- 投稿日:2020-09-15T23:44:12+09:00
《未経験→webエンジニア》実務2日目
この記事の目的
自分がやったこと、知らなかったこと、やるべきことを明確にし
1日あたりの成長速度を速める。【今日やったこと】
APIテスト
postmanを利用して、
主に登録フォームにpost情報を送った際に
期待通りに帰ってくるかのテスト【知らなかったこと】
postmanというツール、使い方
【明日】やるべきこと、読みたい記事など
AWS資格取得のために、やるべきこと
https://qiita.com/x5dwimpejx/items/0b9b7e7b502d8bd255e9Dokerのチュートリアル記事!
https://qiita.com/Michinosuke/items/5778e0d9e9c04038903c
- 投稿日:2020-09-15T23:25:10+09:00
【Ruby】文字列変数のコピーを作る場合は dup メソッドを使う習慣を身につけましょう
前置き
Ruby でプログラミングしてて、ついついはまってしまう、というか、見事にはまってしまったので、忘れないように。
※ 2020/09/16 11:12 : scivola さん指摘を受け、文言、文章を修正しました。(修正箇所が分かるように打ち消し線で修正した方が良いと思ったのですが、修正箇所がかなり多くなってしまったので、直接編集しました。)また変なところあったら、適宜修正します。
環境
一応、バージョン情報も。でも基本的なことなので、バージョン関係ないはずです。
- Windows 10
- Ruby 2.6
変数の値のコピーを取るとき・・・
変数の値のコピーを取るとき、ついつい代入で済ませてしまったりすること、ありませんか?
@bob = "I love you" @carol = @bob # <= ここ! puts "@bob = #{@bob}, @carol = #{@carol} " # => @bob = I love you, @carol = I love you変数の値のコピーを取るときって大抵、「元の変数の値は取っておいて、コピーした変数を使って色々操作しよう」みたいな目的のときが多いと思います。コピーした変数の方は値が変わって壊れてしまっても、元の変数は取ってあるから大丈夫ーてきな感じで。
# --- 上のつづき --- @carol = @carol + ", too" puts "@bob = #{@bob}, @carol = #{@carol} " # => @bob = I love you, @carol = I love you, too上のように、代入先の変数
@carolに文字列に追加をしても、代入元の変数@bobの値は当然変わらないわけです。でも、、、代入先の変数に対して、中の文字列を置換したりするなどの「破壊的操作」を行うと、代入元の値にも影響を与えてしまいます。
@bob = "I love you" @carol = @bob @carol.sub!("love", "hate") puts "@bob = #{@bob}, @carol = #{@carol} " # => @bob = I hate you, @carol = I hate you
@carolの値に変更を加えたはずなのに、@bobの値も変わってしまいました。なんでこうなるのか、というと、Ruby では全てのものがオブジェクトで、代入演算子は、参照先をコピーする「参照渡し」になっているからです。
@carol = @bobとすると、@carolと@bobは同じ文字列オブジェクトを参照している、ということになります。なので、@carolの方で「破壊的操作」を行うと、@bobで参照しているオブジェクトも同じなので、両方変わってしまうことになります。ちなみに、、、同じ操作でも、
sub!ではなくてsubメソッドを使って変更した場合、また挙動が変わります。# --- 上のつづき --- @bob = @bob.sub("hate", "love") puts "@bob = #{@bob}, @carol = #{@carol} " # => @bob = I love you, @carol = I hate you同じように
@bobの文字列をloveに変更したのに、@carolはまだhateのままです。。。嫌われちゃったね bob。。。でも、なんでか?
sub!の場合は、そのオブジェクトの内容を直接変更していますが、subの方は、置換した文字列を「新しいオブジェクトとして生成」して、@bobに改めて代入しているためです。参照しているオブジェクトが@carolと一緒に参照していたオブジェクトから、新しいオブジェクトに変わったのです。最初の例で、
@carolの文字列に ", too" をつけても、@bobの値が変わらなかったのも、同じ理由です。@carolの文字列に別の文字列をつけたことで、結合した文字列の「新しいオブジェクト」が生成されて、@carolに改めて代入されたので、@bob と参照しているオブジェクトが変わったためです。このように、単純に代入で値をコピーした、と思って安心していると、その後に行う処理によっては、代入元の値が変わってしまったり、でも処理の順序によっては大丈夫だったり、ということが起こってしまいます。
じゃあどうするの?
先にも書きましたが、変数をコピーしたい場面って、「コピー元の値を取っておきたい」かからなので、「コピー先の値を変えたら、コピー元の値も変わっちゃう」ことなんて想定しないハズです。変わっていいならコピーする必要ないわけですし。
じゃあどうしたらいいの?
ってことで出てくるのが、
dupメソッドです。dupメソッドは、オブジェクトの複製、つまり、中身は同じで別のオブジェクトを生成するメソッドです。@bob = "I love you" @carol = @bob.dup # <== ここ、dup メソッドで@bobの値をコピーした新しいオブジェクトを作って代入する @carol.sub!("love", "hate") puts "@bob = #{@bob}, @carol = #{@carol} " # => @bob = I love you, @carol = I hate you同じように見えますが、今度は
@carolだけがhateに変わりました。やっぱり嫌われる bob。。。
これは、dupメソッドで生成したオブジェクトは、@bobの持っているオブジェクトと異なっているからです。
object_idメソッドを使うと、オブジェクトが一致しているかどうかが確認できます。@bob = "I love you" @carol = @bob puts @bob.object_id # => 46779560 puts @carol.object_id # => 46779560 @anna = @bob.dup @anna.object_id # => 46931780確かに、そのまま代入した場合は同じオブジェクトIDになっていて、
dupメソッドで作ったときは別のオブジェクトIDになっています。こうしておけば、値は同じでも完全に別のオブジェクトなので、どんな風にいじっても大元の値が勝手に変わっちゃう、ということが無くなります。
実際、「代入」だけでも、その後の操作でオブジェクトが変わることで、問題ないケースは多いと思います。でも、うっかりすると影響しちゃう、という状態はバグを誘発する恐れが高いです。ですので、
変数コピーする場合は代入はダメ、dupメソッドとか使ってちゃんと複製する
ことを無意識にできるように、がんばります(と自分に言い聞かせます・・・)
さらに加えて・・・
オブジェクトの複製には、
dupメソッドの他にcloneメソッドがあります。また、marshal_dump,marshal_loadを使う場合もあります。文字列オブジェクトの複製の場合は、
dupだけで十分です。
cloneは、dupに加えて、特異メソッドのコピー、オブジェクトのフリーズ状態も複製します。
配列やハッシュ、クラスの複製を行う場合は、dupやcloneでは要素や内部変数の複製までは行わないので、不十分になります。その場合は、marshal_dump、marshal_loadを使ったり、必要に応じてメソッドのオーバーライドもしてやる必要があります。この辺り、詳しい話は調べてみて下さい。(自分も勉強しないと・・・)
- 投稿日:2020-09-15T22:27:08+09:00
【自分用メモ】Ruby on Railsの環境構築(Windows)
目的
WindowsでRuby on Railsの環境構築を行った際に詰まったところを自分への備忘録として振り返ります。※Ruby6.0.0以前の手法になります。
こちらを参考にさせていただきました。
Ruby on Railsの環境構築をしてみよう!(Windows) - Progate
Devkit を Windows7 にインストールする手順 - Qiita
msys2 と GNU ツールチェーン類 (gcc, g++, gfortran, findutils ...
Windowsで異なるバージョンのRubyを使う方法(uru) - QiitaRubyのインストール
Downloads - Ruby Installer
太字になっている「Ruby+Devkit 2.6.6-1 (x64) 」のRubyInstallerをダウンロードし、インストールを進めました。
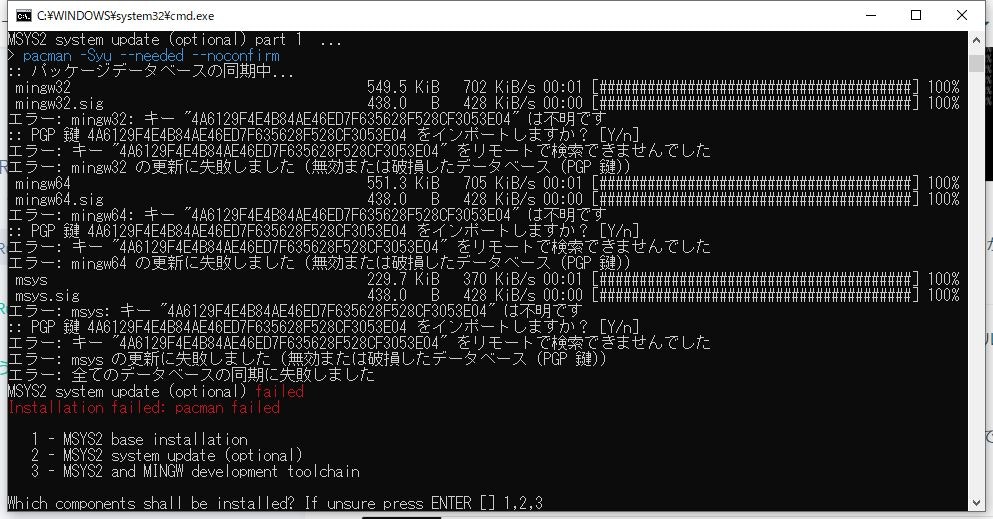
ただMSYS2をインストールする際に「Installation failed」というエラーが発生。
ちなみに、FWを落としても同じ事象が発生しました。 そのため、個別にインストールしていくことにしました。まずRubyのインストール
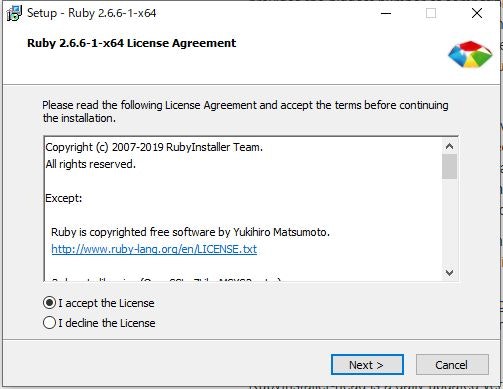
Downloads - Ruby Installerから Ruby 2.6.6-1 (x64)のインストーラをダウンロードし、ダブルクリック
問題なければ「I accept the License」を選択
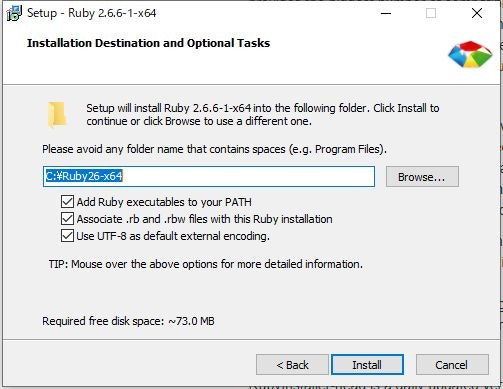
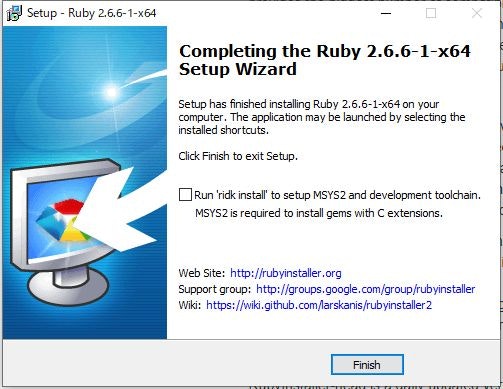
「Add Ruby exexutables to your PATH」、「Associate .rb and .rbw files with this Ruby installation」、「Use UTF-8 as default external encoding」のチェックはつけたまま、[Install]をクリック
「Run 'ridk install' to setup MSYS2 and development toolchain.」のチェックは外して[Finish]をクリック
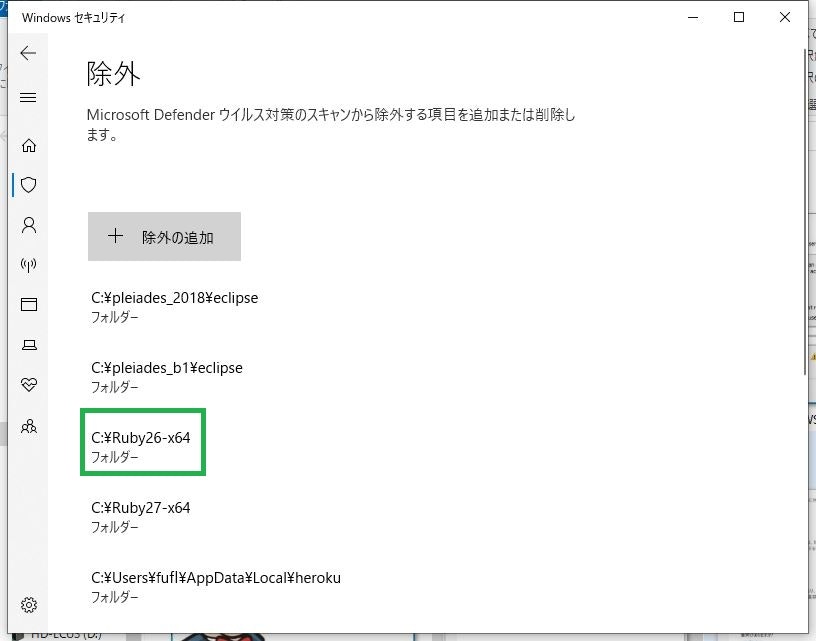
これでRubyのインストールは終了です。念のため、アンチウィルスソフト(私の環境ではWindows Defender)の除外欄に「C:\Ruby26-x64」を追加しておきました。
Devkitのインストール
Download Archives - Ruby Installer
上記サイトの右下のDevkitのインストーラをダウンロード
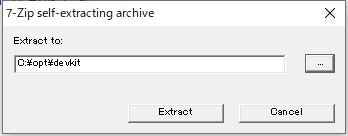
インストーラ(7zの自己解凍ファイル)をダブルクリックし適当なフォルダを選択し、[Extract]をクリック
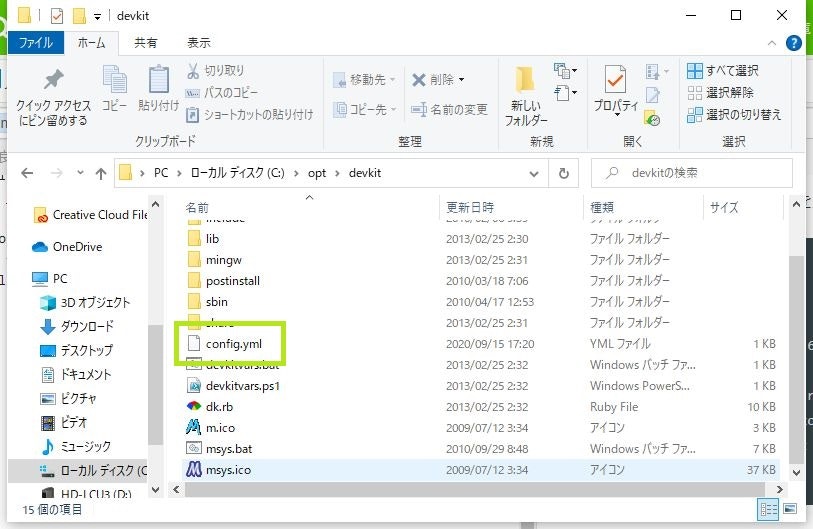
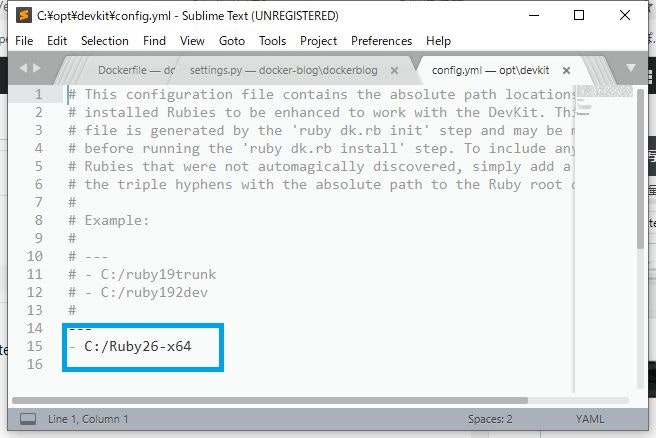
下記コマンドを実行し、config.ymlを生成
cmd.exe> cd c:\opt\devkit > ruby dk.rb init [INFO] found RubyInstaller v2.6.6 at C:/Ruby26-x64 Initialization complete! Please review and modify the auto-generated 'config.yml' file to ensure it contains the root directories to all of the installed Rubies you want enhanced by the DevKit.config.ymlが生成されました。
config.yml をエディタで開き、Rubyのパスが指定されていなければ指定します。
Devkitのインストール
下記コマンドを実行します。cmd.exe> ruby dk.rb install [INFO] Updating existing gem override for 'C:/Ruby26-x64' [INFO] Installing 'C:/Ruby26-x64/lib/ruby/site_ruby/devkit.rb'SQLite3のインストール
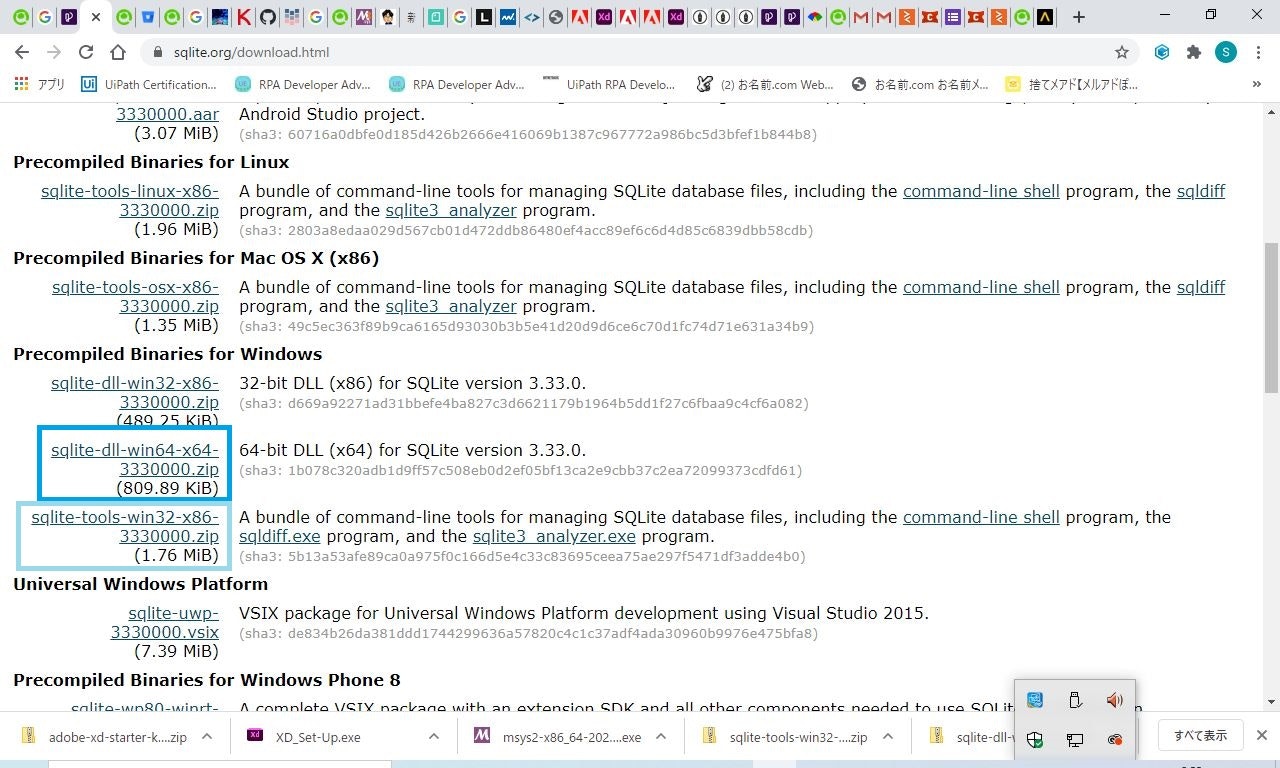
Sqlite3のダウンロードページで「Precompiled Binaries for Windows」のところを確認し「sqlite-dll-win64-x64-3330000.zip」、「sqlite-tools-win32-x86-3330000.zip」ダウンロード。
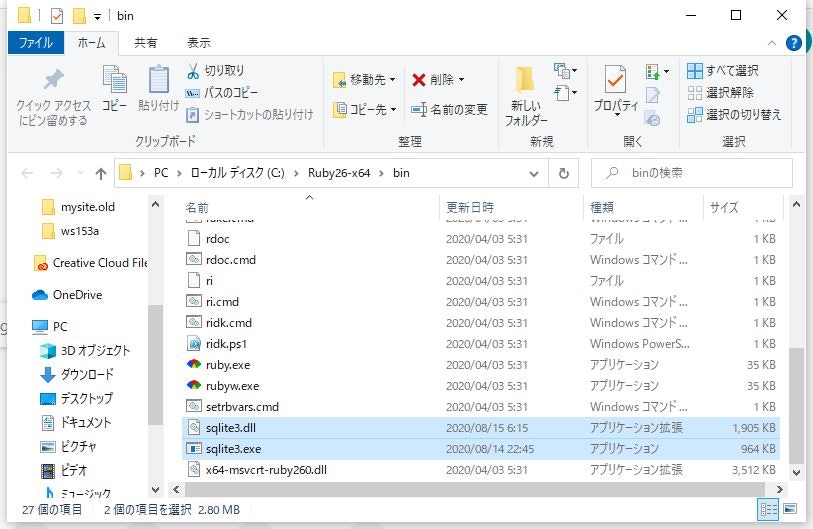
ダウンロードしたフォルダを解凍し「sqlite3.dll」、「sqlite3.exe」というファイルを「C:¥Ruby26-x64¥bin」へコピーします。
(※sqlite3.exeは32bit版しかありませんが、64bitにも対応しているようです。)
ここまで来て、「gem install rails -v "5.2.3"」のコマンドを実行すると、ridk installのコマンドを実施するか、
MSYS2をインストールしてくださいという旨のメッセージが出ました。MSYS2をインストール
MSYS2のサイトよりmsys2-x86_64-20200903.exeをダウンロード。
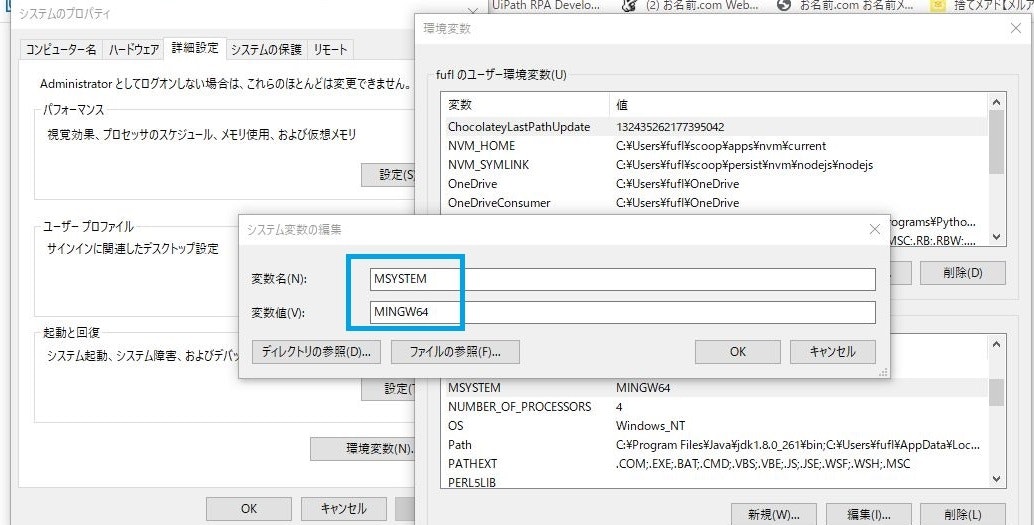
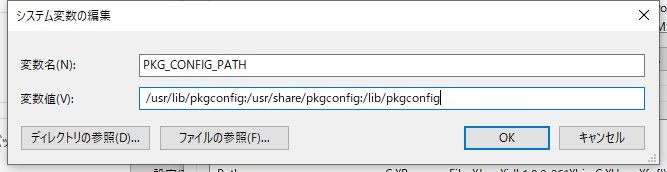
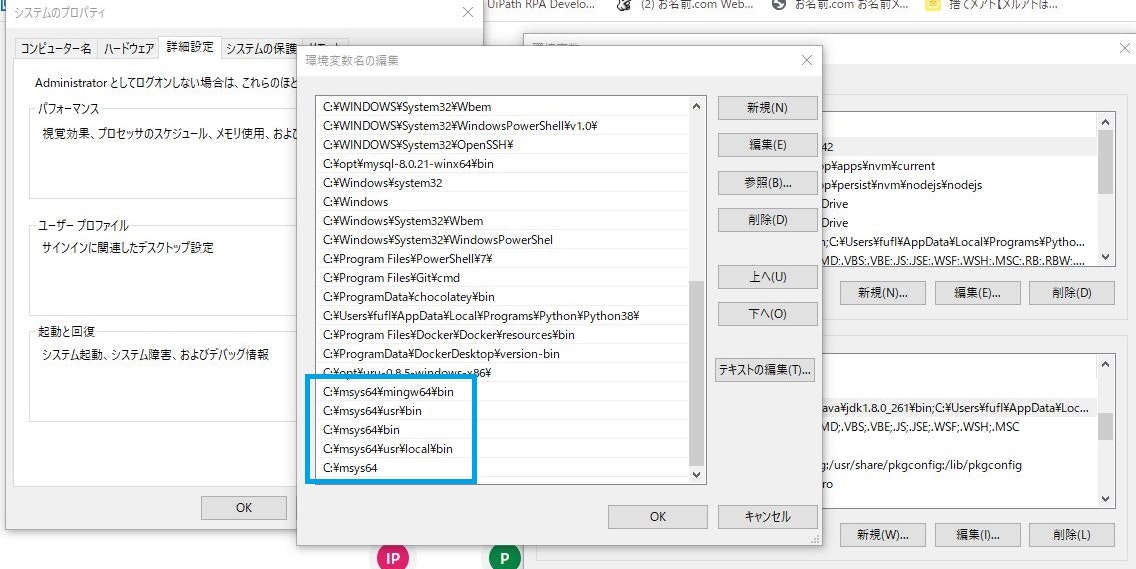
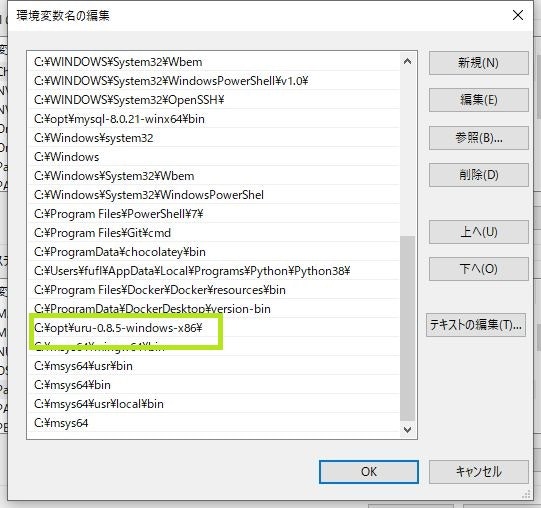
先に[コントロールパネル]-[システムとセキュリティ]-[システム]-[環境変数(N)]より環境変数を設定します。● システム環境変数MSYSTEM: MINGW64
● システム環境変数PKG_CONFIG_PATH: /usr/lib/pkgconfig:/usr/share/pkgconfig:/lib/pkgconfig
● システム環境変数Pathの末尾に追加:
- C:\msys64\mingw64\bin
- C:\msys64\usr\local\bin
- C:\msys64\usr\bin
- C:\msys64\bin
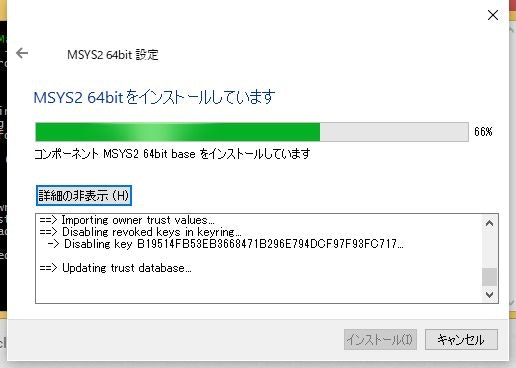
以下Pathが不要と思われる箇所のスクリーンショットです。
ダウンロードしたファイルをダブルクリックしインストールを進めます。 インストールの進行状況は以下になります。 [次へ]を押して進めます。
[詳細の表示]を押すと進捗状況が確認できます。
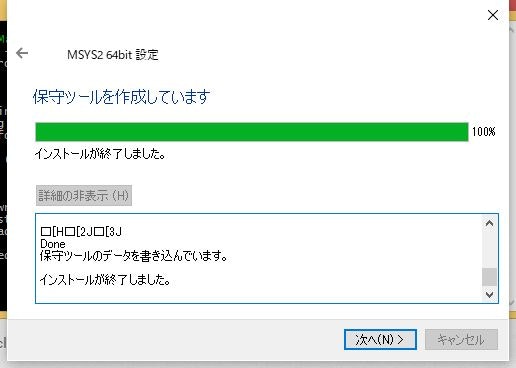
インストールが終了したら[次へ]を押します。
インストールが終了したら[次へ]を押します。
[完了]を押します。
MSYS2のbash画面が起動しますが、一旦閉じます。
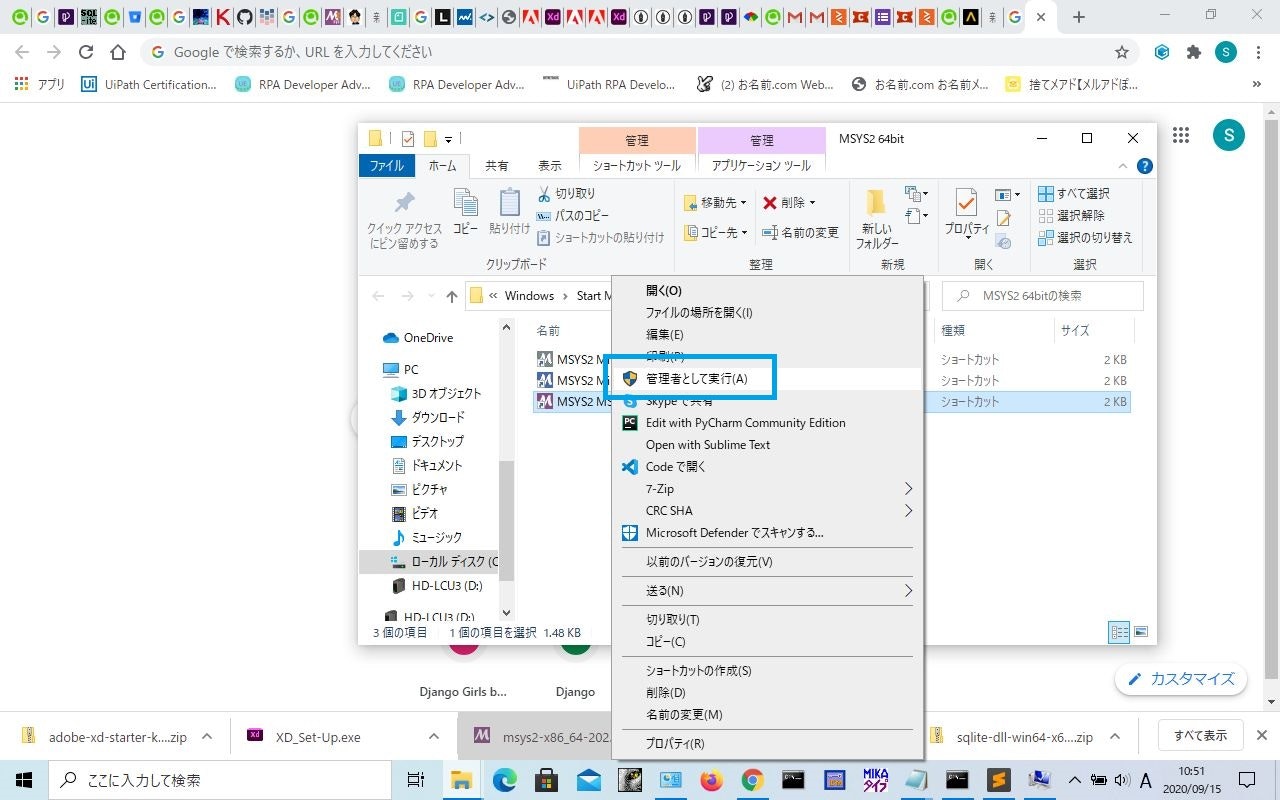
MSYS2のbashを管理者として実行します。
ただ私の環境では右クリックのメニューに[ファイルの場所を開く]しかなかったため、一旦ファイルの場所を開きスタートメニューのショートカット群から「MSYS2 MSYS」の[管理者として実行]をしました。
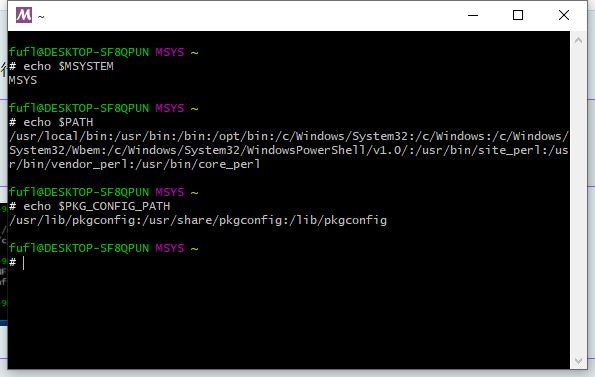
下記コマンドを実行し環境変数を確認。bash>echo $MSYSTEM >echo $PATH >echo $PKG_CONFIG_PATH環境変数が設定できていれば下記のような表示になります。
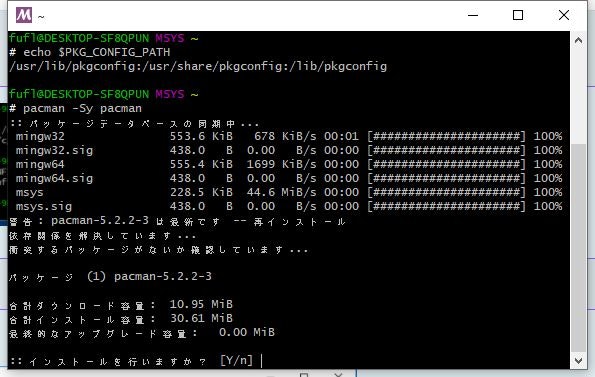
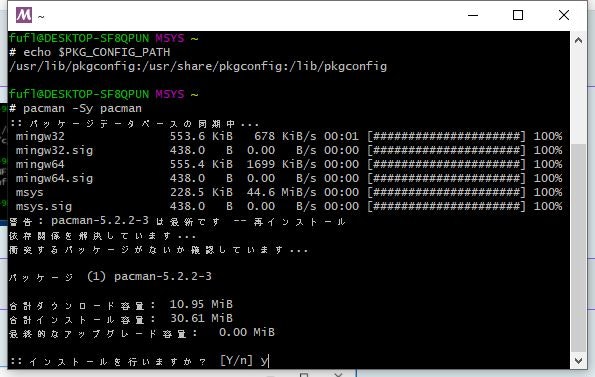
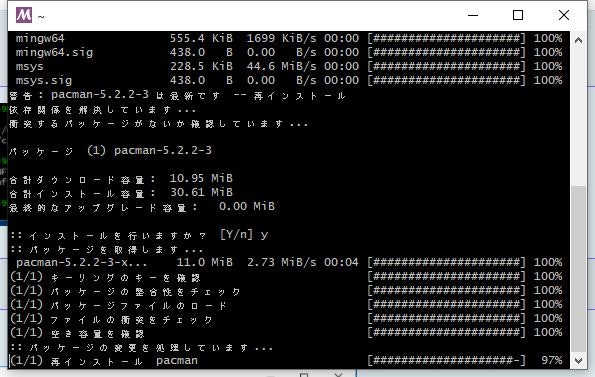
下記コマンドを実行し、何か聞いてきたら[y]を入力しEnterキーを押します。
bash> pacman -Sy pacman
終わったら、一旦MSYSの画面を閉じます。
もう一度、MSYS2 MSYSを[管理者として実行]します。
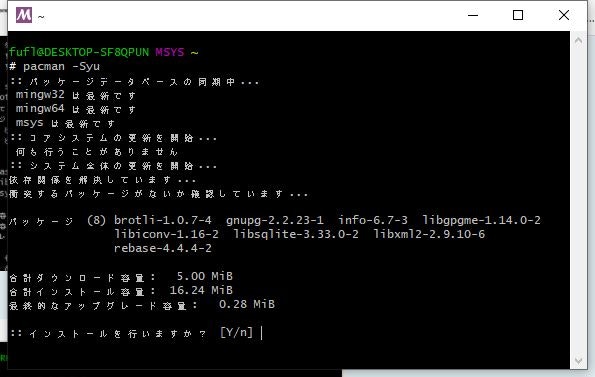
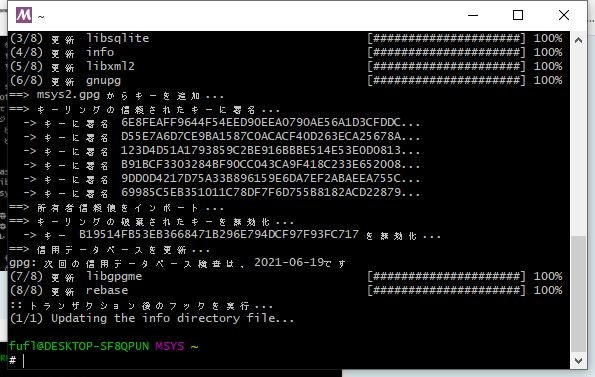
パッケージデータベースと pacman とコアパッケージの更新
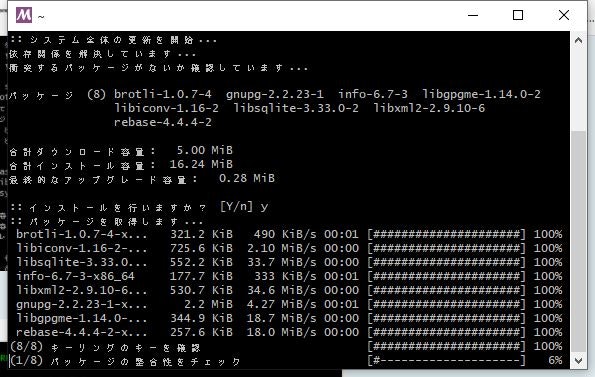
下記コマンドを実行し、何か聞いてきたら[y]を入力し、Enterキーを押します。bash>pacman -Syu
終わったら、一旦MSYS画面を閉じます。パッケージの更新
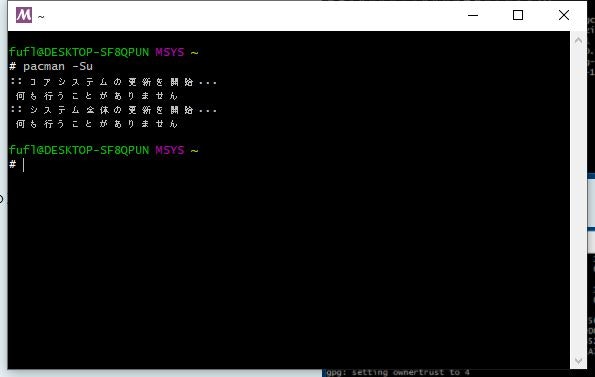
再度MSYS2 MSYSを[管理者として実行]します。 下記コマンドを実行します。bash> pacman -Su
私の環境では「何も行うことがありません」とメッセージが表示されました。
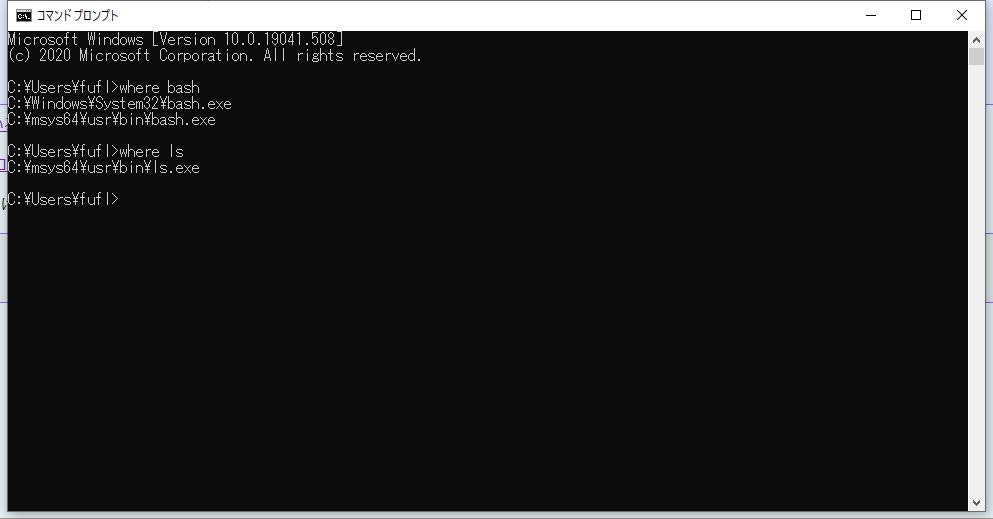
終わったら、MSYS画面を閉じます。Windowsのコマンドプロンプトを起動し、下記コマンドを実行します。
cmd.exe> where bash > where ls
私の環境ではwslをインストールしている影響からか「C:\Windows\System32\bash.exe」が表示されましたが、特に影響はないようです。Windows版Rubyのバージョン管理uruをインストール
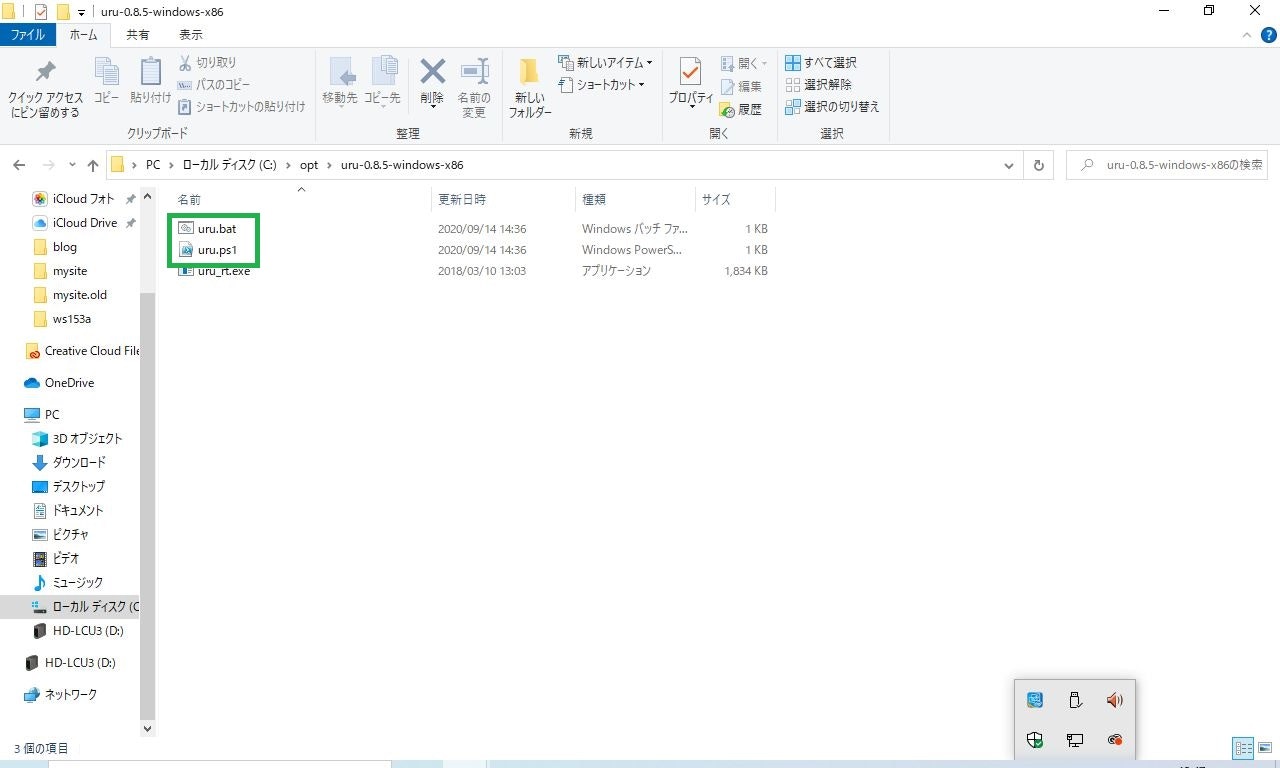
Ruby on Railsを使う環境によっては違うバージョンのRubyを使い分ける場面が出てくると思いますので、uruをインストールしました。
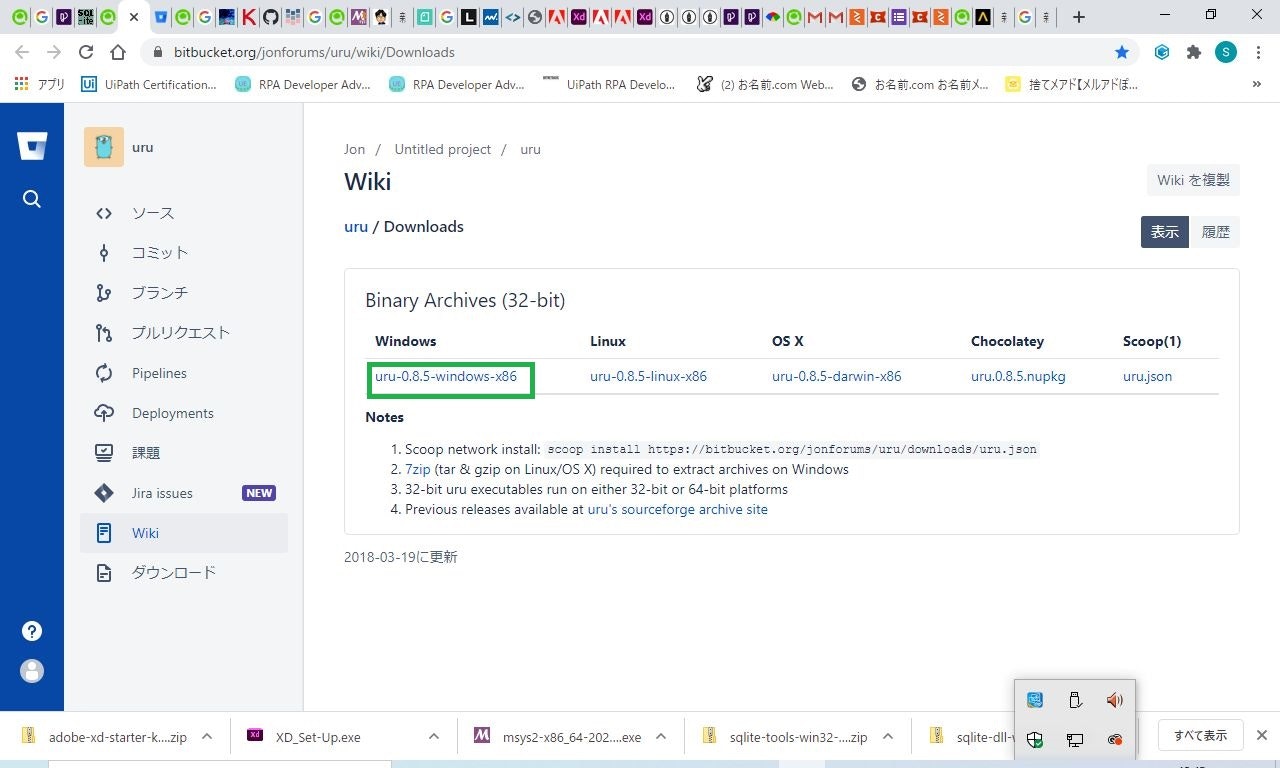
jonforums / uru / wiki / Downloads — Bitbucketよりuru-0.8.5-windows-x86のファイルをダウンロード
※32bit版ですが、64bitにも対応しているようです。
ダウンロードされた7zを解凍し、適当なフォルダに移動します。
私はC:\opt以下に移動しました。
移動したuruフォルダをパスに通します。
コマンドプロンプトで下記コマンドを実行します。
cmd.exe>uru_rt admin install ---> Installing uru into C:\opt\uru-0.8.5-windows-x86「uru.bat」、「uru.ps1」が生成されます。
Rubyへのパスをuruに登録します。
cmd.exe> uru admin add C:\Ruby26-x64\bin ---> Registered ruby at `C:\Ruby26-x64\bin` as `266p146`uruに登録されたか確認。
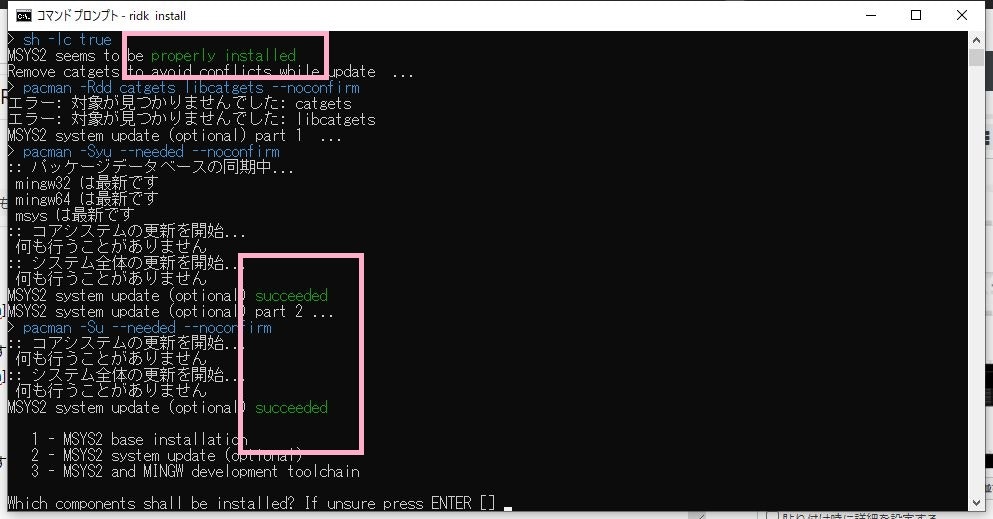
cmd.exe> uru ls 266p146 : ruby 2.6.6p146 (2020-03-31 revision 67876) [x64-mingw32]ridk installを実行
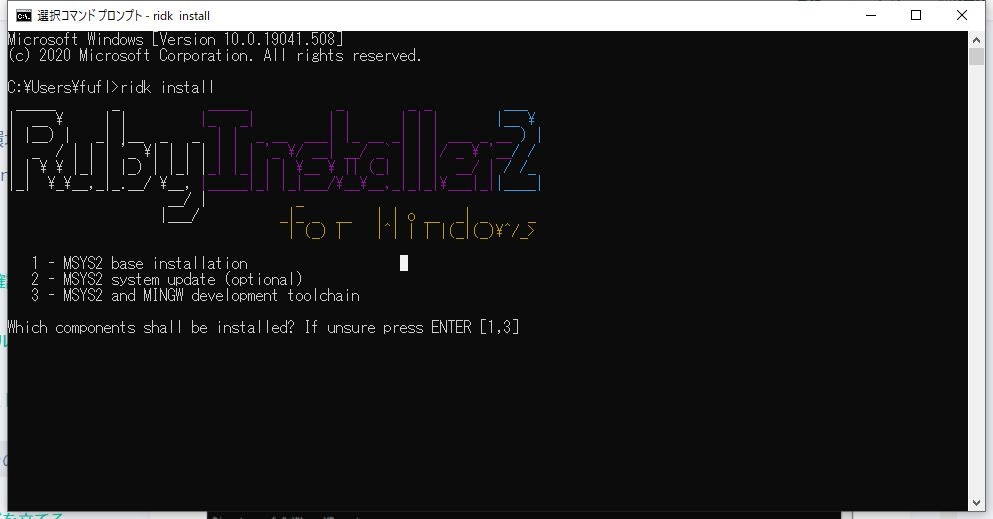
次に、ridk installを実行します。
cmd.exe> ridk install
[1]を入力し、Enterキーを押します。
すでにインストール済のようです。[2]を入力し、Enterキーを押します。
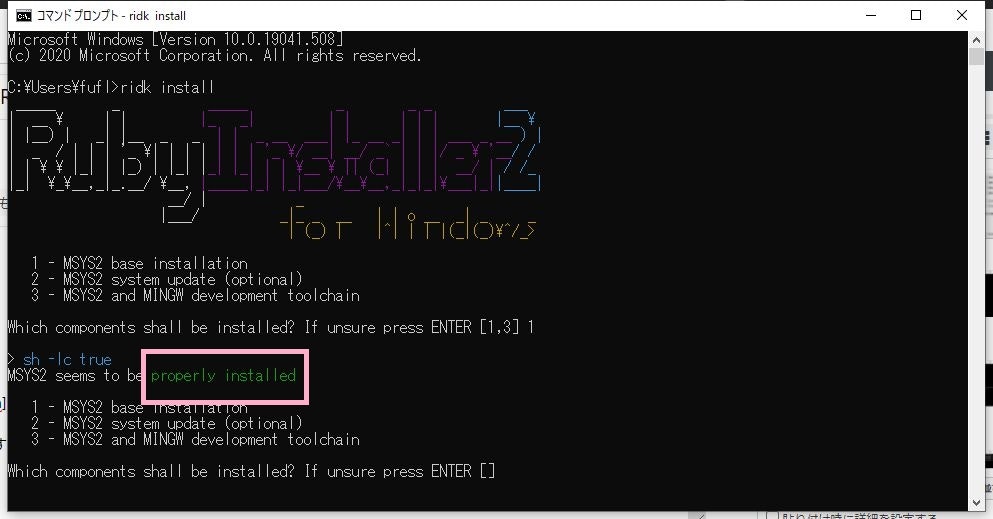
もう最新の状態のようです。もうエラーも出ていません。[3]を入力し、Enterキーを押します。
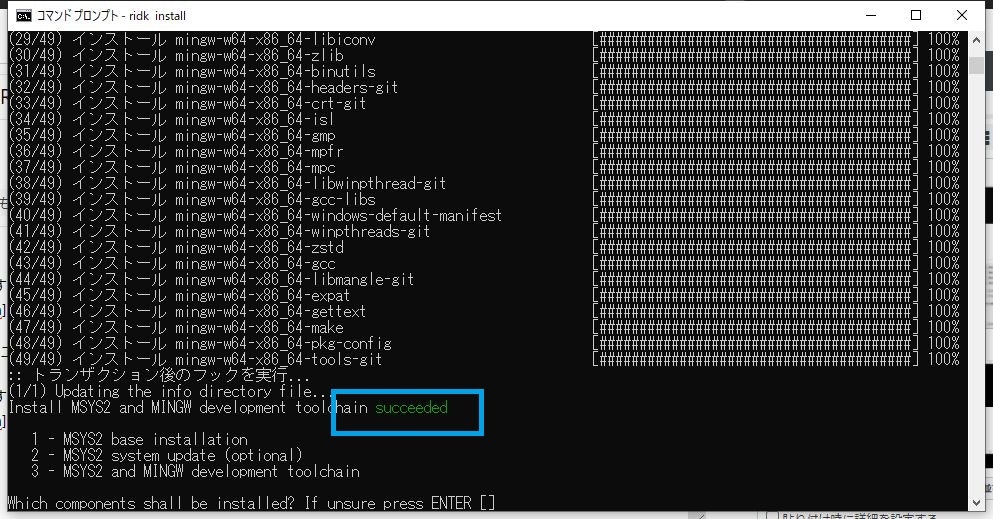
インストール進行中です。
「succeeded」と表示され正常に終了したようです。
Enterキーを押します。Ruby on Railsのインストール
再度コマンドプロンプトを起動し、下記コマンドを実行します。
cmd.exe> gem install rails -v "5.2.3"
「installed」というメッセージが確認できたのでgemのインストールまで終了したようです。
railsのバージョンを確認してみます。
cmd.exe> rails -v Rails 5.2.3Railsのインストールまで正常終了しました。
Railsサンプルアプリの作成
サンプルアプリを作ってみましょう。
下記コマンドを実行します。
cmd.exe> rails new sample_app -Gsample_appはアプリ名ですので自由につけることができます、
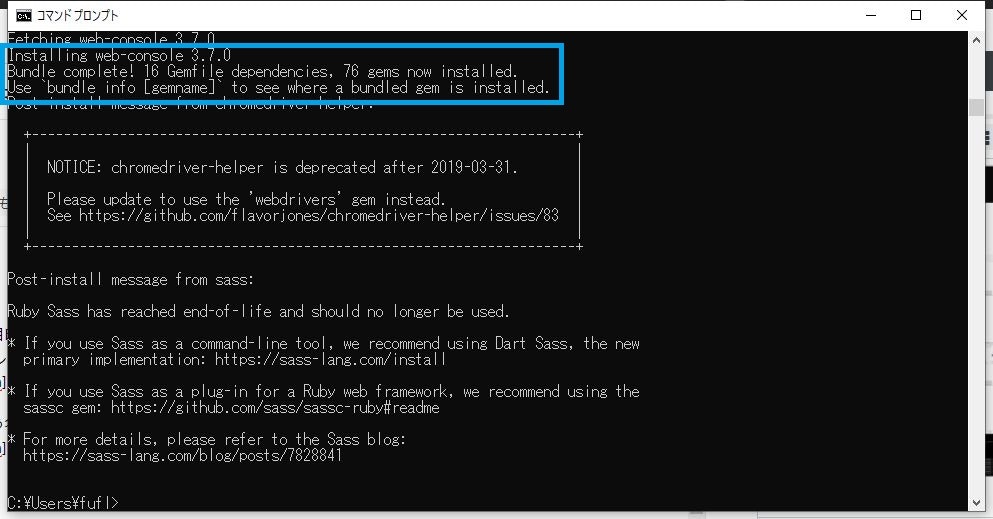
-GオプションはGitをインストールしていない場合につけます。「Bundle complete!」というメッセージが表示され、正常に終了したようです。
NOTICEというところにchromedriver-helperはサポート終了した旨表示が出ていますが、こちらはまたの機会にしたいと思います。
sample_appという名前のフォルダがあるので、Railsアプリケーションの作成が完了したことになります。
Railsを起動
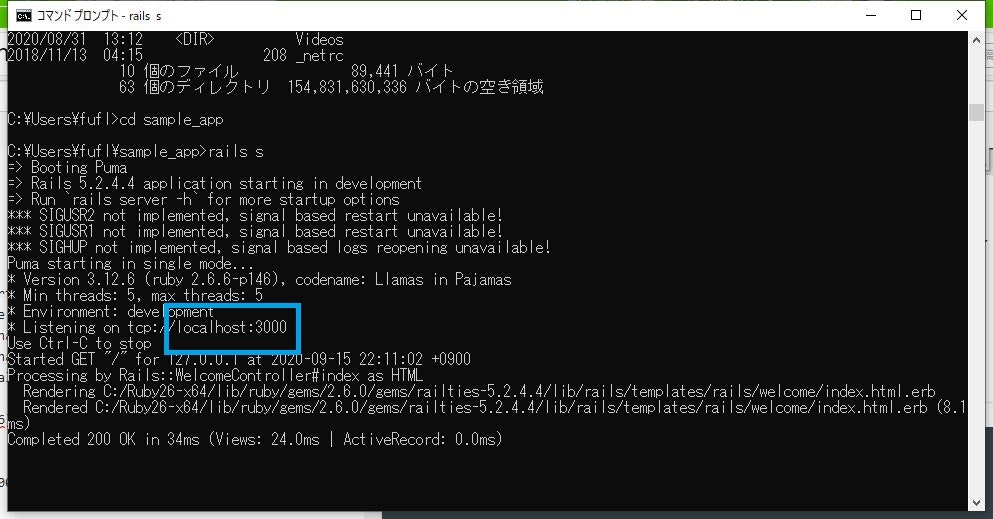
cmd.exe> cd sample_appsample_appフォルダに移動します。
下記コマンドを実行します。
cmd.exe> rails scmd.exerails s => Booting Puma => Rails 5.2.4.4 application starting in development => Run `rails server -h` for more startup options *** SIGUSR2 not implemented, signal based restart unavailable! *** SIGUSR1 not implemented, signal based restart unavailable! *** SIGHUP not implemented, signal based logs reopening unavailable! Puma starting in single mode... * Version 3.12.6 (ruby 2.6.6-p146), codename: Llamas in Pajamas * Min threads: 5, max threads: 5 * Environment: development * Listening on tcp://localhost:3000 Use Ctrl-C to stop「localhost:3000」でサーバが起動しているのがわかります。
ブラウザで「localhost:3000」にアクセスしてみます。
Railsサーバが起動したことが確認できました。
[Ctrl]+[C]キーを押下し、サーバを止めることができます。
完了

- 投稿日:2020-09-15T22:06:27+09:00
【rails】エラーメッセージ とはなんだったのか
エラーメッセージの生成と表示方法
生成
>> user = User.new >> user.save #エラーメッセージ生成 => false >> user.error.full_messages => [Failed"", "invalid"]オブジェクトを保存する際、falseが返ってきた瞬間に配列の要素としてエラーメッセージが生成される。
表示
erb<% @user.errors.full_messages.each do |msg| %> <%= msg %> <% end %>配列の要素をeach文で、それぞれ取り出し、表示させることができる
エラー時にのみ出現するClass属性
class="field_with_errors"
自動でエラー箇所の入力部品を囲んでくれる。実装
パーシャルを使いつつ、どんなオブジェクトでも対応できるように実装させている。
shared/_error_messages.html.erb<% if object.errors.any? %> <div id="error_explanation"> <div class="alert alert-danger alert-form-extend" role="alert"> <%= object.errors.count %>個のエラーがある </div> <ul> <% @user.errors.full_messages.each do |msg| %> <li><%= msg %></li> <% end %> </ul> </div> <% end %>users/new.html.erb<%= form_with(model: @user, url: users_path, local: true) do |form| %> <%= render 'shared/error_messages', object: form.object %>users_controller.rbdef create @user = User.new(user_params) if @user.save ~~ else render 'new' end endapplication.scss#error_explanation { color: red; ul { color: red; padding-bottom: 0; } } .field_with_errors .form-control { border-color: red; }エラーメッセージを日本語化
Gemfilegem 'rails-i18n'$ bundle installエラーメッセージを日本語に設定
config/application.rbmodule SampleApp class Application < Rails::Application config.i18n.default_locale = :ja config.i18n.load_path += Dir[Rails.root.join('config', 'locales', '**', '*.{rb,yml}').to_s] end endどのコードが、どの日本語に対応させるのかを設定
$ mkdir config/locales/models $ touch config/locales/models/ja.ymlja.ymlja: activerecord: models: user: ユーザ attributes: user: name: 名前 email: メールアドレス password: パスワード password_confirmation: パスワード(再入力)エラーメッセージを手動追加 errors.add
user.errors.add(:base, "追加エラー")もちろんエラーを生成してから出ないと、追加できないので、流れとしては以下の通り。
> user = User.new > user.errors > user.errors.add(:base, "追加エラー") > user.errors.full_messages => ["追加エラー"]
- 投稿日:2020-09-15T21:15:50+09:00
(ギリ)20代の地方公務員がRailsチュートリアルに取り組みます【第9章】
前提
・Railsチュートリアルは第4版
・今回の学習は3周目(9章以降は2周目)
・著者はProgate一通りやったぐらいの初学者基本方針
・読んだら分かることは端折る。
・意味がわからない用語は調べてまとめる(記事最下段・用語集)。
・理解できない内容を掘り下げる。
・演習はすべて取り組む。
・コードコピペは極力しない。
続いて第9章、認証システムの開発・第4段回目、ログイン実装後半です。第8章では一時的なセッションだったものを、cookieを利用して永続的なものに切り替えていきます。
セキュリティに関する用語が飛び交いますが、ある程度内容は押さえていきましょう。ドコモ口座の件もありますし、セキュリティの意識を高めねば。
本日のBGMはこちら。
死んだ僕の彼女 "Aki No Hachiouji"
徐々に秋の訪れを感じますね。
【9.1.1 記憶トークンと暗号化 メモと演習】
パスワード:ユーザーが作成・管理
トークン :コンピュータが作成・管理
urlsafe_base64:Ruby標準ライブラリのSecureRandomモジュールにあるメソッド。A–Z、a–z、0–9、"-"、"_"のいずれかの文字 (64種類) からなる長さ22のランダムな文字列を返す。下記の5つの永続的セッション作成方針を頭に入れて進めましょう。
1.記憶トークンにはランダムな文字列を生成して用いる。
2.ブラウザのcookiesにトークンを保存するときには、有効期限を設定する。
3.トークンはハッシュ値に変換してからデータベースに保存する。
4.ブラウザのcookiesに保存するユーザーIDは暗号化しておく。
5.永続ユーザーIDを含むcookiesを受け取ったら、そのIDでデータベースを検索し、記憶トークンのcookiesがデータベース内のハッシュ値と一致することを確認する。1. コンソールを開き、データベースにある最初のユーザーを変数userに代入してください。その後、そのuserオブジェクトからrememberメソッドがうまく動くかどうか確認してみましょう。また、remember_tokenとremember_digestの違いも確認してみてください。
→ 下記。ハッシュ化されたremember_digestが保存されています。>> user = User.first User Load (0.2ms) SELECT "users".* FROM "users" ORDER BY "users"."id" ASC LIMIT ? [["LIMIT", 1]] => #<User id: 1, name: "Rails Tutorial", email: "example@railstutorial.org", created_at: "2020-09-12 09:09:50", updated_at: "2020-09-12 09:09:50", password_digest: "$2a$10$hrOEzw0faSd4yurmH8bQJOnggeNnUqTZg33yE9g7Tnk...", remember_digest: nil> >> user.remember (0.1ms) begin transaction SQL (3.0ms) UPDATE "users" SET "updated_at" = ?, "remember_digest" = ? WHERE "users"."id" = ? [["updated_at", "2020-09-13 22:33:06.439353"], ["remember_digest", "$2a$10$IQ/x1avxRSAG281J18FRi.f2icjx8Kac5y8bWua5IDVae.C.Kdwcu"], ["id", 1]] (5.9ms) commit transaction => true >> user.remember_token => "aGtKYk5iEjSHFs16uB7xTQ" >> user.remember_digest => "$2a$10$IQ/x1avxRSAG281J18FRi.f2icjx8Kac5y8bWua5IDVae.C.Kdwcu"
2. リスト 9.3では、明示的にUserクラスを呼び出すことで、新しいトークンやダイジェスト用のクラスメソッドを定義しました。実際、User.new_tokenやUser.digestを使って呼び出せるようになったので、おそらく最も明確なクラスメソッドの定義方法であると言えるでしょう。しかし実は、より「Ruby的に正しい」クラスメソッドの定義方法が2通りあります。1つはややわかりにくく、もう1つは非常に混乱するでしょう。テストスイートを実行して、ややわかりにくいリスト 9.4の実装でも、非常に混乱しやすいリスト 9.5の実装でも、いずれも正しく動くことを確認してみてください。ヒント: selfは、通常の文脈ではUser「モデル」、つまりユーザーオブジェクトのインスタンスを指しますが、リスト 9.4やリスト 9.5の文脈では、selfはUser「クラス」を指すことにご注意ください。わかりにくさの原因の一部はこの点にあります。
→ 指示通り書くと、両方ともGREENです。ここで出てくる書き方について調べてみました。最初のUser→selfに置き換えたものを特異メソッド方式、class << selfでまとめたものを特異クラス方式と呼ぶようです。詳しくはこちらの記事へ。
【9.1.2 ログイン状態の保持 メモと演習】
permanentメソッド:20年後に期限切れにする。
signedメソッド:デジタル署名と暗号化の両方の処理を行う。
1. ブラウザのcookieを調べ、ログイン後のブラウザではremember_tokenと暗号化されたuser_idがあることを確認してみましょう。
→ たしかに両方とも増えていました!
2. コンソールを開き、リスト 9.6のauthenticated?メソッドがうまく動くかどうか確かめてみましょう。
→ 演習1で確認したremember_tokenを引数に入れればOK。user = User.first 略 user.authenticated?("演習1のremember_token") => true
【9.1.3 ユーザーを忘れる メモと演習】
ユーザーを忘れる=remember_digestをnilで更新する。
1. リスト 9.16で修正した行をコメントアウトし、2つのログイン済みのタブによるバグを実際に確かめてみましょう。まず片方のタブでログアウトし、その後、もう1つのタブで再度ログアウトを試してみてください。
→ NoMethodError in SessionsController#destroy
undefined method `forget' for nil:NilClass
2. リスト 9.19で修正した行をコメントアウトし、2つのログイン済みのブラウザによるバグを実際に確かめてみましょう。まず片方のブラウザでログアウトし、もう一方のブラウザを再起動してサンプルアプリケーションにアクセスしてみてください。
→ 地味にめんどいので省略
3. 上のコードでコメントアウトした部分を元に戻し、テストスイートが red から greenになることを確認しましょう。
→ Yes, GREEN !
【9.1.4 2つの目立たないバグ 演習】
1. 8.1.4の処理の流れが正しく動いているかどうか、ブラウザで確認してみてください。特に、flashがうまく機能しているかどうか、フラッシュメッセージの表示後に違うページに移動することを忘れないでください。
→ 試してみましょう。違うページに行くとフラッシュが消えます。
【9.2. [Remember me]チェックボックス メモと演習】
三項演算子というものが出てきました。if-else文を一行で書けるようです。これでリスト8.21のコードの形がみえてきました(いまだに::はしっくりきてないけど)。つまり、下のコードは
cost = ActiveModel::SecurePassword.min_cost ? BCrypt::Engine::MIN_COST : BCrypt::Engine.costこのようになると。
if cost = ActiveModel::SecurePassword.min_cost BCrypt::Engine::MIN_COST else BCrypt::Engine.cost end
1. ブラウザでcookies情報を調べ、[remember me] をチェックしたときに意図した結果になっているかどうかを確認してみましょう。
→ いけてます。
2. コンソールを開き、三項演算子を使った実例を考えてみてください (コラム 9.2)。
→ 至極シンプルに下記>> x = 6 => 6 >> x % 3 == 0 ? "3の倍数" : "ちゃうな" => "3の倍数"
【9.3.1 [Remember me]ボックスをテストする 演習】
1. リスト 9.25の統合テストでは、仮想のremember_token属性にアクセスできないと説明しましたが、実は、assignsという特殊なテストメソッドを使うとアクセスできるようになります。コントローラで定義したインスタンス変数にテストの内部からアクセスするには、テスト内部でassignsメソッドを使います。このメソッドにはインスタンス変数に対応するシンボルを渡します。例えばcreateアクションで@userというインスタンス変数が定義されていれば、テスト内部ではassigns(:user)と書くことでインスタンス変数にアクセスできます。本チュートリアルのアプリケーションの場合、Sessionsコントローラのcreateアクションでは、userを (インスタンス変数ではない) 通常のローカル変数として定義しましたが、これをインスタンス変数に変えてしまえば、cookiesにユーザーの記憶トークンが正しく含まれているかどうかをテストできるようになります。このアイデアに従ってリスト 9.27とリスト 9.28の不足分を埋め (ヒントとして?やFILL_INを目印に置いてあります)、[remember me] チェックボックスのテストを改良してみてください。
→ userを@userに、ログインテスト該当箇所を下記のとおりに。sessions_controller.rbdef create @user = User.find_by(email: params[:session][:email].downcase) if @user && @user.authenticate(params[:session][:password]) log_in @user params[:session][:remember_me] == '1' ? remember(@user) : forget(@user) redirect_to @user else flash.now[:danger] = "Invalid email/password combination" render 'new' end endusers_login_test.rbtest "login with remembering" do log_in_as(@user, remember_me: '1') assert_equal cookies['remember_token'], assigns(:user).remember_token endこのログインテストのcookies['remember_token']なんですが、当初はcookies[:remember_token]を試したところテスト通過。なぜだろうと思って調べると、こちらの記事が。現在はシンボルでもOKなのかな?でもチュートリアルのRailsのバージョンは古いしなあ…。
【9.3.2 [Remember me]をテストする 演習】
1. リスト 9.33にあるauthenticated?の式を削除すると、リスト 9.31の2つ目のテストで失敗することを確かめてみましょう (このテストが正しい対象をテストしていることを確認してみましょう)。
→ 該当箇所で失敗してました。
第9章まとめ
・cookiesメソッドでユーザーidと記憶トークンを永続化。
・データベースに絡む動作はUserクラスに定義。Sessionコントローラで使用するメソッドは主にSessionヘルパーに定義。前者は後者でも使用。
・remember_me機能は値が1か0かでクッキーを保持するか削除するか分けるスイッチのようなもの。
・current_userはセッションかクッキーの状態・情報によって決まる。
・情報技術用語が飛び交っていたので用語集にまとめています。
この章はややこしいですね…。webページにみえてこない部分なので、どうしてもイメージが描き切れない部分があります。とはいえ、セキュリティに関する部分は疎かにできません。時間がたってからもう一回やってもいいかも。さて次!第10章!未実装のユーザー機能を実装していきます!
⇦ 第8章はこちら
学習にあたっての前提・著者ステータスはこちら
なんとなくイメージを掴む用語集
・セッションハイジャック
通信の当事者でない第三者(攻撃者)が何らかの手段でセッションIDを知ることにより、セッションを乗っ取る攻撃手法。・パケットスニッファ
LANアナライザの俗語。LAN上を通過するトラフィックを監視したり記録するためのハードウェアやソフトウェアのこと。・クロスサイトスクリプティング(XSS)
Webサイトに利用されるアプリケーションの脆弱性もしくはその脆弱性を悪用した攻撃のこと。特にWeb閲覧者側が制作することのできる動的サイト(例:TwitterなどのSNS、掲示板等)に対して、その脆弱性を利用して悪意のある不正なスクリプトを挿入することにより発生するサイバー攻撃。・デジタル署名
書面上の手書き署名のセキュリティ特性を模倣するために用いられる公開鍵暗号技術の一種。・ソルト
パスワードやパスフレーズなどのデータをハッシュ化する際に、一方向性関数の入力に加えるランダムなデータのこと。本文中訳注にあるように、人には念をの塩ひとつまみで暗号を強化する。・assert_empty
obj.emptyはtrueであると主張する。・assert_nil
obj.nil?はtrueであると主張する。
- 投稿日:2020-09-15T20:00:03+09:00
【Ruby】FizzBuzz問題自分なりの解説を載せて
内容
1~100までの数字をターミナルに出力し、3の倍数の時は数字の代わりに文字列でFizz、5の倍数の時はBuzz、両方の倍数である15の倍数の時はFizzBuzzと出力されるプログラムを作ってねという問題について解説を載せて書いてみる。
答え
def fizz_buzz num = 1 while (num <= 100) do if (num % 3 == 0) && (num % 5 == 0) puts "FizzBuzz" elsif (num % 3) == 0 puts "Fizz" elsif (num % 5) == 0 puts "Buzz" else puts num end num = num + 1 end end fizz_buzz解説
変数numに1を代入し、whileメソッドでnumが100以下の時、3の倍数かつ5の倍数の時にFizzBuzzと出力。3の倍数の時にFizzと出力。5の倍数の時Buzzと出力。それ以外はnumを出力し、最後にnumに1を追加する。
- 投稿日:2020-09-15T19:00:52+09:00
[RSpec] WebMockで正規表現とArrayなクエリストリングを扱う
はじめに
WebMockは昔からある有名なモックライブラリですが、RSpecでちょっとした細かい検証を行おうとした際にいろいろ試したことを自分用メモとしてまとめます。
主に外部API等へのリクエストを想定した、HTTPリクエストに対する検証の方法を取り扱っています。環境
Ruby : 2.7.1
RSpec : 3.9.0
webmock : 3.8.3テスト対象のコード
サンプルとして今回は、https://jsonplaceholder.typicode.com/ へリクエストします。
sample.rubyrequire 'net/http' class Sample def request(params = {}) URI.parse('https://jsonplaceholder.typicode.com/todos') .tap { |uri| uri.query = URI.encode_www_form(params) } .then { |uri| Net::HTTP.get_response(uri) } .then { |res| res.body if res.is_a?(Net::HTTPSuccess) } end end基本形
webmockの
stub_requestを使用して、指定のURLへのリクエストをmockにします。
またexpect時の検証にはa_requestを使うパターンで行っています。sample_spec.rbcontext '基本形' do before do stub_request(:get, 'https://jsonplaceholder.typicode.com/todos').and_return(status: 200, body: 'hoge') end it '正しくリクエストされること' do expect(Sample.new.request).to eq 'hoge' expect(a_request(:get, 'https://jsonplaceholder.typicode.com/todos')).to have_been_made.once end end context '基本形その2 クエリストリングも検証' do before do stub_request(:get, 'https://jsonplaceholder.typicode.com/todos?userId=2').and_return(status: 200, body: 'hoge') end it '正しくリクエストされること' do expect(Sample.new.request(userId: 2)).to eq 'hoge' expect( a_request(:get, 'https://jsonplaceholder.typicode.com/todos').with(query: { userId: 2 }) ).to have_been_made.once end end
have_bee_madeはWebMockが用意しているRSpec用のマッチャーです。他にもいくつかのマッチャーが用意されています。onceも同じくWebMockが用意しているマッチャーで、こちらもいろいろなバリエーションがあります。withを使用することで明示的にクエリストリングを検証できます。
withを使用しなくともa_request(:get, 'https://jsonplaceholder.typicode.com/todos?userId=2')というように愚直に書いてもOKです。- クエリストリングの他に
withでは、bodyheadersbasic_authという値を使用した検証も可能です。正規表現でワイルドカード的なやつを使いたい
例えば、リクエストするURLを
todosからtodos/1に変えたい場合や、もっと複数のクエリストリングを指定したりしてテストしたい場合があると思いますが、その場合、毎回リクエストに合わせてstub_requestのURL文字列を変更しないとmockされません。それだと面倒なので、正規表現を使うことで対応します。stub_request(:get, /https:\/\/jsonplaceholder.typicode.com/).and_return(status: 200, body: 'hoge')こうすることで、
https://jsonplaceholder.typicode.com/ドメイン配下のリクエストはすべてmockされて、a_requestで検証可能になります。また、正規表現は
a_requestでも使用することが可能です。expect(a_request(:get, /https:\/\/jsonplaceholder.typicode.com/)).to have_been_madeただし、以下のように
a_requestでwithを使用したクエリストリングの検証はできません。# この書き方はNG expect(a_request(:get, /https:\/\/jsonplaceholder.typicode.com/).with(query: { userId: 2)).to have_been_madeArrayなクエリストリングの検証方法
以下のような同一のキーを複数指定したクエリストリングの検証をしたい場合の方法を説明します。
Railsデフォルトな場合
Railsなアプリケーションの場合、以下のように
[]を付けるのがデフォルトです。([]はエンコードされるので正確には%5B%5D)?userId[]=1&userId[]=2&userId[]=3以下のように
withにqueryのhashで配列を指定すればOKです。railsっぽく書けます。expect( a_request(:get, 'https://jsonplaceholder.typicode.com/todos').with(query: { userID: [1, 2, 3] }) ).to have_been_madeRailsデフォルトじゃない場合
外部APIなどRails以外のアプリケーションの場合、以下のように
[]を付けないパターンがほとんどです。?userId=1&userId=2&userId=3そういうときは、以下のように
:flat_arrayというsymbolをWebMockに設定します。WebMock::Config.instance.query_values_notation = :flat_array検証方法は以下のように
withのqueryhashで値を文字列で指定します。expect( a_request(:get, 'https://jsonplaceholder.typicode.com/todos').with(query: 'userID=1&userID=2&userID=3') ).to have_been_made文字列を直接書くのが嫌な場合は、
URI.encode_www_formなどを使用して文字列に変換すると良いでしょう。expect( a_request(:get, 'https://jsonplaceholder.typicode.com/todos').with(query: URI.encode_www_form(userId: [1, 2, 3])) ).to have_been_made
flat_arrayを設定した場合はwithでクエリストリングがソートされる
WebMock::Config.instance.query_values_notation = :flat_arrayを設定した場合ですが、withでクエリストリングを検証するときはキーを文字順でソートした値を渡す必要があります。表題のテスト対象のコードで以下を実行するとクエリストリングは
userId=1&aa=1とリクエストされますが、withのqueryには並び替えた文字列aa=1&userId=1を渡さないとダメでした。WebMock::Config.instance.query_values_notation = :flat_array Sample.new.request(userId: 1, aa: 1) # OK expect( a_request(:get, 'https://jsonplaceholder.typicode.com/todos').with(query: 'aa=1&userId=1') ).to have_been_made # hashはOK expect( a_request(:get, 'https://jsonplaceholder.typicode.com/todos').with(query: { userId: 1, aa: 1 }) ).to have_been_made # これはNG expect( a_request(:get, 'https://jsonplaceholder.typicode.com/todos').with(query: 'userId=1&aa=1') ).to have_been_made参考
- 投稿日:2020-09-15T18:58:15+09:00
条件式で注意したいこと
【概要】
1.結論
2.具体例
1.結論
上から読み込まれるので書く順番に気をつける!
2.具体例
たとえば、以下の3つの条件を基に出力するプログラムを記載する場合を見てみます。
❶20以下であれば"20以下の数字"と出力
❷20より大きい数字であれば"20より大きい数字"と出力
❸20以下で0以下であれば"0以下の数字"と出力この場合で以下の記載をしています。
int = gets.to_i if int <= 20 puts "20以下の数字" #❶ elsif int <= 0 puts "0以下の数字" #❷ else puts "20より大きい数字" #❸ endこの場合、int に"-1"と記載すると❶の
if int <= 20 puts "20以下の数字"が反応してしまい、本来出したい❷の出力がされません。
これはプログラムは上から下に順番に読み込まれるためです。(defはあとから読み込み、javascriptの関数宣言は先に読み込まれるといった例外はあります。)なので❶と❷の順番を入れ替えて
int = gets.to_i if int <= 0 puts "0以下の数字" #❶ elsif int <= 20 puts "20以下の数字" #❷ else puts "20より大きい数字" #❸ endとすると本来の意図を汲み取ったプログラムになります。
- 投稿日:2020-09-15T18:47:59+09:00
【感想】TechCampを受講してみて
約2ヶ月半のTechCampを卒業して、今後受講を検討している方の参考になればと思い、感想を述べます
誤解のないように申し上げると、上から目線で評論するつもりもなく、批判するつもりもないです。まず私としては短期集中型の受講料65万円という価格ほどの価値はなかったと感じてます。
価値としては40万円程かなと。理由とコメントを述べると、
・教材が基礎に毛が生えたレベル(それでも未経験者にとっては難しいです)
・Udemyや書籍など他の教材で学習できる(自学ができない人は受講の価値あり)
・質問し放題と謳ってはいるが、割と早々に質問するまでのハードルが上がる(正しい質問の仕方を学ぶチャンスではあるが、質問フォーマットを正確に作るためと、メンターと通話が繋がるまでに1〜2学習できるぐらいの時間がとられる)
・メンターの質のレンジが広い(ほとんどが良いメンター様でしたが、さっさと終わらせようという空気を出してくるメンターもいる)
・日々のスケジュールに沿って行動することでトータルで効率のいい1日を送ることができる(ただし人による。私は自分のペースが崩れると一気に集中力が落ちるので中盤以降はチームメイト了承の上、自分のペースでやってました)
・カリキュラム外の質問には答えてもらえない(特に自作アプリ以降は質問に答えてもらえません。本当はここでたくさんのことを教わりたかった)
・毎日解くRubyの問題が面白い(Paizaのようなものです。私のようなクイズ好きだと楽しいです)
・ライフコーチのホスピタリティが高い(改善点は促しつつも、非常に上手に自信とモチベーションを上げてくれる)
・キャリアアドバイザーから得られる情報の8割方がネットで得られる(何をどのように調べればいいかわからない人にとっては有益です)
・必ずしもチームメイトは高め合える存在とは限らない(早々に進捗に差がでても最後まで同じチームメイトです。苦楽を共にする点では◯。ほぼずっとオンラインなので同じ進捗具合の別チームの方と交流する機会を設けてほしかった)こんなところでしょうか。
上記と重複しますが、受講を検討されている方は、まずはProgateでプログラミングを遊んでみて、その後Udemyなどの動画教材で自学してみましょう。
わからないところはMenta等を利用してみましょう。
限定的ではありますが、福岡市内在住の方でしたらTechCampから徒歩5分程度のところに市が運営するエンジニアカフェというコワーキングスペースが無料で利用でき、午後からは駐在のエンジニアに質問することもできます。
上記のようなことをやってみて、どうしてダメだという方は検討してみてもいいかと思います。以上になりますが、満足度は半々と行った感じです。
受講料がもう10〜15万でも安ければ満足が高かったと思います。ただ後悔はしてません。
自分で選んで、そしてやりきった自負があるからです。最後になりますが、TechCampでお世話になった方々、心から感謝しております。
そしてこの記事が誰かの参考に少しでもなれば幸いです。
- 投稿日:2020-09-15T17:44:56+09:00
外部プログラムを直接実行した場合にシェルスクリプトにフォールバックする言語・しない言語
※本記事の内容はWindowsには一切当てはまりません。
https://linuxjm.osdn.jp/html/LDP_man-pages/man3/exec.3.html 等によると、execvpでのみ、ENOEXECが発生したらシェルスクリプトと解釈する機能があるそうです。
スクリプト言語でシェルを使わず外部プログラムを実行した場合、この機能は働くのでしょうか?準備
$ cat lsscript ls実行
Ruby
- 直接実行(例): popenの引数が配列、systemの引数が2要素以上
ruby -e 'p IO.popen(["./lsscript"]).read'process.c proc_exec_cmd
execveを試し、ENOEXECなら/bin/shを付加して再試行Python
- 直接実行(例): check_call(等)の引数が配列
python -c 'import subprocess;subprocess.check_call(["./lsscript"])'Modules/_posixsubprocess.c child_exec
execveを試す。 ENOEXECの場合失敗するPython3も同様。
なおshell=Trueとすると失敗しなくなりますがpipes.quoteやらshlex.quoteやらが必要となります。
(この記事の読者であればこちらの必要性はわかりますよね)Perl
- 直接実行(例): system()の引数が2要素以上
perl -e 'print system("./lsscript","dummy")'doio.c Perl_do_aexec5
execvpを試す。PHP
- 直接実行: pcntl_exec
php -r 'pcntl_exec("./lsscript");'ext/pcntl/pcntl.c pcntl_exec
execveを試す。 ENOEXECの場合失敗する(上はexecですからサブプロセスとするにはfork呼び出し等が必要。その辺が必要ない標準実行系はext/standard/exec.cにありますが、popen固定のようです(つまり必ずシェルが入る))
結論
Python/PHPでシェルを介さずに実行しようとすると、自動でshを付けてくれません。C言語のshebangもどき等を投げる際はご注意ください。
- 投稿日:2020-09-15T15:43:28+09:00
逐次検索機能の実装
概要
今回は、逐次検索機能の実装について
カリキュラムをみながら自分で実装した時の理解度が低かったので、アウトプットの意味も込めて投稿しようと思います。逐次検索機能とは、例えば「ruby」「python」「ruby on rails」というタグがすでにデータベースに存在する場合、rの文字が入力されると、rの文字と一致する「ruby」「ruby on rails」を候補として瞬時に画面上に表示する機能です。
一般的にインクリメンタルサーチと呼ばれます。
インクリメンタルサーチとは、
文字の入力の都度、自動的に検索が行われる検索機能です。
JSのAjaxを用いて実装します。実装
jsファイルの記述
ターボリンクスをコメントアウトしてtag.jsを読み込めるようにします。
javascript/packs/application.jsrequire("@rails/ujs").start() // require("turbolinks").start() require("@rails/activestorage").start() require("channels") require("../tag")tag.jsを作成して編集します。
javascript/tag.jsif (location.pathname.match("posts/new")){ window.addEventListener("load", (e) => { const inputElement = document.getElementById("post_tag_name"); inputElement.addEventListener("keyup", (e) => { const input = document.getElementById("post_tag_name").value; const xhr = new XMLHttpRequest(); xhr.open("GET", `search/?input=${input}`, true); xhr.responseType = "json"; xhr.send(); xhr.onload = () => { const tagName = xhr.response.keyword; const searchResult = document.getElementById('search-result') searchResult.innerHTML = '' tagName.forEach(function(tag){ const parentsElement = document.createElement('div') const childElement = document.createElement('div') parentsElement.setAttribute('id', 'parents') childElement.setAttribute('id', tag.id ) childElement.setAttribute('class', 'child' ) parentsElement.appendChild(childElement) childElement.innerHTML = tag.name searchResult.appendChild(parentsElement) const clickElement = document.getElementById(tag.id) clickElement.addEventListener("click", () => { document.getElementById("post_tag_name").value = clickElement.textContent; clickElement.remove(); }) }) } }); }) };ここからは、コードの詳細を確認していきます。
javascript/tag.jsconst input = document.getElementById("post_tag_name").value; const xhr = new XMLHttpRequest(); xhr.open("GET", `search/?input=${input}`, true); xhr.responseType = "json"; xhr.send();ここでは、post_tag_nameというID名の要素に入力された値を「input」に代入後、Ajaxの記述を行っています。
後の編集で、searchアクションと紐付けるルーティングを設定するので「openメソッド」でsearchアクションへのパスを設定します。この時、「input」に代入されたバリューをqueryパラメータとして設定します。また、レスポンスのデータ型は「json」と指定して、送信を行っています。
また、あとでsearchアクション(タグの検索)をコントローラーで行うための記述を行います。
keywordというキーに対応するバリューとしてセットして、jsonデータとして返す記述をあとでコントローラーにします。
javascript/tag.jsconst parentsElement = document.createElement('div') const childElement = document.createElement('div')ここでは、インクリメンタルサーチの結果を画面上に表示させるために、div要素を作成しています。
作成したdiv要素の中に、インクリメンタルサーチの結果を加えていきます。javascript/tag.jsparentsElement.setAttribute('id', 'parents') childElement.setAttribute('id', tag.id ) childElement.setAttribute('class', 'child' )先ほど作成したdiv要素にIDとクラス名を与えています。
childElementには、表示させるタグのIDを代入します。また、CSSを割り当てるためのクラス名も与えています。javascript/tag.jsparentsElement.appendChild(childElement) childElement.innerHTML = tag.name searchResult.appendChild(parentsElement)この部分では、parentsElementの子要素としてchildElementを加えます。次にchildElementに表示させる、タグのHTMLを生成させます。最後に、searchResultの子要素にparentsElementを加えています。
javascript/tag.jsconst searchResult = document.getElementById('search-result') searchResult.innerHTML = ''二文字目以降に重複して表示されないように、searchResultの中へ空文字の代入をしています。
javascript/tag.jsconst clickElement = document.getElementById(tag.id) clickElement.addEventListener("click", () => { document.getElementById("post_tag_name").value = clickElement.textContent; clickElement.remove();候補として表示させたタグがクリックされると、選択されたタグのテキスト要素を入力フォームのバリューとしてセットします。最後に、選択されたタグは、表示の一覧から削除します。
以上がインクリメンタルサーチの一連の動きになります。
ルーティングを設定
config/routes.rbresources :posts, only: [:index, :new, :create] do collection do get 'search' end endコントローラーを編集
controller/posts_controller.rbclass PostsController < ApplicationController def index @posts = Post.all.order(created_at: :desc) end ---省略--- def search return nil if params[:input] == "" tag = Tag.where(['name LIKE ?', "%#{params[:input]}%"]) render json:{ keyword: tag } end ---省略--- endこれで実装完了です。動作確認をしてみましょう。
エラーが起きた時
今回の実装で考えうるエラーの解決方法は、getElementByIdをした時のId名に注目してみることです。
今回の実装では、formオブジェクトのpost_tagモデルについてインクリメンタルサーチを実装しました。
また、jsの全文をみた時の一行目にパスの記述があります。
今回は新規投稿をする際のタグ入力で逐次検索をする機能を実装したかったので、posts/newとなっています。この二点以外はコピペでもいけるのではないでしょうか。
あ、ターボリンクス切り忘れとか、tag.js読み込み忘れは流石にやめましょう。
感想
javascriptはカリキュラムでも触れる機会が少なく、苦手意識があるので頑張ろうと思います。
- 投稿日:2020-09-15T13:15:38+09:00
(Ruby on Rails6) データーベースのidを取得したデータベースの表示
マシンスペック
・バージョン 10.15.3
・Ruby ruby 2.6.3p62
・Rails 6.0.3.2まえがき
前記事では、データーベースをビューに表示する方法を記録しました。
しかし、せっかくRuby on Railsで作品を作りたいならid取得をやりたい!
ここでは、idによるデーターベース表示を忘却録として記録します。
何かにお役に立てたら嬉しいです。データーベースのidを取得したデータベースの表示
これからの作業は、すでにデーターベースを作成する必要がありますのでご注意ください。
詳しくは→前記事へidのroutesを設定する
routesのイメージ
↓の感じに "投稿・登録" されたら "マイページ・詳細ページ" とかを id の数に合わせて作りたい
1~4がidになります。config/routesRails.application.routes.draw do get 'コントローラー名/index' get 'コントローラー名/1' = 'コントローラー名#アクション名' get 'コントローラー名/2' = 'コントローラー名#アクション名' get 'コントローラー名/3' = 'コントローラー名#アクション名' get 'コントローラー名/4' = 'コントローラー名#アクション名' endこのままでは routes がえらい多い記述になってしまうので↓のように記述します。
config/routesRails.application.routes.draw do get 'コントローラー名/:id' = 'コントローラー名#アクション名' end↓例
config/routesRails.application.routes.draw do get 'posts/:id' = 'posts#index' end先ほどの、1~4の部分を :id で置き換えています。
routesでの注意!
routes上で↓の様になると、エラーになってしまいます。
(エラー)
config/routesRails.application.routes.draw do get 'コントローラー名/:id' = 'コントローラー名#アクション名' ←先に記述 get "/" => "forms#index" endget 'posts/:id' = 'posts#index' の :id ルートを通常のルートより先に記述してしまうとエラーになってしまいます。
なので、↓の様に記述すること。(サクセス)
config/routesRails.application.routes.draw do get "/" => "forms#index" get 'コントローラー名/:id' = 'コントローラー名#アクション名' ←後に記述 end↓例
config/routesRails.application.routes.draw do get "/" => "forms#index" get 'posts/:id' = 'posts#index' ←後に記述 endcontrollerへの記述
controllerは、この地点では初期設定で問題ありません。
app/controllers/任意_controllerclass PostsController < ApplicationController def アクション名 end end例↓
app/controllers/任意_controllerclass PostsController < ApplicationController def index end endURLからidを取得する
idを取得するには、コントローラーのアクションに params[:id] を使用します。
paramsは、値を受け取るメソッドになります。app/controllers/任意_controllerclass PostsController < ApplicationController def アクション名 @id = params[:id] end endcontrollerでは @ を付けなければいけないので @id にすることを忘れないでください。
例↓
app/controllers/任意_controllerclass PostsController < ApplicationController def index @id = params[:id] end endViewで表示する
app/views/任意/index.html.erb<h1>Title</h1> <p>smple text</p> <%= "idが「#{@id}」の画面です" %>ここで一度、ブラウザで確認しましょう
コマンドrails s(URL) http://localhost:3000/posts/1
表示されました。
画像と、Qiitaでは文字の内容が異なりますが、気にしないでください。app/views/任意/index.html.erb<%= "idが「#{@id}」の画面です" %>の #{@id} に idが読み込まれ、
また <%= ~~ %> なので、ビューに表示されてます。ここまでは、URLとidについて設定しました。
ここからは、idに対応したデータを取得しましょう。idに対応したデータを取得
controllerへの設定
idを等しく出力するために
find_by と params[:id] を使用します。
app/controllers/任意_controllerclass PostsController < ApplicationController def アクション名 @テーブル名 = データーベース名.find_by(id: params[:id]) end end↓例
app/controllers/任意_controllerclass PostsController < ApplicationController def index @post = Post.find_by(id: params[:id]) end endfind_by は、等しい値かをチェックしています。
viewsへの設定
最後にviewsへ設定を行います。
ここでは 投稿内容 と 投稿時間 を表示させましょう。app/views/任意/index.html.erb<h1>Title</h1> <p>sample text</p> <%= @post.content %> <%= @post.created_at %>以下
を入力し、ブラウザで確認してください。コマンドrails s
rails console コマンドで test1 を入力したのですが、しっかり反映されています。
要素の説明
app/views/任意/index.html.erb<%= @post.content %> →content(投稿テキスト)の取得 <%= @post.created_at %> →投稿時間を取得おまけ/リンク
もしも、この投稿にリンクさせたい場合は、以下をviewsに記述してください。
app/views/任意/index.html.erb<%= link_to(投稿.content, "/ページ名/#{post.id}") %>例↓
app/views/任意/index.html.erb<%= link_to(post.content, "/posts/#{post.id}") %>以上のコードはGithubで公開しています。
気になるかたは、ダウンロードしてください。
→ Githubあとがき
以上が、データーベースのidを取得したデータベースの表示でした。
idを取得して、URLやデーターベースの内容を出力できるのは非常にありがたいと思います。
工夫をしたら、多くの場面で活用できると思います。
ここまで、お読みいただきありがとうございました。参考リンク
書籍: たのしいRuby 第6版
私のリンク
また、Twitter・ポートフォリオのリンクがありますので、気になった方は
ぜひ繋がってください。プログラミング学習を共有できるフレンドが出来るととても嬉しいです。

- 投稿日:2020-09-15T10:34:10+09:00
Railsで特定のアクションだけバリデーションを有効化する
複数指定している例がなくて微妙に探したのでメモ
onオプションを使用するclass User < ApplicationRecord # on: [:アクション名] validates :email, on: :create # 複数指定する際は配列で指定する validates :email_confirm, on: [:edit, :update] endhttps://railsguides.jp/active_record_validations.html#on
https://stackoverflow.com/questions/7947235/rails-validates-multiple-on-options
- 投稿日:2020-09-15T10:26:12+09:00
【Ruby on Rails】refileでの投稿画像プレビュー機能
目標
開発環境
ruby 2.5.7
Rails 5.2.4.3
OS: macOS Catalina前提
※ ▶◯◯ を選択すると、説明等が出てきますので、
よくわからない場合の参考にしていただければと思います。投稿機能が既にできていると仮定して進めます。
流れ
1 gem refileの導入
2 カラムの追加
3 modelの編集
4 controllerの編集
5 viewの編集gem refileの導入
Gemfilegem 'refile', require: 'refile/rails', github: 'refile/refile'
補足
refileは、ファイルをアップロードできるようにするgemです。ターミナル$ bundle installカラムの追加
ターミナル$ rails g migration AddPostImageIdToPosts post_image_id:stringターミナル$ rails db:migratet.string "post_image_id"が追加されていればOKです。
db/schemacreate_table "posts", force: :cascade do |t| t.integer "user_id" t.string "title" t.string "body" t.datetime "created_at", null: false t.datetime "updated_at", null: false t.string "post_image_id" # <--これがあればOK t.index ["user_id"], name: "index_posts_on_user_id" endmodelの編集
app/models/post.rbattachment :post_image
補足【refile使用のルール】
1 画像アップロードは、<%= f.attachment_field :image %>で実装
2 モデルに画像アップ用のメソッド「attachment」を追加し、imageを指定
※今回はpost_image_idを追加したため、post_imageを指定。controllerの編集
下記を追加することで、post_imageの変更も許可する。
app/controllers/posts_controller.rbdef post_params params.require(:post).permit(:title, :body, :post_image) endviewの編集
今回は先にデフォルトの画像を表示させておくため、
no-image.pngという画像ファイルを事前に用意しました。
保存場所は、app/assets/imagesの中になります。app/views/posts/new.html.erb<% form_with,...%> ... <div> <%= attachment_image_tag @post, :post_image, fallback: "no-image.png", id: "img_prev", style: "height: 250px; width:300px;" %><br> <%= f.attachment_field :post_image %> </div> ... <% end %> ... <script> $(document).on("turbolinks:load", function(){ function readURL(input) { if(input.files && input.files[0]){ var reader = new FileReader(); reader.onload = function (e) { $('#img_prev').attr('src', e.target.result); } reader.readAsDataURL(input.files[0]); } } $("#post_post_image").change(function(){ readURL(this); }); }); </script>
補足【attachment_image_tag】
refileで用意されたヘルパーメソッドで、imgタグを作成。
補足【fallback】
何か問題が発生した際に表示する画像を指定。
補足【turbolinks:load】
初回読み込み、リロード、ページ切り替えで動くよう設定。
補足【Javascript動作について】
id=img_prevの属性を操作し、
changeメソッドでpostモデルのpost_imgの読み込みURLを変更
補足【Runtime Errorが表示された場合】
エラー画面のコード上に
```
Refile.secret_key = ...
```
と表示されています。
そのRefile.secret_key= を含む一行をコピーし、
config/initializers/application_controller_renderer.rbの
一番下に追加すればエラーは解消できます。

- 投稿日:2020-09-15T10:17:06+09:00
Ruby学習2
メソッドとか色々2
現在、Ruby技術者認定試験silverを取得するべく勉強中です。
言語に対する理解がまだまだなので、基本的な事からアウトプットしていきます。正規表現
なぜ使うのかとか、そもそも正規表現って何?という話は割愛して、今回は模擬問題に出てきた、以下の正規表現を分解してみます。
/^[hc].*o$/i/ = スラッシュで囲まれた部分が条件
^ = 行頭の意味。$とセットの関係で、「行頭から行末まで、囲まれた範囲の条件を満たしてくださいね」という意味、だと思ってます。これが無いと、条件を満たしていない文字列が紛れてもパスしてしまう。
$ = 行末。ほぼ同上。railsにおいてはrails4以降は使えず、\Aと\zが使われる。
[hc] = []の範囲内の文字を使って良いよ。この場合はhまたはc。※ただし、後述するiの存在から、h,H,c,Cが使用可能。
.* = 何かしらの文字で0文字以上。要するに何でも良いし、文字が無くても良い。
o = アルファベットのo。※後述iの影響で、oまたはO。
i = 小文字と大文字を区別しない。メソッドの引数指定
まずはよく見る仮引数、実引数の指定
def jojo(name, stand) p "#{name}のスタンド:#{stand}" end jojo("承太郎", "スタープラチナ") => "承太郎のスタンド:スタープラチナ"仮引数が2つ有るので、実引数の数が足りないとエラーを吐く。
デフォルト値の設定
def jojo(name, stand = "無し") #第二引数にデフォルト値を設定する p "#{name}のスタンド:#{stand}" end jojo("ジョナサン") => "ジョナサンのスタンド:無し" #第二引数が無くても値が帰ってくるデフォルト値から変更する事も可能。
def jojo(name, stand = "無し") p "#{name}のスタンド:#{stand}" end jojo("ジョニィ", "タスク") => "ジョニィのスタンド:タスク"キーワード引数
def jojo(name:, stand: "無し") #シンボルのように引数を設定する p "#{name}のスタンド:#{stand}" end jojo(stand: "キラークイーン", name: "吉良吉影") #実引数もキーワード指定で渡す。キーワード指定なので引数の順番は入れ替えても問題ない。 => "吉良吉影のスタンド:キラークイーン"キーワード引数に好きな引数を使用
任意のキーワードと値をハッシュ型で渡す事が出来る。
def jojo(name:, stand: "無し", **z) p "#{name}のスタンド:#{stand}" p z end jojo(name: "ディアボロ",stand: "キングクリムゾン", dododo: "オレのそばに", gogogo: "近寄るなああーーーッ") # キーワード指定されていないキーと値を仮引数zの中に格納 => "ディアボロのスタンド:キングクリムゾン" {:dododo=>"オレのそばに", :gogogo=>"近寄るなああーーーッ"}To_Be_Continued...
- 投稿日:2020-09-15T10:08:15+09:00
Vue.jsをCDNで使う (やることはコピペだけ!)
簡単にいろいろなアクションやイベントを実行することができるVue.js!
そのVue.jsを簡単に導入するには、CDN(コンテンツデリバリーネットワーク)を使うのが最も簡単かと思います。
CDN(コンテンツデリバリーネットワーク)とは
CDNとは、端的に言うと、コンテンツ(ここではVue.jsのこと)を早く簡単に使えるようにできるものです。
詳しく知りたい方はこちら
・[https://business.ntt-east.co.jp/content/cloudsolution/column-66.html]
・[https://www.kagoya.jp/howto/network/cdn/]では実際に実装してみましょう(コピペだけですが!)
どのページでもVue.jsを使用できるようにするには、<head>にCDNを挿入するだけでOK!
もしくはVue.jsを使用するhtmlページに挿入するだけでOK!application.html<head> <script src="https://cdn.jsdelivr.net/npm/vue/dist/vue.js"></script> </head> <body> </body>
以上!超絶簡単ですね!
上記のCDNはVue.jsの最新版を毎回採用
注意点
実際の開発現場では、バグやエラーを回避するために、バージョンを固定する場合が多い!
本番環境での開発は、バージョンが指定されたCDNがおすすめです。
application.html<head> <script src="https://cdn.jsdelivr.net/npm/vue@2.6.12"></script> </head> <body> </body>Vue.jsのCDNをググる↓
[https://jp.vuejs.org/v2/guide/installation.html]
- 投稿日:2020-09-15T08:08:16+09:00
Rails 6で認証認可入り掲示板APIを構築する #10 devise_token_auth導入
←Rails 6で認証認可入り掲示板APIを構築する #9 serializer導入
構成
現在は誰でもAPIを叩けばpostできますが、これをログインしたユーザーに紐付ける構成に変えたいと思います。
devise, devise_token_authの導入
deviseはRailsにおける認証周りのデファクトスタンダードです。
これを入れて設定するだけで、ユーザー作成からログイン・ログアウト、パスワード再発行やログイン回数記録、ログイン失敗ブロック等の多岐にわたる機能が使えます。
多機能ゆえにカスタマイズが逆に難しいのが難点ではありますが…そのdeviseのトークン認証版がdevise_token_authです。
deviseの派生のため、devise_token_authにはdeviseが必要です。Gemfile... + # 認証 + gem "devise" + gem "devise_token_auth"deviseとdevist_token_authの両方をインストールします。
$ rails g devise:install $ rails g devise_token_auth:install User auth参考:[Rails] devise token auth を使う
各種ファイルの変更
実行時にconfig/routes.rbが書き換えられますが、今回はv1のnamespace内に入れたいので直します。
config/routes.rb# frozen_string_literal: true Rails.application.routes.draw do - mount_devise_token_auth_for 'User', at: 'auth' namespace "v1" do resources :posts + mount_devise_token_auth_for 'User', at: 'auth' end endまた、自動生成したファイルがrubocopに引っかかりまくっているので修正します。
ちょっと雑ですが、migrate系やconfig系の除外設定をします。
それ以外は手動で対応していきます。.rubocop.yml... + # メソッドの長さ + Metrics/MethodLength: + Exclude: + - "db/migrate/**/*" + + # AbcSize + Metrics/AbcSize: + Exclude: + - "db/migrate/**/*" + + # 行の長さ + Layout/LineLength: + Exclude: + - "config/initializers/**/*"model, migrationの変更
今回は必要最低限の機能のみ使うので、不要な初期値を消します。
app/models/user.rbdevise :database_authenticatable, :registerable, - :recoverable, :rememberable, :trackable, :validatable + :rememberable, :validatable include DeviseTokenAuth::Concerns::Userdb/migrate/xxxxxxxxxxxxxx_devise_token_auth_create_users.rb## Database authenticatable t.string :encrypted_password, null: false, default: "" - ## Recoverable - t.string :reset_password_token - t.datetime :reset_password_sent_at - t.boolean :allow_password_change, default: false - ## Rememberable t.datetime :remember_created_at - ## Confirmable - t.string :confirmation_token - t.datetime :confirmed_at - t.datetime :confirmation_sent_at - t.string :unconfirmed_email # Only if using reconfirmable - - ## Lockable - # t.integer :failed_attempts, :default => 0, :null => false # Only if lock strategy is :failed_attempts - # t.string :unlock_token # Only if unlock strategy is :email or :both - # t.datetime :locked_at - ## User Info t.string :name - t.string :nickname - t.string :image t.string :email ... add_index :users, :email, unique: true add_index :users, %i[uid provider], unique: true - add_index :users, :reset_password_token, unique: true - add_index :users, :confirmation_token, unique: true - # add_index :users, :unlock_token, unique: true endここまで変更を終えたらmigrateします。
$ rails db:migrateemail, password以外のカラム許可
curlで試してみます。
$ curl localhost:8080/v1/auth -X POST -H 'Content-Type: application/json' -d '{"email": "test@example.com", "password": "password", "name": "hoge"}' {"status":"success","data":{"uid":"test@example.com","id":1,"email":"test@example.com","provider":"email","name":null,"created_at":"2020-09-08T04:40:44.659Z","updated_at":"2020-09-08T04:40:44.827Z"}}無事に登録できましたね。
しかしよく見ると、nameがhogeで指定したにも関わらずnullになっています。この原因の推測ができると、Rails慣れしてきた証拠です。
他のcontroller同様、ストロングパラメータで登録可能なカラムが限られているからです。
そのため以下対応を行います。app/controllers/application_controller.rbclass ApplicationController < ActionController::API include DeviseTokenAuth::Concerns::SetUserByToken rescue_from ActiveRecord::RecordNotFound, with: :render_404 + before_action :configure_permitted_parameters, if: :devise_controller? def render_404 render status: 404, json: { message: "record not found." } end + + def configure_permitted_parameters + devise_parameter_sanitizer.permit(:sign_up, keys: [:name]) + end endこれにより、nameカラムを含めた登録ができるようになります。
$ rails db:reset $ curl localhost:8080/v1/auth -X POST -H 'Content-Type: application/json' -d '{"email": "test@example.com", "password": "password", "name": "hoge"}' {"status":"success","data":{"uid":"test@example.com","id":1,"email":"test@example.com","provider":"email","name":"hoge","created_at":"2020-09-08T04:51:42.527Z","updated_at":"2020-09-08T04:51:42.698Z"}}sign_inの確認
登録はできたので、ログインの確認をしていきます。
$ curl localhost:8080/v1/auth/sign_in -X POST -H 'Content-Type: application/json' -d '{"email": "test@example.com", "password": "password"}' -i HTTP/1.1 200 OK X-Frame-Options: SAMEORIGIN X-XSS-Protection: 1; mode=block X-Content-Type-Options: nosniff X-Download-Options: noopen X-Permitted-Cross-Domain-Policies: none Referrer-Policy: strict-origin-when-cross-origin Content-Type: application/json; charset=utf-8 access-token: T4ZeomARybw3_o5nIHQAfw token-type: Bearer client: Fj772-EYBPnvJdETYhObyQ expiry: 1600751367 uid: test@example.com ETag: W/"8c41022d2e42ca28df0cb958a84ab2f4" Cache-Control: max-age=0, private, must-revalidate X-Request-Id: d4ff732c-f6b5-4213-8984-5d9457b39cbd X-Runtime: 0.510436 Transfer-Encoding: chunked {"data":{"id":1,"email":"test@example.com","provider":"email","uid":"test@example.com","name":"hoge"}}
-iオプションを付けたことでヘッダ情報も一緒に返ってきます。
そして末尾に先程登録したuserの情報が載っており、ヘッダでも200 OKで返ってきていることから、正常にログインできていることが分かります。注目すべきヘッダは
access-token: T4ZeomARybw3_o5nIHQAfwこの3つです。
client: Fj772-EYBPnvJdETYhObyQ
uid: test@example.com
この3つをリクエスト時のヘッダに含めることで、認証されたアカウントのアクセスであると判別されます。余談ですが、誤った認証情報だとどうなるのか。
試しにemailやpasswordを誤った状態でログインを試行してみましょう。$ curl localhost:8OST -H 'Content-Type: application/json' -d '{"email": "test@example.com", "password": "PASSWORD"}' -i HTTP/1.1 401 Unauthorized X-Frame-Options: SAMEORIGIN X-XSS-Protection: 1; mode=block X-Content-Type-Options: nosniff X-Download-Options: noopen X-Permitted-Cross-Domain-Policies: none Referrer-Policy: strict-origin-when-cross-origin Content-Type: application/json; charset=utf-8 Cache-Control: no-cache X-Request-Id: 12832212-9797-465b-a5b1-ecaa7e88a977 X-Runtime: 0.308726 Transfer-Encoding: chunked {"success":false,"errors":["Invalid login credentials. Please try again."]}401で返ってきますね。
続き
→
【連載目次へ】
- 投稿日:2020-09-15T06:51:57+09:00
エラーメッセージを日本語表示にする方法
1.config.i18n.default_locale = :jaを記述する
config/application.rb class Application < Rails::Application # 日本語の言語設定 config.i18n.default_locale = :ja # 省略 end2rails-i18nをインストールする
#Gemfile gem 'rails-i18n'記述した後
ターミナル bundle installrails-i18nに登録された日本語
https://github.com/svenfuchs/rails-i18n/blob/master/rails/locale/ja.ymlこれでrails-i18nに書いてあることは翻訳できた
しかし他の文言は日本語訳できていない。3ログイン用の日本語化用のファイルを作成
config>locales>devise.ja.yml
ファイルを作成するdeviseに関する日本語訳をコピーして先ほど制作したdevise.ja.ymlに貼り付ける
https://github.com/tigrish/devise-i18n/blob/master/rails/locales/ja.yml4その他のフォームに関する日本語訳のファイル(ja.yml)を作成
config>locals>ja.yml
ja: activerecord: attributes: user: nickname: ニックネーム tweet: text: テキスト image: 画像userテーブルのnicknameが日本語訳される
tweetテーブルのtextが日本語訳される
imageが日本語訳される
- 投稿日:2020-09-15T03:54:22+09:00
【超初心者向け(スクショ多数)】Ruby2.6 × Rails6 × CircleCi でECR・ECSに自動デプロイ 【AWSチュートリアル】
対象読者
- ECSに全く触れた事が無い人
- とりあえず手を動かして雰囲気を掴みたい人
- 就活のためにポートフォリオを作成中の人
簡単なRailsアプリ(「Hello World!」と表示するだけ)をAWS ECSにデプロイするまでの手順。がっつりその後の運用まで考慮しているわけではなく、あくまで参考程度にしかならないためその点はご注意ください。
人によって多分色々なやり方がありそうなので、一度流れを掴んだ後は各自お好みで設定していただきたいです。
デプロイ用のアプリを用意する段階から全てハンズオン形式(スクショも多数)で記載しており、書いてある通りに進めれば基本的には上手くいくはず。
要所要所で任意の値(プロフィール名やアプリ名など)を設定する部分があるので、不安な場合は全て筆者と同じように「sample-app」などで統一すると良いかもです。
※初心者向けと銘打っているものの、「まずは実際に手を動かして雰囲気を掴む」という目的に徹しているため、各用語に関する説明はほとんど説明していません。理論派の方はあらかじめ他の記事でECSの概念について学習してからの方が入るのをおすすめします。(筆者は体で覚える派なので...)仕様
- 言語: Ruby2.6
- フレームワーク: Rails6
- データベース: MySQL5.7
- アプリケーションサーバー: Puma
- Webサーバー: Nginx
下準備編
まず、ECSにデプロイするための簡単なRailsアプリを用意。
サンプル
https://github.com/kazama1209/sample-app
$ git clone https://github.com/kazama1209/sample-app.git $ cd sample-appセットアップ
$ docker-compose build $ docker-compose run web bundle exec rails webpacker:install $ docker-compose up -d $ docker-compose run web bundle exec rails db:createlocalhostにアクセス
http://localhostにアクセスしていつもの画面が表示されれば環境構築は完了。デプロイ編
アプリの準備ができたので、ECSにデプロイしていく。
各種ツールをインストール
今回、ECSにデプロイするにあたり以下2つのツールを使用する。
$ brew install awscli $ brew install amazon-ecs-cliaws configureを設定
上記のツールを使用するためにaws configureの設定を行う。
IAMユーザーを作成
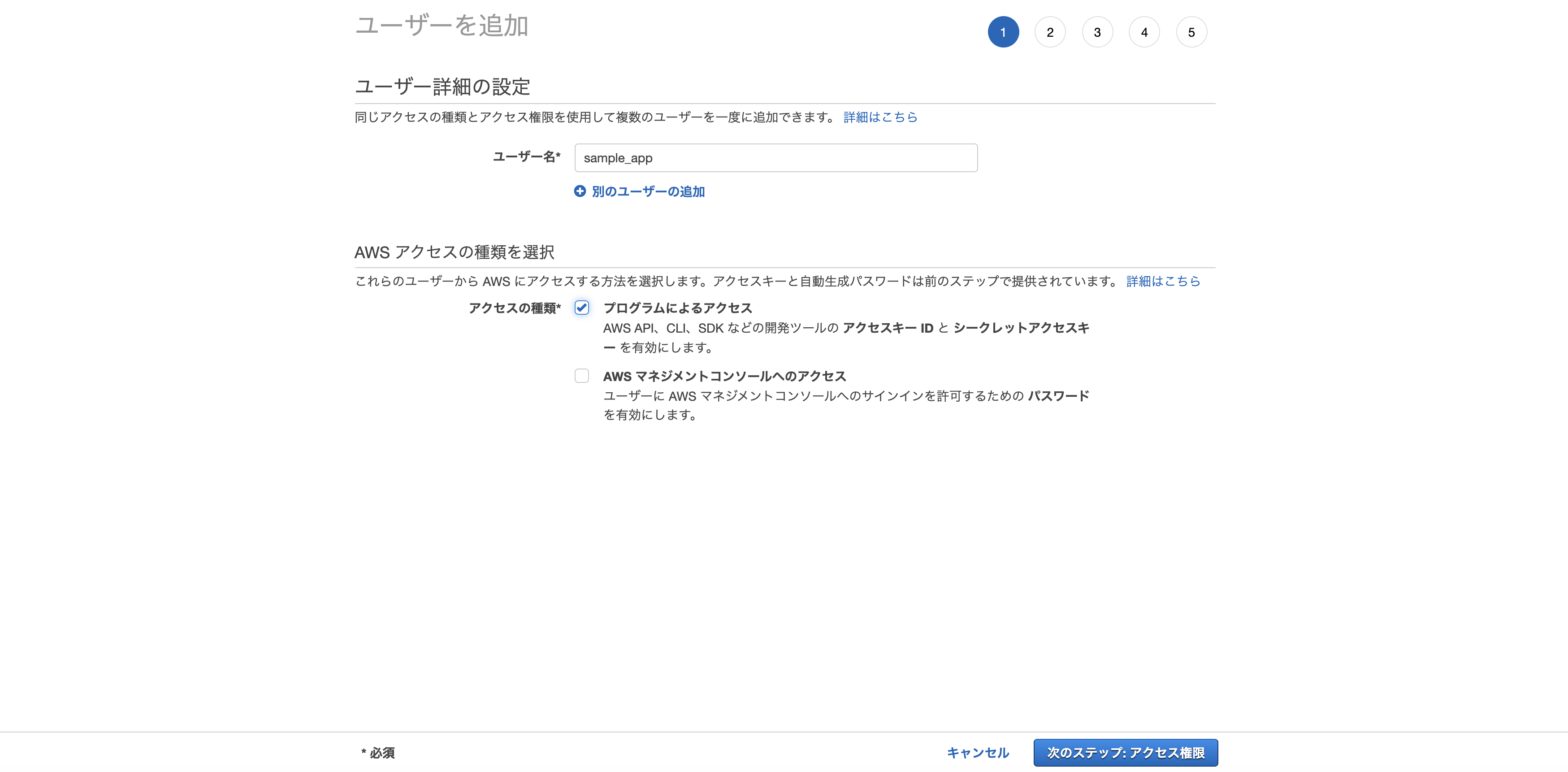
AWSのコンソールからサービス→IAMを選択し、「ユーザーの追加」をクリック。
任意のユーザー名を入力し、「プログラムによるアクセス」にチェックをつけて次のステップへ。
※画像だと「sample_app」になっていますが、実際は「sample-app」にしてください。スクショを撮り間違えてしまいました。
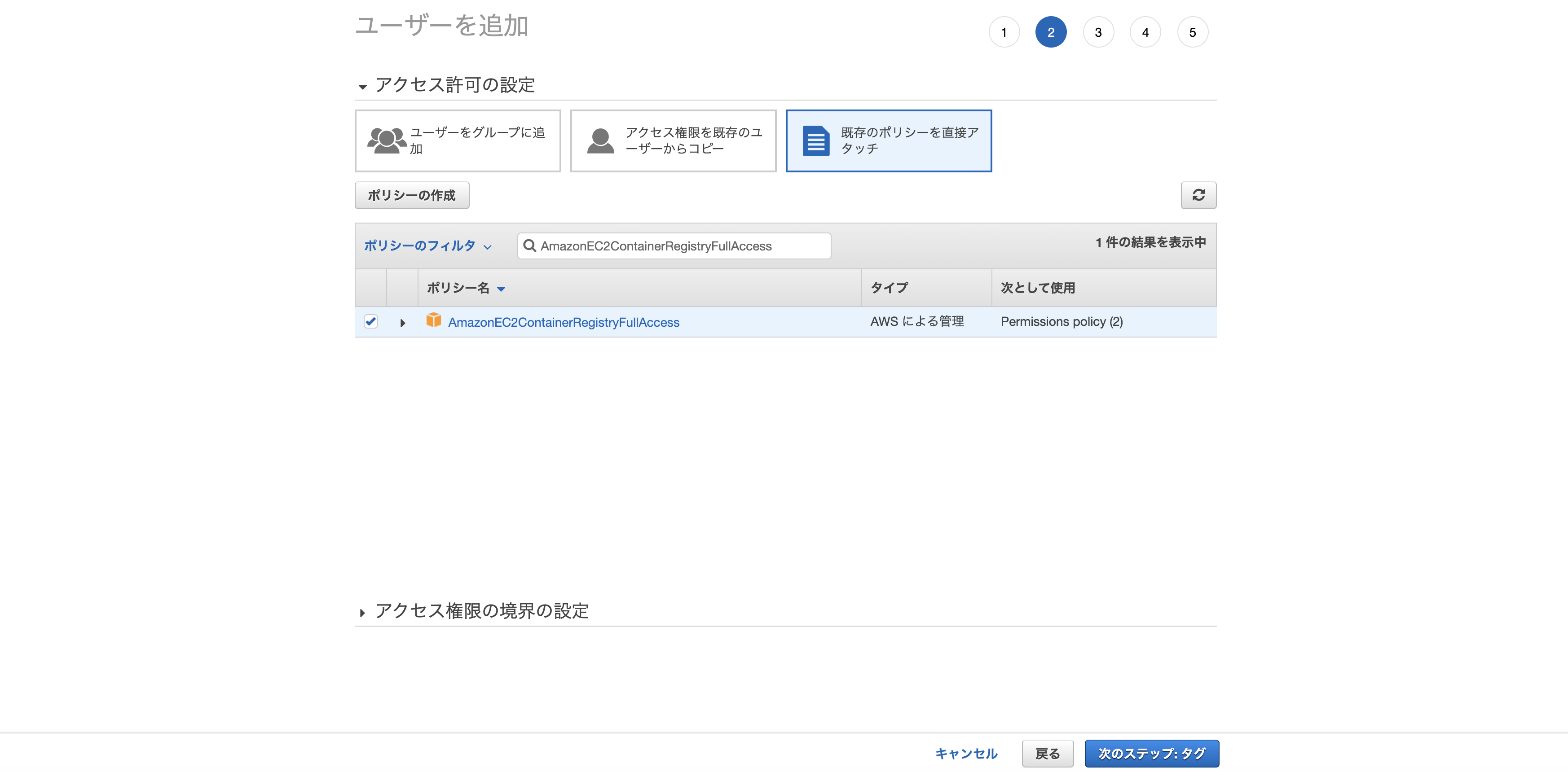
「既存のポリシーを直接アタッチ」から以下の2つのポリシーをアタッチして次のステップへ。
- AmazonECS_FullAccess
- AmazonEC2ContainerRegistryFullAccess
タグに関しては今回はは無視で次のステップへ。
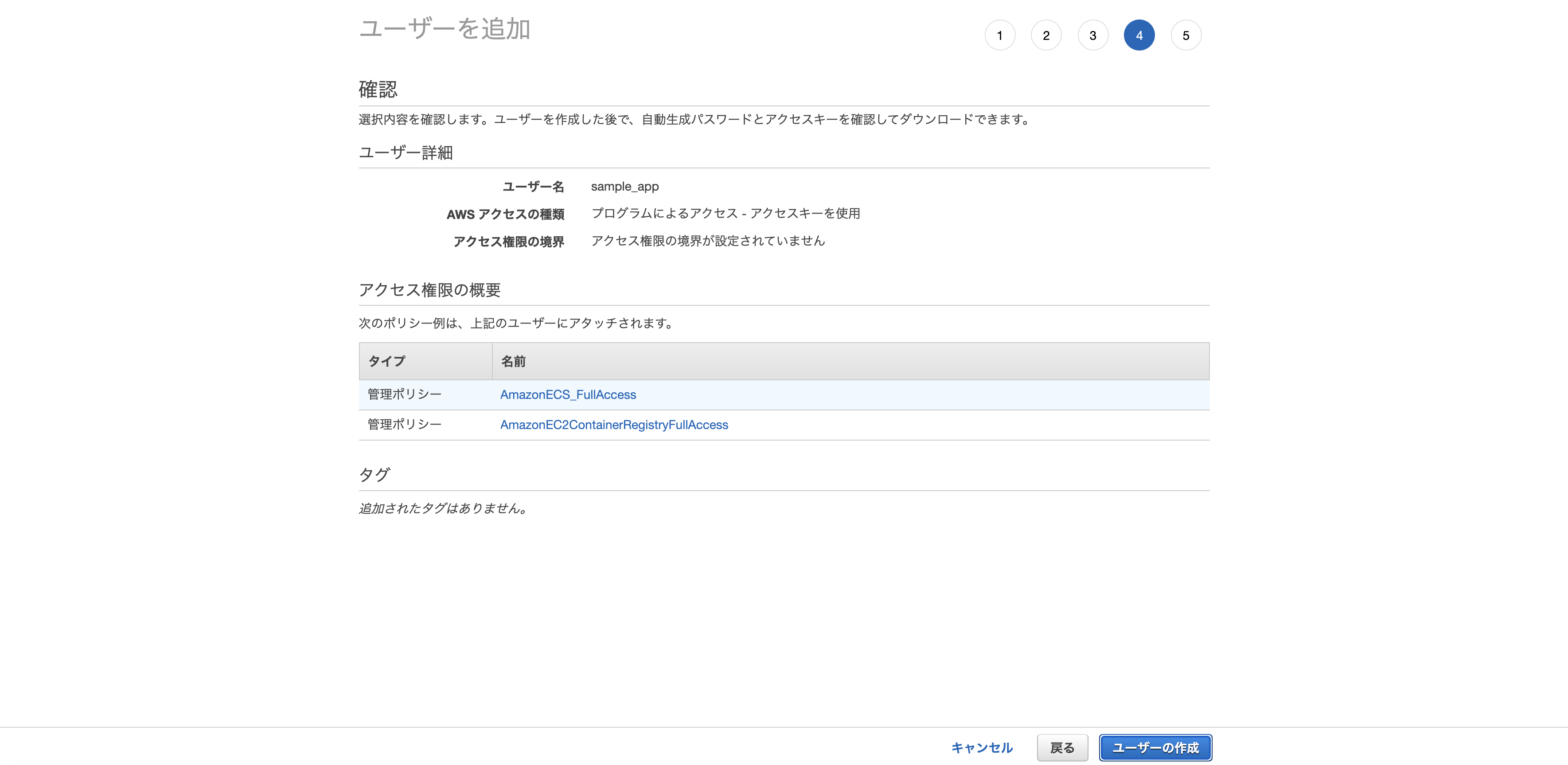
最後に入力情報の確認画面が表示されるので、特に問題無ければ「ユーザーの作成」をクリック。
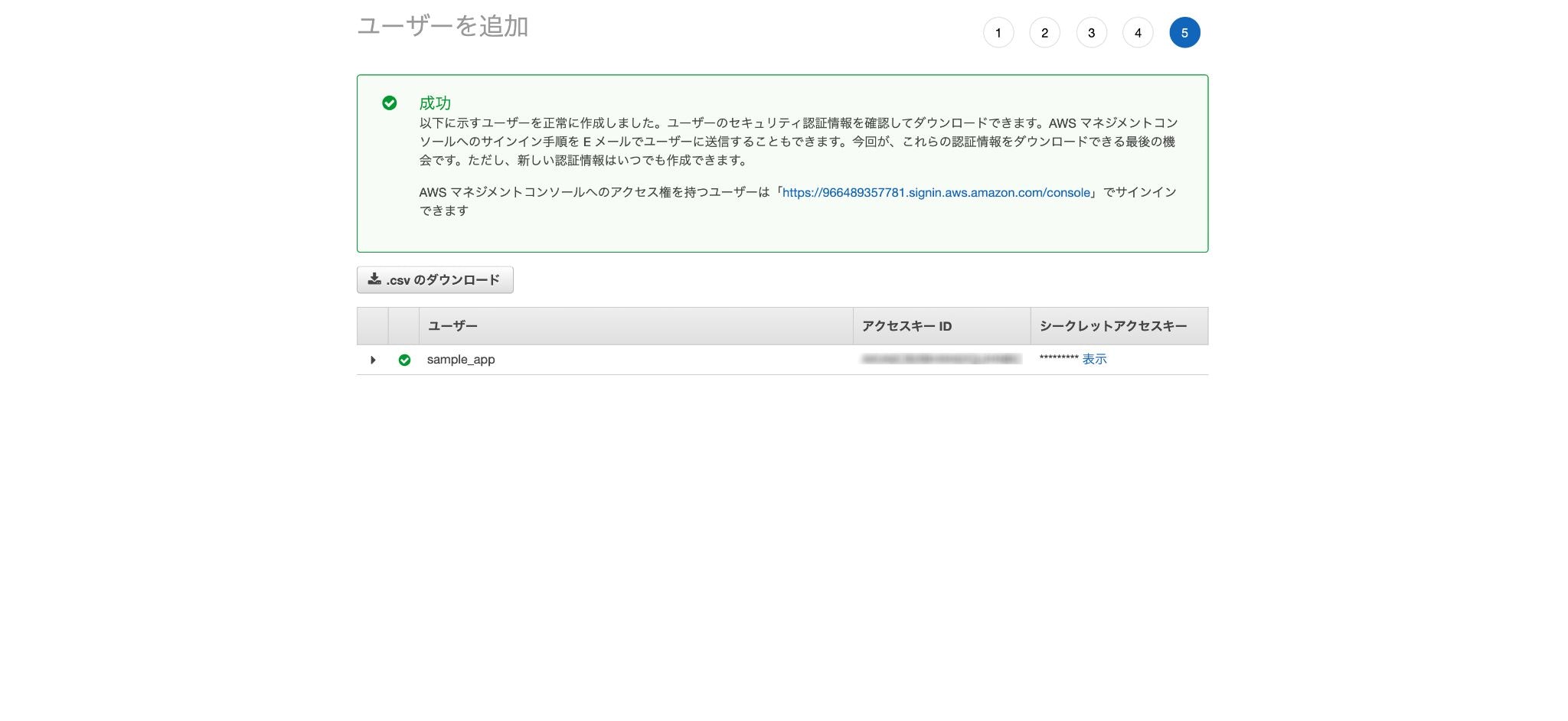
ユーザーの作成に成功すると「アクセスキー」「シークレットアクセスキー」の2つが発行されるので、メモを取るなりcsvファイルをダウンロードするなり大事に保管。
ターミナルで「aws configure」を実行
$ aws configure --profile <先ほど作成したIAMユーザー名(今回は「sample-app」)> AWS Access Key ID # 先ほど作成したアクセスキー AWS Secret Access Key # 先ほど作成したシークレットアクセスキー Default region name # ap-northeast-1 Default output format # jsonそれぞれ上記のように入力。
追加でポリシーを作成
先ほどIAMユーザーを作成した際、
- AmazonECS_FullAccess
- AmazonEC2ContainerRegistryFullAccess
2つのポリシーをアタッチしたが、これだけだとこの後に使用する「ecs-cli」というツールの中で権限エラーが発生するため、ここで別途追加しなければならない。
AWSのコンソールからサービス→IAM→ポリシーを選択し、「ポリシーの作成」をクリック。
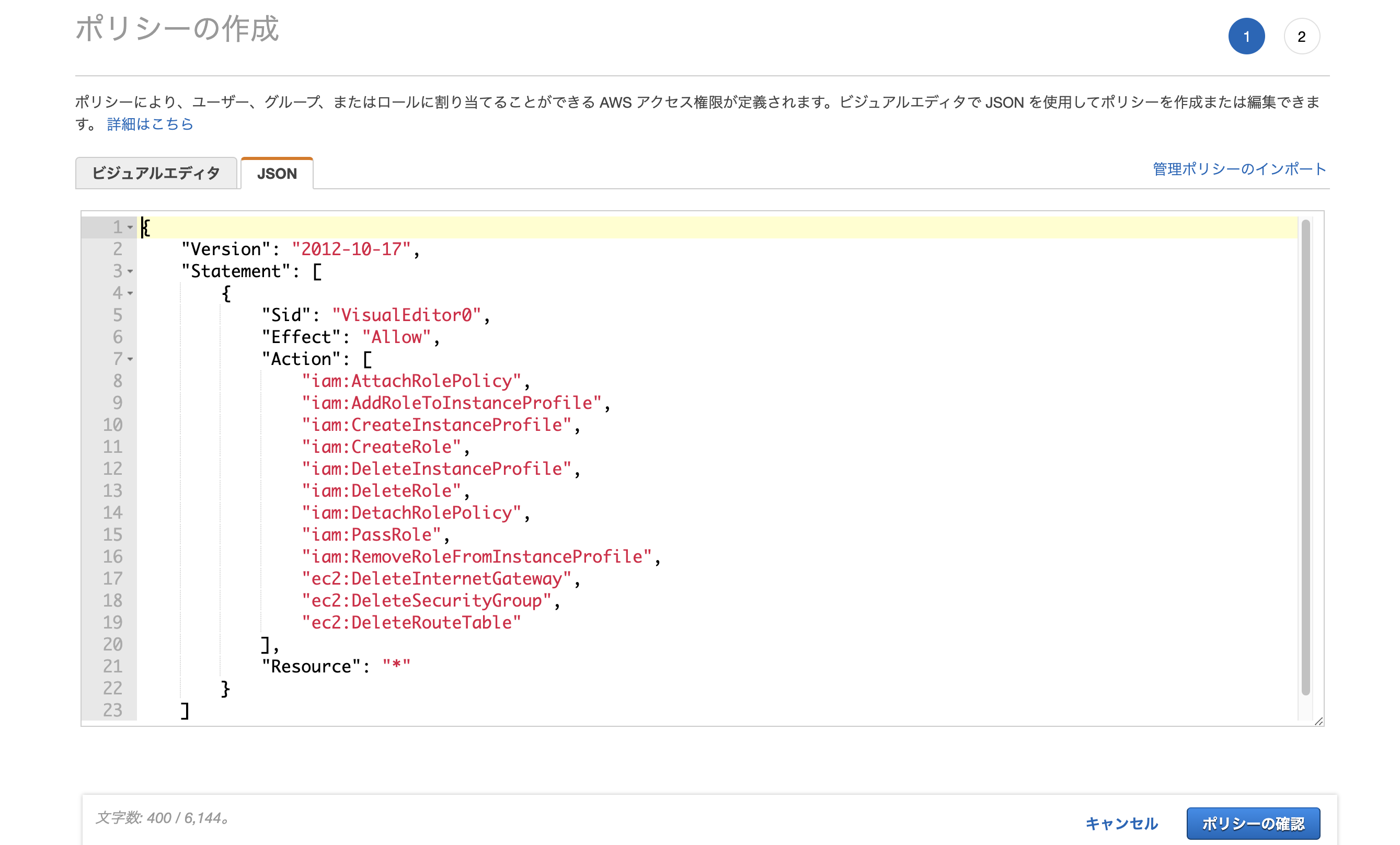
JSONタブを開いて以下の記述を行う。
{ "Version": "2012-10-17", "Statement": [ { "Sid": "VisualEditor0", "Effect": "Allow", "Action": [ "iam:AttachRolePolicy", "iam:AddRoleToInstanceProfile", "iam:CreateInstanceProfile", "iam:CreateRole", "iam:DeleteInstanceProfile", "iam:DeleteRole", "iam:DetachRolePolicy", "iam:PassRole", "iam:RemoveRoleFromInstanceProfile", "ec2:DeleteInternetGateway", "ec2:DeleteSecurityGroup", "ec2:DeleteRouteTable" ], "Resource": "*" } ] }
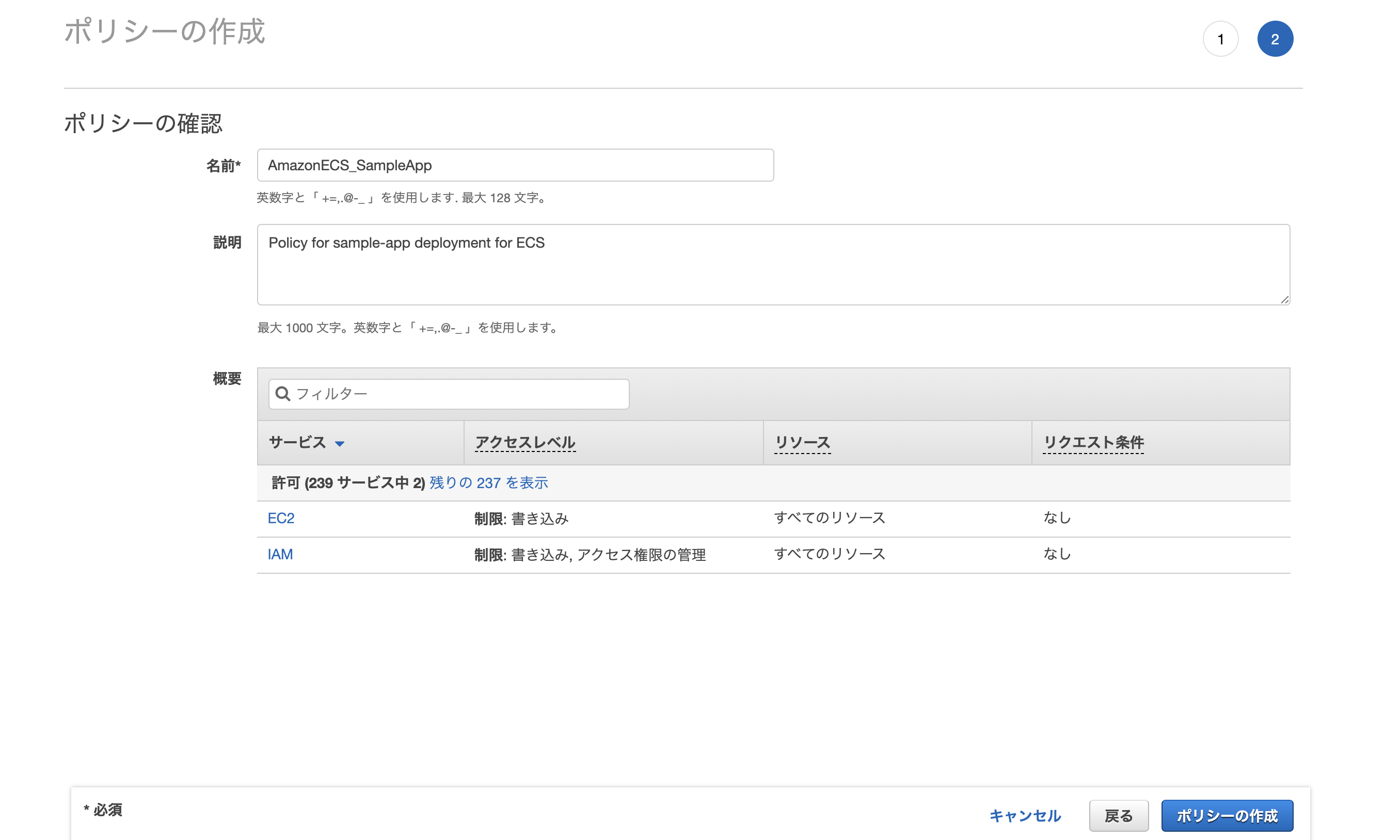
ポリシーの名前や説明を適当に入力し、「ポリシーの作成」をクリック。
ポリシーをユーザーにアタッチ
AWSのコンソールからサービス→IAM→ユーザーを選択し、「アクセス権限の追加」をクリック。
「既存のポリシーをアタッチ」から先ほど作成したポリシーを選択し、アクセス権限を追加。
キーペアを作成
後々EC2内へ入る際などに必要になるのでキーペアを作成しておく。
AWSのコンソールからサービス→EC2→キーペアを選択し、「キーペアの作成」をクリック。
名前とファイル形式を入力し、「キーペアを作成」をクリック。
$ mv Downloads/sample-app.pem .ssh/ $ chmod 600 ~/.ssh/sample-app.pem完了すると「.pem」形式のファイルがダウンロードされるので、「.ssh」ディレクトリに移動させて権限を変更する。
クラスターを作成
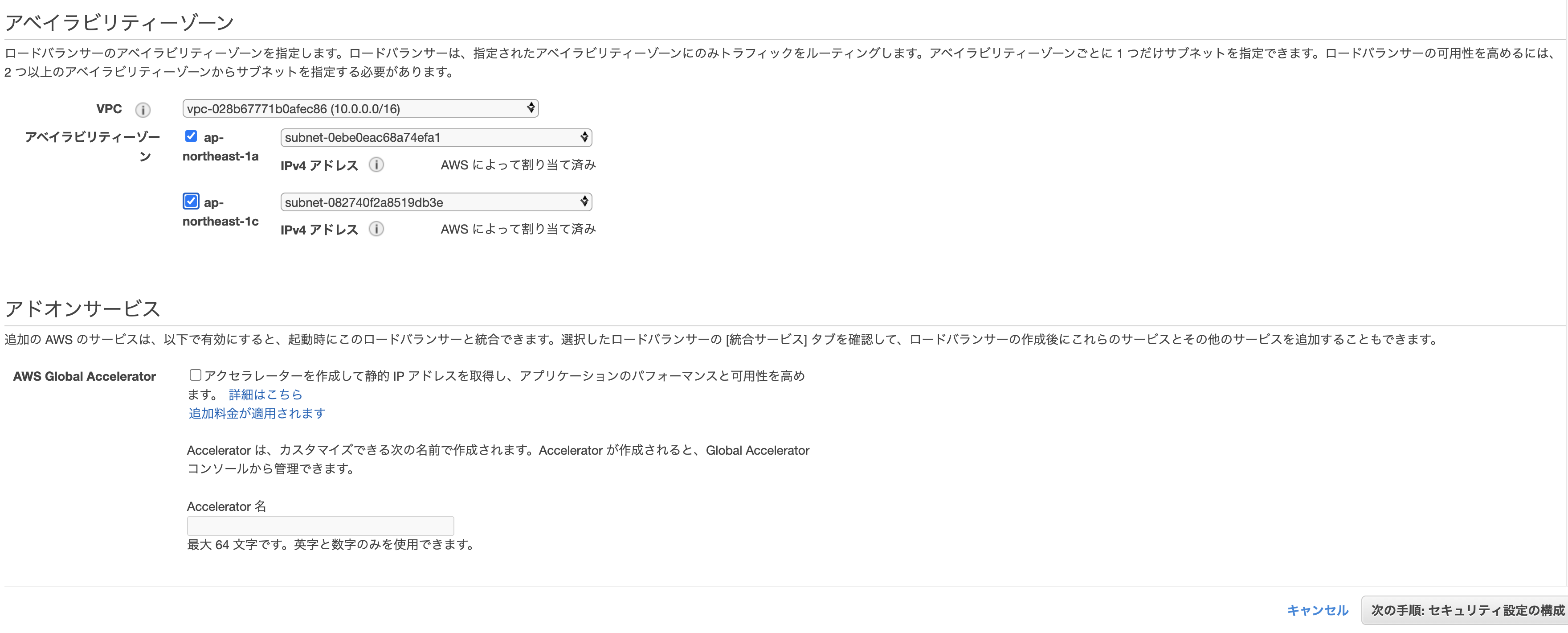
コンソールから手動でぽちぽち作成する事も可能だが、vpcやサブネットなども一緒に作る必要があるため、今回はecs-cliでまとめて作成してしまう。
次のコマンドを実行。
$ ecs-cli configure profile --profile-name <任意のプロフィール名> --access-key <先ほど作成したアクセスキー> --secret-key <先ほど作成したシークレットアクセスキー> $ ecs-cli configure --cluster <任意のクラスター名> --default-launch-type EC2 --config-name <任意の設定名> --region ap-northeast-1 $ ecs-cli up --keypair <先ほど作成したキーペア> --capability-iam --size 2 --instance-type t2.samll --cluster-config <任意の設定名> --ecs-profile <任意のプロフィール名>キーなどの各値は各自異なる。
自分の場合は下記のような感じ。$ ecs-cli configure profile --profile-name sample-app --access-key AKI***************** --secret-key dlj************************************* $ ecs-cli configure --cluster sample-app-cluster --default-launch-type EC2 --config-name sample-app-cluster --region ap-northeast-1 $ ecs-cli up --keypair sample-app --capability-iam --size 2 --instance-type t2.small --cluster-config sample-app-cluster --ecs-profile sample-app INFO[0006] Using recommended Amazon Linux 2 AMI with ECS Agent 1.44.3 and Docker version 19.03.6-ce INFO[0007] Created cluster cluster=sample-app-cluster region=ap-northeast-1 INFO[0009] Waiting for your cluster resources to be created... INFO[0009] Cloudformation stack status stackStatus=CREATE_IN_PROGRESS INFO[0070] Cloudformation stack status stackStatus=CREATE_IN_PROGRESS INFO[0131] Cloudformation stack status stackStatus=CREATE_IN_PROGRESS VPC created: vpc-***************** Security Group created: sg-***************** Subnet created: subnet-***************** Subnet created: subnet-***************** Cluster creation succeeded.上手くいくと↑のようにクラスター用のVPC、セキュリティグループ、サブネットなどが自動で作成される。
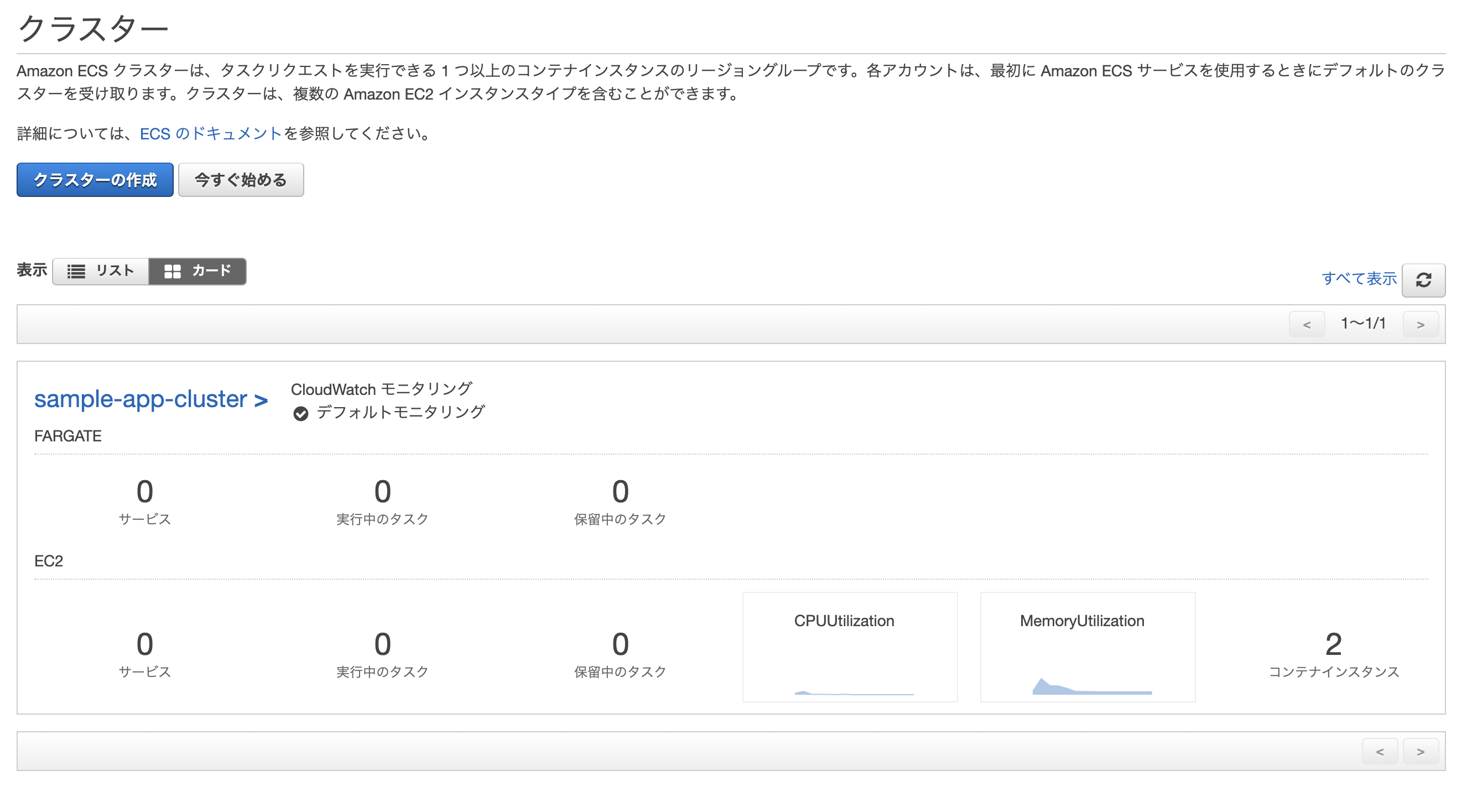
AWSのコンソールからサービス→Elastic Container Service→クラスターを選択し、無事作成されていれば成功。
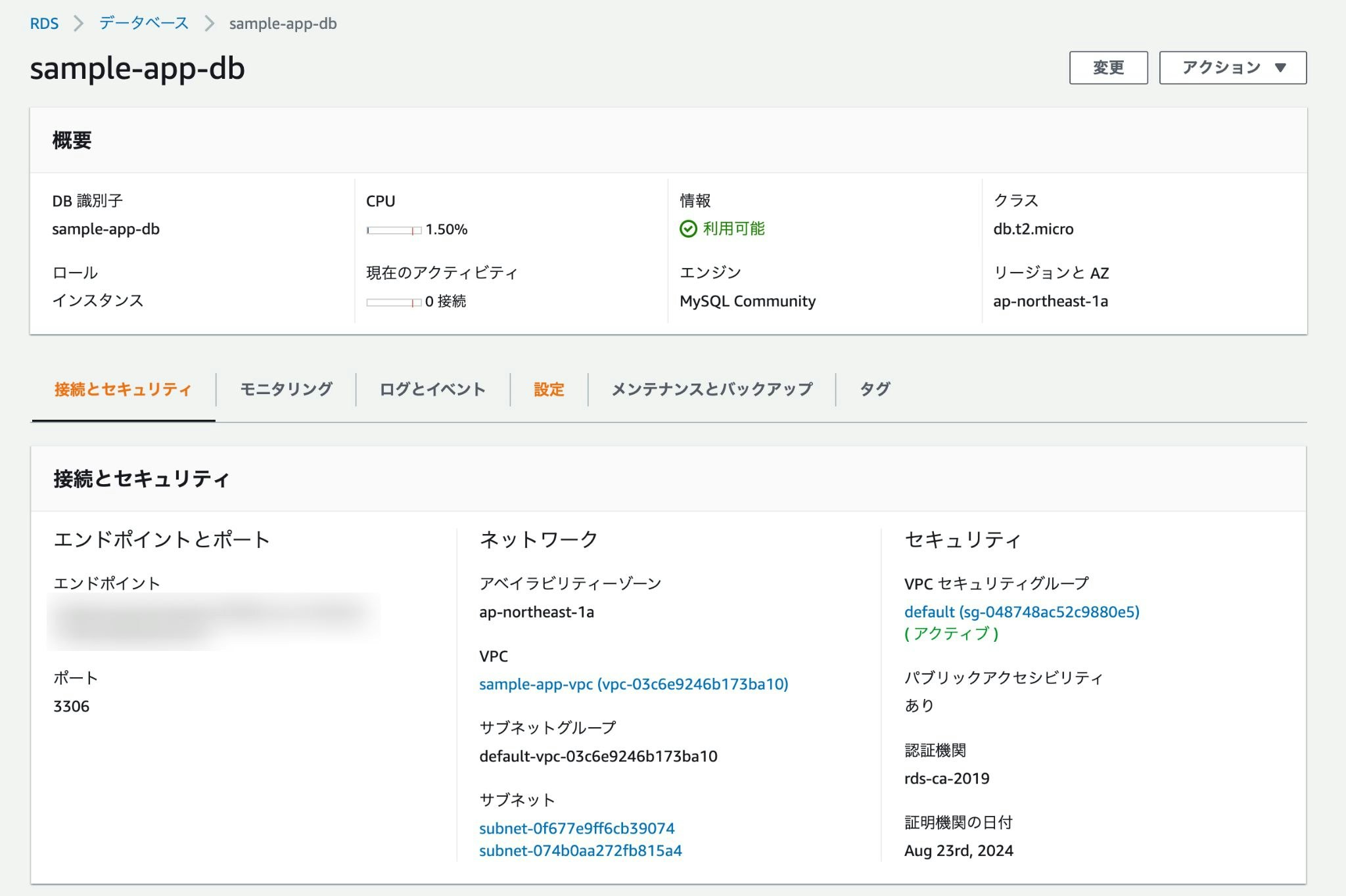
RDSを作成
データベースとして使うRDSを作成。
AWSのコンソールからサービス→RDSを選択し、「データベースの作成」をクリック。
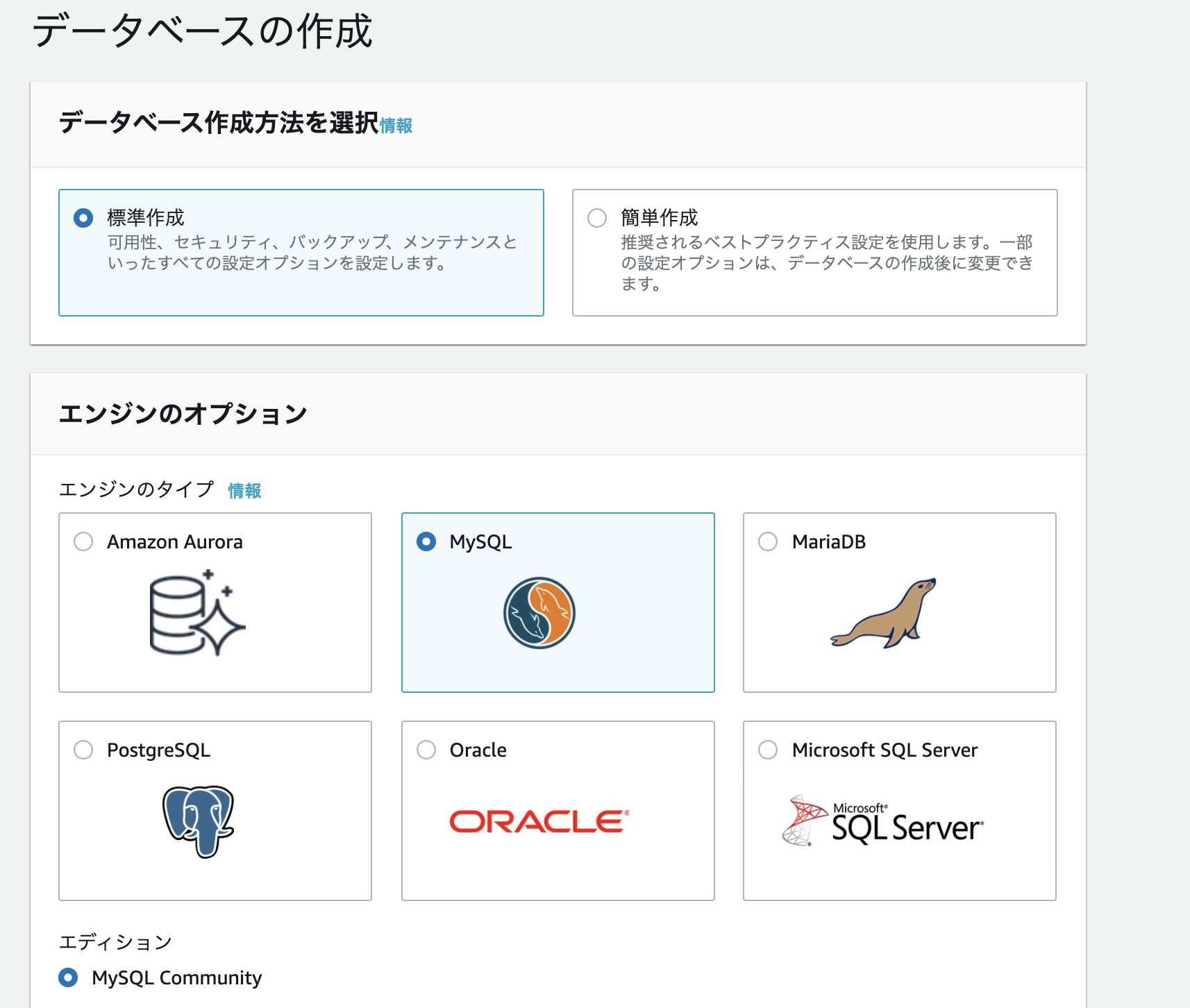
- 作成方法: 標準作成
- エンジンのタイプ: MySQL
- DBインスタンスサイズ: 無料利用枠
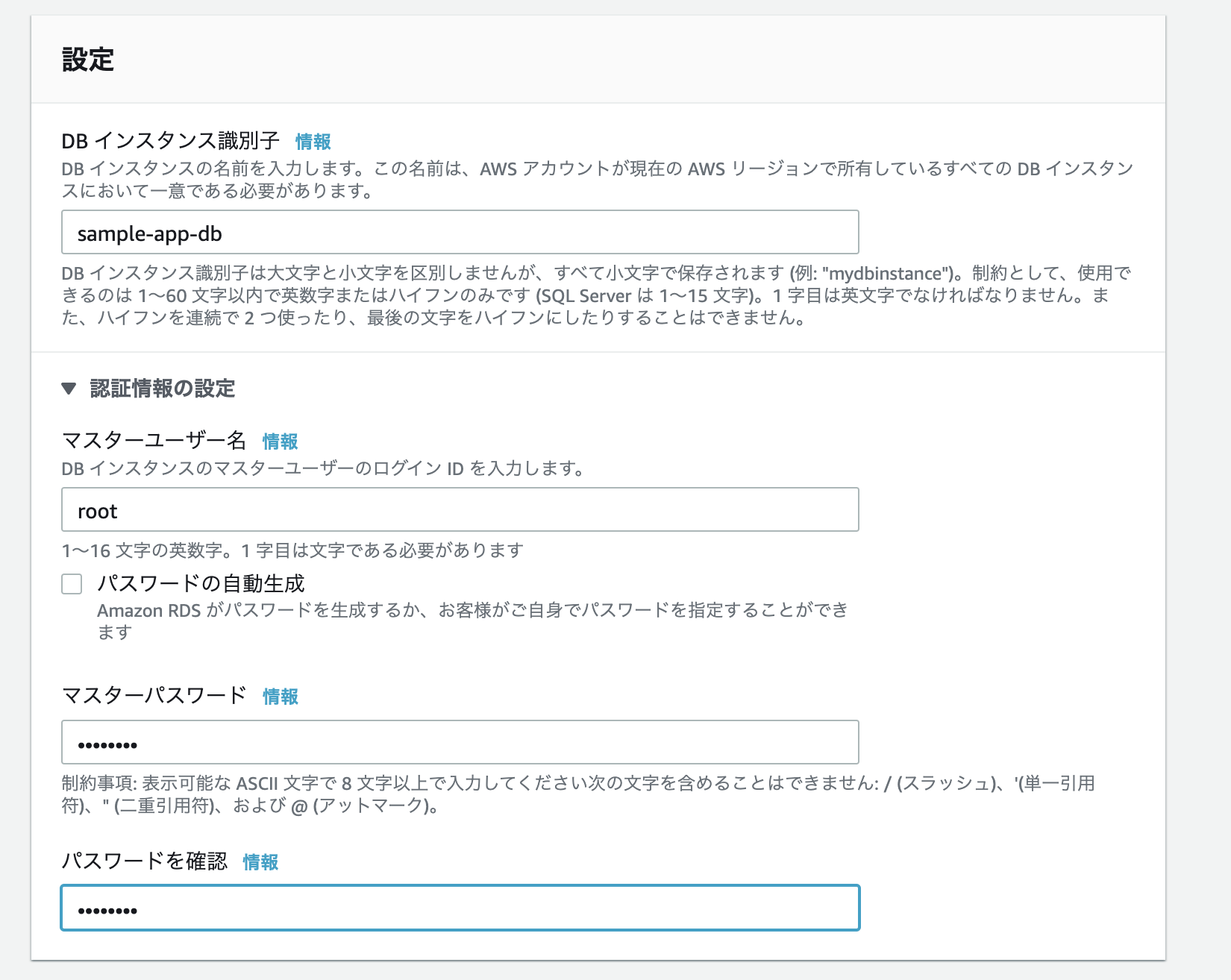
- DBインスタンス識別子: sample-app-db
- マスターユーザー名: root
- パスワード: password
※この辺は全て任意。
vpc: 先ほど作成したvpc
サブネットグループ: 新しいDBサブネットグループの作成
パブリックアクセス: あり
最初のデータベース名: 任意
※特に触れていない部分は空欄もしくはデフォルトのままでOK。問題なければ「データベースの作成」をクリック。
↑こんな感じで作成されていれば成功。
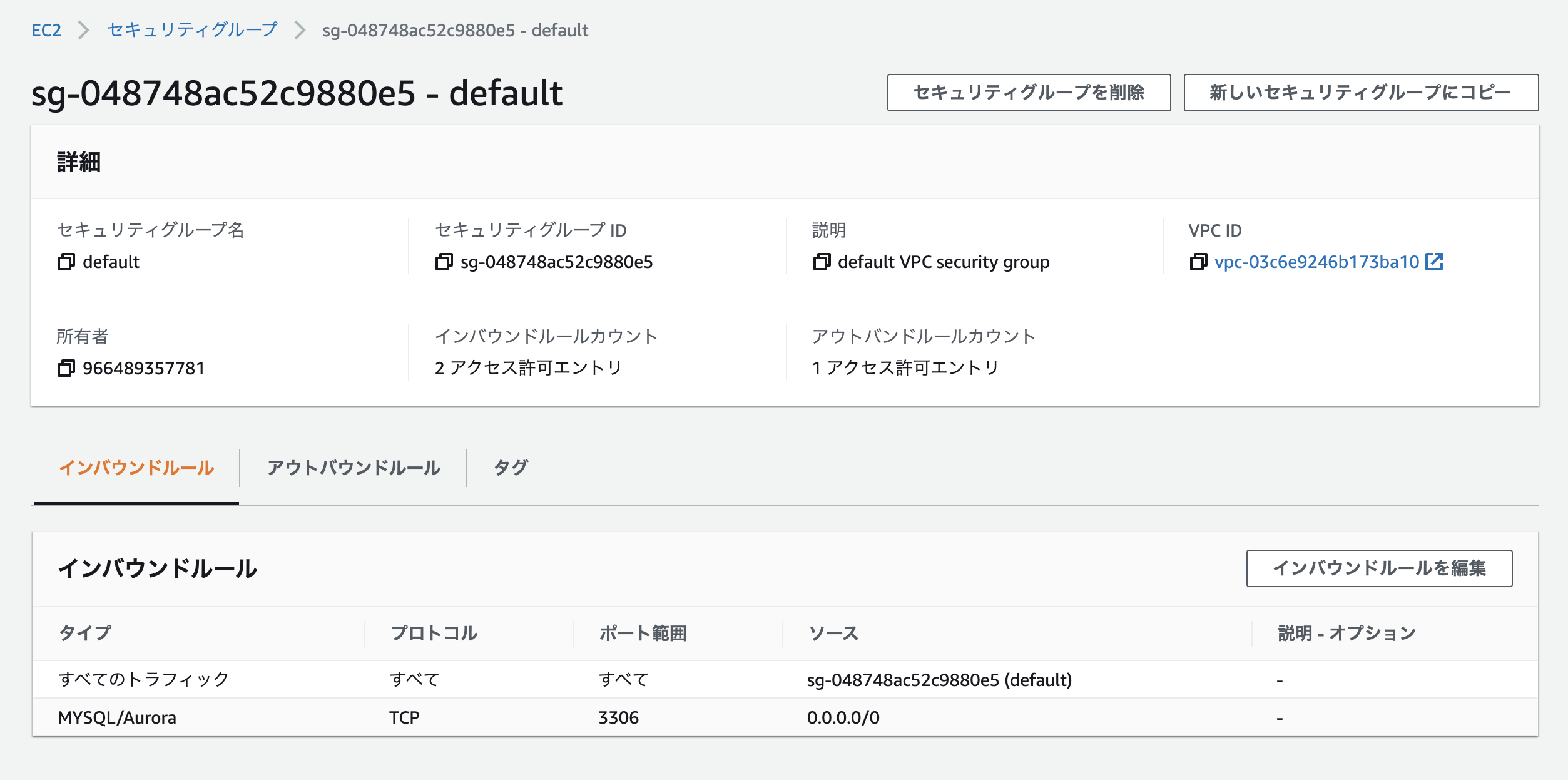
また、セキュリティグループの設定も必要なので「VPCセキュリティグループ」の下に記載されているリンクをクリック。
「インバウンドルールの編集」から次のように設定。
- タイプ: MYSQL/Aurora
- プロトコル: TCP
- ポート範囲
- ソース: 0.0.0.0/0
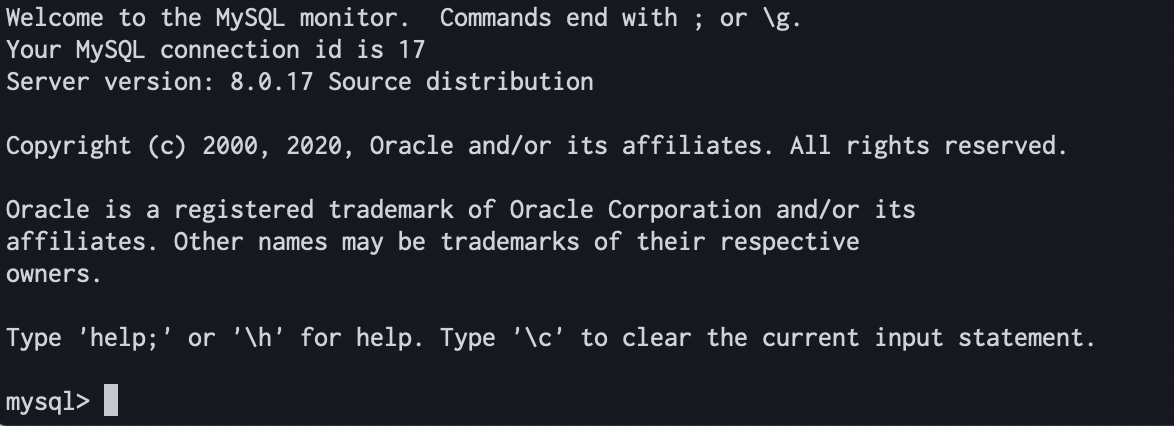
$ mysql -h <RDSのエンドポイント> -u <RDSのユーザー名> -p試しにターミナルで↑のコマンドを叩き、接続できれば成功。
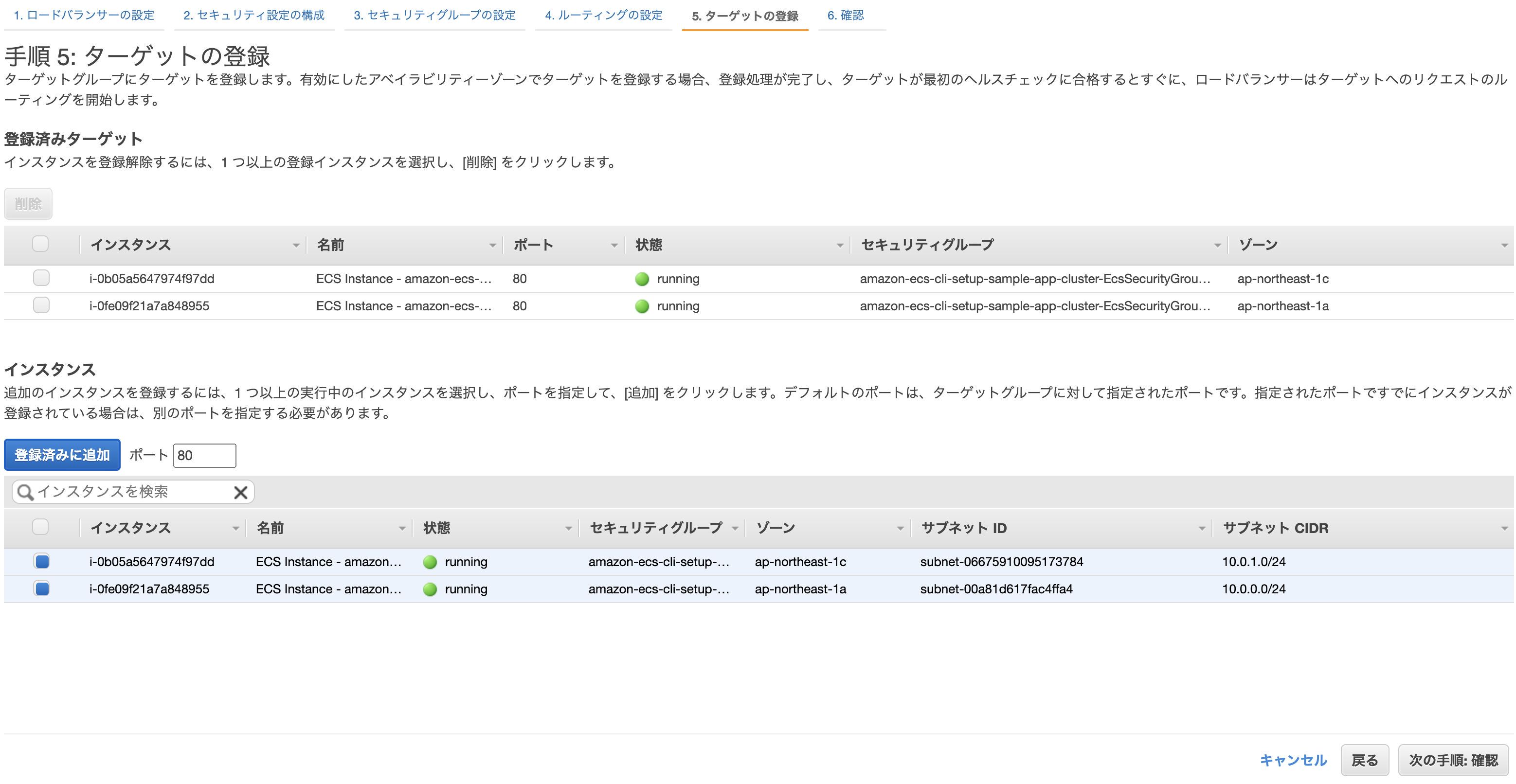
ロードバランサーを作成
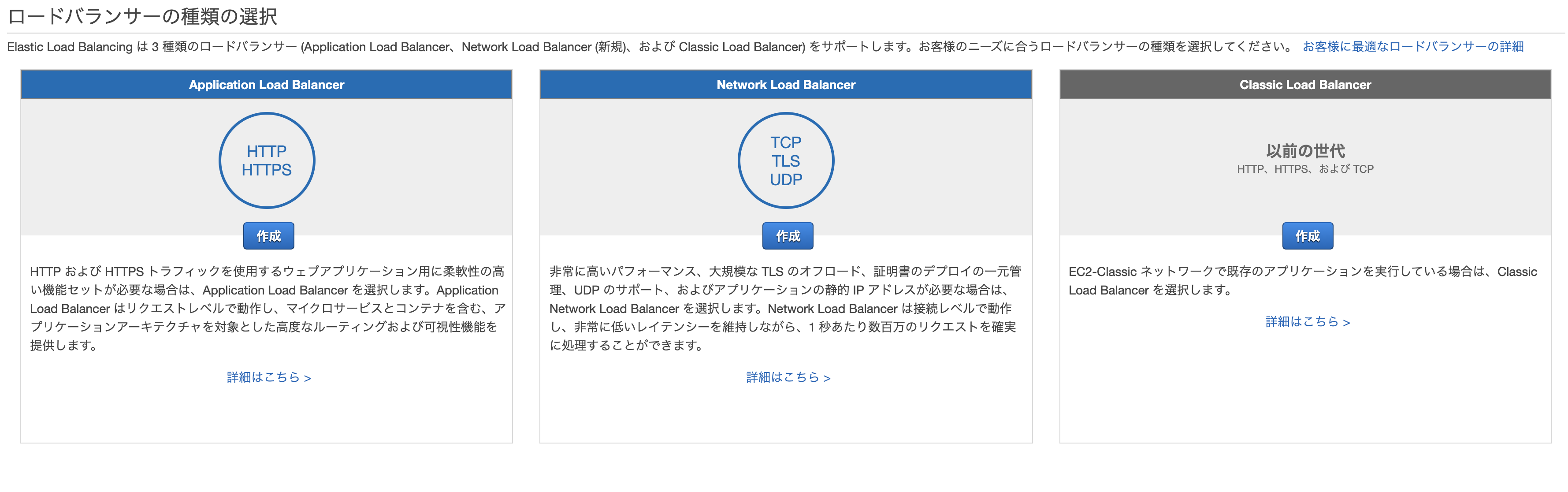
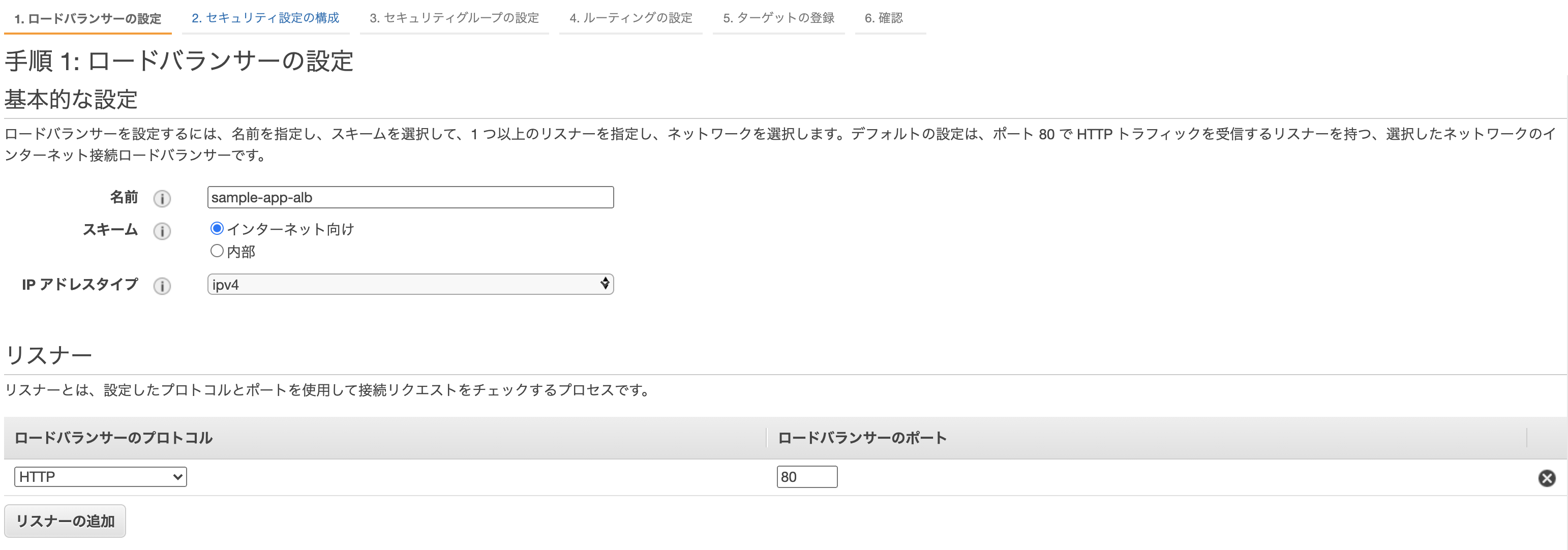
AWSのコンソールからサービス→EC2→ロードバランサーを選択し、「ロードバランサーの作成」をクリック。
3種類あるが、「Application Load Balancer」を選択。
- 名前: 任意
- リスナー: そのままでOK
- VPC: 先ほど自動作成されたものを選択
- subnet: 同上
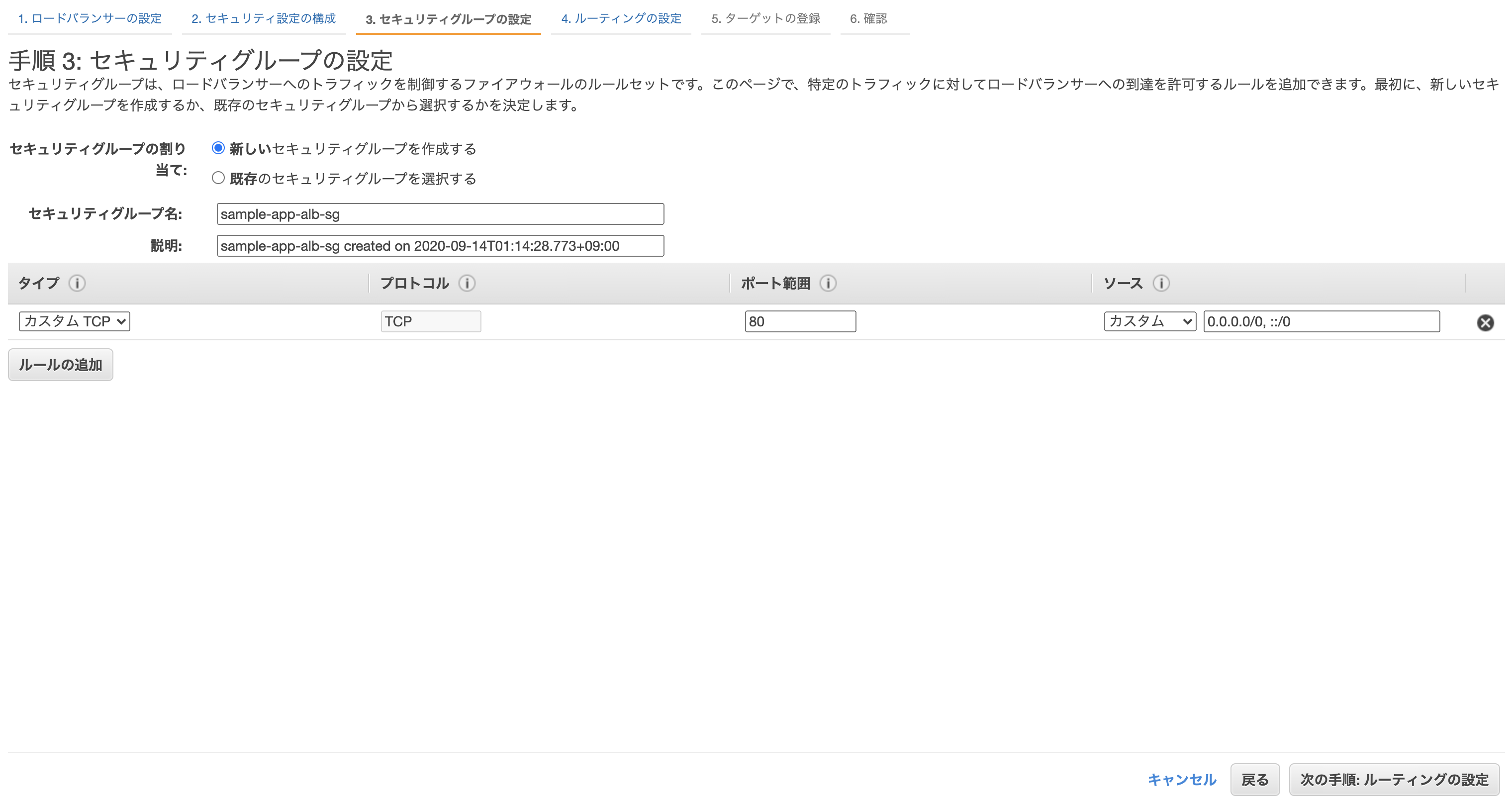
先に進むとセキリュティグループの設定画面になるので、「新しいセキリュティグループを作成する」から適当にセキュリティグループを作成。
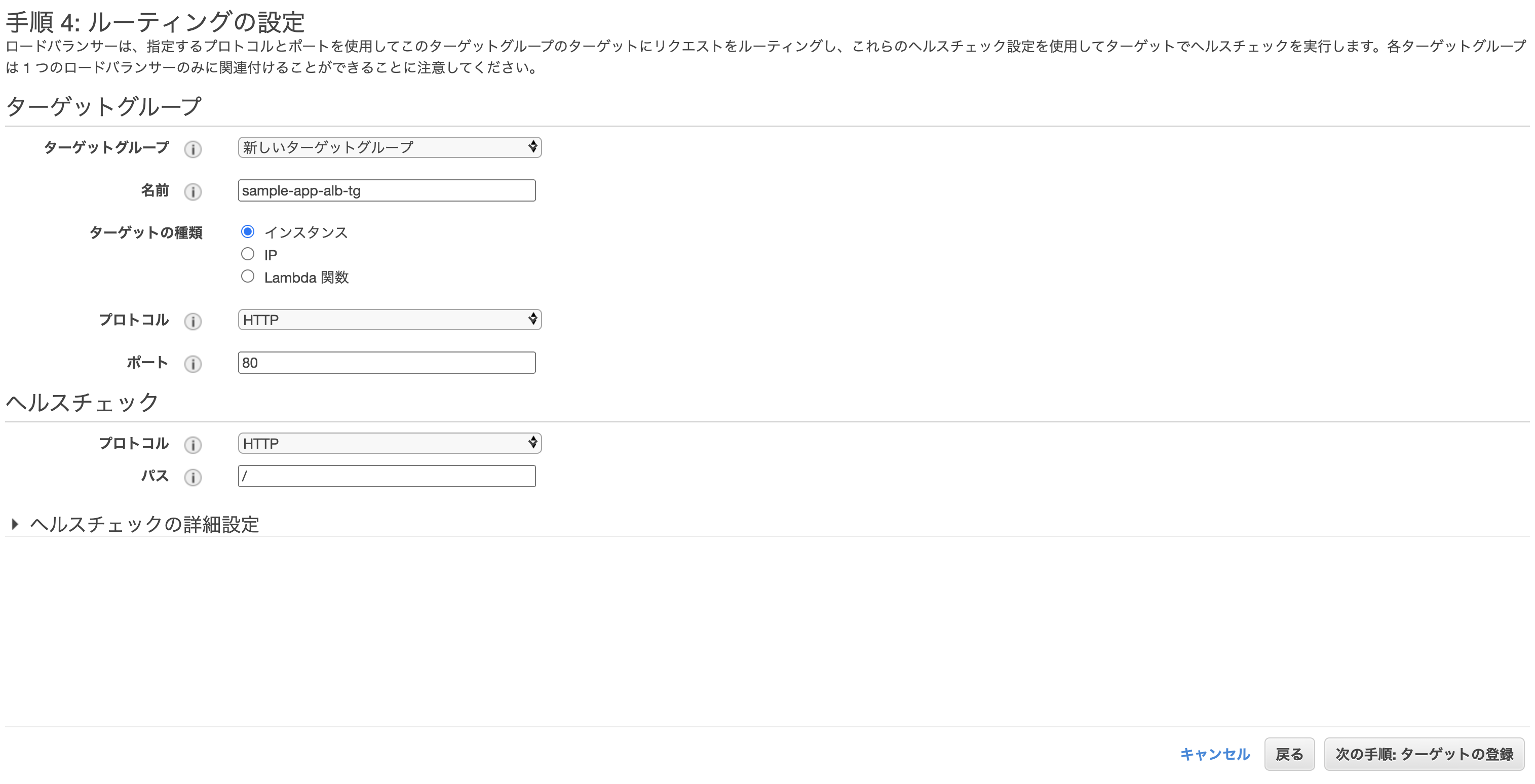
ターゲットグループの設定。
- ターゲットグループ: 新しいターゲットグループ
- 名前: 任意
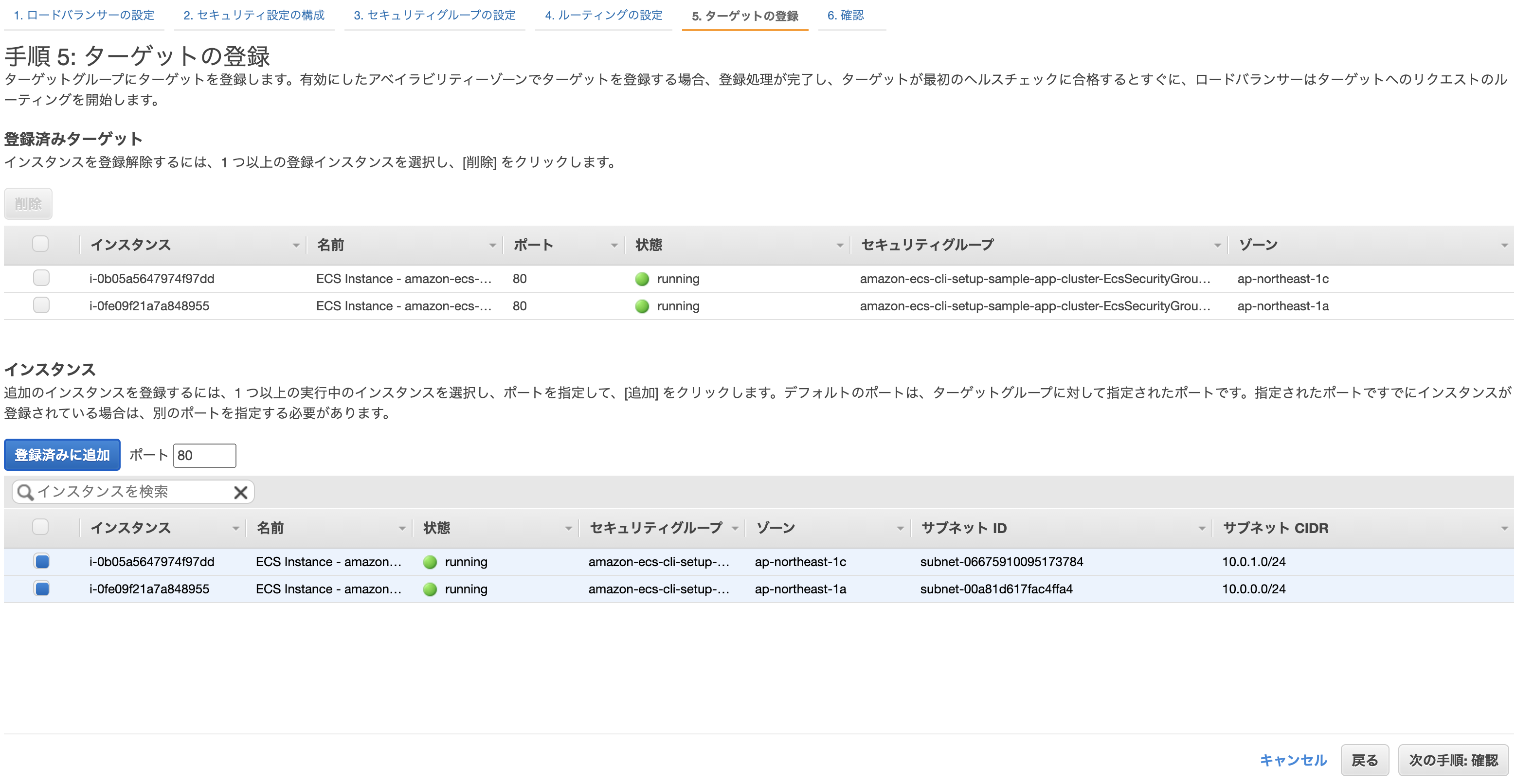
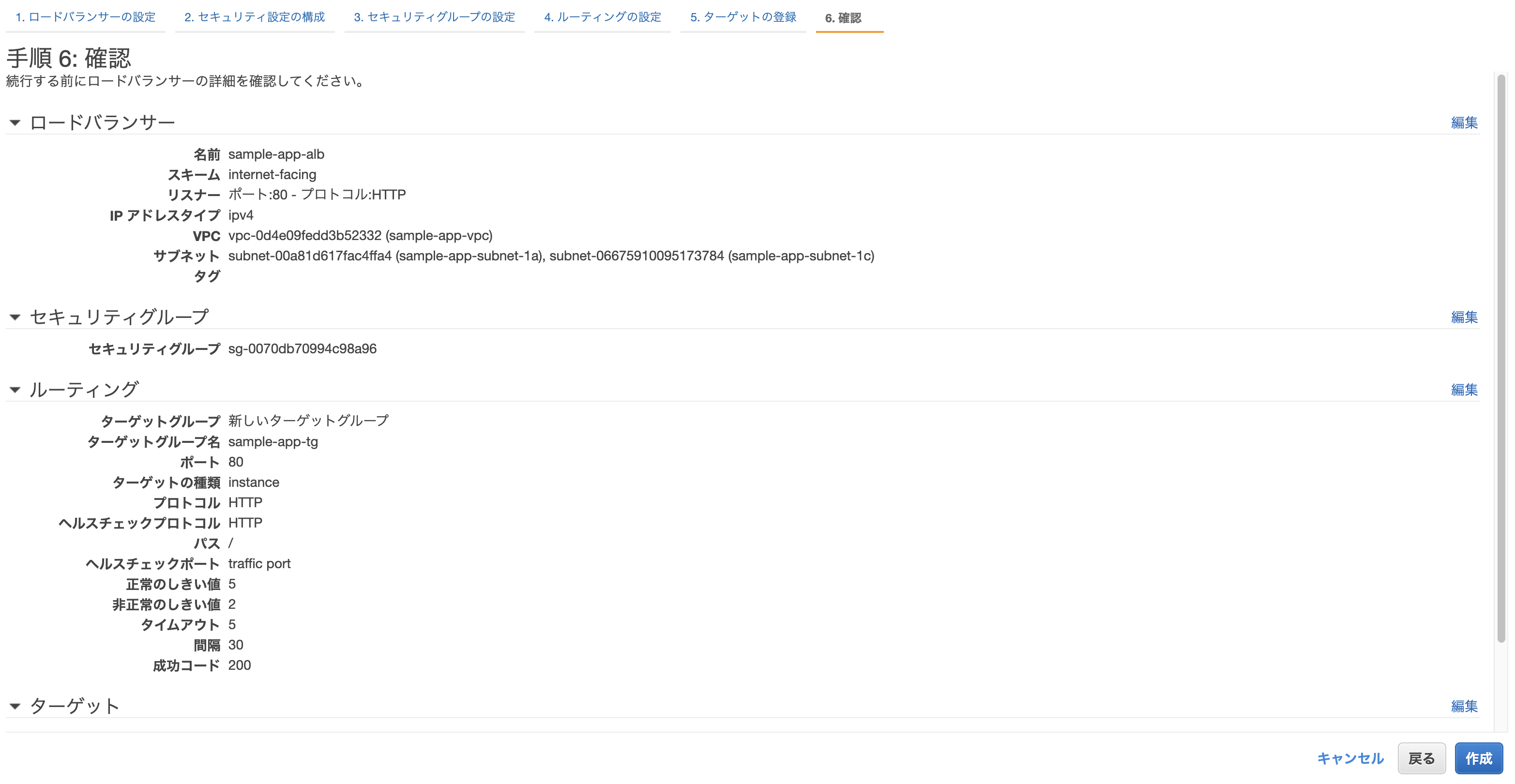
クラスター作成時に自動で作られたEC2を登録し、確認画面から問題なければ「作成」をクリックして完了。
ECRにdockerイメージをpush
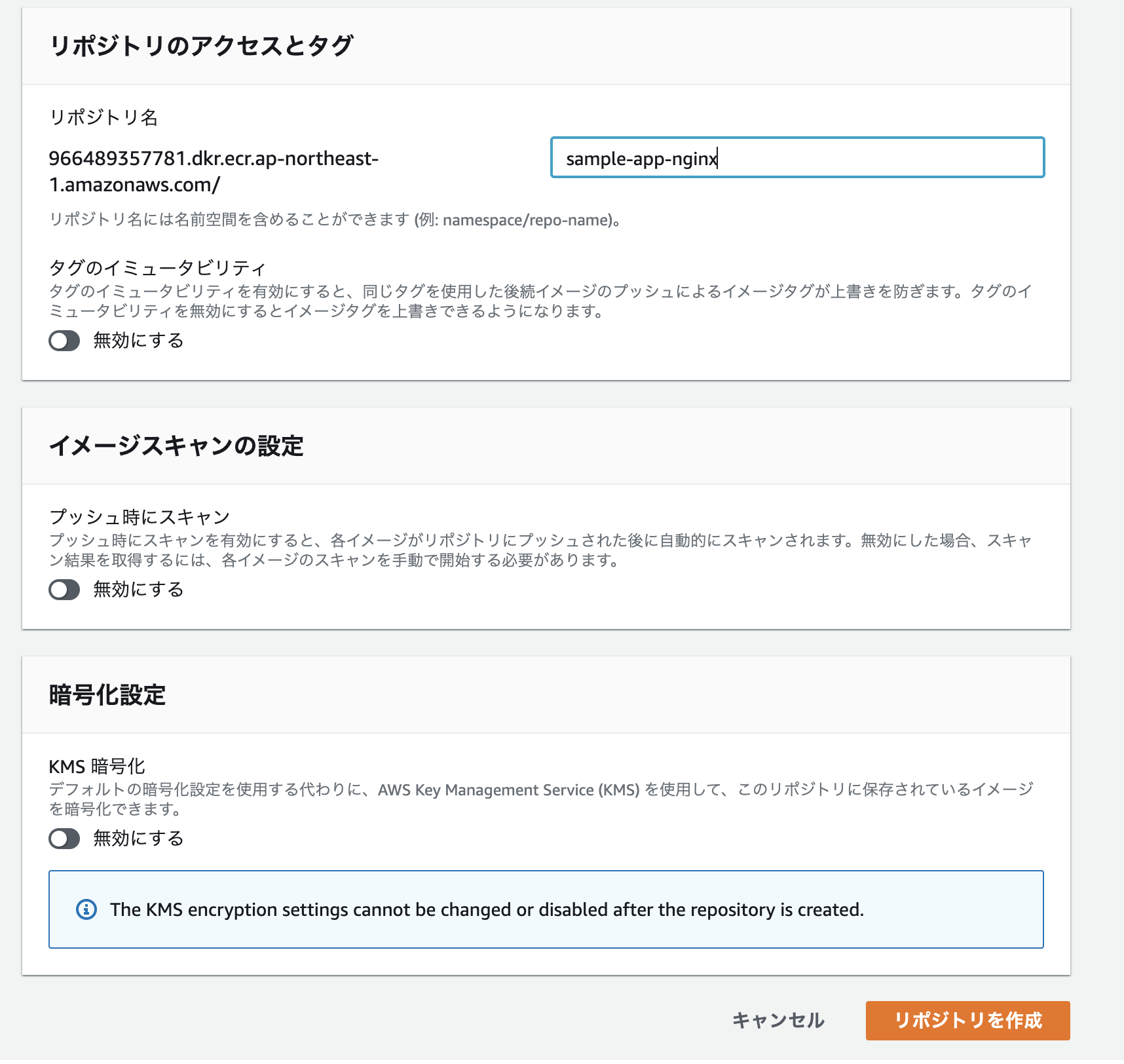
AWSのコンソールからサービス→Amazon Elastic Container Registryを選択し、「リポジトリの作成」をクリック。
それぞれ適当なリポジトリ名を入力し、「リポジトリを作成」をクリック。
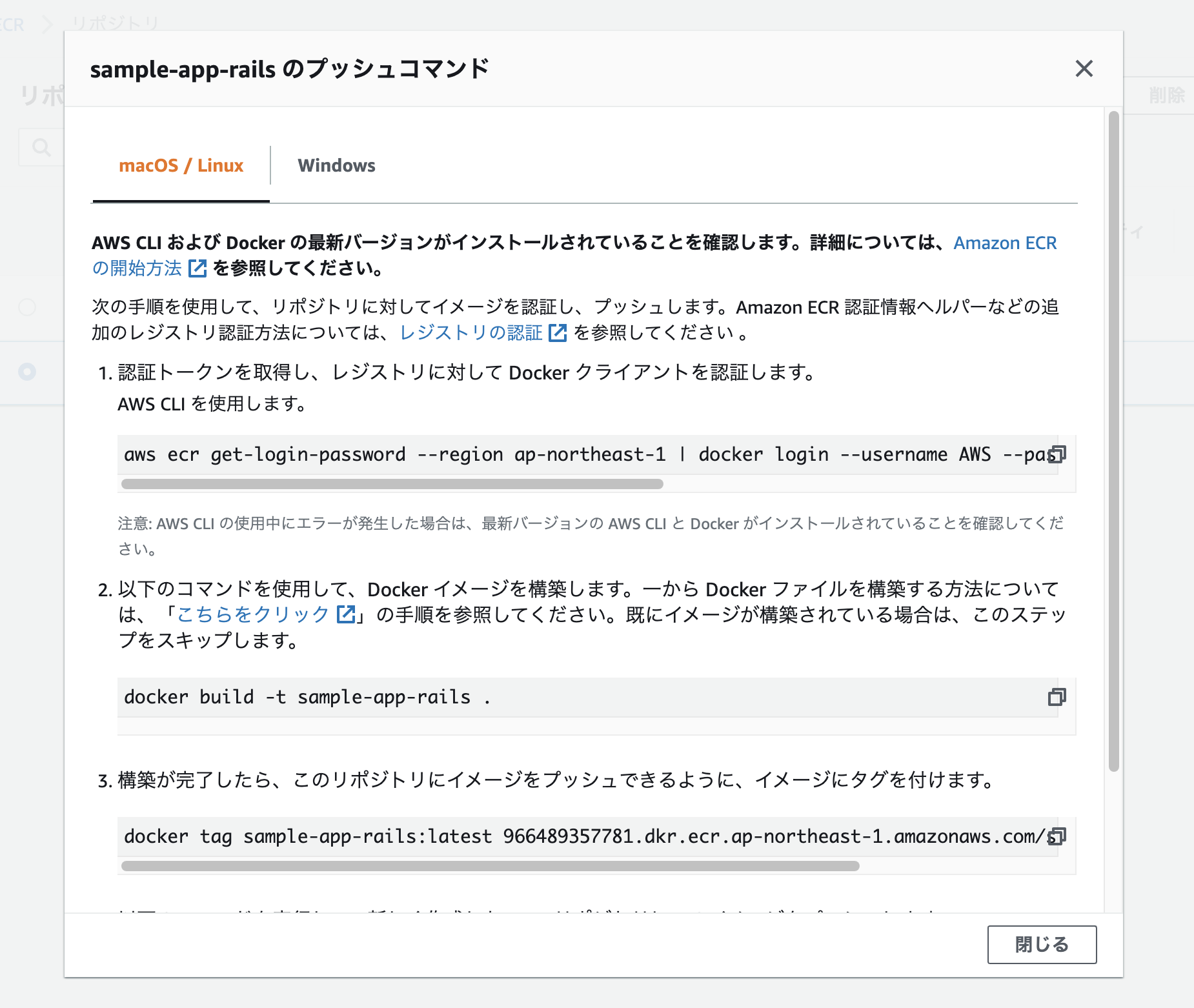
プッシュコマンドを表示し、書いてある通り上から順に4つ実行していく。
※2番目のコマンドでbuildを行う際は-fでDockerfileのコンテキストを変える。
# Rails(本番用のDockerfileを使用する) $ docker build -f ./prod.Dockerfile . -t sample-app-rails # Nginx $ cd containers/nginx $ docker build -f ./Dockerfile . -t sample-app-nginx本番用のDockerfile
$ touch prod.Dockerfile# prod.Dockerfile FROM ruby:2.6.6 ENV LANG C.UTF-8 RUN apt-get update -qq && apt-get install -y build-essential libpq-dev nodejs RUN curl -sL https://deb.nodesource.com/setup_8.x | bash - && \ apt-get install nodejs RUN apt-get update && apt-get install -y curl apt-transport-https wget && \ curl -sS https://dl.yarnpkg.com/debian/pubkey.gpg | apt-key add - && \ echo "deb https://dl.yarnpkg.com/debian/ stable main" | tee /etc/apt/sources.list.d/yarn.list && \ apt-get update && apt-get install -y yarn RUN mkdir /sample-app WORKDIR /sample-app ADD Gemfile /sample-app/Gemfile ADD Gemfile.lock /sample-app/Gemfile.lock RUN gem install bundler:2.1.4 RUN bundle install ADD . /sample-app # Nginxと通信を行うための準備 RUN mkdir -p tmp/sockets VOLUME /sample-app/public VOLUME /sample-app/tmp RUN yarn install --check-files RUN SECRET_KEY_BASE=placeholder bundle exec rails assets:precompile基本的に開発用のものと同じだが、最後の数行でNginxと通信を行うための準備などを行っている。
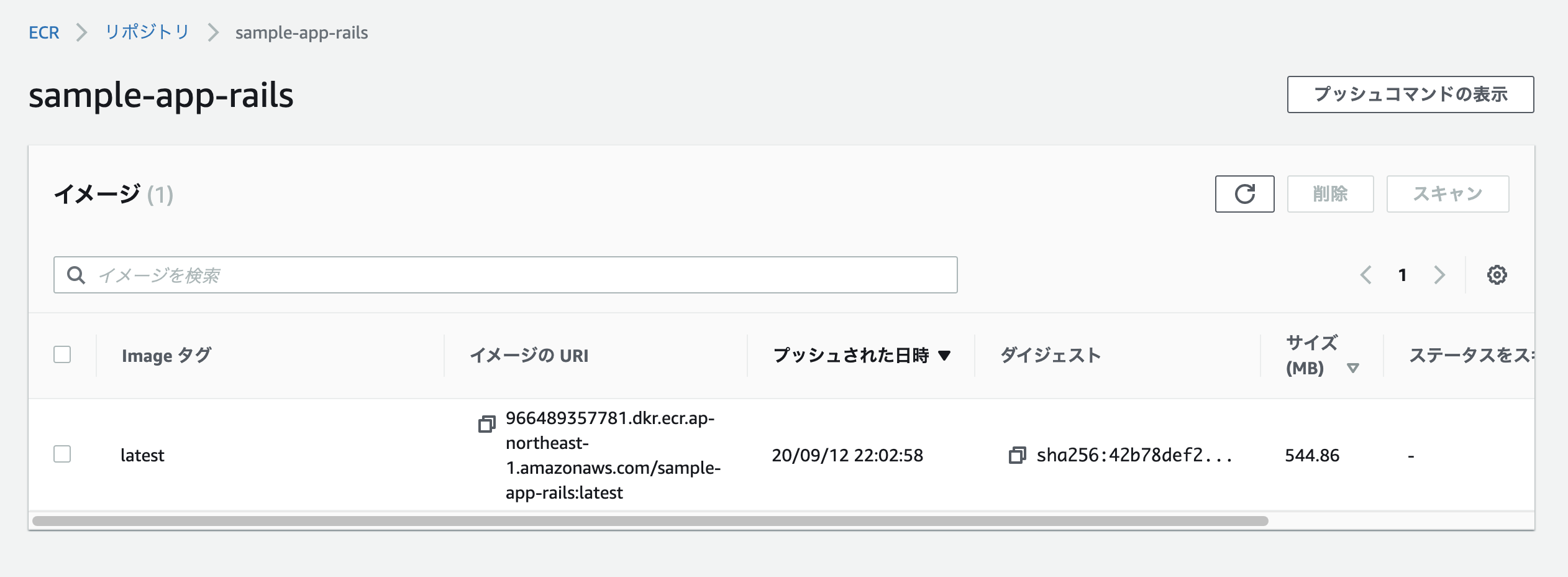
全て打ち終わったらリポジトリを確認し、イメージが追加されていれば成功。
タスクの作成
先ほどpushしたイメージをもとに、タスクの作成を行う。
$ mkdir ecs $ touch ecs/docker-compose.yml# ecs/docker-compose.yml version: 2 services: app: image: # ECRのリポジトリURI(Rails) command: bash -c "bundle exec rails db:migrate && bundle exec rails assets:precompile && bundle exec puma -C config/puma.rb" environment: # 実際はdotenvなどで管理した方が良いかも RAILS_ENV: production RAILS_MASTER_KEY: # config/master.keyの値 DATABASE_NAME: sample_app_production DATABASE_USERNAME: root DATABASE_PASSWORD: password DATABASE_HOST: # RDSのエンドポイント TZ: Japan working_dir: /sample-app logging: driver: awslogs options: awslogs-region: ap-northeast-1 awslogs-group: sample-app-production/app awslogs-stream-prefix: sample-app-production nginx: image: # ECRのリポジトリURI(Nginx) ports: - 80:80 links: - app volumes_from: - app working_dir: /sample-app logging: driver: awslogs options: awslogs-region: ap-northeast-1 awslogs-group: sample-app-production/nginx awslogs-stream-prefix: sample-app-production次のコマンドを実行。
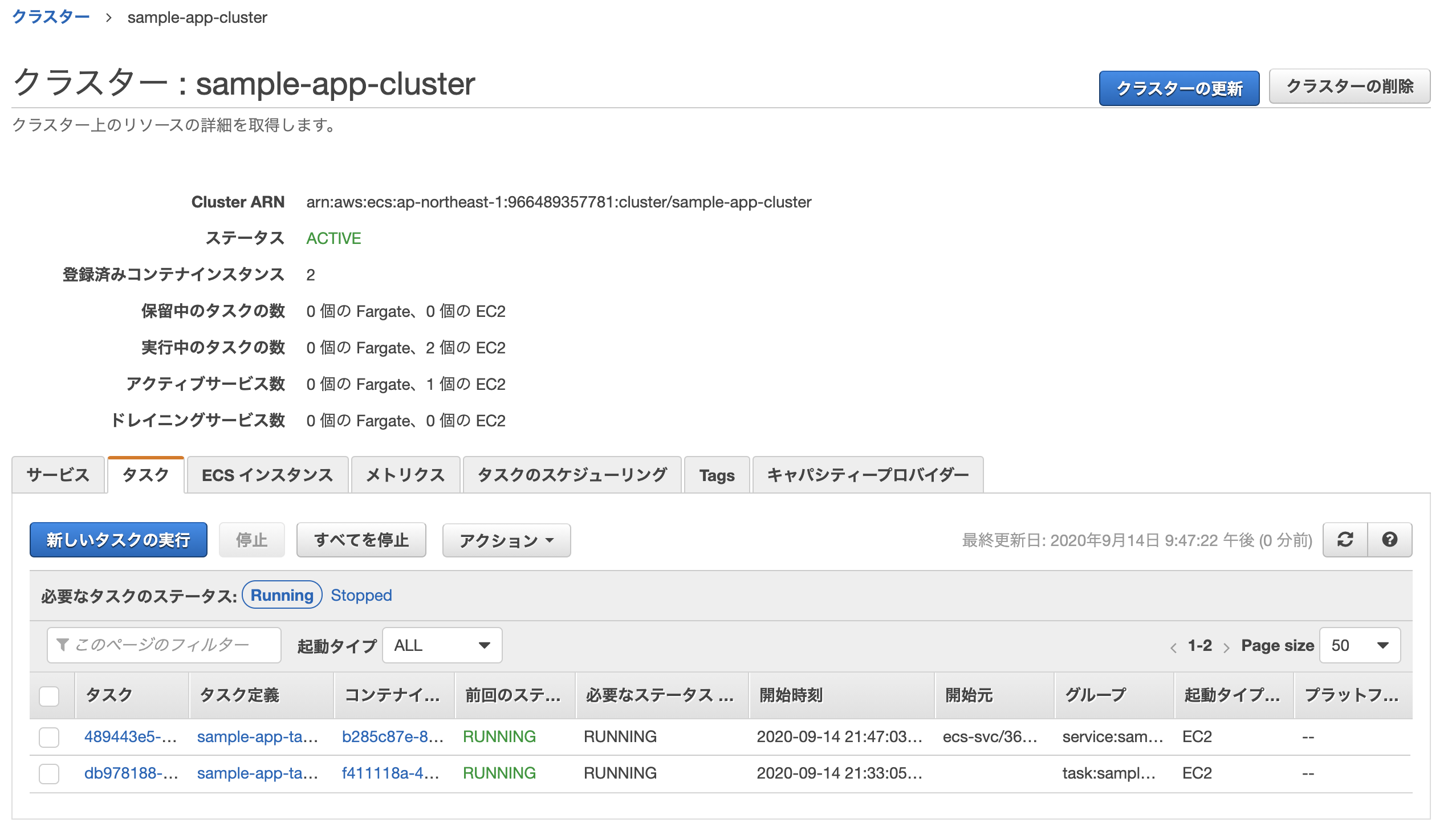
$ ecs-cli compose --project-name sample-app-task -f ./ecs/docker-compose.yml up --create-log-groups --cluster-config sample-app-cluster --ecs-profile sample-app
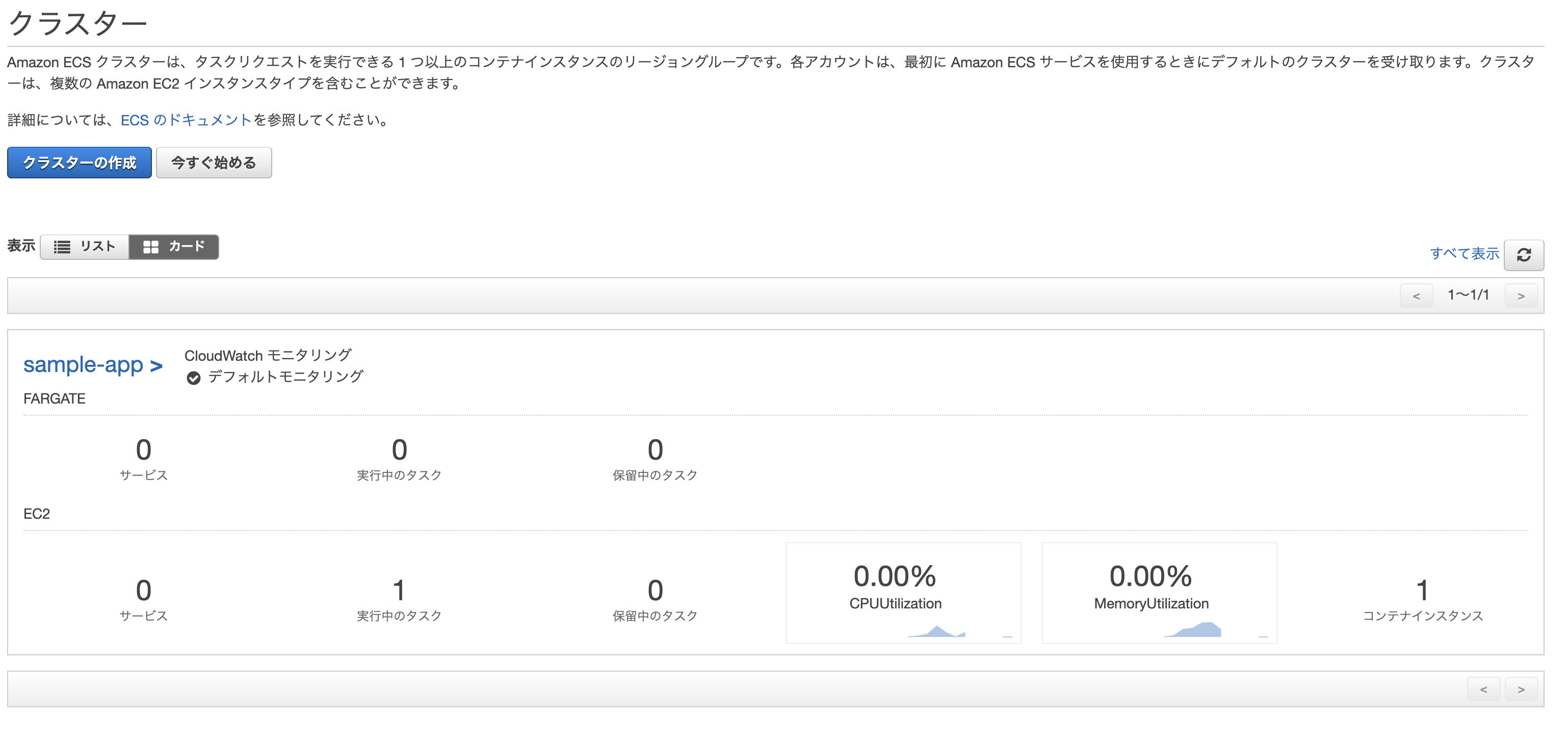
上手く行った場合、実行中のタスクに「1」と表示される。
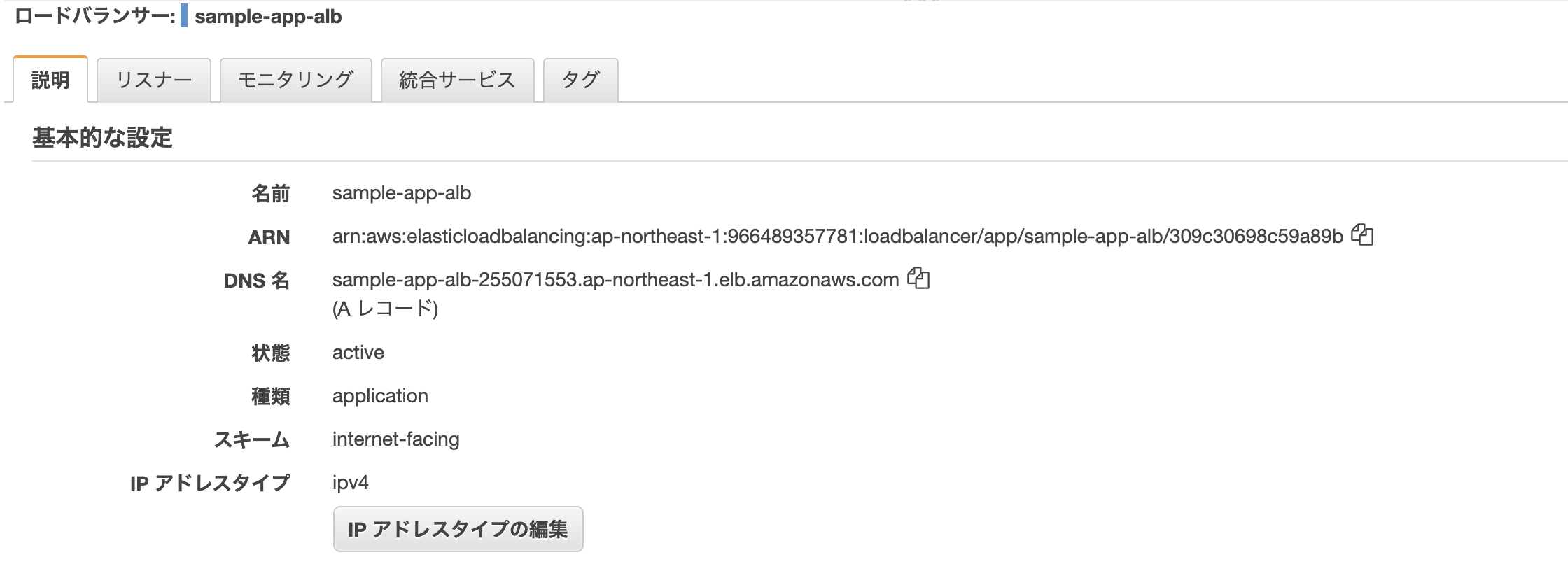
最後に、ロードバランサーのDNS名をURLに貼り付けてアクセス。
「Yay!You're on Rails!」と表示されれば成功。
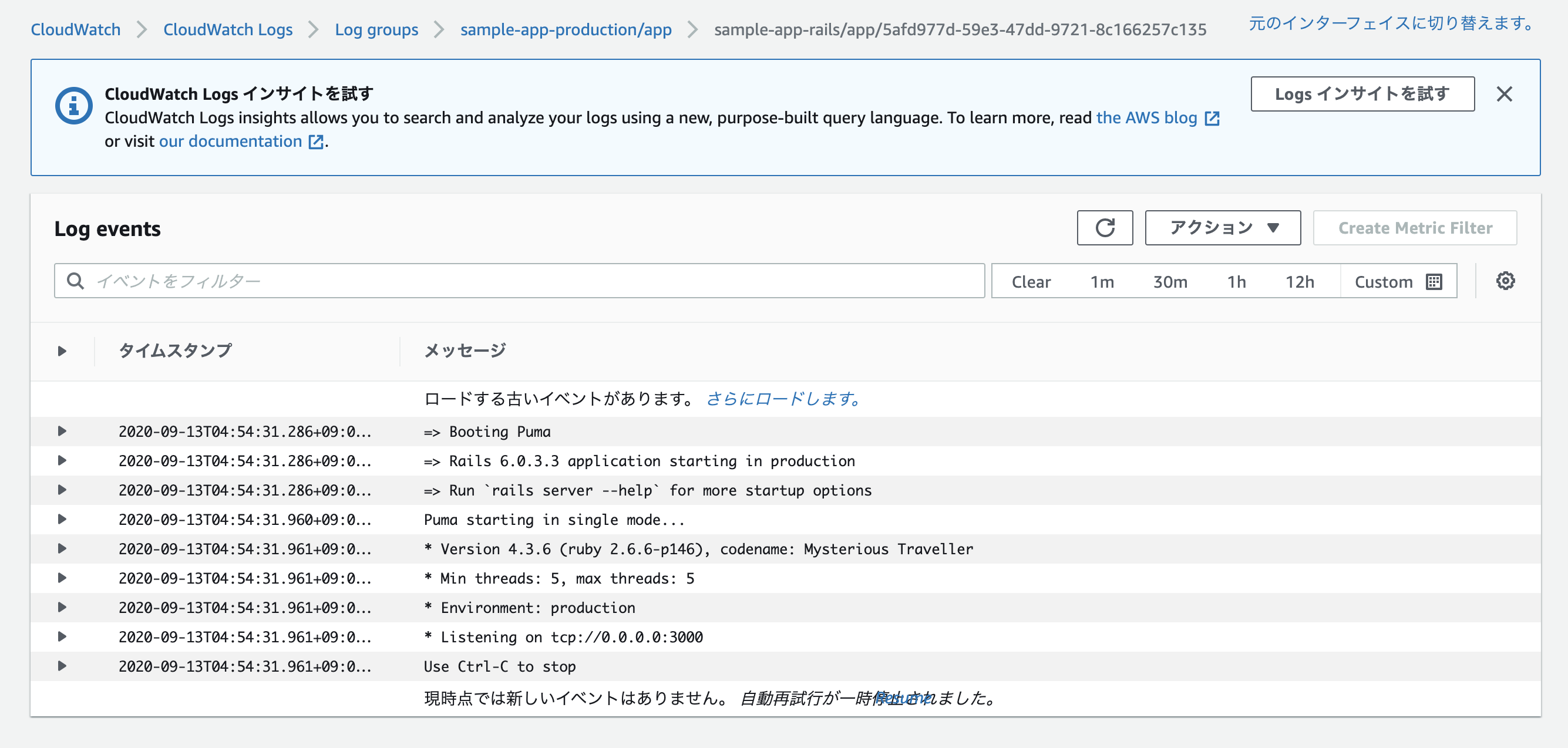
※デプロイに際して何か不具合があった場合はCloudWatchのログを確認して修正。
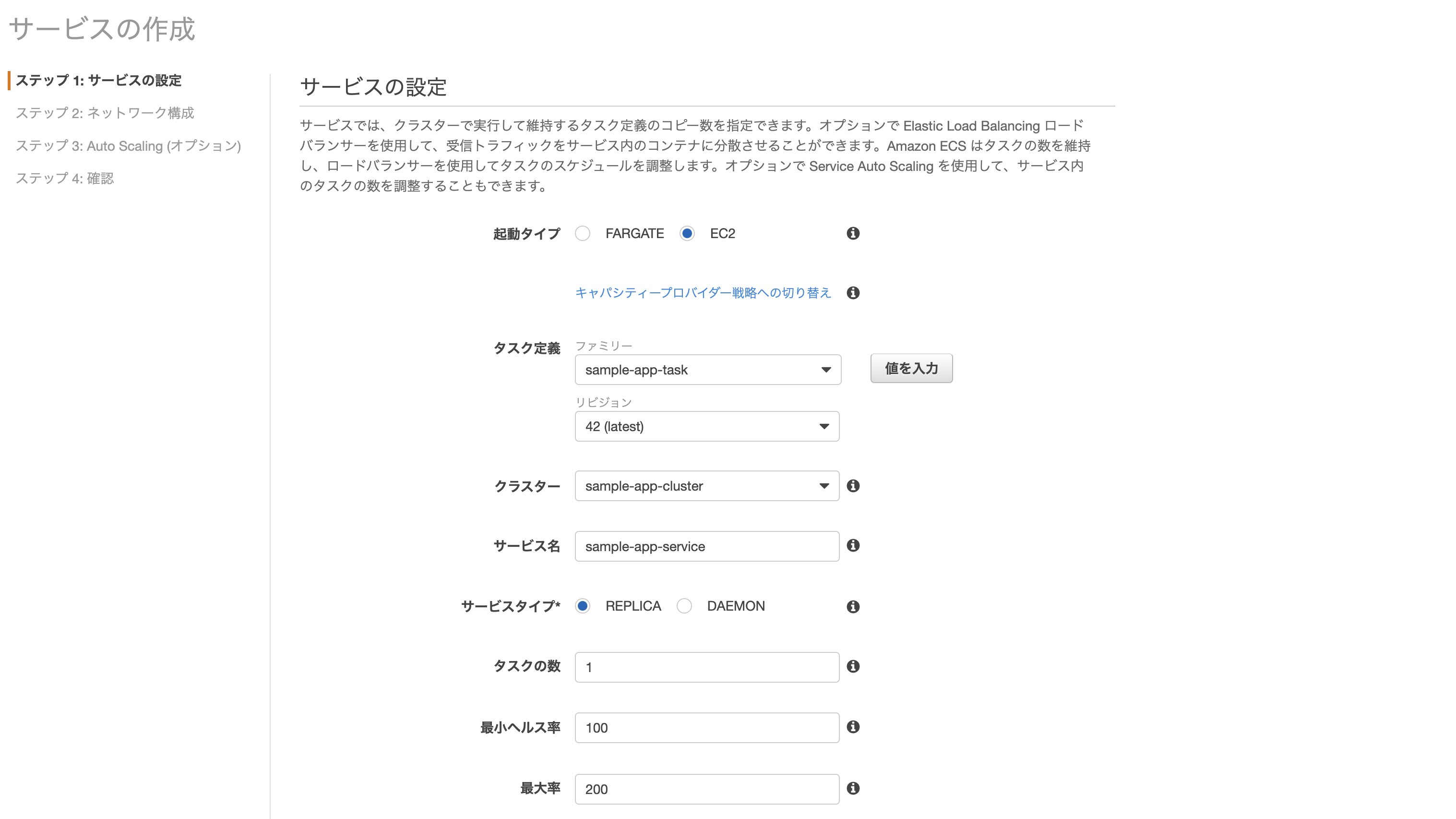
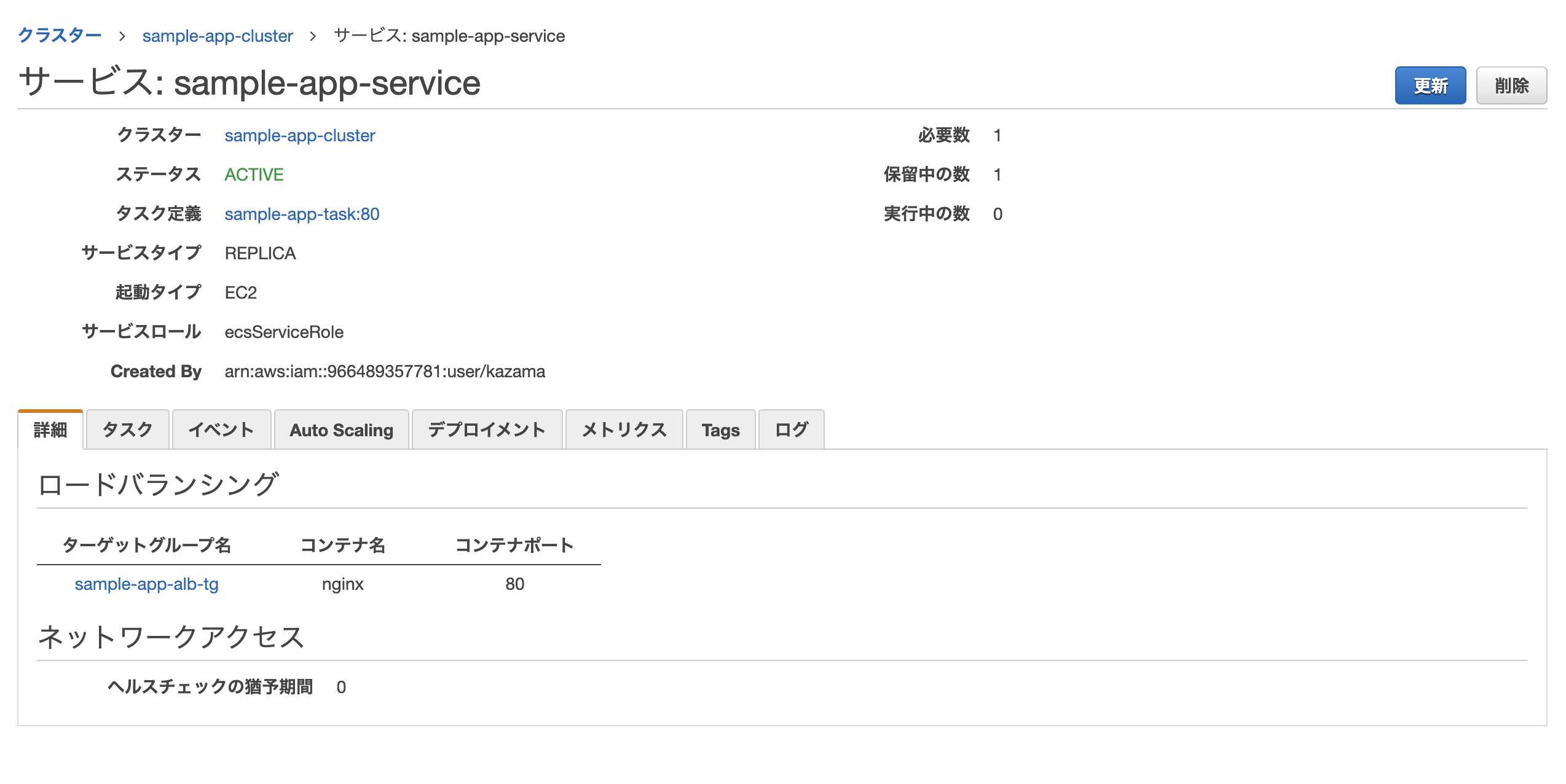
サービスの作成
クラスターとタスクだけでもアプリは動くが、その中間に「サービス」と呼ばれるものを作成すると、コンテナが止まった際に再起動をかけてくれたりロードバランサーを通じてオートスケーリングしてくれたり何かと便利ぽいので作成しておく。
AWSのコンソールからサービス→Amazon Elastic Container Service→ クラスター名をクリックし、「サービス」タブを開いて作成ページに進む。
- 起動タイプ: EC2
- タスク定義: 先ほど作成したもの
- クラスター: 同上
- サービス名: 任意
- その他: 画像の通り
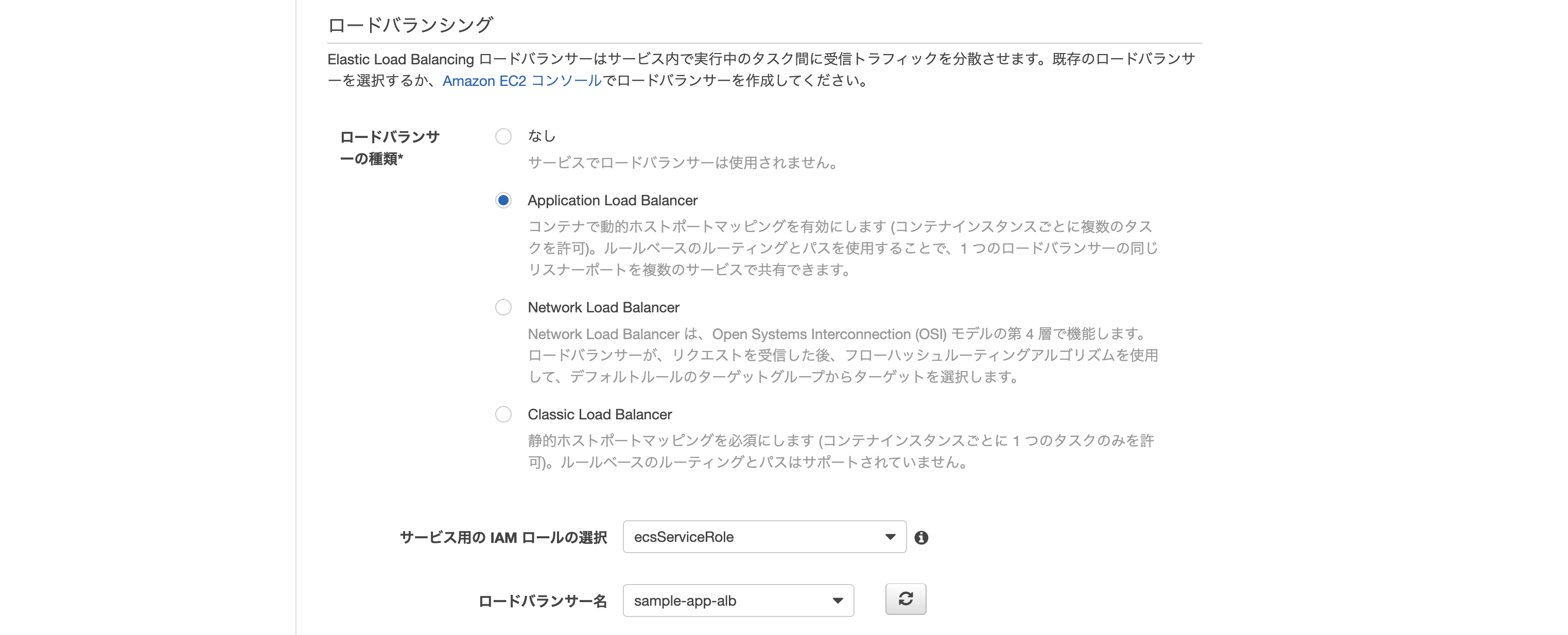
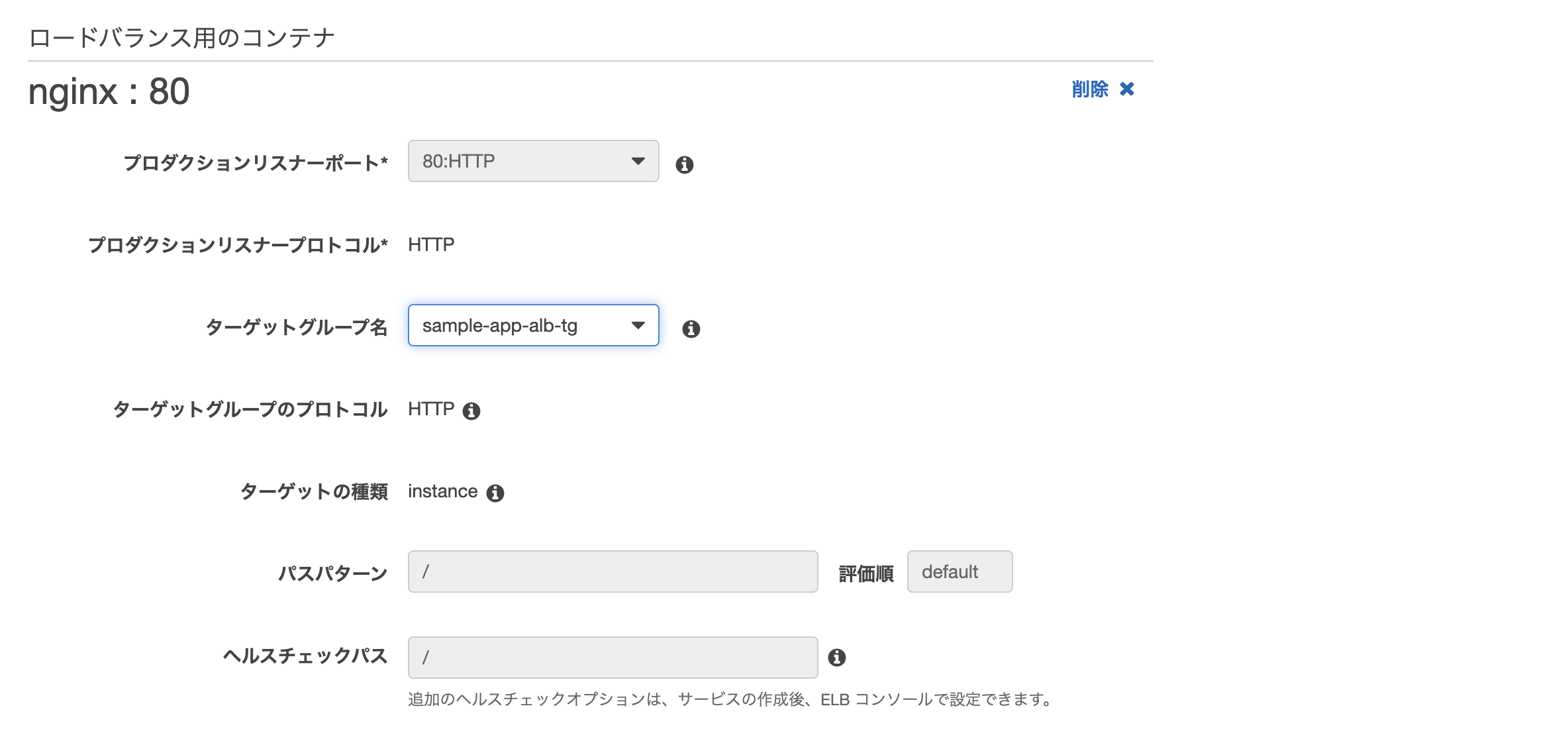
- ロードバランサーの種類: Application Load Balancer
- ロードバランサー名: 先ほど作成したもの
- その他: 画像の通り
- ターゲットグループ名: 先ほど作成したもの
- その他: 画像の通り
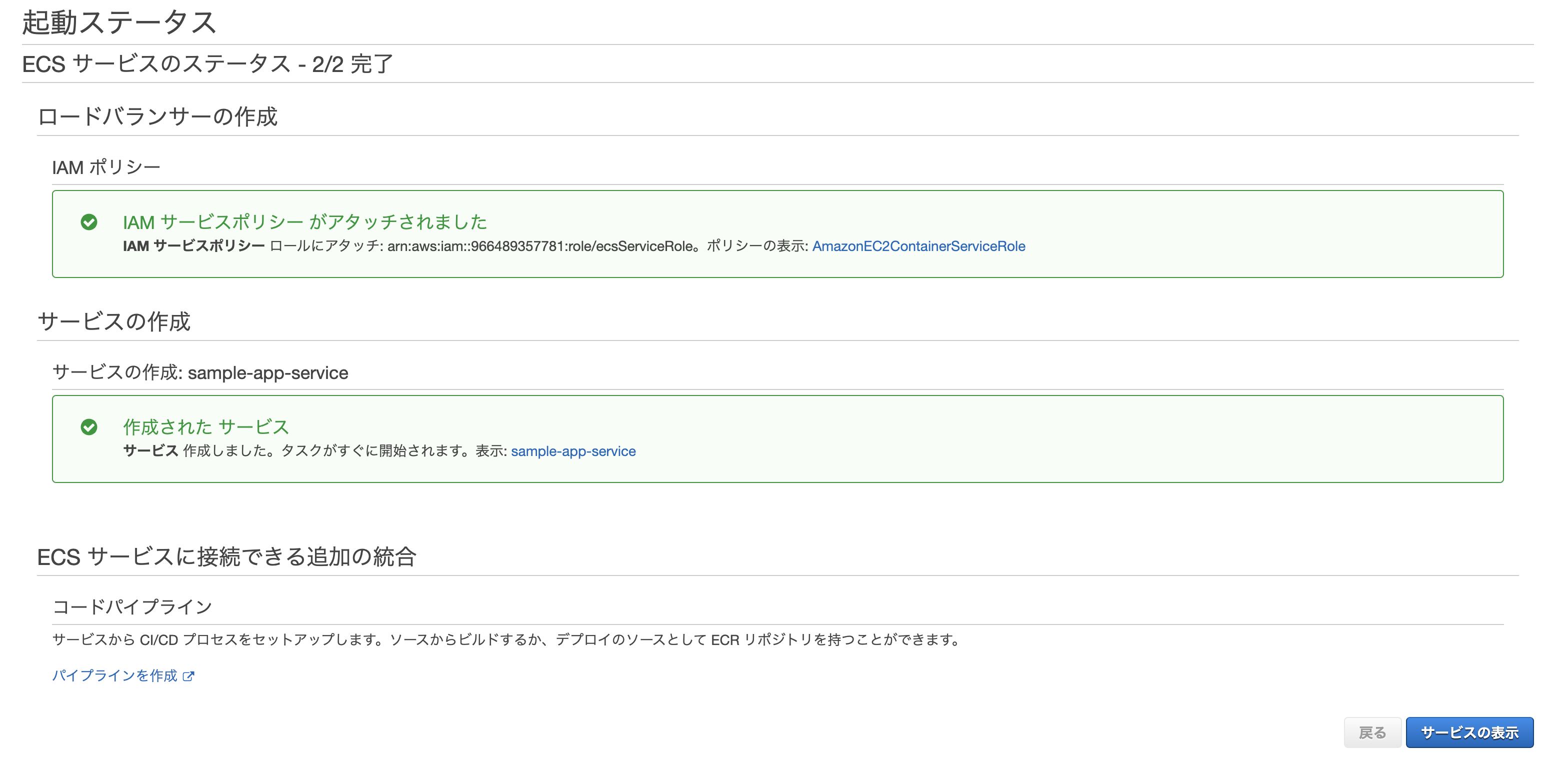
最後に確認画面が表示されるので、問題無ければ作成をクリック。
無事作成されれば完了。
このままだと2つのタスク(片方はecs-cliでターミナルから開始したもの、もう片方はサービスの作成により開始されたもの)が実行中になってしまっているため、前者は停止してしまってOK。
おまけCircleCiと連携して自動デプロイ)
このままだと変更点があるたびに手動で「ビルド→プッシュ→タスク再定義」といった面倒な作業が必要になるため、「CirlcleCiにプッシュ→ビルド&テスト→ECR・ECSへ自動デプロイ」といった良くある仕組みを構築していく。
Rspecを導入
まず、デプロイ前にテストを行うためにRspecを導入する。
gemをインストール
# Gemfile group :development, :test do gem 'rspec-rails' end# Gemfileを更新したので再度ビルド $ docker-compose build各種ファイルを作成&編集
$ docker-compose run web bundle exec rails generate rspec:install create .rspec create spec create spec/spec_helper.rb create spec/rails_helper.rb# .rspec --format documentation↑の1行を追記しておくと、Rspecを実行した際の出力表示が見やすくなる。
# spec/rails_helper.rb Dir[Rails.root.join('spec', 'support', '**', '*.rb')].sort.each { |f| require f }必須ではないが、後ほどテスト用のヘルパーメソッドを作成する事になった場合、ファイルの置き場として「spec/support」を使用するので一応設定しておく。
デフォルトではコメントアウトされているので、それを外せばOK。
# config/application.rb config.generators do |g| g.test_framework :rspec, view_specs: false, helper_specs: false, controller_specs: false, routing_specs: false endこのままだと
rails gコマンドを打ち込んだ際に自動で諸々のテストファイルが作成されてしまうので、余計なものを作成したくない場合は「config/application.rb」で設定を行う。※この辺はお好みで。
rspecを実行
$ docker-compose run web bundle exec rspec No examples found. Finished in 0.00276 seconds (files took 0.12693 seconds to load) 0 examples, 0 failuresまだ何もテストを書いていないので、当然こうなる。
とりあえずRequest Specを書いてみる
手始めに、リクエストに対して正常なレスポンスが返ってくるかどうかを確認するためのRequest Specを書いてみる。
トップページを作成
# コントローラー $ touch app/controllers/home_controller.rb # ビュー $ mkdir app/views/home $ touch app/views/home/index.html.erb# app/controllers/home_controller.rb class HomeController < ApplicationController def index end end# app/views/home/index.html.erb <h1>Hello World!</h1>#config/routes.rb Rails.application.routes.draw do root 'home#index' end
テストファイルを作成
$ docker-compose run web bundle exec rails g rspec:request home create spec/requests/homes_spec.rb# spec/requests/home_spec.rb require 'rails_helper' RSpec.describe "Home", type: :request do describe "GET /" do it "works successfully" do get root_path expect(response).to have_http_status(200) end end end「/」にアクセスした際、 200番のステータスコードが返ってくるかどうかのテスト。
$ docker-compose run web bundle exec rspec Home GET / works successfully Finished in 0.53664 seconds (files took 8.4 seconds to load) 1 example, 0 failures再度rspecを実行し、問題無くパスしていれば成功。
CircleCIと連携
次に、実際にCircleCiと連携するための設定を行う。
gemをインストール
group :development, :test do gem 'database_cleaner' gem 'rspec_junit_formatter' gem 'webdrivers', '~> 3.0' end# Gemfileを更新したので再度ビルド $ docker-compose build各種ファイルを作成&編集
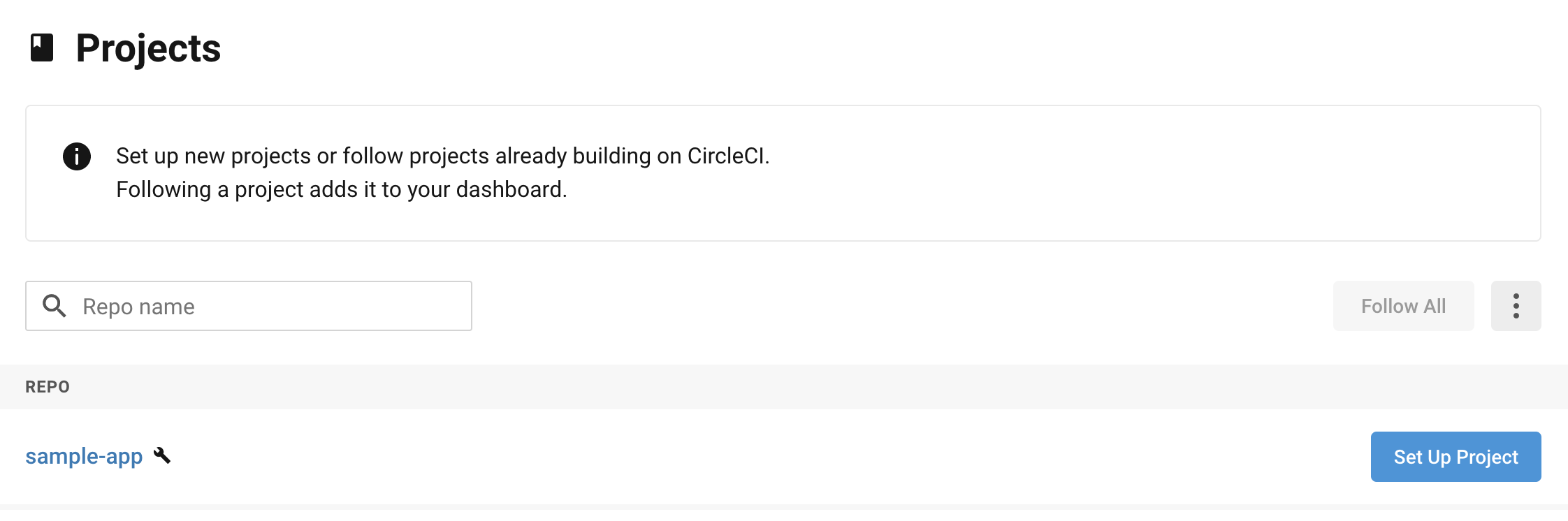
$ mkdir .circleci $ touch .circleci/config.yml $ touch config/database.yml.ci $ docker-compose run web bundle exec rails db:schema:dump# .circleci/config.yml version: 2 jobs: build: docker: - image: circleci/ruby:2.6.6-node-browsers environment: - BUNDLER_VERSION: 2.1.4 - RAILS_ENV: 'test' - image: circleci/mysql:5.7 environment: - MYSQL_ALLOW_EMPTY_PASSWORD: 'true' - MYSQL_ROOT_HOST: '127.0.0.1' working_directory: ~/sample_app steps: - checkout - restore_cache: keys: - v1-dependencies-{{ checksum "Gemfile.lock" }} - v1-dependencies- - run: name: install dependencies command: | gem install bundler -v 2.1.4 bundle install --jobs=4 --retry=3 --path vendor/bundle - save_cache: paths: - ./vendor/bundle key: v1-dependencies-{{ checksum "Gemfile.lock" }} # database setup - run: mv ./config/database.yml.ci ./config/database.yml # database setup - run: name: setup database command: | bundle exec rake db:create bundle exec rake db:schema:load # install yarn - run: name: install yarn command: yarn install # install webpack - run: name: install webpack command: bundle exec bin/webpack # run tests - run: name: run rspec command: | mkdir /tmp/test-results TEST_FILES="$(circleci tests glob "spec/**/*_spec.rb" | \ circleci tests split --split-by=timings)" bundle exec rspec \ --format progress \ --format RspecJunitFormatter \ --out /tmp/test-results/rspec.xml \ --format progress \ $TEST_FILES # collect reports - store_test_results: path: /tmp/test-results - store_artifacts: path: /tmp/test-results destination: test-results# config/database.yml.ci (CircleCiのデータベース設定用) test: adapter: mysql2 encoding: utf8 pool: 5 username: 'root' port: 3306 host: '127.0.0.1' database: sample_app_test# spec/rails_helper.rb RSpec.configure do |config| # config DataBaseCleaner config.before(:suite) do DatabaseCleaner.strategy = :transaction DatabaseCleaner.clean_with(:truncation) Rails.application.load_seed end config.before(:each) do DatabaseCleaner.start end config.after(:each) do DatabaseCleaner.clean end end# db/schema.rb # This file is auto-generated from the current state of the database. Instead # of editing this file, please use the migrations feature of Active Record to # incrementally modify your database, and then regenerate this schema definition. # # This file is the source Rails uses to define your schema when running `rails # db:schema:load`. When creating a new database, `rails db:schema:load` tends to # be faster and is potentially less error prone than running all of your # migrations from scratch. Old migrations may fail to apply correctly if those # migrations use external dependencies or application code. # # It's strongly recommended that you check this file into your version control system. ActiveRecord::Schema.define(version: 0) do endCircleCiとGitHubを接続
https://app.circleci.com/projects/project-dashboard/github/GitHubのアカウント名/
↑CircleCiのダッシュボードから連携したいリポジトリを探し、「Set Up Project」をクリック。画面に表示される指示に従い設定。
これで今後GitHubへ新しいプッシュを行った際、「.circleci/config.yml」に書いた内容に基づき自動でビルド&テストが走るようになる。
特に問題が無ければ「SUCCESS」と表示されるはず。
これで初期設定は完了。自動デプロイ(ECR・ECS)
CircleCiのバージョン2.1から追加されたOrbを使い、masterブランチに変更が加えられた際、CircleCiでのビルド&テストを行い自動でイメージを作成しECRへプッシュし、ECSのサービスを更新してタスクの再定義を行うようにする。
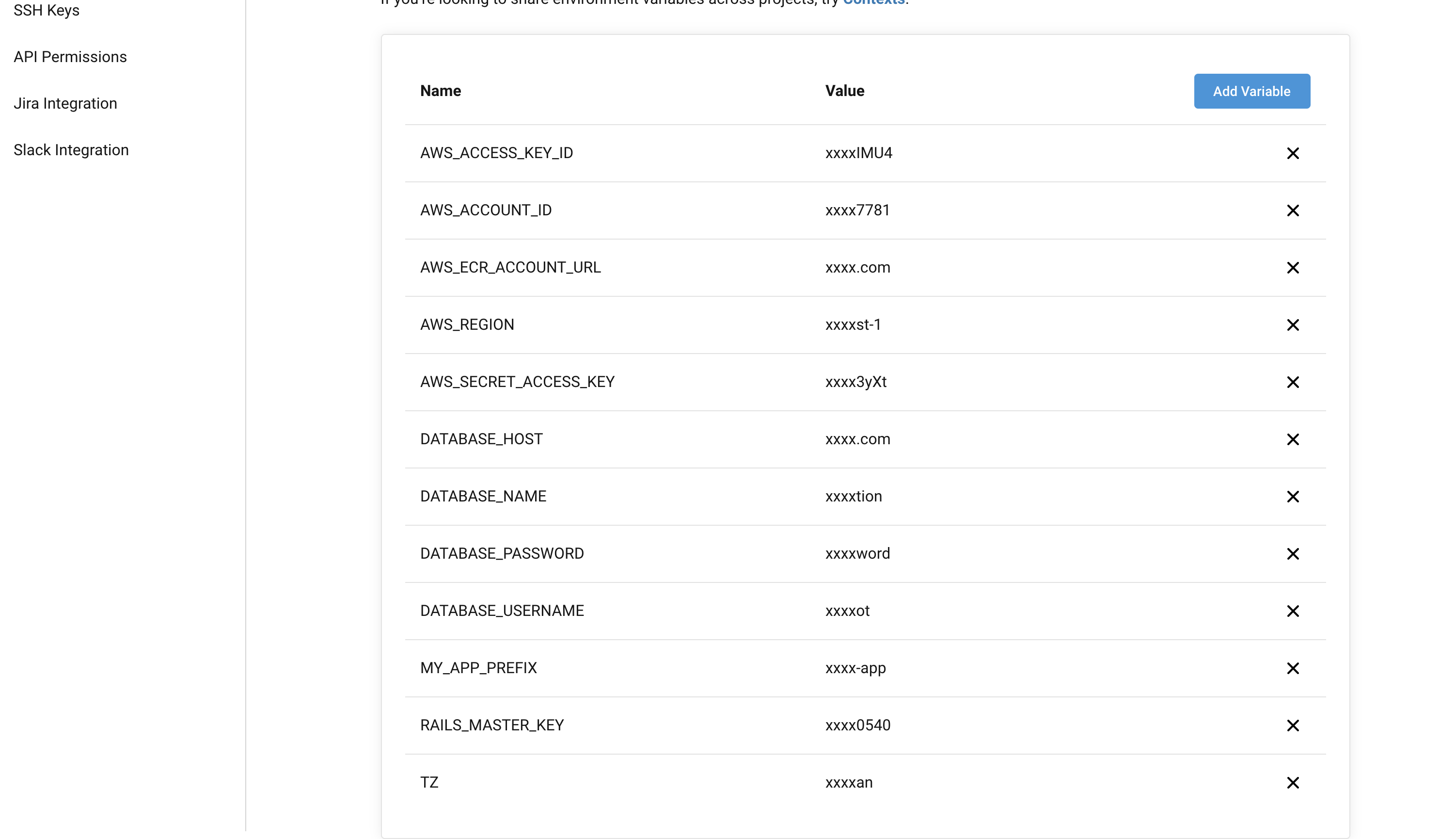
環境変数の登録
あらかじめCircleCiの設定画面からデプロイに必要な環境変数を登録しておく。
- AWS_ACCESS_KEY_ID
- 作成したIAMユーザーのアクセスキー
- AWS_SECRET_ACCESS_KEY
- 作成したIAMユーザーのシークレットキー
- AWS_ACCOUNT_ID
- AWSのアカウントID(コンソールの「マイアカウント」から確認可能)
- AWS_REGION
- ap-northeast-1
- AWS_ECR_ACCOUNT_URL
- ECRのリポジトリURI(例: <アカウントID>.dkr.ecr.ap-northeast-1.amazonaws.com)
- DATABASE_HOST
- RDSのエンドポイント(例: ********.ap-northeast-1.rds.amazonaws.com)
- DATABASE_USERNAME
- RDSのユーザー名(例: root)
- DATABASE_PASSWORD
- RDSのパスワード(例: password)
- DATABASE_NAME
- 使用するデータベース名(例: sample_app_production)
- RAILS_MASTER_KEY
- config/master.keyの値
- TZ
- JAPAN
- MY_APP_PREFIX
- 任意(例: sample-app)
- 変数を使い回してなるべくコンパクトに書けるようにクラスター名やタスク名は共通のワードを含めて作成しておいた方が良い(sample-app-cluster、sample-app-taskなど)。
.circleci/config.ymlを編集
# .circleci/config.yml version: 2.1 orbs: aws-ecr: circleci/aws-ecr@6.7.0 aws-ecs: circleci/aws-ecs@1.1.0 jobs: test: docker: - image: circleci/ruby:2.6.6-node-browsers environment: - BUNDLER_VERSION: 2.1.4 - RAILS_ENV: 'test' - image: circleci/mysql:5.7 environment: - MYSQL_ALLOW_EMPTY_PASSWORD: 'true' - MYSQL_ROOT_HOST: '127.0.0.1' working_directory: ~/project steps: - checkout - restore_cache: keys: - v1-dependencies-{{ checksum "Gemfile.lock" }} - v1-dependencies- - run: name: install dependencies command: | gem install bundler -v 2.1.4 bundle install --jobs=4 --retry=3 --path vendor/bundle - save_cache: paths: - ./vendor/bundle key: v1-dependencies-{{ checksum "Gemfile.lock" }} - run: mv ./config/database.yml.ci ./config/database.yml - run: name: setup database command: | bundle exec rake db:create bundle exec rake db:schema:load - run: name: install yarn command: yarn install - run: name: install webpack command: bundle exec bin/webpack - run: name: run rspec command: | mkdir /tmp/test-results TEST_FILES="$(circleci tests glob "spec/**/*_spec.rb" | \ circleci tests split --split-by=timings)" bundle exec rspec \ --format progress \ --format RspecJunitFormatter \ --out /tmp/test-results/rspec.xml \ --format progress \ $TEST_FILES - store_test_results: path: /tmp/test-results - store_artifacts: path: /tmp/test-results destination: test-results workflows: version: 2 test_and_deploy: jobs: - test # ビルドした後にイメージをECRへプッシュ - aws-ecr/build-and-push-image: requires: - test account-url: AWS_ECR_ACCOUNT_URL region: AWS_REGION aws-access-key-id: AWS_ACCESS_KEY_ID aws-secret-access-key: AWS_SECRET_ACCESS_KEY create-repo: true dockerfile: ./prod.Dockerfile repo: "${MY_APP_PREFIX}-rails" tag: "${CIRCLE_SHA1}" filters: branches: only: - master # ECSのサービスを更新してタスクを再定義 - aws-ecs/deploy-service-update: requires: - aws-ecr/build-and-push-image family: "${MY_APP_PREFIX}-task" cluster-name: "${MY_APP_PREFIX}-cluster" service-name: "${MY_APP_PREFIX}-service" container-image-name-updates: "container=app,tag=${CIRCLE_SHA1}"各環境変数に間違いが無いか良く確認しておく事。
# app/views/home/index.html.erb <h1>Hello World!</h1> <p>Completed auto deploy with CircleCi</p>自動デプロイが上手くいったかわかりやすいようにトップページを少し変えておく。
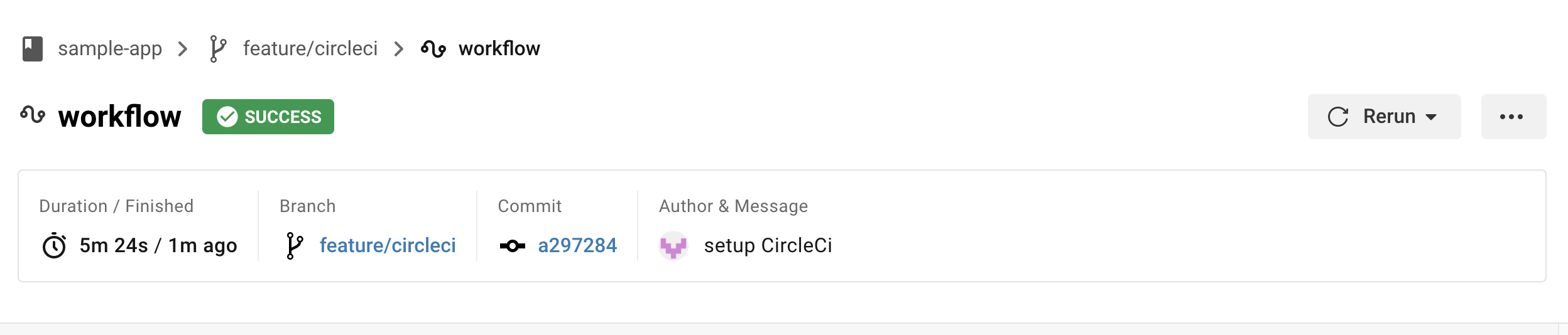
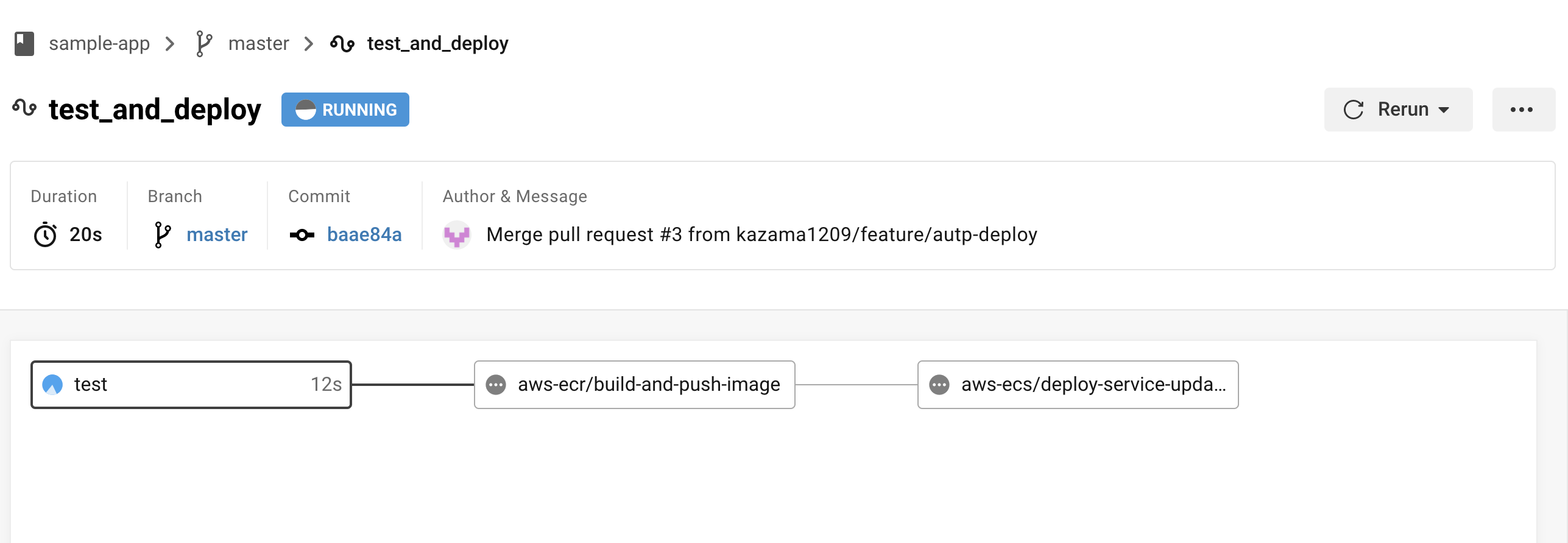
masterブランチに変更を加える
実際にmasterブランチにプッシュして変更を加えてみると、CircleCi上でデプロイ込みのjobsが動き始める。
※全てのフローが完了するまでに大体10〜15分くらいかかるので注意。
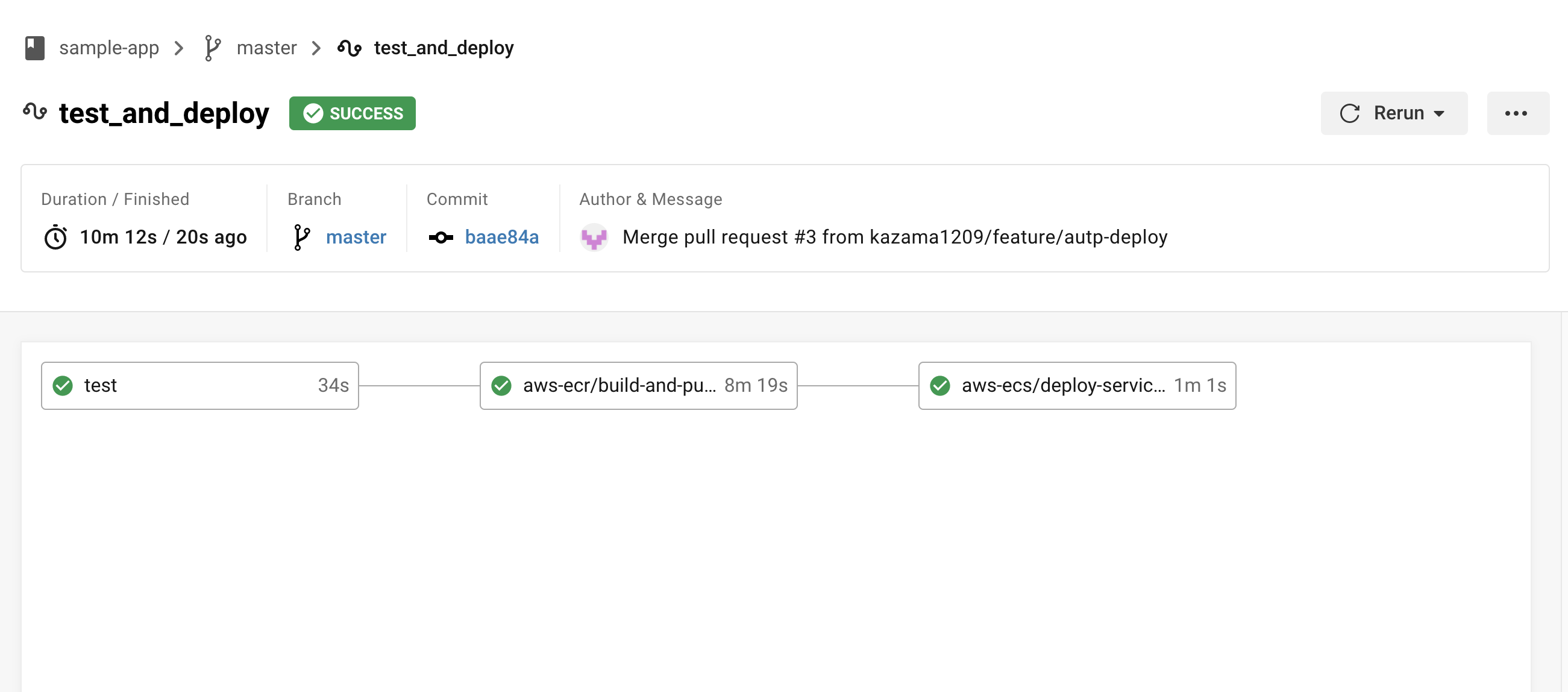
再度ロードバランサーのDNS名にアクセスし、先ほどの変更がちゃんと更新されていれば成功。
※反映されるまで多少時間がかかるので気長に待つ。
古いタスクと新しいタスクの2つが実行されているが、時間の経過で古い方は勝手に消されるため(サービスのおかげ?)そのまま放置でOK。
お疲れ様でした。
あとがき
自分もまだまだ勉強中の身なので、何かあれば随時更新予定です。
現状、コンソール上で手を動かしながら行う作業とターミナルでコマンドを叩いて行う作業がごちゃ混ぜになってしまっているため、できれば全て後者に統一したいと考えていいます。
Terraformとかも使って一発バシっとできるようにしたい...。
どこか詰まった部分やもっとこうした方が良いなどあればコメントいただけると嬉しいです。
個人的に詰まった部分
- Nginxの設定
- nginx.confファイルの中身は各自変更しないと正常に動かない部分があるので、ググりながら適宜修正する必要がある。
appコンテナとnginxコンテナの接続が上手くいかないと
2020/09/13 20:02:57 [crit] 7#7: *456 connect() to unix:///sample-app/tmp/sockets/puma.sock failed (2: No such file or directory) while connecting to upstream, client: *********, server: localhost, request: "GET / HTTP/1.1", upstream: "http://unix:///sample-app/tmp/sockets/puma.sock:/500.html", host: "***********"↑こんな感じのエラーで延々と悩まされる。
- 各環境変数の設定
- CircleCiに登録する環境変数の値がしっかり合っているか何度も確認した方が良い。ビルドするのにやたら時間がかかるので、1回失敗するとそれだけでかなりの時間の無駄になる。















- 投稿日:2020-09-15T03:54:22+09:00
【超初心者向け(スクショ多め)】Ruby2.6 × Rails6 × CircleCi でECR・ECSに自動デプロイ 【AWSチュートリアル】
対象読者
- ECSに全く触れた事が無い人
- とりあえず手を動かして雰囲気を掴みたい人
- 就活のためにポートフォリオを作成中の人
簡単なRailsアプリ(「Hello World!」と表示するだけ)をAWS ECSにデプロイするまでの手順。がっつりその後の運用まで考慮しているわけではなく、あくまで参考程度にしかならないためその点はご注意ください。
人によって多分色々なやり方がありそうなので、一度流れを掴んだ後は各自お好みで設定していただきたいです。
デプロイ用のアプリを用意する段階から全てハンズオン形式(スクショも多数)で記載しており、書いてある通りに進めれば基本的には上手くいくはず。
要所要所で任意の値(プロフィール名やアプリ名など)を設定する部分があるので、不安な場合は全て筆者と同じように「sample-app」などで統一すると良いかもです。
※初心者向けと銘打っているものの、「まずは実際に手を動かして雰囲気を掴む」という目的に徹しているため、各用語に関する説明はほとんど説明していません。
※あくまで「AWS超初心者でもとりあえず書いてある通りに従えばそれっぽくデプロイできる」というのがコンセプト。理論派の方はあらかじめ他の記事でECR・ECSの概念について学習してから入るのをおすすめします。(筆者は体で覚える派なので...)仕様
- 言語: Ruby2.6
- フレームワーク: Rails6
- データベース: MySQL5.7
- アプリケーションサーバー: Puma
- Webサーバー: Nginx
下準備編
まず、ECSにデプロイするための簡単なRailsアプリを用意。
サンプル
https://github.com/kazama1209/sample-app
$ git clone https://github.com/kazama1209/sample-app.git $ cd sample-appセットアップ
$ docker-compose build $ docker-compose run web bundle exec rails webpacker:install $ docker-compose up -d $ docker-compose run web bundle exec rails db:createlocalhostにアクセス
http://localhostにアクセスしていつもの画面が表示されれば環境構築は完了。デプロイ編
アプリの準備ができたので、ECSにデプロイしていく。
各種ツールをインストール
今回、ECSにデプロイするにあたり以下2つのツールを使用する。
$ brew install awscli $ brew install amazon-ecs-cliaws configureを設定
上記のツールを使用するためにaws configureの設定を行う。
IAMユーザーを作成
AWSのコンソールからサービス→IAMを選択し、「ユーザーの追加」をクリック。
任意のユーザー名を入力し、「プログラムによるアクセス」にチェックをつけて次のステップへ。(画像では「sample_app」となっていますが、実際は「sample-app」で作成したと仮定して話を進めます。スクショ撮り間違えました。)
「既存のポリシーを直接アタッチ」から以下の2つのポリシーをアタッチして次のステップへ。
- AmazonECS_FullAccess
- AmazonEC2ContainerRegistryFullAccess
タグに関しては今回はは無視で次のステップへ。
最後に入力情報の確認画面が表示されるので、特に問題無ければ「ユーザーの作成」をクリック。
ユーザーの作成に成功すると「アクセスキー」「シークレットアクセスキー」の2つが発行されるので、メモを取るなりcsvファイルをダウンロードするなり大事に保管。
ターミナルで「aws configure」を実行
$ aws configure --profile <先ほど作成したIAMユーザー名(今回は「sample-app」)> AWS Access Key ID # 先ほど作成したアクセスキー AWS Secret Access Key # 先ほど作成したシークレットアクセスキー Default region name # ap-northeast-1 Default output format # jsonそれぞれ上記のように入力。
追加でポリシーを作成
先ほどIAMユーザーを作成した際、
- AmazonECS_FullAccess
- AmazonEC2ContainerRegistryFullAccess
2つのポリシーをアタッチしたが、これだけだとこの後に使用する「ecs-cli」というツールの中で権限エラーが発生するため、ここで別途追加しなければならない。
AWSのコンソールからサービス→IAM→ポリシーを選択し、「ポリシーの作成」をクリック。
JSONタブを開いて以下の記述を行う。
{ "Version": "2012-10-17", "Statement": [ { "Sid": "VisualEditor0", "Effect": "Allow", "Action": [ "iam:AttachRolePolicy", "iam:AddRoleToInstanceProfile", "iam:CreateInstanceProfile", "iam:CreateRole", "iam:DeleteInstanceProfile", "iam:DeleteRole", "iam:DetachRolePolicy", "iam:PassRole", "iam:RemoveRoleFromInstanceProfile", "ec2:DeleteInternetGateway", "ec2:DeleteSecurityGroup", "ec2:DeleteRouteTable" ], "Resource": "*" } ] }
ポリシーの名前や説明を適当に入力し、「ポリシーの作成」をクリック。
ポリシーをユーザーにアタッチ
AWSのコンソールからサービス→IAM→ユーザーを選択し、「アクセス権限の追加」をクリック。
「既存のポリシーをアタッチ」から先ほど作成したポリシーを選択し、アクセス権限を追加。
キーペアを作成
後々EC2内へ入る際などに必要になるのでキーペアを作成しておく。
AWSのコンソールからサービス→EC2→キーペアを選択し、「キーペアの作成」をクリック。
名前とファイル形式を入力し、「キーペアを作成」をクリック。
$ mv Downloads/sample-app.pem .ssh/ $ chmod 600 ~/.ssh/sample-app.pem完了すると「.pem」形式のファイルがダウンロードされるので、「.ssh」ディレクトリに移動させて権限を変更する。
クラスターを作成
コンソールから手動でぽちぽち作成する事も可能だが、vpcやサブネットなども一緒に作る必要があるため、今回はecs-cliでまとめて作成してしまう。
次のコマンドを実行。
$ ecs-cli configure profile --profile-name <任意のプロフィール名> --access-key <先ほど作成したアクセスキー> --secret-key <先ほど作成したシークレットアクセスキー> $ ecs-cli configure --cluster <任意のクラスター名> --default-launch-type EC2 --config-name <任意の設定名> --region ap-northeast-1 $ ecs-cli up --keypair <先ほど作成したキーペア> --capability-iam --size 2 --instance-type t2.samll --cluster-config <任意の設定名> --ecs-profile <任意のプロフィール名>キーなどの各値は各自異なる。
筆者の場合は下記のような感じ。$ ecs-cli configure profile --profile-name sample-app --access-key AKI***************** --secret-key dlj************************************* $ ecs-cli configure --cluster sample-app-cluster --default-launch-type EC2 --config-name sample-app-cluster --region ap-northeast-1 $ ecs-cli up --keypair sample-app --capability-iam --size 2 --instance-type t2.small --cluster-config sample-app-cluster --ecs-profile sample-app INFO[0006] Using recommended Amazon Linux 2 AMI with ECS Agent 1.44.3 and Docker version 19.03.6-ce INFO[0007] Created cluster cluster=sample-app-cluster region=ap-northeast-1 INFO[0009] Waiting for your cluster resources to be created... INFO[0009] Cloudformation stack status stackStatus=CREATE_IN_PROGRESS INFO[0070] Cloudformation stack status stackStatus=CREATE_IN_PROGRESS INFO[0131] Cloudformation stack status stackStatus=CREATE_IN_PROGRESS VPC created: vpc-***************** Security Group created: sg-***************** Subnet created: subnet-***************** Subnet created: subnet-***************** Cluster creation succeeded.上手くいくと↑のようにクラスター用のVPC、セキュリティグループ、サブネットなどが自動で作成される。
AWSのコンソールからサービス→Elastic Container Service→クラスターを選択し、無事作成されていれば成功。
RDSを作成
データベースとして使うRDSを作成。
AWSのコンソールからサービス→RDSを選択し、「データベースの作成」をクリック。
- 作成方法: 標準作成
- エンジンのタイプ: MySQL
- DBインスタンスサイズ: 無料利用枠
- DBインスタンス識別子: sample-app-db
- マスターユーザー名: root
- パスワード: password
※この辺は全て任意。
vpc: 先ほど作成したvpc
サブネットグループ: 新しいDBサブネットグループの作成
パブリックアクセス: あり
最初のデータベース名: sample_app_production
※特に触れていない部分は空欄もしくはデフォルトのままでOK。問題なければ「データベースの作成」をクリック。
↑こんな感じで作成されていれば成功。
また、セキュリティグループの設定も必要なので「VPCセキュリティグループ」の下に記載されているリンクをクリック。
「インバウンドルールの編集」から次のように設定。
- タイプ: MYSQL/Aurora
- プロトコル: TCP
- ポート範囲
- ソース: 0.0.0.0/0
$ mysql -h <RDSのエンドポイント> -u <RDSのユーザー名> -p試しにターミナルで↑のコマンドを叩き、接続できれば成功。
ロードバランサーを作成
AWSのコンソールからサービス→EC2→ロードバランサーを選択し、「ロードバランサーの作成」をクリック。
3種類あるが、「Application Load Balancer」を選択。
- 名前: sample-app-alb ※任意
- リスナー: そのままでOK
- VPC: 先ほど自動作成されたものを選択
- subnet: 同上
先に進むとセキリュティグループの設定画面になるので、「新しいセキリュティグループを作成する」から適当にセキュリティグループを作成。
ターゲットグループの設定。
- ターゲットグループ: 新しいターゲットグループ
- 名前: sample-app-alb-tg ※任意
クラスター作成時に自動で作られたEC2を登録し、確認画面から問題なければ「作成」をクリックして完了。
ECRにdockerイメージをpush
AWSのコンソールからサービス→Amazon Elastic Container Registryを選択し、「リポジトリの作成」をクリック。
それぞれ適当なリポジトリ名を入力し、「リポジトリを作成」をクリック。
プッシュコマンドを表示し、書いてある通り上から順に4つ実行していく。
※2番目のコマンドでbuildを行う際は-fでDockerfileのコンテキストを変える。
# Rails(本番用のDockerfileを使用する) $ docker build -f ./prod.Dockerfile . -t sample-app-rails # Nginx $ cd containers/nginx $ docker build -f ./Dockerfile . -t sample-app-nginx本番用のDockerfile
$ touch prod.Dockerfile# prod.Dockerfile FROM ruby:2.6.6 ENV LANG C.UTF-8 RUN apt-get update -qq && apt-get install -y build-essential libpq-dev nodejs RUN curl -sL https://deb.nodesource.com/setup_8.x | bash - && \ apt-get install nodejs RUN apt-get update && apt-get install -y curl apt-transport-https wget && \ curl -sS https://dl.yarnpkg.com/debian/pubkey.gpg | apt-key add - && \ echo "deb https://dl.yarnpkg.com/debian/ stable main" | tee /etc/apt/sources.list.d/yarn.list && \ apt-get update && apt-get install -y yarn RUN mkdir /sample-app WORKDIR /sample-app ADD Gemfile /sample-app/Gemfile ADD Gemfile.lock /sample-app/Gemfile.lock RUN gem install bundler:2.1.4 RUN bundle install ADD . /sample-app # Nginxと通信を行うための準備 RUN mkdir -p tmp/sockets VOLUME /sample-app/public VOLUME /sample-app/tmp RUN yarn install --check-files RUN SECRET_KEY_BASE=placeholder bundle exec rails assets:precompile基本的に開発用のものと同じだが、最後の数行でNginxと通信を行うための準備などを行っている。
全て打ち終わったらリポジトリを確認し、イメージが追加されていれば成功。
タスクの作成
先ほどpushしたイメージをもとに、タスクの作成を行う。
$ mkdir ecs $ touch ecs/docker-compose.yml# ecs/docker-compose.yml version: 2 services: app: image: # ECRのリポジトリURI(Rails) command: bash -c "bundle exec rails db:migrate && bundle exec rails assets:precompile && bundle exec puma -C config/puma.rb" environment: # 実際はdotenvなどで管理した方が良いかも RAILS_ENV: production RAILS_MASTER_KEY: # config/master.keyの値 DATABASE_NAME: sample_app_production DATABASE_USERNAME: root DATABASE_PASSWORD: password DATABASE_HOST: # RDSのエンドポイント TZ: Japan working_dir: /sample-app logging: driver: awslogs options: awslogs-region: ap-northeast-1 awslogs-group: sample-app-production/app awslogs-stream-prefix: sample-app-production nginx: image: # ECRのリポジトリURI(Nginx) ports: - 80:80 links: - app volumes_from: - app working_dir: /sample-app logging: driver: awslogs options: awslogs-region: ap-northeast-1 awslogs-group: sample-app-production/nginx awslogs-stream-prefix: sample-app-production次のコマンドを実行。
$ ecs-cli compose --project-name sample-app-task -f ./ecs/docker-compose.yml up --create-log-groups --cluster-config sample-app-cluster --ecs-profile sample-app
上手く行った場合、実行中のタスクに「1」と表示される。
最後に、ロードバランサーのDNS名をURLに貼り付けてアクセス。
「Yay!You're on Rails!」と表示されれば成功。
※デプロイに際して何か不具合があった場合はCloudWatchのログを確認して修正。
サービスの作成
クラスターとタスクだけでもアプリは動くが、その中間に「サービス」と呼ばれるものを作成すると、コンテナが止まった際に再起動をかけてくれたりロードバランサーを通じてオートスケーリングしてくれたり何かと便利ぽいので作成しておく。
AWSのコンソールからサービス→Amazon Elastic Container Service→ クラスター名をクリックし、「サービス」タブを開いて作成ページに進む。
- 起動タイプ: EC2
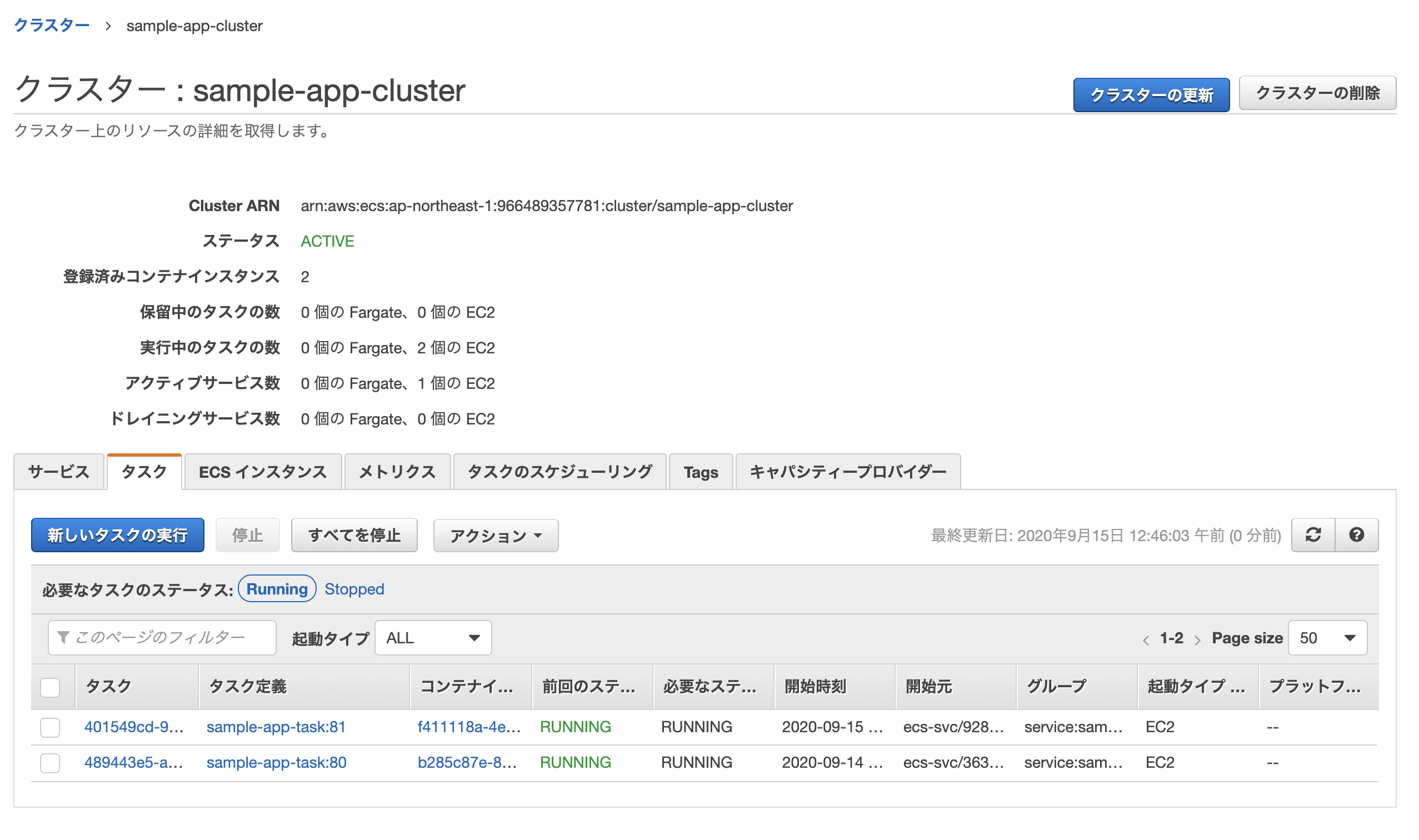
- タスク定義: sample-app-task ※先ほど作成したもの
- クラスター: sample-app-cluster ※同上
- サービス名: sample-app-service ※任意
- その他: 画像の通り
- ロードバランサーの種類: Application Load Balancer
- ロードバランサー名: 先ほど作成したもの
- その他: 画像の通り
- ターゲットグループ名: 先ほど作成したもの
- その他: 画像の通り
最後に確認画面が表示されるので、問題無ければ作成をクリック。
無事作成されれば完了。
このままだと2つのタスク(片方はecs-cliでターミナルから開始したもの、もう片方はサービスの作成により開始されたもの)が実行中になってしまっているため、前者は停止してしまってOK。
おまけ(CircleCiと連携して自動デプロイ)
このままだと変更点があるたびに手動で「ビルド→プッシュ→タスク再定義」といった面倒な作業が必要になるため、「CirlcleCiにプッシュ→ビルド&テスト→ECR・ECSへ自動デプロイ」といった良くある仕組みを構築していく。
Rspecを導入
まず、デプロイ前にテストを行うためにRspecを導入する。
gemをインストール
# Gemfile group :development, :test do gem 'rspec-rails' end# Gemfileを更新したので再度ビルド $ docker-compose build各種ファイルを作成&編集
$ docker-compose run web bundle exec rails generate rspec:install create .rspec create spec create spec/spec_helper.rb create spec/rails_helper.rb# .rspec --format documentation↑の1行を追記しておくと、Rspecを実行した際の出力表示が見やすくなる。
# spec/rails_helper.rb Dir[Rails.root.join('spec', 'support', '**', '*.rb')].sort.each { |f| require f }必須ではないが、後ほどテスト用のヘルパーメソッドを作成する事になった場合、ファイルの置き場として「spec/support」を使用するので一応設定しておく。
デフォルトではコメントアウトされているので、それを外せばOK。
# config/application.rb config.generators do |g| g.test_framework :rspec, view_specs: false, helper_specs: false, controller_specs: false, routing_specs: false endこのままだと
rails gコマンドを打ち込んだ際に自動で諸々のテストファイルが作成されてしまうので、余計なものを作成したくない場合は「config/application.rb」で設定を行う。※この辺はお好みで。
rspecを実行
$ docker-compose run web bundle exec rspec No examples found. Finished in 0.00276 seconds (files took 0.12693 seconds to load) 0 examples, 0 failuresまだ何もテストを書いていないので、当然こうなる。
とりあえずRequest Specを書いてみる
手始めに、リクエストに対して正常なレスポンスが返ってくるかどうかを確認するためのRequest Specを書いてみる。
トップページを作成
# コントローラー $ touch app/controllers/home_controller.rb # ビュー $ mkdir app/views/home $ touch app/views/home/index.html.erb# app/controllers/home_controller.rb class HomeController < ApplicationController def index end end# app/views/home/index.html.erb <h1>Hello World!</h1>#config/routes.rb Rails.application.routes.draw do root 'home#index' end
テストファイルを作成
$ docker-compose run web bundle exec rails g rspec:request home create spec/requests/homes_spec.rb# spec/requests/home_spec.rb require 'rails_helper' RSpec.describe "Home", type: :request do describe "GET /" do it "works successfully" do get root_path expect(response).to have_http_status(200) end end end「/」にアクセスした際、 200番のステータスコードが返ってくるかどうかのテスト。
$ docker-compose run web bundle exec rspec Home GET / works successfully Finished in 0.53664 seconds (files took 8.4 seconds to load) 1 example, 0 failures再度rspecを実行し、問題無くパスしていれば成功。
CircleCIと連携
次に、実際にCircleCiと連携するための設定を行う。
gemをインストール
group :development, :test do gem 'database_cleaner' gem 'rspec_junit_formatter' gem 'webdrivers', '~> 3.0' end# Gemfileを更新したので再度ビルド $ docker-compose build各種ファイルを作成&編集
$ mkdir .circleci $ touch .circleci/config.yml $ touch config/database.yml.ci $ docker-compose run web bundle exec rails db:schema:dump# .circleci/config.yml version: 2 jobs: build: docker: - image: circleci/ruby:2.6.6-node-browsers environment: - BUNDLER_VERSION: 2.1.4 - RAILS_ENV: 'test' - image: circleci/mysql:5.7 environment: - MYSQL_ALLOW_EMPTY_PASSWORD: 'true' - MYSQL_ROOT_HOST: '127.0.0.1' working_directory: ~/sample_app steps: - checkout - restore_cache: keys: - v1-dependencies-{{ checksum "Gemfile.lock" }} - v1-dependencies- - run: name: install dependencies command: | gem install bundler -v 2.1.4 bundle install --jobs=4 --retry=3 --path vendor/bundle - save_cache: paths: - ./vendor/bundle key: v1-dependencies-{{ checksum "Gemfile.lock" }} # database setup - run: mv ./config/database.yml.ci ./config/database.yml # database setup - run: name: setup database command: | bundle exec rake db:create bundle exec rake db:schema:load # install yarn - run: name: install yarn command: yarn install # install webpack - run: name: install webpack command: bundle exec bin/webpack # run tests - run: name: run rspec command: | mkdir /tmp/test-results TEST_FILES="$(circleci tests glob "spec/**/*_spec.rb" | \ circleci tests split --split-by=timings)" bundle exec rspec \ --format progress \ --format RspecJunitFormatter \ --out /tmp/test-results/rspec.xml \ --format progress \ $TEST_FILES # collect reports - store_test_results: path: /tmp/test-results - store_artifacts: path: /tmp/test-results destination: test-results# config/database.yml.ci (CircleCiのデータベース設定用) test: adapter: mysql2 encoding: utf8 pool: 5 username: 'root' port: 3306 host: '127.0.0.1' database: sample_app_test# spec/rails_helper.rb RSpec.configure do |config| # config DataBaseCleaner config.before(:suite) do DatabaseCleaner.strategy = :transaction DatabaseCleaner.clean_with(:truncation) Rails.application.load_seed end config.before(:each) do DatabaseCleaner.start end config.after(:each) do DatabaseCleaner.clean end end# db/schema.rb # This file is auto-generated from the current state of the database. Instead # of editing this file, please use the migrations feature of Active Record to # incrementally modify your database, and then regenerate this schema definition. # # This file is the source Rails uses to define your schema when running `rails # db:schema:load`. When creating a new database, `rails db:schema:load` tends to # be faster and is potentially less error prone than running all of your # migrations from scratch. Old migrations may fail to apply correctly if those # migrations use external dependencies or application code. # # It's strongly recommended that you check this file into your version control system. ActiveRecord::Schema.define(version: 0) do endCircleCiとGitHubを接続
https://app.circleci.com/projects/project-dashboard/github/GitHubのアカウント名/
↑CircleCiのダッシュボードから連携したいリポジトリを探し、「Set Up Project」をクリック。画面に表示される指示に従い設定。
これで今後GitHubへ新しいプッシュを行った際、「.circleci/config.yml」に書いた内容に基づき自動でビルド&テストが走るようになる。
特に問題が無ければ「SUCCESS」と表示されるはず。
これで初期設定は完了。自動デプロイ(ECR・ECS)
CircleCiのバージョン2.1から追加されたOrbを使い、masterブランチに変更が加えられた際、CircleCiでのビルド&テストを行い自動でイメージを作成しECRへプッシュし、ECSのサービスを更新してタスクの再定義を行うようにする。
環境変数の登録
あらかじめCircleCiの設定画面からデプロイに必要な環境変数を登録しておく。
- AWS_ACCESS_KEY_ID
- 先ほど作成したIAMユーザーのアクセスキー
- AWS_SECRET_ACCESS_KEY
- 先ほど作成したIAMユーザーのシークレットキー
- AWS_ACCOUNT_ID
- AWSのアカウントID(コンソールの「マイアカウント」から確認可能)
- AWS_REGION
- ap-northeast-1
- AWS_ECR_ACCOUNT_URL
- ECRのリポジトリURI(例: <アカウントID>.dkr.ecr.ap-northeast-1.amazonaws.com)
- DATABASE_HOST
- RDSのエンドポイント(例: ********.ap-northeast-1.rds.amazonaws.com)
- DATABASE_USERNAME
- RDSのユーザー名(例: root)
- DATABASE_PASSWORD
- RDSのパスワード(例: password)
- DATABASE_NAME
- 使用するデータベース名(例: sample_app_production)
- RAILS_MASTER_KEY
- config/master.keyの値
- TZ
- JAPAN
- MY_APP_PREFIX
- 任意(例: sample-app)
- 変数を使い回してなるべくコンパクトに書けるようにクラスター名やタスク名は共通のワードを含めて作成しておいた方が良い(sample-app-cluster、sample-app-taskなど)。
.circleci/config.ymlを編集
# .circleci/config.yml version: 2.1 orbs: aws-ecr: circleci/aws-ecr@6.7.0 aws-ecs: circleci/aws-ecs@1.1.0 jobs: test: docker: - image: circleci/ruby:2.6.6-node-browsers environment: - BUNDLER_VERSION: 2.1.4 - RAILS_ENV: 'test' - image: circleci/mysql:5.7 environment: - MYSQL_ALLOW_EMPTY_PASSWORD: 'true' - MYSQL_ROOT_HOST: '127.0.0.1' working_directory: ~/project steps: - checkout - restore_cache: keys: - v1-dependencies-{{ checksum "Gemfile.lock" }} - v1-dependencies- - run: name: install dependencies command: | gem install bundler -v 2.1.4 bundle install --jobs=4 --retry=3 --path vendor/bundle - save_cache: paths: - ./vendor/bundle key: v1-dependencies-{{ checksum "Gemfile.lock" }} - run: mv ./config/database.yml.ci ./config/database.yml - run: name: setup database command: | bundle exec rake db:create bundle exec rake db:schema:load - run: name: install yarn command: yarn install - run: name: install webpack command: bundle exec bin/webpack - run: name: run rspec command: | mkdir /tmp/test-results TEST_FILES="$(circleci tests glob "spec/**/*_spec.rb" | \ circleci tests split --split-by=timings)" bundle exec rspec \ --format progress \ --format RspecJunitFormatter \ --out /tmp/test-results/rspec.xml \ --format progress \ $TEST_FILES - store_test_results: path: /tmp/test-results - store_artifacts: path: /tmp/test-results destination: test-results workflows: version: 2 test_and_deploy: jobs: - test # ビルドした後にイメージをECRへプッシュ - aws-ecr/build-and-push-image: requires: - test account-url: AWS_ECR_ACCOUNT_URL region: AWS_REGION aws-access-key-id: AWS_ACCESS_KEY_ID aws-secret-access-key: AWS_SECRET_ACCESS_KEY create-repo: true dockerfile: ./prod.Dockerfile repo: "${MY_APP_PREFIX}-rails" tag: "${CIRCLE_SHA1}" filters: branches: only: - master # ECSのサービスを更新してタスクを再定義 - aws-ecs/deploy-service-update: requires: - aws-ecr/build-and-push-image family: "${MY_APP_PREFIX}-task" cluster-name: "${MY_APP_PREFIX}-cluster" service-name: "${MY_APP_PREFIX}-service" container-image-name-updates: "container=app,tag=${CIRCLE_SHA1}"各環境変数に間違いが無いか良く確認しておく事。
# app/views/home/index.html.erb <h1>Hello World!</h1> <p>Completed auto deploy with CircleCi</p>自動デプロイが上手くいったかわかりやすいようにトップページを少し変えておく。
masterブランチに変更を加える
実際にmasterブランチにプッシュして変更を加えてみると、CircleCi上でデプロイ込みのjobsが動き始める。
※全てのフローが完了するまでに大体10〜15分くらいかかるので注意。
再度ロードバランサーのDNS名にアクセスし、先ほどの変更がちゃんと更新されていれば成功。
※反映されるまで多少時間がかかるので気長に待つ。
古いタスクと新しいタスクの2つが実行されているが、時間の経過で古い方は勝手に消されるため(サービスのおかげ?)そのまま放置でOK。
お疲れ様でした。
あとがき
自分もまだまだ勉強中の身なので、何かあれば随時更新予定です。
現状、コンソール上で手を動かしながら行う作業とターミナルでコマンドを叩いて行う作業がごちゃ混ぜになってしまっているため、できれば全て後者に統一したいと考えていいます。
Terraformとかも使って一発バシっとできるようにしたい...。
どこか詰まった部分やもっとこうした方が良いなどあればコメントいただけると嬉しいです。
個人的に詰まった部分
- Nginxの設定
- nginx.confファイルの中身は各自変更しないと正常に動かない部分があるので、ググりながら適宜修正する必要がある。
appコンテナとnginxコンテナの接続が上手くいかないと
2020/09/13 20:02:57 [crit] 7#7: *456 connect() to unix:///sample-app/tmp/sockets/puma.sock failed (2: No such file or directory) while connecting to upstream, client: *********, server: localhost, request: "GET / HTTP/1.1", upstream: "http://unix:///sample-app/tmp/sockets/puma.sock:/500.html", host: "***********"↑こんな感じのエラーで延々と悩まされる。
- 各環境変数の設定
- CircleCiに登録する環境変数の値がしっかり合っているか何度も確認した方が良い。ビルドするのにやたら時間がかかるので、1回失敗するとそれだけでかなりの時間の無駄になる。