- 投稿日:2020-09-20T23:19:54+09:00
AWS SAA合格体験記
はじめに
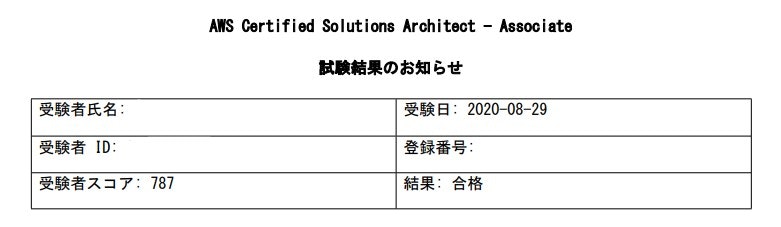
先日(2020/8/29)にAWS認定ソリューションアーキテクト – アソシエイト(SAA)を取得したので、学習で使用した教材や学習方法を書きたいと思います。
これから受験される方の参考にしていただければ幸いです。
合格に必要なスコアは「720点」なのでギリギリまではいかないが、もう少しスコアが欲しかったといったところです。AWS SAAとは
AWS認定資格の中で主にAWSにおけるアーキテクチャ設計に関する知識を問われる試験となっています。
AWS 認定ソリューションアーキテクト – アソシエイト試験は、AWS における分散システムの可用性、コスト効率、高耐障害性およびスケーラビリティの設計に関する 1 年以上の実務経験を持つソリューションアーキテクト担当者を対象としています。
AWS 認定 ソリューションアーキテクト – アソシエイト より引用AWS SAAの試験概要
AWS SAAの試験概要は以下の通りです。
- 形式:複数の選択肢と複数の答えがある問題
- 実施形式:テストセンターまたはオンラインプロクター試験
- 時間:試験時間: 130 分間
- 受験料金:15,000 円(税別)/ 模擬試験 2,000円(税別)
- 言語:英語、日本語、韓国語、中国語 (簡体字)
AWS 認定 ソリューションアーキテクト – アソシエイト より引用コロナ禍ということでリモートでの試験も検討しましたが、私は家だと子供が部屋に乱入してきたりするなど集中できない状況になる可能性があるので、センターで受験しました。。。
AWS SAAの試験範囲
AWS SAAの試験範囲は以下の通りです。
私は資格勉強をする際に勉強の最初は試験範囲の内容を押さえることに時間を割くのですが、AWS公式ページではこれぐらいの記載しかないです。
淡泊だなーという印象を受けました。。学習時点でのスキル、知識
SAAを勉強し始めた筆者のスキル、知識は以下の通りです。
オンプレ系の知識はあるが、クラウドの知見はあまりないといった感じ。
- サーバがメインのインフラエンジニアで設計から運用保守まで対応経験あり
- LPICやWindowsのサーバ系の資格やOracle、SQLServerのDB系の資格などを持っている(失効しているのもあり)
- ネットワーク系の資格はないが、スイッチ、ルータ、FWなどの対応経験あり
- AWSを業務で2か月ほど触ったことがある
学習教材
偉大なる先人の合格記などを調べて以下の教材を使用しました。
- AWS認定資格試験テキスト AWS認定 ソリューションアーキテクト-アソシエイト
- AWS WEB問題集で学習しよう
- 【SAA-C02版】AWS 認定ソリューションアーキテクト アソシエイト模擬試験問題集(6回分390問)
テキストは結果として3日で試験の情報を軽くインプットしただけでそれ以降はあまり使いませんでした。。。
Udemyの問題集も買いましたが以下の理由で、1回解いただけであとは使用しませんでした。
- 問題が本試験に比べて難しい(試験2週間前に解いたのですが、40%ぐらいしか正解できなくて心が折れました)
- 65問すべて解かないと解答のフィードバックを受けることができない
結果として、私にはUdemyの問題集は不要でした。。。
受験前の不安要素を完全に消したいという方はUdemyも勉強されてもいいかもしれません。学習方法
AWS認定資格試験テキストを3日で読み切り、それ以降はWEB問題集の「SAA#80」以降を繰り返し解いていました。
「SAA#80」以降を3周程度、何度も間違える問題は何度も繰り返して知識を定着させました。
WEB問題集はひとつの単元が7問で構成されており、1つの問題を解くごとにフィードバックを受けることが出来るので「65問目を解くころには1問目の問題と解答内容を忘れてしまった」みたいなことはありません。単元ごとの問題数が少ないので、隙間時間に学習ができるのでおススメです。
また、肌感覚で本試験の4割程度はWEB問題集と同じような問題、3~4割程度がWEB問題集の内容が理解できれば解ける問題、2~3割程度がわからない問題といった内容でしたのでこちらをメイン教材として進める形で問題ないと思います。
WEB問題集は有料会員登録をすることで解ける問題や有効期間が変わってくるのですが、SAAを取得するだけであれば「ゴールドプラン」でSAPも視野に入れているのであれば、「ダイヤモンドプラン」がよろしいかと思います。
学習時間は毎日2~3時間で学習期間としては1か月程度なので、トータルの学習時間は80時間前後だと思います。
Udemyに手を付けなければ、70時間弱程度で合格できたと思われます。実際の試験
すべての問題を解くのにほぼ130分フルで使いました。(余談ですが、私は時間配分を気にした上で1問1問丁寧に答えて後戻りはしないタイプです)
試験問題は見たことない問題と何言っているか分からない日本語で惑わせてきますが、しっかり準備して落ち着けば十分に合格可能であるという印象でした。
WEB問題集の「SAA#80」以降を解説含め理解し、6~7問正解出来るようなレベルになったら十分合格できるレベルになっていると思いますので、あまり先延ばしせずに試験を受けに行ってしまった方がよろしいかと思います。
最後に
AWSのSAAはグローバルナレッジ社が発表している「稼げる資格 Top15」に毎年ランクインする資格になります。
ご自身のスキルアップのために皆さんもSAAの受験を検討してみてはいかがでしょうか。

- 投稿日:2020-09-20T21:48:34+09:00
AWS Summit Onlineのちょっとしたメモ①
AWS Summit Onlineのメモ
AWS Summit Onlineの気になったセッションを視聴してのちょっとしたメモになります。
・今だからこそ知りたい、AWSのデータベース2020基礎
◆purpose built
用途に応じてデータベースサービスを選択する◆Relational
トランザクション処理を必要とするサービス
RDS
6つのデータベースを選択できる
クリック1つでフェイルオーバーの設定を行える
Amazon Aurora
Amazonが1から設計したデータベースサービス
MySQLやPostgreSQLと互換性あり◆Key-value
キーとバリューの1対1の関係でデータを取得するシンプルなものなので
高スループット、低レイテンシ
Amazon DynamoDB
サーバレスなマネージドサービス
規模に関係なく数ミリsecのレイテンシ
Amazon Keyspaces
cassandraデータベースと互換あり
cassndraデータベースは運用管理にコストがかかるが、
AWSに運用管理を任せられる◆Document
JSONやXMLで書かれたデータを直接扱うことができる
Amazon DocumentDB
MongoDB互換のデータベースサービス
毎秒数百万のリクエストが来てもミリ秒のレイテンシを実現◆In-memory
マイクロ秒の低レイテンシが必要なサービスに使う
Amazon ElastiCache
Redis/Memcached互換のデータベースサービスで
低レイテンシを実現可能
マネージドサービスで簡単にスケーリングが可能◆ Graph
データ同士の関係性をグラフで表す
Amazon Neptune
マネージドサービスのグラフデータベース
数十億の関係の照会を数ミリsecで可能◆Time-Series
特定の時間で記録され、時間の経過に伴う変化を測定する
リレーショナルデータベースでは高速に変化する時系列データの処理は
難しい
Amazon Timestream
フルマネージド型の時系列データベース
リレーショナルデータベースに対して1000倍速く、1/10のコスト◆Ledger
データが変更されていない事を保証できるデータベース
記録の保持に使用→取引、取引、⼝座の追跡や購⼊商品の所在等々
Amazon Quantum Ledger Database
マネージド型台帳データベース
変更履歴、トラッキングの検証が可能・30分で理解するAWSストレージサービスの全体像
◆ビジネスで重要度が増す大規模データ
大規模データは日々増加していき扱うデータも増えている
このデータをオンプレミスのストレージで保持するのは現実的では無い◆オンプレミスのストレージの課題、クラウドのメリット
・利用できるまでの時間
オンプレミスでは調達やセットアップして利用できるまでに時間がか
かる
クラウドだと必要な時にすぐに割り当てて使用できる・容量の上限
オンプレミスのストレージでは物理要領に上限があるので、領域が枯
渇しないようにやり繰りする必要がある
将来的な利用量を考える必要がある
クラウドだといつでも簡単に容量を追加できるので、容量を気にする
必要が無い・耐障害設計
オンプレミスはディスク障害やコントローラ障害などの対策を利用者
が考える必要がある
クラウドはサービスに冗長化の設計が組み込まれているので耐障害設
計がしやすく、交換用のストレージを用意する必要が無い・パフォーマンス設計
オンプレミスは後からSSD/HDDに変更することができない
クラウドではいつでもシステムに応じたストレージに変更ができる・コスト
オンプレミスはハードウェアサポートの終了を気にする必要がある
運用は利用者が行うので運用コストが下がらない
クラウドは必要なストレージを必要な量だけ使用すればいいのでコス
トを最適化しやすく、運用面はAWSが行う◆ストレージの利用シーン
・データベース
種類ごとに求められるI/O特性が異なるのでそれぞれに適したスト
レージサービスを選択する
EBS
SSDタイプのgp2,io1 HDDタイプのst1,sc1がある
一部のEC2インスタンスにはホストにアタッチされたインスタンス
ストアがある・ファイルサーバー
クライアントやアプリケーションがどのプロトコルでアクセスしたい
のかによってストレージサービスが変わる
NFSならAmazon EFS
SMBならAmazon FSx for Windows File Server
EFS
NFSアクセスを提供する共有ファイルシステムのサービス
複数のAZへの冗長化、保存容量に応じた柔軟な課金体系などクラ
ウド利用を前提としている
FSx for Windows File Server
Windowsファイルサーバの完全マネージドサービス
既存のADと共に動作し、可用性構成、ストレージタイプを選択
できる
容量はオンラインで拡張できる・データレイク
多種多様なデータを扱うことを求められる
どんなサイズにもスケール可能
様々なサービスやアプリケーションと統合できること
Amazon S3
容量制限が無い
高い耐久性
1GB月に約3円の低コストで提供されている
AWSの大多数のサービスと統合されているので簡単に連携できる・高性能コンピューティング
計算量が膨大な処理を高性能なコンピューティングを用いて処理する
FSx fpr Lustre
高速でスケーラブルなファイルシステムを必要な時短期間使用す
る事を前提としている
高スループット、低レイテンシー・バックアップ
どこから何をバックアップするのか考える
AWSのサービスならサービスに付随しているバックアップ機能を使用
例:EBSならEBSスナップショット
オンプレミスのデータバックアップ
オンラインならStorage Gateway
オフラインならSnowball Edge
AWS Backup
複数サービスを含む論理的なグループでバックアップの自動化と
一元管理を行うので管理者の負担軽減ができる
AWS Storage Gateway
オンプレミス環境に配置したゲートウェイVMを通じてAmazon
S3へデータを送るゲートウェイとして機能する
バックアップ、データ移行にも使用可能
AWS Snowball Edge
オンプレミスからクラウドへ大量のデータを高速に移行可能・データ移行
データをオンラインで移行するかオフラインで移行するか、マシンイ
メージとして移行するかファイルやデータだけ移行するかなど条件に
応じて方式を選択
AWS DataSync
オンプレミスとクラウド間のオンライン移行サービス
CloudEndure Migration
短い切り替え時間でサーバのAWS移行を支援するツール
移行テストも本番環境に影響を与えずにできる◆サービス機能強化により広がる利用シーン
・Amazon EFS の AWS Lambda サポート
AWS Lambdaからストレージサービスを利用する際はAmazon S3を利
用していたがEFSを利用できるようになった・AWS Snowcone
現在は米国内だけの提供
AWS Snowball Edgeより軽量な新しいアプライアンス・AWS Transfer Family
SFTP/FTPS/FTPサーバをAWSが管理するマネージドサービス
外部ユーザとセキュアにデータ交換可能
- 投稿日:2020-09-20T19:08:47+09:00
aws RHEL 7.8 GUIコンソール(DISPLAY=:0)にリモートアクセス
課題
訳があって(seleniumを使いたい)LinuxのGUIコンソール(DISPLAY=:0)をアクセスしたいが、サーバーがawsのec2にあり、どうすればよいか?
TL;DR(Too Long, Didn’t Read)
- GUI関連パッケージをインストール
yum groupinstall "Server with GUI"- x0vncserverをインストール
yum install tigervnc-server- ユーザー追加
adduser user1、パスワード変更passwd user1、VNC用パスワードも設定vncpasswd- pam設定
vi /etc/pam.d/xerver、この行を auth required pam_console.so ⇐ pem_permit.soへ変更- SELinux停止
vi /etc/selinux/config、SELINUX=disabled に変更、reboot- firewall停止
systemctl stop firewalld- user1で
startx- user1で
x0vncserver -display :0 -passwordfile ~/.vnc/passwd- vncviewerでサーバーに接続
手順
ゆっくり話そう
aws ec2インスタンスの作成
awsの利用はお金かかる場合があるので、ご理解の上で利用ください。
- aws ec2 console の接続。注意、右上
東京になっているが、必要に応じて修正インスタンス起動をクリック。翻訳のせいか、「インスタンス新規作成」の意味- 検索ボックスに
redhatを入れてエンターを押す- 「AWS Marketplace で
105 件の結果件」をクリック- 今回試験で選ぶのは「RHEL-7.8-20200506-10GiB | 担当 ProComputers.com」、右の
選択をクリックContinueをクリック- STEP2:既に
t2.largeが選ばれた状態である、必要に応じて修正。今回試験はこのまま利用。次のステップ:インスタンスの詳細の設定をクリック- STEP3:今回は修正なし、
次のステップ:ストレージの追加をクリック- STEP4:サイズが
10GBになっているが、今回は余裕をもって20GBにする。次のステップ:タグの追加をクリック- STEP5:今回は修正なし、
次のステップ:セキュリティグループの設定をクリック- STEP6:ソース欄 '0.0.0.0/0'ななっているが、自分のアドレスを調べて、(例えばここで)、
自分のIPアドレス/32を入れる- ----- タイプが'SSH'になっているが、
すべてのトラフィックに変える。警告:↑の行と合わせてやらないとセキュリティーが著しく低下するのでご注意ください- -----
確認と作成をクリック- STEP7:内容確認して、問題なければ
起動をクリック- 'キーペア'の小窓が出る。新規キーペア作成を選ぶ。新規の場合キーペア名を入れる。
キーペアのダウンロードをクリックし、pemファイルを保存する。注意:青い注意書きをよく読んでください。このpemファイルがないと今後このインスタンスがアクセスできなくなること、と、このpemファイルは再度ダウンロードする方法はないこと- 問題なければ、
インスタンスの作成をクリック。作成自体はしばらく(数分程度)かかる環境
試験環境接続
割愛。
tera termと先保存したpemファイルを使って接続する。試験環境確認
/etc/os-releaseNAME="Red Hat Enterprise Linux Server" VERSION="7.8 (Maipo)" ID="rhel" ID_LIKE="fedora" VARIANT="Server" VARIANT_ID="server" VERSION_ID="7.8" PRETTY_NAME="Red Hat Enterprise Linux Server 7.8 (Maipo)" ANSI_COLOR="0;31" CPE_NAME="cpe:/o:redhat:enterprise_linux:7.8:GA:server" HOME_URL="https://www.redhat.com/" BUG_REPORT_URL="https://bugzilla.redhat.com/" REDHAT_BUGZILLA_PRODUCT="Red Hat Enterprise Linux 7" REDHAT_BUGZILLA_PRODUCT_VERSION=7.8 REDHAT_SUPPORT_PRODUCT="Red Hat Enterprise Linux" REDHAT_SUPPORT_PRODUCT_VERSION="7.8"ディスク容量確認
デフォルト10GBだが、余裕をもって20GBのディスクを選んでました。
df-hFilesystem Size Used Avail Use% Mounted on devtmpfs 3.8G 0 3.8G 0% /dev tmpfs 3.9G 0 3.9G 0% /dev/shm tmpfs 3.9G 17M 3.9G 1% /run tmpfs 3.9G 0 3.9G 0% /sys/fs/cgroup /dev/xvda2 20G 1.6G 19G 8% / tmpfs 782M 0 782M 0% /run/user/0 tmpfs 782M 0 782M 0% /run/user/1000GUIのインストール
以降特別説明なければrootで作業する
sudo su -まず利用できる選択肢を確認
yum grouplist出力Available Environment Groups: Minimal Install Infrastructure Server File and Print Server Basic Web Server Virtualization Host Server with GUI ⇐ 今回これを使う Available Groups: Compatibility Libraries Console Internet Tools Development Tools Graphical Administration Tools Legacy UNIX Compatibility Scientific Support Security Tools Smart Card Support System Administration Tools System Management Done今回は
Server with GUIを使う。ちなみにyum grouplist hiddenで詳細な選択肢が出る。yum groupinstall "Server with GUI"途中の質問に
yで答え
しばらく自動実行が続く(約8分)物理モニタがあれば、
/etc/inittabを修正して、起動時自動的にGUIを立ち上げる設定を入れるが、今回は必要ない、というより、上げない方が次の設定がうまくいく。x0vncserverをインストール
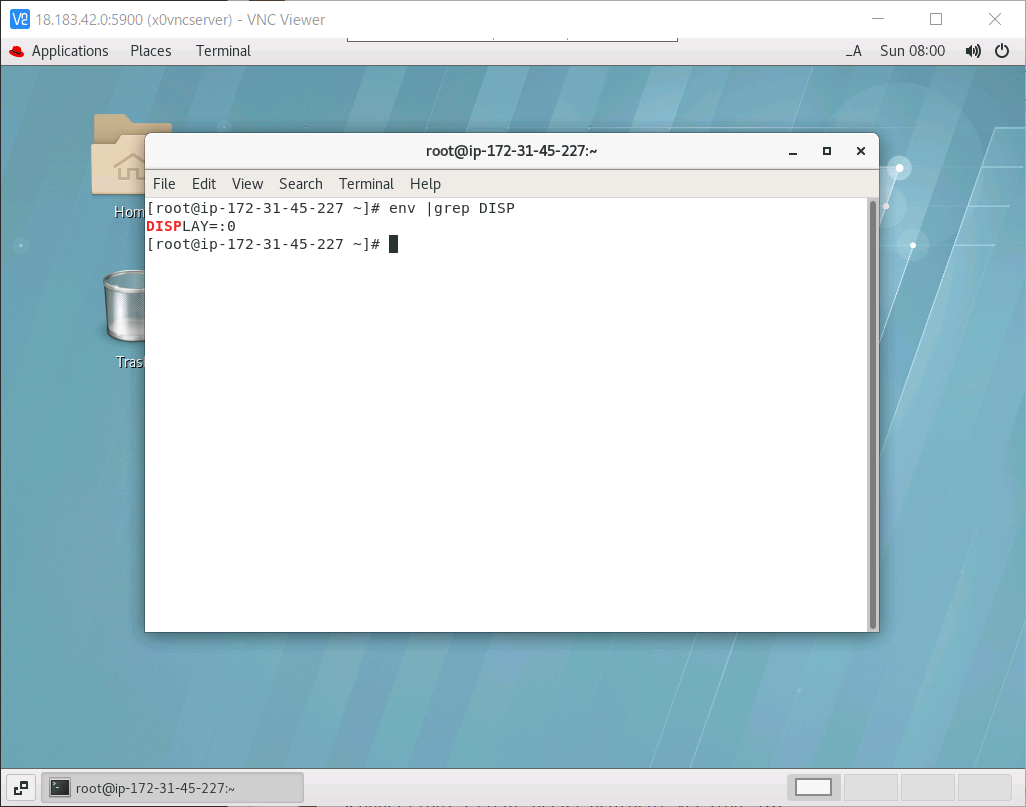
x0vncserverは新規Xサーバーを起動するのではなく、既存のXサーバーを繋げられることができる
yum install tigervnc-serverXを起動
rootユーザーで以下のコマンドを実行
startxVNC準備と起動
別ターミナルで以下のコマンドを実行。これもrootユーザーで、vnc接続用パスワードを設定
vncpasswd出力Password: Verify: Would you like to enter a view-only password (y/n)? n A view-only password is not usedvncサーバーを起動
x0vncserver -display :0 -passwordfile ~/.vnc/passwdポート番号を覚える
出力Sun Sep 20 07:48:15 2020 Geometry: Desktop geometry is set to 1024x768+0+0 Main: XTest extension present - version 2.2 Main: Listening on port 5900 ⇐ ポート番号接続
接続には vnc viewer、或いはUltraVNCを利用できる。
サーバーのIPとポートでつなげ、先設定したパスワードが聞かれる。成功したらこんな感じ
サーバー側サーバー側出力Sun Sep 20 07:48:36 2020 Connections: accepted: 111.98.64.161::58004 SConnection: Client needs protocol version 3.8 SConnection: Client requests security type VncAuth(2) Sun Sep 20 07:48:43 2020 Main: Enabling 8 buttons of X pointer device Main: Allocated basic Xlib image VNCSConnST: Server default pixel format depth 16 (16bpp) little-endian rgb565 VNCSConnST: Client pixel format depth 6 (8bpp) rgb222クライアント側こんな感じ。
初回入るので、初期設定が必要
設定後、環境変数を見ると、コンソール「:0」に繋がっていることが分かる。一般ユーザーで繋ぐ
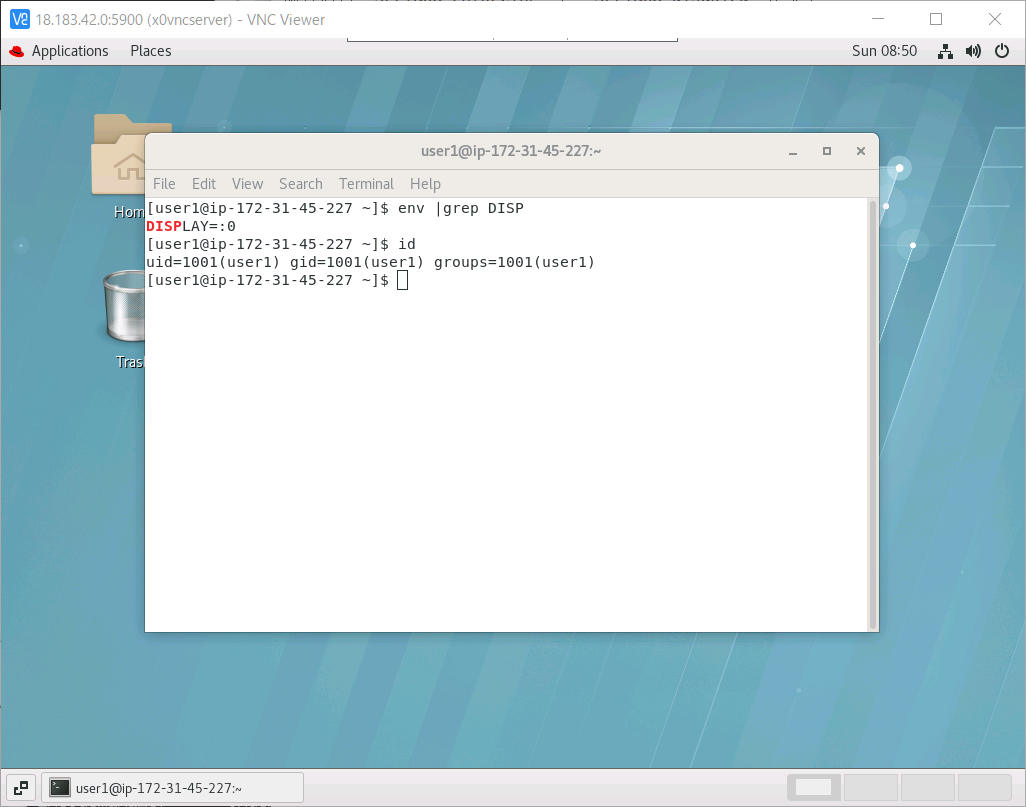
ユーザーを追加
adduser user1 passwd user1 su - user1 vncpasswdpam設定
vi /etc/pam.d/xerver以下の行を修正 参考
/etc/pam.d/xerver#%PAM-1.0 auth sufficient pam_rootok.so auth required pam_console.so ⇐ pem_permit.soへ変更 account required pam_permit.soSELinux停止
現状確認
getenforce出力Enforcing修正
vi /etc/selinux/config既存の行
SELINUX=enforcingをSELINUX=disabledに変更
その後rebootで再起動
再起動後再度getenforceで確認、Disabledになっているなら成功。firewalld停止
systemctl stop firewalld自動起動禁止もできる
systemctl disable firewalld実行(user1で)
Xを起動
startx別タームで
x0vncserver -display :0 -passwordfile ~/.vnc/passwdクライアント側
やはり、一般ユーザーuser1がコンソールに入っていることになります。失敗例
/etc/pam.d/xerver未修正時
/etc/pam.d/xerver未修正時`startx`するとxauth: file /home/user1/.serverauth.15641 does not exist xauth: file /home/user1/.Xauthority does not exist xauth: file /home/user1/.Xauthority does not exist (EE) Fatal server error: (EE) PAM authentication failed, cannot start X server. Perhaps you do not have console ownership? (EE) (EE) Please consult the The X.Org Foundation support at http://wiki.x.org for help. (EE) xinit: giving up xinit: unable to connect to X server: Connection refused xinit: server error Couldn't get a file descriptor referring to the consoleCentOS 8の場合
同じ試験はCentos8環境でもやりました、一部違いだけを記載します。
/etc/os-releaseNAME="CentOS Linux" VERSION="8 (Core)" ID="centos" ID_LIKE="rhel fedora" VERSION_ID="8" PLATFORM_ID="platform:el8" PRETTY_NAME="CentOS Linux 8 (Core)" ANSI_COLOR="0;31" CPE_NAME="cpe:/o:centos:centos:8" HOME_URL="https://www.centos.org/" BUG_REPORT_URL="https://bugs.centos.org/" CENTOS_MANTISBT_PROJECT="CentOS-8" CENTOS_MANTISBT_PROJECT_VERSION="8" REDHAT_SUPPORT_PRODUCT="centos" REDHAT_SUPPORT_PRODUCT_VERSION="8"EPELをインストール
追加パッケージの入手先
sudo rpm -ivh https://dl.fedoraproject.org/pub/epel/epel-release-latest-7.noarch.rpmx0vncserverも問題なく使えるが、x11vncも使える、REHL7.8は以下のエラーでインストールできなかったけど
yum install x11vnc Error: Package: x11vnc-0.9.13-11.el7.x86_64 (epel) Requires: Xvfbpamの代わりにXwrapper記載
以下の行を追加
/etc/X11/Xwrapper.configallowed_users = anybodyx11vnc起動
x11vnc -display :0 -nopw -forever -auth ~/.Xauthority出力20/09/2020 18:22:59 x11vnc version: 0.9.16 lastmod: 2019-01-05 pid: 15614 20/09/2020 18:22:59 Using X display :0 20/09/2020 18:22:59 rootwin: 0x3a8 reswin: 0x2200001 dpy: 0xa71fd690 20/09/2020 18:22:59 20/09/2020 18:22:59 ------------------ USEFUL INFORMATION ------------------ 20/09/2020 18:22:59 X DAMAGE available on display, using it for polling hints. 20/09/2020 18:22:59 To disable this behavior use: '-noxdamage' 20/09/2020 18:22:59 20/09/2020 18:22:59 Most compositing window managers like 'compiz' or 'beryl' 20/09/2020 18:22:59 cause X DAMAGE to fail, and so you may not see any screen 20/09/2020 18:22:59 updates via VNC. Either disable 'compiz' (recommended) or 20/09/2020 18:22:59 supply the x11vnc '-noxdamage' command line option. 20/09/2020 18:22:59 20/09/2020 18:22:59 Wireframing: -wireframe mode is in effect for window moves. 20/09/2020 18:22:59 If this yields undesired behavior (poor response, painting 20/09/2020 18:22:59 errors, etc) it may be disabled: 20/09/2020 18:22:59 - use '-nowf' to disable wireframing completely. 20/09/2020 18:22:59 - use '-nowcr' to disable the Copy Rectangle after the 20/09/2020 18:22:59 moved window is released in the new position. 20/09/2020 18:22:59 Also see the -help entry for tuning parameters. 20/09/2020 18:22:59 You can press 3 Alt_L's (Left "Alt" key) in a row to 20/09/2020 18:22:59 repaint the screen, also see the -fixscreen option for 20/09/2020 18:22:59 periodic repaints. 20/09/2020 18:22:59 20/09/2020 18:22:59 XFIXES available on display, resetting cursor mode 20/09/2020 18:22:59 to: '-cursor most'. 20/09/2020 18:22:59 to disable this behavior use: '-cursor arrow' 20/09/2020 18:22:59 or '-noxfixes'. 20/09/2020 18:22:59 using XFIXES for cursor drawing. 20/09/2020 18:22:59 GrabServer control via XTEST. 20/09/2020 18:22:59 20/09/2020 18:22:59 Scroll Detection: -scrollcopyrect mode is in effect to 20/09/2020 18:22:59 use RECORD extension to try to detect scrolling windows 20/09/2020 18:22:59 (induced by either user keystroke or mouse input). 20/09/2020 18:22:59 If this yields undesired behavior (poor response, painting 20/09/2020 18:22:59 errors, etc) it may be disabled via: '-noscr' 20/09/2020 18:22:59 Also see the -help entry for tuning parameters. 20/09/2020 18:22:59 You can press 3 Alt_L's (Left "Alt" key) in a row to 20/09/2020 18:22:59 repaint the screen, also see the -fixscreen option for 20/09/2020 18:22:59 periodic repaints. 20/09/2020 18:22:59 20/09/2020 18:22:59 XKEYBOARD: number of keysyms per keycode 10 is greater 20/09/2020 18:22:59 than 4 and 100 keysyms are mapped above 4. 20/09/2020 18:22:59 Automatically switching to -xkb mode. 20/09/2020 18:22:59 If this makes the key mapping worse you can 20/09/2020 18:22:59 disable it with the "-noxkb" option. 20/09/2020 18:22:59 Also, remember "-remap DEAD" for accenting characters. 20/09/2020 18:22:59 20/09/2020 18:22:59 X FBPM extension not supported. 20/09/2020 18:22:59 X display is capable of DPMS. 20/09/2020 18:22:59 -------------------------------------------------------- 20/09/2020 18:22:59 20/09/2020 18:22:59 Default visual ID: 0x21 20/09/2020 18:22:59 Read initial data from X display into framebuffer. 20/09/2020 18:22:59 initialize_screen: fb_depth/fb_bpp/fb_Bpl 24/32/4636 20/09/2020 18:22:59 WARNING: Width (1159) is not a multiple of 4. VncViewer has problems with that. 20/09/2020 18:22:59 20/09/2020 18:22:59 X display :0 is 32bpp depth=24 true color 20/09/2020 18:22:59 20/09/2020 18:22:59 Autoprobing TCP port 20/09/2020 18:22:59 Autoprobing selected TCP port 5900 20/09/2020 18:22:59 Autoprobing TCP6 port 20/09/2020 18:22:59 Autoprobing selected TCP6 port 5900 20/09/2020 18:22:59 listen6: bind: Address already in use 20/09/2020 18:22:59 Not listening on IPv6 interface. 20/09/2020 18:22:59 20/09/2020 18:22:59 Xinerama is present and active (e.g. multi-head). 20/09/2020 18:22:59 Xinerama: number of sub-screens: 1 20/09/2020 18:22:59 Xinerama: no blackouts needed (only one sub-screen) 20/09/2020 18:22:59 20/09/2020 18:22:59 fb read rate: 1518 MB/sec 20/09/2020 18:22:59 fast read: reset -wait ms to: 10 20/09/2020 18:22:59 fast read: reset -defer ms to: 10 20/09/2020 18:22:59 The X server says there are 12 mouse buttons. 20/09/2020 18:22:59 screen setup finished. 20/09/2020 18:22:59 The VNC desktop is: localhost.localdomain:0 PORT=5900 ****************************************************************************** Have you tried the x11vnc '-ncache' VNC client-side pixel caching feature yet? The scheme stores pixel data offscreen on the VNC viewer side for faster retrieval. It should work with any VNC viewer. Try it by running: x11vnc -ncache 10 ... One can also add -ncache_cr for smooth 'copyrect' window motion. More info: http://www.karlrunge.com/x11vnc/faq.html#faq-client-caching接続
クライアント側の写真は割愛
まとめ
今回サーバーの物理端末に相当するDISPLAY0にリモートで接続設定方法をRedHat7.8とCentOS8の2環境、特権ユーザーと一般ユーザーの例をご紹介しました。
- 投稿日:2020-09-20T18:05:02+09:00
AWSのIPアドレスを知りたい
AWSの公式ページに各サービスのIPアドレスについて説明があります。
https://docs.aws.amazon.com/ja_jp/general/latest/gr/aws-ip-ranges.htmlただ、実際のIPアドレス範囲はJSON形式になっています。
機械で処理する分には便利ですが、サクッと見たいときには不便なのでスクリプト化していつでも最新の範囲を表示できるスクリプトを備忘録として残します。
確認したのは PowerShell Core です。
ip-ranges.json
Invoke-WebRequestでダウンロードします。wgetやcurlでもお好みで。
Invoke-WebRequest https://ip-ranges.amazonaws.com/ip-ranges.json -OutFile ip-ranges.json抽出
まずJSON形式をオブジェクトへコンバートする。
CloudFrontとAPI GatewayのIPv4範囲をピックアップしてみました。ソートや形式などはお好みで。Get-Content -Path .\ip-ranges.json | ConvertFrom-Json | ForEach-Object prefixes | Where-Object {($_.service -eq "CLOUDFRONT") -or ($_.service -eq "API_GATEWAY")} | Where-Object {($_.region -eq "GLOBAL") -or ($_.region -eq "ap-northeast-1")} | Sort-Object service,region,ip_prefix | Format-Table service,region,ip_prefixIPv6
ForEach-Object prefixesの代わりにForEach-Object ipv6_prefixesになります。CSV化
出力段を
Format-Table ・・・ではなくConvertTo-CSVに置き換えるとCSV形式になるのでファイル保存して加工には便利かも。
- 投稿日:2020-09-20T16:22:10+09:00
AWS HoneyCodeの現状
いつも忘れないように、コンセプトから。
コンセプト
・お金かけてまでやりたくないのでほぼ無料でAWSを勉強する
→ちょっとしたサービスを起動すると結構高額になりやすい。
・高いレベルのセキュリティ確保を目指す
→アカウントを不正に使われるととんでもない額を請求されるので防ぐHoneyCodeの現状
AWS Summitがオンラインで公開されてますが、HoneyCodeは特に特集されてませんね。。。まあベータ版なので仕方ないところかもしれませんが、個人的には非常に残念です。
最新状況を知りたいなと思ってコミュニティを読んでましたが、ちょうどいい感じのページがありました。
https://honeycodecommunity.aws/t/external-integrations-share-your-feedback/5839これは実際に寄せられた意見が書かれています。さまざまなニーズがあるんだなと思います。もちろん現状だとできなくて、検討します、ありがとうみたいな回答にはなっているんですが、逆にこれができるとなると、ITに対してのある意味革命にもなりそうな気がしています。実装されるかわかりませんが、いいなと思うリクエストをピックアップしてみます。
・外部データベースへのアクセス
https://honeycodecommunity.aws/t/feasibility-to-connect-data-to-external-database/1599・Googleドライブ使えないの?
https://honeycodecommunity.aws/t/google-drive-connect/5352・JIRAやGoogleシートへのアップデート
https://honeycodecommunity.aws/t/integrating-with-jira-and-google-sheets/2367/5
確かにJIRAと連携できるといいかも!?・REST APIからデータ読めない?
https://honeycodecommunity.aws/t/read-data-from-rest-api/1237・APIを作らずに外部APIアクセスできないか?
https://honeycodecommunity.aws/t/external-api-access-without-requirement-to-create-app/4875・Amplifyとの統合
https://honeycodecommunity.aws/t/integration-with-aws-amplify-deployment-at-client-end/3706・Quicksightとの統合
https://honeycodecommunity.aws/t/aws-quicksight-integration/1270
これは欲しいかも!?あとはLambdaとの連携とかデータベースアクセスに関する質問が多いですね。現状ベータ版なので、その辺は今後拡充されていくでしょうし、少なくともAWSの全データベースやストレージサービスとは連携できて当たり前って感じがしますね。
個人的に期待しているのは、現状テンプレートとしてそのまま使えるアプリケーション(ToDoリストとか)がありますが、これがどんどん増えて、簡単にカスタマイズできることです。もっと複雑なアプリを第三者が投稿してみんなが使えるようになるといいなと。マーケットプレイスみたいな感じになるといいなと思います。そうなってくると、システムを作ると使うの境界がかなり崩れてきて、システムを使いこなす=自分でカスタムする、みたいな感じになっていくと思います。
- 投稿日:2020-09-20T15:13:29+09:00
Lambdaから引数を指定して AWS Batch起動方法
概要
前回作成したAWS BatchをLambdaから実行するようにします。
準備
AWS Batchは前回のものをそのまま使います。AWS BatchのジョブさえできていればいいのでCodeCommitなどはこのためだけに準備しなくても大丈夫です。
Lambdaの準備
- Lambdaを作成します。今回はpythonで実装していますがほかの言語でも可能です。
- JOB_NAME はジョブ定義の名称
- JOB_DEFINITION はジョブ定義のジョブ定義ARN
- JOB_QUEUE はジョブキューのキューARN
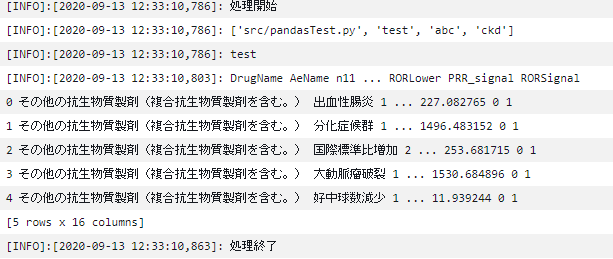
XXXXXXXXXXの部分はAWSのアカウントIDを設定します。commandの部分に引数をリスト形式でenvironmentには環境変数を辞書形式 name,valeの辞書をリスト形式で設定しますimport json import boto3 def lambda_handler(event, context): client = boto3.client('batch') JOB_NAME = 'pandas-envtest' JOB_QUEUE = "arn:aws:batch:ap-northeast-1:XXXXXXXXXX:job-queue/first-run-job-queue" JOB_DEFINITION = "arn:aws:batch:ap-northeast-1:XXXXXXXXXX:job-definition/pandas-envtest:1" response = client.submit_job( jobName = JOB_NAME, jobQueue = JOB_QUEUE, jobDefinition = JOB_DEFINITION, containerOverrides={ 'command': [ 'test','abc','ckd' ], 'environment': [ { 'name': 'DYNAMODB_REGION', 'value': 'test' } ] } ) print(response) return { 'statusCode': 200, 'body': json.dumps('run') }
- 実行結果は以下のようになります。
引数で指定した内容と環境変数が出力されています。
パラメータを外から送信してlambdaを通してバッチを起動するような形にできます。
- 投稿日:2020-09-20T15:09:14+09:00
CloudWatch-Agentを使ってメモリ監視をする
背景
ElasticBeanstalk上のEC2に対しメモリ監視を行いたかったので、CloudWatch-Agentを使うことにしました。
環境
- ElasticBeanstalk
- Python 3.6 running on 64bit Amazon Linux
インストール
AWS公式のCloudWatch エージェントのインストール によれば
- コマンドライン
- Systems Manager
- CloudFormation
この3つの方法のいずれかでインストールできる。今回はコマンドラインでインストールする方法を選択。
IAM
EC2に関連付けられたIAMロールに ポリシー
CloudWatchAgentServerPolicyを追加。Agentのインストール
EC2の中にて
$ wget https://s3.amazonaws.com/amazoncloudwatch-agent/amazon_linux/amd64/latest/amazon-cloudwatch-agent.rpm $ sudo rpm -U ./amazon-cloudwatch-agent.rpmcollectdのインストールと設定
メモリ監視にはAgentの他にcollectdも必要なのでインストール。
$ sudo yum install collectd $ sudo yum install collectd-python $ git clone https://github.com/awslabs/collectd-cloudwatch.git $ cd collectd-cloudwatch/src $ vim setup.py # 編集(後述) $ sudo ./setup.pycollectd-cloudwatchのsetup.py の編集
ハマったところです。
setup.pyはPython2で書かれているが、ElasticBeanstalkのデフォルトのPythonが3.6なので動かない。
そのためsetup.pyの1行目を以下に変更。
sudo python2.7 ./setup.pyとして良いです。#!/usr/bin/env python2.7再度実行しようとすると以下のメッセージが出た。インスタンスmetaデータを取りにいけずリージョンなどの情報が取得できない模様。
INFO:urllib3.connectionpool:Starting new HTTP connection (1): 169.254.169.254 AWS region could not be automatically detected. Cause:Cannot access metadata service. Cause: Timeout value connect was (0.3, 0.5), but it must be an int or float.ソースを見ると、タプルを渡せずrequestsが例外を吐いていました。理由は不明(このEBのpython環境の問題かもしれません)
setup.py_CONNECT_TIMEOUT_IN_SECONDS = 0.3 _RESPONSE_TIMEOUT_IN_SECONDS = 0.5 _REQUEST_TIMEOUT = (_CONNECT_TIMEOUT_IN_SECONDS, _RESPONSE_TIMEOUT_IN_SECONDS) (略) result = session.get(self.metadata_server + request, timeout=self._REQUEST_TIMEOUT)timeout値をベタ書きに変更して対処しました。
result = session.get(self.metadata_server + request, timeout=1)あとは設定を選んでいくだけです。ほぼデフォルト値にしました。
CloudWatchAgentの設定
ウィザードを使用して CloudWatch エージェント設定ファイルを作成する
ウィザードを立ち上げてCloudWatchAgentのほうの設定を行います。これもほぼデフォルトです。
sudo /opt/aws/amazon-cloudwatch-agent/bin/amazon-cloudwatch-agent-config-wizardStatsDは使わないので2。
Do you want to turn on StatsD daemon? 1. yes 2. no default choice: [1]:コア毎は不要なので2
Do you want to monitor cpu metrics per core? Additional CloudWatch charges may apply. 1. yes 2. no default choice: [1]:折角ならメモリ以外の項目も見たいのでStandardを選択。
Which default metrics config do you want? 1. Basic 2. Standard 3. Advanced 4. None default choice: [1]:ログファイルのモニタリングは2。
Do you want to monitor any log files? 1. yes 2. no default choice: [1]:設定内容は
/opt/aws/amazon-cloudwatch-agent/bin/config.jsonに出力されるので以下で起動開始。sudo /opt/aws/amazon-cloudwatch-agent/bin/amazon-cloudwatch-agent-ctl -a fetch-config -m ec2 -s -c file:/opt/aws/amazon-cloudwatch-agent/bin/config.json後はCloudWatchのアラーム設定をすれば完了です(Slack通知させるようにしました)。
参考
ありがとうございました。
- 投稿日:2020-09-20T13:21:29+09:00
Amplify SNS WorkshopでサーバレスなWebアプリ開発を手軽に実践
AWSのWebアプリケーション構築サービスであるAmplifyのワークショップ、
「Amplify SNS Workshop」をやってみたので紹介です。AWS Amplifyとは?
サービス紹介ページはこちら→https://aws.amazon.com/jp/amplify/
AWSの公式マンガでも紹介されています→https://aws.amazon.com/jp/campaigns/manga/vol3-1/AWS AmplifyはWebアプリの構築をサポートするサービス、ツール群です。
ReactやVueなどのモダンフレームワークを使用したフロントエンドに、バックエンドとしてAWSサービスを簡単につなぎこむことができます。Amplifyコンソールを使用して静的Webアプリケーションのホスティングをしたり、Amplifyフレームワークを使用してサーバレスなバックエンドの構築、フロントエンドとの接続をしたり、Webアプリ開発に必要な機能を包括しているサービスとなります。
本ワークショップにおいては、
- Reactアプリのホスティング
- AppSync, DynamoDBなどバックエンドの構築
- GitHub連携によるCI/CD環境構築
上記のようなWebアプリ開発の諸々のインタフェースとして使用します。
Amplify SNS Workshop
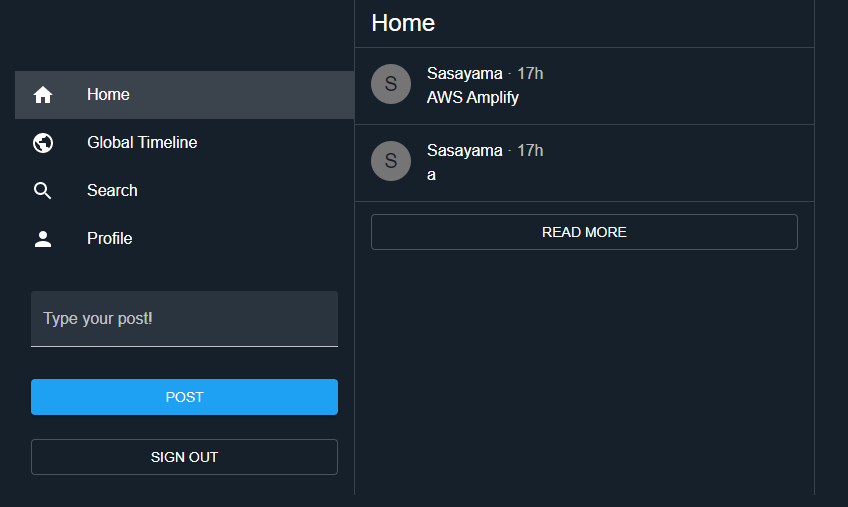
そんなAmplifyの実践入門として公開されているのが、「Amplify SNS Workshop」です。
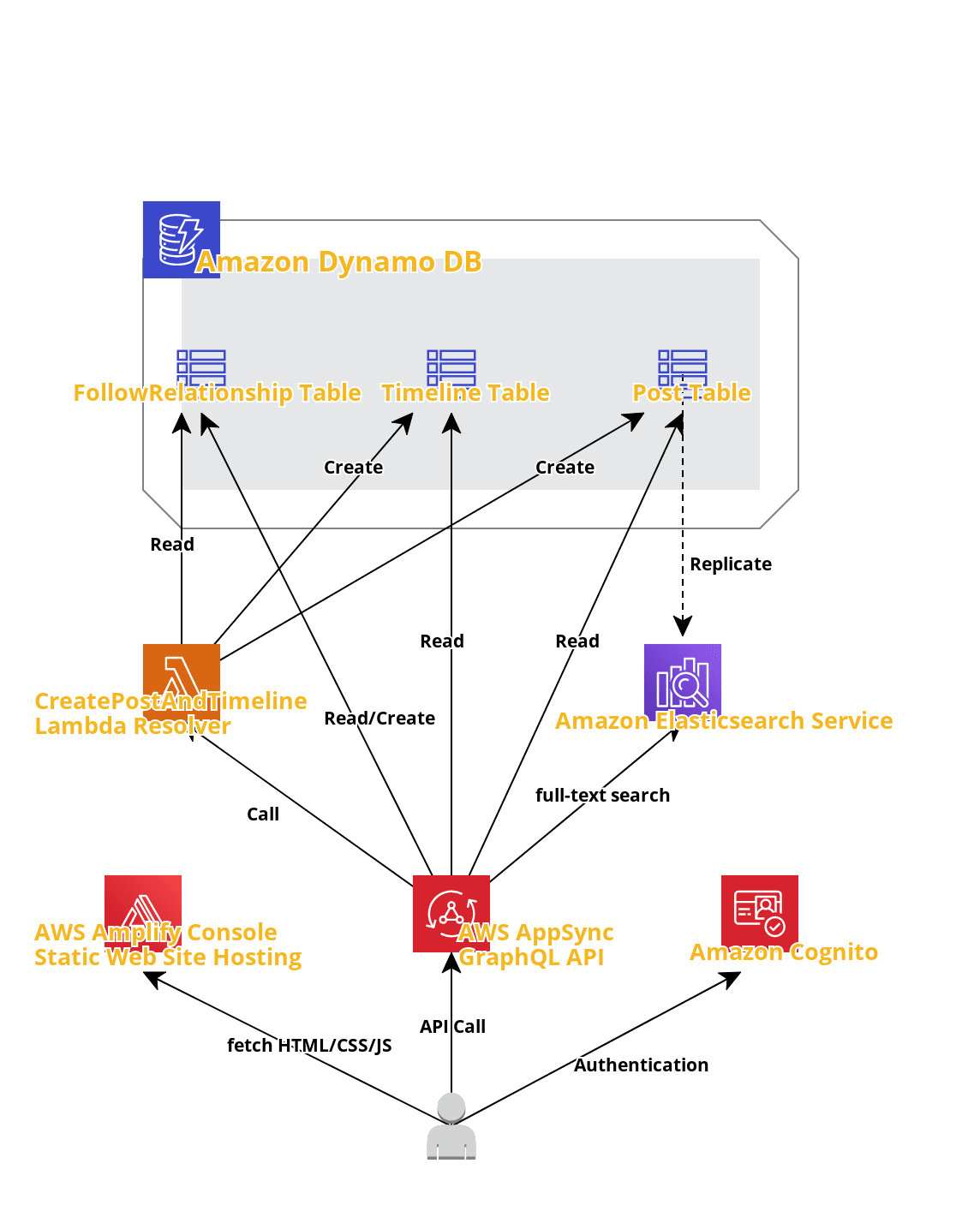
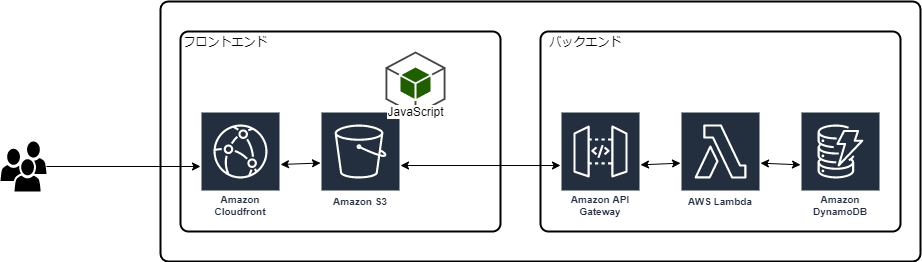
こんな感じのTwitter風SNSアプリの開発を通して、AWSサービスを利用したバックエンドの構築、Reactアプリの開発、デプロイまで、Amplifyを使用したアプリ開発のワークフローを一通り実践することができます。構成は以下のようになっています。
一番下の人型がフロントエンドとなり、Reactで開発しています。ワークショップで使用しているAWSサービス
手順とかをここで説明しても意味がないので、本ワークショップのほうではあまり触れられていない、それぞれのサービスがどういうもので、本ワークショップではどういう役割なのか、について書いていきたいと思います。
AWS AppSync
概要
サービスページ→https://aws.amazon.com/jp/appsync/
これもマンガあった→https://aws.amazon.com/jp/campaigns/manga/vol4-4/GraphQLベースのWebAPIを作成できるサービスです。
サポートされているデータソースとしてはDynamoDB、Elasticsearch、Lambdaなどですが、直接サポートされていないRDSなどにもLambdaを介してアクセスすることができます。
GraphQLでサブスクリプションの定義をすることで、データソースの更新をリアルタイムにフロントエンドに反映することができるようになります。本ワークショップでの役割
- 直接DynamoDBからデータをREADするAPI(subscribe含む)
- Lambdaを介して複数のDynamoDBテーブルにデータをUPDATE, CREATEするAPI
- Elasticsearchにアクセスし、DynamoDBから取得したデータを全文検索するAPI
上記を作成、ホスティングするために使用します。
GraphQLのコーディング自体はローカルで行い、Amplifyフレームワークを利用してPUSHすることで、Amplifyを介してAppSyncに自動でリソースが作成されます。Amazon Cognito
概要
サービスページ→https://aws.amazon.com/jp/cognito/
Webアプリでの認証、認可、ユーザー管理をサポートするサービスです。
Cognitoで直接ユーザーを管理したり、サードバーティのソーシャルサインイン、SAMLなどによる管理も可能です。
AmplifyフレームワークとしてCognitoを使用した認証機能が提供されており、アプリに数行コードを追加するだけでログイン、サインイン、パスワード再発行などのUIとバックエンドが利用できるようになります。本ワークショップでの役割
ユーザー管理はすべてCognitoで行います。
UIもAmplifyフレームワークのReactコンポーネントを利用して作成しています↓import { withAuthenticator } from 'aws-amplify-react'; export default withAuthenticator(App);AWS Lambda
概要
サービスページ→https://aws.amazon.com/jp/lambda/
もはや解説不要のAWS主要サービス。
様々な言語で関数を作成し、サーバレスに動かすことができるサービスです。AppSyncではリゾルバとしてLambdaを選択することができ、
AppSyncからLambdaを呼び出してコードを実行することができます。本ワークショップでの役割
ワークショップの序盤では書き込みもすべてAppSyncから直接DynamoDBにアクセスしていました。
しかし、フォロイーユーザーのPOSTをフォロワーユーザーのHOMEタイムラインに表示させるという要件が追加されたため、
ユーザーがメッセージを投稿した際に、
- 投稿したユーザーのフォロワー検索
- フォロワーのタイムラインへのデータ更新
- 全体のPOSTテーブルへのデータ更新
以上を一度に行うためにLambda関数を利用しています。
Amazon Elasticsearch Service
概要
サービスページ→https://aws.amazon.com/jp/elasticsearch-service/
Elastic社のオープンソースの検索/分析エンジンであるElasticsearchをサポートするサービスです。
ログの分析、全文検索、データ分析などに利用されます。本ワークショップでの役割
ユーザーが投稿した全POSTの中から全文検索するためにAppSyncから呼び出しています。
GraphQLに定義を追加してAmplifyでPUSHするだけで構築してくれます。Amazon DynamoDB
概要
サービスページ→https://aws.amazon.com/jp/dynamodb/
サーバレスなNoSQLデータベースです。
高い可用性とスケーラビリティが売りの主要サービスです。
NoSQLデータベースのため、key-valueペアやドキュメントストレージとして利用します。本ワークショップでの役割
ユーザーのPOSTを保存します。
備考
料金について
AppSyncやLambdaなど、使用量に応じた従量課金なのでワークショップの途中で放置していてもほとんど料金はかからないと思います。
AmplifyでWebアプリをホストするにあたってS3にバケットを作成しているので、そこで少しかかるくらいかと。
また、無料期間中であれば従量課金系のサービスも無料枠内でワークショップが完結するものが多いです。
気になるようでしたら短期間にワークショップを終わらせましょう。
大体1,2日あれば最後までできます。後片付けについて
ワークショップのほうに書いてありますが、
amplify deleteでAppSync, DynamoDB, CloudFormation, Lambdaなど、ほとんどのリソースを削除できます。
Amplifyだけホストしているアプリが残っているようなので、コンソールからアプリを削除しましょう。やってみた感想
少し前からAmplifyでホスティングしたReactアプリの開発をしていましたが(どっちも未経験)、
Reactで一杯いっぱいになっていて、バックエンドについてはふわっとした理解しかできていませんでした。いや、今でもふわっとしているところはあるんですが、ワークショップを通じてGraphQL書いたり、Amplify CLIを叩いたりしていると、何となくバックエンド構築や、フロントエンドのとの繋ぎこみの雰囲気が分かりました。
あと単純にReactの勉強にもなった。
- 投稿日:2020-09-20T12:50:17+09:00
WebSocketで動作はするけどhandshakeでエラーが出るのを修正する
現象
Webサーバに接続したときに、ブラウザのコンソールに、次のエラーが表示される。
WebSocket connection to 'wss://xxx' failed: Error during WebSocket handshake: Unexpected response code: 400ただし、WebSocketの動作自体には問題がない。
環境
AWS EC2 ロードバランサ(Classic Load Balancer)
Node.js
Socket.io修正方法
ロードバランサのリスナーで、通常は、HTTPS -> HTTPとしている転送を、以下のように、SSL -> TCP(80)とする。
原因
たぶん、wssプロトコルでWebSocketが通信するので、ロードバランサが通してくれなかった?(でも、handshakeができていないと言っているのに、その後の通信は問題なし???)
もしかすると、socket.ioがwebsocketの通信が開始できなかったので、自動的にポーリングに切り替えてくれていたのかも?
ここら辺は、いずれ、機会があったら調べてみます。

- 投稿日:2020-09-20T12:29:51+09:00
Elastic Beanstalk ワーカー環境の定期的なタスクとFIFOキューを併用する
概要
If you configure your worker environment with an existing SQS queue and choose an Amazon SQS FIFO queue, periodic tasks aren't supported.
FIFOキューと定期的なタスクが併用できない旨が記載されています。
対策方針
オートスケールによって台数が増減しても、
ワーカー環境の定期的なタスクは重複実行されないようになっています。
その仕組みとしては、DynamoDBのAWSEBWorkerCronLeaderRegistryに書き込みできたインスタンスをリーダー(Leader)として、そのリーダーインスタンスのみで実行することでそれを実現しています。そのリーダーの選出を流用し、ワーカー環境のEC2でcron実行をさせることで表題の併用を実現してみます。
検証環境
Ruby 2.6 running on 64bit Amazon Linux 2/3.1.1

Amazon Linux 2なので注意してください。ステップ
: ダミーのcron.yamlを作成し、
AWSEBWorkerCronLeaderRegistryを書き込みさせるcron.yamlversion: 1 cron: # UTC - name: "dummy-job" # 何でもよい url: "/health" # 何でもよい schedule: "7 7 7 7 7" # 何でもよいステップ
: 自身がLeaderか判定するスクリプトを用意
bin/eb_is_worker_leader#!/usr/bin/env bash # EC2でないときはexit if [[ ! -f /var/lib/cloud/data/instance-id ]]; then exit fi instance_id=$(cat /var/lib/cloud/data/instance-id) # AWSEBWorkerCronLeaderRegistry のテーブル名を取得 table_name=$(awk -F': ' '$1=="registry_table" {printf $2}' /etc/aws-sqsd.d/default.yaml) # 定期的に更新されている、leader_idを取得する (ex: i-XXXXX.${registration-record.worker_id}) leader_id=$(aws dynamodb get-item --region ${AWS_REGION} --table-name ${table_name} --key '{"id": {"S": "leader-election-record"} }' | jq -r .Item.leader_id.S) echo ${leader_id} | grep -q ${instance_id} exit $?ステップ
: cronをセット
ステップ2で作成した
bin/eb_is_worker_leaderが成功したら、処理を実行するようにcronをセットします。
例えば、Rubyでcronをセットするwhenever を使う場合、下記のようになります。
schedule.rbjob_type :leader_runner, "cd :path && bin/eb_is_worker_leader && bin/rails runner -e :environment ':task' :output" every :hour do leader_runner "SomeModel.ladeeda" endなお、whenever で用意されている
runnerは下記のとおりです。
比べるとbin/eb_is_worker_leaderが追加されているだけなのがわかるかと思います。job_type :runner, "cd :path && bin/rails runner -e :environment ':task' :output"
おまけ: wheneverでcronを更新する
.platform/hooks/postdeploy/XX_update_cron.sh#!/usr/bin/env bash # Workerでなければ何もしない env_name=$(jq -r .Name /opt/elasticbeanstalk/config/ebenvinfo/envtier.json) if [[ ! ${env_name} = 'Worker' ]]; then exit fi /opt/elasticbeanstalk/.rbenv/shims/bundle exec whenever --user webapp --update-crontab
まとめ
これらによって、すべてのワーカーインスタンスでcronが実行されます。
cronではリーダーのみ処理が継続されるため、定期的なタスクの重複した実行が防げます。
似たような解決策
- https://github.com/awsdocs/elastic-beanstalk-samples/blob/main/configuration-files/aws-provided/instance-configuration/cron-leaderonly-linux.config
- https://github.com/dignoe/whenever-elasticbeanstalk
Amazon Linux 1が対象ですこれらはインスタンス数でLeaderを判断しています。
この記事のやり方では、AWSEBWorkerCronLeaderRegistryを流用することで、シンプルな実装になるかなと思っています。
- 投稿日:2020-09-20T11:08:11+09:00
Amazon API Gateway概要
Amazon API Gateway 概要
Amazon API Gatewayの概要をまとめる。
API Gateway
APIとは
- Application Programming Interfaceの略称。
- プログラムやソフトウェア同士がやり取りするための取り決め・仕様、機能の提供方法。
API 提供時の共通課題
インフラ管理:可用性とスケーラビリティの保証
API管理:設定やデプロイの制御
認証・認可:アクセス制御
...
API Gatewayとは
API Gatewayは、上記のWeb API提供時の共通課題を解決するためのフルマネージド型AWSサービス。
- オートスケール
- 仮想サーバー管理不要
- 使用料に応じた課金
API Gatewayが扱うAPI
以下の2種類のAPIを扱うことができる。
- REST
- REST= Representational state transfer
- 1HTTPメッセージで1操作情報を扱う(基本)
- 扱う情報をURIで表現する「リソース」として定義。それらをHTTPメソッド(POST,PUT,GET,...)表現で操作
- Websocket
- HTTP上での、クライアント-サーバー間双方向通信仕様
- 1コネクションで継続的なデータ送受信を行う(ステートフル)
REST APIエンドポイントタイプ
REST APIの場合、クライアントから見たアクセス先のエンドポイントの性質を以下の3種類のタイプから選択。
- エッジ最適化
- 一旦エッジロケーション(CloudFrontディストリビューション)にルーティングする。
- リージョン
- リージョンに直接ルーティング
- プライベート
- VPC内からのみアクセス可能
API作成の流れ
- API設計
- 要求および仕様を確認
- プロトコル種別とエンドポイントタイプを選択
- REST をプロトコルとして選択
- リージョン、エッジ最適化、プライベートからエンドポイントを選択(RESTの場合)
- リソース&メソッド設定
- リソースとメソッド
- 「/」を最上位としたツリー構造にて「リソース」を定義。各リソースに受け付けるHTTPメソッドを指定 (パスパラメータの利⽤も可能)。
- 例
- エンドポイント
http https://<api-id>.execute-api.<region-id>.amazonaws.com/<stage-name>/…- API(REST) 例:PetStore
- リソース:
/- リソース:
/pets
- GET
- リソース:
/{petId}- GET,PUT,DELETE,...
- 認証の設定や、受け付けるクエリパラメータ、必須とするHTTPヘッダなど「リクエ ストの受付」に関する設定。
- ルーティング先バックエンドの指定、リクエストの変換。
- レスポンス内容の変換やステータスコードのマッピング。
- リクエストに対する最終的なAPIGatewayとしてのレスポンス。
- デプロイとステージの設定
- ステージ=デプロイ先環境。prod,staging,dev
- ステージ名は、エンドポイントURLの一部として利用。
http https://<api-id>.execute-api.<region-id>.amazonaws.com/prod/…http https://<api-id>.execute-api.<region-id>.amazonaws.com/staging/…その他
* 既存APIのクローンやSwagger設定(Yaml)をインポートによる作成が可能。API Gatewayのユースケース
- インターネットからアクセス可能なパブリックなWeb APIの提供。
- 企業グループ内でのプライベートなWeb APIの提供。
- Dynamo DBなどAWSサービスを独⾃のWeb API化する⼿段として利⽤。
- サーバーレスアーキテクチャの実現する⼿段として利⽤。
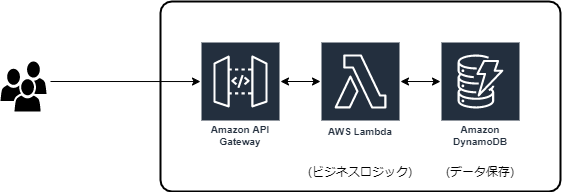
よく見る構成
REST API
SPA
認証・認可
アクセス制御パターン
Open
- APIを保護する必要がない場合。 誰もがAPIへのアクセスを許可されている状態。
IAMアクセス権限
- AM UserやRoleで発行されるアクセスキーを利用してアクセスを検証。
- 該当API Gatewayの呼び出し権限をIAM UserやRoleにアタッチされている場合かつ, アクセスキーが正当なものである場合は呼び出し可。
Cognito Authorizer
- Cognito User Poolと接続し, 発行されたOAuthトークンの検証をAPI Gatewayで実施し、API呼び出しを制御。
Lambda Authorizer
- Lambda関数にトークンなどの認証情報を渡してAPI呼び出しを制御。
参考情報
- 投稿日:2020-09-20T10:44:09+09:00
【firebase hosting】カスタムドメイン(Route53) x 複数サイト x 複数プロジェクトのホスティング
わちゃわちゃしたタイトルですが以下の3つを一緒に行う必要があったので、全部いっぺんにやったよって話です。
①AWS Route53で発行しているカスタムドメインを利用する
②単一のfirebaseプロジェクトで複数のサイトを管理する
③複数のfirebaseプロジェクトに分けてデプロイする前準備
前段階として以下が準備できていることを前提とします。
ここら辺については分かりやすい記事もたくさんあるのでそちらを参考に準備してみてください。
- firebaseプロジェクトを準備しましょう
- firebase CLIをインストールしましょう
- AWS Route53を使ってカスタムドメインを取得しましょう
- firebase hostingを起動し、サイトを作成
さてここまで準備したら今回の本題に入ります。
①AWS Route53で発行しているカスタムドメインを利用する
ゴール: AWS Route53で取得した
hogehoge.jpをfirebase hostingに設定するfirebase hostingを有効化すると
web.app、firebaseapp.comが末尾についているドメイン名がdefaultで割り当てられています。
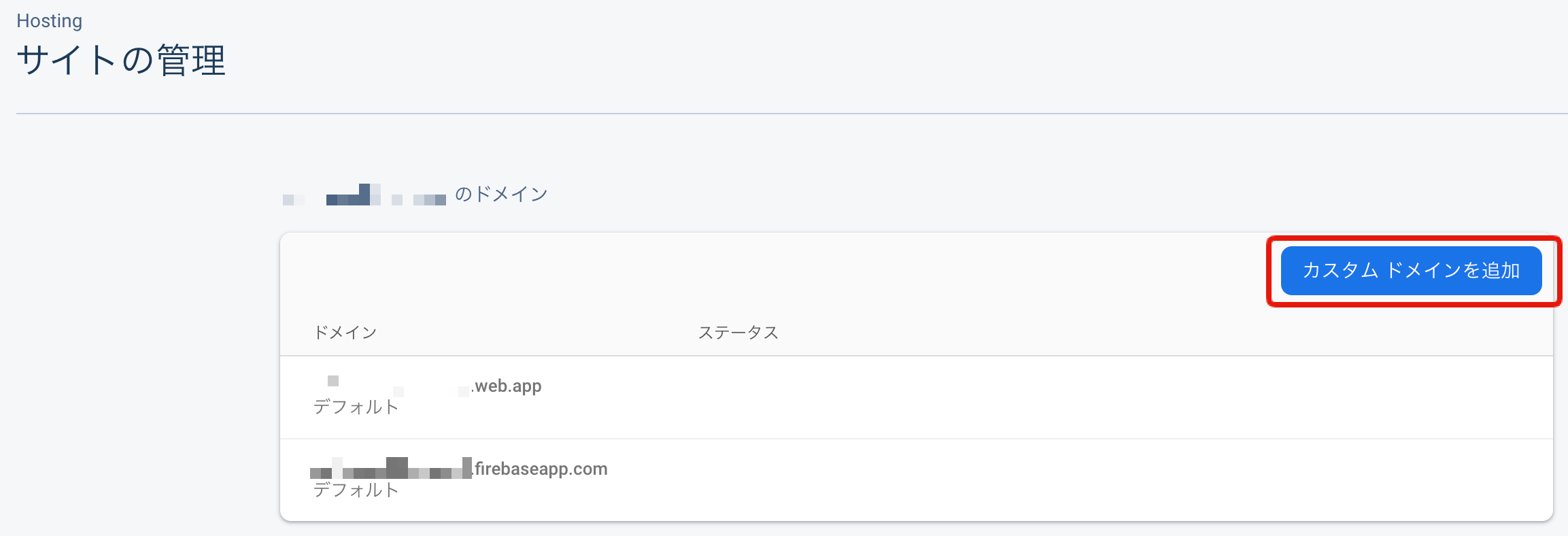
今回はそれらに加えてRoute53で発行したカスタムドメインhogehoge.jpを設定していきましょう。1.
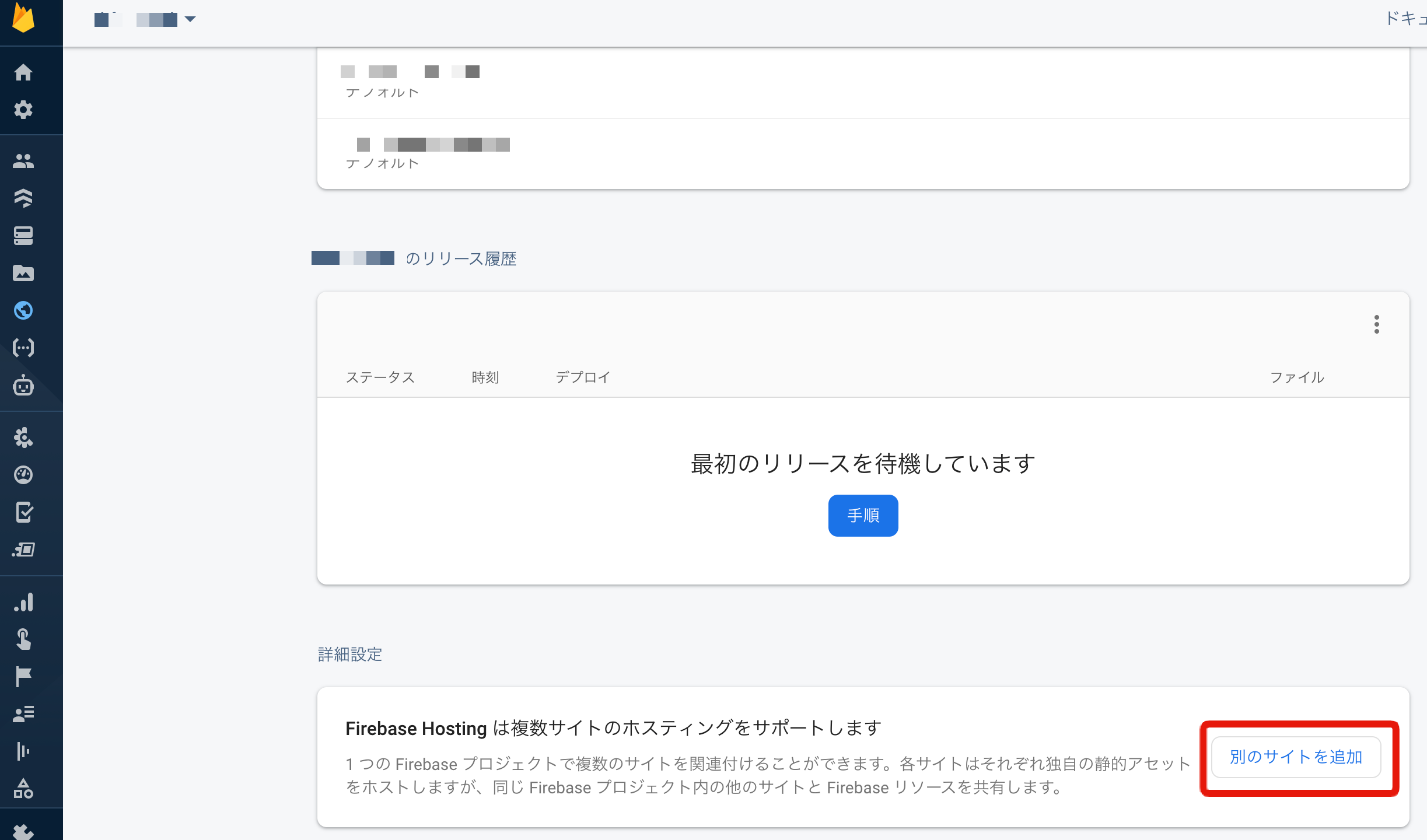
カスタムドメインを追加をクリック
2. 使用するカスタムドメイン(今回は
hogehoge.jp)を入力
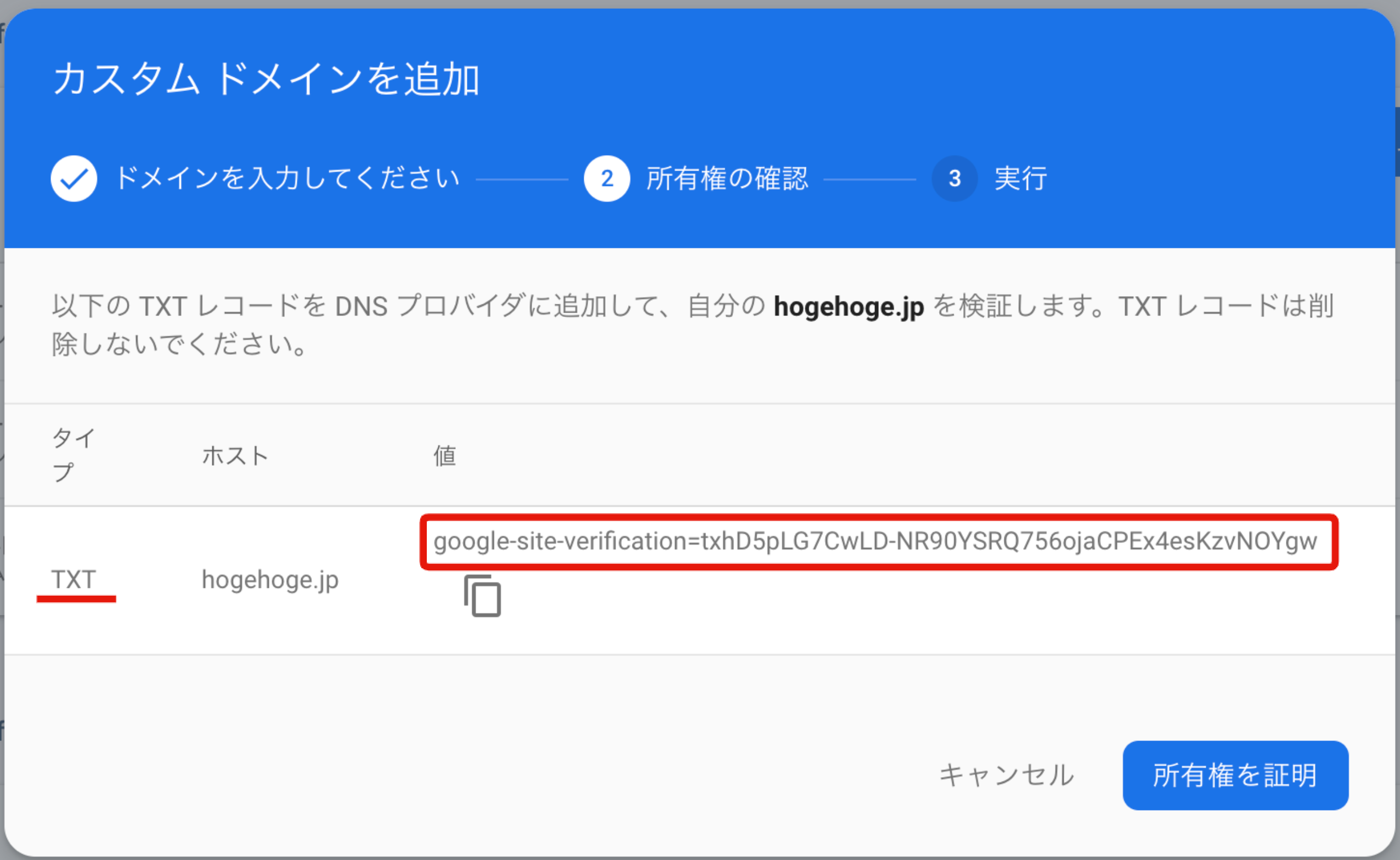
すると下記の様な画面が表示されます。が、まだ先には進みません。google-site-verificationから始まる値をRoute53に設定する事になるので、とりあえずコピーしましょう。画面を消さずにRoute53に移動しましょう。
3. AWS Route53へ移動
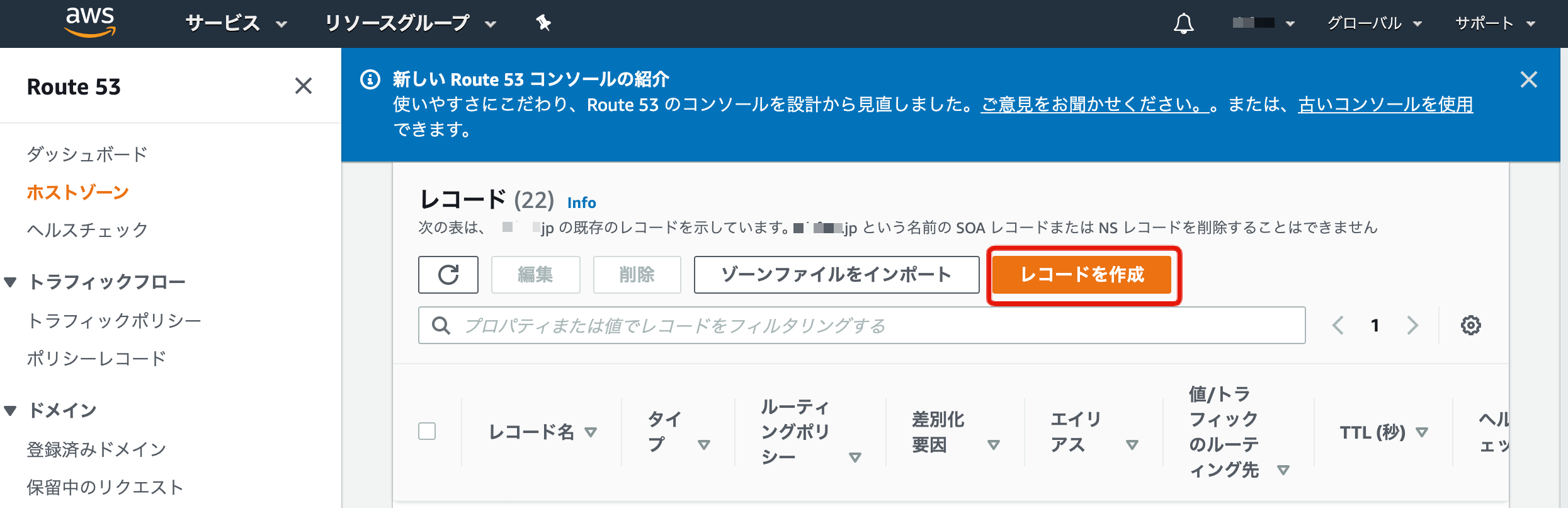
ここでRoute53のコンソールへ移動し、新しいレコードを作成します。
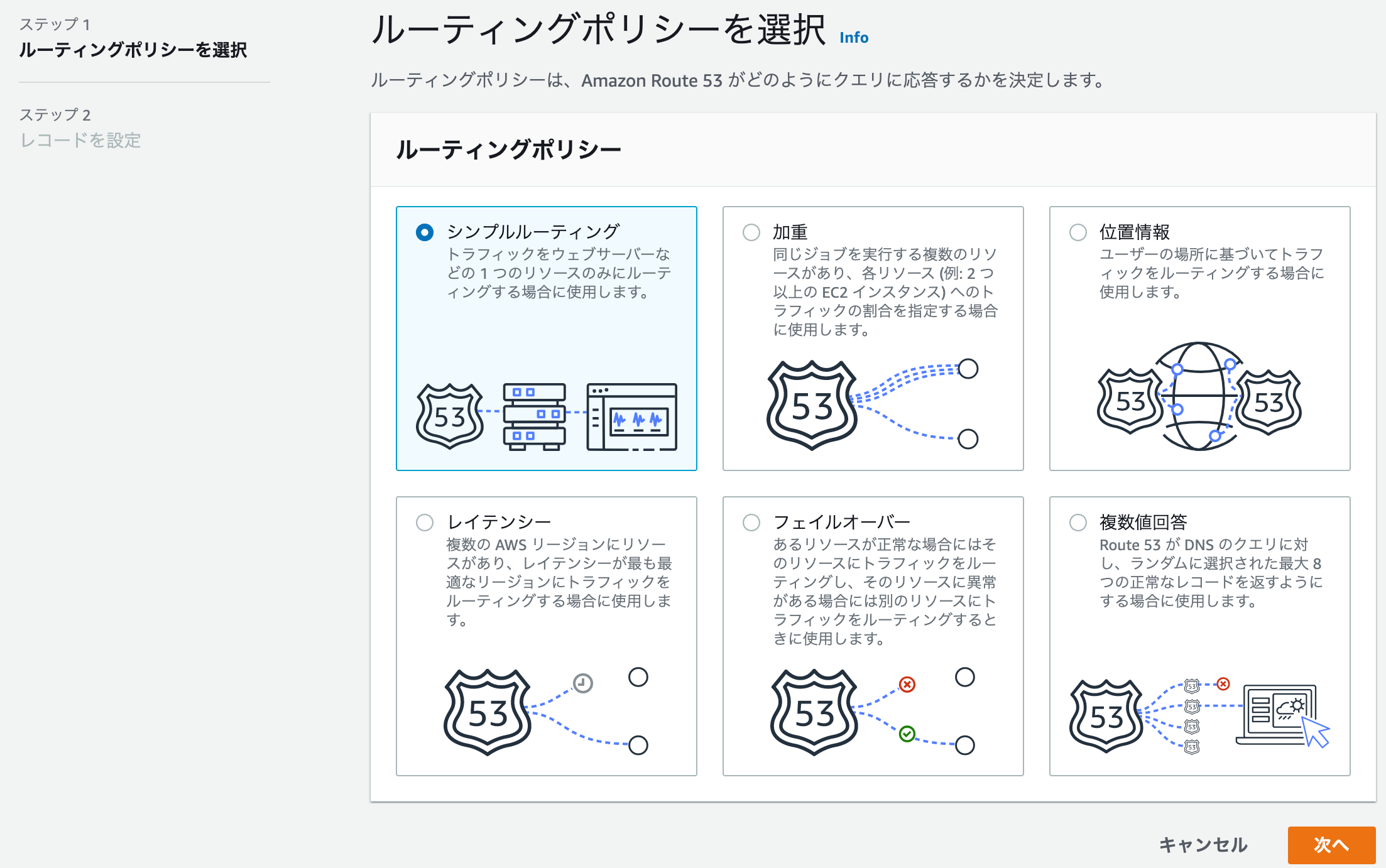
4. ルーティングポリシーを決める
今回はサンプルなのでシンプルルーティングにしましょう。
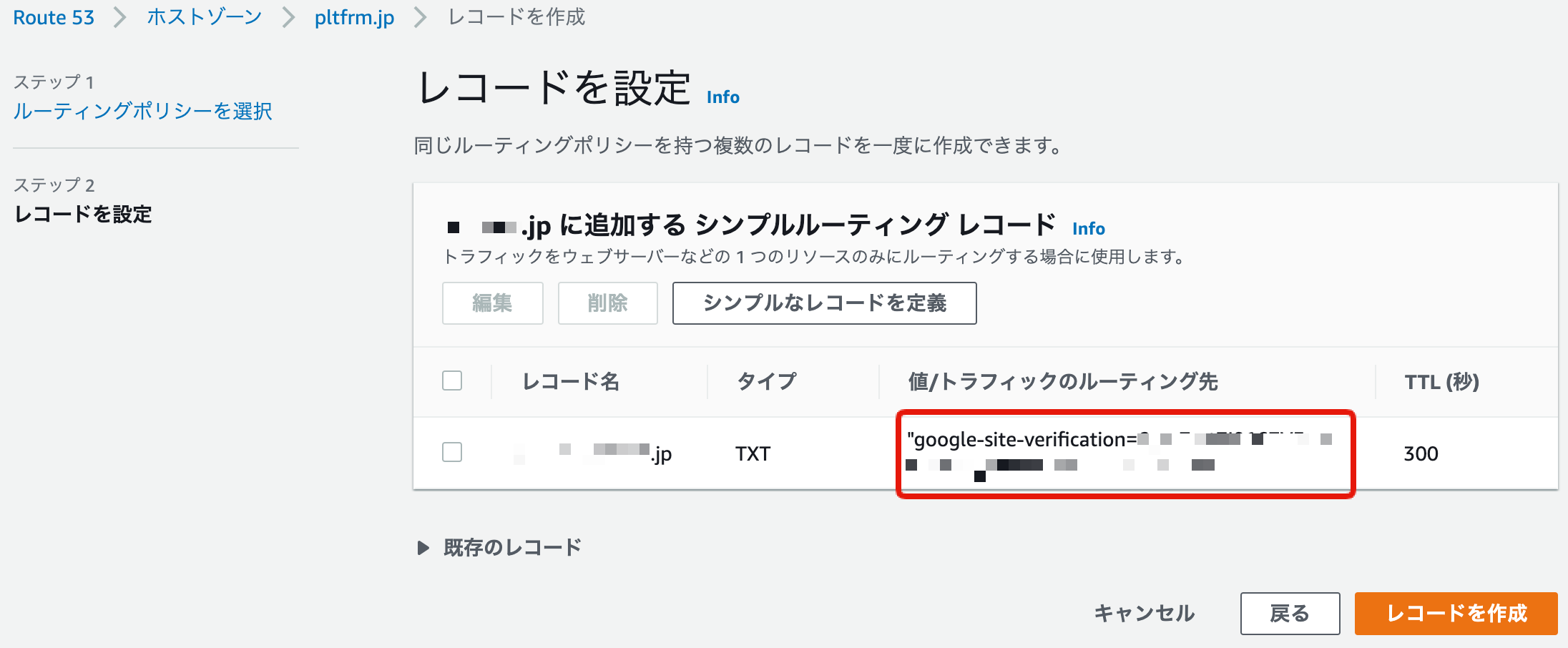
5. TXTレコードを作成
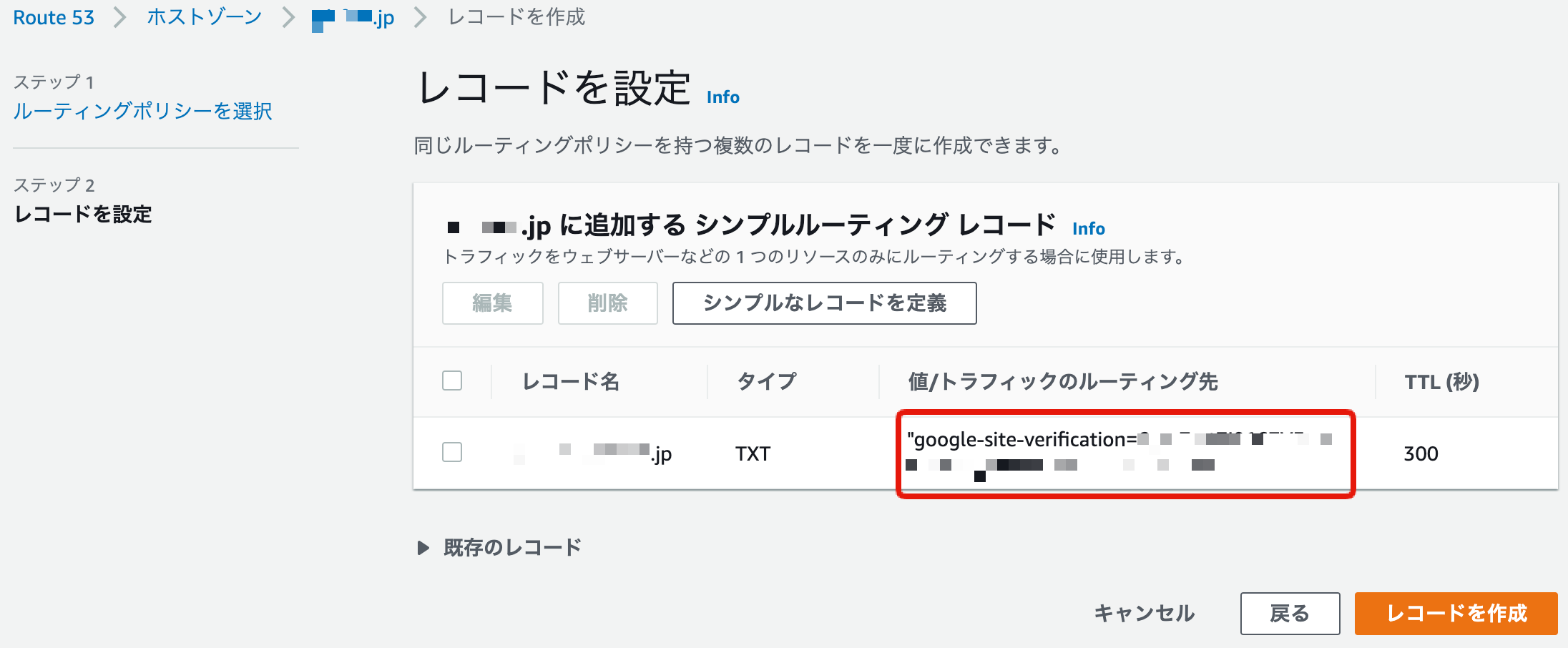
ここで先ほどfirebase hostingのコンソールで入手した
google-site-verificationから始まるルーティング先を指定。またレコードタイプも表示されていた通り、TXTレコードを選びましょう。
指定通り作成しているか確認し、レコードを作成をクリック
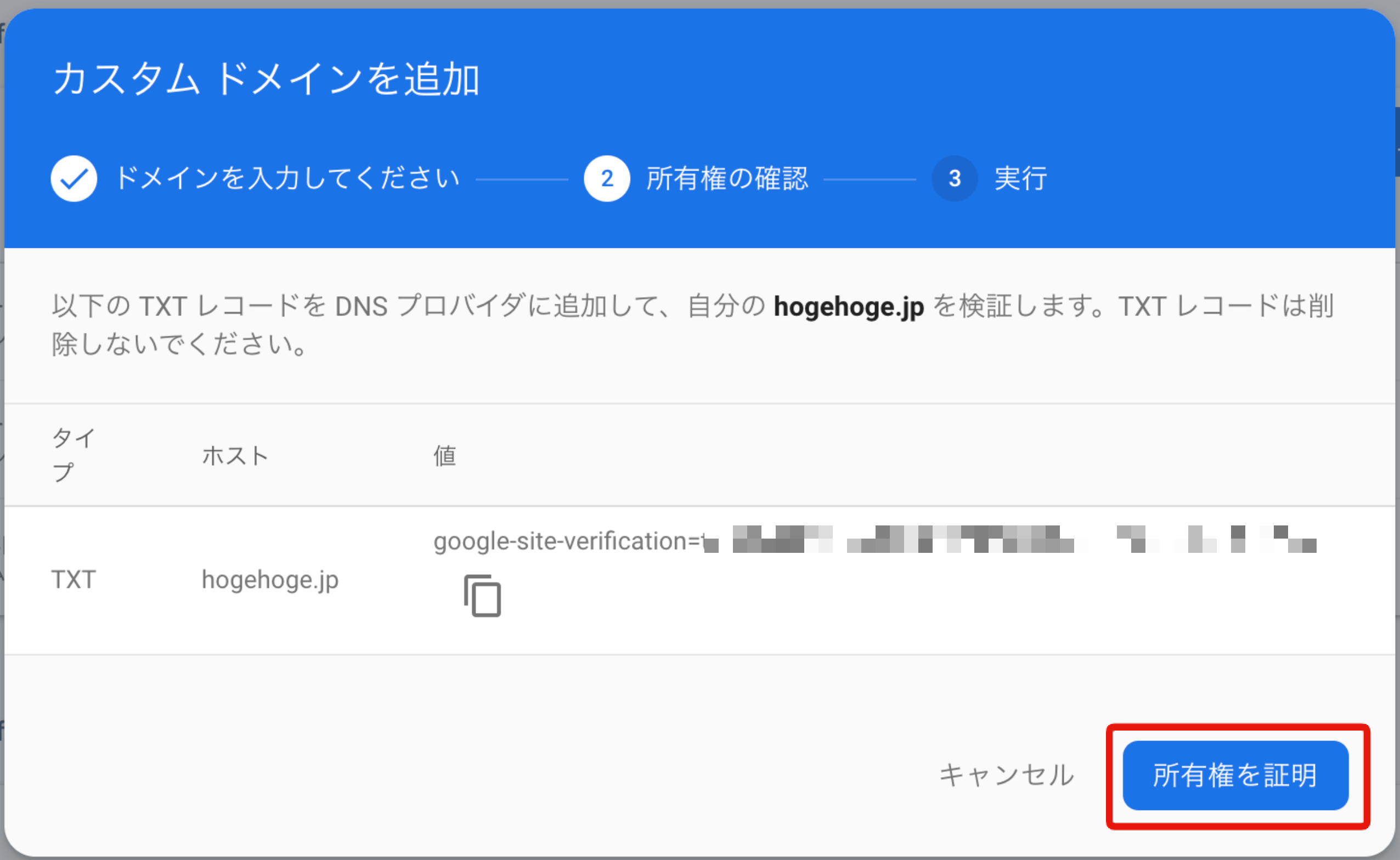
6. firebase hostingへ戻り、先に進む
そのままにしたfirebase hostingのコンソールで
所有権を証明をクリック
すると今度はAレコードの追加を求められます。同じホスト名に対して二つの値が与えられます。仮に195.195.1.195と195.195.2.195としましょう。ここからまたRoute53の方に戻りましょう。
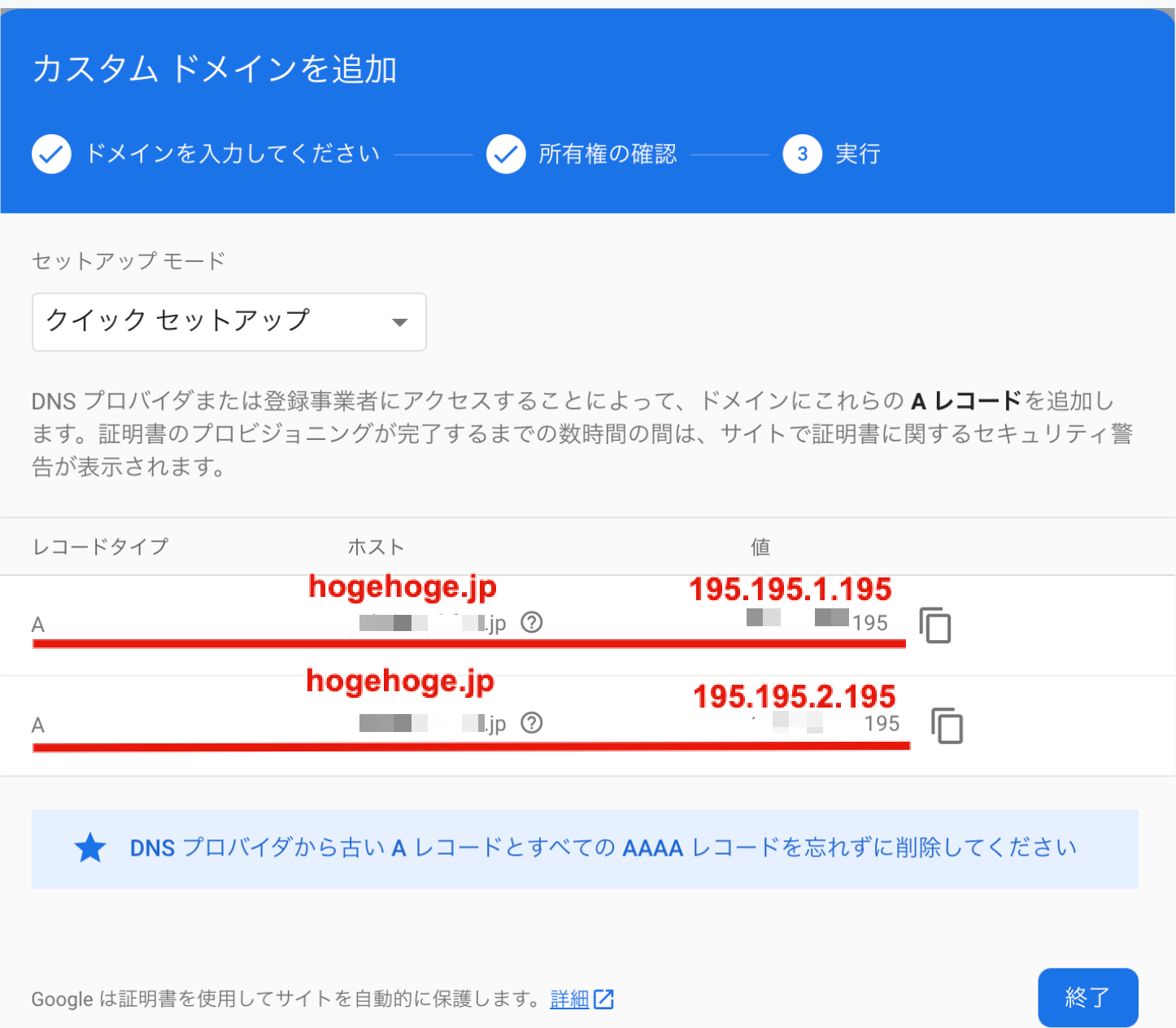
7. Route53でAレコードを作成
先ほどと同じ手順でレコードの作成に進みます。しかし今回作成するのはAレコード。そして設定するのはfirebase hostingから与えられた2つの値両方です。
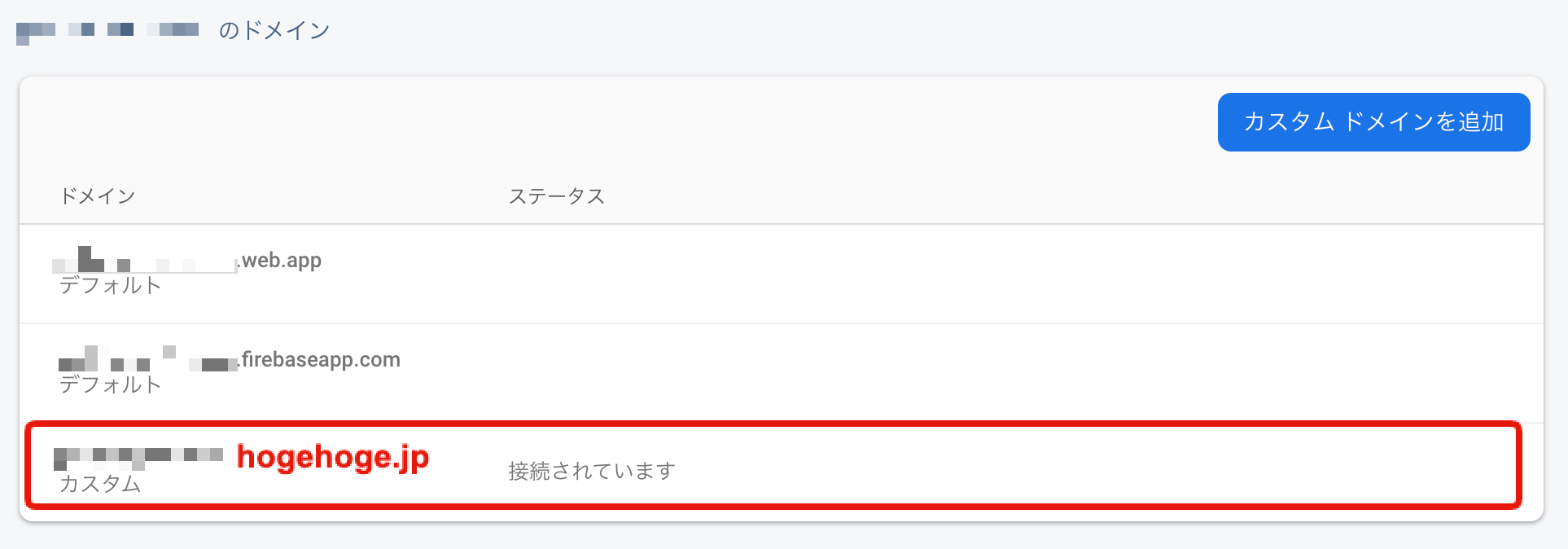
8.終了!
再度firebase hostingに戻り
終了をクリックすれば無事終了!デフォルトのドメインの下にカスタムのドメインが追加されていると思います。
ブラウザからカスタムドメインの
hogehoge.jpにアクセスすれば、ホスティングしているサイトが閲覧出来ます。②単一のfirebaseプロジェクトで複数のサイトを管理する
ゴール:同一のfirebaseプロジェクトにて2つのサイト
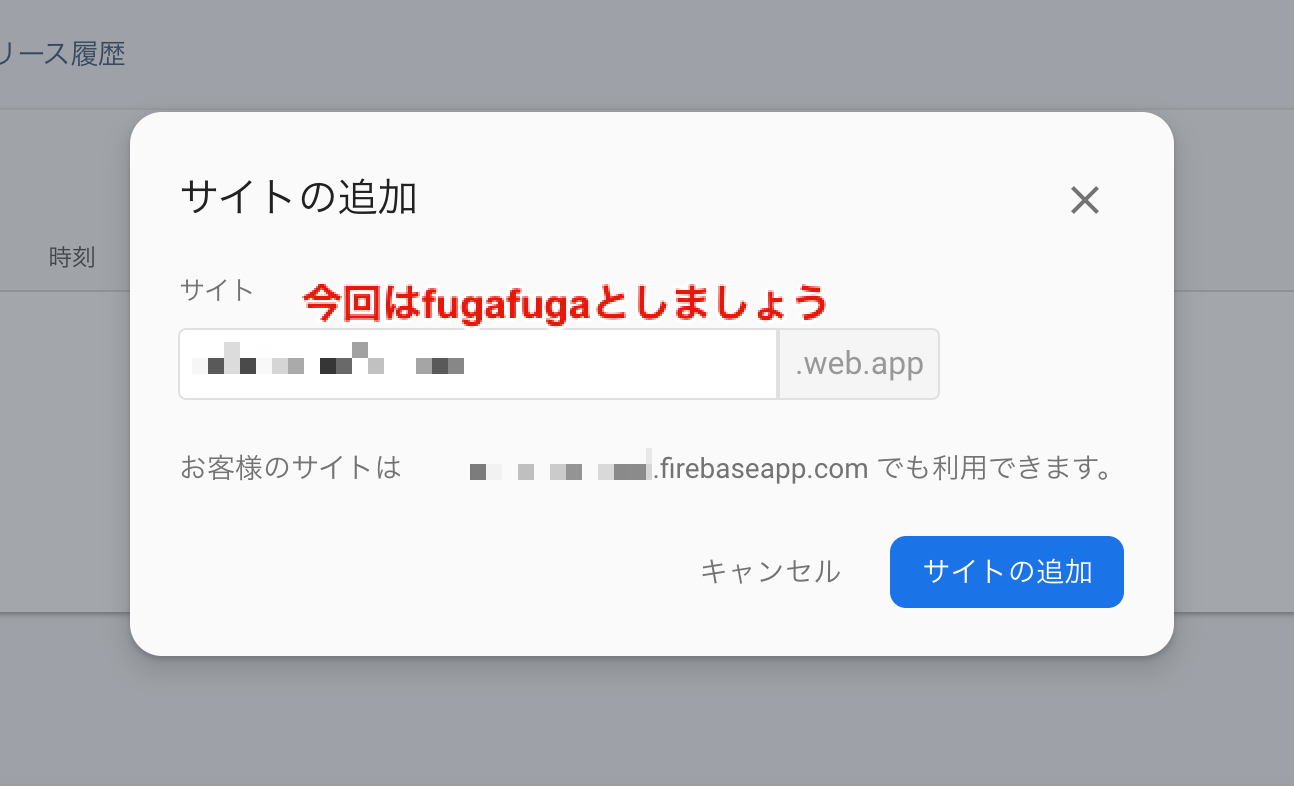
hogehogeとfugafugaをホスティングし、それぞれにデプロイする。1.サイトを追加する
firebase hostingのコンソールよりサイトを追加。
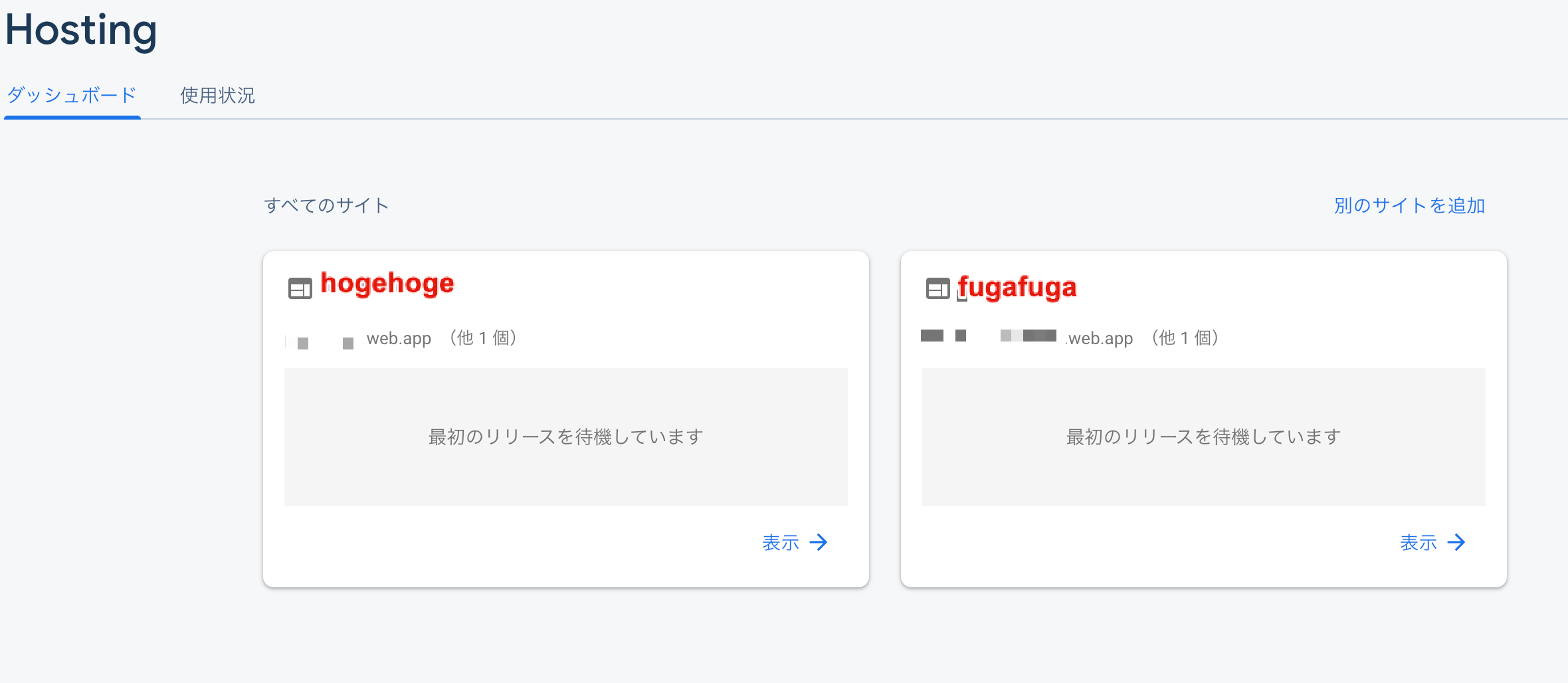
追加するサイト名を記入し、サイトの追加をポチり
これで2つのサイトhogehogeとfugafugaをホスティングしました。
2.それぞれのサイトのコードを用意
hogehogeとfugafugaは違うサイトをデプロイする想定なので、それぞれのコードをディレクトリで分けて用意します。demo-project ├── dir-hogehoge | └── index.html ├── dir-fugafuga | └── index.html ├── .firebaserc └── firebase.json3.target-nameを設定
下記コマンドでデプロイ先のサイトを切り分ける際に必要な任意のtarget-nameを設定します。
$ firebase target:apply hosting <target-name> <resource-name>
target-nameは好きな名前を設定する事ができます。
resource-nameはデプロイ先のプロジェクト名となります。
なので今回は下記の様にしてみましょう。$ firebase target:apply hosting site-hogehoge hogehoge $ firebase target:apply hosting site-fugafuga fugafuga4.firebase.jsonを設定
firebase.jsonにてどのデプロイ元のディレクトリとtarget-nameを紐付けます。
firebase.json{ "hosting": [ { "public": "dir-hogehoge", "target": "site-hogehoge", "ignore": ["firebase.json", "**/.*", "**/node_modules/**"], }, { "public": "dir-fugafuga", "target": "site-fugafuga", "ignore": ["firebase.json", "**/.*", "**/node_modules/**"], } ] }
publicがデプロイ元、targetがデプロイ先となります。5. コードをデプロイ
デプロイは
firebase deploy --only hostingで出来てしまいますが、今回の様に複数のサイトがある場合は全てデプロイされてしまいます。特定のサイトだけデプロイしたい場合は、下記の様に
target-nameを指定する事で指定されたサイトだけデプロイする事が出来ます。$ firebase deploy --only hosting:<YOUR-TARGET-NAME>今回の場合、
$ firebase deploy --only hosting:site-hogehoge //hogehogeだけデプロイしたい場合 $ firebase deploy --only hosting:site-fugafuga //fugafugaだけデプロイしたい場合終了!これで自由に複数のサイトを管理できる様になりました。
③複数のfirebaseプロジェクトに分けてデプロイする
ゴール:環境別に切り替えて、デプロイする
仕事で検証環境、ステージング環境、本番環境など複数の環境を使用する際などに使います。
今回は
my-development-project、my-staging-project、my-production-projectの3つのfirebaseプロジェクトに切り分けてデプロイしていきます。1. .firebasercを設定
以下の様な構成で記述します。
{ "projects": { <プロジェクトのエイリアス>: <firebaseプロジェクト名> }, "targets":{ <プロジェクト名>:{ "hosting":{ <ターゲット名>: [ <デプロイ先のプロジェクト名> ], <次のターゲット名>: [ <次のデプロイ先のプロジェクト名> ] } }, <次のプロジェクト名>:{ ... } } }今回の場合は下記の様になります。
.firebaserc{ "projects": { "default": "my-development-project", "development": "my-development-project", "staging": "my-staging-project", "production": "my-production-project" }, "targets": { "my-development-project": { "hosting": { "site-hogehoge": [ "hogehoge" ], "site-fugafuga": [ "fugafuga" ] } }, "my-staging-project": { "hosting": { "site-hogehoge":[ "hogehoge" ], "site-fugafuga": [ "fugafuga" ] } }, "my-production-project":{ "hosting":{ "site-hogehoge": [ "hogehoge" ], "site-fugafuga":[ "fugafuga" ] } } } }さてこれで準備は整いました。
2. プロジェクトを指定して、コードをデプロイ
下記コマンドでプロジェクトを切り替え、
$ firebase use <プロジェクトのエイリアス>後は通常通り、デプロイするだけです。
$ firebase deploy --only hosting:<ターゲット名>
my-production-projectのfugafugaだけをデプロイしたければ、下記の様になります$ firebase use production $ firebase deploy --only hosting:site-fugafuga以上で終了です。
最後に
普通であれば、一つ一つ切り分けて記事を挙げるべき所ですが、この三つを合わせて対応しないといけない状況で少々調査に時間がかかったのでまとめてみました。
またここまで設定しておくとこの後に続くCI/CDが設定しやすくなります。
参考
https://qiita.com/mag-chang/items/6706f27207f694049423
https://medium.com/@luazhizhan/how-to-deploy-multiple-sites-to-firebase-hosting-part-1-a56949876c64
https://blog.lacolaco.net/2020/08/firebase-hosting-production-staging-with-targets/
https://developers-jp.googleblog.com/2016/08/firebase-hosting.html

- 投稿日:2020-09-20T10:37:30+09:00
CloudFormationをゼロから勉強する。(その5:マッピングと条件式)
はじめに
今回は
MappingsセクションとConditionsセクションを使って、環境ごとの値設定と、条件関数による切り替えを実施してみようと思います。Mappingsセクションについて
キーと名前付きの値が対応付けられたグループ化機能となります。
「AWS CloudFormationユーザガイド」ではリージョンごとに
AMI IDをマッピングした例が紹介されております。Mappingsサンプル(抜粋)Mappings: RegionMap: us-east-1: "HVM64": "ami-0ff8a91507f77f867" us-west-1: "HVM64": "ami-0bdb828fd58c52235"また、
Mappingsセクションで対応付けた値は以下の様にFn::FindInMap:(短縮形!FindInMap)関数で呼び出すことができます。値の呼び出し(抜粋)AWSTemplateFormatVersion: "2010-09-09" Mappings: RegionMap: us-east-1: HVM64: ami-0ff8a91507f77f867 us-west-1: HVM64: ami-0bdb828fd58c52235 Resources: myEC2Instance: Type: "AWS::EC2::Instance" Properties: ImageId: !FindInMap [RegionMap, !Ref "AWS::Region", HVM64] InstanceType: m1.smallConditionsセクションについて
条件式を記載するセクションとなります。
他の開発言語と比べると使用できる条件は少ないですが、よほど凝ったことをしなければ問題にはならないでしょう。
内容 条件関数 完全名関数の構文 短縮形の構文 AND条件 Fn::And Fn::And: [condition] !And [condition] 比較 Fn::Equals Fn::Equals: [value_1, value_2] !Equals [value_1, value_2] IF条件 Fn::If Fn::If: [condition_name, value_if_true, value_if_false] !If [condition_name, value_if_true, value_if_false] 否定 Fn::Not Fn::Not: [condition] !Not [condition] OR条件 Fn::Or Fn::Or: [condition, ...] !Or [condition, ...] 使い方としては
Conditionsセクションで判定方法を記載して、他のセクションでリソース作成の条件等で、Conditionsセクションで指定した名前を呼び出して使用します。最初いまいちイメージが掴みづらかったのですが、シェルスクリプトの
if文でいうtestコマンドによる判定部分がConditionsセクションに当たり、後からCondition名として他セクションから呼び出します。Conditionsサンプル(抜粋)Conditions: CreateProdResources: !Equals [ !Ref EnvType, prod ] Resources: EC2Instance: Type: "AWS::EC2::Instance" Properties: ImageId: !FindInMap [RegionMap, !Ref "AWS::Region", AMI] MountPoint: Type: "AWS::EC2::VolumeAttachment" Condition: CreateProdResources Properties: InstanceId: !Ref EC2Instance VolumeId: !Ref NewVolume Device: /dev/sdh NewVolume: Type: "AWS::EC2::Volume" Condition: CreateProdResources Properties: Size: 100 AvailabilityZone: !GetAtt EC2Instance.AvailabilityZone Outputs: VolumeId: Condition: CreateProdResources Value: !Ref NewVolume今回作成する構成
今回は以下のようなシナリオを想定して構成を作ってみようと思います。
- 開発環境か本番環境かをユーザに選択させる。
- 選択した環境用のキーペアを
EC2インスタンスに紐づける。- 本番環境の場合、追加で
EC2インスタンスを作成して2台構成とする。事前準備
今回は予め各環境用のキーペアを作成しておきます。
環境 キーペア名 開発環境用キーペア staging_key 本番環境用キーペア production_key Parametersセクションへの設定追加
今回も前回作成したテンプレートとパラメータファイルをベースに作成していきます。
前回のテンプレート(展開して下さい)
/home/ec2-user/cloudformation.yamlAWSTemplateFormatVersion: 2010-09-09 Metadata: 'AWS::CloudFormation::Designer': e1390660-013a-4523-9893-ccd6074e430f: size: width: 190 height: 190 position: x: 390 'y': 90 z: 0 embeds: - e6cc612e-5a0f-459b-8329-3a5852613031 e6cc612e-5a0f-459b-8329-3a5852613031: size: width: 140 height: 140 position: x: 410 'y': 130 z: 1 parent: e1390660-013a-4523-9893-ccd6074e430f iscontainedinside: - e1390660-013a-4523-9893-ccd6074e430f Resources: EC2VPC1WR8B: Type: 'AWS::EC2::VPC' Properties: CidrBlock: !Ref VPCRange Metadata: 'AWS::CloudFormation::Designer': id: e1390660-013a-4523-9893-ccd6074e430f EC2SJOWQ: Type: 'AWS::EC2::Subnet' Properties: VpcId: !Ref EC2VPC1WR8B CidrBlock: !Ref SubnetRange Metadata: 'AWS::CloudFormation::Designer': id: e6cc612e-5a0f-459b-8329-3a5852613031 EC2I3Q8S8: Type: 'AWS::EC2::Instance' Properties: ImageId: ami-0cc75a8978fbbc969 InstanceType: t2.micro NetworkInterfaces: - SubnetId: !Ref EC2SJOWQ DeviceIndex: 0 Parameters: VPCRange: Type: String Description: "VPC Subnet Range" SubnetRange: Type: String Description: "Subnet Range" Outputs: VPCRegion: Description: "Region Name" Value: !Ref AWS::Region
前回のパラメータファイル(展開して下さい)
/home/ec2-user/param.json[ { "ParameterKey" : "VPCRange", "ParameterValue" : "172.24.0.0/16" }, { "ParameterKey" : "SubnetRange", "ParameterValue" : "172.24.0.0/24" } ]今回は環境をユーザに選択させたいため
AllowedValuesで選択させるようにしようと思います。ちなみに
AllowedValuesを設定するとデザイナー画面から入力する際に以下のように選択式にすることができます。
まぁ、CLIからやるのであればあまり関係ありませんが・・・
前回
VPCRangeとSubnetRangeのパラメータを作成しているので、その下にEnvTypeを追記してください。本番環境、開発環境の選択Parameters: EnvType: Type: String Description: "Production or Staging" AllowedValues: ["Production", "Staging"]Mappingsセクションの記載
事前作業として作成した各環境のキーペアを指定するように
Mappingsセクションを作成します。各環境ごとのキーペア指定Mappings: Keypair: ★Map名 productionkey: ★キー値 "KEYPAIR": "production_key" ★値 stagingkey: "KEYPAIR": "staging_key"
Mappingsセクションで指定した値は!FindInMap ["Map名", "キー値", "値"]で取得します。Conditionsセクションの記載
先ほど
Parametersセクションで作成したEnvTypeを呼び出し、本番環境を選択しているかどうかを判定します。本番環境判定Conditions: EnvSelect: {"Fn::Equals": [{"Ref" : "EnvType"}, "Production"]}Resourcesセクションの記載
Conditionsセクションで作成した本番環境の判定条件を、本番環境用キーペアの作成と、2台目のEC2インスタンス作成条件として使用します。本番環境用キーペアの作成条件
キーペアを指定する
EC2インスタンスリソースのKeyNameにConditionsセクションで作成した条件を使用して本番環境用キーペアと開発環境用キーペアを指定するようにしたいと思います。前回のテンプレートを使用して
KeyNameを以下のように指定します。キーペアの判定EC2I3Q8S8: Type: 'AWS::EC2::Instance' Properties: ImageId: ami-0cc75a8978fbbc969 InstanceType: t2.micro KeyName: {Fn::If: [EnvSelect, !FindInMap [ Keypair, productionkey, KEYPAIR ], !FindInMap [ Keypair, stagingkey, KEYPAIR ]]} NetworkInterfaces: - SubnetId: !Ref EC2SJOWQ DeviceIndex: 0上記は
Fn::Ifで条件関数を使用し、判定条件をEnvSelectで呼び出し、EnvSelectの結果が真の場合はMappingsセクションのproductionkeyのキーペア名を指定、偽の場合はMappingsセクションのstagingkeyのキーペア名を指定する条件式となります。本番環境用インスタンスの作成
本番環境の場合に、2台目の
EC2インスタンスを作成するようにします。下記1行目のインスタンス名以外、「本番環境用キーペアの作成条件」で作成した内容とほぼ同じですが、最終行の
ConditionでEnvSelectが真の場合にのみEC2インスタンスを作成するようにします。本番環境用EC2インスタンスの作成EC2Instance: Type: 'AWS::EC2::Instance' Properties: ImageId: ami-0cc75a8978fbbc969 InstanceType: t2.micro KeyName: {Fn::If: [EnvSelect, !FindInMap [ Keypair, productionkey, KEYPAIR ], !FindInMap [ Keypair, stagingkey, KEYPAIR ]]} NetworkInterfaces: - SubnetId: !Ref EC2SJOWQ DeviceIndex: 0 Condition: EnvSelectテンプレートの実行
今回もCLIで実行するため、パラメータファイルにも今回追加した設定を記載して実行していきます。
完成したテンプレート(展開して下さい)
/home/ec2-user/cloudformation.yamlAWSTemplateFormatVersion: 2010-09-09 Metadata: 'AWS::CloudFormation::Designer': e1390660-013a-4523-9893-ccd6074e430f: size: width: 190 height: 190 position: x: 390 'y': 90 z: 0 embeds: - e6cc612e-5a0f-459b-8329-3a5852613031 e6cc612e-5a0f-459b-8329-3a5852613031: size: width: 140 height: 140 position: x: 410 'y': 130 z: 1 parent: e1390660-013a-4523-9893-ccd6074e430f iscontainedinside: - e1390660-013a-4523-9893-ccd6074e430f Resources: EC2VPC1WR8B: Type: 'AWS::EC2::VPC' Properties: CidrBlock: !Ref VPCRange Metadata: 'AWS::CloudFormation::Designer': id: e1390660-013a-4523-9893-ccd6074e430f EC2SJOWQ: Type: 'AWS::EC2::Subnet' Properties: VpcId: !Ref EC2VPC1WR8B CidrBlock: !Ref SubnetRange Metadata: 'AWS::CloudFormation::Designer': id: e6cc612e-5a0f-459b-8329-3a5852613031 EC2I3Q8S8: Type: 'AWS::EC2::Instance' Properties: ImageId: ami-0cc75a8978fbbc969 InstanceType: t2.micro KeyName: {Fn::If: [EnvSelect, !FindInMap [ Keypair, productionkey, KEYPAIR ], !FindInMap [ Keypair, stagingkey, KEYPAIR ]]} NetworkInterfaces: - SubnetId: !Ref EC2SJOWQ DeviceIndex: 0 EC2Instance: Type: 'AWS::EC2::Instance' Properties: ImageId: ami-0cc75a8978fbbc969 InstanceType: t2.micro KeyName: {Fn::If: [EnvSelect, !FindInMap [ Keypair, productionkey, KEYPAIR ], !FindInMap [ Keypair, stagingkey, KEYPAIR ]]} NetworkInterfaces: - SubnetId: !Ref EC2SJOWQ DeviceIndex: 0 Condition: EnvSelect Parameters: VPCRange: Type: String Description: "VPC Subnet Range" SubnetRange: Type: String Description: "Subnet Range" EnvType: Type: String Description: "Production or Staging" AllowedValues: ["Production", "Staging"] Outputs: VPCRegion: Description: "Region Name" Value: !Ref AWS::Region Mappings: Keypair: productionkey: "KEYPAIR": "production_key" stagingkey: "KEYPAIR": "staging_key" Conditions: EnvSelect: {"Fn::Equals": [{"Ref" : "EnvType"}, "Production"]}
完成したパラメータファイル(開発環境向け)(展開して下さい)
/home/ec2-user/param.json[ { "ParameterKey" : "VPCRange", "ParameterValue" : "172.24.0.0/16" }, { "ParameterKey" : "SubnetRange", "ParameterValue" : "172.24.0.0/24" }, { "ParameterKey" : "EnvType", "ParameterValue" : "Staging" } ]開発環境用EC2インスタンスの作成
上記のパラメータファイルは
EnvTypeのParameterValueにStagingを指定しているので、以下コマンドを実行すると、開発環境用のキーペアが指定されたEC2インスタンスが作成されます。テンプレートの実行aws cloudformation create-stack --template-body file:///home/ec2-user/cloudformation.yaml --stack-name stack-test --parameters file:///home/ec2-user/param.json
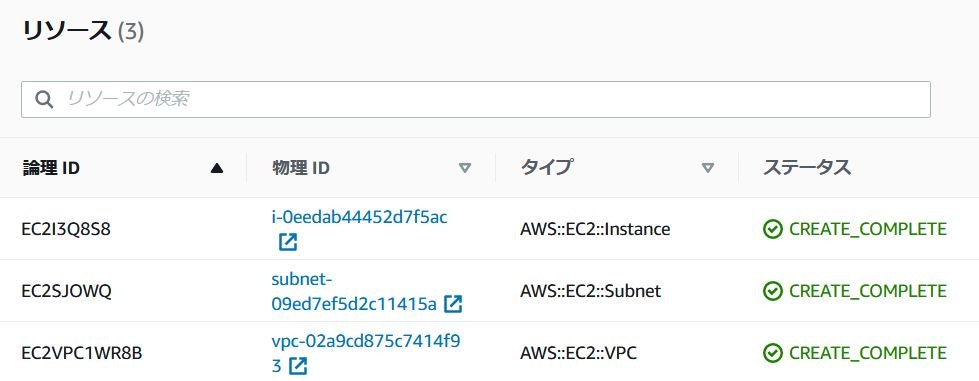
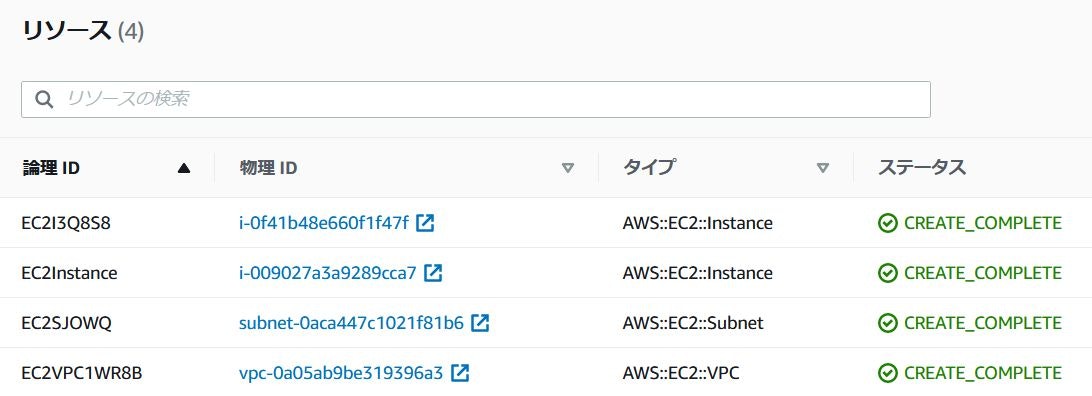
CloudFormationのリソース画面とEC2のインスタンス画面を見ると、開発環境用のキーペアが付与されたEC2インスタンスが1台作成されているのが確認できます。
次の作業のためにいったんテンプレートを削除しておきます。
テンプレートの削除aws cloudformation delete-stack --stack-name stack-test本番環境用EC2インスタンスの作成
パラメータファイルの
EnvTypeのParameterValueをProductionに書き換えて再度テンプレートを作成します。
完成したパラメータファイル(本番環境向け)(展開して下さい)
/home/ec2-user/param.json[ { "ParameterKey" : "VPCRange", "ParameterValue" : "172.24.0.0/16" }, { "ParameterKey" : "SubnetRange", "ParameterValue" : "172.24.0.0/24" }, { "ParameterKey" : "EnvType", "ParameterValue" : "Production" } ]テンプレートの実行aws cloudformation create-stack --template-body file:///home/ec2-user/cloudformation.yaml --stack-name stack-test --parameters file:///home/ec2-user/param.json
CloudFormationのリソース画面とEC2のインスタンス画面を見ると、本番環境用のキーペアが付与されたEC2インスタンスが2台作成されているのが確認できます。
おわりに
MappingsとConditionsを使用することで、1つのソースを複数の環境で使いまわすことができるので、特定の環境だけ追加した設定を反映し忘れたといったことが防げそうです。次回はまだ使っていない
Transformセクションを使ってみようと思います。



- 投稿日:2020-09-20T09:26:22+09:00
bundle exec cap production deployで生じた6つのエラーの解決法
$ bundle exec cap production deploy上記のコマンドで自動デプロイしようとしたときに発生したエラーとその解決法をまとめました。
もし自分が今詰まっているエラーと同じエラーがあり、何らかの参考になれば幸いです。
エラー①〜⑤はエラー文をそのままググって解決法を見つけました。
エラー⑥は$ less log/unicorn.logでunicornのエラーログを見に行かないと気付けませんでした。後から振り返ると、ただエラー文でググるだけじゃなくて、最初からエラーログを確認するコマンドでエラーログを確認しに行っていれば、もっと早く解決できたんじゃないかなと思いました。
エラー① SSHKit::Runner::ExecuteError: Exception while executing as ec2-user@ElasticIP: Authentication failed for user ec2-user@ElasticIP
(Backtrace restricted to imported tasks) cap aborted! SSHKit::Runner::ExecuteError: Exception while executing as ec2-user@ElasticIP: Authentication failed for user ec2-user@ElasticIP解決法
config/deploy/production.rb#デプロイするサーバーにsshログインする鍵の情報を記述 set :ssh_options, keys: '~/.ssh/ssh鍵の名前'ssh鍵の名前が間違っていました。
username@aaaa-MacBook-Air-6 .ssh % ssh ssh鍵の名前EC2に入るときに使うssh鍵の名前に変更したら解決しました。
エラー② NotImplementedError: OpenSSH keys only supported if ED25519 is available
net-ssh requires the following gems for ed25519 support:
NotImplementedError: OpenSSH keys only supported if ED25519 is available
net-ssh requires the following gems for ed25519 support:
* ed25519 (>= 1.2, < 2.0)
* bcrypt_pbkdf (>= 1.0, < 2.0)
See https://github.com/net-ssh/net-ssh/issues/565 for more information
Gem::LoadError : "ed25519 is not part of the bundle. Add it to your Gemfile."
「なんだこのエラーは?」と思いましたが、2つのgemを$ bundle installしたら無事解決しました。解決法
Gemfilegem 'ed25519' gem 'bcrypt_pbkdf'Gemfileにこれらを追加してbundle installしたら解決しました。
エラー③ ERROR linked file /var/www/アプリケーション名/shared/config/settings.yml does not exist on ElasticIP
deploy:check:linked_files ERROR linked file /var/www/アプリケーション名/shared/config/settings.yml does not exist on ElasticIP解決法
config/deploy.rb# before set :linked_files, fetch(:linked_files, []).push('config/settings.yml') # after # set :linked_files, fetch(:linked_files, []).push('config/settings.yml')これは今でもよくわかっていないのですが、このシンボリックファイルの部分をコメントアウトしたら解決しました。
シンボリックファイルとは、公開されてしまうとまずいデータが入っているファイルの仮のファイルを作ってくれる(合ってる?)ようなのですが、必ずしも必要というわけではないんでしょうか?
※今調べているところでして、わかったら追記します?♂️
エラー④ The deploy has failed with an error: Don't know how to build task
The deploy has failed with an error: Don't know how to build task 'unicorn:restart' (See the list of available tasks with `cap --tasks`)unicornの再起動の設定が間違っていたようです。
config/deploy.rbの設定を変えたらうまくいったのですが、いくつかの記事を見てみたところ、deploy.rbの設定も記事によって微妙に違っていて、どれが正しいのか全部正しいのかわからず、モヤモヤしました?解決法
config/deploy.rb# before desc 'Restart application' task :restart do invoke 'unicorn:restart' end # after desc 'Restart application' task :restart do on roles(:app) do invoke 'unicorn:restart' end endエラー⑤ SSHKit::Runner::ExecuteError: Exception while executing as naota@ElasticIP: Don't know how to build task 'unicorn:restart'
SSHKit::Runner::ExecuteError: Exception while executing as naota@ElasticIP: Don't know how to build task 'unicorn:restart' (See the list of available tasks with `cap --tasks`)capistrano3-unicornというgemを使うやり方と使わないやり方とどっちもあって、必ずしも必要というわけではないみたいですが、今回はこれを導入しただけで解決しました。
解決法
https://github.com/tablexi/capistrano3-unicorn
にしたがってcapistrano3-unicornを導入。リンク先のSetupという章にしたがって進めていけばできます。
エラー⑥ kill stderr: cat: /var/www/pfc-master/current/tmp/pids/unicorn.pid: No such file or directory
Exception while executing as naota@ElasticIp: kill exit status: 1 (SSHKit::Runner::ExecuteError) kill stdout: Nothing written kill stderr: cat: /var/www/pfc-master/current/tmp/pids/unicorn.pid: No such file or directory kill: 十分な引数がありません解決法
config/unicorn/production.rb# 修正前 $app_dir = "/var/www/rails/pfc-master" # 修正後 $app_dir = "/var/www/pfc-master/current"これがいちばん苦労しました。
本番環境のunicornの設定をするファイル(たぶん?)config/unicorn/production.rbの中の$app_dirのpathの設定が間違っていました。kill stderr: cat: /var/www/pfc-master/current/tmp/pids/unicorn.pid: No such file or directoryunicornのプロセスを記録するファイルの配置が違っていたために、unicornのプロセスがkillできず、その結果unicornの再起動ができなくなっているのが原因でした。
ここに気づくまでにめちゃくちゃいろいろ遠回りして時間かかりました?
このエラー解決だけまた別で記事書こうかなと思います。
今回は各エラーとその解決法を並べただけですが、1つ1つちゃんと理解できているかというと、結果的に解決したもののちゃんと理解できていないところも結構あるので、そこはしっかり調べて追記するなり別の記事で書いていければと思います。
- 投稿日:2020-09-20T09:04:24+09:00
AWS (/SAM/EB) CLI で IAM Role / MFA を使用する
CLI から IAM ロールを使って AWS にアクセスする方法。
参考
プロファイルを作成する
~/.aws/config を編集して、IAM ロールを使用するためのプロファイルを追加する。プロファイル名は IAM ロールに合うような一意のものをつける。
[profile profile-name] region = ap-northeast-1 output = json role_arn = (ロールARN) source_profile = defaultMFA 設定
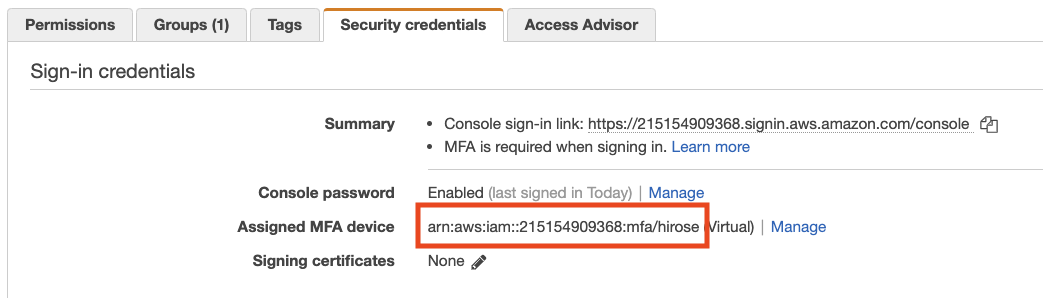
IAM ロールで MFA 必須 (aws:MultiFactorAuthPresent = true) と設定されている場合、IAM ユーザーで MFA を有効にし、プロファイルに mfa_serial を設定しておく。使用できる MFA デバイスは TOTP (仮想デバイス) のみで、U2F キーは現状使用できない1。
[profile profile-name] region = ap-northeast-1 output = json role_arn = (ロールARN) source_profile = default mfa_serial = (MFAシリアル)MFA シリアルは、IAM > ユーザー > 認証情報から確認できる。
AWS CLI
AWS_PROFILE 環境変数に、設定したプロファイル名を指定して実行する。
MFA が必要な場合は MFA コードを聞かれるので、入力する。AWS_PROFILE=profile-name aws ...AWS SAM CLI
AWS_PROFILE 環境変数に、設定したプロファイル名を指定して実行する。
MFA が必要な場合は MFA コードを聞かれるので、入力する。AWS_PROFILE=profile-name sam ...AWS EB CLI
環境変数を使う
AWS_EB_PROFILE 環境変数に、設定したプロファイル名を指定して実行する。(AWS_PROFILE ではないので注意)
MFA が必要な場合は MFA コードを聞かれるので、入力する。AWS_EB_PROFILE=profile-name eb ...特定のプロジェクトで常に固定のプロファイルを使うよう設定する
eb init 時に使用するプロファイルを指定すると、環境変数を設定しない場合にそのプロファイルが使用される。
$ eb init (アプリケーション名) --profile profile-nameこれにより、.elasticbeanstalk/config.yml に設定される。eb init 後であればこれを直接書き換えても良い。
global: profile: profile-name
aws/aws-cli#3607。U2F キーは普段非常に便利なので、AWS さんにはせめてデバイスを複数登録できるようにお願いしたい。。 ↩
- 投稿日:2020-09-20T01:09:40+09:00
さよならFirefox Send(泣)でも大丈夫、自前で構築できます!!
とても便利な
Firefox Sendですが、残念ながらサービスの停止が発表されました。Mozilla、「Firefox Send」の再開を断念 ~無償のファイル送信サービス - 窓の杜
Update on Firefox Send and Firefox Notes - The Mozilla Blog停止の発表とともにすでにサービス停止済みで https://send.firefox.com/ にアクセスしてもmozillaのトップページに転送されます。
Firefox SendのソースコードはGitHubでオープンソースで公開されていますので、そちらを起動してみましょう。
Docker Composeを使いますが、
We don't recommend using docker-compose for production.
だそうですのでお気をつけください。
環境
丁度いいタイミングでAWSからt4g.microインスタンスの年内無料トライアルが発表されたため、こちらを使用してみます。
新しい EC2 T4g インスタンス – AWS Graviton2 によるバースト可能なパフォーマンス – 無料で利用可能 | Amazon Web Services ブログ
構築
Docker
sudo amazon-linux-extras install -y dockersudoなしでdockerコマンドが使えるようになるおまじない
sudo groupadd docker sudo usermod -aG docker $USERDockerサービス起動
sudo systemctl enable docker sudo systemctl start dockerDocker Compose
ちょっと面倒ですが
sudo yum install -y python3 python3-devel libffi-devel openssl-devel gcc make sudo pip3 install docker-compose sudo ln -s /usr/local/bin/docker-compose /usr/bin/Git
sudo yum install -y git環境構築は以上です。
アプリケーションデプロイ
ソースの取得
git clone https://github.com/mozilla/send.gitちなみに2020/09/20時点で、リポジトリはすでに
Archived状態になっています。docker-compose.ymlの修正
2点、変更します。
- selenium-firefoxの削除
docker-compose.yml- selenium-firefox: - image: b4handjr/selenium-firefox - ports: - - "${VNC_PORT:-5900}:5900" - shm_size: 2g - volumes: - - .:/code
- Firefox Account不要化
このままdocker-composeすると起動はするのですが、ファイルのアップロードが失敗します。結構ハマったのですが、Issueを参考に、Firefox Accountを不要化することで解消します。
docker-compose.ymlenvironment: - REDIS_HOST=redis + - FXA_REQUIRED=false修正後はこんな感じ
docker-compose.ymlversion: "3" services: web: build: . links: - redis ports: - "1443:1443" environment: - REDIS_HOST=redis - FXA_REQUIRED=false redis: image: redis:alpinedocker-compose up
Docker Imageのビルドが始まり、しばらくすると起動します。
docker-compose up -d
http://[EC2のパブリックIP]:1443でFirefox Sendが無事起動します。
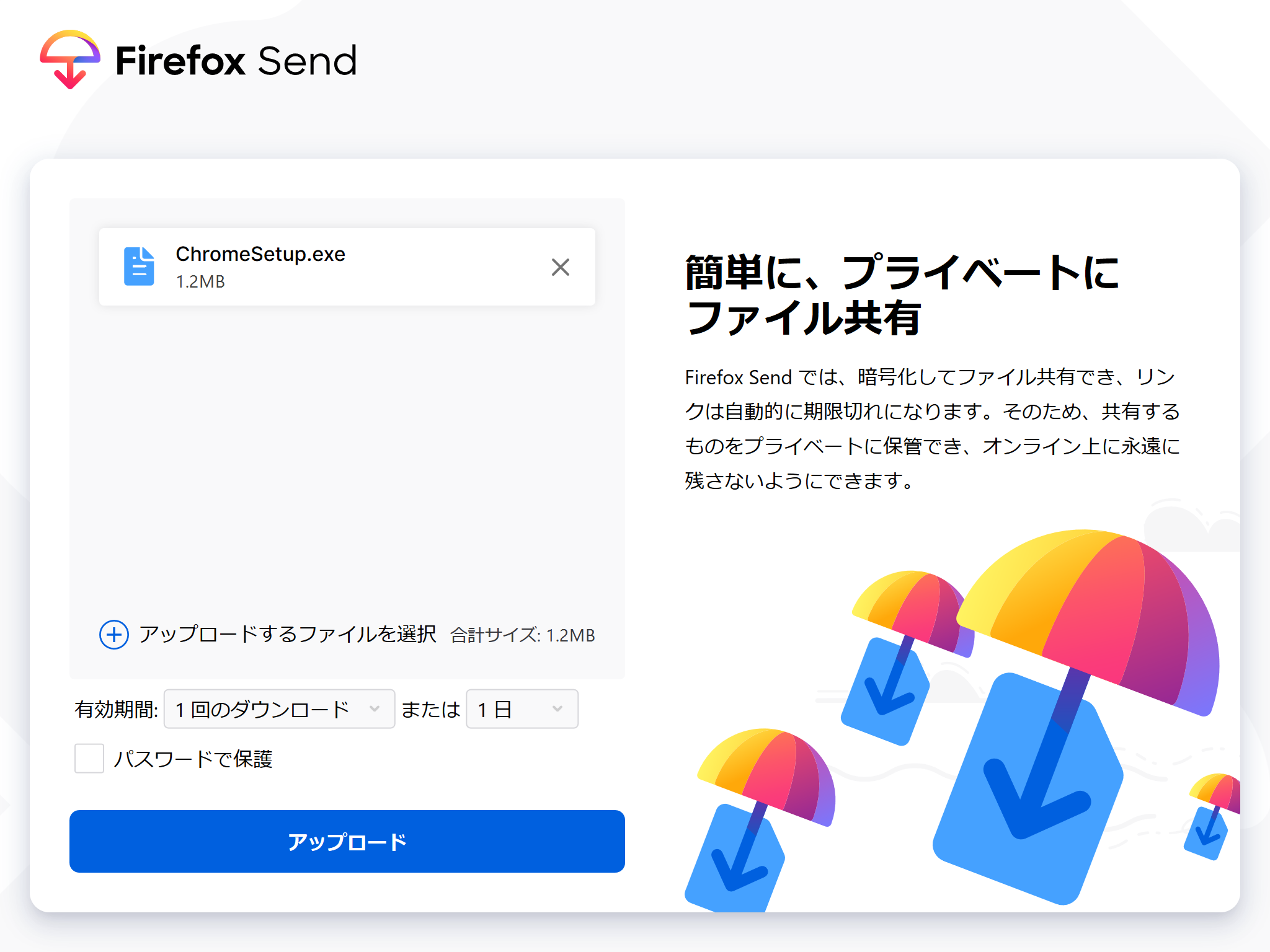
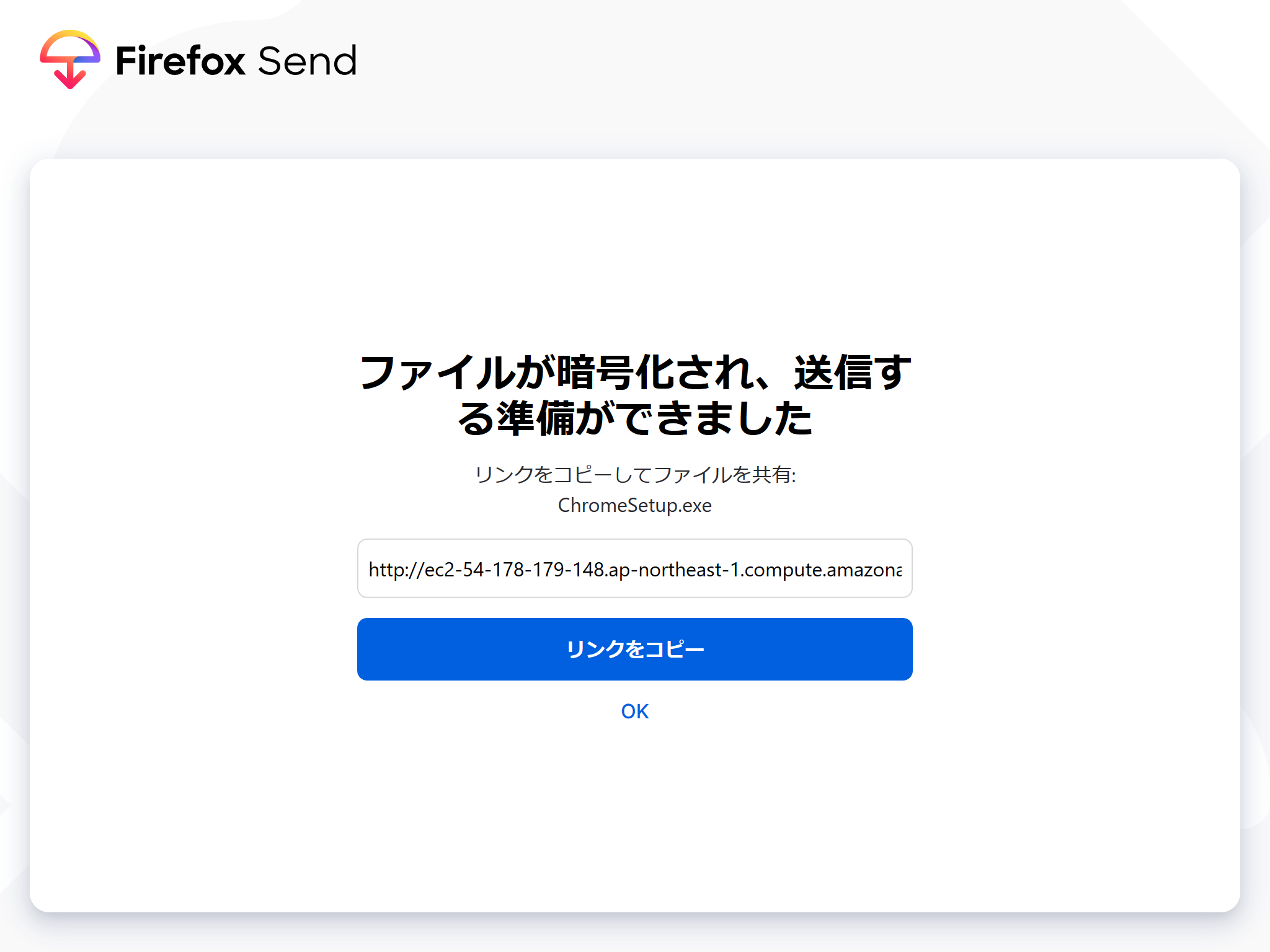
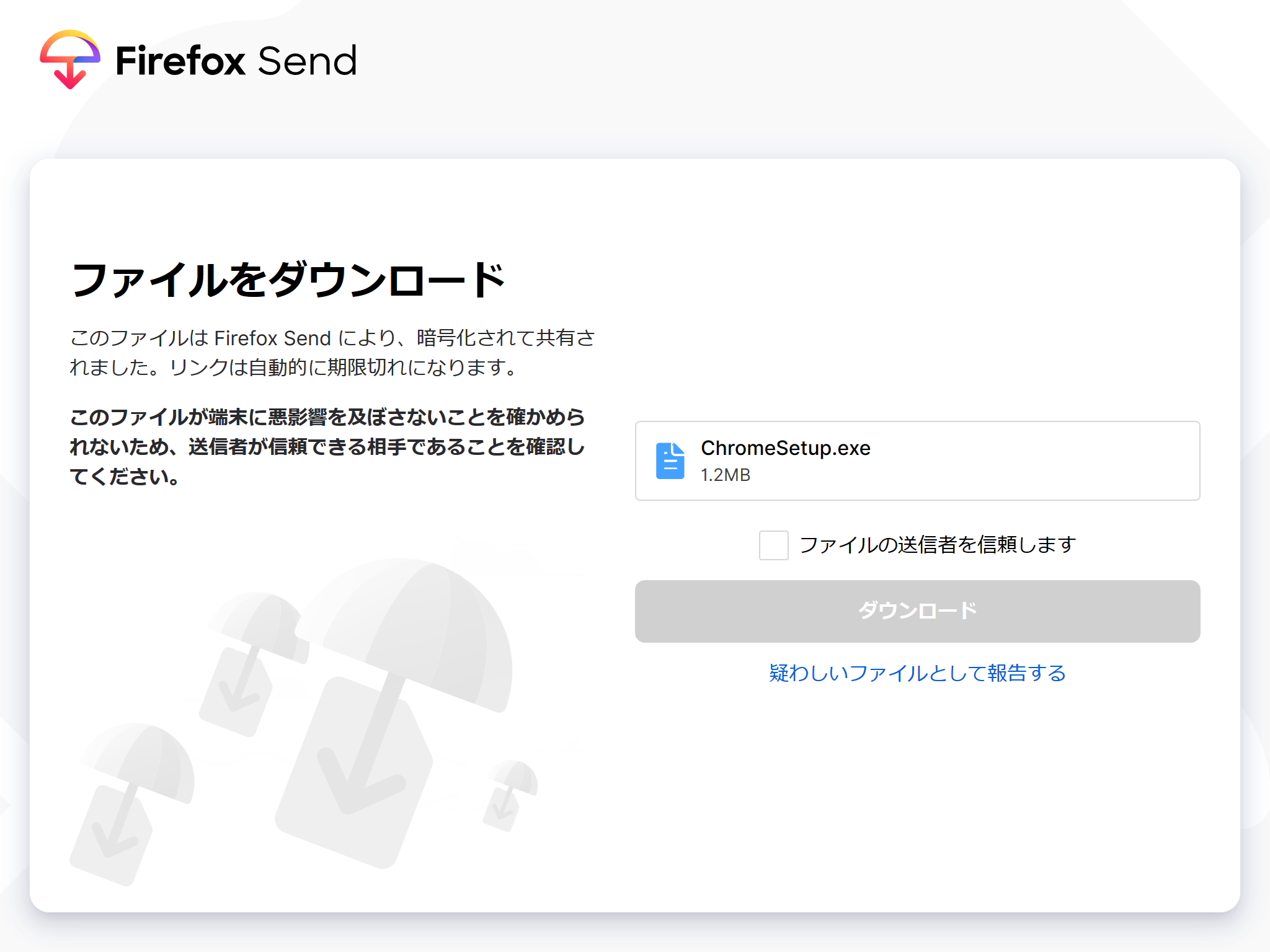
ファイルを登録して
アップロード!!!
発行されたリンクをクリックしてダウンロードできます。
自分用にはこれでなんとかなりそうです。
いいサービスだったのに、残念ですねぇ。。
- 投稿日:2020-09-20T01:09:40+09:00
さようならFirefox Send。あなたは私のT4gインスタンスの中で永遠に生き続けます!!
とても便利な
Firefox Sendですが、残念ながらサービスの停止が発表されました。Mozilla、「Firefox Send」の再開を断念 ~無償のファイル送信サービス - 窓の杜
Update on Firefox Send and Firefox Notes - The Mozilla Blog停止の発表とともにすでにサービス停止済みで https://send.firefox.com/ にアクセスしてもmozillaのトップページに転送されます。
Firefox SendのソースコードはGitHubでオープンソースで公開されていますので、そちらを起動してみましょう。
Docker Composeを使いますが、
We don't recommend using docker-compose for production.
だそうですのでお気をつけください。
環境
丁度いいタイミングでAWSからt4g.microインスタンスの年内無料トライアルが発表されたため、こちらを使用してみます。
新しい EC2 T4g インスタンス – AWS Graviton2 によるバースト可能なパフォーマンス – 無料で利用可能 | Amazon Web Services ブログ
構築
Docker
sudo amazon-linux-extras install -y dockersudoなしでdockerコマンドが使えるようになるおまじない
sudo groupadd docker sudo usermod -aG docker $USERDockerサービス起動
sudo systemctl enable docker sudo systemctl start dockerDocker Compose
ちょっと面倒ですが
sudo yum install -y python3 python3-devel libffi-devel openssl-devel gcc make sudo pip3 install docker-compose sudo ln -s /usr/local/bin/docker-compose /usr/bin/Git
sudo yum install -y git環境構築は以上です。
アプリケーションデプロイ
ソースの取得
git clone https://github.com/mozilla/send.gitちなみに2020/09/20時点で、リポジトリはすでに
Archived状態になっています。docker-compose.ymlの修正
2点、変更します。
- selenium-firefoxの削除
docker-compose.yml- selenium-firefox: - image: b4handjr/selenium-firefox - ports: - - "${VNC_PORT:-5900}:5900" - shm_size: 2g - volumes: - - .:/code
- Firefox Account不要化
このままdocker-composeすると起動はするのですが、ファイルのアップロードが失敗します。結構ハマったのですが、Issueを参考に、Firefox Accountを不要化することで解消します。
docker-compose.ymlenvironment: - REDIS_HOST=redis + - FXA_REQUIRED=false修正後はこんな感じ
docker-compose.ymlversion: "3" services: web: build: . links: - redis ports: - "1443:1443" environment: - REDIS_HOST=redis - FXA_REQUIRED=false redis: image: redis:alpinedocker-compose up
Docker Imageのビルドが始まり、しばらくすると起動します。
docker-compose up -d
http://[EC2のパブリックIP]:1443でFirefox Sendが無事起動します。
ファイルを登録して
アップロード!!!
発行されたリンクをクリックしてダウンロードできます。
自分用にはこれでなんとかなりそうです。
いいサービスだったのに、残念ですねぇ。。