- 投稿日:2020-09-21T13:38:39+09:00
[Tensorflow2系]Grad-CAMについて0から勉強をやり直す
目的
- Grad-CAMの処理内容を理解する
- Tensorflow 2系の書き方を把握する
使用する文献
Visualizing Activation Heatmaps using TensorFlow | by Areeb Gani | Analytics Vidhya | Medium
ソースコードの読解
インポート
import tensorflow as tf import tensorflow.keras.backend as K from tensorflow.keras.applications.inception_v3 import InceptionV3 from tensorflow.keras.preprocessing import image from tensorflow.keras.applications.inception_v3 import preprocess_input, decode_predictions import numpy as np import os import matplotlib.pyplot as plt import cv2 from google.colab.patches import cv2_imshow
モデル
# imagenetの重みを初期値として用いる model = InceptionV3(weights='imagenet') model.summary()Grad-CAMではモデルの最終畳み込み層を用います。
InceptionV3ではconv2s_93がモデルの最終畳み込み層になります。学習準備
画像のダウンロード
!wget https://indiasendangered.com/wp-content/uploads/2011/09/elephant.jpg !wget https://s3.amazonaws.com/cdn-origin-etr.akc.org/wp-content/uploads/2017/11/12234558/Chinook-On-White-03.jpg !wget https://icatcare.org/app/uploads/2018/07/Thinking-of-getting-a-cat.png学習用に像や猫などの画像をダウンロードします。
読解するコードでは像の画像のみ使用します。
*!は Google Colabでソースコード以外を実行するときのコマンドです画像の表示
ORIGINAL = 'elephant.jpg' DIM = 299 # 第一引数は画像パス名,第二引数は画像サイズ img = image.load_img(ORIGINAL, target_size=(DIM, DIM)) cv2_imshow(cv2.imread(ORIGINAL)) # Visualize image
学習のための前処理
x = image.img_to_array(img) x = np.expand_dims(x, axis=0) x = preprocess_input(x) preds = model.predict(x) print(decode_predictions(preds))現在の画像の状態では学習に使用することができないので前処理を行います。
前処理について具体的に記述します。print(type(img)) # <class 'PIL.Image.Image'> x = image.img_to_array(img) print(type(x)) # <class 'numpy.ndarray'> print(x.shape) # (299, 299, 3)print分の実行結果を
#の後ろに記述しました。最初に
imgのクラスタイプはPIL.Image.Imageとなっています。
処理をするために画像データを加工します。
最初にimage.img_to_array(img)を用いてNumpy配列に変更します。結果、
xのタイプは<class 'numpy.ndarray'>となっています。
xの配列の形も(299, 299, 3)になっています。
これは(縦,横:299,299)の画像サイズ分の次元数であり、最後の, 3)はRGBの3つの次元数を持っているという意味です。
x = np.expand_dims(x, axis=0) print(x.shape)# (1, 299, 299, 3) x = preprocess_input(x)
np.expand_dimsを用いてaxisで指定したところ(今回は0次元)に1つ次元を追加します。
そうすることによって[1, height, width, channels]という形になります。これはGrad-CAMでは1枚の画像しか用いませんが、通常ディープラーニングでは
たくさんの画像を使用します。そのため、100枚の画像を使用するとなると[100, height, width, channels]という風にデータの形が変換されるため、次元の形を合わせるためにnp.expand_dimsを使用します。次元拡張後、preprocess_inputに画像の情報を入れることによって前処理を行っています。前処理としては以下のことを行います。
・モデルによって画像の正規化
・ImageNetデータセットのRGB各チャンネルごとの平均値を引くまた、無駄な訓練を行わないという点でも使うメリットはあるそうです。
preds = model.predict(x) print(decode_predictions(preds)) #実行結果 [[('n02504013', 'Indian_elephant', 0.9624098), ('n01871265', 'tusker', 0.015191134)model.predictでモデルに対しての画像の推論を行います。
Grad-CAMの実装
ここから(やっと)Grad-CAMの実装に入っていきます。
TensorFlow1系で実装するときと2系で実装する大きな違いの一つとして以下の
tf.GradientTape(以下:tf.GradientTape)を使用するという点があります。
tf.GradientTapeはグラデーション(勾配)を計算するのに使用します。Grad-CAMのソースコード
以下がGrad-CAMの一番大事の処理のところです。
一行ずつ見ていきましょう。with tf.GradientTape() as tape: last_conv_layer = model.get_layer('conv2d_93') iterate = tf.keras.models.Model([model.inputs], [model.output, last_conv_layer.output]) model_out, last_conv_layer = iterate(x) class_out = model_out[:, np.argmax(model_out[0])] grads = tape.gradient(class_out, last_conv_layer) pooled_grads = K.mean(grads, axis=(0, 1, 2)) heatmap = tf.reduce_mean(tf.multiply(pooled_grads, last_conv_layer), axis=-1)一行ずつ読み解いていく
last_conv_layer = model.get_layer('conv2d_93')
model.get_layerを使用して Inception V3の最終畳み込み層を取得します。iterate = tf.keras.models.Model([model.inputs], [model.output, last_conv_layer.output]) model_out, last_conv_layer = iterate(x)
tf.keras.models.Modelではモデルの入力(第一引数)とモデルの出力(第二引数)を定義します。
今回はmodelの入力はそのままで、出力はmodelの最終出力と最終畳み込み層の二つの勾配を出力するモデルを定義しています。
これの出力がmodel.outのみである場合はiterateをしても一つしか出力はされません。class_out = model_out[:, np.argmax(model_out[0])]モデルの最終出力の中で最も高い数値の確信度を
class_outとして出力します。
model_out自体は"shape=(1, 1000)"の二次元配列であるためmodel_out[0]として取得します。grads = tape.gradient(class_out, last_conv_layer) print(grads.shape) #(1, 8, 8, 192)
tape.gradient(class_out, last_conv_layer)は"class_out(モデルの最終出力勾配)"から"last_conv_layer(最終畳み込み層)"までの勾配です。pooled_grads = K.mean(grads, axis=(0, 1, 2)) print(pooled_grads.shape) # (192,)
K.mean(grads, axis=(0, 1, 2))は先ほどの"class_out(モデルの最終出力勾配)"からlast_conv_layer(最終畳み込み層)までの平均勾配です。heatmap = tf.reduce_mean(tf.multiply(pooled_grads, last_conv_layer), axis=-1)次に最終畳み込み層出力の値に平均勾配を掛けて、さらに平均化します。
ヒートマップを出力する
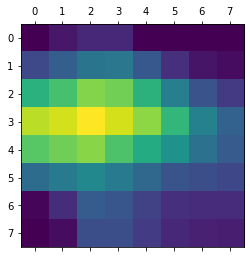
heatmap = np.maximum(heatmap, 0) heatmap /= np.max(heatmap) heatmap = heatmap.reshape((8, 8)) plt.matshow(heatmap) plt.show()一行ずつ読み解いていく
heatmap = np.maximum(heatmap, 0)ここではリスト内の値を"0~1"にして最小値を0にします。
heatmap /= np.max(heatmap)最大値で割ることによってリスト内の最大値を1にします。
heatmap = heatmap.reshape((8, 8)) plt.matshow(heatmap) plt.show()あとは大きさを整形し、plotで表示します。
このとき表示されるものは以下のようになります。
このままでは何かさっぱりわからないので、元の像の画像と
合成することによってヒートマップを完成させます。画像を合成する
img = cv2.imread(ORIGINAL) INTENSITY = 0.5 heatmap = cv2.resize(heatmap, (img.shape[1], img.shape[0])) heatmap = cv2.applyColorMap(np.uint8(255*heatmap), cv2.COLORMAP_JET) img = heatmap * INTENSITY + img cv2_imshow(cv2.imread(ORIGINAL)) cv2_imshow(img)一行ずつ読み解いていく
img = cv2.imread(ORIGINAL) INTENSITY = 0.5もと画像を読み込みます。
またINTENSITYはヒートマップの強度係数というもので、
値が大きくなるとヒートマップで赤くなるところがより濃くなります。
(末尾に番外編として、強度係数を変更したときの画像を載せておきます)heatmap = cv2.resize(heatmap, (img.shape[1], img.shape[0]))先ほど出力したヒートマップをを元画像に合成するためにサイズを元画像と一致させます。
heatmap = cv2.applyColorMap(np.uint8(255*heatmap), cv2.COLORMAP_JET)np.uint8(255*heatmap)で
255を乗算ことによりRGB形式に変化にします。
次にcv2.applyColorMapを用いて疑似カラーマップを生成します。img = heatmap * INTENSITY + img(先ほど記述した)ヒートマップの値、強度係数、もと画像をかけ合わせることにより
ヒートマップを完成させます。cv2_imshow(cv2.imread(ORIGINAL)) cv2_imshow(img)最後に元画像とヒートマップ画像を出力して完成です!
最後に
今まではTensorflow1系でプログラムを書いていたのですが、
2系になったことプログラムの記述の仕方が一部が変わりました。また知識がほんわかとしているところが多々あったため、
勉強をやり直すことを目的にこの記事を作成しました。わからないところは文献や記事を見ながら自分なりに解釈して記述しました。
しかし、間違っているところや誤解しているところがあると思います。
そのような所はご教授していただけますと幸いです。(番外編)強度係数を変更してみる
# もと画像 img = cv2.imread(ORIGINAL) cv2_imshow(img)
INTENSITY = 0.1
INTENSITY = 0.5
INTENSITY = 0.9
参考文献
- Visualizing Activation Heatmaps using TensorFlow | by Areeb Gani | Analytics Vidhya | Medium
- 日本一詳しくGrad-CAMとGuided Grad-CAMのソースコードを解説してみる(Keras実装) - Qiita
- TensorFlow メソッド、shape をいじる系メモ - Qiita
- Kerasで転移学習をする際にはpreprocess_input()を呼ぼう | 10001 ideas
- バックエンド - Keras Documentation
- Grad-CAMでヒートマップを表示 - Qiita
- 【Python】OpenCVで疑似カラー(Pseudo color) - Qiita





- 投稿日:2020-09-21T05:45:18+09:00
EMNISTでアルファベット手書き認識
EMNIST-lettersを学習させました。
— mbotsu (@mb_otsu) September 17, 2020
CODE: https://t.co/D3bP7tHq9U
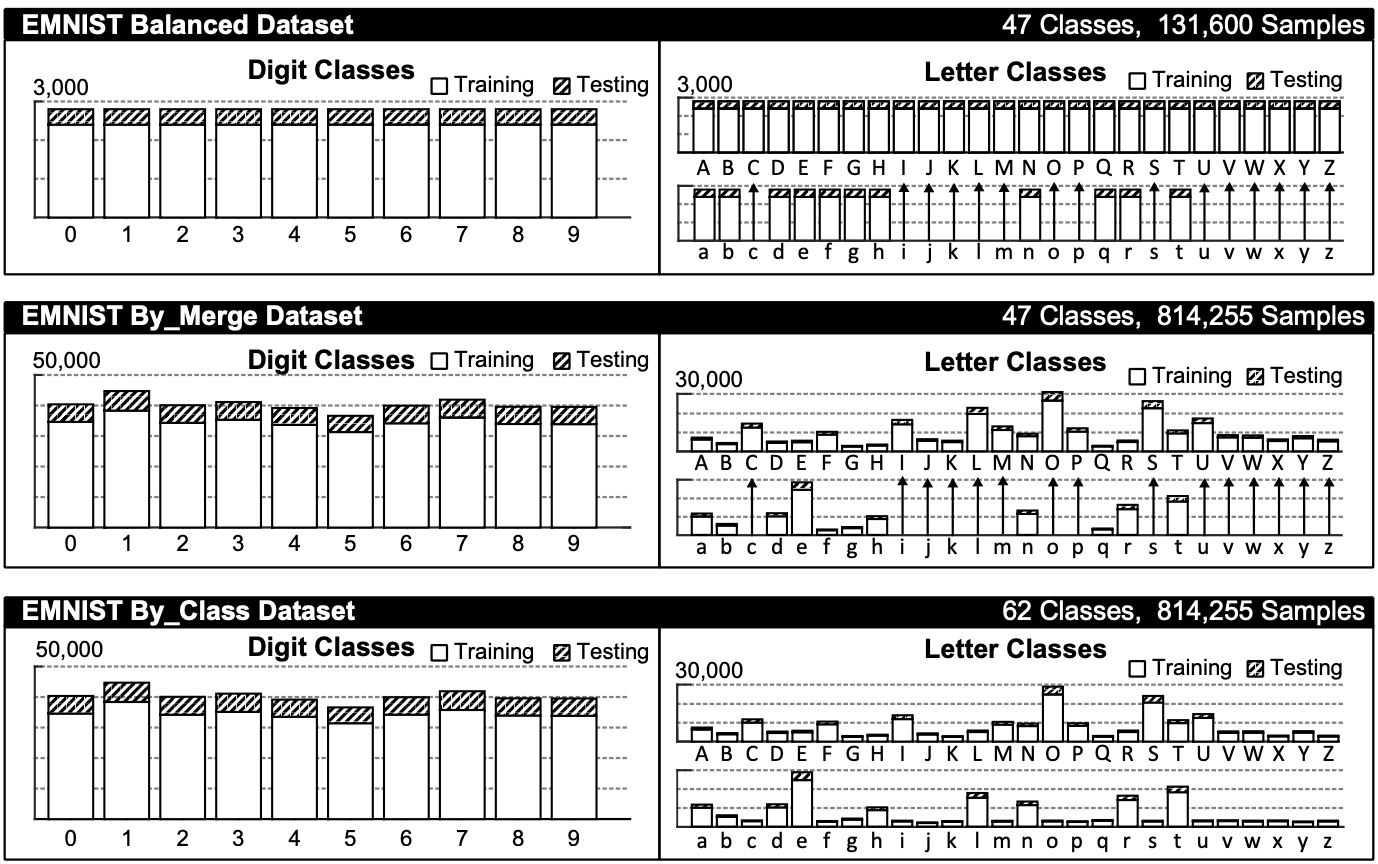
DEMO: https://t.co/8c20CEzLpC pic.twitter.com/gr66WGkQRiEMNISTは2017年にNISTが公開したデータセットになります。
- EMNIST ByClass: 814,255 characters. 62 unbalanced classes.
- 大文字(26) + 小文字(26) + 数字(10)
- EMNIST ByMerge: 814,255 characters. 47 unbalanced classes.
EMNIST Balanced: 131,600 characters. 47 balanced classes.
- ByMergeとBalanced
大文字(26) + abdefghnqrt(11) + 数字(10)
大文字と被るcijklmopsuvwxyzを省いたもの。
ブレンド具合は下記図を参照EMNIST Letters: 145,600 characters. 26 balanced classes.
- 大文字と小文字のセット(26)
EMNIST Digits: 280,000 characters. 10 balanced classes.
EMNIST MNIST: 70,000 characters. 10 balanced classes.
- DigitsとMNISTは元のMNISTと互換性のある手書き数字
はまりどころ
- TensorFlowのデータセットでうまく認識しない?
当初、TensorFlowのデータセットを使ったのですが手書き文字が認識しませんでしたので元のEMNIST-lettesのデータを使いました。
これについては結論は出ていませんがラベルに対してデータ数が少ないのが原因かもしれません。んー
train test Label EMNIST-lettes 124,800 20,800 26 TensorFLow 88,800 14,800 37
- EMNIST-lettesはラベルが1から始まる問題
byclassは0から始まりますがlettersは1から始まりました。
トレーニングにはtf.data.Dataset.from_tensor_slicesを使いましたので、0から始めないとラベル数が正しく扱えませんので調整を行いました。x_train, y_train = extract_training_samples("letters") np.unique(y_train)array([ 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26], dtype=uint8)y_train = y_train - 1 np.unique(y_train)array([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25], dtype=uint8)全体の処理
基本的な処理はKerasを使用したMNISTでのニューラルネットワークのトレーニングを参照しました。
WEBでの表示やモデルはHow to distribute a Tensorflow model as a JavaScript web appを参照しました。
今回試したコードはGitHubに上げています。
以上。後に調べる方の参考になればと思います。
後日譚 (2020/10/02)
EMNIST:手書きアルファベット&数字の画像データセットにtfdsのデータはtransposeが必要とあったので試してみたら認識するようになった。
実験ノート
https://gist.github.com/mbotsu/bf4d16df4020b9c3630e0ccae32d5a88