- 投稿日:2020-09-25T23:31:23+09:00
ABC128 A,B,C解説(python)
A問題
https://atcoder.jp/contests/abc128/tasks/abc128_a
a,p = map(int,input().split()) print((a*3+p)//2)a×3+pを2で割ったものが答えとなる。
B問題
https://atcoder.jp/contests/abc128/tasks/abc128_b
n = int(input()) x = [[input().split(),i+1]for i in range(n)] x = sorted(x, key = lambda x:(x[0][0],-int(x[0][1]))) for i in range(n): print(x[i][1])複数の要素についてソートをかける問題。
x = sorted(x, key = lambda x:(x[0][0],-int(x[0][1])))
でkey を複数指定するとx[0][0]、-int(x[0][1])の順にソートを行う。
出力は番号で行うのでxを入力する際に番号も入れ込んだリストを作成する。C問題
https://atcoder.jp/contests/abc128/tasks/abc128_c
- 投稿日:2020-09-25T23:25:38+09:00
yukicoder contest 267 参戦記
yukicoder contest 267 参戦記
A も B も星の数詐欺すぎて.
A 1236 長針と短針
12時間の間に長針と短針は11回巡り合う. 当然巡り合うのは12時間の秒数を11で割った秒数毎である. その秒数を求めると、現在時刻の次のその秒数との差が答えとなる.
from bisect import bisect_left A, B = map(int, input().split()) x = [i * 12 * 60 * 60 // 11 for i in range(12)] t = (A * 60 + B) % (12 * 60) * 60 print(x[bisect_left(x, t)] - t)C 1238 選抜クラス
K を引いた辺りで、「あれ、同じような問題を過去に解いてるぞ」と思ったのに解けなかった悲しみ. ABC044C - 高橋君とカード と大体同じですね(平均がちょうどXか、平均がX以上かの違い).
ai=Ai-K とすると、aiの合計が0以上になる選び方はいくつあるかという問題になる. DP をすれば簡単に求まる.
m = 1000000007 N, K, *A = map(int, open(0).read().split()) for i in range(N): A[i] -= K dp = {} dp[0] = 1 for a in A: for k in sorted(dp, reverse=True) if a >= 0 else sorted(dp): dp.setdefault(k + a, 0) dp[k + a] += dp[k] dp[0] -= 1 print(sum(dp[k] for k in dp if k >= 0) % m)
- 投稿日:2020-09-25T22:24:04+09:00
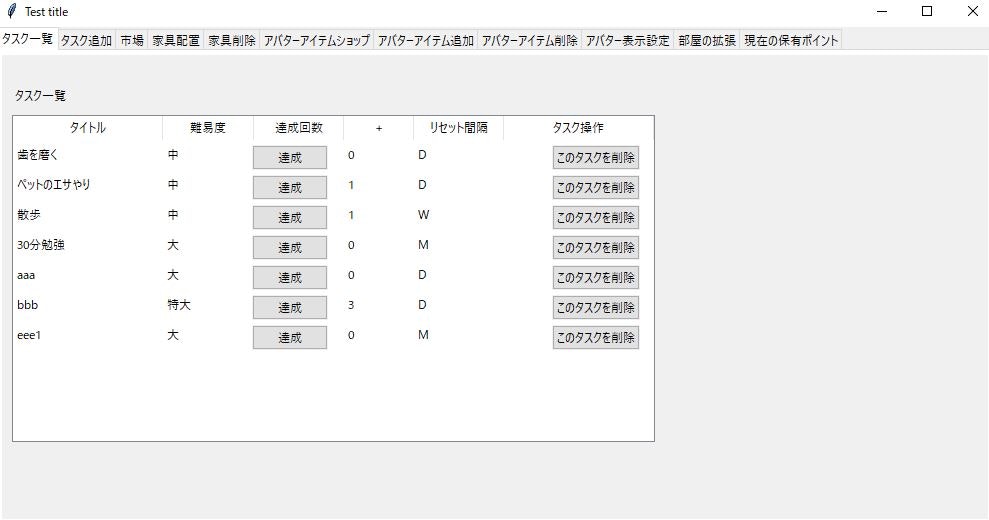
toDoListをこなしながら部屋の模様替えが楽しめるPGM
toDoListをこなしながら部屋の模様替えが楽しめるPGM
toDoListを作成し、達成したタスクに応じてポイントを貯めて、そのポイントに応じて
自分自身のアバター装備や家具を市場・アイテムショップから購入し、楽しめる、PythonでのPGMを作成してみました
gitHubURL:https://github.com/NanjoMiyako/toDoListWithImage
実行PGM:toDoListWithImage3.py
実行画面例
使い方
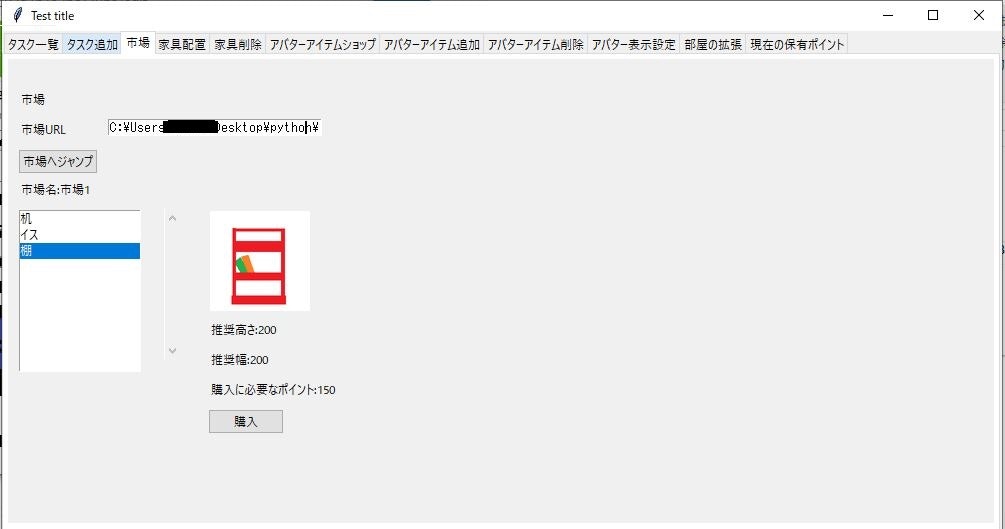
当PGMのアイテムと家具のデータは予め市場用(/アイテム用)ディレクトリを用意しておき、
その場所のURLを指定してからジャンプして、そこからタスクをこなして獲得したポイントから
家具やアイテムを購入し、そこから、またポイントを利用して獲得したアイテムの家具や
アイテムを設置していくようになっています
各ファイルの書式
各ファイルはCSVまたは=記号で区切られた文字列で保存しています。
各ファイルの値の意味は以下のようになっています.MarketInfo.txt(家具購入用の市場情報ファイル):
(先頭の一行目のみ):Name,市場名
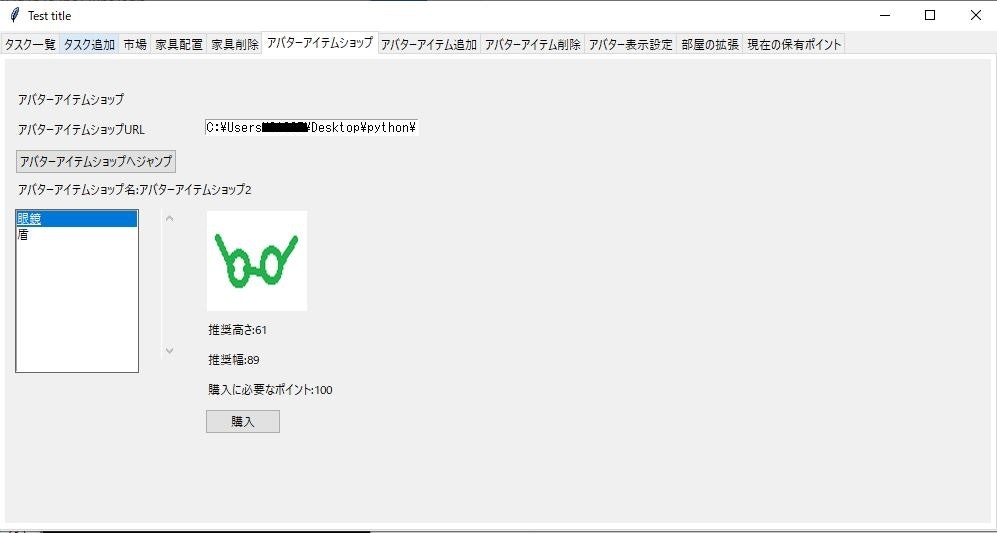
(それ以降):商品ID,商品名,対応する画像ファイル名,値段AvatourItemShopInfo.txt(アバターアイテムショップの商品情報ファイル):
(先頭の一行目のみ):Name,ショップ名
(それ以降):商品ID,商品名,対応する画像ファイル名,値段MyAvatour.txt(アバターの装備情報): アバターアイテム購入元のアバターショップのディレクトリパス, アバターショップ内での商品のID(int型),アバター内のアイテムのx位置,アバター内のアイテムのy位置,アバターアイテムのz位置(手前の時ほどzの値が大きいです),アバターアイテムの高さ,アバターアイテムの幅
MyRoomFaniture.txt(部屋内の家具情報):家具購入元の市場のディレクトリパス, 市場内での商品のID(int型),部屋内の家具のx位置,部屋内の家具のy位置,部屋内の家具のz位置(手前の時ほどzの値が大きいです)家具の高さ,家具の幅
MyHavingAvatourItem.txt(現在持っているアバターアイテムのリスト情報):アバターアイテム購入元のアバターショップのディレクトリパス, アバターショップ内での商品のID(int型)
MyHavingFaniture.txt(現在持っている家具のリスト情報):家具購入元の市場のディレクトリパス, 市場内での商品のID(int型)
TaskData.txt(タスク情報):タイトル,難易度,達成回数,リセット日時,リセット間隔(D,W,M,Y)
UserInfo.txt(ユーザー情報):=で区切られたPGM内での各変数の初期値
作成に当たって参考にしたページ【Python GUIサンプル】TkinterでListbox(リストボックス)を使ってみる | エンジニアになりたいブログ
【tkinter】grid()を使ったWidgetの配置の方法 - どん底から這い上がるまでの記録
Tkinter Listbox - Tkinter による GUI プログラミング - Python 入門
Tkinter grid ジオメトリマネージャ - Tkinter による GUI プログラミング - Python 入門
Tkinter テキストボックスから入力を取得する方法 | Delft スタック
Pythonでメッセージボックスを表示する(tkinter.messagebox) | 鎖プログラム
Pythonで文字列を分割(区切り文字、改行、正規表現、文字数) | note.nkmk.me
Pythonでリスト(配列)の要素を削除するclear, pop, remove, del | note.nkmk.me
Tkinter 入門: 6. Listbox を使ってお花を愛でましょう
Python - Python GUI Tkinterにおけるリストボックスの取り扱い方について|teratail
【Python GUIサンプル】Tkinter ttk.Frameにreliefを指定して境界線を表示してみる | エンジニアになりたいブログ
【Python】文字列が空白・NULLか判定する | 鎖プログラム
python — Tkinter Labelウィジェットの画像を更新する方法は?
python - Image resize under PhotoImage - Stack Overflow
tkinter.ttk --- Tk のテーマ付きウィジェット — Python 3.8.5 ドキュメント
Pythonで日付をYYYYMMDD形式の8桁で:Python
Pythonでカレントディレクトリを取得、変更(移動) | note.nkmk.me
python - Tkinterでツリービュー全体をクリアする方法
折り返し文字列に応じてTkinter Treeviewの行の高さを調整する - python、python-3.x、tkinter、treeview
Python - Tkinterのラベルを削除したい|teratail
【Python】2次元配列を二番目の要素に注目して降順にソートする - Qiita
Tkinter Scrollbar と Listbox - Tkinter による GUI プログラミング - Python 入門


- 投稿日:2020-09-25T21:27:38+09:00
Anacondaで仮想環境を作り、PyCharmと紐付ける。
はじめに
DjangoでRest Apiを作りたい。
その思いからUdemyやQiitaから自分用に仮想環境の構築方法をまとめました。
Pythonでの動作確認も記事にしましたので興味のある方はご覧ください。事前準備&環境
・Anaconda Navigator
・PyCharm CE
・MacOS目次
1.仮想環境を作成
2.フレームワーク等のインストール
3.PyCharmと紐付け
4.動作確認1.仮想環境の作成
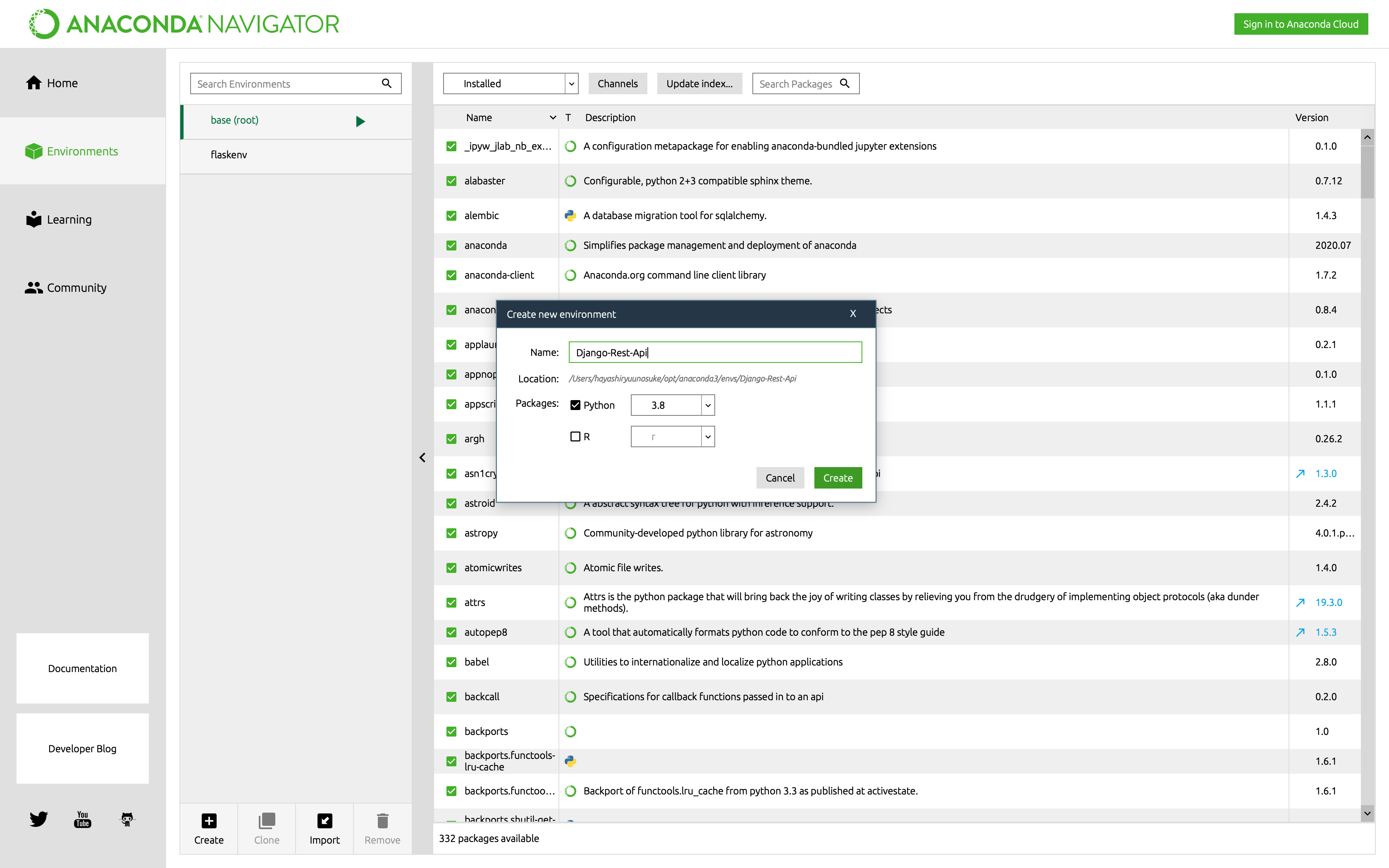
仮想環境の作成はとても簡単です。
Anaconda Navigatorを起動します。
[Enviroments]を選択し、[Create]を押します。
[Name]に好きな仮想環境名を入力し、[Create]を押します。
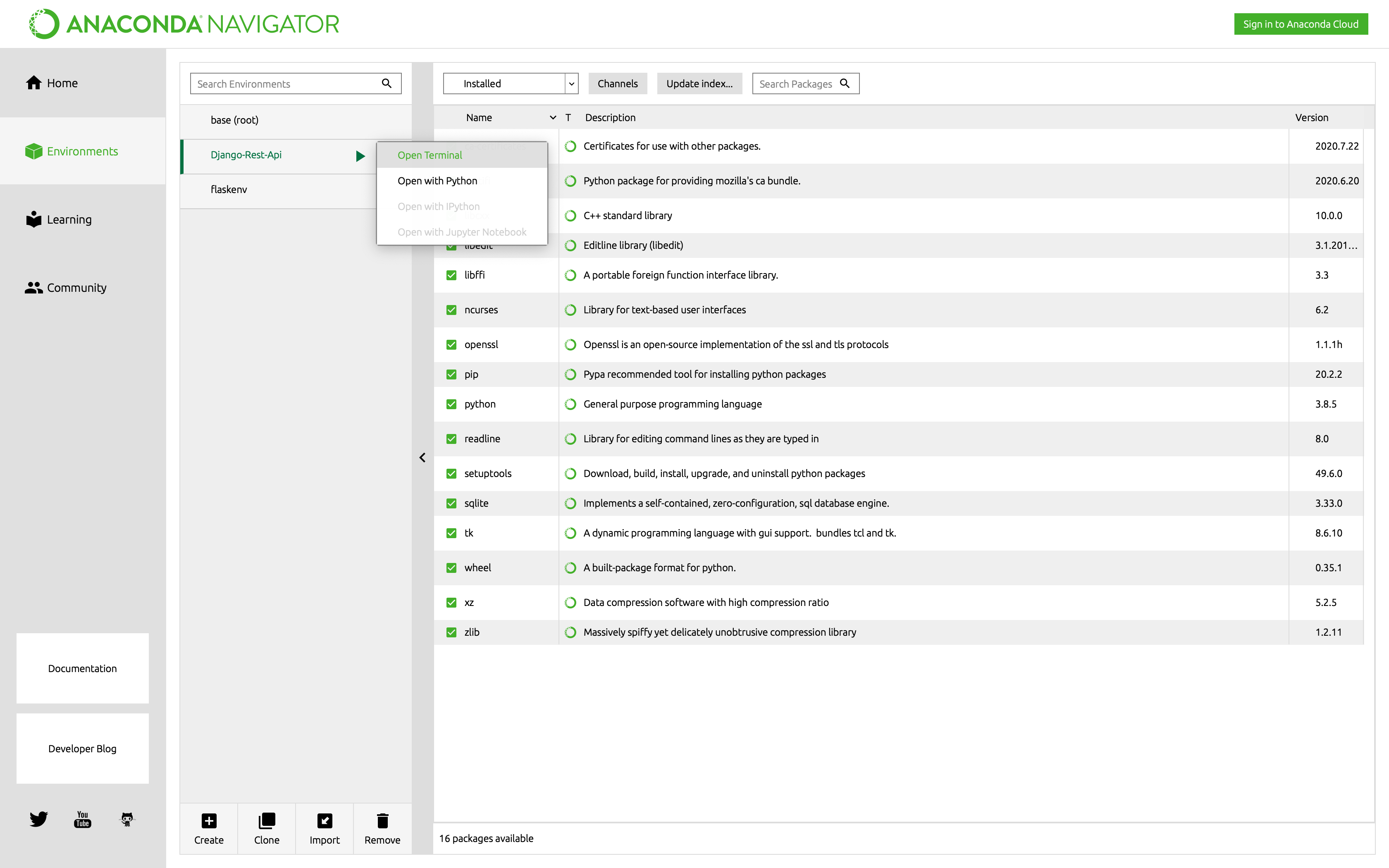
すると、仮想環境を作成してくれます。仮想環境の作成が完了したら、次章のために[Open Terminal]を押しておきましょう。
2.フレームワーク等のインストール
今回はDjangoでREST APIを作成するため、Djangoとdjangorestframeworkをインストールします。
前章で起動したターミナル上で以下のコマンドを入力します。(Django-Rest-Api)$ pip install Django djangorestframework3.PyCharmと紐付け
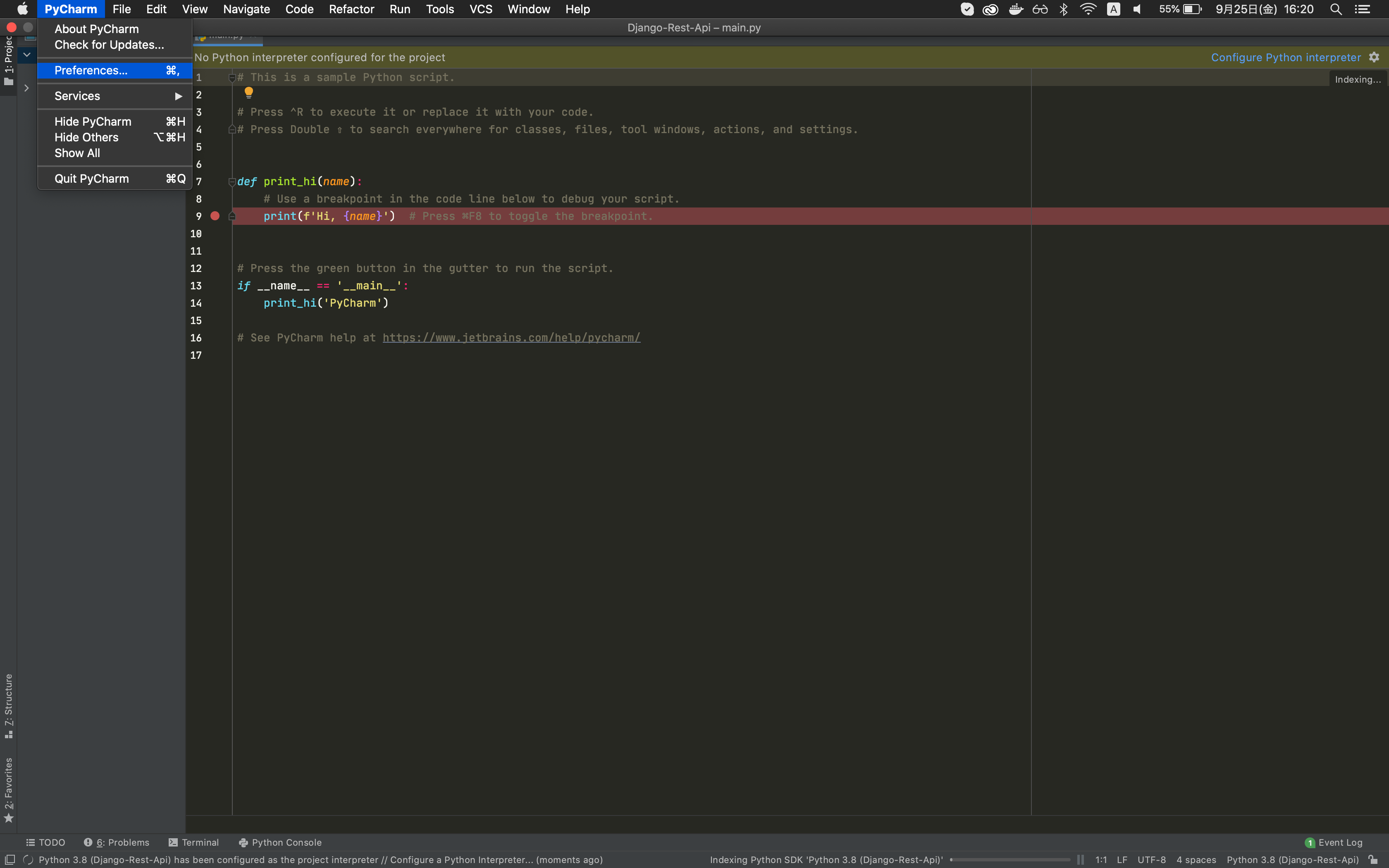
PyCharmを起動し、Openを押します。
[PyCharm] > [Preferences...]を押します。
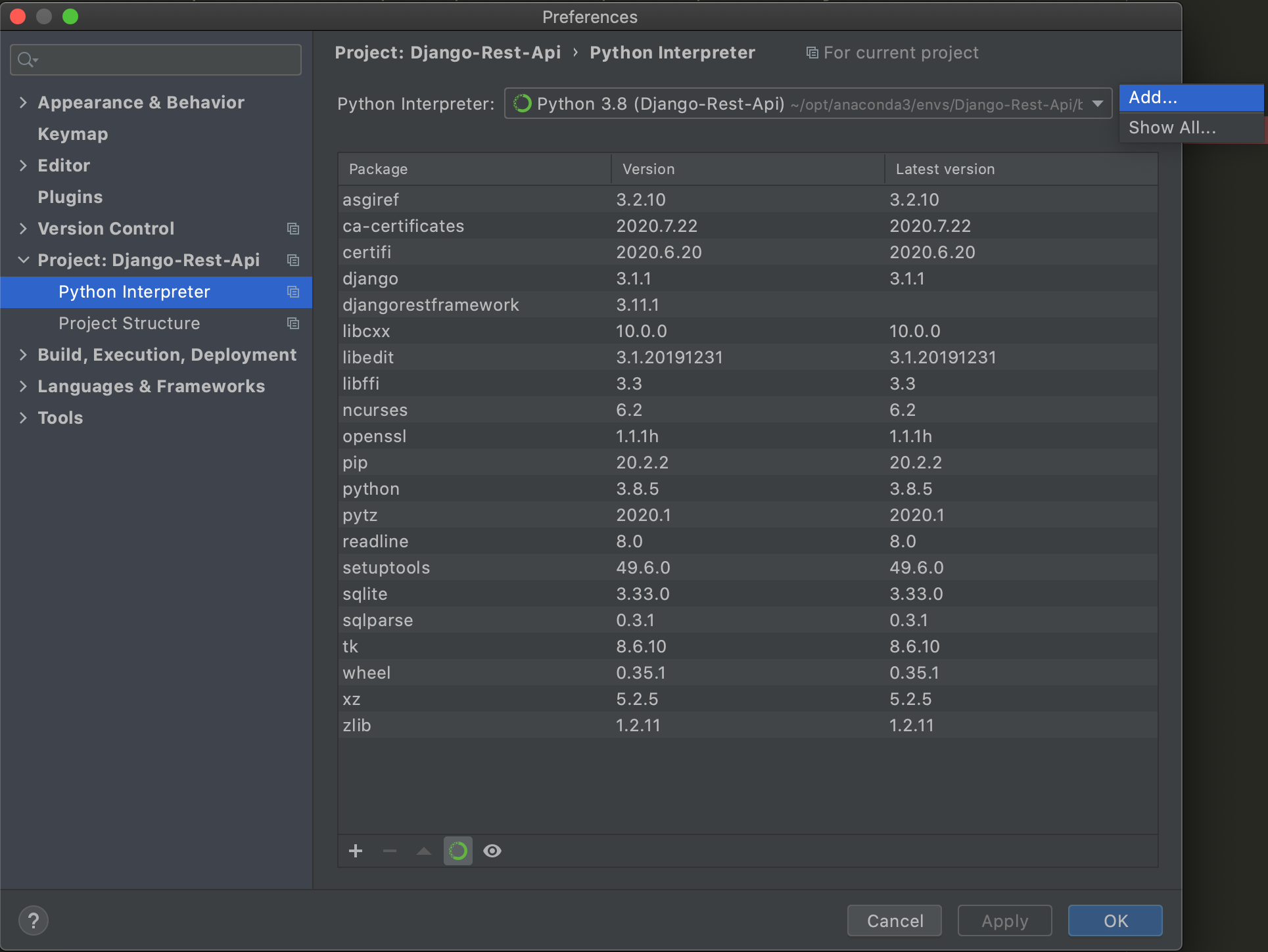
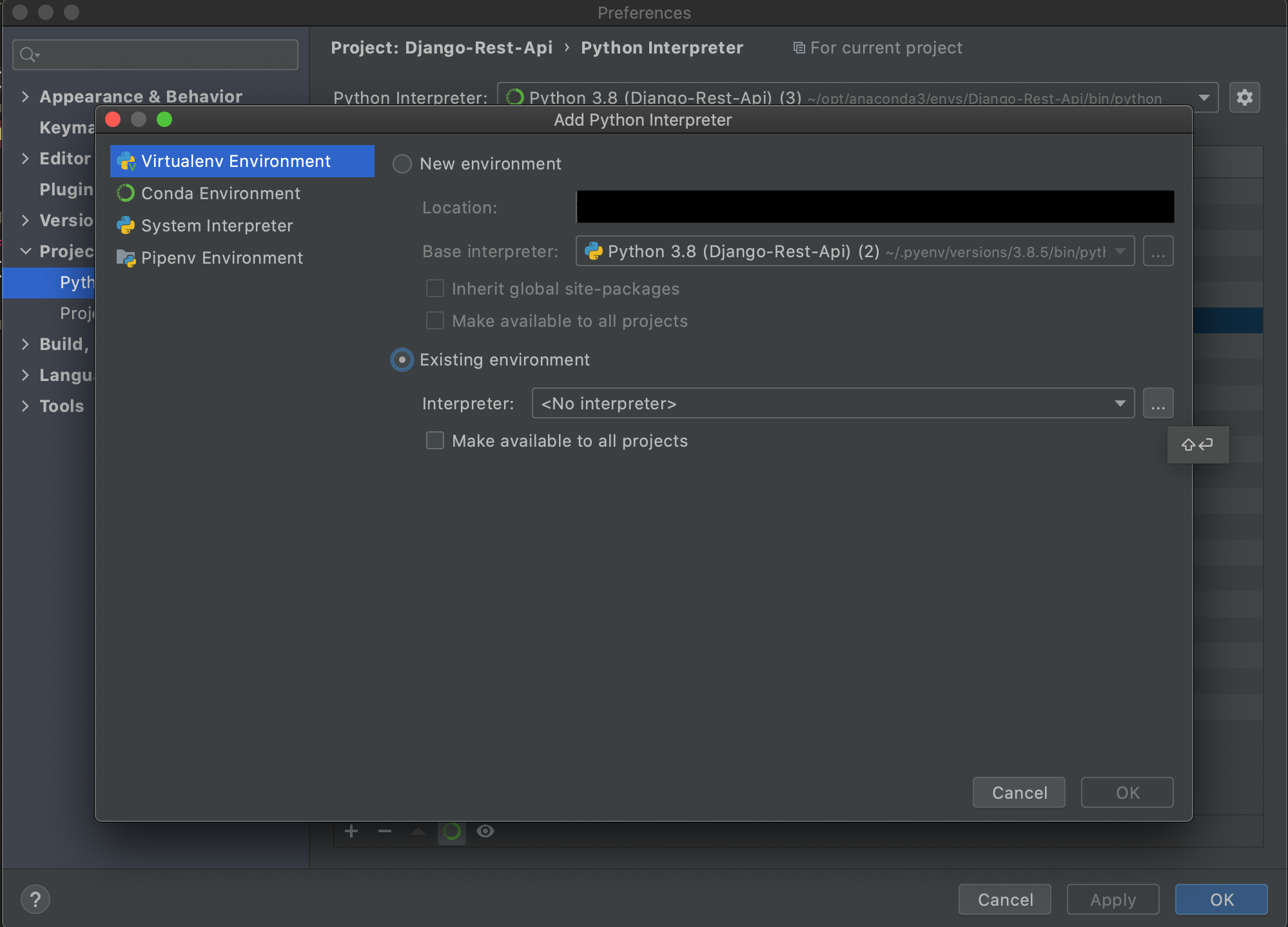
[python interpreter]を選択し、歯車のマークから[Add]を選択します。
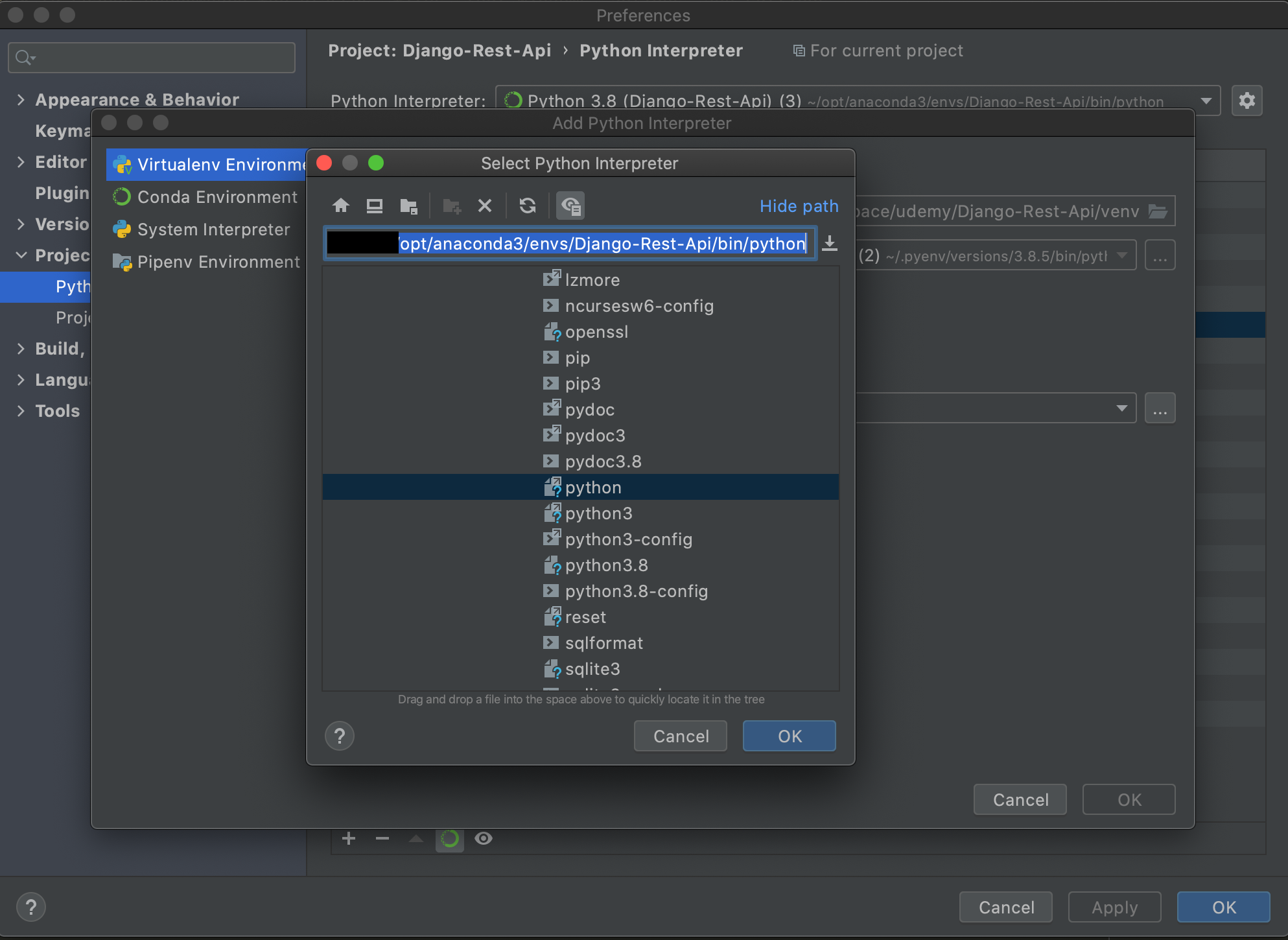
[Existing enviroment]を選択し、...を押します。
[<ご自身のuser>/opt/anaconda3/envs/<仮想環境名>/bin/python]を選択してOKを全て押し、閉じます。
以上で、AnacondaとPyCharmの紐付けは完了です。4.動作確認
PyCharm上でターミナルを起動して、djangoのプロジェクトを構成するコードと専用のapiアプリを作成します。
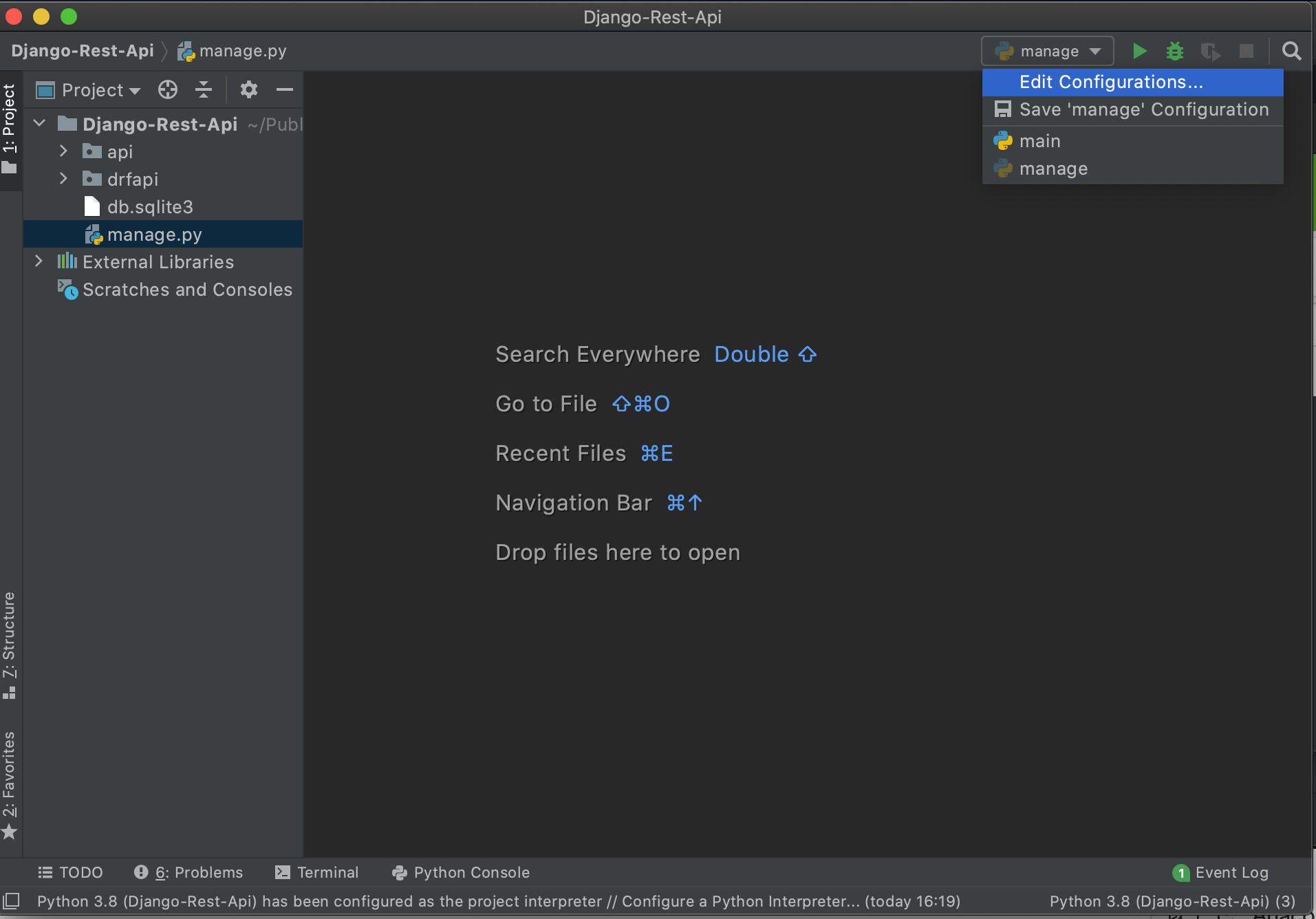
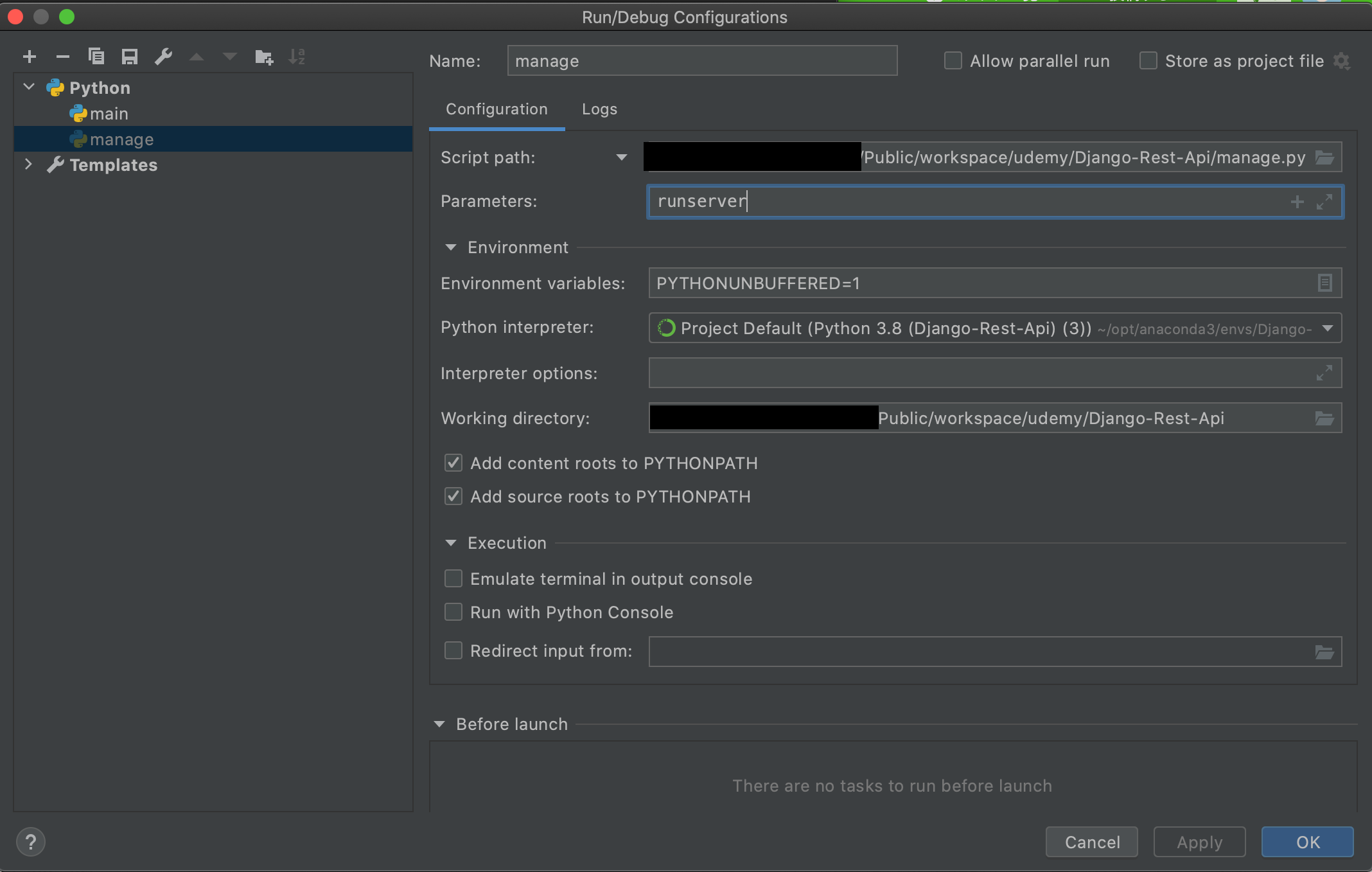
(Django-Rest-Api)$ django-admin startproject dfrapi . (Django-Rest-Api)$ django-admin startapp apimanage.pyを実行すると、画面右上で[Edit Configurations...]を選択できるようになるので押します。
[Parameters]に[runserver]を入力してOKを押します。
右上の実行ボタンを押し、http://127.0.0.1:8000/
でPythonのスタート画面が表示されれば成功です。
参考文献
はじめてのDjangoアプリ作成(https://docs.djangoproject.com/ja/3.1/intro/tutorial01/)
Django REST APIでデバイス管理ツールを作ってみよう(https://www.udemy.com/course/django-rest-api/)
Django REST Framework の使い方メモ(https://qiita.com/__init__/items/f5a5a64a05541fcda713)


- 投稿日:2020-09-25T21:09:44+09:00
pythonによる【高等学校情報科 情報Ⅰ・情報Ⅱ】教員研修用教材まとめ
はじめに
高等学校の新しい学習指導要領の共通教科「情報」では、必修科目として「情報Ⅰ」、選択科目として「情報Ⅱ」が定められております。
これに伴い文部科学省のHPにて、「情報Ⅰ」「情報Ⅱ」の教員研修用教材が公開されています。
この教員研修用教材は高校生でなくても情報技術を学ぶ入門テキストとして優れていると思うのですが、実装例の説明に使われている言語としてpythonとRが多く、「情報Ⅰ」の一部領域に限り他の言語(JavaScript,VBA,ドリトル,swift)の記載が載っており、統一感のない印象を受けました。
様々なスキルの教員の指導用や高校生の学習の為に書かれた教材なので、色々な言語で説明するのは良いとは思うのですが、気になる点がございました。
- 「情報Ⅰ」の「コンピュータとプログラミング」の領域では、python,JavaScript,VBA,ドリトル、swiftの実装例での説明があるが、「情報Ⅱ」では、主にpython,Rで説明されている。
- 高等学校における「情報Ⅰ」「情報Ⅱ」の標準単位数は、それぞれ2単位である。教育の専門家でもないので詳しくはわからないが、この単位数に換算される授業時間でいくつものプログラミング言語も学べるのだろうか?(学習コストの問題)
- 「情報Ⅱ」情報システムとプログラミングの学習内容の発展形として実際にシステム開発をプロセスを学びながらそれなりのアプリケーションを作ろうとなったとき、今までに挙がった言語の中ではpython,JavaScript,VBA,swiftあたりは良さそうだが、ドメイン固有言語のRなどはどうだろうか?
- 「情報Ⅰ」「情報Ⅱ」全体として俯瞰してみたとき、データサイエンス分野に偏っているように思える。
- データサイエンスの項目では深層学習まで踏み込んでいる。深層学習までの内容を説明する際に、pythonとRのどちらが適しているだろうか?
- 高校と大学の接続を考えてRを多くしているのか?大学の先生はデータサイエンスに関してRを使っている人が多いから?pythonだけで解説できない理由がわからない。
上記より「全てpythonで実装・解説したほうがよいのでは?」という結論に至り、主にR→pythonに書き換えを行った記事を書いてきました。
前置きが長くなりましたが、この記事は教員研修用教材内の実装例や解説をpythonベースで学習しようと思ったときに参考になるようにまとめたものです。
他の方が書いてくださった資料や自分で書いた記事などをまぜこぜにしてまとめておりますのでご注意ください。
教材
環境
ipython
Colaboratory - Google Colab情報Ⅰ
教材:高等学校情報科「情報Ⅰ」教員研修用教材(本編):文部科学省
第1章 情報社会の問題解決
実装例なし
第2章 コミュニケーションと情報デザイン
学習6 デジタルにするということ
(9)ファイルの圧縮 図表13 ハフマン木の作成手順の例
解説:【高等学校情報科 情報Ⅰ】【高等学校情報科 情報Ⅰ】教員研修用教材:ハフマン法についてのpythonによる実装 - Qiita
ソースコード:https://colab.research.google.com/gist/ereyester/6a37027afa322d1b76e72b774aa406e8/jouhou1_2_6_huffman.ipynb学習7~学習10
実装例なし
第3章 コンピュータとプログラミング
「第3章 コンピュータとプログラミング」に準拠した内容は、以下のサイトからたくさん引用しております。
基本的なプログラミング(Python入門)- IPSJ MOOC情報処理学会 公開教材
学習11 コンピュータの仕組み
(2)プログラミングで誤差を体験する
解説&ソースコード:プログラムの構造,順次処理,計算 - IPSJ MOOC情報処理学会 公開教材
→「オーバーフローと誤差」参照学習12 外部装置との接続
(5)センサの値をもとにLED を制御するプログラム
ブラウザベースで実行できる
https://python.microbit.org/v/2.0
がおすすめです。
教材のソースコードをコピペで実行。学習13 基本的プログラム
順次の例 - 図表7 コード
解説&ソースコード:プログラムの構造,順次処理,計算 - IPSJ MOOC情報処理学会 公開教材
→「順次処理」参照分岐の例 - 図表10 コード
解説&ソースコード:分岐処理 - IPSJ MOOC情報処理学会 公開教材
→「分岐処理(2分岐)」参照反復の例 - 図表13 コード
解説&ソースコード:反復処理 - IPSJ MOOC情報処理学会 公開教材
→「反復処理(for)」参照分岐と反復を組み合わせた例
解説&ソースコード:反復処理 - IPSJ MOOC情報処理学会 公開教材
→「反復処理と分岐処理の組み合わせ」参照学習14 応用的プログラム
(1)リスト - 図表2 リストを用いたプログラムの例1
解説&ソースコード:応用的プログラミング1 - IPSJ MOOC情報処理学会 公開教材
→「リスト」参照(1)リスト - 図表3 リストを用いたプログラムの例2
解説&ソースコード:応用的プログラミング1 - IPSJ MOOC情報処理学会 公開教材
→「リスト」参照(2)乱数 - 図表4 乱数を用いたプログラムの例1
解説&ソースコード:応用的プログラミング1 - IPSJ MOOC情報処理学会 公開教材
→「乱数」参照(3)関数 - 図表9 関数で分割したプログラムの例
解説&ソースコード:応用的プログラミング2 - IPSJ MOOC情報処理学会 公開教材
→「関数」参照(4)WebAPI - 図表11 WebAPI を用いたプログラムの例
解説&ソースコード:応用的プログラミング2 - IPSJ MOOC情報処理学会 公開教材
→「WebAPI」参照学習15 アルゴリズムの比較
解説&ソースコード:リストと組み込みの関数 - IPSJ MOOC情報処理学会 公開教材
→「リストと組み込みの関数」参照(1)探索アルゴリズム 線形探索と二分探索 - 図表3 コード
解説&ソースコード:基本的な探索 - 線形探索 - IPSJ MOOC情報処理学会 公開教材
→「線形探索」参照(1)探索アルゴリズム 線形探索と二分探索 - 図表6 コード
解説&ソースコード:基本的な探索 - 二分探索 - IPSJ MOOC情報処理学会 公開教材
→「二分探索」参照(1)探索アルゴリズム 線形探索と二分探索 - 図表7 線形探索と二分探索での最大探索回数の比較
解説&ソースコード:基本的な探索 - 線形探索と二分探索の比較 - IPSJ MOOC情報処理学会 公開教材
→「線形探索と二分探索の比較」参照(2)ソートアルゴリズム 選択ソートとクイックソート - 選択ソート - 図表9 コード
解説&ソースコード:基本的なソート - 選択ソート - IPSJ MOOC情報処理学会 公開教材
→「選択ソート」参照(2)ソートアルゴリズム 選択ソートとクイックソート - クイックソート - 図表11 コード
解説&ソースコード:基本的なソート - クイックソート - IPSJ MOOC情報処理学会 公開教材
→「クイックソートの実装例」参照(3)選択ソートとクイックソートの比較
解説&ソースコード:基本的なソート - 選択ソートとクイックソートの比較 - IPSJ MOOC情報処理学会 公開教材
→「4-2. 基本的なソート - 選択ソートとクイックソートの比較」参照学習16 確定モデルと確率モデル
教材記載の実装例(python)を参照 (TBD)
学習17 自然現象のモデル化とシミュレーション
教材記載の実装例(python)を参照 (TBD)
第4章 情報通信ネットワークとデータの活用
学習18 情報通信ネットワークの仕組み
実装例なし
学習19 情報通信ネットワークの構築
実装例なし
学習20 情報システムが提供するサービス
実装例なし
学習21 さまざまな形式のデータとその表現形式
教材記載の実装例(python)を参照 (TBD)
学習22 量的データの分析
教材記載の実装例(Excel)を参照 (TBD)
学習23 質的データの分析
解説:【高等学校情報科 情報Ⅰ】教員研修用教材:MeCabによる形態素解析とWordCloudの作り方(python) - Qiita
ソースコード:https://colab.research.google.com/gist/ereyester/5f1a93311f434b08f1e57fda4fb5398f/jouhou1_4_23.ipynb学習24 データの形式と可視化
解説:【高等学校情報科 情報Ⅰ】教員研修用教材:データの形式と可視化(python) - Qiita
ソースコード:https://colab.research.google.com/gist/ereyester/68b781bd6668005c157b300c5bf22905/jouhou1_4_24.ipynb情報Ⅱ
教材:高等学校情報科「情報Ⅱ」教員研修用教材(本編):文部科学省
第1章 情報社会の進展と情報技術
実装例なし
第2章 コミュニケーションとコンテンツ
実装例なし
第3章 情報とデータサイエンス
学習11 データと関係データベース
教材記載の実装例(python)を参照
学習12 大量のデータの収集と整理・整形
教材記載の実装例(python)を参照
学習13 重回帰分析とモデルの決定
解説:【高等学校情報科 情報Ⅱ】教員研修用教材:重回帰分析とモデルの決定(python) - Qiita
ソースコード:https://colab.research.google.com/gist/ereyester/5c6e5a9b8aa55ba826c7c96a4daf7814/jouhou2_3_13_python.ipynb学習14 主成分分析による次元削減
解説:pythonで主成分分析(Scikit-learn版,pandas&numpy版)(【高等学校情報科 情報Ⅱ】教員研修用教材) - Qiita
ソースコード:https://colab.research.google.com/gist/ereyester/3c2173eb61cbcd64b61f23b3d4d6480c/jouhou2_3_14.ipynb学習15 分類による予測
2 決定木による二値分類
解説:pythonによる決定木による二値分類(【高等学校情報科 情報Ⅱ】教員研修用教材) - Qiita
ソースコード:https://colab.research.google.com/gist/ereyester/dfb4fd6fb3e58c5d0539866f7e2622b4/jouhou2_3_15.ipynb3 k-近傍法による分類
解説:pythonによるk-近傍法(kNN)による分類(【高等学校情報科 情報Ⅱ】教員研修用教材) - Qiita
ソースコード:https://colab.research.google.com/gist/ereyester/01237a69f6b8ae73c55ccca33c931ade/jouhou2_3_15_2.ipynb学習16 クラスタリングによる分類
教材記載の実装例(python)を参照
学習17 ニューラルネットワークとその仕組み
教材記載の実装例(python)を参照
学習18 テキストマイニングと画像認識
2 MeCabを利用したテキストマイニング
解説:pythonによるword2vec等によるテキストマイニング(【高等学校情報科 情報Ⅱ】教員研修用教材) - Qiita
ソースコード:https://colab.research.google.com/gist/ereyester/101ae0da17e747b701b67fe9fe137b84/jouhou2_3_18.ipynb3 TinyYOLOを利用した物体検出
解説:YOLOを利用した物体検出(python)(【高等学校情報科 情報Ⅱ】教員研修用教材) - Qiita
ソースコード:https://colab.research.google.com/gist/ereyester/46a25e70c866c581320a66a77153aa2d/jouhou2_3_18_2.ipynb第4章 情報システムとプログラミング
学習19~学習22
実装例なし
学習23 分割したシステムの制作とテスト
解説&ソースコード:情報II教員研修資料4章.ipynb
→「学習23 分割したシステムの制作とテスト」参照学習24 分割したシステムの結合とテスト
解説&ソースコード:情報II教員研修資料4章.ipynb
→「学習24 分割したシステムの結合とテスト」参照学習25 情報システムの評価・改善
解説&ソースコード:情報II教員研修資料4章.ipynb
→「学習25 情報システムの評価・改善」参照第5章 情報と情報技術を活用した問題発見・解決の探究
活動例1 情報社会と情報技術
実装例なし
活動例2 コミュニケーションのための情報技術の活用
実装例なし
活動例3 データを活用するための情報技術の活用
解説:k-means法を使用したクラスタリングによるデータ分析(python)(【高等学校情報科 情報Ⅱ】教員研修用教材) - Qiita
ソースコード:https://colab.research.google.com/gist/ereyester/ce9370e3022f05f4d7548a8ccaed33cc/jouhou2_5_3.ipynb活動例4 コンピュータや情報システムの基本的な仕組みと活用
実装例なし
コメント
(TBD)の個所はIPSJ MOOC情報処理学会様などで更新がありそうな箇所です。
- 投稿日:2020-09-25T20:49:07+09:00
Codeforces Round #479 (Div. 3) バチャ復習(9/25)
今回の成績
今回の感想
E問題が実装ゲーだったのですが、実装の最終形をイメージせずに無理矢理実装したらバグらせ続けたので反省しています。
途中で切り替えてF問題に移ったのは良かったですが、方針は完全に合っているのに実装を落とすのは勿体ないのでコドフォのバチャで繰り返し鍛錬を積もうと思います。A問題
数を文字列のように捉えて愚直にシミュレートしていくだけです。あまりこのような問題がないので、若干迷っいました。
A.pyn,k=input().split() n=[int(i) for i in n] k=int(k) for i in range(k): if n[-1]==0: n=n[:-1] else: n[-1]-=1 print("".join(map(str,n)))B問題
問題文の意味を理解するのに若干苦労しましたが、連続した二つの文字(以下では単に文字列と書きます)のうちそれぞれの文字列がいくつずつあるかをカウントしていけば良いです。つまり、辞書$check[i]:=$(文字列が$i$となるインデックスの組み合わせが何通りか)とすれば、インデックスの組み合わせは$n-1$通りなので、全てを$check$に記録することができます。辞書に保存した後、インデックスの組み合わせが最大のものを出力すればよく、辞書内の要素を逆順でソートして一番最初のものを解とします。
B.pyn=int(input()) s=input() check=dict() for i in range(n-1): t=s[i:i+2] if t in check: check[t]+=1 else: check[t]=1 c=list(check.items()) c.sort(key=lambda x:x[1],reverse=True) print(c[0][0])C問題
$x \in [1,10^9]$なので、コーナーケースに注意すべきです(気づいてたのに1WAを出しました、注意力…)。
$x$が任意の整数をとることができる場合、数列$a$を昇順で並べた時に$a_0 ,a_1,a_2,…,a_{k-1} \leqq x$かつ$x<a_k$となる$x$を取れば良いです。また、昇順で並べていることから、$a_{k-1} \leqq x <a_k$となる$x$を取れば良いです。また、$x=a_{k-1}$とすれば良いですが、$a_{k-1}=a_k$の場合は条件は満たさないので-1を出力します。
また、$k=0,n$のときは$a_{k-1}$と$a_k$の一方が存在しないので場合分けする必要があります。$k=n$のときは$a_{max}$が高々$10^9$なので、$x=10^9$となります。それに対し、$k=0$のときは$a_0=1$である時に$x \geqq 1$なので条件を満たしません。それ以外の場合は$a_0-1$とすれば条件を満たします。(1WAは$k=n$のときの場合分けを間違えてました…)
C.pyn,k=map(int,input().split()) a=sorted(list(map(int,input().split()))) if k==0: if a[0]==1: print(-1) else: print(a[0]-1) elif k==n: print(a[-1]) else: if a[k-1]==a[k]: print(-1) else: print(a[k-1])D問題
意外と難しいかなと思ったのですが、D問題レベルの問題でした。
(以下の方針では途中まで存在しない場合は-1を出力するものと思って考察を進めたので冗長なとこがありますが、気にしないでください。)(誤読しましたが、誤読した方の問題を作ったら緑前半くらいのレベルの問題は作れそうです。)
$x$は3で割るか2をかけるかの二つの操作しかすることができません。また、例えば、$4,6$といった場合は操作によって作りだせませんが、入力は必ず条件を満たすようになっています(存在しない場合があると考えて問題を解いても結局解けますが、実装が多少減ります)。
まず、操作のうち"3で割る"という操作に注目すると、3で割って3の倍数ではなくなった時に3の倍数がまだ残っている場合は題意を満たさないからです。つまり、3で割るという操作からは、それぞれを$3^i$の倍数であるとした時に$3^i$の大きいものから操作すべきことがわかります。また、同様に2をかけるという操作からは$2^i$の小さいものから操作するべきこともわかります。
よって、$a_i$が$2,3$でそれぞれ何回ずつ割れるかを$x_i,y_i$として求め、$x_i$が小さく$y_i$が大きいものから順に処理していきます(✳︎)。この順で処理すればこの問題の条件下であれば題意を満たす順番に必ず並べ替えることができ、その順番で出力します。
(✳︎)…存在しない場合があるときはここでGCDを考慮しますが、ここでは必要はりません
D.pyfrom math import gcd def gce(x): ret=x[0] for i in x: ret=gcd(ret,i) return ret n=int(input()) a=list(map(int,input().split())) g=gce(a) a=[i//g for i in a] b=[] for i in range(n): d=[0,0] c=a[i] while c%2==0: c//=2 d[0]+=1 while c%3==0: c//=3 d[1]+=1 b.append(d) b.sort(key=lambda x:x[0]) b.sort(reverse=True,key=lambda x:x[1]) ans=[] for i in range(n): ans.append(str((2**b[i][0])*(3**b[i][1])*g)) print(" ".join(ans))E問題
DFS(の再帰)が必要だと思ってC++で書きましたが、結局BFSで実装しました。くだらないミスが多発しましたが、感想の通り実装の最終形のイメージができなかったことが原因だと思います。
問題文を読めば方針は立つと思います。少し長いですが、無向グラフでループ(自身を繋ぐ辺)がなく多重辺もない、よくあるタイプのグラフであることが説明されているだけです。この問題で求めるべきは、一つのサイクルのみで作られている連結成分がいくつ存在するかです。ここでは、サイクルの特徴を捉えてから実装する必要があります。図で表すなら以下です。
また、連結成分を求める場合はUnionFindをいつもは使っているのですが、ここではBFSを使って題意を満たす連結成分を考えることにしました。上図において、BFSの際にある一点を始点として決めれば、その始点から辿っていったときにそれぞれの頂点の次数が2かつ最終的に始点に戻ってくれば(✳︎)その連結成分は一つのサイクルのみを形成すると言えます。しかし、これだけのことを実装すれば良いにも関わらずバグらせてしまったので、より楽な実装方法を考えました。
すると、次のような実装を思いつきました。サイクルになっている時に満たす条件を考えれば思いつく実装だと思います。
まず、始点を選びます。始点は探索済みでない頂点であればどれを選んでも良いです。また、BFSでは始点をdequeに入れ、dequeに入っている頂点と繋がっていてかつ探索済みでない頂点を探索済みにしたうえでdequeに入れてdequeに入ってる要素がなくなるまで繰り返すというのが基本です。しかし、今回は以下のような順番で探索をしたいので、この実装ではうまくいきません($\because$このままだと始点から二方向に進んでしまうので)。
よって、始点を決めて探索済みとした後、その始点と繋がる一点(だけ)を探索済みとしてその点から順に探索を行います。ここで、BFSの探索で用いるdeque(
d)とは別に探索した順序で保持するdeque(e)も用意します。このBFSによる探索を行った後に上記のサイクルの判定をします。この時、探索の順序でeに頂点の情報が保持されているので、「eに含まれる任意の頂点の次数が2であるか」と「eの任意の連続する頂点どうし及び始点と終点のどうしで繋がっているか」の二つを確かめればサイクルの判定となります。また、先ほどのBFSでは始点から繋がる頂点のうち(最大で)二つしか探索しておらず、次数が2以上の場合は探索していない頂点が存在しうるので、始点を再度
dに挿入してBFSを行ってこの連結成分に含まれる残りの頂点も調べておきます。以上より、それぞれの連結成分がサイクルかどうかの判定はできるので、その合計の数が答えとなります。
(いつも最初に思いついた実装で頑張っていますが、時には方針の一部を変えて実装を楽にするのも大事だと思いました。実装しきる力だけでなくより明確でバグらせず容易な実装を考えるのも実装力だと思うので、両方の実装力を付けれるよう努力します。)
追記(2020/09/25)
連結成分がサイクルになる条件は(✳︎)と書いていますが、この条件は任意の頂点の次数が2であることと同値なので、UnionFindを使って連結成分を求めた後に連結成分内の任意の頂点の次数が2であることを確かめればよく、実装がかなり簡単になります。考察力不足でした…。
E.cc//デバッグ用オプション:-fsanitize=undefined,address //コンパイラ最適化 #pragma GCC optimize("Ofast") //インクルードなど #include<bits/stdc++.h> using namespace std; typedef long long ll; //マクロ //forループ //引数は、(ループ内変数,動く範囲)か(ループ内変数,始めの数,終わりの数)、のどちらか //Dがついてないものはループ変数は1ずつインクリメントされ、Dがついてるものはループ変数は1ずつデクリメントされる //FORAは範囲for文(使いにくかったら消す) #define REP(i,n) for(ll i=0;i<ll(n);i++) #define REPD(i,n) for(ll i=n-1;i>=0;i--) #define FOR(i,a,b) for(ll i=a;i<=ll(b);i++) #define FORD(i,a,b) for(ll i=a;i>=ll(b);i--) #define FORA(i,I) for(const auto& i:I) //xにはvectorなどのコンテナ #define ALL(x) x.begin(),x.end() #define SIZE(x) ll(x.size()) //定数 #define INF 1000000000000 //10^12:∞ #define MOD 1000000007 //10^9+7:合同式の法 #define MAXR 100000 //10^5:配列の最大のrange //略記 #define PB push_back //挿入 #define MP make_pair //pairのコンストラクタ #define F first //pairの一つ目の要素 #define S second //pairの二つ目の要素 vector<bool> check; vector<vector<ll>> tree; //実装を整理してイメージしような… ll bfs(ll i){ ll ret=1; deque<ll> d; deque<ll> e; check[i]=true; if(SIZE(tree[i])==0)return 0; e.PB(i); d.PB(tree[i][0]); e.PB(tree[i][0]); check[tree[i][0]]=true; //成り立つと仮定する while(SIZE(d)){ ll l=SIZE(d); REP(_,l){ ll p=d.front(); d.pop_front(); FORA(j,tree[p]){ if(check[j]==false){ check[j]=true; d.PB(j); e.PB(j); } } } } //FORA(i,e)cout<<i<<" "; //cout<<endl; for(auto j=e.begin();j!=e.end();j++){ ll x,y;x=*j; if(j==--e.end()){ y=*e.begin(); }else{ //y=*jにしてた auto k=j;k++;y=*k; } if(SIZE(tree[x])!=2){ ret=0; break; }else{ if(tree[x][0]==y or tree[x][1]==y){ continue; }else{ ret=0; break; } } } d.PB(i); while(SIZE(d)){ ll l=SIZE(d); REP(_,l){ ll p=d.front(); d.pop_front(); FORA(j,tree[p]){ if(check[j]==false){ check[j]=true; d.PB(j); e.PB(j); } } } } return ret; } signed main(){ //入力の高速化用のコード //ios::sync_with_stdio(false); //cin.tie(nullptr); ll n,m;cin>>n>>m; tree=vector<vector<ll>>(n); check=vector<bool>(n,false); REP(i,m){ ll u,v;cin>>u>>v; tree[u-1].PB(v-1); tree[v-1].PB(u-1); } ll ans=0; REP(i,n){ if(check[i]==false){ ans+=bfs(i); } } cout<<ans<<endl; }E_easier.cc//デバッグ用オプション:-fsanitize=undefined,address //コンパイラ最適化 #pragma GCC optimize("Ofast") //インクルードなど #include<bits/stdc++.h> using namespace std; typedef long long ll; //マクロ //forループ //引数は、(ループ内変数,動く範囲)か(ループ内変数,始めの数,終わりの数)、のどちらか //Dがついてないものはループ変数は1ずつインクリメントされ、Dがついてるものはループ変数は1ずつデクリメントされる //FORAは範囲for文(使いにくかったら消す) #define REP(i,n) for(ll i=0;i<ll(n);i++) #define REPD(i,n) for(ll i=n-1;i>=0;i--) #define FOR(i,a,b) for(ll i=a;i<=ll(b);i++) #define FORD(i,a,b) for(ll i=a;i>=ll(b);i--) #define FORA(i,I) for(const auto& i:I) //xにはvectorなどのコンテナ #define ALL(x) x.begin(),x.end() #define SIZE(x) ll(x.size()) //定数 #define INF 1000000000000 //10^12:∞ #define MOD 1000000007 //10^9+7:合同式の法 #define MAXR 100000 //10^5:配列の最大のrange //略記 #define PB push_back //挿入 #define MP make_pair //pairのコンストラクタ #define F first //pairの一つ目の要素 #define S second //pairの二つ目の要素 //以下、素集合と木は同じものを表す class UnionFind{ public: vector<ll> parent; //parent[i]はiの親 vector<ll> siz; //素集合のサイズを表す配列(1で初期化) map<ll,vector<ll>> group; //集合ごとに管理する(key:集合の代表元、value:集合の要素の配列) ll n; //要素数 //コンストラクタ UnionFind(ll n_):n(n_),parent(n_),siz(n_,1){ //全ての要素の根が自身であるとして初期化 for(ll i=0;i<n;i++){parent[i]=i;} } //データxの属する木の根を取得(経路圧縮も行う) ll root(ll x){ if(parent[x]==x) return x; return parent[x]=root(parent[x]);//代入式の値は代入した変数の値なので、経路圧縮できる } //xとyの木を併合 void unite(ll x,ll y){ ll rx=root(x);//xの根 ll ry=root(y);//yの根 if(rx==ry) return;//同じ木にある時 //小さい集合を大きい集合へと併合(ry→rxへ併合) if(siz[rx]<siz[ry]) swap(rx,ry); siz[rx]+=siz[ry]; parent[ry]=rx;//xとyが同じ木にない時はyの根ryをxの根rxにつける } //xとyが属する木が同じかを判定 bool same(ll x,ll y){ ll rx=root(x); ll ry=root(y); return rx==ry; } //xの素集合のサイズを取得 ll size(ll x){ return siz[root(x)]; } //素集合をそれぞれグループ化 void grouping(){ //経路圧縮を先に行う REP(i,n)root(i); //mapで管理する(デフォルト構築を利用) REP(i,n)group[parent[i]].PB(i); } //素集合系を削除して初期化 void clear(){ REP(i,n){parent[i]=i;} siz=vector<ll>(n,1); group.clear(); } }; signed main(){ //入力の高速化用のコード //ios::sync_with_stdio(false); //cin.tie(nullptr); ll n,m;cin>>n>>m; vector<vector<ll>> tree(n); UnionFind uf(n); REP(i,m){ ll u,v;cin>>u>>v; tree[u-1].PB(v-1); tree[v-1].PB(u-1); uf.unite(u-1,v-1); } uf.grouping(); ll ans=0; FORA(i,uf.group){ ll check=1; FORA(j,i.S){ if(SIZE(tree[j])!=2){ check=0; break; } } ans+=check; } cout<<ans<<endl; }F問題
なぜかギャグ問がF問題に置かれていました。個人的にこの問題自体は好きです。
部分列なのでDPを初手で考えようと思いました。この時、この問題では$i$番目まで見た時のある部分列の(最後の値,長さ)の組を持っていれば更新でき、長さからの復元も難しくないと思ったので、DPをすることに決めました。また、情報は以下のように持って、前から順に$a_i$を見ていきます。
$s[j]:=$(部分列の最後の値が$j$のときの最大の部分列の長さ)
$j$の値は最大で$10^9$なので、$s$は辞書で持っています(DPの辞書による効率化!)。
ここで、$a_i$の更新処理は以下のようになります。
(1)$a_i-1$が$s$に含まれるとき
部分列を延長することができるので、$s[a_i-1]=b$として$s[a_i]=b+1$を新たに追加すれば良いです($s[a_i-1]$は削除してもしなくても結果は変わらないのでどちらでも良いです)。
(2)$a_i-1$が$s$に含まれないとき
延長できる部分列がないので、新たに長さが1の部分列として$s$に追加します。すなわち、$s[a_i]=1$とすれば良いです。
以上を任意の$i$で順に行えば最長の部分列は$s$のvalueのうちで最大のものが答えとなります(これを求めるのは$s$を全て舐めるか逆順ソートするかなので難しくないです。)。また、$s[k]=c$が最大のとき、この部分列に含まれるのは$k-c+1,…,k-1,k$であるので、相当する要素を後ろからまたは前から順に探していけば$O(n)$で復元できます。また、求めたいのはインデックスなので、これを復元により適当な配列に格納すればよいだけです。
F.pyn=int(input()) a=list(map(int,input().split())) s=dict() for i in range(n): if a[i]-1 in s: s[a[i]]=s[a[i]-1]+1 else: s[a[i]]=1 ans=[-1,-1] for i in s: if ans[1]<s[i]: ans=[i,s[i]] ans_=[] for i in range(n-1,-1,-1): if ans[0]==a[i]: ans[0]-=1 ans[1]-=1 ans_.append(i+1) if ans[1]==0: break print(len(ans_)) print(" ".join(map(str,ans_[::-1])))


- 投稿日:2020-09-25T20:19:25+09:00
インスタンスメソッドとクラスメソッドの使い分け
インスタンスメソッドとクラスメソッドの使い分け
今回は、インスタンスメソッドとクラスメソッドの使い分け方について書いてみます。
インスタンスメソッド
インスタンスごとで挙動を制御したい場合に使用します
- インスタンスを生成しないと呼び出すことができない
- インスタンス名.メソッド名で呼び出すことができる
- 第一引数には
selfを用いるクラスメソッド
クラス全体で共通の挙動を制御する際に使用します
- インスタンス化しなくてもメソッドを呼び出せる
- クラス名.メソッド名で呼び出すことが可能
- メソッドの一番上に
@classmethodと付けることで定義する- クラスメソッドの第一引数は
clsを用いる学校を例にしたインスタンスメソッドとクラスメソッドの使い分け
学校class Class: # 学校全体の入学者数 all_students_count = 0 def __init__(self, teacher_name, grade, group): self.teachername = teacher_name self.grade = grade self.group = group self.roster=[] def enter(self, name): # インスタンスメソッド self.roster.append(name) Class.all_students_count +=1 @classmethod def reset_students_count(cls, reset): # クラスメソッド cls.all_students_count = reset # インスタンスメソッドで2年3組の入学者を記録 cl_23 = Class("山中", 2, 3) cl_23.enter("平沢") cl_23.enter("秋山") cl_23.enter("田井中") cl_23.enter("琴吹") cl_23.enter("真鍋") print("2年3組の入学者名簿" , cl_23.roster) print(cl_23.all_students_count) #出力: 2年3組の入学者名簿 ['平沢', '秋山', '田井中', '琴吹', '真鍋'], 5 # インスタンスメソッドで1年1組の入学者を記録 cl_11 = Class("豊田", 1, 1) cl_11.enter("金子") cl_11.enter("佐藤") cl_11.enter("清水") print("1年1組の入学者名簿" , cl_11.roster) print(cl_11.all_students_count) #出力: 1年1組の入学者名簿 ['金子', '佐藤', '清水'], 8 # クラスメソッドで全ての入学者数をリセット Class.reset_students_count(0) print(cl_11.all_students_count) #出力:0
- 投稿日:2020-09-25T19:29:41+09:00
Pythonで、日時と時間、秒単位を表すには
Pythonで学習したこと
Python認定技術者に向けて勉強しています。
実際にコードがどのように役立つかについてですが、
使う人の側にたったコードを試したいです。実践したコード
import datetime now = datetime.datetime.now() print(now) print(now.isoformat()) print(now.strftime('%d/%m/%y-%H%M%S%f')) today = datetime.date.today() print(today.isoformat('%d/%m/%y')) t = datetime.time(hour=1, minute=0,second=5,microsecond=100) print(t) print(t.isoformat()) print(t.strftime('%H%_M_%S_%f')) print(now) d = datetime.timedelete(weeks=1) #d = datetime.timedelete(days=1) #d = datetime.timedelete(hours=1) #d = datetime.timedelete(minutes=1) #d = datetime.timedelete(second=1) #d = datetime.timedelete(microsecond=1) //argumentを一つ選ぶ print(now-d) import time #pair print('###') #time.sleep(10) #pair print('###') import os import shutil file_name = 'test.txt' if os.path.exists(file_name): shutil.copy(file_name, "{}.{}".format( file_name, now.strftime('%Y_%m_%d_%H__%M_%S'))) with open(file_name, 'w') as f: f.write('test')エラーが出たコード
該当するソースコード
print(now) d = datetime.timedelete(weeks=1) print(now-d)今後の課題とします。
また、textを生成するコードも載せます。
- 投稿日:2020-09-25T18:55:57+09:00
The Power of Pandas: Python
Pandas Basics
Pandas is a Python package providing fast, flexible, and expressive data structures designed to make working with “relational” or “labeled” data both easy and intuitive. It aims to be the fundamental high-level building block for doing practical, real world data analysis in Python. Additionally, it has the broader goal of becoming the most powerful and flexible open source data analysis / manipulation tool available in any language. It is already well on its way toward this goal.
Pandas is a high-level data manipulation tool developed by Wes McKinney. It is built on the Numpy package and its key data structure is called the DataFrame. DataFrames allow you to store and manipulate tabular data in rows of observations and columns of variables.
pandas is well suited for many different kinds of data:
・Tabular data with heterogeneously-typed columns, as in an SQL table or Excel spreadsheet
・Ordered and unordered (not necessarily fixed-frequency) time series data.
・Arbitrary matrix data (homogeneously typed or heterogeneous) with row and column labels
・Any other form of observational / statistical data sets. The data actually need not be labeled at all to be placed into a pandas data structureHere are just a few of the things that pandas does well:
・Easy handling of missing data (represented as NaN) in floating point as well as non-floating point data
・Size mutability: columns can be inserted and deleted from DataFrame and higher dimensional objects
・Automatic and explicit data alignment: objects can be explicitly aligned to a set of labels, or the user can simply ignore the labels and let Series, DataFrame, etc. automatically align the data for you in computations
・Powerful, flexible group by functionality to perform split-apply-combine operations on data sets, for both aggregating and transforming data
・Make it easy to convert ragged, differently-indexed data in other Python and NumPy data structures into DataFrame objects
・Intelligent label-based slicing, fancy indexing, and subsetting of large data sets
・Intuitive merging and joining data sets
・Flexible reshaping and pivoting of data sets
・Hierarchical labeling of axes (possible to have multiple labels per tick)
・Robust IO tools for loading data from flat files (CSV and delimited), Excel files, databases, and saving / loading data from the ultrafast HDF5 format
・Time series-specific functionality: date range generation and frequency conversion, moving window statistics, date shifting and lagging.
To load the pandas package and start working with it, import the package.
In [1]: import pandas as pd■Creating data
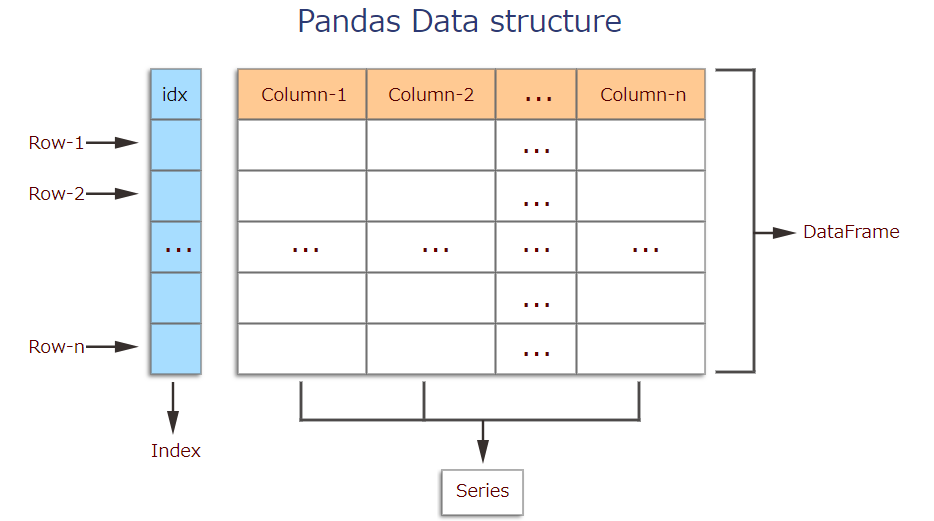
The two primary data structures of pandas, Series (1-dimensional) and DataFrame (2-dimensional).Each column in a DataFrame is a Series.
・DataFrame
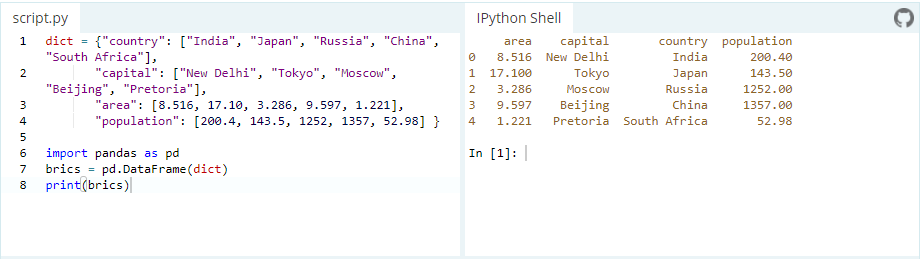
A DataFrame is a table. It contains an array of individual entries, each of which has a certain value. Each entry corresponds to a row (or record) and a column.
For example, consider the following simple DataFrame:In [2]: pd.DataFrame({'Yes': [50, 21], 'No': [131, 2]})Out [2]:
Yes No 0 50 131 1 21 2
DataFrame entries are not limited to integers. For instance, here's a DataFrame whose values are strings:
In [3]: pd.DataFrame({'Bob': ['I liked it.', 'It was awful.'], 'Sue': ['Pretty good.', 'Bland.']})Out [3]:
Bob Sue 0 I liked it. Pretty good. 1 It was awful. Bland. There are several ways to create a DataFrame. One way is to use a dictionary. For example:
・Series
A Series, by contrast, is a sequence of data values. If a DataFrame is a table, a Series is a list. And in fact you can create one with nothing more than a list:
In [4]: pd.Series([1, 2, 3, 4, 5])Out [4]: 0 1 1 2 2 3 3 4 4 5 dtype: int64■Reading data files
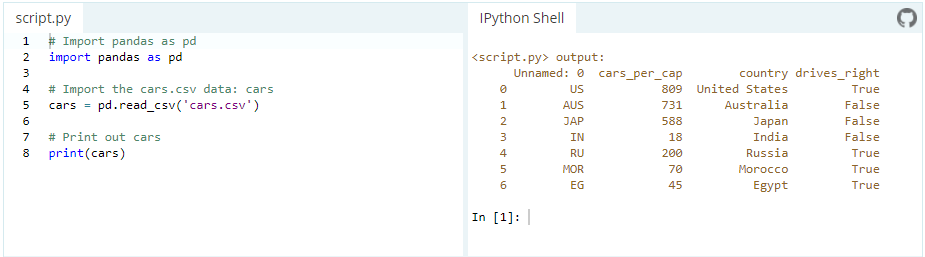
Another way to create a DataFrame is by importing a csv file using Pandas.
Data can be stored in any of a number of different forms and formats. By far the most basic of these is the humble CSV file. Now, the csv cars.csv is stored and can be imported using pd.read_csv:
or we can examine the contents of the resultant DataFrame using the head() command, which grabs the first five rows:
In [5]: pd.head()■ Other Useful Tricks
・Get the current working directory
In [6]: import os In [7]: os.getcwd()・Check how many rows and columns present in the data
(o/p -> no. of rows, no. of columns)In [8]: pd.shape Out [8]: (2200, 15)・Rename the columns
In [9]: pd_new = pd.rename(colums = {'Amount.Requested': 'Amount.Requested_NEW'}) In [10]: pd_new.head()・Write a dataframe in csv or excel
df.to_csv("filename.csv", index = False)
df.to_excel("filename.xlsx", index = False)There are two ways to handle the situation where we do not want the index to be stored in csv file.
- you can use index=False while saving your dataframe to csv file.
df.to_csv("file_name.csv", index=False)2 . Or you can save your dataframe as it is with an index, and while reading you just drop the column unnamed 0 containing your previous index.
df.to_csv("file_name.csv") df_new = pd.read_csv("file_name.csv").drop(['unnamed 0'],axis=1)here is the cheat-sheet for pandas.
https://pandas.pydata.org/Pandas_Cheat_Sheet.pdfEnjoy the Power of Pandas and I hope you found it helpful.
Thank you for spending the time to read this article.
See you in next topic.


- 投稿日:2020-09-25T18:43:15+09:00
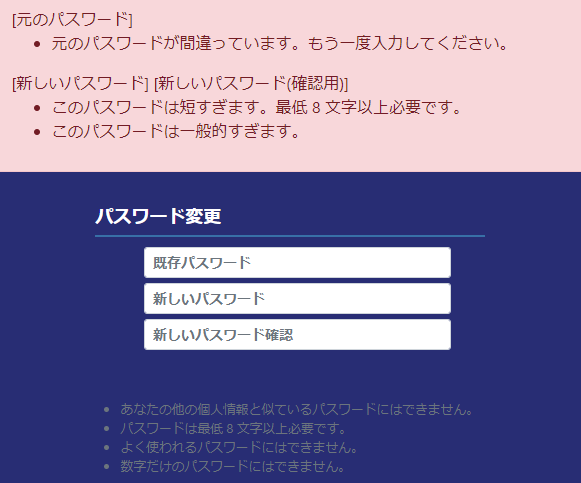
django PasswordChangeFormでエラーメッセージを日本語で出したい
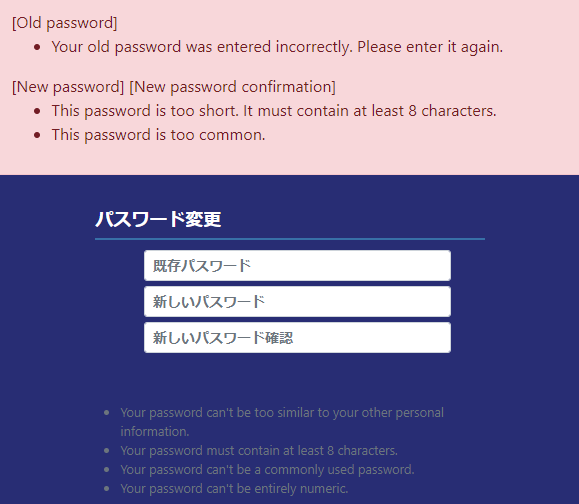
問題
djangoにはでパスワード変更画面用のPasswordChangeFormがあって既定のチェック処理も入ってるが入力チェックエラーのメッセージや注釈をを日本語にしたかった。
メッセージの国際化や多言語化などで探したがいい方法に該当しなかったが、それもそのはずsettings.pyの言語設定を変えるだけだった。うっかり。
というよりdjangoの言語設定すごいな。
同じ間違いに陥った人のために恥を晒しておく。
結論
言語設定が英語の場合
settings.pyLANGUAGE_CODE = 'en-us'
言語設定が日本語の場合
setttings.pyLANGUAGE_CODE = 'ja'
参考
- 投稿日:2020-09-25T18:39:48+09:00
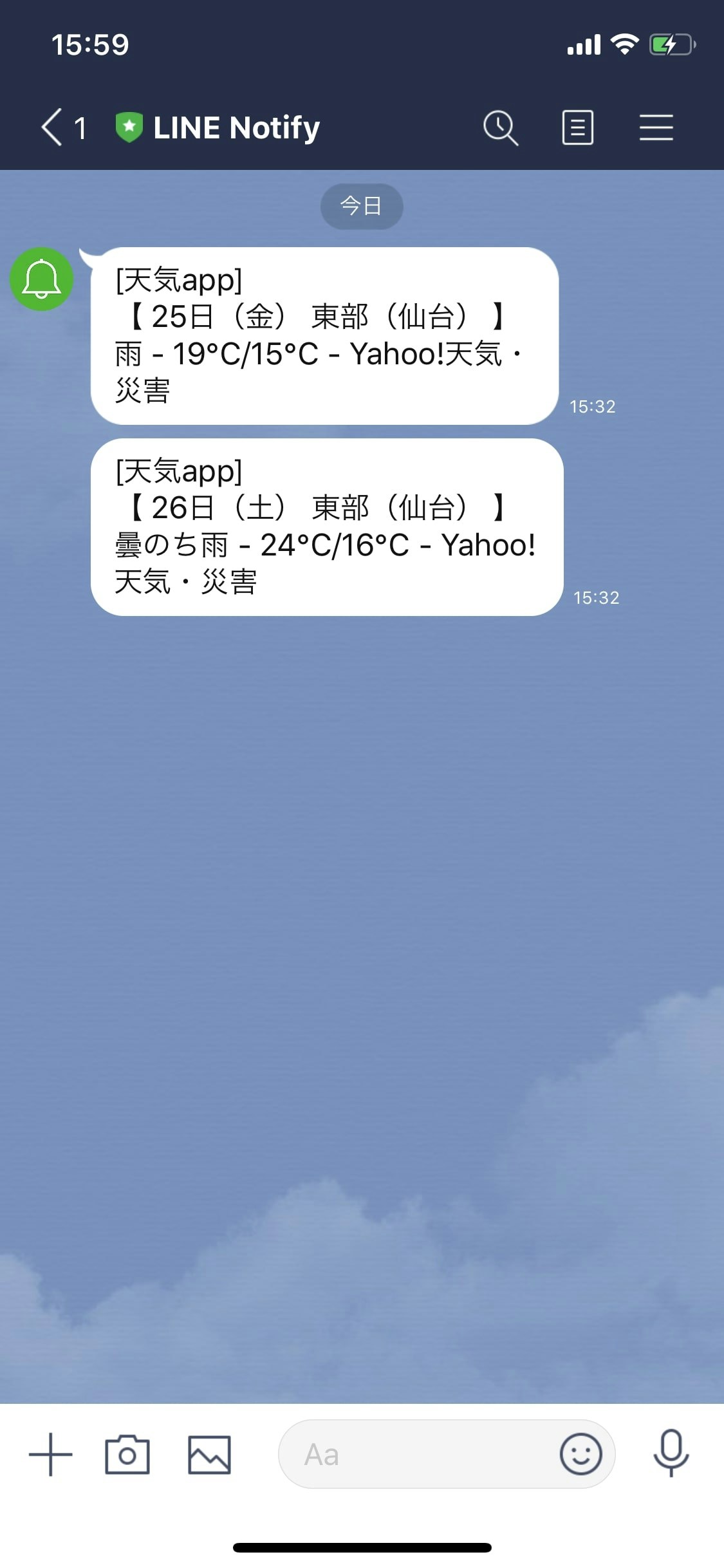
Pythonで天気予報botもどきを作ってみた。
Pythonで天気予報botもどきを作ってみた。
タイトル通りPythonで天気予報botもどきを作ってみました(botではないです)。
天気予報を確認することすらめんどくさがってしまう性格で「LINEで送れたらなー」と思っていた所、既に先人の方達がやっていたので、知恵を借りながら(ほぼパクリながら)作ってみました。やったこと
・スクレイピングでYahooの天気情報を取得
・スクレイピングで取得した情報をLINE Notifyで表示準備
必要なライブラリのインストール
$pip install beautifulsoup4 $pip install requestsトークンの取得
LINENotifyでトークンを発行しておきます。
コード
import urllib.request import requests from bs4 import BeautifulSoup line_notify_token = 'xxxxxxxxxxxxxxxxxxxxx'#発行したトークンを使います。 line_notify_api = 'https://notify-api.line.me/api/notify' rssurl = "https://rss-weather.yahoo.co.jp/rss/days/3410.xml"#このコードでは仙台の天気情報を取得します。 URL = "https://weather.yahoo.co.jp/weather/jp/8/3410/8201.html" tenki = [] detail = [] def Parser(rssurl): with urllib.request.urlopen(rssurl) as res: xml = res.read() soup = BeautifulSoup(xml, "html.parser") for item in soup.find_all("item"): title = item.find("title").string description = item.find("description").string if title.find("[ PR ]") == -1: tenki.append(title) detail.append(description) def Otenki(): Parser(rssurl) for i in range(0,2): message = tenki[i] payload = {'message': "\n" + message} headers = {'Authorization': 'Bearer ' + line_notify_token} line_notify = requests.post(line_notify_api, data=payload, headers=headers) Otenki()実行結果
しっかり送られてきて嬉しい気持ちになりました。感想
本当はAWS,Herokuを使って自動化までやりたかったですが、知識が何も無い状態で飛び込んで高額請求がきたら対処出来ないので、今回はここまでにしておきました笑。
scheduleライブラリをインストールしてみても良いのかも知れません。
自分で動かしてみると分からないなりにも色々出来て楽しかったです。またスキルを身に付けていきながらこの記事も更新していきたいです。
参考記事
【Yahoo!天気リプレース版】LINE Notify + Pythonで天気情報を取得する方法
Pythonで天気予報をLINE通知する
- 投稿日:2020-09-25T18:23:27+09:00
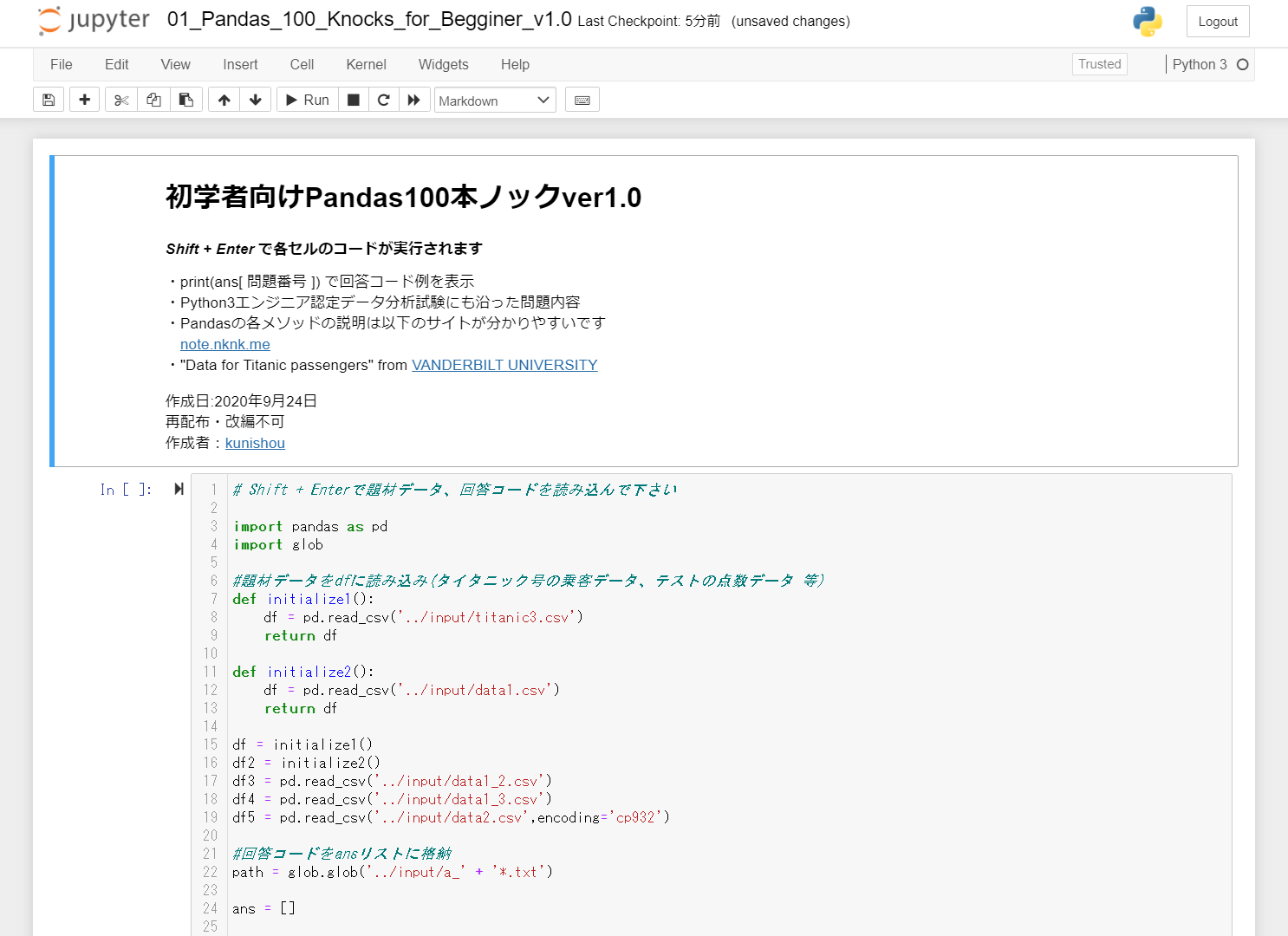
Python初学者のためのPandas100本ノック
はじめに
この度、PythonライブラリであるPandasを効率的に学ぶためのコンテンツとして「Python初学者のためのPandas100本ノック」を作成したので公開します。本コンテンツは、Python3エンジニア 認定データ分析試験の出題内容にも沿っているため、この100本ノックを実施することで資格対策にもなります。また、ノック終盤には、タイタニック号乗客の生存予測問題もあり、Kaggleなどの機械学習コンペへ参加するための練習にもなります。
作成の動機
- 最近、知り合いでPython・機械学習を始める人が増えてきており、そのような人たちに紹介できるコンテンツを自分で作ってみたいと前々から思っていたため。Pandasが使えれば、機械学習まではできなくても、日常のデータ集計・分析業務にも活用できると考え、まずPandasの100本ノックを作ってみることにしました。
- 世の中に参考書は山ほどありますが、頭で理解するよりも、サクサクと手を動かして学べるものが初学者にとって最も上達するコンテンツだと考え、そのようなものを作りたいと考えました。
Pandas100本ノックの概要
- Jupyter Notebook上のセルに記載された、Pandasに関する設問100問を解いていきます。
- 通常版と、問題のランダム表示版の2つが同封されています。
- セクションは、基礎(1-13)、抽出(14-32)、加工(33-58)、マージと連結(59-65)、統計(66-79)、ラベリング(80-81)、Pandasプロット(82-89)、タイタニック号乗客の生存予測(90-100)の8つに分かれています。
- 以下に概要の動画を載せておきます。
問題内容
No. 分類 問題 1 基礎 dfに読み込んだデータの最初の5行を表示 2 基礎 dfに読み込んだデータの最後の5行を表示 3 基礎 dfのDataFrameサイズを確認 4 基礎 inputフォルダ内のdata1.csvファイルを読み込みdf2に格納、最初の5行を表示 5 基礎 dfのfareの列で昇順に並び替えて表示 6 基礎 df_copyにdfをコピーして、最初の5行を表示 7 基礎 ① dfの各列のデータ型を確認
② dfのcabinの列のデータ型を確認8 基礎 ① dfのpclassの列のデータ型をdtypeで確認
② 数値型から文字型に変換し、データ型をdtypeで確認9 基礎 dfのレコード数(行数)を確認 10 基礎 dfのレコード数(行数)、各列のデータ型、欠損値の有無を確認 11 基礎 dfのsex,cabinの列の要素を確認 12 基礎 dfの列名一覧をlist形式で表示 13 基礎 dfのインデックス一覧をndarray形式で表示 14 抽出 dfのnameの列のみ表示 15 抽出 dfのnameとsexの列のみ表示 16 抽出 dfのindex(行)の4行目までを表示 17 抽出 dfのindex(行)の4行目から10行目までを表示 18 抽出 locを使ってdf全体を表示 19 抽出 locを使ってdfのfare列をすべて表示 20 抽出 locを使ってdfのfare列の10行目まで表示 21 抽出 locを使ってdfのnameとticketの列をすべて表示 22 抽出 locを使ってdfのnameからcabinまでの列をすべて表示 23 抽出 ilocを使ってdfのage列を5行目まで表示 24 抽出 dfのname,age,sexの列のみ抽出しdf2に格納
その後outputフォルダにcsvファイルで出力25 抽出 dfのage列の値が30以上のデータのみ抽出 26 抽出 dfのsex列がfemaleのデータのみ抽出 27 抽出 dfのsex列がfemaleでかつageが40以上のデータのみ抽出 28 抽出 queryを用いてdfのsex列がfemaleでかつageが40以上のデータのみ抽出 29 抽出 dfのname列に文字列「Mrs」が含まれるデータを表示 30 抽出 dfの中で文字型の列のみを表示 31 抽出 dfの各列のユニークな要素数のカウント 32 抽出 dfのembarked列の要素と出現回数の確認 33 加工 dfのindex名が「3」のage列を30から40に変更 34 加工 dfのsex列にてmale→0、femlae→1に
変更し、先頭の5行を表示35 加工 dfのfare列に100を足して、
先頭の5行を表示36 加工 dfのfare列を2を掛けて、
先頭の5行を表示37 加工 dfのfare列を小数点以下で丸める 38 加工 dfに列名「test」で値がすべて1のカラムを追加し、先頭の5行を表示 39 加工 dfにcabinとembarkedの列を「_」で結合した列を追加(列名は「test」)し、先頭の5行を表示 40 加工 dfにageとembarkedの列を「_」で結合した列を追加(列名は「test」)し、先頭の5行を表示 41 加工 dfからbodyの列を削除し、最初の5行を表示 42 加工 dfからインデックス名「3」の行を削除し、最初の5行を表示 43 加工 df2の列名を'name', 'class', 'Biology', 'Physics', 'Chemistry'に変更
df2の最初の5行を表示44 加工 df2の列名を'English'をBiology'に変更
df2の最初の5行を表示45 加工 df2のインデックス名「1」を「10」に変更
df2の最初の5行を表示46 加工 dfのすべての列の欠損値数を確認 47 加工 dfのageの列の欠損値に30を代入
その後、ageの欠損値数を確認48 加工 dfでひとつでも欠損値がある行を削除
その後、dfの欠損値数を確認49 加工 dfのsurvivedの列をarray形式(配列)で表示 50 加工 dfの行をシャッフルして表示 51 加工 dfの行をシャッフルし、インデックスを振り直して表示 52 加工 ①df2の重複行数をカウント 53 加工 dfのnameの列をすべて大文字に変換し表示 54 加工 dfのnameの列をすべて小文字に変換し表示 55 加工 dfのsex列に含まれる「female」という単語を
「Python」に置換56 加工 dfのname列1行目の「Allen, Miss. Elisabeth Walton」の
「Elisabeth」を消去(import reが必要)57 加工 df5の都道府県列と市区町村列を空白がないように
「_」で結合(新規列名は「test2」)し、先頭5行を表示58 加工 df2の行と列を入れ替えて表示 59 マージと連結 df2にdf3を左結合し、df2に格納 60 マージと連結 df2にdf3を右結合し、df2に格納 61 マージと連結 df2にdf3を内部結合し、df2に格納 62 マージと連結 df2にdf3を外部結合し、df2に格納 63 マージと連結 df2とdf4を列方向に連結し、df2に格納 64 マージと連結 df2とdf4を列方向に連結し重複している
name列の片方を削除し、df2に格納65 マージと連結 df2とdf2を行方向に連結し重複している
name列の片方を削除し、df2に格納66 統計 dfのage列の平均値を確認 67 統計 dfのage列の中央値を確認 68 統計 ①df2の生徒ごとの合計点(行方向の合計)
②df2の科目ごとの点数の総和(列方向の合計)69 統計 df2のEnglishで得点の最大値 70 統計 df2のEnglishで得点の最小値 71 統計 df2においてclassでグルーピングし、クラスごとの科目の最大値、最小値、平均値を求める(name列は削除しておく) 72 統計 dfの基本統計量を確認(describe) 73 統計 dfの各列間の(Pearson)相関係数を確認 74 統計 scikit-learnを用いてdf2のEnglish、Mathmatics、Historyを標準化する 75 統計 scikit-learnを用いてdf2のEnglish列を標準化する 76 統計 scikit-learnを用いてdf2のEnglish、Mathmatics、History列をMin-Maxスケーリングする 77 統計 dfのfare列の最大値、最小値の行名を取得 78 統計 dfのfare列の0、25、50、75、100パーセンタイルを取得 79 統計 ①dfのage列の最頻値を取得
②value_counts()にてage列の要素数を確認し、①の結果の妥当性を確認80 ラベリング dfのsex列をラベルエンコーディングし、dfの先頭5行を表示 81 ラベリング dfのsex列をOne-hotエンコーディングし、dfの先頭5行を表示 82 Pandasプロット dfのすべての数値列のヒストグラムを表示 83 Pandasプロット dfのage列をヒストグラムで表示 84 Pandasプロット df2のnameごとの3科目合計得点を棒グラフで表示 85 Pandasプロット df2のname列の要素ごとの3科目を棒グラフで並べて表示 86 Pandasプロット df2のname列の要素ごとの3科目を積み上げ棒グラフで表示 87 Pandasプロット dfの各列間の散布図を表示 88 Pandasプロット dfのage列とfare列で散布図を作成 89 Pandasプロット 【88】で描画したグラフに「age-fare scatter」という
グラフタイトルをつける90 タイタニック号の生存者予測 df_copyのsexとembarked列をラベルエンコーディング 91 タイタニック号の生存者予測 df_copyの欠損値を確認 92 タイタニック号の生存者予測 df_copyのage、fare列の欠損値を各列の平均値で補完 93 タイタニック号の生存者予測 df_copyの中で機械学習で使用しない不要な行を削除 94 タイタニック号の生存者予測 ①df_copyのpclass、age、sex、fare、embarkedの列を抽出し、ndarray形式に変換
②df_copyのsurvivedの列を抽出し、ndarray形式に変換95 タイタニック号の生存者予測 【94】で作成したfeatrues、targetを学習データとテストデータに分割 96 タイタニック号の生存者予測 学習データ(features、target)を用いランダムフォレストにて学習を実行 97 タイタニック号の生存者予測 test_Xデータの乗客の生存を予測 98 タイタニック号の生存者予測 予測結果がtest_y(生存有無の答え)とどれぐらい
整合していたかを確認(評価指標はaccuracy)99 タイタニック号の生存者予測 学習における各列(特徴量)の重要度を表示 100 タイタニック号の生存者予測 test_Xの予測結果をcsvでoutputフォルダに出力(ファイル名は「submission.csv」) 利用方法
※Pythonをまだインストールしていない方は、まずanacondaを自身のPCにインストールして下さい。なお、問題内ではPandas以外にも、Scikit-learnなどのライブラリも使用します。
- GitHubよりZIPフォルダをダウンロードした後に、自身のPCのローカル領域に展開する。
- 「notebook」フォルダに格納されているipynbファイルをJupyter Notebookで開く(まずは「01_Pandas_100_Knocks_for_Begginer_v1.0.ipynb」を開いてみて下さい)。
- ipynbファイルが開いた後に、先頭のセルを実行すると回答ファイル、問題で使用するデータセットが読み込まれます。使用するデータセットは、タイタニック号の乗客データ等になっています。
- 各設問のセル内に設問に対するコードを入力していきます。
- 答えが分からない場合は、設問セル内の「#print(ans[])」という記述から「#」を消して実行することで、回答例が表示されます。
ディレクトリ構成
pandas_100_knocks_v1.0
├ notebook/ … 3つのipynbファイルが格納
├ input/ … 100問分の回答ファイル、問題で使用するデータセットが格納
└ output/ … 問題でファイル出力する際にここに格納※ZIPファイルから展開した後に、このディレクトリ構成は変えないで下さい(上手く動作しなくなります)。
このコンテンツの目指すところ
願わくばPython初学者の方がレベル3まで到達できることを意識し、問題を設定しました(3回解けばレベル2までは到達できると思います。)。
- レベル1
Python・Pandasで基本的なデータ集計・分析ができるようになる(業務においてExcel、Accessの代替え手法として、Pythonでデータ集計・分析ができる)- レベル2
データ集計・分析だけでなく一部の機械学習ができる(「notebook」フォルダに格納している03のipynbファイル(タイタニック)を見た時に何を実施しているのか理解できるようになる)。- レベル3
Kaggle等の機械学習コンペに参加できるようになるダウンロード
コンテンツはGitHubよりダウンロードできます。
https://github.com/kunishou/Pandas_100_knocks
使用範囲/注意事項
使用範囲
個人・法人を問わず誰でも使用可能注意事項
コンテンツの再配布・改編は不可その他(Scratchpad)
Jupyter Notebookの拡張機能としてnbextensionsのScratchpadが便利なのでインストールをおすすめしておきます。100本ノックに取り組んでいる途中、データフレームに格納しているデータ内容を確認するためにいちいち「新規セル追加 → df.head()」をするのは面倒です。Scratchpadを使えば、「Ctrl+B」で使い捨てのセル領域を呼び出すことができます。
インストール方法は以下を参考にして下さい。
【Python】jupyter notebookの機能拡張 ~jupyter notebook extensions~
最後に
本コンテンツに関してご質問・ご要望があればご連絡下さい。

- 投稿日:2020-09-25T18:23:23+09:00
VisualStudioCode(vscode)のDefault Dark+テーマでPythonのユーザ関数呼び出しをハイライト表示する
はじめに
VisualStudioCode(1.49.2)のデフォルトテーマ(Default Dark+)でPythonプログラム(*.py)のユーザ関数呼び出し時の関数名、引数名がハイライト表示されなかったため、「settings.json」に設定を追記する事で、表示可能とした。
動作イメージ
設定の追記前
ユーザ関数の呼び出し時の名前(例:print_debug)と引数がハイライト表示されない。
設定の追記後
ハイライト表示される。
設定の追記方法
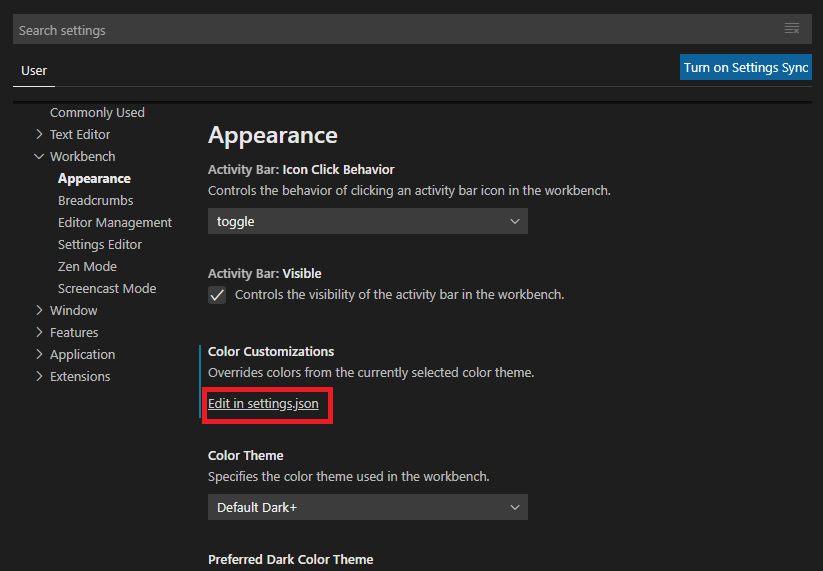
- VisualStudioCodeのメニュー「File」→「Preferences」→「Settings」を開く
- ツリーメニュー「Workbench」→「Appearance」を開き、項目「Color Customizations」の「Edit in settings.json」を開く
- 開かれた「settings.json」に下記コードを追加する
settings.json"editor.tokenColorCustomizations": { "textMateRules": [ { "scope": [ "meta.function-call.python", ], "settings": { "foreground": "#dcdcaa" } },{ "scope": [ "meta.function-call.arguments.python", ], "settings": { "foreground": "#9cdcfe" } },{ "scope": [ "punctuation.definition.list.begin.python", "punctuation.definition.list.end.python" ], "settings": { "foreground": "#fff" } } ] }4.「settings.json」上書き保存して、Pythonプログラムの表示を確認する。「settings.json」に既存の設定が書き込まれている場合は、設定がコンフリクト(競合)しないように注意する。
設定更新後もハイライト表示されない場合は、下記ポイントを確認する。
- 「settings.json」の追記誤り。JSON形式になっているか。既存の設定と競合していないか。
- 「Color Customizations」の「settings.json」を編集しているか。
- Pythonプログラムの拡張子が *.py になっているか。
- 拡張(Extensions)機能と競合していないか。ハイライト対象の変更
ハイライト表示する対象は "scope" で指定している。
この "scope" に指定する値を変更する事で、ハイライト対象も変更される。
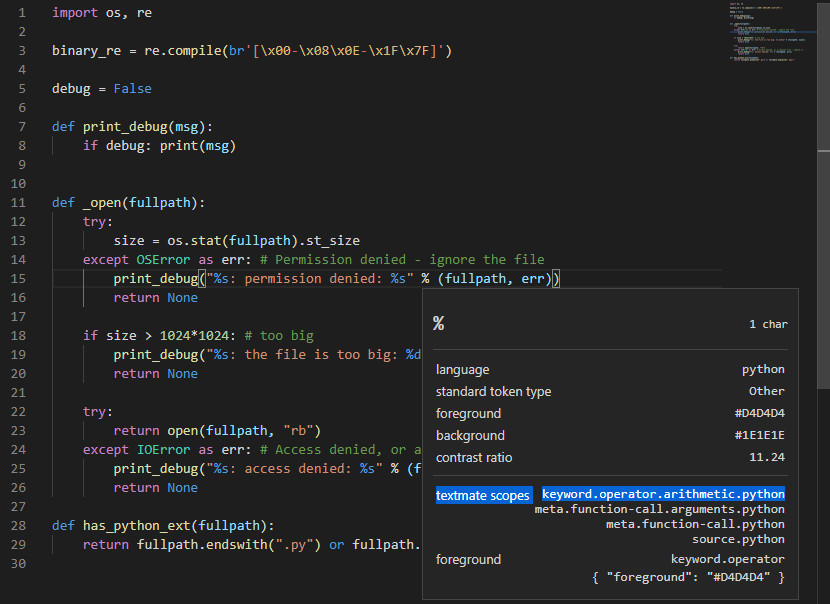
- "scope" に指定する値の調査
コマンドパレット(Win:Ctrl+Shift+P, Mac:⌘ + Shift + P)を開き、「Developer: Inspect Editor Tokens and Scopes」を実行する。
- エディタのカーソルがあるテキストにミニウィンドウが表示され、ウィンドウ中「textmate scopes」に表示されている値を、「settings.json」の "scope" に指定する。
- 投稿日:2020-09-25T18:16:32+09:00
PyTorchのインストール
いい加減、何度もハマっているので、忘れないように記録を残しておくようにします。
PyTorchをインストールするとき
- Anaconda NavigatorのGUIからPyTorchをインストールしないこと!
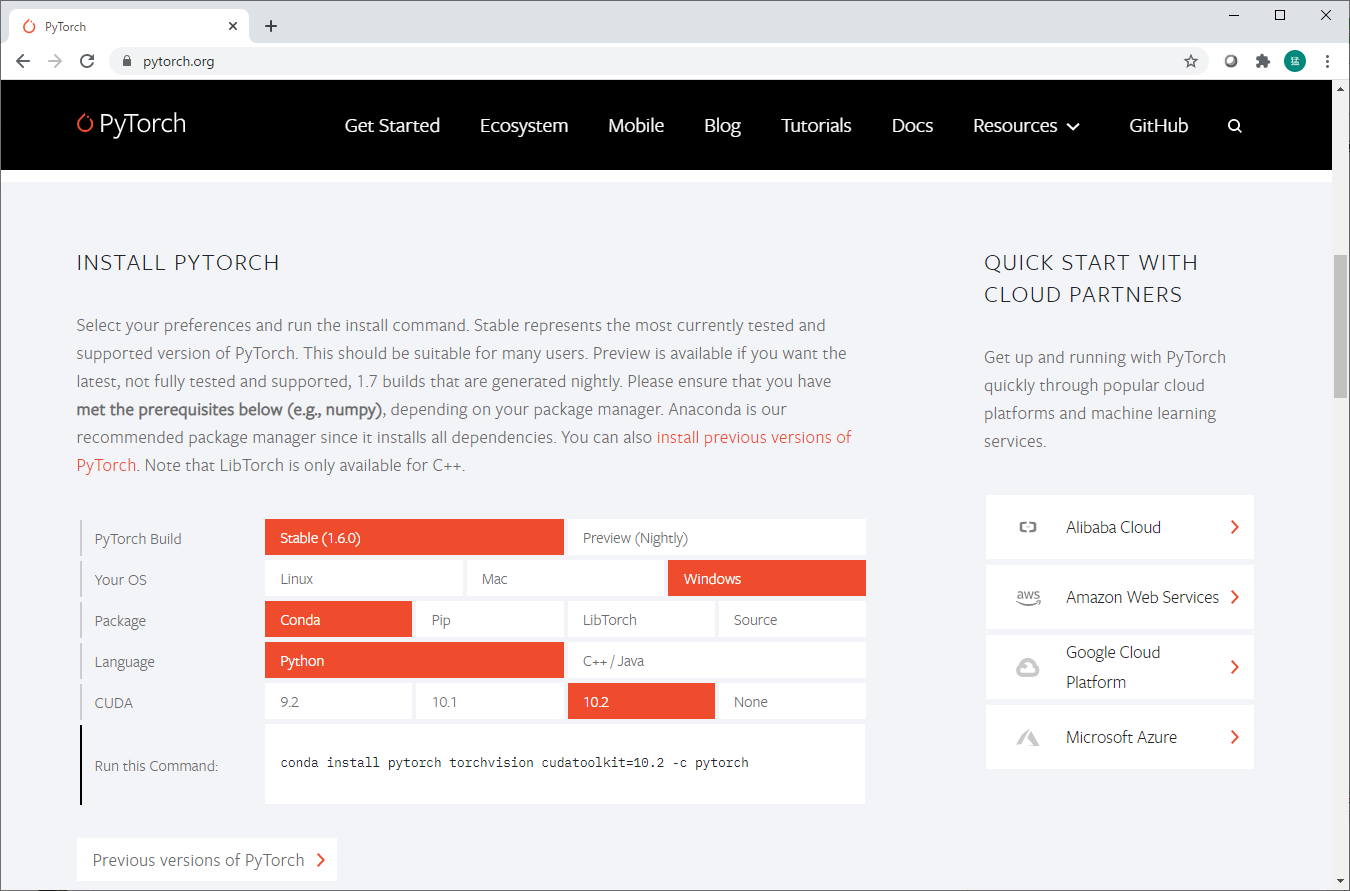
- 必ず https://pytorch.org/ を見ること!
そして、「INSTALL PYTORCH」のところで、自分の環境にあった選択をし、「Run this Command:」の文字列をコピペして実行すること。
今までの失敗
- torchvisionがない
- 直接condaでtorchvisionをインストールする
- PyTorchとバージョンが合わない
- PyTorchがCUDAでコンパイルされていない
- 直接condaでcudatoolkitをインストールする
- バージョンが合わない
- 投稿日:2020-09-25T18:14:12+09:00
Python2のコードをPython3に書き換える(2to3)
なりゆき
ん??これPython2のコードやんけ!?
Python3もよくわかっていないのに勘弁してや...という感じでPythonクソ初心者が書いております。
環境
Windows10
Python 3.7.4今回は全てコマンドプロンプトで行っている。
Python3がインストール済み前提とするため、
コマンドプロンプトでpyと打ってみて、エラーが出ないか確認してみよう。
(quit()でPythonの対話モード終了)2to3
どうやら2to3というPythonのライブラリのプログラムで、
Python2のコードをPython3のコードに自動変換してくれるらしい。実践(ミス)
デスクトップ上に置いた、"Hello.py"を変換したいとする。
まず、変換したいファイルがある場所(ここではデスクトップ)に移動する。
cd C:\Users(ユーザー名)\Desktop
次にいよいよPython2からPython3へ変換!!
2to3 -w Hello.pyこれで、"Hello.py"はPyhon3のコードになり、
元のPython2のコードは"Hello.py.bak"になるはず!! あれ??'2to3' は、内部コマンドまたは外部コマンド、 操作可能なプログラムまたはバッチ ファイルとして認識されていません。というエラーが...
どうやら、
Windows以外ではこれでOKらしいですがWindowsではエラーになります。実践(成功)
上と同じくデスクトップ上に置いた、"Hello.py"を変換したいとする。
PythonがC:¥Python37へインストールされている場合はcd C:\Users\(ユーザー名)\Desktop python C:\Python\Python37\Tools\scripts\2to3.py -w hello.pyこれでいけた!!
あなたが使う上で変更する必要のある箇所は、
- 変換したいファイルがある場所へのパス
C:\Users(ユーザー名)\Desktop
- 2to3.pyへのパス
C:\Python\Python37\Tools\scripts\2to3.py
- 変換したいファイルのファイル名
hello.py
といったところでしょうか参考サイト
Windowsで2to3を使う(2系コードの3系コードへの変換)-メモの倉庫
https://woraise.com/2019/03/11/2to3/2系から3系への変換ツール -Python-izm
https://www.python-izm.com/tips/2to3/2to3 - Python2から3への自動コード変換 -Python
https://docs.python.org/ja/3/library/2to3.html
- 投稿日:2020-09-25T17:00:26+09:00
Python触ってみた(インストール編)
はじめに
SEとして一からプログラムを書く現場はほぼ経験したことがなく。。。
今回も前任者が開発したPythonのプログラムを改修してほしいとの依頼が。。。上記のような状況のSEの方って意外と多くいるのではと思う今日この頃。
今回はPythonを読むのに最低限必要な知識を書き残しておこうと思います。方針とゴール
- 今回は以下のサイトでお勉強していきます。
- https://www.python-izm.com/
- 参考サイトではPythonをPCに直接インストールしています。
- PCは綺麗にしておきたいので仮想マシンを使用します。
- ゴールは「Hello World」相当のものを出力できればと思ってます。
前提
- 今回もVagrantを使って仮想マシン上にPython環境を用意します。
- 以前の記事を参考(宣伝):Mac+Vagrant(CentOS7)+Docker+Jenkinsで優勝してみた
- Pythonのバージョンは3系を使用します。
- Pythonは2系と3系で互換性がありません。
- プリインストールされているのはPython2です。
Python3をインストール
Python3系を明示的にインストールします。
仮想マシン# CentOSデフォルトのPythonバージョンを確認 ## パス確認 $ which python /usr/bin/python # Pythonバージョン:2.7.5 $ /usr/bin/python -V Python 2.7.5 # Python3をyumからインストール $ yum -y install python3 ~省略~ Installed: python3.x86_64 0:3.6.8-13.el7 Dependency Installed: python3-libs.x86_64 0:3.6.8-13.el7 python3-pip.noarch 0:9.0.3-7.el7_7 python3-setuptools.noarch 0:39.2.0-10.el7 Complete! # インストールしたPython3のバージョン確認 ## パス確認 $ which python3.6 /usr/bin/python3.6 ## Pythonバージョン:3.6.8 $ python3.6 -V Python 3.6.8 # Pythonコマンドを2系から3系に切り替え ## デフォルトのPythonコマンドの参照先確認:Python2 $ ls -l /usr/bin/python lrwxrwxrwx. 1 root root 7 Jun 1 2019 /usr/bin/python -> python2 ## デフォルトのシンボリックリンクを退避 $ sudo mv /usr/bin/python /usr/bin/python_bk ## 参照先がなくなったことを確認 $ ls -l /usr/bin/python ls: cannot access /usr/bin/python: No such file or directory ## Python3.6のシンボリックリンクを作成 $ sudo ln -s python3.6 /usr/bin/python ## 変更したPythonコマンドの参照先確認:Python3.6 $ ls -l /usr/bin/python lrwxrwxrwx. 1 root root 9 Sep 25 07:26 /usr/bin/python -> python3.6 # Pythonコマンド切り替え後の確認 ## バス確認 $ which python /usr/bin/python ## Pythonバージョン:3.6.8 $ python -V Python 3.6.8 # pip(pkg管理システム)コマンドも使用可能 $ pip3 search ansible ansible-stubs (0.1.dev1) - ansible-stubs aids in the development and testing of Ansible roles ~以下略~Pythonプログラム(.py)を実行
Python3をインストールしたのでプログラムを実行してみます。
仮想マシン# .pyファイルを作成 $ vi test01.py $ cat test01.py print('python-izm') # Pythonコマンドを使用して作成した.pyファイルを実行 $ python test01.py python-izm対話形式でPython実行
プログラムを用意しなくても対形式で実行することもできます。
仮想マシン# 対話型シェル起動 $ python Python 3.6.8 (default, Apr 2 2020, 13:34:55) [GCC 4.8.5 20150623 (Red Hat 4.8.5-39)] on linux Type "help", "copyright", "credits" or "license" for more information.対話型シェル# .pyファイルに記載したものと同じものを実行 >>> print('python-izm') python-izm # 終了する場合はquit()を実行 >>> quit()おわりに
インストールからプログラムの実行までは他の言語とそんなに遜色なくできました。
対話型シェルがあるのは動作確認などの際に便利そうで期待大です!
次回はソースの基本構文について勉強していこうと思います。
- 投稿日:2020-09-25T16:33:59+09:00
Apache Flink Python API: 歴史、アーキテクチャ、開発環境、主要な演算子
この記事では、Apache Flink Python APIの歴史を紹介し、そのアーキテクチャや開発環境、主要な演算子について解説しています。
本ブログは英語版からの翻訳です。オリジナルはこちらからご確認いただけます。一部機械翻訳を使用しております。翻訳の間違いがありましたら、ご指摘いただけると幸いです。
Apache Flink Python APIの歴史、現状と今後の展開
Apache Flink が Python をサポートする理由
Apache Flinkは、統一されたストリームとバッチデータ処理機能を持つオープンソースのビッグデータコンピューティングエンジンです。Apache Flink 1.9.0では、機械学習(ML)APIと新しいPython APIが提供されています。次に、なぜApache FlinkがPythonをサポートしているのかについて詳しく説明します。
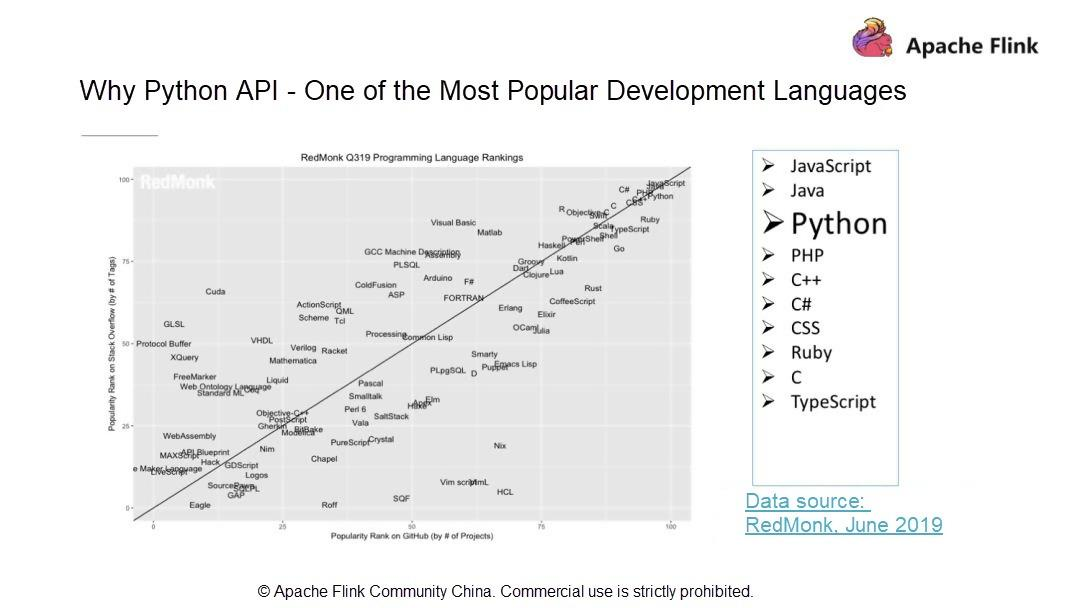
- Pythonは最もポピュラーな開発言語の一つ
RedMonkの統計によると、PythonはJava、JavaScriptに次いで3番目に人気のある開発言語です。RedMonkは、ソフトウェア開発者に焦点を当てた業界アナリスト会社です。Apache Flinkは、ストリームおよびバッチデータ処理機能を持つビッグデータコンピューティングエンジンです。話題のPythonとApache Flinkの関係は?この疑問を踏まえて、現在有名なビッグデータ関連のオープンソースコンポーネントを見てみましょう。例えば、初期のバッチ処理フレームワークであるHadoop、ストリームコンピューティングプラットフォームであるSTORM、最近人気のSpark、データウェアハウスであるHive、KVストレージベースであるHBaseなどは、Python APIをサポートしている有名なオープンソースプロジェクトです。
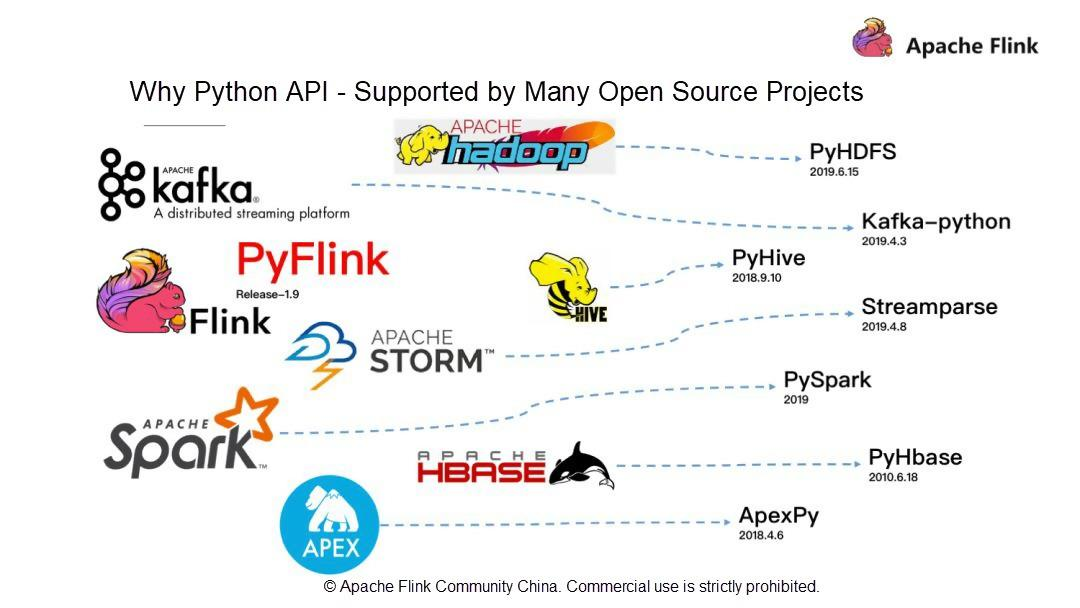
- Pythonは多くのオープンソースプロジェクトでサポートされています。
Pythonの完全なエコシステムを考えると、Apache Flinkはバージョン1.9に多額の投資をして、全く新しいPyFlinkを立ち上げました。ビッグデータとして、人工知能(AI)はPythonと密接な関係があります。
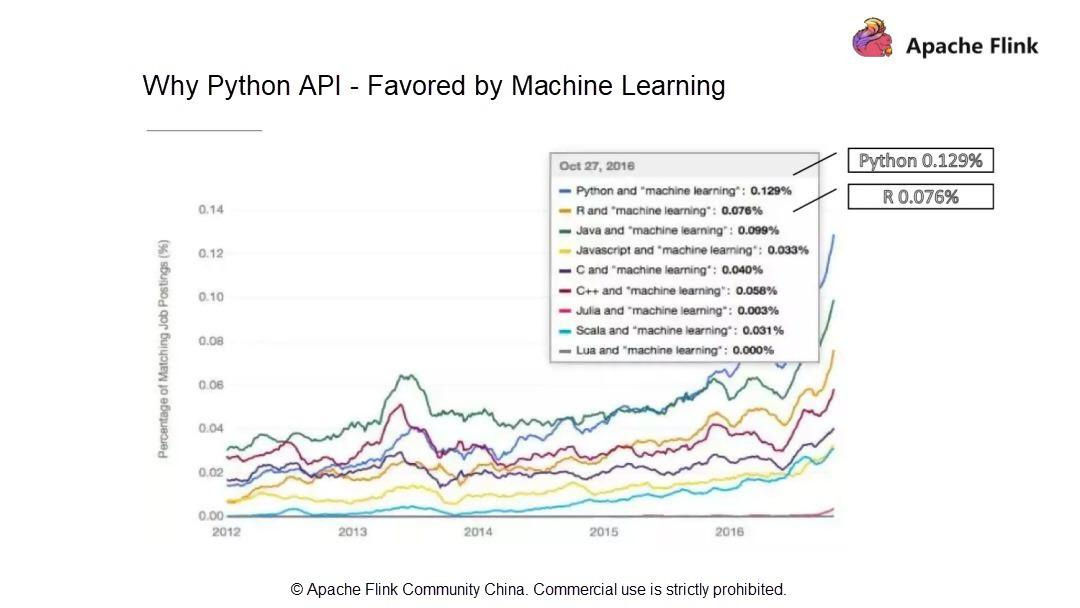
- Pythonは機械学習(ML)に支持されています。
統計によると、ML業界の求人情報の0.129%とマッチングしており、Pythonが最も多く求められる言語となっています。R言語の0.076%と比較すると、ML業界ではPythonの方が好まれていることがわかります。解釈型言語であるPythonは、"物事を行うための方法は一つしかない "という設計理念を持っています。そのシンプルさと使いやすさから、世界で最も人気のある言語の1つであるPythonは、ビッグデータコンピューティングの分野では良いエコシステムとなっています。また、MLの分野でも有望な将来性を持っています。そこで、先日、Apache Flink 1.9で全く新しいアーキテクチャを採用したPython APIを発表しました。
Apache Flinkは、統一されたストリームとバッチデータ処理機能を持つコンピューティングエンジンです。コミュニティはFlinkユーザーを非常に重要視しており、JavaやScalaのようにFlinkへのアクセスやチャンネルをより多く提供したいと考えています。これにより、より多くのユーザーがFlinkをより便利に利用できるようになり、Flinkのビッグデータコンピューティング能力によってもたらされる価値から恩恵を受けることができるようになります。Apache Flink 1.9から、Apache Flinkコミュニティは、JOIN、AGG、WINDOWなどの最も一般的に使用されている演算子をサポートする全く新しい技術的なアーキテクチャを持つPython APIを開始します。
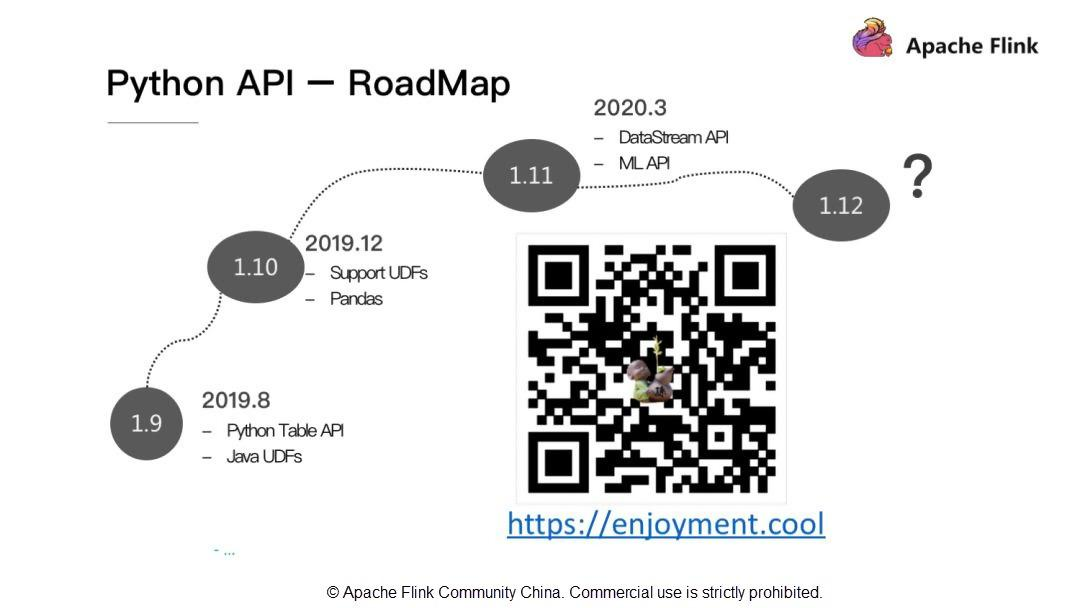
Python API - RoadMap
Apache Flink 1.9では、Pythonはユーザー定義のJava関数を利用することができますが、Pythonネイティブのユーザー定義関数の定義には対応していません。そのため、Apache Flink 1.10ではPythonのユーザー定義関数とPythonのデータ解析ライブラリPandasのサポートを行います。また、Apache Flink 1.11ではDataStream APIとML APIのサポートを追加します。
Apache Flink Python APIのアーキテクチャと開発環境
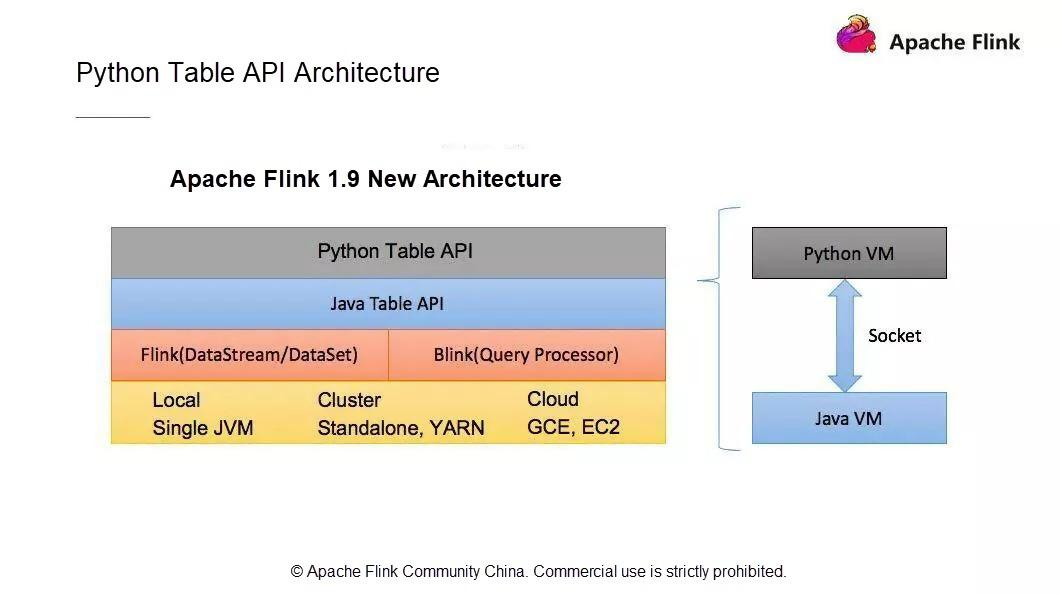
PythonのテーブルAPIアーキテクチャ
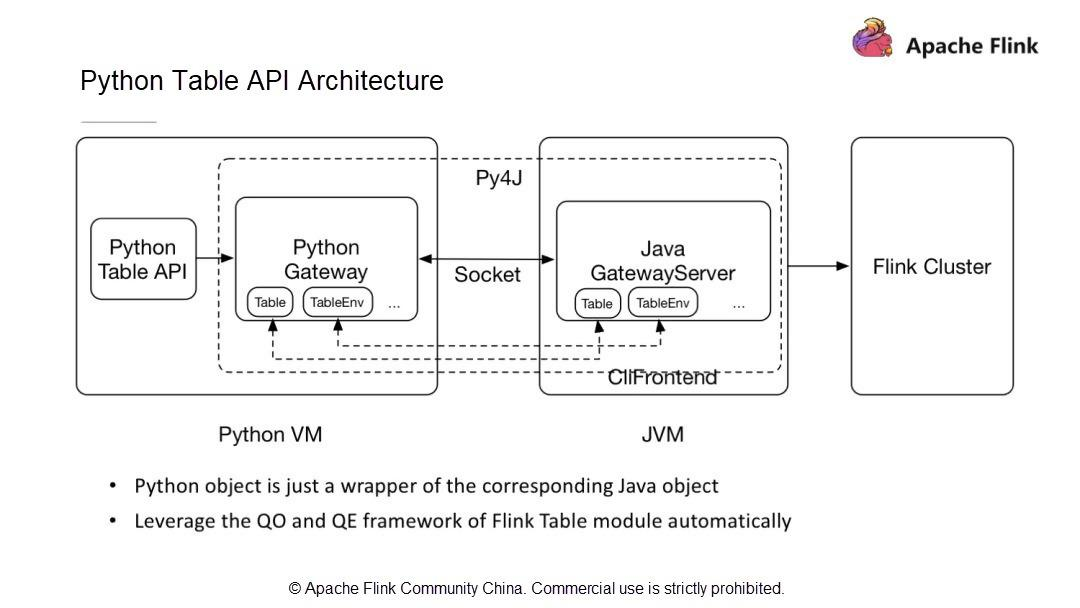
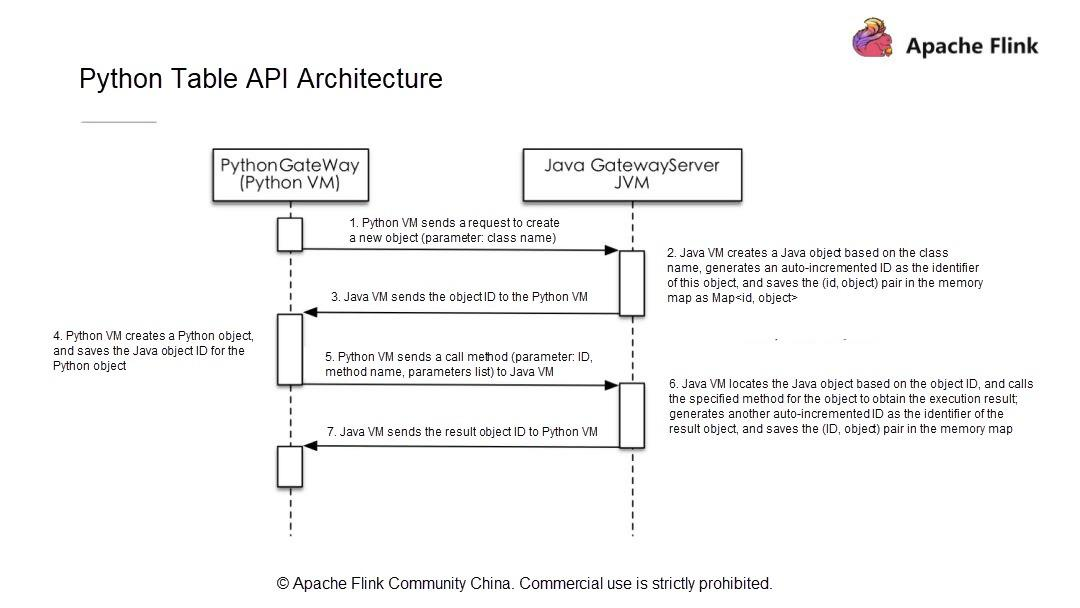
新しいPython APIアーキテクチャは、ユーザーAPIモジュール、Python仮想マシン(VM)とJava VM間の通信モジュール、Flinkクラスタにタスクを投入して運用するモジュールで構成されています。
Python VMとJava VMはどのように通信するのでしょうか?Python VM には、Python VM からの呼び出しを受け取る GateWayServer を持つ Java VM との接続を維持する Python ゲートウェイがあります。
1.9以前のApache Flinkのバージョンでは、すでにDataSetとDataStreamモジュールでPython APIをサポートしています。しかし、それぞれ2つの異なるAPIを使用しています。DataSet API と DataStream API です。Flinkのようにストリームとバッチデータ処理機能を統一したストリームコンピューティングエンジンにとって、統一されたアーキテクチャは極めて重要です。既存のPythonのDataSet APIとDataStream APIはJPythonの技術アーキテクチャを使用しています。しかし、JPythonはPython 3.Xシリーズを適切にサポートすることができません。そのため、既存のPython APIアーキテクチャは放棄し、Flink 1.9からは全く新しい技術アーキテクチャが採用されています。この新しいPython APIはTable APIをベースに実装されています。
Table APIとPython APIの通信は、Python VMとJava VM間の通信で実装されています。Python APIはJava APIと通信し、Python APIは書き込みや呼び出しを行います。Python APIの操作は、JavaのTable APIの操作と似ています。新しいアーキテクチャには次のような利点があります。
- 演算子を新たに作成する必要がなく、代わりにJava Table APIの機能との整合性を簡単に維持することができます。
- Java Table APIの最適化モデルを使用してPython APIを最適化します。これにより、Python APIを使用して書かれたジョブが最適なパフォーマンスを提供することが保証されます。
Python VMがJavaオブジェクトに対してリクエストを開始すると、Java VMはオブジェクトを作成し、ストレージ構造体に保存し、オブジェクトにIDを割り当てます。そして、そのIDをPython VMに送信し、Python VMは対応するオブジェクトIDを持つオブジェクトを操作します。Python VMはJava VMのすべてのオブジェクトを操作できるため、Python Table APIがJava Table APIと同一の機能を持ち、既存のパフォーマンス最適化モデルを利用できることが保証されます。
新しいアーキテクチャと通信モデルでは、Python VMは対応するJavaオブジェクトIDを取得し、呼び出しメソッドの名前とパラメータをJava VMに渡すだけでJava Table APIを呼び出します。したがって、Python Table APIの開発は、Java Table APIの開発と同じ手順に従います。次に、簡単なPython APIのジョブを開発する方法を探ってみましょう。
Python Table API - ジョブ開発
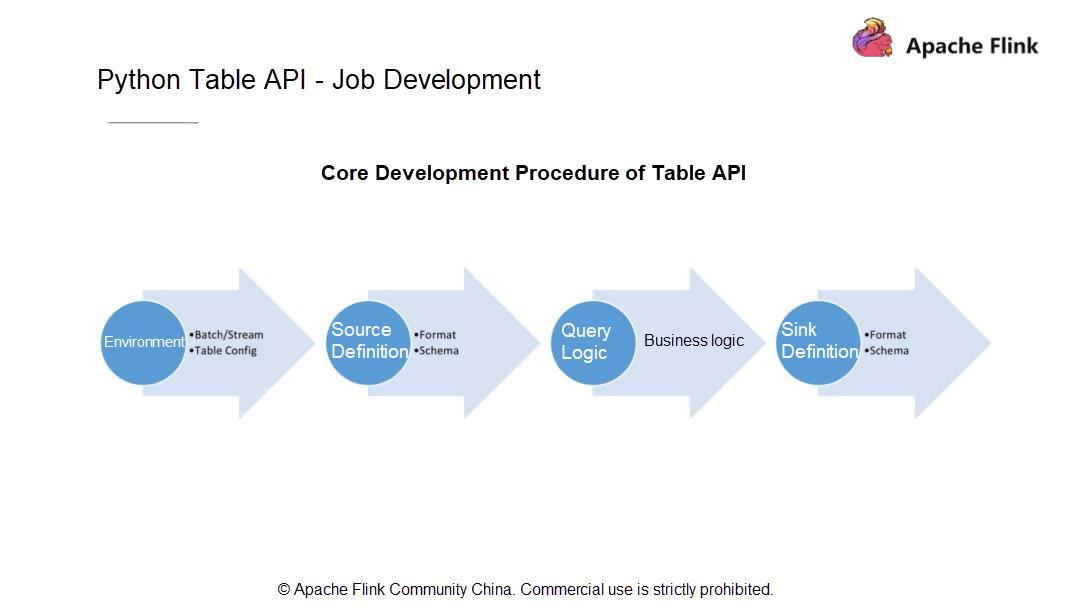
一般的にPythonのテーブルジョブは4つのステップに分かれています。現在の状況を考慮して、まず、ジョブをバッチモードで実行するかストリーミングモードで実行するかを決めます。それ以降のバージョンのユーザはこのステップをスキップすることができますが、Apache Flink 1.9のユーザはこの決定をしなければなりません。
ジョブの実行モードを決めたら、データがどこから来ているのか、データソース、スキーマ、データタイプをどのように定義するかを知っておきます。次に、計算ロジック (データに対して実行される計算操作) を書き、最終的な計算結果を指定したシステムに永続化します。次に、シンクを定義します。データソースを定義するのと同じように、シンクのスキーマとその中のすべてのフィールド型を定義します。
次に、上記の各ステップをPython APIを使ってコーディングする方法を理解しましょう。まず、実行環境を作成しますが、これは最終的にはテーブル環境でなければなりません。このテーブル環境には、実行プロセス中にRunTimeレイヤーに渡されるいくつかの設定パラメータを持つTable Configモジュールが存在しなければなりません。また、このモジュールは、実際のサービス開発段階で使用できるいくつかのカスタム設定項目を提供しなければなりません。
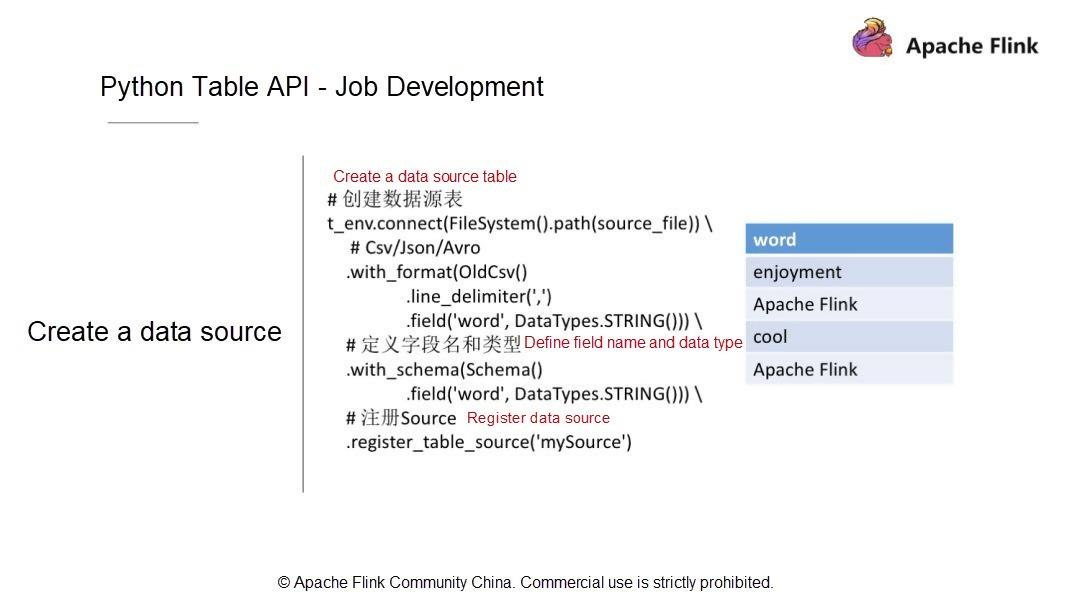
実行環境を作成したら、データソースのテーブルを定義する必要があります。例として、CSVファイル内のデータレコードはカンマ(,)で区切られ、フィールドはフィールド列にリストされています。このテーブルにはワードという1つのフィールドのみが含まれており、このフィールドの型はStringとなっています。
データソースを定義して記述し、データソースの構造をテーブルに変換した後、Table API層ではどのようなデータ構造とデータ型になるのでしょうか。次に、
with_SCHEMAを使ってフィールドとフィールド型を追加する方法を見てみましょう。ここでは、フィールドは1つだけで、データ型はStringです。データソースは、その後のクエリや計算のためにカタログにテーブルとして登録されています。
そして、結果テーブルを作成します。計算が終わったら、計算結果を永続的なシステムに保存します。例えば、WordCountジョブを書くには、まず、ワードとカウントの2つのフィールドを持つストレージテーブルがあります。そして、このテーブルをシンクとして登録します。
テーブルシンクを登録したら、計算ロジックの書き方を見てみましょう。実はPython APIでWordCountを書くのは、Table APIで書くのと同じくらい簡単です。DataStreamとは異なり、Python APIではWordCountのジョブを書くのに必要なのは1行のステートメントだけです。例えば、まずソーステーブルをスキャンし、GROUP BY文を使用してワードごとに行をグループ化します。次にSELECT文を使って単語を選択し、集約関数を使って各単語のカウントを計算します。最後に計算結果を結果テーブルに挿入します。
Python Table API - 開発環境
致命的な問題は、具体的にどのようにWordCountジョブを実行するのかということです。まず、開発環境を設定します。異なるバージョンのソフトウェアが異なるマシンにインストールされている場合があります。ここでは、ソフトウェアのバージョンに必要な要件をいくつか紹介します。
第二に、ソースコードを元にバイナリJavaリリースパッケージを構築します。そのため、マスターブランチのコードをクローンして、1.9ブランチを取得します。もちろん、マスターコードを使っても構いません。しかし、マスターコードは安定性に欠けるので、1.9ブランチコードを使うことをお勧めします。では、手順を進めていきましょう。まず、コードをコンパイルします。例えば、以下のようにします。
//下载源代码 git clone https://github.com/apache/flink.git // 拉取1.9分支 cd flink; git fetch origin release-1.9 git checkout -b release-1.9 origin/release-1.9 //构建二进制发布包 mvn clean install -DskipTests -Dfastコンパイル後、対応するディレクトリにリリースパッケージを配置してください。
cd flink-dist/target/flink-1.9.0-bin/flink-1.9.0 tar -zcvf flink-1.9.0.tar.gz flink-1.9.0Java APIをビルドしたら、APIを検証してPythonのリリースパッケージをビルドします。
すべてのPythonユーザーは、pip installを通じてパッケージをインストールするためには、依存ライブラリをローカルのPython環境と統合するか、これらの依存ライブラリをローカル環境にインストールしなければならないことを知っています。
これはFlinkにも当てはまります。PyFlinkをPypipによって認識されたリソースパッケージにパッケージ化してインストールします。以下のコマンドを使って、パッケージをコピーして自分の環境にインストールします。
cd flink-Python;Python setup.py sdistこの処理は、Java リリースパッケージを、いくつかの Java パッケージといくつかの PyFlink モジュールの Python パッケージと一緒に単純にラップします。新しい
apache-link-1.9.dev0.tar.gzパッケージを dist ディレクトリから探してください。cd dist/distディレクトリにある
apache-flink-1.9.dev0.tar.gzファイルは、pip installでインストールに使えるPyFlinkパッケージです。Apache Flink 1.9 のインストールパッケージには、Flink Table と Flink Table Blink の両方が含まれています。Flinkは同時に2つのプランナーをサポートしています。デフォルトのFlinkプランナーとBlinkプランナーを自由に切り替えることができます。それぞれを自分で試してみることをお勧めします。パッケージ化後、私たちの環境にインストールしてみます。
非常に簡単なコマンドを使って、まず、コマンドが正しいかどうかを確認します。コマンドを実行する前に、pipを使ってリストを確認し、パッケージが既にインストールされているかどうかを確認します。そして、前のステップで用意したパッケージをインストールしてみてください。実際のシナリオでは、アップグレードをインストールするために、新しいパッケージをインストールします。
pip install dist/*.tar.gz pip list|grep flink
パッケージをインストールしたら、先に書いたWordCountジョブを使って環境が正しいかどうかを確認します。環境が正しいかどうかを確認するには、以下のコマンドを実行して、環境コードリポジトリを直接クローンします。
git clone https://github.com/sunjincheng121/enjoyment.code.git cd enjoyment.code; Python word_count.py次に、試してみましょう。このディレクトリに以前作成したwordCountのジョブファイルを探します。直接python
word_count.pyを使って環境に問題がないか確認してみましょう。Apache Flink Python APIを使うと、WordCountジョブを実行するためのミニクラスタが起動するはずです。さて、すでにミニクラスタ上ではジョブが実行されています。この処理では、コードはまずソースファイルを読み込み、その結果をCSVファイルに書き出します。このディレクトリの中に、
sink.csvファイルを見つけます。操作手順の詳細については、Apache Flink Community Chinaに投稿された「The Status Quo and Planning of Apache Flink Python API」というタイトルの動画を参照してください。
では、統合開発環境(IDE)の設定について説明します。Python関連のロジックやジョブの開発にはPyCharmを使うことをお勧めします。
IDEのセットアップの詳細については、QRコードをスキャンするか、ブログ(https://enjoyment.cool)に直接アクセスしてください。 Python環境はたくさんあると思いますが、pipインストールで使用したものを選択する必要があります。これは非常に重要です。操作手順の詳細については、「Apache Flink Python APIの現状と計画」というタイトルの動画を参照してください。
Python Table API - ジョブの投入
ジョブの投入にはどのような方法があるのでしょうか?まず、既存のクラスタにジョブを投入するCLIメソッドを使用します。この方法を使用するには、クラスタを起動する必要があります。ビルドのディレクトリは通常 build-target の下にあります。このコマンドを直接実行してクラスタを起動します。このプロセスでは、外部の Web ポートを使用することに注意してください。
flink-conf.yamlファイルでポート番号を設定します。次に、PPT内のコマンドを使用してクラスタを起動します。クラスタが正常に起動したことを確認するには、ログを確認するか、ブラウザでサイトにアクセスします。クラスタが正常に起動した場合は、ジョブの投入方法を見てみましょう。
Flink runを使用して、以下のコードを実行してジョブを投入します。
./bin/flink run -py ~/training/0806/enjoyment.code/myPyFlink/enjoyment/word_count_cli.pyPythonファイルを指定するにはpyを、Pythonモジュールを指定するにはpymを、Pythonリソースファイルを指定するにはpyfsを、JARパッケージを指定するにはjを使用します。
Apache Flink 1.9では、もっと便利な方法があります。Python Shellを使うと、Python APIで得られた結果を対話的に書き込むことができます。Python Shellはローカルとリモートの2つのモードで実行されますが、大きな違いはありません。まずは、以下のコマンドを実行してローカルモードを試してみましょう。
bin/pyflink-shell.sh localこのコマンドはミニクラスタを起動します。コードを実行すると、FLINK - PYTHON - SHELLというテキスト付きのFlinkロゴと、この機能を示すいくつかのサンプルスクリプトが返されます。これらのスクリプトを入力すると、正しい出力と結果が返されます。ここでは、ストリーミングまたはバッチのいずれかを記述することができます。操作手順の詳細については、ビデオを参照してください。
これで、Apache Flink 1.9のPython Table APIのアーキテクチャと、Python Table APIの環境設定方法についての基本的な理解ができました。IDEでジョブを実行する方法や、Flink runとPython Shellを使ってジョブを投入する方法を見るために、簡単なWordCountの例を考えてみました。また、FlinkのPython APIを利用するためのインタラクティブな方法をいくつか体験しました。Flinkの環境設定と簡単な例のデモを紹介した後、Apache Flink 1.9のキー演算子について説明します。
Flink Python APIのキー演算子の紹介と応用
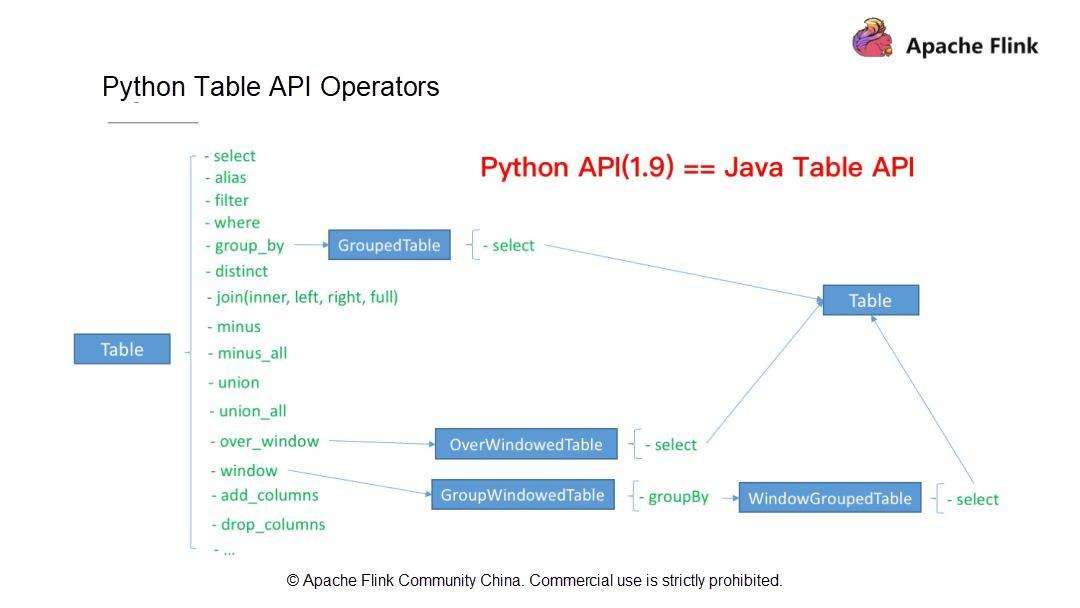
Python のテーブル API 演算子
ジョブを作成する方法についてはすでに説明しました。まず、実行モードを選択します: ストリーミングかバッチかを選択します。次に、使用するテーブル(ソーステーブルと結果テーブル)、スキーマ、データ型を定義します。その後、計算ロジックを記述します。最後に、Python APIの組み込みの集計関数であるCount, Sum, Max, Minを利用します。例えば、WordCountジョブを書いたときは、Count関数を使いました。
Apache Flink 1.9は、ユーザの通常のニーズのほとんどを満たしています。では、これまでに見てきたものとは別に、Apache Flink 1.9でサポートされているFlink Table API演算子を見てみましょう。Flink Table API オペレータ(Python Table API オペレータと Java Table API オペレータ)は、以下のような操作をサポートしています。
第一に、SELECT、FILTER、集約演算、ウィンドウ演算、カラム演算(
add_columns、drop_columns)などのシングルストリーム演算。第二に、JOIN、MINUS、UNIONなどのデュアルストリーム演算。
これらの演算子はすべて Python Table API でサポートされています。Apache Flink 1.9では、Python Table APIは機能的にはJava Table APIとほぼ同じです。次に、上記の演算子の書き方とPython演算子の開発方法を理解していきましょう。
Python Table APIの演算子 - 透かしの定義
この記事を読んでお気づきの方もいるかもしれませんが、データストリームの属性である時系列については触れていません。データストリームの客観的な状態としては、データストリームがアウトオブオーダーになっている可能性があります。Apache Flinkでは、Watermarkの仕組みを利用して、アウトオブオーダーのデータストリームを処理しています。
Python APIでWatermarkを定義するには?
a と DateTime の 2 つのフィールドを含む JSON 形式のデータファイルがあるとします。透かしを定義するには、Schema作成時にrowtimeカラムを追加し、rowtimeデータ型はTimestampにする必要があります。
様々な方法で透かしを定義します。
watermarks_periodic_boundedを使用して、定期的に透かしを送信します。60000という数字は60000msを指しており、これは60秒または1分に相当します。この定義により、プログラムは1分間の期間内に順番外のデータストリームを処理することができます。したがって、値が大きいほど、順序外データに対する耐性が高く、待ち時間が長いことを示します。透かしの仕組みの詳細については、こちらののブログ http://1t.click/7dM を参照してください。PythonテーブルAPI - Java UDF
最後に、Apache Flink 1.9でのJavaユーザ定義関数(UDF)の応用について紹介します。Apache Flink 1.9はPythonのUDFをサポートしていませんが、PythonでJavaのUDFを利用することができます。Apache Flink 1.9では、Tableモジュールを最適化して再構築しています。Java UDFを開発するには、簡単な依存関係をインポートしてPython APIを開発します。Flink-table-commonをインポートします。
次に、JavaのUDFを使ってPythonのAPIを開発する方法に注目します。文字列の長さを計算するUDFを開発する必要があるとします。
t_env.register_java_functionを使って、Java関数の名前とフルパスを渡して、Java関数をPythonに登録する必要があります。その後、登録された名前を使ってUDFを呼び出すことができます。詳しくは、私のブログ http://1t.click/HQF
Java UDFを実行するには?Flinkのrunコマンドを使って実行します。前述したように、UDFのJARパッケージをインクルードするために-jを使用しています。
Java UDFはスカラー関数だけをサポートしていますか?Java UDFはスカラー関数だけでなく,テーブル関数や集約関数もサポートしています.
Python Table APIのリファレンスリンク
よく使われる資料と私のブログのリンクを掲載しています。うまくいけば、それらがあなたの役に立つことを願っています。
概要
本記事では、Apache Flink Python APIの歴史と開発ロードマップを紹介しました。次に、Apache Flink Python APIのアーキテクチャを変更する理由と、利用可能な最新のアーキテクチャについて説明しました。また、Apache Flink Python APIの今後の計画や新機能についても記載されていました。あなたの提案や考えを共有することをお勧めします。
アリババクラウドは日本に2つのデータセンターを有し、世界で60を超えるアベラビリティーゾーンを有するアジア太平洋地域No.1(2019ガートナー)のクラウドインフラ事業者です。
アリババクラウドの詳細は、こちらからご覧ください。
アリババクラウドジャパン公式ページ

















- 投稿日:2020-09-25T15:55:23+09:00
Web3層構造~Webサーバ・APサーバ・DBサーバ~
Web備忘録.
Web3層構造
Web3層アプリケーションとは、Webシステムの構成要素をプレゼンテーション層、アプリケーション層、データ層の3層に分割し、独立したモジュールとして設計するアプリケーション.
Webサーバ(プレゼンテーション層)
クライアントからのHTTPリクエストを最初に受け取る入り口みたいなサーバ. ここでレスポンスを返す. 静的ファイル(hmtl,css,js, 画像ファイル)の受け渡しを行う. 動的な処理が必要な場合は, APサーバに処理要求する. ChromeやFirefoxが担当する.
例)Apache, Nginx, IIS(Internet Information Services)など
APサーバ(アプリケーション層)
プログラムが置いてあるサーバ.
Webサーバからのリクエストに応じてWebサーバに処理を返したり, DBサーバにデータを要求したりする.例)Tomcat, GlassFish, Gunicorn, Unicornなど
DBサーバ(データ層)
- DBサーバ : APサーバのリクエストに応じて, ストレージからSQLでデータの書き込み・引き出し・更新を行い, データを渡すサーバ.
例)Oracle, PostgreSQLなど
Web API
API=アプリケーション・プログラミング・インタフェース(Application Programming Interface).
Webサービスをプログラミングから操作するためのメソッド. Web APIはクライアントからのリクエストに対して, データ(JSON, XML)だけをレスポンスとしてアプリケーションに渡す. Ruby on RailsでRESTfulが提唱されてから, RSETful APIが注目されるようになる.Web2層構造
WebサーバとAPサーバが一体化した構造.
ただし, 最近のWebサイトは基本的にWeb3層構造になっている.WSGI
Python製のWebフレームワークであるDjangoやFlaskといったWebアプリケーションは, WSGI(Web Server Gateway Interface)に則って設計されている(WSGIアプリケーションと呼ばれる).
Python製のWebフレームワークのそれぞれにおいて, WebサーバとWebアプリケーションを接続するためのインターフェースが独立していたため, 使用できるサーバが制限される問題があった. それを解決するため, Pythonにおける, WebアプリケーションとWebサーバを接続する標準仕様を定めた. それがWSGI.備考
- 監視サーバ : サーバの状態を監視するサーバ
- ジョブサーバ : ジョブの管理を行うサーバ
参考
Web3層構造
サーバーとは?WEB3層構造におけるサーバーの種類
Bottle、Flaskを使ってWebサーバを起動する(Apacheも使ってやってみた)
WSGIアプリケーションとは?WebフレームワークからWSGIサーバーまで
Web Server Gateway InterfaceMVCモデル
- 投稿日:2020-09-25T15:39:27+09:00
素人が夏休みの自由研究でゲームAIをゼロから自作した
0. はじめに
こちらは,1ヶ月前まで強化学習に関する知識が完全にゼロ(2ヶ月前までは機械学習の知識がほぼゼロ)だった大学3年生の筆者が,ちょっとしたゲームAIを手探りで作ってみた記録,そんなレベルの記事です.未熟者の私ですが,
- 自分の理解を整理・確認する
- 至らない点を知識のある方々に補っていただく
- 強化学習について何も知らないけど興味はある.でも手元に特に教材がない.という方へのチュートリアルになればいいな
あたりを目的としてこの記事の執筆に至りました.興味があれば暖かく読んでいただけると嬉しいです.コメント等によるご指摘も歓迎いたします.
0-1. 参考文献
筆者が強化学習を学ぶにあたり,「ITエンジニアのための強化学習理論入門」(中井悦司) という書籍をまず教科書として購入し,べたべた読ませていただきました.執筆にあたってもこの上なくお世話になりましたので,この場で紹介させていただきます.
また,記事に載せたソースコードのうち,一部この本に掲載されていたものと非常に似通った部分があることをお断りしておきます.ご了承ください.
それから筆者は,強化学習を学ぶ前に「Pythonではじめる機械学習入門」「ゼロから作るDeepLearning」(ともにオライリー・ジャパン)の2冊を読んで機械学習・深層学習についてある程度オベンキョしましたのでこれも載せておきます.特に後者は,AI実装パートの理解に役立つ部分があるかと思います.
0-2. 記事の大まかな流れ
この記事ではまずAIに習得させるゲームの紹介および目標の設定を行います.次に強化学習および今回用いるDQNアルゴリズムに関する理論的なお話を整理して,最後にソースコードの晒しあげと学習結果の確認,そこで浮かんだ問題点・改善案の列挙,という流れにしようと思います.興味のあるパートだけでも覗いてくださると嬉しいです.
追記.書き上げてみたところ,理論編が予想以上にヘビーになりました.筆者のように理論屋的な性格の方は,べたべたすると楽しいかもしれません.そんなモチベのない方は,程々になぞるくらいにとどめておく方がいいかもしれません.
0-3. 使用する言語
Pythonさんのお力を借ります.筆者は jupyter notebook で実行しております.(おそらく盤面の可視化関数以外はその他の環境でも動きますが,確認はしていません.可視化関数は大したものではないので,そんなに気にしなくてもいいです.)
またクライマックスで,ディープラーニングのフレームワーク「TensorFlow」をちょこっと使います.最後までコードを実行したい!という方は,該当箇所の実行にはインストールが必要ですのでそこだけお願いします.またここではGPUが利用できると高速に処理できるのですが,筆者にはそんな環境も知識もないため,CPU(普通の)でゴリ押しました.Google Colab などを使えばGPUが無償で利用できますが,セッション切れでの事故が嫌すぎて回避しました.このあたりの判断はお任せします.
0-4. 前提知識
記事を読んで雰囲気を掴むだけなら,特別な知識はほぼ不要です.
理論編をきちんと理解するには,高校数学(確率,漸化式くらい)のある程度の理解が,実装編をストレスなく読むには,Pythonの基本文法がわかっていれば十分かと思います(クラスの概念について不安がある方は,軽く見直すとよいです).また,アルゴリズム(動的計画法など)の事前知識があると,理解がしやすくなると思います.
ただ一点,ニューラルネットワークに関してだけは,本記事で解説を行わないかつ,知識があるとないとで結構変わってくる分野かと思います.「こういうものだと思ってください」的な宣言はするので鵜呑みにしてもらえれば理解に支障はないと思いますが,きちんと知りたい方は別個にオベンキョすることを勧めます.
それでは本編行きます!!
1. 取り扱うゲームの紹介
学習のテーマとして選んだのは2048ゲームです(↓こういうの).ご存知でしょうか?
このあとルールを説明しますが,非常に簡単なのでやってみればわかると思います.スマホアプリでもWeb版でもいくらでもあるので,ぜひ遊んでみてください.
1-1. ルール
4$\times$4マスの盤面に,2の累乗の数字が書かれたタイルが置かれています.ゲーム開始時はランダムに選ばれた2マスに,「2」または「4」のタイルが置かれています.
プレイヤーは毎ターンごとに,上下左右4方向のうちひとつ選んで,スワイプするなりボタンを押すなりします.すると,その方向に向かって盤上全てのタイルが滑ります.この際,同じ数字のタイルがぶつかると,合体して数字が大きくなり,1枚のタイルになります.またこのとき,できたタイルに書かれている数字が,スコアとして加算されていきます.
毎ターン終了時に,空いているマスのどこかひとつに,「2」または「4」のタイルが新しく生成されます.どの方向にも動かせなくなったらゲームオーバー.それまでにハイスコアを目指しましょう!というゲームです.一応このゲームの名前通り,はじめは「2048のタイルを作る」ことが目標として設定されています.
↓図解です.本当にルールは簡単です.
2つ目の図で同じ数字のタイルが3枚以上並んでいる場合の挙動を示しています.また複数枚のタイルが同時に完成した場合は,きちんとその分のスコアが加算されます.
1-2. このゲームのコツ
このゲームには運要素もある程度ありますが,スコアにはプレイヤーの練度が多分に反映されます.つまりは「勉強・練習によって上手くなれるゲーム」です.のちにAIくんにゲームの練習をしてもらうわけですが,このタイミングで筆者が掴んだこのゲームのコツを軽く書いておこうと思います.もしAIくんがこのコツを自分で学習することができれば偉いですね.
ただ,「どのくらいのレベルのAIが作れるのかを体感したい!」という方は,このコツを見ないで何回かプレイしてみることを勧めます.自分のはじめの実力がどのくらいのスコアなのか,を知っておくと,今後のAIの学習過程で,今どのレベルなのか,というのが少しわかりやすいと思います.(まあ別にいいやという方は,普通にオープンしちゃっても構いません.)
以上を了解したうえで,この中身を読んでください(左の三角マークをクリック).
このゲーム,最初のうちはどう動かしてもどこかでタイルが合体するのでよいのですが,そのうち大きい数字が邪魔になってきて,どんどん盤面が狭くなってしまいます.そこで,どこかの角に大きい数字を集めるという方針をとるのが非常に有効です.(どうすれば角に集められるのか,というのはまた色々コツがあるんですが.)左の図では,左上方面に大きい数字を集めています.この盤面で,下にスワイプなどをしてしまうと,「256」や「128」が真ん中の方で邪魔なタイルになってしまい,一気に不安定になってしまいます(本当に一気にゲームオーバーまで行きます).
この形を崩さないように丁寧にプレイしていくと,右の図のような盤面まで持ち込めます.ここからなら「2048」まで一直線で行けることがわかるでしょう.一気にタイルを集める瞬間は,このゲームで一番の快感ポイントです.
1-3. 目標
一応ですが今回の目標(夢)を立てておきます.理想は「自分より高スコアを取れるAI」です.私はこのゲームをそれなりに理解しているつもりで,先ほどチラ見せしたスクショでのハイスコア69544点というのは相当高めなのですが,もしこれをAIくんが超えてきたら感動します.
スコアの目安ですが,このゲームを知らない人間が初見プレイをすると,だいたい1000~3000点くらいでゲームオーバーとなります.何回かプレイしてゲームに慣れてくると,5000~7000点くらい出せるようになります.(私の周りの人間ではこんな傾向だった,というだけです.サンプルも少ないので参考程度でお願いします).またのちに述べますが,完全ランダムに手を選ぶと,平均で1000点くらいしか取れません.
では,2048ゲームの話はこれくらいにして,本題の強化学習に入りましょう!
2. 理論武装
実装に先立って,今回のゲームAI作成のベースにある理論を
かいつまんで割としっかりと整理します.強化学習の基礎的なところから,今回用いたDQNに至るまでの流れを辿れればいいかなと思っています.筆者もオベンキョしながら一歩ずつ書き進めるので一緒に頑張りましょう.2-1. 強化学習について
そもそも強化学習とは,教師あり学習・教師なし学習あたりと並ぶ,機械学習のあるひとつの分野です.何らかの環境を動き回るエージェントを定義し,データの収集を繰り返すなかで学習処理を進め,得られる"報酬"を最大化するような最適な行動を学習していく,というのが強化学習の流れです.よく聞く将棋や囲碁のAI,自動運転技術などで,強化学習が応用されているそうです.
以下では2048ゲームをテーマに据えながら,もう少し専門用語も取り入れて整理していこうと思います.
2-1-1. 行動ポリシー
強化学習を始めるにあたっては,まず実際にゲームをプレイする「エージェント」を定義します(今回の実装でエージェントそのものを定義したかと言われると微妙なのですが,仮想的にでもゲームをプレイする存在を意識しておくといい気がします).また,ゲーム内に「報酬」を設定して,エージェントに「ゲーム終了時の報酬を最大化する」という目的を持たせます.報酬の設定の仕方は重要な要素です.また,プレイの中で,エージェントは様々な盤面に遭遇し,そこでとる「行動(アクション)」の選択に迫られます.それぞれの盤面のことを,強化学習的な用語では「状態」と呼びます.
エージェントの学習が完了した,というのは,究極的には「すべての状態sに対して,最善のアクションaがわかっている」ということです.例として「○×ゲーム」を考えるとわかりやすいです.あのゲームは,両者が最善手を打ち続ける限りかならず引き分けになります.ということは,発生しうるすべての状態(盤面)に対してそれを「暗記」しておけば,極論ルールすら知らなくても,その人は不敗の○×ゲームマスターとなります.
ここで「行動ポリシー」という用語を定義します.これは,「各状態に対してエージェントがアクションを選択するルール」のことです.行動ポリシーを固定したエージェントは,まるで機械のように(まあ機械なんですが)一定のルールに従って次の手を選択しゲームをプレイします.強化学習の目的は,この行動ポリシーを最適化すること,最適な行動ポリシーを求めること,と言い換えてもいいかもしれません.○×ゲームの例では,暗記すべきだった最善手たちに従うことが,最適な行動ポリシーにあたります.
なお,行動ポリシーは記号 $\pi$ で表すのが慣例らしいです.
2-1-2. 状態価値関数
さっきから学習学習いってますが,具体的にどう学習するんだ,という話を始めます.
まず,状態価値関数 $v_\pi(s)$ を定義します.これは特定の行動ポリシーπを前提とし,状態sを引数にとる関数です.返り値は「状態sからスタートし,ゲーム終了まで行動ポリシーπに従ってアクションを選択し続けたとき,現在以降に得られる報酬の合計の期待値」です.
?となるかもしれませんが,よく考えれば大したことはないです.行動ポリシーを固定したとき,状態価値関数の値は,「各盤面がどれくらい良い盤面か」を表します.
数式を使った方が(個人的には)気持ちがよくわかるのでそれも示します.いきなり出てきた記号はすべて意味を述べます.
$$
v_\pi(s) = \sum_{a}\left( \pi(a\ |\ s)\sum_{(r,s')} p(r,s'\ |\ s,a) \left( r+v_\pi(s') \right) \right)\tag{1}
$$はいこれが状態価値関数が一般に満たす等式です.これをベルマン方程式と呼ぶそうです.
- $p(r,s'\ |\ s,a)$ は,「状態sからアクションaを選択したときに,報酬としてrが得られ,かつ状態s'に遷移する条件付き確率」を表します.(同じ盤面で同じアクションを選択したとしても,つねに同じ報酬・遷移先が得られるとは限らないためこの措置がとられています.例えば2048ゲームでは,新たに生成されるタイルの位置がランダムです.)
- $r+v_\pi(s')$ は,「はじめの1アクションでaを選択したら報酬rを獲得して状態s'に遷移し,その後はゲーム終了まで行動ポリシーπに従った場合に,今から得られる報酬の和の期待値」を表します.
- $\pi(a\ |\ s)$ は,「行動ポリシーπにおいて,状態sのときアクションaが選択される条件付き確率」を表します.(πが確率的なアクション選択を含まない場合は,ここは削ることができます.)
以上をまとめると,内側のシグマでは「現状態sからアクションaを選択し,その後はずっとπに従って行動した場合に,今から得られる報酬の和の期待値」が表現されています.さらに,外のシグマでアクションに関して和をとることで,「現状態sから行動ポリシーπに従ってアクションを選択し続けた場合に,ゲーム終了までに得られる報酬の合計の期待値」となるわけです.
補足 「割引率」について
(1)のベルマン方程式では,一般には割引率というパラメータが導入されます(記号はγ).しかし今回は,実装パートで $\gamma=1$ としたために結局(1)と等価な式になることと,筆者の理解度が浅いことを理由に扱わないことにしました.ごめんなさい.
上の(1)式は,状態価値関数の定義というより計算法を示しています.ただ一点,終了状態(ゲームオーバー盤面)に対する状態価値関数の値を0と事前に定義しておけば,そこから前の状態,前の状態,と遡っていくことですべての状態について状態価値関数の値を計算することができます.正しい状態価値関数の値が,終了状態から徐々に伝播していくイメージです.高校数学で言えば漸化式,アルゴリズムで言えば動的計画法の考え方になります.
動的計画法についてこれ以上深追いはしません.ただ,この計算を行うには,少なくとも全状態についてのループを回す必要があるということは心に留めておくといいかもしれません.
さて,状態価値関数を定義自体はしましたが,結局「学習」というのは何をするのかがまだ示されていません.次でその問いに答えようと思います.
2-1-3. 行動-状態価値関数
先に述べた状態価値関数は,行動ポリシーπが定まっているという前提のもとで,各状態が良いか悪いかを判定するものです.つまり,それ単体では行動ポリシーπを改善することができません.ここでは,より良い行動ポリシーをどう得るかを説明します.ただしここで,行動ポリシーが「より良い」というのは,
「任意の状態sに対して,$v_{\pi1}(s)\leq v_{\pi2}(s)$ が成り立つこと」
であると定めます.(π1よりも,π2の方が「良い」行動ポリシーです.)非常に名前が似ていますが,行動-状態価値関数 $q_\pi(s,a)$ を定義します.これは,「現状態sからアクションaを選択して,その後はずっと行動ポリシーπに従ってアクションを選び続けた場合,今から得られる総報酬の期待値」を表します.あれ?と思った方もいるかと思いますが,これは(1)式の一部にまるまる登場します.すなわち,
$$
q_\pi(s,a) = \sum_{(r,s')} p(r,s'\ |\ s,a) \left( r+v_\pi(s')\right) \tag{2}
$$です.これを用いると,(1)式は
$$
v_{\pi}(s) = \sum_{a} \pi(a\ |\ s)q_{\pi}(s,a) \tag{3}
$$と表現することができます.
さて一気に結論を述べます.行動ポリシーを改善する方法は,
「現状態sにおいて選択できるすべてのアクションaについて,行動-状態価値関数 $q_{\pi}(s,a)$ の値を参照し,これが最大となるアクションaを選ぶよう,行動ポリシーを修正する」です.これはつまるところ,「1手だけ現状の行動ポリシーを無視して違う世界を見て,一番よさそうな手を選ぶようにポリシーを修正する」ということです.この改善をひたすら続けていけば,「より良い」ポリシーがどんどん得られていくことは直感的にもわかるのでは,と思います.これは一応数式的に示すことも可能ですが,割と面倒なのでここでは割愛します.
2-1-4. ここまでのまとめ
色々言ってきましたが,とりあえず整理が一段落したので簡潔にまとめておきます.エージェントが最適な行動ポリシーを学習するまでの流れは,
- とりあえず適当に行動ポリシー $\pi$ を設定する.
- 状態価値関数 $v_{\pi}(s)$ を動的計画法で計算する.
- 行動-状態価値関数 $q_{\pi}(s,a)$ を,式(2)で計算する.
- 新たな行動ポリシー $\pi'$ を,上で説明した方法で作成する.
- この $\pi'$ をはじめの行動ポリシーπと置き換えて,同じ操作を繰り返す.
です.これをひたすら繰り返すことで,エージェントはどんどん優れた行動ポリシーを得ることができます.これが,強化学習における「学習」の仕組みです.
補足 ちょっとだけごまかしたポイントについて
上のループをひたすら繰り返せば理論上学習ができる的な話をしましたが,実際に計算をしようとすると,(1)や(2)に現れる $p(r,s'\ |\ s,a)$ の値がわかるのか,という問題に直面します.ゲームの仕様を(私たちプログラマが)完全に理解していて理論的に求められるならばそれでいいですが,未知のゲームをプレイするときはここがわからない場合も考えられます.
これについては,のちに2-2-3. TD法で回収しようと思います.2-2. Q-Learning
上でまとめたアルゴリズムは,紛れもなく正しい学習アルゴリズムではあるのですが,ポリシーの改善は1ゲーム終了まで行われず,さらに「現状の行動ポリシーではゲーム終了までこぎつけられるとは限らない」という欠点があります.2048ゲームに関してはそんなことはないのですが,一般のゲームに適用する際(たとえば迷路など)にはここが大きな問題となります.この点を解決したのがQ-Learningのアルゴリズムであり,今回こちらを実装したので以下で解説します.
2-2-1. オフポリシー
ここでは用語の定義だけします.我々はあくまで行動ポリシーの改善を目的としているわけですが,よく考えてみると,エージェントがプレイしてデータを収集する際は,別に現状の最適な行動ポリシーに従ってデータを集める必要はありません.そこで,「改善対象のポリシーとは異なるポリシーに従ってエージェントを動かし,データを収集する」手法について考えます.これをオフポリシーでのデータ収集と呼ぶことにします.
2-2-2. Greedyポリシー
若干今更感がありますが,Greedyポリシーという語を定義します.これは,「確率的な要素を持たず,アクションを選択し続けるような行動ポリシー」のことです.(1)式や(3)式に登場させた条件付き確率 $\pi(a\ |\ s)$ が,ある特定のaについてのみ1,それ以外のアクションについては0となるようなポリシーだと言い換えることもできます.
Greedyポリシーπにおいては,状態sを定めればアクションも1つに確定するので,そのアクションのことを $\pi(s)$ と表現することにします.
このとき一般に,
$$
v_{\pi}(s') = q_{\pi}(s', \pi(s')) \tag{4}
$$というように,状態価値関数を行動-状態価値関数を用いて表すことができます.sではなくs'としたのは形式を合わせるためで,これを(2)式に代入することで,$$
q_\pi(s,a) = \sum_{(r,s')} p(r,s'\ |\ s,a) \left( r+q_{\pi}(s',\pi(s'))\right) \tag{5}
$$という等式が得られます.これは行動-状態価値関数に対するベルマン方程式と呼ばれています.この式により左辺の値は,状態sでアクションaを選択したときの報酬rおよび遷移先の状態s',$q_{\pi}(s',\pi(s'))$ を用いて計算し直すことができます.またこの式ならば,状態価値関数を経由する必要がありません.
次で(5)式を生かしたQ-Learningの概要を示します.
2-2-3. TD法
はじめに説明したアルゴリズムでは,1ゲームの終了を待たないと,ポリシーの改善が行えないと述べました.これに対し,1ターン分のデータを収集した瞬間に,更新処理を行う手法が存在します.これが「TD法(Temporal-Difference法)」と呼ばれるもので,オフポリシーでデータ収集して行うTD法のことを,Q-Learningと呼びます.これならデータ収集中にもAIくんは賢くなれるため,永遠に迷路のゴールにたどり着けない,という事態を回避できます.
更新は式(5)を用いて行います.$p(r,s'\ |\ s,a)$ の値をはじめは未知とし,得られたデータから近似値を計算,さらにデータを集めることでどんどん真の値に近づけていきます.これと同時に行動-状態価値関数の値も修正されていく,という仕組みです.
ただ実際のQ-Learningでは,(5)式ではなく以下の式で値の修正を行うそうです.(行動-状態価値関数の値を $r+q_{\pi}(s',\pi(s'))$ に近づける,という気持ちはそのままです.)
$$
q_{\pi}(s,a) \longrightarrow q_{\pi}(s,a)+ \alpha \left\{ r+q_{\pi}(s',\pi(s') - q_{\pi}(s,a)) \right\} \tag{6}
$$αは修正の重みを調節するパラメータで,学習率とか呼ぶそうです.(これは完全に私の予想ですが,すべての(s,a)の組に対し $p(r,s'\ |\ s,a)$ の値を保持・更新していくというのはメモリ的に厳しい場合が多いのではないでしょうか.)
はい.最後の方少し雑に説明してしまいましたが,正直に言うと実装パートではこの式を使わないので少しモチベが下がってました.とにかく重要なのは,オフポリシーでデータを集めながら行動-状態価値関数の更新を行っていき,この値を最大化するアクションを選ぶことでより良い行動ポリシーが得られる,という考え方です.これに基づいた本番用のアルゴリズムの仕組みを次で示し,長かった理論編を締めます.
2-3. DQN
理論編では,まず強化学習の基本的な仕組みを説明し,それを効率化するQ-Learningという手法を述べました.しかし現状のアルゴリズムでは致命的な問題が残っています.それは,「とりうる状態の数が多すぎる場合に,学習処理が終わらない」という点です.
これまでのアルゴリズムでは,どんなに少なく見積もっても,あり得る状態の数だけ計算を行い,全状態に対して行動-状態価値関数の値を求めなければなりません(もちろんこれを何周も何周もして,より良いポリシーを得ることになります).Pythonが1秒間に行える演算の量はせいぜい $10^{7}$ 回だとかそこいらなのに対し,2048ゲームにおける状態の数は,まあ盤面に16マスありますし $12^{16}$ くらいはありそうですよね.この長さのループを何周もする...と考えると,学習は到底終わらなそうです.将棋や囲碁の状態数とか言い始めたらそれこそ永遠に終わりません.(Pythonの演算速度について私はそんなに詳しくないのでザックリ書きましたが,まあとりあえず終わりません.)
この問題を解決するため,偉大なニューラルネットワークさんを持ち出してきて,Q-Learningをしてやろう,というのがDQNです.DQNは Deep Q Network の頭文字です.
2-3-1. ニューラルネットワーク
改めてですが,ニューラルネットワークの詳しい理論・仕組みに関してはこの記事では追いません.ここでは,2048ゲームAIくんの学習の仕組みを理解するために,最低限必要な世界観を述べます.(というか私も未熟者なので深いことはわからないんですごめんなさい.)
ニューラルネットワークは,深層学習(ディープラーニング)で用いられるものなのですが,本当に平たく言ってしまうとこれは「関数」です.(多変数入力,多変数出力がデフォです).単純な一次関数を多数用意し,入力をそれに通し,チョチョっと処理を加える.この操作を何層にも重ねたのちに,何らかの形で出力がされる.というのがニューラルネットワークです.内部の関数の数や処理の種類,層の数をいじることで,本当に柔軟に,いろんな関数に化けることができます.(以下,ニューラルネットワークのことをたまに「NN」と略します.)
そしてニューラルネットワークにはもう一つ重要な機能があります.それがパラメータのチューニングです.先ほどはNNの中身を固定して関数として働くというものでしたが,入力と同時に「正解」の出力をNNに与えることで,正解に近い値を出力するよう,内部関数に含まれるパラメータの値を修正することができます.望みの性質を持つ関数になるように,ニューラルネットワークは「学習」ができるということです.
実装にあたっては,今回はフレームワークTensorFlowの力を借りるので,中身の理解はこのくらいでもとりあえず大丈夫かと思います.オベンキョはまたの機会に.
2-3-2. 畳み込みニューラルネットワーク(CNN)
畳み込みニューラルネットワークと呼ばれる種類のNNがあります.これは画像認識等に用いられている類のもので,シンプルに入力値を与えるよりも,入力の2次元的な広がり(ちょうど盤面のような)の特徴をつかむのに優れています.ので今回使います.とりあえずそれだけ.
2-3-3. Q-Learningに組み込む
NNをどう使うかというと,「盤面の状態とアクションから行動-状態価値関数の値を計算するニューラルネットワークを作る」です.全状態・アクションについて $q_{\pi}(s,a)$ を求めていくという従来の方法は無理ぽという話でしたが,このようなNNが作れれば,「何となく似ている」「通ずる部分がある」ような盤面を見て,最善と思われるような手を選ぶことができるようになると期待できます.
式で理解します.(5)式(6)式あたりと同様,Q-Learningでは $q_{\pi}(s,a)$ の値を更新するのが目的です.そこでNNの入力も,これと揃えて盤面の状態そのもの+選択したアクションとします.
計算結果を$r+q_{\pi}(s', \pi(s'))$に近づけたいため,これを「正解の値」として,NNの学習処理を行います.あくまで「関数近似」の領域ですが,データ収集&学習処理を繰り返すことで,どんどん性能(近似精度)が良くなると期待できます.
以上が今回用いたDQNの全貌です.具体的な話はコードを見た方が早いと思うので,後に回します.
2-4. 世界観まとめ
理論編が予想以上に長くなってしまいました(ガチ).全体像をここでまとめ直して実装パートに移ります.
- 強化学習では,エージェントにゲームをプレイさせ,得られる報酬を最大化するように行動ポリシーを改善していく.
- 行動-状態価値関数の値をあらゆる状態・アクションについて正確に求められれば,すべての盤面での最善手がわかったことになる.
- オフポリシーでデータ収集を行い,随時 行動-状態価値関数の値の更新を行っていくのがQ-Learningである.
- 状態数が多すぎる場合はそのままだと手に負えないので,ニューラルネットワークを用いて行動-状態価値関数を近似して計算,さらにデータを集めてこのNNの学習処理を行う.(DQN)
以上ですお疲れさまでした!よくわからんという場合も,コードを読んでみたらわかるかもしれないので行ったり来たりしてみてください.単純に私の理論まとめが良くないだけだったら申し訳ありません.少なくとも足りない部分はあるはずなので,もっときちんとお勉強されたい方は,何か他の書籍等に当たってみるといいかと思います.
今度こそ本当に理論終わりですコードに移ります↓↓
3. 実装
それではコードをどんどん載せていきます.おそらく上からベタ貼りして頂ければ,再現することも可能かと思います(乱数が絡むコードだらけなので,完全に同じ結果が得られるはずはないですが).また各所にお見苦しいコードが見られるかと思いますがお許しください.
とりあえずimportすべきものだけここに貼っておきます.以下のコードはすべてこの前提でお願いします.(実は不要なモジュールが含まれてるかもですがご了承ください)
2048.pyimport numpy as np import copy, random, time from tensorflow.keras import layers, models from IPython.display import clear_output import matplotlib.pyplot as plt import seaborn as sns import matplotlib matplotlib.rcParams['font.size'] = 20 import pickle from tensorflow.keras.models import load_model3-1. Gameクラスの定義
まずはコード上で2048ゲームを実装します.やったらと長いですが中身は薄いですのでそのつもりで眺めてください.このコードに限らずですが,後ろに日本語解説をつけていますのでそちらを見てからの方がよいかもしれません.では.
2048.pyclass Game: def __init__(self): self.restart() def restart(self): self.board = np.zeros([4,4]) self.score = 0 y = np.random.randint(0,4) x = np.random.randint(0,4) self.board[y][x] = 2 while(True): y = np.random.randint(0,4) x = np.random.randint(0,4) if self.board[y][x]==0: self.board[y][x] = 2 break def move(self, a): reward = 0 if a==0: for y in range(4): z_cnt = 0 prev = -1 for x in range(4): if self.board[y][x]==0: z_cnt += 1 elif self.board[y][x]!=prev: tmp = self.board[y][x] self.board[y][x] = 0 self.board[y][x-z_cnt] = tmp prev = tmp else: z_cnt += 1 self.board[y][x-z_cnt] *=2 reward += self.board[y][x-z_cnt] self.score += self.board[y][x-z_cnt] self.board[y][x] = 0 prev = -1 elif a==1: for x in range(4): z_cnt = 0 prev = -1 for y in range(4): if self.board[y][x]==0: z_cnt += 1 elif self.board[y][x]!=prev: tmp = self.board[y][x] self.board[y][x] = 0 self.board[y-z_cnt][x] = tmp prev = tmp else: z_cnt += 1 self.board[y-z_cnt][x] *= 2 reward += self.board[y-z_cnt][x] self.score += self.board[y-z_cnt][x] self.board[y][x] = 0 prev = -1 elif a==2: for y in range(4): z_cnt = 0 prev = -1 for x in range(4): if self.board[y][3-x]==0: z_cnt += 1 elif self.board[y][3-x]!=prev: tmp = self.board[y][3-x] self.board[y][3-x] = 0 self.board[y][3-x+z_cnt] = tmp prev = tmp else: z_cnt += 1 self.board[y][3-x+z_cnt] *= 2 reward += self.board[y][3-x+z_cnt] self.score += self.board[y][3-x+z_cnt] self.board[y][3-x] = 0 prev = -1 elif a==3: for x in range(4): z_cnt = 0 prev = -1 for y in range(4): if self.board[3-y][x]==0: z_cnt += 1 elif self.board[3-y][x]!=prev: tmp = self.board[3-y][x] self.board[3-y][x] = 0 self.board[3-y+z_cnt][x] = tmp prev = tmp else: z_cnt += 1 self.board[3-y+z_cnt][x] *= 2 reward += self.board[3-y+z_cnt][x] self.score += self.board[3-y+z_cnt][x] self.board[3-y][x] = 0 prev = -1 while(True): y = np.random.randint(0,4) x = np.random.randint(0,4) if self.board[y][x]==0: if np.random.random() < 0.2: self.board[y][x] = 4 else: self.board[y][x] = 2 break return rewardGameクラスには,
boardとscoreを管理させることにしました.名前の通り盤面と現時点でのスコアです.boardは2次元のnumpy配列で表現しています.
restartメソッドによって,盤上ランダムな2箇所に「2」のタイルを置き,スコアを0にしてゲームをスタートします.(1章のルール説明において,初期盤面では「2」か「4」が置かれていると言いましたが,コード上は「2」しか湧かなくなっています.これは筆者がGameクラス実装時,はじめは「2」だけだと勘違いしていたせいです.ゲーム性にはほぼ影響ないので許してください.)
moveメソッドは,アクションの種類を引数としてとり,それに応じてboardを変化,スコアを加算します.返り値としてこの1ターンで加算された分のスコアを返していますが,これはのちに利用します.(今回の学習において,エージェントが獲得する「報酬」としてはゲーム内のスコアをそのまま採用しました).アクションは0~3の整数で表現し,それぞれ 左,上,右,下,と対応づけました.board変化の実装は無駄に長いインデックスこねこねで,おそらく可読性が低いです.真面目に読まなくても全然OKです.もっと綺麗に書けるのかもですがここは許してください(´×ω×`)また最後のwhileループでは,1枚新たなタイルを生成しています.ここもアルゴリズム的には効率の悪い実装かもですが無理やり殴りました.反省してます.「2」または「4」のタイルが生成されるわけですが,筆者による軽い統計の結果「80%の確率で2が湧く」くらいだったのでそのように実装しました.実際には少しずれているかもですが今回はこれでいきます.
なお
moveメソッドは,「選択可能な」アクションが入力されることを前提にしています.(盤面が動かない方向はプレイ中選べないので.)これについては次の関数で.3-2. 選択可能なアクションの判定
上の
moveメソッドへの入力時など,各盤面で,各アクションが「選択可能か」というのが知りたい場面が今後たくさん出てきます.そこで判定用関数としてis_invalid_actionを用意しました.盤面とアクションを与え,それが選べないアクションだった場合にTrueを返すので注意してください.またこのコードは
moveメソッドと非常に似ており無駄に長いだけなので,下の三角マークに折りたたんであります.中身コピペしたらすぐ閉じちゃってください.ダサいので.
is_invalid_action
2048.pydef is_invalid_action(state, a): spare = copy.deepcopy(state) if a==0: for y in range(4): z_cnt = 0 prev = -1 for x in range(4): if spare[y][x]==0: z_cnt += 1 elif spare[y][x]!=prev: tmp = spare[y][x] spare[y][x] = 0 spare[y][x-z_cnt] = tmp prev = tmp else: z_cnt += 1 spare[y][x-z_cnt] *= 2 spare[y][x] = 0 prev = -1 elif a==1: for x in range(4): z_cnt = 0 prev = -1 for y in range(4): if spare[y][x]==0: z_cnt += 1 elif spare[y][x]!=prev: tmp = spare[y][x] spare[y][x] = 0 spare[y-z_cnt][x] = tmp prev = tmp else: z_cnt += 1 spare[y-z_cnt][x] *= 2 spare[y][x] = 0 prev = -1 elif a==2: for y in range(4): z_cnt = 0 prev = -1 for x in range(4): if spare[y][3-x]==0: z_cnt += 1 elif spare[y][3-x]!=prev: tmp = spare[y][3-x] spare[y][3-x] = 0 spare[y][3-x+z_cnt] = tmp prev = tmp else: z_cnt += 1 spare[y][3-x+z_cnt] *= 2 spare[y][3-x] = 0 prev = -1 elif a==3: for x in range(4): z_cnt = 0 prev = -1 for y in range(4): if spare[3-y][x]==0: z_cnt += 1 elif spare[3-y][x]!=prev: tmp = state[3-y][x] spare[3-y][x] = 0 spare[3-y+z_cnt][x] = tmp prev = tmp else: z_cnt += 1 spare[3-y+z_cnt][x] *= 2 spare[3-y][x] = 0 prev = -1 if state==spare: return True else: return False
3-3. 盤面の可視化
盤面見せる機能がなくてもAIくんは問題なく学習できますが,我々人間が寂しいので作りました.ただまあ本題はここではないので,という言い訳で相当手抜いてます.
2048.pydef show_board(game): fig = plt.figure(figsize=(4,4)) subplot = fig.add_subplot(1,1,1) board = game.board score = game.score result = np.zeros([4,4]) for x in range(4): for y in range(4): result[y][x] = board[y][x] sns.heatmap(result, square=True, cbar=False, annot=True, linewidth=2, xticklabels=False, yticklabels=False, vmax=512, vmin=0, fmt='.5g', cmap='prism_r', ax=subplot).set_title('2048 game!') plt.show() print('score: {0:.0f}'.format(score))ヒートマップを用いて最低限の機能だけ再現しました(本当に最低限です).ここに関しては詳細を読む必要はなく,脳死コピペでいいと思います.実際どんなふうに見えるかは次で示します.
補足 ヒートマップにまつわる葛藤
本当にしょうもない話なのですが,2048ゲームを実装するにあたり,「数字を2の累乗ではなく単に1,2,3...と使う」という案がありました.理由としてはただ一点で,この可視化関数でそっちの方が綺麗に盤面が彩色されるからです.ただそれだとやはりゲームとして2048感が無いというのと,盤面の学習がうまく行えなさそう,という直感が働いたのとで結局こうなりました.そのせいで結局,見ればわかりますが小さい数字たちは非常に近い色合いで見づらくなってしまっています.対数軸で色が変わるヒートマップとか,ないんですか...?
3-4. プレイしてみる
学習させたいだけならこの工程は完全に不要ですが,せっかくなのでpython版2048ゲームをプレイしてみよう,ということでこんな関数を書いてみました.これも相当手抜いてますし,真面目に読む必要なしです.頑張ればいくらでも快適なUIにできるでしょうが,本題ではないので置いときます.
2048.pydef human_play(): game = Game() show_board(game) while True: a = int(input()) if(is_invalid_action(game.board.tolist(),a)): print('cannot move!') continue r = game.move(a) clear_output(wait=True) show_board(game)これで
human_play()と実行してしまえばゲーム開始です.0〜3までの数字を入力して盤面を動かしてください.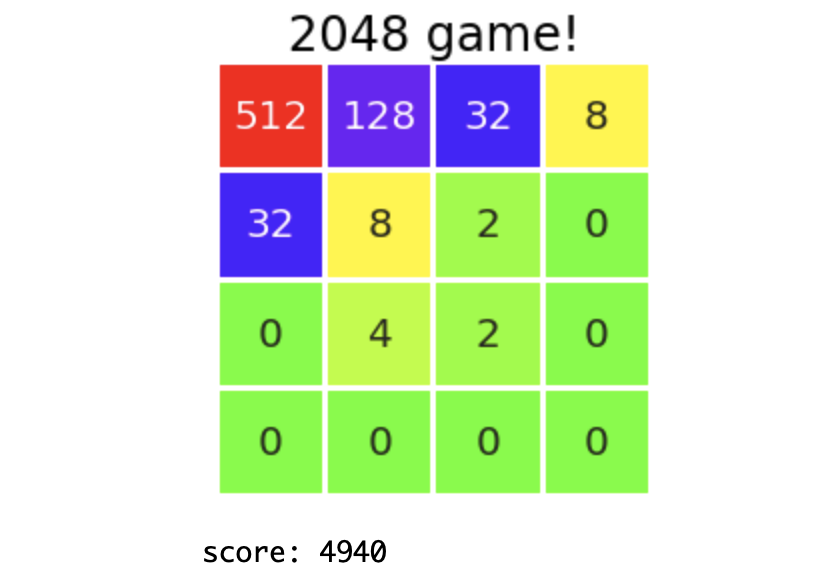
こんな感じで盤面が現れて遊べます.やっぱり盤面見にくいですね.ちなみにこのコードだと,誤って数字以外の入力をしてしまった瞬間バグって問答無用でゲームオーバーです.UIなんて知りません.またこれはゲーム終了判定をつけていないので,動かせなくなったら先の仕様を逆手にとって,変な入力をしてゲームから抜け出しましょう.UIなんて知りません.
このタイミングで,コンピューターにもこのゲームをプレイさせてみましょう.
2048.pydef random_play(random_scores): game = Game() show_board(game) gameover = False while(not gameover): a_map = [0,1,2,3] is_invalid = True while(is_invalid): a = np.random.choice(a_map) if(is_invalid_action(game.board.tolist(),a)): a_map.remove(a) if(len(a_map)==0): gameover = True is_invalid = False else: r = game.move(a) is_invalid = False time.sleep(1) clear_output(wait=True) show_board(game) random_scores.append(game.score)コンピューターにプレイさせると言いましたが,完全ランダムで手を選んだ場合の様子を眺めることができる,という関数です.引数として適当な配列をとります(伏線).眺める分にはこの引数はどうでもいいので,
random_play([])のように適当に実行してみましょう.アニメーションのようにゲームが進みます.眺めているとわかりますが,この段階では意志を持ってプレイしている感が全くありません(ランダムなので当然).そこでこの時点での実力(平均スコアなど)を把握しておきましょう.引数として配列をとっていたのはこれを行うためです.
random_play関数において,盤面の可視化に関わるコード(上から3行目と,下から2~4行目です)をコメントアウトしたのち,以下のコードを実行してみましょう.2048.pyrandom_scores = [] for i in range(1000): random_play(random_scores) print(np.array(random_scores).mean()) print(np.array(random_scores).max()) print(np.array(random_scores).min())1000回テストプレイを行い,その平均点,最高点,最低点を調べてみました.意外とすぐに実行は終わります.実行ごとに結果は多少変わりますが,筆者の手元では
- 平均点:1004.676点
- 最高点:2832点
- 最低点:80点
という結果が出ました.これが何も学習していないAIの実力と言ってもいいでしょう.ということは,平均で1000点を優に上回るようになれば,多少なりとも学習はできていると言ってよいでしょう.また,1000回プレイの最高点がこの程度なので,スコア3000点越えというのは,運だけで到達することは難しい領域だと考えてよいかと思います.この辺りを基準にして,のちの学習結果を考察していきましょう.
3-5. ニューラルネットワークの作成
ここでは,行動-状態価値関数の値を計算する,さらには収集したデータを受けて学習を行う張本人である,ニューラルネットワークを実装します.とはいっても,この面倒なところはすべてTensorFlowに丸投げという形をとるので,ブラックボックスはブラックボックスと捉えていただいても結構です.とりあえずコードをベタ張りします.
2048.pyclass QValue: def __init__(self): self.model = self.build_model() def build_model(self): cnn_input = layers.Input(shape=(4,4,1)) cnn = layers.Conv2D(8, (3,3), padding='same', use_bias=True, activation='relu')(cnn_input) cnn_flatten = layers.Flatten()(cnn) action_input = layers.Input(shape=(4,)) combined = layers.concatenate([cnn_flatten, action_input]) hidden1 = layers.Dense(2048, activation='relu')(combined) hidden2 = layers.Dense(1024, activation='relu')(hidden1) q_value = layers.Dense(1)(hidden2) model = models.Model(inputs=[cnn_input, action_input], outputs=q_value) model.compile(loss='mse') return model def get_action(self, state): states = [] actions = [] for a in range(4): states.append(np.array(state)) action_onehot = np.zeros(4) action_onehot[a] = 1 actions.append(action_onehot) q_values = self.model.predict([np.array(states), np.array(actions)]) times = 0 first_a= np.argmax(q_values) while(True): optimal_action = np.argmax(q_values) if(is_invalid_action(state, optimal_action)): q_values[optimal_action][0] = -10**10 times += 1 else: break if times==4: return first_a, 0, True #gameover return optimal_action, q_values[optimal_action][0], False #not gameover
QValueクラスという形で実装しています.このインスタンスが学習対象そのもの(正確にはそのメンバ変数modelですが)になります.そして前半のbuild_modelメソッドが,インスタンス生成時に実行され,ニューラルネットワークを作成する関数です.
build_modelメソッドの概要を述べますが,それぞれの「NN語」についての詳しい解説はしません.ほーん,ぐらいでいいかと思います.知識のある方はべたべた読む価値はあると思います.(同時に改善の余地がボロボロ見えるかもしれません.ご教授ください...)理論編でちょろっと話した,畳み込みニューラルネットワーク(CNN)を用います.盤面の2次元的な広がりを捉えることを期待したためです.入力としては,盤面にあたる4x4の配列と,アクションの選択にあたる長さ4の配列をとります.アクション選択は0~3の入力ではなく,4箇所のうち1つが1,残りが0の配列で表現するというOne-hotエンコーディングで行います.畳み込みには8種類の3x3フィルターを用います.パディングやバイアス,活性化関数についても指定します.
隠れ層として,ニューロン数が2048のもの,1024のものを1層ずつ用意し,最後に出力層を定義しました.隠れ層の活性化関数はReLUを用います.また,パラメータのチューニングに用いる誤差関数として,最小二乗誤差を採用しています.NNについての説明はここで切り上げます.全くわからなかったという方も,中身は知らんけど要はNNを定義した,とだけ思ってくれればOKです.
もうひとつ,
get_actionというメソッドがあります.これは「ニューラルネットワークで行動-状態価値関数の値を計算する」というステップにあたります.盤面の状態stateを引数にとり,4種類のアクションのOne-hot表現を用意して,NNに4つの入力をぶち込みます.このぶち込みは,tensorflowにもともと用意されているpredictメソッドで行えます.NNの出力としては,stateにおける4種類のアクションに対する行動-状態価値関数の値が返ってきます.このうち値が最大となるアクションをnp.argmax関数で取得する,というのがこのメソッドの大体の役割です.
後半ごちゃごちゃやってますが,これは行動-状態価値関数の値から選択されたアクションが,その盤面で選択可能か(動かすことができるか)を調べています.もし無理なら,次に行動-状態価値関数の値を大きくするアクションを選び直します.このついでに,このメソッドはゲームオーバーの判定も行っています.get_actionメソッドの返り値は3つありますが,順に「選択されたアクション,その盤面・アクションに対する行動-状態価値関数の値,盤面がゲームオーバーか否か」としています.3-6. 学習に基づきゲームをプレイする
先ほどは完全ランダムにプレイさせてみましたが,今回は学習結果を組み込んでプレイさせます.以下の
get_episode関数で,1ゲーム分のプレイが行われます.(強化学習では,1回のゲームのことをエピソードとよく呼びます.)2048.pydef get_episode(game, q_value, epsilon): episode = [] game.restart() while(True): state = game.board.tolist() if np.random.random() < epsilon: a = np.random.randint(4) gameover = False if(is_invalid_action(state, a)): continue else: a, _, gameover = q_value.get_action(state) if gameover: state_new = None r = 0 else: r = game.move(a) state_new = game.board.tolist() episode.append((state, a, r, state_new)) if gameover: break return episode
episodeという配列を用意して1ゲームプレイし,「現状態,選択したアクション,その際に得られた報酬,遷移した先の状態」を1セットにして,配列にどんどん格納していく,というのが基本動作です.ここで収集したデータを用いて,のちに学習処理を行います.アクションの選択には,先ほど定義したq_value.get_actionメソッドを使います.これにより,その場で(かつ現状の実力で)最善と思われる手が選ばれます.また,このメソッドで行っていたゲームオーバー判定を生かし,エピソードの終了を感知しています.1点注意すべきなのは,「毎ターン学習結果に従うとは限らない」ということです.
get_episode関数は引数にepsilonなるものをとっていますが,これは「プレイ中,学習結果に従わずにランダムでアクションを選択する確率」です.ランダムなアクション選択を混ぜることで,より多様な盤面を学習でき,より賢いAIになれると期待できます.このように,「基本はGreedyポリシーでアクションを選択するが,確率 $\epsilon$ でランダムな行動を混ぜる」という行動ポリシーを,ε-Greedyポリシーと呼びます.εの値をどの程度に設定するかは,重要かつ難しい問題です.(通常0.1〜0.2程度とするらしいです.)
またこの関数は,
epsilon=0と設定することで,Greedyポリシーでプレイさせることができます.つまりはランダムなアクションを含まない,その時点での「AIの全力」のプレイです.AIくんの実力を測るための関数show_sampleを以下に示します.2048.pydef show_sample(game, q_value): epi = get_episode(game, q_value, epsilon=0) n = len(epi) game = Game() game.board = epi[0][0] # show_board(game) for i in range(1,n): game.board = epi[i][0] game.score += epi[i-1][2] # time.sleep(0.2) # clear_output(wait=True) # show_board(game) return game.scoreといっても,基本は
get_episode関数をepsilon=0のもと実行するだけで,それ以降はエピソードの記録を用いての盤面の再現です.将棋でいう棋譜を辿るようなものですね.関数内にコメントアウトされた部分がありますが,これを解除すると,アニメーションで眺めることができます.(random_play関数でもそうですが,time.sleepに与える数値を調整することで,アニメーションの速さを制御できます.)
また返り値として最終的なスコアを出力しています.これを用いて,学習処理のはざまにshow_sampleを挟むことで学習の成果をおおむね把握することができます.それではいよいよ学習のアルゴリズムを実装しましょう!
3-7. 学習処理
NNに学習をさせる関数
trainを定義します.少し長めですが,そんなに難しいことはしていないので落ち着いて読んでみてください.少し丁寧めに解説もいたします.2048.pydef train(game, q_value, num, experience, scores): for c in range(num): print() print('Iteration {}'.format(c+1)) print('Collecting data', end='') for n in range(20): print('.', end='') if n%10==0: epsilon = 0 else: epsilon = 0.1 episode = get_episode(game, q_value, epsilon) experience += episode if len(experience) > 50000: experience = experience[-50000:] if len(experience) < 5000: continue print() print('Training the model...') examples = experience[-1000:] + random.sample(experience[:-1000], 2000) np.random.shuffle(examples) states, actions, labels = [], [], [] for state, a, r, state_new in examples: states.append(np.array(state)) action_onehot = np.zeros(4) action_onehot[a] = 1 actions.append(action_onehot) if not state_new: q_new = 0 else: _1, q_new, _2 = q_value.get_action(state_new) labels.append(np.array(r+q_new)) q_value.model.fit([np.array(states), np.array(actions)], np.array(labels), batch_size=250, epochs=100, verbose=0) score = show_sample(game, q_value) scores.append(score) print('score: {:.0f}'.format(score))引数が5つあり,順に「Gameクラスのインスタンス
game,学習対象のモデル(QValueインスタンス)q_value,学習を行う回数num,収集したデータを入れておく配列experience,学習成果(スコア)を入れていく配列scores」です.詳細は追い追い.
numの分だけループを回しています.ここで「1回の学習」というのは,1ゲームプレイとは全く違います.1回の学習の流れを説明します.学習は,データの収集とNNの更新という2ステップに分かれています.データ収集パートでは,
get_episode関数を20回起動しています(要は20回ゲームをプレイする).基本はε=0.1のε-Greedyポリシーでデータを収集しますが,20回中2回だけ,ランダムな行動を混ぜないGreedyポリシー(ε=0)でプレイし,データを集めます.このように2種類のプレイを混ぜることで,幅広い盤面を学び,かつ長めにゲームが進んだときの盤面も学習に組み込みやすくなるそうです.収集したデータはすべて
experienceに入れられます.この配列の長さが50000を超えた場合,古いデータから削除していきます.またデータが5000個集まるまでは,次のモデル更新ステップはスキップしています.モデル更新は,
experienceからデータを抽出し,新たにexample配列を作成して行います.その際直近のデータから1000個,残りの部分からランダムに2000個選び出し,シャッフルするという操作を施しています.こうすることで新しいデータを学習に組み込みつつ,かつ学習結果に偏りが出にくくなるようです.次のfor文では,
exampleの中身をひとつずつ見ていきます.NNの学習は,データひとつひとつを受けて行うよりも,まとめて入力した方が演算速度的な面で効率が良いので,その準備をしていきます.states,actions,labelsにそれぞれ現状態の盤面,選択するアクションのOne-hot表現,そのときの行動-状態価値関数の「正解」の値,を入れていきます.正解の値についてですが,これは理論編
2-2-3. TD法あたりで説明したように,$r+q_{\pi}(s',\pi(s'))$ と設定することで,NNの出力がここに近づくように修正されます.これはコード上ではr+q_newに相当します.q_newというのは「遷移先の状態からずっと現状のポリシーに従って行動した場合に得られる報酬の期待値」であり,これはq_value.get_actionメソッドに次状態を与えたときの2つめの出力(次状態とそこでの最善手に対する行動-状態価値関数の値)に相当しますので,そのように取得します.なお,ゲームオーバー状態に対しては,q_newは0と定めています.次の
q_value.model.fitメソッドで,NNが学習を行います.この中身については別でオベンキョしてください.引数としてはNNの入力statesとactions,正解の値としてlabelsを与えています.batch_sizeやepochsは気にしなくてもよいですが,これらの値の設定は学習の精度に影響します(これが適切な設定である自信は全くないです).verbose=0は,不要なログ出力を抑えているだけです.
fitメソッドによる学習処理が終わったら,show_sample関数を起動して,AIくんに全力でプレイしてもらいます.その最終スコアをログとして出力しつつ,scores配列に格納して,あとで平均点などを計算するのに使おう,という実装にしています.以上が「1回の学習」の全貌です.これを繰り返すのがtrain関数です.
補足
batch_sizeとepochsについて
これらは気にしなくていいと述べましたが,概要だけでも知っておく価値はあると思うので軽く整理します.
NNの学習では,入力データを一気に学習するのではなく,ミニバッチという小さなかたまりに分割してから,各バッチについて学習を行います.このバッチの大きさがbatch_sizeです.上のコードでは入力のサイズが3000,batch_sizeが250なので,12個のミニバッチに分割されます.
そして,入力データすべてについて1度学習処理を施すことを,エポックという単位で数えます.上のコードでは入力3000個,バッチにして12個分の学習で1エポックとなります.パラメータepochsは,学習処理を何エポック繰り返すかを意味しています.ここではepochs=100としたので,バッチ分割→すべてについて学習 の流れを100回繰り返すことになります.
雑なまとめになりますが,ニューラルネットワークって難しいですね\(^^)/
4. 学習実行&観察
以上でモデル・関数の実装はほぼ終了です.あとは実際に学習させて,成長の様子を眺めてみましょう!記事も気楽に書きます...
注意 ここで示す学習結果について
あたかも自分が実行したコードおよびその結果をそのまま記事に載せているかのような口ぶりですが,実際は色々いじりながら・修正しながら学習を進めたため,学習過程が一部異なります.(具体的には,はじめの30回ほどはε=0.2でデータ収集をしていたり,昔はget_actionメソッドの仕様が少し違っていたり,です.途中でデータが吹っ飛んだりもしてます).その点だけご了承ください.
また,この直後に示す10回分の学習の出力は後からコードを実行し直して補ったもの(当時の出力が吹っ飛んでました)で,今後べたべた考察していくモデルの学習記録とは異なります.あんまりじーっと見ないでください><
4-1. trainしてみる
まずは
GameクラスとQValueクラスのインスタンス,およびその他を生成します.2048.pygame1 = Game() q_value1 = QValue() exp1 = [] scores1 = []1というナンバリングには特に意味はありません.なんとなくです.これだけで,もう学習の準備は完了です.
train関数を起動させてみましょう.2048.py%%time train(game1, q_value1, 10, exp1, scores1)これだけです.これで10回分の学習が行われます.1行目の
%%timeはマジックコマンド的なもので,実行にかかった時間を計測してくれます.何故そんなことをするかというと,学習には非常に時間がかかるからです.この10回だけで平気で30分くらいかかります.ただtrain関数は,進捗状況を随時出力するような実装にしているため,先の見えない暗闇を進むよりは気が楽です.のんびり待ちながら,出力を眺めてみましょう.Iteration 1 Collecting data.................... Iteration 2 Collecting data.................... Iteration 3 Collecting data.................... Training the model... score: 716 Iteration 4 Collecting data.................... Training the model... score: 908 Iteration 5 Collecting data.................... Training the model... score: 596 ...
Iteration 3のように,現在何回目のループかがすぐにわかります.Collecting data...と表示されている間はデータ収集パート,Training the model...の間はモデル更新パートです.はじめの2回はexp1の長さが5000に達しておらず,モデル更新がスキップされています.1回の学習が終わるごとに,ランダムなアクションなしで1ゲームプレイし,そのスコアが表示されています.この結果は
scores1に格納されていくので,あとから統計をとるなりできます.あとはこれをひたすら繰り返すだけです.追加で90回学習を行うには以下のコードを実行しましょう.
2048.py%%time train(game1, q_value1, 90, exp1, scores1)
exp1やscores1は再利用され,完全に前回の続きから学習が進められます.やってみればわかりますが,この学習には本当に時間がかかります.筆者の環境では,100回につき5~6時間が目安といった感じでしょうか.ここ最近は筆者が寝ている間にも,Macくんは夜通し唸ってました.もし興味のある方は,地道に時間を見つけて演算を進めていくと同じ体験ができるかと思います.
100回の学習が終わったとして,その最中での「全力スコア」の変化を雑にプロットしてみます.
scores1を使います.2048.pyx = np.arange(len(scores1)) plt.plot(x, scores1) plt.show()
んー.これはちょっと学習ができているとは言い難いですね.平均点は974.45点でした.全然伸びてない.もう少し学習が必要そうです.
4-2. 学習結果を一時保存する
この学習は長旅になりそうなので,保存方法だけ確立させておきましょう.pythonのpickleという機能で,
exp1やscores1を保存できます.tensorflowのモデルにはpickleが使えませんが,save機能がもともと用意されています.以下にコードを示すので,わかりやすい名前で保存してください.2048.pywfile = open('filename1.pickle', 'wb') pickle.dump(exp1, wfile) pickle.dump(scores1, wfile) wfile.close() q_value1.model.save('q_backup.h5')保存しておいたオブジェクトを取り出すには以下のようにします.
2048.pymyfile = open('filename1.pickle', 'rb') exp1_r = pickle.load(myfile) scores1_r = pickle.load(myfile) q_value1_r = QValue() q_value1_r.model = load_model('q_backup.h5')名前の後ろにつけたrはrestoreの頭文字のつもりです.
q_value1の方は,QValueインスタンスではなくその中のmodelを保存しているので,インスタンスだけ生成したのち,modelをロードして置き換えます.なお,Gameクラスのインスタンスは特に学習しているわけではないので,必要なときに新しく作成しても問題ありません.こんな感じで学習の記録をこまめに残しておくことを勧めます.途中でデータが飛んだときの対策になるのはもちろん,学習途中のモデルをあとから引っ張ってきて性能を比較することも可能になります.(筆者はこれを怠ったので後悔しています.)
4-3. trainを繰り返す
100回学習したモデルはまだまだ未熟者,という感じでしたので,ひたすら
train関数を回しました.結論から言うと1500回分学習してもらいました.ノンストップでも丸4日くらいかかるので,マネしたい場合は覚悟してください...とりあえず1500回分の
scoresを軽く分析してみました.scoresを学習100回ずつで,得点帯を1000点ずつで区切り,各得点帯のスコアが出たかを表にしました.平均点も算出したので並べます.言葉でダラダラ説明するのもアレなので,もうベタッと表を貼ります.(参考までに,いつぞやの完全ランダム1000回プレイの得点分布も載せます.)
学習回数 0000~ 1000~ 2000~ 3000~ 4000~ 5000~ average ランダム 529 415 56 0 0 0 1004.68 1~100 61 30 6 1 0 0 974.45 101~200 44 40 9 6 1 0 1330.84 201~300 33 52 12 1 0 0 1234.00 301~400 35 38 18 7 2 0 1538.40 401~500 27 52 18 3 0 0 1467.12 501~600 49 35 11 4 1 0 1247.36 601~700 23 50 20 5 2 0 1583.36 701~800 45 42 11 2 0 0 1200.36 801~900 38 42 16 4 0 0 1396.08 901~1000 19 35 40 4 0 2 1876.84 1001~1100 21 49 26 3 1 0 1626.48 1101~1200 22 47 18 13 0 0 1726.12 1201~1300 18 55 23 4 0 0 1548.48 1301~1400 25 51 21 2 1 0 1539.04 1401~1500 33 59 7 1 0 0 1249.40 ふむ.どうでしょうか.学習が進むにつれてじわじわと平均点が伸びています.ランダム1000回プレイでは1回も到達できなかった3000点というひとつのラインも,少し学習を進めたあとはそこそこ出るようになっています.とりあえず,「学習の爪痕は残せている」と言うことはできるでしょう.
また,学習後のAIくんのプレイを眺めていると,以前とは違い何らかの意志を感じました(まあ人間が勝手に規則性を見出しているだけですが).瞬間盤面だけだとわかりにくいかもですが,そのシーンを切り取ってきたのでご紹介します.
荒削りな部分は多いですが,右下隅に大きい数を集める,という方針が見られました.これは,
1-2. このゲームのコツで私が紹介した方法と同じです.別にこちらから「角にでかい数字を集めるように学べ」的な実装をしたわけではないのに,このコツが学習できてきているのは興味深いですね.個人的にはかなり感動しました.ただそれでも,4000点以上はなかなか出せていないというのが現実です.1500回で学習を止めたのは,単に時間の問題と,ご覧の通りスコアの伸びが止まったように感じたからです.実際のところはわかりませんが,このまま同じ学習アルゴリズムを適用し続けても,明確に性能が上がることはあまり期待できないと感じました.
後半スコアが伸びなかったどころか落ち込み気味なのは,たまたま運が悪かったことも考えられますが,なんとなく普通に性能が落ちているような気がしました.もう少しきちんと述べると,学習に使うデータ
experienceの中身の質が落ちた(先へ進んだ盤面があまり学習できない悪循環に陥った)のではないかと勝手に推測しています.とにかく,1500回学習後のモデルが現状最強だとは言えないと考えます.上の表をじーっと見て,暫定の最強AIとして「1200回学習を終えた時点でのモデル」を選びました.まあ割と五十歩百歩ではあるんですが.冷凍保存しといてよかった.なぜ最強を選んだのかというと,次で「学習済みモデルはそのままに,より良い手を選びそうなアルゴリズム」を実装するからです.
というわけでこのときのモデルくんをロードしておきます.この子にはもう少し頑張ってもらいましょう.
2048.pygame1200 = Game() q_value1200 = QValue() q_value1200.model = load_model('forth_q_value1_1200.h5')※私がこの名前でモデルを保存してただけなので,このコードをベタ貼りされても普通に無理です.この先は,現状ご自分の環境で学習を進めてモデルを作成して頂かないと再現は無理なのが現状です.ごめんなさい.学習済みモデルをどこかで共有するの面倒なんだけど需要あるかな...
4-4. 1手先を読む
この先は学習を行うわけではありません.NNのモデルはそのままに,より上手くゲームをプレイできそうな行動ポリシーを作ります.(コードもう終わりとか言ってごめんなさい.まだあります.)
今までは与えられた状態に対し,「全アクションについて行動-状態価値関数の値を計算し,それが最大となるアクションを選ぶ」という行動ポリシーでした.
get_actionメソッドで行われていた処理がこれにあたります.これを改良して,「次状態のさらに1手先を読み,最善と思われる手を選ぶ」というアルゴリズムを実装します.まずはコードを貼ります.2048.pydef get_action_with_search(game, q_value): update_q_values = [] for a in range(4): board_backup = copy.deepcopy(game.board) score_backup = game.score state = game.board.tolist() if(is_invalid_action(state, a)): update_q_values.append(-10**10) else: r = game.move(a) state_new = game.board.tolist() _1, q_new, _2 = q_value.get_action(state_new) update_q_values.append(r+q_new) game.board = board_backup game.score = score_backup optimal_action = np.argmax(update_q_values) if update_q_values[optimal_action]==-10**10: gameover = True else: gameover = False return optimal_action, gameover従来の
get_actionメソッドに代わる関数,get_action_with_searchです.4つのアクションについてforループを回します.現状態から,まず1回アクションaを選択して次状態へ遷移します.この際の報酬rを保持しておき,次状態からさらに次の一手を考えます.これがq_value.get_action(state_new)にあたります.このメソッドは2つ目の出力として最善のアクションに対する行動-状態価値関数の値を返すので,それをq_newとして受け取ります.ここでr+q_newは,「現状態からアクションaを選択して得られる報酬と,その遷移先からの行動-状態価値関数の値の最大値の和」となります.4種類のアクションaについてこの値を求め,これが最大化するようなアクションを選ぶ,というのがこの関数の仕組みです.(ゲームオーバー判定も同時に行っています.)このポリシーは比喩とかではなく1手先を読んでいるため,従来のアクション選択に比べ,最善手を選ぶ精度がより上がっていると期待できます.他の関数にも,
get_action_with_searchを組み込みましょう.
get_episode2
2048.pydef get_episode2(game, q_value, epsilon): episode = [] game.restart() while(True): state = game.board.tolist() if np.random.random() < epsilon: a = np.random.randint(4) gameover = False if(is_invalid_action(state, a)): continue else: # a, _, gameover = q_value.get_action(state) a, gameover = get_action_with_search(game, q_value) if gameover: state_new = None r = 0 else: r = game.move(a) state_new = game.board.tolist() episode.append((state, a, r, state_new)) if gameover: break return episode
show_sample2
2048.pydef show_sample2(game, q_value): epi = get_episode2(game, q_value, epsilon=0) n = len(epi) game = Game() game.board = epi[0][0] # show_board(game) for i in range(1,n): game.board = epi[i][0] game.score += epi[i-1][2] # time.sleep(0.2) # clear_output(wait=True) # show_board(game) show_board(game) print("score: {}".format(game.score)) return game.score
↑とは言ったものの,本当にアクション選択の関数をすり替えただけで他は全く同じですので折りたたんでおきます.中身見て理解したらすぐ閉じちゃってください.
これで本当に足掻きは終わりです最後に成果を確認して終わります!
4-5. 最終結果
ちょっと前に暫定最強として認定した
q_value1200くんを持ってきます.この子に100回全力プレイしてもらい,4-3. trainを繰り返すで行ったような分析をしました(あとで載せます).2048.pyscores1200 = [] for i in range(100): scores1200.append(show_sample(game1200, q_value1200))さらに同じモデルを使い,1手先読みアルゴリズムを用いて同じく100回プレイしてもらいました.
2048.pyscores1200_2 = [] for i in range(100): scores1200_2.append(show_sample2(game1200, q_value1200))結果を整理します.
モデル 0000~ 1000~ 2000~ 3000~ 4000~ 5000~ 6000~ average 通常 15 63 17 5 0 0 0 1620.24 1手先読み 5 41 32 11 6 2 3 2388.40 はい.従来のアルゴリズムの方はまあ以前見たモデルたちと同等の性能ですが,1手先読みを導入した方はこれは明らかに性能が上がっています.嬉しい.特に6000点越えが3回と,流れがよければ高得点を狙えるポテンシャルがあるのがなんかいいですね.100回中最高点は6744点でした.そのときの最終盤面を載せます.
最後なので乱れちゃってはいますが,割と私たち人間がやってもわんちゃん負ける,そのレベルでのプレイができてそうです.遠い昔に設定した「自分より高スコアをとる」という目標には到底届いていませんが,ひとまずこのあたりで改良は打ち止めようと思います.夏休みももう終わりですし.(いやてか自分のハイスコア69544点って強すぎない...?)
5. おわりに
お疲れさまでした!(ここまで読んでくださった方がもしいればそれは本当にお疲れさまでした.ガチで).拙い上に長々と書き連ねてしまい申し訳ありませんでした.
振り返ってですが,やはりもう少し性能を上げたかったなというのが本音です.ハイスコアとしては悪くないですが,平均点的にはせいぜい人間の初見プレイ程度の知能しか得られていないので...
本当はここからの改善案についてももう少し考察しようと思っていたのですが,また長くなりすぎてしまいそうなのと,明日から急に授業が始まるピンチ(現在AM3:00)ということで,メモ書き程度にして未来の自分にパスしようかと思います.
- 単純にもう少し学習を重ねてみる.(ちょっと厳しい気がするけど...)
epsilonの値を変えてみる.(上げるか下げるかもわからん.ただ学習を進めるにつれεを小さく,とかは試してみる価値はあるかもしれない.)experienceの長さ,およびexampleの長さを大きく?してみる.(学習が進むほど1エピソードが長くなるし.現状のはあまり適切じゃないのかもしれない.)- CNNへの盤面の入力を,ひとつにまとめてではなくタイルごとに分けてみる.(これは結構見込みがあると思ってる.現状NNは「2」と「4」のタイルをあまり区別できてないんじゃないか?みたいな懸念.おそらく計算量は増えるけど,タイルごとに明確に意味が異なるのだから,分けて入力すべきな気もする.)
batch_sizeやepochsをいじる.(これは理解度不足だけど学習精度に影響するよね...という感じ.適切な値を探れる気がしない.)- 自分(筆者)がプレイしている様子を学習させてみる.(時間的な意味で相当めんどそうだけど成果は出そう.将棋とかもプロの棋譜を学習させてるって聞くし.うまく実装できるかな...)
- もっと先の手まで読んでプレイ.(まあいいんだけど,なんかなあ...感がやばい)
ざっとこんな感じでしょうか.せいぜい独学&勉強不足の私が思いつく程度の案ですので,もっとこうしてみたらいい,など教えて頂けるととても嬉しいです.(逆に私に代わってこれらの改善案を試してみるなども是非やってみてください.)
ここまで真面目にまとめてみると,1度理解したつもりの理論からホイホイ間違いやら新発見やらが出てきてとてもよかったです.またいつか弾丸で自由研究したら,こんな感じで記事にするかもしれないので新作をお待ちください.2048ゲームAIくんをもう少し追求するかもしれません.
それでは本当におしまいです.おもしろいな,と思った方は是非強化学習の世界にもっと深く踏み込んでみてください!
おしまい
夏休み終了に1日だけ間に合わなかった.許して.

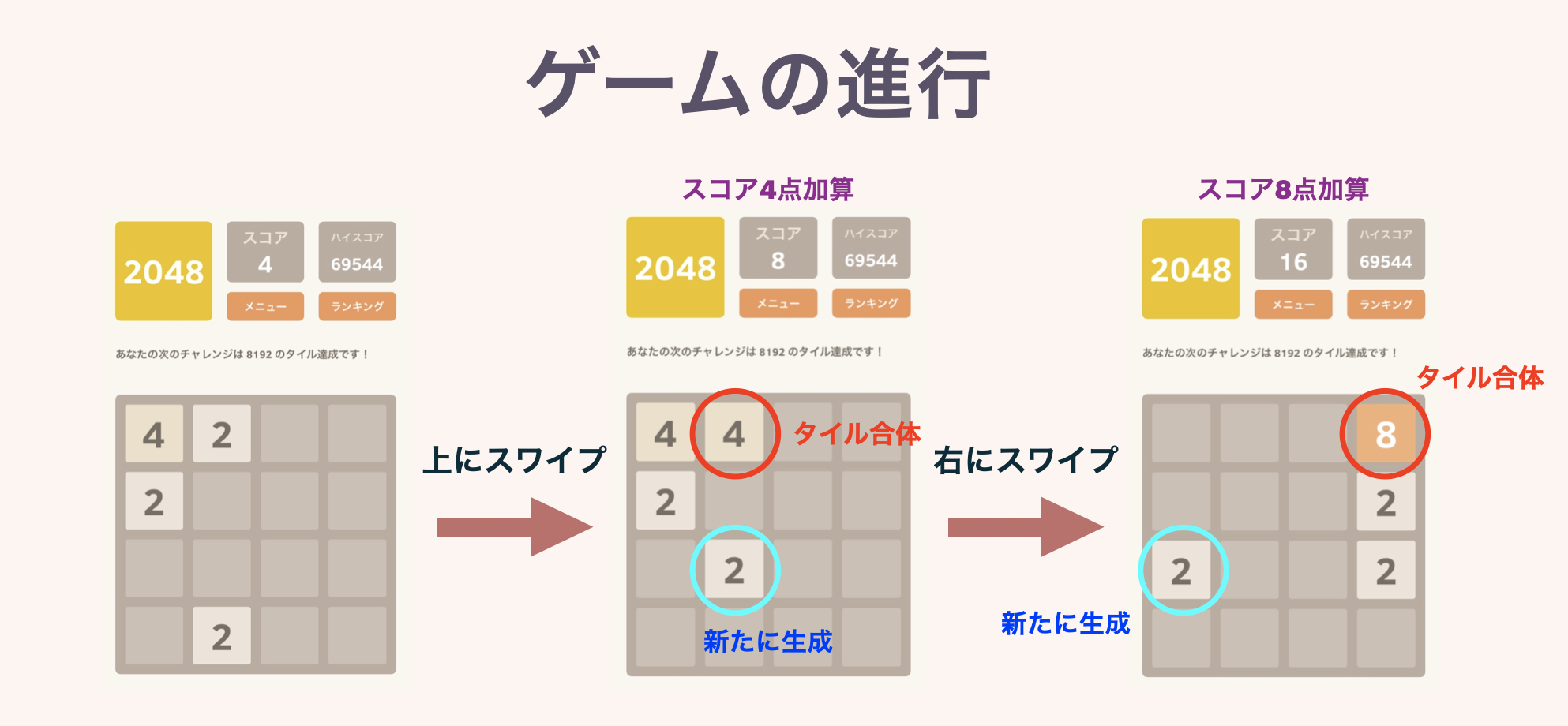
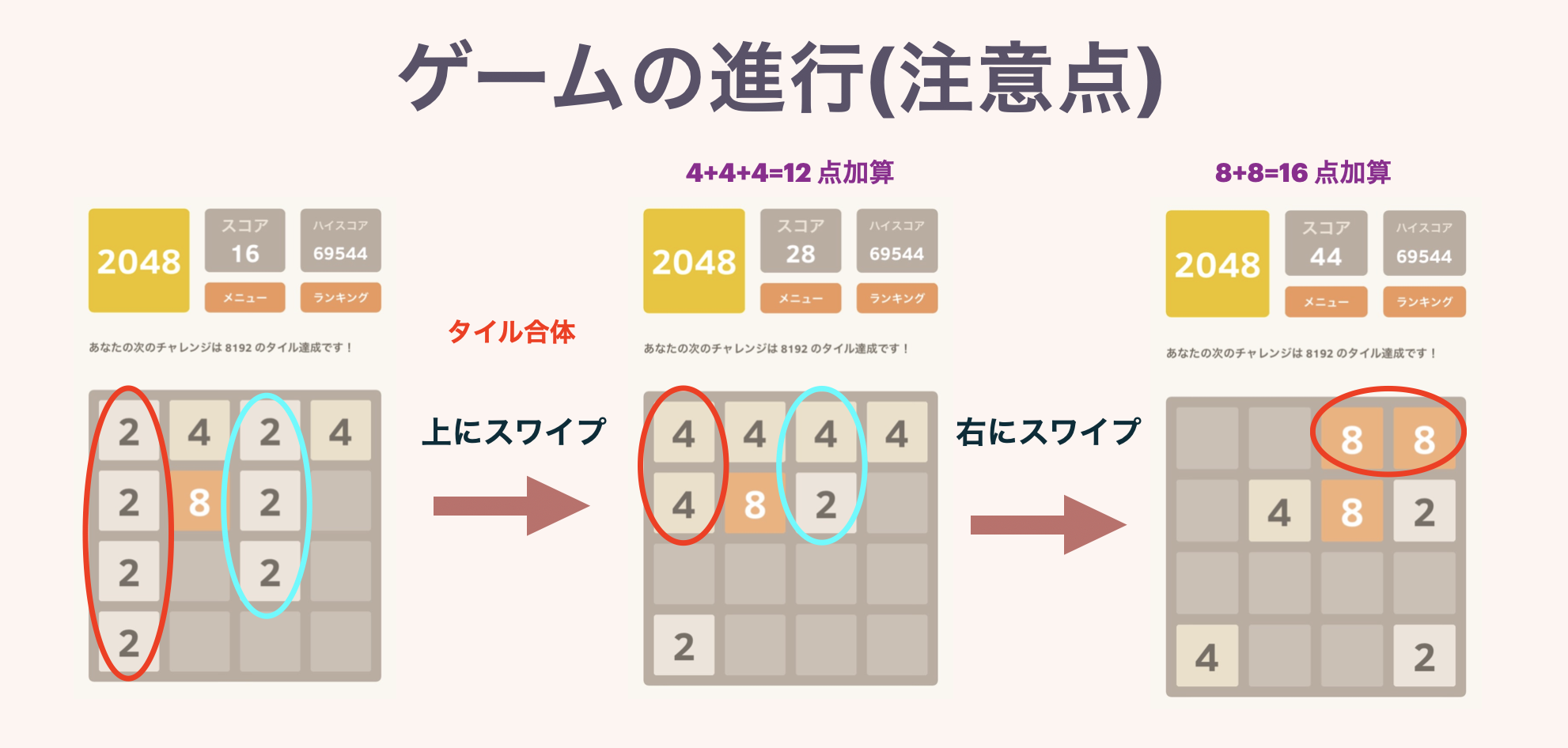

- 投稿日:2020-09-25T15:29:33+09:00
pythonプログラム起動時に「ValueError: Unable to configure handler 'file_output_handler'」
事象
コード自体は問題なさそうなのだが、なぜかエラーになる。
. .. ... LOG_CONFIG = { 'version': 1, ... .. . 'handlers': { 'console': { 'formatter': 'default', 'class': 'logging.StreamHandler', 'stream': 'ext://sys.stderr', }, 'output': { 'level': 'DEBUG', 'class': 'logging.handlers.TimedRotatingFileHandler', 'formatter': 'default', 'filename': '/path/to/application.log', 'when': 'MIDNIGHT', 'interval': 1, 'backupCount': 5, }, }, ... .. . } ... .. .. .. ... File "./main.py", line 7, in <module> load_log_config() File "./configs/log_config.py", line 41, in load_log_config dictConfig(LOG_CONFIG) File "/root/local/python-3.8.5/lib/python3.8/logging/config.py", line 808, in dictConfig dictConfigClass(config).configure() File "/root/local/python-3.8.5/lib/python3.8/logging/config.py", line 570, in configure raise ValueError('Unable to configure handler ' ValueError: Unable to configure handler 'file_output_handler'原因
filenameに指定したディレクトリが存在しない(または誤っている)のが原因
エラーメッセージがわかりづらくて少しハマった・・・. .. ... LOG_CONFIG = { 'version': 1, ... .. . 'handlers': { 'console': { 'formatter': 'default', 'class': 'logging.StreamHandler', 'stream': 'ext://sys.stderr', }, 'output': { 'level': 'DEBUG', 'class': 'logging.handlers.TimedRotatingFileHandler', 'formatter': 'default', 'filename': '/path/to/application.log', ← コレ 'when': 'MIDNIGHT', 'interval': 1, 'backupCount': 5, }, }, ... .. . } ... .. .
- 投稿日:2020-09-25T14:16:19+09:00
PyCharmでDocker上のPythonを使ってプロジェクトを作成しようとしたらダメだったけど、Docker Composeでうまくいった
やりたいこと
PyCharmでPythonプログラムを実行する際、ローカルPCにインストールしたPythonではなく、Docker内のコンテナで実行したい。具体的には、FlaskによるWebアプリをPyCharmからDockerで実行したい。
環境はこちら。
- macOS Catalina 10.15.6
- PyCharm 2020.2.2 Professional Edition
- Docker for Mac 2.3.0.5
この機能は、PyCharm Community Editionでは利用できません。
3行で書くと
- PyCharmから[New Project]で新規プロジェクトを作成するとうまくできません
- フォルダやファイルを作成してから、PyCharmで[Open]しましょう
- DockerではなくDocker Composeを使いましょう
うまく行かなかった方法
まずPyCharmに設定してみた
PyCharmを起動して[Configure]-[Preference]
[Python Interpreter]を選択して、画面右端にある歯車アイコンをクリック→[Add...]
[Docker]を選択→[Server]の[New]をクリック
[Docker for Mac]を選択→画面下部に[Connection Successful]と表示されていることを確認してから[OK]
[Image name]に
python:3.8、[Python interpreter path]にpythonと入力→[OK]
[Python interpreter]が下記のようになっていることを確認→[OK]
いざ新規プロジェクトを作成・・・できない。
[New Project]を選択
[Existing interpreter]を選択→[Interpreter]で作成したDocker内Pythonを選択
[Remote path not provided]と言われるので、適当なパスを入力。すると「This interpreter type does not support remote project creation」などと言われてしまう。[Create]が押せない。
原因を探る
とりあえずさっき出たエラーメッセージでググると、公式サポートページやYouTrack(JetBrainsのイシュートラッキングシステム)が出てくるので、見てみます。
まずはサポートページから見てみると、どうやら同じ現象のようです。
回答には「システム上のPythonでプロジェクトを作って、設定からDocker上のインタープリターを追加してや!」と書いてあります。
しかしこのページ、2017年10月のものがそのままになってますね・・・。
次にYouTrack。これも2017年ですね・・・。
この回答にも「Openでフォルダを開いてからインタープリターを設定したらできたよ!」と書いてあります。
うまく行った方法
JetBrainsサポートページやYouTrackに書いてあった、フォルダやファイルなどを作成してからそれをPyCharmで開く作戦にします。
参考にしたURL
JetBrains公式ブログを参考にしました。(「Flask PyCharm Docker」で検索したらヒットした)
Docker-Compose: Getting Flask up and running
フォルダやファイルなどの作成
flask-docker ├── Dockerfile ├── docker-compose.yml ├── main.py └── requirements.txtDockerfileFROM python:3.8-alpine3.12 RUN mkdir /app WORKDIR /app COPY main.py main.py COPY requirements.txt requirements.txt RUN pip install -r requirements.txt EXPOSE 5000 CMD python main.pydocker-compose.ymlversion: '2' services: web: build: . ports: - "5000:5000"requirements.txtFlask==1.1.1main.pyは後ほど作成します。
PyCharmでOpen + Docker Composeの設定
PyCharm起動画面で[Open]→作成したフォルダを選択します。
Preference→[Project: (プロジェクト名)]-[Python interpreter]→画面右側の歯車アイコンをクリック
[Docker Compose]を選択→[Server]で[Docker](前の手順で作成したもの)、[Configuration file(s)]でプロジェクト内のdocker-compose.yml、[Service]で[web]を選択→[OK]
Flaskなど、requirements.txtに書いたライブラリが含まれていることを確認して[OK]
ソースコードの作成
main.pyfrom flask import * app = Flask(__name__) @app.route('/') def hello(): return "Hello!" if __name__ == '__main__': app.run(host='0.0.0.0', port='5000')Flask関連のものも、PyCharm上で補完が効きます!!!
Docker ComposeではなくDockerにした場合、PyCharm上での補完が効きません。おそらく、Dockerの場合は
docker runコマンドで実行しているっぽいので、Dockerfileが使われないのだと思います。実行
main.py上で右クリック→[Run]またはCtrl+Shift+R(Macの場合)
PyCharmのコンソール/usr/local/bin/docker-compose -f /Users/tada/IdeaProjects/flask-docker/docker-compose.yml -f /Users/tada/Library/Caches/JetBrains/PyCharm2020.2/tmp/docker-compose.override.272.yml up --exit-code-from web --abort-on-container-exit web Recreating flask-docker_web_1 ... Attaching to flask-docker_web_1 web_1 | * Serving Flask app "main" (lazy loading) web_1 | * Environment: production web_1 | WARNING: This is a development server. Do not use it in a production deployment. web_1 | Use a production WSGI server instead. web_1 | * Debug mode: off web_1 | * Running on http://0.0.0.0:5000/ (Press CTRL+C to quit)ターミナルでcurlからアクセス$ curl localhost:5000 Hello!やったね!!

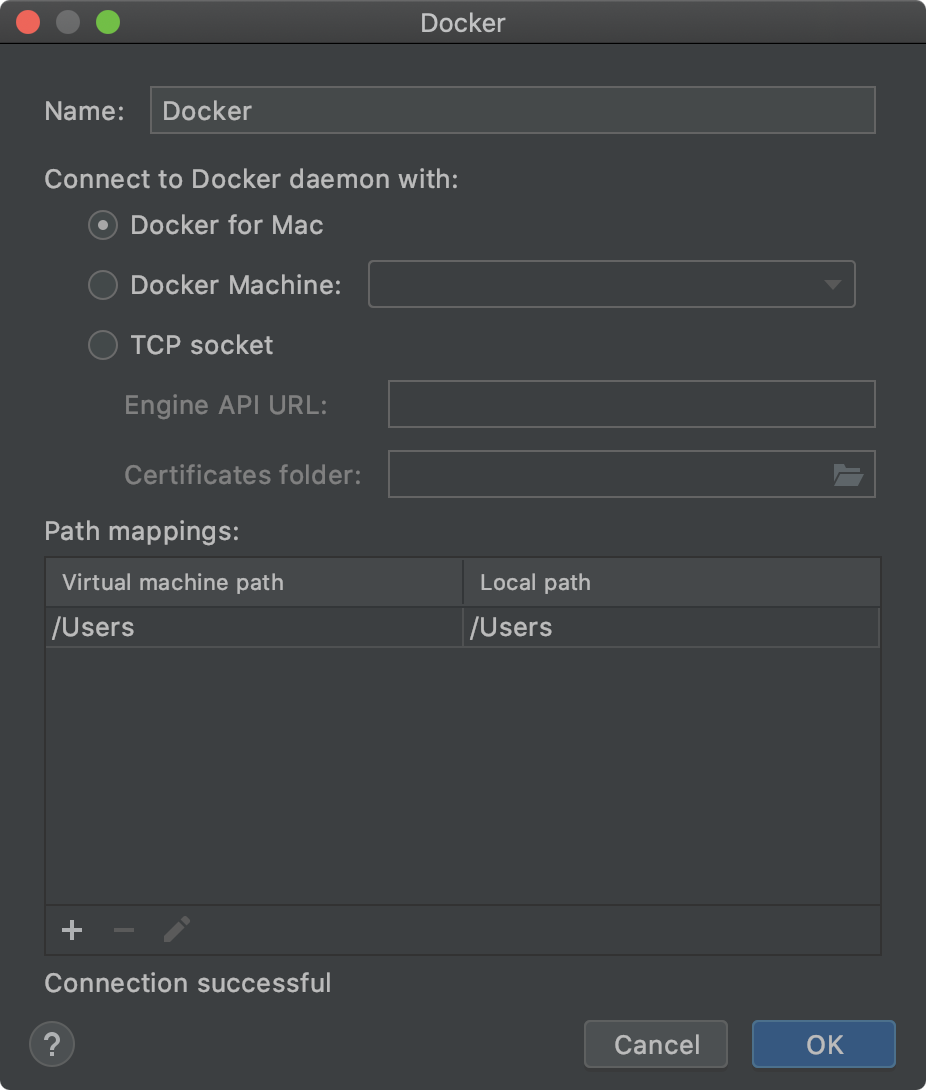


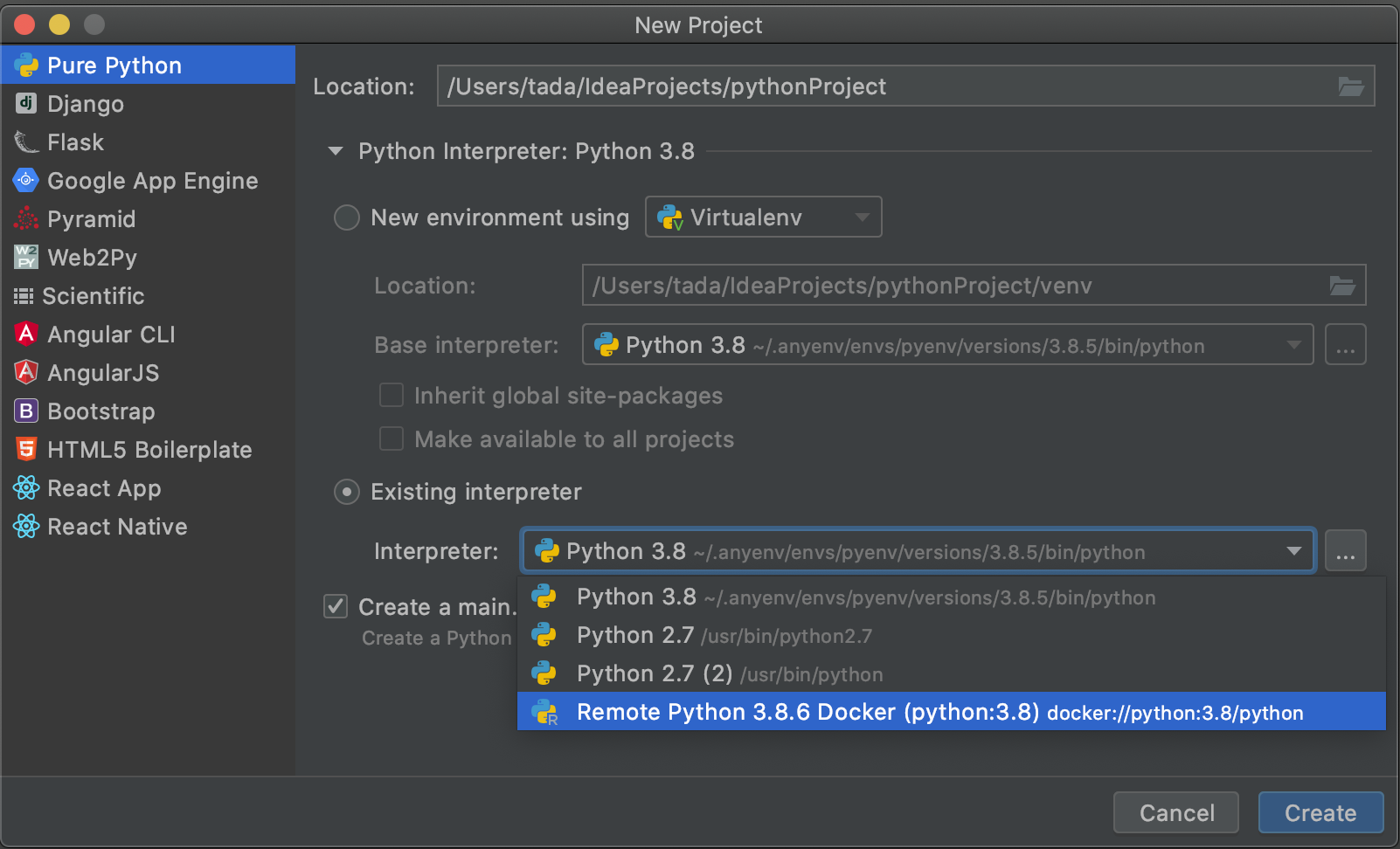
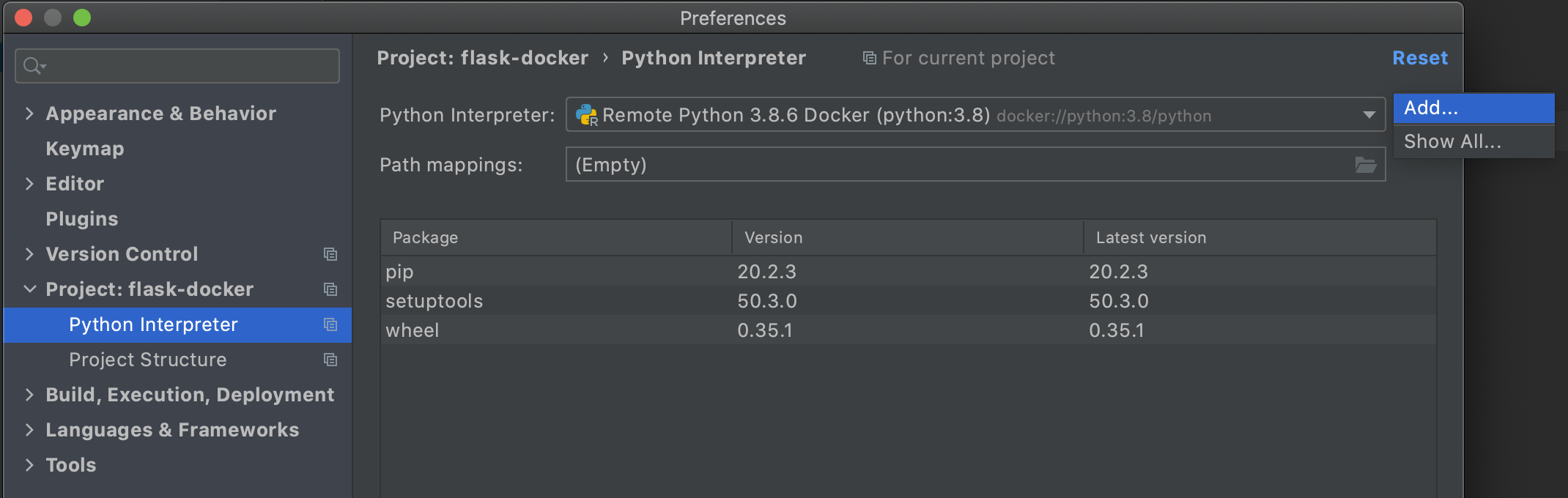
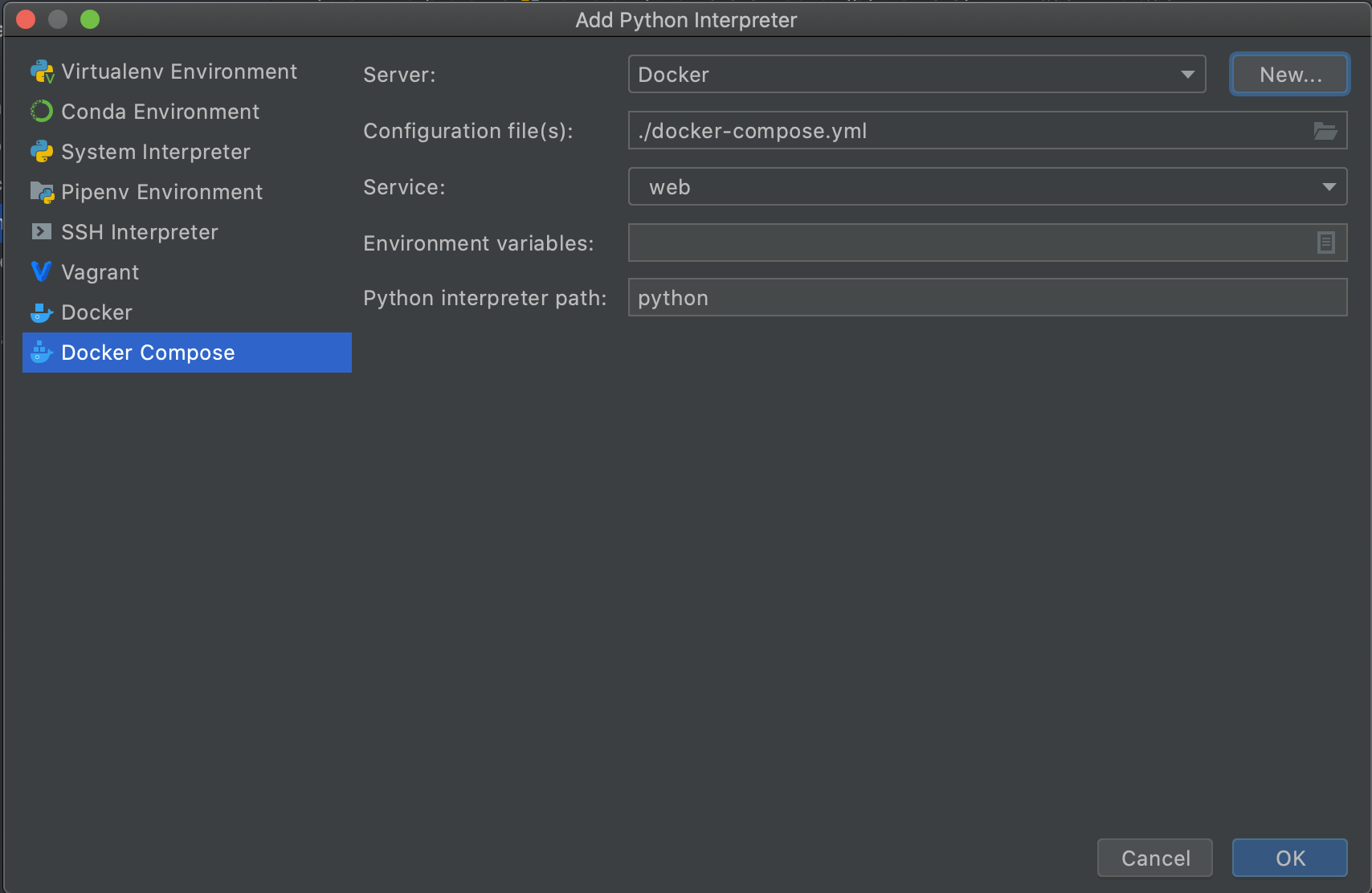
- 投稿日:2020-09-25T13:48:43+09:00
Django 日のシフト情報を修正するための機能を追加する
シフト表を確認しながら編集する機能を実装するために、日ごとの労働時間をクリックすると当日のシフトを修正できるようにしよと思います。
まずは、更新画面を作成していこうと思います。
簡単に作成できるUpdateViewを使って作成していきました…
schedule/views.pyclass ScheduleUpdate(UpdateView): template_name = 'schedule/update.html' model = Schedule fields = ('user', 'date', 'shift_name_1', 'shisetsu_name_1', 'shift_name_2', 'shisetsu_name_2', 'shift_name_3', 'shisetsu_name_3','shift_name_4', 'shisetsu_name_4', 'day_total_worktime') success_url = reverse_lazy('schedule:homeschedule')html/schedule.py{% extends 'schedule/base.html' %} {% block header %} {% endblock header %} {% block content %} <form action="" method="POST">{% csrf_token %} <P >社員名: {{ from.object.user }}</P> <p>日付: {{ form.date }}</p> <p>シフト1: {{ form.shift_name_1 }}</p> <p>施設名1: {{ form.shisetsu_name_1 }}</p> <p>シフト2: {{ form.shift_name_2 }}</p> <p>施設名2: {{ form.shisetsu_name_2 }}</p> <p>シフト3: {{ form.shift_name_3 }}</p> <p>施設名3: {{ form.shisetsu_name_3 }}</p> <p>シフト4: {{ form.shift_name_4 }}</p> <p>施設名4: {{ form.shisetsu_name_4 }}</p> <p>労働合計時間: {{ form.day_total_worktime }}</p> <input class="btn btn-primary" type="submit" value="更新"> <a href="{% url 'schedule:homeschedule' %}" class="btn-secondary btn active">戻る</a> </form> {% endblock content %}こうやって作れたのですが、問題がでてきました…
ユーザー名、日付は編集画面の情報としては、表示したのですが編集はさせたくない…
って時に、どのようにしたらできるか不明…
ここで苦労するとは…この後、シフト名からの時間を取得して表示させる機能を作ることで苦労しそうな気はしていたのですが、
その前につまづいてしまいました…現状の画面はこちら
ユーザー名じゃなくて氏名と名前を並べたいのですが、辞書型でまた受け渡さないといけないのかもしれませんが受渡方もわからない…
ここから何時間格闘するのだろうか…(笑)

- 投稿日:2020-09-25T13:15:58+09:00
uWSGIのmax-requets-delta、マジで効いていない
uWSGIのmax-requets-delta効いてない説
正直、なんかの間違いかと思っていた。
あなたの使ってるuWSGI、本当にmax-requests-delta効いてますか?という記事があったのは知っていたし読んでいた。
でも、あんまり記事にいいねついてないし、公式のドキュメントにもmax-requests-delta載ってるし、多分そんなことないんだろうなーと思っていた(失礼)。Apacheにかわるwebサーバ: uWSGIパフォーマンスチューニング
こっちのいいね100以上ついてる記事ではmax-requests-deltaが紹介されているし、delta効いているでしょう?と思っていた。しかし、負荷テストの際、max-requests-deltaが効いているとは思えない事象が発生した。
max-requests: 30000 max-requests-delta: 3000 #確か3000だったはず worker: 50こんな設定で3h200rpsを流す負荷テストを実施した時、2時間を超えたあたりで毎回エラーが起きていた。
150万リクエストあたりでちょうど
The work of process 18 is done. Seeya!" ... "worker 6 killed successfully (pid: 16)" ... "Respawned uWSGI worker 6 (new pid: 263)" ...というログが出ていて、そのすぐ後に
uWSGI listen queue of socket \":9090\" (fd: 3) full !!! (101/100)というエラーが出ていて、その時間辺りで30秒以上ALBのヘルスチェックに応答できなくなりALBによってTaskが落とされていた。(Flask+Nginx+Fargate構成で開発しています。)
1,500,000 / 200 / 60 = 125
200rps流すと、125分超えた辺りでuWSGIのプロセスが一斉に再起動し、その間にもリクエストは200rpsで送られるから、その間にqueueにリクエストが溜まり過ぎて
uWSGI listen queue of socket \":9090\" (fd: 3) full !!! (101/100)というエラーメッセージが出たと判断。max-requests-deltaが効いていないとすると全て繋がる。
ドキュメントにもしっかり書いてあるのに、そんなことってあるのかな。。と思いながらstrictモードの存在を知る。
This option tells uWSGI to fail to start if any parameter in the configuration file isn’t explicitly understood by uWSGI.
strict: true max-requests: 3000 max-requests-delta: 300こんな感じに設定して、
docker-compose down && docker-compose build && docker-compose up -dしてみた。uWSGIのログを見ようとコンテナ内に入ろうとする。
❯ docker exec -it uwsgi-app bash Error response from daemon: Container b951a8b21f946ad980aedc9792622b6d3c08a91e6aa095fa8fd5ebd3fbe56b8e is not running?
起動してないのでコンテナのログを見る。❯ docker logs -f uwsgi-app [uWSGI] getting YAML configuration from /etc/uwsgi/uwsgi.yml [strict-mode] unknown config directive: max-requests-deltaマジだった。いいねの数に目が眩んでいた。。。ドキュメントにも書いてあったのに。。。
uWSGIのIssue確認
ここでも2.1からサポートされているとあります。
https://github.com/unbit/uwsgi/issues/1488https://github.com/unbit/uwsgi/issues/2037
↑のIssueから
質問When will the new release be tagged? I'm waiting for the max-requests-delta option, and I'm reading things about the version 2.1 since 2017. Any news here?
答え
Hi, unfortunately i do not think there will be a 'supported 2.1' any time soon. Currently the objective is to leave the 2.1 as the 'edge' branch and backport requested features to 2.0. This is completely a fault of mine, not having a proper test suite since the beginning caused a stall in 'commercially supportable' releases after 10 years. @xrmx is doing a great work in backporting. So back to gevent, has someone found the technical issue ? (sorry, maybe there is already a patch but i did not find it)
max-requests-deltaを待望する声は多そうですが、まだ公式にサポートされるのは先みたいです。
ではどうする?
uWSGIのプロセスをちゃんと再起動してやらないと、メモリリークが発生したり、後自分が観測した限りでは負荷がかかっていない時でもuWSGIのプロセスがCPUを一定値使用してしまい、CPU使用率を基準にしたAuto Scalingがちょっとやりづらくなるという問題もあったので、uWSGIプロセスの再起動はちゃんとしたいところ。
自分の中でまだ明確に答えは出ていないですが、uWSGIプロセスの稼働率に応じて動的にuWSGIのプロセス数を調節する設定で対応可能なのではないかと思っています。
コンテナ内のプロセス数を動的に増減するよりも、そこは固定しておいて、ECSのオートスケーリングによってコンテナの数を変える方が良いという意見もあり、確かにそうだなと思う一方で、でもプロセスの一斉再起動問題もあるしな。。といった感じでまだ明確な答えは出ていないです。
cheaper-algo: busyness processes: 100 #最大プロセス数 cheaper: 10 #最低プロセス数 cheaper-initial: 50 #uWSGI起動時のプロセスの数 cheaper-overload: 3 #プロセスの数を調節するために、この時間ごとにプロセスの稼働率が計算される。単位は秒。 cheaper-step: 30 #一度に増やすプロセスの数 cheaper-busyness-multiplier: 30 #プロセスを減らす前に何秒待つか指定 cheaper-busyness-min: 20 #稼働率がこの値以下になった場合、プロセスを減らす cheaper-busyness-max: 70 #稼働率がこの値以上になった場合、プロセスを増やす cheaper-busyness-backlog-alert: 16 #待ち状態のリクエストがこの値以上になった場合、緊急のプロセスを増やす cheaper-busyness-backlog-step: 8 #作成する緊急のプロセスの数 cheaper-busyness-penalty: 2こうして動的にプロセスを増減してやれば、ずっと同じプロセスがメモリ上に存在することをある程度ß防げるので、一応問題の解決にはなるのではないかと現時点では考えています。
(これと合わせればmax-worker-lifetimeも使えそうだけど、それでも全てのプロセスが一斉に再起動する可能性もあるかなと、心配で踏み切れない。)uWSGIの情報は公式のドキュメントの説明があまり充実していなかったりするせいでしっかりとした情報が見つかりづらいですが、その中でもBloombergの記事はしっかりと書いてあって参考になったのでもしよかったら読んでみてください。
Configuring uWSGI for Production Deployment
もうちょっと負荷テストして、答えを出せたら追記します。
解決策(追記)
解決策として、uWSGIの設定ファイルを使用せずに、引数で全ての設定をするようにすることで解決できました。
CMD ["uwsgi", "--yaml", "uwsgi.yml", \ "--max-worker-lifetime", "`awk -v min=1800 -v max=5400 'BEGIN{srand(); print int(min+rand()*(max-min+1))}'`" ]設定ファイルに書かず、コマンドライン引数として
--max-worker-lifetimeに1800から5400までの数をランダムに渡すことで、
プロセスが再起動する間隔がそれぞれのコンテナごとにコンテナ起動の度に30分から90分の範囲内で無作為に決まることになり、全てのFargate TaskのコンテナのuWSGIプロセスが一斉に再起動する問題の発生を防ぐことができました。これにより、ダウンタイムが発生することもなくなると思われます。
- 投稿日:2020-09-25T13:11:22+09:00
【備忘録】Djangoの単体テスト実行時にカバレッジを計測する
目的
Django上で実装した単体テストが網羅出来ていない箇所を探索する為,
coverageを導入してカバレッジの計測を行う.検証
環境
導入
Djangoは既にインストール済みであることを前提とする.
$ pip install coverage計測
全テストを実行し, 計測を行う. この時に
.coverageファイルを生成される.$ coverage run --source=. --omit='*/tests*' manage.py testこの時, 単体テストを集約している任意のディレクトリを対象外にする為,
--omitオプションを使用してカバレッジの計測の対象外としている.
計測時のオプションの種類についてはhelpを参照する.$ coverage run --help結果
計測結果を出力する.
$ coverage report -m Name Stmts Miss Cover Missing ---------------------------------------------------------------------------------- auth/models.py 61 7 89% 15, 28-30, 115-116, 119 ... config/__init__.py 0 0 100% ... ---------------------------------------------------------------------------------- TOTAL 967 207 79%カラム名とその意味については以下の通りである.
Missingは,-mオプションを使用することで出力される.
カラム名 意味 Name カバレッジ計測の対象ファイル名を指す. Stmts Statementsの略称. 実行可能コードの行数を指す. Miss Stmtsの中で実行されなかった行数を指す. Cover カバレッジ(網羅率)を指す. Missing Missの対象となった行番号を指す. 結果出力時のオプションの種類についてはhelpを参照する.
$ coverage report --helpまた, HTMLやXML, JSON形式などでレポートを生成することも可能とのこと. 詳細はドキュメントに記載されている.
まとめ
Djangoの単体テスト実行時にカバレッジを計測することで, 網羅していない箇所を可視化した.
参考
- 投稿日:2020-09-25T11:04:41+09:00
深層学習入門 ~CNN実験編~
概要
前回の記事はこちらです。
ここで作成した実験コードに追加・改変する形でCNNの実験コードを作成します。
実験では実行時間の問題でscikit-learnのMNISTデータセットを用いています。
通常のMNISTデータセットとの差異は
- 画像サイズが$(8, 8)$
- データセットの総画像数は1797枚
であることですね。おかげで学習時間は(僕の環境では)数十秒で済みます。
一応Kerasのフルデータセットでの実験コードも載せてあります。
こちらは僕の環境だと数時間かかるっぽいので断念しました...目次
_TypeManagerクラスの変更まずは
LayerManagerクラスでConvLayerとPoolingLayerを扱えるようにするために、_TypeManagerクラスに追加します。
_type_manager.py
_type_manager.pyclass _TypeManager(): """ 層の種類に関するマネージャクラス """ N_TYPE = 4 # 層の種類数 BASE = -1 MIDDLE = 0 # 中間層のナンバリング OUTPUT = 1 # 出力層のナンバリング CONV = 2 #畳み込み層のナンバリング POOL = 3 #プーリング層のナンバリング REGULATED_DIC = {"Middle": MiddleLayer, "Output": OutputLayer, "Conv": ConvLayer, "Pool": PoolingLayer, "BaseLayer": None} @property def reg_keys(self): return list(self.REGULATED_DIC.keys()) def name_rule(self, name): name = name.lower() if "middle" in name or name == "mid" or name == "m": name = self.reg_keys[self.MIDDLE] elif "output" in name or name == "out" or name == "o": name = self.reg_keys[self.OUTPUT] elif "conv" in name or name == "c": name = self.reg_keys[self.CONV] elif "pool" in name or name == "p": name = self.reg_keys[self.POOL] else: raise UndefinedLayerError(name) return name定数として
CONVとPOOLを追加、REGULATED_DICでレイヤ名からレイヤオブジェクトを取得できるようにしています。
さらにREGURATED_DICのkeysリストが必要になる場面が多かったのでプロパティ化、ネーミングルールに畳み込み層とプーリング層を追加しました。
Trainerクラスの追加学習や予測を行う関数群を
LayerManagerクラスからTrainerクラスとして独立させました。
trainer.py
trainer.pysoftmax = type(get_act("softmax")) sigmoid = type(get_act("sigmoid")) class Trainer(): def __init__(self, x, y): self.x_train, self.x_test = x self.y_train, self.y_test = y self.make_anim = False def forward(self, x): x_in = x n_batch = x.shape[0] switch = True for ll in self.layer_list: if switch and not self.is_CNN(ll.name): x_in = x_in.reshape(n_batch, -1) switch = False x_in = ll.forward(x_in) def backward(self, t): y_in = t n_batch = t.shape[0] switch = True for ll in self.layer_list[::-1]: if switch and self.is_CNN(ll.name): y_in = y_in.reshape(n_batch, *ll.O_shape) switch = False y_in = ll.backward(y_in) def update(self, **kwds): for ll in self.layer_list: ll.update(**kwds) def training(self, epoch, n_batch=16, threshold=1e-8, show_error=True, show_train_error=False, **kwds): if show_error: self.error_list = [] if show_train_error: self.train_error_list = [] if self.make_anim: self.images = [] n_train = self.x_train.shape[0]//n_batch n_test = self.x_test.shape[0] # 学習開始 error = 0 error_prev = 0 rand_index = np.arange(self.x_train.shape[0]) for t in tqdm.tqdm(range(1, epoch+1)): #シーン作成 if self.make_anim: self.make_scene(t, epoch) # 訓練誤差計算 if show_train_error: self.forward(self.x_train) error = lm[-1].get_error(self.y_train) self.train_error_list.append(error) # 誤差計算 self.forward(self.x_test) error = lm[-1].get_error(self.y_test) if show_error: self.error_list.append(error) # 収束判定 if np.isnan(error): print("fail training...") break if abs(error - error_prev) < threshold: print("end learning...") break else: error_prev = error np.random.shuffle(rand_index) for i in range(n_train): rand = rand_index[i*n_batch : (i+1)*n_batch] self.forward(self.x_train[rand]) self.backward(self.y_train[rand]) self.update(**kwds) if show_error: # 誤差遷移表示 self.show_errors(show_train_error, **kwds) def pred_func(self, y, threshold=0.5): if isinstance(self[-1].act, softmax): return np.argmax(y, axis=1) elif isinstance(self[-1].act, sigmoid): return np.where(y > threshold, 1, 0) else: raise NotImplemented def predict(self, x=None, y=None, threshold=0.5): if x is None: x = self.x_test if y is None: y = self.y_test self.forward(x) self.y_pred = self.pred_func(self[-1].y, threshold) y = self.pred_func(y, threshold) print(y[:16], self.y_pred[:16]) print("accuracy rate:", np.sum(self.y_pred == y, dtype=int)/y.shape[0]*100, "%", "({}/{})".format(np.sum(self.y_pred == y, dtype=int), y.shape[0])) def show_errors(self, show_train_error=False, title="error transition", xlabel="epoch", ylabel="error", fname="error_transition.png", log_scale=True, **kwds): fig, ax = plt.subplots(1) fig.suptitle(title) if log_scale: ax.set_yscale("log") ax.set_xlabel(xlabel) ax.set_ylabel(ylabel) ax.grid() if show_train_error: ax.plot(self.train_error_list, label="train accuracy") ax.plot(self.error_list, label="test accuracy") ax.legend(loc="best") #fig.show() if len(fname) != 0: fig.savefig(fname) def ready_anim(self, n_image, x, y, title="animation", xlabel="x", ylabel="y", ex_color="r", color="b", x_left=0, x_right=0, y_down = 1, y_up = 1): self.n_image = n_image self.x = x self.color = color self.make_anim = True self.anim_fig, self.anim_ax = plt.subplots(1) self.anim_fig.suptitle(title) self.anim_ax.set_xlabel(xlabel) self.anim_ax.set_ylabel(ylabel) self.anim_ax.set_xlim(np.min(x) - x_left, np.max(x) + x_right) self.anim_ax.set_ylim(np.min(y) - y_down, np.max(y) + y_up) self.anim_ax.grid() self.anim_ax.plot(x, y, color=ex_color) return self.anim_fig, self.anim_ax def make_scene(self, t, epoch): # シーン作成 if t % (epoch/self.n_image) == 1: x_in = self.x.reshape(-1, 1) for ll in self.layer_list: x_in = ll.forward(x_in) im, = self.anim_ax.plot(self.x, ll.y, color=self.color) self.images.append([im])
forwardやbackward、update関数を関数として分離している理由は、何かオリジナリティある処理をしたい場合はforward関数に順伝播で行って欲しいメソッドを投げるだけでいいようにするためです。もう少し工夫の余地がある気がします...
training関数では学習の流れを記述してあります。訓練データの誤差遷移もみたいな〜と思ったので追加してあります。
また、収束判定にNaNの判定も入れており、学習に失敗したらすぐに訓練を終了するようになっています。
predict関数では文字通りテストデータに対する予測を行っています。オプション引数を用いており、指定しなければレイヤマネージャに持たせているテストデータを利用します。
テストデータを流した後、pred_funcによってデータ形式を変更し、正答率を計算するようにしています。ここも少し変更する必要がありそうですね...これでは分類問題の正答率しか出せません...
LayerManagerクラスの変更
ConvLayerクラスとPoolingクラスが追加されたことで細かい変更が必要になりました。
layer_manager.py
layer_manager.pyimport numpy as np import matplotlib.pyplot as plt import matplotlib.animation as animation import tqdm class LayerManager(_TypeManager, Trainer): """ 層を管理するためのマネージャクラス """ def __init__(self, x, y): super().__init__(x, y) self.__layer_list = [] # レイヤーのリスト self.__name_list = [] # 各レイヤーの名前リスト self.__ntype = np.zeros(self.N_TYPE, dtype=int) # 種類別レイヤーの数 def __repr__(self): layerRepr= "layer_list: " + repr(self.__layer_list) nameRepr = "name_list: " + repr(self.__name_list) ntypeRepr = "ntype: " + repr(self.__ntype) return (layerRepr + "\n" + nameRepr + "\n" + ntypeRepr) def __str__(self): layerStr = "layer_list: " + str(self.__layer_list) nameStr = "name_list: " + str(self.__name_list) ntypeStr = "ntype: " + str(self.__ntype) return (layerStr + "\n" + nameStr + "\n" + ntypeStr) def __len__(self): """ Pythonのビルドイン関数`len`から呼ばれたときの動作を記述。 種類別レイヤーの数の総和を返します。 """ return int(np.sum(self.__ntype)) def __getitem__(self, key): """ 例えば lm = LayerManager() +----------------+ | (lmに要素を追加) | +----------------+ x = lm[3].~~ のように、リストや配列の要素にアクセスされたときに呼ばれるので、 そのときの動作を記述。 sliceやstr, intでのアクセスのみ許可します。 """ if isinstance(key, slice): # keyがスライスならレイヤーのリストをsliceで参照する。 # 異常な値(Index out of rangeなど)が入力されたら # Pythonがエラーを出してくれます。 return self.__layer_list[key] elif isinstance(key, str): # keyが文字列なら各レイヤーの名前リストからインデックスを取得して、 # 該当するレイヤーのリストの要素を返す。 if key in self.__name_list: index = self.__name_list.index(key) return self.__layer_list[index] else: # keyが存在しない場合はKeyErrorを出す。 raise KeyError("{}: No such item".format(key)) elif isinstance(key, int): # keyが整数ならレイヤーのリストの該当要素を返す。 # 異常な値(Index out of rangeなど)が入力されたら # Pythonがエラーを出してくれます。 return self.__layer_list[key] else: raise KeyError(key, ": Undefined such key type.") def __setitem__(self, key, value): """ 例えば lm = LayerManager() +----------------+ | (lmに要素を追加) | +----------------+ lm[1] = x のように、リストや配列の要素にアクセスされたときに呼ばれるので、 そのときの動作を記述。 要素の上書きのみ認め、新規要素の追加などは禁止します。 """ value_type = "" if isinstance(value, list): # 右辺で指定された'value'が'list'なら # 全ての要素が'BaseLayer'クラスかそれを継承していなければエラー。 if not np.all( np.where(isinstance(value, BaseLayer), True, False)): self.AssignError() value_type = "list" elif isinstance(value, BaseLayer): # 右辺で指定された'value'が'BaseLayer'クラスか # それを継承していない場合はエラー。 self.AssignError(type(value)) if value_type == "": value_type = self.reg_keys[self.BASE] if isinstance(key, slice): # keyがスライスならレイヤーのリストの要素を上書きする。 # ただし'value_type'が'list'でなければエラー。 # 異常な値(Index out of rangeなど)が入力されたら # Pythonがエラーを出してくれます。 if value_type != "list": self.AssignError(value_type) self.__layer_list[key] = value elif isinstance(key, str): # keyが文字列なら各レイヤーの名前リストからインデックスを取得して、 # 該当するレイヤーのリストの要素を上書きする。 # ただし'value_type'が'BaseLayer'でなければエラー。 if value_type != self.reg_keys[self.BASE]: raise AssignError(value_type) if key in self.__name_list: index = self.__name_list.index(key) self.__layer_list[index] = value else: # keyが存在しない場合はKeyErrorを出す。 raise KeyError("{}: No such item".format(key)) elif isinstance(key, int): # keyが整数ならレイヤーのリストの該当要素を上書きする。 # ただし'value_type'が'BaseLayer'でなければエラー。 # また、異常な値(Index out of rangeなど)が入力されたら # Pythonがエラーを出してくれます。 if value_type != self.reg_keys[self.BASE]: raise AssignError(value_type) self.__layer_list[key] = value else: raise KeyError(key, ": Undefined such key type.") def __delitem__(self, key): """ 例えば lm = LayerManager() +----------------+ | (lmに要素を追加) | +----------------+ del lm[2] のように、del文でリストや配列の要素にアクセスされたときに呼ばれるので、 そのときの動作を記述。 指定要素が存在すれば削除、さらにリネームを行います。 """ if isinstance(key, slice): # keyがスライスならそのまま指定の要素を削除 # 異常な値(Index out of rangeなど)が入力されたら # Pythonがエラーを出してくれます。 del self.__layer_list[slice] del self.__name_list[slice] elif isinstance(key, str): # keyが文字列なら各レイヤーの名前リストからインデックスを取得して、 # 該当する要素を削除する。 if key in self.__name_list: del self.__layer_list[index] del self.__name_list[index] else: # keyが存在しない場合はKeyErrorを出す。 raise KeyError("{}: No such item".format(key)) elif isinstance(key, int): # keyが整数ならレイヤーのリストの該当要素を削除する。 # 異常な値(Index out of rangeなど)が入力されたら # Pythonがエラーを出してくれます。 del self.__layer_list[key] else: raise KeyError(key, ": Undefined such key type.") # リネームする self._rename() def _rename(self): """ リスト操作によってネームリストのネーミングがルールに反するものになった場合に 改めてルールを満たすようにネーミングリストおよび各レイヤーの名前を変更する。 ネーミングルールは[レイヤーの種類][何番目か]とします。 レイヤーの種類はMiddleLayerならMiddle OutputLayerならOutput のように略します。 何番目かというのは種類別でカウントします。 また、ここで改めて__ntypeのカウントを行います。 """ # 種類別レイヤーの数を初期化 self.__ntype = np.zeros(self.N_TYPE) # 再カウントと各レイヤーのリネーム for i in range(len(self)): for j, reg_name in enumerate(self.REGULATED_DIC): if reg_name in self.__name_list[i]: self.__ntype[j] += 1 self.__name_list[i] = (self.reg_keys[j] + str(self.__ntype[j])) self.__layer_list[i].name = (self.reg_keys[j] + str(self.__ntype[j])) break else: raise UndefinedLayerType(self.__name_list[i]) def append(self, *, name="Middle", **kwds): """ リストに要素を追加するメソッドでお馴染みのappendメソッドの実装。 """ if "prev" in kwds: # 'prev'がキーワードに含まれている場合、 # 一つ前の層の要素数を指定していることになります。 # 基本的に最初のレイヤーを挿入する時を想定していますので、 # それ以外は基本的に自動で決定するため指定しません。 if len(self) != 0: if kwds["prev"] != self.__layer_list[-1].n: # 最後尾のユニット数と一致しなければエラー。 raise UnmatchUnitError(self.__layer_list[-1].n, kwds["prev"]) elif not self.is_CNN(name): if len(self) == 0: # 最初のDNNレイヤは必ず入力ユニットの数を指定する必要があります。 raise UnmatchUnitError("Input units", "Unspecified") else: # 最後尾のレイヤのユニット数を'kwds'に追加 kwds["prev"] = self.__layer_list[-1].n # レイヤーの種類を読み取り、ネーミングルールに則った名前に変更する name = self.name_rule(name) # レイヤーを追加する。 for i, reg_name in enumerate(self.REGULATED_DIC): if name in reg_name: # 種類別レイヤーをインクリメントして self.__ntype[i] += 1 # 名前に追加し name += str(self.__ntype[i]) # ネームリストに追加し self.__name_list.append(name) # 最後にレイヤーを生成してリストに追加します。 self.__layer_list.append(self.REGULATED_DIC[reg_name](name=name, **kwds)) def extend(self, lm): """ extendメソッドでは既にある別のレイヤーマネージャ'lm'の要素を 全て追加します。 """ if not isinstance(lm, LayerManager): # 'lm'のインスタンスがLayerManagerでなければエラー。 raise TypeError(type(lm), ": Unexpected type.") if len(self) != 0: if self.__layer_list[-1].n != lm[0].prev: # 自分の最後尾のレイヤーのユニット数と # 'lm'の最初のレイヤーの入力数が一致しない場合はエラー。 raise UnmatchUnitError(self.__layer_list[-1].n, lm[0].prev) # それぞれ'extend'メソッドで追加 self.__layer_list.extend(lm.layer_list) self.__name_list.extend(lm.name_list) # リネームする self._rename() def insert(self, prev_name, name="Middle", **kwds): """ insertメソッドでは、前のレイヤーの名前を指定しそのレイヤーと結合するように 要素を追加します。 """ # 'prev_name'が存在しなければエラー。 if not prev_name in self.__name_list: raise KeyError(prev_name, ": No such key.") # 'prev'がキーワードに含まれている場合、 # 'prev_name'で指定されているレイヤーのユニット数と一致しなければエラー。 if "prev" in kwds: if kwds["prev"] \ != self.__layer_list[self.index(prev_name)].n: raise UnmatchUnitError( kwds["prev"], self.__layer_list[self.index(prev_name)].n) # 'n'がキーワードに含まれている場合、 if "n" in kwds: # 'prev_name'が最後尾ではない場合は if prev_name != self.__name_list[-1]: # 次のレイヤーのユニット数と一致しなければエラー。 if kwds["n"] != self.__layer_list[ self.index(prev_name)+1].prev: raise UnmatchUnitError( kwds["n"], self.__layer_list[self.index(prev_name)].prev) # まだ何も要素がない場合は'append'メソッドを用いるようにエラーを出す。 if len(self) == 0: raise RuntimeError( "You have to use 'append' method instead.") # 挿入場所のインデックスを取得 index = self.index(prev_name) + 1 # レイヤーの種類を読み取り、ネーミングルールに則った名前に変更する name = self.name_rule(name) # 要素を挿入する for i, reg_name in enumerate(self.REGULATED_DIC): if reg_name in name: self.__layer_list.insert(index, self.REGULATED_DIC[reg_name](name=name, **kwds)) self.__name_list.insert(index, self.REGULATED_DIC[reg_name](name=name, **kwds)) # リネームする self._rename() def extend_insert(self, prev_name, lm): """ こちらはオリジナル関数です。 extendメソッドとinsertメソッドを組み合わせたような動作をします。 簡単に説明すると、別のレイヤーマネージャをinsertする感じです。 """ if not isinstance(lm, LayerManager): # 'lm'のインスタンスがLayerManagerでなければエラー。 raise TypeError(type(lm), ": Unexpected type.") # 'prev_name'が存在しなければエラー。 if not prev_name in self.__name_list: raise KeyError(prev_name, ": No such key.") # 指定場所の前後のレイヤーとlmの最初・最後のレイヤーのユニット数が # それぞれ一致しなければエラー。 if len(self) != 0: if self.__layer_list[self.index(prev_name)].n \ != lm.layer_list[0].prev: # 自分の指定場所のユニット数と'lm'の最初のユニット数が # 一致しなければエラー。 raise UnmatchUnitError( self.__layer_list[self.index(prev_name)].n, lm.layer_list[0].prev) if prev_name != self.__name_list[-1]: # 'prev_name'が自分の最後尾のレイヤーでなく if lm.layer_list[-1].n \ != self.__layer_list[self.index(prev_name)+1].prev: # 'lm'の最後尾のユニット数と自分の指定場所の次のレイヤーの # 'prev'ユニット数と一致しなければエラー。 raise UnmatchUnitError( lm.layer_list[-1].n, self.__layer_list[self.index(prev_name)+1].prev) else: # 自分に何の要素もない場合は'extend'メソッドを使うようにエラーを出す。 raise RuntimeError( "You have to use 'extend' method instead.") # 挿入場所のインデックスを取得 index = self.index(prev_name) + 1 # 挿入場所以降の要素を'buf'に避難させてから一旦取り除き、 # extendメソッドを使って要素を追加 layer_buf = self.__layer_list[index:] name_buf = self.__name_list[index:] del self.__layer_list[index:] del self.__name_list[index:] self.extend(lm) # 避難させていた要素を追加する self.__layer_list.extend(layer_buf) self.__name_list.extend(name_buf) # リネームする self._rename() def remove(self, key): """ removeメソッドでは指定の名前の要素を削除します。 インデックスでの指定も許可します。 """ # 既に実装している'del'文でOKです。 del self[key] def index(self, target): return self.__name_list.index(target) def name(self, indices): return self.__name_list[indices] @property def layer_list(self): return self.__layer_list @property def name_list(self): return self.__name_list @property def ntype(self): return self.__ntype def is_CNN(self, name=None): if name is None: if self.__ntype[self.CONV] > 0 \ or self.__ntype[self.POOL] > 0: return True else: return False else: name = self.name_rule(name) if self.reg_keys[self.CONV] in name \ or self.reg_keys[self.POOL] in name: return True else: return False細かい変更のうち、割とどうでもいい部分は省きます。
省くのは_TypeManagerクラスを充実させたことによる変更の部分ですね。reg_keysプロパティを利用した変更が主です。大きな変更は、レイヤの種類を増やすごとにいちいち条件分岐を増やしていくのはあまりにも無駄なので、ループで行えるようにしたとこです。
一例としてappendメソッドの該当部分を見てみます。layer_manager.py# レイヤーを追加する。 for i, reg_name in enumerate(self.REGULATED_DIC): if name in reg_name: # 種類別レイヤーをインクリメントして self.__ntype[i] += 1 # 名前に追加し name += str(self.__ntype[i]) # ネームリストに追加し self.__name_list.append(name) # 最後にレイヤーを生成してリストに追加します。 self.__layer_list.append(self.REGULATED_DIC[reg_name](name=name, **kwds))
REGULATED_DICをenumerate関数でループさせ、レイヤ名がreg_nameに含まれている場合に、レイヤ番号iを用いて処理を行っています。
このため、_TypeManagerクラスのレイヤ定数とREGULATED_DICの登録インデックスを揃えておく必要があります。
他の部分も似たような感じです。最後に、
is_CNN関数を用意しました。
これは、引数nameに指定がなければLayerMangerクラスが持っているネットワークがCNNかを返します。
nameにレイヤ名が指定されている場合は、そのレイヤ名がCNNに値するか(つまり畳み込み層かプーリング層かどうか)を返します。
Trainerクラスの順伝播や逆伝播の際に使用しています。CNN実験コード本体
さて、それではCNNの実験に移ります。
コード全体はこちらに載せています。自由にクローンして/コピーして実験してみてください。KerasのMNISTデータセットの場合
まずはKerasデータセットの場合から。KerasのMNISTデータセットは訓練データ60000枚、テストデータ10000枚で、画像サイズも$(28, 28)$となっているため、機械学習のデータセットとしては小規模でも、ノートPCなどで学習するには結構大きなデータセットとなっています。
keras_data.pyimport numpy as np from keras.datasets import mnist #from sklearn.model_selection import train_test_split from sklearn.preprocessing import StandardScaler import tqdm # データセット取得 n_class=10 (x_train, y_train), (x_test, y_test) = mnist.load_data() C, B, I_h, I_w = 1, *x_train.shape B_test = x_test.shape[0] # 標準化 sc = StandardScaler() x_train = sc.fit_transform(x_train.reshape(B, -1)).reshape(B, C, I_h, I_w) x_test = sc.fit_transform(x_test.reshape(B_test, -1)).reshape(B_test, C, I_h, I_w) # one-hotラベルへの変換 def to_one_hot(data, n_class): vec = np.zeros((len(data), n_class)) for i in range(len(data)): vec[i, data[i]] = 1. return vec t_train = to_one_hot(y_train, n_class) t_test = to_one_hot(y_test, n_class)今回は
validationデータは作りません。作る場合はscikit-learnのtrain_test_split関数などを利用して訓練データを分割しましょう。
後、scikit-learnのStandardScalerクラスを利用して標準化しています。別に難しい処理をしないので自分で直接コードを書いてもOKです。また、画像認識ですので正規化でもOKです。
scikit-learnのStandardScalerクラスなどは入力が$(B, N)$のデータのみに対応しているので注意しましょう。
最後に正解ラベルが$(60000, )$と$(10000, )$の1次元配列の数値データとなっていますのでone-hot表現と呼ばれるものに変更します。
one-hot表現とは、例えば10クラス分類において、数値ラベルが$3$の正解データを$[0, 0, 0, 1, 0, 0, 0, 0, 0 , 0]$のように、該当部分のみ$1$を取るデータ表現です。
これにより、正解ラベルは$(60000, 10)$と$(10000, 10)$となります。
以上でデータ処理は完了です。scikit-learnのMNISTデータセットの場合
続いてscikit-learnのMNISTデータセットの場合を紹介します。
こちらは最初に述べたとおりかなり小さなデータセットとなっていますので、気軽に機械学習を試すことができます。scikit_learn_data.pyimport numpy as np from sklearn import datasets from sklearn.model_selection import train_test_split from sklearn.preprocessing import StandardScaler import tqdm # データセット取得 n_class=10 C, I_h, I_w = 1, 8, 8 digits = datasets.load_digits() x = digits.data t = digits.target n_data = len(x) # 標準化 sc = StandardScaler() x = sc.fit_transform(x).reshape(n_data, I_h, I_w) x_train, x_test, y_train, y_test = train_test_split(x, t, test_size=0.2, shuffle=True) # one-hotラベルへの変換 def to_one_hot(data, n_class): vec = np.zeros((len(data), n_class)) for i in range(len(data)): vec[i, data[i]] = 1. return vec t_train = to_one_hot(y_train, n_class) t_test = to_one_hot(y_test, n_class)やっていることはKerasの時とほとんど同じです。違うのはデータセットが$(1797, 64)$の形式で渡される点です。
そのため、データを標準化した後reshapeしてtrain_test_split関数で分割しています。CNN学習本体
データセットの準備が完了したらいよいよ学習です。
cnn_test.py# 畳み込み層と出力層を作成 M, F_h, F_w = 10, 3, 3 lm = LayerManager((x_train, x_test), (t_train, t_test)) lm.append(name="c", I_shape=(C, I_h, I_w), F_shape=(M, F_h, F_w), pad=1, wb_width=0.1, opt="AdaDelta", opt_dic={"eta": 1e-2}) lm.append(name="p", I_shape=lm[-1].O_shape, pool=2) lm.append(name="m", n=100, wb_width=0.1, opt="AdaDelta", opt_dic={"eta": 1e-2}) lm.append(name="o", n=n_class, act="softmax", err_func="Cross", wb_width=0.1, opt="AdaDelta", opt_dic={"eta": 1e-2}) # 学習させる epoch = 50 threshold = 1e-8 n_batch = 8 lm.training(epoch, threshold=threshold, n_batch=n_batch, show_train_error=True) # 予測する print("training dataset") lm.predict(x=lm.x_train, y=lm.y_train) print("test dataset") lm.predict()今回は至極簡単なCNNを構築しています。
学習エポック数は50、ミニバッチサイズは8としています。あとはレイヤマネージャにお任せです笑
CNNの構造は上図の通りになります。scikit-learnでの実行結果は下図のようになると思います。
誤判断したデータの表示
ついでにどんなデータで間違えたのかを可視化しましょう。
cnn_test.py# 間違ったデータを表示する col=4 dpi=125 y = lm.pred_func(lm.y_test) fail_index = np.where(y_pred != y)[0] print("incorrect index:", fail_index) if fail_index.size: row = int(np.ceil(fail_index.size/col)) if row * dpi >= 2 ** 16: row = int(np.ceil((2 ** 16 // dpi - 1)/col)) fig, ax = plt.subplots(row, col, figsize=(col, row + 1), dpi=dpi, facecolor="w") if row != 1: for i, f in enumerate(fail_index): ax[i // col, i % col].imshow(lm.x_test[f], interpolation='nearest', cmap='gray') ax[i // col, i % col].tick_params(labelbottom=False, labelleft=False, labelright=False, labeltop=False) ax[i // col, i % col].set_title(str(y[f]) + " => " + str(y_pred[f])) if i >= row * col: break else: for i, f in enumerate(fail_index): ax[i % col].imshow(lm.x_test[f], interpolation='nearest', cmap='gray') ax[i % col].tick_params(labelbottom=False, labelleft=False, labelright=False, labeltop=False) ax[i % col].set_title(str(y[f]) + ' => ' + str(y_pred[f])) if i >= row * col: break fig.tight_layout()これを実行すると下図のようになります。ちなみに先の実験結果とは別物ですので注意してください。
人間が見てもかろうじてって感じですね...これは(このままでは)誤判定しても仕方ないでしょうね。おわりに
実験中バッチサイズを1より大きくするとうまく学習が進まなくてずっと苦戦してました..
結局、活性化関数がバッチに対応していなかったことが原因でした。普通の活性化関数は放っておいてもnumpyのおかげでバッチに対応してくれますが、softmax関数などの一部の例外的な関数はきちんとバッチに対応しておく必要がありました。
同じように苦しんでいる方がいらっしゃったら気にしてみてください。深層学習シリーズ
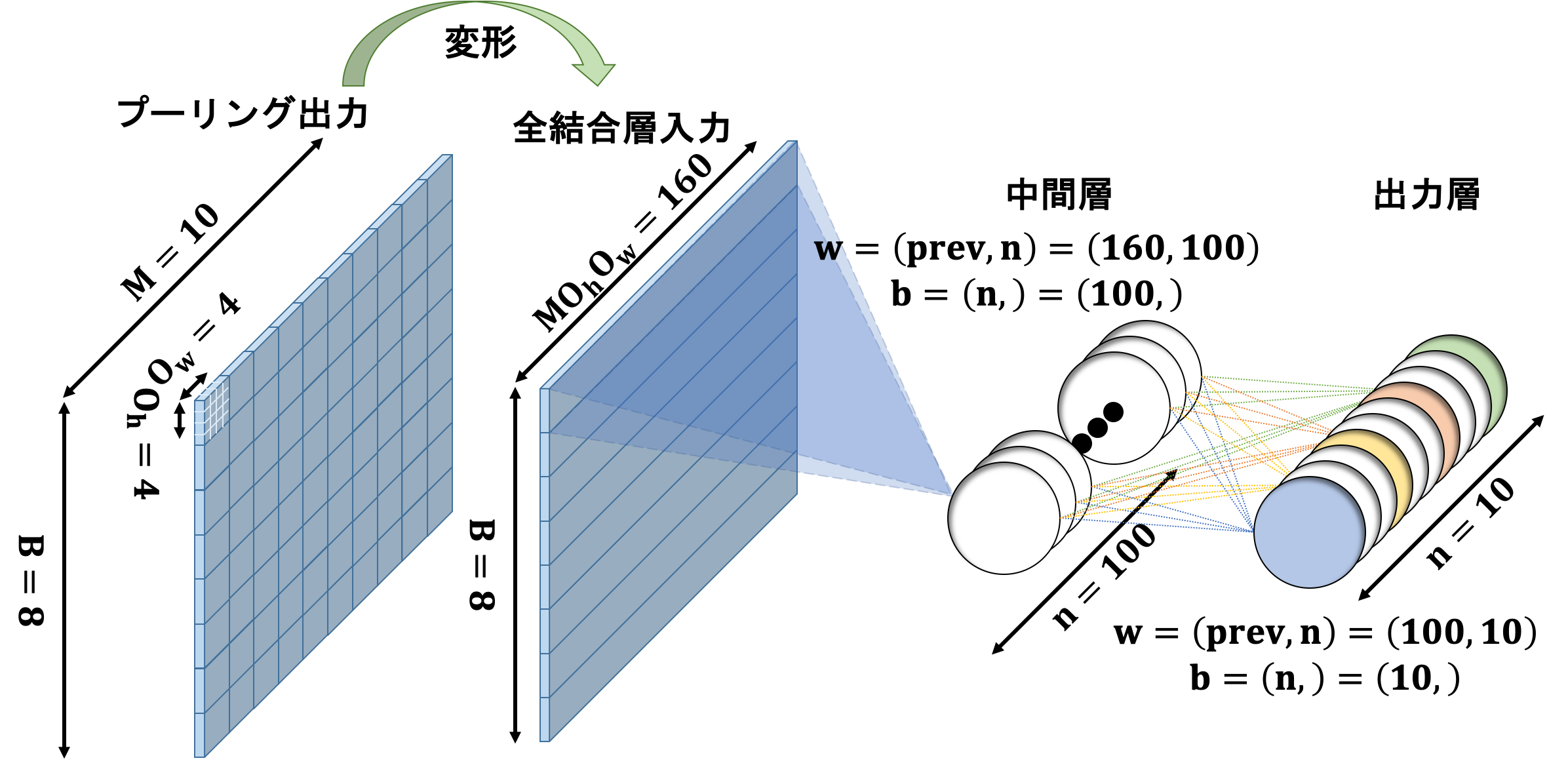

- 投稿日:2020-09-25T10:57:53+09:00
Caused by SSLError("Can't connect to HTTPS URL because the SSL module is not available.")でハマったときの話
はじめに
Webスクレイピングの練習のために
サンプルコードを入手してスクレイピングを試したところ
例外が発生してドハマりしたので事象と解決方法をメモする事象
【Python】スクレイピングで株価データを取得するを参考にして
スクリプトを実行したところ↓↓のエラーが発生して処理が進められなかった。
PCも工場出荷状態に戻した直後だったので結構焦る。スクリプト実行結果のエラーメッセージrequests.exceptions.SSLError: HTTPSConnectionPool(host='***.co.jp', port=443): Max retries exceeded with url: / (Caused by SSLError("Can't connect to HTTPS URL because the SSL module is not available."))環境
anaconda 1.9.12
python 3.8.3解決方法
環境変数に以下のパスを入れたら直った。
:環境変数
%USERPROFILE%\Anaconda3
%USERPROFILE%\Anaconda3\scripts
%USERPROFILE%\Anaconda3\Library\bin
具体的にはこんな感じ。
おわりに
今さら振り返ると、python実行環境はanaconda3なのに、vscode上からpythonを起動したから
anacondaでインストールしたパッケージが参照されなかったのかなぁ…なんて思った。
ともかく、問題解決してよかった。
- 投稿日:2020-09-25T10:48:05+09:00
教師あり学習2 ハイパーパラメーターとチューニング(1)
Aidemy 2020/9/25
はじめに
こんにちは、んがょぺです!バリバリの文系ですが、AIの可能性に興味を持ったのがきっかけで、AI特化型スクール「Aidemy」に通い、勉強しています。ここで得られた知識を皆さんと共有したいと思い、Qiitaでまとめています。以前のまとめ記事も多くの方に読んでいただけてとても嬉しいです。ありがとうございます!
今回は、教師あり学習の二つ目の投稿になります。どうぞよろしくお願いします。*本記事は「Aidemy」での学習内容を「自分の言葉で」まとめたものになります。表現の間違いや勘違いを含む可能性があります。ご了承ください。
今回学ぶこと
・ハイパーパラメータについて
・ロジスティック回帰、線形SVM、非線形SVMのハイパーパラメータハイパーパラメータ
ハイパーパラメータとは
・ハイパーパラメータとは、機械学習モデルの中で、「人が調整しないといけない領域(パラメータ)」のこと。モデルの種類によってパラメータは異なる。(次項以降で個別に見ていく)
・ハイパーパラメータを人為的に調整することをチューニングという。
・モデル構築時にパラメータをチューニングすることができる。(方法は後述)ロジスティック回帰のハイパーパラメータ
パラメータ C
・ロジスティック回帰のハイパーパラメータの一つにCというパラメータがある。(初期値1.0)
・Cは「教師データにどれだけ忠実に境界線を引くか」の指標になる。すなわち、Cの値が高ければ全ての教師データを分類できるような境界線を引くが、過学習に陥りやすいと言える。
・model=LogisticRegression(C=1.0) のようにして指定する。パラメータ penalty
・penaltyというパラメータは、「モデルが複雑になりすぎた際に、特徴量(L1)か全体の重み(L2)を減らして適切に汎化されるようにするもの」である。
・LogisticRegressionの引数にpenalty=L1 のように指定する。パラメータ multi_class
・multi_classというパラメータは「複数のクラス分類を行う際の挙動」を示している。
・ロジスティック回帰では、二項分類では「クラスに属するか/属さないか」の挙動であるovrと指定する。多項分類では「どれくらい属する可能性があるか」の挙動であるmultinomialと指定する。パラメータ random_state
・random_stateは「データの処理順を決める乱数のseed」であり、これを固定することでデータの処理順(=学習の結果)も固定される。
線形SVMのハイパーパラメータ
各パラメータ
・C:内容も使い方も同じ。ただし、Cの値が変化するとロジスティック回帰よりも正解率に大きな影響が出る。
・penalty:ロジスティック回帰と同様。
・multi_class:線形SVMではovrとcrammer_singerを指定できる。基本的にはovrの方が結果が良くなる。また、二項分類の時はこのパラメータを設定する必要はない。
・random_state:線形SVMでは、サポートベクターの決定時にもこの値が影響を及ぼし、結果が若干変わることがある。非線形SVMのハイパーパラメータ
パラメータ C
・C:内容も使い方も同じ。ただし、ペナルティはCの値を調整することで行われる。
パラメータ kernel
・kernelは、非線形SVMの処理の要である「非線形分類を線形分類に直す」動作に使われるカーネル関数を指定するパラメータ。指定できるのは「rbf」「poly」「linear」「sigmoid」「precomputed」の5つだが、デフォルト値であり正解率の高い「rbf」を使うことが多い。
・「rbf」「poly」は立体投影、「linear」は線形SVMと同じ動作(のため使うことはほぼない)、「sigmoid」はロジスティック回帰モデルと同じ動作、「precomputed」はデータが既に整形済みの時に使う。パラメータ decision_function_shape
・decision_function_shapeは、multi_classと同様に、データがどのクラスに属するかを決めるときの挙動を示す。指定できるのは「ovo」と「ovr」である。
・ovoは、クラスを2つで1つの組み合わせにして、その全ての場合に対して各データを二項分類するやり方である。ovrはデータをそのクラスに属するかを(直接)分類する。ovoの方が計算量が多いので、動作が重くなりやすい。パラメータ random_state
・random_state:非線形SVCでは、乱数生成器を別に作成しなければならない。
import numpy as np from sklearn.svm import SVC #乱数生成器の作成 a = np.random.RandomState() model = SVC(random_state = a)まとめ
・モデルの中で人為的に調整をしなければならないパラメータをハイパーパラメータといい、モデルの種類によって設定すべきハイパーパラメータは異なる。
・ロジスティック回帰、線形SVMのハイパーパラメータには「C」「penalty」「multi_class」「random_state」がある。
・非線形SVMのハイパーパラメータには「C」「kernel」「desicion_function_shape」「random_state」がある。今回は以上です。ここまで読んでくださりありがとうございました。
- 投稿日:2020-09-25T09:33:39+09:00
【メモ】PCのJupyter Notebookを等幅フォント表示にする (Mac)
はじめに
PCで動かすJupyter Notebookは、フォントがデフォルトでプロポーショナルになっているため、出力がガタガタしてなにかと不便。これを等幅フォントに変えるための手順です。
動作確認はMacでしています。手順
ターミナルを立ち上げて、以下のコマンドを実行します。
$ cd ~/.jupyter $ mkdir custom $ cd custom $ echo '.CodeMirror pre, .output pre { font-family: Monaco, monospace; }' > custom.cssこの状態で
$ Jupiter notebookとすると、numpyの行列も次のようにきれいに表示されます。
ご参考までに、上記のコードは私の著作「Pythonで儲かるAIをつくる」の実習コードの一部です。
他のコードを含めて下記リンク先にアップされていますので、関心ある方は参照されて下さい。https://github.com/makaishi2/profitable_ai_book_info/blob/master/refs/notebooks.md

- 投稿日:2020-09-25T08:10:17+09:00
Python で feedparser を使ってサクッとフィードリーダーを作った
はじめに
Python3 で feedparser ライブラリを使って RSS を取得してみました。
なお Python は完全な初心者です。環境
- macOS Catalina 10.15.6
- Python3 3.8.5
- feedparser 6.0.1
feedparser
feedparserという便利なものを利用しました。
これは、URL を渡してあげるだけでパースし、いい感じに辞書にまとめてくれるというすぐれものです。最新版のドキュメントはビルドしないと見れないので見れていないのですが、古い情報曰く、RSS・Atom の主要なものには対応しているそうです。
pipでインストール。pip3 install feedparser使い方は簡単。
import feedparser url = 'https://gigazine.net/index.php?/news/rss_2.0/' for entry in feedparser.parse(url).entries: print(entry.title)
出力
「宇宙最大の星」はどの星なのか? 体にかける毛布を重くすると不眠症が改善するかもしれない ロッテリアの人気メニューをWパティ・4種のチーズソース・半熟月見でゴージャスにカスタムした「ロッテリア秋の3大フェア」をまとめて食べてみた 世界的ゲームメーカーの元CEOが新たなゲーム会社を設立、新作ゲームの開発も進行中 陰謀論を広めるグループ「QAnon」が巨大掲示板のRedditを離れた理由とは? 社員の一斉ストライキ・広告主のボイコット・独占禁止法調査など数々の問題に直面したFacebookのCEOは何を考えているのか?を示す音声が流出 2020年9月24日のヘッドラインニュース FacebookやLinkedInでの「偽造プロフィール作成マニュアル」がSNS監視会社から流出 Intelが10nmプロセスの第11世代Coreプロセッサ「Tiger Lake UP3」などをIoTエッジ向けに発表 AWSがアーキテクチャ図を自動作成できるソリューション実装「AWS Perspective」を公開 AMDがGoogleと共同設計のChromebook向けプロセッサ「Ryzen 3000C」シリーズを発表 隕石が「水切り」のように地球の大気でバウンドする現象を捉えたムービー テスラが中国からの輸入パーツへの関税撤廃を求めてアメリカ政府を提訴 失われた視力を回復する「人工の目」の臨床試験に向けた計画が進行中 Googleマップで新型コロナウイルスの流行状況がチェック可能に 光輝く蜂蜜&メープルシロップの甘さがLチキのスパイスの中で際立つローソン「Lチキ ハニーメープル味」を食べてみた スマホでPDFを読みやすく自動で調整できる機能「Liquid Mode」をAdobeが発表 ガソリン車の新規販売禁止をカリフォルニア州が決定 Wikipediaが10年ぶりにデザインを刷新 MCU最新映画「ブラック・ウィドウ」の公開が延期、2020年は「2009年以来初のMCU映画のない年」に GoogleがChromeウェブストアで拡張機能の有料配布を段階的に廃止へ Twitterが「ボイスメッセージ」機能のテストを実施 キツツキの一種は数日にわたる「大規模な戦争」を繰り広げる、戦争の成り行きを観戦する個体も 「朝7時にインターネットが突然つながらなくなる」という怪奇現象が1年半も続いた村、その原因とは? 大手銀行のマネーロンダリング加担を明るみにした「フィンセン文書」から判明したことや問題点まとめ GoogleのAndroid部門重役が「Android 11」について語る ぷりっぷりの海老がゴロゴロ入ったチリソースで白ごはんがモリモリ進む「海老のチリソース定食」を松屋で買って食べてみた ダークウェブの違法業者179人が逮捕され「ダークウェブの黄金時代は終わった」と当局が声明を発表 マインクラフトをファミコンのエミュレーターにしてしまった猛者が登場 Spotifyを悪用して全く無名のアーティストが再生回数を稼ぎまくる方法とは?
すごい。
完成形
#!/usr/bin/env python3 # -*- coding: utf-8 -*- # URLの定義 urls = [ 'https://gigazine.net/index.php?/news/rss_2.0/', 'https://japanese.engadget.com/rss.xml', 'https://jp.techcrunch.com/feed/', 'https://www.gizmodo.jp/index.xml', ] from feedparser import parse from datetime import datetime as dt from webbrowser import open as browserOpen from urllib.parse import urlencode # 日付のパース用関数 def parseDate(dateData): return dt( dateData.tm_year, dateData.tm_mon, dateData.tm_mday, dateData.tm_hour, dateData.tm_min, dateData.tm_sec ) # リスト内包表記でサクッと取得&整形 entries = [ { 'title': entry['title'], 'link': entry['link'], 'date': parseDate(entry['updated_parsed'] or entry['published_parsed']) } for url in urls for entry in parse(url).entries ] # 日付順でソート entries.sort(key=lambda x: x['date'], reverse=True) savedEntries = [] for entry in entries: # タイトルを表示して、 print(entry['title']) # ユーザーに入力を求める userAction = input() if userAction == 'q': # quitだったら終了 break elif userAction == 's': # saveだったら配列に格納 savedEntries.append(entry) print('saved!') for savedEntry in savedEntries: browserOpen(savedEntry['link'])おわりに
自力でデータを集めるので処理に時間がかかります。
tqdmとかで進捗を表示するのもよさそうです。
今回はそこまでたくさんの URL を登録しているわけではないのでまたの機会に。Pocket API などを使えばPocketに自動保存したりもできるでしょう。
それにしても、Python、難しいですね。
簡単だって話でしたが、TypeScriptに慣れた私には相当面倒に感じてしまいます…。
- 投稿日:2020-09-25T06:55:16+09:00
Django シフト表に日ごとの労働時間合計が必要で、残業したらその数字を上書きしている
現在使用しているシフト表をみたら、日ごとの労働時間があったため必要かどうか確認したところ管理者で作成している時に、合計じかんが必要だっとりするとのことで、合計のフィールドを追加しようと思います。
シフト時間と残業時間を持つことも考えてみます。早引き、遅刻した時にシフト時間以下になった時にマイナス時間を入力することで対応可能…
わざわざ別でもつことのメリットは何か考えてみます。
・シフト時間は、特にフィールドで持つ必要はなくなる
・プラスマイナス対応はできそう…
・翌月コピーする時には、残業をのぞいてコピーすればよい
・残業集計を簡単にできるうーん、なんか決定打がないような気もします。
単純に持った場合は、
・翌月コピーする時には計算処理が必要
・残業遅刻は労働時間を直接修正するのでわかりやすい
・残業計算は計算処理が必要あまり別でもつメリットがないと判断しました。
モデルにフィールドを追加
schesule.models.pyfrom django.db import models from shisetsu.models import * from accounts.models import * from django.contrib.auth.models import User from django.core.validators import MaxValueValidator,MinValueValidator # Create your models here. class Shift(models.Model): id = models.AutoField(verbose_name='シフトID',primary_key=True) name = models.CharField(verbose_name='シフト名', max_length=1) start_time = models.TimeField(verbose_name="開始時間") end_time = models.TimeField(verbose_name="終了時間") wrok_time = models.IntegerField(verbose_name='勤務時間') def __str__(self): return self.name class Schedule(models.Model): id = models.AutoField(verbose_name='スケジュールID',primary_key=True) user = models.ForeignKey(User, on_delete=models.CASCADE, verbose_name='社員名') date = models.DateField(verbose_name='日付') year = models.PositiveIntegerField(validators=[MinValueValidator(1),]) month = models.PositiveIntegerField(validators=[MaxValueValidator(12),MinValueValidator(1),]) shift_name_1 = models.ForeignKey(Shift, verbose_name='1シフト名', related_name='shift_name1',on_delete=models.SET_NULL,null= True) shisetsu_name_1 = models.ForeignKey(Shisetsu, verbose_name='1施設', related_name='shisetsu_name1',on_delete=models.SET_NULL,blank=True, null=True) shift_name_2 = models.ForeignKey(Shift, verbose_name='2シフト名', related_name='shift_name2',on_delete=models.SET_NULL,blank=True, null=True) shisetsu_name_2 = models.ForeignKey(Shisetsu, verbose_name='2施設', related_name='shisetsu_name2',on_delete=models.SET_NULL,blank=True, null=True) shift_name_3 = models.ForeignKey(Shift, verbose_name='3シフト名', related_name='shift_name3',on_delete=models.SET_NULL,blank=True, null=True) shisetsu_name_3 = models.ForeignKey(Shisetsu, verbose_name='3施設', related_name='shisetsu_name3',on_delete=models.SET_NULL,blank=True, null=True) shift_name_4 = models.ForeignKey(Shift, verbose_name='4シフト名', related_name='shift_name4',on_delete=models.SET_NULL,blank=True, null=True) shisetsu_name_4 = models.ForeignKey(Shisetsu, verbose_name='4施設', related_name='shisetsu_name4',on_delete=models.SET_NULL,blank=True, null=True) day_total_worktime = models.IntegerField(verbose_name='日労働時間', default=0)) ###追加フィールドを追加したので、マイグレーションします
terminalpython3 manage.py makemigrations python3 manage.py migrateこれでフィールドの完成!
ここから時間を表示させるように改修をします。
苦労せずにいきたいところですが、何かとありそうな気がします(笑)まずは、日ごとに時間を出すことにチャレンジしました。
htmlをほとんど理解していないので2~3時間格闘し表示できるようになりました。コードがこちです。
schedule/month.html{% extends 'schedule/base.html' %} {% block header %} {% endblock header %} {% block content %} <table class="table table-striped table-bordered"> <thead> <tr align="center" class="info"> <!--日付--> <th rowspan="2"></th> {% for item in calender_object %} <th class="day_{{ item.date }}">{{ item.date | date:"d" }}</th> {% endfor %} <tr align="center" class="info"> <!--曜日--> {% for item in youbi_object %} <th class="day_{{ item.date }}">{{ item }}</th> {% endfor %} </tr> </thead> <tbody> {% for staff in user_list %} <tr align="center"> <th rowspan="2" class="staff_name" staff_id="{{ staff.staff_id }}" width="200" >{{ staff.last_name }} {{ staff.first_name }}</th> <!--staff_id要素はjsで使う--> {% for item in object_list %} {% if item.user|stringformat:"s" == staff.username|stringformat:"s" %}<!--usernameが同一なら--> <td class="day" id="s{{ staff.id }}d{{ item.date }}"> {% if item.shift_name_1 != None %} {% if item.shift_name_1|stringformat:"s" == "有" or item.shift_name_1|stringformat:"s" == "休" %} {{ item.shift_name_1 }} {% else %} {% for shisetsu in shisetsu_object %} {% if item.shisetsu_name_1|stringformat:"s" == shisetsu.name|stringformat:"s" %} <span style="background-color:{{ shisetsu.color }}">{{ item.shift_name_1 }}</span> {% endif %} {% endfor %} {% endif %} {% endif %} {% if item.shift_name_2 != None %} {% if item.shift_name_2|stringformat:"s" == "有" or item.shift_name_2|stringformat:"s" == "休" %} {{ item.shift_name_2 }} {% else %} {% for shisetsu in shisetsu_object %} {% if item.shisetsu_name_2|stringformat:"s" == shisetsu.name|stringformat:"s" %} <span style="background-color:{{ shisetsu.color }}">{{ item.shift_name_2 }}</span> {% endif %} {% endfor %} {% endif %} {% endif %} {% if item.shift_name_3 != None %} {% if item.shift_name_3|stringformat:"s" == "有" or item.shift_name_3|stringformat:"s" == "休" %} {{ item.shift_name_3 }} {% else %} {% for shisetsu in shisetsu_object %} {% if item.shisetsu_name_3|stringformat:"s" == shisetsu.name|stringformat:"s" %} <span style="background-color:{{ shisetsu.color }}">{{ item.shift_name_3 }}</span> {% endif %} {% endfor %} {% endif %} {% endif %} {% if item.shift_name_4 != None %} {% if item.shift_name_4|stringformat:"s" == "有" or item.shift_name_4|stringformat:"s" == "休" %} {{ item.shift_name_4 }} {% else %} {% for shisetsu in shisetsu_object %} {% if item.shisetsu_name_4|stringformat:"s" == shisetsu.name|stringformat:"s" %} <span style="background-color:{{ shisetsu.color }}">{{ item.shift_name_4 }}</span> {% endif %} {% endfor %} {% endif %} {% endif %} {% endif %} {% endfor %} </td> <tr align="center"> {% for item in object_list %} {% if item.user|stringformat:"s" == staff.username|stringformat:"s" %}<!--usernameが同一なら--> <td class="day" id="s{{ staff.id }}d{{ item.date }}"> {{ item.day_total_worktime }} </td> {% endif %} {% endfor %} </tr> {% endfor %} </tbody> </table> {% endblock content %}ここからは、日のトータルを入れてい行こうと思います。
調べると、合計を集計する機能がdjangoにあるとのことで、
annotate 機能を調べてviews に追加しましたschedule/views.py#これを追加して from django.db.models import Sum from django.contrib.auth.models import User #辞書型にuserごとの月の合計時間を入れる month_total = Schedule.objects.select_related('User').filter(year = year, month = month).values("user").order_by("user").annotate(month_total_worktime = Sum("day_total_worktime")) context = { 'month_total': month_total, } return render(request,'schedule/month.html', { 'month_total' : month_total, }, )htmlテンプレートに受け渡し、htmlで表示するためhtmlを修正します
schedule/month.py{% extends 'schedule/base.html' %} {% block header %} {% endblock header %} {% block content %} <table class="table table-striped table-bordered"> <thead> <tr align="center" class="info"> <!--日付--> <th rowspan="2"></th> {% for item in calender_object %} <th class="day_{{ item.date }}">{{ item.date | date:"d" }}</th> {% endfor %} <tr align="center" class="info"> <!--曜日--> {% for item in youbi_object %} <th class="day_{{ item.date }}">{{ item }}</th> {% endfor %} </tr> </thead> <tbody> {% for staff in user_list %} <tr align="center"> <th rowspan="1" class="staff_name" staff_id="{{ staff.staff_id }}" width="200" >{{ staff.last_name }} {{ staff.first_name }}</th> <!--staff_id要素はjsで使う--> {% for item in object_list %} {% if item.user|stringformat:"s" == staff.username|stringformat:"s" %}<!--usernameが同一なら--> <td class="day" id="s{{ staff.id }}d{{ item.date }}"> {% if item.shift_name_1 != None %} {% if item.shift_name_1|stringformat:"s" == "有" or item.shift_name_1|stringformat:"s" == "休" %} {{ item.shift_name_1 }} {% else %} {% for shisetsu in shisetsu_object %} {% if item.shisetsu_name_1|stringformat:"s" == shisetsu.name|stringformat:"s" %} <span style="background-color:{{ shisetsu.color }}">{{ item.shift_name_1 }}</span> {% endif %} {% endfor %} {% endif %} {% endif %} {% if item.shift_name_2 != None %} {% if item.shift_name_2|stringformat:"s" == "有" or item.shift_name_2|stringformat:"s" == "休" %} {{ item.shift_name_2 }} {% else %} {% for shisetsu in shisetsu_object %} {% if item.shisetsu_name_2|stringformat:"s" == shisetsu.name|stringformat:"s" %} <span style="background-color:{{ shisetsu.color }}">{{ item.shift_name_2 }}</span> {% endif %} {% endfor %} {% endif %} {% endif %} {% if item.shift_name_3 != None %} {% if item.shift_name_3|stringformat:"s" == "有" or item.shift_name_3|stringformat:"s" == "休" %} {{ item.shift_name_3 }} {% else %} {% for shisetsu in shisetsu_object %} {% if item.shisetsu_name_3|stringformat:"s" == shisetsu.name|stringformat:"s" %} <span style="background-color:{{ shisetsu.color }}">{{ item.shift_name_3 }}</span> {% endif %} {% endfor %} {% endif %} {% endif %} {% if item.shift_name_4 != None %} {% if item.shift_name_4|stringformat:"s" == "有" or item.shift_name_4|stringformat:"s" == "休" %} {{ item.shift_name_4 }} {% else %} {% for shisetsu in shisetsu_object %} {% if item.shisetsu_name_4|stringformat:"s" == shisetsu.name|stringformat:"s" %} <span style="background-color:{{ shisetsu.color }}">{{ item.shift_name_4 }}</span> {% endif %} {% endfor %} {% endif %} {% endif %} {% endif %} {% endfor %} </td> <tr align="center"> {% for month in month_total %} {% if month.user == staff.id %}<!--usernameが同一なら--> <td><b>{{ month.month_total_worktime }}</b></td> {% endif %} {% endfor %} {% for item in object_list %} {% if item.user|stringformat:"s" == staff.username|stringformat:"s" %}<!--usernameが同一なら--> <td class="day" id="s{{ staff.id }}d{{ item.date }}"> {{ item.day_total_worktime }} </td> {% endif %} {% endfor %} </tr> {% endfor %} </tbody> </table> {% endblock content %}htmlは、1~2時間格闘したらできました!
結果は、こちら
いやー、いい感じです!
スタッフごとに太線に変えたり微調整は必要な気はしますが、自分が考えていたものが形になることは最高ですね!
