- 投稿日:2020-09-25T21:22:12+09:00
Spring + MyBatis接続設定方法
MyBatisとは
SQLとJavaオブジェクトをマッピングすることで、JavaからのDBアクセスを間接的に行ってくれるフレームワーク。
特徴としては、SQLを設定ファイルやアノテーションに宣言的に定義することにより、
Javaで書かれたビジネスロジックからSQL自体の存在を隠蔽出来ること。MapperインターフェイスがSQLの隠蔽をしており、MyBatisがMapperインターフェイスのメソッドとSQLを紐づけている。
その為、Javaのビジネスロジックからは、Mapperインターフェイスを呼び出すだけで紐づいているSQLを実行出来る。前提事項
・Eclipse 2018-09 (4.9.0)
・Windows10
・H2
・MyBatisのSQLの指定方法は「マッピングファイル」「アノテーション」の二通りあるが、
今回は「マッピングファイル」を採用する。初期設定
pom.xml<dependency> <groupId>org.mybatis.spring.boot</groupId> <artifactId>mybatis-spring-boot-starter</artifactId> <version>2.1.2</version> </dependency> <dependency> <groupId>org.mybatis</groupId> <artifactId>mybatis</artifactId> <version>3.4.0</version> </dependency>MybatisTestApplication.java@SpringBootApplication @EnableTransactionManagement @MapperScan("com.mybatis.test.domain") public class MybatisTestApplication { //Spring Boot起動メソッド public static void main(String[] args) { SpringApplication.run(MybatisTestApplication.class, args); } //Bean定義 データソース① @Bean public DataSource dataSource() { return new EmbeddedDatabaseBuilder() .setType(EmbeddedDatabaseType.H2) .addDefaultScripts() .build(); } //Bean定義 PlatformTransactionManager② @Bean public PlatformTransactionManager transactionManager() { return new DataSourceTransactionManager(dataSource()); } //Bean定義 SqlSessionFactoryBean③ @Bean public SqlSessionFactoryBean sqlSessionFactory() { SqlSessionFactoryBean sessionFactoryBean = new SqlSessionFactoryBean(); sessionFactoryBean.setDataSource(dataSource()); return sessionFactoryBean; }①データソース
データソースのBeanを定義する。②PlatformTransactionManager
トランザクションマネージャーのBeanを定義する。③SqlSessionFactoryBean
SqlSessionFactoryBeanを利用して、SqlSessionFactoryが生成される。
データソースを設定して、MyBatisの処理の中でSQLを発行すると、ここで指定したデータソースから
コネクションが取得される。MyBatisを使ったDBアクセス
・Mapperインターフェイスの作成
・マッピングファイルの作成MyBatisMapper.javapackage com.mybatis.test.domain; import org.apache.ibatis.annotations.Mapper; import org.apache.ibatis.annotations.Param; //このアノテーションを付けることで、プログラムからMapperインタフェースとして認識される @Mapper public interface MyBatisMapper { //SELECTのテスト用 public PlayerEntity selectTest(String id); //INSERTのテスト用 public void insertTest(@Param("id")String id, @Param("name")String name, @Param("age")String age); //UPDATEのテスト用 public void updateTest(@Param("id")String id, @Param("name")String name); //DELETEのテスト用 public void deleteTest(String id); }MyBatisMapper.xml<?xml version="1.0" encoding="UTF-8"?> <!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN" "http://mybatis.org/dtd/mybatis-3-mapper.dtd"> <mapper namespace="com.mybatis.test.domain.MyBatisMapper"> <!-- id属性はMapperインターフェイスに定義したメソッド名 --> <!-- parameterType属性はメソッド引数のクラス --> <!-- resultType属性は検索結果をマッピングするクラス --> <select id="selectTest" parameterType="string" resultType="com.mybatis.test.domain.PlayerEntity"> SELECT id,name,age FROM player WHERE id=#{id} </select> <insert id="insertTest" parameterType="string" > INSERT INTO player (id, name, age) VALUES (#{id}, #{name}, #{age}) </insert> <update id="updateTest" parameterType="string"> UPDATE player SET name=#{name} WHERE id=#{id} </update> <delete id="deleteTest" parameterType="string"> DELETE FROM player WHERE id=#{id} </delete> </mapper>
XMLは、src/main/resourcesの、Mapperインタフェースを配置したフォルダと同一の場所に、
同一名で配置すること!
こうすることで、MyBatisが自動でマッピングファイルを読み込んでくれる。Mapperオブジェクトの利用
・Serviceクラス
・Controllerクラス
・EntityクラスServicepackage com.mybatis.test.domain; import org.springframework.beans.factory.annotation.Autowired; import org.springframework.stereotype.Service; import org.springframework.transaction.annotation.Transactional; @Service public class MyBatisService { @Autowired MyBatisMapper mapper; @Autowired PlayerRepository playerRepository; //SELECTを行うMapperのメソッドを呼び出す @Transactional public PlayerEntity selectTest(String id) { return mapper.selectTest(id); } //INSERTを行うMapperのメソッドを呼び出す @Transactional public void insertTest(String id, String name, String age) { mapper.insertTest(id, name, age); } //UPDATEを行うMapperのメソッドを呼び出す @Transactional public void updateTest(String id, String name) { mapper.updateTest(id, name); } //DELETEを行うMapperのメソッドを呼び出す @Transactional public void deleteTest(String id) { mapper.deleteTest(id); }Controllerpackage com.mybatis.test.domain; import org.springframework.beans.factory.annotation.Autowired; import org.springframework.stereotype.Controller; import org.springframework.ui.Model; import org.springframework.web.bind.annotation.GetMapping; import org.springframework.web.bind.annotation.PostMapping; import org.springframework.web.bind.annotation.RequestParam; @Controller public class MybatisController { @Autowired MyBatisService myBatisService; @GetMapping() public String index(Model model) { PlayerEntity playerService = new PlayerEntity(); playerService = myBatisService.selectTest("004"); model.addAttribute("play", playerService); myBatisService.insertTest("010", "XXXX", "65"); myBatisService.updateTest("004", "SSSSSS"); myBatisService.deleteTest("001"); return "index"; } 以下省略Entitypackage com.mybatis.test.domain; import javax.persistence.Entity; import javax.persistence.Id; @Entity public class PlayerEntity { @Id private String id; private String name; private String age; getter,setter省略終わりに
次はJOINしたものや、SQL文をもっと複雑にして色々といじってみたいと思います。
- 投稿日:2020-09-25T20:21:53+09:00
Java で Amazon Product Advertising API 5.0 (PA-API v5) をコールする
概要
- Java で Amazon Product Advertising API 5.0 (PA-API v5) をコールする
- AWS が提供している公式の SDK を使わず API を直接コールする
- AWS 署名バージョン 4 (AWS Signature Version 4) の処理を Java 標準ライブラリのみで実装する
- 今回の実行環境: macOS Catalina + Java 15 (AdoptOpenJDK 15) + Jackson Databind 2.11.1 + Gradle 6.6.1
サンプルコード
ファイル一覧
├── build.gradle └── src └── main └── java ├── AwsSignature4.java ├── JsonUtil.java ├── MyApp.java └── PaApi5Wrapper.javabuild.gradle
Gradle の設定ファイル。
JSON 操作ライブラリは Java の標準ライブラリにないため Jackson を使用する。plugins { id 'java' id 'application' } repositories { mavenCentral() } dependencies { // Jackson を使う implementation 'com.fasterxml.jackson.core:jackson-databind:2.11.1' } application { mainClassName = 'MyApp' } sourceCompatibility = JavaVersion.VERSION_15src/main/java/MyApp.java
import java.util.HashMap; import java.util.Map; /** * PA-API v5 をコールするサンプルクラス。 */ public class MyApp { public static void main(String[] args) throws Exception { // PA-API v5 をコールする searchItems(); getItems(); } private static final String ACCESS_KEY = "<YOUR-ACCESS-KEY-HERE>"; // 取得したアクセスキー private static final String SECRET_KEY = "<YOUR-SECRET-KEY-HERE>"; // 取得したシークレットキー private static final String TRACKING_ID = "<YOUR-PARTNER-TAG-HERE>"; // トラッキングID (例: XXXXX-22) // キーワードから商品を検索 public static void searchItems() throws Exception { String keywords = "シェイクスピア"; // リクエスト情報 Map<String, Object> req = new HashMap<>() { { put("ItemCount", 3); // 検索結果の数 put("PartnerTag", TRACKING_ID); // ストアID or トラッキングID put("PartnerType", "Associates"); // パートナータイプ put("Keywords", keywords); // 検索キーワード put("SearchIndex", "All"); // 検索カテゴリー (All, AmazonVideo, Books, Hobbies, Music などを指定可能) put("Resources", new String[]{ // レスポンスに含む値のタイプ "ItemInfo.Title", "ItemInfo.ByLineInfo", "ItemInfo.ProductInfo", "Images.Primary.Large", "Images.Primary.Medium", "Images.Primary.Small" }); } }; // リクエスト情報を JSON 文字列にする String reqJson = new JsonUtil().objectToJson(req); System.out.println("===== キーワードから商品を検索: リクエスト ====="); System.out.println(reqJson); // PA-API v5 をコールして結果を JSON 文字列で受け取る PaApi5Wrapper api = new PaApi5Wrapper(ACCESS_KEY, SECRET_KEY); String resJson = api.searchItems(reqJson); System.out.println("===== キーワードから商品を検索: レスポンス ====="); System.out.println(new JsonUtil().prettyPrint(resJson)); } // ASIN から商品情報を取得 public static void getItems() throws Exception { String[] asinList = new String[]{"4391641585", "B010EB1HR4", "B0125SPF90", "B07V52KSGT"}; // リクエスト情報 Map<String, Object> req = new HashMap<>() { { put("PartnerTag", TRACKING_ID); // ストアID or トラッキングID put("PartnerType", "Associates"); // パートナータイプ put("ItemIds", asinList); // ASINのリスト put("Resources", new String[]{ // レスポンスに含む値のタイプ "ItemInfo.Title", "ItemInfo.ByLineInfo" }); } }; // リクエスト情報を JSON 文字列にする String reqJson = new JsonUtil().objectToJson(req); System.out.println("===== ASIN から商品情報を取得: リクエスト ====="); System.out.println(reqJson); // PA-API v5 をコールして結果を JSON 文字列で受け取る PaApi5Wrapper api = new PaApi5Wrapper(ACCESS_KEY, SECRET_KEY); String resJson = api.getItems(reqJson); System.out.println("===== ASIN から商品情報を取得: レスポンス ====="); System.out.println(new JsonUtil().prettyPrint(resJson)); } }src/main/java/PaApi5Wrapper.java
import java.io.IOException; import java.net.URI; import java.net.URISyntaxException; import java.net.http.HttpClient; import java.net.http.HttpRequest; import java.net.http.HttpResponse; import java.security.InvalidKeyException; import java.security.NoSuchAlgorithmException; import java.time.Duration; import java.util.Map; /** * PA-API v5 ラッパークラス。 */ public class PaApi5Wrapper { private static final String HOST = "webservices.amazon.co.jp"; // Amazon.co.jp の Web API ホスト private static final String REGION = "us-west-2"; // Amazon.co.jp では us-west-2 を指定 private final String accessKey; private final String secretKey; /** * コンストラクタ。 * @param accessKey アクセスキー * @param secretKey シークレットキー */ public PaApi5Wrapper(String accessKey, String secretKey) { this.accessKey = accessKey; this.secretKey = secretKey; } /** * キーワードから商品を検索する。 * @param reqJson リクエスト情報 JSON * @return レスポンス情報 JSON * @throws InterruptedException * @throws IOException * @throws NoSuchAlgorithmException * @throws InvalidKeyException * @throws URISyntaxException */ public String searchItems(String reqJson) throws InterruptedException, IOException, NoSuchAlgorithmException, InvalidKeyException, URISyntaxException { String path = "/paapi5/searchitems"; String target = "com.amazon.paapi5.v1.ProductAdvertisingAPIv1.SearchItems"; return callApi(reqJson, path, target); } /** * ASIN から商品情報を取得する。 * @param reqJson リクエスト情報 JSON * @return レスポンス情報 JSON * @throws InterruptedException * @throws IOException * @throws NoSuchAlgorithmException * @throws InvalidKeyException * @throws URISyntaxException */ public String getItems(String reqJson) throws InterruptedException, IOException, NoSuchAlgorithmException, InvalidKeyException, URISyntaxException { String path = "/paapi5/getitems"; String target = "com.amazon.paapi5.v1.ProductAdvertisingAPIv1.GetItems"; return callApi(reqJson, path, target); } /** * PA-API v5 をコールする。 * @param reqJson リクエスト情報 JSON * @param path API エントリポイントのパス * @param target リクエストの送信先サービスおよびデータのオペレーション * @return レスポンス情報 JSON * @throws URISyntaxException * @throws InvalidKeyException * @throws NoSuchAlgorithmException * @throws IOException * @throws InterruptedException */ public String callApi(String reqJson, String path, String target) throws URISyntaxException, InvalidKeyException, NoSuchAlgorithmException, IOException, InterruptedException { // Java 11 から正式導入された HTTP Client API を使う // HTTP リクエスト情報を構築 HttpRequest.Builder reqBuilder = HttpRequest.newBuilder() .uri(new URI("https://" + HOST + path)) // API コール用の URL .POST(HttpRequest.BodyPublishers.ofString(reqJson)) // API コールのパラメータをセット .timeout(Duration.ofSeconds(10)); // 署名情報を付加したヘッダ情報を取得 AwsSignature4 awsv4Auth = new AwsSignature4(accessKey, secretKey, path, REGION, HOST, target); Map<String, String> signedHeaders = awsv4Auth.getHeaders(reqJson); // リクエスト情報にヘッダをセット signedHeaders.remove("host"); // Host ヘッダは付加しない (jdk.httpclient.allowRestrictedHeaders) for (Map.Entry<String, String> entrySet : signedHeaders.entrySet()) { reqBuilder.header(entrySet.getKey(), entrySet.getValue()); } // HTTP リクエスト情報を生成 HttpRequest req = reqBuilder.build(); // API をコールして結果を取得 HttpClient client = HttpClient.newBuilder() .version(HttpClient.Version.HTTP_1_1) .connectTimeout(Duration.ofSeconds(10)) .build(); HttpResponse<String> res = client.send(req, HttpResponse.BodyHandlers.ofString()); // ステータスコードで成功・失敗を判断 if (res.statusCode() == 200) { return res.body(); } else { throw new RuntimeException(res.body()); } } }src/main/java/AwsSignature4.java
import javax.crypto.Mac; import javax.crypto.spec.SecretKeySpec; import java.nio.charset.StandardCharsets; import java.security.InvalidKeyException; import java.security.MessageDigest; import java.security.NoSuchAlgorithmException; import java.text.DateFormat; import java.text.SimpleDateFormat; import java.util.Date; import java.util.Map; import java.util.TimeZone; import java.util.TreeMap; /** * AWS 署名バージョン 4 (AWS Signature Version 4) */ public class AwsSignature4 { private static final String SERVICE = "ProductAdvertisingAPI"; // PA-API private static final String HMAC_ALGORITHM = "AWS4-HMAC-SHA256"; private static final String AWS_4_REQUEST = "aws4_request"; private final String awsAccessKey; private final String awsSecretKey; private final String path; private final String region; private final String host; private final String target; /** * コンストラクタ。 * @param awsAccessKey アクセスキー * @param awsSecretKey シークレットキー * @param path API エントリポイントのパス * @param region リージョン * @param host API エントリポイントのパス * @param target リクエストの送信先サービスおよびデータのオペレーション */ public AwsSignature4( String awsAccessKey, String awsSecretKey, String path, String region, String host, String target) { this.awsAccessKey = awsAccessKey; this.awsSecretKey = awsSecretKey; this.path = path; this.region = region; this.host = host; this.target = target; } /** * 認証用のヘッダ情報を返す。 * @param payload リクエスト情報 JSON * @return 認証用のヘッダ情報 * @throws NoSuchAlgorithmException * @throws InvalidKeyException */ public Map<String, String> getHeaders(String payload) throws NoSuchAlgorithmException, InvalidKeyException { // ベースになるヘッダ TreeMap<String, String> headers = new TreeMap<>(); headers.put("host", host); headers.put("content-type", "application/json; charset=utf-8"); headers.put("content-encoding", "amz-1.0"); headers.put("x-amz-target", target); // 署名を作成するときに使用されるタイムスタンプ final Date date = new Date(); headers.put("x-amz-date", getXAmzDateString(date)); // 署名付きヘッダー (signed headers) String signedHeaders = createSignedHeaders(headers); // 正規リクエスト (canonical request) String canonicalRequest = createCanonicalRequest(path, headers, signedHeaders, payload); // 署名文字列 (string to sign) String stringToSign = createStringToSign(date, region, canonicalRequest); // 署名 (signature) String signature = calculateSignature(awsSecretKey, date, region, stringToSign); // Authorization ヘッダー値 String authorization = buildAuthorizationString(awsAccessKey, region, signature, signedHeaders, date); headers.put("Authorization", authorization); return headers; } // 署名付きヘッダー (signed headers) private static String createSignedHeaders(TreeMap<String, String> headers) { StringBuilder signedHeaderBuilder = new StringBuilder(); for (String key : headers.keySet()) { signedHeaderBuilder.append(key).append(";"); } return signedHeaderBuilder.substring(0, signedHeaderBuilder.length() - 1); } // 正規リクエスト (canonical request) private static String createCanonicalRequest(String path, TreeMap<String, String> headers, String signedHeaders, String payload) throws NoSuchAlgorithmException { StringBuilder canonicalRequest = new StringBuilder(); canonicalRequest.append("POST").append("\n"); canonicalRequest.append(path).append("\n").append("\n"); for (String key : headers.keySet()) { canonicalRequest.append(key).append(":").append(headers.get(key)).append("\n"); } canonicalRequest.append("\n"); canonicalRequest.append(signedHeaders).append("\n"); canonicalRequest.append(sha256(payload)); return canonicalRequest.toString(); } // 署名文字列 (string to sign) private static String createStringToSign(Date current, String region, String canonicalRequest) throws NoSuchAlgorithmException { return HMAC_ALGORITHM + "\n" + getXAmzDateString(current) + "\n" + getYMDString(current) + "/" + region + "/" + SERVICE + "/" + AWS_4_REQUEST + "\n" + sha256(canonicalRequest); } // 署名 (signature) private static String calculateSignature(String awsSecretKey, Date current, String region, String stringToSign) throws InvalidKeyException, NoSuchAlgorithmException { final String currentDate = getYMDString(current); byte[] signatureKey = getSigningKey(awsSecretKey, currentDate, region); byte[] signature = hmacSha256(signatureKey, stringToSign); return bytesToHex(signature); } // 署名キー (signing key) private static byte[] getSigningKey(String key, String date, String region) throws InvalidKeyException, NoSuchAlgorithmException { // 各ハッシュ関数の結果が次のハッシュ関数の入力になる byte[] kSecret = ("AWS4" + key).getBytes(StandardCharsets.UTF_8); byte[] kDate = hmacSha256(kSecret, date); byte[] kRegion = hmacSha256(kDate, region); byte[] kService = hmacSha256(kRegion, SERVICE); byte[] kSigning = hmacSha256(kService, AWS_4_REQUEST); return kSigning; } // Authorization ヘッダー値 private static String buildAuthorizationString(String awsAccessKey, String region, String signature, String signedHeaders, Date current) { return HMAC_ALGORITHM + " " + "Credential=" + awsAccessKey + "/" + getYMDString(current) + "/" + region + "/" + SERVICE + "/" + AWS_4_REQUEST + "," + "SignedHeaders=" + signedHeaders + "," + "Signature=" + signature; } // ハッシュ関数 SHA-256 private static String sha256(String data) throws NoSuchAlgorithmException { MessageDigest messageDigest = MessageDigest.getInstance("SHA-256"); messageDigest.update(data.getBytes(StandardCharsets.UTF_8)); byte[] digest = messageDigest.digest(); return String.format("%064x", new java.math.BigInteger(1, digest)); } // HMAC-SHA256 関数 private static byte[] hmacSha256(byte[] key, String data) throws NoSuchAlgorithmException, InvalidKeyException { Mac mac = Mac.getInstance("HmacSHA256"); mac.init(new SecretKeySpec(key, "HmacSHA256")); return mac.doFinal(data.getBytes(StandardCharsets.UTF_8)); } // バイナリ値を 16 進数表現に変換 private static String bytesToHex(byte[] data) { final char[] hexCode = "0123456789ABCDEF".toCharArray(); StringBuilder r = new StringBuilder(data.length * 2); for (byte b : data) { r.append(hexCode[(b >> 4) & 0xF]); r.append(hexCode[(b & 0xF)]); } return r.toString().toLowerCase(); } // x-amz-date ヘッダ用日時文字列 (UTC で YYYYMMDD'T'HHMMSS'Z' の ISO 8601 形式) private static String getXAmzDateString(Date date) { DateFormat dateFormat = new SimpleDateFormat("yyyyMMdd'T'HHmmss'Z'"); // ISO 8601 dateFormat.setTimeZone(TimeZone.getTimeZone("UTC")); return dateFormat.format(date); } // 日付文字列 yyyyMMdd 形式 private static String getYMDString(Date date) { DateFormat dateFormat = new SimpleDateFormat("yyyyMMdd"); dateFormat.setTimeZone(TimeZone.getTimeZone("UTC")); return dateFormat.format(date); } }src/main/java/JsonUtil.java
// 外部ライブラリの Jackson を使う import com.fasterxml.jackson.core.json.JsonWriteFeature; import com.fasterxml.jackson.databind.ObjectMapper; import java.io.IOException; import java.io.StringWriter; import java.util.Map; /** * JSON 操作クラス。 */ public class JsonUtil { /** * オブジェクトから JSON 文字列を生成する。 * @param obj オブジェクト * @return JSON 文字列 * @throws IOException */ public String objectToJson(Map<String, Object> obj) throws IOException { StringWriter out = new StringWriter(); ObjectMapper mapper = new ObjectMapper(); // ASCII 文字以外は Unicode escape する mapper.configure(JsonWriteFeature.ESCAPE_NON_ASCII.mappedFeature(), true); mapper.writerWithDefaultPrettyPrinter().writeValue(out, obj); return out.toString(); } /** * JSON を読みやすい形にする。 * @param json JSON 文字列 * @return 読みやすい形になった JSON 文字列 * @throws IOException */ public String prettyPrint(String json) throws IOException { StringWriter out = new StringWriter(); ObjectMapper mapper = new ObjectMapper(); mapper.writerWithDefaultPrettyPrinter().writeValue(out, mapper.readValue(json, Map.class)); return out.toString(); } }サンプルコードの実行結果
実行環境: macOS Catalina + Java 15 (AdoptOpenJDK 15) + Gradle 6.6.1
$ gradle run Starting a Gradle Daemon (subsequent builds will be faster) > Task :run ===== キーワードから商品を検索: リクエスト ===== { "PartnerType" : "Associates", "PartnerTag" : "XXXXX-22", "Keywords" : "\u30B7\u30A7\u30A4\u30AF\u30B9\u30D4\u30A2", "SearchIndex" : "All", "ItemCount" : 3, "Resources" : [ "ItemInfo.Title", "ItemInfo.ByLineInfo", "ItemInfo.ProductInfo", "ItemInfo.ProductInfo", "Images.Primary.Large", "Images.Primary.Medium", "Images.Primary.Small" ] } ===== キーワードから商品を検索: レスポンス ===== { "SearchResult" : { "Items" : [ { "ASIN" : "B06ZZH149Y", "DetailPageURL" : "https://www.amazon.co.jp/dp/B06ZZH149Y?tag=XXXXX-22&linkCode=osi&th=1&psc=1", "Images" : { "Primary" : { "Large" : { "Height" : 500, "URL" : "https://m.media-amazon.com/images/I/41Ms+C0NwNL.jpg", "Width" : 311 }, "Medium" : { "Height" : 160, "URL" : "https://m.media-amazon.com/images/I/41Ms+C0NwNL._SL160_.jpg", "Width" : 100 }, "Small" : { "Height" : 75, "URL" : "https://m.media-amazon.com/images/I/41Ms+C0NwNL._SL75_.jpg", "Width" : 47 } } }, "ItemInfo" : { "ByLineInfo" : { "Contributors" : [ { "Locale" : "ja_JP", "Name" : "河合祥一郎", "Role" : "著", "RoleType" : "author" } ], "Manufacturer" : { "DisplayValue" : "祥伝社", "Label" : "Manufacturer", "Locale" : "ja_JP" } }, "ProductInfo" : { "IsAdultProduct" : { "DisplayValue" : false, "Label" : "IsAdultProduct", "Locale" : "en_US" }, "ReleaseDate" : { "DisplayValue" : "2017-04-21T00:00:00.000Z", "Label" : "ReleaseDate", "Locale" : "en_US" } }, "Title" : { "DisplayValue" : "あらすじで読むシェイクスピア全作品 (祥伝社新書)", "Label" : "Title", "Locale" : "ja_JP" } } }, { "ASIN" : "B015BY1Q6Q", "DetailPageURL" : "https://www.amazon.co.jp/dp/B015BY1Q6Q?tag=XXXXX-22&linkCode=osi&th=1&psc=1", "Images" : { "Primary" : { "Large" : { "Height" : 500, "URL" : "https://m.media-amazon.com/images/I/516XD+o35gL.jpg", "Width" : 375 }, "Medium" : { "Height" : 160, "URL" : "https://m.media-amazon.com/images/I/516XD+o35gL._SL160_.jpg", "Width" : 120 }, "Small" : { "Height" : 75, "URL" : "https://m.media-amazon.com/images/I/516XD+o35gL._SL75_.jpg", "Width" : 56 } } }, "ItemInfo" : { "ByLineInfo" : { "Contributors" : [ { "Locale" : "ja_JP", "Name" : "メル・ギブソン", "Role" : "出演", "RoleType" : "actor" }, { "Locale" : "ja_JP", "Name" : "グレン・クローズ", "Role" : "出演", "RoleType" : "actor" }, { "Locale" : "ja_JP", "Name" : "アラン・ベイツ", "Role" : "出演", "RoleType" : "actor" }, { "Locale" : "ja_JP", "Name" : "ポール・スコフィールド", "Role" : "出演", "RoleType" : "actor" }, { "Locale" : "ja_JP", "Name" : "フランコ・ゼフィレッリ", "Role" : "監督", "RoleType" : "director" }, { "Locale" : "ja_JP", "Name" : "クリストファー・デヴォア", "Role" : "Writer", "RoleType" : "writer" } ] }, "ProductInfo" : { "IsAdultProduct" : { "DisplayValue" : false, "Label" : "IsAdultProduct", "Locale" : "en_US" }, "ReleaseDate" : { "DisplayValue" : "2015-09-16T00:00:00.000Z", "Label" : "ReleaseDate", "Locale" : "en_US" } }, "Title" : { "DisplayValue" : "ハムレット(字幕版)", "Label" : "Title", "Locale" : "ja_JP" } } }, { "ASIN" : "B07WPXRT5W", "DetailPageURL" : "https://www.amazon.co.jp/dp/B07WPXRT5W?tag=XXXXX-22&linkCode=osi&th=1&psc=1", "Images" : { "Primary" : { "Large" : { "Height" : 375, "URL" : "https://m.media-amazon.com/images/I/51CnJBKwu5L.jpg", "Width" : 500 }, "Medium" : { "Height" : 120, "URL" : "https://m.media-amazon.com/images/I/51CnJBKwu5L._SL160_.jpg", "Width" : 160 }, "Small" : { "Height" : 56, "URL" : "https://m.media-amazon.com/images/I/51CnJBKwu5L._SL75_.jpg", "Width" : 75 } } }, "ItemInfo" : { "ByLineInfo" : { "Contributors" : [ { "Locale" : "ja_JP", "Name" : "マーク・ベントン", "Role" : "出演", "RoleType" : "actor" }, { "Locale" : "ja_JP", "Name" : "ジョー・ジョイナー", "Role" : "出演", "RoleType" : "actor" }, { "Locale" : "ja_JP", "Name" : "アンバー・アガ", "Role" : "出演", "RoleType" : "actor" }, { "Locale" : "ja_JP", "Name" : "リチャード・サイニー", "Role" : "監督", "RoleType" : "director" }, { "Locale" : "ja_JP", "Name" : "イアン・バーバー", "Role" : "監督", "RoleType" : "director" }, { "Locale" : "ja_JP", "Name" : "ウィル・トロッター", "Role" : "プロデュース", "RoleType" : "producer" } ] }, "ProductInfo" : { "IsAdultProduct" : { "DisplayValue" : false, "Label" : "IsAdultProduct", "Locale" : "en_US" } }, "Title" : { "DisplayValue" : "第1話", "Label" : "Title", "Locale" : "ja_JP" } } } ], "SearchURL" : "https://www.amazon.co.jp/s?k=%E3%82%B7%E3%82%A7%E3%82%A4%E3%82%AF%E3%82%B9%E3%83%94%E3%82%A2&rh=p_n_availability%3A-1&tag=XXXXX-22&linkCode=osi", "TotalResultCount" : 146 } } ===== ASIN から商品情報を取得: リクエスト ===== { "PartnerType" : "Associates", "PartnerTag" : "XXXXX-22", "Resources" : [ "ItemInfo.Title", "ItemInfo.ByLineInfo" ], "ItemIds" : [ "4391641585", "B010EB1HR4", "B0125SPF90", "B07V52KSGT" ] } ===== ASIN から商品情報を取得: レスポンス ===== { "ItemsResult" : { "Items" : [ { "ASIN" : "4391641585", "DetailPageURL" : "https://www.amazon.co.jp/dp/4391641585?tag=XXXXX-22&linkCode=ogi&th=1&psc=1", "ItemInfo" : { "ByLineInfo" : { "Contributors" : [ { "Locale" : "ja_JP", "Name" : "サンエックス", "Role" : "監修", "RoleType" : "consultant_editor" }, { "Locale" : "ja_JP", "Name" : "主婦と生活社", "Role" : "編集", "RoleType" : "editor" } ], "Manufacturer" : { "DisplayValue" : "主婦と生活社", "Label" : "Manufacturer", "Locale" : "ja_JP" } }, "Title" : { "DisplayValue" : "すみっコぐらし検定公式ガイドブック すみっコぐらし大図鑑 (生活シリーズ)", "Label" : "Title", "Locale" : "ja_JP" } } }, { "ASIN" : "B010EB1HR4", "DetailPageURL" : "https://www.amazon.co.jp/dp/B010EB1HR4?tag=XXXXX-22&linkCode=ogi&th=1&psc=1", "ItemInfo" : { "ByLineInfo" : { "Brand" : { "DisplayValue" : "Hostess Entertainmen", "Label" : "Brand", "Locale" : "ja_JP" }, "Contributors" : [ { "Locale" : "ja_JP", "Name" : "ハロウィン", "Role" : "アーティスト", "RoleType" : "artist" } ], "Manufacturer" : { "DisplayValue" : "ホステス", "Label" : "Manufacturer", "Locale" : "ja_JP" } }, "Title" : { "DisplayValue" : "守護神伝 第二章 <エクスパンデッド・エディション>(リマスター)", "Label" : "Title", "Locale" : "ja_JP" } } }, { "ASIN" : "B0125SPF90", "DetailPageURL" : "https://www.amazon.co.jp/dp/B0125SPF90?tag=XXXXX-22&linkCode=ogi&th=1&psc=1", "ItemInfo" : { "ByLineInfo" : { "Brand" : { "DisplayValue" : "ルービーズジャパン(RUBIE'S JAPAN)", "Label" : "Brand", "Locale" : "ja_JP" }, "Manufacturer" : { "DisplayValue" : "ルービーズジャパン(RUBIE'S JAPAN)", "Label" : "Manufacturer", "Locale" : "ja_JP" } }, "Title" : { "DisplayValue" : "ハロウィン ロッキング パンプキン ホームデコレーション用小物 H 130cm", "Label" : "Title", "Locale" : "ja_JP" } } }, { "ASIN" : "B07V52KSGT", "DetailPageURL" : "https://www.amazon.co.jp/dp/B07V52KSGT?tag=XXXXX-22&linkCode=ogi&th=1&psc=1", "ItemInfo" : { "ByLineInfo" : { "Contributors" : [ { "Locale" : "ja_JP", "Name" : "リアン・リース", "Role" : "出演", "RoleType" : "actor" }, { "Locale" : "ja_JP", "Name" : "ジェイミー・リー・カーティス", "Role" : "出演", "RoleType" : "actor" }, { "Locale" : "ja_JP", "Name" : "ウィル・パットン", "Role" : "出演", "RoleType" : "actor" }, { "Locale" : "ja_JP", "Name" : "ジュディ・グリア", "Role" : "出演", "RoleType" : "actor" }, { "Locale" : "ja_JP", "Name" : "ヴァージニア・ガードナー", "Role" : "出演", "RoleType" : "actor" }, { "Locale" : "ja_JP", "Name" : "ジェファーソン・ホール", "Role" : "出演", "RoleType" : "actor" }, { "Locale" : "ja_JP", "Name" : "アンディ・マティチャック", "Role" : "出演", "RoleType" : "actor" }, { "Locale" : "ja_JP", "Name" : "ニック・キャッスル", "Role" : "出演", "RoleType" : "actor" }, { "Locale" : "ja_JP", "Name" : "ジェームス・ジュード・コートニー", "Role" : "出演", "RoleType" : "actor" }, { "Locale" : "ja_JP", "Name" : "ハルク・ビルギナー", "Role" : "出演", "RoleType" : "actor" }, { "Locale" : "ja_JP", "Name" : "デヴィッド・ゴードン・グリーン", "Role" : "監督", "RoleType" : "director" }, { "Locale" : "ja_JP", "Name" : "デヴィッド・ゴードン・グリーン", "Role" : "Writer", "RoleType" : "writer" }, { "Locale" : "ja_JP", "Name" : "ダニー・マクブライド", "Role" : "Writer", "RoleType" : "writer" }, { "Locale" : "ja_JP", "Name" : "ジェフ・フラッドリー", "Role" : "Writer", "RoleType" : "writer" }, { "Locale" : "ja_JP", "Name" : "マレク・アカッド", "Role" : "プロデュース", "RoleType" : "producer" }, { "Locale" : "ja_JP", "Name" : "ジェイソン・ブラム", "Role" : "プロデュース", "RoleType" : "producer" }, { "Locale" : "ja_JP", "Name" : "ビル・ブロック", "Role" : "プロデュース", "RoleType" : "producer" } ] }, "Title" : { "DisplayValue" : "ハロウィン (字幕版)", "Label" : "Title", "Locale" : "ja_JP" } } } ] } } BUILD SUCCESSFUL in 13s 2 actionable tasks: 2 executed参考資料
- 投稿日:2020-09-25T17:01:57+09:00
【AndroidStudio】アプリ背景に任意の画像を設定する【Java】
元画像(左)と画面サンプル(右)

はじめに
画像を用意してください。著作権フリーのものか自身が作成したものがいいと思います。
著作権フリーの場合でも利用制限を確認してください。
illustAC
illust image
いらすとや などなど
画像を表示させる方法はいくつかあるみたいですが、この記事は drawable にファイルを置き、それを ImageView に書き込んで終了です。drawable フォルダ
練習用に TestImageView というプロジェクトを用意しました。
app → res → drawable
drawable を右クリック、Show in Explorer をクリックしdrawable-v24 フォルダを展開、ここに使用する画像を置いてください。
AndroidStudio の drawable フォルダを開いて画像ファイルがあればOKです。
なお、Java の変数命名規則が働いていると思われます。数値から始まるファイルは置けませんので、その場合はファイル名を変更してください。.xml ファイル
actixity_main.xml<?xml version="1.0" encoding="utf-8"?> <androidx.constraintlayout.widget.ConstraintLayout xmlns:android="http://schemas.android.com/apk/res/android" xmlns:app="http://schemas.android.com/apk/res-auto" xmlns:tools="http://schemas.android.com/tools" android:layout_width="match_parent" android:layout_height="match_parent" tools:context=".MainActivity"> <ImageView android:layout_width="match_parent" android:layout_height="match_parent" android:src="@drawable/momizi"/> </androidx.constraintlayout.widget.ConstraintLayout>上記のコードで表示されたのがこちらの画面。
ちょっと、、上下のサイズが合ってないですね。。大丈夫です、なんとかなります。下に進んでください。
この段階で「java.lang.RuntimeException: Canvas: trying to draw too large(******bytes) bitmap.」というエラーが出る場合は、画像サイズが大きいです。
画像を小さくしてみましょう。
オンライン画像サイズ変更ImageView.ScaleType
Qiita のこちらの記事が参考になります。
【ImageView】ScaleTypeと表示画像の対応表
上記のコードの ImageView に android:scaleType="centerCrop" を追記しました。actixity_main.xml<?xml version="1.0" encoding="utf-8"?> <androidx.constraintlayout.widget.ConstraintLayout xmlns:android="http://schemas.android.com/apk/res/android" xmlns:app="http://schemas.android.com/apk/res-auto" xmlns:tools="http://schemas.android.com/tools" android:layout_width="match_parent" android:layout_height="match_parent" tools:context=".MainActivity"> <ImageView android:layout_width="match_parent" android:layout_height="match_parent" android:src="@drawable/momizi" android:scaleType="centerCrop"/> </androidx.constraintlayout.widget.ConstraintLayout>上記のコードで表示されたのがこちらの画面。
上下左右共に画面に合いました!
参考
nyanのアプリ開発([Android] ImageView 画像を表示させる3つの方法)
nyanのアプリ開発([Android] ImageView画像をScreenのレイアウトにフィットさせるには)
【ImageView】ScaleTypeと表示画像の対応表


- 投稿日:2020-09-25T16:33:59+09:00
Apache Flink Python API: 歴史、アーキテクチャ、開発環境、主要な演算子
この記事では、Apache Flink Python APIの歴史を紹介し、そのアーキテクチャや開発環境、主要な演算子について解説しています。
本ブログは英語版からの翻訳です。オリジナルはこちらからご確認いただけます。一部機械翻訳を使用しております。翻訳の間違いがありましたら、ご指摘いただけると幸いです。
Apache Flink Python APIの歴史、現状と今後の展開
Apache Flink が Python をサポートする理由
Apache Flinkは、統一されたストリームとバッチデータ処理機能を持つオープンソースのビッグデータコンピューティングエンジンです。Apache Flink 1.9.0では、機械学習(ML)APIと新しいPython APIが提供されています。次に、なぜApache FlinkがPythonをサポートしているのかについて詳しく説明します。
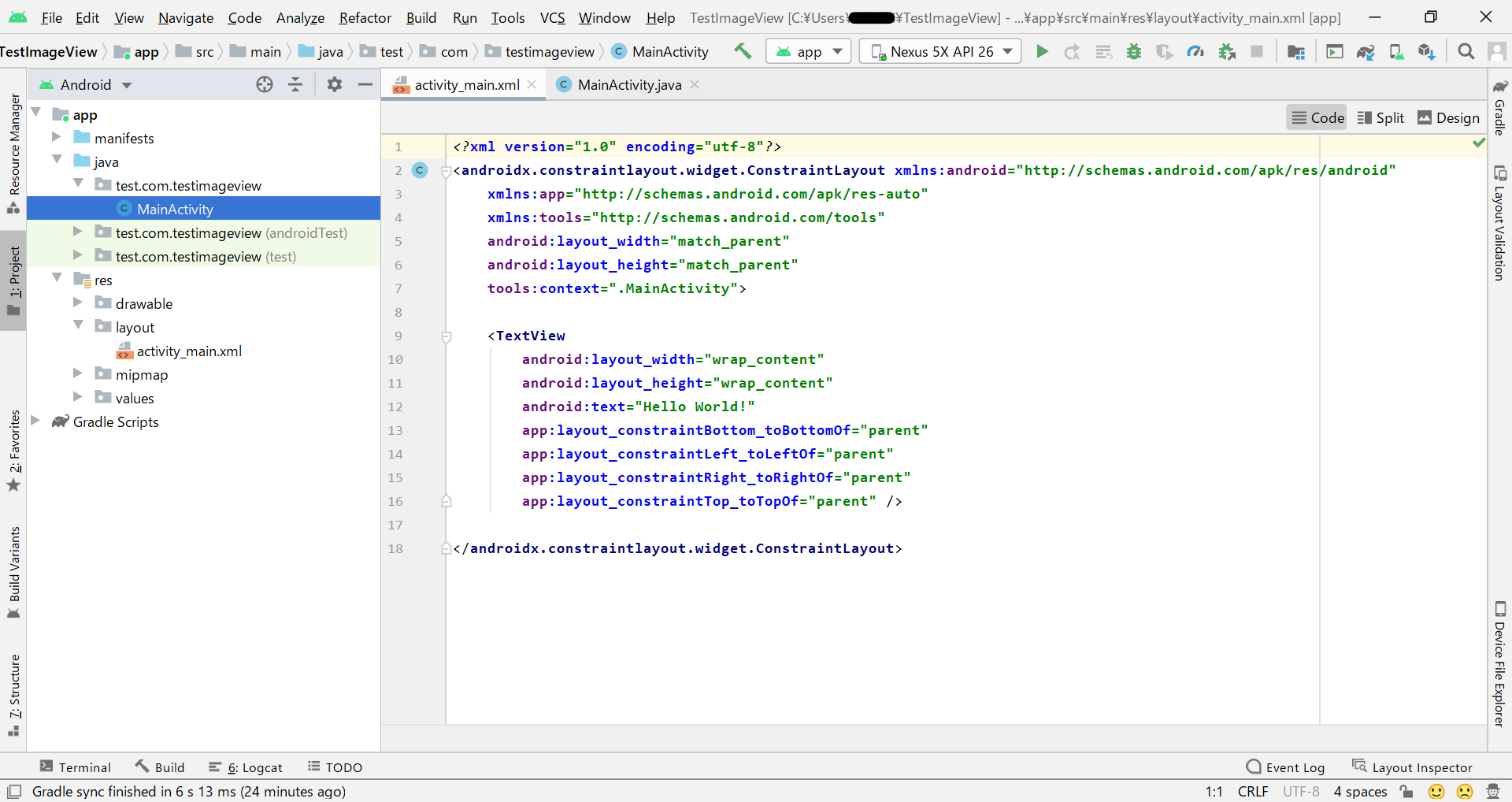
- Pythonは最もポピュラーな開発言語の一つ
RedMonkの統計によると、PythonはJava、JavaScriptに次いで3番目に人気のある開発言語です。RedMonkは、ソフトウェア開発者に焦点を当てた業界アナリスト会社です。Apache Flinkは、ストリームおよびバッチデータ処理機能を持つビッグデータコンピューティングエンジンです。話題のPythonとApache Flinkの関係は?この疑問を踏まえて、現在有名なビッグデータ関連のオープンソースコンポーネントを見てみましょう。例えば、初期のバッチ処理フレームワークであるHadoop、ストリームコンピューティングプラットフォームであるSTORM、最近人気のSpark、データウェアハウスであるHive、KVストレージベースであるHBaseなどは、Python APIをサポートしている有名なオープンソースプロジェクトです。
- Pythonは多くのオープンソースプロジェクトでサポートされています。
Pythonの完全なエコシステムを考えると、Apache Flinkはバージョン1.9に多額の投資をして、全く新しいPyFlinkを立ち上げました。ビッグデータとして、人工知能(AI)はPythonと密接な関係があります。
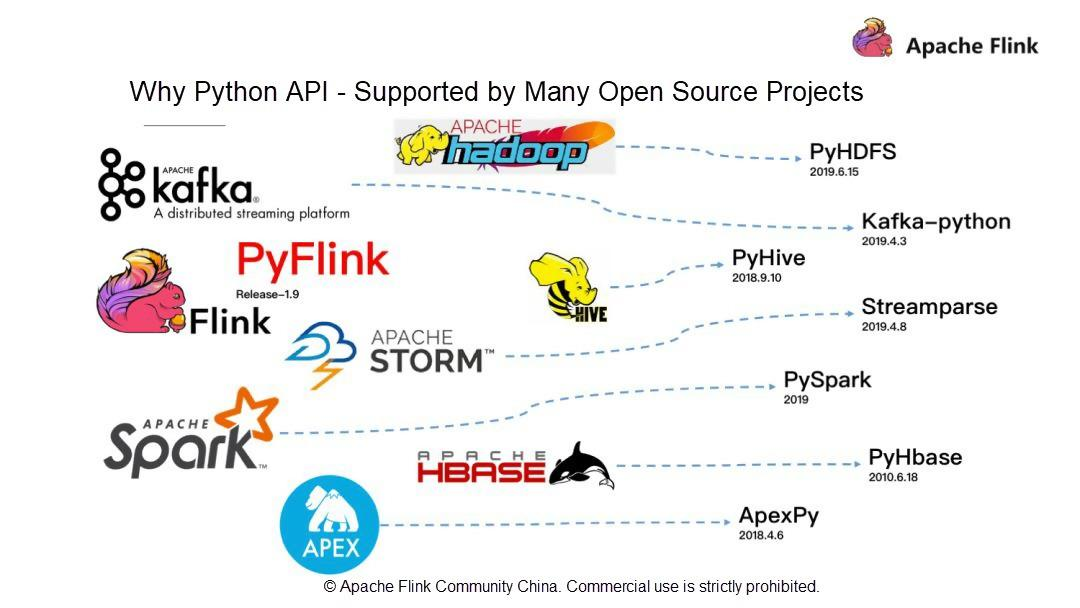
- Pythonは機械学習(ML)に支持されています。
統計によると、ML業界の求人情報の0.129%とマッチングしており、Pythonが最も多く求められる言語となっています。R言語の0.076%と比較すると、ML業界ではPythonの方が好まれていることがわかります。解釈型言語であるPythonは、"物事を行うための方法は一つしかない "という設計理念を持っています。そのシンプルさと使いやすさから、世界で最も人気のある言語の1つであるPythonは、ビッグデータコンピューティングの分野では良いエコシステムとなっています。また、MLの分野でも有望な将来性を持っています。そこで、先日、Apache Flink 1.9で全く新しいアーキテクチャを採用したPython APIを発表しました。
Apache Flinkは、統一されたストリームとバッチデータ処理機能を持つコンピューティングエンジンです。コミュニティはFlinkユーザーを非常に重要視しており、JavaやScalaのようにFlinkへのアクセスやチャンネルをより多く提供したいと考えています。これにより、より多くのユーザーがFlinkをより便利に利用できるようになり、Flinkのビッグデータコンピューティング能力によってもたらされる価値から恩恵を受けることができるようになります。Apache Flink 1.9から、Apache Flinkコミュニティは、JOIN、AGG、WINDOWなどの最も一般的に使用されている演算子をサポートする全く新しい技術的なアーキテクチャを持つPython APIを開始します。
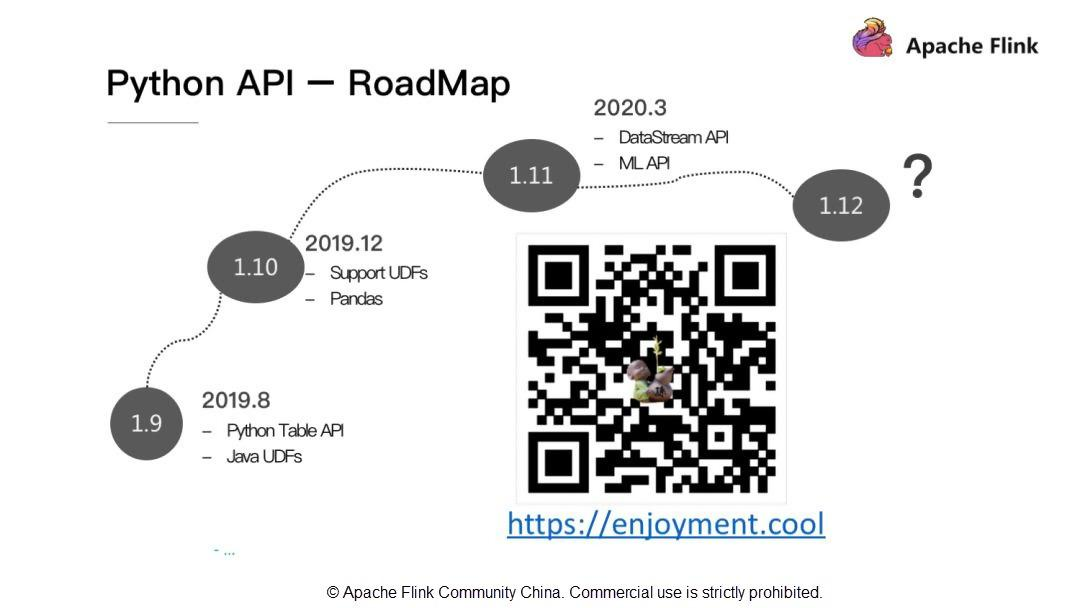
Python API - RoadMap
Apache Flink 1.9では、Pythonはユーザー定義のJava関数を利用することができますが、Pythonネイティブのユーザー定義関数の定義には対応していません。そのため、Apache Flink 1.10ではPythonのユーザー定義関数とPythonのデータ解析ライブラリPandasのサポートを行います。また、Apache Flink 1.11ではDataStream APIとML APIのサポートを追加します。
Apache Flink Python APIのアーキテクチャと開発環境
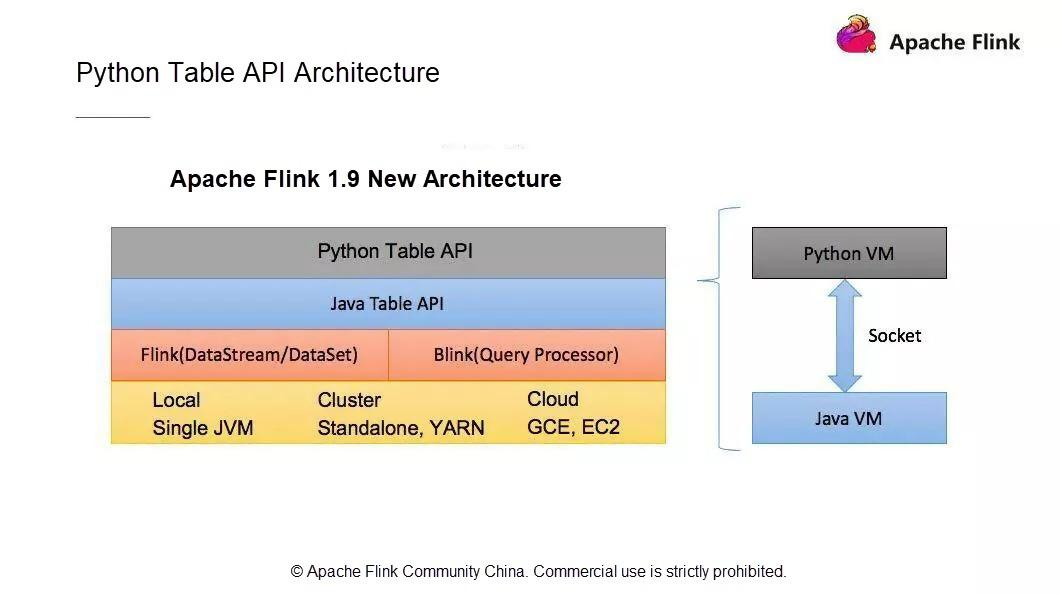
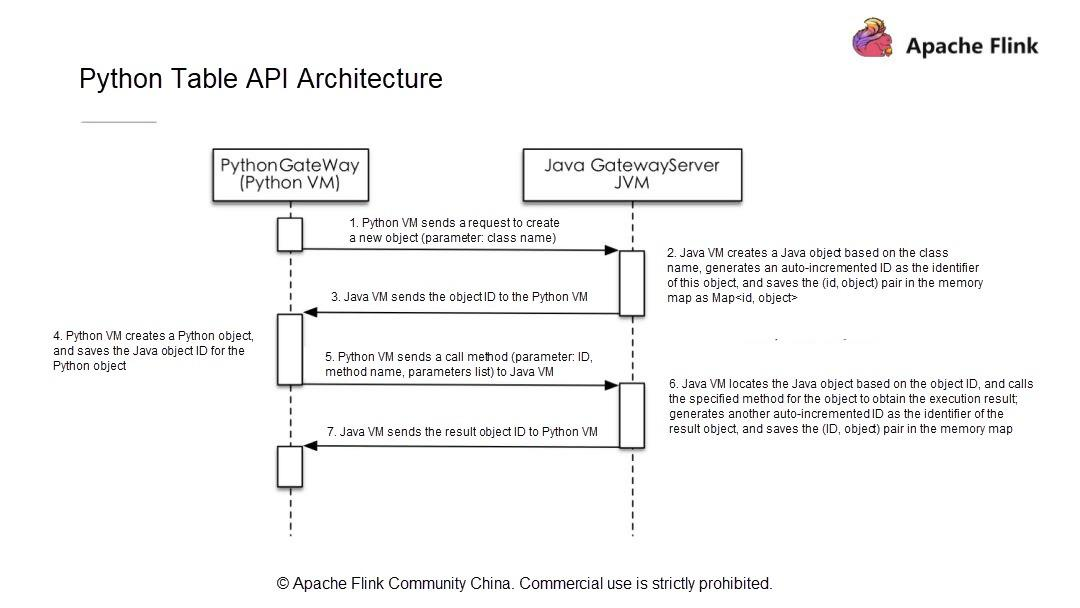
PythonのテーブルAPIアーキテクチャ
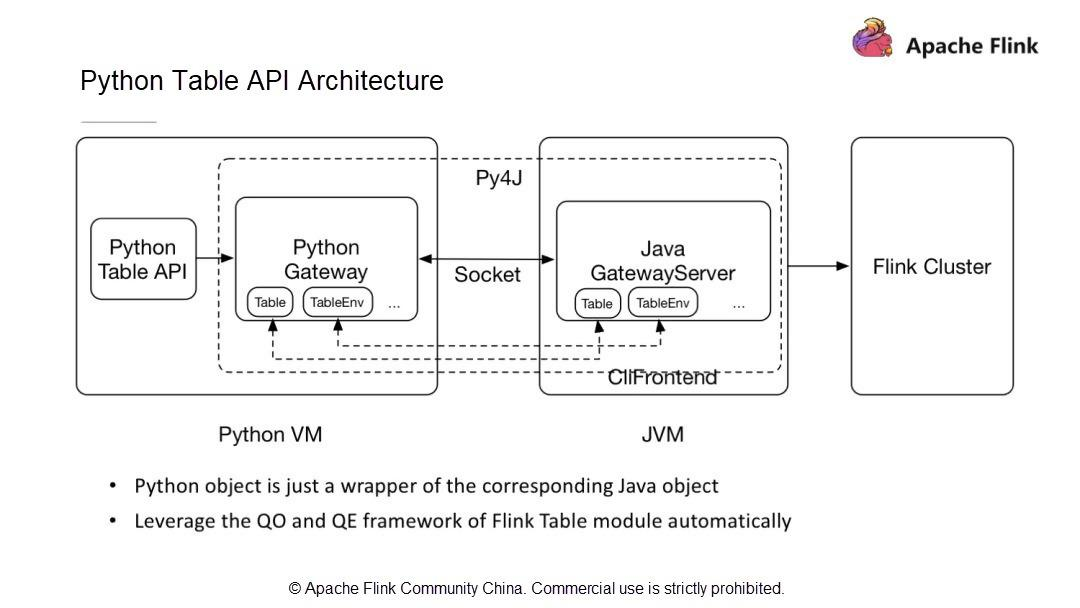
新しいPython APIアーキテクチャは、ユーザーAPIモジュール、Python仮想マシン(VM)とJava VM間の通信モジュール、Flinkクラスタにタスクを投入して運用するモジュールで構成されています。
Python VMとJava VMはどのように通信するのでしょうか?Python VM には、Python VM からの呼び出しを受け取る GateWayServer を持つ Java VM との接続を維持する Python ゲートウェイがあります。
1.9以前のApache Flinkのバージョンでは、すでにDataSetとDataStreamモジュールでPython APIをサポートしています。しかし、それぞれ2つの異なるAPIを使用しています。DataSet API と DataStream API です。Flinkのようにストリームとバッチデータ処理機能を統一したストリームコンピューティングエンジンにとって、統一されたアーキテクチャは極めて重要です。既存のPythonのDataSet APIとDataStream APIはJPythonの技術アーキテクチャを使用しています。しかし、JPythonはPython 3.Xシリーズを適切にサポートすることができません。そのため、既存のPython APIアーキテクチャは放棄し、Flink 1.9からは全く新しい技術アーキテクチャが採用されています。この新しいPython APIはTable APIをベースに実装されています。
Table APIとPython APIの通信は、Python VMとJava VM間の通信で実装されています。Python APIはJava APIと通信し、Python APIは書き込みや呼び出しを行います。Python APIの操作は、JavaのTable APIの操作と似ています。新しいアーキテクチャには次のような利点があります。
- 演算子を新たに作成する必要がなく、代わりにJava Table APIの機能との整合性を簡単に維持することができます。
- Java Table APIの最適化モデルを使用してPython APIを最適化します。これにより、Python APIを使用して書かれたジョブが最適なパフォーマンスを提供することが保証されます。
Python VMがJavaオブジェクトに対してリクエストを開始すると、Java VMはオブジェクトを作成し、ストレージ構造体に保存し、オブジェクトにIDを割り当てます。そして、そのIDをPython VMに送信し、Python VMは対応するオブジェクトIDを持つオブジェクトを操作します。Python VMはJava VMのすべてのオブジェクトを操作できるため、Python Table APIがJava Table APIと同一の機能を持ち、既存のパフォーマンス最適化モデルを利用できることが保証されます。
新しいアーキテクチャと通信モデルでは、Python VMは対応するJavaオブジェクトIDを取得し、呼び出しメソッドの名前とパラメータをJava VMに渡すだけでJava Table APIを呼び出します。したがって、Python Table APIの開発は、Java Table APIの開発と同じ手順に従います。次に、簡単なPython APIのジョブを開発する方法を探ってみましょう。
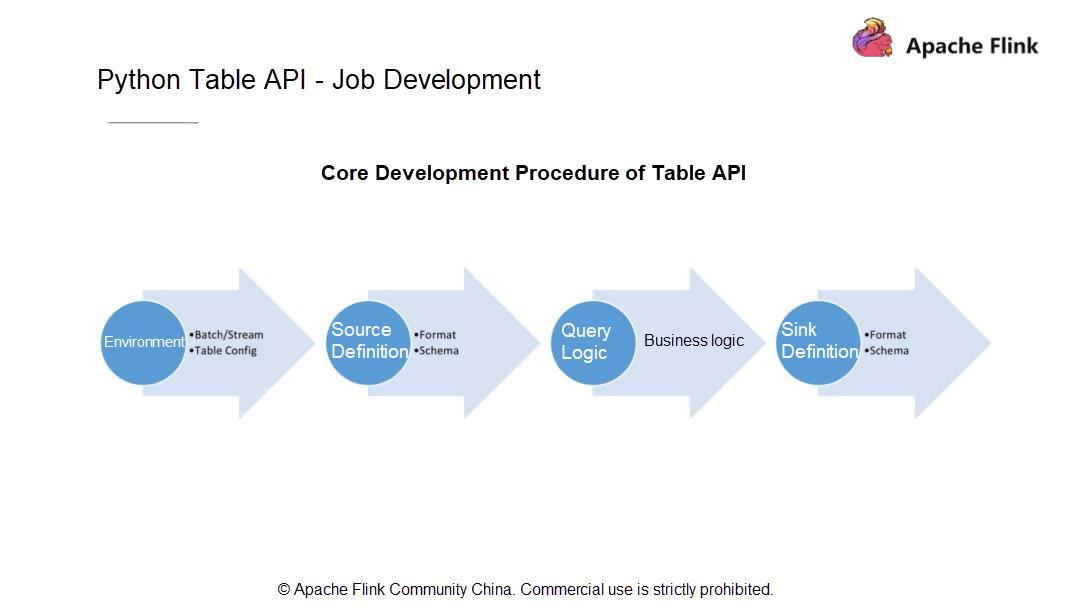
Python Table API - ジョブ開発
一般的にPythonのテーブルジョブは4つのステップに分かれています。現在の状況を考慮して、まず、ジョブをバッチモードで実行するかストリーミングモードで実行するかを決めます。それ以降のバージョンのユーザはこのステップをスキップすることができますが、Apache Flink 1.9のユーザはこの決定をしなければなりません。
ジョブの実行モードを決めたら、データがどこから来ているのか、データソース、スキーマ、データタイプをどのように定義するかを知っておきます。次に、計算ロジック (データに対して実行される計算操作) を書き、最終的な計算結果を指定したシステムに永続化します。次に、シンクを定義します。データソースを定義するのと同じように、シンクのスキーマとその中のすべてのフィールド型を定義します。
次に、上記の各ステップをPython APIを使ってコーディングする方法を理解しましょう。まず、実行環境を作成しますが、これは最終的にはテーブル環境でなければなりません。このテーブル環境には、実行プロセス中にRunTimeレイヤーに渡されるいくつかの設定パラメータを持つTable Configモジュールが存在しなければなりません。また、このモジュールは、実際のサービス開発段階で使用できるいくつかのカスタム設定項目を提供しなければなりません。
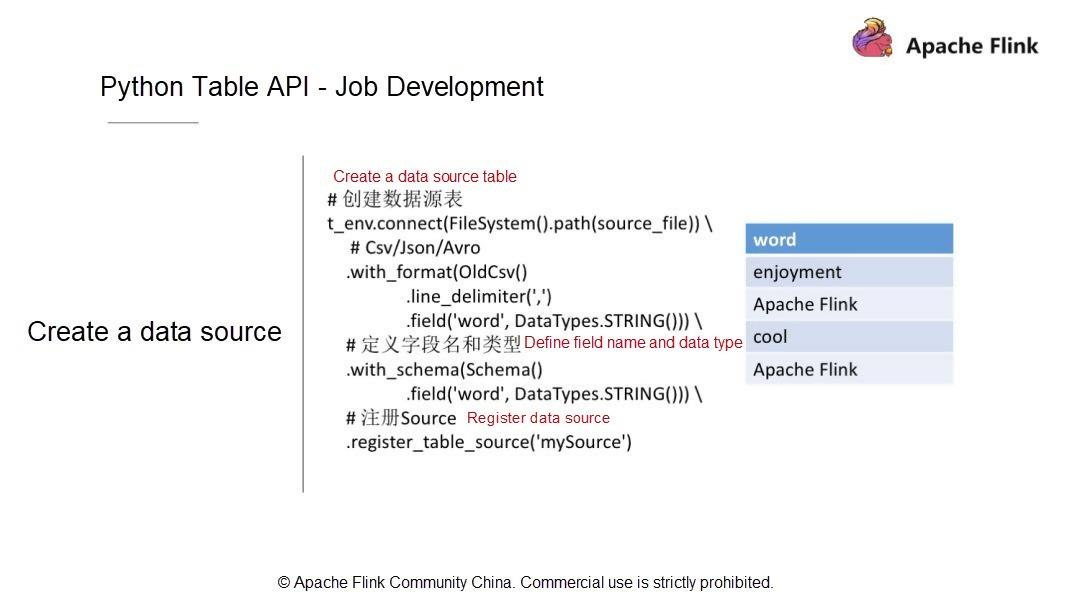
実行環境を作成したら、データソースのテーブルを定義する必要があります。例として、CSVファイル内のデータレコードはカンマ(,)で区切られ、フィールドはフィールド列にリストされています。このテーブルにはワードという1つのフィールドのみが含まれており、このフィールドの型はStringとなっています。
データソースを定義して記述し、データソースの構造をテーブルに変換した後、Table API層ではどのようなデータ構造とデータ型になるのでしょうか。次に、
with_SCHEMAを使ってフィールドとフィールド型を追加する方法を見てみましょう。ここでは、フィールドは1つだけで、データ型はStringです。データソースは、その後のクエリや計算のためにカタログにテーブルとして登録されています。
そして、結果テーブルを作成します。計算が終わったら、計算結果を永続的なシステムに保存します。例えば、WordCountジョブを書くには、まず、ワードとカウントの2つのフィールドを持つストレージテーブルがあります。そして、このテーブルをシンクとして登録します。
テーブルシンクを登録したら、計算ロジックの書き方を見てみましょう。実はPython APIでWordCountを書くのは、Table APIで書くのと同じくらい簡単です。DataStreamとは異なり、Python APIではWordCountのジョブを書くのに必要なのは1行のステートメントだけです。例えば、まずソーステーブルをスキャンし、GROUP BY文を使用してワードごとに行をグループ化します。次にSELECT文を使って単語を選択し、集約関数を使って各単語のカウントを計算します。最後に計算結果を結果テーブルに挿入します。
Python Table API - 開発環境
致命的な問題は、具体的にどのようにWordCountジョブを実行するのかということです。まず、開発環境を設定します。異なるバージョンのソフトウェアが異なるマシンにインストールされている場合があります。ここでは、ソフトウェアのバージョンに必要な要件をいくつか紹介します。
第二に、ソースコードを元にバイナリJavaリリースパッケージを構築します。そのため、マスターブランチのコードをクローンして、1.9ブランチを取得します。もちろん、マスターコードを使っても構いません。しかし、マスターコードは安定性に欠けるので、1.9ブランチコードを使うことをお勧めします。では、手順を進めていきましょう。まず、コードをコンパイルします。例えば、以下のようにします。
//下载源代码 git clone https://github.com/apache/flink.git // 拉取1.9分支 cd flink; git fetch origin release-1.9 git checkout -b release-1.9 origin/release-1.9 //构建二进制发布包 mvn clean install -DskipTests -Dfastコンパイル後、対応するディレクトリにリリースパッケージを配置してください。
cd flink-dist/target/flink-1.9.0-bin/flink-1.9.0 tar -zcvf flink-1.9.0.tar.gz flink-1.9.0Java APIをビルドしたら、APIを検証してPythonのリリースパッケージをビルドします。
すべてのPythonユーザーは、pip installを通じてパッケージをインストールするためには、依存ライブラリをローカルのPython環境と統合するか、これらの依存ライブラリをローカル環境にインストールしなければならないことを知っています。
これはFlinkにも当てはまります。PyFlinkをPypipによって認識されたリソースパッケージにパッケージ化してインストールします。以下のコマンドを使って、パッケージをコピーして自分の環境にインストールします。
cd flink-Python;Python setup.py sdistこの処理は、Java リリースパッケージを、いくつかの Java パッケージといくつかの PyFlink モジュールの Python パッケージと一緒に単純にラップします。新しい
apache-link-1.9.dev0.tar.gzパッケージを dist ディレクトリから探してください。cd dist/distディレクトリにある
apache-flink-1.9.dev0.tar.gzファイルは、pip installでインストールに使えるPyFlinkパッケージです。Apache Flink 1.9 のインストールパッケージには、Flink Table と Flink Table Blink の両方が含まれています。Flinkは同時に2つのプランナーをサポートしています。デフォルトのFlinkプランナーとBlinkプランナーを自由に切り替えることができます。それぞれを自分で試してみることをお勧めします。パッケージ化後、私たちの環境にインストールしてみます。
非常に簡単なコマンドを使って、まず、コマンドが正しいかどうかを確認します。コマンドを実行する前に、pipを使ってリストを確認し、パッケージが既にインストールされているかどうかを確認します。そして、前のステップで用意したパッケージをインストールしてみてください。実際のシナリオでは、アップグレードをインストールするために、新しいパッケージをインストールします。
pip install dist/*.tar.gz pip list|grep flink
パッケージをインストールしたら、先に書いたWordCountジョブを使って環境が正しいかどうかを確認します。環境が正しいかどうかを確認するには、以下のコマンドを実行して、環境コードリポジトリを直接クローンします。
git clone https://github.com/sunjincheng121/enjoyment.code.git cd enjoyment.code; Python word_count.py次に、試してみましょう。このディレクトリに以前作成したwordCountのジョブファイルを探します。直接python
word_count.pyを使って環境に問題がないか確認してみましょう。Apache Flink Python APIを使うと、WordCountジョブを実行するためのミニクラスタが起動するはずです。さて、すでにミニクラスタ上ではジョブが実行されています。この処理では、コードはまずソースファイルを読み込み、その結果をCSVファイルに書き出します。このディレクトリの中に、
sink.csvファイルを見つけます。操作手順の詳細については、Apache Flink Community Chinaに投稿された「The Status Quo and Planning of Apache Flink Python API」というタイトルの動画を参照してください。
では、統合開発環境(IDE)の設定について説明します。Python関連のロジックやジョブの開発にはPyCharmを使うことをお勧めします。
IDEのセットアップの詳細については、QRコードをスキャンするか、ブログ(https://enjoyment.cool)に直接アクセスしてください。 Python環境はたくさんあると思いますが、pipインストールで使用したものを選択する必要があります。これは非常に重要です。操作手順の詳細については、「Apache Flink Python APIの現状と計画」というタイトルの動画を参照してください。
Python Table API - ジョブの投入
ジョブの投入にはどのような方法があるのでしょうか?まず、既存のクラスタにジョブを投入するCLIメソッドを使用します。この方法を使用するには、クラスタを起動する必要があります。ビルドのディレクトリは通常 build-target の下にあります。このコマンドを直接実行してクラスタを起動します。このプロセスでは、外部の Web ポートを使用することに注意してください。
flink-conf.yamlファイルでポート番号を設定します。次に、PPT内のコマンドを使用してクラスタを起動します。クラスタが正常に起動したことを確認するには、ログを確認するか、ブラウザでサイトにアクセスします。クラスタが正常に起動した場合は、ジョブの投入方法を見てみましょう。
Flink runを使用して、以下のコードを実行してジョブを投入します。
./bin/flink run -py ~/training/0806/enjoyment.code/myPyFlink/enjoyment/word_count_cli.pyPythonファイルを指定するにはpyを、Pythonモジュールを指定するにはpymを、Pythonリソースファイルを指定するにはpyfsを、JARパッケージを指定するにはjを使用します。
Apache Flink 1.9では、もっと便利な方法があります。Python Shellを使うと、Python APIで得られた結果を対話的に書き込むことができます。Python Shellはローカルとリモートの2つのモードで実行されますが、大きな違いはありません。まずは、以下のコマンドを実行してローカルモードを試してみましょう。
bin/pyflink-shell.sh localこのコマンドはミニクラスタを起動します。コードを実行すると、FLINK - PYTHON - SHELLというテキスト付きのFlinkロゴと、この機能を示すいくつかのサンプルスクリプトが返されます。これらのスクリプトを入力すると、正しい出力と結果が返されます。ここでは、ストリーミングまたはバッチのいずれかを記述することができます。操作手順の詳細については、ビデオを参照してください。
これで、Apache Flink 1.9のPython Table APIのアーキテクチャと、Python Table APIの環境設定方法についての基本的な理解ができました。IDEでジョブを実行する方法や、Flink runとPython Shellを使ってジョブを投入する方法を見るために、簡単なWordCountの例を考えてみました。また、FlinkのPython APIを利用するためのインタラクティブな方法をいくつか体験しました。Flinkの環境設定と簡単な例のデモを紹介した後、Apache Flink 1.9のキー演算子について説明します。
Flink Python APIのキー演算子の紹介と応用
Python のテーブル API 演算子
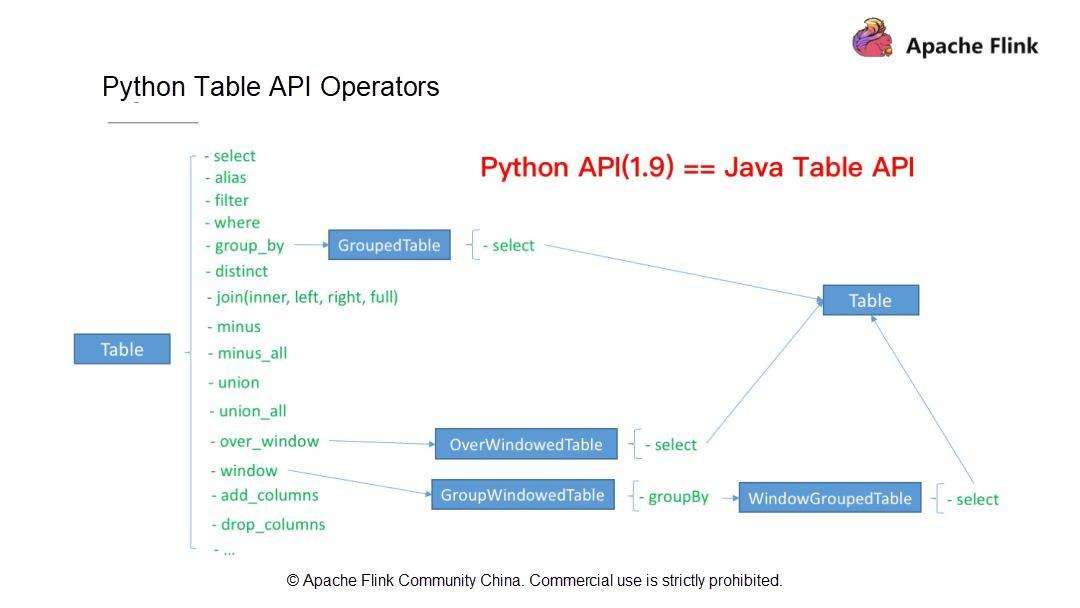
ジョブを作成する方法についてはすでに説明しました。まず、実行モードを選択します: ストリーミングかバッチかを選択します。次に、使用するテーブル(ソーステーブルと結果テーブル)、スキーマ、データ型を定義します。その後、計算ロジックを記述します。最後に、Python APIの組み込みの集計関数であるCount, Sum, Max, Minを利用します。例えば、WordCountジョブを書いたときは、Count関数を使いました。
Apache Flink 1.9は、ユーザの通常のニーズのほとんどを満たしています。では、これまでに見てきたものとは別に、Apache Flink 1.9でサポートされているFlink Table API演算子を見てみましょう。Flink Table API オペレータ(Python Table API オペレータと Java Table API オペレータ)は、以下のような操作をサポートしています。
第一に、SELECT、FILTER、集約演算、ウィンドウ演算、カラム演算(
add_columns、drop_columns)などのシングルストリーム演算。第二に、JOIN、MINUS、UNIONなどのデュアルストリーム演算。
これらの演算子はすべて Python Table API でサポートされています。Apache Flink 1.9では、Python Table APIは機能的にはJava Table APIとほぼ同じです。次に、上記の演算子の書き方とPython演算子の開発方法を理解していきましょう。
Python Table APIの演算子 - 透かしの定義
この記事を読んでお気づきの方もいるかもしれませんが、データストリームの属性である時系列については触れていません。データストリームの客観的な状態としては、データストリームがアウトオブオーダーになっている可能性があります。Apache Flinkでは、Watermarkの仕組みを利用して、アウトオブオーダーのデータストリームを処理しています。
Python APIでWatermarkを定義するには?
a と DateTime の 2 つのフィールドを含む JSON 形式のデータファイルがあるとします。透かしを定義するには、Schema作成時にrowtimeカラムを追加し、rowtimeデータ型はTimestampにする必要があります。
様々な方法で透かしを定義します。
watermarks_periodic_boundedを使用して、定期的に透かしを送信します。60000という数字は60000msを指しており、これは60秒または1分に相当します。この定義により、プログラムは1分間の期間内に順番外のデータストリームを処理することができます。したがって、値が大きいほど、順序外データに対する耐性が高く、待ち時間が長いことを示します。透かしの仕組みの詳細については、こちらののブログ http://1t.click/7dM を参照してください。PythonテーブルAPI - Java UDF
最後に、Apache Flink 1.9でのJavaユーザ定義関数(UDF)の応用について紹介します。Apache Flink 1.9はPythonのUDFをサポートしていませんが、PythonでJavaのUDFを利用することができます。Apache Flink 1.9では、Tableモジュールを最適化して再構築しています。Java UDFを開発するには、簡単な依存関係をインポートしてPython APIを開発します。Flink-table-commonをインポートします。
次に、JavaのUDFを使ってPythonのAPIを開発する方法に注目します。文字列の長さを計算するUDFを開発する必要があるとします。
t_env.register_java_functionを使って、Java関数の名前とフルパスを渡して、Java関数をPythonに登録する必要があります。その後、登録された名前を使ってUDFを呼び出すことができます。詳しくは、私のブログ http://1t.click/HQF
Java UDFを実行するには?Flinkのrunコマンドを使って実行します。前述したように、UDFのJARパッケージをインクルードするために-jを使用しています。
Java UDFはスカラー関数だけをサポートしていますか?Java UDFはスカラー関数だけでなく,テーブル関数や集約関数もサポートしています.
Python Table APIのリファレンスリンク
よく使われる資料と私のブログのリンクを掲載しています。うまくいけば、それらがあなたの役に立つことを願っています。
概要
本記事では、Apache Flink Python APIの歴史と開発ロードマップを紹介しました。次に、Apache Flink Python APIのアーキテクチャを変更する理由と、利用可能な最新のアーキテクチャについて説明しました。また、Apache Flink Python APIの今後の計画や新機能についても記載されていました。あなたの提案や考えを共有することをお勧めします。
アリババクラウドは日本に2つのデータセンターを有し、世界で60を超えるアベラビリティーゾーンを有するアジア太平洋地域No.1(2019ガートナー)のクラウドインフラ事業者です。
アリババクラウドの詳細は、こちらからご覧ください。
アリババクラウドジャパン公式ページ

















- 投稿日:2020-09-25T15:30:14+09:00
DataStream APIを用いたFlinkの開発
この記事では、分散ストリーム処理の基本をレビューし、FlinkとDataStream APIの開発を例として探ります。
本ブログは英語版からの翻訳です。オリジナルはこちらからご確認いただけます。一部機械翻訳を使用しております。翻訳の間違いがありましたら、ご指摘いただけると幸いです。
ストリーム処理の基本概念
ストリーム処理の定義は異なる場合があります。概念的には、ストリーム処理とバッチ処理は同じコインの表裏一体です。それらの関係は、ArrayList, Javaの要素が直接限定されたデータセットとみなされ、添え字(subscripts)でアクセスされるか、イテレータ(iterator)でアクセスされるかによって異なります。
図1. 左側がコイン分類器
コイン分類器をストリーム処理システムと表現することができます。事前に、コインの分類に使用されるすべてのコンポーネントは直列に接続されています。コインは連続的にシステムに入ってきて、将来の使用のために別のキューに出力されます。右の写真も同様です。
ストリーム処理システムには多くの特徴があります。一般的にストリーム処理システムは、無限のデータセットの処理をサポートするために、データ駆動型の処理方式を採用しています。あらかじめ演算子を設定しておき、データを処理します。複雑な計算ロジックを表現するために、Flinkを含む分散型ストリーム処理エンジンでは、一般的にDAGグラフを使用して計算ロジック全体を表現しています。
DAGの各点は、基本的な論理単位である先ほどの演算子を表しています。計算ロジックを有向グラフに整理して、エッジから特別なソースノードからシステムにデータが流れ込むようにします。データは、ネットワーク伝送やローカル伝送などの異なるデータ伝送方法を介して演算子間で伝送され、処理されます。最後に、データの結果は、他の特殊なシンクノードを介して外部システムやデータベースに送信されます。
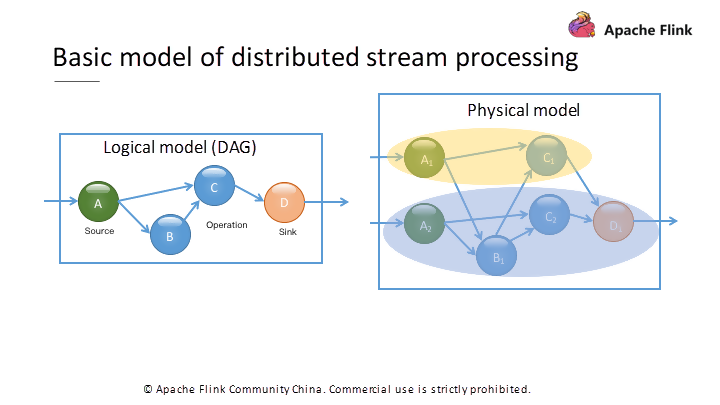
図2. DAGコンピューティングのロジックグラフと実際のランタイム物理モデル。
論理グラフ上の各演算子は、物理グラフ上に複数の同時スレッドを持ちます。分散ストリーム処理エンジンの場合、各演算子が複数のインスタンスを持つ可能性があるため、実際の実行時物理モデルはより複雑になります。図2に示すように、ソース演算子Aは2つのインスタンスを持ち、中間演算子Cも2つのインスタンスを持っています。
論理モデルでは A と B が C の上流ノードであり、それに対応する物理モデルでは、C,A,B のすべてのインスタンス間でデータ交換が存在する可能性があります。
演算子インスタンスを異なるプロセスに分散させる際には、ネットワークを介してデータを伝送します。同一プロセス内の複数のインスタンス間でのデータ転送は、通常、ネットワークを経由する必要はありません。
表1 Apache Stormを使ってDAGの計算グラフを構築したもの。Apache StormのAPI定義は「オペレーション指向」なので低レベルです。
TopologyBuilder builder = new TopologyBuilder(); builder.setSpout("spout", new RandomSentenceSpout(), 5); builder.setBolt("split", new SplitSentence(), 8).shuffleGrouping("spout"); builder.setBolt("count", new WordCount(), 12).fieldsGrouping("split", new Fields("word"));表2 Apache Flinkを用いてDAG計算グラフを構築したもの。Apache FlinkのAPI定義はより「データ指向」なので、より高レベルなものになっています。
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); DataStream<String> text = env.readTextFile ("input"); DataStream<Tuple2<String, Integer>> counts = text.flatMap(new Tokenizer()).keyBy(0).sum(1); counts.writeAsText("output");DAGグラフはストリーム処理の計算ロジックを表しているので、APIのほとんどはこの計算ロジックグラフの構築を中心に設計されています。表1に数年前に流行したApache StormのWordCountの例を示します。
Apache Stormでは、グラフにSpout演算子やBolt演算子を追加し、演算子間の接続方法を指定します。このようにして、グラフ全体を構築した後、リモートまたはローカルのクラスタで実行するためにサブミットします。
対照的に、Apache Flink API も計算論理グラフを構築していますが、Flink の API 定義はよりデータ処理ロジックを指向しています。Flink はデータストリームを無限の集合に抽象化し、その集合に対する操作のグループを定義し、最下層で対応する DAG グラフを自動的に構築します。
そのため、Flink APIはより高レベルなものとなっています。多くの研究者は、期待されるグラフ構造をより簡単に確保できるため、実験にはStormの高い柔軟性を好むかもしれません。しかし、業界全体では、Flink APIのような高度なAPIの方が使いやすいという理由で優先されています。
Flink DataStream APIの概要
これまでのストリーム処理の基本的な考え方をもとに、Flink DataStream APIの使い方を詳しく説明します。まずは簡単な例から説明します。表3は、ストリーミングのWordCountの例です。わずか5行のコードしかありませんが、Flink DataStream APIをベースにしたプログラムを開発するための基本的な構造を提供しています。
表3 Flink DataStream APIをベースにしたWordCountの例
// 1. Set the runtime environment StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); // 2. Configure the data source to read data DataStream<String> text = env.readTextFile ("input"); // 3. Perform a series of transformations DataStream<Tuple2<String, Integer>> counts = text.flatMap(new Tokenizer()).keyBy(0).sum(1); // 4. Configure the Sink to write data out counts.writeAsText("output"); // 5. Submit for execution env.execute("Streaming WordCount");ストリーミングWordCountを実装するには、まずStreamExecutionEnvironmentオブジェクトを取得します。これは、グラフを構築するコンテキストオブジェクトです。このオブジェクトに基づいて演算子を追加します。ストリーム処理レベルの場合は、データにアクセスするためのデータソースを作成します。この例では、Environmentオブジェクトにあるファイルを読み込むための組み込みのデータソースを使用します。
次に、無限のデータセットであるDataStreamオブジェクトを取得します。このデータセットに対して一連の操作を行います。例えば、WordCountの例では、各レコード(つまり、ファイル内の1行)が最初に単語に分離され、FlatMap操作によって実装されます。
FlatMapを呼び出すと、演算子が基礎となるDAGグラフに追加されます。次に、単語のストリームを得るために、ストリーム内の単語をグループ化し(KeyBy)、各単語のデータを累積的に計算します(sum(1))。計算された単語データは新しいストリームを形成し、出力ファイルに書き込まれます。
最後に、env#executeメソッドを呼び出してプログラムの実行を開始します。先ほど呼び出したメソッドがどれもデータを処理していないことを確認して、計算ロジックを表現するためのDAGグラフを構築してください。
グラフ全体を構築し、明示的にExecuteメソッドを呼び出してからにしてください。フレームワークは計算グラフをクラスタに提供し、データにアクセスしてロジックを実行します。
ストリーミングWordCountに基づく例では、Flink DataStream APIに基づくストリーム処理プログラムのコンパイルには、一般的に、データへのアクセス、処理、書き出しの3つのステップが必要であることが示されています。
最後に、Execute メソッドを呼び出します。
図 3. Flink DataStreamの動作概要。
前の例からわかるように、Flink DataStream APIのコアはストリーミングデータを表すDataStreamオブジェクトです。全体の計算ロジックグラフは、DataStreamオブジェクト上で異なる操作を呼び出して新しいDataStreamオブジェクトを生成することに基づいて構築されています。
一般的に、DataStreamに対する操作には4つのタイプがあります。最初のタイプは単一レコード操作で、望ましくないレコードをフィルタリングしたり(Filter操作)、各レコードを変換したり(Map操作)します。第二のタイプは、複数レコード操作である。例えば、1時間以内の注文の総量をカウントするには、1時間以内の全ての注文レコードを追加する。このタイプの操作をサポートするためには、処理のためのウィンドウを介して必要なレコードを結合する必要があります。
3つ目のタイプは、複数のストリームを操作して1つのストリームに変換することです。例えば、複数のストリームをUnion、Join、Connectなどの操作によってマージすることができます。これらの操作は、異なるロジックを使用してストリームをマージしますが、最終的には新しい統一されたストリームを生成するため、いくつかのクロスストリーム操作が可能になります。
4 つ目のタイプは「分割操作」で、DataStream でサポートされており、Merge 操作とは対照的です。これらの操作は、ルールによってストリームを複数のストリームに分割し、各分割ストリームは前のストリームのサブセットとなります。
図4. 異なるタイプのDataStreamサブタイプ。異なるサブタイプは、異なる操作のセットをサポートします。
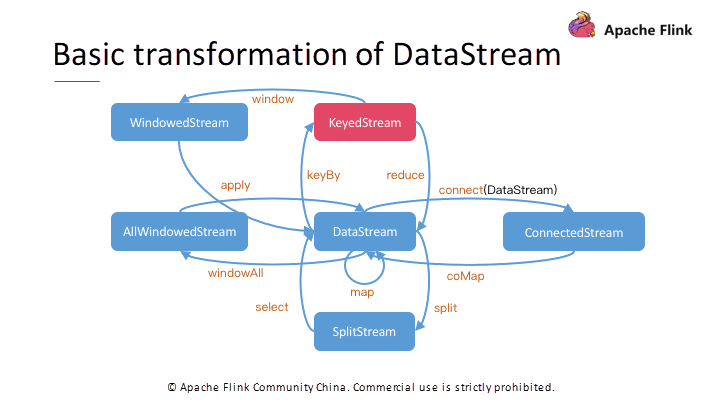
異なるストリーム操作をサポートするために、Flinkは中間ストリームデータセットのタイプを示すために、異なるストリームタイプのセットを導入しています。図4は、変換関係の完全なタイプを示しています。
Mapのような単一レコード操作の場合、結果はDataStream型です。Split操作では、SplitStreamが生成されます。SplitStreamに基づいて、Selectメソッドを使用して、望ましいレコードをフィルタリングし、基本ストリームを得ます。
同様に、Connect操作では、StreamA.connect(StreamB)を呼び出した後、専用のConnectedStreamを取得します。ConnectedStreamでサポートされる操作は、共通のDataStreamでサポートされる操作とは異なります。
これは2つの異なるストリームをマージした結果であり、2つのストリームのレコードの異なる処理ロジックを指定することができ、処理された結果が新しいDataStreamストリームを形成します。処理中に状態情報を共有するように、同じ演算子で異なるレコードを処理します。上層のJoin操作の中には、下層のConnect操作を介して実装する必要があるものもあります。
また、ウィンドウ操作により、時間や数でストリームを分割することもできます。具体的な分割ロジックを選択します。グループ内のすべてのレコードが到着したら、すべてのレコードを取得し、トラバース演算やサム演算を行います。したがって、各グループを処理することで出力データのセットを取得し、すべての出力データが新しい基本ストリームを形成します。
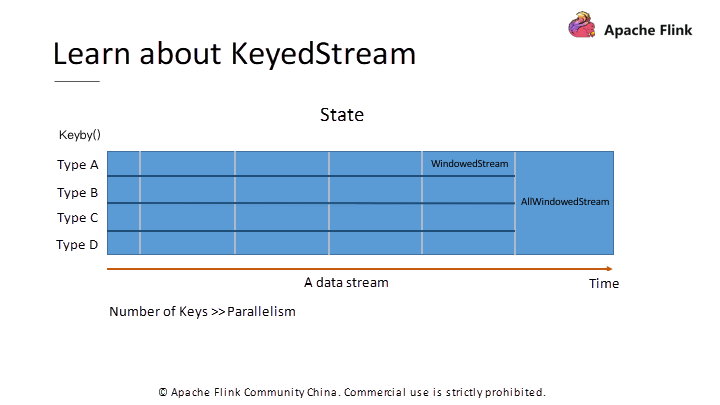
共通のDataStreamに対しては、ストリーム全体の統一されたWindow処理を表すallWindow演算を使用します。そのため、複数の演算子インスタンスを使用して同時計算することはできません。この問題を解決するには、KeyByメソッドを使用して、まずKeyでレコードをグループ化します。その後、異なるキーに対応するレコードに対して別々のWindow処理を並行して実行します。
KeyBy操作は、最も重要で一般的に使用される操作の1つです。以下に詳しく説明します。
図5. 基本ストリームのWindow演算とKeyedStreamの比較
KeyedStream上でのWindow操作により、複数のインスタンスを使用した同時処理が可能になります。図5に基本DataStreamオブジェクトに対するallWindow操作とKeyedStreamオブジェクトに対するWindow操作の比較を示します。複数の並行インスタンスで同時にデータを処理するには、KeyBy演算でデータをグループ化します。
KeyBy操作とWindow操作の両方でデータをグループ化しますが、KeyBy操作ではストリームを横方向に、Window操作ではストリームを縦方向に分割します。
KeyByでデータを分割した後、後続の各オペレータインスタンスは、特定のKeyセットに対応するデータを処理することができます。また、Flinkでは、演算子は特定の状態を維持することができます。KeyedStream上の演算子の状態は、分散して保存されます。
KeyByは確定的なデータの割り当て方法です(次項では他の割り当て方法を紹介します)。失敗したジョブを再起動して並列性が変更された場合、FlinkはKeyグループを再割り当てし、特定のKeyを処理するグループにそのKeyの状態が含まれていなければならないことを保証し、整合性を確保します。
最後に、KeyBy演算は、Keyの数が演算子の同時インスタンス数を超えた場合にのみ動作することに注意してください。同じKeyに対応するデータはすべて同じインスタンスに送信されるため、Keyの数がインスタンスの数よりも少ない場合、一部のインスタンスがデータを受信できず、計算能力が十分に活用されていないことになります。
その他の問題
Flinkでは、オペレータ間でデータをやり取りする際に、KeyBy以外にも物理的なグルーピング方法をサポートしています。図1に示すように、Flink DataStreamにおける物理的なグルーピング方法には次のようなものがあります。
- Global: 上流のオペレータが、下流のオペレータの最初のインスタンスにすべてのレコードを送信します。
- Broadcast:上流のオペレータは、各レコードを下流のオペレータのすべてのインスタンスに送信します。
Forward: 上流のオペレータは、下流のオペレータのすべてのインスタンスにレコードを送信します。各アップストリーム オペレータのインスタンスは、ダウンストリーム オペレータの対応するインスタンスにレコードを送信します。この方法は、アップストリームオペレータのインスタンスの数がダウンストリームオペレータのインスタンスの数と同じ場合にのみ適用されます。
Shuffle: 上流側のオペレータが各レコードに対して下流側のオペレータをランダムに選択します。
Rebalance:上流のオペレータがラウンドロビンベースでデータを送信します。
Rescale: 上流と下流の演算子のインスタンス数がそれぞれ 'n' と 'm' のとき、'n' < 'm' の場合、各上流のインスタンスは、ラウンドロビンベースで ceil(m/n) または floor(m/n) の下流のインスタンスにデータを送信します。n' > 'm' の場合、floor(n/m)またはceil(n/m)のアップストリームインスタンスはラウンドロビンベースでダウンストリームインスタンスにデータを送信します。
PartitionCustomer:ビルトインの割り当て方法がニーズに合わない場合は、グループ化方法をカスタマイズすることを選択します。
図6. KeyBy以外の物理的なグループ化メソッド
グルーピングメソッドに加えて、Flink DataStream APIにおけるもう一つの重要な概念がシステムタイプです。
図7に示すように、Flink DataStreamオブジェクトはシステムタイプが強く設定されています。各 DataStream オブジェクトについて、要素の型を指定する必要があります。Flinkの基礎となるシリアル化メカニズムは、シリアル化を最適化するためにこの情報に依存しています。具体的には、Flinkの最下層では、TypeInformationオブジェクトを使用して型を記述します。TypeInformationオブジェクトは、シリアル化フレームワークが使用するタイプ関連情報の文字列を定義します。
図 7. Flink DataStream APIの型システム
Flinkには、一般的に使用される組み込みの基本型がいくつかあります。これらについては、Flinkはその型情報も提供しており、追加の宣言なしに直接使用することができます。Flinkは型推論の仕組みを使って対応する型を識別することができます。ただし、例外もあります。
例えば、Flink DataStream APIはJavaとScalaの両方をサポートしています。多くのScala APIは暗黙のパラメータを通して型情報を渡すため、Javaを通してScala APIを呼び出す必要がある場合は、暗黙のパラメータを通して型情報を渡す必要があります。もう一つの例として、Javaによる汎用型の消去があります。ストリーム型が汎用型の場合、消去後の情報の型を推論する必要がない場合があります。この場合、情報の型も明示的に指定する必要があります。
Flinkでは、Java APIでは複数のフィールドを結合する際にTuple型を使用するのが一般的ですが、Scala APIではRow型やCase Class型を使用することが多くなっています。タプル型は、Row型に比べて、フィールド数が25を超えることができないことと、すべてのフィールドでNULL値を使用することができないという2つの制限があります。
最後に、Flinkでは、新しい型、TypeInformationをカスタマイズしたり、Kryoを使ってシリアライズしたりすることができます。しかし、これは移行の問題を引き起こす可能性があります。そのため、カスタム型は避けることをお勧めします。
例
もう少し複雑な例を見てみましょう。システム内に注文を監視するデータソースがあるとします。それは、新規発注を行う際に、Tuple2を使用して、発注された商品の種類と取引量を出力します。そして、すべての種類のアイテムの取引量をリアルタイムでカウントします。
表4 リアルタイム注文統計の一例です。
public class GroupedProcessingTimeWindowSample { private static class DataSource extends RichParallelSourceFunction<Tuple2<String, Integer>> { private volatile boolean isRunning = true; @Override public void run(SourceContext<Tuple2<String, Integer>> ctx) throws Exception { Random random = new Random(); while (isRunning) { Thread.sleep((getRuntimeContext().getIndexOfThisSubtask() + 1) * 1000 * 5); String key = "类别" + (char) ('A' + random.nextInt(3)); int value = random.nextInt(10) + 1; System.out.println(String.format("Emits\t(%s, %d)", key, value)); ctx.collect(new Tuple2<>(key, value)); } } @Override public void cancel() { isRunning = false; } } public static void main(String[] args) throws Exception { StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); env.setParallelism(2); DataStream<Tuple2<String, Integer>> ds = env.addSource(new DataSource()); KeyedStream<Tuple2<String, Integer>, Tuple> keyedStream = ds.keyBy(0); keyedStream.sum(1).keyBy(new KeySelector<Tuple2<String, Integer>, Object>() { @Override public Object getKey(Tuple2<String, Integer> stringIntegerTuple2) throws Exception { return ""; } }).fold(new HashMap<String, Integer>(), new FoldFunction<Tuple2<String, Integer>, HashMap<String, Integer>>() { @Override public HashMap<String, Integer> fold(HashMap<String, Integer> accumulator, Tuple2<String, Integer> value) throws Exception { accumulator.put(value.f0, value.f1); return accumulator; } }).addSink(new SinkFunction<HashMap<String, Integer>>() { @Override public void invoke(HashMap<String, Integer> value, Context context) throws Exception { // 每个类型的商品成交量 System.out.println(value); // 商品成交总量 System.out.println(value.values().stream().mapToInt(v -> v).sum()); } }); env.execute(); } }表4に本実施例の実装を示しています。ここでは、RichParallelSourceFunctionを継承した模擬データソースを実装します。RichParallelSourceFunctionは、複数のインスタンスを持つSourceFunctionのAPIです。
RunメソッドとCancelメソッドの2つのメソッドを実装します。Flinkは実行時にRunメソッドを直接ソースに呼び出します。初期ストリームを形成するためにデータを連続的に出力する必要があります。Runメソッドを実装する際には、アイテムタイプとトランザクション量のレコードをランダムに生成し、
ctx#collectメソッドを使用して送信します。Flinkが実行状態をマークして制御するためにVolatile変数で使用されるソースタスクをキャンセルする必要がある場合は、Cancelメソッドを使用します。次に、Mainメソッドでグラフの構築を開始します。まず、StreamExecutionEnviroment オブジェクトを作成します。オブジェクトを作成するために呼び出される
getExecutionEnvironmentメソッドが自動的に環境を決定するので、適切なオブジェクトが作成されます。例えば、IDEで右クリックしてメソッドを実行すると、LocalStreamExecutionEnvironmentオブジェクトが作成されます。実際の環境で実行すると、RemoteStreamExecutionEnvironmentオブジェクトを作成します。Environmentオブジェクトを基に、初期ストリームを取得するためのソースを作成します。そして、アイテムタイプごとのトランザクション量をカウントするために、KeyByを使用してTupleの第1フィールド(アイテムタイプ)を介して入力ストリームをグループ化し、各Keyに対応するレコードの第2フィールド(トランザクション量)の値を合計します。
最下層では、Sum演算子がStateメソッドを使用して、各Key(アイテムタイプ)に対応するトランザクションボリュームの合計値を保持します。新しいレコードが到着すると、Sum演算子は、維持されている取引量合計を更新して、.NETのレコードを出力します。
タイプのボリュームのみをカウントする場合は、ここでプログラムは終了します。Sum演算子の直後にSink演算子を追加して、各アイテムタイプの継続的に更新されたトランザクションボリュームを出力します。ただし,すべてのタイプのトランザクション量をカウントするには,同じ計算ノードのすべてのレコードを出力してください.
KeyByを使用して、全てのレコードに同じKeyを返し、グループ化して、全てのレコードを同じインスタンスに送るようにしています。
次に、Foldメソッドを使用して、演算子内の各アイテムタイプのボリュームを維持します。FoldメソッドはDeprecatedとマークされていますが、今日ではDataStream APIの他の操作で置き換えることができないことに注意してください。したがって、このメソッドは初期値を受け取ります。
次に、後続のストリームの各レコードが到着すると、オペレータは初期値を更新するために渡されたFoldFunctionを呼び出し、更新された値を送信します。
HashMap を使用して、各項目タイプの現在のトランザクション量を保持します。新しいものが到着したら、HashMapを更新します。このように、Sinkを通じて最新のアイテムタイプとトランザクションボリュームのHashMapを受け取り、この値を頼りに各アイテムのトランザクションボリュームとトランザクションボリュームの合計を出力します。
この例では、DataStream APIの使い方を実演しています。より効率的に書くことができます。また、上位のTableやSQLでは、この状況をより良く処理するリトラクト機構もサポートしています。
図8 APIの概略図。
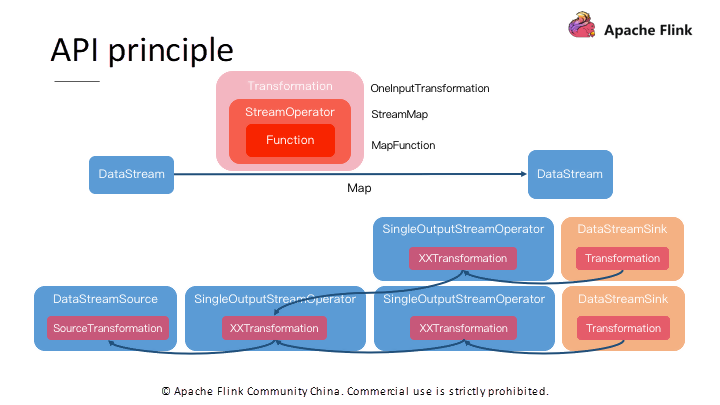
最後に、DataStream APIの原理を見てみましょう。DataStream#mapアルゴリズムを呼び出すと、Flinkは最下層にTransformationオブジェクトを作成します。このオブジェクトは、計算ロジックグラフのノードを表します。これは、ユーザー定義関数(UDF)であるMapFunctionを記録します。
より多くのメソッドを使用することで、より多くの DataStream オブジェクトを作成します。各オブジェクトにはTransformationオブジェクトがあり、これらのオブジェクトは計算依存関係に基づいてグラフ構造を形成します。
これが計算グラフです。その後、Flinkはさらにグラフ構造を変換し、最終的にジョブの提出に必要なJobGraphを生成します。
概要
この記事では、Flinkの下位レベルのAPIであるFlink DataStream APIを紹介します。実際の開発では、StateやTimeなど、APIをベースにして自分でいくつかの概念を使う必要があり、手間がかかります。その後の講座では、より上位レベルのTableやSQL APIについても紹介していきます。将来的にはTableやSQLがFlinkのAPIの主流になるかもしれません。
しかし、下位レベルのAPIは、より強力な表現能力を生み出します。細かい操作が必要な場合は、DataStream APIが必要になるケースもあります。
アリババクラウドは日本に2つのデータセンターを有し、世界で60を超えるアベラビリティーゾーンを有するアジア太平洋地域No.1(2019ガートナー)のクラウドインフラ事業者です。
アリババクラウドの詳細は、こちらからご覧ください。
アリババクラウドジャパン公式ページ




- 投稿日:2020-09-25T15:11:48+09:00
エンジニア就職に向けてマッチングアプリ(Androidアプリ)を作ってみた
はじめに
こんにちは。タイトルにもある通りエンジニア就職のためにマッチングアプリ『Match-com(マッチコン)』を作成しました。
開発期間はおおよそ1ヶ月半です。
1年ちょっと前まではSESに9ヶ月ほど在籍していました。それ以降は少しエンジニアから離れて別のことをやっていましたが最近になってまたこの業界に戻ってきました。(プログラミングの学習自体は続けてました)どんなアプリ?
男性と女性のマッチングアプリです。皆さんも一度は使ったことがあるんじゃないでしょうか。
お互いがいいねをしたらマッチングしてチャットができるようになります。主な機能
・Firebase
・メールログイン/Facebookログイン
・プロフィール登録
・いいね!
・マッチング
・リアルタイムチャット
・ブロック
・写真登録/プロフィール編集
・新規メッセージとマッチング時のPush通知
・退会独自の機能を盛り込んで今あるサービスと差別化を図る予定でしたが細かいところまで拘っていたら思った以上に開発に時間がかかってしまいました。
とりあえず最低限の機能は実装して形にはなったので一旦これで就職活動を始めて落ち着いたらまた色々と機能を追加していく予定です。※現在、丸2日経っても審査中のためまだリリースができていません。リリース次第こちらにURLを貼り付けます。
苦労したこと
・バグ
バグには苦労させられました。一度、完成したと思っても開発を進めていくうちにおかしな挙動を発見したりアプリ自体が落ちてしまうこともありました。達成感に満ち溢れてるところから落とされるのはかなりきついです。何度もアタックしてやっと付き合えた彼女に3日で振られるような、そんな感覚です。
・設計の甘さ
今まで自分がやったことのない機能の開発は初めてのことばかりでかなり時間がかかりました。
これまでも簡単なアプリなら作ったことはあったのですが大体今までの知識の流用で事足りていました。しかし、今回は割と本格的に作ったので色々と調べて自分のコードで動作するように改変しながら実装していきました。特に最初にちゃんとした設計をやっていなかったところもあり、何度も書いたコードを修正したりと設計の重要性を再認識できた一方で変なところで時間が取られてしまったりともう少し効率よく開発できれば良かったと思います。
・わからない言葉が多い
調べごとをしているとわからない言葉がたくさん出てきます。必要そうなことは都度調べて開発していたのですがアプリの完成を第一目標にした場合、さすがに全ての言葉を一回一回調べていると時間がなくなるのでとりあえず後回しにした言葉も結構ありました。実際に開発現場でそういう言葉がバンバン飛び交うのを想像すると少し気が重くなりました。開発してみて良かったこと
・ドキュメントを読む癖
今回の開発ではFirebaseを本格導入したのですがそこでドキュメントを読み解く癖がついたのがいい経験になりました。
もちろん、Qiitaの記事や日本語の参考資料など有益なものもたくさんありましたが細かい話になるとドキュメントや英語の記事を読み漁る必要があったので結果的にドキュメントに対するアレルギーというものが大幅に軽減できました。・英語の重要性
よく「エンジニアになるのに英語は必要か」みたいな議論がありますがエンジニアに就職するためなら必ずしも必要というわけではないですがこれから自分でプログラミングを学んでいく上で絶対できた方が効率いいよね、と思う場面は何度もありました。
日本語で探してやっとたどり着いた記事の内容が英語で検索すると一番上にある、なんていうのはザラにあったからです。今回のアプリを日本語の資料だけで実装しろと言われたらかなり時間がかかると思います。・情報を整理する力
簡単な実装ならチュートリアル的なものを見つけてちょこっと修正すればそれで済むと思います。
しかし、複雑なことをしようと思うと当然1つの情報源で全てが解決するということは稀でインターネット上のいくつかの情報を組み合わせて自分のケースに落とし込むというのが必要になってきます。
しっかりとしたアプリケーションを作ろうと思うと、こうした「情報を総合して解釈する能力」というのが自然と身に付いてくると感じました。・やり切った自信
アプリを作る前と後だとだいぶ開発に対しての自信がつきました。
最初は本当に完成させられるのか不安が90%くらいでしたが実際に完成させてみると、ある程度のアプリなら作れそうと思えるようになりました。
やはり教材でずっと勉強しているよりも何かを作った方が応用力がつくので結果的に実力向上に結びつきやすいです。結局は作りながら学ぶのが一番です。
ただ最初の知識が少なすぎるとパワーで無理やり実装してしまうところも出てくるのである程度体系だった知識を学んでから、実際に作ってみて今ある知識に肉付けしていくというやり方でもいいと思います。アプリ紹介
以上で作ったアプリの簡単な概要はおしまいです。これ以降は作ったアプリの紹介になるので時間がある方は見てみてください。(少し長くなります!)
基本的に上で列挙した機能を順に紹介していくスタイルにしようと思います。直感的にわかるように文字は少なめで画像や動画を多めに使っています。gifではうまくupできなかったのでこちらを参考にしてTwitterに上げたものを使っています。Firebase
今回はバックエンドにFirebaseを使用しました。NoSQLはRDBのようにテーブルの結合ができなかったため最初は戸惑いましたが慣れてくると非常に使い勝手が良くスムーズに使えるようになりました。
使用したサービス
・Authentication
・Realtime Database
・Cloud Firestore
・Cloud Storage(画像の保存に利用)
・Cloud Messaging(Push通知に利用)
・Dynamic Links(メールリンクに使用)メールログイン / Facebookログイン
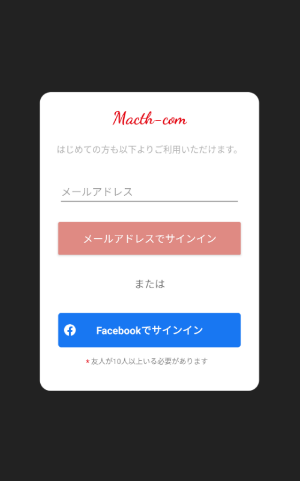
画面はこんな感じです。
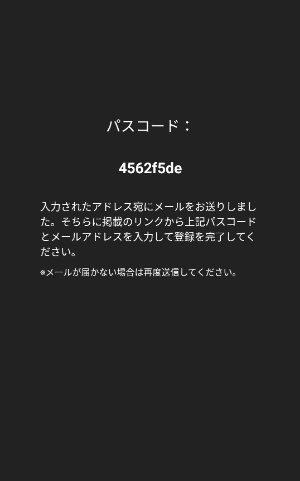
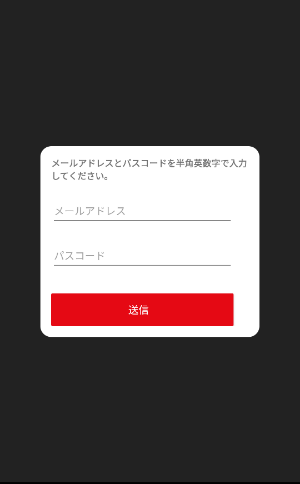
メールアドレスでログインする場合はメールを入力してサインインボタンを押すとパスコードが発行されるので送られてきたメールのリンクからアドレスと発行コードを入力して登録orログインします。
このメールリンクの機能はDynamic Linksを使用しています。
https://firebase.google.com/docs/dynamic-links/android/receive?hl=ja
メールのリンクを開くと入力画面に遷移します。
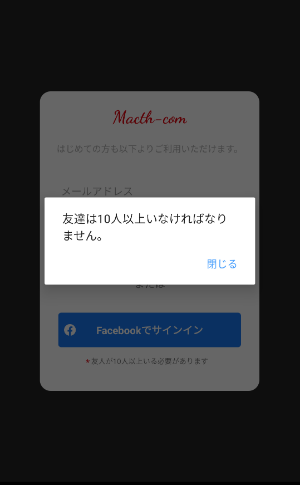
Facebookログインの場合は友達が10人以上いないと登録できません。
ユーザーの友達の数を取得するのにはFacebookのGraph APIというものを使用しました。
https://developers.facebook.com/docs/graph-api/overviewプロフィール登録
上記の方法でログインが完了するとそのユーザーが新規のユーザーかを判定します。
すでに存在するユーザーであればホームスクリーン、新規のユーザーであればプロフィール登録画面に進みます。ここのプロフィールは全て入力しないとボタンが非活性になります。
(※QiitaでうまくgifをupできなかったためTwitterを使ってます。)— komei_401 (@401Komei) September 24, 2020いいね!
ホーム画面はこんな感じです。
右スワイプでいいね、左スワイプでごめんね、となります。
— komei_401 (@401Komei) September 24, 2020
写真をタップすると次の写真に移動できます。名前以下のところをタップするとユーザーの詳細画面に飛ぶことができます。
— komei_401 (@401Komei) September 24, 2020マッチング
相手も自分にいいねをしていた場合、そこでマッチング成立となります。
— komei_401 (@401Komei) September 24, 2020リアルタイムチャット
こちらがチャット一覧画面です。これとチャット画面に一番時間がかかりました。
「マッチングしたお相手」というのがマッチはしたが会話はしてない人、「会話中のお相手」が実際に会話中の人になります。マッチして24時間以内なら上にNew!とつきます。(黒で塗りつぶしてあるのはフリー素材以外の写真を使用していたからです。)
「会話中のお相手」の写真の左上にある◯はそのユーザーのログインステータスになります。
緑 → オンライン
黄色 → 最終ログインから24時間以内
灰色 → 最終ログインから24時間以上メッセージを送ると「会話中のお相手」に移動します。
— komei_401 (@401Komei) September 24, 2020チャット画面はこんな感じです。
意外にメッセージの上にある日付を入れるのに苦労しました笑
別にここは簡単な実装で良かったんですがなるべくreal-world project的なものを作りたかったので地味に拘ってしまいました。今日のメッセージは今日、昨日のものは昨日、それ以外は日付、今年以外のものは年も含めて表示するようにしています。メッセージはもちろん写真も送信することができます。
— komei_401 (@401Komei) September 24, 2020またチャット画面のアイコンからを相手ユーザーの詳細画面に飛べます。
— komei_401 (@401Komei) September 24, 2020ブロック
ユーザーをブロックすると会話中の相手からいなくなります。
— komei_401 (@401Komei) September 24, 2020写真登録/プロフィール編集
プロフィール編集画面はシンプルなものにしました。
写真はクロッピングして登録します。
— komei_401 (@401Komei) September 24, 2020メイン写真と入れ替えることもできます。
— komei_401 (@401Komei) September 24, 2020削除した写真が2枚目だった場合、3枚目の写真は左につめます。間を写真のない状態にしないということですね。
— komei_401 (@401Komei) September 24, 2020プロフィール編集ではユーザーの基本的な情報を編集できます。
趣味と言語を登録する時は入力したものがチップとなって溜まっていきます。最後に更新ボタンを押して更新完了です。
— komei_401 (@401Komei) September 24, 2020新規メッセージとマッチング時のPush通知
新着のメッセージを受信するとPush通知が送られてきます。
— komei_401 (@401Komei) September 24, 2020
また文字だけでなく画像もPush通知で送ることができます。
— komei_401 (@401Komei) September 24, 2020
Push通知を本格的に実装しようとすると結構大変でした。普通にやるとアプリを開いている時は受信できるが閉じると受信できなくなってしまうからです。アプリを閉じたときでも受信できるようにするには1 : FirebaseのCloud Functionsを使用してRealtime Database更新のタイミングでPush通知を送るよう実装する
2 : FirebaseMessagingServiceを継承したクラスを作り、onMessageReceivedメソッドをオーバーライドして通知した際の処理を実装し、デバイス間の通信を実現このどちらかの方法で実装する必要がありました。自分は2の方法で実装しました。デバイス間の通信にはRetrofitを利用しています。
1の方法でもNode.jsなどでローカルで実装してCLIからFirebaseにdeployすればイケると思います。
退会
最後に退会機能です。これはプロフィール編集画面の一番下から行うことができます。
— komei_401 (@401Komei) September 24, 2020まとめ
本格的にアプリを開発したのは初めてだったので作り終わったあとの達成感もありましたが同時に疲労感もありました。これからアプリを開発する人はなるべく設計を意識した方がいいと思います。
じゃないと何度もコードを修正したり、依存性の強いコードを書いたりしてしまいます。
Solid原則を常に意識しておくと良いでしょう。こちらの記事が参考になります。こういうのを読んでみるのもいいかもしれません。(自分はまだ読んだことないですが)
https://www.amazon.co.jp/dp/B07FSBHS2V/ref=dp-kindle-redirect?_encoding=UTF8&btkr=1アウトプットは今回で十分やったのでしばらくはまたインプットの量を増やして学習を継続していこうと思います。
最後まで読んでいただき、ありがとうございました。


- 投稿日:2020-09-25T15:11:48+09:00
マッチングアプリ(Androidアプリ)を作りました
はじめに
こんにちは。エンジニア就職のためにマッチングアプリ『Match-com(マッチコン)』を作成しました。
開発期間はおおよそ1ヶ月半です。どんなアプリ?
男性と女性のマッチングアプリです。皆さんも一度は使ったことがあるんじゃないでしょうか。
お互いがいいねをしたらマッチングしてチャットができるようになります。主な機能
・Firebase
・メールログイン/Facebookログイン
・プロフィール登録
・いいね!
・マッチング
・リアルタイムチャット
・ブロック
・写真登録/プロフィール編集
・新規メッセージとマッチング時のPush通知
・退会独自の機能を盛り込む予定でしたが細かいところまで拘っていたら思った以上に開発に時間がかかってしまいました。
とりあえず最低限の機能は実装して形にはなったので一旦これで就職活動を始めて落ち着いたらまた色々と機能を追加していく予定です。※現在、丸2日経っても審査中のためまだリリースができていません。リリース次第こちらにURLを貼り付けます。
苦労したこと
・バグ
バグには苦労させられました。一度、完成したと思っても開発を進めていくうちにおかしな挙動を発見したりアプリ自体が落ちてしまうこともありました。達成感に満ち溢れてるところから落とされるのはかなりきついです。何度もアタックしてやっと付き合えた彼女に3日で振られるような、そんな感覚です。
・設計の甘さ
今まで自分がやったことのない機能の開発は初めてのことばかりでかなり時間がかかりました。
これまでも簡単なアプリなら作ったことはあったのですが大体今までの知識の流用で事足りていました。しかし、今回は割と本格的に作ったので色々と調べて自分のコードで動作するように改変しながら実装していきました。特に最初にちゃんとした設計をやっていなかったところもあり、何度も書いたコードを修正したりと設計の重要性を再認識できた一方で変なところで時間が取られてしまったりともう少し効率よく開発できれば良かったと思います。
・わからない言葉が多い
調べごとをしているとわからない言葉がたくさん出てきます。必要そうなことは都度調べて開発していたのですがアプリの完成を第一目標にした場合、さすがに全ての言葉を一回一回調べていると時間がなくなるのでとりあえず後回しにした言葉も結構ありました。開発してみて良かったこと
・ドキュメントを読む癖
今回の開発ではFirebaseを本格導入したのですがそこでドキュメントを読み解く癖がついたのがいい経験になりました。
もちろん、Qiitaの記事や日本語の参考資料など有益なものもたくさんありましたが細かい話になるとドキュメントや英語の記事を読み漁る必要があったので結果的にドキュメントに対するアレルギーというものが大幅に軽減できました。・英語の重要性
よく「エンジニアになるのに英語は必要か」みたいな議論がありますがエンジニアに就職するためなら必ずしも必要というわけではないですがこれから自分でプログラミングを学んでいく上で絶対できた方が効率いいよね、と思う場面は何度もありました。
日本語で探してやっとたどり着いた記事の内容が英語で検索すると一番上にある、なんていうのはザラにあったからです。今回のアプリを日本語の資料だけで実装しろと言われたらかなり時間がかかると思います。・情報を整理する力
簡単な実装ならチュートリアル的なものを見つけてちょこっと修正すればそれで済むと思います。
しかし、複雑なことをしようと思うと当然1つの情報源で全てが解決するということは稀でインターネット上のいくつかの情報を組み合わせて自分のケースに落とし込むというのが必要になってきます。
しっかりとしたアプリケーションを作ろうと思うと、こうした「情報を総合して解釈する能力」というのが自然と身に付いてくると感じました。・やり切った自信
アプリを作る前と後だとだいぶ開発に対しての自信がつきました。
最初は本当に完成させられるのか不安が90%くらいでしたが実際に完成させてみると、ある程度のアプリなら作れそうと思えるようになりました。
やはり教材でずっと勉強しているよりも何かを作った方が応用力がつくので結果的に実力向上に結びつきやすいです。結局は作りながら学ぶのが一番です。
ただ最初の知識が少なすぎるとパワーで無理やり実装してしまうところも出てくるのである程度体系だった知識を学んでから、実際に作ってみて今ある知識に肉付けしていくというやり方でもいいと思います。アプリ紹介
以上で作ったアプリの簡単な概要はおしまいです。これ以降は作ったアプリの紹介になるので時間がある方は見てみてください。(少し長くなります!)
基本的に上で列挙した機能を順に紹介していくスタイルにしようと思います。直感的にわかるように文字は少なめで画像や動画を多めに使っています。gifではうまくupできなかったのでこちらを参考にしてTwitterに上げたものを使っています。Firebase
今回はバックエンドにFirebaseを使用しました。NoSQLはRDBのようにテーブルの結合ができなかったため最初は戸惑いましたが慣れてくると非常に使い勝手が良くスムーズに使えるようになりました。
使用したサービス
・Authentication
・Realtime Database
・Cloud Firestore
・Cloud Storage(画像の保存に利用)
・Cloud Messaging(Push通知に利用)
・Dynamic Links(メールリンクに使用)メールログイン / Facebookログイン
画面はこんな感じです。
メールアドレスでログインする場合はメールを入力してサインインボタンを押すとパスコードが発行されるので送られてきたメールのリンクからアドレスと発行コードを入力して登録orログインします。
このメールリンクの機能はDynamic Linksを使用しています。
https://firebase.google.com/docs/dynamic-links/android/receive?hl=ja
メールのリンクを開くと入力画面に遷移します。
Facebookログインの場合は友達が10人以上いないと登録できません。
ユーザーの友達の数を取得するのにはFacebookのGraph APIというものを使用しました。
https://developers.facebook.com/docs/graph-api/overviewプロフィール登録
上記の方法でログインが完了するとそのユーザーが新規のユーザーかを判定します。
すでに存在するユーザーであればホームスクリーン、新規のユーザーであればプロフィール登録画面に進みます。ここのプロフィールは全て入力しないとボタンが非活性になります。
(※QiitaでうまくgifをupできなかったためTwitterを使ってます。)— komei_401 (@401Komei) September 24, 2020いいね!
ホーム画面はこんな感じです。
右スワイプでいいね、左スワイプでごめんね、となります。
— komei_401 (@401Komei) September 24, 2020
写真をタップすると次の写真に移動できます。名前以下のところをタップするとユーザーの詳細画面に飛ぶことができます。
— komei_401 (@401Komei) September 24, 2020マッチング
相手も自分にいいねをしていた場合、そこでマッチング成立となります。
— komei_401 (@401Komei) September 24, 2020リアルタイムチャット
こちらがチャット一覧画面です。これとチャット画面に一番時間がかかりました。
「マッチングしたお相手」というのがマッチはしたが会話はしてない人、「会話中のお相手」が実際に会話中の人になります。マッチして24時間以内なら上にNew!とつきます。(黒で塗りつぶしてあるのはフリー素材以外の写真を使用していたからです。)
「会話中のお相手」の写真の左上にある◯はそのユーザーのログインステータスになります。
緑 → オンライン
黄色 → 最終ログインから24時間以内
灰色 → 最終ログインから24時間以上メッセージを送ると「会話中のお相手」に移動します。
— komei_401 (@401Komei) September 24, 2020チャット画面はこんな感じです。
意外にメッセージの上にある日付を入れるのに苦労しました笑
別にここは簡単な実装で良かったんですがなるべくreal-world project的なものを作りたかったので地味に拘ってしまいました。今日のメッセージは今日、昨日のものは昨日、それ以外は日付、今年以外のものは年も含めて表示するようにしています。メッセージはもちろん写真も送信することができます。
— komei_401 (@401Komei) September 24, 2020またチャット画面のアイコンからを相手ユーザーの詳細画面に飛べます。
— komei_401 (@401Komei) September 24, 2020ブロック
ユーザーをブロックすると会話中の相手からいなくなります。
— komei_401 (@401Komei) September 24, 2020写真登録/プロフィール編集
プロフィール編集画面はシンプルなものにしました。
写真はクロッピングして登録します。
— komei_401 (@401Komei) September 24, 2020メイン写真と入れ替えることもできます。
— komei_401 (@401Komei) September 24, 2020削除した写真が2枚目だった場合、3枚目の写真は左につめます。間を写真のない状態にしないということですね。
— komei_401 (@401Komei) September 24, 2020プロフィール編集ではユーザーの基本的な情報を編集できます。
趣味と言語を登録する時は入力したものがチップとなって溜まっていきます。最後に更新ボタンを押して更新完了です。
— komei_401 (@401Komei) September 24, 2020新規メッセージとマッチング時のPush通知
新着のメッセージを受信するとPush通知が送られてきます。
— komei_401 (@401Komei) September 24, 2020
また文字だけでなく画像もPush通知で送ることができます。
— komei_401 (@401Komei) September 24, 2020
Push通知を本格的に実装しようとすると結構大変でした。普通にやるとアプリを開いている時は受信できるが閉じると受信できなくなってしまうからです。アプリを閉じたときでも受信できるようにするには1 : FirebaseのCloud Functionsを使用してRealtime Database更新のタイミングでPush通知を送るよう実装する
2 : FirebaseMessagingServiceを継承したクラスを作り、onMessageReceivedメソッドをオーバーライドして通知した際の処理を実装し、デバイス間の通信を実現このどちらかの方法で実装する必要がありました。自分は2の方法で実装しました。デバイス間の通信にはRetrofitを利用しています。
1の方法でもNode.jsなどでローカルで実装してCLIからFirebaseにdeployすればイケると思います。
退会
最後に退会機能です。これはプロフィール編集画面の一番下から行うことができます。
— komei_401 (@401Komei) September 24, 2020まとめ
本格的にアプリを開発したのは初めてだったので作り終わったあとの達成感もありましたが同時に疲労感もありました。これからアプリを開発する人はなるべく設計を意識した方がいいと思います。
じゃないと何度もコードを修正したり、依存性の強いコードを書いたりしてしまいます。
Solid原則を常に意識しておくと良いでしょう。こちらの記事が参考になります。こういうのを読んでみるのもいいかもしれません。(自分はまだ読んだことないですが)
https://www.amazon.co.jp/dp/B07FSBHS2V/ref=dp-kindle-redirect?_encoding=UTF8&btkr=1アウトプットは今回で十分やったのでしばらくはまたインプットの量を増やして学習を継続していこうと思います。
最後まで読んでいただき、ありがとうございました。
- 投稿日:2020-09-25T14:51:46+09:00
LocalDateTimeの使用に関連したシリアル化操作時のパフォーマンスの問題
この記事では、アリババのエンジニアがシリアル化処理中に発生した、LocalDateTimeおよびInstant timeフォーマットの使用に関連したパフォーマンスの問題について説明します。
本ブログは英語版からの翻訳です。オリジナルはこちらからご確認いただけます。一部機械翻訳を使用しております。翻訳の間違いがありましたら、ご指摘いただけると幸いです。
Lv Renqi氏より
パフォーマンスの問題
Apache Dubbo の新バージョンで性能圧力テストを行った際、Transfer Object (TO) クラスの属性に関連する問題を発見しました。
DateをLocalDateTimeに変更すると、スループットが5万から2万に低下し、応答時間が9msから90msに増加しました。これらの変更の中で、私たちが最も気になったのは応答時間の変更でした。パフォーマンス指標は、一定の応答時間レベルが確保されて初めて意味を持つため、応答時間は多くの点で優れたパフォーマンス数値の礎となります。ストレステストの場合、ギガビット・パー・セカンド(GPS)やトランザクション・パー・セカンド(TPS)の数値は、目標とする応答時間の数値が満たされた場合にのみ許容されます。純粋な理論上の数字は意味がありません。クラウド・コンピューティングでは、応答時間のすべてのビットが重要です。基盤となるサービスの応答時間が0.1ms増加しただけでも、全体のコストが10%増加することを意味します。
レイテンシーは、リモートユーザーのいるシステムのアキレス腱のようなものです。データパケットの遅延は100kmごとに1ミリ秒ずつ増加します。杭州-上海間の待ち時間は約5ミリ秒で、上海-深セン間の待ち時間は、距離がかなり大きくなるため、当然ながらさらに高くなります。レイテンシーの直接的な結果はレスポンスタイムの増加であり、これは全体的なユーザーエクスペリエンスを悪化させ、コストを膨らませます。
リクエストが異なる単位で同じ行のレコードを変更した場合、たとえ一貫性と整合性を維持できたとしても、コストは非常に高くなります。アリババ内で広く使われている分散型RPCサービスフレームワークであるリモート高速サービスフレームワーク(HSF)サービスや他のリモートデータベースに10回以上アクセスする必要があるリクエストで、1つのサービスが別のサービスを呼び出す場合、レイテンシはすぐに加算され、雪だるま式の効果をもたらします。
Javaにおける普遍性の重要性
時間を扱うことは、コンピュータサイエンスの世界ではどこにでもあることです。時間の厳密な概念がなければ、アプリケーションの99.99%は意味を失い、実用性を失います。特に、最近ではクラウド上のほとんどの監視システムで見られる時間指向のカスタム処理がそうです。
Java Development Kit 8(JDK 8)以前は、
java.util.Dateが日付と時刻を記述するために使用され、java.util.Calendarが時間に関連したコンピューティングに使用されていました。JDK 8では、Instant、LocalDateTime、OffsetDateTime、ZonedDateTimeなど、より便利な時間クラスが導入されました。一般的に、これらのクラスのおかげで、時間処理がより便利になりました。
Instantは、協定世界時(UTC)形式でタイムスタンプを保存し、マシンに面した、または内部の時刻表示を提供します。これは、データベースストレージ、ビジネスロジック、データ交換、およびシリアライズのシナリオに適しています。LocalDateTime、OffsetDateTime、およびZonedDateTimeには、タイムゾーンまたは季節の情報が含まれており、また、ユーザーにデータを入出力するため時間表示を提供します。同じ時間が異なるユーザに出力される場合、その値は異なります。例えば、注文の発送時間は、買い手と売り手に異なる現地時間で表示されます。これら3つのクラスは、アプリケーションの内部作業部分ではなく、外部に向けたツールと考えることができます。要するに、
Instantはバックエンドのサービスやデータベースに向いていますが、LocalDateTimeとそのコホートはフロントエンドのサービスや表示に向いています。この2つは理論的には互換性がありますが、実際には異なる機能を果たしています。国際ビジネスチームは、この点について豊富な経験と考えを持っています。
DateとInstantは、アリババ社内の高速サービスフレームワーク(HSF)とDubboを統合する際によく使われています。パフォーマンス問題の再現
前に見たパフォーマンス問題の背景にあるものを正確に把握するために、その再現を試みることができます。しかし、その前に、簡単なデモを通して
Instantのパフォーマンスの利点を考えてみましょう。そのためには、Date形式で日付を定義し、その後にInstant形式を使用するという一般的なシナリオを考えてみましょう。@Benchmark @BenchmarkMode(Mode.Throughput) public String date_format() { Date date = new Date(); return new SimpleDateFormat("yyyyMMddhhmmss").format(date); } @Benchmark @BenchmarkMode(Mode.Throughput) public String instant_format() { return Instant.now().atZone(ZoneId.systemDefault()).format(DateTimeFormatter.ofPattern( "yyyyMMddhhmmss")); }これを行った後、ローカルの4つのコンカレントスレッドで30秒間ストレステストを実行します。結果は以下のようになります。
Benchmark Mode Cnt Score Error Units DateBenchmark.date_format thrpt 4101298.589 ops/s DateBenchmark.instant_format thrpt 6816922.578 ops/sこれらの結果から、フォーマット性能の面では
Instantが有利であると結論づけられます。実際、他の操作に関しても、Instantは性能面で優位性を持っています。例えば、日付と時刻の足し算と引き算の演算において、Instantは有望な性能を示していることがわかりました。シリアライゼーション操作中のインスタントの落とし穴
次に、上で見た問題のレプリケーションとして、JavaとHessian(タオバオ向けに最適化されている)でそれぞれシリアライズとデシリアライズ操作時のパフォーマンスの変化を見るためのストレステストも行いました。
HessianはHSF 2.2とDubboのデフォルトのシリアライズスキーム:
@Benchmark @BenchmarkMode(Mode.Throughput) public Date date_Hessian() throws Exception { Date date = new Date(); byte[] bytes = dateSerializer.serialize(date); return dateSerializer.deserialize(bytes); } @Benchmark @BenchmarkMode(Mode.Throughput) public Instant instant_Hessian() throws Exception { Instant instant = Instant.now(); byte[] bytes = instantSerializer.serialize(instant); return instantSerializer.deserialize(bytes); } @Benchmark @BenchmarkMode(Mode.Throughput) public LocalDateTime localDate_Hessian() throws Exception { LocalDateTime date = LocalDateTime.now(); byte[] bytes = localDateTimeSerializer.serialize(date); return localDateTimeSerializer.deserialize(bytes); }結果は以下の通りでした。ヘシアンプロトコルを使用することで、
Instant形式とLocalDateTime形式を使用した場合には、スループットが急激に低下しました。実際には、Date形式を使用した場合に比べて100倍もスループットが低下しています。さらに調べてみると、Dateのシリアル化バイトストリームは6バイトであるのに対し、LocalDateTimeのストリームは256バイトであることがわかりました。また、送信のためのネットワーク帯域幅のコストも大きくなっています。Javaのビルトインシリアライズソリューションでは、若干の低下が見られますが、実質的な違いはありません。Benchmark Mode Cnt Score Error Units DateBenchmark.date_Hessian thrpt 2084363.861 ops/s DateBenchmark.localDate_Hessian thrpt 17827.662 ops/s DateBenchmark.instant_Hessian thrpt 22492.539 ops/s DateBenchmark.instant_Java thrpt 1484884.452 ops/s DateBenchmark.date_Java thrpt 1500580.192 ops/s DateBenchmark.localDate_Java thrpt 1389041.578 ops/s課題分析
我々の分析は以下の通りです。Dateはヘシアンオブジェクトのシリアライズの8つの原始型のうちの1つである。
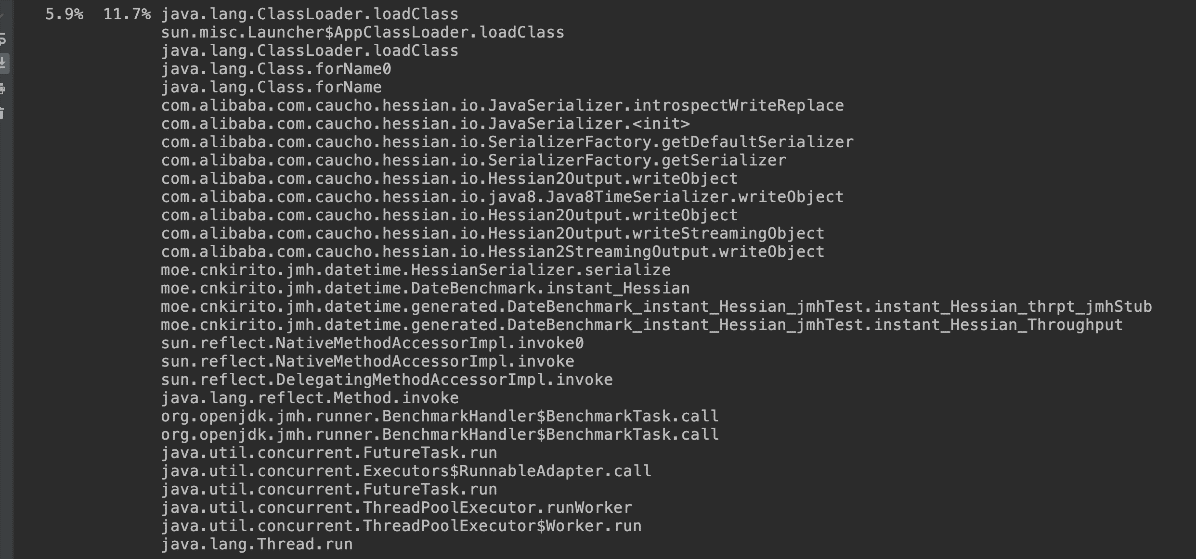
次に、Instantはシリアライズとデシリアライズの両方で
Class.forNameを経由しなければならないため、スループットと応答時間の急激な低下を引き起こしました。したがって、Dateの方が有利です。
最後の感想
Instantなどのクラスにcom.alibaba.com.caucho.hessian.io.Serializerを拡張機能を介して実装し、SerializerFactoryに登録することでHessianをアップグレードして最適化できることがわかりましたので、この記事で取り上げた問題を解消することができます。ただし、それ以前のバージョンや今後のバージョンとの互換性の問題が出てきます。これは深刻な問題です。Alibabaのかなり複雑な依存関係がこれを不可能にしています。この問題を考えると、私たちができる唯一の推奨事項は、TOクラスの好ましい時間属性としてDateを使用することです。
技術的には、HSFのRPCプロトコルはセッション層のプロトコルであり、バージョン認識もここで行われます。しかし、サービスデータのプレゼンテーション層は、Hessianのような自己記述的シリアライズフレームワークで実装されており、バージョン認識には欠けています。そのため、バージョンアップが非常に困難になります。
アリババクラウドは日本に2つのデータセンターを有し、世界で60を超えるアベラビリティーゾーンを有するアジア太平洋地域No.1(2019ガートナー)のクラウドインフラ事業者です。
アリババクラウドの詳細は、こちらからご覧ください。
アリババクラウドジャパン公式ページ
- 投稿日:2020-09-25T14:22:11+09:00
Javaバージョン8以降の機能
この記事では、開発者の視点からJavaのバージョン8以降の機能を説明し、開発者がパフォーマンスを向上させるためにそれらをどのように使用できるかを記しています。
本ブログは英語版からの翻訳です。オリジナルはこちらからご確認いただけます。一部機械翻訳を使用しております。翻訳の間違いがありましたら、ご指摘いただけると幸いです。
アリババグループのシニア技術専門家、陳利彬(Leijuan)より
PythonやJavaScriptなどのプログラミング言語の人気はますます高まっています。しかし、以前に支配的な言語であったJavaは、多少の好意を失ったにもかかわらず、主要なプログラミング言語のさまざまなランキングでトップの座を維持しています。Javaは、メインストリームのエンタープライズ・アプリケーションのアプリケーション開発の第1位の言語であることに変わりはありません。Java 8の発売以来、Javaはパフォーマンスの向上に役立つ多くの有用な新しい言語機能やツールを導入してきました。しかし、多くのプログラマーは、開発のためにJava 8以降のバージョンにアップグレードしていません。この記事では、開発者の視点から、Java 8以降のバージョンのJava言語機能について説明します。
まず、Java 8は間違いなくほとんどのJavaプログラマーの目には画期的なバージョンでしょう。その最も有名な機能はストリームとラムダ式であり、機能的なプログラミングを可能にし、Javaを活性化させています。これはまさに、Oracleがアップデートを停止したにもかかわらず、多くのクラウドベンダーがJava 8に素晴らしいサポートを提供して、長く活動を続けている理由そのものです。
Alibaba Cloud SDK for Javaのインストール
多くのプログラマが開発のためにJava 8よりも後のバージョンにアップグレードしていないため、後のバージョンの言語機能を取り上げています。この記事では、開発に焦点を当て、ガベージコレクション(GC)、コンパイラ、Javaモジュール、プラットフォームをスキップします。これらのトピックは、他の記事でカバーすることができます。コードを書く上では、以下の機能が役割を果たします。
Java 13がまもなくリリースされるので、Java 9からJava 13までのJavaのバージョンがすべて網羅されています。Javaのリリースは調整されており、バージョンに応じてプレビューが導入され、その後、ユーザーのフィードバックに基づいて補強や改善が行われます。この記事では、どのバージョンにどの機能があるのかを具体的に指摘することはありません。ただ、Java 8以降のすべてのバージョンの機能が混在していると考えていただいて構いません。この記事の参照元は、Java公式サイトの「Features and Pluralsight」のセクションにある各Javaバージョンの詳細な紹介です。
Var - ローカル変数型推論
Javaはジェネリックをサポートしていますが、型が長さをあまり気にしないのであれば、varキーワードを使いましょう。これはあなたのコードを大幅に簡素化します。Java IDEはvarで完全に動作するので、頻繁にコードヒントを扱う必要はありません。
Map<String, List<Map<String,Object>>> store = new ConcurrentHashMap<String, List<Map<String,Object>>>(); Map<String, List<Map<String,Object>>> store = new ConcurrentHashMap<>(); Map<String, List<Map<String,Object>>> store = new ConcurrentHashMap<String, List<Map<String,Object>>>(); //lambda BiFunction<String, String, String> function1 = (var s1, var s2) -> s1 + s2; System.out.println(function1.apply(text1, text2));confdファイルをbinディレクトリにコピーしてconfdを起動します。
sudo cp bin/confd /usr/local/bin confd実際には、値をNull値に代入するなど、いくつかの小さな制限が予想されます。しかし、これらは大きな問題ではないので、すぐに始めることができます。
プロセスハンドル
Javaでシステムコマンドを呼び出すことはたまにしかありません。もちろん、そのためにはProcessBuilderを使うことがほとんどです。もう一つの特徴は、他のプロセスの更新情報を取得できるProcessHandleの強化です。ProcessHandleは、すべてのプロセス、特定のプロセスの開始コマンドや開始時刻などを取得するのに役立ちます。
ProcessHandle ph = ProcessHandle.of(89810).get(); System.out.println(ph.info());コレクションファクトリメソッド
まだ新しいメソッドを使ってArrayListやHashSetを作成していませんか?遅れているかもしれません。ファクトリーメソッドを直接使ってみましょう。
Set<Integer> ints = Set.of(1, 2, 3); List<String> strings = List.of("first", "second");文字列クラスの新しいAPI
ここですべての新しい API をリストアップすることは不可能ですが、いくつかの重要な API を使いこなせれば、サードパーティ製の StringUtils を取り除くことができます。次のAPIは、repeat、isEmpty、isBlank、strip、line、indent、transform、trimIndent、formattedです。
HTTP 2 をサポート
OkHTTP 3を使った方が簡単ですが、他の開発パッケージを望まず、HTTP 2に固執したい場合は問題ありません。JavaはHTTP 2をサポートしており、同期型と非同期型の両方のプログラミングモデルをサポートしています。また、コードも基本的には同じです。
HttpClient client = HttpClient.newHttpClient(); HttpRequest req = HttpRequest.newBuilder(URI.create("https://httpbin.org/ip")) .header("User-Agent", "Java") .GET() .build(); HttpResponse<String> resp = client.send(req, HttpResponse.BodyHandlers.ofString()); System.out.println(resp.body());テキストブロック (JDK 13)
以前のバージョンでは、長い文章を入力する必要があり、ダブルクォーテーションを避ける必要があります。可読性が悪くなります。
例えば:String jsonText = "{"id": 1, "nick": "leijuan"}";テキストブロックの新方式:
//language=json String cleanJsonText = """ {"id": 1, "nick": "leijuan"}""";はるかにシンプルですよね?コードを書くことに集中して、ダブルクォーテーションマークのエスケープやコピーの共有と変換を心配する必要はありません。
ちょっと待ってください、 cleanJsonText の前に追加した
//language=jsonとは何でしょうか?これはIntelliJ IDEAの機能で、テキストブロックはセマンティックです。HTML、JSON、SQLのコードに//language=jsonを追加すると、すぐにコードヒントが出てきます。テキストブロックは基本的なテンプレートの特性にも対応しています。テキストブロックにコンテキスト変数を導入し、%sと入力し、フォーマットされたメソッドを呼び出します。これであなたの仕事は完了です。
//language=html String textBlock = """ <span style="color: green">Hello %s</span>"""; System.out.println(textBlock.formatted(nick));スイッチの改善
Arrow Labels(アローラベル)
スイッチ矢印「→」を導入したことで、そんなにたくさんの改行をする必要がなくなりました。以下にサンプルコードを紹介します。
//legacy switch (DayOfWeek.FRIDAY) { case MONDAY: { System.out.println(1); break; } case WEDNESDAY: { System.out.println(2); break; } default: { System.out.println("Unknown"); } } //Arrow labels switch (DayOfWeek.FRIDAY) { case MONDAY, FRIDAY, SUNDAY -> System.out.println(6); case TUESDAY -> System.out.println(7); case THURSDAY, SATURDAY -> System.out.println(8); case WEDNESDAY -> System.out.println(9); }式を切り替える
つまり、スイッチには戻り値があるということです。以下にサンプルコードを示します。
//Yielding a value int i2 = switch (DayOfWeek.FRIDAY) { case MONDAY, FRIDAY, SUNDAY -> 6; case TUESDAY -> 7; case THURSDAY, SATURDAY -> 8; case WEDNESDAY -> 9; default -> { yield 10; } };キーワード yield は、スイッチ式の戻り値を表します。
これらの機能の使用
これらの機能はどれもよくできているように見えますが、まだJava 8で作業をしているときに、どうやってこれらの機能を使うことができるでしょうか?これらの機能を検討する以外に、他に何ができるでしょうか?心配しないでください。解決策を見つけました。
この項目は、すべての JDK 12+ 構文を Java 8 VM に透過的にコンパイルすることをサポートしています。言い換えれば、これらの構文をJava 8上で実行することは問題ではありません。これらの機能はすべて、Java 8 環境でも利用可能です。
では、どのようにして使うことができるのでしょうか?それはすべて非常にシンプルで簡単です。
まず、JDK 13などの最新のJDKをダウンロードし、依存関係にjabel-java-pluginを追加します。
<dependency> <groupId>com.github.bsideup.jabel</groupId> <artifactId>jabel-javac-plugin</artifactId> <version>0.2.0</version> </dependency>そして、Mavenのコンパイラプラグインを調整し、ソースをJava 13など必要なJavaバージョンに設定します。ターゲットとリリースはJava 8に設定することができます。IntelliJ IDEAは自動認識が可能なので調整の必要はありません。
<plugin> <groupId>org.apache.maven.plugins</groupId> <artifactId>maven-compiler-plugin</artifactId> <version>3.8.1</version> <configuration> <source>13</source> <target>8</target> <release>8</release> </configuration> </plugin>さあ、それらの機能を使った快適な体験を始めましょう。
概要
このブログでは、Javaで人気のある便利な機能をいくつか取り上げてきました。APIの調整など、いくつかの便利な機能はこの記事では触れられていません。しかし、ブログやフォーラムを通じて、いつでも私たちのコミュニティと共有することができます。
アリババクラウドは日本に2つのデータセンターを有し、世界で60を超えるアベラビリティーゾーンを有するアジア太平洋地域No.1(2019ガートナー)のクラウドインフラ事業者です。
アリババクラウドの詳細は、こちらからご覧ください。
アリババクラウドジャパン公式ページ
- 投稿日:2020-09-25T10:21:21+09:00
GraphiteとStatsDを使用して、インフラ監視
はじめに
サーバー、アプリケーション、およびトラフィックに関するメトリックを収集することは、アプリケーション開発プロジェクトの重要な部分となります。 本番システムでは問題が発生する可能性のある多くの問題があり、データの収集と整理は、インフラストラクチャのボトルネックと問題を特定するのに役立ちます。
この記事では、GraphiteとStatsD、およびそれらがモニタリングインフラストラクチャの基礎を形成するのにどのように役立つかについて説明していきます。 MetricFireの無料デモを予約し自分のニーズを確認してから、マネージドされたGraphiteサービスであるHosted Graphiteの無料トライアルにサインアップしてみてください。
Graphiteは、いくつかのコンポーネントで構成されるライブラリです。 ここでは、各コンポーネントについて簡単に説明します。
Graphite Webアプリケーション
グラファイトWebアプリケーションは、グラフを作成してデータをプロットできる場所です。 Webアプリケーションでは、グラフのプロパティとレイアウトを保存できます。
Carbon
カーボンはGraphiteのストレージバックエンドです。 Carbonは基本的に、TCP / UDPポートで実行するように構成できるデーモンです。 増加する負荷を処理し、レプリケーションとシャーディングを構成するために、複数のCarbonデーモンを同じホストまたは複数のホストで実行し、Carbonリレーを使用して負荷分散することができます。
Whisper
Whisperは、Graphiteがデータを格納するために使用するデータベース形式です。
Whisperは、最新の高い解像度(1秒あたりの秒数)のデータをより低い解像度に低下させ、履歴データを長期間保持できるようにします。
Graphiteについて説明したので、続いてStatsDについて説明します。
StatsD
StatsDはnode.jsアプリケーションです。 これは、ネットワーク、サーバー、アプリケーションに関するデータポイントを送信するために作成されたもので、グラフにレンダリングできます。
セットアップ
https://hub.docker.com/r/graphiteapp/docker-graphite-statsd/
にあるdockerイメージを使用しますこれは非常にシンプルなdocker-compose.ymlです:
version: "3" services: graphite-statsd: image: graphiteapp/docker-graphite-statsd ports: - 2003-2004:2003-2004 - 2023-2024:2023-2024 - 8125:8125/udp - 8126:8126 - 80:80このDockerイメージを実行した後、http:// localhostにアクセスすると、ブラウザーは以下のようにGraphite Webアプリケーションをロードします。
この時点では、Graphiteのメトリックは空になっているはずです。 デプロイをテストしてみましょう。次のコマンドを使用して、StatsDデーモンに単純なメトリックを送信します。
echo "deploys.test.myservice:1|c" | nc -w 1 -u localhost 8125ここでの構文は次のとおりです。
bucket:value|typeBucket (バケット)
バケットはメトリックの識別子です。 同じバケットと同じタイプのメトリックデータグラムは、サーバーによって同じイベントの発生と見なされます。 上記の例では、バケットとして「deploys.test.myservice」を使用しました。
Value (値)
Valueは、メトリックに関連付けられている数値です。 値の意味は、メトリックのタイプによって異なります。
Type (タイプ)
Typeによって、メトリックのタイプが決まります。 タイマー、カウンター、ゲージ、ヒストグラムなど、さまざまなメトリックタイプがあります。
Timer (タイマー)
タイマーは時間間隔を測定するため、カウンターとは異なります。 たとえば、REST APIが応答するのにかかった時間を測定する場合は、タイマーを使用します。 タイマーの単一のメトリック、たとえば100 msはあまり役に立ちません。 6時間などの時間間隔で組み合わせると、より便利です。 平均、標準偏差、50パーセンタイル、90パーセンタイル、95パーセンタイルなど、さまざまなサブメトリックが各メトリックで自動的に計算されます。
echo "deploys.test.myservice.time:55|ms" | nc -w 1 -u localhost 8125Gauge (ゲージ)
ゲージは、増減できる固定値に使用されます。 たとえば、ゲージを使用して、アプリケーション内のスレッド数、またはキュー内のジョブ数を表すことができます。
これが、1つのグラフにカウンター値とタイマー値の両方を示すカーボンWebアプリケーションです。
Node.jsとの統合
たった今、コマンドラインを介してメトリックを送信する方法を見てきました。 実際には、Node.jsやJavaベースのサーバーを実行するアプリケーションなどの一部のアプリケーションによってメトリックが生成されるため、これらの例は当てはまりません。
ここからは、node.jsで作成されたアプリケーションがメトリックを送信する方法を見てみましょう。 以下に示すように、ポート3000で実行されている高速サーバーを考えてみます。
const express = require("express"); const app = express(); app.get("/", (req, res) => { res.send("Response from a simple GET API"); }); app.listen(3000, () => { console.log("Node server started on port 3000"); });最初に、npmを使用してnode-statsdをインストールする必要があります。
npm i node-statsd --save次に、StatsDクライアントのインスタンスを次のように作成します。
const StatsD = require("node-statsd"), client = new StatsD();StatsDコンストラクターは、StatsDサーバーを実行しているマシンのホストやポートなど、いくつかのオプションの引数を取ります。 完全なドキュメントは
https://github.com/sivy/node-statsd
にあります。私の場合、デフォルトのオプションであるhttp:// localhostとport8125でStatsDを実行していました。
クライアントのインスタンスを作成したら、さまざまなメソッドを呼び出して、アプリケーションにメトリックを送信できます。 たとえば、次のようにAPI呼び出しの数とタイミングを追跡できます。
app.get("/", (req, res) => { res.send("Response from a simple GET API"); client.increment("api_counter"); client.timing("api_response_time", 110); });ブラウザにhttp:// localhost:3000と入力するとすぐに、APIが呼び出され、StatsDクライアントが実行されます。 グラファイトWebアプリケーションで更新されたメトリックを確認できます。
クライアントインスタンスで使用可能なすべての方法については、https://github.com/sivy/node-statsdのドキュメントを確認してください。
Javaとの統合
Javaベースのクライアントとの統合は、Node.jsとよく似ています。 MavenやGradleなどのビルドシステム(強く推奨)を使用している場合は、この統合を容易にするためのユーティリティjarを利用できます。 以下をビルド構成に追加して、自動的に含めるようにします。
Mavenの場合:
<dependency> <groupId>com.timgroup</groupId> <artifactId>java-statsd-client</artifactId> <version>3.1.0</version> </dependency>Gradleの場合:
compile group: 'com.timgroup', name: 'java-statsd-client', version: '3.1.0'クライアントライブラリがインポートされたら、StatsDサーバーが実行されている目的のプレフィックス、ホスト名、およびポートを提供する実装クラスNonBlockingStatsDclientを使用して、StatsDClientインターフェイスのインスタンスを作成します。
以下に示すように、このインターフェースでは、GraphiteをStatsDサーバーに送信するtime()、incrementCounter()などの簡単なメソッドを使用できます。 完全なドキュメントについては、https://github.com/tim-group/java-statsd-clientを参照してください。
package example.statsd; import com.timgroup.statsd.NonBlockingStatsDClient; import com.timgroup.statsd.StatsDClient; public class App { private static final StatsDClient statsd = new NonBlockingStatsDClient("java.statsd.example.prefix", "localhost", 8125); public static void main(String[] args) { statsd.incrementCounter("java_main_method_counter"); statsd.time("java_method_time", 125L); statsd.stop(); } }StatisticsDの水平スケーリング
インフラストラクチャに関しては、単一のStatsDサーバーはすべての負荷を処理することができず、最終的に水平方向のスケーリングが必要になります。 StatsDでも集計を実行できるため、StatsDを使用した水平スケーリングは単純なラウンドロビンロードバランシングにはなりません。 同じキーのメトリックが複数のノードに分散されている場合、単一のStatsDがメトリック全体を正確に集約することはできません。
したがって、SatsDの作成者は、一貫したハッシュを使用して同じメトリックが常に同じインスタンスに送信されることを確認するStatsDクラスタープロキシをリリースしました。
以下は、StatsDクラスタープロキシの非常にシンプルな構成です。
{ nodes: [ {host: 'host1', port: 8125, adminport: 8128}, {host: 'host2', port: 8125, adminport: 8130}, {host: 'host3', port: 8125, adminport: 8132} ], server: './servers/udp', host: '0.0.0.0', port: 8125, mgmt_port: 8126, forkCount: 4, checkInterval: 1000, cacheSize: 10000 }設定ファイルがセットアップされたら、次のように実行するだけです。
node proxy.js proxyConfig.jsProxy.jsは、StatsDインストールディレクトリのルートにあります。
設定キーのいくつかは説明に値します:
- CheckInterval:ヘルスチェックの間隔を決定します。 ノードがオフラインの場合、クラスタープロキシはそのノードを構成から外します。
- サーバー:サーバーバイナリは、「ノード」構成で指定されたノード構成から読み込まれます。
まとめ
StatsDとGraphiteは、インフラストラクチャの監視に最適です。 上記のすべてのコードと構成は、githubリポジトリで入手できます。
主な利点は次のとおりです。
低メモリフットプリント:StatsDは非常にシンプルなnode.jsベースのサーバーであり、その結果、メモリフットプリントが非常に低くなります。つまり、インフラストラクチャでこの設定を簡単に開始できます。
効率的なネットワーク:StatsDは、接続の少ないプロトコルであるUDPを介して動作できるため、大量のデータを非常に短い時間で転送できます。
これらのプロセスを試してみたい方は、MetricFireの日本語対応のデモをご予約ください。
最適な監視ソリューションについてもお話しすることもできます。それでは、またの記事で!

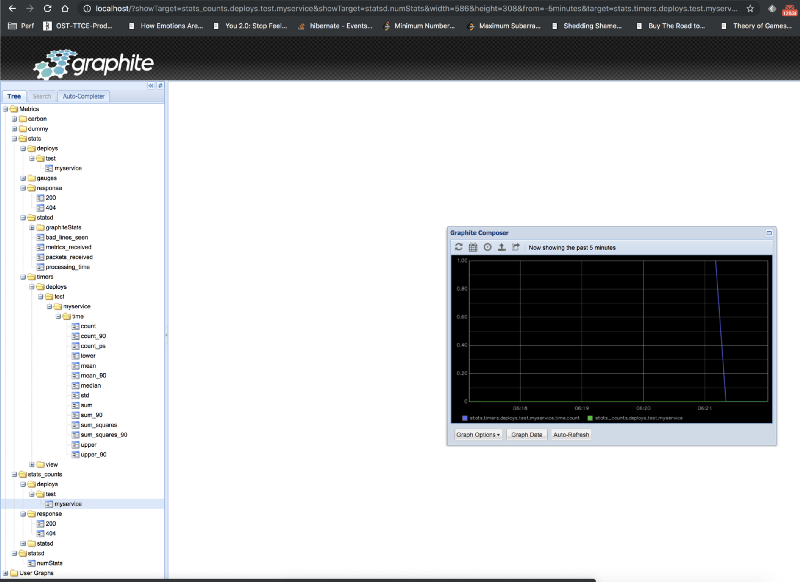
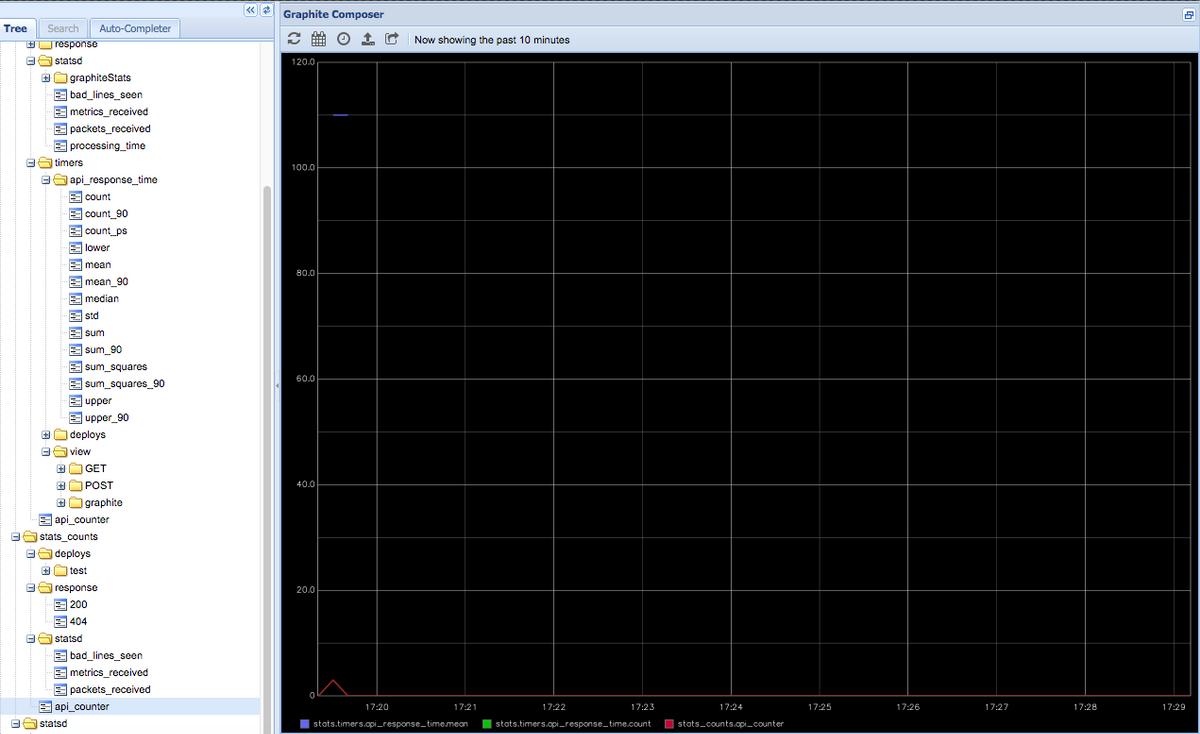
- 投稿日:2020-09-25T09:07:29+09:00
シンプルになぜinterfaceを使うのかを考察
それは実装をシンプルにして部品化を促すため
interfaceはカオスな現実世界と実装をつなぐ、あるいは分離する役割を担っています。
部品化しやすくするために、実装はできるだけシンプルにinterfaceでは多重継承を許し、一般クラスでは許さない理由
interfaceはカオスな現実世界に近い業務仕様を記述するため、多重継承を許容することで、実装レベルの一般クラスの複雑化を代替します。
※補足
多重継承を許容:言語によって差異はありますが、interfaceの意味を尊重するなら、一般クラスをinterfaceようにするなどして、多重継承を自主的に制限することがオブジェクト指向の本来の利点を活用することになると考えます。おまけ
interface間の関係性や条件を規定するのは、業務設計者です。
interface内に実装(処理)条件を持ち込まないように注意が必要です。
逆に実装(処理)にinteface間の(業務)条件を持ち込まないよう注意することが重要です。
業務と処理を関連付ける機能は双方の共通言語になります。
- 投稿日:2020-09-25T09:07:29+09:00
シンプルに「なぜinterfaceを使うのか」を考察
それは実装をシンプルにして部品化を促すため
interfaceはカオスな現実世界と実装をつなぐ、あるいは分離する役割を担っています。
部品化しやすくするために、実装はできるだけシンプルに、複雑さはinterfaceがブロック!interfaceでは多重継承を許し、一般クラスでは許さない理由
interfaceはカオスな現実世界に近い業務仕様を記述するため、多重継承を許容することで、実装レベルの一般クラスの複雑化を代替します。
※補足
シンプル化:問題領域を小さくすることで、問題の連鎖や波及を制限し、部品としての汎用性が向上します。
多重継承を許容:言語によって差異はありますが、interfaceの意味を尊重するなら、他の言語でも一般クラスをinterfaceのようにするなどして、多重継承を自主的に制限することがオブジェクト指向の本来の利点を活用することになると考えます。おまけ
interface間の関係性や条件を規定するのは、業務設計者です。
interface内に実装(処理)条件を持ち込まないように注意が必要です。
逆に実装(処理)にinteface間の(業務)条件を持ち込まないよう注意することが重要です。
業務と処理を関連付ける機能は双方の共通言語になります。
- 投稿日:2020-09-25T01:11:21+09:00
【Java】String型配列の要素一つをInt型に型変換する方法
例えば従業員の情報を、名前、年齢と入力されそれを一つの配列にScannerを使って代入すると
yamada 20Scanner sc = new Scanner( System.in);
String[] employee = sc.nextLine();となるが、年齢を変えたいのにInt型にキャストしなくてはならない
そこでInteger.parseIntメソッドを使うint age = Integer.parseInt( employee[1]);
これでString型からInt型へのキャストは終了
たとえば1歳年を増やしたければint addAge = Integer.parseInt( employee[1] ) + 1;
となる。
()内は引数なのでもちろん普通の変数でも問題ありません。
- 投稿日:2020-09-25T01:11:21+09:00
{Java} String型配列の要素一つをInt型に型変換する方法
例えば従業員の情報を、名前、年齢と入力されそれを一つの配列にScannerを使って代入すると
yamada 20Scanner sc = new Scanner( System.in);
String[] employee = sc.nextLine();となるが、年齢を変えたいのにInt型にキャストしなくてはならない
そこでInteger.parseIntメソッドを使うint age = Integer.parseInt( employee[1]);
これでString型からInt型へのキャストは終了
たとえば1歳年を増やしたければint addAge = Integer.parseInt( employee[1] ) + 1;
となる。
()内は引数なのでもちろん普通の変数でも問題ありません。