- 投稿日:2020-09-11T22:57:19+09:00
AWSを使ってアプリケーションを公開する手順(6)Nginxを導入する
はじめに
AWSを使ってアプリケーションを公開する手順を記載していく。
この記事ではWebサーバであるNginxを導入する。Nginxをインストールする
Nginxとは
NginxとはWebサーバの一種である。
ユーザのリクエストに対して静的なコンテンツの取り出し処理を行い、動的なコンテンツの生成をアプリケーションサーバに依頼する。「.ssh」ディレクトリに移動する
以下のコマンドを実行し、「.ssh」ディレクトリに移動する。
cd ~/.ssh/ssh接続
以下のコマンドを実行し、EC2インスタンスにsshでアクセスする。
(ダウンロードしたpemファイル名が「xxx.pem」、ElasticIPが123.456.789の場合)ssh -i xxx.pem ec2-user@123.456.789Nginxのインストール
以下のコマンドを実行し、Nginxをインストールする。
sudo yum -y install nginxNginxの設定ファイルを編集する
以下のコマンドを実行しvimを使ってNginxの設定ファイルを編集する。
/etcディレクトリ以下のファイルは権限がないと読み書き保存ができないため、sudoで実行する。sudo vim /etc/nginx/conf.d/rails.conf以下のようにrails.confを編集する。
今回はアプリケーション名が「testapp」、Elastic IPが「123.456.789」の場合を例として進める。rails.confupstream app_server { # Unicornと連携させるための設定。 server unix:/var/www/testapp/tmp/sockets/unicorn.sock; } # {}で囲った部分をブロックと呼ぶ。サーバの設定ができる server { # このプログラムが接続を受け付けるポート番号 listen 80; # 接続を受け付けるリクエストURL ここに書いていないURLではアクセスできない server_name 123.456.789; # クライアントからアップロードされてくるファイルの容量の上限を2ギガに設定。デフォルトは1メガなので大きめにしておく client_max_body_size 2g; # 接続が来た際のrootディレクトリ root /var/www/testapp/public; # assetsファイル(CSSやJavaScriptのファイルなど)にアクセスが来た際に適用される設定 location ^~ /assets/ { gzip_static on; expires max; add_header Cache-Control public; } try_files $uri/index.html $uri @unicorn; location @unicorn { proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for; proxy_set_header Host $http_host; proxy_redirect off; proxy_pass http://app_server; } error_page 500 502 503 504 /500.html; }Nginxの権限を変更する
以下のコマンドを実行してNginxの権限を変更する。
ここで権限を変更することでPOSTメソッドでエラーが出なくなる。cd /var/libsudo chmod -R 775 nginx「-R」オプション
「-R」オプションは再帰的に変更するためのオプションである。
つまり、そのディレクトリとディレクトリ内の全てのファイルの権限を変更する。POSTメソッドとは
HTTP通信でクライアントからWebサーバに送るリクエストの一つで、URLで指定したプログラムなどに対してクライアントからデータを送信するためのもの。大きなデータやファイルをサーバに送るために使われる。
Nginxを再起動する
以下のコマンドを実行し、Nginxを再起動し、設定ファイルを再読み込みする。
cd ~sudo service nginx restartunicornの設定を修正する
Nginxを介した処理を行うため、unicornの設定を再度修正する。
unicorn.rbを編集する
開発環境でconfig/unicorn.rbを以下のように編集する。
編集したら、コミットとプッシュ忘れずに行う。config/unicorn.rb#サーバ上でのアプリケーションコードが設置されているディレクトリを変数に入れておく app_path = File.expand_path('../../', __FILE__) #アプリケーションサーバの性能を決定する worker_processes 1 #アプリケーションの設置されているディレクトリを指定 working_directory app_path #Unicornの起動に必要なファイルの設置場所を指定 pid "#{app_path}/tmp/pids/unicorn.pid" #ポート番号を指定 listen "#{app_path}/tmp/sockets/unicorn.sock" #エラーのログを記録するファイルを指定 stderr_path "#{app_path}/log/unicorn.stderr.log" #通常のログを記録するファイルを指定 stdout_path "#{app_path}/log/unicorn.stdout.log" #Railsアプリケーションの応答を待つ上限時間を設定 timeout 60 preload_app true GC.respond_to?(:copy_on_write_friendly=) && GC.copy_on_write_friendly = true check_client_connection false run_once = true before_fork do |server, worker| defined?(ActiveRecord::Base) && ActiveRecord::Base.connection.disconnect! if run_once run_once = false # prevent from firing again end old_pid = "#{server.config[:pid]}.oldbin" if File.exist?(old_pid) && server.pid != old_pid begin sig = (worker.nr + 1) >= server.worker_processes ? :QUIT : :TTOU Process.kill(sig, File.read(old_pid).to_i) rescue Errno::ENOENT, Errno::ESRCH => e logger.error e end end end after_fork do |_server, _worker| defined?(ActiveRecord::Base) && ActiveRecord::Base.establish_connection end本番環境に反映する
以下のコマンドを実行し編集内容を本番環境に反映する。
cd /var/www/testapp(アプリケーションのリポジトリ名が「testapp」の場合)git pull origin masterunicornを再起動する
以下のコマンドを実行し、unicorn masterのプロセスIDを確認する。
ps aux | grep unicorn以下のコマンドを実行し、確認したプロセスIDをkillする。
(ここではunicorn masterのプロセスIDが17877であったとする)kill 17877以下のコマンドを実行し、unicornを起動する。
RAILS_SERVE_STATIC_FILES=1 unicorn_rails -c config/unicorn.rb -E production -DブラウザからElastic IPでアプリケーションにアクセスする
ブラウザからElastic IPでアプリケーションにアクセスする。(今回は:3000をつけなくてよい)
このとき、unicornが起動している必要がある。エラーが出る場合に確認すること
- 502 bad gatewayとエラーが出る場合は/var/log/nginx/error.logを確認する
- /var/www/testapp/log/unicorn.stderr.logを確認しエラーがないか確かめる(リポジトリ名がtestappの場合)
- railsを起動しているか
- EC2インスタンスの再起動を行う(本番環境でMySQLとNginxの再起動が必要)
補足
Webサーバとは
外部から送られてきたリクエストを受け取り、処理を加える。
NginxはWebサーバの一種。
以下の役割がある。
- 静的なコンテンツをレスポンスとしてクライアントに返す
- 動的なコンテンツの生成をアプリケーションサーバに依頼する
- アプリケーションサーバから返ってくる処理結果をレスポンスとしてクライアントに返す静的なコンテンツとは、リクエスト毎に内容が変わらないファイル。
表示するものが決まっているcssや画像ファイルなど。
動的なコンテンツとは、リクエスト毎に内容が変化するファイル。
データベースから検索条件に該当するデータを取得して表示するファイルなど。アプリケーションサーバとは
動的なコンテンツを生成し、処理結果をWebサーバに返す。
Unicornはアプリケーションサーバの一種。
以下の役割がある。
- Webサーバから依頼された情報を基に動的なコンテンツの生成を行う
- 処理結果をWebサーバに返す
- 投稿日:2020-09-11T22:14:11+09:00
《コロナに負けず!!》29歳で営業職からジョブチェンジ。未経験で受託開発企業から内定を頂けました。
はじめに
昨年「エンジニアになるぞ!」と決意をし、
今年の3月に前職を退職(最終出社)、
3月下旬からプログラミングスクールに通いました。現在、29歳(今年で30歳!)です。
新卒からずっと営業職で、プログラミングは未経験。そんな自分でも、webエンジニアのスタートラインに
立つ事が出来ました。自分なりに戦略を立てて行った就活でもありましたので、
就職活動中の方の参考にして頂ければ幸いです。目次
・工夫して就活を行おうとした背景
・就活の結果
・学習開始〜内定までの流れ
・今回の転職活動でのポイント
・ポートフォリオについてのポイント
・学習方法について(おまけ)
・最後に工夫して就活を行おうとした背景
(興味ない方は読み飛ばして下さい!笑)
スクールに入った時点の私は転職に関しての認識が甘く、
「高い金額のスクールで基礎をしっかり学べば、転職はできるはず!」
「スクールからも紹介があるし!」
などと、このくらいの認識でした。ですが、この認識は間違いです!!!
少なくとも、20代前半の若い方でない限りは
エージェントからの紹介案件はごく少数になります。
※SESならいっぱいあります!企業側としてはエージェントを通して採用をすると、
その人の年収の30%程を支払う必要があります。つまり年収350万円の人材なら105万円もお金がかかります。
それならば、エージェント経由ではより若く優秀な人材だけを
選びたいですよね?そのため、エージェントから紹介される案件は
応募者の年齢や経験などが非常に大事になります。そのため、年齢が高くなるほど
そもそも紹介される案件の数は絞られます。そこに、今回はコロナによる経済打撃もあり
自分がスクールでの学習を終えた2020年6月、
「未経験」でのスクール経由の募集案件は3件のみでした。しかし、3社とも書類選考が通らず、、、涙
そこでやっと、このままでは「やばいぞ!!」と
気付かされました。。。そこで、ここから必死に情報の収集と
採用までの戦略を立てることにしました。就活結果について
《内定》
・2社(受託開発)《応募》
・企業HPからの直接応募:20社
・スクールのエージェント経由での応募:3社
・求人サイトでの応募:10社ほど
・DODAのエージェント経由での応募:20社ほど学習開始〜内定までの流れ
◇学習期間
2020年3月末月〜7月末(4ヶ月間)◇転職活動期間
2020年8月(1ヶ月間)《3月末〜5月末まで》
プログラミングスクールにて学習、卒業《6月》
1ヶ月かけて初めての自主制作アプリを作成!ですが、他の方のポートフォリオのレベルの高さを見て絶望し、
2つ目のポートフォリの作成を決意しました!《7月》
2週間程で2つ目のポートフォリを作成!
そこから2週間はインフラの環境構築やCI/CDに
挑戦していました。《8月》
企業HPからのweb応募を開始しました!
8月末に内定を獲得!今回の転職活動でのポイント
しっかり作り込んだポートフォリオを用意した
→スクール卒業後、すぐに転職活動を開始せずにポートフォリオの強化に努めました応募は企業のHPから送ることを徹底した
→書類選考の突破が重要です上記の2点が今回の就活でのポイントになります。
ポートフォリオについてのポイント
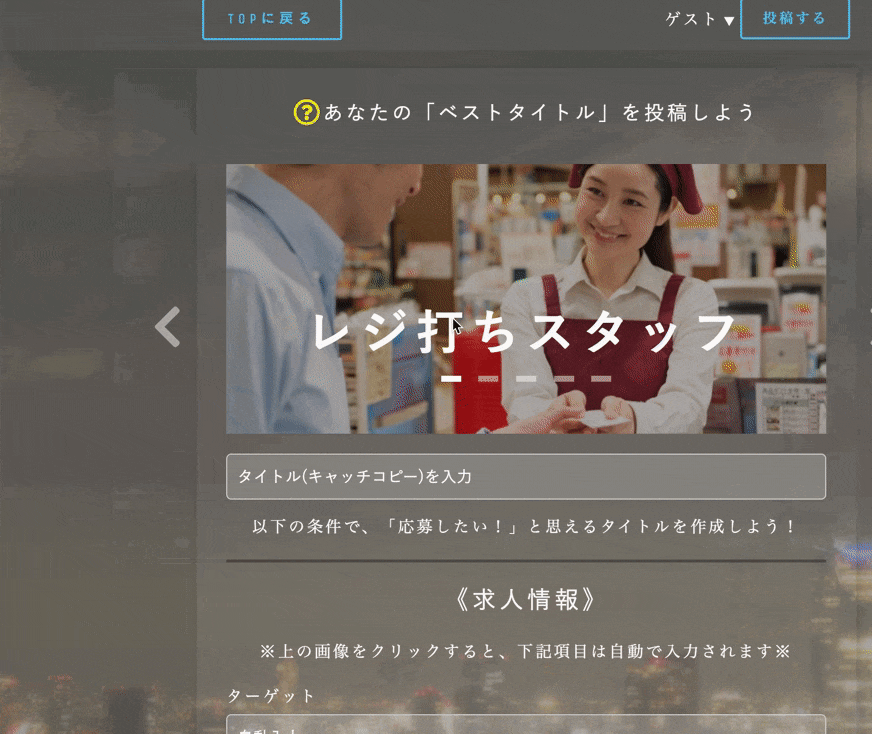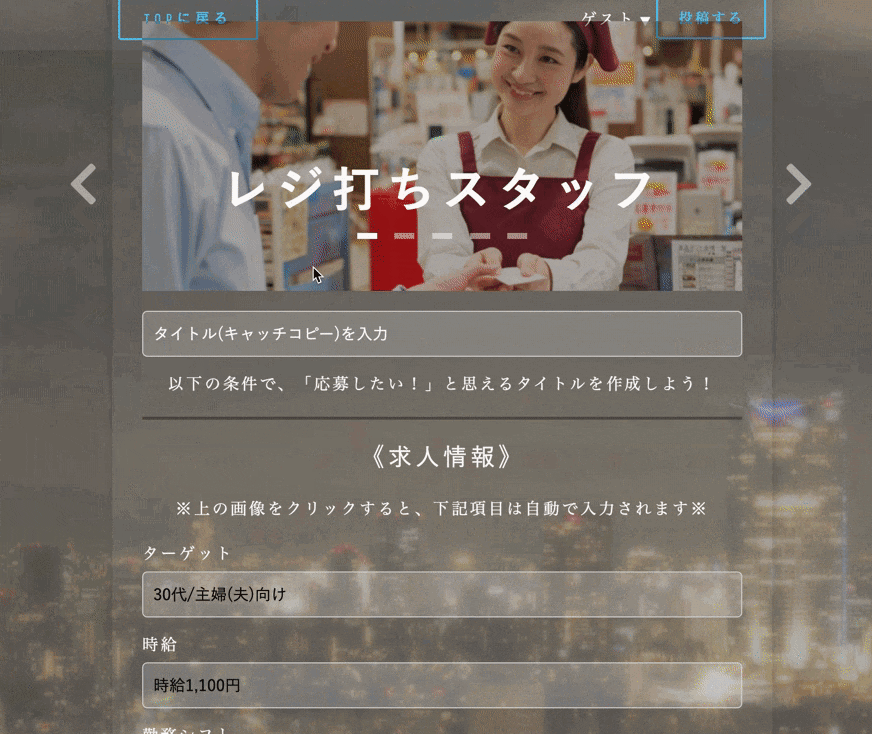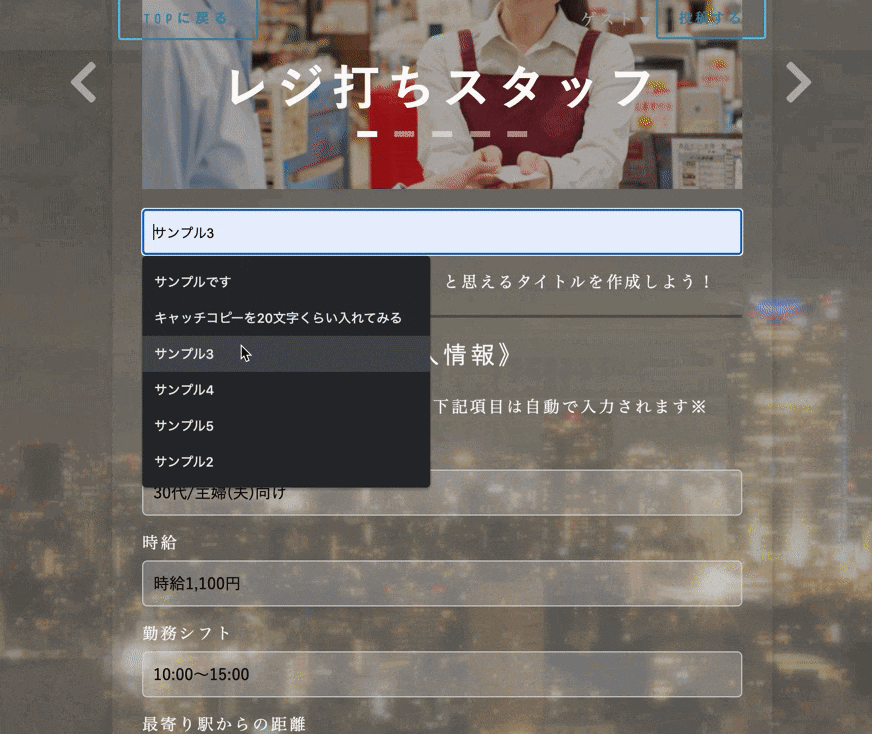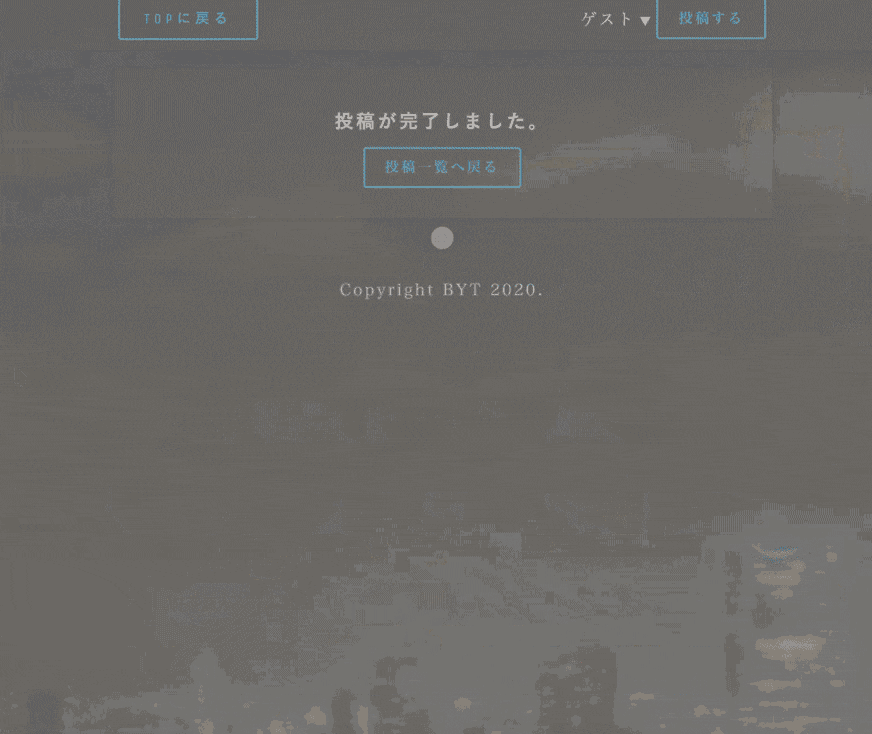
自主制作アプリ:「BestYourTitle」
このアプリは、求人広告のライター初心者や採用担当者が、
求人広告を書く際に「応募したい!」と思ってもらえるような
キャッチコピーを書けるよう、練習出来るサイトです。▼URL
https://www.bestyourtitle.com/
※かんたんログイン機能で、ゲストとしてログイン出来ます。▼GitHub
https://github.com/y-kiku1111/docker_byt
※ポートフォリオに関しての詳細は、上記Githubに記載しています
内定頂いた2社とも、ポートフォリオについて
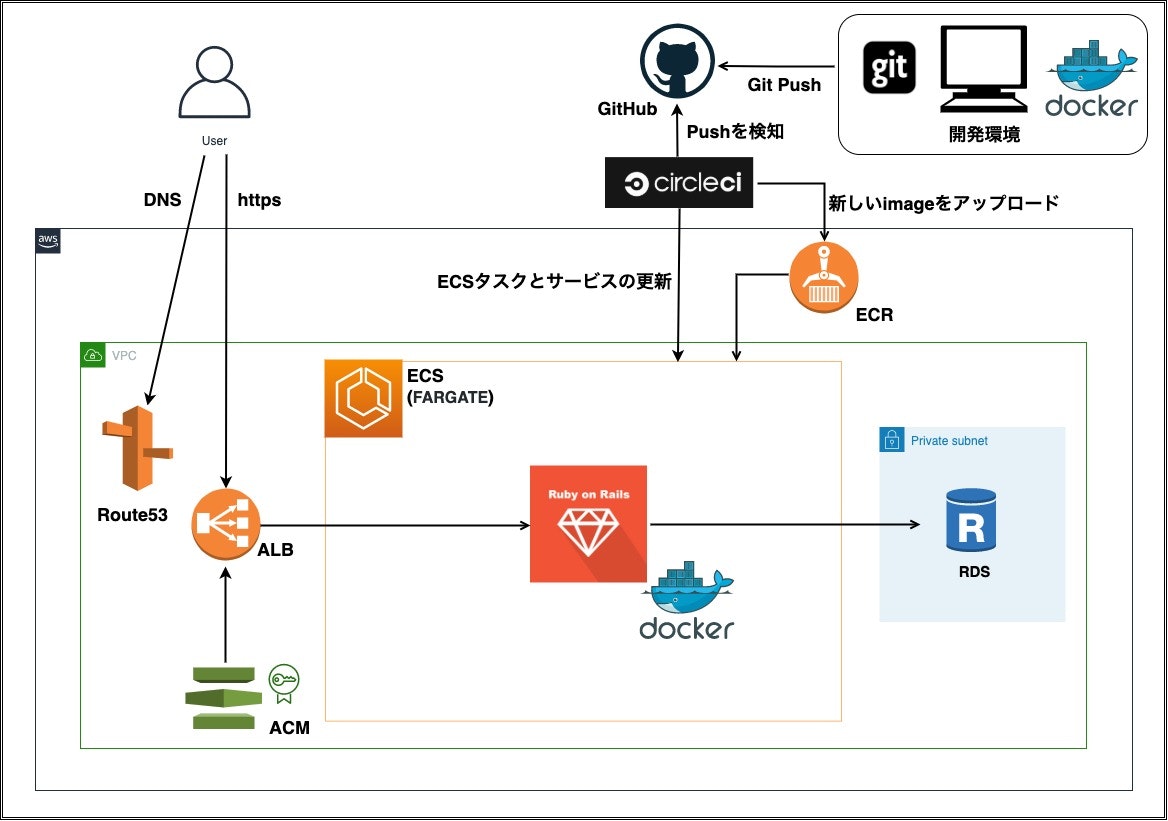
非常に高評価を頂けました。特にDocker、AWSのFargateは
印象が良かったです。ただ、実際に見て頂くと
サイト自体はレベルの高いものではないので、・モダンな技術に挑戦し、その企業で活用している技術とマッチした
・サイトデザインやインフラ構成図など、目に見える差別化を行うこの2点に尽きるのかなと思います。
また、ポートフォリオに関しましては
youtuberの勝又さんの動画やオンラインサロンで
「高評価されるポートフォリオ」がどの程度のレベルなのかを
知ることが出来、とても参考にさせて頂きました!スクールではポートフォリオに関してのアドバイスは
一切ありませんでしたので、実際に採用された初学者のポートフォリオが
数多く見れるのは、非常に有り難かったです。就職活動についてのポイント
・求人サイトを使って応募したい企業のリストアップ
・エージェントサービスを利用しての面接練習や情報の入手(応募もしましょう)
・上記を行った上でHPからの直接応募これが自分の中では、最も効率的かと思います。
リストアップに利用した求人サイト
・wantedly
・Green
・Find job!特にFindjobは、業務未経験OKの企業で絞ることが出来て
重宝しました。基本的には上記のサイトから応募するのではなく、
サイトからリストアップをして直接応募をします。なぜ直接、採用HPから応募をするかと言うと、
求人サイトによっては、エージェントと同じく
掲載は無料だが、採用すると企業にお金がかかるサイトもあるため
企業HPからの応募が、企業側にメリットが大きいためです。採用課金型でなければ、
求人サイトからの応募も一緒にした方が
良いかと思います。例えば、1日10社を目標に各企業のHPから
応募をし続けると良いと思います。
(自分は1日5社と決めていました)書類選考さえ突破すれば、あとはエージェントさんと
練習した面接だけです。しっかりと自分がエンジニアになりたい理由、
また作り込んだポートフォリについて熱弁できれば問題無いはずです!学習方法について(おまけ)
個人的には、強制的に勉強に集中し基礎を学べるスクールは
重宝しましたので、やるかやらないかなら、お勧めです。ただ、スクールはあくまで基礎を学ぶための環境にお金を出すようなイメージです。
そのため、スクール費用が高すぎると割に合わない可能性もあります!スクールを卒業するだけでは、レベルとしては確実に低いと思いますので、
例えばメンターさんを雇いながらポートフォリオのレベルを高めるなど、
基礎を身につけてからの自己学習を強く推奨します。自分はMENTAというサービスを利用していました。
(https://menta.work/about)最後に
ここまで長文を読んで頂き、
本当にありがとうございました!長くなりましたが、上記が自分の転職活動で
意識したことや、実践したことになります。少しでも、お役に立てましたら幸いです。
また、今回やっとエンジニアのひよっことして
スタートラインに立てたのは、自分の転職活動を支えて下さった
周りの方々のお陰です。無職になったのにも関わらず応援してくれた同居人や、
期待を込めて送り出して頂いた前職の上司や同僚、
心配しながらも応援して下さった両親、本当にありがとうございました!!!
就職した企業は、ひよっこではなく
成果を出す人材を期待して頂いているかと思いますので、
その期待を超えられるよう、頑張って行きます!改めまして、最後までお読み頂きありがとうございました!
- 投稿日:2020-09-11T19:51:19+09:00
LambdaでDynamoDBに複数レコードの書き込みをする(Python、JavaScript)
はじめに
DynamoDBに複数レコードを書き込み(更新)する必要があったので、実装してみた結果と注意的なものを書き留めたいと思い記事を投稿した
またPythonとNode.jsの両方での実装を載せようと思います前提
テーブル
今回書き込みをするテーブルは以下を想定
テーブル名:Users
カラムと型(スキーマ自体に型はありませんが、登録するデータの型として便宜上決めておきます)は以下の通り
- id(primary key):Number
- name:String
- address:String
- friends: List[Map]
friendはid, name, addressのキーを持つMapの一覧を想定
今回は複雑めな型(Userテーブルのfriendのような型)であっても、書き込みができることも示しておきたいことの一つなので、そもそもテーブルの設計がベストであるかは一旦無視でいきますLambdaの準備
今回はLambda上で動くコードを掲載するので、Lambdaは各自で準備ができていることを前提とします
記事の流れ
全体のコード例 → 軽い解説
の手順で書いていき、最後に共通する補足事項を載せるPythonでの実装
import boto3 from boto3.dynamodb.conditions import Key def update_users(table, users_friends): with table.batch_writer() as batch: for n in range(3): batch.put_item( Item={ "id": n + 1, "name": "user" + str(n + 1), "address": "address" + str(n + 1), "friends": users_friends[n] } ) def lambda_handler(event, context): try: dynamoDB = boto3.resource("dynamodb") table = dynamoDB.Table("Users") user1_friends = [ { "id": 2, "name": "user2", "address": "address2" }, { "id": 3, "name": "user3", "address": "address3" } ] user2_friends = [ { "id": 1, "name": "user1", "address": "address1" }, { "id": 3, "name": "user3", "address": "address3" } ] user3_friends = [ { "id": 1, "name": "user1", "address": "address1" }, { "id": 2, "name": "user2", "address": "address2" } ] users_friends = [user1_friends, user2_friends, user3_friends] update_users(table, users_friends) return event["message"] # 返すものは適当 except Exception as e: print(e)軽く解説
コードの書き方云々や書き込むデータ自体については本質ではないので、スルーしてもらって大丈夫です
大事なのはupdate_users関数の中身で、DynamoDBのモデルのインスタンスに生えているbatch_writeメソッドを使っているということ
すなわち、複数書き込みをしたいときは以下のブロック内でPUTをするwith table.batch_write() as batch: # ...略また、
PUTする際には例でいうとbatch.put_itemを呼び出してやる
こいつのItemという名前の引数に書き込みの内容を記述していく
そしてもう一点注目したいのが、List[Map]という型であっても問題なく書き込むことができるという点
基本的にどんな型でも指定したキーの値としてちゃんとDBに書き込めるので、要するにItemには更新したい辞書をそのまま渡してあげれば問題ない
最後にちょっとした補足として、batch_writeのブロック内でfor文を回しているが、当然batch.put_itemをベタで複数回書いていってもよいので、もしfor文では書けないときはベタでやればいい
また、一度にできる書き込める上限は25件までと言われているが、どうやら25件以上の場合は再送してくれたりよしなにやってくれているらしいので、件数を気にせずコードを書いていけるっぽいNode.jsでの実装
const AWS = require("aws-sdk"); const dynamoDB = new AWS.DynamoDB.DocumentClient({ region: "ap-northeast-1" }); const tableName = "Users"; exports.handler = (event, context) => { const user1Friends = [ { id: 2, name: "user2", address: "address2" }, { id: 3, name: "user3", address: "address3" } ]; const user2Friends = [ { id: 1, name: "user1", address: "address1" }, { id: 3, name: "user3", address: "address3" } ]; const user3Friends = [ { id: 1, name: "user1", address: "address1" }, { id: 2, name: "user2", address: "address2" } ]; const usersFriends = [user1Friends, user2Friends, user3Friends] const params = { RequestItems: { [tableName]: usersFriends.map((e, i) => ({ PutRequest: { Item: { id: i + 1, name: `user${i + 1}`, address: `address${i + 1}`, friends: e } } })) } }; // callbackは適当 dynamoDB.batchWrite(params, (e, data) => { if (e) { context.fail(e); } else { context.succeed(data); } }); };軽い解説
Pythonでの解説で述べたようにコードやデータの値そのものに関してはスルー
ここで大事なのはAWS.DynamoDB.DocumentClientにあるbatchWriteというプロパティ(関数)
こいつの引数は結構癖があるのでClass: AWS.DynamoDB.DocumentClient — AWS SDK for JavaScriptを参照してください
Node.jsでの複数書き込みについて調べたときによく出てくるのはbatchWriteItemだったのですが、現在(2020年9月時点)のLambdaで用意されている最新のNode.jsの実行環境だとどうやらないっぽいので、動かず意外と手こずる
batchWriteItemとの大きな違いはItemのオブジェクトがDynamoDB特有の型付きのオブジェクト(name: { "S": "user" }みたいなやつ)である必要がなくなっている点
要するに書き込みたい値を気にせずそのままJSONにしてItemの値として渡せば問題なく動く
そのため、当然Map[List]という複雑な型であってもそのまま渡せば書き込み可能です全体の補足
バッチ処理で更新(update)をしたいときは
PUTを使うしかない
理由は単純でUPDATEがないからで、仕方ないので地道にPUTで記述していく必要がある
またバッチ処理内ではDELETEをすることができるので、今回はフォーカスしませんでしたが、一応あるということだけ言っておきます・・・おわりに
いかがでしたでしょうか
複数操作についてはコードと1, 2行程度の解説がある記事はちょこちょこ見かけますが、書き込みに特化して解説されているのはあまり見かけず(あっても複雑な型でもできるのか不明であったり、そもそも実行時エラーになってしまう)、多少やってて手こずったので、備忘の意味も兼ねて書き残してみました
若干ニッチな分野かもしれないですが、少しでも役に立てて貰えれば幸いです参考
Amazon DynamoDB — Boto3 Docs 1.14.56 documentation
Class: AWS.DynamoDB.DocumentClient — AWS SDK for JavaScript
- 投稿日:2020-09-11T19:46:36+09:00
【AWS SAA】プライベートサブネットとパブリックサブネットの使い分け
はじめに
下記URLのようなプライベートサブネットとパブリックサブネットの使い分けに関する問題が、AWS SAAでよく出題されます。
https://awsjp.com/exam/saa-sap/c/exam95.htmlしかし初心者だとサーバーの違いや構成を知らないため、そもそもの問題文の意味の理解もできないのではないかと思います。今回はWebの2層構造を通じて、プライベートサブネットとパブリックサブネットの使い分けを説明したいと思います。
イメージ
[AWS]WordPressの構築方法や【AWS】WordPressを作った時の備忘録のようにWordPressを作成すると、パブリックサブネット内にあるWEBサーバーとプライベートサブネット内のDBサーバーの流れや構成がわかって良いのではないかと思います。
もし時間があれば、実際に作ってみると、問題の理解度も違ってくるかと思います。
説明
現在の主流としてはWEBサーバー、APサーバー、DBサーバーの三層構造がWebシステムの典型的な構成となっていますが、システムによってはWebサーバとAPサーバを1台に統合したり、Webサーバがなかったりなどします。
SAAでは三層構造で出てくることはないと思われるため、WEBサーバーとDBサーバーの二層構造を中心に考えたいと思います。
サーバー 説明 Webサーバー 主に静的コンテンツを提供する役割のサーバー。 DBサーバー データを提供するサーバー。 APサーバー(おまけ) 主に動的コンテンツや業務処理を提供するサーバー。 HTMLファイルや画像などのコンテンツを配置しているWEBサーバーがあり、データが必要な場合WEBサーバーからDBサーバーにデータを要求する仕組みとなっています。
パブリックサブネットのWEBサーバーはアウトバウンドトラフィックを直接インターネットに送信できます。WEBサーバーはプライベートサブネットと同じVPC内でホストされるため、DBインスタンスに接続できます。
その一方プライベートサブネットのDBサーバーはインターネットにアクセスできないため、その分セキュリティがより強固になります。このようにサブネットを分けることで、適切にセキュリティに強い設計が作ることができます。そのためプライベートサブネットとパブリックサブネットの使い分けが非常に重要なってきます。
参考
https://thinkit.co.jp/article/11526?fbclid=IwAR1xhqnZ4CYQllY6dTS3htOVump-I14LJFh2HAWPac-OnZSSmNmu9N0Iiks
https://www.b-architects.com/blog/wiki/web-server
https://docs.aws.amazon.com/ja_jp/AmazonRDS/latest/UserGuide/CHAP_Tutorials.WebServerDB.CreateVPC.html

- 投稿日:2020-09-11T18:22:28+09:00
【AWS x Java】DynamoDB StreamsをKinesis Client Library (KCL) で処理する
はじめに
実案件でDynamoDB StreamsをKinesis Client Library (以下KCL) で処理する機会がありましたので、KCLが実際にどういう挙動をするのか、それを踏まえてどのような実装にしたのか紹介したいと思います。
今回やりたかったこと
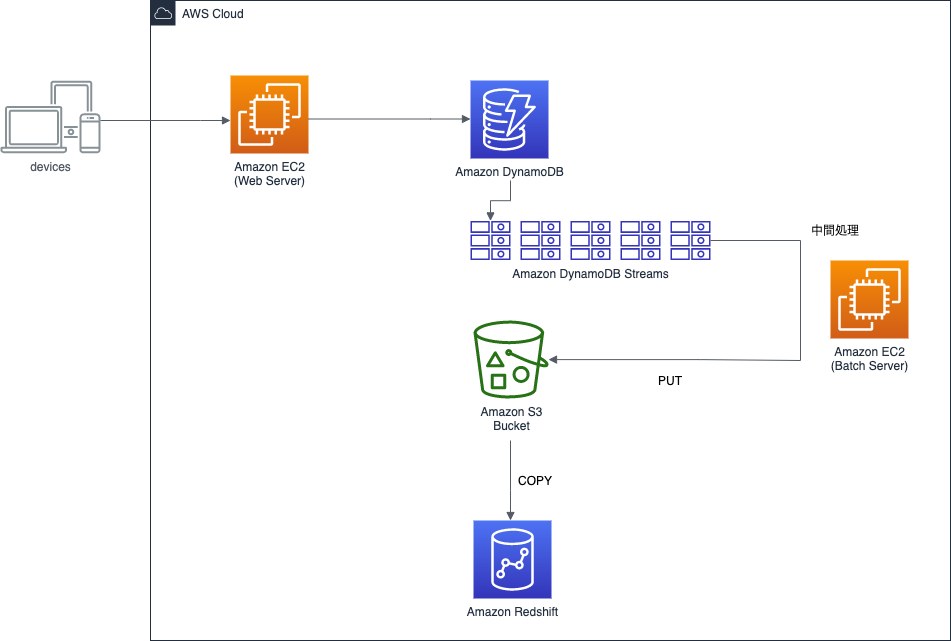
BookLive!のある機能ではDynamoDBを使用しています。
このDynamoDBのデータを、データ追加後できるだけ早いタイミングでRedshiftに転送する必要が出てきました。
現状のテーブル形式を踏まえ様々な検討をした結果、DynamoDB Streamsを設定し、追加されていくデータをいわゆるストリームとして扱うことでRedshiftに持っていくことが最善策という結論に至りました。
また、DynamoDB Streamsの取得方法は公式が推奨しているKCLを使う方法で行うことにしました。
注意点
- KCLを使用するコンシューマアプリケーションは基本的にEC2インスタンスに常駐させる場合が多いと思います。しかし、今回はバッチ風(定期的な実行/クローズ)に処理するので、定石からは少し外れている部分があります。
- DynamoDBのキャパシティモードはオンデマンドに設定しているため、本記事ではキャパシティを考慮する話は出てきません。
本記事の関連技術
- JDK11 (Amazon Coretto 11)
- DynamoDB Streams
- Kinesis Client Library (KCL)
- aws-sdk-java
build.gradledependencies { implementation 'com.amazonaws:aws-java-sdk-dynamodb:1.11.833' implementation 'com.amazonaws:aws-java-sdk-kinesis:1.11.839' }build.gradledependencies { implementation 'com.amazonaws:dynamodb-streams-kinesis-adapter:1.5.2' }DynamoDB StreamsとKCL
DynamoDB Streamsについて
特徴
- DynamoDBに書き込まれた後、データは非常に低レイテンシーな間隔でストリームに追加される
- シャードは自動でスケーリングしてくれる
- また、特定のシャードが使われ続けるわけではなく、適度に新しいシャードが作られていく
- ストリームは追加後24時間保持される
- ストリームの設定はいつでも追加・削除可能
- ただし、ストリームの設定が追加された後にDynamoDBに追加されたデータのみバッファリングされる
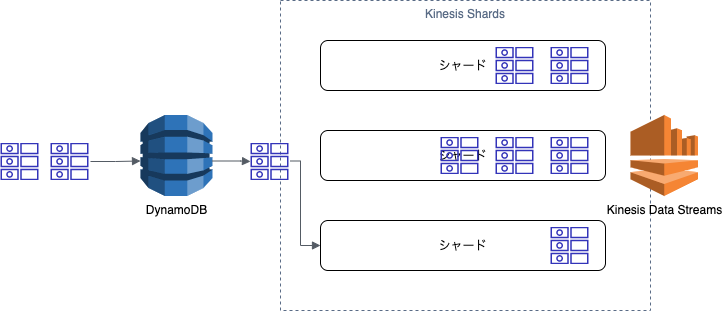
イメージ
あたかもKinesis Data Streamsのようにストリームをバッファリングしてくれます(以下の図のKinesis Shards部分をDynamoDB Streamsとして捉えることが可能です)。
KCLを直接使用することはできませんが、Kinesis Adapterを通して、Kinesis Data Streamsからストリームを取得するのと同等の方法でDynamoDB Streamsを取得することが可能です。
以下の図はあくまでも個人的なイメージであることに注意してください。
Kinesis Client Library (KCL) について
そもそもKinesisとは
ここでは触れませんが、参考記事を掲載しておきます。
特徴
- Kinesis Data Streamsを処理するためのコンシューマアプリケーション用オープンソースライブラリ
- コンシューマとはバッファリングされたストリームを取得して処理する側のこと
- 逆に追加する側はプロデューサー
- Kinesis Data Streamsを扱う上で必要な、どのシャードのどのレコードまで取得したかを記録する処理を、DynamoDBを使用して自動化してくれる
- シャードからのレコード取得もしてくれるため、開発者は基本的にレコードを取得した後の処理を実装するだけで良い
KCLの用語
以下の内容はDynamoDB Streamsを扱う場合においても同義です(Kinesis Data StreamsをDynamoDB Streamsに読み替えられます)。
- Shard(シャード)
- Kinesis Data Streamsのデータを分散バッファリングする本体
- 公式のFAQによると「シャードとは、Amazon Kinesis データストリームの基本的なスループットの単位」と記載されている
- Lease(リース)
- Kinesis Data Streamsのシャードからレコードを取得できるようになっている状態のこと
- Workerにシャードが貸し出されるという意味合いで用いられていそう(内部では、複数のWorkerから同じシャードが取得されないようになっている)
- Leaseテーブル
- Leaseの状態(Workerとシャードのマッピング)やチェックポイントを記録するDynamoDBテーブル
- 存在しなければ、KCLが自動で作ってくれる
- そのため、アプリケーションが動作するEC2インスタンスにDynamoDBテーブルを作成する権限が必要
- もしくは、Primary Keyを
leaseKey::Stringに設定したDynamoDBテーブルを自前で作っても良い
- 当社では、AWSのリソースをTerraformで管理していることもあり、この方法を採用
- この場合、テーブル名がそのままKinesisアプリケーション名となる
- LeaseKey
- Kinesis Data StreamsのシャードID
KCLのロジック(簡易版)
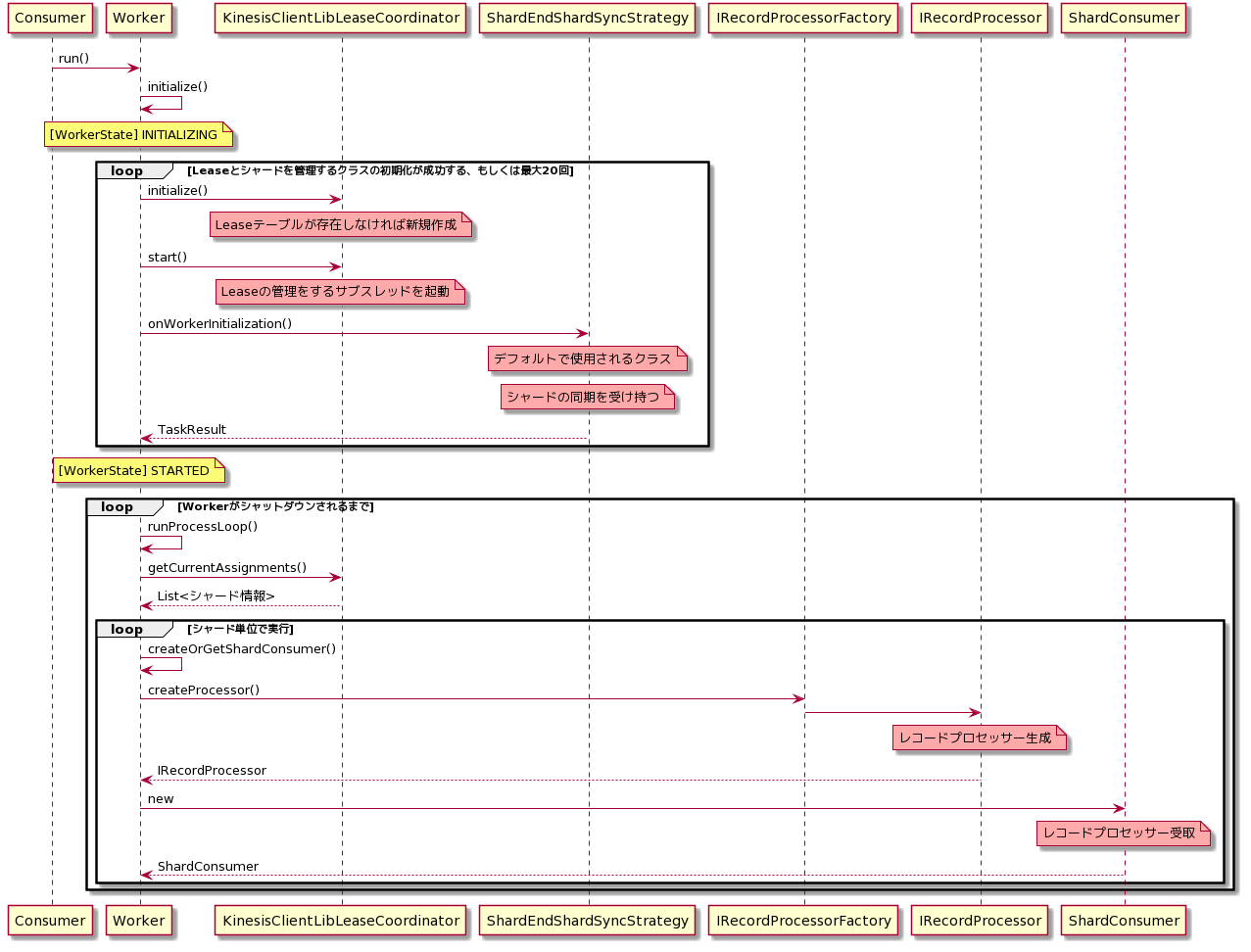
()がついているものはメソッドで、重要な箇所のみ抽出して記載しています。
Consumerは、Workerインスタンスを作成しrun()を呼び出す自分で実装する部分となります。■レコードプロセッサーが生成されるまで
デーモンかバッチか
runProcessLoop()が実行されるループは、実行中のWorkerインスタンスに対して、シャットダウンがリクエストされ、シャットダウンが完了するまで無限ループする作りとなっています。
つまり、
- Workerの
run()メソッドをコンシューマアプリケーションのメインスレッドで実行した場合、基本的にデーモンのように半永久的に動作し続けます- 一方で、今回目的としている定期的に開始/終了を伴うバッチ風に動作させるためには、サブスレッドを作成し、そちらにWorkerインスタンスを渡してあげる必要があります。また、一定時間後にメインスレッドからWorkerに対してシャットダウンリクエストを送ることで、Workerを終了させることができます。
■レコードプロセッサー本体の処理
以下は、上のシーケンス図のWorkerがShardConsumerインスタンスを生成した後の処理になります。
なお、この処理は上のシーケンス図でいうところの[シャード単位で実行]のloop内で実行されます。
RuntimeExceptionを含むExceptionはKCLに握り潰される
IRecordProcessorインターフェースを実装するいわゆるレコードプロセッサー内で発生する例外は全て握り潰されます。
言い換えると、レコードプロセッサー内でどんな例外が発生してもアプリケーションは異常終了しません。
この弊害はチェックポイントの記録時に起きます。
シーケンス図を見れば分かるようにIRecordProcessorの各メソッドはそれぞれサブスレッド上で実行されます。
また、そのスレッド内で発生した例外は先に記載した通り、KCLによって無視されます。
つまり、processRecords()で例外が発生してもスレッドはあたかも正常終了したかのように扱われるということです。
ちなみに、checkpointはprocessRecords()に渡される時点で、そのシャードリースの最新シーケンスと決まっています。
このシーケンスがshutdown()時にも渡されるため、processRecords()のスレッドが異常終了したときのshutdown()時にcheckpointを記録すると、処理に失敗したはずのストリームは欠損してしまいます。KCLの仕様を踏まえたコンシューマアプリケーションの実装
実際の実装とは違いますが、ロジックの基本形だけ伝わるように書いています。
(抜き出しながら記載していったので、そのままでは実行できないかもしれません。)StreamsAdapter
- エントリーポイントのクラス
- 実行/終了を伴うバッチ処理をするため、サブスレッドでWorkerを実行しています(例では5分間有効)
- 30秒おきにShardReadWriteLockから各シャードの処理ステータスをチェックし、1つでもExceptionが発生していれば(ShardProcessStatusがFAILURE)、即座にシャットダウンを実行しています
import com.amazonaws.auth.AWSCredentialsProvider; import com.amazonaws.auth.InstanceProfileCredentialsProvider; import com.amazonaws.regions.Regions; import com.amazonaws.services.cloudwatch.AmazonCloudWatch; import com.amazonaws.services.cloudwatch.AmazonCloudWatchClientBuilder; import com.amazonaws.services.dynamodbv2.AmazonDynamoDB; import com.amazonaws.services.dynamodbv2.AmazonDynamoDBClientBuilder; import com.amazonaws.services.dynamodbv2.AmazonDynamoDBStreams; import com.amazonaws.services.dynamodbv2.AmazonDynamoDBStreamsClientBuilder; import com.amazonaws.services.dynamodbv2.streamsadapter.AmazonDynamoDBStreamsAdapterClient; import com.amazonaws.services.dynamodbv2.streamsadapter.StreamsWorkerFactory; import com.amazonaws.services.kinesis.clientlibrary.interfaces.v2.IRecordProcessorFactory; import com.amazonaws.services.kinesis.clientlibrary.lib.worker.InitialPositionInStream; import com.amazonaws.services.kinesis.clientlibrary.lib.worker.KinesisClientLibConfiguration; import com.amazonaws.services.kinesis.clientlibrary.lib.worker.Worker; import software.amazon.awssdk.regions.Region; import software.amazon.awssdk.services.s3.S3Client; import java.util.Map; import java.util.concurrent.ExecutionException; import java.util.concurrent.ExecutorService; import java.util.concurrent.Executors; public class StreamsAdapter { private static final String tableName = "tableName"; private static final String appName = "appName"; private static final String workerId = "workerId"; private static final AWSCredentialsProvider credentialsProvider = new InstanceProfileCredentialsProvider(true); public static void main(String... args) { // RecordProcessFactory S3Client s3Client = S3Client.builder().region(Region.AP_NORTHEAST_1).build(); ShardReadWriteLock shardReadWriteLock = new ShardReadWriteLock(); IRecordProcessorFactory factory = new RecordProcessorFactory(s3Client, shardReadWriteLock); // DynamoDB AmazonDynamoDB dynamoDB = AmazonDynamoDBClientBuilder.standard().withRegion(Regions.AP_NORTHEAST_1).build(); String streamArn = dynamoDB.describeTable(tableName).getTable().getLatestStreamArn(); // DynamoDB Streams AmazonDynamoDBStreams streams = AmazonDynamoDBStreamsClientBuilder.standard() .withRegion(Regions.AP_NORTHEAST_1).build(); AmazonDynamoDBStreamsAdapterClient adapterClient = new AmazonDynamoDBStreamsAdapterClient(streams); // KCL Configuration KinesisClientLibConfiguration kclConfig = new KinesisClientLibConfiguration(appName, streamArn, credentialsProvider, workerId) .withInitialPositionInStream(InitialPositionInStream.TRIM_HORIZON); // CloudWatch AmazonCloudWatch cloudWatch = AmazonCloudWatchClientBuilder.standard().withRegion(Regions.AP_NORTHEAST_1).build(); // KCL Worker Worker worker = StreamsWorkerFactory.createDynamoDbStreamsWorker(factory, kclConfig, adapterClient, dynamoDB, cloudWatch); System.out.println("Starting stream processing..."); ExecutorService es = Executors.newSingleThreadExecutor(); es.execute(worker); try { // Enable RecordProcessor for 5 minutes. // Check for exception every 30 seconds. boolean allSucceed = true; recordProcess: for (int i = 0; i < 10; i++) { Thread.sleep(30000); Map<String, ShardReadWriteLock.ShardProcessStatus> statusMap = shardReadWriteLock.read(); for (Map.Entry<String, ShardReadWriteLock.ShardProcessStatus> entry : statusMap.entrySet()) { ShardReadWriteLock.ShardProcessStatus status = entry.getValue(); if (status.equals(ShardReadWriteLock.ShardProcessStatus.FAILURE)) { allSucceed = false; break recordProcess; } } } worker.startGracefulShutdown().get(); if (!allSucceed) { throw new RuntimeException("Caught exception in processRecords()."); } } catch (InterruptedException | ExecutionException ex) { ex.printStackTrace(); throw new RuntimeException("Failed to process record of DynamoDB Streams via KCL."); } finally { es.shutdownNow(); } System.out.println("Completed stream processing"); } }RecordProcessorFactory
import com.amazonaws.services.kinesis.clientlibrary.interfaces.v2.IRecordProcessor; import com.amazonaws.services.kinesis.clientlibrary.interfaces.v2.IRecordProcessorFactory; import software.amazon.awssdk.services.s3.S3Client; public class RecordProcessorFactory implements IRecordProcessorFactory { private S3Client s3Client; private ShardReadWriteLock shardReadWriteLock; public RecordProcessorFactory(S3Client s3Client, ShardReadWriteLock shardReadWriteLock) { this.s3Client = s3Client; this.shardReadWriteLock = shardReadWriteLock; } @Override public IRecordProcessor createProcessor() { return new RecordProcessor(s3Client, shardReadWriteLock); } }RecordProcessor
- 分かりやすさのため、processRecords()は受け取ったストリームをS3にPUTするだけの処理にしています
- processRecords()で発生したExceptionとRuntimeExceptionはKCLによって握り潰されるため、全体の処理をExceptionで囲み、例外発生時はメインスレッドから渡されてきたShardReadWriteLockにステータスFAILUREを設定しています
- 一度processRecords()が失敗しても2回目以降呼ばれる可能性があるため、対象のシャードでExceptionが一度でも発生していれば、処理をそれ以上進めないためにスレッドを即座に終了させるようにしています
- processRecords()の冒頭
- シャットダウン時は必ずcheckpointを記録する必要があるため、processRecords()で例外が発生した際に、その時点で取得しているレコード情報を全てログに吐き出すようにしています
- 仕方なく手運用でリカバリを想定していますが、もっといい方法があれば教えてください
import com.amazonaws.services.dynamodbv2.streamsadapter.model.RecordAdapter; import com.amazonaws.services.kinesis.clientlibrary.exceptions.InvalidStateException; import com.amazonaws.services.kinesis.clientlibrary.exceptions.ShutdownException; import com.amazonaws.services.kinesis.clientlibrary.interfaces.IRecordProcessorCheckpointer; import com.amazonaws.services.kinesis.clientlibrary.interfaces.v2.IRecordProcessor; import com.amazonaws.services.kinesis.clientlibrary.interfaces.v2.IShutdownNotificationAware; import com.amazonaws.services.kinesis.clientlibrary.lib.worker.ShutdownReason; import com.amazonaws.services.kinesis.clientlibrary.types.InitializationInput; import com.amazonaws.services.kinesis.clientlibrary.types.ProcessRecordsInput; import com.amazonaws.services.kinesis.clientlibrary.types.ShutdownInput; import com.amazonaws.services.kinesis.model.Record; import software.amazon.awssdk.awscore.exception.AwsServiceException; import software.amazon.awssdk.core.exception.SdkClientException; import software.amazon.awssdk.core.sync.RequestBody; import software.amazon.awssdk.services.s3.S3Client; import software.amazon.awssdk.services.s3.model.PutObjectRequest; public class RecordProcessor implements IRecordProcessor, IShutdownNotificationAware { private final String bucket = "bucket"; private final String objectKey = "objectKey"; private S3Client s3Client; private ShardReadWriteLock shardReadWriteLock; private String shardId; public RecordProcessor(S3Client s3Client, ShardReadWriteLock shardReadWriteLock) { this.s3Client = s3Client; this.shardReadWriteLock = shardReadWriteLock; } @Override public void initialize(InitializationInput initializationInput) { shardId = initializationInput.getShardId(); } @Override public void processRecords(ProcessRecordsInput processRecordsInput) { Map<String, ShardReadWriteLock.ShardProcessStatus> statusMap = shardReadWriteLock.read(); statusMap.forEach((key, value) -> { if (key.equals(shardId) && value.equals(ShardReadWriteLock.ShardProcessStatus.FAILURE)) { throw new RuntimeException("Shard " + shardId + " have failed."); } }); shardReadWriteLock.write(shardId, ShardReadWriteLock.ShardProcessStatus.INITIALIZE); try { for (Record record : processRecordsInput.getRecords()) { if (record instanceof RecordAdapter) { com.amazonaws.services.dynamodbv2.model.Record streamRecord = ((RecordAdapter) record) .getInternalObject(); if (!streamRecord.getEventName().equals("INSERT")) { continue; } s3Client.putObject(PutObjectRequest.builder().bucket(bucket).key(objectKey).build(), RequestBody.fromString(String.valueOf(streamRecord))); } } shardReadWriteLock.write(shardId, ShardReadWriteLock.ShardProcessStatus.SUCCESS); } catch (Exception ex) { shardReadWriteLock.write(shardId, ShardReadWriteLock.ShardProcessStatus.FAILURE); processRecordsInput.getRecords().forEach(s -> System.err.println(((RecordAdapter) s).getInternalObject())); ex.printStackTrace(); throw new RuntimeException("Caught exception in process on shard " + shardId); } } @Override public void shutdown(ShutdownInput shutdownInput) { if (shutdownInput.getShutdownReason() == ShutdownReason.TERMINATE) { try { shutdownInput.getCheckpointer().checkpoint(); } catch (InvalidStateException | ShutdownException ex) { ex.printStackTrace(); } } } @Override public void shutdownRequested(IRecordProcessorCheckpointer checkpointer) { try { checkpointer.checkpoint(); } catch (InvalidStateException | ShutdownException ex) { ex.printStackTrace(); } } }ShardReadWriteLock
- マルチスレッドのデザインパターンであるReadWriteLockパターンを採用しています
- shardsProcessStatusはKeyがシャードID、ValueがShardProcessStatusのMapで、これの読み込み/書き込み時にLockをかけるように実装しています
- INITIALIZE: processRecords()の処理開始時に付与
- SUCCESS: processRecords()の処理が正常終了したときに付与
- FAILURE: processRecords()の処理で例外が発生したときに付与
import java.util.HashMap; import java.util.Map; import java.util.concurrent.locks.Lock; import java.util.concurrent.locks.ReadWriteLock; import java.util.concurrent.locks.ReentrantReadWriteLock; public class ShardReadWriteLock { public enum ShardProcessStatus { INITIALIZE, SUCCESS, FAILURE; } private Map<String, ShardProcessStatus> shardsProcessStatus = new HashMap<>(); private final ReadWriteLock lock = new ReentrantReadWriteLock(); private final Lock readLock = lock.readLock(); private final Lock writeLock = lock.writeLock(); public Map<String, ShardProcessStatus> read() { readLock.lock(); try { return shardsProcessStatus; } finally { readLock.unlock(); } } public void write(String shardId, ShardProcessStatus status) { writeLock.lock(); shardsProcessStatus.put(shardId, status); writeLock.unlock(); } }まとめ
KCLでバッチ風に処理するのは非常に難しかったです。
外部のスレッドから各シャードの処理状況を監視することで、エラーを検知と処理中断をできるようにしました。
processRecords()がどのように呼ばれるのか、例外がどう扱われるのかを知るために、KCLの処理をシーケンス図にまとめました。
コンシューマアプリケーションをデーモンとして実行される方やKinesis Data Streamsをお使いになる方にも参考になればと思います。
課題としては、processRecords()の処理で例外が発生した際に、レコードをログに吐いて手運用するような実装になっている点です。参考

- 投稿日:2020-09-11T17:49:18+09:00
AWSLambdaでPyTorch【EFS編】
はじめに
本記事はAWSのLambda上でPyTorchを動かして見ようという試みについてのまとめです。DeepLearningタグをつけていますが、学習については触れません。ゴールはLambda上で何かしらの推論を動かしてみるというところまでです。
ざっくりまとめ
- EFS使ってみる
- LambdaでPyTorch
- slackからも呼ぶ
の三本立てです。
背景
AWS Lambdaは非常に構築が楽で便利なのですが、様々な制限があります。機械学習をするときにとくに問題になりそうなのが、デプロイパッケージサイズと
/tmp領域サイズです。デプロイパッケージサイズと/tmp領域サイズデプロイパッケージサイズ 50 MB (zip 圧縮済み、直接アップロード) 250 MB (解凍、レイヤーを含む) 3 MB (コンソールエディタ) /tmp ディレクトリのストレージ 512 MBTensorFlow, PyTorchなどのライブラリも益々巨大化していきますしモデルファイルも大きくなってきています。Lambdaに搭載したいが容量オーバーで諦めるということが往々にしてあります。
2020年6月のアップデートでLambdaがAmazon Elastic File System(EFS)をマウントすることができるようになりました。
これにより以下のような恩恵があります。
- /tmpで使用可能な容量(512MB)より大きいデータを処理またはロードする。
- 頻繁に変更されるファイルの最新バージョンをロードする。
- モデルやその他の依存関係をロードするためにストレージ容量を必要とするデータサイエンスパッケージを使用する。
- 呼び出し間で関数の状態を保存する(一意のファイル名またはファイルシステムロックを使用)。
- 大量の参照データへのアクセスを必要とするアプリケーションの構築。
- レガシーアプリケーションをサーバーレスアーキテクチャに移行する。
- ファイルシステムアクセス用に設計されたデータ集約型ワークロードとの相互作用。
- ファイルを部分的に更新する(同時アクセス用のファイルシステムロックを使用)。
- アトミック操作でファイルシステム内のディレクトリとそのすべてのコンテンツを移動する。
特に今回の場合は、
モデルやその他の依存関係をロードするためにストレージ容量を必要とするデータサイエンスパッケージを使用する。が該当するでしょうか。EFSを用意
EFSの準備は、先行事例を大いに参考にさせてもらいます。
EFSの作成とアクセスポイントの準備
PyTorch用のEC2を準備
Python3.7を使用するつもりなので、AmazonLinuxを指定します。(Python3.8ならAmazonLinux2を利用しましょう。)
Python2系しか入っていないのでPython3.7をインストールします。この記事はPython3.8用ですがPython3.7に読み替えておきます。EFSをEC2にマウント
EFSのマウントにEFSマウントヘルパーが必要なので、
$ sudo yum install -y amazon-efs-utilsで入れておきます。
EFSのセキュリティーグループにEC2のセキュリティグループを追加しておきます。
インバウンドルールにタイプをNFSとプロトコルにTCP、ポート範囲2049を指定してソースにEC2インスタンスのセキュリティグループを指定しておきます。EC2にログインして以下のコマンドを叩きましょう。
$ mkdir /mnt/lambda $ sudo mount -t efs [ファイルシステムID]:/ /mnt/lambdaEC2で必要なライブラリをインストール
必要なライブラリをインストールします。
$ sudo pip3 install torch==1.6.0+cpu torchvision==0.7.0+cpu -f https://download.pytorch.org/whl/torch_stable.htmlこれでEFSにPyTorchがインストールできたので、次回Lambdaから読み込みます。
- 投稿日:2020-09-11T15:05:05+09:00
開発環境でゆるふわにec2 spotインスタンスを使ってコストを下げよう
目次
- 対象読者
- 現在のspotインスタンスの仕様
- 実際のオペレーション
- 稼働率、実際の適用効果
対象読者
- クリティカルではない開発環境(~数人利用、落ちても許される環境)のユーザ
- 開発環境のコスト管理責任者
- 部下にawsのコストの使い方が妥当か詰めたい管理者
現在のspotインスタンスの仕様
過去のspotインスタンスの仕様は、下記のようなもので使用者を非常に選ぶものでした。
- AWS都合、自己都合でも停止すると再開不能
- DISKを残しておくことは可能だが、DISKの状態を引き継ぎたい場合はAMIを作ってVM作り直し、、
- CI/CD等で自動構成されるようにしておかないと使いかってが悪い
しかし、現在のspotインスタンスの仕様は、通常のec2にかなり近いものになっています。
- spotインスタンスを通常のオンデマンドインスタンスと同じように停止、再開が可能
- 当然、DISKの状態は引き継がれる
よって、spotインスタンスを時々aws都合で落ちる可能性があるだけのインスタンスとして利用することができます。
コンテナ、ci/cdに無縁な昔ながらのがっつり手動構築、OSに状態持ちまくりの案件でもスポットのメリットを享受することが可能です。実際のオペレーション
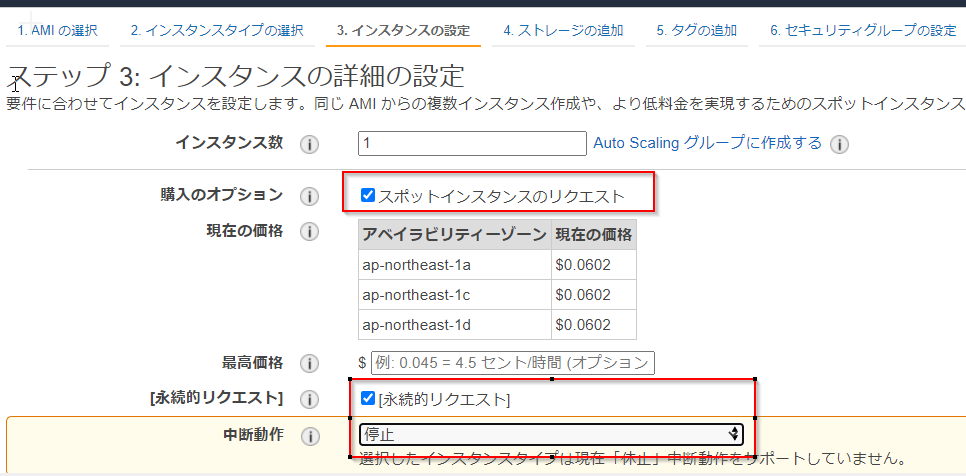
ec2を作るときに、下記のようなオプションを設定するだけとなります。
これだけで、不要な時はec2を止めつつ
- windowsはm5で4割引き
- linuxはm5で7割引き
のコストメリットを受けることができます。
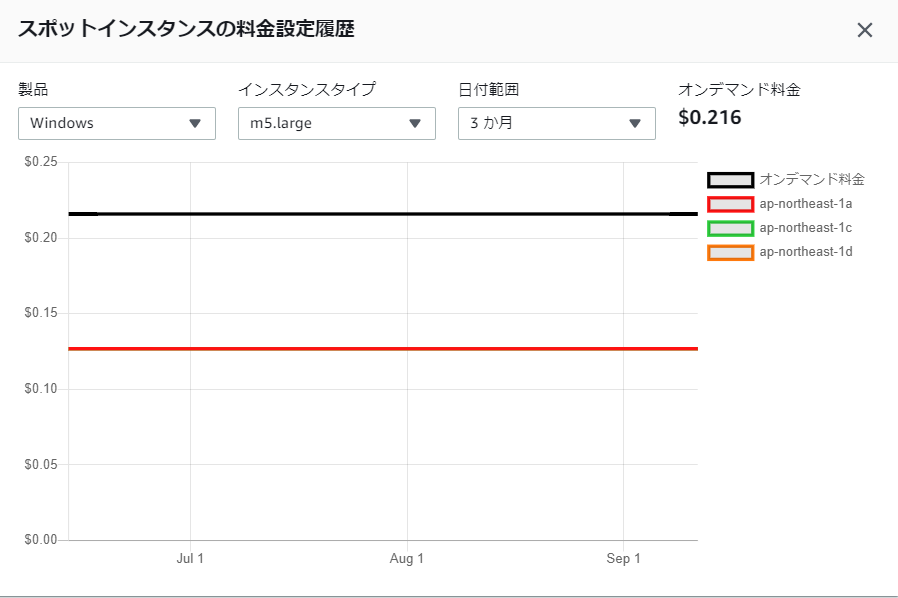
また、今までお使いの電源管理スクリプトをそのまま使い、夜間、休日は今まで通り停止が可能です。参考:3か月のコスト推移
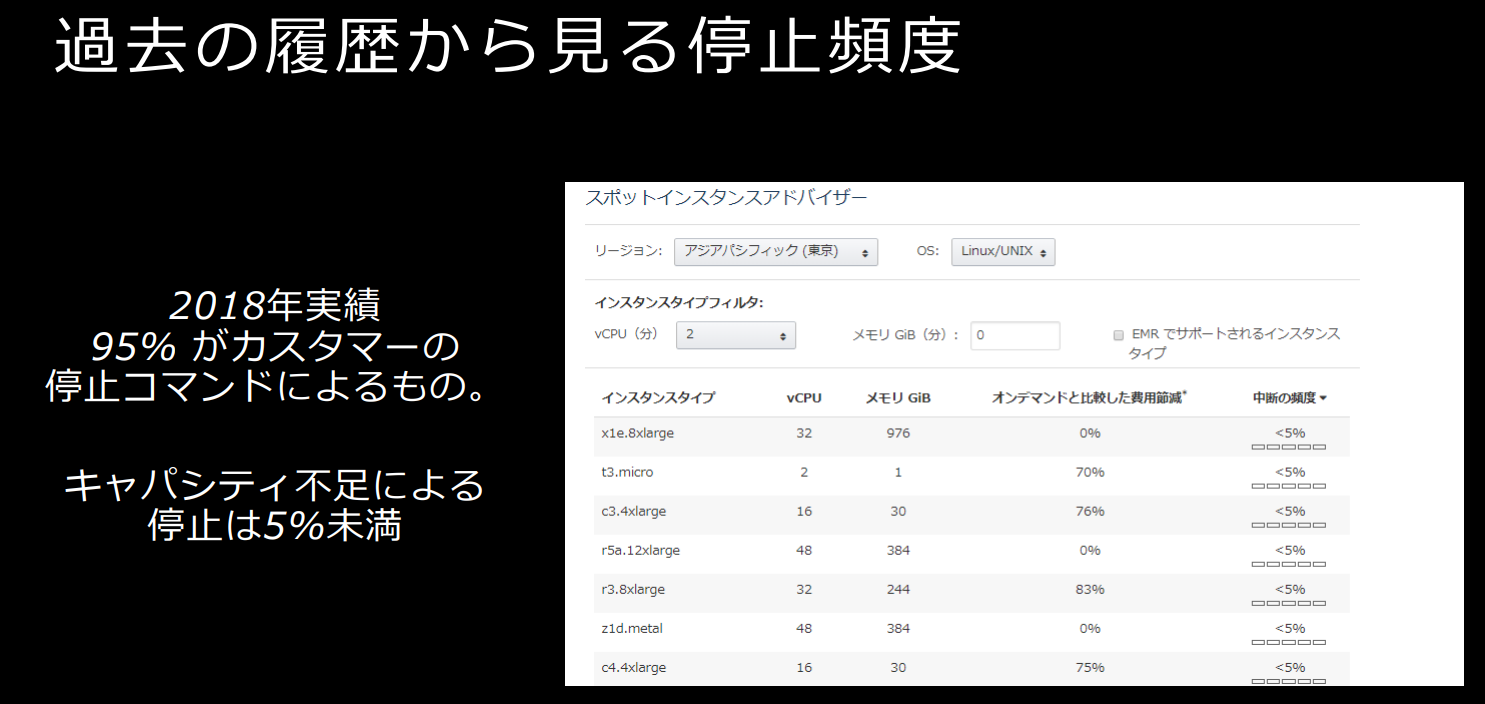
spot稼働率
正確なデータを取っているわけではありませんが、AWS調べによると
キャパシティー不足による停止は5%未満
とのことです。
出典:aws summit 2019:SpotInstance のより効率的な活用を目指して。Spot Instance Update
https://pages.awscloud.com/rs/112-TZM-766/images/L2-08.pdfまた、リージョン、インスタンスタイプごとの詳細は、
https://aws.amazon.com/jp/ec2/spot/instance-advisor/
で確認することができ、インスタンスタイプごとに停止可能性のあたりをつけることが可能です。
機械学習で人気のp系、レガシーすぎる、m1,t2系はある程度の停止リスクがあるのでec2 spot instanceの中断を意識したまともなspotインスタンスが必要でしょう。
しかし、spotインスタンスの種類を適切に選べば、中断リスクは非常に下がるため、環境によっては難しいことを意識せずに通常のインスタンスの代替として使用が可能です。私は、m5,m4,m3を中心に使っており、停止を食らったことはほぼありません。
とくに、古い不人気商品(m3)は落ちにくいだろうという目算で、特に落ちてほしくないシステム等で使っておりましたが、半年以上何もなく動き続けていたこともありました。まとめ
現状のspotインスタンスは、停止リスクがある普通のec2として使う選択肢があります。
また、停止リスクはインスタンスタイプによりかなりコントロール可能なため、非常に限られた停止リスクで、
- windowsで4割コスト削減
- linuxでで7割コスト削減
ができる非常に強力な武器です。
ということで、ゆるふわが許される環境では、ぜひ、spotインスタンスをご検討してみてください。

- 投稿日:2020-09-11T11:32:26+09:00
Exmentでメール送信の設定をする(Amazon SESがおすすめだよ)
Exmentをインストールしたら、早めにやっておきたい設定があります。
それは、メールの送信設定。
Exmentには、レコードを追加したら通知をメールで飛ばす、というようなメール通知の仕組みがあります。ま、そのためにも必要ですが、そもそもメールが送信できないと、パスワード忘れた時に、再発行メールを飛ばせない→詰むということになります。
ですので、できるだけ早めに設定しておいたほうが良いです。
Exmentのメール送信設定箇所
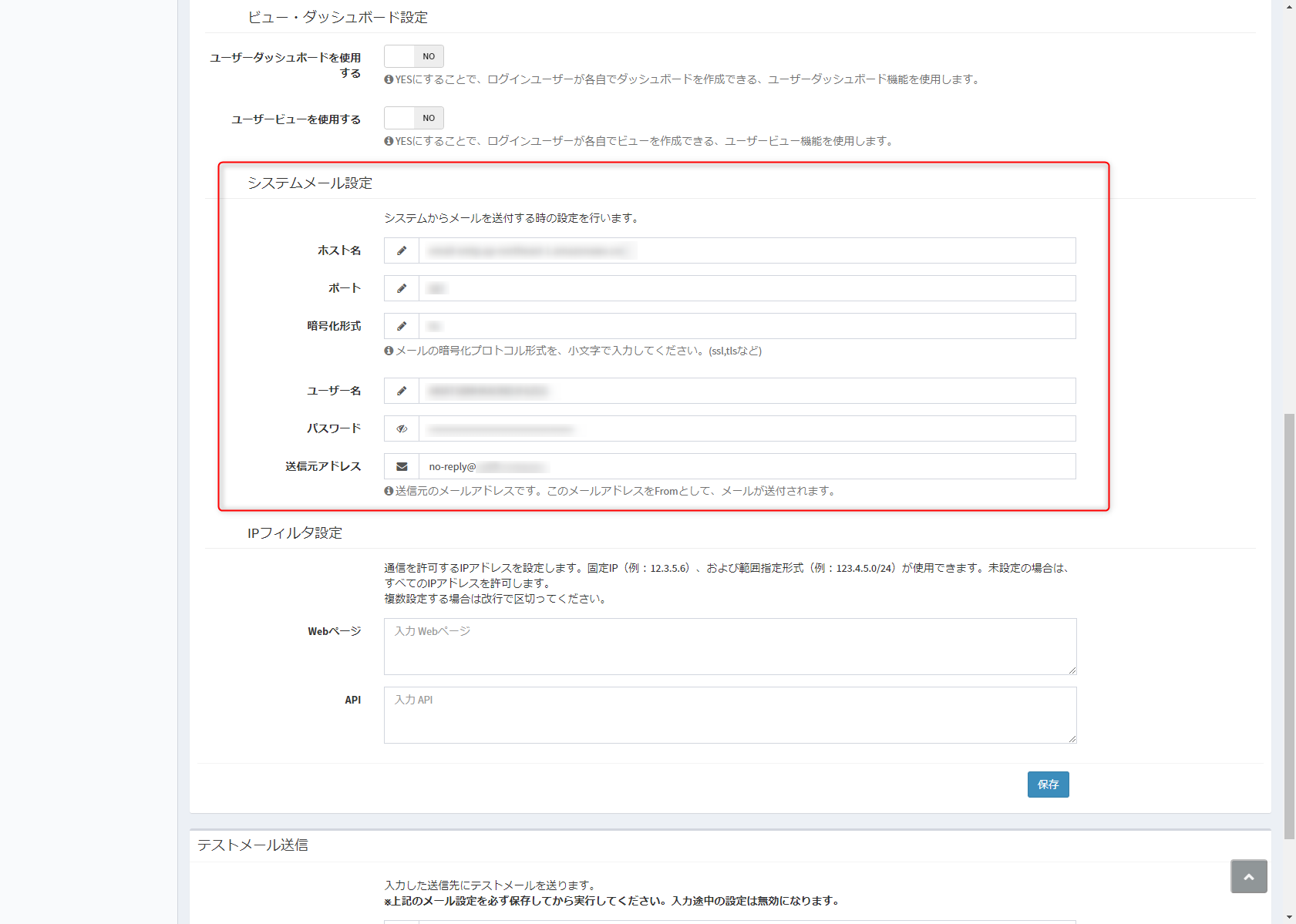
デフォルトでは、左カラムのメニューから、「管理者設定→システム設定」で開いた画面の右上「システム設定」ボタンをクリックし、開いたモーダルの中にある「詳細設定」をクリックします。開いた画面の下のほうに、「システムメール設定」があります。
↓
↓
インストール直後のデフォルトでは、smtp.mailtrap.ioというSMTPサーバーが設定されていると思います。
mailtrap.ioは、開発用のメール送信サービスなので、本番運用では使えないと思います(試してませんが。)
そこで、然るべきメール送信サービスを設定します。
レンタルサーバーで運用している場合、そのレンタルサーバーのメール送信サーバーで良い?
Exmentのウリのひとつとして、さくらインターネットやエックスサーバーといった一般的なレンタルサーバーでも運用できる、というのがあります。
一応、Exmentの公式から、各レンタルサーバーのメールサーバーでの設定ページへのリンクも張られています。
が、一度ここで考えてみましょう。
仮に100人のユーザーがExmentに登録されていて、ある時、5分間に誰かが合計3回レコードを修正したら、通知のメールは一体5分間に何通飛ぶのか? 簡単な算数の問題ですよね。300通です。
一方、レンタルサーバーのメール送信サーバーは、どこまで送信数を許容してくれるのでしょうか?
さくらインターネット公式によると、
3.3. メール送信件数の上限
ライト スタンダード プレミアム ビジネス ビジネスプロ マネージドサーバ 15分毎に約100通程度 (400通/時間 9,600通/日 換算、ただし15分に100通程度を超えない範囲) 15分毎に約250通程度 (1,000通/時間 24,000通/日 換算、ただし15分に250通程度を超えない範囲) 15分毎に約600通程度 (2,400通/時間 57,600通/日 換算、ただし15分に600通程度を超えない範囲) また、エックスサーバー公式では、このようになっています。
メール送信数の目安
1,500通/時間
15,000通/日エックスサーバーはまだ余裕がありますが、結局は
- どれくらいの数のユーザーが
- どれくらいの頻度でレコードを更新するか(あるいはその他のタイミングでメールを送信するイベントが発生するか)
によって、この送信制限数を超えてしまう可能性は否定できません…
そこで、Amazon SESですよ
Amazon SESって何? って方向けに、公式から引用しておきます。
ユースケース
取引 E メール
購入の確認やパスワードのリセットなどのトリガーベースの連絡事項を、お客様のアプリケーションから顧客に即時に送信します。
マーケティング E メール
カスタマイズされたコンテンツと E メールテンプレートを使用して、特別オファーやニュースレターなどの製品やサービスを宣伝します。
Eメールの一括送信
通知やアナウンスを含む一括での連絡を大規模なコミュニティに送信し、設定セットを使用して結果を追跡します。まさに、ExmentのようなWebシステムからの大量メール通知に使ってくださいね、ってことですね。
気になる料金ですが、
お客様の利用状況 お客様の支払い額 追加料金 Amazon EC2 でホストされているアプリケーションからの E メール送信 毎月送信する E メールのうち最初の 62,000 通につき 0 USD、それ以降 1,000 通ごとに 0.10USD。 添付ファイル 1 GB につき 0.12USD。EC2 を使用する場合は追加の料金。 E メールクライアントやその他のソフトウェアパッケージからの E メール送信 送信する各 1,000 通の E メールにつき、0.10USD。 添付ファイル 1 GB につき 0.12USD。 E メール受信 受信する最初の 1,000 通の E メールにつき 0 USD、それ以降 1,000 通ごとに 0.10USD。 受信する E メールチャンク 1,000 通につき、0.09USD (詳細については、料金の詳細を参照してください)。 レンタルサーバー+SESだと、2行目の価格設定に相当するので、1000通ごとに0.1ドル、つまり10円ぐらいです。
100名のユーザーだと10回分になりますが、仮に月1,000回ぐらいメールを100通飛ばすことになるのであっても、月に1,000円の費用負担です。まあまあ安いんじゃないでしょうか。
もし可能であれば、Amazon EC2またはLightsailからの運用だと、1行目の価格設定に相当するので、62,000通は無料になります。これは大きいですね。(LightsailからもSESの無料枠を使えるというのは、非公式ですがこちらがソースです。)
(LightsailでExmentを運用したい方は、こちらの記事もご参照ください。)
あと、SESでない選択肢としてはSendGridになってくるかと思いますが、こちらも無料で月12,000通までは無料だそうです。(私は使ったことがないので、使用感などについてはなんとも言えませんが…)
ExmentでAmazon SESを使う方法
基本的には、
- SESのセットアップ
- Exmentに設定
で完了します。
SESのセットアップはちょっと手間で、不正なメール送信を行わせないようにするため、審査があります。この審査をクリアして、晴れて正式に大量のメール送信ができます。(審査通過前は大量送信ができません)
詳しくは下記記事が詳しいので参考にしてください。
以降は、送信制限緩和が終わった前提で、Exmentへの設定方法を記します。
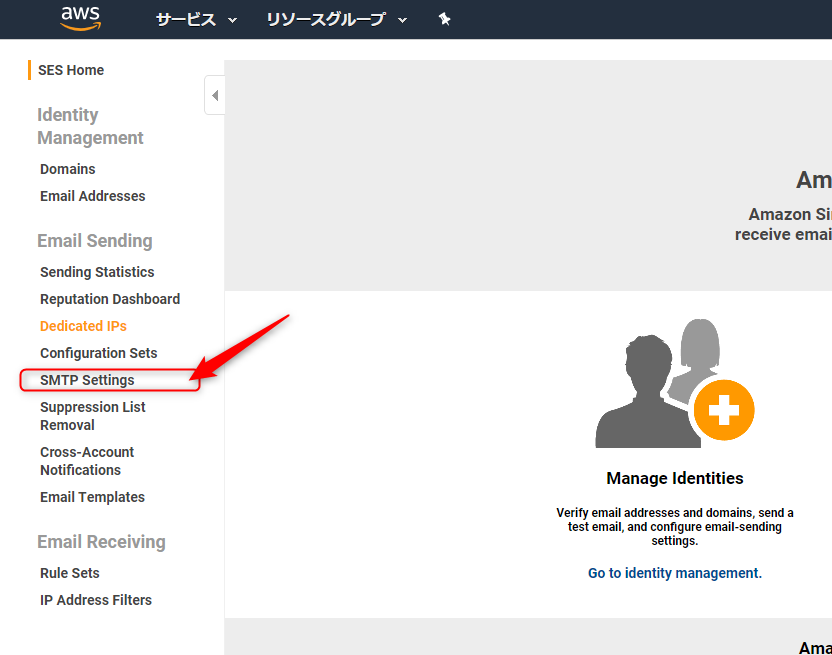
SESのSMTP情報を確認する
Amazon SESのコンソールにログインし、左メニューから「SMTP Settings」をクリックします。
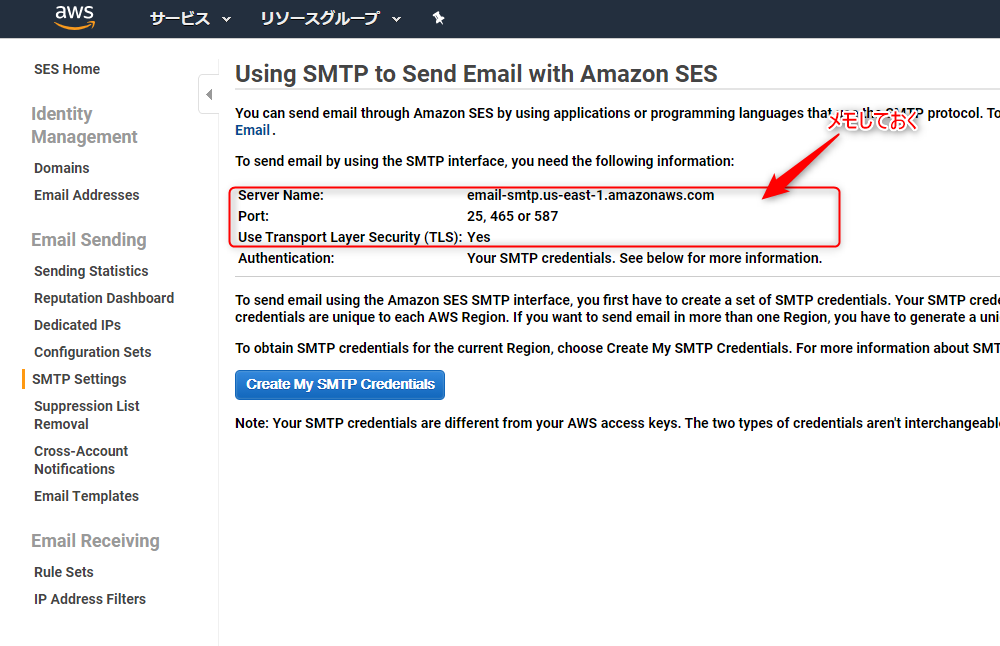
下図の画面が開くので、
- ServerName:
- Port:
- Use Transport Layer Security
をメモっておきましょう。
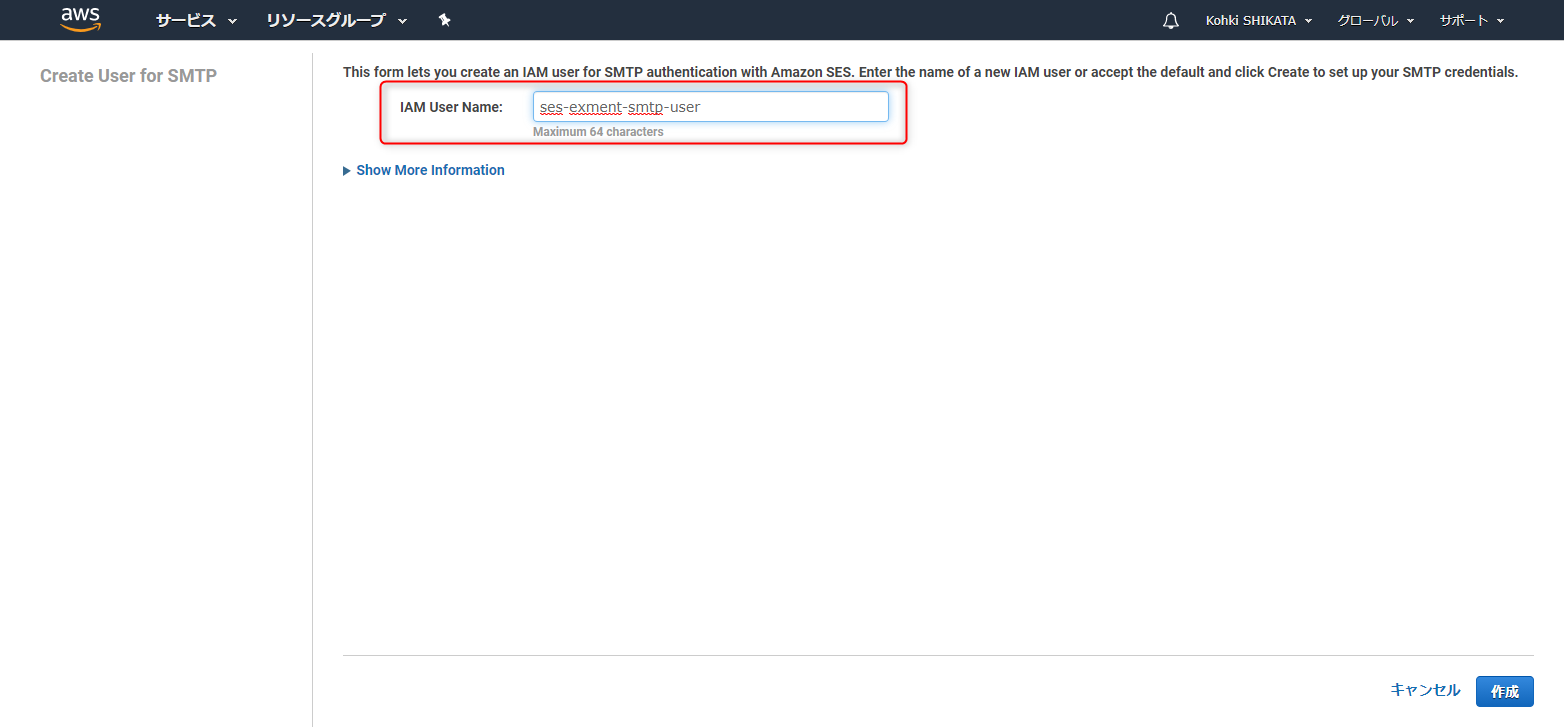
次に、「Create My SMTP Credentials」をクリックします。
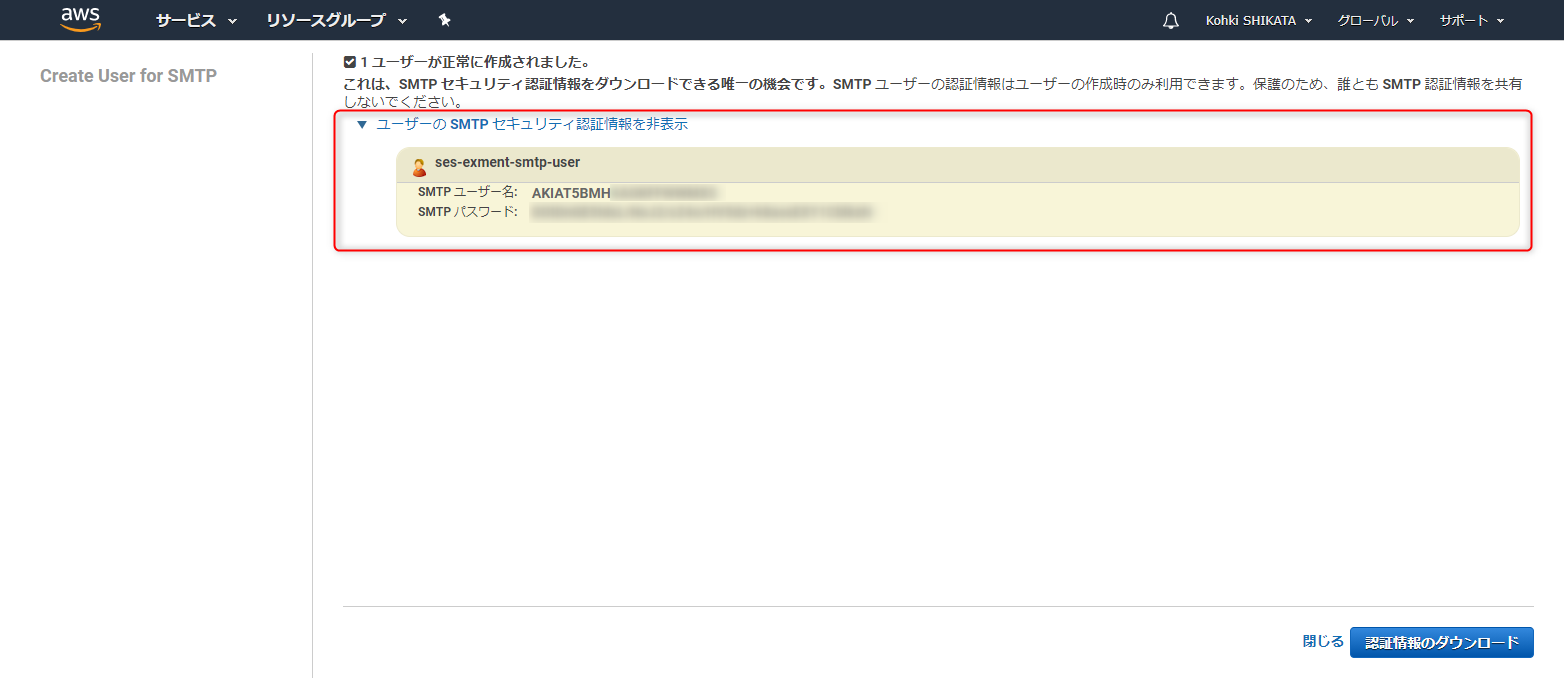
IAMユーザーの作成画面になります。適当なユーザー名をつけましょう。ここでは、ses-exment-smtp-userとしました。
右下の「作成」ボタンを押して次に進みます。
すると、SMTPユーザーアカウントが発行されるので、ユーザー名とパスワードを控えておきます。右下の「認証情報のダウンロード」でもOKです。
次に、Exment側に取得した情報を設定します。
先ほどのメール設定画面を開き、以下の内容で設定します。
設定項目 設定内容 ホスト SESコンソールで控えた内容をペースト ポート 25,465または587 暗号化形式 tls ユーザー名 作成して控えたユーザー名 パスワード 作成して控えたパスワード 送信元アドレス 管理者のメールアドレスか、no-reply@~ 以上の設定を済ませたら、保存ボタンを押して確定しましょう。
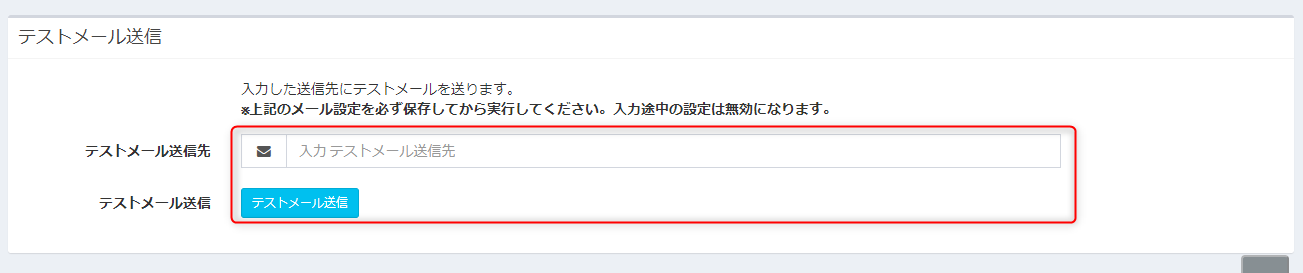
Exmentからテストメールを送信してみよう
Exmentには、きちんとメールが送信されるかテストメールを送信する機能があります。
メール送信設定画面と同じ画面の最下部にあります。
ここに自分のメールアドレスを入力して、きちんと届くかテストしてみましょう。
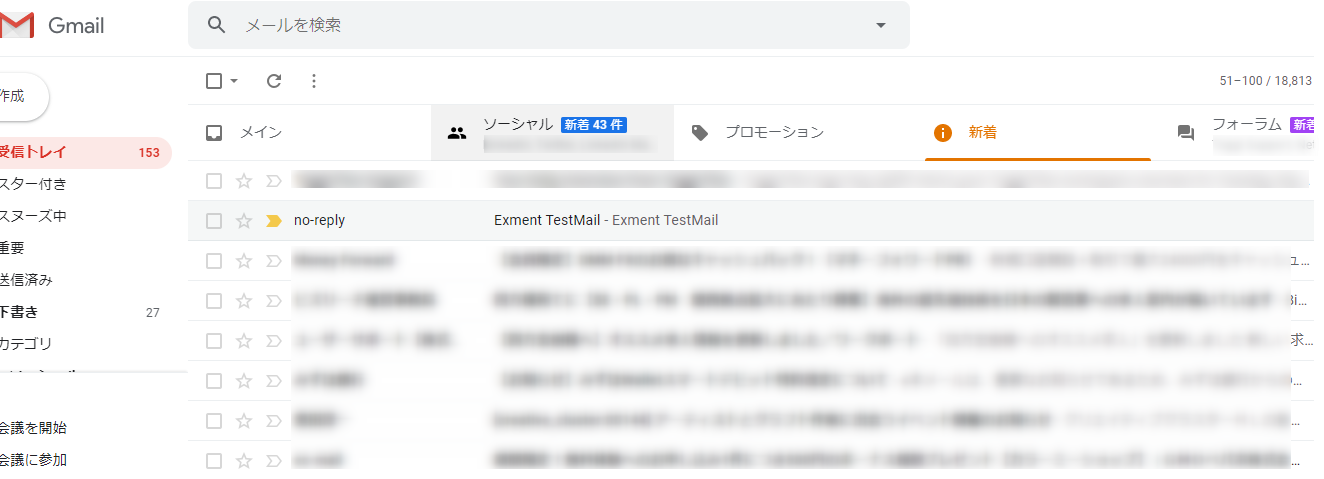
お、きちんと届いておりますな。Gmailの重要フラグもついて、迷惑メール扱いにもなってません。
まとめ
- Exmentでは、インストール後なるはやでメール送信の設定をしておこう
- そうしないとパスワード再発行時に詰む
- レンタルサーバーのメール送信サーバーでは、ユーザー数や送信タイミングによっては送信数上限に達する場合がある
- そういう場合は、Amazon SESやSendGridの利用がおすすめ
- Amazon SES利用には審査がある
こんなところですかね。これでExmentでもそこそこ人数のいる会社でも通知メールばんばん飛ばせるようになりますね!
- 投稿日:2020-09-11T10:43:08+09:00
AWS CloudFormationのテンプレートの雛形
主なセクションの構成
AWSTemplateFormatVersion: "2010-09-09" # Description: Akane's template # Parameters: # Mappings: Resources: # Outputs:AWSTemplateFormatVersion(必須)
形式バージョン: 2010-09-09
https://docs.aws.amazon.com/ja_jp/AWSCloudFormation/latest/UserGuide/format-version-structure.htmlDescription(オプション)
テンプレートの説明を記述する
yamlテンプレート
Parameters: パラメータ名: Description: 説明 Type: String!Refで値を参照する
!Ref パラメータ名jsonファイル
{ "Parameters":[ { "ParameterKey": "パラメータ名", "ParameterValue": "値" } ] }Parameters(オプション)
テンプレートで利用するパラメータを宣言する
Mappings(オプション)
条件付きの値を宣言する
Resources(必須)
AWSリソースを記述する
Outputs(オプション)
AWS CLIや他のスタックから参照できるように値を宣言する
AWSC CLI
aws cloudformation create-stack \ --stack-name スタック名 \ --template-body file://テンプレート.yaml \ --cli-inpu-json file://パラメータ.json
- 投稿日:2020-09-11T08:16:15+09:00
Amazon EKS ExternalDNSでサービスを公開する
はじめに
本記事はAmazon EKSでExternalDNSのデプロイを行ない、サービスを公開する方法について記載しています。
Amazon EKSでクラスターを作成し、ドメインを取得してアプリケーションを外部に公開するためには、ドメインとAmazon EKSを紐付ける作業が必要になります。
ExternalDNSを用いてデプロイすることで動的にServiceとドメインの紐付けができます。また、サブドメインの管理も柔軟に行うことができます。
ExternalDNSの構築
ExternalDNSを使用するためにはドメインの取得が必要です。
ドメインはお名前.comなどのドメイン登録サービスか、Amazon Web Services(AWS)のRoute53で取得します。なお、お名前.com等外部のドメイン登録サービスを利用する場合は、Route53で管理するためネームサーバの設定が必要になります。
本記事ではお名前.comで取得したドメインを、Route53で管理する場合を例に解説します。
Route53
はじめにAWSコンソール画面からRoute53を選択します。
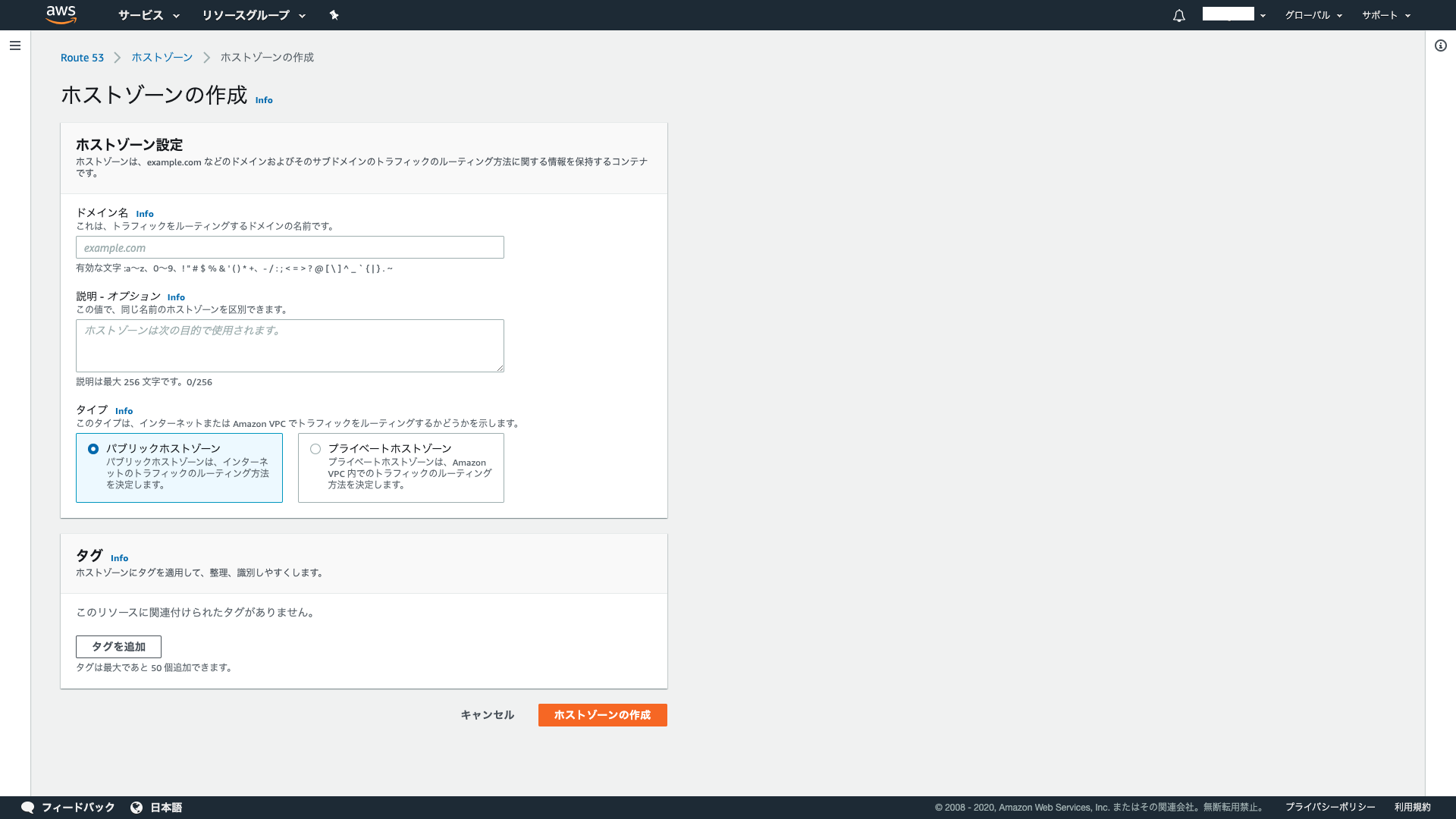
画面左ペインの「ホストゾーン」を選択し、「ホストゾーンの作成」をクリックします。
ドメイン名に取得したドメインの名前を入力し、タイプはパブリックホストゾーンを選択して「ホストゾーンの作成」をクリックします。
作成されたネームサーバの情報は、ドメインを取得したお名前.comなどのドメイン登録サービスのネームサーバ情報に設定します。
IAMのポリシー設定
ExternalDNSからRoute53を操作するための権限を、IAMのポリシーに設定します。
AWSコンソール画面からIAMを選択します。
画面左ペインのポリシーを選択し、「ポリシーの作成」をクリックします。
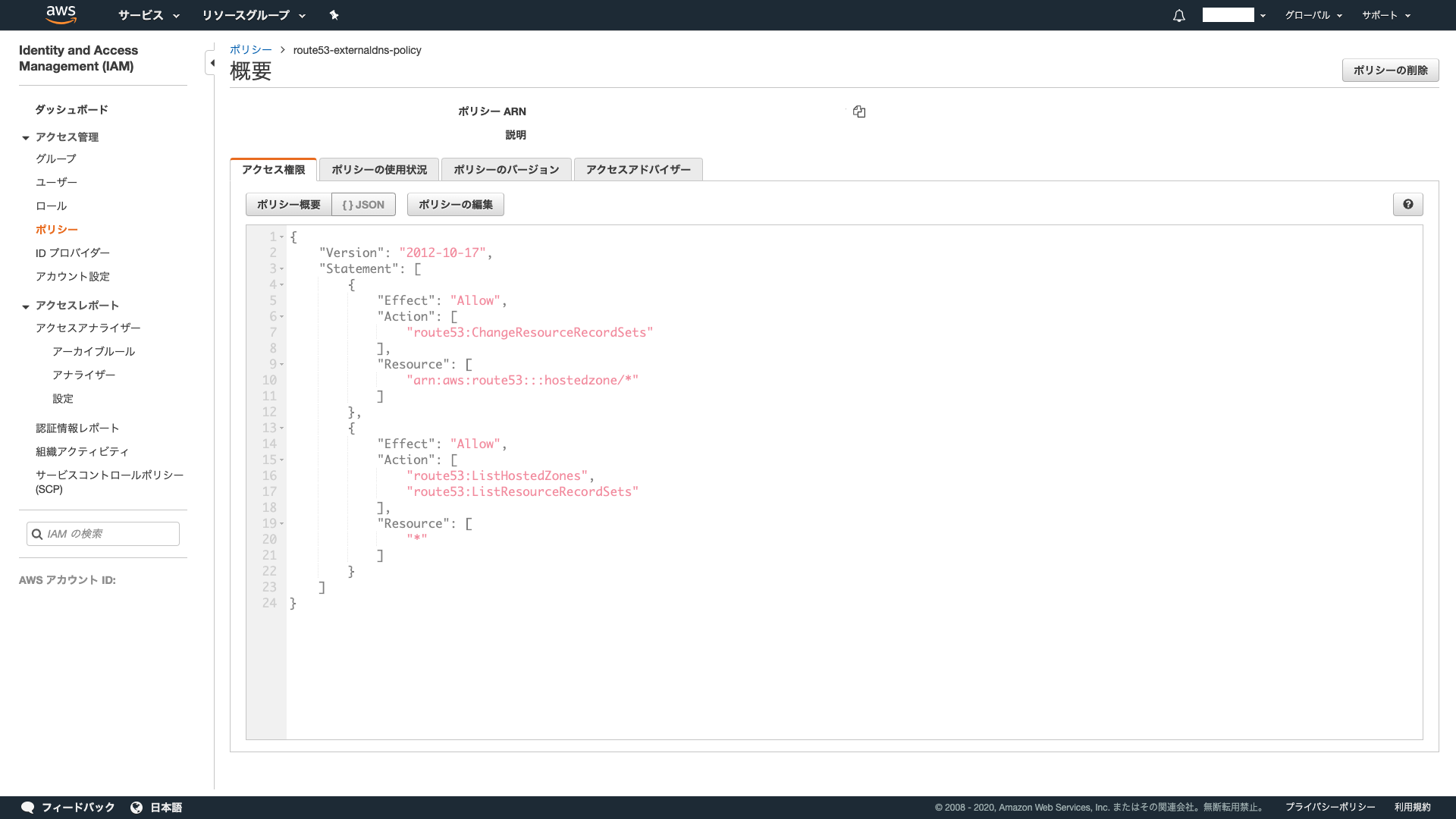
- ポリシーの作成
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": [ "route53:ChangeResourceRecordSets" ], "Resource": [ "arn:aws:route53:::hostedzone/*" ] }, { "Effect": "Allow", "Action": [ "route53:ListHostedZones", "route53:ListResourceRecordSets" ], "Resource": [ "*" ] } ] }ExternalDNSのIAMロールの作成
ExternalDNS用のIAMロールを作成して、先ほど作成したポリシーとAmazon EKSのノードとの紐付けを行います。
AWSコンソール画面からIAMを選択します。
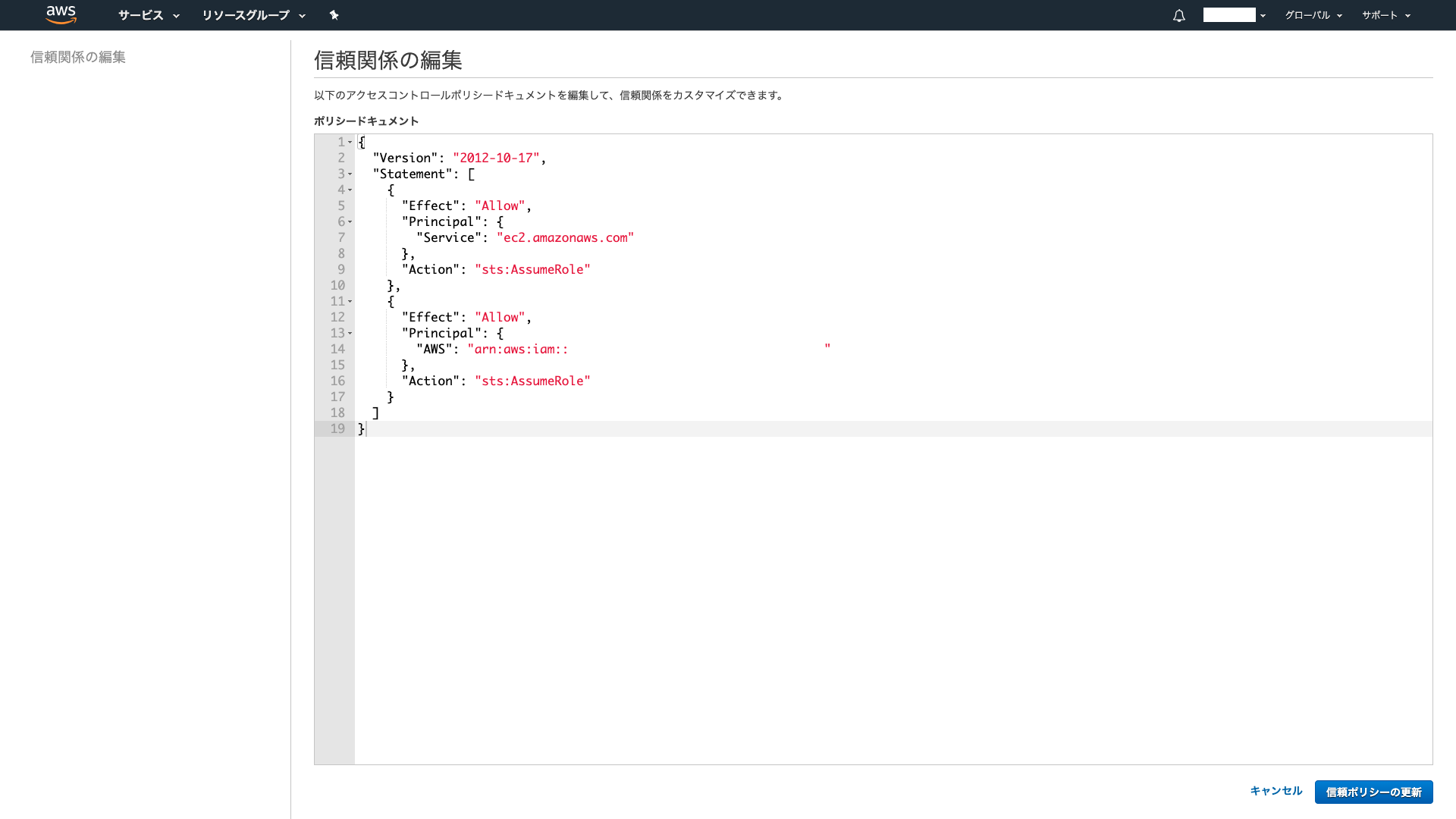
画面左ペインのロールを選択し、「ロールの作成」をクリックします。先ほど作成したポリシーをアタッチし、信頼関係を編集します。
信頼関係は以下のアクセスコントロールポリシードキュメントを編集します。
ポリシードキュメントの<EKSワーカーノードのARN>は、使用するAmazon EKSノードのロールARNの文字列を記載します。
- 信頼関係の編集
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Principal": { "Service": "ec2.amazonaws.com" }, "Action": "sts:AssumeRole" }, { "Effect": "Allow", "Principal": { "AWS": <EKSワーカーノードのARN> }, "Action": "sts:AssumeRole" } ] }マニフェストファイルの作成
デプロイするためのマニフェストファイルを作成します。
annotationsの<EKSワーカーノードのARN>は、使用するAmazon EKSノードのロールARNの文字列を、domain-filterの<取得したドメイン名>は、取得したドメイン名を記載します。apiVersion: v1 kind: ServiceAccount metadata: name: external-dns --- apiVersion: rbac.authorization.k8s.io/v1beta1 kind: ClusterRole metadata: name: external-dns rules: - apiGroups: [""] resources: ["services"] verbs: ["get","watch","list"] - apiGroups: [""] resources: ["pods"] verbs: ["get","watch","list"] - apiGroups: ["extensions"] resources: ["ingresses"] verbs: ["get","watch","list"] - apiGroups: [""] resources: ["nodes"] verbs: ["list","watch"] - apiGroups: [""] resources: ["endpoints"] verbs: ["get","watch","list"] --- apiVersion: rbac.authorization.k8s.io/v1beta1 kind: ClusterRoleBinding metadata: name: external-dns-viewer roleRef: apiGroup: rbac.authorization.k8s.io kind: ClusterRole name: external-dns subjects: - kind: ServiceAccount name: external-dns namespace: default --- apiVersion: apps/v1 kind: Deployment metadata: name: external-dns spec: strategy: type: Recreate selector: matchLabels: app: external-dns template: metadata: labels: app: external-dns annotations: iam.amazonaws.com/role: <EKSワーカーノードのARN> spec: serviceAccountName: external-dns containers: - name: external-dns image: registry.opensource.zalan.do/teapot/external-dns:latest args: - --source=service - --source=ingress - --domain-filter=<取得したドメイン名> - --provider=aws - --policy=sync - --aws-zone-type=public - --registry=txt - --txt-owner-id=example-identifierExternalDNSのデプロイ
マニフェストファイルの作成後、kubectlコマンドでデプロイします。
以下のコマンドを実行し、ExternalDNSのデプロイを行ないます。
$ kubectl apply -f external-dns-manifest.yaml以下はサンプルのデプロイメントとサービスになります。
Serviceとドメインが紐づいているのでServiceを介してNginxにアクセスできます。
- sample-deployment.yaml
apiVersion: apps/v1 kind: Deployment metadata: name: sample-deployment spec: selector: matchLabels: app: sample-app replicas: 2 template: metadata: labels: app: sample-app spec: containers: - name: nginx-container image: nginx:latest ports: - containerPort: 80
- sample-service.yaml
apiVersion: v1 kind: Service metadata: name: sample-service annotations: external-dns.alpha.kubernetes.io/hostname: test.<取得したドメイン> spec: type: LoadBalancer selector: app: sample-app ports: - protocol: TCP port: 80 targetPort: 80以下のコマンドを実行し、デプロイします。
$ kubectl apply -f sample-deployment.yaml
$ kubectl apply -f sample-service.yamlデプロイ後、ブラウザからtest.<取得したドメイン名>にアクセスするとNginxのWelcome画面が表示されます。
以下のコマンドを実行し、リアルタイムでドメインの反映を確認できます。
ドメインは約1分程度で反映されます。
$ while true; do dig test.<取得したドメイン名>; sleep 1;doneおわりに
以上、Amazon EKSでExternalDNSを用いてデプロイする方法でした。
ExternalDNSを使用することで高速デプロイを実現しますが、HTTPSなどは別途考慮が必要です。
- 投稿日:2020-09-11T07:28:30+09:00
CloudFormationをゼロから勉強する。(その4:コマンドからの操作)
はじめに
以前の記事で何度か紹介してきた
Black Belt Online Seminarの記事ですが、2020年度版が公開されたようです。前回からのアップデートの内容や、新たなツールの紹介もされているので、色々と参考になります。
さて、前回はGUI画面上から値を入出力させましたが、今回は今までGUIで行ってきたスタックの作成&削除をコマンドで操作してみようと思います。
CloudFormationコマンド
普段使いそうなコマンドを抜粋しました。
その他のコマンドや詳細は以下を参照して下さい。
内容 コマンド スタックの作成(ローカルファイル) aws cloudformation create-stack --template-body [ファイル格納場所] --stack-name [stack名] スタックの作成(リモートURL) aws cloudformation create-stack --template-url [ファイル格納場所] --stack-name [stack名] スタックの作成(入力項目指定) aws cloudformation create-stack --template-[body/url] [ファイル格納場所] --stack-name [stack名] --parameters [データタイプ(後述)/jsonファイル格納場所] テンプレートの構文チェック aws cloudformation validate-template --template-[body/url] [ファイル格納場所] スタックイベント履歴の表示 aws cloudformation list-stacks リソースのリスト表示 aws cloudformation list-stack-resources --stack-name [stack名] 実行中スタックの表示 aws cloudformation describe-stacks --stack-name [stack名] スタックの削除 aws cloudformation delete-stack --stack-name [stack名]
- Parametersのデータタイプ
内容 コマンド パラメータに関連付けられた値 ParameterKey=[string],ParameterValue=[string] 既存パラメータ値の使用 ParameterKey=[string],UsePreviousValue=[boolean] SSMパラメータのスタック定義に使用される値 ParameterKey=[string],ResolvedValue=[string] 作業用EC2インスタンスへのファイルコピー
前回作成したテンプレートを、「その1:前準備」で準備した作業用EC2インスタンスに格納しておきます。
今回はコピー後のテンプレート名を
cloudformation.yamlとします。テンプレートファイルのコピーaws s3 cp s3://cf-templates-xxxxxxxxxxxx-[リージョン名]/xxxxxxxxxx-designer/new.templatexxxxxxxxxxx ./cloudformation.yamlVS Codeで作業用EC2インスタンスへ接続
「その1:前準備」で書き忘れていましたが
VSCodeの拡張機能であるRemote DevelopmentをインストールしてRemote DevelopmentでEC2インスタンスに接続します。(Remote Developmentのインストール&セットアップは、他サイトを参考にして下さい)EC2インスタンスの追加
前回のテンプレートに
EC2インスタンスを追加してみようと思います。構成は前回作成した
VPC、Subnetの中に新しくEC2インスタンスを追加した構成を想定しています。
上図の構成を組んだ際に生成される
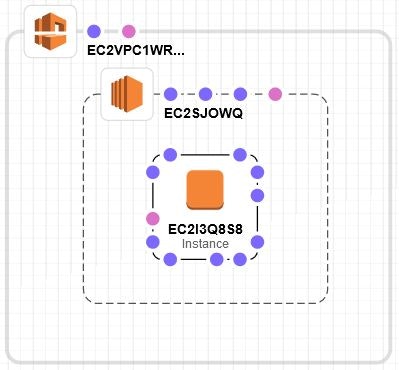
EC2インスタンスのコードは以下となります。
Resourcesセクションの記載は、前回作成したテンプレート内に記載されているので、Resources行を抜かしたコードをVPC、Subnetリソースの後ろにコピペしておきます。EC2インスタンスデフォルト定義Resources: EC2I3Q8S8: Type: 'AWS::EC2::Instance' Properties: NetworkInterfaces: - SubnetId: !Ref EC2SJOWQ必要パラメータの追加(AMI設定)
「EC2インスタンスのテンプレートリファレンス」で必須項目を確認すると
ImageIdが条件付きとなっている以外は特に必須項目は無いようです。
ImageIdはEC2インスタンスを作成する際に選択する以下AMIのIDになります。
今回は
Amazon Linx2 AMI (64ビットx86)のAMIを選択しようと思いますが、EC2インスタンステンプレートのエンティティのうち、InstanceTypeのデフォルト値はm1.smallとなります。ただ、
Amazon Linx2 AMI (64ビットx86)にはm1.smallのインスタンスタイプは無いためInstanceTypeも明示的に指定する必要があります。必要パラメータの追加(NetworkInterface設定)
EC2インスタンステンプレートリファレンスの「NetworkInterface」を確認すると、
DeviceIndexが条件付きとなっており、今回はDeviceIndexの記載も必要となります。EC2インスタンスの設定
最終的な
EC2インスタンスのテンプレートは以下となりました。EC2インスタンス定義EC2I3Q8S8: Type: 'AWS::EC2::Instance' Properties: ImageId: ami-0cc75a8978fbbc969 InstanceType: t2.micro NetworkInterfaces: - SubnetId: !Ref EC2SJOWQ DeviceIndex: 0コマンドからの実行
EC2インスタンスの追加も行ったので、実際にコマンド操作でスタックを作成していこうと思います。尚、後述するコマンドの指定パラメータは以下表の通りとなるので、適宜読み替えて下さい。
内容 パラメータ スタック名 stack-test テンプレートファイルのパス /home/ec2-user/cloudformation.yaml パラメータファイルのパス /home/ec2-user/param.json コマンドからのスタック作成
aws cloudformation create-stackコマンドで作成が可能ですが、前回の作業で入力項目を追加していることから、--parametersオプションで入力項目を追記する必要があります。スタック作成(パラメータ直接指定)aws cloudformation create-stack --template-body file:///home/ec2-user/cloudformation.yaml --stack-name stack-test --parameters ParameterKey=VPCRange,ParameterValue=172.24.0.0/16 ParameterKey=SubnetRange,ParameterValue=172.24.0.0/24パラメータは直接コマンドオプションで記載する以外に、
json形式のファイルを読み込むことも可能です。(yaml形式不可)以下、
/home/ec2-userの配下にparam.jsonというパラメータファイルを作成した場合の例。/home/ec2-user/param.json[ { "ParameterKey" : "VPCRange", "ParameterValue" : "172.24.0.0/16" }, { "ParameterKey" : "SubnetRange", "ParameterValue" : "172.24.0.0/24" } ]スタック作成(パラメータファイル読み込み)aws cloudformation create-stack --template-body file:///home/ec2-user/cloudformation.yaml --stack-name stack-test --parameters file:///home/ec2-user/param.jsonおわりに
インプットパラメータを長々書くのは可読性が悪く分かりづらいと感じていましたが、ファイルにまとめられるのは良いですね。
次回は
Mappingsセクションなどを使ってみようと思います。

- 投稿日:2020-09-11T00:28:13+09:00
【Tips】TerraformでDynamoDBにそこそこの量のアイテムを初期構築でputしておく方法
はじめに
DynamoDBとLambdaで色々試してると、ふと検証のために大量データを予め入れておきたくなったりするよね。
それ、Terraformで簡単に実現できるんです。※そんなのPythonでboto3使ってbatch_writer()で書けば5分で済むだろ、とかそういうツッコミは一旦抜きにして。
どうやってIaCで書くのか
countを使う。以上。
だと終わってしまうので、もう少し解説。
resource "aws_dynamodb_table_item" "batch_items" { count = 100 table_name = aws_dynamodb_table.test.name hash_key = aws_dynamodb_table.test.hash_key range_key = aws_dynamodb_table.test.range_key item = <<ITEM { "id": {"S": "${format("%03d", count.index + 1)}"}, "name": {"S": "テストデータ${count.index + 1}"} } ITEM }ハッシュキーがかぶってしまうと、当然同じアイテム扱いになってしまう。
単純に連番にしたいのであれば、${count.index}で今のループ回数にアクセスできる。
0オリジンなので注意が必要。さらに、001, 002, 003…… と形式が決まっているときは、format関数を使う。
これで「queryやscanで取ってくる件数が変わった時にどれくらい性能差があるの?」と聞かれても焦ることなくデータが作れるようになるぞ!