- 投稿日:2020-09-20T23:54:22+09:00
pandas.DataFrame.locの使い方まとめ
「loc」は、DataFrameの内で条件を満たした行、列を抽出することができます。pandasを利用していると頻繁に出てくる「loc」ですが、データの指定方法にバリエーションがあるので、その辺をまとめていきたいと思います。
データ指定について
locは、大きく分けると以下のデータ指定が可能です。
- 単一ラベル
- ラベルリスト
- ラベルのスライスオブジェクト
- 真偽値リスト
- 条件式の指定
色々な使い方がありますね・・・ (゜_゜)
プログラムを書くときも注意が必要ですが、読むときにどのパターンで実装されているか冷静に見分けないと、「????」ってなりそうです。それぞれのサンプルコードを書いてみて動作を確認してみようと思います。実際に使ってみた
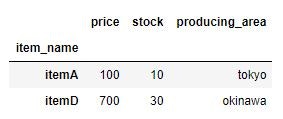
今回動作確認で利用するデータは自分で作ったものです。
import pandas as pd loc_sample_data = pd.read_csv("loc_sample_data.csv",index_col="item_name") loc_sample_data.head()
行インデックスはitem_name、列はprice、stock、producing_areaで構成されています。
単一インデックスラベルの指定
抽出したい行のインデックスラベル(単一)を指定してデータを抽出します。
今回はitemCの抽出をしていきます。loc_sample_data.loc["itemC"]
抽出できました。抽出されたデータはSeries型です。
インデックスラベルリストの指定
上の例は単一行のみの抽出ですが、複数行を指定/抽出することが可能です。複数指定する場合はリストで指定します。
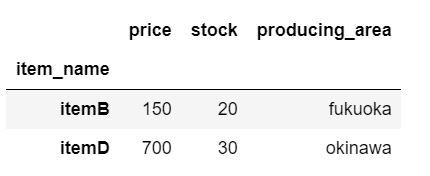
今度はitemA、itemDの抽出をしていきます。loc_sample_data.loc[["itemA", "itemD"]]
抽出できました。抽出されたデータはDataFrame型でした。
単一の行ラベル、列ラベルの指定
行と列のそれぞれのラベルを指定してデータを抽出することも可能です。今回は行→itemB、列→producing_areaを指定してデータ抽出します。
loc_sample_data.loc["itemB", "producing_area"]
抽出できました。抽出されたデータstr型です。今回の例では抽出されたデータstr型ですが、これはDataFrame内に格納されているデータの内容で変わります。スライスを利用した行ラベル、列ラベルの指定
スライスを利用して行、列を複数指定することができます。これを利用してitemA、itemBのpriceを抽出します。
loc_sample_data.loc["itemA":"itemB","price"]
抽出できました。これ使うかな・・・?
真偽値リストを使ったデータ指定
抽出元のデータフレームと同じ長さ(行数)の真偽値リストを指定することで、Trueの行のみを抽出することができます。今回はitemBとitemDを抽出してみる。
loc_sample_data.loc[[False, True, False, True]]
抽出できました。これ単発だと使う機会なさそうですが、事前に各行ごとに抽出条件を満たすかどうかを判定し、リストを作成したら使い道がありそうですね。条件式を利用したデータ指定
一番使いそうなやつですね。今回はpriceが500より大きいデータ(itemC、itemD)を抽出してみます。
loc_sample_data.loc[loc_sample_data["price"] > 500]
抽出できました。やっぱこれ単体だったら一番使いそう。
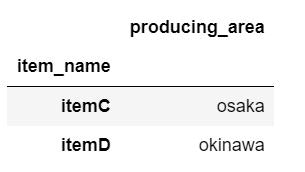
条件式を利用して特定列だけ抽出
さっきの条件式に加えて、特定の列を指定して抽出します。条件は先ほど同様ですが、今回はproducing_area列のみを抽出します。
loc_sample_data.loc[loc_sample_data["price"] > 500, ["producing_area"]]
最後に
色々使い方ありますが、必ず身に付けた方が良いのは条件式を利用したデータ抽出ですかね。今回ちょっと長くて疲れたので終わりにします。それではまた次回の投稿でー!


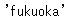


- 投稿日:2020-09-20T23:53:54+09:00
ダイクストラ法:ソフトウェアデザイン 10月号のけんちょんさんの記事内容を元にPythonでAOJの問題を問いてみた
解いた問題
http://judge.u-aizu.ac.jp/onlinejudge/description.jsp?id=DPL_2_A
ソース
- AOJの問題は始点の指定があることに注意
- 蟻本ではフラグを使って更新の有無を確認していたが、けんちょんさんのやり方は、更新されなければ確定(優先度付きキューに入れない)という手法。
- 優先度付きキューをpopして取得した頂点(スタートからの距離が最小の頂点)から探索をする。
import heapq INF = 10**10 class Edge: to = -1 w = -1 def __init__(self, to, w): self.to = to self.w = w def Dijkstra(Graph, s): dist = [INF] * len(Graph) dist[s] = 0 prev = [-1] * len(Graph) #スタート頂点をキューに入れる #[該当頂点までの最短距離(現時点),該当頂点のインデックス] que = [[0,s]] #優先度付きキューに変換 heapq.heapify(que) while len(que) > 0: # 優先度付きキューの先頭の要素を取り出す # vは頂点番号, dは該当頂点までの現在の最短距離 p = heapq.heappop(que) v = p[1] d = p[0] #ソフトウェアデザインだと以下処理があるが不要? #必要性がよくわからん #if d > dist[v]: # continue #該当頂点vから行くことのできる頂点毎に距離を計算 for e in Graph[v]: #最短距離を更新できない場合は何もしない if dist[v] + e.w >= dist[e.to] : continue #以下は、最短距離を更新できた場合 #優先度付きキューに行先頂点の情報をプッシュ heapq.heappush(que,[dist[v] + e.w, e.to]) #行先の最短距離を更新 dist[e.to] = dist[v] + e.w #行先の前のノードを記憶 #AOJの問題では使わない prev[e.to] = v for d in dist: if d == INF: print("INF") else: print(d) return def main(): n, m, s = map(int, input().split()) Graph = [[] for j in range(n)] for i in range(m): a, b, w = map(int, input().split()) Graph[a].append(Edge(b, w)) #AOJの問題は有効グラフ(http://judge.u-aizu.ac.jp/onlinejudge/description.jsp?id=DPL_2_A) #Graph[b].append(Edge(a, w)) Dijkstra(Graph, s) main()
- 投稿日:2020-09-20T23:06:10+09:00
Python 3 + Tkinter で Windows アプリを開発する (準備編)
はじめに
Python の標準ライブラリ「Tkinter」を使用して、Windows の GUI アプリケーションを作成してみる。
準備
Eclipse のインストール
今回は IDE に Eclipse、Python の実行環境に PyDev を使用することにする。
まず以下の URL から、「Pleiades All in One Eclipse」の Python の Full Edition をダウンロードする。
https://mergedoc.osdn.jp/index.html#/pleiades_distros2020.html
ダウンロードした zip ファイルを解凍し、中の
pleiadesフォルダを C ドライブ直下に移動する。Eclipse の設定
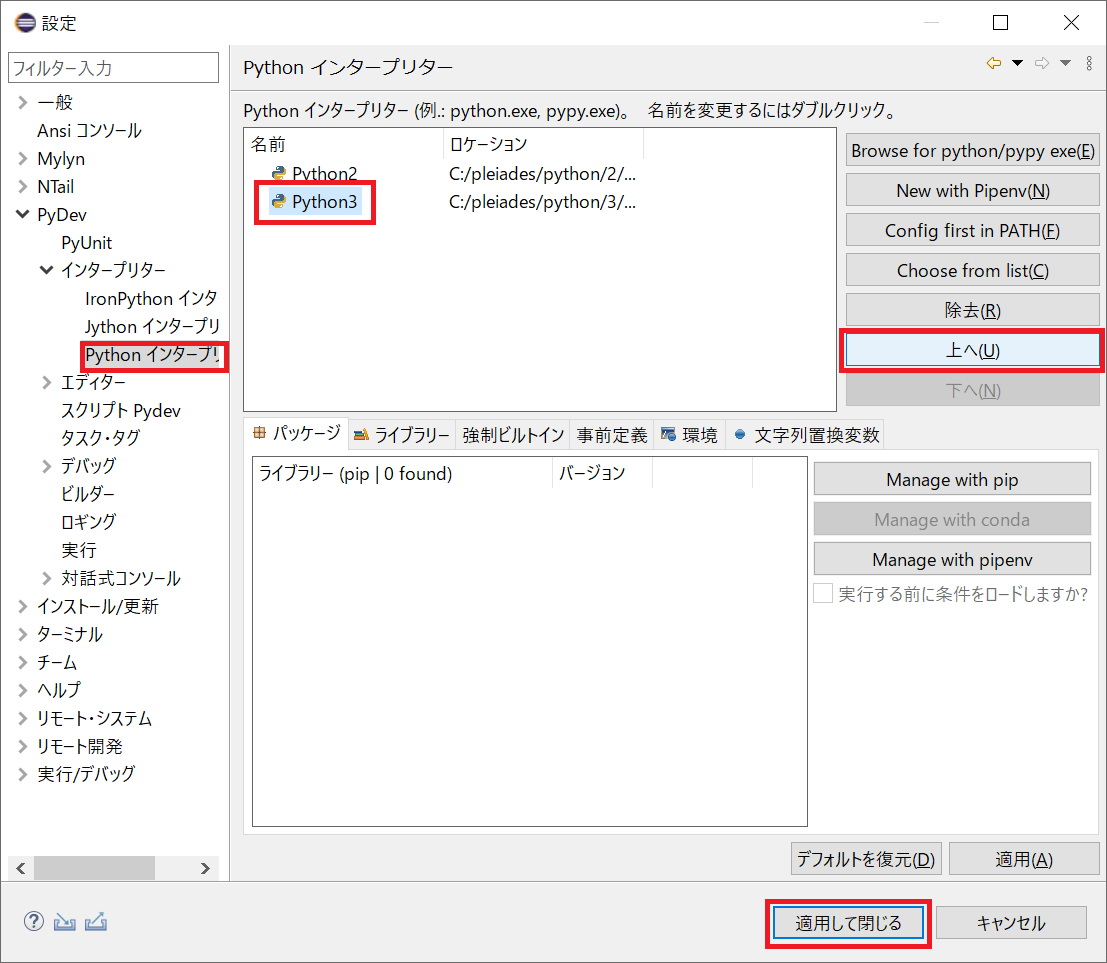
Eclipse のデフォルトのインタプリタを Python 3 に変更する。
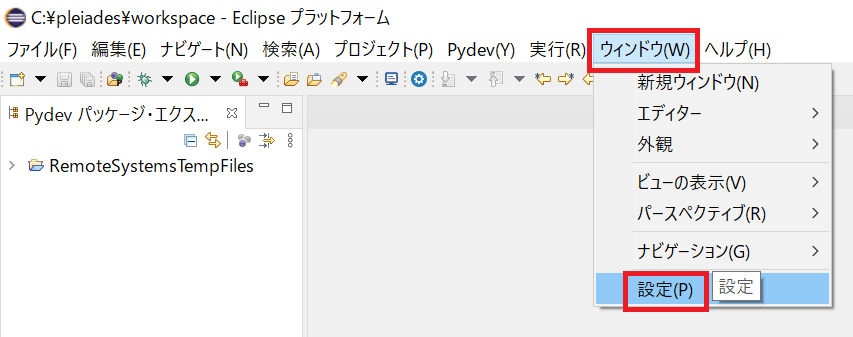
Eclipse (
C:\pleiades\eclipse\) を起動し、メニューの [ウィンドウ] -> [設定] を開く。
eclipse.exe
左側メニューの [PyDev] -> [インタープリター] -> [Python インタープリター] を開く。「Python3」を選択して [上へ] ボタンをクリックして「Python3」を一番上に移動させ、[適用して閉じる] ボタンをクリックする。
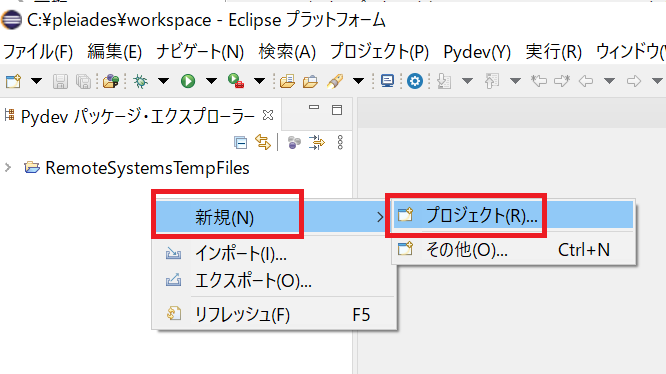
プロジェクトの作成
Eclipse のプロジェクトを作成する。
左側の「Pydev パッケージ・エクスプローラー」の空白部分を右クリックし、[新規] -> [プロジェクト] を開く。
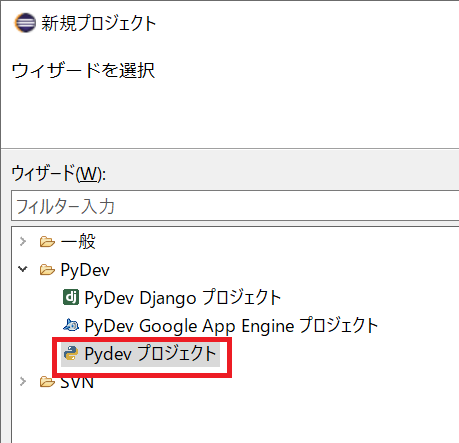
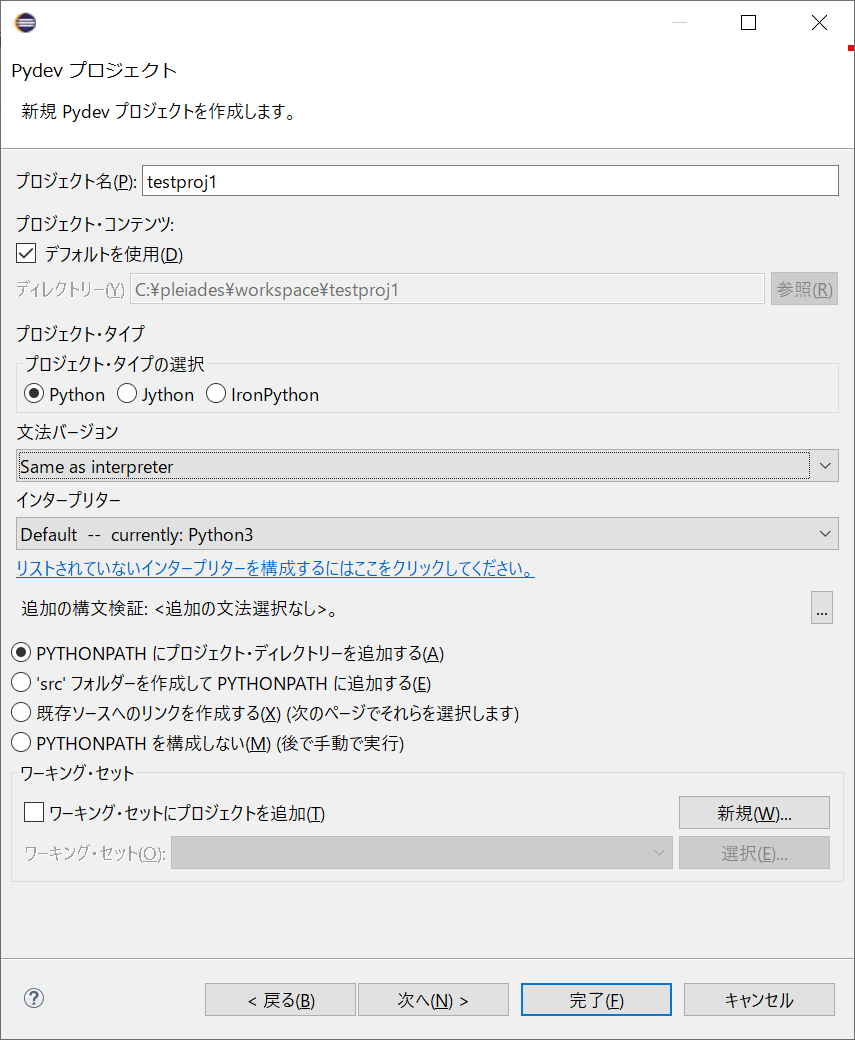
[PyDev] の [Pydev プロジェクト] を選んで [次へ] ボタンをクリックする。
適当なプロジェクト名 (今回は
testproj1) を入力し、[完了] ボタンをクリックする。
Python スクリプトの作成
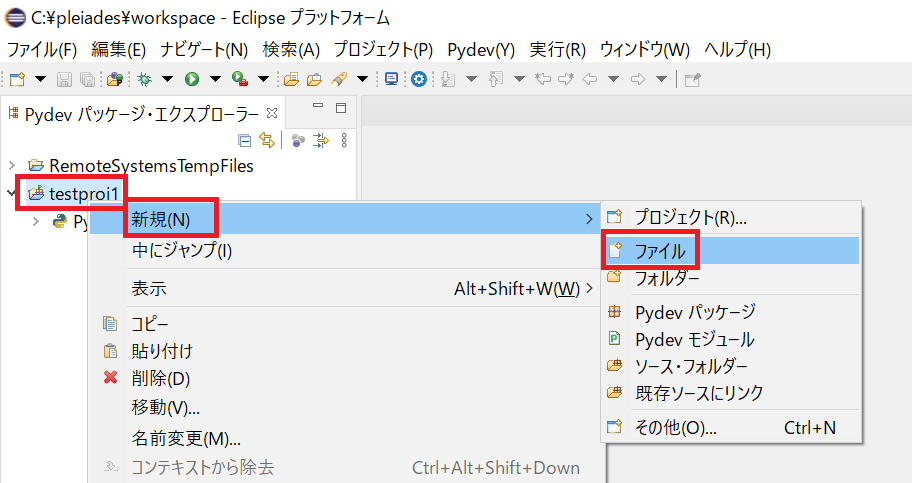
作成したプロジェクトに Python のプログラムを追加する。
左側の「Pydev パッケージ・エクスプローラー」の中にある、先ほど作成したプロジェクトを右クリックし、[新規] -> [ファイル] をクリックする。
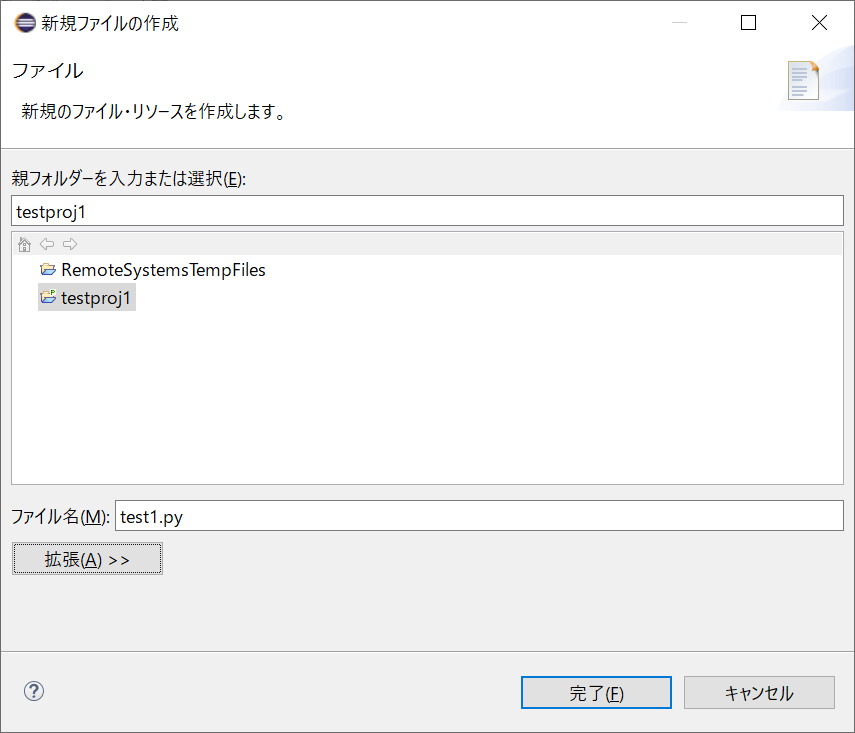
適当なファイル名 (今回は
test1.py) を入力し、[完了] ボタンをクリックする。
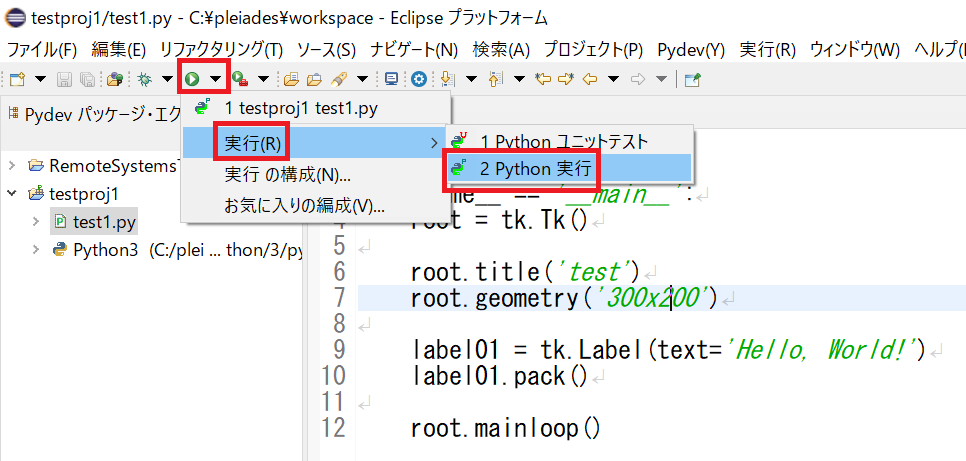
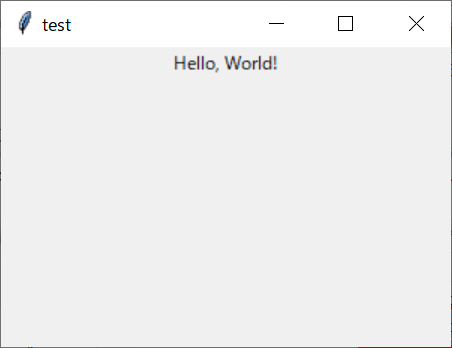
test1.pyに下記のコードを入力して保存する。import tkinter as tk if __name__ == '__main__': root = tk.Tk() root.title('test') root.geometry('300x200') label01 = tk.Label(text='Hello, World!') label01.pack() root.mainloop()Eclipse 上部の再生ボタンの右にある ▼ マークをクリックし、[実行] -> [Python 実行] を選ぶ。
プログラムの実行結果が表示される。
以上で Windows アプリを開発する準備ができた。
次回は、Tkinter の各種 UI コンポーネントを使用してみる。
- 投稿日:2020-09-20T23:03:30+09:00
phthonで背景図、コンター図、ベクトル図を重ね合わせ
やりたいこと
pythonで、背景図・コンター図・ベクトル図・カラープロット図の4種類の図を重ね合わせます。背景図はshpファイル、コンター図、ベクトル図、カラープロット図はいずれも2次元グリッドデータを用います。
背景図
背景図の読み込み、描画はgeopandasで簡単にできます。なお、geopandasをpipでインストールする際は、先にGDAL、Fionaをインストールしておかないとうまくいきませんでした。
import geopandas as gpd import matplotlib.pyplot as plt fig, ax = plt.subplots() #--1.背景図描画------------------- shapefile='line.shp' data = gpd.read_file(shapefile) ax.set_xlim([-100000,0]) ax.set_ylim([-120000,-60000]) data.plot(ax=ax, color='black') #------------------------------- plt.show()カラーコンター図
メッシュデータを読み込み、pcolormeshでカラーコンターを描画します。カラーコンターの上から、上記の背景図に重ねます。
import geopandas as gpd import matplotlib.pyplot as plt from matplotlib.colors import Normalize import numpy as np from matplotlib.cm import ScalarMappable # # (データ読み込み⇒X,Y,Z):省略 fig, ax = plt.subplots() #--2.カラーメッシュ描画------------------------------- fig, ax = plt.subplots() norm = Normalize(vmin=-500,vmax=2000) map = ax.pcolormesh(X,Y,Z, cmap='rainbow', norm=norm) # sm = ScalarMappable(cmap='rainbow', norm=norm) sm.set_clim(-500,2000) pp = fig.colorbar(sm,orientation='horizontal') #---------------------------------------------------- #1.背景図描画:同上・省略 plt.show()コンター図
上記のメッシュデータからコンター図を作成し、重ねて表示します。
# (モジュールインポート):同上・省略 # (データ読み込み⇒X,Y,Z):省略 fig, ax = plt.subplots() #2.カラーメッシュ描画:同上・省略 #--3.コンター図描画----------------------------------- cont=ax.contour(X,Y,Z, 100, colors=['purple']) #---------------------------------------------------- #1.背景図描画:同上・省略 plt.show()ベクトル図
最後にベクトル図を重ねます。ベクトルは、地形の勾配としました。
# (モジュールインポート):同上・省略 # (データ読み込み⇒X,Y,Z):省略 fig, ax = plt.subplots() #2.カラーメッシュ描画:同上・省略 #3.コンター図描画:同上・省略 cont=ax.contour(X,Y,Z, 100, colors=['purple']) #--4.ベクトル図描画----------------------------------- # (ベクトル定義⇒U,V):省略 vect=ax.quiver(X,Y,U,V,color='grey',angles='xy',scale_units='xy', scale=0.0001) ax.quiverkey(vect,0.0,1.1,1.0,'slope') #---------------------------------------------------- #1.背景図描画:同上・省略 plt.show()
- 投稿日:2020-09-20T22:42:03+09:00
Python 学習データ前処理の正規化をscikit-learn[fit_transform]で実装する
学習データの前処理にデータの実数範囲を変更する正規化と呼ばれる処理があります。
正規化の実装はscikit-learn(以下sklearn)にfit_transformと呼ばれる関数が用意されています。
今回は学習データと検証データに対して正規化を行う実装をサンプルコードと共に共有します。sklearn正規化関数
sklearnに用意されている正規化関数は主に3種類、2段階のプロセスがあります。
1. パラメータの算出
2. パラメータを用いた変換fit()
入力データから標準偏差や最大・最小値を算出しパラメータを保存
transform()
fit関数から算出されたパラメータを用いてデータを変換
fit_transform()
上記の処理を連続的に実行する
なぜ3種類の関数があるか?
あるデータに対して正規化をするのであればfit_transorm関数を用いて同時にパラメータの算出とデータ変換を行えばよいはず。。
しかし、学習の際に前処理としてデータを変換する場合、学習用データと検証用データで同様のパラメータ(fit関数の結果)を用いる必要があります。※サンプルコードで簡易な例を表示します。
そのため、あるデータに対してパラメータを算出するfit()と算出されたパラメータを用いて変換を行うtransform関数が用意されています。正規化種類
sklearnのリファレンスで調べたところ27種類もあるようです。私は2、3種類しか用いたことがありませんが興味があればご参照ください。
API Reference sklearn.preprocessing scikit-learn 0.19.2 documentationよく利用される変換手法
・MinMaxScaler() # データの最大・最小値を定義
・StandardScaler() # 標準化サンプルコード
以下、sklearnを用いた正規化のサンプルです。各行に処理の内容をコメントしています。
サンプルコードの手順としては、
- 正規化手法、テスト用データ定義
- fit_transformによる変換
- パラメータ保存->読み込み
- テスト用データ定義
- 保存パラメータによるテストデータ変換(transform)
- テストデータに対してデータ変換(fit_transform)
scaler_sample.py# importしていない場合都度、pip installしてください。 from sklearn import preprocessing import numpy as np import pickle # 正規化手法定義 MinMaxScaler(0<=data<=1) mmscaler = preprocessing.MinMaxScaler() # 学習用生データ定義 train_raw = np.array(list(range(11))) print (train_raw) # [ 0 1 2 3 4 5 6 7 8 9 10] # 学習用データでfit_transform train_transed = mmscaler.fit_transform(train_raw.reshape(-1,1)) # 変換結果表示 # 0から10のデータが0から1に変換されている print (train_transed.flatten()) # [0. 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1. ] # fitによるパラメータをバイナリ形式で保存 # 通常、学習コードと検証コードは分けて実装するためパラメータを保存する方法として紹介 pickle.dump(mmscaler, open('./scaler.sav', 'wb')) # 上記が別関数での実装と仮定して学習データで保存したfitパラメータを読み込み(バイナリファイル) save_scaler = pickle.load(open('./scaler.sav', 'rb')) # パラメータ詳細確認 print(save_scaler,type(save_scaler)) # MinMaxScaler() <class 'sklearn.preprocessing._data.MinMaxScaler'> # テスト用データ定義 test_raw = np.array(list(range(100))) print (test_raw) '''print (test_raw) [ 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99] ''' # 保存したパラメータを用いて変換(tranform) save_scaler_transed = save_scaler.transform(test_raw.reshape(-1,1)) print (save_scaler_transed.flatten()) # 学習データの重みを用いているのでデータ範囲が0から9.9になる '''print (save_scaler_transed.flatten()) [0. 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1. 1.1 1.2 1.3 1.4 1.5 1.6 1.7 1.8 1.9 2. 2.1 2.2 2.3 2.4 2.5 2.6 2.7 2.8 2.9 3. 3.1 3.2 3.3 3.4 3.5 3.6 3.7 3.8 3.9 4. 4.1 4.2 4.3 4.4 4.5 4.6 4.7 4.8 4.9 5. 5.1 5.2 5.3 5.4 5.5 5.6 5.7 5.8 5.9 6. 6.1 6.2 6.3 6.4 6.5 6.6 6.7 6.8 6.9 7. 7.1 7.2 7.3 7.4 7.5 7.6 7.7 7.8 7.9 8. 8.1 8.2 8.3 8.4 8.5 8.6 8.7 8.8 8.9 9. 9.1 9.2 9.3 9.4 9.5 9.6 9.7 9.8 9.9] ''' # テストデータを用いてパラメータ算出+変換(fit_tranform) test_fit_transed = mmscaler.fit_transform(test_raw.reshape(-1,1)) # テスト用データからパラメータを算出しているためデータ範囲が0から1になる print (test_fit_transed.flatten()) '''print (test_fit_transed.flatten()) [0. 0.01010101 0.02020202 0.03030303 0.04040404 0.05050505 0.06060606 0.07070707 0.08080808 0.09090909 0.1010101 0.11111111 0.12121212 0.13131313 0.14141414 0.15151515 0.16161616 0.17171717 0.18181818 0.19191919 0.2020202 0.21212121 0.22222222 0.23232323 0.24242424 0.25252525 0.26262626 0.27272727 0.28282828 0.29292929 0.3030303 0.31313131 0.32323232 0.33333333 0.34343434 0.35353535 0.36363636 0.37373737 0.38383838 0.39393939 0.4040404 0.41414141 0.42424242 0.43434343 0.44444444 0.45454545 0.46464646 0.47474747 0.48484848 0.49494949 0.50505051 0.51515152 0.52525253 0.53535354 0.54545455 0.55555556 0.56565657 0.57575758 0.58585859 0.5959596 0.60606061 0.61616162 0.62626263 0.63636364 0.64646465 0.65656566 0.66666667 0.67676768 0.68686869 0.6969697 0.70707071 0.71717172 0.72727273 0.73737374 0.74747475 0.75757576 0.76767677 0.77777778 0.78787879 0.7979798 0.80808081 0.81818182 0.82828283 0.83838384 0.84848485 0.85858586 0.86868687 0.87878788 0.88888889 0.8989899 0.90909091 0.91919192 0.92929293 0.93939394 0.94949495 0.95959596 0.96969697 0.97979798 0.98989899 1. ] '''おわりに
正規化について学んだ内容を備忘録としてこちらの記事にしました。調べる前はfit_transform()とtransform()の違いに全く気が付きませんでした。。前処理の重要な変換であり、検証するデータの精度にも影響する箇所です。パラメータが不手際で再利用されるケースなどがないことを願っております。
この記事を作成するに当たり、先人の知恵をお借りしました。
後日、記載させていただきます。
ご一読ありがとうございました。LGTMも良ければお願いします!
- 投稿日:2020-09-20T22:18:56+09:00
[Python] Pipelineって何だよ...
※このページは,Pipelineをなんとなく理解したい人を対象としています.
こんにちは.
突然ですが,自分は機械学習や深層学習に興味があったので,最近kaggleのコンペに参加してみたんです.
kaggleにはNotebook機能があるのでそのコードを理解しよう!と意気込んでいたのですが...「何これ,全く意味わからん」
全くプログラミングの知識がない状態なので,kaggleのNotebookのコードを見ても,暗号にしか見えませんでした(笑).
そこで,一つずつゆっくり理解していこうと思ったのでここに日記感覚で記載していきたいと思います.今回は,「Pipeline」についてです.
※今回本記事に載せるデータはirisデータです
import numpy as np import matplotlib.pyplot as plt from sklearn import datasets iris_data = datasets.load_iris() input_data = iris_data.data correct = iris_data.targetとりあえず下記のサイトにアクセスしました.
sklearn.pipeline.Pipeline — scikit-learn 0.23.2 documentationこれによると,基本の形は
from sklearn.pipeline import Pipeline
pipe = Pipeline([(前処理方法), (学習方法)])
pipe.fit(説明変数, 目的変数)のようで,どうやらコードを簡潔化出来るみたいなんです.
これを基にirisデータをランダムフォレストで学習させてみました.
from sklearn.ensemble import RandomForestClassifier as RFC X_train, X_test, y_train, y_test = train_test_split(input_data, correct) pipe = Pipeline([('scaler', StandardScaler()), ('RandomForestClassifier', RFC())]) pipe.fit(X_train, y_train) pipe.score(X_test, y_test) # 0.9473684210526315上記により,説明変数を標準化してランダムフォレストで学習を行っていることになりました.
このように,Pipelineにまとめることで,コードが「簡潔」になります.以下,確認のために記載したコードです.
X_train, X_test, y_train, y_test = train_test_split(input_data, correct) tr_x, te_x, tr_y, te_y = X_train.copy(), X_test.copy(), y_train.copy(), y_test.copy() # 検算用にコピー pipe = Pipeline([('scaler', StandardScaler()), ('Classifier', RFC())]) pipe.fit(X_train, y_train) print("pipe score = " + str(pipe.score(X_test, y_test))) from sklearn.preprocessing import StandardScaler stdsc = StandardScaler() tr_x = stdsc.fit(tr_x).transform(tr_x) te_x = stdsc.fit(te_x).transform(te_x) clf = RFC() clf.fit(tr_x, tr_y) print("RFC score = ", clf.score(te_x, te_y)) # pipe score = 0.9473684210526315 # RFC score = 0.9473684210526315検算でも一致できたので,Pipelineの前処理が正しく動いてくれたことが分かりました.
なるほど,なんとなくPipelineについて分かりました.
でも,前処理っていっても何個もあるのに,一つだけしか実行できないの?どうやら複数の処理をまとめることが出来るようです.
from sklearn.pipeline import Pipeline from sklearn.ensemble import RandomForestClassifier as RFC from sklearn.preprocessing import OneHotEncoder from sklearn.impute import SimpleImputer preprocessing = Pipeline([ ('imputer', SimpleImputer(strategy='constant', fill_value='missing')), # 欠損値除去の処理 ('onehot', OneHotEncoder(handle_unknown='ignore'))]) # ワンホットエンコーディング rf = Pipeline([ ('preprocess', preprocessing), ('classifier', RFC())]) rf.fit(X_train, y_train)このように,
基本形である pipe = Pipeline([(前処理方法), (学習方法)])
の(前処理方法)には,イメージとしてはBNF記法(あくまでもイメージの話です)のようにPipelineを重ね掛けして行うことが一つの方法として挙げられるようです.
- 投稿日:2020-09-20T22:10:50+09:00
python anywhere で作ったWebアプリケーション(Django)に『Hello World!』を表示させてみた!
いよいよpython anywhere で作成した、Webアプリケーションに
『Hello World!』 を表示させてみましょう!
前回作成した、ディレクトリ構造から確認します!
????ディレクトリ構造
mysite/
|
|-manage.py
|-mysite/
|
|-init.py (←変更なし)
|-settings.py (←変更なし)
|-urls.py (←変更を加えます)
|-views.py (←新しいファイルを作成、ファイル名views.pyにしてください)
|-wsgi.py (←変更なし)????
次のステップに進みます。
1、urls.py はクライアントからのリクエストを受け取る場所です!
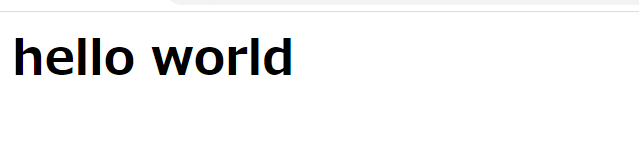
mysite/mysite/urls.pyfrom django.contrib import admin form django.urls import path from .views import hellofunction ←追加コード urlpatterns = [ path('admin/', admin.site.urls), path('hello/', hellofunction), ←追加コード2, views,py は見た目の部分を司るところです。(下記のコードを完成させましょう)
mysite/mysite/views,pyfrom django.http import HttpResponse def hellofunction(request): return HttpResponse('<h1>Hello World!<h1>')すべて、書き終えたらDashbordからReloadをして、
Configuration forの下のURLをクリックし、
次のアドレスを直接ブラウザのアドレスバーに入力してください! /hello/ を追記します。
https://アカウント名.pythonanywhere.com/hello/
これで、成功です?????
MVCモデルのうち、今日はV(view)とC(controller)の部分を扱いました。
次回は、M(model)を説明したいと思います!
- 投稿日:2020-09-20T21:21:39+09:00
Python, OpenCVを使ってPCのカメラからタイムラプスを撮影する
はじめに
蟻を飼うことにしました。クロオオアリです。水曜日に、巣とコロニーが届きます。
せっかくなので研究室に行っている間の彼らも観察したい!だからといってスマホを家に置いたまま外出するのは不便すぎる…。
ちょうどプライベート用のPCを持て余していたので、こいつを使って外出中のコロニーの様子を、タイムラプスで撮影しようと思いました。
プログラミング初心者なので、勉強も兼ねて初歩的な内容も書いています。方法
Python 3.7.3
Anaconda Prompt
PC付属のwebカメラを使用
事前にコマンドプロンプト上で次のように打ち込み、OpenCVをインストールする必要があります。$ pip install opencv-pythonコード
timelaps.pyimport cv2 import glob import os import shutil import time from datetime import datetime ### もろもろの初期設定 date = datetime.now().strftime("%Y%m%d_%H%M%S") if not os.path.exists(date): os.mkdir(date) # 画像保存用のフォルダ作製 # とりあえずwaiting_time秒待ってから撮影をスタートさせる capture_interval = 0.5 # 画像取得間隔(秒) waiting_time = 0 print('Recording will be started in {0} seconds'.format(waiting_time)) time.sleep(waiting_time) print('Start') ### 画像の撮影 def capture(): cap = cv2.VideoCapture(0) # 任意のカメラ番号に変更する。1台だけならカメラ番号は0。 while True: # capture_interval秒ごとに画像の読み込みおよび保存を行う。 ret, frame = cap.read() # カメラからキャプチャされた画像をframeとして読み込む cv2.imshow("camera", frame) # frameを画面に表示。なぜかこいつを残しておかないとenterで操作を止められない。 k = cv2.waitKey(1)&0xff # キー入力を待つ。引数は入力待ち時間。 # カレントディレクトリ内にある「img」フォルダに「(date).jpg」というファイル名でファイルを保存 date_time = datetime.now().strftime("%Y%m%d%H%M%S") path = "./{0}/".format(date) + date_time + ".jpg" cv2.imwrite(path, frame) # 画像をフォルダへ保存 # エンターキーを押したら撮影終了 if k == 13: break time.sleep(capture_interval) cap.release() cv2.destroyAllWindows() ### 画像のタイムラプス化 def timelaps(): images = sorted(glob.glob('{0}/*.jpg'.format(date))) # 撮影した画像の読み込み。 print("画像の総枚数{0}".format(len(images))) if len(images) < 30: #FPS設定 frame_rate = 2 else: frame_rate = len(images)/30 width = 640 height = 480 fourcc = cv2.VideoWriter_fourcc('m','p','4','v') # 動画のコーデックをmp指定。(ちょっと違うが)動画の拡張子を決める、 video = cv2.VideoWriter('{0}.mp4'.format(date), fourcc, frame_rate, (width, height)) # 作成する動画の情報を指定(ファイル名、拡張子、FPS、動画サイズ)。 print("動画変換中...") for i in range(len(images)): # 画像を読み込む img = cv2.imread(images[i]) # 画像のサイズを合わせる。 img = cv2.resize(img,(width,height)) video.write(img) video.release() print("動画変換完了") def capture_delete(): shutil.rmtree(date) if __name__ == '__main__': start = time.time() capture() timelaps() capture_delete() elapsed_time = time.time() - start print ("処理にかかった時間は:{0}".format(elapsed_time) + "[sec]")コードの解説
概要
- 一定間隔で写真撮影し、フォルダに保存
- フォルダに保存した画像をつなげた動画(タイムラプス)を作製、保存
- タイムラプスの材料となった大量の写真をフォルダごと削除
- 最後に、所要時間を報告。
def capture() 以前
画像を保存するフォルダをmkdirにて作成します。フォルダ名は何でも構いません。今回は、2020年9月20日13時57分09秒に作成した場合「20200920_135709」という名前のフォルダが作成されます。同名のフォルダが既に存在するとos.mkdirのところがエラーを吐くので、同名のフォルダがない場合のみフォルダを作成するようにしています。
画像を取得する間隔(waiting_time)を設定します。動かしてからいきなり撮影が始まると、蟻より先に僕が映ってしまうので、waiting_time秒だけ待たせます。capture()
コード中のコメントを読んでいただけると、何をしているかわかると思います。撮影されたのが2020年9月20日12時34分56秒ならファイル名は「20200920123456」になります。容量を食いすぎるのがなんとなく怖いのでpngではなくjpgにしています。k == 13というのはエンターキーが押されることに相当します。保存先を指定するのにformat()メソッドがとても便利でした。
timelaps()
まず、撮影した画像を読み込みます。sorted関数を使って数字の若い順(つまり撮影された順番)にソートされたリストを生成しています。が、ぶっちゃけ今回の方法なら
images = glob.glob('{0}/*.jpg'.format(date))でも問題なく動きます。
次に1秒間に用いられる画像の枚数(FPS)を設定します。とりあえず長時間撮影しても30秒の動画に収まるようにしてみました。
動画の画面サイズを設定(画像のデフォルトが640*480なのでそれに合わせています。)したら動画を作っていきます。cv2.imread()でi番目の画像を読み込み、画像のサイズを動画用のサイズに整えた後に動画へ差し込んでいきます。これを全画像に対して繰り返すことで動画を作成します。capture_delete()
画像の保存用に作ったフォルダ(date)を削除します。
1行なのでわざわざ関数として定義しなくても良いのですが、なんとなく見栄えが良いので関数にしてみました。結果
コマンドプロンプト上で実行すると、以下のような文章が表示されます。
Recording will be started in 0 seconds Start [ WARN:0] global C:\Users\appveyor\AppData\Local\Temp\1\pip-req-build-2b5g8ysb\opencv\modules\videoio\src\cap_msmf.cpp (435) `anonymous-namespace'::SourceReaderCB::~SourceReaderCB terminating async callback 画像の総枚数10 動画変換中... 動画変換完了 処理にかかった時間は:12.048035621643066[sec][WARN:0]のところはよく理解できませんでした。動いたので良しとしています。テキトーですね。
Pythonを動かしたディレクトリにおいて、動画のファイルが得られています。
蟻が届いてから、実際に撮影した動画を載せるつもりです。おわりに
PCのカメラから写真を撮影し、撮影した写真をもとにタイムラプスを作成するプログラムについて、初心者向けに述べました。
ディレクトリ、for, whileなどの知識さえあればそんなに難しくないので、プログラミング初心者の方もぜひやってみてください。
また、勉強中の身ですので、ご指摘・コメント・アドバイス等ございましたら、いただけますと幸いです。参考文献
作成にあたり参考にさせていただいたページを以下に示します。
format() メソッド
https://gammasoft.jp/blog/python-string-format/
OpenCV
OpenCV全般
http://labs.eecs.tottori-u.ac.jp/sd/Member/oyamada/OpenCV/html/py_tutorials/py_gui/py_image_display/py_image_display.html
http://labs.eecs.tottori-u.ac.jp/sd/Member/oyamada/OpenCV/html/py_tutorials/py_gui/py_video_display/py_video_display.html#display-video画像のキャプチャ
http://rikoubou.hatenablog.com/entry/2019/03/07/153430waitKey()関数
https://qrunch.net/@opqrstuvcut/entries/XZsZ0jUEX6RatMER?ref=qrunch
https://www.kishugiken.co.jp/cn/code02.html画像から動画への変換
https://yusei-roadstar.hatenablog.com/entry/2019/11/29/174448os, shutil
https://note.nkmk.me/python-os-remove-rmdir-removedirs-shutil-rmtree/
以上です。ここまで読んでくださりありがとうございました。
- 投稿日:2020-09-20T21:10:15+09:00
Python 優先度付きキュー 殆どの人が興味無さそうなheapify関数の結果の謎
はじめに
Pythonで優先度付きキューの挙動で謎な部分があり調べてみた。
不可解な挙動
こちらを参考に、Pythonで優先度付きキューが調べていたところ、heapqライブラリで実現が可能とのこと。
上記リンク先にでは、heapqの使用例として以下の通り記載されていた。#引用元:https://qiita.com/ell/items/fe52a9eb9499b7060ed6 import heapq # heapqライブラリのimport a = [1, 6, 8, 0, -1] heapq.heapify(a) # リストを優先度付きキューへ print(a) # 出力: [-1, 0, 8, 1, 6] (優先度付きキューとなった a)なぜ出力がこの並び([-1, 0, 8, 1, 6] )なのか?
誰も興味無さそうな疑問が湧いてきた(昇順を期待してたので)。理由:リストの要素をヒープキューアルゴリズムでソートしているため
Pythonでは、優先度付きキューをリストで表現している様であるが、
python documentによると、ヒープキューアルゴリズムでリストの内容を並べ替えしているとのこと。こちらのヒープの説明サイトにて、ヒープのアルゴリズムの説明が詳しく記載されているが、
木構造をリストで表現できるとのこと(親ノードのリストインデックスをiとすると、子の左ノードが2*i、右ノードが2*i+1)。
親子関係が成立する様に、リスト内の要素を入れ替えすると、上記の出力が得られた。ヒープキューアルゴリズムによるソートの流れ
※詳しいアルゴリズムはこちらを参照
ヒープの条件:各ノードがその子ノードより小さいか等しい
初期配列:[1, 6, 8, 0, -1]

- 投稿日:2020-09-20T20:50:09+09:00
Jupyter notebook の ipynb ファイルの中身を見たいときの方法
2020.09.20投稿
必要性
Jupyter notebook 上でコードを書いていて、「あのとき作った Jupyter のコードをコピーしたい!」ということがよくある。その ipynb ファイルが、たまたま今開いている Jupyter のディレクトリの下にあればいいのだが、そうでない場合は、一度 Jupyter notebook を終了・再起動し所要の ipynb ファイルを開いてエディタにコピー、もとの作業に戻るため Jupyter notebook を再起動するという手間をかけていた。
なんとかならないかと思いながら調べていたら、効率よく他の ipynb ファイルの中身を確認する以下の3つの方法があることがわかったので、紹介しておく。
もしここに記載の方法を使ったことにより不都合なことが起きても、筆者は知りません。
自分の責任においてトライしてください。VS code を使う
こちらのサイトに方法が記載されている。
私は VS Cod を使う方法を選択し使ってみた。
Mac の Get info の Open with: で、VS code をデフォルトにしておけば、ipynb ファイルをダブルクリックすることで開くことができる。
Jupyter lab を使う
Jupyter Lab なら複数のタブを開ける!
そこでさっそくインストールして調子を見ているところです。
私のマシンではなんとなく動きがもっさりしている感じ。複数のブラウザで Jupyter を開く
Jupyter notebook でも これ(
http://localhost:8888/?token=xxxxxx......)を url に入れてやると違うブラウザで Jupyter notebook を開ける。
例えば、私の場合、default は Safari であるが、terminal に出てくるこれ(http://localhost:8888/?token=xxxxxx......)を Firefox や Chrome の url にいれることにより、それぞれのブラウザで notebook を開ける。以 上
- 投稿日:2020-09-20T20:42:07+09:00
for文を使わずに、numpy の割り算でやってみよう
ある軸で正規化したいとき
軸毎にスケールが違って、まとめて比較するとつぶれてしまう場合に、軸毎に最大値や合計値で割って正規化して比較したい。
for文でもできるけど、keepdims=True 使うと簡単にできる。
sumした後わざわざ軸追加したけど、keepdimsで同じことができるとは。このためにあるぐらいって気がする。AAA = np.arange(24).reshape((2,3,4)) print("AAA.shape=", AAA.shape) print("AAA=", AAA) sAAA = AAA.sum(-1, keepdims=True) # sAAA = AAA.sum(-1)[..., np.newaxis] と同じ. nAAA = AAA / sAAA print("\nsAAA.shape=", sAAA.shape) print("\nnAAA=", nAAA) mAAA = AAA.max(1, keepdims=True) # mAAA = AAA.max(1)[:, np.newaxis] と同じ nAAA = AAA / mAAA print("\nmAAA.shape=", mAAA.shape) print("\nnAAA=", nAAA) mAAA = AAA.max((0,2), keepdims=True) nAAA = AAA / mAAA print("\nsAAA.shape=", sAAA.shape) print("\nnAAA=", nAAA)AAA.shape= (2, 3, 4) AAA= [[[ 0 1 2 3] [ 4 5 6 7] [ 8 9 10 11]] [[12 13 14 15] [16 17 18 19] [20 21 22 23]]] sAAA.shape= (2, 3, 1) nAAA= [[[0. 0.16666667 0.33333333 0.5 ] [0.18181818 0.22727273 0.27272727 0.31818182] [0.21052632 0.23684211 0.26315789 0.28947368]] [[0.22222222 0.24074074 0.25925926 0.27777778] [0.22857143 0.24285714 0.25714286 0.27142857] [0.23255814 0.24418605 0.25581395 0.26744186]]] mAAA.shape= (2, 1, 4) nAAA= [[[0. 0.11111111 0.2 0.27272727] [0.5 0.55555556 0.6 0.63636364] [1. 1. 1. 1. ]] [[0.6 0.61904762 0.63636364 0.65217391] [0.8 0.80952381 0.81818182 0.82608696] [1. 1. 1. 1. ]]] sAAA.shape= (2, 3, 1) nAAA= [[[0. 0.06666667 0.13333333 0.2 ] [0.21052632 0.26315789 0.31578947 0.36842105] [0.34782609 0.39130435 0.43478261 0.47826087]] [[0.8 0.86666667 0.93333333 1. ] [0.84210526 0.89473684 0.94736842 1. ] [0.86956522 0.91304348 0.95652174 1. ]]]
- 投稿日:2020-09-20T18:30:05+09:00
python3の入門 #2 型と変数について学ぶ
どうも、beatbox4108と申します。
今回は、高度な計算について学ぶ...予定でしたが、説明の必要がある、pythonの型と、変数について学びたいと思います。
注意:今回から、インタラクティブシェルの使用回数が急激に増えます。使い方を確認してください。対象としている人
プログラミング初心者で、pythonを学ぼうとしている方
教育現場で、pythonを使いたいが、説明方法がわからない教員の方前提
python3がpcにインストールされている。
開発環境の使い方がわかる。
前回までの演習を理解している。型について学ぶ
まずざっくりと
pythonで言う型は、データの種類を表すものです。
基本となるものは、次のものです。
型の名前 型の種類 型の使用例 int 整数値を扱います。 4108float 小数値を扱います。 41.08str 文字列を扱います。 "beatbox4108"bool ブールを扱います。 Trueboolなんていう変な型がありますが、後ほど詳しく説明します。
int型、float型って何なんだ!
上の表で見たように数値を扱います。
int型を、強制的にfloat型にするには、float()関数を使います。
float型を、強制的にint型にするには、int()関数を使います。例:
>>> int(41.08) 41 >>> float(4108) 4108.0str型は、何だ!
上の表で見たように、文字列(文字の並び)を扱います。
int型などといった、多くの型は、str()関数を使い、str型に変換できます。str型には、多くの、メソッドがあります。
ちょっと待て、メソッドとはなんぞや!
メソッドとは、型に関する操作をまとめた関数もどきです。(違ってたらすみません。)
メソッドは、データのあとに.(ピリオド)をつけて、関数のように呼び出します。
こんな感じ:>>> "beatbox4108".replace("4108","8192") "beatbox8192"str型のよく使うメソッドを表にまとめておきます。詳しくは調べてみてください。
メソッド名 説明 使用法 戻り値 replace 文字を置き換えます .replace(置き換え前の文字列,置き換え後の文字列)置き換え後の文字列(str型) split 文字列を、特定の文字で分割します .split(区切る文字)分割後のリスト(list型) upper アルファベットを全て大文字にします .upper()変更後の文字列(str型) lower アルファベットを全て小文字にします .lower()変更後の文字列(str型) 戻り値とは、関数を使用したときに、帰ってくるデータのことです。
splitメソッドの戻り値は、list型と、わからないでしょうが、次回以降説明します。bool型なんて、さっぱりわからん!
bool型は、上の表で見たように...って説明できん!!
気を取り直してbool型は、TrueとFalseで表される、特殊な型です。
TrueとFalseには、次のような意味があります。
True False 正 偽 「全くわからん」って声が聞こえそうですが、条件式を勉強する際に説明します。
ちなみに、TrueとFalseは、notで、反転できます。>>> not True False変数について学ぶ
まずざっくりと
pythonで言う、変数は、簡単に言うと値に名前(名札)をつけるようなことです。
変数は、変数名=値の形式で作成・変更できます。
変数を読み出すときは、変数名を値の代わりに入力すれば、読み出せます。数学大好き君:
なんで
x=1と書いたのに、
x=2と入力すると、xが2になるんだよ!ちぇっ例:
>>>hello="こんにちは" >>>print(hello) こんにちは変数を使うときのテクニック
次のように書くと、四則計算の省略ができます。
省略前:x=10 x=x+3 x=x-3 x=x*3 x=x/3 print(x)省略後:
x=10 x+=3 x-=3 x*=3 x/=3 print(x)今回のまとめ
pythonで言う型は、データの種類を表すもの。
pythonで言う、変数は、簡単に言うとデータをいれる箱のようなもの。
変数は、変数名=値の形式で作成・変更できる。
変数を読み出すときは、変数名を値の代わりに入力すれば、読み出せる。今回の演習はここまでです。次回も楽しみにしてください。
目次へ移動
- 投稿日:2020-09-20T18:22:28+09:00
pythonで直感的な相対importができるツール
結論
pip install relpathfrom relpath import add_import_path add_import_path("../") from my_module import some_functionポイント
- pythonでは、相対import時に、そのファイルからの相対パスにならない
概要
このパッケージでできること:
1. 直感的な相対パス参照ができる
- pythonのパス参照の仕様は直感に反する
2. モジュールの相対importに使える
- フォルダが多重で複雑なプロジェクトにも対応できる使い方1: 基本的な例
下記は、pythonファイル自身の場所(ディレクトリ)を取得する例です。
import relpath as rp print(rp.rel2abs("./")) # -> "(このpythonファイルが存在するディレクトリ)"使い方2: 実用的な例
このツールは、下記のような場合に真価を発揮します。
. `-- project_folder |-- parts | |-- data.txt | `-- script_B.py `-- script_A.py上記のように、複数のpythonファイルからなるプロジェクトを考えます。
script_A.pyの中では下記のように、script_B.pyを利用します。# script_A.py # load script_B.py from parts.script_B import get_data print(get_data())この場合に、下記のコード例のように、
script_B.pyから"./data.txt"を相対的に読み込もうとすると失敗します。(注1)(注1) 厳密には、`script_A.py`からの相対パス指定をすれば読み込めますが、 呼び出し元が別の場所に変更された場合、正常に動作しなくなるので、メンテナンス性が悪くなります。 これを回避するため、`relpath`パッケージの利用を推奨します。# script_B.py def get_data(): with open("./data.txt", "r") as f: # -> FileNotFoundError: [Errno 2] No such file or directory: './data.txt' return f.read()そこで、
relpathパッケージを使って下記のように書くと、
"./data.txt"を相対的に読み込めるようになります。(注2)# script_B.py from relpath import rel2abs def get_data(): with open(rel2abs("./data.txt"), "r") as f: # -> NO ERROR!! return f.read()(注2) 相対パスに関するpythonの仕様は、必ずしも間違いというわけではありません。 pythonの仕様(相対パスの指定が、記述するファイルの場所に関わらず、常に最初の呼び出し元を基準として解釈される仕様)には、 プログラムを開発する中でもしファイル読み込み等の命令を記述する場所(ファイル)が変更になった場合でも、 パス指定方法の変更が不要になるという利点があります。 `relpath`パッケージは、pythonの仕様の他に、プログラマーにもう一つの選択肢を与える手段に過ぎないので、 状況に応じて利用の要否を検討することを推奨します。使い方3: 相対importとしての利用
relpathパッケージを利用すると、下記の例のように、
モジュールの直感的な相対importを実現できます。from relpath import add_import_path add_import_path("../") from my_module import some_function some_function()上記の例を見ると、単に
sys.path.append("../")としても動作するように思われます。
しかし、プロジェクトフォルダの階層構造が複雑で、1つのモジュールが別々の場所から使われるような場合には、sys.path.append("../")では対応できないことがあります。
そのため、相対importを実現したいときは、常にrelpathパッケージのadd_import_pathを利用することを推奨します。なお、
add_import_path("../")
は、内部的にはsys.path.append(rel2abs("../"))と等価です。
- 投稿日:2020-09-20T18:22:28+09:00
[Python] 直感的な相対importができるツール
問題提起
- Pythonは、上位のディレクトリや遠く離れたディレクトリからimportできない
- Pythonの相対importは直感的ではない
- 「そのファイル」からの相対位置指定ではない。呼び出し元ファイル(最初に実行されるpythonファイル)が変わると、相対importの参照がずれる
- Pythonでは、自作ツールを複数のプロジェクトからimportするときのディレクトリ構成が難しい
- 上位のディレクトリ・兄弟のディレクトリからのimportが難しいため
結論
相対パス参照のパッケージをインストール
pip install relpathfrom relpath import add_import_path add_import_path("../") # ここで、importしたいツールの場所を相対参照で指定 from my_module import some_function詳細説明 (相対import)
relpathパッケージを利用すると、下記の例のように、
モジュールの直感的な相対importを実現できます。from relpath import add_import_path add_import_path("../") from my_module import some_function some_function()上記の例を見ると、単に
sys.path.append("../")としても動作するように思われます。
しかし、プロジェクトフォルダの階層構造が複雑で、1つのモジュールが別々の場所から使われるような場合には、sys.path.append("../")では対応できないことがあります。
そのため、相対importを実現したいときは、常にrelpathパッケージのadd_import_pathを利用することを推奨します。その他の使い方
relpathパッケージを使うと、importに限らず、
直感的な相対パス参照が可能です。例えば、下記のような複数のpythonファイルからなるプロジェクトを考えます。
. `-- project_folder |-- parts | |-- data.txt | `-- script_B.py `-- script_A.py
script_A.pyの中では下記のように、script_B.pyを利用します。# script_A.py # load script_B.py from parts.script_B import get_data print(get_data())この場合に、下記のコード例のように、
script_B.pyから"./data.txt"を相対的に読み込もうとすると失敗します。(注1)(注1)
厳密には、script_A.pyからの相対パス指定をすれば読み込めますが、
呼び出し元が別の場所に変更された場合、正常に動作しなくなるので、メンテナンス性が悪くなります。
これを回避するため、relpathパッケージの利用を推奨します。# script_B.py def get_data(): with open("./data.txt", "r") as f: # -> FileNotFoundError: [Errno 2] No such file or directory: './data.txt' return f.read()そこで、
relpathパッケージを使って下記のように書くと、
"./data.txt"を相対的に読み込めるようになります。(注2)# script_B.py from relpath import rel2abs def get_data(): with open(rel2abs("./data.txt"), "r") as f: # -> NO ERROR!! return f.read()(注2)
相対パスに関するpythonの仕様は、必ずしも間違いというわけではありません。
pythonの仕様(相対パスの指定が、記述するファイルの場所に関わらず、常に最初の呼び出し元を基準として解釈される仕様)には、
プログラムを開発する中でもしファイル読み込み等の命令を記述する場所(ファイル)が変更になった場合でも、
パス指定方法の変更が不要になるという利点があります。
relpathパッケージは、pythonの仕様の他に、プログラマーにもう一つの選択肢を与える手段に過ぎないので、
状況に応じて利用の要否を検討することを推奨します。参考
relpathパッケージのPyPIリンク
- 投稿日:2020-09-20T17:49:32+09:00
Django スケジュールのためのモデルを作成する
シフト表を作るためのアプリを作成していきます。
terminalpython3 manage.py startapp scheduleセッティングにアプリを追加します。
config/settings.pyINSTALLED_APPS = [ 'django.contrib.admin', 'django.contrib.auth', 'django.contrib.contenttypes', 'django.contrib.sessions', 'django.contrib.messages', 'django.contrib.staticfiles', 'accounts.apps.AccountsConfig', 'shisetsu', 'colorfield', 'schedule' ]作成したscheduleアプリにテーブルを作成していきます。
シフトは、Aが9:00~18:00 といったように管理するようにします。
また、有給を取得した場合ように有っていれることがあります。
そのため、テキストフィールドで持つようにしようと思います。スケジュールについては、1日に複数のシフトに入ることがあり、複数の施設で働くことがあるっていうこと。
3以上のシフトにはいることは今まで発生したことがないとのこと。それを踏まえて以下のテーブルで作ってみようと思います。
schedule/models.pyfrom django.db import models from shisetsu.models import * from accounts.models import * # Create your models here. class Shift(models.Model): id = models.IntegerField(verbose_name='シフトID',primary_key=True) name = models.CharField(verbose_name='シフト名', max_length=1) start_time = models.TimeField(verbose_name="開始時間") end_time = models.TimeField(verbose_name="終了時間") wrok_time = models.IntegerField(verbose_name='勤務時間') def __str__(self): return self.name class Schedule(models.Model): id = models.IntegerField(verbose_name='スケジュールID',primary_key=True) user = models.OneToOneField(User, on_delete=models.CASCADE) date = models.DateField(verbose_name='日付') shift_id_1= models.ForeignKey(Shift, verbose_name='1シフト名', on_delete=models.CASCADE) shisetsu_id_1 = models.ForeignKey(Shisetsu, verbose_name='1施設', on_delete=models.CASCADE) shift_id_2 = models.ForeignKey(Shift, verbose_name='2シフト名', on_delete=models.CASCADE) shisetsu_id_2 = models.ForeignKey(Shisetsu, verbose_name='2施設', on_delete=models.CASCADE) shift_id_3 = models.ForeignKey(Shift, verbose_name='3シフト名', on_delete=models.CASCADE) shisetsu_id_3 = models.ForeignKey(Shisetsu, verbose_name='3施設', on_delete=models.CASCADE) shift_id_4 = models.ForeignKey(Shift, verbose_name='4シフト名', on_delete=models.CASCADE) shisetsu_id_4 = models.ForeignKey(Shisetsu, verbose_name='4施設', on_delete=models.CASCADE)これでは、いけなかったです
これを調べること2~3時間
マイグレーションができたのがこれです。schedule/models.pyfrom django.db import models from shisetsu.models import * from accounts.models import * # Create your models here. class Shift(models.Model): id = models.IntegerField(verbose_name='シフトID',primary_key=True) name = models.CharField(verbose_name='シフト名', max_length=1) start_time = models.TimeField(verbose_name="開始時間") end_time = models.TimeField(verbose_name="終了時間") wrok_time = models.IntegerField(verbose_name='勤務時間') def __str__(self): return self.name class Schedule(models.Model): id = models.IntegerField(verbose_name='スケジュールID',primary_key=True) user = models.OneToOneField(User, on_delete=models.CASCADE) date = models.DateField(verbose_name='日付') shift_name_1 = models.ForeignKey(Shift, verbose_name='1シフト名', related_name='shift_name1',on_delete=models.SET_NULL,null= True) shisetsu_name_1 = models.ForeignKey(Shisetsu, verbose_name='1施設', related_name='shisetsu_name1',on_delete=models.SET_NULL,null= True) shift_name_2 = models.ForeignKey(Shift, verbose_name='2シフト名', related_name='shift_name2',on_delete=models.SET_NULL,null= True) shisetsu_name_2 = models.ForeignKey(Shisetsu, verbose_name='2施設', related_name='shisetsu_name2',on_delete=models.SET_NULL,null= True) shift_name_3 = models.ForeignKey(Shift, verbose_name='3シフト名', related_name='shift_name3',on_delete=models.SET_NULL,null= True) shisetsu_name_3 = models.ForeignKey(Shisetsu, verbose_name='3施設', related_name='shisetsu_name3',on_delete=models.SET_NULL,null= True) shift_name_4 = models.ForeignKey(Shift, verbose_name='4シフト名', related_name='shift_name4',on_delete=models.SET_NULL,null= True) shisetsu_name_4 = models.ForeignKey(Shisetsu, verbose_name='4施設', related_name='shisetsu_name4',on_delete=models.SET_NULL,null= True)やっとできた…
長かったし、ひとつのテーブルで同じテーブルに複数参照する場合、rerated_name をそれぞれ設定しないといけないということです。仮データを入力していた時に、idを自動インクリメントに変更しました
schedule/models.pyfrom django.db import models from shisetsu.models import * from accounts.models import * # Create your models here. class Shift(models.Model): id = models.AutoField(verbose_name='シフトID',primary_key=True) name = models.CharField(verbose_name='シフト名', max_length=1) start_time = models.TimeField(verbose_name="開始時間") end_time = models.TimeField(verbose_name="終了時間") wrok_time = models.IntegerField(verbose_name='勤務時間') def __str__(self): return self.name class Schedule(models.Model): id = models.AutoField(verbose_name='スケジュールID',primary_key=True) user = models.OneToOneField(User, on_delete=models.CASCADE) date = models.DateField(verbose_name='日付') shift_name_1 = models.ForeignKey(Shift, verbose_name='1シフト名', related_name='shift_name1',on_delete=models.SET_NULL,null= True) shisetsu_name_1 = models.ForeignKey(Shisetsu, verbose_name='1施設', related_name='shisetsu_name1',on_delete=models.SET_NULL,null= True) shift_name_2 = models.ForeignKey(Shift, verbose_name='2シフト名', related_name='shift_name2',on_delete=models.SET_NULL,null= True) shisetsu_name_2 = models.ForeignKey(Shisetsu, verbose_name='2施設', related_name='shisetsu_name2',on_delete=models.SET_NULL,null= True) shift_name_3 = models.ForeignKey(Shift, verbose_name='3シフト名', related_name='shift_name3',on_delete=models.SET_NULL,null= True) shisetsu_name_3 = models.ForeignKey(Shisetsu, verbose_name='3施設', related_name='shisetsu_name3',on_delete=models.SET_NULL,null= True) shift_name_4 = models.ForeignKey(Shift, verbose_name='4シフト名', related_name='shift_name4',on_delete=models.SET_NULL,null= True) shisetsu_name_4 = models.ForeignKey(Shisetsu, verbose_name='4施設', related_name='shisetsu_name4',on_delete=models.SET_NULL,null= True)続きとしては、一度作ったシフトを正しく表示させていきたいと思うので、
面倒くさいですが1か月分のシフトを手づくりしようと思いますスケジュールを登録しようとしたら、シフトが必須入力になっているので
解除しました。schedule/models.pyfrom django.db import models from shisetsu.models import * from accounts.models import * # Create your models here. class Shift(models.Model): id = models.AutoField(verbose_name='シフトID',primary_key=True) name = models.CharField(verbose_name='シフト名', max_length=1) start_time = models.TimeField(verbose_name="開始時間") end_time = models.TimeField(verbose_name="終了時間") wrok_time = models.IntegerField(verbose_name='勤務時間') def __str__(self): return self.name class Schedule(models.Model): id = models.AutoField(verbose_name='スケジュールID',primary_key=True) user = models.OneToOneField(User, on_delete=models.CASCADE) date = models.DateField(verbose_name='日付') shift_name_1 = models.ForeignKey(Shift, verbose_name='1シフト名', related_name='shift_name1',on_delete=models.SET_NULL,null= True) shisetsu_name_1 = models.ForeignKey(Shisetsu, verbose_name='1施設', related_name='shisetsu_name1',on_delete=models.SET_NULL,blank=True, null=True) shift_name_2 = models.ForeignKey(Shift, verbose_name='2シフト名', related_name='shift_name2',on_delete=models.SET_NULL,blank=True, null=True) shisetsu_name_2 = models.ForeignKey(Shisetsu, verbose_name='2施設', related_name='shisetsu_name2',on_delete=models.SET_NULL,blank=True, null=True) shift_name_3 = models.ForeignKey(Shift, verbose_name='3シフト名', related_name='shift_name3',on_delete=models.SET_NULL,blank=True, null=True) shisetsu_name_3 = models.ForeignKey(Shisetsu, verbose_name='3施設', related_name='shisetsu_name3',on_delete=models.SET_NULL,blank=True, null=True) shift_name_4 = models.ForeignKey(Shift, verbose_name='4シフト名', related_name='shift_name4',on_delete=models.SET_NULL,blank=True, null=True) shisetsu_name_4 = models.ForeignKey(Shisetsu, verbose_name='4施設', related_name='shisetsu_name4',on_delete=models.SET_NULL,blank=True, null=True)仮で60件のシフトデータを登録しました
ここからシフトを見た目の画面を作成していこうと思います


- 投稿日:2020-09-20T17:34:46+09:00
xgboostで勾配ブースティング木モデリングをしよう
勾配ブースティング木とは?
データ分析コンペでよく使われるアルゴリズムの一つ。
GBDTと略される。G・・・ Gradient(勾配) = 勾配降下法
B・・・ Boosting(ブースティング) = アンサンブル手法の1つ
D・・・ Decision(決定)
T・・・ Tree(木)つまり、「勾配降下法(Gradient)」と「Boosting(アンサンブル)」、「決定木(Decision Tree)」を組み合わせた手法。
勾配降下法
重みを少しずつ更新して誤差の勾配が最小となる点を探索するアルゴリズム。
「誤差が小さくなる=予測が正確になる」と考える。ブースティング
複数のモデルを組み合わせてモデルを作成するアンサンブル手法の一つ。
同じ種類のモデルを直列的に組み合わせ、予測値を補正しながらモデルを学習させる。
弱学習器(予測の精度があまり高くないもの)を複数組み合わせることで強学習機(精度の高いもの)を作ることができる。決定木
樹形図によってデータを分析する手法。
例えば「アイスクリームを買うかどうか」を予測する場合、「気温が30℃以上」 => 購入するだろう
「気温が30℃未満」 => 購入しないだろうという条件を用意し予測を行う。
勾配ブースティング木の特徴
- 特徴量は数値
決定木の分岐を特徴量より大きいか小さいかで判断するため、特徴量は数値である必要がある。- 欠損値を扱うことができる
決定木の分岐により判断するため、欠損値の補完をしなくても使用できる。- 変数間の相互作用が反映される
分岐を繰り返すため、変数間の相互作用が反映される。- 特徴量をスケーリングする必要がない
特徴量の大小関係のみで判断するため、標準化などのスケーリングが不要。勾配ブースティングの流れ
- 目的変数の平均を計算する
- 誤差を計算する
- 決定木を構築する
- アンサンブルを用いて新たな予測値を求める
- 再び誤差を計算する
- 3~5を繰り返す
- 最終予測を行う
予測値と目的変数の差が次の決定木で修正されていくことで精度を上げている。
実装手順
今回は二値分類を行うものとする。
※JupyterNotebook上でのコード例です。ライブラリの読み込み
import xgboost as xgb import numpy as np import pandas as pd import matplotlib.pyplot as plt from sklearn.model_selection import train_test_split from sklearn.metrics import accuracy_score from matplotlib import pyplot as plt %matplotlib inlineデータの読み込み
df = pd.read_csv('hoge.csv') df.head() # 読み込みの確認特徴量を選択する
# 今回は特徴量Xから"foo"、目的変数Yから"bar"を取り除く X = df.drop(['foo', 'bar'], axis=1) y = df['bar'] X.head() # 取り除けたことを確認学習用データと評価用データの分割
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=0, shuffle=True)test_size: 指定した割合を評価用データとして分割(0.3なら30%)
random_state: 乱数生成時のシードを指定
shuffle: データ分割時にランダムに並び替えを行うかどうかDMatrix形式に直す
xgboostではデータセットをDMatrix形式にする必要があります。
dtrain = xgb.DMatrix(X_train, label=y_train) dtest = xgb.DMatrix(X_test, label=y_test)学習用パラメータを設定
xgb_params = { # 二値分類 'objective': 'binary:logistic', # 評価指標loglossを仕様 'eval_metric': 'logloss', }モデルを学習
bst = xgb.train(xgb_params, dtrain, # 学習ラウンド数 num_boost_round=100, # 一定ラウンドを回しても改善が見込めない場合は学習を打ち切る early_stopping_rounds=10, )予測の実行
y_pred = bst.predict(dtest)精度の検証
acc = accuracy_score(y_test, y_pred) print('Accuracy:', acc)これで精度が出力されるので、必要に応じてパラメータを調整する。
以上の流れで勾配ブースティング木での分析は可能なはずです。
本番データの分析等はここでは省略します。
その他xgboostには特徴量の重みを可視化できたりと便利な機能があるので調べてみてください。参考
Python: XGBoost を使ってみる
https://blog.amedama.jp/entry/2019/01/29/235642GBDTの仕組みと手順を図と具体例で直感的に理解する
https://www.acceluniverse.com/blog/developers/2019/12/gbdt.htmlKaggle Masterが勾配ブースティングを解説する
https://qiita.com/woody_egg/items/232e982094cd3c80b3ee書籍:
門脇大輔、阪田隆司、保坂佳祐、平松雄司(2019)『Kaggleで勝つデータ分析の技術』技術評論社
- 投稿日:2020-09-20T17:17:08+09:00
janomeでLineトーク解析 (OSS公開)
はじめに
Lineのトークを解析するPythonスクリプトを作りましたので共有いたします。Twitterをjanomeで自然言語処理して解析する記事はよくありますが、Lineを対象にしたものは無いように思いました。
コード:
https://github.com/nashimo/LineAnalyzer使用例
以下は、私(pythonian)と りんな のトーク履歴をもとに解析した結果です。以下のファイル・画像が生成されます。りんなが良くしゃべるのでノイズ(邪魔な言葉等々)もたくさん入ってますがこんなイメージ、というサンプルです。
グループの会話を解析するととても面白いです。人によって1人称や使う言葉が違うので、その人らしさが現れます。統計情報
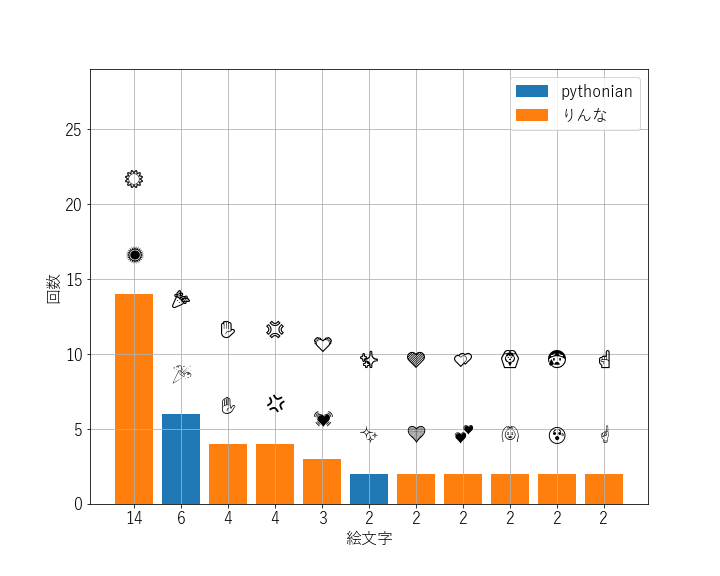
statistics.txt=== 統計情報 === メンバー: りんな pythonian 期間: 2016/05/23~2020/09/20 会話統計 りんな: 244行 9445文字 pythonian: 226行 1310文字 電話時間: 00:00:00 スタンプ: 5回 画像送信: 66回会話量
時間経過に伴う文字数の増加を日ごと、累計で表示します(incl_chars.png)。
返信頻度
りんなが即答するので、0に引っ付いてます (interval.png)。
使用絵文字
よく使う絵文字です (emoji_freq.png)。
Word cloud (りんな分のみ)
使い方
実行環境
実行して動かなかったら適宜パッケージをインストールしてください。自分はanaconda@Windows10で環境を作っています。
- Python 3.7
- janome 0.4.0
- matplotlib 3.3.1
- emoji 0.6.0
- wordcloud 1.8.0
実行方法
- PC or スマートフォンからLineのトーク(グループでも良い)をファイルにエクスポートする
エクスポート方法は例えば以下。
https://www.appbank.net/2020/06/15/iphone-application/1911418.php- エクスポートしたファイルをline_analysis.pyに与える
具体的には、line_analysis.py の main処理の中の fname にファイル名を渡す。
line_analysis.pyif __name__ == "__main__": fname = "[LINE] りんなとのトーク" lta, nlp = file2process(fname, media="Phone")
- プログラムを実行する
VScodeでJupyter実行できるように書いていますが、直接実行でもそのまま動きます。
> Python line_analysis.py注意・オプション
- PC or スマートフォン
どちらの媒体でトークを保存したかで、ファイルフォーマットが若干変化します。上記main処理のfile2process()の引数mediaを指定してあげてください。"PC" or "Phone" です。- 除く文字 (unwanted_word.txt)
?や!もあえて解析対象にしています。除きたい言葉はunwanted_word.txtに書いてあげるとword cloudに表示する際に無視されます。- 文字の結合 (l.522 sanitizenoun())
janomeオプションで復号語に対応するオプションがあり、それを使う手もあるのですが精度がイマイチだったので結合しないようにしています。その代わり、手動で結合したいものは結合するような処理を書いています。人名などは分けられることも多いので、手動で結合するような使い方が良いです。- フォントの追加 (l.388)
Win10標準のSegoeだと化ける絵文字があります。そういう時はsymbolaとかがよくて、必要に応じてFONT2にパスを与えると、絵文字分析でそちらのフォントでも併記してくれます。- 絵文字解析の最小頻度 (l.562)
今は2回以上使った絵文字を解析対象にしています(nlp.show_emoji_freq(min_freq=1))。適宜カウントを変更してください。- Word Cloudの最大文字数 (l.383)
今は130文字です。(wc_max_words = 130)。増やすとごちゃごちゃして、減らすとスッキリします。技術ポイント
基本的には参考文献にある情報を組み合わせただけです。ですが、Line解析はそのまま使えるものが無かったので、この部分で誰かの参考になるかもしれないと思っています。とはいえ、それも面倒くさい作業を地道にやっただけのものです。
- matplotlib で日本語・絵文字を使う
color emojiは表示できなかった。- Lineのトークを要素に分解(正規表現で日付、発言者、メッセージ等々を切り分け)
- 要素に分解したトークをjanomeで解析
参考文献
[1] Pythonのmatplotlibで積み上げ棒グラフを作成しデータラベルを追加してみた
https://qiita.com/s_fukuzawa/items/6f9c1a3d4c4f98ae6eb1
[2] Matplotlib が PC で追加のフォントをインストールしなくても日本語を表示できるようになった
https://qiita.com/yniji/items/2f0fbe0a52e3e067c23c
[3] Python janomeのanalyzerが便利
https://ohke.hateblo.jp/entry/2017/11/02/230000
[4] Word Cloudでツイートを可視化してみた(python)
https://qiita.com/turmericN/items/04cd0b40f91076f0ef42
[5] B'zの歌詞をPythonと機械学習で分析してみた 〜データ入手編〜
https://pira-nino.hatenablog.com/entry/2018/07/27/B%27z%E3%81%AE%E6%AD%8C%E8%A9%9E%E3%82%92Python%E3%81%A8%E6%A9%9F%E6%A2%B0%E5%AD%A6%E7%BF%92%E3%81%A7%E5%88%86%E6%9E%90%E3%81%97%E3%81%A6%E3%81%BF%E3%81%9F_%E3%80%9C%E3%83%87%E3%83%BC%E3%82%BF



- 投稿日:2020-09-20T17:04:55+09:00
VPSサーバ上でTensorFlow2を動かす
準備
- さくらVPS
- Python 3.6.0
- TensorFlow 2.3.0
- Apache2
Flaskを本番環境で使う準備については下記を参照してください。
Apache2+WSGI+Flaskを動かす
TensorFlowのインストール
pipのアップデート
$ pip3 install --upgrade pipTensorFlowのインストール
python3 -m pip install tensorflow確認
$ python3 -c "import tensorflow as tf; print( tf.__version__ )"この記事を執筆時点では2.3.0が帰ってくる。
参考にしたサイト
- 投稿日:2020-09-20T16:47:26+09:00
djangoを用いてWEBアプリケーション開発 ~開発その1~
はじめに
プロジェクトの作成
- 仮想環境を有効化する
cd C:\Python\env1 . Scripts/activate
- プロジェクトを作成する
django-admin startproject mysite現在のディレクトリにmysiteが作成されます。
mysite/ manage.py mysite/ __init__.py settings.py urls.py asgi.py wsgi.py
- トップのmysite・・・ルートディレクトリで任意の名前で作成できる。変更も可。
- manage.py・・・Djangoプロジェクトの様々な操作を行うためのコマンドラインユーティリティ。
- mysite・・・このプロジェクトのパッケージ。
- mysite/init.py・・・このディレクトリがpythonであることの空ファイル。
- mysite/settings.py・・・プロジェクトの設定ファイル。
- mysite/urls.py・・・URLを宣言。
- mysite/asgi.py・・・プロジェクトを提供するASGI互換WEBサーバーのエントリポイント。
- mysite/wsgi.py・・・プロジェクトをサーブするためのWSGI互換WEBサーバーのエントリポイント。
開発用サーバーの起動
- トップのmysiteディレクトリに移動する
cd mysite
- 開発サーバーを起動する
python manage.py runserver起動に成功したら、URLにアクセス(http://127.0.0.1:8000/)
ロケットが離陸しているページが出ていれば、成功。Pollsアプリケーション作成
- アプリケーションを作成
python manage.py startapp pollsこれで、アプリケーションが作成されました。
ビュー作成
- ビューを作成する
polls/views.pyfrom django.http import HttpResponse def index(request): return HttpResponse("Hello, world. You're at the polls index.")ビューを呼ぶためにURLを対応付けします。
- urlを紐付けする
polls/urls.pyfrom django.urls import path from . import views urlpatterns = [ path('', views.index, name='index'), ]
- ルートのURLにモジュールの記述を反映させる
mysite/urls.pyfrom django.contrib import admin from django.urls import include, path urlpatterns = [ path('polls/', include('polls.urls')), path('admin/', admin.site.urls), ]
- サーバーを起動する
python manage.py runserverサーバーを起動したら、動作確認する。(http://localhost:8000/polls/)
「Hello, world. You're at the polls index.」と表示されていることが確認できます。DataBaseの設定
- mysite/settings.pyにはデフォルトでSQLiteが設定されている。
- ほかのデータベース等を使いたい場合は、このファイルを修正する。
python manage.py migrateテーブルが作成される。INSTALL_APPSの設定をもとに、mysite/settings.pyファイルのデータベース設定に従って必要なすべてのテーブルを作成します。
モデルの作成
- pollアプリケーションではQuestionとChoiceの2つのモデルを作成します。
polls/models.pyfrom django.db import models class Question(models.Model): question_text = models.CharField(max_length=200) pub_date = models.DateTimeField('date published') class Choice(models.Model): question = models.ForeignKey(Question, on_delete=models.CASCADE) choice_text = models.CharField(max_length=200) votes = models.IntegerField(default=0)個々のクラス変数はモデルのデータベースフィールドを表現しています。
モデルを有効にする
- pollsアプリケーションをインストールしたので、設定する必要 polls.apps.PollsConfigを設定する。
mysite/settings.pyINSTALLED_APPS = [ 'polls.apps.PollsConfig', 'django.contrib.admin', 'django.contrib.auth', 'django.contrib.contenttypes', 'django.contrib.sessions', 'django.contrib.messages', 'django.contrib.staticfiles', ]設定したら、Djangoのモデルを反映させるため以下のコマンドを実施する。
python manage.py makemigrations polls実施すると、マイグレーションが作成されます。
Migrations for 'polls': polls/migrations/0001_initial.py - Create model Question - Create model Choicepolls/migrations/0001_initial.pyとして作成される。
自動でデータベーススキーマを管理するためのコマンドを実行する。python manage.py sqlmigrate polls 0001sqlmigrateコマンドはマイグレーションの名前を引数にとってSQLを返します。
実際には反映されない、反映されるときに実行されるSQLが表示される。
- テーブルを反映させる
python manage.py migratemigrateは適用されていない、マイグレーションを補足してデータベースに対して実行する。同期をとる。
Djangoが提供するAPIを実施してみる
- QuestionとChoiceモデルの編集を行う
polls/models.pyimport datetime from django.db import models from django.utils import timezone class Question(models.Model): question_text = models.CharField(max_length=200) pub_date = models.DateTimeField('date published') def __str__(self): return self.question_text def was_published_recently(self): return self.pub_date >= timezone.now() - datetime.timedelta(days=1) class Choice(models.Model): question = models.ForeignKey(Question, on_delete=models.CASCADE) choice_text = models.CharField(max_length=200) votes = models.IntegerField(default=0) def __str__(self): return self.choice_text対話モードでの表示を見やすくするためと、Djangoの自動生成adminでオブジェクトの表現として使用されるため、str()メソッドをモデルに追加しました。
- 対話モードを起動する
python manage.py shell対話を始める
>>> from polls.models import Choice, Question >>> Question.objects.all() >>> Question.objects.filter(id=1) >>> Question.objects.filter(question_text__startswith='What') >>> from django.utils import timezone >>> current_year = timezone.now().year >>> Question.objects.get(pub_date__year=current_year) >>> Question.objects.get(pk=1) >>> q = Question.objects.get(pk=1) >>> q.was_published_recently() >>> q = Question.objects.get(pk=1) >>> q.choice_set.all() >>> q.choice_set.create(choice_text='Not much', votes=0) >>> q.choice_set.create(choice_text='The sky', votes=0) >>> c = q.choice_set.create(choice_text='Just hacking again', votes=0) >>> c.question >>> q.choice_set.all() >>> q.choice_set.count( >>> Choice.objects.filter(question__pub_date__year=current_year) >>> c = q.choice_set.filter(choice_text__startswith='Just hacking') >>> c.delete()モデルのリレーションの操作を行っています。
※詳細は別途記載したいと思います。管理ユーザを作成
- ユーザを作成 アプリケーションのadminサイトにログインできるユーザーを作成します。
python manage.py createsuperuserユーザー名は適当につけてください
Username: ユーザ名メールアドレスを入力します
Email address: admin@example.comexampl.comは誰でも使用して問題のない、例示用のドメイン名です。
入力すると、パスワードの入力を求められます。Password: ********** Password (again): ********* Superuser created successfully.これで管理ユーザの作成は以上です。
開発サーバーの起動
- 開発サーバーを起動する サーバーが立ち上がってなければ実施する
python manage.py runserver起動したら、http://localhost:8000/admin/にアクセスします。
管理画面にログインする
- 先ほど管理ユーザ作成時に設定した、usernameとpasswordを入力するログインに成功すると以下の画面が表示される
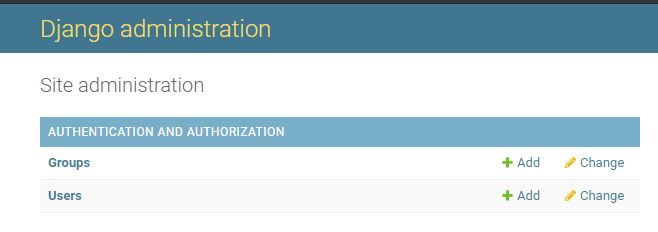
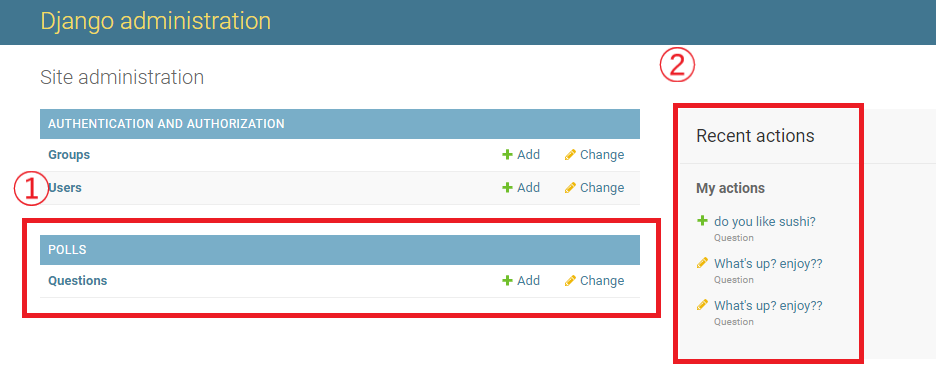
GroupsとUsersは、Djangoの認証機能フレームワークdjango.contrib.authにより提供されているコンテンツです。
Pollアプリをadmin上で編集できるように追加を行う
- polls/admin.pyを開いて編集する。
Questionのオブジェクトがadminのインターフェースを持つことで表示されるようになります。
インターフェースを持ったことをadminに教えます。polls/admin.pyfrom django.contrib import admin from .models import Question admin.site.register(Question)管理画面にpollsが表示されるようになりました。
- ①追加したpolls
- ②操作を行うと履歴として表示される。
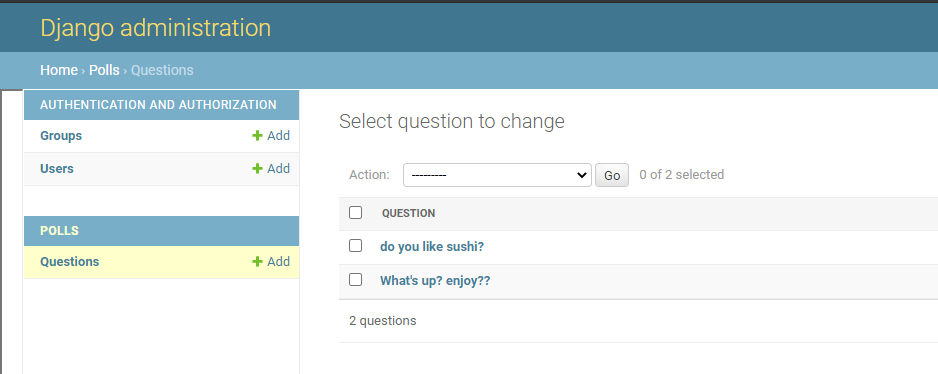
管理画面を操作してみる
pollsのQuestionsを押下
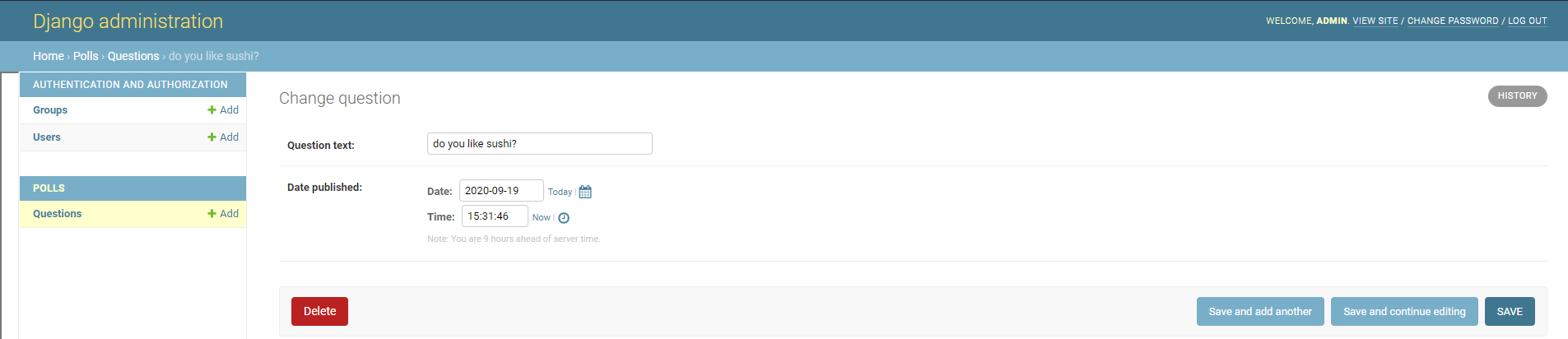
do you like sushi?を押下
色々と更新したりすることができるdjangoを用いてWEBアプリケーション開発 ~開発その2~ >>>
- 投稿日:2020-09-20T16:13:27+09:00
コマンド一つでpipにインストールしたライブラリを全削除
はじめに
たまにpipのライブラリを全削除したくなるのですが,
pip freeze > u.txt pip uninstall -r u.txt -yとするのが面倒なので一行pipのライブラリを削除する方法を考えました.
コマンド
pip uninstall -r <(pip freeze) -y説明
プロセス置換という考え方(1)を参考にしました.
この考え方によって,一時ファイルであるu.txtの部分を<(pip freeze)と書き換えることにより一行に短縮することができました.さいごに
毎回使用する簡単なコマンドを一行にできると作業効率も上がりますし,コマンドの使い方について豆知識もつくので楽しいです.
参考文献
- 投稿日:2020-09-20T16:05:30+09:00
AtCoder Beginner Contest 179 復習
今回の成績
今回の感想
今回も悔しい結果でした。D問題をずっとバグらせていたためにF問題を解く時間が残りませんでした。F問題がBIT(またはセグ木)を持っていればそこまで難しくないので、あと15分くらいあったら解けた気がします。
A問題
判定条件を逆に書いてしまい若干時間を使いました。
A.pys=input() if s[-1]!="s": print(s+"s") else: print(s+"es")B問題
素直に前から等しいかどうかを判定していけば良いです。
配列外参照にだけ気をつけます。B.pyn=int(input()) x,y=[],[] for i in range(n): x_,y_=map(int,input().split()) x.append(x_) y.append(y_) for i in range(n-2): if x[i]==y[i] and x[i+1]==y[i+1] and x[i+2]==y[i+2]: print("Yes") break else: print("No")C問題
$A \times B +C=N$ですが、$A \times B <N$を満たしながら$A,B$を決めれば$C$は一意に決まります。ここで、$1 \leqq A \leqq N-1$として$A$に対応する$B$の場合の数を求めますが、$N \%A=0$のときは$A \times B <N$を満たす$B$は$B=1,2,…,[\frac{N}{A}]-1$の$[\frac{N}{A}]-1$通りになり、$N \%A \neq 0$のときは$A \times B <N$を満たす$B$は$B=1,2,…,[\frac{N}{A}]$の$[\frac{N}{A}]$通りになります。よって、全探索して合計を出力します。
C.pyn=int(input()) ans=0 for a in range(1,n): if n%a==0: ans+=(n//a-1) else: ans+=(n//a) print(ans)D問題
初めてAtCoderの本番のコンテストでBITを使った気がします。また、今回のBITは区間加算ができるもので自分は実装してなかったので、kamiさんのBITをお借りしました。modintを載せ、使い方もよくわかっておらず、1-indexedだったので、永遠にバグらせました。使ったことのないライブラリを使うのはかなり危険ですね…。
まず、移動の仕方の場合の数なので、移動を遷移と捉えたDPを考えます($dp[i]:=$(マス$i$にいる時の移動の仕方の場合の数))。しかし、今回は移動が$k$個の区間あるので、それぞれの遷移を一つずつ処理すると$O(N^2)$となり間に合いません。ここで、$k$は最大で10であることから区間ごとの遷移を上手く処理することを考えます。この時、区間が$[l,r]$でマス$i$にいるとすれば、$dp[i+l]+=dp[i],dp[i+l+1]+=dp[i],…,dp[i+r]+=dp[i]$となります。従って、区間加算を効率良く行えばよく区間加算のBITを用いれば良いです。
よって、$i$を小さい方から順に見ていって順に$k$個の区間それぞれに加算を行えば良く、計算量は$O(Nk\log{N})$となります。また、求めたいのは998244353の余りなので、long longやintではなくmodintをBITに載せる必要があります。
また、imos法により$O(NK)$で解けたり形式的冪級数に帰着して解く方法や形式的冪級数を用いて$O(N \log{N})$で解く方法があるらしい(→maspyさんの記事)ですが、良くわかってないので今回は飛ばします。
D.cc//デバッグ用オプション:-fsanitize=undefined,address //コンパイラ最適化 #pragma GCC optimize("Ofast") //インクルードなど #include<bits/stdc++.h> using namespace std; typedef long long ll; //マクロ //forループ //引数は、(ループ内変数,動く範囲)か(ループ内変数,始めの数,終わりの数)、のどちらか //Dがついてないものはループ変数は1ずつインクリメントされ、Dがついてるものはループ変数は1ずつデクリメントされる //FORAは範囲for文(使いにくかったら消す) #define REP(i,n) for(ll i=0;i<ll(n);i++) #define REPD(i,n) for(ll i=n-1;i>=0;i--) #define FOR(i,a,b) for(ll i=a;i<=ll(b);i++) #define FORD(i,a,b) for(ll i=a;i>=ll(b);i--) #define FORA(i,I) for(const auto& i:I) //xにはvectorなどのコンテナ #define ALL(x) x.begin(),x.end() #define SIZE(x) ll(x.size()) //定数 #define INF 1000000000000 //10^12:∞ #define MOD 998244353 //10^9+7:合同式の法 #define MAXR 100000 //10^5:配列の最大のrange //略記 #define PB push_back //挿入 #define MP make_pair //pairのコンストラクタ #define F first //pairの一つ目の要素 #define S second //pairの二つ目の要素 /* BIT: RAQ対応BIT 初期値は a_1 = a_2 = ... = a_n = 0 ・add(l,r,x): [l,r) に x を加算する ・sum(i): a_1 + a_2 + ... + a_i を計算する 計算量は全て O(logn) */ template <typename T> struct BIT { int n; // 要素数 vector<T> bit[2]; // データの格納先 BIT(int n_) { init(n_); } void init(int n_) { n = n_ + 1; for (int p = 0; p < 2; p++) bit[p].assign(n, 0); } void add_sub(int p, int i, T x) { for (int idx = i; idx < n; idx += (idx & -idx)) { bit[p][idx] += x; } } void add(int l, int r, T x) { // [l,r) に加算 add_sub(0, l, -x * (l - 1)); add_sub(0, r, x * (r - 1)); add_sub(1, l, x); add_sub(1, r, -x); } T sum_sub(int p, int i) { T s(0); for (int idx = i; idx > 0; idx -= (idx & -idx)) { s += bit[p][idx]; } return s; } T sum(int i) { return sum_sub(0, i) + sum_sub(1, i) * i ; } }; template<ll mod> class modint{ public: ll val=0; //コンストラクタ modint(ll x=0){while(x<0)x+=mod;val=x%mod;} //コピーコンストラクタ modint(const modint &r){val=r.val;} //算術演算子 modint operator -(){return modint(-val);} //単項 modint operator +(const modint &r){return modint(*this)+=r;} modint operator -(const modint &r){return modint(*this)-=r;} modint operator *(const modint &r){return modint(*this)*=r;} modint operator /(const modint &r){return modint(*this)/=r;} //代入演算子 modint &operator +=(const modint &r){ val+=r.val; if(val>=mod)val-=mod; return *this; } modint &operator -=(const modint &r){ if(val<r.val)val+=mod; val-=r.val; return *this; } modint &operator *=(const modint &r){ val=val*r.val%mod; return *this; } modint &operator /=(const modint &r){ ll a=r.val,b=mod,u=1,v=0; while(b){ ll t=a/b; a-=t*b;swap(a,b); u-=t*v;swap(u,v); } val=val*u%mod; if(val<0)val+=mod; return *this; } //等価比較演算子 bool operator ==(const modint& r){return this->val==r.val;} bool operator <(const modint& r){return this->val<r.val;} bool operator !=(const modint& r){return this->val!=r.val;} }; using mint = modint<MOD>; //入出力ストリーム istream &operator >>(istream &is,mint& x){//xにconst付けない ll t;is >> t; x=t; return (is); } ostream &operator <<(ostream &os,const mint& x){ return os<<x.val; } signed main(){ //入力の高速化用のコード //ios::sync_with_stdio(false); //cin.tie(nullptr); ll n,k;cin>>n>>k; BIT<mint> dp(n); vector<pair<ll,ll>> sec(k); REP(i,k){ ll l,r;cin>>l>>r; sec[i]=MP(l,r); } dp.add(1,2,1); REP(i,n){ //cout<<i+1<<endl; REP(j,k){ if(i+sec[j].F<=n){ dp.add(i+sec[j].F+1,min(i+sec[j].S+2,n+1),dp.sum(i+1)-dp.sum(i)); //cout<<i+1+sec[j].F<<" "<<min(i+1+sec[j].S+1,n+2)<<endl; } } } //cout<<1<<endl; cout<<dp.sum(n)-dp.sum(n-1)<<endl; }E問題
この前、下位互換の問題が出た気がします。
$A_{i+1}=A_{i}^2\ mod \ m$かつ$A_1=x$であり、$\sum_{i=1}^nA_i$を求めます。この時、$n$は最大で$10^9$なので、全通りを求めることができません。
ここで、それぞれの項は$m$の余りなので高々$m$通りしか存在せず、$(A_i =A_j) \ mod \ m$が成り立つ時、$(A_{i+1}=A_{j+1}) \ mod \ m$が成り立つので、数列$A$には最大$m$の長さのループが現れます。
よって、このループを見つけることができれば、そのループが$A_1$から$A_n$に何回現れるかを考えることで高速に計算を行うことができます。ループの見つけ方の実装を身につけていれば実装も高速に行うことができると思うので、以下ではループの見つけ方の実装を示しておこうと思います。
①余りが二回出てくる$A_i$を探す
v…余りの出てくる順番に格納する配列
s…出てきた余りを保存するset$A_1,A_2,…$と順に見ていって
vとsに格納していきます。この時、sに格納されているのと同じ値の$A_i$が出てきた場合はその値を保存した状態で①を終了します。②ループとループの前を分離する
①において保存した値が初めて出てくる$A_i$より前はループに含まれません。従って、この部分(ループの前)と$A_i$以後の部分(ループ)に分離します。
$A_n$がループの前までの場合はこの時点で操作を終了して出力を行います。$A_n$がループに含まれる場合はループの前までの計算,$n$の残りの項数への更新,
vをループのみになるように更新,の三つを行った後に③に移ります。③ループの計算を行う
②の後に以下の情報を求めることができます。
l…ループの長さ
n…残りの数列の長さ
$[\frac{n}{l}]$…ループが何回現れるのか
n % l…ループがどれだけ回りきってないか
s…ループ内の総和($O(l)$)
t…ループの回りきってない部分の総和②で分離したループの計算を行います。上記の情報は簡単に求められるので、答えは$[\frac{n}{l}] \times s +t$となります。
E.pyn,x,m=map(int,input().split()) cand=[x] cands=set() cands.add(x) for i in range(m): c=(cand[-1]**2)%m if c in cands: break else: cand.append(c) cands.add(c) #ループの初め #print(cand) p=cand.index(c) if x<p: print(sum(cand[:x])) exit() ans=sum(cand[:p]) cand=cand[p:] #print(ans) n-=p #ループの回数 tim=n//len(cand) ama=n%len(cand) ans+=tim*sum(cand) ans+=sum(cand[:ama]) print(ans) #print(p) #print(cand)F問題
Cに引き続き区間加算BITを使えば解くことができます。また、以下では出来るだけ言葉で説明しようとしたのですが、なかなか伝え切れてない部分もあるので、図を書いて実験すると理解が深まるかと思います。
まず見た時に誤読をして最も近いという情報を見落としていました。ここで、問題を図を用いて考えると以下のようになります。
丸数字の順番で操作を行ったと仮定すると、矢印で示した部分を白色で塗ることができます。この時、例えば①に注目すると、それぞれの行を選択した時に塗ることのできるマスの個数が少なくなっています。同様に②に注目すればそれぞれの列を選択した時に塗ることのできるマスの個数を少なくすることができます。また、④については②によってマスの個数を少なくする操作ができないのでその列の任意の黒のマスを白にすることができています。つまり、ある行(または列)を選択した時にある列(または行)の色を変えることの出来るマスの個数を変える操作と変えない操作があることがわかります。
ここで、実験をさらに行った上でまとめると、それまでに選択した中で一番左側の列($r$)と上側の行($d$)を保存しておいてそれを更新する場合はマスの個数を変える操作とみなすことができます(初期値は$r=c=n$とします。)。例えば、$c<r$を満たす$c$を選択して操作を行うと、その後に2~$d$-1行目を選択した際に色を変えることの出来るマスの個数は元々$r-2$であったのが$c-2$に減ります。よって、$r,d$に加え、$i$行目,$i$列目を選択した時に一番インデックスの小さい白色のマスのインデックスを保存した$row,column$も用意します。また、これらの要素は区間更新が必要なのでBITとします。もちろん、SegmentTreeBeatsのようにminの区間更新ができるデータ構造でも良いのですが、色を変えることの出来るマスの個数は選択した区間の変化前後で全て一緒(✳︎)なので、区間加算で処理することが出来るからです。
(✳︎)…図で考えるなら、①で$(d,1)$を選択していたとすれば、$row$の任意の要素は$n$から$d$に置き換わります。つまり、$d-n$を任意の要素に加算するだけです。これと同じことが任意の操作で言えます。
F.cc//デバッグ用オプション:-fsanitize=undefined,address //コンパイラ最適化 #pragma GCC optimize("Ofast") //インクルードなど #include<bits/stdc++.h> using namespace std; typedef long long ll; //マクロ //forループ //引数は、(ループ内変数,動く範囲)か(ループ内変数,始めの数,終わりの数)、のどちらか //Dがついてないものはループ変数は1ずつインクリメントされ、Dがついてるものはループ変数は1ずつデクリメントされる //FORAは範囲for文(使いにくかったら消す) #define REP(i,n) for(ll i=0;i<ll(n);i++) #define REPD(i,n) for(ll i=n-1;i>=0;i--) #define FOR(i,a,b) for(ll i=a;i<=ll(b);i++) #define FORD(i,a,b) for(ll i=a;i>=ll(b);i--) #define FORA(i,I) for(const auto& i:I) //xにはvectorなどのコンテナ #define ALL(x) x.begin(),x.end() #define SIZE(x) ll(x.size()) //定数 #define INF 1000000000000 //10^12:∞ #define MOD 1000000007 //10^9+7:合同式の法 #define MAXR 100000 //10^5:配列の最大のrange //略記 #define PB push_back //挿入 #define MP make_pair //pairのコンストラクタ #define F first //pairの一つ目の要素 #define S second //pairの二つ目の要素 /* BIT: RAQ対応BIT 初期値は a_1 = a_2 = ... = a_n = 0 ・add(l,r,x): [l,r) に x を加算する ・sum(i): a_1 + a_2 + ... + a_i を計算する 計算量は全て O(logn) */ template <typename T> struct BIT { int n; // 要素数 vector<T> bit[2]; // データの格納先 BIT(int n_) { init(n_); } void init(int n_) { n = n_ + 1; for (int p = 0; p < 2; p++) bit[p].assign(n, 0); } void add_sub(int p, int i, T x) { for (int idx = i; idx < n; idx += (idx & -idx)) { bit[p][idx] += x; } } void add(int l, int r, T x) { // [l,r) に加算 add_sub(0, l, -x * (l - 1)); add_sub(0, r, x * (r - 1)); add_sub(1, l, x); add_sub(1, r, -x); } T sum_sub(int p, int i) { T s(0); for (int idx = i; idx > 0; idx -= (idx & -idx)) { s += bit[p][idx]; } return s; } T sum(int i) { return sum_sub(0, i) + sum_sub(1, i) * i ; } }; signed main(){ //入力の高速化用のコード //ios::sync_with_stdio(false); //cin.tie(nullptr); ll n,q;cin>>n>>q; BIT<ll> row(n); row.add(1,n+1,n); BIT<ll> column(n); column.add(1,n+1,n); ll d,r;d=n;r=n; ll ans=0; REP(_,q){ ll x,y;cin>>x>>y; if(x==1){ ans+=column.sum(y)-column.sum(y-1)-2; //cout<<column.sum(y)-column.sum(y-1)-1<<endl; if(y<r){ row.add(1,d,(y-row.sum(1))); r=y; } }else{ ans+=row.sum(y)-row.sum(y-1)-2; //cout<<row.sum(y)-row.sum(y-1)-1<<endl; if(y<d){ column.add(1,r,(y-column.sum(1))); d=y; } } } cout<<(n-2)*(n-2)-ans<<endl; }

- 投稿日:2020-09-20T15:51:49+09:00
DjangoのTemplateDoesNotExistの対処法
TemplateDoesNotExist
Djangoで、以下のコードを実行したときに上記のエラーが出た。
views.pyfrom django.template.response import TemplateResponse def product_list(request): return TemplateResponse(request, 'catalogue/product_list.html')どうすればいいのか。見るべき場所はsetting.pyの中の2箇所。
1.Templateのパス
以下のようになっているか確認する。
setting.pyTEMPLATES = [ { 'BACKEND': 'django.template.backends.django.DjangoTemplates', 'DIRS': [], 'APP_DIRS': True, 'OPTIONS': { 'context_processors': [ 'django.template.context_processors.debug', 'django.template.context_processors.request', 'django.contrib.auth.context_processors.auth', 'django.contrib.messages.context_processors.messages', ], }, }, ]こうなっていればオッケー。デフォルトでこうなっているはずなので、変更していなければ大丈夫なはず。
2.INSTALLED_APPS
筆者のエラーの原因はここだった。
setting.pyINSTALLED_APPS = [ 'django.contrib.admin', 'django.contrib.auth', 'django.contrib.contenttypes', 'django.contrib.sessions', 'django.contrib.messages', 'django.contrib.staticfiles', 'ec.catalogue', ]INSTALLED_APPSには、そのプロジェクト内の全てのアプリケーションを登録する必要がある。
つまり、views.pyやurls.pyが入っている場所も追加しなければならない。
よって、アプリケーションが入っている場所(筆者の場合はec.catalogue)を追加することで、Templateを使えるようになった。
- 投稿日:2020-09-20T15:07:46+09:00
テンプレ AtCoder ABC 179 Python (A~E)
総括
A, Bのみ解けました。
最近パフォーマンスが下がり続けています。問題
https://atcoder.jp/contests/abc179
A. Plural Form
回答
S = input() if S[-1] == 's': answer = S + 'es' else: answer = S + 's' print(answer)問題文通り書きます。
B. Go to Jail
回答
N = int(input()) D = [tuple(map(int, input().split())) for _ in range(N)] answer = 'No' count = 0 for i in range(N): if D[i][0] != D[i][1]: count = 0 else: count += 1 if count == 3: answer = 'Yes' break print(answer)ぞろ目を判定し、
countが3に達したらYesを返します。C. A x B + C
回答
N = int(input()) answer = 0 for a in range(1, N): answer += (N-1) // a print(answer)制約を考えるとforループは1回しか回せそうにないです。
A * B + C = Nを変形してA * B = N - CとするとA * Bの組み合わせの数を数える問題とよみかえられます。D. Leaping Tak
回答
MOD = 998244353 N, K = map(int, input().split()) #Nはマス目の数、Kは区間の数(Kは10以下) kukan = [tuple(map(int, input().split())) for _ in range(K)] dp = [0] * (N+1) dp[1] = 1 sumdp = [0] * (N+1) sumdp[1] = 1 for i in range(2, N+1): for l, r in kukan: li = max(i - l, 0) ri = max(i - r - 1, 0) dp[i] += sumdp[li] - sumdp[ri] dp[i] %= MOD sumdp[i] = sumdp[i-1] + dp[i] print(dp[N])普通に
dpをとると間に合わないので、dpと累積和sumdpを使用します。E. Sequence Sum
回答
N, X, M = map(int, input().split()) count_memo = [-1] * 10**6 # 回数のメモ num_memo = [0] # Aのメモ。1インデックスるにする. a = X count = 1 count_memo[a] = count num_memo.append(a) for i in range(1, N): a = a**2 % M if count_memo[a] == -1: count += 1 count_memo[a] = count num_memo.append(a) else: break if count == N: # サイクルに入る前に終わった場合は全部合計 answer = sum(num_memo) else: # 周期に入るまでの回数と合計 count_before_cycle = count_memo[a] - 1 sum_before_cycle = sum(num_memo[:count_before_cycle+1]) # 1周期の数と合計 count_cycle = count - count_before_cycle sum_cycle = sum(num_memo[count_before_cycle+1:]) # 残りのサイクルの数と合計 cycle_count = (N - count) // count_cycle sum_after_cycle = sum_cycle * cycle_count # あまりの数と合計 remain_count = (N - count) % count_cycle sum_remain = sum(num_memo[count_before_cycle+1:count_before_cycle+1 + remain_count]) answer = sum_before_cycle + sum_cycle + sum_after_cycle + sum_remain print(answer)
Aはどこかでサイクルに入ります。
したがって、
1. サイクルに入る前
2. サイクル
3. サイクルの繰り返し
4. サイクルの途中で終わる余分な回数
の4通りに分けて足し合わせます。





- 投稿日:2020-09-20T14:02:00+09:00
xgboostの使い方:irisデータで多クラス分類
xgboostは、決定木モデルの1種であるGBDTを扱うライブラリです。
インストールし使用するまでの手順をまとめました。
様々な言語で使えますが、Pythonでの使い方について記載しています。GBDTとは
- 決定木モデルの一種
- 勾配ブースティング木
- Gradient Boosting Decision Tree
同じ決定木モデルではランダムフォレストが有名ですが、下記記事が違いを簡潔にまとめられていました。
【機械学習】決定木モデルの違いをまとめてみた - QiitaGBDTの特徴
- 簡単に良い精度が出やすい
- 欠損値を扱える
- 扱えるのは数値データ
使いやすく精度も良いことから、機械学習コンペティションのKaggleで人気があります。
[1] 使い方
scikit-learnのデータセットの1つである、irisデータ(アヤメの品種データ)を利用しました。OSはAmazon Linux2です。
[1-1] インストール
私が利用しているAmazon Linux2では次の通りです。環境ごとのインストール手順は公式に載っています。
Installation Guide — xgboost 1.1.0-SNAPSHOT documentationpip3 install xgboost[1-2] インポート
import xgboost as xgb[1-3] irisデータの取得
特別な手順はありません。irisデータを取得して、pandasのDataFrameとSeriesを作成します。
import pandas as pd from sklearn.datasets import load_iris iris = load_iris() iris_data = pd.DataFrame(iris.data, columns=iris.feature_names) iris_target = pd.Series(iris.target)[1-4] 訓練データとテストデータの取得
ここも特別な手順はなく、scikit-learnの
train_test_splitでデータを訓練用とテスト用に分割します。from sklearn.model_selection import train_test_split train_x, test_x, train_y, test_y = train_test_split(iris_data, iris_target, test_size=0.2, shuffle=True)[1-5] xgboost用の型に変換する
xgboostでは
DMatrixを使用します。dtrain = xgb.DMatrix(train_x, label=train_y)
DMatrixはnumpyのndarrayやpandasのDataFrameから作成できるので、データの扱いに苦労することは無いでしょう。扱えるデータの種類は公式に詳しく載っています。
Python Package Introduction — xgboost 1.1.0-SNAPSHOT documentation[1-6] パラメータの設定
各種パラメータの設定を行います。
param = {'max_depth': 2, 'eta': 1, 'objective': 'multi:softmax', 'num_class': 3}各パラメータの意味は次の通りです。
パラメータ名 意味 max_depth 木の最大深度 eta 学習率 objective 学習目的 num_class クラス数 'objejective'に学習目的(回帰、分類等)を指定します。
今回は多クラス分類なので'multi:softmax'を指定しています。詳細は公式に詳しく載っています。
XGBoost Parameters — xgboost 1.1.0-SNAPSHOT documentation[1-7] 学習
num_roundは学習回数です。num_round = 10 bst = xgb.train(param, dtrain, num_round)[1-8] 予測
dtest = xgb.DMatrix(test_x) pred = bst.predict(dtest)[1-9] 精度の確認
scikit-learnの
accuracy_scoreで正解率を確認します。from sklearn.metrics import accuracy_score score = accuracy_score(test_y, pred) print('score:{0:.4f}'.format(score)) # 0.9667[1-10] 重要度の可視化
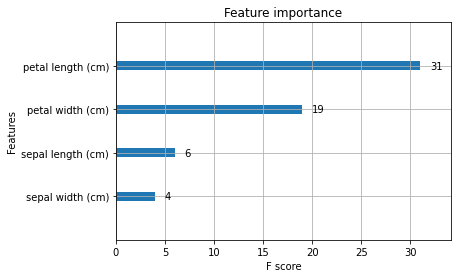
どの特徴量が予測結果に寄与したのかを可視化します。
xgb.plot_importance(bst)
[2] 学習中のバリデーションとアーリーストッピング
検証用データを用いた学習中のバリデーションと、アーリーストッピング(学習の打ち切り)も簡単に行うことができます。
[2-1] データの分割
学習用データの一部を検証用データとして使用します。
train_x, valid_x, train_y, valid_y = train_test_split(train_x, train_y, test_size=0.2, shuffle=True)[2-2] DMatrixの作成
dtrain = xgb.DMatrix(train_x, label=train_y) dvalid = xgb.DMatrix(valid_x, label=valid_y)[2-3] パラメータの追加
バリデーションを行う場合には'eval_metric'をパラメータに追加します。'eval_metric'には、評価指標を指定します。
param = {'max_depth': 2, 'eta': 0.5, 'objective': 'multi:softmax', 'num_class': 3, 'eval_metric': 'mlogloss'}[2-4] 学習
evallistにバリデーションで監視するデータを指定します。検証用データの名称は'eval'、学習用データの名称は'train'を指定します。
xgb.trainの引数として
early_stopping_roundsを追加しています。early_stopping_rounds=5は5回連続して評価指標が改善しなかったら学習を中断する、ことを意味しています。evallist = [(dvalid, 'eval'), (dtrain, 'train')] num_round = 10000 bst = xgb.train(param, dtrain, num_round, evallist, early_stopping_rounds=5) # [0] eval-mlogloss:0.61103 train-mlogloss:0.60698 # Multiple eval metrics have been passed: 'train-mlogloss' will be used for early stopping. # # Will train until train-mlogloss hasn't improved in 5 rounds. # [1] eval-mlogloss:0.36291 train-mlogloss:0.35779 # [2] eval-mlogloss:0.22432 train-mlogloss:0.23488 # # 〜〜〜 途中省略 〜〜〜 # # Stopping. Best iteration: # [1153] eval-mlogloss:0.00827 train-mlogloss:0.01863[2-5] 検証結果の確認
print('Best Score:{0:.4f}, Iteratin:{1:d}, Ntree_Limit:{2:d}'.format( bst.best_score, bst.best_iteration, bst.best_ntree_limit)) # Best Score:0.0186, Iteratin:1153, Ntree_Limit:1154[2-6] 予測
検証結果のうち最も結果が良かったモデルで予測を行います。
dtest = xgb.DMatrix(test_x) pred = ypred = bst.predict(dtest, ntree_limit=bst.best_ntree_limit)終わりに
pandasのDataFrame, Seriesが使えるので、今まで機械学習をやってきた人にとって敷居は低いように感じられました。
今回試したのは多クラス分類ですが、二値分類や回帰にも使用できるので、様々な場面で使うことができるでしょう。
- 投稿日:2020-09-20T13:46:15+09:00
Docker Composeを用いたHPC学習環境の構築(C, Python, Fortran)
以前からGPUを入手したらHPC(High Performance Computing)の勉強をしたいと思っていました。ただ、環境構築は(色々な意味で)非常に面倒くさい作業です。何とか手軽に学習環境を構築出来ないかと考えていた時に、Docker、Docker Composeを活用した環境構築を思いつきました。本記事ではCUDAやOpenCLを初めとするC言語をベースとしたHPC用ライブラリやPythonでHPCを実現するPyCUDAやPyOpenCLが実行出来るコンテナ環境を構築します。
最終目標
Dockerを用いてコンテナ上にHPC関連ライブラリの開発環境を構築します。また、ポートの開放も設定し、SSHで乗り込める用にします。これはVSCodeのRemote Development Extensionの機能を活用して、SSHでコンテナに乗り込んで開発が出来る環境を実現する為に行います。
導入するライブラリ
導入するライブラリを一覧にまとめます。このうち、OpenCLとPyCUDA、PyOpenCL以外のライブラリはNVIDIA HPC SDKに含まれている物をインストールします。
名称 言語 備考 CUDA C CUDAのデフォルトバージョンCベースの独自拡張 CUDA Fortran1 NVIDIA公式のコンパイラnvfortranがリリース OpenCL C CUDAと二大巨頭と言われる並列計算ライブラリ PyCUDA Python PythonからCUDAを実行するためのラッパー PyOpenCL Python PythonからOpenCLを実行するためのラッパー OpenMP C マルチコアCPUを手軽に活用出来るライブラリ OpenACC C GPUを用いた並列計算用ライブラリ Docker Composeeを用いた環境構築
環境構築に使用するDockerfileとdocker-compose.ymlを以下の様に作成します。Docker Composeは本来複数のコンテナを起動し、コンテナ間でネットワークを構築する環境構築に便利なアプリケーションですが、筆者の場合Makeの様な使い方をしていることが多い様に思います。Dockerfileは一部過去の公式コンテナイメージの中身を参考に作成しました。cuDNN、PyCUDA、OpenCL、PyOpenCLはNVIDIA HPC SDKには含まれていない為、CUDA10.1版の公式コンテナイメージをベースにインストールする方法を採用しています。また、コンテナにSSHでログイン出来る様に、ログインパスワードをビルド時に引数として渡して設定出来る様にしています。
DockerfileFROM nvidia/cuda:10.1-cudnn7-devel ARG PASSWD ENV CUDA_VERSION=10.1 # Upgrade OS RUN apt update && apt upgrade -y # Install some ruquirements RUN apt install -y bash-completion build-essential gfortran vim wget git openssh-server python3-pip # Install NVIDA HPC SDK RUN wget https://developer.download.nvidia.com/hpc-sdk/nvhpc-20-7_20.7_amd64.deb \ https://developer.download.nvidia.com/hpc-sdk/nvhpc-2020_20.7_amd64.deb \ https://developer.download.nvidia.com/hpc-sdk/nvhpc-20-7-cuda-multi_20.7_amd64.deb RUN apt install -y ./nvhpc-20-7_20.7_amd64.deb ./nvhpc-2020_20.7_amd64.deb ./nvhpc-20-7-cuda-multi_20.7_amd64.deb # Install cuDNN ENV CUDNN_VERSION=7.6.5.32 RUN apt install -y --no-install-recommends libcudnn7=$CUDNN_VERSION-1+cuda$CUDA_VERSION && \ apt-mark hold libcudnn7 && rm -rf /var/lib/apt/lists/* # Install OpenCL RUN apt update && apt install -y --no-install-recommends ocl-icd-opencl-dev && rm -rf /var/lib/apt/lists/* RUN ln -fs /usr/bin/python3 /usr/bin/python RUN ln -fs /usr/bin/pip3 /usr/bin/pip ENV PATH=/usr/local/cuda-$CUDA_VERSION/bin:$PATH ENV CPATH=/usr/local/cuda-$CUDA_VERSION/include:$CPATH ENV LIBRARY_PATH=/usr/local/cuda-$CUDA_VERSION/lib64:$LIBRARY_PATH # Install PyCUDA RUN pip install pycuda # Install PyOpenCL RUN pip install pyopencl # Setup SSH RUN mkdir /var/run/sshd # Set "root" as root's password RUN echo 'root:'${PASSWD} | chpasswd RUN sed -i 's/#PermitRootLogin prohibit-password/PermitRootLogin yes/' /etc/ssh/sshd_config RUN sed -i 's/#PasswordAuthetication/PasswordAuthetication/' /etc/ssh/sshd_config RUN sed 's@session\s*required\s*pam_loginuid.so@session optional pam_loginuid.so@g' -i /etc/pam.d/sshd EXPOSE 22 CMD ["/usr/sbin/sshd", "-D"]docker-compose.ymlversion: "2.4" services: hpc_env: build: context: . dockerfile: Dockerfile args: - PASSWD=${PASSWD} runtime: nvidia ports: - '12345:22' environment: - NVIDIA_VISIBLE_DEVICES=all - NVIDIA_DRIVER_CAPABILITIES=all volumes: - ../work:/root/work restart: alwaysイメージのビルド
Dockerfileからコンテナイメージを作成します。パスワードが
.bash_historyに残るのは好ましくないので、外部ファイル(auth.txt:ファイル内に設定したいパスワードを記載)から読み込んだ内容を引数渡しする様にします。コマンド操作を記載したシェルファイルを以下に示します。build_env.sh#!/bin/bash cat auth.txt | xargs -n 1 sh -c 'docker-compose build --build-arg PASSWD=$0'ビルドの実行
シェルファイルを実行するだけです。途中の過程は省略していますが、Successfully...と最後に出力されれば成功です。途中cuDNNのセットアップでaptがエラー終了してしまうことが有りますが、何度かやり直すとビルド出来ます。(詳細な理由は不明)
$ ./build_env.sh ... ... Successfully tagged building-hpc-env_hpc_env:latestコンテナの起動
後はコンテナを起動するだけです。PASSWDの値が設定されていないという警告が出ていますが、ビルド時に用いる一時的な値で有る為、無視しても問題有りません。
$ docker-compose up -d WARNING: The PASSWD variable is not set. Defaulting to a blank string. Creating network "building-hpc-env_default" with the default driver Creating building-hpc-env_hpc_env_1 ... doneコンテナへの接続確認
SSHで接続出来るか確認します。無事パスワードログイン出来ました。
$ ssh -p 12345 root@localhost root@localhost's password: Welcome to Ubuntu 18.04.5 LTS (GNU/Linux 5.4.0-45-generic x86_64) * Documentation: https://help.ubuntu.com * Management: https://landscape.canonical.com * Support: https://ubuntu.com/advantage This system has been minimized by removing packages and content that are not required on a system that users do not log into. To restore this content, you can run the 'unminimize' command. The programs included with the Ubuntu system are free software; the exact distribution terms for each program are described in the individual files in /usr/share/doc/*/copyright. Ubuntu comes with ABSOLUTELY NO WARRANTY, to the extent permitted by applicable law. root@bd12d0a840e6:~#おまけ1: VSCodeとの連携
詳細な構築方法は記載しませんが、VSCodeのRemote Development Extensionという拡張機能を用いると以下の様にVSCodeからHPCのお勉強が出来ます。(図はcufファイルを表示している所)
おまけ2: NVIDIA HPC SDK
NVIDIAが2020年8月にリリースしたHigh Performance Computing向けのライブラリやコンパイラまとめて開発環境として提供している物です。技術サポートは有償ですが、ライブラリやコンパイラを使用するだけなら無料で利用出来ます。従来はCUDA FortranのコンパイラはPGIコンパイラという他社製コンパイラが必要でしたが、NVIDIA製のコンパイラでCでもFortranでもCUDAが利用出来る様になります。含まれているコンパイラの一覧表を以下に示します。選り取り見取りといった所です。
/opt/nvidia/hpc_sdk/Linux_x86_64/20.7/compilers/binの中は選り取り見取りな様子# ls addlocalrc jide-common.jar ncu nvaccelinfo nvcudainit nvprof pgaccelinfo pgf77 pgsize tools balloontip.jar jide-dock.jar nsight-sys nvc nvdecode nvsize pgc++ pgf90 pgunzip cuda-gdb llvmversionrc nsys nvc++ nvextract nvunzip pgcc pgf95 pgzip cudarc localrc nv-nsight-cu-cli nvcc nvfortran nvzip pgcpuid pgfortran rcfiles ganymed-ssh2-build251.jar makelocalrc nvaccelerror nvcpuid nvprepro pgaccelerror pgcudainit pgprepro rsyntaxtextarea.jarまとめ
環境構築が煩雑で面倒くさいHPC向けライブラリの開発環境構築をDockerを用いることで簡単かつ手間無く出来る様にしました。HPCの専門書が数冊手元に溜まっているので勉強に活用していこうと思います。
Reference
- CUDA10.2 Dockerfile
- cuDNN Dockerfile
- OpenCL Dockerfile
- Installing PyCUDA on Ubuntu Linux
- Dockerのコンテナを起動したままにする
- NVIDIA HPC SDK
- NVIDIA HPC SDK Version 20.7 Downloads
- NVIDIA HPC SDK の HPC Compilers について
- SSHでログイン出来るコンテナの作り方(Ubuntu18対応版)
Fortranを業務で扱っている友人にも使って貰うのでCUDA Fortranに対応させておくことにしました。 ↩

- 投稿日:2020-09-20T13:40:47+09:00
eclipse(python)ダウンロード、python実行、OpenPyXLダウンロードメモ
★1 eclipseダウンロード
このURL( https://www.sejuku.net/blog/73558 )
に添って開始だだ、
https://mergedoc.osdn.jp/
の中から「Eclipse 4.8 Photon」ダウンロードして、
Eclipseを起動しないと動かない
最新版のは現状起動時に、awt.dllがどうのこうのエラーが出て自分のPCでは利用不可。ダウンロードしたら
上記のURL( https://www.sejuku.net/blog/73558 )
「Pythonの実行」のところまでやってみる★2 openxlpyインストール
まずは、pipeをインストール
このURL( https://se-log.blogspot.com/2018/11/python-windows-eclipse-pip.html )
に添ってやればpipeインストールはできる。pipeインストール完了後、
eclipseで上記のURL( https://se-log.blogspot.com/2018/11/python-windows-eclipse-pip.html )
を参考に「install openpyxl」をすれば完了
- 投稿日:2020-09-20T13:40:47+09:00
勉強メモ1_eclipse(python)ダウンロード、python実行、OpenPyXLダウンロード
★1 eclipseダウンロード
このURL( https://www.sejuku.net/blog/73558 )
に添って開始だだ、
https://mergedoc.osdn.jp/
の中から「Eclipse 4.8 Photon」ダウンロードして、
Eclipseを起動しないと動かない
最新版のは現状起動時に、awt.dllがどうのこうのエラーが出て自分のPCでは利用不可。ダウンロードしたら
上記のURL( https://www.sejuku.net/blog/73558 )
「Pythonの実行」のところまでやってみる★2 openxlpyインストール
まずは、pipeをインストール
このURL( https://se-log.blogspot.com/2018/11/python-windows-eclipse-pip.html )
に添ってやればpipeインストールはできる。pipeインストール完了後、
eclipseで上記のURL( https://se-log.blogspot.com/2018/11/python-windows-eclipse-pip.html )
を参考に「install openpyxl」をすれば完了
- 投稿日:2020-09-20T11:29:52+09:00
Django スケジュール表を作成する
とりあえず、シフトを作成機能をつくっていこうと思いますが、月間のシフトデータがあれば、それをもとに次月コピーができるようにすることでまずは実装し、発展できればそれぞれのスタッフのシフト条件や、休暇申請に基づいて翌月や当月のシフトを自動で作成し手動で修正できるようにしていければと思います
シフト作成する時に前月からコピーしてから、各スタッフの条件からシフトを編集している。
これをExcelで作成しているので面倒くさいとのこと。VBAで作成補助機能は以前に作成してあげましたが…条件は、
・正社員は月○○時間以上労働
・何曜日のみ勤務
・○○時から○○時は2人必須勤務
・スタッフは複数の施設で働くことがあるこれから作るのも、次月の作成するときに、当月をコピーして編集してもらうという形式でいこうと思います。
基本的には、曜日による考え方のようなので第1週の月曜日を次の月の月曜日に入れるといったようにしようかと思います。実装後、便利機能を追加していければよいかなと思っています。
色々テーブルも考えました。
1日に複数のシフトパターンに入るのであれば、それがいくつになっても大丈夫なように作成しようかと考えましたが、
まだまだ技術が足りないし、ユーザーからしたら裏のテーブル構造がきれいかそうでないかなんて関係ないし、
まずは使えるものを提供することを一番と考えて、日付
USER
①施設 シフトパターン
②施設 シフトパターン
③施設 シフトパターン
④施設 シフトパターンという形で実装しようと思います。
条件の○○時から○○時は2人以上必須勤務のチェック機能は難しそうなので後回しか実装しないかもです(笑)
施設テーブルは色々なところで使用されると思ったので、施設用のアプリを作成します
terminalpython3 manage.py startapp shisetsuアプリを追加したら、settingにアプリを追加します
config/settigns.pyINSTALLED_APPS = [ 'django.contrib.admin', 'django.contrib.auth', 'django.contrib.contenttypes', 'django.contrib.sessions', 'django.contrib.messages', 'django.contrib.staticfiles', 'accounts.apps.AccountsConfig', 'shisetsu' ]施設のモデルを指定します。
基本的な情報とシフト表を表示するときに分かりやすくするために色を指定するようにしておきます。shisetsu/models.pyfrom django.db import models from phonenumber_field.modelfields import PhoneNumberField # Create your models here. class Shisetsu(models.Model): id = models.IntegerField(verbose_name='施設ID',primary_key=True) name = models.CharField(verbose_name='施設名', max_length=50) adress = models.CharField(verbose_name='住所', max_length=100) tel = PhoneNumberField(verbose_name='電話番号', null=True, blank=True) fax = PhoneNumberField(verbose_name='FAX番号', null=True, blank=True) color = ColorField(verbose_name='表示色', default='#FF0000')adminサイトで編集をしようと思うので、admin.pyを修正します
shisetsu.pyfrom django.contrib import admin from .models import Profile # Register your models here. admin.site.register(Profile)これで、設定ができたのでマイグレーションを実施します。
terminalpython3 manage.py makemigration実施するとエラーがでました。
from phonenumber_field.modelfields import PhoneNumberField
ないからインポートしてねってことだと思います。
terminalpip install django-phonenumber-field pip install phonenumbers
これでインストールが完了していると思うので再度、マイグレーションを実施してみます。
次は、
terminalcolor = ColorField(verbose_name='表示色', default='#FF0000') NameError: name 'ColorField' is not definedここでエラーがでています。
terminalpip install django-colorfieldインストールして、settingsファイルのアプリに二つを追加します
config/settings.pyINSTALLED_APPS = [ 'django.contrib.admin', 'django.contrib.auth', 'django.contrib.contenttypes', 'django.contrib.sessions', 'django.contrib.messages', 'django.contrib.staticfiles', 'accounts.apps.AccountsConfig', 'shisetsu', 'colorfield', 'phonenumber_field.modelfields', ]そしてもう一度、マイグレーションを実施。
成功したようです。
管理画面から確認してみます。
表示はされていたので、いざ登録しようとしたら、電話番号でエラーになりました。
なんか、日本での電話番号形式と違う気がします…
なので、修正config.setting.pyINSTALLED_APPS = [ 'django.contrib.admin', 'django.contrib.auth', 'django.contrib.contenttypes', 'django.contrib.sessions', 'django.contrib.messages', 'django.contrib.staticfiles', 'accounts.apps.AccountsConfig', 'shisetsu', 'colorfield', ]電話用のアプリを削除
modelsも書き換え
shisetsu.pyfrom django.db import models from colorfield.fields import ColorField # Create your models here. class Shisetsu(models.Model): id = models.IntegerField(verbose_name='施設ID',primary_key=True) name = models.CharField(verbose_name='施設名', max_length=50) adress = models.CharField(verbose_name='住所', max_length=100) tel = models.CharField(verbose_name='電話番号', max_length=20) fax = models.CharField(verbose_name='FAX番号', max_length=20) color = ColorField(verbose_name='表示色', default='#FF0000')これでもう一回マイグレーションを実施します。
これで保存できました。
施設情報もそんなに登録更新をするものではないので、編集用画面は作成しないでいきます。




- 投稿日:2020-09-20T11:20:53+09:00
プログラミングで調べた発音メモ
strftime ストリングフォーマットタイム:(発音) エスティーアールエフタイム
aggfunc アグリゲートファンクション: (発音)アグファンク