- 投稿日:2020-09-21T23:13:40+09:00
GRUによる需要電力予測
1. はじめに
こんにちは。機械学習を学び始めて約3ヶ月ちょい、少しずつ理解が深まってきたように思えます。
今回は、今まで学んだ事を使って電力需要の予測を行いたいと思います。
具体的には、時系列データを扱える深層学習モデルの一種であるGRUを用いて予測をおこないたいと思います。2. 開発環境
OS : Windows 10
python の実行環境 : Google colaboratoryGoogle colaboratory を用いると環境構築を行わずに開発が可能です。また、GoogleからGPU提供されています(時間制限あり)
3. GRUについて
通常のRNNでは,長期間の時系列データを扱う際に勾配が消失/爆発するといった問題が生じて上手く学習が行えないといった問題があります。そこで、LSRMでは,セルと三つのゲート(入力ゲート,出力ゲート,忘却ゲート)という概念を取り入れて状態を保持し、長期依存の学習が行えるモデルとなっています。
GRUは、ざっくりに言うとLSTMの簡単なモデルで、一般的にLSTMと比較して計算量が少ないといわれいます。4. 使用したモジュール
今回は、先ほど挙げたGRUを用いて予測を行っていきたいと思います。
import numpy as np import matplotlib.pyplot as plt import pandas as pd import math from keras.models import Sequential from keras.layers import Dense from keras.layers import Activation from keras.layers import GRU from keras.layers import Dropout from sklearn.preprocessing import MinMaxScaler from sklearn.metrics import mean_squared_error5. 使用したデータとその前処理
●使用したデータ
今回はKaggleのオープンデータ(https://www.kaggle.com/manualrg/spanish-electricity-market-demand-gen-price) を使用しました。
日毎の需要電力のデータをデータフレーム形式で読み込んでいます。そして、元の形式だと時間情報まで含まれているので日付までの表示に変更しています。
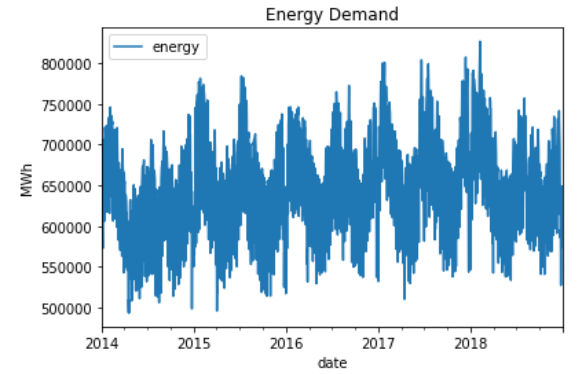
そして,2014年~2017年までのデータを訓練用、2018年のデータをテスト用として分割しています。data = pd.read_csv("/content/drive/My Drive/data/spain_energy_market.csv", sep=",", parse_dates=["datetime"]) data = data[data["name"]=="Demanda programada PBF total"]#.set_index("datetime") data["date"] = data["datetime"].dt.date data.set_index("date", inplace=True) data = data[["value"]] data = data.asfreq("D") data = data.rename(columns={"value": "energy"}) train_series = data.loc["2014":"2017"].values test_series = data.loc["2018"].valuesデータをplot表示すると、このような波形が得られます。
●データの加工
次に、訓練データでの分布を元に、それぞれのデータセットの正規化を行っていきます。
scaler = MinMaxScaler(feature_range=(0, 1)) scaler_train = scaler.fit(train_series) train = scaler_train.transform(train_series) test = scaler_train.transform(test_series)次に、今回は、20点のデータを使用して1期先のデータを予測することを行うので、そのために直近の20点(予測する点から見て後方20点)と、そのラベルデータ(1期先のデータ)とに分割を行っていきます。
def create_dataset(dataset, look_back): data_X, data_Y = [], [] for i in range(look_back, len(dataset)): data_X.append(dataset[i-look_back:i, 0]) data_Y.append(dataset[i, 0]) return np.array(data_X), np.array(data_Y)最後にGRUモデルに加えるためにデータの整形を行います。
train_X = train_X.reshape(train_X.shape[0], train_X.shape[1], 1) test_X = test_X.reshape(test_X.shape[0], test_X.shape[1], 1)6. モデルの定義
今回は機械学習ライブラリの「Keras」を利用してGRUモデル構築を行います。
モデルの構築は以下のようになっています。# GRUモデルの作成 model = Sequential() model.add(GRU(40, return_sequences=False, batch_input_shape=(None, look_back, 1))) model.add(Dropout(0.25)) model.add(Dense(1)) model.add(Activation("linear")) model.compile(loss='mean_squared_error', optimizer='adam')7. データの学習と予測結果
●学習と予測
モデルの学習は、model.fit()で行えます。
ここでエポック(epoch)なので、20回の反復処理が行われ学習が行われます。history = model.fit(train_X, train_Y, epochs=20, batch_size=1, verbose=1)そして、モデルでの予測は、model.predict()で行えます。
これにテストデータを入力として渡すことで、1期先の予測が行われます。train_predict = model.predict(train_X) test_predict = model.predict(test_X)●予測結果
学習時の損失は以下のような結果になりました。
損失関数の値は小さく抑えられることが出来たと思われます。
次に、テストデータを用いて1期先予測を行った結果は、以下のようになりました。
大まかな流れはあってそうですけど、ところどころ大きく外れた結果となってしまいました。
ハイパーパラメーターなどを再度設定しなおして学習すると良い結果が得られるかもしれませんが、
前処理の工程でいろいろ改善すべき点がありそうでした。7. まとめ
今回は、RNNモデルの亜種であるGRUモデルを用いて電力需要の予測をおこないました。
その結果、良い結果は得られませんでした。今後は、良い精度が得られるようデータの前処理方法について見直して再度モデルを組もうと思います。


- 投稿日:2020-09-21T23:09:02+09:00
「ゼロから作るDeep Learning 」でModuleNotFoundError: No module named 'dataset.mnist'が出る理由。
目的
「ゼロから作るDeep Learning 」のGitHubのコードで
ModuleNotFoundError: No module named 'dataset.mnist'が出る理由が
一応、わかったので、
説明。
( 世間の質疑が、なんか、かみ合ってないと感じたので、、、、ちょっと、調べました。)説明
原因
原因は、既に、別の名前の「dataset」というモジュールがあるためです。
以下のとおり、
pythonを起動して、
datasetをインポートして、
場所を調べると、どこにあるかはわかります。C:\_qiita\_zero\deep-learning-from-scratch-master\ch08>python Python 3.7.2 (tags/v3.7.2:9a3ffc0492, Dec 23 2018, 23:09:28) [MSC v.1916 64 bit (AMD64)] on win32 Type "help", "copyright", "credits" or "license" for more information. >>> >>> >>> >>> import dataset >>> dataset.__file__ 'C:\\Users\\XYZZZ\\AppData\\Local\\Programs\\Python\\Python37\\lib\\site-packages\\dataset\\__init__.py' >>>対策
今回のdatasetをdataset_zeroとかに変更するとか、
そんな方法がいいのではないでしょうか?まとめ
この記事は、ちょっとは、役に立つかも。
コメントなどあれば、お願いします。
以前も一回同じようなことを経験したことある気がするので、pythonあるある、かも。
- 投稿日:2020-09-21T22:46:14+09:00
Linux上でPython3でMySQLへアクセスするためのyumコマンド
- 投稿日:2020-09-21T22:42:21+09:00
[python]リストの要素を並べて表示する方法
- 投稿日:2020-09-21T22:24:18+09:00
PythonからMatlabを呼び出して最適化する
はじめに
過去にMatlabで作成した関数をpythonにある最適化ソフト(今回はOptune)で最適化していい感じにしたいことってないですか?なんかできそうだったのでやってみました。
動作環境
Matlab R2018a
Win10
python 3.6 (Anaconda)事前準備
python は3.5とか3.6ぐらいが入ってる前提です(R2020だともう少し先のverでもOKかも?)
私はpyenv で 3.6を入れました。
- matlabengine を読み込めるようにする
http://yusuke-ujitoko.hatenablog.com/entry/2019/08/06/212756
こちらを参考にアナコンダプロンプトを"管理者権限"で開いて下記コマンドを打つ
この際、 anaconda3\"envs\py36" はvirtualenv環境でアナコンダをインストールしていない人には 不要かも?cd C:\Program Files\MATLAB\R2018a\extern\engines\python python setup.py install --prefix="C:\Users\****\anaconda3\envs\py36"****はユーザ名です。これでpython とmatlabの連携ができました。
実行コード
まず、実行するmatlab関数は下記です。これを次のpythonコードと同じフォルダに置きます。
function y = func(x) y = (x-3)^2;その後Spyderを立ち上げ、下記コマンドをspyder上で実行
import sys sys.path.append("C:\\Users\\****\\anaconda3\\envs\\py36lib\\site-packages") import matlab.engine import optuna def objective(trial): x = trial.suggest_uniform('x', -10, 10) #ここでMatlab関数読み出してx に対するscoreを返す score = eng.func(x) return score #ここからメイン関数 eng = matlab.engine.start_matlab() study = optuna.create_study() study.optimize(objective, n_trials=1000)実行結果
下記のようにpython上でMatlab関数funcが呼び出され、その結果がOptuneによって最適化されている
(この場合だと最小値 3 が1000回のトライで予測できている)ことがわかります。
今回は単純な関数なので探索しなくてもわかりますが、過去に作った複雑な関数をこれで最適化できれば楽でしょうね。
変数もpythonの "x = trial.suggest_uniform('x', -10, 10)" を x1,x2・・・と増やしていくだけなので、
Matlabだけが得意でpythonが苦手な方でもいろんなものを最適化できるのではないでしょうか?省略 [I 2020-09-21 20:52:03,537] Trial 997 finished with value: 0.611554463759686 and parameters: {'x': 2.217980522135359}. Best is trial 551 with value: 3.107692752820123e-07. [I 2020-09-21 20:52:03,549] Trial 998 finished with value: 1.5139869920248414 and parameters: {'x': 4.230441787336907}. Best is trial 551 with value: 3.107692752820123e-07. [I 2020-09-21 20:52:03,560] Trial 999 finished with value: 0.5050438774658341 and parameters: {'x': 3.7106643915842654}. Best is trial 551 with value: 3.107692752820123e-07. study.best_value Out[14]: 3.107692752820123e-07 study.best_params Out[15]: {'x': 2.9994425331621684}おわりに
sushiライセンスを貼り付けるスペースがありませんでした。Optunaってすごいですね。
でもきっとMatlabにもこういうことができる関数(ツールボックス)があるんだろうなぁ・・・
だれか教えてください。
- 投稿日:2020-09-21T22:21:07+09:00
Python による2021年の月カレンダー(システム手帳用リフィル)の自動作成
目的:月間カレンダーの作成です。
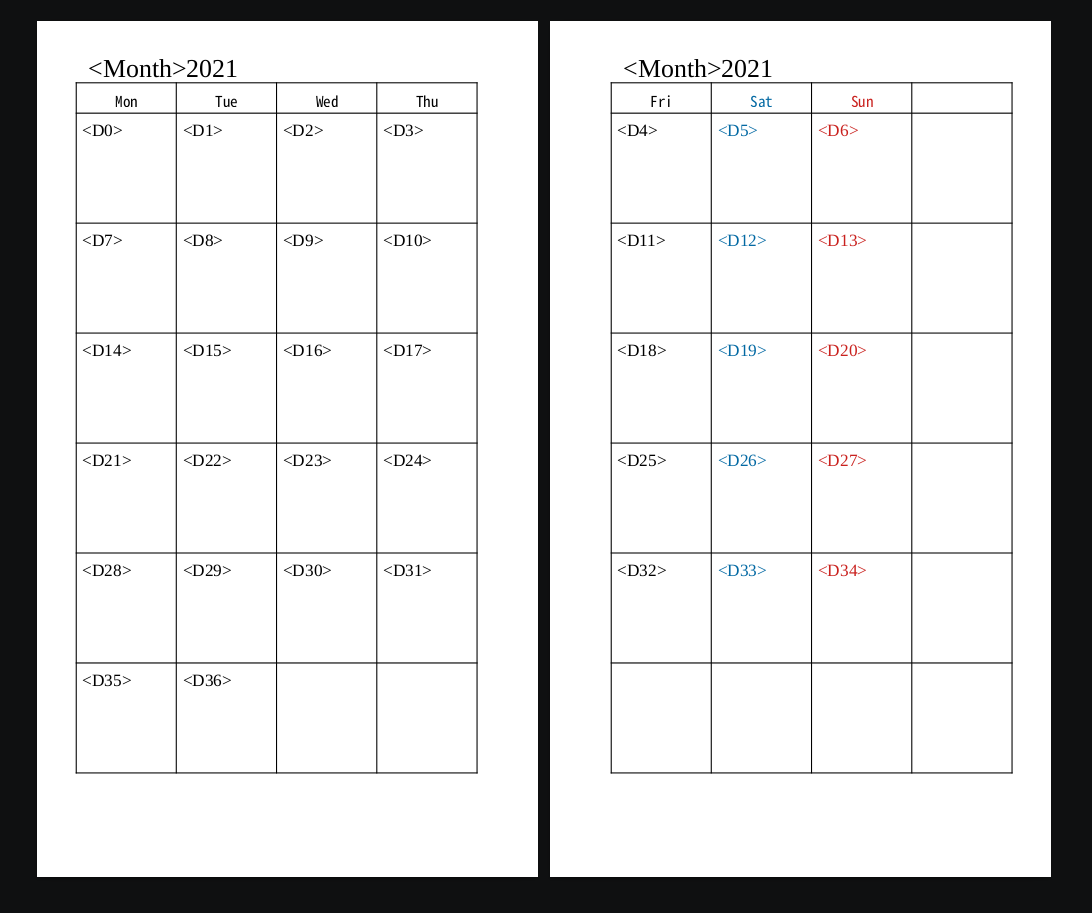
背景;システム手帳を使用していますが、リフィルのサイズ(82mmW x 140mmL)が特殊なため、入手困難で、価格もそこそこ高く、手作りしてしまおうと考えたのは過去のことですが、そのときにリフィル用紙を特注で作ったことがありまして、白紙が、まだ余っていましたので、来年は、久しぶりに手作りしようと考えたこと。年に一度のことなので、手作りでも良いのですが、せっかくのプログラミング環境があるので、毎年、自動でカレンダーが出力できるような仕組みを作成してみようじゃあないか。という理由で、プログラミングしてみました。印刷:ワープロソフトの「差し込み印刷」の機能を用います。従って、差し込み印刷用のカレンダーデータを作れば良い。「差し込み印刷」するテンプレートは、下図のような、見開きで1ヶ月表示となるテンプレートとしました。
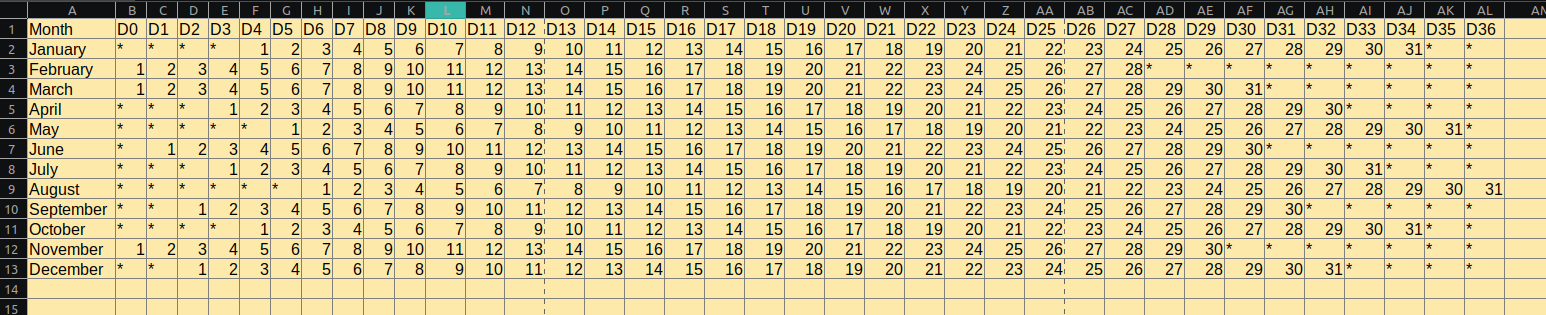
データ:1ヶ月が1レコードになりますので、下図のようなカレンダーデータベースができれば、差し込み印刷に使用できます。この表を、python で作ろうというのが、今回の試みになります。
コードは、下記の通り
monthly_calendar.pyimport pandas as pd import numpy as np import calendar as cl import os """ とりあえずの完成版 """ file='f.csv' fout=open(file,'w',encoding="utf_8") # 作成する年 YEAR=2021 """ while loop でデータを作成する m--> month D--> date out --> ここにデータをためていく """ m=1 out="" while m < 13: MR=cl.monthrange(YEAR,m) out=("{0},".format(cl.month_name[m])) D=0 while D < 37: while D < MR[0]: out+=("*,") D+=1 if D < MR[1]+MR[0]: out+=("{0},".format(str(D-MR[0]+1))) D+=1 else: out+=("*,") D+=1 out=out[:-1] out='{0}\n'.format(out) print(out) fout.write(out) m+=1 fout.close() body_df=pd.read_csv('f.csv',index_col=0, names=['D0','D1','D2','D3','D4','D5','D6','D7','D8','D9','D10', 'D11','D12','D13','D14','D15','D16','D17','D18','D19','D20', 'D21','D22','D23','D24','D25','D26','D27','D28','D29','D30', 'D31','D32','D33','D34','D35' ,'D36']) print(body_df) body_df.to_csv('f_out.csv') os.remove('f.csv')データベースの index 頭の "Month" や、祝日が手入力とか、改善や機能追加は、いくつかあります。気が向いたら手をつけることにします。
- 投稿日:2020-09-21T21:10:54+09:00
PokerStarsのGrandTourの収支を計算した
pokerstarsとは
ネットで遊べるポーカーのサイトで界隈では最大手。
関連のサポートツールなども充実している。なんで?
前述の通りサーポートツールが充実しており基本的には収支計算などはツールに任せることができます。
しかし先日遊べるようになったGrand TourはHoldem Manager3で計算してくれてなさそうだったからです(下写真参照)。
そのうち追加されると思います。
ちなみに現状はこんな風に平らになります(間に別のトーナメントに参加してしまっていて分かりにくくてすみません)。
コード
githubはこちら
git clone https://github.com/na-sudo/pokerstarts_analyze.gitnumpyが必要です。
テスト環境はpython3.8.5です。
gitとかわかんないよ!という方はこちら。
grand_tour.pyimport os,glob,sys import json import numpy as np user = 'username' srcdir = [ 'path to hand history1', 'path to hand history2' ] def make_pathlist(list_): li = [] for path in list_: li += glob.glob(os.path.join(path, '**', '*Varied.txt'), recursive=True) return sorted(li) def getNearestValue(list, num): """ https://qiita.com/icchi_h/items/fc0df3abb02b51f81657 概要: リストからある値に最も近い値を返却する関数 @param list: データ配列 @param num: 対象値 @return 対象値に最も近い値 """ # リスト要素と対象値の差分を計算し最小値のインデックスを取得 idx = np.abs(np.asarray(list) - num).argmin() return list[idx] user_prize = user + ' wins $' user_win = user + ' wins the tournament' user_lose = user + ' finished the tournament' pathlist = make_pathlist(srcdir) game = [0]*6 debug = [0]*6 debug_diff = 0 cost = 0 prize = 0 buyin_list = [1, 2, 5, 12, 25, 60] completed = 0 for path in pathlist: with open(path, 'r', encoding='utf-8')as f: txt = f.read().split('\n') buyin = 100 for line in txt[2:6]: for word in line.split(' ')[::-1]: if '$' in word: buyin = min(buyin, float(word.replace('$',''))) break buyin = getNearestValue(buyin_list, buyin/0.9) index = buyin_list.index(buyin) game[index] += 1 cost += buyin for line in txt: if user_prize in line: prize += float(line.split(' ')[2].replace('$', '')) elif user_win in line: if buyin!=len(buyin_list): cost -= buyin_list[index+1] else: completed += 1 elif user_lose in line: pass else: pass #print(game, cost, buyin) #print(game, cost, prize, completed) print('net prize :', round(prize - cost, 3))コピペして使ってください
使い方
grand_tour.pyをエディタで開きuserやsrcdirに自分のパスを入れて実行してください。
再帰的に探すので親ディレクトリを指定すればokです。user = 'username' ←自分のstarsID srcdir = [ 'path to hand history1', ←pokerstarsのアプリで設定した場所 'path to hand history2' ←HM3などを使用している方はそちらのパスも使ってなかったら消してください。 ]公式のページでは下になってるようです。
C:\Users\YourUsername\AppData\Local\PokerStars\HandHistory\結果はこんな感じ
& python grand_tour.py net prize : 22.54私は
$22.54のプラスみたいです!
普段は5nlzで負けているのでGrand Tourおいしいかも!ちなみに68行目(下から2行目)のコメントアウトを取ってもらえれば詳細が出ます。
& python grand_tour.py [109, 36, 13, 3, 1, 0] 109 131.54 0 net prize : 22.54[挑戦したステージ], cost, prize, completed
がprintされます。costは総バイイン、prizeは賞金合計、completedは完走回数です。
挑戦したステージはバイインが[$1, $2, $5, $12, $25, $60]の挑戦回数になっています。私は$1には109回挑戦していますが、$60が0なのでまだ挑戦したことがありません。
一応$5とかから挑戦してもちゃんと計算してくれると思います。最後に
Qiitaもgithubも初めてですのでいろいろご指摘いただけたらうれしいです!
参考(コード中で使用しました)

- 投稿日:2020-09-21T21:05:25+09:00
良書「ゼロから作るDeep Learning -- Pythonで学ぶディープラーニングの理論と実装」のGitHub
目的
「ゼロから作るDeep Learning -- Pythonで学ぶディープラーニングの理論と実装」
(2017年7月28日 初版第10刷発行, 発行所 株式会社オライリー・ジャパン)この書籍は、かなりいい書籍だと思います。
というような記事を1年以上前に書いた。今回、
なんとなく、Deep Learningを、いろんなフレームワークを使わずに、動かしてみたいと、ネットを検索していて、
結局、
この書籍が提供するコードにたどりついた。
しかも、今時のために、GitHubで公開されていた。GitHub
GitHubで公開されているので、
昔の書籍のおまけのコードで、微妙に、秘密のコードでなくて、、、、
完全に公開されていると思うので、ご紹介。以下です。
https://github.com/oreilly-japan/deep-learning-from-scratch動かしてみた
(後報。まだ、動かしていないので。。。)
まとめ
特にありません。
書籍が横にないと使いにくい場合は、ごめんさなさい。たぶん、トータルとしては、そんなことないと思います。
- 投稿日:2020-09-21T21:05:25+09:00
良書「ゼロから作るDeep Learning 」のGitHub
目的
「ゼロから作るDeep Learning -- Pythonで学ぶディープラーニングの理論と実装」
(2017年7月28日 初版第10刷発行, 発行所 株式会社オライリー・ジャパン)この書籍は、かなりいい書籍だと思います。
というような記事を1年以上前に書いた。今回、
なんとなく、Deep Learningを、いろんなフレームワークを使わずに、動かしてみたいと、ネットを検索していて、
結局、
この書籍が提供するコードにたどりついた。
しかも、今時のために、GitHubで公開されていた。GitHub
GitHubで公開されているので、
昔の書籍のおまけのコードで、微妙に、秘密のコードでなくて、、、、
完全に公開されていると思うので、ご紹介。以下です。
https://github.com/oreilly-japan/deep-learning-from-scratch動かしてみた
プロなので、ちょっと、トラブりましたが、ch08を5分で動かしました。
トラブルの内容は、↓。
「ゼロから作るDeep Learning 」でModuleNotFoundError: No module named 'dataset.mnist'が出る理由。(その他、詳細後報。)
まとめ
特にありません。
書籍が横にないと使いにくい場合は、ごめんさなさい。たぶん、トータルとしては、そんなことないと思います。
- 投稿日:2020-09-21T20:22:16+09:00
PythonでA*(A-star)アルゴリズムを書く
概要
- 勉強のためA*(A-star)アルゴリズムによる探索をPythonで書いてみます。
- 簡単なグリッドの迷路を使います。迷路のコードなどは以前書いた「深さ優先探索をPythonで書く 」のものを流用します。
使うもの
- Python 3.8.5
A*アルゴリズムとは
現時点までの距離としてのgと、ゴールまでの推定値hの和の値を探索時のパラメーターとして使い、経路の最短距離を比較的少ない探索コストで算出するアルゴリズムです。ゲームなどでよく使われます。
探索コストが低めな一方で最短距離が算出されないケースがある深さ優先探索(depth-first search / DFS)や最短距離は算出できるものの計算コストが高くなりがちな幅優先探索(breadth-first search / BFS)よりも優れた結果になる傾向があります。
元々は1968年に発表された論文によるものになっています。最短距離を見つけるアルゴリズム群を論文中で「許容的 - Admissible」と表記していたことにちなんで先頭のAをそのアルゴリズムの集合、最短経路算出の評価回数が最適になるものをA*と表記していたことがアルゴリズムの名前の由来になっています。
論文リンク : A formal Basis for the Heuristic Determination of Minimum Cost Paths
計算内容
ある位置(ノード・node)のnへの移動のコストのトータルを$f(n)$、開始位置からnの位置のノードまでのコストを$g(n)$、ヒューリスティック(heuristic)と呼ばれる値(ゴールまでの距離の推定値)を算出する関数を$h(n)$とすると、$f(n)$は以下のような和で算出されます。
f(n) = g(n) + h(n)厳密ではないのですが、本記事では計算をシンプルにするために$g(n)$の計算を、単純にスタートから移動したノードの数として計算します(シンプルに1つ移動する度に1加算する形で対応)。
また、$h(n)$の計算は今回解く迷路はグリッドの形式で上下左右に移動が可能なタイプで進めるため、上下左右の移動1つ分を距離1とするマンハッタン距離を使います。
Pythonでの実装
理解のためにPythonでコードを書いていきます。
グリッドの迷路を作るコードの対応
迷路のグリッドを作る処理は「深さ優先探索をPythonで書く」のものを流用します。説明の詳細はリンク先に書いてあるので割愛しますが、大雑把にまとめると以下のようなものになります。
- 定義されている行と列数によるグリッドで表現される。
- 迷路の入口(Start)をS、出口(Goal)をG、壁(Wall)の通れない部分をW、通れる箇所を空のセル、算出された経路をアスタリスク(*)で表現する。
- 壁のセルはランダムに生成されるので、出口にたどり着けない生成結果が発生しうる。
from __future__ import annotations from typing import Optional from typing import List import random # 入口用の定数値。 CELL_TYPE_START: str = 'S' # 通路用の定数値。 CELL_TYPE_PASSAGE: str = ' ' # 壁の定数値。 CELL_TYPE_WALL: str = 'W' # 出口の定数値。 CELL_TYPE_GOAL: str = 'G' # 算出されたルートのパス用の定数値。 CELL_TYPE_PATH: str = '*' class Location: def __init__(self, row: int, column: int) -> None: """ 迷路のグリッドの位置情報単体を扱うクラス。 Parameters ---------- row : int 位置の行番号。0からスタートし、上から下に向かって1ずつ 加算される。 column : int 位置の列番号。0からスタートし、左から右に向かって1ずつ 加算される。 """ self.row: int = row self.column: int = column class Maze: # 生成する迷路のグリッドの縦の件数。 _ROW_NUM: int = 7 # 生成する迷路のグリッドの横の件数。 _COLUMN_NUM: int = 15 # 生成する壁の比率。1.0に近いほど壁が多くなる。 _WALL_SPARSENESS: float = 0.3 def __init__(self) -> None: """ ランダムな迷路のグリッドの生成・制御などを扱うクラス。 Notes ----- ランダムに各セルタイプが設定されるため、必ずしもスタートから ゴールに到達できるものができるわけではない点には注意。 """ self._set_start_and_goal_location() self._grid: List[List[str]] = [] self._fill_grid_by_passage_cell() self._set_wall_type_to_cells_randomly() self._set_start_and_goal_type_to_cell() def _set_start_and_goal_location(self) -> None: """ 開始地点(入口)とゴール(出口)の座標の属性を設定する。 """ self.start_loc: Location = Location(row=0, column=0) self.goal_loc: Location = Location( row=self._ROW_NUM - 1, column=self._COLUMN_NUM - 1) def _fill_grid_by_passage_cell(self) -> None: """ 全てのセルに対してセルの追加を行い、通路のセルタイプを設定する。 """ for row in range(self._ROW_NUM): row_cells: List[str] = [] for column in range(self._COLUMN_NUM): row_cells.append(CELL_TYPE_PASSAGE) self._grid.append(row_cells) def _set_wall_type_to_cells_randomly(self) -> None: """ グリッドの各セルへ、ランダムに壁のセルタイプを設定する。 """ for row in range(self._ROW_NUM): for column in range(self._COLUMN_NUM): probability = random.uniform(0.0, 1.0) if probability >= self._WALL_SPARSENESS: continue self._grid[row][column] = CELL_TYPE_WALL def _set_start_and_goal_type_to_cell(self) -> None: """ 開始(入口)とゴール(出口)の位置にそれぞれの セルタイプを設定する。 """ self._grid[self.start_loc.row][self.start_loc.column] = \ CELL_TYPE_START self._grid[self.goal_loc.row][self.goal_loc.column] = \ CELL_TYPE_GOAL def is_goal_loc(self, location: Location) -> bool: """ 指定された位置がゴールの位置かどうかの真偽値を取得する。 Parameters ---------- location : Location 判定用の位置。 Returns ------- result : bool ゴールの位置であればTrueが設定される。 """ if (location.row == self.goal_loc.row and location.column == self.goal_loc.column): return True return False def get_movable_locations(self, location: Location) -> List[Location]: """ 指定された位置から、移動が可能な位置のリストを取得する。 Parameters ---------- location : Location 基準となる位置のインスタンス。 Returns ------- movable_locations : list of Location 移動可能な位置のインスタンスを格納したリスト。 """ movable_locations: List[Location] = [] # 上に移動可能かどうかの判定処理。 if location.row + 1 < self._ROW_NUM: is_wall: bool = self._grid[location.row + 1][location.column] \ == CELL_TYPE_WALL if not is_wall: movable_locations.append( Location(row=location.row + 1, column=location.column)) # 下に移動可能かどうかの判定処理。 if location.row - 1 >= 0: is_wall = self._grid[location.row - 1][location.column] \ == CELL_TYPE_WALL if not is_wall: movable_locations.append( Location(row=location.row - 1, column=location.column)) # 右に移動可能かどうかの判定処理。 if location.column + 1 < self._COLUMN_NUM: is_wall = self._grid[location.row][location.column + 1] \ == CELL_TYPE_WALL if not is_wall: movable_locations.append( Location(row=location.row, column=location.column + 1)) # 左に移動可能かどうかの判定処理。 if location.column - 1 >= 0: is_wall = self._grid[location.row][location.column - 1] \ == CELL_TYPE_WALL if not is_wall: movable_locations.append( Location(row=location.row, column=location.column - 1)) return movable_locations def set_path_type_to_cells(self, path: List[Location]) -> None: """ 入口と出口までの指定されたパス内に含まれるセルに対して、 パスのセルタイプを設定する。 Parameters ---------- path : list of Location 探索で得られた入口から出口までの各セルの位置情報を 格納したリスト。 """ for location in path: self._grid[location.row][location.column] = CELL_TYPE_PATH # パス内に含まれている入口と出口の部分は、それぞれ元の # セルタイプを反映する。 self._grid[self.start_loc.row][self.start_loc.column] = \ CELL_TYPE_START self._grid[self.goal_loc.row][self.goal_loc.column] = \ CELL_TYPE_GOAL def __str__(self) -> str: """ グリッドの各セルのタイプの文字列を取得する。 Returns ------- grid_str : str グリッドの各セルのタイプの文字列。 """ grid_str: str = '' for row_cells in self._grid: grid_str += '-' * self._COLUMN_NUM * 2 grid_str += '\n' for cell_type in row_cells: grid_str += cell_type grid_str += '|' grid_str += '\n' return grid_str class Node: def __init__(self, location: Location, parent: Optional[Node]): """ 迷路の位置や推移の情報などを保持するためのノード単体のデータを 扱うクラス。 Parameters ---------- location : Location 対象の位置情報を扱うインスタンス。 parent : Node or None 移動前の位置情報を扱うノードのインスタンス。探索開始時 などにはNoneとなる。 """ self.location: Location = location self.parent: Optional[Node] = parent def get_path_from_goal_node(goal_node: Node) -> List[Location]: """ 出口のノードから、探索で取得できた入口 → 出口までのパスを 取得する。 Parameters ---------- goal_node : Node 対象の出口(ゴール)のノードのインスタンス。 Returns ------- path : list of Location 入口から出口までの各位置のインスタンスを格納したリスト。 """ path: List[Location] = [goal_node.location] node: Node = goal_node while node.parent is not None: node = node.parent path.append(node.location) path.reverse() return path試しに生成した迷路を出力してみると、以下のようにグリッドで表示されます。
if __name__ == '__main__': maze = Maze() print(maze)------------------------------ S| |W| |W| | | |W| |W| |W| |W| ------------------------------ W| | | | | |W| | | |W|W| |W|W| ------------------------------ W| | | | |W| | | |W|W| | | | | ------------------------------ | |W| |W|W| | | | | | | |W|W| ------------------------------ W|W|W| | | |W| | | | | | | |W| ------------------------------ W|W| | | | | | | |W| |W| | | | ------------------------------ W|W| | | | |W| | | | | | | |G|優先度付きキューの作成とNodeクラスの調整
A*のアルゴリズムではデータ構造として優先度付きキュー(priority queue)を使います。これは、キューへ値を優先度付きで追加し、値を取り出す際にも最も高い優先度を持つ値が対象になるという特殊なキューです。
優先度の値の算出にはキューに追加するノードのインスタンスに対するless thanの比較のオペレーター( < )で行われるため、Nodeクラスに
__lt__のメソッドを追加する必要があります。
__lt__メソッドの中ではコストの計算式における$g(n) + h(n)$の算出と、別のノードに対する比較が行われます。また、計算で必要になるため$g(n)$の値と$h(n)$の値もクラスの属性に持つように調整します。
class Node: def __init__( self, location: Location, parent: Optional[Node], cost: float, heuristic:float) -> None: """ 迷路の位置や推移の情報などを保持するためのノード単体のデータを 扱うクラス。 Parameters ---------- location : Location 対象の位置情報を扱うインスタンス。 parent : Node or None 移動前の位置情報を扱うノードのインスタンス。探索開始時 などにはNoneとなる。 cost : float 開始位置から該当のノードの位置までのコスト値(g(n)で 得られる値)。 heuristic : float このノードから出口までの距離の推定値(h(n)で得られる値)。 """ self.location: Location = location self.parent: Optional[Node] = parent self.cost = cost self.heuristic = heuristic def __lt__(self, other_node: Node) -> bool: """ 比較のオペレーター( < )による処理のためのメソッド。 優先度付きキューの制御のために利用される。 Parameters ---------- other_node : Node 比較対象となる他のノードのインスタンス。 Returns ------- result_bool : bool 比較結果。算出処理は入口からのコスト(g(n))と ヒューリスティックの値(h(n))の合算値の比較で 行われる。 """ left_value: float = self.cost + self.heuristic right_value: float = other_node.cost + other_node.heuristic result_bool: bool = left_value < right_value return result_bool今まで自前で
__lt__のメソッドを使ったことが無かったので、試しに複数のインスタンスを作ってみて比較して結果を確認してみます。costとheuristicの合算値で比較がされるので、最初の比較がFalse、次がTrueになって返ってきます。if __name__ == '__main__': node_1 = Node( location=Location(row=0, column=0), parent=None, cost=2, heuristic=2) node_2 = Node( location=Location(row=0, column=0), parent=None, cost=1, heuristic=2) node_3 = Node( location=Location(row=0, column=0), parent=None, cost=3, heuristic=2) print(node_1 < node_2) print(node_1 < node_3)False True続いて優先度付きキュー(priority queue)の方を用意していきます。優先度付きキューの処理は、Python標準モジュールのheapqパッケージを使うことで対応ができます。
import heapq ... class PriorityQueue: def __init__(self) -> None: """ 優先度付きキューの制御を行うためのクラス。 """ self._container: List[Node] = [] @property def empty(self) -> bool: """ キューが空かどうかの属性値。 Returns ------- result : bool 空の場合にTrueが設定される。 """ return not self._container def push(self, node: Node) -> None: """ キューへのノードのインスタンスの追加を行う。 Parameters ---------- node : Node 追加対象のノードのインスタンス。 """ heapq.heappush(self._container, node) def pop(self) -> Node: """ キューから優先度の一番高いノードのインスタンスを取り出す。 Returns ------- node : Node 取り出されたNodeクラスのインスタンス。 """ return heapq.heappop(self._container)優先度を加味した形で処理がされているかどうかの実際に少し動かして試してみます。
注意すべき点として、「コストが低い方が好ましい(=優先度が高い)」形になります。コストの合算値の高い方からpopで取り出されるわけではありません。if __name__ == '__main__': priority_queue = PriorityQueue() priority_queue.push( node=Node( location=Location(row=0, column=0), parent=None, cost=1, heuristic=1)) priority_queue.push( node=Node( location=Location(row=0, column=0), parent=None, cost=3, heuristic=3)) priority_queue.push( node=Node( location=Location(row=0, column=0), parent=None, cost=2, heuristic=3)) node: Node = priority_queue.pop() print(node.cost, node.heuristic) node = priority_queue.pop() print(node.cost, node.heuristic) node = priority_queue.pop() print(node.cost, node.heuristic)出力結果が、コストの合算値が低い順に取り出されていることが確認できます。
1 1 2 3 3 3対象の位置と出口(ゴール)の位置とのマンハッタン距離の取得処理の追加
今回ヒューリスティック($h(n)$)の算出にはグリッド形式の迷路なためマンハッタン距離を使うのでその関数をMazeクラスに追加しておきます。
def get_manhattan_distance(self, location: Location) -> int: """ 対象の位置と出口(ゴール)の位置間でのマンハッタン距離を 取得する。 Parameters ---------- location : Location 対象の位置のインスタンス。 Returns ------- distance : int 対象の位置と出口の位置間のマンハッタン距離。列方向の 差異の絶対値と行方向の差異の絶対値の合計が設定される。 """ x_distance: int = abs(location.column - self.goal_loc.column) y_distance: int = abs(location.row - self.goal_loc.column) distance: int = x_distance + y_distance return distanceA*アルゴリズムの関数の追加
諸々の必要な準備が出来たので、A*アルゴリズム用の関数を作っていきます。
関数名はastarとしました。from typing import Callable, Dict ... def astar( init_loc: Location, is_goal_loc_method: Callable[[Location], bool], get_movable_locations_method: Callable[[Location], List[Location]], hueristic_method: Callable[[Location], int], ) -> Optional[Node]: """ A*アルゴリズムによる探索処理を行う。 Parameters ---------- init_loc : Location 探索開始位置(迷路の入口の位置)。 is_goal_loc_method : callable 対象の位置が出口(ゴール)かどうかの判定を行うメソッド。 get_movable_locations_method : callable 対象の位置からの移動先のセルの位置のリストを取得するメソッド。 hueristic_method : callable 対象の位置から出口(ゴール)までの位置の間の距離を取得する ためのヒューリスティック用のメソッド。 Returns ------- goal_node : Node or None 算出された出口の位置のノードのインスタンス。出口までの 経路が算出できないケースではNoneが設定される。 """ frontier_queue: PriorityQueue = PriorityQueue() frontier_queue.push( node=Node( location=init_loc, parent=None, cost=0, heuristic=hueristic_method(init_loc))) explored_loc_cost_dict: Dict[Location, float] = {init_loc: 0.0} while not frontier_queue.empty: current_node: Node = frontier_queue.pop() current_loc: Location = current_node.location if is_goal_loc_method(current_loc): return current_node movable_locations = get_movable_locations_method(current_loc) for movable_location in movable_locations: new_cost: float = current_node.cost + 1 # 新しい移動先が既に探索済みで、且つコスト的にも優位ではない # 場合にはスキップする。 if (movable_location in explored_loc_cost_dict and explored_loc_cost_dict[movable_location] <= new_cost): continue explored_loc_cost_dict[movable_location] = new_cost frontier_queue.push( node=Node( location=movable_location, parent=current_node, cost=new_cost, heuristic=hueristic_method(movable_location))) return None以前書いた「深さ優先探索をPythonで書く
」の記事内のdfs関数と似たような流れになっています。部分的に処理が異なっているのでその差異を中心に説明していきます。まずは引数ですがヒューリスティック用のCallableのもの(hueristic_method)が追加になっています。これは今回のサンプルでは少し前に追加したマンハッタン距離を算出するメソッドを指定します。
frontier_queue: PriorityQueue = PriorityQueue() frontier_queue.push( node=Node( location=init_loc, parent=None, cost=0, heuristic=hueristic_method(init_loc)))また、キューも優先度付きキューのものに差し替えてあります(frontier_queue)。
このキューに探索予定のノードを追加していっています。explored_loc_cost_dict: Dict[Location, float] = {init_loc: 0.0}探索済みのノードを保持する辞書は、キーに位置、値にコスト($g(n)$)の値を保持する形にしてあります。1回移動する度に1インクリメントしていくシンプルな方式なので、最初は0.0を設定します。
while not frontier_queue.empty: current_node: Node = frontier_queue.pop() current_loc: Location = current_node.location探索予定のノードがキューから無くなるまでwhileループで処理を繰り返すところは変わりません。
if is_goal_loc_method(current_loc): return current_node対象のノードが出口(ゴール)であれば、出口のノードを返却して処理を終えるところも同じです。
movable_locations = get_movable_locations_method(current_loc) for movable_location in movable_locations: new_cost: float = current_node.cost + 1現在の探索対象のノードから移動先となる各位置に対してforループでそれぞれ処理をしています。
今回は移動するごとにコスト($g(n)$)を1インクリメントするシンプルな形で実装してあります。# 新しい移動先が既に探索済みで、且つコスト的にも優位ではない # 場合にはスキップする。 if (movable_location in explored_loc_cost_dict and explored_loc_cost_dict[movable_location] <= new_cost): continue探索済みの位置であっても、コスト的に優位であれば探索する価値があります。もし探索済みで且つコスト的にも変わらない、もしくは悪化する位置の場合には探索するメリットが無いのでスキップします。
explored_loc_cost_dict[movable_location] = new_cost frontier_queue.push( node=Node( location=movable_location, parent=current_node, cost=new_cost, heuristic=hueristic_method(movable_location)))探索する価値がある条件であれば、探索済みの辞書にコストなどの値の設定と探索対象の優先度付きキューにノードを追加しています。
優先度の高いものから先に処理されていくので、探索コストに優れた探索をすることができます。
return None生成される迷路によっては出口までの経路が無い場合もあるのでその場合にはNoneを返却しています。
実行してみます。
if __name__ == '__main__': maze: Maze = Maze() print(maze) goal_node: Optional[Node] = astar( init_loc=maze.start_loc, is_goal_loc_method=maze.is_goal_loc, get_movable_locations_method=maze.get_movable_locations, hueristic_method=maze.get_manhattan_distance, ) if goal_node is None: print('出口が算出できない迷路です。') else: print('-' * 20) path: List[Location] = get_path_from_goal_node( goal_node=goal_node) maze.set_path_type_to_cells(path=path) print('算出されたパス :') print(maze)算出されたパス : ------------------------------ S|*|*|*|*| | | |W| | | |W|W|W| ------------------------------ W| | |W|*|*|W|W|W| | | | |W| | ------------------------------ W|W| |W|W|*|W| | | | |W|W|W|W| ------------------------------ W|W|W| | |*|*|W| |W| | | | | | ------------------------------ |W|W|W| | |*|W| | | | | |W| | ------------------------------ | | | | |W|*|*|*|*|*| | |W| | ------------------------------ |W| | |W|W|W| |W| |*|*|*|*|G|グリッドのSが入口(スタート)、Gが出口(ゴール)、アスタリスクの部分が探索によって算出されたパスです。
無事入口から出口までのパスが算出できています。探索結果が直角気味になる幅優先探索などと比べると、対角気味なパスが得られているのがA*の特徴とのことです。実際に今回試したサンプルでも対角気味なパスになっています。
コード全体
from __future__ import annotations from typing import Optional from typing import List import random import heapq from typing import Callable, Dict # 入口用の定数値。 CELL_TYPE_START: str = 'S' # 通路用の定数値。 CELL_TYPE_PASSAGE: str = ' ' # 壁の定数値。 CELL_TYPE_WALL: str = 'W' # 出口の定数値。 CELL_TYPE_GOAL: str = 'G' # 算出されたルートのパス用の定数値。 CELL_TYPE_PATH: str = '*' class Location: def __init__(self, row: int, column: int) -> None: """ 迷路のグリッドの位置情報単体を扱うクラス。 Parameters ---------- row : int 位置の行番号。0からスタートし、上から下に向かって1ずつ 加算される。 column : int 位置の列番号。0からスタートし、左から右に向かって1ずつ 加算される。 """ self.row: int = row self.column: int = column class Maze: # 生成する迷路のグリッドの縦の件数。 _ROW_NUM: int = 7 # 生成する迷路のグリッドの横の件数。 _COLUMN_NUM: int = 15 # 生成する壁の比率。1.0に近いほど壁が多くなる。 _WALL_SPARSENESS: float = 0.3 def __init__(self) -> None: """ ランダムな迷路のグリッドの生成・制御などを扱うクラス。 Notes ----- ランダムに各セルタイプが設定されるため、必ずしもスタートから ゴールに到達できるものができるわけではない点には注意。 """ self._set_start_and_goal_location() self._grid: List[List[str]] = [] self._fill_grid_by_passage_cell() self._set_wall_type_to_cells_randomly() self._set_start_and_goal_type_to_cell() def _set_start_and_goal_location(self) -> None: """ 開始地点(入口)とゴール(出口)の座標の属性を設定する。 """ self.start_loc: Location = Location(row=0, column=0) self.goal_loc: Location = Location( row=self._ROW_NUM - 1, column=self._COLUMN_NUM - 1) def _fill_grid_by_passage_cell(self) -> None: """ 全てのセルに対してセルの追加を行い、通路のセルタイプを設定する。 """ for row in range(self._ROW_NUM): row_cells: List[str] = [] for column in range(self._COLUMN_NUM): row_cells.append(CELL_TYPE_PASSAGE) self._grid.append(row_cells) def _set_wall_type_to_cells_randomly(self) -> None: """ グリッドの各セルへ、ランダムに壁のセルタイプを設定する。 """ for row in range(self._ROW_NUM): for column in range(self._COLUMN_NUM): probability = random.uniform(0.0, 1.0) if probability >= self._WALL_SPARSENESS: continue self._grid[row][column] = CELL_TYPE_WALL def _set_start_and_goal_type_to_cell(self) -> None: """ 開始(入口)とゴール(出口)の位置にそれぞれの セルタイプを設定する。 """ self._grid[self.start_loc.row][self.start_loc.column] = \ CELL_TYPE_START self._grid[self.goal_loc.row][self.goal_loc.column] = \ CELL_TYPE_GOAL def is_goal_loc(self, location: Location) -> bool: """ 指定された位置がゴールの位置かどうかの真偽値を取得する。 Parameters ---------- location : Location 判定用の位置。 Returns ------- result : bool ゴールの位置であればTrueが設定される。 """ if (location.row == self.goal_loc.row and location.column == self.goal_loc.column): return True return False def get_movable_locations(self, location: Location) -> List[Location]: """ 指定された位置から、移動が可能な位置のリストを取得する。 Parameters ---------- location : Location 基準となる位置のインスタンス。 Returns ------- movable_locations : list of Location 移動可能な位置のインスタンスを格納したリスト。 """ movable_locations: List[Location] = [] # 上に移動可能かどうかの判定処理。 if location.row + 1 < self._ROW_NUM: is_wall: bool = self._grid[location.row + 1][location.column] \ == CELL_TYPE_WALL if not is_wall: movable_locations.append( Location(row=location.row + 1, column=location.column)) # 下に移動可能かどうかの判定処理。 if location.row - 1 >= 0: is_wall = self._grid[location.row - 1][location.column] \ == CELL_TYPE_WALL if not is_wall: movable_locations.append( Location(row=location.row - 1, column=location.column)) # 右に移動可能かどうかの判定処理。 if location.column + 1 < self._COLUMN_NUM: is_wall = self._grid[location.row][location.column + 1] \ == CELL_TYPE_WALL if not is_wall: movable_locations.append( Location(row=location.row, column=location.column + 1)) # 左に移動可能かどうかの判定処理。 if location.column - 1 >= 0: is_wall = self._grid[location.row][location.column - 1] \ == CELL_TYPE_WALL if not is_wall: movable_locations.append( Location(row=location.row, column=location.column - 1)) return movable_locations def set_path_type_to_cells(self, path: List[Location]) -> None: """ 入口と出口までの指定されたパス内に含まれるセルに対して、 パスのセルタイプを設定する。 Parameters ---------- path : list of Location 探索で得られた入口から出口までの各セルの位置情報を 格納したリスト。 """ for location in path: self._grid[location.row][location.column] = CELL_TYPE_PATH # パス内に含まれている入口と出口の部分は、それぞれ元の # セルタイプを反映する。 self._grid[self.start_loc.row][self.start_loc.column] = \ CELL_TYPE_START self._grid[self.goal_loc.row][self.goal_loc.column] = \ CELL_TYPE_GOAL def get_manhattan_distance(self, location: Location) -> int: """ 対象の位置と出口(ゴール)の位置間でのマンハッタン距離を 取得する。 Parameters ---------- location : Location 対象の位置のインスタンス。 Returns ------- distance : int 対象の位置と出口の位置間のマンハッタン距離。列方向の 差異の絶対値と行方向の差異の絶対値の合計が設定される。 """ x_distance: int = abs(location.column - self.goal_loc.column) y_distance: int = abs(location.row - self.goal_loc.column) distance: int = x_distance + y_distance return distance def __str__(self) -> str: """ グリッドの各セルのタイプの文字列を取得する。 Returns ------- grid_str : str グリッドの各セルのタイプの文字列。 """ grid_str: str = '' for row_cells in self._grid: grid_str += '-' * self._COLUMN_NUM * 2 grid_str += '\n' for cell_type in row_cells: grid_str += cell_type grid_str += '|' grid_str += '\n' return grid_str class Node: def __init__( self, location: Location, parent: Optional[Node], cost: float, heuristic:float) -> None: """ 迷路の位置や推移の情報などを保持するためのノード単体のデータを 扱うクラス。 Parameters ---------- location : Location 対象の位置情報を扱うインスタンス。 parent : Node or None 移動前の位置情報を扱うノードのインスタンス。探索開始時 などにはNoneとなる。 cost : float 開始位置から該当のノードの位置までのコスト値(g(n)で 得られる値)。 heuristic : float このノードから出口までの距離の推定値(h(n)で得られる値)。 """ self.location: Location = location self.parent: Optional[Node] = parent self.cost = cost self.heuristic = heuristic def __lt__(self, other_node: Node) -> bool: """ 比較のオペレーター( < )による処理のためのメソッド。 優先度付きキューの制御のために利用される。 Parameters ---------- other_node : Node 比較対象となる他のノードのインスタンス。 Returns ------- result_bool : bool 比較結果。算出処理は入口からのコスト(g(n))と ヒューリスティックの値(h(n))の合算値の比較で 行われる。 """ left_value: float = self.cost + self.heuristic right_value: float = other_node.cost + other_node.heuristic result_bool: bool = left_value < right_value return result_bool def get_path_from_goal_node(goal_node: Node) -> List[Location]: """ 出口のノードから、探索で取得できた入口 → 出口までのパスを 取得する。 Parameters ---------- goal_node : Node 対象の出口(ゴール)のノードのインスタンス。 Returns ------- path : list of Location 入口から出口までの各位置のインスタンスを格納したリスト。 """ path: List[Location] = [goal_node.location] node: Node = goal_node while node.parent is not None: node = node.parent path.append(node.location) path.reverse() return path class PriorityQueue: def __init__(self) -> None: """ 優先度付きキューの制御を行うためのクラス。 """ self._container: List[Node] = [] @property def empty(self) -> bool: """ キューが空かどうかの属性値。 Returns ------- result : bool 空の場合にTrueが設定される。 """ return not self._container def push(self, node: Node) -> None: """ キューへのノードのインスタンスの追加を行う。 Parameters ---------- node : Node 追加対象のノードのインスタンス。 """ heapq.heappush(self._container, node) def pop(self) -> Node: """ キューから優先度の一番高いノードのインスタンスを取り出す。 Returns ------- node : Node 取り出されたNodeクラスのインスタンス。 """ return heapq.heappop(self._container) def astar( init_loc: Location, is_goal_loc_method: Callable[[Location], bool], get_movable_locations_method: Callable[[Location], List[Location]], hueristic_method: Callable[[Location], int], ) -> Optional[Node]: """ A*アルゴリズムによる探索処理を行う。 Parameters ---------- init_loc : Location 探索開始位置(迷路の入口の位置)。 is_goal_loc_method : callable 対象の位置が出口(ゴール)かどうかの判定を行うメソッド。 get_movable_locations_method : callable 対象の位置からの移動先のセルの位置のリストを取得するメソッド。 hueristic_method : callable 対象の位置から出口(ゴール)までの位置の間の距離を取得する ためのヒューリスティック用のメソッド。 Returns ------- goal_node : Node or None 算出された出口の位置のノードのインスタンス。出口までの 経路が算出できないケースではNoneが設定される。 """ frontier_queue: PriorityQueue = PriorityQueue() frontier_queue.push( node=Node( location=init_loc, parent=None, cost=0, heuristic=hueristic_method(init_loc))) explored_loc_cost_dict: Dict[Location, float] = {init_loc: 0.0} while not frontier_queue.empty: current_node: Node = frontier_queue.pop() current_loc: Location = current_node.location if is_goal_loc_method(current_loc): return current_node movable_locations = get_movable_locations_method(current_loc) for movable_location in movable_locations: new_cost: float = current_node.cost + 1 # 新しい移動先が既に探索済みで、且つコスト的にも優位ではない # 場合にはスキップする。 if (movable_location in explored_loc_cost_dict and explored_loc_cost_dict[movable_location] <= new_cost): continue explored_loc_cost_dict[movable_location] = new_cost frontier_queue.push( node=Node( location=movable_location, parent=current_node, cost=new_cost, heuristic=hueristic_method(movable_location))) return None if __name__ == '__main__': maze: Maze = Maze() print(maze) goal_node: Optional[Node] = astar( init_loc=maze.start_loc, is_goal_loc_method=maze.is_goal_loc, get_movable_locations_method=maze.get_movable_locations, hueristic_method=maze.get_manhattan_distance, ) if goal_node is None: print('出口が算出できない迷路です。') else: print('-' * 20) path: List[Location] = get_path_from_goal_node( goal_node=goal_node) maze.set_path_type_to_cells(path=path) print('算出されたパス :') print(maze)余談
- 元々デザイン方面の学校卒なので、コンピューターサイエンス方面で知識的に雑な点などへの強めのマサカリはご容赦くださいmm
参考文献・サイトまとめ
- 投稿日:2020-09-21T20:00:16+09:00
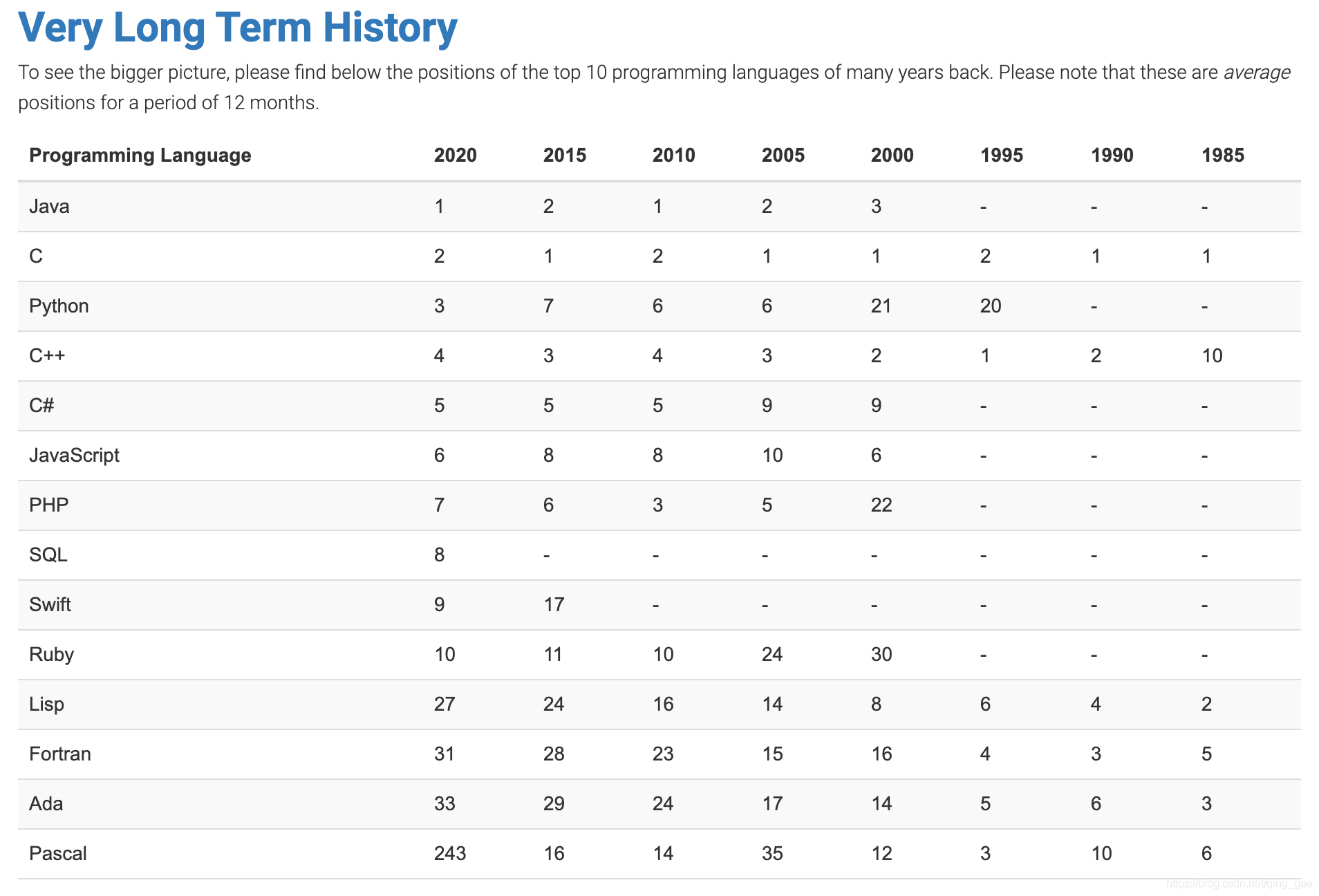
2020年に最も人気があるプログラミング言語 10選
元記事: https://jp.scrapestorm.com/tutorial/10-most-popular-programming-languages-in-2020/
プログラミングの初心者について、より良い見通しがある言語を選択するは非常に重要です。本文は十種類の2020年に最も人気があるプログラミング言語を紹介します。
まずTIOBEランキングを見てみます。非常に権威のあるランキングです。次の14つは長く生きているので、SQLがGOに置き換えられたことを除いて、他の9つのプログラミング言語がすべて存在し、長い間リストを支配していることがわかります。これから一つずつ紹介しましょう。
1.Java
Javaは実際にはC ++の代替品です。Sunは当初、C ++よりも簡単なオブジェクト指向プログラミング言語を開発したいと考えていました。時間の経過とともに、Javaは学習とクロスプラットフォーム化が容易になるため、Javaの人気はC ++の人気をはるかに超えています。
Java仮想マシンの助けを借りて、JavaはLinux、Windows、Mac-OSなどのさまざまなオペレーティングシステムで自由に使用できるため、エンタープライズレベルの開発で非常に人気があります。2.C++
名前からわかるように、C ++はC言語の拡張機能であり、C言語のオブジェクト指向関数の作成を目的としています。
C ++はすべてのプラットフォームで実行でき、あらゆるタイプのハードウェアを効果的に利用できるため、リソースが限られたプラットフォームで最高のパフォーマンスを発揮できます。3.C
C言語は1960年に誕生し、作成者チームはC言語に対して1つの要件しか持っていませんでした。それは、普遍的であり、システムリソースを効果的に使用できる必要があります。 当時、メモリのすべてのバイトが高価だったからです。C言語は非常に早い時期に誕生しましたが、依然として最も一般的に使用されているプログラミング言語の1つです。
C ++と同様に、Cもメモリに直接アクセスしてハードウェアを制御できます。 Cはオペレーティングシステムと密接に関連しており、プログラマーはメモリ割り当ての詳細を処理する必要があるため、把握するのが困難です。4.Python
学習コストは非常に低いため、すべてのプログラマーはPythonを好みますが、現在の非常に深い人工知能、機械学習、データ分析などのアプリケーションレベルは非常に高くなっています。
Pythonの構文はシンプルでエレガントで、コミュニティも非常に活発です。 しかし、言うべきことの1つは、Pythonの職位には高い学歴が必要であることです。5.JavaScript
JavaScriptは高級なダイナミンクプログラミング言語です。非常に人気のあるフロントエンドフレームワークVue.jsはjsJavaScriptで作成しました。フロントエンド開発に従事したい場合は、JavaScriptは必須であると言えます。
6.C
当初、C#はJavaのコピーと見なされていましたが、それらには著しい類似点があり、Javaとほぼ同じ構文であり、コンパイルして実行する必要があります。 時間の開発とMicrosoftによる多大な努力により、C#は豊富なクラスライブラリとフレームワークを蓄積し、開発者はこれに基づいて.NETプラットフォームに基づくさまざまなアプリケーションをすばやく作成できます。
7.Swift
Swiftは、Appleによって作成された強力で直感的なプログラミング言語であり、iOS、Mac、Apple TV、およびApple Watch用のアプリの開発に使用できます。 開発者に完全な自由を提供することを目的としています。 Swiftは使いやすくオープンソースであり、アイデアさえあれば、誰でも素晴らしいものを作成できます。
8.Go
Go言語のデザインは非常に洗練されており、使用方法も非常に簡単で、開発と拡張を解決する能力も非常に優れています。 重要なのは、学習が非常に簡単であり、これらの利点がGo言語の急速な成長に貢献していることです。
Google、AWS、Cloudflare、CoreOSなどはすべて、クラウドコンピューティング関連製品の開発にGolangを大規模に使用し始めています。 未来はとても明るいと言えます。9.PHP
PHPは35年以上にわたってWebアプリケーションの開発に使用されてきました2010年頃、PHPは常にWeb開発の王様でした。特に、WordPressなどのコンテンツ管理プラットフォームの人気とFacebook(PHPが開発した)の支持が相まって、業界でのPHPの地位が強化されました。
10.Ruby
Rubyはもともとオブジェクト向けのスクリプトプログラミング言語でしたが、時間が経つにつれて、徐々に解釈された高水準の汎用プログラミング言語に発展しました。 開発者の生産性を向上させるのに非常に役立ちます。シリコンバレーでは、Rubyは非常に人気があり、クラウドコンピューティング時代のWebプログラミング言語として知られています。
- 投稿日:2020-09-21T19:34:57+09:00
ExcelからPython起動しよう。VBAは使わないよ。
初めての投稿です。
Excelにデータを溜めて、Python実行することありませんか?
データ変更⇔実行を繰り返す場合、ExcelからPythonを起動したくありませんか?ネット調べるとVBAを使う方法はありますが、私は好きじゃないのでこの方法を試しました。
※マクロ実行でセキュリティがどうのこうの聞かれるのがね。。。対象
下の全部が当てはまっている人
・Excelに溜めたデータを、Pythonで分析したい
・Excelをフロントエンドにしたい
・VBAは使いたくない
・Windowsを使っている概要
Excelのハイパーリンクを使って、batを起動します。
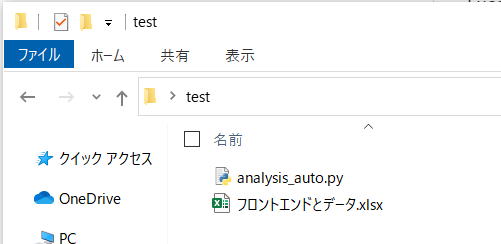
batファイルにPython起動の文を書いておけば、Excelからリンクを押しただけでPythonが動きますよ。0.最初の状態
下図のように、Excelファイルと、実行したいPythonファイルがあるとします。
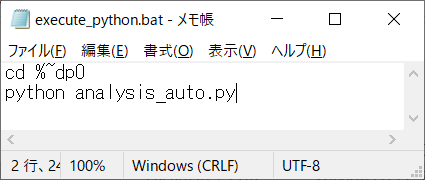
1.batファイルの作成
下図のようなbatファイルを作成します。
保存場所は上のファイルと同じ場所です。
1行目は、cdで「%~dp0」まで移動します。「%~dp0」とは、このbatファイルが保存されたパスを示す値です。
2行目は、Pythonを起動文です。
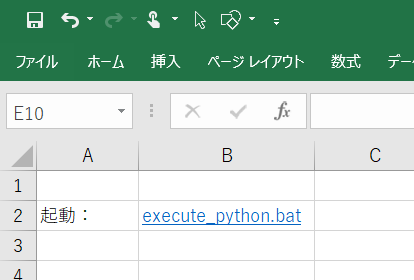
2.Excelにハイパーリンクを作成
Excelの好きなセルを右クリックし、「リンク」で先ほど作ったbatファイルを選択しましょう。
※ちなみにバージョンは2016です。
3.実行
このハイパーリンクを押せば、自動的にbatが開き、そして自動的にPythonが起動します。
Pythonの中ではpandasでExcelデータを読み込むように設定しておけば良いですね。終わり
小技でしたが、VBAを使わなくても目的は達成できました。
宜しければお使いください。
- 投稿日:2020-09-21T19:15:50+09:00
関数だけを使って自然数(チャーチ数)が定義できる
この記事は株式会社LIFULLの数学同好会あなぐま会のための発表資料です。
アナリストやデータサイエンティストが多いので、「彼らが普段使っているPythonで(普段あまりあまり触れないであろう)コンピュータ・サイエンスの数学とつながる話をしよう」という意図です。実は「圏論の初歩をPythonプログラミングで説明する」という資料も用意しつつあったのですが、夜の回(飲み会)の題材にしては重すぎたのと、Pythonでは説明しづらい概念(射の集合など)があったので断念しました。
自己紹介
名前: 二宮健(たけし)
所属: AI戦略室データサイエンスG(嶋村さんチーム)
→ PE3U4G(須藤さんチーム)機械科学専攻(修士)から、2015年にLIFULLにエンジニアとして新卒入社。
広告運用自動化(MAM)やAIシステムの実装に従事。プログラミングや情報科学は就職後に学んだことのほうが多い気がする。
チャーチ数について
関数(ラムダ式)で次のように整数を定義すると、(0を含む)自然数として計算できる。これをチャーチ数という。
zero = lambda f: lambda x: x one = lambda f: lambda x: f(x) two = lambda f: lambda x: f(f(x)) three = lambda f: lambda x: f(f(f(x))) ...
Pythonでの実装例
加算、乗算、累乗が定義できることを確かめる。数値に変換する
to_int以外では関数(lambda)しか登場していないことに注目。church.pyfrom __future__ import annotations from numbers import Number from typing import Callable class ChurchNumber(Number): def __init__(self, church: Callable): self.ch = church def to_int(self) -> int: """チャーチ数を組み込みのint型に変換する""" return self.ch(lambda n: n + 1)(0) def succ(self) -> ChurchNumber: """チャーチ数に+1する""" return ChurchNumber(lambda f: lambda x: f(self.ch(f)(x))) def __add__(self, other: ChurchNumber) -> ChurchNumber: """チャーチ数同士を足し算する""" return ChurchNumber(lambda f: lambda x: self.ch(f)(other.ch(f)(x))) def __mul__(self, other: ChurchNumber) -> ChurchNumber: """チャーチ数の掛け算(*)を定義する""" return ChurchNumber(lambda f: lambda x: other.ch(self.ch(f))(x)) def __pow__(self, exponent: ChurchNumber) -> ChurchNumber: """チャーチ数の累乗(**)を定義する""" return ChurchNumber(lambda f: lambda x: exponent.ch(self.ch)(f)(x))
次のように動作します。
test.pyfrom church import ChurchNumber zero = ChurchNumber(lambda f: lambda x: x) assert zero.to_int() == 0 # succのテスト one = zero.succ() two = one.succ() three = two.succ() assert (one.to_int(), two.to_int(), three.to_int()) == (1, 2, 3) # 加算、乗算、累乗の確認 assert (one + two).to_int() == three.to_int() assert (two ** three).to_int() == 8 assert (two * three).to_int() == 6
説明のしやすさのために
ChurchNumberクラスを導入していますが、ラムダ式だけを使って書ける。zero = lambda f: lambda x: x succ = lambda c: lambda f: lambda x: f(c(f)(x)) to_int = lambda c: c(lambda n: n + 1)(0) # lambda c1, c2: ...ともできますが、λ計算の理論では全ての関数が1引数なので、それに合わせています add = lambda c1: lambda c2: lambda f: lambda x: c1(f)(c2(f)(x)) ...ただ、コードを読んでも何をやってるか分からなくなって断念した?
減算や除算は自然数に対して閉じてないので書いていないが、負の数まで拡張した記事も見つかった。
動作の説明
- 「関数を
fをx回適用する」という形で数字を表現しているto_intでは「0に対して+1を行う関数」を適用して、int型に変換しているsuccではfを1つ増やしている__add__では「otherの回数関数を実行した後、selfの回数実行する」関数を用意して合計している- 後の実装は興味があったら調べてください
チャーチ数って何の役に立つの?
- 普段のプログラミングでチャーチ数を実行することはない
- データ量がでかい。
intで数十バイトで済むのにわざわざ関数を使っている- 「表現したい数だけ関数を実行する」なので、
intに比べると非常に遅い- チャーチ数はλ計算の理論で重要。λ計算はチューリングマシンと同等の数学的モデルで、プログラミング言語理論ではλ計算の理論を使って解析されることが多いように思う。
ここでは、データ型さえ必要なく,すべて関数だけで(数値を)導入できることを説明しよう.(中略)これは,1940年代にλ算法(今日の関数プログラミングに関する研究の論拠となる形式的数学体系)に関する仕事の中でAlonzo Churchが目指した目論みの一部である.
―――『関数プログラミング入門』より。括弧内は追記λ計算の理論の中で「関数だけの世界で様々なデータ型を導入できるか」という問題でチャーチ数が提案されたらしい(後述)。他にもチャーチ真理値などもある。
(参考)ペアノの公理
ペアノの公理は以下の様に定義される。
自然数は次の5条件を満たす。
- 自然数$0$が存在する。
- 任意の自然数$a$にはその後者 (successor)、$suc(a)$が存在する($suc(a)$は$a + 1$の "意味")。
- $0$はいかなる自然数の後者でもない($0$より前の自然数は存在しない)。
- 異なる自然数は異なる後者を持つ:$a \neq b$のとき$suc(a) \neq suc(b)$となる。
- $0$がある性質を満たし、$a$がある性質を満たせばその後者$suc(a)$もその性質を満たすとき、すべての自然数はその性質を満たす。
5番目の公理は、数学的帰納法の原理である。
――― Wikipediaより
ペアノの公理を満たすものはノイマンの構成法という別の方法もある。
λ計算の軽い紹介
λ計算の構文は次の3つから成り立っている。
\begin{align} t ::=&\qquad&項:\\ &x &変数\\ &\lambda x.\, t\qquad &ラムダ抽象\\ &t \, t &関数適用 \end{align}見ての通り関数の宣言と適用だけで、数値や条件式やループの構文は無い。しかし、チャーチ数と同様に、チャーチ真理値で条件分岐を、不動点コンビネータで再帰(ループ)を導入できるので、任意のプログラムが実行できる。
ちなみに、Pythonを含む多くの言語では、具象構文が抽象構文木(AST)として解釈された上で実行されており、そのときにλ計算の理論が活かされているらしい。
Pythonのプログラマーとしての主張
- 同じ「自然数」の仕様を表現するためにも、複数の実装方法がある。目的にとって効率のよいデータ構造を選ばなくてはならない。
- メモリ上で2進数として表現されている(詳しくはWebで学ぶ 情報処理概論)
- 実際のPythonの
int型は自動でメモリ領域を増やしたり、小さい整数を共有していたりいろいろやってる- また『型システム入門』によると、λ計算でもブール値や数値を導入した拡張された体系を使うこともあるらしい
更に話すと面白そうな話題
- ラムダ計算
- 不動点コンビネータ(Yコンビネータ)による無名関数の再帰
- 評価戦略
- 型理論
- 代数的データ型(Pythonでは未実装)を使うと一瞬でチャーチ数が宣言できること
参考
書籍
記事
- 投稿日:2020-09-21T19:05:42+09:00
中学生なら分かるハフ(Hough)変換
はじめに
この記事を読むと約10分ほどでハフ変換の基本的な仕組みが理解できます。
最近は画像認識技術の発展が著しいですが、自動運転などの実アプリケーションでは深層学習技術だけではなく、もちろん古典的な画像処理アルゴリズムも使われています。
例えば画像内の直線(道路の白線など)検出には、今回紹介するのはハフ変換、またはその進化手法が使われていることがあります。ハフ変換とは画像の中から直線や円を見つけるための最も基本的なアルゴリズムの1種でOpenCVなどにも関数が実装されています。
今回はハフ変換を、できるだけ簡単に分かりやすく説明しようと思います。
直線検出
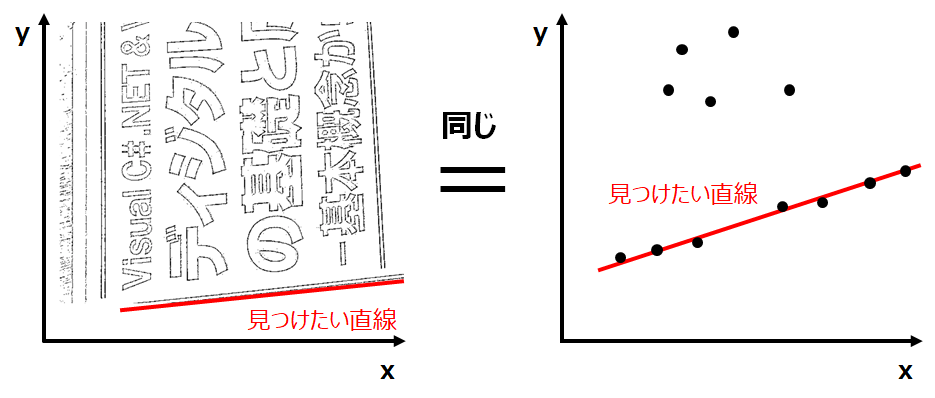
【問題】左下図のような2値化(エッジ抽出)された画像上で、直線を探します。
これは、右下図のようなxy平面上の点群から、直線を探すことと同じですね。
直線の方程式
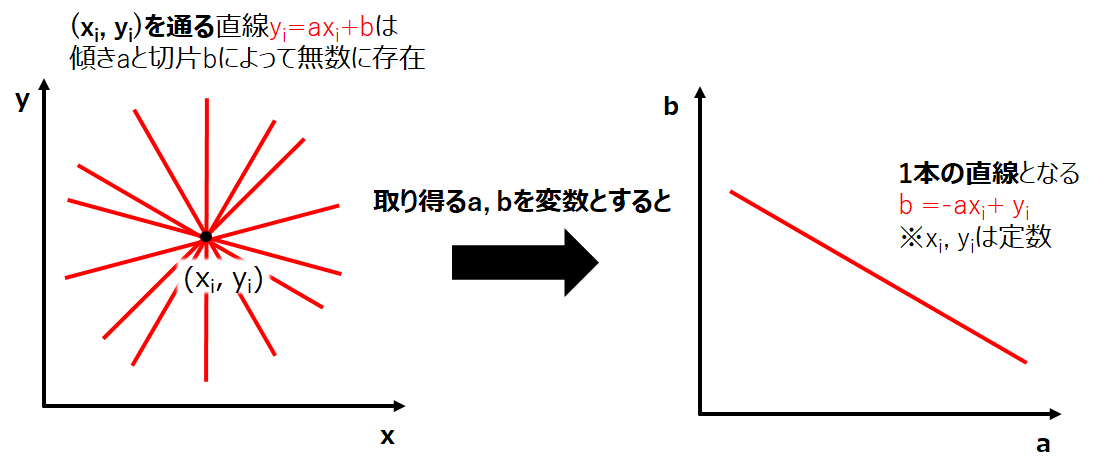
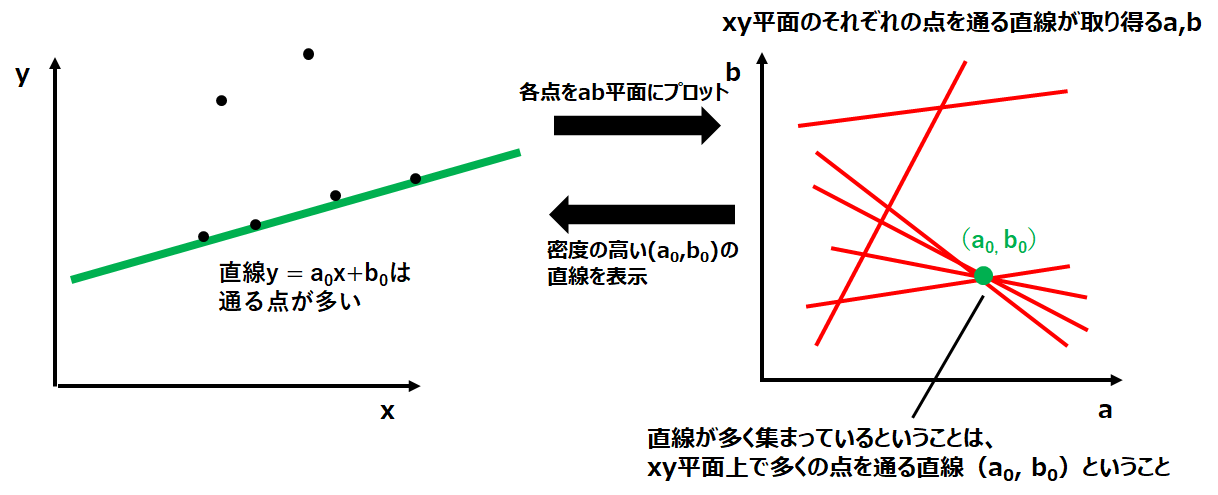
上記の問題を解くために、まず直線の方程式について考えてみます。中学1年生?で習いましたが、二次元平面上の直線は$y=ax+b$で表すことができます。また、$y=ax+b$の直線が点$(x_i,y_i)$を通る場合、この直線は$y_i=ax_i+b$を満たす必要があります。左下図のようなイメージです。そして、点$(x_i,y_i)$を通る直線方程式のa,bを変数として右下図のようにab平面の上にプロットすると1本の直線になります。
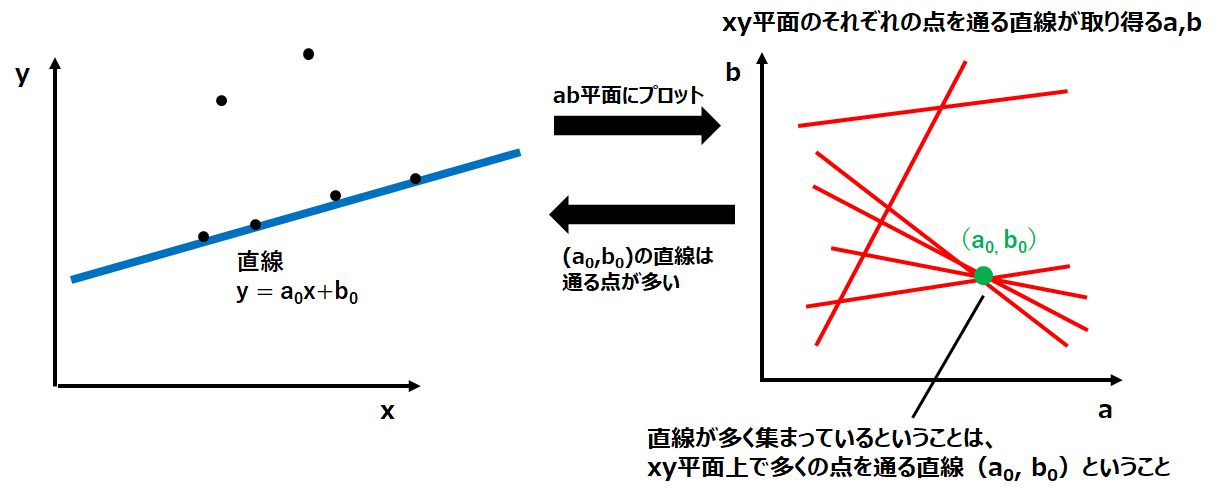
これを複数の点に適用してみると、右下図になります。そして、右下図のab平面について考えてみると、例えばab平面上で2つの直線が交差している点は「そのa,bにより、xy平面上の2つの点を通る直線が引ける」という意味を持っていることが分かります。
同様に、3つの直線が交差している場合は、そのa, bを持つ直線はxy平面上で3つの点を通るということです。
つまりab平面上での直線の密度を調べることで、x, y平面上であるa, bの直線が通る点が何点あるかを知ることができます。
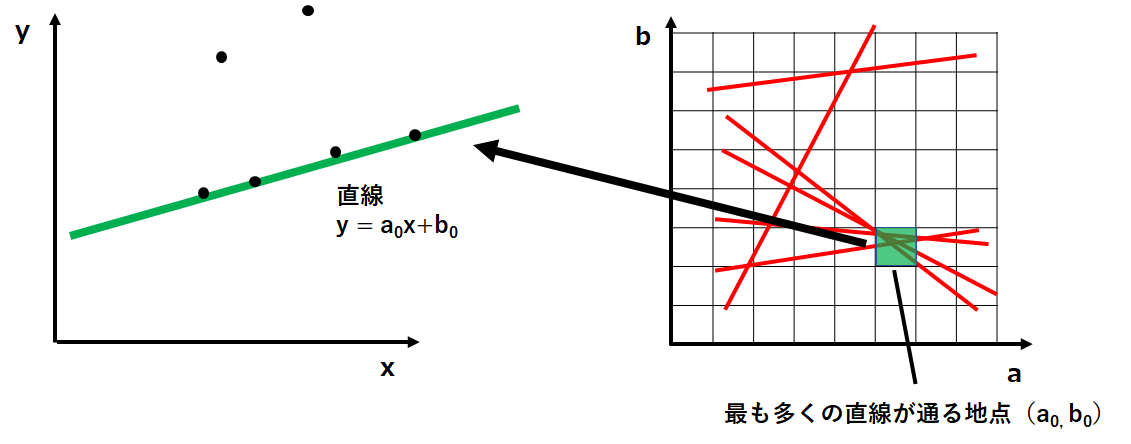
多数決
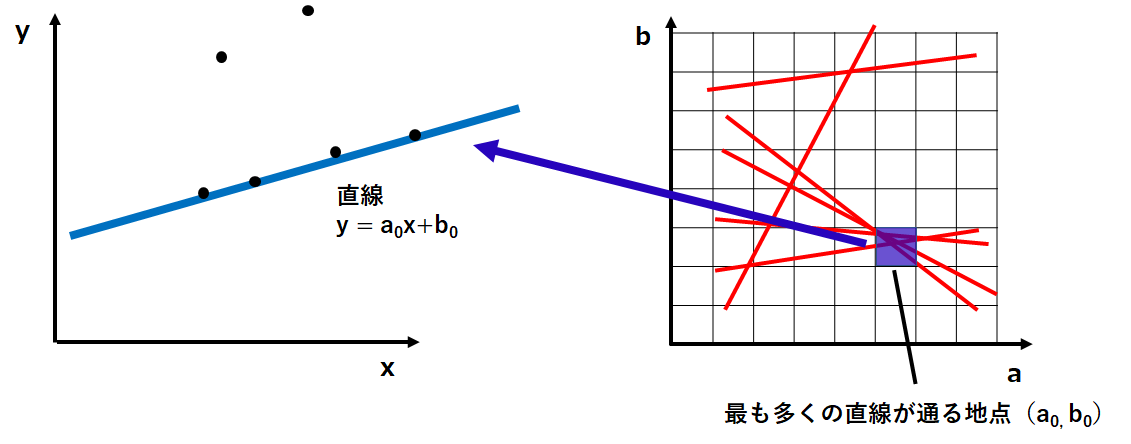
直線を検出するためにab平面上での直線の密度を調べていきます。方法はとてもシンプルで、左下図のように格子を作ってその中を通る直線をカウントするだけです。
ちなみにこの格子の幅は大きすぎると分解能が低くなってしまい、小さすぎると誤検知の原因となるので慎重に決定する必要があります。
※このような方法を用いることから、ハフ変換は投票と多数決原理による手法と言われています。
※実際には、傾きaが∞の直線も扱えるように極座標系でハフ変換を考えることがほとんどですが、軸の取り方が違うだけで基本的な考え方は変わりません。
実装
PythonのOpencvによる実装は以下の記事が参考になります。
OpenCVで直線の検出
画像解析 opencv python入門参考
以下の記事を参考にさせて頂きました。
画像のエッジ抽出(ラプラシアンフィルタ)
やさしいハフ(Hough)変換講座
0から始める自動運転 for FPT2018 FPGA Design Competition 〜ライントレース編〜最後に
最後まで読んで頂きありがとうございました。よろしければLGTMお願いします。
- 投稿日:2020-09-21T19:05:42+09:00
中学生でも分かるハフ(Hough)変換
はじめに
この記事を読むと約10分ほどでハフ変換の基本的な仕組みが理解できます。
最近は画像認識技術の発展が著しいですが、自動運転などの実アプリケーションでは深層学習技術だけではなく、もちろん古典的な画像処理アルゴリズムも使われています。
例えば画像内の直線(道路の白線など)検出には、今回紹介するのはハフ変換、またはその進化手法が使われていることがあります。ハフ変換とは画像の中から直線や円を見つけるための最も基本的なアルゴリズムの1種でOpenCVなどにも関数が実装されています。
今回はハフ変換を、できるだけ簡単に分かりやすく説明しようと思います。
直線検出
【問題】左下図のような2値化(エッジ抽出)された画像上で、直線を探します。
これは、右下図のようなxy平面上の点群から、直線を探すことと同じですね。
直線の方程式
上記の問題を解くために、まず直線の方程式について考えてみます。中学1年生?で習いましたが、二次元平面上の直線は$y=ax+b$で表すことができます。また、$y=ax+b$の直線が点$(x_i,y_i)$を通る場合、この直線は$y_i=ax_i+b$を満たす必要があります。左下図のようなイメージです。そして、点$(x_i,y_i)$を通る直線方程式のa,bを変数として右下図のようにab平面の上にプロットすると1本の直線になります。
これを複数の点に適用してみると、右下図になります。そして、右下図のab平面について考えてみると、例えばab平面上で2つの直線が交差している点は「そのa,bにより、xy平面上の2つの点を通る直線が引ける」という意味を持っていることが分かります。
同様に、3つの直線が交差している場合は、そのa, bを持つ直線はxy平面上で3つの点を通るということです。
つまりab平面上での直線の密度を調べることで、x, y平面上であるa, bの直線が通る点が何点あるかを知ることができます。
多数決
直線を検出するためにab平面上での直線の密度を調べていきます。方法はとてもシンプルで、左下図のように格子を作ってその中を通る直線をカウントするだけです。
ちなみにこの格子の幅は大きすぎると分解能が低くなってしまい、小さすぎると誤検知の原因となるので慎重に決定する必要があります。
※このような方法を用いることから、ハフ変換は投票と多数決原理による手法と言われています。
※実際には、傾きaが∞の直線も扱えるように極座標系でハフ変換を考えることがほとんどですが、軸の取り方が違うだけで基本的な考え方は変わりません。
実装
PythonのOpencvによる実装は以下の記事が非常に参考になります。
OpenCVで直線の検出
画像解析 opencv python入門参考
以下の記事を参考にさせて頂きました。
画像のエッジ抽出(ラプラシアンフィルタ)
やさしいハフ(Hough)変換講座
0から始める自動運転 for FPT2018 FPGA Design Competition 〜ライントレース編〜最後に
最後まで読んで頂きありがとうございました。
- 投稿日:2020-09-21T18:39:46+09:00
【Swift】機械学習(=ML)とAIとの違いを学んだのち、Core ML を実装してみる。
機械学習(= ML) とは?
機械学習は英語で、「
Machine Learning」
簡単に言うと、以下を指します。
- 『AIが自律的に物事を学ぶための技術』
- 『機械に大量のデータ・パターン・ルールを学習させることにより、判別や予測をする技術』
ML は、意外と歴史のある AI 分野のひとつ
機械学習はAIという概念の中の、1つの分野です。
1959年、機械学習の「父」とされている Arthur Samuel は、
機械学習を以下のように定義しています。「明示的にプログラムしなくても学習する能力」を、コンピュータに与える研究分野。
“Field of study that gives computers the ability to learn without being explicitly programmed”
-- Arthur Samuel --「AI=機械学習」ではなく、
AI > 機械学習 > ディープラーニングのイメージです。
なぜ近年、「機械学習」が大きな話題となっているのか
必要性
これまで人間はデータを分析し、そのデータに基づいてシステムや手順を変更してきました。
しかし、世界のデータ量が増大し、管理できなくなってきており、
データから学習し、それに応じて適応できる自動システムが必要とされています。技術の進歩
- AI技術の進歩
- 大量データの出現
- コンピューター処理能力の向上
使用例
- アマゾンエコーは、機械を使用してトレーニングされた音声テキストと音声認識を使用します
- 疾患の早期発見のために、医学界でも使用されています
- 自動運転車は、機械学習に依存して自分自身を運転します
AI と ML と DL の違い
人工知能【Artificial Intelligence】
人間のような知能をもつアルゴリズム。
※ アルゴリズム ...
「何を」「どのような順番で」「何に対して行うのか」を記述したもの。機械学習【Machine Learning】
AIが自律的に物事を学ぶための技術。
ディープラーニング(= 深層学習)【Deep Learning】
多層のニューラルネットワークを活用し、物事の特徴を抽出する技術。
因みに...
機械学習が「人間が判断・調整する」のに対し、
ディープラーニングは「機械が自動的に行う」ことが特徴。ディープラーニングで、人間が見つけられない パターンやルールの発見、特徴量の設定が可能になり、
人の認識・判断では限界があった
画像認識・翻訳・自動運転といった技術が飛躍的に上がった。機械学習は、3つに分けられる
機械学習の主な手法には、
「教師あり学習」「教師なし学習」「強化学習」がある。教師あり学習 (= Supervised Learning)
正解データを元に、入力データの特徴やルールを学習します。
✅「過去のデータから、将来起こりそうな事象を予測すること」に使われます。
- 回帰: 連続する数値を予測する
- 分類: あるデータがどのクラスに属するかを予測する
例.
【回帰】 "天候"と"お弁当の販売個数" の関係を学習し、お弁当の販売個数を予測する、
不動産価値、商品価格、株価、会社業績 etc【分類】 果物をサイズ別に分ける、画像や音声を種類別に分ける、
電子メールがスパム(迷惑メール)かどうかを判定する etc教師なし学習 (= Unsupervised Learning)
正解データなしでデータの特徴やルールを学習します。
✅「データに潜む傾向を、見つけ出すため」に使われます。
- クラスタリング: データのグループ分け
- アソシエーション分析: データ間の関連を発見する
- 異常検知: 人による指導なく、正常なものと不正常なもの(異常)を検知する
例. 【クラスタリング】 FacebookやInstagramの「あなたの友達かも..?」機能
【アソシエーション分析】 紙おむつを購入する人はビールも購入するetc強化学習 (= Reinforcement Learning)
失敗や成功を繰り返させ、どの行動が最適か学習します。
✅ 成功に対して「報酬」を与えることで学習効率を上げる方法です。
ロボットの歩行制御
ロボットに「歩けた距離」を報酬として与えます。するとロボットは、
歩行距離を最大化するために、自らさまざまな歩き方を試行錯誤します。
そうすることで、歩行可能距離の長いアルゴリズムが構築されます。囲碁AIの「Alpha Go」
囲碁は手のパターンが膨大過ぎて、既存の最新のコンピュータでも、手を読み切ることは不可能です。
よって、強化学習により、勝ちまでの手を読み切る代わりに、「どの手を打てば勝ちに近づくか」を学習させます。
試合にて失敗や成功を繰り返すと、最適な行動のみを選択するようになります。こうして「Alpha Go」は強くなっていったのです。参考サイト
© 2020 データアーティスト株式会社
機械学習をどこよりもわかりやすく解説!Core MLの実装については、後日追記または別投稿。
少しでも参考になれば?お願い致します。おしまい。


- 投稿日:2020-09-21T18:30:27+09:00
Pythonパッケージ公開のロードマップ
Pythonパッケージを作成、公開する際に必要な手順の概要をまとめました。ツールの具体的な使用方法や詳細については参考となる資料へのリンクを後日追加、または別の記事を作成する予定です。
私自身2020年2月ごろにパッケージを公開しよう!と思い立ったのですが、何から始めればよいかわからず苦労しました。開発を進める中で得られた知見をまとめていますので、これから公開を考えていらっしゃる方の参考になれば幸いです!
対象となるパッケージ:
- Pythonのパッケージとして公開し、一般に使ってもらいたい
- GitHubなどでコードを公開し、ユーザーとも協議しながら開発を進めたい
概要
0. 内容の検討
検討の必要な事項:
- ユーザー層:背景知識はどの程度必要か、Pythonや他のパッケージに関する知識はどの程度必要か
- 使用目的:ユーザーは何を得られるか
- 開発期間
ツール:
- マインドマップ
- アウトライン作成ツール:WorkFlowy
1. 開発環境の整備
ローカルPCに開発環境を構築しつつ、作成したコードを公開するしくみを整える必要があります。またGitを使用して変更履歴を随時記録することで、開発状況を効率よく把握できるようになります。
リポジトリ(コードの保管/変更履歴の記録)
GitHubに開発用のRemote repositoryを作成し、ローカル環境にクローンして開発を行います。作業完了後、ローカル環境でコミットし、Remote repositoryにプッシュします。
Pythonの実行環境
Windows 10を使用している場合、可能であればWSL (Windows Subsystem for Linux)あるいはWSL2の使用をおすすめします。
Editorの導入
EditorもしくはIDE (Integrated Development Environment, 統合開発環境)をローカル環境に用意します。
Visual Studio Code (VScode)がおすすめです。多数のプラグインが用意されており、Git操作についてもより簡単に扱えるようになります。
依存パッケージの管理
pipenvやpoetryが有望のようです。pipenvを使用していますが、頻繁にエラーが出る&遅いため、poetryへの移行を検討中です。(poetryのほうが早いのかなどは未検証です...)
開発ワークフロー
Git Flow, GitHub Flowなど、ブランチの使用方法やマージのタイミングについて色々な考え方があるようです。個人もしくは数人レベルで開発を行う場合は、そのなかでもシンプルなGitlab Flowの使用をおすすめします。
また、GitHubのissue機能をtodo-list & 議論の場として使うと便利です。issueやpull requestには個別の番号が
#1などと割り当てられますので、issue#1で問題提起し、issue番号をもとにブランチissue1にて作業を行い、pull requestによりデフォルトのブランチにマージするという手順です。Versioning
大きな流れとして「開発版(GitHubで管理)」と「安定版(PyPIで管理)」の2本立てで開発を行うと便利かと思います。開発版は、前述の開発フローによって作成します。
開発バージョンの名前の付け方はあまり定まったものはなさそうでした。私の場合は、マージが発生してissueを閉じた直後に開発版のバージョンを1つあげています。
(例)バグ修正にてissue#2を閉じたとき:2.0.1-alpha.new.1 → 2.0.1-beta.new.1.fix.2
また、多数のissueが閉じた場合や安定版のバグを緊急に修正する必要が発生した場合は安定版のバージョンをSemantic Versioningにしたがってバージョンを上げてください。
2. コーディング
フォルダ構成などコーディング時に注意の必要な事項をまとめました。
パッケージの名前
パッケージの1行説明文を英語で作成、そのなかからアルファベットを選んでパッケージ名にすると、あまり悩まなくて済むと思います。アルファベットの選び順については私は気にしてません(笑)
例:Python package for COVID-19 anal ysis with phase-dependent SIR-derived ODE models = CovsirPhy
またGoogle検索を使って、他のサービス名と被らないようにしたほうが良いかもしれません。
インストール方法が変わるなど大騒動になるので、後から変更するのは難しいと思います。
パッケージの識別情報
poetryを使用する場合は、別ファイルに記載することになりますが、pipenvを依存パッケージの管理に使用している場合は
setup.py,setup.cfgというファイルをrepositoryのトップに作成してください。setup.pyfrom setuptools import setup setup()setup.cfg[metadata] name = パッケージ名 version = attr: パッケージ名.__version__.__version__ url = レポジトリなどのURL author = 著者名 author_email = メールアドレス license = Apache License 2.0 license_file = LICENSE description = パッケージの1行説明 long_description = file: README.rst keywords = キーワード classifiers = Development Status :: 5 - Production/Stable License :: OSI Approved :: Apache Software License Programming Language :: Python :: 3.7 Programming Language :: Python :: 3.8 [options] packages = find: install_requires = # 依存パッケージ名 numpy matplotlib日本語で記載した部分やライセンス名などは適宜置き換えてください!また、依存パッケージを追加した場合は随時"install_requires"欄への追加が必要となります。
フォルダ構成
Repositoryのトップに、パッケージ名のフォルダ(またはsrcフォルダ)を作成してください。その中にまず、
__version__.py及び__init__.pyという空ファイルを作成してください。そしてフォルダ構成(モジュール構成)を決めましょう。循環インポート1に要注意です。
src/A/a1.pyをsrc/B/b1.pyがインポートしかつsrc/B/b2.pyをsrc/A/a2.pyがインポートする、ということが起こらないようにしましょう。開発環境ではエラーにならないが安定版をpip installするとエラーになる場合があるようで、苦労したことがあります。この修正だけのために安定版のバッチ番号を2回上げました。
setup.cfgではなくsrc/__version__.pyで管理すると、パッケージ内でもバージョン番号を取得・表示できるようになるので便利です。前述のsetup.cfgの記載例ではversion = attr: パッケージ名.__version__.__version__によりこのファイルを呼び出しています。__version__.py__version__ = "0.1.0"以下は
src/util/plotting.pyにline_plotという関数を作成した場合です。from src.util.plotting import line_plotと書くことで、pip installした際にfrom src.util.plotting import line_plotではなくfrom src import line_plotと呼び出せるようになります。__init__.py#!/usr/bin/env python # -*- coding: utf-8 -*- # version from src.__version__ import __version__ # util from src.util.plotting import line_plot def get_version(): """ Return the version number, like パッケージ名 v0.0.0 """ return f"パッケージ名 v{__version__}" __all__ = ["line_plot"]
__all__ = ["line_plot"]と書くと、pylintなどのコード整形ツールの修正確認を回避できるようになります(pylintの設定を変更して修正確認を表示させないこともできますが)。また、from src import *とするだけでline_plotを使用できるようになりますが、import *は推奨されていません...PyPIへの登録
コード、setupファイル, version番号が最低限整っていれば、test-PyPIやPyPIにパッケージを登録できます!
3. テストの運用
バグが発生するのはやむを得ないですが(開発の原動力にもなり得る)、精神をすり減らさないためにもバグは公開前に可能な限りなくしておきたいものです。100%きっちりとテストを書く必要はないと思いますが、少なくともユーザーがメインで使用する方法に関しては、テストコードを書いて事前に動作確認することが開発者には求められていると思います。
テストの作成
unittest,pytest,doctest,noseなど、テストコードの作成/実行パッケージがいくつか知られています。個人的にはpytestを使用しています。テストの自動実行
基本的には「ローカルで開発&ローカルでテスト」ですが、テストコードが増え、1回のテストに10分以上かかるようになってくるとローカルでは対応しきれなくなるのではないでしょうか。
そうした場合は、Continuous integration (CI) toolの手を借りてテストの自動実行をご検討ください。GitHub Actions (GitHub repository画面から作成可能)やTravis CI, Semaphoreなどが知られています。Open sourceのプロジェクトであればある程度無料で使用できます。
Semaphoreに結構お世話になっています。日本語の記事があまりなさそうなので後日記事を作成予定です。
データサイエンス用の場合
データサイエンス用のパッケージ(データベースからCSVファイルをダウンロードする/データを解析するもの)の場合、各関数や各クラスへの入力引数が刻一刻と変わり、開発者側で入力値をすべて予想してテストを作るのは困難です。解決策としては次の3パターンが考えられるかと思います。
- 入力データの型をチェックする(
isinstance(data, pandas.DataFrame),set(data.columns).issubset(fields))- 出力データの型をチェックする
- 仮想の入力データを作成し、出力データが想定通りとなるかを確認する
4. ドキュメントの作成
パッケージの使い方や使用例を伝え、宣伝するためにもドキュメントは必須です。
docstringの作成
まずはPythonの各関数/クラス/メソッドのdocstringを(なるべく英語で)書いてください。コードの実装時に同時並行で書いたほうが良いと思います。
記法としてはreStructuredText-style, Google-style, numpy-styleがありますが、上下に冗長になりにくいGoogle-styleがおすすめです。(Private projectのみでPythonを使っていた頃はNumpy-styleに似た自己流で書いていましたが、Google-styleに移りました。)
使用例のドキュメント
使用例をドキュメントとして残す場合、Jupyter Notebook式(.ipynb)が便利かと思います。説明とコード、結果を一緒に表示できます。
例:CovsirPhy: Usage (quickest version)
Markdown/htmlへの変換
pandocやsphinx (api-doc)を使用すると、docstringや.ipynbファイルを半自動でmarkdown/html形式に変換できます。長くなるので本記事では省略しますが、HTMLやCSSの詳細を知らなくてもPythonのみでホームページを作成できるので楽です。
ドキュメントの公開
GitHub Pagesを使えば、GitHub repositoryのhtmlファイルを随時更新するだけでドキュメントを公開、更新できます。
あとがき
詳細を省略し駆け足になりましたが、閲覧ありがとうございました。過不足や他の方法がありましたらご教示ください。随時更新予定です。
お疲れさまでした!
- 投稿日:2020-09-21T17:43:55+09:00
GooglePlayMusicからダウンロードしたmp3をPython使って自動整理した
はじまり
Google Play Musicが12月末で終了というニュースが発表されました。
購入やアップロードした楽曲はYouTube musicへそのまま移行できるのですが、同サービスもいつ終了になるかわからないので、念のためローカル環境にもバックアップすることに。
楽曲をダウンロードしたところ、全データが同一フォルダ内に一括ダウンロードされる仕様だったので、Pythonを使って「アーティスト名」や「アルバム名」ごとにフォルダ分けを行う事にしました。
私のようなプログラミングのド素人でも、この程度の事はできそうです。ダウンロード
楽曲のダウンロードは下記ページに従って行いました。
https://support.google.com/googleplaymusic/answer/1250232?hl=jaフォルダ階層
フォルダ階層は以下の通りに設定する事とします。
Root
├アーティストA
│ └アルバム名
│ └ 楽曲_1.mp3
│ └ 楽曲_2.mp3
├アーティストB
├アーティストCディレクトリ構成図の記入方法はこちらを参考にしました。
https://qiita.com/paty-fakename/items/c82ed27b4070feeceff6mp3のタグ情報を取得
楽曲名、アーティスト名、アルバム名など、mp3に内包されたタグ情報を取得するには
EasyID3を利用します。
こちらのサイトを参考にさせていただきました。
https://note.nkmk.me/python-mutagen-mp3-id3/完成したコード
いきなりですが完成したコードは下記の通りです。
from mutagen.easyid3 import EasyID3 import os import shutil import re def replace(string): return(re.sub(r'[\\/:*?"<>|]+', '-', string)) def arrange_data(mp3_path): tags = EasyID3(mp3_path) try: artistname = (tags['albumartist']) except KeyError: artistname = (tags['artist']) albumname = (tags['album']) artistname = replace(artistname[0]).strip() albumname = replace(albumname[0]).strip() title = os.path.basename(mp3_path) artist_dir = os.path.join(globalpath, artistname) album_dir = os.path.join(artist_dir, albumname) new_mp3_path = os.path.join(album_dir, title) if not artistname in artist_list: if not os.path.isdir(artist_dir): os.makedirs(artist_dir) artist_list.append(artistname) if not albumname in album_list: album_list.append(albumname) if not os.path.isdir(album_dir): os.makedirs(album_dir) album_list.append(albumname) try: shutil.copyfile(mp3_path, new_mp3_path) print(title + " is done.") except shutil.SameFileError: print(title + " is already exists.") def data_check(file_list, path): for i in file_list: if os.path.isdir(os.path.join(path, i)): new_path = os.path.join(path, i) new_file_list = os.listdir(new_path) data_check(new_file_list, new_path) else: arrange_data(os.path.join(path, i)) globalpath = r"楽曲が入っているフォルダ" file_list = os.listdir(globalpath) album_list = [] artist_list = [] data_check(file_list, globalpath)引っかかったポイント
KeyError:が発生する
Windowsではファイル名として使えない無効文字
\/:*?"<>|があるのですが、アーティスト名やアルバム名の中に無効文字を含むものが複数ありました。こちらはre.subを利用して無効文字を_に置き換えました。ディレクトリpathに空白が入る
アーティスト名やアルバム名の末尾に空白が含まれているものがある場合、実際のフォルダ名とフォルダパスが不一致を起こして、読み込みエラーが発生しました。
こちらは.strip()を利用して解決しました。feat.問題
アーティスト名が「feat.〇〇」みたいになっていて、アーティスト名での振り分けが難しい楽曲に関してはアルバムアーティスト名を利用しました。アルバムアーティスト名がある楽曲はそれを優先し、ついてないものはアーティスト名を利用します。
おわりに
無事データを整理する事ができました。多少でもPythonが使えると便利ですね。
楽曲によっては正常に動作しないものがありそうですが、ローカルデータは全て処理できたので良しとします。ありがとうございました!
- 投稿日:2020-09-21T17:40:48+09:00
Visual Studio Code でpythonの外部ライブラリを自動補完させるようにする
Pythonの勉強がてらメモ
vscode でpython を書いていたら、外部ライブラリが補完されず、開発の効率が悪いので
外部ライブラリも補完できるようにしたい。解決方法
setting.json にライブラリが格納されているパスを記載すればOK
ライブラリのパスを確認
pip3 install ライブラリ名インストールされていたら、
Requirement already satisfied: ライブラリ名 in /usr/local/lib/python3.8/site-packages (0.6.3)のように表示されるはず
このパスに格納されているファイルも一応確認
ls /usr/local/lib/python3.8/site-packagesライブラリ一覧が表示されたら問題なさそう
setting.json にパスを記載
setting.json を開く
coomand + shit + pコマンドパレットで、「setting json」 と入力
↓
Open Setting(JSON) を開くsetting.json にパス追加
"python.autoComplete.extraPaths": ["/usr/local/lib/python3.8/site-packages "]これで保存すれば、外部ライブラリも補完きくし、doc にもジャンプできます。
- 投稿日:2020-09-21T17:37:57+09:00
プログラミング初心者はとりあえず『ゲーム』を作ればいいんじゃないか?っていう話
はじめに
プログラミング始めたんだけど、これが何の役に立つのか分からない。何ができるようになるのかイメージがつかめないって初心者さんは意外と多いんじゃないでしょうか?
そりゃあ、例えばpythonだったら自動化だったり機械学習だったり画像認識だったりできるっていうのは知っているでしょう。私だって知ってます。
でも、実際に勉強し始めると最初は『変数』だとか『データ型』だとか『リスト』だとか……
で、それが何なの?美味しいの??
ってなりませんか。私はバカだからなりました。さて、
前置きが長くなりましたね。私は現在のプログラミング教育ってハードルが高いと思っています。賢い人は別なんでしょうけど、私みたいな人には学習コストが高いです。
だから、もっと簡単なことから始めてもいいんじゃないかと思うのです。
で、なにするの?
『ゲーム』を作ります。
しかし、ゲームと言っても死ぬほど簡単です。
推しキャラと『じゃんけん』するだけの簡単なゲームです。プログラミング初心者向けの本でも度々登場するじゃんけんゲームですね。これを自分なりにアレンジしたものを作ります。
たかがじゃんけん1つでも、愛情たっぷり丹精込めて作ったじゃんけんはそれなりに面白いと思うんですよね。
実装
1. まずは単純なじゃんけんをします
janken.pyimport random # janken head print("ジャンケンだYO!") print("最初はドーン! ジャンケンッ ホイッ!!") # define function def janken(): global myhand global mynum global yournum yournum = random.randint(1,3) mynum = 0 myhand = input(":") if myhand == "goo": mynum = 1 elif myhand == "choki": mynum = 2 elif myhand == "paa": mynum = 3 else: print("真面目にやってください!") if yournum == 1: yourhand = "goo" print(yourhand) elif yournum == 2: yourhand = "choki" print(yourhand) elif yournum == 3: yourhand = "paa" print(yourhand) i = 1 while i ==1: result = (yournum - mynum) % 3 if result == 0: print("あいこでしょ!") janken() elif result == 1: print("負けました~") break elif result == 2: print("私の勝ちですねっ!") break # execute function janken()なんか藤原書記っぽい人とじゃんけんするゲームができあがりました。
じゃんけんプログラムの肝は2点あって、
1つは、["goo","choki","paa"]を[1,2,3]と数値で表すこと。そして、相手と自分の数値の差を3の合同式を使って勝敗を決めることです。
例えば、相手が"goo"で自分も"goo"を出したら、1-1=0 0%3=0なのであいこ。
相手が"goo"で自分が"choki"なら、1-2=-1 -1%3=2なので自分の負け。
相手が"goo"で自分が"paa"なら、1-3=-2 -2%3=1なので自分の勝ち。といった具合に。2つは、あいこの場合をうまく表現すること。じゃんけんはあいこの時だけループが発生するアルゴリズムとなっています。
なので、あいこの時は、最初からやり直す処理を記述する必要があります(私は関数を再び呼び出していますが、もっと良いやり方があるかもしれませんね)さて、藤原書記っぽい人とじゃんけんをするだけでもそれなりに楽しいですし、一般的な学習本ならこの程度で終わりなのですが、今回はもっとアレンジしていきたいと思います。
2. 3本先取にする
じゃんけんと言えばだいたい3本先取ですよね。なので、こちらのプログラムを3本先取にしていきます。
janken.pyimport random # janken head print("3本先取ジャンケンだYO!") print("最初はドーン! ジャンケンッ ホイッ!!") count = [0,0] # [mypoint,yourpoint] # define function def janken(): global myhand global mynum global yournum yournum = random.randint(1,3) mynum = 0 myhand = input(":") if myhand == "goo": mynum = 1 elif myhand == "choki": mynum = 2 elif myhand == "paa": mynum = 3 else: print("真面目にやってください!") if yournum == 1: yourhand = "goo" print(yourhand) elif yournum == 2: yourhand = "choki" print(yourhand) elif yournum == 3: yourhand = "paa" print(yourhand) global count i = 1 while i ==1: result = (yournum - mynum) % 3 if result == 0: print("あいこでしょ!") janken() elif result == 1: print("負けました~") if count[0] < 2: print("次は負けませんよ~") count[0] += 1 print(str(count[0]) + "勝"+ str(count[1]) + "敗ですね!") janken() elif count[0] == 2: print("やられちゃいました~") break elif result == 2: print("私の勝ちですねっ!") if count[1] < 2: print("負けた人は勝った人の言うことをなんでも聞くんですよね~") count[1] += 1 print(str(count[0]) + "勝"+ str(count[1]) + "敗ですね!") janken() elif count[1] == 2: print("わーい! 勝ちました~") break # execute function janken()これで3本先取にすることができました。勝率は5割くらいでしょうか。実際にやってみると案外勝てません。
今回はcountという変数を作って、勝敗ごとに勝ち点1を加算していくだけなので実装は簡単ですね。
3本先取するまでは、先のあいこと同じように関数を呼び出してループさせています。さて、藤原書記とじゃんけんするだけでもそれなりに楽しいですし、ともすれば藤原書記とじゃんけんをしているだけで1日が過ぎ去るんですが、
なにか、こう……物足りないですよね。3. キャラを増やす
そうですね。物足りなさの正体はキャラの少なさです。
そりゃあまあ、藤原書記も可愛いですけど、1日中藤原書記とじゃんけんばかりしていても飽きますよね(というか、藤原書記に飽きられる)
なので、キャラを増やしましょう。janken.pyimport random # 勝ち数をカウントする count = [0,0] # [mypoint,yourpoint] # define class and function class Shuchiin: def __init__(self,name,words_list): self.name = name self.words_list = words_list def janken_head(self,words_list): self.words_list = words_list print(words_list[0]) print(words_list[1]) def janken(self,words_list): self.words_list = words_list global myhand global mynum global yournum yournum = random.randint(1,3) mynum = 0 myhand = input(":") if myhand == "goo": mynum = 1 elif myhand == "choki": mynum = 2 elif myhand == "paa": mynum = 3 else: print(words_list[2]) if yournum == 1: yourhand = "goo" print(yourhand) elif yournum == 2: yourhand = "choki" print(yourhand) elif yournum == 3: yourhand = "paa" print(yourhand) global count i = 1 while i ==1: result = (yournum - mynum) % 3 if result == 0: print(words_list[3]) self.janken(words_list) elif result == 1: if count[0] < 2: print(words_list[4]) print(words_list[5]) count[0] += 1 print(str(count[0]) + "勝"+ str(count[1]) + "敗ですね") self.janken(words_list) elif count[0] == 2: print(words_list[6]) break elif result == 2: if count[1] < 2: print(words_list[7]) print(words_list[8]) count[1] += 1 print(str(count[0]) + "勝"+ str(count[1]) + "敗ですね") self.janken(words_list) elif count[1] == 2: print(words_list[9]) break # define each words_list Kei_list = ["じゃんけんですか?","最初はぐー、じゃんけん、ほいっ","真面目にしないならやめますよ","あいこでしょ","うぅ","次こそ……","強いんですね。でも、次は負けませんから","ふっ","まだやりますか?","私の勝ちですね。まずはこんにち殺法の練習から始めた方がいいですよ"] Huziwara_list = ["3本先取ジャンケンだYO!","最初はドーン! ジャンケンッ ホイッ!!","真面目にやってください!","あいこでしょ!","負けました~","次は負けませんよ~","やられちゃいました~","私の勝ちですねっ!","負けた人は勝った人の言うことをなんでも聞くんですよね~","わーい! 勝ちました~"] Shinomiya_list = ["あら、私とじゃんけんをしたいのですか? お可愛いこと。3本先取でいいですね?","最初はグー、じゃんけん、ほい","真面目にしていただけませんか","おあいこですね","あら、負けましたわ","次は負けないですからね","認めましょう、私の負けです","あら、私の勝ちですね","遺言を考えておいた方が良いですよ","お可愛いこと"] # create each instance Kei = Shuchiin("Kei",Kei_list) Huziwara = Shuchiin("Huziwara",Huziwara_list) Shinomiya = Shuchiin("Shinomiya",Shinomiya_list) # execute function player = input("誰と対戦しますか?:") if player == "kei": Kei.janken_head(Kei_list) Kei.janken(Kei_list) elif player == "huziwara": Huziwara.janken_head(Huziwara_list) Huziwara.janken(Huziwara_list) elif player == "shinomiya": Shinomiya.janken_head(Shinomiya_list) Shinomiya.janken(Shinomiya_list) else: print("今日はもう帰りましょう")藤原書記の他に圭ちゃんとかぐや様を呼んできました(女性陣ばかりなのはたまたまです)
これでバラエティ豊かになりましたね。
変更点はキャラごとに台詞を変えたことと、開始時に対戦プレイヤーを選択できるようにしました。ふぅ、これで1日中遊べますね。
おわりに
さて、簡単なゲームを実装して思ったことですが、プログラミングは条件分岐や繰り返しを含む『手続き』を表現できることがわかりましたね。
じゃんけんは、勝敗の条件分岐と連戦という繰り返しを含む最も簡単な手続きをするゲームだと言えます。
そして、じゃんけん一つとっても、四則演算や条件分岐、関数やクラスが必要なことがわかりました。
なんでも小さいことをコツコツと続けることが最強だと思っております。
私もプログラミング初心者ですが、一歩ずつプログラミング道を歩んでいきたいと思います
- 投稿日:2020-09-21T16:56:51+09:00
AtCoderBeginnerContest179復習&まとめ
AtCoder ABC179
2020-09-19(土)に行われたAtCoderBeginnerContest179の問題をA問題から順に考察も踏まえてまとめたものとなります.(時間なかったので,考察は時間があるときに追加します汗)
問題は引用して記載していますが,詳しくはコンテストページの方で確認してください.
コンテストページはこちら
公式解説PDFA問題 Plural Form
問題文
AtCoder 王国では、英小文字を用いる高橋語という言語が使われています。
高橋語では、名詞の複数形は次のルールで綴られます。
・単数形の末尾が"s"以外なら、単数形の末尾に"s"をつける
・単数形の末尾が"s"なら、単数形の末尾に"es"をつける
高橋語の名詞の単数形$S$が与えられるので、複数形を出力してください。abc179a.pyn = input() if n[-1] == "s": print(n + "es") else: print(n + "s")B問題 Go to Jail
問題文
高橋君は、「サイコロを$2$個振る」という行動を$N$回行いました。$i$回目の出目は$D_{i,1},D_{i,2}$です。
ゾロ目が$3$回以上続けて出たことがあるかどうか判定してください。 より正確には、$D_{i,1}=D_{i,2}$かつ$D_{i+1,1}=D_{i+1,2}$かつ$D_{i+2,1}=D_{i+2,2}$を満たすような$i$が少なくとも一つ存在するかどうか判定してください。abc179b.pyn = int(input()) check_list = [] for i in range(n): d1, d2 = map(int, input().split()) if d1 == d2: check_list.append(1) else: check_list.append(0) flag = 0 for i in range(n - 2): if sum(check_list[i:(i+3)]) == 3: flag = 1 break if flag: print("Yes") else: print("No")C問題 A x B + C
問題文
正整数$N$が与えられます。$A×B+C=N$を満たす正整数の組$(A,B,C)$はいくつありますか?abc179c.pyn = int(input()) count = 0 for a in range(1, n): count += (n - 0.5) // a print(int(count)) print(count)D問題 Leaping Tak
問題文
一列に並んだ$N$マスから成るマス目があり、マスには左から順番に$1,2,…,N$の番号がついています。
このマス目で暮らしている高橋君は、現在マス$1$にいて、後述の方法で移動を繰り返してマス$N$へ行こうとしています。
$10$以下の整数$K$と、共通部分を持たない$K$個の区間$[L_1,R_1],[L_2,R_2],…,[L_K,R_K]$が与えられ、これらの区間の和集合を$S$とします。ただし、区間$[l,r]$は$l$以上$r$以下の整数の集合を表します。
・マス$i$にいるとき、$S$から整数を$1$つ選んで($d$とする)、マス$i+d$に移動する。ただし、マス目の外に出るような移動を行ってはならない。
高橋君のために、マス$N$に行く方法の個数を$998244353$で割った余りを求めてください。abc179d.pyn, k = map(int, input().split()) s_list = [] a_list = [0] * (n + 1) b_list = [0] * (n + 1) a_list[1] = 1 b_list[1] = 1 for i in range(k): l, r = map(int, input().split()) s_list.append([l, r + 1]) for i in range(2, n + 1): for l, r in s_list: t2 = max(0, i - l) t1 = max(0, i - r) a_list[i] += b_list[t2] - b_list[t1] b_list[i] = (b_list[i - 1] + a_list[i]) % 998244353 print(a_list[n] % 998244353)E問題 Sequence Sum
問題文
$x$を$m$で割った余りを$f(x,m)$と表します。
初期値$A_1=X$および漸化式$A_{n+1}=f(A_n^2,M)$で定まる数列を$A$とします。
$\sum_{i=1}^{N}A_i$を求めてください。abc179e.pyn, x, m = map(int, input().split()) x_set = set() x_list = [] for i in range(n): if x not in x_set: x_set.add(x) x_list.append(x) else: break x = x**2 % m total = 0 start = n for i in range(n): if x_list[i] == x: start = i break else: total += x_list[i] if start != n: m = len(x_list) - start k = (n - start) // m total += k * sum(x_list[start:]) for i in range(0, n - k * m - start): total += x_list[start + i] print(total)
- 投稿日:2020-09-21T16:14:51+09:00
3行のコードでBERTによるテキスト分類ができる時代
目次
1. はじめに
2. ライブラリの紹介
3. livedoor-corpusでのテストコードはじめに
本記事ではBERTによるテキストのマルチクラス分類を手軽に行えるライブラリの紹介をします。
タイトルの3行というのはそのライブラリのメソッド的な意味です。BERTとは
BERTとは、Bidirectional Encoder Representations from Transformers の略で
「Transformerによる双方向のエンコード表現」と訳され、2018年10月にGoogleのJacob Devlinらの論文で発表された自然言語処理モデルです。
翻訳、文書分類、質問応答など自然言語処理の仕事の分野のことを「(自然言語処理)タスク」と言いますが、BERTは、多様なタスクにおいて当時の最高スコアを叩き出しました。
引用:Ledge.ai「BERTとは|Googleが誇る自然言語処理モデルの特徴、仕組みを解説」参考:Qiita「自然言語処理の王様「BERT」の論文を徹底解説」
BERTによるテキスト分類
ありがたいことにBERTによるテキスト分類のサンプル記事は既に多く存在しています。
が、結構長かったりして取っ掛かりにくいんですよね。参考:
自然言語処理モデル(BERT)を利用した日本語の文章分類
BERTを用いて、日本語文章の多値分類を行う
【PyTorch】BERTを用いた日本語文書分類入門なので少し調べてみたら手軽なライブラリにパッキングしてくれた方がいらっしゃいました↓↓
「Simple Transformers」
元記事:Simple Transformers — Multi-Class Text Classification with BERT, RoBERTa, XLNet, XLM, and DistilBERT
このライブラリは「そのまま動作する」Transformerライブラリです。
技術的な詳細を気にすることなく、3行のコードでTransformerを使用する場合は、これが最適です。
(元記事訳)BERTにはいくつか種類がありますが、
BERT,GPT,GPT-2,Transformer-XL,XLNet,XLM,RoBERTa,DistliBERTの8つを似た書き方で実行できるのがTransformersというライブラリです。
この「Simple Transformers」はそれをさらに使いやすくしたライブラリです。導入
公式ではcondaを推奨していますが僕はvenv仮想環境で行いました。
前提系:
$ pip install pandas tqdm scipy scikit-learn transformers tensorboardx simpletransformers
これらに加えてpytorchが必要になります。
GPUを使う場合は別途CUDAの導入が必要になるので調べてみてください。
CPUの場合はpytorchのみのインストールで大丈夫です。
インストールコマンドは公式から自分の環境に合わせたものを取得できます。→Pytorch公式ちなみに僕の環境ではGPUのメモリ不足エラーを回避できなかったのでCPUで実行しました。長いです。
使ってみる
まずは公式に乗っているDemoを日本語でまとめると
データ取得
- ここからデータをダウンロード
data/ディレクトリにtrain.csvとtest.csvを展開前処理
import pandas as pd train_df = pd.read_csv('data/train.csv', header=None) train_df['text'] = train_df.iloc[:, 1] + " " + train_df.iloc[:, 2] train_df = train_df.drop(train_df.columns[[1, 2]], axis=1) train_df.columns = ['label', 'text'] train_df = train_df[['text', 'label']] train_df['text'] = train_df['text'].apply(lambda x: x.replace('\\', ' ')) train_df['label'] = train_df['label'].apply(lambda x:x-1) eval_df = pd.read_csv('data/test.csv', header=None) eval_df['text'] = eval_df.iloc[:, 1] + " " + eval_df.iloc[:, 2] eval_df = eval_df.drop(eval_df.columns[[1, 2]], axis=1) eval_df.columns = ['label', 'text'] eval_df = eval_df[['text', 'label']] eval_df['text'] = eval_df['text'].apply(lambda x: x.replace('\\', ' ')) eval_df['label'] = eval_df['label'].apply(lambda x:x-1)インスタンス生成
from simpletransformers.classification import ClassificationModel model = ClassificationModel('roberta', 'roberta-base', num_labels=4)訓練
model.train_model(train_df)評価
result, model_outputs, wrong_predictions = model.eval_model(eval_df)以上が元記事に掲載されているサンプルです。簡単ですね。
日本語ではどうなん?
次に日本語の文章ではどれくらい使えるんだろうということで(BERTの理解が足りていませんが)
おなじみlivedoorコーパスで試してみました。前処理
ダウンロードしたままの状態だとドメインごとに.txtで散らばっているのでCSVにまとめました。
その際にドメインをラベルに置き換え、ラベルと本文のみの状態にします。
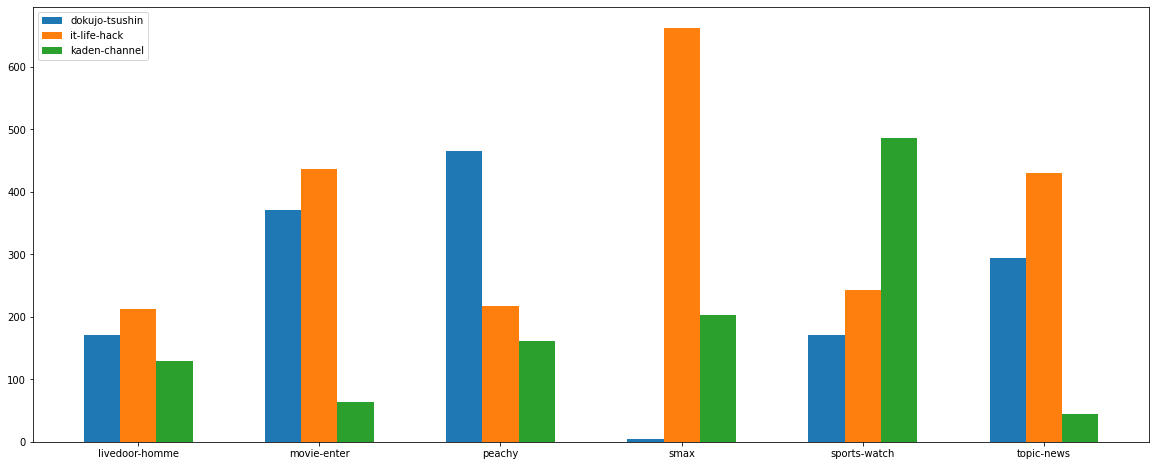
ちょっとCPUだとしんどいのでテストは0~2の3ドメインで行いました。
(dokujo-tsushin、it-life-hack、kaden-channel)
これをtrainとtestに分割します
X_train_df, X_test_df, y_train_s, y_test_s = train_test_split( data["text"], data["label"], test_size=0.2, random_state=0, stratify=data["label"] ) train_df = pd.DataFrame([X_train_df,y_train_s]).T test_df = pd.DataFrame([X_test_df,y_test_s]).T train_df["label"] = train_df["label"].astype("int") test_df["label"] = test_df["label"].astype("int")訓練&評価
from simpletransformers.classification import ClassificationModel model = ClassificationModel('roberta', 'roberta-base', num_labels=3,use_cuda=False) model.train_model(train_df) result, model_outputs, wrong_predictions = model.eval_model(test_df)結果
精度:0.8798329801724872 損失:0.24364208317164218でした。
元データをまともに読んでいないのでそれぞれのドメインの特徴は把握していませんが、良い精度ですね。おまけに他のドメイン記事にpredictをかけるとこんな感じになりました。
ITライフハックとガジェットサイトのS-MAXが似ていると言えそうですね。
全体の確率
ドメイン分けずに雑にプロットしましたが結構分かれてますね。
ドメインごとの確率
おわり
こんな感じでデータを用意するだけで簡単にBERTによるテキスト分類が実行できます。
github見た感じ詳細な設定や他タスクにも活用できるようですね。
BERTについて学ぶ前に触ってしまったので少し勉強してからまた色々なデータで試してみようと思います。
ぜひ使ってみてください。

- 投稿日:2020-09-21T16:14:26+09:00
matplotlib で ヒストグラム
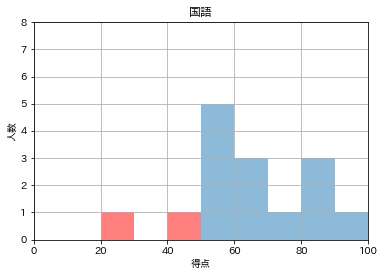
matplotlibで模擬試験の5教科・合計点の記録から、ヒストグラムを作りました。
・matplotib
・ヒストグラム(plt.hist)
・for文でグラフ出力
・patchesでヒストグラムの棒に対する色分け模擬試験のヒストグラム
・対象は国語、数学、英語、社会、理科、合計点。
・国語、数学、英語、社会、理科は各100点満点
・csv https://drive.google.com/file/d/1EzctLYN5-UvkmkOgZ7usPgtsQn7bdq5y/view?usp=sharing
・合計点は500点満点
ライブラリを積み込んで
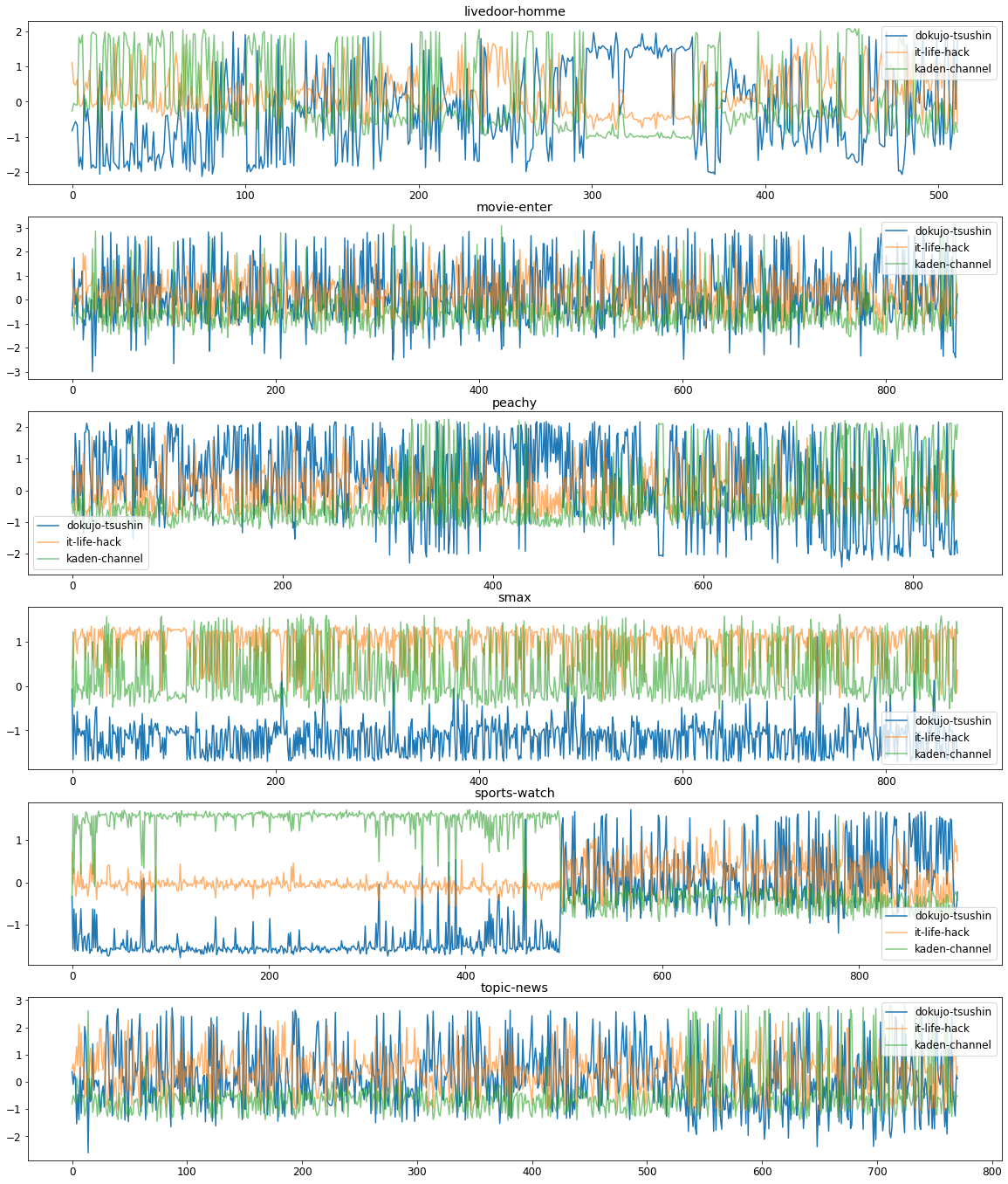
import numpy as np import pandas as pd import matplotlib.pyplot as pltデータフレームを作る。1~6列目にnameを与える。
(csvはpythonの.ipynbと同じディレクトリにあれば「〜〜〜.csv」でいけます。)df = pd.read_csv("honmachi.csv", names=['国語','数学','英語','社会','理科','合計'])格納状況を確認。(これで先頭の行が見れる。)
df.head()
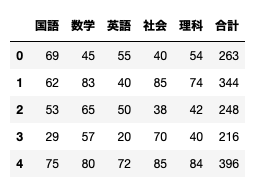
今回は分析するわけではないが、describe()で全体像も。
df.describe()
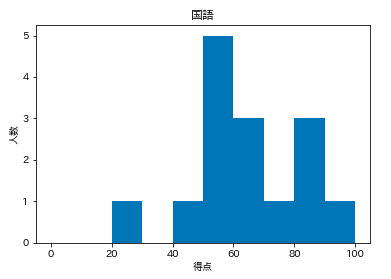
matplotlibに、まずはデフォルトで df['国語'] のヒストグラムを書いてもらいます。
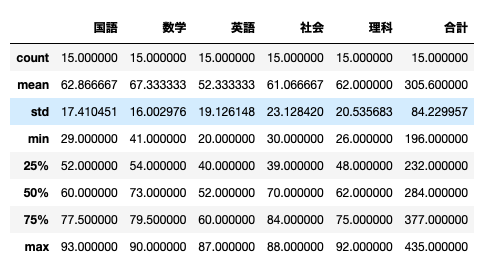
plt.hist(df['国語']) plt.title('国語') plt.xlabel('得点') plt.ylabel('人数') plt.show()
デフォルトだと微妙。
テストの点数という性質上
・0~100点の範囲 range=(0, 100)
・棒が10本 bins=10
くらいが見やすいか。というわけで、rangeとbinsをmatplotlibのhistの()の中に注文する。
# hist()内に追加 plt.hist(df['国語'], range=(0,100), bins=10,) plt.title('国語') plt.xlabel('得点') plt.ylabel('人数') plt.show()
次は軸。
・x軸
0~100なので plt.xlim(0, 100)
・y軸
科目によって高さが揺らぐと比較し辛い。
今回は15人分なので、とりあえず8人で plt.ylim(0,8)とします。
ここで指定しておけば、8人オーバーした際も、ここで調節可能。plt.hist(df['国語'], range=(0,100), bins=10,) # ここに追加 plt.xlim(0,100) plt.ylim(0,8) plt.title('国語') plt.xlabel('得点') plt.ylabel('人数') plt.show()
原型はこんな感じにします。
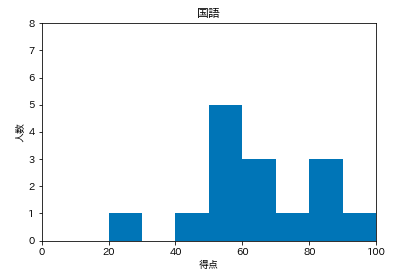
少し細かいデザインを調整します。
1.目盛りを読むグリッド線が欲しい
2.点数が半分以下の色を変えてみる
1.人数に横線を引く。
plt.grid(True)plt.hist(df['国語'], range=(0,100), bins=10) plt.xlim(0,100) plt.ylim(0,8) # 追加 plt.grid(True) plt.title('国語') plt.xlabel('得点') plt.ylabel('人数') plt.show()
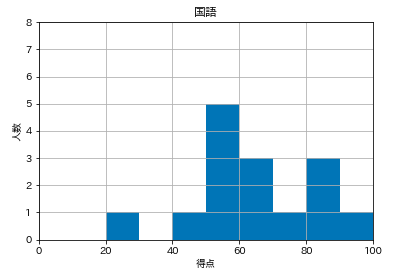
2.点数が半分以下の色を変える。
手こずりました。
plt.hist()の中で
if(49点以下):
range=(0,50), bins=5
else(50点以上):
range=(51,100), bins=5
で色分けを考えるも、ハードそう。データフレームの各科目に対して毎回50点以下と50点以上に分割し直すようなこともできるでしょうか。
ただ、今回は性質上、綺麗に固定の棒が生えるので、棒に対して色分けできないか。
つまり、棒に対して、1~5本目を赤くしたい。
ここでは、histにある戻り値を使いました。参考
n, bins, patches = hist(○○)
n :Y軸の値のデータ
bins :X軸の値のデータ
patches :patchのリスト
(patch = ヒストグラムの各棒のオブジェクト)このpatchの1〜5本目に対して色分けがしたい。
# 1本目のpatch(棒)を対象にして、facecolor(棒の色)にredをset(塗る) patches[0].set_facecolor('red')これを1本目から5本目まで繰り返せばいいのでfor文を使いました。
for i in range(0, 5): patches[i].set_facecolor('red')これで色分けの準備が完了したので、このfor文を追記します。
plt.hist(df['国語'], range=(0,100), bins=10) plt.xlim(0,100) plt.ylim(0,8) plt.grid(True) plt.title('国語') plt.xlabel('得点') plt.ylabel('人数') # 追記 for i in range(0, 5): patches[i].set_facecolor('red') plt.show()
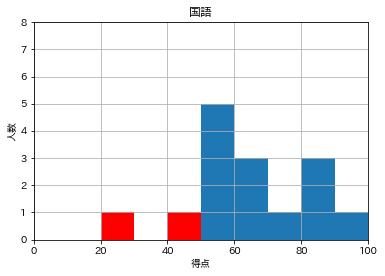
patches が定義されていないと出てしまいます。
どこかにpathchesを置く必要があるのか?
先ほどのを拝借して
n, bins, patches = hist( ) を付けたら上手くいきました。# ここに追加 n, bins, patches = plt.hist(df['国語'], range=(0,100), bins=10) plt.xlim(0,100) plt.ylim(0,8) plt.grid(True) plt.title('国語') plt.xlabel('得点') plt.ylabel('人数') for i in range(0, 5): patches[i].set_facecolor('red') plt.show()
完成。
血のような赤というのも縁起が悪いので、透明度(alpha)を調整します。alpha=0.5
これはhist()の中に追加で注文しておきます。# hist()の中にalphaも追加 n, bins, patches = plt.hist(df['国語'], range=(0,100), bins=10, alpha=0.5) plt.xlim(0,100) plt.ylim(0,8) plt.grid(True) plt.title('国語') plt.xlabel('得点') plt.ylabel('人数') for i in range(0, 5): patches[i].set_facecolor('red') plt.show()
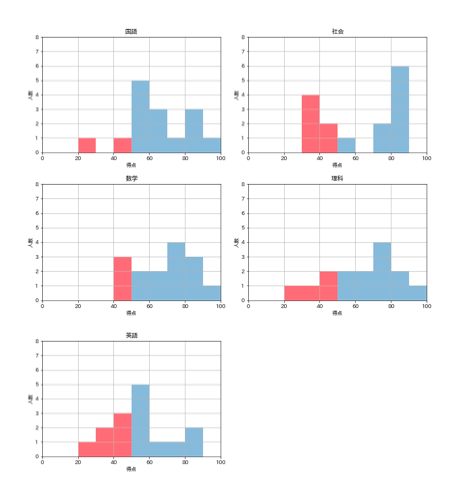
あとはfor文で一気に回します。
import numpy as np import pandas as pd import matplotlib.pyplot as plt df = pd.read_csv("honmachi.csv", names=['国語','数学','英語','社会','理科','合計']) # subject という変数を設定して、1科目ずつ処理していきます。 for subject in ['国語','数学','英語','社会','理科']: # df[ ]の中身はsubjectに合わせて変わるようにしています。 n, bins, patches = plt.hist(df[subject], range=(0,100), bins=10, alpha=0.5) plt.xlim(0,100) plt.ylim(0,8) plt.grid(True) #title( ) の中身もsubjectになっているとタイトルラベルも自動で変わります。 plt.title(subject) plt.xlabel('得点') plt.ylabel('人数') for i in range(0, 5): patches[i].set_facecolor('red') plt.show()
これで5枚一気に出てこれました。
これで残りは、合計得点。500点満点にするだけです。
データフレームの合計を拾って
・range=(0,500)
・plt.xlim(0,500)
に変更して終わりです。最後に、注釈なしで今回の要件で使ったコードをまとめて置いておきます。
import numpy as np import pandas as pd import matplotlib.pyplot as plt df = pd.read_csv("honmachi.csv", names=['国語','数学','英語','社会','理科','合計']) for subject in ['国語','数学','英語','社会','理科']: n, bins, patches = plt.hist(df[subject], range=(0,100), bins=10, alpha=0.5) plt.xlim(0,100) plt.ylim(0,8) plt.grid(True) plt.title(subject) plt.xlabel('得点') plt.ylabel('人数') for i in range(0, 5): patches[i].set_facecolor('red') plt.show() n, bins, patches = plt.hist(df['合計'], range=(0,500), bins=10, alpha=0.5) plt.xlim(0,500) plt.ylim(0,8) plt.grid(True) plt.title('合計') plt.xlabel('得点') plt.ylabel('人数') for i in range(0, 5): patches[i].set_facecolor('red') plt.show()
pythonでから出力するだけならば、これで問題なさそうですが、現実的に使ってもらうとなると、ユニバーサルなものにするにはネットワークで動く、最終的な実装の仕組みに出来ないとなと思いました。


- 投稿日:2020-09-21T15:49:41+09:00
AtCoder Beginner Contest 179
A - Plural Form
PythonS = str(input()) if S[len(S)-1] == 's': print(S + 'es') else: print(S + 's')B - Go to Jail
C++#include<iostream> #include<vector> #include<algorithm> #include<iomanip> #include<utility> #include<iomanip> #include<map> #include<queue> #include<cmath> #include<cstdio> #define rep(i,n) for(int i=0; i<(n); ++i) #define pai 3.1415926535897932384 using namespace std; using ll =long long; using P = pair<int,int>; int main(int argc, const char * argv[]) { int N; cin >> N; vector<int> d1(N); vector<int> d2(N); int Ans = 0; int sum = 0; for(int i=0; i<N; i++){ cin >> d1[i] >> d2[i]; if(d1[i] == d2[i]){ sum++; Ans = max(Ans, sum); }else{ sum=0; } } if(Ans>=3) cout << "Yes" << endl; else cout << "No" << endl; return 0; }C - A x B + C
C++#include<iostream> #include<vector> #include<algorithm> #include<iomanip> #include<utility> #include<iomanip> #include<map> #include<queue> #include<cmath> #include<cstdio> #define rep(i,n) for(int i=0; i<(n); ++i) #define pai 3.1415926535897932384 using namespace std; using ll =long long; using P = pair<int,int>; int main(int argc, const char * argv[]) { ll N; cin >> N; ll Ans = 0; for(ll A=1; A<N; A++){ for(ll B=1; A*B<N; B++){ ll C = N - (A * B); if(C > 0) Ans++; } } cout << Ans << endl; return 0; }
- 投稿日:2020-09-21T15:32:57+09:00
お仕事の備忘録(pymongo) その2. 割と便利な操作(bulk_write)編
この記事について
この記事は先日投稿した記事の続きです。
今回はpymongoのbulk_write(一括書き込み)について書いていきます。
bulk_writeとは?
- dbへの書き込みを1件ごとにクエリを作成し、書き込むのではなく、クエリを大量に生成しておき、bulk_write関数で一括書き込みを行うといったもので、dbの書き込みをまとめて行い、ネットワークの往復を減らすことで、スループットを向上を図るのにとても便利な操作です 。
参照:pymongo 3.9.0 document:Bulk Write Operations
どんな操作が可能か?
下記が可能な操作で、通常と同じ操作が使えます。
- InsertOne ※複数の挿入はinsert_manyで可能
- ReplaceOne,
- UpdateOne, UpdateMany,
- DeleteOne, DeleteMany
操作方法
基本的に操作ごとにオブジェクトを作成し、リストにまとめてbulk_write関数に渡すだけです。
普通に書き込みを行う
※ 書き込みの順番はオプションを付けなかった場合、デフォルトで、リストの1番目から順に書き込み操作が実行されていきます。
(不正な操作をした場合は、不正が発生するまでの書き込みがされる。)main.pyfrom pprint import pprint from pymongo import MongoClient from pymongo import UpdateOne,InsertOne from pymongo.errors import BulkWriteError client = MongoClient() db = client["Collection"]["table"] # dbのドキュメント全件削除 # db.delete_many({}) # _idとxをインクリメントして1000件のドキュメントを挿入する opList = [ InsertOne({"_id":i,"x":i}) for i in range(0,1000)] # 書き込み成功時は戻り値から、 # 例外発生時はスローされたエラーから詳細が取得できる try: result = db.bulk_write(opList) print("正常終了時") pprint(result.bulk_api_result) except BulkWriteError as bwe: print("例外発生時") pprint(bwe.details) ''' {'writeErrors': [], 'writeConcernErrors': [], 'nInserted': 1000, 'nUpserted': 0, 'nMatched': 0, 'nModified': 0, 'nRemoved': 0, 'upserted': []} '''順番を気にせず書き込みを行う場合
bulk_writeのオプションでorderd = Falseを指定するだけ
(不正な操作をしていても全ての操作が試され、戻り値 or 例外から詳細がわかる。)
- まず、上記のスクリプトを実行した後で、さらに_id 500~1500までのドキュメントをインクリメントしながらインサートしてみる (順番通りにインサートされるので、一件も挿入できずにエラーが出るはず。)
main.py# _idとxをインクリメントして1000件のドキュメントを挿入する opList = [ InsertOne({"_id":i,"x":i}) for i in range(500,1500)] # 書き込み成功時は戻り値から、例外発生時はスローされたエラーから # 詳細が取得できる try: result = db.bulk_write(opList) print("正常終了時") pprint(result.bulk_api_result) except BulkWriteError as bwe: print("例外発生時") pprint(bwe.details) # 出力結果 # (1件目のドキュメントの挿入で失敗して以降の書き込みができていないことがわかる) ''' 例外発生時 {'nInserted': 0, 'nMatched': 0, 'nModified': 0, 'nRemoved': 0, 'nUpserted': 0, 'upserted': [], 'writeConcernErrors': [], 'writeErrors': [{'code': 11000, 'errmsg': 'E11000 duplicate key error collection: ' 'Collection.table index: _id_ dup key: { _id: 500 ' '}', 'index': 0, 'keyPattern': {'_id': 1}, 'keyValue': {'_id': 500}, 'op': {'_id': 500, 'x': 500}}]} '''
- 次に,bulk_writeのオプションでorderd = Falseにして一括書き込みを行う
main.py# _idとxをインクリメントして1000件のドキュメントを挿入する opList = [ InsertOne({"_id":i,"x":i}) for i in range(500,1500)] # 書き込み成功時は戻り値から、例外発生時はスローされたエラーから # 詳細が取得できる try: result = db.bulk_write(opList,ordered=False) print("正常終了時") pprint(result.bulk_api_result) except BulkWriteError as bwe: print("例外発生時") pprint(bwe.details) # 例外がスローされるが、500件のドキュメントがインサートできて、 # 失敗した書き込み1つ1つの失敗した理由が取得できているのが確認できる ''' 例外発生時 {'nInserted': 500, 'nMatched': 0, 'nModified': 0, 'nRemoved': 0, 'nUpserted': 0, 'upserted': [], 'writeConcernErrors': [], 'writeErrors': [{'code': 11000, 'errmsg': 'E11000 duplicate key error collection: ' 'Collection.table index: _id_ dup key: { _id: 500 ' '}', 'index': 0, 'keyPattern': {'_id': 1}, 'keyValue': {'_id': 500}, 'op': {'_id': 500, 'x': 500}}, {'code': 11000, 'errmsg': 'E11000 duplicate key error collection: ' 'Collection.table index: _id_ dup key: { _id: 501 ' '}', 'index': 1, 'keyPattern': {'_id': 1}, 'keyValue': {'_id': 501}, 'op': {'_id': 501, 'x': 501}}, {'code': 11000, 'errmsg': 'E11000 duplicate key error collection: ' 'Collection.table index: _id_ dup key: { _id: 502 ' '}', ~~~~以下略 ~~~~ '''
pymongoのbulk_writeは大体こんな感じです。
要望があれば、いろいろ追記していきます。
- 投稿日:2020-09-21T15:27:51+09:00
データクレンジング2 DataFlameを用いたデータクレンジング
Aidemy https:// aidemy.net 2020/9/21
はじめに
こんにちは、んがょぺです!文系大学生ですが、AI分野に興味が湧いたのでAI特化型スクール「Aidemy」に通い、勉強しています。前回が初投稿でしたが、多くの方に読んでいただけたようで、とても嬉しいです。ありがとうございます!
今回は、データクレンジングの2つ目の投稿になります。どうぞよろしくお願いします。*本記事は「Aidemy」での学習内容を「自分の言葉で」まとめたものになります。表現の間違いや勘違いを含む可能性がありますがご了承ください。
今回学ぶこと
・CSVについて
・欠損値(NaN)に対する処理
・辞書でキーごとにデータを処理する1 CSV
PandasでCSVを読み込む
・CSVとは、データ分析でよく使われるデータファイルのこと。まずはPandasを使って読み込む。
・pd.read_csv("データのファイル名",header=ヘッダーとなる列の指定)
*headerの指定が特にない時はNoneimport pandas as pd # wine.csvの読み込み df = pd.read_csv("./4050_data_cleansing_data/wine.csv", header=None) # カラムの名前を設定 df.columns = [省略] # 出力 dfCSVライブラリでCSVの作成
・Pythonに内蔵されている「CSVライブラリ」を使ってCSVを作成する。
・with open("ファイル名","w") as csvfile: とし、その中で
writer=csv.writer(csvfile, lineterminator="\n")
(csvfileと改行コードを引数とするwriterメソッド)を作成し、これを用いて
writer.writerow([データ]) でデータを入力する。import csv with open("ファイル名","w") as csvfile: writer=csv.writer(csvfile, lineterminator="\n") writer.writerow(["version","year","gen"]) #1行目はカラム名 writer.writerow(["赤緑",1996,1]) writer.writerow(["金銀",1999,2]) writer.writerow(["RS",2002,3]) #読み込み with open("ファイル名","r") as csvfile: print(csvfile.read()) # version,year,gen # 赤緑,1996,1 # 金銀,1999,2 # RS,2003,3PandasでCSVの作成
・DataFrameをCSVにする時はこちらの方が簡単
・DataFrameのデータ.to_csv("ファイル名")data={"version":["赤緑","金銀","RS"],"year":[1996,1999,2002],"gen":[1,2,3]} df=pd.DataFrame(data) df.to_csv("ファイル名")2 欠損値(NaN)に対する処理
NaNを含む行や列の削除
・NaNを含む行や列の削除のことを「リストワイズ削除」という。リストワイズ削除はdropna()関数で行う。引数を指定しなければ行が、axis=1に指定すれば列が削除される。
・DataFrameのデータ.dropna()・リストワイズ削除を使うとデータ数が少なくなりすぎる場合は、欠損の少ない列を残し、そこからNaNを含む行を削除すると良い。これを「ペアワイズ削除」という。
・DataFrameのデータ[[残す列]].dropna()data={"version":["赤緑","金銀","RS"],"year":[1996,1999],"gen":[1]} df=pd.DataFrame(data) # リストワイズ削除だとデータが少ないので、version,year列だけ残して、NaNを含む行を削除 df[[0,1]].dropna() #version year #赤緑 1996 #金銀 1999欠損値の補完(1)
・削除ではなく代替データの代入で補完する。fillna()関数を使う。引数には「代替データ」または「method="ffill"」(前行の値を適用する)を設定する。
・DataFrameのデータ.fillna()data={"version":["赤緑","金銀","RS"],"year":[1996,1999],"gen":[1]} df=pd.DataFrame(data) # NaNを前のデータで置き換え df.fillna(method="ffill") #version year gen #赤緑 1996 1 #金銀 1999 1 #RS 1999 1欠損値の補完(2)
・fillna()の引数にmean()関数を使うことで、代替データを「その列の平均値」で置き換えられる。
・DataFrameのデータ.fillna(DataFrameのデータ.mean())data={"version":["赤緑","金銀","RS"],"year":[1996,1999],"gen":[1]} df=pd.DataFrame(data) # NaNを前のデータで置き換え df.fillna(method="ffill") #version year gen #赤緑 1996 1 #金銀 1999 1 #RS 1997.5 13 辞書でキーごとにデータを処理する
キーごとに計算する
・辞書やCSV(DataFrame)のキーごとの平均値や最大値などを、mean()やmax()などの統計関数を使って算出できる。
・辞書やdf[キー].統計関数df = pd.read_csv("./4050_data_cleansing_data/wine.csv", header=None) df.columns = ["","Alcohol",(省略)] # "Alcohol"の平均値算出 df["Alcohol"].mean() # 13.000617977528091重複データの抽出、削除
・全く同じデータの抽出はduplicated()メソッドを使う。削除はdrop_duplicates()メソッドを使う。
・重複のあるデータ.duplicated()
・重複のあるデータ.drop_duplicates()data={"version":["赤緑","金銀","RS","赤緑"],"year":[1996,1999,2002,1996],"gen":[1,2,3,1]} df=pd.DataFrame(data) # 重複データの削除 df.drop_duplicates() # version,year,gen # 赤緑,1996,1 # 金銀,1999,2 # RS,2003,3すでにあるキーに対応する新しいキーを作る
・すでにあるキーに対応する新しいキーを作ることを「マッピング」という。
・DataFrameのデータ[新キー] = DataFrameのデータ[参照元のキー].map(辞書型の対応表)data={"version":["赤緑","金銀","RS"],"year":[1996,1999,2002],"gen":[1,2,3]} df=pd.DataFrame(data) # 辞書型の対応表を作成してからマッピング version_map={"赤緑":"Kanto","金銀":"Johto","RS":"Hoenn"} df["region"] = df["version"].map(version_map) df # version,year,gen,region # 赤緑,1996,1,Kanto # 金銀,1999,2,Johto # RS,2003,3,Hoenn数値データの範囲を設定してカテゴリ分け
・「0〜5」「6〜10」のように範囲を設定して、範囲ごとにデータを分けたり集計したりする。このような処理のことを「ビン分割」という。ビン分割はpd.cut()で行う。
・pd.cut(データ[範囲を指定するキー], [範囲のリスト], labels=[範囲ごとの名前のリスト]) #ビン分割
・分割数を指定し、自動で範囲を振り分けてくれる方法もある
・pd.cut(データ[範囲を指定するキー], 分割数)
・pd.value_counts(ビン分割したデータ)#分割した範囲ごとのデータ数の集計data={"version":["赤緑","金銀","RS","DP"],"year":[1996,1999,2002,2006],"gen":[1,2,3,4]} df=pd.DataFrame(data) # yearで範囲指定、先に範囲のリストを作成する。 range = [1996,2000,2007] range_name = ["1996-2000","2000-2007"] cut_df = pd.cut(df["year"], range, labels=range_name) pd.value_counts(cut_df) #1996-2000 2 #2000-2007 2まとめ
・データ分析ではCSVというデータファイルがよく使われる。CSVはpython標準のライブラリかPandasを使って作成される。
・欠損値はdropna()で削除したり、fillna()で補完したりして処理する。
・辞書やDataFlameではキーを参照してvalueの計算をしたり、重複データを削除したり(drop_duplicates)、新キーを作ったり(map)、範囲を指定して分割したり(pd.cut)できる。
- 投稿日:2020-09-21T15:27:51+09:00
データクレンジング2
Aidemy https:// aidemy.net 2020/9/21
はじめに
こんにちは、んがょぺです!文系大学生ですが、AI分野に興味が湧いたのでAI特化型スクール「Aidemy」に通い、勉強しています。前回が初投稿でしたが、多くの方に読んでいただけてとても嬉しいです。ありがとうございます!
今回は、データクレンジングの2つ目の投稿になります。どうぞよろしくお願いします。*本記事は「Aidemy」での学習内容を「自分の言葉で」まとめたものになります。表現の間違いや勘違いを含む可能性があります。ご了承ください。
今回学ぶこと
・CSVについて
・欠損値(NaN)に対する処理
・辞書でキーごとにデータを処理する1 CSV
PandasでCSVを読み込む
・CSVとは、データ分析でよく使われるデータファイルのこと。まずはPandasを使って読み込む。
・pd.read_csv("データのファイル名",header=ヘッダーとなる列の指定)
*headerの指定が特にない時はNoneimport pandas as pd # wine.csvの読み込み df = pd.read_csv("./4050_data_cleansing_data/wine.csv", header=None) # カラムの名前を設定 df.columns = [省略] # 出力 dfCSVライブラリでCSVの作成
・Pythonに内蔵されている「CSVライブラリ」を使ってCSVを作成する。
・with open("ファイル名","w") as csvfile: とし、その中で
writer=csv.writer(csvfile, lineterminator="\n")
(csvfileと改行コードを引数とするwriterメソッド)を作成し、これを用いて
writer.writerow([データ]) でデータを入力する。import csv with open("ファイル名","w") as csvfile: writer=csv.writer(csvfile, lineterminator="\n") writer.writerow(["version","year","gen"]) #1行目はカラム名 writer.writerow(["赤緑",1996,1]) writer.writerow(["金銀",1999,2]) writer.writerow(["RS",2002,3]) #読み込み with open("ファイル名","r") as csvfile: print(csvfile.read()) # version,year,gen # 赤緑,1996,1 # 金銀,1999,2 # RS,2003,3PandasでCSVの作成
・DataFrameをCSVにする時はこちらの方が簡単
・DataFrameのデータ.to_csv("ファイル名")data={"version":["赤緑","金銀","RS"],"year":[1996,1999,2002],"gen":[1,2,3]} df=pd.DataFrame(data) df.to_csv("ファイル名")2 欠損値(NaN)に対する処理
NaNを含む行や列の削除
・NaNを含む行や列の削除のことを「リストワイズ削除」という。リストワイズ削除はdropna()関数で行う。引数を指定しなければ行が、axis=1に指定すれば列が削除される。
・DataFrameのデータ.dropna()・リストワイズ削除を使うとデータ数が少なくなりすぎる場合は、欠損の少ない列を残し、そこからNaNを含む行を削除すると良い。これを「ペアワイズ削除」という。
・DataFrameのデータ[[残す列]].dropna()data={"version":["赤緑","金銀","RS"],"year":[1996,1999],"gen":[1]} df=pd.DataFrame(data) # リストワイズ削除だとデータが少ないので、version,year列だけ残して、NaNを含む行を削除 df[[0,1]].dropna() #version year #赤緑 1996 #金銀 1999欠損値の補完(1)
・削除ではなく代替データの代入で補完する。fillna()関数を使う。引数には「代替データ」または「method="ffill"」(前行の値を適用する)を設定する。
・DataFrameのデータ.fillna()data={"version":["赤緑","金銀","RS"],"year":[1996,1999],"gen":[1]} df=pd.DataFrame(data) # NaNを前のデータで置き換え df.fillna(method="ffill") #version year gen #赤緑 1996 1 #金銀 1999 1 #RS 1999 1欠損値の補完(2)
・fillna()の引数にmean()関数を使うことで、代替データを「その列の平均値」で置き換えられる。
・DataFrameのデータ.fillna(DataFrameのデータ.mean())data={"version":["赤緑","金銀","RS"],"year":[1996,1999],"gen":[1]} df=pd.DataFrame(data) # NaNを前のデータで置き換え df.fillna(method="ffill") #version year gen #赤緑 1996 1 #金銀 1999 1 #RS 1997.5 13 辞書でキーごとにデータを処理する
キーごとに計算する
・辞書やCSV(DataFrame)のキーごとの平均値や最大値などを、mean()やmax()などの統計関数を使って算出できる。
・辞書やdf[キー].統計関数df = pd.read_csv("./4050_data_cleansing_data/wine.csv", header=None) df.columns = ["","Alcohol",(省略)] # "Alcohol"の平均値算出 df["Alcohol"].mean() # 13.000617977528091重複データの抽出、削除
・全く同じデータの抽出はduplicated()メソッドを使う。削除はdrop_duplicates()メソッドを使う。
・重複のあるデータ.duplicated()
・重複のあるデータ.drop_duplicates()data={"version":["赤緑","金銀","RS","赤緑"],"year":[1996,1999,2002,1996],"gen":[1,2,3,1]} df=pd.DataFrame(data) # 重複データの削除 df.drop_duplicates() # version,year,gen # 赤緑,1996,1 # 金銀,1999,2 # RS,2003,3すでにあるキーに対応する新しいキーを作る
・すでにあるキーに対応する新しいキーを作ることを「マッピング」という。
・DataFrameのデータ[新キー] = DataFrameのデータ[参照元のキー].map(辞書型の対応表)data={"version":["赤緑","金銀","RS"],"year":[1996,1999,2002],"gen":[1,2,3]} df=pd.DataFrame(data) # 辞書型の対応表を作成してからマッピング version_map={"赤緑":"Kanto","金銀":"Johto","RS":"Hoenn"} df["region"] = df["version"].map(version_map) df # version,year,gen,region # 赤緑,1996,1,Kanto # 金銀,1999,2,Johto # RS,2003,3,Hoenn数値データの範囲を設定してカテゴリ分け
・「0〜5」「6〜10」のように範囲を設定して、範囲ごとにデータを分けたり集計したりする。このような処理のことを「ビン分割」という。ビン分割はpd.cut()で行う。
・pd.cut(データ[範囲を指定するキー], [範囲のリスト], labels=[範囲ごとの名前のリスト]) #ビン分割
・分割数を指定し、自動で範囲を振り分けてくれる方法もある
・pd.cut(データ[範囲を指定するキー], 分割数)
・pd.value_counts(ビン分割したデータ)#分割した範囲ごとのデータ数の集計data={"version":["赤緑","金銀","RS","DP"],"year":[1996,1999,2002,2006],"gen":[1,2,3,4]} df=pd.DataFrame(data) # yearで範囲指定、先に範囲のリストを作成する。 range = [1996,2000,2007] range_name = ["1996-2000","2000-2007"] cut_df = pd.cut(df["year"], range, labels=range_name) pd.value_counts(cut_df) #1996-2000 2 #2000-2007 2まとめ
・データ分析ではCSVというデータファイルがよく使われる。CSVはpython標準のライブラリかPandasを使って作成される。
・欠損値はdropna()で削除したり、fillna()で補完したりして処理する。
・辞書やDataFlameではキーを参照してvalueの計算をしたり、重複データを削除したり(drop_duplicates)、新キーを作ったり(map)、範囲を指定して分割したり(pd.cut)できる。以上です。ここまで読んでくださりありがとうございます。
- 投稿日:2020-09-21T15:07:51+09:00
Django シフト表を表示する!20日締めに対応
1日から月末までのシフト表示だ作成していました。
色々ひっかかり全然だめでした…
まずは、スケジュールのホームページとしては、当月のスケジュール表を表示させようとしたけど、redirect で正しく呼び出せない…(これは現在も解消できていない)
そして、スケジュール表として上部に日付と曜日をならべることに現在挑戦しているところです。
schedule/views.pyfrom django.shortcuts import render from shisetsu.models import * from accounts.models import * from .models import * from django.shortcuts import redirect import calendar import datetime from datetime import timedelta from datetime import datetime as dt # Create your views here. def homeschedule(request): from datetime import datetime now = datetime.now() return redirect('schedule/monthschedule/%s/%s/' % (now.year,now.month,)) # 自動的に今月のシフト画面にリダイレクト def monthschedulefunc(request,year_num,month_num): year, month = int(year_num), int(month_num) object_list = Schedule.objects.filter(date__year= year, date__month= month).order_by('date') #シフト範囲の日数を取得する startdate = datetime.date(year,month-1,21) enddate = datetime.date(year,month,20) kaisu = enddate - startdate kaisu = int(kaisu.days) #日付と曜日のリストを作成する hiduke = str(year) + "-" + str(month) + "-" + str(20) date_format = "%Y-%m-%d" hiduke = dt.strptime(hiduke, date_format) calender_object = [hiduke] for i in range(kaisu): hiduke = hiduke + timedelta(days=1) calender_object.append(hiduke)
20日から20日になっちゃってますね(笑)
修正して、曜日を表示できるように挑戦していますが、もう2時間ぐらい…schedule/views.pyuser_list = User.objects.all() context = { 'object_list': Schedule.objects.all(), 'staff_list' : User.objects.all(), } return render(request,'schedule/month.html', { 'object_list': object_list, 'user_list': user_list, 'calender_object': calender_object, 'weekdays':['月','火','水','木','金','土','日',], }, )ここでweekdaysで曜日を渡して、html側で曜日の値から取り出したいのですが、それがわからない…
でこの状況…
templasts/schedule.month.html{% extends 'schedule/base.html' %} {% block header %} {% endblock header %} {% block content %} <table class="table table-striped table-bordered"> <thead> <tr align="center" class="info"> <!--日付--> <th rowspan="2"></th> {% for item in calender_object %} <th class="day_{{ item.date }}">{{ item.date | date:"d" }}</th> {% endfor %} <tr align="center" class="info"> <!--曜日--> {% for item in calender_object %} <th class="day_{{ item.date }}">{{ item.date | date:"w" }}</th> {% endfor %} </tr> </thead>最後のところで、曜日を数字では取得できているのですが、それをweekdyasからその番号の値を取って表示する方法が全然わからずです。
ここは、切替て曜日のオブジェクトを作成してそれを引き渡すことにしましたschedule/views.pyfrom django.shortcuts import render from shisetsu.models import * from accounts.models import * from .models import * from django.shortcuts import redirect import calendar import datetime from datetime import timedelta from datetime import datetime as dt # Create your views here. def homeschedule(request): from datetime import datetime now = datetime.now() return redirect('schedule/monthschedule/%s/%s/' % (now.year,now.month,)) # 自動的に今月のシフト画面にリダイレクト def monthschedulefunc(request,year_num,month_num): year, month = int(year_num), int(month_num) object_list = Schedule.objects.filter(date__year= year, date__month= month).order_by('date') #シフト範囲の日数を取得する startdate = datetime.date(year,month-1,21) enddate = datetime.date(year,month,20) kaisu = enddate - startdate kaisu = int(kaisu.days) #日付と曜日のリストを作成する hiduke = str(year) + "-" + str(month) + "-" + str(20) date_format = "%Y-%m-%d" hiduke = dt.strptime(hiduke, date_format) weekdays = ["月","火","水","木","金","土","日"] calender_object = [] youbi_object = [] for i in range(kaisu): hiduke = hiduke + timedelta(days=1) calender_object.append(hiduke) youbi = weekdays[hiduke.weekday()] youbi_object.append(youbi)
とりあえずやりたいことはできたのでOKです!
きれいにコードを書ければ最高ですが、まずやりたいことをできるようにすることが大切だと思っています(言い訳(笑))カレンダーの中身を作成していこうと思いますが、なかなか難しそうです。
まずは、それぞれのスタッフの勤務を表示させれるようにしようと思います。中身を表示させることに取りかかったのですが、またうまくいきません。
開発って本当に大変です(笑)だれか師匠がいると、段階段階で教えてもらえるとすすみが早くなりそうなきがします
なにがだめかというと、スタッフ(ユーザー)ごとに処理していこうと思って、userを取り出し、スケジュール情報が入ったオブジェクトを順番に取り出し、usernameが同一なら処理をするってやりましたが、どうしても
schedule.html{% if staff.username == item.user %} 処理 {% endif %}この部分がうまく判定してくれません…
これも調べましたがわからないので違った方法を考えてみます
内部結合してそれを表示できるのではないかと考えていますが、まだまだわかりません。
特にわからないのは、UserテーブルはDjangoの標準で実装しているから、それを普通に扱えるのかも理解ができていない…どうやったらやりたいことが実現できるのだろうか…
DjangoだとSQL文でないからそれもまたわからない原因なのだろうプログラミングでこける人が多いのは本当によくわかる…
ひとつ解決してもまたすぐにつまずくし、考慮不足だらけ(笑)でも動いた時の感動のために頑張ろう



- 投稿日:2020-09-21T15:00:59+09:00
Contextual Bandit【Open Bandit Pipeline】アルゴリズム実装【Python】
はじめに
この記事は、Open Bandit Pipeline のアルゴリズム実装を行うことによりパッケージに採用されているアルゴリズムの理解を試みています。
先ずはこの記事の構成を示します。
- オープンソースの紹介 (Abstract: Open Bandit Dataset (OBD) & Open Bandit Pipeline (OBP))
- Open Bandit Pipeline のアルゴリズム実装 (実装)
2.1. Open Bandit Dataset (Open Bandit Dataset)
2.1.2. 必要なライブラリの読み込み
2.1.3. データの理解
2.2. Off-Policy Evaluation wih Open Bandit Pipeline(Open Bandit Pipeline)
2.2.1. 意思決定 policy のオフラインシミュレーション
2.2.2. Contextual Logistic Thompson Sampling のオフライン評価
2.2.3. 信頼区間の算出
2.2.4. 性能の比較
- まとめ (まとめ)
- 参考資料 (参考資料)
Abstract: Open Bandit Dataset (OBD) & Open Bandit Pipeline (OBP)
株式会社ZOZOテクノロジーズに所属するZOZO研究所からバンディットに関する興味深いオープンソースが発表されています。
Open Bandit Dataset: https://research.zozo.com/data.html
Open Bandit Pipeline: https://github.com/st-tech/zr-obp/tree/master/obpオープンソースの概要について論文とGitHubから抜粋します。
<Open Bandit Dataset>
Our goal is to implement and evaluate OPE of bandit algorithms in realistic and reproducible ways. We release the Open Bandit Dataset, a logged bandit feedback collected on a large-scale fashion e-commerce platform, ZOZOTOWN.
When the platform produced the data, it used Bernoulli Thompson Sampling (Bernoulli TS) and Random policies to recommend fashion items to users. The dataset includes an A/B test of these policies and collected over 26 million records of users’ clicks and the ground-truth about the performance of BernoulliTS and Random.
To streamline and standardize the analysis of the Open Bandit Dataset, we also provide the Open Bandit Pipeline, a series of implementations of dataset preprocessing, behavior bandit policy simulators, and OPE estimators.
(A Large-scale Open Dataset for Bandit Algorithms)<Open Bandit Pipeline>
Open Bandit Pipeline is a series of implementations of dataset preprocessing, offline bandit simulation, and evaluation of OPE estimators. This pipeline allows researchers to focus on building their OPE estimator and easily compare it with others’ methods in realistic and reproducible ways. Thus, it facilitates reproducible research on bandit algorithms and off-policy evaluation.
Structure of Open Bandit PipelineOpen Bandit Pipeline consists of the following main modules.
◇dataset module: This module provides a data loader for Open Bandit Dataset and a flexible interface for handling logged bandit feedback. It also provides tools to generate synthetic bandit datasets.
◇policy module: This module provides interfaces for online and offline bandit algorithms. It also implements several standard algorithms.
◇simulator module: This module provides functions for conducting offline bandit simulation.
◇ope module: This module provides interfaces for OPE estimators. It also implements several standard OPE estimators.
(GitHub Open Bandit Pipeline)モチベーションについてはZOZOテクノロジーズ TECH BLOG に丁寧な記載があるのでそちらを抜粋します。
機械学習は予測のための技術としてもてはやされています。実際多くの論文が、解く意味があるとされているタスクにおいてより良い予測精度を達成することを目指しています。もちろん予測値をそのまま活用する場面も多くあるでしょう。しかしとりわけウェブ産業における機械学習の応用場面に目を向けてみると、機械学習による予測値をそのまま使うのではなく、予測値に基づいて何かしらの意思決定を行っていることが多くあります。例えば、各ユーザーとアイテムのペアごとのクリック率を予測し、その予測値に基づいてユーザーごとにどのアイテムを推薦すべきか選択する。または、商品の購入確率予測に基づいてユーザーごとにどの商品の広告を提示するか決定する、などです。これらの例ではクリック率や購入確率の予測そのものよりもそれに基づいて作られる推薦や広告配信などの意思決定が重要です。
本記事の興味は、機械学習による予測値などに基づいて作られる意思決定policyの性能を評価することにあります。例えばクリック率の予測値に基づいてアイテム推薦の意思決定を行う場合、オフラインでクリック率の予測精度を評価指標としていることがあるでしょう。しかし、これは非直接的な評価方法です。予測値をそのままではなく何らかの意思決定を行うために用いているのならば、最終的に出来上がる意思決定policyの性能を直接評価するべきです。
意思決定policyの性能評価として理想的なのは、policyをサービスに実装してしまい興味があるKPIの挙動を見るというオンライン実験でしょう。しかし、何でもかんでもオンライン実験ができるわけではありません。なぜならば、オンライン実験には大きな実装コストが伴うからです。性能の悪い意思決定policyをオンライン実験してしまったときに、実験期間においてユーザー体験を害してしまったり、収入を減らしてしまう恐れもあります。従って、古い意思決定policyにより蓄積されたデータのみを用いて、新しい意思決定policyをオンラインに実装したときの性能を事前に見積もりたい、というモチベーションが生まれます。
このように、新たな意思決定policyの性能を過去の蓄積データを用いて推定する問題のことをOff-Policy Evaluation (OPE)と呼びます。NetflixやSpotify、Criteoなどの研究所がこぞってトップ国際会議でOPEに関する論文を発表しており、特にテック企業から大きな注目を集めています。正確なOPEは、多くの実務的メリットをもたらします。例えば、ある旧ロジックをそれとは異なる新ロジックに変えようと思ったとき、新ロジックがもたらすKPIの値を旧ロジックが蓄積したデータを用いて見積もることができます。また、ハイパーパラメータや機械学習アルゴリズムの組み合わせを変えることによって多数生成される意思決定policyの候補のうち、どれをオンライン実験に回すべきなのかを事前に絞り込むこともできます。
(Off-Policy Evaluationの基礎とZOZOTOWN大規模公開実データおよびパッケージ紹介)実装
Open Bandit Pipeline のコードのアルゴリズム実装を行っていきます。
Open Bandit Dataset
扱うデータを取得します。
(今回は、大規模実験公開データと同質な少量データを GitHub から読み込み Cloud Storage のバケットにコピーしています。)<Cloud Shell> $ gcloud beta compute instances set-scopes git --scopes https://www.googleapis.com/auth/devstorage.read_write,trace --zone=<zone> --service-account=<service_account> >> Updated [https://www.googleapis.com/compute/beta/projects/<project_id>/zones/<zone>/instances/git]. $ gcloud beta compute instances set-scopes git --scopes https://www.googleapis.com/auth/devstorage.full_control,trace --zone=<zone> --service-account=<service_account> >> Updated [https://www.googleapis.com/compute/beta/projects/<project_id>/zones/<zone>/instances/git].<Compute Engine VM> $ ssh-keygen -t rsa $ sudo apt-get install git $ ssh -vT git@github.com $ ssh -T git@github.com $ git clone git@github.com:st-tech/zr-obp.git $ gcloud auth login $ gsutil cp -r /home/<user_name>/zr-obp/obd/bts/women gs://<bucket_name><必要なライブラリの読み込み>
import pandas as pd import numpy as np from tqdm import tqdm from pathlib import Path from dataclasses import dataclass from obp.dataset import OpenBanditDataset from obp.policy import LogisticTS from obp.simulator import run_bandit_simulation from obp.ope import ( OffPolicyEvaluation, RegressionModel, ReplayMethod, DirectMethod, DoublyRobust, InverseProbabilityWeighting ) from typing import Dict, Optional, Union from sklearn.preprocessing import LabelEncoder from sklearn.utils import check_random_state from sklearn.ensemble import RandomForestClassifier as RandomForest from scipy.optimize import minimize<データの理解>
data_path = Path('.').resolve().parents[1] / 'python_code_/analysis_/Contextual' # 「女性向けキャンペーン」において Bernoulli Thompson Sampling policyが集めたログデータを読み込む(これらは引数に設定) # C:\Users\<user_name>\python_code_\analysis_\Contextual\bts\women\women.csv dataset = OpenBanditDataset(behavior_policy = 'bts', campaign = 'women', data_path = data_path) # 過去の意思決定policyによる蓄積データ`bandit feedback`を得る bandit_feedback = dataset.obtain_batch_bandit_feedback() print(bandit_feedback.keys()) >> dict_keys(['n_rounds', 'n_actions', 'action', 'position', 'reward', 'pscore', 'context', 'action_context'])bandit_feedback は dataset(前回の Policy により得られたフィードバックデータ) から OPE に必要なデータを抽出し加工したデータです。
bandit_feedback は women.csv と item_context.csv から構成されています。data = pd.read_csv('Contextual/bts/women/women.csv') user_cols = data.columns.str.contains('user_feature') context = pd.get_dummies(data.loc[:, user_cols], drop_first = True).values item_context = pd.read_csv('Contextual/bts/women/item_context.csv') item_feature_0 = item_context['item_feature_0'] item_feature_cat = item_context.drop(['item_feature_0', 'item_id'], axis = 1).apply(LabelEncoder().fit_transform) action_context = pd.concat([item_feature_cat, item_feature_0], axis = 1).values print(data.columns) >> Index(['timestamp', 'item_id', 'position', 'click', 'propensity_score', 'user_feature_0', 'user_feature_1', 'user_feature_2', 'user_feature_3', 'user-item_affinity_0', 'user-item_affinity_1', 'user-item_affinity_2', 'user-item_affinity_3', 'user-item_affinity_4', 'user-item_affinity_5', 'user-item_affinity_6', 'user-item_affinity_7', 'user-item_affinity_8', 'user-item_affinity_9', 'user-item_affinity_10', 'user-item_affinity_11', 'user-item_affinity_12', 'user-item_affinity_13', 'user-item_affinity_14', 'user-item_affinity_15', 'user-item_affinity_16', 'user-item_affinity_17', 'user-item_affinity_18', 'user-item_affinity_19', 'user-item_affinity_20', 'user-item_affinity_21', 'user-item_affinity_22','user-item_affinity_23', 'user-item_affinity_24', 'user-item_affinity_25', 'user-item_affinity_26', 'user-item_affinity_27', 'user-item_affinity_28', 'user-item_affinity_29', 'user-item_affinity_30','user-item_affinity_31', 'user-item_affinity_32','user-item_affinity_33', 'user-item_affinity_34', 'user-item_affinity_35', 'user-item_affinity_36','user-item_affinity_37', 'user-item_affinity_38', 'user-item_affinity_39', 'user-item_affinity_40', 'user-item_affinity_41', 'user-item_affinity_42','user-item_affinity_43', 'user-item_affinity_44','user-item_affinity_45'], dtype='object') print(item_context.columns) >> Index(['item_id', 'item_feature_0', 'item_feature_1', 'item_feature_2', 'item_feature_3'], dtype='object')bandit_feedback
◇n_rounds: サンプルサイズ
◇n_actions: クリエイティブ数(クリエイティブの候補)
◇action: バンディットアルゴリズムにより選択されたクリエイティブ
◇position: クリエイティブの表示位置(今回は3ヵ所の候補があるとしています)
◇reward: 報酬(not CV: 0 / CV: 1)
◇pscore: Propensity Score
◇context: ダミー変数化されたユーザー特徴量
◇action_context: item_context から item_id を除いたデータwomen.csv
◇timestamp: timestamps of impressions.
◇item_id: index of items as arms (index ranges from 0-80 in "All" campaign, 0-33 for "Men" campaign, and 0-46 "Women" campaign).
◇position: the position of an item being recommended (1, 2, or 3 correspond to left, center, and right position of the ZOZOTOWN recommendation interface, respectively).
◇click: target variable that indicates if an item was clicked (1) or not (0).
◇propensity_score: the probability of an item being recommended at each position.
◇user feature 0-4: user-related feature values.
◇user-item affinity 0-: user-item affinity scores induced by the number of past clicks observed between each user-item pair.item_context.csv
◇item_id: index of items as arms (index ranges from 0-80 in "All" campaign, 0-33 for "Men" campaign, and 0-46 "Women" campaign).
◇item feature 0-3: item related feature valuesOpen Bandit Pipeline
「旧ロジックである Bernoulli Thompson Sampling policy が収集した過去データを用いて、新ロジックである Contextual Logstic Thompson Sampling policy の性能をオフライン評価する」という例を用います。
このセクションでは Open Bandit Pipeline とアルゴリズム実装それぞれのコードを順に載せていきます。<意思決定 policy のオフラインシミュレーション>
前回の意思決定 policy により得られたフィードバックデータを新しい意思決定 policy におけるアルゴリズム(Contextual Logistic Thompson Sampling)に学習させることでシミュレーションを行います。
<Open Bandit Pipeline> counterfactual_policy = LogisticTS(n_actions = dataset.n_actions, len_list = dataset.len_list, random_state = 0, dim = bandit_feedback['context'].shape[1]) selected_actions = run_bandit_simulation(bandit_feedback = bandit_feedback, policy = counterfactual_policy) >> 100%|███████████████████████████████████████████████████████████████████████████| 10000/10000 [00:13<00:00, 739.71it/s] print(selected_actions ) >> array([[45, 11, 20], [45, 11, 20], [45, 11, 20], ..., [26, 22, 10], [29, 15, 6], [26, 22, 10]], dtype=int64)dim = 19 # bandit_feedback["context"].shape[1] n_actions = 46 len_list = 3 batch_size = 1 alpha = 1.0 beta = 1.0 lambda_ = 1.0 random_state = 0 reward_counts = np.zeros(n_actions) action_counts = np.zeros(n_actions, dtype=int) for key_ in ['action', 'position', 'reward', 'pscore', 'context']: if key_ not in bandit_feedback: raise RuntimeError(f"Missing key of {key_} in 'bandit_feedback'.") context = bandit_feedback['context'] action = bandit_feedback['action'] reward = bandit_feedback["reward"] position = bandit_feedback["position"] pscore = bandit_feedback["pscore"] n_trial = 0 action_counts_temp = np.zeros(n_actions, dtype = int) reward_counts_temp = np.zeros(n_actions) selected_actions_list = list() dim_context = bandit_feedback["context"].shape[1] reward_lists = [[] for _ in np.arange(n_actions)] context_lists = [[] for _ in np.arange(n_actions)] # policy_type = "contextfree" policy_type = "contextual" @dataclass class Model: """MiniBatch Online Logistic Regression Model.""" lambda_: float alpha: float dim: int random_state: Optional[int] = None def __post_init__(self) -> None: """Initialize Class.""" self._m = np.zeros(self.dim) self._q = np.ones(self.dim) * self.lambda_ self.random_ = check_random_state(self.random_state) def predict_proba_with_sampling(self, X: np.ndarray) -> np.ndarray: """Predict extected probability by the sampled coefficient.""" return sigmoid(X.dot(self.sample_())) def sample_(self) -> np.ndarray: """Sample coefficient vector from the prior distribution.""" sd = self.alpha * self._q ** (-1.0) return self.random_.normal(self._m, sd, size = self.dim) def fit(self, X: np.ndarray, y: np.ndarray): """Update coefficient vector by the mini-batch data.""" self._m = minimize( fun = loss, x0 = self._m, args = (X, y, self._q, self._m), jac = grad, method="L-BFGS-B", options={"maxiter": 20, "disp": False} ).x P = (1 + np.exp(1 + X.dot(self._m))) ** (-1) self._q = self._q + (P * (1 - P)).dot(X ** 2) def sigmoid(x: Union[float, np.ndarray]) -> Union[float, np.ndarray]: """Calculate sigmoid function.""" return 1.0 / (1.0 + np.exp(-x)) def loss(w: np.ndarray, *args) -> float: """Calculate loss function.""" X, y, _q, _m = args return 0.5 * (_q * (w - _m)).dot(w - _m) + np.log(1 + np.exp(-y * w.dot(X.T))).sum() def grad(w: np.ndarray, *args) -> np.ndarray: """Calculate gradient.""" X, y, _q, _m = args return _q * (w - _m) + (-1) * (((y * X.T) / (1.0 + np.exp(y * w.dot(X.T)))).T).sum(axis=0) alpha_list = alpha * np.ones(n_actions) lambda_list = lambda_ * np.ones(n_actions) model_list = [ Model( lambda_ = lambda_list[i], alpha = alpha_list[i], dim = 19, random_state = 0, ) for i in np.arange(n_actions) ] for action_, reward_, position_, context_ in tqdm( zip(bandit_feedback["action"], bandit_feedback["reward"], bandit_feedback["position"], bandit_feedback["context"], ), total = bandit_feedback['n_rounds'], ): if policy_type == "contextfree": # Returns # selected_actions: array-like shape (len_list, ) # List of selected actions. predicted_rewards = random_.beta( a = reward_counts + alpha, b = (action_counts - reward_counts) + beta, ) selected_actions = predicted_rewards.argsort()[::-1][: len_list] elif policy_type == "contextual": # Returns # selected_actions: array-like shape (len_list, ) # List of selected actions. theta = np.array( [model.predict_proba_with_sampling(context_.reshape(1, dim_context)) for model in model_list] ).flatten() selected_actions = theta.argsort()[::-1][: len_list] action_match_ = action_ == selected_actions[position_] if action_match_: if policy_type == "contextfree": n_trial += 1 action_counts_temp[action_] += 1 reward_counts_temp[action_] += reward_ # batch update if n_trial % batch_size == 0: action_counts = np.copy(action_counts_temp) reward_counts = np.copy(reward_counts_temp) elif policy_type == "contextual": n_trial += 1 action_counts[action_] += 1 reward_lists[action_].append(reward_) context_lists[action_].append(context_.reshape(1, dim_context)) if n_trial % batch_size == 0: for action, model in enumerate(model_list): if not len(reward_lists[action]) == 0: model.fit( X = np.concatenate(context_lists[action], axis=0), y = np.array(reward_lists[action]), ) reward_lists = [[] for _ in np.arange(n_actions)] context_lists = [[] for _ in np.arange(n_actions)] selected_actions_list.append(selected_actions) >> 100%|███████████████████████████████████████████████████████████████████████████| 10000/10000 [00:13<00:00, 739.71it/s] selected_actions_list = np.array(selected_actions_list) print(selected_actions_list) >> array([[45, 11, 20], [45, 11, 20], [45, 11, 20], ..., [26, 22, 10], [29, 15, 6], [26, 22, 10]], dtype=int64)文脈付きバンディット問題を扱っているため
policy_type = "contextual"が設定されており if 文の条件分岐ではpolicy_type == "contextual"が選択されます。今回の実装に用いている例では、Contextual Thompson Sampling はユーザーごとに報酬構造が変化することを仮定した上で各クリエイティブの選択において期待値の最大化を図るアルゴリズムです。
今回はロジスティック回帰においてシグモイド関数を用いているため解析的にパラメータを求めることは難しくラプラス近似を行います。
上記のコードから、シグモイド関数のパラメータ更新のために対数尤度を2次近似した目的関数の最小化問題を解いていると解釈できます。
loss関数の数式は2次近似を行った目的関数(ニュートン法により求まった MAP 推定量の周りで負の対数尤度を2次近似した関数)であり(np.log(1 + np.exp(-y * w.dot(X.T)))).sum()の部分はロジスティック回帰における負の対数尤度を表しています。grad関数の数式はminimize関数(L-BFGS-Bを指定することでニュートン法により多変数関数における最適化を実行)における最適化の際に勾配方向にパラメータを更新するために必要なヤコビアンを表しています。
loss関数に対しての最適化問題を解くことでシグモイド関数のパラメータの事後分布に近似させる正規分布に必要なパラメータ(_m: ニュートン法により求められる MAP 推定量,sd: ヘッセ行列_qの逆行列を持つ標準偏差)を算出しています。
sample関数の正規分布からサンプリングされた値を更新されたパラメータとしてsigmoid関数が受け取ります。Open Bandit Pipeline では
LogisticTSクラスを宣言するとクリエイティブの数だけロジスティック回帰モデルが生成されます。アルゴリズム実装コードのmodel_listにあたります。
モデルの更新はif n_trial % batch_size == 0をトリガーとしてfit関数により行われています。
batch_size = 1を設定しているため for 文により各ユーザーのフィードバックデータが流れてくる度にモデルを更新していく仕組みです。
各クリエイティブに対応するモデル、今回であれば 0 から 45 までの 46 のモデルに対し報酬を受け取ったクリエイティブに対応するモデルを更新します。アルゴリズム実装コードのif not len(reward_lists[action]) == 0にあたります。
更新の際にはラプラス近似を行うため、各ユーザーのフィードバックデータにおいて報酬を受け取ったクリエイティブ(選択されたクリエイティブ)番号に対応するcontext_lists:X (ユーザー特徴量) とreward_lists: y (予測対象である報酬) を引数として与えシグモイド関数のパラメータの更新が行われています。
predict_proba_with_sampling関数によりユーザーの特徴量に対し各モデルにおいて reward = 1 となる確率を予測し確率の高いクリエイティブの上位 3 つをselected_actions_listに格納します。<Contextual Logistic Thompson Sampling のオフライン評価>
シュミレーションの結果に基づき、Doubly Robust を用いて Contextual Logistic Thompson Sampling のオフライン評価(OPE)を行います。
<Open Bandit Pipeline> ope = OffPolicyEvaluation( bandit_feedback = bandit_feedback, regression_model = RegressionModel(base_model = RandomForest(n_estimators = 100, random_state = 0)), action_context = dataset.action_context, ope_estimators = [DoublyRobust()] ) estimator_inputs = ope._create_estimator_inputs(selected_actions = selected_actions) print(estimator_inputs) >> {'reward': array([0, 0, 0, ..., 0, 0, 0], dtype=int64), 'pscore': array([0.02173913, 0.023865 , 0.02101 , ..., 0.0102 , 0.00839, 0.016595 ]), 'action_match': array([False, False, False, ..., False, False, False]), 'estimated_rewards_by_reg_model': array([0., 0., 0., ..., 0., 0., 0.])} estimated_policy_value = ope.estimate_policy_values(selected_actions = selected_actions) print(estimated_policy_value) >> {'dr': 0.0009044371394456017}def create_estimator_inputs(selected_actions_list: np.ndarray) -> Dict[str, np.ndarray]: """Create input dictionary to estimate policy value""" estimator_inputs = { input_: bandit_feedback[input_] for input_ in ['reward', 'pscore'] } estimator_inputs['action_match'] = ( bandit_feedback['action'] == selected_actions_list[np.arange(bandit_feedback['n_rounds']), bandit_feedback['position'] ] ) regression_model = True if regression_model == True: context = bandit_feedback["context"] position = bandit_feedback["position"] action = bandit_feedback['action'] selected_actions_at_positions = selected_actions_list[np.arange(position.shape[0]), position] base_model = RandomForest(n_estimators = 100, random_state = 0) X = np.c_[context, action_context[action]] X_ = np.c_[context, action_context[selected_actions_at_positions]] fitting_method = 'normal' if fitting_method == "normal": # Method to fit the regression method. base_model.fit(X, bandit_feedback['reward']) estimator_inputs[ "estimated_rewards_by_reg_model" ] = base_model.predict_proba(X_)[:, 1] elif fitting_method == 'iw': # Method to fit the regression method. # 'iw' stands for importance weighting. sample_weight = np.mean(bandit_feedback['pscore']) / bandit_feedback['pscore'] base_model.fit(X, bandit_feedback['reward'], sample_weight = sample_weight) estimator_inputs[ "estimated_rewards_by_reg_model" ] = base_model.predict_proba(X_)[:, 1] elif fitting_method == 'mrdr': # Method to fit the regression method. # 'mrdr' stands for more robust doubly robust. sample_weight = (1.0 - bandit_feedback['pscore']) / bandit_feedback['pscore'] ** 2 base_model.fit(X, bandit_feedback['reward'], sample_weight = sample_weight) estimator_inputs[ "estimated_rewards_by_reg_model" ] = base_model.predict_proba(X_)[:, 1] return estimator_inputs def estimate_policy_values(selected_actions_list: np.ndarray, method) -> Dict[str, float]: """Estimate policy value of a counterfactual policy.""" policy_value_dict = dict() estimator_inputs = create_estimator_inputs( selected_actions_list = selected_actions_list ) if method == 'DirectMethod': # DirectMethod policy_value_dict['DirectMethod'] = np.mean(estimator_inputs['estimated_rewards_by_reg_model']) if method == 'InverseProbabilityWeighting' : # InverseProbabilityWeighting estimated_rewards = (estimator_inputs['action_match'] * estimator_inputs['reward']) / estimator_inputs['pscore'] policy_value_dict['InverseProbabilityWeighting'] = np.mean(estimated_rewards) elif method == 'DoublyRobust': # DoublyRobust estimated_rewards = ( (estimator_inputs['action_match'] * (estimator_inputs['reward'] - estimator_inputs['estimated_rewards_by_reg_model'])) / estimator_inputs['pscore'] ) + estimator_inputs['estimated_rewards_by_reg_model'] policy_value_dict['DoublyRobust'] = np.mean(estimated_rewards) return estimated_rewards, policy_value_dict estimator_inputs = create_estimator_inputs(selected_actions_list = selected_actions_list) print(estimator_inputs) >> {'reward': array([0, 0, 0, ..., 0, 0, 0], dtype=int64), 'pscore': array([0.02173913, 0.023865 , 0.02101 , ..., 0.0102 , 0.00839, 0.016595 ]), 'action_match': array([False, False, False, ..., False, False, False]), 'estimated_rewards_by_reg_model': array([0., 0., 0., ..., 0., 0., 0.])} estimated_policy_value = estimate_policy_values(selected_actions_list, method = 'DoublyRobust') print(estimated_policy_value[0]) >> array([0., 0., 0., ..., 0., 0., 0.]) print(estimated_policy_value[1]) >> {'DoublyRobust': 0.0009044371394456017}<OffPolicyEvaluation>
Open Bandit Pipeline ではOffPolicyEvaluationクラスを宣言するとbase_modelとして設定したRandomForestに対し fit と predict_proba を実行します。OffPolicyEvaluationクラスを宣言する際の引数RegressionModelにfitting_methodを引数として渡していないためデフォルト値の fitting_method = "normal" が選択されています。アルゴリズム実装コードのif fitting_method == "normal"にあたります。
fitはフィードバックデータの「ユーザー特徴量(context)と各ユーザーに対して選択されたクリエイティブの特徴量(action_context[action])」を入力として「報酬(bandit_feedback['reward'])」を予測したモデルを返します。<_create_estimator_inputs>
Open Bandit Pipeline の_create_estimator_inputs関数はestimate_policy_valuesに必要なデータが格納されたestimator_inputsを返します。OffPolicyEvaluationクラスと_create_estimator_inputs関数 はどちらもアルゴリズム実装コードのcreate_estimator_inputsにあたります。
predict_probaは「フィードバックデータのユーザー特徴量(context)と各ユーザーに対して Contextual Logistic Thompson Sampling により選択されたクリエイティブの特徴量(selected_actions_at_positions)」を入力として「期待される報酬(not CV: 0 / CV: 1)それぞれの確率」を返します。
predict_probaにより得られた reward = 1 (CV = 1) となる確率をestimated_rewards_by_reg_modelとしてestimator_inputsに格納しています。
action_matchは前回の意思決定 policy により選択されたクリエイティブと Contextual Logistic Thompson Sampling により選択されたクリエイティブが同じであるか否かに対応する True または False からなるデータです。<estimate_policy_values>
Open Bandit Pipeline のestimate_policy_valuesでは Contextual Logistic Thompson Sampling のオフライン評価(OPE)を行います。
つまり、前回の意思決定 policy に対して新しい意思決定 policy はどの程度の性能を有するのかについて評価を行います。
論文では ground-truth に対して「Direct Method(DM)」「Inverse Probability Weighting(IPW)」「Doubly Robust(DR)」による評価の比較が行われていますが今回は Doubly Robust のみを実装しています。アルゴリズム実装コードには DM と IPW のアルゴリズムも載せてあるので引数methodに ['Direct Method', 'InverseProbabilityWeighting', 'DoublyRobust'] を渡せば評価を比較することができます。DM は報酬の真の期待値と推定値とが大きく異なる場合にバイアスが大きくなり、IPW は前回の意思決定 policy と新しい意思決定 policy の性能が大きく異なる場合やサンプルサイズが小さい場合にバリアンスが大きくなる傾向にあります。ただしサンプルサイズが大きい場合には IPW は普遍推定量であるため A/Bテスト に近似されます。
DM と IPW の折衷案にあたるのが DR です。
DR は「IPW(${\pi_k}$ の推定精度に大きく依存するという意味で介入を予測する回帰モデル)」と「DR(${\hat{\mu}}$ の推定精度に大きく依存するという意味で結果変数(報酬)を予測する回帰モデル)」のどちらかが正確であれば結果変数(報酬)の真の期待値に対し一致推定量として扱えます。
ただしその条件を満たしていなければ IPW よりも性能が劣る(MSE の値が高い)ことがあります。
estimate_policy_valuesのDoublyRobustに関してより具体的には以下の数式を計算しています。\begin{aligned}\widehat{V}_{DR}^\pi(\pi;D) = \frac{1}{T} \sum_{t = 1}^{T}\sum_{a = 1}^{m} \Big\{ ({Y_t - \hat{\mu}(a_t|X_t))D_{ta} \frac{\pi(a_t|X_t)}{\pi{_b(a_t|X_t)}} } + \pi(a_t|X_t)\hat{\mu}(a_t|X_t) \Big\} \end{aligned} \\ where \ D = { \{ {x_t}, {a_t}, {Y_t} \} }_{t = 1}^T• ${\hat{\mu}}$ is independent of ${z_n}$.
• ${\pi_k}$ is conditionally independent of $\{x_l, a_l, Y_l \}_{l\geq{k}}$ conditioned on ${z_{k-1}}$.
(${z_k = (x_1, a_1, Y_1,...,x_k, a_k, Y_k)}$)
The first assumption means that ${\hat{\mu}}$ can be assumed fixed and determined before we see the input data ${z_n}$, for example, by initially splitting the input dataset and using the first part to obtain ${\hat{\mu}}$ and the second part to evaluate the policy. In our analysis, we condition on ${\hat{\mu}}$ and ignore any randomness in its choice.
The second assumption means that ${\pi_k}$ is not allowed to depend on future. A simple way to satisfy this assumption is to split the dataset to form an estimator (and potentially also include data ${z_{k-1}}$).
If we have some control over the exploration process, we might also have access to “perfect logging”, that is, recorded probabilities ${\pi_{k}(a_k|x_k)}$. With perfect logging, we can achieve ${\hat\pi_k = \pi_{k}}$, respecting our assumptions.${D}$ は過去の意思決定 policy から得られるデータです。
つまり、観測される特徴量ごとに過去の意思決定 policy における行動は ${a_t ∼ \pi_b(⋅|x_{t})}$ により選択されており結果として潜在目的変数 ${Y_t = Y_t(a_t)}$ が観測されることでサンプルサイズ ${T}$ のフィードバックデータが構成されることを意味しています。完璧な推定を行うことは実際には難しく、「介入を予測する回帰モデルと結果変数(報酬)を予測する回帰モデルとして振る舞う」${\widehat{V}_{DR}^\pi}$ が真の値からどれだけ離れているかに興味があります。
より詳しいことは ZOZOテクノロジーズ TECH BLOG の記事(Off-Policy Evaluationの基礎とZOZOTOWN大規模公開実データおよびパッケージ紹介)や論文(Doubly Robust Policy Evaluation and Optimization)に記載されています。
<信頼区間の算出>
ブートストラップ法(推定量に対しリサンプリングを行うことで母集団からの標本抽出を疑似的に再現)により信頼区間(真の値が取り得る範囲)を算出します。
<Open Bandit Pipeline> estimated_policy_value, estimated_interval = ope.summarize_off_policy_estimates(selected_actions = selected_actions_list, random_state = 0) print(estimated_policy_value) >> estimated_policy_value dr 0.000904 print(estimated_interval ) >> 95.0% CI (lower) 95.0% CI (upper) mean dr -0.00105 0.00215 0.000765def estimate_confidence_interval_by_bootstrap(alpha, n_boostrap_samples, random_state ): boot_samples = list() random_ = check_random_state(random_state) estimator_inputs = create_estimator_inputs(selected_actions_list = selected_actions_list) estimated_policy_value = estimate_policy_values(selected_actions_list, method = 'DoublyRobust') samples = estimated_policy_value[0] for _ in np.arange(n_boostrap_samples): boot_samples.append(np.mean(random_.choice(samples, size = samples.shape[0]))) lower_bound = np.percentile(boot_samples, 100 * (alpha / 2)) upper_bound = np.percentile(boot_samples, 100 * (1.0 - alpha / 2)) return { 'mean': np.mean(boot_samples), f"{100 * (1. - alpha)}% CI (lower)": lower_bound, f"{100 * (1. - alpha)}% CI (upper)": upper_bound } print(estimate_confidence_interval_by_bootstrap(alpha = 0.05, n_boostrap_samples = 100, random_state = 0)) >> {'mean': 0.0007653177020632711, '95.0% CI (lower)': -0.0010498451155268806, '95.0% CI (upper)': 0.002150102018984923}ブートストラップ法はリサンプリング回数が 100 のような少ない回数であったとしてもサンプルサイズが大きい場合には精度が高くなります。
今回は
n_boostrap_samples = 100を設定しており DR により得られた Contextual Logistic Thompson Sampling の性能の推定値に対し 95% 信頼区間を算出しています。
Open Bandit Pipeline ではvisualize_off_policy_estimates関数を用いることで信頼区間の幅を seaborn の barplot で表示することができます。今回であれば barplot の引数である ci と n_boot にはそれぞれ 0.95 と 100 が渡されます。<性能の比較>
意思決定 policy における旧ロジック(Bernoulli Thompson Sampling)と新ロジック(Contextual Logistic Thompson Sampling)の性能を比較します。
relative_policy_value_of_contextual_logistic_ts = estimated_policy_value[1]['DoublyRobust'] / bandit_feedback['reward'].mean() pritn(relative_policy_value_of_contextual_logistic_ts ) >> 0.19661676944469603新ロジックの性能は OPE(DR) による推定値を、旧ロジックの性能はフィードバックデータの報酬の平均をとることで推定できる真の値を用いています。
結果として、新ロジック(Contextual Logistic Thompson Sampling)の性能は旧ロジック(Bernoulli Thompson Sampling)と比較して 19.66% 上回ると推定されています。まとめ
Open Bandit Pipeline のアルゴリズムを実装してみました。
コードや数学に関しての間違いなどありましたらご指摘のほどよろしくお願いいたします。参考資料
<論文>
A Large-scale Open Dataset for Bandit Algorithms (Yuta Saito, Shunsuke Aihara, Megumi Matsutani, Yusuke Narita)
An Empirical Evaluation of Thompson Sampling (Olivier Chapelle, Lihong Li)
Doubly Robust Policy Evaluation and Optimization (Miroslav Dud´ık, Dumitru Erhan, John Langford and Lihong Li)<サイト>
Contextual Bandits in Recommendation (James Mclnerney)
Off-Policy Evaluationの基礎とZOZOTOWN大規模公開実データおよびパッケージ紹介 (齋藤 優太)
ZOZO研究所、ZOZOTOWNのファッション推薦データとアルゴリズム研究開発基盤をオープンソースで公開
バンディットアルゴリズムと因果推論 / Bandit Algorithm And Casual Inference (安井 翔太)
最急降下法による非線形最適化MATLAB&Pythonサンプルプログラム
ロボティクスにおける線形代数<GitHub>
Open Bandit Dataset
Open Bandit Pipeline
description of「Open Bandit Dataset and Open Bandit Pipeline」
- 投稿日:2020-09-21T14:29:34+09:00
Pythonでめっちゃ簡単にできるベイズ最適化
前置き
仕事でパラメータの最適化をすることがあるのと、職場で最適化問題の相談を受けることが多いので、めっちゃ簡単にベイズ最適化ができる
scikit-optimizeのgp_minimizeについて、まとめておこうと思います。インストール
pipで簡単インストール
pip install scikit-optimizeソースコード全文
今回のソースコード全文。
ここでは要所のみ、実際には描画用のコードがあったりする。import numpy as np from skopt import gp_minimize def func(param=None): ret = np.cos(param[0] + 2.34) + np.cos(param[1] - 0.78) return -ret if __name__ == '__main__': x1 = (-np.pi, np.pi) x2 = (-np.pi, np.pi) x = (x1, x2) result = gp_minimize(func, x, n_calls=30, noise=0.0, model_queue_size=1, verbose=True)インポート周り
import numpy as np from skopt import gp_minimizenumpyとgp_minimizeだけ。
転用される場合は必要に応じて変更。最適化関数
def func(param=None): ret = np.cos(param[0] + 0.34) + np.cos(param[1] - 0.78) return -ret今回は二つの入力を受け取り、それぞれのコサイン関数値の合計が最大化する入力値を求める問題とした。
分かりやすいから。
ただ、さすがに芸がなさすぎるので、入力値にオフセット(0.34, -0.78)を加えた。
最終的にこのオフセットを相殺する(-0.34, 0.78)が求められれば、最適化成功と言えるものである。なお、
gp_minimizeという名前の通り、最小化しかできないので、戻り値は-をつけて負値にすることで、最小化を最大化としている。探索空間の設定
x1 = (-np.pi, np.pi) x2 = (-np.pi, np.pi) x = (x1, x2)今回はコサイン関数と知っているので、二つの入力変数の空間は同じで、(-π ~ π)が取りうる範囲。
変数ごとに取りうる最小と最大をListかTupleで指定し、最後にひとつのListかTupleにまとめて渡す必要があるので、最後にひとつにまとめている。最適化
result = gp_minimize(func, x, n_calls=30, noise=0.0, model_queue_size=1, verbose=True)これだけで、サンプリングが回りだす。
とりあえず、今回は使いそうなパラメータだけ指定している。最初の
funcとxは最適化関数と探索空間を指定。
n_callsはサンプリング回数。
noiseは指定しないとガウス分布のノイズを載せて探索するので、必要に応じて変更。今回は0.0でノイズなしで評価する。
model_queue_sizeはgp_minimizeはscikit-learnのGaussianProcessRegressorを使って、空間の評価値の予測と次のサンプリング点を探しているので、都度都度のGaussianProcessRegressorのインスタンスを保持する数。
指定しないと全部残していくので、メモリをどんどん食いつぶしていく。今回は1を指定して、常に最新のみ保持するようにした。
verboseはサンプリング中の標準出力をありにしているだけ。Falseを指定すると何も出ない。この最適化の結果が
resultに返される。resultの中身について
dir関数で中身を参照してみると下記のメンバーが存在している。
In [1]:dir(result) Out[1]: ['fun', 'func_vals', 'models', 'random_state', 'space', 'specs', 'x', 'x_iters']概ね、下記の解釈でよいと思われる。
メンバー 値 解釈 fun -1.9999999997437237 最適化中のもっともよかった評価値 func_vals array([ 0.72436992, -0.2934671 , ・・・・・ -1.99988708, -1.99654543]) 最適化中の都度都度の関数の戻り値(評価値) models list(GaussianProcessRegressor) 先の説明の通り、保持した GaussianProcessRegressorのインスタンスのListrandom_state RandomState(MT19937) at 0x22023222268 乱数のシード space Space([
Real(low=-3.141592653589793, high=3.141592653589793, prior='uniform', transform='normalize'),
Real(low=-3.141592653589793, high=3.141592653589793, prior='uniform', transform='normalize')])探索空間のオブジェクト specs (多いので省略)
Dictionaryが入っているどうも最適化の仕様がまとめて入っているっぽい x [-2.3399919472084387, 0.7798573940377893] 最適化された入力変数の値 x_iters (多いので省略)
List都度都度、どんな値をサンプリングしたかが入っている 結果のまとめ
最後に
resultに入っていた値を用いて、プロットしたやつを張り付けておく。
ちょぉっと見にくいが、左図は実際のヒートマップ、縦軸がx1で横軸がx2なので、縦軸には下の方、横軸には少し右のほうに最小値(正負反転したので本当は最大値)がある。右図は最適化の結果ですが、ヒートマップの色自体も
GaussianProcessRegressorの予測値で作ったもの。
30回のサンプリングで実空間とほぼ同じものを作りだすことができ、最適値も求めることができた。
○のマーカーは都度都度のサンプリング点、わかりにくいが、端っこをサンプリングし、空間の予測がある程度できてからは最小値付近を重点的にサンプリングしたように見える。
☆のマーカーが最終的に見つかった最適値。
Callbackの使い方
scikit-optimizeの使い方の記事は少ないながらもあるのに、今回これを書いたのは、実はCallbackの使い方を説明している日本語記事が全く見つからなかったから。
というわけで、Callbackの使い方は別記事にして、ここにリンクを貼ります。