- 投稿日:2020-09-18T23:28:42+09:00
yukicoder contest 266 参戦記
yukicoder contest 266 参戦記
A 1229 ラグビーの得点パターン
N≦100なので全探索で問題ないので、「コンバージョンはトライ後のキックなので必ずトライ数以下になることに注意してください」だけ注意して全探索すれば良い.
N = int(input()) result = 0 for i in range(N // 5 + 1): for j in range(i + 1): for k in range(N // 3 + 1): if i * 5 + j * 2 + k * 3 == N: result += 1 print(result)B 1230 Hall_and_me
すべての確率を計算して最大値を取ればいい. ある宝箱にダイヤモンドが入っている確率を x とすると、STAY の場合は入ってた時に当たるので確率 x、CHANGE の場合は入ってなかった時に当たる(何故なら指定しなかったハズレの宝箱を開けてもらえるので、もし指定した宝箱に入っていなかったら CHANGE 先が確実に入っている宝箱になる)ので確率 1 - x となる.
P, Q, R = map(int, input().split()) a = P / (P + Q + R) b = Q / (P + Q + R) c = R / (P + Q + R) print(max(a, b, c, 1 - a, 1 - b, 1 - c))C 1231 Make a Multiple of Ten
DPの典型問題. それぞれのカードを取る取らないを、カードに書かれた整数の総和を10で割った余りをインデックス、取ったカードの枚数を値とし、取ったカードの枚数の最大値を取る DP をすれば良い.
N, *A = map(int, open(0).read().split()) dp = [[-1] * 10 for _ in range(N + 1)] dp[0][0] = 0 for i in range(N): for j in range(10): if dp[i][j] == -1: continue dp[i + 1][(j + A[i]) % 10] = max(dp[i + 1][(j + A[i]) % 10], dp[i][j] + 1) dp[i + 1][j] = max(dp[i + 1][j], dp[i][j]) print(dp[N][0])
- 投稿日:2020-09-18T23:17:35+09:00
試験の数理 その5(受験者paramter推定)
試験の数理 その4(問題paramter推定の実装) の続きです。
前回は、「3PL modelの問題paramter推定の実装について」でした。
今回は、「受験者の能力parameter の推定」です。用いた環境は、
- python 3.8
- numpy 1.19.2
- matplotlib 3.3.1
です。
理論
問題設定
問題パラメータ$a, b, c$が既知であるときに、問題に対する反応ベクトル$u_j$から3PL modelの受験者parameter $\theta_j$を推定することとなります。
目的関数
ここでは、最尤推定で解くこととします。$P_{ij}$を3PL modelで問題$i$に受験者$j$が正答する確率、$Q_{ij} = 1 - P_{ij}$としたときに尤度は
\begin{align} \Pr\{U_j = u_j|\theta_j, a, b, c\} &= \prod_{i} \Pr\{U_{ij} = u_{ij}|\theta, a, b, c\}\\ &= \prod_{i}P_{ij}^{u_{ij}}Q_{ij}^{1-u_{ij}} \end{align}となるので、対数尤度は
\begin{align} \mathcal{L}(u_j, \theta_j, a, b, c) &= \ln \Pr\{U_j = u_j|\theta_j, a, b, c\}\\ &= \sum_{i}u_{ij}\ln P_{ij} + (1-u_{ij})\ln Q_{ij} \end{align}となります。ここで、目的のparamter $\hat{\theta_j}$は
\begin{align} \hat{\theta_j} = \arg \max_{\theta}\mathcal{L}(u_j, \theta, a, b, c) \end{align}となります。
微分係数
問題を解くために微係数を計算しておきます。$\partial_\theta := \frac{\partial}{\partial \theta}$としたとき、
\begin{align} \partial_\theta\mathcal{L}(u_j, \theta, a, b, c) &= \sum_i a_i\left(\frac{u_{ij}}{P_{ij}} - 1\right)P_{ij}^* \\ \partial_\theta^2\mathcal{L}(u_j, \theta, a, b, c) &= \sum_i a_i^2\left(\frac{c_iu_{ij}}{P_{ij}^2} - 1\right)P_{ij}^* Q_{ij}^* \end{align}となります。ここで$P^*_{ij}, Q^*_{ij}$は2PL modelで問題$i$に受験者$j$が正答する確率です。ここから、解では、$\partial_\theta\mathcal{L} = 0, \partial_\theta^2\mathcal{L} < 0$となっているはずです。
解法
ここでは、Newton Raphson法を用いて、計算を行います。具体的な手順は以下のとおりです。
- $\theta$として乱数で値を決める。
- $\theta^{(new)} = \theta^{(old)} - \partial_\theta\mathcal{L}(\theta^{(old)})/\partial_\theta^2\mathcal{L}(\theta^{(old)})$で値を逐次更新し、$\partial_\theta\mathcal{L} < \delta$の時、終了する。
- $\partial_\theta^2\mathcal{L} < 0$となっているか、および値が発散していないか判定し、条件に満たない場合1からやりなおす。
- $N$回やりなおしても値が見つからない場合、解なしとする。
実装
pythonを用いて次のように実装しました。
import numpy as np from functools import partial # 定数の定義 delta: 収束判定、 Theta_: 発散判定、 N:繰り返し判定 delta = 0.0001 Theta_ = 20 N = 20 def search_theta(u_i, item_params, trial=0): # 繰り返しが規定回数に到達したらNoneを返す if trial == N: return None # thetaを乱数で決める。 theta = np.random.uniform(-2, 2) # NR法 for _ in range(100): P3_i = np.array([partial(L3P, x=theta)(*ip) for ip in item_params]) P2_i = np.array([partial(L2P, x=theta)(*ip) for ip in item_params]) a_i = item_params[:, 0] c_i = item_params[:, 2] res = (a_i *( u_i / P3_i - 1) * P2_i).sum() d_res = (a_i * a_i * ( u_i * c_i/ P3_i / P3_i - 1) * P2_i * (1 - P2_i)).sum() theta -= res/d_res # 収束判定 if abs(res) < delta: if d_res < -delta and -Theta_ < theta < Theta_: return theta else: break return search_theta(u_i, item_params, trial + 1)実行と結果
上の関数を用いて数値計算を行いました。実行には問題parameterとして前回の推定結果の
a / 識別力 b / 困難度 c / 当て推量 問 1 3.49633348 1.12766137 0.35744497 問 2 2.06354365 1.03621881 0.20507606 問 3 1.64406087 -0.39145998 0.48094315 問 4 1.47999466 0.95923840 0.18384673 問 5 1.44474336 1.12406269 0.31475672 問 6 3.91285332 -1.09218709 0.18379076 問 7 1.44498535 1.50705016 0.20601461 問 8 2.37497907 1.61937999 0.10503096 問 9 3.10840278 1.69962392 0.22051818 問 10 1.79969976 0.06053145 0.29944448 を用いました。
params = np.array( [[ 3.49633348, 1.12766137, 0.35744497], [ 2.06354365, 1.03621881, 0.20507606], [ 1.64406087, -0.39145998, 0.48094315], [ 1.47999466, 0.9592384 , 0.18384673], [ 1.44474336, 1.12406269, 0.31475672], [ 3.91285332, -1.09218709, 0.18379076], [ 1.44498535, 1.50705016, 0.20601461], [ 2.37497907, 1.61937999, 0.10503096], [ 3.10840278, 1.69962392, 0.22051818], [ 1.79969976, 0.06053145, 0.29944448]] )さて、受験者paramterの推定についてですが、実は今回は問題数が10しかなく、入力としてありえる受験結果は
[0, 0, ..., 0]から[1, 1, ..., 1]の1024通りしかありません。実際問題の応答は正誤の2通りしかないのですから、ありえる入力は問題数を$I$とすれば、$2^I$ 通りになってしまいます。それゆえ、実数parameter$\theta$を完全に精度良くみることは不可能です。例えば、ある受験者のparameterが0.1224程度だっとし、そこから、[0, 1, 1, 0, 1, 1, 1, 0, 0, 1]という結果を得たとしましょう。ここで、search_theta(np.array([0, 1, 1, 0, 1, 1, 1, 0, 0, 1]), params)と計算すると、結果は
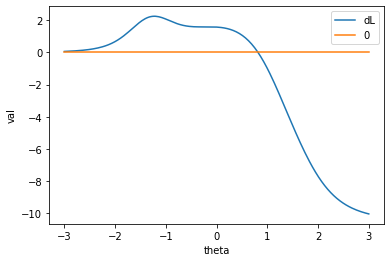
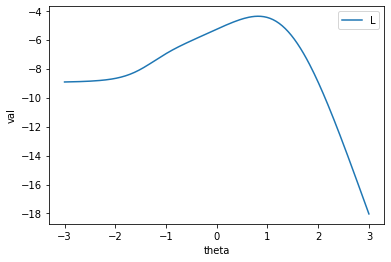
0.8167程度となります。グラフにplotすると次のようになります。import matplotlib.pyplot as plt y = [] y_ = [] x = np.linspace(-3, 3, 201) u_ = np.array([0, 1, 1, 0, 1, 1, 1, 0, 0, 1]) for t in x: theta = t P3_i = np.array([partial(L3P, x=theta)(*ip) for ip in params]) P2_i = np.array([partial(L2P, x=theta)(*ip) for ip in params]) a_i = params[:, 0] # 対数尤度 res = (u_ * np.log(P3_i) + (1 - u_) * np.log(1 - P3_i)).sum() # 微分係数 res_ = (a_i *( u_ / P3_i - 1) * P2_i).sum() y.append(res) y_.append(res_) # plot # 微分係数 plt.plot(x, y_, label="dL") plt.plot(x, x * 0, label="0") plt.xlabel("theta") plt.ylabel("val") plt.legend() plt.show() # 対数尤度 plt.plot(x, y, label="L") plt.xlabel("theta") plt.ylabel("val") plt.legend() plt.show()
実際は
0.1224程度だったので、かなり高い数値となります。これは、問2や問5などを運良く正解できたことによります。これは問題数が少なかったことによると思われるので、問題数がより多ければ、より精度の良い推定が得られやすくなるでしょう。おまけ
入力にもちいるbinaryですが、たとえば、
n_digits = 10 num = 106 u_ = np.array([int(i) for i in f'{num:0{n_digits}b}'])とすれば、
array([0, 0, 0, 1, 1, 0, 1, 0, 1, 0])などと得ることができます。0 <= num <= 1023
全入力に対する最適値をこれでみることができます。ただし、[1, 1, ..., 1]などいくつかはまともな値を得られません。結び
5記事に渡って書いた「試験の数理」シリーズですが、今回で一応の完結です。この記事やこれまでの記事をを見てくださり、ありがとうございました。
項目反応理論は奥が深く、例えば、全部に答えてくれていない(歯抜けの)データはどうするんだ?とかそもそもバイナリでなくて多段階だったり、実数値でデータが出ている場合にはどうなんだ?とか様々な応用や発展が考えられます。また機会があればそのあたりも勉強して記事にしたいと思っています。
なにか、質問やつっこみなどがありましたら、気軽にコメントなり修正依頼などを出していただければ嬉しいです。参考文献
- 投稿日:2020-09-18T23:03:05+09:00
Python演算
はじめに
この回の記事ではPythonでの演算について取り上げます。
四則演算の基本
Pythonでの四則演算をざっと復讐します。
python足し算 : + 引き算 : - 掛け算 : * 割り算 : / 割り算の商 : // 割り算の余り : % 累乗 : **複合演算子
a = a + 1を省略したものです。
python足し算 : += 引き算 : -= 掛け算 : *= 割り算 : /= 割り算の商 : //= 割り算の余り : %= 累乗 : **=1からnまでの合計
pythonn * (n + 1) / 2実数誤差
0.1を10回足すと10になるのが普通ですが、プログラミングの世界では必ずしもそうなりません。
pythona = 0 for i in range(10): a += 0.1 a #0.9999999999.... #改善策 #0.1を1桁右に動かし1にする #1を10回たし、小数点に戻す a = 0 b = 0.1 * 10 for i in range(10): a += b a = a / 10 a #10シフト演算
先ほどの実数誤差の改善策と同じように、2進数のビットを右や左に動かす。
python#左にシフト 15 << 1 #12を左に1ビットシフト #30 15 << 2 #12を左に2ビットシフト #60 15 << 3 #12を左に3ビットシフト #120 #式に直す 15 << n 15 * (2 ** n) #右にシフト 15 >> 1 #12を右に1ビットシフト #7 15 >> 2 #12を右に2ビットシフト #3 15 >> 3 #12を右に3ビットシフト #1 #式に直す 15 >> n 15 // (2 ** n)演算
AND演算
2つのビットが「1」の時「1」を返し、「0」の時「0」を返す。
python1 & 1 # 1 1 & 0 # 0OR演算
2つのビットのうちどちらかが「1」の時「1」を返し、両方「0」の時「0」を返す。
python1 | 1 # 1 1 | 0 # 1 0 | 0 # 0XOR演算
両方の値が同じ時に「0」を返し、違う時に「1」を返す。
python1 ^ 1 # 1 1 ^ 0 # 0 0 ^ 0 # 0NOT演算
全てのビットを反転させる。
python~1 #00000001 #-2 #11111110
- 投稿日:2020-09-18T22:23:03+09:00
Python python-docxライブラリとフリーソフト「縮小専用。」でフォルダ中の写真のサムネイルを貼り付けたdocxファイルを作成する
Python 3.8でpython-docxライブラリとフリーソフト「縮小専用。」を使用してあるフォルダのサブフォルダに含まれるJPEGファイルのサムネイルを貼り付けたdocxファイルを作成するサンプルコードです。
いつかの自分のためにpython-docx、subprocess等の参考として記載します。
コード
import docx import subprocess from pathlib import Path rootpath = Path(r"<写真フォルダをまとめたフォルダのパス>") shukusenpath = Path(r"<縮小専用。のパス>") thumbdirname = "thumb" # 縮小専用。で指定したサブフォルダの名前 for folderpath in rootpath.glob("*"): if not folderpath.is_dir(): continue newfilepath = rootpath / (folderpath.stem + ".docx") if newfilepath.is_file(): continue thumbpath = folderpath / thumbdirname # JPEGのみ貼り付け # 他の拡張子も貼り付ける場合はここを編集します。 picpaths = list(folderpath.glob("*.jpg")) if len(picpaths) == 0: continue subprocess.run([shukusenpath, *picpaths]) doc = docx.Document() for picpath in picpaths: thumbpicpath = thumbpath / picpath.name try: doc.add_picture(str(thumbpicpath)) doc.add_paragraph() doc.add_page_break() except Exception: pass doc.save(newfilepath)メモ
python-docxはpip install python-docxでインストールできます。pathlib.Pathは/演算子でパスを結合できます。subprocessは第1引数に実行ファイルと引数のリストを与えることで実行ファイルを起動して終了を待ちます。- リテラルと展開後のリストやジェネレータを要素とするリストを作成するには
[literal, *list, *generator]のようにします。*はリストやジェネレータの展開です。docx.Document.add_pictureにpathlib.Pathを直接与えるとエラーが発生します。str(pathlib.Path)で文字列に変換することで回避できます。pathlib.Pathではstemは括弧不要ですが、通常の用法でis_dir()は括弧必須です。is_dirはエラーにはなりませんが、メソッドそのものを返すのでifに与えると常に真となります。参考
- 投稿日:2020-09-18T21:45:48+09:00
【Fenwick_Tree編】緑コーダーと読み進めるAtCoder Library 〜Pythonでの実装まで〜
0. はじめに
2020年9月7日にAtCoder公式のアルゴリズム集 AtCoder Library (ACL)が公開されました。
自分はACLに収録されているアルゴリズム、データ構造のほとんどが初見だったのでいい機会だと思い、アルゴリズムの勉強からPythonでの実装までを行いました。この記事ではFenwick_Tree (フェニック木) をみていきます。
対象としている読者
- ACLのコードを見てみたけど何をしているのかわからない方。
- C++はわからないのでPythonで読み進めたい方。
対象としていない読者
- ACLのPythonに最適化されたコードが欲しい方。
→極力ACLと同じになるように実装したのでPythonでの実行速度等は全く考慮していません。Cythonから直接使えるようにするという動きがあるようなのでそちらを追ってみるといいかもしれません。参考にしたもの
フェニック木の仕組みについて
- Binary indexed tree (スライド) 非常に分かりやすいです
- Wikipedia - フェニック木
ビット演算について
1. フェニック木とは
「フェニック木とは何か?」を理解するためにまずは次の問題を考えてみます。
長さ$N$の数列 $a_1, a_2, \cdots, a_N$ が与えられ、この数列に対する以下の2種類のクエリがたくさん投げられます。これを処理してください。
- add : $i, x$ が与えられるので、$a_i$ に $x$ を加算する。
- sum : $i$ が与えられるので、先頭から $i$ 番目までの和を求める。
なお以降では、与えられる値を明示して add(i, x), sum(i) と書くこともあります。
1.1. まずは愚直解
まずは問題に書かれている通りに考えてみます。クエリaddは
a_i \leftarrow a_i+xとすればいいので計算量 $O(1)$ で処理できます。
一方、クエリsumはa_1+a_2+\cdots+a_iを計算する必要があるので、計算量は $O(N)$ となります。
1.2. 部分和といえば累積和
クエリsumのような数列の部分和といえば累積和が思いつくでしょう。実際、数列 $a$ の累積和をとった配列を用意すればクエリsumは $O(1)$ で処理できます。
しかし、クエリaddはどうでしょうか。数列 $a$ の1箇所を変更すると累積和を計算し直す必要があるので結局、計算量は $O(N)$ となります。1.3. そんなときにフェニック木
愚直解も累積和もadd,sum両方のクエリを処理するためには1回あたり計算量 $O(N)$ が必要でした。もちろんこれで間に合う場合はいいのですがもっと速くしたい。。。
そんなときに登場するのがフェニック木です。フェニック木はクエリadd, sumの両方を1回あたり $O(\log N)$ で処理できます!
フェニック木は Binary Indexed Tree(BIT) とも呼ばれます。2. フェニック木ってどんな木?
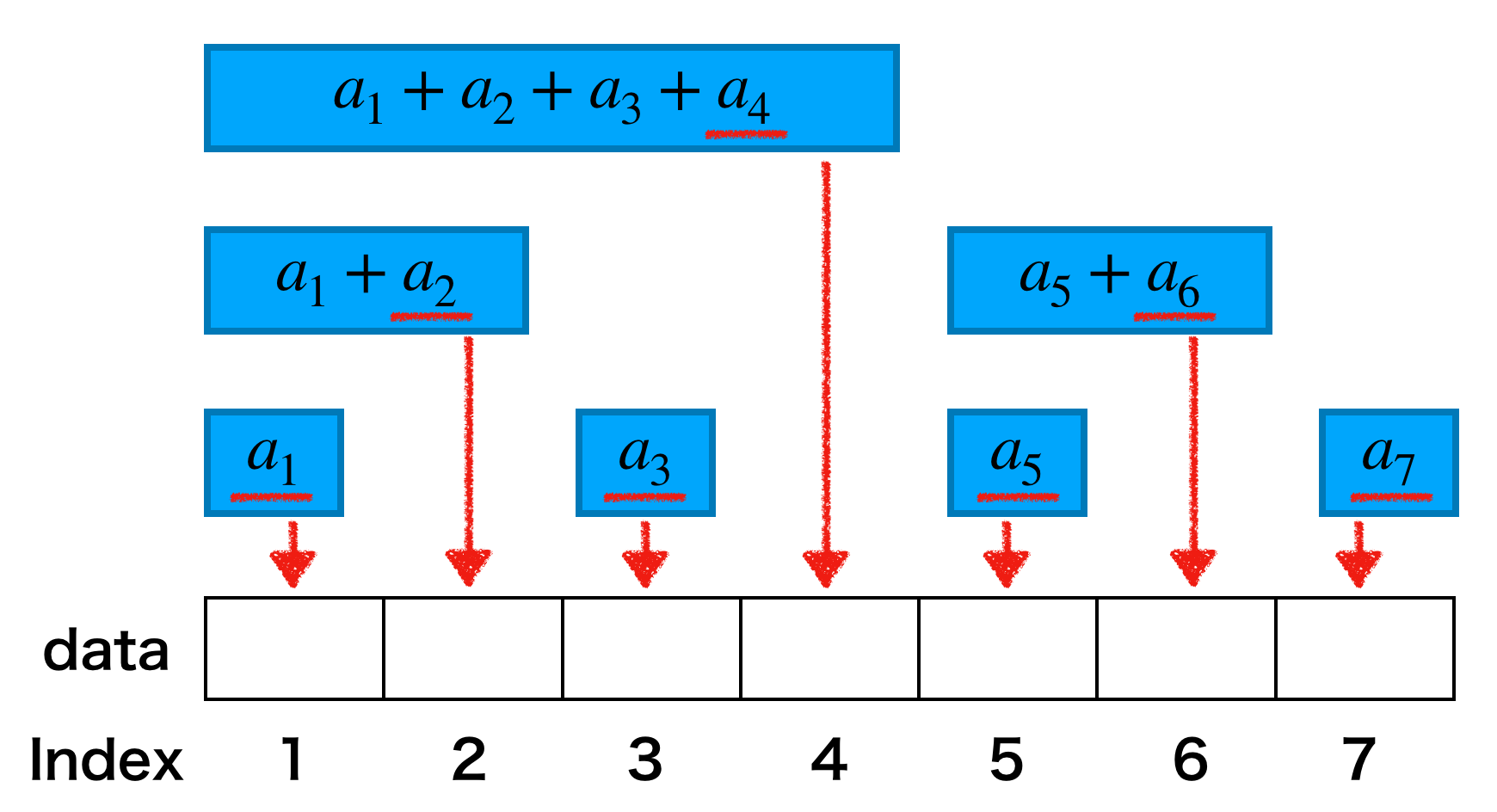
それではフェニック木の構造を見ていきます。そのために数列 $a$ の長さとして具体的に $N=7$ の場合を考えてみましょう。
2.1. とりあえず木をつくる
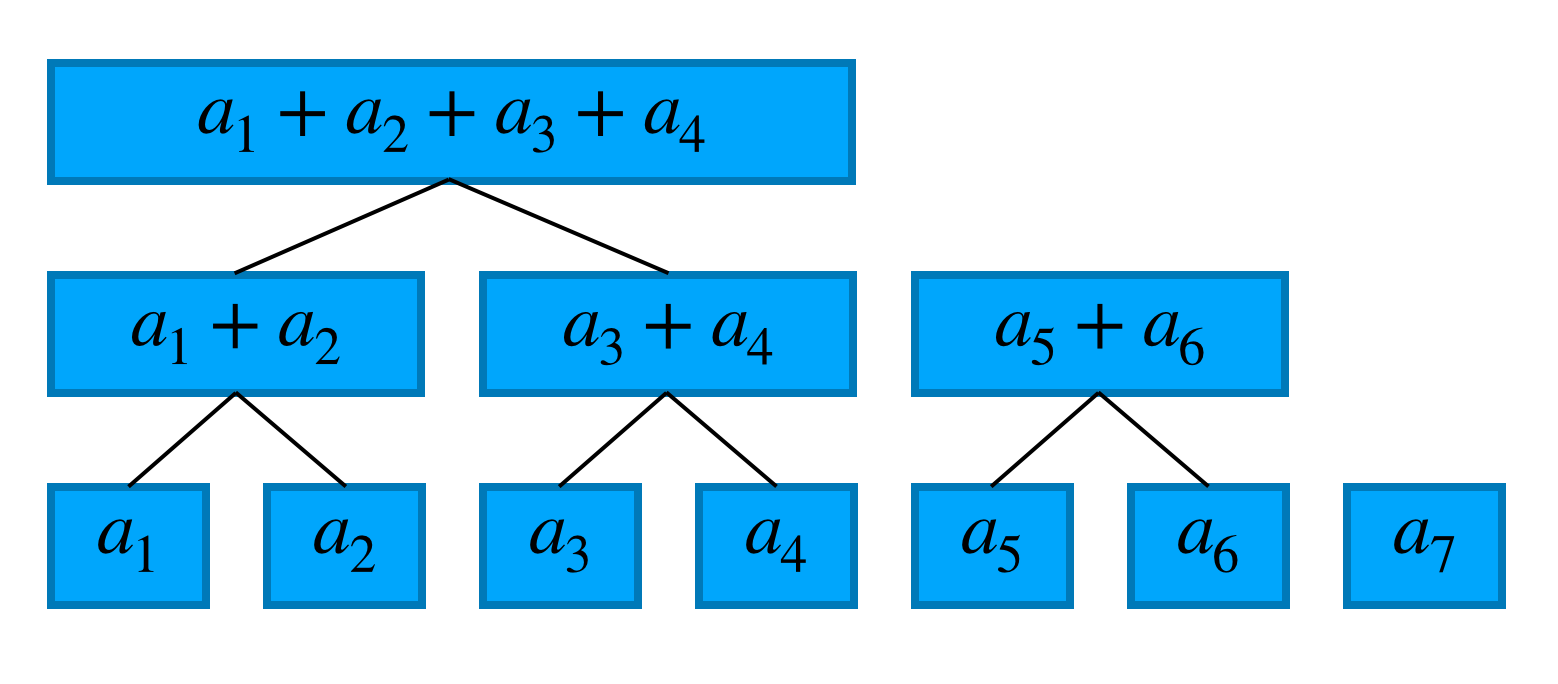
フェニック『木』というからには木構造であるはずなので数列 $a$ から木をつくります。具体的には下図のように数列の各項を葉として2項の和を親として木をつくります。
木(森?)ができたので、この木を使って前章の問題を解いてみます。
まずはクエリaddです。例として $a_3$ を更新する場合を考えましょう。$a_3$ が関係するのは3箇所あるのでこれらを更新すれば良いです。より一般的には更新すべき場所は木の高さ程度の数あります。この木の高さはおおよそ $\log N$ なので計算量は $O(\log N)$ となります。
クエリsumはどうでしょうか。例えば、7番目までの和を求める場合\sum_{i=1}^{7}{a_i}=(a_1+a_2+a_3+a_4)+(a_5+a_6)+(a_7)なので3箇所見れば良いです。こちらも一般的には木の高さ程度の場所を見れば良いので計算量は $O(\log N)$ となります。
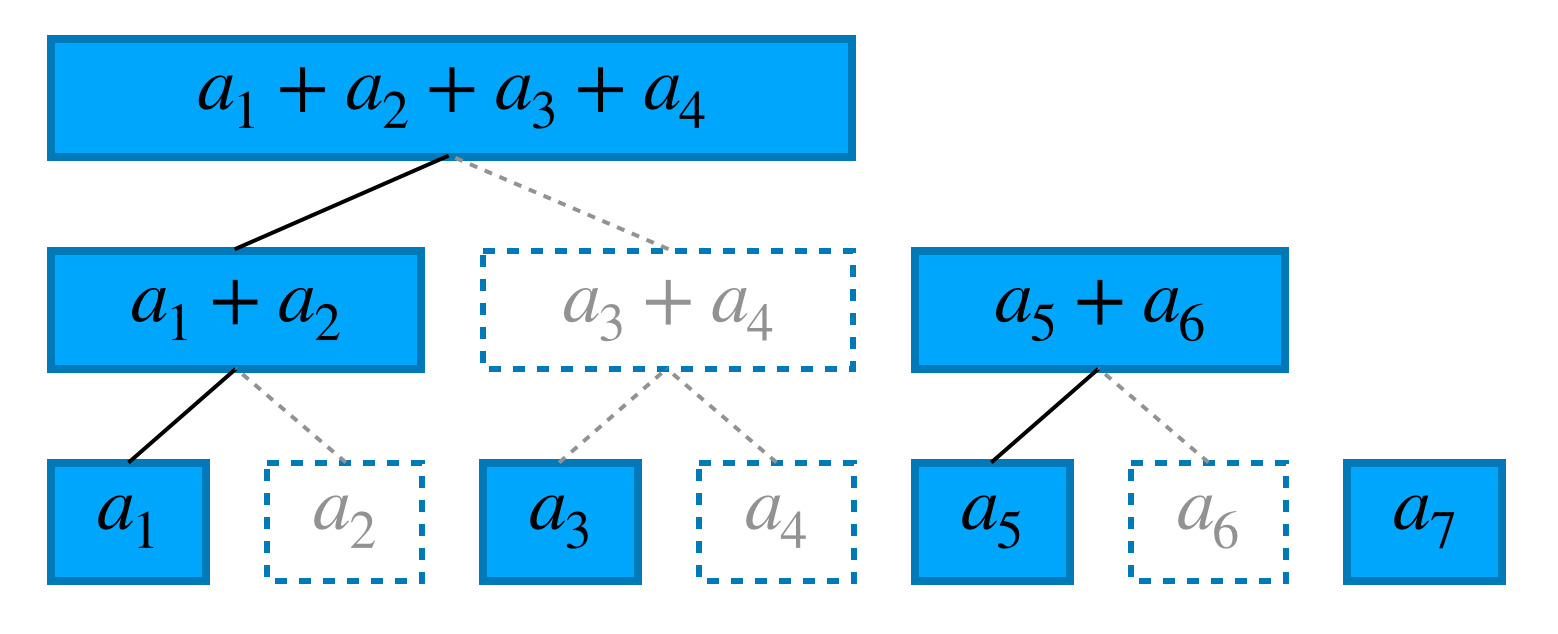
2.2. よりスマートに
ということでadd, sum両クエリに対して $O(\log N)$ で処理ができそうです。めでたしめでたし・・・と言いたいところですが、実は先ほどつくった木には無駄があります。実際に、1番目までの和、2番目までの和、$\cdots$ 、7番目までの和と全て確認してみると一度も見ない場所がいくつかあります。それらを取り除くと下図のようになります。この中にクエリsumを処理するために必要な情報が全て入っています。(クエリaddは関係ある場所を更新するだけなので問題ないです。)
2.3. フェニック木の本当の姿
さて、ここまで「フェニック木ってどんな木?」を知るために木構造を示してきましたが、ACLのフェニック木のコードを見てみると、
dataという長さ $N$ の1次元配列しかありません。木はどこにあるのでしょうか?
実はこのdataに木構造が詰まっています。具体的には配列のindexを使って「辿るべき道順」の情報を持っています。
それでは、上でみた木を1次元配列に直しましょう。気づいた方もいるかもしれませんが先ほど無駄な部分を取り除いたことで残っている場所はちょうど$N$箇所になりました。そして各場所で、部分和をとるindexの最大値(下図の赤下線部)が異なります。この値を使うことでdataをつくることができます。
というわけで、フェニック木の実態は(実装上は)、部分和をなんかいい感じに詰め込んだ1次元配列だとわかりました。
3. 奇妙な配列の歩き方
我々の目的はこの奇妙な配列
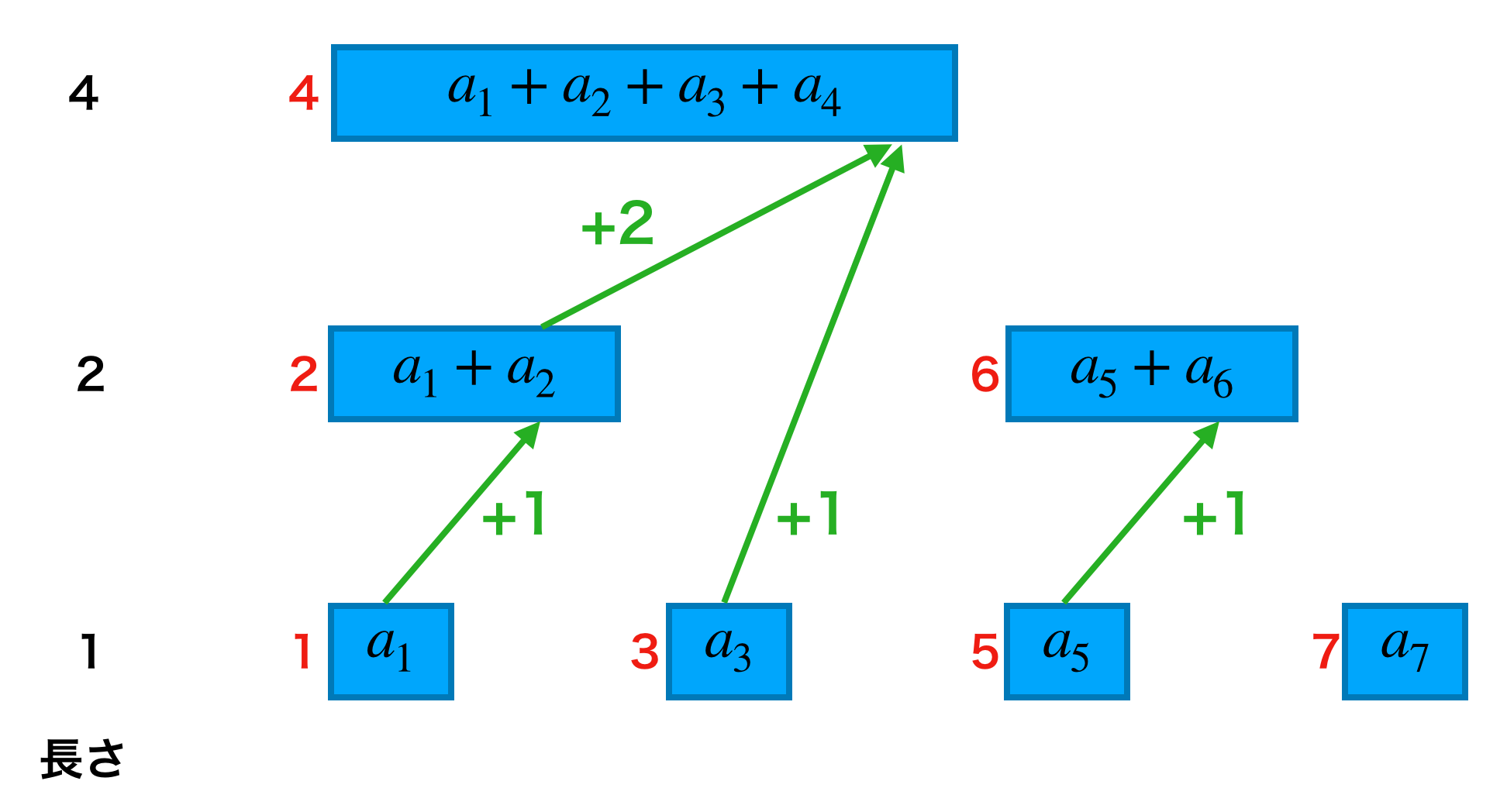
dataを使ってクエリadd, sumを処理することです。この章ではそれぞれのクエリで「辿るべき道順」がどのように得られるかをみていきます。3.1. クエリadd
まずはクエリaddです。クエリadd(i, x)は $a_i$ を含む場所すべてを辿ればいいです。いくつか例をみてみましょう。
更新するindex 辿るべき道順 1 1 → 2 → 4 2 2 → 4 5 5 → 6 これだけだとなかなか法則性は見えてきませんね。ところが、「今いるインデックスと次にみたいインデックスの差分」に注目すると一気に見通しが良くなります。
赤字が
dataのインデックスで緑矢印が道順、緑字がインデックスの差分を表します。この図を見ると下段からは +1、中段からは +2 をすれば良いことが分かります。この図の上段、中段、下段は「和をとる項の数」で分けられており、これを「長さ」と呼ぶことにします。例えば「data[6]の長さ」は 2 です。こうすると、クエリadd(i, x)を処理するためには以下のようにすれば良いと言えます。
インデックスを
i^\prime = i + (data[i]の長さ)と更新しつつ、
data[i]に x を加算する。
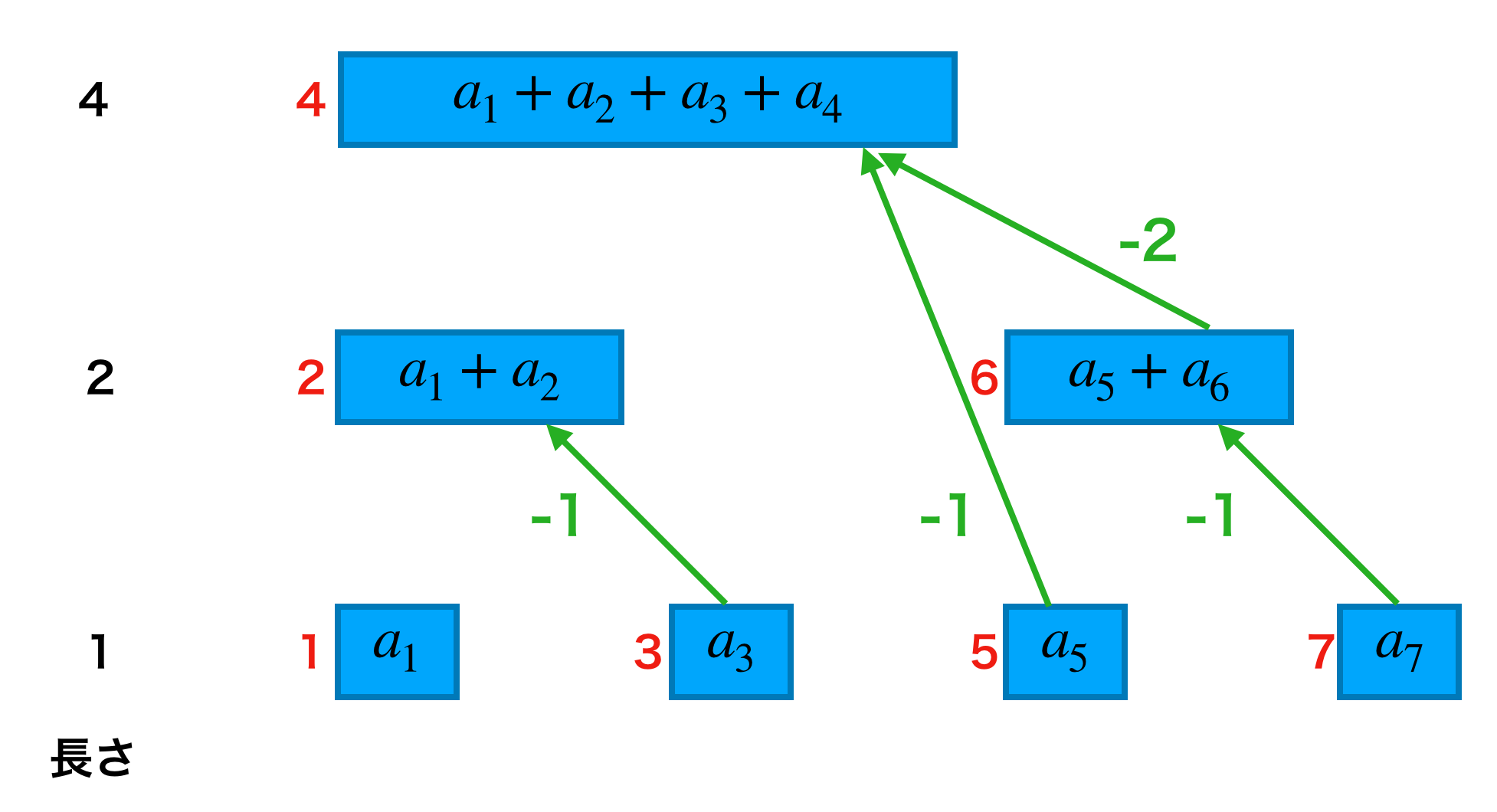
3.2. クエリsum
つづいて、クエリsumをみていきます。クエリsum(i)は $a_1, \cdots, a_i$ を網羅するように辿り、それらの総和を取れば良いです。こちらも先ほどのクエリaddと同様に、「今いるインデックスと次にみたいインデックスの差分」に注目してみましょう。
やはり、「長さ」を使うことで次にみたいインデックスが分かります。したがって、クエリsum(i)を処理するためには以下のようにすれば良いと言えます。
インデックスを
i^\prime = i - (data[i]の長さ)と更新しつつ、各
data[i]の総和をとる。
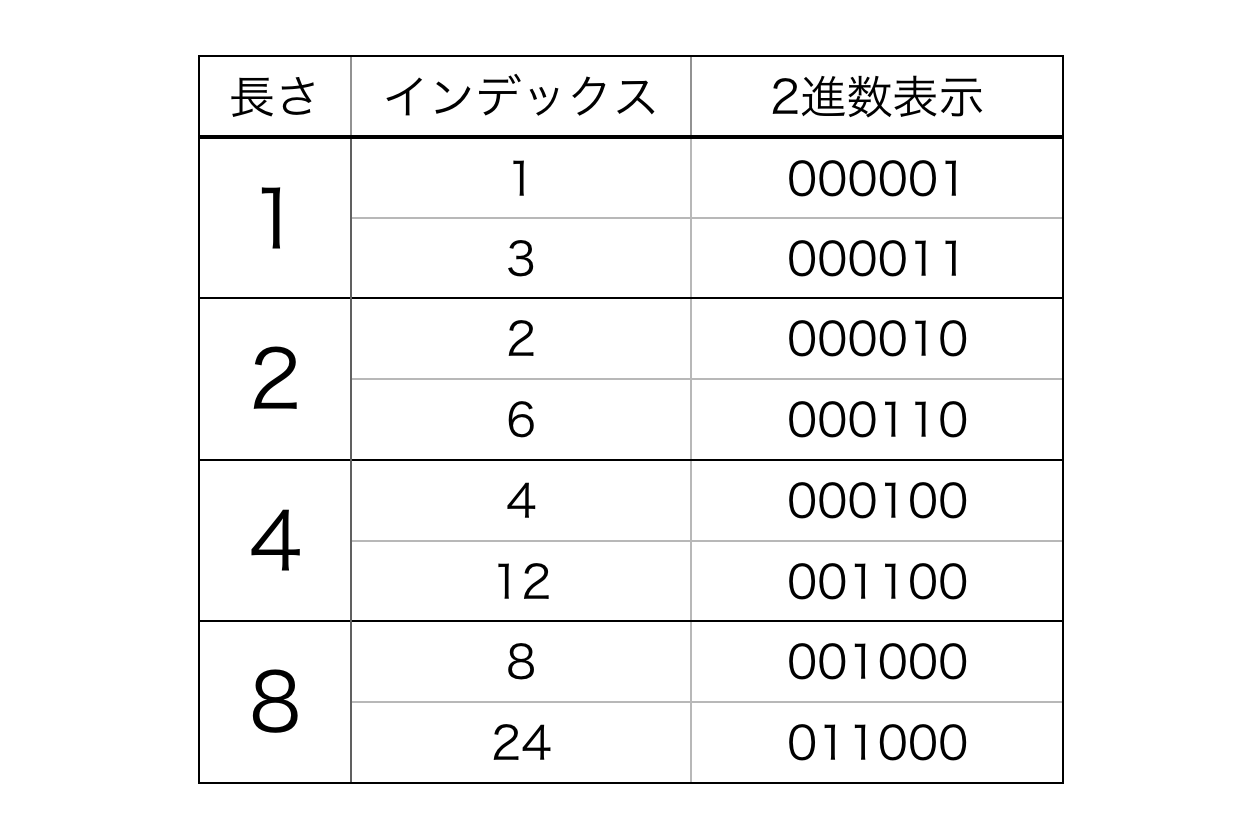
3.3. 長さ
なんと、どちらのクエリも「
data[i]の長さ」さえ得られれば処理できることが分かりました。では i からdata[i]の長さを得るにはどうすれば良いでしょうか。ここでフェニック木が Binary Indexed Tree とも呼ばれることを思い出しましょう。長さごとにインデックスとその2進数表示を示します。
この表から、長さは「インデックスを2進数表示し、右から見たときに初めて'1'が現れる場所」すなわち「'1'の最下位ビット」に対応していることが分かります。最下位ビットはよく英語で Least Significant Bit (LSB) と書かれます。
そして、「i における'1'のLSB」(= LSB(i)と書きます) はビット演算によって簡単に求めることができます。LSB(i) \quad=\quad i\quad\&\quad(-i)ここで&はビット毎のAND演算です。負の数に対するビット演算は、その数が2の補数表現で表されているとして処理されます(参考)。
いくつか例をみてみましょう。ここでは8ビットの2の補数表現で考えていきます。
$i = 6$ のとき\begin{aligned} LSB(6) &= 6 \quad\&\quad(-6)\\ &= (00000110)_2 \quad\&\quad (11111010)_2\\ &= (00000010)_2\\ &= 2 \end{aligned}$i = 7$ のとき
\begin{aligned} LSB(7) &= 7 \quad\&\quad(-7)\\ &= (00000111)_2 \quad\&\quad (11111001)_2\\ &= (00000001)_2\\ &= 1 \end{aligned}$i = 24$ のとき
\begin{aligned} LSB(24) &= 24 \quad\&\quad(-24)\\ &= (00011000)_2 \quad\&\quad (11101000)_2\\ &= (00001000)_2\\ &= 8 \end{aligned}さあ、これでフェニック木を実装する準備が整いましたので実装していきましょう。
4. 実装
それでは実装していきます。変数名、メソッド名等はなるべくACLに沿って実装します。
4.1. コンストラクタ
クラスFenwick_Treeを作成しコンストラクタを実装します。
class Fenwick_Tree: def __init__(self, n): self._n = n # 要素数 self.data = [0] * n要素数をインスタンス変数
_nに保持し、長さ n のリストdataを作成します。初期化時点では全てが0です。これは数列$a = \{0,\cdots ,0\}$に対応します。0でない数列で初期化したい場合は各 i について$add(i, a_i)$を実行すれば良いです。
注意
前章までdataは1-indexedでしたが実装上は0-indexedとなります。フェニック木の仕組みは 1-indexed で成り立つので以降dataへのアクセスの際に1ずらす必要があることに注意してください。4.2. add
まずメソッドaddから実装しましょう。このメソッドはクエリadd(p, x)に対応します。
def add(self, p, x): assert 0 <= p < self._n p += 1 # 0-indexed -> 1-indexed while p <= self._n: self.data[p - 1] += x # dataを更新 p += p & -p # pにLSB(p)を加算3.1章でみたようにクエリaddではLSBを加算することで次に見るべきインデックスが分かります。このインデックスの更新と
dataの更新を配列の参照外になるまで繰り返します。4.3. sum
つづいてメソッドsumですが、ACLではクエリsum(i)に対応するものは内部の(privateな)関数として実装されており、実際に使用する外部の(publicな)関数はより汎用的なものが実装されています。具体的には、2つの値 l, r を指定することで左閉右開の半開区間 [l, r) の部分和
\sum_{i = l}^{r - 1}{a_i}を返します。(aは0-indexed)
まず、クエリsumに対応する内部の関数から実装します。こちらは r に対して半開区間 [0, r)の部分和$a_0 + \cdots+ a_{r - 1}$を返します。ただし、$r = 0$のときは0を返します。また、内部の関数であることを表すために先頭にアンダーバー( _ )をつけました。def _sum(self, r): s = 0 # 総和を入れる変数 while r > 0: s += self.data[r - 1] r -= r & -r # rからLSB(r)を減算 return s3.2章でみたようにクエリsumではLSBを減算することで次に見るべきインデックスが分かります。これを更新しつつ各
data[r]の総和を取ります。
この内部関数を使って上で述べた汎用的な外部関数を実装します。def sum(self, l, r): assert 0 <= l <= r <= self._n return self._sum(r) - self._sum(l)([l, r) の部分和) = (r - 1 までの部分和) - (l - 1までの部分和)です。
4.4. まとめ
fenwicktree.pyclass Fenwick_Tree: def __init__(self, n): self._n = n self.data = [0] * n def add(self, p, x): assert 0 <= p < self._n p += 1 while p <= self._n: self.data[p - 1] += x p += p & -p def sum(self, l, r): assert 0 <= l <= r <= self._n return self._sum(r) - self._sum(l) def _sum(self, r): s = 0 while r > 0: s += self.data[r - 1] r -= r & -r return s5. 使用例
本来は必要ないですが数列a自体を見るためにaに直接addを行なっています。
n = 8 a = [0, 1, 2, 3, 4, 5, 6, 7] fw = Fenwick_Tree(n) for i, a_i in enumerate(a): fw.add(i, a_i) # 数列aで初期化 print(fw.sum(2, 4)) # 5 print(fw.sum(6, 7)) # 6 sum(i, i + 1)でa[i]が得られる fw.add(2, 6) # a[2] += 6 a[2] += 6 fw.add(5, -1) # a[5] += -1 a[5] += -1 print(a) # [0, 1, 8, 3, 4, 4, 6, 7] print(fw.sum(0, 3)) # 9 print(fw.sum(3, 7)) # 176. 問題例
AtCoder Library Practice Contest B "Fenwick Tree"
7. おわりに
フェニック木の仕組みの解明からPythonでの実装までができました。フェニック木は応用が色々あるようなのでいずれ勉強してみたいです。
説明の間違いやバグ、アドバイス等ありましたらお知らせください。
- 投稿日:2020-09-18T21:09:36+09:00
OpenCV(CUDA)によるtemplate matching
動機
- CUDA有効化OpenCV(Python)をインストールしたはいいものの、(日/英)ドキュメント、サンプルコードが見つからなかったので、c++版を参考に書いてみた
- CUDA万歳がしてみたかった
- Qiita記事を書いてみたかった
まとめ
- UbuntuにCUDAが有効化されたOpenCVをインストールした
- Python上のOpenCVで、リサイズ及びテンプレートマッチングを行った
- 結論
- CUDA万歳
- 処理や画像サイズの大きさによってはCPUの方が速いこともある(今の環境だと尚更かもしれない)
- Template MatchingはCUDAが圧倒的に速い
- 転送が意外とかかる
環境
- 2*Xeon E5-2667 v3 @3.20 GHz
- DDR4-2133 4*8 GB RAM
- ubuntu LTS 20.04 @ Samsung Evo Plus 970 (500GB)
- GTX 1080 (RTX 30XXがほしい)
- OpenCV 4.3.0 (環境構築)
- cuda 10.2, cnDNN 7.6.5
コード
前処理
まず、諸々を読み込んでから200*200のmaharo.jpgを取得します。
これはサンシャイン水族館にいるカワウソのマハロくんの画像です。import cv2 as cv import numpy as np from matplotlib import pyplot as plt src = cv.imread("maharo.jpg", cv.IMREAD_GRAYSCALE) w, h = src.shape[::-1] # w=200, h=200次にGPU周りの変数を設定します。
GPUが有効になっているかどうかは、cv2.cuda.getCudaEnabledDeviceCount()で1以上の数字が返ってくるかどうかで確認できます。
基本的には、CUDA有効化されたOpenCVは、cv2.functionをcv2.cuda.functionと書き換えることで用いることができます。(例外がいくつかあり、今回のtemplate matchingなどがそうです。詳しくはdir(cv2.cuda)参照)
また、変数とGPUのメモリをcv2.cuda_GpuMat()により確保し、.upload()/.download()によりメモリ間の情報のやり取りを行います。print(cv.cuda.getCudaEnabledDeviceCount()) g_src = cv.cuda_GpuMat() g_dst = cv.cuda_GpuMat() g_src.upload(src)とりあえずマハロくんの画像をGPUにも移しました。
Resize
情報の読み出し/書き出しをループに含めないただのResize (512 -> 2K)で、GPUの素材の味を実感してみようと思います。
ちなみに、CUDAの方はLanczos補完に対応していません。(結構全体的にこういうのある)CPU
%%timeit cpu_dst = cv.resize(src, (h*10, w*10), interpolation=cv.INTER_CUBIC) # 777 µs ± 8.06 µs per loop (mean ± std. dev. of 7 runs, 1000 loops each)CUDA
%%timeit g_dst = cv.cuda.resize(g_src, (h*4, w*4), interpolation=cv.INTER_CUBIC) # 611 µs ± 6.34 µs per loop (mean ± std. dev. of 7 runs, 1000 loops each)素材の味が遅い
これはちょっとGPUの恩恵を受けていない結果になってしまいました。ちなみにCPUからの読み込み書き出しを考慮した実行速度はもっと遅いです。%%timeit g_src.upload(src) g_dst = cv.cuda.resize(g_src, (h*4, w*4), interpolation=cv.INTER_CUBIC) gpu_dst = g_dst.download() # 1.51 ms ± 16.9 µs per loop (mean ± std. dev. of 7 runs, 1000 loops each)苦労してCUDA入れたのにこんなんだと嫌になっちゃいますね。まあそんな並列じゃなさそうだし難しいのかな?
読み込み書き出しは800 μs程度かかるようです。これ何依存なんだろう。PCIe 3.0がボトルネックになってそうな気がする(根拠なし)Template Matching
気を取り直して並列が活きそうなtemplate matchingをやります。
ex_src = cv.resize(src, (h*10, w*10), interpolation=cv.INTER_CUBIC) tmpl = ex_src[1000:1200, 1000:1200] tw, th = tmpl.shape[::-1]CPU
%%timeit result = cv.matchTemplate(ex_src, tmpl, cv.TM_CCOEFF_NORMED) # 138 ms ± 5.03 ms per loop (mean ± std. dev. of 7 runs, 10 loops each)思ったより遅くない…
result = cv.matchTemplate(ex_src, tmpl, cv.TM_CCOEFF_NORMED) min_val, max_val, min_loc, max_loc = cv.minMaxLoc(result) top_left = max_loc bottom_right = (top_left[0] + tw, top_left[1] + th) cv.rectangle(ex_src,top_left, bottom_right, 255, 2) plt.subplot(121),plt.imshow(result,cmap = 'gray') plt.title('Matching Result'), plt.xticks([]), plt.yticks([]) plt.subplot(122),plt.imshow(ex_src,cmap = 'gray') plt.title('Detected Point'), plt.xticks([]), plt.yticks([]) plt.show()
CUDA
CUDA版のtemplate maching は(Pythonとしては)若干特殊ですが、
createTemplateMatching(precision, METHOD)のように定義します。gsrc = cv.cuda_GpuMat() gtmpl = cv.cuda_GpuMat() gresult = cv.cuda_GpuMat() gsrc.upload(ex_src) gtmpl.upload(tmpl) matcher = cv.cuda.createTemplateMatching(cv.CV_8UC1, cv.TM_CCOEFF_NORMED)%%timeit gresult = matcher.match(gsrc, gtmpl) # 10.5 ms ± 406 µs per loop (mean ± std. dev. of 7 runs, 1 loop each)素材の味が良い
CPU: 138 msに比べて、CUDAは10.5 msと10倍程度の高速化が達成できています。%%timeit gsrc.upload(ex_src) gtmpl.upload(tmpl) matcher = cv.cuda.createTemplateMatching(cv.CV_8UC1, cv.TM_CCOEFF_NORMED) gresult = matcher.match(gsrc, gtmpl) resultg = gresult.download() # 16.6 ms ± 197 µs per loop (mean ± std. dev. of 7 runs, 100 loops each)読み込み書き出しを計算しても、やはり8倍程度高速になります。GTX 1080でこうなので、最近話題のAmpere世代GPUなら更に高速に…?
自分はmax_locgだけしか要らないんですが、gresultの段階でmax_locgを取り出す方法ってないのでしょうか。gresult = matcher.match(gsrc, gtmpl) resultg = gresult.download() min_valg, max_valg, min_locg, max_locg = cv.minMaxLoc(resultg) top_leftg = max_locg bottom_rightg = (top_leftg[0] + tw, top_leftg[1] + th) cv.rectangle(src,top_leftg, bottom_rightg, 255, 2) plt.subplot(121),plt.imshow(resultg,cmap = 'gray') plt.title('Matching Result'), plt.xticks([]), plt.yticks([]) plt.subplot(122),plt.imshow(ex_src,cmap = 'gray') plt.title('Detected Point'), plt.xticks([]), plt.yticks([]) plt.show()
print(max_loc,max_locg) # (1000, 1000) (1000, 1000)同じ結果が得られています。
今回使用したコード(Jupyter Notebook)はGithubに公開しています。
参考


- 投稿日:2020-09-18T19:01:13+09:00
衛星画像より東京湾の船数のトレンドを求めてみた.
概要
前回のGoogle Earth Engineより入手した衛星画像より東京ディズニーランドの駐車場の車数の推移を求めました.
今回は,前回と同様にGoogle Earth Engineより衛星画像を入手し,東京湾の船舶数の推移を求めてみます.
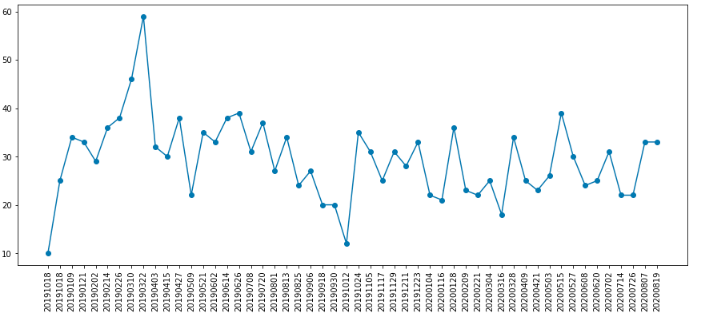
こちらは,東京湾入り口付近の人工衛星の撮影画像にある船舶をカウントし,そのトレンドを求めたものです.
このグラフの説明も含めてこの記事で紹介します.
また,記事で紹介したコードは Githubに置きましたので,ご自身で試したい方はこちらをご利用ください.Google colaboratoryを用いていますので,ネットワーク環境さえあればPCによらずご利用できます.1.はじめに
前回は東京ディズニーランドの駐車場の車の数を,衛星画像のなかの電波センサ(SAR)画像を用いてトレンドを求めました.
SAR画像は車かトラックかなどの車種の特定は難しいのですが,駐車場に多数の車が駐車されているかどうかであれば定性的には評価することができ,かつ雲の影響を受けないため安定して評価することができます.
そのため,今回もSAR画像を用いて,東京湾の入口付近の衛星画像から船舶数を求めてみます.これは,新型コロナウィルスの影響で船舶数がどのように変わったのか,変わっていないのか,その程度が評価できるのではないか,と思ったからです.
SAR画像にて船舶がどのように見られるのか,こちらのサイトが参考になるかと思います.
陸域観測技術衛星2号「だいち2号」(ALOS-2)初期機能確認期間中の観測画像について
(その5・船舶編)だいち2号のこの撮像画像は,分解能3mの観測モードでの画像であり,大型の船舶であればその形状もわかるかと思います.ここで重要なポイントは,船舶は明るく写り,周囲の海は暗く写る,ということです.
SAR衛星は電波を地球に照射し,その反射信号の強度を画像化しています.このとき,電波を地表面に対して斜め方向から放射するため,地表面が平坦だと多くのものは電波の入射方向,つまり放射した電波を受信する衛星とは逆方向に反射します.そのため,対象の地表面が平坦であれば受信する信号が弱いため暗い画像となります.湖や海などの水面は極めめて平坦なためより暗く写ります.
一方,建物やビル,車や船などの構造物がある場合は,対象物が凹凸しているため,入射方向と同じ方向へ反射する電波が多くなり,その為明るく写ります.
この明るく写る箇所を船とし,衛星画像内の船舶数を数えてみます.2.衛星画像の取得と評価
2.1 環境準備(構築).
GEEでの衛星画像の取得方法については,以下の記事で詳しく説明されていますのでご参考ください.
Google Earth EngineとGoogle Colabによる人工衛星画像解析 〜無料で始める衛星画像解析(入門編)〜また,GEEより入手した衛星画像の解析方法については,以下の記事をご参考ください.
重複する部分もありますが,衛星画像の取得,およびその処理を紹介します.
import ee import numpy as np import matplotlib.pyplot as plt ee.Authenticate() ee.Initialize()最初にこちらを実行し,GEEの接続認証を行います.実行するとリンクが帰ってきますので,そちらをクリックし認証手続きを行い,アクセスコードをコピーして入力ください.
次に,Google Driveへの接続認証を行います.こちらも,GEEの認証とフローは同じですね.
from google.colab import drive drive.mount('/content/drive')次に,取得した衛星画像の閲覧や数値化して解析するために必要なモジュールのインストール等の作業を行います.
# パッケージのインストール&インポート !pip install rasterio import numpy as np import matplotlib.pyplot as plt import rasterio import json import os import glob import time from datetime import datetime from dateutil.parser import parseよく利用されるモジュールはGoogle Colaboratoryにすでにインストールされているために追加の作業は必要ありませんが,今回は地図情報が付加された画像であるGeotiffを用いるため,画像処理のために必要なRasterioをイントールします.
次に,設定した対象地域を地図上で確認するためにfoliumというモジュールをインストールします.
!pip install folium import foliumこれで環境の準備ができましたので,衛星画像をGEEより取得します.
2.2 関心域(対象域)の設定
GEEから衛星画像を取得するためには,自分が関心がある対象地域の緯度・経度情報を入力する必要があります.
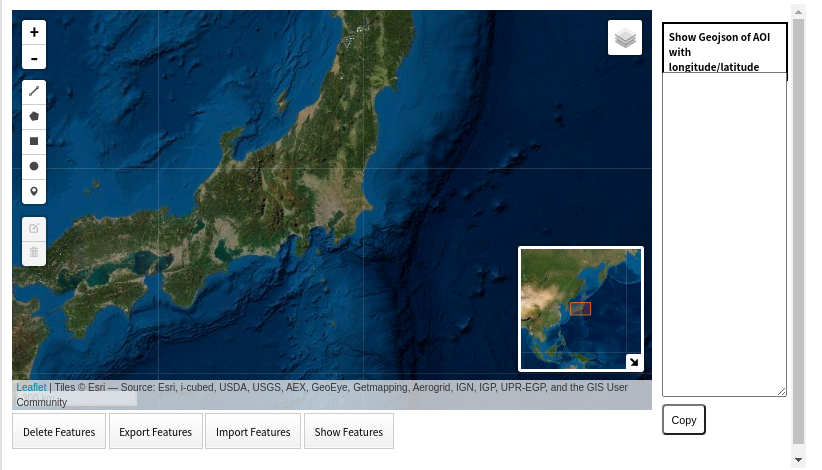
今回も,簡単に関心域の緯度経度が調べかつ入手するために作成した以下のサイトを用いて取得します.#関心領域のポリゴン情報の取得. from IPython.display import HTML HTML(r'<iframe width="1000" height="580" src="https://gispolygon.herokuapp.com/" frameborder="0"></iframe>')こちらを実行すると,以下の画面が表示されます.
関心地域を拡大した後,左のアイコンより四角のポリゴンを選んで,関心域のポリゴンを表示させます.その後,Show Featuresをクリックすると,右のウィンドウにポリゴンの地理情報が表示されます.このあと,下部のCopyをクリックして,この地理情報をコピーします.
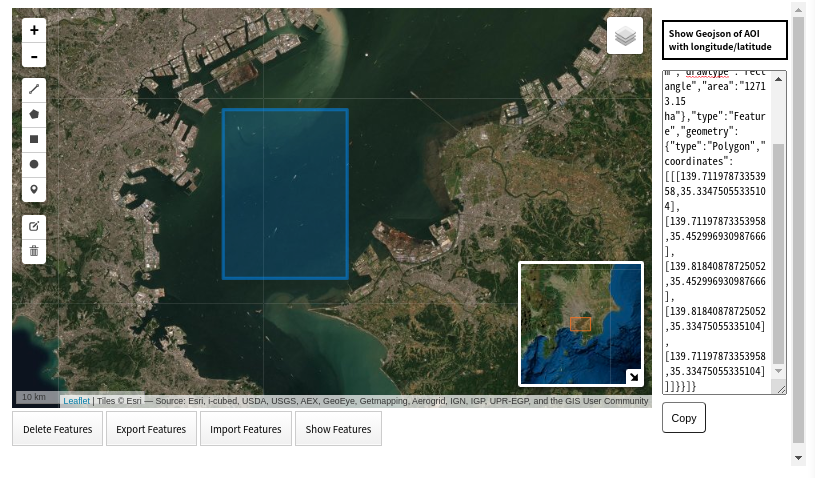
今回は東京湾入口付近のこのエリアの衛星画像を取得します.
そしてコピーした地図情報を下記にペーストして入力します.
A = {"type":"FeatureCollection","features":[{"properties":{"note":"","distance":"35937.06 m","drawtype":"rectangle","area":"12713.15 ha"},"type":"Feature","geometry":{"type":"Polygon","coordinates":[[[139.71197873353958,35.33475055335104],[139.71197873353958,35.452996930987666],[139.81840878725052,35.452996930987666],[139.81840878725052,35.33475055335104],[139.71197873353958,35.33475055335104]]]}}]}この地理情報をGEEへの入力フォーマットに,そしてFoliumでの表示用に加工します.
#今後使用する任意のファイル名をセットする. 例えば,地域の名前など. object_name = 'tokyobay3'with open(str(object_name) +'_2.geojson', 'w') as f: json.dump(A, f) json_file = open(str(object_name) +'_2.geojson') json_object = json.load(json_file) #jsonから関心域の緯度・経度情報のみを抽出する. AREA = json_object["features"][0]["geometry"]['coordinates'][0]それでは,設定した関心域を確認します.
m = folium.Map([(AREA[0][1]+AREA[len(AREA)-2][1])/2,(AREA[0][0]+AREA[len(AREA)-3][0])/2], zoom_start=15) folium.GeoJson(str(object_name) +'_2.geojson').add_to(m) m出力
2.3 GEEから衛星画像の取得
GEEには多くの衛星画像や,すで解析された多くの情報がセットされています.詳しくはデータカタログをご参考んください.Sentinel-1と2は以下となります.
Sentinel-1 SAR GRD: C-band Synthetic Aperture Radar Ground Range Detected, log scaling
このページから,Sentinel-1の観測画像は2014年10月3日から,のデータが利用できます.
では,GEEよりSentinel-1の画像を取得し,Google colaboratoryに保存します.
最初に,GEEに設定する地理情報のフォーマットを準備します.
region=ee.Geometry.Polygon(AREA)次に,取得する情報のパラメータを設定します.今回は,取得する画像の期間と,取得した画像の保存先を指定しています.
# 期間を指定 from_date='2019-01-01' to_date='2020-08-31' # 保存するフォルダ名 dir_name_s1 = 'GEE_Sentinel1_' + object_nameでは,Sentinel-1の画像条件の設定です.
def ImageExport(image,description,folder,region,scale): task = ee.batch.Export.image.toDrive(image=image,description=description,folder=folder,region=region,scale=scale) task.start() Sentinel1 = ee.ImageCollection('COPERNICUS/S1_GRD').filterBounds(region).filterDate(parse(from_date),parse(to_date)).filter(ee.Filter.eq('orbitProperties_pass', 'ASCENDING')).select(['VV']) imageList_s1 = Sentinel1.toList(300)ここで,Sentinel-1の観測画像は,B衛星の午後6時の観測画像のみを用いるため,'orbitProperties_pass'で 'ASCENDING'を選択しています.”Descending”にすると午前6時の観測画像になります.
では,上記の衛星画像の取得条件で,Sentinel-1の関心域の画像を取得します.
for i in range(imageList_s1.size().getInfo()): image = ee.Image(imageList_s1.get(i)) ImageExport(image.reproject(crs='EPSG:4326',scale=10),image.get('system:index').getInfo(),dir_name_s1,region['coordinates'][0],10)2.4 衛星画像の表示と信号強度の評価
取得した衛星画像を表示し確認します.
衛星画像はGoogle driveのmy driveに設定したディレクトリ(フォルダ)に保存されています.それを呼び出し表示します.# 時系列で可視化 s1_path = '/content/drive/My Drive/' + dir_name_s1 + '/' files =os.listdir(s1_path) files.sort() plt.figure(figsize=(20, 40)) j=0 v = len(files)//5 +1 for i in range(len(files)): # 画像を1シーンずつ取得して可視化 with rasterio.open(s1_path + files[i]) as src: arr = src.read() j+=1# 画像のプロット位置をシフトさせ配置 plt.subplot(v,5,j) plt.imshow(arr[0], cmap='gray') plt.title(files[i][33:41])# ファイル名から日付を取得 plt.tight_layout()
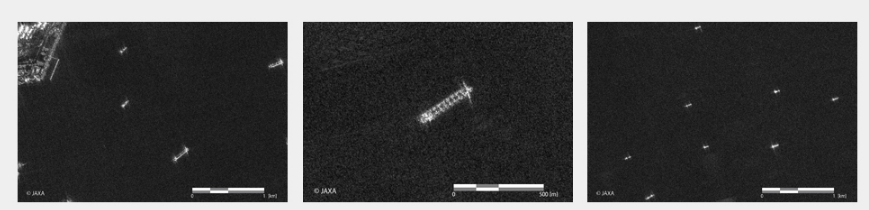
SAR衛星の観測画像は白黒画像であり,この画像内の明るい部分が船舶と思われます.次に,画像内の明るい部分を船舶としてその数をカウントします.
# データの読み込み n = 2 with rasterio.open(s1_path + files[n]) as src: arr = src.read() print(files[n][33:41]) # 可視化 plt.imshow(arr[0], cmap='gray')
衛星画像を拡大してみると,明るい点が多数あるのが確認されました.では,この画像の強度分布を求めます.
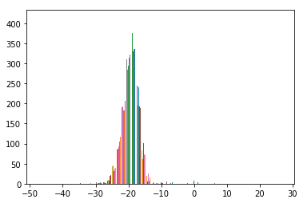
fig = plt.figure() ax = fig.add_subplot(1,1,1) ax.hist(arr[0], bins=50) fig.show()
信号強度は0以下が多いのですが,いくつか0以上の信号も観測されています.この条件より,0以上とそれ以下とで2値化処理をまずは行います.
2.5 衛星画像より船舶数を算出する.
画像内の物体のカウント方法について,以下のサイトを参考にさせていただきました.
この方法は,任意の信号強度で2値化を行い,広がりがある場合は中心位置を求め,その中心位置が同じ物体かそうでないのかを任意のウィンドウにあるかないかを調べ,物体の数を数えます.
では,具体的にその方法をご紹介します.
まず,サンプル画像は取得した画像内の最新の撮像画像としました.# データの読み込み n = len(files) -1 with rasterio.open(s1_path + files[n]) as src: arr = src.read() print(files[n][33:41]) # 可視化 plt.imshow(arr[0], cmap='gray')
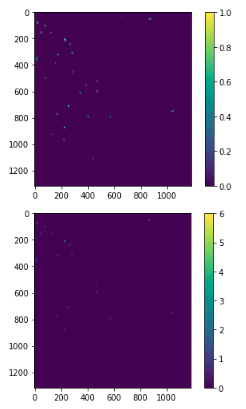
多数の明るい点があるのがわかるかと思います.次に,二値化処理を行います.ここでは,先の信号強度分布を参考に0以上とそれ以下にて二値化処理を行います.また,求めた2値化画像から中心位置のマップを作成します.
#二値化処理 import cv2 binimg = (arr[0]>0) #0をしきい値とする. plt.imshow(binimg) plt.colorbar() plt.show() #距離マップ(distance map)を計算する binimg = binimg.astype(np.uint8) distmap = cv2.distanceTransform(binimg,1,3) plt.imshow(distmap) plt.colorbar() plt.show()
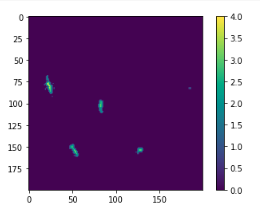
多数の船が撮像された部分を拡大します.
plt.imshow(distmap[0:200,0:200]) plt.colorbar() plt.show()
船舶と思われる信号がある方向に伸びているのがわかります.
次に,この画像から信号強度が最大値をとる分布を取得します.このとき,船のサイズを30ピクセルとしました.つまり,30ピクセル内に船は一艘のみである,と定義しています.#距離マップの極大値をもつ場所を計算する out = distmap*0 ksize=30 #30ピクセル以内の最大値 for x in range(ksize,distmap.shape[0]-ksize*2): for y in range(ksize,distmap.shape[1]-ksize*2): if distmap[x,y]>0 and distmap[x,y]==np.max(distmap[x-ksize:x+ksize,y-ksize:y+ksize]): out[x,y]=1 plt.imshow(distmap[0:200,0:200]) plt.colorbar() plt.show()次に,船と思われる位置の近くの画素で高い信号強度となった場合誤検知する可能性があるため,ある範囲内にある場合は無視するように処理します.
#膨張させ、輪郭検出し、数える out = cv2.dilate(out,(10,10)) #10*10に膨張させ,同じ範囲に入っていたらカウントしない contours, _ = cv2.findContours(out.astype(np.uint8), cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_NONE) arr=[] for i in contours: x_=0 y_=0 for j in i: x_ += j[0][0] y_ += j[0][1] arr.append([x_/len(i), y_/len(i)]) arr = np.array(arr) plt.imshow(distmap[0:200,0:200]) plt.colorbar() plt.show() print("船の数: ", len(arr)) print(arr)
ここでは,船舶の数,およびその位置が出力されました.
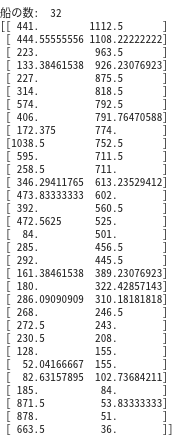
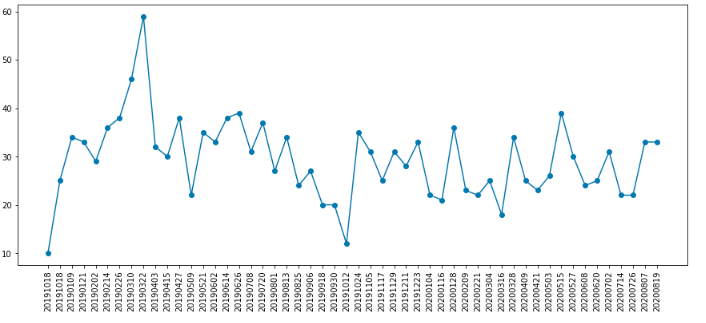
この方法を用いて,取得した衛星画像より船舶数を求め,その推移をグラフにします.# 当該エリアの推定された船の数を時系列グラフ化 # 時系列で可視化 s1_path = '/content/drive/My Drive/' + dir_name_s1 + '/' files =os.listdir(s1_path) files.sort() sum_ship = [] label_signal = [] for i in range(len(files)): label_signal.append(files[i][33:41]) # 画像を1シーンずつ取得して可視化 with rasterio.open(s1_path + files[i]) as src: arr = src.read() #二値化処理 binimg = (arr[0]>0) #距離マップ(distance map)を計算する binimg = binimg.astype(np.uint8) distmap = cv2.distanceTransform(binimg,1,3) out = distmap*0 ksize=30 #30ピクセル以内の最大値 for x in range(ksize,distmap.shape[0]-ksize*2): for y in range(ksize,distmap.shape[1]-ksize*2): if distmap[x,y]>0 and distmap[x,y]==np.max(distmap[x-ksize:x+ksize,y-ksize:y+ksize]): out[x,y]=1 out = cv2.dilate(out,(10,10)) #10*10に膨張させ,同じ範囲に入っていたらカウントしない contours, _ = cv2.findContours(out.astype(np.uint8), cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_NONE) num=[] for i in contours: x_=0 y_=0 for j in i: x_ += j[0][0] y_ += j[0][1] num.append([x_/len(i), y_/len(i)]) num = np.array(num) sum_ship.append(len(num)) # 可視化 fig,ax = plt.subplots(figsize=(15,6)) plt.plot(sum_ship, marker='o') ax.set_xticks(np.arange(0,len(files))) ax.set_xticklabels(label_signal, rotation=90) plt.show()
横軸が観測日,縦軸が観測画像より算出した船舶数になります.
2019年3月付近に極大値をとりますが,それ以降は平均30隻程度になります.2020年3月以降のコロナ禍では船による移動が制限もしくは減衰しているのかと思いましたが,これを見る限り東京ティズニーランドの駐車数のように,極端に減少しているようには見えません.
実際,東京湾の船舶の航行数がどうなっているのかインターネットにて調べてみましたが,クルーズ船は運行を控えている記事を見つけましたが,その他の多くの船が減少しているものはありませんでした.コロナ禍でも物流の安定のために,みなさん安全に留意しつつ運行されていたのかと思います.ありがとうございます.
東京湾以外の船舶の航行が多い箇所も同様の方法で調べてみましたが,今回と同様にコロナ禍であっても極端に減少するなどの傾向はなく,船舶を運行されている方々のご努力によって,安定した物流が維持されているのだと実感しました.3. 最後に
Google が提供するGoogle Earth Engineを用いて,衛星画像の取得および解析例として東京湾の船舶数の求め方を紹介しました.
これを機会に衛星画像に関心を持つ方が増えると嬉しいです.
ご意見や質問などありましたら,お気軽にコメントください.嬉しいので.参考記事
無料で最新の衛星画像を入手する方法.
人工衛星(Sentinel-2)の観測画像をAPIを使って自動取得してみた.
PyTorchによる人工衛星画像から車の推定分布地図を作成してみる.
衛星画像より駐車場の利用状況を調べてみた.【続編】Google Earth EngineとGoogle Colabによる人工衛星画像解析 〜無料で始める衛星画像解析(実践編)〜
Google Earth EngineとGoogle Colabによる人工衛星画像解析 〜無料で始める衛星画像解析(入門編)〜
6. PythonによるローカルからのGEE実行衛星データのキホン~分かること、種類、頻度、解像度、活用事例
~
人工衛星から人は見える?~衛星別、地上分解能・地方時まとめ~Sentinel-1 SAR GRD: C-band Synthetic Aperture Radar Ground Range Detected, log scaling



- 投稿日:2020-09-18T18:56:48+09:00
入門書には載っていない割と新しいPythonの文法と機能
セイウチ演算子とは何ぞ。
先日、Qiitaで記事のトレンドを見ていると"セイウチ演算子"なるもの見かけました。
セイウチ演算子自体は、Pythonの新しい文法なのですが、自分自身、あまり最新仕様というものは追っかけていませんでした。
過去には、「たぶん知らないPythonマイナー文法の世界」という記事を書きましたが、そろそろ自分の知識もアップデートしたい。と思って、最近追加された文法を追ってみることにしました。
プログラミング言語を触るだけなら、for,if,関数定義,クラス定義あたりを覚えていれば大抵何とかはなりますが、短く綺麗に書こうと思うと、専用の構文を使うと非常に効果的です。私としては、Pythonはこの選び方が秀逸なので好きです。
ここでは、すべては紹介しませんが、自分が使いやすそうだなぁ。と思うもののみ取り上げます。
※わかりやすい例が提示できる自信がなかったので、非同期構文は取り上げていません。
※Type Hinting系も話が多岐にわたるので、省略します。
※割と新しいとか言いながら、Python3.5は5年前ぐらいです(PEP 448 - 追加可能なアンパッキングへの一般化
PEP 448 によって、 * イテラブルアンパッキング演算子と ** 辞書アンパッキング演算子の利用方法が拡張されました。 関数呼び出し で任意の数のアンパッキングで使えるようになりました:
へぇ。と思いました。例えば、Python2.7系だと以下のような動きになります。
>>> def f(a,b,c,d): ... return 1 ... >>> f(*[0,1,2,3]) 1 >>> f(*[0,1],*[2,3]) File "<stdin>", line 1 f(*[0,1],*[2,3]) ^ SyntaxError: invalid syntaxこのように
*を使い、リストをアンパックしつつ、関数を呼び出す場合、リストは1つしか指定することはできませんでした。しかし、Python3.5からは複数も動くようになっています。>>> def f(a,b,c,d): ... return 1 ... >>> f(*[0,1,2,3]) 1 >>> f(*[0,1],*[2,3]) 1おー。
Python公式のドキュメントだと、以下のような、タプル、辞書の例も取り上げられています。>>> {*range(4), 4, *(5, 6, 7)} {0, 1, 2, 3, 4, 5, 6, 7} >>> {'x': 1, **{'y': 2}} {'x': 1, 'y': 2}ちょっと面白いのが
range(4)のようなgeneratorも出来るようになってるんですね。導入:Python3.5
PEP 498: フォーマット済み文字列リテラル
フォーマット済み文字列リテラルはプレフィックスに 'f' をとり str.format() による書式文字列に似ています。これらには中括弧で囲まれた置換フィールドがあります。置換フィールドは実行時に評価される式で、 format() プロトコルによってフォーマットされます:
>>> name = "Fred" >>> f"He said his name is {name}." 'He said his name is Fred.'これは普通に便利なやつです。頭に
fのついた文字列だと、{name}の形式で書くだけで文字列展開をやってくれます。これは以前まではショートハンドとして、name = "Fred" "He said his name is {name}.".format(**locals())みたいな書き方は出来ましたが、そんなめんどくさい書き方するぐらいなら、
%でいいや。と思って、使っていませんでした。しかし、f文字列が導入されて、こちらの方が圧倒的に打鍵数が少ないですね。Pythonの公式だと、
{}部分を入れ子にする複雑な例も取り上げられていました。>>> width = 10 >>> precision = 4 >>> value = decimal.Decimal("12.34567") >>> f"result: {value:{width}.{precision}}" # nested fields 'result: 12.35'しかし、ちょっと試したところ変数に入れた後の再展開はされないのですね。
>>> template = "{name}" >>> f"{template}" '{name}'(まぁそこをやろうとするとf文字列だけでチューリング完全とかになりそうですよね・・・)
導入:Python3.6
PEP 515: 数値リテラル内のアンダースコア
PEP 515 により、可読性向上のために数値リテラル内でアンダースコアを使えるようになりました。
>>> 1_000_000_000_000_000 1000000000000000 >>> 0x_FF_FF_FF_FF 4294967295まぁあんまり業務では使わないですね・・・しかし、数値計算系でループをぶん回すときに、パッと見た感じで、10万か100万か分かりにくいので、こういうは良いですね。
導入:Python3.6
PEP 553: 組み込みの breakpoint()
文法ではないのですが、デバッグをするうえで非常に便利なので紹介します。
break.pyi = 1 print(i) breakpoint() i += 1 print(i)というコードを書いたとします。これを実行すると、
$ python break.py 1 > /home/kotauchisunsun/work/python_practice/break.py(4)<module>() -> i += 1 (Pdb) i 1というかたちで、
breakpoint()呼び出したところで、pdbが動き出して、変数の内容が確認できたりします。
IDEビルトインされている場合はあまり関係ありませんが、コマンドラインのみでやりたい場合はこれが便利だったりします。導入:Python3.7
dict オブジェクトの挿入順序を保存する
dict オブジェクトの挿入順序を保存するという性質が、公式に Python 言語仕様の一部であると 宣言されました 。
Python3.7の好きな新機能という記事で知ったのですが、 辞書型が順序保存するようになりました。 マジか。
python2.7の場合、
$ python2.7 Python 2.7.17 (default, Nov 7 2019, 10:07:09) [GCC 7.4.0] on linux2 Type "help", "copyright", "credits" or "license" for more information. >>> {"c":1,"b":2,"a":3}.keys() ['a', 'c', 'b'] >>> {"a":1,"b":2,"c":3}.keys() ['a', 'c', 'b']python3.8系の場合
$ python Python 3.8.0 (default, Jun 27 2020, 00:43:29) [GCC 7.5.0] on linux Type "help", "copyright", "credits" or "license" for more information. >>> {"c":1,"b":2,"a":3}.keys() dict_keys(['c', 'b', 'a']) >>> {"a":1,"b":2,"c":3}.keys() dict_keys(['a', 'b', 'c'])前には、それ専用のクラスとして
OrderedDictがcollectionsにありますが、dictが挿入順になったのですね。
これ自身は良いことですが、逆にPython3.7系を想定して書いたコードを、Python3.5系とかに持っていくときにハマりそうですね。この変更は頭に置いておく方が良さそうです。導入:Python3.7
セイウチ演算子
大きな構文の一部として、変数に値を割り当てる新しい構文 := が追加されました。 この構文は セイウチの目と牙 に似ているため、「セイウチ演算子」の愛称で知られています。
if (n := len(a)) > 10: print(f"List is too long ({n} elements, expected <= 10)")公式のこの例だとうーん?そんなに嬉しくはない・・・という感じでしたが、以下の例が良かったです。
[clean_name.title() for name in names if (clean_name := normalize('NFC', name)) in allowed_names]この例は良いな。と思って、旧来の書き方だと
normailze_name_list = map(x: normalize('NFC',x),names) clean_name_list = filter(x: x in allowed_names, normalize_name_list) [x.title() for x in clean_name_list]という書き方など、結構冗長な部分が多かったのですが、短めにすっきり書けますね。
たまに内包表現のif文として判定に利用した結果を要素として持ち込みたいことがあったので、これは割とうれしいです。導入:Python3.8
f-string での = を用いたオブジェクトの表現
フォーマット済み文字列リテラル(f-string) において = 指定子が有効になりました。f'{expr=}' のようなf-string は、f-string に書かれた式、イコール記号、式を評価されたものの文字列表現、の順で表示されます。
user = 'eric_idle' member_since = date(1975, 7, 31) f'{user=} {member_since=}' "user='eric_idle' member_since=datetime.date(1975, 7, 31)"私としては、「えっ・・・なぜ・・・」と思いましたが、導入されたようです。
個人的に否定的な意見なのは、これが働くのは基本的にはデバッグの時のみで、あまり本番のコードには入らない構文なので、うーん。と思ってしまいました。それ以外の用途あるのかな?と思って、元の議論を見に行きましたが、やはり主にはデバッグ用途のようです。https://bugs.python.org/issue36817
導入:Python3.8
感想
割と新しめの言語を見ていると、genericsが入る入らない。だったり、null合体演算子がーとか。エルビス演算子がどうのこうの。みたいな話を聞いたりするのですが、Pythonは割とそういう話を聞かないな。という印象でした。Type Hintingは確かに大きな話ですが、Optionalな話ですし、async/awaitは個人ではあんまり使わず、興味が湧いていませんでした。そんな中で、セイウチ演算子という変なものがPythonに入る。と聞いて、ちょっとそそられたので調べました。この辺の文法は知ってると嬉しい。という程度なので、あまり入門書には載っていない内容だと思います。そういうものはやっていくうちに知るのか、こういう記事で知るのか。というのは結構難しい課題だなぁ。と思います。
参考
https://docs.python.org/ja/3.5/whatsnew/3.5.html
https://docs.python.org/ja/3.6/whatsnew/3.6.html
https://docs.python.org/ja/3.7/whatsnew/3.7.html
https://docs.python.org/ja/3.8/whatsnew/3.8.html
- 投稿日:2020-09-18T18:51:33+09:00
Google Maps API キーをHTMLから隠す方法
Maps JavaScript API を使うとき、APIキーが心配
Google は、公式サイトで
API キーをコードに直接埋め込まないでくださいと言っている割には、[公式サンプル]のコーディングが以下の様になっていて、堂々とHTMLの中にYOUR_API_KEYが登場している。
これでwebページ作ったら世界中にAPI キーを公開してしまうことになる。まるで、堂々とフリチンで公道を歩いている様な状態。公式サンプルは裸の王様か?<script defer src="https://maps.googleapis.com/maps/api/js?key=YOUR_API_KEY&callback=initMap"> </script>一応 Google のドキュメント[API キーの制限を適用する]には「HTTP リファラー(ウェブサイト)」による制限が必須だと書いてはあるが、これだけでは非常に心許ない。
皆さんご存じの通り、ウエブページの名前なんてローカルにwebサーバー建てて hosts をいじれば簡単に詐称できるし・・・(私はそんなことやってませんよ。念のため)
もちろん、知らない間に課金されないように、[API 使用の上限設定]は実施しているが、どこかの誰かにAPIキーを勝手に使われて100万回とかアクセスされたらどうしよう?と思うと夜も眠れない・・・APIキーは見えないところに隠そう
やっぱりAPIキーは、HTMLで公開したくない!!
ということで CGI を使って API キーをサーバーの中に隠しておくことにしました。1.環境変数にセット
CGI にはAPIキーを環境変数にセットした状態で渡します。私の環境は nginx + fcgiwrap で CGI を動かしているので、/etc/nginx/fcgiwrap.conf の一番下に以下の様にセット。
fcgiwrap.conflocation /cgi-bin/ { ・・・・・・ fastcgi_param GOOGLE_MAPS_API_KEY YOUR_API_KEY; <=YOUR_API_KEYを自分のキーに置き換えてください }ここは、皆さんの環境(apacheなど)毎に設定方法が異なるので、ご自分の環境に合わせて設定してください。
2.CGI を用意
方針としては、公式サンプルの
src="https://maps.googleapis.com/maps/api/jsの部分を CGI で置き換える。
私の環境では python を使っているので、こんな感じになります。getapijs.py#!/usr/bin/python # -*- coding: utf-8 -*- import requests import os url = 'https://maps.googleapis.com/maps/api/js' # 公式サンプルの HTML が src= で読んでたurl key = os.environ['GOOGLE_MAPS_API_KEY'] # 環境変数に入っている APIキーを取り出す mysrc = url + "?key=" + key # url に APIキーを連結する response = requests.get(mysrc) # google マップのサイトにアクセスして src を持ってくる print("'Content-Type': 'text/javascript; charset=UTF-8'") # HTML に返してあげるためのヘッダー print("") print(response.text)この部分も皆さんの環境毎に異なる部分なので、ご自分の使える言語で記述してください。
要は、サーバーの環境変数からAPIキーを持ってきて、url 指定して google のサイトから javascript を頂戴するということです。ヘッダーの部分は、'Content-Type': 'text/javascript; charset=UTF-8'にしましょう。3.javascript の window.onload で CGI を呼ぶ
main.jsfunction initMap() { // 公式サンプルの内容と同じ // Initialize and add the map // The location of Uluru var uluru = {lat: -25.344, lng: 131.036}; // The map, centered at Uluru var map = new google.maps.Map(document.getElementById('map'), {zoom: 4, center: uluru}); // The marker, positioned at Uluru var marker = new google.maps.Marker({position: uluru, map: map}); } window.onload = function() { // ページを表示した後に、実行したい処理を書く。ここからが今回のポイント! fetch("/cgi-bin/getapijs.py").then(res=>{ // CGI 実行して、結果の TEXT だけを次にパスする return res.text(); }).then(mytext => { // 受け取った javascript を EVAL で実行する。 eval(mytext); }).then(() => { // 実行後の処理。公式サンプル HTML が &callback= でコールしていた部分 initMap(); }).catch(() =>{ // お好きなエラー処理をどうぞ }); }HTML には、ヘッダー部分に
<script src="main.js"></script>を記載してます。この辺の流儀は人によって違うところなので、お好きなスタイルで良いと思います。
要は、HTML の要素を読み込んだ後(サンプルHTMLの defer の部分。私の例では window.onload)に、CGIを実行して javascript をTEXTで受け取りEVAL で実行する、という手順です。これで安心して眠れるか?
APIキー は環境変数の中にしかないので、ソースをGITHUBで公開しても問題ないし、WEBサイトのユーザーが Chrome のデベロッパーツールで HTML や JS を見ても、APIキーは見つからない。
公式サンプルが堂々とフリチンで公道を歩いているのに比べれば、奥ゆかしい出来上がりになっています。
唯一、気持ち悪いところがあるとすると「邪悪な EVAL」を使っていることです。邪悪なwebページだと思われてしまうかもしれない・・・
EVAL が禁じ手として封じられている方は今回の手法は使えませんが、APIキーを公開の場に晒すのはEVAL使うよりも危険だと思います。止めましょう。会社でEVAL禁止されている人は諦めて JAVA で重いアプリ作ってください。私は軽くHTML + javascript + python で行きます。ご参考
index.html<!DOCTYPE html> <html> <head> <style> /* Set the size of the div element that contains the map */ #map { height: 400px; /* The height is 400 pixels */ width: 100%; /* The width is the width of the web page */ } </style> <title>Hello World</title> <script src="main.js"></script> </head> <body> <h3>My Google Maps Demo</h3> <!--The div element for the map --> <div id="map"></div> </body> </html>なお、こちらの記事を参考にさせて頂いています。
[私がよく使うJSからの外部JSの読み込み方法]
- 投稿日:2020-09-18T18:00:24+09:00
Pythonでのファイル処理
Pythonでのファイル処理
ファイル
ファイルには大きく分けて、プログラムファイルとデータファイルの2種類があります。
プログラムファイル OSやアプリケーションとこれらに関連するソフトウェア全般を指します。 データファイル 撮影した画像や動画、パソコンで作成したワード、エクセルファイルや文章など、ユーザーが自分で作成したオリジナルのファイルを指します。ファイル形式
ファイルには、そのファイルの種類を示した拡張子(かくちょうし)という文字列が割り当てられていて、それぞれに対応したアプリケーションが存在します。 例として「txt」、「xlsx」、「jpg」、「gif」、「PNG」、といったようにファイル名の末尾を確認することで、そのファイルがどういう形式なのかを知ることができます。メモリ
メモリではデータを電気的にそして、一時的に保存しておく。
高速で読み書きを行なってくれることが利点。
open()
Pythonでファイルを開く場合、 open関数を使用します。
open関数は、Pythonの組み込み関数の1つなので特別な宣言などを行う必要はなく、
新規ファイルの作成や書き込み、読み込み、追記、保存等の作業を行うことができ、ファイルオブジェクトを受け取ることができます。
open関数は、下記の記述で使用することができます。実行方法
open('開きたいファイル名')
エラー絡み発生した場合以下のように取得することができるようです。
try:
with open(‘hatamoto’, encoding='utf-8') as fin:
pass
except FileNotFoundError:
print(‘対象のファイルが見つかりませんでした')オプションを指定したい場合は、以下にする。
open('hatamoto', mode='rb')
オプション 説明 r 読み込み用に開く (デフォルト) w 書き込み用に開き、まずファイルを切り詰める x 排他的な生成に開き、ファイルが存在する場合は失敗する a 書き込み用に開き、ファイルが存在する場合は末尾に追記する b バイナリモード t テキストモード (デフォルト) + 複数のオプションを使用するためのものです。 デフォルトのモードは 'rt' となります
第三引数にはエンコードを渡しますが、デフォルトの文字コードは「UTF-8」として扱われます。ファイルの読み込み
メソッド 説明 read() ファイルから指定したデータを読みこむ。デフォルトはファイルの内容全てを読み出します。 readline() ファイルから1行読みこむ readlines() ファイルの内容を全て読み出し、1行ごとのリストにします。 書き込みメソッド
メソッド 説明 write( 文字列を書き込む。数値などを書き込みたい場合は、str()で一度文字列に変換する。 writelines() 文字列のリストをまとめて書き込む。数値などを書き込みたい場合はstr()で文字列に変換する。
- バイナリファイル
バイナリファイルはテキストファイル以外のファイル
画像データや動画、Excelファイル、プログラム開発ファイル、などのこと。
バイナリファイルを開きたい場合は、「b」オプションを使用する。
バイナリファイルの場合は、エンコードを指定する必要はない。
- 関数型
プログラミングは問題をいくつかの関数にわけて考えます。
できるだけ人間にわかりやすく、テスト管理がしやすい、を目的としているようです。
Javaなどのオブジェクト思考と同じく概念的なものと考えています。
- 投稿日:2020-09-18T17:47:00+09:00
MayaのbackgroundColorの色見本
UIに彩りを加えるbackGroundColorについて、実際どんな色になるのよ?と気になったので調べてみました。
一通り表示してみます。
import maya.cmds as cmds import pymel.core as pm windowtitle = 'ColorCheck' wndwName = 'ColorCheck' if pm.window(wndwName, ex=True): pm.deleteUI(wndwName) win = pm.window(wndwName, t=windowtitle, w=True ) with win: SCL = pm.scrollLayout() with SCL: column = pm.columnLayout(adj=True) with column: for i in range(0,11): for j in range(0,11): RCL = pm.rowColumnLayout(numberOfColumns=22) with RCL: for k in range(0,11): a = i * 0.1 b = j * 0.1 c = k * 0.1 pm.button( l=u'%s %s %s'%(str(a), str(b), str(c)), bgc=(a, b ,c), c="print %s, %s, %s"%(str(a), str(b), str(c)), w=80, h=30, ) pm.separator(st="none", w=5) pm.separator(st="none", h=5)実行結果
鮮やかですね!

- 投稿日:2020-09-18T17:46:32+09:00
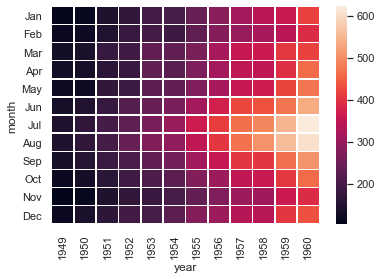
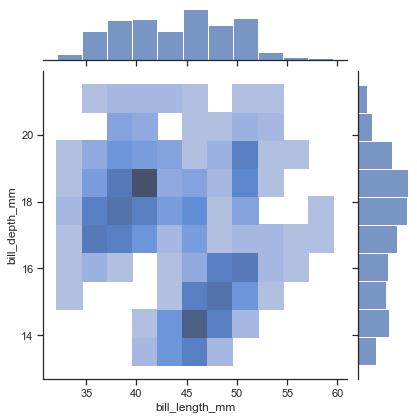
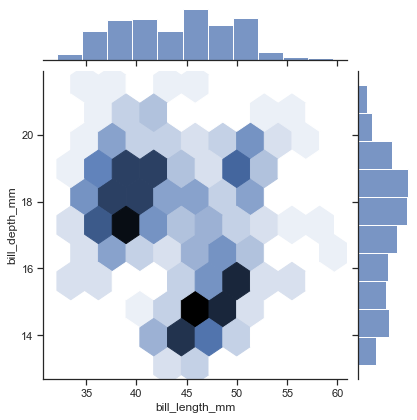
最新のseabornAPIを全て試してデータ可視化スキルを高める【可視化のおっさん, 2020/9/9-ver0.11.0】
2020年9月9日にseabornの新バージョンがでましたね
今回はそんなver0.11.0を使いながら可視化の振り返りをしていきますseaborn公式のギャラリーと関数を参考に全べてのAPIを使ってみたいと思います
可視化だけ興味のある人は真ん中まで飛んでくだし
長いのでctrl + F で検索かけてください
検証環境
conda create -n eda python==3.8
conda activate edanotebook==6.1.4
ipykernel==5.3.4seaborn==0.11.0
pandas==1.1.2
matplotlib==3.3.2
statsmodels==0.12.0
scipy==1.5.2
scikit-learn==0.23.2
numpy==1.19.2前のバージョンとの差分
・distributionの可視化コードの見直し
・カラーマップ調整
・dis,hist,ecdf 関数と機能追加
・kde,rug 関数の見直し(statsmodelsが計算していた部分の削除,平滑化がbw_adjによって調節できる,log_scale変換を処理として選択できる)
・jointplotでhistを選択できるようになった
・縦持ち,横持ちデータの両方に対応
・上記 + 細かい変更私は新バージョン前まで0.10.1を使っていましたが、set_themeとかもいつの間にか追加されていて設定がだいぶ楽になっていました
アップデートによって非推奨になった項目
・今後distplotがなくなります、dis,hist関数に早いうちに移行してください
seabornって何ぞ
seabornについて簡単におさらい
seabornとはmatplotlibのラッパーで、コードを簡単に、そして綺麗な描画をしてくれるパッケージです
背後にはmatplotが動いていますが、だいぶコードの書き方がシンプルになり複雑な図を一行で表現できたりします
いくつかの関数では前処理に似たフィルターや計算も行ってくれることから、EDA用にも適していると感じますseabornの思想
seabornの面白い思想を紹介します
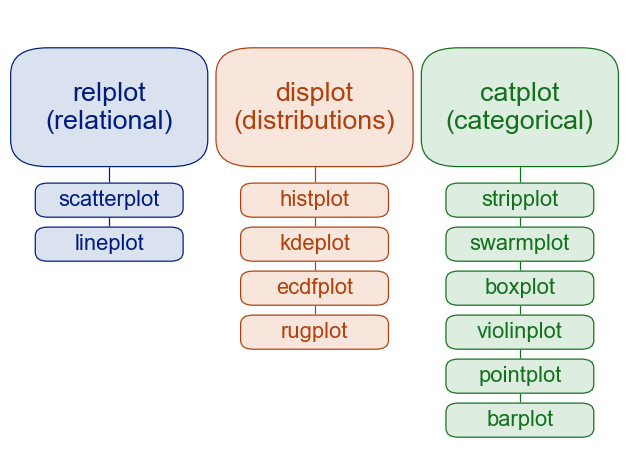
seabornはaxes,figureの二つの観点から描画方法を設計しています。
描画する関数のグループ分けは図のようになっており、rel,dis,cat(figure側の関数)によって細かい(axes側の関数による)描画を一括制御することができます。
もちろん個別の関数を呼び出しても使えます。細かい関数で描画したほうがスクリプトがわかりやすくない?
一括管理するfigure側の関数では、描画したいキャンバス数を自動的に生成し、グループ分けの処理を行い、描画単位を区切る(facet)ことができます
また、axes側の関数では(指定しなければ)
・軸の名前なども変更し辛い
・凡例を図中に示してしまうなどの問題があります。
figure側の関数であれば軸や判例を別物として扱い、
set_axis_labelsなどを使うことで一行でラベルや判例の制御を簡単に行うことができます。そんなことより可視化だ!!
紹介内容を大きく二分割して、
・最初にオプション(色、軸、凡例、等)
・メジャーなfigure側のrel,dis,catをメインで紹介
・発展的な描画を紹介に分けていきたいと思います
【opt-0】オプション的な話
オプション的な話を事前に概要だけでも知ってもらうことで、
以降のplotでの話の入ってきやすさを上げておくそもそも最新版が入っているのか確認しておきましょう
import pandas as pd from matplotlib.pyplot as plt %matplotlib inline import seaborn as sns print(sns.__version__) 0.11.0【opt-1】データを呼び出す
お手軽に有名なデータを使いたい時
seabornのサポートしているデータはgithub上に保存されているので、
使いたいデータを選びload_datasetで呼び出すことができます
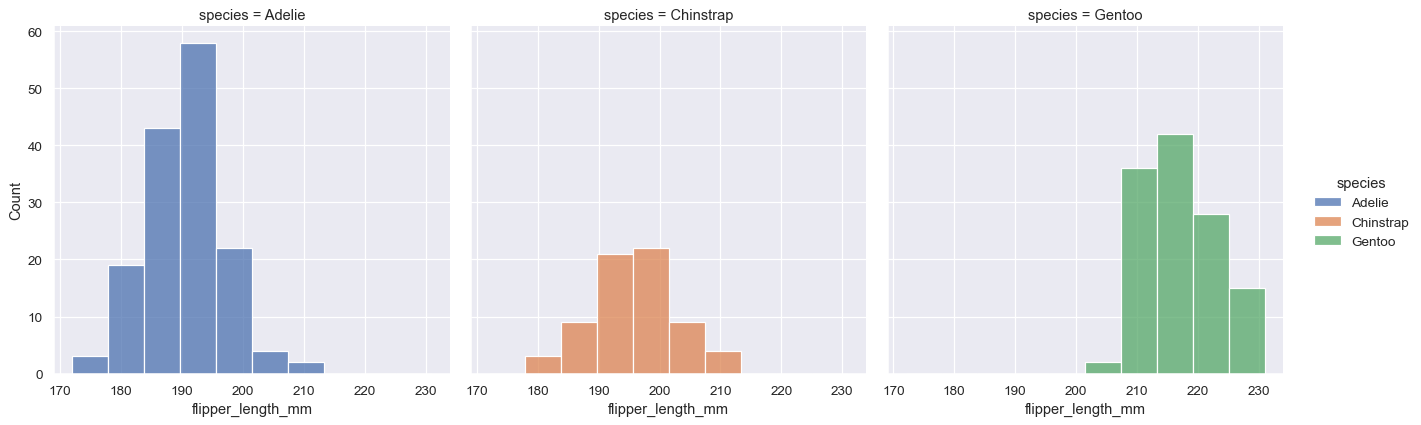
呼び出されたデータはpandasのdataframe形式で操作できますpenguins = sns.load_dataset("penguins")【opt-2】描画テーマを設定
現在のテーマを確認しつつ、使いたいテーマを選ぶ
sns.set_theme <function seaborn.rcmod.set_theme(context='notebook', style='darkgrid', palette='deep', font='sans-serif', font_scale=1, color_codes=True, rc=None)>styleはグラフ背景の色味を制御します
white, dark, whitegrid, darkgridpalletはグラフ図形の色パターンを調整します
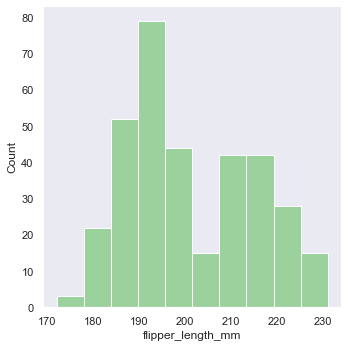
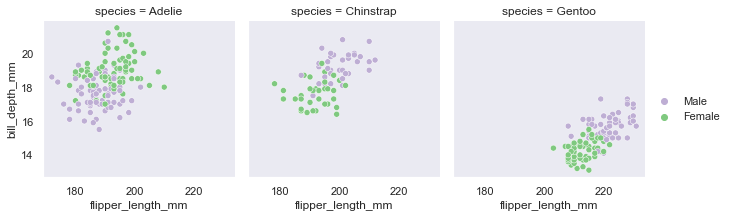
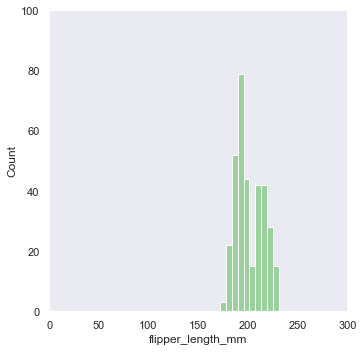
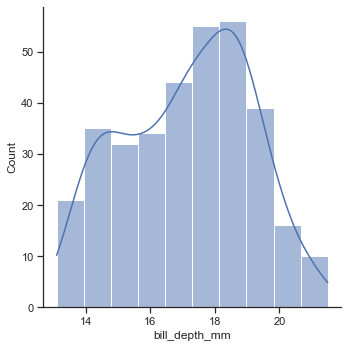
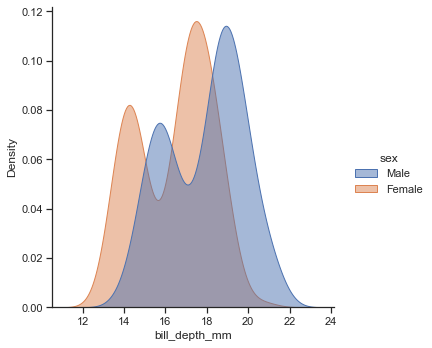
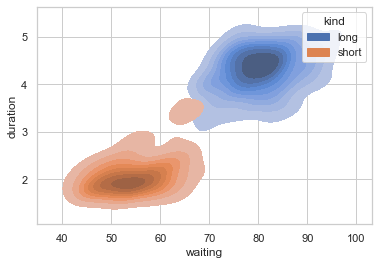
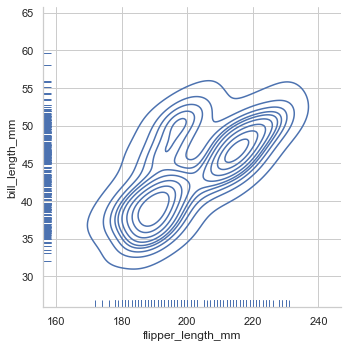
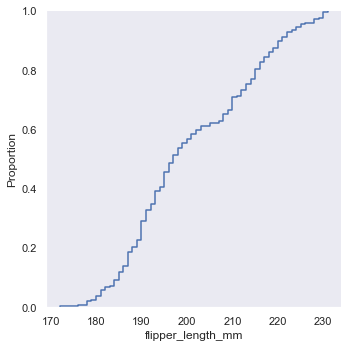
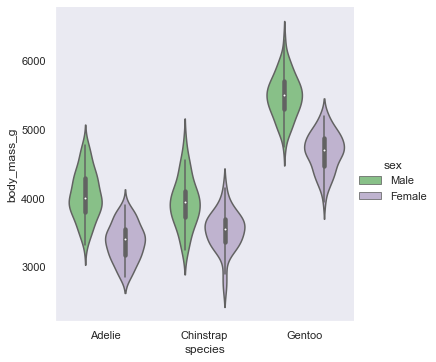
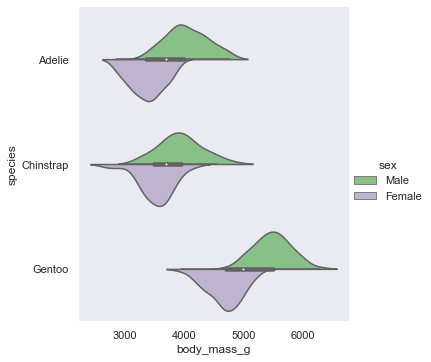
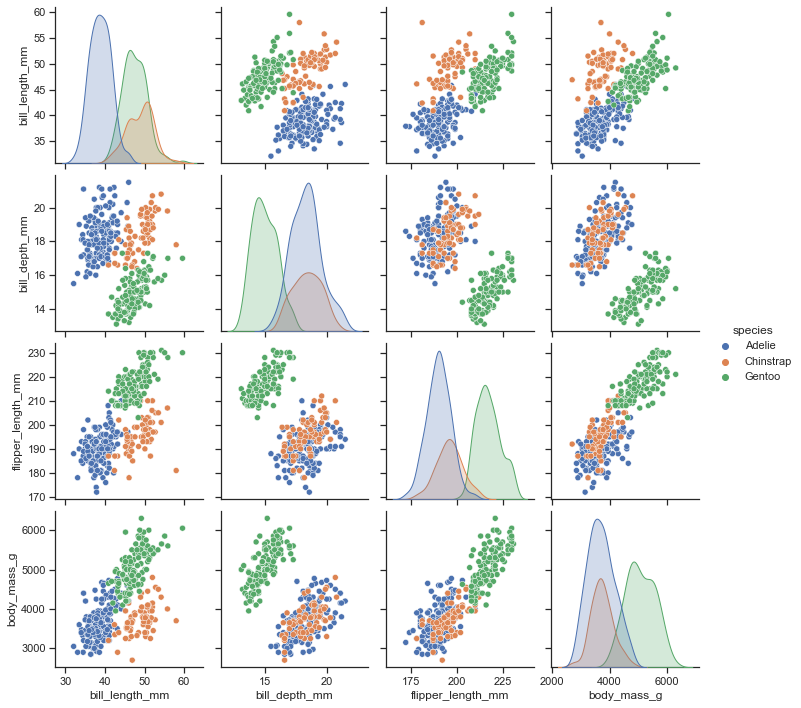
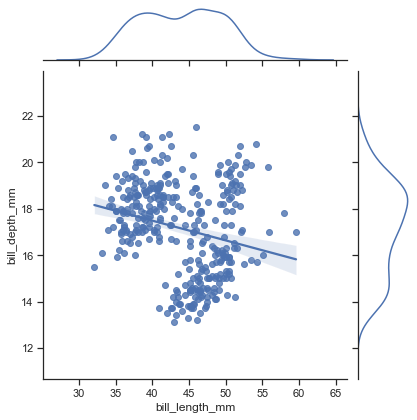
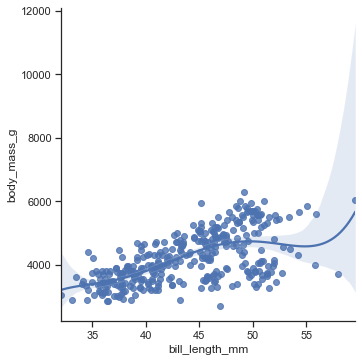
'Accent', 'Accent_r', 'Blues', 'Blues_r', 'BrBG', 'BrBG_r', 'BuGn', 'BuGn_r', 'BuPu', 'BuPu_r', 'CMRmap', 'CMRmap_r', 'Dark2', 'Dark2_r', 'GnBu', 'GnBu_r', 'Greens', 'Greens_r', 'Greys', 'Greys_r', 'OrRd', 'OrRd_r', 'Oranges', 'Oranges_r', 'PRGn', 'PRGn_r', 'Paired', 'Paired_r', 'Pastel1', 'Pastel1_r', 'Pastel2', 'Pastel2_r', 'PiYG', 'PiYG_r', 'PuBu', 'PuBuGn', 'PuBuGn_r', 'PuBu_r', 'PuOr', 'PuOr_r', 'PuRd', 'PuRd_r', 'Purples', 'Purples_r', 'RdBu', 'RdBu_r', 'RdGy', 'RdGy_r', 'RdPu', 'RdPu_r', 'RdYlBu', 'RdYlBu_r', 'RdYlGn', 'RdYlGn_r', 'Reds', 'Reds_r', 'Set1', 'Set1_r', 'Set2', 'Set2_r', 'Set3', 'Set3_r', 'Spectral', 'Spectral_r', 'Wistia', 'Wistia_r', 'YlGn', 'YlGnBu', 'YlGnBu_r', 'YlGn_r', 'YlOrBr', 'YlOrBr_r', 'YlOrRd', 'YlOrRd_r', 'afmhot', 'afmhot_r', 'autumn', 'autumn_r', 'binary', 'binary_r', 'bone', 'bone_r', 'brg', 'brg_r', 'bwr', 'bwr_r', 'cividis', 'cividis_r', 'cool', 'cool_r', 'coolwarm', 'coolwarm_r', 'copper', 'copper_r', 'crest', 'crest_r', 'cubehelix', 'cubehelix_r', 'flag', 'flag_r', 'flare', 'flare_r', 'gist_earth', 'gist_earth_r', 'gist_gray', 'gist_gray_r', 'gist_heat', 'gist_heat_r', 'gist_ncar', 'gist_ncar_r', 'gist_rainbow', 'gist_rainbow_r', 'gist_stern', 'gist_stern_r', 'gist_yarg', 'gist_yarg_r', 'gnuplot', 'gnuplot2', 'gnuplot2_r', 'gnuplot_r', 'gray', 'gray_r', 'hot', 'hot_r', 'hsv', 'hsv_r', 'icefire', 'icefire_r', 'inferno', 'inferno_r', 'jet', 'jet_r', 'magma', 'magma_r', 'mako', 'mako_r', 'nipy_spectral', 'nipy_spectral_r', 'ocean', 'ocean_r', 'pink', 'pink_r', 'plasma', 'plasma_r', 'prism', 'prism_r', 'rainbow', 'rainbow_r', 'rocket', 'rocket_r', 'seismic', 'seismic_r', 'spring', 'spring_r', 'summer', 'summer_r', 'tab10', 'tab10_r', 'tab20', 'tab20_r', 'tab20b', 'tab20b_r', 'tab20c', 'tab20c_r', 'terrain', 'terrain_r', 'turbo', 'turbo_r', 'twilight', 'twilight_r', 'twilight_shifted', 'twilight_shifted_r', 'viridis', 'viridis_r', 'vlag', 'vlag_r', 'winter', 'winter_r'sns.set_theme(style="dark",palette='Accent') df = sns.load_dataset("penguins") sns.displot(df.flipper_length_mm)
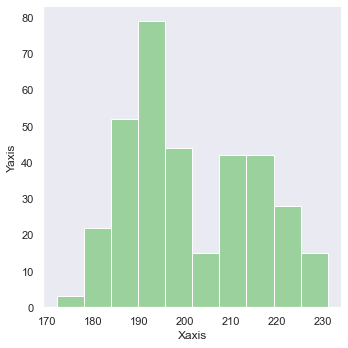
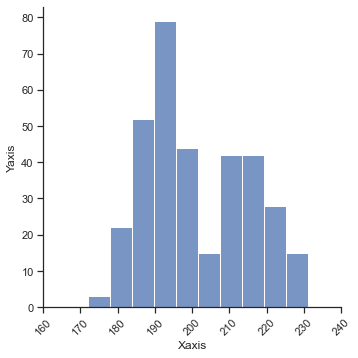
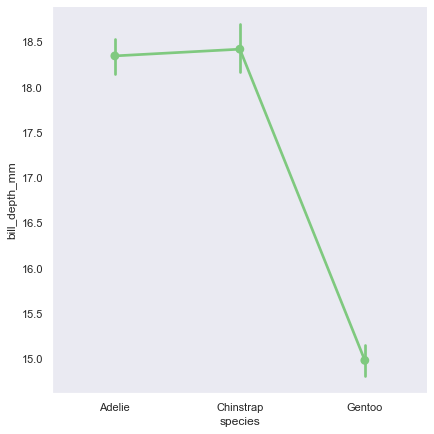
【opt-3】軸ラベルaxisの変更
g = sns.displot(df.flipper_length_mm) g.set_axis_labels("Xaxis", "Yaxis")
図形に対して外側から上書きすることができます
軸ラベル回転もできる
g = sns.displot(df.flipper_length_mm) g.set_axis_labels("Xaxis", "Yaxis") g.set_xticklabels(rotation=-45)
ラベルの間隔を20刻みに変える場合は
g.set_xticklabels(step=20)【opt-4】凡例の描画と色分け
色分けは関数内のhueで指定する
axes関数では
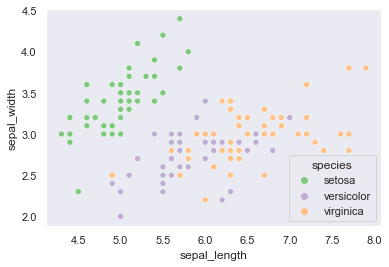
df = sns.load_dataset("iris") sns.scatterplot(data=df,x='sepal_length',y='sepal_width',hue='species')
凡例が自動的に内側に入ってしまうが、
figure側の関数を使えば自動的に外側に出るdf = sns.load_dataset("iris") sns.relplot(data=df,x='sepal_length',y='sepal_width',hue='species',kind='scatter')
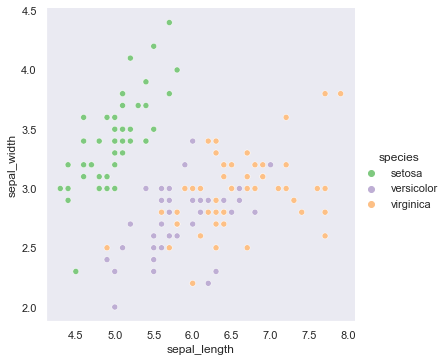
【opt-5】複数描画と凡例
散布図を書きたいが、グループごとに散布図を書きたくなることもある
データに対して複数描画するのはFacetGridで実現できる
どの軸でグループ分けするかはcolによって指定する
(colはcolorでなくcolumn)
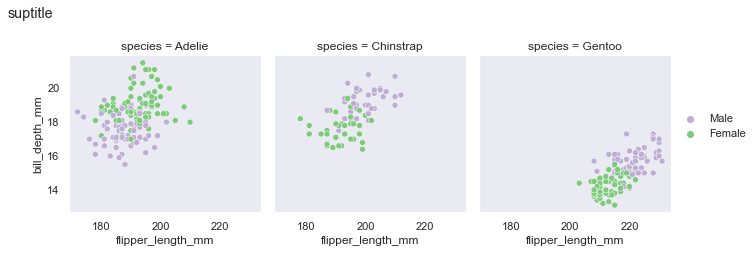
グループ分けする軸の質的変数の値から描画エリア数は自動的に決めてくれるdf = sns.load_dataset("penguins") sns.FacetGrid(df,col='species')
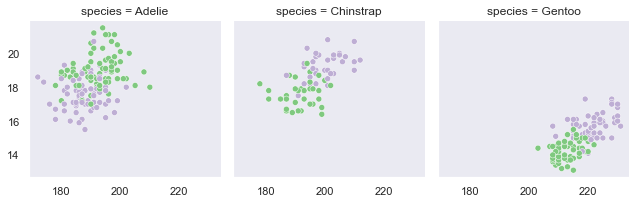
作った描画エリアにマッピング(map)していく
df = sns.load_dataset("penguins") g=sns.FacetGrid(df,col='species') g.map_dataframe(sns.scatterplot,x='flipper_length_mm',y='bill_depth_mm',hue="sex")
凡例ほしいという時にはadd_legendによって後付けする
df = sns.load_dataset("penguins") g=sns.FacetGrid(df,col='species') g.map_dataframe(sns.scatterplot,x='flipper_length_mm',y='bill_depth_mm',hue="sex") g.set_axis_labels('flipper_length_mm','bill_depth_mm') g.add_legend()
もう一つ描画の軸を追加したい場合はFacetGridのrowに指定してやれば、さらに分割できる
tips = sns.load_dataset("tips") g = sns.FacetGrid(tips, col="time", row="sex") g.map(sns.scatterplot, "total_bill", "tip")
【opt-6】全体に対してのタイトルが欲しい
各gridでなく全体にタイトルを付ける時はsuptitleで表示する
matplotが後ろで動いてるのでsuptitleも使えるdf = sns.load_dataset("penguins") g=sns.FacetGrid(df,col='species') g.map_dataframe(sns.scatterplot,x='flipper_length_mm',y='bill_depth_mm',hue="sex") g.set_axis_labels('flipper_length_mm','bill_depth_mm') g.add_legend() g.fig.suptitle('suptitle',y=1.1,x=0,size=18)
【opt-7】前処理として変数を対数化してほしい
そのままでは値の幅が広すぎてよくわからない
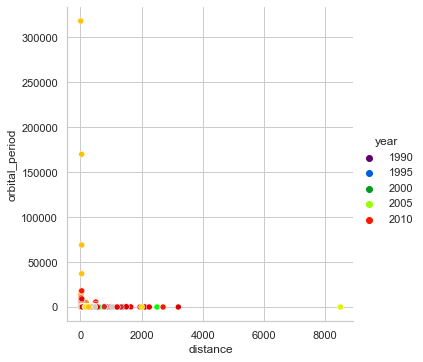
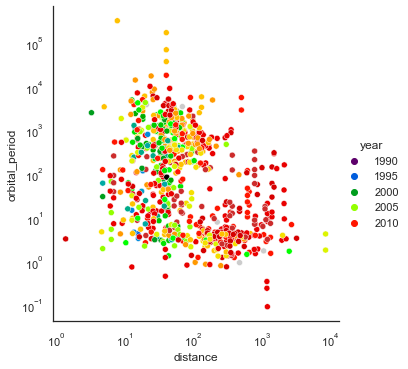
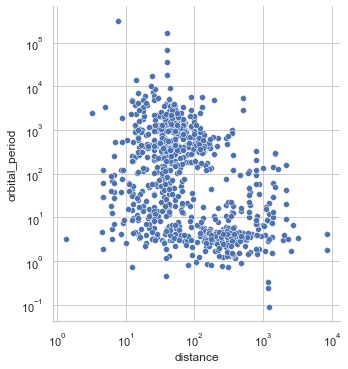
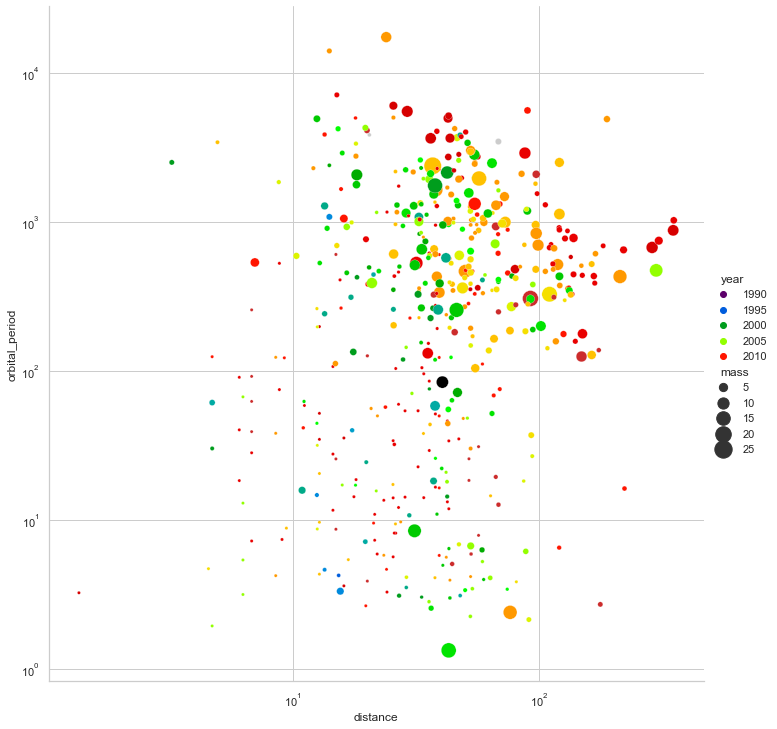
planets = sns.load_dataset("planets") sns.relplot(data=planets,x="distance", y="orbital_period",hue="year",palette='nipy_spectral')
scaleを指定することで値の前処理をしてくれる
planets = sns.load_dataset("planets") g=sns.relplot(data=planets,x="distance", y="orbital_period",hue="year",palette='nipy_spectral') g.set(xscale="log", yscale="log")
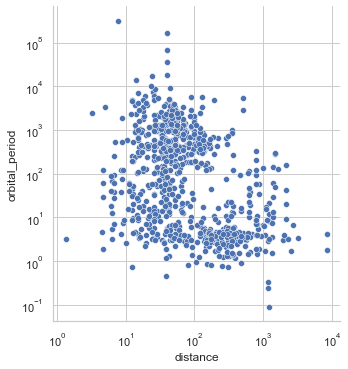
【opt-8】軸の棒を消してほしい
背景gridはテーマで消えるけど、X,Y軸の棒は消えない
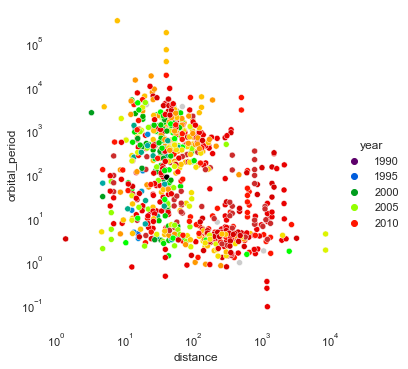
sns.set_theme(style="white") planets = sns.load_dataset("planets") g=sns.relplot(data=planets,x="distance", y="orbital_period",hue="year",palette='nipy_spectral') g.set(xscale="log", yscale="log")
despineを使って消す
sns.set_theme(style="white") planets = sns.load_dataset("planets") g=sns.relplot(data=planets,x="distance", y="orbital_period",hue="year",palette='nipy_spectral') g.set(xscale="log", yscale="log") g.despine(left=True, bottom=True)
【opt-9】xlimとylimを指定する
sns.set_theme(style="dark",palette='Accent') df = sns.load_dataset("penguins") g=sns.displot(df.flipper_length_mm) g.set(xlim=(0, 300), ylim=(0, 100))
もしくはFacetGrid側で設定する
sns.FacetGrid(df,col='species',xlim=[0,10],ylim=[0,10])
【main-0】メジャーplot紹介
【main-1】relplotによるscatterとline
【main-1.1】デフォルトのrel
sns.set_theme(style="whitegrid") planets = sns.load_dataset("planets") g=sns.relplot(data=planets,x="distance", y="orbital_period",palette='Dark2_r') g.set(xscale="log", yscale="log")デフォルトで実行した場合scatterになる
sns.set_theme(style="whitegrid") planets = sns.load_dataset("planets") g=sns.relplot(data=planets,x="distance", y="orbital_period",palette='Dark2_r',kind='scatter') g.set(xscale="log", yscale="log")kindでscatterを指定しても同じ
【main-1.2】relのkind指定
kindでlineを指定すると点をつないで線形にしてくれる
sns.set_theme(style="whitegrid") planets = sns.load_dataset("planets") g=sns.relplot(data=planets,x="distance", y="orbital_period",palette='Dark2_r',kind='line') g.set(xscale="log", yscale="log")
【main-1.3】scatterを値に応じてサイズを変える(bubble plot)
散布図の値をbubble plotのように値によって図形を変化させたい
そんなときはsize引数に値の入っているデータ列を指定する
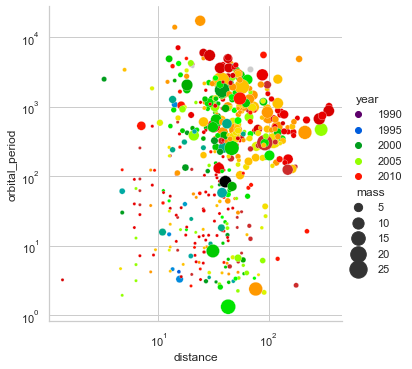
どの程度の大きさにしたいか上限下限をsizesにlistかtupleで渡すplanets = sns.load_dataset("planets") cmap = sns.cubehelix_palette(rot=-.2, as_cmap=True) g = sns.relplot(data=planets,x="distance", y="orbital_period",hue="year", size="mass",palette='nipy_spectral', sizes=(10, 300)) g.set(xscale="log", yscale="log")
【main-1.4】図の出力サイズ変更
出力する図の大きさはheightから操作する
planets = sns.load_dataset("planets") cmap = sns.cubehelix_palette(rot=-.2, as_cmap=True) g = sns.relplot(data=planets,x="distance", y="orbital_period",hue="year", size="mass",palette='nipy_spectral', sizes=(10, 300),height=10) g.set(xscale="log", yscale="log")
【main-1.5】lineでの信頼区間
散布図で分かりにくいデータも
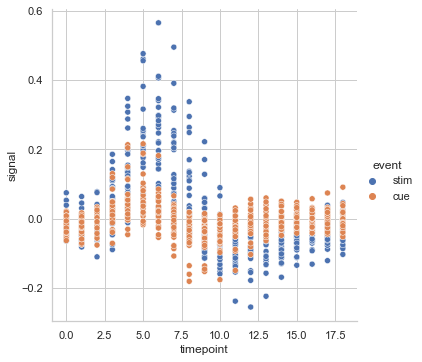
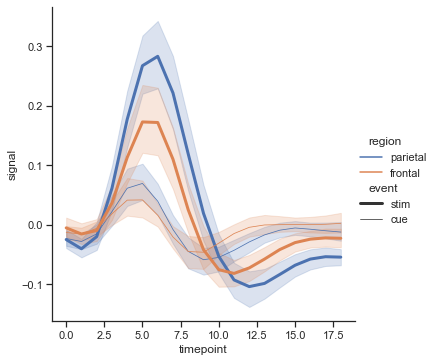
fmri = sns.load_dataset("fmri") sns.relplot(data=fmri,x="timepoint", y="signal", hue="event",kind='scatter')
lineならわかりやすい
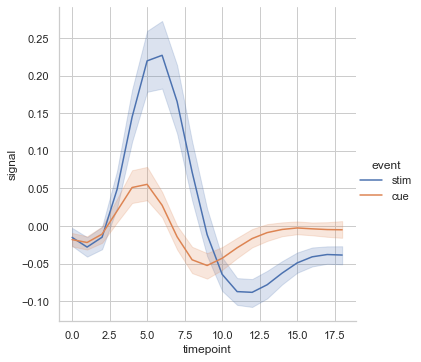
fmri = sns.load_dataset("fmri") sns.relplot(data=fmri,x="timepoint", y="signal", hue="event",kind='line')
信頼区間はciで指定する。
sdか実数を渡すことができ、実数の場合〇%信頼区間を表す
sdは観測地から計算されたsdをそのまま使うfmri = sns.load_dataset("fmri") sns.relplot(data=fmri,x="timepoint", y="signal", hue="event",kind='line',ci=20)20%信頼区間に指定した
【main-1.6】マーカーの指定
イベント点ごとでマーカーを付けたり、信頼区間をエリアでなく棒にすることもできる
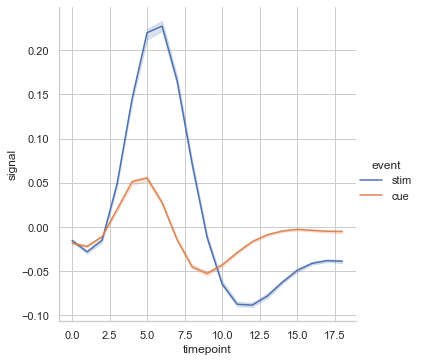
sns.relplot(data=fmri, x="timepoint", y="signal", hue="event", err_style="bars", ci=95,markers=True,kind='line')
【main-1.7】指定した分析軸で線を増やす
先ほど紹介したscatterの時のサイズのように、styleで分析軸をわけることができる
fmri = sns.load_dataset("fmri") sns.relplot(data=fmri,x="timepoint", y="signal", hue="region", style="event",kind='line')
もちろんsizeも指定できる
fmri = sns.load_dataset("fmri") sns.relplot(data=fmri,x="timepoint", y="signal", hue="region", size="event", kind='line')
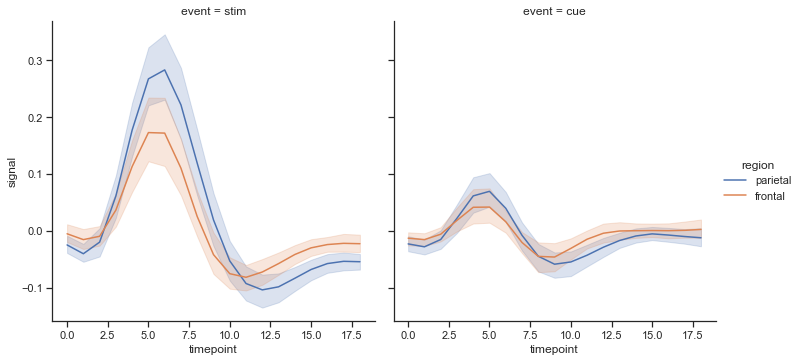
【main-1.8】指定した分析軸で画面を分ける
描画画面自体を分けたい場合はcolに分けたい軸を指定する
fmri = sns.load_dataset("fmri") sns.relplot(data=fmri,x="timepoint", y="signal", hue="region", col="event", kind='line')
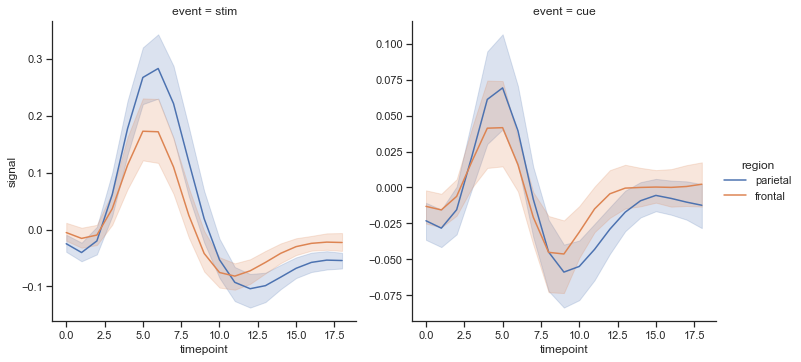
複数軸での描画の場合、facet_kwsでx軸やy軸のスケールを各図で共有するかどうかを指定できる
fmri = sns.load_dataset("fmri") sns.relplot(data=fmri,x="timepoint", y="signal", hue="region", col="event", kind='line',facet_kws=dict(sharey=False,sharex=False))ラベル消してビックリグラフにならないように注意
どうしても別の方法で分けたい場合はfigure側の関数でなく、axes側の関数を指定してFacetGridを使うこともできる
fmri = sns.load_dataset("fmri") g=sns.FacetGrid(fmri,col='event') g.map_dataframe(sns.lineplot,data=fmri,x='timepoint',y='signal',hue="region")
【main-2】displotによるhistとkedとecdfとrug
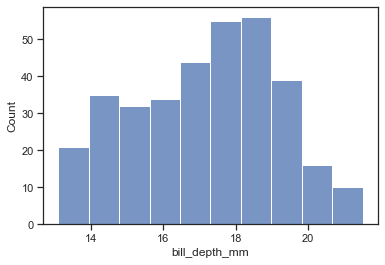
【main-2.1】displotのデフォルト hist
デフォルトはkind='hist'になっている
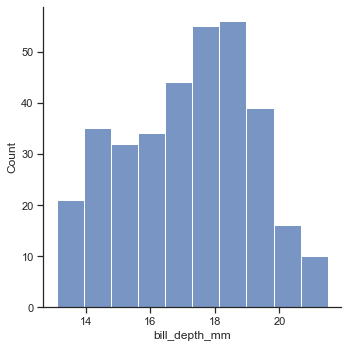
penguin = sns.load_dataset("penguins") sns.displot(data=penguin,x='bill_depth_mm') #sns.displot(data=penguin,x='bill_depth_mm',kind='hist')
elementという引数で表現方法を変化できる
デフォルトはbarsns.displot(data=penguin,x='bill_depth_mm',kind='hist',element='poly') sns.displot(data=penguin,x='bill_depth_mm',kind='hist',element='step')poly
step
binsで区切る細かさも変えられる
sns.displot(data=penguin,x='bill_depth_mm',kind='hist',element='poly',bins=100)
【main-2.2】histgramにkde(kernel density estimate)を付け加える
sns.displot(data=penguin,x='bill_depth_mm',kind='hist',kde=True)
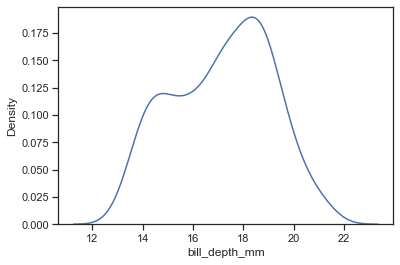
もちろんkind='kde'を指定してあげればhistは消える
sns.displot(data=penguin,x='bill_depth_mm',kind='kde')
【main-2.2】histとkdeの元関数でもplotしてみる
sns.histplot(data=penguin,x='bill_depth_mm')
sns.kdeplot(data=penguin,x='bill_depth_mm')
【main-2.3】kdeの動きを確認する
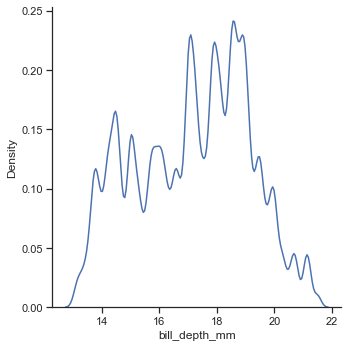
平滑化の際にどれだけのデータ幅を見て平滑化するかを決めるbw_adjust
sns.displot(data=penguin,x='bill_depth_mm',kind='kde',bw_adjust=.2)0.2のとき
100のとき
【main-2.4】別の軸で色を変える
いつも通り
hueで色分け
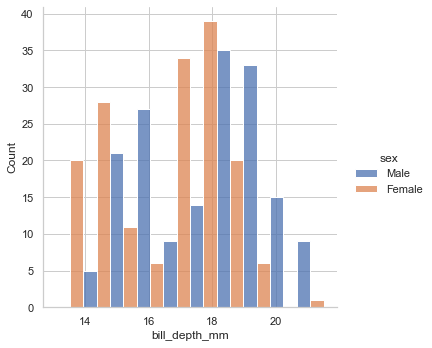
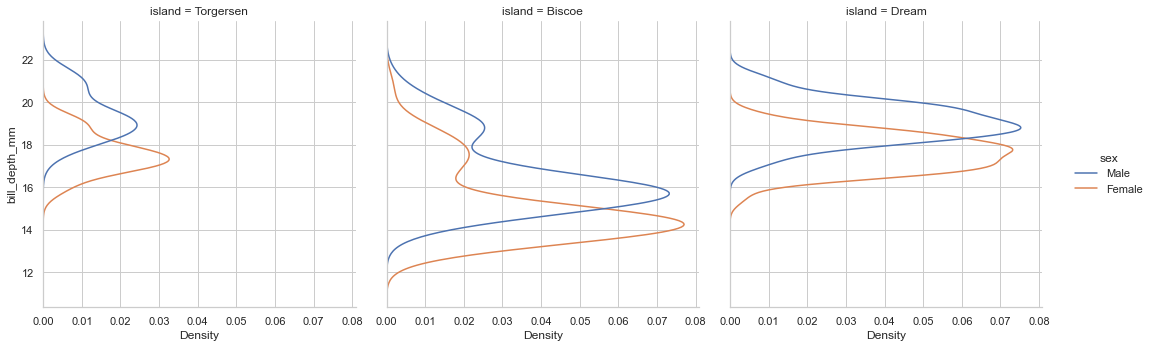
colで画面分けsns.displot(data=penguin,x='bill_depth_mm',kind='kde',hue='sex',col='island')
【main-2.5】積み上げグラフにする
密度関数を積み上げたい場合はstackを指定する
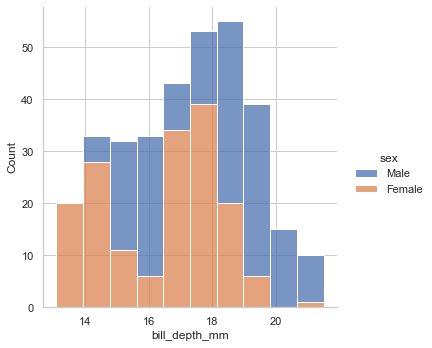
上に乗っかるだけなので、乗っている側のほうが多いと勘違いしないように注意histでもkdeでも使える
sns.displot(data=penguin,x='bill_depth_mm',kind='kde',hue='sex',col='island',multiple="stack")
積み上げ時の境界面を消したいときはlinewidth=0を指定する
sns.displot(data=penguin,x='bill_depth_mm',kind='kde',hue='sex',col='island',multiple="stack",linewidth=0)
ほかにもedgecolor="0.1"と指定してあげれば境界線を強めにかいたりできる
積み上げグラフで中の色を抜きたい時にはfillをFalseにする
いよいよ勘違いしそうなグラフになってきたsns.displot(data=penguin,x='bill_depth_mm',kind='kde',hue='sex',multiple="stack",fill=False)
【main-2.6】積み上げない、透かしを入れる、alphaについて
alphaを調整することで色の透けを調節できる
sns.displot(data=penguin,x='bill_depth_mm',kind='kde',hue='sex',fill=True,alpha=0.5)
【main-2.7】multipleについて、面積比として表現する、かぶせ、横に置く
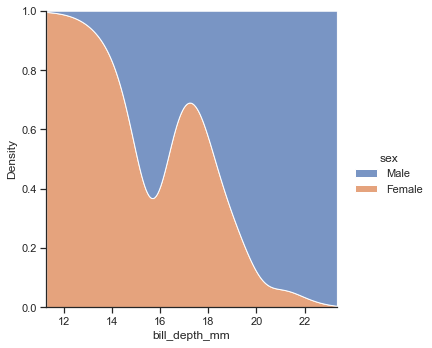
stackでなくfillを指定することで、全体を1とする面積のなかで、どちらの割合が多いかをplotしてくれるようになる
sns.displot(data=penguin,x='bill_depth_mm',kind='kde',hue='sex',multiple="fill")
histで変化を見てみる
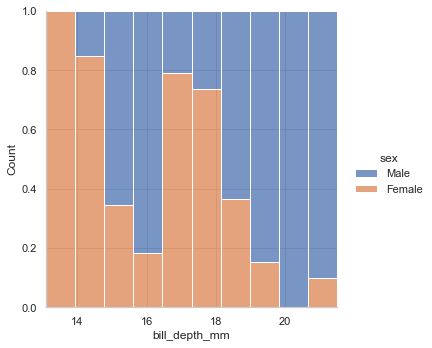
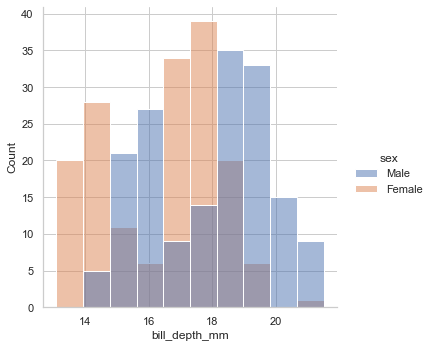
sns.displot(data=penguin,x='bill_depth_mm',kind='hist',hue='sex',fill=True,multiple="fill") sns.displot(data=penguin,x='bill_depth_mm',kind='hist',hue='sex',fill=True,multiple="layer") sns.displot(data=penguin,x='bill_depth_mm',kind='hist',hue='sex',fill=True,multiple="dodge") sns.displot(data=penguin,x='bill_depth_mm',kind='hist',hue='sex',fill=True,multiple="stack")fill
layer
dodge
stack
【main-2.8】2次元でのplot
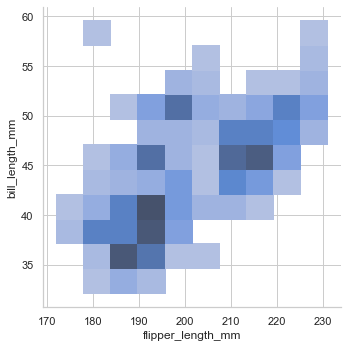
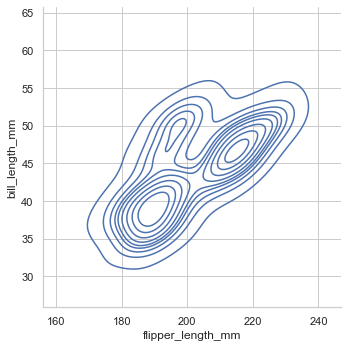
histでもkdeでもx,yを指定することで二次元plotにしてくれる
イメージとしては地図の等高線sns.displot(data=penguin, x="flipper_length_mm", y="bill_length_mm",kind='hist') sns.displot(data=penguin, x="flipper_length_mm", y="bill_length_mm",kind='kde')
色分けはhue
塗りつぶしはfill
画面分けはcol
という規則に変わりはない
【main-2.9】2次元での色グラデーション
色のグラデーションを付けたければパターンをcmapに指定して
値の入っていない(確率の低い)ところも塗りつぶすthresh = 0 (1より小さい正の値)
グラデーションの段階の細かさを指定levelsで調整sns.displot(data=penguin, x="flipper_length_mm", y="bill_length_mm", kind="kde",fill=True, thresh=0, levels=10, cmap='cubehelix')thresh=0, levels=10
thresh=0.8, levels=10
thresh=0, levels=100
【main-2.10】rug plotとは
rugとは軸のそばについている細かいヒゲのようなもののこと
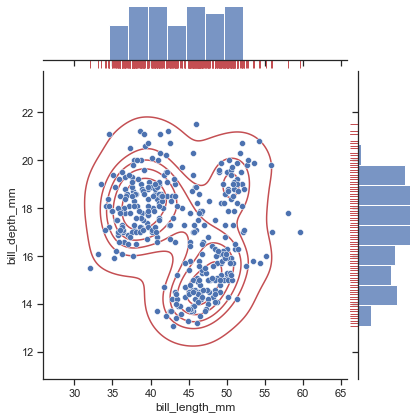
kdeで密度を見ながらrugでもどのくらい密集しているのか確認できるsns.displot(data=penguin, x="flipper_length_mm", y="bill_length_mm", kind="kde", rug=True)
散布図と合わせたりもできる
sns.scatterplot(data=penguin, x="flipper_length_mm", y="bill_length_mm") sns.rugplot(data=penguin, x="flipper_length_mm", y="bill_length_mm")
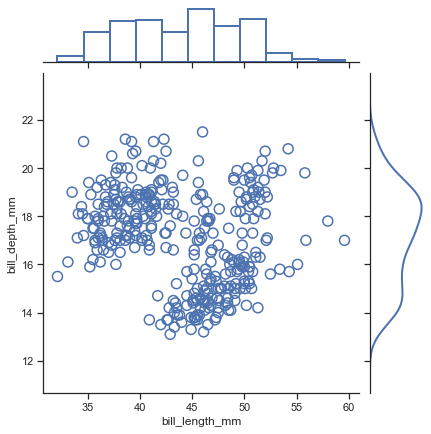
【main-2.11】横向きにplotする
histgramといえばx軸に値の入った積み上げグラフのイメージだが、
yに値を指定することで自動的に横向きに描画してくれるsns.displot(data=penguin,y='bill_depth_mm',kind='kde',hue='sex',col='island')
【main-2.12】plotの小タイトルの指定
オプションの時に全体タイトルの話はした
各小タイトルを変えるにはgに一旦グラフ情報を入れてcol_nameからとってくることも可能
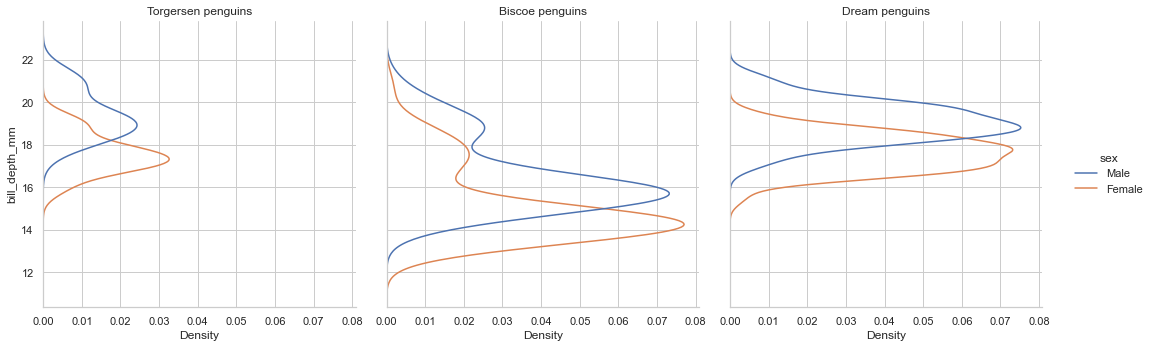
(くわしくはset_titlesを参照)g=sns.displot(data=penguin,y='bill_depth_mm',kind='kde',hue='sex',col='island') g.set_titles("{col_name} penguins")
【main-2.13】ecdf累積plot
累積確率として出力できる
sns.displot(data=penguin, x="flipper_length_mm", kind="ecdf") sns.displot(data=penguin, x="flipper_length_mm", kind="ecdf",complementary=True)
complementary=True
生存時間分析などに使えそう
【main-2.14】描画画面を複数に分けるcol_wrapと、対数処理をするlog_scale
displotにも内部でlog処理するかを指定できる機能がある
片方の軸だけ対数処理することも可能描画は普段colで行い自然に分割されるが、
〇列で表示したい等の指定も可能diamonds = sns.load_dataset("diamonds") sns.displot(data=diamonds, x="depth", y="price", log_scale=(True, False), col="clarity",col_wrap=5,kind='kde')
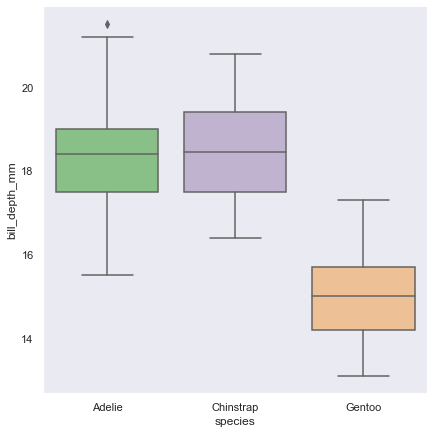
【main-3】catplotによるstrip,swarm,box.box,violin,point,bar,boxen,count
【main-3.1】catplotのデフォルト
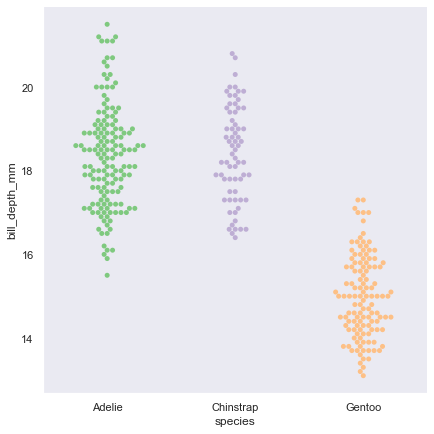
通常ではstripに指定されている
カテゴリーに向いた可視化ツールなので質的変数に対応させる
sns.catplot(data=penguin,x='species',y='bill_depth_mm',height=6,kind='strip')
kindの種類をみていく
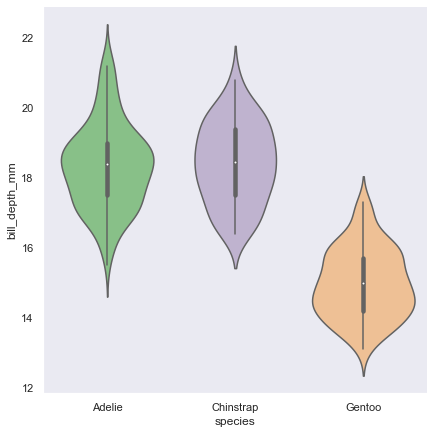
sns.catplot(data=penguin,x='species',y='bill_depth_mm',height=6,kind='box') sns.catplot(data=penguin,x='species',y='bill_depth_mm',height=6,kind='boxen') sns.catplot(data=penguin,x='species',height=6,kind='count') sns.catplot(data=penguin,x='species',y='bill_depth_mm',height=6,kind='bar') sns.catplot(data=penguin,x='species',y='bill_depth_mm',height=6,kind='violin') sns.catplot(data=penguin,x='species',y='bill_depth_mm',height=6,kind='swarm') sns.catplot(data=penguin,x='species',y='bill_depth_mm',height=6,kind='point')box
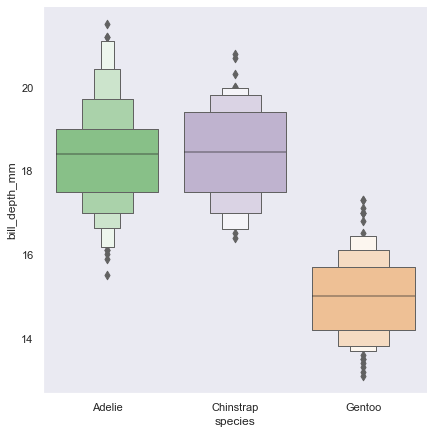
boxen
count
bar(countのy軸を見る)
violin
swarm
point
群間比較、分散分析などに使えそう
上記を見てもらって信頼区間があるのはわかってもらえたと思う
ciで設定可能【main-3.2】boxやviolinの表現
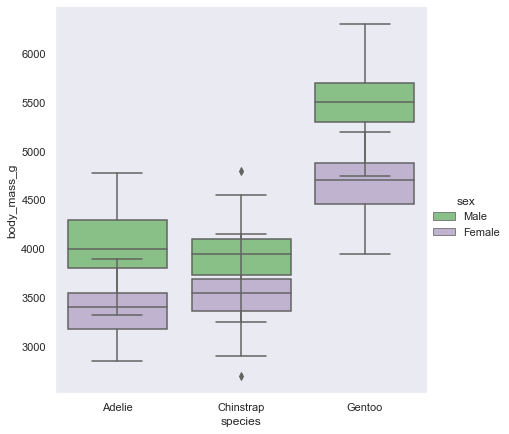
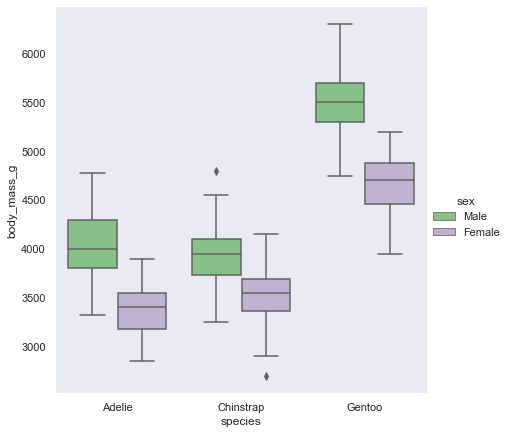
同じ列で描画するか、分けるか dodge
sns.catplot(data=penguin, kind="box",x="species", y="body_mass_g", hue="sex", dodge=False,height=6)
sns.catplot(data=penguin, kind="box",x="species", y="body_mass_g", hue="sex", dodge=True,height=6)
swarmやviolinでも同じ
barでdodgeをFalseにすると混乱を招きそうな図になる
本当は乗っかっているのでなく後ろに隠れている
violinはsplitが選択できる
sns.catplot(data=penguin, kind="violin",x="species", y="body_mass_g", hue="sex", split=True)
yとxを入れ替えて横向きにもできる
sns.catplot(data=penguin, kind="violin",y="species", x="body_mass_g", hue="sex", split=True)
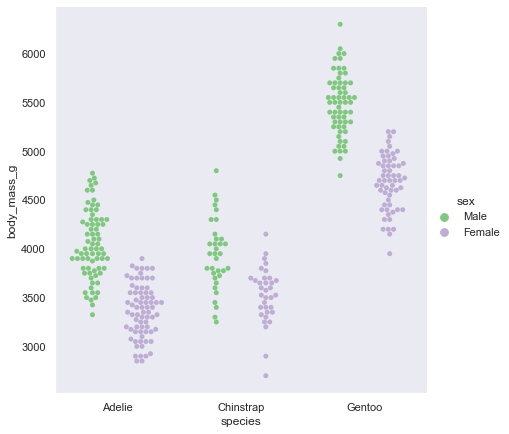
【main-3.3】swarmとboxやviolin
swarmは点が多くなりやすい
描画できない時、本来描画すべき点ができていないという警告を出してくれる
やさしい
boxやviolinの後から書き足すことで、重ねて表示してくれる機能もある
sns.catplot(data=penguin, kind="box",x="species", y="body_mass_g",height=6) sns.swarmplot(data=penguin,x="species", y="body_mass_g",hue='sex',palette="Set1")
【adv】発展的な使い方
【adv-1】pair plot
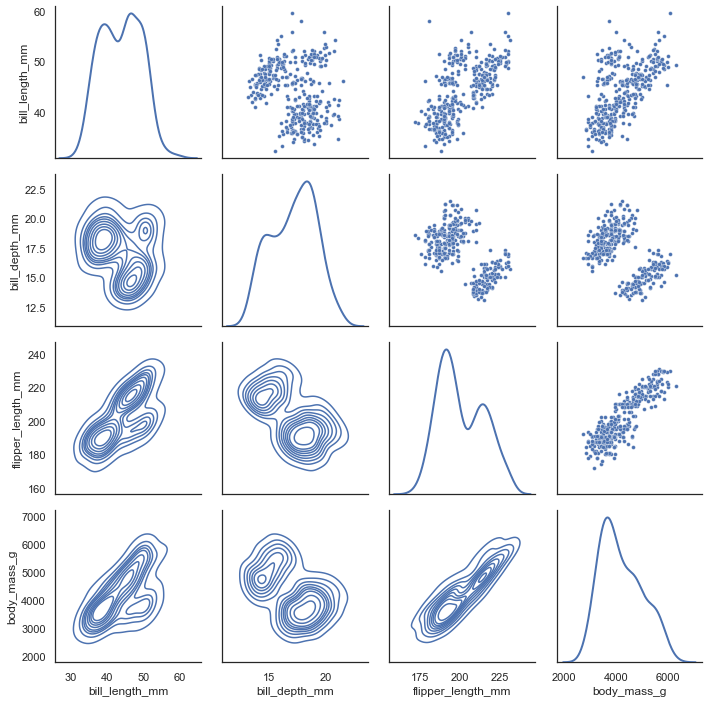
データフレーム全体を俯瞰するときに便利なpairを使ってみる
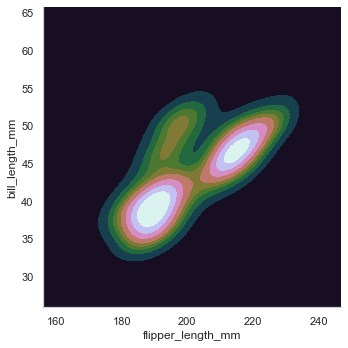
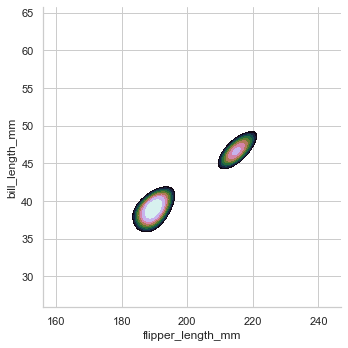
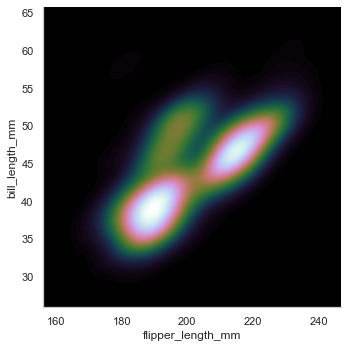
pairplot関数を呼んだ場合、よく見る図となるが
penguin = sns.load_dataset("penguins") sns.pairplot(penguin) sns.pairplot(penguin, hue="species)
PairGridを使うと上側、下側のplot形式を改めて指定できる
penguin = sns.load_dataset("penguins") g = sns.PairGrid(penguin, diag_sharey=False) g.map_upper(sns.scatterplot, s=15) g.map_lower(sns.kdeplot) g.map_diag(sns.kdeplot, lw=2)
【adv-2】heat map
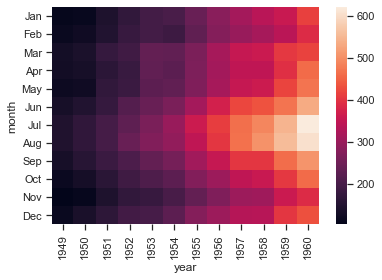
行列形式のデータに対してheatmapを返す
flights = sns.load_dataset("flights") flights = flights.pivot("month","year", "passengers") sns.heatmap(flights)
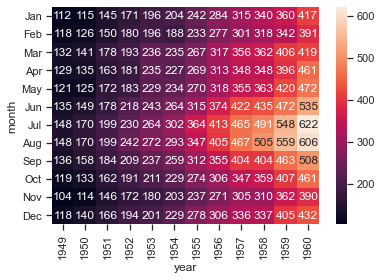
数値も一緒にのせたい場合はannotをTrueにして、数字が暴れないようにfmtを使う
sns.heatmap(flights, annot=True, fmt="d")
境界を書きたいときにはlinewidthsで指定する
sns.heatmap(flights, linewidths=.5)
numpyの三角行列を作ってくれるtriu_indices_fromを使い、
T,F 1,0で作られたような行列をmaskに入れることで、
形を整えて出力できるcorr = np.corrcoef(np.random.randn(10, 200)) mask = np.zeros_like(corr) mask[np.triu_indices_from(mask)] = True with sns.axes_style("white"): f, ax = plt.subplots(figsize=(7, 5)) ax = sns.heatmap(corr, mask=mask, vmax=.3, square=True)
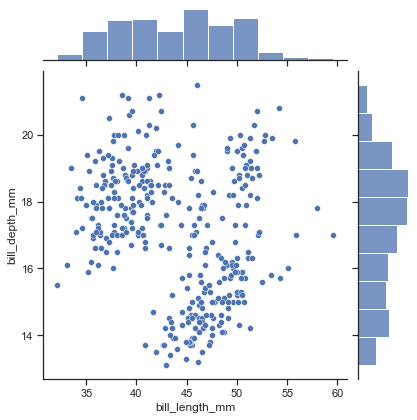
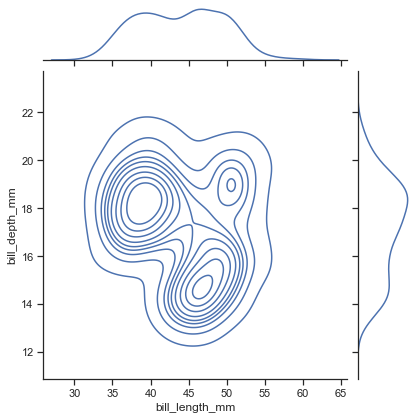
【adv-3】joint plot
二つの変数間の関係を密度として見つつ、各変数の分布も確認する
sns.jointplot(x='bill_length_mm', y='bill_depth_mm', data=penguin)
これも種類があってkindで指定することができる
デフォルトの上記はscatterkde
hist
hex
reg(regression)
residモデル残差確認のためのplot(後述)
jointgridを使うことで組み合わせを考えながらplotすることもできる
メインと側面の図を任意で指定する
g=sns.JointGrid(x='bill_length_mm', y='bill_depth_mm', data=penguin) g.plot(sns.regplot, sns.kdeplot)
rugの付け足しや、散布図にkdeをかける等を
plot_jointやmarginalsを使って付け足していくg = sns.jointplot(data=penguin, x="bill_length_mm", y="bill_depth_mm") g.plot_joint(sns.kdeplot, color="r", zorder=0, levels=6) g.plot_marginals(sns.rugplot, color="r", height=-.15, clip_on=False)
メイン、上、右の順に指定することで任意の組み合わせをつくる
g = sns.JointGrid() x, y = penguin["bill_length_mm"], penguin["bill_depth_mm"] sns.scatterplot(x=x, y=y, ec="b", fc="none", s=100, linewidth=1.5, ax=g.ax_joint) sns.histplot(x=x, fill=False, linewidth=2, ax=g.ax_marg_x) sns.kdeplot(y=y, linewidth=2, ax=g.ax_marg_y)
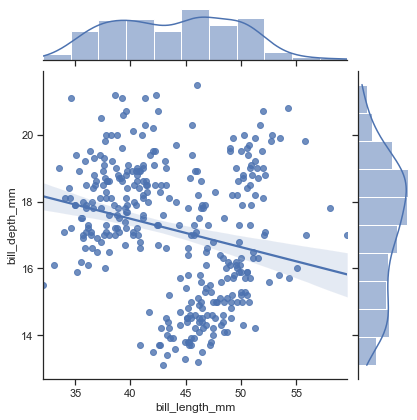
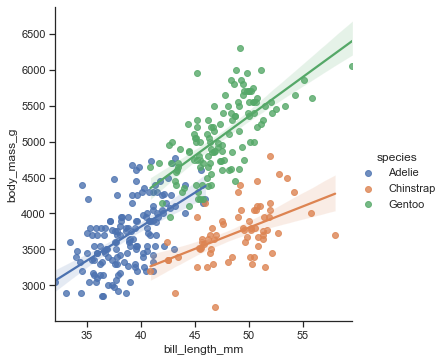
【adv-4】linear model plot
どうやらFacetとregplotを組み合わせたものがlmplotな様子なので、基本的にlmplotで説明する
pairplotやjointplotで動いているのもregplotらしい線形回帰を可視化
sns.lmplot(x='bill_length_mm', y='body_mass_g', data=penguin)
hueで色分け
orderで多項式回帰の次数を決める
sns.lmplot(x='bill_length_mm', y='body_mass_g', data=penguin, order=5)
logisticを行うオプションもある
penguin['male'] = pd.get_dummies(penguin.sex)['Male'] sns.lmplot(x='bill_length_mm', y='male',data=penguin, logistic=True)モデルを作ったら残差も比較したくなる
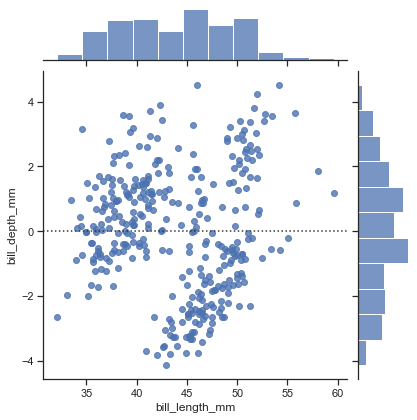
作図したlmモデル(線形や多項式)がどれだけデータを説明できているのかについては残差確認を行う
線形モデルの判定として、残差が正規分布に従っていそうならばモデルはある程度良いモデルと判定できるおそらくregとlmの関係からして、
jointplotの"resid"で動いている背景の関数がresidplotかな?sns.jointplot(x='bill_length_mm', y='body_mass_g', data=penguin,order=1,kind='resid') sns.jointplot(x='bill_length_mm', y='body_mass_g', data=penguin,order=10,kind='resid')1次の残差
10次の残差
sklearnのモデルと比較
import sklearn from sklearn import datasets,linear_model penguin=penguin.dropna(how='any') model = linear_model.LinearRegression() X = np.array(penguin["bill_length_mm"]).reshape(-1, 1) Y = np.array(penguin["body_mass_g"]).reshape(-1, 1) model.fit(X, Y) pred_y = model.predict(X) plt.scatter(x=X, y=Y-pred_y)
たしかに残差を計算してくれていそう。
【adv-5】clustermap
iris = sns.load_dataset("iris") species = iris.pop("species") g = sns.clustermap(iris)階層クラスタリングを可視化しながらしてくれる
どの距離基準でグループ化していくかはmethodで指定このあたりは説明しんどいので階層クラスタリングを学んでもらったほうがはやい
methodはscipyの計算から取得scipy.cluster.hierarchy.linkage
mathod
single complete average weighted centroid median wardsingle
最後に
可視化方法はまだまだ紹介していく予定
コードは汚くても間違った図の使い方にはなるべく気を付けたい参考
リリースnews-v0.11.0 (September 2020)








- 投稿日:2020-09-18T17:46:03+09:00
Set Up for Mac(Python)
これは何か
macPCを新しく買い替えた時用に、Pythonでの開発環境を構築するためのメモを記す。
システム環境設定
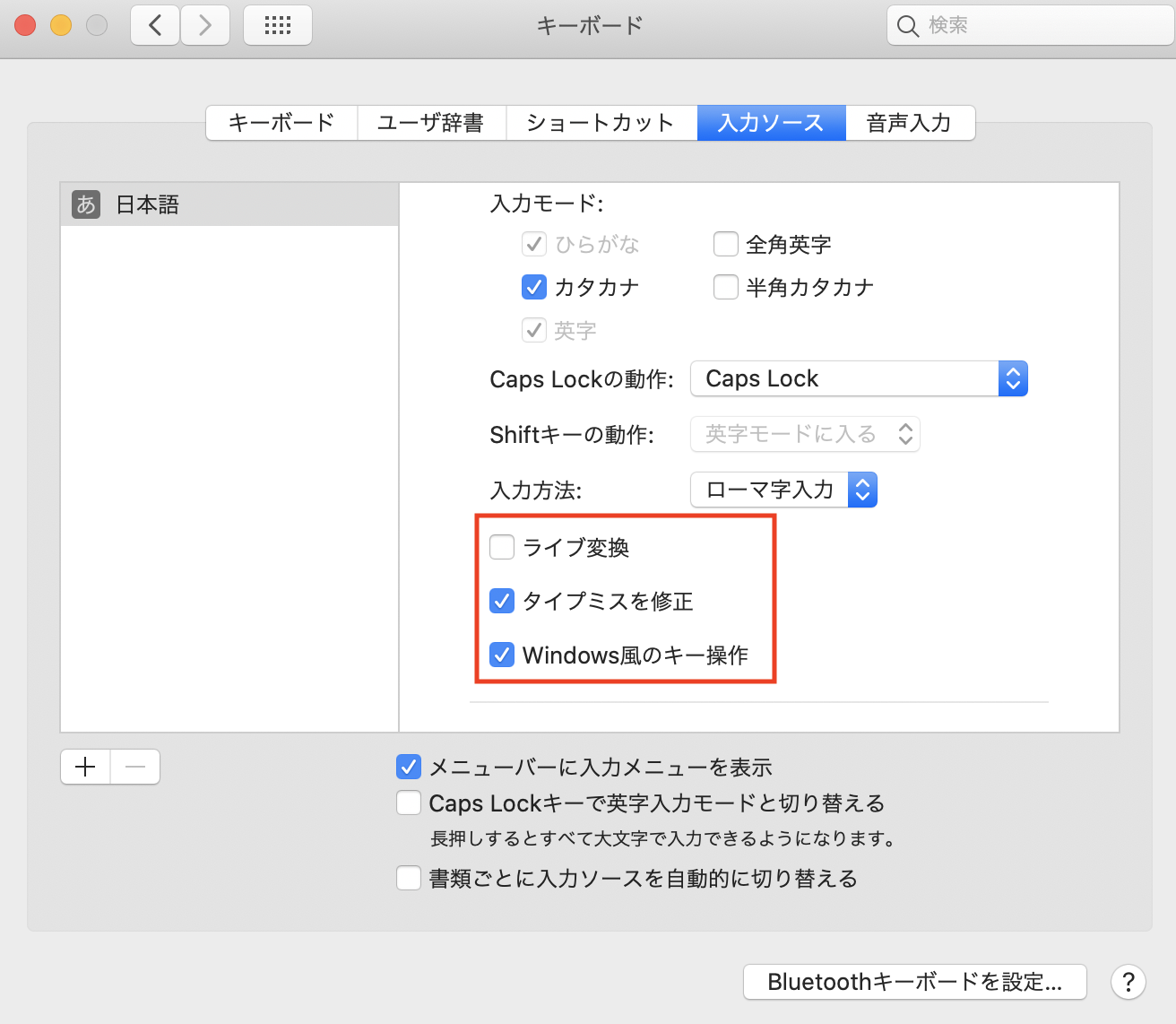
日本語入力での変換確定を2回ではなく1回にする
開発とは関係ないけど何だか気持ち悪いので変える。
- Launchpadなどから「システム環境設定」->「キーボード」->「入力ソース」を選択する。
- 画面左部より日本語を選択した状態で右画面をスクロールし、「Windows風のキー操作」にチェックを入れる。
- お好みにはなるが、「ライブ変換」のチェックを外しておくと、勝手に変換されなくなる。
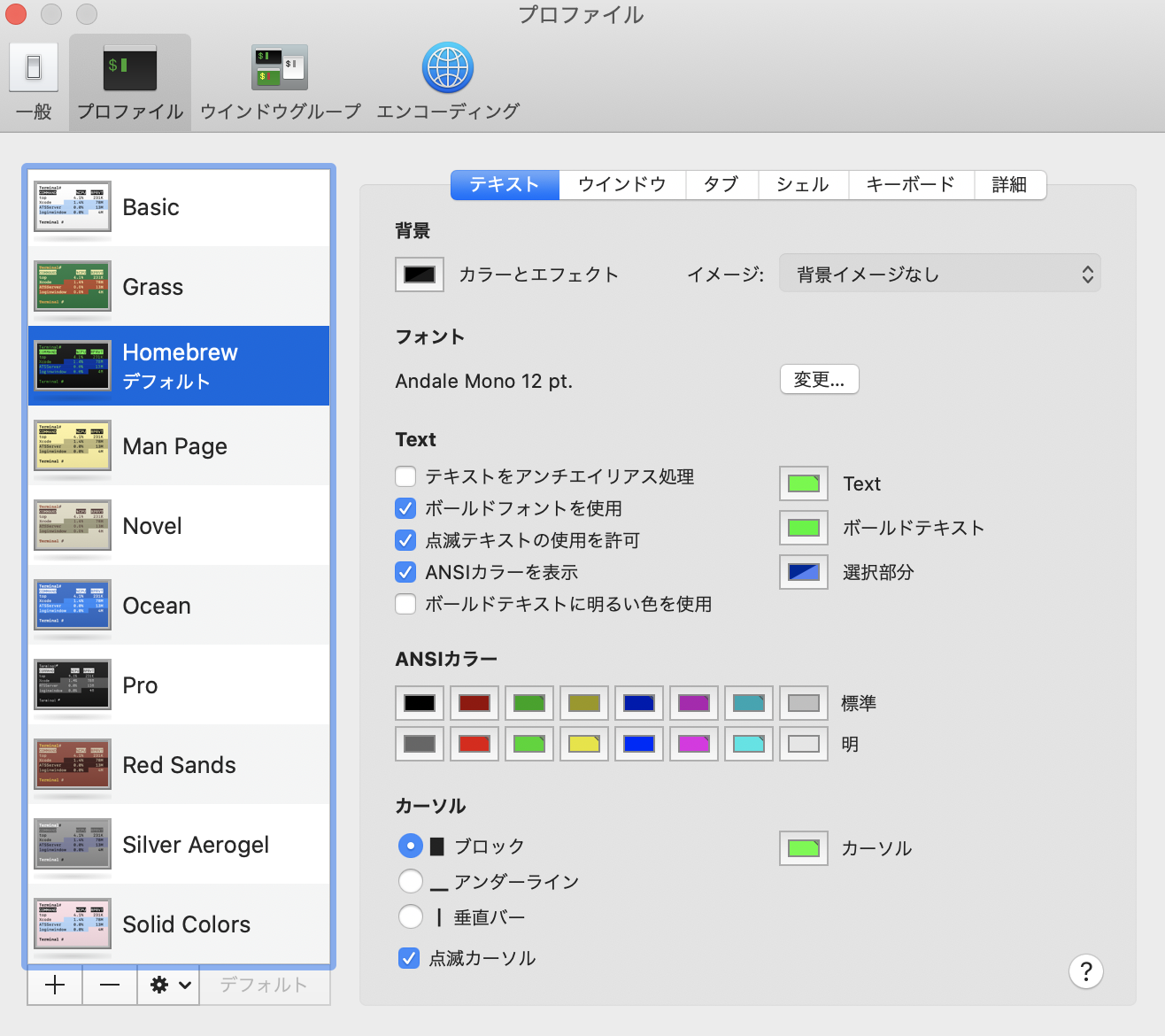
ターミナルの背景色を変更する
初期設定だと白地に黒で目が疲れるし落ち着かないので変更する(大体こういうのって黒地が多いイメージ)。
- Launchpadなどからターミナルを開く
- 画面左上のメニューから「ターミナル」->「環境設定」->「プロファイル」を選択する。
- 「テキスト」タブで自由に変更ができる。また画面左部にテンプレートがあるので、そちらから設定もできる(テンプレートを選択した場合、画面下部の「デフォルト」を選択する)。
Homebrew
mac用のパッケージ管理システム。
- こちらのサイトからインストールするためのコマンドをコピーし、ターミナルで実行する(インストールに少々時間がかかる)。 例.
$ /bin/bash -c "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/master/install.sh)"
- 下記コマンドを実行し、インストールが正常に完了したか確かめる。
$ brew --version Homebrew 2.5.Git
バージョン管理システム。
- 下記コマンドを実行し、gitをインストールする。
$ brew install git
- 下記コマンドを実行し、インストールが正常に完了したか確かめる。
$ git —-version git version 2.28.0※Gitアカウントを持っている場合は、下記コマンドでconfigに設定しておくといいかもしれない。
$ git config --global user.name "John Doe" $ git config --global user.email johndoe@example.comPython
インタープリタ型プログラミング言語。機械学習などでよく用いられる。
- 下記コマンドを実行する。
$ brew install python3
- 対話モードにて、実行確認を行う。なお、
exit()と入力すれば対話モードを終了できる。$ python3 >>> print("Hello world!") Hello world!ANACONDA
Data Scientist向けのPythonおよびR言語用のディストリビューション。
- こちらのページを開く。
- 画面を下の方にスクロールしていくと、下記スクリーンショットに行き着く。
- 赤枠で囲まれている
64-Bit Graphical Installer (462 MB)をクリックし、ダウンロードする。- インストールされた.pkgファイルをクリックし、案内にしたがってインストールを行う。
pip
Pythonで書かれたパッケージソフトウェアをインストール・管理するためのパッケージ管理システム。
- /usr/bin/easy_installがあるか確認する(大概、プレインストールされているはず)。
- コマンド例:
ls /usr/bin/easy_install- 下記コマンドを実行する。
sudo easy_install pip
- 実行確認を行う。
$ pip --version pip 20.2.3Visual Studio Code(以下、VSCode)
Microsoftが開発したエディタ。
- こちらを開く。
Download for Macをクリックし、ダウンロードする。- ダウンロードしたzipファイルを展開する。
- Visual Studio Codeと書かれたアプリケーションをアプリケーションフォルダにドラッグ&ドロップさせる。
VSCodeの設定について
普段、自分が開発するときに設定しているものを記載しておく。
- 事前にインストールしておくパッケージ。$ pip install flake8 $ pip install autopep8
VSCodeでの拡張機能
- Python
- Python for VSCode
- Python Docstring Generator
setting.json
{ "python.linting.pylintEnabled": false, "python.linting.flake8Enabled": true, "files.autoSave": "afterDelay", "files.autoSaveDelay": 1000, "python.linting.lintOnSave": true, "python.formatting.provider": "autopep8", "python.linting.flake8Args": [ "--ignore=E501", ], "python.formatting.autopep8Args": [ "--aggressive", "--aggressive", ], "autoDocstring.docstringFormat": "numpy", }終わりに
自分が何入れたか忘れない備忘録として記した。記載漏れなどあったら随時追記していきます。

- 投稿日:2020-09-18T17:43:08+09:00
[Python]pythonからcの関数を呼び出す方法(ctypes編)
pythonからcの関数を呼び出す方法(ctypes編)
pythonからcの関数を呼び出す方法はいくつかありますが、今回はctypesを使った方法を説明します。
実行環境はwindowsを使用しました。全体の手順は、以下のようになります。
1. Visual Studio でdllを作成する。
2. pythonから呼び出す1. Dllの作成
DLLはVisual Studioを使って作成します。
- Visual Studioを起動し、「Create a new project」を選択します。
- Dynamic-Link Library (DLL)を選択
- Project nameを入力(ctypes_sample1)
- Createボタンを押す
- Solution ExplorerのSource Filesで右クリックしAdd->New ItemからC++ File (.cpp)を選び、ファイル名を入力する。(ctypes_sample1.cpp)
- Solution ExplorerのHeader Filesで右クリックしAdd->New ItemからHeader File (.h)を選び、ファイル名を入力する。(ctypes_sample1.h)
- 関数を記述する
- Build->Build SolutionでDLLを作成する。
今回はVisual Studio 2019を使用しました。
ctypes_sample1.h
#pragma once #ifdef CTYPES_SAMPLE1_EXPORTS #define CTYPES_SAMPLE1_API __declspec(dllexport) #else #define CTYPES_SAMPLE1_API __declspec(dllimport) #endif struct Vector3D { int x; int y; int z; }; extern "C" CTYPES_SAMPLE1_API double add_double(double a, double b); extern "C" CTYPES_SAMPLE1_API int add_int(int a, int b); extern "C" CTYPES_SAMPLE1_API double accumulate(const double *x, int len); extern "C" CTYPES_SAMPLE1_API bool copy(const double *from, double *to, int n); extern "C" CTYPES_SAMPLE1_API bool copy2d(const double **from, double ** to, int m, int n); extern "C" CTYPES_SAMPLE1_API Vector3D AddVector(Vector3D a, Vector3D b);ctypes_sample1.cpp
#include"pch.h" #include "ctypes_sample1.h" double add_double(double a, double b) { return a + b; } int add_int(int a, int b) { return a + b; } double accumulate(const double* x, int len) { double sum = 0; for (int i = 0; i < len; i++) { sum += x[i]; } return sum; } bool copy(const double* from, double* to, int n) { for (int i = 0; i < n; i++) { to[i] = from[i]; } return true; } bool copy2d(const double** from, double** to, int m, int n) { for (int j = 0; j < n; j++) { for (int i = 0; i < m; i++) { to[j][i] = from[j][i]; } } return true; } Vector3D AddVector(Vector3D a, Vector3D b) { Vector3D v; v.x = a.x + b.x; v.y = a.y + b.y; v.z = a.z + b.z; return v; }2. pythonから呼び出す
作成したdllを.pyの直下に置きます。
関数の呼び出しは、以下の手順になります。
- ctypes.cdll.LoadLibraryでdllを読み込む
- argtypesで引数の型を設定する
- restypeで戻り値の型を設定する
参考URL:https://docs.python.org/3/library/ctypes.html
変数の場合
add_int
import ctypes mydll=ctypes.cdll.LoadLibrary('ctypes_sample1') addi=mydll.add_int addi.argtypes=(ctypes.c_int,ctypes.c_int) addi.restype=ctypes.c_int addi(1,2)3
add_doulbe
import ctypes mydll=ctypes.cdll.LoadLibrary('ctypes_sample1') addd=mydll.add_double addd.restype=ctypes.c_double addd.argtypes=(ctypes.c_double,ctypes.c_double) addd(1.1,2.1)3.2
ポインタの場合
引数に配列を渡す方法は、ctypesのarrayを使用するか、numpyを使用する方法があります。
一次元配列
ctypes array
ctypesで配列を作成する場合は*で配列の大きさを指定します。
c_int * 5
さらに配列のポインタがほしい場合は、ctypes.pointer()を使用します。
引数がポインタであることを示す場合は、ctypes.POINTER(ctypes.c_doulbe)のように大文字のPOINTERを使います。
import ctypes mydll=ctypes.cdll.LoadLibrary('ctypes_sample1') accumulate = mydll.accumulate accumulate.restype=ctypes.c_double accumulate.argtypes=(ctypes.POINTER(ctypes.c_double),ctypes.c_int) _arr1=[1.0,2.0,3.0,4.0] arr1 = (ctypes.c_double*len(_arr1))(*_arr1) accumulate(cast(pointer(arr1),ctypes.POINTER(ctypes.c_double)),len(arr1))10.0
import ctypes mydll=ctypes.cdll.LoadLibrary('ctypes_sample1') copy1d=mydll.copy copy1d.argtypes=(ctypes.POINTER(ctypes.c_double),ctypes.POINTER(ctypes.c_double),ctypes.c_int) copy1d.restype=ctypes.c_bool arr1 = (ctypes.c_double*10)(*range(10)) arr2 = (ctypes.c_double*10)(*([0]*10)) copy1d(cast(pointer(arr1),POINTER(ctypes.c_double)),cast(pointer(arr2),POINTER(ctypes.c_double)),len(arr1)) for i in range(len(arr1)): print('arr1[{0:d}]={1:.1f} arr2[{0:d}]={2:.1f}'.format(i,arr1[i],arr2[i]))arr1[0]=0.0 arr2[0]=0.0
arr1[1]=1.0 arr2[1]=1.0
arr1[2]=2.0 arr2[2]=2.0
arr1[3]=3.0 arr2[3]=3.0
arr1[4]=4.0 arr2[4]=4.0
arr1[5]=5.0 arr2[5]=5.0
arr1[6]=6.0 arr2[6]=6.0
arr1[7]=7.0 arr2[7]=7.0
arr1[8]=8.0 arr2[8]=8.0
arr1[9]=9.0 arr2[9]=9.0numpy array
numpyのデータを引数に渡す場合は、ctypes.data_as()を使って、ctypes objectのポインタを取得し引数に渡します。
参考URL: https://numpy.org/doc/stable/reference/generated/numpy.ndarray.ctypes.html
import ctypes import numpy as np mydll=ctypes.cdll.LoadLibrary('ctypes_sample1') accumulate = mydll.accumulate accumulate.restype=ctypes.c_double accumulate.argtypes=(ctypes.POINTER(ctypes.c_double),ctypes.c_int) arr1=np.array([1.0,2.0,3.0,4.0],dtype=np.float) accumulate(arr1.ctypes.data_as(ctypes.POINTER(ctypes.c_double)),len(arr1))10.0
import ctypes import numpy as np mydll=ctypes.cdll.LoadLibrary('ctypes_sample1') copy1d=mydll.copy copy1d.argtypes=(ctypes.POINTER(ctypes.c_double),ctypes.POINTER(ctypes.c_double),ctypes.c_int) copy1d.restype=ctypes.c_bool arr1=np.random.rand(10) arr2=np.zeros_like(arr1) copy1d(arr1.ctypes.data_as(ctypes.POINTER(ctypes.c_double)),arr2.ctypes.data_as(ctypes.POINTER(ctypes.c_double)),len(arr1)) for i in range(len(arr1)): print('arr1[{0:d}]={1:f} arr2[{0:d}]={2:f}'.format(i,arr1[i],arr2[i]))arr1[0]=0.062427 arr2[0]=0.062427
arr1[1]=0.957770 arr2[1]=0.957770
arr1[2]=0.450949 arr2[2]=0.450949
arr1[3]=0.609982 arr2[3]=0.609982
arr1[4]=0.351959 arr2[4]=0.351959
arr1[5]=0.300281 arr2[5]=0.300281
arr1[6]=0.148543 arr2[6]=0.148543
arr1[7]=0.094616 arr2[7]=0.094616
arr1[8]=0.379529 arr2[8]=0.379529
arr1[9]=0.810064 arr2[9]=0.810064二次元配列
ctypes array
二次元配列を渡す場合は、ポインタの配列を渡します。
import ctypes mydll=ctypes.cdll.LoadLibrary('ctypes_sample1') copy2d = mydll.copy2d copy2d.argtypes=((ctypes.POINTER(ctypes.c_double*5)*2),(ctypes.POINTER(ctypes.c_double*5)*2),ctypes.c_int,ctypes.c_int) copy2d.restype=ctypes.c_bool _arr1 = [ [1,2,3,4,5], [6,7,8,9,10] ] arr1=((ctypes.c_double*5)*2)() for j in range(2): for i in range(5): arr1[j][i] = _arr1[j][i] arr2=((ctypes.c_double*5)*2)() app1p=(ctypes.POINTER(ctypes.c_double*5)*2)() for j in range(2): app1p[j] = ctypes.pointer(arr1[j]) app2p=(ctypes.POINTER(ctypes.c_double*5)*2)() for j in range(2): app2p[j] = ctypes.pointer(arr2[j]) copy2d(app1p,app2p,5,2) for j in range(2): for i in range(5): print('arr1[{0:d},{1:d}]={2:f} arr2[{0:d},{1:d}]={3:f}'.format(j,i,arr1[j][i],arr2[j][i]))arr1[0,0]=1.000000 arr2[0,0]=1.000000
arr1[0,1]=2.000000 arr2[0,1]=2.000000
arr1[0,2]=3.000000 arr2[0,2]=3.000000
arr1[0,3]=4.000000 arr2[0,3]=4.000000
arr1[0,4]=5.000000 arr2[0,4]=5.000000
arr1[1,0]=6.000000 arr2[1,0]=6.000000
arr1[1,1]=7.000000 arr2[1,1]=7.000000
arr1[1,2]=8.000000 arr2[1,2]=8.000000
arr1[1,3]=9.000000 arr2[1,3]=9.000000
arr1[1,4]=10.000000 arr2[1,4]=10.000000numpy array
numpyの場合も、ポインタの配列を渡します。
ポインタの配列の型は、numpy.ctypeslib.ndpointerを使って作ります。dtypeはポインタなのでuintpを指定します。
arr1._array_interface_['data'][0]'で先頭のポインタを取得します。
arr1.strides[0]で1行移動したときのバイト数を取得します。import ctypes import numpy as np mydll=ctypes.cdll.LoadLibrary('ctypes_sample1') copy2d = mydll.copy2d _doublepp = np.ctypeslib.ndpointer(dtype=np.uintp, ndim=1, flags='C') copy2d.argtypes=(_doublepp,_doublepp,ctypes.c_int,ctypes.c_int) copy2d.restype=ctypes.c_bool arr1=np.random.rand(4*7).reshape(4,7) arr2=np.zeros_like(arr1) arr1pp = (arr1.__array_interface__['data'][0] + np.arange(arr1.shape[0])*arr1.strides[0]).astype(np.uintp) arr2pp = (arr2.__array_interface__['data'][0] + np.arange(arr2.shape[0])*arr2.strides[0]).astype(np.uintp) copy2d(arr1pp,arr2pp,arr1.shape[1],arr2.shape[0]) for j in range(arr2.shape[0]): for i in range(arr2.shape[1]): print('arr1[{0:d},{1:d}]={2:f} arr2[{0:d},{1:d}]={3:f}'.format(j,i,arr1[j,i],arr2[j,i]))arr1[0,0]=0.301684 arr2[0,0]=0.301684
arr1[0,1]=0.423735 arr2[0,1]=0.423735
arr1[0,2]=0.761370 arr2[0,2]=0.761370
arr1[0,3]=0.990014 arr2[0,3]=0.990014
arr1[0,4]=0.547852 arr2[0,4]=0.547852
arr1[0,5]=0.773549 arr2[0,5]=0.773549
arr1[0,6]=0.695525 arr2[0,6]=0.695525
arr1[1,0]=0.156089 arr2[1,0]=0.156089
arr1[1,1]=0.619667 arr2[1,1]=0.619667
arr1[1,2]=0.602623 arr2[1,2]=0.602623
arr1[1,3]=0.555263 arr2[1,3]=0.555263
arr1[1,4]=0.670706 arr2[1,4]=0.670706
arr1[1,5]=0.483012 arr2[1,5]=0.483012
arr1[1,6]=0.318976 arr2[1,6]=0.318976
arr1[2,0]=0.336153 arr2[2,0]=0.336153
arr1[2,1]=0.518378 arr2[2,1]=0.518378
arr1[2,2]=0.440815 arr2[2,2]=0.440815
arr1[2,3]=0.165265 arr2[2,3]=0.165265
arr1[2,4]=0.370611 arr2[2,4]=0.370611
arr1[2,5]=0.249356 arr2[2,5]=0.249356
arr1[2,6]=0.798799 arr2[2,6]=0.798799
arr1[3,0]=0.216579 arr2[3,0]=0.216579
arr1[3,1]=0.028188 arr2[3,1]=0.028188
arr1[3,2]=0.529525 arr2[3,2]=0.529525
arr1[3,3]=0.381811 arr2[3,3]=0.381811
arr1[3,4]=0.495189 arr2[3,4]=0.495189
arr1[3,5]=0.339180 arr2[3,5]=0.339180
arr1[3,6]=0.131087 arr2[3,6]=0.131087構造体を渡す場合
構造体を渡す場合はctypes.Structureを使用します。_fields_にメンバー変数の型を指定します。
import ctypes mydll=ctypes.cdll.LoadLibrary('ctypes_sample1') class VECTOR3D(ctypes.Structure): _fields_ = [("x", ctypes.c_int), ("y", ctypes.c_int), ("z", ctypes.c_int)] vector_a = VECTOR3D(1, 2, 3) vector_b = VECTOR3D(2, 3, 4) AddVector = mydll.AddVector AddVector.argtypes=(VECTOR3D,VECTOR3D) AddVector.restype = VECTOR3D vector_c = AddVector(vector_a, vector_b) print('x={},y={},z={}'.format(vector_c.x,vector_c.y,vector_c.z))x=3,y=5,z=7
- 投稿日:2020-09-18T17:03:32+09:00
EDFファイルの可視化について
Overview
このドキュメントはmneモジュールを用いたEDFファイルの可視化を行う方法について紹介するものです。この記事で紹介したすべてのプログラムはここからダウンロードできます。
Requirement
本ドキュメントでは次のバージョンのPython、モジュールを使用します。
Python 3.8.3 matplotlib 3.2.2 numpy 1.18.5 mne 0.20.0プログラムを理解するにあたり、Pythonの最低限の知識(for文、
listやtupleの操作)が必要になります。本文
このドキュメントではそれぞれの公式リファレンスの必要な部分のみ使っています。文中で紹介した各関数にはリンクが埋め込まれています。option等の詳しい部分については公式リファレンスを参照して下さい。
Step1 環境構築
linux(Ubuntu20.04 LTS)での環境構築について紹介します。既に用意されている場合、conda等の環境を使っている場合は適宜読み飛ばし・読み替えを行って下さい。$sudo apt install python3 $sudo apt install python3-pip $pip3 install matplotlib==3.2.2 $pip3 install numpy==1.18.5 $pip3 install mne==0.20Step2 EDFファイルのロード
EDFファイルをロードします。適当な場所にEDFファイルを配置してください。手元に扱えるEDFファイルがない場合は、サンプルのデータをgithub等からダウンロードできます。mneモジュールではmne.io.read_raw_edfでEDFファイルのロードを行うことができます。
input:import matplotlib.pyplot as plt import mne import numpy as np EDF_NAME = 'edf_name.edf' data=mne.io.read_raw_edf(EDF_NAME) print(type(data)) print(data)output:
<class 'mne.io.edf.edf.RawEDF'> <RawEDF | test_generator.edf, 11 x 120000 (600.0 s), ~26 kB, data not loaded>Step3 infoの取得
EDFファイルが持つ基本的な情報を取得します。
input:import matplotlib.pyplot as plt import mne import numpy as np EDF_NAME = 'edf_name.edf' data=mne.io.read_raw_edf(EDF_NAME) print(type(data.info)) print(data.info)output:
<class 'mne.io.meas_info.Info'> <Info | 7 non-empty values bads: [] ch_names: squarewave, ramp, pulse, noise, sine 1 Hz, sine 8 Hz, sine ... chs: 11 EEG custom_ref_applied: False highpass: 0.0 Hz lowpass: 100.0 Hz meas_date: 2011-04-04 12:57:02 UTC nchan: 11 projs: [] sfreq: 200.0 Hz >
infoの特定の情報を参照したいときは、dictライクに表記できます。
input:import matplotlib.pyplot as plt import mne import numpy as np EDF_NAME = 'edf_name.edf' data=mne.io.read_raw_edf(EDF_NAME) print(data.info['sfreq'])output:
200.0Step4 EEGの表示
mneモジュールには、GUIで操作できるグラフを描画する機能があります。生成したインスタンスのplotメソッドを単に呼び出すだけです(option等は公式リファレンスを参照して下さい)。下の図のようなグラフが描画されます。この図は時間軸や表示するチャンネル等をGUIで操作できます。教師データ等のデータを作るときには向きませんが、データの中身をとりあえず確認したい、というような状況には非常に有効です。
input:import matplotlib.pyplot as plt import mne import numpy as np EDF_NAME = 'edf_name.edf' data=mne.io.read_raw_edf(EDF_NAME) data.plot() plt.show()output:
Step5 波形のロード
波形の
ndarrayはget_dataで取得することができます。波形のndarrayは(チャンネル数,サンプリング数)の形になっています。特定の列のみ抽出したいとき、例えば0~1(s)の波形のみ抽出したい場合、data_eeg[:,:int(data.info['sfreq'])].shapeのようにndarrayのスライスを使って表現することができます。get_dataメソッドのoptionで開始/終了時刻を指定することができますが、一括でデータを確保して、必要なもののみスライスで取り出していくほうが(多分)高速です。
input:import matplotlib.pyplot as plt import mne import numpy as np EDF_NAME = 'edf_name.edf' data=mne.io.read_raw_edf(EDF_NAME) data_eeg=data.get_data() print(type(data_eeg)) print(data_eeg.shape) print(data_eeg)output:
<class 'numpy.ndarray'> (11, 120000) [[ 9.99923705e-05 9.99923705e-05 9.99923705e-05 ... -9.99618524e-05 -9.99618524e-05 -9.99618524e-05] [-9.99618524e-05 -9.89547570e-05 -9.79781796e-05 ... 9.70016022e-05 9.80086976e-05 9.89852750e-05] [ 9.99923705e-05 9.99923705e-05 9.99923705e-05 ... 1.52590219e-08 1.52590219e-08 1.52590219e-08] ... [ 4.53955901e-05 8.08880751e-05 9.87716487e-05 ... -8.08575570e-05 -4.53650721e-05 1.52590219e-08] [ 5.09193561e-05 8.76325628e-05 9.99618524e-05 ... -8.76020447e-05 -5.08888380e-05 1.52590219e-08] [ 9.99923705e-05 1.52590219e-08 -9.99618524e-05 ... 1.52590219e-08 -9.99618524e-05 1.52590219e-08]]Step6 教師データ化
Step5でロードした脳波信号を機械学習で与えることができるフォーマットに変換していきます。ラベル付をするにあたり、脳波信号を適当なウィンドウで区切り、区切ったそれぞれのデータにラベル付けを行います。ラベル付けは、データセットによって参照する方法が異なると思うので、それぞれのフォーマットに従って下さい。ウィンドウで区切ったデータは
matplotlib.pyplot内のplot()メソッドを用いることでグラフとして描画することができます。CNNに渡すための教師データとして画像を渡す場合と画像の画素値の配列を渡す場合の2パターンについて紹介します。(1) 画像を保存
画像を保存する場合は単に
matplotlib.pyplot内のsavefigメソッドを用います。for文を回してウィンドウを区切り、その都度画像化していきます。
input:import matplotlib.pyplot as plt import mne import numpy as np import os EDF_NAME='edf_name.edf' data=mne.io.read_raw_edf(EDF_NAME) data_eeg=data.get_data() freq=data.info['sfreq'] for j in range(int(data_eeg.shape[1]/freq)): data_window=data_eeg[:,j*freq:(j+1)*freq] plt.clf() fig=plt.figure(dpi=100,figsize=(3,3),tight_layout=True) plt.gca().xaxis.set_visible(False) plt.gca().yaxis.set_visible(False) plt.tick_params(labelbottom=False, labelleft=False, labelright=False, labeltop=False) for i,k in enumerate(data_window): plt.plot(k+0.00010*i,color='black',linewidth=1) plt.ylim(-0.001,0.0015) plt.savefig('../img/'+os.path.splitext(os.path.basename(EDF_NAME))[0]+'/'+os.path.splitext(os.path.basename(EDF_NAME))[0]+'-'+str(j)+'.jpg')output:
下のような画像が../img/ (file name) / (file name)-(枚目).jpgに測定時間分の枚数生成されます。(../img/ (file name)のディレクトリは予め作成しておいて下さい。)
(2) 画素の配列を保存
画像の画素値を
numpy配列として保存する場合は、matplotlibのcanvas.renderer.buffer_rgbaを用いて画素を配列として保存します。imとして返されるndarrayは(300,300,4)の形です。4番目の要素は透明度を表すので、1~3番目のみスライスして抽出しています。input:
import numpy as np import mne from PIL import Image from matplotlib import pyplot as plt data=mne.io.read_raw_edf('edf_name.edf') data_eeg=data.get_data() freq=int(data.info['sfreq']) data_window=data_eeg[:,0*freq:1*freq] fig=plt.figure(dpi=100,figsize=(3,3),tight_layout=True) plt.gca().xaxis.set_visible(False) plt.gca().yaxis.set_visible(False) plt.tick_params(labelbottom=False, labelleft=False, labelright=False, labeltop=False) for i,k in enumerate(data_window): plt.plot(k+0.00010*i,color='black',linewidth=1) plt.ylim(0,0.0015) fig.canvas.draw() im = np.array(fig.canvas.renderer.buffer_rgba()) #imのshapeは(300,300,4) #4番目の要素は透明度のためスライス rgb_arr = im[:,:,:3] #rgb_arrのshapeは(300,300,3) #テストとしてrgb_arrから画像を表示してみる made_img = Image.fromarray(rgb_arr) made_img.show()output:
次のような画像が表示されます。正しく画素の値が
ndarrayに変換できているのがわかるかと思います。
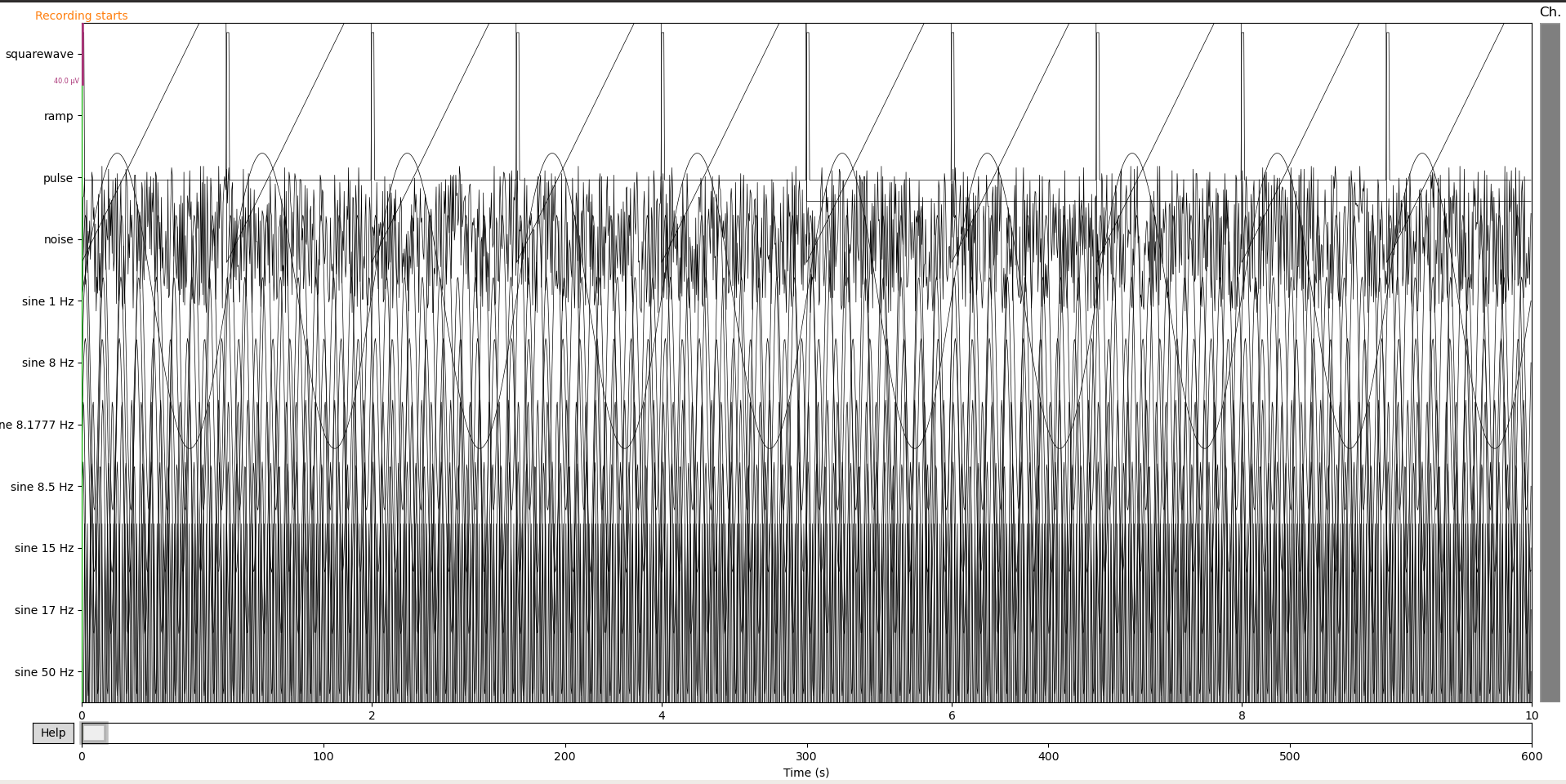
- 投稿日:2020-09-18T16:40:17+09:00
Django(Python)アプリをDockerで環境構築したメモ
はじめに
- Python,Djangoのwebフレームワークを学びたかったが、環境構築が複雑だったため、仮想環境で立ちあげることにした。
- 基本はDockerの公式ページ通りだが、公式通り書くとエラーがおきるため、一部修正した
- 公式はDjango × Postgresの構成
環境
- Docker on Mac
手順(準備と立ち上げ)
- プロジェクト用のディレクトリを作成し、移動。 ここではlinebotというアプリ名で進める。
MacBook-Air ~ % mkdir jinolinebot MacBook-Air ~ % cd jinolinebot MacBook-Air jinolinebot %
- Dockerfileを作成し、エディターで開く。
MacBook-Air jinolinebot % touch Dockerfile
- Dockerfileを編集し、保存。
DockerfileFROM python:3 ENV PYTHONUNBUFFERED 1 RUN mkdir /code WORKDIR /code ADD requirements.txt /code/ RUN pip install -r requirements.txt ADD . /code/
- requirements.txt を作成し、以下のように編集する
MacBook-Air jinolinebot % touch requirements.txtrequirements.txtDjango>=1.8,<2.0 psycopg2
- docker-compose.ymlを作成し、以下のように編集する
MacBook-Air jinolinebot % touch docker-compose.ymldocker-compose.ymlversion: '3' services: db: image: postgres environment: - POSTGRES_DB=postgres - POSTGRES_USER=postgres - POSTGRES_PASSWORD=postgres web: build: . command: python3 manage.py runserver 0.0.0.0:8000 volumes: - .:/code ports: - "8000:8000" depends_on: - db
- これで3つのファイルが準備が完了したのでアプリを立ち上げる。
MacBook-Air jinolinebot % docker-compose run web django-admin.py startproject アプリ名 Creating network "jinolinebot_default" with the default driver Building web Step 1/7 : FROM python:3 ---> 28a4c88cdbbf ~ Creating jinolinebot_db_1 ... done Creating jinolinebot_web_run ... done
- 立ち上がったら、次はデータベースへの接続設定をおこなう さきほどのコマンドで生成された設定ファイルの中を以下のように編集し、保存。
アプリ名/settings.py~ DATABASES = { 'default': { 'ENGINE': 'django.db.backends.postgresql', 'NAME': 'postgres', 'USER': 'postgres', 'PASSWORD': 'postgres', 'HOST': 'db', 'PORT': 5432, } } ~
- コンテナを立ち上げ、以下の表示が一番したに表示されたら、http://0.0.0.0:8000/にアクセス
MacBook-Air jinolinebot % docker-compose up ~ Starting development server at http://0.0.0.0:8000/ web_1 | Quit the server with CONTROL-C.
- It worked! Congratulations on your first Django-powered page.と表示されたら成功.
参考文献
- 投稿日:2020-09-18T16:16:33+09:00
SPSS Modelerの重複レコード・ノードをPythonで書き換える。①最初に購入したアイテムの特定。②商品カテゴリ内の売上1位アイテムの特定
SPSS Modelerで重複レコードをまとめるのが重複ノードです。この重複ノードを解説するとともに、Pythonのpandasで書き換えてみます。
重複ノードは、文字通り完全に重複したレコードを削除することにも使えますが、Modelerで使う場合には、グループ化したなかでの1番目のレコードを取得するために使うことが多いと思います。
そのためここではID付POSデータをつかって、以下の2つのユースケースで解説します。
①最初に購入したアイテムの特定
②商品カテゴリ内の売上1位アイテムの特定0.元データ
以下のID付POSデータを対象に行います。
誰(CUSTID)がいつ(SDATE)何(PRODUCTID、L_CLASS商品大分類、M_CLASS商品中分類)をいくら(SUBTOTAL)購入したかが記録されたID付POSデータを使います。6フィールド、28,599件あります。
1m.①最初に購入したアイテムの特定 Modeler版
最初に購入したものでその後の購買行動がわかってくることがあったりします。最初にある商品を買った人は優良顧客になりやすい、ある商品を買った人は2度目の購入がなく離反しやすいというような商品の特性がみえてくれば、優良顧客になりやすい商品が目立つような棚割りやバナー配置をするなどの方策を考えることができます。
ID付POSのデータからCUSTID毎に最初の購入トランザクションを抽出してみます。
重複レコードノードのモードを「各グループの最初のレコードだけを含める」にします。
グループ化のキーフィールドはCUSTIDのみにします。これによって一つのCUSTIDに対して1レコードだけを抽出します。
「グループ内でレコードをソート」でSDATEを昇順で指定します。これでCUSTID毎にもっとも古いトランザクションが選ばれます。
結果は以下のようになります。
100001番のCUSTIDの人が一番最初に購入したのはBAG01の9937845という商品でした。
1p.①最初に購入したアイテムの特定 pandas版
pandasで重複行を1行にまとめる場合はsort_valuesとdrop_duplicates関数を使います。
まずsort_valuesで’CUSTID'毎にSDATE順に並べ替えをします。
そしてdrop_duplicatesで各CUSTID毎に先頭行のみを抽出します。subsetで’CUSTID'のみで重複を検出することがポイントです。#CUSTIDとSDATEでソート df_sorted=df.sort_values(['CUSTID','SDATE']) #CUSTID毎に先頭行を抽出 df_sorted.drop_duplicates(subset='CUSTID')
- 参考
- pandas.DataFrame, Seriesの重複した行を抽出・削除 | note.nkmk.me
- https://note.nkmk.me/python-pandas-duplicated-drop-duplicates/
2m.②商品カテゴリ内の売上1位アイテムの特定 Modeler版
重複レコードノードはレコード集計ノードと合わせて、集計結果の中のナンバーワンやワーストワンのレコードを抽出することにもよく使います。
ここではBAG、COSMETICS、SHOESの商品大分類内で最も売り上げの大きい商品を抽出してみます。
まず、レコード集計でL_CLASSとPRODUCTIDでグループ化して、SUBTOTALの合計を計算します。
これで商品ごとの総売り上げ額が計算されました。
次に重複ノードで以下のように設定します。
モードを「各グループの最初のレコードだけを含める」にします。
グループ化のキーフィールドはL_CLASSのみにします。これによって一つのL_CLASSに対して1レコードだけを抽出します。
「グループ内でレコードをソート」でSUBTOTAL_Sumを昇順で指定します。これでL_CLASS毎にもっとも売り上げの大きい商品が選ばれます。
結果は以下のようになります。
BAGの中で一番売れたのはの9900307という商品で、1,781,615円の売上がありました。
2p.②商品カテゴリ内の売上1位アイテムの特定 pandas版
pandasで集計結果からナンバーワンを抽出する場合はgroupby、sort_values、drop_duplicates関数を使います。Modelerで集計ノード、重複レコードノードを使うのと同じ処理になります。
まずgroupbyでL_CLASSとPRODUCTIDでグループ化して、SUBTOTALの合計を計算します。
次にsort_valuesで’L_CLASS'毎に'SUBTOTAL'の大きい順に並べ替えをします。
そしてdrop_duplicatesで各L_CLASS毎に先頭行のみを抽出します。#大分類とPRODUCTIDで売上合計算出 df_sum=df[['L_CLASS','PRODUCTID','SUBTOTAL']].groupby(['L_CLASS','PRODUCTID'],as_index=False).sum() #大分類内で売上順にソート df_sum_sorted=df_sum.sort_values(['L_CLASS','SUBTOTAL'],ascending=[True,False]) #大分類の先頭行を抽出 df_sum_sorted.drop_duplicates(['L_CLASS'])以下のように抽出できました。
- 参考
- Pandas の groupby の使い方 - Qiita
- https://qiita.com/propella/items/a9a32b878c77222630ae
3. サンプル
サンプルは以下に置きました。
ストリーム
https://github.com/hkwd/200611Modeler2Python/raw/master/distinct/distinct.str
notebook
https://github.com/hkwd/200611Modeler2Python/blob/master/distinct/distinct.ipynb
データ
https://raw.githubusercontent.com/hkwd/200611Modeler2Python/master/data/sampletranDEPT4en2019S.csv■テスト環境
Modeler 18.2.1
Windows 10 64bit
Python 3.6.9
pandas 0.24.14. 参考情報
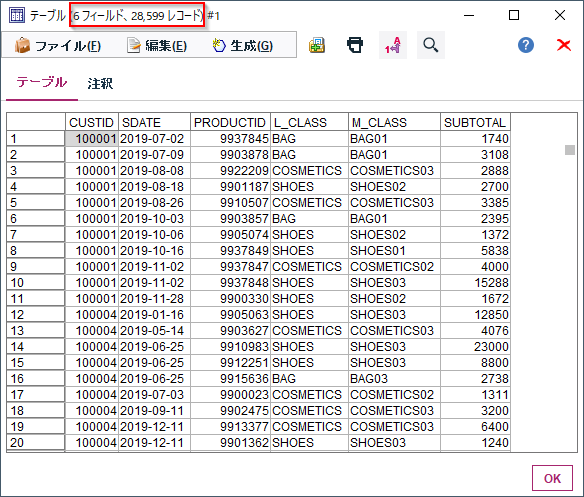
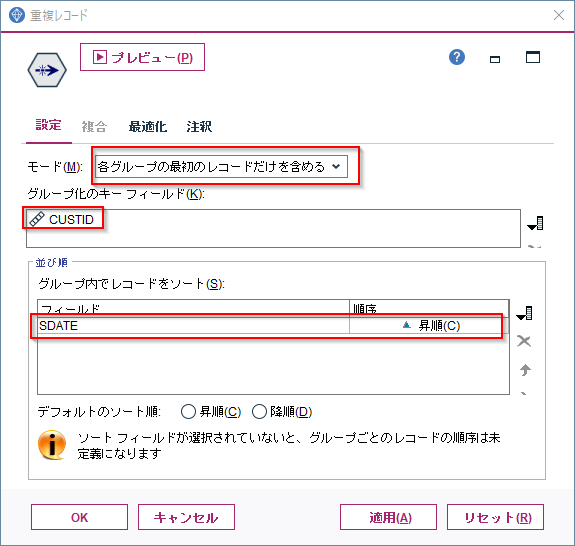
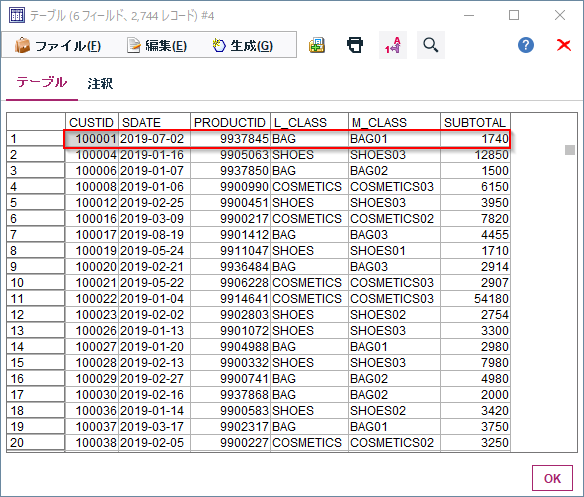
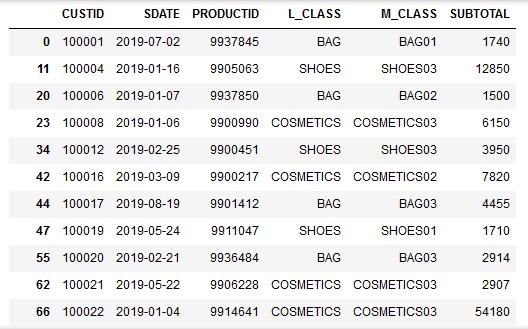

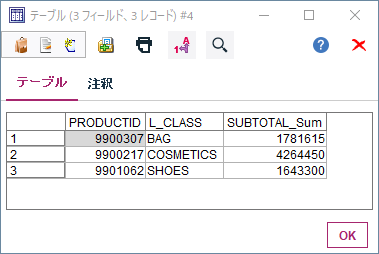
- 投稿日:2020-09-18T15:45:23+09:00
【Python anywhere】 でデプロイした、ディレクトリ?の中身気になりませんか❓ Python 初心者向け (2020年9月)
python anywhereでデプロイ ?(part2へ)https://qiita.com/iwasaki-hub/items/241ede0367d0d9a4a9d7
その前に、
Web フレームワークは、いくつかのディレクトリとファイルで構成されています!
Python ➡ Django (web フレームワーク) に限らず、
Ruby ➡ Ruby on Rails
JavaScript ➡ React
PHP ➡ Laravel
も同様です!

実は、言語は違えどすべてに共通していることがあります!
それが " M・V・Cモデル " を基本構造にしているということです?!!
MVCモデル❓❓と思われた方も多いと思います!
これを理解すれば、フレームワークの理解度がグッと増すので、
しかもどのフレームワークにも応用がきくので是非、学んでみてください
このことについても、近日公開するので興味のある方は、ぜひJunm in!
してください(^_-)-☆
?????
それでは、中身を覗いてみましょう?
今回は、ハンズオン?で進めていきましょう!
1、[Files] をクリックします。
2、Directories の mysite/ (もしくは、自分で作った ディレクトリ名/ )をクリック。
➡クリック後に、表示されているのがディレクトリ内の構造です!
Files にある manage.pyはDjangoに備わっている便利な機能が記されています。3、さらに Directories の mysite/ (もしくは、自分で作った ディレクトリ名/ )をクリックします。
➡ここがブラウザに表示されている見た目を司る部分になります。
それぞれに役割があります。
urls.py は、クライアントからのリクエストを受け取る場所。
settings.py は、設定(言語、時刻など)にかかわる場所。
wsgi.py は、内部での複雑な処理を準備する場所。と、認識していただければ大丈夫です!
近日公開 ➡ MVCモデル(part4)?

- 投稿日:2020-09-18T14:50:15+09:00
GPUありなしでの、画像キャプチャー・OpenCV速度比較
概要
最近、PCを新調しました。
以前、OpenCVで遊んでいたとき、画像処理のfpsが10fps程度しか出なくて、微妙だな~と思っていたので、PCを変えてどんな感じになったのか調べようと思います。
ついでにGPUについて、GTX1660superとIntel内蔵グラフィックで比較します。すでに、たぶん誰かやってると思うのですが、見つからなかったので書いてます。
ほかに同じことをしている記事があったら教えてください。読みたい。環境
- Python3 (anaconda3導入-Spyderで実行)
- Windows 10 Home 64bit
比較対象PCスペック
旧PC
- core i5-6200U @2.3GHz 2core-4threads
- Intel HD Graphics 520
- 12GBメモリ
- SSD
新PC-内蔵GPU
- core i9-9900k @3.6GHz 8core-16threads
- Intel HD Graphics 630
- SSD
新PC-GPU
- core i9-9900k @3.6GHz
- Zotac GTX1660-super
- SSD
Cine-bench R20 結果
PC ベンチ結果 旧PC 613 新PC-内蔵GPU 4741 新PC-GPU 4839 GPUには全く依存しません。
FFXV_bench
1920*1080,標準品質
PC ベンチ結果 旧PC 547:動作困難 新PC-内蔵GPU 708:動作困難 新PC-GPU 8379:快適 メモリがギリギリなのと、GPUがないと全然だめですね
画像キャプチャー bench
画像キャプチャー(mssライブラリ利用)
mss というライブラリの中で画面キャプチャができます。
pip install mssが必要です。
time というライブラリで経過時間$[s]$を取得します。
1000回画面をキャプチャするのにかかった時間を比較します。
どこにボトルネックがあるかはわかりません。画像取得をせずに$while$ループさせると秒レベルでは計測できなかったので、画像キャプチャー部分sct.grab(monitor)に時間がかかっているので間違いないと思います。
PC 秒 旧PC 16.7(60fps) 新PC-内蔵GPU 16.7(60fps) 新PC-GPU 16.7(60fps) PCに接続しているディスプレイのリフレッシュレートが59.94Hzに設定されているため、こうなったと予想されます。
capture_test.pyimport cv2 # OpenCVライブラリ import numpy as np # Numpyライブラリ from mss import mss import time sct = mss() """ 動作確認用:動作確認後はコメントアウト """ #windowName = "capture" #cv2.namedWindow(windowName) n= 0 while True: if n == 0: start_time = time.time() if n>= 1000: #1000回 繰り返した end_time = time.time() break """ 画像取得 """ monitor = {"top": 300, "left": 170, "width": 600, "height": 200} img = np.array(sct.grab(monitor)) """ 動作確認部 """ """ img = img[:,:,0:3] img = cv2.cvtColor(img, cv2.COLOR_RGB2BGR) img = np.asarray(img) cv2.imshow(windowName,img) key = cv2.waitKey(1) if key ==ord('q'): # end 処理 break """ n = n+ 1 cv2.destroyAllWindows() img[0][0][0] = 1 #一回も使わないと、ダメかなと思い追加 print(end_time-start_time)画像キャプチャー(pyautoguiライブラリ利用)
有名なライブラリ"pyautogui"でやってみます。
PC 秒 旧PC 68.1(15fpsに近い) 新PC-内蔵GPU 34.1(30fpsに近い) 新PC-GPU 33.4(30fpsに近い) 15,30,60fpsとPCの性能に合わせて切りのいい数になるよう調整している可能性があります。
mssと比べて、GPU,CPUともに負荷が少し高くなりました。キャプチャー範囲の影響はほぼなかったです。どのPCでも負荷率は上限から余裕があるので、なぜ性能差が出るのか不思議です。ただ、旧PCの15fpsは流石に低すぎて使いにくいです。
capture_test_pyautogui.pyimport cv2 # OpenCVライブラリ import numpy as np # Numpyライブラリ import pyautogui import time """ 動作確認用:動作確認後はコメントアウト """ """ windowName = "capture" cv2.namedWindow(windowName) """ monitor = {"top": 300, "left": 170, "width": 600, "height": 600} n= 0 while True: if n == 0: start_time = time.time() if n>= 1000: #100回 繰り返した end_time = time.time() break """ 画像取得 """ home = pyautogui.screenshot(region=(0,0,600,200)) img = np.asarray(home) img = cv2.cvtColor(img, cv2.COLOR_RGB2BGR) """ 動作確認部 """ """ img = img[:,:,0:3] img = cv2.cvtColor(img, cv2.COLOR_RGB2BGR) img = np.asarray(img) cv2.imshow(windowName,img) key = cv2.waitKey(1) if key ==ord('q'): # end 処理 break """ n = n+ 1 cv2.destroyAllWindows() img[0][0][0] = 1 #一回も使わないと、ダメかなと思い追加 print(end_time-start_time)OpenCV bench
試してみたい関数を列挙します。
- $cv2.matchTemplate$
- $cv2.circle$
- カメラキャプチャ(使用カメラは30fps)
- $cv2.imshow$
- $cv2.minMaxLoc$
基本的に、画像認識をしたいのでこんな感じです。
cv2.imshow
"同じ"画像を繰り返し表示するので、”違う画像”ではちょっと違う結果になるかもしれません。
画像の大きさに大きく影響を受けていました。
CPU負荷が高い気がします
画像サイズ100*100
PC 秒 旧PC 新PC-内蔵GPU 0.015~0.017 新PC-GPU 0.017
画像サイズ300*300
PC 秒 旧PC 新PC-内蔵GPU 0.08 新PC-GPU 0.083~0.084
画像サイズ800*800
PC 秒 旧PC 新PC-内蔵GPU 1.20~1.23 新PC-GPU 1.11~1.13
画像サイズ2000*2000
PC 秒 旧PC 新PC-内蔵GPU 8.5~8.9 新PC-GPU 8.0~8.2 結果
- GPUの影響はほぼなく、CPU依存
- 画面サイズの影響を強く受ける
ベンチコード
opencv_imshow.pyimport cv2 # OpenCVライブラリ import numpy as np # Numpyライブラリ import time windowName = "capture" cv2.namedWindow(windowName) img = np.zeros((2000,2000,3)) n= 0 while True: if n == 0: start_time = time.time() if n>= 1000: #100回 繰り返した end_time = time.time() break cv2.imshow(windowName,img) """ #動作テスト key = cv2.waitKey(1) if key ==ord('q'): # end 処理 break """ n = n+ 1 cv2.destroyAllWindows() img[0][0][0] = 1 #一回も使わないと、ダメかなと思い追加 print(end_time-start_time)cv2.circle
PC 秒 旧PC 0.0239~0.0269 新PC-内蔵GPU 0.012 新PC-GPU 0.013 全然負荷はかからないようです。
opencv_circle.pyimport cv2 # OpenCVライブラリ import numpy as np # Numpyライブラリ import time windowName = "capture" cv2.namedWindow(windowName) img = np.zeros((500,500,3)) n= 0 while True: if n == 0: start_time = time.time() if n>= 1000: #100回 繰り返した end_time = time.time() break cv2.circle(img, (int(n*0.5),50), 10, (0, 0, 255), 4) """ 動作確認部 """ """ cv2.imshow(windowName,img) key = cv2.waitKey(1) if key ==ord('q'): # end 処理 break """ n = n+ 1 cv2.destroyAllWindows() img[0][0][0] = 1 #一回も使わないと、ダメかなと思い追加 print(end_time-start_time)cv2.matchTemplate
この処理は一番処理が重いイメージがあります。
また、画像サイズの影響を強く受けました。
PC 100回実行するのにかかった秒 旧PC 新PC-内蔵GPU 新PC-GPU 4.413 import cv2 # OpenCVライブラリ import numpy as np # Numpyライブラリ import time windowName = "capture" cv2.namedWindow(windowName) x = 100 y = 100 depth = 3 img = np.zeros((1000,1000,depth),dtype = np.uint8) object1 = np.random.randint(0,255,(x,y,depth),dtype = np.uint8) n= 0 while True: if n == 0: start_time = time.time() if n>= 100: #100回 繰り返した end_time = time.time() break img_ccoeff = cv2.matchTemplate(img, object1, cv2.TM_CCOEFF_NORMED) n = n+ 1 cv2.destroyAllWindows() print(end_time-start_time)カメラキャプチャ(使用カメラは30fps)
cv2.minMaxLoc
PC 1000回実行するのにかかった秒 旧PC 新PC-内蔵GPU 新PC-GPU 0.255 まったく時間がかかっていないことがわかります。
minmaxLoc_bench.pyimport cv2 # OpenCVライブラリ import numpy as np # Numpyライブラリ import time windowName = "capture" cv2.namedWindow(windowName) x = 100 y = 100 depth = 3 img = np.zeros((1000,1000,depth),dtype = np.uint8) object1 = np.random.randint(0,255,(x,y,depth),dtype = np.uint8) img_ccoeff = cv2.matchTemplate(img, object1, cv2.TM_CCOEFF_NORMED) n= 0 while True: if n == 0: start_time = time.time() if n>= 1000: #100回 繰り返した end_time = time.time() break cMin, cMax1, pMin, pMax1 = cv2.minMaxLoc(img_ccoeff) n = n+ 1 cv2.destroyAllWindows() print(end_time-start_time)すみません.dbdが楽しすぎてそれどころではなくなったので,とりあえず今はこれで公開して,余裕のある時に更新します.
- 投稿日:2020-09-18T14:38:33+09:00
【Python学習中】 4桁のパスコードを総当たりするのに、何秒かかるのか randint/for/time/
やりたいこと
手元のiPhoneをみていたら、4桁のパスコードロックはどのくらいで破られるのかが気になりました。
さっと計算すると、「0000」から「9999」まで、10の4乗で10000通りの組み合わせがあるはず。
これをPythonをつかって総当たりしていくと、一体何秒でパスコードを見破れるのかを測ってみました。「8400rpm。420馬力
あなたがこの文章を読み終える時間で
時速100kmまで加速する。」
10年前くらいの自動車雑誌に掲載されていた、BMW M3クーペの宣伝文句です。果たしてそれよりも早いのか、遅いのか。
BMW M3クーペと勝負!背景
・Python初習者です。
・基本的なことは学んだが、どう応用して良いかわからず、仕事で使うわけでもなく、モチベーション低下気味です。考え方
・4桁のPINコードは、銀行の暗証番号やスマホのロック画面でよく使われる0から9の数字を4桁に組み合わせて使うものを想定。
・PINコードはわからない前提で、ランダム関数を使ってランダムに生成。
・「0000」から「9999」まで総当たりで試していき、マッチした場合に「iPhone unlocked」というメッセージを表示することにする。コード
pin_code_breaker.pyfrom random import randint import time pin_n = randint(0, 9999) def iphone_unlock(pin_n): for i in range(0, 9999): print(format(i, '04')) if i == pin_n: print(f"PIN is {pin_n}, iPhone unlocked.") break else: print('Process finished.') start = time.time() iphone_unlock(pin_n) elapsed_time = time.time() - start print(f"elapsed time: {elapsed_time}")考察
・0000から総当たりでマッチングを試していくので、生成されたPINコードが若い(0000に近い)ほど処理時間は短く、大きいほど(9999に近い)処理時間が長くなる。
・しかし、長くても3秒以内には処理が終わる。
・4桁のパスワードそのものは無防備であることがわかった。
- 投稿日:2020-09-18T13:27:06+09:00
素数生成プログラム
中身のないprime.txtを別途用意してください。
prime.pyimport math num = 3 #探索を開始する数 prime = [2] #素数に2を追加 prm_cnt = 1 #発見した素数をカウントする変数 prime_cnt = 100000000000 #loop回数 pfile = 'prime.txt' #発見した素数を書き込むファイル #################################################################### #Function Description: 前回実施した素数リストのファイル読込関数 #################################################################### def load_prime(): global prm_cnt global prime global num file_data = open(pfile, "r")#ファイル読み込み print("!! load start !!\n") for line in file_data: print("・") prime.append(int(line)) num = int(line) print("!! load end !!\n") file_data.close() prm_cnt = len(prime) #################################################################### #Function Description: 素数を発見したらフラグを立てる関数 #Arg1: 素数か判定する数 これまで出現してきた素数で割って余りが出ないかチェック #Arg2: これまでに発見された素数の数 #Arg3: 素数のリスト 関数外から参照可能 #Return: 素数判定FLAG #################################################################### def prime_func(num ,prm_lp, prm ): cnt = 0 ret = "FALSE" for j in range(0,prm_lp): rem = num % prm[j] if rem == 0: cnt = 1#FALSE break if cnt == 0: prm_lp = prm_lp + 1#新しい素数をカウント、次の素数発見のための割り算回数が1増える prm.append(num)#新しい素数をリストに追加 ret = "TRUE" return ret #################################################################### #Function Description: 素数探索 #################################################################### def calc_prime(): global prime global prm_cnt global num pfile = 'prime.txt' E_OK = "TRUE" for i in range(0,prime_cnt): num = num + 2 #奇数の中にしか素数はないため2ずつ探索 ret = prime_func( num, #素数か判定する数 prm_cnt, #素数の発生した数 prime #素数のリスト ) if E_OK == ret: #素数発見 print(str(prime[len(prime)-1]) ) prm_cnt = prm_cnt + 1 out_file = open(pfile,'a') out_file.write(str(num) + "\n") out_file.close() #print(prime) #################################################################### #Function Description: main関数 #################################################################### def Main(): load_prime() calc_prime() if __name__=="__main__": Main()
- 投稿日:2020-09-18T13:24:04+09:00
【MNIST】自分の数字をAIに認識させよう
1. はじめに
mnisterツールを作成しました。このツールで自分の手書き数字をAIに認識させることができます。
2. なぜ
mnisterツールを作ったのか
MNISTを利用した数字認識モデルを作って「認識精度が99%だった、スゲー!」
「………………ん??………………でっ!?」ってなりますよね?AIって何ぞやから始まって色々とモデルを作るために様々な知恵熱を絞り出して作りだした俺のMNISTモデル。そのやっとこ出来上がったモデルを「他人が用意したテストデータで、認識精度を確認して終わり!」とするのは、どうも納得できませんでした。3.
mnisterツールで遊ぼうということで、精魂込めて自分で作りあげた
俺のMNISTモデルの効果を簡単に確認できるツールを作ってみました。自分の手書き文字が正しく認識されるか、意地悪に書いても正しく認識できるのか、なぜ認識されないのか、どうすれば認識するようになるのか、など色々考えて遊びましょう。(1) 環境構築
mnisterツールをGithubに公開しており、環境構築手順などはこちらのREADME.mdに記載していますので、こちらを参照してください。なお、Google Colabでも、Local PCでも、どちらでも遊ぶことができますが、Google Colabの方が超簡単なのでオススメです。※Google Colabの使用方法が良く分からない方は、こちらの記事を参考にしてください。
(2) 遊ぼう
webブラウザの黒いキャンバスのところにマウスで0~9の数字を書いたら、「
Predict」をクリックしてください。結果が表示されます。
(3) 意外と認識できない
MNISTで99%認識できるモデルなので、ちょっとくらい意地悪してみても問題ないかなと思ったら、普通に書いても認識できないものも結構ありますね。一般並みに実用化するにはもっと色々と工夫がいることが分かりました。
4. 自分でMNISTモデルを作ってみよう
ここまででも十分かもしれませんが、他人が作ったMNISTモデルで認識させてもイマイチ楽しくないかもしれません。mnisterツールに同梱している
CreateMnistModel.ipynbから簡単に俺のMNISTモデルを自作することができます。モデルを自作したらmnisterツールに読み込ませているモデルを置き換えてmnisterツールを再起動させてください。※
CreateMnistModel.ipynbで、そのままでもモデルを作ることができますが、ハイパーパラメータ、ネットワーク定義、データの読み込ませ方など色々考えて適宜プログラムを変更してください。
5. 使用した技術など
ブラウザで文字入力させたものをAI認識させる様にできないかなぁと思ったら、AI処理部(Python)だけでも大変だったのに、flask、javascript、jQuery(Ajax)、json、base64、Createjs、html、公開プログラム格納のためのGithub………、などなど、色々と幅広い基礎知識が必要となってしまいとても結構大変でした。でも、おかげさまで幅広く勉強することができて良かったと思っています?
■サーバ機能 (server.py)
技術 説明 Flask webサーバ起動とバックエンドでpython(AI)を使用したいため Tensorflow 推定処理(AI)のため ■クライアント機能 (Input.js、index.html)
技術 説明 Createjs 文字入力インタフェースのため jQuery(Ajax) サーバ側との非同期通信のため 6. 以上
もしこの記事が、あなたに貢献することができたなら、ぜひLGTM、またはストックをお願い致します?
お疲れ様でした!
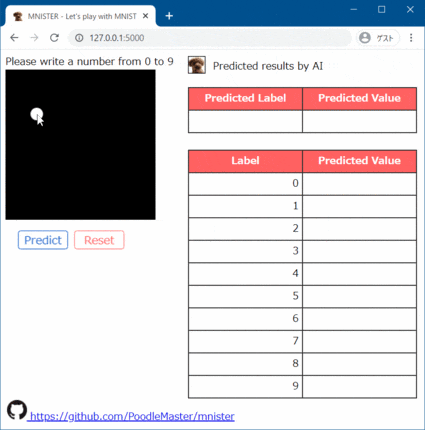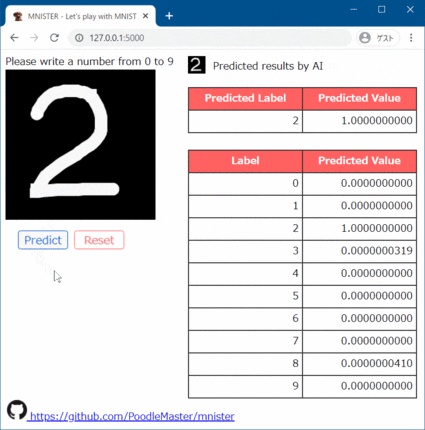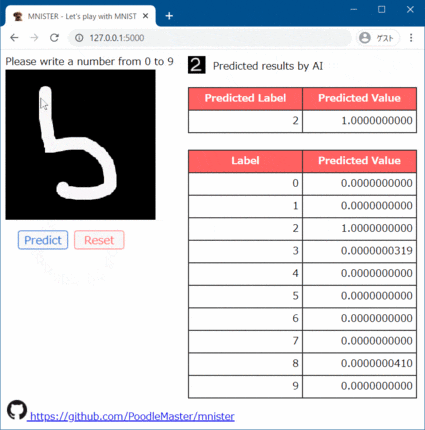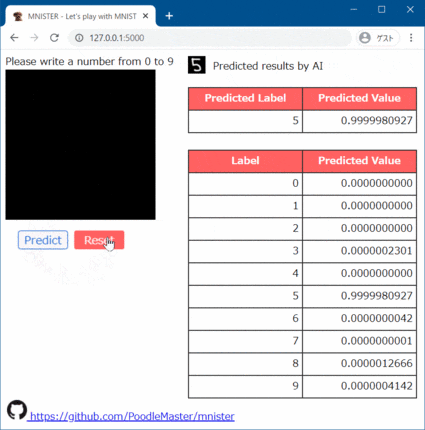





- 投稿日:2020-09-18T12:24:43+09:00
VSCodeのPython ExtensionでSort importsが動かなくなったときの対処法(2020/09ぐらい)
Sort imports 終わらない…。
https://github.com/microsoft/vscode-python/issues/13312#issuecomment-694285071
But great workaround using the locally installed isort via python.sortImports.path! It actually works without any issues along with the isort arguments and everything.
なんかよくわからんが
isortを virtualenv に入れてpython.sortImports.pathを設定すると良いらしい。poetry add -D isortで
dev-dependenciesにしたあとに.vscode/settings.jsonに"python.sortImports.path": "${workspaceFolder}/.venv/bin/isort"を設定。
- 投稿日:2020-09-18T12:04:24+09:00
djangoでログイン画面の実装にはまった話
こんにちは、rickyです。
最近本格的にDjangoを使い始めて、アプリ作成をしています。
そんな中ログイン画面の実装にはまったので備忘録として記事にします。
原因はsetting.pyにtemplatesの情報を記入していなかったためです。
DjangoGirlsなどのチュートリアルもしっかり実装できたので、自分で考えたアプリを作ろうとしたら、上記の点でではまりました。
詳しく説明をするとdjangoではtemplatesディレクトリにアプリの名前のディレクトリを作成し、その中にhtmlを記述し利用するのですが、その設定をsetting.pyに記載する必要があります。
そのため、Templatesディレクトリを作成し、アプリ名のディレクトリにhtmlを入れても、エラーが出るのでTemplatesディレクトリの中にhtmlを作っていました。(これで中途半端に動いてしまったのでその後のエラー解消に時間がかかりました。)
そしていざログイン画面に遷移しようとしたら、エラーが発生しました。
原因はlogin.htmlをregistrationのディレクトリに配備していなかったことが原因でした。
なぜ配備していなかったというと先のTemplatesが機能していなかったため、login.htmlをディレクトリに配備していませんでいした。
やっぱり基本の部分をしっかり理解しておかないと簡単な処理でさえ作りこめないなと思い知らされました。
- 投稿日:2020-09-18T11:52:56+09:00
sphinx-quickstart が面倒になり代替コマンドを作ってみたらストレスがなくなった
はじめに
sphinx はドキュメント作成が非常に便利です。
ただし、sphinx-quickstart は基本的にはリターンだけでよいのですが、
もう少しだけなんとかならないのかと思っていました。
sphinx を使えば使うほど、この面倒だと思う気持ちが強くなり、
sphinx-express なるものを作ってみました。独り言: 力技です。かっこよくも美しくもないスクリプトです。
まぁ、click モジュールの習作みたいなものですが、
期待どおりには動いてくれます。使い方
初回は
--setupオプションを与えて実行します。$ sphinx-express.py --setup You should install follows packages. python -m pip install sphinx-rtd-theme sphinx-charts pallets_sphinx_themes sphinxcontrib-runcmd sphinxcontrib-napoleon your configfile: /Users/goichiiisaka/.sphinx/quickstartrc your templatedir: /Users/goichiiisaka/.sphinx/templates/quickstart quickstart templates of sphinx into your templatedir.これで、$HOME/.sphinx 以下に
quickstartrc と sphinx が持っている テンプレートファイルをコピーしてくれます。$ tree ~/.sphinx/ /Users/goichiiisaka/.sphinx/ ├── quickstartrc └── templates └── quickstart ├── Makefile.new_t ├── Makefile_t ├── conf.py_t ├── make.bat.new_t ├── make.bat_t └── master_doc.rst_t 2 directories, 7 files~/.sphinx/quickstartrc はデフォルトでは次のようにしています。
sep: true language: ja suffix: .rst master: index makefile: true batchfile: true autodoc: true doctest: false intersphinx: false todo: false coverage: false imgmath: true mathjax: true ifconfig: true viewcode: true project: sample version: 0.0.1 release: 0.0.1 lang: ja make_mode: true ext_mathjax: true extensions: - pallets_sphinx_themes - sphinx_rtd_theme - sphinx.ext.autodoc - sphinx.ext.mathjax - sphinx.ext.autosectionlabel - sphinxcontrib.blockdiag - sphinxcontrib.seqdiag - sphinxcontrib.blockdiag - sphinxcontrib.nwdiag - sphinxcontrib.rackdiag - sphinxcontrib.httpdomain - sphinxcontrib.runcmd - recommonmark mastertocmaxdepth: 2 project_underline: ======後はこのファイルを修正すれば、
shpinx-express.py が読み込んでくれるので、
コマンド一発で sphinx のプロジェクトディレクトリが整います。$ sphinx-express.py sample Welcome to the Sphinx 3.2.1 quickstart utility. Please enter values for the following settings (just press Enter to accept a default value, if one is given in brackets). Selected root path: sample Creating file /Users/goichiiisaka/docs/sample/source/conf.py. Creating file /Users/goichiiisaka/docs/sample/source/index.rst. Creating file /Users/goichiiisaka/docs/sample/Makefile. Creating file /Users/goichiiisaka/docs/sample/make.bat. Finished: An initial directory structure has been created. You should now populate your master file /Users/goichiiisaka/docs/sample/source/index.rst and create other documentation source files. Use the Makefile to build the docs, like so: make builder where "builder" is one of the supported builders, e.g. html, latex or linkcheck.sphinx のプロジェクトディレクトリは、なければ作成するようにしています。
$ ./sphinx-express.py --help Usage: sphinx-express.py [OPTIONS] [PROJECT_DIR] Create required files for a Sphinx project. Options: -p, --project TEXT project name -a, --author TEXT author name. default is "goichiiisaka" -v, --version TEXT version of project -l, --lang TEXT document language. default is 'ja' -t, --templatedir PATH template directory for template files. default: /Users/goichiiisaka/.sphinx/templates/quickstart -c, --configfile PATH sphinx-quickstart configfile. default: /Users/goichiiisaka/.sphinx/quickstartrc -N, --new Ignore least configures. --setup Copy quickstart templates and exit. --help Show this message and exit.テンプレート
~/.sphinx/templates/quickstart/conf.py_t は、
コピーするだけでなく次のような地味な修正をしています。# -- Options for HTML output ------------------------------------------------- # The theme to use for HTML and HTML Help pages. See the documentation for # a list of builtin themes. # # Avilable Themes: # alabaster, sphinx_rtd_theme # babel, click, flask, jinja, platter, pocoo, werkzeug # html_theme = "sphinx_rtd_theme"{%- if 'sphinxcontrib.seqdiag' in extensions %} # -- Options for seqdiag output ------------------------------------------- # curl -O https://ja.osdn.net/projects/ipafonts/downloads/51868/IPAfont00303.zip import os basedir = os.path.abspath(os.path.dirname(__file__)) seqdiag_fontpath = basedir + '/_fonts/IPAfont00303/ipagp.ttf' seqdiag_html_image_format = 'SVG' {%- endif %} {%- if 'sphinxcontrib.nwdiag' in extensions %} # -- Options for nwdiag output -------------------------------------------- nwdiag_html_image_format = 'SVG' rackiag_html_image_format = 'SVG' packetdiag_html_image_format = 'SVG' {%- endif %} {%- if 'sphinxcontrib.blockdiag' in extensions %} # -- Options for blockdiag output ------------------------------------------ blockdiag_html_image_format = 'SVG' {%- endif %} {%- if 'sphinxcontrib.actdiag' in extensions %} # -- Options for actdiag output -------------------------------------------- actdiag_html_image_format = 'SVG' {%- endif %} {%- if 'sphinxcontrib.httpdomain' in extensions %} # -- Options for httpdomain output ------------------------------------------ # List of HTTP header prefixes which should be ignored in strict mode: http_headers_ignore_prefixes = ['X-'] # Strips the leading segments from the endpoint paths # by given list of prefixes: # http_index_ignore_prefixes = ['/internal', '/_proxy'] # Short name of the index which will appear on every page: # http_index_shortname = 'api' # Full index name which is used on index page: # http_index_localname = "My Project HTTP API" # When True (default) emits build errors when status codes, # methods and headers are looks non-standard: http_strict_mode = True {%- endif %} {%- if 'recommonmark' in extensions %} # -- Options for recommonmark output ---------------------------------------- import recommonmark from recommonmark.transform import AutoStructify # At the bottom of conf.py def setup(app): app.add_config_value('recommonmark_config', { 'url_resolver': lambda url: github_doc_root + url, 'auto_toc_tree_section': 'Contents', }, True) app.add_transform(AutoStructify) {%- endif %}TODO
パッケージにしたい。いや、するべきだろうなぁ...
- 投稿日:2020-09-18T10:51:40+09:00
フライトシミュレータのSDKとか必要そうなサイト
目次
Microsoft Flight Simulator (MSFS2020)
Prepar3D (P3D)Microsoft Flight Simulator (MSFS2020)
オフィシャルサイト
https://www.xbox.com/ja-JP/games/microsoft-flight-simulator
SDK概要
https://docs.microsoft.com/en-us/previous-versions/microsoft-esp/cc526948(v=msdn.10)
Event IDs
https://docs.microsoft.com/en-us/previous-versions/microsoft-esp/cc526980(v=msdn.10)
Simulation Variables
https://docs.microsoft.com/en-us/previous-versions/microsoft-esp/cc526981(v=msdn.10)
physin
https://pypi.org/project/SimConnect/
physin git
https://github.com/hankhank10/MSFS2020-cockpit-companion
Prepar3D (P3D)
オフィシャルサイト
SDK概要
http://www.prepar3d.com/SDKv4/LearningCenter.php
Event IDs
http://www.prepar3d.com/SDKv4/LearningCenter.php
Simulation Variables
- 投稿日:2020-09-18T10:36:26+09:00
訓練データとテストデータ(X_trainとy_trainとは?)①
今回は教師あり学習における
訓練データとテストデータについて説明します。■ 訓練データとテストデータ
訓練データ:モデル式(データの関連性を表す式)を作るデータ
テストデータ:作成した式がどのくらい正確性のあるものかを確認するデータ自分がデータの関連性を式で表せたとしても、それを試すデータがなかったら困りますよね。
では、簡単な具体例を挙げて説明していきます。
例えば、下記のようなデータがあるとします。
ここで、この表のデータを下記のように分割します。訓練データ
テストデータ
このとき、まずデータの関連性を見つけたいので
訓練データから y と x の式(モデル式)の候補を考えます。候補1:$y=3x$
候補2:$y=2x+1$訓練データを用いてモデル式を作成しました。
ただこれだけでは、本当にこの式が成り立つのかは分かりません。
そのために、検証用としてテストデータがあるのです。作成したモデル式に対して、下記のデータでも成り立つか確認をします。
確かめる方法は、モデル式にテストデータの x を代入して、本当に y となるかどうかです。
候補1:$y=3x=3\times3=9$
候補2:$y=2x+1=2\times3+1=7$
正解:$y=7$このことから、今回用意したデータに関しては
候補1ではなく候補2の方が正確性が高いことが分かりました。このように、機械学習では訓練データからデータの関連性を見つけ出し(モデル式の作成)
テストデータにて実際に正確であるかどうかをチェックする仕組みを取っています。■ X_train, y_train を当てはめる
では、X_train, y_train, X_test, y_test とはいったい何なのでしょうか?
train:訓練データ(トレーニングの略)
test:テストデータ(モデル式を検証するデータ)今回用意したデータに当てはめるとこのようになります。
訓練データ
テストデータ
先ほどと同じように、訓練データからモデル式を考えます。候補1:$y=3x$
候補2:$y=2x+1$これでモデル式が完成しました。
あとは、これらがどのくらいの正確性を示すのかを、テストデータを用いて検証します。先ほどは、モデル式にテストデータの x を代入して、予測値 y を出し
実際の y と一致するかといったように検証をしました。このときの予測値を y_pred と表記します。(predict:予測する)
テストデータ
候補1:$y_{pred}=3x_{test}=3\times3=9$
候補2:$y_{pred}=2x_{test}+1=2\times3+1=7$
正解:$y_{test}=7$よって、今回作成したモデル式では
候補2の方が正確性が高いということが分かりました。教師あり学習(テストデータあり)では、基本的にこの考え方をもとに
様々なモデル式の作成・検証を行っています。
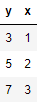




- 投稿日:2020-09-18T10:36:26+09:00
訓練データとテストデータ(X_trainとy_trainとは?)
今回は教師あり学習における
訓練データとテストデータについて説明します。■ 訓練データとテストデータ
訓練データ:モデル式(データの関連性を表す式)を作るデータ
テストデータ:作成した式がどのくらい正確性のあるものかを確認するデータ自分がデータの関連性を式で表せたとしても、それを試すデータがなかったら困りますよね。
では、簡単な具体例を挙げて説明していきます。
例えば、下記のようなデータがあるとします。
ここで、この表のデータを下記のように分割します。訓練データ
テストデータ
このとき、まずデータの関連性を見つけたいので
訓練データから y と x の式(モデル式)の候補を考えます。候補1:$y=3x$
候補2:$y=2x+1$訓練データを用いてモデル式を作成しました。
ただこれだけでは、本当にこの式が成り立つのかは分かりません。
そのために、検証用としてテストデータがあるのです。作成したモデル式に対して、下記のデータでも成り立つか確認をします。
確かめる方法は、モデル式にテストデータの x を代入して、本当に y となるかどうかです。
候補1:$y=3x=3\times3=9$
候補2:$y=2x+1=2\times3+1=7$
正解:$y=7$このことから、今回用意したデータに関しては
候補1ではなく候補2の方が正確性が高いことが分かりました。このように、機械学習では訓練データからデータの関連性を見つけ出し(モデル式の作成)
テストデータにて実際に正確であるかどうかをチェックする仕組みを取っています。■ X_train, y_train を当てはめて考える
では、X_train, y_train, X_test, y_test とはいったい何なのでしょうか?
train:訓練データ(トレーニングの略)
test:テストデータ(モデル式を検証するデータ)今回用意したデータに当てはめるとこのようになります。
訓練データ
テストデータ
先ほどと同じように、訓練データからモデル式を考えます。候補1:$y=3x$
候補2:$y=2x+1$これでモデル式が完成しました。
あとは、これらがどのくらいの正確性を示すのかを、テストデータを用いて検証します。先ほどは、モデル式にテストデータの x を代入して、予測値 y を出し
実際の y と一致するかといったように検証をしました。このときの予測値を y_pred と表記します。(predict:予測する)
テストデータ
候補1:$y_{pred}=3x_{test}=3\times3=9$
候補2:$y_{pred}=2x_{test}+1=2\times3+1=7$
正解:$y_{test}=7$よって、今回作成したモデル式では
候補2の方が正確性が高いということが分かりました。教師あり学習(テストデータあり)では、基本的にこの考え方をもとに
様々なモデル式の作成・検証を行っています。
- 投稿日:2020-09-18T08:51:27+09:00
【シミュレーション入門】サイン波のマスゲーム♬
今回もハマった。
Twitterで流れてきた、以下の振り子。
Wonder of Science@wonderofscienceさんそれぞれ独立なので、集団運動に見える。しかも、あのポアンカレの再帰定理を思い起こさせるような動き。
「力学系は、ある種の条件が満たされれば、その任意の初期状態に有限時間内にほぼ回帰する」
まあ、今回は単純な単振り子なので、周期さえコントロールすれば当たり前。。。なのだが、そんなに簡単ではないと直感的には感じた。以下のようなスナップも取ってみた。
一番短い振り子の周期は、約1秒なのが分かるし、一番長い振り子の周期は約4/3倍の周期のようだ。
しかし、この情報だけでは、間の振り子の周期をどうすればあのように綺麗にそろうのかが不明でした。
散々悩んでいろいろやった後、参考の元ネタを読んだ。最初から元ネタへのリンクが張ってあったんだけど、この時に限って読んでいませんでした。
【参考】元ネタ
Pendulum Waves@Harvard Natural Sciences Lecture Demonstrations
ネ・タ・バ・レ。
「ダンスの完全な1サイクルの期間は60秒です。最長の振り子の長さは、この60秒間に51回振動するように調整されています。連続する短い振り子の長さは、この期間にさらに1つの振動を実行するように注意深く調整されます。したがって、15番目の振り子(最短)は65回振動します。 15のすべての振り子が一緒に開始されると、それらはすぐに同期から外れます。相対振動の周期が異なるため、相対位相は連続的に変化します。ただし、60秒後、それらはすべて整数倍の振動を実行し、その瞬間に再び同期し、ダンスを繰り返す準備ができます。」もちろん、これを参考のように本物の振り子で実現するのはかなり大変だろう。しかし、ここではシミュレーションしてしまおうということで、さらにいろいろ試してみようと思う。
【参考】
蛇振り子@アマゾン単振り子のおさらい
【参考】
解説: 単振り子の運動
微分方程式の数値解でもいいけど、ここは以下の解析解を使うこととしました。\theta = \theta_0\sin(\omega t+\delta) \\ \omega = \sqrt{\frac{g}{L}}\\ T=\frac{2\pi}{\omega}\\ \theta = \theta_0\sin(\frac{2\pi t}{T}+\delta) \\ T;sec \\ t; sec\\ L=\frac{g}{\omega ^2}=g(\frac{T}{2\pi})^2\\ g=980 cm/s^2\\ L=24.82 cmのとき、\\ T=1.000sec上のネタバレを表にすると以下のとおり
n 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 T 60/65=0.923 60/64 60/63 60/62 60/61 60/60 60/59 60/58 60/57 60/56 60/55 60/54 60/53 60/52 60/51=1.176 L $L_0=21.15$ $L_0(65/64)^2$ $L_0(65/63)^2$ $L_0(65/62)^2$ ... ... ... ... ... ... ... ... ... $L_0(65/52)^2$ $L_{14}=34.36$ $T_n/T_{n-1}$ - 65/64 64/63 63/62 62/61 61/60 60/59 59/58 58/57 57/56 56/55 55/54 54/53 53/52 52/51 コード解説
コードはおまけに全体を置きました。
先日のAxes3Dのアニメーションとほぼ同様です。
肝心な部分は、以下のとおりです。def genxy(n,L=20,z0=0): phi = 0 #時間初期値 g = 980 #重力加速度 x0=2.5 #振幅初期値 omega = np.sqrt(g/L) theta0 = np.arcsin(x0/L) #初期角度 while phi < 600: #最大振幅から開始のためpi/2を追加 yield np.array([L*np.sin(np.sin(phi*omega+np.pi/2)*theta0), 0,z0-L+L*(1-np.cos(np.sin(phi*omega+np.pi/2)*theta0))]) phi += 1/n #1secをn分割するこれを、以下のコードで呼び出して利用します
ここで、N=60,Lは、それぞれの振り子の長さです。z0は支点の高さです。
datazを計算して、それをlinezでプロットします。dataz = np.array(list(genxy(N,L=L0*Fc[0]**2,z0=z0))).T linez, = ax.plot(dataz[0, 0:1], dataz[1, 0:1], dataz[2, 0:1],'o')これを、以下のupdate関数で逐次numで指定して表示します。
def update(num, data, line,s): line.set_data(data[:2,num-1 :num]) line.set_3d_properties(data[2,num-1 :num]) ax.set_xticklabels([]) ax.grid(False)今回は二次元でも同じ絵が得られますが、振り子をよりリアルに(y方向に並べたりして)、ぐりぐりマウスで回せるので、一応3dプロットで描いています。
そして、一番肝心なLの計算は上の表を参考にして以下で実施しました。
これから計算できるFcを利用して、それぞれの振り子の長さは$L=L_0*F_c[i]**2$で計算できます。L0=980*(60/65)**2/(2*np.pi)**2 Fc=[] fc=1 Fc.append(fc) for i in range(1,15,1): fc=fc*((66-i)/(65-i)) Fc.append(fc)再現;15個の振り子
0.2-30 sec
30.2-60 sec
拡大;30個の振り子
倍の数でやってみた。
0.2-30 sec
30.2-60 sec
ちょっと議論
出来ちゃうと、なーんだだけど、実際ゼロからコード書くと悩むと思います。
こんなに綺麗に勢ぞろいさせられるのかという不思議感がなかなか抜けません。
そして、実は個数は3個から順に増やしてみました。少ないときも同じように動くのが面白いです。もちろんこの方式だと、上のLを求めるためのFcの計算が出来るところまでは、同じように計算できます。
そして、さらに増やしたければ、60秒でそろう部分を変更すれば、さらに異なるバリエーションができます。ということで、50個に挑戦してみました。
まず、リスト使ってdataz, linezを簡単にfor文で計算できるようにしました。dataz=[] linez=[] for j in range(50): dataz0 = np.array(list(genxy(N,L=L0*Fc[j]**2,z0=z0))).T linez0, = ax.plot(dataz0[0, 0:1], dataz0[1, 0:1], dataz0[2, 0:1],'o') dataz.append(dataz0) linez.append(linez0)表示する部分も以下のように簡素化しています。
for j in range(50): update(num,dataz[j],linez[j],s0)これで、50個の場合は、以下のように3mにもなるんですね。
これは、これで作ってみたくなります。まとめ
・サイン波のマスゲームをシミュレーションしてみた
・単純なものだが、美しく動く・いろいろな拡張が出来そうで楽しみ
・本物も動かしたくなったおまけ
from matplotlib import pyplot as plt import numpy as np import mpl_toolkits.mplot3d.axes3d as p3 from matplotlib import animation fig, ax = plt.subplots(1,1,figsize=(1.6180 * 4, 4*1),dpi=200) ax = p3.Axes3D(fig) def genxy(n,L=20,z0=0): phi = 0 #時間初期値 g = 980 #重力加速度 x0=2.5 #振幅初期値 omega = np.sqrt(g/L) theta0 = np.arcsin(x0/L) #初期角度 while phi < 600: #最大振幅から開始のためpi/2を追加 yield np.array([L*np.sin(np.sin(phi*omega+np.pi/2)*theta0), 0,z0-L+L*(1-np.cos(np.sin(phi*omega+np.pi/2)*theta0))]) phi += 1/n #1secをn分割する def update(num, data, line,s): line.set_data(data[:2,num-1 :num]) line.set_3d_properties(data[2,num-1 :num]) ax.set_xticklabels([]) ax.grid(False) N = 360 z0 =50 L0=980*(60/65)**2/(2*np.pi)**2 Fc=[] fc=1 Fc.append(fc) for i in range(1,15,1): fc=fc*((66-i)/(65-i)) Fc.append(fc) dataz=[] linez=[] for j in range(50): dataz0 = np.array(list(genxy(N,L=L0*Fc[j]**2,z0=z0))).T linez0, = ax.plot(dataz0[0, 0:1], dataz0[1, 0:1], dataz0[2, 0:1],'o') dataz.append(dataz0) linez.append(linez0) # Setting the axes properties ax.set_xlim3d([-10., 10]) ax.set_xlabel('X') ax.set_ylim3d([-10.0, 10.0]) ax.set_ylabel('Y') ax.set_zlim3d([0.0, z0-L0]) ax.set_zlabel('Z') elev=0 azim=90 ax.view_init(elev, azim) frames =30*60 fr0=60 s0=30*60 s=s0 while 1: s+=1 num = s for j in range(50): update(num,dataz[j],linez[j],s0) if s%fr0==0: print(s/fr0) plt.pause(0.001)







- 投稿日:2020-09-18T08:16:32+09:00
Pythonによる画像処理100本ノック#3 二値化
はじめに
どうも、らむです。
これまた画像処理ではお馴染みの二値化を実装します。3本目:二値化
二値化は画像を白黒の2色のみのモノクロ画像に変換する処理です。
通常グレースケール画像に対し行います。
また、二値化の際に閾値と呼ばれる基準の値を決めます。閾値未満の画素値は白、閾値以上の画素値を持つ画素は黒に置き換えます。binarization.pyimport numpy as np import cv2 import matplotlib.pyplot as plt plt.gray() def binarization(img): # 画像コピー dst = img.copy() # グレースケール化 gray = cv2.cvtColor(dst, cv2.COLOR_BGR2GRAY) # 閾値 th = 128 # 二値化 idx = np.where(gray < th) gray[idx] = 0 idx = np.where(gray >= th) gray[idx] = 255 return gray # 画像読込 img = cv2.imread('../assets/imori.jpg') # 二値化 mono = binarization(img) # 画像保存 cv2.imwrite('result.jpg', mono) # 画像表示 plt.imshow(mono) plt.show()

画像左は入力画像、画像右は出力画像です。
グレースケール画像のように灰色が無く白と黒のみの画像になっています。おわりに
もし、質問がある方がいらっしゃれば気軽にどうぞ。
imori_imoriさんのGithubに公式の解答が載っているので是非そちらも確認してみてください。
