- 投稿日:2020-09-09T23:20:56+09:00
上司を納得させるための図を描くのに必要なmatplotlibの早見表
機械学習などで特徴量を検討していると、色々と図を描きたくなります。
他人(特に上司とか、上司とか、上司とか。。。)に説明するのにも図が重要です。
分かりやすく書かないと、やり直しさせられます。
その時に役立ちそうな処理を一覧にしました。インポート
import matplotlib.pyplot as plt図(fig, ax)の作成
単体
import matplotlib.pyplot as plt fig = plt.figure(figsize=(15, 8), dpi=100) ax1 = plt.axes()なお、figsizeは(横, 縦)のインチ、dpiはインチ当たりの画素数。
つまり、この場合、1500 x 800の画像になる。
dpi=100はデフォルト、figsizeのデフォルトは(6,4)だが、
最近のディスプレイはもっと横長で高画質なので(15,8)にしてみた。複数
fig = plt.figure(figsize=(15, 8), dpi=100) ax1 = plt.subplot(2, 2, 1) # 1行1列目 ax2 = plt.subplot(2, 2, 2) # 1行2列目 ax3 = plt.subplot(2, 2, 3) # 2行1列目 ax4 = plt.subplot(2, 2, 4) # 2行2列目あるいはまとめて、
fig, ax = plt.subplots(2, 2, figsize=(15, 8), dpi=100) ax1 = ax[0, 0] # 1行1列目 ax2 = ax[0, 1] # 1行2列目 ax3 = ax[1, 0] # 2行1列目 ax4 = ax[1, 1] # 2行2列目あるいは動的に追加もできる。
fig = plt.figure(figsize=(15, 8), dpi=100) ax1 = fig.add_subplot(2, 2, 1) ax2 = fig.add_subplot(2, 2, 2) ax3 = fig.add_subplot(2, 2, 3) ax4 = fig.add_subplot(2, 2, 4)図の描画
線を引く
import numpy as np y = np.random.randn(100) # 標準正規分布から100個をサンプリング x = np.arange(y.shape[0]) ax1.plot(y, x, linewidth=0.5)linewidthは線の太さ。あと使いそうなのは、color, linestype, marker, label, zorderなどなど。
- linewidth ... 線の太さ。
- linestyle ... 実践や点線などを指定。詳細はこちら
- marker ... マーカー指定。詳細はこちら。
- color ... 線の色。詳細はこちら
- label ... 凡例に使用。後述のax.legend()で表示させることが可能。
- zorder ... どれを表側、裏側に表示させるかの順番を指定。
matplotlib.pyplot.plotが使えるkwargsは上記以外にもあり、Line2Dプロパティが使える。
一応ここにその一覧がある。散布図
普通の散布図や、波形上のマーカーとしてよく使います。
ax.scatter(0.5, 0.5, s=600, c="red", alpha=0.1)sはサイズ、cは色、alphaは透過性を設定できます。
文字
例えば、マーカー部分の具体的な数値を表したい場合に使います。
最大値っていうけど、具体的にどのくらい?とかをメモリを読み取らせずに説明できます。ax.text(0.5, 0.5, "test", va="bottom", ha="left", color="red")参考
描画できるものの一覧はここにあります。
それぞれのaxを整える
タイトルをつける
ax1.set_title("タイトル")軸の範囲を制限する。
ax1.set_xlim([0.0, 1.0]) ax1.set_ylim([0.0, 1.0])メモリの間隔を制御する。
ax1.set_xticks([0.0, 0.5, 1.0]) ax1.set_yticks([0.0, 0.5, 1.0])実際はnp.linspace(最小, 最大, tick数)で作成するのが実用的。
設定したメモリ間隔にラベルを付与
ax1.set_yticklabels(["小", "中", "大"])凡例を表示
ax1.legend(["test"], fontsize=7, loc="upper left")plot時にlabelプロパティを指定している場合、["test"]の部分は不要。
fontsizeで文字の大きさ、locで表示する場所を制御できる。
locの設定値はここのLocation Stringを参照。軸ラベルを表示
ax1.set_ylabel("X軸") ax1.set_ylabel("Y軸")グリッドを表示
ax.grid(b=True, linestyle=":")すべてのaxを表示した後の調整
なんとなく整える呪文
plt.tight_layout()図の出力
画面上に表示。
plt.show()表示できるものがない環境では以下のように画像で出力。
plt.savefig("aaa.png")図のクローズ・削除
showしている場合はclose。
plt.close()さらに図を破棄する。破棄しないとメモリを占有する可能性あり。
plt.clf()
- 投稿日:2020-09-09T22:30:20+09:00
[Python] Typetalk APIの使い方
はじめに
当記事では、PythonでのTypetalk APIの使い方を紹介します。
ちなみに、私はカレー判定ボット作りました。
事前準備
ボットの作成と、トークンとURLの取得を行います。
ボット作成
「トピック設定」から「ボット」タブを開きます。
新規追加を押すと、ボット設定画面が開きます。
項目は以下のようになっています。それぞれ設定して下さい。
項目 説明 ボットID ボットのユニークID ボット名 ボットのユーザー名 説明 ボットの説明 APIスコープ ボットの権限 Outgoing Webhook 当記事では使いません 設定できたら、
作成を押して下さい。
すると、下の方にトークンやURLが表示されるはずです。
取得
表示されたら、トークンとURLをメモして下さい。
事前準備はこれで完了です。
環境
Python 3.8.5
ライブラリのインストール
RequestsというPythonのHTTP通信ライブラリを使います。
pip install requestsソースコード
tokenとurlにメモしたトークンとURLを記述して下さい。サンプル
公式のサンプルを少しだけ改変しました。
sample.pyimport requests token = '' url = '' data = {'message':'Hello, Typetalk!'} headers = {'X-TYPETALK-TOKEN': token} r = requests.post(url, json = data, headers = headers) print(r.status_code) print(r.json())実行すると、ボットがトピックに
Hello, Typetalk!と投稿するはずです。
また、レスポンスが表示されるはずです。
投稿したメッセージの詳細情報が記載されています。
メッセージ取得
メッセージを取得します。
レスポンスを見やすくするためにpprintを使います。get.pyimport requests import pprint token = '' url = '' headers = {'X-TYPETALK-TOKEN': token} r = requests.get(url, headers = headers) print(r.status_code) pprint.pprint(r.json())レスポンスの例
公式の例を引用しました。
example.json{ "bookmark": { "postId": 172371, "updatedAt": "2019-03-11T08:37:40Z" }, "exceedsAttachmentLimit": false, "postContentsSettings": { "collapsedAccountIds": [] }, "myTopic": { "id": 15376, "topicId": 3557, "accountId": 2488, "kind": "grouped", "topicGroupId": 1703, "exTopicGroupId": 1702, "orderNo": 0, "createdAt": "2019-02-13T08:27:22Z", "updatedAt": "2019-02-13T08:27:22Z" }, "topic": { "createdAt": "2016-02-05T06:13:44Z", "lastPostedAt": "2019-03-11T08:38:04Z", "isArchived": false, "suggestion": "UX改善", "name": "UX改善", "description": "UXの改善に関するトピックです。\nデザインやUX、その他気づいた点について気軽に話しましょう。\n\nサイト改善についてのまとめWiki\n- https://xxxxx.backlog.jp/wiki/WEBSITE/Kaizen\n\nまた、関連イベントの周知もこのトピックで行います。", "isDirectMessage": false, "id": 3557, "updatedAt": "2018-10-18T01:54:18Z" }, "onboarding": null, "hasNext": false, "team": null, "mySpace": { "space": { "key": "XXXXXXX", "name": "Nulab Inc", "enabled": true, "imageUrl": "https://apps.nulab.com/spaces/XXXXXXX/photo/large" }, "myRole": "ADMIN", "isPaymentAdmin": true, "invitableRoles": [ "ADMIN", "USER", "GUEST" ], "myPlan": { "plan": { "key": "typetalk.standard25", "name": "スタンダード 25 ユーザー", "limitNumberOfUsers": 25, "limitNumberOfAllowedAddresses": 25, "limitTotalAttachmentSize": 268435456000 }, "enabled": true, "trial": null, "numberOfUsers": 5, "numberOfAllowedAddresses": 0, "totalAttachmentSize": 14356, "createdAt": "2016-01-19T09:29:10Z", "updatedAt": "2019-08-28T08:19:49Z" } }, "favorite": true, "posts": [ { "attachments": [ { "attachment": { "contentType": "application/octet-stream", "fileKey": "1", "fileName": "1.jpg", "fileSize": 472263 }, "webUrl": "https://typetalk.com/topics/3557/posts/154010/attachments/1/1.jpg", "apiUrl": "https://typetalk.com/api/v1/topics/3557/posts/154010/attachments/1/1.jpg" }, { "attachment": { "contentType": "application/octet-stream", "fileKey": "2", "fileName": "2.jpg", "fileSize": 494376 }, "webUrl": "https://typetalk.com/topics/3557/posts/154010/attachments/2/2.jpg", "apiUrl": "https://typetalk.com/api/v1/topics/3557/posts/154010/attachments/2/2.jpg" }, { "attachment": { "contentType": "application/octet-stream", "fileKey": "3", "fileName": "5.jpg", "fileSize": 218100 }, "webUrl": "https://typetalk.com/topics/3557/posts/154010/attachments/3/5.jpg", "apiUrl": "https://typetalk.com/api/v1/topics/3557/posts/154010/attachments/3/5.jpg" }, { "attachment": { "contentType": "application/octet-stream", "fileKey": "4", "fileName": "6.jpg", "fileSize": 627926 }, "webUrl": "https://typetalk.com/topics/3557/posts/154010/attachments/4/6.jpg", "apiUrl": "https://typetalk.com/api/v1/topics/3557/posts/154010/attachments/4/6.jpg" } ], "quotedPosts": [], "message": "トップ画面の改善案できました。http://nulab-inc.com/ja/", "mention": null, "createdAt": "2019-03-02T06:13:44Z", "topicId": 3557, "contents": null, "mentions": [], "talks": [], "replyTo": null, "links": [ { "id": 3148, "url": "http://nulab-inc.com/ja/", "contentType": "text/html; charset=UTF-8", "title": "チームにさらなるコラボレーションを | ヌーラボ", "description": "数百万人ものユーザーがヌーラボのサービスを使用して、チームのコミュニケーションを改善しています。ヌーラボのオンラインコラボレーションツールで、あなたのチームの仕事をもっと楽しくしましょう。", "imageUrl": "https://nulab-inc.com/ogp_dft.png", "embed": null, "createdAt": "2015-06-15T06:41:24Z", "updatedAt": "2017-03-03T10:11:08Z" } ], "id": 154010, "account": { "id": 2492, "name": "hayashi", "fullName": "hayashi", "suggestion": "hayashi", "imageUrl": "https://typetalk.com/accounts/2492/profile_image.png?t=1453871047310", "isBot": false, "createdAt": "2016-01-26T08:19:01Z", "updatedAt": "2019-09-04T07:25:45Z" }, "likes": [], "updatedAt": "2019-03-02T06:13:44Z" }, { "attachments": [], "quotedPosts": [], "message": "まささん、この画面の色はどう思いますか?", "mention": null, "createdAt": "2019-03-03T06:13:44Z", "topicId": 3557, "contents": null, "mentions": [], "talks": [], "replyTo": null, "links": [], "id": 154011, "account": { "id": 2489, "name": "yoshizawa", "fullName": "Yoshi", "suggestion": "Yoshi", "imageUrl": "https://typetalk.com/accounts/2489/profile_image.png?t=1564389095614", "isBot": false, "createdAt": "2016-01-26T08:18:12Z", "updatedAt": "2019-09-04T07:25:45Z" }, "likes": [], "updatedAt": "2019-03-03T06:13:44Z" } ] }この中で注目するのが、
postsです。posts.json"posts": [ { "attachments": [ { "attachment": { "contentType": "application/octet-stream", "fileKey": "1", "fileName": "1.jpg", "fileSize": 472263 }, "webUrl": "https://typetalk.com/topics/3557/posts/154010/attachments/1/1.jpg", "apiUrl": "https://typetalk.com/api/v1/topics/3557/posts/154010/attachments/1/1.jpg" }, { "attachment": { "contentType": "application/octet-stream", "fileKey": "2", "fileName": "2.jpg", "fileSize": 494376 }, "webUrl": "https://typetalk.com/topics/3557/posts/154010/attachments/2/2.jpg", "apiUrl": "https://typetalk.com/api/v1/topics/3557/posts/154010/attachments/2/2.jpg" }, { "attachment": { "contentType": "application/octet-stream", "fileKey": "3", "fileName": "5.jpg", "fileSize": 218100 }, "webUrl": "https://typetalk.com/topics/3557/posts/154010/attachments/3/5.jpg", "apiUrl": "https://typetalk.com/api/v1/topics/3557/posts/154010/attachments/3/5.jpg" }, { "attachment": { "contentType": "application/octet-stream", "fileKey": "4", "fileName": "6.jpg", "fileSize": 627926 }, "webUrl": "https://typetalk.com/topics/3557/posts/154010/attachments/4/6.jpg", "apiUrl": "https://typetalk.com/api/v1/topics/3557/posts/154010/attachments/4/6.jpg" } ], "quotedPosts": [], "message": "トップ画面の改善案できました。http://nulab-inc.com/ja/", "mention": null, "createdAt": "2019-03-02T06:13:44Z", "topicId": 3557, "contents": null, "mentions": [], "talks": [], "replyTo": null, "links": [ { "id": 3148, "url": "http://nulab-inc.com/ja/", "contentType": "text/html; charset=UTF-8", "title": "チームにさらなるコラボレーションを | ヌーラボ", "description": "数百万人ものユーザーがヌーラボのサービスを使用して、チームのコミュニケーションを改善しています。ヌーラボのオンラインコラボレーションツールで、あなたのチームの仕事をもっと楽しくしましょう。", "imageUrl": "https://nulab-inc.com/ogp_dft.png", "embed": null, "createdAt": "2015-06-15T06:41:24Z", "updatedAt": "2017-03-03T10:11:08Z" } ], "id": 154010, "account": { "id": 2492, "name": "hayashi", "fullName": "hayashi", "suggestion": "hayashi", "imageUrl": "https://typetalk.com/accounts/2492/profile_image.png?t=1453871047310", "isBot": false, "createdAt": "2016-01-26T08:19:01Z", "updatedAt": "2019-09-04T07:25:45Z" }, "likes": [], "updatedAt": "2019-03-02T06:13:44Z" }, { "attachments": [], "quotedPosts": [], "message": "まささん、この画面の色はどう思いますか?", "mention": null, "createdAt": "2019-03-03T06:13:44Z", "topicId": 3557, "contents": null, "mentions": [], "talks": [], "replyTo": null, "links": [], "id": 154011, "account": { "id": 2489, "name": "yoshizawa", "fullName": "Yoshi", "suggestion": "Yoshi", "imageUrl": "https://typetalk.com/accounts/2489/profile_image.png?t=1564389095614", "isBot": false, "createdAt": "2016-01-26T08:18:12Z", "updatedAt": "2019-09-04T07:25:45Z" }, "likes": [], "updatedAt": "2019-03-03T06:13:44Z" } ]メッセージIDや添付ファイル、いいねの数などの様々なことを取得するができます。
返信
メッセージIDを利用して、ボットが投稿したメッセージにボット自身で返信します。
JSON文字列を扱うため、jsonを使います。reply_to_me.pyimport requests import pprint import json token = '' url = '' msg = {'message':'Hello, Typetalk!'} headers = {'X-TYPETALK-TOKEN': token} r = requests.post(url, json = msg, headers = headers) dict = json.loads(r.text) id = dict['post']['id'] reply = {'message':'こんにちは!', 'replyTo': id} q = requests.post(url, json = reply, headers = headers) print(q.status_code) pprint.pprint(q.json())実行すると、ボットが
こんにちは!と返信するはずです。
解説
dic = json.loads(r.text)JSON文字列を辞書型に変換します。
id = dict['post']['id']公式のレスポンスの例より、メッセージIDは
postキー下のidキーのバリューであることが分かります。reply = {'message':'こんにちは!', 'replyTo': id}パラメーターを設定することで様々ことができます。
メッセージ投稿では、replyToにメッセージIDを記述することで返信することができます。いいね
ボットが投稿したメッセージにボット自身でいいねします。
like.pyimport requests import pprint import json token = '' url = '' msg = {'message':'Hello, Typetalk!'} headers = {'X-TYPETALK-TOKEN': token} r = requests.post(url, json = msg, headers = headers) dic = json.loads(r.text) id = dic['post']['id'] like = url + '/posts/' + str(id) + '/like' q = requests.post(like, headers = headers) print(q.status_code) pprint.pprint(q.json())実行すると、ボットがいいねするはずです。
解説
like = url + '/posts/' + str(id) + '/like'URLパラメーターを設定することで様々なことができます。
いいね追加はhttps://typetalk.com/api/v1/topics/:topicId/posts/:postId/likeとなっています。
おわりに
以上が使い方の紹介になります。
他にも、メッセージ削除や添付ファイルのダウンロードなど色々なことができます。
Typetalk APIのドキュメントの左にあるドロワーのTypetalk APIから様々なパラメーターを見ることができます。
なお、以上の方法だとtopic.postとtopic.readスコープのAPIのみアクセスできます。参考文献







- 投稿日:2020-09-09T22:01:17+09:00
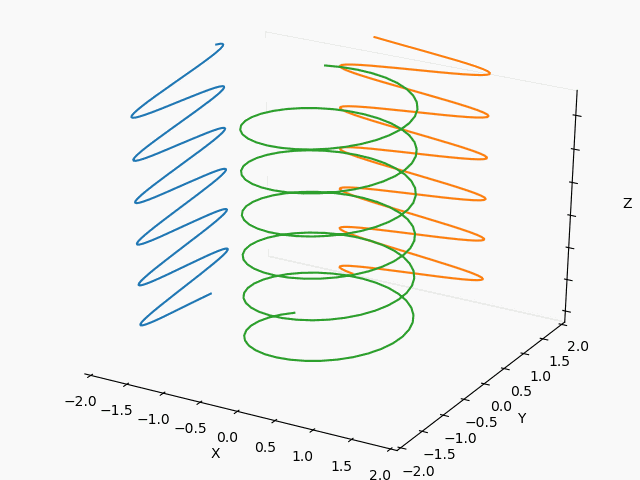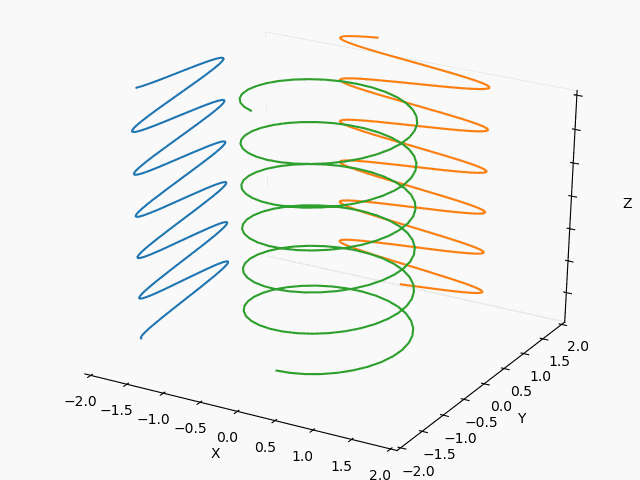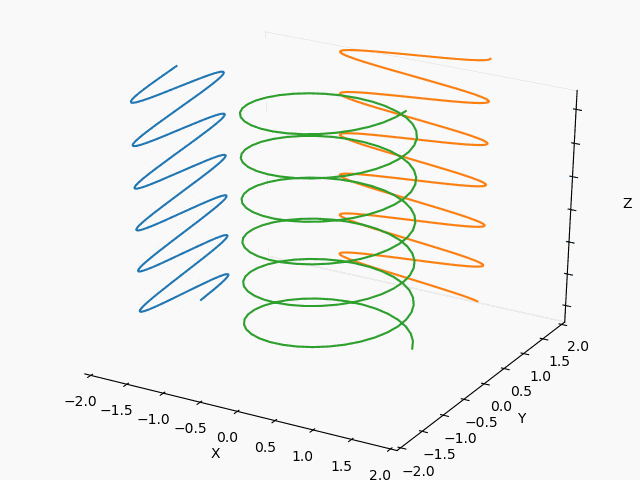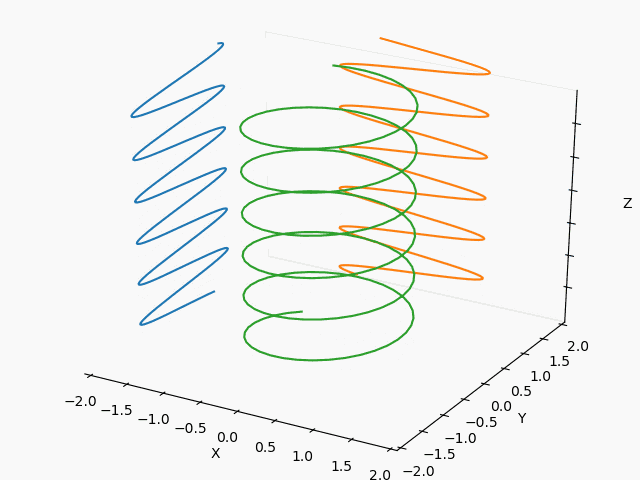
【Matplotlib入門】Axes3Dアニメーション:3Dリサジュー図形で遊んでみた♬
3日前にTwitterに流れて来た以下のSin-Cos-tの3Dアニメ、ハマったのでまとめておきます。
普通のリサジュー図形だろという軽いノリでもっと面白そうなリサジュー図形を描きたくて、。。。いやハマりました。
https://twitter.com/i/status/1302164499139502080
同じ絵を描こうと思いましたが、切りのいい以下のところで断念。
※あと、⇒とSinとCosの先端から渦巻の先端を結ぶだけで、やり方見えたけどここで止めます。
やったこと
・Axes3Dのアニメーション
・Sin-Cos-tのアニメーション
・update()関数を直接呼んで描画する
・Z軸をずらす
・図形の回転
・3Dリサジュー図形・Axes3Dのアニメーション
当初、3Dとはいえ、参考のようなもので行けるだろうともやっと考えていました。
【参考】
【matplotlib基本】動的グラフを書いてみる♬~動画出力;Gifアニメーション
実際、sin-cos-tでは、ググると似たようなものは以下のようなコードが見つかります。
【参考】
②[Matplotlib] 3次元データの可視化import numpy as np import matplotlib.pyplot as plt from mpl_toolkits.mplot3d import Axes3D # Figureを追加 fig = plt.figure(figsize = (8, 8)) # 3DAxesを追加 ax = fig.add_subplot(111, projection='3d') # Axesのタイトルを設定 ax.set_title("Helix", size = 20) # 軸ラベルを設定 ax.set_xlabel("x", size = 14) ax.set_ylabel("y", size = 14) ax.set_zlabel("z", size = 14) # 軸目盛を設定 ax.set_xticks([-1.0, -0.5, 0.0, 0.5, 1.0]) ax.set_yticks([-1.0, -0.5, 0.0, 0.5, 1.0]) # 円周率の定義 pi = np.pi # パラメータ分割数 n = 256 # パラメータtを作成 t = np.linspace(-6*pi, 6*pi, n) # らせんの方程式 x = np.cos(t) y = np.sin(t) z = t # 曲線を描画 ax.plot(x, y, z, color = "red") plt.show()出力は以下のとおり、動かないけど似たような図が得られました。
あとは、動かせばいいということで、アニメーションを探します。
簡単に見つかるのは、matplotlib.orgのAn animated plot in 3D.が見つかりますが、以下でより近いものが見つかりました。・Sin-Cos-tのアニメーション
【参考】
3D animation using matplotlib
これは、ほぼ答えになりそうです。from matplotlib import pyplot as plt import numpy as np import mpl_toolkits.mplot3d.axes3d as p3 from matplotlib import animation fig = plt.figure() ax = p3.Axes3D(fig) def gen(n): phi = 0 while phi < 2*np.pi: yield np.array([np.cos(phi), np.sin(phi), phi]) phi += 2*np.pi/n def update(num, data, line): line.set_data(data[:2, :num]) line.set_3d_properties(data[2, :num]) N = 100 data = np.array(list(gen(N))).T line, = ax.plot(data[0, 0:1], data[1, 0:1], data[2, 0:1]) # Setting the axes properties ax.set_xlim3d([-1.0, 1.0]) ax.set_xlabel('X') ax.set_ylim3d([-1.0, 1.0]) ax.set_ylabel('Y') ax.set_zlim3d([0.0, 10.0]) ax.set_zlabel('Z') ani = animation.FuncAnimation(fig, update, N, fargs=(data, line), interval=10000/N, blit=False) #ani.save('matplot003.gif', writer='imagemagick') plt.show()
ところが、3つのアニメーションを描こうとすると、以下のようになります。aniy = animation.FuncAnimation(fig, update, N, fargs=(datay, liney), interval=10000/N, blit=False) anix = animation.FuncAnimation(fig, update, N, fargs=(datax, linex), interval=10000/N, blit=False) aniz = animation.FuncAnimation(fig, update, N, fargs=(dataxy, linexy), interval=10000/N, blit=False)この方式だと、絵的には似たようなアニメーションが得られますが、この3つのアニメーションをまとめて保存する方法が思いつきません。
・update()関数を直接呼んで描画する
以下のようにそれぞれをplt.pause(0.001)でまとめてプロットし、その図を保存することとしました。最後にそれらの図から、gif_animationを生成することとしました。
frames =100 s=180 for n in range(frames): s+=1 num = s%800+200 update(num,datax,linex) update(num,datay,liney) update(num,dataz,linez) plt.pause(0.001) plt.savefig('./sin_wave/'+str(n)+'.png'.format(elev, azim)) from PIL import Image,ImageFilter images = [] for n in range(frames): exec('a'+str(n)+'=Image.open("./sin_wave/'+str(n)+'.png")') images.append(eval('a'+str(n))) images[0].save('./sin_wave/sin_wave_el{}_az{}.gif'.format(elev, azim), save_all=True, append_images=images[1:], duration=100, loop=0)そして、以下のコードのようにline.set_data(data[:2,num-200 :num])とnum = s%800+200により描画範囲を限定することにより、結果は所望のものに近づきました。
from matplotlib import pyplot as plt import numpy as np import mpl_toolkits.mplot3d.axes3d as p3 from matplotlib import animation fig = plt.figure() ax = p3.Axes3D(fig) def genxy(n,fx,fy,fxc=0,fyc=0): phi = 0 sk = 0 while phi < 360: yield np.array([fx*np.cos(phi)+fxc, fy*np.sin(phi)+fyc,phi]) phi += 36*5/n def update(num, data, line): line.set_data(data[:2,num-200 :num]) #描画区間を制限する line.set_3d_properties(data[2,num-200 :num]) N = 960 datay = np.array(list(genxy(N,fx=0,fy=1,fxc=-2,fyc=0))).T liney, = ax.plot(datay[0, 0:1], datay[1, 0:1], datay[2, 0:1]) datax = np.array(list(genxy(N,fx=1,fy=0,fxc=0,fyc=2))).T linex, = ax.plot(datax[0, 0:1], datax[1, 0:1], datax[2, 0:1]) dataz = np.array(list(genxy(N,fx=1,fy=1,fxc=0,fyc=0))).T linez, = ax.plot(dataz[0, 0:1], dataz[1, 0:1], dataz[2, 0:1]) # Setting the axes properties ax.set_xlim3d([-2.0,2.0]) ax.set_xlabel('X') ax.set_ylim3d([-2.0, 2.0]) ax.set_ylabel('Y') ax.set_zlim3d([36.0, 80.]) ax.set_zlabel('Z') frames =36 s=180 for n in range(frames): s+=1 num = s%800+200 update(num,datax,linex) update(num,datay,liney) update(num,dataz,linez) plt.pause(0.001) plt.savefig('./sin_wave/'+str(n)+'.png'.format(0, 0)) from PIL import Image,ImageFilter images = [] for n in range(frames): exec('a'+str(n)+'=Image.open("./sin_wave/'+str(n)+'.png")') images.append(eval('a'+str(n))) images[0].save('./sin_wave/sin_wave_el{}_az{}.gif'.format(0, 0), save_all=True, append_images=images[1:], duration=100, loop=0)・Z軸をずらす
update()関数を以下のように書き換えて、Z軸をずらすことにします。
これによって、画像のZ軸方向は同じ位置に描画されるようになりました。
ここで軸の表示も消去します。
※因みに、Z軸の目盛も消したいところですが、最後まで消せませんでしたdef update(num, data, line): line.set_data(data[:2,num-200 :num]) line.set_3d_properties(data[2,num-200 :num]) ax.set_zlim3d([0+data[2,num-200], 34+data[2,num-200]]) ax.set_zticklabels([]) ax.grid(False)
・図形の回転
さて、あとは座標軸をあの配置に持っていければとりあえずの完成です。
が、これが難しかったのです。
まず、軸の回転は以下で行えます。
以下では初期値の絵を軸を変えて出力しています。for elev in range(0,360,10): #仰角の変更 for azim in range(-180,180,5): #方位角の変更 ax.view_init(elev, azim) #ここで座標軸の向きを調整 frames =1 #34 s=180 for n in range(1): #frames s+=1 num = s%800+200 update(num,datax,linex) update(num,datay,liney) update(num,dataz,linez) plt.pause(0.001) plt.savefig('./sin_wave/'+str(n)+'{}{}.png'.format(elev, azim))結果、あの配置は得られませんでした。
イマジネーションが足りないのですね。
上記の角度範囲以外が思いつきません。
しかし、X-Y-Zの軸見出しを変更することを思いつきました。
yield np.array([phi,fx*np.cos(phi)+fxc, fy*np.sin(phi)+fyc])
としています。
つまり、軸見出しを変更すれば螺旋が横に寝てくれます。
ということで、以下のコードにたどり着きました。from matplotlib import pyplot as plt import numpy as np import mpl_toolkits.mplot3d.axes3d as p3 from matplotlib import animation fig = plt.figure() ax = p3.Axes3D(fig) def genxy(n,fx,fy,fxc=0,fyc=0): phi = 0 while phi < 360: yield np.array([phi,fx*np.cos(phi)+fxc, fy*np.sin(phi)+fyc]) phi += 36*5/n def update(num, data, line): line.set_data(data[:2,num-200 :num]) line.set_3d_properties(data[2,num-200 :num]) ax.set_xlim3d([0+data[0,num-200], 36+data[0,num-200]]) ax.set_xticklabels([]) ax.grid(False) N = 960 datay = np.array(list(genxy(N,fx=0,fy=1,fxc=-2,fyc=0))).T liney, = ax.plot(datay[0, 0:1], datay[1, 0:1], datay[2, 0:1]) datax = np.array(list(genxy(N,fx=1,fy=0,fxc=0,fyc=-2))).T linex, = ax.plot(datax[0, 0:1], datax[1, 0:1], datax[2, 0:1]) dataz = np.array(list(genxy(N,fx=1,fy=1,fxc=0,fyc=0))).T linez, = ax.plot(dataz[0, 0:1], dataz[1, 0:1], dataz[2, 0:1]) # Setting the axes properties ax.set_xlim3d([20, 70.0]) ax.set_xlabel('Z') ax.set_ylim3d([-2.0, 2.0]) ax.set_ylabel('X') ax.set_zlim3d([-2.0, 2.0]) ax.set_zlabel('Y') elev=20. azim=35. ax.view_init(elev, azim) frames =100 s=180 for n in range(frames): #frames s+=1 num = s%800+200 update(num,datax,linex) update(num,datay,liney) update(num,dataz,linez) plt.pause(0.001) plt.savefig('./sin_wave/'+str(n)+'.png'.format(elev, azim)) from PIL import Image,ImageFilter images = [] for n in range(frames): exec('a'+str(n)+'=Image.open("./sin_wave/'+str(n)+'.png")') images.append(eval('a'+str(n))) images[0].save('./sin_wave/sin_wave_el{}_az{}.gif'.format(elev, azim), save_all=True, append_images=images[1:], duration=100, loop=0)こうして、最初に掲載した3Dアニメーションが出力できました。
・3Dリサジュー図形
もっとも、本来やりたかったのは3Dリサジュー図形なので、いくつかやってみます。
以下を変更して滑らかに繋がるようにframes=200を変更すれば出来ます。
yield np.array([phi,fx*np.cos(3*phi/2)+fxc, fy*np.sin(2*phi/3)+fyc])X : Y = 1 : 2
X : Y = 1/2 : 2/3
X : Y = 3/2 : 2/3
まとめ
・Sin-Cos-tの3Dアニメーションを描いて見た
・3Dアニメーションが描けるようになった
・3Dリサジュー図形を描いてみた※二次元リサジュー図形(上記のXY面への写像)はググってみてください
おまけ
完成版
原点にリサジュー図形を描画するように改良しました
3d_animation_Risajyu/3D_animation_risajyu.py








- 投稿日:2020-09-09T21:58:02+09:00
[Python] ADI法(交互方向陰解法)による2次元の熱拡散方程式の数値計算
はじめに
私は大学で半導体物性を研究しています。
半導体材料にレーザーを照射し、光吸収による熱膨張を圧電素子(膨張や収縮を電圧に変換する素子)で計測する実験などを行っており、実験結果を計算で再現することで熱伝導率などの物性値を算出しようとしています。その計算のために熱拡散方程式を数値計算で解きたいのです。
実験結果を再現するには1次元では不十分だったので、2次元の熱拡散方程式を解きました。この記事では、2次元の熱拡散方程式を
ADI法(Alternating direction implicit method,交互方向陰解法)で解きます。
間違いやより良いプログラムの書き方があればどうか教えて下さい。解きたい方程式は以下の通りです。
\frac{\partial T}{\partial t}=\lambda \left(\frac{\partial^2 T}{\partial x^2}+\frac{\partial^2 T}{\partial y^2}\right)ここで、$T$は温度、$t$は時間、$\lambda$は熱拡散率、$x,y$は座標です。
熱拡散方程式については、熱伝導方程式の導出などで勉強しました。
また、1次元の熱拡散方程式の数値計算は流体シミュレーション : 拡散方程式を実装するなどで勉強しました。
1次元では棒状、2次元では面状、3次元では立体の温度を計算できます。
1次元の熱拡散方程式の数値計算でよく使われるクランクニコルソン法を2次元に適用すると計算量が膨大になります。一方、ADI法を用いると計算量を抑えつつ2次元の計算が可能になります。
ADI法のイメージ
ADI法ではある時刻$k$での温度がすべて求められているとして次の$k+1$時刻を求める時、図のように$y$座標$j=1,2,...m$のそれぞれで$x$方向に$i=1,2,...n$を計算することで面全体の温度を求めます。
その次の$k+2$時刻を求める時は$x$座標$i=1,2,...n$のそれぞれで$y$方向に$j=1,2...m$を計算することで全体の温度を求めます。
$k+3$時刻は$x$方向に、$k+4$時刻は$y$方向に...と繰り返します。
$x$方向と$y$方向を交互に計算するので交互方向陰解法と言われているのだと思います。
(普通は左下に原点があり、横方向にx軸、上方向にy軸を書きますが、Spyderの変数エクスプローラで解のndarrayを開いたときに左上に0があって下方向にx、右方向にyの解があるので私の中でそのイメージになってしまっています。わかりにくくてすみません。)
ADI法の計算
第$k$時刻での$T_{i,j}^{k}$がすべて計算されたとして、次の第$k+1$時刻での$T_{i,j}^{k+1}$を計算するために「はじめに」で示した熱拡散方程式を次のように差分化する。
$$
\frac{T_{i,j}^{k+1} - T_{i,j}^k}{\Delta t} = \lambda \left(\frac{T_{i-1,j}^{k+1} - 2 T_{i,j}^{k+1} + T_{i+1,j}^{k+1} }{\Delta x^2} + \frac{T_{i,j-1}^k - 2 T_{i,j}^k + T_{i,j+1}^k }{\Delta y^2}\right)
$$これを左辺に$k+1$右辺に$k$となるように式変形すると次のようになる。
$$
T_{i-1,j}^{k+1}-\left(2+\frac{\Delta x^2}{\lambda \Delta t}\right)T_{i,j}^{k+1}+T_{i+1,j}^{k+1} = \left[2 \left( \frac{\Delta x^2}{\Delta y^2}\right)-\frac{\Delta x^2}{\lambda \Delta t}\right]T_{i,j}^k-\frac{\Delta x^2}{\Delta y^2} \left( T_{i,j-1}^k + T_{i,j+1}^k \right)
$$
これを次のように置く
$$
T_{i-1,j}^{k+1}-dT_{i,j}^{k+1}+T_{i+1,j}^{k+1} = BT_{i,j}^k-\frac{\Delta x^2}{\Delta y^2} \left( T_{i,j-1}^k + T_{i,j+1}^k \right)
$$ここで、
$$
d = -\left(2+\frac{\Delta x^2}{\lambda \Delta t}\right), B=\left[2 \left( \frac{\Delta x^2}{\Delta y^2}\right)-\frac{\Delta x^2}{\lambda \Delta t}\right]
$$$i=1,2,...m$とおき、これを行列で表すと、
\left( \begin{array}{cccc} d & 1 & 0 & \ldots & \ldots & 0 \\ 1 & d & 1 & 0 & \ldots & 0 \\ 0 &1 & d & 1 & 0 & \ldots \\ \vdots & \ddots & \ddots & \ddots & \ddots & \ddots\\ 0 & 0 & \ddots & 1 & d & 1 \\ 0 & 0 & \ldots & 0 & 1 & d \end{array} \right) \left( \begin{array}{c} T_{1,j}^{k+1} \\ T_{2,j}^{k+1} \\ T_{3,j}^{k+1} \\ \vdots \\ T_{m-1,j}^{k+1} \\ T_{m,j}^{k+1} \end{array} \right)= \left( \begin{array}{c} B T_{1,j}^{k} -\frac{\Delta x^2}{\Delta y^2} \left( T_{1,j-1}^k + T_{1,j+1}^k \right)- T_{0,j}^k \\ B T_{2,j}^{k} -\frac{\Delta x^2}{\Delta y^2} \left( T_{2,j-1}^k + T_{2,j+1}^k \right) \\ B T_{3,j}^{k} -\frac{\Delta x^2}{\Delta y^2} \left( T_{3,j-1}^k + T_{3,j+1}^k \right) \\ \vdots \\ B T_{m-1,j}^{k} -\frac{\Delta x^2}{\Delta y^2} \left( T_{m-1,j-1}^k + T_{m-1,j+1}^k \right) \\ B T_{m,j}^{k} -\frac{\Delta x^2}{\Delta y^2} \left( T_{m,j-1}^k + T_{m,j+1}^k \right)-T_{m+1,j}^k \end{array} \right)$m$元連立一次方程式が得られる。
この式変形ではディリクレ境界条件(境界の温度が一定であるという条件)使っている。
$T_{0,j}^k$や$T_{m+1,j}^k$は境界の温度であり既知数であるから未知数は$m$個。この連立方程式を$j=1$から$j=n$のそれぞれの場合に対して解くと第$k+1$時刻での温度が求まる.
次に、第$k+1$時刻での$T_{i,j}^{k}$がすべて計算されたとして、次の第$k+2$時刻での$T_{i,j}^{k+1}$を計算するために次のように差分化する。
$$
\frac{T_{i,j}^{k+2} - T_{i,j}^{k+1}}{\Delta t} = \lambda \left(\frac{T_{i-1,j}^{k+1} - 2 T_{i,j}^{k+1} + T_{i+1,j}^{k+1} }{\Delta x^2} + \frac{T_{i,j-1}^{k+2} - 2 T_{i,j}^{k+2} + T_{i,j+1}^{k+2} }{\Delta y^2}\right)
$$同様にして
$$
T_{i,j-1}^{k+2}-\left(2+\frac{\Delta y^2}{\lambda \Delta t}\right)T_{i,j}^{k+2}+T_{i,j+1}^{k+2} = \left[2 \left( \frac{\Delta y^2}{\Delta x^2}\right)-\frac{\Delta y^2}{\lambda \Delta t}\right]T_{i,j}^{k+1}-\frac{\Delta y^2}{\Delta x^2} \left( T_{i-1,j}^{k+1} + T_{i+1,j}^{k+1} \right)
$$
これを次のように置く
$$
T_{i,j-1}^{k+2}-eT_{i,j}^{k+2}+T_{i,j+1}^{k+2} = CT_{i,j}^{k+1}-\frac{\Delta y^2}{\Delta x^2} \left( T_{i-1,j}^{k+1} + T_{i+1,j}^{k+1} \right)
$$ここで、
$$
e=-\left(2+\frac{\Delta y^2}{\lambda \Delta t}\right), C=\left[2 \left( \frac{\Delta y^2}{\Delta x^2}\right)-\frac{\Delta y^2}{\lambda \Delta t}\right]
$$第$k+1$時刻から次の第$k+2$時刻の温度を計算する場合も同様にして行列を書ける。(省略します)
$j=1,2,...n$とおくと、$n$個の未知数に対する$n$元連立1次方程式が得られる。
その連立方程式を$i=1$から$i=m$までの各場合にそれぞれ解くと第$k+2$時刻の温度が求まる。ADI法では1回に解くべき連立方程式の元数は$m$元か$n$元で良いことになる。
クランクニコルソン法で同じように計算しようとすると$m\times n$元連立1次方程式を解かなければならない。
プログラム
計算の条件は
- 縦10、横10の大きさ、熱拡散率が0.1の物体
- $dx=dy=0.1$, $dt=0.1$として計算
- 時刻0の時物体全体の温度が0度
- 物体の4辺の温度は100度で固定されている
# -*- coding: utf-8 -*- """ 交互方向陰解法による2次元の熱拡散方程式の計算 """ import numpy as np import numpy.matlib from decimal import Decimal, ROUND_HALF_UP import scipy.sparse.linalg as spla from scipy.sparse import csr_matrix import matplotlib.pyplot as plt import seaborn as sns import time dtnum = 5001 #時間をいくつに分割して計算するか 一の位を1とした方が良い 時刻tのfor文の終わりの数字に関係あり dxnum = 101 #xとyをいくつに分割して計算するか dynum = 101 thick = 10 #x方向の大きさ width = 10 #y方向の大きさ time_calc = 500 #計算する時間 beta = 0.1 #上の式中ではラムダ 温度拡散率 lambda = 熱伝導率/(密度*比熱) """計算準備""" #空の解を用意 solution_k1 = np.zeros([dxnum,dynum]) solution_k2 = np.zeros([dxnum,dynum]) #solution_k2の初期値が初期条件になる #境界条件 irr_boundary = 100 #表面の境界条件 (0,t)における温度 rear_boundary = 100 #裏面と反対側の境界条件 (x,t)における温度 0を基準となる温度とした side_0 = 100 #y=0の温度 side_y = 100 #y=0とは反対側の境界の温度 dt = time_calc / (dtnum - 1) dx = thick / (dxnum - 1) dy = width / (dynum - 1) d = -(2+(dx**2)/(beta*dt)) B = (2*((dx/dy)**2)-((dx**2)/(beta*dt))) e = -(2+(dy**2)/(beta*dt)) C = (2*((dy/dx)**2)-((dy**2)/(beta*dt))) """Ax=bのAを用意""" a_matrix_1 = np.identity(dxnum) * d \ + np.eye(dxnum, k=1) \ + np.eye(dxnum, k=-1) a_matrix_2 = np.identity(dynum) * e \ + np.eye(dynum, k=1) \ + np.eye(dynum, k=-1) #疎行列を格納 csr方式 a_matrix_csr1 = csr_matrix(a_matrix_1) a_matrix_csr2 = csr_matrix(a_matrix_2) #ADI法ではk+1時刻とk+2時刻を計算するので、for文の回数は半分になる number = Decimal(str(dtnum/2)).quantize(Decimal('0'), rounding=ROUND_HALF_UP) number = int(number) solution = np.zeros([dxnum,dynum,number]) #解を代入する行列を作成 #temp_temperature_arrayは、ずれた列を作成して、足すためのもの temp_temperature_array1 = np.zeros([dxnum,dynum+2]) temp_temperature_array1[:,0] = side_0 temp_temperature_array1[:,-1] = side_y temp_temperature_array2 = np.zeros([dxnum+2,dynum]) temp_temperature_array2[0,:] = irr_boundary temp_temperature_array2[-1,:] = rear_boundary #ADI法の計算 for k in range(number): #時刻tについて for j in range(dynum):#xを計算し、yの数繰り返すことで、時刻k+1のTijを計算 temp_temperature_array1[:,1:dynum+1] = solution_k2 b_array_1 = B * temp_temperature_array1[:,j+1] \ - ((dx/dy)**2) * (temp_temperature_array1[:,j] + temp_temperature_array1[:,j+2]) # bの最初と最後に境界条件 b_array_1[0] -= irr_boundary b_array_1[-1] -= rear_boundary #解を求める temperature_solve1 = spla.dsolve.spsolve(a_matrix_csr1, b_array_1)#xについての解 solution_k1[:,j] = temperature_solve1 for i in range(dxnum):#yを計算し、xの数繰り返すことで、時刻k+2のTijを計算 temp_temperature_array2[1:dxnum+1,:] = solution_k1 b_array_2 = C * temp_temperature_array2[i+1,:] \ - ((dy/dx)**2) * (temp_temperature_array2[i,:] + temp_temperature_array2[i+2,:]) # bの最初と最後に境界条件 b_array_2[0] -= side_0 b_array_2[-1] -= side_y #解を求める temperature_solve2 = spla.dsolve.spsolve(a_matrix_csr2, b_array_2)#yについての解 solution_k2[i,:] = temperature_solve2 solution[:,:,k] = solution_k2 ax = sns.heatmap(solution[:,:,10], linewidth=0, vmin=0, vmax=100) plt.show() ax = sns.heatmap(solution[:,:,100], linewidth=0, vmin=0, vmax=100) plt.show() ax = sns.heatmap(solution[:,:,500], linewidth=0, vmin=0, vmax=100) plt.show() ax = sns.heatmap(solution[:,:,2000], linewidth=0, vmin=0, vmax=100) plt.show()実行していただくと私のパソコンだと50秒ぐらいかかって計算結果が出てきます。
計算結果は以下の通りです。
初期条件の0度から時間の経過とともに境界付近から次第に熱が伝わり100度に近づいていく様子が計算できています。
終わりに
適切な刻み幅ってあるんでしょうか。
物体の大きさがマイクロやナノメートルオーダーで計算する時刻がミリ秒オーダーの時はどの程度の刻み幅が必要でしょうか。
陰解法でも$dx$と$dy$は$dt$より小さい方が良いのでしょうか。
教えていただけますと幸いです。参考文献
- 山崎郭滋, 偏微分方程式の数値解法入門, 森北出版株式会社 (1993).
- http://nalab.mind.meiji.ac.jp/~mk/labo/text/heat-fdm-1.pdf
- https://qiita.com/KQTS/items/97daa509991bb9777a4a


- 投稿日:2020-09-09T21:45:47+09:00
Jupyterで簡単な画像認識を出来るようにするまで
初めに
ふとある画像判別のアプリが作りたくなったのでまずはWindow環境でjupyterをつかって
簡単に画像を判別するプログラムを動かすところまでを作ってみた。開発環境
OS: Windows10 Home
GPU: Geforce GTX1660Ti
Anaconda: 4.8.2各種インストール
まずは以下のサイトからAnacondaをダウンロードしインストール
https://www.anaconda.com/products/individual続いて画像認識に必要なライブラリであるTensorFlowを導入する。
そのまえに一応いま使用しているPCにGPUが入っているためせっかくなのでGPUを使って計算させたい。しかしNvidiaドライバとCUDAとcuDNNというものをインストールする必要があるらしく、しかもこれらのツールは最新ならよいというわけではなくバージョンに気を付けないとGPUが認識しないらしい...
ということで、まずはNvidiaドライバを以下のサイトから自分のGPUを検索してダウンロード・インストール
https://www.nvidia.co.jp/Download/index.aspx?lang=jp
ダウンロードタイプはよくわからないけどGame Readyドライバーのほうを選択。
自分がインストールした際はバージョン445.87だった。先ほど書いたように各バージョンの対応に注意しながらインストールする必要があるのでこちらのサイトの対応表を見て
Nvidiaドライバのバージョン⇒対応するCUDAのインストール⇒さらに対応するcuDNNのダウンロードを行う
対応表が載ってるページ
https://docs.nvidia.com/cuda/cuda-toolkit-release-notes/index.html
https://www.tensorflow.org/install/source_windows
ダウンロードページ
CUDA: https://developer.nvidia.com/cuda-downloads
cuDNN: https://developer.nvidia.com/cudnn-download-survey
私の場合はCUDAのバージョンが10.0.130、cuDNNが7.4.2 for CUDA10.0となった。インストール後下記をそれぞれ行う。
・ダウンロードしたcudnnのフォルダ内のデータをすべて
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v10.0内へコピー・システム環境変数に
変数名: CUDNN_PATH
値: "C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v10.0"
を新規で追加これでGPU側で必要なインストールが終わったので最後にTensorFlowのライブラリのインストールを行う。
まずはAnaconda上でTensorFlow用の環境を別で作る。conda create -n tf37 python=3.7 anaconda conda activate tf37その環境の中で
tensorflowをインストールconda install tensorflow-gpu==2.0.0最後にpython上でコマンドを動かしてちゃんとGPUが認識されていることを確認。
from tensorflow.python.client import device_lib print(device_lib.list_local_devices())
これで各種インストールが終わりTensorFlowを使用できるようになった。
以下少しつまずいたところ
最初他の記事を頼りにpipでインストールを行っていたがいざtensorflowを使うときに以下のようなエラーが出てしまった。
おそらくjupyterなどで使う際はcondaでインストールしないとだめっぽい。

- 投稿日:2020-09-09T21:35:42+09:00
Pythonの a += b と a = a + b は違う
いくつかのサイトで演算子
a += bがa = a + bと同じと書いてありますがミュータブルなオブジェクトでは厳密には異なります。
同じオブジェクトを指す変数がある場合は注意が必要です。(NumPy を使ってる人は特に!)概要
一言でまとめると以下の違いがあります。
ミュータブルなオブジェクトでは、
a += bでは代入の前後でaが指すオブジェクトは変化しない。a = a + bでは代入の前後でaが指すオブジェクトは変化する。ただし、イミュータブルなオブジェクトではどちらの場合も変化します(@shiracamusさんのコメントに例があります)。
実験
[1, 2]に[3]を追加して[1, 2, 3]を作成する実験をしてみます。
yは代入前のxのオブジェクトを指します。
組み込み関数id(x)でオブジェクトのIDを取得できます。
a += b>>> x = y = [1, 2] # y は代入前の x と同じオブジェクト >>> >>> id(x) 4397797440 >>> id(y) 4397797440 >>> >>> x += [3] >>> >>> x [1, 2, 3] >>> y # y にも追加されている [1, 2, 3] >>> >>> id(x) # 代入前と同じオブジェクト 4397797440 >>> id(y) 4397797440
a = a + b>>> x = y = [1, 2] # y は代入前の x と同じオブジェクト >>> >>> id(x) 4397797440 >>> id(y) 4397797440 >>> >>> x = x + [3] >>> >>> x [1, 2, 3] >>> y # y には追加されていない [1, 2] >>> >>> id(x) # 代入前と異なるオブジェクトを指している 4395937472 >>> id(y) 4397797440
- 投稿日:2020-09-09T20:34:13+09:00
Dockerでflask+Herokuのための環境構築からデプロイまで
はじめに
およそ1年前にDjangoを使って簡単なWebアプリを開発した。
データ収集からAI開発、Webアプリ公開まで全てPythonで済ませた話
入力されたURLからスクレイピングでデータ取得→学習済み機械学習モデルで推論→答えを返す
という非常にシンプルなものである。アプリはこちら↓
キー判別AI久しぶりに使ってみたところ、スクレイピング先のサイトの仕様変更により、正しい結果を得られなくなってしまった。これはマズイと思い改修することにした。
久しぶりにコードを覗いてみたが、自分でもよくわからない…開発当時はとにかく動かすことを目標にしていたこともあり、コードも汚いし、デプロイ方法もすっかり分からなくなっている…
というわけで、今後も不定期的に改修することを考え、開発やデプロイをしやすくするためにDockerでの環境構築を実施した。クローンしてdocker-composeすれば開発できて、なおかつコンテナからherokuにデプロイできるようにするのを目標とする。
また、このアプリ自体がDBも使わず非常にシンプルなので、明らかにDjangoを使う必要もないので、この機会にflaskに書き換えちゃいます。
Githubにコードを公開しています。
https://github.com/hatena-hanata/KJA_appディレクトリ構造
最終的なディレクトリ構造はこちらです。
KJA_APP ├── Dockerfile ├── Procfile ├── app.py ├── docker-compose.yml ├── requirements.txt └── src ├── modules │ ├── module.py │ └── music_class.py ├── static │ └── model │ ├── le.pkl │ └── model.pkl └── templates環境構築
docker-compose.ymlversion: '3' services: web: build: . ports: - "8080:8080" volumes: - .:/home/KJA_APP tty: true environment: TZ: Asia/Tokyo command: flask run --host 0.0.0.0 --port 8080DockerfileFROM python:3.8.0 USER root # install google chrome RUN wget -q -O - https://dl-ssl.google.com/linux/linux_signing_key.pub | apt-key add - RUN sh -c 'echo "deb [arch=amd64] http://dl.google.com/linux/chrome/deb/ stable main" >> /etc/apt/sources.list.d/google-chrome.list' RUN apt-get -y update && apt-get install -y google-chrome-stable && apt-get install -yqq unzip # install chromedriver RUN wget -O /tmp/chromedriver.zip http://chromedriver.storage.googleapis.com/`curl -sS chromedriver.storage.googleapis.com/LATEST_RELEASE`/chromedriver_linux64.zip RUN unzip /tmp/chromedriver.zip chromedriver -d /usr/local/bin/ # install heroku cli RUN curl https://cli-assets.heroku.com/install.sh | sh # set display port to avoid crash ENV DISPLAY=:99 # upgrade pip RUN apt-get update && apt-get install -y \ && pip install --upgrade pip # change dir WORKDIR /home/KJA_APP # install module COPY requirements.txt /home RUN pip install -r /home/requirements.txt # flask setting ENV FLASK_APP '/home/KJA_APP/app.py' ENV FLASK_DEBUG 1今回、seleniumでchromeを動かしてスクレイピングするため、最初にchromeとchrome driverをインストールしています。こちらのdockerfileを参考にしました。
また、herokuへのデプロイのために、heroku cliもインストールしています。最後の2行flask settingでは、flaskに関する設定を行っています。
FLASK_APPでは、flaskのメイン関数のあるpyファイルを指定することで、flask runコマンドでそのファイルが実行されるようになります。
FLASK_DEBUGを1にすることでデバッグモードになり、ファイルの更新がリアルタイムで反映されるようになります。これにて、git clone→docker-composeですぐに開発ができるようになりました。docker-composeの際に
flask runコマンドを実行しているので、http://localhost:8080/にアクセスすればアプリが走っていることが分かります。
Herokuにデプロイ
Herokuへの会員登録は済ませているものとします。
準備
- requirements.txt
必要なライブラリをrequirements.txtに書き込みます。デプロイのためにgunicornが必要なので、pipで忘れずにインストールしておきましょう。- Procfile
プロジェクト直下に作成します。以下のように書きます。
左のappがプロジェクト直下のapp.pyのことで、右のappはapp.pyで定義したFlaskインスタンスの変数名?です。 ちょっと何言ってるか分かりづらいと思うので、こちらを読んでください。
https://stackoverflow.com/questions/19352923/gunicorn-causing-errors-in-herokuProcfileweb: gunicorn app:app --log-file -アプリ作成
ターミナルからでもできますが、ブラウザからの方が分かりやすいので、ブラウザでやります。
- ブラウザからHerokuにログイン
https://id.heroku.com/login- New -> Create new app でアプリを作成
適当に名前をつけます。- ビルドパックの追加
今回のアプリがpythonであることを明示するために、作成したアプリのページで Settings -> Buildpacks からheroku/pythonを追加します。 (デプロイ時に自動でpythonを追加してくれる場合もあるそうですが、自分のディレクトリ構造が悪かったせいか、pythonプロジェクトと認識されず困ったので、予め手動で追加しておくことをオススメします。)
また、今回はseleniumとchromeを利用したスクレイピングをするため、chromeとchrome driverが必要になります。これもビルドパックの追加で対応できます。
https://qiita.com/nsuhara/items/76ae132734b7e2b352dd#chrome%E3%81%A8driver%E3%81%AE%E8%A8%AD%E5%AE%9Aデプロイ
ここからはDockerのコンテナに入ってデプロイします。
1. herokuにログイン
リンクが出てくると思うので、それをクリックして認証する。root@a59194fe1893:/home/KJA_APP# heroku login
- herokuのアプリ用リポジトリにpushする。 urlは
https://git.heroku.com/[上の2.で作成したアプリ名].gitです。(ブラウザのSettingsでも確認できます)。
下のコマンドは、今のブランチの内容をherokuのリポジトリのmasterブランチにpushする、という意味です。root@a59194fe1893:/home/KJA_APP# git push https://git.heroku.com/[上の2.で作成したアプリ名].git masterエラーがでなければこれにてデプロイ完了となります。
最後に
docker-compose便利ですね。

- 投稿日:2020-09-09T19:27:50+09:00
[CovsirPhy] COVID-19データ解析用Pythonパッケージ: SIR-F model
Introduction
COVID-19のデータ(PCR陽性者数など)のデータを簡単にダウンロードして解析できるPythonパッケージ CovsirPhyを作成しています。パッケージを使用した解析例、作成にあたって得られた知識(Python, GitHub, Sphinx,...)に関する記事を今後公開する予定です。
英語版のドキュメントはCovsirPhy: COVID-19 analysis with phase-dependent SIRs, Kaggle: COVID-19 data with SIR modelにて公開しています。
今回はSIR-F modelについてご紹介します。実データは出てきません。
英語版:Usage (details: theoretical datasets)1. 実行環境
CovsirPhyは下記方法でインストールできます!
Python 3.7以上, もしくはGoogle Colaboratoryをご使用ください。
- 安定版:
pip install covsirphy --upgrade- 開発版:
pip install "git+https://github.com/lisphilar/covid19-sir.git#egg=covsirphy"# データ表示用 from pprint import pprint # CovsirPhy import covsirphy as cs cs.__version__ # '2.8.2'
実行環境 OS Windows Subsystem for Linux Python version 3.8.5 2. SIR-F modelとは
SIR-F modelは、広く知られた基本モデルSIR model1をもとに作成した派生モデルです。Kaggleのデータを用いて解析を進める中で作成しました2。
(新規性のあるモデルだと考えておりますが、2020年2月以前に公開された原著論文などご存知でしたら教示ください!筆者は感染症の専門家ではございません...)
SIR model
まずSIR modelでは、Susceptible(感受性保持者)がInfected(感染者)と接触したとき、感染する確率をEffective contact rate $\beta$ [1/min]と定義します。$\gamma$ [1/min]はInfectedからRecovered(回復者)に移行する確率です34。
\begin{align*} \mathrm{S} \overset{\beta I}{\longrightarrow} \mathrm{I} \overset{\gamma}{\longrightarrow} \mathrm{R} \\ \end{align*}SIR-D model
しかしSIR modelではFatal(死亡症例数)が考慮されいない、もしくはRecoveredの中に含まれてしまっています。COVID-19の場合は確定症例数(PCR陽性者数)、回復者数、死亡者数のデータがジョンズ・ホプキンス大学などによって収集5されており、モデルの変数としてそれぞれ使用することができます。なお確定症例数は感染者数$I$、回復者数$R$、死亡者数$D$の合計です。
SIR-D model:
$\alpha_2$ [1/min]を感染者の死亡率として、\begin{align*} \mathrm{S} \overset{\beta I}{\longrightarrow}\ & \mathrm{I} \overset{\gamma}{\longrightarrow} \mathrm{R} \\ & \mathrm{I} \overset{\alpha_2}{\longrightarrow} \mathrm{D} \\ \end{align*}SIR-F model
さらにCOVID-19の場合は感染の確定診断が難しく、特に初期においては確定診断前に亡くなる症例が多数報告されました。こうした事例を反映させたモデルは次の通りです。$S^{\ast}$は確定診断がついた感染者、$\alpha_1$ [-]は$S^{\ast}$のうち確定診断の時点で亡くなっていた感染者の割合(単位なし)を示しています。
SIR-F model:
\begin{align*} \mathrm{S} \overset{\beta I}{\longrightarrow} \mathrm{S}^\ast \overset{\alpha_1}{\longrightarrow}\ & \mathrm{F} \\ \mathrm{S}^\ast \overset{1 - \alpha_1}{\longrightarrow}\ & \mathrm{I} \overset{\gamma}{\longrightarrow} \mathrm{R} \\ & \mathrm{I} \overset{\alpha_2}{\longrightarrow} \mathrm{F} \\ \end{align*}$\alpha_1=0$のとき、SIR-F modelはSIR-D modelに一致します。
3. 連立常微分方程式
総人口$N = S + I + R + F$として、
\begin{align*} & \frac{\mathrm{d}S}{\mathrm{d}T}= - N^{-1}\beta S I \\ & \frac{\mathrm{d}I}{\mathrm{d}T}= N^{-1}(1 - \alpha_1) \beta S I - (\gamma + \alpha_2) I \\ & \frac{\mathrm{d}R}{\mathrm{d}T}= \gamma I \\ & \frac{\mathrm{d}F}{\mathrm{d}T}= N^{-1}\alpha_1 \beta S I + \alpha_2 I \\ \end{align*}4. 無次元パラメータ
このまま扱っても良いですが、パラメータの範囲を$(0, 1)$に限定するため無次元化します。今回の記事では出てきませんが、実データからパラメータを計算する際に効果を発揮します。
$(S, I, R, F) = N \times (x, y, z, w)$, $(T, \alpha_1, \alpha_2, \beta, \gamma) = (\tau t, \theta, \tau^{-1}\kappa, \tau^{-1}\rho, \tau^{-1}\sigma)$, $1 \leq \tau \leq 1440$ [min]として、
\begin{align*} & \frac{\mathrm{d}x}{\mathrm{d}t}= - \rho x y \\ & \frac{\mathrm{d}y}{\mathrm{d}t}= \rho (1-\theta) x y - (\sigma + \kappa) y \\ & \frac{\mathrm{d}z}{\mathrm{d}t}= \sigma y \\ & \frac{\mathrm{d}w}{\mathrm{d}t}= \rho \theta x y + \kappa y \\ \end{align*}このとき、
\begin{align*} & 0 \leq (x, y, z, w, \theta, \kappa, \rho, \sigma) \leq 1 \\ \end{align*}5.(基本/実効)再生産数
SIR-F modelの(基本/実効)再生産数 Reproduction numberは、SIR modelの定義式6を拡張して次のように定義しました。
\begin{align*} R_t = \rho (1 - \theta) (\sigma + \kappa)^{-1} = \beta (1 - \alpha_1) (\gamma + \alpha_2)^{-1} \end{align*}6. データ例
パラメータ$(\theta, \kappa, \rho, \sigma) = (0.002, 0.005, 0.2, 0.075)$及び初期値を設定してグラフ化します。
# Parameters pprint(cs.SIRF.EXAMPLE, compact=True) # {'param_dict': {'kappa': 0.005, 'rho': 0.2, 'sigma': 0.075, 'theta': 0.002}, # 'population': 1000000, # 'step_n': 180, # 'y0_dict': {'Fatal': 0, # 'Infected': 1000, # 'Recovered': 0, # 'Susceptible': 999000}}(基本/実効)再生産数:
# Reproduction number eg_dict = cs.SIRF.EXAMPLE.copy() model_ins = cs.SIRF( population=eg_dict["population"], **eg_dict["param_dict"] ) model_ins.calc_r0() # 2.5グラフ表示:
# Set tau value and start date of records example_data = cs.ExampleData(tau=1440, start_date="01Jan2020") # Add records with SIR-F model model = cs.SIRF area = {"country": "Full", "province": model.NAME} example_data.add(model, **area) # Change parameter values if needed # example_data.add(model, param_dict={"kappa": 0.001, "kappa": 0.002, "rho": 0.4, "sigma": 0.0150}, **area) # Records with model variables df = example_data.specialized(model, **area) # Plotting cs.line_plot( df.set_index("Date"), title=f"Example data of {model.NAME} model", y_integer=True, filename="sirf.png" )
7. 次回
次回は実データをダウンロードして確認する手順をご説明します。

- 投稿日:2020-09-09T19:26:07+09:00
Anaconda,Python学習に参考になったサイトまとめ
実行環境
・Windows10 Laptop&Desktop
・Anaconda
・VScode
・Python3.8.5参考
基本,環境構築
・【超入門コース】Python|プログラミング初心者向け講座 キノコード
・Windows環境でのAnacondaのアップデート
・Anacondaのcondaとpipのinstallコマンドを使い分ける方法(管理上の方針)
・Anaconda Prompt の作業フォルダを変更GUI
・AnacondaでKivyをインストールする
・Python GUI kivyで電卓を作ってみる
・Kivy + PythonでイケてるGUIアプリを作ってみる
・Pythonでデスクトップアプリ作成入門 - Tkinterで肥満判定ツールを作ろう
・Tkinterを使うのであればPySimpleGUIを使ってみたらという話スクレイピング
・【完全版】PythonとSeleniumでブラウザを自動操作(クローリング/スクレイピング)するチートシート
・Pythonでブラウザ操作を自動化するSelenium WebDriverの使い方
・python+seleniumでChromeとEdgeを操作する/インストールと環境設定と動作確認
・【Anaconda】condaコマンドで仮想環境を構築する方法
・WebページのスクレイピングとYouTube Data APIで動画情報取得(ホロライブの動画配信予定を収集)
・Python + Selenium で Chrome の自動操作を一通り
・テストオートメーションに WebDriver (Chromium) を使用する
・Webアプリケーションを自動で操作してみよう
・Pythonでseleniumを試してみる(InternetExploer)
・Selenium webdriverよく使う操作メソッドまとめYoutube
・YouTubeから動画をダウンロードしてくるGUIツール(Python)
・PythonでYouTubeの動画を取得する方法
・Youtube Data APIを使ってPythonでYoutubeデータを取得する
・【Python】youtube-dlを使ってYoutubeの動画をダウンロード(mp4, mp3)(Pytube不使用)Unity
・IronPythonを使ってUnity上でPythonのコードを実行する
・C#からPythonを実行する方法【Unity】その他
・Pythonプログラム用のショートカットをつくる(Windows10)
・コマンドプロンプト非表示でPythonスクリプトを実行する方法
- 投稿日:2020-09-09T18:52:03+09:00
python - Matplotlibによる2次元ヒストグラムを配列で書き出し
2次元のヒストグラムをpythonで描画する方法は、MatplotlibやOpenCVを用いたものが有名です。
本記事ではMatplotlibで2次元ヒストグラムを作成した際に、ヒストグラムを2次元配列として
テキストファイルに書き出す方法をメモしておきます。[Python] Matplotlibで2次元のヒストグラム
Matplotlibを用いて2次元のヒストグラム画像を作成する方法については@supersaiakujinさんの記事がおすすめです。
[Python]Matplotlibで2次元ヒストグラムを作成する方法
概要は、「Matplotlib」ライブラリの 「hist2d」関数 に元データとなる2つのnumpy配列を渡すことで
2次元ヒストグラムを作成しています。元データとなる2つのnumpy配列はそれぞれ、「x座標のみの配列」、「y座標のみの配列」を
作成する必要があることは注意が必要です。
このような2次元ヒストグラムは以下のサンプルプログラムで書けます。hist2dimport numpy as np import matplotlib.pyplot as plt import matplotlib.cm as cm #元データ x = (1.1,1.1,3.2,3.1,1.1,2.1,1.1) y = (-1.1,-2.1,-2.1,-2.1,-3.1,-2.1,-2.1) #グラフ描画のための前準備 fig = plt.figure() ax = fig.add_subplot(111) #ヒストグラム作成 hist2d(配列,配列, 描画範囲指定(下限、上限、分割数), カラーバーの色合い指定) H = ax.hist2d(x,y, bins=[np.linspace(-5,5,10),np.linspace(-5,5,10)], cmap=cm.jet) ax.set_title('1st graph') ax.set_xlabel('x') ax.set_ylabel('y') fig.colorbar(H[3],ax=ax) plt.show()2次元ヒストグラムの値を配列で書き出す
2次元ヒストグラムの値を配列としてテキストファイルやcsvに書き出すには
numpyのsave関数が便利です。savetxt#ヒストグラム作成 hist2d(配列,配列, 描画範囲指定(下限、上限、分割数), カラーバーの色合い指定) H = ax.hist2d(x,y, bins=[np.linspace(-5,5,10),np.linspace(-5,5,10)], cmap=cm.jet) np.savetxt("2Dhist-array.txt", H[0], fmt = "%s")hist2dの返り値をMatplotlibの公式マニュアルで確認すると1つ目の返り値がヒストグラムの値であることが分かります。
そのためH[0]を取り出します。fmt = "%s"は文字列でフォーマット指定しています。
hist2d H[0] ヒストグラムの値(2次元配列) H[1] x軸の分割値(1次元配列) H[2] y軸の分割値(1次元配列) H[3] カラーバー情報(QuadMesh) #ヒストグラム作成 hist2d(配列,配列, 描画範囲指定(下限、上限、分割数), カラーバーの色合い指定) H = ax.hist2d(x,y, bins=[np.linspace(-5,5,10),np.linspace(-5,5,10)], cmap=cm.jet) print(H[0]) >>>[[0. 0. 0. 0. 0. 0. 0. 0. 0.] [0. 0. 0. 0. 0. 0. 0. 0. 0.] [0. 0. 0. 0. 0. 0. 0. 0. 0.] [0. 0. 0. 0. 0. 0. 0. 0. 0.] [0. 0. 0. 0. 0. 0. 0. 0. 0.] [0. 1. 2. 1. 0. 0. 0. 0. 0.] [0. 0. 1. 0. 0. 0. 0. 0. 0.] [0. 0. 2. 0. 0. 0. 0. 0. 0.] [0. 0. 0. 0. 0. 0. 0. 0. 0.]]出力される配列を見る限り、y軸に沿って1次元配列が生成されています。
今回のコードをまとめました。
import numpy as np import matplotlib.pyplot as plt import matplotlib.cm as cm #元データ x = (1.1,1.1,3.2,3.1,1.1,2.1,1.1) y = (-1.1,-2.1,-2.1,-2.1,-3.1,-2.1,-2.1) #グラフ描画のための前準備 fig = plt.figure() ax = fig.add_subplot(111) #ヒストグラム作成 hist2d(配列,配列, 描画範囲指定, カラーバーの色合い指定) H = ax.hist2d(x,y, bins=[np.linspace(-5,5,10),np.linspace(-5,5,10)], cmap=cm.jet) ax.set_title('1st graph') ax.set_xlabel('x') ax.set_ylabel('y') fig.colorbar(H[3],ax=ax) plt.show() #2Dヒストグラムのテキストファイルへの書き出し np.savetxt("2Dhist-array.txt", H[0], fmt = "%s")

- 投稿日:2020-09-09T16:57:20+09:00
Pythonに指を代行してもらう、その後は目と脳も…
背景
タブレットとかで作業してて、しばらくの間タップ続ける必要があるときってありますよね。
でもちょっと別の作業してて手が離せない、とか両手骨折でギブスしてて、とか。
そんなときもタップを代行してくれる「指」になるものをPythonとArduinoとサーボモーターで作ってみました。
これが動けば、次はタブレットの画面をキャプチャして、AIが判断して指に指示を出すやつを作ります。ArduinoUNOスターターキット購入
まずはマイコンボードを。今回の目的ならArduinoで十分よねーって感じでセンサーとかついてるキット探してたら、Amazonで3000円ちょっとでこんなんが買える!安いですねー。
早速Arduino専用の開発言語SketchのIDEをインストールしてLED点滅の入門編、いわゆる「Lチカ」を試してみました。うんうん、簡単。
Sketchって、PC上でコンパイルして、そのモジュールをArduinoにUSB転送して動かす仕組みなんですね。ふむふむ。
で、指の代行をしてもらうサーボモーターにも登場していただくことに。
こんな感じで3cm四方くらいの大きさで、角度指定するとその角度まで移動してくれるやつ。クルクル回るモーターではないです。
このサーボをコントロールするSketchは下記のような感じでめちゃ簡単。サーボがつながるArduinoのピンを指定して、そこに角度を入力するだけで動きます。適当にディレイ入れて、良い感じに動くことを確認。
指を作る
サーボが動作することが確認できたので、タブレットをタップするための指を製作します。
サーボモーターの先に針金を括り付けて、その先に静電部分をつけます。電気を通して柔らかい感じが指に似てるので、イヤホンのイヤーパッドをアルミホイルで包んでます。そこにジャンパーワイヤーを差し込んで、GNDに接地してます。
サーボモーターは軽いので、大型の鉄のクリップで固定してます。
Pythonでサーボをコントロールするための準備(Firmata)
さて、このままでは動かすプログラムはPC上でSketchIDEを使ってコンパイルしたものをロードするため、いろいろ状況に応じて指示を出すことができません。
そこで、PCとリアルタイムに連携できる仕組みに変えていきます。
そのためのライブラリが「Firmata」になります。これは、PCとやり取りするためのプロトコルのようなもので、Sketchに入っているサンプルのFirmataコードをコンパイルしてArduinoにロードするだけで、PCからの指示待ち状態になります。
今回は「ServoFirmata」というサーボ用のプログラムをロードしました。
Pythonでサーボを動かそう(Pyfirmata)
あとはPythonでサーボを動かすプログラムを書くだけです。
そのためには「Pyfirmata」ライブラリをインポートする必要があります。pipでサクッとインストール。pip install pyfirmataインポートさえすれば、あとはArduinoがつながってるポートに接続して、サーボのピンを指定して、そこに角度を書き込むだけです。下記サンプルは適当に動いて、休んで、朝4:50には終了する、みたいなコードになってます。ランダムにスリープしてるのは、人間らしい挙動にするためです。(あくまでも動作確認のためのコードなので、何に使ったかは聞かないでくださいw)
import pyfirmata import time import sys import random import datetime # >python servo.py [wait] [loop] args = sys.argv wt = 40.0 lp = 15 if len(args) > 2: wt = float(args[1]) if len(args) == 3: lp = int(args[2]) # setup servo moter for arduino UNO board = pyfirmata.Arduino('COM3') it = pyfirmata.util.Iterator(board) it.start() pin9 = board.get_pin('d:9:s') while True: loop_n = random.randint(lp, lp + 5) for i in range(loop_n): pin9.write(110) time.sleep(0.25 + random.random() * 0.1) pin9.write(100) time.sleep(1.2 + random.random() * 1.0) time.sleep(wt + random.random() * 5.0 - float(loop_n - lp)) # terminate at 04:50 dt_now = datetime.datetime.now() if dt_now.hour == 4 and dt_now.minute > 50: break終わりに
ここまでで、Pythonを使って指の代わりのサーボを動かすことに成功しました。
あとは、タブレットの状況に応じて指示を自動で変化させるところに着手します。具体的にはタブレット画面をキャプチャしてPCに取り込み、予め学習しておいたAIの分類モデルを通して現在の状況を見極め、的確な指示を出すプログラムを作る予定です。
ここまでできると、目と脳と指を人間から代行することができそうです。意味があるかどうかは別問題ですがw





- 投稿日:2020-09-09T15:18:11+09:00
*Android*【HTTP通信_2】FlaskとHTTP通信をする(WebAPIを叩く[GET, POST])
はじめに
前回の記事では,httpbinをWebAPIとして使用し,HttpURLConnectionの使い方について解説しました.今回は,FlaskをWebAPIとして使用し,AndroidとFlask間でHTTP通信(GET/POST)を行ってみます.HttpURLConnectionやcurlコマンドの詳しい解説は,前回の記事を参考にしてください.
前提
*Android Studio 4.0.1
*targetSdkVersion 28
*Google Nexus 5xcurlコマンド, Python
*Ubuntu 20.04 LTS (WSL 2)
*Python 3.7.3GETメソッド
GETメソッドを使ったHTTP通信は簡単に実現できます.Android側は前回の記事を参考にしてください.最後に示すサンプルコードにはAndroid側のコードも記述します.ここではFlask側に関して記述します.
app.pyfrom flask import Flask, jsonify app = Flask(__name__) @app.route('/api/get', methods=['GET']) def get(): # GETリクエストに対するレスポンスを作成 response = {'result': 'success', 'status': 200} # JSONオブジェクトとして返す return jsonify(response)curlコマンドを使ってリクエストを送ってみます.
curl http://127.0.0.1:5000/api/get以下のようなレスポンスが出力されるはずです.
{ "result": "success", "status": 200 }POSTメソッド
POSTメソッドを使ったHTTP通信について説明します.
flaskでJSON形式のデータを読み込む
JSON形式のデータを読み込む方法としては3つあります.今回は,POSTリクエストで受け取ったデータを読み込むことになります.
app.pyfrom flask import Flask, request, jsonify import json app = Flask(__name__) @app.route('/api/post', methods=['POST']) def post(): # 方法1 # POSTで受け取ったデータをrequest.dataを取り出すとbytes型であることがわかる print(type(request.data)) # 出力してもbytes型であることがわかる print(request.data) # bytes型なので文字列に直すためにdecodeする print(request.data.decode('utf-8')) # JSON形式で書かれている文字列をloadsメソッドによってディクショナリ型に変換できる data = json.loads(request.data.decode('utf-8')) print(data) # 方法2 # loadsメソッドでは,文字列以外にbytes型,bytearray型を入れることができる data = json.loads(request.data) print(data) # 方法3 # request.jsonメソッドを使うことで,POSTで受け取ったデータをディクショナリ型として扱うことができる # この書き方が1番早いので推奨する print(request.json) # 方法3を採用し,戻り値としてJSONオブジェクトを返す data = request.json return jsonify(data) if __name__ == '__main__': app.run(host='0.0.0.0', debug=True)app.pyを実行して,試しにcurlを使ってPOSTリクエストを送ってみる.新しいターミナルを開き,以下のコマンドを実行する.bodyは,JSON形式で文字列を記述する.
curl -X POST -H 'Content-Type:application/json' -d `{"name": "foge", "value": "fogefoge"}` http://127.0.0.1:5000/api/postcurlコマンドを実行すると,app.pyを実行したターミナルに以下のように出力される.下3行の出力が同じであることが確認できる.
<class 'bytes'> b'{"name": "foge", "value": "fogefoge"}' {"name": "foge", "value": "fogefoge"} {'name': 'foge', 'value': 'fogefoge'} {'name': 'foge', 'value': 'fogefoge'} {'name': 'foge', 'value': 'fogefoge'}AndroidでのJsonのフォーマット
Androidから送信したJSON形式で書かれた文字列のデータをPythonで読み込むには,Androidの方でJSONの形式に則ってボディを記述する必要がある.具体的には以下のようにする.
String postData = "{\"name\": \"foge\", \"value\": \"fogefoge\"}";このように,文字列の中に二重引用符を記述する必要があるためエスケープシーケンスを使って記述する.また,文字列の中に変数のデータを埋め込みたい場合は以下のように記述する.
String name = "foge"; int value = 100; String postData = String.format("{\"name\": \"%s\", \"value\": %d}", name, value);しかし,このように記述するのは非常に面倒なため,一般的には以下のように記述する.
// 連想配列を作成する HashMap<String, Object> jsonMap = new HashMap<>(); jsonMap.put("name", "foge"); jsonMap.put("value", 100); // 連想配列をJSONObjectに変換 JSONObject responseJsonObject = new JSONObject(jsonMap); // JSONObjectを文字列に変換 String postData = responseJsonObject.toString();サンプルコード
では,以下にサンプルコードを示す.
app.pyfrom flask import Flask, request, jsonify app = Flask(__name__) # jsonifyの結果に日本語が含まれる場合,以下の1行を記述することで文字化けを回避できる app.config['JSON_AS_ASCII'] = False @app.route('/api/get', methods=['GET']) def get(): response = {"result": "success", "status": 200} return jsonify(response) @app.route('/api/post', methods=['POST']) def post(): data = request.json name = data['name'] value = data['value'] array = data['array'] print(f'data: {data}') print(f'data["name"]: {name}') print(f'data["value"]: {value}') print(f'data["array"]: {array}') print(f'data["array[0]"]: {array[0]}') print(f'data["array[1]"]: {array[1]}') print(f'data["array[2]"]: {array[2]}') return jsonify(data) if __name__ == '__main__': app.run(host='0.0.0.0', debug=True)Androidのサンプルコードを記述する前にcurlで一度HTTP通信ができるかどうか確認を行ってください.
curl http://127.0.0.1:5000/api/getcurl -X POST -H 'Content-Type:application/json' -d '{"name": "foge", "value": 100, "array":["おはよう", "こんにちは", "こんばんは"]}' http://127.0.0.1:5000/api/post以下にAndroidのサンプルコードを示します.
AndroidManifest.xml<?xml version="1.0" encoding="utf-8"?> <manifest xmlns:android="http://schemas.android.com/apk/res/android" package="com.example.samplehttpconnection"> <uses-permission android:name="android.permission.INTERNET"/> <application android:allowBackup="true" android:icon="@mipmap/ic_launcher" android:label="@string/app_name" android:roundIcon="@mipmap/ic_launcher_round" android:supportsRtl="true" android:theme="@style/AppTheme"> <activity android:name=".MainActivity"> <intent-filter> <action android:name="android.intent.action.MAIN" /> <category android:name="android.intent.category.LAUNCHER" /> </intent-filter> </activity> </application> </manifest>activity_main.xml<?xml version="1.0" encoding="utf-8"?> <androidx.constraintlayout.widget.ConstraintLayout xmlns:android="http://schemas.android.com/apk/res/android" xmlns:app="http://schemas.android.com/apk/res-auto" xmlns:tools="http://schemas.android.com/tools" android:layout_width="match_parent" android:layout_height="match_parent" tools:context=".MainActivity"> <TextView android:id="@+id/textView" android:layout_width="wrap_content" android:layout_height="wrap_content" android:layout_marginTop="100dp" android:gravity="center" android:text="" app:layout_constraintLeft_toLeftOf="parent" app:layout_constraintRight_toRightOf="parent" app:layout_constraintTop_toBottomOf="@+id/button2" /> <Button android:id="@+id/button" android:layout_width="wrap_content" android:layout_height="wrap_content" android:layout_marginTop="100dp" android:text="GET" app:layout_constraintEnd_toEndOf="parent" app:layout_constraintStart_toStartOf="parent" app:layout_constraintTop_toTopOf="parent" /> <TextView android:id="@+id/textView2" android:layout_width="wrap_content" android:layout_height="wrap_content" android:layout_marginTop="100dp" android:gravity="center" android:text="" app:layout_constraintEnd_toEndOf="parent" app:layout_constraintStart_toStartOf="parent" app:layout_constraintTop_toBottomOf="@+id/textView" /> <Button android:id="@+id/button2" android:layout_width="wrap_content" android:layout_height="wrap_content" android:layout_marginTop="50dp" android:text="POST" app:layout_constraintEnd_toEndOf="parent" app:layout_constraintStart_toStartOf="parent" app:layout_constraintTop_toBottomOf="@+id/button" /> </androidx.constraintlayout.widget.ConstraintLayout>MainActivity.javapackage com.example.samplehttpconnection; import androidx.appcompat.app.AppCompatActivity; import android.os.Bundle; import android.os.Handler; import android.view.View; import android.widget.Button; import android.widget.TextView; import org.json.JSONException; import org.json.JSONObject; import java.io.BufferedReader; import java.io.BufferedWriter; import java.io.IOException; import java.io.InputStream; import java.io.InputStreamReader; import java.io.OutputStream; import java.io.OutputStreamWriter; import java.net.HttpURLConnection; import java.net.MalformedURLException; import java.net.URL; import java.util.ArrayList; import java.util.HashMap; import java.util.Locale; public class MainActivity extends AppCompatActivity { private Handler handler = new Handler(); private Button button; private Button button2; private TextView textView; private TextView textView2; // IPアドレスは各自変更してください.Pythonのプログラムを実行しているPCのIPアドレスを記述 private String urlGetText = "http://192.168.0.10:5000/api/get"; private String urlPostText = "http://192.168.0.10:5000/api/post"; private String getResultText = ""; private String postResultText = ""; @Override protected void onCreate(Bundle savedInstanceState) { super.onCreate(savedInstanceState); setContentView(R.layout.activity_main); button = findViewById(R.id.button); button2 = findViewById(R.id.button2); textView = findViewById(R.id.textView); textView2 = findViewById(R.id.textView2); button.setOnClickListener(new View.OnClickListener() { @Override public void onClick(View v) { Thread thread = new Thread(new Runnable() { @Override public void run() { String response = ""; try { response = getAPI(); JSONObject rootJSON = new JSONObject(response); getResultText = rootJSON.toString(); } catch (JSONException e) { e.printStackTrace(); } handler.post(new Runnable() { @Override public void run() { textView.setText(getResultText); } }); } }); thread.start(); } }); button2.setOnClickListener(new View.OnClickListener() { @Override public void onClick(View v) { Thread thread = new Thread(new Runnable() { @Override public void run() { String response = ""; try { response = postAPI(); JSONObject rootJSON = new JSONObject(response); postResultText = rootJSON.toString(); } catch (JSONException e) { e.printStackTrace(); } handler.post(new Runnable() { @Override public void run() { textView2.setText(postResultText); } }); } }); thread.start(); } }); } public String getAPI(){ HttpURLConnection urlConnection = null; InputStream inputStream = null; String result = ""; String str = ""; try { URL url = new URL(urlGetText); urlConnection = (HttpURLConnection) url.openConnection(); urlConnection.setConnectTimeout(10000); urlConnection.setReadTimeout(10000); urlConnection.addRequestProperty("User-Agent", "Android"); urlConnection.addRequestProperty("Accept-Language", Locale.getDefault().toString()); urlConnection.setRequestMethod("GET"); urlConnection.setDoInput(true); urlConnection.setDoOutput(false); urlConnection.connect(); int statusCode = urlConnection.getResponseCode(); if (statusCode == 200){ inputStream = urlConnection.getInputStream(); BufferedReader bufferedReader = new BufferedReader(new InputStreamReader(inputStream, "utf-8")); result = bufferedReader.readLine(); while (result != null){ str += result; result = bufferedReader.readLine(); } bufferedReader.close(); } } catch (MalformedURLException e) { e.printStackTrace(); } catch (IOException e) { e.printStackTrace(); } return str; } public String postAPI(){ HttpURLConnection urlConnection = null; InputStream inputStream = null; OutputStream outputStream = null; String result = ""; String str = ""; try { URL url = new URL(urlPostText); urlConnection = (HttpURLConnection) url.openConnection(); urlConnection.setConnectTimeout(10000); urlConnection.setReadTimeout(10000); urlConnection.addRequestProperty("User-Agent", "Android"); urlConnection.addRequestProperty("Accept-Language", Locale.getDefault().toString()); urlConnection.addRequestProperty("Content-Type", "application/json; charset=UTF-8"); urlConnection.setRequestMethod("POST"); urlConnection.setDoInput(true); urlConnection.setDoOutput(true); urlConnection.connect(); outputStream = urlConnection.getOutputStream(); HashMap<String, Object> jsonMap = new HashMap<>(); jsonMap.put("name", "foge"); jsonMap.put("value", 100); ArrayList<String> array = new ArrayList<>(); array.add("おはよう"); array.add("こんにちは"); array.add("こんばんは"); jsonMap.put("array", array); JSONObject responseJsonObject = new JSONObject(jsonMap); String jsonText = responseJsonObject.toString(); BufferedWriter bufferedWriter = new BufferedWriter(new OutputStreamWriter(outputStream, "utf-8")); bufferedWriter.write(jsonText); bufferedWriter.flush(); bufferedWriter.close(); int statusCode = urlConnection.getResponseCode(); if (statusCode == 200){ inputStream = urlConnection.getInputStream(); BufferedReader bufferedReader = new BufferedReader(new InputStreamReader(inputStream)); result = bufferedReader.readLine(); while (result != null){ str += result; result = bufferedReader.readLine(); } bufferedReader.close(); } urlConnection.disconnect(); } catch (MalformedURLException e) { e.printStackTrace(); } catch (IOException e) { e.printStackTrace(); } return str; } }参照してもらいたいページ
- 投稿日:2020-09-09T13:48:19+09:00
【Python】CSVファイルの読み込み
csvfile.csvAさん,1,月 Bさん,2,火 Cさん,3,水main.pyimport csv #ファイルの読み込みを行います csv_file = open("csvfile.csv", "r", encoding="utf-8", errors="", newline="" ) print(type(csv_file)) """ <class '_io.TextIOWrapper'> """ #CSV文字列をパースします。 csvData = csv.reader(csv_file, delimiter=",", doublequote=True, lineterminator="\r\n", quotechar='"', skipinitialspace=True) print(type(csvData)) """ <class '_csv.reader'> """ #_csv.reader型をリストに変換 csvData = [row for row in csvData] print(type(csvData)) print(csvData) """ <class 'list'> [['Aさん', '1', '月'], ['Bさん', '2', '火'], ['Cさん', '3', '水']] """
- 投稿日:2020-09-09T12:09:03+09:00
2020年にRealsense SR300をMacBookで利用するTips
Realsenseの少し古いバージョンであるSR300をMacBookで動かそうとしたら、少し躓いたのでメモです。
まとめは以下の通りです。
- Latest Legacy Releaseのlibrealsenseを利用
- pyrealsenseはsetup.pyのビルドフラグを変えてインストール
- USB給電は電力が十分なものを使用
1. Latest Legacy Releaseのlibrealsenseを利用
最新版のSDKでは下記のようなエラーが出て、Realsenseデバイスへの接続に失敗することがあります。
Could not open device command transfer failed to execute bulk transfer, error: RS2_USB_STATUS_TIMEOUTそこで、下記の旧バージョンのSDK使います。
https://github.com/IntelRealSense/librealsense/tree/v1.12.1
cloneしたら、最新版と同じくcmakeすればOKです。
cmakeしたらXCodeを開いて、installターゲットでビルドしてlibrealsenseのインストールを済ませておくのを忘れずに!2. pyrealsenseはsetup.pyのビルドフラグを変えてインストール
Python連携はこちらの旧版のものを使います。
https://github.com/toinsson/pyrealsense
pipでインストールしようとすると、最新版のXCode環境ではビルドでコケます。
XCodeのstdlibの参照先が変わっているのが原因なので、setup.pyで指定し直してあげます。setup.pymodule = cythonize( [Extension( name='pyrealsense.rsutilwrapper', sources=["pyrealsense/rsutilwrapper.pyx", "pyrealsense/rsutilwrapperc.cpp"], libraries=['realsense'], include_dirs=inc_dirs, library_dirs=lib_dirs, language="c++", extra_compile_args=["-O3", "-stdlib=libc++"], # ここを追加 extra_link_args=["-stdlib=libc++"], # ここを追加 )])編集したら、
python setup.py installでインストールできます。3. USB給電は電力が十分なものを使用
デプスセンサが結構電力を食うので、安いUSB-C変換コネクタだと、起動してすぐ落ちてしまうことがあります。
Apple純正の変換コネクタなど、電力が十分なものを使うようにしましょう。
以上です。誰かの役に立ちますように!
- 投稿日:2020-09-09T11:50:53+09:00
Azure FunctionsでのPythonによるストレージ入出力メモ
はじめに
Azure FunctionsがPythonランタイムに対応しています。
ただ、ストレージのへの入力をトリガー→Functions処理→ストレージへの出力、を行う方法がなかなか見つけられなかったので備忘録を兼ねてメモします。手順
※ Functionsリソースの作成等は終わっている前提です。
1.バインドするAzureストレージの情報を記載します。local.settings.json{ "IsEncrypted": false, "Values": { "FUNCTIONS_WORKER_RUNTIME": "python", "AzureWebJobsStorage": "DefaultEndpointsProtocol=https;AccountName=<ストレージアカウント>;AccountKey=<アカウントキー>;EndpointSuffix=core.windows.net" } }2.入力元と出力先のパスを記載します。
function.json{ "scriptFile": "__init__.py", "bindings": [ { "name": "inputblob", "type": "blobTrigger", "direction": "in", "path": "container/input/{name}", "connection": "" }, { "name": "outputblob", "type": "blob", "direction": "out", "path": "container/output/{name}.csv", "connection": "" } ] }3.Pythonスクリプト内に処理を書きます。
__init__.pydef main(inputblob: func.InputStream, outputblob: func.Out[str]): logging.info(f"Python blob trigger function processed blob. v2.0\n" f"Name: {inputblob.name}\n" f"Blob Size: {inputblob.length} bytes\n") input_text = inputblob.read(size=-1).decode("utf-8") # 行いたい処理 output_text = input_text += "hoge" outputblob.set(output_text)これで2.で設定したpath "container/output/{name}.csv"へファイルが出力されます。ファイル名はこの場合だと入力ファイル名の末尾に".csv"が付いた形となります。
- 投稿日:2020-09-09T11:11:51+09:00
【Maya Python】スクリプトの中身を噛み砕く2 ~リストノード編
この記事の目的
自作ツールの中身を一つ一つ確認しながら理解を深め、今後のツール開発に役立てます。
今までなんとなくコピペで動いてたからいいやとスルーしてきたことを徹底理解します。
同じようにスクリプトを書いていてなんとなく動いてるからいっか、で終わってる人への一助になればと思います。
今回はPyQt、QTreeView、QStandardItemModelがメインです。ツール概要
シーン内のNotesを一覧を表示します。
各ノードにはNotesというアトリビュートが備わっています。AttributeEditorの一番下にこの機能がありますが使っていますか?
ここにメモを残すことでこのノードが何をやっているか把握しやすくなります。僕はMayaファイル内に各ノードのメモを残すときによく使っています。しかし、すべてのNotesを一覧表示する方法が見つからなかったためツールにしました。
GIF画像のようにシーン内のNotesが残されているノードを一括表示します。
ノードの選択や、Notesの編集が可能です。動作環境:Maya2019.3,Maya2020.1
Pyside2を使用しているので2016以前では動作しません。コード全文
# -*- coding: utf-8 -*- from maya.app.general.mayaMixin import MayaQWidgetBaseMixin from PySide2 import QtWidgets, QtCore, QtGui from maya import cmds class Widget(QtWidgets.QWidget): def __init__(self): super(Widget, self).__init__() # グリッドレイアウト作成 layout = QtWidgets.QGridLayout(self) # ツリービュー追加 treeView = TreeView() layout.addWidget(treeView, 0, 0, 1, -1) # ツリービューにアイテム設定 self.stockItemModel = StockItemModel() treeView.setModel(self.stockItemModel) # ツリービューに選択アイテム設定 self.itemSelectionModel = QtCore.QItemSelectionModel(self.stockItemModel) treeView.setSelectionModel(self.itemSelectionModel) # セレクトボタン button = QtWidgets.QPushButton('Select') button.clicked.connect(self.select) layout.addWidget(button, 1, 0) # リフレッシュボタン button = QtWidgets.QPushButton('Refresh') button.clicked.connect(self.refresh) layout.addWidget(button, 1, 1) # 初期読み込み self.refresh() # セレクトボタンの動作 def select(self): cmds.select(cl=True) indexes = self.itemSelectionModel.selectedIndexes() for index in indexes: (node, notes) = self.stockItemModel.rowData(index.row()) cmds.select(node, noExpand=True ,add=True) # リフレッシュボタンの動作 def refresh(self): # 空の辞書を作成 list = {} # notesがあるアトリビュートを辞書で取得 for node in cmds.ls(allPaths=True): if cmds.attributeQuery ('notes',node=node,exists=True): list[node] = cmds.getAttr(node+'.notes') # アイテムモデルを空にする self.stockItemModel.removeRows(0, self.stockItemModel.rowCount()) # 取得した辞書からアイテムを追加する for note in list: self.stockItemModel.appendItem(note, list[note]) class TreeView(QtWidgets.QTreeView): def __init__(self): super(TreeView, self).__init__() # 選択の種類を変更する(エクセルみたいな感じ) self.setSelectionMode(QtWidgets.QTreeView.ExtendedSelection) # ツリービューの行の色を交互に変更する self.setAlternatingRowColors(True) class StockItemModel(QtGui.QStandardItemModel): def __init__(self): super(StockItemModel, self).__init__(0, 2) # ヘッダー設定 self.setHeaderData(0, QtCore.Qt.Horizontal, 'Node Name') self.setHeaderData(1, QtCore.Qt.Horizontal, 'Notes') # 編集したときの動作 def setData(self, index, value, role=QtCore.Qt.EditRole): if role: # 編集したデータを取得 (node, attr) = self.rowData(index.row()) # Notesアトリビュートを変更 cmds.setAttr(node+'.notes', value, type='string') # 編集したアイテムを変更 self.item(index.row(), index.column()).setText(value) # 成功したことを報告 return True # 指定の行からnode,attrを返す def rowData(self, row): # ノードとアトリビュート取得 node = self.item(row, 0).text() attr = self.item(row, 1).text() return (node, attr) # アイテムを追加する def appendItem(self, nodename, notes): # ノードは編集不可で作成 nodeItem = QtGui.QStandardItem(nodename) nodeItem.setEditable(False) # Notesは編集可で作成 notesItem = QtGui.QStandardItem(notes) notesItem.setEditable(True) # 行を追加 self.appendRow([nodeItem, notesItem]) class MainWindow(MayaQWidgetBaseMixin, QtWidgets.QMainWindow): def __init__(self): super(MainWindow, self).__init__() self.setWindowTitle('List Notes') self.resize(430, 260) widget = Widget() self.setCentralWidget(widget) def main(): window = MainWindow() window.show() if __name__ == "__main__": main()ツールの設計図
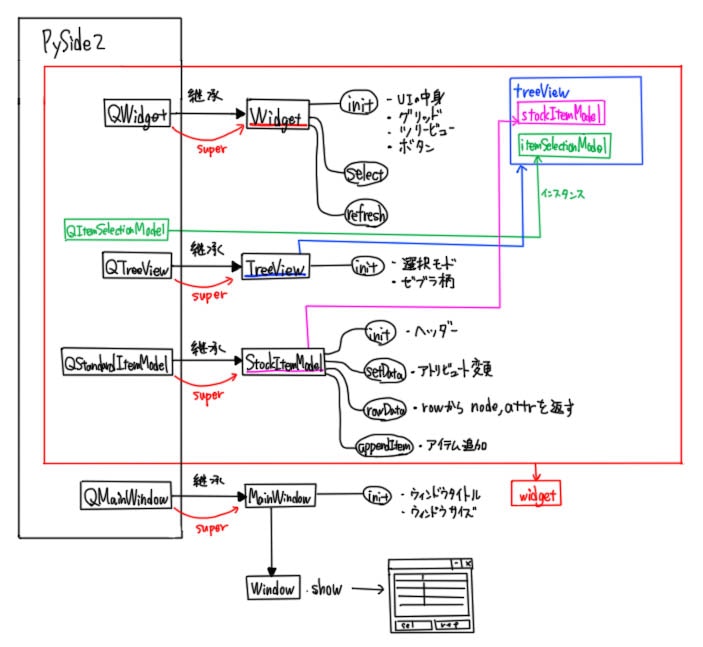
おおよそこのような感じ。
ツールの動作を把握するためにも設計図を描くとわかりやすい。詳細を見ていく
以前書いた部分に関しては下記参照。新しく出てきた項目について書いて行きます。
【Maya Python】スクリプトの中身を噛み砕く1 ~カメラスピードエディタ編ツリービューの見た目設定(QTreeView)
# ツリービュー追加 treeView = TreeView() layout.addWidget(treeView, 0, 0, 1, -1)
TreeView()クラスをインスタンスし、グリッドレイアウトに追加します。
ちなみにクラス名は頭文字大文字がPEP8で推奨されています。僕はわかりやすいように、クラス名は頭文字大文字、インスタンス名は頭文字小文字にして区別しています。少し飛びますが先に
TreeViewクラスを見ましょう。class TreeView(QtWidgets.QTreeView): def __init__(self): super(TreeView, self).__init__() # 選択の種類を変更する(エクセルみたいな感じ) self.setSelectionMode(QtWidgets.QTreeView.ExtendedSelection) # ツリービューの行の色を交互に変更する self.setAlternatingRowColors(True)QtWidgets.QTreeViewをTreeViewに継承します。
基本的にはそのまま使うのでオーバーライド部分は少ないです。
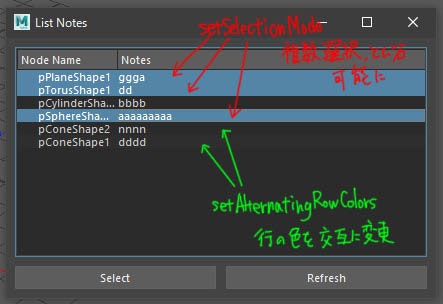
self.setSelectionMode(QtWidgets.QTreeView.ExtendedSelection)
選択のモード変更を行います。
デフォルトのままだと一つしか選択できないので複数選択できるように変更します。ExtendedSelectionを使用するとエクセルのような飛び石選択ができるようになります。
self.setAlternatingRowColors(True)
行の色を交互に変更します。
こういったツリービューは量が増えると見づらくなるのでゼブラ柄にして見やすくします。
このようにQTreeViewではツリービューの見た目や動作を設定します。ツリービューにアイテムを設定(StockItemModel、QItemSelectionModel)
# ツリービューにアイテム設定 self.stockItemModel = StockItemModel() treeView.setModel(self.stockItemModel) # ツリービューに選択アイテム設定 self.itemSelectionModel = QtCore.QItemSelectionModel(self.stockItemModel) treeView.setSelectionModel(self.itemSelectionModel)
StockItemModel()クラスをself.stockItemModelという名前でインスタンス
先程作ったツリービューに作成したアイテムをセットします。
QtCore.QItemSelectionModelを使い、self.stockItemModelの選択状態を取得できるように設定しておきます。
継承してオーバーライドする必要がないのでそのままインスタンスして使います。
setSelectionModelでtreeViewにself.itemSelectionModelを選択モデルとしてセットします。では、次に
StockItemModel()クラスについて見てみます。StockItemModel
初期化、ヘッダーの設定(init)
class StockItemModel(QtGui.QStandardItemModel): def __init__(self): super(StockItemModel, self).__init__(0, 2) # ヘッダー設定 self.setHeaderData(0, QtCore.Qt.Horizontal, 'Node Name') self.setHeaderData(1, QtCore.Qt.Horizontal, 'Notes')
QStandarItemModelをStockItemModelとして継承します。
初期設定でヘッダーの設定をします。
super(StockItemModel, self).__init__(0, 2)
初期化時に、0行、2列のアイテムモデルを作ります。
self.setHeaderData(0, QtCore.Qt.Horizontal, 'Node Name')
0列目に、Node Nameという名前でヘッダーを作成します。
self.setHeaderData(1, QtCore.Qt.Horizontal, 'Notes')
1列目に、Notesという名前でヘッダーを作成します。
QtCore.Qt.Horizontalは向きの設定、ここではヘッダーなので水平を指定します。編集したときの動作を設定(setData)
# 編集したときの動作 def setData(self, index, value, role=QtCore.Qt.EditRole): if role: # 編集したデータを取得 (node, attr) = self.rowData(index.row()) # Notesアトリビュートを変更 cmds.setAttr(node+'.notes', value, type='string') # 編集したアイテムを変更 self.item(index.row(), index.column()).setText(value) # 成功したことを報告 return True編集されたときにどういう動作をするか設定します。
indexは編集した場所、valueは編集内容、roleは役割を指定します。QtCore.Qt.EditRoleで編集に適した形式を指定します。編集したデータのrowから、
rowDataクラスを使いnode,attrを取得します。
rowDataについては後述します。
cmds.setAttr(node+'.notes', value, type='string')
Mayaコマンドです。編集したアトリビュートをノードに反映します。
self.item(index.row(), index.column()).setText(value)
編集した部分をツリービューのアイテムにも反映します。指定の行からノード、アトリビュートを取得(rowData)
先ほど出てきたrowDataクラスについての説明です。
# 指定の行からnode,attrを返す def rowData(self, row): # ノードとアトリビュート取得 node = self.item(row, 0).text() attr = self.item(row, 1).text() return (node, attr)指定した行(row)から、
node,attr(ノード名、アトリビュート内容)として値を返します。
itemクラスは(行、列)で要素の取得ができます。
そのままだとオブジェクトデータになので、.text()で文字列に変換しています。アイテムを追加する(appendItem)
アイテムを追加する機能を作っておきます。
このあとボタン等から呼び出します。# アイテムを追加する def appendItem(self, nodename, notes): # ノードは編集不可で作成 nodeItem = QtGui.QStandardItem(nodename) nodeItem.setEditable(False) # Notesは編集可で作成 notesItem = QtGui.QStandardItem(notes) notesItem.setEditable(True) # 行を追加 self.appendRow([nodeItem, notesItem])ノード名、Notesから、アイテムを追加します。
QtGui.QStandardItem(nodename)アイテムの表示内容を設定します。
nodeItem.setEditable(False)ノードの方は編集不可にします。
notesItem.setEditable(True)Notesの方は編集可能にします。
self.appendRow([nodeItem, notesItem])
設定した内容を行(row)に追加します。
appendRowはQStandardItemModelのファンクションです。
こういった機能をそのまま使えるのがPySideの強みですね。ボタンの作成
# セレクトボタン button = QtWidgets.QPushButton('Select') button.clicked.connect(self.select) layout.addWidget(button, 1, 0) # リフレッシュボタン button = QtWidgets.QPushButton('Refresh') button.clicked.connect(self.refresh) layout.addWidget(button, 1, 1)基本的には【Maya Python】スクリプトの中身を噛み砕く1 ~カメラスピードエディタ編と同じです。
次は、ボタンの中身を見ていきます。セレクトボタンの動作
# セレクトボタンの動作 def select(self): cmds.select(cl=True) indexes = self.selItemModel.selectedIndexes() for index in indexes: (node, notes) = self.itemModel.rowData(index.row()) cmds.select(node, noExpand=True ,add=True)
cmds.select(cl=True)現在の選択状態をなくします。
selectedIndexes()はQItemSelectionModelのファンクションで、選択しているインデックスをリストで返してくれます。
for index in indexes:選択している回数分繰り返します。
self.itemModel.rowData(index.row())選択した行のノード名、notesを取得。
詳細は先程の指定の行からノード、アトリビュートを取得(rowData)参照
cmds.select(node, noExpand=True ,add=True)取得したノードを追加選択。
noExpand=Trueは選択セットのオブジェクトではなく、選択セットを選択できるようにします。
add=True追加選択モードに変更します。リフレッシュボタンの動作
# リフレッシュボタンの動作 def refresh(self): # 空の辞書を作成 list = {} # notesがあるアトリビュートを辞書で取得 for node in cmds.ls(allPaths=True): if cmds.attributeQuery ('notes',node=node,exists=True): list[node] = cmds.getAttr(node+'.notes') # アイテムモデルを空にする self.stockItemModel.removeRows(0, self.stockItemModel.rowCount()) # 取得した辞書からアイテムを追加する for note in list: self.stockItemModel.appendItem(note, list[note])
for...
notesがあるノードを辞書形式でリストアップします。
self.stockItemModel.removeRows(0, self.stockItemModel.rowCount())
0行目から行数分(self.stockItemModel.rowCount())まで削除します。
self.stockItemModel.appendItem(note, list[note])
取得した辞書(list)からアイテムを追加します。
先ほど作成したアイテムを追加する(appendItem)を参照。初期読み込み
# 初期読み込み self.refresh()最後に最初に立ち上げたときにNotesを取得します。
refreshの挙動と同じなのでそれを使いまわします。おわりに
今回はPyQtの記述が多かったですが、なかなかネットで情報収集が難しかったです。
公式のドキュメントの見方がもう少しわかりやすければ。。
でもようやくPySideの使い方が少しわかってきた気がする。参考一覧

- 投稿日:2020-09-09T11:11:51+09:00
【Maya Python】スクリプトの中身を噛み砕く2 ~list Notes編
この記事の目的
自作ツールの中身を一つ一つ確認しながら理解を深め、今後のツール開発に役立てます。
今までなんとなくコピペで動いてたからいいやとスルーしてきたことを徹底理解します。
同じようにスクリプトを書いていてなんとなく動いてるからいっか、で終わってる人への一助になればと思います。
今回はPyQt、QTreeView、QStandardItemModelがメインです。ツール概要
シーン内のNotesを一覧を表示します。
各ノードにはNotesというアトリビュートが備わっています。AttributeEditorの一番下にこの機能がありますが使っていますか?
ここにメモを残すことでこのノードが何をやっているか把握しやすくなります。僕はMayaファイル内に各ノードのメモを残すときによく使っています。しかし、すべてのNotesを一覧表示する方法が見つからなかったためツールにしました。
GIF画像のようにシーン内のNotesが残されているノードを一括表示します。
ノードの選択や、Notesの編集が可能です。動作環境:Maya2019.3,Maya2020.1
Pyside2を使用しているので2016以前では動作しません。コード全文
# -*- coding: utf-8 -*- from maya.app.general.mayaMixin import MayaQWidgetBaseMixin from PySide2 import QtWidgets, QtCore, QtGui from maya import cmds class Widget(QtWidgets.QWidget): def __init__(self): super(Widget, self).__init__() # グリッドレイアウト作成 layout = QtWidgets.QGridLayout(self) # ツリービュー追加 treeView = TreeView() layout.addWidget(treeView, 0, 0, 1, -1) # ツリービューにアイテム設定 self.stockItemModel = StockItemModel() treeView.setModel(self.stockItemModel) # ツリービューに選択アイテム設定 self.itemSelectionModel = QtCore.QItemSelectionModel(self.stockItemModel) treeView.setSelectionModel(self.itemSelectionModel) # セレクトボタン button = QtWidgets.QPushButton('Select') button.clicked.connect(self.select) layout.addWidget(button, 1, 0) # リフレッシュボタン button = QtWidgets.QPushButton('Refresh') button.clicked.connect(self.refresh) layout.addWidget(button, 1, 1) # 初期読み込み self.refresh() # セレクトボタンの動作 def select(self): cmds.select(cl=True) indexes = self.itemSelectionModel.selectedIndexes() for index in indexes: (node, notes) = self.stockItemModel.rowData(index.row()) cmds.select(node, noExpand=True ,add=True) # リフレッシュボタンの動作 def refresh(self): # 空の辞書を作成 list = {} # notesがあるアトリビュートを辞書で取得 for node in cmds.ls(allPaths=True): if cmds.attributeQuery ('notes',node=node,exists=True): list[node] = cmds.getAttr(node+'.notes') # アイテムモデルを空にする self.stockItemModel.removeRows(0, self.stockItemModel.rowCount()) # 取得した辞書からアイテムを追加する for note in list: self.stockItemModel.appendItem(note, list[note]) class TreeView(QtWidgets.QTreeView): def __init__(self): super(TreeView, self).__init__() # 選択の種類を変更する(エクセルみたいな感じ) self.setSelectionMode(QtWidgets.QTreeView.ExtendedSelection) # ツリービューの行の色を交互に変更する self.setAlternatingRowColors(True) class StockItemModel(QtGui.QStandardItemModel): def __init__(self): super(StockItemModel, self).__init__(0, 2) # ヘッダー設定 self.setHeaderData(0, QtCore.Qt.Horizontal, 'Node Name') self.setHeaderData(1, QtCore.Qt.Horizontal, 'Notes') # 編集したときの動作 def setData(self, index, value, role=QtCore.Qt.EditRole): if role: # 編集したデータを取得 (node, attr) = self.rowData(index.row()) # Notesアトリビュートを変更 cmds.setAttr(node+'.notes', value, type='string') # 編集したアイテムを変更 self.item(index.row(), index.column()).setText(value) # 成功したことを報告 return True # 指定の行からnode,attrを返す def rowData(self, row): # ノードとアトリビュート取得 node = self.item(row, 0).text() attr = self.item(row, 1).text() return (node, attr) # アイテムを追加する def appendItem(self, nodename, notes): # ノードは編集不可で作成 nodeItem = QtGui.QStandardItem(nodename) nodeItem.setEditable(False) # Notesは編集可で作成 notesItem = QtGui.QStandardItem(notes) notesItem.setEditable(True) # 行を追加 self.appendRow([nodeItem, notesItem]) class MainWindow(MayaQWidgetBaseMixin, QtWidgets.QMainWindow): def __init__(self): super(MainWindow, self).__init__() self.setWindowTitle('List Notes') self.resize(430, 260) widget = Widget() self.setCentralWidget(widget) def main(): window = MainWindow() window.show() if __name__ == "__main__": main()ツールの設計図
おおよそこのような感じ。
ツールの動作を把握するためにも設計図を描くとわかりやすい。詳細を見ていく
以前書いた部分に関しては下記参照。新しく出てきた項目について書いて行きます。
【Maya Python】スクリプトの中身を噛み砕く1 ~カメラスピードエディタ編ツリービューの見た目設定(QTreeView)
# ツリービュー追加 treeView = TreeView() layout.addWidget(treeView, 0, 0, 1, -1)
TreeView()クラスをインスタンスし、グリッドレイアウトに追加します。
ちなみにクラス名は頭文字大文字がPEP8で推奨されています。僕はわかりやすいように、クラス名は頭文字大文字、インスタンス名は頭文字小文字にして区別しています。少し飛びますが先に
TreeViewクラスを見ましょう。class TreeView(QtWidgets.QTreeView): def __init__(self): super(TreeView, self).__init__() # 選択の種類を変更する(エクセルみたいな感じ) self.setSelectionMode(QtWidgets.QTreeView.ExtendedSelection) # ツリービューの行の色を交互に変更する self.setAlternatingRowColors(True)QtWidgets.QTreeViewをTreeViewに継承します。
基本的にはそのまま使うのでオーバーライド部分は少ないです。
self.setSelectionMode(QtWidgets.QTreeView.ExtendedSelection)
選択のモード変更を行います。
デフォルトのままだと一つしか選択できないので複数選択できるように変更します。ExtendedSelectionを使用するとエクセルのような飛び石選択ができるようになります。
self.setAlternatingRowColors(True)
行の色を交互に変更します。
こういったツリービューは量が増えると見づらくなるのでゼブラ柄にして見やすくします。
このようにQTreeViewではツリービューの見た目や動作を設定します。ツリービューにアイテムを設定(StockItemModel、QItemSelectionModel)
# ツリービューにアイテム設定 self.stockItemModel = StockItemModel() treeView.setModel(self.stockItemModel) # ツリービューに選択アイテム設定 self.itemSelectionModel = QtCore.QItemSelectionModel(self.stockItemModel) treeView.setSelectionModel(self.itemSelectionModel)
StockItemModel()クラスをself.stockItemModelという名前でインスタンス
先程作ったツリービューに作成したアイテムをセットします。
QtCore.QItemSelectionModelを使い、self.stockItemModelの選択状態を取得できるように設定しておきます。
継承してオーバーライドする必要がないのでそのままインスタンスして使います。
setSelectionModelでtreeViewにself.itemSelectionModelを選択モデルとしてセットします。では、次に
StockItemModel()クラスについて見てみます。StockItemModel
初期化、ヘッダーの設定(init)
class StockItemModel(QtGui.QStandardItemModel): def __init__(self): super(StockItemModel, self).__init__(0, 2) # ヘッダー設定 self.setHeaderData(0, QtCore.Qt.Horizontal, 'Node Name') self.setHeaderData(1, QtCore.Qt.Horizontal, 'Notes')
QStandarItemModelをStockItemModelとして継承します。
初期設定でヘッダーの設定をします。
super(StockItemModel, self).__init__(0, 2)
初期化時に、0行、2列のアイテムモデルを作ります。
self.setHeaderData(0, QtCore.Qt.Horizontal, 'Node Name')
0列目に、Node Nameという名前でヘッダーを作成します。
self.setHeaderData(1, QtCore.Qt.Horizontal, 'Notes')
1列目に、Notesという名前でヘッダーを作成します。
QtCore.Qt.Horizontalは向きの設定、ここではヘッダーなので水平を指定します。編集したときの動作を設定(setData)
# 編集したときの動作 def setData(self, index, value, role=QtCore.Qt.EditRole): if role: # 編集したデータを取得 (node, attr) = self.rowData(index.row()) # Notesアトリビュートを変更 cmds.setAttr(node+'.notes', value, type='string') # 編集したアイテムを変更 self.item(index.row(), index.column()).setText(value) # 成功したことを報告 return True編集されたときにどういう動作をするか設定します。
indexは編集した場所、valueは編集内容、roleは役割を指定します。QtCore.Qt.EditRoleで編集に適した形式を指定します。編集したデータのrowから、
rowDataクラスを使いnode,attrを取得します。
rowDataについては後述します。
cmds.setAttr(node+'.notes', value, type='string')
Mayaコマンドです。編集したアトリビュートをノードに反映します。
self.item(index.row(), index.column()).setText(value)
編集した部分をツリービューのアイテムにも反映します。指定の行からノード、アトリビュートを取得(rowData)
先ほど出てきたrowDataクラスについての説明です。
# 指定の行からnode,attrを返す def rowData(self, row): # ノードとアトリビュート取得 node = self.item(row, 0).text() attr = self.item(row, 1).text() return (node, attr)指定した行(row)から、
node,attr(ノード名、アトリビュート内容)として値を返します。
itemクラスは(行、列)で要素の取得ができます。
そのままだとオブジェクトデータになので、.text()で文字列に変換しています。アイテムを追加する(appendItem)
アイテムを追加する機能を作っておきます。
このあとボタン等から呼び出します。# アイテムを追加する def appendItem(self, nodename, notes): # ノードは編集不可で作成 nodeItem = QtGui.QStandardItem(nodename) nodeItem.setEditable(False) # Notesは編集可で作成 notesItem = QtGui.QStandardItem(notes) notesItem.setEditable(True) # 行を追加 self.appendRow([nodeItem, notesItem])ノード名、Notesから、アイテムを追加します。
QtGui.QStandardItem(nodename)アイテムの表示内容を設定します。
nodeItem.setEditable(False)ノードの方は編集不可にします。
notesItem.setEditable(True)Notesの方は編集可能にします。
self.appendRow([nodeItem, notesItem])
設定した内容を行(row)に追加します。
appendRowはQStandardItemModelのファンクションです。
こういった機能をそのまま使えるのがPySideの強みですね。ボタンの作成
# セレクトボタン button = QtWidgets.QPushButton('Select') button.clicked.connect(self.select) layout.addWidget(button, 1, 0) # リフレッシュボタン button = QtWidgets.QPushButton('Refresh') button.clicked.connect(self.refresh) layout.addWidget(button, 1, 1)基本的には【Maya Python】スクリプトの中身を噛み砕く1 ~カメラスピードエディタ編と同じです。
次は、ボタンの中身を見ていきます。セレクトボタンの動作
# セレクトボタンの動作 def select(self): cmds.select(cl=True) indexes = self.selItemModel.selectedIndexes() for index in indexes: (node, notes) = self.itemModel.rowData(index.row()) cmds.select(node, noExpand=True ,add=True)
cmds.select(cl=True)現在の選択状態をなくします。
selectedIndexes()はQItemSelectionModelのファンクションで、選択しているインデックスをリストで返してくれます。
for index in indexes:選択している回数分繰り返します。
self.itemModel.rowData(index.row())選択した行のノード名、notesを取得。
詳細は先程の指定の行からノード、アトリビュートを取得(rowData)参照
cmds.select(node, noExpand=True ,add=True)取得したノードを追加選択。
noExpand=Trueは選択セットのオブジェクトではなく、選択セットを選択できるようにします。
add=True追加選択モードに変更します。リフレッシュボタンの動作
# リフレッシュボタンの動作 def refresh(self): # 空の辞書を作成 list = {} # notesがあるアトリビュートを辞書で取得 for node in cmds.ls(allPaths=True): if cmds.attributeQuery ('notes',node=node,exists=True): list[node] = cmds.getAttr(node+'.notes') # アイテムモデルを空にする self.stockItemModel.removeRows(0, self.stockItemModel.rowCount()) # 取得した辞書からアイテムを追加する for note in list: self.stockItemModel.appendItem(note, list[note])
for...
notesがあるノードを辞書形式でリストアップします。
self.stockItemModel.removeRows(0, self.stockItemModel.rowCount())
0行目から行数分(self.stockItemModel.rowCount())まで削除します。
self.stockItemModel.appendItem(note, list[note])
取得した辞書(list)からアイテムを追加します。
先ほど作成したアイテムを追加する(appendItem)を参照。初期読み込み
# 初期読み込み self.refresh()最後に最初に立ち上げたときにNotesを取得します。
refreshの挙動と同じなのでそれを使いまわします。おわりに
今回はPyQtの記述が多かったですが、なかなかネットで情報収集が難しかったです。
公式のドキュメントの見方がもう少しわかりやすければ。。
でもようやくPySideの使い方が少しわかってきた気がする。参考一覧
- 投稿日:2020-09-09T11:03:20+09:00
Educational Codeforces Round 94 バチャ復習(9/3)
今回の成績
今回の感想
B問題でかなりの時間をかけてしまったせいで時間が無限に溶けてしまいました。B問題の反省としては解析的に解こうとしてしまったところです。直感的に貪欲法を行えば解けたと思うので反省しています。
A問題
初めに見たときは01を交互にする?などと考えていましたが、位置がずれてしまうので面倒だと感じました。そこで位置によらないように全ての文字が同じであれば良いのではと考えました。このとき、問題の条件からいずれの文字列にも$s[n]$が含まれることがわかります。したがって、この文字を$n$個つなげた文字列を作れば、$s[n]$に対応する文字でいずれの文字列とも等しくなります。よってこれが答えとなります。
A.pyfor _ in range(int(input())): n=int(input()) s=input() print(n*s[n-1])B問題
感想にもある通り、通常の貪欲法で解くことができます。
できるだけ多くを選ぶには軽いものから選ぶ方が最適であることを意識して考察を行います。また、$s \leqq w$とします(そうでない場合は値をswapします)。まずは自分が奪うものを選びますが、組み合わせによっては重いものを取っておいた方が良い場合もあるので、自分は$i(0 \leqq i \leqq cnts)$個だけ軽いものを選ぶとします。また、この時、$i \times s \leqq p$を満たす必要があります。この下で自分の選べる重い方のものの個数は$min(\frac{p-i \times s}{w},cntw)$となります。また、それぞれのものがいくつだけ残っているかはここまでで簡単に求められるので、自分のフォロワーは軽いものから順に貪欲に選べば良いです。よって、$i$を定めた時の奪えるものの個数は$O(1)$で求められ、十分に高速なプログラムを書くことができます。
B.pyfor _ in range(int(input())): p,f=map(int,input().split()) cnts,cntw=map(int,input().split()) s,w=map(int,input().split()) if s>w: s,w=w,s cnts,cntw=cntw,cnts ans=0 for i in range(cnts+1): if i*s>p:break ans_sub=0 nows=cnts-i ans_sub+=i #sは選びずみ rest1=p-i*s #wの方 noww=cntw-min(rest1//w,cntw) ans_sub+=min(rest1//w,cntw) #次のひと #sの方 ans_sub+=min(f//s,nows) rest2=f-min(f//s,nows)*s #wの方 ans_sub+=min(noww,rest2//w) ans=max(ans,ans_sub) print(ans)C問題
$s$が与えられているので$w$を復元します。ここで、$s_i=1$のときは$w_{i-x}=1$か$w_{i+x}=1$のどちらかが成り立つという条件で$w$を復元しにくいので、$s_i=0$のときに$w_{i-x}=1$と$w_{i+x}=1$のいずれも成り立つという条件から$w$を復元することにしました。
また、この方法では$w$の一部が復元されていませんが、$s_i=1$という条件を満たすように復元されてない部分は全て1にします。以上より$w$を復元することができましたが、実際に$w$から$s$に変形できるかはわからないので、最後に変形できるかの確認が必要です。
C.pyfor _ in range(int(input())): s=list(map(int,input())) x=int(input()) n=len(s) w=[1]*n for i in range(n): if s[i]==0: if i-x>=0: w[i-x]=0 if i+x<n: w[i+x]=0 t=[1]*n for i in range(n): g=0 if i-x>=0: if w[i-x]==1: g+=1 if i+x<n: if w[i+x]==1: g+=1 if g>0: t[i]=1 else: t[i]=0 if s==t: print("".join(map(str,w))) else: print(-1)D問題
MLEになって焦りましたが時間内に解き終わって安心しました。
pair<ll,ll>をllへ変換したりllをintにしたりといった工夫をしました。この問題は考察自体はそこまで難しくなく実装が少し面倒と感じました。
$i<j<k<l$のもとで$a_i=a_k$かつ$a_j=a_l$が成り立つような$i,j,k,l$を探します。この時、$(a_i,a_j)=(a_k,a_l)$が成り立つことに注目しました。また、$n$は高々3000通りなので$_{3000}C_2$の組を全て生成することができます。また、組が同じものをmapによってまとめておきます。つまり、$m$をmapオブジェクトとして、keyを二要素の組,valueをvectorとしてその二要素となるインデックスの組を含むとすれば良いです。
この下で$(a_i,a_j)=(a_k,a_l)$となるには$a_j<a_k$でなければなりません。したがって、それぞれの二要素の組についてこれを満たすものの個数をupper_boundを使って求めます。しかし、そのインデックスを知るにはdistance関数を使うと線形時間かかってしまうので、自作で二分探索を実装してインデックスを返すようにします。二分探索の実装では自分のこの記事を参考にしました。
D.cc//デバッグ用オプション:-fsanitize=undefined,address //コンパイラ最適化 #pragma GCC optimize("Ofast") //インクルードなど #include<bits/stdc++.h> using namespace std; typedef int ll; //マクロ //forループ //引数は、(ループ内変数,動く範囲)か(ループ内変数,始めの数,終わりの数)、のどちらか //Dがついてないものはループ変数は1ずつインクリメントされ、Dがついてるものはループ変数は1ずつデクリメントされる //FORAは範囲for文(使いにくかったら消す) #define REP(i,n) for(ll i=0;i<ll(n);i++) #define REPD(i,n) for(ll i=n-1;i>=0;i--) #define FOR(i,a,b) for(ll i=a;i<=ll(b);i++) #define FORD(i,a,b) for(ll i=a;i>=ll(b);i--) #define FORA(i,I) for(const auto& i:I) //xにはvectorなどのコンテナ #define ALL(x) x.begin(),x.end() #define SIZE(x) ll(x.size()) //定数 #define INF 1000000000000 //10^12:∞ #define MOD 4000 //10^9+7:合同式の法 #define MAXR 100000 //10^5:配列の最大のrange //略記 #define PB push_back //挿入 #define MP make_pair //pairのコンストラクタ #define F first //pairの一つ目の要素 #define S second //pairの二つ目の要素 //MLE signed main(){ //入力の高速化用のコード //ios::sync_with_stdio(false); //cin.tie(nullptr); ll t;cin>>t; REP(_,t){ ll n;cin>>n; vector<ll> a(n); REP(i,n)cin>>a[i]; //それぞれの値で管理 map<ll,vector<ll>> m; REP(i,n){ FOR(j,i+1,n-1){ m[a[i]*MOD+a[j]].PB(i*MOD+j); } } long long ans=0; FORA(i,m){ //二分探索 ll m=SIZE(i.S); REP(j,m-1){ ll l,r;l=j+1;r=m-1; if(i.S[j]%MOD<ll(i.S[l]/MOD)){ ans+=(m-j-1); continue; } if(i.S[j]%MOD>=ll(i.S[r]/MOD)){ continue; } while(l+1<r){ ll k=l+(r-l)/2; if(ll(i.S[k]/MOD)>i.S[j]%MOD){ r=k; }else{ l=k; } } ans+=(m-r); } } cout<<ans<<endl; } }E問題
再帰はPyPyだと簡単にMLEになります、何故でしょうか…。ともかくC++で再帰は書くようにします。
以下の二つの操作を行います。
①ある区間を選んでその区間に含まれる数は個数を一つずつ減らす操作(ただし、それらの数はそれぞれ少なくとも一つ存在する)
②一つの数を選んでその個数を0にする。
これらの操作を行って数列を全て空にする時の最小の操作回数を考えます。②の操作はその区間の長さ分の操作回数を計算するだけで容易に求めることができます。それに対し、①の操作は以下のように少し複雑です。
①の操作については、その区間をできるだけ長く選択するのが最適です。証明は今回はしませんが、区間を選択して操作を行う時に全体を選択すれば良いというパターンは頻出な気がします(今回は区間を狭くすることで操作回数を減らせることが直感的にないと思ったのでこの方針で進めました。本来は妥当性を示すべきですが…。)。
また、①の操作を行う際には、1ずつではなくその区間の最小のものずつ操作をまとめて行います。また、操作後に0となる要素が存在し、①の操作条件からこのままだと区間全体を操作できないので、DFSにより分割された区間ごとでの最小の操作回数を求めます。
したがって、DFSの実装を考えれば以下のようになります。
(1)与えられた区間$x$の長さが1の場合
区間$x$に含まれる要素の個数(①の操作回数)と1(②の操作回数)の$min$を取って返します。
(2)与えられた区間$x$の長さが1より大きい場合
区間の長さを$l$,その区間に含まれる数の中での最小個数を$m$,返り値を$ret=0$,分割された区間をそれぞれ代入するvectorを$nex=${ }とします。
この下で、$i=$0~$l$-1で$x[i]$を見ていきますが、$x[i]!=m$の時、nexに代入することができます。また、$i=l$-1の時は区間が確定してるので、nexを区間とするdfsを呼んでその返り値をretに足します。$x[i]=m$の時、$nex$が空でなければ区間が確定してるので、$nex$を区間とするdfsを呼んでその返り値をretに足します。この際に$nex$を次の区間のために空にしておきます。
以上のDFSを行うだけで解を求めることができます。また、DFSを完璧にしていないとこの程度の問題でも詰まるので意識して精進したいと思います。
E.cc//デバッグ用オプション:-fsanitize=undefined,address //コンパイラ最適化 #pragma GCC optimize("Ofast") //インクルードなど #include<bits/stdc++.h> using namespace std; typedef int ll; //マクロ //forループ //引数は、(ループ内変数,動く範囲)か(ループ内変数,始めの数,終わりの数)、のどちらか //Dがついてないものはループ変数は1ずつインクリメントされ、Dがついてるものはループ変数は1ずつデクリメントされる //FORAは範囲for文(使いにくかったら消す) #define REP(i,n) for(ll i=0;i<ll(n);i++) #define REPD(i,n) for(ll i=n-1;i>=0;i--) #define FOR(i,a,b) for(ll i=a;i<=ll(b);i++) #define FORD(i,a,b) for(ll i=a;i>=ll(b);i--) #define FORA(i,I) for(const auto& i:I) //xにはvectorなどのコンテナ #define ALL(x) x.begin(),x.end() #define SIZE(x) ll(x.size()) //定数 #define INF 1000000000000 //10^12:∞ #define MOD 1000000007 //10^9+7:合同式の法 #define MAXR 100000 //10^5:配列の最大のrange //略記 #define PB push_back //挿入 #define MP make_pair //pairのコンストラクタ #define F first //pairの一つ目の要素 #define S second //pairの二つ目の要素 ll dfs(vector<ll>& x){ ll l=SIZE(x); //0の場合 if(l==1)return min(1,x[0]); ll m=*min_element(ALL(x)); ll ret=m; vector<ll> nex; REP(i,l){ if(x[i]!=0){ nex.PB(x[i]-m); if(i==l-1)ret+=dfs(nex); }else{ if(SIZE(nex)){ ret+=dfs(nex); nex.clear(); } } } return min(ret,l); } signed main(){ ll n;cin>>n; vector<ll> a(n);REP(i,n)cin>>a[i]; cout<<dfs(a)<<endl; }F問題以降
今回は飛ばします

- 投稿日:2020-09-09T10:44:57+09:00
Educational Codeforces Round 89 バチャ復習(9/8)
今回の成績
今回の感想
D問題は考察が甘かったのですが、後から立て直すことができ良かったです。立て直しは良いですが、自分の目標である確度の高い方針を立てることには程遠いので精進したいと思います。
A問題
$shovel$を$x$,$sword$を$y$だけ作るとすると、$0 \leqq 2x+y \leqq a$かつ$0 \leqq x+2y \leqq b$が成り立ちます。この時、両式を足し合わせれば$0 \leqq x+y \leqq \frac{a+b}{3}$となります。
また、求めたいのは$x+y$なので$[\frac{a+b}{3}]$が最大値であるとしたいのですが、$[\frac{a+b}{3}]$は$a$以下かつ$b$以下でなければなりません($ \because x,y$は0以上なので)。よって、求めるのは$min([\frac{a+b}{3}],a,b)$となります。
A.pyfor _ in range(int(input())): a,b=map(int,input().split()) print(min((a+b)//3,a,b))B問題
途中まで誤読していて危なかったです。コドフォの英語はたまに読みにくい問題がありますね…。
swapしていく中で最終的に1にしうるインデックスがいくつあるかを考えます。また、swapできるのは$l_i$から$r_i$の範囲になります。1にしうるインデックスを全て調べたいので、$i$の時点で1にしうるインデックスの範囲を求めて徐々にその範囲を広げていくことで解を求めることができます。
つまり、初めは$[x,x]$として小さい$i$から順に考えていきます。図で書いた方がわかりやすいので、ここからは図で説明します。
上記のようにして結果として1にすることのできる区間が順に求まるので、最終的に求まった区間の長さを解として求めれば良いです。
B.pyfor _ in range(int(input())): n,x,m=map(int,input().split()) ans=[x,x] for i in range(m): l,r=map(int,input().split()) if r<ans[0] or l>ans[1]: continue else: ans=[min(ans[0],l),max(ans[1],r)] print(ans[1]-ans[0]+1)C問題
CodeforcesはBFSやDFSが多い感じがします。個人的には実装に慣れてないので嬉しいです。よく考えたらこの問題ではBFSを使わずとも求めることができます。
(説明の都合上、マスは0-indexedに変えています。)
任意のパスについて辿ったマスに書いてある数を並べた時に対称になります。まず、任意のパスについてという条件から、$(0,0)$から$(n-1,m-1)$に向かって辿る際に同じ距離にあるマスは全て同じ数となります。さらに、対称という条件から距離が$i$であるマスと距離が$n+m-2-i$であるマスは同じ数となります。したがって、$n \times m$個のそれぞれのマスについて距離が同じマスどうしをBFSで探して
candに同じマスごとで格納していきます。実際には、$(i,j)$にある時その距離は$(i,j)$なので、BFSを使わずとも求めることができます。BFSで求めた後、
candの中で距離が$i$であるマスと距離が$n+m-2-i$であるマスをさらに一つにまとめ、その中の0と1の数を数えて少ない方を多い方に合わせるようにします。また、$(n+m)\%2=0$の時、距離が$\frac{n+m-2}{2}$のマスは任意のパスの中心になるのでそのマスはどの数でも良いです。深さごとにマスを分ける部分と深さごとでの計算を行う部分に実装を分けることを意識すれば実装は難しくありません。
C.pyfrom collections import deque def bfs(dep): global a,n,m,ans,d,check,cand while len(d): cand.append(list(d)) l=len(d) for i in range(l): p=d.popleft() if p[1]<m-1: if not check[p[0]][p[1]+1]: d.append([p[0],p[1]+1]) check[p[0]][p[1]+1]=True if p[0]<n-1: if not check[p[0]+1][p[1]]: d.append([p[0]+1,p[1]]) check[p[0]+1][p[1]]=True for _ in range(int(input())): n,m=map(int,input().split()) a=[list(map(int,input().split())) for i in range(n)] d=deque([[0,0]]) check=[[False]*m for i in range(n)] check[0][0]=True cand=[] bfs(0) ans=0 for i in range((n+m-1)//2): x=[a[j[0]][j[1]] for j in cand[i]+cand[n+m-1-1-i]] ans+=min(x.count(0),x.count(1)) print(ans)D問題
TL2000msに対し1949msで通すという奇跡を起こしました。確実に通るとは思っていたのですが危なかったです。
まず、$gcd(d_1+d_2,a_i)=1$となるような$d_1$及び$d_2$が存在するかを考えます。ここで、素因数分解した時に素数を一つしか持たない場合、$d_1$と$d_2$のどちらもその素数の倍数なので$gcd(d_1+d_2,a_i) \neq 1$になります。
したがって、以下では$a_i$を素因数分解した時に二つ以上の素数を持つ時の条件を考えます。この時、
任意の素数を適当に選んで足し合わせたら良いなどと考えていましたが、全くの誤りです。ここでは足し算であることに注目して偶奇による場合分けを思いつきました。まず、奇数の場合は素因数分解に含まれる素数(奇数)のなかで最小の$a,b$を選ぶことができ、その和は偶数になります。さらに、この偶数は$\frac{a+b}{2} \times 2$として表せますが、$\frac{a+b}{2}$より小さく$a_i$の素因数分解に含まれる素数は$a$のみですが$\frac{a+b}{2}$と$a$は互いに素であり、2も$a_i$の素因数分解に含まれないので、このような$a,b$が解の$d_1,d_2$となります(小さい数という極端な場合に注目!)。
次に、偶数の場合は$d_1,d_2$のいずれも奇数を選ぶと和が偶数となるので、$d_1$には2,$d_2$には都合の良い奇数を選ぶ必要があります。この時、$d_2$には(2以外の全ての奇数をかけたもの)を選べば良いです(大きい数という極端な場合に注目!)。なぜなら、この時、$d_1+d_2$は$a_i$の素因数分解に含まれる任意の素数で割り切ることができないからです。
(奇数の場合は自明でしたが、偶数の場合は任意の素数と異なるようにという条件を解釈するのが難しいかもしれません。この辺は慣れだと思われます。)
以上より、偶数と奇数の場合がわかったので、解を求めることがでます。また、上記では自明のものとして挙げませんでしたが、素因数分解の計算量を対数にするためにエラトステネスの篩により高速化しています。
D.cc//デバッグ用オプション:-fsanitize=undefined,address //コンパイラ最適化 #pragma GCC optimize("Ofast") //インクルードなど #include<bits/stdc++.h> using namespace std; typedef long long ll; //マクロ //forループ //引数は、(ループ内変数,動く範囲)か(ループ内変数,始めの数,終わりの数)、のどちらか //Dがついてないものはループ変数は1ずつインクリメントされ、Dがついてるものはループ変数は1ずつデクリメントされる //FORAは範囲for文(使いにくかったら消す) #define REP(i,n) for(ll i=0;i<ll(n);i++) #define REPD(i,n) for(ll i=n-1;i>=0;i--) #define FOR(i,a,b) for(ll i=a;i<=ll(b);i++) #define FORD(i,a,b) for(ll i=a;i>=ll(b);i--) #define FORA(i,I) for(const auto& i:I) //xにはvectorなどのコンテナ #define ALL(x) x.begin(),x.end() #define SIZE(x) ll(x.size()) //定数 #define INF 1000000000000 //10^12:∞ #define MOD 1000000007 //10^9+7:合同式の法 #define MAXR 10000000 //10^5:配列の最大のrange //略記 #define PB push_back //挿入 #define MP make_pair //pairのコンストラクタ #define F first //pairの一つ目の要素 #define S second //pairの二つ目の要素 //MAXR=10^5であることに注意 #define PN 1 //素数のマークは1 vector<ll> PN_chk(MAXR+1,PN);//0-indexed(0~MAXR) //素因数分解に含まれる素数を保存するset set<ll> prime; //O(MAXR) void init_eratosthenes(){ ll MAXRR=sqrt(MAXR)+1; //2以上の数の素因数分解をするので無視して良い PN_chk[0]=0;PN_chk[1]=0; FOR(i,2,MAXRR){ //たどり着いた時に素数と仮定されているなら素数 //ある素数の倍数はその素数で割り切れるのでマークづけ if(PN_chk[i]==1) FOR(j,i,ll(MAXR/i)){PN_chk[j*i]=i;} } } //O(logn) //mapなのでprimeは整列済 //二個しかいらぬ void prime_factorize(ll n){ if(n<=1) return; //if(SIZE(prime)==2)return; //1の場合はnは素数 if(PN_chk[n]==1){prime.insert(n);return;} //マークされている数は素数 prime.insert(PN_chk[n]); //マークされている数でnを割った数を考える prime_factorize(ll(n/PN_chk[n])); } signed main(){ //入力の高速化用のコード //ios::sync_with_stdio(false); //cin.tie(nullptr); init_eratosthenes(); ll n;cin>>n; vector<ll> a(n);REP(i,n)cin>>a[i]; vector<ll> ans0(n,-1); vector<ll> ans1(n,-1); REP(i,n){ if(a[i]%2==1){ prime_factorize(a[i]); if(SIZE(prime)>1){ ans0[i]=*prime.begin(); ans1[i]=*++(prime.begin()); } prime.clear(); }else{ prime_factorize(a[i]); if(SIZE(prime)>1){ ans0[i]=2;ans1[i]=1; for(auto j=++prime.begin();j!=prime.end();j++){ ans1[i]*=(*j); } } prime.clear(); } } REP(i,n){ if(i==n-1)cout<<ans0[i]<<"\n"; else cout<<ans0[i]<<" "; } REP(i,n){ if(i==n-1)cout<<ans1[i]<<"\n"; else cout<<ans1[i]<<" "; } }E問題
コンテスト内には解けなかったのでコンテスト後に考えました。思ったより難しくなかったので、E問題までに時間をたっぷり残せるようにしたいです。
実験を行うと、分割する区間の端が取りうる範囲の制約がかなり厳しいことに気づきました。また、$b_j$の$j$が小さい方から考えると$min$がどこに現れるかが考えにくいので、$b_j$の$j$が大きい方から考えることにしました(逆側から走査!)。
この時、区間の左端の値の取りうる範囲は独立かつ一意に決めることができます。
(1)一番右側は?
$a_i=b_j$が成り立つ中で最大の$i$が一番右側となります。また、その$i$よりも大きいところで$a_i<b_j$が成り立つ時は$min$の条件を満たさないので0通りです。(2)一番左側は?
(一番右側と同じかより左にあるという条件のもとで、)$a_i<b_j$が初めて成り立つ$i$に+1したところが一番左側になります。また、$j=0$でこれが成り立つ時は$min$の条件を満たさないので0通りです。また、$j=0$の時は左端は1通り($a_0$)であることには注意が必要です。さらに、(1),(2)についていずれもwhile文を用いて$a_i$の$i$を減らして区間の左端の範囲を走査しますが、走査のうちに$j \neq 0$で全ての$a_i$を走査してしまった場合についても題意を満たさないので0通りです。
以上のコーナーケースに注意して、それぞれの$j$で左端の取りうる値の区間を求めれば、その掛け算により解が求まります。
E.pymod=998244353 n,m=map(int,input().split()) a=list(map(int,input().split())) b=list(map(int,input().split())) ans=1 i=n-1 for j in range(m-1,-1,-1): l,r=-1,-1 while i!=-1: if a[i]<b[j]: print(0) exit() if a[i]==b[j]: r=i break i-=1 else: print(0) exit() while i!=-1: if a[i]<b[j]: l=i+1 if j==0: print(0) exit() break i-=1 else: if j!=0: print(0) exit() if j!=0: ans*=(r-l+1) ans%=mod #print(l,r) print(ans)F問題以降
今回は飛ばします


- 投稿日:2020-09-09T09:30:32+09:00
【備忘録】atom-runnerで、日本語が文字化けする


- 投稿日:2020-09-09T06:29:22+09:00
IvyFEM(.NET向け有限要素法ライブラリ)をPythonから使用する
1. はじめに
.NET向け有限要素法ライブラリIvyFEM.dllを開発中です。
C#で利用することを想定したライブラリですが、Pythonからも利用できそうなことがわかったので記事にします。2. Windows10でPythonから.NETを呼び出す方法(Python.NET)
Python.NETを使うことにしました。
http://pythonnet.github.io/以下、Windows環境にPythonが既にインストールされていることとします。
2.1. Python.NETのインストール
コマンドプロンプトから以下を実行してください。
py -m pip install pythonnet3. IvyFEM.dllパッケージ
GithubのIvyFEMページから最新のパッケージをダウンロードして、作業ディレクトリに展開してください(IvyFEMページのインストール方法を参照してください、VC++のruntimeが必要)。
IvyFEM: https://github.com/ryujimiya/IvyFEM/展開すると以下のようになります。
4. PythonからIvyFEMを呼び出す
PythonでPoissonの方程式を解いてみました。
正方形領域をとり、辺上はポテンシャル0の境界条件を課しています。
領域内部に円の領域をとり、その領域に電荷を印加したときの領域全体のポテンシャル分布を計算しています。
main2.pyimport clr clr.AddReference("System") from System import UInt32 clr.AddReference("System.Collections") from System.Collections.Generic import List, IList clr.AddReference('IvyFEM') from IvyFEM \ import \ Cad2D, Mesher2D, FEWorld, \ FiniteElementType, \ PoissonMaterial, \ CadElementType, FieldValueType, FieldFixedCad, \ Poisson2DFEM clr.AddReference('IvyFEM') from IvyFEM.Linear \ import \ LapackEquationSolver, LapackEquationSolverMethod, \ IvyFEMEquationSolver, IvyFEMEquationSolverMethod clr.AddReference('OpenTK') from OpenTK import Vector2d cad = Cad2D() pts = List[Vector2d]() pts.Add(Vector2d(0.0, 0.0)) pts.Add(Vector2d(1.0, 0.0)) pts.Add(Vector2d(1.0, 1.0)) pts.Add(Vector2d(0.0, 1.0)) lId1 = cad.AddPolygon(pts).AddLId print("lId1 = " + str(lId1)) # ソース lId2 = cad.AddCircle(Vector2d(0.5, 0.5), 0.1, lId1).AddLId print("lId2 = " + str(lId2)) eLen = 0.05 mesher = Mesher2D(cad, eLen) # 座標を参照 vecs = mesher.GetVectors() cnt = len(vecs) print("len(vecs) = " + str(cnt)) coId = 0 for vec in vecs: print("vec[" + str(coId) + "] " + str(vec.X) + ", " + str(vec.Y)) coId += 1 world = FEWorld() world.Mesh = mesher dof = 1 # スカラー feOrder = 1 quantityId = world.AddQuantity(dof, feOrder, FiniteElementType.ScalarLagrange) world.ClearMaterial() ma1 = PoissonMaterial() ma1.Alpha = 1.0 ma1.F = 0.0 ma2 = PoissonMaterial() ma2.Alpha = 1.0 ma2.F = 100.0 maId1 = world.AddMaterial(ma1) maId2 = world.AddMaterial(ma2) lId1 = 1 world.SetCadLoopMaterial(lId1, maId1) lId2 = 2 world.SetCadLoopMaterial(lId2, maId2) zeroEIds = [1, 2, 3, 4] zeroFixedCads = List[FieldFixedCad]() for eId in zeroEIds: #スカラー # オーバーロードであることに注意 fixedCad = FieldFixedCad.Overloads[UInt32, CadElementType, FieldValueType](eId, CadElementType.Edge, FieldValueType.Scalar) zeroFixedCads.Add(fixedCad) world.SetZeroFieldFixedCads(quantityId, zeroFixedCads) #DEBUG zeroFixedCads = world.GetZeroFieldFixedCads(quantityId) print("len(zeroFixedCads) = " + str(len(zeroFixedCads))) world.MakeElements() feIds = world.GetTriangleFEIds(quantityId) feCnt = len(feIds) print("feCnt = " + str(feCnt)) for feId in feIds: print("--------------") print("feId = " + str(feId)) triFE = world.GetTriangleFE(quantityId, feId) nodeCoIds = triFE.NodeCoordIds elemNodeCnt = nodeCoIds.Length for iNode in range(elemNodeCnt): print("coId[" + str(iNode) + "] = " + str(nodeCoIds[iNode])) # ポアソン方程式FEM FEM = Poisson2DFEM(world) # リニアソルバー ''' solver = LapackEquationSolver() solver.IsOrderingToBandMatrix = True solver.Method = LapackEquationSolverMethod.Band FEM.Solver = solver ''' solver = IvyFEMEquationSolver() solver.Method = IvyFEMEquationSolverMethod.NoPreconCG FEM.Solver = solver # 解く FEM.Solve() U = FEM.U # 結果 nodeCnt = len(U) for nodeId in range(nodeCnt): print("-------------") coId = world.Node2Coord(quantityId, nodeId) value = U[nodeId] print(str(nodeId) + " " + str(coId) + " " + "{0:e}".format(value))5. 実行
py -m main25. まとめ
IvyFEM.dllを使ってPythonからPoissonの方程式を解きました。


- 投稿日:2020-09-09T05:23:32+09:00
過去の電力使用量取得 中国電力編
はじめに
電力使用量予測のセミナーをしていて、各電力会社の公表されている過去の使用電力量の形式がまちまちなので取得するのが難しいというご意見を聞いていました。
そこで、それぞれの電力会社別にデータの取得方法をまとめてみます。ちなみに、対象とする電力会社は、北海道電力、東北電力、東京電力、北陸電力、中部電力、関西電力、中国電力、四国電力、九州電力、沖縄電力で、今回は中国電力さんを扱ってみます。
注:大量のダウンロードを繰り返すとサーバに負担がかかるので、ダウンロードは一回だけにするか、対象期間を限定して行うよう心がけて下さい。
動作環境
GoogleさんのCoraboratoryという環境で動作させます。
Webサイト
以下のWebサイトからデータをダウンロードできそうです。
ダウンロード
for y in range(2016, 2020): url = "https://www.energia.co.jp/nw/jukyuu/sys/juyo-{:04}.csv".format(y) print(url) !wget $url2020年9月現在、実行してみると2018年4月からのデータまで公開されているようです。
読込と可視化
from glob import glob import pandas as pd files = glob("j*.csv") files.sort() print(files) df_juyo = pd.DataFrame() for f in files: df = pd.read_csv(f, skiprows=2, encoding="Shift_JIS") df_juyo = pd.concat([df_juyo, df]) print(df_juyo.shape) print(df_juyo.columns) df_juyo.index = pd.to_datetime(df_juyo["DATE"] + " " + df_juyo["TIME"]) df_juyo["実績(万kW)"].plot(figsize=(15,5))
できた!
過去の電力使用量実績は公開を終了される場合もあるので、継続的なデータ収集が必要ですね。
電気使用量を見ると、色々な気付きがありますね。
以上、現場からきむらがお伝えしました。補足
記事を読んだ人から「時間がかかり過ぎるので、手っ取り早くデータが欲しい場合にはどうしたら良いか?」という質問があったので、ちょっとだけデータを販売してみることにしました。
データに興味があれば以下のURLをご覧下さい。https://ticket.tsuku2.jp/eventsDetail.php?ecd=16260900020422

- 投稿日:2020-09-09T05:21:24+09:00
Python で多重配列からブロック多重配列をスライスする方法
概要
Python で多重配列
numpy.ndarrayもしくはtorch.Tensorからブロック多重配列をスライスするときは関数numpy.ix_を使う。詳細
Julia で
# Julia # 多重配列を作る (i, j, k) = (2, 3, 4) x = reshape(1:i * j * k, i, j, k) # 多重配列を多重添字でスライスする (is, js, ks) = ([2, 1], [1, 3], 2:3) x[is, js, ks] |> printlnみたいにして多重配列を多重添字でスライスするのを Python でどうやるのか調べてもなかなか情報にたどり着かなかったのでメモ。
numpy.ix_が所望のものである。 NumPy や PyTorch はデフォルトだと Julia の Array とは多重配列の次元の並べ方が逆であることに注意。# Python + NumPy import numpy # 多重配列を作る i, j, k = 2, 3, 4 x = (numpy.arange(k * j * i) + 1).reshape(k, j, i) # 多重配列を多重添字でスライスする # (Python では is は予約語かなんかのようなので is_ とする) is_, js, ks = numpy.array([2, 1]) - 1, numpy.array([1, 3]) - 1, numpy.arange(2 - 1, 3) print(x[numpy.ix_(ks, js, is_)])# Python + PyTorch import torch import numpy # 多重配列を作る i, j, k = 2, 3, 4 x = (torch.arange(k * j * i) + 1).reshape(k, j, i) # 多重配列を多重添字でスライスする # (Python では is は予約語かなんかのようなので is_ とする) is_, js, ks = torch.tensor([2, 1]) - 1, torch.tensor([1, 3]) - 1, torch.arange(2 - 1, 3) print(x[numpy.ix_(ks, js, is_)])
- 投稿日:2020-09-09T03:42:28+09:00
Jupyter セル移動 ショートカット
Jupyter Lab にはセルを上下させるショートカットキーが割り当てられていない。
また、マウスによる操作も煩雑だったので、ショートカットキーを自作した。
その備忘録として書き残しておく。設定方法
- Jupyter Lab を立ち上げる。
Settings -> Advanced Settings Editorを開く。Keyboard Shortcutsを選択し、右側のUser Preferencesに以下を記入して保存する。UserPreferences{ "shortcuts": [ { "command": "notebook:move-cell-up", "keys": [ "Ctrl Shift K" ], "selector": ".jp-Notebook:focus" }, { "command": "notebook:move-cell-down", "keys": [ "Ctrl Shift J" ], "selector": ".jp-Notebook:focus" }, ] }これで、セルモード中に
Ctrl Shift Kでセルを上に、Ctrl Shift Jでセルを下に移動することができる。説明
Ctrl K (Ctrl J)で選択中のセルの上(下)のセルを選択する、というショートカットキーが割り当てられていたので、今回のショートカットをCtrl Shift K (Ctrl Shift J)にした。他にもショートカットキーを作成したい場合、
System Defaultsを探索すれば、なんとなく分かるはず。その他の設定
行番号の設定
ちなみに、行番号を表示させることも同じように設定できる。
Settings -> Advanced Settings Editor -> NotebookのUser Preferencesに以下を記入して保存する。UserPreferences{ "codeCellConfig":{ "lineNumbers": true, }, }
- 投稿日:2020-09-09T01:37:59+09:00
ターミナルのスクショを簡単に共有する.
はじめに
研究室の友人が作成したrubyのgemを自分のマシンにインストールする際に出た,エラーを共有する際に,いちいち画面の写真をスマホで撮り,lineにて共有するのが面倒だと感じたのでこれを作成することにした.
実装
discordに投稿
pythonからDiscordのwebhookでメッセージ投稿する備忘録
こちらを参考に,apiを用いて,discordに画像を投稿する.
screenshotを撮る
ターミナルで,
$ screencapture -i -x ~/screenshot/test.pngこれで,キャプチャの範囲を自分で指定して,シャッター音なしで,指定のフォルダにtest.pngで保存する.
組み合わせて完成
ss.pyimport json import requests import os path = "{0}/tmp.png".format(os.environ['HOME']) os.system(f"screencapture -i -x {path}") WEBHOOK_URL = "your webhook url" # 画像添付 with open(path, 'rb') as f: file_bin = f.read() files_qiita = { "ss": ("tmp.png", file_bin), } res = requests.post(WEBHOOK_URL, files=files_qiita) print(res.status_code) os.system(f"rm {path}")設定
fishのconfigにaliasを設定する.
config.fishalias ss='python3 ~/screenshot/ss.py'課題
今は,discordのチャンネルに投稿するようになっている.
これでは,特定の友人を選んで送ることができない.
例えば,lineの個人トークに画像を送ることができないかなど試行する.
- 投稿日:2020-09-09T01:20:28+09:00
【AWS】CDKでECS Clusterを構築しよう
【AWS】CDKでECRを構築しようのECS Clusterバージョンです
前提などは省きますので前回の記事を参照してください環境


インストール
pipenv install aws_cdk.aws_ec2 aws_cdk.aws_ecs実装
props/ecs_cluster.py
ECS Clusterを作成する時に既存のVPCを利用したい場合は、VPC IDをもとにルックアップして既存VPCをStack内で利用できるようにする必要があります。そのためVpcForEcsClusterというクラスでパラメータ管理をします。
あとはAPI Referenceを参照しながら、設定可能なパラメータを定義しています。Container Insightsは有効化しておいた方が監視で役に立つので、デフォルトでTrueにしてあります。
props/ecs_cluster.pyfrom dataclasses import dataclass from typing import Optional from aws_cdk.aws_ecs import CloudMapNamespaceOptions from src.props.base import Base @dataclass(frozen=True) class VpcForEcsCluster(Base): id: str vpc_id: str @dataclass(frozen=True) class EcsCluster(Base): id: str cluster_name: str container_insights: bool = True default_cloud_map_namespace: Optional[CloudMapNamespaceOptions] = Noneentity/ecs_cluster.py
ECS Clusterの場合は環境によってパラメータが違う、具体的にいうとVPC IDが異なるので環境ごとのentityを作成します。今回はステージングだけを書いていますが、本番の場合は同じファイルにProdEcsClusterクラスを定義すればいいでしょう。
entity/ecs_cluster.pyfrom src.entity.base import Base from src.props.ecs_cluster import EcsCluster, VpcForEcsCluster class EcsClusterBase(Base): vpc: VpcForEcsCluster cluster: EcsCluster class StgEcsCluster(EcsClusterBase): id = 'StgEcsCluster' vpc = VpcForEcsCluster( id='StgVpc', vpc_id='vpc-xxxxxxxx' ) cluster = EcsCluster( id='StgEcsCluster', cluster_name='sample' )stack/ecs_cluster.py
stackはどの環境でも使いまわせるようになっています。
Clusterでは、既存VPCを利用したい場合は引数に
vpcの指定が必要なのでVpc.from_lookupというクラスメソッドを利用して、VPC IDをもとに取得しています。stack/ecs_cluster.pyfrom typing import Any, Type from aws_cdk.aws_ec2 import Vpc from aws_cdk.aws_ecs import Cluster from aws_cdk.core import Construct, Stack from src.entity.ecs_cluster import EcsClusterBase class EcsClusterStack(Stack): def __init__( self, scope: Construct, entity: Type[EcsClusterBase], **kwargs: Any) -> None: super().__init__(scope, entity.id, **kwargs) vpc = Vpc.from_lookup(self, **entity.vpc.to_dict()) Cluster(self, **entity.cluster.to_dict(), vpc=vpc)app.py
それではapp.pyに構築したいリソースのスタックを追加しましょう。
既存VPCを利用してECS Clusterを構築したい場合は、region/accountの環境設定もEcsClusterStackに渡してあげます。CDKが自動でContextを作成して、デプロイ時に変更されるとまずいデータ(今回は既存VPC)を保持してくれます。キャッシュ的な意味もあります。app.py#!/usr/bin/env python3 from aws_cdk import core from src.entity.ecr import SampleEcr from src.entity.ecs_cluster import StgEcsCluster from src.stack.ecr import EcrStack from src.stack.ecs_cluster import EcsClusterStack app = core.App() # 全てのリソースに設定するタグ tags = {'CreatedBy': 'iscream'} # 環境設定 (既存VPCを利用するために必須) env_stg = {'region': 'ap-northeast-1', 'account': 'xxxxxxxx'} # 前回作成したECR EcrStack(app, entity=SampleEcr, tags=tags) # ECS Cluster EcsClusterStack(app, StgEcsCluster, tags=tags, env=env_stg) app.synth(skip_validation=False)デプロイ
いざ、デプロイ!!!
pipenv run cdk deploy StgEcsClusterReference
