- 投稿日:2020-09-29T23:24:47+09:00
エンジニアの本棚卸し
目的
自分がインプットしてきた技術関連知識の足跡整理。
文字にするとキリがないので、面倒ではない視覚的に集約されているという点で本棚の書籍写真でペタペタ整理。足跡
入り口はC言語
猫でも分かるC言語で自分が猫未満であることを悟り、苦しんで〜みたいな名前の書籍を読んだ記憶。
DXLibraryを使用してゲーム製作をしたり、遺伝的アルゴリズムでレースゲームのゴール時間を最適化したり、TCP/IPレイヤをイジったり、二度デストラクタを呼び壊したり、ダングリングポインタを参照して壊したり、壊したり。Webアプリケーションに興味が出てPHPあたり
Webアプリケーションを作りたくてPHP(時代を感じる)。
当時はLaravelではなくCakePHP,Symfonyとかの時代。Cakeを使ってWebアプリケーションを作っていたもののフレームワーク特有のブラックボックに薄気味悪さを覚えたため、一旦それは捨ててMVCフレームワークの自作に舵を切り替えた。
その後、数年してからREST APIでバックエンドとフロントエンドを接続するみたいなものが流行りだしたときにLaravelとReactでチーム開発した。オブジェクトモデリングに興味が出てJava
現実世界の写像(モデリング)ってなんぞ、と思いJava。
とやかく言われることの多い言語であるものの、複雑度の高いシステム構築においては安定している。エンジニアとして知識領域を開拓する礎になった恋のキューピッド的な言語。
OSが知りたいです
私達人間に何を隠しているのOSさん、ということでOS。
LINUXプログラミングインタフェースは学生のときに夏休みを使って読み切った(覚えてないけど)。CPUが知りたいです
演算あたりの機構が知りたくてパタヘネ本とか、CPUの創りかたとか。
左のほうにある本はAPI設計やら、正規表現エンジンやら、Androidアプリとかに興味を持ったときの。副作用のない言語?
保守性や疎結合などの文脈で関数型言語に興味を持った(ように記憶している)。
最初はCommonLisp。本屋でリスプエイリアンと目が合った。今はRustが好き。
メモリ安全、ゼロコスト抽象化、GCのない軽量なランタイム。機械学習やスクレイピング、デバッガ
脳内シナプスによるネットワークを模倣ってなにを言ってるの、と興味を持ち自作系のお魚本から。
テンソルフローの計算グラフが作れないので基本Keras(に逃げた)。その他、Pythonはスクレイピングやデバッガのカスタマイズなどでちょくちょく使う。
私はパケットになりたい
ネットワークってなにそれどうやって制御してるの、知りたい。
MPLSなにそれ、剥がされたい。攻撃は最大の防御
避けがたいクラッキングという中二病。
もちろん隔離された自分だけの環境で。コンピューティングリソースに対する抜本的な認識刷新
このあたりのコンピューティングリソースの変化はコペルニクス的転回(言いたいだけ)をもたらしましたね。マークアップとスタイル
あまり得意ではないものの、意思疎通を図るために必要なので最低限は知っておきたい。
右の砂川物理学は関係ない。DBさん腹のウチを見せてごらん
性能改善系のプロジェクトに配属されたついでにDB解体。鳥になって鳥瞰したい
システムの設計というものを真剣に考え始めたときに。無限多味スルメ
実践UML、コード・クラフト、コードコンプリートあたりは読むたびに味が変わる。その他1
リファクタとか、GC、コンパイラなど。その他2
テスト手法やらGitの仕組みやら。振り返った所感
まだ埋もれた書籍はクローゼットに大量にあるものの、とりあえず本棚にあるもので振り返ってみた。
結論:「頭でっかちになってはいけない」
物事の正しさというものは話し手5割・聞き手5割の双方の責任のもとに成立している。
書籍においても同様に書き手5割・読み手5割。誰かが言っていたらから正しいとか、あの本に書いてあったから正しいのような
話し手や書き手10割の責とするような姿勢でいてはいけないな、と最近は特に強く感じるようになった。
















- 投稿日:2020-09-29T23:15:35+09:00
Oracleから公開されたTribuoを気を取り直してやってみたら中の人は熱い感じの人だった
前置き
リアルタイムでいろいろ更新されているため、情報整理のために、再度チュートリアルの内容をまとめました。本記事はこちらの内容を元に書いたものです。
資料について
元ネタはこちらを参照してください。
日本語が必要ならこちらを参照してください。
アヤメデータのダウンロードはこちらを参照してください。
ソースコードはこちらを参照してください。
Java Docはこちらを参照してください。変更点
CSVデータロードの不具合は修正されています。v4.0.1 ※
CSVReaderで、末尾に余計な改行があるファイルを読み込めない問題を修正しました。
IDX(すなわちMNIST)フォーマットのデータセットを読めるようにIDXDataSourceを追加しました。
libsvmファイルではなくIDXファイルからMNISTを読み込むように設定チュートリアルを更新しました。
中の人の話では、ドキュメントにv4.0.0て書いてるの見落としてたわー、直しておいたわーって言ってました。
一応気が付いているので書いておくと、Introductionに出てくる下のコードの3行目は、第一引数にmodelが必要です。
1. var trainSet = new MutableDataset<>(new LibSVMDataSource(Paths.get("train-data"),new LabelFactory())); 2. var model = new LogisticRegressionTrainer().train(trainSet); 3. var eval = new LabelEvaluator().evaluate(new LibSVMDataSource(Paths.get("test-data"),trainSet.getOutputFactory()));var eval = new LabelEvaluator() .evaluate(model, new LibSVMDataSource(Paths.get("test-data"), trainSet.getOutputFactory()));追記 2020/09/30
直してコミットしておいたって返事来てました。その他のネタ
あれとか、これとかはgitのIssuesにあげてみたのですが、まじめに回答されてしまいました。ネタ記事のつもりだったのですが、真剣に付き合っていただきありがとうございました。
中の人の話では、Tribuoの公式ページは、もう直したわーとのことです。nullチェックとjavadocは今週直しておくわーとのことです。対応が早い。
この中の人Tensorflow javaのコミッターとのこと。本人が言ってました。
FP16でGPUを使った計算については、JVMはすでにaarch64をサポートしてるから、Tensorflow JavaとONNX RuntimeのJava APIが、すぐ対応すはずだよ、Tribuoもこいつら追いかけるぜーって中の人。が言ってました。現状でも、Tensorflow JavaかONNX Runtime使えばできるぜーって言ってました。
熱量すごいなこの人たち。私は日本でこんなことしたい。
OpenAIが全然オープンじゃないし。セットアップ(Getting Started)
前回からバージョン変更しています。
mavenでは下記のように設定します。
<dependency> <groupId>org.tribuo</groupId> <artifactId>tribuo-all</artifactId> <version>4.0.1</version> <type>pom</type> </dependency>gradleではドキュメント記載の方法ではうまくjarがダウンロード出来ません。pomファイルだけダウンロードされます。
下記のように設定する必要があります。api ('org.tribuo:tribuo-all:4.0.1@pom') { transitive = true }kotlinだとまた違う動作するらしいです。ドキュメントにタブ追加して、書いておくけど、gradleのために、わざわざタブ作ってGroovyとkotlinで2重に記載するのは嫌だとお怒りです。
アヤメのデータを取得します。
アヤメデータのダウンロード先https://archive.ics.uci.edu/ml/machine-learning-databases/iris/bezdekIris.data通常のmainメソッドを持つクラスを作成して、Getting Startedの通りに実装を行います。
SampleTribuopackage org.project.eden.adam; import java.io.IOException; import java.nio.file.Paths; import org.tribuo.DataSource; import org.tribuo.Model; import org.tribuo.MutableDataset; import org.tribuo.Prediction; import org.tribuo.classification.Label; import org.tribuo.classification.LabelFactory; import org.tribuo.classification.dtree.CARTClassificationTrainer; import org.tribuo.classification.evaluation.LabelEvaluation; import org.tribuo.classification.evaluation.LabelEvaluator; import org.tribuo.classification.sgd.linear.LogisticRegressionTrainer; import org.tribuo.data.csv.CSVLoader; import org.tribuo.evaluation.TrainTestSplitter; /** * @author jashika * */ public class SampleTribuo { /** * @param args mainメソッドの引数。 * @throws IOException ファイルの読み込みエラー時にスローされる。 */ public static void main(String[] args) throws IOException { // ラベル付きアヤメデータを読み込む var irisHeaders = new String[] { "sepalLength", "sepalWidth", "petalLength", "petalWidth", "species" }; DataSource<Label> irisData = new CSVLoader<>(new LabelFactory()).loadDataSource(Paths.get("bezdekIris.data"), irisHeaders[4], irisHeaders); // ※読み込むデータのパスが埋め込まれているため、各自の環境に合わせてください。 // 読み込んだアヤメデータをトレーニング用に70%、テスト用に30%に分割 var splitIrisData = new TrainTestSplitter<>(irisData, 0.7, 1L); var trainData = new MutableDataset<>(splitIrisData.getTrain()); var testData = new MutableDataset<>(splitIrisData.getTest()); // 決定木学習を使用することができる var cartTrainer = new CARTClassificationTrainer(); Model<Label> tree = cartTrainer.train(trainData); // ロジスティック回帰を使用することもできる var linearTrainer = new LogisticRegressionTrainer(); Model<Label> linear = linearTrainer.train(trainData); // 最終的には、未知のデータから予測を行う // 予測は、出力名(すなわちラベル)と、スコア/確率となる。 Prediction<Label> prediction = linear.predict(testData.getExample(0)); // 完全なテストデータセットを評価して、精度、F1などを計算してもよい。 LabelEvaluation evaluation = new LabelEvaluator().evaluate(linear, testData); // 手動で評価を検査することもできる double acc = evaluation.accuracy(); // 0.978を返す // フォーマットされた評価文字列を表示する。 System.out.println(evaluation.toString()); } }SampleTribuoという名前で、1クラスを作ったのみです。
そのまま実行します。実行結果9月 29, 2020 5:12:51 午後 org.tribuo.data.csv.CSVIterator getRow 警告: Ignoring extra newline at line 151 9月 29, 2020 5:12:51 午後 org.tribuo.classification.sgd.linear.LinearSGDTrainer train 情報: Training SGD classifier with 105 examples 9月 29, 2020 5:12:51 午後 org.tribuo.classification.sgd.linear.LinearSGDTrainer train 情報: Labels - (0,Iris-versicolor,34), (1,Iris-virginica,35), (2,Iris-setosa,36) Class n tp fn fp recall prec f1 Iris-versicolor 16 16 0 1 1.000 0.941 0.970 Iris-virginica 15 14 1 0 0.933 1.000 0.966 Iris-setosa 14 14 0 0 1.000 1.000 1.000 Total 45 44 1 1 Accuracy 0.978 Micro Average 0.978 0.978 0.978 Macro Average 0.978 0.980 0.978 Balanced Error Rate 0.022各項目の説明
作成したSampleTribuoのコードの中で、下記の部分が、アヤメデータのヘッダー部分になります。
// ラベル付きアヤメデータを読み込む var irisHeaders = new String[] { "sepalLength", "sepalWidth", "petalLength", "petalWidth", "species" };ヘッダーの名称があらわしているのは、下記のようになります。
・sepalLength = がく(へた)の長さ
・sepalWidth = がく(へた)の幅
・petalLength = 花びらの長さ
・petalWidth = 花びらの幅
・species = 種類またアヤメデータの種類に着目すると、下記の3種類のデータが含まれているのがわかります。下記はダウンロードしたアヤメデータから抜粋したものです。
・5.8,4.0,1.2,0.2,
Iris-setosa
・6.7,2.5,5.8,1.8,Iris-virginica
・5.5,2.6,4.4,1.2,Iris-versicolor種類については下記のようになります。アヤメの種類らしいです。
・Iris setosa = ヒオウギアヤメ
・Iris versicolor = バージカラー
・Iris virginica = バージニカ(コバノズイナ?)Tribuoのサンプルコードで、一番最後にsystem.out.printlnで出力しているのは、LabelEvaluationクラスです。そして、LabelEvaluationクラスは、linearTrainerの学習済みModelと、テストデータを受け取っています。下記が該当箇所となります。前項で既出の出力結果はデータセットの評価結果となります。
SampleTribuo中略 // ロジスティック回帰を使用することもできる var linearTrainer = new LogisticRegressionTrainer(); Model<Label> linear = linearTrainer.train(trainData); // 完全なテストデータセットを評価して、精度、F1などを計算してもよい。 LabelEvaluation evaluation = new LabelEvaluator().evaluate(linear, testData); 中略 // フォーマットされた評価文字列を表示する。 System.out.println(evaluation.toString());LabelEvaluationクラスのJava Docをのぞいてみると、下記のような内容が書かれていました。個別に出力させたり、HTMLで出力させたるする機能が実装されています。
JavaDocのLabelEvaluation項目から抜粋double accuracy() 評価の総合的な精度。 double accuracy(Label label) 評価のラベルあたりの精度。 double AUCROC(Label label) ROC曲線の下の面積。 double averageAUCROC(boolean weighted) ラベル間で平均化されたROC曲線の下の面積。 double averagedPrecision(Label label) 所定の閾値での精度の加重平均を取ることで、精度-リコール曲線を要約し、重みはその閾値で達成されたリコールを表します。 LabelEvaluationUtil.PRCurve precisionRecallCurve(Label label) 単一ラベルの精度リコール曲線を計算します。 static String toFormattedString(LabelEvaluation evaluation) このメソッドは、ターミナルでの表示に適した、適切なタブと改行付きのきれいにフォーマットされた文字列出力を生成します。 default String toHTML() この評価を表すHTML形式の文字列を返します。 static String toHTML(LabelEvaluation evaluation) このメソッドは、Webページへの組み込みに適した、適切なタブと改行付きのHTMLフォーマットの文字列出力を生成します。 static String toFormattedString(LabelEvaluation evaluation) このメソッドは、ターミナルでの表示に適した、適切なタブと改行付きのきれいにフォーマットされた文字列出力を生成します。 static String toHTML(LabelEvaluation evaluation) このメソッドは、Webページへの組み込みに適した、適切なタブと改行付きのHTMLフォーマットの文字列出力を生成します。下記の部分が未知のデータの予測を行っている部分になります。とはいっても、未知のデータはもっていないので、分割された30%分のデータですが。
中略 // 最終的には、未知のデータから予測を行う。 // 予測は、出力名(すなわちラベル)と、スコア/確率となる。 Prediction<Label> prediction = linear.predict(testData.getExample(0)); // 追加しました。 // 未知のデータ(テストデータ)の内容を出力する。 System.out.println("入力するテストデータ: " + testData.getExample(0)); // Modelから予測データを出力する。 System.out.println("予測結果: " + prediction.getOutput()); 中略元ネタをそのまま実装していますが、テストデータの1件目を予測して、そのままなにもしていませんので、こちらを出力してみます。
9月 29, 2020 9:34:34 午後 org.tribuo.data.csv.CSVIterator getRow 警告: Ignoring extra newline at line 151 9月 29, 2020 9:34:34 午後 org.tribuo.classification.sgd.linear.LinearSGDTrainer train 情報: Training SGD classifier with 105 examples 9月 29, 2020 9:34:34 午後 org.tribuo.classification.sgd.linear.LinearSGDTrainer train 情報: Labels - (0,Iris-versicolor,34), (1,Iris-virginica,35), (2,Iris-setosa,36) 入力するテストデータ: ArrayExample(numFeatures=4,output=Iris-setosa,weight=1.0,features=[(petalLength, 1.3)(petalWidth, 0.3), (sepalLength, 4.5), (sepalWidth, 2.3), ]) 予測結果: (Iris-setosa,0.8752021370239595)入力されたデータは、ヒオウギアヤメ(Iris-setosa)のデータでそれぞれ、がくの長さ(sepalLength)は4.5、がくの幅は(sepalWidth)は2.3、花びらの長さ(petalLength)は1.3、花びらの幅(petalWidth)は0.3となります。
それに対して予測結果は87%の確立で、ヒオウギアヤメ(Iris-setosa)と予測されました。当たってますね。
これだけでは、あまり面白くないので、30%のデータを予測してみます。下記のようにコードを変更しました。
SampleTribuo中略 for (var example : testData) { // 正解 var correctAnswer = example.getOutput().getLabel(); // 予測結果 var predictResult = linear.predict(example); if (correctAnswer.equals(predictResult.getOutput().getLabel())) { System.out.println("予測結果->正解: " + predictResult.getOutputScores()); } else { System.out.println("予測結果->不正解: " + predictResult.getOutputScores() + "正解->" + correctAnswer); } } 中略実行結果9月 29, 2020 10:35:18 午後 org.tribuo.data.csv.CSVIterator getRow 警告: Ignoring extra newline at line 151 9月 29, 2020 10:35:18 午後 org.tribuo.classification.sgd.linear.LinearSGDTrainer train 情報: Training SGD classifier with 105 examples 9月 29, 2020 10:35:18 午後 org.tribuo.classification.sgd.linear.LinearSGDTrainer train 情報: Labels - (0,Iris-versicolor,34), (1,Iris-virginica,35), (2,Iris-setosa,36) 予測結果->正解: {Iris-versicolor=(Iris-versicolor,0.12465430241942166), Iris-virginica=(Iris-virginica,1.4356055661867684E-4), Iris-setosa=(Iris-setosa,0.8752021370239595)} 予測結果->正解: {Iris-versicolor=(Iris-versicolor,0.022985338660181973), Iris-virginica=(Iris-virginica,4.886599414569194E-6), Iris-setosa=(Iris-setosa,0.9770097747404035)} 予測結果->正解: {Iris-versicolor=(Iris-versicolor,0.8743791900480306), Iris-virginica=(Iris-virginica,0.11972594367759447), Iris-setosa=(Iris-setosa,0.005894866274374883)} 予測結果->正解: {Iris-versicolor=(Iris-versicolor,0.13752628567026762), Iris-virginica=(Iris-virginica,0.8624557718013333), Iris-setosa=(Iris-setosa,1.794252839916067E-5)} 予測結果->正解: {Iris-versicolor=(Iris-versicolor,0.754662316591029), Iris-virginica=(Iris-virginica,0.24288192724655125), Iris-setosa=(Iris-setosa,0.00245575616241976)} 予測結果->正解: {Iris-versicolor=(Iris-versicolor,0.1114591917841135), Iris-virginica=(Iris-virginica,0.8885339140853985), Iris-setosa=(Iris-setosa,6.89413048798891E-6)} 予測結果->正解: {Iris-versicolor=(Iris-versicolor,0.018368556099769975), Iris-virginica=(Iris-virginica,2.8979851163953406E-6), Iris-setosa=(Iris-setosa,0.9816285459151136)} 予測結果->正解: {Iris-versicolor=(Iris-versicolor,0.8336662376434194), Iris-virginica=(Iris-virginica,0.16052879318949909), Iris-setosa=(Iris-setosa,0.005804969167081375)} 予測結果->正解: {Iris-versicolor=(Iris-versicolor,0.7401640849157867), Iris-virginica=(Iris-virginica,0.25814459323929695), Iris-setosa=(Iris-setosa,0.0016913218449164506)} 予測結果->正解: {Iris-versicolor=(Iris-versicolor,0.37734213887670864), Iris-virginica=(Iris-virginica,0.6225430896188512), Iris-setosa=(Iris-setosa,1.1477150444008675E-4)} 予測結果->正解: {Iris-versicolor=(Iris-versicolor,0.08165259920209698), Iris-virginica=(Iris-virginica,0.9183413054167227), Iris-setosa=(Iris-setosa,6.095381180367614E-6)} 予測結果->正解: {Iris-versicolor=(Iris-versicolor,0.9166451164592634), Iris-virginica=(Iris-virginica,0.0710098849793183), Iris-setosa=(Iris-setosa,0.012344998561418293)} 予測結果->正解: {Iris-versicolor=(Iris-versicolor,0.12496197859394245), Iris-virginica=(Iris-virginica,0.8750207513327715), Iris-setosa=(Iris-setosa,1.7270073286161786E-5)} 予測結果->正解: {Iris-versicolor=(Iris-versicolor,0.08832616235771579), Iris-virginica=(Iris-virginica,0.9116697571921494), Iris-setosa=(Iris-setosa,4.080450134879567E-6)} 予測結果->正解: {Iris-versicolor=(Iris-versicolor,0.7606313121553816), Iris-virginica=(Iris-virginica,0.23595375784889286), Iris-setosa=(Iris-setosa,0.0034149299957255148)} 予測結果->正解: {Iris-versicolor=(Iris-versicolor,0.2838330052617929), Iris-virginica=(Iris-virginica,0.7160953733169281), Iris-setosa=(Iris-setosa,7.162142127894781E-5)} 予測結果->正解: {Iris-versicolor=(Iris-versicolor,0.8962905028787402), Iris-virginica=(Iris-virginica,0.076593124958417), Iris-setosa=(Iris-setosa,0.027116372162842753)} 予測結果->正解: {Iris-versicolor=(Iris-versicolor,0.8781294741330369), Iris-virginica=(Iris-virginica,0.11263604829308826), Iris-setosa=(Iris-setosa,0.009234477573874762)} 予測結果->正解: {Iris-versicolor=(Iris-versicolor,0.02598246093746204), Iris-virginica=(Iris-virginica,9.258026355622071E-6), Iris-setosa=(Iris-setosa,0.9740082810361823)} 予測結果->正解: {Iris-versicolor=(Iris-versicolor,0.4125332441403861), Iris-virginica=(Iris-virginica,0.5874113240653356), Iris-setosa=(Iris-setosa,5.54317942782377E-5)} 予測結果->正解: {Iris-versicolor=(Iris-versicolor,0.005480793710204649), Iris-virginica=(Iris-virginica,3.36057635603426E-7), Iris-setosa=(Iris-setosa,0.9945188702321598)} 予測結果->正解: {Iris-versicolor=(Iris-versicolor,0.7157983219006878), Iris-virginica=(Iris-virginica,0.28236588916463473), Iris-setosa=(Iris-setosa,0.0018357889346774156)} 予測結果->正解: {Iris-versicolor=(Iris-versicolor,0.041785356794614356), Iris-virginica=(Iris-virginica,1.63804767321482E-5), Iris-setosa=(Iris-setosa,0.9581982627286535)} 予測結果->正解: {Iris-versicolor=(Iris-versicolor,0.03557299656267042), Iris-virginica=(Iris-virginica,1.572396823310113E-5), Iris-setosa=(Iris-setosa,0.9644112794690964)} 予測結果->正解: {Iris-versicolor=(Iris-versicolor,0.7445227755500248), Iris-virginica=(Iris-virginica,0.25336879249494487), Iris-setosa=(Iris-setosa,0.0021084319550302984)} 予測結果->正解: {Iris-versicolor=(Iris-versicolor,0.23201927045744059), Iris-virginica=(Iris-virginica,0.7679353747675968), Iris-setosa=(Iris-setosa,4.535477496262948E-5)} 予測結果->正解: {Iris-versicolor=(Iris-versicolor,0.6136153688335659), Iris-virginica=(Iris-virginica,0.38487059274540525), Iris-setosa=(Iris-setosa,0.0015140384210286877)} 予測結果->正解: {Iris-versicolor=(Iris-versicolor,0.0037281020760574794), Iris-virginica=(Iris-virginica,1.291282392314054E-7), Iris-setosa=(Iris-setosa,0.9962717687957032)} 予測結果->正解: {Iris-versicolor=(Iris-versicolor,0.04755707288123218), Iris-virginica=(Iris-virginica,1.934947705107781E-5), Iris-setosa=(Iris-setosa,0.9524235776417168)} 予測結果->正解: {Iris-versicolor=(Iris-versicolor,0.19993977432885074), Iris-virginica=(Iris-virginica,0.8000350473542086), Iris-setosa=(Iris-setosa,2.5178316940654208E-5)} 予測結果->正解: {Iris-versicolor=(Iris-versicolor,0.04523347766974972), Iris-virginica=(Iris-virginica,2.000119721397452E-5), Iris-setosa=(Iris-setosa,0.9547465211330363)} 予測結果->正解: {Iris-versicolor=(Iris-versicolor,0.029794358762199272), Iris-virginica=(Iris-virginica,8.7737002425928E-6), Iris-setosa=(Iris-setosa,0.9701968675375582)} 予測結果->不正解: {Iris-versicolor=(Iris-versicolor,0.5733177742115076), Iris-virginica=(Iris-virginica,0.42626475284848847), Iris-setosa=(Iris-setosa,4.1747294000396004E-4)}正解 -> Iris-virginica 予測結果->正解: {Iris-versicolor=(Iris-versicolor,0.029877036683050945), Iris-virginica=(Iris-virginica,7.161847786201107E-6), Iris-setosa=(Iris-setosa,0.970115801469163)} 予測結果->正解: {Iris-versicolor=(Iris-versicolor,0.7821104478321824), Iris-virginica=(Iris-virginica,0.21391875776045305), Iris-setosa=(Iris-setosa,0.003970794407364584)} 予測結果->正解: {Iris-versicolor=(Iris-versicolor,0.019534516466634153), Iris-virginica=(Iris-virginica,5.375894384912967E-6), Iris-setosa=(Iris-setosa,0.9804601076389811)} 予測結果->正解: {Iris-versicolor=(Iris-versicolor,0.05383775370019657), Iris-virginica=(Iris-virginica,0.9461587580877066), Iris-setosa=(Iris-setosa,3.4882120966764877E-6)} 予測結果->正解: {Iris-versicolor=(Iris-versicolor,0.12393648653270413), Iris-virginica=(Iris-virginica,0.8760476481453248), Iris-setosa=(Iris-setosa,1.58653219710635E-5)} 予測結果->正解: {Iris-versicolor=(Iris-versicolor,0.8991747020299696), Iris-virginica=(Iris-virginica,0.09631094366524456), Iris-setosa=(Iris-setosa,0.004514354304785789)} 予測結果->正解: {Iris-versicolor=(Iris-versicolor,0.8925507000636339), Iris-virginica=(Iris-virginica,0.10101559809853458), Iris-setosa=(Iris-setosa,0.00643370183783148)} 予測結果->正解: {Iris-versicolor=(Iris-versicolor,0.759603537166626), Iris-virginica=(Iris-virginica,0.23777484597390816), Iris-setosa=(Iris-setosa,0.00262161685946576)} 予測結果->正解: {Iris-versicolor=(Iris-versicolor,0.01560114791426806), Iris-virginica=(Iris-virginica,2.3647440157063515E-6), Iris-setosa=(Iris-setosa,0.9843964873417164)} 予測結果->正解: {Iris-versicolor=(Iris-versicolor,0.23490596676084197), Iris-virginica=(Iris-virginica,0.7650569443472615), Iris-setosa=(Iris-setosa,3.708889189648049E-5)} 予測結果->正解: {Iris-versicolor=(Iris-versicolor,0.5604116022032899), Iris-virginica=(Iris-virginica,0.4392143166585561), Iris-setosa=(Iris-setosa,3.740811381540314E-4)} 予測結果->正解: {Iris-versicolor=(Iris-versicolor,0.13060096881100045), Iris-virginica=(Iris-virginica,0.8693951745606155), Iris-setosa=(Iris-setosa,3.856628384041485E-6)}1件不正解となっていますが、バージカラー(Iris-versicolor)の可能性は57% バージニカ(Iris-virginica)の可能性は42%と予測されています。逆に正解しているデータでも、バージカラー(Iris-versicolor)の可能性56%と、結構低い確率での正解も存在しています。学習させるデータが少ないので偏りが出るのでしょう。ここから、精度を上げていくのが楽しいはずです。
SampleTribuoでは、ロジスティクス回帰を利用して学習していますが、他にも利用できるクラスが準備されています。Trainerインターフェースの実装はたくさんあるので、これらを試していくだけでも結構時間がかかりそうです。やはりCPUでの学習よりも、GPUでの学習を行うようにしていきたいと思いますので、学習モデルそのものよりも先に、ONNXの連携部分か、TensorFlowの連携部分から見ていくのが良いような気がします。
まぁ機械学習なんて、ここ2、3日しかやったことないですが・・・。あとがき
作成したSampleTribuoでは、毎回テストデータを読み込んで学習をすることになるので、学習済みデータを保存する方法を探していたのですが、ドキュメントからは見つかりませんでした。ソースコードからは、Tensorfrowを使ってTensorflowModelを保存する方法と、CSVを保存する方法は提供されてるっぽいことが分かるのですが、初めて触るコードなのでいまいち、癖というか思想が分かりません。こんなのが、ここにあるはずっていう感が働かないというか・・・。
自前でシリアライズ、デシリアライズするのかと勝手に考えていたら、Issuesに出てました。
質問内容は下記のようなものです。
モデルやデータセットをディスクにシリアライズする例をチュートリアルやドキュメントに含めることはできますか?ONNXの使用方法についての追加のヘルプもあると助かります。それに対する回答がこちらです。
確かに、ドキュメントにシリアライズの例を追加することができます。現時点では、シリアライズは標準的なjava.io.Serializableメカニズムを使用しています。モデルやデータセットをロードして保存する例は、Tribuoに付属のデモプログラムで見ることができます。デシリアライズ攻撃を防ぐために、シリアライズ許可リストを使用する必要があることに注意してください。 現時点でのONNXローダの最良の例は、ユニットテストにあります。サードパーティ製モデルのロードプロセスを経たチュートリアルを追加する予定です。つまり、ドキュメントに載っていないですし、java.io.Serializableをつかって自前でどうぞってことみたいです。ONNXローダの使い方は、テストコードにあると・・・。自分でソース検索しろってことですね。
テストコード探してみたけど、ロードはしてました。あれ?セーブは?OnnxRuntimeの中を見たのですが、ロードのみですね。「JNI バインディング用のスタティックローダー。パブリックAPIはありませんが、このパッケージの様々なクラスから呼び出されます。」って書いてますし。
ai.onnxruntimeのパッケージの中も、org.tribuo.interop.onnxのパッケージの中にもなさそう。そもそも、現時点では、「シリアライズは標準的なjava.io.Serializableメカニズムを使用しています。」と言ってますから、Tensorflowで出来そうなだけで、公式には、今のところは無いんでしょうね。機能はそこそこ出来上がっているのですが、いかんせん、英語でもドキュメントが追い付いていないです。ところどころjavadoc入っていないとかありますし。聞けば教えてくれそうではありますが、いちいち聞くよりも、試したほうが早いし、でもめんどくさいし見たいな感じです。いまのところは、うーんといった感じがありますが、何となく一気に化けそうな気もしますよ。中の人結構熱い人ですしね。
次はどこに手を付けていくか考えてみます。
- 投稿日:2020-09-29T21:25:30+09:00
Java初学者がeclipseでショートカットキーを使えるように設定してみた
eclipseでJavaの学習をするにあたり、ショートカットキーがうまく効かずに困ったので、解決策をメモします。
使用環境
macOS CataLina
eclipse2019/ Full Editioneclipseについては、Pleiades All in One というパッケージを使用しています。日本語化プラグインもそのまま使えるので便利です。
ちなみに、こちらからダウンロードできます。
https://mergedoc.osdn.jp/手順
Eclipseの設定 > 一般 > キー
の 「スキーム」 が "デフォルト" の箇所を"Emacs" に変更。
→ 「適用して閉じる」を選択。
これだけです!!
少しでもお役に立てれば幸いです。
- 投稿日:2020-09-29T21:13:28+09:00
Doma入門 - Criteria APIで動的にWHERE句を組み立てる
はじめに
データベースアクセスライブラリの評価項目はいくつかありますが、その中でも動的なSQLをどれだけ組み立てやすいかというのは優先度が高い項目なのではと思います。静的なSQLは簡単に書けるのに、動的なSQLとなると途端に大変になってしまうというのはありがちですね。特に業務系のアプリケーションの場合、画面に複数の検索項目があり、指定されていたら検索条件に含め指定されていなければ含めないというような要件がありますが、ライブラリが提供する機能によってはアプリケーションのコードが条件分岐だらけになり可読性が低下してしまいます。
この記事ではDoma 2.43.0のCriteria APIを使って動的にSQLのWHERE句を組み立てる機能を紹介し、Domaでは上述した問題をどのように解決できるかを示します。
DomaやCriteria APIの概要については、Doma入門 - Criteria APIの紹介 もお読みください。
この記事で使うサンプルコード
データベースには従業員を表すemployeeテーブルが1つだけあります。
schema.sqlcreate table employee ( id integer not null primary key, name varchar(255) not null, age integer not null, version integer not null);employeeテーブルに対応するエンティティクラスとして
Employeeクラスを用意します。Employee.java@Entity(metamodel = @Metamodel) public class Employee { @Id public Integer id; public String name; public Integer age; @Version public Integer version; }従業員を年齢で検索するRepositoryとして
EmployeeRepositoryを用意します。
検索する際、年齢の上限と下限をオプションで指定できる(指定されていれば検索条件に含めるし、指定されなければ含めない)ものとし、この機能はselectByAgeRangeメソッドで実装します。EmployeeRepository.javapublic class EmployeeRepository { private final Entityql entityql; public EmployeeRepository(Config config) { this.entityql = new Entityql(config); } public List<Employee> selectByAgeRange(Integer min, Integer max) { // ここをCriteria APIでどのように実装するかがこの記事の主眼です } }nullと比較する検索条件の自動除去機能
DomaのCriteria APIは、nullと比較するような検索条件を指定するとその条件を自動でWHERE句から除外する機能を持ちます。したがって、この機能を利用すると
selectByAgeRangeの実装では条件分岐を記述する必要がありません。次のように実装できます。EmployeeRepository.javaの一部public List<Employee> selectByAgeRange(Integer min, Integer max) { Employee_ e = new Employee_(); return entityql .from(e) .where( c -> { c.ge(e.age, min); c.le(e.age, max); }) .fetch(); }以下では、このメソッドをいくつかのパターンで呼び出した時に生成されるSQLを見てみます。
minにもmaxにも非nullな値を渡す場合
以下、
repositoryはEmployeeRepositoryクラスのインスタンスを表します。List<Employee> list = repository.selectByAgeRange(30, 40);この時生成されるSQLは次のようなものになります。年齢の上限と下限を指定した検索条件がちゃんとWHERE句に現れていますね。
select t0_.id, t0_.name, t0_.age, t0_.version from Employee t0_ where t0_.age >= ? and t0_.age <= ?minに非null、maxにnullを渡す場合
List<Employee> list = repository.selectByAgeRange(30, null);上限を指定する検索条件がWHERE句に現れません。
select t0_.id, t0_.name, t0_.age, t0_.version from Employee t0_ where t0_.age >= ?minにnull、maxに非nullを渡す場合
List<Employee> list = repository.selectByAgeRange(null, 40);今度は下限を指定する検索条件がWHERE句に現れません。
select t0_.id, t0_.name, t0_.age, t0_.version from Employee t0_ where t0_.age <= ?minにもmaxにもnullを渡す場合
List<Employee> list = repository.selectByAgeRange(null, null);どういう結果になるか予想できると思います。そう、上限と下限を指定する検索条件がどちらも現れなくなります。
select t0_.id, t0_.name, t0_.age, t0_.version from Employee t0_ブロック内での明示的な条件分岐
では、nullではない値を見て検索条件に含めるかどうか判断したい場合はどのように書くべきでしょうか?例えば、年齢の下限が0以下の時は条件に含めない(0より大きい場合にのみ条件に含める)という要件があったとします。その場合は次のように明示的な条件分岐を書けます。
EmployeeRepository.javaの一部public List<Employee> selectByAgeRange(Integer min, Integer max) { Employee_ e = new Employee_(); return entityql .from(e) .where( c -> { if (min != null && min > 0) { c.ge(e.age, min); } c.le(e.age, max); }) .fetch(); }単にwhereメソッドに渡すラムダ式のブロックの中で条件分岐をしています。条件が評価されない限りは検索条件に含まれません。
List<Employee> list = repository.selectByAgeRange(-1, 40);上記のように呼び出すと、次のようなSQLが生成され、下限を指定する検索条件がWHERE句に登場しないことがわかります。
select t0_.id, t0_.name, t0_.age, t0_.version from Employee t0_ where t0_.age <= ?おわりに
この記事ではDomaのCriteria APIを使って簡潔にSQLの動的なWHERE句を組み立てられることを紹介しました。
ここに示したの全く同じではないのですが、似たようなコードが下記のプロジェクトにあり動かして試すことができます。
- 投稿日:2020-09-29T18:58:18+09:00
【Java開発】Javaのメモリ
初めに
皆さん。こんにちは!
DreamHanksの254cmです。
今回は今までのjava記事で少しずつ言及されましたが
扱ってなかったメモリについて簡単に扱おうと思います。
Java記事のまとめはこちらです。
JVM
メモリについて話す前にJVMというものを分かる必要があります。
JVMは「Java Virtual Machine」の略であり、Javaプログラムを実際に実行するものです。
JVMはCPUやオペレーティングシステムに関係せず、Javaプログラムを実行することができます。
そのJVMの中にはClass Loader,Execution Engine, Garbage Collector, Runtime Data Areaなどで
構成されていますが、今回は「Garbage Collector」「Runtime Data Area」だけを扱います。
Garbage Collector
Garbage CollectorはJVMのメモリ管理を担当するものです。
Garbage Collectorはオブジェクトの中でもう使わないオブジェクトのメモリを除去するものです。
Runtime Data Area
Runtime Data AreaはJavaプログラムが実行するとき、実際のデータが格納される空間です。
この空間は大きくMethod領域、Heap領域、Stack領域、PC Resister領域、Native Method Stack領域で分かれています。
今回はMethod, Heap, Stack領域だけを扱います。
Method領域
Method領域はクラスの情報が集まれています。
クラスのフィールド変数の名前、データ型、アクセス制御子情報のようなフィールド情報、
メソッドの名前、戻り値のデータ型、引数、アクセス制御子のようなメソッド情報、
static変数、final class変数などが格納されている領域です。
ここでstatic変数はJVMがJavaプログラムを実行するときにメモリを割り当てられ、
プログラムが終了される時にメモリが解除されます。
ですから、static変数はプログラムが実行される間に生成されているまま維持されるのでどこでも使えます。
Heap領域
Heap領域も詳しく説明するといくつかの領域で別れていますが、今回は無視します。
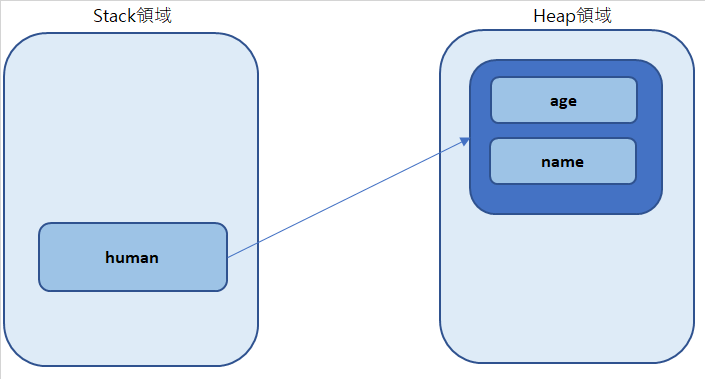
Heap領域はnewで生成されたオブジェクトと配列のデータが格納される領域です。
サンプル
public class ExampleCalss { public static void main(String[] args) { Human human = new Human(); } } class Human { int age; String name; }クラスのフィールドの情報はMethod領域に格納されています。
newでクラスのコンストラクタを呼び出すとインスタンスが生成され、Heap領域に格納されます。
そのとき、各インスタンスのフィールドにメモリが割り当てられて値を代入したりすることができるようになります。
そしてHumanクラスの変数「human」はそのインスタンスのアドレスを保存します。
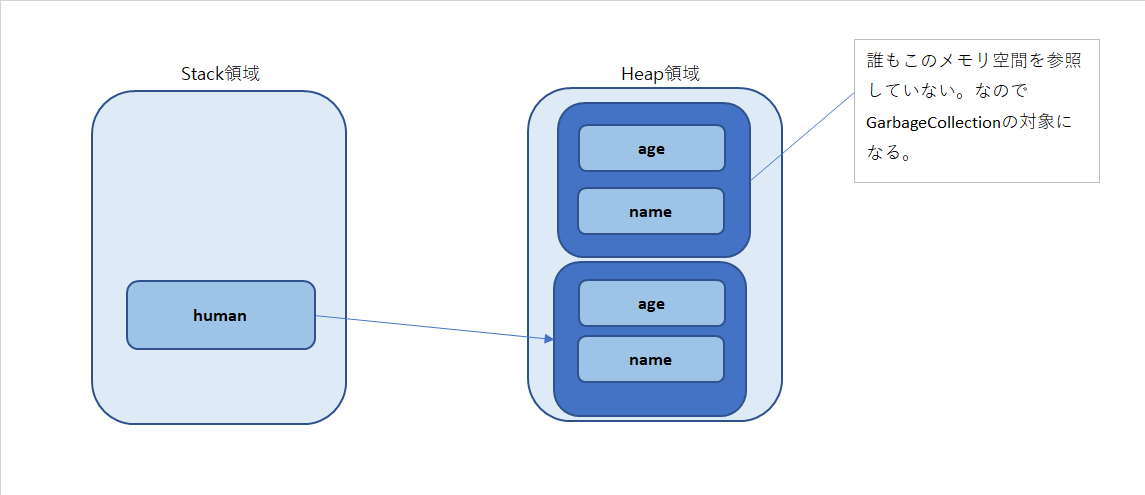
Heap領域でGarbage Collectorの役割
Garbage Collectorは誰も参照しないメモリ空間を対象にして削除します。
サンプル
public class ExampleCalss { public static void main(String[] args) { Human human = new Human(); human = null; human = new Human(); } } class Human { int age; String name; }上記のサンプルを見るとhumanが指しているメモリのアドレスをnullにしています。
そしてhumanに新しいインスタンスを生成して参照させています。
つまり、一つ目に割り当てられたインスタンスは誰も参照していないです。
そういうメモリ空間(一つ目のインスタンス)がGarbage Collectionの対象になります。
※Garbage CollectionはGarbage Collectorが誰も参照しないメモリを消す動作を意味します。
Stack領域
ローカル変数、引数、戻り値とかのデータが格納される領域です。
Stack領域には基本型の変数は変数とそのデータが一緒に格納されますが、
参照型(オブジェクト)はインスタンスのアドレスだけを格納して、実際のデータはHeap領域に格納されます。
Stack領域はメソッドを呼び出すたび、個物的に生成されます。
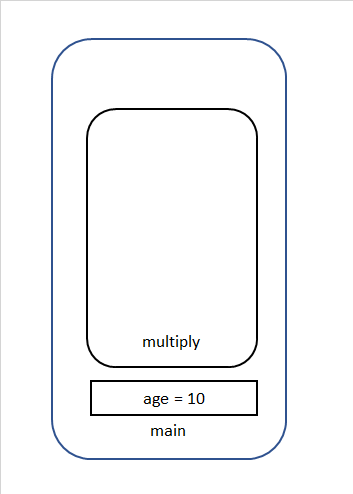
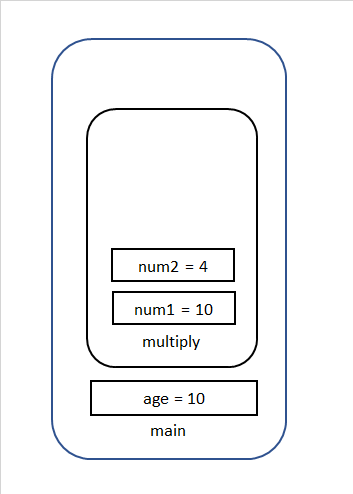
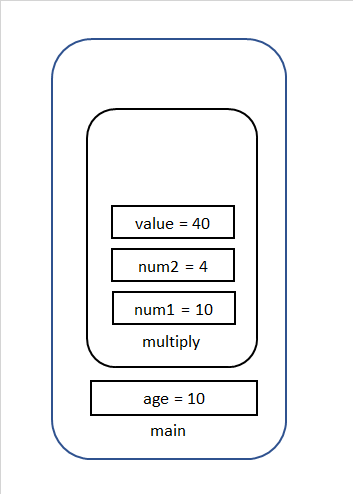
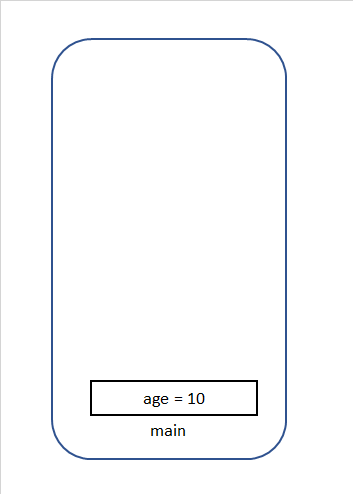
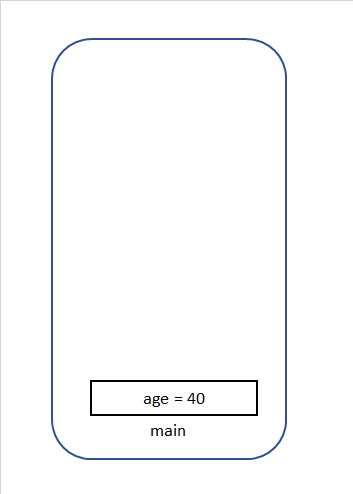
サンプル
public class ExampleCalss { public static void main(String[] args) { int age = 10; age = mutiply(age, 4); } static int mutiply(int num1, int num2) { int result = num1*num2; return result; } }上記の場合を順に説明すると(argsは無視します。)
① mainメソッドのStack領域が生成されます。
② ageが生成され、10で初期化されます。
③ multiplyメソッドが実行され、Stack領域が生成されます。
④ multiplyの引数が生成され、渡された値で初期化されます。
⑤ valueが生成され、演算の結果が代入されます。
⑥ returnが実行され、mutiplyの実行が終了されます。そしてmultiplyで使われた変数はStackで削除されます。
⑦ multiplyメソッドの実行結果がageに代入されます。
⑧ mainメソッドが終了され、mainメソッドで使われた変数が削除されます。
終わりに
今回の記事は以上になります。
ご覧いただきありがとうございます。


- 投稿日:2020-09-29T17:34:20+09:00
一緒に覚えるとわかりやすい「Dependency Injection」と「継承」について
はじめに
DreamHanksの松下です。今回は「Dependency Injection」と「継承(extends)」について解説していきます。
「Dependency Injection」と「継承」とは
Dependency Injectionとは
他のクラスやインターフェースのオブジェクトを実装したいクラス内で生成することによって、
他のクラスのメソッドを使えるようにするもの。継承(extends)とは
実装しているクラスをサブクラス(子クラス)だとして、スーパークラス(親クラス)を継承(extends)
することによって親のクラスのメソッドを使えるようにすること要するに両者とも実装したいJavaクラスに他のクラスのメソッドを使えるようにしたいというものです。
他にも「コンストラクタインジェクション」、「setter/getterインジェクション」
- 投稿日:2020-09-29T16:07:30+09:00
【Java】STS (Eclipse) に AdoptOpen JDK を設定する
STS(Eclipse) に JDK を設定したい
・Eclipse を 2020-09 に更新したら jre で Eclipse 動かしてるよ!ってメッセージが出る
・メモリ状態の把握のために MissionControl 入れようとしたらJDKで動いてないと駄目だった!・・・という理由でEclipseを jdk で動かしたいがどのJDKにすれば良いか迷ったので忘備録です。
環境
・Windows10 64bit
・STS4 (Eclipse2020-09)
・AdoptOpenJDK 11,15(15だとエラー出ます、不具合直るまで待ったほうがよいかも)JDKって色々ありますね・・・
・Oracle JDK (Java SE)
https://www.oracle.com/java/technologies/javase-downloads.html
jdk download とか検索すると出る、元々は商用利用可能だったが今はライセンスが必要な jdk。・Open JDK
https://openjdk.java.net/install/
オープンソースな jdk。商用利用可。
最初はコレを Eclipse の起動 vm に設定してみたところ、起動はするがビルドでエラーが出てしまった。・AdoptOpen JDK
https://adoptopenjdk.net/
Eclipse Foundation に参加したオープンソースの jdk。設定してみたら特にエラーも出ずビルドできました。ダウンロード
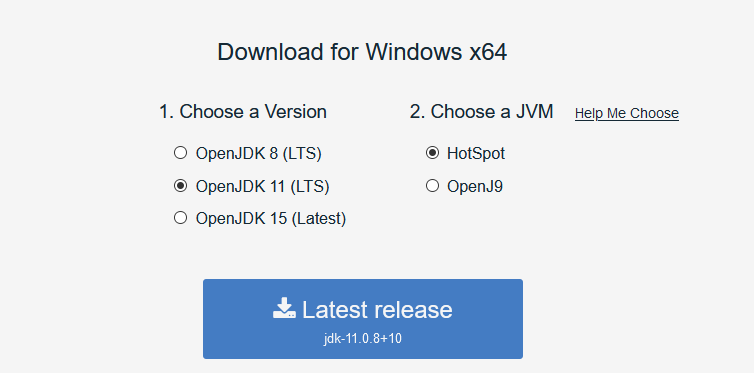
1. https://adoptopenjdk.net/ にアクセス
2. バージョンとJVMを選択 (11, HotSpotを選択) <- 15を設定したらビルドの際にエラーになりました…
3. ダウンロードしたインストーラーを起動
4. 完了したら ini ファイルを編集
・SpringToolsSuite4.ini
vm の下にインストールした bin ディレクトリのパスを設定する-startup plugins/org.eclipse.equinox.launcher_1.5.800.v20200727-1323.jar --launcher.library plugins/org.eclipse.equinox.launcher.win32.win32.x86_64_1.1.1300.v20200819-0940 -product org.springframework.boot.ide.branding.sts4 --launcher.defaultAction openFile -vm C:/Program Files/AdoptOpenJDK/jdk-11.0.8.10-hotspot/bin ;plugins/org.eclipse.justj.openjdk.hotspot.jre.full.win32.x86_64_14.0.2.v20200815-0932/jre/bin -vmargs -Dosgi.requiredJavaVersion=11 -Dosgi.dataAreaRequiresExplicitInit=true -Xms1024m -Xmx4096m --add-modules=ALL-SYSTEM -Xverify:none -javaagent:dropins/MergeDoc/eclipse/plugins/jp.sourceforge.mergedoc.pleiades/pleiades.jar・eclipse.ini
Eclipse でも試してみましたが大丈夫でした。-vm C:\Program Files\AdoptOpenJDK\jdk-11.0.8.10-hotspot\bin ;plugins/org.eclipse.justj.openjdk.hotspot.jre.full.win32.x86_64_14.0.2.v20200815-0932/jre/bin -startup plugins/org.eclipse.equinox.launcher_1.5.800.v20200727-1323.jar --launcher.library plugins/org.eclipse.equinox.launcher.win32.win32.x86_64_1.1.1300.v20200819-0940 -product org.eclipse.epp.package.jee.product -showsplash org.eclipse.epp.package.common --launcher.defaultAction openFile --launcher.defaultAction openFile --launcher.appendVmargs -vmargs -javaagent:dropins/MergeDoc/eclipse/plugins/jp.sourceforge.mergedoc.pleiades/pleiades.jar -javaagent:lombok.jar -Xverify:none -Dorg.eclipse.ecf.provider.filetransfer.retrieve.closeTimeout=30000 -Dorg.eclipse.ecf.provider.filetransfer.retrieve.readTimeout=30000 -Dosgi.requiredJavaVersion=11 -Dosgi.instance.area.default=@user.home/eclipse-workspace -XX:+UseG1GC -XX:+UseStringDeduplication --add-modules=ALL-SYSTEM -Dosgi.requiredJavaVersion=11 -Dosgi.dataAreaRequiresExplicitInit=true -Xms3G -Xmx5G --add-modules=ALL-SYSTEM5.STS (Eclipse) を起動
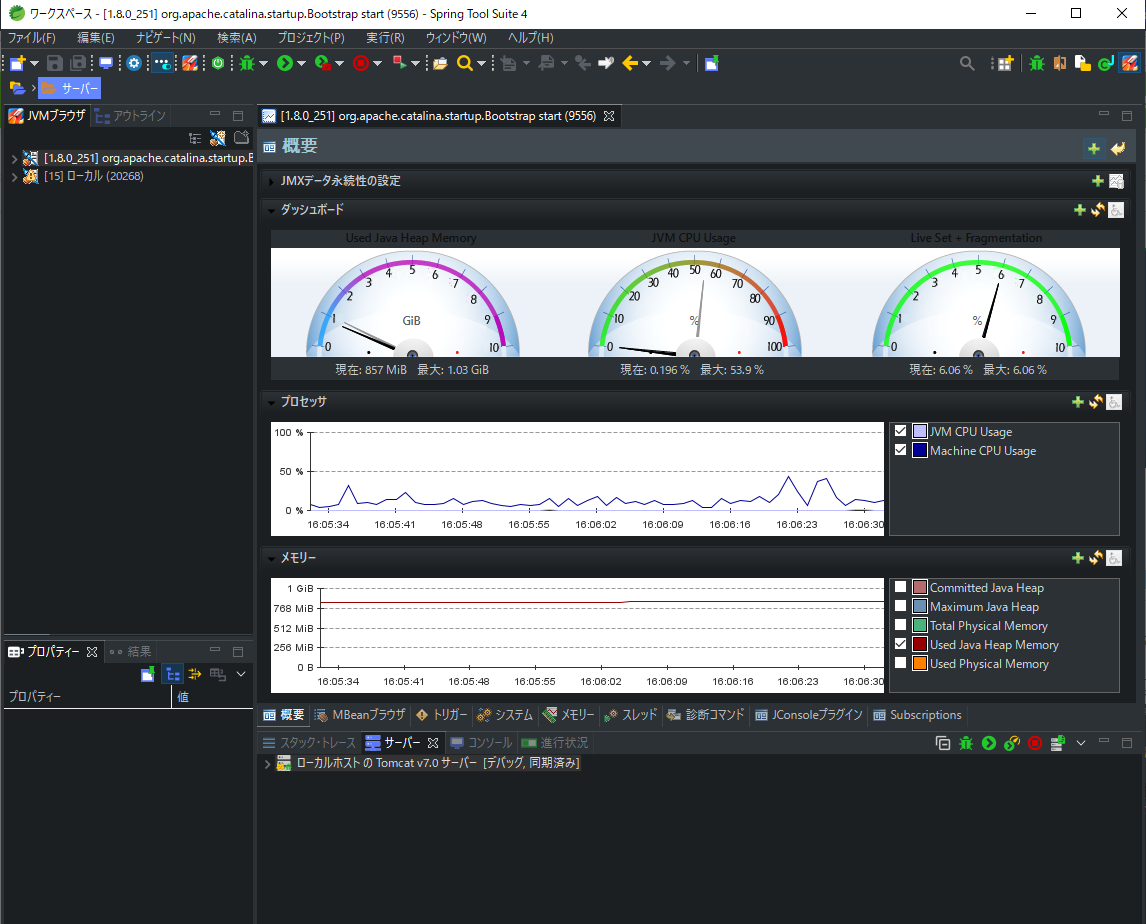
MissionControl
ちゃんと動いているようです。
以上です、お疲れさまでした!

- 投稿日:2020-09-29T15:57:35+09:00
【Android / Java】 フラグメントでの画面遷移と戻る処理
はじめに
Android Studio で Javaを用いたモバイルアプリの開発を学んでいます。
layoutファイルについてはあまり力を入れて記述していません(ざっくりです)。画面切り替えの動作等にフォーカスしているため、stringファイルは使用しませんでした。学んだ内容
FragmentManagerFragmentTransactionを用いた表示フラグメントの切り替え(画面遷移)addToBackStackpopBackStackを用いたアクションバー戻るボタンクリックで戻る動作学習のために作成したサンプルアプリの概要
1つのアクティビティにメインとなるフラグメントを用意し、そこからボタンを押すことによって2つのフラグメントに行き来ができるだけの簡単なアプリ。
アクティビティ:1つ
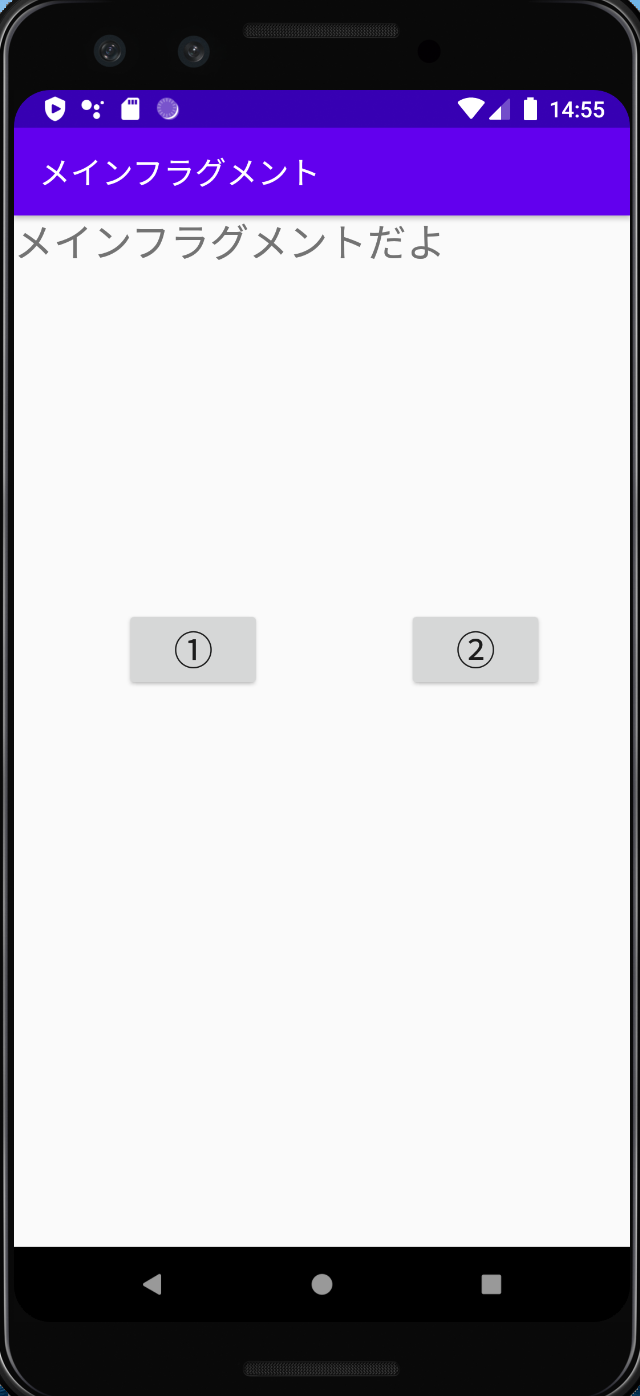
フラグメント:3つ(メイン1つ、サブ2つ)この①、②ボタンでサブフラグメント1、サブフラグメント2にそれぞれ遷移する
メイン画面(MainFragment)
サブ1画面(SubFragment1)
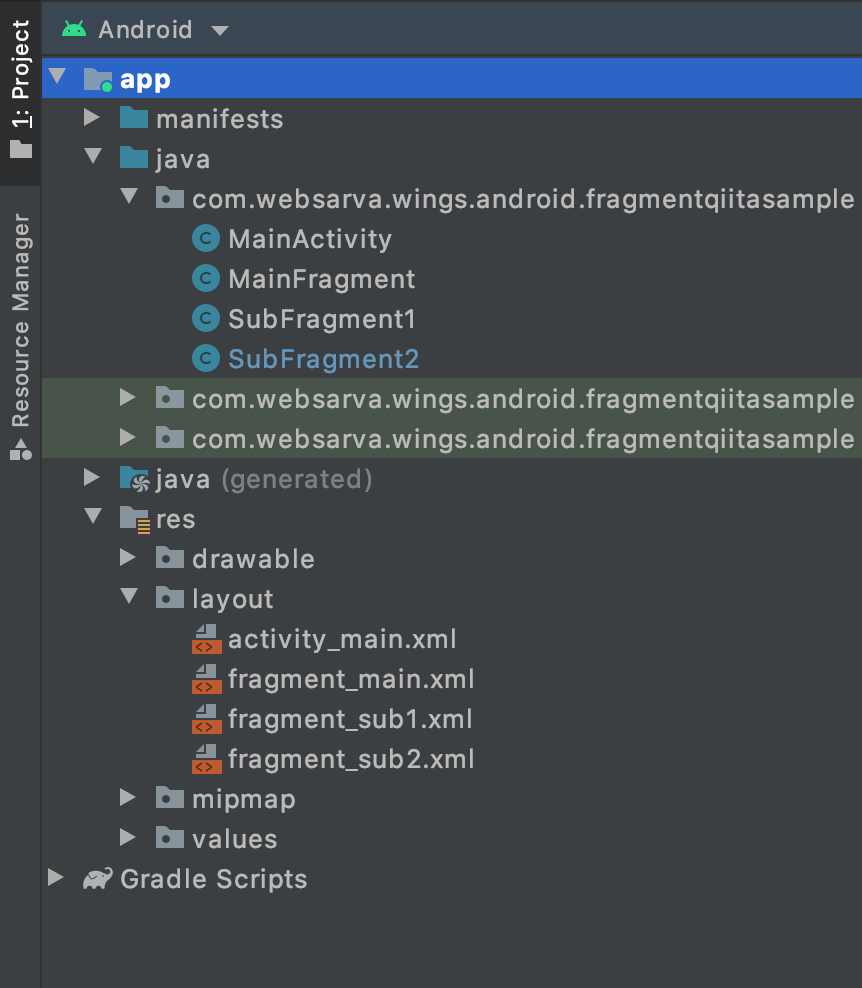
サブ2画面(SubFragment2) ディレクトリ構成
各javaファイルの処理内容
MainActivity.java
- MainFragmentの表示
- SubFragmentのアクションバーに戻るボタン「←」を表示するメソッドを定義
MainFragment.java
- Fragmentの表示を切り替えるメソッドを定義
- 設置したボタンのクリックリスナとFragmentを切り替えるメソッドの呼び出し
SubFragment(1, 2).java
- アクションバーに戻るボタンの表示
- 戻るボタンをクリックしたときに戻る処理を記述
ファイルのコードと解説
それぞれ、ファイルのコードを記載
layoutファイル
activity_main.xml<?xml version="1.0" encoding="utf-8"?> <FrameLayout xmlns:android="http://schemas.android.com/apk/res/android" xmlns:tools="http://schemas.android.com/tools" android:id="@+id/activityMain" android:layout_width="match_parent" android:layout_height="match_parent" tools:context=".MainActivity"> </FrameLayout>fragment_main.xml<?xml version="1.0" encoding="utf-8"?> <FrameLayout xmlns:android="http://schemas.android.com/apk/res/android" xmlns:tools="http://schemas.android.com/tools" android:id="@+id/fragmentMain" android:layout_width="match_parent" android:layout_height="match_parent" tools:context=".MainFragment"> <TextView android:layout_width="match_parent" android:layout_height="match_parent" android:textSize="25dp" android:text="メインフラグメントだよ"/> <Button android:id="@+id/bt1" android:layout_width="wrap_content" android:layout_height="wrap_content" android:layout_marginTop="250dp" android:layout_marginLeft="70dp" android:textSize="25dp" android:text="①"/> <Button android:id="@+id/bt2" android:layout_width="wrap_content" android:layout_height="wrap_content" android:layout_marginTop="250dp" android:layout_marginLeft="250dp" android:textSize="25dp" android:text="②"/> </FrameLayout>fragment_sub1.xml<?xml version="1.0" encoding="utf-8"?> <FrameLayout xmlns:android="http://schemas.android.com/apk/res/android" xmlns:tools="http://schemas.android.com/tools" android:id="@+id/SubFragment1" android:layout_width="match_parent" android:layout_height="match_parent" tools:context=".SubFragment1"> <TextView android:layout_width="match_parent" android:layout_height="match_parent" android:textSize="25dp" android:text="サブフラグメント1だよ"/> </FrameLayout>fragment_sub2.xml<?xml version="1.0" encoding="utf-8"?> <FrameLayout xmlns:android="http://schemas.android.com/apk/res/android" xmlns:tools="http://schemas.android.com/tools" android:id="@+id/SubFragment2" android:layout_width="match_parent" android:layout_height="match_parent" tools:context=".SubFragment2"> <TextView android:layout_width="match_parent" android:layout_height="match_parent" android:textSize="25dp" android:text="サブフラグメント2だよ" /> </FrameLayout>javaファイル
※package, import 文は記載していません。
MainActivity.java
MainActivity.javapublic class MainActivity extends AppCompatActivity { @Override protected void onCreate(Bundle savedInstanceState) { super.onCreate(savedInstanceState); setContentView(R.layout.activity_main); // メソッドを呼び出し、デフォルトでMainFragmentを表示 addFragment(new MainFragment()); } // Fragmentを表示させるメソッドを定義(表示したいFragmentを引数として渡す) private void addFragment(Fragment fragment) { // フラグメントマネージャーの取得 FragmentManager manager = getSupportFragmentManager(); // フラグメントトランザクションの開始 FragmentTransaction transaction = manager.beginTransaction(); // MainFragmentを追加 transaction.add(R.id.activityMain, fragment); // フラグメントトランザクションのコミット。コミットすることでFragmentの状態が反映される transaction.commit(); } // 戻るボタン「←」をアクションバー(上部バー)にセットするメソッドを定義 public void setupBackButton(boolean enableBackButton) { // アクションバーを取得 ActionBar actionBar = getSupportActionBar(); // アクションバーに戻るボタン「←」をセット(引数が true: 表示、false: 非表示) actionBar.setDisplayHomeAsUpEnabled(enableBackButton); } }画面表示に指定したフラグメントを表示したいので
transaction.addをする引数はこのような値をいれる
transaction.add(追加先のレイアウト画面部品のR値, 追加する(表示したい)Fragmentオブジェクト);MainFragment.java
MainFragment.javapublic class MainFragment extends Fragment { @Override public View onCreateView(LayoutInflater inflater, ViewGroup container, Bundle savedInstanceState) { // フラグメントで表示する画面をlayoutファイルからインフレートする View view = inflater.inflate(R.layout.fragment_main, container, false); // 所属している親アクティビティを取得 MainActivity activity = (MainActivity) getActivity(); // アクションバーにタイトルをセット activity.setTitle("メインフラグメント"); // 戻るボタンは非表示にする(MainFragmentでは戻るボタン不要) // ここをfalseにしておかないとサブフラグメントから戻ってきた際に戻るボタンが表示されたままになってしまう activity.setupBackButton(false); // ボタン要素を取得 Button bt1 = view.findViewById(R.id.bt1); Button bt2 = view.findViewById(R.id.bt2); // ①ボタンをクリックした時の処理 bt1.setOnClickListener(new View.OnClickListener() { @Override public void onClick(View view) { // SubFragment1に遷移させる replaceFragment(new SubFragment1()); } }); // ②ボタンをクリックした時の処理 bt2.setOnClickListener(new View.OnClickListener() { @Override public void onClick(View view) { // SubFragment2に遷移させる replaceFragment(new SubFragment2()); } }); return view; } // 表示させるFragmentを切り替えるメソッドを定義(表示したいFragmentを引数として渡す) private void replaceFragment(Fragment fragment) { // フラグメントマネージャーの取得 FragmentManager manager = getFragmentManager(); // アクティビティではgetSupportFragmentManager()? // フラグメントトランザクションの開始 FragmentTransaction transaction = manager.beginTransaction(); // レイアウトをfragmentに置き換え(追加) transaction.replace(R.id.activityMain, fragment); // 置き換えのトランザクションをバックスタックに保存する transaction.addToBackStack(null); // フラグメントトランザクションをコミット transaction.commit(); } }すでにメインフラグメントを表示しており、ボタンクリックで表示を切り替えたいので
transaction.replaceを使用
引数はaddの処理と同じイメージ
transaction.replace(表示先のレイアウト画面部品のR値, 置き換える(表示したい)Fragmentオブジェクト);メインフラグメントから遷移したサブフラグメントではアクションバーの戻るボタン「←」でメインフラグメントに戻れるようにしたいため
transaction.addToBackStack(null);
を記述することにより、遷移前に表示していたフラグメントを保存している。
この記述により遷移先のフラグメントで
getFragmentManager().popBackStack();
を呼び出すことで、戻るボタン「←」をクリックしたときに戻る処理ができるようになるSubFragment1.java / SubFragment2.java
SubFragment1.javapublic class SubFragment1 extends Fragment { @Override public View onCreateView(LayoutInflater inflater, ViewGroup container, Bundle savedInstanceState) { // フラグメントで表示する画面をlayoutファイルからインフレートする View view = inflater.inflate(R.layout.fragment_sub1, container, false); // 所属親アクティビティを取得 MainActivity activity = (MainActivity) getActivity(); // アクションバーにタイトルをセット activity.setTitle("サブフラグメント1"); // 戻るボタンを表示する activity.setupBackButton(true); // この記述でフラグメントでアクションバーメニューが使えるようになる setHasOptionsMenu(true); return view; } // アクションバーボタンを押した時の処理 @Override public boolean onOptionsItemSelected(MenuItem item) { switch (item.getItemId()) { // android.R.id.homeで戻るボタン「←」を押した時の動作を検知 case android.R.id.home: // 遷移前に表示していたFragmentに戻る処理を実行 getFragmentManager().popBackStack(); return true; default: return super.onOptionsItemSelected(item); } } }SubFragment2.javapublic class SubFragment2 extends Fragment { @Override public View onCreateView(LayoutInflater inflater, ViewGroup container, Bundle savedInstanceState) { // フラグメントで表示する画面をlayoutファイルからインフレートする View view = inflater.inflate(R.layout.fragment_sub2, container, false); // 所属親アクティビティを取得 MainActivity activity = (MainActivity) getActivity(); // アクションバーにタイトルをセット activity.setTitle("サブフラグメント2"); // 戻るボタンを表示する activity.setupBackButton(true); // この記述でフラグメントでアクションバーメニューが使えるようになる setHasOptionsMenu(true); // View viewのが良い? return view; } // アクションバーのボタンを押した時の処理 @Override public boolean onOptionsItemSelected(MenuItem item) { switch (item.getItemId()) { // 戻るボタン「←」を押した時android.R.id.homeに値が入る case android.R.id.home: // 遷移前に表示していたFragmentに戻る処理を実行 getFragmentManager().popBackStack(); return true; default: return super.onOptionsItemSelected(item); } } }
getFragmentManager().popBackStack();この記述で一つ前のフラグメントに戻る。最後に
今回は内容に含みませんでしたが、今後フラグメント間のデータの受け渡しについても書けたら良いと思っています。
Java / Android を学び始めて1ヶ月弱程度の初心者です。ご指摘等ありましたらコメントください。
参考にさせていただいた資料
- https://developer.android.com/training/basics/fragments/fragment-ui?hl=ja
- https://qiita.com/tagfa/items/a1e2b7302ad36aa99dab
- https://akira-watson.com/android/fragment-code.html
非常にわかりやすく助かりました!ありがとうございました!


- 投稿日:2020-09-29T15:37:49+09:00
SpringBootで/errorに対応する自作Controllerを作成する方法
想定外の例外をログ出力するのに必要だったので、
SpringBootで/errorに対応する自作Controllerを作成する方法を調べた。下記URLの通りにやれば可能。
https://www.logicbig.com/tutorials/spring-framework/spring-boot/implementing-error-controller.htmlURLがリンク切れになった時ようにソースをコピペしておく。
@Controller public class MyCustomErrorController implements ErrorController { @RequestMapping("/error") @ResponseBody public String handleError(HttpServletRequest request) { Integer statusCode = (Integer) request.getAttribute("javax.servlet.error.status_code"); Exception exception = (Exception) request.getAttribute("javax.servlet.error.exception"); return String.format("<html><body><h2>Error Page</h2><div>Status code: <b>%s</b></div>" + "<div>Exception Message: <b>%s</b></div><body></html>", statusCode, exception==null? "N/A": exception.getMessage()); } @Override public String getErrorPath() { return "/error"; } }APIの例外ハンドリングの情報は多いけど、この情報はなかなか出てこなかった。。
- 投稿日:2020-09-29T14:18:26+09:00
【Java7以降】一時ファイル削除漏れを防ぐ
目的
一時ファイルの削除し忘れや、異常終了時にファイル削除されずに終了してしまうことを防ぐ。
実装例
delete文を使用してファイル削除
delete文で一時ファイル削除Path path = null; try { // 一時ファイル作成 path = Files.createTempFile("test", ".tmp"); OutputStream out = Files.newOutputStream(path); String data = "test"; out.write(data.getBytes()); // ファイルに書き込み out.flush(); } catch (IOException e) { e.printStackTrace(); } finally { // 処理終了時にファイル削除 Files.deleteIfExists(path); }この実装では、JVM異常終了時には削除されないこともあるようです。
DELETE_ON_CLOSEを使用してファイル削除
DELETE_ON_CLOSEを使用した一時ファイル削除Path path = null; try { // 一時ファイル作成 path = Files.createTempFile("test", ".temp"); try (BufferedWriter bw = Files.newBufferedWriter(path, StandardOpenOption.DELETE_ON_CLOSE)) { String data = "test"; // ファイルに書き込み bw.write(data); } } catch (IOException e) { e.printStackTrace(); }StandardOpenOptionのDELETE_ON_CLOSEは、ファイルのオープン時のオプションとして利用すると
ストリームをクローズした時に自動的にファイルが削除される。
さらに「try-with-resources」構文を使用することで、close処理を実装しなくても自動的にクローズとファイル削除が実行されるので、実装もすっきりして削除漏れもなくなります。
- 投稿日:2020-09-29T13:58:50+09:00
YellowfinのAPIとwebserviceを使ってダッシュボードのレポートを全てExcelでダウンロードする
やりたいこと
またまたタイトル通りなのですが、前回の記事FetchでExcelファイルがダウンロードできるページに条件をPOSTしてブラウザダウンロードするでExcelのダウンロードをできるようになったので、Yellowfinのダッシュボードにある全てのレポートをExcelでダウンロードしたいってところです。
検証しているのはversion9.2.2ではBaseAPI,reportAPI,filterAPI,DashboardAPIとコードモードでいろいろなことができるようになっているので、そこで各レポートの情報を取得し、foreachで回す感じです。前準備をします
ダッシュボードを作成後に、コードwidgetからボタンのwidgetをドラッグ・アンド・ドロップして名前をつけます。例)export
これは次のJSタブに記述する部分で使います。また、Excelをエクスポートするwebservice用スクリプトを/Yellowfinインストールディレクトリ/appserver/webapps/ROOT/の下に配置します。
これはExcel以外にも対応してるのでPOSTするキーのformatを他のPDF・CSVに変更してもformatをそれぞれに合わせれば使用できます。
また何もしてしなければPDFファイルで出力されます。output.jsp<%@ page language="java" contentType="text/html; charset=UTF-8" %> <%@ page import="java.util.*, java.text.*" %> <%@ page import="com.hof.mi.web.service.*" %> <%@ page import="java.net.URLEncoder" %> <% String host = "localhost"; Integer port = 8080; String userid = "admin@yellowfin.com.au"; String password = "test"; String orgid = "1"; String uuid = request.getParameter("uuid"); String fname = request.getParameter("fname"); String path = "/services/ReportService"; String suffix = ""; String format = request.getParameter("format"); String contentType = "application/octet-stream"; if (format == null) format = "PDF"; if (format.equals("CSV")) { contentType = "text/comma-separated-values"; suffix = ".csv"; } else if (format.equals("PDF")) { contentType = "application/pdf"; suffix = ".pdf"; } else if (format.equals("XLS")) contentType = "application/vnd.ms-excel"; else if (format.equals("XLSX")) { contentType = "application/vnd.openxmlformats-officedocument.spreadsheetml.sheet"; suffix = ".xlsx"; } else if (format.equals("RTF")) contentType = "application/rtf"; else if (format.equals("TEXT")) contentType = "text/tab-separated-values"; HashMap filters = new HashMap(); boolean cleared = filters.size() == 0; Iterator f = request.getParameterMap().keySet().iterator(); while (f.hasNext()) { String key = (String) f.next(); if (key.startsWith("filter")) { if (!cleared) { filters.clear(); cleared = true; } String value = request.getParameter(key); int pipeIndex = value.indexOf("|"); if (pipeIndex == -1) continue; key = value.substring(0, pipeIndex); value = value.substring(pipeIndex + 1); filters.put(key, value); } } ReportServiceClient rsc = new ReportServiceClient(host, port, userid, password, path); i4Report report = rsc.loadReportForUser(uuid, userid, password, orgid); f = filters.keySet().iterator(); while (f.hasNext()) { String key = (String) f.next(); String value = (String) filters.get(key); report.setFilter(key, value); } HashMap elementStorage = new HashMap(); report.run(elementStorage, format); response.setContentType(contentType); fname = fname + suffix; String encodedFilename = URLEncoder.encode( fname , "UTF-8"); response.setHeader("Content-Disposition","attachment;" + "filename=\"" + encodedFilename + "\""); java.io.BufferedOutputStream o = new java.io.BufferedOutputStream(response.getOutputStream(), 32000); o.write(report.renderBinary()); o.flush(); %>ダッシュボードのJSタブ
ここに前回やった部分を少し改造して全てのレポートをエクスポートできるようにDashboardAPIを駆使します。
let button = this.apis.canvas.select('export');の部分でダッシュボード上に設置したボタンの名前を指定することでこれをeventlistenerで取得できます。
他の前回の記事で解説していないこととしては、こちらの部分です。
var dash = this.apis.dashboard;
var allrep = dash.getAllReports();
これはYellowfinのdashboardAPIを呼び出し、getAllReports()でダッシュボード上のレポート情報を全て取得しています。
該当のYellowfinのwiki部分
それぞれのレポートをfoeachで回し、uuidとformatをbodyで渡してリンクを生成させてます。レポート名も取得したい場合はさらにwebservice用のjsp作らないといけないのでまた次の機会に。
JSタブthis.onRender = function () { // ここにコードを記述します。これは、イベントリスナーを設定するのに理想的な場所です let button = this.apis.canvas.select('export'); button.addEventListener('click', () => { var dash = this.apis.dashboard; var allrep = dash.getAllReports(); allrep.forEach( item => { var uuid = item.reportUUID; var obj = { fname: uuid, uuid: uuid, format: 'XLSX' }; var method = "POST"; var body = Object.keys(obj).map((key)=>key+"="+encodeURIComponent(obj[key])).join("&"); var headers = { 'Accept': 'application/vnd.openxmlformats-officedocument.spreadsheetml.sheet', 'Content-Type': 'application/x-www-form-urlencoded; charset=utf-8', 'responseType' : "blob", }; fetch("./output_file.jsp", {method, headers, body}) .then((res)=> res.blob()) .then(blob => { let anchor = document.createElement("a"); anchor.href = window.URL.createObjectURL(blob); anchor.download = uuid+".xlsx"; anchor.click();}) .then(console.log) .catch(console.error); }); }); };結果
ダッシュボードに設置しているレポートがどんどん落ちてきます。たぶん初回はブラウザ側でダウンロードの許可を求めるダイアログが出るので許可してあげれば大丈夫です。
※今の所レポートにダッシュボードで使用していたフィルターの内容を渡せないようなので、これがやりたい場合は、動的ではなく予め条件毎にダッシュボードを作っておく必要があります。。。この辺がなんとかなればかなり使えると思うんですけどね。

- 投稿日:2020-09-29T13:36:41+09:00
Javaノート
Javaノート
codic=変数名を日本語から英語に変換するツール
◎JVMとは
JavaVirtualMachine(Java仮想マシン)
OSに依存せず、どんな環境でもJavaのプログラムを動かせる。実際に動かしてるのはこれ◎JDKとは
JavaDevelopmentKit(Java開発環境)、JDKの中にある。
・javac(コンパイラ)
・jar(jarファイルの関連機能)➡️なにこれ?
・javadoc(仕様書の自動生成)◎JREとは(Java Runtime Environment)
Javaの実行で必要になる機能群。JDKの中にある。◎変数の型(ちなみに変数名はキャメルケース。定義の横にコメントを書け!)
int(こっちが数値メイン) 整数(22億ぐらいまで)
long(たまに使う) 無量大数までいける数値。語尾に「L」をつけろ!
double 小数点を表す(floatより正確だから基本こっち使え!)
String(最初大文字で) 文字列。ダブルクォーテーション
char(キャラと読む) 1文字限定、シングルクォーテーションで囲む。
boolean 真偽値。変数名の頭に「is」をつける習慣があるらしい。◎定数
finalです。constじゃなくてfinalです。大文字+スネークケースで書け!◎デバッグツールの起動(vscode)
command + shift + D◎エスケープシーケンス
バックスラッシュで打つやつ。「\n」は改行。「\”」は「”」はダブクオがつく。◎文字〜整数の型変換
文字列➡️整数:Integer.parseint(int型にしたい文字列)
整数➡️文字列:String.valueOf(string型にしたい整数)◎キャスト演算子
一時的な型変換ができる。例)int y = int(x); この際の変数xは、本来int型じゃない。longとかだよ。◎Javaの配列
定義方法:型名[] 配列名 = new 型名 [] [‘1’,’2’]
省略:char[] singou = { '赤', '黄', '青' };
多次元配列:int[][] rooms = { { 101, 102, 103 }, { 201, 202, 203 } };
➡️注意事項:intの型定義で配列を2個指定、角括弧「[ ]」ではなく波括弧「{ } 」で◎コマンドライン引数
人間が打ち込んだ時に入力できる(投げられる)変数◎プリミティブ型と参照型は違いがある
◎ガベージコレクション
メモリを自動的にお掃除するやつ。Javaが初めて導入した。昔はメモリを明示的に消さないと残り続けた。おじさんプログラマーがJava好きな理由の一つ。◎for分
for(変数宣言 i =0; 継続条件 i <= 5; 継続処理 i++ ){ }
順番は変数宣言➡️継続条件見て1ループ目➡️継続処理➡️継続条件で判断する◎while文とdo~while文の違い
while:条件を先に見る。先判定。1回も処理しない時有り。先見えみたいだな
do~while:条件を後に見る。後判定。最初の一回は絶対に実行する。絶対ニダ。
大事なこと:while文はfalseだったら終了する。サイコロ問題で、input == 6 じゃループする。ほぼfalseになるから。input != 6 で6以外だったらtrueになるので。◎for文おまけ
・ラベルつけられる(ネストされてる) uzuz1:for~~ break uzuz1
・coninue 次の処理へ移動◎クラス
1つのjavaファイルには1つのクラス。ファイル名とクラス名は同じにしてね。お願い。
class クラス名 { }◎メソッド
パーツ(一分機能)の設計図。関数とも呼ぶ?一つの機能ごとに1つのメソッド
修飾子 戻り値の型 メソッド名 {引数の型 引数名, …) { 命令群 }
static int sum(int num1, int num2) {
return(return文:戻り値を返す) calcResult(実際に帰る戻り値) }◎void
return文を書くとエラーになる。定義する型がないから、しょうがなく書くイメージ◎main
プログラムが起動されて必ず一番初めに実行される特殊なメソッド。
mainメソッド内の処理を実行したらプログラム終了。mainで始まり、mainで終わる。◎ポリモフィズム
オーバーロードやオーバーライドの仕組みのこと?◎オーバーロードとは
メソッドは、メソッド名だけじゃなく引数の型や数でも区別できる。
型や数が違ってたらクラス内で同盟のメソッドを複数定義できる。this is オーバーロード。◎オーバーライドとは
メソッドをそもそも上書きしちゃって重複させないこと。◎フィールドとは
クラスの中、メソッドの外で宣言した変数。あるメソッドで更新後に他のメソッドで参照可
逆に複数のスレッドが一つのオブジェクト(メソッドの外で宣言した変数?)を使う時はフィールドに気をつける。他のスレッド(処理)でも参照するから。◎ローカル変数
メソッドの中(mainとか)で宣言した変数。メソッドの中でしか使えません。当たり前。◎API
Javaが提供してる便利なソースコード群。
printlnやparseIntメソッドもAPI。◎io
input outputの略◎import
APIはパッケージで管理されてる。
基本的にインポートすることで使用可能になる。
APIでjava.langパッケージで管理されてるクラス群は利用頻度高くimport不要 例)println◎ArrayList
要素数を自由に変更できる配列。import必要➡️15-3の2行参照
List <型> 変数名 = new ArrayList<型>( );
主要メソッド:get(インデックス)、add(データ)、size()、isEmpty、remove
参照型しか扱えない。プリミティブ型のデータを扱う場合は、対応するラッパークラス参照◎equalメソッド
文字列の照合は、イコールでやらない!◎replaceメソッド
文字列の置換(置き換え)、空文字「” “」にしたりして文字列を消したりでも代用できる◎パッケージ
複数のクラスをグループ化するためのもの。
全てのJavaプログラムは必ず何かしらのパッケージに属してる。逆に属してないとjavaのコードじゃない。
先頭でパッケージ宣言をすることで所属するパッケージを定義できる。
・例外あり
宣言不要のパッケージ:実行ファイルが存在するカレントディレクトリだと、自動的に無名のパッケージとして扱われる。つまりパッケージ宣言が不要
- 投稿日:2020-09-29T13:36:41+09:00
Java 基礎概念まとめ
なにこれ
Javaの基礎を学習したので、見返せるようにまとめました。
余談
codic=変数名を日本語から英語に変換するツール
JVMとは
JavaVirtualMachine(Java仮想マシン)
OSに依存せず、どんな環境でもJavaのプログラムを動かせる。実際に動かしてるのはこれJDKとは
JavaDevelopmentKit(Java開発環境)、JDKの中にある。
・javac(コンパイラ)
・jar(jarファイルの関連機能)➡️なにこれ?
・javadoc(仕様書の自動生成)JREとは(Java Runtime Environment)
Javaの実行で必要になる機能群。JDKの中にある。
変数の型(ちなみに変数名はキャメルケース。定義の横にコメントを書け!)
int(こっちが数値メイン) 整数(22億ぐらいまで)
long(たまに使う) 無量大数までいける数値。語尾に「L」をつけろ!
double 小数点を表す(floatより正確だから基本こっち使え!)
String(最初大文字で) 文字列。ダブルクォーテーション
char(キャラと読む) 1文字限定、シングルクォーテーションで囲む。
boolean 真偽値。変数名の頭に「is」をつける習慣があるらしい。定数
finalです。constじゃなくてfinalです。大文字+スネークケースで書け!
デバッグツールの起動(vscode)
command + shift + D
エスケープシーケンス
バックスラッシュで打つやつ。「\n」は改行。「\”」は「”」はダブクオがつく。
文字〜整数の型変換
文字列➡️整数:Integer.parseint(int型にしたい文字列)
整数➡️文字列:String.valueOf(string型にしたい整数)キャスト演算子
一時的な型変換ができる。例)int y = int(x); この際の変数xは、本来int型じゃない。longとかだよ。
Javaの配列
定義方法:型名[] 配列名 = new 型名 [] [‘1’,’2’]
省略:char[] singou = { '赤', '黄', '青' };
多次元配列:int[][] rooms = { { 101, 102, 103 }, { 201, 202, 203 } };
➡️注意事項:intの型定義で配列を2個指定、角括弧「[ ]」ではなく波括弧「{ } 」でコマンドライン引数
人間が打ち込んだ時に入力できる(投げられる)変数
プリミティブ型と参照型は違いがある
ガベージコレクション
メモリを自動的にお掃除するやつ。Javaが初めて導入した。昔はメモリを明示的に消さないと残り続けた。おじさんプログラマーがJava好きな理由の一つ。
for分
for(変数宣言 i =0; 継続条件 i <= 5; 継続処理 i++ ){ }
順番は変数宣言➡️継続条件見て1ループ目➡️継続処理➡️継続条件で判断するwhile文とdo~while文の違い
while:条件を先に見る。先判定。1回も処理しない時有り。先見えみたいだな
do~while:条件を後に見る。後判定。最初の一回は絶対に実行する。絶対ニダ。
大事なこと:while文はfalseだったら終了する。サイコロ問題で、input == 6 じゃループする。ほぼfalseになるから。input != 6 で6以外だったらtrueになるので。for文おまけ
・ラベルつけられる(ネストされてる) uzuz1:for~~ break uzuz1
・coninue 次の処理へ移動クラス
1つのjavaファイルには1つのクラス。ファイル名とクラス名は同じにしてね。お願い。
class クラス名 { }メソッド
パーツ(一分機能)の設計図。関数とも呼ぶ?一つの機能ごとに1つのメソッド
修飾子 戻り値の型 メソッド名 {引数の型 引数名, …) { 命令群 }
static int sum(int num1, int num2) {
return(return文:戻り値を返す) calcResult(実際に帰る戻り値) }void
return文を書くとエラーになる。定義する型がないから、しょうがなく書くイメージ
main
プログラムが起動されて必ず一番初めに実行される特殊なメソッド。
mainメソッド内の処理を実行したらプログラム終了。mainで始まり、mainで終わる。ポリモフィズム
オーバーロードやオーバーライドの仕組みのこと?
オーバーロードとは
メソッドは、メソッド名だけじゃなく引数の型や数でも区別できる。
型や数が違ってたらクラス内で同盟のメソッドを複数定義できる。this is オーバーロード。オーバーライドとは
メソッドをそもそも上書きしちゃって重複させないこと。
フィールドとは
クラスの中、メソッドの外で宣言した変数。あるメソッドで更新後に他のメソッドで参照可
逆に複数のスレッドが一つのオブジェクト(メソッドの外で宣言した変数?)を使う時はフィールドに気をつける。他のスレッド(処理)でも参照するから。ローカル変数
メソッドの中(mainとか)で宣言した変数。メソッドの中でしか使えません。当たり前。
API
Javaが提供してる便利なソースコード群。
printlnやparseIntメソッドもAPI。io
input outputの略
import
APIはパッケージで管理されてる。
基本的にインポートすることで使用可能になる。
APIでjava.langパッケージで管理されてるクラス群は利用頻度高くimport不要 例)printlnArrayList
要素数を自由に変更できる配列。import必要➡️15-3の2行参照
List <型> 変数名 = new ArrayList<型>( );
主要メソッド:get(インデックス)、add(データ)、size()、isEmpty、remove
参照型しか扱えない。プリミティブ型のデータを扱う場合は、対応するラッパークラス参照equalメソッド
文字列の照合は、イコールでやらない!
replaceメソッド
文字列の置換(置き換え)、空文字「” “」にしたりして文字列を消したりでも代用できる
パッケージ
複数のクラスをグループ化するためのもの。
全てのJavaプログラムは必ず何かしらのパッケージに属してる。逆に属してないとjavaのコードじゃない。
先頭でパッケージ宣言をすることで所属するパッケージを定義できる。
・例外あり
宣言不要のパッケージ:実行ファイルが存在するカレントディレクトリだと、自動的に無名のパッケージとして扱われる。つまりパッケージ宣言が不要