- 投稿日:2020-10-14T22:56:16+09:00
pandas.read_excelで読み込んだExcelの日付がシリアル値だったのでdatetime.datetimeに変換した
ことのほったん
pandas.read_excelでExcelの日付を読み込むと書式設定によってデータが数値のシリアル値になった。
datetime.datetimeで統一して処理したいので変換することにした。
intのシリアル値をdatetime.datetimeに変換する方法# date_int : シリアル値 if date_int < 60: # 1900-03-01より前の場合 days = date_int -1 else: # 1900-03-01以降の場合 days = date_int - 2 date_time = pandas.to_datetime('1900/01/01') + datetime.timedelta(days=days)こんな感じでやってみた
- 環境
- macOS Catalina バージョン10.15.7
- Microsoft Excel for Mac バージョン16.42
- Python 3.8.5
- pandas 1.1.3
- 参考
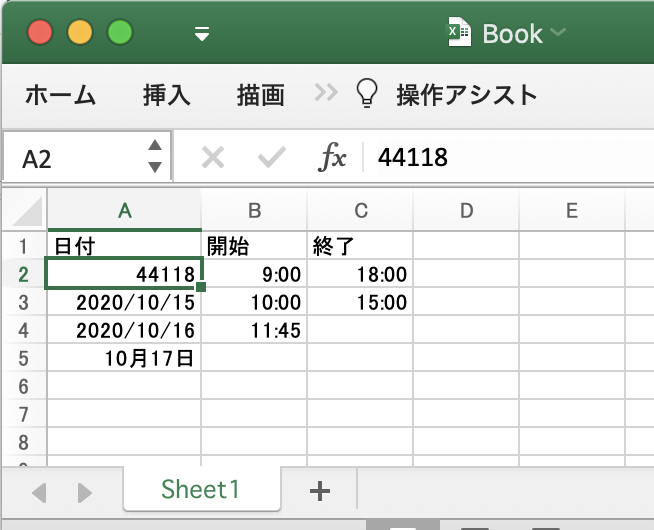
読み込むExcelファイルはこんな感じ
import datetime import pandas def get_datetime(val: object) -> datetime.datetime: """日付を取得する. :param val: 日付の元になる値 :return: 日付かシリアル値であれば日付、それ以外はNone """ val_type = type(val) # datetime.datetimeだったらそのまま返却 if val_type is datetime.datetime: return val # pandas.Timestampはdatetime.datetimeを継承していてdatetime.datetimeとして処理できそうなのでそのまま返却 if issubclass(val_type, datetime.datetime): return val # intだったらシリアル値としてdatetime.datetimeに変換して返却 if val_type is int: if val < 60: # 1900-03-01より前の場合 days = val -1 else: # 1900-03-01以降の場合 days = val - 2 return pandas.to_datetime('1900/01/01') + datetime.timedelta(days=days) return None if __name__ == '__main__': # pandasでExcelを読み込む sheet = pandas.read_excel('Book.xlsx', sheet_name='Sheet1', header=None) for index, row in sheet.iterrows(): date = get_datetime(row[0]) if date is not None: print(date.strftime('%Y/%m/%d'))出力2020/10/14 2020/10/15 2020/10/16 2020/10/17
- 投稿日:2020-10-14T22:54:16+09:00
Fusion360APIで押し出し三昧
背景
今年も「Fusion360押し出しコンペ」(詳細は別ブログ記事()にて)が始まるらしいとの
噂が流れてきました。
Fusion360にはスクリプトというマクロみたいな機能があります。
こいつを使えば優勝間違いない!?という訳で挑戦してみました。準備
スクリプトを新規作成する、または既にあるスクリプトを編集する方法は
次の記事を参考ください。公式ヘルプを日本語訳して下さってます。最初から入っているサンプルスクリプトを「編集」して(上書き保存しないよう注意!)
中身を確認する事もできます。
また(英語しかないのが辛いですが)公式ヘルプのスクリプトのページにも
色んなサンプルがあったので、大変参考になりました。
下記リンクは色んな押し出しを実行するやつ。Extrude Feature API Sample API Sample
スクリプト内容
スケッチで丸を描いて押し出し、その上に違う丸を書いて押し出し、を繰り返します。
積み上げるピッチ高さ(=各押し出し高さ)、丸の位置と直径のデータを
CSVファイルにして読み込ませると、自動で押し出しまくります。色んなサンプルを組み合わせて何とか動くようになりました。
以下、コードを少し区切って説明します。
順番に全てを繋げれば動くはずですが、必要に応じて適時修正お願いします。import adsk.core, adsk.fusion, traceback, math, io def run(context): ui = None try: app = adsk.core.Application.get() ui = app.userInterface # Get all components in the active design. product = app.activeProduct design = adsk.fusion.Design.cast(product) # Get the root component of the active design rootComp = design.rootComponent # Get extrude features extrudes = rootComp.features.extrudeFeatures title = 'Import csv file' if not design: ui.messageBox('No active Fusion design', title) return dlg = ui.createFileDialog() dlg.title = 'Open CSV File' dlg.filter = 'Comma Separated Values (*.csv);;All Files (*.*)' if dlg.showOpen() != adsk.core.DialogResults.DialogOK : return filename = dlg.filenameここまで、初期設定とCSVファイルを選択させる画面を実行。
ほぼサンプルスクリプトそのままです。# Set 1st-sketch plane sketches = rootComp.sketches sketch = sketches.add(rootComp.xZConstructionPlane) cnt = 0 # Read the csv file. with io.open(filename, 'r', encoding='utf-8-sig') as f: line = f.readline() data = [] while line: pntStrArr = line.split(',') for pntStr in pntStrArr: try: data.append(float(pntStr)) except: break # csv file line 1 is pitch of extrude if cnt == 0: distance = adsk.core.ValueInput.createByReal(data[0]/10)XZ平面にスケッチを書いてY方向に押し出すように設定。
CSVファイルを一行づつ読み込み。
1行目のデータである、積み上げるピッチ高さ(=各押し出し高さ)を設定。# csv file after line 2 are sketch of extrude elif cnt == 1: sketchCircles = sketch.sketchCurves.sketchCircles centerPoint = adsk.core.Point3D.create(data[0]/10, data[1]/10, 0) circle = sketchCircles.addByCenterRadius(centerPoint, data[2]/10) prof = sketch.profiles.item(0) extrude = extrudes.addSimple(prof, distance, adsk.fusion.FeatureOperations.NewBodyFeatureOperation) else: sketch = sketches.addWithoutEdges(extrude.endFaces.item(0) ) sketchCircles = sketch.sketchCurves.sketchCircles centerPoint = adsk.core.Point3D.create(data[0]/10, data[1]/10, 0) circle = sketchCircles.addByCenterRadius(centerPoint, data[2]/10) prof = sketch.profiles.item(0) extrude = extrudes.addSimple(prof, distance, adsk.fusion.FeatureOperations.JoinFeatureOperation) line = f.readline() data.clear() cnt += 1 ui.messageBox('Finished') except: if ui: ui.messageBox('Failed:\n{}'.format(traceback.format_exc()))CSVファイル2行目以降のデータである、丸の中心位置X,Yと直径を読み取り
スケッチに描いて、設定したピッチで押し出します。
一段目はXY平面にスケッチを描いて、新規ボディで押し出し実行。
二段目以降はボディの平面上にスケッチを描いて、結合で押し出し実行。
CSVファイルの末行まで繰り返します。最後に
エクセルのマクロのように「記録」ボタンがあれば、API解析も捗るのですが
日本語の情報が少なく、分かっていない事も多々あります。
乱雑なコードかもしれませんが、御容赦ください。正円以外に、楕円(SketchEllipses)も描けそうでした。
四角は直線を組み合わせて描く方法しかググっても見つからず、分かっていません。本当はXY平面ではなく、任意の平面を選んで開始させたかったのですが
これも分からなかったので、御存知でしたら教えていただけると幸いです。記事で紹介した以外に、次のQiita記事も参考にさせていただきました。
シリーズで連載されており、丁寧に解説されてたので分かりやすかったです。感謝!Fusion 360 を Pythonで動かそう その1 スクリプトの新規作成
ちなみに今回、2020年の押し出しコンペでは「スクリプトなど使用不可」と明記されてました。
使うと反則になってしまうのでご注意ください(笑)
- 投稿日:2020-10-14T22:32:17+09:00
pandasで欠損値nanじゃないデータを抽出する方法
ちょうど千葉県 Go To EATの加盟店一覧の抽出方法考えてたところだったので記事を参考にまとめました
import pandas as pd import io data = """ 名前,回数,開始,終了 ぽんすけ,1,9:00,18:00 ぽんすけ,2,18:00, ぽんすけ,3,9:00,13:00 ぽんすけ,4,, ぽんすけ,5,9:00, ぽんすけ,6,18:00, ぽんすけ,7,12:00, ぽんすけ,8,12:00, ぽんすけ,9,,18:00 ぽんすけ,10,, """ df = pd.read_csv(io.StringIO(data)) df
名前 回数 開始 終了 0 ぽんすけ 1 9:00 18:00 1 ぽんすけ 2 18:00 nan 2 ぽんすけ 3 9:00 13:00 3 ぽんすけ 4 nan nan 4 ぽんすけ 5 9:00 nan 5 ぽんすけ 6 18:00 nan 6 ぽんすけ 7 12:00 nan 7 ぽんすけ 8 12:00 nan 8 ぽんすけ 9 nan 18:00 9 ぽんすけ 10 nan nan 1つのカラムがNaNじゃないデータを抽出する
df[(df.loc[:, "開始"].notnull() == True)]2つのカラム両方NaNじゃないデータを抽出する
df[(df.loc[:, ["開始", "終了"]].notnull() == (True, True)).all(axis=1)]2つのカラムどっちかがNaNじゃないければデータを抽出する
df[(df.loc[:, ["開始", "終了"]].notnull() == (True, True)).any(axis=1)]「1つのカラムがNaNじゃない」&「1つのカラムがNaN」のデータを抽出する
df[(df.loc[:, ["開始", "終了"]].notnull() == (False, True)).all(axis=1)]
- 投稿日:2020-10-14T22:29:51+09:00
os.path.splitext
os.path.splitextとは引数を「.」より前と「.」以降に分けてくれるコマンドです。ファイルの拡張子を取り出す際などに使います。
import os print(os.path.splitext('sample.txt')出力
('sample', '.txt')
- 投稿日:2020-10-14T22:15:10+09:00
【CRUD】【Django】PythonフレームワークDjangoを使ってCRUDサイトを作成する~1~
CRUDとは?
Create(登録)、Read(参照)、Update(更新)、Delete(削除)機能のことを指します。
これらの機能をDangoで実装していきます。アプリを作るのか
ブログサイトを作りたいと思います。
設計図などは考え中ですが、主な機能を以下に挙げます。ブログ機能
- 記事投稿(Create)
- 記事参照(Read)
- 記事更新(Update)
- 記事削除(Delete)
ユーザ管理機能
- ユーザログイン
- ユーザログアウト
開発環境を作成する
今回の開発では仮想環境を使っていきます。
仮想環境だとPipFileを参照すれば各パッケージのバージョンがまとまっているので、複数人開発などでは開発環境を共有しやすいと思います。Pipfile[[source]] name = "pypi" url = "https://pypi.org/simple" verify_ssl = true [dev-packages] flake8 = "*" autopep8 = "*" [packages] django = "==3.1.1" [requires] python_version = "3.8"ちなみに以下コマンドで私と同じ環境が構築できます。
pip install pipenv pipenv shell pipenv install django==3.1.1 pipenv install --dev flake8 autopep8プロジェクトを作成する
プロジェクト名は何でもよいのですが、このコマンドで作成されるフォルダはプロジェクト全体の設定ファイル群が格納されるフォルダなのでconfigとしています。
django-admin startproject config .アプリケーションを作成する
Djangoではプロジェクトの中にアプリ(機能)を作成していきます。
まずは、ブログ機能を作成するのでblogとします。python manage.py startapp blogアプリを作成したらプロジェクトに「アプリ作成しました!」と設定してあげなければいけません。
/crud/config/settings.pyに以下を追加します。
ついでに言語設定、タイムゾーン設定も行っていきましょう。/crud/config/settings.pyINSTALLED_APPS = [ 'blog.apps.BlogConfig', *** ] LANGUAGE_CODE = 'ja' TIME_ZONE = 'Asia/Tokyo'本日はここまでです。以下のようなディレクトリ・ファイルはできているでしょうか。
ありがとうございました。
- 投稿日:2020-10-14T21:45:30+09:00
BeautifulSoupより気軽に使えるスクレイピング用モジュール「ガスパチョ」
最近知った
gazpachoというPythonモジュールが素敵だったので紹介します。gazpachoとは
gazpachoは、「シンプルかつ高速で、モダンなウェブスクレイピング用のライブラリ」です。
gazpacho is a simple, fast, and modern web scraping library. The library is stable, actively maintained, and installed with zero dependencies.
(https://pypi.org/project/gazpacho/)Star数は400とまだマイナーなため、個人利用に留めるのがよいかと思います。
メリット
- このライブラリひとつで、HTMLの取得と解析ができる
BeautifulSoupなどを使う場合は、まずrequestsなどでHTMLを取得する必要がありました- 覚えるメソッドが少なくてすむ
findコマンドひとつで解析します- 依存しているモジュールがない
使い方
まずはモジュールをインストール。
pip install gazpachoチュートリアルで取り上げられている下記のサイトより、本のタイトルをスクレイピング、出力してみます。
from gazpacho import get, Soup # 指定されたURLをもとに、HTMLを取得 html = get('https://scrape.world/books') # 解析用のインスタンスをつくる soup = Soup(html) # 必要な要素を取得。複数見つかればList[Soup]を返す(単数の場合はSoup) # 1つめの引数はHTMLタグ # 2つめの引数はidやclassの指定 # 3つめの指定は部分一致を許すかどうか # 例では、クラスが"book-"となっているので、"book-early"などがマッチする books = soup.find('div', {'class': 'book-'}, partial=True) for book in books: name_header = book.find('h4') # textフィールドにタグの中身が入っている name = name_header.text print(name)まとめ
個人的には、下のような感じで使い分けています。
- 簡単なスクレイピング -> gazpachoを使う
- gazpachoでは難しい(※) -> selenium(chromedriver-library)BeautifulSoupを使ってなんとかやる
※とくに動的なサイトを指しています。
gazpachoはモジュール自体もシンプルなので、時間を見つけて読んでみようかなと思っています。
この記事を読んで使ってみる人が増えれば嬉しいです!
- 投稿日:2020-10-14T21:03:53+09:00
pandasのread_excelでExcelファイルを読み込んだ後の型
pandas.read_excelでExcelを読み込んだ後のデータ型はExcelでの書式設定が影響するようなのでちょっと気になったので実験してみた。ちょっとづつ貯めていく。
日付
- 環境
- macOS Catalina バージョン10.15.7
- Microsoft Excel for Mac バージョン16.42
- Python 3.8.5
- pandas 1.1.3
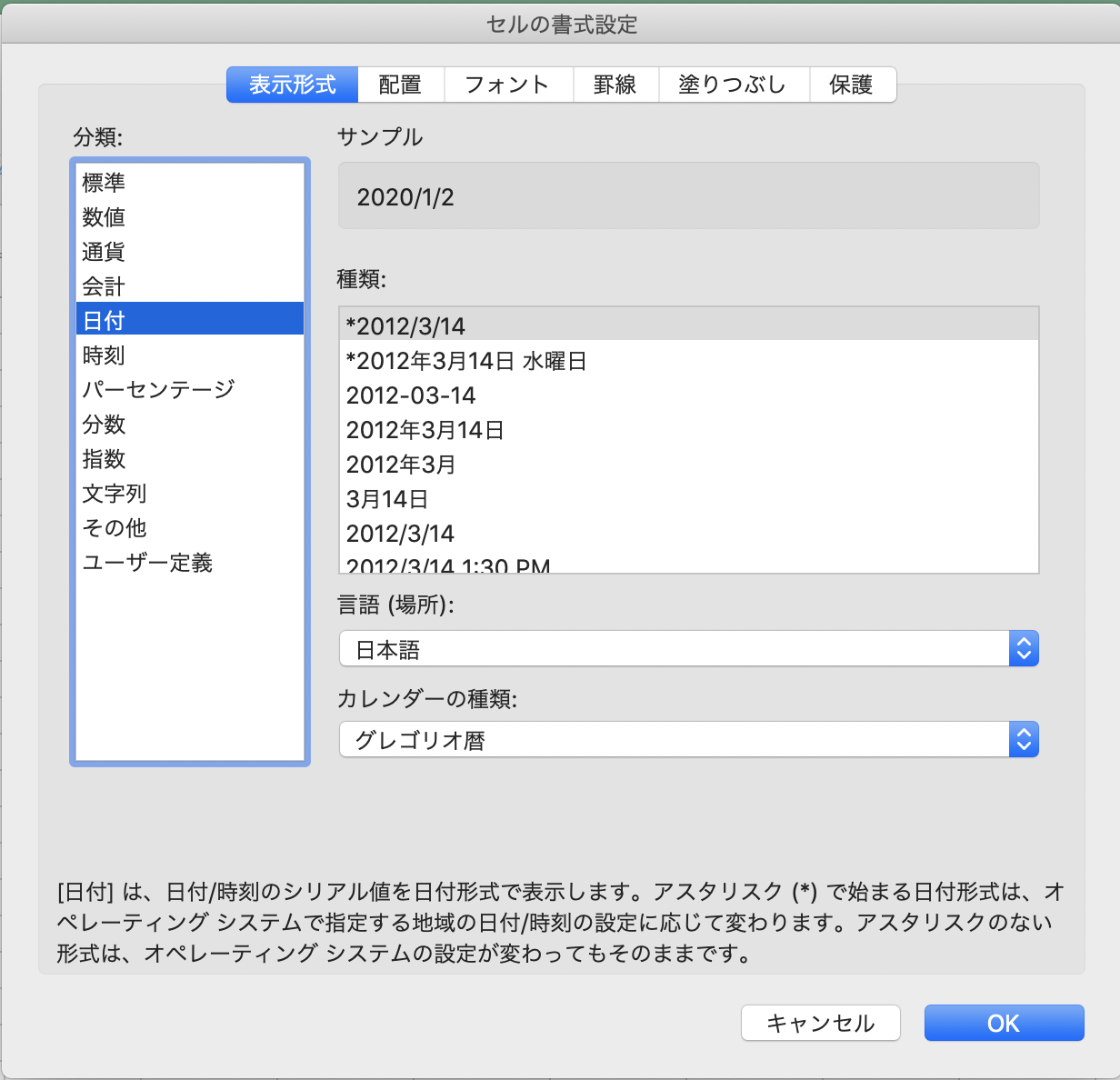
Excel書式(分類) Excel書式(表示) pandasで読み込んだ後の型 標準 43831 int 日付 2020/1/2 datetime.datetime 日付 2020年1月3日 金曜日 datetime.datetime 日付 2020-01-04 pandas.Timestamp 日付 2020年1月5日 pandas.Timestamp 日付 2020年1月 pandas.Timestamp 日付 1月7日 pandas.Timestamp 日付 2020/1/8 pandas.Timestamp 日付 2020/1/9 12:00 AM pandas.Timestamp 日付 2020/1/10 0:00 pandas.Timestamp 日付 1/11 pandas.Timestamp 日付 1/12/20 pandas.Timestamp 日付 01/13/20 pandas.Timestamp 日付 14-Jan pandas.Timestamp 日付 15-Jan-20 pandas.Timestamp 日付 16-Jan-20 pandas.Timestamp 日付 Jan-20 pandas.Timestamp 日付 January-20 pandas.Timestamp 日付 J pandas.Timestamp 日付 J-20 pandas.Timestamp
- 投稿日:2020-10-14T21:02:23+09:00
AWS Lambdaでmimetypesを使う際はtypes_mapを確認しよう(Python)
前提・環境
AWS Lambda Python環境
事象
AWS LambdaのPython環境で
.webpをguess_typeしようとしたところ。import mimetypes print(mimetypes.guess_type('.webp')) # nonenoneになってしまった。
import mimetypes print(mimetypes.types_map['.webp']) # nonetypes_mapにwebpが存在しないので、追加してあげて
import mimetypes mimetypes.add_type('image/webp', '.webp') print(mimetypes.guess_type('.webp')) # image/webp解決した。
まとめ
mimetypesの辞書は環境依存なので、
guess_typeやguess_extentionできないときは辞書に対象が存在するか確認する。
存在しない場合はadd_typeで追加することができる。
- 投稿日:2020-10-14T19:49:30+09:00
pybind11 +cmake で Python interpreter を C++ アプリに embed する
いつの頃からか, pybind11 でお手軽に python interpreter を埋め込んで exe ビルドできるようになっていました.
https://pybind11.readthedocs.io/en/stable/advanced/embedding.html
C++ がメインだったり, エントリポイントが C/C++ のプログラムの場合に役立ちます.
デフォルトでは, システムを探索して見つかった libPython とリンクします(conda などの場合は conda 環境の python など)
Python を明示的に指定したい場合は
cmake -DPYTHON_EXECUTABLE=/path/to/bin/python ...と,PYTHON_EXECUTABLEでしていします.
(lib も bin ディレクトリをベースに見つけてくれるっぽい)pybind11 が内部的には
find_package(PythonInterp)しているためです.https://cmake.org/cmake/help/v3.18/module/FindPythonInterp.html
ちなみに python3.8m など suffix がついていたりしますが, suffix の意味はこちら.
TODO
- 自前でビルドした Python ライブラリを指定してリンクする
- python-cmake-buildsystem で libpython を自前 C/C++ アプリに組み込む https://qiita.com/syoyo/items/5a935fdcbdf89e0a2635
- 投稿日:2020-10-14T19:42:11+09:00
Torchvisionのmodelの最後にsoftmaxがいらない件について。
背景
以下のコードを見てくれればわかるが、最終層はLinerでsoftmax層が入っていない。
https://github.com/pytorch/vision/blob/master/torchvision/models/vgg.py「え、これで大丈夫なの?」と思ったので、
理由
以下に全て書いてあった。
https://discuss.pytorch.org/t/torchvision-models-dont-have-softmax-layer/18071学習時には、
nn.CrossEntoropyLoss()を使うが、nn.LogSoftmaxとnn.NLLLoss.から成り立ってるので、必要ないとのこと。推論する際も、各クラスの確率が欲しいなら
nn.functional.softmax()が必要だが、予測ならtorch.maxなどで最も大きい値のidxを抜いてこればいいとのこと。クラス分類時は脳死で最終層はsoftmaxと考えていたけど、よくよく考えればloss計算に必要なだけなので、「なるほどな〜」と思った。
- 投稿日:2020-10-14T19:40:57+09:00
【python】ソートプログラムを自分で作ってみる。(選択ソート、挿入ソート、バブルソート)
【python】ソートプログラムを自分で作ってみる。(選択ソート、挿入ソート、バブルソート)
選択ソート
最少値を見つけて先頭の要素と交換する。
実際の処理としては、複数の考え方を合わせる必要がある。
(1) 最少値を求める
(2) 最少値を先頭の値と入れ替える
(3) (1)と(2)を先頭が確定していない値の中で繰り返す
選択ソートdef min_init(arr, x): min = x for i in range(x, len(arr)): if arr[min] > arr[i]: arr[i], arr[min] = arr[min], arr[i] def min_sort(arr): for j in range(0, len(arr)-1): min_init(arr, j) print(arr)実行例a = [2,4,5,3,10,1,8,6] min_sort(a) #[1, 2, 3, 4, 5, 6, 8, 10]考え方
(1) 最少値を求める
まずは最少値を求める式を考える。
minの初期値を0番目として、次の数値と比較する。
次の数値が小さい場合に、minを入れ替える#最少値を求める def min_val(arr): min = 0 for i in range(1, len(arr)): if arr[min] > arr[i]: min = i print(a[min]) #確認 a = [2,4,5,3,10,1,8,6,3,2] min_val(a) #1(2) 最少値を先頭の値と入れ替える
上記の最少値を求めるプログラムを応用して、最少値が見つかったタイミングで、その値と先頭の値を交換する。
最終的に、最少値が先頭にきた配列を求める。
#最少値を見つけて配列の先頭に移動する def min_first(arr): min = 0 for i in range(1, len(arr)): if arr[min] > arr[i]: arr[i], arr[min] = arr[min], arr[i] print(a) #確認 a = [2,4,5,3,10,1,8,6] min_first(a) #[1, 4, 5, 3, 10, 2, 8, 6](3) (1)と(2)を先頭が確定していない値の中で繰り返す
上記を応用して処理を繰り返す。
注意点は、minの初期値を変数にする。こうすることで比較対象範囲がひとつづつ後ろにずれていく。定数にしてしまうと、常に同じ値と比較することになり狙った出力にならない。
def min_init(arr, x): min = x for i in range(x, len(arr)): if arr[min] > arr[i]: arr[i], arr[min] = arr[min], arr[i] def min_sort(arr): for j in range(0, len(arr)-1): min_init(arr, j) print(arr) #確認 a = [2,4,5,3,10,1,8,6] min_sort(a) #[1, 2, 3, 4, 5, 6, 8, 10]
挿入ソート
先頭をソート済みとして、次の数値をどこに追加していくかを判断していく方法。
・未ソートの先頭の値とその前の値を比較
・未ソートの方が小さければ、未ソートがあった値を大きい値で上書きする。(未ソートの値は変数で保管しておく)
・未ソートの方が大きくなったところで確定するdef insert_sort(arr): for i in range(1,len(arr)): tmp = arr[i] #未ソートの先頭 j = i -1 #ソート済みの一番後ろ(未ソートの一個前) #要素を比較して、tmpの方が小さければj+1の値を置き換えていく while arr[j] > tmp and j >= 0: arr[j+1] = arr[j] j -= 1 #tmpの方が大きいなら、j+1をtmpで確定する arr[j+1] = tmp確認a = [2,4,5,3,10,1,8,6] insert_sort(a) print(a) #[1, 2, 3, 4, 5, 6, 8, 10]tmpとは
変数。値が順次追加されたり、削除されたりしていく一時的な変数を明示するために使う。temporaryの略。
バブルソート
後ろから、隣合う要素を比較して交換していく。
一番先頭の2つを比較し終わった時点で、先頭が確定する。
残りの要素で同じ操作を繰り返す。処理の流れとしては、
(1) 最後の値を隣り合う値と比較して、より小さければ交換する。
(2) (1)の作業を繰り返す。先頭は1回づつ固定していく。def bubble_sort(arrs): for j in range(0, len(arrs)): exchange(arrs, j) def exchange(arr, j): for i in range(len(arr)-1, j, -1): if arr[i-1] > arr[i]: arr[i-1], arr[i] = arr[i], arr[i-1]#確認 a = [2,4,5,3,10,1,8,6] bubble_sort(a) print(a) #[1, 2, 3, 4, 5, 6, 8, 10]▼(参考)隣り合う値を比較し交換する
#小さい数値を前方に移動する def exchange(arr): for i in range(len(arr)-1, 0, -1): if arr[i-1] > arr[i]: arr[i-1], arr[i] = arr[i], arr[i-1] print(arr) #確認 a=[8,2,6,1] exchange(a) #[1, 8, 2, 6]
- 投稿日:2020-10-14T19:36:49+09:00
python3.9にpillowをインストール時の対応
python3.9にpillowをインストールしようとしたらエラーになった時の対応メモ。
結論は、python3.9をpython3.8系にダウングレードしてインストール成功。$ python3 -V Python 3.9.0 $ pip3 list Package Version ---------- ------- pip 19.2.3 setuptools 41.2.0 six 1.15.0 wheel 0.33.1pillowをインストール。
$ pip3 install pillow Collecting pillow Using cached Pillow-7.2.0.tar.gz (39.1 MB) Using legacy 'setup.py install' for pillow, since package 'wheel' is not installed. Installing collected packages: pillow Running setup.py install for pillow ... error ERROR: Command errored out with exit status 1: command: /Library/Frameworks/Python.framework/Versions/3.9/bin/python3.9 -u -c 'import sys, setuptools, tokenize; sys.argv[0] = '"'"'/private/var/folders/bh/qn_1nbf10t93r800p2nf70840000gn/T/pip-install-2tumuz0z/pillow/setup.py'"'"'; __file__='"'"'/private/var/folders/bh/qn_1nbf10t93r800p2nf70840000gn/T/pip-install-2tumuz0z/pillow/setup.py'"'"';f=getattr(tokenize, '"'"'open'"'"', open)(__file__);code=f.read().replace('"'"'\r\n'"'"', '"'"'\n'"'"');f.close();exec(compile(code, __file__, '"'"'exec'"'"'))' install --record /private/var/folders/bh/qn_1nbf10t93r800p2nf70840000gn/T/pip-record-mj6xe2pw/install-record.txt --single-version-externally-managed --compile --install-headers /Library/Frameworks/Python.framework/Versions/3.9/include/python3.9/pillow (略)調べてみるとpillowがpython3.9.0に未対応の様子。
python3.9.0をアンインストール。$ sudo rm -rf /Library/Frameworks/Python.frameworkpython3.8系をインストールするため、まずはpyenvをインストール。
$ brew install pyenvpyenvにパスを通す。
$ echo 'export PYENV_ROOT="$HOME/.pyenv"' >> ~/.bash_profile $ echo 'export PATH="$PYENV_ROOT/bin:$PATH"' >> ~/.bash_profile $ echo 'eval "$(pyenv init -)"' >> ~/.bash_profilepython3.8.6をインストールする。
$ pyenv install 3.8.6 $ pyenv versions * system (set by /Users/hoge/.pyenv/version) 3.8.6 $ python3 -V Python 3.8.6pillowを再インストール。
$sudo pip3 install pillow $ pip3 list Package Version ---------- ------- Pillow 7.2.0 ★ pip 19.2.3 setuptools 41.2.0 six 1.15.0 wheel 0.33.1以上。
- 投稿日:2020-10-14T19:29:34+09:00
Twitterの特定キーワードを含むツイートをリアルタイムにSlackに転送するスクリプト
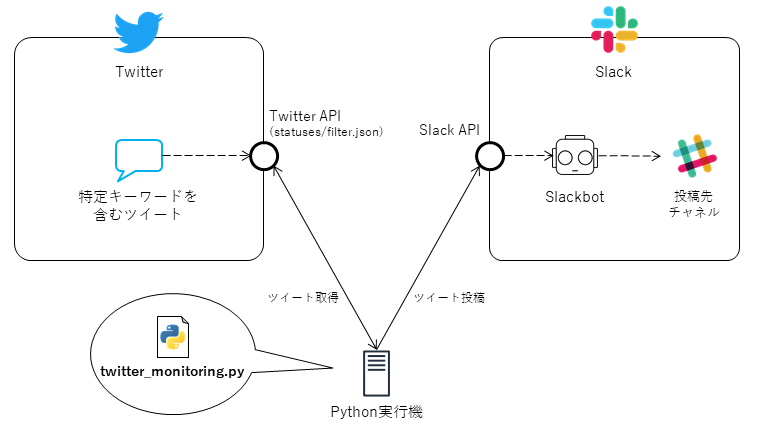
Twitterをモニタリングして、特定キーワードを含むツイートをリアルタイムにSlackに転送する方法について紹介します。スプリプトはpython3で、ツイートのリアルタイム取得には、Twitter APIの
statuses/filter.jsonを利用しています。システム概略図
こんなシステム構成を想定します。この記事では、この図の左下にある
twitter_monitoring.pyのスクリプトの例を紹介します。
スクリプトの動作としては、Twitter APIの
statuses/filter.jsonで特定キーワードを含むツイートを取得し、Slack API経由でそのツイートをSlackbotが任意のチャネルに投稿するようにします。事前準備
Twitter APIとSlack APIを利用するための準備をします。
Twitter APIアカウント作成
取得対象トークン
Twitter APIアカウントを作成し、下記の4つのトークンを入手できたらOKです。
- API key
- API secret key
- Access token
- Access token secret
作成方法
アカウント作成方法については、下記サイトが参考になりました。
- https://www.itti.jp/web-direction/how-to-apply-for-twitter-api/
- https://dev.classmethod.jp/articles/twitter-api-approved-way/
- https://cre8cre8.com/python/twitter-api.htm
Slackbotの作成
Slack APIのページから、ツイートの投稿ユーザとなるBotを作成します。
取得対象トークン
Slackbot作成後に、Slack API管理サイトの
OAuth & Permissionsのページから、下記のトークンを入手できたらOKです。
- Bot User OAuth Access Token
作成方法
Slackbotの作成方法については、下記サイトが参考になりました。
スコープ(権限)
Slackbotのスコープ(権限)設定は、今回の用途では
chat:writeのみ許可すれば十分です。Pythonスクリプト
今回作成する
twitter_monitoring.pyについて解説します。コード全体
下記はPythonスクリプトのコーディング例(全45行)です。
twitter_monitoring.py# coding: utf-8 import json import logging from time import sleep import requests_oauthlib import slack # Parameters keyword = 'keyword' # 任意の検索キーワードを指定する # Twitter parameters consumer_key = 'xxxxxxxxxxxxxxxxxxxxxxxxx' # Twitter API key consumer_secret = 'xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx' # Twitter API secret key access_token = '9999999999999999999-xxxxxxxxxxxxxxxxxxxxxxxxxxxxxx' # Twitter Access token access_token_secret = 'xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx' # Twitter Access token secret # Slack parameters bot_token = "xoxb-999999999999-9999999999999-xxxxxxxxxxxxxxxxxxxxxxxx" # Slack Bot User OAuth Access Token channel_id = 'xxxxxxxxxxx' # Slack channel ID # Logging logging.basicConfig(filename='twitter_monitoring.log', format='%(asctime)s %(levelname)-8s %(message)s', datefmt='%Y-%m-%d %H:%M:%S', level=logging.WARNING) # 処理 uri = 'https://stream.twitter.com/1.1/statuses/filter.json' twitter_session = requests_oauthlib.OAuth1Session(consumer_key, consumer_secret, access_token, access_token_secret) slack_client = slack.WebClient(token = bot_token) while True: try: logging.info("Request to Twitter API.") twitter_response = twitter_session.post(uri, data=dict(track=keyword), stream=True) if twitter_response.status_code != 200: # Twitter rate limitに引っかかった場合など logging.warning("status_code:%s, reason:%s", twitter_response.status_code, twitter_response.reason) sleep(900) # 15分待機 continue for line in twitter_response.iter_lines(): if not line: # 該当ツイート無し logging.info("No any tweets.") continue tweet_dict = json.loads(line.decode("utf-8")) tweet_link = 'https://twitter.com/i/web/status/' + tweet_dict['id_str'] slack_response = slack_client.chat_postMessage(channel = channel_id , text = tweet_link) # ツイートのリンクをSlackに転送 except Exception as e: logging.error(f'{e}')設定パラメータ
コード自体が短いので、この例ではスクリプト内に設定パラメータを埋め込んでいます。下記の変数に、各種トークンとパラメータの値を指定します。
分類 対象 変数名 説明 トークン consumer_key Twitter API key トークン consumer_secret Twitter API secret key トークン access_token Twitter Access token トークン access_token_secret Twitter Access token secret トークン Slack bot_token Slack Bot User OAuth Access Token パラメータ keyword Twitterの検索キーワード パラメータ Slack channel_id 投稿先Slack チャネルID1 キーワードに一般的な用語を指定してこのスクリプトを実行すると、転送先のSlackチャネルが大量のツイートで溢れかえってしまう可能性があるため、まずはテスト用のSlackチャネルで試すことを推奨します。
ロギング設定
デバッグ用に
loggingの設定を入れていますが、不要であれば削除しても大丈夫です。このまま実行すると、下記の動作をします。
- 実行時に同じディレクトリ上に
twitter_monitoring.logのログファイルが出力される。logging.infoで定義されたログも出力するには、事前にコード内のlogging.basicConfigのlevelパラメータをlogging.INFOに変更しておく。スクリプト実行方法
下記の方法で、Pythonスクリプトを実行します。
Pythonライブラリ
必要なPythonライブラリを、事前にインストールしておきます。
sudo pip install --upgrade pip sudo pip install slackclient sudo pip install requests_oauthlib sudo pip install logging実行コマンド
下記コマンドで、pythonスクリプトを実行します。
nohup python twitter_monitoring.py &nohupで実行することで、Python実行機からログアウトしても、スクリプトが実行され続けるようにします。
以上で完了です。実行後、keywordに指定した文字列を含むツイートのリンクが、転送先のSlackチャネルにリアルタイムに転送され続けることを確認します。
備考
SlackチャネルのリンクURLの末尾部分。 ↩
- 投稿日:2020-10-14T19:26:00+09:00
【Python3エンジニア認定データ分析試験】受験・合格体験記
はじめに
以前受験したPython3エンジニア認定基礎試験に続いて、Python3エンジニア認定データ分析試験を受験し、合格しました。
合格のための勉強法や受験して思ったことを基礎試験同様まとめていきたいと思います。そもそもPython3エンジニア認定データ分析試験って?
一般社団法人Pythonエンジニア育成推進協会が実施している民間資格試験です。
2020年春からPythonを使ったデータ分析の基礎や方法を問う試験として始まりました。受験方式はCBTで全国の試験センターでいつでも受験でき、受験料は1万円(税別)。
筆者のレベル
- プログラミング歴4ヶ月
- 1ヶ月前にPython3エンジニア認定基礎試験合格
- Udemyで関連するコースをいくつか受講
- SIGNATEのBeginner限定コンペを経験、Tier5に昇格
- 実務未経験
出題範囲
「Pythonによるあたらしいデータ分析の教科書」(翔泳社)より出題、とされています。
私は上記教材を利用しましたが、そこまで目新しい情報はないのでなくても大丈夫かもしれません。
というか指定教材は内容も薄く索引が使いにくいので、正直微妙です。
ただし、基礎試験同様指定教材にあるコードがそのまま出たりするので、あると試験には有利です。
(唐突にライブラリに標準で入ってるデータセットの話とかが出てくるので知らないとぎょっとします。)勉強方法
- SIGNATEのBeginner限定コンペなどに挑戦し、実際に手を動かす。
- 認定スクールであるPrime StrategyとDIVE INTO EXAM※の模試を受験する。
- 理解できていないところがわかるのでチュートリアルやGoogle先生で調べる。
- 調べた内容をまとめてEvernoteに残しておく。
2〜4を繰り返し勉強しました。
※DIVE INTO EXAMの模試は2020年10月に始まったばかりで、まだ誤字がちらほら見られるので注意が必要です。
勉強期間
試験のために集中して勉強したのは丸一週間程度。
試験関係なくデータ分析の勉強をしたのは約50時間程度でした。受験して思ったこと
実際受験してみてどうだったか?
難易度は?
指定教材をしっかり読み込んだり、実際にデータ分析をした経験がある程度あれば難しくはないです。
基礎試験同様模試のほうがちょっと難しいです。模試と全く同じ問題が出たりもします。
実際にライブラリを触った経験があったほうが圧倒的に理解が早いので一度SIGNATEやKaggleのコンペティションを通してデータ分析に挑戦することをおすすめします。
試験ではメモ用紙が与えられないので、ある程度暗算・暗記が必要です。正直ちょっと焦りました・・・。良かった点
- 自分が使ったことがないコードやその仕組みを知ることができた
- 試験を意識することで短期間で集中して勉強できた
- 未経験だけどちゃんと勉強してまっせ、という箔が付いた(と、思いたい)
悪かった点
- やっぱり受験料11000円は高いよね・・・
- 資格の価値が未知なのでコスパとしてはどうだったのか
- 試験結果が点数しか出ないのでどこの問題を間違えたのかわからない
ちなみに
基礎試験同様試験に合格し、合格体験記を応募すると、公式
ネタグッズが貰えます。
データ分析試験合格者のみステッカーも選択することができます。
最近グッズにサーモスの水筒が追加されたようです。実用性ならこれ。おわりに
こういった民間資格は意味がない!と言う人もいますが勉強のモチベーションを得るきっかけや知識の証明にもなるので個人的にはアリだと思っています。
(ある程度実績が担保されている人が今更受けるのはさすがに無意味だと思いますが・・・。)今後は統計検定2級などを目指したいですが、難易度が跳ね上がるのでしばらく先になると思います。
- 投稿日:2020-10-14T17:46:16+09:00
pythonでpytestを使ってテスト駆動開発するときのディレクトリ構造
概略
ただの箇条書きです。
pytestで階層がしっかりしたドキュメントが見つからなかったため、
サンプルコードを載せておきます。ストーリー
以下の構造のように階層が深い時のサンプルコードが、
ググっても見つからなかったので記事にしました。. ├tests │├mod ││└test_module.py ├src │├mod ││└module.py以下のようなものは多く見かけました。
. ├tests │└test_module.py ├src │└module.pyテスト結果
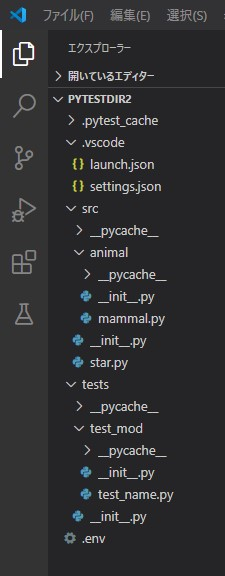
ディレクトリ構造
__init__.pyファイルの中身はすべて空です。
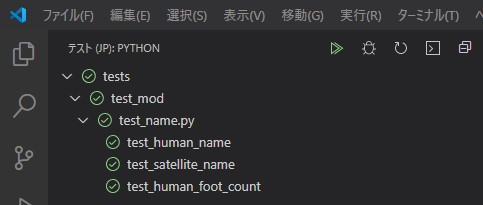
テスト
test_name.pyimport pytest from src.animal.mammal import human from src.star import satellite def test_human_name(): target=human("Jane Doe") ans=target.name assert ans=="Jane Doe" def test_satellite_name(): target=satellite("lua") ans=target.name assert ans=="lua" def test_human_foot_count(): ans=human.howmanyfoot() assert ans==2 if __name__ == "__main__": passテスト対象モジュール
star.pyclass satellite(): def __init__(self, name:str): self.name=name def name(self) -> str: return self.name class planet(): def __init__(self, name:str): self.name=name def name(self) -> str: return self.namemammal.pyclass human(): def __init__(self, name:str): self.name=name @classmethod def name(self) -> str: return self.name @staticmethod def howmanyfoot() -> int: return 2パスの設定
「Currrentfile デバッグ時」の
from importの処理をするときのエラー回避策です。
これを置いてあげることで、「Pythonのパス」や「他の階層の自作モジュール」を認識してくれるみたいです。.envPYTHONPATH=./デバッグ構成
3種類のデバッグ方法を定義しています。
上から順に、
- test_name モジュールをモジュールデバッグ
- mammalモジュールをモジュールデバッグ
- vscodeでカーソルを置いているファイルをデバッグ
launch.json{ // IntelliSense を使用して利用可能な属性を学べます。 // 既存の属性の説明をホバーして表示します。 // 詳細情報は次を確認してください: https://go.microsoft.com/fwlink/?linkid=830387 "version": "0.2.0", "configurations": [ { "name": "Python: モジュール test_name", "type": "python", "request": "launch", "cwd": "${workspaceFolder}", "module": "tests.test_mod.test_name" },{ "name": "Python: モジュール mammal", "type": "python", "request": "launch", "cwd": "${workspaceFolder}", "module": "src.animal.mammal" }, { "name": "Python: Current File", "type": "python", "request": "launch", "program": "${file}", "console": "integratedTerminal" } ] }ワークスペース設定
- テストモジュールを置いているフォルダ
- どのテスト用フレームワークを使用するか
- python環境はどれを使用するのか記述したファイルを指定
settings.json{ "python.testing.pytestArgs": [ "tests" ], "python.testing.unittestEnabled": false, "python.testing.nosetestsEnabled": false, "python.testing.pytestEnabled": true, "python.envFile": "${workspaceFolder}/.env" }
- 投稿日:2020-10-14T17:21:40+09:00
【Django】ログ出力機能について初心者でもわかるように簡単にまとめる
はじめに
DjangoのLogging機能って初見だとよくわからない内容もありますよね。特に設定ファイル。
簡単・簡潔にまとめていきます。本番環境想定の設定ファイル
ログの設定ですが、自分で設定を行わない場合(settings.pyにLOGGINGの定義が無い場合)Djangoソース内に含まれているデフォルト設定が使用されます。
しかし、出力されるログがあまり見やすくないので自分で設定する場合がほとんどです。
以下、本番環境を想定した設定例です。settings.pyに以下内容を追記します。settings.pyLOGGING = { 'version': 1, 'disable_existing_loggers': False, # ログ出力フォーマットの設定 'formatters': { 'production': { 'format': '%(asctime)s [%(levelname)s] %(process)d %(thread)d ' '%(pathname)s:%(lineno)d %(message)s' }, }, # ハンドラの設定 'handlers': { 'file': { 'level': 'INFO', 'class': 'logging.FileHandler', 'filename': '/var/log/{}/app.log'.format(PROJECT_NAME), 'formatter': 'production', }, }, # ロガーの設定 'loggers': { # 自分で追加したアプリケーション全般のログを拾うロガー '': { 'handlers': ['file'], 'level': 'INFO', 'propagate': False, }, # Django自身が出力するログ全般を拾うロガー 'django': { 'handlers': ['file'], 'level': 'INFO', 'propagate': False, }, }, }使用例
views.pyimport logging logger = logging.getLogger(__name__) logger.info("log info test!") logger.error("log error test!")ログには重要度に応じた5段階のレベルが設定されています。
上記使用例のようにloggerにログレベルと同名のメソッドを実行させることでログを出力することができます。
名前 用途 DEBUG デバッグの記録 INFO 正常動作の記録 WARNING 警告の記録 ERROR エラーなど重大な問題 CRITICAL システム自体の停止など致命的な問題 主要設定項目を見ていく
disable_existing_loggers
Tureの場合は設定ファイルで定義されていないloggerが全て無効化されます。
この段階だと「設定ファイルで定義されてないloggerってなに?」と思うかもしれませんが、意味としては後述するlogger項目で定義されていない名称のloggerが全て無効化されることになります。
基本的にFalseでOKだと思いますがこちらの記事で詳しく検証されているので気になる方はご確認ください。formatters
ログ出力の書式設定です。
ここできちんと設定しておくとログの出力フォーマットが揃ってログが見やすくなるので、設定必須と思っても良いです。
%(asctime)や%(levelname)が何を意味しているかは公式ドキュメントに日本語でわかりやすく記載されています。handlers
ログの出力方法についての設定です。
- level
ここで設定したログレベル以下のログは出力されなくなります。- class
ログ出力に使用するクラスです。この例ではファイルに出力するクラスを指定しています。
ログファイルをローテーションしたい(ファイルサイズや日付単位でファイルが分かれて欲しい)場合は'logging.handlers.RotatingFileHandler'や'logging.handlers.TimedRotatingFileHandler'を使用すると便利です(実際のやり方はこちらの記事に詳しく書かれています)。
他には例えば'logging.StreamHandler'を指定するとコンソールに出力されます。- filename
ログ出力するファイルのパスとファイル名を指定できます。- formatter
先に定義したformatterのうちどれを使用するかを指定します。loggers
実際にアプリから使用するloggerの設定です。
「''」で定義しているロガーは出力例にならった記述でimport logging logger = logging.getLogger(__name__)各アプリケーションから取得できます。
基本的にはこれとdjango自身が出力するloggerの設定があれば十分です。
- handlers
先に定義したhandlersのうちどれを使用するかを指定します。- level
handlersでの定義同様、ここで設定したログレベル以下のログは出力されなくなります。- propagate
これは+αの内容になるので興味が無い方は基本にFalseでOKぐらいに思っておいても問題無いです。以下、propagateについての解説です。
loggerは実は名前空間を持つことができます。
例として下記のような'logA'と'logA.logB'を定義します。'logger': { 'logA': { 'handlers': ['file'], 'level': 'INFO', 'propagate': False, }, 'logA.logB': { 'handlers': ['file'], 'level': 'INFO', 'propagate': False, },そしてアプリケーションから以下のようにloggerを取得します。
views.pyimport logging logger = logging.getLogger('logA.logB.logC') logger.info("log info test!")この時logCは定義されていないので結果としてlogBが取得されます。
指定されたloggerが無い場合は上の名前空間に上がっていって、最初に見つけたものを取得するイメージです。ここで、もしlogBとlogCも定義されており、かつpropagateがTrueだった場合、logA,logB,logC全てに対して
logger.info("log info test!")が実行されます。つまり、logA,logB,logCの設定が名前以外同じだった場合、全く同じ内容のログが3重に出力されます。
propagate(伝播)の名前通り、上の階層のloggerにもログ出力命令が伝播するんですね。
使いどころとしてはlogAにファイル出力用の設定、logBにコンソール出力用の設定をしておいて、ファイルだけで良い場合はlogAを取得、開発環境等でコンソールにも出したい場合はlogBを取得するようなイメージでしょうか(使ったこと無いですが…)。
以上です。最後は少し込み入った内容になってしまいましたが、複雑なことをしない限りこの記事に書いてある内容だけで基本的な設定はOKだと思います。
お疲れ様でした
- 投稿日:2020-10-14T16:59:46+09:00
ルービックキューブロボットのソフトウェアをアップデートした 1. 基本関数
この記事はなに?
私は現在2x2x2ルービックキューブを解くロボットを開発中です。これはそのロボットのプログラムの解説記事集です。
かつてこちらの記事に代表される記事集を書きましたが、この時からソフトウェアが大幅にアップデートされたので新しいプログラムについて紹介しようと思います。該当するコードはこちらで公開しています。
関連する記事集
「ルービックキューブを解くロボットを作ろう!」
1. 概要編
2. アルゴリズム編
3. ソフトウェア編
4. ハードウェア編「ルービックキューブロボットのソフトウェアをアップデートした」
1. 基本関数(本記事)
2. 事前計算
3. 解法探索
4. 状態認識
5. 機械操作(Python)
6. 機械操作(Arduino)
7. 主要処理今回は基本関数編として、
basic_functions.pyを紹介します。パズルを回転させる関数
パズルを配列として保持するやり方、およびパズルを回転させる処理の実装について説明します。
''' キューブを回転させる関数 ''' ''' Functions for twisting cube ''' # 回転処理 CP # Rotate CP def move_cp(cp, arr): # surfaceとreplace配列を使ってパーツを置換 surface = [[3, 1, 7, 5], [1, 0, 6, 7], [0, 2, 4, 6], [2, 3, 5, 4]] replace = [[3, 0, 1, 2], [2, 3, 0, 1], [1, 2, 3, 0]] res = [i for i in cp] for i, j in zip(surface[arr[0]], replace[-(arr[1] + 1)]): res[surface[arr[0]][j]] = cp[i] return res # 回転処理 CO # Rotate CO def move_co(co, arr): # surfaceとreplace配列を使ってパーツを置換した後pls配列を使って90度回転時のCOの変化を再現 surface = [[3, 1, 7, 5], [1, 0, 6, 7], [0, 2, 4, 6], [2, 3, 5, 4]] replace = [[3, 0, 1, 2], [2, 3, 0, 1], [1, 2, 3, 0]] pls = [2, 1, 2, 1] res = [i for i in co] for i, j in zip(surface[arr[0]], replace[-(arr[1] + 1)]): res[surface[arr[0]][j]] = co[i] if arr[1] != -2: for i in range(4): res[surface[arr[0]][i]] += pls[i] res[surface[arr[0]][i]] %= 3 return res2x2x2ルービックキューブ(の色がついているパーズ)には図のように1種類のパーツが8つあります。
このパズルの状態を、例えば色の配置で持っていたらとてもではありませんがメモリ使用量が多く、何より扱いにくいです。そこで、パズルの状態を2つの配列に保持することにします。
- 各パーツの並び順を表すCP(Corner Permutation)配列
- 各パーツの向きを表すCO(Corner Orientation)配列
の2種類です。それぞれ要素数8の配列で表します。なお、パーツは8つあるため、CP配列の要素は
0, 1, 2, 3, 4, 5, 6, 7、各パーツの向きには3種類あるため、CO配列の要素は0, 1, 2です。紹介した関数は基本的にパズルを回す行為を配列の置換で表します。CO配列に関してはパズルの回し方によってはパーツの向きが変化するため、追加の処理があります。
状態のインデックス化
パズルをいつでも配列として保持しておくのはあまり良くはありません。処理に時間がかかる上にメモリも食います。そこで、次回の記事(事前計算)では、パズルの状態1つ1つに固有の値を紐付けます。この時に大活躍する配列と値をつなぐ関数を解説します。
''' 配列のインデックス化 ''' ''' Indexing''' # cp配列から固有の番号を作成 # Return the number of CP def cp2idx(cp): # 階乗進数でインデックス化 res = 0 for i in range(8): cnt = cp[i] for j in cp[:i]: if j < cp[i]: cnt -= 1 res += fac[7 - i] * cnt return res # co配列から固有の番号を作成 # Return the number of CO def co2idx(co): # 3進数でインデックス化。7つのパーツを見れば状態が一意に定まる res = 0 for i in co[:7]: res *= 3 res += i return res # 固有の番号からcp配列を作成 # Return the array of CP def idx2cp(cp_idx): # 階乗進数から配列への変換 res = [-1 for _ in range(8)] for i in range(8): candidate = cp_idx // fac[7 - i] marked = [True for _ in range(i)] for _ in range(8): for j, k in enumerate(res[:i]): if k <= candidate and marked[j]: candidate += 1 marked[j] = False res[i] = candidate cp_idx %= fac[7 - i] return res # 固有の番号からco配列を作成 # Return the array of CO def idx2co(co_idx): # 3進数から配列への変換 res = [0 for _ in range(8)] for i in range(7): res[6 - i] = co_idx % 3 co_idx //= 3 res[7] = (3 - sum(res) % 3) % 3 return resインデックス化には、CP配列は要するに順列の番号づけをすれば良いので階乗進数を使います。CO配列は配列自体を7桁の3進数と見なしてそれを10進数に変換します。
階乗進数の計算についてはこちらのサイトに書いてあることを実装しただけです。
CO配列のインデックス化について、「なぜ要素数は8なのに7桁の3進数とみなすんだ?」と思った方がいらっしゃると思います。パズルのCOは揃えられる状態である限り、7つのパーツを見れば残り1つのパーツの状態がわかってしまうのです。だから7桁の3進数で事足りるのです。
よく使う定数
複数のプログラムで使ったりとよく使う定数、配列をまとめて書いています。
''' 定数 ''' ''' Constants ''' # 階乗の値 fac = [1] for i in range(1, 9): fac.append(fac[-1] * i) # よく使う値と配列 grip_cost = 1 j2color = ['g', 'b', 'r', 'o', 'y', 'w'] dic = {'w':'white', 'g':'green', 'r':'red', 'b':'blue', 'o':'magenta', 'y':'yellow'} parts_color = [['w', 'o', 'b'], ['w', 'b', 'r'], ['w', 'g', 'o'], ['w', 'r', 'g'], ['y', 'o', 'g'], ['y', 'g', 'r'], ['y', 'b', 'o'], ['y', 'r', 'b']] parts_place = [[[0, 2], [2, 0], [2, 7]], [[0, 3], [2, 6], [2, 5]], [[1, 2], [2, 2], [2, 1]], [[1, 3], [2, 4], [2, 3]], [[4, 2], [3, 1], [3, 2]], [[4, 3], [3, 3], [3, 4]], [[5, 2], [3, 7], [3, 0]], [[5, 3], [3, 5], [3, 6]]] twist_lst = [[[0, -1]], [[0, -2]], [[2, -1]], [[0, -1], [2, -1]], [[0, -2], [2, -1]], [[0, -1], [2, -2]], [[1, -1]], [[1, -2]], [[3, -1]], [[1, -1], [3, -1]], [[1, -2], [3, -1]], [[1, -1], [3, -2]]] cost_lst = [1, 2, 1, 1, 2, 2, 1, 2, 1, 1, 2, 2] solved_cp = [[0, 1, 2, 3, 4, 5, 6, 7], [2, 3, 4, 5, 6, 7, 0, 1], [4, 5, 6, 7, 0, 1, 2, 3], [6, 7, 0, 1, 2, 3, 4, 5], [1, 7, 3, 5, 2, 4, 0, 6], [3, 5, 2, 4, 0, 6, 1, 7], [2, 4, 0, 6, 1, 7, 3, 5], [0, 6, 1, 7, 3, 5, 2, 4], [7, 6, 5, 4, 3, 2, 1, 0], [5, 4, 3, 2, 1, 0, 7, 6], [3, 2, 1, 0, 7, 6, 5, 4], [1, 0, 7, 6, 5, 4, 3, 2], [6, 0, 4, 2, 5, 3, 7, 1], [4, 2, 5, 3, 7, 1, 6, 0], [5, 3, 7, 1, 6, 0, 4, 2], [7, 1, 6, 0, 4, 2, 5, 3], [2, 0, 3, 1, 5, 7, 4, 6], [3, 1, 5, 7, 4, 6, 2, 0], [5, 7, 4, 6, 2, 0, 3, 1], [4, 6, 2, 0, 3, 1, 5, 7], [6, 4, 7, 5, 1, 3, 0, 2], [7, 5, 1, 3, 0, 2, 6, 4], [1, 3, 0, 2, 6, 4, 7, 5], [0, 2, 6, 4, 7, 5, 1, 3]] solved_co = [[0, 0, 0, 0, 0, 0, 0, 0], [2, 1, 1, 2, 2, 1, 1, 2], [0, 0, 0, 0, 0, 0, 0, 0], [2, 1, 1, 2, 2, 1, 1, 2], [1, 2, 2, 1, 1, 2, 2, 1], [1, 2, 2, 1, 1, 2, 2, 1], [1, 2, 2, 1, 1, 2, 2, 1], [1, 2, 2, 1, 1, 2, 2, 1], [0, 0, 0, 0, 0, 0, 0, 0], [2, 1, 1, 2, 2, 1, 1, 2], [0, 0, 0, 0, 0, 0, 0, 0], [2, 1, 1, 2, 2, 1, 1, 2], [1, 2, 2, 1, 1, 2, 2, 1], [1, 2, 2, 1, 1, 2, 2, 1], [1, 2, 2, 1, 1, 2, 2, 1], [1, 2, 2, 1, 1, 2, 2, 1], [0, 0, 0, 0, 0, 0, 0, 0], [2, 1, 1, 2, 2, 1, 1, 2], [0, 0, 0, 0, 0, 0, 0, 0], [2, 1, 1, 2, 2, 1, 1, 2], [0, 0, 0, 0, 0, 0, 0, 0], [2, 1, 1, 2, 2, 1, 1, 2], [0, 0, 0, 0, 0, 0, 0, 0], [2, 1, 1, 2, 2, 1, 1, 2]] neary_solved_depth = 15それぞれの定数と配列の意味するところは実際にそれを使うときに解説します。
まとめ
ルービックキューブロボットの基本関数を解説しました。全ての他のプログラムでこの関数や定数を使っています。


- 投稿日:2020-10-14T16:26:11+09:00
【Udemy Python3入門+応用】 68. Import文とAS
※この記事はUdemyの
「現役シリコンバレーエンジニアが教えるPython3入門+応用+アメリカのシリコンバレー流コードスタイル」
の講座を受講した上での、自分用の授業ノートです。
講師の酒井潤さんから許可をいただいた上で公開しています。■import文とas
◆import
こんな風にディレクトリとファイルを用意する。
lesson_package ├ __init__.py └ utils.py lesson.pyutils.pydef say_twice(word): return (word + '!') * 2lesson.pyimport lesson_package.utils r = lesson_package.utils.say_twice('hello') print(r)resulthello!hello!
import lesson_package.utilsのようにフルパスで書いてあげることで、他のファイルにある関数を読み込むことができる。
◆fromとimport
import lesson_package.utilsは、
from lesson_package import utilsという風に書いてもOK。その際は、
lesson.pyfrom lesson_package import utils r = utils.say_twice('hello') print(r)という風に使うことができる。
◆as
lesson.pyfrom lesson_package import utils as ut r = ut.say_twice('hello') print(r)asで文字列を指定してあげることで、好きな文字列で呼び出すことができる。
- 投稿日:2020-10-14T16:00:01+09:00
【Udemy Python3入門+応用】 67. コマンドライン引数
※この記事はUdemyの
「現役シリコンバレーエンジニアが教えるPython3入門+応用+アメリカのシリコンバレー流コードスタイル」
の講座を受講した上での、自分用の授業ノートです。
講師の酒井潤さんから許可をいただいた上で公開しています。■コマンドライン引数
terminalpython3 test.py arg1 arg2import sys print(sys.argv)result['test.py', 'arg1', 'arg2']ターミナルからPythonファイルを実行する際、Pythonファイル名の後ろに引数を渡すことができる。
これらの引数はsys.argvにリストとして格納される。従って、
import sys for i in sys.argv: print(i)resulttest.py arg1 arg2こういった使い方が可能。
- 投稿日:2020-10-14T15:24:43+09:00
kerasを用いたオートエンコーダによる異常検知【初心者向け実装例】
この記事でやったこと
- kerasを使ってオートエンコーダの実装にチャレンジ
- 教師なし学習による異常検知を実装
- 再現率と適合率から効果を評価はじめに
教師なし学習は一般的に教師あり学習と比較すると精度が落ちますが、その代わりに様々なメリットがあります。具体的に教師なし学習が役に立つシーンとして
- パターンがあまりわかっていないデータ
- 時間的に変動するデータ
- 十分にラベルがついていないデータなどが挙げられます。
教師なし学習ではデータそのものから、データの背後にある構造を学習します。これによってラベルのついていないデータをより多く活用できるので、新たなアプリケーションへの道が開けるかもしれません。
というわけで、今回は教師なし学習を使った異常検知の方法について紹介します。異常検知にも色々な種類がありますが、ここではオートエンコーダを用いたときの異常検知のコードを紹介します。
データやコードは「pythonによる教師なし学習」を参考にさせて頂いています。
扱うデータ
クレジットカードの不正検知に関するデータセットを用います。元々はkaggleで用いられたデータみたいです。
下記よりデータがダウンロードできます。
https://github.com/aapatel09/handson-unsupervised-learning/blob/master/datasets/credit_card_data/credit_card.csvライブラリのインポート
参考図書のまんまなので、少し不要なものも含まれています。
'''Main''' import numpy as np import pandas as pd import os, time, re import pickle, gzip '''Data Viz''' import matplotlib.pyplot as plt import seaborn as sns color = sns.color_palette() import matplotlib as mpl %matplotlib inline '''Data Prep and Model Evaluation''' from sklearn import preprocessing as pp from sklearn.model_selection import train_test_split from sklearn.model_selection import StratifiedKFold from sklearn.metrics import log_loss from sklearn.metrics import precision_recall_curve, average_precision_score from sklearn.metrics import roc_curve, auc, roc_auc_score '''TensorFlow and Keras''' import tensorflow as tf import keras from keras import backend as K from keras.models import Sequential, Model from keras.layers import Activation, Dense, Dropout from keras.layers import BatchNormalization, Input, Lambda from keras import regularizers from keras.losses import mse, binary_crossentropy sns.set("talk")データのダウンロード
data = pd.read_csv("credit_card.csv") dataX = data.copy().drop(["Class","Time"],axis=1) dataY = data["Class"].copy() print("dataX shape:{},dataY shape:{}".format(dataX.shape,dataY.shape)) dataX.head()こんな感じのデータ出力されると思います。実際には29列あるはず。
- dataXには284807人のカードの利用を表すデータが含まれている
- dataYには284807人の破産したかどうかのデータがある
ということになります。カードのどのような利用を表しているかなどはこのデータからだけではわかりまりませんね。
異常検知手法の概要
次にどうやって異常検知を行うかを紹介します。
上記のデータでは、利用者の約0.2%が不正利用されているということになっています。すなわち殆どが正常に使われているデータということになります。そこで、この不正利用されているデータではなにがしかデータ構造が正常データと異なると考えます。このデータ構造の違いをオートエンコーダを使ってあぶり出してやろう、という試みです。
ではどうやってオートエンコーダで異常データを炙り出せるのでしょうか。オートエンコーダとは下記のように、一度次元数を落としたデータに圧縮したのちに、再び同じ次元数のデータに再構成します。
再構成されたデータでは、通常では元のデータと同じ値になっています。しかしながら、異常なデータでは通常のデータと異なり、元のデータとは異なるデータになります。
この元のデータと再構成されたデータの誤差をとってやることで異常データかどうかを判断します。
最初は自分はあまりすっきりしない方法でしたが、よくよく考えるとめちゃくちゃ合理的です。ただ、注意としてこの手法では異常データの数が通常データと比較して非常に少ないことが前提となっています。異常データがいっぱいあると、通常データの再構成もうまくいかなくなってしまうためです。
訓練データと評価データの作成
#全ての特徴量の平均が0、標準偏差が1となるようにスケール変換する featuresToScale = dataX.columns sX = pp.StandardScaler(copy=True, with_mean=True, with_std=True) dataX.loc[:,featuresToScale] = sX.fit_transform(dataX[featuresToScale]) #訓練データとテストデータに振り分ける X_train, X_test, y_train, y_test = \ train_test_split(dataX,dataY,test_size=0.33,random_state=2018,stratify=dataY) X_train_AE = X_train.copy() X_test_AE = X_test.copy()オートエンコーダの実装
次にオートエンコーダの実装方法です。
ここでは2層の線形活性化関数を用いたオートエンコーダを作成します。
普段と違うのは正解データを用いないので、正解データも学習データと同じものを入力しているところですね。#2層の線形活性化関数を用いたオートエンコーダの構築 model = Sequential() model.add(Dense(units=27,activation="linear",input_dim=29)) #unitsでいくつの層にデータを凝縮するかを決定する。 model.add(Dense(units=29,activation="linear")) model.compile(optimizer="adam",loss="mean_squared_error",metrics="accuracy") num_epochs = 3 batch_size = 32 history = model.fit(x=X_train_AE,y=X_train_AE, epochs=num_epochs, batch_size=batch_size, shuffle=True, validation_data=(X_train_AE,X_train_AE), verbose=1)評価関数の作成
ここまでで、オートエンコーダができました。次に、このオートエンコーダを評価するために
- 元のデータと最高性されたデータの誤差を計算する関数
- 適合率-再現率曲線、AUC曲線を描画する関数を作成します。
まずは、再構成誤差を計算する関数です。こちらは二乗誤差をとるだけなのでそこまで難しくはなさそうです。
#元の特徴量と新たに再構成された特徴量行列の間の最高性誤差を計算する異常スコア関数 #二乗誤差の和を計算して正規化し、0と1の間にする #1に近いと異常、0に近いと正常 def anomalyScores(originalDF,reduceDF): loss = np.sum((np.array(originalDF)-np.array(reduceDF))**2,axis=1) loss = pd.Series(data=loss,index=originalDF.index) loss = (loss-np.min(loss))/(np.max(loss)-np.min(loss)) return loss次に適合率-再現率曲線、AUC曲線を描画する関数です。
#適合率-再現率曲線、平均適合率、auROC曲線をプロットする def plotResults(trueLabels, anomalyScores,returnPreds=False): preds = pd.concat([trueLabels,anomalyScores],axis=1) preds.columns = ["trueLabel","anomalyScore"] #各しきい値のときの適合率(precision)と再現率(recall)を計算 precision, recall, thresholds = precision_recall_curve(preds["trueLabel"],preds["anomalyScore"]) average_precision = average_precision_score(preds["trueLabel"],preds["anomalyScore"]) # 適合率-再現率曲線 plt.step(recall,precision,color="k",alpha=0.7,where="post") plt.fill_between(recall,precision,step="post",alpha=0.3,color="k") plt.xlabel("Recall") plt.ylabel("Precision") plt.ylim([0,1.05]) plt.xlim([0,1.0]) plt.title("Precision-Recall Curve:Average Precision={0:0.2f}".format(average_precision)) fpr,tpr,thresholds = roc_curve(preds["trueLabel"],preds["anomalyScore"]) areaUnderROC = auc(fpr,tpr) #AUC曲線 plt.figure() plt.plot(fpr,tpr,color="r",lw=2,label="ROC curve") plt.plot([0,1],[0,1],color="k",lw=2,linestyle="--") plt.xlabel("False positive Rate") plt.ylabel("True Postive Rate") plt.ylim([0,1.05]) plt.xlim([0,1.0]) plt.title("Receiver operating characteristic: Area under the curve = {0:0.2f}".format(areaUnderROC)) plt.legend(loc="lower right") plt.show() if returnPreds == True: return predsこの関数では、正解データのラベルと異常値を格納したdataframeを作成しています。
ポイントとなる関数はprecision_recall_curveとroc_curveです。precision_recall_curveではしきい値を1から0に変化させたときの適合率と再現率を計算する関数です。
例えば、しきい値が0のとき、0以上をすべてエラーと判断します。つまり全てがエラーと判断されるわけです。こうなると、適合率は0に再現率は1になります。これを各しきい値ごとに計算してくれる便利な関数です。
roc_curveでは偽陽性率(False Positive Rate)と真陽性率(True Positive Rate)を各しきい値ごとに計算します。
例えば、しきい値が0のとき、0以上をすべて陽性と判断します。そうすると真陽性率は偽陰性が0件のため1となります。また、偽陽性率も真陰性が0件のため1となります。こんなふうに様々なしきい値での割合をけいしてくれる便利な関数です。
オートエンコーダによる異常検知の評価結果
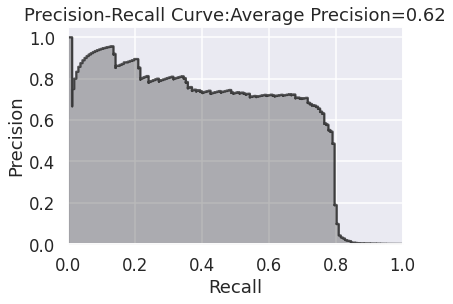
それでは、実際にさきほど実装したオートエンコーダの評価結果です。
まずは適合率-再現率のグラフから。
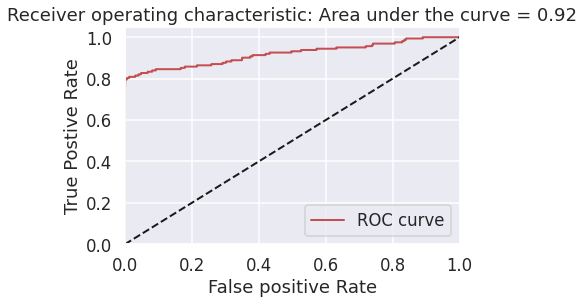
横軸の再現率が75%のとき、縦軸の適合率の値は60%ほどになっていますね。これはつまり、不正利用の75%を捉えることができて、そうやって捉えた不正利用の60%が実際に不正データである、ということを示しています。次にauROC曲線です。
偽陽性率を低く抑えながら真陽性率を高くするための指標になります。このときの指標は0.92となりました。
これらの結果より、正解データを用いた学習をさせなくともある程度の分類が可能であることがわかりました。更に精度を上げるためには、学習に
- dropoutを導入する
- 活性化関数を変化させる
- 圧縮させるときのノード数を変化させる
が考えられます。
終わりに
教師なし学習では、ラベルデータが大量になくとも学習が可能なこと、データの変化に対して柔軟なことが強みです。
個人的には、機械学習で勝手にデータの背後にある構造を理解しているのが面白く感じます。いったいどうやって学習しているんだろうか...。なかなか想像して言語化するのが難しい世界ですね。
本の中では、他にも識別するのみでなく、実際にデータを生成するための方法も紹介されています。(制限付きボルツマンマシン、深層学習、GANなど)
皆様の学習の参考になりましたら幸いです。

- 投稿日:2020-10-14T14:25:37+09:00
Alibaba CloudでACMEを暗号化:ACMEエンドポイント、ディレクトリ、ACMEアカウントの作成
今回の多部構成の記事では、Pythonを使ったLet's Encrypt ACME version 2 APIをSSL証明書に利用する方法を学びます。
本ブログは英語版からの翻訳です。オリジナルはこちらからご確認いただけます。一部機械翻訳を使用しております。翻訳の間違いがありましたら、ご指摘いただけると幸いです。
APIエンドポイントを暗号化しよう
Let's Encrypt ACMEは、異なるエンドポイントを使用して2つのモードをサポートしています。本物の証明書を発行し、レートが制限される本番モードと、テスト用の証明書を発行するテスト用のステージングモードです。本番用のエンドポイントでは、1日にできるリクエストの数を制限します。Let's Encrypt 用のソフトウェアを開発している間は、ステージングエンドポイントを使用していることを確認してください。
Staging Endpoint:https://acme-staging-v02.api.letsencrypt.org/directory
Production Endpoint:https://acme-v02.api.letsencrypt.org/directory
ACMEディレクトリ
最初のAPIコールでは、ACMEディレクトリを取得する必要があります。ディレクトリは、様々なコマンドのために呼び出すURLのリストです。getディレクトリからのレスポンスは、以下のようなJSON構造になっています。
{ "LPTIN-Jj4u0": "https://community.letsencrypt.org/t/adding-random-entries-to-the-directory/33417", "keyChange": "https://acme-staging-v02.api.letsencrypt.org/acme/key-change", "meta": { "caaIdentities": [ "letsencrypt.org" ], "termsOfService": "https://letsencrypt.org/documents/LE-SA-v1.2-November-15-2017.pdf", "website": "https://letsencrypt.org/docs/staging-environment/" }, "newAccount": "https://acme-staging-v02.api.letsencrypt.org/acme/new-acct", "newNonce": "https://acme-staging-v02.api.letsencrypt.org/acme/new-nonce", "newOrder": "https://acme-staging-v02.api.letsencrypt.org/acme/new-order", "revokeCert": "https://acme-staging-v02.api.letsencrypt.org/acme/revoke-cert" }最初の行は無視してください。ACMEはランダムなキーと値を生成し、JSONの期待値をコードにハードコーディングしないようにしています。
返されるデータ部分をそれぞれ見てみましょう。
keyChange
このURLは、アカウントに関連付けられた公開鍵を変更するために使用されます。これは、鍵の危殆化から回復するために使用されます。meta.caaIdentities
CAAレコードの検証のために、ACMEサーバが自分自身を参照していると認識するホスト名の配列。サンプルコードではこれらのレコードは使用していません。meta.termsOfService
現在の利用規約を示すURLです。https://letsencrypt.org/documents/LE-SA-v1.2-November-15-2017.pdf の利用規約に関する参照文書を時間をかけて読んでください。サンプルコードでは、利用規約を受け入れるフィールドをデフォルトで設定しています。meta.website
ACMEサーバーに関する詳細な情報を提供するウェブサイトを検索するURL。このレコードはサンプルコードでは使用していません。このレコードについての詳細はこちらをご覧ください https://letsencrypt.org/docs/staging-environment/newAccount
これは重要なAPIであり、ACME APIを呼び出す際には2回目の呼び出しを行う必要があります。nonce は、リプレイ攻撃から保護する一意のランダムな値です。(ディレクトリを除く) 各APIコールは、一意のnonce値を必要とします。newNonce
このエンドポイントは、新しいアカウントを作成するために使用されます。newOrder
このエンドポイントは、このSSL証明書の発行を要求するために使用されます。revokeCert
このエンドポイントは、同じアカウントで発行された既存の証明書を失効させるために使用されます。ACMEディレクトリを取得するためのコード例
これは、examples パッケージの中で最もシンプルな ACME API の例です。この例では、ACMEメインエンドポイントを呼び出すだけです。返されるデータは、上記で説明したようにAPIエンドポイントを定義するJSON構造体です。このプログラムからの出力を確認し、以下の例のほとんどで使用される様々な URL に精通してください。
Source: get_directory.py
""" Let's Encrypt ACME Version 2 Examples - Get Directory""" # This example will call the ACME API directory and display the returned data # Reference: https://ietf-wg-acme.github.io/acme/draft-ietf-acme-acme.html#rfc.section.7.1.1 import sys import requests import helper path = 'https://acme-staging-v02.api.letsencrypt.org/directory' headers = { 'User-Agent': 'neoprime.io-acme-client/1.0', 'Accept-Language': 'en' } try: print('Calling endpoint:', path) directory = requests.get(path, headers=headers) except requests.exceptions.RequestException as error: print(error) sys.exit(1) if directory.status_code < 200 or directory.status_code >= 300: print('Error calling ACME endpoint:', directory.reason) sys.exit(1) # The output should be json. If not something is wrong try: acme_config = directory.json() except Exception as ex: print("Error: Cannot load returned data:", ex) sys.exit(1) print('') print('Returned Data:') print('****************************************') print(directory.text) acme_config = directory.json() print('') print('Formatted JSON:') print('****************************************') helper.print_dict(acme_config, 0)新規アカウントを作成するためのコード例
次のステップは、ACMEサーバーに新しいアカウントを作成することです。これには、パート2で作成したaccount.keyを使用します。ACMEサーバーは、アカウントデータベースに会社名などの情報を追跡しません。
この例では、EmailAddress パラメータを自分のメールアドレスに変更します。この例では、複数のメールアドレスを含める方法を示しています。ACME サーバでは、電子メール・アドレスの入力は任意であるため、必須ではありません。ACMEサーバはメールアドレスを確認しません。
このコードについて、いくつかの重要なポイントを確認してみましょう。
1. ACMEディレクトリを取得する
acme_config = get_directory()2. 「newAccount」のURLを取得する
url = acme_config["newAccount"]3. 最初の ACME API 呼び出しに対して nonce を要求
最初の ACME API 呼び出しの後、各 ACME API 呼び出しの後、ヘッダ "Replay-Nonce" に新しい nonce が返されます。nonce = requests.head(acme_config['newNonce']).headers['Replay-Nonce']4. HTMLヘッダを組み立てる
重要な項目は Content-Type: application/jose+jsonheaders = { 'User-Agent': 'neoprime.io-acme-client/1.0', 'Accept-Language': 'en', 'Content-Type': 'application/jose+json' }5. HTMLボディをACME APIパラメータで組み立てる
HTTPボディの作成については、その4で詳しく解説します。payload = {} payload["termsOfServiceAgreed"] = True payload["contact"] = EmailAddresses body_top = { "alg": "RS256", "jwk": myhelper.get_jwk(AccountKeyFile), "url": url, "nonce": nonce }6. HTML本体「jose」のデータ構造を組み立てる
すべてがbase64でエンコードされていることに注目してください。body_top_b64 = myhelper.b64(json.dumps(body_top).encode("utf8")) payload_b64 = myhelper.b64(json.dumps(payload).encode("utf8")) jose = { "protected": body_top_b64, "payload": payload_b64, "signature": myhelper.b64(signature) }7. 最後に、ACME API を呼び出します。
これは、JSONボディを持つHTTP POSTで行われます。resp = requests.post(url, json=jose, headers=headers)8. ACME APIの後、HTTPレスポンスヘッダには2つの項目が返されます。
LocationはアカウントのURLです。Replay-Nonceは、次のACME APIコールの "nonce "値です。
resp.headers['Location'] resp.headers['Replay-Nonce']ほとんどのACME APIコールでは、HTTPヘッダが含まれていることが必要です。
Content-Type: application/jose+jsonソース: new_account.py
""" Let's Encrypt ACME Version 2 Examples - New Account""" # This example will call the ACME API directory and create a new account # Reference: https://ietf-wg-acme.github.io/acme/draft-ietf-acme-acme.html#rfc.section.7.3.2 import os import sys import json import requests import myhelper # Staging URL path = 'https://acme-staging-v02.api.letsencrypt.org/directory' # Production URL # path = 'https://acme-v02.api.letsencrypt.org/directory' AccountKeyFile = 'account.key' EmailAddresses = ['mailto:someone@eexample.com', 'mailto:someone2@eexample.com'] def check_account_key_file(): """ Verify that the Account Key File exists and prompt to create if it does not exist """ if os.path.exists(AccountKeyFile) is not False: return True print('Error: File does not exist: {0}'.format(AccountKeyFile)) if myhelper.Confirm('Create new account private key (y/n): ') is False: print('Cancelled') return False myhelper.create_rsa_private_key(AccountKeyFile) if os.path.exists(AccountKeyFile) is False: print('Error: File does not exist: {0}'.format(AccountKeyFile)) return False return True def get_directory(): """ Get the ACME Directory """ headers = { 'User-Agent': 'neoprime.io-acme-client/1.0', 'Accept-Language': 'en', } try: print('Calling endpoint:', path) directory = requests.get(path, headers=headers) except requests.exceptions.RequestException as error: print(error) return False if directory.status_code < 200 or directory.status_code >= 300: print('Error calling ACME endpoint:', directory.reason) print(directory.text) return False # The following statements are to understand the output acme_config = directory.json() return acme_config def main(): """ Main Program Function """ headers = { 'User-Agent': 'neoprime.io-acme-client/1.0', 'Accept-Language': 'en', 'Content-Type': 'application/jose+json' } if check_account_key_file() is False: sys.exit(1) acme_config = get_directory() if acme_config is False: sys.exit(1) url = acme_config["newAccount"] # Get the URL for the terms of service terms_service = acme_config.get("meta", {}).get("termsOfService", "") print('Terms of Service:', terms_service) nonce = requests.head(acme_config['newNonce']).headers['Replay-Nonce'] print('Nonce:', nonce) print("") # Create the account request payload = {} if terms_service != "": payload["termsOfServiceAgreed"] = True payload["contact"] = EmailAddresses payload_b64 = myhelper.b64(json.dumps(payload).encode("utf8")) body_top = { "alg": "RS256", "jwk": myhelper.get_jwk(AccountKeyFile), "url": url, "nonce": nonce } body_top_b64 = myhelper.b64(json.dumps(body_top).encode("utf8")) data = "{0}.{1}".format(body_top_b64, payload_b64).encode("utf8") signature = myhelper.sign(data, AccountKeyFile) # # Create the HTML request body # jose = { "protected": body_top_b64, "payload": payload_b64, "signature": myhelper.b64(signature) } try: print('Calling endpoint:', url) resp = requests.post(url, json=jose, headers=headers) except requests.exceptions.RequestException as error: resp = error.response print(resp) except Exception as ex: print(ex) except BaseException as ex: print(ex) if resp.status_code < 200 or resp.status_code >= 300: print('Error calling ACME endpoint:', resp.reason) print('Status Code:', resp.status_code) myhelper.process_error_message(resp.text) sys.exit(1) print('') if 'Location' in resp.headers: print('Account URL:', resp.headers['Location']) else: print('Error: Response headers did not contain the header "Location"') main() sys.exit(0)アカウント情報を取得するためのコード例
さて、account.keyを使ってアカウントを作成したので、ACMEサーバと通信して、サーバにどのような情報が保存されているかを確認してみましょう。この例では、設定パラメータをソースコードにハードコーディングする代わりに、設定ファイル「acme.ini」を導入しています。
acme.iniを修正して、メールアドレスなどの特定の情報を含めるようにします。
ソース: acme.ini
[acme-neoprime] UserAgent = neoprime.io-acme-client/1.0 # [Required] ACME account key AccountKeyFile = account.key # Certifcate Signing Request (CSR) CSRFile = example.com.csr ChainFile = example.com.chain.pem # ACME URL # Staging URL # https://acme-staging-v02.api.letsencrypt.org/directory # Production URL # https://acme-v02.api.letsencrypt.org/directory ACMEDirectory = https://acme-staging-v02.api.letsencrypt.org/directory # Email Addresses so that LetsEncrypt can notify about SSL renewals Contacts = mailto:example.com;mailto:someone2@example.com # Preferred Language Language = enソース: get_acount_info.py
""" Let's Encrypt ACME Version 2 Examples - Get Account Information """ ############################################################ # This example will call the ACME API directory and get the account information # Reference: https://ietf-wg-acme.github.io/acme/draft-ietf-acme-acme.html#rfc.section.7.3.3 # # This program uses the AccountKeyFile set in acme.ini to return information about the ACME account. ############################################################ import sys import json import requests import helper import myhelper ############################################################ # Start - Global Variables g_debug = 0 acme_path = '' AccountKeyFile = '' EmailAddresses = [] headers = {} # End - Global Variables ############################################################ ############################################################ # Load the configuration from acme.ini ############################################################ def load_acme_parameters(debug=0): """ Load the configuration from acme.ini """ global acme_path global AccountKeyFile global EmailAddresses global headers config = myhelper.load_acme_config(filename='acme.ini') if debug is not 0: print(config.get('acme-neoprime', 'accountkeyfile')) print(config.get('acme-neoprime', 'csrfile')) print(config.get('acme-neoprime', 'chainfile')) print(config.get('acme-neoprime', 'acmedirectory')) print(config.get('acme-neoprime', 'contacts')) print(config.get('acme-neoprime', 'language')) acme_path = config.get('acme-neoprime', 'acmedirectory') AccountKeyFile = config.get('acme-neoprime', 'accountkeyfile') EmailAddresses = config.get('acme-neoprime', 'contacts').split(';') headers['User-Agent'] = config.get('acme-neoprime', 'UserAgent') headers['Accept-Language'] = config.get('acme-neoprime', 'language') headers['Content-Type'] = 'application/jose+json' return config ############################################################ # ############################################################ def get_account_url(url, nonce): """ Get the Account URL based upon the account key """ # Create the account request payload = {} payload["termsOfServiceAgreed"] = True payload["contact"] = EmailAddresses payload["onlyReturnExisting"] = True payload_b64 = myhelper.b64(json.dumps(payload).encode("utf8")) body_top = { "alg": "RS256", "jwk": myhelper.get_jwk(AccountKeyFile), "url": url, "nonce": nonce } body_top_b64 = myhelper.b64(json.dumps(body_top).encode("utf8")) # # Create the message digest # data = "{0}.{1}".format(body_top_b64, payload_b64).encode("utf8") signature = myhelper.sign(data, AccountKeyFile) # # Create the HTML request body # jose = { "protected": body_top_b64, "payload": payload_b64, "signature": myhelper.b64(signature) } # # Make the ACME request # try: print('Calling endpoint:', url) resp = requests.post(url, json=jose, headers=headers) except requests.exceptions.RequestException as error: resp = error.response print(resp) except Exception as error: print(error) if resp.status_code < 200 or resp.status_code >= 300: print('Error calling ACME endpoint:', resp.reason) print('Status Code:', resp.status_code) myhelper.process_error_message(resp.text) sys.exit(1) if 'Location' in resp.headers: print('Account URL:', resp.headers['Location']) else: print('Error: Response headers did not contain the header "Location"') # Get the nonce for the next command request nonce = resp.headers['Replay-Nonce'] account_url = resp.headers['Location'] return nonce, account_url ############################################################ # ############################################################ def get_account_info(nonce, url, location): """ Get the Account Information """ # Create the account request payload = {} payload_b64 = myhelper.b64(json.dumps(payload).encode("utf8")) body_top = { "alg": "RS256", "kid": location, "nonce": nonce, "url": location } body_top_b64 = myhelper.b64(json.dumps(body_top).encode("utf8")) # # Create the message digest # data = "{0}.{1}".format(body_top_b64, payload_b64).encode("utf8") signature = myhelper.sign(data, AccountKeyFile) # # Create the HTML request body # jose = { "protected": body_top_b64, "payload": payload_b64, "signature": myhelper.b64(signature) } # # Make the ACME request # try: print('Calling endpoint:', url) resp = requests.post(url, json=jose, headers=headers) except requests.exceptions.RequestException as error: resp = error.response print(resp) except Exception as error: print(error) if resp.status_code < 200 or resp.status_code >= 300: print('Error calling ACME endpoint:', resp.reason) print('Status Code:', resp.status_code) myhelper.process_error_message(resp.text) sys.exit(1) nonce = resp.headers['Replay-Nonce'] # resp.text is the returned JSON data describing the account return nonce, resp.text ############################################################ # ############################################################ def load_acme_urls(path): """ Load the ACME Directory of URLS """ try: print('Calling endpoint:', path) resp = requests.get(acme_path, headers=headers) except requests.exceptions.RequestException as error: print(error) sys.exit(1) if resp.status_code < 200 or resp.status_code >= 300: print('Error calling ACME endpoint:', resp.reason) print(resp.text) sys.exit(1) return resp.json() ############################################################ # ############################################################ def acme_get_nonce(urls): """ Get the ACME Nonce that is used for the first request """ global headers path = urls['newNonce'] try: print('Calling endpoint:', path) resp = requests.head(path, headers=headers) except requests.exceptions.RequestException as error: print(error) return False if resp.status_code < 200 or resp.status_code >= 300: print('Error calling ACME endpoint:', resp.reason) print(resp.text) return False return resp.headers['Replay-Nonce'] ############################################################ # Main Program Function ############################################################ def main(debug=0): """ Main Program Function """ acme_urls = load_acme_urls(acme_path) url = acme_urls["newAccount"] nonce = acme_get_nonce(acme_urls) if nonce is False: sys.exit(1) nonce, account_url = get_account_url(url, nonce) # resp is the returned JSON data describing the account nonce, resp = get_account_info(nonce, account_url, account_url) info = json.loads(resp) if debug is not 0: print('') print('Returned Data:') print('##################################################') #print(info) helper.print_dict(info) print('##################################################') print('') print('ID: ', info['id']) print('Contact: ', info['contact']) print('Initial IP:', info['initialIp']) print('Created At:', info['createdAt']) print('Status: ', info['status']) def is_json(data): try: json.loads(data) except ValueError as e: return False return True acme_config = load_acme_parameters(g_debug) main(g_debug)概要
パート4では、ACME APIをさらに深く掘り下げて、JSONボディの各部分を構築し、ペイロードに署名し、結果を処理する方法を学びます。
アリババクラウドは日本に2つのデータセンターを有し、世界で60を超えるアベラビリティーゾーンを有するアジア太平洋地域No.1(2019ガートナー)のクラウドインフラ事業者です。
アリババクラウドの詳細は、こちらからご覧ください。
アリババクラウドジャパン公式ページ
- 投稿日:2020-10-14T14:08:19+09:00
「ゼロから作るDeep Learning」自習メモ(その11)CNN
「ゼロから作るDeep Learning」(斎藤 康毅 著 オライリー・ジャパン刊)を読んでいる時に、参照したサイト等をメモしていきます。 その10 ←
7章 畳み込みニューラルネットワーク になると、6章までやってきたのとかなり違うように見えます。これまでと違うことをいろいろやっているように見えますが、最後には重みとバイアスの勾配を求めて格納することになります。
つまり、基本原理はまったく変わらず、変わったのは入力データでP207
入力データが画像の場合、画像は通常、縦・横・チャンネル方向の3 次元の形状です。しかし、全結合層に入力するときには、3 次元のデータを平ら―― 1 次元のデータ――にする必要があります。実際、これまでのMNIST データセットを使った例では、入力画像は(1, 28, 28)―― 1 チャンネル、縦28 ピクセル、横28 ピクセル――の形状でしたが、それを1 列に並べた784 個のデータを最初のAffine レイヤへ入力しました。
・・・
一方、畳み込み層(Convolution レイヤ)は、形状を維持します。画像の場合、入力データを3 次元のデータとして受け取り、同じく3 次元のデータとして、次の層にデータを出力します。そのため、CNN では、画像などの形状を有したデータを正しく理解できる(可能性がある)のです。実際、私自身もこの自習メモその6の2で、Kaggleの猫と犬のデータセットを処理するときには、3次元のデータを1次元に変換して使っています。これを3次元で処理できれば、認識率も向上するかもしれません。
畳み込み層、パディング、ストライド
これらの説明は、決して難しいわけではなく、それなりにわかるのですが、P212に、突然こんな式が出てくるので、これは何だ? ホントにそうか? ということで、考えてみました。
$OH = \frac{H + 2P - FH}{S} + 1$
$OW = \frac{W + 2P - FW}{S} + 1$とりあえず、S(ストライド)は無い事にして考えて見ます。
入力サイズとフィルタのサイズについて、いくつか確認してみると
入力サイズ(n、n)とフィルタサイズ(m、m)のとき、
出力サイズは(n-m+1、n-m+1)となるようです。
左上隅にフィルタをあてると、右側にあと(n-m)回動ける。下に(n-m)回動けます。
だから、左上隅の分1を足して、n-m+1 ということでしょうか。では、ストライドsがあるとどうなるか?
ストライドが2のとき、右側に(n-m)回動けたのが、半分になります。(n-m)/2
3のときは3分の1になります。つまり、動ける回数が(n-m)/s になるので、
出力サイズは(n-m)/s+1 ということになります。入力データのサイズが(H、W)、パディングがP、フィルタサイズが(FH、FW)とすると
n=H+2×P 同じく n=W+2×P
m=FH n=FW
なので、
出力サイズは
OH=(H+2×P-FH)/s + 1
OW=(W+2×P-FW)/s + 1MNISTデータの学習とテスト
P230から、MNISTデータを学習させるための例として、クラスSimpleConvNetの説明があります。
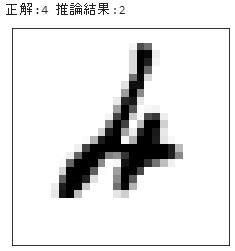
このクラスを使って学習させimport sys, os sys.path.append(os.pardir) # 親ディレクトリのファイルをインポートするための設定 import numpy as np from dataset.mnist import load_mnist from common.simple_convnet import SimpleConvNet from common.trainer import Trainer # データの読み込み (x_train, t_train), (x_test, t_test) = load_mnist(flatten=False) max_epochs = 20 network = SimpleConvNet(input_dim=(1,28,28), conv_param = {'filter_num': 30, 'filter_size': 5, 'pad': 0, 'stride': 1}, hidden_size=100, output_size=10, weight_init_std=0.01) trainer = Trainer(network, x_train, t_train, x_test, t_test, epochs=max_epochs, mini_batch_size=100, optimizer='Adam', optimizer_param={'lr': 0.001}, evaluate_sample_num_per_epoch=1000, verbose=False) trainer.train()テストデータの判定内容を検証してみました。
import numpy as np from common.simple_convnet import SimpleConvNet from dataset.mnist import load_mnist import pickle import matplotlib.pyplot as plt def showImg(x): example = x.reshape((28, 28)) plt.figure() plt.xticks([]) plt.yticks([]) plt.grid(False) plt.imshow(example, cmap=plt.cm.binary) plt.show() return # テストデータで評価 x = x_test t = t_test network = SimpleConvNet(input_dim=(1,28,28), conv_param = {'filter_num': 30, 'filter_size': 5, 'pad': 0, 'stride': 1}, hidden_size=100, output_size=10, weight_init_std=0.01) network.load_params("params.pkl") y = network.predict(x) accuracy_cnt = 0 for i in range(len(x)): p= np.argmax(y[i]) #print(str(x[i]) + " : " + str(p)) if p == t[i]: accuracy_cnt += 1 else: print("正解:"+str(t[i])+" 推論結果:"+str(p)) showImg(x[i]) print("Accuracy:" + str(float(accuracy_cnt) / len(x)))結果、正解率は
Accuracy:0.988
不正解だったものはこんな感じ
しかし、6万件のデータ処理に何時間もかかりました。
さらに、学習した後、テストデータの処理をしようとしても、メモリ不足の問題に足をとられて、なかなか先に進めませんでした。メモリ4GぽっちではDeep Learningはムリなのでしょうか?とりあえず、CNNで精度が高い学習ができたことは確認できました。
で
例によって、プログラムの内容を追って見たいと思います。
SimpleConvNetクラス
# coding: utf-8 import sys, os sys.path.append(os.pardir) # 親ディレクトリのファイルをインポートするための設定 import pickle import numpy as np from collections import OrderedDict from common.layers import * from common.gradient import numerical_gradient class SimpleConvNet: def __init__(self, input_dim=(1, 28, 28), conv_param={'filter_num':30, 'filter_size':5, 'pad':0, 'stride':1}, hidden_size=100, output_size=10, weight_init_std=0.01): filter_num = conv_param['filter_num'] filter_size = conv_param['filter_size'] filter_pad = conv_param['pad'] filter_stride = conv_param['stride'] input_size = input_dim[1] conv_output_size = (input_size - filter_size + 2*filter_pad) / filter_stride + 1 pool_output_size = int(filter_num * (conv_output_size/2) * (conv_output_size/2)) # 重みの初期化 self.params = {} self.params['W1'] = weight_init_std * \ np.random.randn(filter_num, input_dim[0], filter_size, filter_size) self.params['b1'] = np.zeros(filter_num) self.params['W2'] = weight_init_std * \ np.random.randn(pool_output_size, hidden_size) self.params['b2'] = np.zeros(hidden_size) self.params['W3'] = weight_init_std * \ np.random.randn(hidden_size, output_size) self.params['b3'] = np.zeros(output_size) # レイヤの生成 self.layers = OrderedDict() self.layers['Conv1'] = Convolution(self.params['W1'], self.params['b1'], conv_param['stride'], conv_param['pad']) self.layers['Relu1'] = Relu() self.layers['Pool1'] = Pooling(pool_h=2, pool_w=2, stride=2) self.layers['Affine1'] = Affine(self.params['W2'], self.params['b2']) self.layers['Relu2'] = Relu() self.layers['Affine2'] = Affine(self.params['W3'], self.params['b3']) self.last_layer = SoftmaxWithLoss() def predict(self, x): for layer in self.layers.values(): x = layer.forward(x) return x def loss(self, x, t): y = self.predict(x) return self.last_layer.forward(y, t) def accuracy(self, x, t, batch_size=100): if t.ndim != 1 : t = np.argmax(t, axis=1) acc = 0.0 for i in range(int(x.shape[0] / batch_size)): tx = x[i*batch_size:(i+1)*batch_size] tt = t[i*batch_size:(i+1)*batch_size] y = self.predict(tx) y = np.argmax(y, axis=1) acc += np.sum(y == tt) return acc / x.shape[0] def gradient(self, x, t): # forward self.loss(x, t) # backward dout = 1 dout = self.last_layer.backward(dout) layers = list(self.layers.values()) layers.reverse() for layer in layers: dout = layer.backward(dout) # 設定 grads = {} grads['W1'], grads['b1'] = self.layers['Conv1'].dW, self.layers['Conv1'].db grads['W2'], grads['b2'] = self.layers['Affine1'].dW, self.layers['Affine1'].db grads['W3'], grads['b3'] = self.layers['Affine2'].dW, self.layers['Affine2'].db return grads def save_params(self, file_name="params.pkl"): params = {} for key, val in self.params.items(): params[key] = val with open(file_name, 'wb') as f: pickle.dump(params, f) def load_params(self, file_name="params.pkl"): with open(file_name, 'rb') as f: params = pickle.load(f) for key, val in params.items(): self.params[key] = val for i, key in enumerate(['Conv1', 'Affine1', 'Affine2']): self.layers[key].W = self.params['W' + str(i+1)] self.layers[key].b = self.params['b' + str(i+1)]レイヤを積み上げているところが違ってるだけで、他はMultiLayerNetクラスとたいして変わりません。
self.layers['Conv1'] = Convolution(self.params['W1'], self.params['b1'], conv_param['stride'], conv_param['pad'])Convolutionクラスもlayers.pyの中で定義されていて
class Convolution: def __init__(self, W, b, stride=1, pad=0): self.W = W self.b = b self.stride = stride self.pad = pad # 中間データ(backward時に使用) self.x = None self.col = None self.col_W = None # 重み・バイアスパラメータの勾配 self.dW = None self.db = None def forward(self, x): FN, C, FH, FW = self.W.shape N, C, H, W = x.shape out_h = 1 + int((H + 2*self.pad - FH) / self.stride) out_w = 1 + int((W + 2*self.pad - FW) / self.stride) col = im2col(x, FH, FW, self.stride, self.pad) col_W = self.W.reshape(FN, -1).T out = np.dot(col, col_W) + self.b out = out.reshape(N, out_h, out_w, -1).transpose(0, 3, 1, 2) self.x = x self.col = col self.col_W = col_W return out def backward(self, dout): FN, C, FH, FW = self.W.shape dout = dout.transpose(0,2,3,1).reshape(-1, FN) self.db = np.sum(dout, axis=0) self.dW = np.dot(self.col.T, dout) self.dW = self.dW.transpose(1, 0).reshape(FN, C, FH, FW) dcol = np.dot(dout, self.col_W.T) dx = col2im(dcol, self.x.shape, FH, FW, self.stride, self.pad) return dxim2col
その肝になるのが im2col 関数。util.pyで定義されていて
def im2col(input_data, filter_h, filter_w, stride=1, pad=0): N, C, H, W = input_data.shape out_h = (H + 2*pad - filter_h)//stride + 1 out_w = (W + 2*pad - filter_w)//stride + 1 img = np.pad(input_data, [(0,0), (0,0), (pad, pad), (pad, pad)], 'constant') col = np.zeros((N, C, filter_h, filter_w, out_h, out_w)) for y in range(filter_h): y_max = y + stride*out_h for x in range(filter_w): x_max = x + stride*out_w col[:, :, y, x, :, :] = img[:, :, y:y_max:stride, x:x_max:stride] col = col.transpose(0, 4, 5, 1, 2, 3).reshape(N*out_h*out_w, -1) return colで、こいつがメモリ不足を引き起こす元凶のようです。
処理するデータ行数が増えると、ここでMemorryErrorになります。最初の3行では、入力データのサイズを確認し、入力サイズとフィルタサイズから出力サイズを計算しています。ストライドでの割り算で // を使っているのは、割り切れなかった場合には小数点以下を切り捨てるためのようです。
今回の入力データMNISTのテストデータのサイズの確認
len(x_test) #データ数10000
len(x_test[0]) #チャネル1
len(x_test[0][0]) #高さ28
len(x_test[0][0][0]) #横幅28
フィルタW1のサイズ確認
len(network.params['W1']) #フィルタ数30
len(network.params['W1'][0]) #チャネル数1
len(network.params['W1'][0][0]) #フィルタ高さ5
len(network.params['W1'][0][0][0]) #フィルタ横幅5
パディング、ストライドの確認
conv_param = {'filter_num': 30, 'filter_size': 5, 'pad': 0, 'stride': 1},networkオブジェクト生成時に、パディング0、ストライド1を指定している。
畳み込み層(Convolution レイヤ)の出力サイズ
$OH = \frac{H + 2P - FH}{S} + 1$ = (28 + 0 - 5)/1 +1 = 24
$OW = \frac{W + 2P - FW}{S} + 1$ = (28 + 0 - 5)/1 +1 = 24
となるはず。len(network.layers['Conv1'].forward(x_test)) #データ数10000
len(network.layers['Conv1'].forward(x_test)[0]) #フィルタ数30
len(network.layers['Conv1'].forward(x_test)[0][0]) #出力の高さ24
len(network.layers['Conv1'].forward(x_test)[0][0][0]) #出力の横幅24
Convolution レイヤの追跡
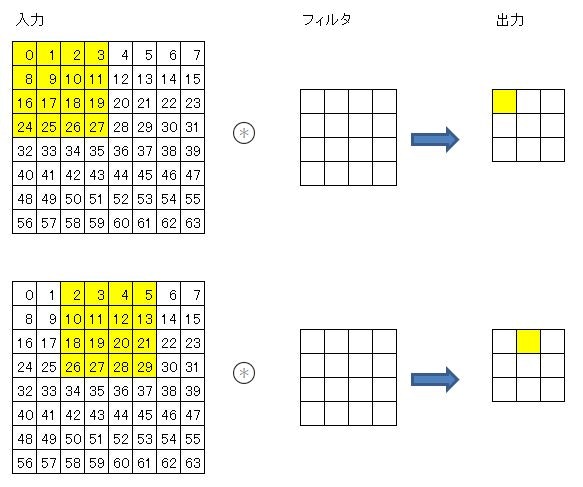
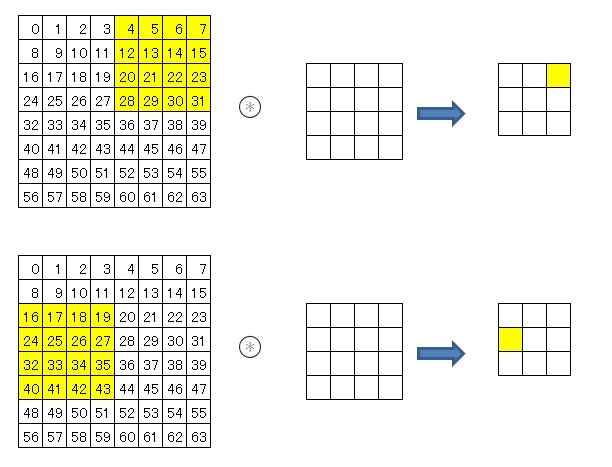
self.layers['Conv1'] = Convolution(self.params['W1'], self.params['b1'], conv_param['stride'], conv_param['pad'])class Convolution: (略) def forward(self, x): FN, C, FH, FW = self.W.shape # 30, 1, 5, 5 N, C, H, W = x.shape # 10000, 1, 28, 28 out_h = 1 + int((H + 2*self.pad - FH) / self.stride) # 24 out_w = 1 + int((W + 2*self.pad - FW) / self.stride) # 24 col = im2col(x, FH, FW, self.stride, self.pad) (略)def im2col(input_data, filter_h, filter_w, stride=1, pad=0): N, C, H, W = input_data.shape # 10000, 1, 28, 28 out_h = (H + 2*pad - filter_h)//stride + 1 # 24 out_w = (W + 2*pad - filter_w)//stride + 1 # 24 img = np.pad(input_data, [(0,0), (0,0), (pad, pad), (pad, pad)], 'constant')input_data は4次元で(データ行数10000、チャネル1、高さ28、横幅28)
pad=0 のときは、[(0,0), (0,0), (0, 0), (0, 0)]パディングしない。
pad=1 のときは、[(0,0), (0,0), (1, 1), (1, 1)]高さと横幅の上下左右に1つずつパディングする。
pad=2のときは、[(0,0), (0,0), (2, 2), (2, 2)]高さと横幅の上下左右に2つずつパディングする。
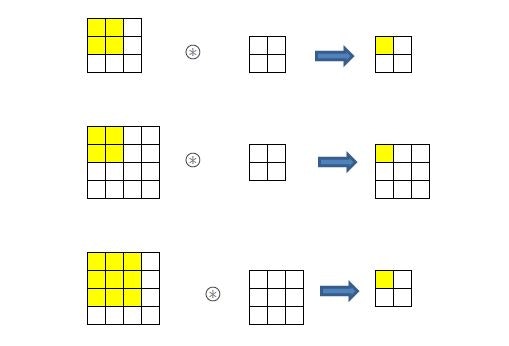
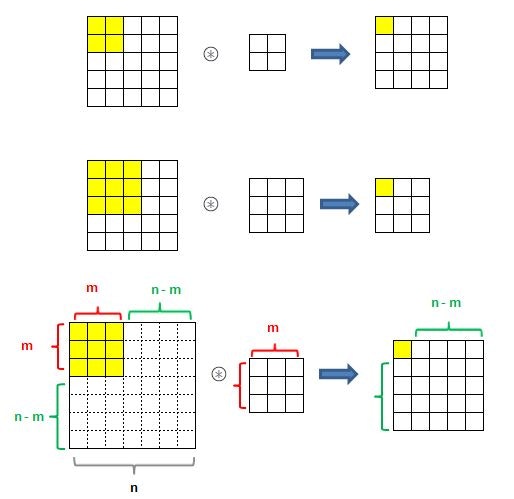
今回のプログラム例では、pad=0です。input_dataと同じものがimgにセットされます。col = np.zeros((N, C, filter_h, filter_w, out_h, out_w)) #10000, 1, 5, 5, 24, 24入力データ(画像イメージ)を、配列colに展開するのだが、データを展開する入れ物として、(データ数、チャネル、フィルタ高さ、フィルタ横幅、出力高さ、出力横幅)のサイズの配列を作ります。
for y in range(filter_h): y_max = y + stride*out_h for x in range(filter_w): x_max = x + stride*out_w col[:, :, y, x, :, :] = img[:, :, y:y_max:stride, x:x_max:stride] col = col.transpose(0, 4, 5, 1, 2, 3).reshape(N*out_h*out_w, -1) return colここのイメージがまったくつかめないので、次のような簡略化した配列でテストしてみた。
import numpy as np N=1 C=1 H=8 W=8 filter_h=4 filter_w=4 stride=2 out_h=3 out_w=3 img= np.arange(64).reshape(N, C, 8, 8) col = np.zeros((N, C, filter_h, filter_w, out_h, out_w)) for y in range(filter_h): y_max = y + stride*out_h for x in range(filter_w): x_max = x + stride*out_w col[:, :, y, x, :, :] = img[:, :, y:y_max:stride, x:x_max:stride] col = col.transpose(0, 4, 5, 1, 2, 3).reshape(N*out_h*out_w, -1) colarray([[ 0., 1., 2., 3., 8., 9., 10., 11., 16., 17., 18., 19., 24., 25., 26., 27.],
[ 2., 3., 4., 5., 10., 11., 12., 13., 18., 19., 20., 21., 26., 27., 28., 29.],
[ 4., 5., 6., 7., 12., 13., 14., 15., 20., 21., 22., 23., 28., 29., 30., 31.],
[16., 17., 18., 19., 24., 25., 26., 27., 32., 33., 34., 35., 40., 41., 42., 43.],
[18., 19., 20., 21., 26., 27., 28., 29., 34., 35., 36., 37., 42., 43., 44., 45.],
[20., 21., 22., 23., 28., 29., 30., 31., 36., 37., 38., 39., 44., 45., 46., 47.],
[32., 33., 34., 35., 40., 41., 42., 43., 48., 49., 50., 51., 56., 57., 58., 59.],
[34., 35., 36., 37., 42., 43., 44., 45., 50., 51., 52., 53., 58., 59., 60., 61.],
[36., 37., 38., 39., 44., 45., 46., 47., 52., 53., 54., 55., 60., 61., 62., 63.]])col[0]は、入力データの中の最初にフィルタを適用させる部分が抜き出されている。
col[1]は、ストライド2で右に2つずらしてフィルタを適用させる部分である。
以下、9回フィルタを適用させる部分を抜き出して並べた配列になっている。
途中経過は、はっきり言って何をやっているのかよくわからないのですが、出てきた結果はなんとなくわかります。
4×4のフィルタを1列にreshapeして、colとdot演算すれば、9回フィルタを適用した結果を1回の演算で求める事ができます。
#Convolution.forward col = im2col(x, FH, FW, self.stride, self.pad) col_W = self.W.reshape(FN, -1).T out = np.dot(col, col_W) + self.b out = out.reshape(N, out_h, out_w, -1).transpose(0, 3, 1, 2)参考
numpy.pad関数完全理解
二次元配列を自在に操れ。【初期化・参照・抽出・計算・転置】その10 ←



- 投稿日:2020-10-14T13:44:49+09:00
【django】環境構築手順の忘備録
TL;DR
python + djangoを使用した開発のための環境構築手順の忘備録
手順
フォルダ作成
> cd work > mkdir sample > cd sample仮想環境作成
> python -m venv develop仮想環境の有効化
> source develop/bin/activate必要なライブラリのインストール
> pip install djangodjangoプロジェクトの作成
> django-admin startproject myporject作成したdjangoプロジェクトへ移動
> cd myprojectマイグレーション実施
> python manage.py makemigrations > python manage.py migrateスーパユーザーの作成
コマンドを打ち込んだあとに、ユーザ名やメールアドレス、パスワードを設定する。
> python manage.py createsuperuserサーバーを起動
> python manage.py runserver
- 投稿日:2020-10-14T13:40:12+09:00
【python】メソッドを使わず最少値・最大値を求めるプログラム
【python】メソッドを使わず最少値を求める方法
minやmaxメソッドを使わずに最少値を求める方法。
考え方
2つの要素の比較を繰り返す。
▼最少値を求める場合
・1つ目の要素:
初期値は0番目の値。これを現時点での最少値とする。2つ目の要素と比較して小さい方を現時点での最少値に入れ替える。
・2つ目の要素:
次の要素。1つづつ繰り上げていく。
常に現時点での最少値と比較される。
最少値を求める
def min_val(arr): min = 0 #初回は0番目を現在の最少値とする(配列番号で指定) for i in range(1, len(arr)): if arr[min] > arr[i]: #比較して次の数値の方が小さければ、現在の最少値の配列番号を入れ替え min = i print(a[min])a = [2,4,5,3,10,1,8,6,3,2] min_val(a) #1
最大値を求める
if文の中の不等号を入れ替えるだけ。
def max_val(arr): max = 0 for i in range(1, len(arr)): if arr[max] < arr[i]: max = i print(a[max])a = [2,4,5,3,10,1,8,6,3,2] max_val(a) #10
- 投稿日:2020-10-14T13:12:24+09:00
【python】配列の値を入れ替える方法
【python】配列の入れ替え
要素の番号をイコールでつなぐことで要素を簡単に入れ替えることができる。
例えば、1~5の整数が入った配列の先頭と末尾を入れ替えたい場合、それぞれの値を左右で入れ替えてイコールでつなげばOK。
a = [1,2,3,4,5] a[0], a[4] = a[4], a[0] print(a) #[5, 2, 1, 4, 5]
何をしているか?
指定した値に、指定した値を入力できる処理を応用している。
a = [1,2,3,4,5] a[0], a[1], a[2] = a[4], a[4], 5 print(a) #[5, 5, 5, 4, 5]シンプル版
変数名をつけていなくても使える。
a,b,c,d =1,2,3,4 a,c = c, a print(a,b,c,d) #3 2 1 4数が合わない場合
左側の値が一つ以外の場合はエラーになる。
左側がひとつの時は、まとまった値が入る。a = [1,2,3,4,5] a[0] = a[4], a[4], a[4] print(a) #[(5, 5, 5), 2, 3, 4, 5]a = [1,2,3,4,5] a[0], a[1] = a[4], a[4], a[4] print(a) #ValueError: too many values to unpack (expected 2)
- 投稿日:2020-10-14T13:12:21+09:00
Python + Django Rest framework + igGrid で REST API を利用したCRUDの実装
こんにちは。インフラジスティックス・ジャパン株式会社 テクニカルコンサルティングチームの中江です。
普段はお客様へ技術サポートやトレーニングコンテンツの提供などを主な業務として行っています。Infragistics(以下IG) は 開発ツールのソフトウェアベンダーです。主に UI コンポーネントの開発・提供を様々なプラットフォームに対して行っています。今回はバックエンドの言語にとらわれず IG の豊富な UI コンポーネントを Web アプリケーションに導入できる Ignite UI for jQuery という製品を取りあげます。
Ignite UI for jQuery
https://jp.infragistics.com/products/ignite-uiIG の UI コンポーネント郡の中でも特に利用頻度の高いものとして、グリッドコンポーネントがあります。グリッドコンポーネントはデータを表組みで表示するコンポーネントのことです。Ignite UI for jQuery の igGrid は以下のような機能が組み込まれています。
- 列の集計
- グループ化
- ソート
- フィルタリング
- ページング
- 列の固定
- 列の移動
- 行の新規追加、更新(編集)、削除
- セルの結合
- 複数行レイアウト
- 仮想化
本記事では Python + Django で構築したウェブアプリケーションと Ignite UI for jQuery を組み合わせて、CRUD の機能を持った igGrid を実装する方法をご紹介します。
Django には Django REST framework という Web API の実装がかなり簡単にできるフレームワークがあります。
Django REST framework
https://www.django-rest-framework.org/また、Ignite UI for jQuery の igGrid には データソースとして REST で取得したデータをバインディングすることが可能です。グリッド上の新規行追加、更新、削除の内容に基づいて適切な処理を REST に対して行います。
REST の更新 (igGrid)
https://jp.igniteui.com/help/iggrid-rest-updatingこの2つの機能(Django REST framework と REST 連携可能な igGrid)を組み合わせることでとても簡単に CRUD の機能を持った igGrid を実装することが可能です。
最終的な実現イメージは以下のようになります。
データをグリッドコンポーネントを使って一覧表示し、新規追加、更新、削除の処理をUIで操作しています。Saveボタンをクリックするとそれぞれの処理がAPIによって実行され、データベースが更新されます。
Python + Django で REST を実装する
Django において、データベースとアプリの連携までは実装できているという前提で進めていきます。
もし今回はじめて Django を始めてみようという方がいらっしゃいましたら、以下のドキュメントを参考に、「はじめての Django アプリ作成、その2」までの内容を進めたうえで以降の内容をご覧ください。Django 2.2 ドキュメント
https://docs.djangoproject.com/ja/2.2/contents/また今回は、
- python 3.7
- Django 2.2.14
- Ignite UI for jQuery 20.1にて実装を行なっています。
Django REST framework のインストールと初期設定
django-filter も合わせてインストールします。
$ pip install djangorestframework $ pip install django-filtersettting.pyINSTALLED_APPS = [ ... 'rest_framework', ]API 用のアプリを作成
$ python manage.py startapp apiモデルの設定
今回は以下ような注文管理用のモデルを作成しました。
api/models.pyfrom django.db import models # Create your models here. class Ordering(models.Model): Shop = models.CharField(max_length=100) #出荷名 Address = models.CharField(max_length=200) #配送先住所 TotoalNumber = models.IntegerField(default=0) #項目の合計数 TotalPrice = models.FloatField(default=0) #総額また、すでにデモ用のデータは以下のようなものを入れ込んでいる前提で進めます。
id Shop Address TotoalNumber TotalPrice 1 小料理ひろ 味美白山町 1-9-X 27 440 2 食所あんどう 志免町御手洗 51-X 49 1863.4 ... ... ... ... ... Serializer の定義
新規に serializer.py というファイルを作成して、以下のように設定します。
api/serializer.py# coding: utf-8 from rest_framework import serializers from .models import Ordering class orderingSerializer(serializers.ModelSerializer): class Meta: model = Ordering fields = ('id', 'Shop', 'Address', 'TotoalNumber', 'TotalPrice')View の設定
View ではモデルと先ほど用意した Serializer を組み合わせた ViewSet を定義します。
api/views.py# coding: utf-8 import django_filters from rest_framework import viewsets, filters from .models import Ordering from .serializer import orderingSerializer class orderingViewSet(viewsets.ModelViewSet): queryset = Ordering.objects.all() serializer_class = orderingSerializerURL の設定
URL の設定をします。
まず api/urls.py を新規作成し、以下のように記述します。api/urls.py# coding: utf-8 from rest_framework import routers from .views import orderingViewSet router = routers.DefaultRouter() router.register(r'order', orderingViewSet)ルートの urls.py には以下のようなルーティング設定を行います。
urls.pyfrom django.contrib import admin from django.conf.urls import url, include from django.urls import include, path from api.urls import router as api_router urlpatterns = [ path('admin/', admin.site.urls), url(r'^api/', include(api_router.urls)), ]以上で API を利用したデータのやり取りが出来るようになりました。サーバーを起動して以下の URL にアクセスしてみます。
http://127.0.0.1:8000/api/order/
JSON 形式でデータの一括取得が出来ていることを確認できます。
同じ要領で、以下のように ID を指定した URL にアクセスすると、
http://127.0.0.1:8000/api/order/1
該当のデータのみ表示することが出来ますし、PUT による情報の更新や DELETE による削除の処理もこの画面で行うことが可能で、データベースとの連携も対応してくれます。
これで Django 側の準備が整いましたので igGrid の実装に移っていきます。
igGrid の実装と、REST との連携
バックエンドの受け入れ態勢は整いましたので、フロントエンドの組み込みを行なっていきます。
まず igGrid 用のアプリを新たに追加します。igGrid 用のアプリを作成
$ python manage.py startapp gridigGrid 用のテンプレートを作成
grid/templates/grid ディレクトリにテンプレート用の html を新規作成し、編集していきます。今回は
部分やスクリプトをパーツ分けするなどの処理はせずに、全て1枚の index.html に収める形で記述していきます。まず必要なライブラリの読み込みは以下のように CDN から読み込む形としました。
grid/templates/grid/index.html<!DOCTYPE html> <html lang="ja"> <head> <meta http-equiv="Content-type" content="text/html; charset=utf-8" /> <meta http-equiv="X-UA-Compatible" content="IE=edge"> <meta name="viewport" content="width=device-width, initial-scale=1"> <title>ig-grid on Django</title> <link href="https://cdn-na.infragistics.com/igniteui/2020.1/latest/css/themes/infragistics/infragistics.theme.css" rel="stylesheet"> <link href="https://cdn-na.infragistics.com/igniteui/2020.1/latest/css/structure/infragistics.css" rel="stylesheet"> <link href="https://igniteui.github.io/help-samples/css/apiviewer.css" rel="stylesheet" type="text/css"> <style type="text/css"> input.button-style { margin-top: 10px; } </style> </head> <body> ... <script src="https://ajax.aspnetcdn.com/ajax/modernizr/modernizr-2.8.3.js"></script> <script src="https://code.jquery.com/jquery-2.1.3.min.js"></script> <script src="https://code.jquery.com/ui/1.10.3/jquery-ui.min.js"></script> <script src="https://cdn-na.infragistics.com/igniteui/2020.1/latest/js/i18n/infragistics-ja.js"></script> <script src="https://cdn-na.infragistics.com/igniteui/2020.1/latest/js/infragistics.core.js"></script> <script src="https://cdn-na.infragistics.com/igniteui/2020.1/latest/js/infragistics.lob.js"></script> <script src="https://igniteui.github.io/help-samples/js/apiviewer.js"></script> <script src="https://cdn-na.infragistics.com/igniteui/2020.1/latest/js/modules/i18n/regional/infragistics.ui.regional-ja.js"></script> <!-- Used to add modal loading indicator for igGrid --> <script src="https://www.igniteui.com/js/grid-modal-loading-inicator.js"></script> </body> </html>また、今回の実装方法として、グリッドの各行への変更内容を一旦保持して、保存ボタンのクリックによって全ての変更をまとめてデータベースにコミットするような形としております。
本記事では一括でのコミットに関しての説明は省略いたします。以下のドキュメントに詳細が書かれておりますので参考にしていただければ幸いです。グリッド - 編集
https://jp.igniteui.com/grid/basic-editing更新の概要 (igGrid)
https://jp.igniteui.com/help/iggrid-updatingREST データのデータバインディング
REST をサポートするために DataSource から拡張された RESTDataSource を用いてグリッドにデータバインディングを行います。
ig.RESTDataSource
https://jp.igniteui.com/help/api/2020.1/ig.restdatasourcegrid/templates/grid/index.html<script type="text/javascript"> $(function () { var ds = new $.ig.RESTDataSource({ dataSource : "/api/order/", restSettings: { create: { url: "/api/order/", //APIのエンドポイントを指定 }, } }); var grid = $("#grid").igGrid({ dataSource: ds, //RESTDataSource をバインド type: "json", columns: [ ... ], primaryKey: "id", autoGenerateColumns: false,上記の例では restSettings の create の エンドポイントに /api/order/ を指定していますので、グリッドで新規に行を作成した際に /api/order/ に対して POST を行なってくれます。
また、その他のエンドポイントを特に指定しなくても、DELETE や PUT なども適宜エンドポイントを /api/order/1 のように解釈してくれます。ルーティングの調整をして、こちらの状態で一度テストしてみます。
グリッドにデータの一覧を表示することが出来ました。これはREST によって GET 処理が成功したことを意味しています。
では POST の処理はどうでしょうか。新規行の追加処理のテストをしてみます。
POST の処理はエラーとなります。
これは ajax を通して POST の処理をした際に Django 側でセキュリティの保護処理が行われたためのエラーです。クロスサイトリクエストフォージェリ(CSRF)対策のために ajax を利用する場合にはトークンを生成して付与する必要があります。しかしながら ig.RESTDataSource にはトークンを指定する組み込みのオプションはないため、別の方法での実装が必要です。
CSRF トークンの設定
jQuery の ajaxSetup() メソッド の beforeSend パラメーターを利用することで、ajax 通信が発生する前の処理を設定することが可能です。以下のようにリクエストヘッダーの X-CSRFToken に対してトークンを指定します。
Django には CSRF 対策用のトークンが簡単に取得できるテンプレートタグがはじめから用意されているため、以下の記述をスクリプトに追加します。
grid/templates/grid/index.html$.ajaxSetup({ beforeSend: function(xhr, settings) { xhr.setRequestHeader("X-CSRFToken", "{{ csrf_token }}"); } });もう一度テストしてみましょう。
無事新しいデータが POST されました。
データベースでも新しいデータの存在が確認できます。% python manage.py shell >>> from api.models import Ordering >>> Ordering.objects.filter(id=21) <QuerySet [<Ordering: Ordering object (21)>]>続けて PUT と DELETE の動作テストをします。
先ほど新規に追加したデータを削除し、ID20 のデータの総額を変更します。
Save ボタンをクリックしコミットすると以下のエラー文とともに、PUT の処理にエラーが発生していることが確認できます。
You called this URL via PUT, but the URL doesn't end in a slash and you have APPEND_SLASH set. Django can't redirect to the slash URL while maintaining PUT data. Change your form to point to 127.0.0.1:8000/api/order/20/ (note the trailing slash), or set APPEND_SLASH=False in your Django settings.Django は PUT のエンドポイントの URL がスラッシュで終わっていない形の場合、エラーを返します。また、ig.RESTDataSource のデフォルトの PUT のエンドポイントは最後にスラッシュがつかない /api/order/20 のような形になるため、このエラーが発生します。
Django 側の設定変更によってスラッシュなしを受け入れることも可能ですが、ig.RESTDataSource もエンドポイントのテンプレートをカスタマイズ可能ですので、ig.RESTDataSource を修正していきます。
Django の仕様に合わせて ig.RESTDataSource の restSettings を変更
grid/templates/grid/index.htmlvar ds = new $.ig.RESTDataSource({ dataSource : "/api/order/", type: "json", restSettings: { create: { url: "/api/order/", template: "/api/order/" }, update: { template: "/api/order/${id}/" //スラッシュで終わる形に変更 }, remove: { url: "/api/order/" } } });この時、update に対して行なったテンプレート設定が create にも及ぶため、create にも元々与えているエンドポイントと同じ URL を template の URL としても指定しておきます。
最後に、保存ボタンを押した時の処理として以下の2行を加えます。
grid/templates/grid/index.htmlgrid.igGrid("commit"); grid.igGrid("dataBind");グリッドの ID 列は、データベースのテーブル上のプライマリキーである id と対応していますが、フロントエンドで割り振られた id が、データベース上で割り振られるべき id と一致するとは限りません。そのためデータベースへのコミットを行った後に再度データバインドを行うことによって、データベース上で割り当てられた id をグリッドで反映するという処理を行っています。
改めて、今回作成したデモの最終的な振る舞いを見てみましょう。
GET, POST, PUT, DELETE の処理を REST と igGrid によってスムーズに一括で行えるようになりました。また、今回 Django REST framework を利用することによってバックエンドとフロントエンドの役割分担が出来ている点が特徴かと思います。
今回作成したデモアプリケーションは以下にアップロードしておりますのでご興味のある方は触ってみていただければと思います。
https://github.com/igjp-kb/Ignite-UI-for-JavaScript/tree/master/igGrid/rest_iggrid
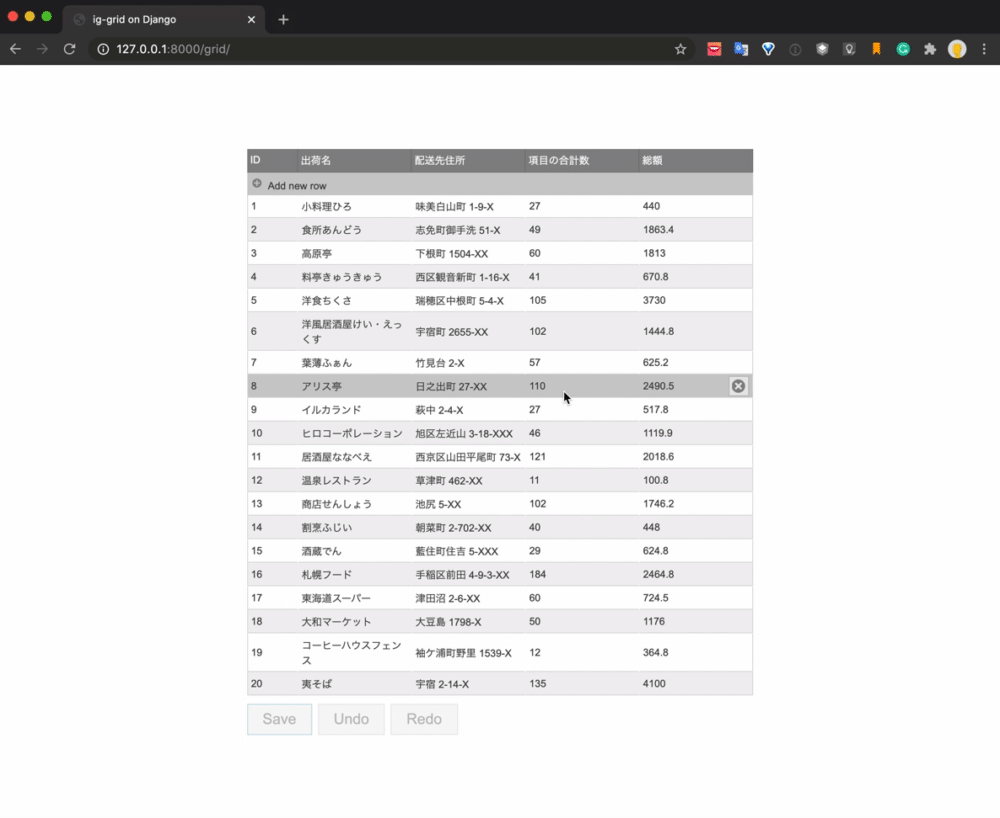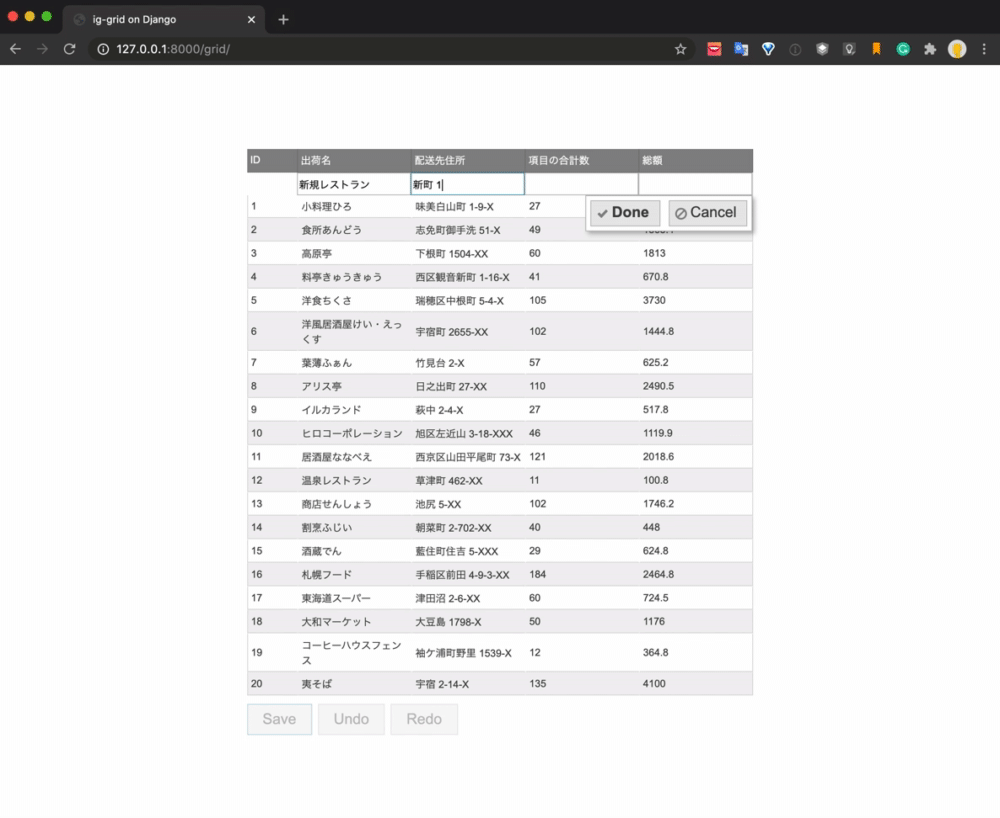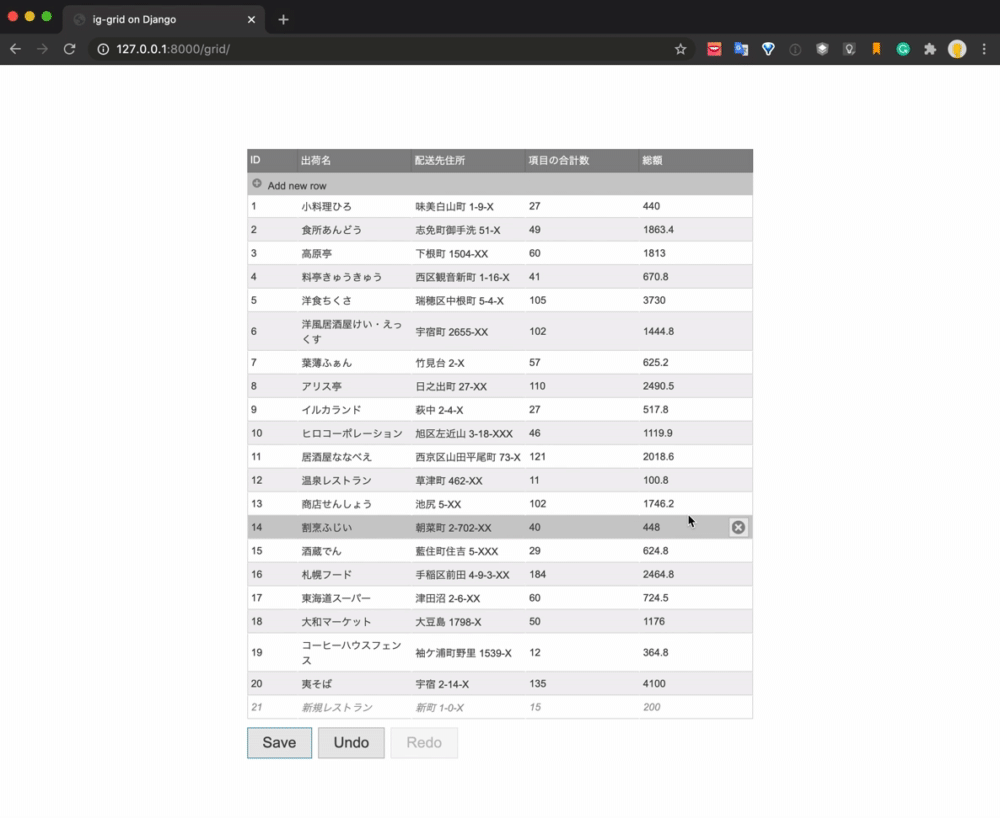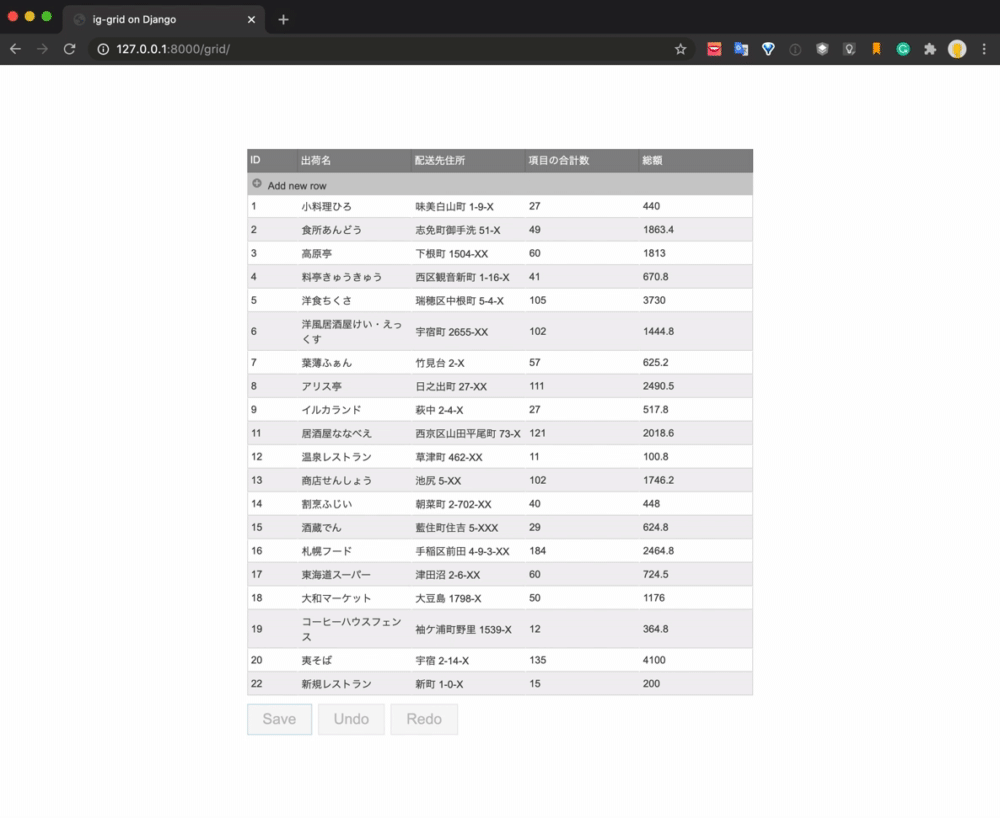
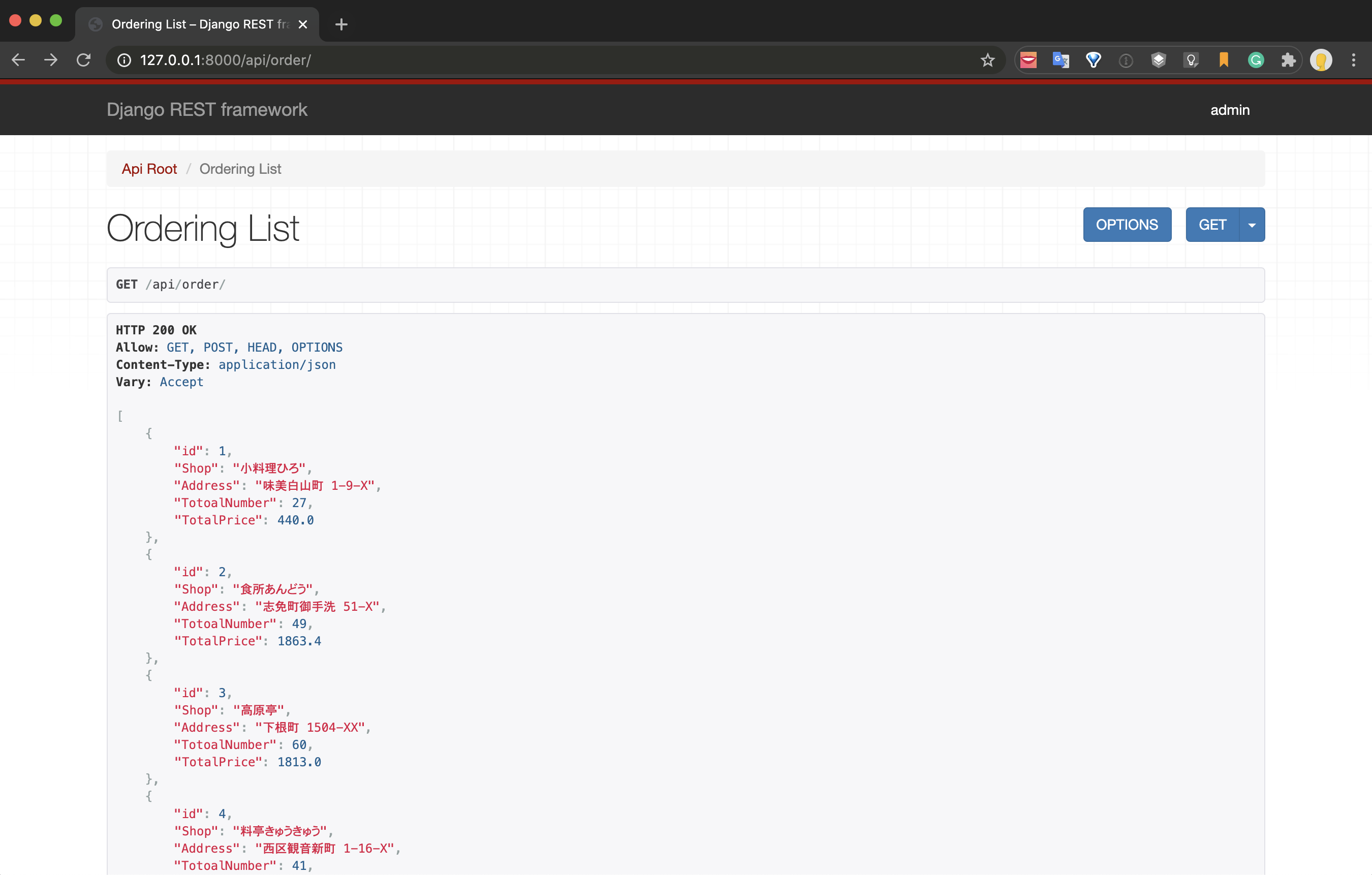
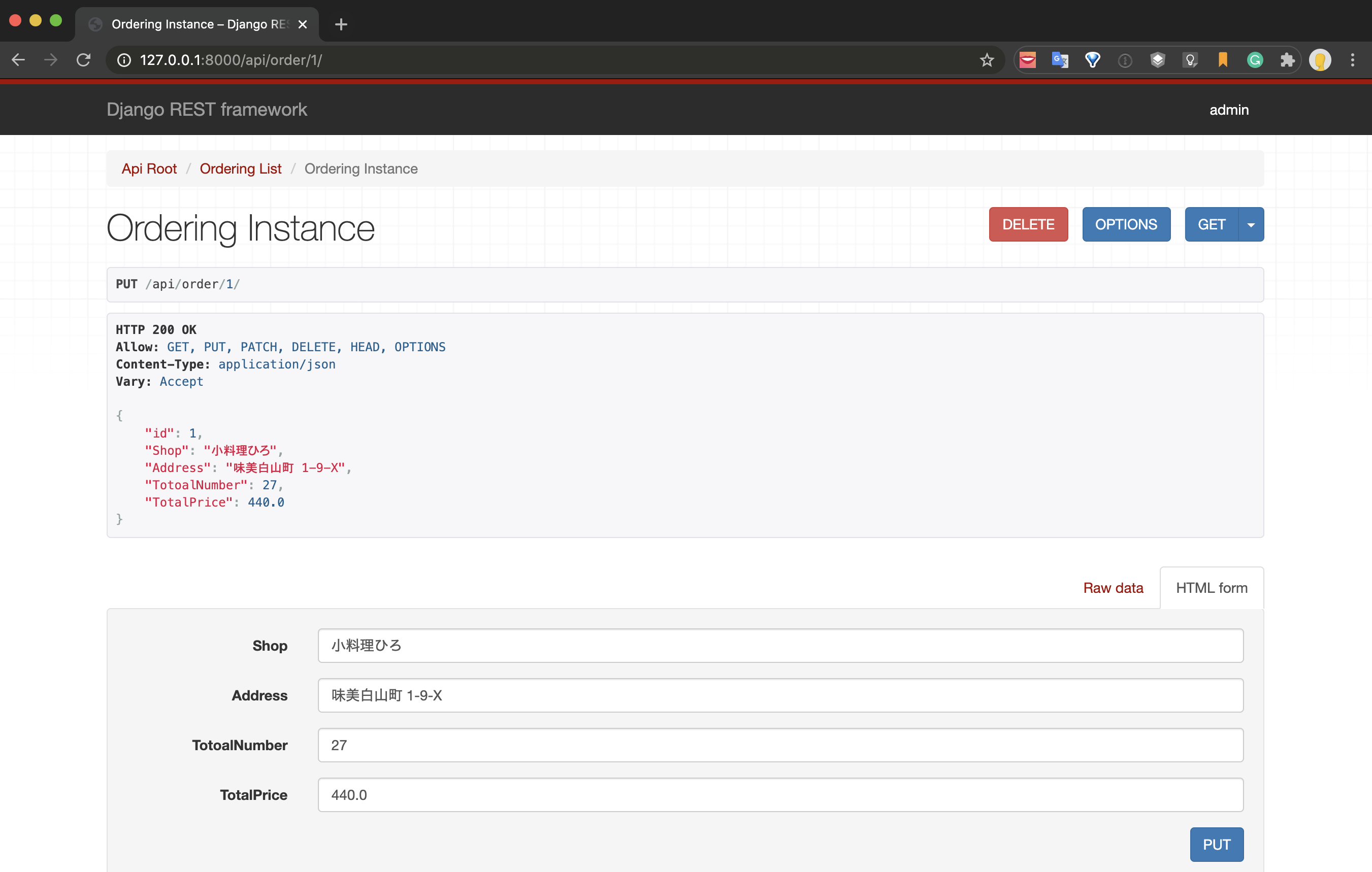
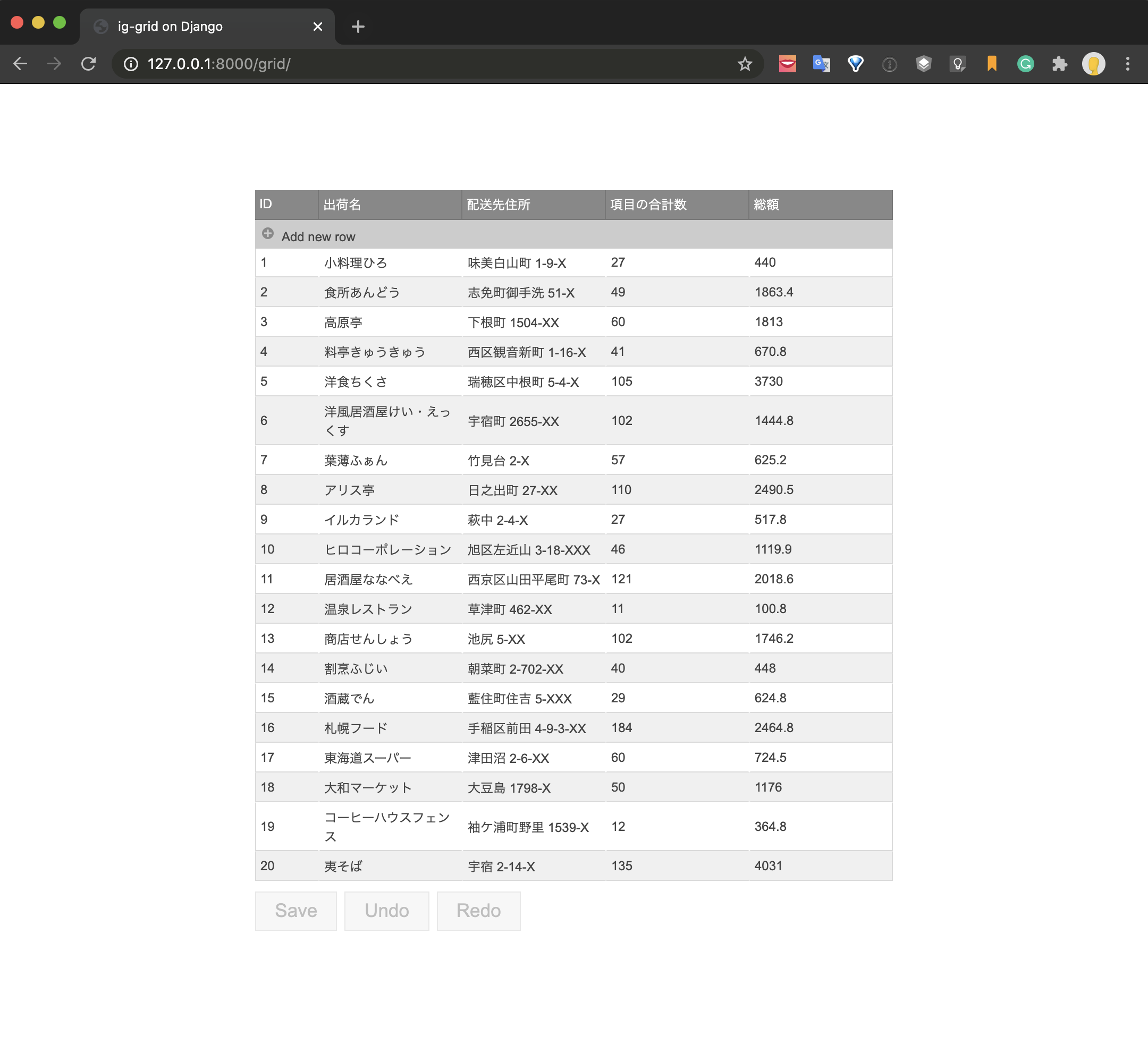

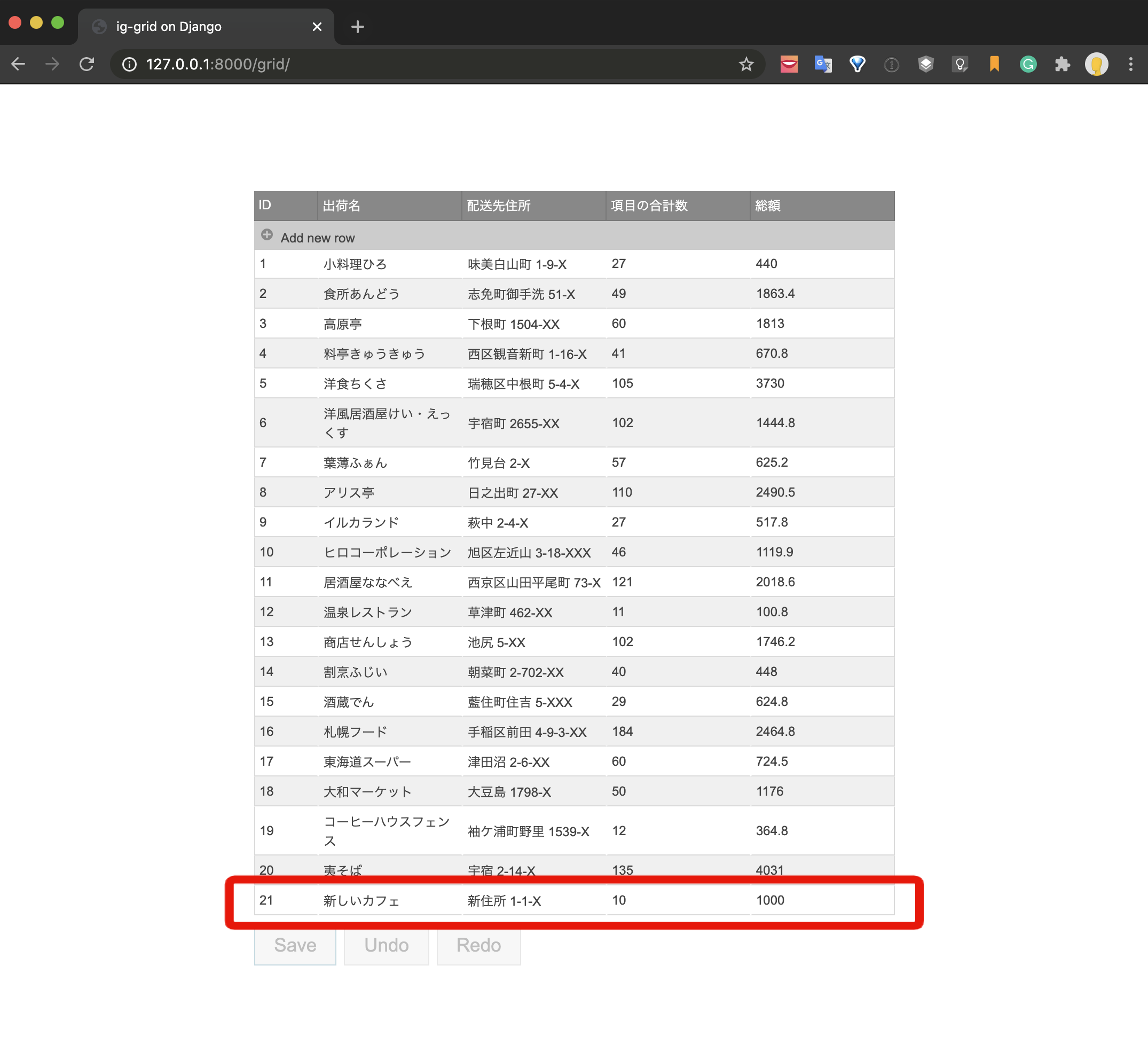
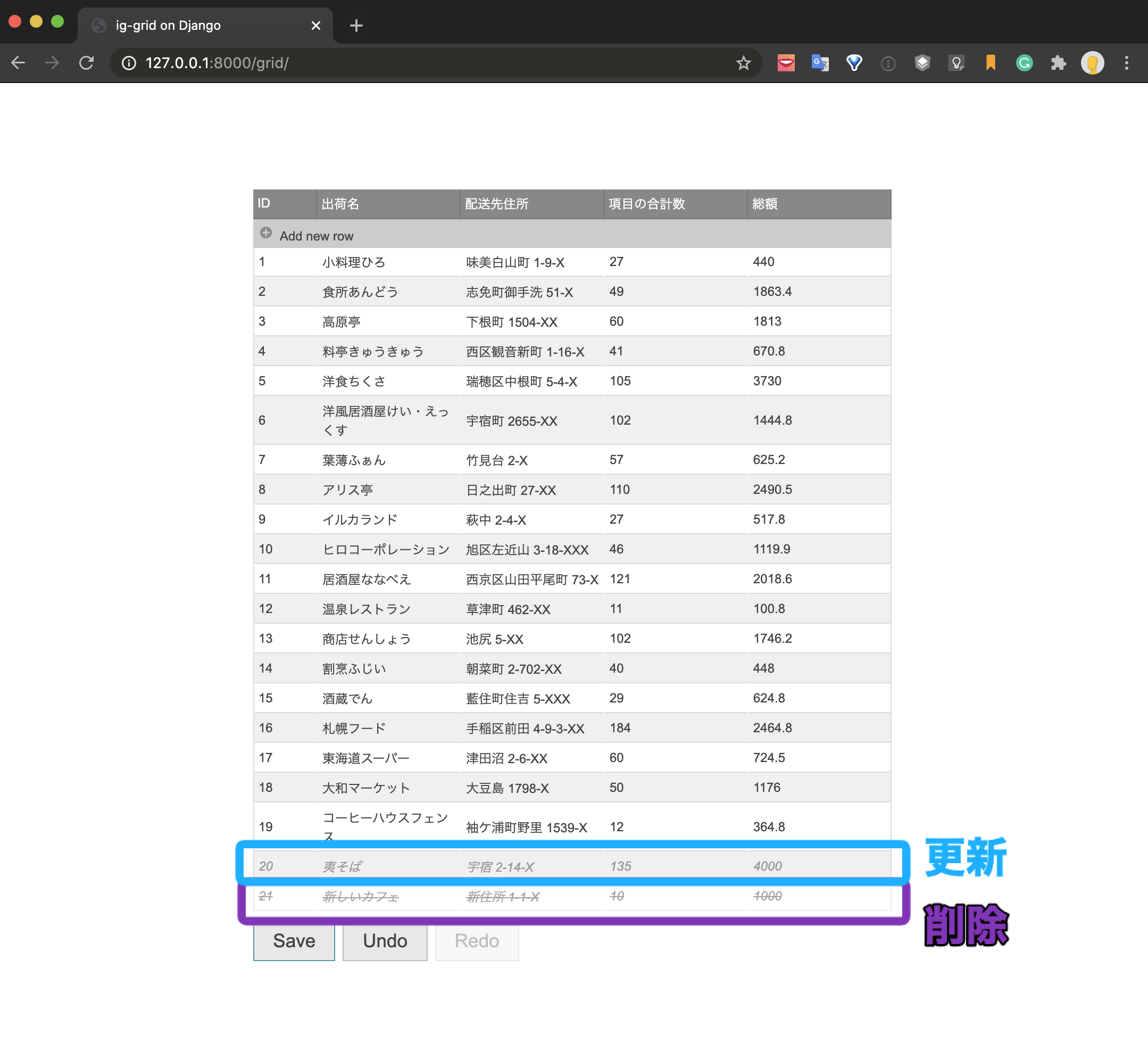
- 投稿日:2020-10-14T13:08:06+09:00
【機械学習】線形回帰 - 直線フィッティング、曲線フィッティング
はじめに
機械学習を勉強しています。
自分用にまとめます。
数学的に厳密ではないと思います。
理論中心です。
この記事では、「直線フィッティング」と「曲線フィッティング」をやります。直線フィッティング
要件
$N$個のデータ$\{(x_1,t_1),\cdots,(x_N,t_N)\}$に当てはまる直線を求めたい。
モデルの定義
予測直線(モデル)を$y=w_0+w_1x$とする。
目的関数の定義
あるデータ$(x_i,t_i)$に着目する。
$x_n$の予測値は$w_0+w_1x_n$である。
$t_n$との差の2乗は$(w_0+w_1x_n-t_n)^2$である。
これを全データについて足し合わせたものを目的関数とする。
$E(w_0,w_1)=\frac{1}{2}\sum_{n=1}^N(w_0+w_1x_n-t_n)^2$
$\frac{1}{2}$は$w_0,w_1$で偏微分した式を奇麗に見せるためのものである。目的関数の最小化
目的関数を最小化するために$w_0,w_1$で偏微分し、$=0$とおくと
以下の2式からなる連立方程式ができる。
$\frac{\partial}{\partial w_0}E=\sum_{n=1}^N(w_0+w_1x_n-t_n)=0$
$\frac{\partial}{\partial w_1}E=\sum_{n=1}^Nx_n(w_0+w_1x_n-t_n)=0$
これを解くと$w_0,w_1$が求まり、予測直線が決定する。
(ここでは解かない。直線フィッティングは曲線フィッティングに含まれるため。)曲線フィッティング
要件
要件は「直線フィッティング」の時とほぼ同じ。
$N$個のデータ$\{(x_1,t_1),\cdots,(x_N,t_N)\}$に当てはまる曲線を求めたい。
モデルの定義
予測曲線(モデル)を$y=w_0+w_1x+w_2x^2+\cdots+w_{D-1}x^{D-1}$とする。
目的関数の定義
あるデータ$(x_i,t_i)$に着目する。
$x_n$の予測値は$w_0+w_1x_n+w_2x_n^2+\cdots+w_{D-1}x_n^{D-1}$である。
$t_n$との差の2乗は$(w_0+w_1x_n+w_2x_n^2+\cdots+w_{D-1}x_n^{D-1}-t_n)^2$である。
これを全データについて足し合わせたものを目的関数とする。
$E(w_0,\cdots,w_{D-1})=\frac{1}{2}\sum_{n=1}^N(w_0+w_1x_n+w_2x_n^2+\cdots+w_{D-1}x_n^{D-1}-t_n)^2$
$\frac{1}{2}$は$w_0,\cdots,w_{D-1}$で偏微分した式を奇麗に見せるためのものである。モデルと目的関数を簡潔に表す
${\bf w}=(w_0, w_1, w_2, \cdots, w_{D-1})^T$、
$\phi_i(x)=x^i$、
${\boldsymbol\phi}(x)=(\phi_0(x), \phi_1(x), \phi_2(x), \cdots, \phi_D(x))^T$とおくと、モデルは $y={\bf w}^T\boldsymbol\phi(x)$ と表せる。
また、目的関数は $E({\bf w})=\frac{1}{2}\sum_{n=1}^N({\bf w}^T\boldsymbol\phi(x_n)-t_n)^2$と書ける。
さらに、$\Phi=\begin{pmatrix}
\boldsymbol\phi(x_1)^T \\
\vdots \\
\boldsymbol\phi(x_D)^T\\
\end{pmatrix},{\bf t}=(t_1,\cdots,t_N)^T$
とおくと
目的関数は $E({\bf w})=\frac{1}{2}||\boldsymbol\Phi{\bf w}-{\bf t}||^2$ と書ける。目的関数の最小化
目的関数を最小化するために${\bf w}$で偏微分し、$={\bf 0}$とし、
これについて解くと${\bf w}$が定まり、予測曲線が決定する。
以下導出\begin{eqnarray} \frac{\partial}{\partial {\bf w}}E&=&\frac{\partial}{\partial {\bf w}}\frac{1}{2}||\boldsymbol\Phi{\bf w}-{\bf t}||^2\\ &=&\frac{1}{2}\frac{\partial}{\partial {\bf w}}(\boldsymbol\Phi{\bf w}-{\bf t})^T(\boldsymbol\Phi{\bf w}-{\bf t})\\ &=&\frac{1}{2}\frac{\partial}{\partial {\bf w}}({\bf w}^T\boldsymbol\Phi^T-{\bf t}^T)(\boldsymbol\Phi{\bf w}-{\bf t})\\ &=&\frac{1}{2}\frac{\partial}{\partial {\bf w}}({\bf w}^T\boldsymbol\Phi^T\boldsymbol\Phi{\bf w}-{\bf w}^T\boldsymbol\Phi^T{\bf t}-{\bf t}^T\boldsymbol\Phi{\bf w}+{\bf t}^T{\bf t})\\ &=&\frac{1}{2}\frac{\partial}{\partial {\bf w}}({\bf w}^T\boldsymbol\Phi^T\boldsymbol\Phi{\bf w}-2{\bf w}^T\boldsymbol\Phi^T{\bf t}+||{\bf t}||^2)\\ &=&\frac{1}{2}(2\boldsymbol\Phi^T\boldsymbol\Phi{\bf w}-2\boldsymbol\Phi^T{\bf t})\\ &=&\boldsymbol\Phi^T\boldsymbol\Phi{\bf w}-\boldsymbol\Phi^T{\bf t}\\ &&={\bf 0}とすると\\ &&\boldsymbol\Phi^T\boldsymbol\Phi{\bf w}-\boldsymbol\Phi^T{\bf t}={\bf 0}\\ &&\Leftrightarrow \boldsymbol\Phi^T\boldsymbol\Phi{\bf w}=\boldsymbol\Phi^T{\bf t}\\ &&\Leftrightarrow {\bf w}=(\boldsymbol\Phi^T\boldsymbol\Phi)^{-1}\boldsymbol\Phi^T{\bf t}\\ &&\boldsymbol\Phi^T\boldsymbol\Phiは正則であるとする。 \end{eqnarray}ソース
こちらからGoogleColabで動作させることができます。
################################### # 線形回帰 - 曲線フィッティング ################################### import numpy as np import matplotlib.pyplot as plt # 行列φを求める def get_phi_matrix(N, M, x): Phi = np.zeros((N, M)) # N行M列(初期化されていいない) for i in range(M): Phi[:, i] = x.T ** i # 1列ずつ格納する Phi[:, i].shape は (N,) なので、xを転置する必要がある return Phi; # 乱数を固定 np.random.seed(1) # 多項式の最大べき乗数(w0 * x^0+...+wM-1*x^M-1) M = 4 # 訓練データ数 N = 10 # 訓練データの列ベクトル(N行1列の行列として列ベクトルを表現) x = np.linspace(0, 1, N).reshape(N, 1) # 訓練データtの列ベクトル t = np.sin(2 * np.pi * x.T) + np.random.normal(0, 0.2, N) # sinに正規分布に従う誤差を与える t = t.T # 列ベクトルにする(実際にはN行1列の行列) t = t.reshape(N, 1)でもOK # 行列φを求める Phi = get_phi_matrix(N, M, x); # wを解析的に求める w = np.linalg.inv(Phi.T @ Phi) @ Phi.T @ t # 求めた係数wを元に、新たな入力x2に対する予測値yを求める x2 = np.linspace(0, 1, 100).reshape(100, 1) # 点を0から1まで100個、等間隔(1/99)で発生させる # 行列Phi2を作成 Phi2 = get_phi_matrix(100, M, x2) # 予測する y = w0*x^0 + ... + wM-1*x^M-1 y = Phi2 @ w # 正則化無 # 結果の表示 plt.ylim(-0.1, 1.1) # xの表示範囲を制限する plt.ylim(-1.1, 1.1) # yの表示範囲を制限する plt.scatter(x, t, color="red") # 学習データの表示 plt.plot(x2, y, color="blue") # 正則化無の予測曲線を描画 plt.show() # グラフ描画目的関数は凸関数である
目的関数が凸関数であること示すには、目的関数のヘッセ行列が半正定値行列であることを示せばよい。
以下証明まず、目的関数のヘッセ行列を求める。
\begin{eqnarray} \frac{\partial}{\partial {\bf w}}\left(\frac{\partial}{\partial {\bf w}}E\right)&=&\frac{\partial}{\partial {\bf w}}(\boldsymbol\Phi^T\boldsymbol\Phi{\bf w}-\boldsymbol\Phi^T{\bf t})\\ &=&\boldsymbol\Phi^T\boldsymbol\Phi \\ \end{eqnarray}\\次に、ヘッセ行列が半正定値行列であることを示す。
{\bf x}\in\mathbb{R}^Dとする\\ \begin{eqnarray} {\bf x}^T\boldsymbol\Phi^T\boldsymbol\Phi{\bf x}&=&(\boldsymbol\Phi{\bf x})^T(\boldsymbol\Phi{\bf x})\\ &=&||\boldsymbol\Phi{\bf x}||^2\geq0\\ \end{eqnarray}\\目的関数のヘッセ行列は半正定値行列であることが示せた。
よって、目的関数は凸関数である。
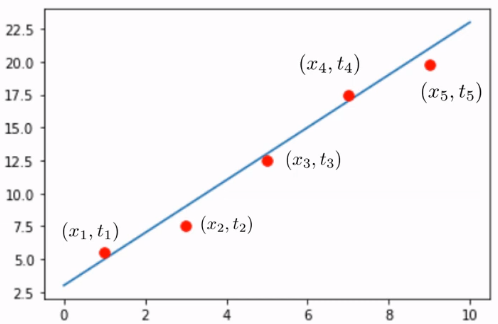
- 投稿日:2020-10-14T12:57:13+09:00
pythonで推薦システムを作る
概要
ハッカソンで推薦システムを作ることになったので、備忘録的にメモしておきます。
お酒に合ったおつまみを推薦するシステムを作る。
機械学習的なモデルにしたかったが、知識と時間が足りないため協調フィルタリングを用ることとした。参考
Pythonでレコメンドシステムを作る(ユーザベース協調フィルタリング)
Pythonで簡単な協調フィルタリングを実装するためのノート
協調フィルタリングを利用した推薦システム構築協調フィルタリング
協調フィルタリング(レコメンドシステム)とは一言で言うと
「あなたへのおすすめ」「この商品を買った人はこんな商品も買っています」
のアレです。amazonやyoutubeでおなじみですね。ユーザーベースと、アイテム(商品)ベースとの2つの方法に大別される。
ユーザーベースの強調フィルタリングは、他ユーザーの既知の評価からtargetユーザーの評価(未知)を推定するものです。クロス集計、ユークリッド距離、ピアソン相関係数、
類似性の算出方法
類似性を「同じ商品への評価が高い(低い)と類似性が高い」と定義する。
各ユーザーの商品に対する評価値を用いて類似性を算出する・類似しているものほどユークリッド距離の値が小さくなる
・逆数をとって、類似しているものほど高いスコアになるようにする
・類似性が最大の場合はユークリッド距離が0なので、1を足すscore= \frac{1}{(1+ユークリッド距離)}・scoreは0から1の値を返し、大きいほうが類似性が高いことを示す
詳しい解説は協調フィルタリングを利用した推薦システム構築のユーザーベース協調フィルタリングを見てください
実装の流れ
①エクセルデータから、target酒の評価が5の人を抜きだす(sampleおつまみデータ)
②targetおつまみの評価(既知の分のみ)とsampleおつまみデータの類似度を求める
③類似度から未知の分のtargetおつまみの評価値を予測するデータの用意
ここで使うデータは酒の評価と、おつまみを1~5で評価したものになります。
テスト段階なのでデータは4つしか用意していません。
未知ユーザーのデータは以下のように定義しました。このユーザーの他の値の予想値を求めます。
target_data = [-1, -1, 5.0, -1, 4.0, -1, -1, 1.0, -1, -1, -1] #-1はNONEsake3を選択したときのおつまみ評価の予想値をおつまみ2,5の評価値を用いて予想します。
①エクセルデータから、target酒の評価が5の人を抜きだす(sampleおつまみデータ)
def findSameSakeList(sheet, userSakeReputation): SameSakeList = [] #画像の酒の評価が5のデータを二次元リスト化する sampleLen = len(sheet.col_values(0))-1 for i in range(sampleLen): row = sheet.row_values(i+1) if row[userSakeReputation] == 5: SameSakeList.append(row) else: pass return SameSakeList sake_number = 2 wb = xlrd.open_workbook(r'C:\Users\daisuke\Desktop\voyage\testdata.xlsx') sheet = wb.sheet_by_index(0) samePersonList = findSameSakeList(sheet, sake_number) #該当する②targetおつまみの評価(既知の分のみ)とsampleおつまみデータの類似度を求める
def get_similarities(samePersonList, target_data): similarities = [] sampleLen = len(samePersonList) for j in range(sampleLen):#sheetのrow番号 distance_list = [] for i, value in enumerate(target_data): if value == -1: pass else: distance = value - samePersonList[j][i] distance_list.append(pow(distance, 2)) similarities.append([j, 1/(1+np.sqrt(sum(distance_list)))]) return sorted(similarities, key=lambda s: s[1], reverse=True)③類似度から未知の分のtargetおつまみの評価値を予測する
評価値の予測は
sampleユーザーの該当おつまみの重み付き評価値 = 類似性 × sample評価値その後 、評価値の合計をとって正規化する
正規化したscore= \frac{上で求めた重み付き評価値の全ユーザー分の合計点数}{評価者の類似度の合計}def predict(samePersonList, similarities):#全samepersonに対して類似度×評価値をして予測評価値を出す predict_list = [] for index, value in similarities: samePersonList[index] = [round(i*value,5) for i in samePersonList[index]] #round で小数を丸める np_samePerson = np.array(samePersonList) np_samePerson = list(np.mean(np_samePerson, axis=0)) for index, value in enumerate(np_samePerson): predict_list.append([index, value]) return sorted(predict_list, key= lambda s: s[1], reverse=True) samePersonList = findSameSakeList(sheet, sake_number ) #選んだ酒の評価が5の人のヴァリューのリスト similarities = get_similarities(samePersonList, target_data) ranking = predict(samePersonList, similarities) pprint.pprint(ranking) #正規化したsocreをランキング付けして出力 #[[2, 1.225635], #[5, 1.100635], #[3, 0.850635], #[1, 0.745125], #[4, 0.725635], #[8, 0.620125], #[9, 0.6103799999999999], #[7, 0.605505], #[0, 0.48538], #[6, 0.125], #[10, 0.0]]酒も一緒に予想評価を出してます

- 投稿日:2020-10-14T12:55:18+09:00
Python3 で websockets の async/await を隠蔽する
asyncioが入る websockets を使用した関数が上部に波及してどこまでもasync/awaitになってしまうのか…と思っていたところ自作ライブラリでなんとかなったのでその部分の忘備録解決策
- デコレータを使いました
環境
- Python 3.8.5
- websockets 8.1
コード
my_library.py
import websockets import asyncio class EntitySpec(object): def __init__(self, ctx): self.ctx = ctx self.uri = "ws://{}:{}".format( ctx.hostname, ctx.port, ) def __call__(self, func): async def stream(func): async with websockets.connect(self.uri) as ws: while not ws.closed: try: response = await ws.recv() func(response) except websockets.exceptions.ConnectionClosedOK: self.loop.stop() self.loop = asyncio.get_event_loop() self.loop.create_task(stream(func)) return stream def run(self): self.loop.run_forever() class Context(object): def __init__( self, hostname='localhost', port=8765, ): self.hostname = hostname self.port = port self.websocket = EntitySpec(self)main.py
import my_library api = my_library.Context( hostname = 'localhost', port = 8765, # websockets server サンプル標準ポート ) @api.websocket def reciever(msg): print(msg) api.websocket.run()
- 投稿日:2020-10-14T12:49:06+09:00
初心者がやりがちな変数命名のアンチパターン
はじめに
ご存知のようにPythonはその書きやすさからプログラミング初心者にも敷居の低い言語として親しまれており、「初めて触れる言語がPython」という方も少なくありません。
しかしそんなPythonにもやってはいけないアンチパターン(禁じ手)があり、初心者が知らずに踏んでしまうと対処に苦しむ事になってしまいます。
そこで、Pythonのアンチパターンのうち、特に初心者が注意すべき「変数の命名」の中でも特に致命的な同名変数定義による代入についてご紹介させていただこうと思います。悪い例
下のコードは、タプル型変数
tupleの中身をリスト型に変換して、リスト型変数listと結合させるものです。
一見至って普通のデータ操作ですが、これ実は動きません。エラーが出ます。>>> list = ["Apple", "Orange", "Grape"] >>> tuple = ("Peach", "Strawberry") >>> list.append(list(tuple))Traceback (most recent call last): File "<stdin>", line 1, in <module> TypeError: 'list' object is not callable何がまずかった?
原因は1行目にあります。
全体として、Pythonにはlist()という標準組み込み関数があり、これで引数に与えたIterableなオブジェクトをリスト型に変換することができます。3行目の
append()の中身list(tuple)ではこの関数を呼び出そうとしているのですが、1行目でlistの名前でリスト変数を定義してしまったことで、listの参照先が上書きされてしまったのです。
そのためこのコードでは今後listが組み込み関数のlist()ではなく変数の["Apple", "Orange", "Grape"]を参照するようになります。残念ながらこのコード内では再代入しない限り
list()関数は二度と使えません。対策
同じように使用を強く非推奨される命名は他にもあり、
str、list、int、dict、id、bool等も、一時変数に使いたくなる魅力を放ちながらも、実際に定義してしまうと同名の関数を潰してしまうことになる危険なものとなっています。
たとえ書き捨てコードであっても、これらの命名は決して使ってはいけません。
そこで、個人的なおすすめの命名は、これらを接尾辞として変数名の一部に入れることです。
上記の例であれば、list = ["Apple", "Orange", "Grape"] tuple = ("Peach", "Strawberry")を、
fruits_list = ["Apple", "Orange", "Grape"] fruits_tuple = ("Peach", "Strawberry")のように、
[リストの抱える要素の総称]_[データ型]の命名が、入っているデータの内容と型を容易に判別できるのでおすすめです。命名はできるだけ一意なものが望ましい
組み込み関数だけでなく、同名のオブジェクトが存在する命名は避けたほうが幸せ
今回上げた例は
list()という関数の話ですが、Pythonでは予約語以外のあらゆる変数を自由に定義・代入できてしまうという特性があり、注意しないと変数の上書きや関数へのアクセスを失ってしまうことになるので、変数は「他と被らない命名」をできるだけ心がけるといいと思います。
標準組み込み関数だけでなく、コード内やimportしたパッケージに存在するメソッドとの競合も気をつけてるべきでしょう。
コードサジェスト機能が存在するエディタなら、新規変数を定義しようとしたとき、サジェストに同一名の候補が列挙されたら使用しないという手も有効かもしれません(下画像はVisualStudioCodeのサジェスト)。
まとめ
- 同一名の関数/変数が存在する変数を新たに定義してしまうと、関数が使えなくなってしまったり、その前に定義されていた変数の値を失うことになる。
- 変数の命名は
[リストの抱える要素の総称]_[データ型]が、安全かつ可読性に優れた例としておすすめ- キーワードサジェストを参考に変数命名アンチパターンを回避できる。
変数名に注意を払うようになると、可読性がぐっと上がり、コード全体の処理過程も追いやすくなります。
これによりバグの早期発見の確率も上がり生産性の大きな向上も見込めるでしょう。コードを書く際には変数の命名を見直してみてください。
最後まで読んでいただきありがとうございましたm(_ _)m
修正点、加筆すべきことありましたら教えていただけると幸いです。
