/Yuki_Nagaoka/items/1f0b814e52e603613556
共通
psコマンドを使用することでプロセスを確認することができます。
psコマンドについて参考にした記事
https://eng-entrance.com/linux-command-ps$ ps -x #現在実行中のプロセスを確認するコマンド
アプリケーション関連
デプロイ先のアプリケーションで
we're sorry, but something went wrong.と表示されてしまった場合。アプリに問題があるか確認しますサーバー環境 /var/www/rails/アプリ名$ cd log $ tail -n 30 production.logエラーの記載があるとアプリケーションに問題があります。特にエラーの記載がなければ、Webサーバーの設定に問題があり、正常にデプロイできていない可能性が高いです。
nginx関連
・nginxが起動しているか確認
サーバー環境$ sudo systemctl status nginx
Active: active (running)と表示されていれば起動しています。・再起動コマンド
サーバー環境$ sudo service nginx restart・nginxのファイルにエラーがあるか確認
サーバー環境$ sudo nginx -tエラーがある場合はエラー箇所を教えてくれる便利なコマンドです。特にnginxのファイルに問題がなければこのように表示されると思います。
nginx: the configuration file /etc/nginx/nginx.conf syntax is ok
nginx: configuration file /etc/nginx/nginx.conf test is successful
Unicorn関連
Unicornのログを確認するコマンド。
よくあるエラーとしては、不要なプロセスが残っている場合に発生するAlready running on PID:(プロセス番号)が挙げられると思います。サーバー環境/アプリのディレクトリ$ cat log/unicorn.log -nUnicornのプロセスの確認コマンド
サーバー環境$ ps -ef | grep unicorn | grep -v grepUnicornのプロセスを終了するコマンド
Already running on PID:(プロセス番号)のエラーが発生した際は、こちらのコマンドで不要なプロセスを消すことでエラーが解決すると思います。サーバー環境$ kill (プロセス番号)
PostgreSQL関連
PostgreSQLが起動しているか確認するコマンド
Active: active (running)となっていれば起動しています。サーバー環境$ systemctl status postgresql.servicePostgreSQLを起動させる
サーバー環境$ sudo systemctl enable postgresql $ sudo systemctl start postgresql
その他
GoogleChrome, http関連
GoogleChromeでデプロイしたアプリケーションにアクセスすると、強制的にhttps(https化未実施の時)にアクセスして、アプリケーションが開きませんでした。
解決策は、Chromeの履歴→閲覧履歴データの削除→キャッシュされた画像とファイルにチェックを入れ、履歴データを削除することでした。下記のコマンドでレスポンスを確認することができます。
webサーバのファイルにエラーもなく、curlコマンドでレスポンスがしっかりと返って来るのに、httpsにリダイレクトしてしまう場合は、この問題の可能性もあります。$ curl http://example.com #http://example.com はアプリのドメイン。また、httpで接続する場合は
config.force_ssl = falseにしておく必要があります。config/environment/production.rb$ config.force_ssl = falsehttps化
当初はWebサーバーのファイルを編集することで、https化をしようと考えましたが、AWSのALBというサービスを使用する方がhttps化は容易であると知ったため、ALBを使用しました。初学者の方でhttps化に手こずっている方は、ALBを使用するのが個人的におすすめかなと思います。
ALBを使用することで、httpリクエストをhttpsにリダイレクトすることができます。[htttps化の参考にした記事]
https://aws.amazon.com/jp/premiumsupport/knowledge-center/elb-redirect-http-to-https-using-alb/
https://dev.classmethod.jp/articles/alb-redirects/
この他にも「ALB https リダイレクト」と検索すると参考になる記事がたくさん出てきます!
- 投稿日:2020-10-16T20:59:29+09:00
AWS WAF概要
AWS WAFの概要記事。
AWS WAFとは
- AWSが提供するWAF(Web Application Firewall)。
- WAFとは...
- Webアプリケーションの脆弱性を突いた攻撃からWebアプリケーションを守るためのセキュリティ対策ソリューション。
- 一般的なWebアプリケーションに対する攻撃手法(SQLインジェクションやXSSなど)からWebアプリを保護する。
- 利用形態には、ソフトウェア、ハードウェア、サービスなどがある。
- L7保護のためのもので、L3/L4保護のためのファイアウォールとは異なる役割を持つ。
- CloudFront、 ALB、API Gatewayにアタッチして利用する。
提供機能
- 悪意のあるリクエストのブロック
- SQLインジェクション、クロスサイトスクリプティングなど。
- AWSや他のパートナーが提供するマネージドルールに基づいたブロック処理。
- カスタムルールに基づいたWebトラフィックのフィルタ
- ルールベースフィルタリング
- IPベース、正規表現・文字列
- サイズ制限
- ルール判定結果に応じたアクション(アクセス許可/拒否)
- モニタリングとチューニング
- CloudWatchと連携した状態の可視化・アラート。
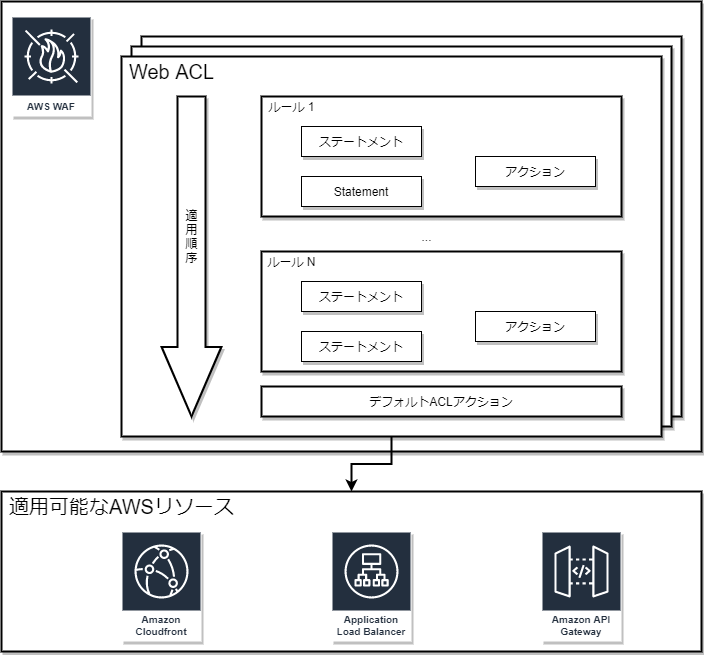
概念
- ルール
- リクエスト(攻撃)に対する戦略を定義する設定。
- ステートメント:リクエストの検査条件
- アクション:条件に一致した際のリクエストの処理方法。ALLOW(許可)/BLOCK(拒否)/COUNT(カウント)の3種。
- ルールグループ
- 複数のルールをまとめて管理する際の単位。
- Web ACL
- CloudFront、ALB、API Gatewayへの設定単位。
- 1リソースあたり1ACLの設定が可能。
- 同一ACLを複数のリソースで共有可能。
- ルール/ルールグループを包含管理。
ステートメント
判定内容
- リクエスト発生国の一致
- リクエスト送信元IPアドレスの一致
- サイズ制約
- SQL injection
- XSS injection
- 文字列の一致
- 正規表現パターンセット
判定対象
- リクエストヘッダー
- HTTPメソッド
- クエリ文字列
- 単一クエリパラメータ
- すべてのクエリパラメータ
- UR
- Body
ルール
レートベースルール
- 5 分あたりの同一IPからのリクエスト数が設定閾値を超過した場合、Block/Countする。
- 5 分あたりの閾値の設定範囲は、100 〜 20,000,000。
- ルール作成時にRate-based Ruleを選択。
- 全リクエストを対象にするか、ステートメント内の条件に一致したリクエストだけを対象にするかを選択可能。
AWS Managed Rules for AWS WAF (AMR)
- AWS WAFに組み込み可能なルールセット。
- AWS Threat Research Team (TRT)が作成及びメンテナンス。
- OWASP Top 10 をメインに対応。
- WAF Capacity Unit(WCU) は消費するが、それ以外の追加費用は不要。
- WCU:WAFのルールに対する処理コストの考え方。
- ルールに応じて、消費するWCUは異なる。
AWS WAF導入(Web ACL設定)の流れ
- Web ACL名の入力と適用対象AWSリソースの選択。
- ルールの設定。
- 利用ルールの選択(+AWS マネージドルール追加)
- デフォルトアクション(Allow/Block)を選択
- ルールの適用順序を設定
- CloudWatchメトリクスを選択。
- 設定内容を確認し、作成完了。
参考情報
- 投稿日:2020-10-16T19:10:35+09:00
Raspberry Piで温度を測って、AWS CloudWatchの無料枠をつかってロギングする
- サーバールームの温度測って、遠隔で確認したい。
- アラームとかあると助かる。
- AWS無料枠でできる(はず)?
必要なもの
- Raspberry Pi
- インターネットにつながる程度にはセットアップしておくこと
- 温度センサー
- DS18B20。アマゾンで五個で1,500円しないくらい
- 正しく接続できると、
/sys/bus/w1/devices/28-XXXXXXXXXXXX/temperatureで温度x1,000が読める- raspi-configで1-wireドライバを有効にして接続。詳細はググろう。
- AWSアカウント
前準備
RasPiにboto3(AWS SDK for Python)をインストールしておく
pip3 install boto3AWS上にユーザーを作る
- IAMでユーザー作って、APIキーを取得しておくこと
- 以下のアクセス権限が必要
- AmazonAPIGatewayPushToCloudWatchLogs
- cloudwatch:PutMetricData
AWS CloudWatch APIを使うための、設定ファイルを作る
cronで回すので、回すユーザーのhomeに下記の内容のファイルを作ること
~/.aws/credentials
[default] aws_access_key_id = アクセスキー aws_secret_access_key = 秘密キー~/.aws/config
東京リージョン。
[default] region=ap-northeast-1温度測定結果をAWS CloudWatchのメトリックとして放り込む
Python慣れてない。エラーハンドリングは適宜足して。
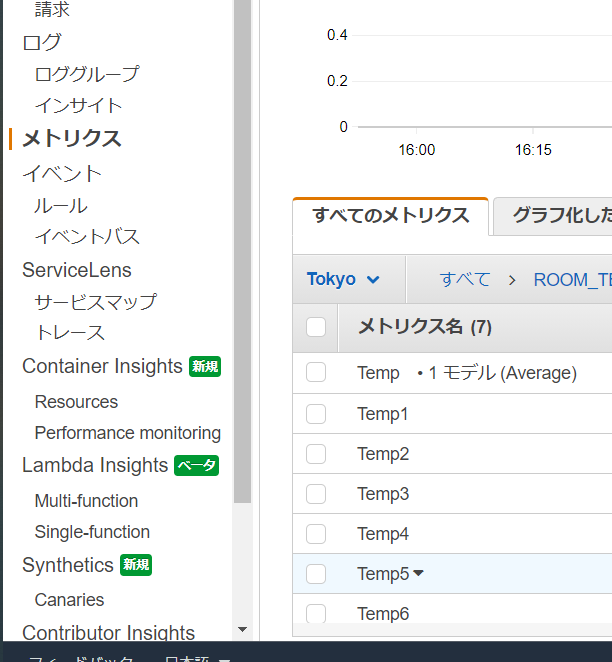
devsに温度計のデバイス名を辞書にして突っ込んでおく。import boto3 import pathlib def readTemp(id): devpath="/sys/bus/w1/devices/"+id+"/temperature" p=pathlib.Path(devpath) temp=float(p.read_text())/1000 return temp devs = { "Temp1":"28-3c01d6072f18", "Temp2":"28-3c01d6077511", "Temp3":"28-3c01b6079c8d", "Temp4":"28-3c01b607eb45", "Temp5":"28-3c01b607b648", "Temp6":"28-3c01b607cdb1" } metrics=[] namespace="ROOM_TEMP" for k in devs: temp=readTemp(devs[k]) metric={'MetricName':k, 'Unit':'None', 'Value':temp} metrics.append(metric) cloudwatch = boto3.client('cloudwatch') cloudwatch.put_metric_data(MetricData=metrics, Namespace=namespace)RasPiのcronで回す
詳細は割愛。
とりあえず毎分更新にしてみた。CloudWatch側で、メトリクスからグラフを作る
センサーがつながってスクリプトが正しく動いていたら、CloudWatch側で見えるようになる。
("Temp"は実験データの残骸。Pythonで放り込んだのはTemp1~6)
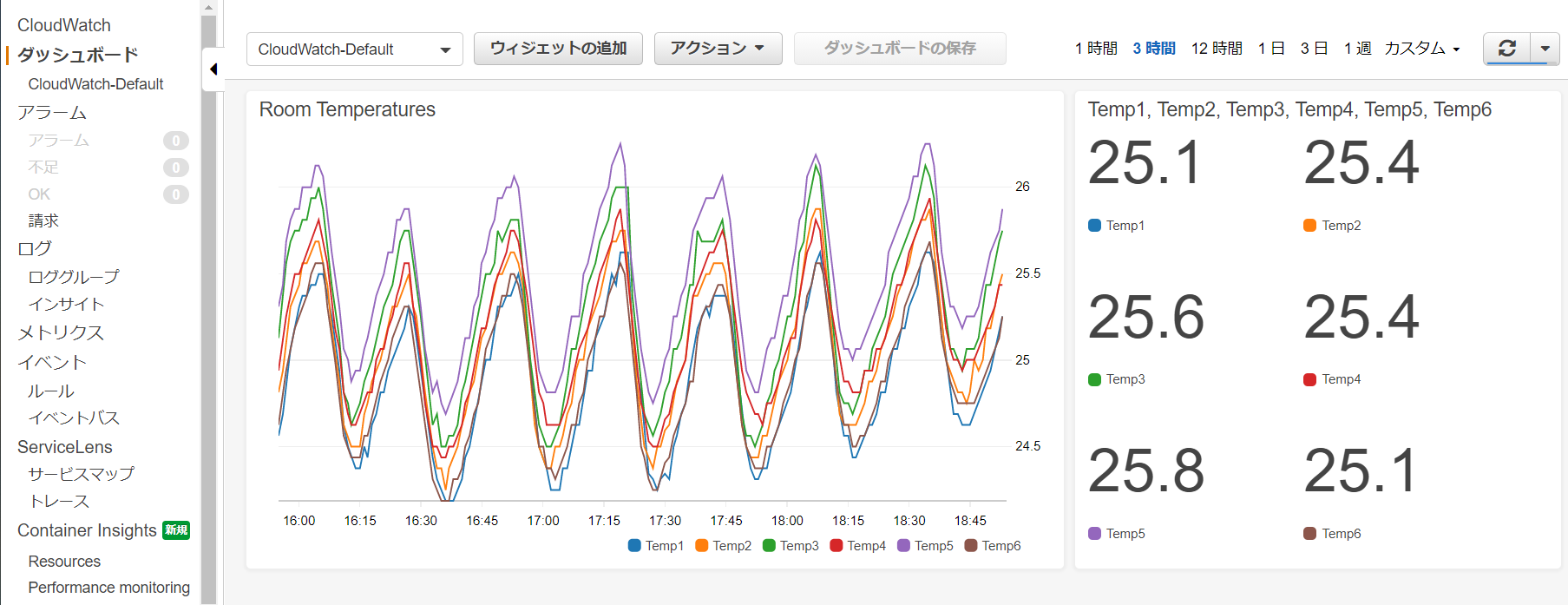
これを、ダッシュボードのウィジェットで可視化すると、こんな感じになる。
いいんじゃないでしょうか
宿題
- アラームでメール飛ばす方法を調べる
- AWS SNSとか使えばいいっぽい。
- 投稿日:2020-10-16T18:33:34+09:00
1つのクラウドベンダーに一途なあなたも Go CDK の採用を検討すべき理由
Go CDK とは
Go CDK とは The Go Cloud Development Kit の略で、主要クラウドベンターが提供しているほぼ同一の機能を持ったサービスを統一的な API で扱うためのプロジェクトです(旧称 Go Cloud)。
例えばクラウドストレージサービスにオブジェクトを保存・取得する処理は Go CDK を使うことで次のように書くことができます1。
- Amazon S3
package main import ( "context" "fmt" "log" "gocloud.dev/blob" _ "gocloud.dev/blob/s3blob" ) func main() { ctx := context.Background() bucket, err := blob.OpenBucket(ctx, "s3://bucket") if err != nil { log.Fatal(err) } defer bucket.Close() // 保存 if err := bucket.WriteAll(ctx, "sample.txt", []byte("Hello, world!"), nil); err != nil { log.Fatal(err) } // 取得 data, err := bucket.ReadAll(ctx, "sample.txt") if err != nil { log.Fatal(err) } fmt.Println(string(data)) }
- Google Cloud Storage
package main import ( "context" "fmt" "log" "gocloud.dev/blob" _ "gocloud.dev/blob/gcsblob" ) func main() { ctx := context.Background() bucket, err := blob.OpenBucket(ctx, "gs://bucket") if err != nil { log.Fatal(err) } defer bucket.Close() // 保存 if err := bucket.WriteAll(ctx, "sample.txt", []byte("Hello, world!"), nil); err != nil { log.Fatal(err) } // 取得 data, err := bucket.ReadAll(ctx, "sample.txt") if err != nil { log.Fatal(err) } fmt.Println(string(data)) }
- Azure Blob Storage
package main import ( "context" "fmt" "log" "gocloud.dev/blob" _ "gocloud.dev/blob/azureblob" ) func main() { ctx := context.Background() bucket, err := blob.OpenBucket(ctx, "azblob://bucket") if err != nil { log.Fatal(err) } defer bucket.Close() // 保存 if err := bucket.WriteAll(ctx, "sample.txt", []byte("Hello, world!"), nil); err != nil { log.Fatal(err) } // 取得 data, err := bucket.ReadAll(ctx, "sample.txt") if err != nil { log.Fatal(err) } fmt.Println(string(data)) }異なるクラウドベンダーを使用する場合のコードの違いはドライバーの import 部分と
blob.OpenBucket()に与えている URL の scheme のみです。素晴らしいですね!このように Go CDK を使うことでマルチクラウドなアプリケーションやクラウドポータビリティの高いアプリケーションを容易に実装することができます。
Go CDK についてより詳しく知りたい方は公式の情報をご参照ください。
大変便利な Go CDK ですが2020年10月現在のプロジェクトステータスは「API は alpha だけど production-ready」2 という感じらしいです。導入される際は自己責任でお願いします。
マルチクラウド・ポータビリティ以外にもある Go CDK のメリット
本題です。
「AWS しか使わない!ベンダーロックイン上等!」といった考えの人もいると思います。
本稿ではそういった方でも Go CDK を使うメリットは十分あるということを、「S3 のオブジェクト操作(保存・取得)」を例にご紹介したいと思います。API が分かりやすい・扱いやすい
Go CDK の API は直観的に理解しやすく扱いやすい設計です。
Go CDK でのクラウドストレージへのオブジェクトの読み書きは
blob.Bucketの
NewReader()及びNewWriter()によって得られるblob.Reader(io.Readerを実装) とblob.Writer(io.Writerを実装) を使います。
オブジェクトの取得(読み込み)をblob.Reader(io.Reader)、保存(書き込み)をio.Writer(io.Writer) で行えるというのは非常に直観的です。これにより、ローカルファイルを操作するかのような感覚でクラウド上のオブジェクトを扱うことができます。AWS SDK を使う場合と比べてどうわかりやすくなるかを、具体例を挙げつつ見ていきます。
S3 にオブジェクトを保存する場合
AWS SDK の場合、
s3manager.UploaderのUpload()を使うことになります。
アップロードするオブジェクトの内容はio.Readerとしてメソッドに渡します。ローカルにあるファイルをアップロードする場合ならos.Fileをそのまま渡せて便利なのですが、厄介なのはメモリ上にあるデータを何らかの形式でエンコードしてそのまま保存したい場合です。例えば JSON エンコードしてそのまま S3 という処理は、AWS SDK では次のようになります。
package main import ( "encoding/json" "io" "log" "github.com/aws/aws-sdk-go/aws" "github.com/aws/aws-sdk-go/aws/session" "github.com/aws/aws-sdk-go/service/s3/s3manager" ) func main() { sess, err := session.NewSession(&aws.Config{ Region: aws.String("ap-northeast-1"), }) if err != nil { log.Fatal(err) } uploader := s3manager.NewUploader(sess) data := struct { Key1 string Key2 string }{ Key1: "value1", Key2: "value2", } pr, pw := io.Pipe() go func() { err := json.NewEncoder(pw).Encode(data) pw.CloseWithError(err) }() in := &s3manager.UploadInput{ Bucket: aws.String("bucket"), Key: aws.String("sample.json"), Body: pr, } if _, err := uploader.Upload(in); err != nil { log.Fatal(err) } }JSON をエンコードするための
io.Writerとs3manager.UploadInputに渡すio.Readerとを繋ぐためにio.Pipe()を使う必要があります。Go CDK であれば、書き込みは
blob.Writer(io.Writer) で行うのでそのままjson.NewEncoder()に渡すだけです。package main import ( "context" "encoding/json" "log" "gocloud.dev/blob" _ "gocloud.dev/blob/s3blob" ) func main() { ctx := context.Background() bucket, err := blob.OpenBucket(ctx, "s3://bucket") if err != nil { log.Fatal(err) } defer bucket.Close() data := struct { Key1 string Key2 string }{ Key1: "value1", Key2: "value2", } w, err := bucket.NewWriter(ctx, "sample.json", nil) if err != nil { log.Fatal(err) } defer w.Close() if err := json.NewEncoder(w).Encode(data); err != nil { log.Fatal(err) } }もちろんローカルファイルをアップロードする場合もシンプルに書けます。
ファイルからファイルへとコピーするかのごとくio.Copyを使うだけです。package main import ( "context" "io" "log" "os" "gocloud.dev/blob" _ "gocloud.dev/blob/s3blob" ) func main() { ctx := context.Background() bucket, err := blob.OpenBucket(ctx, "s3://bucket") if err != nil { log.Fatal(err) } defer bucket.Close() file, err := os.Open("sample.txt") if err != nil { log.Fatal(err) } defer file.Close() w, err := bucket.NewWriter(ctx, "sample.txt", nil) if err != nil { log.Fatal(err) } defer w.Close() if _, err := io.Copy(w, file); err != nil { log.Fatal(err) } }ちなみに、
s3blobの Writer はs3manager.Uploaderを wrap する形で実装されているためs3manager.Uploaderの持つ並列アップロード機能の恩恵を受けることができます。S3 からオブジェクトを取得する場合
S3 から JSON を取得してデコードする場合を考えてみましょう。
AWS SDK の場合、
s3.GetObject()を使います。
s3manager.Uploaderと対になるs3manager.Downloaderは出力先がio.WriterAtを実装している必要があるため、このケースでは使えないことに注意が必要です。package main import ( "encoding/json" "fmt" "log" "github.com/aws/aws-sdk-go/aws" "github.com/aws/aws-sdk-go/aws/session" "github.com/aws/aws-sdk-go/service/s3" ) func main() { sess, err := session.NewSession(&aws.Config{ Region: aws.String("ap-northeast-1"), }) if err != nil { log.Fatal(err) } svc := s3.New(sess) data := struct { Key1 string Key2 string }{} in := &s3.GetObjectInput{ Bucket: aws.String("bucket"), Key: aws.String("sample.json"), } out, err := svc.GetObject(in) if err != nil { log.Fatal(err) } defer out.Body.Close() if err := json.NewDecoder(out.Body).Decode(&data); err != nil { log.Fatal(err) } fmt.Printf("%+v\n", data) }Go CDK の場合はアップロードの時と逆になるように書くだけです。
package main import ( "context" "encoding/json" "fmt" "log" "gocloud.dev/blob" _ "gocloud.dev/blob/s3blob" ) func main() { ctx := context.Background() bucket, err := blob.OpenBucket(ctx, "s3://bucket") if err != nil { log.Fatal(err) } defer bucket.Close() r, err := bucket.NewReader(ctx, "sample.json", nil) if err != nil { log.Fatal(err) } defer r.Close() data := struct { Key1 string Key2 string }{} if err := json.NewDecoder(r).Decode(&data); err != nil { log.Fatal(err) } fmt.Printf("%+v\n", data) }取得したオブジェクトをローカルファイルに書き込む場合は
s3manager.Downloaderを使うことができます。package main import ( "log" "os" "github.com/aws/aws-sdk-go/aws" "github.com/aws/aws-sdk-go/aws/session" "github.com/aws/aws-sdk-go/service/s3" "github.com/aws/aws-sdk-go/service/s3/s3manager" ) func main() { sess, err := session.NewSession(&aws.Config{ Region: aws.String("ap-northeast-1"), }) if err != nil { log.Fatal(err) } downloader := s3manager.NewDownloader(sess) file, err := os.Create("sample.txt") if err != nil { log.Fatal(err) } defer file.Close() in := &s3.GetObjectInput{ Bucket: aws.String("bucket"), Key: aws.String("sample.txt"), } if _, err := downloader.Download(file, in); err != nil { log.Fatal(err) } }Go CDK ではこの場合もアップロードの時と逆になるように書けば OK です。
package main import ( "context" "io" "log" "os" "gocloud.dev/blob" _ "gocloud.dev/blob/s3blob" ) func main() { ctx := context.Background() bucket, err := blob.OpenBucket(ctx, "s3://bucket") if err != nil { log.Fatal(err) } defer bucket.Close() file, err := os.Create("sample.txt") if err != nil { log.Fatal(err) } defer file.Close() r, err := bucket.NewReader(ctx, "sample.txt", nil) if err != nil { log.Fatal(err) } defer r.Close() if _, err := io.Copy(file, r); err != nil { log.Fatal(err) } }ただしこの方法はシンプルですが欠点もあります。
s3manager.Downloderの場合は出力先にio.WriterAtを要求する代わりに並列ダウンロード機能を備えておりパフォーマンスに優れていますが、Go CDK の場合そのままでは並列ダウンロードを行うことができません。
Go CDK で並列ダウンロードを行たい場合はNewRangeReader()を使って自前で実装する必要があります。
Go CDK での並列ダウンロード実装例 (長いので折りたたみます)
package main import ( "context" "errors" "fmt" "io" "log" "os" "sync" "gocloud.dev/blob" _ "gocloud.dev/blob/s3blob" ) const ( downloadPartSize = 1024 * 1024 * 5 downloadConcurrency = 5 ) func main() { ctx := context.Background() bucket, err := blob.OpenBucket(ctx, "s3://bucket") if err != nil { log.Fatal(err) } defer bucket.Close() file, err := os.Create("sample.txt") if err != nil { log.Fatal(err) } defer file.Close() d := &downloader{ ctx: ctx, bucket: bucket, key: "sample.txt", partSize: downloadPartSize, concurrency: downloadConcurrency, w: file, } if err := d.download(); err != nil { log.Fatal(err) } } type downloader struct { ctx context.Context bucket *blob.Bucket key string opts *blob.ReaderOptions partSize int64 concurrency int w io.WriterAt wg sync.WaitGroup sizeMu sync.RWMutex errMu sync.RWMutex pos int64 totalBytes int64 err error partBodyMaxRetries int } func (d *downloader) download() error { d.getChunk() if err := d.getErr(); err != nil { return err } total := d.getTotalBytes() ch := make(chan chunk, d.concurrency) for i := 0; i < d.concurrency; i++ { d.wg.Add(1) go d.downloadPart(ch) } for d.getErr() == nil { if d.pos >= total { break } ch <- chunk{w: d.w, start: d.pos, size: d.partSize} d.pos += d.partSize } close(ch) d.wg.Wait() return d.getErr() } func (d *downloader) downloadPart(ch chan chunk) { defer d.wg.Done() for { c, ok := <-ch if !ok { break } if d.getErr() != nil { continue } if err := d.downloadChunk(c); err != nil { d.setErr(err) } } } func (d *downloader) getChunk() { if d.getErr() != nil { return } c := chunk{w: d.w, start: d.pos, size: d.partSize} d.pos += d.partSize if err := d.downloadChunk(c); err != nil { d.setErr(err) } } func (d *downloader) downloadChunk(c chunk) error { var err error for retry := 0; retry <= d.partBodyMaxRetries; retry++ { err := d.tryDownloadChunk(c) if err == nil { break } bodyErr := &errReadingBody{} if !errors.As(err, &bodyErr) { return err } c.cur = 0 } return err } func (d *downloader) tryDownloadChunk(c chunk) error { r, err := d.bucket.NewRangeReader(d.ctx, d.key, c.start, c.size, d.opts) if err != nil { return err } defer r.Close() if _, err := io.Copy(&c, r); err != nil { return err } d.setTotalBytes(r.Size()) return nil } func (d *downloader) getErr() error { d.errMu.RLock() defer d.errMu.RUnlock() return d.err } func (d *downloader) setErr(err error) { d.errMu.Lock() defer d.errMu.Unlock() d.err = err } func (d *downloader) getTotalBytes() int64 { d.sizeMu.RLock() defer d.sizeMu.RUnlock() return d.totalBytes } func (d *downloader) setTotalBytes(size int64) { d.sizeMu.Lock() defer d.sizeMu.Unlock() d.totalBytes = size } type chunk struct { w io.WriterAt start int64 size int64 cur int64 } func (c *chunk) Write(p []byte) (int, error) { if c.cur >= c.size { return 0, io.EOF } n, err := c.w.WriteAt(p, c.start+c.cur) c.cur += int64(n) return n, err } type errReadingBody struct { err error } func (e *errReadingBody) Error() string { return fmt.Sprintf("failed to read part body: %v", e.err) } func (e *errReadingBody) Unwrap() error { return e.err }※
s3manager.Downloaderの実装を参考にしています
ローカル実行が容易になる
Go CDK は全てのサービスに対しローカル実装を提供するように開発が進められています。そのため、クラウドサービスの操作を簡単にローカル実装に差し替えることができます。
例えば開発用のローカルサーバなどでは全てのサービスをローカル実装に差し替えておくと AWS や GCP へのアクセスを発生させずに動作させることができるので便利です。クラウドストレージを扱う
gocloud.dev/blobパッケージの場合、fileblobというローカルファイルの読み書きを行う実装が提供されています。以下はエンコードした JSON の出力先をオプションに応じて S3 とローカルとに切り替える例です。
package main import ( "context" "encoding/json" "flag" "log" "github.com/aws/aws-sdk-go/aws" "github.com/aws/aws-sdk-go/aws/session" "gocloud.dev/blob" "gocloud.dev/blob/fileblob" "gocloud.dev/blob/s3blob" ) func main() { var local bool flag.BoolVar(&local, "local", false, "output to a local file") flag.Parse() ctx := context.Background() bucket, err := openBucket(ctx, local) if err != nil { log.Fatal(err) } defer bucket.Close() data := struct { Key1 string Key2 string }{ Key1: "value1", Key2: "value2", } w, err := bucket.NewWriter(ctx, "sample.json", nil) if err != nil { log.Fatal(err) } defer w.Close() if err := json.NewEncoder(w).Encode(data); err != nil { log.Fatal(err) } } func openBucket(ctx context.Context, local bool) (*blob.Bucket, error) { if local { return openLocalBucket(ctx) } return openS3Bucket(ctx) } func openLocalBucket(ctx context.Context) (*blob.Bucket, error) { return fileblob.OpenBucket("output", nil) } func openS3Bucket(ctx context.Context) (*blob.Bucket, error) { sess, err := session.NewSession(&aws.Config{ Region: aws.String("ap-northeast-1"), }) if err != nil { return nil, err } return s3blob.OpenBucket(ctx, sess, "bucket", nil) }そのまま実行すると S3 に
sample.jsonが保存されますが、-localオプションを付けて実行するとローカルのoutput/sample.jsonに保存されます。
この際、オブジェクトのプロパティがoutput/sample.json.attrsとして保存されます。これにより保存したオブジェクトのプロパティも問題なく取得できる仕組みになっています。テスタビリティが圧倒的に向上する
AWS のような外部サービスの API を呼び出すようなコードではどのようにしてテストしやすい実装にするかということで常に頭を悩ませることになりますが、Go CDK ではその心配はありません。
通常は外部サービスを interface として抽象化して mock を実装し、テストでは mock に差し替える・・・ということになるかと思いますが、Go CDK ではすでに各サービスが適切に抽象化され、そのローカル実装が提供されているのでそのまま使うだけで OK です。例えば以下のような エンコードした JSON をクラウドストレージにアップロードするための interface を実装する構造体をテストすることを考えてみます。
type JSONUploader interface { func Upload(ctx context.Context, key string, v interface{}) errorAWS SDK の場合、各種サービスクライアントの interface が提供されているのでそれを使うことでテスタビリティを担保します。
s3managerならs3managerifaceというパッケージで interface が提供されています。type jsonUploader struct { bucketName string uploader s3manageriface.UploaderAPI } func (u *jsonUploader) Upload(ctx context.Context, key string, v interface{}) error { pr, pw := io.Pipe() go func() { err := json.NewEncoder(pw).Encode(v) pw.CloseWithError(err) }() in := &s3manager.UploadInput{ Bucket: aws.String(u.bucketName), Key: aws.String(key), Body: pr, } if _, err := u.uploader.UploadWithContext(ctx, in); err != nil { return err } return nil }このような実装にしておけばテストでは
jsonUploader.uploaderに適当な mock を入れておけば実際に S3 にアクセスせずにテストが可能です。ただしこの mock 実装は公式には提供されていないので、自分で実装するか適当な外部パッケージを見つける必要があります。Go CDK の場合はそのまま実装するだけでテスタビリティの高い構造体となります。
type jsonUploader struct { bucket *blob.Bucket } func (u *jsonUploader) Upload(ctx context.Context, key string, v interface{}) error { w, err := u.bucket.NewWriter(ctx, key, nil) if err != nil { return err } defer w.Close() if err := json.NewEncoder(w).Encode(v); err != nil { return err } return nil }テストでは
memblobというインメモリのblob実装を使うと便利です。func TestUpload(t *testing.T) { bucket := memblob.OpenBucket(nil) uploader := &jsonUploader{bucket: bucket} ctx := context.Background() key := "test.json" type data struct { Key1 string Key2 string } in := &data{ Key1: "value1", Key2: "value2", } if err := uploader.Upload(ctx, key, in); err != nil { t.Fatal(err) } r, err := bucket.NewReader(ctx, key, nil) if err != nil { t.Fatal(err) } out := &data{} if err := json.NewDecoder(r).Decode(out); err != nil { t.Fatal(err) } if !reflect.DeepEqual(in, out) { t.Error("unmatch") } }まとめ
Go CDK 導入によるマルチクラウド対応やクラウドポータビリティ以外のメリットについてご紹介しました。
複数のクラウドベンダーを統一的に扱うという性質上、特定のクラウドベンダー固有の機能は使えないなど弱点は勿論あるので、各クラウドベンダーの SDK とは要件に合わせて使い分けることになるとは思います。Go CDK 自体もまだまだ発展途上なので今後さらに機能が充実することを期待したいですね。
- 投稿日:2020-10-16T18:22:45+09:00
「サイトが見れない!!!!」ってなったときの対応
タイトル見ただけで心臓がキュッってなりますが…
今までの経験からメモ書きしてみました
半分くらい自分用原因究明に使える指標
HTTPのステータスコード
https://developer.mozilla.org/ja/docs/Web/HTTP/Status
これらのうちエラーになるのは400系と500系
ざっくりとした違いは下記
- 400系:アクセス自体ができてない
- 名前解決ができてない
- 権限がない
- サーバーが落ちてる
- 500系:サーバー内部の処理でエラーを吐いて止まってる
- サーバー設定が間違ってる
- サイトを動かしているフレームワークのエラー
どっちかによって対応が変わるのでまずはここを切り分けます
ログファイル
linux系で出力のパスをいじってないなら/var/log/の中に大体のログがあると思います。
apache: /var/log/httpd/ nginx : /var/log/nginx/ nginx+phpならphp-fpmも要確認: /var/log/php-fpm/何が動いてるのかを確認するなら
ps aux
大量の情報が出てくるので、あたりがついてるならさらにgrepも併用AWSモニタリング
AWSなら結構な情報がコンソールから確認できます
- EC2:
- CPU使用率
- リクエスト数
- ELB:
- レイテンシー
- 稼働サーバー数
- RDS:
- CPU使用率
- 接続数
- 書き込み/読み込みスループット
対応
1、 落ち着く
わりと重要です。
人間テンパるとろくなことをしません…
現状を整理するなり偉い人に相談するなりして心を落ち着かせましょう2、 ステータスコードを確認する
上記の通りアクセスできない原因はいっぱいあるので、これから切り分けます
大概のブラウザで画面にステータスコードが出てるはず3-1、 400系だった場合
原因によってコードが細かく分かれてるので対応はしやすいです
よく見るのは下記
- 400 Bad Request
- リクエストが無効です。新しい機能のリリース直後なら内部で送ってるリクエストがおかしいとか?
- 403 Forbidden
- 権限問題です。IP制限やファイルのパーミッションを確認します
- 404 Not Found
- 後述します
3-2、 500系だった場合
よく見るのは下記
ひとまずエラーログを確認するところから始まります
対応内容はログによって多岐に渡るので割愛
- 500 Internal Server Error
- サーバー内部で何か起きてます。下に出会ったことがあるエラーの一例を載せてます。
- 502 Bad Gateway
- ゲートウェイやProxyとして動作しているサーバがリクエストを実行しようとしたら不正なレスポンスを受け取ってます。
ここからは実例
404 Not Foundの対応
原因が多岐に渡るので別枠にします
あり得るのは
1、サーバーが落ちてる
2、名前解決ができてない
あたりなのでこの辺をチェックします。pingしてみる
ping {IP/ホスト名}で通信テストしてみます
(これはダミーとしてlocalhostにしてます)$ ping localhost PING localhost (127.0.0.1): 56 data bytes 64 bytes from 127.0.0.1: icmp_seq=0 ttl=64 time=6.893 ms 64 bytes from 127.0.0.1: icmp_seq=1 ttl=64 time=0.115 ms 64 bytes from 127.0.0.1: icmp_seq=2 ttl=64 time=0.076 ms 64 bytes from 127.0.0.1: icmp_seq=3 ttl=64 time=0.117 ms ^C --- localhost ping statistics --- 4 packets transmitted, 4 packets received, 0.0% packet loss round-trip min/avg/max/stddev = 0.076/1.800/6.893/2.940 ms生きてればとりあえず帰ってきます。
ポート番号を指定したいなら素のpingだとできないので別の方法を使います。
私はnping使ってます。便利
https://qiita.com/Yu-s/items/4b4f683fda374c8ddcc9ログインしてみる
大概sshか何かでログインできるようにしてるはず
前まで出来てたはずのコマンドでログインできないなら落ちてる可能性が高いですAWSならコンソールから確認する
EC2ダッシュボード > インスタンス > インスタンスの状態
から確認できます。stopになってたら落ちてます。
(aws-cliとかオートスケールとか使ってない場合、誰かが意図的に止めた可能性も…自動でstopにはならないはず…)
ステータスチェックが失敗してるかどうかも確認できるので、これが失敗してても落ちてます。ただしインスタンスが自動で再起動を繰り返している場合(=実質落ちてる)でもrunningになってることがありますので注意
ここまででサーバーが生きてるのが確認できたのにドメインでアクセスできない場合おそらく名前解決ができてません
digしてみる
手っ取り早く確認するならこれ
https://www.atmarkit.co.jp/ait/articles/1711/09/news020.htmlnslookupでもできます
https://www.atmarkit.co.jp/ait/articles/1710/27/news021.html$ dig www.google.com ; <<>> DiG 9.10.6 <<>> www.google.com ;; global options: +cmd ;; Got answer: ;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 3344 ;; flags: qr rd ra; QUERY: 1, ANSWER: 1, AUTHORITY: 0, ADDITIONAL: 1 ;; OPT PSEUDOSECTION: ; EDNS: version: 0, flags:; udp: 512 ;; QUESTION SECTION: ;www.google.com. IN A ;; ANSWER SECTION: www.google.com. 89 IN A 172.217.24.132 ;; Query time: 13 msec ;; SERVER: 8.8.8.8#53(8.8.8.8) ;; WHEN: Fri Sep 11 13:51:58 JST 2020 ;; MSG SIZE rcvd: 59
;; ANSWER SECTION:がなければ名前解決できてないです500 Internal Server Errorの対応
エラーが起きてる可能性があるのは
- サーバーソフトウェア
- コードを動かしているフレームワーク
の二択なのでとりあえずその二通りのログを見ます。
対応方法はエラー内容によって色々ですが、下記に私が出会ったことのあるエラーを紹介します。ログローテート忘れ
nginxのエラーログで下記が出てました
write() to "/var/log/nginx/access.log" was incomplete: 83 of 314 while logging request「アクセスログを書き込めなかったよ」とのこと。
見に行くと当日のアクセスログだけめちゃくちゃなサイズになってたのでこれでストレージが枯渇したと推測しました。
該当ファイルを削除するととりあえず解消するはずですがアクセスログを削除しても解消せず…
(多分他にも重たいファイルがあったんだと思います)
探す時間が惜しい&オートスケールしてたので新しいサーバーを立ち上げて入れ替えてとりあえず対処しました。で、その間に根本的な原因を調査するとログローテートされてないことに気づきました…
この数日前にnginxのアップデートをしたのですが、その際にログローテート周りの設定ファイルを戻し忘れたようです。
これ以外にもストレージやメモリ枯渇したらアクセスできなくなるので、それを調べるコマンドはメモっておくといいかもですね$ df -h //ストレージ確認 $ free -m //メモリ確認設定変更を起動設定に反映し忘れ@オートスケール
ある日サイトが急に落ちて500エラーが出てたのでエラーログをチェック
cakephp2のログを見ると、数日前に出した新機能関連のエラーが!
直したはず…?と考えてすぐ気付きましたが、その設定変更を起動設定に反映し忘れてました…
どうやら
トラフィックが上がる
=>エラーが再現するオートスケールサーバー起動
=>アクセスできない
の流れだったようです。cakephp2のキャッシュ周りのエラーでキャッシュファイルを削除すれば直る類のものだったので、
キャッシュを再び削除
=>その状態でAMI作成
=>起動設定に指定
で対応できましたまとめ
死ぬほど焦りますが、、
・落ち着く
・原因の切り分け
・偉い人に相談
で大体なんとかなります。
- 投稿日:2020-10-16T17:57:34+09:00
AWS 苦手克服用まとめ 【完全自分用】
【AWS 苦手克服用まとめ】
AWS基礎の苦手克服のためにまとめました。
随時追加予定。・AWS Snowmobile
超大容量データを AWS に移動するために使用できるエクサバイト規模のデータ転送サービス
セミトレーラートラックが牽引する長さ14 m の丈夫な輸送コンテナで、Snowmobile 1台あたり 100 PB まで転送できます。50TBのデータ転送には容量が大きすぎるためコスト効率的ではありません。・Amazon Dynamo DB
シームレスで拡張性のある高速で予測可能なパフォーマンスを提供
完全に管理されたNOSQLデータベースサービス
セッションデータの処理に向いており、高速で処理を実行できる・Amazon Neptune
高速かつ信頼性の高いフルマネージドグラフデータベースサービス
高度に接続されたデータセットと連携するアプリケーションを簡単に構築および実行が可能
利用することで、洗練されたインタラクティブなグラフアプリケーションを作成することができる・AWS Lambda
データのプロセス処理に使用できるサービス
様々なプログラミング言語に対応してコードの実行によりサーバレスで処理を実施することが可能。
S3イベントと連携して、Lambda関数の処理を実行することができる。・AWS環境セットアップの自動化に使用できるAWSツール
CloudFormation
インフラ構築をコード化して自動セットアップを支援するサービス
テンプレートファイルを使用して、あらゆるリージョンとあらゆるアカウントでアプリケーションに対して、AWSリソースをモデル化し、自動でプロビジョニングできるElastic BeansStalk
AWSにアプリケーションをデプロイするための最も速くて簡単な方法。
AWS マネジメントコンソール、Git リポジトリ、統合開発環境を使用してアプリケーションをアップロードするだけで自動的にデプロイメントの詳細(容量のプロビジョニング、負荷分散、AutoScaling、アプリケーションのヘルスモニタリングなど)を処理する。・パブリックサブネット
インスタンスにパブリックIPアドレスを割り当てるように構成される
インターネットゲートウェイへのルートを持つサブネットである。EC2インスタンスにパブリックIPアドレスがなければインターネットアクセスはできない。
- 投稿日:2020-10-16T12:55:39+09:00
LambdaをALBのターゲットに指定した際のメモ
ターゲット登録手順
- Lambda Function作成
- Lambda Function宛のTarget Group作成
- ALBのリスナールールで転送先にTarget Groupを指定
MultiValueHeaderの使用
- Target Group で設定。 後からでも変更可。
- Attributes -> Multi value headers
- デフォルトは Disabled
リクエスト・レスポンス
- API Gateway だとメソッドリクエスト・メソッドレスポンスで色々設定できるが、ALBにそんなものはない
- ので Lambda でよしなにやる
リクエスト
- Lambda Function の event から取得
- MultiValueHeaderの設定によって構造が変わる
MultivalueHeader:Disabled{ "requestContext": { "elb": { "targetGroupArn": "***" } }, "httpMethod": "GET", "path": "/", "queryStringParameters": { "redirect_uri": "***", }, "headers": { ~ "user-agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/85.0.4183.121 Safari/537.36 Edg/85.0.564.63", "x-amzn-trace-id": "Root=***", ~ }, "body": "", "isBase64Encoded": false }MultiValueHeader:Enabled{ "requestContext": { "elb": { "targetGroupArn": "***" } }, "httpMethod": "GET", "path": "/", "multiValueQueryStringParameters": { "redirect_uri": [ "***" ] }, "multiValueHeaders": { ~ "user-agent": [ "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/85.0.4183.121 Safari/537.36 Edg/85.0.564.63" ], "x-amzn-trace-id": [ "Root=***" ], }, "body": "", "isBase64Encoded": false }なおGetパラメータは queryStringParameters ないし multiValueQueryStringParameters で取得できるが、
Postパラメータは body にBase64エンコードされた状態で渡されるので適当にデコードする# Postパラメータをデコードして整形 tmp = parse_qs(base64.b64decode(event.get('body')).decode()) for key in tmp: post_params[key] = tmp[key][0] # こんな感じになる post_params = { 'param1': 'value1', 'param2': 'value2', }レスポンス
- httpレスポンス内容をreturnしてやる
- MultiValueHeaderによって若干変わる
- 必須項目
- StatusCode
- isBase64Encoded (リダイレクトの場合はいらない)
- headers
sample:MultiValueHeader:Disableの場合response = { 'statusCode': 200, 'statusDescription': '200 OK.', 'isBase64Encoded': False, 'headers': { 'Content-Type': 'application/json; charset=utf-8' } 'body': json, }sample:MultiValueHeader:Enableの場合response = { 'statusCode': 200, 'statusDescription': '200 OK.', 'isBase64Encoded': False, 'multiValueHeaders': { 'Content-Type': ['text/html'], 'Set-Cookie': [ 'cookie-1=value; Expires=3600', 'cookie-2=value;', ] }, 'body': html, }sample:リダイレクトresponse = { 'statusCode': 302, 'headers': { 'Location': redirect_url } }なんか、そんな感じ。
- 投稿日:2020-10-16T12:27:44+09:00
AWSでエラーの原因が分からない場合は設定値を見直してみよう
はじめに
自分が設定したCodeBuildのプロジェクトでエラーが起き、原因究明に時間をかけたあげくただの設定値ミスだったことが結構あったので記事にしました。
起きたこと
CodeBuildのプロジェクト内でコマンドがコケました。
echo ${DOCKER_PASSWORD} | docker login -u ${DOCKER_USERNAME} --password-stdinエラーメッセージとして「Cannnot perform an interactive login from a non TTY device」が出力されていたため、「dockerのログインがうまくできていないのかな」と思いこのエラーメッセージを中心に調べましたが特に解決策がなく、途方に暮れていました。
ロール、環境変数等は既に動いている他のプロジェクトと同様に設定したつもりであり、ビルドの詳細を確認しても特に他のプロジェクトと設定が異なっている風には見えませんでした。
1時間ぐらい格闘した後、「環境変数を設定し直してみよう」という話になり、テキストボックスに予め入力されていた既存の設定値に対してマウスをドラッグし範囲選択したところ、、、、
「DOCKER_USERNAME 」と文字列の後ろにスペースが混ざってしまっていました。。。
スペースを消すとすぐに動いてくれました。
なぜ起きたのか
他のプロジェクトと同じ値を設定するので「同じ値だしタイポ怖いからコピペでええやろ」と考え入力値をコピペしていました。
その際に混じってしまったと思われます。なぜ気づけなかったのか
画面に表示されている値の確認はしていて、「DOCKER_PASSWORD」などの値にタイポはないか?という視点でチェックはしていました。
ですが後ろにスペースがあるかどうかはぱっと見ではわからず、また値を範囲選択しても後ろのスペースまでは表示されていなかったので気づけませんでした。
対策
- 他に影響がないことを確認してとりあえず動かしてみる
CodeBuildであれば適当な場所(ECRとか)にイメージをプッシュするのが大体の目的だと思うのでとりあえず動作確認をしましょう。
一番確実な確認方法だと思います。
- 入力値のダブルチェック
本番で運用しているサービスに係わるところであれば、他の人に確認してもらいましょう。
(ただし、上記のような場合だと気づけないかもしれません。。)
- 既に他に設定したものがあり、JSONなどで設定値を出力できるのであれば自分の設定値とdiffを取ってみる
他と同様の値(System Managerに設定した値とか)を使うのであれば有効だと思います。
終わりに
しょうもないようなミスほど、問題解決に時間がかかりますよね。。
エラーメッセージだけではどうも解決しなさそうな場合は参考にしていただけると状況が好転するかもしれません。


- 投稿日:2020-10-16T10:35:20+09:00
【AWS lambda】lambdaで各種ライブラリを含めてデプロイする(パスワード付きzipを生成し、s3にアップロードする) @ Python
やりたいこと
タイトルそのまんまですが、lbxxx.soなどのライブラリを含めてデプロイし、AWS lambda上でパスワード付きのzipを生成し、S3のバケットに格納します。
立ちふさがる壁
そんな私のやりたいことの前に壁が立ちふさがります。
1. zipfile(Pythonで標準で用意されているzipファイルの作成などを行うモジュール)では、パスワード付きzipファイルの暗号化がサポートされていない!
2. ローカルのソースコードをzipファイルに固めて、lambdaにデプロイしただけでは、パスワード付きzipを作成することができない!いかにして、この壁を乗り越えたのかをここに残したいと思います。
環境
ローカル開発環境
- Win10(ホストOS)
- Docker
- Linux 10(DockerコンテナのOS)
- VS Code
- Python 3.8.6
- pip 20.2.3
- aws-cli 2.0.56
VS Codeの「Remote-Containers」機能を使って、便利に開発しておりました。
Remote-Containers についてはこちらの記事を参考にしてくださいませ。※上記のDockerや、VS Codeのインストールなどはあらかじめ完了していることとします。
AWS環境
- lambda pythonランタイム 3.8
特に書くことはないですね・・・
壁にぶつかる前まで
AWS マネジメントコンソール - Lambda - 「関数の作成」
- 「一から作成」
- 関数名「zip-sample」
- ランタイム「Python3.8」
ローカルにて、VS Codeを立ち上げ、以下のディレクトリ構成を作る
zip-sample/ └ .devcontainer/ ├ Dockerfile └ devcontainer.json └ package/ └ lambda_hundler.py └ requirements.txtDockerfileとdevcontainer.jsonについては、こちらのソースコードからいただきました。
lambda_hundler.pyは以下になります。lambda_hundler.py# lambdaの素のソースコードです import json def lambda_handler(event, context): # TODO implement return { 'statusCode': 200, 'body': json.dumps('Hello from Lambda!') }壁①の乗り越え方
準備ができたところで早速取り掛かりましょう。
なんと、zipfileモジュールではパスワード付きzipファイルを生成できないではありませんか!(唐突)
調べてみたところ、pyminizipではパスワード付きzipファイルが生成できるらしいです。
早速確かめてみましょう。準備
pyminizipはzlib(データの圧縮および伸張を行うためのフリーのライブラリ)が必要なので、インストールします。
$ sudo apt install zlib Reading package lists... Done Building dependency tree Reading state information... Done E: Unable to locate package zlib怒られました。
代わりに、「zlib1g」を使用します。$ sudo apt install zlib1grequirements.txtに以下を記載し、
pip installコマンドを打ちます。requirements.txtpyminizip==0.2.4$ cd /workspaces/zip-sample $ pip install -r requirements.txt -t ./packagelambda_hundler.pyに以下を追記します。
lambda_hundler.pyimport json import os import pyminizip def lambda_handler(event, context): # 後々lambdaに上げることを考慮して、tmpディレクトリを利用します。 zip_path = "/tmp/zip/" # /tmp/zipディレクトリがなければディレクトリを作成します。 if not os.path.isdir(zip_path): os.mkdir(zip_path) KEY = "/tmp/hello.txt" with open(KEY, mode='w') as f: f.write('this is test.') password = "password" compression_level = 9 # 圧縮レベル1-9、大きいほど圧縮が強い # 第一引数は、zipファイルに含めるファイルのパスの配列 # 第二引数は、zipファイル内の階層 # 第三引数は、zipファイルの配置先及びファイル名 # 第四引数は、パスワード # 第五引数は、圧縮レベル pyminizip.compress_multiple([KEY], ["\\"], "/tmp/zip/sample.zip", password, compression_level) return { 'statusCode': 200, 'body': json.dumps('Hello from Lambda!') } # 以下はデプロイ時に除きます。 lambda_hundler('a','a')以下で起動してみましょう。
$ python lambda_hundler.py$ ls /tmp/zip sample.zip無事できましたね!
壁②の乗り越え方
無事にローカル(dockerコンテナ)で、パスワード付きzipファイルが生成できたので、lambdaにデプロイしてみましょう。
- MFA制限をしている場合は、事前にaws-mfaなどで、aws-cliを使えるようにしてください。
- lambda_handler.pyの、
lambda_hundler('a','a')はコメントアウトなり、削除するなりしておいてください。$ cd /workspaces/zip-sample/package $ zip -r ../function.zip . $ aws lambda update-function-code --function-name sample-zip --zip-file fileb://../function.zipデプロイが完了したら、AWSマネジメントコンソール - lambda - sample-zipより、「テスト」を実行してみましょう。
[ERROR] OSError: error in closing \tmp\zip\sample.zip (-102) Traceback (most recent call last): File "/var/task/lambda_function.py", line 78, in lambda_handler pyminizip.compress_multiple([KEY], ["\\"], r"\tmp\zip\sample.zip", "password03", 1)怒られた
色々と調べてみると、zlibがデプロイパッケージに含まれていないために起きているらしい・・・
※解決した後にカスタムランタイムを利用する解決方法もあるらしいですが、そちらは割愛します。zlibをデプロイパッケージに含める戦いが始まる・・・!
以下のコマンドを打っていけばデプロイパッケージに含められました。
$ wget http://www.zlib.net/zlib-1.2.11.tar.gz $ tar -xvzf zlib-1.2.11.tar.gz $ cd zlib-1.2.11 $ ./configure --prefix=/workspaces/sample-zip share lib includeが/workspaces/sample-zip/にできるはず $ sudo make install $ cd /workspaces/sample-zip/ zipファイルにshare lib includeを含める $ zip -gr function.zip lambda_function.py share lib include デプロイ $ aws lambda update-function-code --function-name sample-zip --zip-file fileb://function.ziplinuxのライブラリについては一度上記をやれば変更しなくてよいので、以降はソースコードのzip化のみでよいです。
$ cd /workspaces/zip-sample/package $ zip -r ../function.zip . $ aws lambda update-function-code --function-name sample-zip --zip-file fileb://../function.zipデプロイが完了したら、AWSマネジメントコンソール - lambda - sample-zipより、「テスト」を実行してみましょう。
成功!(するはず)完成系
壁を乗り越えた後のソースコードは以下になります。
lambda_hundler.pydef lambda_handler(event, context): zip_path = "/tmp/zip/" if not os.path.isdir(zip_path): os.mkdir(zip_path) KEY = '/tmp/hello.txt' with open(KEY, mode='w') as f: f.write("this is test.") password = "password" compression_level = 9 # 圧縮レベル1-9、大きいほど圧縮が強い pyminizip.compress_multiple([KEY], ["\\"], "/tmp/zip/sample.zip", password, compression_level) # 作成したzipファイルをs3にアップロードします s3 = boto3.resource('s3') s3.Bucket(BUCKET).upload_file(Filename="/tmp/zip/sample.zip", Key="sample.zip") return { 'status': 200, 'body': '処理が終了しました' }まとめ
- Pythonでパスワード付きzipファイルを作成したかったら、「pyminizip」!
- lambdaにデプロイするときは、「zlib」もデプロイパッケージに含める!
参考にさせていただいた記事など
- 投稿日:2020-10-16T07:44:07+09:00
Twitter の障害情報を調べようとしてつまずいた話
この記事の内容は私が独自に調査したものであり、障害の真因を示すものではありません。
情報の取り扱いには十分ご注意ください。出来事
2020 年 10 月 16 日、朝起きて Twitter を見ようとしたら・・・あれ、見れない。
最新のタイムラインと通知が見られない。トレンドはなぜか知らないが見ることができる。AWS とかの障害?と予測したものの
Twitter 使えねぇとか言う前にどっかのサーバに障害が起こったのかな?と思って、AWS 障害とかGCP 障害とかでググってみる。
そうすると、 AWS も GCP も障害情報が Twitter に発信されているということが分かった←
これじゃなにもわかんないw素直に検索してみる
素直に
twitter 障害と検索すると、何やら手掛かりとなるサイトを発見した。
Downdetectorというサイトで Twitter の障害情報が閲覧できるらしい。
Twitter 以外にも、私たちが利用している身近なサービスなどの障害情報を、Downdetectorに提出されたレポートや他のデータソースから検出して報告する仕組みとなっている。そして私が Twitter を閲覧する前日から障害が起こっていたらしいということもわかった。
ちなみに App Store と Google Play でもアプリ版が配信されている。
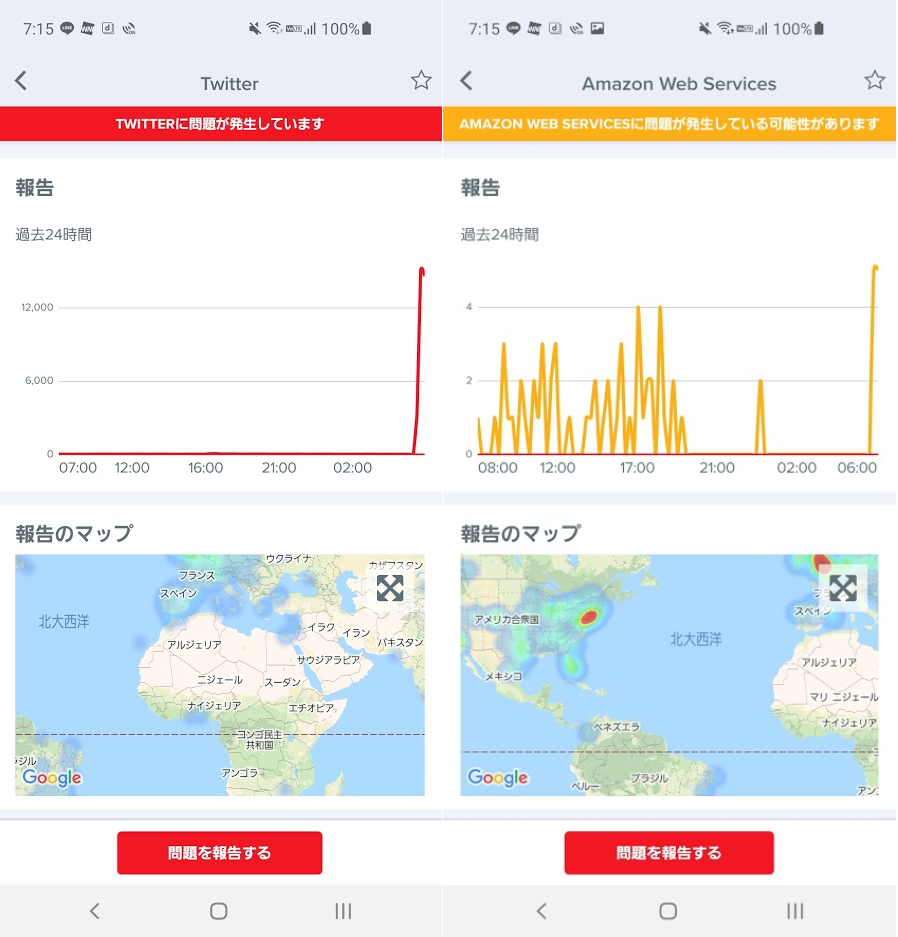
アプリで見てみるとさらなる事実が
アプリで見てみたところ、 Twitter と AWS で朝に報告が増えているのが見えた。
AWS の報告件数が少ないので断定はできないが、おそらく AWS に何らかのトラブルがあったのではないかと推測される。
他にも Amazon や Apex Legends など同時間帯に報告が増えているのが確認できた。
まとめ
情報源やソースが複数存在していることは重要
AWS さんは障害情報を Twitter に報告していたが、今回 Twitter に障害があったため、私は状況を確認するのに非常に苦労した。
でも情報源が複数あったので、一部に障害があっても他の情報源で確認できた。
これは「バックアップに助けられた」という見方ができるかもしれない。
自社サービスなどで顧客データのバックアップを取っていなかった場合に障害などでデータが消失した場合、データを取り戻すことができず、お客様に多大な迷惑(では済まない)がかかってしまう。
そうならないように、何事にも最悪の事態を想定して取り組みたいと思った。エンジニアになってから思うこと
スマホアプリとか Web サービスが一時的に使えなくなったときに、以前は原因がわからずムズムズして
このゲームクソとか言っていたが、エンジニアになって、現在配信されているサービスの多くがサーバ環境をこういった外部サービスに頼っていることを知ってからは、う~がんばれ Twitter ! って心から思えるようになった。
また、外部サービスに頼るサービスを開発・提供する場合、今回のようなリスクがあるということを忘れず認識しておきたい。
そして、不具合の起こっているサービスを頭ごなしにけなす人が減ることを切に願う。それにしても AWS はすごい、いつもありがとうございます?♀️?♂️