- 投稿日:2020-10-14T23:56:18+09:00
AWS日記19 (CloudWatch Events)
はじめに
今回は AWS CloudWatch Events を試します。
スケジュールをcron式で設定し、Lambda関数を実行するページを作成します。
Lambda関数・SAMテンプレート準備
[AWS CloudWatch Eventsの資料]
AWS CloudWatch EventsAWS SAM テンプレート作成
AWS SAM テンプレートで API-Gateway , Lambda, CloudWatch Eventsの設定をします。
[参考資料]
AWS SAM テンプレートを作成する
template.yml
template.ymlAWSTemplateFormatVersion: '2010-09-09' Transform: AWS::Serverless-2016-10-31 Description: Serverless Application Cron Parameters: ApplicationName: Type: String Default: 'ServerlessApplicationCron' CronEventRuleName: Type: String Default: 'CronEventRule' CronMainFunctionName: Type: String Default: 'CronMainFunction' FrontPageApiStageName: Type: String Default: 'ProdStage' Metadata: AWS::ServerlessRepo::Application: Name: Serverless-Application-Cron Description: 'This application is test for CloudWatch Events.' Author: tanaka-takurou SpdxLicenseId: MIT LicenseUrl: LICENSE.txt ReadmeUrl: README.md Labels: ['ServerlessRepo'] HomePageUrl: https://github.com/tanaka-takurou/serverless-application-cron-page-go SemanticVersion: 0.0.1 SourceCodeUrl: https://github.com/tanaka-takurou/serverless-application-cron-page-go Resources: FrontPageApi: Type: AWS::Serverless::Api Properties: EndpointConfiguration: REGIONAL StageName: !Ref FrontPageApiStageName FrontPageFunction: Type: AWS::Serverless::Function Properties: CodeUri: bin/ Handler: main MemorySize: 256 Runtime: go1.x Description: 'Cron Front Function' Events: FrontPageApi: Type: Api Properties: Path: '/' Method: get RestApiId: !Ref FrontPageApi Environment: Variables: REGION: !Ref 'AWS::Region' API_PATH: !Join [ '', [ '/', !Ref FrontPageApiStageName, '/api'] ] MainFunction: Type: AWS::Serverless::Function Properties: FunctionName: !Ref CronMainFunctionName CodeUri: api/bin/ Handler: main MemorySize: 256 Runtime: go1.x Description: 'Cron API Function' Policies: - Statement: - Effect: 'Allow' Action: - 'logs:CreateLogGroup' - 'logs:CreateLogStream' - 'logs:PutLogEvents' Resource: '*' - Effect: 'Allow' Action: - 'lambda:*' - 'events:DescribeRule' - 'events:PutRule' Resource: '*' Environment: Variables: LAST_EVENT: "" EVENT_NAME: !Ref CronEventRuleName FUNCTION_NAME: !Ref CronMainFunctionName REGION: !Ref 'AWS::Region' Events: FrontPageApi: Type: Api Properties: Path: '/api' Method: post RestApiId: !Ref FrontPageApi CronApiPermission: Type: AWS::Lambda::Permission Properties: Action: lambda:InvokeFunction FunctionName: !Ref MainFunction Principal: apigateway.amazonaws.com CronEventRule: Type: AWS::Events::Rule Properties: Name: !Ref CronEventRuleName Description: CronRule ScheduleExpression: 'cron(0 12 * * ? *)' State: 'ENABLED' Targets: - Arn: !GetAtt MainFunction.Arn Id: TargetCronFunction PermissionForEventsToInvokeLambda: Type: AWS::Lambda::Permission Properties: FunctionName: !Ref MainFunction Action: 'lambda:InvokeFunction' Principal: 'events.amazonaws.com' SourceArn: !GetAtt CronEventRule.Arn Outputs: APIURI: Value: !Join [ '', [ 'https://', !Ref FrontPageApi, '.execute-api.',!Ref 'AWS::Region','.amazonaws.com/',!Ref FrontPageApiStageName,'/'] ]CloudWatch Eventsの設定は以下の部分
CronEventRule: Type: AWS::Events::Rule Properties: Name: !Ref CronEventRuleName Description: CronRule ScheduleExpression: 'cron(0 12 * * ? *)' State: 'ENABLED' Targets: - Arn: !GetAtt MainFunction.Arn Id: TargetCronFunction PermissionForEventsToInvokeLambda: Type: AWS::Lambda::Permission Properties: FunctionName: !Ref MainFunction Action: 'lambda:InvokeFunction' Principal: 'events.amazonaws.com' SourceArn: !GetAtt CronEventRule.ArnLambda関数作成
※ Lambda関数は aws-lambda-go を利用し、CloudWatch Events周りの処理は aws-sdk-go-v2 を利用しました。
AWS SDK for Go API Reference V2ルールを追加・更新するには PutRule を使う
func putRule(ctx context.Context, minute string, hour string, day string, month string, year string) error { var m_ int var h_ int var d_ int var o_ int var y_ int m_, _ = strconv.Atoi(minute) h_, _ = strconv.Atoi(hour) d_, _ = strconv.Atoi(day) o_, _ = strconv.Atoi(month) y_, _ = strconv.Atoi(year) if m_ < 0 { m_ = 0 } sm := strconv.Itoa(m_) if h_ < 0 { h_ = 0 } sh := strconv.Itoa(h_) sd := "*" if d_ > 0 { sd = strconv.Itoa(d_) } so := "*" if o_ > 0 { so = strconv.Itoa(o_) } sy := "*" if y_ >= 1970 { sy = strconv.Itoa(y_) } if cloudwatcheventsClient == nil { cloudwatcheventsClient = getCloudwatcheventsClient() } params := &cloudwatchevents.PutRuleInput{ Name: aws.String(os.Getenv("EVENT_NAME")), ScheduleExpression: aws.String("cron(" + sm + " " + sh + " " + sd + " " + so + " ? " + sy + ")"), } res, err := cloudwatcheventsClient.PutRule(ctx, params) if err != nil { log.Print(err) return err } log.Printf("%+v\n", res) return nil }ルールの内容を取得するには DescribeRule を使う
func describeRule(ctx context.Context)(string, error) { if cloudwatcheventsClient == nil { cloudwatcheventsClient = getCloudwatcheventsClient() } params := &cloudwatchevents.DescribeRuleInput{ Name: aws.String(os.Getenv("EVENT_NAME")), } res, err := cloudwatcheventsClient.DescribeRule(ctx, params) if err != nil { log.Print(err) return "", err } return stringValue(res.ScheduleExpression), nil }終わりに
cron式で指定するタイムゾーンはUTCのため、時差を考慮する必要があります。
Lambda関数以外も CloudWatch Eventから実行できるため、今後試していこうと思います。
- 投稿日:2020-10-14T23:48:46+09:00
最強のデータ分析基盤を目指して~汎用的なデータ分析基盤の選定方法の提案~
概要
本記事にて、データ分析基盤の検討の進め方を記載します。データ分析基盤の概念モデルを検討した上で、それにサービスをマッピングを行い選定を行うプロセスを紹介します。
サービスを選定する際には、ガートナーなどの外部期間の評価報告レポートが参考になります。ガートナーは、特定の分野ごとにマジック・クアドラントを発表しており、製品ごとの弱点も記載されているなど参考になる情報が記載されております。最新のトレンドを反映された評価となっていることから、IT投資による優位性を保ちたいのであれば、適切な評価をされているサービスを選定すべきです。ガートナーの報告書は有料コンテンツではありますが、ソフトウェアベンダー(特にその分野でリーダーとなっている会社)が無償で公開していることがあるので探してみてください
製品の選定を行う際には、ソフトウェアベンダーの言葉を鵜呑みにせずに、自分で言葉の定義を行いながら進めることが重要です。単純な比較表を作成するだけでは製品の特徴の理解は難しく、想定シナリオでの性能や使い勝手の評価を行うことで製品に対する理解が深まります。サービス評価を下記の観点で、初期評価・中間評価・最終評価を行うことが有用です。
- 機能(機能を保持しているか)
- 性能(機能がどれぐらいの性能ができるのか)
- 使い勝手(機能を使いやすいか)
- コスト(購入・開発・運用・廃棄のライフサイクル全体のコスト)
データ分析基盤の選定
下記のステップで、データ分析基盤を選定するプロセスを紹介します。
STEP1.データ分析基盤に関する前提知識の獲得
STEP2.データ分析基盤の概念モデルを作成
STEP3.利用コンポーネントの決定
STEP4.論理モデル(利用コンポーネントにサービスをマッピングした図)の検討
STEP5.PoCの実施と機能・性能・使い勝手・コストの観点での最終レポート作成STEP1.データ分析基盤に関する前提知識の獲得
データ分析基盤の定義を行います。データマネジメントの領域に関する調査を実施する際には、下記の書籍やサイトの情報を探索します。
- DAMA-DMBOK: Data Management Body of Knowledge: 2nd Edition
- データマネジメント知識体系ガイド 第二版
- The DAMA Dictionary of Data Management, 2nd Edition: Over 2,000 Terms Defined for IT and Business Professionals (English Edition)
- Gartner Glossary
データ分析基盤の検討する際には、下記のマイクロソフト様ドキュメントも参考になります。
データ分析基盤を検討する上で、必要となる主な知識は下記です。
- ラムダアーキテクチャ
- SMPとMPP
- ディメンションナルモデリング
- 構造化データ・半構造データ・非構造データの違い
- 列指向フォーマット(ParquetからDelta Lakeへ)
- 同時実行性(一般的なDWHは同時実行性が低く、BIから接続する際の同時実行数に注意)
- データストアの拡張性
- 最近の話題
- データ仮想化
- データプリパレーション
- データカタログ
STEP2.データ分析基盤の概念モデルを作成
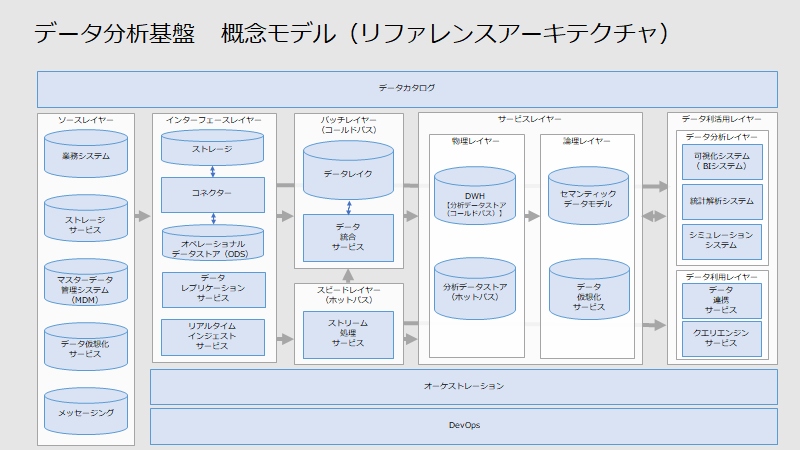
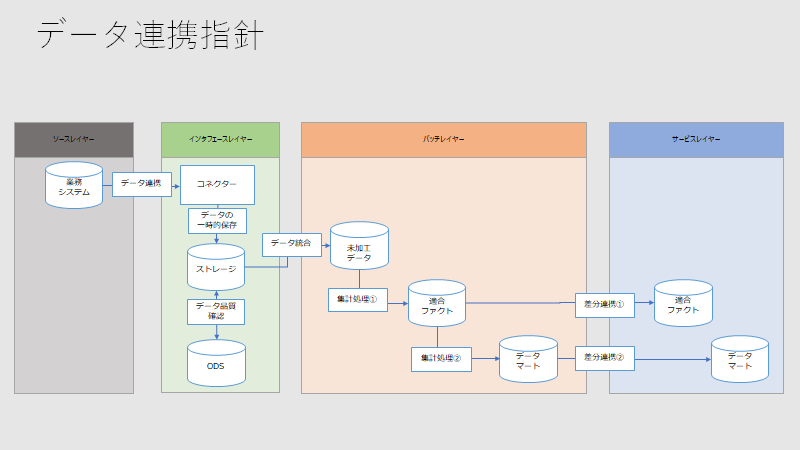
2020年10月14日時点で、私が考えるデータ分析基盤の概念モデルは下記図であり、下記の箇条書きの観点でモデル化しております。最近のデータ分析基盤のトレンドを反映することで網羅的に記載しておりますので、参考にしてください。
- ビックデータの3V(Volume、Variety、Velocity)に対応できる拡張性のあるアーキテクチャとすること
- データ分析レイヤーにて、可視化・統計解析(AI)シミュレーションの3つに分けて、それぞれのツールを選定できるようにすること
- データ仮想化サービス、データレプリケーションサービス、データプリパレーション(データ連携サービス)などのサービスの位置付けの明確化を行うこと
詳細の記事については、下記の記事をご確認ください。
番号 記事 詳細記事リンク 1 データ分析基盤における概念モデルとは リンク 2 ソースレイヤーとは リンク 3 インタフェースレイヤーとは リンク 4 バッチレイヤーとは リンク 5 スピードレイヤーとは リンク 6 サービスレイヤーとは リンク 7 データ利活用レイヤーとは リンク 8 データカタログとは リンク 9 オーケストレーションとは リンク 10 DevOpsとは リンク STEP3.利用コンポーネントの決定
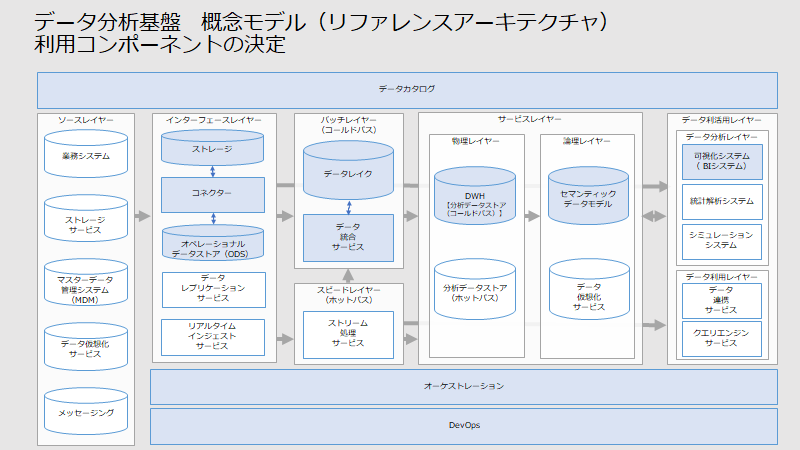
概念モデルに基づき、スコープの対象とするコンポーネントを決定します。下記の前提をもとに、概念モデルの図にて利用するコンポーネントを塗りつぶし、利用しないコンポーネントを塗りつぶしなしにします。
- BI(ビジネス・インテリジェンス)システムを導入すること
- データレイクに格納する前に、ODSにてデータの品質確認を行うこと
- リアルタイム分析・統計解析・シミュレーション・データ利用レイヤーは実装しないこと
STEP4.論理モデル(利用コンポーネントにサービスをマッピングした図)の検討
利用コンポーネントを整理した概念モデル図に、実際のサービスをマッピングします。下記の前提で、概念モデル図の上にサービスを配置します。
- Azureで実装すること
- データカタログとして、Informatica社のデータカタログを検討すること
- サービス間の連携を疎結合をするためにAzure Storageで連携を行うこと
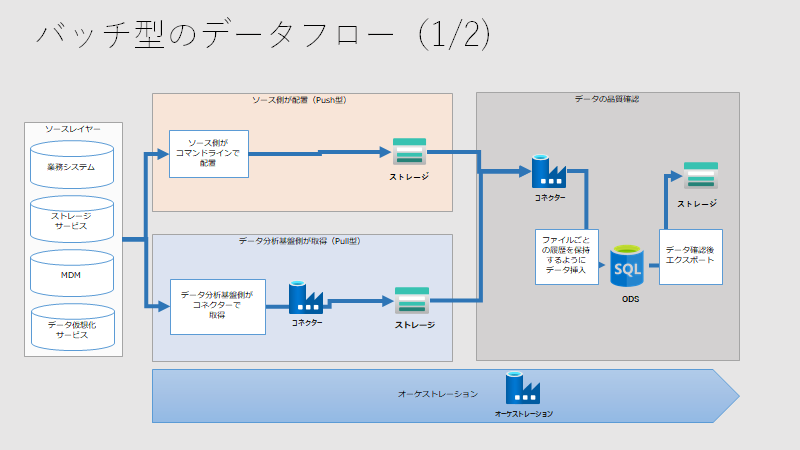
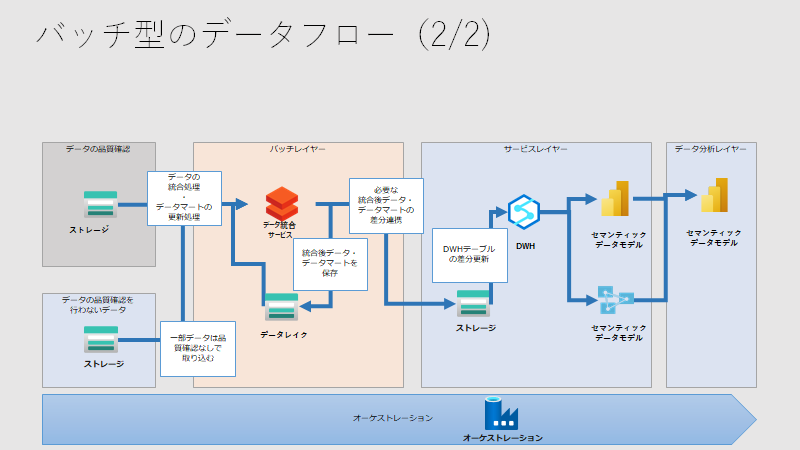
データフローの検討も必要です。サービス間の関係性を下記のように整理します。
バッチレイヤーにて集計ロジックを集中させ、サービスレイヤーでは単純な差分連携のみを行うことを示すために、下記のように整理します。
そして、データレイクにどのようなファイル形式として保存するのか、また、サービス間でどのようなファイル形式で連携するのかに関する指針をきめます。
番号 フォーマット 説明 データ分析基盤での利用推奨 1 区切り型テキストファイル(CSV、TSV) カンマ区切り、あるいは、タブ区切りによりデータを保持したファイルフォーマットであり、容易に利用できる。データストアに取り込む際には、最も高速に取り込むことができることが多い。 データレイク:×
業務システム:〇
バッチレイヤーへの連携時:◎
サービスレイヤーへの連携時:◎
リアルタイム処理時:〇
データ連携サービス:〇
クエリエンジン:×2 json システムで利用されるデータ形式。 × 3 xml システムで利用されるデータ形式。 × 4 Apache Parquet 列指向のデータ形式。スキーマの自動読み込みが可能。 データレイク:〇
業務システム:×
バッチレイヤーへの連携時:〇
サービスレイヤーへの連携時:×
リアルタイム処理時:×
データ連携サービス:〇
クエリエンジン:◎5 Delta Lake ACID特性などを保持させなどのParquetを拡張させたデータ形式。データレイクにおけるスタンダードとなりそうなファイル形式。ただし、利用するサービスで対応しているか確認する必要がある。 データレイク:◎
業務システム:×
バッチレイヤーへの連携時:×
サービスレイヤーへの連携時:×
リアルタイム処理時:〇
データ連携サービス:〇
クエリエンジン:〇6 Apache Avro スキーマ情報を保持しており、システム間でデータ交換を行うための行指向のデータ形式。 データレイク:×
業務システム:×
バッチレイヤーへの連携時:×
サービスレイヤーへの連携時:×
リアルタイム処理時:◎
データ連携サービス:×
クエリエンジン:×7 ORC Hiveの処理に最適化された列指向のデータ形式。 × 8 Common Data Model 標準の共通データ モデル形式のスキーマ化されたデータとして保存するデータ形式。 データレイク:×
業務システム:◎
バッチレイヤーへの連携時:×
サービスレイヤーへの連携時:×
リアルタイム処理時:×
データ連携サービス:〇
クエリエンジン:×引用元:データ分析基盤におけるデータレイクでの保持ファイル形式、および、インターフェースファイルの形式について
STEP5.PoCの実施と機能・性能・使い勝手・コストの観点での最終レポート作成
機能要件・非機能要件に基づいて詳細なアーキテクチャ(物理モデル)を定義をし、それに対するPoCの実施を行った上で、機能・性能・使い勝手・コストの観点での最終レポートを作成します。
Q&A
アジャイル的にデータ分析基盤を検討してよいのか?
アジャイル的にデータ分析基盤を拡張していくことは有効ですが、捨てる覚悟をもつべきです。システムを初期構築時には手探りの状態で進めることがよくありますが、初期のシステムとして構築したもののなかには技術的負債が多く残ってしまうことがあります。アジャイル的に進めるのであれば、実装済みのシステムのスクラップの検討を行うべきであり、その意識がないのであれば考えることを放棄しているだけです。

- 投稿日:2020-10-14T23:20:59+09:00
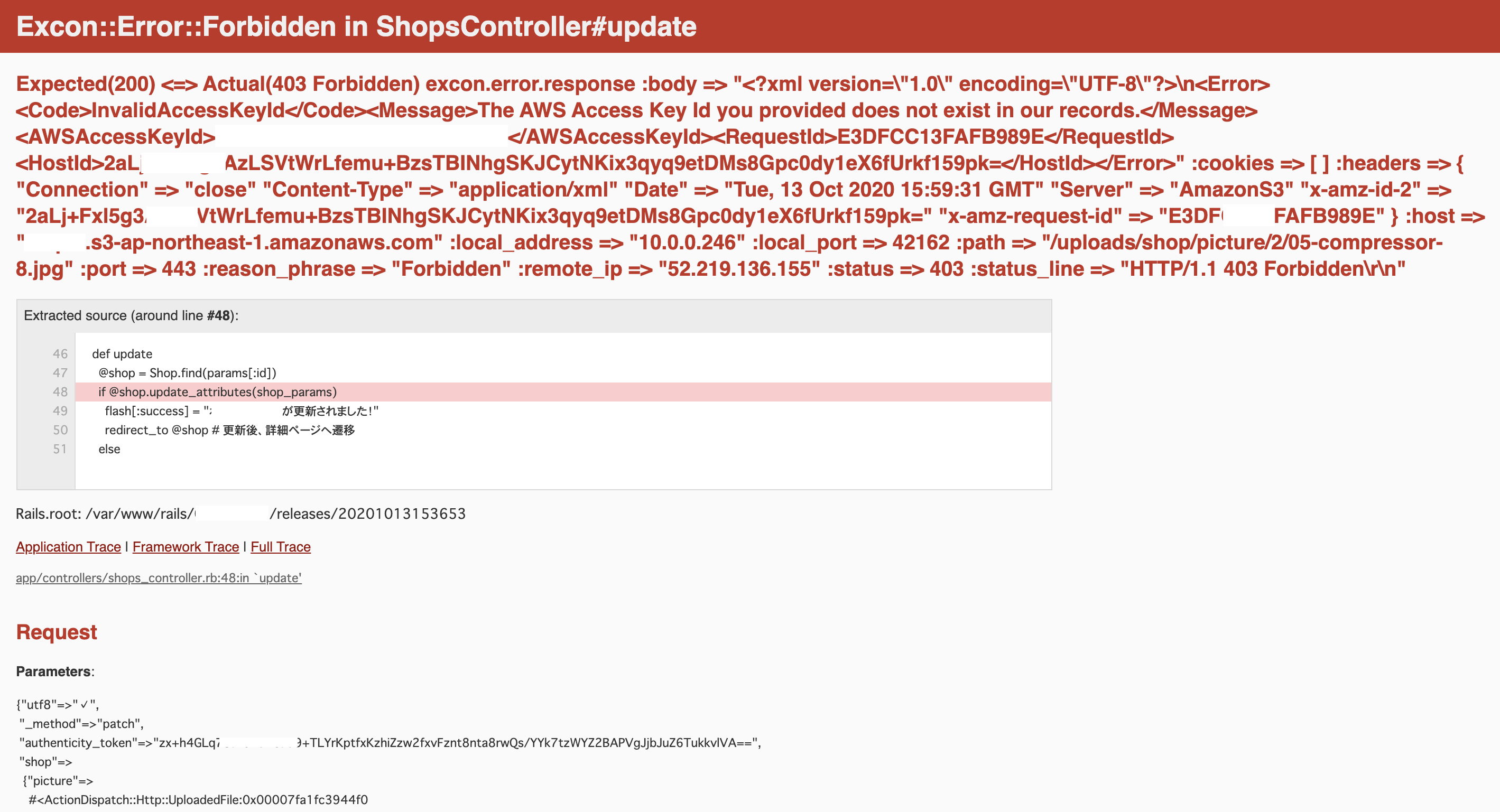
【AWS S3】AWS Access Key Id you provided does not exist in our records エラー【Rails AWS EC2】
エラー内容
本番環境(EC2)で画像投稿(carrierwave)をしようとすると、下記のようなエラーが起きる。
表示されている(読み込まれている)AWSAccessKeyIdは以前使用していた古いキー。
エラー文から古いアクセスキーが読み込まれているため整合性が取れず起きたエラーと判断した。エラーに対するTRY
- .bash_profileの更新
- .envファイルの確認
- .awsディレクトリ以下の確認(config,credentials)
- aws configure の確認
- AWS IAMによりポリシー等の確認
.bash_profileでexportしていたアクセスキーIDが確かに古いものであった。
それを新しいアクセスキーに更新し、.envファイルやIAM、aws configure listを確認し、最新のアクセスキーIDに更新されたことを確認したが、画像を投稿すると同じエラーが生じる。Dockerを利用しているため、古いイメージなどを消去するも、変化なし。ローカル$ aws configure list AWS Access Key ID [None]: AKIA...(新しいアクセスキー) AWS Secret Access Key [None]: KEY...(新しいアクセスキー) Default region name: ーーー Default output format: json解決方法
途方に暮れていたところ、
「EC2で不具合が起きた時はまずEC2インスタンスを再起動させよ」という先人の言葉をふと思い出した。
「あぁ、これが正解だ」と思った。恐らく、EC2インスタンスを再起動させないと上手く読み込まれない。EC2インスタンスからexitでログアウトし、再ログイン(ssh)ではダメだった。
EC2インスタンスを再起動させると予想通り解決し、正常に画像を投稿できた。
学び
AWS CLIにより、ターミナルから古いキーを新しいキーに変更した場合は必ずEC2インスタンスを再起動させる!
AWSアクセスキーID等は最新なのに私と同じようなエラーが起きるという方はまずは使用しているEC2インスタンスを再起動させてみてください。
- 投稿日:2020-10-14T22:47:13+09:00
DynamoDB基礎知識とboto3での簡単な使用方法
記事について
DynamoDBを使用するために学習した内容まとめ用
DynamoDB
NoSQLデータベースサービス
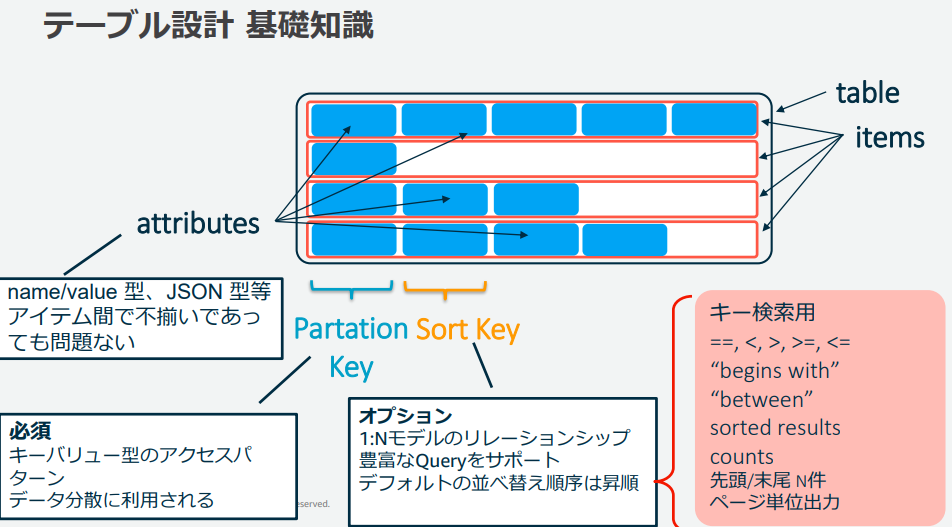
DB構造、用語
table
RDSでのtableitem
RDSでのrecordattribute
RDSでのcolumn
item間でattributeは一致しなくてよい
以下Partition Key、Sort Keyとなるattribute以外はtable生成時に設定不要Primary Key
DynamoDBでItemを一意に決定するためのキー
主キーとも言うらしいPartition Key
table生成時に設定(必須)
単体でPrimary Keyとして使用可能Sort Key
table生成時に設定
Partition Key + Sort KeyでPrimary Keyとして使用可能
Partition Keyの値が同じでSort Keyの値が異なる場合に、Partition Key + Sort KeyでItemを一意に決定Primary Key
table生成時にPrimary Keyを以下2パターンから選択
- Partition Key
- Partition Key + Sort Key
1の場合、Partition Keyが同じデータは登録不可
2の場合、Partition Key、Sort Keyが共に同じデータは登録不可Index
Key(Partition Key、Sort Key)として設定した以外のattributeで絞込検索(クエリ)を行うために、
Partition Key、Sort Keyを別のattributeで設定したもの
ローカルセカンダリインデックス(LSI)と、グローバルセカンダリインデックス(GSI)の2種類あり
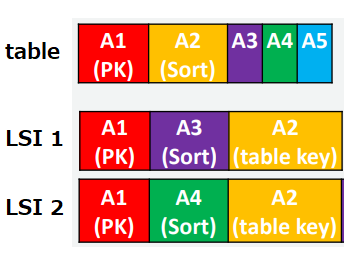
ローカルセカンダリインデックス(LSI)
以下のようにSort Keyのみ別のattributeに変更したもの
※Primary KeyをPartition Key + Sort Keyとしている場合のみ作成可能
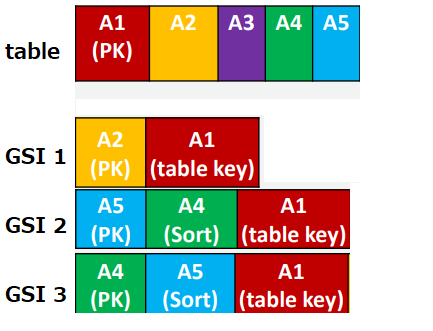
※LSIを設定する場合、table作成時に設定する必要あり、設定方法は後述グローバルセカンダリインデックス(GSI)
以下のようにPartition Key、Sort Keyを別のattributeに変更したもの
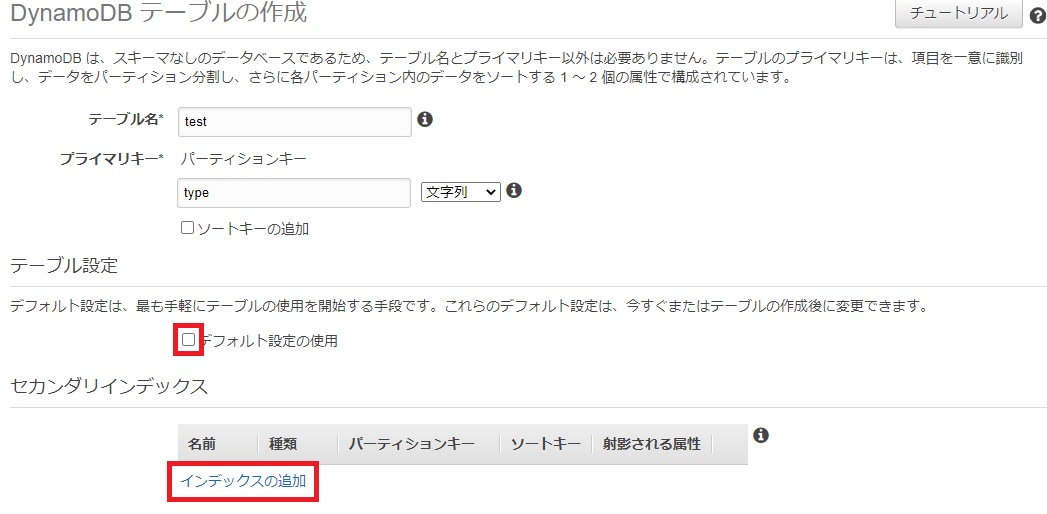
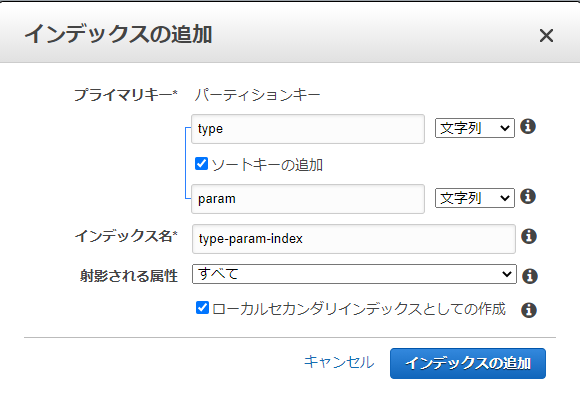
LSI設定方法
以下のようにテーブル設定欄のデフォルト設定の使用のチェックを外して、インデックスの追加をクリック
LSIとして設定する場合は、パーティションキーは、tableのパーティションキーを指定
ソートキーに絞込検索に使用するattributeを設定、ローカルセカンダリインデックスとしての作成にチェック
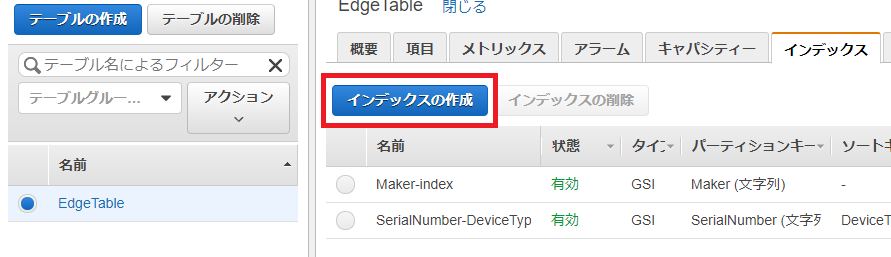
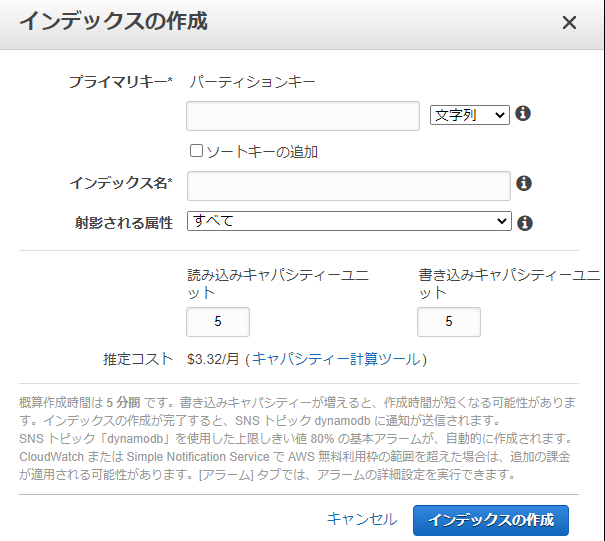
GSI設定方法
以下のようにインデックスタブからインデックスの作成をクリック
データ取得パターン
getitem
Primary Keyを使用した検索
取得できるItemが一意に決定される場合のみquery
Primary Key = Partition Key + Sort Key設定時にPartition Keyでの絞込検索
LSI、GSIでの絞込検索scan(全レコード取得)
Key設定と、データ取得可/不可
Key設定 scan get item query Primary Key (Partition Key) 〇 〇 × Primary Key (Partition Key + Sort Key) 〇 〇 〇 LSI - - 〇 GSI - - 〇 boto3を使用したデータ取得例
テーブル定義
【テーブル】
- Primary Key
Partition Key(SerialNumber) + Sort Key(BuildingId)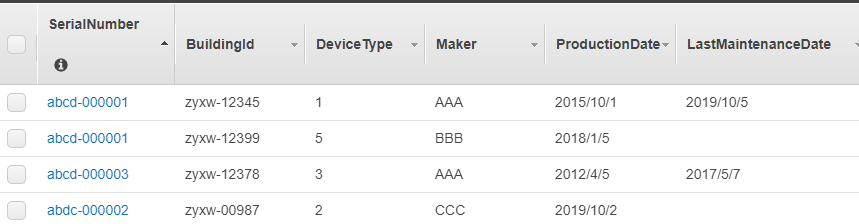
【GSI】
- Partition Key(Maker)

データ取得コード
import boto3 import json from boto3.dynamodb.conditions import Key, Attr dynamodb = boto3.resource("dynamodb", region_name='ap-northeast-1') table = dynamodb.Table("EdgeTable") # Primary Key(SerialNumber + BuildingId)を使用した検索 def get_item(SerialNumber, BuildingId): response = table.get_item( Key={ 'SerialNumber': SerialNumber, 'BuildingId': BuildingId } ) return response['Item'] # Partition Key(SerialNumber)での絞込検索 def query_SerialNumber(SerialNumber): response = table.query( KeyConditionExpression=Key('SerialNumber').eq(SerialNumber) ) return response['Items'] # Partition Key + Sort Key(SerialNumber + BuildingId)での絞込検索 def query_SerialNumber_BuildingId(SerialNumber, BuildingId): response = table.query( KeyConditionExpression= Key('SerialNumber').eq(SerialNumber) & Key('BuildingId').eq(BuildingId) ) return response['Items'] # GSI(Maker-index)のPartition Key(Maker)での絞込検索 def query_Maker_index(Maker): response = table.query( IndexName='Maker-index', KeyConditionExpression=Key('Maker').eq(Maker) ) return response['Items'] response = get_item('abdc-000002', 'zyxw-00987') # response = {'BuildingId': 'zyxw-00987', 'DeviceType': '2', 'Maker': 'CCC', 'ProductionDate': '2019/10/2', 'SerialNumber': 'abdc-000002'} response = query_SerialNumber('abcd-000001') # response[0] = {'BuildingId': 'zyxw-12345', 'DeviceType': '1', 'LastMaintenanceDate': '2019/10/5', 'Maker': 'AAA', 'ProductionDate': '2015/10/1', 'SerialNumber': 'abcd-000001'} # response[1] = {'BuildingId': 'zyxw-12399', 'DeviceType': '5', 'Maker': 'BBB', 'ProductionDate': '2018/1/5', 'SerialNumber': 'abcd-000001'} response = query_SerialNumber_BuildingId('abcd-000001', 'zyxw-12399') # response[0] = [{'BuildingId': 'zyxw-12399', 'DeviceType': '5', 'Maker': 'BBB', 'ProductionDate': '2018/1/5', 'SerialNumber': 'abcd-000001'}] response = query_Maker_index('AAA') # response[0] = {'BuildingId': 'zyxw-12378', 'DeviceType': '3', 'LastMaintenanceDate': '2017/5/7', 'Maker': 'AAA', 'ProductionDate': '2012/4/5', 'SerialNumber': 'abcd-000003'} # response[1] = {'BuildingId': 'zyxw-12345', 'DeviceType': '1', 'LastMaintenanceDate': '2019/10/5', 'Maker': 'AAA', 'ProductionDate': '2015/10/1', 'SerialNumber': 'abcd-000001'}データ追加
import boto3 import json from boto3.dynamodb.conditions import Key, Attr dynamodb = boto3.resource("dynamodb", region_name='ap-northeast-1') table = dynamodb.Table("EdgeTable") def put_item(): table.put_item( Item={ 'SerialNumber': 'abcd-000001', 'BuildingId': 'zyxw-12399', 'DeviceType': '5' } )参考
https://qiita.com/UpAllNight/items/a15367ca883ad4588c05
https://d1.awsstatic.com/webinars/jp/pdf/services/20181225_AWS-BlackBelt_DynamoDB.pdf
- 投稿日:2020-10-14T22:42:54+09:00
RDS作成メモ
- 投稿日:2020-10-14T19:49:14+09:00
AWS 認定ソリューションアーキテクト – プロフェッショナル 試験で問われるシナリオの特性
- 投稿日:2020-10-14T18:36:57+09:00
【AWS初学者用】 AWS ELBとは?
本記事について
本記事はAWS初学者の私が学習していく中でわからない単語や概要をなるべくわかりやすい様にまとめたものです。
もし誤りなどありましたらコメントにてお知らせいただけるとありがたいです。ELBとは?
Elastic Load Balancing は受信したアプリケーションまたはネットワークトラフィックを、Amazon EC2 インスタンス、コンテナ、IP アドレス、複数のアベイラビリティーゾーンなど、複数のターゲットに分散させます。Elastic Load Balancing はアプリケーションへのトラフィックが時間の経過とともに変化するのに応じてロードバランサーをスケーリングします。また、大半のワークロードに合わせて自動的にスケーリングできます。
上の文はAWS公式ページからの引用です。私の知識不足のせいか分かりませんが、この文章ではいまいちピンときませんね...
ELB(Elastic Load Balancing)
「Elastic」は弾力性のある・伸縮性のある、という意味です。
「load」は負荷という意味。
「Balancing」はバランスとるやつ、みたいな意味と思ってください。この訳通りに行くと「伸縮性があって負荷のバランスをとるやつ」。
要するにELBとはEC2などの他のサービスへの通信トラフィックを分散して、安定した稼働をサポートしますっていうやつですね!いわゆるロードバランサーです。
EC2に適用したい場合はEC2インスタンスを登録するだけで利用でき、この登録されたEC2インスタンスをバックエンドインスタンスと呼びます。
ELBの主な機能としては「通信トラフィックの分散」、「セキュリティ機能(SSL)」、「ヘルスチェック」、「高可用性」があります。通信トラフィックの分散
通信トラフィックの分散は、複数のサーバーに通信トラフィックを分散してサーバーへの通信トラフィックの集中によってサーバーダウンすることを防ぎます。
セキュリティ機能(SSL)
ELBはセキュリティ機能としてSSLの復号機能があります。これによりSSLの証明書や設定の管理が行えます。
ヘルスチェック
ELBは常に接続しているサーバーをモニタリングし、正常に動作しているかをヘルスチェックしています。ヘルスチェックで以上が検知された場合は、そのサーバーへの振り分けを停止して他の正常なサーバーで通信を行います。
また、ELBを解除するときにそのサーバーの処理が残っていると処理が中断してしまう危険があります。そんな時は「Connection Draining」という機能を使いサーバーの処理が終わってからELBを解除できるようにします。高可用性
ELBは通信トラフィックを複数のAZに分散する事ができ、例えAZに障害が発生したとしても通信トラフィックは正常なバックエンドインスタンスにのみに振り分けられるので通信を継続する事が可能とのことです。
ELBの種類
ELBには3種類あり、それぞれに特性があります。
Classic load Balancer (CLB)
EC2インスタンスへの標準的な負荷分散を行う。標準的なロードバランサーです。
AWS VPCを使用する場合はCLBではなく以下で紹介するALBかNLBを使用しましょうとのことです。Application Load Balancer (ALB)
3つの中でもっとも評価の高いロードバランサーです。CLBの機能に加え、HTTP・HTTPSトラフィックの負荷を分散し、柔軟なアプリケーションの管理ができます。
最新のアプリケーションアーキテクチャにも対応しています。Network Load Balancer (NLB)
低レイテンシで高いスループットを実現し、高度なパフォーマンスが必要なときに使用する。
送信元のアドレスを保持し、レスポンスはクライアントへ直接返す。TCP/UDP/TLSのトラフィックの負荷分散にも向いているようです。まとめ
AWS ELBは3種類あるロードバランスの総称という感じですね。
トラフィックの分散をし、セキュリティも強化でき可用性も上げられる大変便利なサービスです!
ELBには無料利用枠などはなく使用した分だけ支払う料金体系のようです。
- 投稿日:2020-10-14T18:11:50+09:00
IAM認証のAWS API GatewayにC#からIAMユーザでSigV4署名してアクセスするには
IAM認証を使っているAWSのAPI Gatewayは、APIリクエスト時にSigV4署名が必要です。
S3にSigV4署名でアクセスする方法は、AWS公式の以下のページにJavaとC#でのサンプルがあります。
これをベースにIAM認証を使っているAPI GatewayにC#でアクセスしてみます。
Pythonならば、以前の記事(IAM認証のAWS API GatewayにPythonからSigV4署名してアクセスするには)で似たことをしました。
前提
IAMユーザのアクセスキーが
~/.aws/credentialsに設定されていて、そのIAMユーザでAPI Gatewayにアクセスするものとします。API GatewayのリソースポリシーにはそのIAMユーザからのAPIアクセスを許可してあるものとします。動作確認した環境はUbuntu 20.04です。
C#の環境は以下の通り。
$ dotnet --version 3.1.402以下は私の記事でして、このとおりC#をほとんど始めて触っています。C#の流儀と違うところがあったらごめんなさい。
サンプルコードダウンロード
AWS公式のS3アクセスのサンプルをダウンロードします。
$ mkdir sample $ cd sample $ mkdir tmp $ cd tmp $ wget https://docs.aws.amazon.com/AmazonS3/latest/API/samples/AmazonS3SigV4_Samples_CSharp.zip $ unzip AmazonS3SigV4_Samples_CSharp.zip $ cd .. $ tree . └── tmp ├── AmazonS3SigV4_Samples_CSharp.zip ├── AWSSignatureV4-S3-Sample │ ├── App.config │ ├── AWSSignatureV4-S3-Sample.csproj │ ├── GetS3ObjectSample.cs │ ├── POSTExampleForm.html │ ├── PostS3ObjectSample.cs │ ├── PresignedUrlSample.cs │ ├── Program.cs │ ├── Properties │ │ └── AssemblyInfo.cs │ ├── PutS3ObjectChunkedSample.cs │ ├── PutS3ObjectSample.cs │ ├── Signers │ │ ├── AWS4SignerBase.cs │ │ ├── AWS4SignerForAuthorizationHeader.cs │ │ ├── AWS4SignerForChunkedUpload.cs │ │ ├── AWS4SignerForPOST.cs │ │ └── AWS4SignerForQueryParameterAuth.cs │ └── Util │ └── HttpHelpers.cs └── AWSSignatureV4-S3-Sample.sln 5 directories, 18 filesIAMユーザを使ってS3アクセスするサンプルです。今回はこのうち、
SignersとUtilというディレクトリだけ使います。$ mv tmp/AWSSignatureV4-S3-Sample/Signers ./ $ mv tmp/AWSSignatureV4-S3-Sample/Util ./ $ rm -r tmpこのサンプルはnamespaceが
AWSSignatureV4_S3_Sampleとなっています。今回はS3ではないので、適当な名前Sampleに全置換します。(このコマンドの説明は sedコマンドでディレクトリ内の全ファイルをテキスト全置換するには)$ grep -rl AWSSignatureV4_S3_Sample Signers | xargs sed -i 's/AWSSignatureV4_S3_Sample/Sample/g' $ grep -rl AWSSignatureV4_S3_Sample Util | xargs sed -i 's/AWSSignatureV4_S3_Sample/Sample/g'ここまでで以下のようなディレクトリ構成になります。
$ tree . ├── Signers │ ├── AWS4SignerBase.cs │ ├── AWS4SignerForAuthorizationHeader.cs │ ├── AWS4SignerForChunkedUpload.cs │ ├── AWS4SignerForPOST.cs │ └── AWS4SignerForQueryParameterAuth.cs └── Util └── HttpHelpers.cs 2 directories, 6 filesC#のプロジェクト作成
dotnetコマンドでプロジェクトを作成します。$ dotnet new console以下のようなディレクトリ構成になります。
$ tree . ├── obj │ ├── project.assets.json │ ├── project.nuget.cache │ ├── sample.csproj.nuget.dgspec.json │ ├── sample.csproj.nuget.g.props │ └── sample.csproj.nuget.g.targets ├── Program.cs ├── sample.csproj ├── Signers │ ├── AWS4SignerBase.cs │ ├── AWS4SignerForAuthorizationHeader.cs │ ├── AWS4SignerForChunkedUpload.cs │ ├── AWS4SignerForPOST.cs │ └── AWS4SignerForQueryParameterAuth.cs └── Util └── HttpHelpers.cs 3 directories, 13 files
sample.csprojに以下のようにRootNamespaceの項目を追加します。サンプルダウンロード後に全置換したnamespaceを指定します。<Project Sdk="Microsoft.NET.Sdk"> <PropertyGroup> <OutputType>Exe</OutputType> <TargetFramework>netcoreapp3.1</TargetFramework> <RootNamespace>Sample</RootNamespace> </PropertyGroup> </Project>必要なパッケージをダウンロードします。
AWSSDK.Coreだけで大丈夫です。今回はHTTP(S)でAPIアクセスするだけですので、API Gatewayのパッケージは不要です。$ dotnet add package AWSSDK.CoreC#のソースコード
Program.csは以下です。using System; using System.Collections.Generic; using System.Threading.Tasks; using Amazon.Runtime.CredentialManagement; using Sample.Signers; using Sample.Util; namespace Sample { class Program { private static void Run() { // ~/.aws/credentials からアクセスキー、シークレットキーを読み取る var sharedFile = new SharedCredentialsFile(); sharedFile.TryGetProfile("default", out CredentialProfile credentialProfile); var uri = new Uri("https://xxxxxxxxxx.execute-api.ap-northeast-1.amazonaws.com/Prod/hello"); // 署名するためのソースとなるヘッダ情報 var headers = new Dictionary<string, string> { {AWS4SignerBase.X_Amz_Content_SHA256, AWS4SignerBase.EMPTY_BODY_SHA256}, {"content-type", "text/plain"} }; // 署名を作成 var signer = new AWS4SignerForAuthorizationHeader { EndpointUri = uri, HttpMethod = "GET", Service = "execute-api", Region = "ap-northeast-1" }; var authorization = signer.ComputeSignature(headers, "", // no query parameters AWS4SignerBase.EMPTY_BODY_SHA256, credentialProfile.Options.AccessKey, credentialProfile.Options.SecretKey); // リクエストヘッダに署名を追加 headers.Add("Authorization", authorization); // リクエスト実行 // HttpHelpers はUtilで定義 HttpHelpers.InvokeHttpRequest(uri, "GET", headers, null); } static void Main(string[] args) { Run(); } } }
uriはAPI GatewayのAPIのURLを入れます。実行
以下のコマンドで実行できます。
$ dotnet runダウンロードしたサンプルコードの
SignersとUtilにデバッグ用出力があるので、いろいろ表示されますが、最後にAPI Gatewayからのレスポンスが表示されます。
- 投稿日:2020-10-14T17:08:59+09:00
RDSを自動停止・自動起動する
RDSの自動停止と自動起動の設定方法。
CloudWatchEvent と SSMAutomation を利用します。他にも「lambdaを使って特定のタグがついた全てのインスタンスの停止APIを呼び出す」みたいなのがありますが、こちらはインスタンスIDを指定するだけで設定できます。
ポリシーの作成
実行用のポリシーとロールの作成が必要です。
すでにある場合は イベントルールの作成 までスキップしてください。
IAM>ポリシー>ポリシーの作成をクリック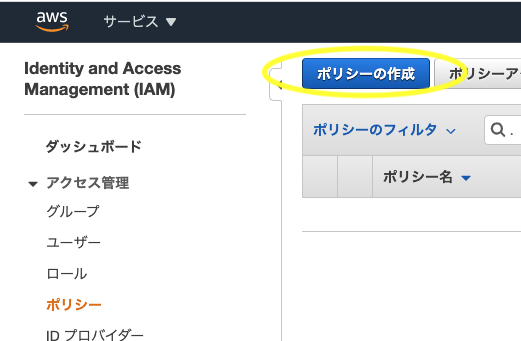
RDSに対するアクセス許可
サービスで「RDS」を選択
- 「rds」を入力するとすぐに出てくる
アクションで「StartDBInstance」と「StopDBInstance」を選択
- 「start」「stop」を入力するとすぐに出てくる
リソースで「このアカウント内のいずれか」にチェックを入れる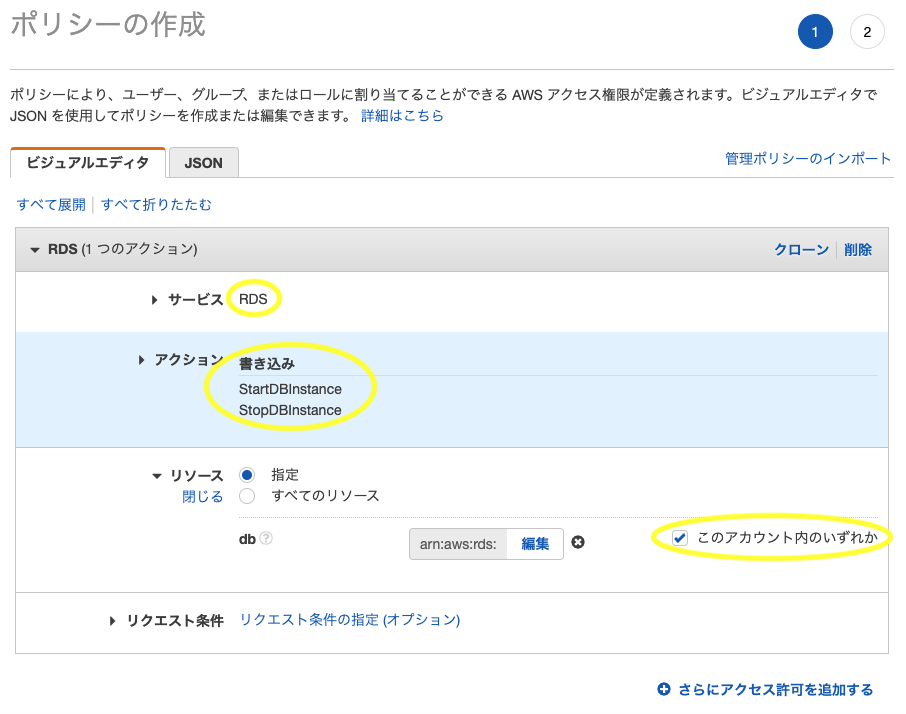
SNSに対するアクセス許可
- 「さらにアクセス許可を追加する」をクリック
サービスで「SNS」を選択アクションで「書き込み」にチェックを入れるリソースで「このアカウント内のいずれか」にチェックを入れる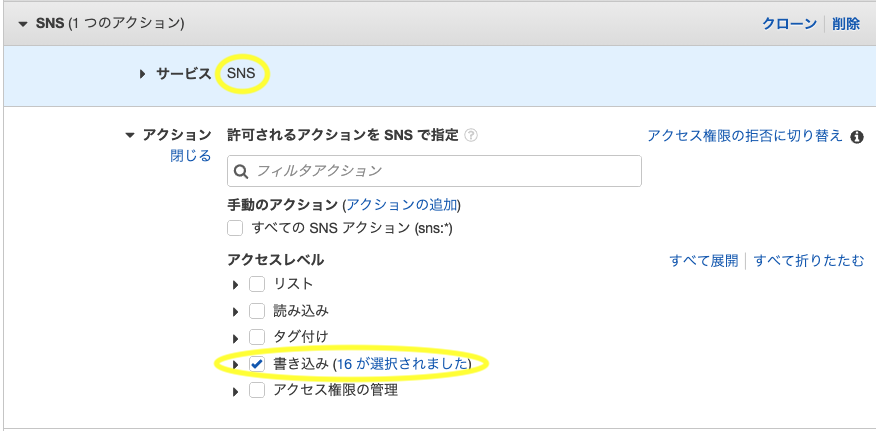
SystemsManagerに対するアクセス許可
- 「さらにアクセス許可を追加する」をクリック
サービスで「SystemsManager」を選択
- 「system」を入力するとすぐに出てくる
アクションで「すべての Systems Manager アクション (ssm:*)」にチェックを入れるリソースで「このアカウント内のいずれか」にチェックを入れる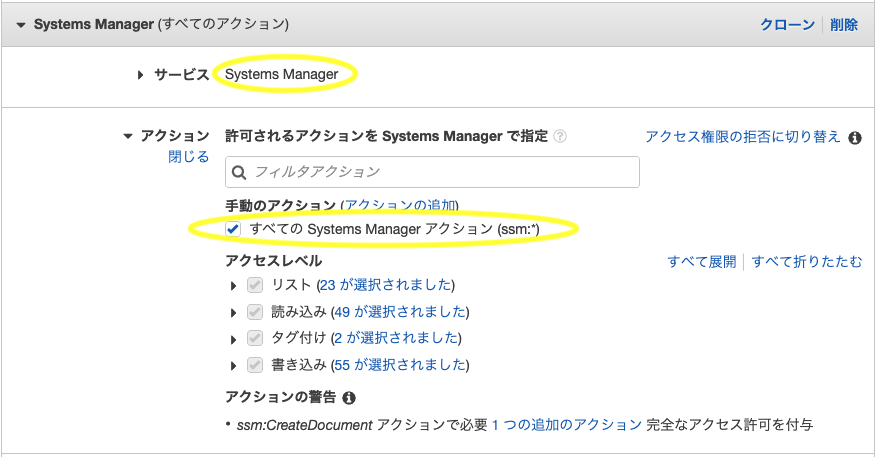
作成
- 任意のポリシー名を入力し「ポリシーの作成」をクリック
ロールの作成
IAM>ロール>ロールの作成をクリック
AWSサービス>SystemsManager>SystemsManagerを選択して次のステップへ
- 先ほど作成したポリシーを選択して次のステップへ
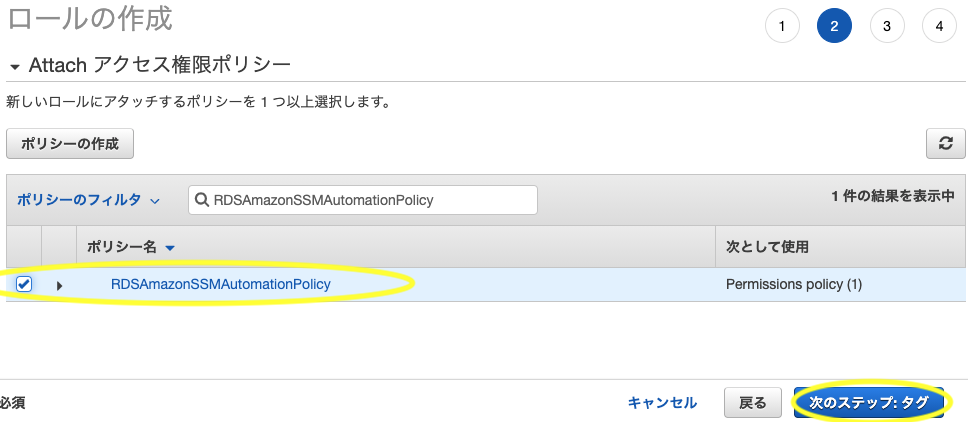
- タグは特に必要ないので次のステップへ
- 任意の「ロール名」を設定し「ロールの作成」をクリック

ロールの信頼関係を修正
- IAMロール一覧から作成したロールを選択
信頼関係>信頼関係の編集をクリック
Principal > Serviceを["events.amazonaws.com","rds.amazonaws.com","ssm.amazonaws.com"]にして更新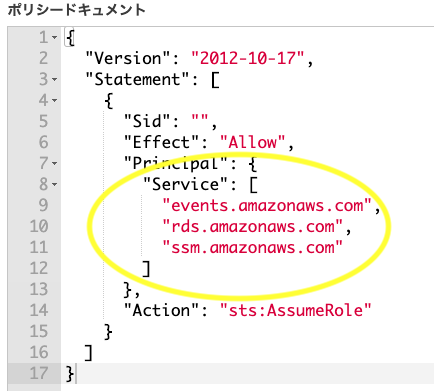
イベントルールの作成
CloudWatch>ルール>ルールの作成をクリック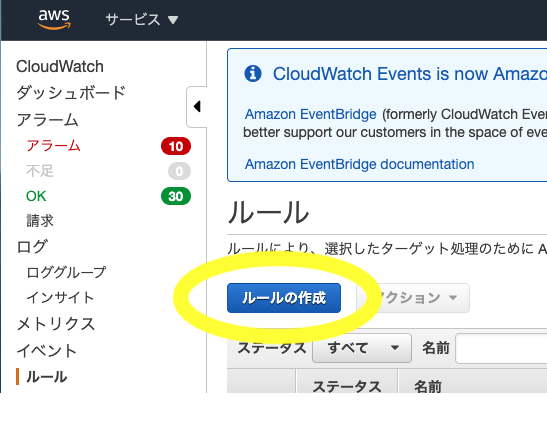
スケジュールでCron式を選択- 自動停止または起動させたい時間をcron式で入力する
- GMTなので日本時間に合わせるために -9時間 する
- 例: 毎日23:00に停止させたい →
00 14 ? * * *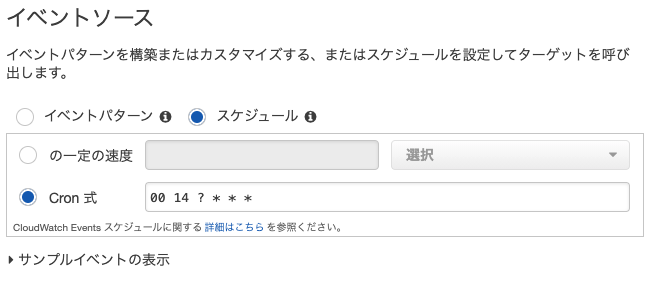
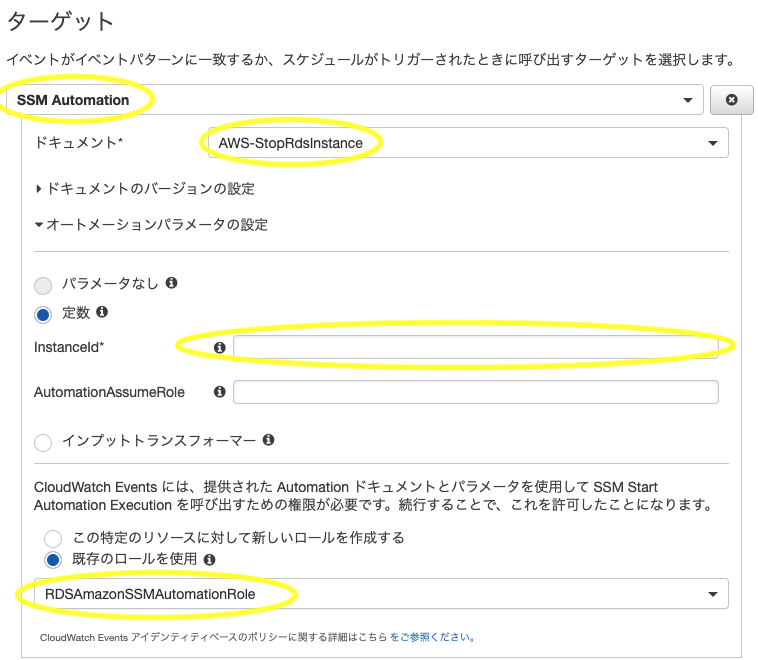
ターゲットのアクションから「SSM Automation」を選択
- 「ssm」を入力するとすぐに出てくる
- 停止する場合:
ドキュメントで「AWS-StopRdsInstance」を選択
- 「stop」を入力するとすぐに出てくる
- 起動する場合:
ドキュメントで「AWS-StartRdsInstance」を選択
- 「start」を入力するとすぐに出てくる
定数>InstanceIdに対象のDBインスタンスの DB識別子 を入力- 「既存のロールを使用」を選択
- 先ほど作成したロールを選択する
- ロール名で絞り込み出来る
- ターゲットを追加したい場合は同様にして追加する
- 「設定の詳細」をクリック
- 任意のルール名と説明を入力
- ルール名は後から変更できないので注意
- 有効化にチェックが入っていることを確認して「ルールの作成」をクリック
注意点1
本番環境におけるRDSインスタンスの停止は推奨されないようです。
あくまで開発・検証用の機能として存在するのでご注意ください。一時的に Amazon RDS DB インスタンスを停止する より
一時的なテストや毎日の開発作業のために、断続的に DB インスタンスを使用する場合、コスト削減のため、Amazon RDS DB インスタンスを一時的に停止できます。
RDSを本番環境で停止運用しないほうが良い理由について より
キャパシティ不足時に対応する手段が限られている
これが、RDSを本番環境では停止・開始することが推奨できない最も厳しい理由となります。注意点2
インスタンスを停止できる最大期間は7日間です。 以降は自動的に起動されます。
一時的に Amazon RDS DB インスタンスを停止する より
インスタンスは最大 7 日間停止できます。
7 日後に DB インスタンスを手動で起動しなかった場合、DB インスタンスは自動的に起動されるため、必要なメンテナンス更新
が遅れることはありません。関連
- 投稿日:2020-10-14T15:54:12+09:00
EC2を自動停止・自動起動する
使用していない時間の稼働費用ってもったいないですよね...!
お高いインスタンスを止め忘れて連休明けに絶望したことはありませんか。
そんな時に役立つEC2の自動停止と自動起動の設定方法をまとめました。(今更感ありますが)
CloudWatchEvent と SSMAutomation を利用します。自動停止
自動停止の方が簡単。
CloudWatch>ルール>ルールの作成をクリック
スケジュールでCron式を選択- 自動停止させたい時間をcron式で入力する
- GMTなので日本時間に合わせるために -9時間 する
- 例: 毎日23:00に停止させたい →
00 14 ? * * *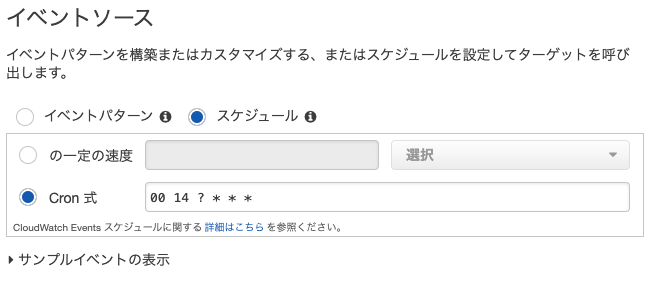
ターゲットのアクションから「EC2 StopInstances API 呼び出し」を選択
- 「stop」を入力するとすぐに出てくる
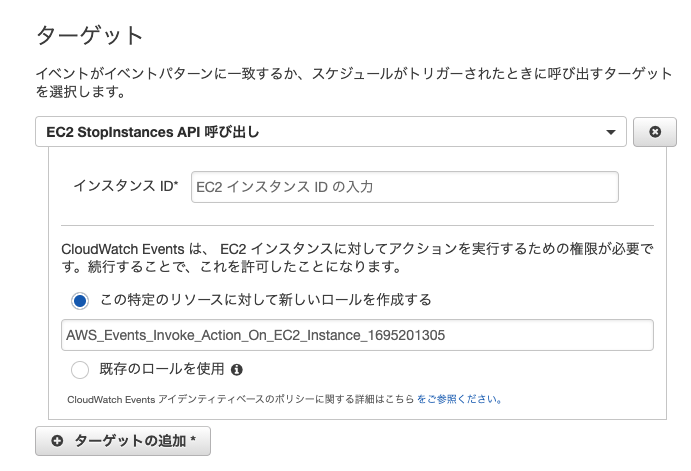
インスタンスIDに対象のインスタンスIDを入力- 他にも停止させたいインスタンスがある場合は「ターゲットの追加」をクリックし同様に追加
- 完了したら「設定の詳細」をクリック
- 任意のルール名と説明を入力
- ルール名は後から変更できないので注意
- 有効化にチェックが入っていることを確認して「ルールの作成」をクリック
自動起動
SSMAutomation実行用ロールが必要。
すでにある場合は イベントルールの作成 へ。SSMAutomation実行用ロールの作成
IAM>ロール>ロールの作成をクリック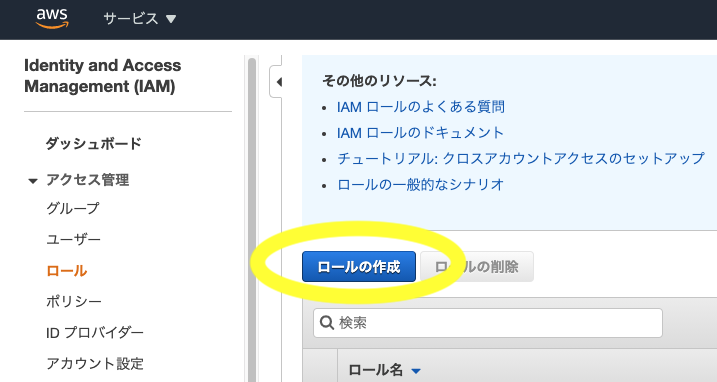
AWSサービス>EC2を選択して次のステップへ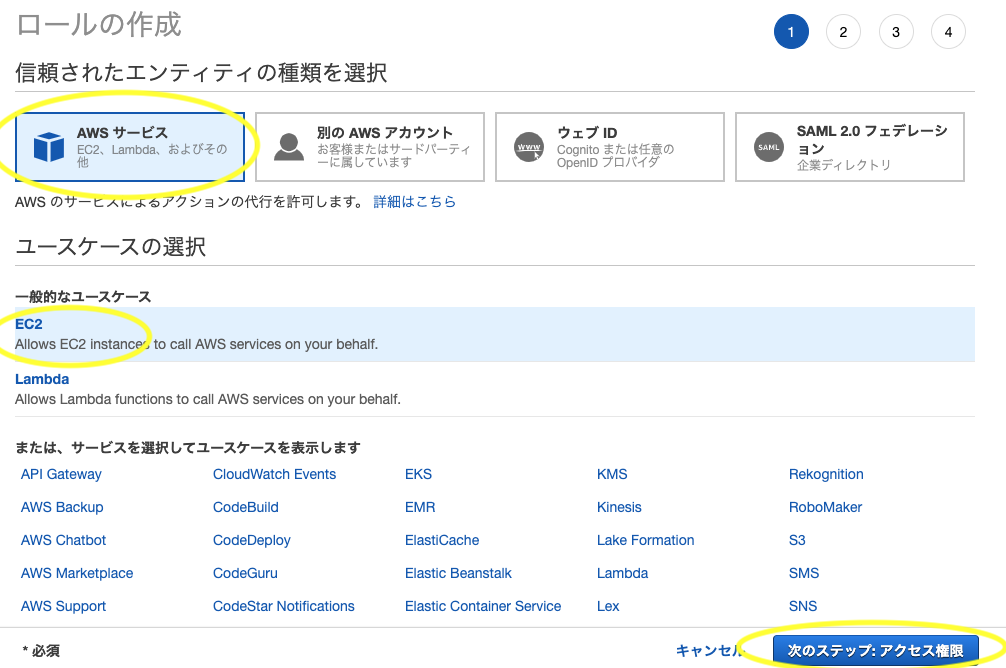
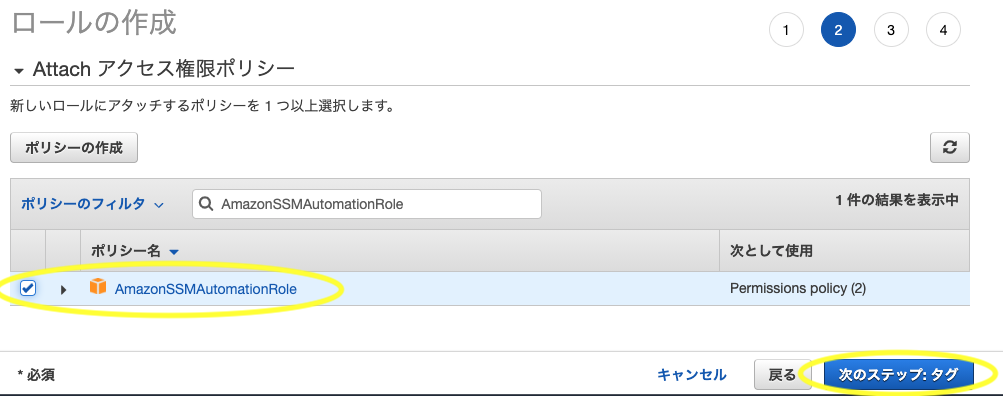
- 「AmazonSSMAutomationRole」を選択して次のステップへ
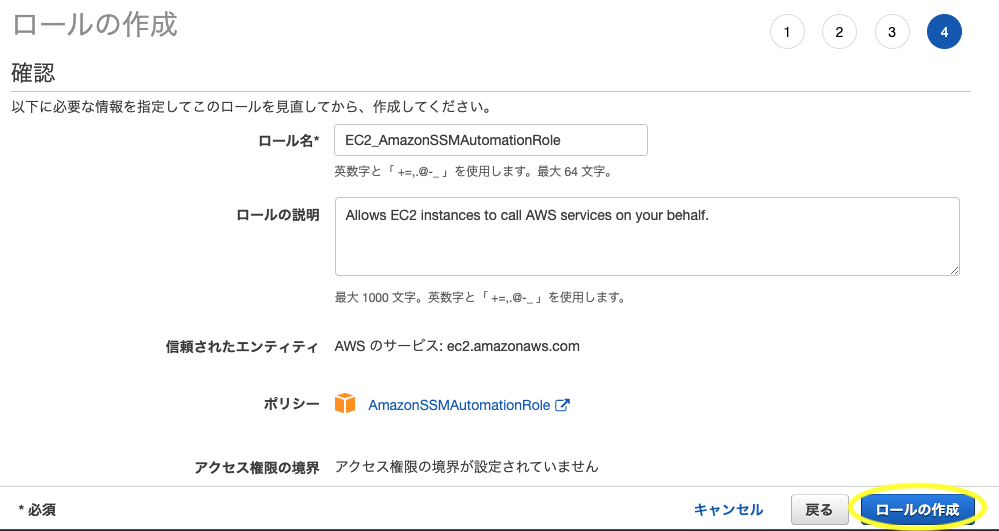
- タグは特に必要ないので次のステップへ
- 任意の「ロール名」を設定し「ロールの作成」をクリック
- ロール一覧から作成したロールを選択
信頼関係>信頼関係の編集をクリック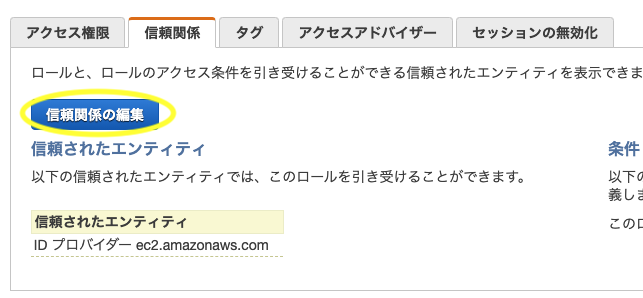
Principal > Serviceを["ec2.amazonaws.com","events.amazonaws.com"]にして更新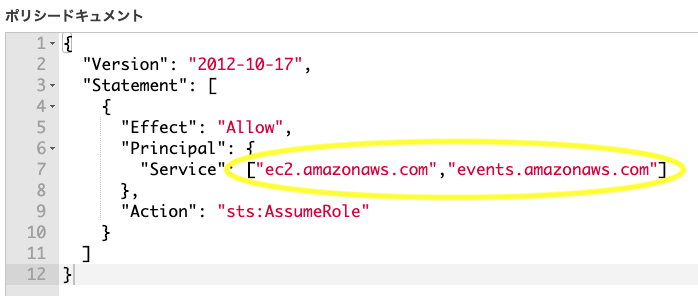
イベントルールの作成
ターゲットの選択以前は 自動停止の手順と同じ。
ターゲットのアクションから「SSM Automation」を選択
- 「ssm」を入力するとすぐに出てくる
ドキュメントで「AWS-StartEC2Instance」を選択
- 「start」を入力するとすぐに出てくる
定数>InstanceIdに対象のインスタンスIDを入力- 「既存のロールを使用」を選択
- 先ほど作成したロールを選択する
- ロール名で絞り込み出来る
- ターゲットを追加したい場合は同様にして追加する
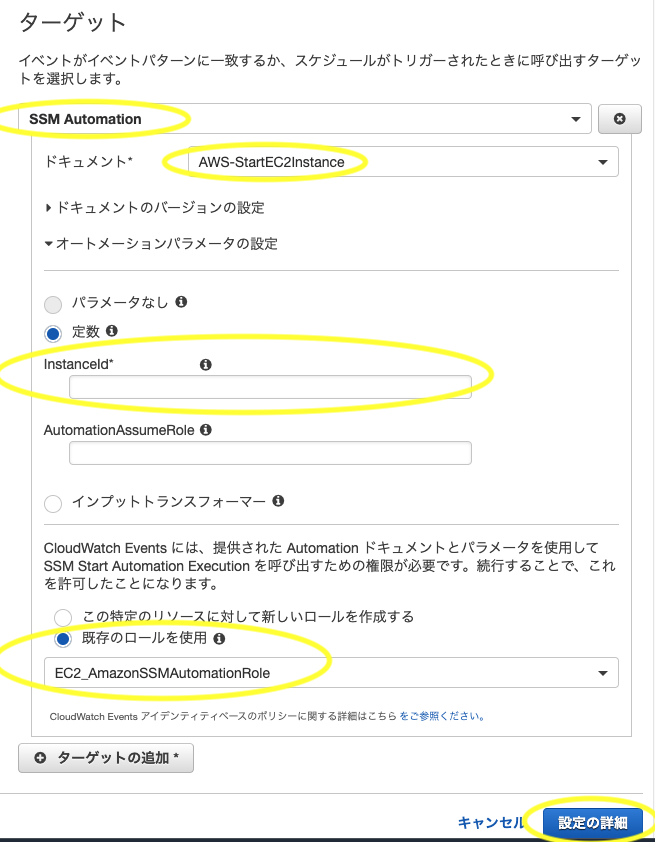
- 「設定の詳細」をクリック
- 任意のルール名と説明を入力
- ルール名は後から変更できないので注意
- 有効化にチェックが入っていることを確認して「ルールの作成」をクリック
cron式サンプル
cron式は
分 時間 日 月 曜日 年となっている平日(月曜〜金曜)のAM8:00に実行
0 23 ? * SUN-THU *
- 英字3文字で曜日指定が出来る
- -9時間した時にマイナスになってしまう場合は、前日の曜日になる点に注意
毎月1日のPM23:00に実行
0 14 1 * ? *参考
関連
- 投稿日:2020-10-14T15:29:26+09:00
データ分析基盤における概念モデル(リファレンスアーキテクチャ)
概要
データ分析基盤における概念モデル(リファレンスアーキテクチャ)の詳細を記載します。
下記の観点で、コンポーネントを整理しております。特定のベンダーによらないように汎用的なデータ分析基盤のモデルを目指して検討しました。
- ビックデータの3V(Volume、Variety、Velocity)に対応できる拡張性のあるアーキテクチャとすること
- データ分析レイヤーにて、可視化・統計解析(AI)シミュレーションの3つに分けて、それぞれのツールを選定できるようにすること
- データ仮想化サービス、データレプリケーションサービス、データプリパレーション(データ連携サービス)などのサービスの位置付けの明確化を行うこと
概念モデル
概念モデル図
レイヤー詳細
番号 レイヤー 説明 1 ソースレイヤー データ分析基盤がソースとするデータを保持したシステム、および、データストアを保持した層。 2 インタフェースレイヤー ソースレイヤーとデータ分析基盤の仲介を行い、必要に応じてデータの一時的保存や処理を行う層。 3 バッチレイヤー リアルタイムデータ処理を行い、短期的に少量データのみを保持する層。 4 スピードレイヤー バッチ処理にてデータ処理を行い、永続的に大量のデータを保持する層。 5 サービスレイヤー データ活用を行う上で最適なクエリを発行できるようにデータを保持する層。 6 物理レイヤー (サービスレイヤー) 物理的にデータを保持することで、最適なクエリを発行できるようにする層。 7 論理レイヤー (サービスレイヤー) 論理的に構造化したデータモデルを保持することで、想定文脈内での意味を結びつけたクエリを発行できるようにする層。 8 データ利活用レイヤー データ基盤にて管理したデータに対して、データ分析やデータ提供を行う層。 9 データ分析レイヤー (データ利活用レイヤー) ある目的に従い、可視化・統計解析・シミュレーションにより、価値を創造する活動を行うためのシステムを保持した層。 10 データ利用レイヤー (データ利活用レイヤー) データ分析基盤におけるデータを提供する層。 11 データカタログ データモデルとData Integration and Interoperability(データ統合と相互運用性)のメタデータに関する、カタログの作成(定義・抽出・蓄積)、および、カタログの利用(探索・把握・共有・配信)によるデータガバナンス支援システム層。 12 オーケストレーション ETL(データ抽出・変換・取り込み)や他プログラミングの実行などの処理の実施、データフローの開始から終了までの処理フローをパイプラインとして定義のの実施、および、パイプラインをトリガー(スケジュールトリガー、イベントトリガー等)トリガー登録によりプロセスコントロールの実施を行うシステム層。 DMBOKにおける下記コンポーネントを含めることを想定している。
・データ変換エンジン/ETLツール
・オーケストレーション
・プロセスコントロール13 DevOps 運用チームと開発チーム間のコラボレーションを向上させるために、IT の迅速なサービス提供を可能とするシステム層。 コンポーネント詳細
番号 データ基盤におけるレイヤー コンポーネント名 説明 サービス例 1 ソースレイヤー 業務システム 業務を実施するために利用するシステム。 SAP、Dynamics 2 ソースレイヤー マスターデータ管理システム(MDM) マスタデータの値と識別子の制御によるシステム間で一貫した利用を行うための運用を支援するシステム。データ分析基盤においては、管理されたマスターデータと参照データによる適合ディメンションの利用が可能となる。マスターデータと参照データを別のデータストアから連携することもある。 Informatica MDM 3 ソースレイヤー ストレージサービス データをファイルとして保存できるサービス。 AWS S3、Azure Storage、BOX、SharePoint Onlineドキュメント 4 ソースレイヤー メッセージング メッセージを一方向または双方向で送受信するサービス。利用される通信プロトコルには、HTTP、MQTT、AMQPがある。 Fluentd 5 ソースレイヤー データ仮想化サービス データストアやサービスに対して、データの抽出、変換、統合を仮想的に実行するサービス。 denodo 6 インタフェースレイヤー ストレージ データストアやサービスからのデータの配置、および、コネクター経由で取得したデータの配置を実施するためのデータストア。 HDFS、Amazon S3、Azure Storage 7 インタフェースレイヤー コネクター データストアやサービスから、データの抽出・ロードを実施する機能。 ODBC、REST API 8 インタフェースレイヤー オペレーショナルデータストア (ODS) ソースから抽出したデータに対して、クレンジング・統合・標準形式への変換により品質を保証したデータを、短期間(30日から60日)を保持させる、運用データの統合データストア。 データレイクに連携前に、本コンポーネントにより、データ品質を確認することにより、データスワンプ(沼)化をさけることが可能となる。 インターフェースレイヤーにて、インターフェース側のシステム担当者の仲介を果たすこともある。 RDB(MySQL、SQL Server、PostgreSQL) 9 インタフェースレイヤー データレプリケーションサービス あるプライマリーデータストアにおけるデータを1つ以上のセカンダリデータストアへ、定期的にデータを同期するサービス。 CData Sync、Qlik Replicate 10 インタフェースレイヤー リアルタイムインジェスト メッセジングのエンドポイントとなり、メッセジングとストリーム処理サービスとのデータの仲介を行い、データを一時的に保持するサービス。 Amazon Kinesis、Azure IoT Hub、Apatch Kafka 11 バッチレイヤー データレイク 様々な構造であるデータ、大量のデータ、多頻度で発生するデータを保存できるサービス。Sparkなどのデータ統合サービスやETLツールを含める場合もある。管理がされていないデータや一貫性がないデータを含む場合には、データスワンプと呼ばれることがある。 HDFS、Amazon S3、Azure Storage 12 バッチレイヤー データ統合サービス 様々な構造のデータを抽出し、そのデータを変換・標準化の処理を行い、マージを含むロード処理を行うサービス。 Hadoop、Spark、Databricks、Google Big Query 13 スピードレイヤー ストリーム処理サービス リアルタイムインジェストから連続したデータを取得し、処理を行ったうえでデータの提供を低遅延で行うサービス。 Amazon Kinesis、Azure Stream Analytics 14 サービスレイヤー (物理レイヤー) データウェアハウス(DWH)【分析データストア(コールドパス)】 バッチレイヤーにて統合されたデータをデータ活用を行うために提供することに最適化したデータストア。 今までは一元的に統合された意思決定支援データベースとして扱われてたが、データレイクの概念の普及によりデータ提供機能が主たる目的となってきた。 Amazon Redshift 、Azure Synapase Analytics 15 サービスレイヤー (物理レイヤー) 分析データストア(ホットパス) ストリーム処理サービスのターゲットとなり、リアルタイムまたは低レイテンシのデータ処理を取り込み、データ活用レイヤーにデータを提供するデータストア。 Amazon DyanamoDB、Azure CosmosDB 16 サービスレイヤー (論理レイヤー) セマンティックデータモデル 利用者がデータ構造を意識せずにデータ要素の意味の推論を行いながらデータ活用を実施可能となるように、基となるデータモデルをベースとして想定文脈内での意味を結びつけたデータモデルを保持したデータストア。 基となるデータモデリング手法としてはディメンションナルモデリングが多く、スキーマの項目をビジネス用語へ変換やテーブル間のリレーションシップ・メジャー(集計値)の定義を事前に実施しておき、ユーザーはGUIで必要なデータを抽出させることが多い。 Azure Analytsis Servcies、SAP BW、Tableau Hyper、Power BI dataset 17 サービスレイヤー (論理レイヤー) データ仮想化ソリューション データストアやサービスに対して、データの抽出、変換、統合を仮想的に実行するサービス。 denodo 18 データ利活用レイヤー (データ分析レイヤー) 可視化システム(Business Interigence(BI)ツール) データに基づき、集計や可視化によるデータの比較により洞察を主たる目的としたシステム。 Tableau、Power BI、 20 データ利活用レイヤー (データ分析レイヤー) 解析システム データに基づき、事象を数学的に定式化(モデル化)することを主たる目的としたシステム。 SAS、Datarobot、Amazon SageMake、Azure Machine Learning 22 データ利活用レイヤー (データ分析レイヤー) シミュレーションシステム データに基づき、作成済みのモデルに制約条件を設定したうえで、期待値の算出、組み合わせの最適化、または、想定事象の現出の実施を主たる目的としたシステム。 Anaplan、Python 21 データ利活用レイヤー (データ利用レイヤー) データ連携サービス バッチレイヤー、スピードレイヤー、サービスレイヤーにて保持しているデータに対して、データの抽出・変換・出力や多様な接続方法(REST API、MQTT等)によりデータを提供するサービスがある。 Amazon Athena、Azure Synapse Analytics SQLオンデマンド 、Apache Presto 22 データ利活用レイヤー (データ利用レイヤー) クエリエンジン バッチレイヤー、スピードレイヤー、サービスレイヤーにて保持しているデータに対して、データへの接続環境を提供するサービス。 23 データカタログ データカタログ データモデルとData Integration and Interoperability(データ統合と相互運用性)のメタデータに関する、カタログの作成(定義・抽出・蓄積)、および、カタログの利用(探索・把握・共有・配信)によるデータガバナンス支援システム群。 Informatica Data Catalog、Glue Catalog 24 オーケストレーション オーケストレーション ETL(データ抽出・変換・取り込み)や他プログラミングの実行などの処理の実施、データフローの開始から終了までの処理フローをパイプラインとして定義のの実施、および、パイプラインをトリガー(スケジュールトリガー、イベントトリガー等)トリガー登録によりプロセスコントロールの実施を行うシステム群。 DMBOKにおける下記コンポーネントを含めることを想定している。 ・データ変換エンジン/ETLツール ・オーケストレーション ・プロセスコントロール JP1、Amazon Glue、Azure Data Factory 25 DevOps DevOps 運用チームと開発チーム間のコラボレーションを向上させるために、IT の迅速なサービス提供を可能とするシステム群。 Github、Azure DevOps 関連知識
ラムダアーキテクチャ
ラムダアーキテクチャについては、下記のマイクロソフト様の資料が詳しいです。本記事ではラムダアーキテクチャの概念のみを利用しており、ラムダアーキテクチャ思想に準拠しているわけではないです。
引用元:ビッグ データ アーキテクチャ
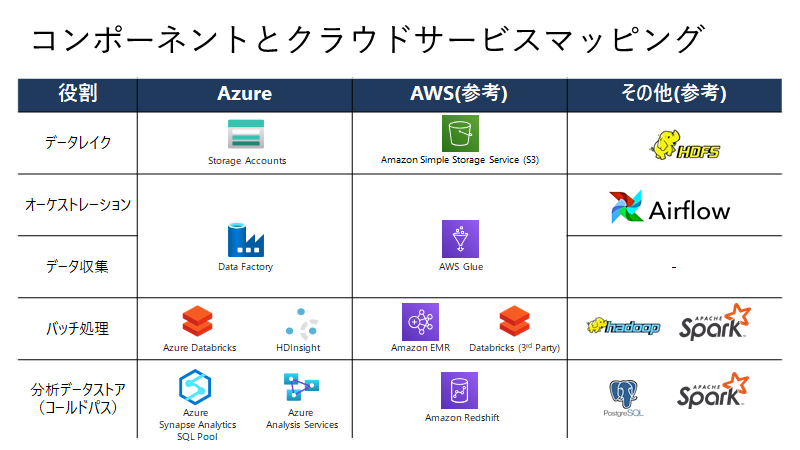
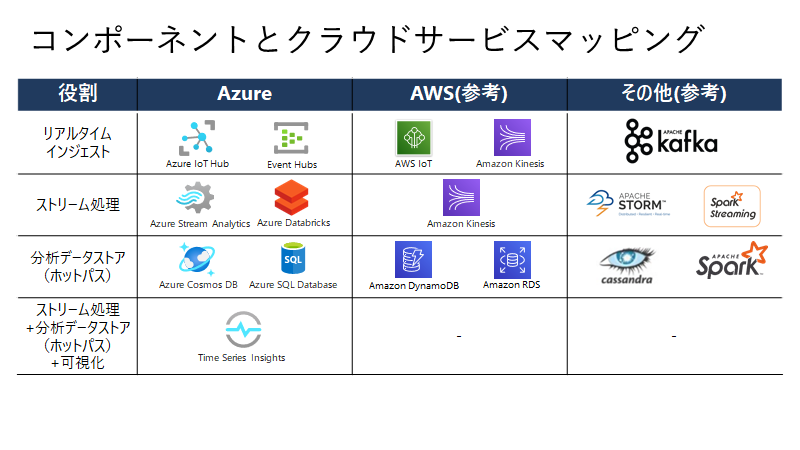
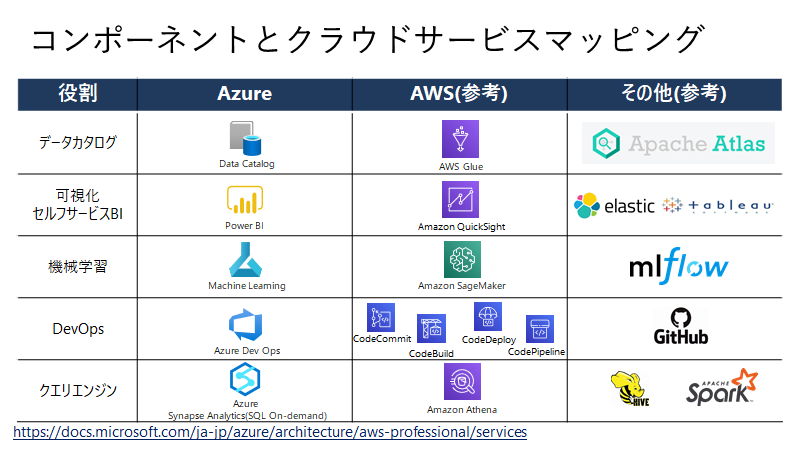
利用を検討すべきサービスについて
利用すべきサービスとしては、下記のものがあります。バッチ処理や分析データストア(コールドパス)に、Snowflakeを検討してもよいかもしれません。

- 投稿日:2020-10-14T14:29:48+09:00
ラズパイ4からSORACOMのVPG Type-EとBeamでAPI Gatewayに接続してみる
はじめに
SORACOMのSIMをまともに使ったことがなかったので検証してみました。
検証の背景
- SORACOMを使ってデバイスからAmazon API Gatewayにセキュアに接続したいです。
- VPG Type-Fを使えば閉域網になるため最も安全ですが、まずは手軽で安く使えるVPG Type-Eで検証したいと思います。
- VPG Type-EでグローバルIPを固定し、API GatewayのリソースポリシーでそのグローバルIPにしぼります。
- かつ暗号処理のオフロードとしてBeamも使いたいので、http -> https変換をsoracom網で行ったうえでAPI Gatewayにつなげてみます。
主な利用サービスと検証ポイント
SORACOM VPG Type-Eとは
- インターネット接続ができ、グローバルIPも固定できるサービスのようです。
SORACOM Beamとは
- SIMからインターネットに出るのですが、その前にSORACOM網のなかで暗号化や接続先の切り替えなどをやってくれるようです。
両方使うとどうなるのか?
私はどちらも使うのが初めてです。
Type-Eを使うとインターネット接続ができるというのはわかるのですが、その状態でBeamを使った場合のイメージが湧きませんでした。というのも私はBeamは全てのhttpをhttpsに変換するサービスというイメージを抱いていたので、通常のインターネット接続に何らかの影響がでるのでは?というイメージを持っていました。サイトの説明をみると両立できるように見えましたが、SORACOMの練習も兼ねて実際に検証してみました。ラズパイ4の環境と設定
ラズパイ4にsoracom SIMの入ったUSBドングルをつなげています。
Raspberry Pi
- Raspberry Pi 4 Model B / 4GB を使い、ヒートシンクもつけています。
- https://www.switch-science.com/catalog/6030/
- https://www.switch-science.com/catalog/5986/
- なお、このヒートシンク(PIMORONI-COM1203)はギリギリサイズなので、つけるときには少し注意が必要です。GPIOピンに接触しないように気持ち下に離すといいです。なお両面テープの接着力は強力ではないため失敗しても付け直しは可能です。
- なお、SORACOM SIMを検証するのにラズパイを使う必然性はありません。今回は環境的に独立させたほうが検証が楽であり、かつWindows10などではバックグラウンドで様々な通信をされて通信費用が嵩んでしまうため、Raspbian OSなラズパイを使っています。
SORACOM Air
- soracom SIMはplan-dの標準サイズを使っています。
- s1.standard(512 kbps)を利用してます。
- https://soracom.jp/products/sim/plan-d/
USBドングル
- USBドングルはLTEも使えるHuawei MS2372h-607を使っています。
以下はドングルにSIMを挿した状態です。
ドングルは幅があります。ラズパイ4のUSB口に直接挿すと隣にUSBを挿すのがきつくなるため、USBハブを使っています。
※なお、ラズパイの背面には小型のタッチモニタをつけています。YOMON8さんが勧めていたのものを買いました。
https://yomon.hatenablog.com/entry/2020/09/monitor_rpi
ラズパイでSIMのセットアップ
- 設定方法は以下の通り。
- https://dev.soracom.io/jp/start/device_setting/
- 一度自宅のwifiにつなげてからsetup_air.shを実施しましたが、10分くらい?かかりました。
私の場合、コマンド完了直後はSIMの接続が有効化されていないようでした。OS再起動後に以下コマンドを実施すると反応がありました。
root@raspberrypi:~# ifconfig ppp0 ppp0: flags=4305<UP,POINTOPOINT,RUNNING,NOARP,MULTICAST> mtu 1500 inet 10.213.188.XXX netmask 255.255.255.255 destination 10.64.64.XXX ppp txqueuelen 3 (Point-to-Pointプロトコル) RX packets 16 bytes 1061 (1.0 KiB) RX errors 0 dropped 0 overruns 0 frame 0 TX packets 17 bytes 818 (818.0 B) TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0wifi有効状態でも、ルーティング的にsimのpoint to point接続のほうが優先されているようでしたが、念の為wifiはOFFにしておきました。
wifiを無効化した状態でも、ブラウザでふつうにインターネット接続ができました。
とりあえず SORACOM Airは正常に使えているようです。SORACOM Airの使用状態でグローバルIPを確認すると、soracom所管のIPのようです。
root@raspberrypi:~# curl ifconfig.io 103.67.xxx.xxxVPG Type-Eの設定
- 費用は以下の通りです。
- https://soracom.jp/services/vpg/price/
- 利用料金は安いのですが、セットアップに 198 円/回 (日本カバレッジの場合)かかるという点が検証の注意ポイントです。
Type-Eのセットアップ
- Type-Eの手順は以下を参考にしました。
- https://dev.soracom.io/jp/docs/gate_access_between_devices/
- ただし今回はGateを使わないので、「ステップ3: デバイス間通信を利用するIoT SIMをグループに登録する」までしか実施していません。
VPGに今回のSIMが所属しているグループを入れると、以下のようになります。
- ラズパイを再起動します。(そこまでしなくてもいいのかもしれませんが念の為)
- スマホであれば機内モードのオン・オフでいいようです。
- 遠隔地にある場合はSORACOMのコンソールからSIMの「セッション切断」を行うことで、 デバイスからの再接続時に有効化できるようです。
状態の確認
再起動後、グローバルIPを確認すると、AWS東京リージョンのIPのようです。
(soracom側のAWSのインターネットゲートウェイのIPなんですかね?)root@raspberrypi:~# curl ifconfig.io 13.231.XXX.XXX他のユーザと共有されているグローバルIPなのかは私だけでは確認できませんが、以下の情報を見ると、他ユーザとは共有されなさそうな書きっぷりです。
*1 VPG(Virtual Private Gateway)は、SORACOM プラットフォーム上のお客様専用のネットワークゲートウェイ(インターネット側の出口)です。
なお、インターネット接続もブラウザで正常にサイト閲覧ができました。
API Gatewayの設定
前提
- 詳細は省きますが、検証用として以下のPetStoreというサンプルをREST APIとして作成済みです。
- https://docs.aws.amazon.com/ja_jp/apigateway/latest/developerguide/api-gateway-create-api-from-example.html
- エンドポイントはリージョン(インターネットフェイシング)型としています。HTTP APIだとリソースポリシーが使えないのでREST APIを使っています。
リソースポリシーで実行できるIPを制限しているため、ラズパイからType-Eを有効化した状態でそのまま叩くと拒否されます。
root@raspberrypi:~# curl https://xxxxxxxx.execute-api.ap-northeast-1.amazonaws.com/dev/pets/2/ {"Message":"User: anonymous is not authorized to perform: execute-api:Invoke on resource: arn:aws:execute-api:ap-northeast-1:************:xxxxxxxx/dev/GET/pets/2/"} root@raspberrypi:~#リソースポリシーの編集
対象のAPIのリソースポリシーを編集し、さきほどのType-EのグローバルIPを登録します。(リソース名やIPは読み替えてください)
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Principal": "*", "Action": "execute-api:Invoke", "Resource": "arn:aws:execute-api:ap-northeast-1:<account id>:<resource id>/*", "Condition": { "IpAddress": { "aws:SourceIp": "13.231.XXX.XXX/32" } } } ] }テスト
APIを再デプロイし、ラズパイからさきほどと同じGETメソッドを実行すると、正常に取得できていることが確認できました。
root@raspberrypi:~# curl https://xxxxxxxx.execute-api.ap-northeast-1.amazonaws.com/dev/pets/2/ { "id": 2, "type": "cat", "price": 124.99 } root@raspberrypi:~#Beamの設定
Beamのセットアップ
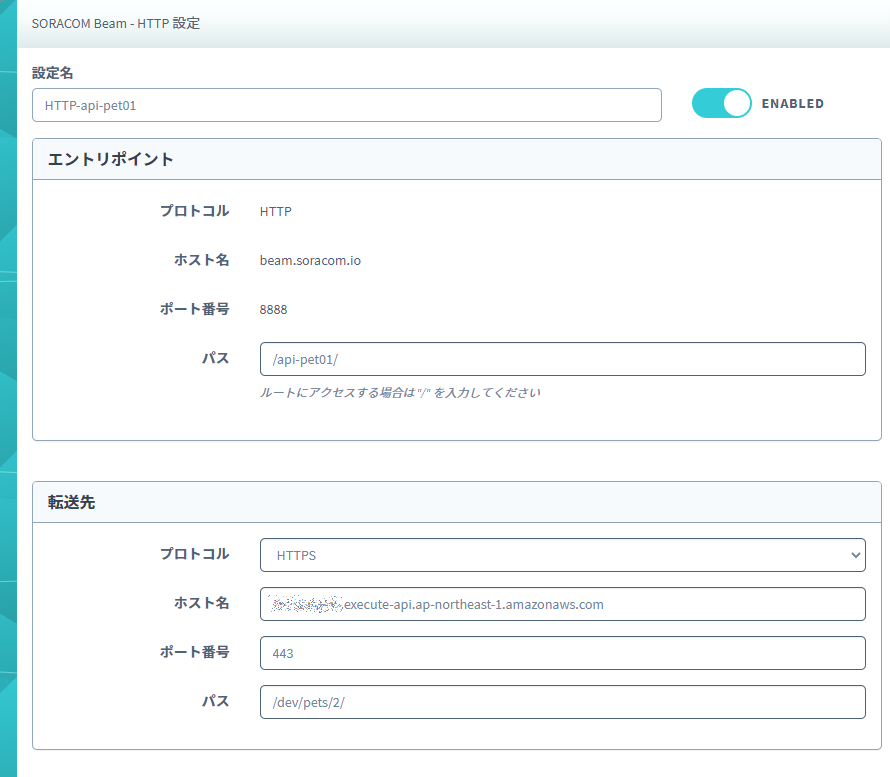
- 今回のSIMが所属しているSIMグループにBeamの設定を追加します。
- 転送先
- 今回のAPI Gatewayのエンドポイントをそのままホスト名とパスに分解して設定しました。
設定すると以下のようになります。
テスト
ラズパイからBeamで設定したhttpのエントリポイントを叩いてみます。
root@raspberrypi:~# curl http://beam.soracom.io:8888/api-pet01/ { "id": 2, "type": "cat", "price": 124.99 } root@raspberrypi:~#正常にAPIが実行されました。
レスポンスも、API Gateway直打ちと同一の内容です。まとめ
- VPG(Type-E)でBeamを使う場合は基本的には固定GIPのインターネット接続でしかなく、Beamであらかじめ指定したURLのみBeamとして扱われるということのようです。
- SORACOM AirではグローバルIPがSORACOM所管のものとなり、VPG Type-EではAWS所管のものに切り替わります。
- VPG Type-E下でBeamを使う場合でもソースのグローバルIPはVPG Type-EのGIPのままです。
- ですので既存のインターネット接続をしつつ、API GatewayはBeamで使う、ということができることがよくわかりました。
以上です。




- 投稿日:2020-10-14T13:55:59+09:00
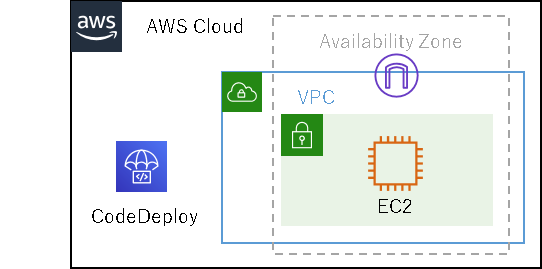
インスタンスを使い捨てない。WebアプリのBule/Green風デプロイ(for PHP)
こんにちは。AWS歴3年生の人です。最近、アプリケーションのデプロイやAWSのCI/CDサービスについて勉強しています。その中でAWS CodeDeploy+EC2+PHPのインプレースデプロイをBule/Green風にしたのでご紹介します。(あくまで”風”です)
注意
本記事は2020年8月28日時点でのバージョンで確認しました。
記載のコードにつきましては参考となりますので、利用時の不具合について一切の責任を負いません。
デプロイタイプについて軽くおさらい
インプレース(In-place)デプロイ
- 稼働中のインスタンス上に、新しいアプリケーションをインストールします。デプロイの前後で同じインスタンスが利用されます。
- デプロイ中のサービス影響を回避するために、ロードバランサから切り離して1台ずつデプロイする構成をとることも可能です。
ブルーグリーン(Blue/Green)デプロイ
- 稼動中とは別に新しくインスタンスを作成し、アプリケーションをインストールします。新旧インスタンスの切り替えはロードバランサでトラフィックをコントロールしサービス投入をします。
- デプロイの前後で異なるインスタンスを利用します。旧インスタンスは破棄するか、障害時のロールバック用として待機、利用ができます。
アプリケーションデプロイの勉強はこちらの資料を参考にしました。説明図が分かりやすいです。
AWS Black Belt Online Seminar AWS Code Series Part 2
Blue/Greenではなく、In-placeで”Blue/Green風”にした経緯
Blue/Greenのメリットを知っている方は「なぜ、最初からBlue/Greenデプロイを選択しないの?」と、思うかもしれません。
Blue/Greenデプロイを実運用にのせるためには「インフラ(インスタンス)」と「アプリケーション」の2つを、適切なバージョンでリリースするので、インフラ運用チームとアプリ開発チームが一緒に運用設計を進めていくのがベターだと感じています。
しかし実際のプロジェクトでは、運用要件、性能要件、システムの難易度、体制と役割、コストなどさまざまな制約、条件があります。その中で、”必ずしも最新のアーキテクチャやテクノロジーがいつもベストな選択とはかぎらない” ということが、気づきになりその過程で、インプレースデプロイでBlue/Green風という手法を選択しました。
また、PHPのようなスクリプト言語でSSHを利用しないデプロイの事例紹介や記事があまりなく苦労したので、どなたかの参考になれば幸いです。
どこがBule/Green風なのか
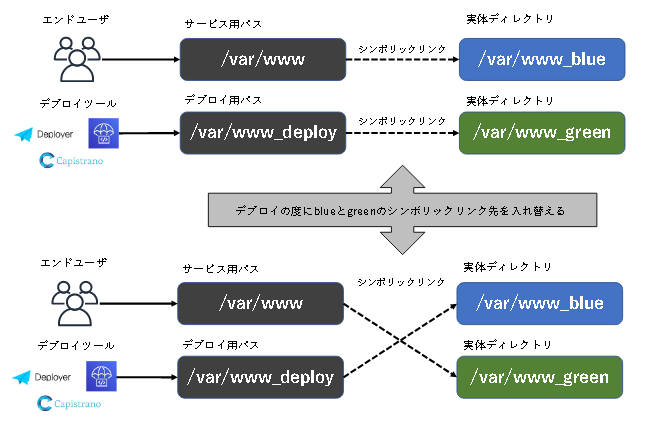
1. サービス稼働用とデプロイ用、2つのアプリケーションバージョンを持つ
インスタンスの代わりにアプリケーションの実体を格納するディレクトリをblueとgreenの2つ用意します。サービス用パスはシンボリックリンクにしてblue(もしくはgreen)の実体に向けておきます。デプロイ用パスもシンボリックリンクにしてgreen(もしくはblue)の実体に向けておきます。
2. 旧から新へきりかえる
稼働中のシンボリック先をblueとしたとき、新しいアプリケーションはgreenにデプロイされます。その後、シンボリックリンクを切り替えることで、新しいアプリケーションを瞬時にリリースします。
3. 一つ前のバージョンに戻すことも可能
新しいバージョンで問題が発生したときは、再度シンボリックリンクを切りかえることでロールバックができます
(注:緊急避難的に手動でシンボリックリンクを切りかえてロールバックもできますが、デプロイツールを使っている場合はその後のデプロイ整合性を合わせるために、手動ではなくデプロイツールを使ってロールバックすることをおすすめします)
AWS CodeDeploy+インプレースの課題も併せて回避できる
SSHを使わずに済むので、デプロイツールはAWS CodeDeployのインプレースデプロイを選択したのですが、以下のような課題がでてきました。
アプリケーションリビジョンの展開中、ファイル参照ができない時間が発生する(AWS CodeDeployの仕様)
- 特にアプリケーションリビジョンのサイズが大きすぎる場合はその時間が長くなります
- 1台しかインスタンスが無い場合、その間はアプリケーションの実行はできません
ロードバランサでサービスから切り離してデプロイもできるが、一時的に縮退構成になる
- リリースの時間帯やタイミングの考慮が必要
- 毎回深夜帯の更新運用は避けたい
Bule/Green風にすることで、AWS CodeDeploy+インプレースの持つこれらの課題も回避することができます。
- インスタンス1台でもデプロイ時の切り替えによる影響は、ほぼ一瞬
- サービス中のインスタンスを切り離す必要がない
- 全台ほぼ同時にデプロイができるので、時間も短くなります
試したAWS構成例
AWS CodeDeployとEC2で確認をしました。台数は1台から可能です。
AWS CodeDeployの設定
押さえておく設定だけ挙げておきます。
設定名 値 補足 デプロイタイプ インプレース デプロイ設定 AllAtOnce 全インスタンス同時にデプロイします Load balancer OFF ロードバランシングは無効にしておきます ロールバック 無効にする AWS CodeDeployのロールバックはデプロイ中にエラーが発生したときに一つ前のリビジョンに自動で戻してくれる便利な機能ですが無効にしておきます。今回のBlue/Green風ではサービス投入(切り替え)のコントロールはスクリプトで行います。 AppSpecの設定
ポイント
- filesセクションのdestinationの値をデプロイ用のパスにしておきます
- フックセクション(hooks)で実行するスクリプトを指定します
そのほかの値は参考となります。
version: 0.0 os: linux files: - source: / destination: /var/www_deploy/ overwrite: true permissions: - object: /var/www_deploy owner: hoge group: fuga mode: 744 type: - file - object: /var/www_deploy owner: hoge group: fuga mode: 755 type: - directory hooks: AfterInstall: - location: hooks/AfterInstall.sh timeout: 180 owner: hoge ValidateService: - location: hooks/ValidateService.sh timeout: 180 owner: hogeAppSpecのフックセクション
フックセクションではデプロイの進行に応じてイベント実行するスクリプトを指定することができます。
セクション名 イベント説明 Blue/Green風のスクリプト内容 AfterInstall アプリケーションファイルの展開後、アプリケーションの設定やファイル権限の変更など使用します。 AfterInstall.shでは、サービスパスとデプロイパスのシンボリックリンクの入れ替え処理を行います。 ValidateService 最後にデプロイが正常に完了したことを確認するために使用されます。 ValidateService.shではチェック処理を行います。問題が発生した場合はシンボリックリンクを戻すなど必要な処理を実装することもできます。 使っているセクションだけ挙げています。その他の説明についてはこちらをご確認ください。
AWS > ドキュメント > AWS CodeDeploy >ユーザーガイド
AWS AppSpec 「フック」セクションAfterInstall.sh(シンボリックリンクの切り替え)の例
最低限ですが、このようなスクリプトでリンク先のblueとgreenを切りかえることができます。
#!/bin/bash SERVICE_PATH='/var/www' SERVICE_DIR=`readlink ${SERVICE_PATH}` DEPLOY_PATH='/var/www_deploy' DEPLOY_DIR=`readlink ${DEPLOY_PATH}` `ln -nfs ${DEPLOY_DIR} ${SERVICE_PATH}` `ln -nfs ${SERVICE_DIR} ${DEPLOY_PATH}`実際に試して感じたこと
軽微なアプリケーションの更新作業などには向いています
- 大規模改修や投入前検証で高い品質担保を毎回求められる場合は、メンテナンス計画や他の手法も検討したほうがよいかもしれません。
サービス切り替えやロールバックのスクリプト開発工数が増える
- アプリケーションの配置はAWS CodeDeployがしてくれますが、その他の処理はhooksスクリプトで行います。そのため、実運用ではこれらのスクリプトの作りこみ、エラーハンドリングの実装など、品質を保持したデプロイを実現するための工数は多くなります。
逆に、 柔軟な処理もスクリプトに実装できる(またそのスキルが必要)
- AWS CodeBuildも同じく、ビルド環境はAWSが用意してくれますがビルドの設計と開発は自分たちで実装する必要があります。そのため、今後はデプロイやビルドを設計して実装するスキルが大事になってくるのかな、と思いました。
デプロイ全体の進行管理やログはAWSのサービスにお任せ
- ログ状況やエラーはAWSコンソールで確認ができるので、運用者やデプロイのデバッグは楽になります。
以上です。最後まで読んでいただき、ありがとうございました。
- 投稿日:2020-10-14T13:19:53+09:00
AWS Backupを使ってバックアップを作成する
はじめに
大規模災害等で事業サービスや業務に影響があった場合に、復旧させ事業・業務を継続するDRP((Disaster Recovery Plans:災害復旧計画))やBCP(Business Continuity Planning:事業継続計画)について考えることがあり、その対応の1つとして、重要なリソースのバックアップを行う方法としてAWS Backupを検討し使ってみました。
AWS Backupとは
完全マネージド型のバックアップサービスで、複数のサービスのバックアップを一元管理し自動化できます。
より詳細な情報は公式ドキュメントのAWS Backupとは。をご確認ください。AWS Backup使ってバックアップを作成する
AWS Backupにアクセスすると以下のダッシュボードが表示されます。
1度だけバックアップを作成
1度だけバックアップを作成する場合、『オンデマンドバックアップを作成』を選択します。
以下のような画面が表示され、対象のリソースやバックアップの作成するタイミング、有効期限を指定することができます。
指定できるリソースタイプ(サービス)とリソースは以下です。
リソースタイプ リソース Aurora クラスターID DynamoDB テーブル名 EBS ボリュームID EC2 インスタンスID EFS ファイルシステムID RDS データベース名 Starage Gateway ボリュームID バックアップウィンドウではバックアップを作成するタイミングを、ライフサイクルでは『日・週・月・年』数単位で有効期限のタイミングを指定できます。
定期的にバックアップを作成
定期的にバックアップを作成する場合は、『バックアッププランの管理』を選択します。
まず、バックアップを作成する頻度やルールを決めます。
次に作成したバックアップルールにリソースを割り当てます。
バックアップを作成したい対象リソースを割り当てることで、バックアップルールも従ってバックアップが作成されます。
リソースの割り当ては、『リソースID』と『タグ』があります。
リソースの指定の場合は、ECS・EBS・RDSをそれぞれ指定することができます。
タグの場合は、指定されたタグのkey/valueが付与されているリソースをグループ化して指定できます。復元
作成されたバックアップを復元する場合は、『バックアップの復元』を選択します。
作成されたバックアップ一覧から復旧したいポイント(バックアップの作成日時)のリソースを選択します。
EC2の復元の場合は、デフォルトでバックアップを作成したインスタンスのインスタンスタイプやVPC、サブネット、セキュリティグループが入力されています。
インスタンスタイプなどを変更して復元することもできます。
最後に
AWS Backupを使うことで簡単にバックアップの作成と復元ができました。
また、自動で定期的にバックアップを作成することができ、とても便利なサービスです。
バックアップを作成する対象とライフサイクルなどを考えてみるのも重要ですね。
EC2,EBS, RDSなどバックアップを作成したい対象が多い場合はIDで指定するよりもタグを利用した方が簡単なので、タグの利用についても考えてみるのも良さそうです。




