- 投稿日:2020-09-15T23:57:46+09:00
EC2 (Amazon Linux) にPHP7.2 をインストールし、php.ini を設定するまでのまとめ
タイトルのとおりの備忘録です。
LAMP環境を作り、PHPの初期設定をします。後々同じことをやる方のググる手間を省ければと思い、まとめました。
「とりあえずEC2でPHPを動かしたいぞ!!!」というあなたのお役に立てれば幸いです前提
■ 先にVPCやサブネットの用意を終わらせておくとスムーズです。
(ECインスタンス作成時に紐付けられるため)もしよろしければ、以下の記事を参考になさってみてください!
・VPC作成 〜 パブリック・プライベートサブネットを作るまでの手順①
・VPC作成 〜 パブリック・プライベートサブネットを作るまでの手順②■ CloudFormation を使った構築手順については今回触れません。
ざっくりの流れ
- EC2 インスタンスを作成
- LAMP環境をインストールする
mbモジュールをインストールするphp.iniを設定する1. EC2 インスタンスを作成
▼ 参考:
AWSコンソールからEC2インスタンスを作成する手順LAMP環境をインストールする際、EC2インスタンスにssh接続する必要があります。
EC2インスタンス作成時には既存のキーペアの選択or新しいキーペアの作成を選ぶようにしてください。▼ EC2インスタンスにssh接続するコマンド:
ssh -i [キーペアのパス] ec2-user@[パブリック IPv4 アドレス]2. LAMP環境をインストールする
▼ 参考:
チュートリアル: Amazon Linux AMI を使用して LAMP ウェブサーバーをインストールする - Amazon Elastic Compute Cloud3.
mbモジュールをインストールする▼ 参考:
Amazon Linuxでphpでmbstringを使う - QiitaPHPにはマルチバイト文字列を扱うための関数がいろいろあります。(例:
mb_substr)
mbモジュールをインストールしておかないと、PHPを実行した際にFatal errorが出てしまいます。4.
php.iniを設定する▼ 参考:
【PHP】PHPをインストールしたらやっておきたい設定 - Qiita初期状態の
/etc/php.iniをコピーしてバックアップを取っておいてから設定を変更するようにすれば、何かあったときに戻せるので安心です。上記の記事で「セキュリティに関する設定」として記載されている
session.hash_functionなどはPHP 7.1.0から削除されているので設定不要です。参考
- 投稿日:2020-09-15T23:45:56+09:00
Laravel 環境構築 AWS EC2(nginx + PHP) + RDS
前提
ec2インスタンス作成済み
sshできるパッケージアップデート
sudo yum updatePHP
2020/09/11現在
amazon-linux-extras リポジトリにPHP7.4がありますsudo amazon-linux-extras enable php7.4 ##こんな出力があります Now you can install: # yum clean metadata # yum install php-cli php-pdo php-fpm php-json php-mysqlnd有効化の後yum を使用してトピックをインストールします。
Now you can install:のコマンド突っ込めば大丈夫ですsudo yum install php-cli php-pdo php-fpm php-json php-mysqlnd -yphp -v PHP 7.4.9 (cli) (built: Aug 21 2020 21:45:11) ( NTS ) Copyright (c) The PHP Group Zend Engine v3.4.0, Copyright (c) Zend Technologies足りない拡張追加
Laravelのサーバー要件
※Laravel 7.x
PHP >= 7.2.5
BCMath PHP拡張
Ctype PHP拡張
Fileinfo PHP extension
JSON PHP拡張
Mbstring PHP拡張
OpenSSL PHP拡張
PDO PHP拡張
Tokenizer PHP拡張
XML PHP拡張これに従い追加します
追加済みの拡張を調べますphp -m | grep -e bcmath -e PDO -e ctype -e fileinfo -e json -e mbstring -e openssl -e pdo -e tokenizer -e ^xml$
php -mでインストール済み拡張が出力されます
コマンド | grep [オプション] 検索パターンでコマンドでの出力に対してgrep(絞り込み)
が掛かります
-e 検索パターンをたくさん使用して複数の単語に対して引っかかる検索かけています。私の環境ですと下記の拡張がインストール済みのようでした。
なので、そのほかをインストールしていきますctype fileinfo json openssl PDO pdo_mysql pdo_sqlite tokenizer # 足りないもの # bcmath # mbstring # xml
bcmath,mbstring,xmlが足りないので追加しますsudo yum install php-bcmath php-mbstring php-xml -yopcache
インストール
設定ではないけど、opcacheを入れます
sudo yum install php-opcache確認
php -v #PHP 7.4.9 (cli) (built: Aug 21 2020 21:45:11) ( NTS ) #Copyright (c) The PHP Group #Zend Engine v3.4.0, Copyright (c) Zend Technologies # with Zend OPcache v7.4.9, Copyright (c), by Zend Technologies設定値の変更
php.iniの場所を調べますphp --iniphp --ini Configuration File (php.ini) Path: /etc Loaded Configuration File: /etc/php.ini Scan for additional .ini files in: /etc/php.d Additional .ini files parsed: /etc/php.d/10-opcache.ini, /etc/php.d/20-bcmath.ini, /etc/php.d/20-bz2.ini, /etc/php.d/20-calendar.ini, #...
opcache.iniで設定を変えますsudo vi /etc/php.d/10-opcache.inihttps://www.php.net/manual/ja/opcache.installation.php
推奨設定に合わせて編集しますopcache.memory_consumption=128
opcache.interned_strings_buffer=8
opcache.max_accelerated_files=4000
opcache.revalidate_freq=60
opcache.fast_shutdown=1
opcache.enable_cli=1php-fpm
FPMとは、FastCGI Process Managerの略でPHP5.4.0から公式サポートされたPHP標準のアプリケーションサーバです。名前にあるFastCGIというプロトコルで通信するよう実装されています。 FastCGIは、Webサーバとアプリケーションサーバの間で使われるプロトコルの一つで、ここでの例ではnginxとPHP-FPMの間で交わされるプロトコルとなります。
参考
https://hacknote.jp/archives/27419/
https://hackers-high.com/linux/php-fpm-config/起動
sudo service php-fpm start確認
sudo systemctl status php-fpm php-fpm.service - The PHP FastCGI Process Manager Loaded: loaded (/usr/lib/systemd/system/php-fpm.service; enabled; vendor preset: disabled) Active: active (running) since 金 2020-09-11 17:15:02 JST; 1 day 17h ago自動起動
sudo systemctl enable php-fpmComposer
インストール
https://getcomposer.org/download/
公式のコマンドを叩いていきます
php -r "copy('https://getcomposer.org/installer', 'composer-setup.php');" php -r "if (hash_file('sha384', 'composer-setup.php') === '795f976fe0ebd8b75f26a6dd68f78fd3453ce79f32ecb33e7fd087d39bfeb978342fb73ac986cd4f54edd0dc902601dc') { echo 'Installer verified'; } else { echo 'Installer corrupt'; unlink('composer-setup.php'); } echo PHP_EOL;" php composer-setup.php php -r "unlink('composer-setup.php');"移動
sudo mv composer.phar /usr/local/bin/composer確認
composer ______ / ____/___ ____ ___ ____ ____ ________ _____ / / / __ \/ __ `__ \/ __ \/ __ \/ ___/ _ \/ ___/ / /___/ /_/ / / / / / / /_/ / /_/ (__ ) __/ / \____/\____/_/ /_/ /_/ .___/\____/____/\___/_/ /_/ Composer version 1.10.13 2020-09-09 11:46:34nginx
インストール
PHPと同様にamazon-linux-extras リポジトリにあります
sudo amazon-linux-extras enable nginx1 ##こんな出力があります Now you can install: # yum clean metadata # yum install nginxインストール
sudo yum install nginx -ynginx -v nginx version: nginx/1.18.0起動
インストールしただけだと、起動していない
sudo systemctl start nginx(上記コマンドを叩いても出力はなにもないです)
起動しているか確認します
sudo systemctl status nginx nginx.service - The nginx HTTP and reverse proxy server Loaded: loaded (/usr/lib/systemd/system/nginx.service; disabled; vendor preset: disabled) Drop-In: /usr/lib/systemd/system/nginx.service.d └─php-fpm.conf Active: active (running) since 金 2020-09-11 08:15:02 UTC; 2s ago自動起動設定
現状EC2再起動するたび、自力で立ち上げないといけない
sudo systemctl enable nginx画面確認
EC2のIPをブラウザで入力
Gitインストール
sudo yum install git git --version # >git version 2.23.3PHP + nginx設定
両方のインストールが終わったので疎通していきます
php-fpm設定
設定変更する前にコピーとっておくと良いかもしれません
sudo vi /etc/php-fpm.d/www.conf下記の内容に更新します
それぞれ/検索ワードとかで検索して書き換えましょうuser = nginx group = nginx listen.owner = nginx listen.group = nginx listen.mode = 0660 # 以下はお好み pm = static pm.max_children = 5 pm.max_requests = 1500ちなみに、
pm関係の設定値はデフォルトでも良いです
下記が参考になるので、チューニングしたい方はどうぞ
https://hackers-high.com/linux/php-fpm-config/nginx設定
sudo vi /etc/nginx/nginx.confドキュメントルートは自由に
server { listen 80; listen [::]:80; server_name _; root /var/www; index index.php index.html index.htm; location / { try_files $uri $uri/ /index.php?$query_string; } location ~ \.php$ { root /var/www; fastcgi_pass unix:/run/php-fpm/php-fpm.sock; fastcgi_index index.php; fastcgi_param SCRIPT_FILENAME $document_root$fastcgi_script_name; include fastcgi_params; } #~中略~確認
sudo mkdir /var/www sudo chmod 777 /var/www cd /var/www echo "<?php phpinfo(); " > index.phpドキュメントルートの内
phpinfo()だけの、index.php作ってます
IPをブラウザで確認して、表示されてればPHP使えるようになりました
RDS
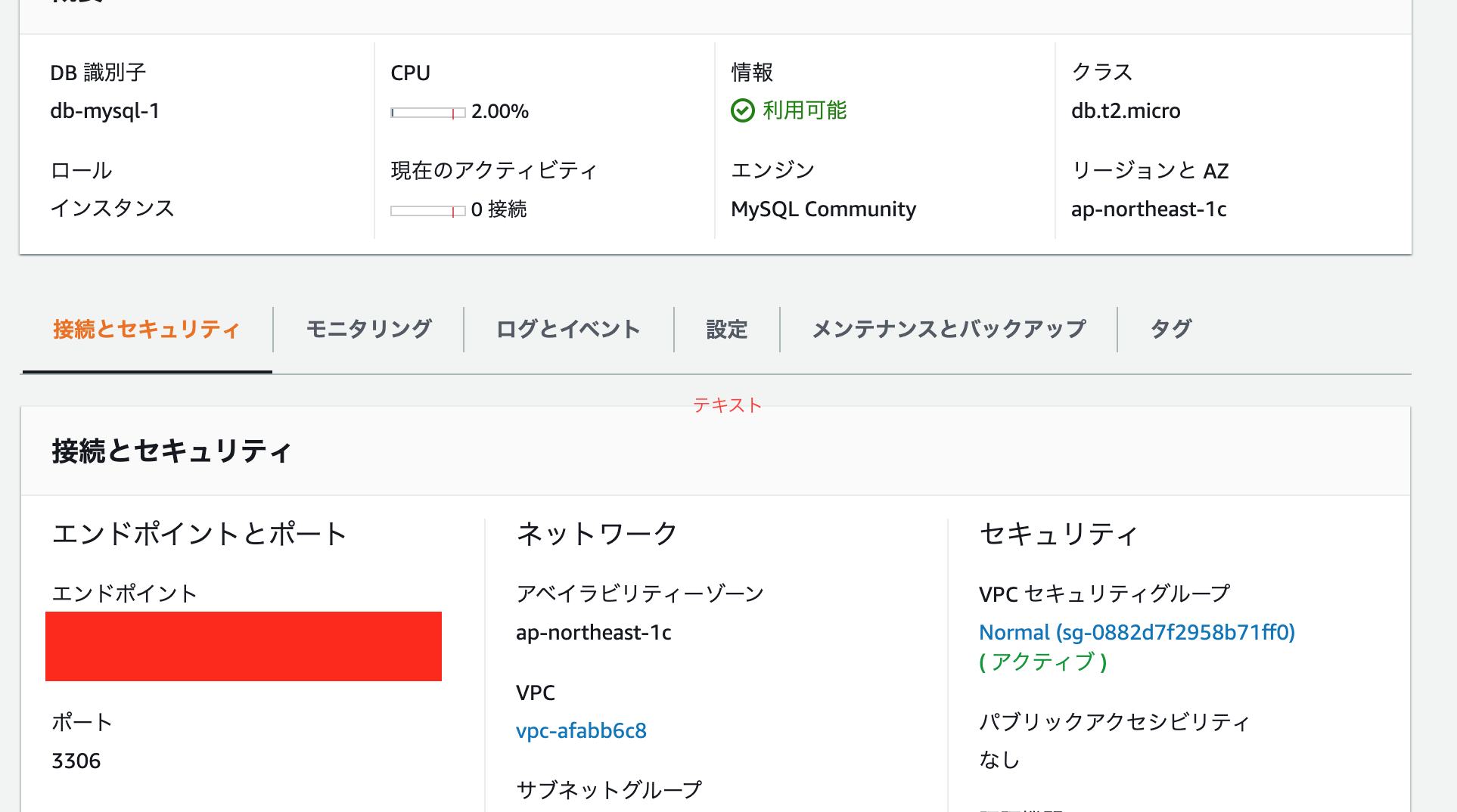
AWSにログインしRDS on MySQLでDBを作成しておきます
(参考 -> https://noumenon-th.net/programming/2020/04/10/ec2-rds-laravel/エンドポイントと、ユーザーとパスワードを用いるのでとっておきましょう
EC2にSSH接続し、下記コマンドでmysqlをインストールします
sudo yum install mysql -y終わったら、エンドポイントとユーザー、パスワードを用いて接続します
うまくつながらなかったら、だいたいセキュリティグループとかなので、AWSのRDS等見直してみてくださいmysql -h エンドポイント -u ユーザー名 -p Enter password:つながればOK
Welcome to the MariaDB monitor. Commands end with ; or \g. Your MySQL connection id is 47 Server version: 8.0.17 Source distribution Copyright (c) 2000, 2018, Oracle, MariaDB Corporation Ab and others. Type 'help;' or '\h' for help. Type '\c' to clear the current input statement. MySQL [(none)]>データベースを作成していなかったら(RDS作成時に指定できる)
CREATE DATABASEで作成してください
(参考 => https://www.dbonline.jp/mysql/database/index1.html#section1)Laravel
これまででLaravelの下準備は整っています
デプロイの場合もgitからcloneすれば良いので大丈夫ですまずはドキュメントルートに移動します
nginxで/var/wwwを指定していたのでそこに移動しますcd /var/wwwComposerからLaravelを入れます
composer create-project --prefer-dist laravel/laravel 【名前】【名前】は自由に
今回はlaravel-appにしました
ちなみに、Laravelのバージョン指定したい場合、【名前】のあとに、5.8とか6.xとか入れたら良いです
メモリ足りなくて下記のようなエラー出たら、下記の記事の手順でswapを作成してください
https://qiita.com/ntm718/items/88d3fc787f4f18ad1f20mmap() failed: [12] Cannot allocate memory mmap() failed: [12] Cannot allocate memoryインストールしたら、指定した名前のディレクトリに移動します
私はlaravel-appにしたので、今後置き換えてお読みくださいcd laravel-app php artisan key:generate --ansi sudo chmod -R 777 storag sudo chmod -R 777 bootstrap/cache/この段階でブラウザで下記のようにアクセスすると、Laravelの初期画面が出ます
ipアドレス/laravel-app/public
ここまで来たら、あと少しです
vi .envDBの接続情報を書き換えます
.envDB_CONNECTION=mysql DB_HOST=エンドポイント名 DB_PORT=3306 DB_DATABASE=作ったDB名 DB_USERNAME=ユーザー名 DB_PASSWORD=パスワード保存し、
php artisan migrateします
ちゃんと実行されたらOKMigration table created successfully. Migrating: 2014_10_12_000000_create_users_table Migrated: 2014_10_12_000000_create_users_table (51.33ms) Migrating: 2014_10_12_100000_create_password_resets_table Migrated: 2014_10_12_100000_create_password_resets_table (38.25ms) Migrating: 2019_08_19_000000_create_failed_jobs_table Migrated: 2019_08_19_000000_create_failed_jobs_table (39.88ms)最後にドキュメントルートを変更しましょう
現状だとipアドレス/laravel-app/publicなので、laravel-app/publicまでをドキュメントルートに設定したら良さそうですねsudo vi /etc/nginx/nginx.conf
laravelのpublicがドキュメントルートに来るように修正しますserver { listen 80; listen [::]:80; server_name _; root /var/www/laravel/public; index index.php index.html index.htm; location / { try_files $uri $uri/ /index.php?$query_string; } location ~ \.php$ { root /var/www/laravel/public; fastcgi_pass unix:/run/php-fpm/www.sock; fastcgi_index index.php; fastcgi_param SCRIPT_FILENAME $document_root$fastcgi_script_name; include fastcgi_params; } ~中略~再起動
sudo systemctl restart nginxipアドレスにアクセスしたら、laravelの画面が出たら終了
Route53でドメイン設定して、SSLしたらそれっぽくなるはず
https://docs.aws.amazon.com/ja_jp/AWSEC2/latest/UserGuide/SSL-on-amazon-linux-2.html終わりに
Docker使うならECR ECSのがいいんだろうか
そもそも、個人でやるにはAWSは料金が怖すぎて無料期間あるやつしか使う気がしない...
勉強で作ったらVPSとかのがいいんでしょうか...

- 投稿日:2020-09-15T23:18:37+09:00
AWS EC2について
EC2(Elastic Compute Cloud)
仮想サーバーとは、サーバー上に論理的なサーバーを作成した物で、サーバーに必要なこれら各種コンポーネントが論理的に作成されています。
OS → AMI
CPU、Memory → インスタンスタイプ
SSD → EBS
NIC → ENIAMIとは
・AMI(Amazon Machine Image)
・EC2インスタンスが起動する時に必要となる設定(テンプレート)ファイル
・ひとつのAMIでEC2を何台も複製できる
・OSやアプリケーションの情報が設定されている
・OSは選択可能AmazonLinuxが一般的
-各種Linuxディストリビューション(Redhat,Ubuntu…)
-windows Serverインスタンスタイプとは
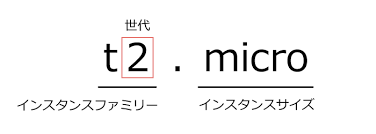
・EC2のCPU、メモリなどのスペックの構成パターン
・スペックの構成により、「インスタンスファミリー」と分類分け
・更にmicro,small.msdium,large,xlargeのように性能の選択肢が用意されている

元SEママの情シスなりきりAWS奮闘記 よりt系 テスト向き、CPUバースト
m系 本番向き、バランスが良い
c系 CPU重視、多処理や科学技術
g系 GPU重視、3Dグラフィックや動画処理
r系 メモリ重視、データベース系
d系 ストレージ重視、データウェアハウス系
i系 ストレージ重視、NoSQL系世代については数字が大きいものほど最新で料金が最適化されていたりするので、特に理由がなければ最新の世代を使う。
EBSとは
・EBS(Elastic Block Store)
・EC2のインスタンスが使用するストレージのサービスソリッドステートドライブ(SSD)
-汎用SSD(gp2)
デフォルト、基本的にこれ使用、容量課金-プロビジョンドIOPS SSD(io1)
高性能DBへ接続する時など、容量・IOPS課金ハードディスクドライブ(HDD)
-スループット最適化HDD(st1)
データウェアハウス、ビックデータ、ログ処理に使用-Cold HDD(sc1)
安い、アーカイブ保管EBSのスナップショット
・スナップショットとは
-EBSをバックアップとして所得したファイル
-保管場所はS3
-スナップショット自体をEC2にアタッチ/デタッチできない
-増分バックアップ方式
-AZサービスキーペアとは
・EC2インスタンスへログインする為に使用する秘密鍵、公開鍵のペア
-公開鍵_公開鍵で暗号化したデータは秘密鍵でしか開けることが出来ません。
秘密鍵は拡張子が.pem形式のファイルとなっています。ダウンロードして厳重に管理し、外部からアクセス出来ない場所に保管しましょう。
LinuxタイプのEC2にログインする場合
ssh -i 秘密鍵 ec2-user@IPアドレス秘密鍵の所に設定した物を入力、設定されているIPアドレスも入力
インスタンスメタデータ
・EC2インスタンスに埋め込まれている自分の情報
EC2が起動中にcurlコマンドで自身の情報が所得出来ます。
例えば、使用しているAMIのIDやローカルのIPアドレス、所属しているサブネットIDなどが所得出来ます。
ユーザーデータ
・インスタンス起動時に一回だけ実行するスクリプト
再起動時に実行されるものではない
rootユーザーで実行されることに注意
作成されたファイルもroot権限インタラクティブではない
× yum update
⚪︎ yum update -yCloud -init
・クラウド系インスタンスの初期構築を手助けするオープンソースのアプリケーション
Amazon Linuxにはデフォルトで /etc/cloud/ 配下に設定ファイルが存在し、インスタンス作成時にどういった動きをするか指定できる。
プレスメントグループとは
・複数のEC2を論理的にグルーピングすること
AZ、リージョンは跨げない
・クラスター
-AZ内でグループ化してHPC(ハイパフォーマンスコンピューティング)などの高度な演算処理に向いています。
複数のコンピュータを結合して一つの高度な処理や計算を行う基本的な使い方。
この塊をクラスターと呼び、これに所属しているコンピュータ一つ一つをノードと呼ぶ。このノード同士のネットワークは密接に結合している必要がある為拡張ネットワークサービスの使用を推移。
Amazon LinuxではデフォルトでENAモジュールが入っているので、AWS CLIコマンドで有効化されているか確認できます。同じAMIで使用する事。
・パーティション
配置するラックを分けることで、ハード障害を防止する。
・スプレット
個々のEC2を独立したラックに配置。
1つのAZにつきEC2を7つまで
1つのリージョンにつきAZを3つまでDedicatedホスト/インスタンス
・AWSの物理サーバーのリソースを占有できること
通常AWSの物理サーバーは他のアカウントと共有しています。これはコンプライアンス違反になる可能性がある。
(医療データを電子化する際のルール)
- 投稿日:2020-09-15T23:10:19+09:00
【AWS】WorkSpaces + FSx + Microsoft AD でテレワーク環境を構築する
はじめに
はじめまして。
本記事が初投稿となります。
至らぬ点が多々あると思いますが、ご容赦くださいませ。
初回なので気合を入れた結果、長文となってしまいました。。
次回以降は要約した記事作成を心がけたいと思います。対象者
- テレワーク用途で仮想デスクトップの利用をお考えの方
- WorkSpaces、Fsxの導入方法を知りたい方
背景
最近、テレワークが当たり前になりつつありますね。
テレワーク環境を用意する場合、いろいろなやり方がありますが、クラウドサービスを活用して仮想デスクトップを導入するのが安全で楽な方法です。
ハードウェアの追加購入が不要で初期投資を抑えられますし、利用者は自宅のPCとインターネット回線を使ってすぐに利用できるというメリットがあります。AWSのサービスを活用し、仮想デスクトップ+AD+ファイルサーバの3点セットで簡単にテレワークをスタートできますので、今回はその構築方法を紹介します。
構築にあたっては、なるべく手順を簡素化したいと思い、一部テンプレート化にもチャレンジしています。実現したいこと
WorkSpacesを利用し、テレワークを想定した仮想デスクトップ環境を構築します。
仮想デスクトップでは以下の機能が利用できることを確認します。
- インターネット接続
- ファイルサーバ接続
- Microsoft Office利用
- アンチウイルス機能
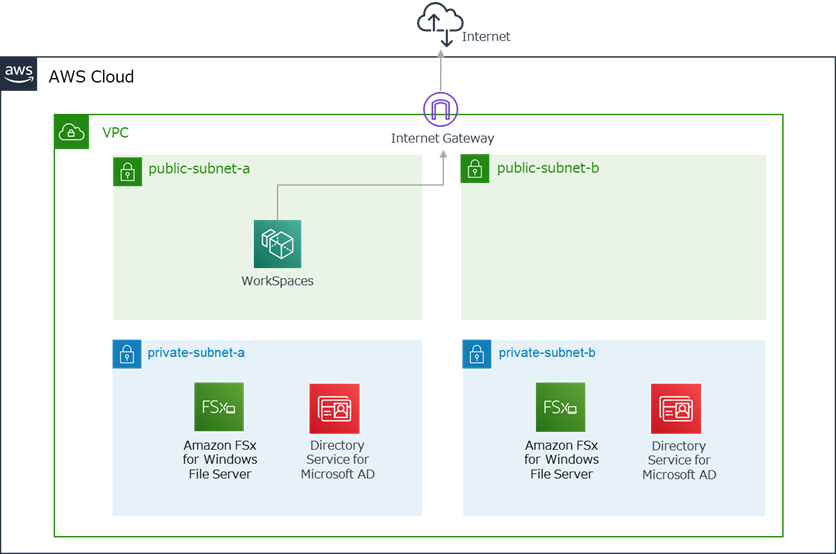
構成
できる限りAWSのマネージドサービスを活用し、管理の手間がかからない構成とします。
環境
AWSリージョン
- 東京リージョン(ap-northeast-1)
WorkSpaces
- Windows スタンダードバンドル(2vCPU/メモリ4GB)
- ルートボリューム80GB/ユーザボリューム50GB
- プラスアプリケーションバンドル利用(Microsoft + ウイルス対策ソフト)
FSx for Windows File Server
- マルチAZ
- SSD
- 容量100GB
Active Directory
- AWS Directory Service for Microsoft Active Directory(Standard Edition)
使用するAWSサービス
WorkSpaces
WorkSpacesは、AWSが提供する仮想デスクトップ配信サービスです。
利用者は専用のクライアントもしくはWebブラウザを使用して仮想デスクトップを利用することができます。使用するOSはWindowsかLinuxを選択でき、ユースケースに合わせたバンドル(vCPU数/メモリサイズ/ボリュームサイズの組み合わせ)を選んで仮想デスクトップを即座にデプロイできます。
Microsoft Officeやアンチウイルスソフトがセットになったプラスアプリケーションバンドルを追加することも可能です。FSx for Windows File Server
FSxはAWSが提供するマネージド型のファイルストレージです。
FSx for Windows File Serverを利用することで、ADと統合されたWindowsファイル
サーバを簡単に導入できます。AWSのマネージドサービスですので、サーバ管理も不要です。Windowsのファイルサーバを導入することで、ADのユーザ情報やグループ情報に基づくアクセス制御が可能となります。
Directory Service for Microsoft Active Directory
FSx for Windows ファイルサーバにはMicrosoft ADが必須となります。
今回はDirectory Serviceを利用してMicrosoft ADを構築します。こちらもAWSのマネージドサービスですので、サーバの管理が不要です。
デフォルトで2つのドメインコントローラが作成されますので、意識せずとも可用性が高い
AD環境を作成することができます。WorkSpacesもMicrosoft ADと連携し、このADを使ってWorkSpacesとユーザの管理を行います。
注意点
- 2020年9月時点の情報です。
- AWSマネジメントコンソールを使用します。ルートユーザもしくは権限を満たすIAMユーザを利用できる前提で進めます。
- AWS利用料にご注意ください。利用料については、リンク先のAWSの公式ページをご参照ください。
構築の流れ
1.VPC作成
2.AD作成
3.FSx作成
4.WorkSpaces作成
5.WorkSpaces初期設定
6.WorkSpaces動作確認1.VPC作成
まずはじめに、AD、FSx、WorkSpacesを配置するVPCを作成します。
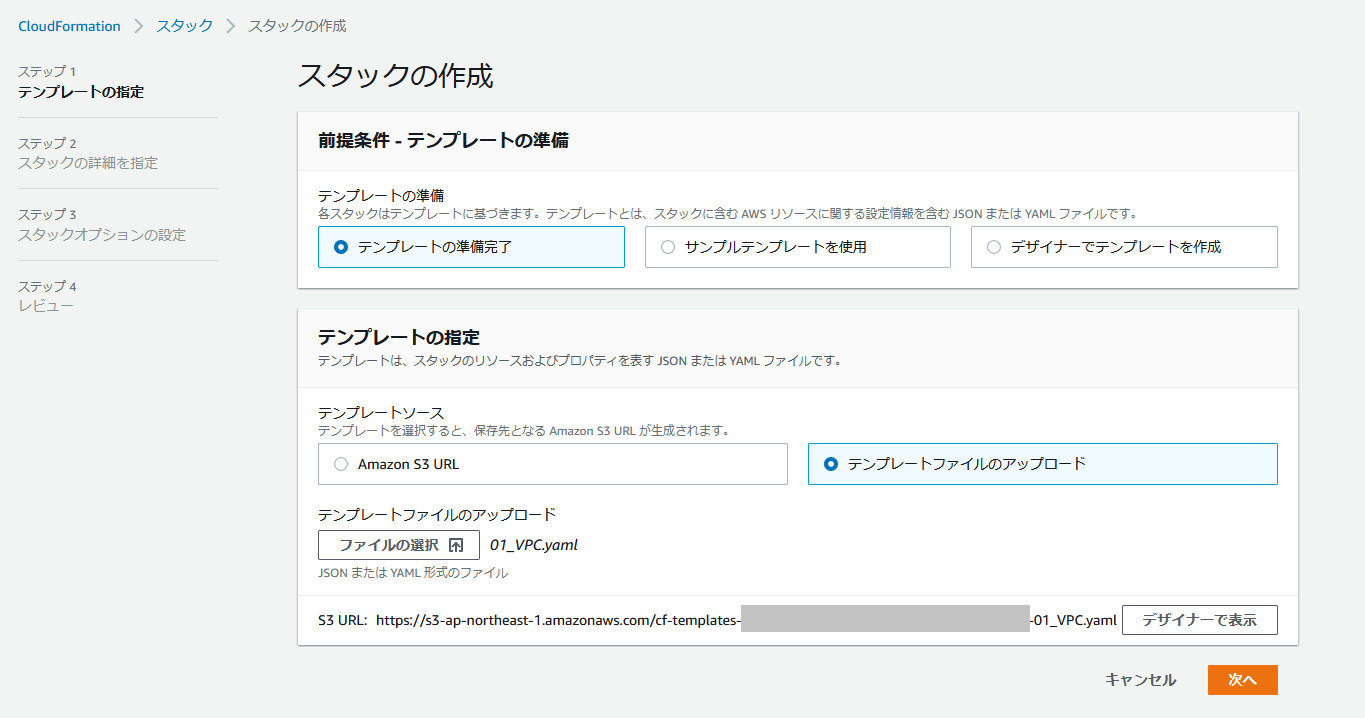
VPC、パブリックサブネット、プライベートサブネット、ルートテーブル、インターネットゲートウェイを作成するCloudFormation用のテンプレートをGithubで公開していますので、こちらをご利用ください。
https://github.com/COSMEDIA-cloud/cloudformation-template.git
「01_vpc.yaml」を使用します。ローカルPCにyamlを保存したら、AWSのマネジメントコンソールでCloudFormationの画面を開き、[スタックの作成]をクリックします。
ステップ1では、[テンプレートファイルのアップロード]を選択し、S3 URLが表示されることを確認して[次へ]をクリックします。
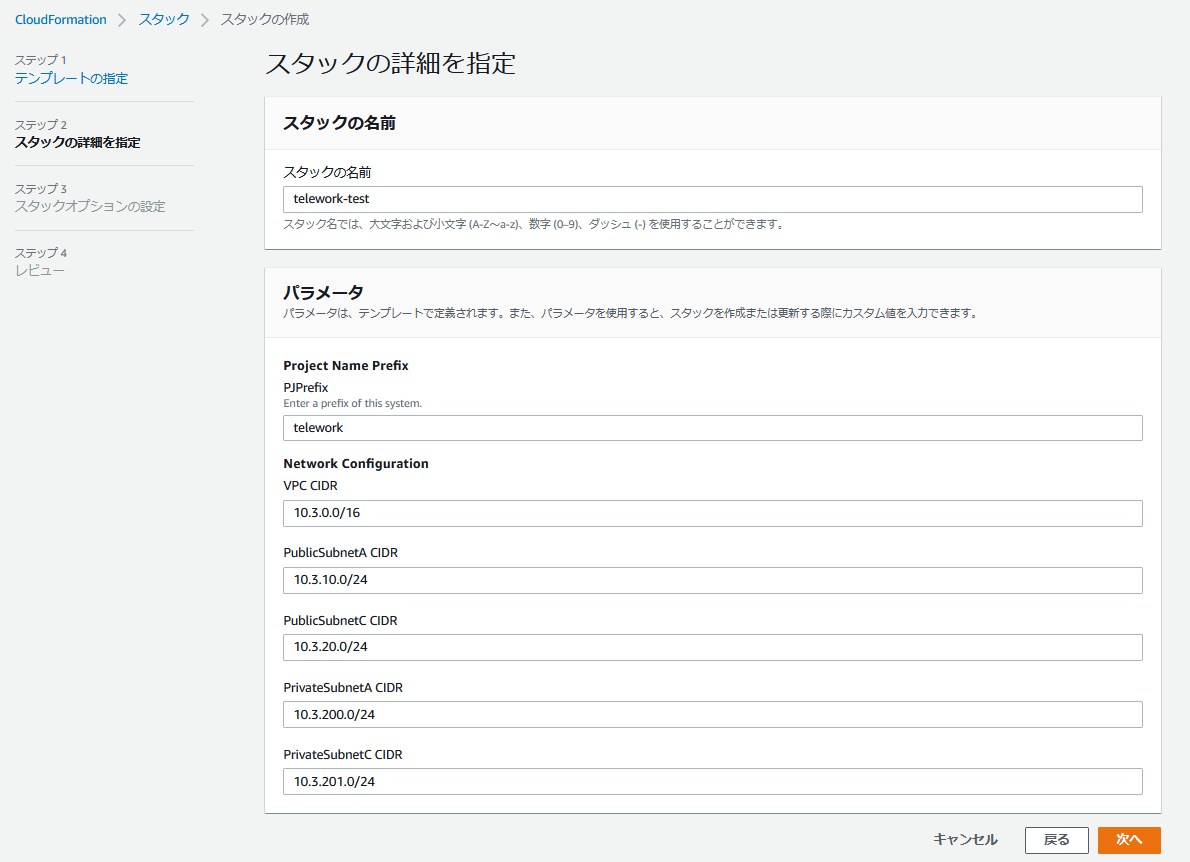
ステップ2では、任意のパラメータを入力し、[次へ]をクリックします。
・スタックの名前…CloudFormationのコンソール画面に表示されるスタックの名前です。
・Project Name Prefix…ここに入力したプレフィックスが作成後の各リソースのNmaeタグに付与されます。
・Network Configuration…VPCおよび各サブネットのIPv4 CIDRを入力します。
ステップ3は特に何も設定しなくても問題ありません。そのまま[次へ]をクリックします。
ステップ4で設定内容を確認し、問題なければ[スタックの作成]をクリックします。
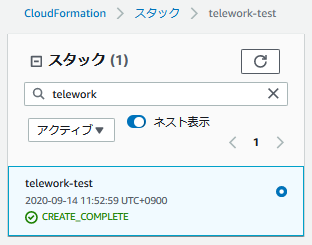
スタックの一覧で作成したスタックのステータスを確認します。
緑文字で「CREATE_COMPLETE」と表示されていればOKです。(作成までに5分ほどかかります)
- VPC
- パブリックサブネット(AZ-aとAZ-c)
- プライベートサブネット(AZ-aとAZ-c)
- ルートテーブル
- ネットワークACL
- インターネットゲートウェイ
が作成されています。
2.AD作成
プライベートサブネットにMicrosoft ADを作成します。
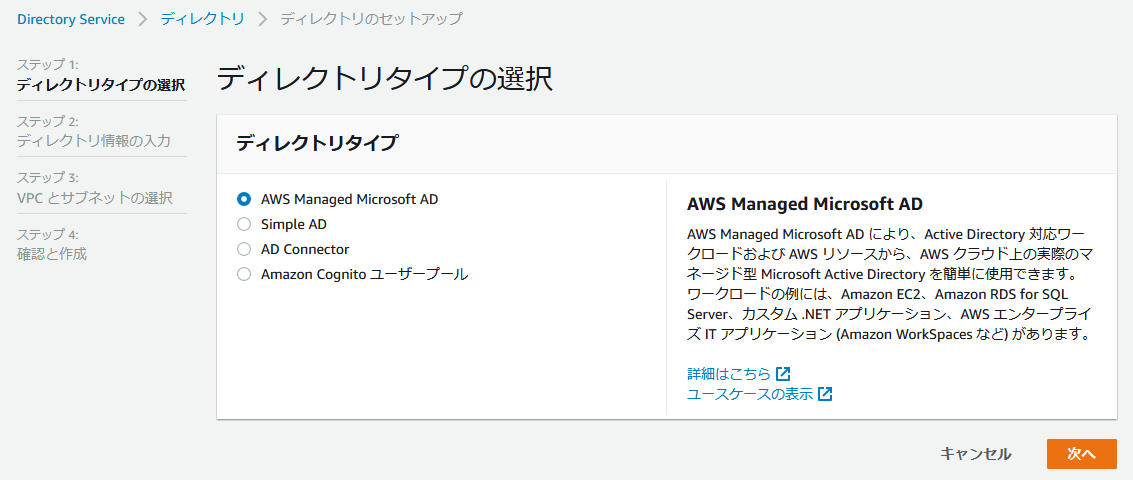
AWSのマネジメントコンソールでDirectory Serviceの画面を開き、「AWS Managed Microsoft AD」を
選択して[ディレクトリのセットアップ]をクリックします。
ステップ1では、「AWS Managed Microsoft AD」が選択されていることを確認し、[次へ]をクリックします。
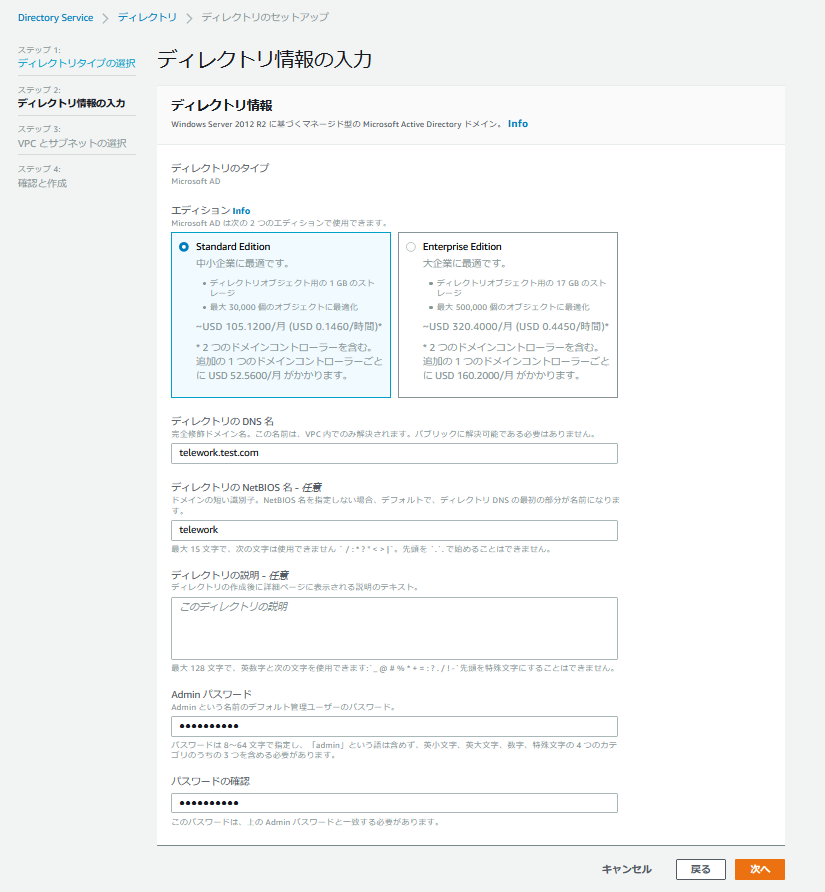
ステップ2では、ディレクトリ情報を入力します。
「Standard Edition」を選択し、ディレクトリのDNS名とNetBIOS名、ディレクトリの管理者ユーザ(Admin)のパスワードを入力します。
入力が終わったら[次へ]をクリックします。
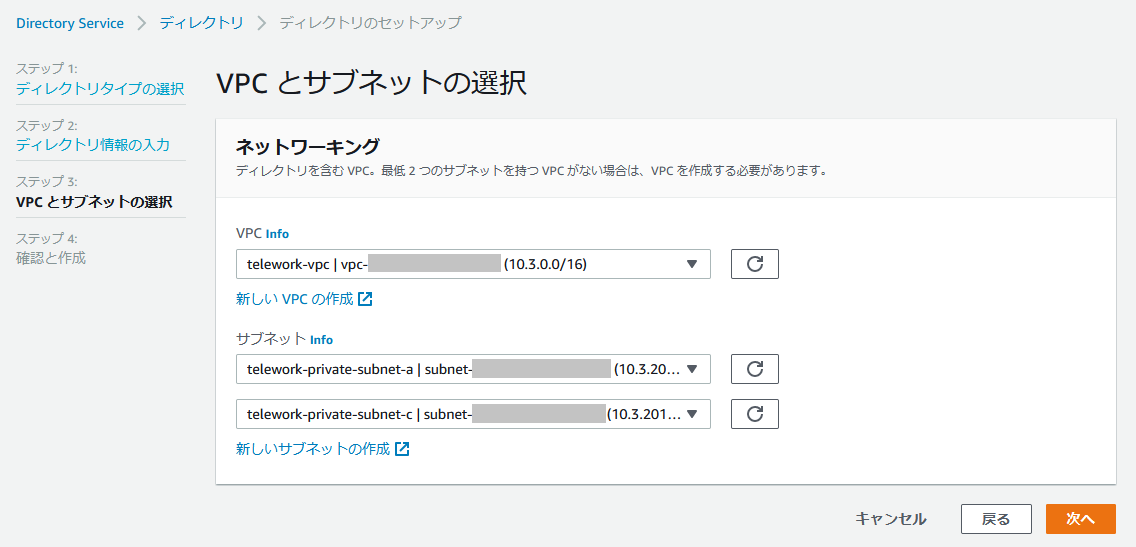
ステップ3では、ADを起動するVPCとサブネットを選択します。
作成したVPCとプライベートサブネット(AZ-aとAZ-c)を選択し、[次へ]をクリック。
ステップ4で設定内容を確認し、問題なければ[ディレクトリの作成]をクリックします。
ディレクトリの一覧に対象のディレクトリが表示されます。
ステータスが「作成中」から「アクティブ」に変わったら作成完了です。
(アクティブに変わるまで30分前後かかります)
3.FSx作成
プライベートサブネットにFSx for Windowsファイルサーバを作成します。
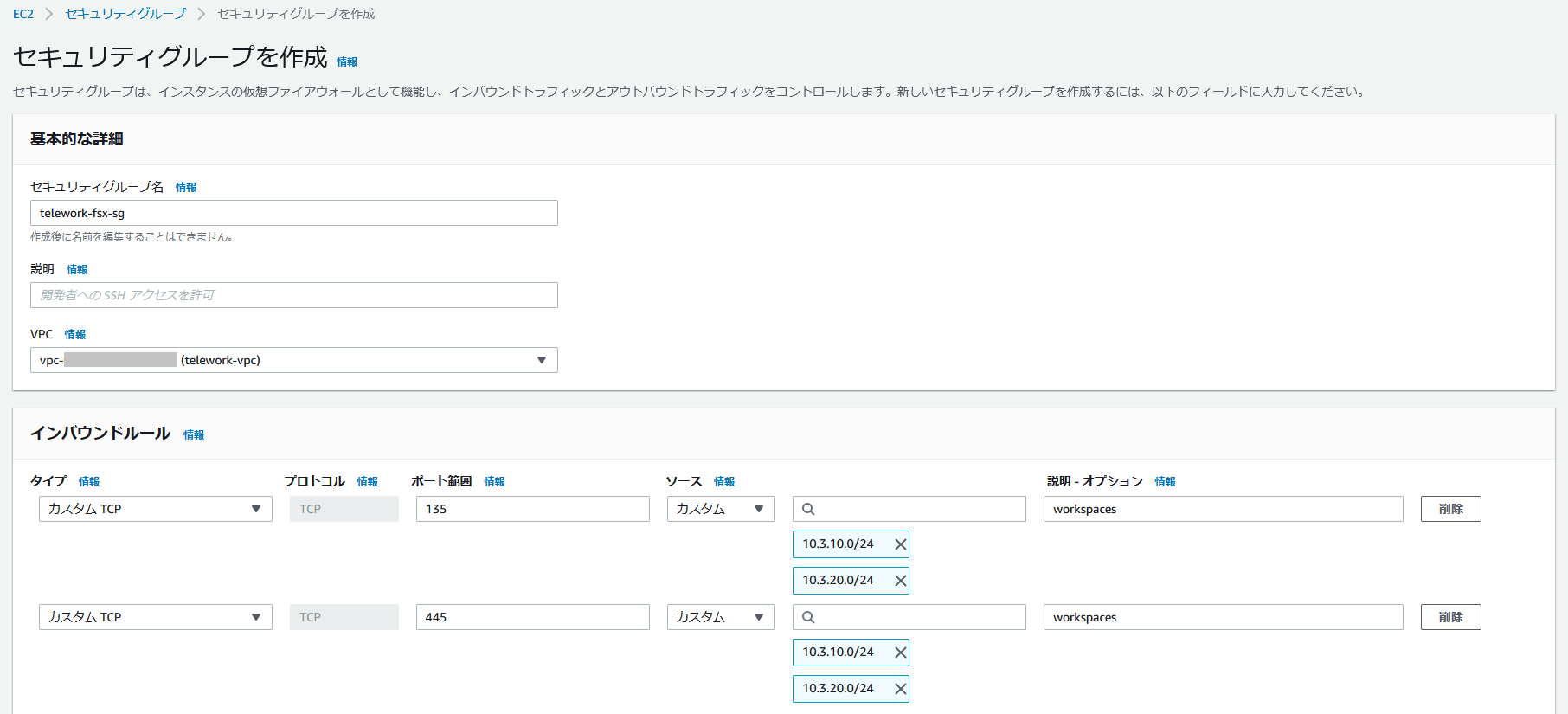
まず、FSxで使用するセキュリティグループを作成します。
AWSマネジメントコンソールでEC2の画面を開き、左のメニューから[セキュリティグループ]をクリックします。
インバウンドルールでパブリックサブネットからのTCP/135、TCP445の通信を許可します。
これによりWorkSpacesからFSxへのアクセスが可能となります。
設定が終わったら、[セキュリティグループの作成]をクリックします。
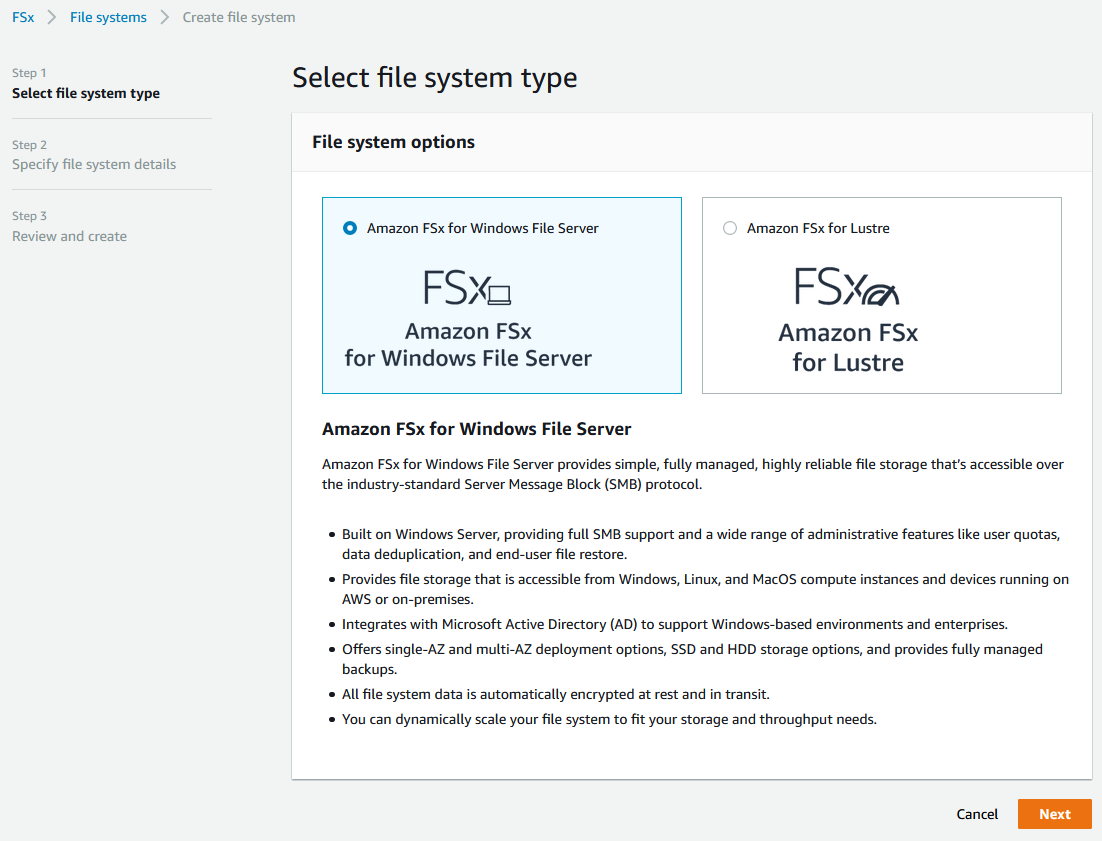
次に、AWSのマネジメントコンソールでFSxの画面を開き、Get startedの
[Create file system]をクリックします。
ステップ1で、ファイルシステムを選択します。
今回はAmazon FSx for Windows File Serverを選択し、[Next]をクリックします。
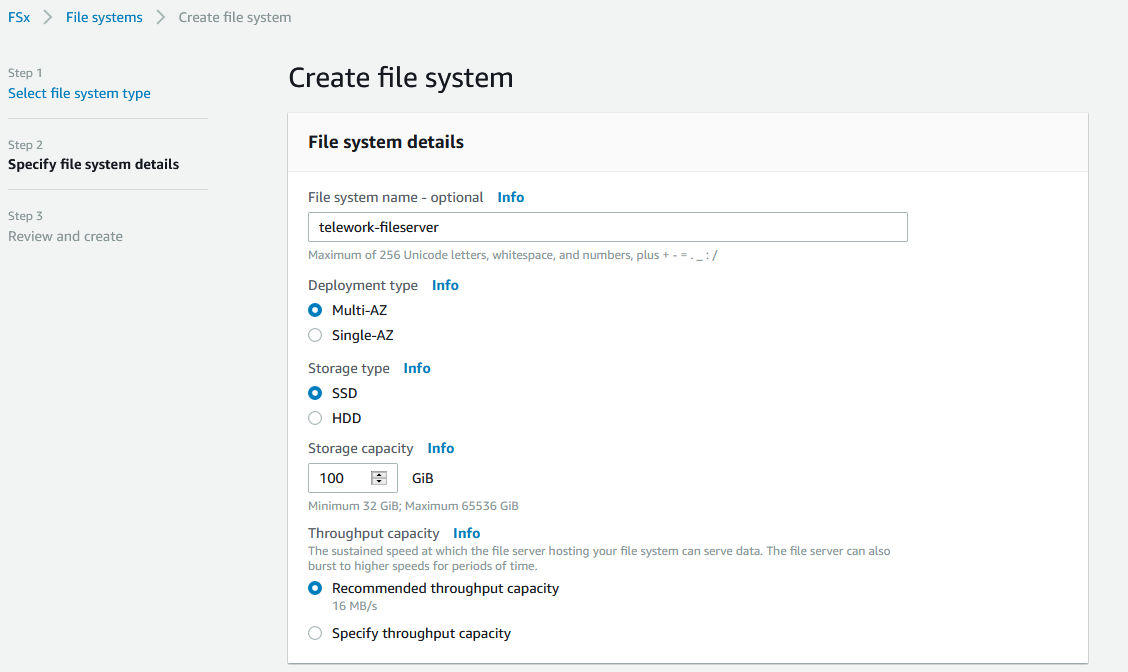
ステップ2で、ファイルシステムの詳細を設定します。
画面では可用性を考慮してマルチ-AZ構成とし、ストレージタイプはSSD、サイズは100GB、スループット容量は推奨値を設定しています。
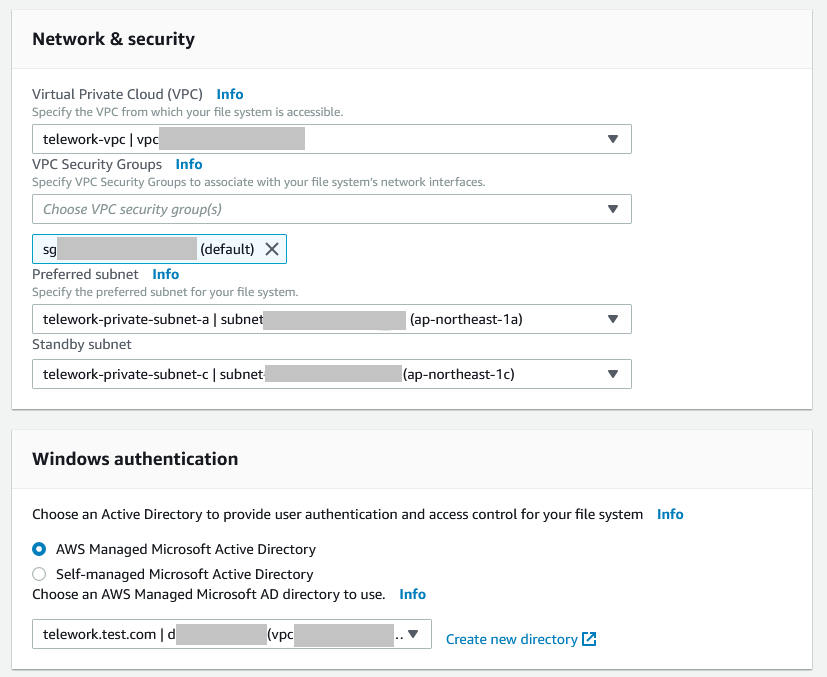
ネットワーク設定については、作成したVPCとプライベートサブネット(AZ-aとAZ-c)を選択してください。
また、認証先のADは作成したMicrosoft ADを選択してください。
(注)セキュリティグループについて、画面ではデフォルトのものを設定していますが、ここでは作成済みのFSx用のセキュリティグループを設定してください。
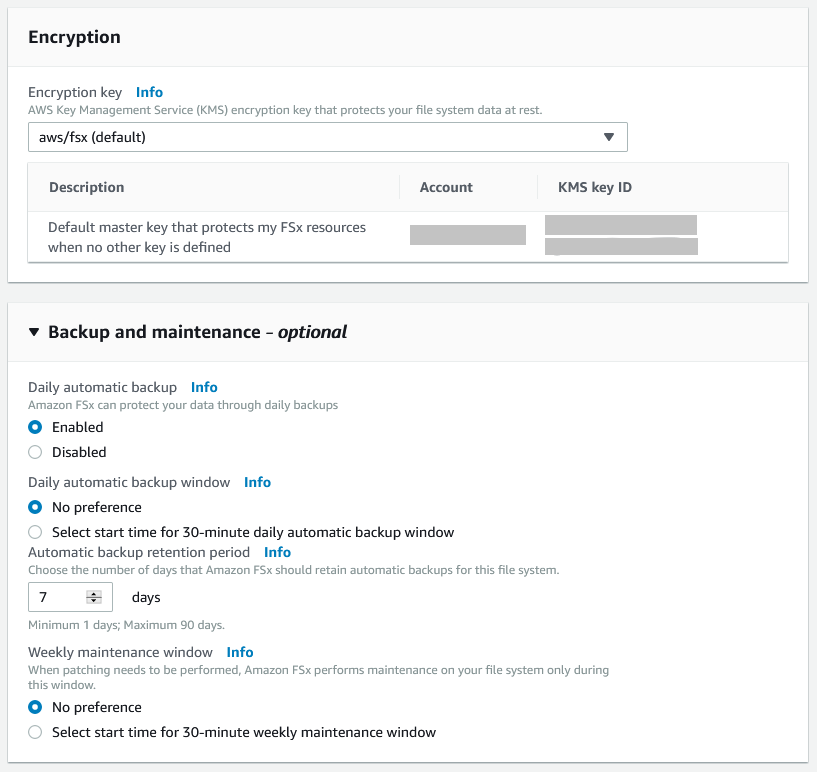
暗号化キーとバックアップ設定を入力します。
画面では特に変更せず、デフォルトの値を使用しています。
タグ設定はお好みで設定してください。
すべて入力し終えたら[Next]をクリックします。
ステップ3で設定内容を確認し、問題なければ[Create file system]をクリックします。
ファイルシステムの一覧に作成中のファイルシステムが表示されます。
ステータスが「Creating」から「Available」に変わったら作成完了です。
(Availableに変わるまでに20分前後かかります)
Directory Serviceの画面で手順2で作成したディレクトリを確認すると、「AWSアプリおよびサービス」の中でFSxのステータスが有効になっているのを確認できます。
4.WorkSpaces作成
続いて、WorkSpacesを作成します。
AWSのマネジメントコンソールでWorkSpacesの画面を開き、[WorkSpacesの起動]をクリックします。
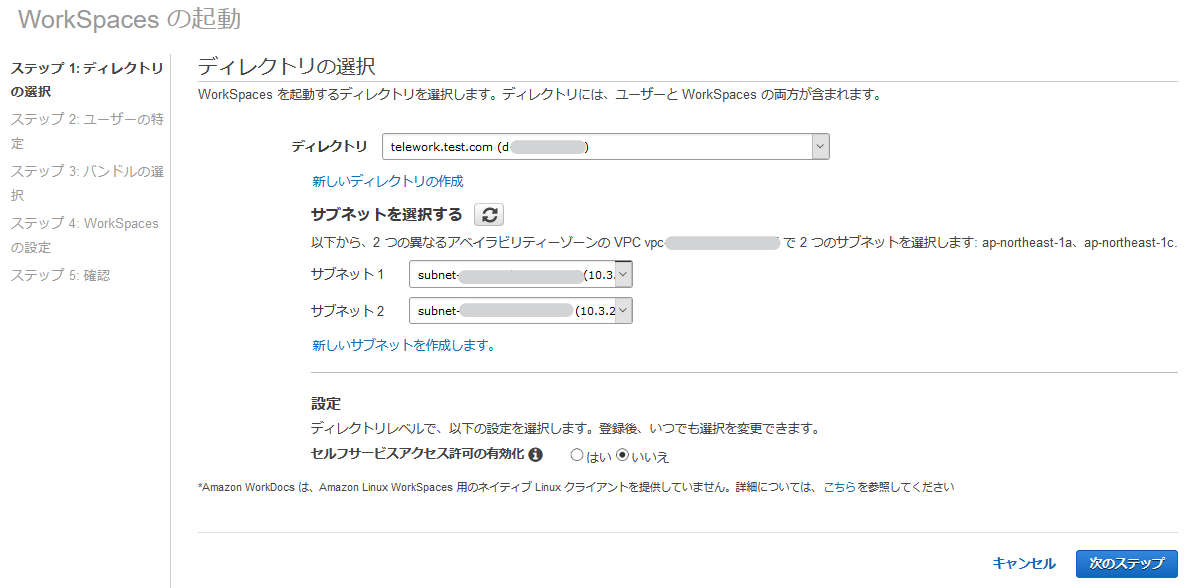
ステップ1ではWorkSpacesを起動するディレクトリを選択します。
作成したディレクトリ、パブリックサブネットを設定し、[次のステップ]をクリックしてください。
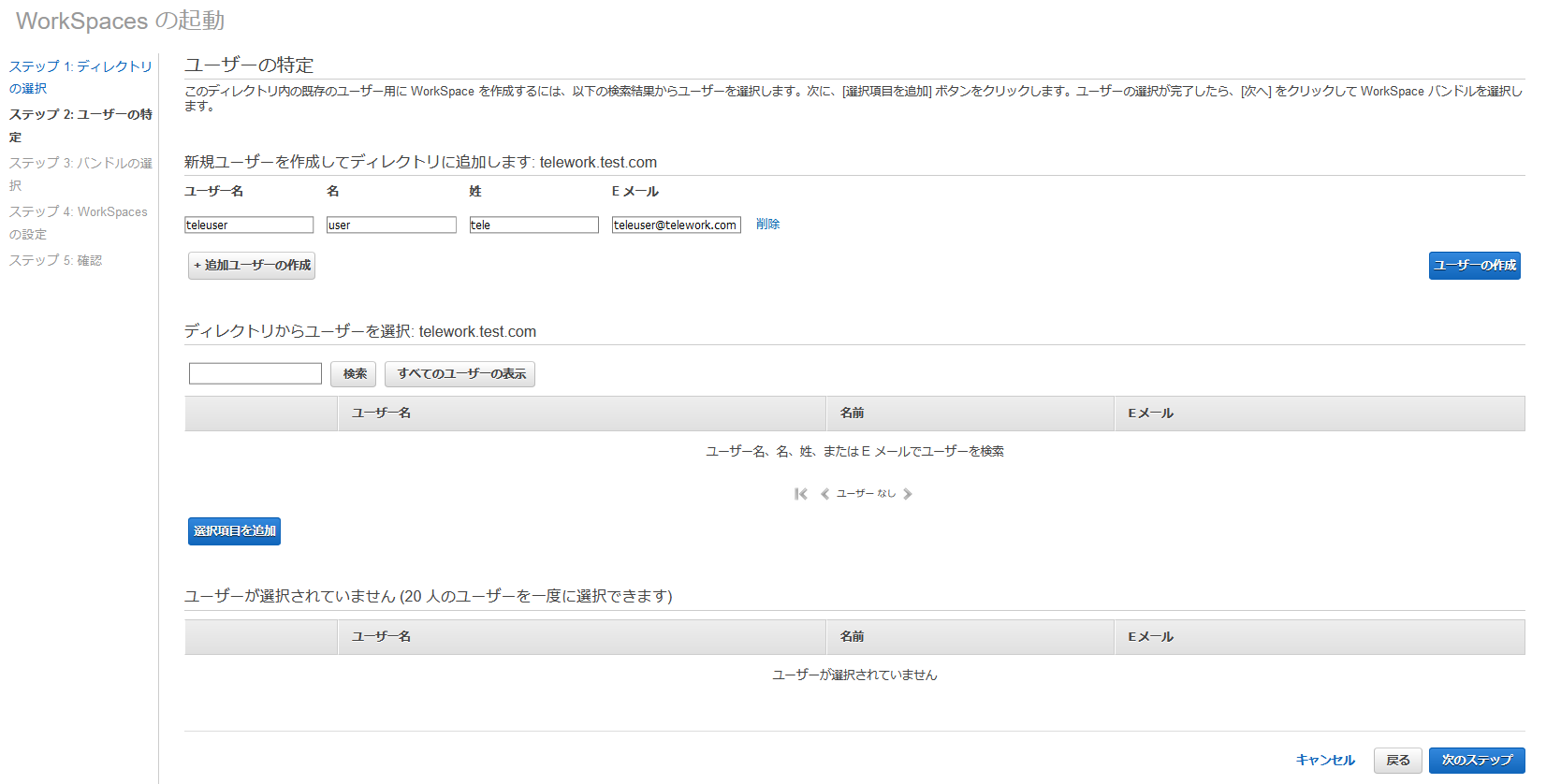
ステップ2でWorkSpacesを利用するユーザーを設定します。
ADに登録済みのユーザーを設定することもできますし、ここで新規ユーザーを作成することもできます。
今回は新規ユーザーを作成します。
ユーザー名、名、姓、Eメールアドレスを入力し、ユーザーを作成してください。
ユーザーが追加されたら、[次のステップ]をクリック。
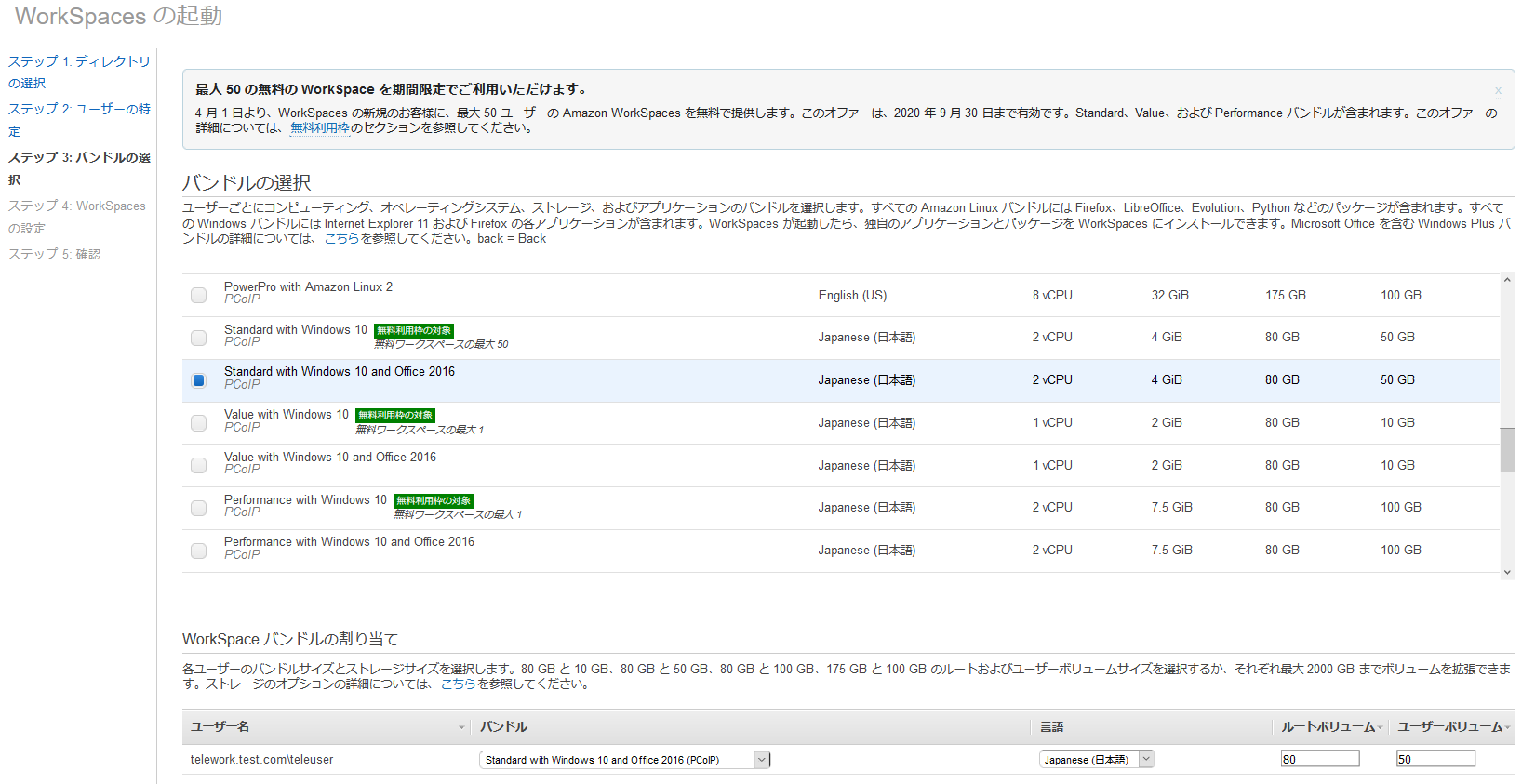
ステップ3で起動するWorkSpacesのスペックを決めます。
以下の画面では、日本語の「Standard with Windows 10 and Office 2016」を選択しています。
※バンドルについては、Standardより安価なValueも選択できますが、Windowsだとかなり動作がもっさりしますので、個人的にはお勧めしません。
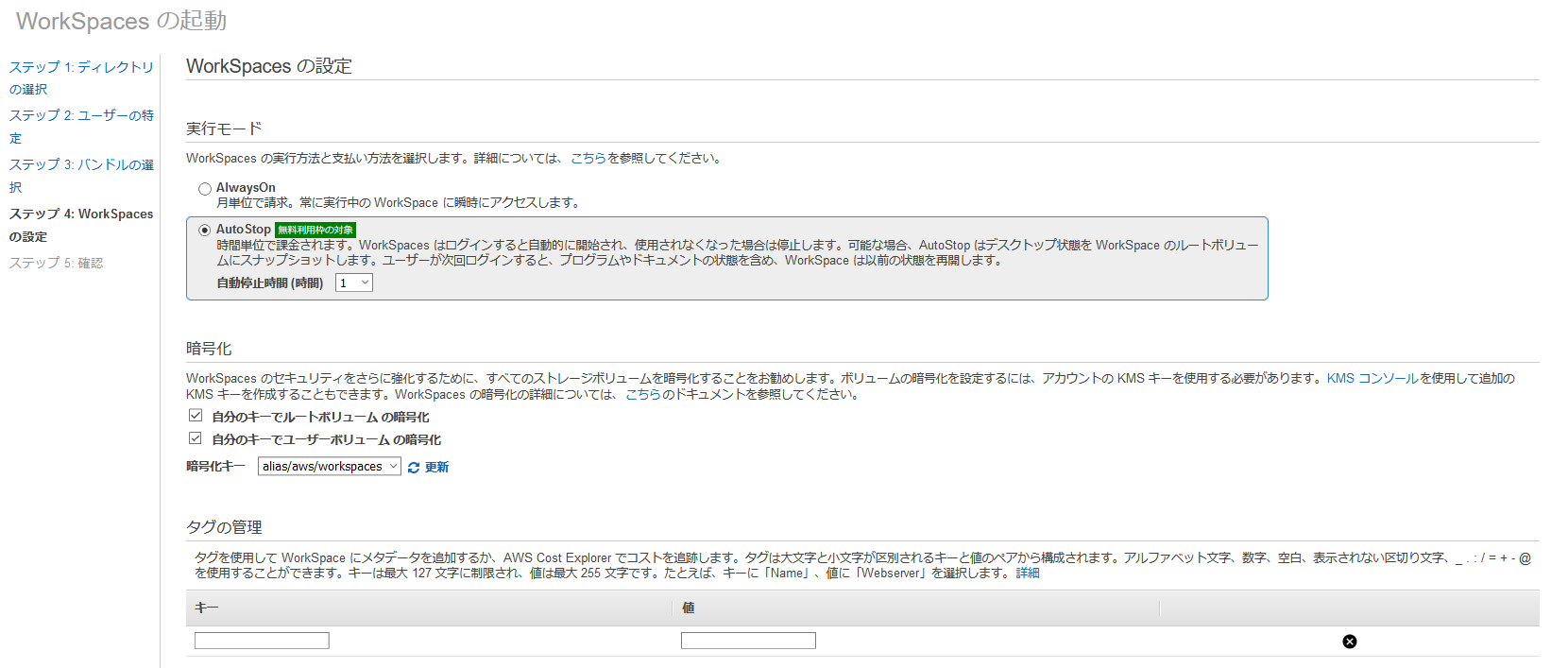
ステップ4では、実行モードや暗号化の設定を行います。
実行モードはAuto Stop(時間課金)を選択します。
※月に80時間以上利用する場合には、AlwaysOn(月単位で課金)のほうが安価となります。
セキュリティを考慮し、ボリュームは暗号化しておきます。
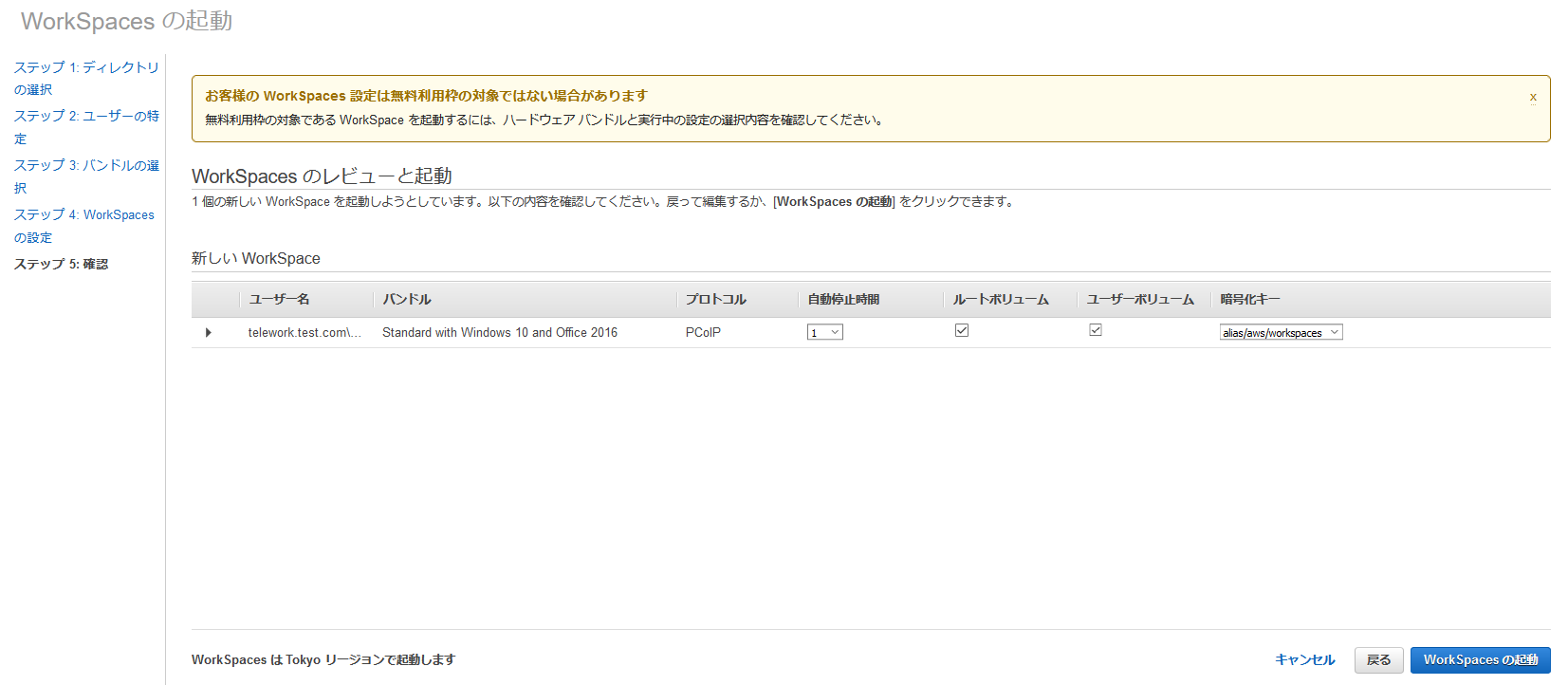
最後にステップ5で設定内容の確認を行い、問題なければ[WorkSpacesの起動]をクリック。
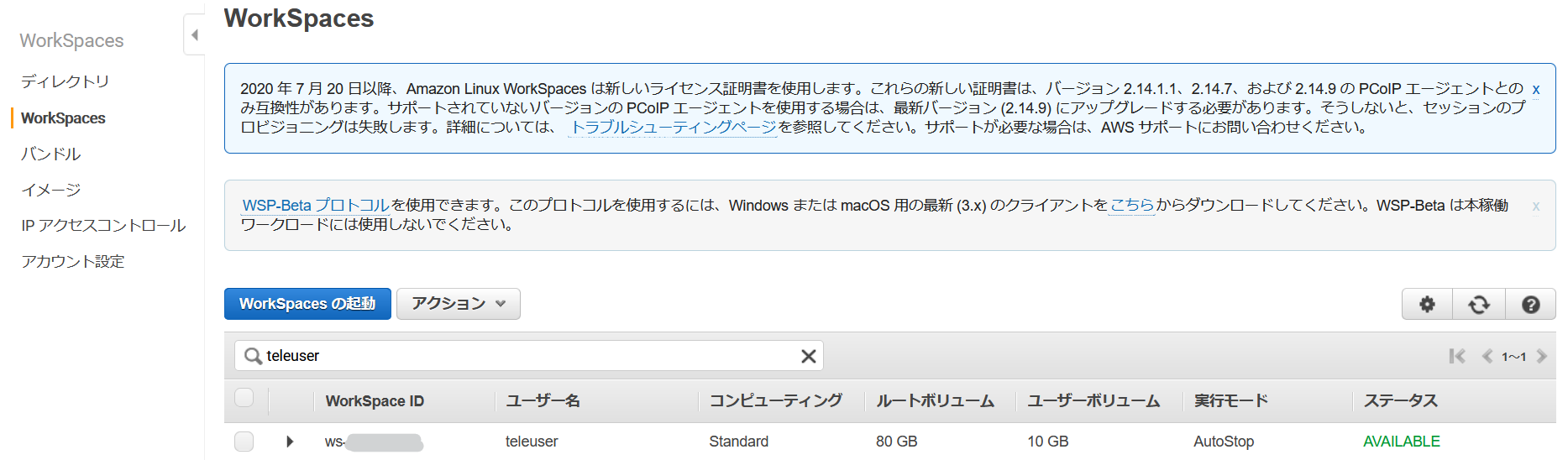
ステータスが「Available」になったら作成完了です。(20~30分ほどかかります)
ステータスが「Available」になると、登録したメールアドレス宛にWorkSpacesからメールが届きます。
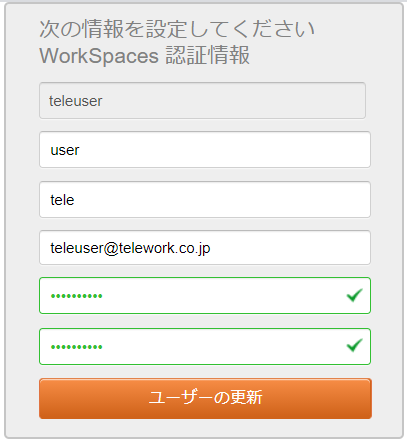
メールにはユーザー初期設定用のURL、登録コード、WorkSpacesユーザー名が記載されています。
まず、初期設定用のURLにアクセスし、認証情報の登録を行います。
登録が終わると、クライアントツールのダウンロードサイトに飛びますので、自身が利用しているデバイスのツールをダウンロードします。
クライアントツールをインストールして起動します。
登録コードを入力して[登録]をクリック。
認証画面でユーザー名、パスワードを入力し、[サインイン]をクリックするとWorkSpacesが起動します。
5.WorkSpaces初期設定
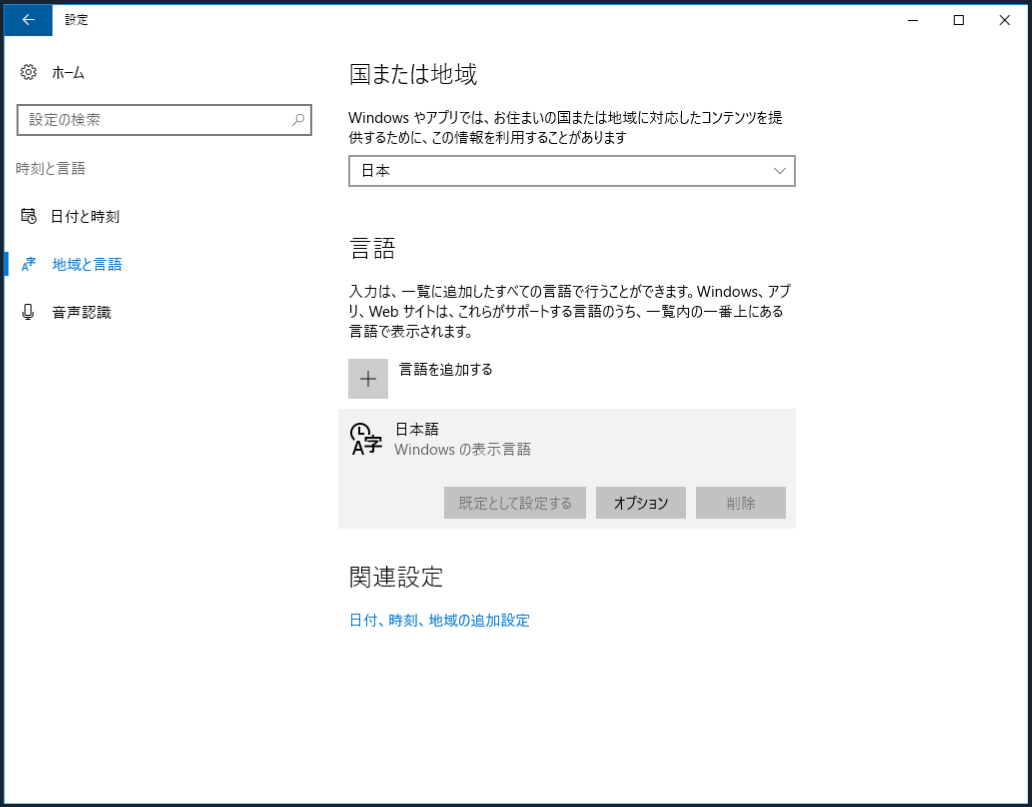
キーボードの日本語化
日本語版のバンドルで起動してもキーボードレイアウトが日本語キーボードになっていないため、まずこれを変更します。
デスクトップ画面左下のWindowsロゴをクリックし、設定から[音声認識、日付、言語]をクリックします。
[地域と言語]を選択し、日本語の[オプション]をクリックします。
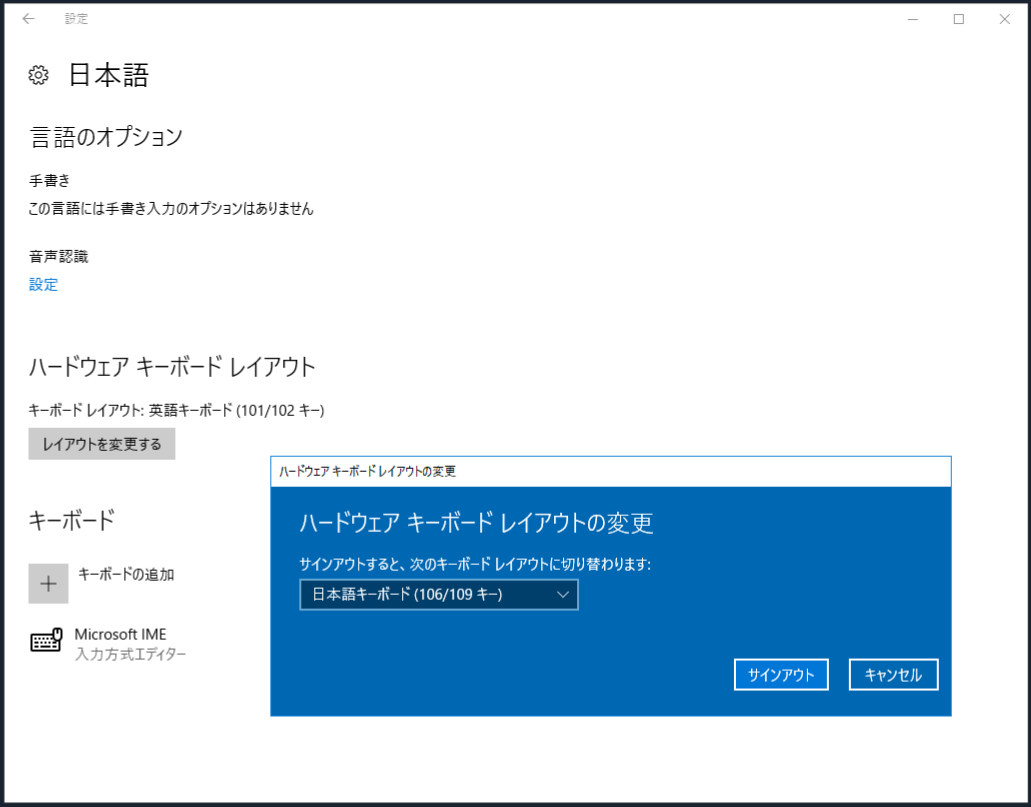
ハードウェア キーボード レイアウトの[レイアウトを変更する]をクリックし、日本語キーボードを選択してサインアウトします。
再ログインすると日本語キーボードが有効になります。
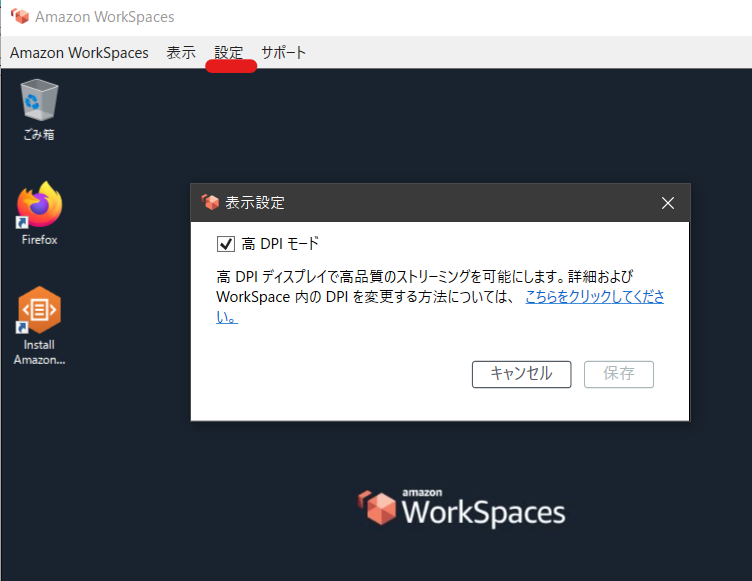
ディスプレイ解像度の設定
WorkSpacesはローカルデバイスのウィンドウ枠の大きさに従い、解像度が自動でスケーリングします。
ただし、ローカルで高解像度のディスプレイを使用している場合、WorkSpacesの画面が荒く感じることがあります。
この場合、高DPIモードを有効にすることで事象が改善される場合があります。
有効にするには、クライアント画面上部の[設定]から[表示設定]を選択し、高DPIモードにチェックを入れます。
6.WorkSpaces動作確認
インターネット利用
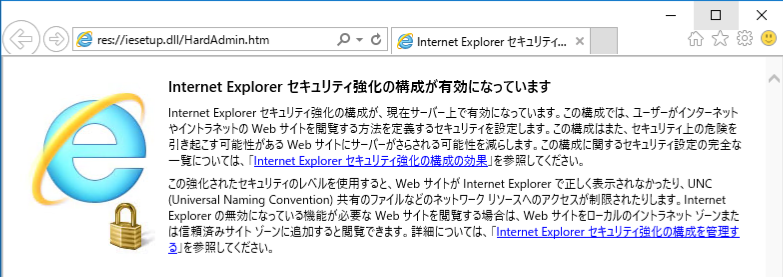
WorkSpacesにはデフォルトでFirefoxとInternet Explorerがインストールされており、すぐに利用することができます。
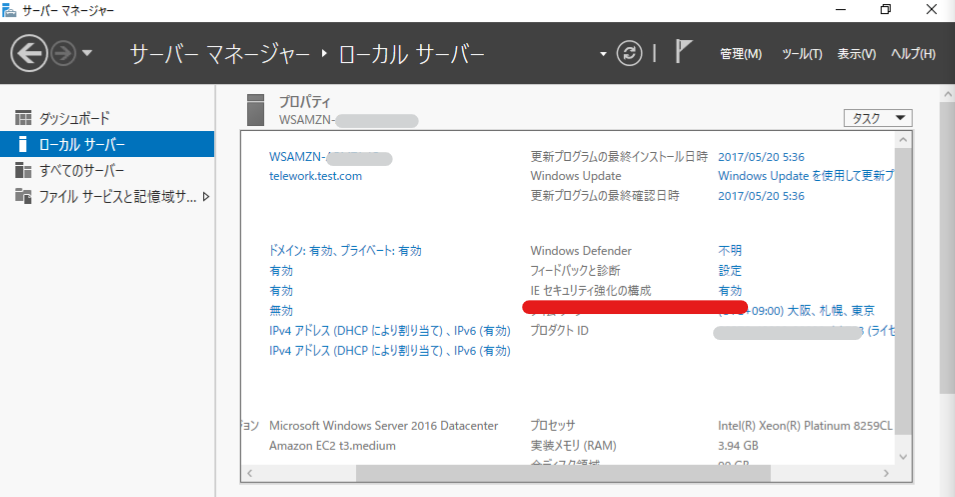
※Internet Explorerではセキュリティ強化の構成が有効になっています。
無効にしたい場合は、サーバーマネージャーで無効化できます。
以下の画面でIEセキュリティ強化の構成の「有効」をクリックすると設定を変更できます。
ファイルサーバ利用
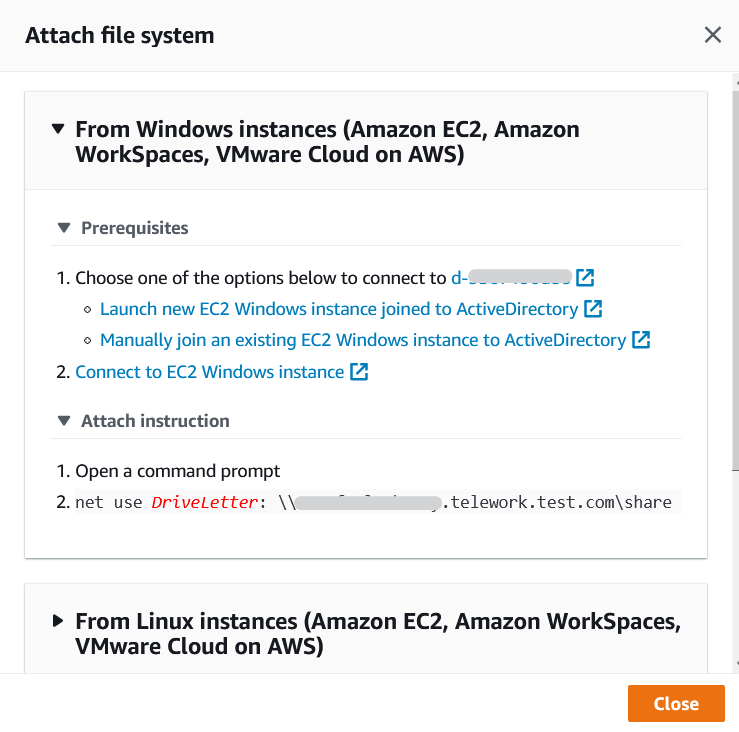
WorkSpacesからFSxのWindowsファイルサーバが利用できることを確認します。
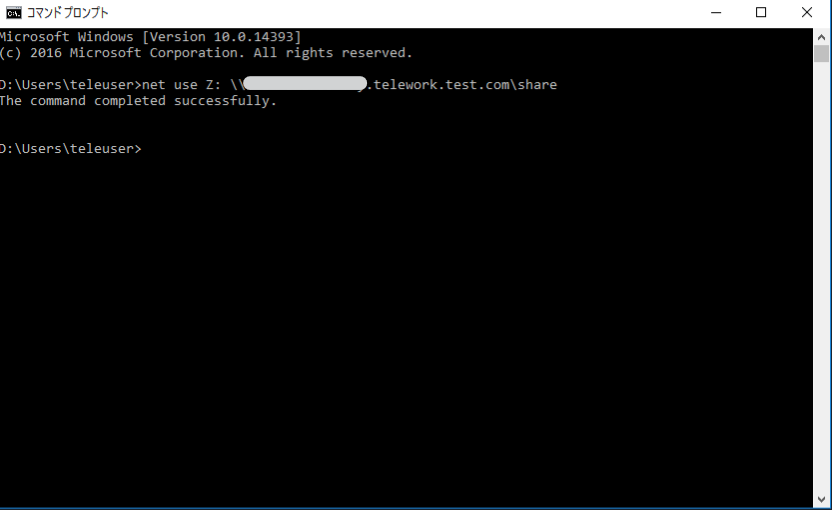
WorkSpacesでコマンドプロンプトを起動し、net useコマンドを使用してFSxをWorkSpacesのボリュームに割り当てたいと思います。
コマンドは、AWSマネジメントコンソールでFSxの画面を開き、作成したファイルシステムを選択して、右上の[Attach]をクリックすると確認できます。
コマンドを実行し、「The command completed successfully」と表示されればOKです。
画面ではZドライブに設定しています。
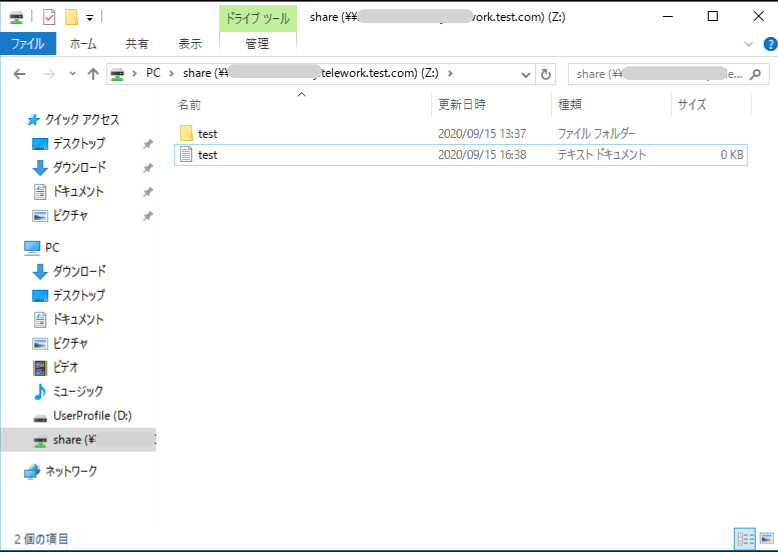
エクスプローラーを開き、FSxが指定したドライブに割り当てられていることを確認します。
net useコマンドで一度設定を行えば、再起動しても自動的に割り当てられるため、コマンド実行は初回のみでOKです。
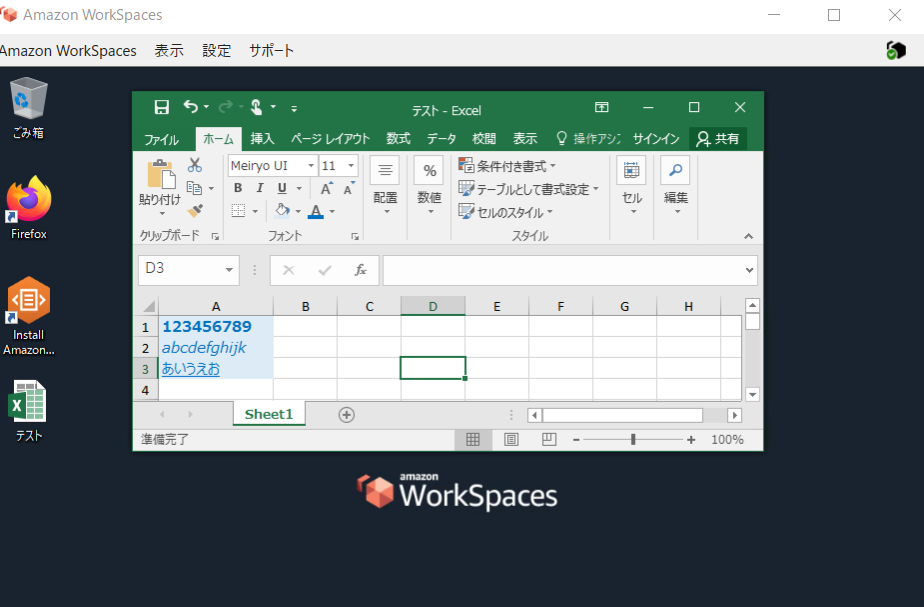
Microsoft Office利用
プラスアプリケーションバンドルを適用したため、Microsoft Office 2016がインストールされています。
問題なく利用できることを確認します。
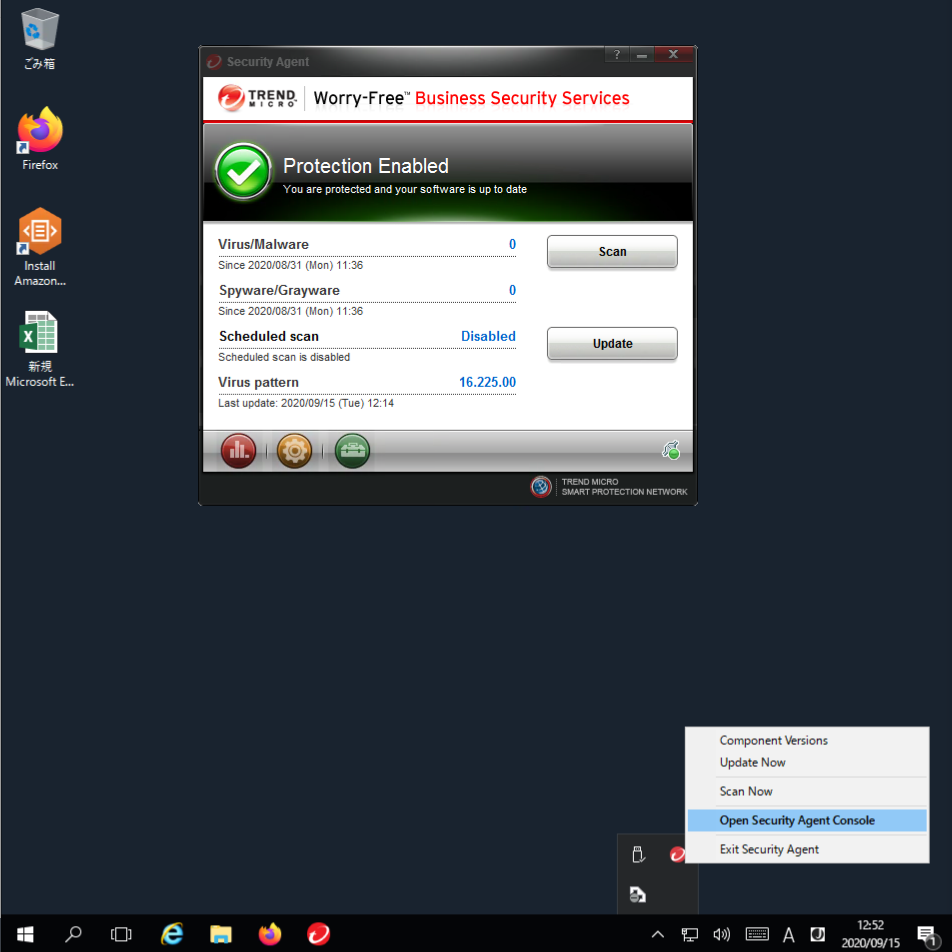
アンチウイルス
プラスアプリケーションバンドルの適用により、TrendMicro社のウイルスバスタービジネスセキュリティサービスがインストールされています。
ウイルスバスターのコンソール画面は、デスクトップ画面右下のインジケーターからウイルスバスターのアイコンをクリックすると、立ち上げることができます。
画面のように緑のチェックが表示されていれば保護が有効になっています。
参考元
Amazon FSx for WindowsをWorkspacesで試してみた
さいごに
WorkSpacesやFSxといったAWSのサービスを活用したテレワーク環境の構築方法を紹介しました。
仮想デスクトップ+AD+ファイルサーバの3点セットのみでも、リモート環境でセキュアなファイルのやり取りが可能です。
スモールスタートで始めたいという方は、本構成のみで十分テレワークをスタートできると思います。今後の取り組み
本構成については、プロキシの導入、ローカルデバイス⇔仮想デスクトップ間のコピー&ペースト禁止、デバイス認証の追加などにより、セキュリティ面を強化することもできます。
今回は割愛しましたが、ファイルサーバについてはアクセス権限の設定も可能です。
また、実際に作った環境を運用していく場合には、CloudWatchによる監視や通知の仕組みが必要です。セキュリティや監視を考慮した環境のバージョンアップについては、次回以降の記事で扱いたいと思います。
また、今回はVPCのみテンプレートを使用し、CloudFormationで環境を作成しましたが、その他のリソースについても同じことができると思います。
環境を楽に構築できますので、テンプレートは積極的に活用したいところです。このあたりも引き続き取り組んでいきたいと思います。










- 投稿日:2020-09-15T22:40:58+09:00
Amazon Linux2(CentOS)をGUI化する
Amazon Linux2(CentOS)をGUI化する
今回はAmazon Linux2(CentOS 7)で、Mateをインストールし、GUI化してみます。ただGUI化するだけでは味気ないので、Google Chromeをインストールしてネットサーフィンできるようにしたいと思います。
またコマンド操作ではなくWindowsっぽくGoogle chromeでインターネットへアクセスしてWebサイトを閲覧できるようにしていきたいと思います。今回のゴール
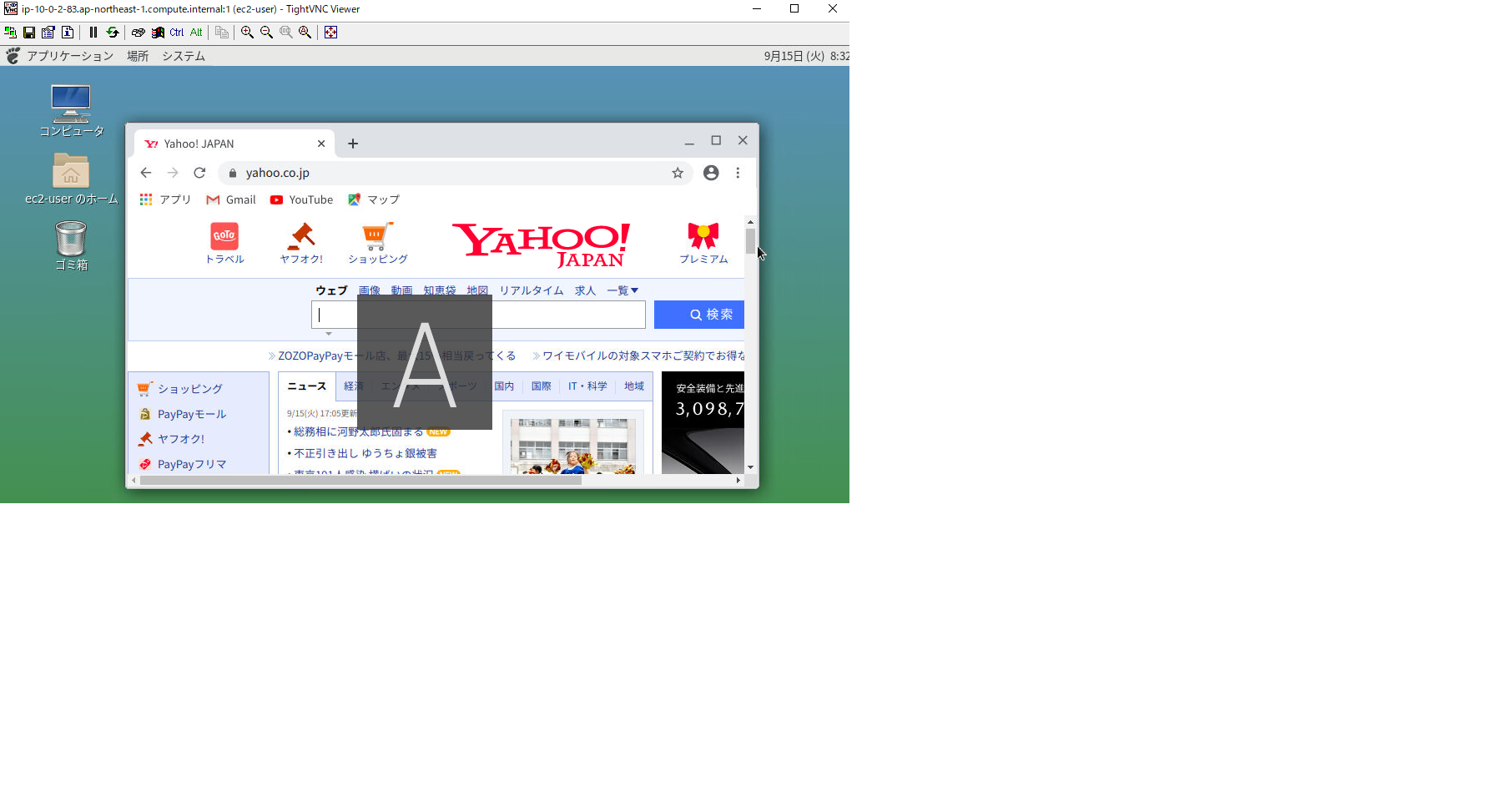
以下の画像みたいに利用できるようにする。
前提環境
- 利用するEC2 AMIはAmazon Linux2 (CentOS)
- EC2はクライアント端末(自宅のWindows 10)からSSHおよびVNCでアクセスできるようにセキュリティグループを設定
- VNCソフトはtigerVNCを利用
- デスクトップ環境はMATE(読み:マテ)をインストールして利用
- VNCクライアントにUltraVNC viewerをインストールする
- VNCログインに利用するユーザはec2-user
手順
- EC2 をデプロイし、SSHで接続できる環境を構築する
- EC2 にGUI化ソフト(MATE),tigerVNC(VNCソフト),Google chromeのパッケージをインストールする
- クライアント端末にUltra VNC viewer をインストールする
- クライアント端末からEC2にVNC接続を行う
実際にやってみた
1.については詳しい記事がたくさんありますので、割愛します。それでは2.から始めていきます。
まずSSHでEC2に接続して、ユーザはec2-userで進めていきます。# MATEパッケージをインストールします。 sudo amazon-linux-extras install mate-desktop1.x # MATE をデフォルトのデスクトップとして定義します。またすべてのユーザーに対して MATE を定義します。 sudo bash -c 'echo PREFERRED=/usr/bin/mate-session > /etc/sysconfig/desktop' # TigerVNC をインストールします。 sudo yum install tigervnc-server # ec2-userに対して6~8 文字の VNC 固有のパスワードを設定します。 vncpasswd 表示専用のパスワードを入力するかどうかを確認するメッセージが表示されたら、「n」を押します。 # 表示番号 1 で VNC サーバーを起動します。 vncserver :1 # デフォルトで作成されているvncserverのsystemd ユニットをコピーして、別に新しい systemd ユニットを作成します。 sudo cp /lib/systemd/system/vncserver@.service /etc/systemd/system/vncserver@.service # 新しいユニット内のすべての <USER>という記載を 実際に利用するユーザ(ec2-user) に置き換えます。 sudo sed -i 's/<USER>/ec2-user/' /etc/systemd/system/vncserver@.service # systemd マネージャー設定を再ロードします。 sudo systemctl daemon-reload # サービスを有効にします。 sudo systemctl enable vncserver@:1 #サービスを起動します。 sudo systemctl start vncserver@:1これでGUI化の設定は環境です。ただこのままだと英語表記だし、Google chromeがインストールされていないのでデスクトップ環境の日本語化とGoogle chromeのインストールを行います。
# まず のデスクトップ環境の日本語化設定を行います。日本語入ができるようにIME ibus と日本語のフォントのgoogle-noto-sans-japanese-fontsをインストールします。 sudo yum install ibus-kkc sudo yum install google-noto-sans-japanese-fonts # ibusの設定をbashrcに記載します。 vi ~/.bashrc # ファイルの最後に以下を追加して、ファイルを保存します。 export GTK_IM_MODULE=ibus export XMODIFIERS=@im=ibus export QT_IM_MODULE=ibus ibus-daemon -drx # ロケールの設定を変更します。 sudo localectl set-locale LANG=ja_JP.UTF-8 # 設定変更反映のため再起動させます。 rebootこれで日本語は完了です。続いてGoogle Chrome パッケージをインストールしていきます。
ここから先はroot権限のあるユーザでコマンドを実行してください。#リポジトリファイルを作成します。 sudo vi /etc/yum.repos.d/google-chrome.repo # ファイル内容は以下を記述します。 [google-chrome] name=google-chrome baseurl=http://dl.google.com/linux/chrome/rpm/stable/$basearch enabled=1 gpgcheck=1 gpgkey=https://dl-ssl.google.com/linux/linux_signing_key.pub # yum をアップデートします sudo yum update # パッケージをインストールしていきます。 sudo yum install google-chrome-stable # 正しくインストールできたか確認します。 google-chrome --version バージョンが表示されればOKです。これでEC2側で行う設定は全て完了です。あとはクライアント端末にVNC viewerをインストールして、アクセスしてみましょう。
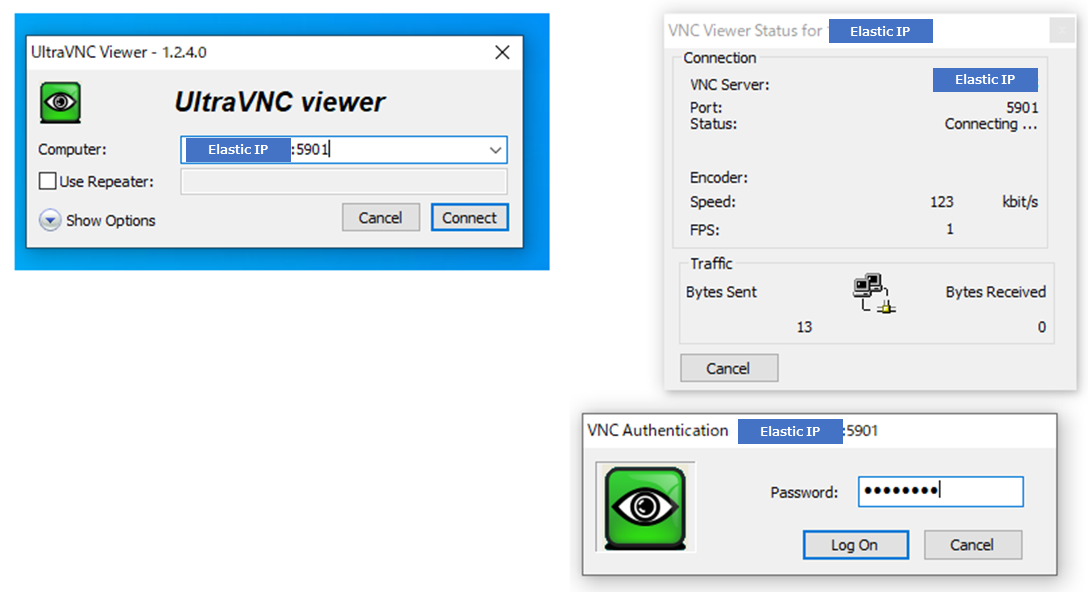
以下サイトからUltraVNC viewerをインストールしてします。
窓の社Ultra VNC viewerを起動し
["ELastic IPアドレス":5901] という形式で入力し、登録したPWを入力します。
こんな感じで表示されればOKです。
次にGoogle Chromeを起動します。
無事ネットサーフィンできそうです。
これで設定は完了です。最後に
メモリ1GBでもサクサク動きます(笑)。Linuxってやっぱり軽いですね!
諸事情あって、直接PCからネットワークサーフィンできないときとかに便利かもです。参考にしたWebサイト
Amazon Linux2 にGUIデスクトップ環境(MATE)をインストールする手順
CentOS7×Chromeでスクレイピング環境を構築するチュートリアル
AWS公式
- 投稿日:2020-09-15T16:20:11+09:00
AWS Redshiftに関して
Redshiftに関して
ReddhiftとはAWSが提供しているデータウエアハウスサービス。Redshiftでは並列コンピューティングをサポートしており、大量のデータを短時間で読み出し分析することが可能になります。強みとしては「コスト」「パフォーマンス」「アジリティ」があげられる。「コスト」はイニシャルコストが不要であり、使っただけの従量課金制になります。「パフォーマンス」はノードを追加することによりパフォーマンスを向上することができ、スケールアップ・スケールアウトどちらも対応可能。「アジリティ」はすぐに始められることができ、パフォーマンスも容易に上げることが可能。AWSの各サービスとの連携もしやすいのも強みであると思います。MPP(超並列処理)でありカラム指向でもあるのでデータウエアハウスとしてのパフォーマンスがいいというのが特徴です。データ分析基盤は大きく三つの層に分けることが出来ます。「データレイク層」「データウエアハウス層」「マート層」です。データレイク層は元データを格納している層。データレイクに保存されているデータは加工せずに元のデータをそのまま格納することが重要になってきます。データウエアハウス層はデータレイクにあるデータを分析向けに使いやすく加工した層。データレイクにあるデータというのはシステムの都合に合わせて設計されています。そのため、データ分析に最適なデータではないこともあります。そのためデータレイクにあるデータを加工して分析しやすい形に直し、データウェアハウスに格納します。マート層は特定の用途のために加工・整理したデータを格納した層。特定の分析や分析システムに特化したデータを格納している。Redshiftはこのうちの「データウェアハウス層」「マート層」で使用されます。
<参考にさせていただいたサイト>
[AWS]RedshiftをAWS Command Line toolから使ってみる
- 投稿日:2020-09-15T15:58:10+09:00
Enterprise Cloud Service Public Preview on AWS - Enterprise Security 編についてまとめて和訳してみた④
はじめに
今回は、2020年6月12日に Vinay Wagh 氏と Abhinav Garg 氏によって投稿されました「 Enterprise Cloud Service Public Preview on AWS 」で紹介されている Enterprise Security の1つである「 Customer managed keys for notebooks 」に関する内容を翻訳し、まとめてみました。
本記事のリンクは下記参照。
■リンク
・Customer managed keys for notebooks
・Enterprise Cloud Service Public Preview on AWSエンタープライズセキュリティ
今回の AWS 上での Databricks のエンタープライズクラウドサービスにおけるエンタープライズセキュリティの主な内容は以下の4つです。
今回は、この5つの内の「Notebook の為の顧客管理キー」について、紹介したいと思います。■エンタープライズセキュリティ
①Data Lake の真のポテンシャルを妨げないセキュリティ
②顧客管理VPC
③セキュアなクラスタ接続
④Notebook の為の顧客管理キー
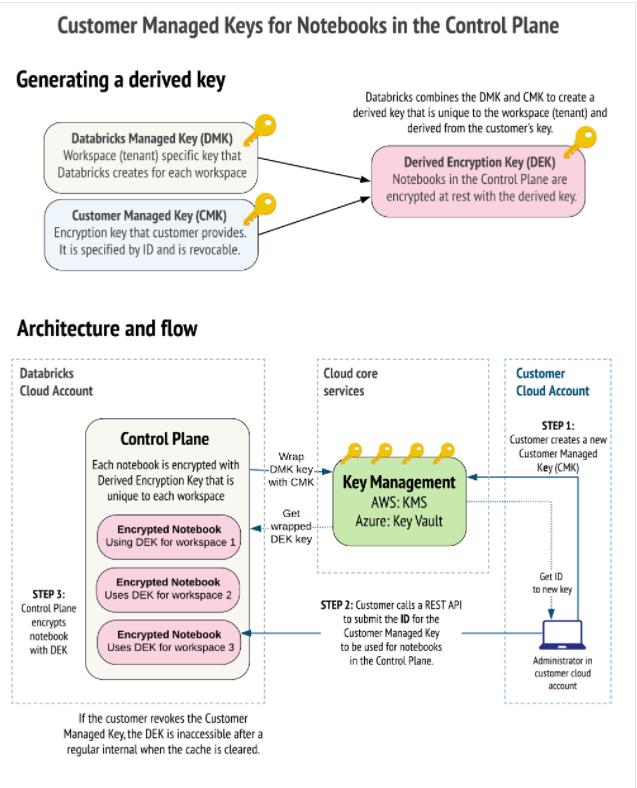
⑤IAM 証明パススルーNotebook の為の顧客管理キー
概要
セキュリティを重視する組織は、パブリッククラウドの使用、SaaS アプリケーション、そしてサードパーティサービスのリスクを評価するリスク管理プロセスがあります。
サードパーティのサービスプロバイダのリスクを軽減することで、外部サービスを使用するための強力なケースを構築できます。一部の規制された産業では、管理キーを使用して特定のタイプのデータを暗号化する必要があります。
これは、個人データやその他の機密情報を定期的に使用する部門にとって特に重要です。ワークスペースノートブックは、主にデータベースの Databricks コントロールプレーン内に保存されます。Databricks プラットフォームでは独自のキーでノートブックを暗号化でき、キーはワークスペースの作成時に提供する必要があります。
操作方法
顧客管理のキーは、コントロールプレーンのワークスペースのノートブックを暗号化します。顧客は、クラウドサービスのキー管理システムのIDで指定された顧客管理キー(CMK)と呼ばれる取り消し可能な秘密キーを提供します。AWS では、顧客キーは AWS Key Management Service(KMS)によって管理されます。
さらに、Databricks では、ワークスペースごとに Databricks が管理するキー(DMK)を作成します。 DMKは、データ暗号化キー(DEK)と呼ばれる結合暗号化キーを生成するために、CMK にラップされます。Databricks は DEK を使用して、ワークスペースのノートブックを暗号化します。
DEK は、数回の読み込み/書き取り操作のためにメモリにキャッシュされ、定期的にメモリから削除されるため、新しいリクエストがあった場合は、クラウドサービスの鍵管理システムへの別のリクエストが必要になります。
キーを削除、あるいは取り消すと、キャッシュ時間間隔の終了時にノートブックの読み取りや書き込みが失敗します。
ノートブック用の顧客管理キーの追加
顧客管理のノートブックを追加するには、アカウント API を使用してワークスペースを作成する際に CMK を追加する必要があります。
CMK の設定方法:
- AWS KMS で対称キーを作成または選択するには、「対称 CMK の作成」または「キーの表示」の手順に従います。
- ワークスペース作成の際は、下記の3つの値が必要となるのでコピーを取りましょう。
- Key ARN
- Key alias
- Key region
- キーポリシータブで、ポリシー表示に切り替えてキーポリシーを編集し、Databricks がキーを使用して暗号化および復号化処理を実行できるようにします。下記の様に編集します。
{ "Version": "2012-10-17", "Id": "key-policy-databricks", "Statement": [ { "Sid": "Allow Databricks to use KMS key for Notebooks", "Effect": "Allow", "Principal": { "AWS": "arn:aws:iam::414351767826:root" }, "Action": [ "kms:Encrypt", "kms:Decrypt" ], "Resource": "*" } ] }
- キーを登録するには、「アカウント API を使用して新しいワークスペースを作成する」、の「ステップ 4:ノートブック用の顧客管理キーを構成する(オプション)」の指示に従います。
おわりに
Notebook の為の顧客管理キーに関するまとめは以上です。
詳細については、元記事をご参照ください。
- 投稿日:2020-09-15T15:01:12+09:00
AWS EBSボリューム追加方法
前提条件
環境:Amazon Linux AMI release 2015.09
やりたいこと:バックアップボリュームへ50GB追加EBSボリュームを追加するには?
AWSコンソールで追加して追加したボリュームを割り当てると良い。
具体的な手順
①teratermで対象環境へログインしroot権限になる
# sudo -s②以下コマンドで現状のボリュームを把握する
# lsblk # df -h③AWSコンソール上で対象仮想マシンのボリュームを変更する
④teratermで対象環境へ再度ログインし、root権限になる
# sudo -s⑤サイズ変更を実施する
# resize2fs /dev/xvda [変更するボリューム名]⑥サイズが変更されたことを確認する
# lsblk # df -h以上がEBSのボリューム拡張方法でした。
お役に立てれば幸いです。
- 投稿日:2020-09-15T13:48:19+09:00
AWS SAAテスト対策ノート:EC2に関する暗記事項
一問一答集
Question Answer インスタンスがインターネットに接続できない原因 1.PublicIP,ElasticIPが付与されていない
2.NACLで許可されていない
3.セキュリティグループで許可されていない
4.インターネットゲートウェイにルーティングされていない
5.インスタンスがDNSを受け取っていない(VPCの設定の問題)CloudWatchの①標準メトリクス、②カスタムメトリクス で取得できる情報 ①CPU使用率・DiskReadBytes・NetworkInOut・インスタンスの状態
②OSメモリ使用率・ディスク使用率インスタンスの停止時・終了時・再起動時のそれぞれで、インスタンスストアのデータは維持されるか? 再起動時のみ維持される。 インスタンス終了時にルートボリュームを維持する方法は? DeleteOnTerminationをfalseに設定する インスタンスファミリーの選び方
タイプ 特徴 M 基本 T バースト可能(要求されるCPUが変動するときとか) C,Z CPU性能が求められるとき R,X メモリ性能が求められるとき I,D,H ストレージ(IはSSD, D,HはHDD)性能が求められるとき F,P,G GPUやFPGAを使いたい(高速コンピューティング) A ARMのチップを使いたい 購入オプション
リザーブドインスタンス
項目 説明 契約期間 1年 or 3年 支払い方法 全額前払・一部前払い・前払いなし スタンダードで変更可能な点 AZ・サイズダウン コンバーティブルのみで変更可能な点 インスタンスファミリー・OS・支払い方法・サイズアップ オンデマンドとの比較 稼働率が70%を超える場合はリザーブドを選んだ方が安い スポットインスタンス
項目 説明 選び方 バッチ処理等に向いている。※ミッションクリティカルなタスクには不向き スポットブロック 1~6Hの間で継続時間を指定する(停止しないようにブロックする) スポットフリート インスタンスが停止しても指定台数の稼働を維持してくれるオプション ハードウェア占有インスタンス(Dedicated Instance)
- 他利用者とは分離したハードウェアで実行できる。※物理ホストの指定はできない!
専用ホスト(Dedicated Hosts)
- 他利用者とは分離したハードウェアで実行できる。
- 物理ホストを指定可能なので、BYOLのソフトウェアライセンスを使いたいときに選択する。’
ネットワーク関連
項目 説明 Elastic IPが課金される条件は? 1. EIPがインスタンスにアタッチされていない。
2. EIPがアタッチされているインスタンスが停止している。
2. 複数のEIPがインスタンスにアタッチされている。インスタンスを停止して起動した場合のIP Private IP → 変更されない
Public IP → 変更される
- 投稿日:2020-09-15T13:48:19+09:00
AWS SAAテスト対策ノート:試験に出るポイントまとめ 〜EC2〜
一問一答集
Question Answer インスタンスがインターネットに接続できない原因 1.PublicIP,ElasticIPが付与されていない
2.NACLで許可されていない
3.セキュリティグループで許可されていない
4.インターネットゲートウェイにルーティングされていない
5.インスタンスがDNSを受け取っていない(VPCの設定の問題)CloudWatchの①標準メトリクス、②カスタムメトリクス で取得できる情報 ①CPU使用率・DiskReadBytes・NetworkInOut・インスタンスの状態
②OSメモリ使用率・ディスク使用率インスタンスの停止時・終了時・再起動時のそれぞれで、インスタンスストアのデータは維持されるか? 再起動時のみ維持される。 インスタンス終了時にルートボリュームを維持する方法は? DeleteOnTerminationをfalseに設定する インスタンスファミリーの選び方
タイプ 特徴 M 基本 T バースト可能(要求されるCPUが変動するときとか) C,Z CPU性能が求められるとき R,X メモリ性能が求められるとき I,D,H ストレージ(IはSSD, D,HはHDD)性能が求められるとき F,P,G GPUやFPGAを使いたい(高速コンピューティング) A ARMのチップを使いたい 購入オプション
リザーブドインスタンス
項目 説明 契約期間 1年 or 3年 支払い方法 全額前払・一部前払い・前払いなし スタンダードで変更可能な点 AZ・サイズダウン コンバーティブルのみで変更可能な点 インスタンスファミリー・OS・支払い方法・サイズアップ オンデマンドとの比較 稼働率が70%を超える場合はリザーブドを選んだ方が安い スポットインスタンス
項目 説明 選び方 バッチ処理等に向いている。※ミッションクリティカルなタスクには不向き スポットブロック 1~6Hの間で継続時間を指定する(停止しないようにブロックする) スポットフリート インスタンスが停止しても指定台数の稼働を維持してくれるオプション ハードウェア占有インスタンス(Dedicated Instance)
- 他利用者とは分離したハードウェアで実行できる。※物理ホストの指定はできない!
専用ホスト(Dedicated Hosts)
- 他利用者とは分離したハードウェアで実行できる。
- 物理ホストを指定可能なので、BYOLのソフトウェアライセンスを使いたいときに選択する。’
ネットワーク関連
項目 説明 Elastic IPが課金される条件は? 1. EIPがインスタンスにアタッチされていない。
2. EIPがアタッチされているインスタンスが停止している。
2. 複数のEIPがインスタンスにアタッチされている。インスタンスを停止して起動した場合のIP Private IP → 変更されない
Public IP → 変更される
- 投稿日:2020-09-15T13:35:04+09:00
Fargateのスケールアウトを高速化する
はじめに
ALB+Fargateという構成で動くWebサービスのスケールアウトが遅く、メディア露出や
DM配信によるスパイクアクセスに耐えられない、という問題があり改善策を検討していた
ところ下記記事を見つけました。爆速でFargateをスケールさせる「aws-fargate-fast-autoscaler」を試してみた
記事抜粋簡単に動作原理を説明すると、Fargateをオートスケールさせる場合、通常はECSのターゲット追跡 スケーリングポリシーなどを利用しECSサービスにおけるCloudWatchメトリクスとアラームを利用して タスク数などを制御します。 ただ、この場合、CloudWatchメトリクスからアラーム発報までにどうしてもタイムラグが有り数秒単位 でのスケーリングが難しく基本は分単位でのスケーリングとなっていました。 そこを、この「aws-fargate-fast-autoscaler」では、Step Functionsを利用して3秒毎に Fargateタスクへのコネクション数を取得し、その結果に応じて即ecs service updateでタスク数の 上限を引き上げることで、ターゲット追跡スケーリングポリシーでは実現できない高速なスケーリングを 実現しています。これを導入するか検討した結果、後述する理由により自作ツールを作ることにしました。
(nginxのstub_statusで検知するというアイデアは面白いのでそのまま活用しています!)
この記事はそのツール紹介です。自作する理由
- 最大実行時間の制限が1年
- Step Functions版は、1年を超えて連続稼働できない
- コスト抑えたい
- Step Functions版は、月あたり約65USDかかる
- 自作ツールだと月額11USD程度
- 複数サービスに対応したい
- Step Functions版は、対象URLが1つ
- 弊社では
ALB+Fargate構成の複数Webサービスを運用しているためfast-autoscaler紹介
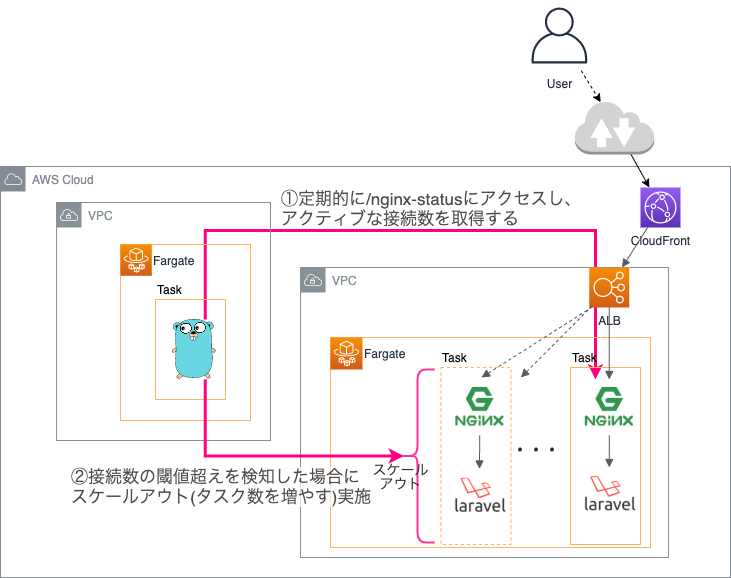
概要
/nginx-status(stub_status)に定期的にアクセスし、Active Connectionsの値を取得し
閾値を超えていた場合にスケールアウトルールに従いタスク数を変更し、Slack通知します。対象となるURL/閾値/Slack通知要WebhookURLは、起動時にパラメータストアから取得します。
コードはこちら
処理フロー
- コンテナ起動時にパラメータストアから設定情報(json形式,詳細後述)を取得
- 指定された
/nginx-statusURLにリクエスト送信し、Active Connectionsの値を確認- 閾値を超えていた場合)
->スケールアウト実行->/nginx-statusチェック停止->猶予期間経過後チェック再開
- 閾値を超えていない場合)
->一定周期での/nginx-statusチェックを継続処理イメージ
使い方
セットアップ手順
CloudFormationテンプレートを使用して、パラメータストア、IAMロール、ECSタスク定義、
ECSクラスタ、ECSサービスを作ります。
CloudFormationテンプレートをダウンロード
curl -sLO https://raw.githubusercontent.com/senbazuru/fast-autoscaler/master/cfn-template.ymlCloudFormationコンソールで上記テンプレートを使用してスタックを作成
- スタック名(=ECSクラスタ/サービス名)を指定(任意)
- 以降、fast-autoscalerを指定した前提で記載
- あとは、コンテナが動くVPC、Subnet、SGを環境に合わせて指定して作成する
作成した時点ではパラメータストアの設定が空なので、CloudWatchLogsにはエラーが
出ている状態ですが問題ありません。
パラメータストアの設定を編集
/ecs/fast-autoscaler/config.jsonという名前のパラメータを編集- 後述する設定情報の説明を参照して書き換えて保存
設定変更を反映
- awscliでタスクを停止(その後自動的に起動されることで設定が反映される)
export AWS_PROFILE={AWSクレデンシャルのプロファイル名} TASK_ID=$(aws ecs list-tasks --cluster fast-autoscaler | jq -r '.taskArns[]' | awk -F/ '{print $NF}') aws ecs stop-task --cluster fast-autoscaler --task ${TASK_ID}設定情報
- json形式でパラメータストアに保存
- タイプはString or SecureStringどちらでもOK
- 上述CFnで作成した場合はStringになります
設定例{ "Services": [ { "StatusUrl":"https://example-a.com/nginx-status", "StatusAuthName":"Status-Auth-Key", "StatusAuthValue":"hogefuga", "ScaleoutThreshold":100, "EcsClusterName":"example-app", "EcsServiceName":"example-app", "SlackWebhookUrl":"https://hooks.slack.com/services/XXXXXXXXX/XXXXXXXXX/xxxxxxxx" }, { "StatusUrl":"https://example-b-1234567890.ap-northeast-1.elb.amazonaws.com/nginx-status", "ScaleoutThreshold":150, "MinDesiredCount":2, "CheckInterval":10, "EcsClusterName":"example-app-b", "EcsServiceName":"example-app-b" } ] }
フィールド名 説明 必須 デフォルト 例 StatusUrl nginx-statusのURL ○ https://example-a.com/nginx-status StatusAuthName 認証用HTTPヘッダ名 Status-Auth-Key StatusAuthValue 認証用HTTPヘッダ値 hogefuga ScaleoutThreshold スケールアウト発動するActiveConnectionsの閾値 150 150 MinDesiredCount スケールアウト時に現在のタスク数とみなす最小数 5 5 CheckInterval nginx-statusをチェックする間隔(秒) 3 3 EcsClusterName ECSクラスタ名 ○ example-app EcsServiceName ECSサービス名 ○ example-app SlackWebhookUrl Slack通知用WebhookURL https://hooks.slack.com/services/XXXXXXXXX/XXXXXXXXX/xxxxxxxx 補足
- StatusUrlには
nginxに到達できるドメイン+stub_statusパスを指定してください
- verifyをスキップするので、SSL証明書のコモンネームとの不一致は許容されます
(つまり、ALBドメイン名を直接指定可能)- スケールアウトは現在のタスク数を2倍にします
- ただし、現在のタスク数が1の場合に2倍にしても2にしかならずスケール不足となる可能性があります
その場合はMinDesiredCountを指定してください。この値をタスク数の下限値として動作します
例)現在タスク数=3、MinDesiredCount=5の場合、3<5なので現在のタスク数を5とみなし、その2倍の10にDesiredCountを変更します。- StatusAuthName/StatusAuthValueで指定した値が
/nginx-statusへのリクエストにヘッダとして追加されます
- fast-autoscaler以外から
/nginx-statusへのリクエストを防ぐため
ALBルーティング設定のヘッダ認証で使用します- SlackWebhookUrlに指定があればスケールアウト時にSlackに通知を行います
- 下記イメージ

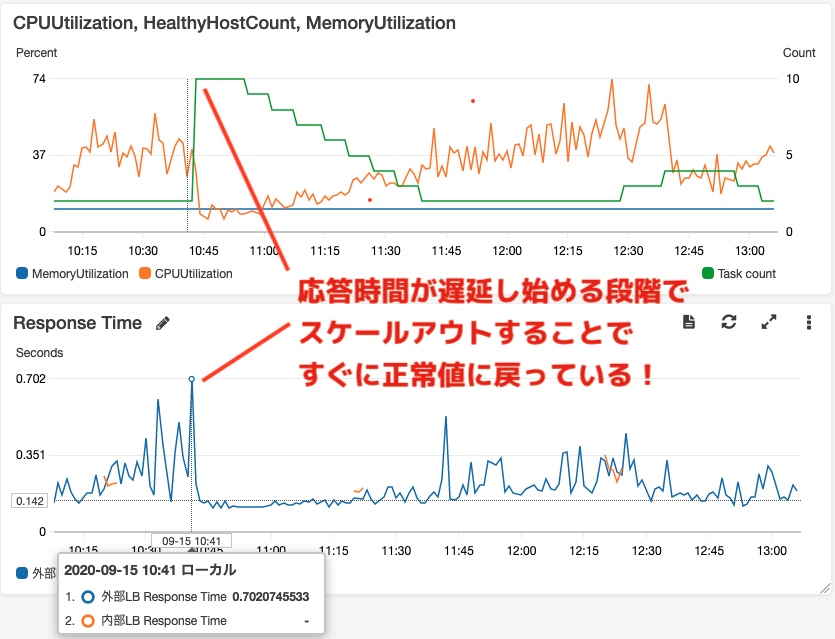
効果(例)
リクエスト数が急増し負荷がかかったために応答速度が遅延し始めていますが、その直後に
fast-autoscalerがスケールアウト(タスク数2->10)したことですぐに正常な応答速度に
戻っていることがわかります!
その後は、ターゲット追跡スケーリングポリシーでタスク数が徐々に減っています。
上がCPU/Mem使用率(左軸)、タスク数(右軸)
下が応答時間のグラフまとめ
これで安心して眠れます!
もしよければお使いください。
- 投稿日:2020-09-15T13:23:53+09:00
Route53のALIASとCNAMEレコード
Zone apexとは(前提知識)
サブドメインを含まないドメイン名
例:
example.jp(○○○.example.jpの○○○の部分がないやつ)?
www.example.jp じゃなくて example.jpRoute53のレコードタイプ
Aレコード
ドメイン名:IPアドレス(1:N)
※IPv4対応AAAAレコード
ドメイン名:IPアドレス(1:N)
※IPv6対応CNAMEレコード
ドメイン名:参照ドメイン名
すでに定義されているドメイン名の別名を定義するALIASレコード
ドメイン名:AWSリソースのドメイン名
ALIASレコードについて
Route53でホストゾーンを作成するとホストゾーンと同じ名前のNSレコードが自動的に作成される。
CNAMEレコードでは同じドメインやサブドメインを使うことができないので、Zone apexのCNAMEは書けない。これはダメ↓
example.com NS ns-2048.awsdns-64.com (Route53が作ったやつ) example.com CNAME yyy.example.com Aレコードなら登録できる
これはOK↓
example.com NS ns-2048.awsdns-64.com (Route53が作ったやつ) example.com A yyy.example.com でもELBをマッピングしたい時、ELBのIPアドレスは変動するからちょっと無理み?
そんな時!
ALIASレコードが使える!これはOK↓
example.com NS ns-2048.awsdns-64.com (Route53が作ったやつ) example.com A(ALIAS) AWSリソースのドメイン名 ALIASとCNAMEの違い
Zone apexでなければCNAMEを使えるけど、やっぱりAliasを使った方が良い
ALIASはAレコードと同じ振る舞いをするから?CNAMEの振る舞い
yyy.sample.com → AWSリソースのドメイン名 → IPアドレス
ALIASの振る舞い
yyy.sample.com → IPアドレス
ドメイン名ふっとばしてくれる?
参考
https://blog.serverworks.co.jp/tech/2016/07/07/zone-apex-cname/
- 投稿日:2020-09-15T12:14:41+09:00
AWS Elastic Beanstalkを使ってみる
AWS Elastic Beanstalkを実際に使用してみましょう。
アプリケーションと環境を作成する
サンプルアプリケーションを作成するには、 ウェブアプリの作成コンソールウィザードを使用します。Elastic Beanstalk アプリケーションを作成し、その中に環境を起動します。環境は、アプリケーションコードを実行するために必要な AWS リソースのコレクションです。
*オレンジ色のCreateApplicationボタンをクリック
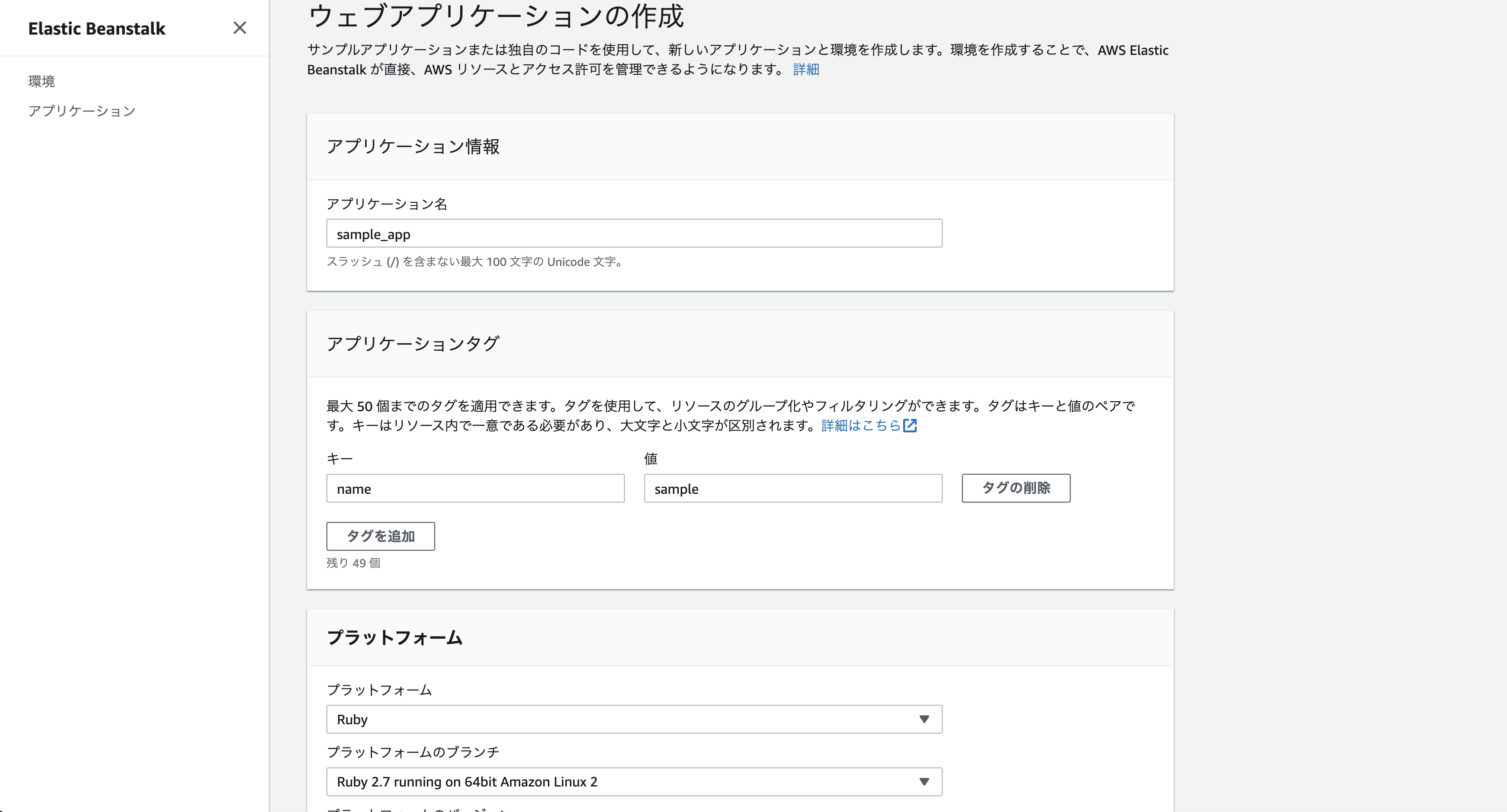
必要に応じて、アプリケーションタグを追加します。
アプリケーション名はとりあえずサンプル用のアプリを作って見たかったので「sample」とします。
[プラットフォーム] でプラットフォームを選択し(下の方見切れちゃってますけどサンプルを選択しています。)
そして[アプリケーションの作成] を選択します。
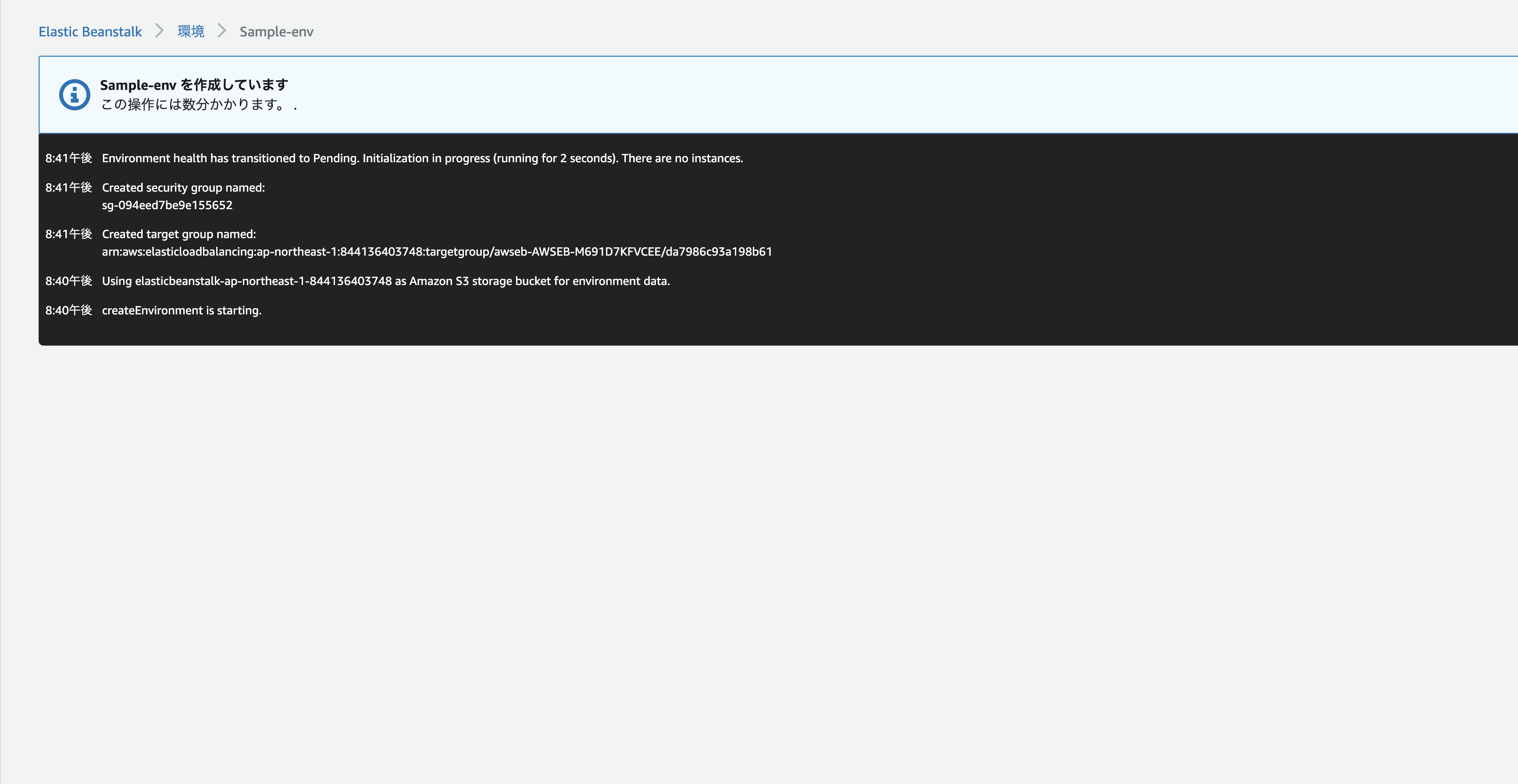
これで5分程コーヒーでも飲みながら待っていると、、、。
環境の作成プロセス中、コンソールでは進捗状況が追跡され、イベントが表示されます。
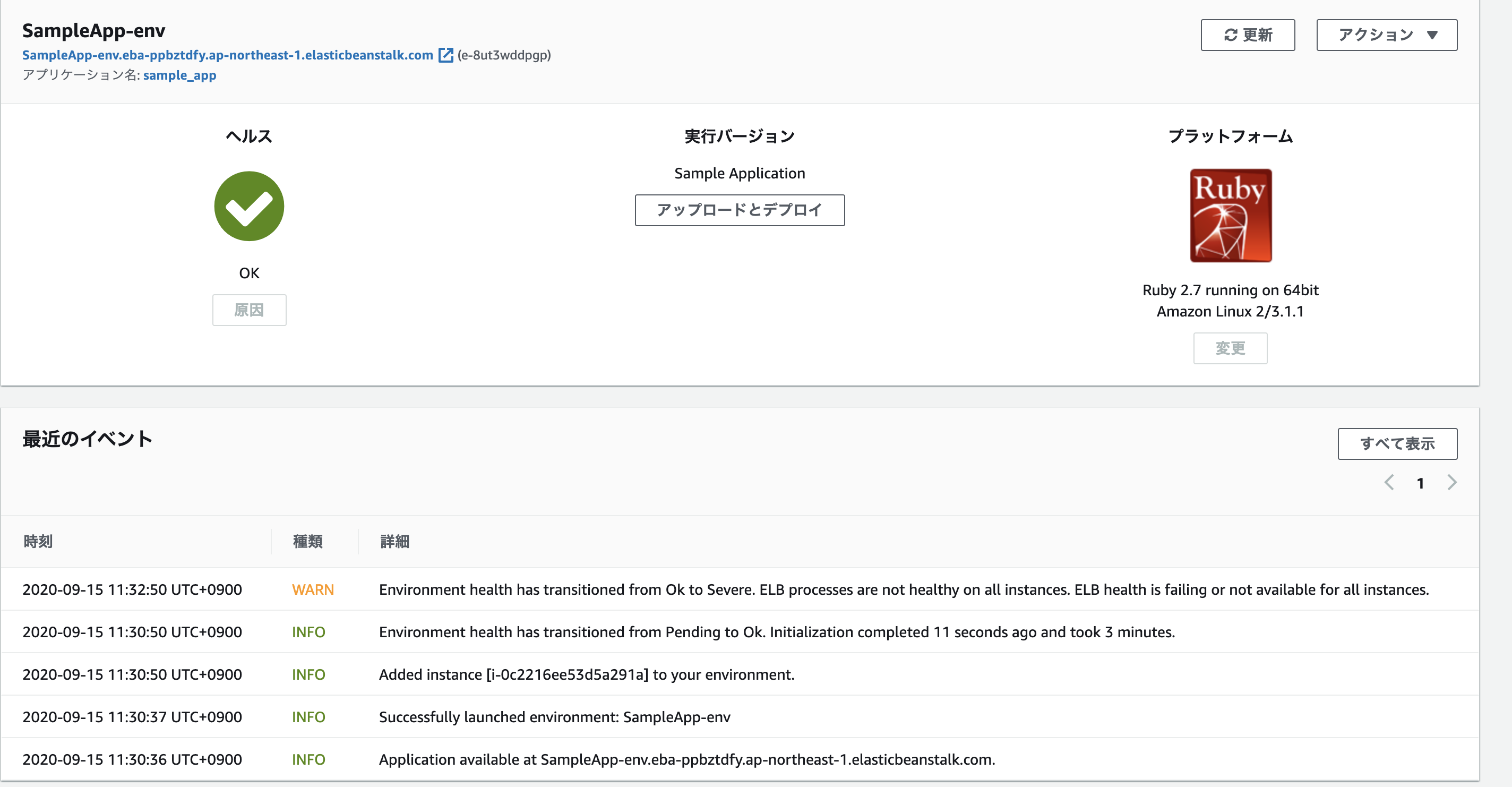
こんな感じですぐに環境が設定できました!
すべてのリソースが起動され、アプリケーションを実行している EC2 インスタンスがヘルスチェックに合格すると、環境のヘルス状態が Ok に変わります。これで、ウェブアプリケーションのウェブサイトを使用できるようになりました。サンプルアプリケーション用に作成された AWS リソース
サンプルアプリケーションを作成すると、Elastic Beanstalk によって以下の AWS リソースが作成されます。各プラットフォームは、それぞれ特定の言語バージョン、フレームワーク、ウェブコンテナ、またはそれらの組み合わせをサポートするための、さまざまなソフトウェア、設定ファイル、スクリプトを実行します。ほとんどのプラットフォームでは、ウェブアプリケーションの前にウェブトラフィックを処理するリバースプロキシとして Apache または nginx のいずれかを使用します。そのプロキシがリクエストをアプリケーションに転送し、静的アセットを提供して、アクセスログとエラーログを生成します。
インスタンスセキュリティグループ – ポート 80 上の受信トラフィックを許可するように設定された Amazon EC2 セキュリティグループ。このリソースでは、ロードバランサーからの HTTP トラフィックが、ウェブアプリケーションを実行している EC2 インスタンスに達することができます。デフォルトでは、トラフィックは他のポート上で許可されません。
Amazon S3 バケット – Elastic Beanstalk の使用時に作成されるソースコード、ログ、その他のアーティファクトの保存場所。
Amazon CloudWatch アラーム – お客様の環境内のインスタンスの負荷をモニタリングする 2 つの CloudWatch アラーム。負荷が高すぎたり低すぎたりする場合にトリガーされます。アラームがトリガーされると、Auto Scaling グループはレスポンスとしてスケールアップまたはダウンを行います。
AWS CloudFormation スタック – Elastic Beanstalk はAWS CloudFormation を使用して環境内のリソースを起動し、設定の変更を伝達します。リソースは、AWS CloudFormation コンソールに表示できるテンプレートで定義されます。
ドメイン名 – ウェブアプリケーションまでのルートとなるドメイン名であり、subdomain.region.elasticbeanstalk.com の形式です。
と今回は以上です。
- 投稿日:2020-09-15T11:37:28+09:00
AWS は ”銀行” に例えるとわかりやすい説 ①
AWS 初心者がイメージを掴める助けになるように書きました。
AWSの学習に非常に苦戦しました。そもそもインフラとかネットワークの知識が皆無でなにもイメージができず、苦労しました。
自分は最初インターネットの適当なAWSハンズオンの記事でとりあえずWebサーバーを立ててみたんですがそのときとりあえずできたっていうだけでイメージが全く掴めなかったです。しかしそのとき、銀行に例えてみたらイメージしやすかったので紹介します。
一部無理やり銀行に置き換えているところがあるような気もします。。。最終ゴール
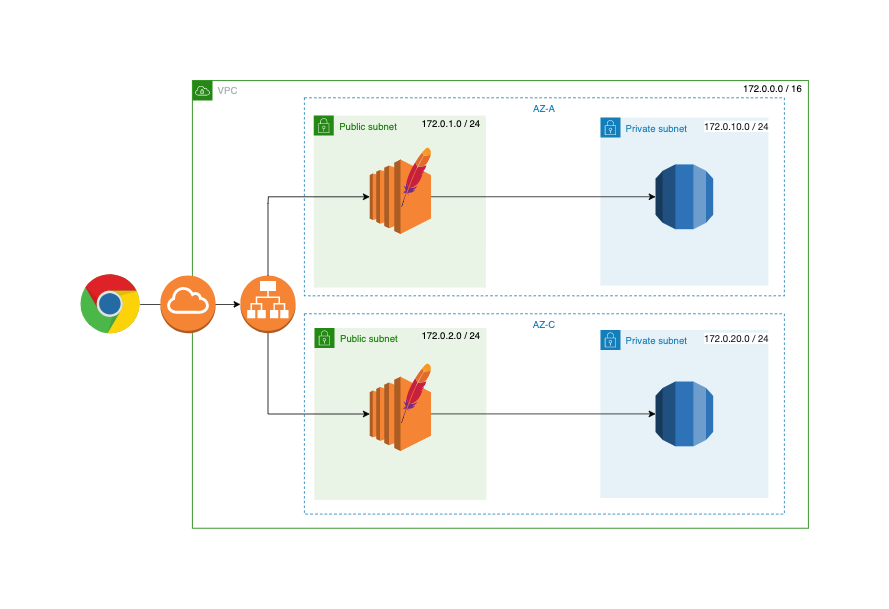
最終的に目指すゴールはこんな感じです。マルチ AZ 化した Web サーバーと RDS があるというよくある構成にする予定です。ロードバランサで負荷分散をしています。
これを目指して一つ一つ作っていきます。AWS
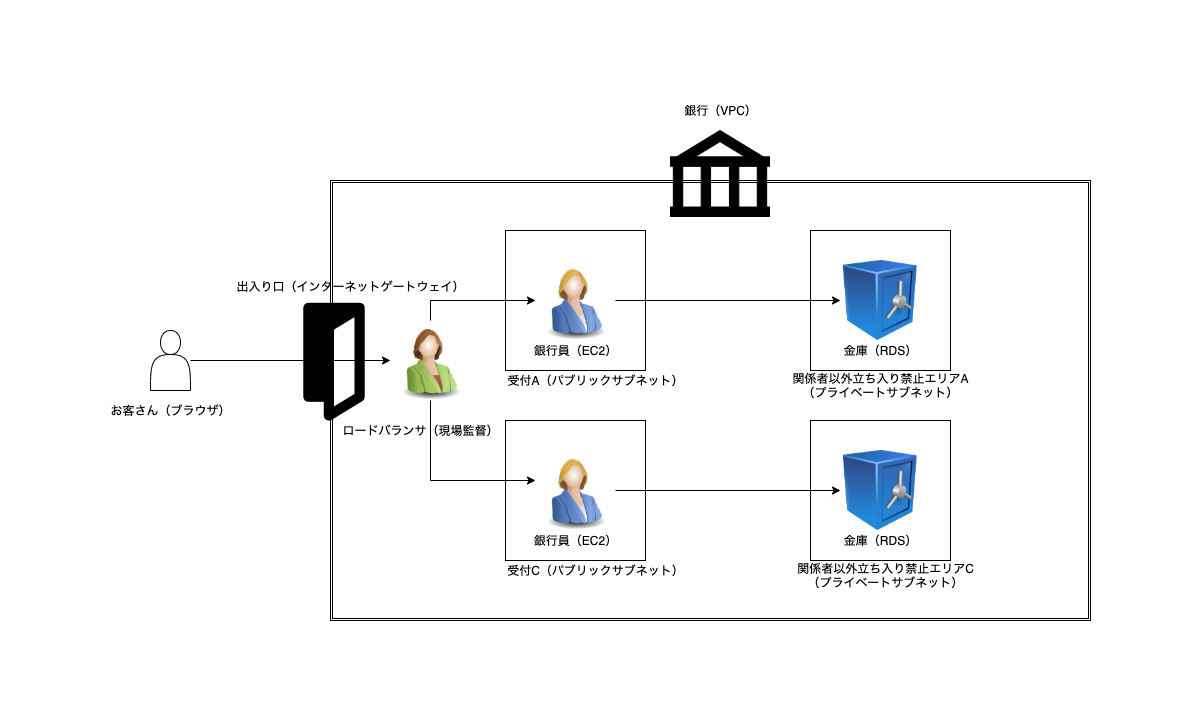
銀行で例えると最終的にこんな感じの銀行を作るイメージになります。
銀行
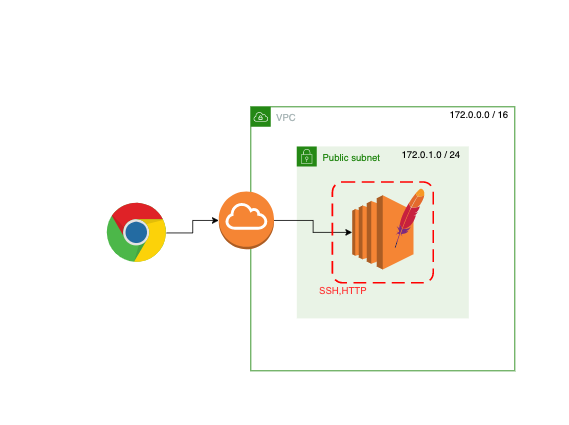
シンプルなWebサーバーを立てる
まず今回作るのは EC2 に Apache を載せた最低限のWebサーバーです。ブラウザでアクセスするとページが返ってきます。(赤い点線はセキュリティグループです。)
銀行に置き換えた図にするとこうなります。
では作っていきます。
上の非常にシンプルなWebサーバーを立ててみます。
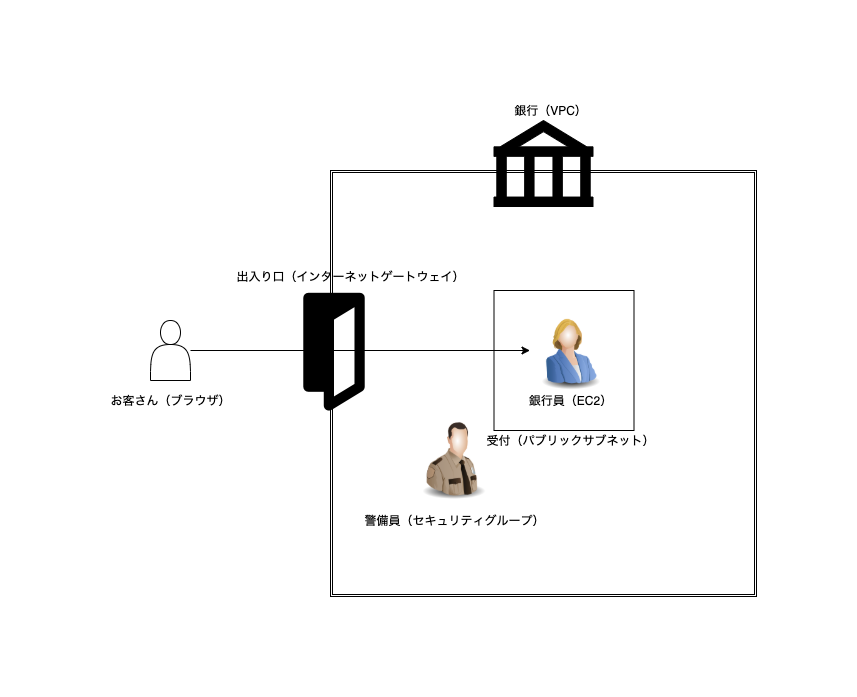
このサーバーで使うAWSの各サービスを銀行に例えると次のような対応になります。
AWS 銀行 VPC 銀行(建物そのもの) Internet Gateway 出入り口 Public Subnet (銀行員が待機している)受付窓口 EC2 銀行員 セキュリティグループ 警備員 ブラウザ お客さん 今回作るものは図で表すとこんな感じです。Apache をインストールさせた最低限のWebサーバーです。ブラウザでアクセスするとページが返ってきます。
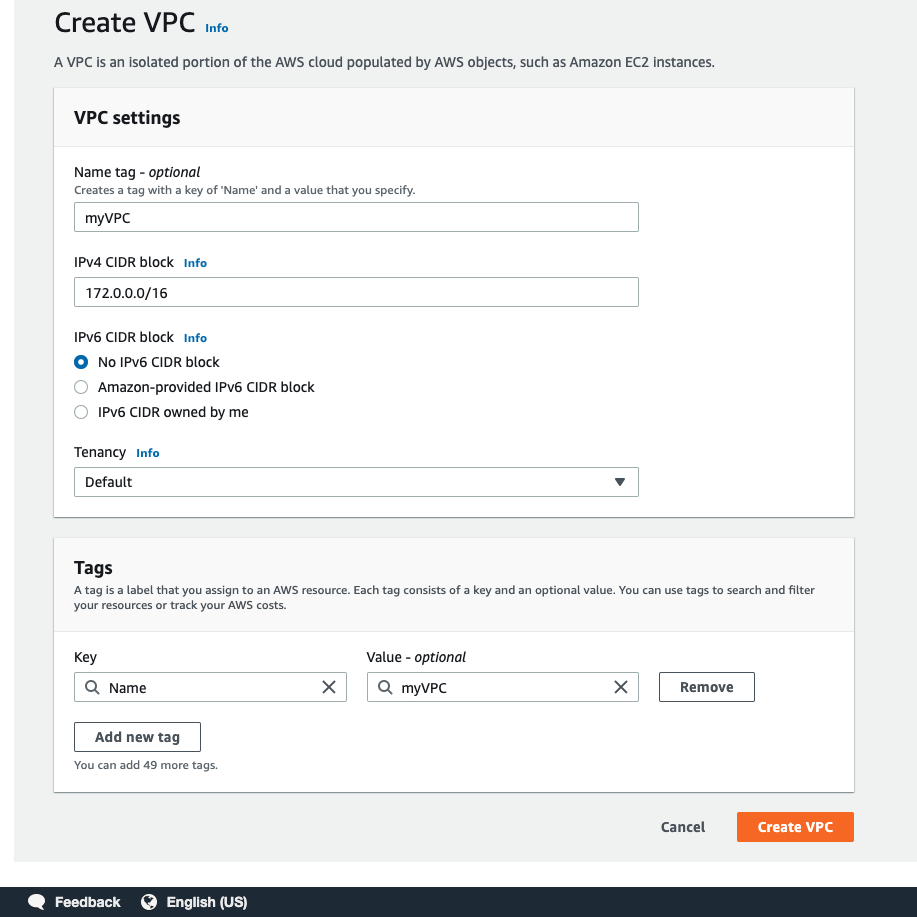
VPC 作成 (銀行の建設)
とりあえず銀行を建設しないと始まりません。すなわちVPCを作成します。
Tenancyはサーバーを占有するかしないかを決めれるみたいです。
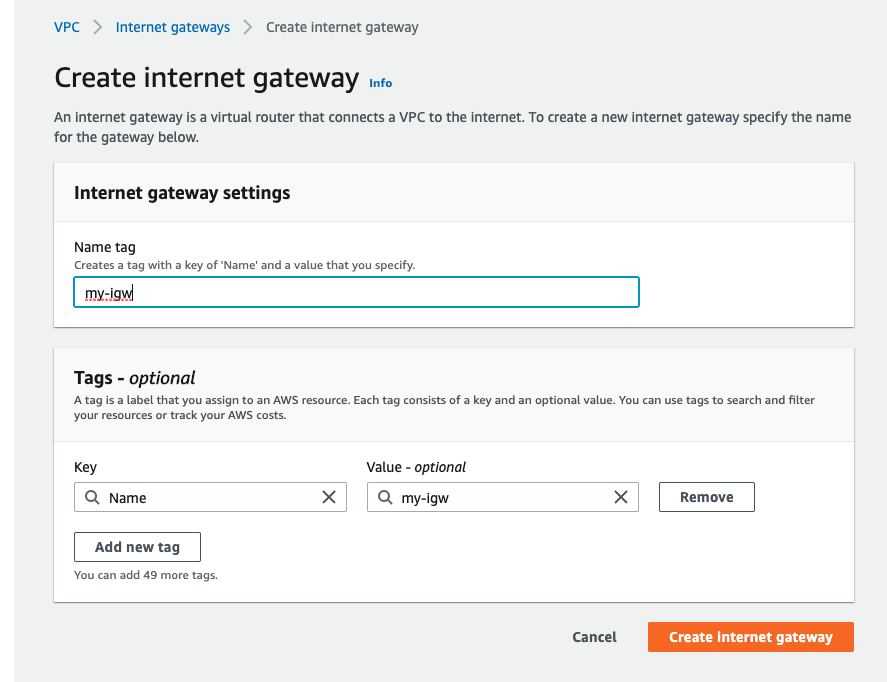
Internet Gateway 作成 (出入り口の設置)
銀行があっても出入り口がないと誰も入れません。「my-igw」という名前の Internet Gateway を作って 「Action」 から 「Attach to VPC」を選択し、 VPC にアタッチすなわち銀行に出入り口を設置します。ただしこのままでは開閉せずずっとしまったままなのでPublic Subnet の作成時に開閉できるようにします。
Public Subnet 作成 (窓口の設置)
ここまでよくある自動ドア付きの銀行そのものは完成しました。しかし建物だけではお客さんがきてもなにもできません。
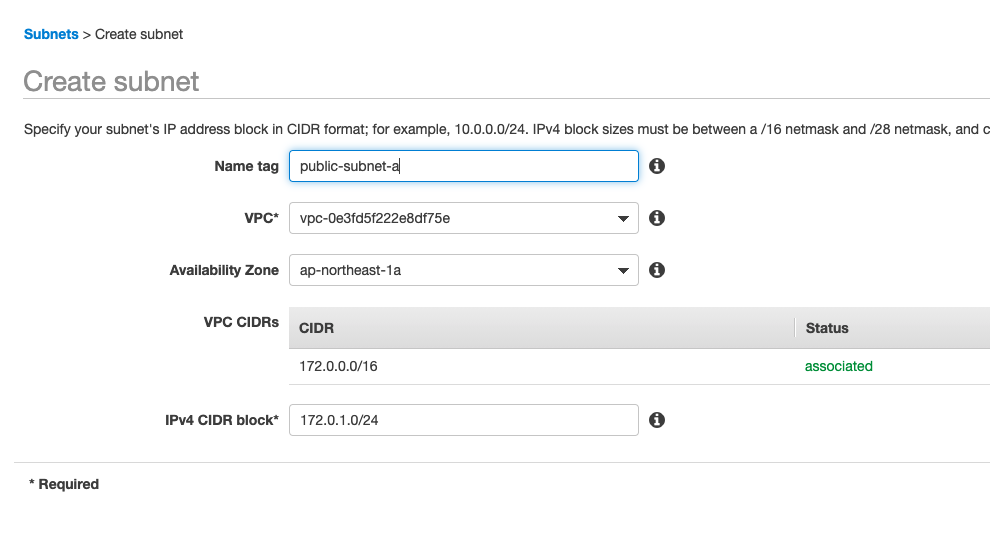
そこで次は銀行の内部を作っていきます。まずは窓口がないと受付できないので窓口となる Public Subnet を設置します。
名前は「public-subnet-a」、VPCはさっき作った「myVPC」を選択し、AZ、CIDR block は図のように設定します。
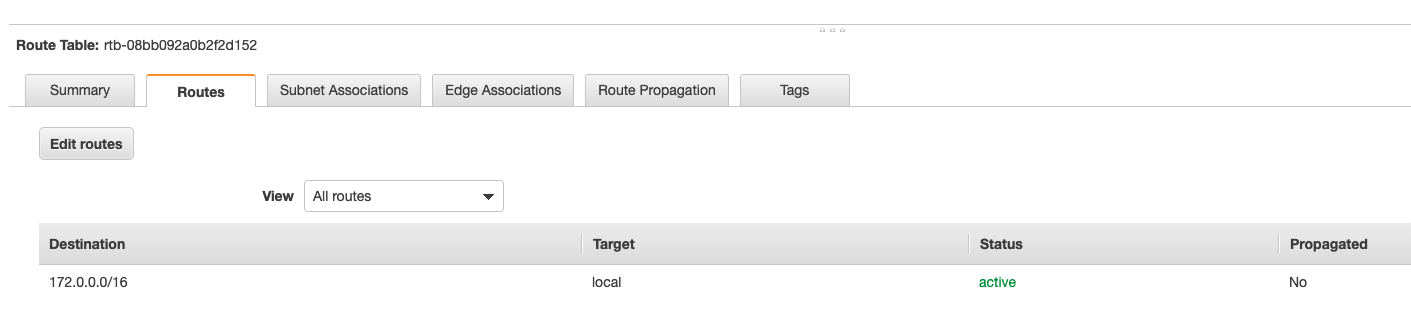
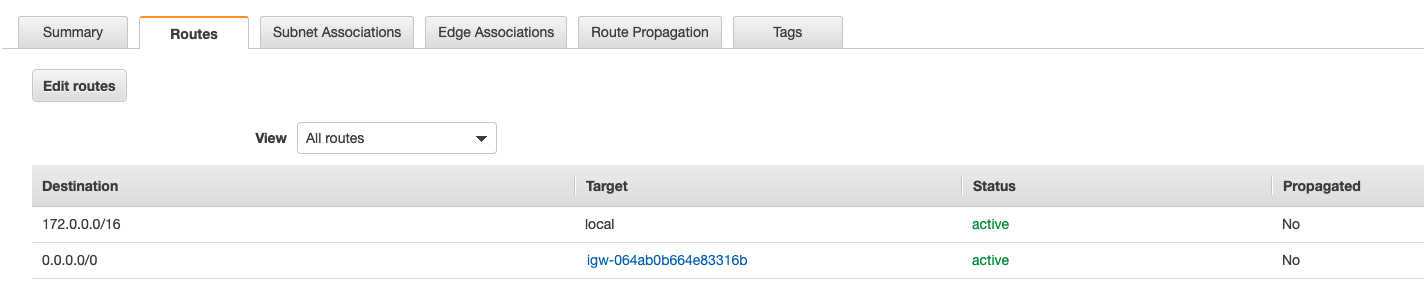
名前は「public」とついていますが、このままでは機能的にはPrivate Subnet なので、入り口にあたる Internet Gateway をつけて Public Subnet にしていきます。そこで使うのがルートテーブルです。ルートテーブルをクリックすると身に覚えのないルートテーブルが作成されていますが、これはVPCを作成した時に勝手に作られるメインルートテーブルです。Destination は送信先、Target は送信元と思うとわかりやすいです。すなわちメインルートテーブルはVPCの通信は全部VPC内で完結する(インターネットなどの外部とつながらない)ということを表しています。「my-main」と名前の変更だけしておきました。
メインルートテーブルは基本そのままで、カスタムルートテーブルを作って関連付けしていきます。
「my-custom」というルートテーブルを作り、Routes は下のように「my-igw」を設定し、さっき作った「public-subnet-a」を Subnet Association で選択して関連付けを行います。
これで名実ともに「public-subnet-a」は Public Subnet になり、 Internet Gateway はインターネットと繋がる、すなわち出入り口は誰に対しても開閉することところまでできました。EC2 作成 (銀行員さん設置)
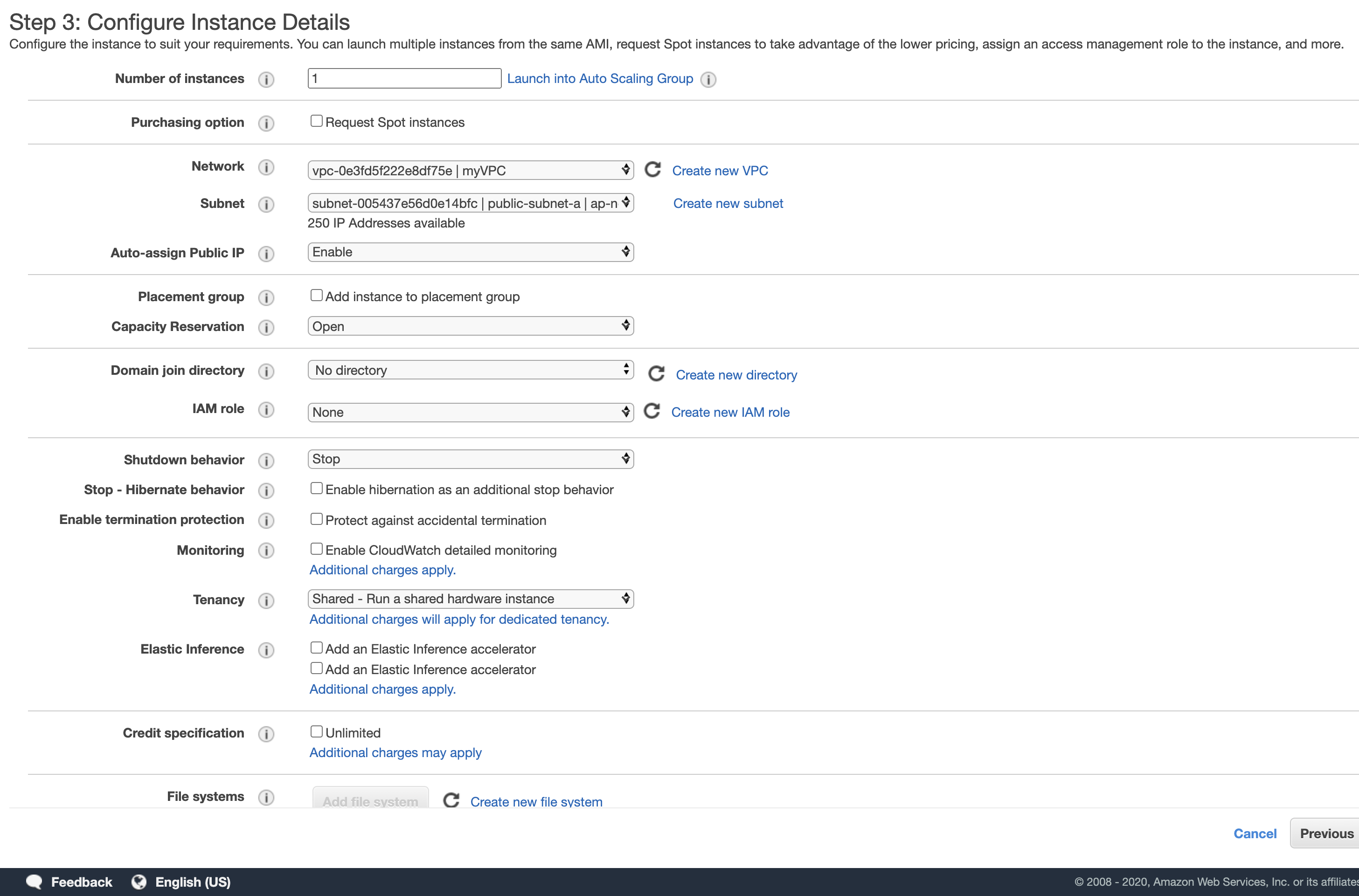
Step1 で Amazon Linux2 を選択し、Step2 で t2.micro を選択し、Step3は、 Networking に自分で作った「myVPC」、Subnet に自分で作った「public-subnet-a」、Auto-assign Public IP を「Enable」に変更します。他はデフォルトのままです。Step3は下のような感じです。
ちなみにAuto-assign Public IP を「Enable」にしたのはEC2に後からssh接続して Apache のインストールなどを行うためで、Public IPとはこの銀行の住所に当たるものです。
Step4はそのまま、Step5 で Nameタグに 「my-web」 と付けました。Step6 でssh接続するためにこのようなセキュリティグループを作成しました。
Step7の確認で Launch をクリックし、Key Pair で「my-key」というキーペアを作り、my-key.pemファイルをダウンロードしました。
このファイルはこの後のssh接続でも使うのでダウンロードしておきます。
ssh接続では銀行員さんとのコミュニケーション方法だと思うとわかりやすいと思います。すなわち ssh というコミュニケーション方法がとれる銀行員さんが設置できました。
ここまでで銀行を立てて出入り口を設置し、受付にsshというコミュニケーション方法ならコミュニケーションができる銀行員さん(EC2)がいるという状況まできました。Apache インストール (銀行員さんの職業研修)
今、銀行員さんはただそこにいるだけで、仕事のやり方を教わっていません。なので仕事のやり方を教えてあげます。
やってほしい仕事は Apatche のデフォルトページを返してもらうことなのでそれを教えてあげます。 sshでしかコミュニケーションを取れないのでsshでコミュニケーションをとって教えてあげます。具体的にはこのようにします。cd Downloads # Downloadsにpemファイルがあるため chmod 600 my-key.pem ssh -i "my-key.pem" ec2-user@13.231.164.108 # PublicIPを代入(自分の場合今回は12.231.164.108) __| __|_ ) _| ( / Amazon Linux 2 AMI ___|\___|___| [ec2-user@ip-172-0-1-209 ~]$ sudo yum install httpd -y # Apacheインストール [ec2-user@ip-172-0-1-209 ~]$ sudo yum start httpd.service # Apacheスタート [ec2-user@ip-172-0-1-209 ~]$ sudo systemctl status httpd.service # Apacheが動いてるか確認 [ec2-user@ip-172-0-1-209 ~]$ sudo systemctl enable httpd.service # Apache自動化これで研修が終了し、仕事のやり方を覚えることができました。
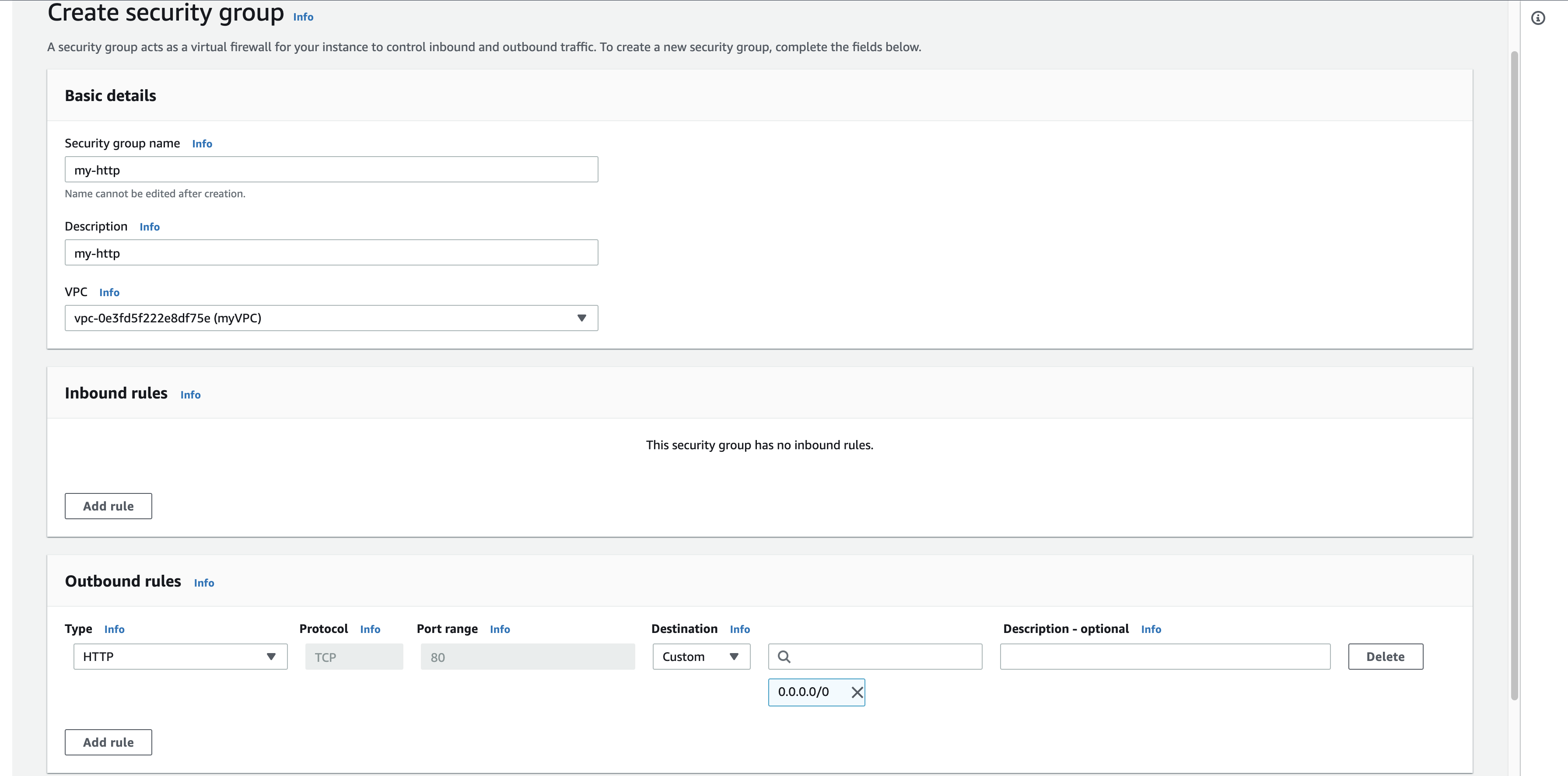
セキュリティグループ追加 (銀行員さんとお客さんのコミュニケーションを可能にする)
銀行員さんは仕事を覚え、お客さんにページ見せてて言われたらいつでも見ることができます。しかしまだ銀行員はお客さんとコミュニケーションが取れません。なぜなら銀行員さんはsshというコミュニケーション方法しかとれず、お客さんであるブラウザはhttpというコミュニケーション方法しか取れないからです。
なので銀行員さんにhttpというコミュニケーション方法をできるようになってもらわなくてはなりません。
セキュリティグループで新たに「my-http」を作り、「my-web」にアタッチします。これでsshとhttpという2つの方法でコミュニケーションが可能な銀行員さんが生まれました。設定はこんな感じです
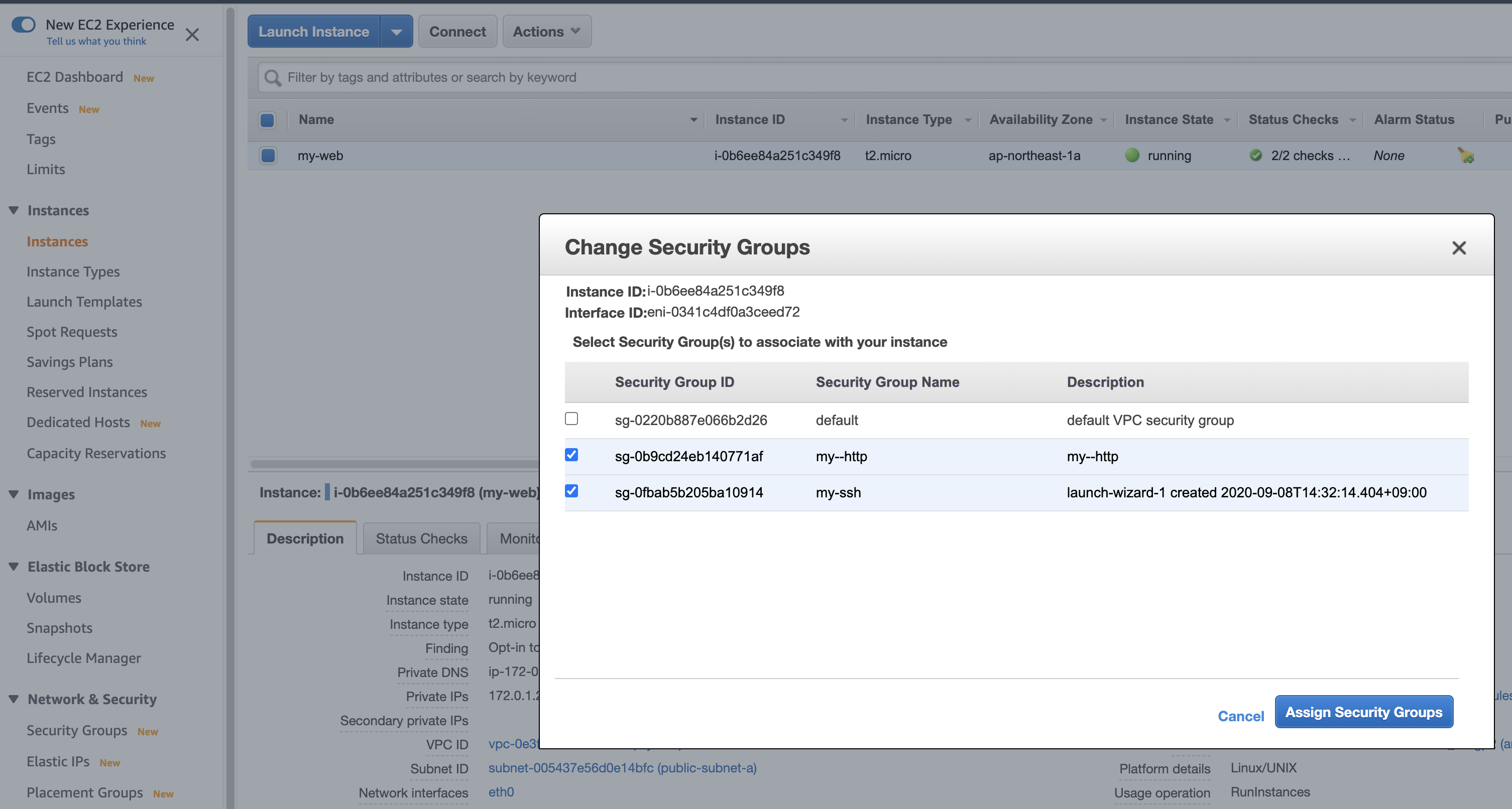
次に EC2のinstances ▶︎ Actions ▶︎ Networking ▶︎ Change Security Groups を押して「my-http」を追加します。
そうしたらsshとhttpの2種類のコミュニケーションが取れる銀行員さんができました。
これでお客さんであるブラウザからのリクエストを受け取れるはずです。 PublicIP にアクセスすると。。。できました!
お客さんと銀行員がコミュニケーションをとることができました。
オマケ
ここまででブラウザとサーバーがコミュニケーションが取れたので機能的には完成しました。がおまけとしてElastic IP とRoute53 にも触れておこうと思います。
イメージとしては、この銀行は異常な広さです。VPC に比べたらかなり小さいですが、受付エリアである Public Subnet も席が数百個くらいある広さです。この銀行員はそのなかのどれかにランダムで毎回座ります。Elastic IP を設定すると Public IP を固定できます。すなわち毎回座る場所が固定されます。Elastic IP 設定 (銀行員の席固定)
EC2インスタンスのステータスは銀行でいうと次のような対応になります。
EC2インスタンスステータス 銀行(窓口) running 出勤中 pending 退社準備中(閉め作業中) stopped 退社中(営業時間外) terminated 退職 このままだとインスタンスを停止し(stopped)、また再開(running) した時 Public IP が変わってしまいます。これでは毎回再起動のたびに私たちがPublic IP をチェックしてブラウザに教えてあげなくてはいけません。面倒なのでElastic IP を使って再起動してもいつも同じ IP を打ち込んでアクセスできるよう変更します。
設定方法は簡単なので飛ばします。これで stopped からの running でも銀行員の席固定ができました。Route53 設定
私たちから見ると IP アドレスで場所を教えられても経度と緯度で教えられているような感じがします。
例えばディズニーランドってどこ?と言われたときに「経度と緯度でいうと、35.6359322 139.8786311 だよ。」と言われてる感じです。わかりづらいので住所をつけると「千葉県浦安市舞浜1-1 だよ。」となり、覚えやすいです。
すなわち Rout53 でやることは 「35.6359322 139.8786311」と「千葉県浦安市舞浜1-1」紐づけることです。
今回はお名前.comでとった「souofficial-portfolio.xyz」を EIP で固定した「54.199.119.1」に紐付けました。
これでブラウザで「souofficial-portfolio.xyz」とアクセスすると同じページが表示されます。
これも簡単なので設定方法は省略します。次回は RDS 設置とマルチ AZ 化
次回はマルチAZ化と RDS の設置を引き続き銀行に例えてしていきます。
僕のようなイメージが掴めていなかった人にぜひ読んで欲しいです!

- 投稿日:2020-09-15T10:34:16+09:00
AWS lambdaで、node httpsモジュールでpostする
AWS lambda node、標準のhttpsモジュールで、chatwork APIにpostしたいと思ったが、検索してもrequest-promiseを追加しろみたいな話しかなく、AWS lambdaの標準パッケージでサクッと試したいだけだったのにサクっといかなかった。
https://nodejs.org/api/https.html#https_https_request_options_callback
公式にはgetの記述しかないのでpostができないのか、と思ったらできた。writeにたどりつかなかった……
(参考)
https://qastack.jp/programming/6158933/how-is-an-http-post-request-made-in-node-jsconst https = require('https'); const querystring = require('querystring'); exports.handler = function(event, context){ var postMessage = 'テスト' var post_data = querystring.stringify({body:postMessage}); let options = { host: 'api.chatwork.com', path: '/v2/rooms/{roomid}/messages', port: 443, headers: { 'X-ChatWorkToken': '{X-ChatWorkToken}', 'Content-Type': 'application/x-www-form-urlencoded', }, method: 'POST', }; var post_req = https.request(options, function(res) { res.setEncoding('utf8'); res.on('data', function (chunk) { console.log('Response: ' + chunk); context.succeed(); }); res.on('error', function (e) { console.log("Got error: " + e.message); context.done(null, 'FAILURE'); }); }); post_req.write(post_data); post_req.end(); };
- 投稿日:2020-09-15T03:54:22+09:00
【超初心者向け(スクショ多数)】Ruby2.6 × Rails6 × CircleCi でECR・ECSに自動デプロイ 【AWSチュートリアル】
対象読者
- ECSに全く触れた事が無い人
- とりあえず手を動かして雰囲気を掴みたい人
- 就活のためにポートフォリオを作成中の人
簡単なRailsアプリ(「Hello World!」と表示するだけ)をAWS ECSにデプロイするまでの手順。がっつりその後の運用まで考慮しているわけではなく、あくまで参考程度にしかならないためその点はご注意ください。
人によって多分色々なやり方がありそうなので、一度流れを掴んだ後は各自お好みで設定していただきたいです。
デプロイ用のアプリを用意する段階から全てハンズオン形式(スクショも多数)で記載しており、書いてある通りに進めれば基本的には上手くいくはず。
要所要所で任意の値(プロフィール名やアプリ名など)を設定する部分があるので、不安な場合は全て筆者と同じように「sample-app」などで統一すると良いかもです。
※初心者向けと銘打っているものの、「まずは実際に手を動かして雰囲気を掴む」という目的に徹しているため、各用語に関する説明はほとんど説明していません。理論派の方はあらかじめ他の記事でECSの概念について学習してからの方が入るのをおすすめします。(筆者は体で覚える派なので...)仕様
- 言語: Ruby2.6
- フレームワーク: Rails6
- データベース: MySQL5.7
- アプリケーションサーバー: Puma
- Webサーバー: Nginx
下準備編
まず、ECSにデプロイするための簡単なRailsアプリを用意。
サンプル
https://github.com/kazama1209/sample-app
$ git clone https://github.com/kazama1209/sample-app.git $ cd sample-appセットアップ
$ docker-compose build $ docker-compose run web bundle exec rails webpacker:install $ docker-compose up -d $ docker-compose run web bundle exec rails db:createlocalhostにアクセス
http://localhostにアクセスしていつもの画面が表示されれば環境構築は完了。デプロイ編
アプリの準備ができたので、ECSにデプロイしていく。
各種ツールをインストール
今回、ECSにデプロイするにあたり以下2つのツールを使用する。
$ brew install awscli $ brew install amazon-ecs-cliaws configureを設定
上記のツールを使用するためにaws configureの設定を行う。
IAMユーザーを作成
AWSのコンソールからサービス→IAMを選択し、「ユーザーの追加」をクリック。
任意のユーザー名を入力し、「プログラムによるアクセス」にチェックをつけて次のステップへ。
※画像だと「sample_app」になっていますが、実際は「sample-app」にしてください。スクショを撮り間違えてしまいました。
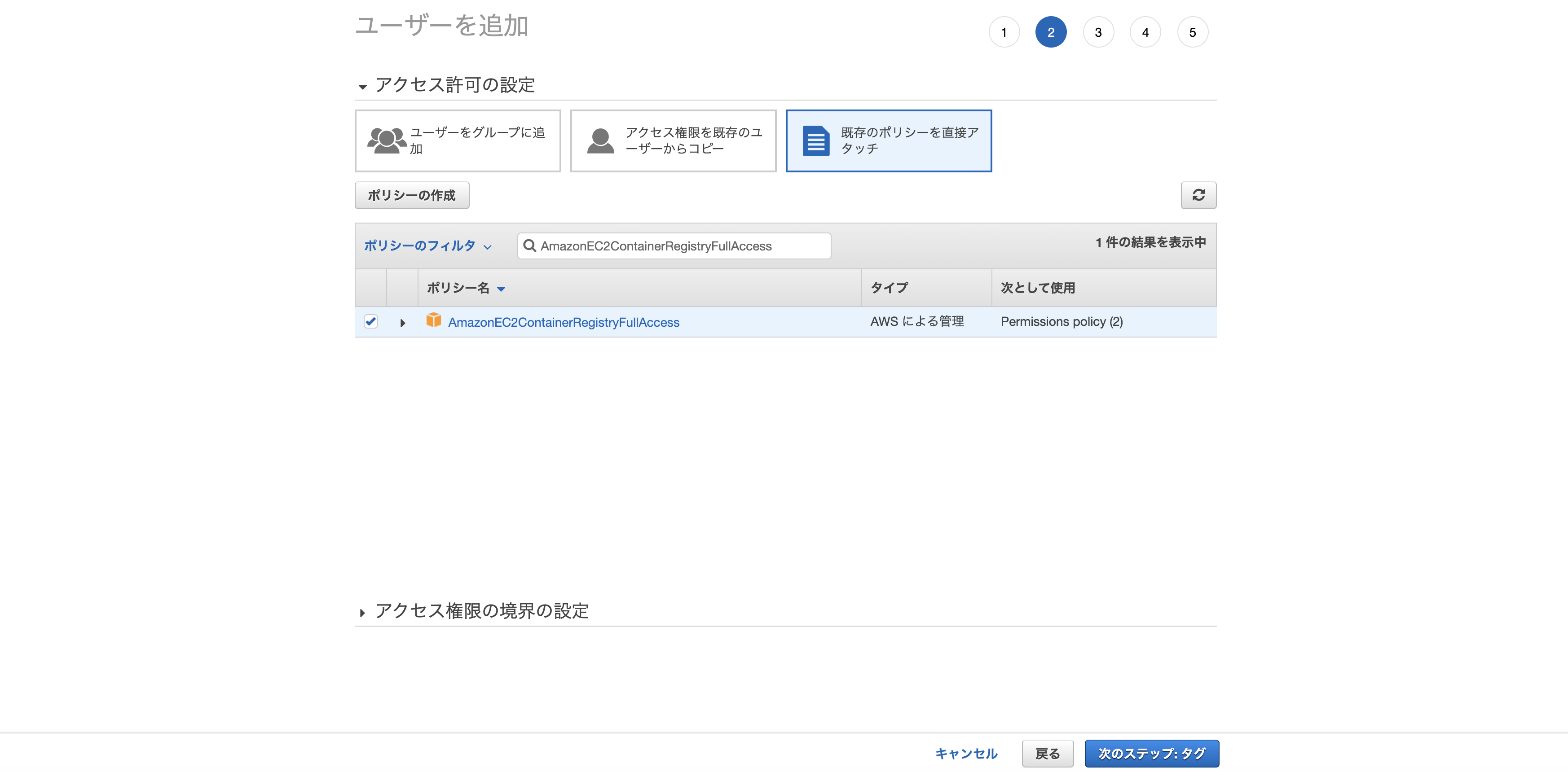
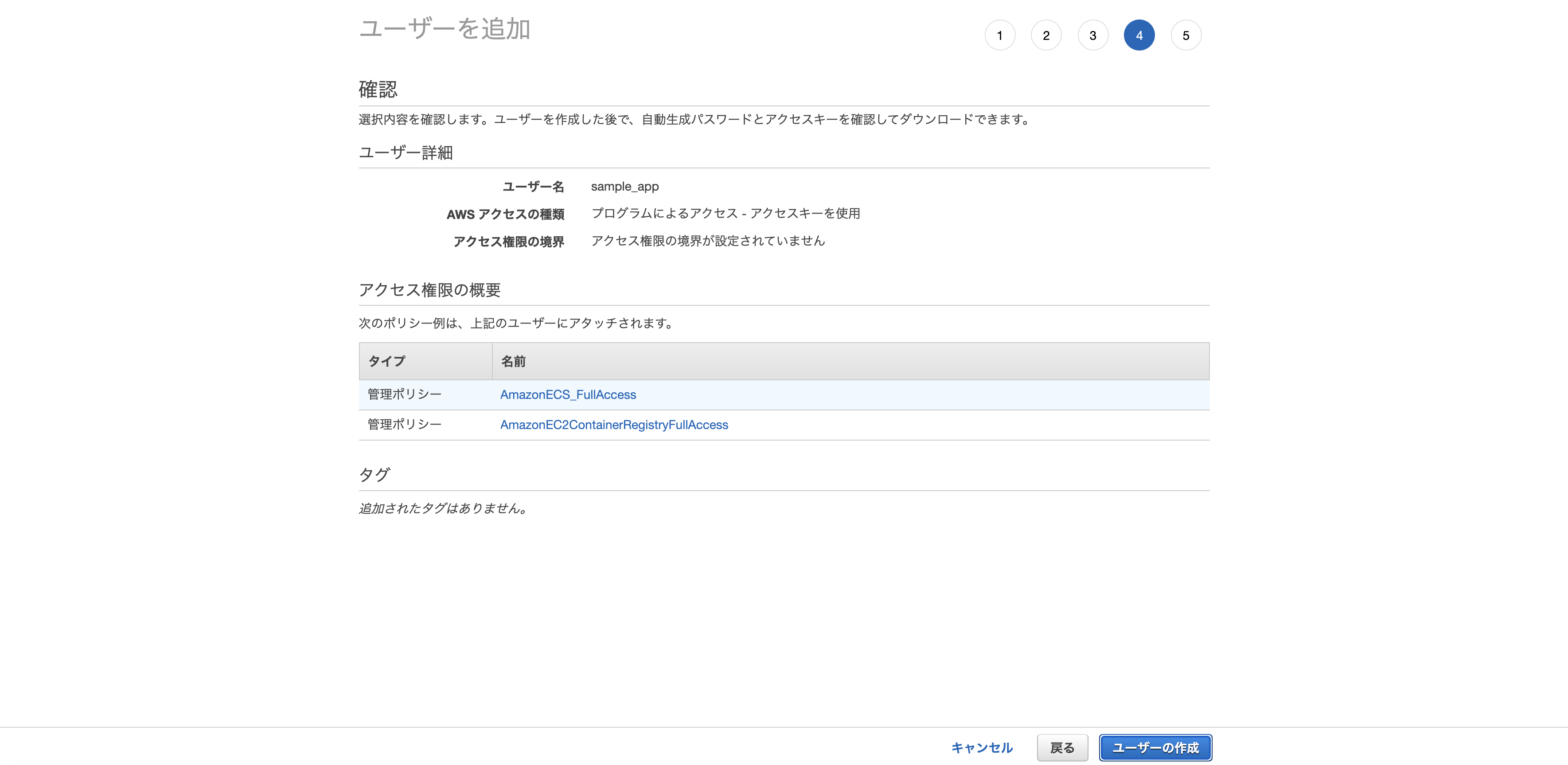
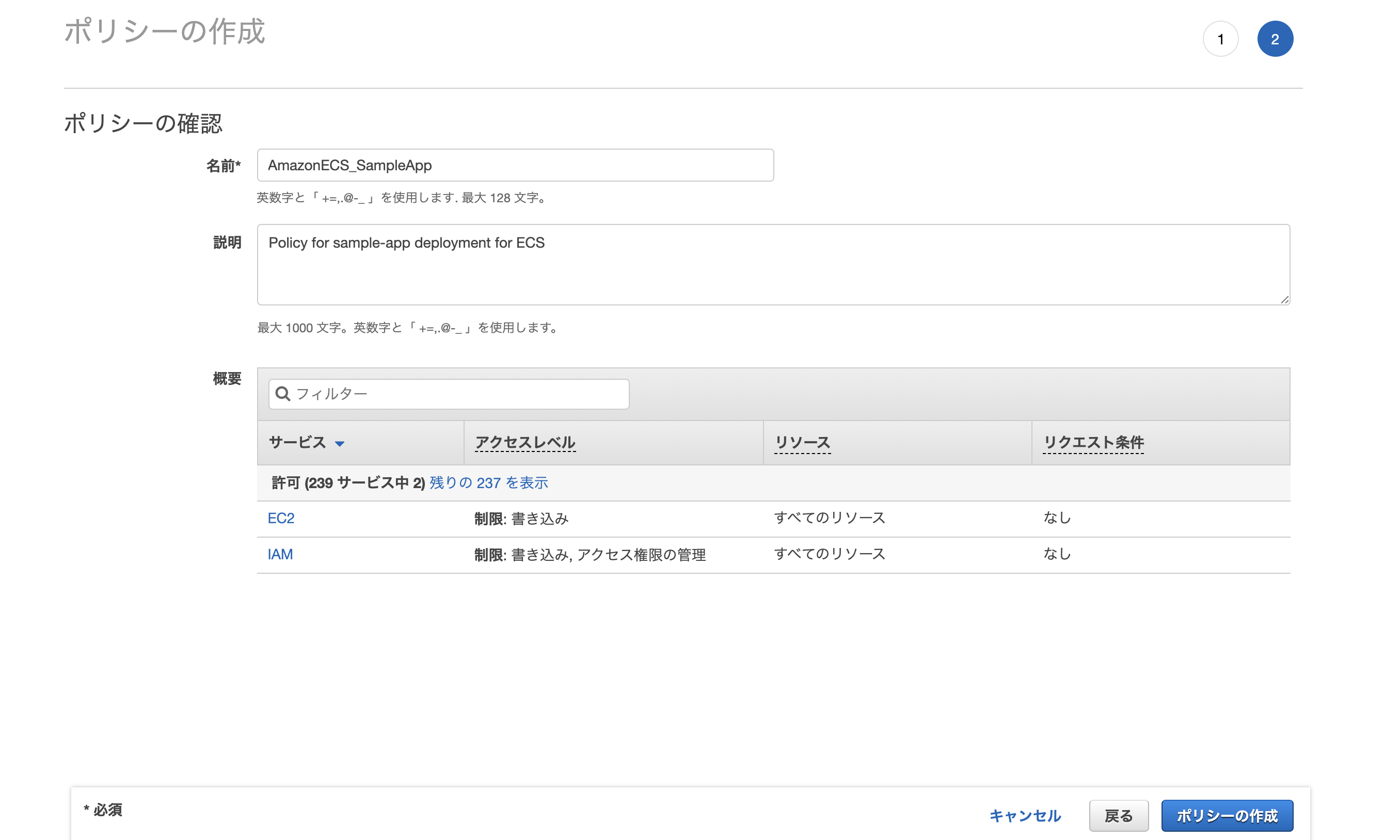
「既存のポリシーを直接アタッチ」から以下の2つのポリシーをアタッチして次のステップへ。
- AmazonECS_FullAccess
- AmazonEC2ContainerRegistryFullAccess
タグに関しては今回はは無視で次のステップへ。
最後に入力情報の確認画面が表示されるので、特に問題無ければ「ユーザーの作成」をクリック。
ユーザーの作成に成功すると「アクセスキー」「シークレットアクセスキー」の2つが発行されるので、メモを取るなりcsvファイルをダウンロードするなり大事に保管。
ターミナルで「aws configure」を実行
$ aws configure --profile <先ほど作成したIAMユーザー名(今回は「sample-app」)> AWS Access Key ID # 先ほど作成したアクセスキー AWS Secret Access Key # 先ほど作成したシークレットアクセスキー Default region name # ap-northeast-1 Default output format # jsonそれぞれ上記のように入力。
追加でポリシーを作成
先ほどIAMユーザーを作成した際、
- AmazonECS_FullAccess
- AmazonEC2ContainerRegistryFullAccess
2つのポリシーをアタッチしたが、これだけだとこの後に使用する「ecs-cli」というツールの中で権限エラーが発生するため、ここで別途追加しなければならない。
AWSのコンソールからサービス→IAM→ポリシーを選択し、「ポリシーの作成」をクリック。
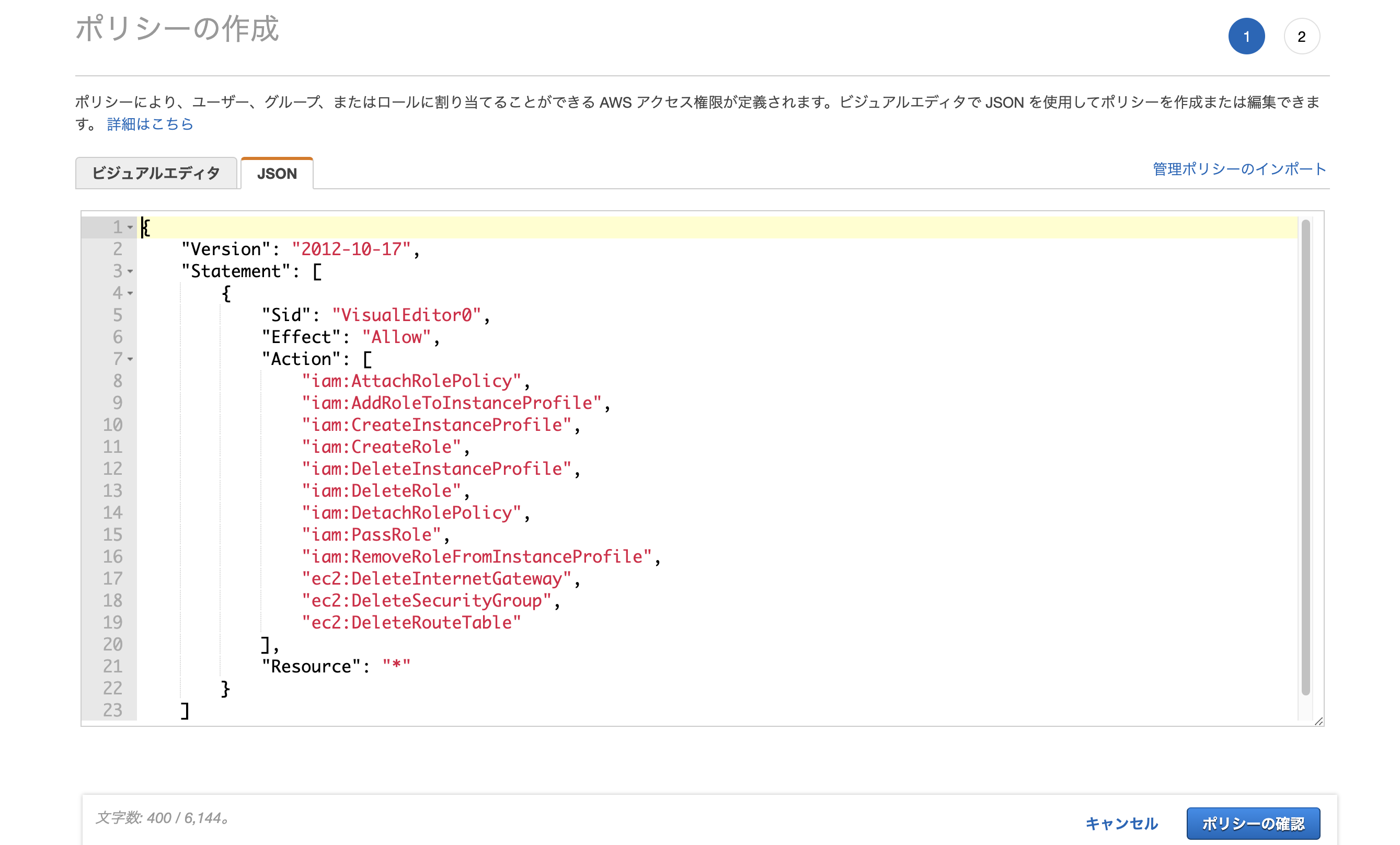
JSONタブを開いて以下の記述を行う。
{ "Version": "2012-10-17", "Statement": [ { "Sid": "VisualEditor0", "Effect": "Allow", "Action": [ "iam:AttachRolePolicy", "iam:AddRoleToInstanceProfile", "iam:CreateInstanceProfile", "iam:CreateRole", "iam:DeleteInstanceProfile", "iam:DeleteRole", "iam:DetachRolePolicy", "iam:PassRole", "iam:RemoveRoleFromInstanceProfile", "ec2:DeleteInternetGateway", "ec2:DeleteSecurityGroup", "ec2:DeleteRouteTable" ], "Resource": "*" } ] }
ポリシーの名前や説明を適当に入力し、「ポリシーの作成」をクリック。
ポリシーをユーザーにアタッチ
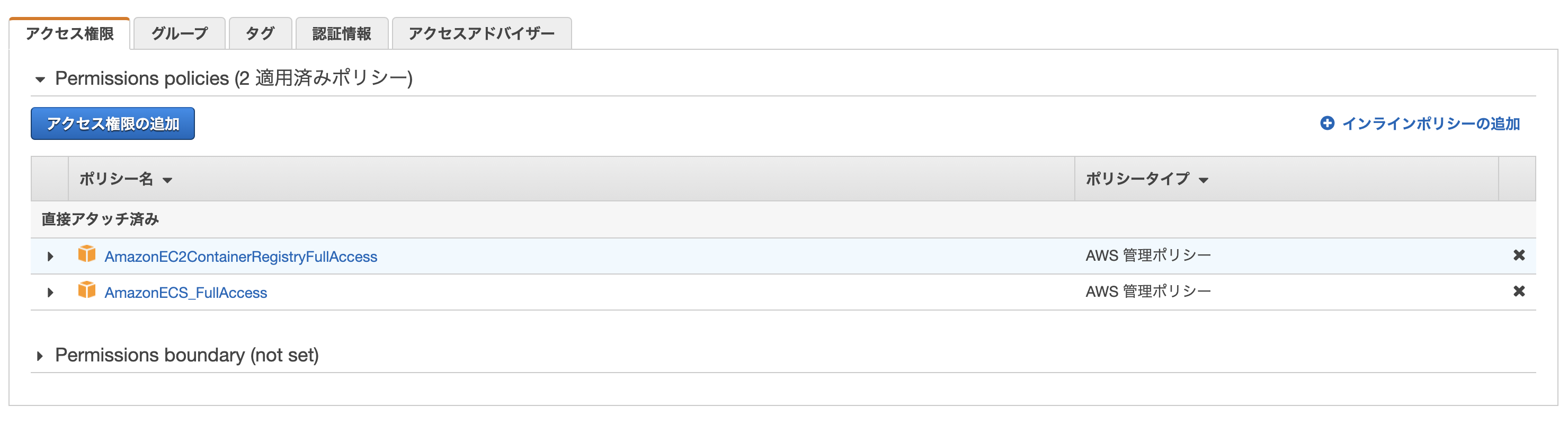
AWSのコンソールからサービス→IAM→ユーザーを選択し、「アクセス権限の追加」をクリック。
「既存のポリシーをアタッチ」から先ほど作成したポリシーを選択し、アクセス権限を追加。
キーペアを作成
後々EC2内へ入る際などに必要になるのでキーペアを作成しておく。
AWSのコンソールからサービス→EC2→キーペアを選択し、「キーペアの作成」をクリック。
名前とファイル形式を入力し、「キーペアを作成」をクリック。
$ mv Downloads/sample-app.pem .ssh/ $ chmod 600 ~/.ssh/sample-app.pem完了すると「.pem」形式のファイルがダウンロードされるので、「.ssh」ディレクトリに移動させて権限を変更する。
クラスターを作成
コンソールから手動でぽちぽち作成する事も可能だが、vpcやサブネットなども一緒に作る必要があるため、今回はecs-cliでまとめて作成してしまう。
次のコマンドを実行。
$ ecs-cli configure profile --profile-name <任意のプロフィール名> --access-key <先ほど作成したアクセスキー> --secret-key <先ほど作成したシークレットアクセスキー> $ ecs-cli configure --cluster <任意のクラスター名> --default-launch-type EC2 --config-name <任意の設定名> --region ap-northeast-1 $ ecs-cli up --keypair <先ほど作成したキーペア> --capability-iam --size 2 --instance-type t2.samll --cluster-config <任意の設定名> --ecs-profile <任意のプロフィール名>キーなどの各値は各自異なる。
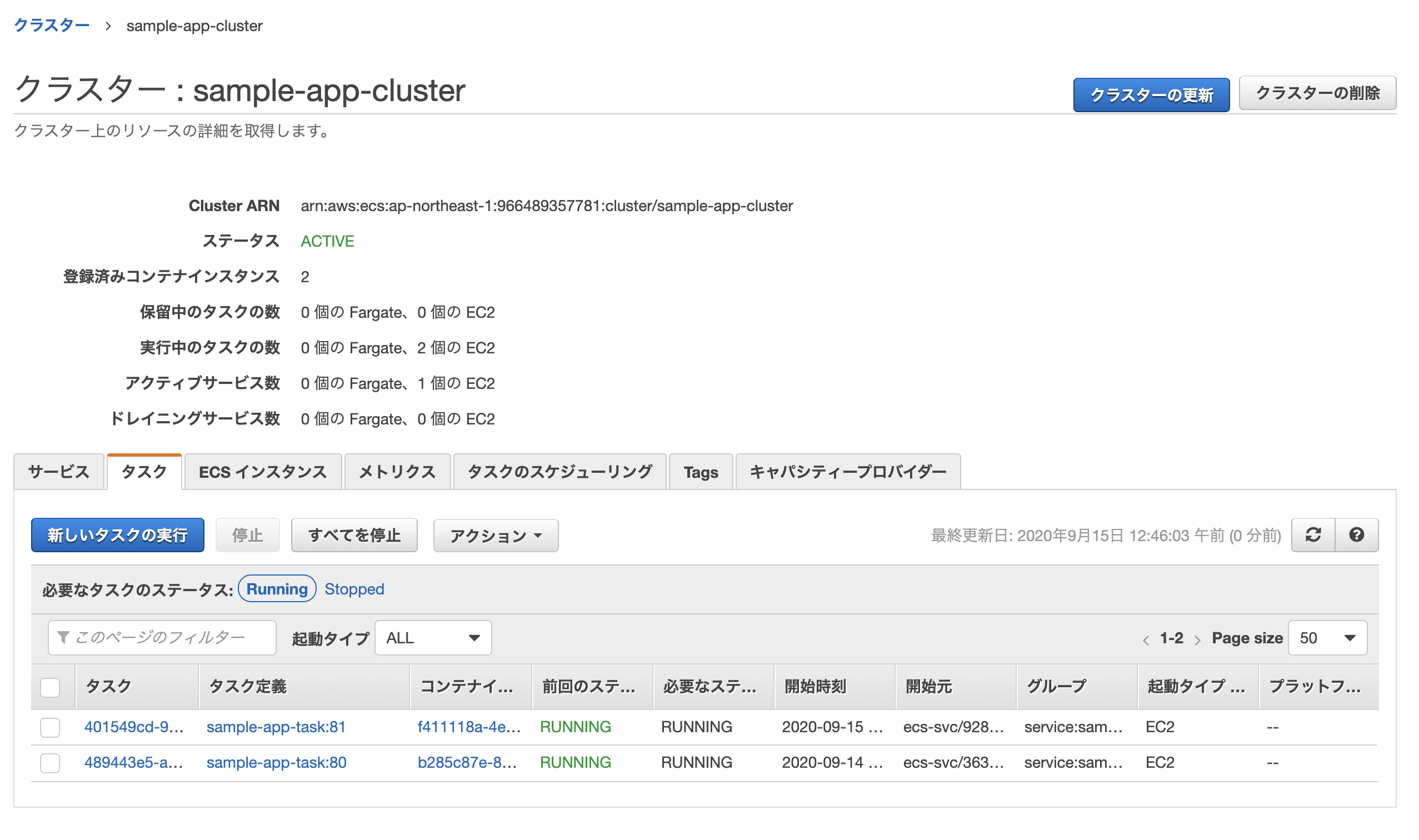
自分の場合は下記のような感じ。$ ecs-cli configure profile --profile-name sample-app --access-key AKI***************** --secret-key dlj************************************* $ ecs-cli configure --cluster sample-app-cluster --default-launch-type EC2 --config-name sample-app-cluster --region ap-northeast-1 $ ecs-cli up --keypair sample-app --capability-iam --size 2 --instance-type t2.small --cluster-config sample-app-cluster --ecs-profile sample-app INFO[0006] Using recommended Amazon Linux 2 AMI with ECS Agent 1.44.3 and Docker version 19.03.6-ce INFO[0007] Created cluster cluster=sample-app-cluster region=ap-northeast-1 INFO[0009] Waiting for your cluster resources to be created... INFO[0009] Cloudformation stack status stackStatus=CREATE_IN_PROGRESS INFO[0070] Cloudformation stack status stackStatus=CREATE_IN_PROGRESS INFO[0131] Cloudformation stack status stackStatus=CREATE_IN_PROGRESS VPC created: vpc-***************** Security Group created: sg-***************** Subnet created: subnet-***************** Subnet created: subnet-***************** Cluster creation succeeded.上手くいくと↑のようにクラスター用のVPC、セキュリティグループ、サブネットなどが自動で作成される。
AWSのコンソールからサービス→Elastic Container Service→クラスターを選択し、無事作成されていれば成功。
RDSを作成
データベースとして使うRDSを作成。
AWSのコンソールからサービス→RDSを選択し、「データベースの作成」をクリック。
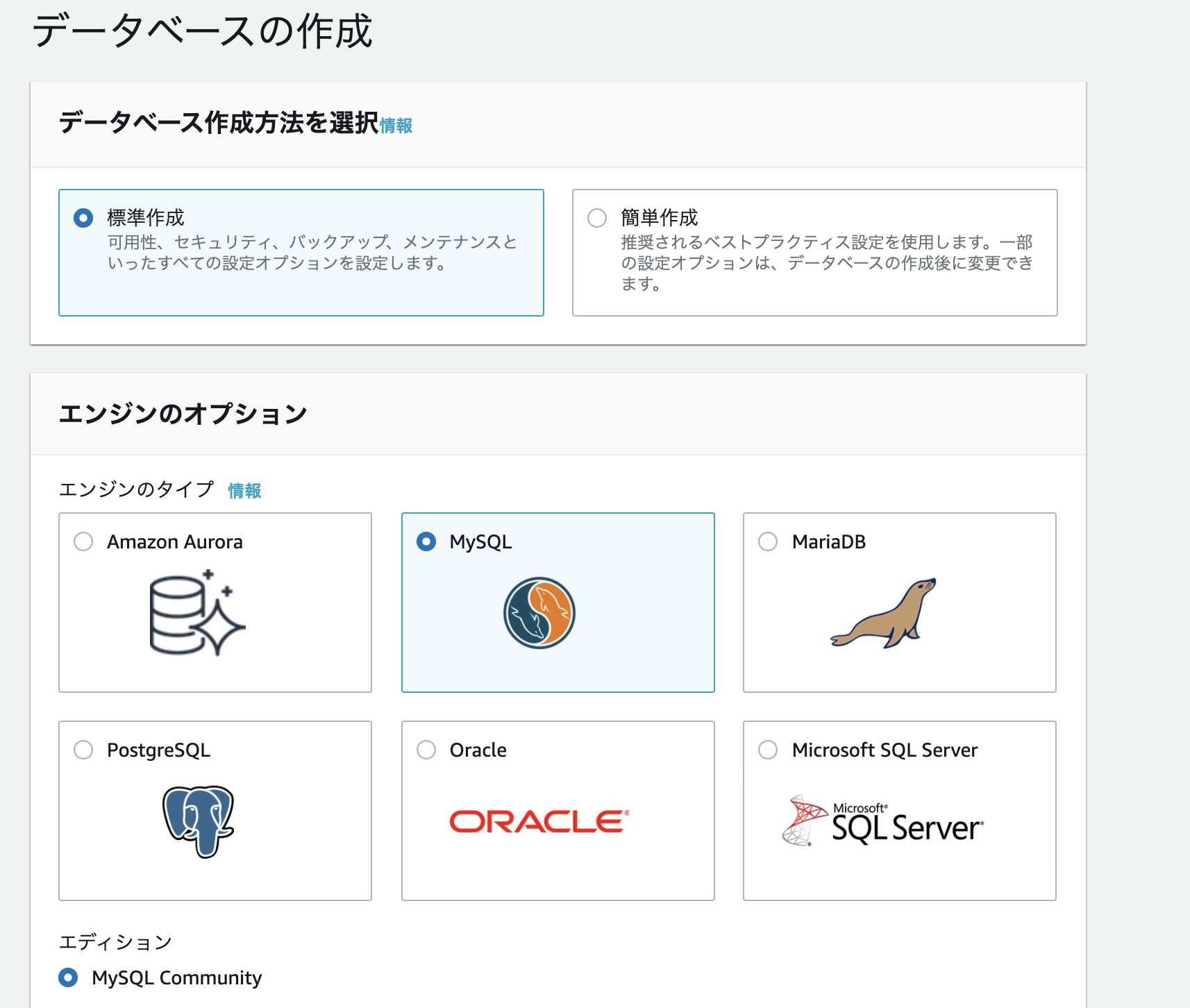
- 作成方法: 標準作成
- エンジンのタイプ: MySQL
- DBインスタンスサイズ: 無料利用枠
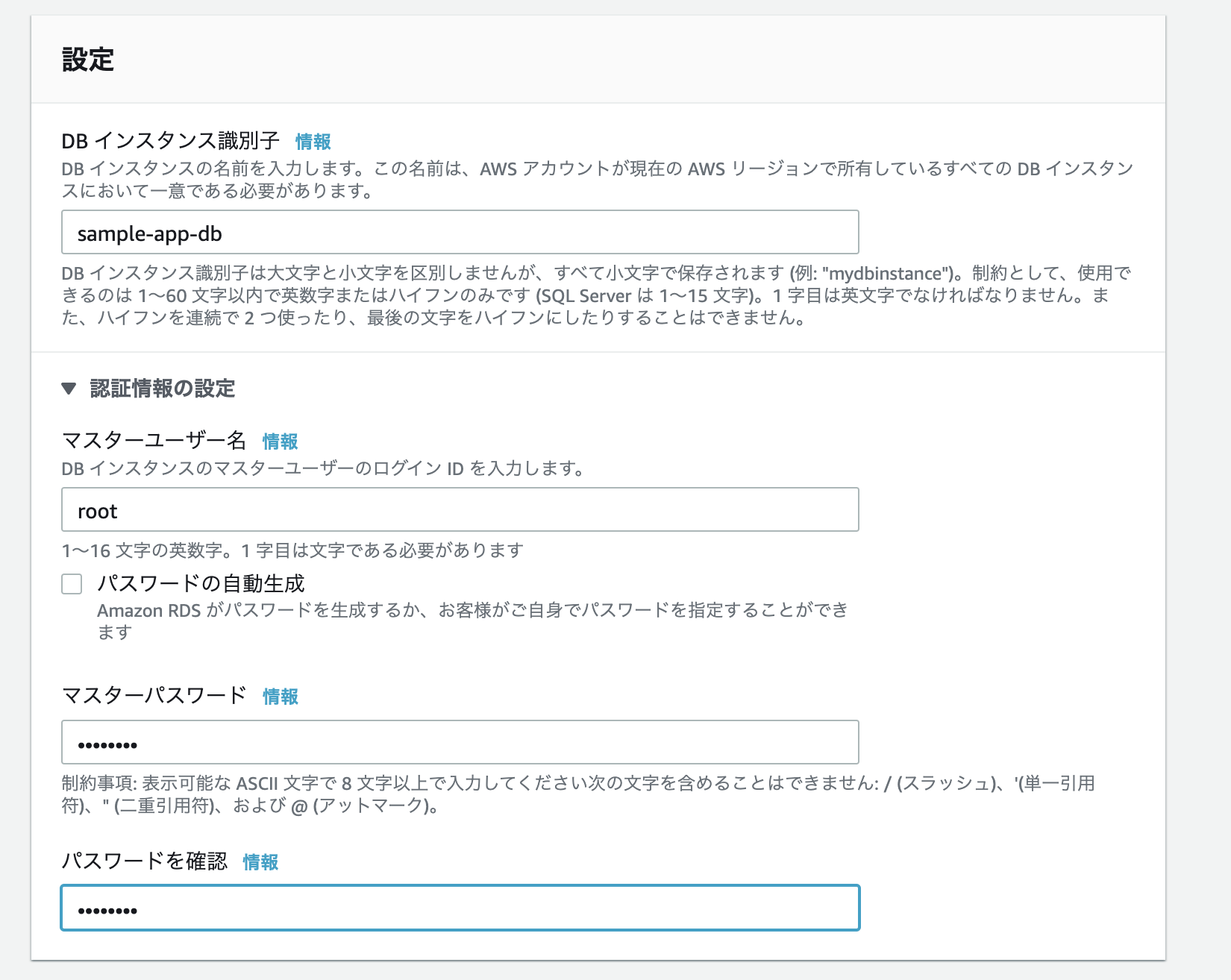
- DBインスタンス識別子: sample-app-db
- マスターユーザー名: root
- パスワード: password
※この辺は全て任意。
vpc: 先ほど作成したvpc
サブネットグループ: 新しいDBサブネットグループの作成
パブリックアクセス: あり
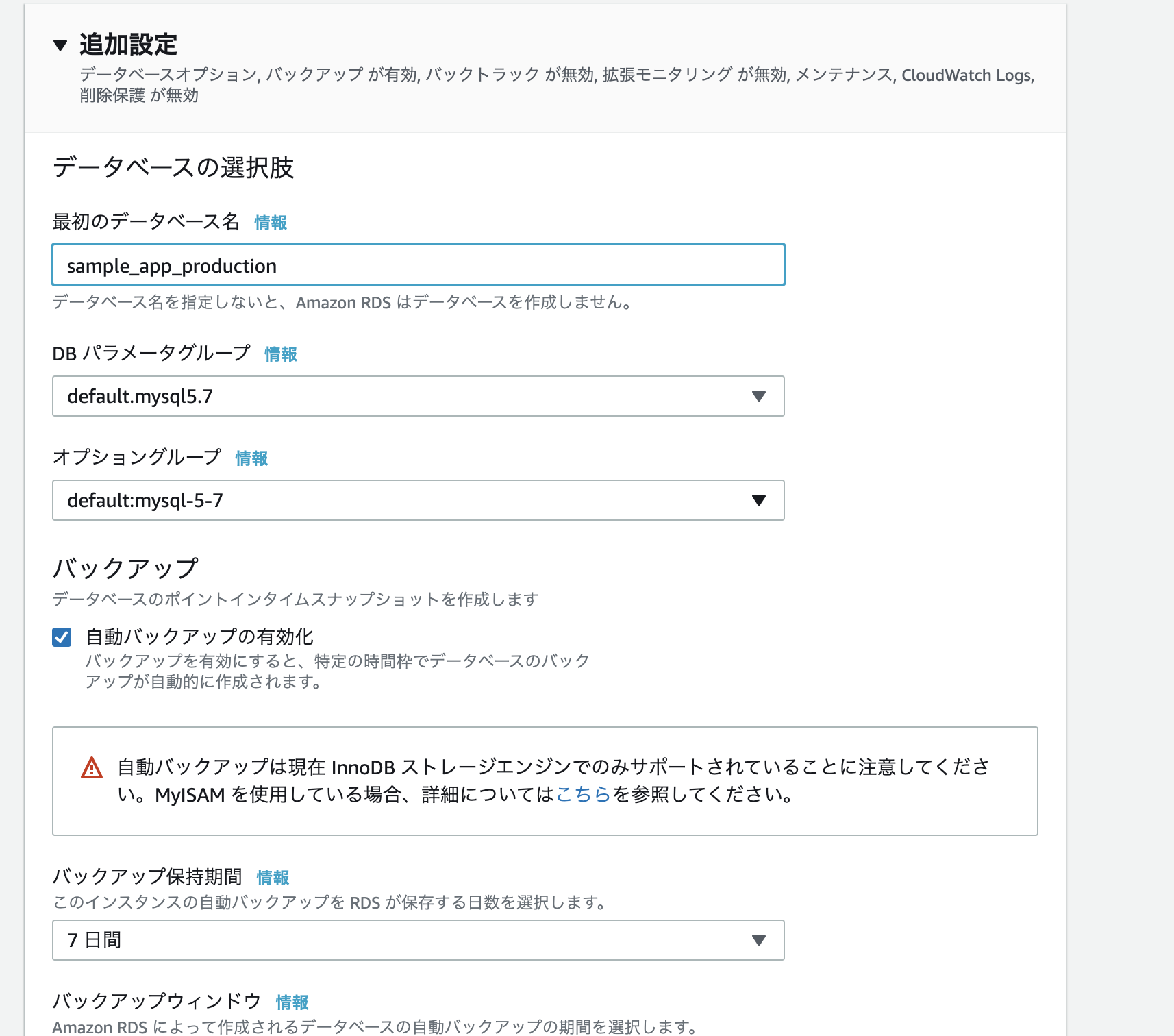
最初のデータベース名: 任意
※特に触れていない部分は空欄もしくはデフォルトのままでOK。問題なければ「データベースの作成」をクリック。
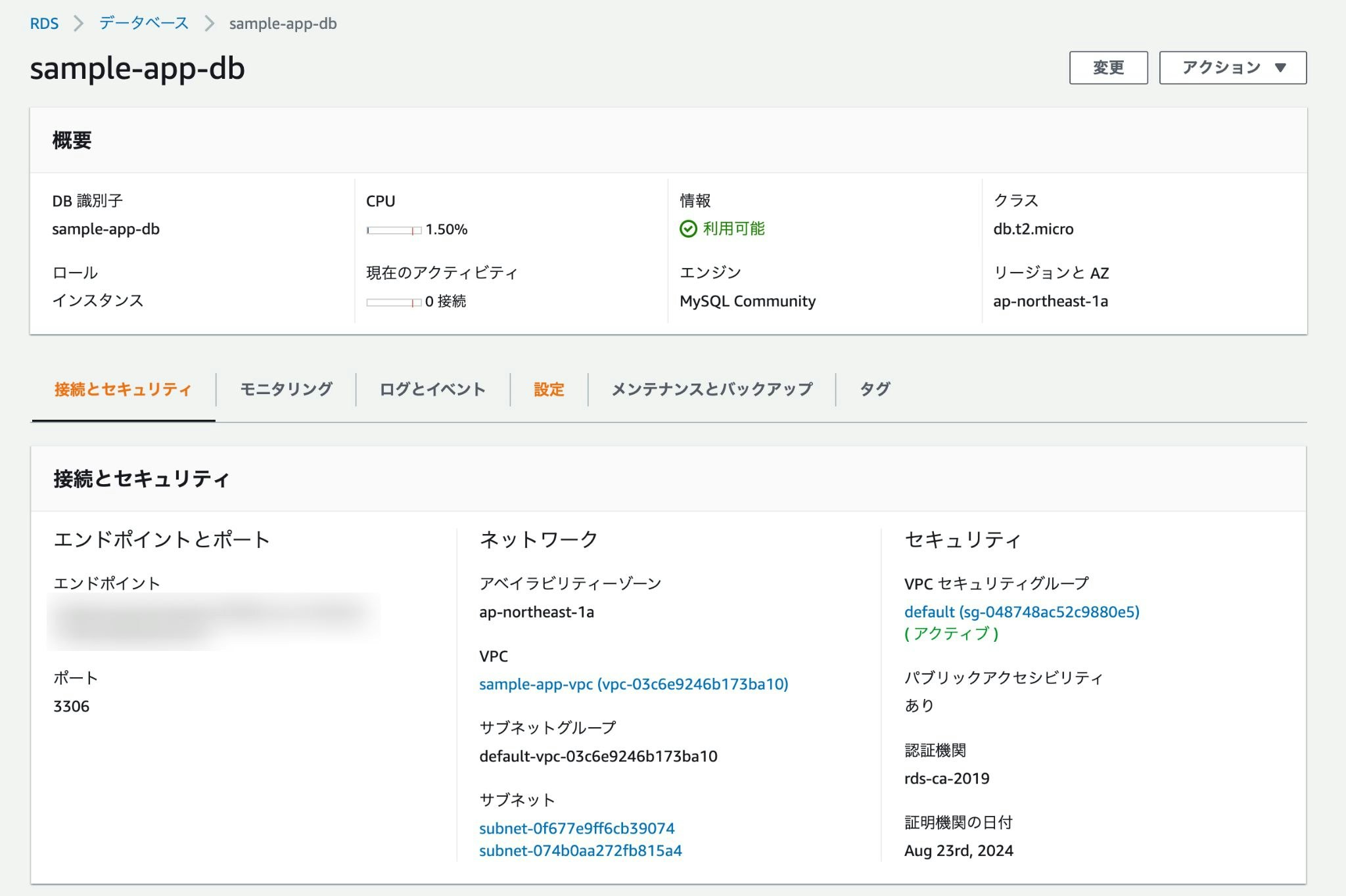
↑こんな感じで作成されていれば成功。
また、セキュリティグループの設定も必要なので「VPCセキュリティグループ」の下に記載されているリンクをクリック。
「インバウンドルールの編集」から次のように設定。
- タイプ: MYSQL/Aurora
- プロトコル: TCP
- ポート範囲
- ソース: 0.0.0.0/0
$ mysql -h <RDSのエンドポイント> -u <RDSのユーザー名> -p試しにターミナルで↑のコマンドを叩き、接続できれば成功。
ロードバランサーを作成
AWSのコンソールからサービス→EC2→ロードバランサーを選択し、「ロードバランサーの作成」をクリック。
3種類あるが、「Application Load Balancer」を選択。
- 名前: 任意
- リスナー: そのままでOK
- VPC: 先ほど自動作成されたものを選択
- subnet: 同上
先に進むとセキリュティグループの設定画面になるので、「新しいセキリュティグループを作成する」から適当にセキュリティグループを作成。
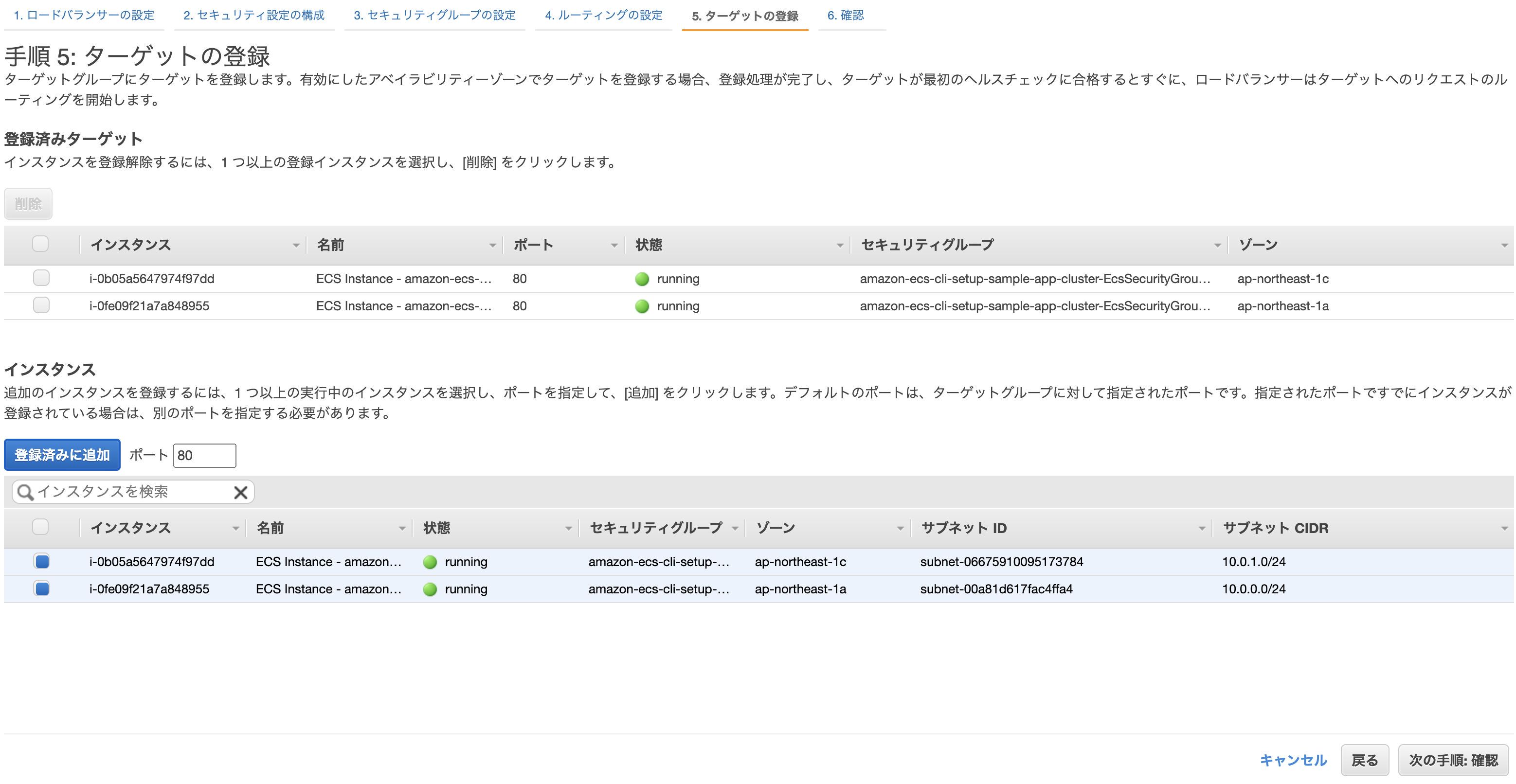
ターゲットグループの設定。
- ターゲットグループ: 新しいターゲットグループ
- 名前: 任意
クラスター作成時に自動で作られたEC2を登録し、確認画面から問題なければ「作成」をクリックして完了。
ECRにdockerイメージをpush
AWSのコンソールからサービス→Amazon Elastic Container Registryを選択し、「リポジトリの作成」をクリック。
それぞれ適当なリポジトリ名を入力し、「リポジトリを作成」をクリック。
プッシュコマンドを表示し、書いてある通り上から順に4つ実行していく。
※2番目のコマンドでbuildを行う際は-fでDockerfileのコンテキストを変える。
# Rails(本番用のDockerfileを使用する) $ docker build -f ./prod.Dockerfile . -t sample-app-rails # Nginx $ cd containers/nginx $ docker build -f ./Dockerfile . -t sample-app-nginx本番用のDockerfile
$ touch prod.Dockerfile# prod.Dockerfile FROM ruby:2.6.6 ENV LANG C.UTF-8 RUN apt-get update -qq && apt-get install -y build-essential libpq-dev nodejs RUN curl -sL https://deb.nodesource.com/setup_8.x | bash - && \ apt-get install nodejs RUN apt-get update && apt-get install -y curl apt-transport-https wget && \ curl -sS https://dl.yarnpkg.com/debian/pubkey.gpg | apt-key add - && \ echo "deb https://dl.yarnpkg.com/debian/ stable main" | tee /etc/apt/sources.list.d/yarn.list && \ apt-get update && apt-get install -y yarn RUN mkdir /sample-app WORKDIR /sample-app ADD Gemfile /sample-app/Gemfile ADD Gemfile.lock /sample-app/Gemfile.lock RUN gem install bundler:2.1.4 RUN bundle install ADD . /sample-app # Nginxと通信を行うための準備 RUN mkdir -p tmp/sockets VOLUME /sample-app/public VOLUME /sample-app/tmp RUN yarn install --check-files RUN SECRET_KEY_BASE=placeholder bundle exec rails assets:precompile基本的に開発用のものと同じだが、最後の数行でNginxと通信を行うための準備などを行っている。
全て打ち終わったらリポジトリを確認し、イメージが追加されていれば成功。
タスクの作成
先ほどpushしたイメージをもとに、タスクの作成を行う。
$ mkdir ecs $ touch ecs/docker-compose.yml# ecs/docker-compose.yml version: 2 services: app: image: # ECRのリポジトリURI(Rails) command: bash -c "bundle exec rails db:migrate && bundle exec rails assets:precompile && bundle exec puma -C config/puma.rb" environment: # 実際はdotenvなどで管理した方が良いかも RAILS_ENV: production RAILS_MASTER_KEY: # config/master.keyの値 DATABASE_NAME: sample_app_production DATABASE_USERNAME: root DATABASE_PASSWORD: password DATABASE_HOST: # RDSのエンドポイント TZ: Japan working_dir: /sample-app logging: driver: awslogs options: awslogs-region: ap-northeast-1 awslogs-group: sample-app-production/app awslogs-stream-prefix: sample-app-production nginx: image: # ECRのリポジトリURI(Nginx) ports: - 80:80 links: - app volumes_from: - app working_dir: /sample-app logging: driver: awslogs options: awslogs-region: ap-northeast-1 awslogs-group: sample-app-production/nginx awslogs-stream-prefix: sample-app-production次のコマンドを実行。
$ ecs-cli compose --project-name sample-app-task -f ./ecs/docker-compose.yml up --create-log-groups --cluster-config sample-app-cluster --ecs-profile sample-app
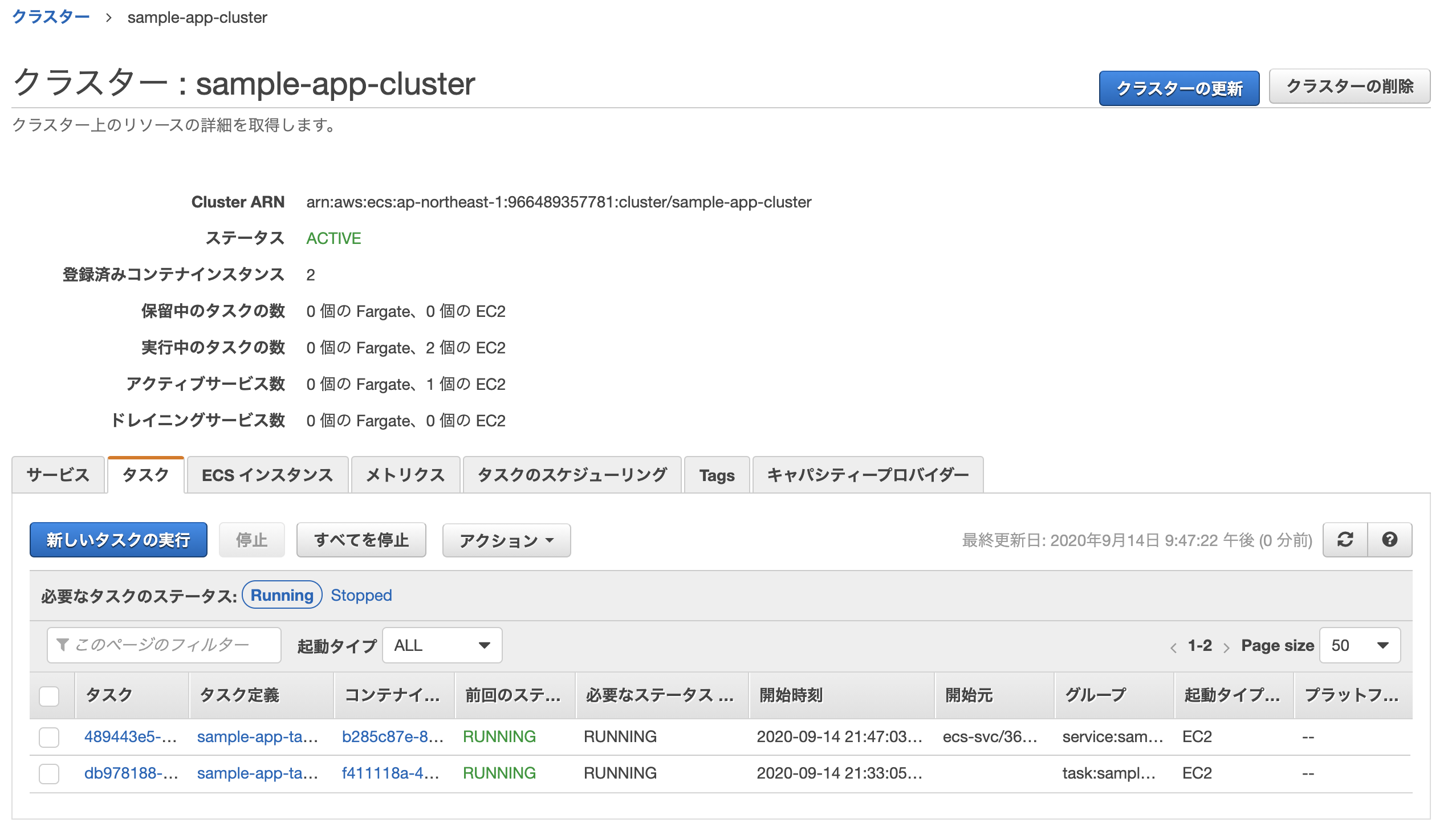
上手く行った場合、実行中のタスクに「1」と表示される。
最後に、ロードバランサーのDNS名をURLに貼り付けてアクセス。
「Yay!You're on Rails!」と表示されれば成功。
※デプロイに際して何か不具合があった場合はCloudWatchのログを確認して修正。
サービスの作成
クラスターとタスクだけでもアプリは動くが、その中間に「サービス」と呼ばれるものを作成すると、コンテナが止まった際に再起動をかけてくれたりロードバランサーを通じてオートスケーリングしてくれたり何かと便利ぽいので作成しておく。
AWSのコンソールからサービス→Amazon Elastic Container Service→ クラスター名をクリックし、「サービス」タブを開いて作成ページに進む。
- 起動タイプ: EC2
- タスク定義: 先ほど作成したもの
- クラスター: 同上
- サービス名: 任意
- その他: 画像の通り
- ロードバランサーの種類: Application Load Balancer
- ロードバランサー名: 先ほど作成したもの
- その他: 画像の通り
- ターゲットグループ名: 先ほど作成したもの
- その他: 画像の通り
最後に確認画面が表示されるので、問題無ければ作成をクリック。
無事作成されれば完了。
このままだと2つのタスク(片方はecs-cliでターミナルから開始したもの、もう片方はサービスの作成により開始されたもの)が実行中になってしまっているため、前者は停止してしまってOK。
おまけCircleCiと連携して自動デプロイ)
このままだと変更点があるたびに手動で「ビルド→プッシュ→タスク再定義」といった面倒な作業が必要になるため、「CirlcleCiにプッシュ→ビルド&テスト→ECR・ECSへ自動デプロイ」といった良くある仕組みを構築していく。
Rspecを導入
まず、デプロイ前にテストを行うためにRspecを導入する。
gemをインストール
# Gemfile group :development, :test do gem 'rspec-rails' end# Gemfileを更新したので再度ビルド $ docker-compose build各種ファイルを作成&編集
$ docker-compose run web bundle exec rails generate rspec:install create .rspec create spec create spec/spec_helper.rb create spec/rails_helper.rb# .rspec --format documentation↑の1行を追記しておくと、Rspecを実行した際の出力表示が見やすくなる。
# spec/rails_helper.rb Dir[Rails.root.join('spec', 'support', '**', '*.rb')].sort.each { |f| require f }必須ではないが、後ほどテスト用のヘルパーメソッドを作成する事になった場合、ファイルの置き場として「spec/support」を使用するので一応設定しておく。
デフォルトではコメントアウトされているので、それを外せばOK。
# config/application.rb config.generators do |g| g.test_framework :rspec, view_specs: false, helper_specs: false, controller_specs: false, routing_specs: false endこのままだと
rails gコマンドを打ち込んだ際に自動で諸々のテストファイルが作成されてしまうので、余計なものを作成したくない場合は「config/application.rb」で設定を行う。※この辺はお好みで。
rspecを実行
$ docker-compose run web bundle exec rspec No examples found. Finished in 0.00276 seconds (files took 0.12693 seconds to load) 0 examples, 0 failuresまだ何もテストを書いていないので、当然こうなる。
とりあえずRequest Specを書いてみる
手始めに、リクエストに対して正常なレスポンスが返ってくるかどうかを確認するためのRequest Specを書いてみる。
トップページを作成
# コントローラー $ touch app/controllers/home_controller.rb # ビュー $ mkdir app/views/home $ touch app/views/home/index.html.erb# app/controllers/home_controller.rb class HomeController < ApplicationController def index end end# app/views/home/index.html.erb <h1>Hello World!</h1>#config/routes.rb Rails.application.routes.draw do root 'home#index' end
テストファイルを作成
$ docker-compose run web bundle exec rails g rspec:request home create spec/requests/homes_spec.rb# spec/requests/home_spec.rb require 'rails_helper' RSpec.describe "Home", type: :request do describe "GET /" do it "works successfully" do get root_path expect(response).to have_http_status(200) end end end「/」にアクセスした際、 200番のステータスコードが返ってくるかどうかのテスト。
$ docker-compose run web bundle exec rspec Home GET / works successfully Finished in 0.53664 seconds (files took 8.4 seconds to load) 1 example, 0 failures再度rspecを実行し、問題無くパスしていれば成功。
CircleCIと連携
次に、実際にCircleCiと連携するための設定を行う。
gemをインストール
group :development, :test do gem 'database_cleaner' gem 'rspec_junit_formatter' gem 'webdrivers', '~> 3.0' end# Gemfileを更新したので再度ビルド $ docker-compose build各種ファイルを作成&編集
$ mkdir .circleci $ touch .circleci/config.yml $ touch config/database.yml.ci $ docker-compose run web bundle exec rails db:schema:dump# .circleci/config.yml version: 2 jobs: build: docker: - image: circleci/ruby:2.6.6-node-browsers environment: - BUNDLER_VERSION: 2.1.4 - RAILS_ENV: 'test' - image: circleci/mysql:5.7 environment: - MYSQL_ALLOW_EMPTY_PASSWORD: 'true' - MYSQL_ROOT_HOST: '127.0.0.1' working_directory: ~/sample_app steps: - checkout - restore_cache: keys: - v1-dependencies-{{ checksum "Gemfile.lock" }} - v1-dependencies- - run: name: install dependencies command: | gem install bundler -v 2.1.4 bundle install --jobs=4 --retry=3 --path vendor/bundle - save_cache: paths: - ./vendor/bundle key: v1-dependencies-{{ checksum "Gemfile.lock" }} # database setup - run: mv ./config/database.yml.ci ./config/database.yml # database setup - run: name: setup database command: | bundle exec rake db:create bundle exec rake db:schema:load # install yarn - run: name: install yarn command: yarn install # install webpack - run: name: install webpack command: bundle exec bin/webpack # run tests - run: name: run rspec command: | mkdir /tmp/test-results TEST_FILES="$(circleci tests glob "spec/**/*_spec.rb" | \ circleci tests split --split-by=timings)" bundle exec rspec \ --format progress \ --format RspecJunitFormatter \ --out /tmp/test-results/rspec.xml \ --format progress \ $TEST_FILES # collect reports - store_test_results: path: /tmp/test-results - store_artifacts: path: /tmp/test-results destination: test-results# config/database.yml.ci (CircleCiのデータベース設定用) test: adapter: mysql2 encoding: utf8 pool: 5 username: 'root' port: 3306 host: '127.0.0.1' database: sample_app_test# spec/rails_helper.rb RSpec.configure do |config| # config DataBaseCleaner config.before(:suite) do DatabaseCleaner.strategy = :transaction DatabaseCleaner.clean_with(:truncation) Rails.application.load_seed end config.before(:each) do DatabaseCleaner.start end config.after(:each) do DatabaseCleaner.clean end end# db/schema.rb # This file is auto-generated from the current state of the database. Instead # of editing this file, please use the migrations feature of Active Record to # incrementally modify your database, and then regenerate this schema definition. # # This file is the source Rails uses to define your schema when running `rails # db:schema:load`. When creating a new database, `rails db:schema:load` tends to # be faster and is potentially less error prone than running all of your # migrations from scratch. Old migrations may fail to apply correctly if those # migrations use external dependencies or application code. # # It's strongly recommended that you check this file into your version control system. ActiveRecord::Schema.define(version: 0) do endCircleCiとGitHubを接続
https://app.circleci.com/projects/project-dashboard/github/GitHubのアカウント名/
↑CircleCiのダッシュボードから連携したいリポジトリを探し、「Set Up Project」をクリック。画面に表示される指示に従い設定。
これで今後GitHubへ新しいプッシュを行った際、「.circleci/config.yml」に書いた内容に基づき自動でビルド&テストが走るようになる。
特に問題が無ければ「SUCCESS」と表示されるはず。
これで初期設定は完了。自動デプロイ(ECR・ECS)
CircleCiのバージョン2.1から追加されたOrbを使い、masterブランチに変更が加えられた際、CircleCiでのビルド&テストを行い自動でイメージを作成しECRへプッシュし、ECSのサービスを更新してタスクの再定義を行うようにする。
環境変数の登録
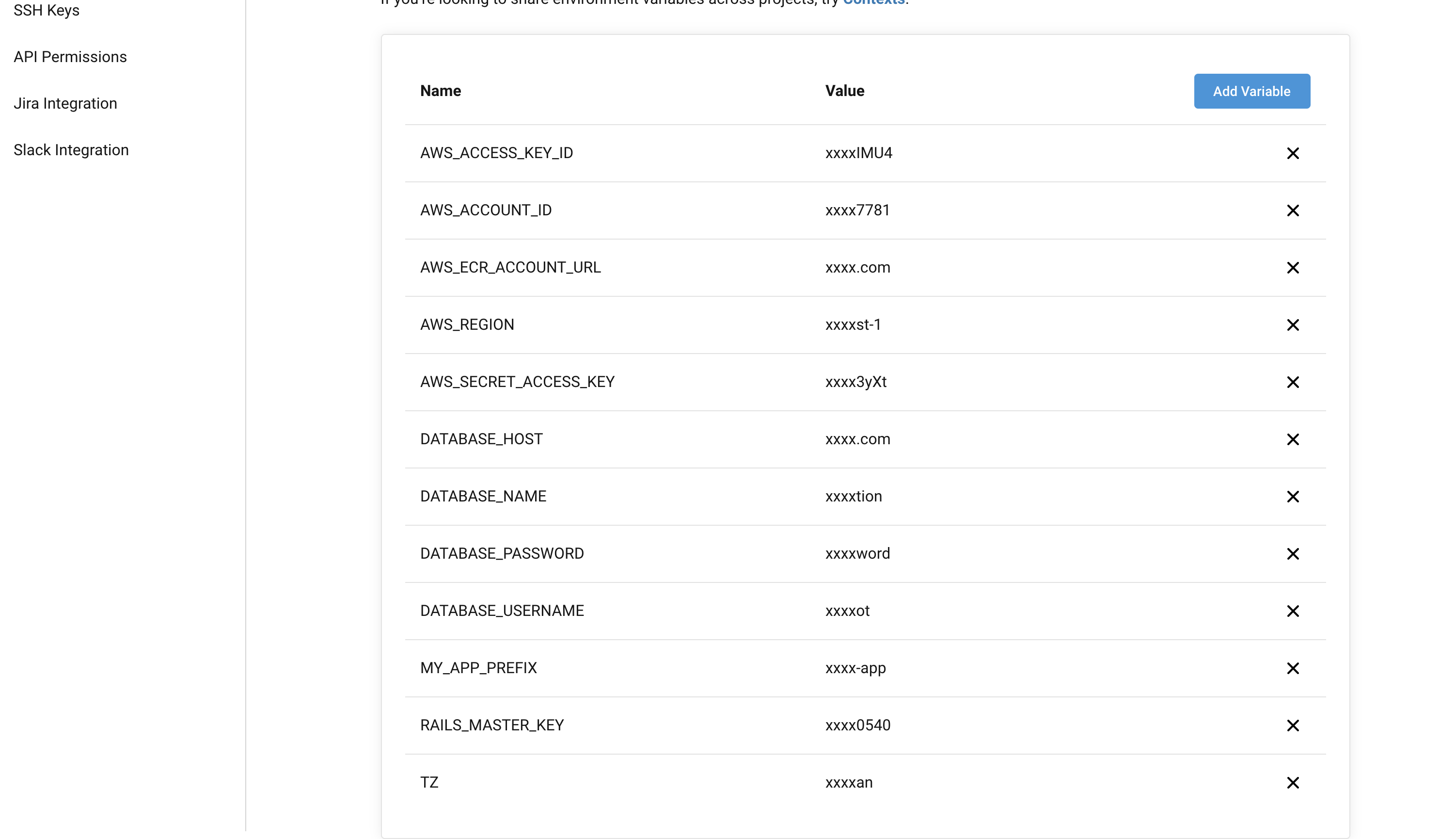
あらかじめCircleCiの設定画面からデプロイに必要な環境変数を登録しておく。
- AWS_ACCESS_KEY_ID
- 作成したIAMユーザーのアクセスキー
- AWS_SECRET_ACCESS_KEY
- 作成したIAMユーザーのシークレットキー
- AWS_ACCOUNT_ID
- AWSのアカウントID(コンソールの「マイアカウント」から確認可能)
- AWS_REGION
- ap-northeast-1
- AWS_ECR_ACCOUNT_URL
- ECRのリポジトリURI(例: <アカウントID>.dkr.ecr.ap-northeast-1.amazonaws.com)
- DATABASE_HOST
- RDSのエンドポイント(例: ********.ap-northeast-1.rds.amazonaws.com)
- DATABASE_USERNAME
- RDSのユーザー名(例: root)
- DATABASE_PASSWORD
- RDSのパスワード(例: password)
- DATABASE_NAME
- 使用するデータベース名(例: sample_app_production)
- RAILS_MASTER_KEY
- config/master.keyの値
- TZ
- JAPAN
- MY_APP_PREFIX
- 任意(例: sample-app)
- 変数を使い回してなるべくコンパクトに書けるようにクラスター名やタスク名は共通のワードを含めて作成しておいた方が良い(sample-app-cluster、sample-app-taskなど)。
.circleci/config.ymlを編集
# .circleci/config.yml version: 2.1 orbs: aws-ecr: circleci/aws-ecr@6.7.0 aws-ecs: circleci/aws-ecs@1.1.0 jobs: test: docker: - image: circleci/ruby:2.6.6-node-browsers environment: - BUNDLER_VERSION: 2.1.4 - RAILS_ENV: 'test' - image: circleci/mysql:5.7 environment: - MYSQL_ALLOW_EMPTY_PASSWORD: 'true' - MYSQL_ROOT_HOST: '127.0.0.1' working_directory: ~/project steps: - checkout - restore_cache: keys: - v1-dependencies-{{ checksum "Gemfile.lock" }} - v1-dependencies- - run: name: install dependencies command: | gem install bundler -v 2.1.4 bundle install --jobs=4 --retry=3 --path vendor/bundle - save_cache: paths: - ./vendor/bundle key: v1-dependencies-{{ checksum "Gemfile.lock" }} - run: mv ./config/database.yml.ci ./config/database.yml - run: name: setup database command: | bundle exec rake db:create bundle exec rake db:schema:load - run: name: install yarn command: yarn install - run: name: install webpack command: bundle exec bin/webpack - run: name: run rspec command: | mkdir /tmp/test-results TEST_FILES="$(circleci tests glob "spec/**/*_spec.rb" | \ circleci tests split --split-by=timings)" bundle exec rspec \ --format progress \ --format RspecJunitFormatter \ --out /tmp/test-results/rspec.xml \ --format progress \ $TEST_FILES - store_test_results: path: /tmp/test-results - store_artifacts: path: /tmp/test-results destination: test-results workflows: version: 2 test_and_deploy: jobs: - test # ビルドした後にイメージをECRへプッシュ - aws-ecr/build-and-push-image: requires: - test account-url: AWS_ECR_ACCOUNT_URL region: AWS_REGION aws-access-key-id: AWS_ACCESS_KEY_ID aws-secret-access-key: AWS_SECRET_ACCESS_KEY create-repo: true dockerfile: ./prod.Dockerfile repo: "${MY_APP_PREFIX}-rails" tag: "${CIRCLE_SHA1}" filters: branches: only: - master # ECSのサービスを更新してタスクを再定義 - aws-ecs/deploy-service-update: requires: - aws-ecr/build-and-push-image family: "${MY_APP_PREFIX}-task" cluster-name: "${MY_APP_PREFIX}-cluster" service-name: "${MY_APP_PREFIX}-service" container-image-name-updates: "container=app,tag=${CIRCLE_SHA1}"各環境変数に間違いが無いか良く確認しておく事。
# app/views/home/index.html.erb <h1>Hello World!</h1> <p>Completed auto deploy with CircleCi</p>自動デプロイが上手くいったかわかりやすいようにトップページを少し変えておく。
masterブランチに変更を加える
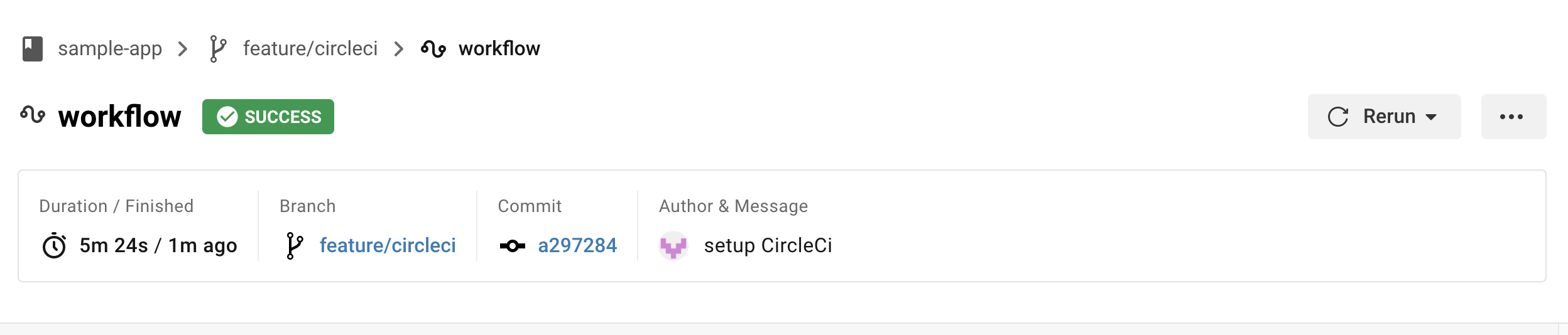
実際にmasterブランチにプッシュして変更を加えてみると、CircleCi上でデプロイ込みのjobsが動き始める。
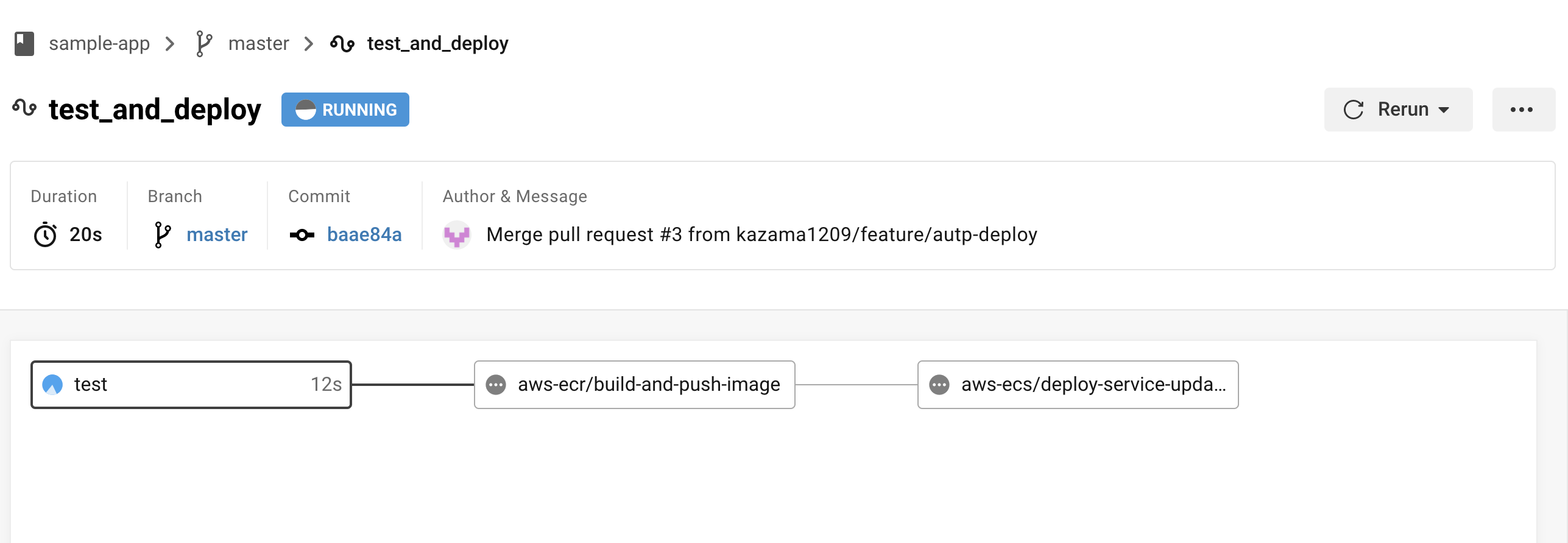
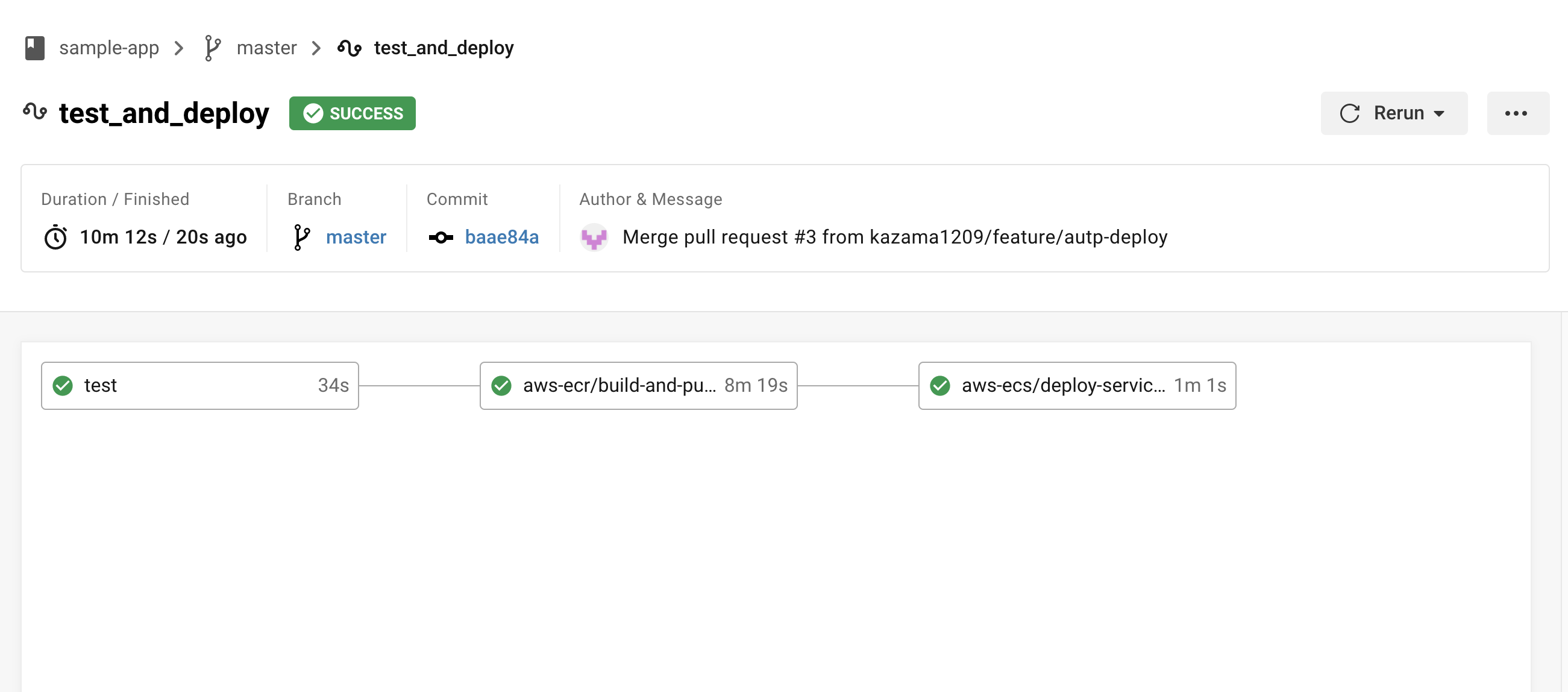
※全てのフローが完了するまでに大体10〜15分くらいかかるので注意。
再度ロードバランサーのDNS名にアクセスし、先ほどの変更がちゃんと更新されていれば成功。
※反映されるまで多少時間がかかるので気長に待つ。
古いタスクと新しいタスクの2つが実行されているが、時間の経過で古い方は勝手に消されるため(サービスのおかげ?)そのまま放置でOK。
お疲れ様でした。
あとがき
自分もまだまだ勉強中の身なので、何かあれば随時更新予定です。
現状、コンソール上で手を動かしながら行う作業とターミナルでコマンドを叩いて行う作業がごちゃ混ぜになってしまっているため、できれば全て後者に統一したいと考えていいます。
Terraformとかも使って一発バシっとできるようにしたい...。
どこか詰まった部分やもっとこうした方が良いなどあればコメントいただけると嬉しいです。
個人的に詰まった部分
- Nginxの設定
- nginx.confファイルの中身は各自変更しないと正常に動かない部分があるので、ググりながら適宜修正する必要がある。
appコンテナとnginxコンテナの接続が上手くいかないと
2020/09/13 20:02:57 [crit] 7#7: *456 connect() to unix:///sample-app/tmp/sockets/puma.sock failed (2: No such file or directory) while connecting to upstream, client: *********, server: localhost, request: "GET / HTTP/1.1", upstream: "http://unix:///sample-app/tmp/sockets/puma.sock:/500.html", host: "***********"↑こんな感じのエラーで延々と悩まされる。
- 各環境変数の設定
- CircleCiに登録する環境変数の値がしっかり合っているか何度も確認した方が良い。ビルドするのにやたら時間がかかるので、1回失敗するとそれだけでかなりの時間の無駄になる。















- 投稿日:2020-09-15T03:54:22+09:00
【超初心者向け(スクショ多め)】Ruby2.6 × Rails6 × CircleCi でECR・ECSに自動デプロイ 【AWSチュートリアル】
対象読者
- ECSに全く触れた事が無い人
- とりあえず手を動かして雰囲気を掴みたい人
- 就活のためにポートフォリオを作成中の人
簡単なRailsアプリ(「Hello World!」と表示するだけ)をAWS ECSにデプロイするまでの手順。がっつりその後の運用まで考慮しているわけではなく、あくまで参考程度にしかならないためその点はご注意ください。
人によって多分色々なやり方がありそうなので、一度流れを掴んだ後は各自お好みで設定していただきたいです。
デプロイ用のアプリを用意する段階から全てハンズオン形式(スクショも多数)で記載しており、書いてある通りに進めれば基本的には上手くいくはず。
要所要所で任意の値(プロフィール名やアプリ名など)を設定する部分があるので、不安な場合は全て筆者と同じように「sample-app」などで統一すると良いかもです。
※初心者向けと銘打っているものの、「まずは実際に手を動かして雰囲気を掴む」という目的に徹しているため、各用語に関する説明はほとんど説明していません。
※あくまで「AWS超初心者でもとりあえず書いてある通りに従えばそれっぽくデプロイできる」というのがコンセプト。理論派の方はあらかじめ他の記事でECR・ECSの概念について学習してから入るのをおすすめします。(筆者は体で覚える派なので...)
※AWSの各リソース名などに関しては基本的に任意なので各自お好みで(ただし、ecs-cliでコマンドを打つ際やCircleCiのconfig内の記述をそれに合わせる必要あり)。また、特に触れていない部分に関してはとりあえずデフォルトの状態もしくは空欄で大丈夫だと思います。
※スクショ撮ったタイミングが違ったりしてリビジョンナンバーなどにバラつきがあるかもしれませんが、無視してください(汗)仕様
- 言語: Ruby2.6
- フレームワーク: Rails6
- データベース: MySQL5.7
- アプリケーションサーバー: Puma
- Webサーバー: Nginx
下準備編
まず、ECSにデプロイするための簡単なRailsアプリを用意。
サンプル
https://github.com/kazama1209/sample-app
$ git clone https://github.com/kazama1209/sample-app.git $ cd sample-appセットアップ
$ docker-compose build $ docker-compose run web bundle exec rails webpacker:install $ docker-compose up -d $ docker-compose run web bundle exec rails db:createlocalhostにアクセス
http://localhostにアクセスしていつもの画面が表示されれば環境構築は完了。デプロイ編
アプリの準備ができたので、ECSにデプロイしていく。
各種ツールをインストール
今回、ECSにデプロイするにあたり以下2つのツールを使用する。
$ brew install awscli $ brew install amazon-ecs-cliaws configureを設定
上記のツールを使用するためにaws configureの設定を行う。
IAMユーザーを作成
AWSのコンソールからサービス→IAMを選択し、「ユーザーの追加」をクリック。
任意のユーザー名を入力し、「プログラムによるアクセス」にチェックをつけて次のステップへ。(画像では「sample_app」となっていますが、実際は「sample-app」で作成したと仮定して話を進めます。スクショ撮り間違えました。)
「既存のポリシーを直接アタッチ」から以下の2つのポリシーをアタッチして次のステップへ。
- AmazonECS_FullAccess
- AmazonEC2ContainerRegistryFullAccess
タグに関しては今回はは無視で次のステップへ。
最後に入力情報の確認画面が表示されるので、特に問題無ければ「ユーザーの作成」をクリック。
ユーザーの作成に成功すると「アクセスキー」「シークレットアクセスキー」の2つが発行されるので、メモを取るなりcsvファイルをダウンロードするなり大事に保管。
ターミナルで「aws configure」を実行
$ aws configure --profile <先ほど作成したIAMユーザー名(今回は「sample-app」)> AWS Access Key ID # 先ほど作成したアクセスキー AWS Secret Access Key # 先ほど作成したシークレットアクセスキー Default region name # ap-northeast-1 Default output format # jsonそれぞれ上記のように入力。
追加でポリシーを作成
先ほどIAMユーザーを作成した際、
- AmazonECS_FullAccess
- AmazonEC2ContainerRegistryFullAccess
2つのポリシーをアタッチしたが、これだけだとこの後に使用する「ecs-cli」というツールの中で権限エラーが発生するため、ここで別途追加しなければならない。
AWSのコンソールからサービス→IAM→ポリシーを選択し、「ポリシーの作成」をクリック。
JSONタブを開いて以下の記述を行う。
{ "Version": "2012-10-17", "Statement": [ { "Sid": "VisualEditor0", "Effect": "Allow", "Action": [ "iam:AttachRolePolicy", "iam:AddRoleToInstanceProfile", "iam:CreateInstanceProfile", "iam:CreateRole", "iam:DeleteInstanceProfile", "iam:DeleteRole", "iam:DetachRolePolicy", "iam:PassRole", "iam:RemoveRoleFromInstanceProfile", "ec2:DeleteInternetGateway", "ec2:DeleteSecurityGroup", "ec2:DeleteRouteTable" ], "Resource": "*" } ] }
ポリシーの名前や説明を適当に入力し、「ポリシーの作成」をクリック。
ポリシーをユーザーにアタッチ
AWSのコンソールからサービス→IAM→ユーザーを選択し、「アクセス権限の追加」をクリック。
「既存のポリシーをアタッチ」から先ほど作成したポリシーを選択し、アクセス権限を追加。
キーペアを作成
後々EC2内へ入る際などに必要になるのでキーペアを作成しておく。
AWSのコンソールからサービス→EC2→キーペアを選択し、「キーペアの作成」をクリック。
名前とファイル形式を入力し、「キーペアを作成」をクリック。
$ mv Downloads/sample-app.pem .ssh/ $ chmod 600 ~/.ssh/sample-app.pem完了すると「.pem」形式のファイルがダウンロードされるので、「.ssh」ディレクトリに移動させて権限を変更する。
クラスターを作成
コンソールから手動でぽちぽち作成する事も可能だが、vpcやサブネットなども一緒に作る必要があるため、今回はecs-cliでまとめて作成してしまう。
次のコマンドを実行。
$ ecs-cli configure profile --profile-name <任意のプロフィール名> --access-key <先ほど作成したアクセスキー> --secret-key <先ほど作成したシークレットアクセスキー> $ ecs-cli configure --cluster <任意のクラスター名> --default-launch-type EC2 --config-name <任意の設定名> --region ap-northeast-1 $ ecs-cli up --keypair <先ほど作成したキーペア> --capability-iam --size 2 --instance-type t2.samll --cluster-config <任意の設定名> --ecs-profile <任意のプロフィール名>キーなどの各値は各自異なる。
筆者の場合は下記のような感じ。$ ecs-cli configure profile --profile-name sample-app --access-key AKI***************** --secret-key dlj************************************* $ ecs-cli configure --cluster sample-app-cluster --default-launch-type EC2 --config-name sample-app-cluster --region ap-northeast-1 $ ecs-cli up --keypair sample-app --capability-iam --size 2 --instance-type t2.small --cluster-config sample-app-cluster --ecs-profile sample-app INFO[0006] Using recommended Amazon Linux 2 AMI with ECS Agent 1.44.3 and Docker version 19.03.6-ce INFO[0007] Created cluster cluster=sample-app-cluster region=ap-northeast-1 INFO[0009] Waiting for your cluster resources to be created... INFO[0009] Cloudformation stack status stackStatus=CREATE_IN_PROGRESS INFO[0070] Cloudformation stack status stackStatus=CREATE_IN_PROGRESS INFO[0131] Cloudformation stack status stackStatus=CREATE_IN_PROGRESS VPC created: vpc-***************** Security Group created: sg-***************** Subnet created: subnet-***************** Subnet created: subnet-***************** Cluster creation succeeded.上手くいくと↑のようにクラスター用のVPC、セキュリティグループ、サブネットなどが自動で作成される。
AWSのコンソールからサービス→Elastic Container Service→クラスターを選択し、無事作成されていれば成功。
RDSを作成
データベースとして使うRDSを作成。
AWSのコンソールからサービス→RDSを選択し、「データベースの作成」をクリック。
- 作成方法: 標準作成
- エンジンのタイプ: MySQL
- DBインスタンスサイズ: 無料利用枠
- DBインスタンス識別子: sample-app-db
- マスターユーザー名: root
- パスワード: password
※この辺は全て任意。
- vpc: 先ほど作成したvpc
- サブネットグループ: 新しいDBサブネットグループの作成
- パブリックアクセス: あり
最初のデータベース名: sample_app_production
※記事冒頭で用意したサンプル(sample-app)を使用する場合、※データベース名はsample-appの「config/database.yml」内で定義しているため「sample_app_production」で固定
※特に触れていない部分は空欄もしくはデフォルトのままでOK。問題なければ「データベースの作成」をクリック。
↑こんな感じで作成されていれば成功。
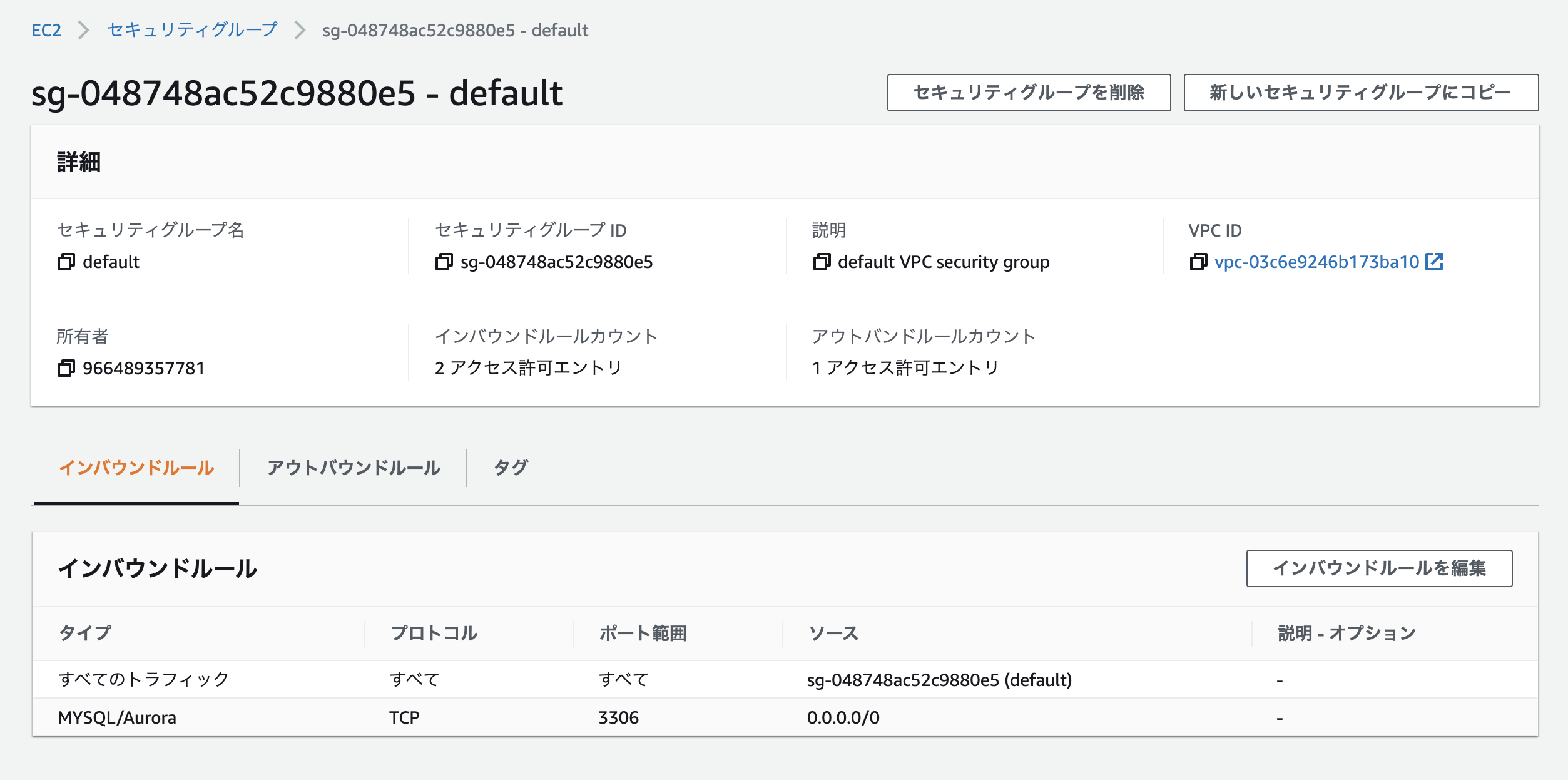
また、セキュリティグループの設定も必要なので「VPCセキュリティグループ」の下に記載されているリンクをクリック。
「インバウンドルールの編集」から次のように設定。
- タイプ: MYSQL/Aurora
- プロトコル: TCP
- ポート範囲
- ソース: 0.0.0.0/0
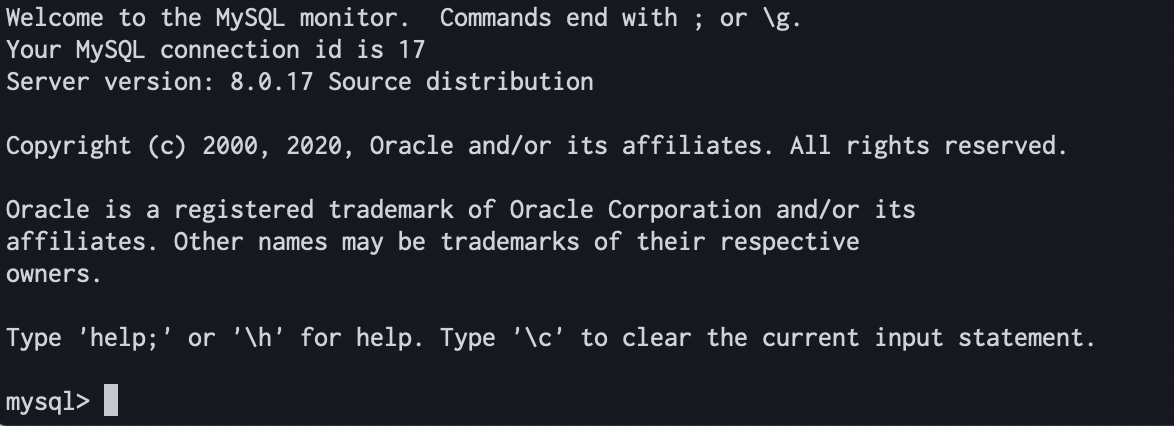
$ mysql -h <RDSのエンドポイント> -u <RDSのユーザー名> -p試しにターミナルで↑のコマンドを叩き、接続できれば成功。
ロードバランサーを作成
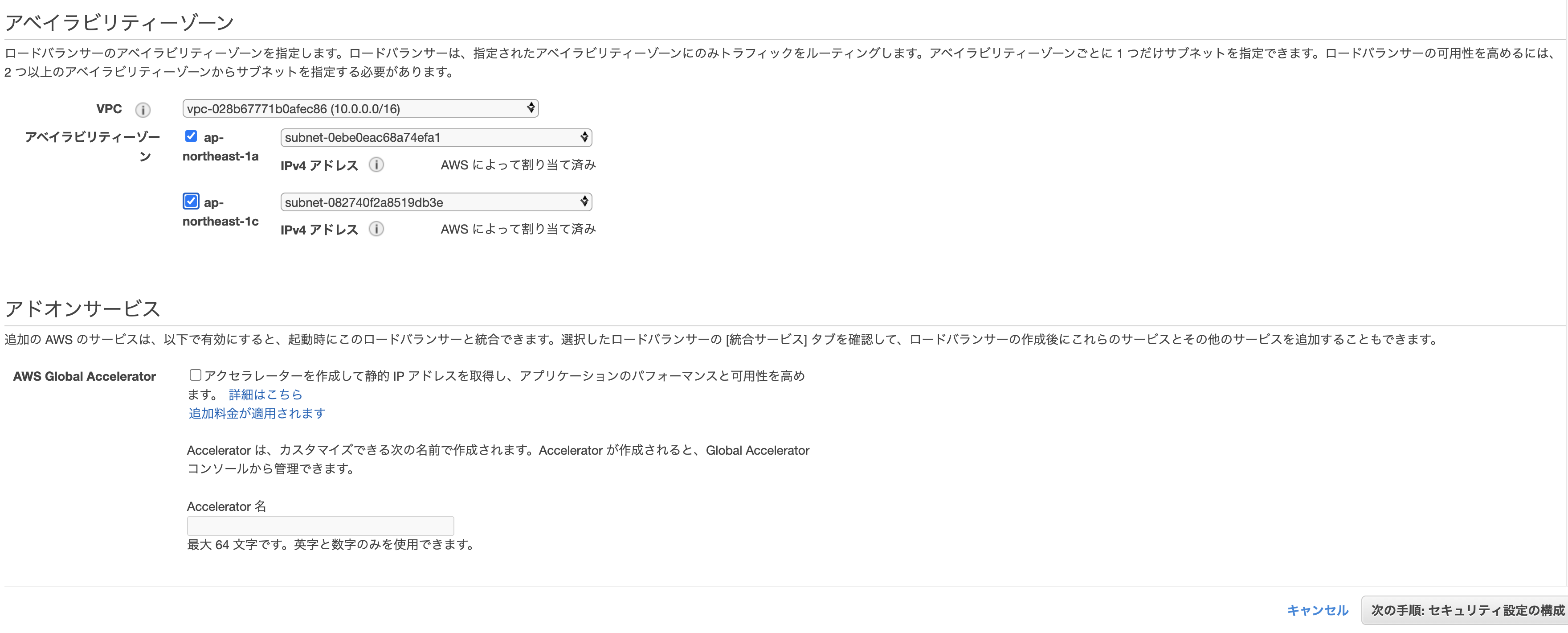
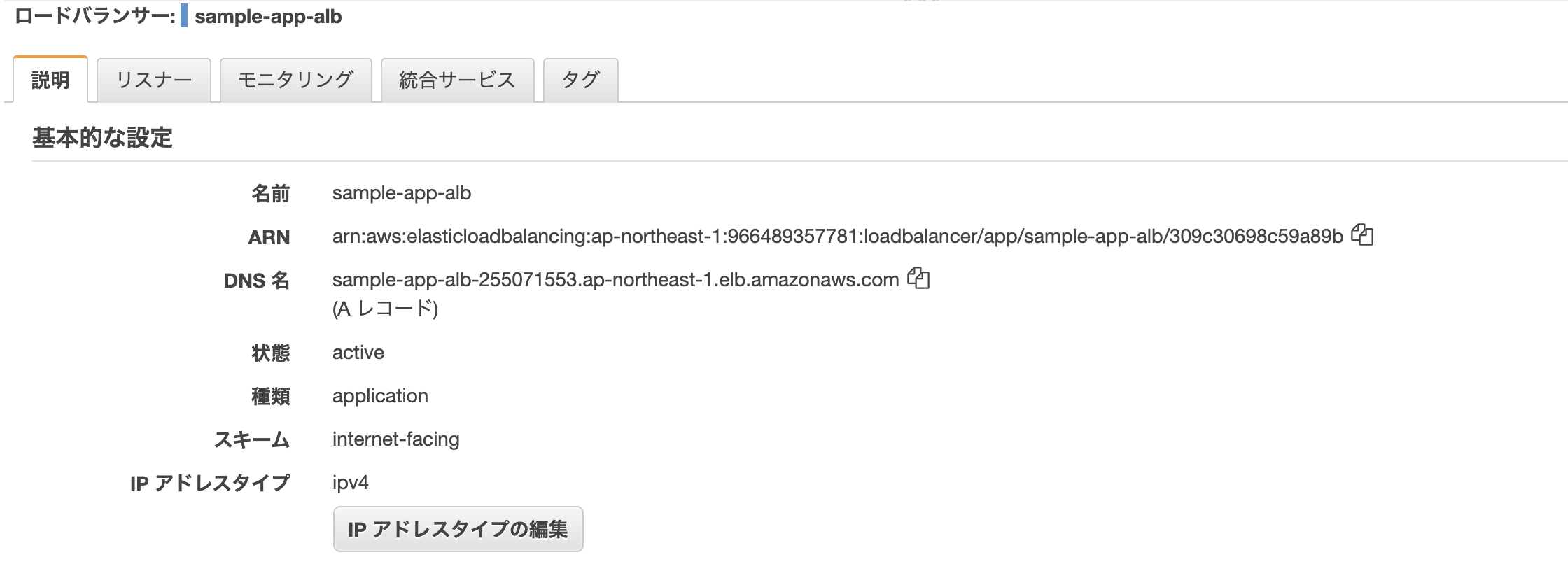
AWSのコンソールからサービス→EC2→ロードバランサーを選択し、「ロードバランサーの作成」をクリック。
3種類あるが、「Application Load Balancer」を選択。
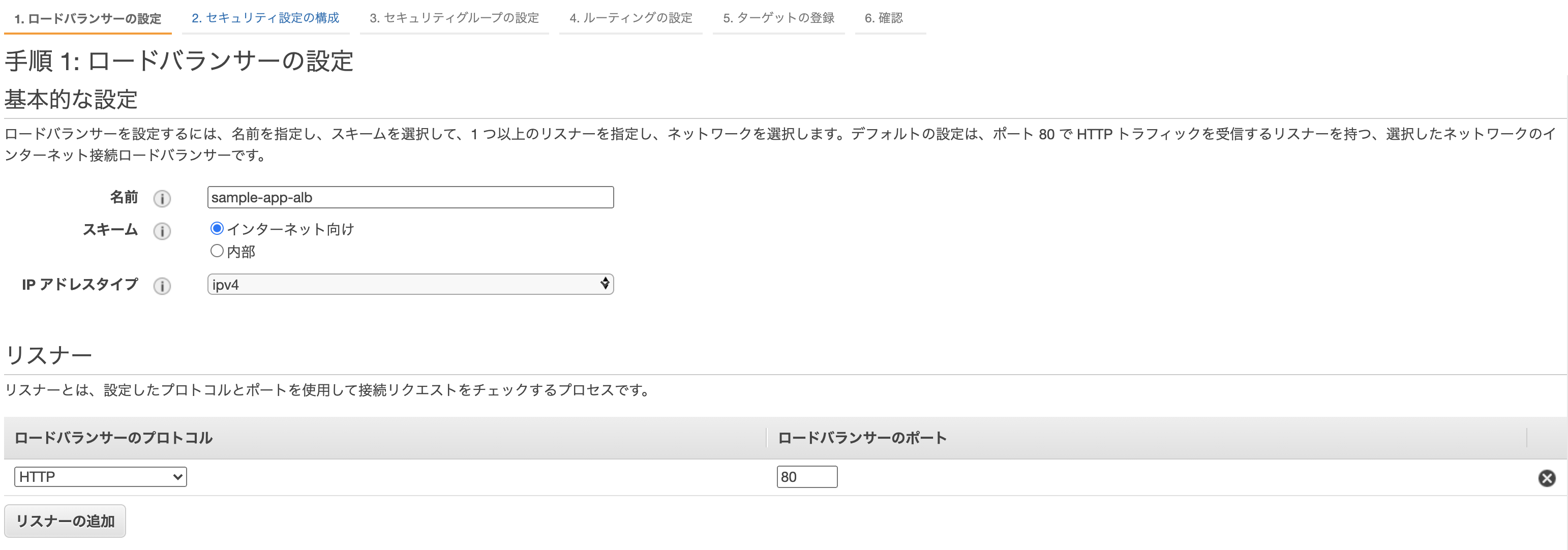
- 名前: sample-app-alb ※任意
- リスナー: そのままでOK
- VPC: 先ほど自動作成されたものを選択
- subnet: 同上
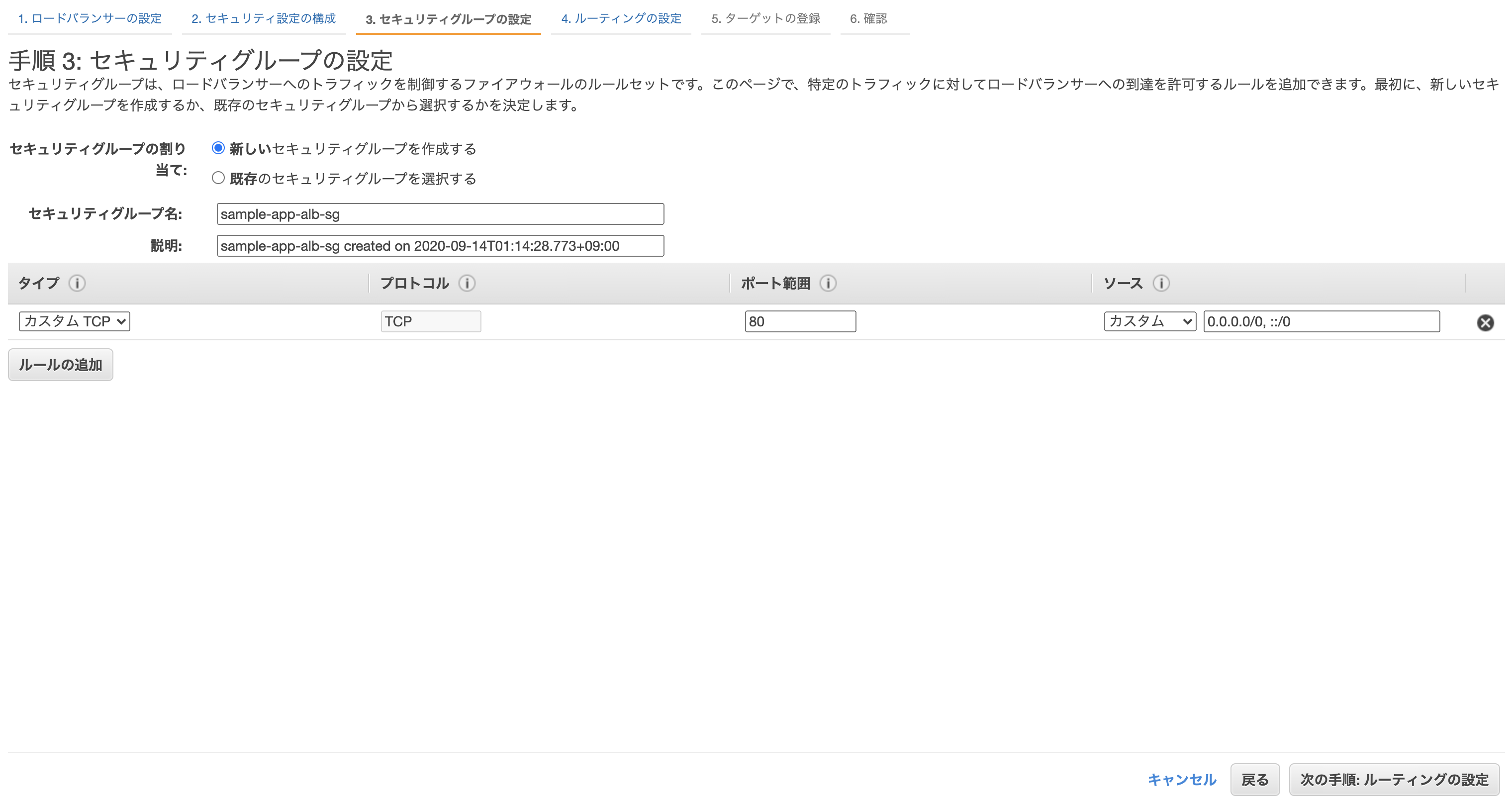
先に進むとセキリュティグループの設定画面になるので、「新しいセキリュティグループを作成する」から適当にセキュリティグループを作成。
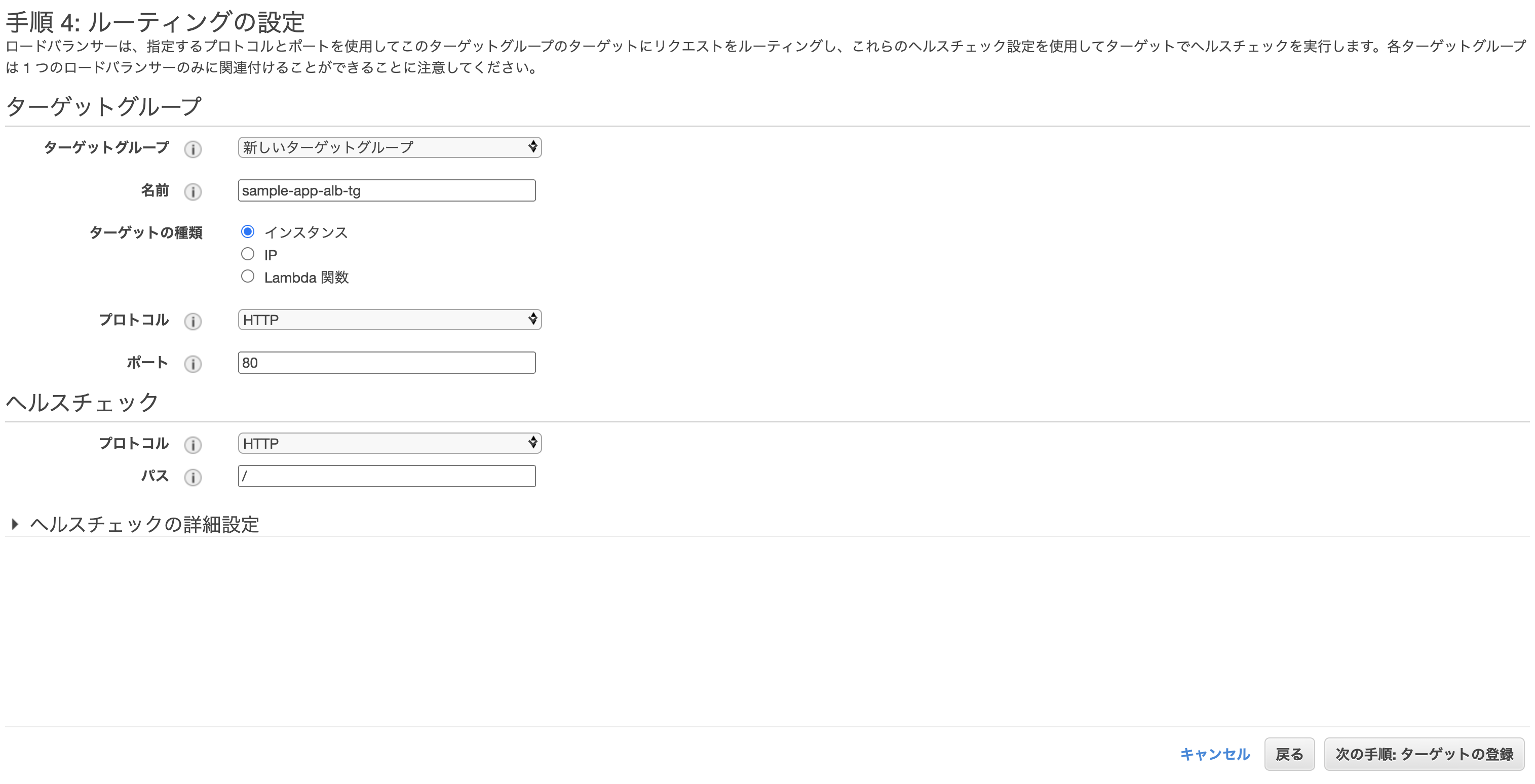
ターゲットグループの設定。
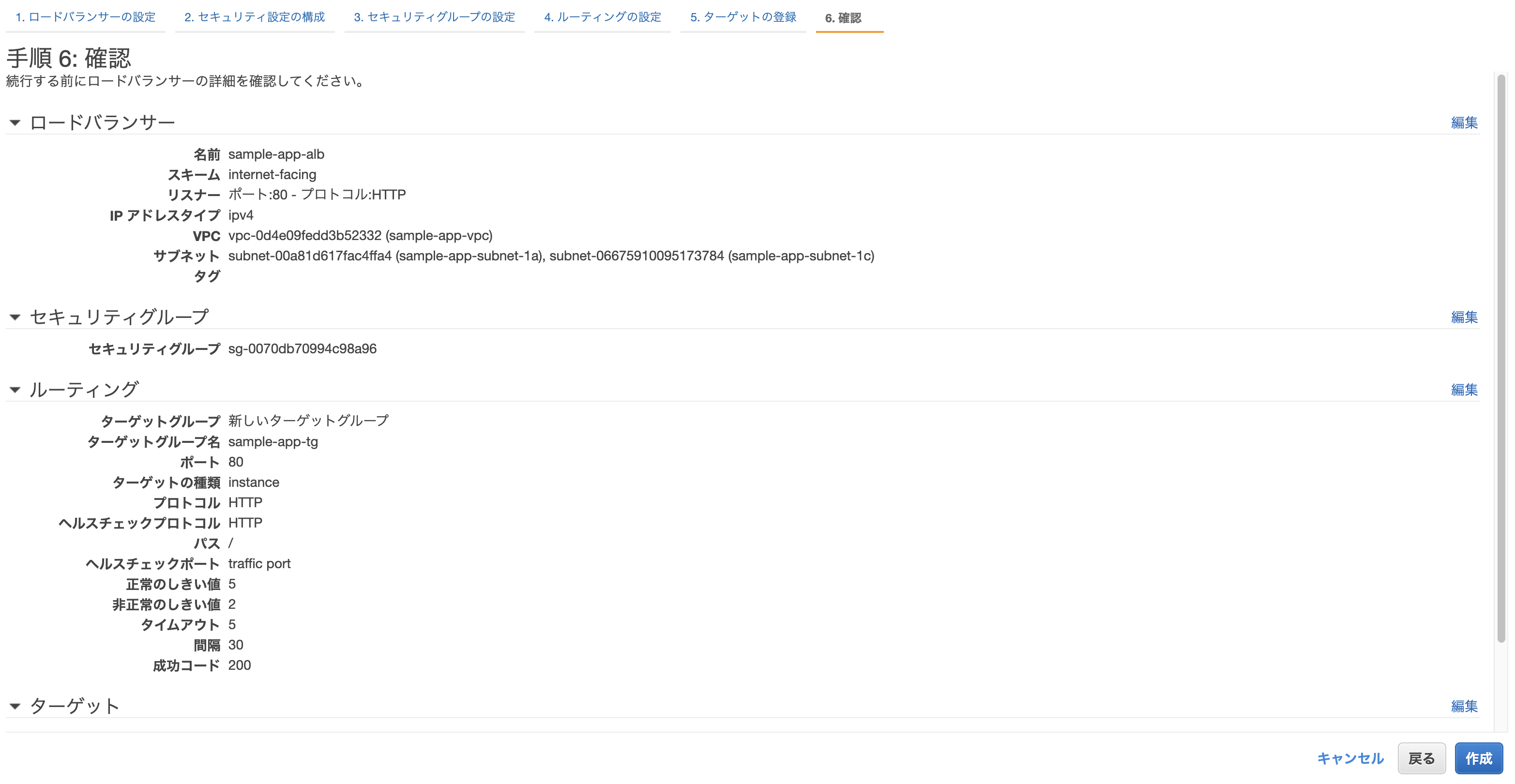
- ターゲットグループ: 新しいターゲットグループ
- 名前: sample-app-alb-tg ※任意
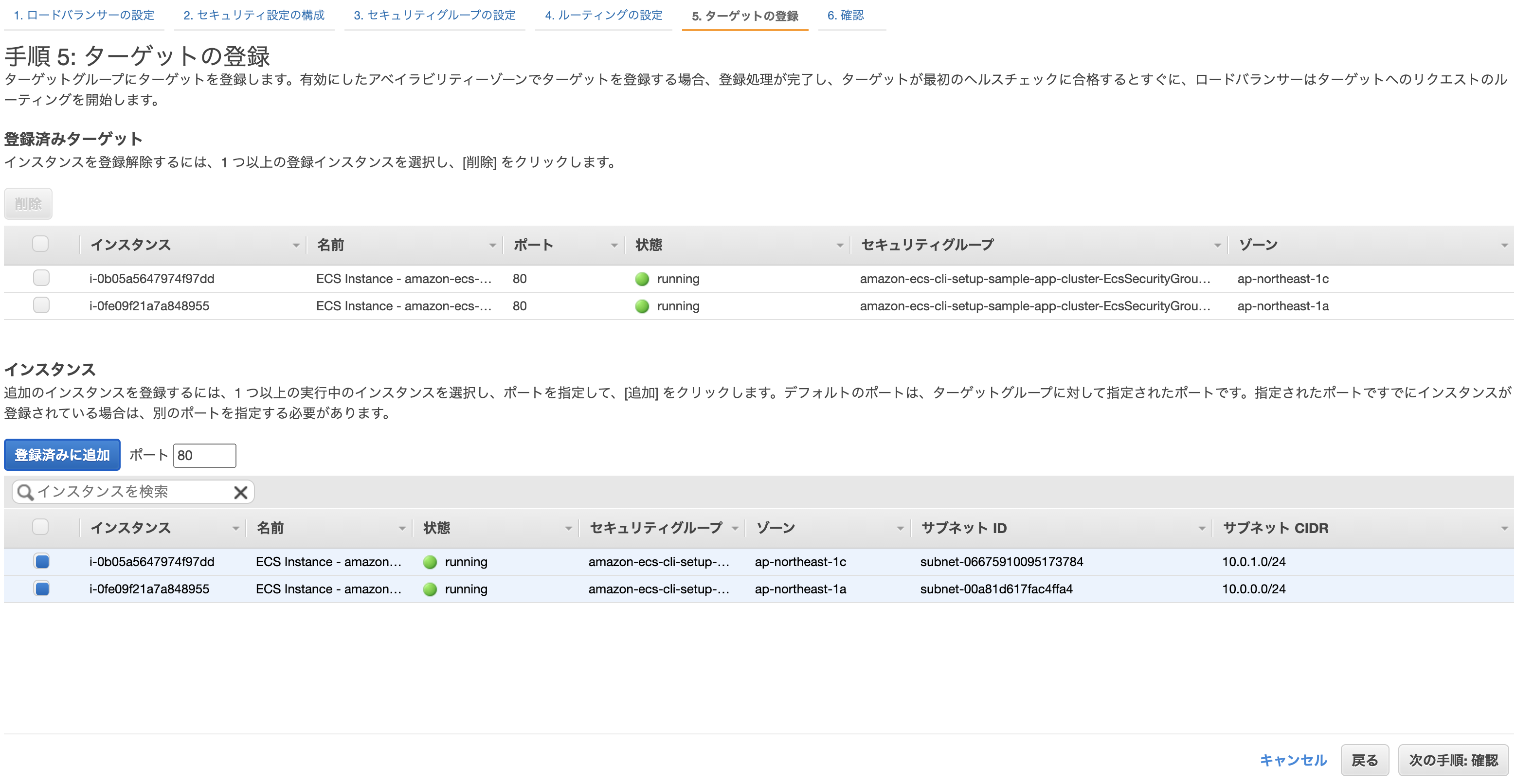
クラスター作成時に自動で作られたEC2を登録し、確認画面から問題なければ「作成」をクリックして完了。
ECRにdockerイメージをpush
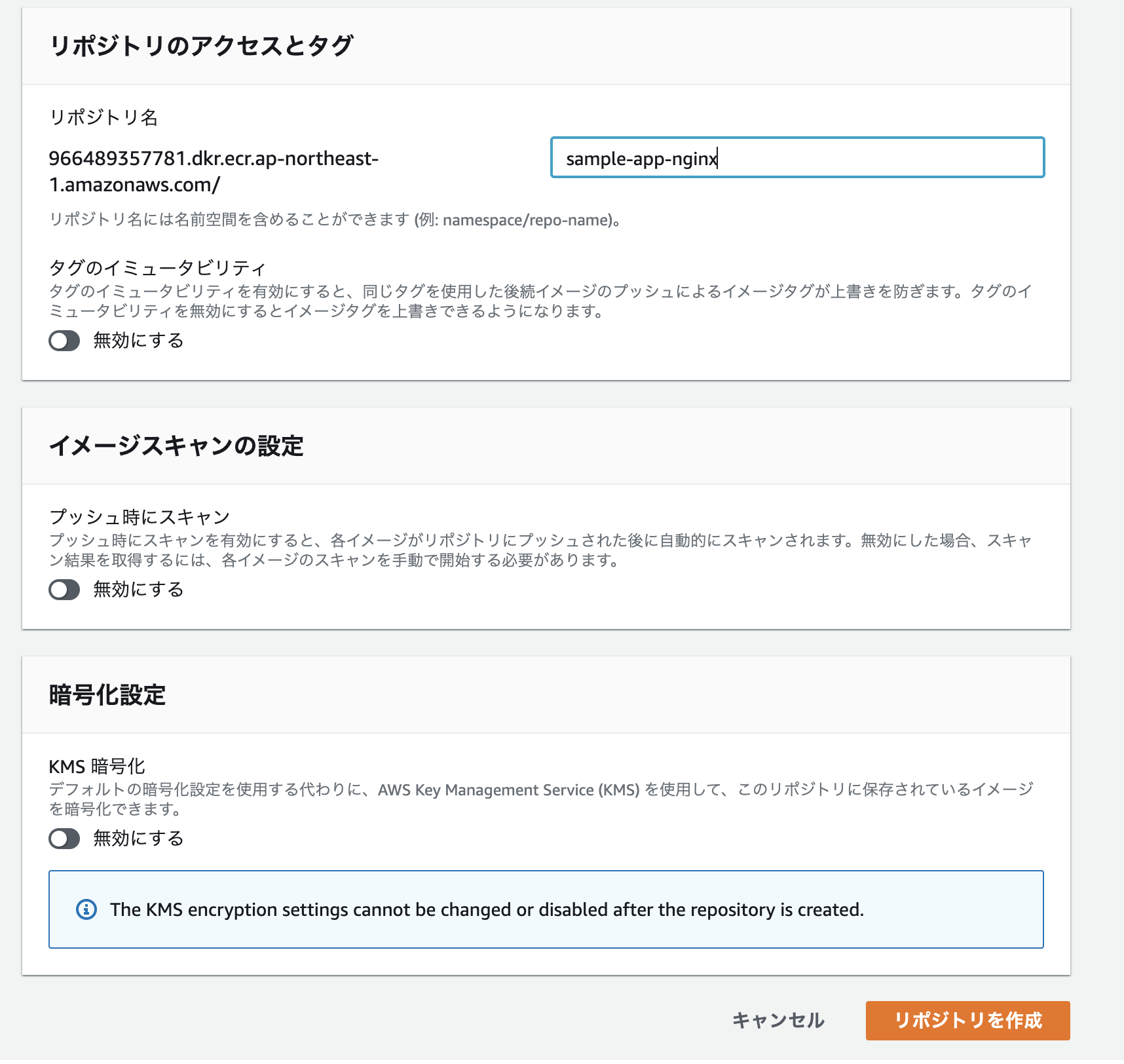
AWSのコンソールからサービス→Amazon Elastic Container Registryを選択し、「リポジトリの作成」をクリック。
それぞれ適当なリポジトリ名を入力し、「リポジトリを作成」をクリック。
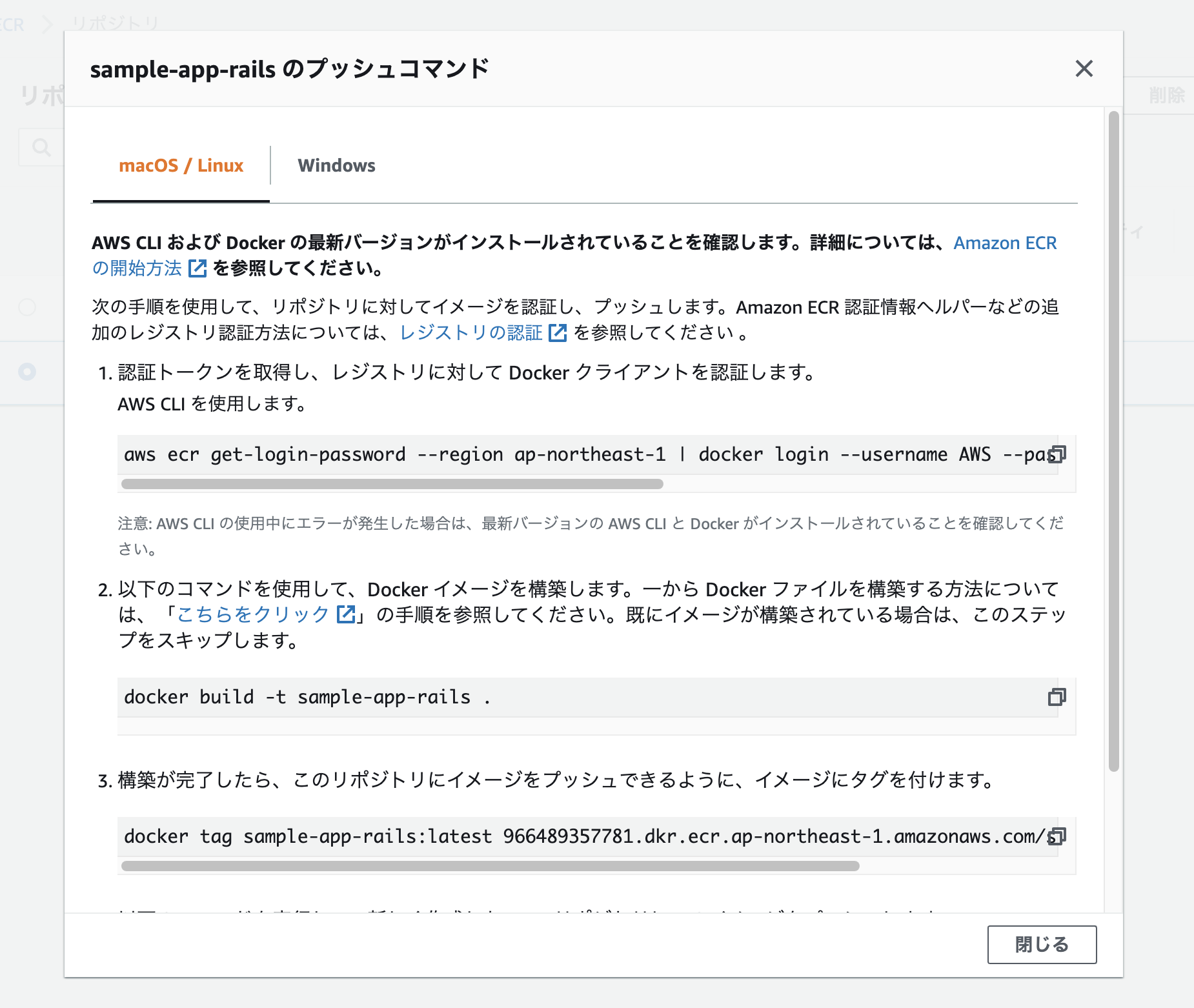
プッシュコマンドを表示し、書いてある通り上から順に4つ実行していく。
※2番目のコマンドでbuildを行う際は-fでDockerfileのコンテキストを変える。
# Rails(本番用のDockerfileを使用する) $ docker build -f ./prod.Dockerfile . -t sample-app-rails # Nginx $ cd containers/nginx $ docker build -f ./Dockerfile . -t sample-app-nginx本番用のDockerfile
$ touch prod.Dockerfile# prod.Dockerfile FROM ruby:2.6.6 ENV LANG C.UTF-8 RUN apt-get update -qq && apt-get install -y build-essential libpq-dev nodejs RUN curl -sL https://deb.nodesource.com/setup_8.x | bash - && \ apt-get install nodejs RUN apt-get update && apt-get install -y curl apt-transport-https wget && \ curl -sS https://dl.yarnpkg.com/debian/pubkey.gpg | apt-key add - && \ echo "deb https://dl.yarnpkg.com/debian/ stable main" | tee /etc/apt/sources.list.d/yarn.list && \ apt-get update && apt-get install -y yarn RUN mkdir /sample-app WORKDIR /sample-app ADD Gemfile /sample-app/Gemfile ADD Gemfile.lock /sample-app/Gemfile.lock RUN gem install bundler:2.1.4 RUN bundle install ADD . /sample-app # Nginxと通信を行うための準備 RUN mkdir -p tmp/sockets VOLUME /sample-app/public VOLUME /sample-app/tmp RUN yarn install --check-files RUN SECRET_KEY_BASE=placeholder bundle exec rails assets:precompile基本的に開発用のものと同じだが、最後の数行でNginxと通信を行うための準備などを行っている。
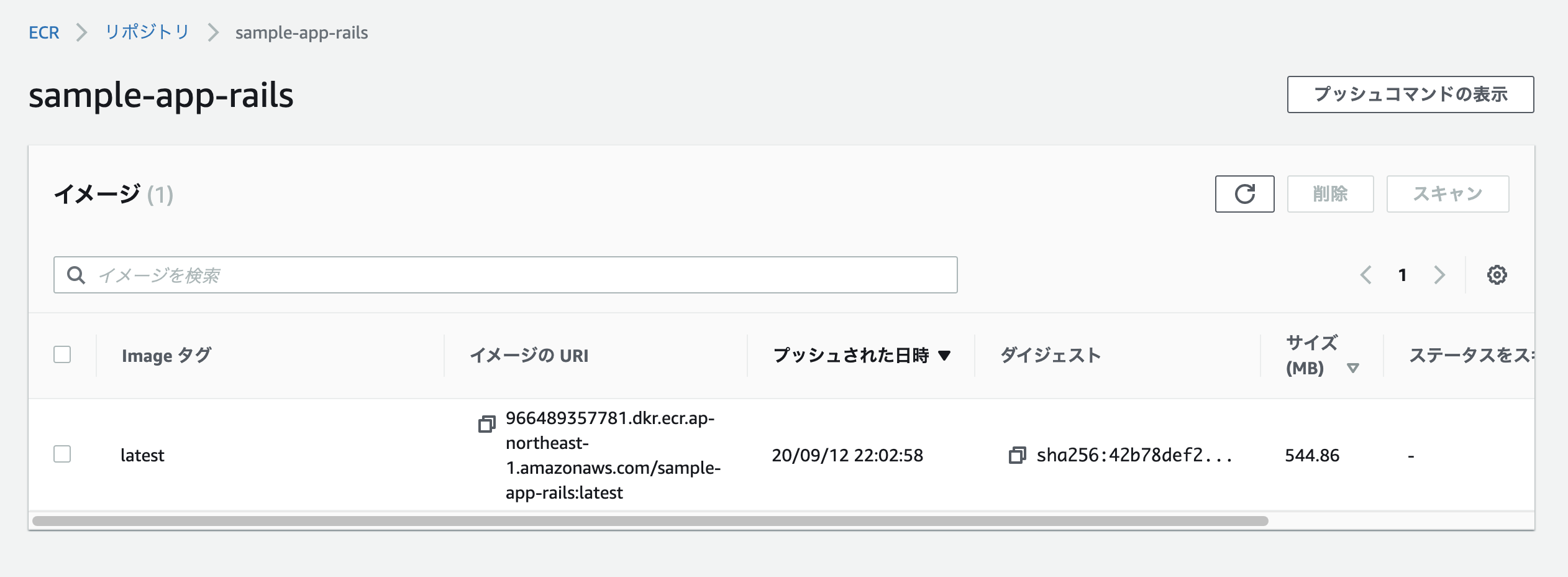
全て打ち終わったらリポジトリを確認し、イメージが追加されていれば成功。
タスクの作成
先ほどpushしたイメージをもとに、タスクの作成を行う。
$ mkdir ecs $ touch ecs/docker-compose.yml# ecs/docker-compose.yml version: 2 services: app: image: # ECRのリポジトリURI(Rails) command: bash -c "bundle exec rails db:migrate && bundle exec rails assets:precompile && bundle exec puma -C config/puma.rb" environment: # 実際はdotenvなどで管理した方が良いかも RAILS_ENV: production RAILS_MASTER_KEY: # config/master.keyの値 DATABASE_NAME: sample_app_production DATABASE_USERNAME: root DATABASE_PASSWORD: password DATABASE_HOST: # RDSのエンドポイント TZ: Japan working_dir: /sample-app logging: driver: awslogs options: awslogs-region: ap-northeast-1 awslogs-group: sample-app-production/app awslogs-stream-prefix: sample-app-production nginx: image: # ECRのリポジトリURI(Nginx) ports: - 80:80 links: - app volumes_from: - app working_dir: /sample-app logging: driver: awslogs options: awslogs-region: ap-northeast-1 awslogs-group: sample-app-production/nginx awslogs-stream-prefix: sample-app-production次のコマンドを実行。
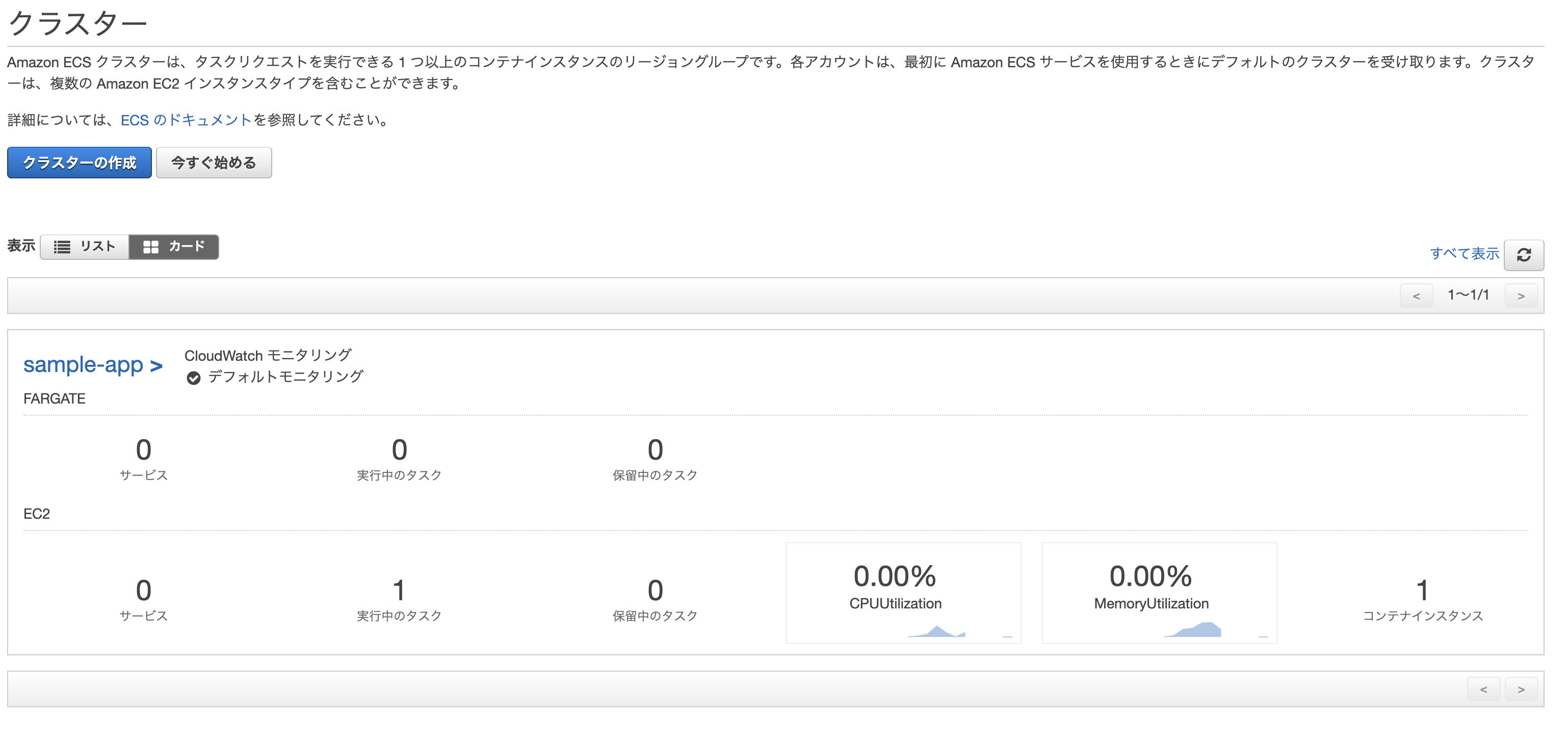
$ ecs-cli compose --project-name sample-app-task -f ./ecs/docker-compose.yml up --create-log-groups --cluster-config sample-app-cluster --ecs-profile sample-app
上手く行った場合、実行中のタスクに「1」と表示される。
最後に、ロードバランサーのDNS名をURLに貼り付けてアクセス。
「Yay!You're on Rails!」と表示されれば成功。
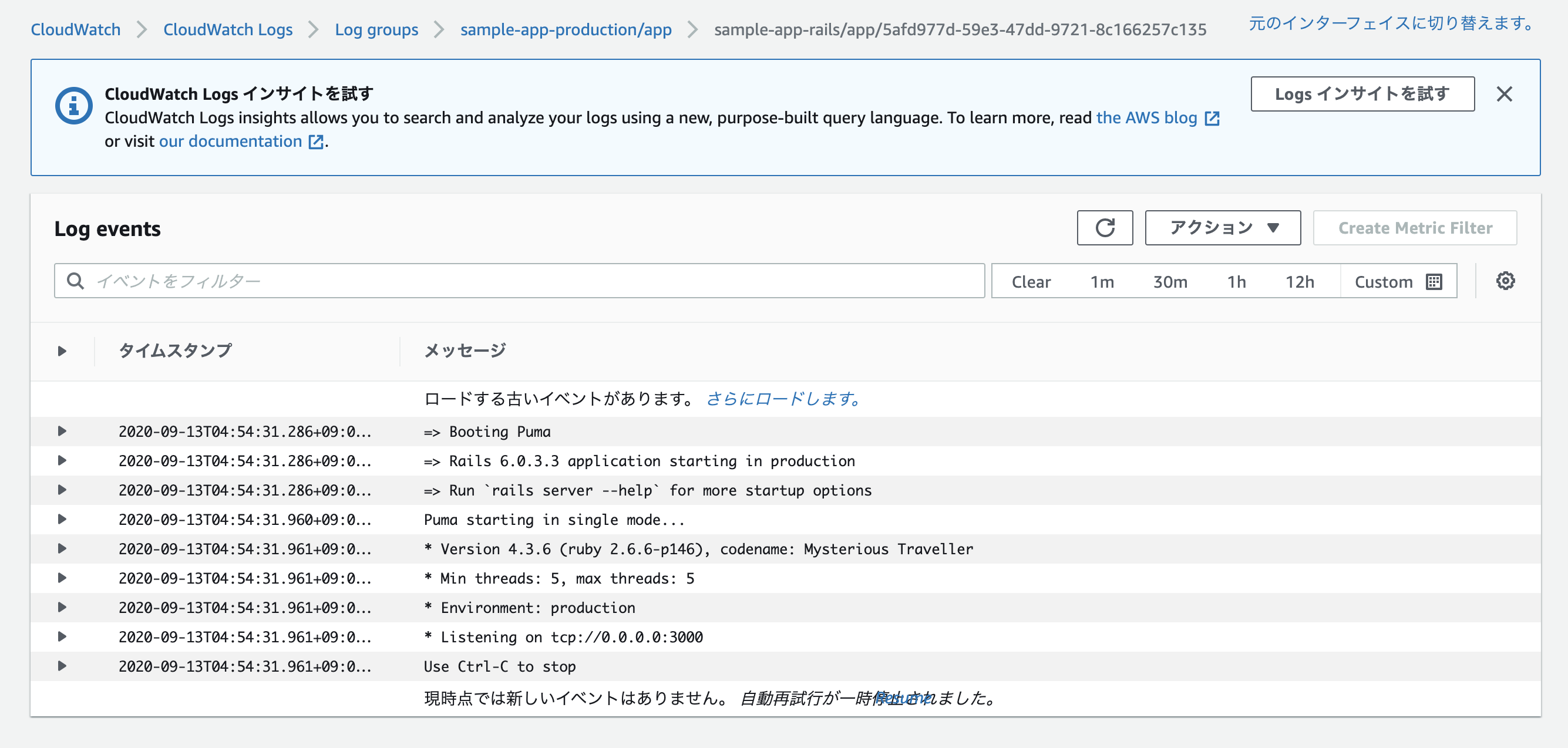
※デプロイに際して何か不具合があった場合はCloudWatchのログを確認して修正。
サービスの作成
クラスターとタスクだけでもアプリは動くが、その中間に「サービス」と呼ばれるものを作成すると、コンテナが止まった際に再起動をかけてくれたりロードバランサーを通じてオートスケーリングしてくれたり何かと便利ぽいので作成しておく。
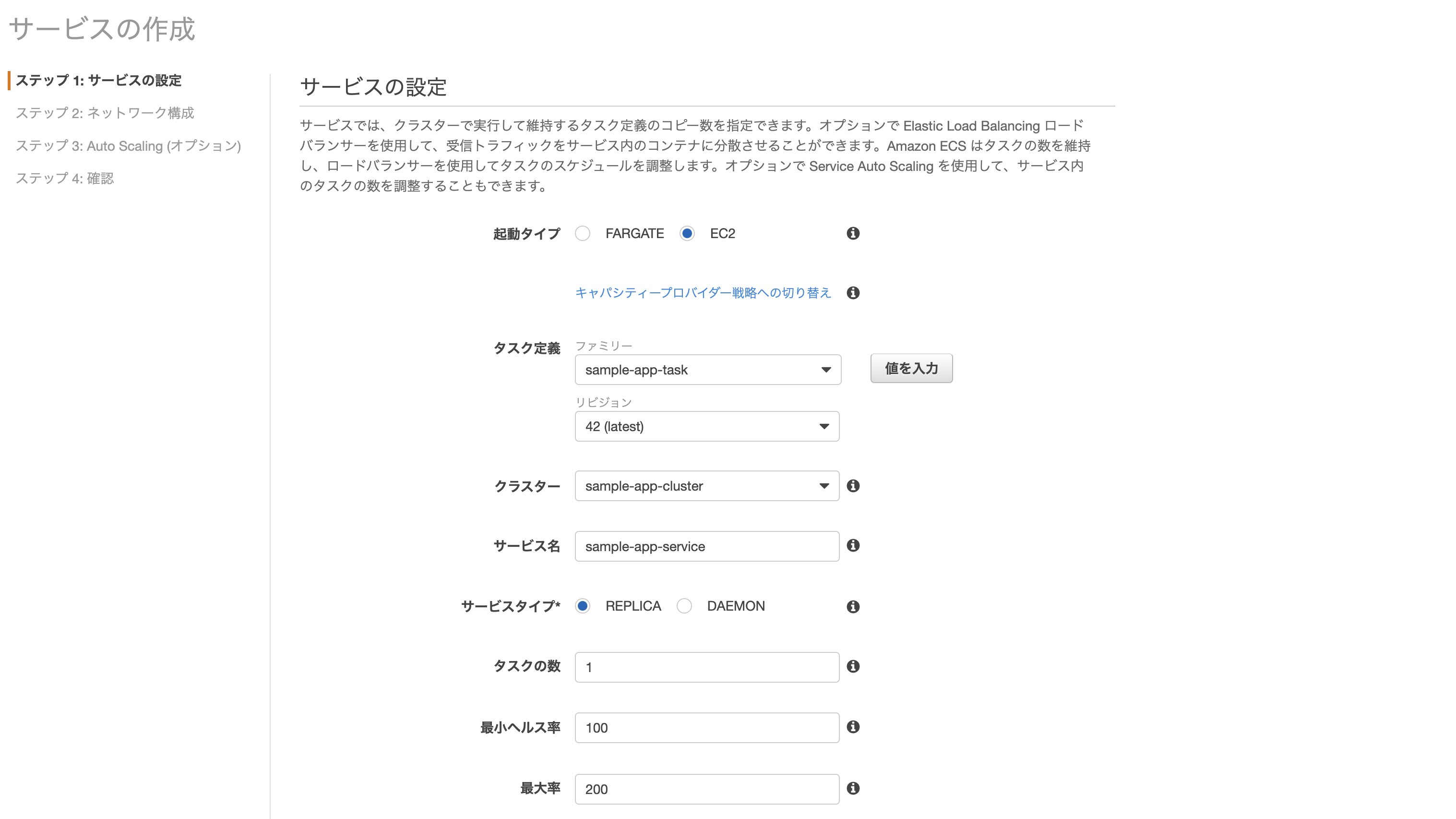
AWSのコンソールからサービス→Amazon Elastic Container Service→ クラスター名をクリックし、「サービス」タブを開いて作成ページに進む。
- 起動タイプ: EC2
- タスク定義: sample-app-task ※先ほど作成したもの
- クラスター: sample-app-cluster ※同上
- サービス名: sample-app-service ※任意
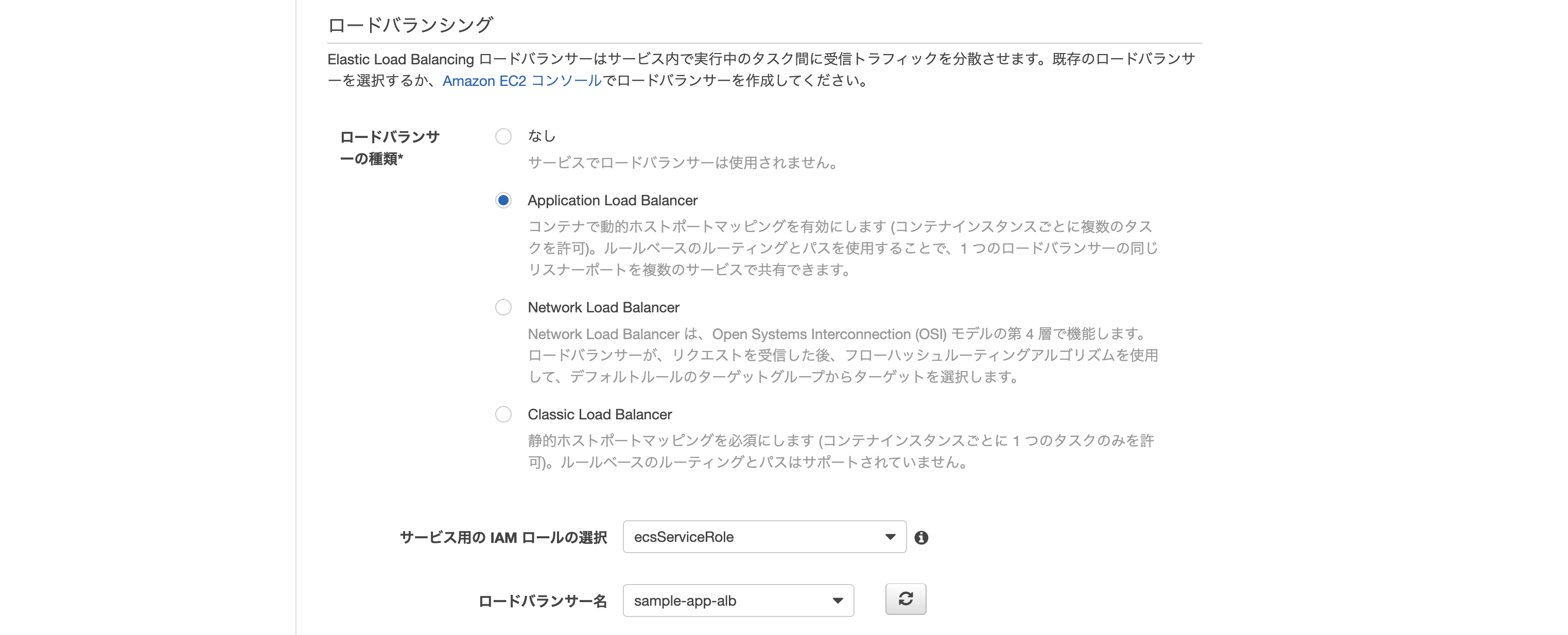
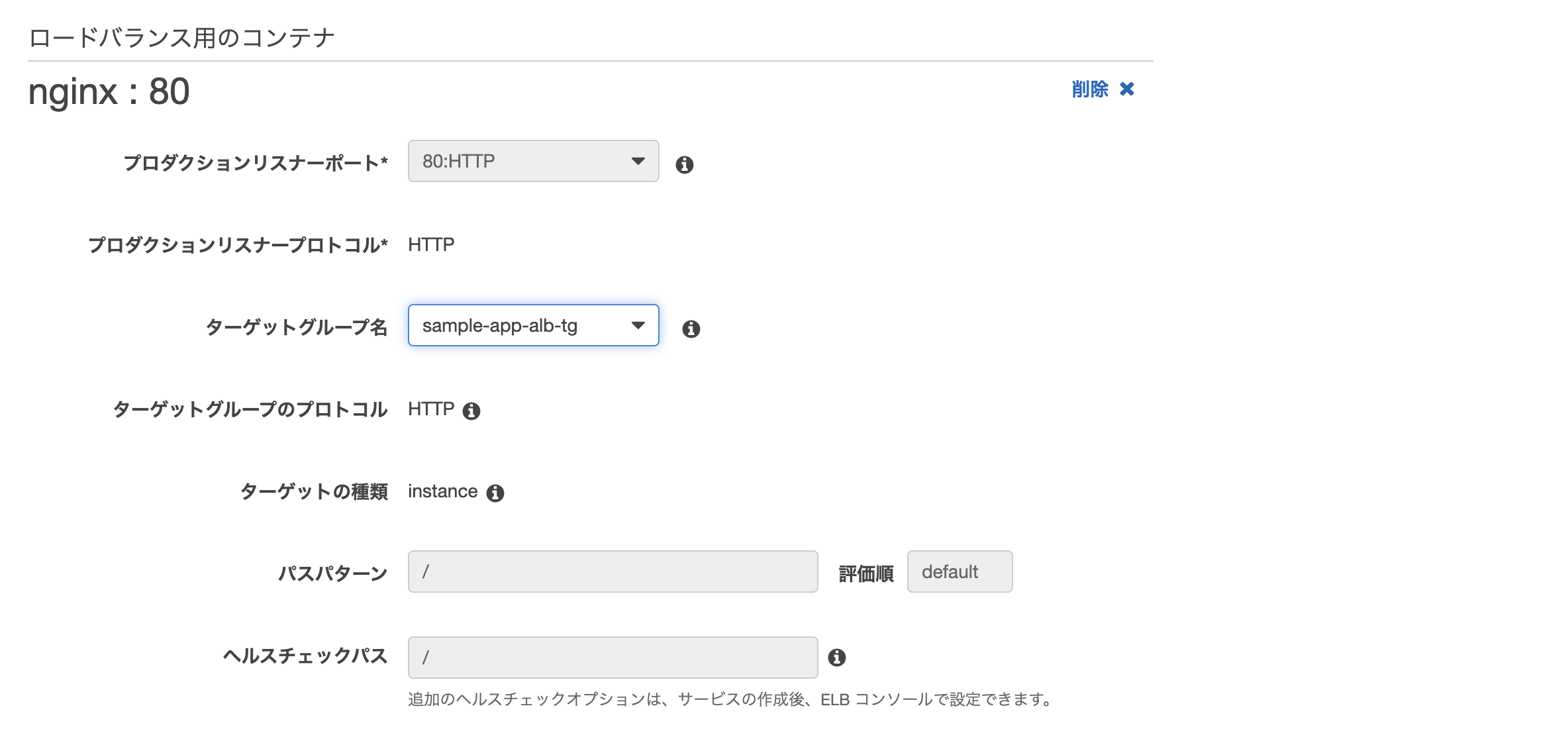
- その他: 画像の通り
- ロードバランサーの種類: Application Load Balancer
- ロードバランサー名: 先ほど作成したもの
- その他: 画像の通り
- ターゲットグループ名: 先ほど作成したもの
- その他: 画像の通り
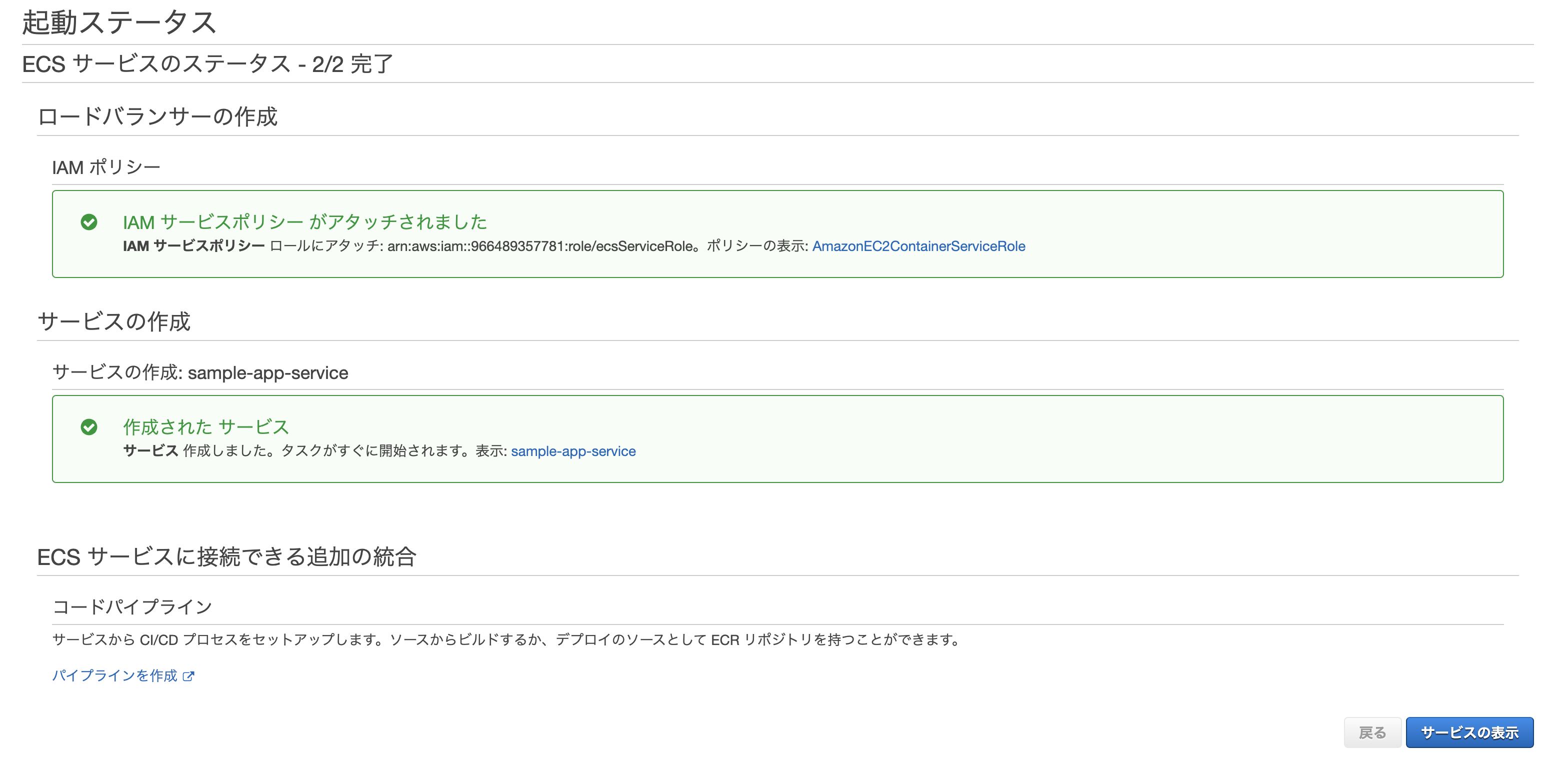
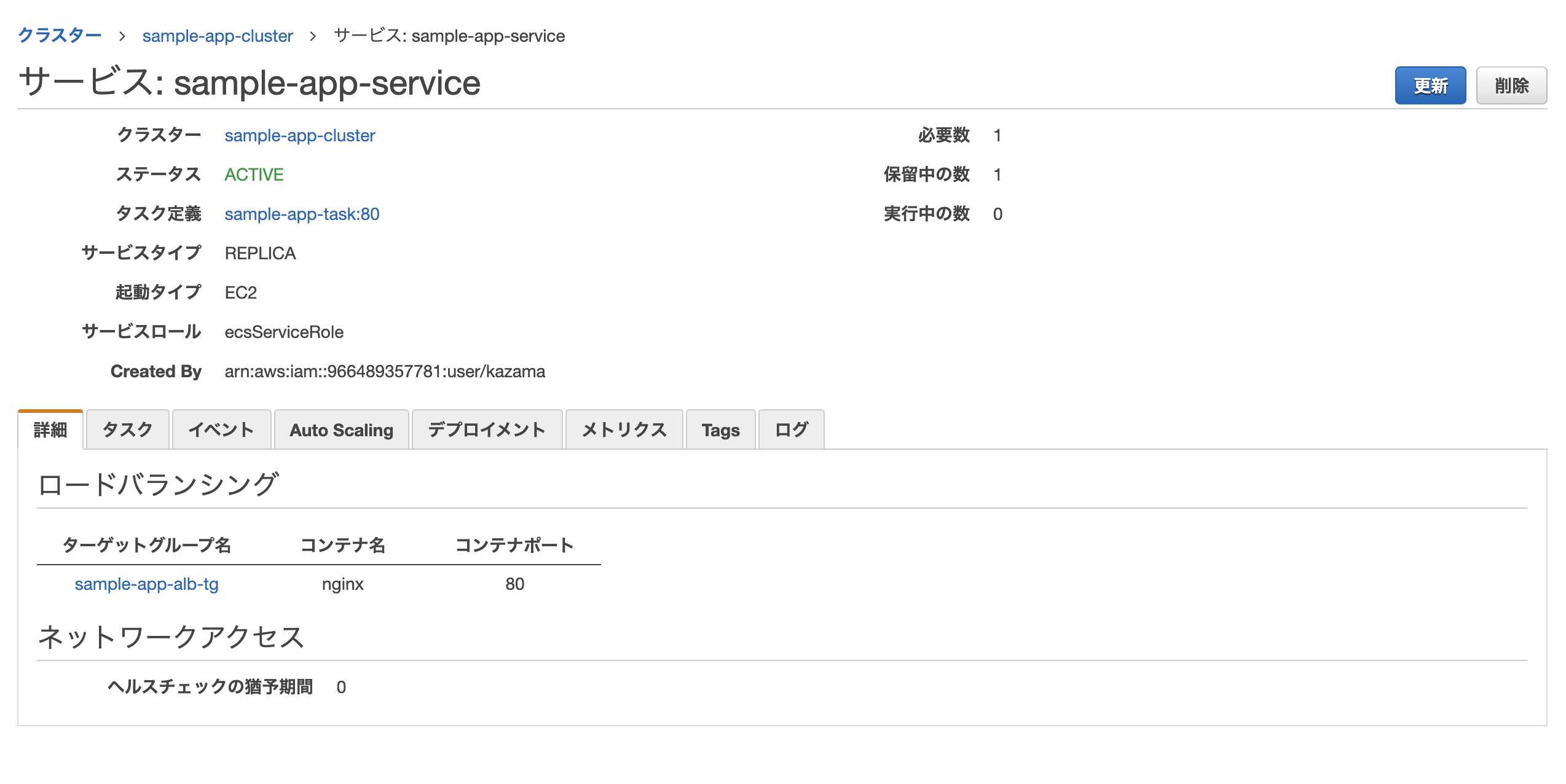
最後に確認画面が表示されるので、問題無ければ作成をクリック。
無事作成されれば完了。
このままだと2つのタスク(片方はecs-cliでターミナルから開始したもの、もう片方はサービスの作成により開始されたもの)が実行中になってしまっているため、前者は停止してしまってOK。
おまけ(CircleCiと連携して自動デプロイ)
このままだと変更点があるたびに手動で「ビルド→プッシュ→タスク再定義」といった面倒な作業が必要になるため、「CirlcleCiにプッシュ→ビルド&テスト→ECR・ECSへ自動デプロイ」といった良くある仕組みを構築していく。
Rspecを導入
まず、デプロイ前にテストを行うためにRspecを導入する。
gemをインストール
# Gemfile group :development, :test do gem 'rspec-rails' end# Gemfileを更新したので再度ビルド $ docker-compose build各種ファイルを作成&編集
$ docker-compose run web bundle exec rails generate rspec:install create .rspec create spec create spec/spec_helper.rb create spec/rails_helper.rb# .rspec --format documentation↑の1行を追記しておくと、Rspecを実行した際の出力表示が見やすくなる。
# spec/rails_helper.rb Dir[Rails.root.join('spec', 'support', '**', '*.rb')].sort.each { |f| require f }必須ではないが、後ほどテスト用のヘルパーメソッドを作成する事になった場合、ファイルの置き場として「spec/support」を使用するので一応設定しておく。
デフォルトではコメントアウトされているので、それを外せばOK。
# config/application.rb config.generators do |g| g.test_framework :rspec, view_specs: false, helper_specs: false, controller_specs: false, routing_specs: false endこのままだと
rails gコマンドを打ち込んだ際に自動で諸々のテストファイルが作成されてしまうので、余計なものを作成したくない場合は「config/application.rb」で設定を行う。※この辺はお好みで。
rspecを実行
$ docker-compose run web bundle exec rspec No examples found. Finished in 0.00276 seconds (files took 0.12693 seconds to load) 0 examples, 0 failuresまだ何もテストを書いていないので、当然こうなる。
とりあえずRequest Specを書いてみる
手始めに、リクエストに対して正常なレスポンスが返ってくるかどうかを確認するためのRequest Specを書いてみる。
トップページを作成
# コントローラー $ touch app/controllers/home_controller.rb # ビュー $ mkdir app/views/home $ touch app/views/home/index.html.erb# app/controllers/home_controller.rb class HomeController < ApplicationController def index end end# app/views/home/index.html.erb <h1>Hello World!</h1>#config/routes.rb Rails.application.routes.draw do root 'home#index' end
テストファイルを作成
$ docker-compose run web bundle exec rails g rspec:request home create spec/requests/homes_spec.rb# spec/requests/home_spec.rb require 'rails_helper' RSpec.describe "Home", type: :request do describe "GET /" do it "works successfully" do get root_path expect(response).to have_http_status(200) end end end「/」にアクセスした際、 200番のステータスコードが返ってくるかどうかのテスト。
$ docker-compose run web bundle exec rspec Home GET / works successfully Finished in 0.53664 seconds (files took 8.4 seconds to load) 1 example, 0 failures再度rspecを実行し、問題無くパスしていれば成功。
CircleCIと連携
次に、実際にCircleCiと連携するための設定を行う。
gemをインストール
group :development, :test do gem 'database_cleaner' gem 'rspec_junit_formatter' gem 'webdrivers', '~> 3.0' end# Gemfileを更新したので再度ビルド $ docker-compose build各種ファイルを作成&編集
$ mkdir .circleci $ touch .circleci/config.yml $ touch config/database.yml.ci $ docker-compose run web bundle exec rails db:schema:dump# .circleci/config.yml version: 2 jobs: build: docker: - image: circleci/ruby:2.6.6-node-browsers environment: - BUNDLER_VERSION: 2.1.4 - RAILS_ENV: 'test' - image: circleci/mysql:5.7 environment: - MYSQL_ALLOW_EMPTY_PASSWORD: 'true' - MYSQL_ROOT_HOST: '127.0.0.1' working_directory: ~/sample_app steps: - checkout - restore_cache: keys: - v1-dependencies-{{ checksum "Gemfile.lock" }} - v1-dependencies- - run: name: install dependencies command: | gem install bundler -v 2.1.4 bundle install --jobs=4 --retry=3 --path vendor/bundle - save_cache: paths: - ./vendor/bundle key: v1-dependencies-{{ checksum "Gemfile.lock" }} # database setup - run: mv ./config/database.yml.ci ./config/database.yml # database setup - run: name: setup database command: | bundle exec rake db:create bundle exec rake db:schema:load # install yarn - run: name: install yarn command: yarn install # install webpack - run: name: install webpack command: bundle exec bin/webpack # run tests - run: name: run rspec command: | mkdir /tmp/test-results TEST_FILES="$(circleci tests glob "spec/**/*_spec.rb" | \ circleci tests split --split-by=timings)" bundle exec rspec \ --format progress \ --format RspecJunitFormatter \ --out /tmp/test-results/rspec.xml \ --format progress \ $TEST_FILES # collect reports - store_test_results: path: /tmp/test-results - store_artifacts: path: /tmp/test-results destination: test-results# config/database.yml.ci (CircleCiのデータベース設定用) test: adapter: mysql2 encoding: utf8 pool: 5 username: 'root' port: 3306 host: '127.0.0.1' database: sample_app_test# spec/rails_helper.rb RSpec.configure do |config| # config DataBaseCleaner config.before(:suite) do DatabaseCleaner.strategy = :transaction DatabaseCleaner.clean_with(:truncation) Rails.application.load_seed end config.before(:each) do DatabaseCleaner.start end config.after(:each) do DatabaseCleaner.clean end end# db/schema.rb # This file is auto-generated from the current state of the database. Instead # of editing this file, please use the migrations feature of Active Record to # incrementally modify your database, and then regenerate this schema definition. # # This file is the source Rails uses to define your schema when running `rails # db:schema:load`. When creating a new database, `rails db:schema:load` tends to # be faster and is potentially less error prone than running all of your # migrations from scratch. Old migrations may fail to apply correctly if those # migrations use external dependencies or application code. # # It's strongly recommended that you check this file into your version control system. ActiveRecord::Schema.define(version: 0) do endCircleCiとGitHubを接続
https://app.circleci.com/projects/project-dashboard/github/GitHubのアカウント名/
↑CircleCiのダッシュボードから連携したいリポジトリを探し、「Set Up Project」をクリック。画面に表示される指示に従い設定。
これで今後GitHubへ新しいプッシュを行った際、「.circleci/config.yml」に書いた内容に基づき自動でビルド&テストが走るようになる。
特に問題が無ければ「SUCCESS」と表示されるはず。
これで初期設定は完了。自動デプロイ(ECR・ECS)
CircleCiのバージョン2.1から追加されたOrbを使い、masterブランチに変更が加えられた際、CircleCiでのビルド&テストを行い自動でイメージを作成しECRへプッシュし、ECSのサービスを更新してタスクの再定義を行うようにする。
環境変数の登録
あらかじめCircleCiの設定画面からデプロイに必要な環境変数を登録しておく。
- AWS_ACCESS_KEY_ID
- 先ほど作成したIAMユーザーのアクセスキー
- AWS_SECRET_ACCESS_KEY
- 先ほど作成したIAMユーザーのシークレットキー
- AWS_ACCOUNT_ID
- AWSのアカウントID(コンソールの「マイアカウント」から確認可能)
- AWS_REGION
- ap-northeast-1
- AWS_ECR_ACCOUNT_URL
- ECRのリポジトリURI(例: <アカウントID>.dkr.ecr.ap-northeast-1.amazonaws.com)
- DATABASE_HOST
- RDSのエンドポイント(例: ********.ap-northeast-1.rds.amazonaws.com)
- DATABASE_USERNAME
- RDSのユーザー名(例: root)
- DATABASE_PASSWORD
- RDSのパスワード(例: password)
- DATABASE_NAME
- 使用するデータベース名(例: sample_app_production)
- RAILS_MASTER_KEY
- config/master.keyの値
- TZ
- JAPAN
- MY_APP_PREFIX
- 任意(例: sample-app)
- 変数を使い回してなるべくコンパクトに書けるようにクラスター名やタスク名は共通のワードを含めて作成しておいた方が良い(sample-app-cluster、sample-app-taskなど)。
.circleci/config.ymlを編集
# .circleci/config.yml version: 2.1 orbs: aws-ecr: circleci/aws-ecr@6.7.0 aws-ecs: circleci/aws-ecs@1.1.0 jobs: test: docker: - image: circleci/ruby:2.6.6-node-browsers environment: - BUNDLER_VERSION: 2.1.4 - RAILS_ENV: 'test' - image: circleci/mysql:5.7 environment: - MYSQL_ALLOW_EMPTY_PASSWORD: 'true' - MYSQL_ROOT_HOST: '127.0.0.1' working_directory: ~/project steps: - checkout - restore_cache: keys: - v1-dependencies-{{ checksum "Gemfile.lock" }} - v1-dependencies- - run: name: install dependencies command: | gem install bundler -v 2.1.4 bundle install --jobs=4 --retry=3 --path vendor/bundle - save_cache: paths: - ./vendor/bundle key: v1-dependencies-{{ checksum "Gemfile.lock" }} - run: mv ./config/database.yml.ci ./config/database.yml - run: name: setup database command: | bundle exec rake db:create bundle exec rake db:schema:load - run: name: install yarn command: yarn install - run: name: install webpack command: bundle exec bin/webpack - run: name: run rspec command: | mkdir /tmp/test-results TEST_FILES="$(circleci tests glob "spec/**/*_spec.rb" | \ circleci tests split --split-by=timings)" bundle exec rspec \ --format progress \ --format RspecJunitFormatter \ --out /tmp/test-results/rspec.xml \ --format progress \ $TEST_FILES - store_test_results: path: /tmp/test-results - store_artifacts: path: /tmp/test-results destination: test-results workflows: version: 2 test_and_deploy: jobs: - test # ビルドした後にイメージをECRへプッシュ - aws-ecr/build-and-push-image: requires: - test account-url: AWS_ECR_ACCOUNT_URL region: AWS_REGION aws-access-key-id: AWS_ACCESS_KEY_ID aws-secret-access-key: AWS_SECRET_ACCESS_KEY create-repo: true dockerfile: ./prod.Dockerfile repo: "${MY_APP_PREFIX}-rails" tag: "${CIRCLE_SHA1}" filters: branches: only: - master # ECSのサービスを更新してタスクを再定義 - aws-ecs/deploy-service-update: requires: - aws-ecr/build-and-push-image family: "${MY_APP_PREFIX}-task" cluster-name: "${MY_APP_PREFIX}-cluster" service-name: "${MY_APP_PREFIX}-service" container-image-name-updates: "container=app,tag=${CIRCLE_SHA1}"各環境変数に間違いが無いか良く確認しておく事。
# app/views/home/index.html.erb <h1>Hello World!</h1> <p>Completed auto deploy with CircleCi</p>自動デプロイが上手くいったかわかりやすいようにトップページを少し変えておく。
masterブランチに変更を加える
実際にmasterブランチにプッシュして変更を加えてみると、CircleCi上でデプロイ込みのjobsが動き始める。
※全てのフローが完了するまでに大体10〜15分くらいかかるので注意。
再度ロードバランサーのDNS名にアクセスし、先ほどの変更がちゃんと更新されていれば成功。
※反映されるまで多少時間がかかるので気長に待つ。
古いタスクと新しいタスクの2つが実行されているが、時間の経過で古い方は勝手に消されるため(サービスのおかげ?)そのまま放置でOK。
お疲れ様でした。
あとがき
自分もまだまだ勉強中の身なので、何かあれば随時更新予定です。
現状、コンソール上で手を動かしながら行う作業とターミナルでコマンドを叩いて行う作業がごちゃ混ぜになってしまっているため、できれば全て後者に統一したいと考えていいます。
Terraformとかも使って一発バシっとできるようにしたい...。
どこか詰まった部分やもっとこうした方が良いなどあればコメントいただけると嬉しいです。
個人的に詰まった部分
EC2のインスタンスタイプ
- 「t2.small」以上を推奨。無料枠での使用だと「t2.micro」が定番だと思うが、筆者の場合、t2.microだとメモリ不足になる不具合が生じた。
service sample-app-service was unable to place a task because no container instance met all of its requirements. The closest matching container-instance c4b1a3e7-3209-408c-9501-7b3ea30f97f7 has insufficient memory available. For more information, see the Troubleshooting section.参照: https://aws.amazon.com/jp/premiumsupport/knowledge-center/ecs-container-instance-cpu-error/
本記事内だと、クラスター作成時のコマンド
$ ecs-cli up --keypair sample-app --capability-iam --size 2 --instance-type t2.small --cluster-config sample-app-cluster --ecs-profile sample-app↑この部分でインスタンスタイプを指定している。
Nginxの設定
- nginx.confファイルの中身は各自変更しないと正常に動かない部分があるので、ググりながら適宜修正する必要がある。
appコンテナとnginxコンテナの接続が上手くいかないと
2020/09/13 20:02:57 [crit] 7#7: *456 connect() to unix:///sample-app/tmp/sockets/puma.sock failed (2: No such file or directory) while connecting to upstream, client: *********, server: localhost, request: "GET / HTTP/1.1", upstream: "http://unix:///sample-app/tmp/sockets/puma.sock:/500.html", host: "***********"↑こんな感じのエラーで延々と悩まされる。
各環境変数の設定
- CircleCiに登録する環境変数の値がしっかり合っているか何度も確認した方が良い。ビルドするのにやたら時間がかかるので、1回失敗するとそれだけでかなりの時間の無駄になる。
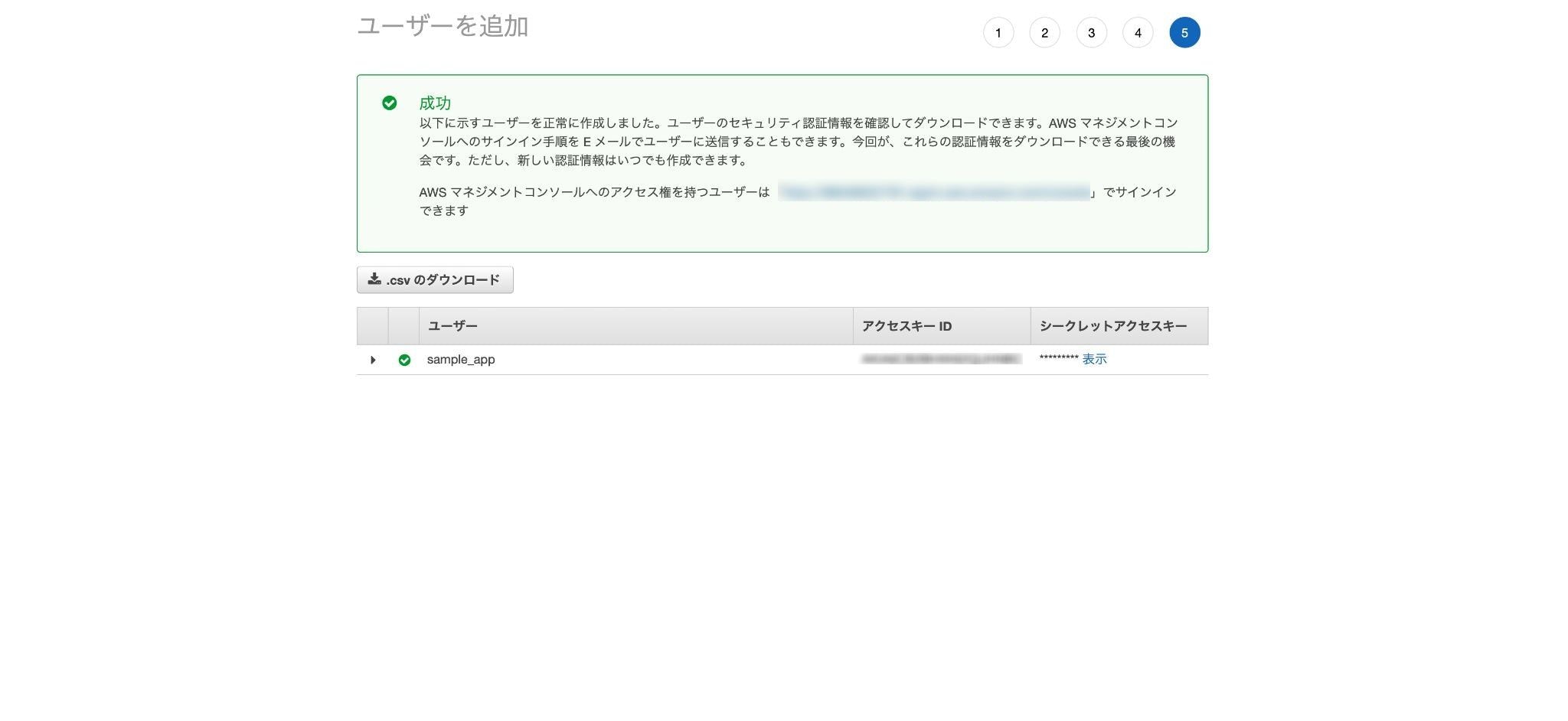
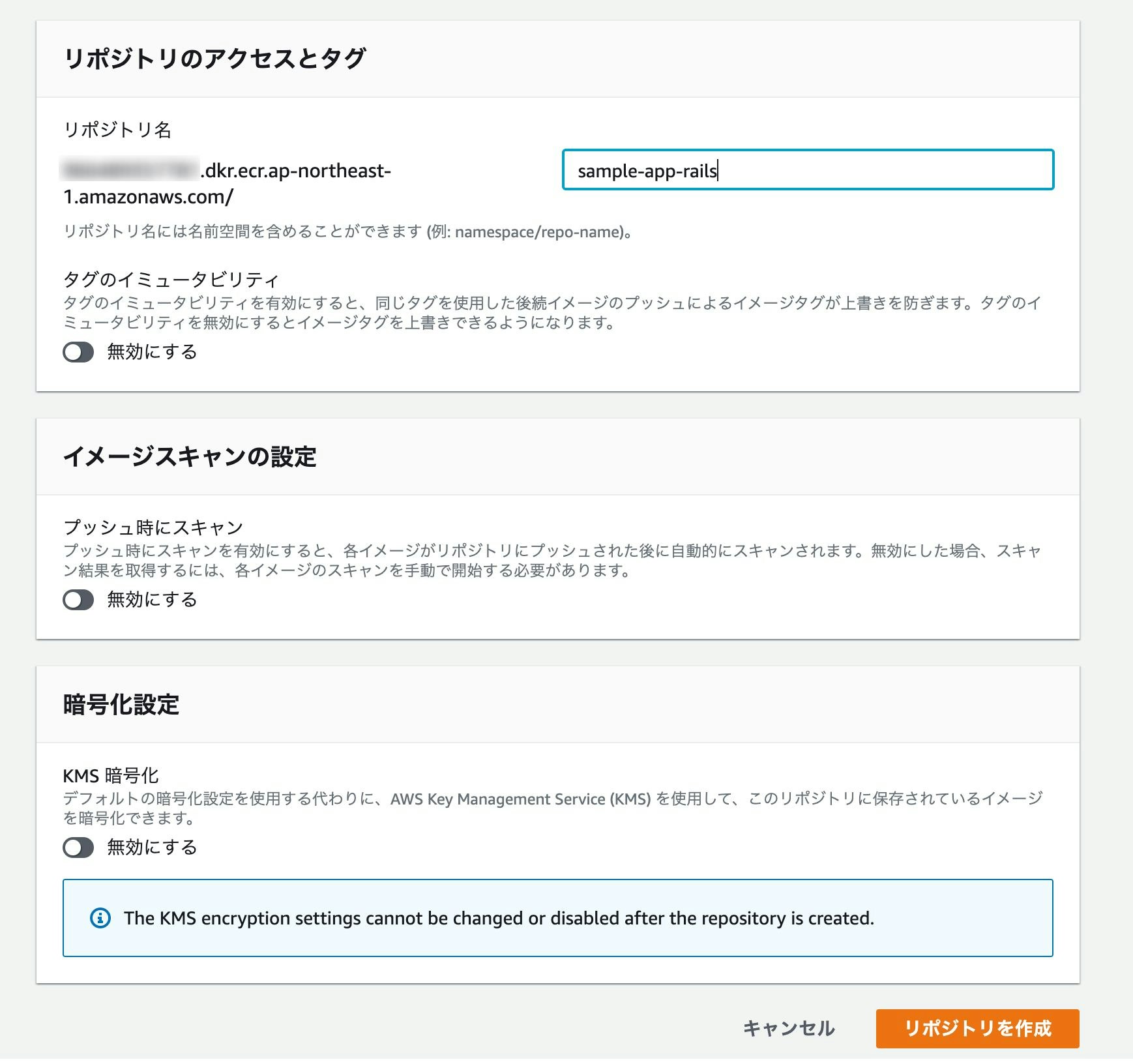
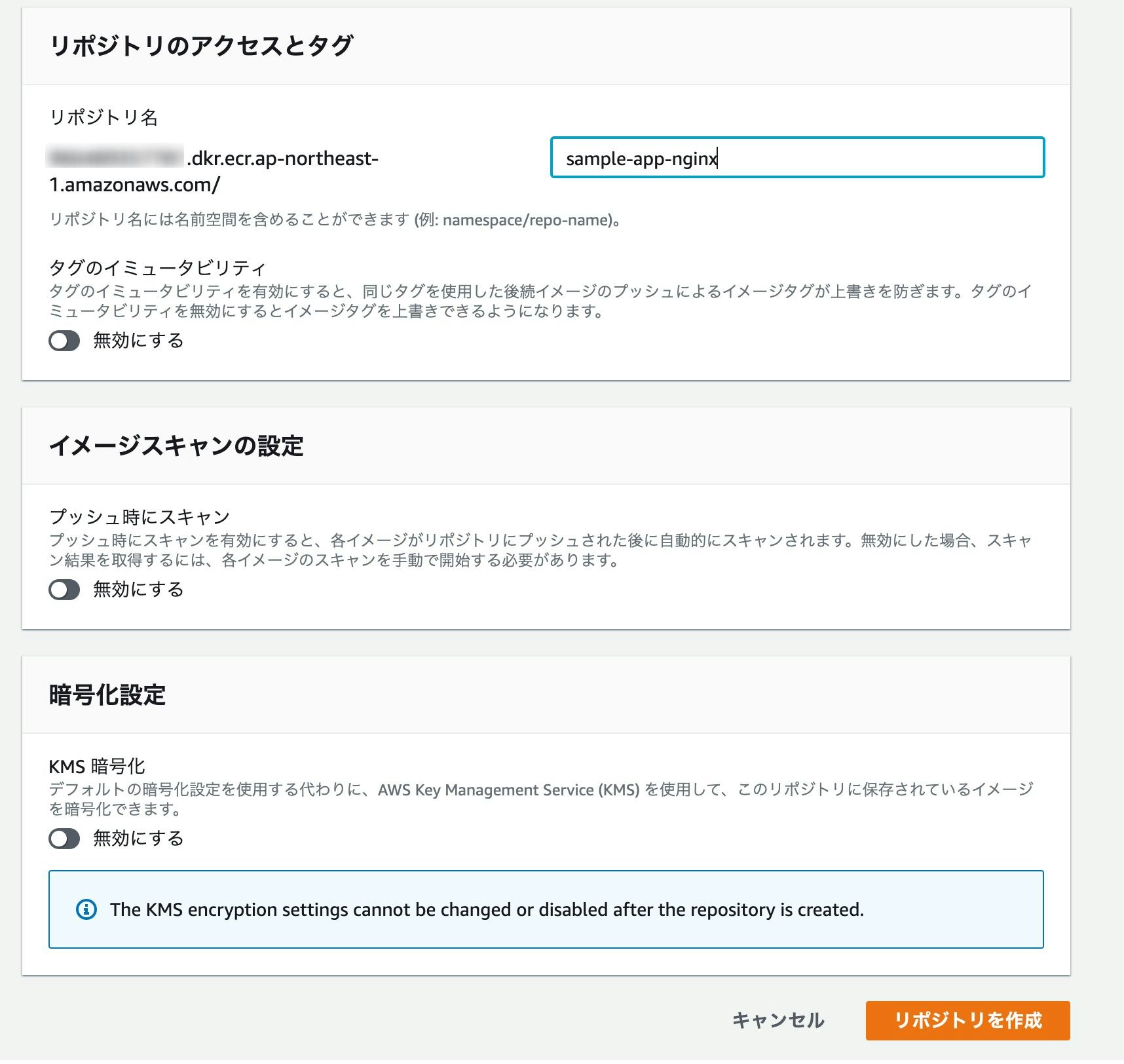
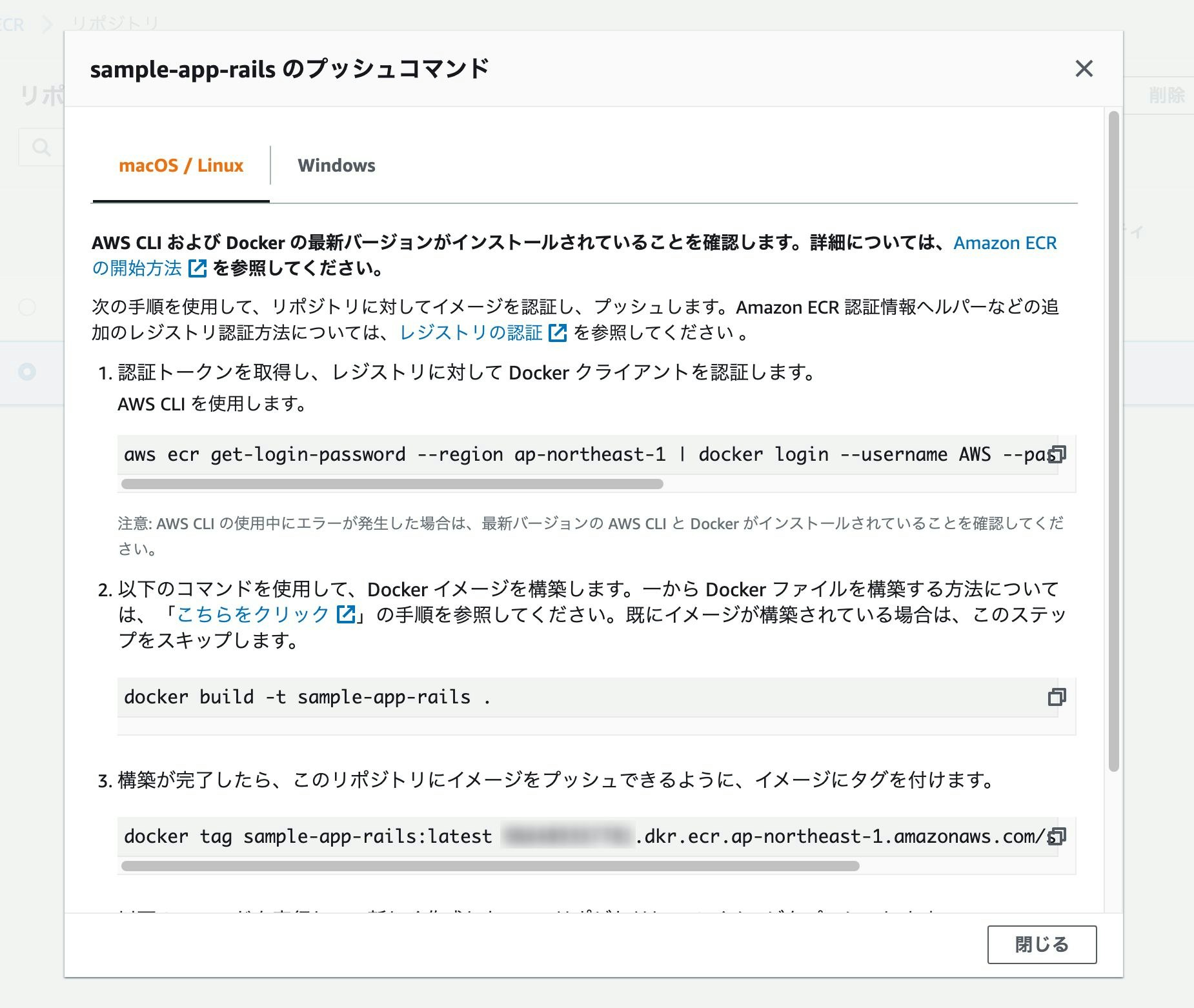
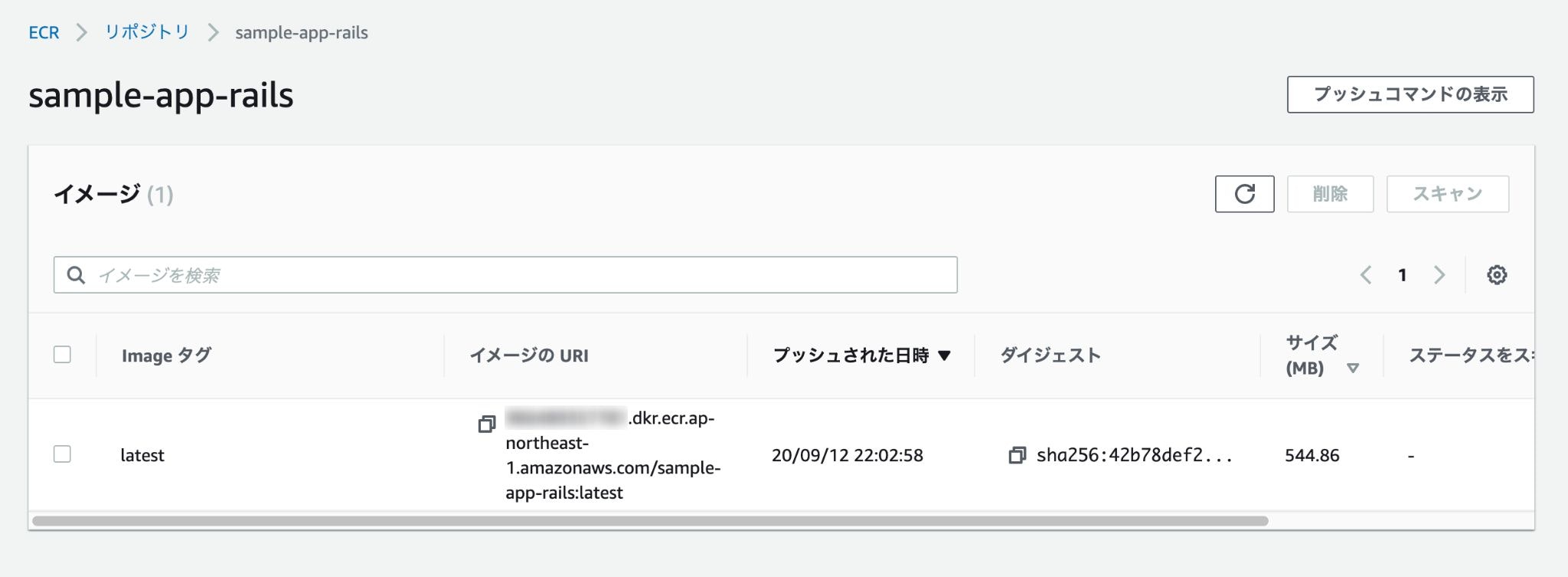
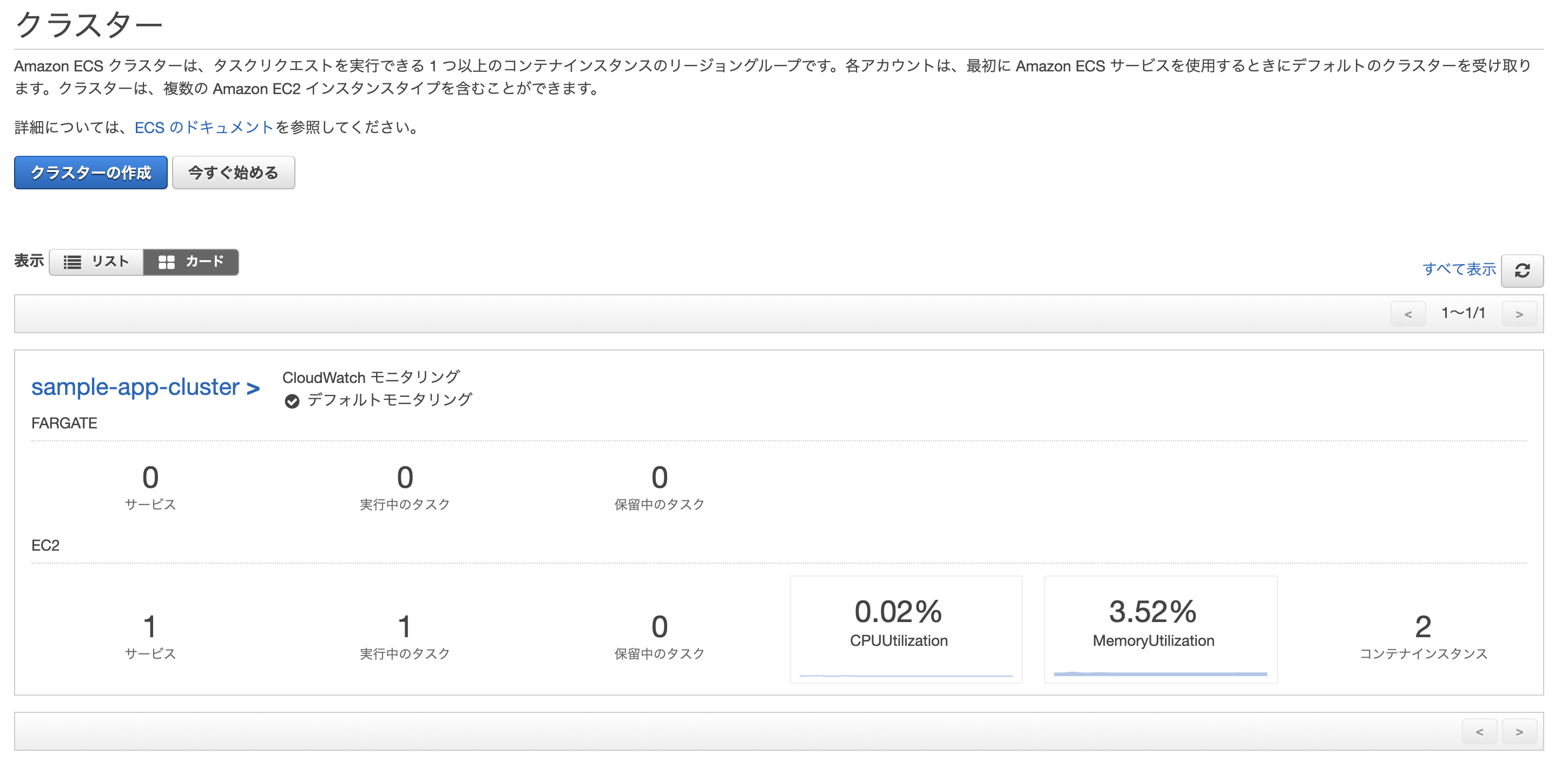
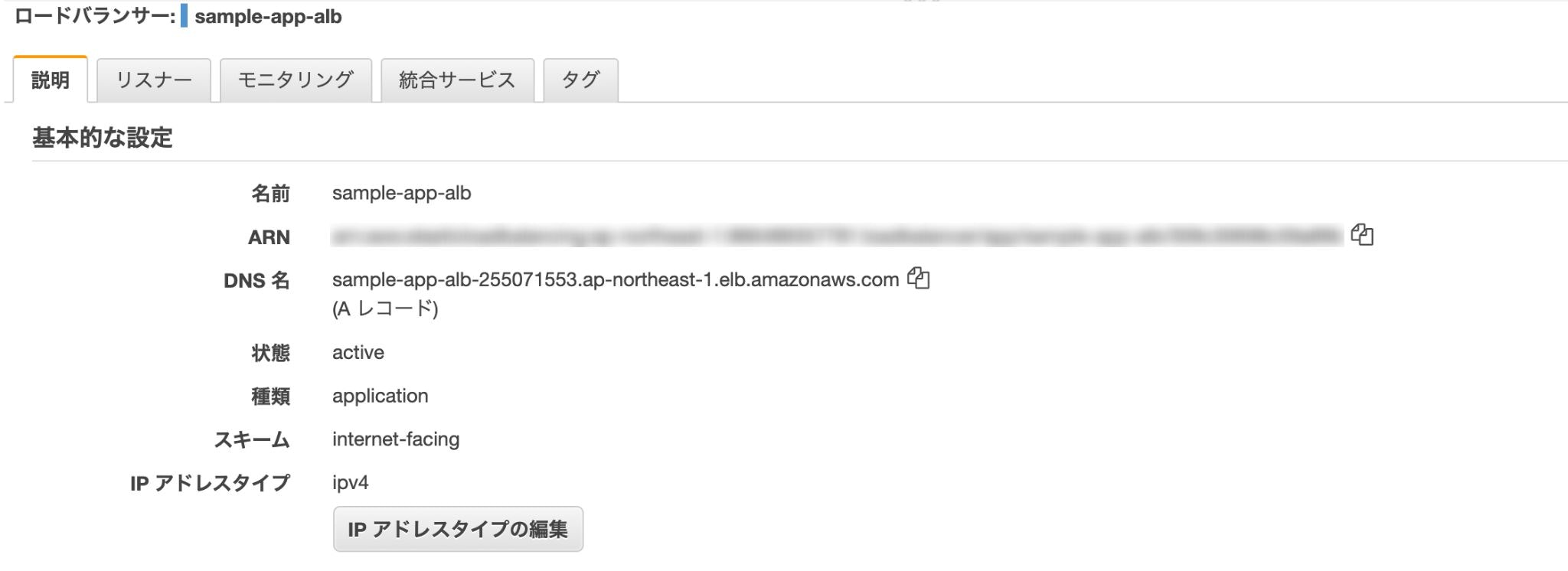

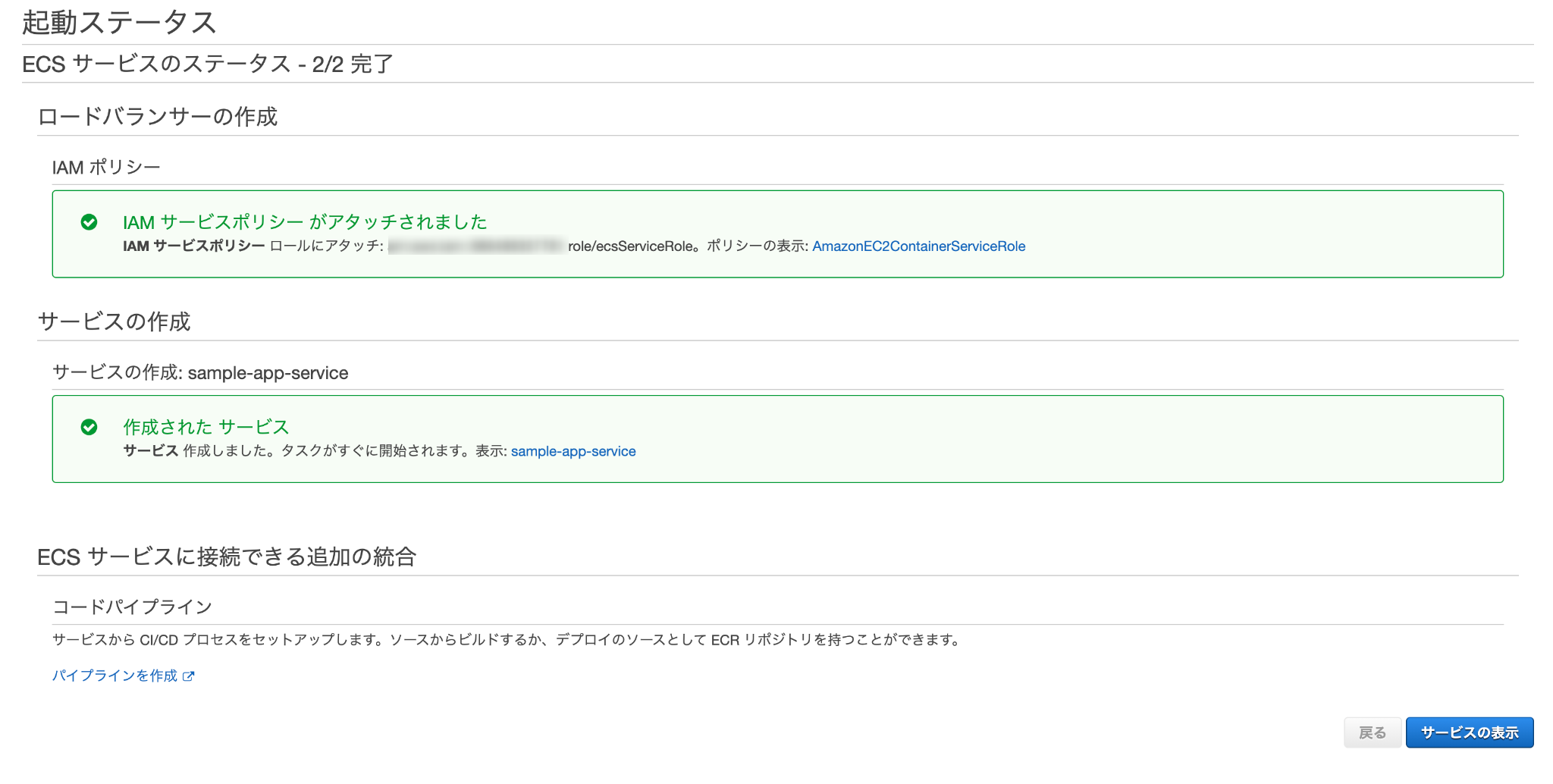
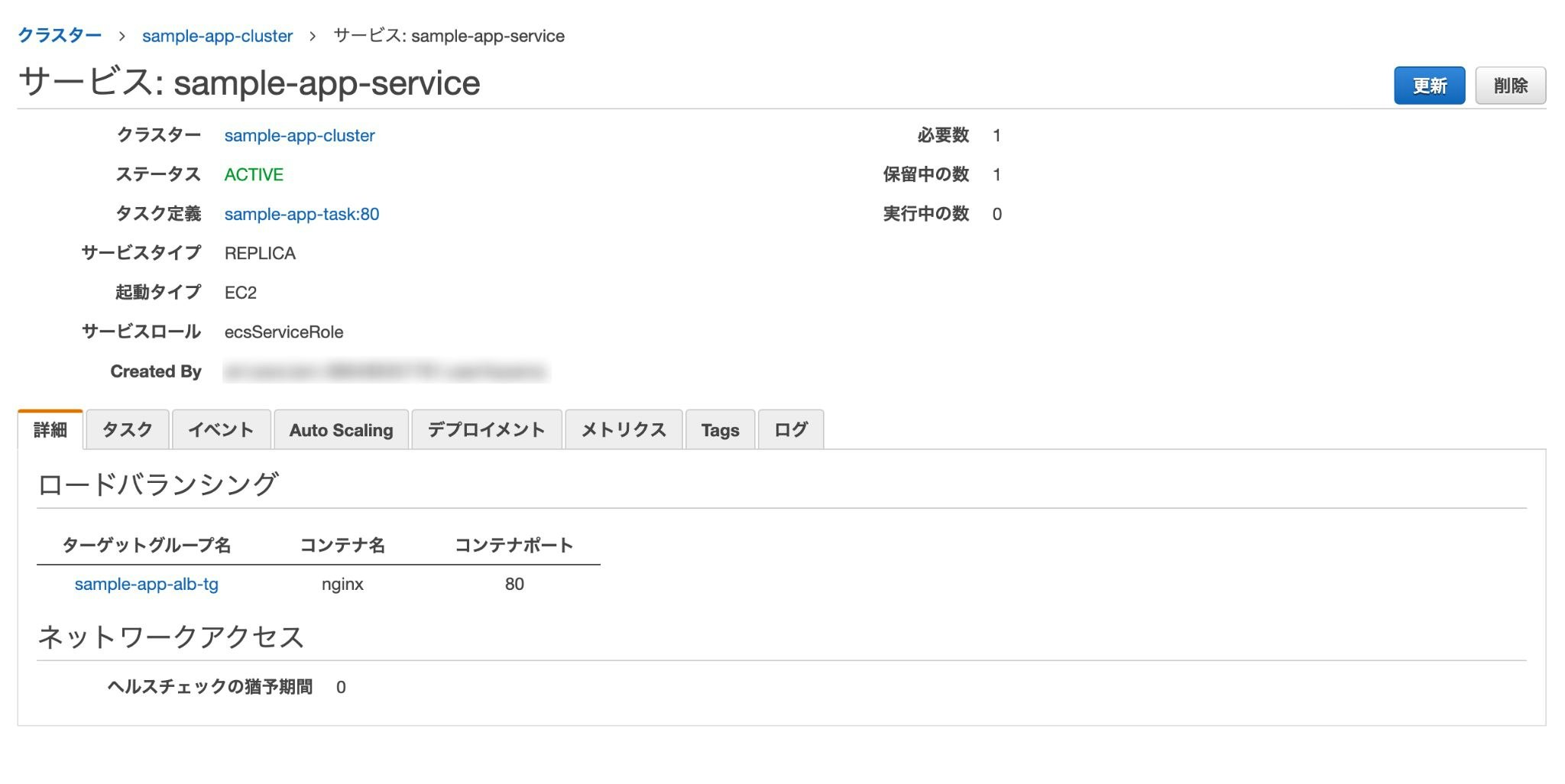
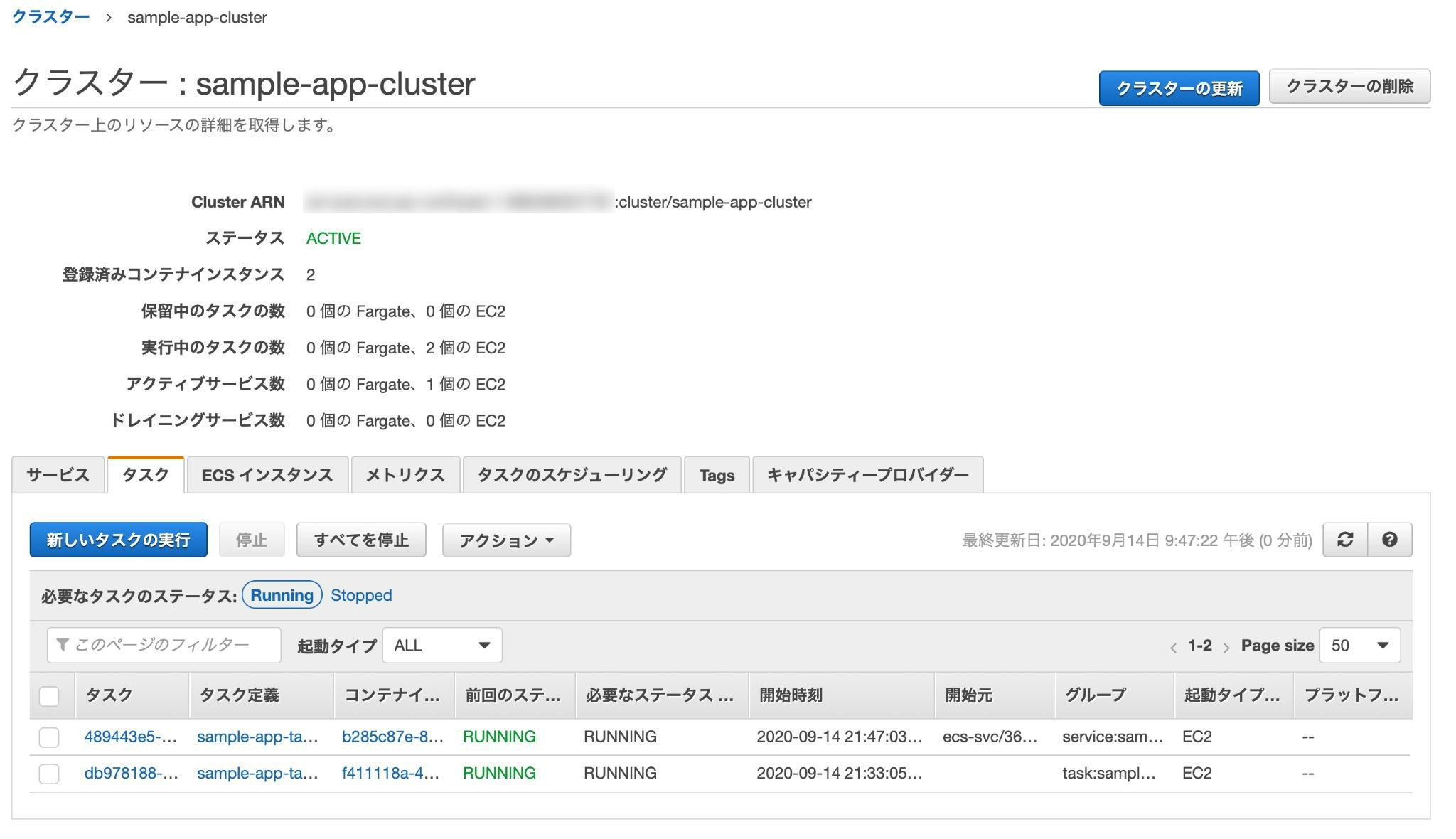
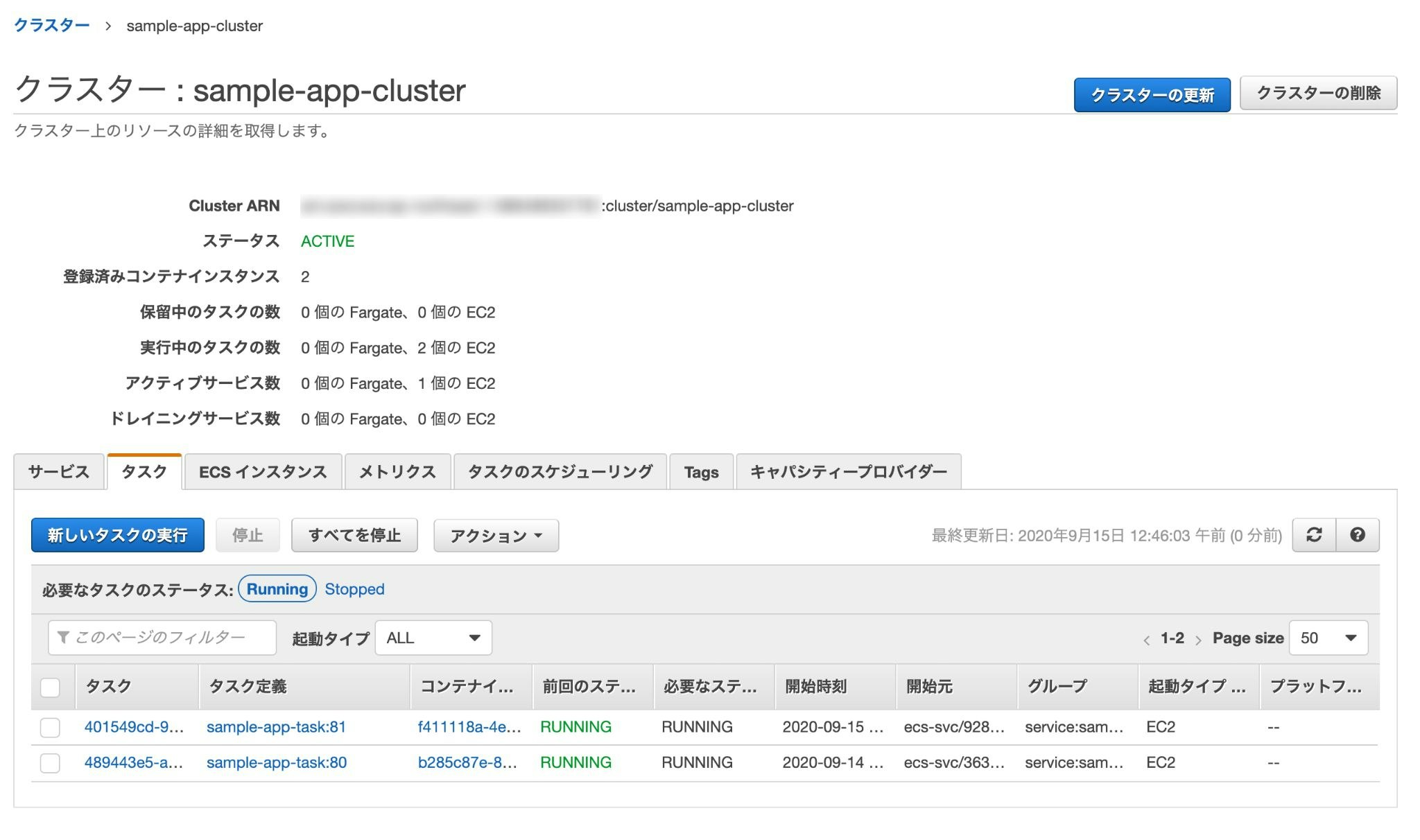
- 投稿日:2020-09-15T03:23:55+09:00
AWS ALBにWAFを設定して海外からのアクセスを遮断してみる
AWS ALBにWAFを設定して海外からのアクセスを遮断してみる
AWS WAF (Web Application Firewall)
クラウド上で動作するファイヤーウォール
IPアドレスや、国情報、ヘッダーの内容をもとにアクセスを許可、遮断できるAmazon CloudFrontや、Application Load Balancer (ALB)にデプロイして利用できる
WAF(Web アプリケーションファイアウォール)とは?| AWS2016年から後発でALBでも使用できるようになったとこと
AWS WAFがALB(Application Load Balancer)で利用出来るようになりました | Developers.IO
目標
- 日本国内からはEC2にアクセス可能
- ALBにWAFを設定し海外からのアクセスを遮断する
アーキテクチャ - 構成図
上が目標物、下はCloudfrontを使用するパターン
基本はweb serverの前に置く、よりクライアントに近い側に設置するのがいいと思われる
既存のALBにWAFを設定する
web ACL (Access Control List)の作成
- ホワイトリスト、ルールなしで作成(すべてのトラフィックを遮断)
- ALBにアクセスできなくなることを確認
Create web ACLDescribe web ACL and associate it to AWS resources
Web ACL details Name: 任意 CloudWatch metric name: (自動) Resource type: CloudFront distributions Regional resources (Application Load Balancer and API Gateway) #こっちを選択 Region: Asia Pasific (Tokyo) #後で選択することも可能 Associated AWS resources - optional Add AWS resources > Application Load Balancer 適当なALBを選択 > ADD
NextAdd rules and rule groups
Rules #後で追加します Default web ACL action for requests that don't match any rules Default action: Block
Default action: Blockとすることでホワイトリスト化、後で追加するルールのみalllowにする
Next>Next>Create web ACLこの時点でブラウザからドメインにアクセスすると403エラーを返すことを確認する
Allow Ruleを追加
- Allow Rule (country - JP) を追加
- allow条件でリクエストが成功することを確認
作成したweb ACLを選択して
Rules > Add rules > Add my own rules and rule groups
Rule type Rule type: Rule builder Rule builder Rule Name: 任意 Type: Regular rule If a request: matches the statement #(AND, OR, NOT指定可) Statement Inspect: Originates from country in # 他にIPやリクエストの内容を選択可 Country codes: Japan - Ja Source IP address #こっちを選択 IP address in header Then Action Action: Allow
Add rule再びブラウザからドメインにアクセスすると今度はリクエストが成功する
IP address in headerオプションの使用に注意
ヘッダーのIPは書き換えられる場合があり、それによって意図せずアクセスコントロールを通過するリスクが有り、注意が必要
When a request comes through a CDN or other proxy network, the source IP address identifies the proxy and the original IP address is sent in a header. Use caution with the option, IP address in header, because headers can be handled inconsistently by proxies and they can be modified to bypass inspection.
検証
以下のサイトで海外からのアクセスをシュミレート可能
WebPageTest - Website Performance and Optimization Test
Location: Tokyo, Japan 以外で"403 Forbidden"を確認

- 投稿日:2020-09-15T01:58:56+09:00
AWSソリューションアーキテクトアソシエイト受験記録
AWS ソリューションアーキテクトアソシエイトを受けたので勉強した内容と方法を残します
勉強期間2週間くらいでソリューションアーキテクトアソシエイトも受けました。
ご参考まで。前提知識の有無
社会人ももう15年目くらいのおじさんなので、一通りのIT用語はわかります。
20代の頃にソフトウェア開発技術者とテクニカルエンジニアネットワーク(呼び方古い。。。)を取っているので知識の下地はある感じ。
昨年の10月くらいにプラクティショナーに合格しています。
ただ仕事ではほぼ関わっておらず、趣味でもほぼノータッチ。
ソリューションアーキテクトアソシエイト受験用のzoom研修を1回受けています。
(ぶっちゃけ会社の認定数を稼ぐために受けさせられただけとも。。。)教材
参考書
プラクティショナーに引き続きこのシリーズ。
読み物として1週、問題だけ解く形でもう1週。計5時間くらい。Web問題集
AWSの認定試験の問題集サイトがあったので、ゴールドプラン(2か月参照可能)のやつに登録してみました。
約4000円やったこと
動画を見る
これは皆さん受けれるかわからないのですが、AWSのトレーナーが開催しているzoomの研修に参加しました。
まぁ、原則聞くだけだったのでUdemyとかで受験勉強用のコースを買ってひとなめするとかでもいいかもです。
必須かと言われると。。。まぁここで聞いた内容も数問は出題されました。白本を読む
大体4時間くらいで読めました。
プラクティショナーと違って多少各サービスの中身、使いどころあたりが出てきます。
サービス名とか受験範囲とかを確認する意味で有効だったかな。と。Web問題集を解きまくる
有償ですが、最短の道かと思います。
ソリューションアーキテクトアソシエイトの問題だけで1000問くらいあるので、
これを淡々と解きました。間違ったところは解説がついているので、ここ読むのと関連情報をググる感じ。
問題自体は徐々に追加しているようなので、後半のほうが最近出題された問題に近いようです。
なので、逆順で解いていくほうがよいかと。
本当は1000問全部ひと舐めしようと思ったのですが、準備期間的な意味で700問くらいで試験当日を迎えちゃいました。
が、さすがに数百問単位で問題を見ていると大体出てくる問題の傾向が見えるので数をこなすのは大事かもしれません。試験当日。
白本の章末問題だけをつらっと舐めて受験。結果
試験はAWS講習をzoomで受けた後約2週間後に設定しました。あまり遠くに置くとダレそうだったので。
平日は毎日じゃないですが1日1-2時間。試験前日と当日午前で詰込みした結果、無事合格。
ちなみに合格時の点数は822/1000点。(合格ラインは720点)感想
VPC関係の設計みたいな内容が多かったです。これこれの要件を満たすような構成はどれか?みたいな。
とりあえずWell-Architected フレームワーク+サービス内でできることを白本レベルで押さえておけば何となく答えには行きつきました。
何々なサービスを応えよ、みたいな言葉を言わせる問題はほぼなかったので、試験受けてる時は手応え的なものはあまり感じませんでしたが。。。
ソリューションアーキテクトはNW、DB、ストレージ、VMあたりの予備知識が多少あればAWSコンソール自体はそこまで触らなくても受かるかな。
という印象でした。以上。
- 投稿日:2020-09-15T01:15:03+09:00
【初心者】AWS Wavelengthを使ってみる
目的
- エッジコンピューティングがこれからのトレンドになるかなと思い、まずはAWSのエッジコンピューティングサービスであるWavelengthをいち早く触って、基本概念を理解しておく。
AWS Wavelength とは(自分の理解)
- AWSが提供するMEC的なサービスで、モバイルキャリア網から低遅延でのアクセスを可能とするサービス。
- 2020/9現在、北米2拠点(Boston, San Francisco Bay Area)のみで提供されている。
やったこと
- Wavelength Zone(今回はSan Francisco Bay Area)にて基本構成を確認する。
- Wavelength Zone内にSubnet、EC2インスタンスを作成する。
- Carrier Gateway(外部との接続口)を作成し、外部からEC2インスタンスへCarrier Gateway経由でアクセスする。
構成図
- 設定手順
- アクセス経路
- Wavelengthサービスにおける新規要素は以下の通り。
- Carrier Gateway(CAGW): Wavelength内のEC2インスタンスを外部(キャリア網、インターネット)と接続するためのゲートウェイ。従来のリージョンサービスのInternet Gatewayに相当する。
- Carrier IP(CIP): Wavelength内のEC2インスタンス(ENI)に関連付けを行い、インスタンスと外部との間の疎通を可能にするIPアドレス。従来のリージョンサービスのElastic IPに相当する。EIP同様、グローバルIPアドレスだが、インターネットとの疎通には制約がある。なお用語の定義としては以下のようになる様子。
- 従来のElastic IP(Internet Gatewayを経由しての外部接続用のIP)はPublic IPと呼ぶ
- Carrier IPとPublic IPの両方をElastic IPと呼ぶ
作業手順
利用申請
- 2020/9現在、利用には事前申請及びAWSからの承認が必要。以下のフォームにて利用目的、AWSアカウント等を入力して申請する。
基本環境構築
1. 事前準備(VPC/Subnetの作成)
- 構成図の通り、以下のVPC/Subnetを作成する。
- VPC: 10.0.0.0/16
- Subnet(Public): 10.0.1.0/24
- 踏み台用/内部接続用のEC2インスタンス(Public Subnetに作成)
- VPCはWavelength(San Francisco Bay Area) の親リージョンであるオレゴンリージョン(us-west-2)に作成する。
2. Wavelength Zone内にSubnetを作成
- Subnetの作成画面にて、AZの選択肢からWavelength Zone「us-west-2-wl1-sfo-wlz-1」を選択し、Subnet(Wavelength)を作成する。
3. Carrier Gateway 作成及びルーティング設定
- 「VPC - キャリアゲートウェイ - キャリアゲートウェイの作成」にて、Carrier Gatewayを作成する。以下の内容の設定を行う。
- Carrier Gatewayの名前 (mksamba-cagw)
- Carrier GatewayをアタッチするVPC (上記1.で作成したVPC)
- Carrier Gatewayへのルートを作成するsubnet(上記2.で作成したSubnet)
- 上記設定にて「キャリアゲートウェイを作成」のボタンを押すと、Carrier Gatewayが作成される。それに加えて、デフォルトルートがCarrier Gatewayに設定されたRoute Table が作成され、Subnetに関連付けが行われる。該当のRoute Tableの設定内容は以下の通り。デフォルトルート(0.0.0.0/0)の宛先がCarrier Gatewayになっている。
4. Wavelength Zone内にEC2インスタンスを作成
- インスタンスの作成画面にて、Wavelength Zone内のSubnetを指定してインスタンスを作成する。
5. Carrier IPの取得とインスタンスへの関連付け
- 「VPC - Elastic IPアドレス - Elastic IPアドレスの割り当て」にて、ネットワークボーダーグループに「us-west-2-wl1-sfo-wlz-1」を指定し、割り当てを実行する(ネットワークボーダーグループの指定により、従来のEIPを取得するのか、Wavelength用のCIPを取得するのかを選択可能)。
- ネットワークボーダーグループに「us-west-2」を選択: オレゴンリージョンの通常のEIP(Public IP)
- ネットワークボーダーグループに「us-west-2-wl1-sfo-wlz-1」を選択: WavelengthのCIP ⇒ こちらを選択
- 「VPC - Elastic IPアドレス - Elastic IPアドレスの関連付け」にて、取得したCarrier IPをインスタンスに関連付けする。
疎通確認
注意事項
- 公式ドキュメントの「Wavelength considerations and quotas」にて、以下の注意事項がある。
Networking considerations
The following controls are enabled by the carrier gateway for Internet flows by default and cannot be removed:
- TCP is allowed for outbound and response
- UDP is denied
- ICMP is allowed
In addition, inbound routing from the carrier network is optimized for devices in the location of the Wavelength Zone. For example, a Wavelength Zone in the San Francisco Bay area allows low latency access only from devices that are in that metro area and carrier network. Other metro areas and other carriers are not able to access the Wavelength Zone.
- まとめると、許可されている通信は以下の通り。(以下はWavelengthサービスとしての制限であり、別途SecurityGroup等で追加の制限を行う)
SRC DST Protocol Action 同一VPC内 Wavelength内のインスタンス Any Allow Wavelength内のインスタンス 同一VPC内 Any Allow キャリア(Verizon)網 Wavelength内のインスタンス Any Allow Wavelength内のインスタンス キャリア(Verizon)網 Any Allow インターネット Wavelengthのインスタンス icmp Allow Wavelengthのインスタンス インターネット icmp,tcp Allow
- 今回はキャリア網(米国のVerizon網)からのアクセス手段は用意できず、Wavelengthのインスタンスには日本からのインターネット経由でのアクセスとなり、Carrier Gateway経由でのアクセスはicmpでしか確認することができない。
VPC内(リージョン側Subnet) からの疎通確認
- オレゴンリージョンのSubnet(Public)内のインスタンスから、Wavelength内のインスタンスへpingやsshが可能。
# Public SubnetのインスタンスからWavelength内のインスタンスへssh [ec2-user@ip-10-0-1-204 ~]$ ssh ec2-user@10.0.0.111 -i oregon.key Last login: Mon Sep 14 15:21:06 2020 from 10.0.1.204 __| __|_ ) _| ( / Amazon Linux 2 AMI ___|\___|___| https://aws.amazon.com/amazon-linux-2/ [ec2-user@ip-10-0-0-111 ~]$インターネットへの疎通確認
- Wavelength内のインスタンスから、インターネット上のサーバへpingやhttpアクセスが可能。
# Wavelength内のインスタンスから阿部寛ホームページにhttpアクセス [ec2-user@ip-10-0-0-111 ~]$ curl http://abehiroshi.la.coocan.jp/ <html> <head> <meta http-equiv="Content-Type" content="text/html; charset=Shift_JIS"> ~中略~ </html> [ec2-user@ip-10-0-0-111 ~]$インターネットからの疎通確認
- 自宅PC(日本)からWavelength内のインスタンスへはpingのみ可能。(インターネットからのアクセスはicmpのみ許可となっておりssh等は不可)
c:\work>ping 155.x.x.x 155.x.x.x に ping を送信しています 32 バイトのデータ: 155.x.x.x からの応答: バイト数 =32 時間 =132ms TTL=238 155.x.x.x からの応答: バイト数 =32 時間 =132ms TTL=238 155.x.x.x からの応答: バイト数 =32 時間 =134ms TTL=238 155.x.x.x からの応答: バイト数 =32 時間 =132ms TTL=238 155.x.x.x の ping 統計: パケット数: 送信 = 4、受信 = 4、損失 = 0 (0% の損失)、 ラウンド トリップの概算時間 (ミリ秒): 最小 = 132ms、最大 = 134ms、平均 = 132ms所感
- 基本的な構成は確認できたため、リージョンサービスとの連携、コンテナ系サービスとの組み合わせ利用等、引き続き検証していきたい。
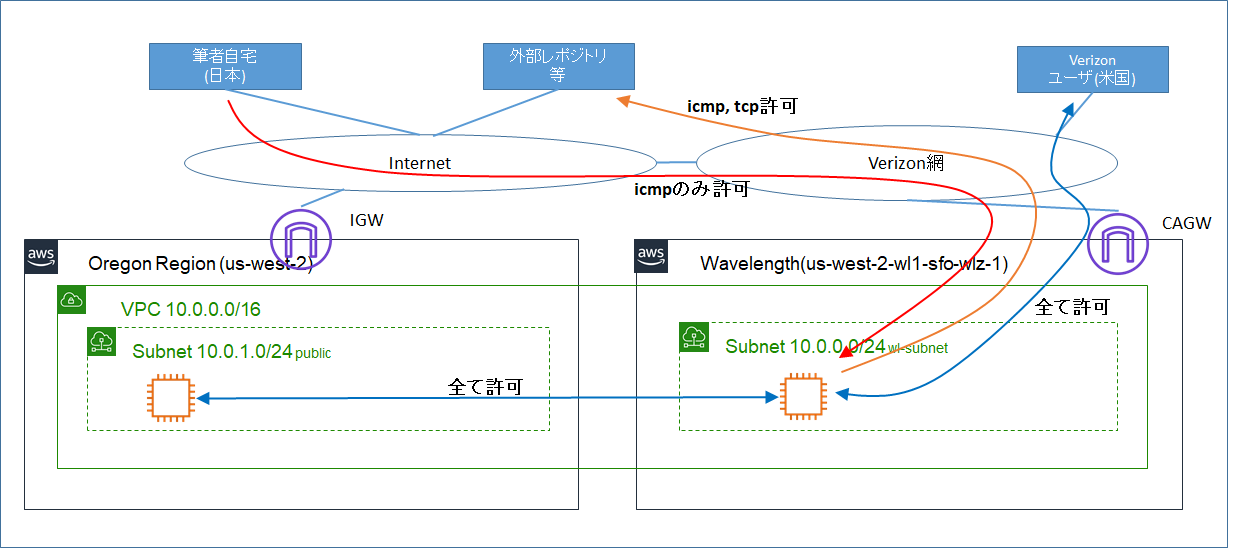
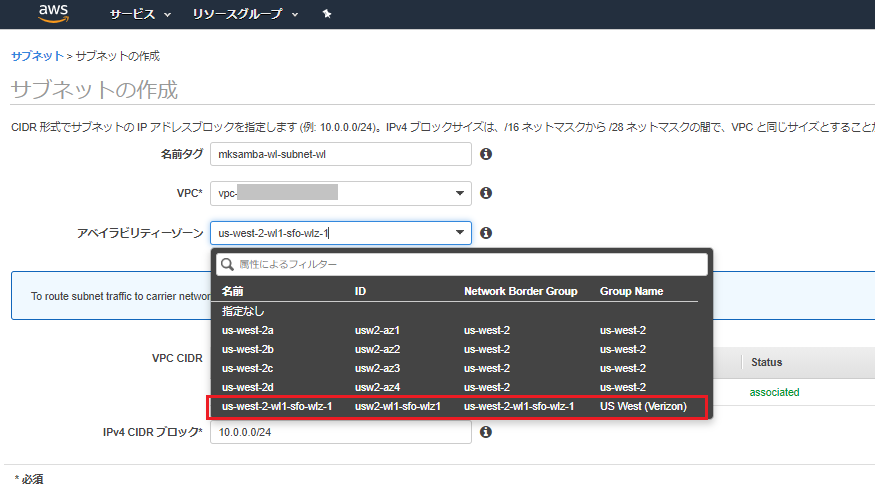
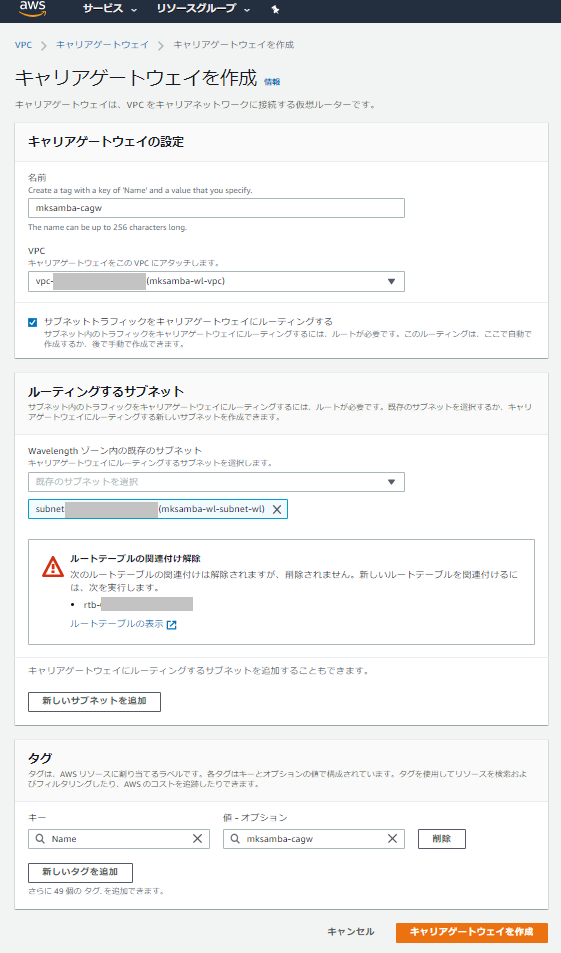
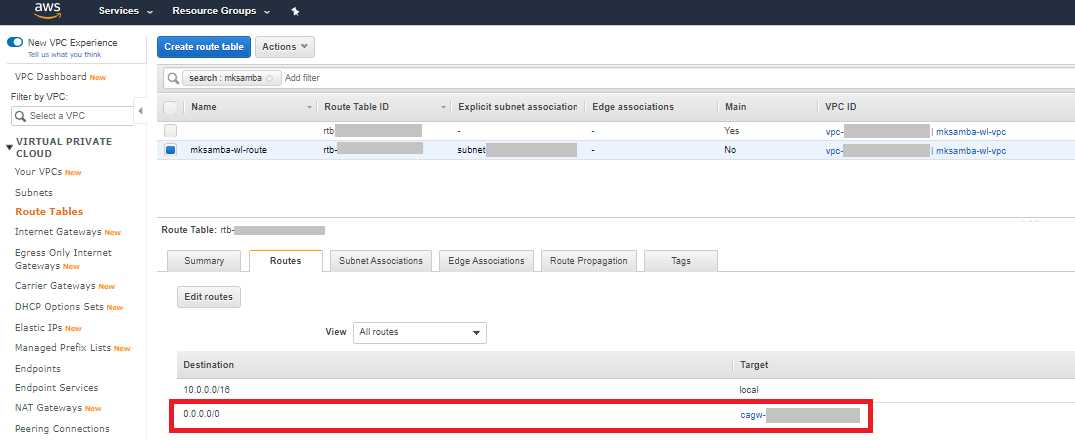
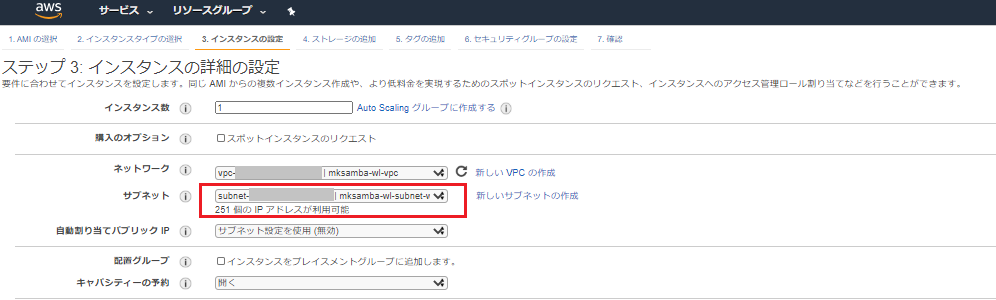
- 投稿日:2020-09-15T00:24:56+09:00
【AWS】AthenaでCloudFrontのログを集計するときのSQL
調べてもズバリこれといったものが見つけられなかったので自分用の備忘録として。
あるいは同じことを求めてる人が他にいたら参考になれば幸いです。前提条件
- CloudFrontのログが格納されているS3のフォルダがyear=2020、month=09、day=12みたいな感じでパーティションされてること 実際に格納されているパスはこんな感じ↓
s3://mybucket/cloudfront_log/year=2020/month=09/day=12/EXXXXXXXXXXXXX.2020-09-12-00.f96e98c5.gz
- 「パスに"year=2020"とか、"="いれて大丈夫なのか??」と最初思ったが全然大丈夫である。
- Athenaがパーティティションテーブルとして作成されていること
当日のログを時間昇順で全部見る
select * from (select cast(concat(request_date,' ',request_time) as timestamp) at time zone 'Asia/Tokyo' request_datetime_jst ,* from cloudfront_log ) where 0=0 and date (concat(year , '-' , month , '-' , day)) between current_date - interval '1' day and current_date and request_datetime_jst between date_trunc('day' , current_timestamp at time zone 'Asia/Tokyo') and current_timestamp at time zone 'Asia/Tokyo' order by request_datetime_jst
- CloudFrontのログはUTCなので、日本時間(JST)に合わせるとちょっと使いづらい。
なので一度副問い合わせ内でJSTの日時をつくっている。
- JSTに合わせると、見るべきパーティションは当日と前日になる
(例:日本時間で2020/9/12の場合、year=2020/month=09/day=11とyear=2020/month=09/day=12の2つのパーティションを見る必要がある)前日のログを集計する
select count(1) cnt_all from (select * ,concat(request_date,' ',request_time) request_datetime ,cast(concat(request_date,' ',request_time) as timestamp) at time zone 'Asia/Tokyo' request_datetime_jst from cloudfront_log ) where 0=0 and date (concat(year , '-' , month , '-' , day)) between current_date - interval '2' day and current_date - interval '1' day and request_datetime_jst between date_trunc('day' , current_timestamp at time zone 'Asia/Tokyo' - interval '1' day) and date_trunc('day' , current_timestamp at time zone 'Asia/Tokyo' - interval '1' second)
- 条件の考え方は基本的に↑と同じ。
「前日」になったのに合わせて見るべきパーティションとrequest_date、request_timeの条件を変えただけ。
count(1)は単純に全レコードの件数カウントしてるだけなので、有象無象の全ログが対象になる。
実際にはもう少し具体的な条件、例えばsc_statusの値(=HTTPステータス)とか、cs_uri_stemの内容(=リクエスト先のパス)とかで分類した結果を集計したくなると思う。
例えばsum(case when sc_status = '200' thne 1 else 0 end) as cnt_successとするとHTTPステータスコード200のログの数だけ集計する。
任意の日付のログを集計する
select count(1) cnt_all from (select * ,concat(request_date,' ',request_time) request_datetime ,cast(concat(request_date,' ',request_time) as timestamp) at time zone 'Asia/Tokyo' request_datetime_jst from cloudfront_log ) where 0=0 -- (1) and concat(year , '-' , month , '-' , day) between '2020-08-31' and '2020-09-01' -- (2) and request_datetime_jst between timestamp '2020-08-31 15:00 UTC' at time zone 'Asia/Tokyo' and timestamp '2020-09-01 14:59 UTC' at time zone 'Asia/Tokyo'
- やはり基本的な条件の考え方は↑と同じ。
「任意の日付」の部分だけ文字列で固定で指定してる形。(もっといい感じのやり方はあるのかなー)- (1)では見るべきパーティションを指定している。
見たい日付が2020/09/01なら2020-08-31と2020-09-01になる。
- (2)では実際に検索対象にするリクエストの日時をJSTに変換したうえで指定している。
見たい日付が2020/9/1分ならUTCに直すと2020-08-31 15:00~2020-09-01 14:59までがJSTにおける「2020/09/01」になるのでそこを指定している。
おまけ:CloudFrontの移動処理(Lambda)
ランタイムはNode.js。
const AWS = require('aws-sdk'); const s3 = new AWS.S3({region: 'ap-northeast-1'}); const destS3Bucket = 'destbucket'; const destS3PathPrefix = 'cloudfront_log_moved'; exports.handler = async function(event) { var responseBody = []; for(e of event.Records) { var sourceBucket = e.s3.bucket.name; // mybucket var sourceKey = e.s3.object.key; // cloudfront_log/EXXXXXXXXXXXXX.2020-08-20-14.78e51f19.gz var sourceObject = `${sourceBucket}/${sourceKey}`; var originalObjectName = sourceKey.split('/')[1]; // EXXXXXXXXXXXXX.2020-08-20-14.78e51f19.gz var destPaths = sourceKey.split('.')[1].split('-'); // [2020,08,20,14] var destPathYYYY = `year=${destPaths[0]}`; // year=2020/ var destPathMM = `month=${destPaths[1]}`; // month=08/ var destPathDD = `day=${destPaths[2]}`; // day=20/ var destPath = `${destS3PathPrefix}/${destPathYYYY}/${destPathMM}/${destPathDD}`; // cloudfront_log_moved/year=2020/month=08/day=20/EXXXXXXXXXXXXX.2020-08-20-14.78e51f19.gz var destKey = `${destPath}/${originalObjectName}`; console.log(`sourceObject:${sourceObject} , destPath:${destPath} , destKey:${destKey}`); var copyObjectParam = { Bucket: destS3Bucket, Key: destKey, CopySource: sourceObject }; var copyResult = await s3.copyObject(copyObjectParam).promise(); var deleteResult = await s3.deleteObject({Bucket: sourceBucket , Key: sourceKey}).promise(); responseBody.push({ copyResult: copyResult, deleteResult: deleteResult }); } const response = { statusCode: 200, body: JSON.stringify(responseBody), }; return response; };
- S3へのオブジェクトPUTのイベントは
event.Recordsという配列に含まれるので一応これを基準にループさせている。
でも色々調べてみると0番目を固定で取得している処理→event.Records[0]しか見つからないので、いちいちループさせる必要ないのかもしれない。
アクセス数が少なくて、たまにぽつんと単独でアクセスされる程度なら、多分それでも問題ない(移動漏れは起きない)。
短い時間で連続でPUTされるとまとめて配列になってくる…とかなのかな?- CloudFrontのログファイル名を相手にすることを前提にしているコードなので、それ以外のファイルのPUTを受けると落ちる。。
呼び出し条件として、元バケットでCloudFrontのログが格納されているパスのprefixでも指定しておく。
- 移動元バケットに対するGetObject+DeleteObject、移動先バケットに対するPutObjectのアクセス権が必要。
ただ、DeleteObjectのほうはS3のLifeCycleに任せる(1日で削除とか)なら設定不要&↑のコードにおけるawait s3.deleteObject({Bucket: sourceBucket , Key: sourceKey}).promise();も不要。