- 投稿日:2020-09-15T23:37:54+09:00
初めてのISUCONにチーム「らんちぅ」で参加しました #ISUCON10予選
TL;DR
Rustの参考実装は早い
New Relicに圧倒的感謝。ISUCON10予選お疲れ様でした
最終スコアは
722(参考値)でした。
isuumo、面白い問題だったなと思います。
当日までの準備を進めながら数々の対応をしてくれた運営さん、一緒に戦ったメンバー、ありがとう!お疲れ様でした!らんちぅ
同じ大学のM1の先輩2人(Masapyon, koba)とB3の僕(Hiroya_W)の学生3人チームです。
当時、ISUCON10予選参加枠が一気に埋まりそうだ、という情報を聞き、急いでソロで参加登録。
その後、メンバー募集をされていたので、入れてもらえることになりました!
「ISUCON 夏期講習2020 座学&もくもく会」に参加して初めてISUCONを知り、座学ともくもく会の両方参加するからには、実際にも参加しよう!と思っていました。
当初、もくもく会は、各自もくもくと問題を解くのかと思っていました。しかし、実際に参加してみたら、全て用意されていて、なおかつ全員で足並み揃えて手取り足取り教えて頂ける会となっていました。
「過去、ISUCONに参加したことがない方のみが対象」とされていただけに、とても良い講習会だったと思っています。事前準備
たまたま別件でGoを使う予定だったのとGoで参加している人が多いことから、Goで参加する予定でした。
そこで、まずは「A Tour of Go」をとりあえず触りました。
そこからは、GoのWebフレームワークのチュートリアルを触ってみようかな、と思いましたが、結局触っていません。これは、New Relicが開催した「せっかく無料なのでISUCONでNew Relicをスッと使う方法」というウェビナーに参加したからです。
GoにNew RelicのAgentを導入する場合、
- 計測のために、各自でミドルウェアを書く必要がある
- それに伴い、メソッドを別のものに置き換えるので、最後はまたメソッドを元に戻す必要がある
ということを知り、まずここで詰まりそうだという印象を受けました。
それに比べ、PythonやRubyはアプリにパッケージとしてインストールするだけでほとんどの場合、自分で記述する必要がありません。
それなら、Pythonでも全員自信を持って読めるので、New Reilcを確実に使っていきたい!という方針に切り替えました。そこから本番までひたすらISUCON9予選だけ1を使って必要な知識をつけていきました。
ISUCON9 オンライン予選 関連エントリまとめを片っ端から読み漁り、個人で練習する時は、VagrantでISUCON環境を作り、メンバーで集まって練習する時はGCPにISUCON環境を作って練習しました。やったことは、esa.ioに記事として試したことをひたすら書きなぐり、最後はGitHubのリポジトリのWikiに項目を分けて整理しておきました。
New Relicのライセンスキーが平文で書いてあるので公開出来ないのは申し訳ない2。
Makefile3、New Relicなどのログのとり方、秘伝のタレ、DBまわりのINDEXの張り方など基本的なところが中心になったと思います。
トラブルシューティングする時に、参考になりそうなところの記事まとめみたいな感じにも使えるようにまとめておきました。当日
先輩方は研究室に集まり、僕は自宅からオンラインで参戦しました。
チーム全員の作業画面を見れるようにしたい、ということからwherebyというサービスを利用しましたが、使いやすくてとても良かったです4。開始が12:20にずれ込んだこともあり、11:30頃に集合することにし、それまでに軽く腹ごしらえをしておきました。
午前中は運営がリアルISUCONしてる…って見守ることしか出来ませんでした。
問題の用意は大変だったと思いますが、改めて、本当にお疲れ様でした。後は、ISUCON10はRust実装があるの面白いな〜早そうやなぁって話してました。これは伏線です。
役割分担
予定では、
- Hiroya_W: App
- koba: DB
- Masapyon: Infra
でしたが、僕が当日までにインフラ周りの勉強が出来たおかげで、本番の役割分担は、
- Hiroya_W: App Infra
- koba: DB
- Masapyon: App Infra
という感じに、僕も少しインフラの面倒を見る形になり、その間にMasapyonにAppを手伝ってもらうという形になりました。
ここからは、当日僕がやったことと、覚えている範囲でメンバーがやっていたことを書いてみます。
12:20 ~ 13:11
SSHしてサーバーにアクセス出来たので、MasapyonがGitHubにpushしてくれました。
また、構成も調べてくれて、Nginx、MySQLだったのでISUCON9予選と一緒だな〜ってちょっと安心しました。その間にHiroya_Wとkobaはマニュアルを読み、大事そうなところをwikiにまとめつつ、実際にアプリを触ります。
しかし、ポートフォワーディングしてブラウザにアプリを表示させるところで苦戦しました…。
マニュアルにコマンドの使い方が書いてあったんですが、そんな使い方をしたことがなかったので、それだけでは引数をどうやって与えれば良いのか分からず悩みました。Google先生に聞いたら、SSHポートフォワーディングを知った話を見つけました。
なるほど。立っている3つのインスタンス間は通信出来ることが分かったので、サーバ2にSSHしてそこからサーバ1の指定したポートへ流すと出来るのでは???と理解して、$ ssh -L localhost:8080:10.162.41.101:80 isucon-server2ってやって繋がって喜びました。13:11頃です。終了後、サーバ1にSSHしてサーバ1から見たlocalhost:80に対してポートフォワードすればいいと別チームの人に教えてもらった。これで確かに繋がる。
$ ssh -L localhost:8080:localhost:80 isucon-server1SSHまわりは、ISUCONを通して本当に勉強になりました5。
13:11 ~ 13:30
アプリをなんとなく触り、過去のISUCONとは違い、手で触る程度だったらisuumoがそんなに重たくない、目に見えて遅いみたいな状況が無くてすぐに遅いところは判断出来ませんでした。
なので、ベンチ回して、ログ取ってみないことには進まないねって言いながらも、まずは確認がてらログ取らずにPythonでベンチを数回回します。ベンチ中は
htopを眺めてたんだけど、CPU1コア、RAM2GBでとかでマジ????とか言ってた。
練習した環境はマシンスペックがある程度あったのでパラメータチューニングも見直す必要がありそうだなと感じ始めてました。また、2台構成の練習を誰も出来ていなかったこと、再起動試験で落ちるのが怖くて、今回は1台でチューニングする予定で進んでいました。
が、このスペックを見て、少なくとも2台構成にしないと話が進まないなと思って、Hiroya_Wが対応することをひっそりと決意しました。13:30 ~ 15:00
何はともあれログです。ログの出力と集計、Slackで共有まではHiroya_Wが担当します。
まずはNew Relicではなく、Python向けのラインプロファイラであるwsgi_lineprofを導入しました6。(後で分かりますが、結果的には何故かログが出力されませんでした)が、たしかここら当たりでベンチの不具合によりベンチマークを実行することが出来ず、ログが手に入りません。
その時間を使って、ローカルに開発環境を整えることにしました。
が、ローカルでアプリを実行して、http://localhost:1323にアクセスしても404が返ってくる。
FlaskがGunicornに乗っていないし、Flaskでrender_templateを返していないのでアレ?ってなってきてる。
nginx.confを読んで、/www/data/に置かれている静的ファイルをNginxが返していることを確認しました。
ベンチもAPIに対して行われるようだったので、あー…じゃあローカルではcurlでPOSTしたりGETしたりして確認しようってことになりました。
動作確認はgitでbranch切って、適宜サーバーでpullして試す、といった感じ。15:00 ~ 15:40
ベンチマーカーが復活したらしいです。早速、
wsgi_lineprofでログを出力しようとしましたが、上手く出力されず。
とりあえず、同時に出力させていたMySQLのスロークエリをpt-query-digest集計してSlackで共有。
DB周りをkobaとMasapyonに見てもらっている間に、原因究明をするまでもなく、すぐにNew Relicを試す方向へ切り替えました。そうして15:40にようやく、New Relicにログが見え始め、MySQLのクエリもが全部上がってきました。
New Relic凄いです、全部見える。この時点でのスコアは
353ですね。ようやくISUCONスタートラインに立った気がします。
15:40 ~ 16:50
ここからは、AppとDBの二台構成に挑戦します。
ISUCON9予選のエントリを読んで書いていたメモを頼りに
- 環境変数の MYSQL_HOST を立てたインスタンスの IP アドレスに設定する
- MySQL の bind-address オプションをコメントアウトする
- MySQL を外部接続できるようにするを見ながら、isuconユーザに権限を付加する
を試します。Server001からServer002へ接続したかったのに、Server002からServer001への接続が出来るようになってた事件がありましたが、なんとか二台構成をやり遂げます。
ここで、435にスコアが微増します。
16:50 ~ 18:33(koba, Masapyon)
ここから、kobaとMasapyonがやってくれた修正を適用していきます。
でも、ベンチ結果を見てみると分かるけど、本当に何をしても上がらない。何回か回してみても、良くならない。
kobaが張ってくれたINDEXのコミットがこんな感じ(後で分かるけど、実はこれだけではINDEX張るのが実行されてなかった)
isuumo/webapp/mysql/db/3_IndexEstate.sqlCREATE INDEX idx_door_height ON isuumo.estate(door_height); CREATE INDEX idx_door_width ON isuumo.estate(door_width);isuumo/webapp/mysql/db/init.sh- cat 0_Schema.sql 1_DummyEstateData.sql 2_DummyChairData.sql | mysql --defaults-file=/dev/null -h $MYSQL_HOST -P $MYSQL_PORT -u $MYSQL_USER $MYSQL_DBNAME + cat 0_Schema.sql 1_DummyEstateData.sql 2_DummyChairData.sql 3_IndexEstate.sql | mysql --defaults-file=/dev/null -h $MYSQL_HOST -P $MYSQL_PORT -u $MYSQL_USER $MYSQL_DBNAMEMasapyonが実装してくれたBotの通信に
503 Service Unavailableを返す機能7がこんな感じ。app.pybot_user_agent = re.compile( r'ISUCONbot(-Mobile)?|ISUCONbot-Image\/|Mediapartners-ISUCON|ISUCONCoffee|ISUCONFeedSeeker(Beta)?|crawler \(https:\/\/isucon\.invalid\/(support\/faq\/|help\/jp\/)|isubot|Isupider|Isupider(-image)?\+|(bot|crawler|spider)(?:[-_ .\/;@()]|$)/i')app.pydef block_bot(request): user_agent = request.headers.get('User-Agent') if user_agent: if bot_user_agent.match(user_agent): return True return Falseapp.py# 各エンドポイントで最初に実行するようにする if block_bot(request): return jsonify({'message': 'Service Unavailable'}), 503が、スコアは伸びません…。
curlで試してちゃんと502を返すのを確認してくれていたが、ベンチ中には502を返したログが取れなかったので不思議に思ってたけど、負荷が弱すぎてボットのアクセスが無かったのでは、とお話を聞いた。
他にも、kobaがCOUNT(*)をCOUNT(id)に変更してくれたり、
app.py- query = f"SELECT COUNT(*) as count FROM chair WHERE {search_condition}" + query = f"SELECT COUNT(id) as count FROM chair WHERE {search_condition}" - query = f"SELECT COUNT(*) as count FROM estate WHERE {search_condition}" + query = f"SELECT COUNT(id) as count FROM estate WHERE {search_condition}"Masapyonが椅子をドアに通るかチェックするところを工夫してくれたり、
app.pyw, h, d = chair["width"], chair["height"], chair["depth"] query = ( "SELECT * FROM estate" " WHERE (door_width >= %s AND door_height >= %s)" " OR (door_width >= %s AND door_height >= %s)" " OR (door_width >= %s AND door_height >= %s)" - " OR (door_width >= %s AND door_height >= %s)" - " OR (door_width >= %s AND door_height >= %s)" - " OR (door_width >= %s AND door_height >= %s)" " ORDER BY popularity DESC, id ASC" " LIMIT %s" ) - estates = select_all(query, (w, h, w, d, h, w, h, d, d, w, d, h, LIMIT)) + estates = select_all(query, (w, min(h, d), h, min(w, d), d, min(w, h), LIMIT))
/api/estate/searchと/api/chair/searchでSQLでcountするんじゃなくて、Pythonでcountするようにしたり、app.py# これはestateの部分 search_condition = " AND ".join(conditions) query = f"SELECT * FROM estate WHERE {search_condition} ORDER BY popularity DESC, id ASC" chairs = select_all(query, params) count = len(chairs) chairs = chairs[per_page * page:per_page * page + per_page] return {"count": count, "estates": camelize(chairs)}してくれていたことがcommitログから分かりました。
僕は、この改善の議論に参加できていなかったのですが、色々試してくれていてありがたいなぁとエントリを書きながら改めて感じています。スコアの改善が見られないのが非常に辛かったです。
18:33 ~ ??
INDEXが張れてないことに気がつきます。気がつけて良かった…。
New Relicでログを確認しても変わってる雰囲気が無かったので、本当にINDEX張られてる?みたいな雰囲気になってきてました。
MySQLから、コマンドでINDEX張ってあるか確認しようかって言ってたら、MasapyonがINDEX張る部分が実行されてないことを見つけてくれた。
app.py@app.route("/initialize", methods=["POST"]) def post_initialize(): sql_dir = "../mysql/db" sql_files = [ "0_Schema.sql", "1_DummyEstateData.sql", "2_DummyChairData.sql", ]
sql_filesってやつがあるんか…。ISUCON9予選では、initializeでsubprocess.call(["../sql/init.sh"])が実行されていたので、そうゆうもんなんだろうと思いこんで、
koba> INDEX張るのってinit.shに書くんでいいんやんな〜? Hiroya_W, Masapyon> 合ってると思う〜って会話してたのを覚えてる。張れてないじゃん…。
そしたら、初めてスコアが微増した。これまで340~380を行ったり来たりしていたので、400近くなって喜びました。
もうこの時点で、18:30とかでようやく来た!嬉しい嬉しい!って言ってました。
今まで張ったINDEXがちゃんと貼れてなくてちゃんとスコアを調べられていなかったので、もう一度INDEXを張ってベンチを回して計測したりしてた。16:50 ~ ??(Hiroya_W)
時間軸は少し戻り、kobaとMasapyonが修正を取り込んでベンチを回している間、Hiroya_WはMySQL5.7からMySQL8へのアップグレードを試していました。
これは、単純に「MySQL8にすると早い」という超大雑把な情報を得たからです。MySQL8にある機能がISUCON10で使えるなんて知る由もありません。また、App,DB,DBにしろ、App,App,DBにしろ、3台構成にする方法を僕らのチームは誰も勉強出来ていません。なので、1台余らせてしまっているので、壊しても良いという思いで挑戦させてくれました。
MySQL8にアップグレードし、ベンチを回した結果ですが、こんな感じになりました。
0でFinishしているのは、アプリケーションの整合性チェックに引っかかっています。
かと思えば、その直後に実行したベンチは、スコアが付きかけ、結局Cancelledされてしまいます。他にも、スコアがついたとしても100台とMySQL5.7より良くなっている気配がしません。
ちゃんと理解出来ていない上、アプリケーション整合性チェックが何故通らないのかも分からず、ベンチが不安定で運営の追試でFailするのも嫌なのでMySQL8へのアップグレードは諦めました。これは、本番中に問い合わせてみても良かったかもしれないなと書きながら思ってます。
MySQL8に関しても、ちゃんと復習しておきたいなと思うポイントですね。?? ~ 20:20
僕は用意したMySQLとNginxの秘伝のタレを投入。
kobaがINDEXを更に張り、
3_IndexEstate.sqlCREATE INDEX idx_door_height ON isuumo.estate(door_height); - CREATE INDEX idx_door_width ON isuumo.estate(door_width); + CREATE INDEX idx_door_width ON isuumo.estate(door_width); + CREATE INDEX idx_latitude ON isuumo.estate(latitude); + CREATE INDEX idx_longitude ON isuumo.estate(longitude); + CREATE INDEX idx_rent ON isuumo.estate(rent); + CREATE INDEX idx_popularity ON isuumo.estate(popularity);4_IndexChair.sqlCREATE INDEX idx_popularity ON isuumo.chair(popularity); CREATE INDEX idx_price ON isuumo.chair(price); CREATE INDEX idx_color ON isuumo.chair(color); CREATE INDEX idx_height ON isuumo.chair(height); CREATE INDEX idx_width ON isuumo.chair(width); CREATE INDEX idx_kind ON isuumo.chair(kind); CREATE INDEX idx_stock ON isuumo.chair(stock); CREATE INDEX idx_features ON isuumo.chair(features);Masapyonが変更を適用してベンチを回してくれていました。
数ある変更をmasterへマージしていってベンチを回していき、chairにINDEXを張る変更によって590スコアを記録します。
回すたびにスコアが伸びていって凄い凄い言ってたと思います。
上3つのベンチは、僕のOS周りのチューニングが施された結果なのですが、スコアが下がってしまったので、直ぐに元に戻して無かったことにしました。
20:20 ~ 21:00
終了1時間を切ったので、再起動試験をしようってなったのですが、その前にRustの参照実装でどれくらいスコアが出るのか気になる、ということでベンチを走らせることに。
無事最高得点を叩き出します。
チューニングを施したPython実装よりも早いじゃねーか8!!もう大爆笑ですね。アプリまわりの修正がスコアに効かなかったこともあり、そのアプリの修正を全て捨ててRust実装へ切り替えることに。
DBのINDEXを張る部分と別のインスタンスのMySQLにアクセスするように修正し、20:30。再起動後、ベンチを回して最終スコアを更に更新して
722。
しっかり再起動試験App→DB、DB→Appを試して、ちゃんと動いていることを確認してFinish。
反省点
ISUCON9予選でMySQL5.7からMySQL8へのアップグレードが効果的になる話を読んでいたので、事前に試しておくべきだったなぁと感じています。そこからMySQL8にある機能をちゃんと理解しておくべきでした。
また、今回はメンバー全員のNginxやMySQLに関する知識が薄かったのが刺さったと思います。
特に今回は、DBが中心的な印象があり、Appだけでは現状から抜け出すチューニングが出来なかったな、と感じています。感想
結果的に、Rustの初期実装とDBにINDEX張っただけになってしまいました。
それでも、そこにたどり着く過程が面白かったのでOKです。結果はどうであれ、ログを見て、遅いところを探し、正解に近い部分を修正しようと出来ていたような気がします。
環境を整え、この段階に持っていくことがISUCONの最初の難しいところだと思うので、それが本番でちゃんと出来たのは良かったなと思います。また、このエントリを書くにあたって、commitログから色々と試してくれていたメンバーの様子が分かり、ありがたいなぁという思いでいっぱいです。
任して良かったと思うし、逆に、僕に任して挑戦させてくれたことにもメンバーに感謝したいです。この経験を次のISUCON11に活かして挑戦します!次も対戦よろしくお願いします!
一応他の問題も手を出したが、ISUCON8予選はNew Relicを入れるとベンチが落ちる(原因はbrowser_monitoringらしい)ので諦めた。ISUCON9本戦はDockerが分からなくて諦めた。ISUCON9予選だけとは言うが、やってもやってもやること、知らないことが出てくるので、ISUCON9予選"しか"つかっていないの方が正しいかもしれない。 ↩
いつかはどこかで公開したい。 ↩
直前にMake勉強会をしたので、ここぞとばかりに「ISUCON9予選1日目で最高スコアを出しました」を参考に整えた。タイムリーだった。 ↩
当初はZoomを使う予定だったが、Zoomで全員の画面共有をしてみるも、自分が画面共有をしながら相手の画面を見る方法が分からず断念。ただし、wherebyでも他にしても、画面共有をしながらブラウジングしたり、VSCodeでコーディングするのは自分のPCのスペックでは限界だったらしく、作業に支障をきたす事が発覚し、途中から僕の画面共有は適宜、という形になってしまった。CPU:Core i5 4210, RAM:8GBですが、CPU使用率が張り付き、CPU温度が80℃をキープするようになったので慌ててノートPC用の冷却ファンを取り出した。 ↩
事前準備で鍵の配置、権限、フィンガープリントといった問題で、ことごとく詰まってたので知見が自然と溜まっていった。 ↩
ISUCON9予選のPython実装ででNew Relic素振りしたら、MySQLのクエリログがset, commit, rollBack以外上がってこなくて、肝心のSELECTが一切見れてなかった。New RelicのExplorer Hubに書いて調査してもらっても良かったな。他にも、ISUCON8予選でベンチ回すとDOM構造が〜って言われてベンチが落ちる現象(原因はbrowser_monitoringらしい)になって、New Relic使うのどうしようって話にもなり、その時用に別の方法を確立させてた。 ↩
Pythonのアプリで実装するものだと思ってたのですが、どうやらNginxで実現できるそうですね…。知らなかった。 ↩
PythonでNew Relic外した時のスコアを計測していないような気がする。 ↩










- 投稿日:2020-09-15T23:10:32+09:00
スタッキングで分類・回帰 (scikit-learn)
複数の機械学習モデルを組み合わせる方法の一つとしてスタッキングがありますが、Python の scikit-learnのStackingClassifierとStackingRegressorを使ってみました。
StackingClassifier
スタッキングによる分類
分類モデルの性能を確認するため、乳がんデータを使ってみます。
from sklearn.datasets import load_breast_cancer X, y = load_breast_cancer(return_X_y=True)from sklearn.model_selection import train_test_split X_train, X_test, y_train, y_test = train_test_split(X, y, stratify=y)ろくなパラメータチューニングもしてないので改良の余地はありますが、とりあえず
from sklearn.ensemble import RandomForestClassifier from sklearn.pipeline import make_pipeline from sklearn.preprocessing import StandardScaler from sklearn.svm import SVC from sklearn.ensemble import StackingClassifier from sklearn.neural_network import MLPClassifier from sklearn.linear_model import LogisticRegression estimators = [ ('svc', make_pipeline(StandardScaler(), SVC())), ('rf', RandomForestClassifier()), ('mlp', MLPClassifier(max_iter=10000)) ] clf = StackingClassifier( estimators=estimators, final_estimator=LogisticRegression(max_iter=10000) ) clf.fit(X_train, y_train) clf.score(X_test, y_test)0.972027972027972単独の分類モデルの性能
比較として、単独の分類モデルの正解率を計算してみます。
make_pipeline(StandardScaler(), SVC()).fit(X_train, y_train).score(X_test, y_test)0.965034965034965RandomForestClassifier().fit(X_train, y_train).score(X_test, y_test)0.951048951048951MLPClassifier(max_iter=10000).fit(X_train, y_train).score(X_test, y_test)0.9090909090909091LogisticRegression(max_iter=10000).fit(X_train, y_train).score(X_test, y_test)0.958041958041958単独で使うよりも、組み合わせた方が良いという結果になりました。
ですが、train_test_split から計算し直すと、分割のされ方によっては単独の分類モデルのほうが性能が良くなったりします。
性能比較には、ランダムシードを固定せずに、何度も計算を繰り返して、その性能がどのくらい安定なのかを確認した方がいいと思っています。
StackingRegressor
スタッキングによる回帰
回帰モデルの性能を確認するため、糖尿病データを使ってみます。
from sklearn.datasets import load_diabetes X, y = load_diabetes(return_X_y=True)from sklearn.model_selection import train_test_split X_train, X_test, y_train, y_test = train_test_split(X, y)こちらも、ろくなパラメータチューニングしてないので改良の余地はありますが、
from sklearn.ensemble import RandomForestRegressor from sklearn.pipeline import make_pipeline from sklearn.preprocessing import StandardScaler from sklearn.svm import SVR from sklearn.ensemble import StackingRegressor from sklearn.neural_network import MLPRegressor from sklearn.cross_decomposition import PLSRegression estimators = [ ('svr', make_pipeline(StandardScaler(), SVR())), ('rf', RandomForestRegressor()), ('mlp', MLPRegressor(max_iter=10000)) ] clf = StackingRegressor( estimators=estimators, final_estimator=PLSRegression(), ) clf.fit(X_train, y_train) clf.score(X_test, y_test)0.4940607294168183単独の回帰モデルの性能
比較として、単独の回帰モデルののR2値を計算してみます。
make_pipeline(StandardScaler(), SVR()).fit(X_train, y_train).score(X_test, y_test)0.17571936903725216RandomForestRegressor().fit(X_train, y_train).score(X_test, y_test)0.46261715392586217MLPRegressor(max_iter=10000).fit(X_train, y_train).score(X_test, y_test)0.4936782755875562PLSRegression().fit(X_train, y_train).score(X_test, y_test)0.4927059150604132こちらも、単独で使うよりも、組み合わせた方が良いという結果になりました。
ですが、train_test_split から計算し直すと、分割のされ方によっては単独の回帰モデルのほうが性能が良くなったりします。
性能比較には、ランダムシードを固定せずに、何度も計算を繰り返して、その性能がどのくらい安定なのかを確認した方がいいと思っています。
- 投稿日:2020-09-15T22:43:07+09:00
テストの数理 その2
テストの数理 その1 の続きです。
前回は、「問題設定とデータの生成について」でした。
今回は、「項目反応理論で使われる数理モデルについて」です。用いた環境は、
- python 3.8
- numpy 1.19.2
- matplotlib 3.3.1
です。
項目特性曲線
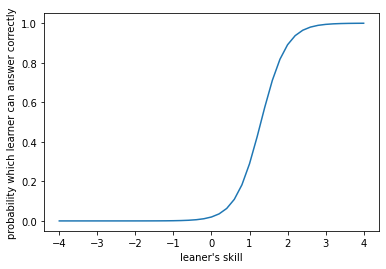
前回書いたようにここでの問題意識は、テストの結果が与えられた時に受験者の能力と問題の難易度を推定することでした。これを推定するために、ある特定の問題に注目して、その問題をどれぐらいの能力の受験者が正答することができるのかをグラフにしてみます。極端な場合には次のようなグラフが得られます。
import numpy as np import matplotlib.pyplot as plt x = np.linspace(-4, 4, 41) y = x > 1.3 plt.step(x, y) plt.xlabel("leaner's skill") plt.ylabel("probability which learner can answer correctly") plt.show()
横軸は受験者の能力を表す数値、縦軸はその能力の学習者がその問題を正答する確率です。このような、グラフのことを項目特性曲線といいます。
この例は、学習者の能力が1.3を超えた時に常に正答し、そうでない時に常に誤答するというものになります。このような問題があれば、この問題をテストに入れることで、学習者の能力が1.3を超えているかどうかを測定することができます。ここで、学習者の能力の数値とは何?という疑問が当然浮かぶことと思います。結論を言ってしまうと、この数値の絶対値に意味はありません。ただし、相対的に2つの問題があった時、例えば上を問1として、もう一つ問2が
という項目特性曲線を持つとしましょう。このとき、問1は問2より難しいと判断することができます。実際、
受験者 1 受験者 2 受験者 3 問 1 誤 誤 正 問 2 誤 正 正 という結果が得られた時、能力の値は、受験者1 < 受験者2 < 受験者3となるでしょう。また、この状況に置いて、「問1(正) かつ 問2(誤)」は起こりません。
さて、この状況は正答できるか誤答するかの2者が決定的になっており、少し極端です。実際の統計処理を考えると、正答誤答はある程度確率的であることが予想されます。特に、正誤の境あたりの能力の受験者は問題によっては、ある程度の確率で正答することができるでしょう。そういう意味で、実際に項目特性曲線として使用されるのは、例えば、次のようなものになります。
性質の良い問題(難易度と正答率に逆転がおこらない問題)であれば、確率分布の累積密度関数が、モデルとしては良さそうです。
項目反応理論では、その中でも数理的にも扱いやすい関数として、ロジスティック分布をよく用います。ロジスティック分布を用いたモデルをロジスティックモデル(logistic model)といい。問題毎のparameterの数に応じて、1 ~ 3 parameter logistic modelがよく知られています。
以下では、この1 ~ 3 parameter logistic modelについて述べます。1 parameter logistic model (1PL model, Rasch model)
1 parameter logistic model は項目特性曲線としては扱われている中で最も簡単なもののうちの1つで、以下の式で表せます。
\Pr\{u_{ij} = 1|\theta, a, b\} = \frac{1}{1 + \exp(-a(\theta_j - b_i))}ここで、前回の記事と同様に問題に関するparameterは$i$で、受験者に関するparameterは$j$で添字づけます。$u_{ij}$は問題$i$を受験者$j$が正答できるかどうかを示す確率変数です。問題の総数を$I$、受験者の総数を$J$とすると、このモデルのparamterの数は問題に関わるものが$I$個($=b_i$)、受験者に関わるものが$J$個($=\theta_j$)、全体に関わるものが1個($=a$)の$I+J+1$個あります。
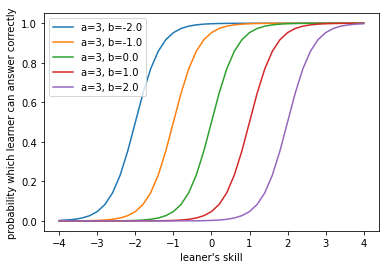
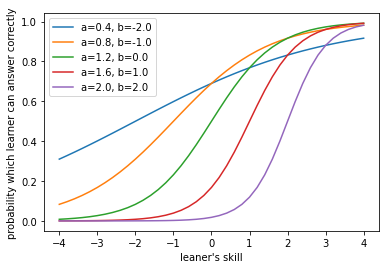
項目特性曲線を描くと次のようになります。a = 3 def L1P(b, x, a=a): return 1 / (1 + np.exp(- a * (x - b))) x = np.linspace(-4, 4, 41) for b in np.linspace(-2, 2, 5): y = partial(L1P, b)(x) plt.plot(x, y, label=f"{a=}, {b=}") plt.xlabel("leaner's skill") plt.ylabel("probability which learner can answer correctly") plt.legend() plt.show()
見ての通り、傾きが一斉に変わるのが特徴です。つまり、問題毎の難易度の識別のしやすさが同じとなります。なお、このように$a$は識別のしやすさに関わる量なので、識別力と呼ばれます。識別力の範囲は正の実数で、識別力が大きい方が識別しやすいことがわかります。また、$b$は問題の難かしさを表すことから、困難度と呼ばれます。困難度のとりうる範囲は実数全体1で、困難度が高いほど問題は難しいと判定されます。
このモデルは1960年代初頭にデンマークの数学者Raschが研究していたことにより、Raschモデルとも呼ばれます。2 parameter logistic model (2PL model)
2 parameter logistic model は標準的なモデルであり、pythonのpackageであるpyirtに搭載されている唯一の2モデルです。Raschモデルとほとんど同じ数式であり、次のように表せます。
\Pr\{u_{ij} = 1|\theta, a, b\} = \frac{1}{1 + \exp(-a_i(\theta_j - b_i))}つまり、問題によらなかった識別力$a$が問題に依存するようになった($a \rightarrow a_j$)ということです。このモデルのparamterの数は問題に関わるものが$2I$個($=a_i, b_i$)、受験者に関わるものが$J$個($=\theta_j$)の$2I+J$個あります。
項目特性曲線を描くと次のようになります。def L2P(a, b, x): return 1 / (1 + np.exp(- a * (x - b))) x = np.linspace(-4, 4, 41) for idx in range(5): a = 2 * (idx + 1) / 5 b = -2.0 + idx y = partial(L2P, a, b)(x) plt.plot(x, y, label=f"{a=}, {b=}") plt.xlabel("leaner's skill") plt.ylabel("probability which learner can answer correctly") plt.legend() plt.show()
3 parameter logistic model (3PL model)
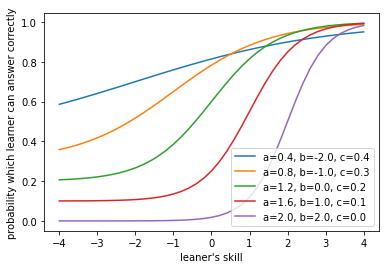
3 parameter logistic model は2PL modelに当て推量とよばれる量を加えたモデルです。TOEICなどのテストでは問題が択一式(3択問題、4択問題など)となっています。この択一問題で受験者に正答する能力がなかった場合、受験者がとる行動とはなんでしょうか?それは、ランダムに選択することです。このようなときには、例えば4択問題であれば、最低でも25%の正答率が確保されることとなります。この25%の部分が当て推量です。数式で表すと、次のようになります。
\Pr\{u_{ij} = 1|\theta, a, b, c\} = c_i + \frac{1 - c_i}{1 + \exp(-a_i(\theta_j - b_i))}ここで、$c_i$が問題$i$における当て推量であり、とりうる値の範囲は$0 \leq c_i \leq 1$となります。このモデルのparamterの数は問題に関わるものが$3I$個($=a_i, b_i, c_i$)、受験者に関わるものが$J$個($=\theta_j$)の$3I+J$個あります。
項目特性曲線を描くと次のようになります。def L3P(a, b, c, x): return c + (1 - c) / (1 + np.exp(- a * (x - b))) x = np.linspace(-4, 4, 41) for idx in range(5): a = 2 * (idx + 1) / 5 b = -2.0 + idx c = (4 - idx) / 10 y = partial(L3P, a, b, c)(x) plt.plot(x, y, label=f"{a=}, {b=}, {c=}") plt.xlabel("leaner's skill") plt.ylabel("probability which learner can answer correctly") plt.legend() plt.show()
次回
3PL modelについて、parameter推定の方法について紹介します。
参考文献



- 投稿日:2020-09-15T22:43:07+09:00
試験の数理 その2(項目反応理論の数理モデル)
試験の数理 その1(問題設定とデータの生成) の続きです。
前回は、「問題設定とデータの生成について」でした。
今回は、「項目反応理論で使われる数理モデルについて」です。用いた環境は、
- python 3.8
- numpy 1.19.2
- matplotlib 3.3.1
です。
項目特性曲線
前回書いたようにここでの問題意識は、試験の結果が与えられた時に受験者の能力と問題の難易度を推定することでした。これを推定するために、ある特定の問題に注目して、その問題をどれぐらいの能力の受験者が正答することができるのかをグラフにしてみます。極端な場合には次のようなグラフが得られます。
import numpy as np import matplotlib.pyplot as plt x = np.linspace(-4, 4, 41) y = x > 1.3 plt.step(x, y) plt.xlabel("leaner's skill") plt.ylabel("probability which learner can answer correctly") plt.show()
横軸は受験者の能力を表す数値、縦軸はその能力の学習者がその問題を正答する確率です。このような、グラフのことを項目特性曲線といいます。
この例は、学習者の能力が1.3を超えた時に常に正答し、そうでない時に常に誤答するというものになります。このような問題があれば、この問題を試験に入れることで、学習者の能力が1.3を超えているかどうかを測定することができます。ここで、学習者の能力の数値とは何?という疑問が当然浮かぶことと思います。結論を言ってしまうと、この数値の絶対値に意味はありません。ただし、相対的に2つの問題があった時、例えば上を問1として、もう一つ問2が
という項目特性曲線を持つとしましょう。このとき、問1は問2より難しいと判断することができます。実際、
受験者 1 受験者 2 受験者 3 問 1 誤 誤 正 問 2 誤 正 正 という結果が得られた時、能力の値は、受験者1 < 受験者2 < 受験者3となるでしょう。また、この状況に置いて、「問1(正) かつ 問2(誤)」は起こりません。
さて、この状況は正答できるか誤答するかの2者が決定的になっており、少し極端です。実際の統計処理を考えると、正答誤答はある程度確率的であることが予想されます。特に、正誤の境あたりの能力の受験者は問題によっては、ある程度の確率で正答することができるでしょう。そういう意味で、実際に項目特性曲線として使用されるのは、例えば、次のようなものになります。
性質の良い問題(難易度と正答率に逆転がおこらない問題)であれば、確率分布の累積密度関数が、モデルとしては良さそうです。
項目反応理論では、その中でも数理的にも扱いやすい関数として、ロジスティック分布をよく用います。ロジスティック分布を用いたモデルをロジスティックモデル(logistic model)といい。問題毎のparameterの数に応じて、1 ~ 3 parameter logistic modelがよく知られています1。
以下では、この1 ~ 3 parameter logistic modelについて述べます。1 parameter logistic model (1PL model, Rasch model)
1 parameter logistic model は項目特性曲線としては扱われている中で最も簡単なもののうちの1つで、以下の式で表せます。
\Pr\{u_{ij} = 1|\theta, a, b\} = \frac{1}{1 + \exp(-a(\theta_j - b_i))}ここで、前回の記事と同様に問題に関するparameterは$i$で、受験者に関するparameterは$j$で添字づけます。$u_{ij}$は問題$i$を受験者$j$が正答できるかどうかを示す確率変数です。問題の総数を$I$、受験者の総数を$J$とすると、このモデルのparamterの数は問題に関わるものが$I$個($=b_i$)、受験者に関わるものが$J$個($=\theta_j$)、全体に関わるものが1個($=a$)の$I+J+1$個あります。
項目特性曲線を描くと次のようになります。a = 3 def L1P(b, x, a=a): return 1 / (1 + np.exp(- a * (x - b))) x = np.linspace(-4, 4, 41) for b in np.linspace(-2, 2, 5): y = partial(L1P, b)(x) plt.plot(x, y, label=f"{a=}, {b=}") plt.xlabel("leaner's skill") plt.ylabel("probability which learner can answer correctly") plt.legend() plt.show()
見ての通り、傾きが一斉に変わるのが特徴です。つまり、問題毎の難易度の識別のしやすさが同じとなります。なお、このように$a$は識別のしやすさに関わる量なので、識別力と呼ばれます。識別力の範囲は正の実数で、識別力が大きい方が識別しやすいことがわかります。また、$b$は問題の難かしさを表すことから、困難度と呼ばれます。困難度のとりうる範囲は実数全体2で、困難度が高いほど問題は難しいと判定されます。
このモデルは1960年代初頭にデンマークの数学者Raschが研究していたことにより、Raschモデルとも呼ばれます。2 parameter logistic model (2PL model)
2 parameter logistic model は標準的なモデルであり、pythonのpackageであるpyirtに搭載されている唯一の3モデルです。Raschモデルとほとんど同じ数式であり、次のように表せます。
\Pr\{u_{ij} = 1|\theta, a, b\} = \frac{1}{1 + \exp(-a_i(\theta_j - b_i))}つまり、問題によらなかった識別力$a$が問題に依存するようになった($a \rightarrow a_j$)ということです。このモデルのparamterの数は問題に関わるものが$2I$個($=a_i, b_i$)、受験者に関わるものが$J$個($=\theta_j$)の$2I+J$個あります。
項目特性曲線を描くと次のようになります。def L2P(a, b, x): return 1 / (1 + np.exp(- a * (x - b))) x = np.linspace(-4, 4, 41) for idx in range(5): a = 2 * (idx + 1) / 5 b = -2.0 + idx y = partial(L2P, a, b)(x) plt.plot(x, y, label=f"{a=}, {b=}") plt.xlabel("leaner's skill") plt.ylabel("probability which learner can answer correctly") plt.legend() plt.show()
3 parameter logistic model (3PL model)
3 parameter logistic model は2PL modelに当て推量とよばれる量を加えたモデルです。TOEICなどの試験では問題が択一式(3択問題、4択問題など)となっています。この択一問題で受験者に正答する能力がなかった場合、受験者がとる行動とはなんでしょうか?それは、ランダムに選択することです。このようなときには、例えば4択問題であれば、最低でも25%の正答率が確保されることとなります。この25%の部分が当て推量です。数式で表すと、次のようになります。
\Pr\{u_{ij} = 1|\theta, a, b, c\} = c_i + \frac{1 - c_i}{1 + \exp(-a_i(\theta_j - b_i))}ここで、$c_i$が問題$i$における当て推量であり、とりうる値の範囲は$0 \leq c_i \leq 1$となります。このモデルのparamterの数は問題に関わるものが$3I$個($=a_i, b_i, c_i$)、受験者に関わるものが$J$個($=\theta_j$)の$3I+J$個あります。
項目特性曲線を描くと次のようになります。def L3P(a, b, c, x): return c + (1 - c) / (1 + np.exp(- a * (x - b))) x = np.linspace(-4, 4, 41) for idx in range(5): a = 2 * (idx + 1) / 5 b = -2.0 + idx c = (4 - idx) / 10 y = partial(L3P, a, b, c)(x) plt.plot(x, y, label=f"{a=}, {b=}, {c=}") plt.xlabel("leaner's skill") plt.ylabel("probability which learner can answer correctly") plt.legend() plt.show()
次回
3PL modelについて、parameter推定の方法について紹介します。
参考文献
- 投稿日:2020-09-15T21:03:41+09:00
緑コーダーと読み進めるAtCoder Library 〜Pythonでの実装まで〜【DSU編】
0. はじめに
2020年9月7日にAtCoder公式のアルゴリズム集 AtCoder Library (ACL)が公開されました。
自分はACLに収録されているアルゴリズム、データ構造のほとんどが初見だったのでいい機会だと思い、アルゴリズムの勉強からPythonでの実装までを行いました。この記事ではDSUをみていきます。
対象としている読者
- ACLのコードを見てみたけど何をしているのかわからない方。
- C++はわからないのでPythonで読み進めたい方。
対象としていない読者
- ACLのPythonに最適化されたコードが欲しい方。
→極力ACLと同じになるように実装したのでPythonでの実行速度等は全く考慮していません。Cythonから直接使えるようにするという動きがあるようなのでそちらを追ってみるといいかもしれません。参考にしたもの
AtCoder公式によるわかりやすい解説があります。
- スライド
- youtube解説動画(ABC157の解説動画です)
1. DSUとは
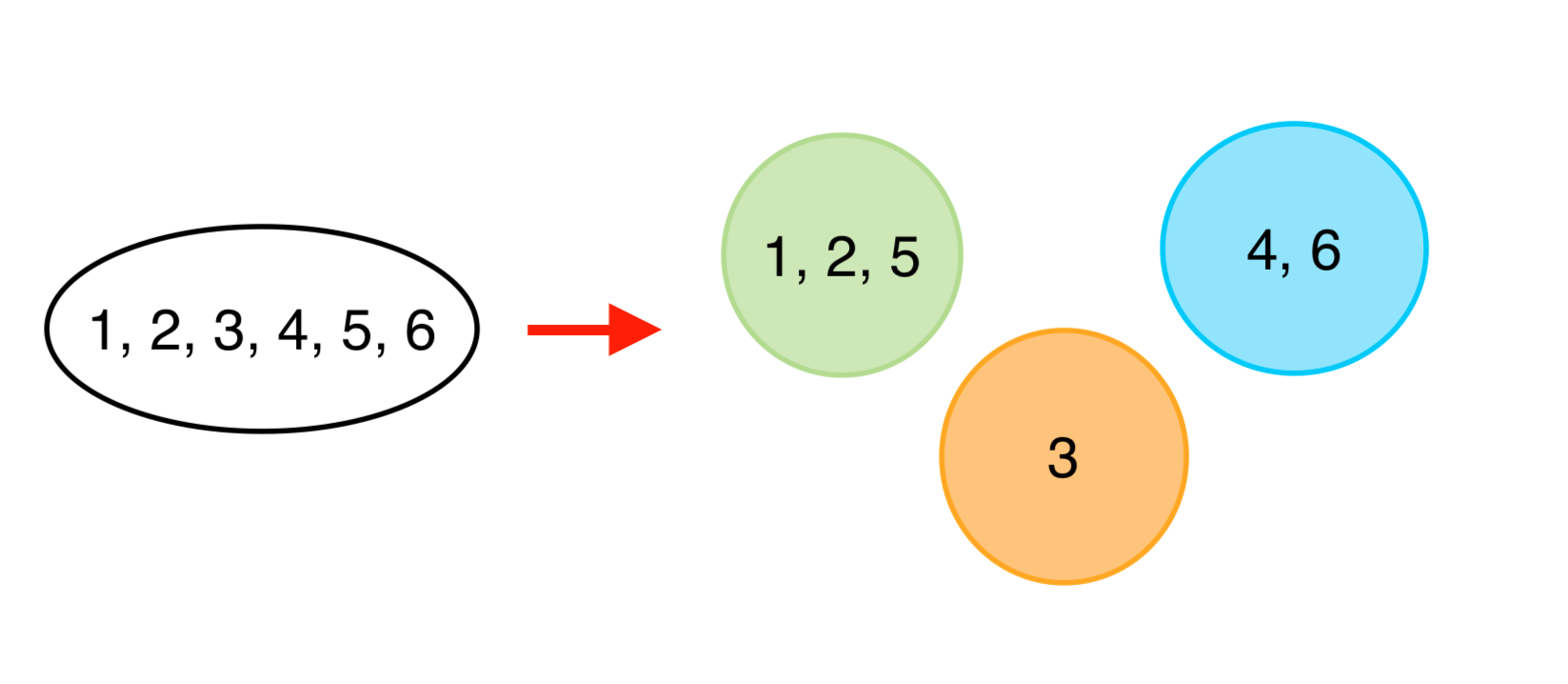
DSU (Disjoint Set Union, 素集合データ構造)はあるデータ集合を素集合(グループ)に分割して保持するデータ構造です。すなわち各データが1つのグループに属し、2つ以上のグループに属することはありません。
このデータ構造は以下の2つの便利な操作をサポートしています。
- Union: 2つのグループを1つに統合する。
- Find: ある要素がどのグループに属するかを求める。
このことから、このデータ構造をUnionFindと呼ぶこともあります。こちらの名称の方が馴染みがあるかもしれません。
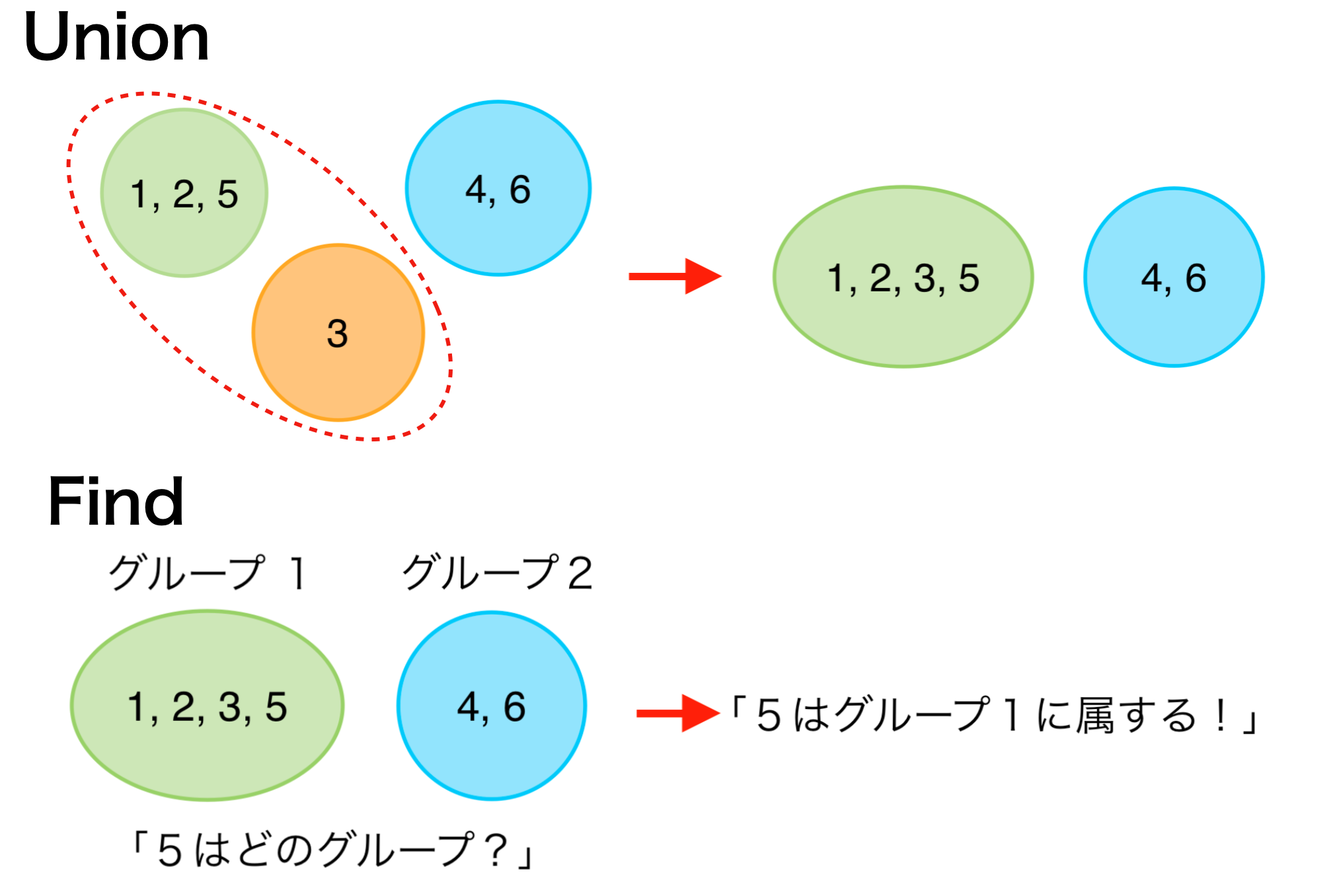
実装上は...
Unionはグループではなく要素を2つ指定し、それらの属するグループを統合します。また、各グループ内で1つの要素をリーダーとして選び、これをいわば”グループ名”として管理します。(上図での”グループ1”や”グループ2”は例えば1や4になります。)
2. 実装
それでは実装していきます。変数名、メソッド名等はなるべくACLに沿って実装します。
2.1. コンストラクタ
まずクラスDSUを作成し、コンストラクタを実装します。
class DSU: def __init__(self, n): # n:要素数 self._n = n self.parent_or_size = [-1] * nnは要素数で、インスタンス変数
_nに保持しておきます。
また、各要素についての情報を格納するリストparent_or_sizeを作成します。名前の示す通り、このリストの各要素parent_or_size[i]は、要素 i の parent (リーダー)もしくは要素 i の属するグループの size (大きさ)を表します。具体的には
parent_or_size[i]が負 :- 要素 i はグループのリーダーであり、属するグループの大きさは
abs(parent_or_size[i])
parent_or_size[i]が 0以上 :- 要素 i の属するグループのリーダーは
parent_or_size[i]です。つまり初期化時点では全ての要素が、「自分をリーダーとする大きさ1のグループ(要素が自分だけのグループ)」に属しているということになります。
2.2. Find
操作FindはACLではleaderという名前で実装されています。このメソッドは要素を指定することで、その要素が属するグループのリーダーを返します。
def leader(self, a): assert 0 <= a < self._n if self.parent_or_size[a] < 0: return a # 負ならリーダー self.parent_or_size[a] = self.leader(self.parent_or_size[a]) return self.parent_or_size[a]まず、3行目で
parent_or_size[a]が負ならば a はリーダーなのでそのままreturnします。そうでないならばparent_or_size[a]は a のリーダー (仮) です。なぜなら、グループの統合があった場合片方のリーダーはリーダーではなくなるからです。そこで、このリーダー(仮)から再帰的に 真の リーダーを探します。4行目で右辺を直接returnせずに代入することでリーダーの情報を更新しています。メモ化していると言ってもいいかもしれません。これによって次回以降の探索が短くなります。2.3. Union
操作UnionはACLではmergeという名前で実装されています。このメソッドは要素を2つ指定することで、それらの属するグループを統合します。
def merge(self, a, b): assert 0 <= a < self._n assert 0 <= b < self._n x, y = self.leader(a), self.leader(b) if x == y: return x if -self.parent_or_size[x] < -self.parent_or_size[y]: x, y = y, x self.parent_or_size[x] += self.parent_or_size[y] # xの大きさにyの大きさを加算 self.parent_or_size[y] = x # yのリーダーはx return xまず、a, bそれぞれのリーダーx, yを求めます。これらが一致していれば、すでにa, bは同じグループに属しているので何もする必要はありません(5行目)。そうでない場合、yのグループをxのグループに統合します。この時、6行目のようにすることで常に小さいグループを大きいグループに統合するようにします。yのグループメンバーはリーダーの情報を更新する必要があるので、これによって計算量を減らすことができます。
2.4. その他のメソッド
ACLのDSUには他にもいくつかのメソッドが実装されているので、それらも実装していきます。
same
メソッドsameは要素を2つ指定することで、それらが同じグループに属しているかの真偽値を返します。
def same(self, a, b): assert 0 <= a < self._n assert 0 <= b < self._n return self.leader(a) == self.leader(b)size
メソッドsizeは指定した要素が属するグループの大きさ(要素数)を返します。
def size(self, a): assert 0 <= a < self._n return -self.parent_or_size[self.leader(a)]groups
メソッドgroupsは全要素をグループごとにまとめたリストを返します。
def groups(self): leader_buf = [self.leader(i) for i in range(self._n)] result = [[] for _ in range(self._n)] for i in range(self._n): result[leader_buf[i]].append(i) return [r for r in result if r != []]2.5. まとめ
dsu.pyclass DSU: def __init__(self, n): self._n = n self.parent_or_size = [-1] * n def merge(self, a, b): assert 0 <= a < self._n assert 0 <= b < self._n x, y = self.leader(a), self.leader(b) if x == y: return x if -self.parent_or_size[x] < -self.parent_or_size[y]: x, y = y, x self.parent_or_size[x] += self.parent_or_size[y] self.parent_or_size[y] = x return x def same(self, a, b): assert 0 <= a < self._n assert 0 <= b < self._n return self.leader(a) == self.leader(b) def leader(self, a): assert 0 <= a < self._n if self.parent_or_size[a] < 0: return a self.parent_or_size[a] = self.leader(self.parent_or_size[a]) return self.parent_or_size[a] def size(self, a): assert 0 <= a < self._n return -self.parent_or_size[self.leader(a)] def groups(self): leader_buf = [self.leader(i) for i in range(self._n)] result = [[] for _ in range(self._n)] for i in range(self._n): result[leader_buf[i]].append(i) return [r for r in result if r != []]3. 使用例
n = 8 # 全要素数 d = DSU(n) d.merge(0, 1) d.merge(1, 3) d.merge(0, 4) d.merge(5, 6) d.merge(3, 7) print(d.groups()) # [[0, 1, 3, 4, 7], [2], [5, 6]] print(d.leader(3)) # 0 print(d.same(1, 7)) # True print(d.same(0, 5)) # False print(d.size(6)) # 24. 問題例
AtCoder Library Practice Contest A "Disjoint Set Union"
AtCoder Typical Contest 001 B "Union Find"5. おわりに
DSUの仕組みの解明からPythonでの実装までができました。また、実装上では様々な工夫がされていることがわかりました。特に必要な情報を一つの配列で表現する工夫には感動しました。
説明の間違いやバグ、アドバイス等ありましたらお知らせください。
- 投稿日:2020-09-15T21:01:36+09:00
Python から Julia を呼び出す Pyjulia のメモ
背景
- Python では数値計算が遅い状態になっている.
- Julia で早くなりそうな気がするので Julia 使ってみたい
- Windows, Linux 両方で動くのが必要
- とはいえ Python 資産がそれなりにあり完全に移行できるわけではないので, 計算の一部だけ julia で処理してみたい.
- Python から呼べる pyjulia を使ってみます.
インストール
https://github.com/JuliaPy/pyjulia
ドキュメントにあるとおりです.
ただ,
julia.install()では julia がパスに通っている必要があります.ソースコードを見ると, julia のパスを指定できるのがわかりました.
julia.install(julia="/path/to/julia")で, julia コマンドのパスを設定できます. Windows 環境で julia コマンドのパスを
PATHに登録するのが面倒なときに利用するといいかもです.Julia 自体は Linux の場合は musl(glibc などよりもポータブルな libc)版が用意されていたりと, それなりにクロスプラットホームであるのが想定できます.
Windows の場合も特に不都合なく動いてくれているようです.
(コンパイルも LLVM 使っているので Visual Studio とか入れなくても動く... はず)あとはドキュメントを参考にいろいろ Julia を呼び出すだけです!
- 投稿日:2020-09-15T20:42:15+09:00
初投稿!
はじめまして。
独学でPythonを学んでいます。
これから少しずつ投稿していきます。
【プログラミングを始めたきっかけ】
一般社団法人 日本ディープラーニング協会(以下、JDLAとする)が主催しているG(ジェネラリスト)検定という資格試験をきっかけにプログラミングに興味を持ちました。人工知能や機械学習などにはPythonがよく使われており、初心者にもシンプルで学びやすいと調べたら書いてあったのでまずは学んでみようと思ったのがきっかけです。
結果は、合格だったのですが試験問題の内容が難しすぎて、夏のエアコンが効いた部屋で受験したのですが、冷や汗を書きながら問題を解いていたのが懐かしいです。笑
【コード】
簡単なfor文です。
for i in range(5): print(i)【結 果】
4今回は、初めての投稿ということで簡単なfor文とさせていただきました。
徐々に投稿のクオリティを上げていきたいと思っています。
では、また!!



- 投稿日:2020-09-15T20:42:15+09:00
Qiita初投稿 〜プログラミングを始めたきっかけ〜
はじめまして。
独学でPythonを学んでいます。
これから少しずつ投稿していきます。
【プログラミングを始めたきっかけ】
一般社団法人 日本ディープラーニング協会(以下、JDLAとする)が主催しているG(ジェネラリスト)検定という資格試験をきっかけにプログラミングに興味を持ちました。人工知能や機械学習などにはPythonがよく使われており、初心者にもシンプルで学びやすいと調べたら書いてあったのでまずは学んでみようと思ったのがきっかけです。
結果は、合格だったのですが試験問題の内容が難しすぎて、夏のエアコンが効いた部屋で受験したのですが、冷や汗を書きながら問題を解いていたのが懐かしいです。笑
【コード】
簡単なfor文です。
for i in range(5): print(i)【結 果】
4今回は、初めての投稿ということで簡単なfor文とさせていただきました。
徐々に投稿のクオリティを上げていきたいと思っています。
では、また!!
- 投稿日:2020-09-15T20:42:15+09:00
Qiita初投稿(始めたきっかけ)
はじめまして。
独学でPythonを学んでいます。
これから少しずつ投稿していきます。
【プログラミングを始めたきっかけ】
一般社団法人 日本ディープラーニング協会(以下、JDLAとする)が主催しているG(ジェネラリスト)検定という資格試験をきっかけにプログラミングに興味を持ちました。人工知能や機械学習などにはPythonがよく使われており、初心者にもシンプルで学びやすいと調べたら書いてあったのでまずは学んでみようと思ったのがきっかけです。
結果は、合格だったのですが試験問題の内容が難しすぎて、夏のエアコンが効いた部屋で受験したのですが、冷や汗を書きながら問題を解いていたのが懐かしいです。笑
【コード】
簡単なfor文です。
for i in range(5): print(i)【結 果】
0 1 2 3 4今回は、初めての投稿ということで簡単なfor文とさせていただきました。
徐々に投稿のクオリティを上げていきたいと思っています。
では、また!!
- 投稿日:2020-09-15T20:38:04+09:00
【言語処理100本ノック 2020】第9章: RNN, CNN
はじめに
自然言語処理の問題集として有名な言語処理100本ノックの2020年版が公開されました。
この記事では、以下の第1章から第10章のうち、「第9章: RNN, CNN」を解いてみた結果をまとめています。
- 第1章: 準備運動
- 第2章: UNIXコマンド
- 第3章: 正規表現
- 第4章: 形態素解析
- 第5章: 係り受け解析
- 第6章: 機械学習
- 第7章: 単語ベクトル
- 第8章: ニューラルネット
- 第9章: RNN, CNN
- 第10章: 機械翻訳
事前準備
解答にはGoogle Colaboratoryを利用しています。
Google Colaboratoryのセットアップ方法や基本的な使い方は、こちらの記事が詳しいです。
本章ではGPUを利用するため、事前に「ランタイム」 -> 「ランタイムのタイプを変更」から、ハードウェアアクセラレータを「GPU」に変更し、保存しておいてください。
なお、以降の解答の実行結果を含むノートブックはgithubにて公開しています。第9章: RNN, CNN
80. ID番号への変換
問題51で構築した学習データ中の単語にユニークなID番号を付与したい.学習データ中で最も頻出する単語に
1,2番目に頻出する単語に2,……といった方法で,学習データ中で2回以上出現する単語にID番号を付与せよ.そして,与えられた単語列に対して,ID番号の列を返す関数を実装せよ.ただし,出現頻度が2回未満の単語のID番号はすべて0とせよ.まずは、指定のデータをダウンロード後、データフレームとして読込みます。そして、学習データ、検証データ、評価データに分割し、保存します。
ここまでは、第6章の問題50とまったく同じ処理のため、そちらで作成したデータを読み込んでも問題ありません。# データのダウンロード !wget https://archive.ics.uci.edu/ml/machine-learning-databases/00359/NewsAggregatorDataset.zip !unzip NewsAggregatorDataset.zip# 読込時のエラー回避のためダブルクォーテーションをシングルクォーテーションに置換 !sed -e 's/"/'\''/g' ./newsCorpora.csv > ./newsCorpora_re.csvimport pandas as pd from sklearn.model_selection import train_test_split # データの読込 df = pd.read_csv('./newsCorpora_re.csv', header=None, sep='\t', names=['ID', 'TITLE', 'URL', 'PUBLISHER', 'CATEGORY', 'STORY', 'HOSTNAME', 'TIMESTAMP']) # データの抽出 df = df.loc[df['PUBLISHER'].isin(['Reuters', 'Huffington Post', 'Businessweek', 'Contactmusic.com', 'Daily Mail']), ['TITLE', 'CATEGORY']] # データの分割 train, valid_test = train_test_split(df, test_size=0.2, shuffle=True, random_state=123, stratify=df['CATEGORY']) valid, test = train_test_split(valid_test, test_size=0.5, shuffle=True, random_state=123, stratify=valid_test['CATEGORY']) # 事例数の確認 print('【学習データ】') print(train['CATEGORY'].value_counts()) print('【検証データ】') print(valid['CATEGORY'].value_counts()) print('【評価データ】') print(test['CATEGORY'].value_counts())出力【学習データ】 b 4501 e 4235 t 1220 m 728 Name: CATEGORY, dtype: int64 【検証データ】 b 563 e 529 t 153 m 91 Name: CATEGORY, dtype: int64 【評価データ】 b 563 e 530 t 152 m 91 Name: CATEGORY, dtype: int64続いて、単語の辞書を作成します。
学習データの単語をカウントし、2回以上登場するものをキーとして頻度順位(ID)を登録していきます。from collections import defaultdict import string # 単語の頻度集計 d = defaultdict(int) table = str.maketrans(string.punctuation, ' '*len(string.punctuation)) # 記号をスペースに置換するテーブル for text in train['TITLE']: for word in text.translate(table).split(): d[word] += 1 d = sorted(d.items(), key=lambda x:x[1], reverse=True) # 単語ID辞書の作成 word2id = {word: i + 1 for i, (word, cnt) in enumerate(d) if cnt > 1} # 出現頻度が2回以上の単語を登録 print(f'ID数: {len(set(word2id.values()))}\n') print('---頻度上位20語---') for key in list(word2id)[:20]: print(f'{key}: {word2id[key]}')出力ID数: 9405 ---頻度上位20語--- to: 1 s: 2 in: 3 on: 4 UPDATE: 5 as: 6 US: 7 for: 8 The: 9 of: 10 1: 11 To: 12 2: 13 the: 14 and: 15 In: 16 Of: 17 a: 18 at: 19 A: 20最後に、辞書を用いて与えられた単語列をID番号の列に変換する関数を定義します。このとき、問題文の指示に従い、辞書にない単語には
0を返すようにします。def tokenizer(text, word2id=word2id, unk=0): """ 入力テキストをスペースで分割しID列に変換(辞書になければunkで指定した数字を設定)""" table = str.maketrans(string.punctuation, ' '*len(string.punctuation)) return [word2id.get(word, unk) for word in text.translate(table).split()]2つ目の文で確認します。
# 確認 text = train.iloc[1, train.columns.get_loc('TITLE')] print(f'テキスト: {text}') print(f'ID列: {tokenizer(text)}')出力テキスト: Amazon Plans to Fight FTC Over Mobile-App Purchases ID列: [169, 539, 1, 683, 1237, 82, 279, 1898, 4199]81. RNNによる予測
ID番号で表現された単語列$\boldsymbol{x} = (x_1, x_2, \dots, x_T)$がある.ただし,$T$は単語列の長さ,$x_t \in \mathbb{R}^{V}$は単語のID番号のone-hot表記である($V$は単語の総数である).再帰型ニューラルネットワーク(RNN: Recurrent Neural Network)を用い,単語列$\boldsymbol{x}$からカテゴリ$y$を予測するモデルとして,次式を実装せよ.
\overrightarrow h_0 = 0,\\ \overrightarrow h_t = {\rm \overrightarrow{RNN}}(\mathrm{emb}(x_t), \overrightarrow h_{t-1}), \\ y = {\rm softmax}(W^{(yh)} \overrightarrow h_T + b^{(y)})ただし,$\mathrm{emb}(x) \in \mathbb{R}^{d_w}$は単語埋め込み(単語のone-hot表記から単語ベクトルに変換する関数),$\overrightarrow h_t \in \mathbb{R}^{d_h}$は時刻$t$の隠れ状態ベクトル,${\rm \overrightarrow{RNN}}(x,h)$は入力$x$と前時刻の隠れ状態$h$から次状態を計算するRNNユニット,$W^{(yh)} \in \mathbb{R}^{L \times d_h}$は隠れ状態ベクトルからカテゴリを予測するための行列,$b^{(y)} \in \mathbb{R}^{L}$はバイアス項である($d_w, d_h, L$はそれぞれ,単語埋め込みの次元数,隠れ状態ベクトルの次元数,ラベル数である).RNNユニット${\rm \overrightarrow{RNN}}(x,h)$には様々な構成が考えられるが,典型例として次式が挙げられる.
{\rm \overrightarrow{RNN}}(x,h) = g(W^{(hx)} x + W^{(hh)}h + b^{(h)})ただし,$W^{(hx)} \in \mathbb{R}^{d_h \times d_w},W^{(hh)} \in \mathbb{R}^{d_h \times d_h}, b^{(h)} \in \mathbb{R}^{d_h}$はRNNユニットのパラメータ,$g$は活性化関数(例えば$\tanh$やReLUなど)である.
なお,この問題ではパラメータの学習を行わず,ランダムに初期化されたパラメータで$y$を計算するだけでよい.次元数などのハイパーパラメータは,$d_w = 300, d_h=50$など,適当な値に設定せよ(以降の問題でも同様である).
解答に入る前に、ニューラルネットを用いた自然言語処理、特にテキスト分類における処理の流れを整理しておきます。
ニューラルネットを用いたテキスト分類は、主に以下の4つの工程からなります。
- 文をトークン(例えば単語)の列に分割
- それぞれのトークンをベクトルに変換
- トークンベクトルを文ベクトルとして1つに集約
- 文ベクトルを入力としてラベルを分類
それぞれの工程について、いろいろな方法が考えられますが、例えば第8章では、
- 文をトークン(例えば単語)の列に分割 ⇒ スペースで分割
- それぞれのトークンをベクトルに変換 ⇒ 事前学習済みWord2Vecで変換
- トークンベクトルを文ベクトルとして1つに集約 ⇒ トークンベクトルを平均
- 文ベクトルを入力としてラベルを分類 ⇒ 全結合層で分類
の流れを実装し、No.4のパラメータを学習していました(日本語文書を対象とする場合は、No.1で第4章の形態素解析が必要となります)。
それに対し、本章では、
- 文をトークン(例えば単語)の列に分割 ⇒ スペースで分割
- それぞれのトークンをベクトルに変換 ⇒ 埋め込み層で変換
- トークンベクトルを文ベクトルとして1つに集約 ⇒ RNNまたはCNNで集約
- 文ベクトルを入力としてラベルを分類 ⇒ 全結合層で分類
となり、No.2~4を繋げたネットワークのパラメータを学習していきます。
なお、本章の問題のように、便宜的に分割したトークンを対応するIDに変換しておくことも多いですが、工程としてはNo.1に含まれます。それでは、早速本問のネットワークを実装します。
埋め込み層にはnn.Embeddingを使います。この層は、単語IDを与えるとone-hotベクトルに変換した後、指定したサイズ(emb_size)のベクトルに変換します。
続くRNN部分は、全結合層を再帰的に通す処理で実現できますが、nn.RNNを用いることでシンプルに書くことができます。
最後に全結合層を繋げれば完成です。import torch from torch import nn class RNN(nn.Module): def __init__(self, vocab_size, emb_size, padding_idx, output_size, hidden_size): super().__init__() self.hidden_size = hidden_size self.emb = nn.Embedding(vocab_size, emb_size, padding_idx=padding_idx) self.rnn = nn.RNN(emb_size, hidden_size, nonlinearity='tanh', batch_first=True) self.fc = nn.Linear(hidden_size, output_size) def forward(self, x): self.batch_size = x.size()[0] hidden = self.init_hidden() # h0のゼロベクトルを作成 emb = self.emb(x) # emb.size() = (batch_size, seq_len, emb_size) out, hidden = self.rnn(emb, hidden) # out.size() = (batch_size, seq_len, hidden_size) out = self.fc(out[:, -1, :]) # out.size() = (batch_size, output_size) return out def init_hidden(self): hidden = torch.zeros(1, self.batch_size, self.hidden_size) return hidden次に、前章と同様に
Datasetを作成するクラスを定義します。
今回は、テキストとラベルを受け取り、テキストを指定したtokenizerでID化した後、それぞれをTensor型で出力する機能を持たせます。from torch.utils.data import Dataset class CreateDataset(Dataset): def __init__(self, X, y, tokenizer): self.X = X self.y = y self.tokenizer = tokenizer def __len__(self): # len(Dataset)で返す値を指定 return len(self.y) def __getitem__(self, index): # Dataset[index]で返す値を指定 text = self.X[index] inputs = self.tokenizer(text) return { 'inputs': torch.tensor(inputs, dtype=torch.int64), 'labels': torch.tensor(self.y[index], dtype=torch.int64) }上記を用いて
Datasetを作成します。tokenizerには、前問で定義した関数を指定します。# ラベルベクトルの作成 category_dict = {'b': 0, 't': 1, 'e':2, 'm':3} y_train = train['CATEGORY'].map(lambda x: category_dict[x]).values y_valid = valid['CATEGORY'].map(lambda x: category_dict[x]).values y_test = test['CATEGORY'].map(lambda x: category_dict[x]).values # Datasetの作成 dataset_train = CreateDataset(train['TITLE'], y_train, tokenizer) dataset_valid = CreateDataset(valid['TITLE'], y_valid, tokenizer) dataset_test = CreateDataset(test['TITLE'], y_test, tokenizer) print(f'len(Dataset)の出力: {len(dataset_train)}') print('Dataset[index]の出力:') for var in dataset_train[1]: print(f' {var}: {dataset_train[1][var]}')出力len(Dataset)の出力: 10684 Dataset[index]の出力: inputs: tensor([ 169, 539, 1, 683, 1237, 82, 279, 1898, 4199]) labels: 1本問では学習しないため、
Datasetからinputsをモデルに与え、Softmax後にそのまま出力を確認します。# パラメータの設定 VOCAB_SIZE = len(set(word2id.values())) + 1 # 辞書のID数 + パディングID EMB_SIZE = 300 PADDING_IDX = len(set(word2id.values())) OUTPUT_SIZE = 4 HIDDEN_SIZE = 50 # モデルの定義 model = RNN(VOCAB_SIZE, EMB_SIZE, PADDING_IDX, OUTPUT_SIZE, HIDDEN_SIZE) # 先頭10件の予測値取得 for i in range(10): X = dataset_train[i]['inputs'] print(torch.softmax(model(X.unsqueeze(0)), dim=-1))出力tensor([[0.2667, 0.2074, 0.2974, 0.2285]], grad_fn=<SoftmaxBackward>) tensor([[0.1660, 0.3465, 0.2154, 0.2720]], grad_fn=<SoftmaxBackward>) tensor([[0.2133, 0.2987, 0.3097, 0.1783]], grad_fn=<SoftmaxBackward>) tensor([[0.2512, 0.4107, 0.1825, 0.1556]], grad_fn=<SoftmaxBackward>) tensor([[0.2784, 0.1307, 0.3715, 0.2194]], grad_fn=<SoftmaxBackward>) tensor([[0.2625, 0.1569, 0.2339, 0.3466]], grad_fn=<SoftmaxBackward>) tensor([[0.1331, 0.5129, 0.2220, 0.1319]], grad_fn=<SoftmaxBackward>) tensor([[0.2404, 0.1314, 0.2023, 0.4260]], grad_fn=<SoftmaxBackward>) tensor([[0.1162, 0.4576, 0.2588, 0.1674]], grad_fn=<SoftmaxBackward>) tensor([[0.4685, 0.1414, 0.2633, 0.1268]], grad_fn=<SoftmaxBackward>)82. 確率的勾配降下法による学習
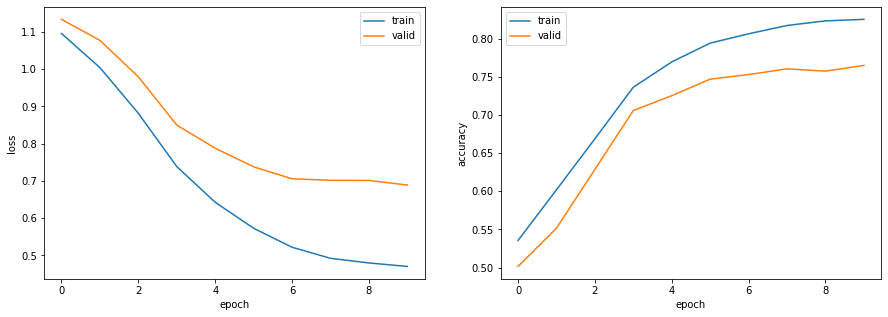
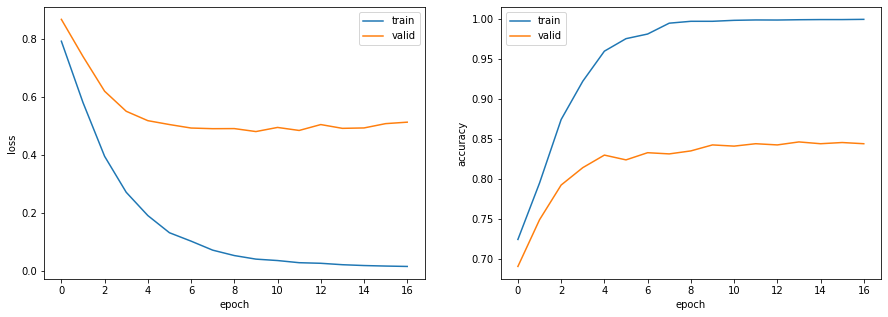
確率的勾配降下法(SGD: Stochastic Gradient Descent)を用いて,問題81で構築したモデルを学習せよ.訓練データ上の損失と正解率,評価データ上の損失と正解率を表示しながらモデルを学習し,適当な基準(例えば10エポックなど)で終了させよ.
こちらも前章同様に、学習のための一連の処理を
train_model関数として定義します。from torch.utils.data import DataLoader import time from torch import optim def calculate_loss_and_accuracy(model, dataset, device=None, criterion=None): """損失・正解率を計算""" dataloader = DataLoader(dataset, batch_size=1, shuffle=False) loss = 0.0 total = 0 correct = 0 with torch.no_grad(): for data in dataloader: # デバイスの指定 inputs = data['inputs'].to(device) labels = data['labels'].to(device) # 順伝播 outputs = model(inputs) # 損失計算 if criterion != None: loss += criterion(outputs, labels).item() # 正解率計算 pred = torch.argmax(outputs, dim=-1) total += len(inputs) correct += (pred == labels).sum().item() return loss / len(dataset), correct / total def train_model(dataset_train, dataset_valid, batch_size, model, criterion, optimizer, num_epochs, collate_fn=None, device=None): """モデルの学習を実行し、損失・正解率のログを返す""" # デバイスの指定 model.to(device) # dataloaderの作成 dataloader_train = DataLoader(dataset_train, batch_size=batch_size, shuffle=True, collate_fn=collate_fn) dataloader_valid = DataLoader(dataset_valid, batch_size=1, shuffle=False) # スケジューラの設定 scheduler = optim.lr_scheduler.CosineAnnealingLR(optimizer, num_epochs, eta_min=1e-5, last_epoch=-1) # 学習 log_train = [] log_valid = [] for epoch in range(num_epochs): # 開始時刻の記録 s_time = time.time() # 訓練モードに設定 model.train() for data in dataloader_train: # 勾配をゼロで初期化 optimizer.zero_grad() # 順伝播 + 誤差逆伝播 + 重み更新 inputs = data['inputs'].to(device) labels = data['labels'].to(device) outputs = model(inputs) loss = criterion(outputs, labels) loss.backward() optimizer.step() # 評価モードに設定 model.eval() # 損失と正解率の算出 loss_train, acc_train = calculate_loss_and_accuracy(model, dataset_train, device, criterion=criterion) loss_valid, acc_valid = calculate_loss_and_accuracy(model, dataset_valid, device, criterion=criterion) log_train.append([loss_train, acc_train]) log_valid.append([loss_valid, acc_valid]) # チェックポイントの保存 torch.save({'epoch': epoch, 'model_state_dict': model.state_dict(), 'optimizer_state_dict': optimizer.state_dict()}, f'checkpoint{epoch + 1}.pt') # 終了時刻の記録 e_time = time.time() # ログを出力 print(f'epoch: {epoch + 1}, loss_train: {loss_train:.4f}, accuracy_train: {acc_train:.4f}, loss_valid: {loss_valid:.4f}, accuracy_valid: {acc_valid:.4f}, {(e_time - s_time):.4f}sec') # 検証データの損失が3エポック連続で低下しなかった場合は学習終了 if epoch > 2 and log_valid[epoch - 3][0] <= log_valid[epoch - 2][0] <= log_valid[epoch - 1][0] <= log_valid[epoch][0]: break # スケジューラを1ステップ進める scheduler.step() return {'train': log_train, 'valid': log_valid}さらに、ログを可視化するための関数も定義しておきます。
import numpy as np from matplotlib import pyplot as plt def visualize_logs(log): fig, ax = plt.subplots(1, 2, figsize=(15, 5)) ax[0].plot(np.array(log['train']).T[0], label='train') ax[0].plot(np.array(log['valid']).T[0], label='valid') ax[0].set_xlabel('epoch') ax[0].set_ylabel('loss') ax[0].legend() ax[1].plot(np.array(log['train']).T[1], label='train') ax[1].plot(np.array(log['valid']).T[1], label='valid') ax[1].set_xlabel('epoch') ax[1].set_ylabel('accuracy') ax[1].legend() plt.show()パラメータを設定し、モデルを学習します。
# パラメータの設定 VOCAB_SIZE = len(set(word2id.values())) + 1 EMB_SIZE = 300 PADDING_IDX = len(set(word2id.values())) OUTPUT_SIZE = 4 HIDDEN_SIZE = 50 LEARNING_RATE = 1e-3 BATCH_SIZE = 1 NUM_EPOCHS = 10 # モデルの定義 model = RNN(VOCAB_SIZE, EMB_SIZE, PADDING_IDX, OUTPUT_SIZE, HIDDEN_SIZE) # 損失関数の定義 criterion = nn.CrossEntropyLoss() # オプティマイザの定義 optimizer = torch.optim.SGD(model.parameters(), lr=LEARNING_RATE) # モデルの学習 log = train_model(dataset_train, dataset_valid, BATCH_SIZE, model, criterion, optimizer, NUM_EPOCHS)出力epoch: 1, loss_train: 1.0954, accuracy_train: 0.5356, loss_valid: 1.1334, accuracy_valid: 0.5015, 86.4033sec epoch: 2, loss_train: 1.0040, accuracy_train: 0.6019, loss_valid: 1.0770, accuracy_valid: 0.5516, 85.2816sec epoch: 3, loss_train: 0.8813, accuracy_train: 0.6689, loss_valid: 0.9793, accuracy_valid: 0.6287, 78.9026sec epoch: 4, loss_train: 0.7384, accuracy_train: 0.7364, loss_valid: 0.8498, accuracy_valid: 0.7058, 78.4496sec epoch: 5, loss_train: 0.6427, accuracy_train: 0.7696, loss_valid: 0.7878, accuracy_valid: 0.7253, 83.4453sec epoch: 6, loss_train: 0.5730, accuracy_train: 0.7942, loss_valid: 0.7378, accuracy_valid: 0.7470, 79.6968sec epoch: 7, loss_train: 0.5221, accuracy_train: 0.8064, loss_valid: 0.7058, accuracy_valid: 0.7530, 79.7377sec epoch: 8, loss_train: 0.4924, accuracy_train: 0.8173, loss_valid: 0.7017, accuracy_valid: 0.7605, 78.2168sec epoch: 9, loss_train: 0.4800, accuracy_train: 0.8234, loss_valid: 0.7014, accuracy_valid: 0.7575, 77.8689sec epoch: 10, loss_train: 0.4706, accuracy_train: 0.8253, loss_valid: 0.6889, accuracy_valid: 0.7650, 79.4202sec# ログの可視化 visualize_logs(log) # 正解率の算出 _, acc_train = calculate_loss_and_accuracy(model, dataset_train) _, acc_test = calculate_loss_and_accuracy(model, dataset_test) print(f'正解率(学習データ):{acc_train:.3f}') print(f'正解率(評価データ):{acc_test:.3f}')
出力正解率(学習データ):0.825 正解率(評価データ):0.77383. ミニバッチ化・GPU上での学習
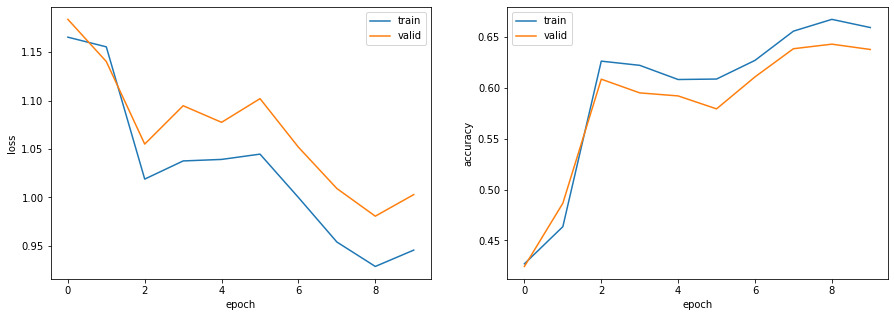
問題82のコードを改変し,$B$事例ごとに損失・勾配を計算して学習を行えるようにせよ($B$の値は適当に選べ).また,GPU上で学習を実行せよ.
現在は文ごとに系列長が異なりますが、ミニバッチとしてまとめるには系列長を揃える必要があります。
そこで、複数の文の最大系列長に合わせてパディングする機能を持つPadsequenceクラスを新たに定義します。これをDataloaderの引数collate_fnに与えることで、ミニバッチを取り出すごとに系列長を揃える処理を実現することができます。class Padsequence(): """Dataloaderからミニバッチを取り出すごとに最大系列長でパディング""" def __init__(self, padding_idx): self.padding_idx = padding_idx def __call__(self, batch): sorted_batch = sorted(batch, key=lambda x: x['inputs'].shape[0], reverse=True) sequences = [x['inputs'] for x in sorted_batch] sequences_padded = torch.nn.utils.rnn.pad_sequence(sequences, batch_first=True, padding_value=self.padding_idx) labels = torch.LongTensor([x['labels'] for x in sorted_batch]) return {'inputs': sequences_padded, 'labels': labels}# パラメータの設定 VOCAB_SIZE = len(set(word2id.values())) + 1 EMB_SIZE = 300 PADDING_IDX = len(set(word2id.values())) OUTPUT_SIZE = 4 HIDDEN_SIZE = 50 LEARNING_RATE = 5e-2 BATCH_SIZE = 32 NUM_EPOCHS = 10 # モデルの定義 model = RNN(VOCAB_SIZE, EMB_SIZE, PADDING_IDX, OUTPUT_SIZE, HIDDEN_SIZE) # 損失関数の定義 criterion = nn.CrossEntropyLoss() # オプティマイザの定義 optimizer = torch.optim.SGD(model.parameters(), lr=LEARNING_RATE) # デバイスの指定 device = torch.device('cuda') # モデルの学習 log = train_model(dataset_train, dataset_valid, BATCH_SIZE, model, criterion, optimizer, NUM_EPOCHS, collate_fn=Padsequence(PADDING_IDX), device=device)出力epoch: 1, loss_train: 1.2605, accuracy_train: 0.3890, loss_valid: 1.2479, accuracy_valid: 0.4162, 12.1096sec epoch: 2, loss_train: 1.2492, accuracy_train: 0.4246, loss_valid: 1.2541, accuracy_valid: 0.4424, 12.0607sec epoch: 3, loss_train: 1.2034, accuracy_train: 0.4795, loss_valid: 1.2220, accuracy_valid: 0.4686, 11.8881sec epoch: 4, loss_train: 1.1325, accuracy_train: 0.5392, loss_valid: 1.1542, accuracy_valid: 0.5210, 12.2269sec epoch: 5, loss_train: 1.0543, accuracy_train: 0.6214, loss_valid: 1.0623, accuracy_valid: 0.6175, 11.8767sec epoch: 6, loss_train: 1.0381, accuracy_train: 0.6316, loss_valid: 1.0556, accuracy_valid: 0.6145, 11.9757sec epoch: 7, loss_train: 1.0546, accuracy_train: 0.6165, loss_valid: 1.0806, accuracy_valid: 0.5913, 12.0352sec epoch: 8, loss_train: 0.9924, accuracy_train: 0.6689, loss_valid: 1.0150, accuracy_valid: 0.6587, 11.9090sec epoch: 9, loss_train: 1.0123, accuracy_train: 0.6517, loss_valid: 1.0482, accuracy_valid: 0.6310, 12.0953sec epoch: 10, loss_train: 1.0036, accuracy_train: 0.6623, loss_valid: 1.0319, accuracy_valid: 0.6504, 11.9331sec# ログの可視化 visualize_logs(log) # 正解率の算出 _, acc_train = calculate_loss_and_accuracy(model, dataset_train, device) _, acc_test = calculate_loss_and_accuracy(model, dataset_test, device) print(f'正解率(学習データ):{acc_train:.3f}') print(f'正解率(評価データ):{acc_test:.3f}')
出力正解率(学習データ):0.662 正解率(評価データ):0.64984. 単語ベクトルの導入
事前学習済みの単語ベクトル(例えば,Google Newsデータセット(約1,000億単語)での学習済み単語ベクトル)で単語埋め込み$emb(x)$を初期化し,学習せよ.
前章と同様に事前学習済み単語ベクトルをダウンロードします。
# 学習済み単語ベクトルのダウンロード FILE_ID = "0B7XkCwpI5KDYNlNUTTlSS21pQmM" FILE_NAME = "GoogleNews-vectors-negative300.bin.gz" !wget --load-cookies /tmp/cookies.txt "https://docs.google.com/uc?export=download&confirm=$(wget --quiet --save-cookies /tmp/cookies.txt --keep-session-cookies --no-check-certificate 'https://docs.google.com/uc?export=download&id=$FILE_ID' -O- | sed -rn 's/.*confirm=([0-9A-Za-z_]+).*/\1\n/p')&id=$FILE_ID" -O $FILE_NAME && rm -rf /tmp/cookies.txt事前学習済み単語ベクトルをモデルに利用する場合、その単語をすべて利用する方法(辞書を置き換える方法)と、手元のデータの辞書はそのまま利用し、それらの単語ベクトルの初期値としてのみ利用する方法があります。
今回は後者の方法を採用し、すでに作成している辞書に対応する単語ベクトルを抽出します。from gensim.models import KeyedVectors # 学習済みモデルのロード model = KeyedVectors.load_word2vec_format('./GoogleNews-vectors-negative300.bin.gz', binary=True) # 学習済み単語ベクトルの取得 VOCAB_SIZE = len(set(word2id.values())) + 1 EMB_SIZE = 300 weights = np.zeros((VOCAB_SIZE, EMB_SIZE)) words_in_pretrained = 0 for i, word in enumerate(word2id.keys()): try: weights[i] = model[word] words_in_pretrained += 1 except KeyError: weights[i] = np.random.normal(scale=0.4, size=(EMB_SIZE,)) weights = torch.from_numpy(weights.astype((np.float32))) print(f'学習済みベクトル利用単語数: {words_in_pretrained} / {VOCAB_SIZE}') print(weights.size())出力学習済みベクトル利用単語数: 9174 / 9406 torch.Size([9406, 300])ネットワークの埋め込み層に初期値を設定できるように変更します。
また、次の問題用に双方向化、多層化のための設定も追加しておきます。class RNN(nn.Module): def __init__(self, vocab_size, emb_size, padding_idx, output_size, hidden_size, num_layers, emb_weights=None, bidirectional=False): super().__init__() self.hidden_size = hidden_size self.num_layers = num_layers self.num_directions = bidirectional + 1 # 単方向:1、双方向:2 if emb_weights != None: # 指定があれば埋め込み層の重みをemb_weightsで初期化 self.emb = nn.Embedding.from_pretrained(emb_weights, padding_idx=padding_idx) else: self.emb = nn.Embedding(vocab_size, emb_size, padding_idx=padding_idx) self.rnn = nn.RNN(emb_size, hidden_size, num_layers, nonlinearity='tanh', bidirectional=bidirectional, batch_first=True) self.fc = nn.Linear(hidden_size * self.num_directions, output_size) def forward(self, x): self.batch_size = x.size()[0] hidden = self.init_hidden() # h0のゼロベクトルを作成 emb = self.emb(x) # emb.size() = (batch_size, seq_len, emb_size) out, hidden = self.rnn(emb, hidden) # out.size() = (batch_size, seq_len, hidden_size * num_directions) out = self.fc(out[:, -1, :]) # out.size() = (batch_size, output_size) return out def init_hidden(self): hidden = torch.zeros(self.num_layers * self.num_directions, self.batch_size, self.hidden_size) return hidden埋め込み層の初期値を指定して学習します。
# パラメータの設定 VOCAB_SIZE = len(set(word2id.values())) + 1 EMB_SIZE = 300 PADDING_IDX = len(set(word2id.values())) OUTPUT_SIZE = 4 HIDDEN_SIZE = 50 NUM_LAYERS = 1 LEARNING_RATE = 5e-2 BATCH_SIZE = 32 NUM_EPOCHS = 10 # モデルの定義 model = RNN(VOCAB_SIZE, EMB_SIZE, PADDING_IDX, OUTPUT_SIZE, HIDDEN_SIZE, NUM_LAYERS, emb_weights=weights) # 損失関数の定義 criterion = nn.CrossEntropyLoss() # オプティマイザの定義 optimizer = torch.optim.SGD(model.parameters(), lr=LEARNING_RATE) # デバイスの指定 device = torch.device('cuda') # モデルの学習 log = train_model(dataset_train, dataset_valid, BATCH_SIZE, model, criterion, optimizer, NUM_EPOCHS, collate_fn=Padsequence(PADDING_IDX), device=device)出力epoch: 1, loss_train: 1.1655, accuracy_train: 0.4270, loss_valid: 1.1839, accuracy_valid: 0.4244, 9.7483sec epoch: 2, loss_train: 1.1555, accuracy_train: 0.4635, loss_valid: 1.1404, accuracy_valid: 0.4865, 9.7553sec epoch: 3, loss_train: 1.0189, accuracy_train: 0.6263, loss_valid: 1.0551, accuracy_valid: 0.6085, 10.0445sec epoch: 4, loss_train: 1.0377, accuracy_train: 0.6221, loss_valid: 1.0947, accuracy_valid: 0.5951, 10.1138sec epoch: 5, loss_train: 1.0392, accuracy_train: 0.6082, loss_valid: 1.0776, accuracy_valid: 0.5921, 9.8540sec epoch: 6, loss_train: 1.0447, accuracy_train: 0.6087, loss_valid: 1.1020, accuracy_valid: 0.5793, 9.8598sec epoch: 7, loss_train: 0.9999, accuracy_train: 0.6270, loss_valid: 1.0519, accuracy_valid: 0.6108, 9.7565sec epoch: 8, loss_train: 0.9539, accuracy_train: 0.6557, loss_valid: 1.0092, accuracy_valid: 0.6385, 9.7457sec epoch: 9, loss_train: 0.9287, accuracy_train: 0.6674, loss_valid: 0.9806, accuracy_valid: 0.6430, 9.6464sec epoch: 10, loss_train: 0.9456, accuracy_train: 0.6593, loss_valid: 1.0029, accuracy_valid: 0.6377, 9.6835sec# ログの可視化 visualize_logs(log) # 正解率の算出 _, acc_train = calculate_loss_and_accuracy(model, dataset_train, device) _, acc_test = calculate_loss_and_accuracy(model, dataset_test, device) print(f'正解率(学習データ):{acc_train:.3f}') print(f'正解率(評価データ):{acc_test:.3f}')
出力正解率(学習データ):0.659 正解率(評価データ):0.64585. 双方向RNN・多層化
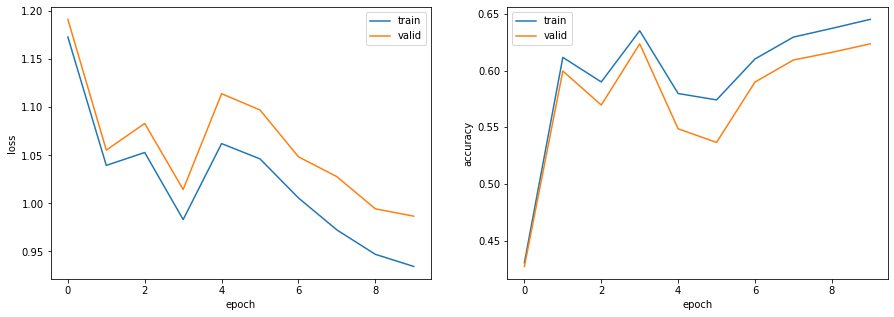
順方向と逆方向のRNNの両方を用いて入力テキストをエンコードし,モデルを学習せよ.
\overleftarrow h_{T+1} = 0, \\ \overleftarrow h_t = {\rm \overleftarrow{RNN}}(\mathrm{emb}(x_t), \overleftarrow h_{t+1}), \\ y = {\rm softmax}(W^{(yh)} [\overrightarrow h_T; \overleftarrow h_1] + b^{(y)})ただし,$\overrightarrow h_t \in \mathbb{R}^{d_h}, \overleftarrow h_t \in \mathbb{R}^{d_h}$はそれぞれ,順方向および逆方向のRNNで求めた時刻$t$の隠れ状態ベクトル,${\rm \overleftarrow{RNN}}(x,h)$は入力$x$と次時刻の隠れ状態$h$から前状態を計算するRNNユニット,$W^{(yh)} \in \mathbb{R}^{L \times 2d_h}$は隠れ状態ベクトルからカテゴリを予測するための行列,$b^{(y)} \in \mathbb{R}^{L}$はバイアス項である.また,$[a; b]$はベクトル$a$と$b$の連結を表す。
さらに,双方向RNNを多層化して実験せよ.
双方向を指定する引数である
bidirectionalをTrueとし、またNUM_LAYERSを2に設定して学習を実行します。# パラメータの設定 VOCAB_SIZE = len(set(word2id.values())) + 1 EMB_SIZE = 300 PADDING_IDX = len(set(word2id.values())) OUTPUT_SIZE = 4 HIDDEN_SIZE = 50 NUM_LAYERS = 2 LEARNING_RATE = 5e-2 BATCH_SIZE = 32 NUM_EPOCHS = 10 # モデルの定義 model = RNN(VOCAB_SIZE, EMB_SIZE, PADDING_IDX, OUTPUT_SIZE, HIDDEN_SIZE, NUM_LAYERS, emb_weights=weights, bidirectional=True) # 損失関数の定義 criterion = nn.CrossEntropyLoss() # オプティマイザの定義 optimizer = torch.optim.SGD(model.parameters(), lr=LEARNING_RATE) # デバイスの指定 device = torch.device('cuda') # モデルの学習 log = train_model(dataset_train, dataset_valid, BATCH_SIZE, model, criterion, optimizer, NUM_EPOCHS, collate_fn=Padsequence(PADDING_IDX), device=device)出力epoch: 1, loss_train: 1.1731, accuracy_train: 0.4307, loss_valid: 1.1915, accuracy_valid: 0.4274, 19.3181sec epoch: 2, loss_train: 1.0395, accuracy_train: 0.6116, loss_valid: 1.0555, accuracy_valid: 0.5996, 18.8118sec epoch: 3, loss_train: 1.0529, accuracy_train: 0.5899, loss_valid: 1.0832, accuracy_valid: 0.5696, 18.9088sec epoch: 4, loss_train: 0.9831, accuracy_train: 0.6351, loss_valid: 1.0144, accuracy_valid: 0.6235, 18.8913sec epoch: 5, loss_train: 1.0622, accuracy_train: 0.5797, loss_valid: 1.1142, accuracy_valid: 0.5487, 19.0636sec epoch: 6, loss_train: 1.0463, accuracy_train: 0.5741, loss_valid: 1.0972, accuracy_valid: 0.5367, 19.0612sec epoch: 7, loss_train: 1.0056, accuracy_train: 0.6102, loss_valid: 1.0485, accuracy_valid: 0.5898, 19.0420sec epoch: 8, loss_train: 0.9724, accuracy_train: 0.6294, loss_valid: 1.0278, accuracy_valid: 0.6093, 19.3077sec epoch: 9, loss_train: 0.9469, accuracy_train: 0.6371, loss_valid: 0.9943, accuracy_valid: 0.6160, 19.2803sec epoch: 10, loss_train: 0.9343, accuracy_train: 0.6451, loss_valid: 0.9867, accuracy_valid: 0.6235, 19.0755sec# ログの可視化 visualize_logs(log) # 正解率の算出 _, acc_train = calculate_loss_and_accuracy(model, dataset_train, device) _, acc_test = calculate_loss_and_accuracy(model, dataset_test, device) print(f'正解率(学習データ):{acc_train:.3f}') print(f'正解率(評価データ):{acc_test:.3f}')
出力正解率(学習データ):0.645 正解率(評価データ):0.63486. 畳み込みニューラルネットワーク (CNN)
ID番号で表現された単語列$\boldsymbol x = (x_1, x_2, \dots, x_T)$がある.ただし,$T$は単語列の長さ,$x_t \in \mathbb{R}^{V}$は単語のID番号のone-hot表記である($V$は単語の総数である).畳み込みニューラルネットワーク(CNN: Convolutional Neural Network)を用い,単語列$\boldsymbol x$からカテゴリ$y$を予測するモデルを実装せよ.
ただし,畳み込みニューラルネットワークの構成は以下の通りとする.
- 単語埋め込みの次元数: $d_w$
- 畳み込みのフィルターのサイズ: 3 トークン
- 畳み込みのストライド: 1 トークン
- 畳み込みのパディング: あり
- 畳み込み演算後の各時刻のベクトルの次元数: $d_h$
- 畳み込み演算後に最大値プーリング(max pooling)を適用し,入力文を$d_h$次元の隠れベクトルで表現 すなわち,時刻$t$の特徴ベクトル$p_t \in \mathbb{R}^{d_h}$は次式で表される.
p_t = g(W^{(px)} [\mathrm{emb}(x_{t-1}); \mathrm{emb}(x_t); \mathrm{emb}(x_{t+1})] + b^{(p)}) $]ただし,$W^{(px)} \in \mathbb{R}^{d_h \times 3d_w}, b^{(p)} \in \mathbb{R}^{d_h}$はCNNのパラメータ,$g$は活性化関数(例えば$\tanh$やReLUなど),$[a; b; c]$はベクトル$a, b, c$の連結である.なお,行列$W^{(px)}$の列数が$3d_w$になるのは,3個のトークンの単語埋め込みを連結したものに対して,線形変換を行うためである.
最大値プーリングでは,特徴ベクトルの次元毎に全時刻における最大値を取り,入力文書の特徴ベクトル$c \in \mathbb{R}^{d_h}$を求める.$c[i]$でベクトル$c$の$i$番目の次元の値を表すことにすると,最大値プーリングは次式で表される.c[i] = \max_{1 \leq t \leq T} p_t[i]最後に,入力文書の特徴ベクトル$c$に行列$W^{(yc)} \in \mathbb{R}^{L \times d_h}$とバイアス項$b^{(y)} \in \mathbb{R}^{L}$による線形変換とソフトマックス関数を適用し,カテゴリ$y$を予測する.
y = {\rm softmax}(W^{(yc)} c + b^{(y)})なお,この問題ではモデルの学習を行わず,ランダムに初期化された重み行列で$y$を計算するだけでよい.
指定のネットワークを実装します。
埋め込み層に続き、nn.Conv2dで畳み込みを計算します。max_poolで系列長方向に最大値を取得しており、この部分で文単位にベクトルが集約されています。from torch.nn import functional as F class CNN(nn.Module): def __init__(self, vocab_size, emb_size, padding_idx, output_size, out_channels, kernel_heights, stride, padding, emb_weights=None): super().__init__() if emb_weights != None: # 指定があれば埋め込み層の重みをemb_weightsで初期化 self.emb = nn.Embedding.from_pretrained(emb_weights, padding_idx=padding_idx) else: self.emb = nn.Embedding(vocab_size, emb_size, padding_idx=padding_idx) self.conv = nn.Conv2d(1, out_channels, (kernel_heights, emb_size), stride, (padding, 0)) self.drop = nn.Dropout(0.3) self.fc = nn.Linear(out_channels, output_size) def forward(self, x): # x.size() = (batch_size, seq_len) emb = self.emb(x).unsqueeze(1) # emb.size() = (batch_size, 1, seq_len, emb_size) conv = self.conv(emb) # conv.size() = (batch_size, out_channels, seq_len, 1) act = F.relu(conv.squeeze(3)) # act.size() = (batch_size, out_channels, seq_len) max_pool = F.max_pool1d(act, act.size()[2]) # max_pool.size() = (batch_size, out_channels, 1) -> seq_len方向に最大値を取得 out = self.fc(self.drop(max_pool.squeeze(2))) # out.size() = (batch_size, output_size) return out# パラメータの設定 VOCAB_SIZE = len(set(word2id.values())) + 1 EMB_SIZE = 300 PADDING_IDX = len(set(word2id.values())) OUTPUT_SIZE = 4 OUT_CHANNELS = 100 KERNEL_HEIGHTS = 3 STRIDE = 1 PADDING = 1 # モデルの定義 model = CNN(VOCAB_SIZE, EMB_SIZE, PADDING_IDX, OUTPUT_SIZE, OUT_CHANNELS, KERNEL_HEIGHTS, STRIDE, PADDING, emb_weights=weights) # 先頭10件の予測値取得 for i in range(10): X = dataset_train[i]['inputs'] print(torch.softmax(model(X.unsqueeze(0)), dim=-1))出力tensor([[0.2607, 0.2267, 0.2121, 0.3006]], grad_fn=<SoftmaxBackward>) tensor([[0.2349, 0.2660, 0.2462, 0.2529]], grad_fn=<SoftmaxBackward>) tensor([[0.2305, 0.2649, 0.2099, 0.2948]], grad_fn=<SoftmaxBackward>) tensor([[0.2569, 0.2409, 0.2418, 0.2604]], grad_fn=<SoftmaxBackward>) tensor([[0.2610, 0.2149, 0.2355, 0.2886]], grad_fn=<SoftmaxBackward>) tensor([[0.2627, 0.2363, 0.2388, 0.2622]], grad_fn=<SoftmaxBackward>) tensor([[0.2694, 0.2434, 0.2224, 0.2648]], grad_fn=<SoftmaxBackward>) tensor([[0.2423, 0.2465, 0.2365, 0.2747]], grad_fn=<SoftmaxBackward>) tensor([[0.2591, 0.2695, 0.2468, 0.2246]], grad_fn=<SoftmaxBackward>) tensor([[0.2794, 0.2465, 0.2234, 0.2507]], grad_fn=<SoftmaxBackward>)87. 確率的勾配降下法によるCNNの学習
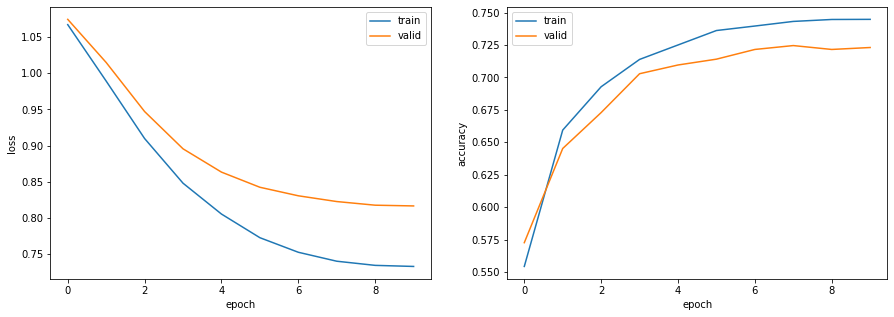
確率的勾配降下法(SGD: Stochastic Gradient Descent)を用いて,問題86で構築したモデルを学習せよ.訓練データ上の損失と正解率,評価データ上の損失と正解率を表示しながらモデルを学習し,適当な基準(例えば10エポックなど)で終了させよ.
# パラメータの設定 VOCAB_SIZE = len(set(word2id.values())) + 1 EMB_SIZE = 300 PADDING_IDX = len(set(word2id.values())) OUTPUT_SIZE = 4 OUT_CHANNELS = 100 KERNEL_HEIGHTS = 3 STRIDE = 1 PADDING = 1 LEARNING_RATE = 5e-2 BATCH_SIZE = 64 NUM_EPOCHS = 10 # モデルの定義 model = CNN(VOCAB_SIZE, EMB_SIZE, PADDING_IDX, OUTPUT_SIZE, OUT_CHANNELS, KERNEL_HEIGHTS, STRIDE, PADDING, emb_weights=weights) # 損失関数の定義 criterion = nn.CrossEntropyLoss() # オプティマイザの定義 optimizer = torch.optim.SGD(model.parameters(), lr=LEARNING_RATE) # デバイスの指定 device = torch.device('cuda') # モデルの学習 log = train_model(dataset_train, dataset_valid, BATCH_SIZE, model, criterion, optimizer, NUM_EPOCHS, collate_fn=Padsequence(PADDING_IDX), device=device)出力epoch: 1, loss_train: 1.0671, accuracy_train: 0.5543, loss_valid: 1.0744, accuracy_valid: 0.5726, 12.9214sec epoch: 2, loss_train: 0.9891, accuracy_train: 0.6594, loss_valid: 1.0148, accuracy_valid: 0.6452, 12.6483sec epoch: 3, loss_train: 0.9098, accuracy_train: 0.6928, loss_valid: 0.9470, accuracy_valid: 0.6729, 12.7305sec epoch: 4, loss_train: 0.8481, accuracy_train: 0.7139, loss_valid: 0.8956, accuracy_valid: 0.7028, 12.7967sec epoch: 5, loss_train: 0.8055, accuracy_train: 0.7250, loss_valid: 0.8634, accuracy_valid: 0.7096, 12.6543sec epoch: 6, loss_train: 0.7728, accuracy_train: 0.7361, loss_valid: 0.8425, accuracy_valid: 0.7141, 12.7423sec epoch: 7, loss_train: 0.7527, accuracy_train: 0.7396, loss_valid: 0.8307, accuracy_valid: 0.7216, 12.6718sec epoch: 8, loss_train: 0.7403, accuracy_train: 0.7432, loss_valid: 0.8227, accuracy_valid: 0.7246, 12.5854sec epoch: 9, loss_train: 0.7346, accuracy_train: 0.7447, loss_valid: 0.8177, accuracy_valid: 0.7216, 12.4846sec epoch: 10, loss_train: 0.7331, accuracy_train: 0.7448, loss_valid: 0.8167, accuracy_valid: 0.7231, 12.7443sec# ログの可視化 visualize_logs(log) # 正解率の算出 _, acc_train = calculate_loss_and_accuracy(model, dataset_train, device) _, acc_test = calculate_loss_and_accuracy(model, dataset_test, device) print(f'正解率(学習データ):{acc_train:.3f}') print(f'正解率(評価データ):{acc_test:.3f}')
出力正解率(学習データ):0.745 正解率(評価データ):0.71988. パラメータチューニング
問題85や問題87のコードを改変し,ニューラルネットワークの形状やハイパーパラメータを調整しながら,高性能なカテゴリ分類器を構築せよ.
今回はConvolutional Neural Networks for Sentence Classificationで提案されたTextCNNをシンプルにしたネットワークを試してみます。
前問までのCNNでは幅が3のフィルターのみを学習していましたが、このネットワークでは2、3、4の3種類の幅のフィルターを利用します。from torch.nn import functional as F class textCNN(nn.Module): def __init__(self, vocab_size, emb_size, padding_idx, output_size, out_channels, conv_params, drop_rate, emb_weights=None): super().__init__() if emb_weights != None: # 指定があれば埋め込み層の重みをemb_weightsで初期化 self.emb = nn.Embedding.from_pretrained(emb_weights, padding_idx=padding_idx) else: self.emb = nn.Embedding(vocab_size, emb_size, padding_idx=padding_idx) self.convs = nn.ModuleList([nn.Conv2d(1, out_channels, (kernel_height, emb_size), padding=(padding, 0)) for kernel_height, padding in conv_params]) self.drop = nn.Dropout(drop_rate) self.fc = nn.Linear(len(conv_params) * out_channels, output_size) def forward(self, x): # x.size() = (batch_size, seq_len) emb = self.emb(x).unsqueeze(1) # emb.size() = (batch_size, 1, seq_len, emb_size) conv = [F.relu(conv(emb)).squeeze(3) for i, conv in enumerate(self.convs)] # conv[i].size() = (batch_size, out_channels, seq_len + padding * 2 - kernel_height + 1) max_pool = [F.max_pool1d(i, i.size(2)) for i in conv] # max_pool[i].size() = (batch_size, out_channels, 1) -> seq_len方向に最大値を取得 max_pool_cat = torch.cat(max_pool, 1) # max_pool_cat.size() = (batch_size, len(conv_params) * out_channels, 1) -> フィルター別の結果を結合 out = self.fc(self.drop(max_pool_cat.squeeze(2))) # out.size() = (batch_size, output_size) return outまた、パラメータのチューニングには第6章と同様にoptunaを使います。
!pip install optunaimport optuna def objective(trial): # チューニング対象パラメータのセット emb_size = int(trial.suggest_discrete_uniform('emb_size', 100, 400, 100)) out_channels = int(trial.suggest_discrete_uniform('out_channels', 50, 200, 50)) drop_rate = trial.suggest_discrete_uniform('drop_rate', 0.0, 0.5, 0.1) learning_rate = trial.suggest_loguniform('learning_rate', 5e-4, 5e-2) momentum = trial.suggest_discrete_uniform('momentum', 0.5, 0.9, 0.1) batch_size = int(trial.suggest_discrete_uniform('batch_size', 16, 128, 16)) # 固定パラメータの設定 VOCAB_SIZE = len(set(word2id.values())) + 1 PADDING_IDX = len(set(word2id.values())) OUTPUT_SIZE = 4 CONV_PARAMS = [[2, 0], [3, 1], [4, 2]] NUM_EPOCHS = 30 # モデルの定義 model = textCNN(VOCAB_SIZE, EMB_SIZE, PADDING_IDX, OUTPUT_SIZE, out_channels, CONV_PARAMS, drop_rate, emb_weights=weights) # 損失関数の定義 criterion = nn.CrossEntropyLoss() # オプティマイザの定義 optimizer = torch.optim.SGD(model.parameters(), lr=learning_rate, momentum=momentum) # デバイスの指定 device = torch.device('cuda') # モデルの学習 log = train_model(dataset_train, dataset_valid, batch_size, model, criterion, optimizer, NUM_EPOCHS, collate_fn=Padsequence(PADDING_IDX), device=device) # 損失の算出 loss_valid, _ = calculate_loss_and_accuracy(model, dataset_valid, device, criterion=criterion) return loss_validパラメータ探索を実行します。
# 最適化 study = optuna.create_study() study.optimize(objective, timeout=7200) # 結果の表示 print('Best trial:') trial = study.best_trial print(' Value: {:.3f}'.format(trial.value)) print(' Params: ') for key, value in trial.params.items(): print(' {}: {}'.format(key, value))出力Best trial: Value: 0.469 Params: emb_size: 300.0 out_channels: 100.0 drop_rate: 0.4 learning_rate: 0.013345934577557608 momentum: 0.8 batch_size: 32.0探索したパラメータでモデルを学習します。
# パラメータの設定 VOCAB_SIZE = len(set(word2id.values())) + 1 EMB_SIZE = int(trial.params['emb_size']) PADDING_IDX = len(set(word2id.values())) OUTPUT_SIZE = 4 OUT_CHANNELS = int(trial.params['out_channels']) CONV_PARAMS = [[2, 0], [3, 1], [4, 2]] DROP_RATE = trial.params['drop_rate'] LEARNING_RATE = trial.params['learning_rate'] BATCH_SIZE = int(trial.params['batch_size']) NUM_EPOCHS = 30 # モデルの定義 model = textCNN(VOCAB_SIZE, EMB_SIZE, PADDING_IDX, OUTPUT_SIZE, OUT_CHANNELS, CONV_PARAMS, DROP_RATE, emb_weights=weights) print(model) # 損失関数の定義 criterion = nn.CrossEntropyLoss() # オプティマイザの定義 optimizer = torch.optim.SGD(model.parameters(), lr=LEARNING_RATE, momentum=0.9) # デバイスの指定 device = torch.device('cuda') # モデルの学習 log = train_model(dataset_train, dataset_valid, BATCH_SIZE, model, criterion, optimizer, NUM_EPOCHS, collate_fn=Padsequence(PADDING_IDX), device=device)出力textCNN( (emb): Embedding(9406, 300, padding_idx=9405) (convs): ModuleList( (0): Conv2d(1, 100, kernel_size=(2, 300), stride=(1, 1)) (1): Conv2d(1, 100, kernel_size=(3, 300), stride=(1, 1), padding=(1, 0)) (2): Conv2d(1, 100, kernel_size=(4, 300), stride=(1, 1), padding=(2, 0)) ) (drop): Dropout(p=0.4, inplace=False) (fc): Linear(in_features=300, out_features=4, bias=True) ) epoch: 1, loss_train: 0.7908, accuracy_train: 0.7239, loss_valid: 0.8660, accuracy_valid: 0.6901, 12.2279sec epoch: 2, loss_train: 0.5800, accuracy_train: 0.7944, loss_valid: 0.7384, accuracy_valid: 0.7485, 12.1637sec epoch: 3, loss_train: 0.3951, accuracy_train: 0.8738, loss_valid: 0.6189, accuracy_valid: 0.7919, 12.1612sec epoch: 4, loss_train: 0.2713, accuracy_train: 0.9217, loss_valid: 0.5499, accuracy_valid: 0.8136, 12.1877sec epoch: 5, loss_train: 0.1913, accuracy_train: 0.9593, loss_valid: 0.5176, accuracy_valid: 0.8293, 12.1722sec epoch: 6, loss_train: 0.1322, accuracy_train: 0.9749, loss_valid: 0.5042, accuracy_valid: 0.8234, 12.4483sec epoch: 7, loss_train: 0.1033, accuracy_train: 0.9807, loss_valid: 0.4922, accuracy_valid: 0.8323, 12.1556sec epoch: 8, loss_train: 0.0723, accuracy_train: 0.9943, loss_valid: 0.4900, accuracy_valid: 0.8308, 12.0309sec epoch: 9, loss_train: 0.0537, accuracy_train: 0.9966, loss_valid: 0.4903, accuracy_valid: 0.8346, 11.9471sec epoch: 10, loss_train: 0.0414, accuracy_train: 0.9966, loss_valid: 0.4801, accuracy_valid: 0.8421, 11.9275sec epoch: 11, loss_train: 0.0366, accuracy_train: 0.9978, loss_valid: 0.4943, accuracy_valid: 0.8406, 11.9691sec epoch: 12, loss_train: 0.0292, accuracy_train: 0.9983, loss_valid: 0.4839, accuracy_valid: 0.8436, 11.9665sec epoch: 13, loss_train: 0.0271, accuracy_train: 0.9982, loss_valid: 0.5042, accuracy_valid: 0.8421, 11.9634sec epoch: 14, loss_train: 0.0222, accuracy_train: 0.9986, loss_valid: 0.4912, accuracy_valid: 0.8458, 11.9298sec epoch: 15, loss_train: 0.0194, accuracy_train: 0.9988, loss_valid: 0.4925, accuracy_valid: 0.8436, 11.9375sec epoch: 16, loss_train: 0.0176, accuracy_train: 0.9988, loss_valid: 0.5074, accuracy_valid: 0.8451, 11.9333sec epoch: 17, loss_train: 0.0163, accuracy_train: 0.9991, loss_valid: 0.5124, accuracy_valid: 0.8436, 11.9137sec# ログの可視化 visualize_logs(log) # 正解率の算出 _, acc_train = calculate_loss_and_accuracy(model, dataset_train, device) _, acc_test = calculate_loss_and_accuracy(model, dataset_test, device) print(f'正解率(学習データ):{acc_train:.3f}') print(f'正解率(評価データ):{acc_test:.3f}')
出力正解率(学習データ):0.999 正解率(評価データ):0.85189. 事前学習済み言語モデルからの転移学習
事前学習済み言語モデル(例えばBERTなど)を出発点として,ニュース記事見出しをカテゴリに分類するモデルを構築せよ.
【PyTorch】BERTを用いた文書分類入門として別の記事に切り出しています。
ここでは、正解率の結果のみ転記します。正解率(学習データ):0.993 正解率(評価データ):0.948おわりに
言語処理100本ノックは自然言語処理そのものだけでなく、基本的なデータ処理や汎用的な機械学習についてもしっかり学ぶことができるように作られています。
オンラインコースなどで機械学習を勉強中の方も、とても良いアウトプットの練習になると思いますので、ぜひ挑戦してみてください。

- 投稿日:2020-09-15T18:39:39+09:00
Tensorflow-gpuを使う際にはまったこと
tensorflowを用いて機械学習をしようとした際にはまったことがあったので記述していく
環境
環境 version OS Windows tensorflow 2.3.0 CUDA 11.0 問題
import tensorflow as tf mnist = tf.keras.datasets.mnist (x_train, y_train),(x_test, y_test) = mnist.load_data() x_train, x_test = x_train / 255.0, x_test / 255.0 model = tf.keras.models.Sequential([ tf.keras.layers.Flatten(input_shape=(28, 28)), tf.keras.layers.Dense(512, activation=tf.nn.relu), tf.keras.layers.Dropout(0.2), tf.keras.layers.Dense(10, activation=tf.nn.softmax) ]) model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['accuracy']) model.fit(x_train, y_train, epochs=5) model.evaluate(x_test, y_test)上のようなコードを実行しようとした際に
F .\tensorflow/core/kernels/random_op_gpu.h:232] Non-OK-status: GpuLaunchKernel(FillPhiloxRandomKernelLaunch<Distribution>, num_blocks, block_size, 0, d.stream(), gen, data, size, dist) status: Internal: invalid configuration argumentというエラーが発生し実行ができなくなった。
このエラーは
import os os.environ["CUDA_VISIBLE_DEVICES"] = "-1"としてGPUを使わない設定にすることで回避できた。
CUDAが原因かと思いダウンロードしなおしてみたりパスの設定を見直してみたが結果は変わらなかった・・・解決策
pip install tf-nightly-gpuとすることで解決できた。
どうやらtf-nightly-gpuってなんだと思ったがtensorflowの最新版で2.3.0よりも新しいもののようだった。pip listで調べてみると
tf-estimator-nightly 2.4.0.dev2020091501 tf-nightly-gpu 2.4.0.dev20200912となっており開発段階のものらしかった。
どうしてこれでエラーを解決できたのかはわからなかった...
参考
https://itips.krsw.biz/tensorflow-keras-gpu-deactivate/
https://github.com/tensorflow/tensorflow/issues/30665
- 投稿日:2020-09-15T18:04:47+09:00
[Python]サブクラスのメソッドに特定の処理を強制する方法
サブクラスに特定の処理を強制したい
Pythonでとあるクラスを継承したサブクラスを設計するとき、継承先には必ずこんな処理をして欲しい...なんてことがあります。
例えば
__init__が呼ばれた時に必ずsuper().init()を呼んで欲しい...などの場合です。
__init__に限らず「親クラスのメソッドをオーバーライドしたいけど、親クラスのメソッドもそのまま呼び出したい!」なんて処理はよくよく現れるものですが、親クラスのメソッドを呼び出す処理を書き忘れてしまってエラーを吐かせるのはいやですし、そもそも親クラスのメソッドを呼び出す仕様そのものが面倒くさかったりしますね。今回は子クラスのメソッド
fが呼ばれるとき、その処理の後で必ず親クラスのメソッドfが呼ばれるような実装を実現してみます。やり方
「子クラスの関数f」を「子クラスの関数fと親クラスの関数fを実行する関数new_f」に書き換える
ってことをやってくれるメタクラスをかくメタクラスってなんや?って話はまた今度違うところでします。とりあえずはクラスの定義のされ方をいじるクラスだと思っておいてください。
よくわからない人でも下記コードをコピーペーストして
decorateメソッドを書き換えるだけでなんでもできると信じています。前提
Python: 3.7.2 (Python3なら多分OK、Python2でもmetaclassの指定方法が違うだけなはず)
コード
class ParentCaller(type): def __new__(cls, name, base, attr): # ParentクラスのfがParentクラスのfを呼ぶのを防ぐ if name != "Parent": # クラス生成時、関数fは自動的にデコレートされる仕様にする attr["f"] = cls.decorate(attr["f"]) return super().__new__(cls, name, base, attr) @classmethod def decorate(cls, f): # 関数fを受け取ると、fとParent.fをセットで実行するnew_fを返す def new_f(self, x): f(self, x) Parent.f(self, x) return new_f class Parent(metaclass=ParentCaller): def f(self, x): print(f"parent's f says: {x}") class Child(Parent): def f(self, x): print(f"child's f says: {x}") child = Child() child.f("Hello World!") # child's f says: Hello World! # parent's f says: Hello World!まとめ
Tensorflowのように人に継承して使ってもらうライブラリを書くときにはなるべく「ここでhogehogeを実行してね!」っていうお約束を避けたいものです。そんな時はメタクラスを書いて相手の知らないところで勝手にhogehogeを呼び出してしまいましょう。
集団での開発ではメタプログラミングって読みにくくて嫌われちゃうらしいですけどね...。個人で開発する分には工数を最小にしてくれるエッセンスなのではないかと思っています。
- 投稿日:2020-09-15T18:04:00+09:00
テストの数理 その1
テストの数理として有名な項目反応理論について、理論的に追うのと、パラメータ推定をある程度スクラッチでかけるようにします。
複数の記事にする予定ですが、今回はその1として「問題設定とデータの生成について」です。
問題設定
たとえば、TOEICやセンター試験などのテストを考えます。複数人の受験者が複数問の問題を解き、次のような結果が得られたとします。
受験者 1 受験者 2 受験者 3 受験者 4 受験者 5 受験者 6 受験者 7 正答数 問 1 正 正 正 正 正 誤 正 6 問 2 誤 誤 誤 正 誤 誤 誤 1 問 3 正 正 正 正 正 正 誤 6 問 4 誤 誤 誤 正 誤 正 正 3 問 5 誤 誤 誤 正 誤 誤 正 2 問 6 正 正 正 正 誤 正 正 6 問 7 正 誤 正 正 正 正 正 6 問 8 誤 正 誤 誤 正 誤 正 3 問 9 正 正 誤 正 正 正 正 6 問 10 正 正 正 誤 誤 正 正 5 素点 6 6 5 8 5 6 8 表の見方は、受験者と問題の交点がその受験者のその問題における正誤です。たとえば、「受験者1は問3に正答」しており、「受験者6は問5に誤答」しています。正答数 は、その問の受験者全体での正答数であり、行毎の正の数。素点は正答を等しく1点としたときの合計点数で、列ごとの正の数です。
さてこの状況で、受験者の能力と問題の難易度を推定したいとします。受験者の能力の方は、受験などで順位をつけ合否を出すのに使えるでしょうし、問題の難易度のほうは、問題を使いまわしたいときにテスト全体の難易度を調整するのに使えそうです。
どう考えるか
受験者の能力は、素点をそのまま使えば良いでしょうか?そうしてしまうと、難しい問題と易しい問題の得点が同じになってしまいます。難しい問題が解けるのに、易しい問題をたまたまミスしてしまったという状況に対応できません。
それでは、正答数の逆数を得点としてみるのはどうでしょうか?良さそうな気もしますが、この点数の差というのは果たして正当性がどの程度あるのでしょうか?例えば上の表の状況だと、問2の点数は問1の点数の6倍になりますがそれは良いのでしょうか?
項目反応理論
この受験者の能力と問題の難易度を推定するというのを目的として発展してきた理論が項目反応理論 (Item Response Theory, IRT)です。IRTはテストの作成、実施、評価に非常に有用な数理モデルであり、実際にTOEFL(留学用の英語の試験)やITパスポート試験1などに使われているようです。
データ
以降の記事で項目反応理論について、理論的背景も含めて自分である程度実装できるように述べるつもりではいますが、まずは実データやデータを生成するところをここでは紹介します。実際のデータや生成したデータを使って、どの程度この理論が使えるのか試してみると良いのではないでしょうか?
実データ
実データは、たとえばKDDCUP2にあるようです。こちらのデータは、単純に受験者と正誤のデータとなっていないので、処理をする必要があります。それについては、このデータが紹介されている記事pyirtを用いた能力値推定にあるようです。
生成データ
少しIRTの知識を使ってしまいますが、例えば次のようにすれば、データを得ることができます。
なお、環境は、
- python 3.8
- numpy 1.19.2
です。
import numpy as np from functools import partial # 3 parameter logistic model の定義 def L3P(a, b, c, x): return c + (1 - c) / (1 + np.exp(- a * (x - b))) # model parameterの定義 # aは正の実数, bは実数, cは0より大きく1未満であれば良い a_min = 0.3 a_max = 1 b_min = -2 b_max = 2 c_min = 0 c_max = .4 # 何問、何人にするか、下なら10問7人 num_items = 10 num_users = 7 # 問題parameterの生成 item_params = np.array( [np.random.uniform(a_min, a_max, num_items), np.random.uniform(b_min, b_max, num_items), np.random.uniform(c_min, c_max, num_items)] ).T # 受験者parameterの生成 user_params = np.random.normal(size=num_users) # 項目反応行列の作成、 要素は1(正答)か0(誤答) # i行j列は問iに受験者jがどう反応したか ir_matrix_ij = np.vectorize(int)( np.array( [partial(L3P, *ip)(user_params) > np.random.uniform(0, 1, num_users) for ip in item_params] ) )これで生成すれば、上で書いた表のような1, 0の行列が得られるはずです。$i$行$j$列は問$i$に受験者$j$がどう反応したかを表します。0は誤答1は正答です。以降の記事でも書きますが、ここでは添字$i$は問題を表すのに、添字$j$は受験者を表すのに使うこととします。
なお、素点は
raw_score_j = ir_matrix_ij.sum(axis=0)正答数は
num_correct_i = ir_matrix_ij.sum(axis=1)で得られます。
次回
項目反応理論でよく用いられる1, 2, 3 parameter logistic modelについて紹介します。
テストの数理 その2参考文献
- Qiita記事 pyirtを用いた能力値推定
- 書籍 項目反応理論 (シリーズ〈行動計量の科学〉)(amazon.co.jp)
- 書籍 項目反応理論・理論編―テストの数理 (統計ライブラリー)(amazon.co.jp)
https://www3.jitec.ipa.go.jp/JitesCbt/html/about/range.html ↩
pyirtを用いた能力値推定で紹介されています。こちらでは、pythonのパッケージであるpyirtで推定しているようです。pyirtも良いツールですが推定できるのが2PLのみと少し自由度に欠くところがあります。 ↩
- 投稿日:2020-09-15T18:04:00+09:00
試験の数理 その1(問題設定とデータの生成)
試験の数理として有名な項目反応理論について、理論的に追うのと、パラメータ推定をある程度スクラッチでかけるようにします。
複数の記事にする予定ですが、今回はその1として「問題設定とデータの生成について」です。
問題設定
たとえば、TOEICやセンター試験などの試験を考えます。複数人の受験者が複数問の問題を解き、次のような結果が得られたとします。
受験者 1 受験者 2 受験者 3 受験者 4 受験者 5 受験者 6 受験者 7 正答数 問 1 正 正 正 正 正 誤 正 6 問 2 誤 誤 誤 正 誤 誤 誤 1 問 3 正 正 正 正 正 正 誤 6 問 4 誤 誤 誤 正 誤 正 正 3 問 5 誤 誤 誤 正 誤 誤 正 2 問 6 正 正 正 正 誤 正 正 6 問 7 正 誤 正 正 正 正 正 6 問 8 誤 正 誤 誤 正 誤 正 3 問 9 正 正 誤 正 正 正 正 6 問 10 正 正 正 誤 誤 正 正 5 素点 6 6 5 8 5 6 8 表の見方は、受験者と問題の交点がその受験者のその問題における正誤です。たとえば、「受験者1は問3に正答」しており、「受験者6は問5に誤答」しています。正答数 は、その問の受験者全体での正答数であり、行毎の正の数。素点は正答を等しく1点としたときの合計点数で、列ごとの正の数です。
さてこの状況で、受験者の能力と問題の難易度を推定したいとします。受験者の能力の方は、受験などで順位をつけ合否を出すのに使えるでしょうし、問題の難易度のほうは、問題を使いまわしたいときに試験全体の難易度を調整するのに使えそうです。
どう考えるか
受験者の能力は、素点をそのまま使えば良いでしょうか?そうしてしまうと、難しい問題と易しい問題の得点が同じになってしまいます。難しい問題が解けるのに、易しい問題をたまたまミスしてしまったという状況に対応できません。
それでは、正答数の逆数を得点としてみるのはどうでしょうか?良さそうな気もしますが、この点数の差というのは果たして正当性がどの程度あるのでしょうか?例えば上の表の状況だと、問2の点数は問1の点数の6倍になりますがそれは良いのでしょうか?
項目反応理論
この受験者の能力と問題の難易度を推定するというのを目的として発展してきた理論が項目反応理論 (Item Response Theory, IRT)です。IRTは試験の作成、実施、評価に非常に有用な数理モデルであり、実際にTOEFL(留学用の英語の試験)やITパスポート試験1などに使われているようです。
データ
以降の記事で項目反応理論について、理論的背景も含めて自分である程度実装できるように述べるつもりではいますが、まずは実データやデータを生成するところをここでは紹介します。実際のデータや生成したデータを使って、どの程度この理論が使えるのか試してみると良いのではないでしょうか?
実データ
実データは、たとえばKDDCUP2にあるようです。こちらのデータは、単純に受験者と正誤のデータとなっていないので、処理をする必要があります。それについては、このデータが紹介されている記事pyirtを用いた能力値推定にあるようです。
生成データ
少しIRTの知識を使ってしまいますが、例えば次のようにすれば、データを得ることができます。
なお、環境は、
- python 3.8
- numpy 1.19.2
です。
import numpy as np from functools import partial # 3 parameter logistic model の定義 def L3P(a, b, c, x): return c + (1 - c) / (1 + np.exp(- a * (x - b))) # model parameterの定義 # aは正の実数, bは実数, cは0より大きく1未満であれば良い a_min = 0.3 a_max = 1 b_min = -2 b_max = 2 c_min = 0 c_max = .4 # 何問、何人にするか、下なら10問7人 num_items = 10 num_users = 7 # 問題parameterの生成 item_params = np.array( [np.random.uniform(a_min, a_max, num_items), np.random.uniform(b_min, b_max, num_items), np.random.uniform(c_min, c_max, num_items)] ).T # 受験者parameterの生成 user_params = np.random.normal(size=num_users) # 項目反応行列の作成、 要素は1(正答)か0(誤答) # i行j列は問iに受験者jがどう反応したか ir_matrix_ij = np.vectorize(int)( np.array( [partial(L3P, *ip)(user_params) > np.random.uniform(0, 1, num_users) for ip in item_params] ) )これで生成すれば、上で書いた表のような1, 0の行列が得られるはずです。$i$行$j$列は問$i$に受験者$j$がどう反応したかを表します。0は誤答1は正答です。以降の記事でも書きますが、ここでは添字$i$は問題を表すのに、添字$j$は受験者を表すのに使うこととします。
なお、素点は
raw_score_j = ir_matrix_ij.sum(axis=0)正答数は
num_correct_i = ir_matrix_ij.sum(axis=1)で得られます。
次回
項目反応理論でよく用いられる1, 2, 3 parameter logistic modelについて紹介します。
試験の数理 その2(項目反応理論の数理モデル)参考文献
- Qiita記事 pyirtを用いた能力値推定
- 書籍 項目反応理論 (シリーズ〈行動計量の科学〉)(amazon.co.jp)
- 書籍 項目反応理論・理論編―テストの数理 (統計ライブラリー)(amazon.co.jp)
https://www3.jitec.ipa.go.jp/JitesCbt/html/about/range.html ↩
pyirtを用いた能力値推定で紹介されています。こちらでは、pythonのパッケージであるpyirtで推定しているようです。pyirtも良いツールですが推定できるのが2PLのみと少し自由度に欠くところがあります。 ↩
- 投稿日:2020-09-15T18:03:38+09:00
super()についてハッキリさせる
概要
pythonのクラス継承を行うsuper()、スーパークラスについて出てくるたびに調べ直していたので、使用方法をハッキリさせようと思う
用途
super()とは親クラスを継承する用途で使用する
class Parent(): def __init__(self, plus): self.min = 20 self.plus = plus def plus(self): age = self.min + self.plus return age class Child(Parent): def __init__(self): self.plus = 8この状態で
().plus()をしてもclass Parentの__init__が上書きされてしまう(self.minが無くなる)ため、エラーとなってしまう従って、下記のようにすると親クラスのの
__init__を継承するワケだclass Parent(): def __init__(self, plus): self.min = 20 self.plus = plus def plus(self): age = self.min + self.plus return age class Child(Parent): def __init__(self): super().__init__(plus) self.plus = 8
self.minの値は継承され、28という値を出力できる
super()の後は__init__か?
super()の後は__init__でなくてはいけないワケではなく、親クラスのメソッドであれば良いclass Parent(): def message(self, text): print('your name is: {}'.format(text)) class Child(Parent): def message(self): print('your friend is: {}'.format(text)) super().message(text)文法
super()内の引数についてpython2系と3系で異なる
python2系
super(親クラス名, self).親クラスのメソッドpython3系
super().親クラスのメソッド上記が標準のようだ
__init__()内の引数について先ほどの例にコメントで記載した
class Parent(): def __init__(self, plus): self.min = 20 self.plus = plus def plus(self): age = self.min + self.plus return age class Child(Parent): # selfとsuper()のinit()内で使われている引数を記載、引数の追加も可能 def __init__(self, plus): # init()内はselfは省略して良い、デフォルト変数も省略可*、親クラスのinitと引数の数を揃える super().__init__(plus) self.plus = 8※今回はデフォルト変数は使用していない
つまり、子クラスに関して
def __init__(引数)の引数は
- selfを記載
- super()のinit()内で使われている引数を記載
- 引数の追加も可能
super().__init__(引数)の引数は
- selfは書かない
- 親クラスのinitと引数の数を揃える
- デフォルト変数は省略可能である
以上
- 投稿日:2020-09-15T18:02:16+09:00
tkinterで画像が表示できない時の解決【python】
tkinterで画像を表示させようとしたら
"~.png"は認識できませんでした。
となったので備忘録
環境
Python 3.7.9
Tvl/Tk 8.6
Pillow==7.2.0tkinterのバージョン確認
import tkinter tkinter._test()本題
問題のコード
import tkinter root = tkinter.Tk() #前部省略 canvas = tkinter.Canvas(root, width=800, height=600) canvas.pack() img = tkinter.PhotoImage(file="my_picture.png") canvas.create_image(400, 300, image=img) #後部省略どうやらtkinterのPhotoImageはかなり限定的な拡張子しか触れない様子。
pillowを使って解決
解決コード
import tkinter from PIL import ImageTk, Image root = tkinter.Tk() #前部省略 canvas = tkinter.Canvas(root, width=400, height=600, bg="skyblue") canvas.pack() image = Image.open("my_picture.png") photo = ImageTk.PhotoImage(image, master=root) canvas.create_image(200, 300, image=photo) #後部省略以上
- 投稿日:2020-09-15T17:58:37+09:00
ディクショナリ型2
ディクショナリ型2
get()
引数にキーを指定し、キーが存在する場合は対応する値が返り、キーが存在しない場合はNoneが返ります。
hatamoto = {'kokugo': 65, 'suugaku': 82}print(hatamoto.get('kokugo'))
実行結果
65
print(hatamot.get(‘rika’))
実行結果
None
setdefault()
第一引数に「キー」、「第二引数に値」を指定する。
第一引数に指定した「キー」が対象のディクショナリに存在していない場合は、新たな要素が追加される。hatamoto = {'kokugo': 65, 'suugaku': 82}
hatamoto.setdefault('eigo', 70)
print(hatamoto)
{'kokugo': 65, 'suugaku': 82,'eigo':70}setdefault()で値を省略すると値がNoneの要素が追加される。
hatamoto = {'kokugo': 65, 'suugaku': 82}
hatamoto.setdefault('eigo')
print(hatamoto)
{'kokugo': 65, 'suugaku': 82, 'eigo': None}キーがすでに存在している場合は、値を指定しても元のオブジェクトのまま変更されず、エラーは発生しない
hatamoto = {'kokugo': 65, 'suugaku': 82}
hatamoto.setdefault(kokugo': 62)
print(hatamoto)
hatamoto = {'kokugo': 65, 'suugaku': 82}items()
items()メソッドはdict_itemsクラスを返します。hatamoto = {'kokugo': 65, 'suugaku': 82}
items = hatamot.items()
print(items)dict_items([(kokugo': 65), (suugaku': 82)])
- 投稿日:2020-09-15T17:56:32+09:00
Pythonでゼロから始める業務効率化
ボウリングのレーン配当表作成が、面倒くさい。よし、PCにやらせよう。
情報系に疎いプログラミング未経験者がツール実装に初挑戦してみました。初心者でもできる業務効率化の一例として、参考になればと思います。
はじめに
競技ボウリングの大会では、プレイヤーをレーンに配当するための表が必要となります。
この配当表には、「一人のプレイヤーが2度以上同じボックスに配当されない」ことと、「任意の2人が、同じタイミングで同一ボックスに2度以上配当されない(要するに『またお前と同じボックスかよ』が発生しない)」ことが要求されます。ボウリング界隈以外の人はよく分からないと思うので、読み飛ばしてもらって構いません。
とにかく、これを手作業で作成+眼力でチェックするのは結構しんどい(人間がやると1時間以上かかる)ので、ツールを用いて自動化してみましょう。
ページの最後に完成品を置いたので、良ければどうぞ(需要、あるのか?)。0.配当表完成までの大まかな流れ
①プレイヤーに乱数でレーンを割り振る
②条件を満たさない箇所を見つけ出す
③問題箇所に限ってシャッフルをかける
④問題箇所が0になるまで②③を繰り返す
⑤必要な情報を出力する1. Excelでやってみよう!
ひとまずExcelで乱数を使って手作業でレーン配当表を作り、問題箇所の検出のみを自動化しました。Excelの関数さえよく分からない状況からの出発なので、いろいろとググりながらチェック機構を実装しました。Excel関連の情報はネットに山ほど転がっているのでありがたい。
問題点
・各大会ごとにプレイヤー数や使用ボックス数が異なるので、チェック機構を毎回手作業で組む必要がある(面倒くさい)。
・Excelと組み合わせ列挙の相性がめちゃめちゃ悪い。2. Python編
面倒なので、さらに自動化を進めたくなってきました。よし、プログラミングでやってみよう。でもプログラミング言語何も使えないじゃん。ということでPython3を学びます1。Pythonは視覚的にもめちゃくちゃわかりやすいので、初めての言語としてオススメです。ExcelVBA(いわゆる「マクロ」)も検討しましたが、扱いにくい&汎用性が低そうなのでやめました。
実装はひたすらやるだけなのですが、結構大変でした(AtCoderで言ったら、Diff800程度くらいの実装をひたすら繋げていく感じ)。最終的には400行くらいになりました。コーナーケース潰しの大変さも実感しました。
問題点
・Python上で文字列として入出力するので、Excelファイルとの間でコピペする必要があり、少々使いにくい3. openpyxl編
ここからは、入出力方式の改善を目指しました。
今回は、Python上でExcelファイルを扱えるopenpyxlモジュールを使いました。モジュールとは、道具箱みたいなもので、これをインポートすることによりPython上で出来ることが拡張されます。Pythonは特にモジュールが充実しているので、めちゃめちゃありがたい。このモジュールを用いることで、入出力をExcel上で行えるようになりました。openpyxlは特に有用なので、今後も積極的に使っていきたい。
問題点
・Pythonをインストールしていない人にはこのツールが共有できない4. tkinter編
さらに発展させて、枠に文字を入力することで動作し、レーン配当表をExcelファイルとして出力してくれるようなGUIアプリケーションにすることを目指しました。実際には、Pythonのtkinterモジュール(tinderじゃないよ)を使いました。前提知識0なのでひたすらググり続ける感じでしたが、学びも多かった。
書き上げたPythonのソースコードをpyinstallerを用いてexeファイル化することにより、GUIアプリケーションとして完成しました。これでPythonを使えない人でもツールを使えるようになりました。
↑こんな感じで入力すると…
↑こんな感じでExcelファイルとして出力される。名前リストは2019年のPBA賞金ランキングから取ってきました。夢のような大会ですね。
完成品
完成したアプリケーションはこちら(Dropbox)よりダウンロード可能です。
ぜひ遊んでみてください。
※Windows用とMac用で分かれているので、正しい方のフォルダをダウンロードしてください。最後に
最後まで読んでいただきありがとうございました。実はこのツールをWEBアプリケーション化することも考えたのですが、htmlの知識もゼロなのでひとまず断念しました。htmlに挑戦したらまた報告します。
番外編
このツールの実装と並行して、プログラミングコンテストのAtcoderも始めました。競技プログラミングは役に立たん!みたいな話も聞きますが、リスト等の基本的な扱いに慣れるのには有用で、少なくとも緑色前半くらいまでの内容は非情報系の人々の実生活にも役立つような気がします。
やさしいPython(高橋麻奈,SBクリエイティブ社), この本は名前に反して分かりやすかった、オススメです。 ↩
- 投稿日:2020-09-15T17:44:56+09:00
外部プログラムを直接実行した場合にシェルスクリプトにフォールバックする言語・しない言語
※本記事の内容はWindowsには一切当てはまりません。
https://linuxjm.osdn.jp/html/LDP_man-pages/man3/exec.3.html 等によると、execvpでのみ、ENOEXECが発生したらシェルスクリプトと解釈する機能があるそうです。
スクリプト言語でシェルを使わず外部プログラムを実行した場合、この機能は働くのでしょうか?準備
$ cat lsscript ls実行
Ruby
- 直接実行(例): popenの引数が配列、systemの引数が2要素以上
ruby -e 'p IO.popen(["./lsscript"]).read'process.c proc_exec_cmd
execveを試し、ENOEXECなら/bin/shを付加して再試行Python
- 直接実行(例): check_call(等)の引数が配列
python -c 'import subprocess;subprocess.check_call(["./lsscript"])'Modules/_posixsubprocess.c child_exec
execveを試す。 ENOEXECの場合失敗するPython3も同様。
なおshell=Trueとすると失敗しなくなりますがpipes.quoteやらshlex.quoteやらが必要となります。
(この記事の読者であればこちらの必要性はわかりますよね)Perl
- 直接実行(例): system()の引数が2要素以上
perl -e 'print system("./lsscript","dummy")'doio.c Perl_do_aexec5
execvpを試す。PHP
- 直接実行: pcntl_exec
php -r 'pcntl_exec("./lsscript");'ext/pcntl/pcntl.c pcntl_exec
execveを試す。 ENOEXECの場合失敗する(上はexecですからサブプロセスとするにはfork呼び出し等が必要。その辺が必要ない標準実行系はext/standard/exec.cにありますが、popen固定のようです(つまり必ずシェルが入る))
結論
Python/PHPでシェルを介さずに実行しようとすると、自動でshを付けてくれません。C言語のshebangもどき等を投げる際はご注意ください。
- 投稿日:2020-09-15T17:44:39+09:00
地方国公立情報系大学生がKaggleに挑む(備忘録)
スタート時のスキル
AI Academy https://aiacademy.jp/sign_in/
というサイトで2ヶ月間の学習を行い、Kaggleのタイタニックの問題に取り組む今後の学習計画
[Kaggleで勝つデータ分析の技術]https://www.amazon.co.jp/dp/B07YTDBC3Z/ref=dp-kindle-redirect?_encoding=UTF8&btkr=1
[Kaggleに登録したら次にやること ~ これだけやれば十分闘える!Titanicの先へ行く入門 10 Kernel ~]
https://qiita.com/upura/items/3c10ff6fed4e7c3d70f0
を参照し学習を行う。
最初に参加するコンペ
[OpenVaccine: COVID-19 mRNA Vaccine Degradation Prediction]https://www.kaggle.com/c/stanford-covid-vaccine
というコロナウイルスのワクチンに関するコンペへの参加を考えるも、ウイルスや遺伝子に関する知識が一切なく有効な特徴量が作れるとは思ずスルー
[Predict Future Sales]https://www.kaggle.com/c/competitive-data-science-predict-future-sales
に参加
- 投稿日:2020-09-15T16:56:06+09:00
Google ColabでOxford_iiit_petを使用した画像セグメン
tensorflowを使って画像のセグメンテーションを勉強中のかわたくです。
今回はoxfordのデータセットを使ってみました。
実行環境
macos
Google Colab詰まったところ
vscodeで一旦コードは書き終えたのですが、やはりGPUを使えないため処理が遅いという悩みが残ったまま。
そこで、Google先生が公表しているGoogle Colabを使うことにしました。
こちらはGPUを無料で使うことができます。まず、自分のコードを貼ったのですが、Oxfordのデータセットをダウンロードできていないとの表示。
あれ〜、おかしいな。VScodeでは普通にできたんだけどな〜って思いながら、色々調べてみたところ、
"u-netによる画像セグメンテーション"
こちらの記事が見つかりましたので、参考にさせてもらったところ、!pip install -q git+https://github.com/tensorflow/examples.git !pip install -q -U tfds-nightlyこれらのコードを最初に書く必要があったみたいでした。
まとめ
どうやらpcのterminalで一旦ダウンロードしていたとしても、google colabで使う時は、colab上でまたダウンロードする必要がありそうですね。
そしてやはりGPUはCPUよりも高速な処理が可能でした!
- 投稿日:2020-09-15T16:55:31+09:00
AWSLambdaでPyTorch【Lambda import編】
はじめに
本記事はAWSのLambda上でPyTorchを動かして見ようという試みについてのまとめです。DeepLearningタグをつけていますが、学習については触れません。ゴールはLambda上で何かしらの推論を動かしてみるというところまでです。(EFS設定編はこちら)
ざっくりまとめ
- EFS使ってみる
- LambdaでPyTorch←今回ココ
- slackからも呼ぶ
の三本立てです。
Lambdaで動かすモデル
今回Lambdaで動かしてみるのは、EML-NETです。Githubのプロジェクトページを参照すると詳細が書いてありますが、SaliencyMapを生成するモデルです。SaliencyMapとは人の視線の向く位置をヒートマップで表現したものになります。
pipで色々入れる
前回の記事で/mntにEFSをマウントしたのですが、EFSにLambdaからimportしたいライブラリをポンポコ入れていきましょう。
$ cd /mnt/lambda $ sudo pip3 install -t . torch==1.6.0+cpu torchvision==0.7.0+cpu -f https://download.pytorch.org/whl/torch_stable.html $ sudo pip3 install --upgrade -t . opencv-python==4.4.0.42 scipy==1.5.2これによって、
- torch==1.6.0+cpu
- torchvision==0.7.0+cpu
- numpy==1.19.2
- future==0.18.2
- pillow==7.2.0
- opencv==4.4.0.42
が
/mnt/lambda以下に入りました。Lambdaでimport
Lambdaを用意する
関数の作成->一から作成をチェック -> 関数名を入力 -> ランタイムをPython3.7にする ->関数の作成をクリックしましょうVPC
このあたりになにやら書いてありますが、LambdaからEFSに接続するためにはLambdaをVPC内に配置する必要があります。デフォルトのVPCで大丈夫でしょう。セキュリティグループに関しては、EFS内にライブラリを用意するために使ったEC2の設定があると思うのでそちらを指定しておきます。
保存をクリックすると、以下のようなエラーが出てしまいます。
権限が足りないようです。こちらによると、ec2:CreateNetworkInterface ec2:DescribeNetworkInterfaces ec2:DeleteNetworkInterfaceの権限がLambdaに必要なようです。
AWS管理ポリシーAWSLambdaVPCAccessExecutionRoleに含まれているので、このポリシーをLambdaのロールにアタッチしておきましょう。そうするとVPCが設定できるはずです。EFSに接続
用意しておいたEFSとLambdaをつなぎます。コンソールの
ファイルシステムからファイルシステムの追加をクリックします。EFSファイルシステムとアクセスポイントを指定し、ローカルマウントパスを/mnt/lambdaとして保存をクリックします。Lambdaでテスト
LambdaからEFSに置いているライブラリを読み込めるかテストしてみます。
EFSは/mnt/lambdaにマウントされているので、/mnt/lambdaをpythonのpathに追加しておきます。lambda_function.pyimport json import sys sys.path.append("/mnt/lambda") import torch import torchvision import PIL import cv2 import numpy as np def lambda_handler(event, context): print(f"torch:{torch.__version__}") print(f"torchvision:{torchvision.__version__}") print(f"PIL:{PIL.__version__}") print(f"cv2:{cv2.__version__}") print(f"numpy:{np.__version__}") return { 'statusCode': 200, 'body': json.dumps('Hello from Lambda!') }コンソール上で適当なテストイベントを作ってテストを実行すると、下のような結果が得られます。ちゃんとPyTorch読み込めてますね。
START RequestId: 35329cd4-50f6-4eb7-8950-f27daf75462b Version: $LATEST OpenBLAS WARNING - could not determine the L2 cache size on this system, assuming 256k torch:1.6.0+cpu torchvision:0.7.0+cpu PIL:7.2.0 cv2:4.4.0 numpy:1.19.2 END RequestId: 35329cd4-50f6-4eb7-8950-f27daf75462b REPORT RequestId: 35329cd4-50f6-4eb7-8950-f27daf75462b Duration: 29212.21 ms Billed Duration: 29300 ms Memory Size: 128 MB Max Memory Used: 129 MBモデルを動かす
準備は整ったのでモデルを動かしてみます。EMLのgithubページ内に学習済みのモデルの場所が載せてあるのでダウンロードしてきます。READMEの教えに従って、scpなりなんなりでEC2にマウントしておいたEFSの
/mnt/lambda/backboneに3つのファイル、res_imagenet.pth, res_places.pth, res_decoder.pthを置きます。eval_combined.pyをベースにLambda上で動かせるように修正していきます。
lambda_function.pyimport sys sys.path.append("/mnt/lambda") import os import torch import torch.nn as nn import torch.backends.cudnn as cudnn import torchvision.transforms as transforms from PIL import Image import cv2 import numpy as np import resnet import decoder # このあたりの環境変数は不要なのでは?という気もしている。 os.environ["CUDA_DEVICE_ORDER"] = "PCI_BUS_ID" os.environ["CUDA_VISIBLE_DEVICES"] = "0" image_model_path = "/mnt/lambda/backbone/res_imagenet.pth" place_model_path = "/mnt/lambda/backbone/res_places.pth" decoder_model_path = "/mnt/lambda/backbone/res_decoder.pth" size = (480, 640) num_feat = 5 def normalize(x): x -= x.min() x /= x.max() def post_process(pred): pred = cv2.GaussianBlur(pred, (5,5), 10.0) normalize(pred) pred_uint = (pred * 255).astype(np.uint8) return pred, pred_uint def draw_heatmap(pred, img): # saliency mapをもとの画像サイズに変換する。 resized_pred = np.asarray(Image.fromarray(pred).resize((img.size[0], img.size[1])), dtype=np.uint8) resized_colormap = cv2.applyColorMap(resized_pred, cv2.COLORMAP_JET) resized_colormap = cv2.cvtColor(resized_colormap, cv2.COLOR_BGR2RGB) # 元画像もnumpy ndarrayに変換しておく。 img_array = np.asarray(img) # ブレンディング alpha = 0.5 blended = cv2.addWeighted(img_array, alpha, resized_colormap, 1-alpha, 0) return blended def predict(image_model_path, place_model_path, decoder_model_path, pil_img): img_model = resnet.resnet50(image_model_path).eval() pla_model = resnet.resnet50(place_model_path).eval() decoder_model = decoder.build_decoder(decoder_model_path, size, num_feat, num_feat).eval() preprocess = transforms.Compose([ transforms.Resize(size), transforms.ToTensor(), ]) processed = preprocess(pil_img).unsqueeze(0) with torch.no_grad(): img_feat = img_model(processed, decode=True) pla_feat = pla_model(processed, decode=True) pred = decoder_model([img_feat, pla_feat]) pred_origin = pred.squeeze().detach().cpu().numpy() pred, pred_uint = post_process(pred_origin) heatmap = draw_heatmap(pred_uint, pil_img) return heatmap def lambda_handler(event, context): # 空のレスポンス empty_response = { "statusCode": 200, "body": "{}" } pil_img = Image.open("/mnt/lambda/image/examples/115.jpg").convert("RGB") heatmap = predict(image_model_path, place_model_path, decoder_model_path, pil_img) print(heatmap.shape) return empty_responseちょっと長いですが、これでLambda上でSaliencyMapの生成ができます。Lambda上ではGPUが使えないので、元のコードからcuda関連の部分の記述を修正しています。
実行すると、START RequestId: 6f9baccf-b758-4e9a-b43a-b92bdd9757ec Version: $LATEST OpenBLAS WARNING - could not determine the L2 cache size on this system, assuming 256k Model loaded /mnt/lambda/backbone/res_imagenet.pth Model loaded /mnt/lambda/backbone/res_places.pth Loaded decoder /mnt/lambda/backbone/res_decoder.pth (511, 681, 3) END RequestId: 6f9baccf-b758-4e9a-b43a-b92bdd9757ec REPORT RequestId: 6f9baccf-b758-4e9a-b43a-b92bdd9757ec Duration: 20075.02 ms Billed Duration: 20100 ms Memory Size: 1024 MB Max Memory Used: 614 MBとなって無事に実行できているようですね。EFS側にファイル出力したかったのですが、若干面倒な感じだったので次回のSlackからの呼び出しのついでにS3に出力できるように修正しましょう。
まとめ
EFSをLambdaに繋いで、ライブラリの読み込み・モデルファイルの読み込みができるようになりました。これによって従来のようにLambdaの容量を気にせずモデルの推論が実行できるようになるのではないでしょうか。
次回はslack呼び出し編として、今回のLambdaをslackから呼び出して見ようと思います。蛇足
この記事を書くにあたり、一度作成した構成を確認用にもう一度一から作成したのですが、これをやるくらいならAWS CDKとかでズドンとやっておけば執筆が捗ったのになぁと後悔しています。


- 投稿日:2020-09-15T16:54:46+09:00
Python(numpy, cv2) で画像データに対する画素位置操作のメモ
背景
- github などにある他者の python(numpy, cv2)で画像データを処理しているコードが読解できない
[...,::-1]とかで記号的なので検索もしづらい
BGR -> RGB
cv2 だと標準で BGR 画像として処理するようです. 保存や matplotlib で表示時に RGB に並び替える必要あります.
(H, W, C) な配列とします.
[:, :, ::-1]で C 次元(チャンネル)の要素が入れ替わります.https://stackoverflow.com/questions/4661557/pil-rotate-image-colors-bgr-rgb
:は slice((start, end, step)) でその次元の全要素を指す(None, None, 1)(?) or(0, n-1, 1)相当.
::-1も slice で(0, n-1, -1)で end から start へと逆方向に 1 づつ進む.RGB(3 要素) の場合は
[2, 1, 0]のインデクシングとなる.したがって BGR -> RGB と並び替えができます.
...
img[...,::-1]なケース.
初見者からすると謎すぎてまったくわかりません.
...は検索性低くてつらいですね.https://www.scivision.dev/numpy-image-bgr-to-rgb/
...=:, :の省略形でした. 各次元で全要素選択という感じでしょうか.
[..., ::-1]=[:, :, ::-1]=[:, :, [2, 1, 0]]という感じです.特定の channel だけに処理をしたい
たとえば G channel だけ 1 を設定したいなど
img[:, :, 1] = 1とします.
alpha を RGB にブロードキャストしたい
numpy だけかも.
rgb(3 channels) と alpha(1 channel) の画像があるときに, 単純に
rgb * alphaでは乗算できません.alpha の値を RGB にブロードキャスト(複製)する必要があります.
fg * alpha[:, :, None]として,Noneを指定するとブロードキャストしてくれます.
https://stackoverflow.com/questions/51091560/numpy-indexing-using-none-for-pairwise-operations
None = np.newaxis として次元を一つ増やす振る舞いになっています(わかりずらい...)
ast(構文木)をきちんと考慮しているようで,
bg * (1 - alpha[:, :, None])みたいになにか演算してから RGB と乗算もうまく行きます.画素要素を判定して代入するなど
for i in range(len(pixels)): pixels[i] = pixels[i] < 0.5 ? 0 : pixels[i]みたいな操作をしたい.
pixels[pixels < 0.5] = 0とすると, 全画素で処理してくれます.
shape(画像サイズやチャネル数)があっていれば, 他の ndarray を使うのも可能です.
e.g.
alpha[trimap_np[:, :, 0] == 1] = 0alpha 画像で, trimap_np の R channel が 1 の画素位置の値を 0 にする
fg[alpha == 1] = image_np[alpha == 1]T.B.W.
画像を部分領域(tile)に分割する
slice 記法では, step で 4 ピクセルおきなどは指定できますが, 4 pixel づつというのはできないので, for 文などで slide
(start, end, 1)で start, end をそれぞれ指定するか, numpy, cv2 あたりで部分領域に分割する関数を使います.
(ちなみに numpy.tile は画像を tile 状にリピートして並べる関数なので分割には使えない)その他
視覚的に説明してくれている記事
Numpy’s indexing and slicing notation explained visually
https://medium.com/@buch.willi/numpys-indexing-and-slicing-notation-explained-visually-67dc981c22c1
- 投稿日:2020-09-15T16:40:13+09:00
tkinterで”too early to create image”と出てしまう
TL;DR
先にTk()を実行しておこう
状況
tkinterを使ってGUIプログラムを作ろうとしていたとき、canvas上で画像を表示しようとして、書いたところエラーが出たためipythonで中身を確認しようとした。
ipythonfrom PIL import Image, ImageTk import tkinter as tk img = Image.open("hoge.png") imgtk = ImageTk.PhotoImage(img)すると、
RuntimeError: Too early to create imageとなって先に進めなかった
原因
tk.Tk()を先に呼び出しておかないとPhotoImage()は使えない
対処
ipythonで解析しようとしていたとき、もとのスクリプトにあるtk.Tk()が反映されていなかったため、この様になった。もともと困っていたエラーは画像の方に出ていたものだから、混乱して発見が遅れた。ipython上ではroot=tk.Tk()と適当にTk()を呼んでおけば、後は問題ない。
- 投稿日:2020-09-15T16:07:52+09:00
Seleniumで好きな画像を生成できるプログラムを作る
はじめに
最近、個人的な趣味で地震の震度分布図を作画してツイートするプログラムを作成したのですが、そこで使った画像生成が他のものでも使えるのではないかということで備忘録として書こうかと思います。
原理
PythonのSeleniumと呼ばれるフレームワークは、Webアプリなどのテストをするものなんですが動的サイトのスクレイピングなどにも用いられています。
レンダリングは、Google ChromeのヘッドレスプラウザというCUIベースで動くChromeでレンダリングしています。その、Seleniumにはスクリーンショットの機能があるためローカルサーバーを立てそこに必要な情報をGETしてあげることで好きな画像をHTML/CSSで作成することが可能です。
必要なもの
Python
Selenium
一応、SeleniumはRubyやJSにもあるみたいです。
Webページをキャプチャするためのフレームワーク。
pipでのインストール方法は以下pip install selenium
- Docker
WindowsやMacなどにすでにChromeが入っている場合はなくてもいいのですが、VPN上で実行する際などではChromeをDocker内に入れることで実行します。
- ローカルサーバー
Node.js、DenoなどでもOK。今回はPythonのフレームワークのFlsakを使用します。
作る
今回作ったソースコードは、ここにおいてあります。
Webサーバーを作る
今回はFlaskで作成し、Docker composeでコンテナとしてまとめます。そのため、Pythonのモジュールはpipenvで管理しようかと思います。
以下を入力してPipenvをインストールし、Flaskをインストールします。
pip install pipenv pipenv --python 3.8 pipenv install flask更に、たりないファイルなどを追加して以下のようにします。
ディレクトリ構成は以下です。server ├── Dockerfile ├── Pipfile ├── Pipfile.lock ├── run.py ├── static │ └── css │ └── style.css └── templates └── index.html
run.py、index.html、style.cssは自分の好きなように作ってください。
今回は、URLパラメータでGETした文字列を画面に表示するだけにします。Dockerfileは以下のように記述します。出力ポートは5000になっていますが任意で大丈夫だと思います。
DockerfileFROM python:3.8 COPY run.py /run.py COPY templates /templates COPY static /static COPY Pipfile /Pipfile COPY Pipfile.lock /Pipfile.lock RUN pip install pipenv RUN pipenv install --system --deploy EXPOSE 5000
pipenv shell && python run.pyを試してみて、ブラウザなどで正常に表示できたらOKです。キャプチャ部分を作る
先程つくった
serverディレクトリの上部に生成用のプログラムファイルなどを作成します。
ディレクトリはこのようにします。. ├── docker-compose.yml ├── Dockerfile ├── images ├── main.py ├── Pipfile ├── Pipfile.lock ├── README.md └── serverpipenvでインストールするモジュールはSeleniumです。
pipenv install selenium画像生成のDockerfileは以下のようにします。こちらは、Google Chromeも一緒にインストールする必要があります。
DockerfileFROM python:3.8 COPY main.py /main.py COPY Pipfile /Pipfile COPY Pipfile.lock /Pipfile.lock RUN apt-get update && apt-get install -y unzip #install google-chrome, rsvg-convert, vim RUN wget -q -O - https://dl-ssl.google.com/linux/linux_signing_key.pub | apt-key add && \ echo 'deb [arch=amd64] http://dl.google.com/linux/chrome/deb/ stable main' | tee /etc/apt/sources.list.d/google-chrome.list && \ apt-get update && \ apt-get install -y google-chrome-stable RUN apt-get install -y vim #install ChromeDriver ADD https://chromedriver.storage.googleapis.com/84.0.4147.30/chromedriver_linux64.zip /opt/chrome/ RUN cd /opt/chrome/ && \ unzip chromedriver_linux64.zip ENV PATH /usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin:/opt/chrome RUN pip install pipenv RUN pipenv install --system --deploy
ADD https://chromedriver.storage.googleapis.com/84.0.4147.30/chromedriver_linux64.zip /opt/chrome/は現在のChromeのバージョンのリンクが必要ですhttps://chromedriver.storage.googleapis.com/index.html
から、現在のバージョンのリンクを貼り付けます。
さらに、サーバーのコンテナとこのコンテナをつなげるため
docker-compose.ymlを作成します。docker-compose.ymlversion: '3' services: server: container_name: server build: context: server dockerfile: Dockerfile ports: - '5000:5000' tty: true # restart: always command: python3 run.py main: container_name: main build: . tty: true # restart: always links: - server volumes: - ./images/:/images/ command: python3 main.pyここで重要なのは生成した画像をDocker外で使用する場合はその保存するディレクトリを
volumesに指定してあげる必要があります。
main.pyはSeleniumのキャプチャ方法として調べるとたくさん出てきますが、今回はこのように作成します。main.pyimport os from selenium import webdriver def main(): image_save_path = os.path.join('images', 'image.png') text = 'Hello' captcha(image_save_path, text) def captcha(image_save_path: str, text: str) -> None: url = f'http://server:5000/?text={text}' options = webdriver.ChromeOptions() options.add_argument('--headless') options.add_argument('--no-sandbox') driver = webdriver.Chrome(options=options) driver.set_window_size(1920, 1080) driver.execute_script("document.body.style.zoom='100%'") driver.get(url) driver.implicitly_wait(3) driver.save_screenshot(image_save_path) driver.quit() if __name__ == "__main__": main()動かしてみる
docker-compose upを入力してみて実際に
imagesディレクトリに画像が生成されていたら成功です。ソースコード: https://github.com/yuto51942/image-generate
最後に
私が最近趣味で作ったEarthquake-alertにも同じようにして画像生成しているのでぜひ見てみてください。なんならStarも欲しいです。
他の方法でも画像を生成できるかもしれませんが、自分の中ではこの方法が一番自由に色々な画像を生成することができるのではと思います。ぜひ試してみてください。
- 投稿日:2020-09-15T15:52:05+09:00
discord.py入門(3) 音声を使用する
はじめに
discord.pyの非公式のサーバーを運用しています(開発者の方もいますが)。
ここでは質問も受け付けています。また、長期的にサポートが欲しい方向けに、個人チャンネルを作成しそこでサポートを受けることもできます。
個人サポートを受けたい方は、下の招待urlから入り、@すみどら#8931にDMをお願いします。
https://discord.gg/KPp2Wsu この記事についての質問もこちらにお願いしますこの記事について
この記事はdiscord.pyについて段階を踏んで勉強していくための記事になります。
まず始めに基本の書き方を学び、次に発展的な内容を学びます。
【シリーズ】discord.py入門(1)
discord.py入門(2)
discord.py入門(3)注意
この記事は少しでもPythonができる人向けになります。
ただし、コピペするだけでも使えますが、その後書けなくなるので、もっと個別に機能を作りたい場合は、
本やpaizaラーニング、ドットインストール、Progate、京大のテキスト を使って勉強することをお勧めします。
私がお勧めな本は、辻真吾さんのPythonスタートブックです。筆者の動作環境
Python 3.8.3
Mac OS Catalina 10.15.5
discord.py-1.4.1この記事について
この記事では、今までのそれぞれの紹介のようなシステムではなく、順々に使い方を辿っていくような記事になります。
discord.pyを音声付きでインストールする
今まで皆さんは
pip install discord.pyとインストールしていましたが、こうすると音声用のライブラリがインストールされません。ですので、音声用のライブラリも一緒にインストールする必要があります。pip install discord.py[voice]最後に
[voice]と書くことで音声のライブラリも一緒にインストールされます。もし既にインストールしている場合は、先に
pip uninstall discord.pyでアンインストールしてください。音声に接続する
まず、音声に接続するコードを書きましょう。
今回は、
!joinと打つと接続し、!leaveと打つと切断する機能を作成します。メッセージの送信者がボイスチャンネルに接続しているかどうかを判断する
メッセージの送信者がボイスチャンネルに接続していないと、どのボイスチャンネルに接続すれば良いかわからなくなってしまいます。
そこで、まずメッセージの送信者がボイスチャンネルに接続しているかどうかを判別する必要があります。
ここでは、
discord.Member.voice変数を使用します。この変数は、もしボイスチャンネルに接続していた場合はdiscord.VoiceStateインスタンス、接続していない場合はNoneを返します。# in on_message if message.content == "!join": if message.author.voice is None: await message.channel.send("あなたはボイスチャンネルに接続していません。") return ...ボイスチャンネルに接続する
上の項で判定したら、次はボイスチャンネルに接続します。
discord.VoiceChannel.connectコルーチン関数で接続できますが、まずdiscord.VoiceChannelインスタンスを取得する必要があります。これは、
discord.Client.get_channel関数でも取得できますが、discord.VoiceState.channel変数も同じくVoiceChannelインスタンスであるので、それを使うことができます。# in on_message if message.content == "!join": if message.author.voice is None: await message.channel.send("あなたはボイスチャンネルに接続していません。") return # ボイスチャンネルに接続する await message.author.voice.channel.connect() await message.channel.send("接続しました。")これだけで、ボイスチャンネルに接続できます!
ボイスチャンネルから切断する
次は、ボイスチャンネルから切断します。これは、少し特殊な方法を使う必要があります。
まず、ボイスチャンネルから切断するためには、
discord.VoiceClient.disconnectコルーチン関数を実行する必要がありますが、このdiscord.VoiceClientインスタンスをdiscord.Guildから取得する必要があります。voice_client = message.guild.voice_clientこの値はもし接続していれば
discord.VoiceClient、接続していなければNoneになります。これを使うと、
import discord client = discord.Client() @client.event async def on_message(message: discord.Message): # メッセージの送信者がbotだった場合は無視する if message.author.bot: return if message.content == "!join": if message.author.voice is None: await message.channel.send("あなたはボイスチャンネルに接続していません。") return # ボイスチャンネルに接続する await message.author.voice.channel.connect() await message.channel.send("接続しました。") elif message.content == "!leave": if message.guild.voice_client is None: await message.channel.send("接続していません。") return # 切断する await message.guild.voice_client.disconnect() await message.channel.send("切断しました。")こう書くことができます。
ボイスチャンネルを移動する
discord.VoiceClient.move_toコルーチン関数を使用します。move_toにはあたらしい音声チャンネルのインスタンスを渡します。# メッセージを送信したユーザーがいるボイスチャンネルに移動する message.guild.voice_client.move_to(message.author.voice.channel)音声を再生・一時停止する
ボイスチャンネルに接続したら、次は音声を再生してみましょう。ここでは、
example.mp3というファイルがあることを前提とします。また、ffmpegという物も必要となるので、入れておいてください(検索したら入れ方はたくさん出ます)
!playと打つと再生するようにしてみましょう。音声を再生する
if message.content == "!play": if message.guild.voice_client is None: await message.channel.send("接続していません。") return message.guild.voice_client.play(discord.FFmpegPCMAudio("example.mp3"))これだけで再生ができます!意外かもしれませんが、play関数はコルーチン関数ではありません。
音声を止める
discord.VoiceClient.pause関数で一時停止をすることができます。また、
discord.VoiceClient.stop関数で停止(再開できない)することができます。音声の再生を再開する
discord.VoiceClient.resume関数で再生再開できます。音声の音量を変える
discord.PCMVolumeTransformerを使うことで変更できます。source = discord.PCMVolumeTransformer(discord.FFmpegPCMAudio("example.mp3"), volume=0.5) message.guild.voice_client.play(source)volumeに音量を指定することができます。元音量が1で、最低が0です。(0.5で半分)
Youtubeの音楽を流す
注意
ここから先の内容はYoutubeのTOSに抵触する可能性があるので、自己責任で行ってください。ここでは例だけを示します。
ここを参考にできますが、この内容は高度(自分で書くと難しい)ので、簡単にしたものを紹介します。
まず、
pip install youtube_dlとシェルで実行し、youtube_dlライブラリをインストールしてください。次に、これをファイルの先頭に書いてください:
import asyncio import discord import youtube_dl # Suppress noise about console usage from errors youtube_dl.utils.bug_reports_message = lambda: '' ytdl_format_options = { 'format': 'bestaudio/best', 'outtmpl': '%(extractor)s-%(id)s-%(title)s.%(ext)s', 'restrictfilenames': True, 'noplaylist': True, 'nocheckcertificate': True, 'ignoreerrors': False, 'logtostderr': False, 'quiet': True, 'no_warnings': True, 'default_search': 'auto', 'source_address': '0.0.0.0' # bind to ipv4 since ipv6 addresses cause issues sometimes } ffmpeg_options = { 'options': '-vn' } ytdl = youtube_dl.YoutubeDL(ytdl_format_options) class YTDLSource(discord.PCMVolumeTransformer): def __init__(self, source, *, data, volume=0.5): super().__init__(source, volume) self.data = data self.title = data.get('title') self.url = data.get('url') @classmethod async def from_url(cls, url, *, loop=None, stream=False): loop = loop or asyncio.get_event_loop() data = await loop.run_in_executor(None, lambda: ytdl.extract_info(url, download=not stream)) if 'entries' in data: # take first item from a playlist data = data['entries'][0] filename = data['url'] if stream else ytdl.prepare_filename(data) return cls(discord.FFmpegPCMAudio(filename, **ffmpeg_options), data=data)これは https://github.com/Rapptz/discord.py/blob/master/examples/basic_voice.py にあるものです。
次に、これを使用してyoutubeの音楽を再生できるようにします。
import asyncio import discord import youtube_dl # Suppress noise about console usage from errors youtube_dl.utils.bug_reports_message = lambda: '' ytdl_format_options = { 'format': 'bestaudio/best', 'outtmpl': '%(extractor)s-%(id)s-%(title)s.%(ext)s', 'restrictfilenames': True, 'noplaylist': True, 'nocheckcertificate': True, 'ignoreerrors': False, 'logtostderr': False, 'quiet': True, 'no_warnings': True, 'default_search': 'auto', 'source_address': '0.0.0.0' # bind to ipv4 since ipv6 addresses cause issues sometimes } ffmpeg_options = { 'options': '-vn' } ytdl = youtube_dl.YoutubeDL(ytdl_format_options) class YTDLSource(discord.PCMVolumeTransformer): def __init__(self, source, *, data, volume=0.5): super().__init__(source, volume) self.data = data self.title = data.get('title') self.url = data.get('url') @classmethod async def from_url(cls, url, *, loop=None, stream=False): loop = loop or asyncio.get_event_loop() data = await loop.run_in_executor(None, lambda: ytdl.extract_info(url, download=not stream)) if 'entries' in data: # take first item from a playlist data = data['entries'][0] filename = data['url'] if stream else ytdl.prepare_filename(data) return cls(discord.FFmpegPCMAudio(filename, **ffmpeg_options), data=data) client = discord.Client() @client.event async def on_message(message: discord.Message): # メッセージの送信者がbotだった場合は無視する if message.author.bot: return if message.content == "!join": if message.author.voice is None: await message.channel.send("あなたはボイスチャンネルに接続していません。") return # ボイスチャンネルに接続する await message.author.voice.channel.connect() await message.channel.send("接続しました。") elif message.content == "!leave": if message.guild.voice_client is None: await message.channel.send("接続していません。") return # 切断する await message.guild.voice_client.disconnect() await message.channel.send("切断しました。") elif message.content.startswith("!play "): if message.guild.voice_client is None: await message.channel.send("接続していません。") return # 再生中の場合は再生しない if message.guild.voice_client.is_playing(): await message.channel.send("再生中です。") return url = message.content[6:] # youtubeから音楽をダウンロードする player = await YTDLSource.from_url(url, loop=client.loop) # 再生する await message.guild.voice_client.play(player) await message.channel.send('{} を再生します。'.format(player.title)) elif message.content == "!stop": if message.guild.voice_client is None: await message.channel.send("接続していません。") return # 再生中ではない場合は実行しない if not message.guild.voice_client.is_playing(): await message.channel.send("再生していません。") return message.guild.voice_client.stop() await message.channel.send("ストップしました。")終わりに
いかがだったでしょうか。音声の使い方を説明しました。他にも説明して欲しい箇所があればコメントやサーバーにてお願いいたします。
次の記事ではcommandsフレームワークについて解説できればと思います。
それでは。
- 投稿日:2020-09-15T14:34:15+09:00
【Maya Python】QtDesignerで作成した.uiをMayaで表示する
はじめに
【Maya Python】スクリプトの中身を噛み砕く1、2、3で書いたスクリプトの書き方では小さいスクリプトでは問題ありませんが、複雑なUIを作ろうとすると大変な労力がかかります。
そこでQtDesignerを使用しUIを組み立ててみようと思います。
CGアーティストとしてはスクリプトで悩むよりこういったわかりやすいツールがあるといいですね。
今回はとりあえず触ってみて感じを掴むためにMayaでUIを表示して簡単な動作をさせるところまで作ってみたいと思います。
PySideとPySide2、PyQt5などやり方が散見されているので自分の備忘録も兼ねて書きます。
動作環境はMaya2019,2020です。UIファイルを用意する
とりあえずこんな感じにUIを作ってみました。
作り方についてはこちらのサイトを参考。
PyQt5とpython3によるGUIプログラミング:実践編[0]
第5章 Qt Designerを使ってみよう
QtDesignerでUIを作る少し詰まったところをメモ
レイアウトの設定をしっかりやる
そのまま配置しただけだと、ウィンドウサイズを変更してもUIが追従してくれなかったり、ウィンドウ立ち上げ時にウィンドウが小さすぎるなど起こってしまう。
図のようにcentralwidgetがbrakeLayoutになっていると全部表示してくれない。
レイアウトを設定し、ウインドウサイズを調整後、Size Constraintsで最小サイズを設定する。するとちゃんと収まった状態のウィンドウを作ることができる。ウィンドウサイズを変更してもUIが追従してくれる。
レイアウト設定後の初期起動時図ウィンドウを表示するプログラムを用意する
ひとまずコード全文
# -*- coding: utf-8 -*- from PySide2 import QtWidgets from PySide2.QtUiTools import QUiLoader from maya.app.general.mayaMixin import MayaQWidgetBaseMixin # パスを直接指定 UIFILEPATH = 'C:/Users/YN/Desktop/testUI.ui' ## MainWindowを作るクラス class MainWindow(MayaQWidgetBaseMixin, QtWidgets.QMainWindow): def __init__(self, parent=None): super(MainWindow, self).__init__(parent) # UIのパスを指定 self.UI = QUiLoader().load(UIFILEPATH) # ウィンドウタイトルをUIから取得 self.setWindowTitle(self.UI.windowTitle()) # ウィジェットをセンターに配置 self.setCentralWidget(self.UI) # ボタンを接続 self.UI.refreshPushButton.clicked.connect(self.refreshPushButton) def refreshPushButton(self): print ('refresh') ## MainWindowの起動 def main(): window = MainWindow() window.show() if __name__ == '__main__': main()スクリプトエディターにコピペして、
UIFILEPATHを先ほど作成したuiのパスに設定します。
そして実行すればひとまず作成したUIをMayaで確認できます。
プログラム詳細
UIをロード
from PySide2.QtUiTools import QUiLoader
UIをロードするにはQtUiToolsからQUiLoaderをインポートします。
self.UI = QUiLoader().load(UIFILEPATH)
UIFILEPATHを読み込み、self.UIとしてインスタンスします。UIから値を取得
self.setWindowTitle(self.UI.windowTitle())
ウィンドウタイトルを指定しないと適当な名前でウィンドウが作成されるためウィンドウタイトルを作成したUIファイルから取得します。もちろんここにstringで入力することも可能です。
self.UI.windowTitle()
UIの中のプロパティ名を指定すればそこに設定されている値を取得できます。
このように設定しておけばプログラムで書き換えずともUIファイルを変更すればいいので便利です。UIを配置
self.setCentralWidget(self.UI)
UIを配置します。ボタンの動作を作成
self.UI.refreshPushButton.clicked.connect(self.refreshPushButton)
objectNameがrefreshPushButtonのボタンに、クリックしたときの機能を接続します。
このようにQtDesignerでオブジェクト名を指定しておきます。def refreshPushButton(self): print ('refresh')ボタンを押したときに、refreshとプリントするような機能をつけました。
実際は、ここにこのボタンに設定したい機能を書き込んで行きます。おわりに
私も、はじめはどこから手を付ければいいか暗中模索状態だったので、なにかの役に立てればと思います。
MayaでとりあえずサクッとUI表示してあー、こうなってるのねというのがわかってくればどんどんUIを複雑にしていけるんじゃないでしょうか。MayaのPySide2は途中でPySideからアップデートがあり、記述の仕方が変わったため混乱しました。また似たようなPyQt5など検索にヒットしてしまうため更にややこしいですね。。
参考
大変参考になりました。ありがとうございます。
PyQt5とpython3によるGUIプログラミング:実践編[0]
第5章 Qt Designerを使ってみよう
QtDesignerでUIを作る

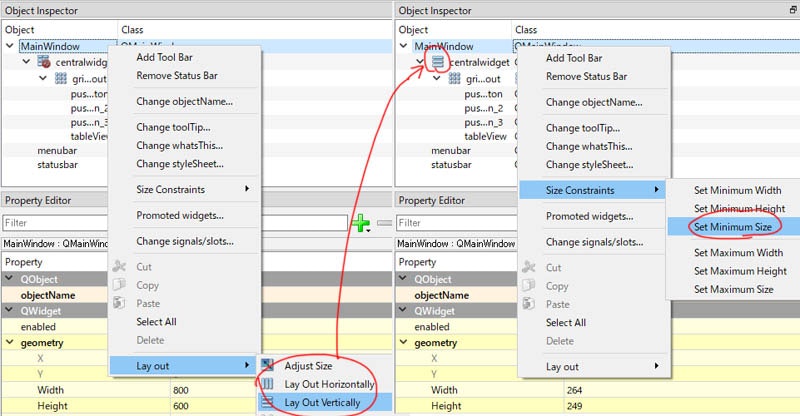
- 投稿日:2020-09-15T13:44:39+09:00
[Python] クロージャとUnboundLocalError: local variable 'x' referenced before assignment
本記事は Python 3.7.6 の動作結果を元にして書かれている。
Python でクロージャを作ろうと、次のようなコードを書いた。
def f(): x = 0 def g(): x += 1 g() f()関数
gから 関数fのスコープ内で定義された変数xを参照し、それに 1 を足そうとしている。
これを実行するとx += 1の箇所でエラーが発生する。UnboundLocalError: local variable 'x' referenced before assignment
local変数
xが代入前に参照された、とある。これは、fのxを参照するのではなく、新しく別の変数をg内に作ってしまっているため。
前述のコードを宣言と代入を便宜上分けて書き直すと次のようになる。varを変数宣言のための構文として擬似的に利用している。# 注: var は正しい Python の文法ではない。上記参照のこと def f(): var x # f の local変数 'x' を宣言 x = 0 # x に 0 を代入 def g(): # f の内部関数 g を定義 var x # g の local変数 'x' を宣言 # たまたま f にも同じ名前の変数があるが、それとは別の変数 x += 1 # x に 1 を加算 (x = x + 1 の糖衣構文) # 加算する前の値を参照しようとするが、まだ代入されていないためエラー g()当初の意図を表現するには、次のように書けばよい。
def f(): x = 0 def g(): nonlocal x ## (*) x += 1 g()
(*)のように、nonlocalを追加する。これにより一つ外側のスコープ (gの一つ外側 =f) で定義されているxを探しに行くようになる。
- 投稿日:2020-09-15T12:36:21+09:00
【Python】動的に変数名を設定する方法と速度比較
追記
locals()は関数内では正常に使用できないとのご指摘をいただきました(そもそも公式ドキュメントでは使うなとまで書いてある)。
使用する際はご注意を。はじめに
ほとんど無いと思いますが、動的に変数名を設定したい場合があったりなかったりしちゃったりしちゃわなかったりするかもしれないので、その方法を調べてみました。(外部ファイルからデータを読み込んでそのままファイル名を変数名にしたい場合とか?)
2(+α)通りの方法を発見しましたので、紹介を兼ねて速度を比較したいと思います。
速度比較のルールと準備
ルール
・Jupyter Notebook上で%%timeitコマンドを用いて測定。
・ランダムな小文字アルファベット5文字を変数名とする。
・値として0から9までの整数が入ったリストを代入する。
・1,000回ループした平均を測定する。準備
測定に影響しないように、予め変数名を用意する。import random chrs = [chr(i) for i in range(ord('a'), ord('z')+1)] names = [''.join(random.sample(chrs, 10)) for i in range(10)]方法1
exec()を使う一番よく見かける方法。
%%timeit for i in range(1000): exec(f'{names[i]} = [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]')結果
20.7 ms ± 75.7 µs per loop (mean ± std. dev. of 7 runs, 10 loops each)方法2
locals()orglobals()を使う
locals()やglobals()はそれぞれローカル変数、グローバル変数を管理している辞書という認識です(違ったらごめんなさい)。
通常のディクショナリ型と同様に、インデクサや.get()で値を取得、.update()で更新などといった操作ができます。%%timeit for i in range(1000): locals().update({f'{names[i]}':[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]})結果
386 µs ± 24.2 µs per loop (mean ± std. dev. of 7 runs, 1000 loops each)少し方法を変えて
%%timeit for i in range(1000): locals()[names[i]] = [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]結果
248 µs ± 387 ns per loop (mean ± std. dev. of 7 runs, 1000 loops each)まとめ
exec()比で、
・exec(): 1倍
・locals().update(): 53倍
・locals()[]: 83倍
の早さで定義できました。結論
locals() (or globals())が早いよ。