- 投稿日:2020-09-11T23:56:56+09:00
たった3行でVSCode(codeserver)をGoogle Colabで使う方法
packageをインストール
!pip install colabcodeGitHub
https://github.com/abhishekkrthakur/colabcode/colabcodeを起動
from colabcode import ColabCode ColabCode(port=10000)上記を実行すると、ngrokのリンクがJupyte Notebookに表示されるので、そのリンクをクリックするとVSCode(codesever)が表示されます。
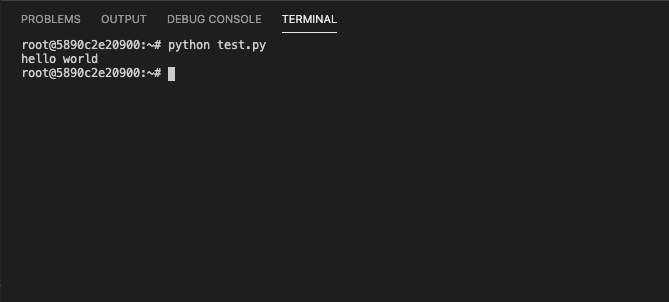
python
あとはターミナルを開いて、普通に
python test.pyで実行できます。
ちなみに、エディタのサイドバーのGearアイコンをクリックするとテーマが簡単に変更できます。
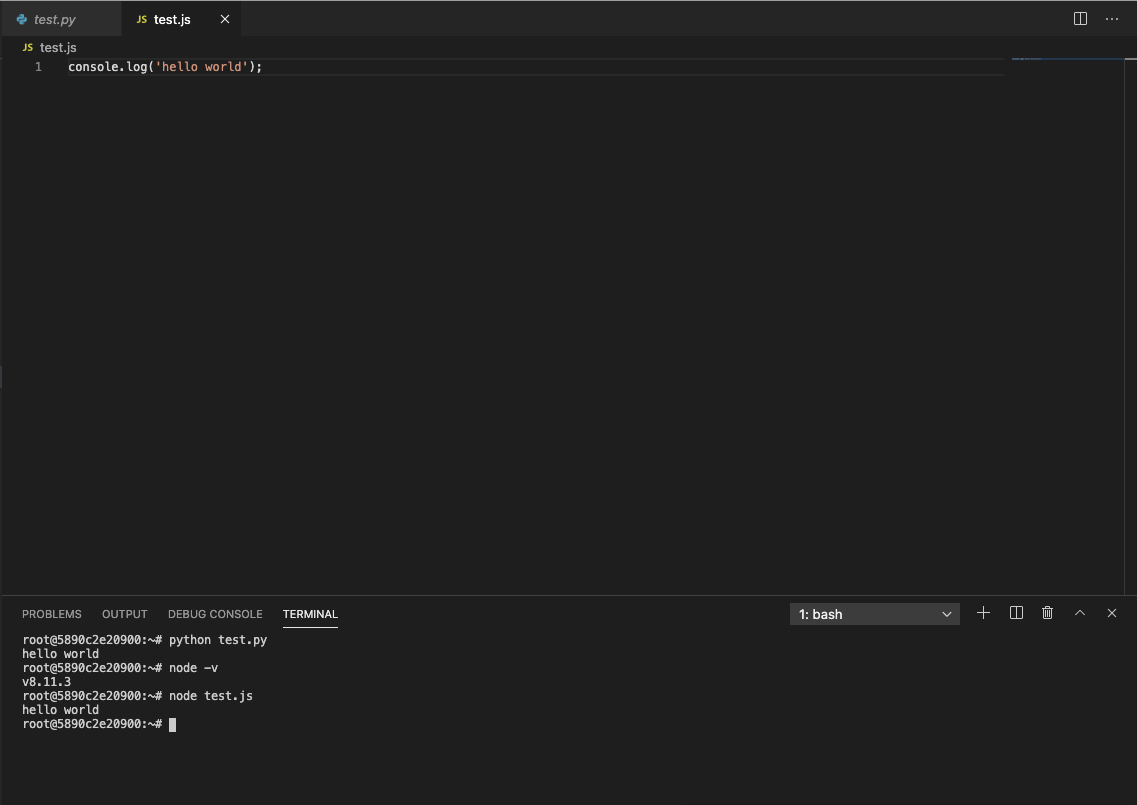
nodejs
nodejsも使えます。インストールされているのは、v8.11.3と古いですが、普通に動きました。

- 投稿日:2020-09-11T23:21:49+09:00
yukicoder contest 265 参戦記
yukicoder contest 265 参戦記
A 1223 I hate Golf
ABC177A - Don't be late かなと思ったが、座標がマイナスの可能性があった. まあ、abs つけるだけだよねと思いつつ、ABC177 のときにはやらなかった = 付け忘れをやらかすなどした.
N, K, T = map(int, input().split()) if K * T >= abs(N): print('Yes') else: print('No')B 1224 I hate Sqrt Inequality
a,b≤1018 を見て、素因数分解して共通の素数で割りたいけど、エラトステネスの篩が使えない値域じゃん、どうすればいいんだと悩んでいた. はい、GCDで割ればいいだけですね orz. 割り切れるということは、a×10N%b=0 ということなので、aとbのGCDで割ったbが2N×5MになっていればOK.
from math import gcd a, b = map(int, input().split()) t = gcd(a, b) b //= t while b % 2 == 0: b //= 2 while b % 5 == 0: b //= 5 if b == 1: print('No') else: print('Yes')C 1225 I hate I hate Matrix Construction
typo で自爆しまくった(笑). まず S にも T にも2がある場合は、もう論理和が0になることはありえないので、1と2しかないことが保証され、2が指定されたところ以外に1を置く必要はない. S か T のどちらかだけに2がある場合、無い方は全部論理和が1になること確定. 2がある方は、1の数だけ適当にどこかに1を置けば良い. S にも T にも2がない場合には、1の数だけ1を置いていくことになるが、1個置くごとに S, T のノルマを一つづつ消せるので、それぞれの1の数の大きい方の数だけ置けば良い.
N = int(input()) S = list(map(int, input().split())) T = list(map(int, input().split())) m = [[0] * N for _ in range(N)] s1 = S.count(1) t1 = T.count(1) s2 = S.count(2) t2 = T.count(2) if s2 == 0 and t2 == 0: print(max(s1, t1)) elif s2 > 0 and t2 > 0: print(s2 * N + t2 * N - s2 * t2) elif s2 == 0: print(t1 + t2 * N) elif t2 == 0: print(s1 + s2 * N)
- 投稿日:2020-09-11T22:25:16+09:00
【Udemy Python3入門+応用】 64. 名前空間とスコープ
※この記事はUdemyの
「現役シリコンバレーエンジニアが教えるPython3入門+応用+アメリカのシリコンバレー流コードスタイル」
の講座を受講した上での、自分用の授業ノートです。
講師の酒井潤さんから許可をいただいた上で公開しています。■名前空間とスコープ
animal = 'cat' def f(): print(animal) f()resultcatここでの
animalはグローバル変数なので、もちろんf()内で呼び出すことができる。
animal = 'cat' def f(): animal = 'dog' print('after:', animal) f()resultafter: dogもちろんこれでは
dogが出力されるが、これはグローバル変数のanimalを上書きしているわけではない。
animal = 'cat' def f(): print(animal) animal = 'dog' print('after:', animal) f()resultUnboundLocalError: local variable 'animal' referenced before assignment最初に
animalをprintしようとするとエラーとなった。
これは、関数内にローカル変数を宣言する記述があり、それが記述される前にprintしようとしているというエラー。
animal = 'cat' def f(): # print(animal) animal = 'dog' print('local:', animal) f() print('global:', animal)resultlocal: dog global: cat
f()内ではローカル変数のanimalを宣言してそれをprint、
最終行のprintではグローバル変数のanimalをprintしている。
animal = 'cat' def f(): global animal animal = 'dog' print('local:', animal) f() print('global:', animal)resultlocal: dog global: dog関数内で
globalを使うことでグローバル変数のanimlalを呼び出すと、そのグローバル変数を上書きすることになる。
animal = 'cat' def f(): animal = 'dog' print(locals()) f() print(globals())result{'animal': 'dog'} {'__name__': '__main__', '__doc__': None, '__package__': None, '__loader__': <_frozen_importlib_external.SourceFileLoader object at 0x7fd8f9f687f0>, '__spec__': None, '__annotations__': {}, '__builtins__': <module 'builtins' (built-in)>, '__file__': 'test.py', '__cached__': None, 'animal': 'cat', 'f': <function f at 0x7fd8f9db9160>}
locals()やglobals()を使うことで、ローカル変数やグローバル変数をdictionaryとして呼び出すことができる。
printしたグローバル変数を見てみると、予めpython側で定義している変数があることがわかる。
def TestFunc(): """Test func doc""" print(TestFunc.__name__) print(TestFunc.__doc__) TestFunc() print('global:', __name__)resultTestFunc Test func doc global: __main__関数名を指定すると、その関数の
__name__や__doc__が出力できる。
- 投稿日:2020-09-11T22:07:34+09:00
Herokuに入れたPostgreSQLの並び順を変更する
背景
Djangoに関して。データベースに入っている投稿を作成順(ID順)に並べる際に、ローカル環境ではデフォルトで入っているMySQLがID順で格納されていくため、特に苦労することはなかった。
しかしHerokuでデプロイした後はMySQLが使えないので、PostgreSQLを使うことになる。PostgreSQLのデータの並び順はデフォルトではID順ではないため(更新順?いまだにどう並んでいるか分かりません)、自分で設定する必要がある。
対応策
データベースの中に入ってそこでORDER_BY句を設定することも考えたが(おそらくこれが王道)、慣れていないためより簡単なDjangoのviews.py上に一つコードを加える対応をとった。
ordering = ['id']を入れることで表示上は問題なくなる。views.pyclass DataList(ListView): template_name = "list.html" model = DataModel ordering = ['-id']orderingについて
なお
''で囲まれた文字列はデータベースのフィールドの名前を書ける。
また降順に並べる場合はオプションで'-'を先頭に付ける。
順番をランダムにするには"?"で対応可能。参考
Djangoのソートがあいうえお順にならない時の対処法
Django v1.0 documentation モデルのMetaオプション
- 投稿日:2020-09-11T21:53:35+09:00
【Udemy Python3入門+応用】 63. ジェネレーター内包表記
※この記事はUdemyの
「現役シリコンバレーエンジニアが教えるPython3入門+応用+アメリカのシリコンバレー流コードスタイル」
の講座を受講した上での、自分用の授業ノートです。
講師の酒井潤さんから許可をいただいた上で公開しています。■ジェネレーター内包表記
◆普通に記述した場合
def g(): for i in range(10): yield i g = g() print(type(g)) print(next(g)) print(next(g)) print(next(g)) print(next(g)) print(next(g))result<class 'generator'> 0 1 2 3 4◆ジェネレーター内包表記で記述した場合
g = (i for i in range(10)) print(type(g)) print(next(g)) print(next(g)) print(next(g)) print(next(g)) print(next(g))result<class 'generator'> 0 1 2 3 4一見tupleになりそうな見た目だが、ただ
()を使うだけだとジェネレーターとなる。g = tuple(i for i in range(10)) print(type(g)) print(g)result<class 'tuple'> (0, 1, 2, 3, 4, 5, 6, 7, 8, 9)
()の頭にtupleをつけることで、tupleを生成できる。
- 投稿日:2020-09-11T20:14:10+09:00
pythonでスゴロクゲームと足し算ゲーム
同じ変数への代入等あり
テキストにあった内容を使ってpythonの挙動確認と備忘録
30までの交互スゴロクゲーム
pl_pos = 1 com_pos = 1 while True: input("enter-playerが動く") pl_pos = pl_pos + random.randint(1,6) if pl_pos>30: pl_pos = 30 banmen() if pl_pos ==30: print("plのかち") break input("enter-comが動く") com_pos = com_pos + random.randint(1,6) if com_pos>30: com_pos = 30 banmen() if com_pos ==30: print("comのかち") break足し算ゲーム
A = random.randint(1,100) B = random.randint(1,100) correct = A + B ans = input("A = "+ str(A) + " B = "+str(B) +" A+Bの合計は?") if ans == str(correct): print("正解") else: print("違います" + str(correct) +"です")以上
- 投稿日:2020-09-11T20:10:48+09:00
Windows10でBleakを使ってSwitchBotを動かす
はじめに
この記事は、Windows10でBleakを用いたSwitchBotのBLE通信を行いたい人向けのチュートリアルの記事です。SwitchBotに接続して命令バイトを送信するまでを行います。言語はpythonです。
また、今回の記事ではSwitchBotを用いていますが、接続して命令バイトを送信しているだけなので、Bleakを用いたBLE通信として他のBrueTooth機器にも利用できると思います。(おそらく)要件
- Windows10
- python 3.7.6
- bleak 0.7.1
- SwitchBot
- Bluetooth_Dongle 5.0(PCに内蔵の送受信機がなければ必要)
SwitchBot
Bluetoothによって遠隔で操作できるスイッチです。複数の種類がありますが、今回は以下のSwitchBotを使用します
https://www.switchbot.jp/botBLE通信
BLE(Bluetooth Low Energy)通信はBluetoothバージョン4.0から追加された低電力でBluetooth機器と通信ができる規格です。この辺りは先人の記事を参考にして頂く方が分かりやすいと思います。
https://houwa-js.co.jp/blog/2018/06/20180629/
https://jellyware.jp/kurage/bluejelly/ble_guide.htmlWindows環境下でpybluesは使用できない
Windows環境下でSwitchBotのBLE通信を行いたい場合、主に使われているBLE通信のライブラリであるpybluezはWindowsでは使用できません。
(参考:https://atatat.hatenablog.com/entry/2020/07/09/003000#3-Bleak%E3%81%AE%E5%88%A9%E7%94%A8)
おまけに、SwitchBotにはPCでのBLE通信を行うためのgithubが公開されていますが、そちらはpybluesでのみ対応したコードなので、そのまま使用というわけには行きません。Bleakの利用
こちらの記事から、BleakというモジュールがWindows環境下のBLE通信に利用できるとあったため、利用します。以下のpipコマンドを実行します。
pip install bleakSwitchBotのMACアドレスを調べる
公式ドキュメントを参考にしながら、PC上で周辺のBluetooth機器を探索するプログラムを実行します。
Discover.pyimport asyncio from bleak import discover async def run(): devices = await discover() for d in devices: #見つかった機器のmacアドレス、名前、距離を表示 print(d.address,d.name,d.rssi) print(d) loop = asyncio.get_event_loop() loop.run_until_complete(run())ここで、SwitchBotが見つかった場合、SwitchBotのMACアドレスが表示されるのでそれをコピーしておきます。
見つからない場合、こちらからBluetoothのドライバのダウンロードを行い、SwitchBotが正しく認識されるかを確認してください
また、SwitchBotの初期不良の可能性もあるので、Android/iOSアプリで提供されているSwitchBotアプリから接続テストを行うことをお勧めします。詳しい方法はSwitchbot同封のクイックスタートガイドに書かれています。SwutchBotとの接続
MACアドレスが取得できた場合、BLE通信を使ってSwitchBotに対して接続→命令を送信 を行っていきます。以下のプログラムは作成した接続、送信のサンプルです。
Bleak_Connect_SwitchBot.pyimport asyncio from bleak import discover async def run(): import asyncio from bleak import BleakClient import time #switchbotのMacアドレス.[Discover.py]で調べる必要がある address = " " #switchbotのUUID.SwitchBotのgithubから発掘した UUID = "cba20002-224d-11e6-9fb8-0002a5d5c51b" async def run(address, loop): async with BleakClient(address, loop=loop) as client: #同期ミスを防止するため一時停止。 time.sleep(5) #以下で接続テスト。[Connected: False]と表示されると接続に失敗している x = await client.is_connected() print("Connected: {0}".format(x)) #現在のswitchbotの状態を確認 y = await client.read_gatt_char(UUID) print(y) print("接続に成功しました。コマンドを入力してください。\nコマンド → press,on,off,exit") while True: #入力受け取り。コマンド毎に送信する命令を変更する。exitなら終了する command = input() if command == "press": write_byte = bytearray(b'\x57\x01\x00') elif command == "on": write_byte = bytearray(b'\x57\x01\x01') elif command == "off": write_byte = bytearray(b'\x57\x01\x02') elif command == "exit": #[exit]と入力した場合、1秒後に終了 await asyncio.sleep(1.0, loop=loop) break else: print("コマンドを入力してください。\nコマンド → press,on,off,exit") continue #switchbotに命令を送信 await client.write_gatt_char(UUID, write_byte) #現在のswitchbotの状態を確認 y = await client.read_gatt_char(UUID) print(y) #同期ミスが起こるので一時停止 time.sleep(2) #bleakによるswitchbotとの通信開始 loop = asyncio.get_event_loop() loop.run_until_complete(run(address, loop))このプログラムでは、接続に成功した場合、標準入出力から入力を待機します。次のコマンドが入力できます。
- press : SwitchBotのon,offを切り替える (b'\x57\x01\x00')
- on : SwitchBotをonにする(b'\x57\x01\x01')
- off : SwitchBotをoffにする(b'\x57\x01\x02')
- exit : 終了する
行いたい動作に合わせて命令バイトを切り替え、client.write_gatt_char(UUID, write_byte)によってSwitchbotに命令を送信します。SwitchBotが正しく動けば成功です。
まとめ
Windows環境下でSwitchBotによるBLE通信(python)のやり方について説明しました。本記事で説明した内容は接続と送信しかできておらず、SwtichBotのモード切替などをどのように行うかは自分の勉強不足でまだわかっていません。
今後公式ドキュメントやgithubからモードの切り替え方法等が見つかった際には追記、別記事にて記述したいと考えています。
追記(2020/09/11):SwitchBotAPIではBlueZを使っているためWindowsでは利用できませんでした。https://github.com/RoButton/switchbotpy
- 投稿日:2020-09-11T20:09:13+09:00
メモ : CmdStanPyの環境をdockerで用意する
「StanとRでベイズ統計モデリング」を読むために、CmdStanPy環境をdockerで用意しました。CmdStanPyの環境構築については日本語の資料はほとんどなさそうだったので、もしかしたら誰かの役に立つかもしれないと思い、メモに残しておきます。
はじめに
公式documentにもある通り、PyStanを既にインストールした環境を使っている方はご注意ください。
Note for PyStan users: PyStan and CmdStanPy should be installed in separate environments. If you already have PyStan installed, you should take care to install CmdStanPy in its own virtual environment.
他にも依存性の問題などでもろもろ面倒になりそうなので、筆者はdockerで環境を用意しました1。
CmdStanPyとは
PythonによるCmdStanの軽量wrapper
- 公式document : https://cmdstanpy.readthedocs.io/en/latest/index.html
- github : https://github.com/stan-dev/cmdstanpy
なぜCmdStanPyか?
PythonからStanを使いたい場合、一般的にはPyStanを利用することが多いかと思います2。ではなぜCmdStanPyを使うことにしたかというと、PyStanより(現状では)速く動くからです。
詳しい経緯は以下の通りです :
筆者も最初はPyStan環境を用意したのですが、Eight schoolsという簡単な例(PyStanのdocumentのこの部分参照)でのモデルのコンパイルに1分以上かかってしまいました。
筆者のインストール方法が悪かったのか、はたまたこれが普通なのか調べたところ、StanのCommunityでのこちらのやりとりを見つけました。曰く、
Stan compilation speedup was introduced in Stan 2.20, but Rstan is only up to Stan 2.19.2.
right now we have lightweight wrappers CmdStanPy 11 (still in beta) and CmdStanR 18 (almost to beta release) which use the latest CmdStan (now at 2.21, 2.22 coming soon) - or any version of CmdStan that you’d like.
このやりとり自体は2年前だったのですが、筆者のPyStan環境のPyStanのversionを確認すると2.19.1.1で、speedup導入前のもののようでした3。また、こちらのStackoverflowの書き込みでも、CmdStanPyにすることで3倍以上コンパイルが速くなったとの記述がありました。
そこで、CmdStanPyを試してみることにしました。
環境
- OS : macOS Mojave 10.14.6
- docker : 19.03.12
Dockerでの環境構築
DockerfileFROM ubuntu:20.04 RUN apt-get -y update RUN apt-get -y install python3 RUN apt-get -y install python3-pip RUN pip3 install --upgrade pip RUN pip3 install cmdstanpy[all] RUN python3 -c 'import cmdstanpy; cmdstanpy.install_cmdstan()' WORKDIR /workdirこのDockerfile4があるdirectoryで次のようにbuildし(YOUR_TAGは適当なTAG名に変えてください)、
docker image build -t YOUR_TAG .起動します(localのソースコードを利用したいので、カレントディレクトリを
/workdirにマウントしています。)docker container run -it --rm --net=host \ --mount type=bind,src=`pwd`,dst=/workdir \ YOUR_TAG \ bash実行
dockerコンテナを起動したディレクトリに
- stan file(
8schools.stan5)- データ(
8schools.data.json)- python script(
run-cmdstanpy.py)を用意しておきます。
8schools.standata { int<lower=0> J; // number of schools vector[J] y; // estimated treatment effects vector<lower=0>[J] sigma; // s.e. of effect estimates } parameters { real mu; real<lower=0> tau; vector[J] eta; } transformed parameters { vector[J] theta; theta = mu + tau * eta; } model { eta ~ normal(0, 1); y ~ normal(theta, sigma); }8schools.data.json{ "J": 8, "y": [28, 8, -3, 7, -1, 1, 18, 12], "sigma": [15, 10, 16, 11, 9, 11, 10, 18] }run-cmdstanpy.pyfrom cmdstanpy import CmdStanModel print("Compile started") model = CmdStanModel(stan_file="8schools.stan") print("Compile finished") print(model) print("========================================") data = "8schools.data.json" print("Sampling started") fit = model.sample(data=data) print("Sampling finished") print(fit)「Dockerでの環境構築」の節で起動したコンテナ内の
/workdirでpython3 run-cmdstanpy.pyを実行して以下のような結果が出ればひとまず成功です。Compile started INFO:cmdstanpy:compiling stan program, exe file: /workdir/8schools INFO:cmdstanpy:compiler options: stanc_options=None, cpp_options=None INFO:cmdstanpy:compiled model file: /workdir/8schools Compile finished CmdStanModel: name=8schools stan_file=/workdir/8schools.stan exe_file=/workdir/8schools compiler_optons=stanc_options=None, cpp_options=None ======================================== Sampling started INFO:cmdstanpy:start chain 1 INFO:cmdstanpy:start chain 2 INFO:cmdstanpy:start chain 3 INFO:cmdstanpy:start chain 4 INFO:cmdstanpy:finish chain 3 INFO:cmdstanpy:finish chain 1 INFO:cmdstanpy:finish chain 4 INFO:cmdstanpy:finish chain 2 Sampling finished CmdStanMCMC: model=8schools chains=4['method=sample', 'algorithm=hmc', 'adapt', 'engaged=1'] csv_files: /tmp/tmpd0ii4fo_/8schools-202009110125-1-0qknvwdc.csv /tmp/tmpd0ii4fo_/8schools-202009110125-2-qfoj4mom.csv /tmp/tmpd0ii4fo_/8schools-202009110125-3-cbn8wxph.csv /tmp/tmpd0ii4fo_/8schools-202009110125-4-h_5980t6.csv output_files: /tmp/tmpd0ii4fo_/8schools-202009110125-1-0qknvwdc-stdout.txt /tmp/tmpd0ii4fo_/8schools-202009110125-2-qfoj4mom-stdout.txt /tmp/tmpd0ii4fo_/8schools-202009110125-3-cbn8wxph-stdout.txt /tmp/tmpd0ii4fo_/8schools-202009110125-4-h_5980t6-stdout.txt deleting tmpfiles dir: /tmp/tmpd0ii4fo_ doneCmdStanPyの詳しい使い方などは公式document をご覧ください。
appendix : PyStanとの速度比較
PyStanとの速度比較についても軽く記録しておきます。stan fileはいずれも「実行」の節に書いた
8schools.stanで共通です。CmdStanPy
docker環境は「Dockerでの環境構築」に書いたとおりのものです。python fileは次のものを用いました:
test-cmdstanpy.pyfrom cmdstanpy import CmdStanModel import time print("Compile started") t1 = time.time() model = CmdStanModel(stan_file="8schools.stan") t2 = time.time() data = "8schools.data.json" print("Sampling started") t3 = time.time() fit = model.sample(data=data) t4 = time.time() print("Compile time :", t2 - t1, "seconds") print("Sampling time :", t4 - t3, "seconds")PyStan
利用したDockerfileは次の通りです:
DockerfileFROM ubuntu:20.04 RUN apt-get -y update RUN apt-get -y install python3 RUN apt-get -y install python3-pip RUN pip3 install --upgrade pip RUN pip3 install pystan WORKDIR /workdir「Dockerでの環境構築」と同様にbuild, 起動します。また、python fileは以下のものを利用しました。:
test-pystan.pyimport pystan import time schools_dat = {'J': 8, 'y': [28, 8, -3, 7, -1, 1, 18, 12], 'sigma': [15, 10, 16, 11, 9, 11, 10, 18]} print("Compile started") t1 = time.time() sm = pystan.StanModel(file='8schools.stan') t2 = time.time() print("Sampling started") t3 = time.time() fit = sm.sampling(data=schools_dat, iter=1000, chains=4) t4 = time.time() print("Compile time :", t2 - t1, "seconds") print("Sampling time :", t4 - t3, "seconds")結果
CmdStanPy
Compile time : 12.916020393371582 seconds Sampling time : 0.16101527214050293 secondsPyStan
Compile time : 98.87509870529175 seconds Sampling time : 0.45189523696899414 seconds何度か測ってみましたが、モデルのコンパイルについては、基本的にCmdStanPyがPyStanより7倍程度速いという結果になりました67。
ただし、筆者はdockerを雰囲気で使っているところがあるので、ここに書いたdocker環境の構築法は最善のものでない可能性があります。 ↩
「Python Stan」でGoogle検索して真っ先に出てきたのはPyStanのdocumentとgithubのpageでした。 ↩
PyStanのversionの数字がStanのversionの数字と対応しているという認識であっているのでしょうか...? ↩
CmdStanPyのインストールを行う部分の詳細は https://cmdstanpy.readthedocs.io/en/latest/getting_started.html#installation を参照。 ↩
PyStanのgetting started のページからダウンロードしました。 https://pystan.readthedocs.io/en/latest/getting_started.html ↩
CmdStanPyの場合は「exe fileとstan fileの更新時刻を比べて、後者が前者より新しい場合はコンパイルをしない」という気の利いた機能がついているので、繰り返し測る場合はご注意ください。 ↩
PyStanのbase imageをubuntu:16.04にしたときはPyStanも50秒程度で済んだのですが、原因は調べていません。 ↩
- 投稿日:2020-09-11T19:52:57+09:00
Python フォルダ内の全Zipを解凍処理(再帰的)文字化け対応 (Qiita初投稿)
初Qiita投稿
普段はRとかPythonとデータ可視化をTableauでやっています。ZipをPythonで解凍したいけど文字化けするしてしまうとき
import
from zipfile import ZipFile文字化けしないで解凍
for file in zip_files: with ZipFile(file) as zip: for info in zip.infolist(): info.filename = info.filename.encode('cp437').decode('cp932') zip.extract(info)人によってはunicodeとかでもできるらしい。
これで解凍できます。Qiita初投稿
何年も私、助けられすぎているので少しずつノウハウを更新できれば。
がんばります
- 投稿日:2020-09-11T19:51:19+09:00
LambdaでDynamoDBに複数レコードの書き込みをする(Python、JavaScript)
はじめに
DynamoDBに複数レコードを書き込み(更新)する必要があったので、実装してみた結果と注意的なものを書き留めたいと思い記事を投稿した
またPythonとNode.jsの両方での実装を載せようと思います前提
テーブル
今回書き込みをするテーブルは以下を想定
テーブル名:Users
カラムと型(スキーマ自体に型はありませんが、登録するデータの型として便宜上決めておきます)は以下の通り
- id(primary key):Number
- name:String
- address:String
- friends: List[Map]
friendはid, name, addressのキーを持つMapの一覧を想定
今回は複雑めな型(Userテーブルのfriendのような型)であっても、書き込みができることも示しておきたいことの一つなので、そもそもテーブルの設計がベストであるかは一旦無視でいきますLambdaの準備
今回はLambda上で動くコードを掲載するので、Lambdaは各自で準備ができていることを前提とします
記事の流れ
全体のコード例 → 軽い解説
の手順で書いていき、最後に共通する補足事項を載せるPythonでの実装
import boto3 from boto3.dynamodb.conditions import Key def update_users(table, users_friends): with table.batch_writer() as batch: for n in range(3): batch.put_item( Item={ "id": n + 1, "name": "user" + str(n + 1), "address": "address" + str(n + 1), "friends": users_friends[n] } ) def lambda_handler(event, context): try: dynamoDB = boto3.resource("dynamodb") table = dynamoDB.Table("Users") user1_friends = [ { "id": 2, "name": "user2", "address": "address2" }, { "id": 3, "name": "user3", "address": "address3" } ] user2_friends = [ { "id": 1, "name": "user1", "address": "address1" }, { "id": 3, "name": "user3", "address": "address3" } ] user3_friends = [ { "id": 1, "name": "user1", "address": "address1" }, { "id": 2, "name": "user2", "address": "address2" } ] users_friends = [user1_friends, user2_friends, user3_friends] update_users(table, users_friends) return event["message"] # 返すものは適当 except Exception as e: print(e)軽く解説
コードの書き方云々や書き込むデータ自体については本質ではないので、スルーしてもらって大丈夫です
大事なのはupdate_users関数の中身で、DynamoDBのモデルのインスタンスに生えているbatch_writeメソッドを使っているということ
すなわち、複数書き込みをしたいときは以下のブロック内でPUTをするwith table.batch_write() as batch: # ...略また、
PUTする際には例でいうとbatch.put_itemを呼び出してやる
こいつのItemという名前の引数に書き込みの内容を記述していく
そしてもう一点注目したいのが、List[Map]という型であっても問題なく書き込むことができるという点
基本的にどんな型でも指定したキーの値としてちゃんとDBに書き込めるので、要するにItemには更新したい辞書をそのまま渡してあげれば問題ない
最後にちょっとした補足として、batch_writeのブロック内でfor文を回しているが、当然batch.put_itemをベタで複数回書いていってもよいので、もしfor文では書けないときはベタでやればいい
また、一度にできる書き込める上限は25件までと言われているが、どうやら25件以上の場合は再送してくれたりよしなにやってくれているらしいので、件数を気にせずコードを書いていけるっぽいNode.jsでの実装
const AWS = require("aws-sdk"); const dynamoDB = new AWS.DynamoDB.DocumentClient({ region: "ap-northeast-1" }); const tableName = "Users"; exports.handler = (event, context) => { const user1Friends = [ { id: 2, name: "user2", address: "address2" }, { id: 3, name: "user3", address: "address3" } ]; const user2Friends = [ { id: 1, name: "user1", address: "address1" }, { id: 3, name: "user3", address: "address3" } ]; const user3Friends = [ { id: 1, name: "user1", address: "address1" }, { id: 2, name: "user2", address: "address2" } ]; const usersFriends = [user1Friends, user2Friends, user3Friends] const params = { RequestItems: { [tableName]: usersFriends.map((e, i) => ({ PutRequest: { Item: { id: i + 1, name: `user${i + 1}`, address: `address${i + 1}`, friends: e } } })) } }; // callbackは適当 dynamoDB.batchWrite(params, (e, data) => { if (e) { context.fail(e); } else { context.succeed(data); } }); };軽い解説
Pythonでの解説で述べたようにコードやデータの値そのものに関してはスルー
ここで大事なのはAWS.DynamoDB.DocumentClientにあるbatchWriteというプロパティ(関数)
こいつの引数は結構癖があるのでClass: AWS.DynamoDB.DocumentClient — AWS SDK for JavaScriptを参照してください
Node.jsでの複数書き込みについて調べたときによく出てくるのはbatchWriteItemだったのですが、現在(2020年9月時点)のLambdaで用意されている最新のNode.jsの実行環境だとどうやらないっぽいので、動かず意外と手こずる
batchWriteItemとの大きな違いはItemのオブジェクトがDynamoDB特有の型付きのオブジェクト(name: { "S": "user" }みたいなやつ)である必要がなくなっている点
要するに書き込みたい値を気にせずそのままJSONにしてItemの値として渡せば問題なく動く
そのため、当然Map[List]という複雑な型であってもそのまま渡せば書き込み可能です全体の補足
バッチ処理で更新(update)をしたいときは
PUTを使うしかない
理由は単純でUPDATEがないからで、仕方ないので地道にPUTで記述していく必要がある
またバッチ処理内ではDELETEをすることができるので、今回はフォーカスしませんでしたが、一応あるということだけ言っておきます・・・おわりに
いかがでしたでしょうか
複数操作についてはコードと1, 2行程度の解説がある記事はちょこちょこ見かけますが、書き込みに特化して解説されているのはあまり見かけず(あっても複雑な型でもできるのか不明であったり、そもそも実行時エラーになってしまう)、多少やってて手こずったので、備忘の意味も兼ねて書き残してみました
若干ニッチな分野かもしれないですが、少しでも役に立てて貰えれば幸いです参考
Amazon DynamoDB — Boto3 Docs 1.14.56 documentation
Class: AWS.DynamoDB.DocumentClient — AWS SDK for JavaScript
- 投稿日:2020-09-11T17:55:03+09:00
Keras好きがPyTorchに挑戦してみた
はじめに
ずっとKerasでばかりDeep Learningのプログラムを書いてきたが、いよいよPyTorchで書かなくてはいけない状況になってきたので、お勉強がてら、MNISTを例にとりあえず動くものを作ってみました。
まずはチュートリアル
とりあえず最初はチュートリアルだろうということで、PyTorchのチュートリアルを最初から始めてみました。
しかし、これが実に分かりづらい。
「Autograd」が感覚的につかめず、モチベーションが10%以下まで落ち込みました。今では、最初からではなく、「What is torch.nn really?」から初めて、わからないところを調べたほうがよかったと思っています。
バックアップ
そんな予感がしていたので、チュートリアルを始めるとともに、書籍の購入を行いました。
色々調べて、以下の2冊を選びました。
- 「現場で使える!PyTorch開発入門」
- 同じシリーズでkerasが分かりやすかったので、信用買い
まずはこの本から読んでいこうかと思っています- 「つくりながら学ぶ! PyTorchによる発展ディープラーニング」
- ネットでの評判がよいのと、著者の方のQiita記事が分かりやすかったので
ただ、届いてみると分厚く、持ち運びにはちょっと辛いこちらは、写経しながら、これからじっくりと読んでいこうと思います。
そしてMNIST
ということで、やっぱり最初はMNISTだろ?ということで、PyTorch公式のコードを参考に、必要な部分だけ抜き出して、自分がわかりやすいように改造してみました。
環境
とりあえずWindows 10+Anaconda+CUDAでやってます。
import
from __future__ import print_function import argparse import torch import torch.nn as nn import torch.optim as optim from torch.optim.lr_scheduler import StepLR from torchvision import datasets, transforms from torchsummary import summary基本的にはサンプルの万ですが、確認用に「torchsummary」を増やしました。
残念ながらcondaではインストールできないので、pipでインストールしました。
あと、torchvisionもバージョンが合わず、GUIからインストールできませんでした。(condaでインストールしました)パラメータ
seed = 1 epochs = 14 batch_size = 64 log_interval = 100 lr = 1.0 gamma = 0.7サンプルでは引数になってましたが、必要な変数だけ抜き出して固定値にしました。
値はデフォルトになっていた数値です。(log_intervalだけ変えました)モデル
class Net(nn.Module): def __init__(self): super(Net, self).__init__() self.conv1 = nn.Conv2d(1, 32, kernel_size=3, stride=1) self.conv2 = nn.Conv2d(32, 64, kernel_size=3, stride=1) self.relu = nn.ReLU(inplace=True) self.maxpool = nn.MaxPool2d(kernel_size=2) self.dropout1 = nn.Dropout2d(0.25) self.dropout2 = nn.Dropout2d(0.5) self.fc1 = nn.Linear(9216, 128) self.fc2 = nn.Linear(128, 10) def forward(self, x): x = self.conv1(x) x = self.relu(x) x = self.conv2(x) x = self.relu(x) x = self.maxpool(x) x = self.dropout1(x) x = torch.flatten(x, 1) x = self.fc1(x) x = self.relu(x) x = self.dropout2(x) x = self.fc2(x) output = nn.functional.log_softmax(x, dim=1) return outputなるべく__init__()で内部変数にしました。
nn.functional.log_softmax()はnn.Softmax()にすると負の値になるので、泣く泣くforward()に残しました。
flatten()とともに気持ちが悪いので、何とかしたいです。なお、モデルをSequential APIで書くことも考えたのですが、今後これをベースにいろいろいじりそうな気がするので、Functional APIのままにしました。
学習
def train(model, device, train_loader, optimizer, epoch): model.train() for batch_idx, (data, target) in enumerate(train_loader): data, target = data.to(device), target.to(device) optimizer.zero_grad() output = model(data) loss = nn.functional.nll_loss(output, target) loss.backward() optimizer.step() if batch_idx % log_interval == 0: print('Train Epoch: {} [{}/{} ({:.0f}%)]\tLoss: {:.6f}'.format( epoch, batch_idx * len(data), len(train_loader.dataset), 100. * batch_idx / len(train_loader), loss.item()))基本的にはサンプルのままです。
nn.functional.nll_loss()が気にいらないのですが、自分で式を書くのも汚くなるので、そのままにしています。なお、呼び出し側でepochを回し、ここでバッチを回すという仕組みは、わかりやすくて気に入っています。
評価
def test(model, device, test_loader): model.eval() test_loss = 0 correct = 0 with torch.no_grad(): for data, target in test_loader: data, target = data.to(device), target.to(device) output = model(data) test_loss += nn.functional.nll_loss(output, target, reduction='sum').item() # sum up batch loss pred = output.argmax(dim=1, keepdim=True) # get the index of the max log-probability correct += pred.eq(target.view_as(pred)).sum().item() test_loss /= len(test_loader.dataset) print('\nTest set: Average loss: {:.4f}, Accuracy: {}/{} ({:.0f}%)\n'.format( test_loss, correct, len(test_loader.dataset), 100. * correct / len(test_loader.dataset)))ここでもnn.functional.nll_loss()の部分が気に入らないのですが、目をつぶります。
PyTorchには「predict」という概念がないようなので、あとで学習済みモデルを使って推論するときは、このあたりのコードが参考になると思っています。
(まだ推論のコードは書いていません)view_as()とか、まだまだ勉強しなくてはいけない関数が残っています。
メイン処理
torch.manual_seed(seed) device = torch.device("cuda" if torch.cuda.is_available() else "cpu")まず、ランダムの種を埋め込み、実行環境(CUDA)を指定します。
transform=transforms.Compose([ transforms.ToTensor(), transforms.Normalize((0.0,), (1.0,)) ]) kwargs = {'batch_size': batch_size, 'num_workers': 1, 'pin_memory': True, 'shuffle': True} dataset1 = datasets.MNIST('../data', train=True, download=True, transform=transform) dataset2 = datasets.MNIST('../data', train=False, transform=transform) train_loader = torch.utils.data.DataLoader(dataset1,**kwargs) test_loader = torch.utils.data.DataLoader(dataset2, **kwargs)次に、MNISTデータセットを読み込みます。
読み込んだ時に、平均0、標準偏差1にしてます。(ここはサンプルから変えました)で、データローダーを用意します。こいつはなかなか便利です。
こいつでデータ拡張してくれないかなと期待しています。(まだ調べていない)model = Net().to(device) summary(model, (1,28,28)) optimizer = optim.Adadelta(model.parameters(), lr=lr) scheduler = StepLR(optimizer, step_size=1, gamma=gamma)モデルを作成し、その内容を表示しています。
torchsummary、優れものです。keras好きの人は必須です。これ見ないと安心できないです。
ちなみに、今回はこんな感じに表示されます。---------------------------------------------------------------- Layer (type) Output Shape Param # ================================================================ Conv2d-1 [-1, 32, 26, 26] 320 ReLU-2 [-1, 32, 26, 26] 0 Conv2d-3 [-1, 64, 24, 24] 18,496 ReLU-4 [-1, 64, 24, 24] 0 MaxPool2d-5 [-1, 64, 12, 12] 0 Dropout2d-6 [-1, 64, 12, 12] 0 Linear-7 [-1, 128] 1,179,776 ReLU-8 [-1, 128] 0 Dropout2d-9 [-1, 128] 0 Linear-10 [-1, 10] 1,290 ================================================================ Total params: 1,199,882 Trainable params: 1,199,882 Non-trainable params: 0 ---------------------------------------------------------------- Input size (MB): 0.00 Forward/backward pass size (MB): 1.04 Params size (MB): 4.58 Estimated Total Size (MB): 5.62 ----------------------------------------------------------------見慣れた表示でうれしいです。
そういえば、配列の順番が違っているのは注意が必要です。ずっと(バッチ, 高さ, 幅, チャンネル)だったので(バッチ, チャンネル, 高さ, 幅)に違和感を感じます。あと、最適化アルゴリズムと学習率の調整方法を決めます。簡単に学習率を変える仕組みを組み込めるのはいいですね。
for epoch in range(1, epochs + 1): train(model, device, train_loader, optimizer, epoch) test(model, device, test_loader) scheduler.step()epochで学習を回していきます。
学習→評価→学習率調整
と、非常にわかりやすいです。学習済みモデルの保存/読み込み
torch.save(model.state_dict(), "mnist_cnn.pt") model.load_state_dict(torch.load("mnist_cnn.pt"))おまけで、学習済みモデルの保存方法と読み込み方法を書いておきました。
バイナリエディタで中身を見てみたのですが、さっぱりでした。まとめ
まだなじめないですが、以下の特徴があると感じました。
- 流れがつかみやすい
- 細かく記述ができる
- コード量が増える
もっと勉強します!
- 投稿日:2020-09-11T17:54:13+09:00
set型で利用できるメソッド
set型で利用できるメソッド
以下の例では数上記のを使用しましたが、文字列でも同様に動作します。
- union()メソッド
重複のない和集合を返すメソッドです、演算子「 | 」と同じように使えます。
a1 = {1, 2, 3}
a2 = {2, 3, 4}
a3 = {aa, bb, cc}
a3 = {bb, cc, dd}union_a = a1.union(a2)
print(union_a)
# {0, 1, 2, 3}上記のような結果となります。union()メソッドは重複しない和集合を返すので「2,3」が重複して返って来ることはないです。
- intersection()メソッド
重複している集合体を返します。演算子「 & 」と同じように使えます。
a1 = {1, 2, 3}
a2 = {2, 3, 4}intersection_a = a1.intersection(a2)
print(intersection_a)
# {2, 3}上記のような結果となります。intersection()メソッドは重複している集合を返すので「2,3」が返って来ます。
- difference()メソッド
差集合を返します。演算子「 - 」と同じように使えます。
以下の例では「a1」に存在して「a2」存在しないものを返します。a1 = {1, 2, 3}
a2 = {2, 3, 4}difference_a = a1.difference(a2)
print(difference_a)
# {1}「4」は「a2」のみに存在しているもののため返ってきません。
- symmetric difference()
対比差を返します。演算子「 ^ 」と同じように使えます。
a1 = {1, 2, 3}
a2 = {2, 3, 4}symmetric_difference_a = s1.symmetric_difference(s2)
print(symmetric_difference_a )
# {1, 4}「a1」と「a2」で重複しない箇所が返ってきます。
- add()
setの値に引数が追加されます。
a= {1, 2, 3}
a.add(4)
print(a)
# {1, 2, 3, 4}s = set()
s.add(aa)
s.add(bb)
s.add(cc)
print(s)
# {aa, bb, cc}
- remove()
引数を削除します。削除する要素として渡された引数が登録されていない場合「KeyError」が発生します。
a= {1, 2, 3}
a.remove(3)
print(a)
# {1, 2}
- 投稿日:2020-09-11T17:26:50+09:00
【PySpark】dataframe操作サンプルコード集
筆者はpython・dataframe・glue等の事前知識がなく都度対応しているので効率的でない、間違っているやり方もあると思います。
その際はご指摘いただけると助かります。環境構築
AWS Glueのテスト環境をローカルに構築の記事を参考に開発環境を構築
記事内では対話式だがpythonファイルを実行する際は
/aws-glue-libs/bin/gluesparksubmit /src/sample.py --JOB_NAME='dummy'
のようなコマンドを実行すればpythonファイルの実行が可能となる。
docekr run -v
コマンドでボリュームをマウントすればローカルでファイル編集が可能。サンプルデータの作成
都度ファイルの読み込みは面倒なので配列からdataframeを作成しており、そのコードが以下
from pyspark.sql.types import StructField from pyspark.sql.session import SparkSession from pyspark.sql.types import StructType from pyspark.sql.types import StringType row_schema = StructType( [ StructField("name", StringType(), True), StructField("code", StringType(), True) ] ) spark = SparkSession.builder.master("local").appName("sample").config("spark.some.config.option", "some-value").getOrCreate() values = [ ("あいうえお", "4") ] df = spark.createDataFrame(values, row_schema)カラム追加
df = df.withColumn('column_name', 'value')正規表現で置換
df = df.withColumn('name', F.regexp_replace('goagle', 'go+gle', 'o'))正規表現で文字列を抽出して置換
df = df.withColumn("name", F.regexp_extract('1234foo', '^\d{3,4}', 0))特定の条件時に先頭0埋めでカラムを追加
df = df.withColumn("new_name", F.when(F.col("name").rlike("^\d{3,4}"), lpad(F.regexp_extract(F.col('name'), '^\d{3,4}', 0), 6, '0')))カラムのリネーム
right_df.withColumnRenamed('name', 'new_name')カラム削除
left_df = left_df.drop('name')結合
left_df = left_df.join(right_df, left_df.name == right_df.name, 'left_outer')
left_outerのところにはinner、cross、outer、full、left、left_outer、right、right_outer、left_semi、left_antiのどれかが入る改行文字で行を分割(その他のレコードは同じ値を入れる)
row_schema = StructType( [ StructField("name", StringType(), True), StructField("code", StringType(), True) ] ) spark = SparkSession.builder.master("local").appName("sample").config("spark.some.config.option", "some-value").getOrCreate() values = [ ("\nあいう\nえお", "4") ] df = spark.createDataFrame(values, row_schema) df = df.withColumn('name', F.split(F.col('name'), '\n')) # ameを配列化 df = df.select(F.explode(F.col('name')).alias('name'), 'code') # 分割処理結果
+---------+-------+ |name |code | +---------+-------+ |あいう |4 | |えお |4 | +---------+-------+改行文字で行を分割し行数のカラムを追加(その他のレコードは同じ値を入れ)
row_schema = StructType( [ StructField("name", StringType(), True), StructField("code", StringType(), True) ] ) spark = SparkSession.builder.master("local").appName("sample").config("spark.some.config.option", "some-value").getOrCreate() values = [ ("\nあいう\nえお", "4") ] df = spark.createDataFrame(values, row_schema) df = df.withColumn('name', F.split(F.col('name'), '\n')) # nameを配列化 df = df.select(F.posexplode(F.col('name')).alias('index', 'name'), 'code') # 分割処理結果
+-----+---------+-------+ |index|name |code | +-----+---------+-------+ |0 |あいう |4 | |1 |えお |4 | +-----+---------+-------+メモ
Athenaのviewテーブルは参照できない
An error occurred while calling o59.getCatalogSource. : java.lang.Error: No classification or connection in db_name.table_nameAthenaのviewテーブルを参照しようとするとエラーメッセージが表示された。
2020年8月現在viewテーブルは参照できないようです。
- 投稿日:2020-09-11T16:20:26+09:00
Python組み込み関数~Zip~
はじめに
今回の記事では、Pythonの組み込み関数である「zip関数」について取り上げていきたいと思います。
僕自身以前から「zip関数」の存在を知っていて、なんとなく使っているくらいなので、今回を期に「zip関数」の理解を深めていきたいと思います。zip関数とは?
そもそも「zip関数」とはなんでしょうか?
簡単に言えば引数に与えられた複数のリストをまとめるものです。
もっとしっかり知りたいという方はこちらをご覧ください。
Python 標準ライブラリ基本的な使い方
基本的な使い方としては、for文で使うものが上げられます。
#名前と年齢のリストを作成 names = ['sato', 'suzuki', 'ito'] ages = [23, 21, 25] for name, age in zip(names, ages): print('名前:{}, 年齢:{}'.format(name, age)) # 名前:sato, 年齢:23 # 名前:suzuki, 年齢:21 # 名前:ito, 年齢:25このように2つのリストをまとめることができます。
3つのリストでも可能です。
#名前と年齢と出身地のリストを作成 names = ['sato', 'suzuki', 'ito'] ages = [23, 21, 25] birthplaces = ['東京都', '愛知県', '北海道'] for name, age, birthplace in zip(names, ages, birthplaces): print('名前:{}, 年齢:{}, 出身地:{}'.format(name, age, birthplace)) # 名前:sato, 年齢:23, 出身地:東京都 # 名前:suzuki, 年齢:21, 出身地:愛知県 # 名前:ito, 年齢:25, 出身地:北海道リストをまとめたい時に便利なことがわかると思います。
まとめるだけであればもっと短くすることができます。
list(zip(names, ages)) #[('sato', '23'), ('suzuki', '21'), ('ito', '25')]こうするとタプルで返ってきます。
unzip(元に戻す)
zipでまとめたものを元に戻すにはどうすれば良いでしょうか?
答えは引数に「*」をつければできます。zips = list(zip(names, ages)) names2, ages2 = zip(*zips) print(names2) #('sato', 'suzuki', 'ito') print(ages2) #(23, 21, 25)このようにタプルで返ってきます。
リストで出力したい場合は、「list()」で囲めば良いです。zips = list(zip(names, ages)) names2, ages2 = list(zip(*zips)) print(names2) #[('sato', 'suzuki', 'ito')] print(ages2) #[(23, 21, 25)]リストの長さが違う時
ではリストの長さが違うときはどのようになるのかみていきましょう。
#名前と年齢のリストを作成 names = ['sato', 'suzuki', 'ito', 'kato', 'saitou'] ages = [23, 21, 25] for name, age in zip(names, ages): print('名前:{}, 年齢:{}'.format(name, age)) # 名前:sato, 年齢:23 # 名前:suzuki, 年齢:21 # 名前:ito, 年齢:25これをみると短い方に合わせていることがわかります。
リストの長さが違う時に値を埋める
先ほどはリストの長さが違うときは、短い方に合わせることを確認できたと思います。
では、長い方に合わせるのはどうしたら良いのか。
それは「zip_longestモジュール」を使用すればできます。
詳しくはこちらをみてください。
zip_longestモジュールではみていきましょう。
#名前と年齢のリストを作成 names = ['sato', 'suzuki', 'ito', 'kato', 'saitou'] ages = [23, 21, 25] for name, age in zip_longest(names, ages): print('名前:{}, 年齢:{}'.format(name, age)) # 名前:sato, 年齢:23 # 名前:suzuki, 年齢:21 # 名前:ito, 年齢:25 # 名前:kato, 年齢:None # 名前:saitou, 年齢:Noneこのように「None」で埋められていることが確認できます。
「None」だと味気ないので、代わりに平均年齢を入れていきましょう。#zip_longestのインポート from itertools import zip_longest #名前と年齢のリストを作成 names = ['sato', 'suzuki', 'ito', 'kato', 'saitou'] ages = [23, 21, 25] #平均年齢を算出 age_mean = sum(ages) // len(ages) #fillvalueで埋める値を指定 for name, age in zip_longest(names, ages, fillvalue=age_mean): print('名前:{}, 年齢:{}'.format(name, age)) # 名前:sato, 年齢:23 # 名前:suzuki, 年齢:21 # 名前:ito, 年齢:25 # 名前:kato, 年齢:23 # 名前:saitou, 年齢:23年齢の平均値で埋められていることが確認できます。
最後に3つ以上のリストの長さがバラバラな時を確認しましょう。
#zip_longestのインポート from itertools import zip_longest #名前と年齢と出身地のリストを作成 names = ['sato', 'suzuki', 'ito'] ages = [23, 21, 25] birthplaces = ['東京都', '愛知県', '北海道', '山梨県'] #平均年齢を算出 age_mean = sum(ages) // len(ages) #fillvalueで埋める値を指定 for name, age, birthplace in zip_longest(names, ages, birthplaces, fillvalue=age_mean): print('名前:{}, 年齢:{}, 出身地:{}'.format(name, age, birthplace)) # 名前:sato, 年齢:23, 出身地:東京都 # 名前:suzuki, 年齢:21, 出身地:愛知県 # 名前:ito, 年齢:25, 出身地:北海道 # 名前:kato, 年齢:23, 出身地:山梨県 # 名前:saitou, 年齢:23, 出身地:23出力結果を確認すると一番最後の行の出身地が「23」になっています。
このように埋める値は1つしかしていできないので注意が必要です。その際の対策はこの記事を参考にしてください。
Python, zip関数の使い方: 複数のリストの要素をまとめて取得最後に
今回は「zip関数」について取り上げました。
お役に立てれば幸いです。
これからも関数やモジュールについての記事を上げていくので、よければ見ていってください。
- 投稿日:2020-09-11T16:12:28+09:00
RADEXの環境構築で詰まったメモ
環境
・MacBook Pro 2017
・Mojave 10.14.5RADEXの環境構築
下記のページ通りに環境を構築する手順を踏む.
https://personal.sron.nl/~vdtak/radex/index.shtml#install
ソースコードをダウンロードし,解凍.
$ tar xf radex_public.tar作成された
Radexディレクトリ内のsrcに移動.$ cd Radex/src
Makefileを編集し,makeする際のコンパイラを指定.最初は編集せずにデフォルトのgfortranを使用する.
Radex.incを編集し,分子データの置き場所と光子の脱出確率の計算方法を指定.parameter(radat = '/.../Radex/data/')parameter (method = 1) ! uniform sphere
srcディレクトリで$ makeを叩く.
すると長々とエラーーーーーー.
$ make gfortran -O2 -c main.f -o main.o gfortran -O2 -c io.f -o io.o io.f:47:62: 47 | $ molfile = radat(1:length(radat))//molfile(1:length(molfile)) | 1 Warning: Character length of actual argument shorter than of dummy argument 'st' (120/200) at (1) [-Wargument-mismatch] io.f:47:36: 47 | $ molfile = radat(1:length(radat))//molfile(1:length(molfile)) | 1 Warning: Character length of actual argument shorter than of dummy argument 'st' (120/200) at (1) [-Wargument-mismatch] io.f:47:36: 47 | $ molfile = radat(1:length(radat))//molfile(1:length(molfile)) | 1 Warning: Character length of actual argument shorter than of dummy argument 'st' (120/200) at (1) [-Wargument-mismatch] io.f:48:36: 48 | write(13,20) molfile(1:length(molfile)) | 1 Warning: Character length of actual argument shorter than of dummy argument 'st' (120/200) at (1) [-Wargument-mismatch] io.f:52:36: 52 | write(13,20) outfile(1:length(outfile)) | 1 Warning: Character length of actual argument shorter than of dummy argument 'st' (120/200) at (1) [-Wargument-mismatch] io.f:234:31: 234 | $ //version(1:length(version)) | 1 Warning: Character length of actual argument shorter than of dummy argument 'st' (20/200) at (1) [-Wargument-mismatch] io.f:234:31: 234 | $ //version(1:length(version)) | 1 Warning: Character length of actual argument shorter than of dummy argument 'st' (20/200) at (1) [-Wargument-mismatch] io.f:234:31: 234 | $ //version(1:length(version)) | 1 Warning: Character length of actual argument shorter than of dummy argument 'st' (20/200) at (1) [-Wargument-mismatch] gfortran -O2 -c readdata.f -o readdata.o gfortran -O2 -c matrix.f -o matrix.o gfortran -O2 -c background.f -o background.o background.f:405:72: 405 | if (h.eq.0.d0) pause 'Warning: bad xin input in splintrp ' | Warning: Deleted feature: PAUSE statement at (1) gfortran -O2 -c slatec.f -o slatec.o slatec.f:824:72: 824 | IF (INCX .EQ. INCY) IF (INCX-1) 5,20,60 | Warning: Fortran 2018 deleted feature: Arithmetic IF statement at (1) slatec.f:1204:72: 1204 | IF (INCX .EQ. INCY) IF (INCX-1) 5,20,60 | Warning: Fortran 2018 deleted feature: Arithmetic IF statement at (1) slatec.f:1512:72: 1512 | IF (INCX .EQ. INCY) IF (INCX-1) 5,20,60 | Warning: Fortran 2018 deleted feature: Arithmetic IF statement at (1) gfortran -O2 main.o io.o readdata.o matrix.o background.o slatec.o -o radex strip radex install -m 755 -p -s radex ../bin/ rm *.o rm radex引数の文字数が合ってないらしいので,編集.
io.f内のFUNCTION length(str)を編集.radex.inc内のcharacterに一致させた.CHARACTER*200 str → CHARACTER*120 strすると,
length(radat)に関するエラーは消えた.length(version)のエラーも消しにかかる.
radex.inc内のversionのcharacterを変更.radatに揃える.character*20 version → character*120 version
length(version)のエラーも消えた.しかし,
gfortran -O2 -c background.f -o background.o background.f:405:72: 405 | if (h.eq.0.d0) pause 'Warning: bad xin input in splintrp ' | Warning: Deleted feature: PAUSE statement at (1) gfortran -O2 -c slatec.f -o slatec.o slatec.f:824:72: 824 | IF (INCX .EQ. INCY) IF (INCX-1) 5,20,60 | Warning: Fortran 2018 deleted feature: Arithmetic IF statement at (1)この2種類のエラーが消えない.
Homebrewで古いgccをダウンロードしてみる.現時点でもっとも新しいのは9.1.0なので一個前をインストール.
$ brew install gcc@8その後,
MakefileのコンパイラをFC = gfortran-8に変更.
するとFortran 2018 deleted featureのエラーは消え,PAUSE statementのみに.直接
background.fを編集.if (h.eq.0.d0) pause 'Warning: bad xin input in splintrp ' → if (h.eq.0.d0) then write(*,*) 'Warning: bad xin input in splintrp ' read(*,*) endifエラーなくなった!
- 投稿日:2020-09-11T16:10:01+09:00
cos類似度の実装【Pytorch, Tensorflow】
SimCLRなどの対照学習(Contrastive Learning)の手法で,特徴量空間における類似度の指標として用いられるものの一つにCos(コサイン)類似度があります.
Tensorflow,Pytorchそれぞれで実装を行ったので,メモ程度に記録しておきます.(参考までに)
Pytorch
# input_sizeは (batchsize*次元数) def cosine_matrix(a, b): dot = torch.matmul(a, torch.t(b)) norm = torch.matmul(torch.norm(a, dim=1).unsqueeze(-1), torch.norm(b, dim=0).unsqueeze(0)) return dot / normTensorflow
def cosine_matrix(a, b): a_normed, _ = tf.linalg.normalize(a, axis=-1) b_normed, _ = tf.linalg.normalize(b, axis=-1) matrix = tf.matmul(a_normed, b_normed, transpose_b=True) return matrix
- 投稿日:2020-09-11T16:10:01+09:00
cos類似度行列の実装【Pytorch, Tensorflow】
SimCLRなどの対照学習(Contrastive Learning)の手法で,特徴量空間における類似度の指標として用いられるものの一つにCos(コサイン)類似度があります.
Tensorflow,Pytorchそれぞれで実装を行ったので,メモ程度に記録しておきます.(参考までに)
Pytorch
# input_sizeは (batchsize*次元数) def cosine_matrix(a, b): dot = torch.matmul(a, torch.t(b)) norm = torch.matmul(torch.norm(a, dim=1).unsqueeze(-1), torch.norm(b, dim=0).unsqueeze(0)) return dot / normTensorflow
def cosine_matrix(a, b): a_normed, _ = tf.linalg.normalize(a, axis=-1) b_normed, _ = tf.linalg.normalize(b, axis=-1) matrix = tf.matmul(a_normed, b_normed, transpose_b=True) return matrix
- 投稿日:2020-09-11T15:47:34+09:00
Python - execとevalの違い
はじめに
皆さんはexec関数や、eval関数を使って、エラーが起きたことはありますか?
僕の場合は、結構よく引っ掛かりました。
この記事では、exec関数とeval関数について、簡単な解説と例を挙げて説明します。exec関数とは
exec関数は、文を実行する関数です。
例えば、sample.pyexec("x=5") print(x) #実行結果: 5この例ではexec関数は、xに5を代入するという文を実行させています。
sample.pyx = exec("5+5") print(x) #実行結果: Noneexec関数は、文を実行する関数なので、式を渡しても実行結果を返しません。
eval関数とは
eval関数は、式を計算して結果を返す関数です。
例えば、sample.pyx = eval("5+5") print(x) #実行結果: 10exec関数では式を渡しても計算結果を返しませんでしたが、eval関数は返しました。
sample.pyeval("x=5") print(x) #SyntaxError: invalid syntax in line 1eval関数は、式を計算する関数なので、文を渡すとSyntaxErrorを起こします。
最後に
この記事を読んで、exec関数とeval関数の違いについて参考になったことはありましたか?
もし意見があったら、コメント欄に書いておいてください。
- 投稿日:2020-09-11T15:35:56+09:00
LibTorch(PyTorch C++)アプリをCMakeを(最初だけしか)使わずにWindowsでGPU有効ビルド
要約
- サンプルソースコードを用意して、CMakeで
*.slnと*.vcxprojを出力。*.vcxprojからプロパティシートを作成。- 次からはVisual Studioの「空のプロジェクト(など)」にプロパティシートを適用すれば、簡単にGPU有効でEXEをビルドできる。
初めに
他のライブラリと連携するために、できればCMakeを挟まずにVisual StudioだけでLibTorchアプリを作りたい、という状況になった。(設定次第でCMakeでできると思うが)
VisualStudioだけでもインクルードパスや依存ファイルを設定すればCPU版LibTorchは使えるが、いろいろな所をこねくり回してもGPU有効にならなかった。
CMakeを使えば(まあまあ)簡単にGPU有効のアプリがビルドできるが、Visual StudioだけでGPU有効にする記事が自分が探した限りだと無かったため、ここに記す。また、筆者はCMakeやC++、Visual Studioに精通はしていないので、より良い情報があればご教示ください。
実行環境
OS: Windows 10 Enterprise
CPU: Core i7-8700K
GPU: RTX 2080 SUPER
RAM: 8.0x2 GBVisual Studio 2019 Community
CUDA 10.1
cuDNN 7.5.1
LibTorch 1.6.0
C++17
CMake 3.18.0準備
まず、PyTorch公式サイトからLibTorchをダウンロード。
Debug版とRelease版両方ダウンロードする。
ダウンロードしたライブラリを解凍して、C直下に移動。
Debug版を"Debug"、Release版を"Release"と名前を変え、フォルダ階層を以下のようにする。
C:\libtorch\1_6_0\(Debug, Release)\(bin, include, libなど)\.....次にCUDA10.1を公式サイトからダウンロードしてインストールする。
環境変数PATHへの追加を必ずする。次にcuDNN 7.5.1を公式サイトからダウンロードして、
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v10.1
へ、bin, include, libをコピーする。
ダウンロードにはアカウント作成が必要。CMakeでビルドシステムを出力し、プロパティシートを作成
CMakeでソリューションを作成
CMakeを使って、ビルドシステム(Visual Studioのソリューションやプロジェクトファイル)を出力する。
ここではコマンドで操作するが、VSCodeならば直感的にCMakeを操作できるのでオススメ。
適当な場所にフォルダを作り(ここでは、D直下にcmake_sampleフォルダを作成)、sample.cppとCMakeLists.txtを作成する。
2つのファイルを以下のように編集する。また、今回はC++17を対象とする。sample.cpp#include <iostream> #include <torch/torch.h> int main() { torch::DeviceType device_type; if (torch::cuda::is_available()) { std::cout << "CUDA available!\n"; device_type = torch::kCUDA; } else { std::cout << "CPU only.\n"; device_type = torch::kCPU; } torch::Device device(device_type); auto tensor = torch::randn({2, 3}); tensor = tensor.to(device); std::cout << tensor << std::endl; }CMakeLists.txtcmake_minimum_required(VERSION 3.0 FATAL_ERROR) project(cmake_sample) set(CMAKE_CXX_STANDARD 17) #add find_package(Torch REQUIRED) set(CMAKE_CXX_FLAGS "${CMAKE_CXX_FLAGS} ${TORCH_CXX_FLAGS}") add_executable(sample sample.cpp) target_link_libraries(sample "${TORCH_LIBRARIES}") # set_property(TARGET example-app PROPERTY CXX_STANDARD 14) # The following code block is suggested to be used on Windows. # According to https://github.com/pytorch/pytorch/issues/25457, # the DLLs need to be copied to avoid memory errors. if (MSVC) file(GLOB TORCH_DLLS "${TORCH_INSTALL_PREFIX}/lib/*.dll") add_custom_command(TARGET sample POST_BUILD COMMAND ${CMAKE_COMMAND} -E copy_if_different ${TORCH_DLLS} $<TARGET_FILE_DIR:sample>) endif (MSVC)
x64_x86 Cross Tools Command Prompt for VS 2019を管理者権限で開き、以下のコマンドを実行していく。$ D: $ cd cmake_sample $ mkdir build $ cd build $ cmake .. -G "Visual Studio 16 2019" -DCMAKE_PREFIX_PATH=C:\libtorch\1_6_0\Debug実行結果
プロパティシートの作成(Debug構成)
buildフォルダ内に
cmake_sample.slnという名前のVisual Studioのソリューションができているので開く。
構成をDebug|x64へ変更してビルド(Ctrl + Shift + B)。
プロジェクトsampleをスタートアップへ変更してF5。
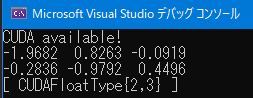
CUDA available!とCUDAFloatTypeのテンソルが表示されれば、正しくビルドできている。
CPUになってしまった場合、ファイルの配置、環境変数、コマンドを見直す。
実行が上手くいったことを確認したら、Visual Studioで「空のプロジェクト」を作成し、プロパティマネージャを開く。
Debug|x64を右クリック、新しいプロジェクトプロパティシートを追加し、プロパティシートlibtorch_1_6_0.propを作成する。
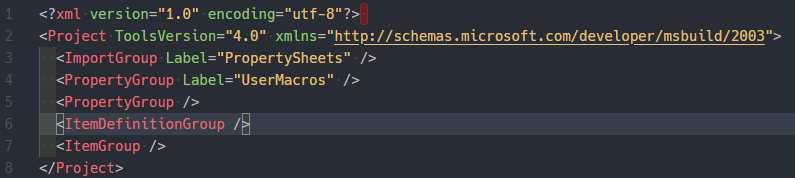
テキストエディタでプロパティシートを開き、<ItemDefinitionGroup />の行を削除。
テキストエディタで
sample.vcxprojファイルを開く。
sample.vcxprojの、
<ItemDefinitionGroup Condition="'$(Configuration)|$(Platform)'=='Debug|x64'">
から
</ItemDefinitionGroup>
までをコピーし、libtorch_1_6_0.prop内の<Project>タグ内へペースト。
この時、sample.cppに依存する部分は全て消去する。
両者を保存して閉じる。プロパティシートの作成(Release構成)
(先程とほとんど同じのため、いくつか省略している。)
buildフォルダ内の
CMakeCache.txtを削除する。(重要)
その後、buildフォルダ内で次のコマンド$ cmake .. -G "Visual Studio 16 2019" -DCMAKE_PREFIX_PATH=C:\libtorch\1_6_0\Releaseを実行し、buildフォルダ内のVisual Studioのソリューションを開く。
構成をRelease|x64へ変更、ビルドして実行。
CUDA available!とCUDAFloatTypeのテンソルが表示されれば、正しくビルドできている。実行が上手くいったことを確認したら、またプロパティシート
libtorch_1_6_0.propをテキストエディタで開く。
テキストエディタでsample.vcxprojファイルを再度開く。
sample.vcxprojの、
<ItemDefinitionGroup Condition="'$(Configuration)|$(Platform)'=='Release|x64'">
から
</ItemDefinitionGroup>
までをコピーし、libtorch_1_6_0.prop内の<Project>タグ範囲内へペースト。
両者を保存して閉じる。動作確認
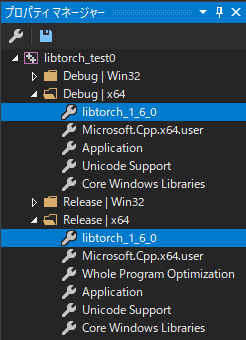
VisualStudioで適当な「空のプロジェクト」を作成する。
プロパティマネージャのDebug|x64とRelease|x64へlibtorch_1_6_0.propを追加する。
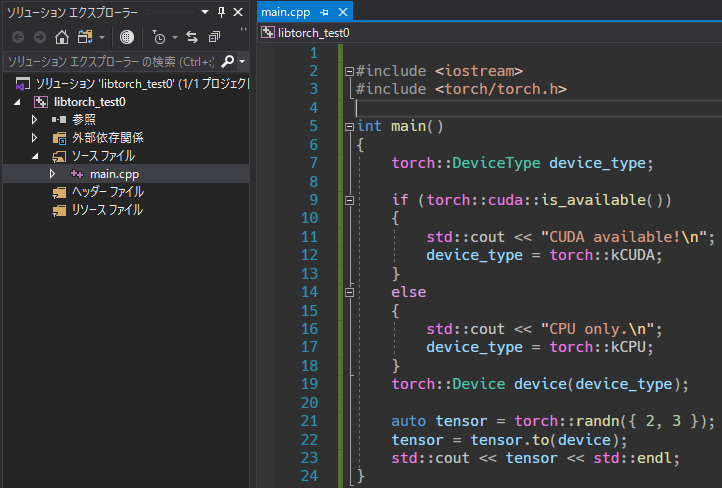
ソースファイルを追加し、先ほどの
sample.cppと同じ内容を書き込む。
構成を
Debug|x64へ変更してF5。
また、構成を
Release|x64へ変更してF5。
初回は
*.dllをコピーしてくるため、実行に時間が掛かる。
両者においてCUDA available!とCUDAFloatTypeのテンソルが表示されれば、正しく設定ができている。
ブレークポイントを打ってデバッグ実行が効くかどうか試してみても良い。次からはこのプロパティシートを使いまわすことで、GPU対応のプログラムをすぐに作成できる。
結言
もっときれいにやる方法はないだろうか



- 投稿日:2020-09-11T14:46:48+09:00
リモートルンバを作ろう【ソフトウェア編】
はじめに
本記事はリモートルンバを作ろう【ハードウェア編】の続編となります。まだ前編をご覧になられていない方ははじめにそちらをご覧ください。
目標
今回は前回までに準備したルンバを実際に制御していきます。
環境
使用したプログラミング言語はPython3.7です。ラズパイOSには標準でインストールされているかと思います。一般的にルンバを制御する場合ROSを用いる方が多いようなのですが、当方ROSはあまり使ったことがなく慣れておりません。今後のルンバを発展させる上で柔軟性や理解し易さの観点から、本記事ではPythonのみを使用したルンバの制御となります。
ソースコード
1.制御
1-1.実機準備
基本的にはルンバを制御するコードはiRobotが公式にだしている仕様書iRobot Roomba 500 Open Interface (OI) Specificationに公開されており、それをシリアル信号でルンバに送ればそれ通りの動作を行ってくれます。(仕様書には500と記載されていますがどのシリーズでもコマンドに変更はありません)
しかしながらこの仕様書を読んでいくと、細かな動作を行うにはそれなりにコードを上手く記述しなければなりません。そこでMartin Schaef氏が過去にPython用ルンバAPIを製作して公開してくださっているのでそちらを拝借いたします。
martinschaef/roomba
↑ソースコードはこちらです。問題はこのコード自体は古く、Python2.7用にプログラムされている点です。したがって該当コードをコピペしただけでは全く動作しません。自らで多少修正する必要があります。
修正するコードは
create.pyです。こちらが大元のルンバAPIとなります。はじめに、このコードではシリアル用コマンドがすべて
chr型で記述されています。create.pySTART = chr(128) # already converted to bytes... BAUD = chr(129) # + 1 byte CONTROL = chr(130) # deprecated for Create SAFE = chr(131) FULL = chr(132) POWER = chr(133) SPOT = chr(134) # Same for the Roomba and Create CLEAN = chr(135) # Clean button - Roomba etc...このコードをPython3で実行した場合、以下のようなエラーが返ってきます。
TypeError: unicode strings are not supported, please encode to bytes: '\x80'意味合いは、シリアル通信に
str型は対応していませんという意味です。しかしこれがPython2.7ではしっかり動作します。これはいったい?その答えは Python 2 と Python 3 でchr型の扱いが変わったという事です。具体的には以下のように変更されています。
Python2 Python3 int to bytes chr(i) bytes([i]) ここでわたしはドツボにはまってしまったのですが、よく見ると
bytes型は()の中に[]を用いて数字を記載する必要があるという事です。皆様はお忘れなく記載ください。ところで単に
chr型をbytesに変換するだけなら.encode()を付随させればいいのでは、と思われる方も多いと思います。たしかにそうするとプログラム自体のエラーは無くなるのですが、ルンバは全く動作しません。そこで.encode()を付随させた場合の文字列を確認してみると以下のように表記されます。128 b'\xc2\x80' 129 b'\xc2\x81' 130 b'\xc2\x82' 131 b'\xc2\x83' 132 b'\xc2\x84' 133 b'\xc2\x85'本来、16進数で数値を送信する場合は
0x80または/x80と表記されるはずです。しかし結果では全ての値に/xc2という値が付随してしまっています。これは何かというとUTF-8であるという情報が加えられているという事です。たしかに思えば単純なint型を変換したのではなく、str型をバイトに変換しているのでその情報も付け加えられていたのです。したがってこの場合はU+0081という値が変換されていたことのなるわけで、この結果から単純に.encode()を付随させた場合ではルンバは動作しないわけであります。ですので皆様には大変お手数ですが、このコード内で
chr(i)型に該当する箇所全てをbytes([i])に変換していただきたく存じます。create.pySTART = bytes([128]) # already converted to bytes... BAUD = bytes([129]) # + 1 byte CONTROL = bytes([130]) # deprecated for Create SAFE = bytes([131]) FULL = bytes([132]) POWER = bytes([133]) SPOT = bytes([134]) # Same for the Roomba and Create CLEAN = bytes([135]) # Clean button - Roomba etc...また上記の修正で動作自体はするようになるのですが、本来記載されていた
create.pyprint 'Serial port did open, presumably to a roomba...' ↓ print('Serial port did open, presumably to a roomba...')ここまで来ましたら、実際にルンバと接続できているか試してみましょう。確認には以下のコードを用います。
test_roomba.pyimport create import time ROOMBA_PORT="/dev/ttyAMA0" robot = create.Create(ROOMBA_PORT) robot.printSensors() robot.toSafeMode() robot.go(0,10) robot.close()ラズパイとルンバを接続して上記のコードを実行すると、ルンバのセンサーの値を取得してコマンドラインに表示され、ルンバは多少回転するはずです。
もしエラーが出力され
KeyError:とか表示された場合は、ルンバとラズパイが上手く接続されていない可能性があります。考えられる要因として1.ルンバが起動していない、2.ケーブルが断線している、という2つがあります。前者の場合はルンバ中央のCLEANボタンを軽く押して起動させ再度試してみてください。後者の場合はケーブルの導通をご確認ください。また、センサーの値は取得できるがルンバが全く動かないという方は以下のコードを実行してみてください。
test_roomba.pyimport serial ser = serial.Serial('/dev/ttyAMA0', 115200) ser.write(b'0x80')上記のコードでルンバが充電ドックを探し始めた場合は、シリアル通信がRS232Cレベルで行われている可能性があります。TTLレベルに変換しなおして再度接続してください。
次にキーボードからの入力によるルンバ制御を行います。先ほどのMartin Schaef氏のソースコードmartinschaef/roombaから
game.pyを多少修正して使用します。game.pyROOMBA_PORT = "/dev/tty.usbserial-DA017V6X" ↓ ROOMBA_PORT = "/dev/ttyAMA0"元のソースコードでは接続先が異なっているので、21行目を上記のように修正してください。
game.pyif event.key == pygame.K_x: robot.seekDock() time.sleep(2.0) pygame.quit() returngame.pyscreen.blit( font.render("Clean Mode Roomba with c, press key x make Roomba back to the dock.", 1, (10, 10, 10)), (10, 580))またリモート制御時に自動で充電ドックに戻る機能が欲しかったので、上記のコードを115行目と166行目にそれぞれ追加しました。
最後にこれらの実行ファイルがあるディレクトリに新たに
imgフォルダを製作し、その中にroomba.pngを置いて実機の準備は完了です。1-2.ホストコンピュータ準備
リモートでルンバを制御したいのでこちらも準備が必要です。VcXsrv(Xサーバー)を利用してラズパイに表示される制御画面をホストコンピュータに移します。
VcXsrv(Xサーバー)をWindowsにインストールしてLinuxのGUIをリモート操作する
↑この項目の詳細はこちらの方のページに大変詳しく、わかりやすくまとめられております。こちらをご参照ください。1-3.動作確認
上記の項目がすべて完了すると実際にルンバを制御できるようになります。早速Python3で実行してみてください。詳しい制御方法は表示された画面に記載されてるとは思いますが、一応簡単にご説明いたしますと、
wで前進、sで後退、a、dそれぞれで左右方向へ回転です。spaceで一時ポーズでescで終了となっております。その他各センサーのリアルタイムに取得された値が表示されていると思います。2.映像転送
次にWebカメラで取得した映像データをホストコンピューターへ転送するプログラムを作っていこうと思います。はじめはopen_cvを用いてラズパイ上で映像を開き、そのウインドウをVcXsrvでホストコンピュータへ転送しようと思ったのですが、あまりうまくいかなかったのでsocket通信による映像転送の方法を取ることにしました。
ライブラリに
opencv-pythonをpipでインストールしてください。尚、現在最新であるopencvのバージョン4.4.0.42をインストールしようとするとPython3.7の場合、永遠にビルトが終わらないことがあります。そういう場合は少しバージョンを下げて4.1.0.25あたりでインストールするとすんなりいくようです。pip3 install opencv-python==4.1.0.25以下がラズパイ上で実行するプログラムです。
video_server.pyimport socketserver import cv2 import sys HOST = "192.168.XXX.XXX"#ここはラズパイのIPアドレス PORT = 5569 class TCPHandler(socketserver.BaseRequestHandler): videoCap = '' def handle(self): self.data = self.request.recv(1024).strip() ret, frame = videoCap.read() encode_param = [int(cv2.IMWRITE_JPEG_QUALITY), 100] jpegsByte = cv2.imencode('.jpeg', frame, encode_param)[1].tostring() self.request.send(jpegsByte) videoCap = cv2.VideoCapture(0) socketserver.TCPServer.allow_reuse_address = True server = socketserver.TCPServer((HOST, PORT), TCPHandler) try: server.serve_forever() except KeyboardInterrupt: server.shutdown() sys.exit()以下がホストコンピュータで実行するプログラムです。
video_client.pyimport socket import numpy import cv2 HOST = "192.168.XXX.XXX"#ここはラズパイのIPアドレス PORT = 5569 def getimage(): sock=socket.socket(socket.AF_INET,socket.SOCK_STREAM) sock.connect((HOST,PORT)) buf=b'' recvlen=100 while recvlen>0: receivedstr=sock.recv(1024*8) recvlen=len(receivedstr) buf += receivedstr sock.close() narray=numpy.fromstring(buf,dtype='uint8') return cv2.imdecode(narray,1) while True: img = getimage() cv2.imshow('Capture',img)これらのプログラムを
server.pyから起動させ、上手く接続されるとホストコンピュータ側に映像が転送されているはずです。3.自動起動
最後にラズパイの電源を入れるとこれまでのプログラムが自動で起動するように設定します。Systemdに則ってサービスファイルを作成していきます。
ラズパイにて
/etc/systemd/system/に移動してroomba.serviceファイルを作成してください。内容は以下のものを記載してください。[Unit] Description = Roomba [Service] ExecStart=/bin/bash /home/pi/roomba.sh Restart=always [Install] WantedBy=multi-user.targetここでわざわざシェルスクリプトで各プログラムを起動しているのは、今後も変更が行われることを考慮して楽に編集できるようにするためです。
したがって次に
/home/pi/roomba.shファイルを作成してください。#!/bin/sh sudo python3 /home/pi/roomba/server.py & sudo python3 /home/pi/roomba/game.py &サービスを確認して有効にして完了です。
$ sudo systemctl enable roomba $ sudo systemctl start roombaまとめ
ここまででとりあえずホストコンピュータから映像と制御の2つが確認できるはずです。
↑こんな感じで表示されているかとおもいます。実際操作してみると、カメラの映像だけでは大変難しく、また既存のコードである
game.pyではカーブする際にかなりぎこちない動作をするようです。ただ、わざわざすべての処理をPythonで行っているだけあって自由度は非常に高いはずです。自動運転のプログラムや画像処理による人物検知など、追加できそうなシステムはたくさんあるのでいろいろ発展させていこうと思います。皆さんも是非ためしてみてください。
最後までお付き合いいただきありがとうございました。
参考文献
1.iRobot Roomba 500 Open Interface (OI) Specification
2.martinschaef/roomba
3.Python 2 と Python 3 のユニコード文字列、バイト列の違いメモ
4.PythonとOpenCVで動画送信

- 投稿日:2020-09-11T14:45:39+09:00
リモートRoombaを作ろう【ハードウェア編】
はじめに
皆さんはルンバは制御できるという事をご存じでしたか?ルンバには標準でシリアルポートが搭載されており、そのポートを使用すれば任意にプログラムしたとおりにルンバを動かすことができるそうです(大分昔から有名な話だそうで)。
私も最近ルンバを手に入れ、せっかくなので色々遊んでみることにしました。最後までお付き合いいただけると幸いです。
目標
本記事ではルンバをリモートで操作することを目標にしています。【ハードウェア編】と【ソフトウェア編】で記事は分かれており、今回はルンバを制御する前の下準備についてまとめたものとなります。
某ウイルスの影響で帰れない実家等でも、ルンバがあれば気軽にリモートで帰省とかできちゃうかも。
使用機器
1.Roomba
制御可能なルンバには限りがあります。基本的には500、600、700、800シリーズまでしかシリアルポートはないそうです。しかし900シリーズにはシリアルポートの代わりにmicroUSBが搭載されているようです。ところで上記のルンバは多少古いシリーズなので、最近ではヤフオク等で非常に安く手に入れることが可能です。もしお持ちでない方はこれを機に一台入手してみてはいかがでしょうか?
【iRobot Roomba770】ジャンクエッセイ
↑ みたいな感じでジャンク品でも手入れすると結構使えますよ。2.Raspberry Pi
ラズベリーパイは制御するのに使用します。GPIOがあれば基本的にはどのタイプでも大丈夫ですが、リモートで操作したい場合には3がお勧めです。3 Model B+や4といった上位機種は電力消費がこれよりも増加するため、モバイルバッテリーで駆動しなくなる可能性が非常に高いというのが理由です。
3.モバイルバッテリー
ラズパイ駆動用です。USB Type-Aで2.4[A]以上の供給力がある必要があります。
4.Webカメラ
リモートで操作する際に映像も見たいので使用します。USB接続であればなんでも大丈夫だと思います。オートフォーカス機能とかあると便利かも。
5.ルンバとラズパイの接続ケーブル
ルンバとラズパイを接続する際に使用します。が、基本的にこのケーブルは売っていないので自作する必要があります。ので、下記に作り方を記載しておきました。外見に特にこだわりのない方はオス-メスのジャンパーワイヤーでも大丈夫です。
製作
1.接続ケーブル製作
はじめにケーブルを作っていきます。Mini-DIN7Pinのオスのコネクターを用意します。秋葉原では千石通商の2Fとかで150円くらいで入手できます。
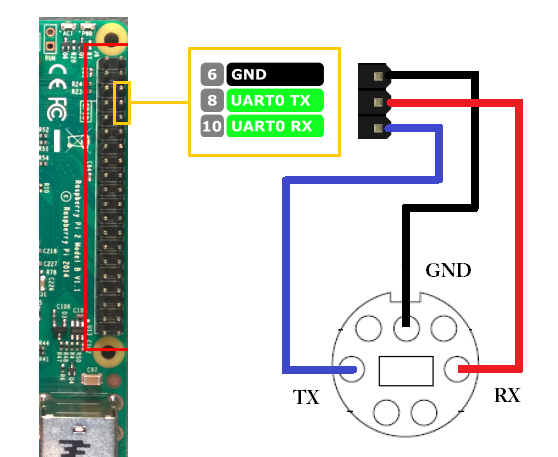
iRobotが公式にだしているルンバの仕様書によると、シリアルの送受信には3,4番ピンが使用されるそうです。また、シリアル通信の信号レベルが0-5[V]と記載されているためRS232Cの信号レベルではなく、TTLレベルでの通信が必要のようです。ですのでレベル変換機がないとコンピュータから直接制御することはできません。そこで今回はラズパイのGPIOとルンバを接続して通信させることにします。
具体的にはこの図のように配線します。お互いのTXとRXが接続するように配線してくださいね。TX-TXやRX-RXでは通信できないので注意してください。
余談ですがケーブルにはダイソー製300円スピーカーの3.5φステレオミニプラグケーブルが太さ長さ共に最適でお勧めです。(ただしスピーカーは使えなくなりますけど)
同じくダイソー商品の収縮チューブを使用すると見栄えもきれい製作にできるのでこれまたお勧めです。
2.ラズパイセットアップ
ラズパイを設定していきます。OSはRaspberry Pi OSが無難でよいと思います。
2-1.WiFiに接続
ラズパイを任意のWiFiに接続します。この場合はGUIからでもなんでも設定できればOKです。ですが後々ホストコンピューターからアクセスしたいので、固定IPをつけることをお勧めします。
Raspberry Pi 3 (Raspbian Jessie)の無線LANに固定IPアドレスを設定する
↑こちらの方の説明がわかりやすく参考になると思います。2-2.SSH有効化
その後コマンドラインによる制御を行っていきたいのでSSHを有効にします。
Raspberry Pi3のLAN外からのSSH接続設定方法
↑こちらの方の説明がわかりやすく参考になると思います。この場合だとまさしくローカルエリア外から接続する方法を詳しく説明なさっているので、リモートで制御するという意味では最適です。しかしはじめは動作だけ確認して楽しみたいという方はSSHのみ有効にしていただければOKです。2-3.ホストコンピュータからの接続
ターミナルはラズパイに接続できればなんでもOKです。当方ではTera Termを使用しております。任意のIPアドレスにユーザー名とパスワードを打ち込み接続できたらとりあえずアップデートしておきましょう。
$ sudo apt-get update $ sudo apt-get upgrade $ sudo apt-get dist-upgrade2-4.UARTの有効化
ラズパイはデフォルトでシリアル通信が無効化されているので有効化する必要があります。
Raspberry PiでUARTの有効化+シリアル通信
↑こちらの方の説明がわかりやすく参考になると思います。3.ケーブルの導通確認
とりあえずここまで来たら気になるのは正しくケーブルが製作できているかです。そこで実際に信号を送ってみてセルフで受信してみましょう。上手く導通していれば正しく受信できるはずです。
$pip3 install PySerialpython3にpipで上記のライブラリを追加してください。
test_serial.pyimport serial def main(): #'/dev/serial0' #'/dev/ttyAMA0' port = '/dev/ttyAMA0' ser = serial.Serial('COM3', 115200, timeout=0.1) while True: tx = bytes([128]) ser.write(tx) print("tx:", tx) rx = ser.readline() print("rx: ", rx) if __name__ == '__main__': main()使用言語はPython3.7です。これをラズパイ上で実行してMini-DINの3番ピンと4番ピンをクリップか何かでショートさせてください。上手くいけばショートしている間だけ
rx:b'\x80'という値を受信しているはずです。値が
rx:b''となっている方はどこかで断線している可能性が高いです。could not open port '/dev/ttyAMA0'となった方はUARTの有効化に失敗している可能性があるのでそちらをご確認ください。またラズパイでPythonを実行する際にデフォルトで2.7が呼び出されるようになっていますので、必ずPython3で実行するようにお願いいたします。(Python2には
bytesという関数がないはずなのでエラーになると思われます。)4.より快適に使用するために
ここからは余談です。ルンバを制御する際に各機器をルンバの上に置くとごちゃごちゃするし見栄えもあまりよくありません。そこでわたしはこんな感じにしてますよっていう紹介です。
こちらはダイソーに売っていた三脚と結束バンド。使用したWebカメラには三脚固定用のネジ穴があり、安価で丁度良いと思ってこの三脚を使用しました。カメラの画角も調整しやすいため、今後画像処理等のシステムを追加する際には最適です。また各機器はすべてこの三脚に固定しており、普通にルンバを使用する際は三脚をどけるだけでよいという構造になっております。
ラズパイそのものは付属のケースにあった固定用の穴を用いて、適当なサイズと厚さのプラバンに穴をあけ結束バンドで三脚に固定しました。モバイルバッテリーなどの取り外しを頻繁に行う機器には、マジックテープを貼り付け使用しています。次回
ここまで完了すればひとまずハードウェアのセットアップは完了です。しかしこれではルンバは動作しないので、次回、リモートRoombaを作ろう【ソフトウェア編】にて基本的なルンバ制御とカメラを用いたリモートシステムを構築していきたいと思います。
参考文献
1.iRobot Roomba 500 Open Interface (OI) Specification
2.Raspberry Pi 3 (Raspbian Jessie)の無線LANに固定IPアドレスを設定する
3.Raspberry PiでUARTの有効化+シリアル通信







- 投稿日:2020-09-11T12:43:45+09:00
【Maya Python】スクリプトの中身を噛み砕く3 ~List unknownPlugins編
この記事の目的
自作ツールの中身を一つ一つ確認しながら理解を深め、今後のツール開発に役立てます。
下記シリーズの続きです。1,2と重複する部分は省略します。ツール概要
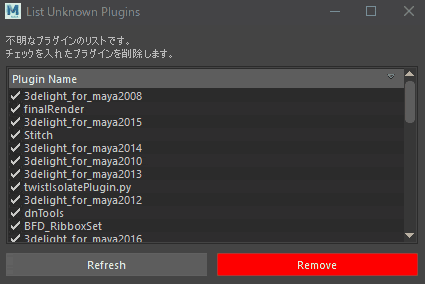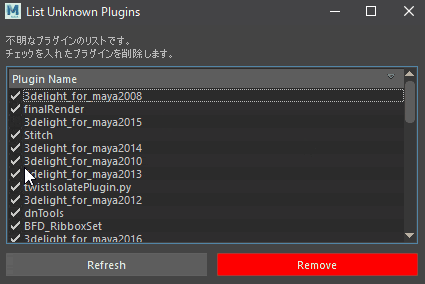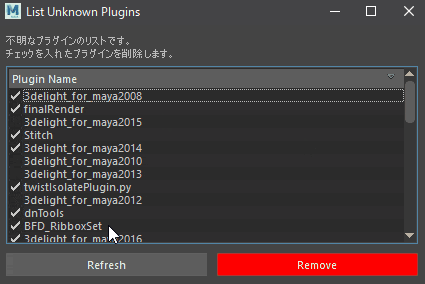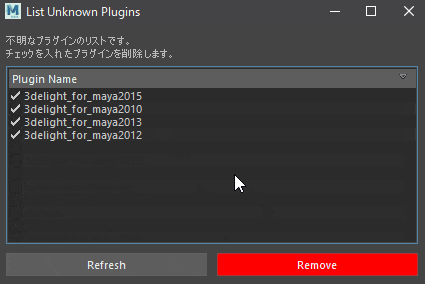
シーンに保存されているプラグイン読み込み情報を削除します。
妙にファイル読み込みに時間がかかる場合試してみてください。プラグイン情報をリストしチェックを入れた情報のみ削除します。
コード全文
# -*- coding: utf-8 -*- from maya.app.general.mayaMixin import MayaQWidgetBaseMixin from PySide2 import QtWidgets, QtCore, QtGui from maya import cmds class Widget(QtWidgets.QWidget): def __init__(self): super(Widget, self).__init__() layout = QtWidgets.QGridLayout(self) label = QtWidgets.QLabel( u'不明なプラグインのリストです。\n'\ u'チェックを入れたプラグインを削除します。') layout.addWidget(label, 0, 0) treeView = TreeView() layout.addWidget(treeView, 1, 0, 1, 2) self.standardItemModel = StandardItemModel() treeView.setModel(self.standardItemModel) button = QtWidgets.QPushButton('Refresh') button.clicked.connect(self.refresh) layout.addWidget(button, 2, 0) button = QtWidgets.QPushButton('Remove') # ボタンのバックグラウンドカラーを変更 button.setStyleSheet("background-color: red") button.clicked.connect(self.remove) layout.addWidget(button, 2, 1) self.refresh() # Refreshボタンの動作 def refresh(self): self.standardItemModel.removeRows(0, self.standardItemModel.rowCount()) # unknownPluginをリスト unknownPluginList = cmds.unknownPlugin(q=True,list=True) # unknownPluginがなければFalseを返す if not unknownPluginList: return False # アイテムにunknownPluginを追加 for name in unknownPluginList: self.standardItemModel.appendItem(name) return True # Removeボタンの動作 def remove(self): # rowカウントを取得 count = self.standardItemModel.rowCount() # rowカウント分繰り返す for num in range(count): # チェック状態と名前を取得 (check,name) = self.standardItemModel.rowData(num) # チェックされていればunknownPluginを消す if check: cmds.unknownPlugin(name,remove=True) print (u'deleted %s\n'%(name)), # リスト内容を更新 self.refresh() class TreeView(QtWidgets.QTreeView): def __init__(self): super(TreeView, self).__init__() self.setSelectionMode(QtWidgets.QTreeView.ExtendedSelection) self.setAlternatingRowColors(True) # ソートできるように変更 self.setSortingEnabled(True) class StandardItemModel(QtGui.QStandardItemModel): def __init__(self): super(StandardItemModel, self).__init__(0, 1) self.setHeaderData(0, QtCore.Qt.Horizontal, 'Plugin Name') def appendItem(self, name): standardItem = QtGui.QStandardItem() standardItem.setText(str(name)) standardItem.setEditable(False) # チェック項目を追加 standardItem.setCheckable(True) # チェック状態にする standardItem.setCheckState(QtCore.Qt.Checked) self.appendRow([standardItem]) def rowData(self, index): check = self.item(index, 0).checkState() name = self.item(index, 0).text() return (check,name) class MainWindow(MayaQWidgetBaseMixin, QtWidgets.QMainWindow): def __init__(self): super(MainWindow, self).__init__() self.setWindowTitle('List Unknown Plugins') self.resize(430, 260) widget = Widget() self.setCentralWidget(widget) def main(): window = MainWindow() window.show() if __name__ == "__main__": main()詳細をみていく
プログラム途中の改行
label = QtWidgets.QLabel( u'不明なプラグインのリストです。\n'\ u'チェックを入れたプラグインを削除します。')長いプログラムを改行する場合は
'で閉じ、最後に\を入れる。次に行の開始にはuをつける。ボタンの色を変える
# ボタンのバックグラウンドカラーを変更 button.setStyleSheet("background-color: red")ボタンの色を赤に変更。他にも枠を変えたり色々できる模様。
今回は消す動作の注意喚起の意味も込めて赤に設定。Removeボタンの動作
# Removeボタンの動作 def remove(self): # rowカウントを取得 count = self.standardItemModel.rowCount() # rowカウント分繰り返す for num in range(count): # チェック状態と名前を取得 (check,name) = self.standardItemModel.rowData(num) # チェックされていればunknownPluginを消す if check: cmds.unknownPlugin(name,remove=True) print (u'deleted %s\n'%(name)), # リスト内容を更新 self.refresh()rowの数を取得し、
rangeを使い、カウントアップ処理します。
countが5の場合、range(count)は0,1,2,3,4となり、各row番号からcheck,nameを取得します。
checkがTrueならプラグイン情報を削除し、プリントします。一通り処理したら
self.refreshでunknownPluginを再取得、リスト内容を更新します。アイテムにチェック項目を追加する
# チェック項目を追加 standardItem.setCheckable(True) # チェック状態にする standardItem.setCheckState(QtCore.Qt.Checked)アイテムにチェック項目を追加して、チェックできるようにします。
QStandardItemModelはアイテムごとにチェックボックスを追加できたり便利ですね。おわりに
今回は下記で作成したスクリプトの流用、一部改変で作成しました。
このようにPySideでUIを作っておけば中身は一部変更のみで様々なスクリプトが作れるようになります。
MayaでPythonスクリプトを作る際は、ぜひPySideでUIを作成してみてください。
- 投稿日:2020-09-11T12:43:31+09:00
h5pyのcompressionのベンチマークをとってみた
今回はデカい画像データをh5形式で保存しなおしました.
h5pyでは,以下の様に書くと変数をgzipで圧縮できます.x = cv2.imread("デカい画像1.png") y = cv2.imread("デカい画像2.png") with h5py.File("out.h5", "w") as f: f.create_dataset("data1", data=X, compression="gzip", compression_level=4) f.create_dataset("data2", data=y, compression="gzip", compression_level=4)何度かやった結果の平均とかではないので,時間については不確かです.
圧縮レベル 出力ファイルサイズ(GB) 出力時間(sec) 読み込み時間(sec) 無圧縮 6.83 7.7 10.1 1 1.48 81.3 53.7 4(デフォルト) 1.47 107.8 57.2 9 1.46 204.3 56.6 データが変わると結果も変わるのかもしれませんが,
- 圧縮なしと圧縮ありでは,ファイルサイズに大きな差があるが,入出力にかかる時間も大幅に増える.
- 圧縮レベルを上げると,処理時間は割と長くなるが,圧縮率はそんなに上がらない
- 読み込み時間は圧縮レベルに関わらずあんまり変わらない
シンプルにgzipのベンチマークと同じような傾向だと思いますが,
圧縮有り,無しの入出力時間の差は気になるケースがありそうですね.
- 投稿日:2020-09-11T12:29:17+09:00
倫理委員会で却下された臨床研究のためのコードの記録
下記のコードは麻酔科の臨床研究用に作成した物です。
テーマは「顔認証による術前気道評価(仮)」でした。企画自体は倫理委員会で却下となりました。別機関様で似た臨床研究が進行していますが当方とは関係ありません。用途は、顔の正面画像を認識し、仮の座標点を作成し、そこから顔パーツデータを取得する事です。
利用意図に関して
全身麻酔では人工呼吸につなげる気管挿管が必要なのですが,難易度が患者個人によって異なります。麻酔で眠ってもらった後に気道チューブを入れる時、cormackという数値で実際に気道がどれくらい見えているかを分類します。
これをアウトプットのデータとして、顔パーツデータとの相関関係を調べたり、機械学習を行いで術前診察に役立てられないかと思い作成しました。# import cv2 import pandas as pd %matplotlib inline import numpy as np import matplotlib.pyplot as plt import dlib detector = dlib.get_frontal_face_detector() predictor = dlib.shape_predictor('filepath/shape_predictor_68_face_landmarks.dat') frame = cv2.imread('filepathofimage.jpg') dets = detector(frame[:, :, ::-1]) print(predictor) dets=detector(frame[:,:,::-1]) if len(dets)>0: parts=predictor(frame,dets[0]).parts() #確認 img = frame*0 for i in parts: cv2.circle(img,(i.x,i.y),3,(255,0,0),-1) #cv2imshowが無理なのでpltで plt.imshow(img) dets=detector(frame[:,:,::-1]) if len(dets)>0: parts=predictor(frame,dets[0]).parts() #確認用 img = frame*0 for i in parts: cv2.circle(img,(i.x,i.y),3,(255,0,0),-1) print(parts) pd.DataFrame(data=parts)最後にデータフレームに格納されます。
参考にしたhpが多数あり、それを複合カスタムした物です。先人の方々に感謝致します。著作権のあるhpではありませんでしたが問題があるようでしたらご指摘ください。
- 投稿日:2020-09-11T12:04:39+09:00
指定ディレクトリ以下のファイルをリストに列挙する方法(複数条件・サブディレクトリ検索)
以下のようにファイルが置かれているディレクトリを想定します。
c:\pics\ a.png b.jpg subfolder\ c.png d.jpgコード
こんな関数を作ってみました。「exts」はファイル拡張子としていますが、別に拡張子以外の条件を指定しても動くと思います。
from pathlib import Path def file_search(file_path, exts, search_subfolder): """ # file_path: 検索するディレクトリ # exts: ファイル拡張子(例: ['*.jpg', '*.png'] """ files = [] p = Path(file_path) for ext in exts: if search_subfolder: files.extend(list(p.glob('**\\'+ext))) else: files.extend(list(p.glob(ext))) return filesmainからこんな感じで呼んでみます。
def main(): file_path = r'C:\pics' + '\\' exts = ['*.jpg', '*.png'] files = file_search(file_path, exts, True) pprint(files)実行結果
py searchpic.py [WindowsPath('C:/pics/b.jpg'), WindowsPath('C:/pics/subfolder/d.jpg'), WindowsPath('C:/pics/a.png'), WindowsPath('C:/pics/subfolder/c.png')]というわけでサブフォルダ以下の複数拡張子のファイルを検索できました。
この場合、返ってくるfilesの中身は文字列ではなくWindowsPathです。
文字列の方が都合がいい場合には、filesに対しfiles_str = list(map(lambda x: str(x), files))といった感じで変換をかければ文字列のリストにすることができます。
- 投稿日:2020-09-11T11:30:36+09:00
Pythonで拡張子を変換するコード
備忘録やOUTPUT的な意味での蓄積
作成目的
作業用の画像をすべてpngに変換したいことが定期的に起こるので、対象フォルダに格納されている画像をすべてpngに変換する
作成環境
・windows10
・Anaconda
・python3
・Jupyter Notebookドキュメント
①PNGに変換したいフォルダ名を入力
②folderがなければcurrent_folder内に、png_folder を作成し画像をpngへ変換
③すでに同じフォルダ名がある場合、誤操作を防ぐためにErrorになるライブラリの読み込み
All Necessary Libraries.pyimport pathlib import os import shutil import pprint import numpy as np #numpy使ってないです.癖です. from glob import glob from PIL import Image from tqdm import tqdm from pathlib import PathPG
change_pngextension_code# フォルダ名を入力 folder_name = input('Enter the folder name :') # Pathを指定 p = Path('[対象Pathの入力]' + folder_name) # folder_name + _png_folderの名前にする new_folder_name = '_png_folder' # 現在のpathから新しいpng_folderを作成 new_folder_path = os.path.join(p, new_folder_name) # Pathの確認(必要あれば) #print(new_folder_path) # フォルダがなければコピーして作成 if not os.path.exists(new_folder_path): # ディレクトリ内のファイルを取得 shutil.copytree(p, new_folder_path) # 新たなpathを取得し、中身の画像をlistで取得 new_p = Path(new_folder_path) files = list(new_p.glob('*.*')) # 拡張子を取得して、pngに変換し上書き for i,f in tqdm(enumerate(files)): print('画像変換数:{0}/{1}'.format(i+1,len(files)) shutil.move(f, f.with_name(f.stem + ".png")) else: print('すでにfolderが存在します.')課題
・関数化していない
・pngだけではなく、任意の拡張子に変えられるように(汎用化)
・画像数が増えると時間かかりそう(未テスト)まとめ
作業時間が1時間から1分になりました。
あと、もっといい書き方がある気がする。
- 投稿日:2020-09-11T10:41:50+09:00
Pythonで指数表現のfloatをstrに変換する
Pythonでは、数値型を文字列型に変更するためにはstr()でキャストすればよいが、指数表現のfloatをstr()でキャストすると何だかイケてない結果になった。
Python 3.8.0 (tags/v3.8.0:fa919fd, Oct 14 2019, 19:37:50) [MSC v.1916 64 bit (AMD64)] on win32 Type "help", "copyright", "credits" or "license" for more information. >>> a = 0.1 >>> str(a) '0.1' >>> b = 0.00000000000000000000000000000000000000001 >>> str(b) '1e-41'この時、str(b)は
'0.00000000000000000000000000000000000000001'
となってほしい。以下に記載されている関数を使わせていただくと、うまくできた。
def float_to_str(f): float_string = repr(f) if 'e' in float_string: # detect scientific notation digits, exp = float_string.split('e') digits = digits.replace('.', '').replace('-', '') exp = int(exp) zero_padding = '0' * (abs(int(exp)) - 1) # minus 1 for decimal point in the sci notation sign = '-' if f < 0 else '' if exp > 0: float_string = '{}{}{}.0'.format(sign, digits, zero_padding) else: float_string = '{}0.{}{}'.format(sign, zero_padding, digits) return float_stringPython 3.8.0 (tags/v3.8.0:fa919fd, Oct 14 2019, 19:37:50) [MSC v.1916 64 bit (AMD64)] on win32 Type "help", "copyright", "credits" or "license" for more information. >>> a = 0.1 >>> str(a) '0.1' >>> b = 0.00000000000000000000000000000000000000001 >>> str(b) '1e-41' >>> def float_to_str(f): ... float_string = repr(f) ... if 'e' in float_string: # detect scientific notation ... digits, exp = float_string.split('e') ... digits = digits.replace('.', '').replace('-', '') ... exp = int(exp) ... zero_padding = '0' * (abs(int(exp)) - 1) # minus 1 for decimal point in the sci notation ... sign = '-' if f < 0 else '' ... if exp > 0: ... float_string = '{}{}{}.0'.format(sign, digits, zero_padding) ... else: ... float_string = '{}0.{}{}'.format(sign, zero_padding, digits) ... return float_string ... >>> float_to_str(b) '0.00000000000000000000000000000000000000001'
- 投稿日:2020-09-11T10:03:08+09:00
DatabricksのNotebookの単体テストを行う
はじめに
以下のNotebookの単体テストを行います
MyNotebookdef hoge(i): return 'hoge'*i def fuga(i): return 'fuga'*iテスト用Notebookの作成
Notebook
MyNotebookと同じフォルダに、テスト用NotebookMyNotebookTestを作成しますMyNotebookTest# Cmd1 %run "./MyNotebook" # Cmd2 import unittest class MyNotebookTests(unittest.TestCase): def test_hoge(self): self.assertEqual(hoge(3), 'hogehogehoge') self.assertNotEqual(hoge(2), 'hoge') def test_fuga(self): self.assertEqual(fuga(3), 'fugafugafuga') self.assertNotEqual(fuga(2), 'fuga') suite = unittest.TestLoader().loadTestsFromTestCase(MyNotebookTests) runner = unittest.TextTestRunner(verbosity=2) runner.run(suite)作成するポイントとして、
Cmd 1で先に%runコマンドを実行してテスト対象となるNotebookを実行します%run "./MyUnittest"
Cmd 2以降でpythonテストフレームワークであるunittestを用いてテストケースを書きます実行結果
以下のようにテストOKとなることを確認します
test_fuga (__main__.MyNotebookTests) ... ok test_hoge (__main__.MyNotebookTests) ... ok ---------------------------------------------------------------------- Ran 2 tests in 0.000s OK Out[50]: <unittest.runner.TextTestResult run=2 errors=0 failures=0>
- 投稿日:2020-09-11T07:54:58+09:00
Django で初期設定とスタッフアプリを作成する
プロジェクトを作成したので、Setteingに設定をします。
setting.pyTEMPLATES = [ { 'BACKEND': 'django.template.backends.django.DjangoTemplates', 'DIRS': [[os.path.join(BASE_DIR, 'templates')],templates のフォルダを作成し、テンプレートを保存場所として使用していこうと思います。
言語を日本語に設定し、タイムゾーンをアジア東京にする。
ここまでで、基本設定ができました。
ここからアプリを作成していきたいと思います。まずは、従業員を管理するアプリを作成します。
django-admin startapp staffこれでアプリを作成したので、忘れないうちにsetting.py にアプリを追加します。
setting.pyINSTALLED_APPS = [ 'django.contrib.admin', 'django.contrib.auth', 'django.contrib.contenttypes', 'django.contrib.sessions', 'django.contrib.messages', 'django.contrib.staticfiles', 'staff' ]これでスタッフdjangoが新しく作ったアプリを認識するようになります。
次にurlsにstaffアプリへの設定を追加する
config.urls.pyfrom django.contrib import admin from django.urls import path, include urlpatterns = [ path('staff/',include('staff.urls') ), path('admin/', admin.site.urls), ]これで、最初のURLがstaffの場合、Staffアプリのurlsに引き渡されるようになるはず。
次は、スタッフを登録したり画面を作っていきたいと思います。
アプリを作成するためには本当に時間を要するけど動いた時の感動、すごーいって言ってくれることを夢見て勉強を続けようと思う40歳バリバリ成長中です


- 投稿日:2020-09-11T07:39:44+09:00
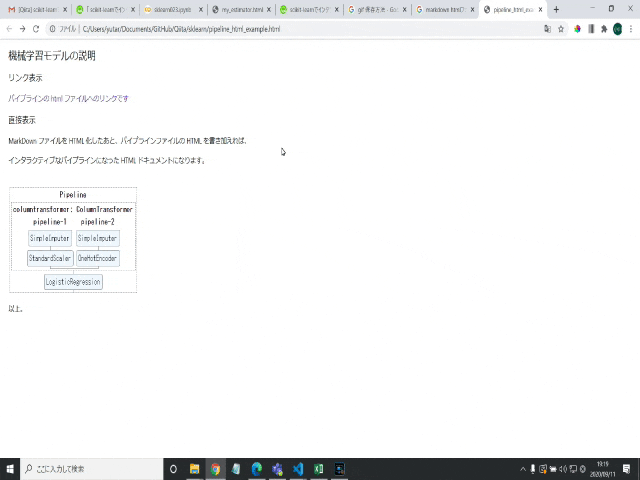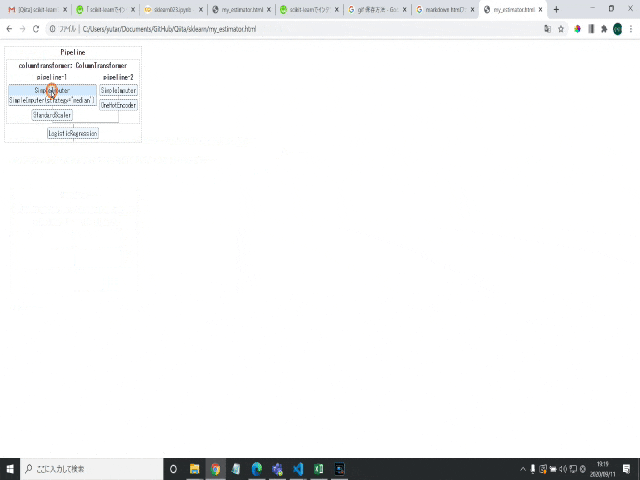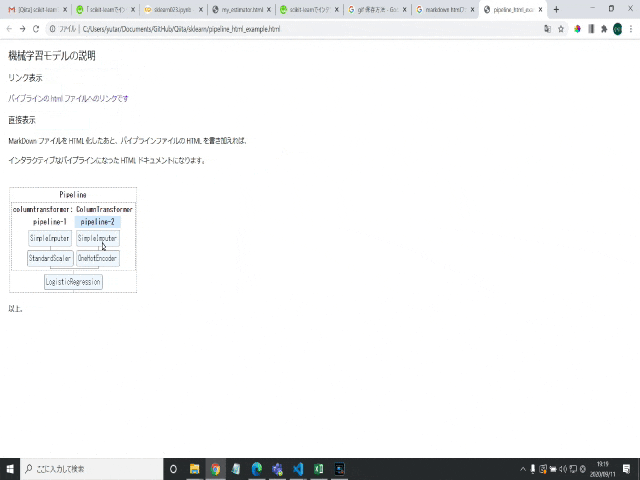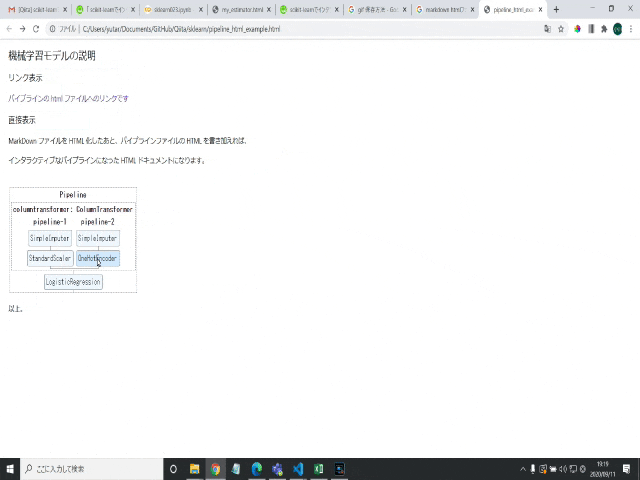
scikit-learnでインタラクティブにパイプラインを描画、HTML保存する方法
本記事では、scikit-learnのv0.23から搭載された、インタラクティブなパイプライン確認の実装を解説します
環境
- scikit-learn==0.23.2
- Google Colaboratory
本記事の実装コードはこちらに置いています
https://github.com/YutaroOgawa/Qiita/tree/master/sklearn実装
[1] バージョン更新
まず、Google Colaboratoryのscikit-learnのバージョンが2020年9月ではv0.22なので、v0.23へと更新します。
!pip install scikit-learn==0.23.2pipで更新したあとは、Google Colaboratoryの「ランタイム」→「ランタイムを再起動」を実行し、
ランタイムを再起動します。
(これで、scikit-learnがpipで入れた新しいv0.23になります)[2] パイプライン構築
例えば、以下のようにして、前処理と機械学習モデルを組み合わせた
機械学習パイプラインを構築します。[必要なimportを実施]
from sklearn.pipeline import make_pipeline from sklearn.preprocessing import OneHotEncoder, StandardScaler from sklearn.impute import SimpleImputer from sklearn.compose import make_column_transformer from sklearn.linear_model import LogisticRegression[パイプラインを構築]
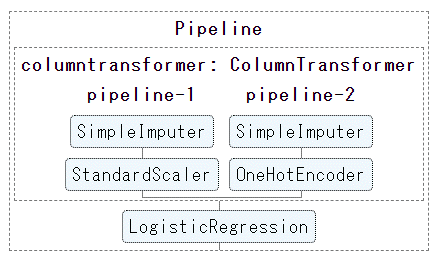
# 数値データの前処理(中央値で欠損値補完して、標準化) num_proc = make_pipeline(SimpleImputer(strategy='median'), StandardScaler()) # カテゴリデータの前処理(欠損値には"misssing"を代入補完し、ワンホットエンコーディング) cat_proc = make_pipeline( SimpleImputer(strategy='constant', fill_value='missing'), OneHotEncoder(handle_unknown='ignore')) # 前処理クラスを作成 preprocessor = make_column_transformer((num_proc, ('feat1', 'feat3')), (cat_proc, ('feat0', 'feat2'))) # 前処理と機械学習モデルを1つのパイプラインにする clf = make_pipeline(preprocessor, LogisticRegression())[3] インタラクティブにパイプラインを可視化
インタラクティブにパイプラインを可視化するには、単純で、
sklearn.set_config(display="diagram")を加えるだけです。
[インタラクティブに可視化]
# パイプラインを表示させる設定 from sklearn import set_config set_config(display="diagram") # 描画 clfすると、JupyterNotebook(Google Colabortory)の結果欄に、以下のようにパイプラインが描画されます。
このパイプラインの図の各要素をクリックすると、
インタラクティブに画像が変化し、その要素の詳細設定が表示されます。
(以下の図は、カラム前処理の欠損値処理方法を詳細確認する場合:pipeline-2のSimpleImputerをクリック)
パイプラインをHTMLとして保存する方法
コメント欄でいただいたように、このインタラクティブなパイプラインをHTML化して保存することができます。
「JupyterNotebook上でしか動かないのでは、ちょっとな・・・」
と思っていたので、非常に嬉しい情報です。
@DataSkywalker さま、誠にありがとうございます。
実装としては最後に、
from sklearn.utils import estimator_html_repr with open('my_estimator.html', 'w') as f: f.write(estimator_html_repr(clf))を実行します。すると、my_estimator.htmlとして、インタラクティブなパイプラインのHTMLが保存されます。
Google Colaboratoryであれば、
# Google Colaboratoryからダウンロード from google.colab import files files.download('my_estimator.html')を実行することで、my_estimator.htmlをダウンロードすることができます
(HTMLファイルにCSSのstyleも含まれ300行ほどの内容でした)。インタラクティブにパイプラインを説明する資料として、
HTMLをドキュメントなどに貼り付ける、などができそうです。mdファイルにリンクとして入れても良いですし、無理やりmdファイルをhtml化してから結合しても良いです。
(mdファイルにそのままhtmlを読み込むのは難しい・・・?)
このあたりのファイルもすべて、こちらに置いています
https://github.com/YutaroOgawa/Qiita/tree/master/sklearnまとめ
scikit-learnのバージョンをv0.23以上にして、
sklearn.set_config(display="diagram")を加えるだけで、
パイプラインをインタラクティブに可視化(そして、HTMLで保存)することができます。ぜひお試しください♪
備考
【執筆者】電通国際情報サービス(ISID)AIトランスフォーメーションセンター 開発Gr
小川 雄太郎(主書「つくりながら学ぶ! PyTorchによる発展ディープラーニング」 、その他「自己紹介詳細」)【Twitter】
IT・AI関連やビジネス・経営系を中心に、私が面白いと思った記事や最近読んだ新刊書籍の感想などを発信しています。これらの分野の情報を収集したい方はぜひフォローしてみてください♪(海外情報が多めです)【その他】
私がリードする、「AIトランスフォーメーションセンター 開発チーム」ではメンバを募集中です。ご興味、ご関心をお持ちの方は、こちらのページから、応募をお待ちしております。【そくめん君】
いきなり応募は・・・という方は、カジュアル面談を「そくめん君」で行わせていただいております。
こちらもぜひご利用ください♪
https://sokumenkun.com/2020/08/17/yutaro-ogawa/【免責】本記事の内容そのものは著者の意見/発信であり、著者が属する企業等の公式見解ではございません
(参考)
https://scikit-learn.org/stable/auto_examples/release_highlights/plot_release_highlights_0_23_0.html
https://towardsdatascience.com/9-things-you-should-know-about-scikit-learn-0-23-9426d8e1772c