- 投稿日:2020-09-29T23:59:05+09:00
猿でもわかる!discord.pyのIntentsについて!
※筆者も完全に理解してるわけではないので間違った情報が掲載されている可能性があることをご了承ください
記事の作成にあたり、公式ドキュメントの日本語訳をapple502j#6852様よりご提供頂きました。この場を借りて感謝申し上げます。Intentsとは?
Intentsはdiscord.py1.5の新機能です。
これを用いると、「一部のイベントを受け取り、一部のイベントは受け取らない」という選択ができ、
通信量やメモリの使用量を削減することができます。
※どの程度削減できるのかは未検証ですHow To Use
ClientやBotのオブジェクト生成時に引数として渡すことで適用されます。
ただし、一部のIntent(Privieged Intents)には制限がかかっています
これを有効にするには、コードへの記述に加えDeveloper Portalへ行き、アプリケーションを選択してからBotのタブ(トークンを入手/リセットする場所)で手動で有効化する必要があります。
画像にある2つのボタンをクリックして有効化してください。(画像では既に有効化されています)
Privieged Intentsについての説明をdiscord.py 公式Discordサーバー #ニュース より引用します。
- Presence Intent(上):
Member.status、Member.activity、on_member_update(statusとactivityに限る)を受け取るのに必要です。設定時はpresences=True- Server Members Intent(下):
on_memberで始まるイベントと、on_user_updateを受け取るのに必要です。また、Guild.get_memberなどにも必要です。設定時はmembers=True注意: 100サーバー以上に所属するボットでは、Privileged Intentsの使用はDiscord側の認証を得ないとできません。もしボットがすでに認証済みの場合は、Discordに連絡してください。
上記の設定が出来たら実際に使ってみましょう!
on_typingはあまり使われる機会がないので、on_typingを受け取らない場合の例を示します。main.pyimport discord intents = discord.Intents.default() # デフォルトのIntentsオブジェクトを生成 intents.typing = False # typingを受け取らないように client = discord.Client(intents=intents) # discord.extを用いる場合 # from discord.ext import commands # bot = commands.Bot(command_prefix="/", intents=intents) # or # super().__init__(command_prefix="/", intents=intents)2行目の
discord.Intents.default()でデフォルトのIntentsオブジェクトを生成しています。
デフォルトではmembersとpresencesがFalseでそれ以外はTrueに設定されています。
※デフォルトではメンバーの一覧がキャッシュされなくなるため、いくつかの属性やメソッドが使用不可となります。その場合は前述したDeveloper Portalでの設定は不要です。
default()以外にはall()ですべてをTrueの、none()ですべてがFalseのIntentsオブジェクトを生成するメソッドがあります。
手動でTrueFalseを設定する際の、Intentsの属性についてはdiscord.Intentsのリファレンスを参照してください。はいはい質問です!どのIntentsを使えばいいんですか?
人によりますが、小規模なbotの場合(従来のコードをそのまま使い続け、かつサーバー数が100未満の場合)はすべてのIntentを
Trueにするintents=discord.Intents.all()で問題有りません!上記の方法で殆どのユーザーは問題無いのですが、大規模なbotを運営しているユーザーは個別相談が必要だと思います。
on_ready()がなかなか発火しません!どうしてですか?
Discord APIの変更により、メンバーの読み込みにも変更が加わりました。以前は75サーバー同時にリクエストでき、
Guild.largeがTrueである(=メンバーが250以上である)サーバーのみでよかったのが、現在はすべてのサーバーで必要になり、さらに1リクエストあたり1サーバーのみリクエスト出来るようになりました。
これにより、約75倍の速度低下が発生しています。以下、公式ドキュメントの速度検証を引用します。
例: 840サーバー(うち95サーバーが250人以上所属(
Guild.large== True))に所属するボット。現在: 約60秒(75サーバー、20サーバー)
Intents.members == True and Intents.presences == False: 約7分 (840リクエスト、速度制限は120サーバー/分)
Intents.members == True and Intents.presences == True: 約100秒 (95リクエスト)公式ドキュメントにも書かれている解決方法を紹介します。
リクエストの仕組みを戻す
まず、PresencesとServer Membersの両方のPrivileged Intentsを有効にする方法があります。これで、リクエストの仕組みは一部以前のものと同じとなるため、起動速度も以前と同じになります。
※前述したように100サーバー以上に所属するbotの場合はDiscord側の認証を得る必要があります。メンバーの読み込みをずらす
次に、
ClientやBotのchunk_guilds_at_startup引数をFalseにすると、開始時にメンバーを読み込まなくなるため、起動が速くなります。
その後は(必要に応じて)Guild.cunkなどを用いて、サーバーのメンバーを取得してください。
他の取得方法はリファレンスに記載があります。この仕様が気に入りません!どうすればいいですか?
現時点では、古いAPIはまだ使用できるため、discord.py 1.4がv6ゲートウェイのサポート終了まで使用できますが、botの将来性のためにもコードを新しい方法にアップデートすることが得策です。
ダウングレードには# Windows py -3 -m pip install -U discord.py>=1.4, 1.5 # Linux Mac python3 -m pip install -U "discord.py>=1.4,<1.5"をターミナルで実行することで可能です。
しかし、v6ゲートウェイのサポート終了日時が不明なため、コードを更新することを推奨します。重要: 10月7日以降は、discord.pyのバージョンに関わらず(使う場合は)Developer Portalでの設定が必要になります。
Discord APIの変更や方向性を本当に嫌うならサポートに連絡することも出来ます。
要約
Intentsを設定することで受け取るイベントを制限することが出来る。
殆どのユーザーはintent=discord.Intents.all()と設定し、Developer Portalで両方のIntentにチェックを入れればいい。

- 投稿日:2020-09-29T23:24:47+09:00
エンジニアの本棚卸し
目的
自分がインプットしてきた技術関連知識の足跡整理。
文字にするとキリがないので、面倒ではない視覚的に集約されているという点で本棚の書籍写真でペタペタ整理。足跡
入り口はC言語
猫でも分かるC言語で自分が猫未満であることを悟り、苦しんで〜みたいな名前の書籍を読んだ記憶。
DXLibraryを使用してゲーム製作をしたり、遺伝的アルゴリズムでレースゲームのゴール時間を最適化したり、TCP/IPレイヤをイジったり、二度デストラクタを呼び壊したり、ダングリングポインタを参照して壊したり、壊したり。Webアプリケーションに興味が出てPHPあたり
Webアプリケーションを作りたくてPHP(時代を感じる)。
当時はLaravelではなくCakePHP,Symfonyとかの時代。Cakeを使ってWebアプリケーションを作っていたもののフレームワーク特有のブラックボックに薄気味悪さを覚えたため、一旦それは捨ててMVCフレームワークの自作に舵を切り替えた。
その後、数年してからREST APIでバックエンドとフロントエンドを接続するみたいなものが流行りだしたときにLaravelとReactでチーム開発した。オブジェクトモデリングに興味が出てJava
現実世界の写像(モデリング)ってなんぞ、と思いJava。
とやかく言われることの多い言語であるものの、複雑度の高いシステム構築においては安定している。エンジニアとして知識領域を開拓する礎になった恋のキューピッド的な言語。
OSが知りたいです
私達人間に何を隠しているのOSさん、ということでOS。
LINUXプログラミングインタフェースは学生のときに夏休みを使って読み切った(覚えてないけど)。CPUが知りたいです
演算あたりの機構が知りたくてパタヘネ本とか、CPUの創りかたとか。
左のほうにある本はAPI設計やら、正規表現エンジンやら、Androidアプリとかに興味を持ったときの。副作用のない言語?
保守性や疎結合などの文脈で関数型言語に興味を持った(ように記憶している)。
最初はCommonLisp。本屋でリスプエイリアンと目が合った。今はRustが好き。
メモリ安全、ゼロコスト抽象化、GCのない軽量なランタイム。機械学習やスクレイピング、デバッガ
脳内シナプスによるネットワークを模倣ってなにを言ってるの、と興味を持ち自作系のお魚本から。
テンソルフローの計算グラフが作れないので基本Keras(に逃げた)。その他、Pythonはスクレイピングやデバッガのカスタマイズなどでちょくちょく使う。
私はパケットになりたい
ネットワークってなにそれどうやって制御してるの、知りたい。
MPLSなにそれ、剥がされたい。攻撃は最大の防御
避けがたいクラッキングという中二病。
もちろん隔離された自分だけの環境で。コンピューティングリソースに対する抜本的な認識刷新
このあたりのコンピューティングリソースの変化はコペルニクス的転回(言いたいだけ)をもたらしましたね。マークアップとスタイル
あまり得意ではないものの、意思疎通を図るために必要なので最低限は知っておきたい。
右の砂川物理学は関係ない。DBさん腹のウチを見せてごらん
性能改善系のプロジェクトに配属されたついでにDB解体。鳥になって鳥瞰したい
システムの設計というものを真剣に考え始めたときに。無限多味スルメ
実践UML、コード・クラフト、コードコンプリートあたりは読むたびに味が変わる。その他1
リファクタとか、GC、コンパイラなど。その他2
テスト手法やらGitの仕組みやら。振り返った所感
まだ埋もれた書籍はクローゼットに大量にあるものの、とりあえず本棚にあるもので振り返ってみた。
結論:「頭でっかちになってはいけない」
物事の正しさというものは話し手5割・聞き手5割の双方の責任のもとに成立している。
書籍においても同様に書き手5割・読み手5割。誰かが言っていたらから正しいとか、あの本に書いてあったから正しいのような
話し手や書き手10割の責とするような姿勢でいてはいけないな、と最近は特に強く感じるようになった。
















- 投稿日:2020-09-29T22:41:11+09:00
文字列をひらがなで分割したい
文章をひらがなで分割
漢字の文章のルビを振ることになった。その過程で作った。
以下コードdef hiragana_split(s): # 元の文章をひらがなで分割 # 50音のリスト fifty_text = [chr(i) for i in range(12353, 12436)] + ['。', '、'] split_list = [] # ひらがなかどうか start_point = 0 section = '' for i in range(len(s) - 1): if not (s[i] in fifty_text) == (s[i + 1] in fifty_text): split_list += [s[start_point:i + 1]] start_point = i + 1 return split_list if __name__ == '__main__': s = 'どこで生れたかとんと見当けんとうがつかぬ。何でも薄暗いじめじめした所でニャーニャー泣いていた事だけは記憶している。' print(hiragana_split(s)) # ['どこで', '生', 'れたかとんと', '見当', 'けんとうがつかぬ。', '何', 'でも', '薄暗', 'いじめじめした', '所', 'で', 'ニャーニャー泣', 'いていた', '事', 'だけは', '記憶']
- 投稿日:2020-09-29T22:35:42+09:00
将棋AIで学ぶディープラーニング on Mac and Google Colab 単語
shogi.BB_SQUARES
[0b000・・・0001, 0b000・・・0010, 0b000・・・0100, ・・・, 0b100・・・0000]。要素81個。
shogi.COLORS
range(0, 2)のこと。0,1。
shogi.CSA.Parser.parse_file(filepath)
CSAファイルからnames、sfen、moves、winの4つのキーを持ったディクショナリに変換される。このディクショナリが1要素としてリストに入っている。(filepath)の後ろに[0]をつければディクショナリだけ取り出せる。
shogi.PIECE_TYPES_WITH_NONE
range(0, 16)のこと。0,1,・・・,15。0は空白、1以降は駒の種類を表す。
shogi.MAX_PIECES_IN_HAND
[0, 18, 4, 4, 4, 4, 2, 2, 0, 0, 0, 0, 0, 0, 0]のこと。
持ち駒の数の意味。インデックス1~7はおそらく下記のような感じ。
shogi.MAX_PIECES_IN_HAND[1] = 18 :歩
shogi.MAX_PIECES_IN_HAND[2] = 4 :香車
shogi.MAX_PIECES_IN_HAND[3] = 4 :桂馬
shogi.MAX_PIECES_IN_HAND[4] = 4 :銀
shogi.MAX_PIECES_IN_HAND[5] = 4 :金
shogi.MAX_PIECES_IN_HAND[6] = 2 :角
shogi.MAX_PIECES_IN_HAND[7] = 2 :飛車shogi.SQUARES
range(0, 81)のこと。
Moveクラス
from_square
盤面を0~80の数値で表したときの移動元を表す変数。
9で割ったときの商がy座標、余りがx座標となる。xy座標は0オリジン。x座標 0 1 2 3 4 5 6 7 8 0 1 2 3 4 5 6 7 8 0 y座標 9 10 11 12 13 14 15 16 17 1 18 19 20 21 22 23 24 25 26 2 27 28 29 30 31 32 33 34 35 3 36 37 38 39 40 41 42 43 44 4 45 46 47 48 49 50 51 52 53 5 54 55 56 57 58 59 60 61 62 6 63 64 65 66 67 68 69 70 71 7 72 73 74 75 76 77 78 79 80 8to_square
同上(移動先)。
Boardクラス
局面を表すクラス。ちなみにprint(board)で盤面を2次元表示できる。
piece_bb
15要素の配列。各要素は各駒の配置を示す。0:空白、1:歩、2:香、・・・
bit board。bit boardとは下記のようなもの。
各要素が81桁(=81マス)の2進数(つまりbit board)の10進数表示である。
2進数81桁表示したいときはprint('{:0=81b}'.format(10進数の値)) でできる。occupied
2要素の配列。各要素は先手後手の占有している駒の位置。bit board。
pieces_in_hand
2要素の配列。各要素は先手後手がどの駒(=key)を何枚(=value)持っているかを示すディクショナリ型。
- 投稿日:2020-09-29T22:28:44+09:00
AI自動運転ラジコンカープロト (2-2 Dimming Turn Signal)
はじめに
サーボ制御に使用されるPWMコントローラですが、LEDの輝度の制御にも使用できます。これを使って、Mazda 3のターンシグナルを模擬してみました(Mazdaファン以外には分かりにくいですが...)。
前提
- デバイス:HiLetgo PCA9685
- ライブラリ: Adafruit Python PCA9685
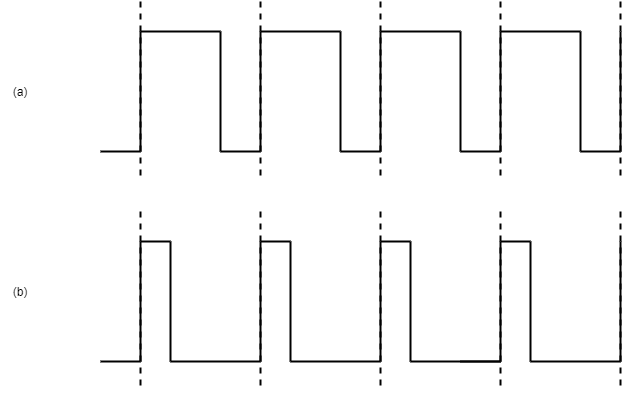
LEDのPWM制御について
PWMコントローラは、周波数とHighからLowにタイミングを設定することができます。例えば、下記の図(a)は(b)と比較してHighの期間が長いため相対的に明るく見えます。常にHighであれば最大輝度、常にLowであれば消灯になります。
インストール
sudo apt-get install git build-essential python3-dev cd ~ git clone https://github.com/adafruit/Adafruit_Python_PCA9685.git cd Adafruit_Python_PCA9685 sudo python3 setup.py install実装
PWM周波数はサーボ制御の関係で57.8Hz、点滅の周波数は1.5Hz、4096階調で30ステップごとに輝度を変化させるとそれっぽく見えます。
結果
Dimming Turn Signal pic.twitter.com/33uruU7WKn
— tutu (@tutu68018594) September 28, 2020目次ページへのリンク
- 投稿日:2020-09-29T22:25:29+09:00
numpy-stlで使いそうな操作をまとめてみた
はじめに
3Dプリンタで造形するものがパターン化してきて、数字を入れたら勝手にモデルができたら楽だなーと思ってググってたら、numpy-stlなるものを知ったのでメモ的にまとめてみた。
numpy-stlってなに?
公式ドキュメントをざっくり翻訳するとこんなかんじ。
STLファイル(ならびに一般的な3Dモデル)を素早く簡単に扱うためのシンプルなライブラリです。
すべての操作がnumpyに大きく依存しており、Python用のSTL向けライブラリの中で最も高速なものの一つです。要はnumpy的に3Dモデルを作ったり、既存のSTLファイルをいじってみたりできるライブラリという所。
公式サイトとか参考資料
- numpy-stlプロジェクトページ https://pypi.org/project/numpy-stl/
- numpy-stl ドキュメンテーション https://numpy-stl.readthedocs.io/en/latest/
- 3Dプリント×Python ~コードからアプローチする3Dプリンティング~ https://www.slideshare.net/TakuroWada/3dpython3d
インストール
基本的にはpipでOK。
今回はmacOS Catalina 10.15.6, python 3.7.7で実行した。installpip3 install numpy-stl生成した3Dモデルを確認する場合は以下のライブラリもインストールしておく。
installpip3 install mpl_toolkits pip3 install matplotlib操作いろいろ
回転に関しても気が向いたら追加します。(とはいえ、numpy-stlでググるとそれっぽい記事が結構出てきたりする。)
立方体(正六面体)作りたい
せっかくなので関数化しました。引数のscale_x, scale_y, scale_zに大きさを入れます。
単位系にもよりますが、引数無しのデフォルト状態で縦横高さがともに1の立方体ができるはず。cube_model.pyimport numpy as np from stl import mesh def cube_model(scaleX=1, scaleY=1, scaleZ=1): scaleX = scaleX / 2 scaleY = scaleY / 2 scaleZ = scaleZ / 2 vertices = np.array([\ [-1*scaleX, -1*scaleY, -1*scaleZ], [+1*scaleX, -1*scaleY, -1*scaleZ], [+1*scaleX, +1*scaleY, -1*scaleZ], [-1*scaleX, +1*scaleY, -1*scaleZ], [-1*scaleX, -1*scaleY, +1*scaleZ], [+1*scaleX, -1*scaleY, +1*scaleZ], [+1*scaleX, +1*scaleY, +1*scaleZ], [-1*scaleX, +1*scaleY, +1*scaleZ]]) faces = np.array([\ [0,3,1], [1,3,2], [0,4,7], [0,7,3], [4,5,6], [4,6,7], [5,1,2], [5,2,6], [2,3,6], [3,7,6], [0,1,5], [0,5,4]]) cube = mesh.Mesh(np.zeros(faces.shape[0], dtype=mesh.Mesh.dtype)) cube.remove_duplicate_polygons=True for i, f in enumerate(faces): for j in range(3): cube.vectors[i][j] = vertices[f[j],:] return cube読み込むプログラムはこちら
test_plot.pyimport numpy as np from stl import mesh from mpl_toolkits import mplot3d from matplotlib import pyplot from cube_model import cube_model figure = pyplot.figure() axes = mplot3d.Axes3D(figure) your_mesh = cube_model(10,10,10) axes.add_collection3d(mplot3d.art3d.Poly3DCollection(your_mesh.vectors)) scale = your_mesh.points.flatten() print(scale) axes.auto_scale_xyz(scale, scale, scale) pyplot.show()自分のSTLを読み込みたい
your_stl_model.stlに自身のSTLファイルを指定する。
read_stl_file.pyimport numpy as np from stl import mesh from mpl_toolkits import mplot3d from matplotlib import pyplot figure = pyplot.figure() axes = mplot3d.Axes3D(figure) your_mesh = mesh.Mesh.from_file('your_stl_model.stl') axes.add_collection3d(mplot3d.art3d.Poly3DCollection(your_mesh.vectors)) scale = cube_comb.points.flatten() axes.auto_scale_xyz(scale, scale, scale) pyplot.show()3Dモデルを原点に揃えたい
読み込んだSTLが変な方向に飛んでいた場合に、モデルの中心を(0,0,0)に合わせる際などに使う。
引数のmy_meshにはSTLファイルなどを読み込んだ際のmeshオブジェクトを入れる。mesh_location_zero.pyimport numpy as np from stl import mesh def mesh_location_zero(my_mesh): midPosRel = (my_mesh.max_ - my_mesh.min_)/2 my_mesh.x = my_mesh.x - (midPosRel[0] + my_mesh.min_[0]) my_mesh.y = my_mesh.y - (midPosRel[1] + my_mesh.min_[1]) my_mesh.z = my_mesh.z - (midPosRel[2] + my_mesh.min_[2]) return my_meshmeshの情報を更新する
meshオブジェクト内のメンバを更新するため、座標系をあわせることも含め移動したり、モデルを拡大、回転させたり変化を加えた際にはこれも実行しておく。引数は同じく。
mesh_update.pyimport numpy as np from stl import mesh def mesh_update(my_mesh): my_mesh.update_areas() my_mesh.update_max() my_mesh.update_min() my_mesh.update_units() return my_mesh3Dモデルを拡大・縮小したい
拡大・縮小も関数化した。my_meshには各自の3Dモデルのものを入れ、scale_x, scale_y, scale_zには1.0を100%として拡大率を入れる。
mesh_scale.pyimport numpy as np from stl import mesh def mesh_scale(my_mesh, scale_x, scale_y, scale_z): my_mesh.x = my_mesh.x * scale_x my_mesh.y = my_mesh.y * scale_y my_mesh.z = my_mesh.z * scale_z return my_mesh3Dモデルを移動したい
mesh.translateで移動できる。引数はnumpy.arrayで指定する。(今回はcube_model.pyもあわせて使っています。)
move_model.pyimport numpy as np from stl import mesh from mpl_toolkits import mplot3d from matplotlib import pyplot from cube_model import cube_model figure = pyplot.figure() axes = mplot3d.Axes3D(figure) your_mesh = cube_model(5,20,5) your_mesh.translate(np.array([1,3,1])) axes.add_collection3d(mplot3d.art3d.Poly3DCollection(your_mesh.vectors)) scale = cube_comb.points.flatten() print(scale) axes.auto_scale_xyz(scale, scale, scale) pyplot.show()3Dモデルを結合したい
なんとnumpy.concatenateでモデルを結合できる。numpyでモデルを作れることを名売っているだけあるなぁ。(今回はcube_model.pyもあわせて使っています。)
mesh_scale.pyimport numpy as np from stl import mesh from mpl_toolkits import mplot3d from matplotlib import pyplot from cube_model import cube_model figure = pyplot.figure() axes = mplot3d.Axes3D(figure) your_mesh = cube_model(10,10,10) your_mesh2 = cube_model(5,20,5) your_mesh2.translate(np.array([1,1,1])) cube_comb = mesh.Mesh(np.concatenate([ your_mesh.data.copy(), your_mesh2.data.copy(), ])) axes.add_collection3d(mplot3d.art3d.Poly3DCollection(cube_comb.vectors)) scale = cube_comb.points.flatten() print(scale) axes.auto_scale_xyz(scale, scale, scale) pyplot.show()3Dモデルを保存したい
mesh.saveで保存できる。引数は保存先のパスおよびファイル名。
save_model.pyimport numpy as np from stl import mesh from cube_model import cube_model your_mesh = cube_model(10,10,10) your_mesh2 = cube_model(5,20,5) your_mesh2.translate(np.array([1,1,1])) cube_comb = mesh.Mesh(np.concatenate([ your_mesh.data.copy(), your_mesh2.data.copy(), ])) cube_comb.save('your_model.stl')おまけ
XYZprinting製3Dプリンタで造形データを流したりするために使うソフトウェア"XYZprint”に作成したSTLデータを流してみた。ちゃんと積層データも作れているようで嬉しい。
おわりに
今回はnumpy-stlを一通り操作してみました。
一般的に使いそうな操作が他にあったら気が向いたときに追加します。


- 投稿日:2020-09-29T21:54:39+09:00
Pythonによる画像処理100本ノック#12 モーションフィルタ
はじめに
どうも、らむです。
今回は画像中に動きを付けるフィルターであるモーションフィルタを実装します。12本目:モーションフィルタ
平滑化フィルタとは画像の平滑化を行うフィルタです。このフィルタを適用することによって画像全体をぼやかしたような加工ができます。特にこのモーションフィルタでは流動的なぼかしが可能です。
このフィルタでは注目画素を周辺画素の対角線の平均値で置き換えます。
例えば、3×3や5×5のモーションフィルタは以下のようになります。
$\frac{1}{3}$ $0$ $0$ $0$ $\frac{1}{3}$ $0$ $0$ $0$ $\frac{1}{3}$
$\frac{1}{5}$ $0$ $0$ $0$ $0$ $0$ $\frac{1}{5}$ $0$ $0$ $0$ $0$ $0$ $\frac{1}{5}$ $0$ $0$ $0$ $0$ $0$ $\frac{1}{5}$ $0$ $0$ $0$ $0$ $0$ $\frac{1}{5}$ 注目画素が中心だとすると、周辺画素と対応するフィルタ値の積の総和を注目画素に代入すれば良いですね。
3×3フィルタであれば$I(x_0,y_0)×\frac{1}{3} + I(x_1,y_1)×\frac{1}{3} + I(x_2,y_2)×\frac{1}{3}$の値を注目画素に代入します。これで、周辺画素の対角線の平均値が注目画素に代入されていますね。また、前回同様、画像の端部分はフィルタリング処理が行えないので存在しない画素は0を用いる0パディング処理を行います。
ソースコード
motionFilter.pyimport numpy as np import cv2 import matplotlib.pyplot as plt def motionFilter(img,k): w,h,c = img.shape size = k // 2 # 0パディング処理 _img = np.zeros((w+2*size,h+2*size,c), dtype=np.uint8) _img[size:size+w,size:size+h] = img.copy().astype(np.uint8) dst = _img.copy() # フィルタ作成 ker = np.zeros((k,k), dtype=np.float) for i in range(-1*size,k-size): ker[i+size,i+size] = 1/k # フィルタリング処理 for x in range(w): for y in range(h): for z in range(c): dst[x+size,y+size,z] = np.sum(ker*_img[x:x+k,y:y+k,z]) dst = dst[size:size+w,size:size+h].astype(np.uint8) return dst # 画像読込 img = cv2.imread('image.jpg') # モーションフィルタ # 第2引数:フィルタサイズ img = motionFilter(img,21) # 画像保存 cv2.imwrite('result.jpg', img) # 画像表示 plt.imshow(cv2.cvtColor(img, cv2.COLOR_BGR2RGB)) plt.show()

画像左は入力画像、画像右は出力画像です。
ぼやけた感じの出力画像になっており、平滑化が行えていることが分かります。また、他の平滑化フィルタとは違い、フィルタの対角線の方向に流れています。おわりに
もし、質問がある方がいらっしゃれば気軽にどうぞ。
imori_imoriさんのGithubに公式の解答が載っているので是非そちらも確認してみてください。
それから、pythonは初心者なので間違っているところがあっても優しく指摘してあげてください。

- 投稿日:2020-09-29T21:34:08+09:00
深層学習外伝 ~GPUプログラミング編~
概要
前回の記事はこちら
前回記事で「KerasのMNISTデータセットで学習しようとすると数時間かかる」と書きました。MNISTデータセット程度の小さなデータセットでそんなにかかるのはやってられないので高速化します。
深層学習の高速化といえばGPUやTPUの利用ですね〜
ということで、本記事ではNVIDIA製のGPUを用いるためのGPUプログラミングをやっていきます。
使用するパッケージはCuPyにしました。理由は後ほど...目次
おわりに深層学習の高速化
注:だらだら喋るのでスキップしてもらって構いません
昨今のコンピュータアーキテクチャの発展は日進月歩どころではないレベルの速度で進んでいます。例えば私が子どもの頃はゲームボーイアドバンスが流行っていましたが、そこで動くゲームのデータ容量は最大でも32MBだったそうです。ところが今やPS4やPS5、Switchなんかのとんでもスペックなゲームハードで動くゲームで言えば、当たり前のように10数GBなんかのデータ容量があるそうです。GBはMBの1024倍ですから、たった10何年かで1000倍近くのデータ量を扱えるようになったことになります。このことからHDDやSSDといった記憶媒体の進歩具合が伺えますね。
もちろん扱うデータ容量が増えるならコンピュータが処理する命令も飛躍的に増大します。
CPUに求められる処理能力は尽きるところを知りませんが、CPUの発展はそれに応えるように「ムーアの法則」と呼ばれる経験則に則り18ヶ月(最近は24ヶ月)で倍になっていきました1。これはつまり15年でコンピュータの処理性能が1024倍になることを意味します。すごいことですね〜しかしながら、先にも述べた通りCPUに求められる処理能力というのは、CPUが性能向上してできることが増えるたび青天井に求められます。そのため、いつの時代も性能不足が嘆かれてきました。
深層学習が脚光を浴びた背景には間違いなくCPUの性能向上があり、またそのためにCPUの性能不足が嘆かれる場面が多くあります。その一つが画像認識及び畳み込みニューラルネットワーク(CNN)です。
画像データは2次元ですので、ちょっと大きな画像データセットを学習に使おうとするとあっという間に万単位以上の要素を持つテンソルになってしまい、現行のCPUでは圧倒的に性能不足です。
前回の記事では具体的に述べていませんが、実験したところ、KerasのMNISTデータセットを用いて学習しようとすると、google colaboratory上で1エポック30分もかかります。google colaboratoryは12時間制限があるので(外部に途中経過一時保存&再読み込みからの学習再開をしなければ)24エポックしか学習できません。まあそれでもMNISTデータセットくらいなら十分な精度の学習ができますが。とにかく、これでは気軽に実験することもできません。そこで注目されたのがGPUです。
GPU
CPUがCentral Processing Unit:中央処理装置であるのに対し、GPUはGraphics Processing Unit:グラフィック処理装置と呼ばれます。名前の通り、画面描画のための計算に特化した半導体プロセッサです。
CPUは汎用計算に優れているのに対して、GPUは画像処理のための計算に特化している分その速度は圧倒的です。数千個以上のコアで超並列計算を行うため、画面描画は基本的にラグなく行われます。
そしてここがミソなのですが、この超並列計算と行列計算には親和性があります。
この図はただの喩えというか、実際にGPU上でこのような処理が行われているということではありませんので注意してください。この図から読み取って欲しいことは、行列計算は並列実行できるというただ1点のみです。
ちなみに上図はCPUの並列化でも実現できますが、GPUは規模が桁違いなのです。そんなこんなで、深層学習に目をつけられたGPUはGPGPU: General-Purpose computing on Graphics Processing Units: グラフィック処理装置を汎用計算に用いる技術などの登場を経てその発展に多大な貢献をします。
TPU
さて、GPU及びGPGPUの登場で深層学習は急速な発展を遂げましたが、それで飽き足りないのが人間の性ですね。ということで登場したのがTPU: Tensor Processing Unit: テンソル処理装置です。
GPUはあくまでグラフィック用に設計されていたものですが、そこからさらに深層学習のための高速テンソル計算を実現するために設計されたのがTPUです。汎用性と少しばかりの演算精度を犠牲に、GPUをも圧倒する、どころか足元にすら及ばないような高速化を成し遂げました。
テンソル計算に特化しているためGPUよりもさらに汎用性が落ち、また通常は32bitや64bitで計算されるところを8bitや16bitに落とすことで高速化しています。
さらに、キャッシュメモリへの書き込みすらも減らすために演算回路内でデータやり取りを行うなど、とにかく高速にテンソル計算ができるような工夫がなされています。その圧倒的な威力を示す代表例がAlphaGo Zeroです。単純計算でCPU換算すると3万年くらいかかる量の計算を、複数のTPUなどを用いて3日で済ませてしまいました。意味がわかりませんね。笑
そんなこんなで、超並列計算が深層学習に及ぼす恩恵は非常に大きなものとなっています。
CuPyによるGPUプログラミングさて、本題に入ります。本記事では
CuPyを用いてGPUプログラミングを行います。
CuPyは元々ChainerでのGPUプログラム実装(CUDAプログラミング)のために開発されたパッケージだったそうです。
最大の利点はnumpyを踏襲しているため、ほとんどのコードでnp(import numpy as np)をcp(import cupy as cp)と書き換えるだけで動くことです。これが本記事でCuPyを利用することにした理由です。簡単って素晴らしい!笑ぶっちゃけほとんど考えることはありません。というかプロトタイプとして実装したので汚いです...いずれ整理していきます。デコレータとか使うといいのかなぁ...いいアイデアあればぜひ教えてください。
コードはこちらです。ちなみに、google colaboratoryでGPUを利用するには、ランタイムのタイプにGPUを選択する必要があります。
CuPyのインストールと確認
CuPyのインストールは以下のコードを入力したセルを実行します。!curl https://colab.chainer.org/install | sh -% Total % Received % Xferd Average Speed Time Time Time Current Dload Upload Total Spent Left Speed 100 1580 100 1580 0 0 6666 0 --:--:-- --:--:-- --:--:-- 6666 + apt -y -q install cuda-libraries-dev-10-0 Reading package lists... Building dependency tree... Reading state information... cuda-libraries-dev-10-0 is already the newest version (10.0.130-1). 0 upgraded, 0 newly installed, 0 to remove and 11 not upgraded. + pip install -q cupy-cuda100 chainer |████████████████████████████████| 348.0MB 51kB/s + set +ex Installation succeeded!これで自動的に必要なバージョンの
CuPyがインストールされます。ついでにChainerも。使いませんがまあいいでしょう。
以下のコードできちんとインストールされているか確認できます。!python -c 'import chainer; chainer.print_runtime_info()'Platform: Linux-4.19.112+-x86_64-with-Ubuntu-18.04-bionic Chainer: 7.4.0 ChainerX: Not Available NumPy: 1.18.5 CuPy: Not Available iDeep: 2.0.0.post3こんな感じの出力が確認できればOKです。
CuPyプログラミング例として活性化関数(の一部)を挙げておきます。
activator.pyimport numpy as np import cupy as cp class Activator(): def __init__(self, *args, mode="cpu", **kwds): self.mode = mode if self.mode == "cpu": self.forward = self.cpu_forward self.backward = self.cpu_backward self.update = self.cpu_update elif self.mode == "gpu": self.forward = self.gpu_forward self.backward = self.gpu_backward self.update = self.gpu_update def cpu_forward(self, *args, **kwds): raise NotImplemented def gpu_forward(self, *args, **kwds): raise NotImplemented def cpu_backward(self, *args, **kwds): raise NotImplemented def gpu_backward(self, *args, **kwds): raise NotImplemented def cpu_update(self, *args, **kwds): raise NotImplemented def gpu_update(self, *args, **kwds): raise NotImplemented class step(Activator): def cpu_forward(self, x, *args, **kwds): return np.where(x > 0, 1, 0) def gpu_forward(self, x, *args, **kwds): return cp.where(x > 0, 1, 0) def cpu_backward(self, x, *args, **kwds): return np.zeros_like(x) def gpu_backward(self, x, *args, **kwds): return cp.zeros_like(x)脳死で書いてます。なんかこう、もっとスマートなやり方があるはず...
やっていることとしては、Pythonが関数をある種のオブジェクトとして代入できることを利用して分岐させています。
関数の実装の部分も、npとcpが違うだけですね!これがCuPyのいいところです。お手軽便利にGPUプログラミングができますね〜効果の確認
ではKerasのMNISTデータセットで実験してみましょう。実行は実験コードまでの全てのセルを実行し、Kerasのデータを読み込むセルを実行、最後にCNN実験コード本体を実行します。
cnn_main.py%matplotlib inline # 畳み込み層と出力層を作成 M, F_h, F_w = 10, 3, 3 lm = LayerManager((x_train, x_test), (t_train, t_test), mode="gpu") #lm.append(name="c", I_shape=(C, I_h, I_w), F_shape=(M, F_h, F_w), pad=1, # wb_width=0.1, opt="AdaDelta", opt_dic={"eta": 1e-2}) lm.append(name="c", I_shape=(C, I_h, I_w), F_shape=(M, F_h, F_w), pad=1) lm.append(name="p", I_shape=lm[-1].O_shape, pool=2) #lm.append(name="m", n=100, wb_width=0.1, # opt="AdaDelta", opt_dic={"eta": 1e-2}) lm.append(name="m", n=100) #lm.append(name="o", n=n_class, act="softmax", err_func="Cross", wb_width=0.1, # opt="AdaDelta", opt_dic={"eta": 1e-2}) lm.append(name="o", n=n_class, act="softmax", err_func="Cross") # 学習させる epoch = 5 threshold = 1e-8 n_batch = 8 lm.training(epoch, threshold=threshold, n_batch=n_batch, show_train_error=True) # 予測する print("training dataset") _ = lm.predict(x=lm.x_train, y=lm.y_train) print("test dataset") if lm.mode == "cpu": y_pred = lm.predict() elif lm.mode == "gpu": y_pred = lm.predict().get() progress:[XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX]483s/514s training dataset correct: [5 0 4 1 9 2 1 3 1 4 3 5 3 6 1 7] predict: [5 0 4 1 9 2 1 3 1 4 3 5 3 6 1 7] accuracy rate: 98.58 % (59148/60000) test dataset correct: [7 2 1 0 4 1 4 9 5 9 0 6 9 0 1 5] predict: [7 2 1 0 4 1 4 9 5 9 0 6 9 0 1 5] accuracy rate: 97.58 % (9758/10000)
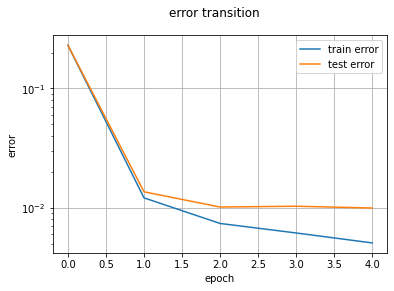
特に意味はありませんが、活性化関数や重みレンジwb_width、最適化子などをデフォルトにしています。つまり活性化関数はReLU、wb_widthは0.05、最適化子はAdamとなっています。学習エポックは5に設定しています。実行結果は、1エポックあたり約100秒ですね!実に18倍の高速化に成功しました。まだまだ遅いですが、まあ実用には耐えられるでしょう。MNIST以外は...(遠い目)
さらなる高速化に向けて
ところで、テストコードの一番下にはKerasでのMNISTデータセット学習コードを載せてあります。
こちらからコピペしました。
mnist_cnn.py
mnist_cnn.py'''Trains a simple convnet on the MNIST dataset. Gets to 99.25% test accuracy after 12 epochs (there is still a lot of margin for parameter tuning). 16 seconds per epoch on a GRID K520 GPU. ''' from __future__ import print_function import keras from keras.datasets import mnist from keras.models import Sequential from keras.layers import Dense, Dropout, Flatten from keras.layers import Conv2D, MaxPooling2D from keras import backend as K batch_size = 128 num_classes = 10 epochs = 12 # input image dimensions img_rows, img_cols = 28, 28 # the data, split between train and test sets (x_train, y_train), (x_test, y_test) = mnist.load_data() if K.image_data_format() == 'channels_first': x_train = x_train.reshape(x_train.shape[0], 1, img_rows, img_cols) x_test = x_test.reshape(x_test.shape[0], 1, img_rows, img_cols) input_shape = (1, img_rows, img_cols) else: x_train = x_train.reshape(x_train.shape[0], img_rows, img_cols, 1) x_test = x_test.reshape(x_test.shape[0], img_rows, img_cols, 1) input_shape = (img_rows, img_cols, 1) x_train = x_train.astype('float32') x_test = x_test.astype('float32') x_train /= 255 x_test /= 255 print('x_train shape:', x_train.shape) print(x_train.shape[0], 'train samples') print(x_test.shape[0], 'test samples') # convert class vectors to binary class matrices y_train = keras.utils.to_categorical(y_train, num_classes) y_test = keras.utils.to_categorical(y_test, num_classes) model = Sequential() model.add(Conv2D(32, kernel_size=(3, 3), activation='relu', input_shape=input_shape)) model.add(Conv2D(64, (3, 3), activation='relu')) model.add(MaxPooling2D(pool_size=(2, 2))) model.add(Dropout(0.25)) model.add(Flatten()) model.add(Dense(128, activation='relu')) model.add(Dropout(0.5)) model.add(Dense(num_classes, activation='softmax')) model.compile(loss=keras.losses.categorical_crossentropy, optimizer=keras.optimizers.Adadelta(), metrics=['accuracy']) model.fit(x_train, y_train, batch_size=batch_size, epochs=epochs, verbose=1, validation_data=(x_test, y_test)) score = model.evaluate(x_test, y_test, verbose=0) print('Test loss:', score[0]) print('Test accuracy:', score[1])Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/mnist.npz 11493376/11490434 [==============================] - 0s 0us/step x_train shape: (60000, 28, 28, 1) 60000 train samples 10000 test samples Epoch 1/12 469/469 [==============================] - 4s 9ms/step - loss: 2.2889 - accuracy: 0.1426 - val_loss: 2.2611 - val_accuracy: 0.2889 Epoch 2/12 469/469 [==============================] - 4s 9ms/step - loss: 2.2432 - accuracy: 0.2350 - val_loss: 2.2046 - val_accuracy: 0.4885 Epoch 3/12 469/469 [==============================] - 4s 9ms/step - loss: 2.1837 - accuracy: 0.3312 - val_loss: 2.1279 - val_accuracy: 0.5908 Epoch 4/12 469/469 [==============================] - 4s 9ms/step - loss: 2.1039 - accuracy: 0.4035 - val_loss: 2.0235 - val_accuracy: 0.6492 Epoch 5/12 469/469 [==============================] - 4s 9ms/step - loss: 1.9959 - accuracy: 0.4669 - val_loss: 1.8864 - val_accuracy: 0.6989 Epoch 6/12 469/469 [==============================] - 4s 9ms/step - loss: 1.8604 - accuracy: 0.5193 - val_loss: 1.7149 - val_accuracy: 0.7420 Epoch 7/12 469/469 [==============================] - 4s 9ms/step - loss: 1.6990 - accuracy: 0.5681 - val_loss: 1.5179 - val_accuracy: 0.7688 Epoch 8/12 469/469 [==============================] - 4s 9ms/step - loss: 1.5315 - accuracy: 0.6014 - val_loss: 1.3180 - val_accuracy: 0.7912 Epoch 9/12 469/469 [==============================] - 4s 9ms/step - loss: 1.3717 - accuracy: 0.6327 - val_loss: 1.1394 - val_accuracy: 0.8029 Epoch 10/12 469/469 [==============================] - 4s 9ms/step - loss: 1.2431 - accuracy: 0.6562 - val_loss: 0.9945 - val_accuracy: 0.8171 Epoch 11/12 469/469 [==============================] - 4s 9ms/step - loss: 1.1369 - accuracy: 0.6757 - val_loss: 0.8818 - val_accuracy: 0.8263 Epoch 12/12 469/469 [==============================] - 4s 9ms/step - loss: 1.0520 - accuracy: 0.6957 - val_loss: 0.7949 - val_accuracy: 0.8356 Test loss: 0.7948545217514038 Test accuracy: 0.8356000185012817は、速い...さらに20倍も高速ですね...ということはまだまだ高速化の余地が残されているということですね!
では現状のぼくのコードで計算速度のボトルネックはどこなのかを調べてみます。
処理時間の計測はtimeitマジックを利用しています。これを使うとうまいこと処理時間を計測してくれます。誤差計算の時間計測
まずは誤差計算にかかる時間を計測してみます。
search_bottleneck.py# 訓練誤差の計算 %%timeit lm.forward(lm.x_train) error = lm[-1].get_error(lm.y_train) #----------output---------- # 1 loop, best of 3: 957 ms per loop #-------------------------- # テスト誤差の計算 %%timeit lm.forward(lm.x_test) error = lm[-1].get_error(lm.y_test) #----------output---------- # 10 loops, best of 3: 160 ms per loop #--------------------------訓練データの誤差計算はデータ量が60000ですので、まあこんなものでしょう。ていうかもっと少なくていいのでは...ここは改良できそうですね。テストデータと同じく10000個に減らせば1エポックあたり約0.8秒の短縮になりそうです。まあそれこそ誤差みたいなものですが。
全体(1エポックあたり100秒)から考えると、誤差計算が占める割合は総じて1%程度なので、ここはボトルネックではないでしょう。ということは学習部分が問題そうですね。学習部分の時間計測
学習部分の処理時間を計測していきます。1エポックあたりの処理時間のうち99%を占めているのが学習のどこかにあるはず...
search_bottleneck.py# ミニバッチ1つ分のデータを計測対象とする。 rand_index = np.arange(lm.x_train.get().shape[0]) np.random.shuffle(rand_index) rand = rand_index[0 : n_batch] # 順伝播の計算 %%timeit lm.forward(lm.x_train[rand]) #----------output---------- # 1000 loops, best of 3: 1.32 ms per loop #-------------------------- # 逆伝播の計算 %%timeit lm.backward(lm.y_train[rand]) #----------output---------- # 100 loops, best of 3: 10.3 ms per loop #-------------------------- # 重み更新計算 %%timeit lm.update() #----------output---------- # 1000 loops, best of 3: 1.64 ms per loop #--------------------------明らかに逆伝播だけ異常に時間がかかっていますね。順伝播と重み更新に対して10倍かかっています。
今回学習データは60000個で、ミニバッチサイズが8なので、この計算過程が7500回繰り返されることになりますから、トータルで$(1.32+10.3+1.64) \times 7500 \times 10^{-3} = 23.92s$かかることになります。あれ、思ったより少ない...?十分時間かかっていますが、それでもなんか足りないですね...まあ結構振れ幅ありますし、とりあえずは気にしないでおきましょう。
ただの計算ミスでした...電卓の仕様はちゃんと理解しないとですね汗
$(1.32+10.3+1.64) \times 7500 \times 10^{-3} = 99.45s$
とにかく、逆伝播が異常に遅いので、さらに細かく計測していきます。逆伝播の時間計測
ということで、逆伝播の処理を分割して計測していきます。
search_bottleneck.py# 事前準備 err3 = lm[3].backward(lm.y_train[rand]) err2 = lm[2].backward(err3) err2 = err2.reshape(n_batch, *lm[1].O_shape) err1 = lm[1].backward(err2) err0 = lm[0].backward(err1) # 出力層の逆伝播 %%timeit err3 = lm[3].backward(lm.y_train[rand]) #----------output---------- # 10000 loops, best of 3: 152 µs per loop #-------------------------- # 中間層の逆伝播 %%timeit err2 = lm[2].backward(err3) err2 = err2.reshape(n_batch, *lm[1].O_shape) #----------output---------- # 1000 loops, best of 3: 224 µs per loop #-------------------------- # プーリング層の逆伝播 %%timeit err1 = lm[1].backward(err2) #----------output---------- # 1000 loops, best of 3: 9.72 ms per loop #-------------------------- # 畳み込み層の逆伝播 %%timeit err0 = lm[0].backward(err1) #----------output---------- # 1000 loops, best of 3: 442 µs per loop #--------------------------プーリング層が桁違いに遅いことがわかりました。逆伝播の計算時間に占めるプーリング層の処理時間は約93.6%にもなります。ちなみにこちらは足すと大体10msちょっとになりますので、大体一致していますね。
プーリング層の逆伝播の時間計測
ということで、問題のプーリング層の逆伝播をさらに細かくみていきます。
search_bottleneck.py# 事前準備 B, C, O_h, O_w = n_batch, *lm[1].O_shape grad = err2.transpose(0, 2, 3, 1).reshape(-1, 1) grad_x = cp.zeros((grad.size, lm[1].pool*lm[1].pool)) grad_x1 = grad_x.copy() grad_x1[:, lm[1].max_index] = grad grad_x2 = grad_x1.reshape(B*O_h*O_w, C*lm[1].pool*lm[1].pool).T # 誤差の次元入れ替えと変形 %%timeit grad = err2.transpose(0, 2, 3, 1).reshape(-1, 1) #----------output---------- # 100000 loops, best of 3: 17.1 µs per loop #-------------------------- # 空の行列生成 %%timeit grad_x = cp.zeros((grad.size, lm[1].pool*lm[1].pool)) #----------output---------- # 100000 loops, best of 3: 7.89 µs per loop #-------------------------- # 値埋め %%timeit grad_x1[:, lm[1].max_index] = grad #----------output---------- # 1000 loops, best of 3: 9.5 ms per loop #-------------------------- # 変形と転置 %%timeit grad_x2 = grad_x1.reshape(B*O_h*O_w, C*lm[1].pool*lm[1].pool).T #----------output---------- # 1000000 loops, best of 3: 1.86 µs per loop #-------------------------- # col2im %%timeit grad_x3 = lm[1].col2im(grad_x2, (n_batch, *lm[1].I_shape), lm[1].O_shape, stride=lm[1].pool, pad=lm[1].pad_state) #----------output---------- # 10000 loops, best of 3: 112 µs per loop #--------------------------値埋めが他より圧倒的に遅いですね...ということはここがボトルネックなわけです。値埋めがプーリング層の逆伝播に占める割合は実に約98.6%となっています。
GPUは単純な計算には強いですが、こういったちょっと複雑な処理になると一気に遅くなってしまい、せっかくの性能をうまく活かし切ることができなくなります。
ということで改善案を考えてみます。プーリング層の高速化
高速化にあたり、値埋めのうまい方法はないかなぁと考えてみました。
まず考えたのは、こういう複雑な処理はCPUの方が向いているのでGPUではなくCPUで処理することです。しかしながら、全体をCPUで処理したときのボトルネックもやはり同じ部分にあることが実験でわかったので、この案はボツとなりました。続いて考えたのは、この部分の処理を別の形に書き換えることです。つまり「この代入処理をGPUが得意な計算処理で代替しよう」と考えました。
ということはインデックスを保持するのではなく、入力(をim2col関数に投げたもの)と同じ形状をした疎行列を保持すればいいわけですね。最大値に対応する場所だけ1、それ以外は0です。
必要なメモリ量は通常の$pool^2$倍になりますが、$pool$は大抵小さいのでいいでしょう。pool.pyimport numpy as np import cupy as cp class PoolingLayer(BaseLayer): def __init__(self, *, mode="cpu", I_shape=None, pool=1, pad=0, name="", **kwds): self.mode = mode self.name = name if I_shape is None: raise KeyError("Input shape is None.") if len(I_shape) == 2: C, I_h, I_w = 1, *I_shape else: C, I_h, I_w = I_shape self.I_shape = (C, I_h, I_w) # im2col関数とcol2im関数を保持 if self.mode == "cpu": self.im2col = cpu_im2col self.col2im = cpu_col2im elif self.mode == "gpu": self.im2col = gpu_im2col self.col2im = gpu_col2im if self.mode == "cpu": _, O_shape, self.pad_state = self.im2col( np.zeros((1, *self.I_shape)), (pool, pool), stride=pool, pad=pad) elif self.mode == "gpu": _, O_shape, self.pad_state = self.im2col( cp.zeros((1, *self.I_shape)), (pool, pool), stride=pool, pad=pad) self.O_shape = (C, *O_shape) self.n = np.prod(self.O_shape) self.pool = pool self.F_shape = (pool, pool) def forward(self, x): B = x.shape[0] C, O_h, O_w = self.O_shape self.x, _, self.pad_state = self.im2col(x, self.F_shape, stride=self.pool, pad=self.pad_state) self.x = self.x.T.reshape(B*O_h*O_w*C, -1) if self.mode == "cpu": #self.max_index = np.argmax(self.x, axis=1) self.y = np.max(self.x, axis=1, keepdims=True) self.max_index = np.where(self.y == self.x, 1, 0) self.y = self.y.reshape(B, O_h, O_w, C).transpose(0, 3, 1, 2) elif self.mode == "gpu": #self.max_index = cp.argmax(self.x, axis=1) self.y = cp.max(self.x, axis=1, keepdims=True) self.max_index = cp.where(self.y == self.x, 1, 0) self.y = self.y.reshape(B, O_h, O_w, C).transpose(0, 3, 1, 2) return self.y def backward(self, grad): B = grad.shape[0] I_shape = B, *self.I_shape C, O_h, O_w = self.O_shape grad = grad.transpose(0, 2, 3, 1).reshape(-1, 1) if self.mode == "cpu": self.grad_x = np.zeros((grad.size, self.pool*self.pool)) elif self.mode == "gpu": self.grad_x = cp.zeros((grad.size, self.pool*self.pool)) #self.grad_x[:, self.max_index] = grad self.grad_x = self.max_index*grad self.grad_x = self.grad_x.reshape(B*O_h*O_w, C*self.pool*self.pool).T self.grad_x = self.col2im(self.grad_x, I_shape, self.O_shape, stride=self.pool, pad=self.pad_state) return self.grad_x def update(self, **kwds): passでは実験してみましょう。
search_bottleneck.py# プーリング層の逆伝播 %%timeit err1 = lm[1].backward(err2) #----------output---------- # 1000 loops, best of 3: 280 µs per loop #-------------------------- # 値埋め %%timeit grad_x1 = lm[1].max_index*grad #----------output---------- # 100000 loops, best of 3: 16.3 µs per loop #--------------------------ちなみに上記の結果は以前の実験結果とは異なるGPUにアサインされているものだと考えられますので、一概にその結果を比べていいかは微妙ですが、とりあえず高速化することには成功していることは間違い無いでしょう。こうなると今度は
col2im関数などが問題になってきますので、そのあたりにまだまだ高速化の余地がありますね。また、全体としても
progress:[XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX]287s/285s training dataset correct: [5 0 4 1 9 2 1 3 1 4 3 5 3 6 1 7] predict: [5 0 4 1 9 2 1 3 1 4 3 5 3 6 1 7] accuracy rate: 99.21333333333334 % (59528/60000) test dataset correct: [7 2 1 0 4 1 4 9 5 9 0 6 9 0 1 5] predict: [7 2 1 0 4 1 4 9 5 9 0 6 9 0 1 5] accuracy rate: 98.03 % (9803/10000)このように、1エポックあたり50s程度に短縮することができました!
また、1ミニバッチあたりの学習時間が6msくらいなので、1エポックあたりの学習時間は$6\times 7500 \times 10^{-3} = 45s$となっています。おり、先のミスマッチも解消されています...結局何だったんでしょう。同じGPUへのアサイン中に実験したはずなんですが...まあいいでしょう。おわりに
こんな感じでボトルネック部分を探して改善、高速化していきます。今後も随時改良していきます。
深層学習シリーズ
- 深層学習入門 ~基礎編~
- 深層学習入門 ~コーディング準備編~
- 深層学習入門 ~順伝播編~
- 深層学習入門 ~逆伝播編~
- 深層学習入門 ~学習則編~
- 深層学習入門 ~ローカライズと損失関数編~
- 深層学習入門 ~関数近似編~
- 深層学習入門 ~畳み込みとプーリング編~
- 深層学習入門 ~CNN実験編~
- 深層学習外伝 ~GPUプログラミング編~
- 活性化関数一覧 (2020)
- 勾配降下法一覧 (2020)
- 見てわかる!最適化手法の比較 (2020)
- im2col徹底理解
- col2im徹底理解
- numpy.pad関数完全理解
厳密には「半導体の集積率が18ヶ月(24ヶ月)で倍になる」です。 ↩

- 投稿日:2020-09-29T21:23:19+09:00
【個人メモ】DynamoDBスクリプトメモ(Python)
本記事について
AWS の Dynamo DB を、Python を用いて操作するコードを書きました。
その際の基本的なスクリプトと、 Dynamo DB 特有の考え方について、備忘としてまとめておきます。
全てを網羅してはいませんが、最低限のことプラスアルファ は記載したつもりです。
見知らぬどなたかのお役に立てれば嬉しいです。Dynamo DB について
- AWS が提供する No SQL のデータベース。
- Amazon DynamoDB(マネージド NoSQL データベース)| AWS
- Key-Value の形式で高速。
- JSON も Value として保存できるが、オブジェクト型のDBではない。
- 結果整合性のため、更新直後の読み込み時には更新内容が間に合っていないこともある(注意!)
Python の環境構築
- 例によって、AWS の Python 向け SDK である Boto3を利用する。
- ローカルマシンで開発をする場合は、事前に AWS のアクセスキーを取得し、AWS CLI に認証情報を設定しておく必要がある。
- Cloud9 を利用する場合も同じく認証情報の設定が必要。注意として、preference 内にある temporary の認証情報トグルをオフにしておかないと、後々厄介なことになる。(機会があったら記事を書きます。)
Dynamo DB の操作には、どのクラスを用いればいいのか?
DynamoDB — Boto3 Docs documentation
最初に...
- Boto3 には、 Dynamo DB の操作用に、主に Resource class と Client class の2つがあり、どちらのクラスを使っても、テーブルへのアイテムの追加や検索は可能。
- 私も詳しくなく多くを語れないが、以下のサイトを参考にさせてもらうと、「Client class の方が抽象度が低い」とのこと。
- AWS Chalice で必要な IAM ポリシーが正しく作成されなかったときの話
- 一点だけ補足すると、上記サイトには Client class でコードを書けば、 Chalice (※Python向けAWSサーバレスフレームワーク)は 必要な IAM ポリシー を自動生成できると書いてあるが、筆者の環境では Client class でも自動生成されなかった。(※ Chalice を利用した際に限った話です。)
Resource class でのインスタンスの作り方
Resource class の方が 実装しやすい印象。
import boto3 dynamodb = boto3.resource('dynamodb') table = dynamodb.Table('name')Client class でのインスタンスの作り方
Client class は 各サービスの API をほぼ網羅していて、「基本的」な印象
import boto3 client = boto3.client('dynamodb') # テーブル名は、テーブル操作の際に指定する。スクリプトメモ
- 個人検証時のメモなので、みなさんの参考にどこまでなるか...
テーブルの定義・内容
- 駅の情報(都道府県や座標情報)が入っている。
- プライマリーキーとして、prefectureをパーティションキー、idをソートキーに設定。
プライマリーキー(注:パーティションキーとソートキーのこと)も、アトリビュートも、全て文字型。
《注意!》 本記事では、パーティションキーに日本語文字列を使用していますが、あくまで説明上の都合です。
- 英数字文字列や数字列を使うのが一般的かと思います。
共通部分のコード(Resource class を使用)
import boto3 from boto3.dynamodb.conditions import Key, Attr dynamodb = boto3.resource('dynamodb') table = dynamodb.Table('table_name')put_item
- 追加したいアイテムを Item に辞書型で記述する。
- プライマリーキーの内容は必須。アトリビュートは任意
- すなわち、プライマリーキーとしてパーティションキーとソートキーの両方を設定している場合は、パーティションキーとソートキーの両方を Item に記述する必要がある。片方しか記述していない場合にはエラーが発生する。
- Key - Value 型 DB のため、アトリビュートを他のアイテムと揃える必要はない。
- 下記例の場合、座標情報などを Item に記述していないが問題はない。nullで登録される訳でもない。
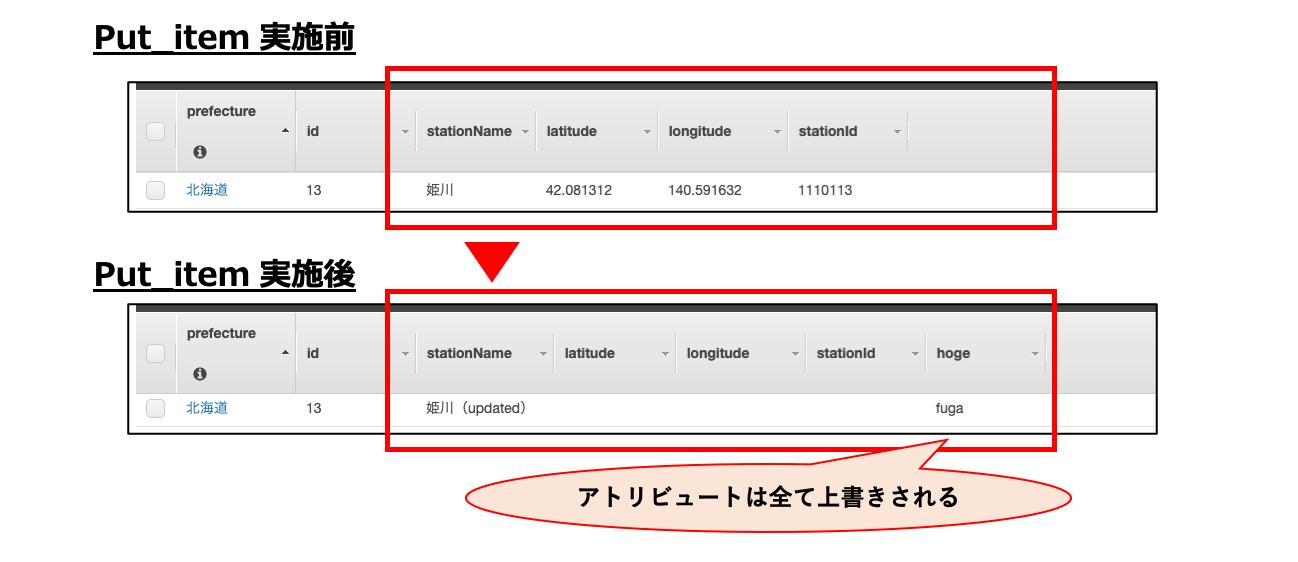
response = table.put_item( Item = { 'prefecture':'岩手', 'id':'5', 'stationName':'盛岡' } ) print(response) # {'ResponseMetadata': {'RequestId': 'ABCDEFGHIJKLMNOPQRSTUVWXYZ0123456789ABCDEFGHIJKLMNO', 'HTTPStatusCode': 200, 'HTTPHeaders': {'server': 'Server', 'date': 'Mon, 28 Sep 2020 14:24:47 GMT', 'content-type': 'application/x-amz-json-1.0', 'content-length': '2', 'connection': 'keep-alive', 'x-amzn-requestid': 'ABCDEFGHIJKLMNOPQRSTUVWXYZ0123456789ABCDEFGHIJKLMNO', 'x-amz-crc32': '2745614147'}, 'RetryAttempts': 0}}put_item での Item 更新
- 同一のプライマリーキーの Item がテーブル上に既存の場合は、Item が更新される。
- その際、アトリビュートは全て上書きされる。
response = table.put_item( Item = { 'prefecture':'北海道', 'id':'13', 'stationName':'姫川(updated)', 'hoge': 'fuga' } ) print(response) # {'ResponseMetadata': {'RequestId': 'ABCDEFGHIJKLMNOPQRSTUVWXYZ0123456789ABCDEFGHIJKLMNO', 'HTTPStatusCode': 200, 'HTTPHeaders': {'server': 'Server', 'date': 'Mon, 28 Sep 2020 15:02:47 GMT', 'content-type': 'application/x-amz-json-1.0', 'content-length': '2', 'connection': 'keep-alive', 'x-amzn-requestid': 'ABCDEFGHIJKLMNOPQRSTUVWXYZ0123456789ABCDEFGHIJKLMNO', 'x-amz-crc32': '2745614147'}, 'RetryAttempts': 0}}
get_item
- プライマリーキーとして、パーティションキーのみを設定している場合は、パーティションキーを Key に設定する。
- プライマリーキーとして、パーティションキーとソートキーの両方を設定している場合は、パーティションキーとソートキーの両方を Key に設定する。(サンプルコードはこのパターン)
- この場合、パーティションキーのみでの検索はできない。
- パーティションキーのみでの検索を行いたい場合は、後述のqueryメソッドを利用する
response = table.get_item( Key={ 'prefecture':'北海道', 'id':'1' } ) print(response['Item']) # {'stationName': '函館', 'prefecture': '北海道', 'id': '1', 'latitude': '41.773709', 'stationId': '1110101', 'longitude': '140.726413'}query
使い方 例①
ライマリーキーとして、パーティションキーとソートキーの両方を設定している場合でも、queryメソッドであればパーティションキーのみでの検索が可能
response = table.query( KeyConditionExpression = Key('prefecture').eq('北海道') ) print(response['Items']) # [{'stationName': '函館', 'prefecture': '北海道', 'id': '1', 'latitude': '41.773709', 'stationId': '1110101', 'longitude': '140.726413'}, {'stationName': '赤井川', 'prefecture': '北海道', 'id': '10', 'latitude': '42.003267', 'stationId': '1110110', 'longitude': '140.642678'}, {'stationName': '駒ケ岳', 'prefecture': '北海道', 'id': '11', 'latitude': '42.038809', 'stationId': '1110111', 'longitude': '140.610476'}, {'stationName': '東山', 'prefecture': '北海道', 'id': '12', 'latitude': '42.06172', 'stationId': '1110112', 'longitude': '140.605222'}]使い方 例②
- KeyConditionExpression パラメーターにパーティションキーとソートキーの検索条件を記載できる
- KeyConditionExpression の書き方は、こちらのドキュメント↓
- DynamoDB customization reference — Boto3 Docs documentation
- ScanIndexForward パラメーターはデフォルトで True 。 True の時は昇順でのレスポンスとなる。 False にすると降順になる。
- Limit パラメーターと併用することで、例えば最新の1件のみ取得。等が可能 (ソートキーに時刻を設定している場合)
response = table.query( KeyConditionExpression = Key('prefecture').eq('北海道')&Key('id').begins_with('1'), ScanIndexForward = False, Limit = 2, ) print(response['Items']) # [{'stationName': '銚子口', 'prefecture': '北海道', 'id': '16', 'latitude': '42.015471', 'stationId': '1110116', 'longitude': '140.720656'}, {'stationName': '流山温泉', 'prefecture': '北海道', 'id': '15', 'latitude': '42.003483', 'stationId': '1110115', 'longitude': '140.716358'}]GSI(グローバルセカンダリインデックス)がある場合
- GSI(グローバルセカンダリインデックス)とは、テーブルのパーティションキー・ソートキーとは別に、新しくパーティションキー・ソートキーを設定できるというもの。
- LSI(ローカルセカンダリインデックス)というものもあるが、 LSI はパーティションキーはそのまま、ソートキーのみ新しく設定するというもの。
- こちらのページがわかりやすい。
- GSIの作り方はこちら↓
query
- GSIで設定したパーティションキーに対して、上述のget_itemメソッドは使えない。
- 使えるのはqueryメソッドのみ。
- 使い方は基本的に同じだが、IndexName パラメーターに GSI のインデックス名を指定する必要がある。
response = table.query( IndexName = 'stationName-stationId-index', KeyConditionExpression = Key('stationName').eq('流山温泉'), ) print(response['Items']) # [{'stationName': '流山温泉', 'prefecture': '北海道', 'id': '15', 'latitude': '42.003483', 'longitude': '140.716358', 'stationId': '1110115'}]キー以外でフィルターをかけたい場合
- FilterExpression パラメーターを用いる
response = table.query( KeyConditionExpression = Key('prefecture').eq('北海道'), FilterExpression = Attr('stationId').begins_with('1110114'), ScanIndexForward = False ) print(response['Items']) # [{'stationName': '池田園', 'prefecture': '北海道', 'id': '14', 'latitude': '41.990692', 'stationId': '1110114', 'longitude': '140.700333'}]補足・おすすめサイト
- DynamoDB を使用した設計とアーキテクチャの設計に関するベストプラクティス - Amazon DynamoDB
- Dynamo DB のベストプラクティスはここを見ろ! と AWS の SA さんから教えていただきました。
- パーティションキーを設計してワークロードを均等に分散する - Amazon DynamoDB
- パーティションキーの設計ガイド。 こちらも AWS のSA さんから教えていただきました。
- DynamoDB Advanced Workshop & Labs
- Dynamo DB のハンズオン。資料を読むよりも手を動かして学習したい方向け。全て英語。
- 【初心者向け】DynamoDBを理解する〜Pythonを用いた取得パターン特化編〜 - Qiita
- こちらのページも綺麗にまとまっていて初心者には便利。(もっと早く見つけたかったなぁ...)

- 投稿日:2020-09-29T21:12:57+09:00
pandasでネストされたjsonを読み込む
pandasでネストされたjsonを読み込む
read nested json with pandas環境
Google Corab
事象
pandasで、
import pandas as pd pd.read_json('file.json')をしたときに、
index title content 1 aaa {"col1": "a", "col2": "aa"... 2 bbb {"col1": "b", "col2": "bb"... のようになるjsonファイルがあったとします。(contentに更にjson形式の文字列が入れ子になって格納された形です。)
これを、
index title col1 col2 1 aaa a aa 2 bbb b bb と読み込みたかったんですね。
normalizeとかflattenとかで少し検索したら
pd.json_normalize('file.json')がそれっぽかったので使ってみたところ、AttributeError: 'str' object has no attribute 'values'と怒られてしまいました。解決方法
試行錯誤の末、
import pandas as pd df = pd.read_json('file.json') df = pd.DataFrame(df.content.to_list())で正しく読み込めたので記事にしておきます。
- 投稿日:2020-09-29T20:56:40+09:00
Pytorch Lightning 使い方入門 ~ 自作モデルを整形して tensorboard に出力するまで ~
この記事でやること
「我流 DNN モデル作ったけどコード汚い」「事務作業(保存、ログ、DNN共通のコード)だるい」人向け
- AI 開発爆速ライブラリ Pytorch Lightning で
- きれいなコード管理&学習& tensorboard の可視化まで全部やる
Pytorch Lightning とは?
- 深層学習モデルのお決まり作業自動化 (モデルの保存、損失関数のログetc)!
- 可読性高い&コード共有も楽々に!
してくれるpythonライブラリ。
他を抑えてトップの github star 数&流行中のディープラーニングフレームワークである。使い方
1. まずはinstall
console$ pip install pytorch-lightning
2. 深層学習モデルを pytorch_lightning に従って書いていく
pytorch_lightning.LightningModuleを継承して、
- ネットワーク
- forward(self, x)、training_step(self, batch, batch_idx)、configure_optimizers(self)の3メソッド
の二つを定義すれば早速使える。ただし、関数名と引数の組は変えられないので注意!
(e.g. batch_idx いらなくてもtraining_step(self, batch)みたいに定義するとバグったりする)MyModel.pyimport torch from torch.nn import functional as F from torch import nn from pytorch_lightning.core.lightning import LightningModule class LitMyModel(LightningModule): def __init__(self): super().__init__() # mnist images are (1, 28, 28) (channels, width, height) self.layer_1 = torch.nn.Linear(28 * 28, 128) self.layer_2 = torch.nn.Linear(128, 10) def forward(self, x): batch_size, channels, width, height = x.size() # (b, 1, 28, 28) -> (b, 1*28*28) x = x.view(batch_size, -1) x = self.layer_1(x) x = F.relu(x) x = self.layer_2(x) x = F.log_softmax(x, dim=1) return x def training_step(self, batch, batch_idx): x, y = batch logits = self(x) loss = F.nll_loss(logits, y) return loss三つの関数はそれぞれ
「return ネットワークの出力」「1 loop 中の作業 & return 損失関数」「return オプティマイザ」
であればどんな処理でもOK
長いけど見たい人向けにVAEの例 (Click)
# MNIST を学習するFCの例 import pytorch_lightning as pl class LitMyModel(pl.LightningModule): def __init__(self): # layers self.fc1 = nn.Linear(self.out_size, 400) self.fc4 = nn.Linear(400, self.out_size) def forward(self, x): mu, logvar = self.encode(x.view(-1, self.out_size)) z = self.reparameterize(mu, logvar) return self.decode(z), mu, logvar def training_step(self, batch, batch_idx): recon_batch, mu, logvar = self.forward(batch) loss = self.loss_function( recon_batch, batch, mu, logvar, out_size=self.out_size) return loss def configure_optimizers(self): optimizer = optim.Adam(model.parameters(), lr=1e-3) return optimizerもちろん、既にモデルがある人はコードを移動するだけでOK
あとはデータローダーとモデルをpl.Trainer()のfit()に入れればもう学習スタート!!実行時dataloader = #Your own dataloader or datamodule model = LitMyModel() trainer = pl.Trainer() trainer.fit(model, dataloader)lightning 簡単、シュゴい。
3. 他の作業もこのクラスのメソッドに追加していく
上までで学習はできるようになったので、今度は** test ・validation・その他オプション**のメソッドをクラスに追加していく。
test
クラスメソッドに
test_step(self, batch, batch_idx)を追加する。だけ。実行はtest実行時trainer.test()validation
これも
val_step()メソッド、val_dataloader()メソッドを追加すれば完成〜dataloader
これもクラスメソッドにまとめて良いが、データセット&データローダーは別クラスの
pytorch_lightning.LightningDataModuleを継承してMyDataModuleclassを定義するのが推奨。
長いけど見たい人向けにMNISTの例 (Click)
class MyDataModule(LightningDataModule):
def init(self):
super().init()
self.train_dims = None
self.vocab_size = 0def prepare_data(self): # called only on 1 GPU download_dataset() tokenize() build_vocab() def setup(self): # called on every GPU vocab = load_vocab() self.vocab_size = len(vocab) self.train, self.val, self.test = load_datasets() self.train_dims = self.train.next_batch.size() def train_dataloader(self): transforms = ... return DataLoader(self.train, batch_size=64) def val_dataloader(self): transforms = ... return DataLoader(self.val, batch_size=64) def test_dataloader(self): transforms = ... return DataLoader(self.test, batch_size=64)
これを学習&テスト時に.fit()に噛ませればdata_loaderを渡さなくても勝手に解釈してくれる。実行時datamodule = MyDataModule() model = LitMyModel() trainer = pl.Trainer() trainer.fit(model, datamodule)callback
「trainの初めだけやる処理」「エポック終わりにやる処理」のようなものも
https://pytorch-lightning.readthedocs.io/en/latest/introduction_guide.html#callbacks
あたりにいっぱい情報が載ってる。処理したいタイミング用の関数を定義してあげればOKfrom pytorch_lightning.callbacks import Callback class MyPrintingCallback(Callback): def on_init_start(self, trainer): print('Starting to init trainer!') def on_init_end(self, trainer): print('Trainer is init now') def on_train_end(self, trainer, pl_module): print('do something when training ends') trainer = Trainer(callbacks=[MyPrintingCallback()])みたく別クラスに定義すれば簡潔に書けますね〜
4. tensorboard と連携させる&記録設定の追加
さて、ここからメインの記録の保存関係です。tensorboardに数値(lossやaccuracyなど)、画像、音声などを表示するためには、
tensorflowの例with tf.name_scope('summary'): tf.summary.scalar('loss', loss) merged = tf.summary.merge_all() writer = tf.summary.FileWriter('./logs', sess.graph)見たいなコードを途中でぶっ刺したりして汚コードを作りがちでしたが、 pytorch_lightning は簡潔に書けて、
MyModel.pydef training_step(self, batch, batch_idx): # ... loss = ... self.logger.summary.scalar('loss', loss, step=self.global_step) # equivalent result = TrainResult() result.log('loss', loss) return resultのように記録する際のメソッド内で
logger.summaryに追加、もしくはreturn lossの部分をpytorch_lightning.LightningModule.TrainResult()クラスにいったん噛ませるだけで、自動的に保存ディレクトリ先に保存してくれます!loggerは
Trainer()クラスのコンストラクタに追加すればOKで、保存ディレクトリもここで決定します。from pytorch_lightning import loggers as pl_loggers tb_logger = pl_loggers.TensorBoardLogger('logs/') trainer = Trainer(logger=tb_logger)また、テキストや画像などのデータに関しても
logger.experimentオブジェクトの.add_hogehoge()を使って保存することができます!MyModel.pydef training_step(...): ... # the logger you used (in this case tensorboard) tensorboard = self.logger.experiment tensorboard.add_histogram(...) tensorboard.add_figure(...)Callbackのタイミングなんかもおすすめだよ、って公式も言ってますね。
シュゴい...(大事なことなので2回言いまs(ry
終わりに
使ってみた所感として Pytorch Lightning は
(ignite が処理を差し込みまくって可読性悪いのとかに比べると)ルールが分かりやすいし、クラス設計もドキュメント整備もちゃんとしていたので、最初に使ってみるのにおすすめなディープラーニングフレームワークであるなと感じました〜
- 投稿日:2020-09-29T19:43:40+09:00
Pythonによる画像処理100本ノック#11 平滑化フィルタ(平均フィルタ)
はじめに
どうも、らむです。
今回は画像中のノイズを除去するメディアンフィルタを実装します。11本目:平滑化フィルタ(平均フィルタ)
平滑化フィルタとは画像の平滑化を行うフィルタです。このフィルタを適用することによって画像全体をぼやかしたような加工ができます。
このフィルタでは注目画素を周辺画素の平均値で置き換えます。
例えば、3×3や5×5の平均フィルタは以下のようになります。
$\frac{1}{9}$ $\frac{1}{9}$ $\frac{1}{9}$ $\frac{1}{9}$ $\frac{1}{9}$ $\frac{1}{9}$ $\frac{1}{9}$ $\frac{1}{9}$ $\frac{1}{9}$
$\frac{1}{25}$ $\frac{1}{25}$ $\frac{1}{25}$ $\frac{1}{25}$ $\frac{1}{25}$ $\frac{1}{25}$ $\frac{1}{25}$ $\frac{1}{25}$ $\frac{1}{25}$ $\frac{1}{25}$ $\frac{1}{25}$ $\frac{1}{25}$ $\frac{1}{25}$ $\frac{1}{25}$ $\frac{1}{25}$ $\frac{1}{25}$ $\frac{1}{25}$ $\frac{1}{25}$ $\frac{1}{25}$ $\frac{1}{25}$ $\frac{1}{25}$ $\frac{1}{25}$ $\frac{1}{25}$ $\frac{1}{25}$ $\frac{1}{25}$ 注目画素が中心だとすると、周辺画素と対応するフィルタ値の積の総和を注目画素に代入すれば良いですね。
3×3フィルタであれば$I(x_0,y_0)×\frac{1}{9} + I(x_0,y_1)×\frac{1}{9} + ... I(x_2,y_2)×\frac{1}{9}$の値を注目画素に代入します。これで、周辺画素の平均値が注目画素に代入されていますね。また、前回同様、画像の端部分はフィルタリング処理が行えないので存在しない画素は0を用いる0パディング処理を行います。
ソースコード
meanFilter.pyimport numpy as np import cv2 import matplotlib.pyplot as plt def meanFilter(img,k): w,h,c = img.shape size = k // 2 # 0パディング処理 _img = np.zeros((w+2*size,h+2*size,c), dtype=np.uint8) _img[size:size+w,size:size+h] = img.copy().astype(np.uint8) dst = _img.copy() # フィルタ作成 ker = np.zeros((k,k), dtype=np.float) for x in range(-1*size,k-size): for y in range(-1*size,k-size): ker[x+size,y+size] = (1/k**2) # フィルタリング処理 for x in range(w): for y in range(h): for z in range(c): dst[x+size,y+size,z] = np.sum(ker*_img[x:x+k,y:y+k,z]) dst = dst[size:size+w,size:size+h].astype(np.uint8) return dst # 画像読込 img = cv2.imread('image.jpg') # 平均フィルタ img = meanFilter(img,9) # 画像保存 cv2.imwrite('result.jpg', img) # 画像表示 plt.imshow(cv2.cvtColor(img, cv2.COLOR_BGR2RGB)) plt.show()
画像左は入力画像、画像右は出力画像です。
ぼやけた感じの出力画像になっており、平滑化が行えていることが分かります。おわりに
もし、質問がある方がいらっしゃれば気軽にどうぞ。
imori_imoriさんのGithubに公式の解答が載っているので是非そちらも確認してみてください。
それから、pythonは初心者なので間違っているところがあっても優しく指摘してあげてください。

- 投稿日:2020-09-29T19:28:04+09:00
AWS Lambdaでselenium×chromeを動かす時の AWS Lambda Layers のつくり方
この記事では
AWS Lambdaから、selenium×chromeでブラウザ操作したい時に、
Layer の作り方でハマったので投稿します。やりたいこと
AWS Lambdaでselenium×chromeを動かしたい。
環境
windows 10 Pro
python 3.7
chromdriver 2.37
headless-chromium 64.0.3282.167記載しないこと
-AWS lambda の関数作成、呼出方法
-selenium webdriverによるブラウザ操作ができるpythonプログラムの作り方。つまづいたところ
1.AWS Lambda Layersを作る単位
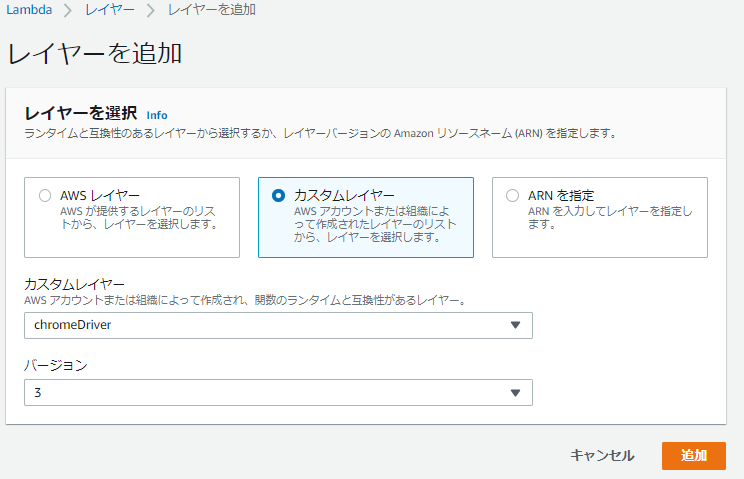
2.AWS Lambda Layersへの搭載方法と呼び出し方1.AWS Lambda Layersを作る単位
まず、AWS Lambda Layers とはlamda から共通的に使える共通関数のようなものです。
下記のようにLambda本体から参照される形で呼び出すことができます。
機能の1部を切り出すことで、lambda本体の軽くすることができます。
軽くすることで、例えば下記のような、モジュール一式の容量が大きすぎるためにコードが表示できないデメリットを回避することができます。
今回は、python からselenium でchromeDriverで実装したかったので、
以下2点のLayer を作ります。1.seleniumのライブラリを格納するLayer
2.chromeDriverを格納するLayer↓Layer の構成
以下に作り方を記載します。
1.seleniumのライブラリを格納するLayer
1.搭載するライブラリ一式の準備
任意のフォルダで下記コマンドを実行します。
既にpip install selenium をしていると思いますが、
搭載するライブラリを準備する作業なので、実行モジュールとは別の場所で行います。seleniumモジュールの準備pip install -t ./python/lib/python3.7/site-packages selenium2.以下の構成ができあがります。(windows環境で実施しています。)
3.zip 圧縮
python フォルダからzip圧縮します。
4.AWS Lambda Layers の作成
lambdaのコンソール画面から、Layers を新規作成します。
作成時に、3のzipファイルを指定して作成します。
5.Lambda関数へのLayer追加
Lambda関数から4で作ったLayers を参照設定します。
Layer の設定画面からカスタムレイヤーを選択すると、選択肢に表示されるようになります。
6.import で呼び出し
lambdaからimport で呼び出します。
import文from selenium import webdriverもし、上記構成を間違った場合、下記エラーとなります。
error文[ERROR] Runtime.ImportModuleError: Unable to import module 'lambda_function': No module named 'selenium'2.chromeDriverを格納するLayer
1.driverの準備
公式配布されているdriver (2点)を準備します。
chromdriver 配布元:https://chromedriver.storage.googleapis.com/index.html?path=2.37/
headless-chromium 配布元:https://github.com/adieuadieu/serverless-chrome/releases/download/v1.0.0-37/stable-headless-chromium-amazonlinux-2017-03.zip2.zip 圧縮
上記2点を同じフォルダに配置し、linux環境でzip 圧縮します。
もし、windows環境でzip圧縮した場合、lamdaを実行しても下記のエラーとなります。
error文[ERROR] WebDriverException: Message: 'chromedriver' executable may have wrong permissions. Please see https://sites.google.com/a/chromium.org/chromedriver/home3.Lambda関数へのLayer追加
Lambda関数から4で作ったLayers を参照設定します。
※先ほどと同じ手順となります。4.lambdaから呼出
lambdaから 以下パスを指定して呼びます。
AWS Lambda layersの仕様で、/opt に配置されるため、下記のように指定します。import文driver = webdriver.Chrome(executable_path ="/opt/chromedriver", chrome_options=options)もし、optが無いなどパスを誤った場合、エラーとなります。
error文[ERROR] WebDriverException: Message: 'chromedriver' executable needs to be in PATH. Please see https://sites.google.com/a/chromium.org/chromedriver/homeもう一つ注意点
lamda もseleniumも処理が遅いので、lamdaのtimeout値を長めに設定してやります。
デフォルトは、3秒ですので、ほぼtimeoutし、下記のエラーとなります。error文Task timed out after XX.XX secondstimeout値の設定
実装
lamdaのコードは、最終的に下記となります。
lamda_function.pyfrom selenium import webdriver from selenium.webdriver.chrome.options import Options def lambda_handler(event, context): LINE_NOTIFY_URL = "https://notify-api.line.me/api/notify" options = Options() options.binary_location = '/opt/headless-chromium' options.add_argument('--headless') options.add_argument('--no-sandbox') options.add_argument('--single-process') options.add_argument('--disable-dev-shm-usage') driver = webdriver.Chrome(executable_path ='/opt/chromedriver', chrome_options=options) driver.get("https://xxxxxxxxxxx")まとめ
他の記事を見ていると、serverless.ymlやcloudFormationを使ったものが多かったのですが、
私はそのあたりの知識が弱かったため、上記方法をとりました。
初めてサーバレスでseleniumを組み込む方の参考になれば幸いです。







- 投稿日:2020-09-29T18:50:17+09:00
Pythonで度数分布表を一発で自動生成する
はじめに
数学・統計の分野で階級、階級値、度数、累積度数、相対度数、累積相対度数がセットの表を見ることがあると思います。どういうものかというと、こういうものです。
階級 階級値 度数 累積度数 相対度数 累積相対度数 0以上3未満 1.5 1 1 0.07143 0.0714 3以上6未満 4.5 6 7 0.42857 0.5000 6以上9未満 7.5 2 9 0.14286 0.6429 9以上12未満 10.5 2 11 0.14286 0.7857 12以上15未満 13.5 3 14 0.21429 1.0000 合計 - 14 - 1.00000 - これをPythonで一発で出してくれる関数が意外と見つからないなということで作ってみました。
既存の便利関数
全部まとまった表を作成する関数はありませんが、以下の便利な関数で部分的に必要な情報を取り出せたりはします。それに加えて多少の計算を行うことで必要な値は全て揃います。
# numpyのcumsum()で累積度数を取得する data.cumsum() # pandasのvalue_counts()で各値の出現頻度を数える pd.Series(data).value_counts()自動化のための工夫
階級の数と階級の幅の決定
階級の数や階級の幅を決めるのに明確なルールはありません。しかし目安を知るためのスタージェスの公式というものがあるのでそれを使います。
スタージェスの公式
度数分布表やヒストグラムを作成するときに階級の数を決定する目安を得られる公式。Nをサンプルサイズ、kを階級数とすると、次のように計算することができる。階級の幅は、データの最小値から最大値をkで割り求める。k=log_2N+1# スタージェスの公式から階級の数を求める class_size = 1 + np.log2(len(data)) class_size = int(round(class_size)) # 階級幅を求める class_width = (max(data) - min(data)) / class_size # 分母は階級の数、分子は範囲。 class_width = round(class_width)ただ、やはり明確なルールはなく、階級の幅を5など任意のキリがいい値にしたいこともあると思うのでそれにも対応できるようにします。
スタージェスの公式で出た値を使いたい場合は関数の第二引数にNoneを指定します。
任意の値を使いたい場合は第二引数にその任意の値を指定します。階級の数はそれに合わせて変更させます。def Frequency_Distribution(data, class_width): if class_width == None: # 階級幅を求める class_width = (max(data) - min(data)) / class_size #分母は階級の数、分子は範囲。 class_width = round(class_width) # 四捨五入 else: class_width = class_width class_size = max(x) // class_width階級のインデックスを動的に変更
階級は「〜以上・・・未満」というやつです。度数分布表を作成するにあたり、インデックスとして階級を設定して表に記述しておきたいわけですが、入力したデータに合わせて手動で打ち込んでいては大変です。
そこで、階級の幅と階級の数、フォーマット演算子を用いてリスト型内包表記でfor文を回すことにより、インデックスのラベルが生成できます。class_width = 5 # 階級の幅 class_size = 10 # 階級の数 ['%s以上%s未満'%(w, w+class_width) for w in range(0, class_size*class_width*2, class_width)] # ['0以上5未満','5以上10未満','10以上15未満','15以上20未満','20以上25未満','25以上30未満']表の作成
あとはpandasの操作で行や列の追加とカラム名やインデックス名の更新などの修正を加えるだけです。
コード全体
import pandas as pd import numpy as np # 度数分布表を作る def Frequency_Distribution(data, class_width): # スタージェスの公式から階級の数を求める class_size = 1 + np.log2(len(data)) class_size = int(round(class_size)) if class_width == None: # 階級幅を求める class_width = (max(data) - min(data)) / class_size # 分母は階級の数、分子は範囲。 class_width = round(class_width) # 四捨五入 else: class_width = class_width class_size = max(x) // class_width # print('階級の数:', class_size) # print('階級幅:', class_width) # 階級に振り分ける # 各観測値を階級値にする cut_data = [] for row in data: cut = row // class_width cut_data.append(cut) #頻度を数える Frequency_data = pd.Series(cut_data).value_counts() Frequency_data = pd.DataFrame(Frequency_data) #インデックスでソートし、任意の位置に行を挿入したいので一旦転置 F_data = Frequency_data.sort_index().T # 度数0の階級があればデータフレームに挿入する for i in range(0, max(F_data.columns)): if (i in F_data) == False: F_data.insert(i, i, 0) F_data = F_data.T.sort_index() #インデックスとカラムの名前を変える F_data.index = ['%s以上%s未満'%(w, w + class_width) for w in range(0, class_size * class_width * 2, class_width)][:len(F_data)] F_data.columns = ['度数'] F_data.insert(0, '階級値', [((w + (w + class_width)) / 2) for w in range(0, class_size * class_width * 2, class_width)][:len(F_data)]) F_data['累積度数'] = F_data['度数'].cumsum() F_data['相対度数'] = F_data['度数'] / sum(F_data['度数']) F_data['累積相対度数'] = F_data['累積度数'] / max(F_data['累積度数']) F_data.loc['合計'] = [None, sum(F_data['度数']), None, sum(F_data['相対度数']), None] return F_data # サンプルデータ x = [0, 3, 3, 5, 5, 5, 5, 7, 7, 10, 11, 14, 14, 14] Frequency_Distribution(x, None)結果
階級 階級値 度数 累積度数 相対度数 累積相対度数 0以上3未満 1.5 1 1 0.07143 0.0714 3以上6未満 4.5 6 7 0.42857 0.5000 6以上9未満 7.5 2 9 0.14286 0.6429 9以上12未満 10.5 2 11 0.14286 0.7857 12以上15未満 13.5 3 14 0.21429 1.0000 合計 - 14 - 1.00000 - 参考
上記のコード作成にあたり、主に以下のサイトを参考にさせていただきました
いっかくのデータサイエンティストをいく
統計用語集
- 投稿日:2020-09-29T18:34:39+09:00
OpenCVで猫背を検知する
はじめに
デスクワークで作業に集中してると気づかぬうちに猫背になってしまうことありますよね。
リモートワークだと他人の目がないので尚更です。そこで姿勢が悪くなるとアラートを出す仕組みを作ってみました!
環境
Python 3.7.4
Webカメラ(Logicool HD Webcam C615)OpenCV
インストール
$ pip install opencv-python
まず、カメラ映像をキャプチャして目の検出をしていきます。
OpenCVでの物体検出の方法は以下が参考になります。
「Haar Cascadesを使った顔検出」
http://labs.eecs.tottori-u.ac.jp/sd/Member/oyamada/OpenCV/html/py_tutorials/py_objdetect/py_face_detection/py_face_detection.html#face-detection今回は目を検出したいので、分類器に「haarcascade_eye.xml」を使います。以下リンクよりダウンロードできます。
https://github.com/opencv/opencv/tree/master/data/haarcascades
capture.pyimport numpy as np import cv2 # カメラのデバイス番号 # 使用できるカメラが 0 から順番付けされている DEVICE_ID = 0 # 分類器を選択 cascade = cv2.CascadeClassifier('haarcascade_eye.xml') # カメラ映像をキャプチャ cap = cv2.VideoCapture(DEVICE_ID, cv2.CAP_DSHOW) while cap.isOpened(): # フレームの取得 ret, frame = cap.read() # グレースケールに変換 img_gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY) # 目を検出 eyes = cascade.detectMultiScale(img_gray, minSize=(30, 30)) # 検出した目を四角で囲む for (x, y, w, h) in eyes: color = (255, 0, 0) cv2.rectangle(img_gray, (x, y), (x+w, y+h), color, thickness=3) # 表示 cv2.imshow('capture', img_gray) # ESCキーでループを抜ける if cv2.waitKey(1) & 0xFF == 27: break # 終了処理 cv2.destroyAllWindows() cap.release()25行目の
yが検出された目の高さの情報です。
したがって、この値を記録してその落ち具合を見ていけばOK!移動平均
さて、目の高さが取得できましたが、この値をそのまま用いてしまってはあまり良くありません。
ほんの一瞬下を向いただけで猫背と判定されてしまってはたまったものではないので、そのために一定時間の平均値を扱うことにします。そこで登場するのが「移動平均」です。株やFXをする方は馴染みがあるかもしれません。
今回は移動平均の中でも最も簡単な「単純移動平均」を使いました。単純移動平均 (英: Simple Moving Average; SMA) は、直近の n 個のデータの重み付けのない単純な平均である。例えば、10日間の終値の単純移動平均とは、直近の10日間の終値の平均である。それら終値を${\displaystyle p_{M}}p_{{M}}, {\displaystyle p_{M-1}}p_{{M-1}}, ..., {\displaystyle p_{M-9}}p_{{M-9}}$ とすると、単純移動平均 SMA(p,10) を求める式は次のようになる:
{\text{SMA}}_{M}={p_{M}+p_{M-1}+\cdots +p_{M-9} \over 10}翌日の単純移動平均を求めるには、新たな終値を加え、一番古い終値を除けばよい。つまり、この計算では、改めて総和を求め直す必要はない。
{\text{SMA}}_{{\mathrm {today}}}={\text{SMA}}_{{\mathrm {yesterday}}}-{p_{{M-n+1}} \over n}+{p_{{M+1}} \over n}※ wikipedia引用
要は、データの各要素に対してそれの過去 n 個分を平均化すれば良いわけです。
この単純移動平均の時系列データの最初と最後の差がある閾値より大きくなれば猫背であると判定できます。
投影変換
今まで話してきた目の高さ情報
yというのはカメラ映像のピクセルの位置情報でしかありません。
なので、yの値の変化が現実世界の何cmに相当するのかというのは別途計算しないといけません。そこで投影変換というものを考えてやります。
カメラの映像というのは2次元なので、映像化する際は3次元の世界を2次元の平面に投影する必要があります。
今回は、透視投影変換として考えます。透視投影変換は3次元の座標 $(x, y, z)$ に対して $\left(\frac{x}{z}, \frac{y}{z}, 0\right)$ のように変換します。
「遠いものは小さく見える」という直観と合致するので分かりやすいかと思います。したがって、カメラ映像の高さの差 $\Delta y_d$ (px)と現実世界の高さの差 $\Delta y_v$ (cm)との関係は以下のようになります。
\begin{equation} \frac{\Delta y_d}{f} = \frac{\Delta y_v}{z_v} \tag{1} \end{equation}$z_v$ はカメラと対象物との距離、$f$ はカメラの焦点距離です。
三角形の相似を考えれば簡単です。
カメラの焦点距離はカメラの機種等によりまちまちなので、キャリブレーションによって取得する必要があります。
カメラのキャリブレーションもOpenCVによって提供されています。「カメラ・キャリブレーション」
http://whitewell.sakura.ne.jp/OpenCV/py_tutorials/py_calib3d/py_calibration/py_calibration.htmlキャリブレーションによって得たカメラの内部パラメータの中身は以下のようになっているので、ここから焦点距離が分かります。
K = \left[ \begin{array}{ccc} f & 0 & x_c \\ 0 & f & y_c \\ 0 & 0 & 1 \end{array} \right]$x_c, y_c$ は投影面の中心点です。
ただこのキャリブレーション、実際にカメラでチェスボードを撮影した画像を用意しないといけないので少々面倒。。。
私が使っているWebカメラ(Logicool HD Webcam C615)だと $f$ が大体500ぐらいでしたので参考までに。猫背の判定
$f$ が取得できてしまえばもう終わりです。
目の高さの単純移動平均の時系列データで先頭と末尾の差を $\Delta y_d$ として、(1)式で判定してやればいいだけです。
カメラからパソコンまでの距離 $z_v$ は大体 45cm ぐらい。また、現実世界の目の高さの差の閾値 $\Delta y_v$ は 3cm にしました。全体のコード
データの可視化のために pyplot でプロットしています。
また、アラートは Tkinter の messagebox を使っています。
detect_posture.pyimport numpy as np from matplotlib import pyplot as plt import cv2 import tkinter as tk from tkinter import messagebox WINDOW_NAME = "capture" # Videcapute window name CAP_FRAME_WIDTH = 640 # Videocapture width CAP_FRAME_HEIGHT = 480 # Videocapture height CAP_FRAME_FPS = 30 # Videocapture fps (depends on user camera) DEVICE_ID = 0 # Web camera id SMA_SEC = 10 # SMA seconds SMA_N = SMA_SEC * CAP_FRAME_FPS # SMA n PLOT_NUM = 20 # Plot points number PLOT_DELTA = 1/CAP_FRAME_FPS # Step of X axis Z = 45 # (cm) Distance from PC to face D = 3 # (cm) Limit of lowering eyes F = 500 # Focal length def simple_moving_average(n, data): """ Return simple moving average """ result = [] for m in range(n-1, len(data)): total = sum([data[m-i] for i in range(n)]) result.append(total/n) return result def add_simple_moving_average(smas, n, data): """ Add simple moving average """ total = sum([data[-1-i] for i in range(n)]) smas.append(total/n) if __name__ == '__main__': # Not show tkinter window root = tk.Tk() root.iconify() # Chose cascade cascade = cv2.CascadeClassifier("haarcascade_eye.xml") # Capture setup cap = cv2.VideoCapture(DEVICE_ID, cv2.CAP_DSHOW) cap.set(cv2.CAP_PROP_FRAME_WIDTH, CAP_FRAME_WIDTH) cap.set(cv2.CAP_PROP_FRAME_HEIGHT, CAP_FRAME_HEIGHT) cap.set(cv2.CAP_PROP_FPS, CAP_FRAME_FPS) # Prepare windows cv2.namedWindow(WINDOW_NAME) # Time series data of eye height eye_heights = [] sma_eye_heights = [] # Plot setup ax = plt.subplot() graph_x = np.arange(0, PLOT_NUM*PLOT_DELTA, PLOT_DELTA) eye_y = [0] * PLOT_NUM sma_eye_y = [0] * PLOT_NUM eye_lines, = ax.plot(graph_x, eye_y, label="realtime") sma_eye_lines, = ax.plot(graph_x, sma_eye_y, label="SMA") ax.legend() while cap.isOpened(): # Get a frame ret, frame = cap.read() # Convert image to gray scale img_gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY) # Detect human eyes eyes = cascade.detectMultiScale(img_gray, minSize=(30, 30)) # Mark on the detected eyes for (x, y, w, h) in eyes: color = (255, 0, 0) cv2.rectangle(img_gray, (x, y), (x+w, y+h), color, thickness=3) # Store eye heights if len(eyes) > 0: eye_average_height = CAP_FRAME_HEIGHT - sum([y for _, y, _, _ in eyes]) / len(eyes) eye_heights.append(eye_average_height) if len(eye_heights) == SMA_N: sma_eye_heights = simple_moving_average(SMA_N, eye_heights) elif len(eye_heights) > SMA_N: add_simple_moving_average(sma_eye_heights, SMA_N, eye_heights) # Detect bad posture if sma_eye_heights and (sma_eye_heights[0] - sma_eye_heights[-1] > F * D / Z): res = messagebox.showinfo("BAD POSTURE!", "Sit up straight!\nCorrect your posture, then click ok.") if res == "ok": # Initialize state, and restart from begening eye_heights = [] sma_eye_heights = [] graph_x = np.arange(0, PLOT_NUM*PLOT_DELTA, PLOT_DELTA) continue # Plot eye heights graph_x += PLOT_DELTA ax.set_xlim((graph_x.min(), graph_x.max())) ax.set_ylim(0, CAP_FRAME_HEIGHT) if len(eye_heights) >= PLOT_NUM: eye_y = eye_heights[-PLOT_NUM:] eye_lines.set_data(graph_x, eye_y) plt.pause(.001) if len(sma_eye_heights) >= PLOT_NUM: sma_eye_y = sma_eye_heights[-PLOT_NUM:] sma_eye_lines.set_data(graph_x, sma_eye_y) plt.pause(.001) # Show result cv2.imshow(WINDOW_NAME, img_gray) # Quit with ESC Key if cv2.waitKey(1) & 0xFF == 27: break # End processing cv2.destroyAllWindows() cap.release()参考

- 投稿日:2020-09-29T18:16:14+09:00
Djangoでmysqlの曖昧検索を行う
mysqlの曖昧検索について
https://www.softel.co.jp/blogs/tech/archives/1877
クエリについてはこちらを参考にさせていただきましたDjangoでどう書くか
特殊なクエリは
filterでは無理なのでextraを使いますdef get_ambiguous_queryset(self, queryset, value, columns): """ 曖昧検索用のquerysetを返す :param queryset: :param value: :param columns: :return: """ query_text = '' count = 0 for column in columns: if query_text != '': query_text += ' OR ' temp_value = value if isinstance(value, list): if len(value) > count: temp_value = value[count] else: temp_value = value[0] query_text += f"CONVERT({column} USING utf8) COLLATE utf8_unicode_ci LIKE '%%{temp_value}%%'" count += 1 return queryset.extra(where=[query_text])使い方
# queryset、検索したい値、検索対象のカラムを渡す self.get_ambiguous_queryset(queryset, value, ['name', 'code', 'description']) # 検索したい値は配列でも渡せます(検索対象のカラムと連動してます) self.get_ambiguous_queryset(queryset, [value, self.convert_tel(value)], ['name', 'tel'])joinが必要な場合には注意
# NGのパターン(shopがjoinされずエラーになります) self.get_ambiguous_queryset(queryset, value, ['shop.name', 'shop.code']) # OKのパターン(filterにshopを書いておくとjoinされる) self.get_ambiguous_queryset(queryset, value, ['shop.name', 'shop.code']).filter(shop__name__isnull=False)所感
クエリでの書き方がわかっていても、それをDjangoでどう書いたらいいかはいつも悩みます
- 投稿日:2020-09-29T18:11:18+09:00
自動モザイク生成
どうも、Deep learningを勉強中のかわたくです。
今回は画像に自動でモザイクを生成するプログラムをやってみました。実行環境
MacOS, VScode, python3.6(anaconda)
実行プログラム
今回のプログラムを書く上では、
30行で顔認識(OpenCV)してファイル出力!
Python, OpenCVで画像にモザイク処理(全面、一部、顔など)
opencv の基本的な画像変形: 全12実例!
これらの記事を参考にさせていただきました!# Man〜Womenみたいにstr型で格納されているフォルダはこのpathに付け加えてからじゃないと画像を表示できない DATADIR = "/Users/ユーザー名/Documents/書類 - MacBook Pro/HelloWorld.py/"まずは、こちらのように画像ファイルが保存されている、フォルダがあると思いますが、その1つ前までのパスを変数に代入します。
今回ですと、HelloWorld.pyというフォルダの中に、Man〜Womenのフォルダが入っています。# haarcascadeのxmlファイルの読み込み(正面の顔を読み込む) xml_path = "./haarcascade_frontalface_default.xml"Cascadeで部位を検出することが可能です。
・正面の顔検出:haarcascade_frontalface_default_xml
・瞳検出:haarcascade_eye.xml
・笑顔検出:haarcascade_smile.xmlそれぞれ何を検出したいのかを考えて読み込みをすると良いです。
Categories = ["Man", "Men", "Woman", "Women"] img_size = 250 mosaic_size = 10 training_data = [] # 顔検出のためのプログラム + データセット生成 def create_training_data(): # Man->Womenの順に引数 # 顔領域識別器をセット classifier = cv2.CascadeClassifier(xml_path) cnt = 1 for class_num, category in enumerate(Categories): # enumerateでインデックスと要素の2つを取り出せる path = os.path.join(DATADIR, category) # Categoriesの1つずつの要素とDATADIRを結合 -> Man〜Womenにアクセスが可能 for image_name in os.listdir(path): # ManやWomanの写真の一覧を取得 -> image_nameは全部str型 # グレースケール画像(識別用) <- 1枚ずつ画像を取り出す gray_img = cv2.imread(os.path.join(path, image_name), cv2.IMREAD_GRAYSCALE) # 一連のpathじゃなきゃimreadは読み込めない -> image_nameだけではエラーが出る # x座標、y座標、横幅、縦幅が戻り値となる face_points = classifier.detectMultiScale(gray_img, minSize=(20, 20)) # 識別結果よりカラー画像をトリミングする for x, y, width, height in face_points: # 顔領域の座標点取得 # 顔領域をトリミング dst_img = gray_img[y:y+height, x:x+width] # 画像は縦×横になっている face_img = cv2.resize(dst_img, (mosaic_size, mosaic_size), interpolation=cv2.INTER_NEAREST) # 画像のリサイズ -> resize(リサイズする画像, (行, 列)) mosaic_img = cv2.resize(face_img, (width, height), interpolation=cv2.INTER_NEAREST) # 元のサイズに戻す -> (width, height)で戻っている gray_img[y:y+height, x:x+width] = mosaic_img # モザイクした部分を元の画像に挿入している cv2.imwrite('mosaic' + str(cnt) + '.jpg', gray_img) # 画像を保存 try: training_data.append([gray_img, class_num]) # 画像データ、ラベル情報を追加 -> class_numでインデックス番号もリストに格納 except Exception as e: # Exceptionという例外の型が来たらエラーにせず、スルー pass cnt += 1 create_training_data()cv2.imread():画像ファイルの読み込みが可能
しかし、データの型が3次元ndarrayの形になりますので注意が必要です。
第2引数で画像のタイプを決定できます。今回ですと、グレースケール画像です。detectMultiScale:画像の中で検出できる物体のレベルを変化させられる
・scaleFactor:大きいほど誤検出するし、小さいほど未検出する。1.01に近づけるほど細かく検出ができる
┗大きいと広い範囲を検出できる
・minNeighbors:大きいほど信頼性が高い⇄顔を見逃す可能性が上がる
┗検出する場所が重複する→重複している物体は信頼性が高い
・minSize:物体が取りうる最小のサイズ、これより小さい物体は無視される*戻り値は(x座標、y座標、横幅、縦幅)になる
imwrite:画像ファイルを保存できる
・第一引数→ファイルのpath(.jpgとかを最後につける)
・第二引数→保存したい画像の変数(ndarray)モザイク生成方法
①モザイクを行いたい領域をトリミングする。
②その部分の画像サイズを一回小さくする。
③元のサイズに戻す
④モザイク化された部分を元の画像に入れ込む*②→③のタイミングで画像の粗さを粗くしているため、元のサイズにしたら画像がモザイク状になる。
*inter_nearestをinterpolationに代入→1番滑らかさが雑→モザイクに適しているrandom.shuffle(create_training_data) # データをシャッフル x_train = [] # 画像データ t_train = [] # 正解ラベル # データセット作成 -> featureには奇数番目が、labelには偶数番目が入っていく for feature, label in create_training_data: x_train.append(feature) t_train.append(label) # numpy配列に変換 x_train = np.array(x_train) t_train = np.array(t_train) # データセットの確認 for i in range(0, 4): print("学習のデータのラベル", t_train[i]) plt.subplot(2, 2, i+1) # subplot(何行, 何列, 描きたい領域) plt.axis('off') # 座標軸を非表示にする # インデックス番号が0か1なら男性を、2か3なら女性とラベルつける if t_train[i] == 0 or t_train[i] == 1: plt.title(label = "Man") # plt.title("男性", fontname="MS Gothic") # -> 日本語表記が可能 else: plt.title(label = 'Woman') # plt.title("女性", fontname="MS Gothic") # -> 日本語表記が可能 plt.imshow(x_train[i], cmap='gray') plt.show()こっち側のコードはモザイク生成には関係のないコードですが、一応モザイクがきちんと行われているかの確認のためにも使わせてもらいました。
あとは、データセットは今回作る必要はなかったのですが、データセットができる流れも掴むことができました。今回は使わなかったメモ
isinstance:その変数がその型かどうかをTrueかFalseで返す
・第一引数に調べたい変数
・第二引数に型setメソッド
{}で囲む、重複のある要素は無視される
os.remove(‘ファイルパス’):不要ファイルを削除
感想
当初の想像していたよりも簡単な実装に終わりました。
データセットを作成してから、複雑な処理をしなければならないのかなと思っていましたが、全然そんなことなくてすぐに終わりました。
やはり、顔検出のCascadeが便利だったなと思います。
あとは、モザイクの方法がめちゃくちゃ簡単だったというのもあげられますね。最初は難しいと思っていて、もっと準備必要かなと思っていましたが、作り始めてみたら楽しかったです。
めちゃくちゃコメントの多いコードになりましたが、その処理が何をしているのかをメモしておかないと忘れてしまい、パニックになるので、書かせてもらいました。
まとめ
今回初めて自分の力で最初から最後まで実装することができました。
まだ全然大したことないプログラムですが、ここからたくさんのプログラムを書けていければ良いなと思います。
- 投稿日:2020-09-29T17:14:55+09:00
Pythonによる画像処理100本ノック#10 メディアンフィルタ
はじめに
どうも、らむです。
今回は画像中のノイズを除去するメディアンフィルタを実装します。10本目:メディアンフィルタ
メディアンフィルタとは画像の平滑化・ノイズ除去を行うフィルタです。このフィルタを適用することによって画像全体をぼやかしたような加工ができます。
このフィルタでは注目画素を周辺画素の中央値で置き換えます。
また、前回同様、画像の端部分はフィルタリング処理が行えないので存在しない画素は0を用いる0パディング処理を行います。
ソースコード
medianFilter.pyimport numpy as np import cv2 import matplotlib.pyplot as plt def medianFilter(img,k): w,h,c = img.shape size = k // 2 # 0パディング処理 _img = np.zeros((w+2*size,h+2*size,c), dtype=np.float) _img[size:size+w,size:size+h] = img.copy().astype(np.float) dst = _img.copy() # フィルタリング処理 for x in range(w): for y in range(h): for z in range(c): dst[x+size,y+size,z] = np.median(_img[x:x+k,y:y+k,z]) dst = dst[size:size+w,size:size+h].astype(np.uint8) return dst # 画像読込 img = cv2.imread('image.jpg') # メディアンフィルタ # 第2引数:フィルタサイズ img = medianFilter(img,15) # 画像保存 cv2.imwrite('result.jpg', img) # 画像表示 plt.imshow(cv2.cvtColor(img, cv2.COLOR_BGR2RGB)) plt.show()


画像左は入力画像、画像中央は前回のガウシアンフィルタによる出力画像、画像右は今回の出力画像です。
メディアンフィルタでは点状のノイズがきれいさっぱり除去できていることが分かります。
引数が違うのであまりいい比較にはなっていないですが、メディアンフィルタの方が点状のノイズをきれいに除去できています。おわりに
もし、質問がある方がいらっしゃれば気軽にどうぞ。
imori_imoriさんのGithubに公式の解答が載っているので是非そちらも確認してみてください。
それから、pythonは初心者なので間違っているところがあっても優しく指摘してあげてください。

- 投稿日:2020-09-29T16:42:17+09:00
Pythonによる画像処理100本ノック#9 ガウシアンフィルタ
はじめに
どうも、らむです。
今回は画像中のノイズを除去するガウシアンフィルタを実装します。9本目:ガウシアンフィルタ
ガウシアンフィルタとは画像の平滑化を行うフィルタです。このフィルタを適用することによって画像全体をぼやかしたような加工ができます。
このフィルタでは注目画素の周辺画素をガウス分布によって重み付けし、フィルタの中心画素に近いほど大きな重みを付けます。ガウス分布による重み付けは以下のように定義されます。
g(x,y) = \frac{1}{2\pi\sigma^2}e^{-\frac{x^2+y^2}{2\sigma^2}}例えば、3×3や5×5のガウシアンフィルタは以下のフィルタがよく用いられます。おそらく引数のsに$σ=0.85$あたりを指定するとこの値になるかと思います。
$\frac{1}{16}$ $\frac{2}{16}$ $\frac{1}{16}$ $\frac{2}{16}$ $\frac{4}{16}$ $\frac{2}{16}$ $\frac{1}{16}$ $\frac{2}{16}$ $\frac{1}{16}$
$\frac{1}{256}$ $\frac{4}{256}$ $\frac{6}{256}$ $\frac{4}{256}$ $\frac{1}{256}$ $\frac{4}{256}$ $\frac{16}{256}$ $\frac{24}{256}$ $\frac{16}{256}$ $\frac{4}{256}$ $\frac{6}{256}$ $\frac{24}{256}$ $\frac{36}{256}$ $\frac{24}{256}$ $\frac{6}{256}$ $\frac{4}{256}$ $\frac{16}{256}$ $\frac{24}{256}$ $\frac{16}{256}$ $\frac{4}{256}$ $\frac{1}{256}$ $\frac{4}{256}$ $\frac{6}{256}$ $\frac{4}{256}$ $\frac{1}{256}$ 注目画素が中心だとすると、周辺画素と対応するフィルタ値の積の総和を注目画素に代入すれば良いですね。
3×3フィルタであれば$I(x_0,y_0)×\frac{1}{16} + I(x_0,y_1)×\frac{2}{16} + ... I(x_2,y_2)×\frac{1}{16}$の値を注目画素に代入します。また、画像の端部分はフィルタリング処理が行えないので存在しない画素は0を用います。これを0パディングといいます。
ソースコード
gaussianFilter.pyimport numpy as np import cv2 import matplotlib.pyplot as plt def gaussianFilter(img,k,s): w,h,c = img.shape size = k // 2 # 0パディング処理 _img = np.zeros((w+2*size,h+2*size,c), dtype=np.uint8) _img[size:size+w,size:size+h] = img.copy().astype(np.uint8) dst = _img.copy() # フィルタ作成 ker = np.zeros((k,k), dtype=np.float) for x in range(-1*size,k-size): for y in range(-1*size,k-size): ker[x+size,y+size] = (1/(2*np.pi*(s**2)))*np.exp(-1*(x**2+y**2)/(2*(s**2))) ker /= ker.sum() # フィルタリング処理 for x in range(w): for y in range(h): for z in range(c): dst[x+size,y+size,z] = np.sum(ker*_img[x:x+k,y:y+k,z]) dst = dst[size:size+w,size:size+h].astype(np.uint8) return dst # 画像読込 img = cv2.imread('image.jpg') # ガウシアンフィルタ # 第2引数:フィルタサイズ、第3引数:標準偏差(σ) img = gaussianFilter(img,21,2) # 画像保存 cv2.imwrite('result.jpg', img) # 画像表示 plt.imshow(cv2.cvtColor(img, cv2.COLOR_BGR2RGB)) plt.show()
画像左は入力画像、画像右は出力画像です。
点状のノイズが低減されていることが分かります。おわりに
もし、質問がある方がいらっしゃれば気軽にどうぞ。
imori_imoriさんのGithubに公式の解答が載っているので是非そちらも確認してみてください。
それから、pythonは初心者なので間違っているところがあっても優しく指摘してあげてください。
- 投稿日:2020-09-29T15:37:33+09:00
プログラミング経験者がPythonを勉強し始めたときにありがちなミス
はじめに
元々、サーバーサイドがメインでPHP、あるいは学校の授業でC言語を主に触っていました。今回、就活のコーディングテスト対策としてPythonが効率よさそうなので勉強し始めました。
Pythonを触った感想としては、他の言語よりシンプルすぎて、言われてる通り、まさに英語という感じです。非常にシンプルであるがゆえに、他の言語とは違い、少し戸惑ってしまいました。そこで、自分のよくある凡ミスをまとめます。Python初心者なので、そこのとこよろしくです。
コロンの付け忘れ
自分はこれがめちゃくちゃ多いです。pythonはfor文とif文で{}を使わない分忘れてしまいます。
for文の書き方が全然違う
ほとんどの言語は、
for(i=0;i<N;i++){ #hogehoge }という書き方ですが、pythonでは、
for i in range(0,N) : #hogehoge else: #forが終わった後の処理といった書き方です。forが終わった後の処理をelseで書けるのは見やすくていいですね!
配列の扱い方が楽すぎる
if s in str : print('s is in str') if s not in str : print('s in not in str')といったようにほぼ英語で書けます。その分、コロンを忘れやすいのですが。。。まあ、慣れですね。
pythonは書いてて楽しい!
といった感じで他の言語とは一線をなしてる感はあるのですが、書いててめちゃくちゃ楽しいです。あと、記述量がめちゃくちゃ少なくていいですね!!もっと勉強頑張ります。
- 投稿日:2020-09-29T15:00:18+09:00
Pandas100本ノック on Google Colaboratory
Python初学者のためのPandas100本ノック
https://qiita.com/kunishou/items/bd5fad9a334f4f5be51cColabでPandas100本ノック動きます。
https://colab.research.google.com/drive/1xITqd8wQC-EfYlPZlMydeCZDJl1nNNAy?usp=sharing
- 投稿日:2020-09-29T12:51:29+09:00
MuJoCoライセンス取得,更新から実行まで
MuJoCo
MuJoCoはロボティクス分野などの研究開発の促進を目的とした物理エンジンです.楽しそうなデモ
MuJoCoを利用するにはライセンスが必要です.
この記事では,ライセンス取得から簡単なコード実行まで紹介します.
MuJoCo Personal License: 1 yearに登録
MuJoCoにアクセスしてユーザー情報を登録します.
料金体系は以下の通り,学生は無料で使えます!
ライセンスは1年間ですが,再申請すればまた利用できるので,学生の間は使い放題です!
ユーザー情報の入力
名前や所属期間などの情報を入力します.
Request licenseボタンを押して,Successと表示されれば成功です.3日以内にMuJoCoからメールが届きます.
メールが届いたら次のステップです.Account numberとComputer id の登録
メールにはAccount numberが記載されているはずです.
Computer id は上の画像の青文字をクリックするとダウンロードされるgetidファイルを用いて取得します.
例)$ chmod +x getid_linux $ ./getid_linuxgetidファイルを実行するとComputer idが取得できるので,それをコピペしてRegister computerをクリックします.するとまたメールが届きます.このメールにactivation keyが添付されてくるので, .mujocoに置きましょう.
更新も全く同じ手順です.MuJoCoを動かしてみよう!
[test.py]1 import gym 2 import mujoco_py 3 4 env = gym.make('Humanoid-v2') 5 env.reset() 6 for _ in range(1000): 7 env.render() 8 env.step(env.action_space.sample())実行すると,以下のような画面が立ち上がります.
これでmujocoが使えるか確認できます!





- 投稿日:2020-09-29T12:48:07+09:00
将棋AIで学ぶディープラーニング on Mac and Google Colab 第7章5~7
7.5~7.7
read_kifu.py
read_kifu()
引数:棋譜ファイルのパスを羅列したテキストファイル
出力:(「局面図」「指し手」「勝敗」)を局面ごとに算出し、1局面を1要素としてリストに追加していき、全棋譜を読み込み終わったら一つのリストとして出力する。
1局面のデータは下記5要素で構成。
-piece_bb:15要素
-occupied:2要素
-pieces_in_hand:2要素
-move_label:1要素
-win:1要素
最終的な出力は[([15要素], [2要素], [2要素], [1要素], [1要素]), (同じセット), ・・・が手数 x 対局数]python-dlshogi\pydlshogi\read_kifu.py#!/usr/bin/env python3 # -*- coding: utf-8 -*- import shogi import shogi.CSA import copy from pydlshogi.features import * from pydlshogi.common import * ##################test # read kifu def read_kifu(kifu_list_file): i = 0 positions = [] with open(kifu_list_file, 'r') as f: for line in f.readlines(): filepath = line.rstrip('\r\n') i += 1 print(i) # 棋譜データを変数kifuに代入。 # 棋譜データはnames、sfen、moves、winの4つのキーを持ったディクショナリ。 # このディクショナリが1要素としてリストに入っている。[0]でディクショナリだけ取り出す。 kifu = shogi.CSA.Parser.parse_file(filepath)[0] win_color = shogi.BLACK if kifu['win'] == 'b' else shogi.WHITE board = shogi.Board() for move in kifu['moves']: # ■board:print(board)で盤面を2次元表示できる。 # ■piece_bb:15要素の配列。各要素は各駒の配置を示す。0:空白、1:歩、2:香、・・・ # bit board。bit boardとは下記のようなもの。 # 各要素が81桁(=81マス)の2進数(つまりbit board)の10進数表示である。 # 2進数81桁表示したいときはprint('{:0=81b}'.format(10進数の値)) でできる。 # ■occupied:2要素の配列。各要素は先手後手の占有している駒の位置。bit board。 # ■pieces_in_hand:2要素の配列。各要素は先手後手がどの駒(=key)を何枚(=value)持っているかを示すディクショナリ型。 if board.turn == shogi.BLACK: piece_bb = copy.deepcopy(board.piece_bb) occupied = copy.deepcopy((board.occupied[shogi.BLACK], board.occupied[shogi.WHITE])) pieces_in_hand = copy.deepcopy((board.pieces_in_hand[shogi.BLACK], board.pieces_in_hand[shogi.WHITE])) else: piece_bb = [bb_rotate_180(bb) for bb in board.piece_bb] occupied = (bb_rotate_180(board.occupied[shogi.WHITE]), bb_rotate_180(board.occupied[shogi.BLACK])) pieces_in_hand = copy.deepcopy((board.pieces_in_hand[shogi.WHITE], board.pieces_in_hand[shogi.BLACK])) # move label i_move = shogi.Move.from_usi(move) # 指し手の変数moveを引数としてMoveクラスのインスタンスを生成 move_label = make_output_label(i_move, board.turn) # ■ Moveクラス # from_square変数 :盤面を0~80の数値で表したときの移動元の値。 # 9で割ったときの商がy座標、余りがx座標となる。xy座標は0オリジン。 # to_square変数 :同上(移動先)。 # # x座標 # 0 1 2 3 4 5 6 7 8 # # 0 1 2 3 4 5 6 7 8 0 y座標 # 9 10 11 12 13 14 15 16 17 1 # 18 19 20 21 22 23 24 25 26 2 # 27 28 29 30 31 32 33 34 35 3 # 36 37 38 39 40 41 42 43 44 4 # 45 46 47 48 49 50 51 52 53 5 # 54 55 56 57 58 59 60 61 62 6 # 63 64 65 66 67 68 69 70 71 7 # 72 73 74 75 76 77 78 79 80 8 # # print(board) # # try: # y_from, x_from = divmod(s.from_square, 9) # y_to, x_to = divmod(s.to_square, 9) # print('from:',x_from, y_from) # print('to :',x_to, y_to) # # move_direction = DOWN # print('moved:', move_direction) # except: # pass # result win = 1 if win_color == board.turn else 0 # 変数positionsに局面(最初の3つの変数)、その局面での指し手、勝敗を追加 positions.append((piece_bb, occupied, pieces_in_hand, move_label, win)) # 1手進める board.push_usi(move) return positions
- 投稿日:2020-09-29T12:25:13+09:00
備忘録(pandasによる擬似Vlookup)
はじめに
https://qiita.com/wellwell3176/items/e6a17609c7398dd7d496
上記で作成したプログラムが改良できたので取りまとめ。
エクセル上に入力せず、python上で全部計算して結果だけエクセルに放り込めばいいんじゃね?
という、当たり前すぎる事に気づいたのでだいぶコンパクトになった気がする。
これまではopenpyxlを用いていたが、今回はpandasを使用。両者の差は未だによく分かっていない。成果
図:出力されたエクセル(色分けは後で塗った)
区分+業務の内容から設定1・設定2に該当するものを検索し、出力できているので良しとする。
最終提出時に不要になる無駄な行も無く、スッキリ。
https://qiita.com/wellwell3176/items/e6a17609c7398dd7d496
の図2と比べると、使い物になるレベルの出力がされているのがよく分かる。programimport pandas as pd df_master=pd.read_excel('/content/drive/My Drive/Colab Notebooks/table.xlsx') df_test=pd.read_excel('/content/drive/My Drive/Colab Notebooks/data5.xlsx') row_count=len(df_test.index) #for文のループ回数を決めるために表の長さを取得 for i in range(0,row_count): #.iterrowsは何故か上手く動かなかった kubun = df_test.at[(i,"区分")] gyomu = df_test.at[(i,"業務")] kubun_gyomu=(df_master['区分'] == kubun) & (df_master["業務"] == gyomu) #区分と業務が一致する行をBoolで判定 row_true=df_master[kubun_gyomu] #データフレームの中からtrue行だけを抜き取り set1_val=row_true.iat[0,3] set2_val=row_true.iat[0,4] #設定1/2の位置は一意に定まるので位置は数値で指定。0行目”設定2”列みたいな事はできなかった。 #変数が多すぎる気もするが、これくらい分割しないと後で何してるかさっぱりになりそうだったので分けた。 df_test.at[(i,"設定1")]=set1_val df_test.at[(i,"設定2")]=set2_val #こっちの指定はi行目”設定2”列が可能。よく分からん。 df_test.to_excel('/content/drive/My Drive/Colab Notebooks/data6.xlsx',index=False)作成中に見かけたエラーメッセージと失敗
ValueError: At based indexing on an integer index can only have integer indexers
for i in df_test.iterrows(): kubun = df_test.at[(i,"区分")] gyomu = df_test.at[(i,"業務")] -->ValueError: At based indexing on an integer index can only have integer indexers #i=[0]から[データフレーム最終行数]まで、という指定で動いてくれるかと思ったが、ダメ #理由はまだ分かっていない。iに整数値が入っていないらしいのだが・・・ #完成品のようにrange関数で長さを指定して解決した.at[0,"hogehoge"]を使ったときのkey error
失敗バージョンfor i in range(0,45): kubun = df_test.at[(i,"区分")] #テストファイルから区分の値を引っ張り出す kubun_correct=(df_master['区分'] == kubun) #マスターファイルと検索して引っ掛ける row_true=df_master[kubun_correct] #true行だけ引っ張り出す set1_val=row_true.at[0,"設定1"] #trueを出した先頭行”設定1”列のデータを出そうとして、ここで引っかかった df_test.at[(i,"設定1")]=set1_val #該当する設定1のデータをエクセルに代入したかった -->key error 0 #原因は.atが文字列参照だという点への不理解。i=10(区分=工事)のときにエラーが起きた。 #その時のprint(kubun_correct)の結果が下記 0 False 1 False 2 True 3 True #print(row_true)すると下記のようになる 区分 業務 設定1 設定2 2 工事 平日 定期B 南 3 工事 休日 不定期B 北 #このとき、row_true.at[0,"設定1"]は、”0”行の”設定1”列を読み込みに行くが、0行はあるものの"0"行がないため参照不可 #よって、完成品のように.iatで0行3列を参照するようにして解決参考文献
Pandas DataFrame のセルの値を取得する方法
https://www.delftstack.com/ja/howto/python-pandas/how-to-get-a-value-from-a-cell-of-a-dataframe/
Pandasで抽出したデータから値だけを取り出す方法
https://tipstour.net/python-pandas-get-value
pandasで複数条件のAND, OR, NOTから行を抽出(選択)
https://note.nkmk.me/python-pandas-multiple-conditions/
- 投稿日:2020-09-29T12:03:07+09:00
Python + Janomeでマルコフ連鎖人工無脳(2)マルコフ連鎖入門
前書き
前回
Python + Janomeでマルコフ連鎖人工無脳(1)Janome入門
今回はマルコフ連鎖の下準備として、Janomeを使ってまとまった文章をばらばらにしたり、簡単な単純マルコフ連鎖を実装してみます。マルコフ連鎖とは?
導入
マルコフ連鎖(マルコフれんさ、英: Markov chain)とは、確率過程の一種であるマルコフ過程のうち、とりうる状態が離散的(有限または可算)なもの(離散状態マルコフ過程)をいう。
(Wikipediaより)シンプルなすごろくを想像してください。あるマスでサイコロを振り、出た目の分だけ前進します。
スタート地点がどこだとしても、それまでのサイコロが出してきた値も、「4マス先に進む」という未来の事象には一切関係しません。これがマルコフ性です。
マスとマスの間に挟まるようなことはなく、いずれかのマスにたどりつきます。これが離散的であるということです。
このようなマルコフ過程は単純マルコフ連鎖といいますが、たとえば
「前回の目と今回の目の和だけ進む」
というようなルールを設ければ、これは2階マルコフ連鎖になります。文章生成への応用
文章生成では、N階マルコフ連鎖を利用します。
次の文章を例に考えます。マルコフ過程とは、マルコフ性をもつ確率過程のことをいう。
未来の挙動が現在の値だけで決定され、過去の挙動と無関係であるという性質を持つ確率過程である。これらをJanomeを使ってばらすと、このようになります。
マルコフ|過程|と|は|、|マルコフ|性|を|もつ|確率|過程|の|こと|を|いう|。
未来|の|挙動|が|現在|の|値|だけ|で|決定|さ|れ|、|過去|の|挙動|と|無関係|で|ある|という|性質|を|持つ|確率|過程|で|ある|。まず、始点を任意に定めてやります。「マルコフ」にしましょう。
現在の状態「マルコフ」を参考に、次のブロックを決めます。
「マルコフ」とつながっているのは「過程」と「性」ですから、そのいずれかを選びます。「過程」にしましょう。
単純マルコフ連鎖なら次は「過程」に続く「と」「の」「で」から選び、
2階マルコフ連鎖なら「マルコフ」「過程」の2ブロックに続く「と」を選びます。
今回はカンタンに、N=1の単純マルコフ連鎖を実装してみましょう。実装(単純マルコフ過程)
from janome.tokenizer import Tokenizer import random t = Tokenizer() s = "マルコフ過程とは、マルコフ性をもつ確率過程のことをいう。\ 未来の挙動が現在の値だけで決定され、過去の挙動と無関係であるという性質を持つ確率過程である。" line = "" for token in t.tokenize(s): line += token.surface line += "|" word_list = line.split("|") word_list.pop() dictionary = {} queue = "" for word in word_list: if queue != "" and queue != "。": if queue not in dictionary: dictionary[queue] = [] dictionary[queue].append(word) else: dictionary[queue].append(word) queue = word def generator(start): sentence = start now_word = start for i in range (1000): if now_word == "。": break else: next_word = random.choice(dictionary[now_word]) now_word = next_word sentence += next_word return sentence for i in range(5): print(generator("マルコフ"))===========以下注釈===========
from janome.tokenizer import Tokenizer import random t = Tokenizer() s = "マルコフ過程とは、マルコフ性をもつ確率過程のことをいう。\ 未来の挙動が現在の値だけで決定され、過去の挙動と無関係であるという性質を持つ確率過程である。" line = "" for token in t.tokenize(s): line += token.surface line += "|" word_list = line.split("|") word_list.pop()前半部分では、上の文章をバラバラにして格納した配列を生成しています。
上に述べたような|区切りの文字列を生成し、|でsplit。
しんがりに空文字が残っているので、popで除きます。dictionary = {} queue = "" for word in word_list: if queue != "" and queue != "。": if queue not in dictionary: dictionary[queue] = [] dictionary[queue].append(word) else: dictionary[queue].append(word) queue = word中間部分では、前半で作った配列を使って辞書(dict型オブジェクト)を作っています。
queueに現在の単語を入れておき、
(項目がない場合は新しく作って)後続の単語wordを追加しています。
追加した後は、queueを後続の単語wordに差し替えます。
辞書の中身は{'マルコフ': ['過程', '性'], '過程': ['と', 'の', 'で'], 'と': ['は', '無関係'], 'は': ['、'], '、': ['マルコフ', '過去'], '性': ['を'], 'を': ['もつ', 'いう', '持つ'], 'もつ': ['確 率'], '確率': ['過程', '過程'], 'の': ['こと', '挙動', '値', '挙動'], 'こと': ['を'], 'いう': ['。'], '未来': ['の'], '挙動': ['が', 'と'], 'が': ['現在'], '現在': ['の'], '値': ['だ け'], 'だけ': ['で'], 'で': ['決定', 'ある', 'ある'], '決定': ['さ'], 'さ': ['れ'], 'れ': ['、'], '過去': ['の'], '無関係': ['で'], 'ある': ['という', '。'], 'という': ['性質'], '性 質': ['を'], '持つ': ['確率']}こんな感じです。
def generator(start): sentence = start now_word = start for i in range (1000): if now_word == "。": break else: next_word = random.choice(dictionary[now_word]) now_word = next_word sentence += next_word return sentence for i in range(5): print(generator("マルコフ"))後半部分では、いよいよ文章生成です。
現在の単語の後続の単語群から次の単語をランダムに選び取って、sentenceにくっつけていきます。
"。"が来たら終了するように書きましたが、確率的には永遠に"。"が選ばれないこともありえるので繰り返しはせいぜい1000回で終わるように指定しています。
"マルコフ"から始まる文章を5本書き出してもらいましょう。マルコフ性をもつ確率過程と無関係である。 マルコフ性を持つ確率過程と無関係である。 マルコフ性を持つ確率過程の挙動が現在のことをいう。 マルコフ性をいう。 マルコフ過程のことを持つ確率過程である。(だぶっちゃった)
しかし、それらしい文章は生めましたね。次回への展望
単純マルコフ連鎖は過去との脈絡が一切ないだけ、上のように支離滅裂になりがちです。
また、今回は辞書が貧弱すぎたのもあり、似たり寄ったりな文章になってしまっています。
次回は複数個の連鎖をもとに次の単語を選び出して文章を生成するN階マルコフ連鎖を、
もっと大きな辞書で実装してみようと思います。
- 投稿日:2020-09-29T10:58:40+09:00
スクレイピング2 スクレイピングのやり方
Aidemy 2020/9/29
はじめに
こんにちは、んがょぺです!バリバリの文系ですが、AIの可能性に興味を持ったのがきっかけで、AI特化型スクール「Aidemy」に通い、勉強しています。ここで得られた知識を皆さんと共有したいと思い、Qiitaでまとめています。以前のまとめ記事も多くの方に読んでいただけてとても嬉しいです。ありがとうございます!
今回は、スクレイピングの2つめの投稿になります。どうぞよろしくお願いします。*本記事は「Aidemy」での学習内容を「自分の言葉で」まとめたものになります。表現の間違いや勘違いを含む可能性があります。ご了承ください。
今回学ぶこと
・スクレイピングの方法(前準備であるクローリングはスクレイピング1を参照)
・複数ページをスクレイピングするスクレイピングする
スクレイピングの方法
・(復習)スクレイピングとは、Webページを取得し、そこから必要なデータを抜き出すことである。
・スクレイピングの方法は「正規表現(reモジュール)」を使う、または「サードパーティ製のライブラリを使う」の2種類があるが、今回はメジャーな方法である「サードパーティ製のライブラリを使う」方法でスクレイピングを行う。HTML、XMLについて
・XMLはHTMLと同じWebページを直接構築するマークアップ言語である。HTMLよりも拡張性に優れる。
・HTML,XMLでは、<title><\title>のような感じで囲まれたテキストがあり、このうち全体を要素と言い、< title>のことをタグと言う。
・また<html lang="ja">のような表記もあり、これはlang属性がjaである、すなわち、言語は日本語であると言う意味である。
・今回スクレイピングで使う「BeautifulSoup」ライブラリでは、この要素名からタイトルなどを取得する。BeautifulSoupでスクレイピング(解析準備)
・BeautifulSoup(デコードしたWebページ,"パーサー")メソッドを使うことで、簡単にスクレイピングできる。
・パーサーとは、文字列の解析(パース)を行うプログラムのことであり、特徴別に何種類かあり、そこから一つを指定する。例として、追加のライブラリが必要ない「html.parser」、高速に処理ができる「lxml」、XMLに対応する「xml」などがある。#クローリングするrequestsとスクレイピングするBeautifulSoupをインポート from bs4 import BeautifulSoup import requests #urlの取得 url=requests.get("https://www.google.co.jp") #スクレイピング(デコードはrequestモジュールのurl.textで行う、パーサーは"xml"に指定) soup=BeautifulSoup(url.text,"xml")BeautifulSoupでスクレイピング(必要なデータを抜き出す)
・前項で行ったパースをしたデータからは、必要なデータを抜き出すことができる。方法は以下の二種類である。
・パース済みデータを変数soupに入れたとするとsoup.find("タグ名or属性名")でそのタグか属性を持つ要素を最初の一つだけ抜き出す。またfindの部分をfind_allとすれば指定した要素を全てリスト化して抜き出す。
・また、クラス属性からスクレイピングしたい時は、引数にclass_="クラス属性名"を加える。・パース済みデータを変数soupに入れたとするとsoup.selected_one("CSSセレクタ")で、これを満たす要素を最初の一つだけ抜き出す。またselected_oneの部分をselectとすれば指定した要素を全てリスト化して抜き出す。
・CSSセレクタとは、要素をCSSの表現で示す方法である。これを使えば、要素の中の要素を指定することもできる(ex)body要素の中のh1要素は"body > h1")。・また、裏技ではあるが、Chromeの開発者ツールで要素やCSSセレクタをコピーできる。そのため、わざわざデコードしたデータを出力することなく、視覚的にわかりやすく欲しいデータを抜き出せる。
Google_title = soup.find("title") #<title>Google</title> Google_h1 = soup.select("body > h1") #[] (body要素のh1要素がないので空リストが出力)・上記のままだとGoogle_titleはtitleタグがついたまま出力されてしまうが、textを使うことで、このうちのテキストのみを取得できる。
print(Google_title.text) #Google複数ページをスクレイピングする
・ここまでの方法だと1ページずつしかスクレイピングできない。複数ページをスクレイピングしたい時は、トップページなどにある他ページへのリンクから他ページのURLを取得し、繰り返し処理で全てのURLに対してスクレイピングを行えば良い。
・他ページのURLはトップページのURL + 要素のhref属性(各ページのリンク)で取得できる。top="http://scraping.aidemy.net" r=requests.get(top) soup=BeautifulSoup(r.text,"lxml") url_lists=[] #他ページのURLをリンクから取得 #(方法は、まずaタグを全て取得し、そのそれぞれについてgetを使ってhref属性を文字コード化し、topURLとつなげることでURLとする) urls = soup.find_all("a") for url in urls: url = top + url.get("href") url_lists.append(url)・他ページのURLが取得できたら、実際にスクレイピングする。先述の通り、繰り返し処理で全てのURLに対してスクレイピングを行えば良い。
・以下では、前項で取得した全ページから写真のタイトル(h3タグに記載されている)をスクレイピングして全て取得し、リストとして表示する。photo_lists=[] #前項で取得したページをエンコードしてから写真のタイトルをBeautifulSoupでスクレイピング for url in url_lists: r2=requests.get(url) soup=BeautifulSoup(r2.text,"lxml") photos=soup.find_all("h3") #スクレイピングして取得した写真のタイトルを、h3タグを抜いてリストに追加 for photo in photos: photo_text=photo.text photo_lists.append(photo_text) print(photo_lists) #['Minim incididunt pariatur', 'Voluptate',...(略)]まとめ
・クローリングしたページをスクレイピングするときは、まずBeautifulSoupメソッドでパースする。
・パースしたデータからは任意のデータを抜き出せる。抜き出すにはfind()あるいはselected_one()を使う。
・抜き出したデータにtextをつけると、タグなどが省略され、要素のみ抽出できる。
・複数のページをまとめてスクレイピングする時は、トップページなどからリンクを抜き取り、ベースのURLとつなげることでクローリングできるので、それを個別にスクレイピングする。今回は以上です。ここまで読んでくださりありがとうございました。
- 投稿日:2020-09-29T09:42:38+09:00
KubernetesとDockerを使用してPython APIを開発およびデプロイする
はじめに
Dockerは最も人気のあるコンテナー化テクノロジーの1つです。使いやすく、開発者にとって使いやすいツールであり、スムーズかつ簡単に使用できることもあり、他の同様のテクノロジーよりも人気があります。 2013年3月の最初のオープンソースリリース以来、Dockerは開発者や運用エンジニアから注目を集め、Docker Inc.によると、Dockerユーザーは1,050億を超えるコンテナーをダウンロードし、Docker Hubに580万のコンテナーをドッキングしました。プロジェクトのGithubには32,000以上のスターがあります。
現在、Dockerはそれほど主流になりました。 10万を超えるサードパーティプロジェクトがこのテクノロジ-
を使用しており、コンテナ化のスキルを持つ開発者の需要が高まっているのも事実です。この記事は、最初にDockerを使用してアプリケーションをコンテナ化する方法を説明し、次にDocker Composeを使用して開発環境で実行する方法を解説していきます。メインアプリとしてPython APIを使用します。
MetricFireでは、Docker、Kubernetes、Pythonのセットアップの監視について、お助けできます。どのように役立つかをご確認いただくには、是非デモをご予約ください。
開発環境のセットアップ
開始する前に、いくつかの要件をインストールしていきます。 ここではFlaskで開発されたMini Python APIを使用します。 FlaskはPythonフレームワークであり、APIを迅速にプロトタイプ化するための優れた選択肢であり、私たちのアプリケーションはFlaskを使用して開発されます。 Pythonに慣れていない場合は、このAPIを作成する手順を以下に示します。
まず、Python仮想環境を作成して、依存関係を残りのシステム依存関係から分離します。 その前に、人気のあるPythonパッケージマネージャーであるPIPが必要です。
インストールは非常に簡単です。次の2つのコマンドを実行してみてください。
curl https://bootstrap.pypa.io/get-pip.py -o get-pip.py python get-pip.py参考までに、Python 3がインストールされている必要があります。 これを確認するには、次のように入力してください。
python --versionPIPをインストールした後、次のコマンドを使用して仮想環境をインストールします。
pip install virtualenv公式ガイドに従って他のインストール方法を見つけることができます。 次に、仮想環境を作成するフォルダーのプロジェクトを作成し、アクティブ化します。 また、アプリのフォルダーとapp.pyというファイルを作成します。
mkdir app cd app python3 -m venv venv . venv/bin/activate mkdir code cd code touch app.py特定の都市の天気を表示する簡単なAPIを作成します。 たとえば、ロンドンの天気を表示したいとします。 ルートを使用してリクエストする必要があります:
/london/ukPIPを使用して「flask」および「requests」と呼ばれるPython依存関係をインストールする必要があります。 後でそれらを使用します:
pip install flask requests依存関係をrequirements.txtというファイルで「Freeze」することを忘れないでください。 このファイルは、後でアプリの依存関係をコンテナーにインストールするために使用されます。
pip freeze > requirements.txt要件ファイルは次のようになります。
certifi==2019.9.11 chardet==3.0.4 Click==7.0 Flask==1.1.1 idna==2.8 itsdangerous==1.1.0 Jinja2==2.10.3 MarkupSafe==1.1.1 requests==2.22.0 urllib3==1.25.7 Werkzeug==0.16.0APIのイニシャルコードは
from flask import Flask app = Flask(__name__) @app.route('/') def index(): return 'App Works!' if __name__ == '__main__': app.run(host="0.0.0.0", port=5000)テストするには、python app.pyを実行し、http://127.0.0.1:5000 /にアクセスする必要があります。 「AppWorks!」が表示されます。 Webページで。 openweathermap.orgのデータを使用するので、必ず同じWebサイトでアカウントを作成し、APIキーを生成してください。
次に、APIに特定の都市の気象データを表示させるための便利なコードを追加する必要があります。
@app.route('/<string:city>/<string:country>/') def weather_by_city(country, city): url = 'https://samples.openweathermap.org/data/2.5/weather' params = dict( q=city + "," + country, appid= API_KEY, ) response = requests.get(url=url, params=params) data = response.json() return dataそして、全体のコードは以下のようになります。
from flask import Flask import requests app = Flask(__name__) API_KEY = "b6907d289e10d714a6e88b30761fae22" @app.route('/') def index(): return 'App Works!' @app.route('/<string:city>/<string:country>/') def weather_by_city(country, city): url = 'https://samples.openweathermap.org/data/2.5/weather' params = dict( q=city + "," + country, appid= API_KEY, ) response = requests.get(url=url, params=params) data = response.json() return data if __name__ == '__main__': app.run(host="0.0.0.0", port=5000)127.0.0.1:5000/london/ukにアクセスすると、次のようなJSONが表示されるはずです。
{ "base": "stations", "clouds": { "all": 90 }, "cod": 200, "coord": { "lat": 51.51, "lon": -0.13 }, ...Mini APIが機能しています。 Dockerを使用してコンテナ化しましょう。
Dockerを使用してアプリのコンテナーを作成する
APIのコンテナを作成しましょう。 最初のステップは、Dockerfileを作成することです。 Dockerfileは、イメージを構築するためにDockerデーモンが従う必要のあるさまざまな手順と指示を含む説明的なテキストファイルです。 イメージをビルドしたら、コンテナーを実行できるようになります。
Dockerfileは常にFROM命令で始まります。
FROM python:3 ENV PYTHONUNBUFFERED 1 RUN mkdir /app WORKDIR /app COPY requirements.txt /app RUN pip install --upgrade pip RUN pip install -r requirements.txt COPY . /app EXPOSE 5000 CMD [ "python", "app.py" ]上記のファイルでは、次のことを行いました。
- 「python:3」というベースイメージを使用
- PYTHONUNBUFFEREDを1に設定。PYTHONUNBUFFEREDを1に設定すると、ログメッセージをバッファリングせずにストリームにダンプできます。
- フォルダー/ appを作成し、それをworkdirとして設定。
- 要件をコピーし、それを使用してすべての依存関係をインストール。
- アプリケーションを構成するすべてのファイル、つまりapp.pyファイルをworkdirにコピー。
- アプリがこのポートを使用するため、最終的にポート5000を公開し、app.pyを引数としてpythonコマンドを起動。 これにより、コンテナの起動時にAPIが起動。
Dockerfileを作成したら、イメージ名と選択したタグを使用してDockerfileをビルドする必要があります。 この例では、名前として「weather」を使用し、タグとして「v1」を使用します。
docker build -t weather:v1 .Dockerfileとapp.pyファイルを含むフォルダー内からビルドしていることを確認してください。
コンテナをビルドした後、次を使用して実行できます。
docker run -dit --rm -p 5000:5000 --name weather weather:v1-dオプションを使用するため、コンテナーはバックグラウンドで実行されます。 コンテナは「weather」(-name weather)と呼ばれます。 また、ホストポート5000を公開されたコンテナーポート5000にマップしたため、ポート5000でも到達可能です。
コンテナの作成を確認したい場合は、次を使用できます。
docker ps次の出力と非常によく似た出力が表示されるはずです。
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES 0e659e41d475 weather:v1 "python app.py" About a minute ago Up About a minute 0.0.0.0:5000->5000/tcp weatherこれでAPIをクエリできるはずです。 CURLを使用してテストしてみましょう。
curl http://0.0.0.0:5000/london/uk/最後のコマンドがJSONを返す必要がある場合:
{ "base": "stations", "clouds": { "all": 90 }, "cod": 200, "coord": { "lat": 51.51, "lon": -0.13 ... }開発のためのDocker Composeの使用
Docker Composeは、マルチコンテナーDockerアプリケーションを定義および実行するためにDockerInc。によって開発されたオープンソースツールです。 Docker Composeは、開発環境で使用することを目的としたツールでもあります。これにより、コンテナーを手動で再起動したり、変更のたびにイメージを再構築したりすることなく、コードの更新時にコンテナーを自動再ロードできます。 Composeがないと、Dockerコンテナのみを使用して開発するのにイライラは避けられないでしょう。
実装部分では、「docker-compose.yaml」ファイルを使用します。
これは、APIで使用している「docker-compose.yaml」ファイルです。
version: '3.6' services: weather: image: weather:v1 ports: - "5000:5000" volumes: - .:/app上記のファイルで、イメージ「weather:v1」を使用するようにサービス「weather」を構成したことがわかります。 ホストポート5000をコンテナポート5000にマップし、現在のフォルダをコンテナ内の「/ app」フォルダにマウントします。
イメージの代わりにDockerfileを使用することもできます。 すでにDockerfileがあるので、この場合はこれをお勧めします。
version: '3.6' services: weather: build: . ports: - "5000:5000" volumes: - .:/app次に、「docker-compose up」を実行してサービスの実行を開始するか、「docker-compose up --build」を実行してビルドしてから実行します。
まとめ
この投稿では、Mini Python API用のDockerコンテナーを作成する方法を確認し、DockerComposeを使用して開発環境を作成しました。 GoやRailsなどの別のプログラミング言語を使用している場合は、いくつかの小さな違いを除いて、通常は同じ手順に従います。 MetricFireの無料デモを予約して、MetricFireがモニタリング環境に適合するかどうかをご相談ください。

- 投稿日:2020-09-29T08:39:25+09:00
PILで背景透過。(putalphaがNoneType Objectを返す時の対処法)【Pillow】
たとえば、上記のような画像にマスク画像を適用して背景を透過したいとします。
以下でOK。from PIL import Image img.putalpha(mask) img.save(writepath)このときに、作った背景透過画像を変数に当て込むとエラーになります。
putalphaメソッドがNoneタイプのオブジェクトを返すからだそうです。from PIL import Image img = img.putalpha(mask) img.save(writepath) """ PIL: AttributeError: 'NoneType' object has no attribute 'save'最初のコードとのちがいわかりましたか?
最初のコードでやると保存できます。ちなみに、人型のマスクで切り抜く方法はこちらの記事。
?
お仕事のご相談こちらまで
rockyshikoku@gmail.comCore MLを使ったアプリを作っています。
機械学習関連の情報を発信しています。



- 投稿日:2020-09-29T07:35:23+09:00
Django シフト表 シフトデータ作成機能完成
結果的には、機能を作ってから気づいたのですがシフトって本人が全部まず入力した後に、シフト決定者が調整するってことで対応ができないのかなって思いました。
また、そこらへんは、ユーザに確認して機能変更をする必要がありますね長々となりましたが、Viewsです
schedule/views.pyfrom django.shortcuts import render, redirect, HttpResponseRedirect from shisetsu.models import * from accounts.models import * from .models import * import calendar import datetime from datetime import timedelta from datetime import datetime as dt from django.db.models import Sum from django.contrib.auth.models import User from django.views.generic import FormView, UpdateView, ListView, CreateView, DetailView, DeleteView from django.urls import reverse_lazy from .forms import * from dateutil.relativedelta import relativedelta from django.contrib.auth.models import User # Create your views here. def homeschedule(request): from datetime import datetime now = datetime.now() return HttpResponseRedirect('/schedule/monthschedule/%s/%s/' % (now.year,now.month,)) # 自動的に今月のシフト画面にリダイレクト def monthschedulefunc(request,year_num,month_num): user_list = User.objects.all() profile_list = Profile.objects.select_related().values().order_by('hyoujijyun') year, month = int(year_num), int(month_num) shisetsu_object = Shisetsu.objects.all() shift_object = Shift.objects.all() object_list = Schedule.objects.filter(year = year, month = month).order_by('user', 'date') month_total = Schedule.objects.select_related('User').filter(year = year, month = month).values("user").order_by("user").annotate(month_total_worktime = Sum("day_total_worktime")) #シフト範囲の日数を取得する enddate = datetime.date(year,month,20) startdate = enddate + relativedelta(months=-1) kaisu = enddate - startdate kaisu = int(kaisu.days) kikan = str(startdate) +"~"+ str(enddate) #日付と曜日のリストを作成する hiduke = str(startdate) date_format = "%Y-%m-%d" hiduke = dt.strptime(hiduke, date_format) weekdays = ["月","火","水","木","金","土","日"] calender_object = [] youbi_object = [] for i in range(kaisu): hiduke = hiduke + timedelta(days=1) calender_object.append(hiduke) youbi = weekdays[hiduke.weekday()] youbi_object.append(youbi) kaisu = str(kaisu) context = { 'year': year, 'month': month, 'kikan': kikan, 'object_list': object_list, 'user_list': user_list, 'shift_object': shift_object, 'calender_object': calender_object, 'youbi_object': youbi_object, 'kaisu': kaisu, 'shisetsu_object': shisetsu_object, 'month_total' : month_total, 'profile_list' : profile_list, } return render(request,'schedule/month.html', context) def scheduleUpdatefunc(request,pk): Schedule_list = Schedule.objects.get(pk = int(pk)) User_list = User.objects.get(username = Schedule_list.user) shift_object = Shift.objects.all() if request.method == 'POST': form = ScheduleUpdateForm(data=request.POST) year = Schedule_list.year month = Schedule_list.month #更新ボタン処理 if form.is_valid(): Schedule_list.shift_name_1 = form.cleaned_data['shift_name_1'] Schedule_list.shisetsu_name_1 = form.cleaned_data['shisetsu_name_1'] Schedule_list.shift_name_2 = form.cleaned_data['shift_name_2'] Schedule_list.shisetsu_name_2 = form.cleaned_data['shisetsu_name_2'] Schedule_list.shift_name_3 = form.cleaned_data['shift_name_3'] Schedule_list.shisetsu_name_3 = form.cleaned_data['shisetsu_name_3'] Schedule_list.shift_name_4 = form.cleaned_data['shift_name_4'] Schedule_list.shisetsu_name_4 = form.cleaned_data['shisetsu_name_4'] #更新ボタン if "updatebutton" in request.POST: Schedule_list.day_total_worktime = form.cleaned_data['day_total_worktime'] #シフトから計算して更新ボタン elif "sumupdatebutton" in request.POST: # 日の労働合計時間をシフトから計算 sum_work_time = 0 for shift in shift_object: if str(form.cleaned_data['shift_name_1']) == str(shift.name): sum_work_time = shift.wrok_time + sum_work_time if str(form.cleaned_data['shift_name_2']) == str(shift.name): sum_work_time = shift.wrok_time + sum_work_time if str(form.cleaned_data['shift_name_3']) == str(shift.name): sum_work_time = shift.wrok_time + sum_work_time if str(form.cleaned_data['shift_name_4']) == str(shift.name): sum_work_time = shift.wrok_time + sum_work_time Schedule_list.day_total_worktime = sum_work_time Schedule_list.save() return HttpResponseRedirect('/schedule/monthschedule/%s/%s/' % (year,month,)) else: item = { "shift_name_1":Schedule_list.shift_name_1, "shisetsu_name_1": Schedule_list.shisetsu_name_1, "shift_name_2": Schedule_list.shift_name_2, "shisetsu_name_2": Schedule_list.shisetsu_name_2, "shift_name_3": Schedule_list.shift_name_3, "shisetsu_name_3": Schedule_list.shisetsu_name_3, "shift_name_4": Schedule_list.shift_name_4, "shisetsu_name_4": Schedule_list.shisetsu_name_4, "day_total_worktime": Schedule_list.day_total_worktime, } form = ScheduleUpdateForm(initial=item) context = { 'form' : form, 'Schedule_list': Schedule_list, 'User_list': User_list, 'shift_object': shift_object, } return render(request,'schedule/update.html', context ) def schedulecreatefunc(request,year_num,month_num): year, month = int(year_num), int(month_num) #対象年月のscheduleをすべて削除する Schedule.objects.filter(year = year, month = month).delete() #シフト範囲の日数を取得する enddate = datetime.date(year,month,20) startdate = enddate + relativedelta(months=-1) #希望シフトから対象期間の希望を抽出する kiboushift_list = KibouShift.objects.filter(date__range=[startdate, enddate]) kiboushift_list = list(kiboushift_list) shift_list = Shift.objects.all() #希望シフトを反映 for kibou in kiboushift_list: sum_work_time = 0 for shift in shift_list: if str(kibou.shift_name_1) == str(shift.name): sum_work_time = shift.wrok_time + sum_work_time if str(kibou.shift_name_2) == str(shift.name): sum_work_time = shift.wrok_time + sum_work_time if str(kibou.shift_name_3) == str(shift.name): sum_work_time = shift.wrok_time + sum_work_time if str(kibou.shift_name_4) == str(shift.name): sum_work_time = shift.wrok_time + sum_work_time new_object = Schedule( user = kibou.user, date = kibou.date, year = year, month = month, shift_name_1 = kibou.shift_name_1, shisetsu_name_1 = kibou.shisetsu_name_1, shift_name_2 = kibou.shift_name_2, shisetsu_name_2 = kibou.shisetsu_name_2, shift_name_3 = kibou.shift_name_3, shisetsu_name_3 = kibou.shisetsu_name_3, shift_name_4 = kibou.shift_name_4, shisetsu_name_4 = kibou.shisetsu_name_4, day_total_worktime = sum_work_time, ) new_object.save() #希望シフト以外を作成 user_list = User.objects.all() #シフト範囲の日数を取得する enddate = datetime.date(year,month,20) startdate = enddate + relativedelta(months=-1) kaisu = enddate - startdate kaisu = int(kaisu.days) #前月 if month != 1 : zengetsu = month - 1 else: zengetsu = 12 year = year - 1 #ユーザーごとに処理をする for user in user_list: kongetsu_list = Schedule.objects.filter(year = year, month = month, user = user.id).order_by('date') zengetsu_list = Schedule.objects.filter(year = year, month = zengetsu, user = user.id).order_by('date') sakusei_date = startdate shift_list = Shift.objects.all() for new_shift in range(kaisu): sakusei_date = sakusei_date + timedelta(days=1) if kongetsu_list.filter(user = user.id, date = sakusei_date).exists(): print("ok") else: hukushadate = sakusei_date + relativedelta(months=-1) hukusha_list = zengetsu_list.filter(date = hukushadate, user = user.id) if zengetsu_list.filter(date = hukushadate, user = user.id).exists(): for hukusha in hukusha_list: # 日の労働合計時間をシフトから計算 sum_work_time = 0 for shift in shift_list: if str(hukusha.shift_name_1) == str(shift.name): sum_work_time = shift.wrok_time + sum_work_time if str(hukusha.shift_name_2) == str(shift.name): sum_work_time = shift.wrok_time + sum_work_time if str(hukusha.shift_name_3) == str(shift.name): sum_work_time = shift.wrok_time + sum_work_time if str(hukusha.shift_name_4) == str(shift.name): sum_work_time = shift.wrok_time + sum_work_time new_object=Schedule( user = hukusha.user, date = sakusei_date, year = year, month = month, shift_name_1 = hukusha.shift_name_1, shisetsu_name_1 = hukusha.shisetsu_name_1, shift_name_2 = hukusha.shift_name_2, shisetsu_name_2 = hukusha.shisetsu_name_2, shift_name_3 = hukusha.shift_name_3, shisetsu_name_3 = hukusha.shisetsu_name_3, shift_name_4 = hukusha.shift_name_4, shisetsu_name_4 = hukusha.shisetsu_name_4, day_total_worktime = sum_work_time, ) new_object.save() else: useradd = User.objects.get(id=user.id) shiftadd = Shift.objects.get(id=2) new_object=Schedule( user = useradd, date = sakusei_date, year = year, month = month, shift_name_1 = shiftadd, shisetsu_name_1 = None, shift_name_2 = None, shisetsu_name_2 = None, shift_name_3 = None, shisetsu_name_3 = None, shift_name_4 = None, shisetsu_name_4 = None, day_total_worktime = 0, ) new_object.save() return HttpResponseRedirect('/schedule/monthschedule/%s/%s/' % (year,month,)) def kiboulistfunc(request): KibouShift_list = KibouShift.objects.all().order_by('-date') User_list = User.objects.all() shift_object = Shift.objects.all() context = { 'KibouShift_list': KibouShift_list, 'User_list': User_list, 'shift_object': shift_object, } return render(request,'schedule/kiboushift/list.html', context ) class KibouCreate(CreateView): template_name = 'schedule/kiboushift/create.html' model = KibouShift fields = ('user', 'date', 'shift_name_1', 'shisetsu_name_1', 'shift_name_2', 'shisetsu_name_2', 'shift_name_3', 'shisetsu_name_3', 'shift_name_4', 'shisetsu_name_4') success_url = reverse_lazy('schedule:KibouList') class KibouUpdate(UpdateView): template_name = 'schedule/kiboushift/update.html' model = KibouShift fields = ('user', 'date', 'shift_name_1', 'shisetsu_name_1', 'shift_name_2', 'shisetsu_name_2', 'shift_name_3', 'shisetsu_name_3', 'shift_name_4', 'shisetsu_name_4') success_url = reverse_lazy('schedule:KibouList') class KibouDelete(DeleteView): template_name = 'schedule/kiboushift/delete.html' model = KibouShift fields = ('user', 'date', 'shift_name_1', 'shisetsu_name_1', 'shift_name_2', 'shisetsu_name_2', 'shift_name_3', 'shisetsu_name_3', 'shift_name_4', 'shisetsu_name_4') success_url = reverse_lazy('schedule:KibouList')これで作成機能が完成しました。
希望シフトデータを作成してから、他の日については、前月同日で作成するという機能にしました。同じ処理(シフト名前から労働時間を計算する)を関数で呼び出して値を返すとしたかったのですが、まだわからないので別々で書いてしまいました。これからそういったことも覚えて、コードを短くしていくことも覚えていきたいと思います。
前月がなかった場合は、休みで作成するようにしています。
次は、まだまだ未知の世界であるcss や js の世界に踏み入れなければならないかもしれません…(笑)
実際20人近くを登録するので全体表示したときには、表のヘッダを固定しないとみにくくて…こんな感じ
いつの日のシフトかなぞ状態になります…
スマホでもみやすいように変えたい思っています。
スマホ対応は、まだまだできるかわかりませんが、表示固定は実装をしていきたいと思います。


- 投稿日:2020-09-29T07:24:56+09:00
Python3.6.10でDeepFloorPlanを動かしてみた
はじめに
ICCV2019で発表された「Deep Floor Plan Recognition Using a Multi-Task Network with Room-Boundary-Guided Attention」(以下、DeepFloorPlan)をpython3版に書き直して動かしてみました。[paper, github, github(python3版)]
タスクが具体的でビジネス的なニーズがありそうだなと思って気になってました。
今回の記事では、DeepFloorPlanについて簡単に紹介した後、デモプログラムを動かしてみた結果を書いてみます。
学習プログラムを動かした結果もDeepFloorPlanとは
一言で言うと「部屋の間取りを認識する」DNNです。
部屋の境界予測タスク、部屋タイプ予測タスクごとにデコーダを分けているのが特徴的です。
また、部屋タイプ予測には部屋の境界情報をアテンションとして使用しています。ネットワーク自体は割とシンプルですがPSPNetやDeepLabV3+よりも良い性能が出ています。
実行環境
OS: windows10 64bit
GPU: GeForce GTX1060 6GBデモプログラム実行結果
学習済みのモデルを使用してデモプログラムを動かしてみました。
ここでは、推論が比較的うまく出来ている例とそうでない例を挙げてみたいと思います。推定できている例
ホール部分が一部クローゼットやトイレと認識されていますが、背景と各部屋タイプ、ドアと窓まで比較的正しく認識されています。推定できてない例
バルコニーとダイニングルームの境界が正しく認識されていません。ドアのタイプが少し特殊なのが影響していそうです。
また、このデータでは背景と部屋の境界が一部正しく認識されていません。入力画像の背景部分に図面の注釈が入っているのが原因っぽいです。考察
この他いくつかのデータを見てみましたが、以下の点が難しそうです。
- ドアのタイプが特殊なもの
- 背景部分に注釈や寸法が入っている
- 部屋の形がいびつなもの(単純な矩形ではなく、円形や台形のような部屋)
この辺を対処するような改良を今後加えてみたいと思います。
学習プログラム実行結果
改良して結果を含めて後日追記したいと思います。
精度改良案があれば是非是非コメントお願いします!