- 投稿日:2020-09-09T20:47:10+09:00
【ECS】Rails+Nuxtの疎結合サービスをCircleCIで自動本番デプロイする【ECR】
この記事を書くにあたって
AWSについての知識が全くなかった状態からポートフォリオを作成し、個人的にAWSへのデプロイと、CircleCIの自動デプロイが一番難しかったので、備忘録・これからポートフォリオを作るよ・これからAWS使うよって方向けの記事があれば良いなと思い書きました。
私が作ったポートフォリオの概要は
【AWS?Docker?】ポートフォリオで必要な知識を自分なりに分かりやすくまとめる【terraform?CircleCI?】この記事の前身となる記事は
【API】RailsとNuxtとCircleCIを使ってモダンですぐ開発出来る開発環境を構築(導入篇)【自動テスト付】是非ご覧いただけると有り難いです。
この記事で目指すゴール
- VPC・IGW・サブネット・ルートテーブル・セキュリティグループ等のネットワークの基本的な設定が出来る。
- Route53・ACM・ALBを使って常時SSL通信が出来るWEBサービスが構築出来る。
- ECS・ECRを使って本番環境にデプロイ出来る。
- CircleCIを使ってmasterへプッシュすると同時に自動デプロイする事が出来る。
前提
- AWSのアカウント・IAMアカウント・キーペアを取得済み(ぐぐったらすぐ出来るはず)
- aws-cliをインストール済み
- 使用リージョンは東京(ap-northeast-1)
- 前回の記事まで実装を進めている。
【API】RailsとNuxtとCircleCIを使ってモダンですぐ開発出来る開発環境を構築(導入篇)【自動テスト付】完成品
注意
この記事で出来る事は普通にAWSの無料枠を超えて有料になります。
また、お名前.comでドメインを取得するため、そこにもお金がかかります。
勉強代だと思って割り切れる方のみお読み下さい。
とりあえずECSとECRを使って、疎結合なウェブサービスを公開してみたい!という方向けです。ネットワークの構築
まずはネットワークをAWSの画面上でぽちぽち作っていきます。
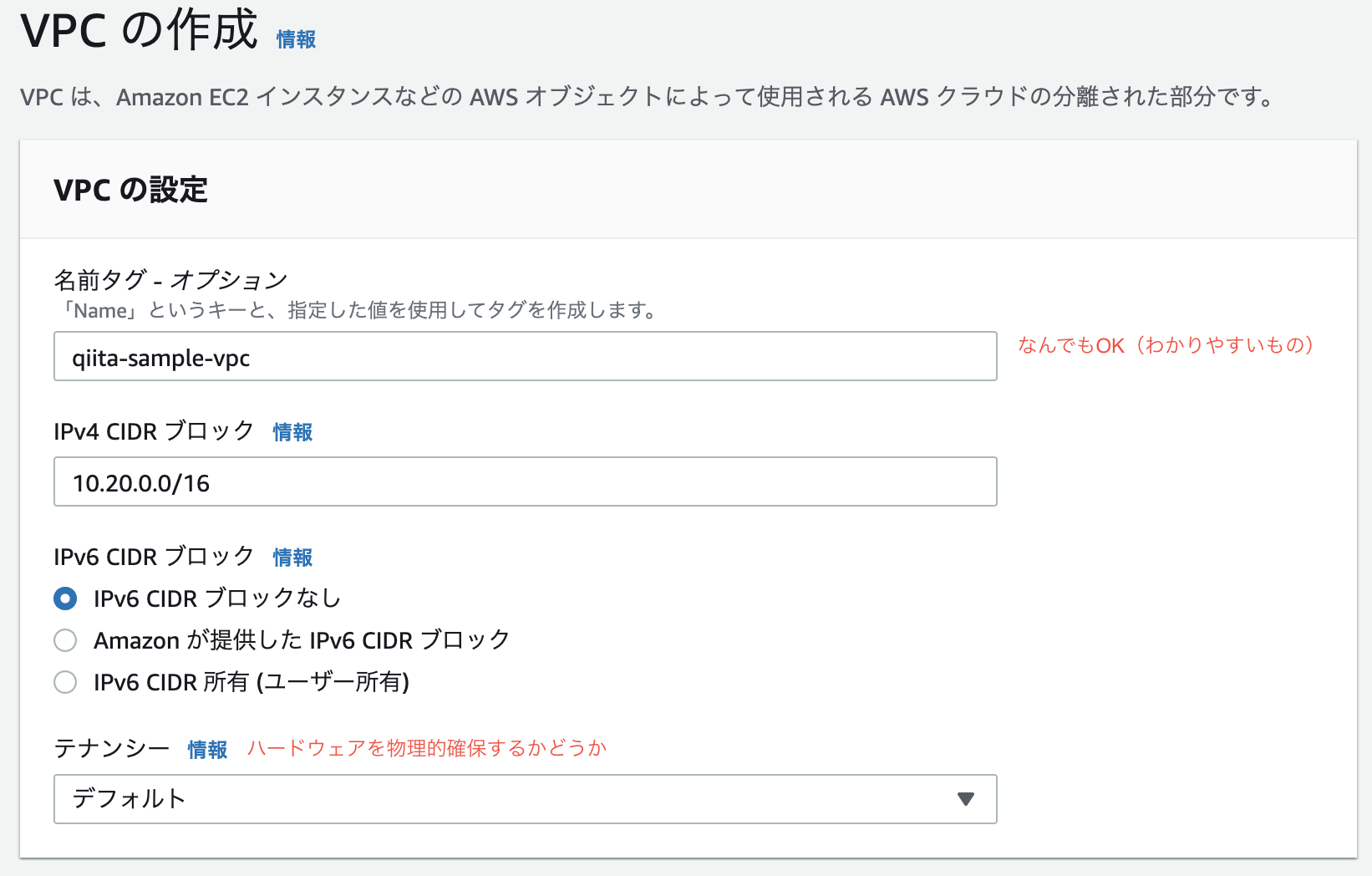
張り切っていきましょう!VPC作成
豆知識
CIDRブロックとはClassless Inter-Domain Routingの略です。
IPアドレスの表記方法の一つ。簡単に言うと、VPCの範囲のことです。ちなみにここでは
/16のような表示のことです。
CIDR表記では、/16、/24、32といった表記がされます。
/16というのは、第3オクテッドまでを指定出来ます。
例えば、10.20.0.0の0.0
この部分を指定出来ます。
/24というのは、第4オクテッドまでを指定出来ます。
例えば、10.20.0.0の最後の0
この部分を指定出来ます。
/32というのは、特定のIPアドレスを指定出来ます。VPCを作成する際、中にサブネットやAZでIPを確保せざるを得ない上に、変更が効かないため、
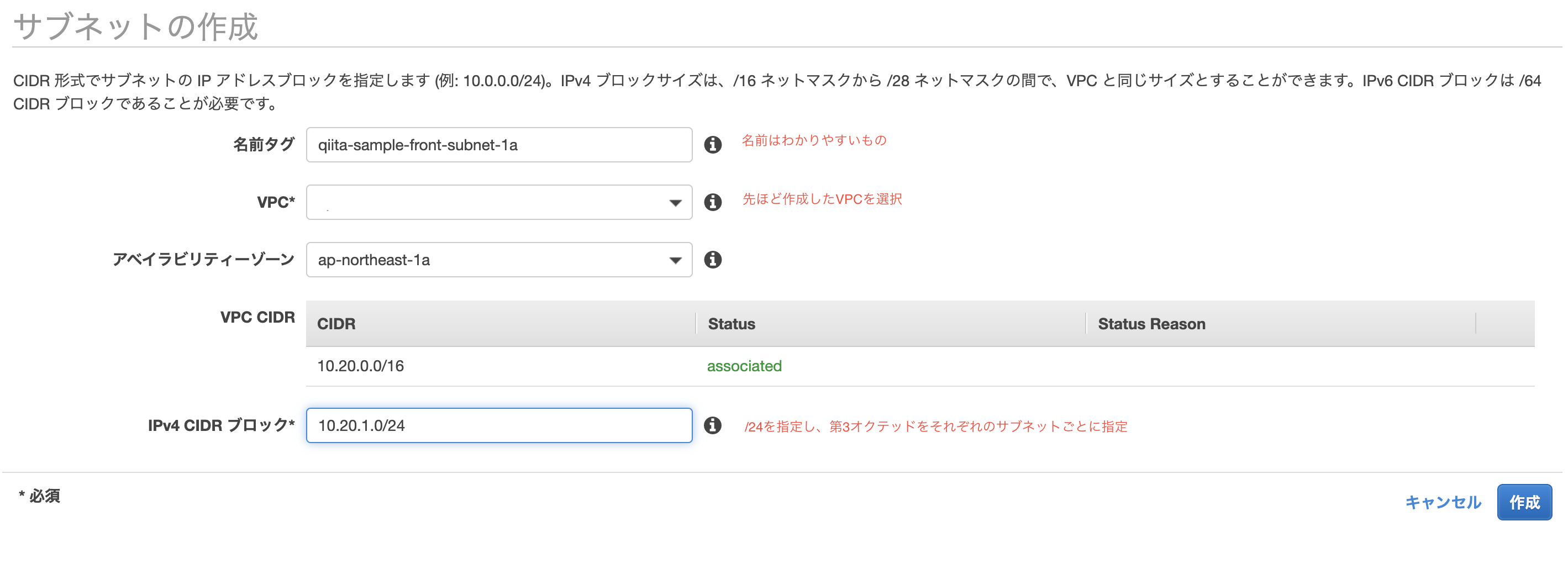
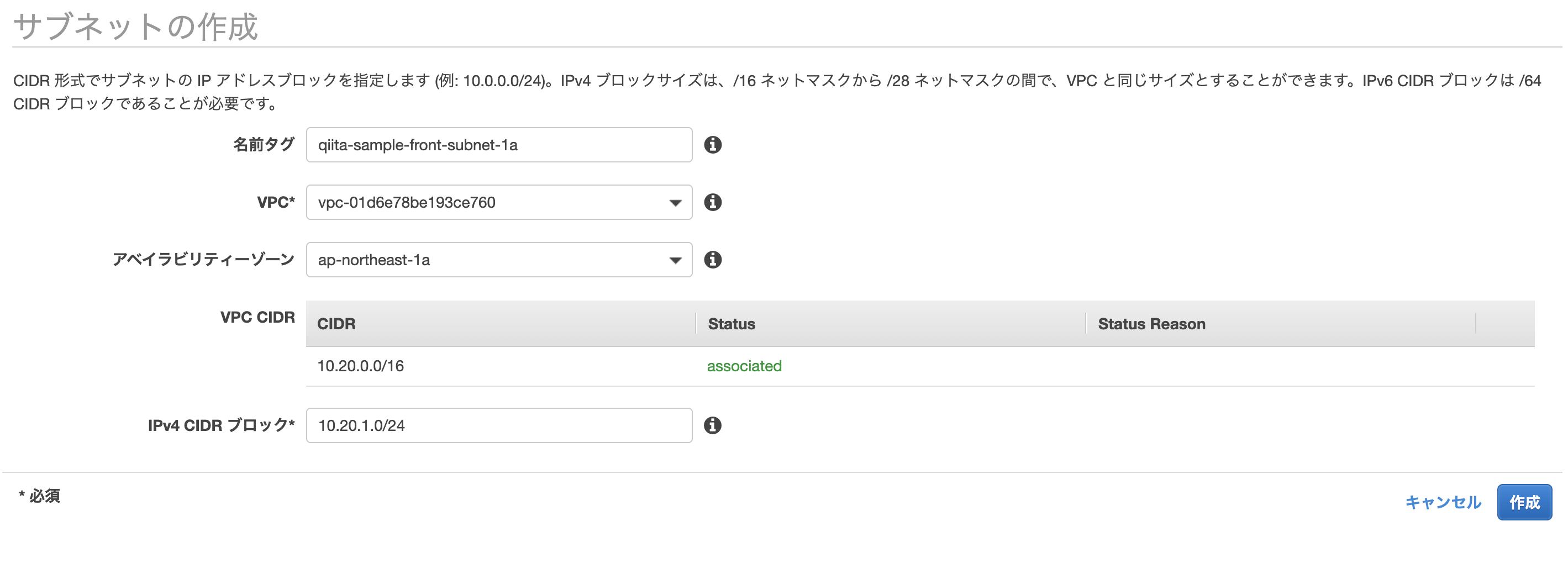
/16を指定して利用可能なIPを多く確保することが多いです。サブネット作成
ここでは、AZをap-northeast-1aとap-northeast-1cを使用します。
2つのAZを利用する理由は、後々にALBを利用するからです。サブネット>サブネット作成より、以下のサブネットを作成して下さい。
name CIDRブロック Region/AZ qiita-sample-front-subnet-1a 10.20.1.0/24 ap-northeast-1a qiita-sample-front-subnet-1c 10.20.2.0/24 ap-northeast-1c qiita-sample-back-subnet-1a 10.20.3.0/24 ap-northeast-1a qiita-sample-back-subnet-1c 10.20.4.0/24 ap-northeast-1c qiita-sample-rds-subnet-1a 10.20.5.0/24 ap-northeast-1a qiita-sample-rds-subnet-1c 10.20.6.0/24 ap-northeast-1c ルートテーブルの作成
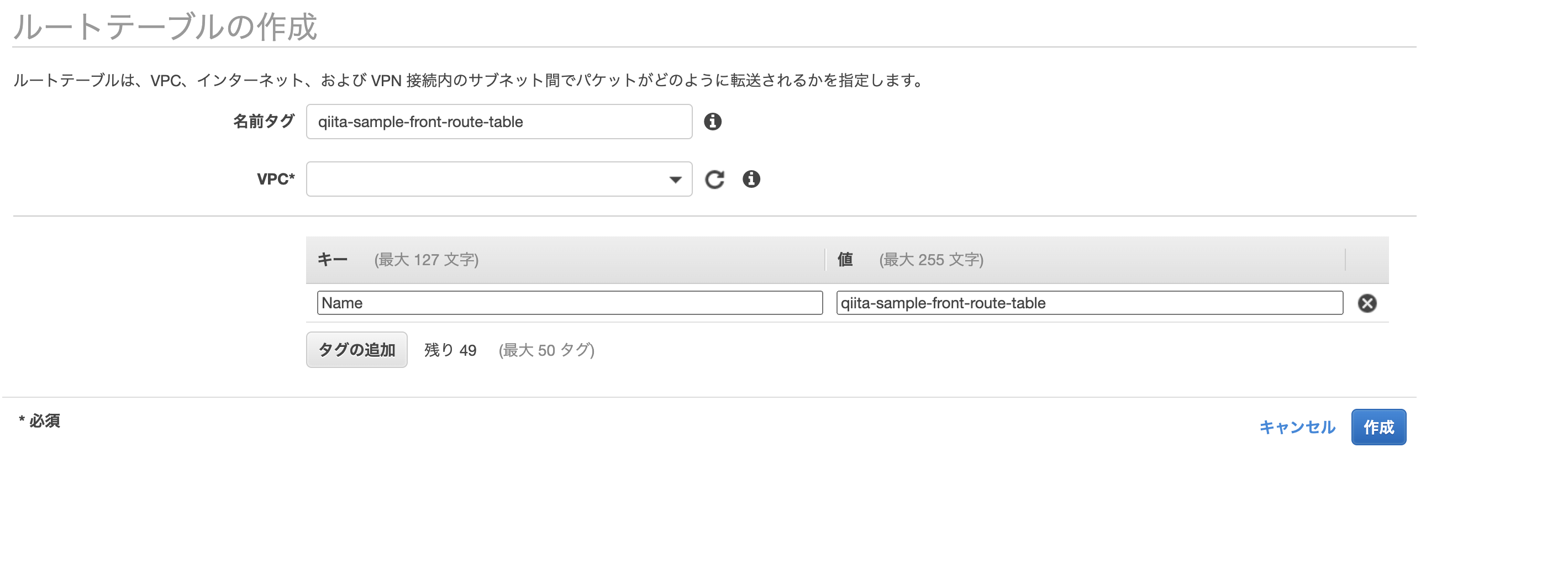
ルートテーブル>ルートテーブル作成より、以下のルートテーブルを作成して下さい。
name qiita-sample-front-route-table qiita-sample-back-route-table qiita-sample-rds-route-table IGWの作成
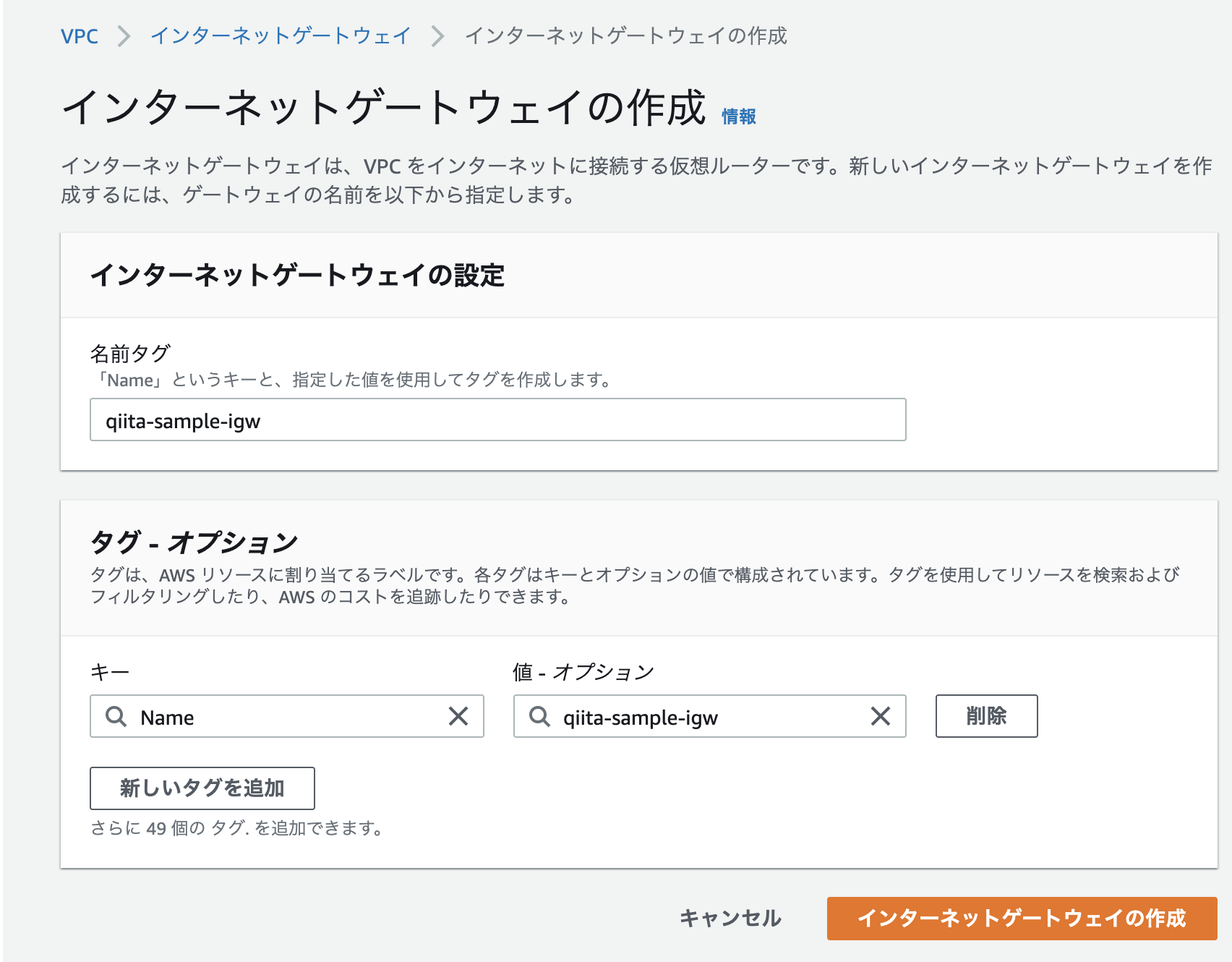
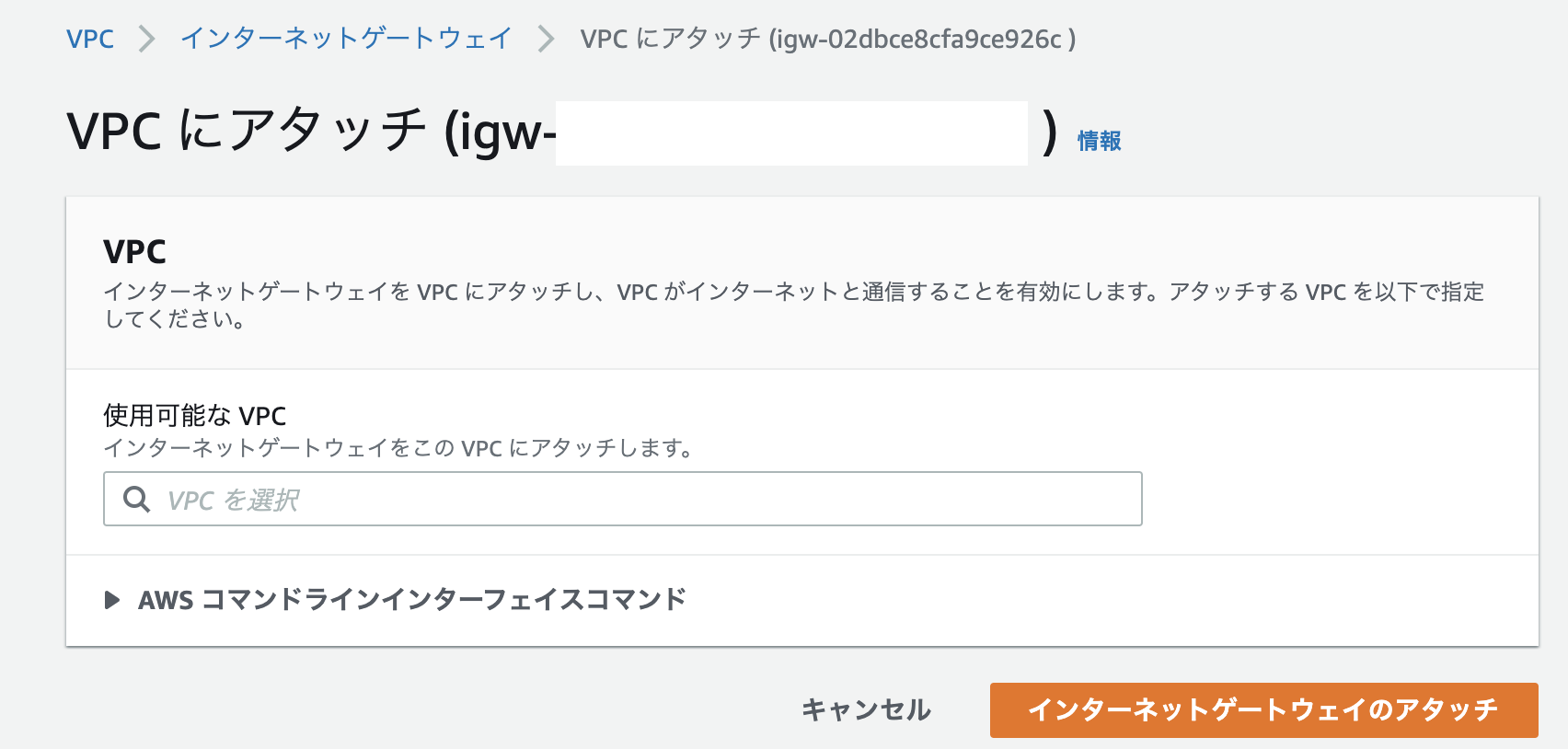
インターネットゲートウェイ>インターネットゲートウェイの作成より、以下のインターネットゲートウェイを作成してください。
VPCとIGWの関連付けをします。
name qiita-sample-igw サブネットとルートテーブルの関連付け
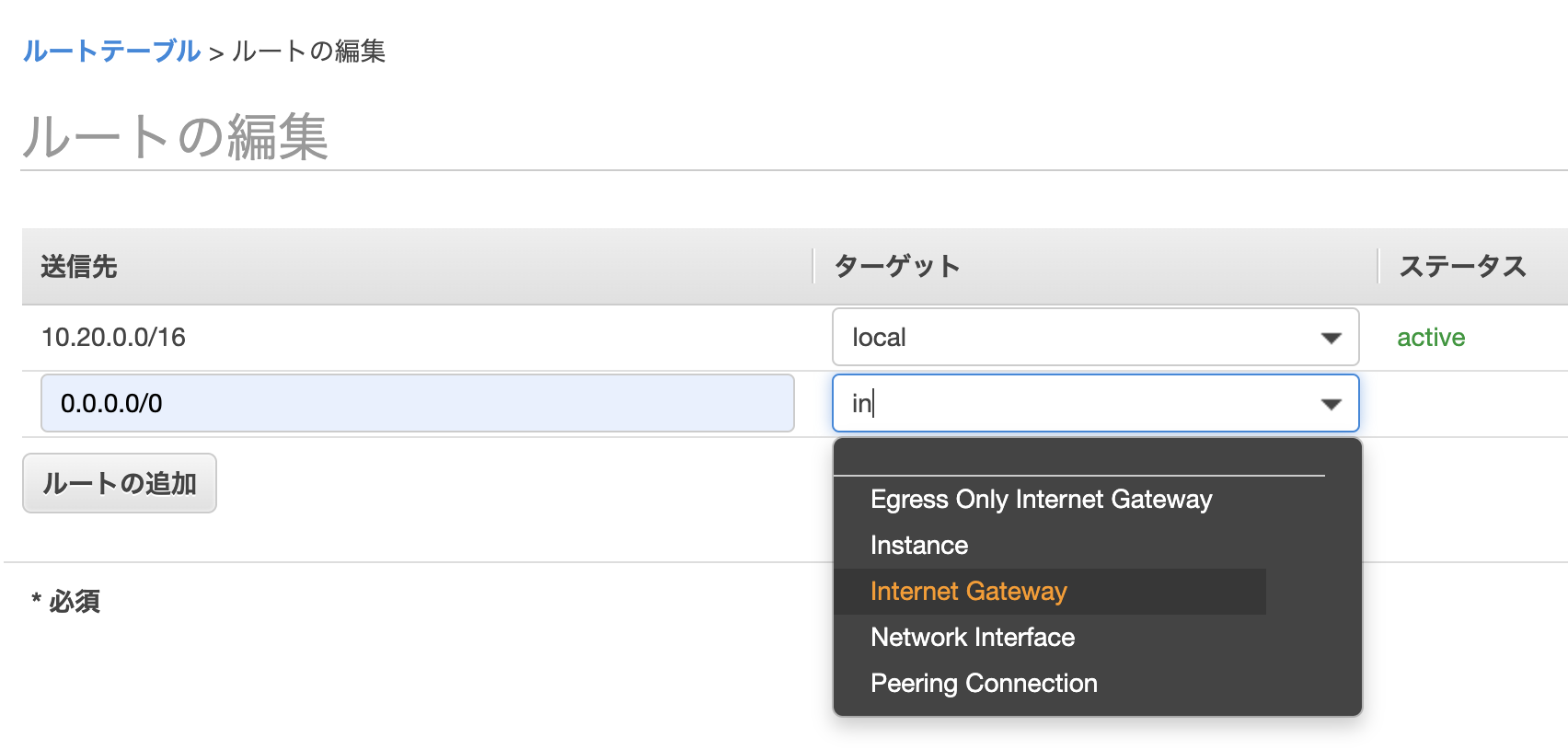
- ルートテーブルの編集タブを選択し、RDS以外のルートテーブルに対し、0.0.0.0に先ほど作ったIGWを関連付け
- サブネット関連付けタブを選択し、以下の表のように関連付け
サブネット ルートテーブル qiita-sample-front-subnet-1a qiita-sample-front-route-table qiita-sample-front-subnet-1c qiita-sample-front-route-table qiita-sample-back-subnet-1a qiita-sample-back-route-table qiita-sample-back-subnet-1c qiita-sample-back-route-table qiita-sample-rds-subnet-1a qiita-sample-rds-route-table qiita-sample-rds-subnet-1c qiita-sample-rds-route-table セキュリティグループの作成
下記の表のセキュリティグループを作成
セキュリティグループ名 タイプ プロトコル ポート範囲 ソース qiita-sample-front-sg HTTP TCP 80 0.0.0.0/0 同上 SSH TCP 22 ご自身のIP 同上 HTTPS TCP 443 0.0.0.0/0 同上 カスタム TCP 3000 0.0.0.0/0 qiita-sample-back-sg カスタム TCP 3000 0.0.0.0/0 同上 HTTPS TCP 443 0.0.0.0/0 qiita-sample-rds-sg MYSQL/Aurora TCP 3306 qiita-sample-back-sg ネットワークはここまでで終わり。
Route53の作成(ここから有料です。)
ドメインの取得
お名前.comより、ドメインの取得をします。
この記事を参照している方のお好きなドメイン(できれば1円とかのやつ)を取得して下さい。お名前.comでのドメイン取得方法については、【ドメイン取得】お名前.comとawsでドメイン取得を参照すると良いです。
※ドメイン自動更新設定はオフにしておきましょう!(1年ごとにお金かかっちゃう)
今回、私の環境では、以下のドメインを取得しました。
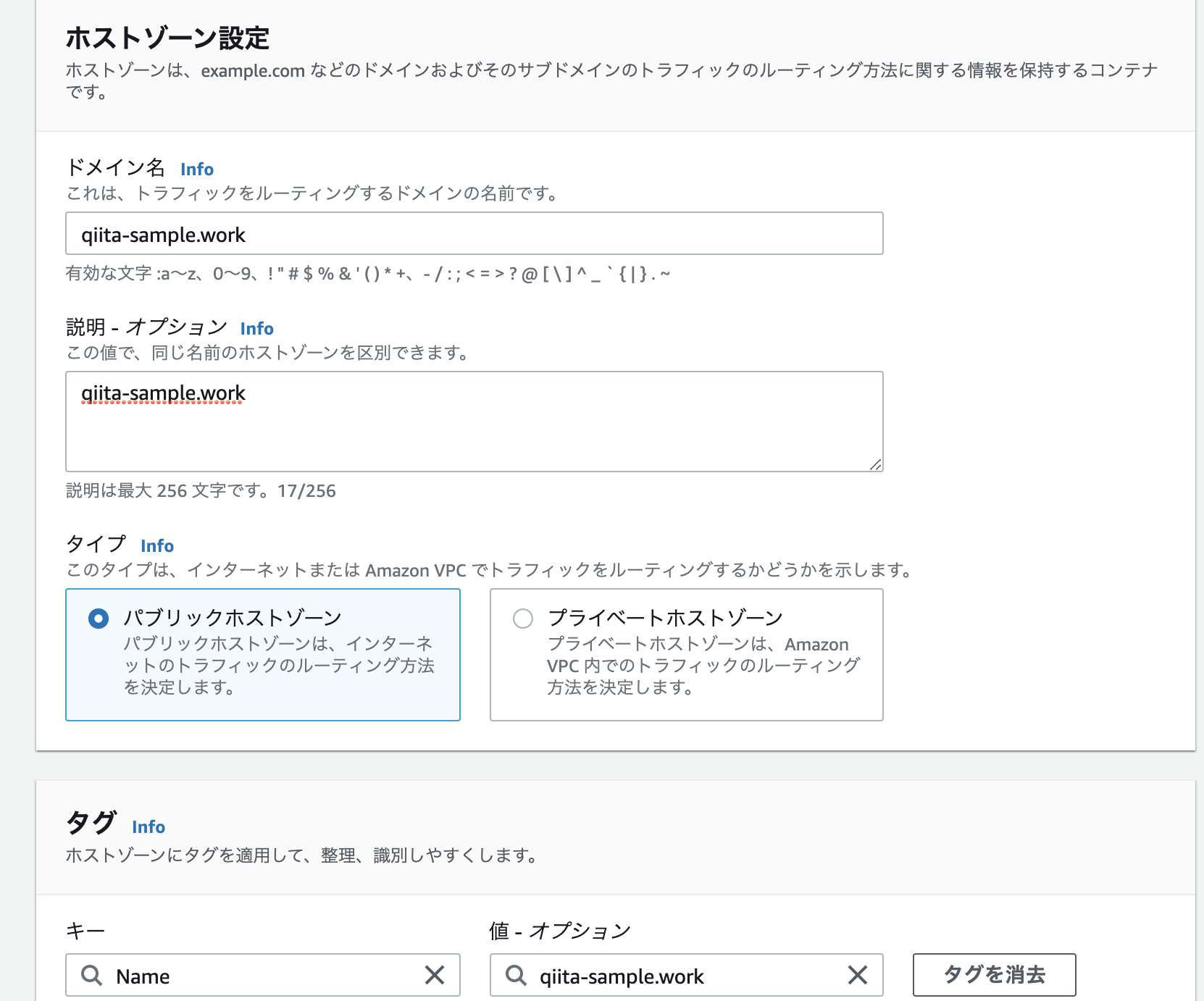
ドメイン名 役割 qiita-sample.work front qiita-sample-api.work back ホストゾーンの作成
Route53より、ホストゾーンの作成をします。
ホストゾーン詳細より、NSレコードの値/トラフィックのルーティング先をコピーして下さい。
お名前.comのネームサーバにNSレコードの値を登録
反映まで結構時間かかります。(1日とか最大でかかるかも)
dig qiita-sample.work(取得したドメイン) +short NSをterminalから打ち、無事登録したNSレコードが表示されていれば反映されています。
ACMを使ってドメインに証明書を発行する
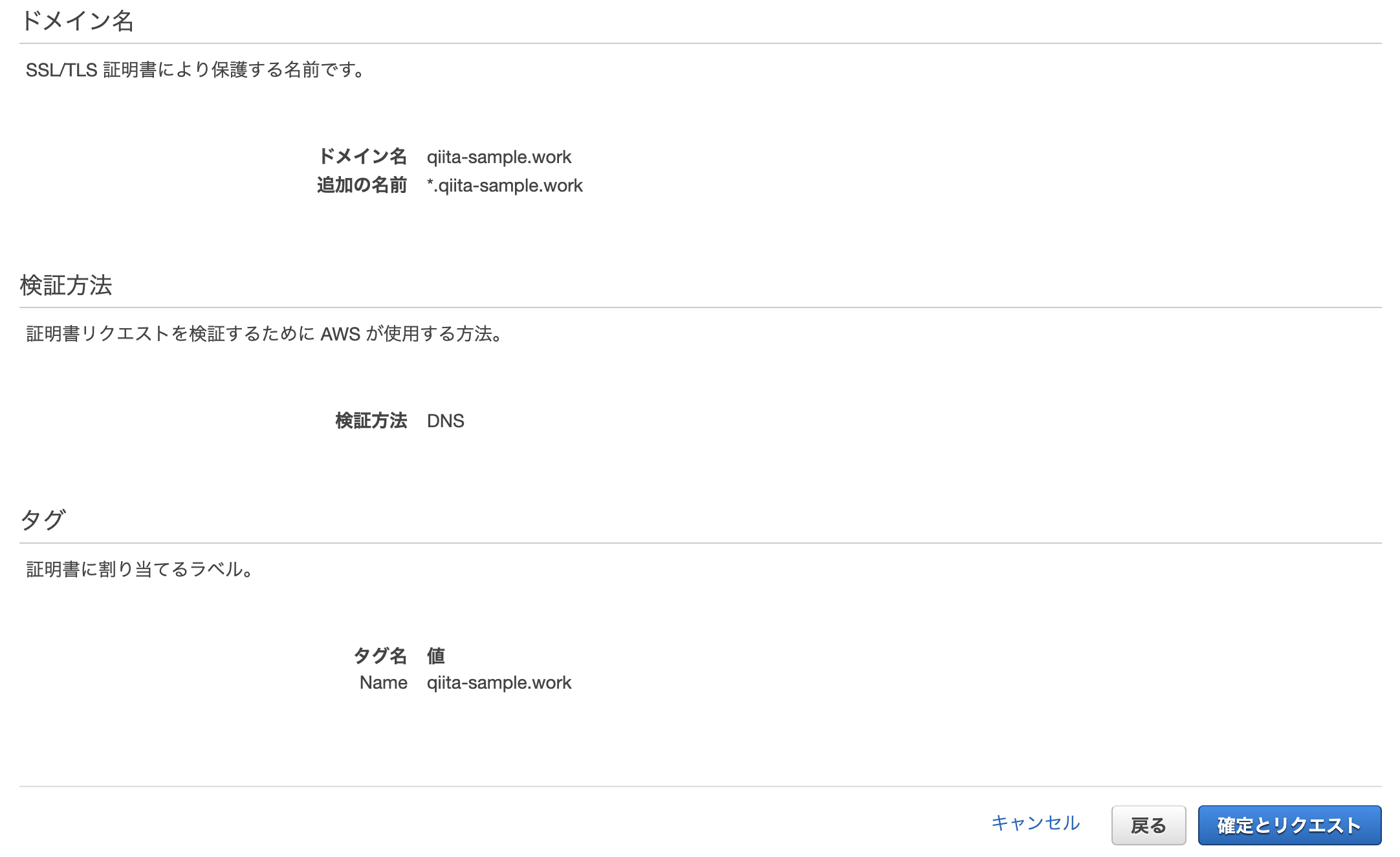
ACMより、証明書のリクエストをします。
パブリック証明書のリクエストを選択し、証明書をリクエストします。
ドメイン名 qiita-sample.work *.qiita-sample.work 以上のドメイン名を記入し、DNS検証を選択します。
同様に、qiita-sample-api.workにも同様の処理をします。
すると、検証画面にいくので、そこでRoute53でのレコード作成をします。(上記のドメイン全てにレコードの作成をして下さい。)
しばらくすると検証保留中から、発行済みステータスとなります。
ずっと検証保留中になるのは、だいたいNSサーバの設定が遅れている可能性があります。
digコマンドで確認してみましょう。RDSの作成
Route53・ドメインネームサーバの設定にやや時間がかかるので、ここでRDSをサクッと作成しておきましょう。
サブネットグループの作成
RDSの作成・設定
以下の設定を参考に、RDS>データベースの作成よりRDSの作成をして下さい。
設定 備考 エンジンのタイプ MySQL バージョン 5.7.30 今回は5.7 テンプレート 開発/テスト 無料枠でも良いのですが、今回は勉強のため DB インスタンス識別子 qiita-sample-rds なんでもOK マスターユーザー名 ** 何でもOK マスターパスワード ** 何でもOK・流出させないように DB インスタンスクラス情報 db.t2.micro 最安のものにしておきます ストレージタイプ 汎用SSD ストレージ割り当て 20 20が最小です Virtual Private Cloud (VPC) 先ほど作ったVPC サブネットグループ 先ほど作ったサブネットグループ 既存の VPC セキュリティグループ 先ほど作ったセキュリティグループ データベース認証 パスワード認証 最初のデータベース名 production DB パラメータグループ default 今回はdefaultにします。(自分で作ってもOK!) オプショングループ default 今回はdefaultにします。(自分で作ってもOK!) しばらくすると利用可能ステータスとなるので、そうしたらRDS作成完了です。
database.yml、credentials.yml.encの修正
./back/config/database.ymlproduction: <<: *default host: <%= Rails.application.credentials.rds[:host] %> database: <%= Rails.application.credentials.rds[:database] %> username: <%= Rails.application.credentials.rds[:username] %> password: <%= Rails.application.credentials.rds[:password] %>./docker-compose run -e EDITOR="vi" back rails credentials:editすると、vim画面が現れるので、以下の設定を記入して下さい。
rds: host: {エンドポイント} database: {databaseの名前(初期で作ったもの)} username: {設定したユーザーネーム} password: {設定したパスワード}ロードバランサーの作成
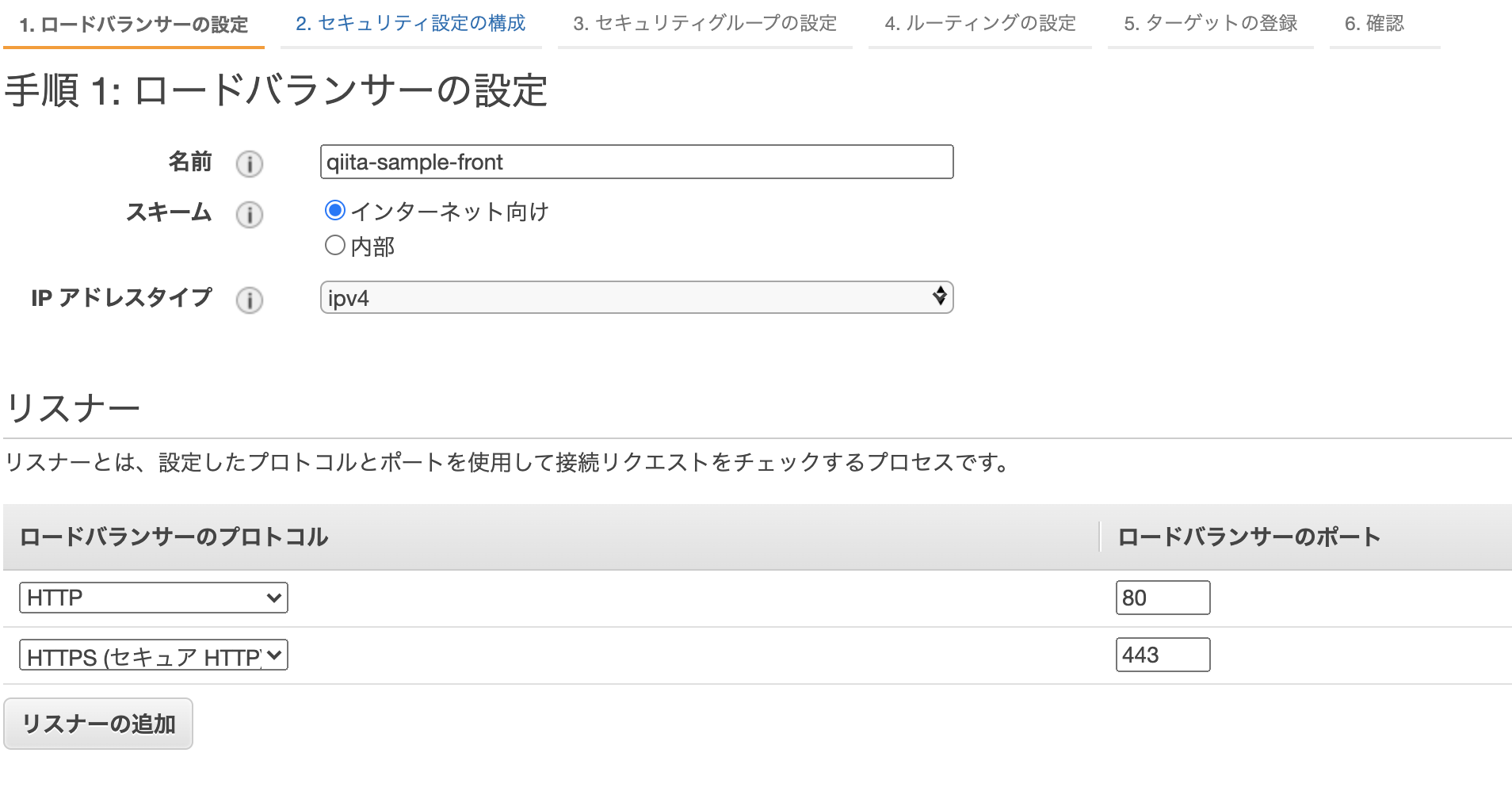
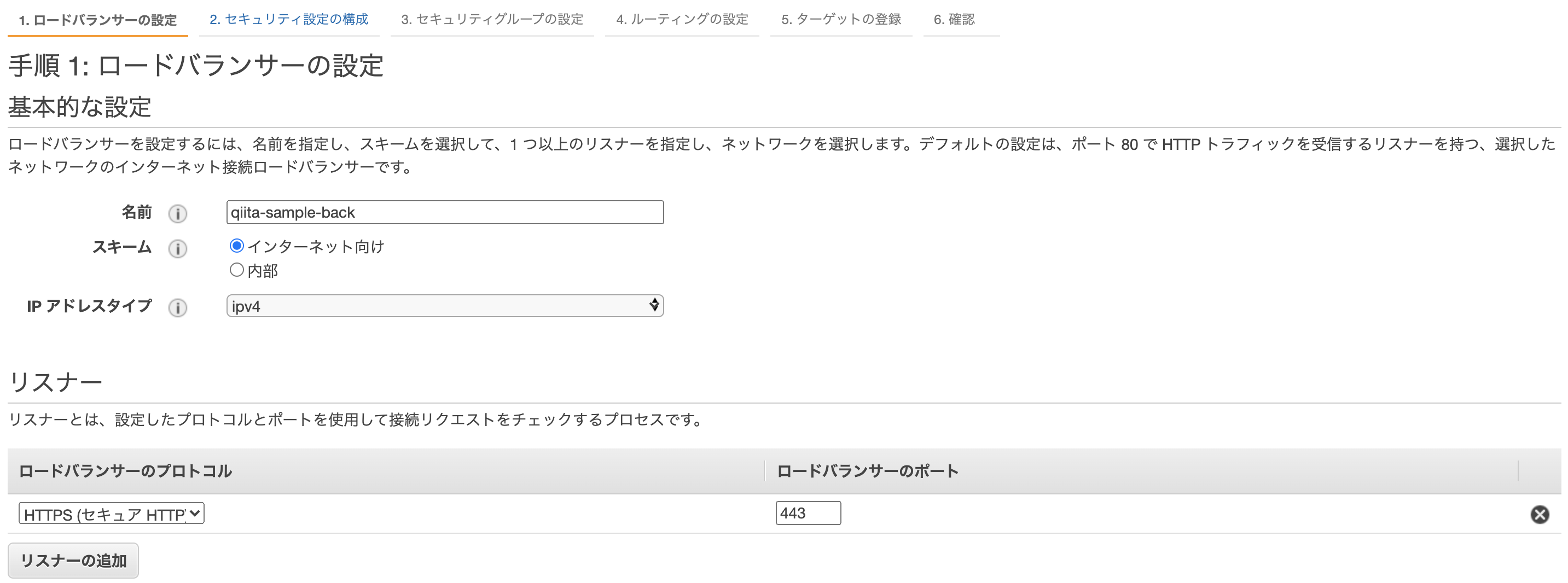
EC2>ロードバランサーの作成より、ロードバランサーを作成しましょう。
ロードバランサーの設定
front
back
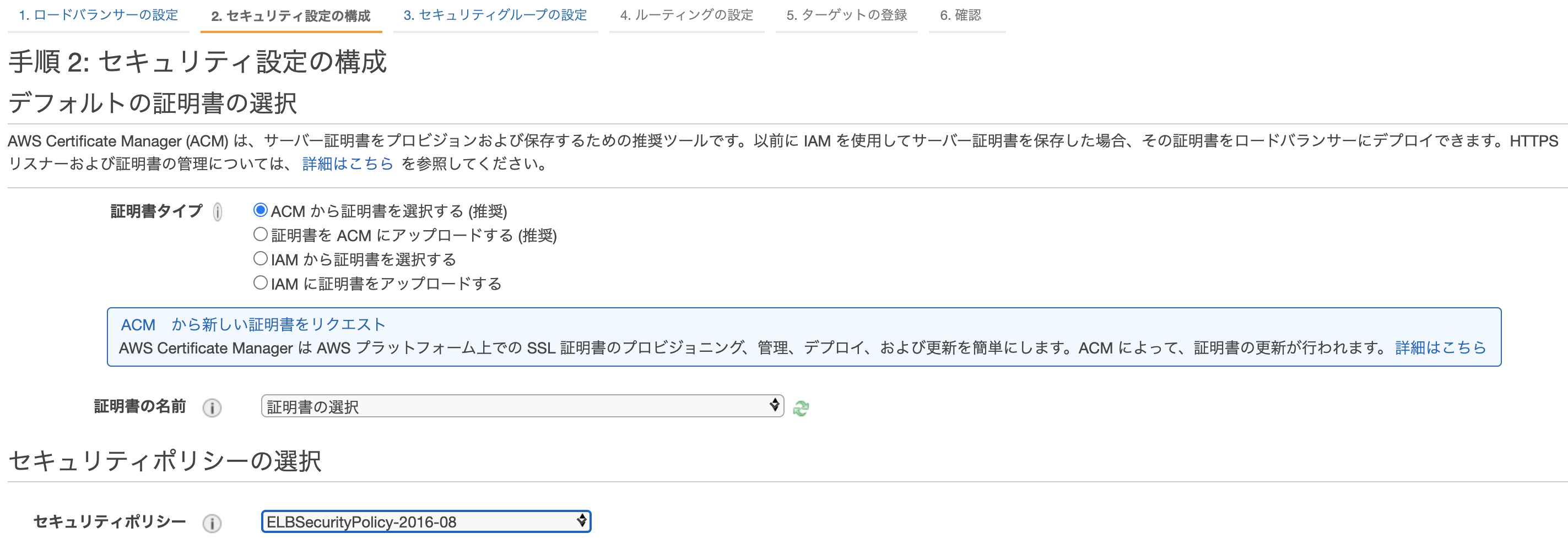
アベイラビリティーゾーンには、先ほど作ったVPCとサブネットを登録しましょう。セキュリティ設定の構成
先ほど作った証明書を選択しましょう。
まだ認証されていなかったら、少し待ってね。セキュリティグループの設定
先ほど作ったセキュリティーグループをアタッチして下さい。
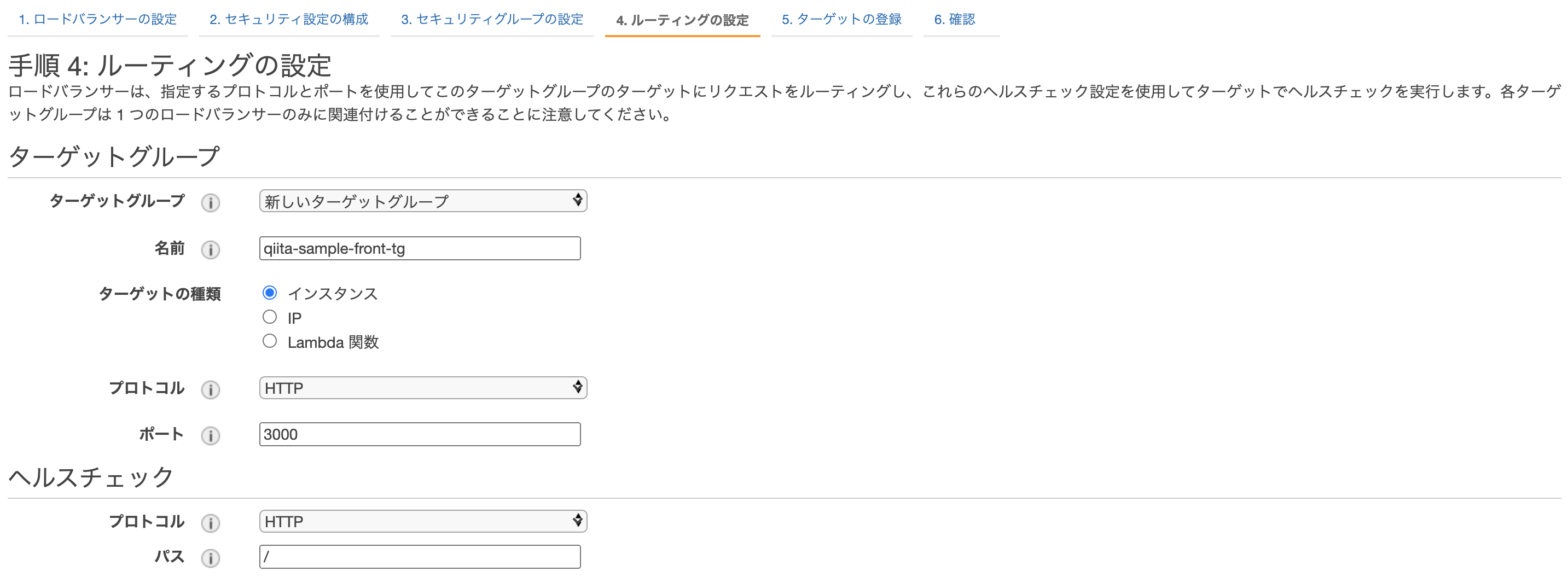
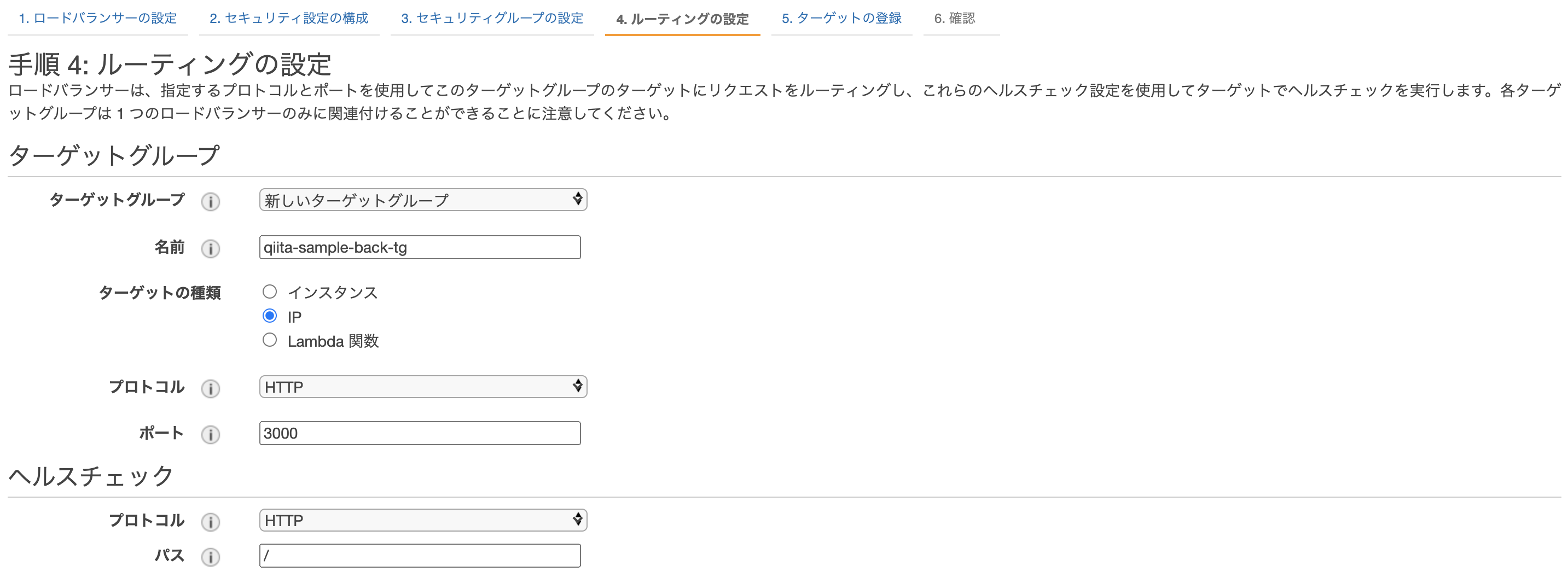
ルーティングの設定
新しくターゲットグループを作成します。
今回frontでは、ECSで生成されるEC2内でhost modeで起動するため
ターゲットをインスタンスに設定し、ポートを3000で受け付けるようにします。
backでは、ECSのインスタンス内のコンテナでawsvpc modeで起動するため、ターゲットをipにしています。これは、コンテナのプライベートIPを指します。front
back
ターゲットの登録
後述しますが、ECSのサービス起動時に自動的にターゲットが選択されるため、心配ご無用です。
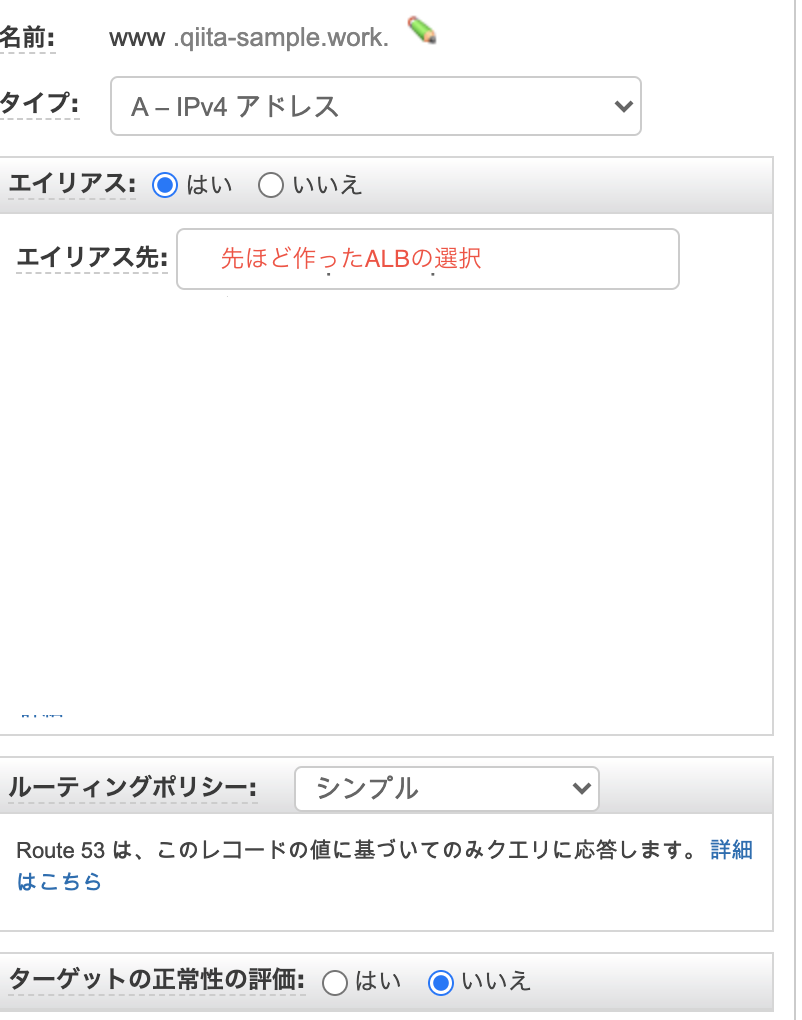
そのままロードバランサーを作成しましょう!Route53にAレコードを追加
Route53>ホストゾーンより、Aレコードの追加をし、以下の設定にしてください。
frontとback、同様に処理して下さい。
ECRにリポジトリを作成・イメージのプッシュ
frontのAPIの向きを本番用に変えておきましょう。
./front/plugins/axios.jsimport axios from "axios" export default axios.create({ //baseURL: "http://localhost:3000" baseURL: "https://www.qiita-sample-api.work" })※aws cliを使えるようにしておきましょう!
macOS に AWS CLI バージョン 1 をインストールする
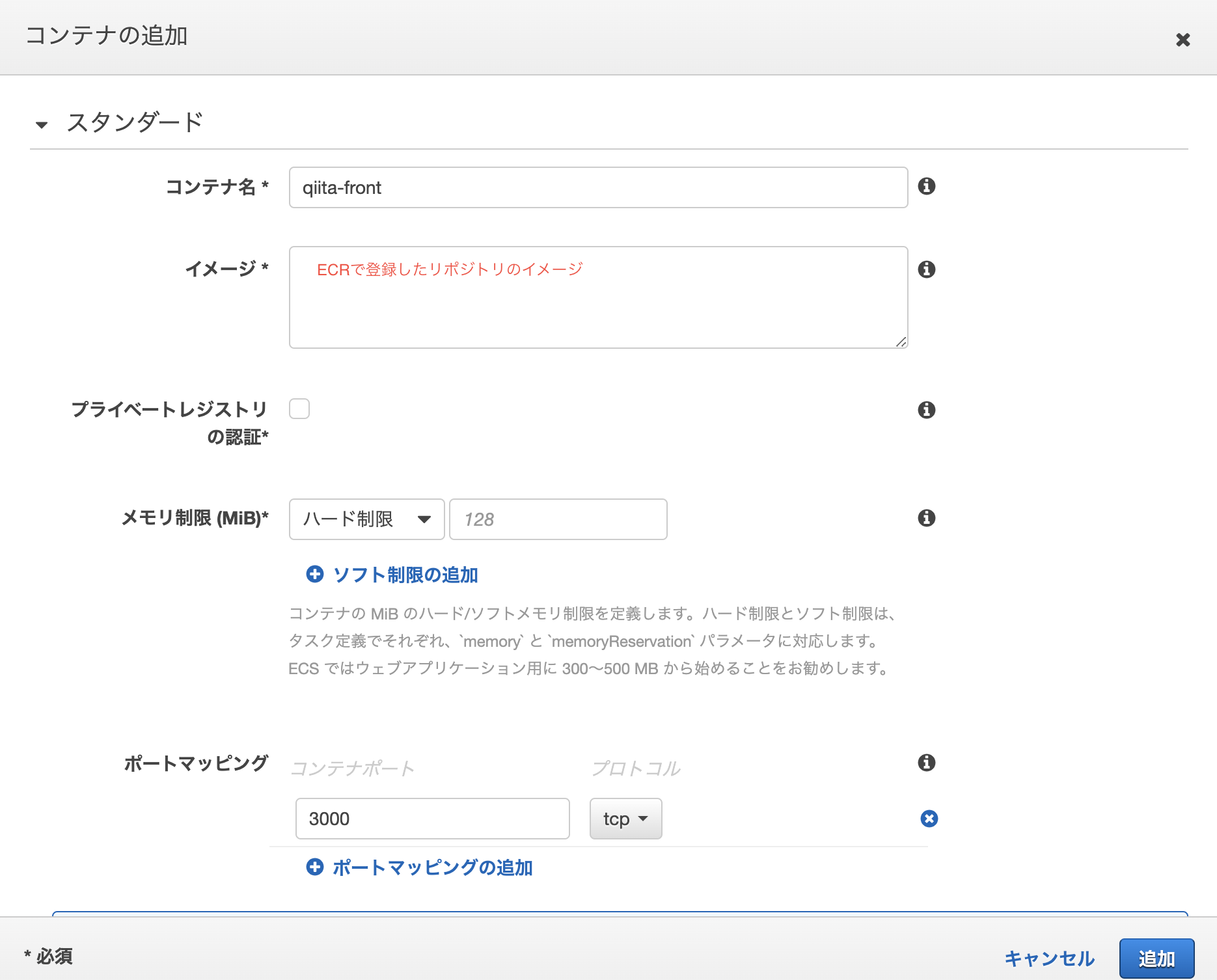
AWS CLIのインストールAmazon ECRより、リポジトリを作成。リポジトリ名を記入してそのまま作成して下さい。
リポジトリを選択し、プッシュコマンドを押すとリポジトリにプッシュするためのコマンドが表示されるため、frontとback共にリポジトリを作成してローカル環境で実行して下さい。これらのコマンドを実行すると、ディレクトリ上にあるDockerfileを元にイメージを作成します。
ローカル環境でdocker-compose buildをした時と同じ状態になります。
ここで作成し、ECRにプッシュしたイメージを使って、ECS上で読み込み、起動させます。ここで注意したいのが、frontとback、それぞれどちらのリポジトリにプッシュするのか確認した上でDockerfileがあるディレクトリに移動してから実行して下さい。
ECSの作成・設定
全体像
ECSでは、
クラスター>サービス>タスク
という粒度になっています。
クラスターは論理的な枠組み、箱です。
サービスはクラスター上で起動するオートスケーリング+ALBのような存在です。
タスクの数を自動で管理したり、ネットワーキングの設定をします。
タスクはDockerイメージを実行する単位だと考えて下さい。サービスは、タスク定義を元にタスクを生成していきます。
無理やり例えると、たい焼きの鋳型がサービス、たい焼き自体がタスクのような感じです。
クラスタはたい焼き屋さんの屋台。
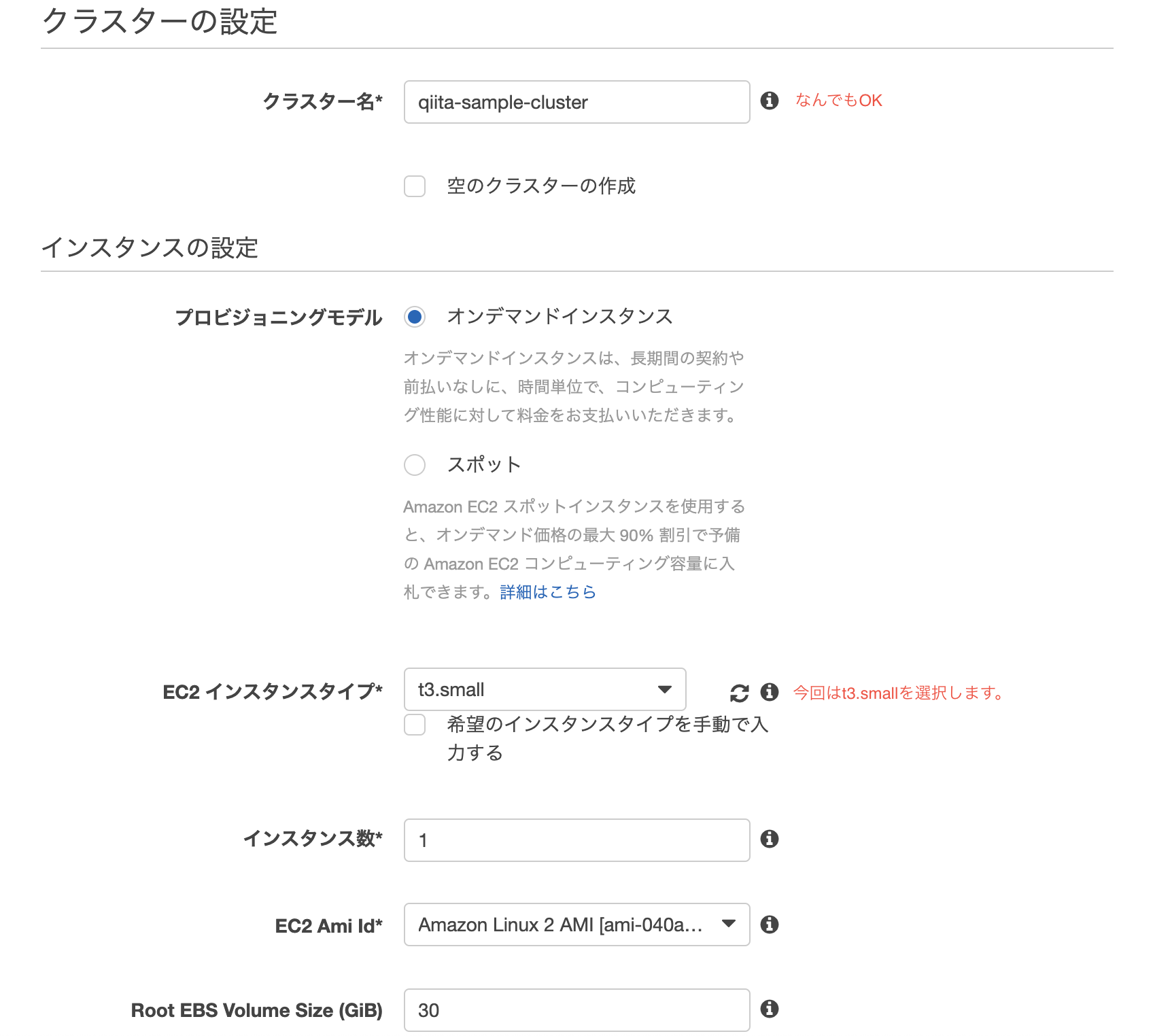
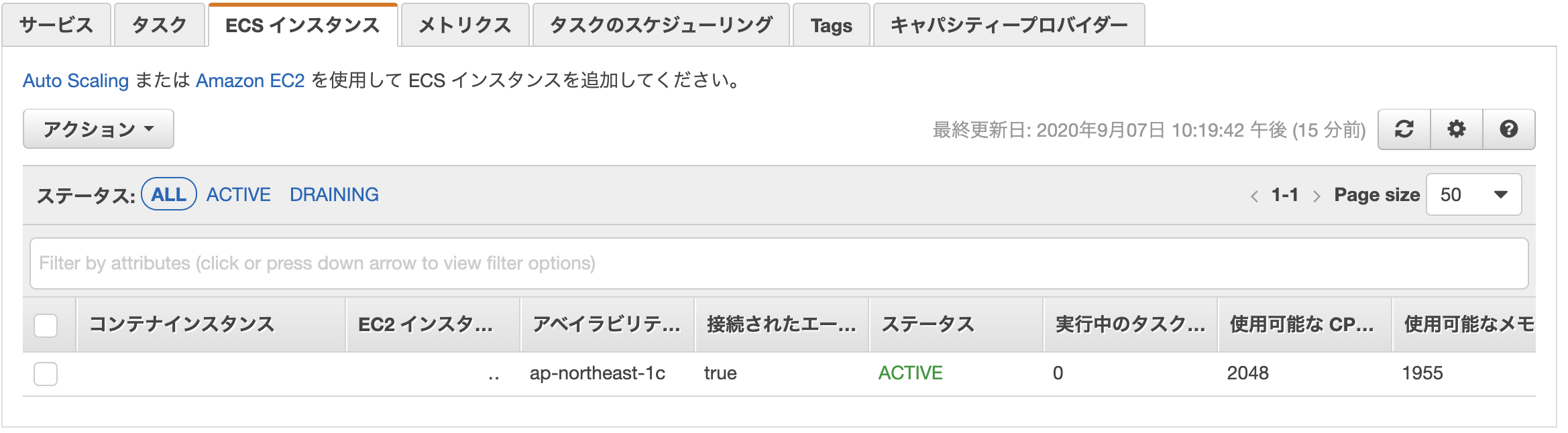
ECSクラスターの作成
今回はEC2 Linux+ネットワーキングを選択
ネットワーキングは先ほど作成したVPC・サブネット(front)を選択します。
また、Auto assign public IPは、Enabledを選択。
ssh接続出来るよう、キーペアを設定しておきましょう。Cluster作成後、以下のようにEC2インスタンスが起動されたら成功です。
うまいことEC2インスタンスが紐づけされない場合、セキュリティグループやルートテーブルが問題な事が多いです。
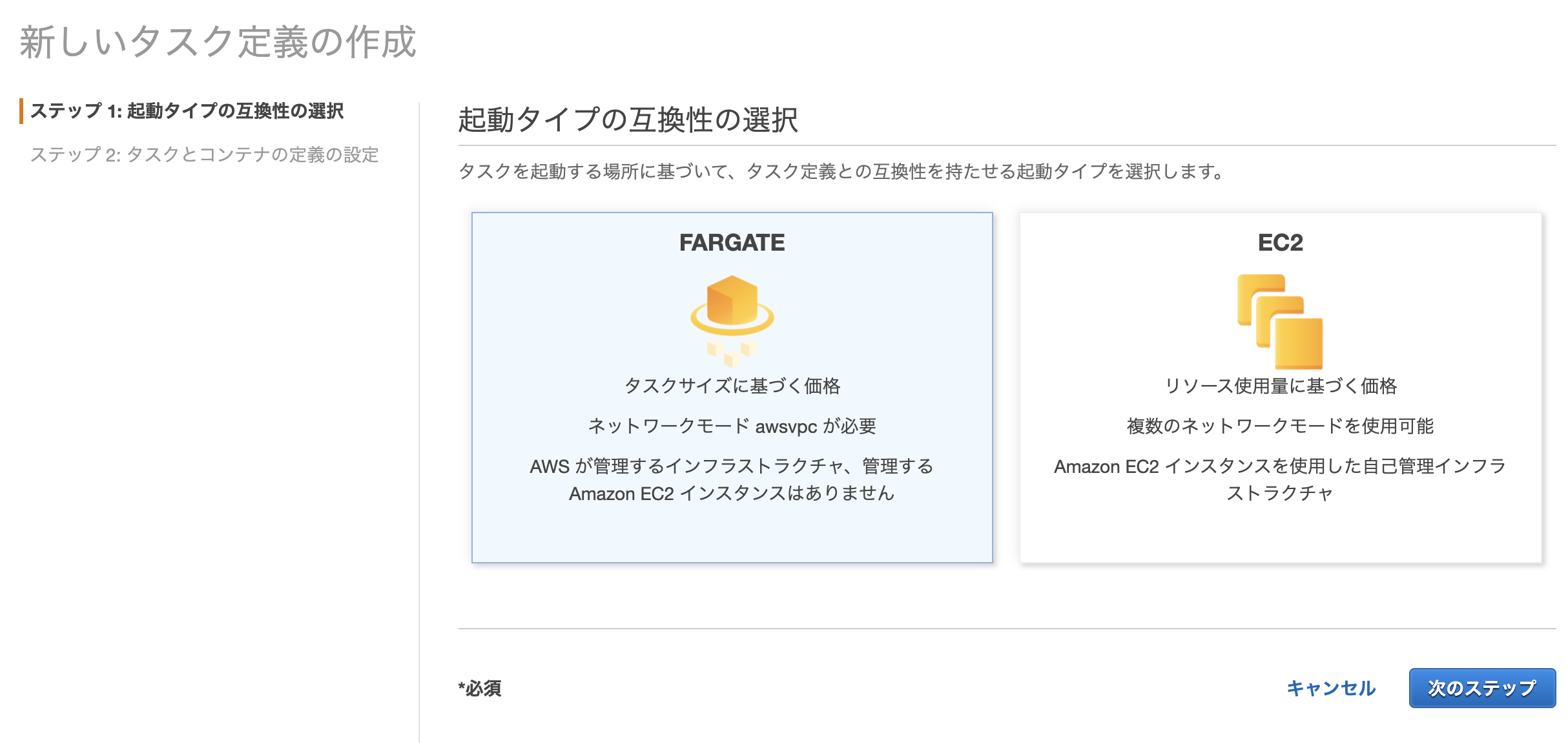
タスク定義の作成
ECSより、新しいタスク定義の作成を選択
EC2を選択
front
設定 備考 タスク定義名 qiita-sample-front 何でもOK タスクロール ECSを実行する権限をもつロール ネットワークモード ホスト タスク実行ロール ECSを実行する権限をもつロール タスクメモリ (MiB) 700 インスタンスのサイズ内で納めること タスク CPU (単位) 256 インスタンスのサイズ内で納めること
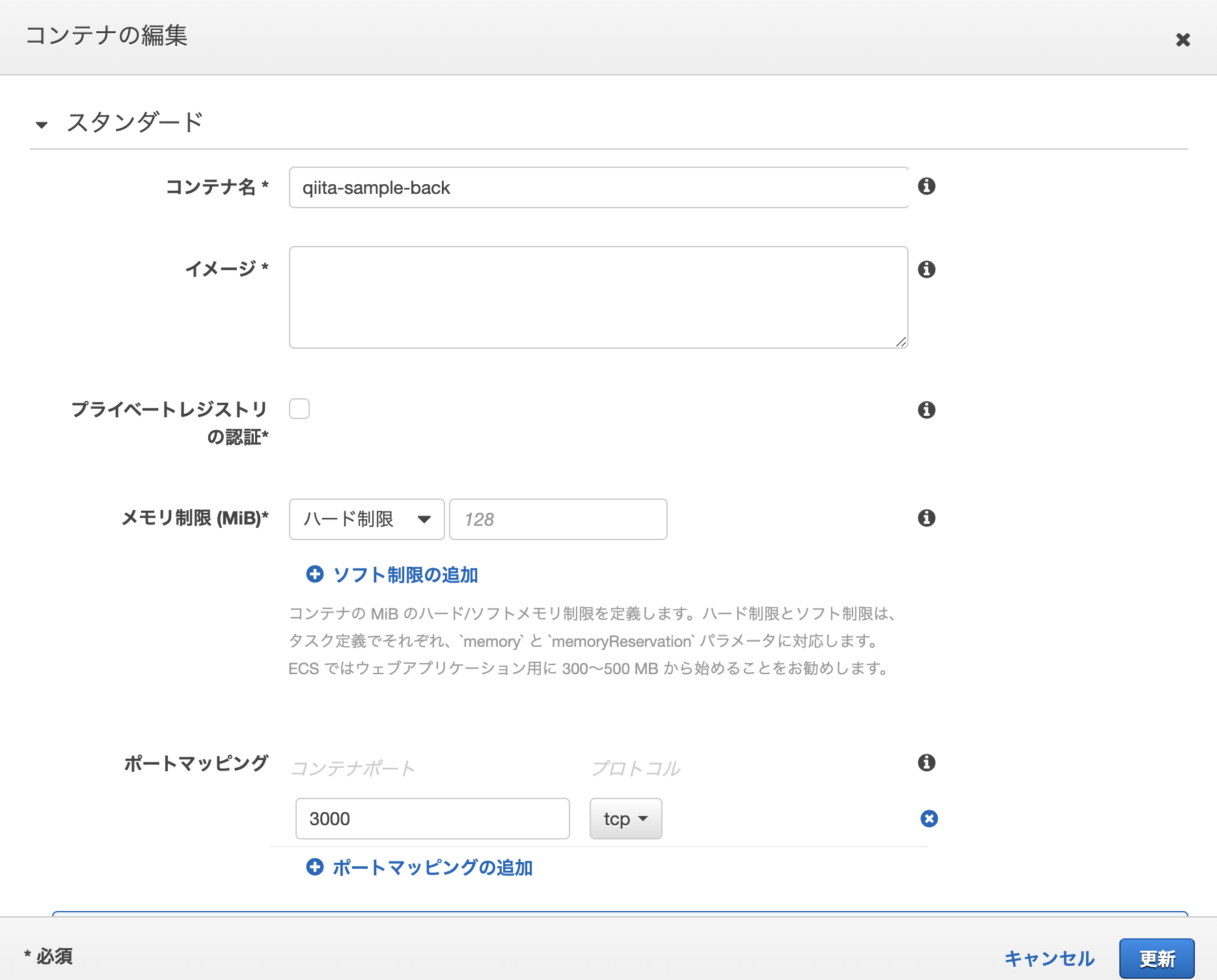
back
設定 備考 タスク定義名 qiita-sample-back 何でもOK タスクロール ECSを実行する権限をもつロール ネットワークモード aws-vpc タスク実行ロール ECSを実行する権限をもつロール タスクメモリ (MiB) 400 インスタンスのサイズ内で納めること タスク CPU (単位) 128 インスタンスのサイズ内で納めること
サービスの作成
クラスターのサービスタグより、サービスの作成をします。
front
設定 備考 起動タイプ EC2 タスク定義 先ほど作成したもの サービス名 qiita-front 何でもOK サービスタイプ REPLICA タスクの数 1 1~以上ならなんでもOK ロードバランシングはApplication Load Balancerを選択し、先ほど作成したALBとターゲットを選択
back
設定 備考 起動タイプ EC2 タスク定義 先ほど作成したもの サービス名 qiita-back 何でもOK サービスタイプ REPLICA タスクの数 1 1~以上ならなんでもOK ネットワーク構成では、先ほど作成したVPCとbackのサブネット・セキュリティグループを選択
ロードバランシングはApplication Load Balancerを選択し、先ほど作成したALBとターゲットを選択ECSサービスの起動
上記のように作成されると、自動的にタスクが一つ追加されているはずです。
以下のようになっていればOK!無事イメージからEC2内部でコンテナが起動されているはずです。
db:migrate
タスク定義を作ってタスクを実行しても良いのですが、今回はEC2インスタンスの中にssh接続し、その上でdockerコンテナ内に入り込み
rails db:migrateしてみます。
本来DBを作成しなければならないのですが(db:create)、今回はRDSを作成時に初期のDBにproductionと設定し、作成済みのため、必要ありません。ssh -i {pemファイルのパス} ec2-user@{インスタンスのpublicIP} __| __| __| _| ( \__ \ Amazon Linux 2 (ECS Optimized) ____|\___|____/ For documentation, visit http://aws.amazon.com/documentation/ecsEC2インスタンス内docker psで、現在起動しているコンテナが表示されます。
railsを起動しているコンテナのCONTAINER IDを指定して、以下コマンドを打つと、Dockerコンテナ内部に入れます。EC2インスタンス内docker exec -it {CONTAINER ID} shここで、環境を指定してdb:migrateしましょう!
Dockerコンテナ内rails db:migrate RAILS_ENV=production起動確認
長々とお疲れ様でした!
ttps://www.{自分で設定したfrontのドメイン}/users
にアクセスし、以下の画面のようになり、ユーザーをローカル同様登録できればOKです。
ttps://www.{自分で設定したbackのドメイン}/users
にアクセスし、登録したユーザーのjsonが返ってきていればOKです。
CircleCIでの自動デプロイ
ラスト、CircleCIでmasterにpushしたら、自動的にタスク定義を更新し、ECSのサービスを更新、タスクをアップデート出来るようにしていきましょう。
全体の流れ
ローカルからgithubへpush →githubからCircleCI起動 →CircleCI上でdocker buildを実行 →CircleCI上でECRにイメージをpush →ECSのサービスを更新・・・となります。
豆知識
ローカルでbuildする時との違いは、環境変数の有無です。
CircleCIで実行されたbuildは、gitリポジトリのソースコードを参照しており、さらに仮想マシンの中で実行されています。
Railsの実行に必要な環境変数がgitリポジトリ上に存在しない場合は環境変数を参照出来ずに失敗します。
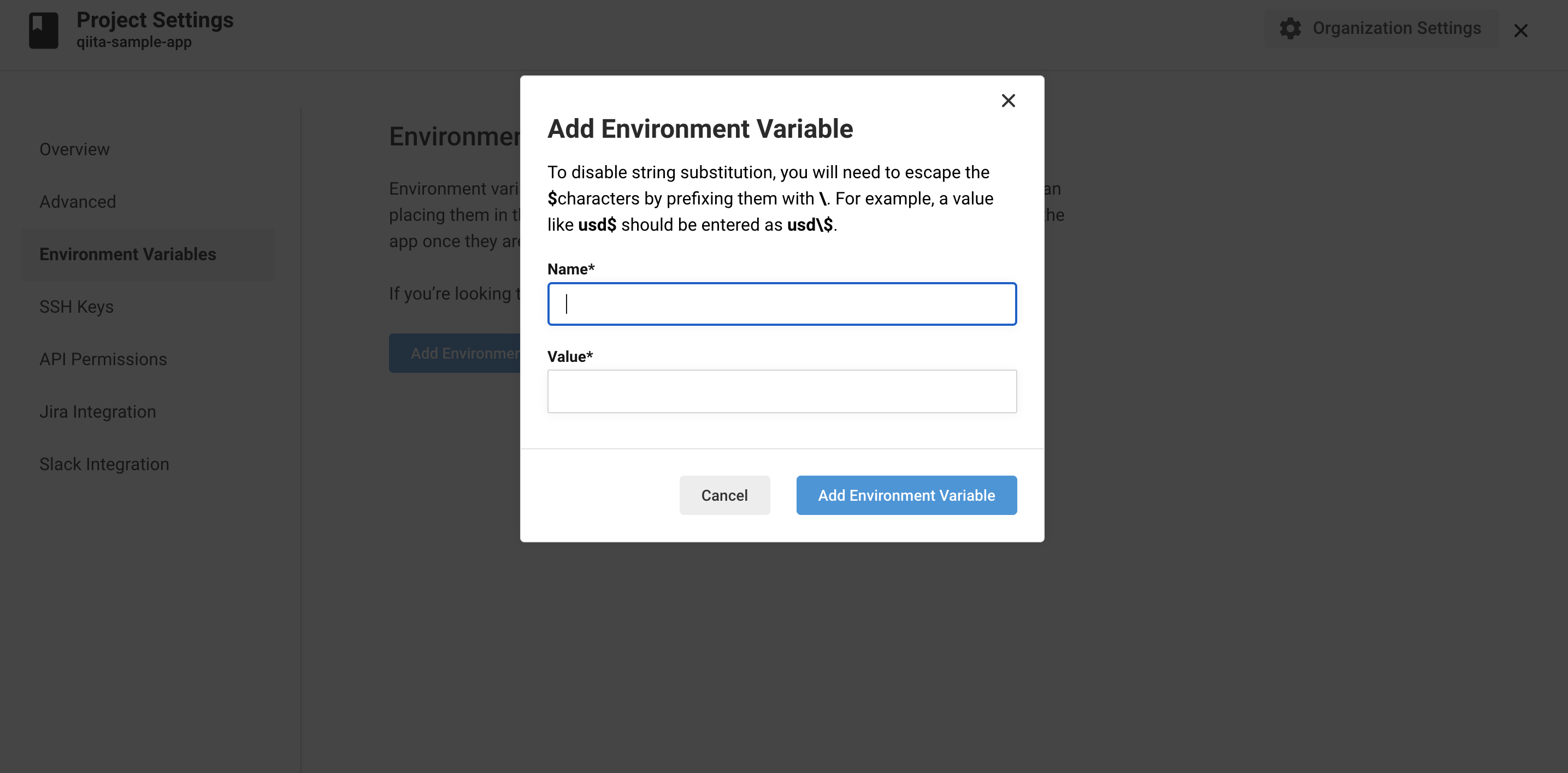
ですが、CircleCIには仮想マシン上に環境変数を設定出来ます。環境変数の設定
Project Settings>Environment Variables
AWS_ACCESS_KEY_ID // AWSのアクセスキー AWS_SECRET_ACCESS_KEY // AWSのシークレットアクセスキー AWS_ACCOUNT_ID //以下URL参照 AWS_ECR_ACCOUNT_URL // ECRのURL 例:{アカウントID}.dkr.ecr.{リージョン}.amazonaws.com AWS_REGION // リージョン RAILS_MASTER_KEY // ./back/config/以下にあるmaster.keyの値 AWS_RESOURCE_NAME_PREFIX // 自身で作成したサービスのprefix(今回だとqiita-sample) CLUSTER_NAME // 先ほど作成したClusterの名称 REPO_NAME_FRONT // frontのECRリポジトリ名称 REPO_NAME_BACK // backのECRリポジトリ名称 FAMILY_NAME_FRONT // frontのタスク定義の名称 FAMILY_NAME_BACK // backのタスク定義の名称 SERVICE_NAME_FRONT // 先ほど作成したfrontのECSサービスの名称 SERVICE_NAME_BACK // 先ほど作成したfrontのECSサービスの名称config.ymlの設定
./front/.circleci/config.ymlversion: 2.1 orbs: aws-ecr: circleci/aws-ecr@6.2.0 aws-ecs: circleci/aws-ecs@1.2.0 # 実行するjob jobs: # buildするjob build: machine: image: circleci/classic:edge steps: - checkout - run: name: docker-compose build command: docker-compose build # testするjob test: machine: image: circleci/classic:edge steps: - checkout - run: name: docker-compose up -d command: docker-compose up -d - run: sleep 30 - run: name: docker-compose run back rails db:create RAILS_ENV=test command: docker-compose run back rails db:create RAILS_ENV=test - run: name: docker-compose run back rails db:migrate RAILS_ENV=test command: docker-compose run back rails db:migrate RAILS_ENV=test - run: name: docker-compose run back bundle exec rspec spec command: docker-compose run back bundle exec rspec spec - run: name: docker-compose down command: docker-compose down # 順番を制御するworkflow workflows: build_and_test_and_deploy: jobs: - build - test: requires: - build - aws-ecr/build-and-push-image: name: 'build-and-push-back' account-url: AWS_ECR_ACCOUNT_URL region: AWS_REGION repo: ${REPO_NAME_BACK} tag: "${CIRCLE_SHA1}" path: './back' dockerfile: back/Dockerfile.pro extra-build-args: '--build-arg RAILS_MASTER_KEY=$RAILS_MASTER_KEY' requires: - test filters: branches: only: - master - aws-ecr/build-and-push-image: name: 'build-and-push-front' account-url: AWS_ECR_ACCOUNT_URL region: AWS_REGION repo: ${REPO_NAME_FRONT} tag: "${CIRCLE_SHA1}" path: './front' dockerfile: front/Dockerfile.pro requires: - test filters: branches: only: - master - aws-ecs/deploy-service-update: family: ${FAMILY_NAME_BACK} service-name: ${SERVICE_NAME_BACK} cluster-name: ${CLUSTER_NAME} #"container="はTask Definitionで設定したコンテナ名になるので、注意してください。 container-image-name-updates: 'container=${AWS_RESOURCE_NAME_PREFIX}-back,image-and-tag=${AWS_ECR_ACCOUNT_URL}/${REPO_NAME_BACK}:${CIRCLE_SHA1}' requires: - build-and-push-back filters: branches: only: - master - aws-ecs/deploy-service-update: family: ${FAMILY_NAME_FRONT} service-name: ${SERVICE_NAME_FRONT} cluster-name: ${CLUSTER_NAME} #"container="はTask Definitionで設定したコンテナ名になるので、注意してください。 container-image-name-updates: 'container=${AWS_RESOURCE_NAME_PREFIX}-front,image-and-tag=${AWS_ECR_ACCOUNT_URL}/${REPO_NAME_FRONT}:${CIRCLE_SHA1}' requires: - build-and-push-front filters: branches: only: - master本番用のDockerfileを作成
./back.Dockerfile.pro# イメージの指定 FROM ruby:2.6.3-alpine3.10 # 必要パッケージのダウンロード ENV RUNTIME_PACKAGES="linux-headers libxml2-dev make gcc libc-dev nodejs tzdata mysql-dev mysql-client yarn" \ DEV_PACKAGES="build-base curl-dev" \ HOME="/app" \ LANG=C.UTF-8 \ TZ=Asia/Tokyo # 作業ディレクトリに移動 WORKDIR ${HOME} # ホスト(自分のパソコンにあるファイル)から必要ファイルをDocker上にコピー ADD Gemfile ${HOME}/Gemfile ADD Gemfile.lock ${HOME}/Gemfile.lock RUN apk update && \ apk upgrade && \ apk add --update --no-cache ${RUNTIME_PACKAGES} && \ apk add --update --virtual build-dependencies --no-cache ${DEV_PACKAGES} && \ bundle install -j4 && \ apk del build-dependencies && \ rm -rf /usr/local/bundle/cache/* \ /usr/local/share/.cache/* \ /var/cache/* \ /tmp/* \ /usr/lib/mysqld* \ /usr/bin/mysql* # ホスト(自分のパソコンにあるファイル)から必要ファイルをDocker上にコピー ADD . ${HOME} # ポート3000番をあける EXPOSE 3000 # コマンドを実行 CMD ["bundle", "exec", "rails", "s", "puma", "-b", "0.0.0.0", "-p", "3000", "-e", "production"]./front/Dockerfile.proFROM node:12.5.0-alpine ENV HOME="/app" \ LANG=C.UTF-8 \ TZ=Asia/Tokyo ENV HOST 0.0.0.0 WORKDIR ${HOME} COPY package.json . COPY . . RUN apk update && \ apk upgrade && \ npm install -g n && \ yarn install &&\ rm -rf /var/cache/apk/* RUN yarn run build EXPOSE 3000 CMD ["yarn", "start"]./docker-compose.ymlversion: "3" services: db: image: mysql:5.7 env_file: - ./back/environments/db.env restart: always volumes: - db-data:/var/lib/mysql:cached back: build: back/ # rm -f tmp/pids/server.pidしとくとrailsのサーバ消し損ねたときに便利 command: /bin/sh -c "rm -f tmp/pids/server.pid && bundle exec rails s -p 3000 -b '0.0.0.0'" env_file: - ./back/environments/db.env environment: # 追加 RAILS_MASTER_KEY: ${RAILS_MASTER_KEY} volumes: - ./back:/app:cached depends_on: - db # ホストコンピュータのポート:Docker内のポート ports: - 3000:3000 front: build: front/ command: yarn run dev volumes: - ./front:/app:cached ports: # ホストコンピュータのポート:Docker内のポート - 8080:3000 depends_on: - back volumes: public-data: tmp-data: log-data: db-data:デプロイ
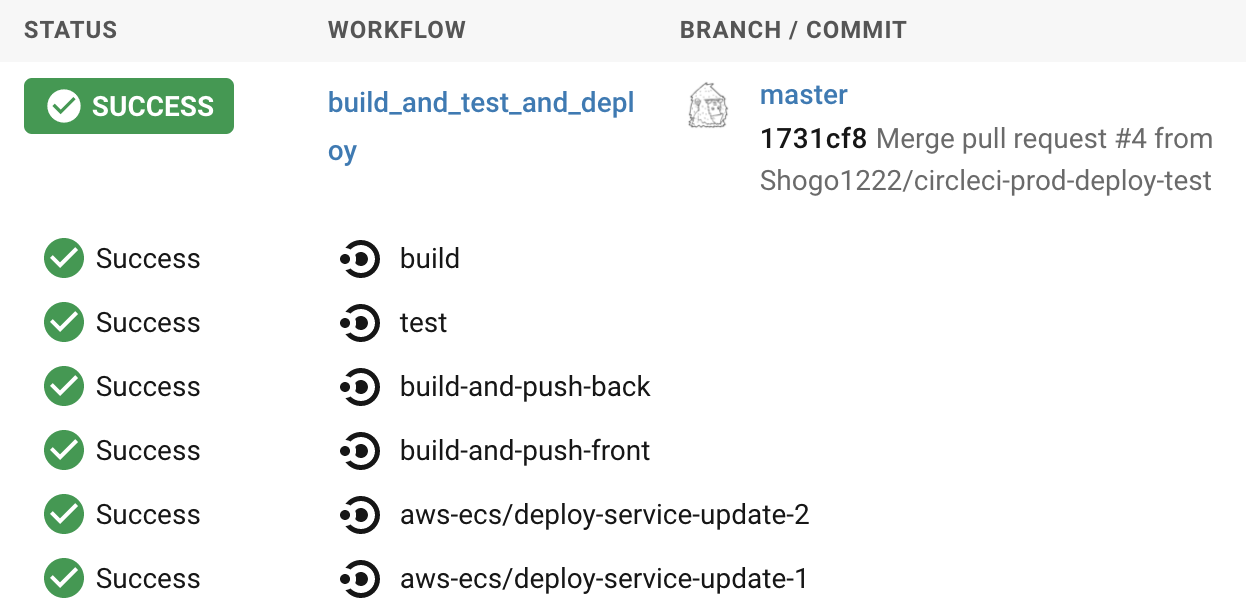
お疲れ様でした!
以下のように、全ての工程がSuccessしたら無事にデプロイが完了しています。
参考
VPC、AWSのネットワークなどを学びたい方
動画で学ぶAWS講座 VPC編 【section1】 リージョン, アベイラビリティゾーン, サブネットDockerのネットワーク、ECSについて深く知りたい方
今から追いつくDocker講座!AWS ECSとFargateで目指せコンテナマスター!〜シリーズ1回目〜動画で学べるなんて、本当に便利な時代ですね・・・。30回くらい繰り返してみました。
最後に
お疲れ様でした。
これでNuxtとRailsを、ECS・ECR・CircleCIを使って本番環境にデプロイする事ができました。
これは一例であり、他にも良い構成があると思います。
ですが、一度構築・デバッグしてしまえば、あとはやり方が自分なりにわかってくると思います。(私はまだまだですが
もしかしたら、この記事でタイポや間違った部分があるかもしれません。
そういった際は、優しくマサカリを投げていただけると有り難いです。




- 投稿日:2020-09-09T20:47:10+09:00
【中編】Rails+Nuxt+MySQL+Dockerで作ったWEBサービスをECS・ECR・CircleCIで自動テスト・デプロイしてterraform化する
この記事を書くにあたって
AWSについての知識が全くなかった状態からポートフォリオを作成し、個人的にAWSへのデプロイと、CircleCIの自動デプロイが一番難しかったので、備忘録・これからポートフォリオを作るよ・これからAWS使うよって方向けの記事があれば良いなと思い書きました。
私が作ったポートフォリオの概要は
【AWS?Docker?】ポートフォリオで必要な知識を自分なりに分かりやすくまとめる【terraform?CircleCI?】この記事の前身となる記事は
【前編】Rails+Nuxt+MySQL+Dockerで作ったWEBサービスをECS・ECR・CircleCIで自動テスト・デプロイしてterraform化する是非ご覧いただけると有り難いです。
第一弾:【前編】Rails+Nuxt+MySQL+Dockerで作ったWEBサービスをECS・ECR・CircleCIで自動本番デプロイしてterraform化する
第二弾:本記事
第三弾:【後編】Rails+Nuxt+MySQL+Dockerで作ったWEBサービスをECS・ECR・CircleCIで自動本番デプロイしてterraform化するこの記事で目指すゴール
- VPC・IGW・サブネット・ルートテーブル・セキュリティグループ等のネットワークの基本的な設定が出来る。
- Route53・ACM・ALBを使って常時SSL通信が出来るWEBサービスが構築出来る。
- ECS・ECRを使って本番環境にデプロイ出来る。
- CircleCIを使ってmasterへプッシュすると同時に自動デプロイする事が出来る。
前提
- AWSのアカウント・IAMアカウント・キーペアを取得済み(ぐぐったらすぐ出来るはず)
- aws-cliをインストール済み
- 使用リージョンは東京(ap-northeast-1)
- 前回の記事まで実装を進めている。
【前編】Rails+Nuxt+MySQL+Dockerで作ったWEBサービスをECS・ECR・CircleCIで自動テスト・デプロイしてterraform化する完成品
注意
この記事で出来る事は普通にAWSの無料枠を超えて有料になります。
また、お名前.comでドメインを取得するため、そこにもお金がかかります。
勉強代だと思って割り切れる方のみお読み下さい。
とりあえずECSとECRを使って、疎結合なウェブサービスを公開してみたい!という方向けです。ネットワークの構築
まずはネットワークをAWSの画面上でぽちぽち作っていきます。
張り切っていきましょう!VPC作成
豆知識
CIDRブロックとはClassless Inter-Domain Routingの略です。
IPアドレスの表記方法の一つ。簡単に言うと、VPCの範囲のことです。ちなみにここでは
/16のような表示のことです。
CIDR表記では、/16、/24、32といった表記がされます。
/16というのは、第3オクテッドまでを指定出来ます。
例えば、10.20.0.0の0.0
この部分を指定出来ます。
/24というのは、第4オクテッドまでを指定出来ます。
例えば、10.20.0.0の最後の0
この部分を指定出来ます。
/32というのは、特定のIPアドレスを指定出来ます。VPCを作成する際、中にサブネットやAZでIPを確保せざるを得ない上に、変更が効かないため、
/16を指定して利用可能なIPを多く確保することが多いです。サブネット作成
ここでは、AZをap-northeast-1aとap-northeast-1cを使用します。
2つのAZを利用する理由は、後々にALBを利用するからです。サブネット>サブネット作成より、以下のサブネットを作成して下さい。
name CIDRブロック Region/AZ qiita-sample-front-subnet-1a 10.20.1.0/24 ap-northeast-1a qiita-sample-front-subnet-1c 10.20.2.0/24 ap-northeast-1c qiita-sample-back-subnet-1a 10.20.3.0/24 ap-northeast-1a qiita-sample-back-subnet-1c 10.20.4.0/24 ap-northeast-1c qiita-sample-rds-subnet-1a 10.20.5.0/24 ap-northeast-1a qiita-sample-rds-subnet-1c 10.20.6.0/24 ap-northeast-1c ルートテーブルの作成
ルートテーブル>ルートテーブル作成より、以下のルートテーブルを作成して下さい。
name qiita-sample-front-route-table qiita-sample-back-route-table qiita-sample-rds-route-table IGWの作成
インターネットゲートウェイ>インターネットゲートウェイの作成より、以下のインターネットゲートウェイを作成してください。
VPCとIGWの関連付けをします。
name qiita-sample-igw サブネットとルートテーブルの関連付け
- ルートテーブルの編集タブを選択し、RDS以外のルートテーブルに対し、0.0.0.0に先ほど作ったIGWを関連付け
- サブネット関連付けタブを選択し、以下の表のように関連付け
サブネット ルートテーブル qiita-sample-front-subnet-1a qiita-sample-front-route-table qiita-sample-front-subnet-1c qiita-sample-front-route-table qiita-sample-back-subnet-1a qiita-sample-back-route-table qiita-sample-back-subnet-1c qiita-sample-back-route-table qiita-sample-rds-subnet-1a qiita-sample-rds-route-table qiita-sample-rds-subnet-1c qiita-sample-rds-route-table セキュリティグループの作成
下記の表のセキュリティグループを作成
セキュリティグループ名 タイプ プロトコル ポート範囲 ソース qiita-sample-front-sg HTTP TCP 80 0.0.0.0/0 同上 SSH TCP 22 ご自身のIP 同上 HTTPS TCP 443 0.0.0.0/0 同上 カスタム TCP 3000 0.0.0.0/0 qiita-sample-back-sg カスタム TCP 3000 0.0.0.0/0 同上 HTTPS TCP 443 0.0.0.0/0 qiita-sample-rds-sg MYSQL/Aurora TCP 3306 qiita-sample-back-sg ネットワークはここまでで終わり。
Route53の作成(ここから有料です。)
ドメインの取得
お名前.comより、ドメインの取得をします。
この記事を参照している方のお好きなドメイン(できれば1円とかのやつ)を取得して下さい。お名前.comでのドメイン取得方法については、【ドメイン取得】お名前.comとawsでドメイン取得を参照すると良いです。
※ドメイン自動更新設定はオフにしておきましょう!(1年ごとにお金かかっちゃう)
今回、私の環境では、以下のドメインを取得しました。
ドメイン名 役割 qiita-sample.work front qiita-sample-api.work back ホストゾーンの作成
Route53より、ホストゾーンの作成をします。
ホストゾーン詳細より、NSレコードの値/トラフィックのルーティング先をコピーして下さい。
お名前.comのネームサーバにNSレコードの値を登録
反映まで結構時間かかります。(1日とか最大でかかるかも)
dig qiita-sample.work(取得したドメイン) +short NSをterminalから打ち、無事登録したNSレコードが表示されていれば反映されています。
ACMを使ってドメインに証明書を発行する
ACMより、証明書のリクエストをします。
パブリック証明書のリクエストを選択し、証明書をリクエストします。
ドメイン名 qiita-sample.work *.qiita-sample.work 以上のドメイン名を記入し、DNS検証を選択します。
同様に、qiita-sample-api.workにも同様の処理をします。
すると、検証画面にいくので、そこでRoute53でのレコード作成をします。(上記のドメイン全てにレコードの作成をして下さい。)
しばらくすると検証保留中から、発行済みステータスとなります。
ずっと検証保留中になるのは、だいたいNSサーバの設定が遅れている可能性があります。
digコマンドで確認してみましょう。RDSの作成
Route53・ドメインネームサーバの設定にやや時間がかかるので、ここでRDSをサクッと作成しておきましょう。
サブネットグループの作成
RDSの作成・設定
以下の設定を参考に、RDS>データベースの作成よりRDSの作成をして下さい。
設定 備考 エンジンのタイプ MySQL バージョン 5.7.30 今回は5.7 テンプレート 開発/テスト 無料枠でも良いのですが、今回は勉強のため DB インスタンス識別子 qiita-sample-rds なんでもOK マスターユーザー名 ** 何でもOK マスターパスワード ** 何でもOK・流出させないように DB インスタンスクラス情報 db.t2.micro 最安のものにしておきます ストレージタイプ 汎用SSD ストレージ割り当て 20 20が最小です Virtual Private Cloud (VPC) 先ほど作ったVPC サブネットグループ 先ほど作ったサブネットグループ 既存の VPC セキュリティグループ 先ほど作ったセキュリティグループ データベース認証 パスワード認証 最初のデータベース名 production DB パラメータグループ default 今回はdefaultにします。(自分で作ってもOK!) オプショングループ default 今回はdefaultにします。(自分で作ってもOK!) しばらくすると利用可能ステータスとなるので、そうしたらRDS作成完了です。
database.yml、credentials.yml.encの修正
./back/config/database.ymlproduction: <<: *default host: <%= Rails.application.credentials.rds[:host] %> database: <%= Rails.application.credentials.rds[:database] %> username: <%= Rails.application.credentials.rds[:username] %> password: <%= Rails.application.credentials.rds[:password] %>./docker-compose run -e EDITOR="vi" back rails credentials:editすると、vim画面が現れるので、以下の設定を記入して下さい。
rds: host: {エンドポイント} database: {databaseの名前(初期で作ったもの)} username: {設定したユーザーネーム} password: {設定したパスワード}ロードバランサーの作成
EC2>ロードバランサーの作成より、ロードバランサーを作成しましょう。
ロードバランサーの設定
front
back
アベイラビリティーゾーンには、先ほど作ったVPCとサブネットを登録しましょう。セキュリティ設定の構成
先ほど作った証明書を選択しましょう。
まだ認証されていなかったら、少し待ってね。セキュリティグループの設定
先ほど作ったセキュリティーグループをアタッチして下さい。
ルーティングの設定
新しくターゲットグループを作成します。
今回frontでは、ECSで生成されるEC2内でhost modeで起動するため
ターゲットをインスタンスに設定し、ポートを3000で受け付けるようにします。
backでは、ECSのインスタンス内のコンテナでawsvpc modeで起動するため、ターゲットをipにしています。これは、コンテナのプライベートIPを指します。front
back
ターゲットの登録
後述しますが、ECSのサービス起動時に自動的にターゲットが選択されるため、心配ご無用です。
そのままロードバランサーを作成しましょう!Route53にAレコードを追加
Route53>ホストゾーンより、Aレコードの追加をし、以下の設定にしてください。
frontとback、同様に処理して下さい。
ECRにリポジトリを作成・イメージのプッシュ
frontのAPIの向きを本番用に変えておきましょう。
./front/plugins/axios.jsimport axios from "axios" export default axios.create({ //baseURL: "http://localhost:3000" baseURL: "https://www.qiita-sample-api.work" })※aws cliを使えるようにしておきましょう!
macOS に AWS CLI バージョン 1 をインストールする
AWS CLIのインストールAmazon ECRより、リポジトリを作成。リポジトリ名を記入してそのまま作成して下さい。
リポジトリを選択し、プッシュコマンドを押すとリポジトリにプッシュするためのコマンドが表示されるため、frontとback共にリポジトリを作成してローカル環境で実行して下さい。これらのコマンドを実行すると、ディレクトリ上にあるDockerfileを元にイメージを作成します。
ローカル環境でdocker-compose buildをした時と同じ状態になります。
ここで作成し、ECRにプッシュしたイメージを使って、ECS上で読み込み、起動させます。ここで注意したいのが、frontとback、それぞれどちらのリポジトリにプッシュするのか確認した上でDockerfileがあるディレクトリに移動してから実行して下さい。
ECSの作成・設定
全体像
ECSでは、
クラスター>サービス>タスク
という粒度になっています。
クラスターは論理的な枠組み、箱です。
サービスはクラスター上で起動するオートスケーリング+ALBのような存在です。
タスクの数を自動で管理したり、ネットワーキングの設定をします。
タスクはDockerイメージを実行する単位だと考えて下さい。サービスは、タスク定義を元にタスクを生成していきます。
無理やり例えると、たい焼きの鋳型がサービス、たい焼き自体がタスクのような感じです。
クラスタはたい焼き屋さんの屋台。
ECSクラスターの作成
今回はEC2 Linux+ネットワーキングを選択
ネットワーキングは先ほど作成したVPC・サブネット(front)を選択します。
また、Auto assign public IPは、Enabledを選択。
ssh接続出来るよう、キーペアを設定しておきましょう。Cluster作成後、以下のようにEC2インスタンスが起動されたら成功です。
うまいことEC2インスタンスが紐づけされない場合、セキュリティグループやルートテーブルが問題な事が多いです。
タスク定義の作成
ECSより、新しいタスク定義の作成を選択
EC2を選択
front
設定 備考 タスク定義名 qiita-sample-front 何でもOK タスクロール ECSを実行する権限をもつロール ネットワークモード ホスト タスク実行ロール ECSを実行する権限をもつロール タスクメモリ (MiB) 700 インスタンスのサイズ内で納めること タスク CPU (単位) 256 インスタンスのサイズ内で納めること
back
設定 備考 タスク定義名 qiita-sample-back 何でもOK タスクロール ECSを実行する権限をもつロール ネットワークモード aws-vpc タスク実行ロール ECSを実行する権限をもつロール タスクメモリ (MiB) 400 インスタンスのサイズ内で納めること タスク CPU (単位) 128 インスタンスのサイズ内で納めること
サービスの作成
クラスターのサービスタグより、サービスの作成をします。
front
設定 備考 起動タイプ EC2 タスク定義 先ほど作成したもの サービス名 qiita-front 何でもOK サービスタイプ REPLICA タスクの数 1 1~以上ならなんでもOK ロードバランシングはApplication Load Balancerを選択し、先ほど作成したALBとターゲットを選択
back
設定 備考 起動タイプ EC2 タスク定義 先ほど作成したもの サービス名 qiita-back 何でもOK サービスタイプ REPLICA タスクの数 1 1~以上ならなんでもOK ネットワーク構成では、先ほど作成したVPCとbackのサブネット・セキュリティグループを選択
ロードバランシングはApplication Load Balancerを選択し、先ほど作成したALBとターゲットを選択ECSサービスの起動
上記のように作成されると、自動的にタスクが一つ追加されているはずです。
以下のようになっていればOK!無事イメージからEC2内部でコンテナが起動されているはずです。
db:migrate
タスク定義を作ってタスクを実行しても良いのですが、今回はEC2インスタンスの中にssh接続し、その上でdockerコンテナ内に入り込み
rails db:migrateしてみます。
本来DBを作成しなければならないのですが(db:create)、今回はRDSを作成時に初期のDBにproductionと設定し、作成済みのため、必要ありません。ssh -i {pemファイルのパス} ec2-user@{インスタンスのpublicIP} __| __| __| _| ( \__ \ Amazon Linux 2 (ECS Optimized) ____|\___|____/ For documentation, visit http://aws.amazon.com/documentation/ecsEC2インスタンス内docker psで、現在起動しているコンテナが表示されます。
railsを起動しているコンテナのCONTAINER IDを指定して、以下コマンドを打つと、Dockerコンテナ内部に入れます。EC2インスタンス内docker exec -it {CONTAINER ID} shここで、環境を指定してdb:migrateしましょう!
Dockerコンテナ内rails db:migrate RAILS_ENV=production起動確認
長々とお疲れ様でした!
ttps://www.{自分で設定したfrontのドメイン}/users
にアクセスし、以下の画面のようになり、ユーザーをローカル同様登録できればOKです。
ttps://www.{自分で設定したbackのドメイン}/users
にアクセスし、登録したユーザーのjsonが返ってきていればOKです。
CircleCIでの自動デプロイ
ラスト、CircleCIでmasterにpushしたら、自動的にタスク定義を更新し、ECSのサービスを更新、タスクをアップデート出来るようにしていきましょう。
全体の流れ
ローカルからgithubへpush →githubからCircleCI起動 →CircleCI上でdocker buildを実行 →CircleCI上でECRにイメージをpush →ECSのサービスを更新・・・となります。
豆知識
ローカルでbuildする時との違いは、環境変数の有無です。
CircleCIで実行されたbuildは、gitリポジトリのソースコードを参照しており、さらに仮想マシンの中で実行されています。
Railsの実行に必要な環境変数がgitリポジトリ上に存在しない場合は環境変数を参照出来ずに失敗します。
ですが、CircleCIには仮想マシン上に環境変数を設定出来ます。環境変数の設定
Project Settings>Environment Variables
AWS_ACCESS_KEY_ID // AWSのアクセスキー AWS_SECRET_ACCESS_KEY // AWSのシークレットアクセスキー AWS_ACCOUNT_ID //以下URL参照 AWS_ECR_ACCOUNT_URL // ECRのURL 例:{アカウントID}.dkr.ecr.{リージョン}.amazonaws.com AWS_REGION // リージョン RAILS_MASTER_KEY // ./back/config/以下にあるmaster.keyの値 AWS_RESOURCE_NAME_PREFIX // 自身で作成したサービスのprefix(今回だとqiita-sample) CLUSTER_NAME // 先ほど作成したClusterの名称 REPO_NAME_FRONT // frontのECRリポジトリ名称 REPO_NAME_BACK // backのECRリポジトリ名称 FAMILY_NAME_FRONT // frontのタスク定義の名称 FAMILY_NAME_BACK // backのタスク定義の名称 SERVICE_NAME_FRONT // 先ほど作成したfrontのECSサービスの名称 SERVICE_NAME_BACK // 先ほど作成したfrontのECSサービスの名称config.ymlの設定
./front/.circleci/config.ymlversion: 2.1 orbs: aws-ecr: circleci/aws-ecr@6.2.0 aws-ecs: circleci/aws-ecs@1.2.0 # 実行するjob jobs: # buildするjob build: machine: image: circleci/classic:edge steps: - checkout - run: name: docker-compose build command: docker-compose build # testするjob test: machine: image: circleci/classic:edge steps: - checkout - run: name: docker-compose up -d command: docker-compose up -d - run: sleep 30 - run: name: docker-compose run back rails db:create RAILS_ENV=test command: docker-compose run back rails db:create RAILS_ENV=test - run: name: docker-compose run back rails db:migrate RAILS_ENV=test command: docker-compose run back rails db:migrate RAILS_ENV=test - run: name: docker-compose run back bundle exec rspec spec command: docker-compose run back bundle exec rspec spec - run: name: docker-compose down command: docker-compose down # 順番を制御するworkflow workflows: build_and_test_and_deploy: jobs: - build - test: requires: - build - aws-ecr/build-and-push-image: name: 'build-and-push-back' account-url: AWS_ECR_ACCOUNT_URL region: AWS_REGION repo: ${REPO_NAME_BACK} tag: "${CIRCLE_SHA1}" path: './back' dockerfile: back/Dockerfile.pro extra-build-args: '--build-arg RAILS_MASTER_KEY=$RAILS_MASTER_KEY' requires: - test filters: branches: only: - master - aws-ecr/build-and-push-image: name: 'build-and-push-front' account-url: AWS_ECR_ACCOUNT_URL region: AWS_REGION repo: ${REPO_NAME_FRONT} tag: "${CIRCLE_SHA1}" path: './front' dockerfile: front/Dockerfile.pro requires: - test filters: branches: only: - master - aws-ecs/deploy-service-update: family: ${FAMILY_NAME_BACK} service-name: ${SERVICE_NAME_BACK} cluster-name: ${CLUSTER_NAME} #"container="はTask Definitionで設定したコンテナ名になるので、注意してください。 container-image-name-updates: 'container=${AWS_RESOURCE_NAME_PREFIX}-back,image-and-tag=${AWS_ECR_ACCOUNT_URL}/${REPO_NAME_BACK}:${CIRCLE_SHA1}' requires: - build-and-push-back filters: branches: only: - master - aws-ecs/deploy-service-update: family: ${FAMILY_NAME_FRONT} service-name: ${SERVICE_NAME_FRONT} cluster-name: ${CLUSTER_NAME} #"container="はTask Definitionで設定したコンテナ名になるので、注意してください。 container-image-name-updates: 'container=${AWS_RESOURCE_NAME_PREFIX}-front,image-and-tag=${AWS_ECR_ACCOUNT_URL}/${REPO_NAME_FRONT}:${CIRCLE_SHA1}' requires: - build-and-push-front filters: branches: only: - master本番用のDockerfileを作成
./back.Dockerfile.pro# イメージの指定 FROM ruby:2.6.3-alpine3.10 # 必要パッケージのダウンロード ENV RUNTIME_PACKAGES="linux-headers libxml2-dev make gcc libc-dev nodejs tzdata mysql-dev mysql-client yarn" \ DEV_PACKAGES="build-base curl-dev" \ HOME="/app" \ LANG=C.UTF-8 \ TZ=Asia/Tokyo # 作業ディレクトリに移動 WORKDIR ${HOME} # ホスト(自分のパソコンにあるファイル)から必要ファイルをDocker上にコピー ADD Gemfile ${HOME}/Gemfile ADD Gemfile.lock ${HOME}/Gemfile.lock RUN apk update && \ apk upgrade && \ apk add --update --no-cache ${RUNTIME_PACKAGES} && \ apk add --update --virtual build-dependencies --no-cache ${DEV_PACKAGES} && \ bundle install -j4 && \ apk del build-dependencies && \ rm -rf /usr/local/bundle/cache/* \ /usr/local/share/.cache/* \ /var/cache/* \ /tmp/* \ /usr/lib/mysqld* \ /usr/bin/mysql* # ホスト(自分のパソコンにあるファイル)から必要ファイルをDocker上にコピー ADD . ${HOME} # ポート3000番をあける EXPOSE 3000 # コマンドを実行 CMD ["bundle", "exec", "rails", "s", "puma", "-b", "0.0.0.0", "-p", "3000", "-e", "production"]./front/Dockerfile.proFROM node:12.5.0-alpine ENV HOME="/app" \ LANG=C.UTF-8 \ TZ=Asia/Tokyo ENV HOST 0.0.0.0 WORKDIR ${HOME} COPY package.json . COPY . . RUN apk update && \ apk upgrade && \ npm install -g n && \ yarn install &&\ rm -rf /var/cache/apk/* RUN yarn run build EXPOSE 3000 CMD ["yarn", "start"]./docker-compose.ymlversion: "3" services: db: image: mysql:5.7 env_file: - ./back/environments/db.env restart: always volumes: - db-data:/var/lib/mysql:cached back: build: back/ # rm -f tmp/pids/server.pidしとくとrailsのサーバ消し損ねたときに便利 command: /bin/sh -c "rm -f tmp/pids/server.pid && bundle exec rails s -p 3000 -b '0.0.0.0'" env_file: - ./back/environments/db.env environment: # 追加 RAILS_MASTER_KEY: ${RAILS_MASTER_KEY} volumes: - ./back:/app:cached depends_on: - db # ホストコンピュータのポート:Docker内のポート ports: - 3000:3000 front: build: front/ command: yarn run dev volumes: - ./front:/app:cached ports: # ホストコンピュータのポート:Docker内のポート - 8080:3000 depends_on: - back volumes: public-data: tmp-data: log-data: db-data:デプロイ
お疲れ様でした!
以下のように、全ての工程がSuccessしたら無事にデプロイが完了しています。
参考
VPC、AWSのネットワークなどを学びたい方
動画で学ぶAWS講座 VPC編 【section1】 リージョン, アベイラビリティゾーン, サブネットDockerのネットワーク、ECSについて深く知りたい方
今から追いつくDocker講座!AWS ECSとFargateで目指せコンテナマスター!〜シリーズ1回目〜動画で学べるなんて、本当に便利な時代ですね・・・。30回くらい繰り返してみました。
最後に
お疲れ様でした。
これでNuxtとRailsを、ECS・ECR・CircleCIを使って本番環境にデプロイする事ができました。
これは一例であり、他にも良い構成があると思います。
ですが、一度構築・デバッグしてしまえば、あとはやり方が自分なりにわかってくると思います。(私はまだまだですが
もしかしたら、この記事でタイポや間違った部分があるかもしれません。
そういった際は、優しくマサカリを投げていただけると有り難いです。次回はterraform化まで書けたらいいな。
- 投稿日:2020-09-09T20:04:45+09:00
[AWS] ローカルPCから、セキュアな接続でEC2インスタンスにssh/scpする
はじめに
この記事では「[AWS] Private Subnet内のEC2インスタンスにローカルPCのターミナルからSession Managerでアクセスする」の内容を改善し、もっと簡単に環境を構築できる手順を解説します。
事前準備
まず、最初にクライアント環境に以下のツールが必要ですので、必要に応じてご用意ください。
また、AWSのクレデンシャル情報も事前に設定してくおいてください。
環境変数AWS_ACCESS_KEY_ID AWS_SECRET_ACCESS_KEYもし必要であれば、
AWS_DEFAULT_REGIONも設定してください。
もしくは、$ aws configureで設定しても、どちらでも構いません。
キーペアの作成
クライアントからssh/scpでアクセスするためのキーペアを作成します。
この手順は、既にキーペアが存在し、ローカル環境に.pemファイルをダウンロード済みの場合はスキップして構いません。$ aws ec2 create-key-pair --key-name [キーペア名] --query 'KeyMaterial' --output text > [ローカル保存する.pemファイル名]例
$ aws ec2 create-key-pair --key-name ssm-key --query 'KeyMaterial' --output text > ssm-key.pem作成したファイルは、アクセス権を変更しておいてください。
$ chmode 400 ssm-key.pemCloudFormationの実行
テンプレート
構成概説
以下テンプレートは、以下の環境を構築します。
- VPC
- Subnet(Private Subnetとして作成)
- ルートテーブル(EndPointにのみルーティング)
- セキュリティグループ(443のみ許可)
- エンドポイント(ssm、ssmmessages、ec2messages、s3)
- EC2インスタンス
- EBS
AWSTemplateFormatVersion: "2010-09-09" Description: Create Session Manager Environment Metadata: "AWS::CloudFormation::Interface": ParameterGroups: - Label: default: "Project Name Prefix" Parameters: - ProjectPrefix - Label: default: "Network Configuration" Parameters: - VPCCIDR - PrivateSubnetCIDR - Label: default: "EC2" Parameters: - AmiID - InstanceType - KeyPair ParameterLabels: VPCCIDR: default: "VPC CIDR" PrivateSubnetCIDR: default: "PrivateSubnet CIDR" Parameters: ProjectPrefix: Type: String Default: "SSM-ACCESS-ENV" VPCCIDR: Type: String Default: "10.1.0.0/16" PrivateSubnetCIDR: Type: String Default: "10.1.100.0/24" AmiID: Type: String Default: "ami-0053d11f74e9e7f52" InstanceType: Type: String Default: "t3.xlarge" KeyPair: Type: String Default: "ssm-key" Resources: VPC: Type: "AWS::EC2::VPC" Properties: CidrBlock: !Ref VPCCIDR EnableDnsSupport: "true" EnableDnsHostnames: "true" InstanceTenancy: default Tags: - Key: Name Value: !Sub "${ProjectPrefix}-vpc" PrivateSubnet: Type: "AWS::EC2::Subnet" Properties: AvailabilityZone: !Sub "${AWS::Region}a" CidrBlock: !Ref PrivateSubnetCIDR VpcId: !Ref VPC Tags: - Key: Name Value: !Sub "${ProjectPrefix}-private-subnet" PrivateRouteTable: Type: "AWS::EC2::RouteTable" Properties: VpcId: !Ref VPC Tags: - Key: Name Value: !Sub "${ProjectPrefix}-private-route" PrivateSubnetRouteTableAssociation: Type: "AWS::EC2::SubnetRouteTableAssociation" Properties: SubnetId: !Ref PrivateSubnet RouteTableId: !Ref PrivateRouteTable PrivateSecurityGroup: Type: "AWS::EC2::SecurityGroup" Properties: GroupDescription : "Private SecurityGroup" VpcId: !Ref VPC Tags: - Key: Name Value: !Sub "${ProjectPrefix}-security-group" SecurityGroupIngress: - IpProtocol: "tcp" FromPort: "443" ToPort: "443" CidrIp: !Ref VPCCIDR SecurityGroupEgress: - CidrIp: "127.0.0.1/32" IpProtocol: "-1" EndPointSSM: Type: "AWS::EC2::VPCEndpoint" Properties: PrivateDnsEnabled: true SecurityGroupIds: - !Ref PrivateSecurityGroup ServiceName: !Sub "com.amazonaws.${AWS::Region}.ssm" SubnetIds: - !Ref PrivateSubnet VpcEndpointType: "Interface" VpcId: !Ref VPC EndPointSSMMessages: Type: "AWS::EC2::VPCEndpoint" Properties: PrivateDnsEnabled: true SecurityGroupIds: - !Ref PrivateSecurityGroup ServiceName: !Sub "com.amazonaws.${AWS::Region}.ssmmessages" SubnetIds: - !Ref PrivateSubnet VpcEndpointType: "Interface" VpcId: !Ref VPC EndPointEC2Messages: Type: "AWS::EC2::VPCEndpoint" Properties: PrivateDnsEnabled: true SecurityGroupIds: - !Ref PrivateSecurityGroup ServiceName: !Sub "com.amazonaws.${AWS::Region}.ec2messages" SubnetIds: - !Ref PrivateSubnet VpcEndpointType: "Interface" VpcId: !Ref VPC EndPointS3: Type: "AWS::EC2::VPCEndpoint" Properties: RouteTableIds: - !Ref PrivateRouteTable ServiceName: !Sub "com.amazonaws.${AWS::Region}.s3" VpcEndpointType: "Gateway" VpcId: !Ref VPC EC2IAMRole: Type: "AWS::IAM::Role" Properties: RoleName: !Sub "${ProjectPrefix}-role" AssumeRolePolicyDocument: Version: "2012-10-17" Statement: - Effect: Allow Principal: Service: - "ec2.amazonaws.com" Action: - "sts:AssumeRole" Path: "/" ManagedPolicyArns: - "arn:aws:iam::aws:policy/AmazonSSMManagedInstanceCore" EC2InstanceProfile: Type: "AWS::IAM::InstanceProfile" Properties: Path: "/" Roles: - Ref: EC2IAMRole InstanceProfileName: !Sub "${ProjectPrefix}-PROFILE" EC2SecurityGroup: Type: "AWS::EC2::SecurityGroup" Properties: GroupDescription : "EC2 SecurityGroup" VpcId: !Ref VPC Tags: - Key: Name Value: !Sub "${ProjectPrefix}-ec2-security-group" SecurityGroupIngress: - IpProtocol: "tcp" FromPort: "22" ToPort: "22" CidrIp: "0.0.0.0/0" EC2Instance: Type: AWS::EC2::Instance Properties: InstanceType: !Ref InstanceType SubnetId: !Ref PrivateSubnet ImageId: !Ref AmiID SecurityGroupIds: - !Ref EC2SecurityGroup IamInstanceProfile: !Ref EC2InstanceProfile BlockDeviceMappings: - DeviceName: /dev/xvda Ebs: VolumeSize: 100 VolumeType: gp2 EbsOptimized: true SourceDestCheck: true KeyName: !Ref KeyPair Tags: - Key: Name Value: !Sub "${ProjectPrefix}-ec2" Outputs: VPC: Value: !Ref VPC Export: Name: !Sub "${ProjectPrefix}-vpc" VPCCIDR: Value: !Ref VPCCIDR Export: Name: !Sub "${ProjectPrefix}-vpc-cidr" PrivateSubnet: Value: !Ref PrivateSubnet Export: Name: !Sub "${ProjectPrefix}-private-subnet" PrivateRouteTable: Value: !Ref PrivateRouteTable Export: Name: !Sub "${ProjectPrefix}-private-route" PrivateSecurityGroup: Value: !Ref PrivateSecurityGroup Export: Name: !Sub "${ProjectPrefix}-private-securitygroup" EndPointSSM: Value: !Ref EndPointSSM Export: Name: !Sub "${ProjectPrefix}-endpoint-ssm" EndPointSSMMessages: Value: !Ref EndPointSSMMessages Export: Name: !Sub "${ProjectPrefix}-endpoint-ssmmessages" EndPointEC2Messages: Value: !Ref EndPointEC2Messages Export: Name: !Sub "${ProjectPrefix}-endpoint-ec2messages" EndPointS3: Value: !Ref EndPointS3 Export: Name: !Sub "${ProjectPrefix}-endpoint-s3" EC2SecurityGroup: Value: !Ref EC2SecurityGroup Export: Name: !Sub "${ProjectPrefix}-ec2-security-group" EC2Instance: Value: !Ref EC2Instance Export: Name: !Sub "${ProjectPrefix}-ec2"以下の内容をファイルに保存してください。以降、テンプレートファイル名を「ssmenv.yml」という前提で記述します。
スタックの作成
$ aws cloudformation create-stack --stack-name SSMEnvStack --template-body file://ssmenv.yml --capabilities CAPABILITY_NAMED_IAM { "StackId": "arn:aws:cloudformation:ap-northeast-1:767054379442:stack/DPM-DATA-MIGRATION-ENV-Stack/0e0b65d0-f268-11ea-be88-06e06928d272" }もし、KeyPareを、上記で作成したものと違うものを指定する場合は、コマンドの最後に
--parameters ParameterKey=KeyPair,ParameterValue="キーペア名"のようにしてデフォルトのパラメータ名を上書きしてください。
他に上書き可能なパラメータは、以下の通りです。
パラメータ名 設定値 デフォルト値 ProjectPrefix 各リソースに設定する名称の接頭子 SSM-ACCESS-ENV VPCCIDR VPCのCIDR 10.1.0.0/16 PrivateSubnetCIDR SubnetのCIDR 10.1.100.0/24 AmiID EC2のAMI ID ami-0053d11f74e9e7f52 InstanceType EC2のインスタンスタイプ t3.xlarge KeyPair EC2のキーペア名 ssm-key なお、AMIは、Amazon Linux 2 64bitを前提にしていますが、リージョンによってはIDが異なります。上記は、ap-northeast-1が前提です。
sshの準備
sshコマンドでSession Manager経由でEC2インスタンスに接続するためには
ホームディレクトリ/.ssh/config
に、以下の記述を行います。confighost i-* mi-* ProxyCommand sh -c "aws ssm start-session --target %h --document-name AWS-StartSSHSession --parameters 'portNumber=%p'"ssh実行
sshでEC2インスタンスに接続するには、以下の構文で行います。
$ ssh -i [pemファイル] ec2-user@[EC2インスタンスのインスタンスID]です。
例
$ ssh -i ssm-key.pem ec2-user@i-0af4afe4df0b3900b __| __|_ ) _| ( / Amazon Linux 2 AMI ___|\___|___| https://aws.amazon.com/amazon-linux-2/ [ec2-user@ip-10-1-100-148 ~]$EC2インスタンスのインスタンスID
以下のいずれかの方法で取得できます。
- マネジメントコンソールのEC2のインスタンスの一覧から取得する
AWS Cliでインスタンス一覧にフィルターをかけて取得する
$ aws ec2 describe-instances --filters "Name=tag:Name,Values={ProjectPrefixの値}-ec2" --query "Reservations[].Instances[].InstanceId"例
$ aws ec2 describe-instances --filters "Name=tag:Name,Values=SSM-ACCESS-ENV-ec2" --query "Reservations[].Instances[].InstanceId" [ "i-0af4afe4df0b3900b" ]まとめ
CloudFormationで構成しているため、スタックを削除すると、全て綺麗に消えてくれます。
今回はVPCごと作成するようになっていますが、少しテンプレートをいじることで、既存のVPCに接続することももちろんできます。
その場合は、EndPointの接続先になるサブネットなどにご注意ください。
- 投稿日:2020-09-09T20:04:45+09:00
[AWS] 踏み台サーバ不要!ローカルPCから、Private Subnet上のEC2インスタンスにssh/scpする
はじめに
この記事では「[AWS] Private Subnet内のEC2インスタンスにローカルPCのターミナルからSession Managerでアクセスする」の内容を改善し、もっと簡単に環境を構築できる手順を解説します。
そして、何がセキュアかというと、Private Subnetに配置したEC2インスタンスに直接接続できる、という点に注目したいと思います。そう、踏み台サーバが不要なのです。
事前準備
まず、最初にクライアント環境に以下のツールが必要ですので、必要に応じてご用意ください。
また、AWSのクレデンシャル情報も事前に設定してくおいてください。
環境変数AWS_ACCESS_KEY_ID AWS_SECRET_ACCESS_KEYもし必要であれば、
AWS_DEFAULT_REGIONも設定してください。
もしくは、$ aws configureで設定しても、どちらでも構いません。
キーペアの作成
クライアントからssh/scpでアクセスするためのキーペアを作成します。
この手順は、既にキーペアが存在し、ローカル環境に.pemファイルをダウンロード済みの場合はスキップして構いません。$ aws ec2 create-key-pair --key-name [キーペア名] --query 'KeyMaterial' --output text > [ローカル保存する.pemファイル名]例
$ aws ec2 create-key-pair --key-name ssm-key --query 'KeyMaterial' --output text > ssm-key.pem作成したファイルは、アクセス権を変更しておいてください。
$ chmode 400 ssm-key.pemCloudFormationの実行
テンプレート
構成概説
以下テンプレートは、以下の環境を構築します。
- VPC
- Subnet(Private Subnetとして作成)
- ルートテーブル(EndPointにのみルーティング)
- セキュリティグループ(443のみ許可)
- エンドポイント(ssm、ssmmessages、ec2messages、s3)
- EC2インスタンス
- EBS
AWSTemplateFormatVersion: "2010-09-09" Description: Create Session Manager Environment Metadata: "AWS::CloudFormation::Interface": ParameterGroups: - Label: default: "Project Name Prefix" Parameters: - ProjectPrefix - Label: default: "Network Configuration" Parameters: - VPCCIDR - PrivateSubnetCIDR - Label: default: "EC2" Parameters: - AmiID - InstanceType - KeyPair ParameterLabels: VPCCIDR: default: "VPC CIDR" PrivateSubnetCIDR: default: "PrivateSubnet CIDR" Parameters: ProjectPrefix: Type: String Default: "SSM-ACCESS-ENV" VPCCIDR: Type: String Default: "10.1.0.0/16" PrivateSubnetCIDR: Type: String Default: "10.1.100.0/24" AmiID: Type: String Default: "ami-0053d11f74e9e7f52" InstanceType: Type: String Default: "t3.xlarge" KeyPair: Type: String Default: "ssm-key" Resources: VPC: Type: "AWS::EC2::VPC" Properties: CidrBlock: !Ref VPCCIDR EnableDnsSupport: "true" EnableDnsHostnames: "true" InstanceTenancy: default Tags: - Key: Name Value: !Sub "${ProjectPrefix}-vpc" PrivateSubnet: Type: "AWS::EC2::Subnet" Properties: AvailabilityZone: !Sub "${AWS::Region}a" CidrBlock: !Ref PrivateSubnetCIDR VpcId: !Ref VPC Tags: - Key: Name Value: !Sub "${ProjectPrefix}-private-subnet" PrivateRouteTable: Type: "AWS::EC2::RouteTable" Properties: VpcId: !Ref VPC Tags: - Key: Name Value: !Sub "${ProjectPrefix}-private-route" PrivateSubnetRouteTableAssociation: Type: "AWS::EC2::SubnetRouteTableAssociation" Properties: SubnetId: !Ref PrivateSubnet RouteTableId: !Ref PrivateRouteTable PrivateSecurityGroup: Type: "AWS::EC2::SecurityGroup" Properties: GroupDescription : "Private SecurityGroup" VpcId: !Ref VPC Tags: - Key: Name Value: !Sub "${ProjectPrefix}-security-group" SecurityGroupIngress: - IpProtocol: "tcp" FromPort: "443" ToPort: "443" CidrIp: !Ref VPCCIDR SecurityGroupEgress: - CidrIp: "127.0.0.1/32" IpProtocol: "-1" EndPointSSM: Type: "AWS::EC2::VPCEndpoint" Properties: PrivateDnsEnabled: true SecurityGroupIds: - !Ref PrivateSecurityGroup ServiceName: !Sub "com.amazonaws.${AWS::Region}.ssm" SubnetIds: - !Ref PrivateSubnet VpcEndpointType: "Interface" VpcId: !Ref VPC EndPointSSMMessages: Type: "AWS::EC2::VPCEndpoint" Properties: PrivateDnsEnabled: true SecurityGroupIds: - !Ref PrivateSecurityGroup ServiceName: !Sub "com.amazonaws.${AWS::Region}.ssmmessages" SubnetIds: - !Ref PrivateSubnet VpcEndpointType: "Interface" VpcId: !Ref VPC EndPointEC2Messages: Type: "AWS::EC2::VPCEndpoint" Properties: PrivateDnsEnabled: true SecurityGroupIds: - !Ref PrivateSecurityGroup ServiceName: !Sub "com.amazonaws.${AWS::Region}.ec2messages" SubnetIds: - !Ref PrivateSubnet VpcEndpointType: "Interface" VpcId: !Ref VPC EndPointS3: Type: "AWS::EC2::VPCEndpoint" Properties: RouteTableIds: - !Ref PrivateRouteTable ServiceName: !Sub "com.amazonaws.${AWS::Region}.s3" VpcEndpointType: "Gateway" VpcId: !Ref VPC EC2IAMRole: Type: "AWS::IAM::Role" Properties: RoleName: !Sub "${ProjectPrefix}-role" AssumeRolePolicyDocument: Version: "2012-10-17" Statement: - Effect: Allow Principal: Service: - "ec2.amazonaws.com" Action: - "sts:AssumeRole" Path: "/" ManagedPolicyArns: - "arn:aws:iam::aws:policy/AmazonSSMManagedInstanceCore" EC2InstanceProfile: Type: "AWS::IAM::InstanceProfile" Properties: Path: "/" Roles: - Ref: EC2IAMRole InstanceProfileName: !Sub "${ProjectPrefix}-PROFILE" EC2SecurityGroup: Type: "AWS::EC2::SecurityGroup" Properties: GroupDescription : "EC2 SecurityGroup" VpcId: !Ref VPC Tags: - Key: Name Value: !Sub "${ProjectPrefix}-ec2-security-group" SecurityGroupIngress: - IpProtocol: "tcp" FromPort: "22" ToPort: "22" CidrIp: "0.0.0.0/0" EC2Instance: Type: AWS::EC2::Instance Properties: InstanceType: !Ref InstanceType SubnetId: !Ref PrivateSubnet ImageId: !Ref AmiID SecurityGroupIds: - !Ref EC2SecurityGroup IamInstanceProfile: !Ref EC2InstanceProfile BlockDeviceMappings: - DeviceName: /dev/xvda Ebs: VolumeSize: 100 VolumeType: gp2 EbsOptimized: true SourceDestCheck: true KeyName: !Ref KeyPair Tags: - Key: Name Value: !Sub "${ProjectPrefix}-ec2" Outputs: VPC: Value: !Ref VPC Export: Name: !Sub "${ProjectPrefix}-vpc" VPCCIDR: Value: !Ref VPCCIDR Export: Name: !Sub "${ProjectPrefix}-vpc-cidr" PrivateSubnet: Value: !Ref PrivateSubnet Export: Name: !Sub "${ProjectPrefix}-private-subnet" PrivateRouteTable: Value: !Ref PrivateRouteTable Export: Name: !Sub "${ProjectPrefix}-private-route" PrivateSecurityGroup: Value: !Ref PrivateSecurityGroup Export: Name: !Sub "${ProjectPrefix}-private-securitygroup" EndPointSSM: Value: !Ref EndPointSSM Export: Name: !Sub "${ProjectPrefix}-endpoint-ssm" EndPointSSMMessages: Value: !Ref EndPointSSMMessages Export: Name: !Sub "${ProjectPrefix}-endpoint-ssmmessages" EndPointEC2Messages: Value: !Ref EndPointEC2Messages Export: Name: !Sub "${ProjectPrefix}-endpoint-ec2messages" EndPointS3: Value: !Ref EndPointS3 Export: Name: !Sub "${ProjectPrefix}-endpoint-s3" EC2SecurityGroup: Value: !Ref EC2SecurityGroup Export: Name: !Sub "${ProjectPrefix}-ec2-security-group" EC2Instance: Value: !Ref EC2Instance Export: Name: !Sub "${ProjectPrefix}-ec2"以下の内容をファイルに保存してください。以降、テンプレートファイル名を「ssmenv.yml」という前提で記述します。
スタックの作成
$ aws cloudformation create-stack --stack-name SSMEnvStack --template-body file://ssmenv.yml --capabilities CAPABILITY_NAMED_IAM { "StackId": "arn:aws:cloudformation:ap-northeast-1:767054379442:stack/DPM-DATA-MIGRATION-ENV-Stack/0e0b65d0-f268-11ea-be88-06e06928d272" }もし、KeyPareを、上記で作成したものと違うものを指定する場合は、コマンドの最後に
--parameters ParameterKey=KeyPair,ParameterValue="キーペア名"のようにしてデフォルトのパラメータ名を上書きしてください。
他に上書き可能なパラメータは、以下の通りです。
パラメータ名 設定値 デフォルト値 ProjectPrefix 各リソースに設定する名称の接頭子 SSM-ACCESS-ENV VPCCIDR VPCのCIDR 10.1.0.0/16 PrivateSubnetCIDR SubnetのCIDR 10.1.100.0/24 AmiID EC2のAMI ID ami-0053d11f74e9e7f52 InstanceType EC2のインスタンスタイプ t3.xlarge KeyPair EC2のキーペア名 ssm-key なお、AMIは、Amazon Linux 2 64bitを前提にしていますが、リージョンによってはIDが異なります。上記は、ap-northeast-1が前提です。
また、上記以外のEBSのボリュームサイズなどは、適宜テンプレートを修正してください。
sshの準備
sshコマンドでSession Manager経由でEC2インスタンスに接続するためには
ホームディレクトリ/.ssh/config
に、以下の記述を行います。confighost i-* mi-* ProxyCommand sh -c "aws ssm start-session --target %h --document-name AWS-StartSSHSession --parameters 'portNumber=%p'"ssh実行
sshでEC2インスタンスに接続するには、以下の構文で行います。
$ ssh -i [pemファイル] ec2-user@[EC2インスタンスのインスタンスID]です。
例
$ ssh -i ssm-key.pem ec2-user@i-0af4afe4df0b3900b __| __|_ ) _| ( / Amazon Linux 2 AMI ___|\___|___| https://aws.amazon.com/amazon-linux-2/ [ec2-user@ip-10-1-100-148 ~]$EC2インスタンスのインスタンスID
以下のいずれかの方法で取得できます。
- マネジメントコンソールのEC2のインスタンスの一覧から取得する
AWS Cliでインスタンス一覧にフィルターをかけて取得する
$ aws ec2 describe-instances --filters "Name=tag:Name,Values={ProjectPrefixの値}-ec2" --query "Reservations[].Instances[].InstanceId"例
$ aws ec2 describe-instances --filters "Name=tag:Name,Values=SSM-ACCESS-ENV-ec2" --query "Reservations[].Instances[].InstanceId" [ "i-0af4afe4df0b3900b" ]まとめ
CloudFormationで構成しているため、スタックを削除すると、全て綺麗に消えてくれます。
今回はVPCごと作成するようになっていますが、少しテンプレートをいじることで、既存のVPCに接続することももちろんできます。
その場合は、EndPointの接続先になるサブネットなどにご注意ください。
- 投稿日:2020-09-09T18:51:31+09:00
AWS IoT Greengrass CoreをRaspberry Piにサイレントインストールする手順
こちらにある
gg-device-setup-latest.shスクリプトを利用します。サイレントインストールの元情報もここを参考にしています。https://docs.aws.amazon.com/greengrass/latest/developerguide/quick-start.html
以下の項目を組み合わせてサイレントインストールします。
事前準備
SSHを有効化して、作業フォルダを作成します。
mkdir ~/work cd ~/work作業PC側で、以下のワンライナーでAWS認証情報を取得します。
aws sts get-session-token --query 'Credentials | {A:AccessKeyId,B:SecretAccessKey,C:SessionToken}' --output yaml | awk 'NR==1{print "export AWS_ACCESS_KEY_ID="$2} NR==2{print "export AWS_SECRET_ACCESS_KEY="$2} NR==3{print "export AWS_SESSION_TOKEN="$2}'変数の設定
# ワンライナーで取得したAWS認証情報 export AWS_ACCESS_KEY_ID=AKIAIOSFODNN7EXAMPLE export AWS_SECRET_ACCESS_KEY=wJalrXUtnFEMI/K7MDENG/bPxRfiCYEXAMPLEKEY export AWS_SESSION_TOKEN=AQoDYXdzEJr1K...o5OytwEXAMPLE= # 以下は適当に調整します MAC_ADDR=$(ethtool -P eth0 | cut -d" " -f3 | tr -d :) export GG_GROUP_NAME=otomo-pi-grp-${MAC_ADDR} export GG_CORE_NAME=otomo-pi-core--${MAC_ADDR} export AWS_REGION=ap-northeast-1OS設定とConfigの生成
wget -q -O ./gg-device-setup-latest.sh https://d1onfpft10uf5o.cloudfront.net/greengrass-device-setup/downloads/gg-device-setup-latest.sh && chmod +x ./gg-device-setup-latest.sh && sudo -E ./gg-device-setup-latest.sh bootstrap-greengrass \ --region ${AWS_REGION} \ --group-name ${GG_GROUP_NAME} \ --core-name ${GG_CORE_NAME} \ --ggc-root-path / --log-path ./ --deployment-timeout 300 \ --verboseスクリプトが完了した時点で、以下のように
GreengrassDeviceSetup.config.infoが出力されています。
cgroup等のOS設定を反映させるため再起動します。
sudo rebootGreengrass Coreのインストール
Raspbean再度SSHにてログオンします。
# AWS認証情報の設定 export AWS_ACCESS_KEY_ID=AKIAIOSFODNN7EXAMPLE export AWS_SECRET_ACCESS_KEY=wJalrXUtnFEMI/K7MDENG/bPxRfiCYEXAMPLEKEY export AWS_SESSION_TOKEN=AQoDYXdzEJr1K...o5OytwEXAMPLE= # ワークディレクトリに移動 cd ~/work # プロンプトの答えのyesを流し込みスクリプトを実行 echo "yes" | sudo -E ./gg-device-setup-latest.sh bootstrap-greengrass以下のように表示されればインストール完了です。
[Option] Python3.7のgreengrasssdkインストール
greengrasssdkは初期では導入されてないので、必要に応じてインストールします。
curl -kL https://bootstrap.pypa.io/get-pip.py | sudo python3.7 sudo pip3.7 install greengrasssdk[Option] systemdの設定
以下のコマンドでGreengrass Coreをサービス化します。
# systemdの設定を投入 cat <<EOF | sudo tee /etc/systemd/system/greengrassd.service [Unit] Description=Greengrass Daemon [Service] Type=forking PIDFile=/var/run/greengrassd.pid Restart=on-failure ExecStart=/greengrass/ggc/core/greengrassd start ExecReload=/greengrass/ggc/core/greengrassd restart ExecStop=/greengrass/ggc/core/greengrassd stop [Install] WantedBy=multi-user.target EOF# サービスを有効化 sudo systemctl daemon-reload sudo systemctl enable greengrassd.service sudo systemctl start greengrassd.serviceAnsible化
こちらの自分のブログ記事でAnsible化もしてみました。

- 投稿日:2020-09-09T18:45:44+09:00
Glueに関して
ETLに関して
普段取得しているデータというのはそのままでは分析することが出来ないです。それは取得したデータにはデータフォーマットがばらばらであったり、非構造化データがあったりするからです。そのため、ETLという処理が必要になってきます。ETLとは「Extract」「Transform」「Load」の略になります。簡単にETLの説明するとさまざまな形式のデータを一定の形式に統一して保存する処理のことです。 一般的に、データウェアハウスにデータを保存する際の前処理として行われます。AWSのサービスではGlueがこれに当たります。
Glueに関して
AWSのGlueはデータの抽出や変換、ロードなどを簡単に行える完全マネージド型のサービスになります。サーバーレスであるため、自分たちでインフラ周り管理する必要がないです。Glueは大きく3つの機能に分かれます。「データカタログ」、「サーバーレスエンジン」、「オーケストレーション」です。
データカタログとは…メタデータを管理するリポジトリ機能のこと。このデータカタログを作成する方法は3つあります。「Glueクローラー」「GlueのAPI」「Hive DDL(Athena , EMR , Redshift , spectrum)」です。データソースとしてはAmazon DynamoDB , S3 ,Redshift , RDS などがあります。管理しているメタデータはAmazon Redshift spectrum,Amazon Athena , Amazon EMRに連携することが可能。データカタログはデータのスキーマ情報(データのカラム名やデータ型)を持ち、データベースごとに管理します。データそのものは持っていません。あくまでもデータの情報を持っているという感じです。使い方としてはAthenaで分析する際にデータレイクのS3からデータを持ってきます。その際にS3にあるデータがどのようなデータであるのかが分からないのでGlueクローラーで分析してカタログを作成し、それを参照しながらAthenaはクエリを行う流れになります。データカタログはクローラーで解析したメタデータを管理するっていう感じです。接
Apache hiveメタストアとは…Apache hiveで実データとは別に表の定義だけ格納する仕組みです。実データはHDFSやS3などに保存します。
クローラーとは…Glueのデータカタログにメタデータを作成するプログラムのこと。クローラを使用せずにテーブル定義をAPI経由で登録することも可能。
スキーマの管理…Glueではスキーマをバージョン管理することが可能。
接続方法…S3とDynamoDBに接続する際にはIAMロールでアクセスする。Redshift,RDS,オンプレミスDB,RDB on EC2に接続する際には事前に接続設定を追加して接続を行う。
ジョブとは…ETLの処理単位をジョブという。ジョブは3種類から選択することが可能です。「python shell」「spark」「spark streaming」の3つです。sparkによる並列分散処理なんかが行えたりします。これはS3のデータをデータカタログ経由でデータをとってくると何かと便利だったりします。ジョブはトリガーにて実行のタイミングを定義することができる。ジョブではGlueが自動生成したコード、自身で作成するスクリプト、既存のコードが実行可能。
DPUとは…DPUとはジョブ実行時に割り当てられる処理能力のこと。1DPU = 4vCPU , 16GBメモリ。
DynamicFrameとは…DynamicFrameとはSparkSQL DataFrameと似たGlue特有の抽象化の概念。DynamicFrameはスキーマ不一致を明示的にエンコードするschema on the fly を採用している。複数の型の可能性を残し、あとで決定できるようにするchoice型というのがある。そのため、一つの列に複数のデータ型を持つことが可能です。DynamicFrameとDataFrameではそれぞれ変換することが可能。しかし、pandasのDataFrameとは異なるため注意が必要になります。
ブックマーク機能…ジョブの実行状態を保持する機能であり、定常的にETL処理が必要な場合において有効。
トリガー…ジョブを開始するための定義を設定できる機能。スケジュール(日時、曜日)、ジョブイベント、手動で指定することが可能。
とりあえず実装してみる。
今回はS3 にあるjsonデータを変更してS3 に戻すというETL作業を行っていきたいと思う。
今S3にこのようなデータがあるとします。
データの中身はこんな感じになっています。
[{
"user": "太郎",
"age": "23",
"gender": "男"
},
{
"user": "次郎",
"age": "18",
"gender": "男"
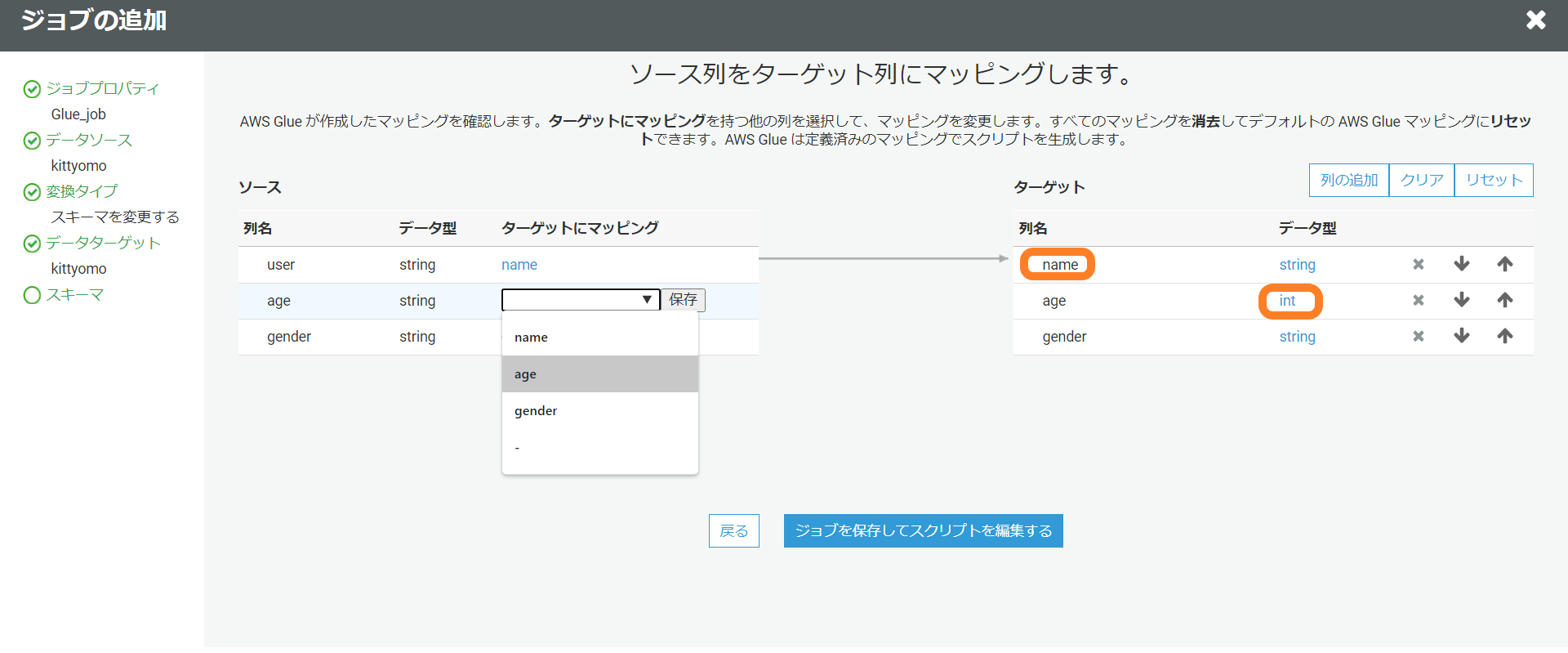
…………今回はageのデータ型を変更して、"user"を"name"に変更していきたいとをもいます。
まず初めにGlueのクローラーを使用してテーブルを作成します。
AWSのGlueの画面でクローラを選択します。次にクローラの追加を選択します。
クローラの名前は適当に入力します。
Specify crawler source typeはData Storesを選択。
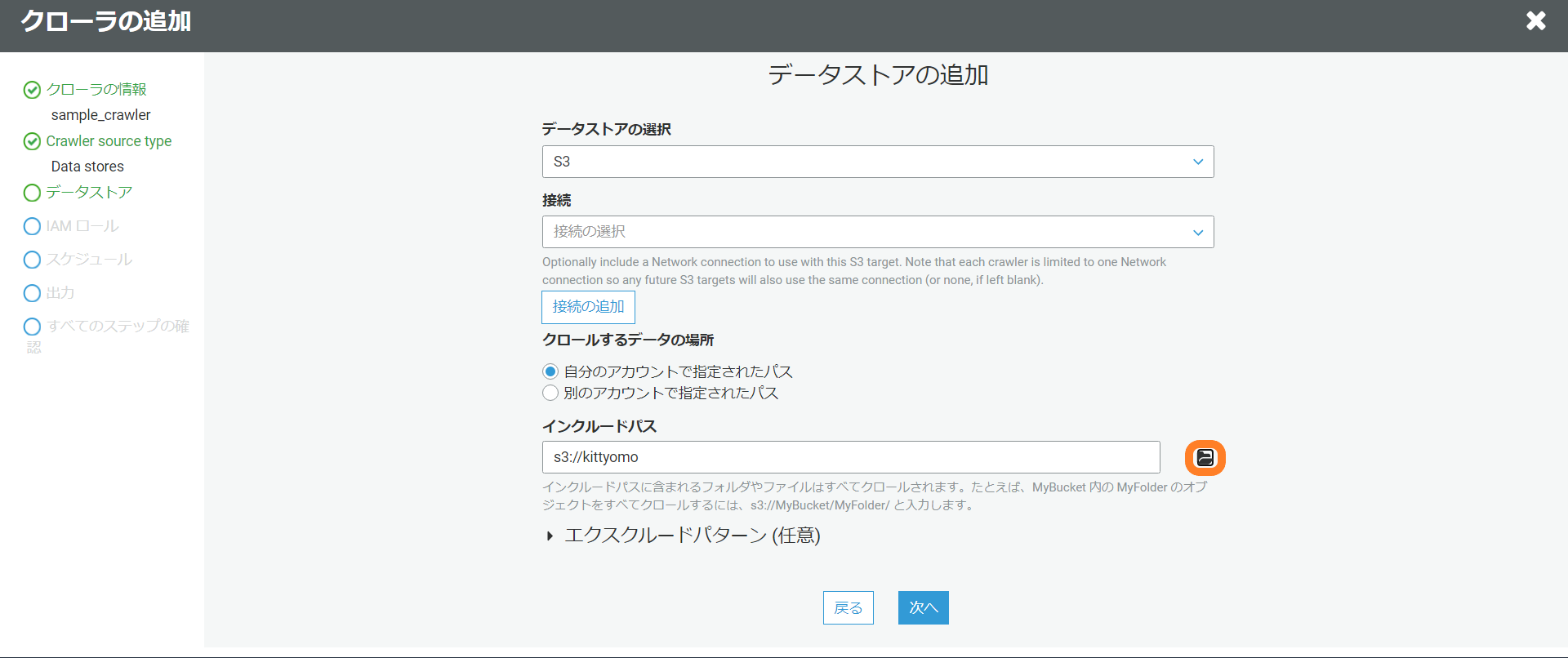
データストアの追加でどこからデータを取得するのか設定します。
別のデータストアの追加はしないのでいいえを選択。
IAM ロールの選択は・IAM ロールを作成するを選択、名前は適当に入力。
クローラのスケジュールを設定は特に時間とか指定しないのでオンデマンドで実行を選択。
クローラの出力を設定では今回はデータベースの追加で新しくデータベースを作成しました。
これで内容を確認して大丈夫であれば完了になります。完了するとクローラの画面で作成されているのが確認できるので実行します。
実行が完了するとテーブルにスキーマが登録されているのが確認できます。
次にジョブの作成を行います。
Glueが自動生成してくれるスクリプトを利用します。
データソースは先ほど作成したものを使用します。今回はageのデータ型を変更して、"user"を"name"に変更していくのが目的だったのでポチポチしながら行っていきます。マッピングも簡単に行うことが出来ました。
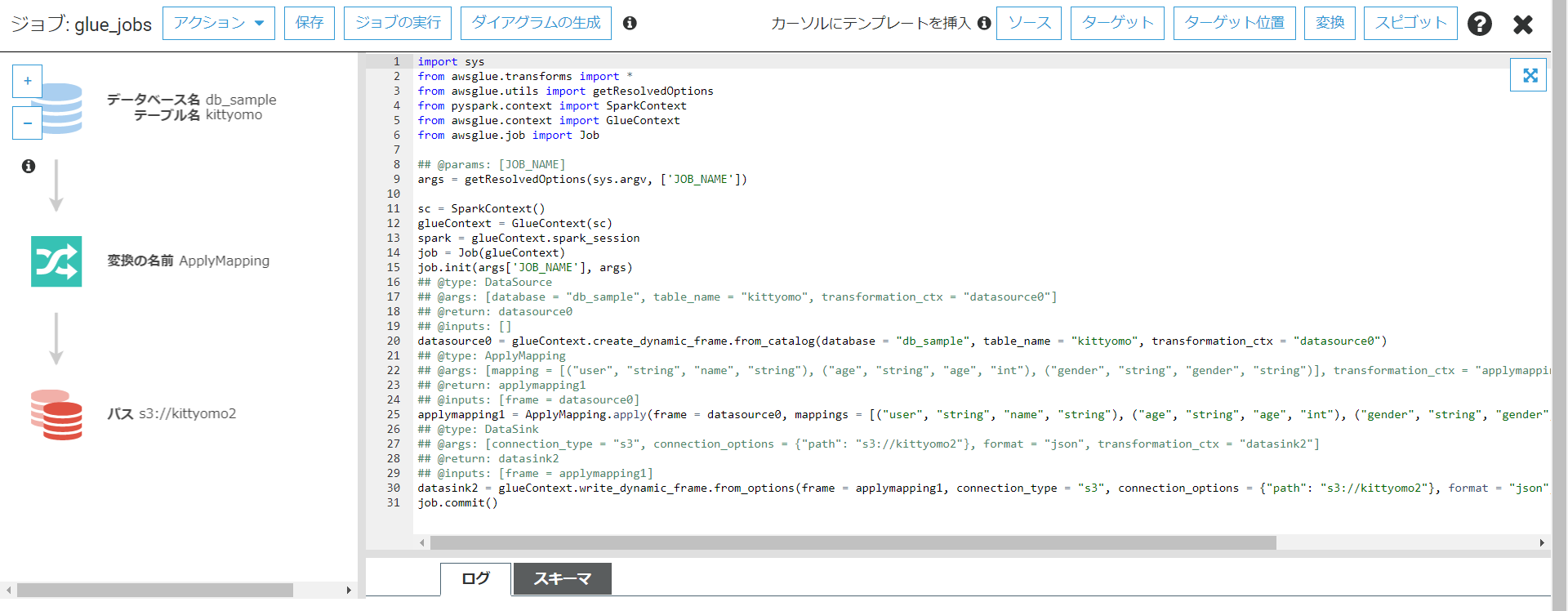
そうするとGlue JObスクリプトが自動生成されます。
ジョブの実行をします。
- 投稿日:2020-09-09T18:26:34+09:00
CloudFormationでEC2を作成
はじめに
前回はCloudFormationでVPC周りを作ったので、
CloudFormationでも実現するようにしていきたいと思います。CloudFormationの書き方としてはレイヤ毎に分けて書くのが推奨なので、
SecurityGroup / EC2 の作成のYAMLをそれぞれ書きました。内容についてはコメント記載しています。
みなさんの役に立ったら嬉しいです。VPC周りのリソースを引っ張って構成しているので、SecrutiyGroupとEC2のデプロイする前にVPCをデプロイしてから実施してください。
VPCの記事はこちらです。SecurityGroupのYAML
# 最新のテンプレートの形式バージョンは 2010-09-09 であり、現時点で唯一の有効な値です。 AWSTemplateFormatVersion: 2010-09-09 # 本テンプレートの説明です。 Description: Security Group Template # スタック作成時にMyIPを手動で入力します。 Parameters: MyIP: Description: IP address allowed to access EC2 Type: String # EC2のセキュリティグループ作成 # 許可IPはスタック作成時に設定したMyIP Resources: SecurityGroupEC2: Type: AWS::EC2::SecurityGroup Properties: GroupDescription: SecurityGroupEC2 GroupName: SecurityGroupEC2 SecurityGroupIngress: - IpProtocol: tcp FromPort: 80 ToPort: 80 CidrIp: !Ref MyIP - IpProtocol: tcp FromPort: 443 ToPort: 443 CidrIp: !Ref MyIP - IpProtocol: tcp FromPort: 22 ToPort: 22 CidrIp: !Ref MyIP Tags: - Key: Name Value: SecurityGroupEC2 VpcId: !ImportValue nnagashimaVPC # RDSのセキュリティグループ作成 # Private環境なので許可IPは0.0.0.0/0としている # postgresqlとmysqlだけを想定したポート許可 SecurityGroupRDS: Type: AWS::EC2::SecurityGroup Properties: GroupDescription: SecurityGroupRDS GroupName: SecurityGroupRDS SecurityGroupIngress: - IpProtocol: tcp FromPort: 3306 ToPort: 3306 CidrIp: 0.0.0.0/0 - IpProtocol: tcp FromPort: 5432 ToPort: 5432 CidrIp: 0.0.0.0/0 Tags: - Key: Name Value: SecurityGroupRDS VpcId: !ImportValue nnagashimaVPC # ALBのセキュリティグループ作成 # 443ポートのみを許可 SecurityGroupALB: Type: AWS::EC2::SecurityGroup Properties: GroupDescription: SecurityGroupALB GroupName: SecurityGroupALB SecurityGroupIngress: - IpProtocol: tcp FromPort: 443 ToPort: 443 CidrIp: 0.0.0.0/0 Tags: - Key: Name Value: SecurityGroupALB VpcId: !ImportValue nnagashimaVPC # 最後にCloudFormation上で作成した各セキュリティグループのIDを表示させます。 Outputs: SecurityGroupEC2: Value: !Ref SecurityGroupEC2 Export: Name: SecurityGroupEC2 SecurityGroupRDS: Value: !Ref SecurityGroupRDS Export: Name: SecurityGroupRDS SecurityGroupALB: Value: !Ref SecurityGroupALB Export: Name: SecurityGroupALBEC2のYAML
# 最新のテンプレートの形式バージョンは 2010-09-09 であり、現時点で唯一の有効な値です。 AWSTemplateFormatVersion: 2010-09-09 # 本テンプレートの説明です。 Description: EC2 Template # 事前パラメータの定義 Parameters: # EC2インスタンスの認証キーの指定(デフォルトではnn-ec2を指定) KeyName: Description: The EC2 Key Pair to allow SSH access to the instance Type: "AWS::EC2::KeyPair::KeyName" Default: nn-ec2 # 作成できるEC2インスタンスタイプの制限 InstanceType: Description: WebServer EC2 instance type Type: String Default: t2.micro AllowedValues: - t2.micro - t2.small - t3.medium Resources: # EIPを新規アサイン ElasticIP: Type: AWS::EC2::EIP Properties: Domain: vpc Tags: - Key: Name Value: nn-ec2-test # EC2インスタンスをデプロイ、AMZ2を起動している。 EC2: Type: AWS::EC2::Instance Properties: ImageId: ami-00d101850e971728d KeyName: !Ref KeyName InstanceType: !Ref InstanceType NetworkInterfaces: - AssociatePublicIpAddress: "true" DeviceIndex: "0" SubnetId: !ImportValue PublicSubnetD GroupSet: - !ImportValue SecurityGroupEC2 BlockDeviceMappings: - DeviceName: '/dev/xvda' Ebs: VolumeType: 'gp2' VolumeSize: 10 Tags: - Key: Name Value: nn-ec2-test # EC2インスタンスをデプロイ、AMZ2を起動している。 IPAssoc: Type: AWS::EC2::EIPAssociation Properties: InstanceId: !Ref EC2 EIP: !Ref ElasticIP # EC2インスタンスをデプロイした結果を出力 Outputs: InstanceId: Value: !Ref EC2 Export: Name: InstanceId AZ: Value: Fn::GetAtt: - EC2 - AvailabilityZone Export: Name: AZ PublicIP: Value: Fn::GetAtt: - EC2 - PublicIp Export: Name: PublicIp最後に
ここまでコード管理できるようになると最初の準備がとても楽で、且つ上物の構築するだけになるので工数がだいぶ下がるようになると思います。
なにより構成管理が楽になるのがメリットです。
ただ既存のリソースを書き換える時だけは変更箇所をよくみてやらないと痛い目に合うので、注意が必要ですね。
これを機にもっと極めてCloudFormationだけで作れるようになっていきたいと思います。
- 投稿日:2020-09-09T17:48:04+09:00
【Rust】rusoto_dynamodbが使いやすくなるdynomiteの紹介
はじめに
RustでDynamoDBを扱うときはrusoto_dynamodbを使いますが、
dynomiteというCrateを組みあわせると非常に使いやすくなります。
カッコよく言えば、ハイレベルなインターフェースを提供してくれます。DynamoDBの
Booksというテーブルに項目を作成するコードを、
「rusoto_dynamodbのみで書いた場合」と「dynomiteを使った場合」で比較してみます。rusoto_dynamodbのみで書いた場合
rusoto_dynamodbでテーブルに項目を作成するときは、
PutItemInput構造体のインスタンスを生成する必要があります。
作成したい項目の情報はHashMap<String, AttributeValue>でitemにセットします。pub struct PutItemInput { pub item: HashMap<String, AttributeValue>, pub table_name: String, ... }
AttributeValueはDynamoDBのデータ型1に対応したフィールドを持ちます。pub struct AttributeValue { pub b: Option<Bytes>, // Binary pub bool: Option<bool>, // Boolean pub bs: Option<Vec<Bytes>>, // Binary Set pub l: Option<Vec<AttributeValue>>, // List pub m: Option<HashMap<String, AttributeValue>>, // Map pub n: Option<String>, // Number pub ns: Option<Vec<String>>, // Number Set pub null: Option<bool>, // Null pub s: Option<String>, // String pub ss: Option<Vec<String>>, // String Set }例えば、下の表のような項目を作成するとします。
名前 値 データ型 id 101 Number title Book 101 Title String price 2 Number このときのコードはこんな感じです。
rusoto_dynamo.rslet mut new_item = HashMap::new(); new_item.insert( "id".to_string(), AttributeValue { n: Some("101".to_string()), ..AttributeValue::default() }, ); new_item.insert( "title".to_string(), AttributeValue { s: Some("Book 101 Title".to_string()), ..AttributeValue::default() }, ); new_item.insert( "price".to_string(), AttributeValue { n: Some("2".to_string()), ..AttributeValue::default() }, ); let input = PutItemInput { table_name: "Books".to_string(), item: new_item, ..PutItemInput::default() };dynomiteを使った場合
まずは項目を表す構造体を定義します。
use dynomite::Item; #[derive(Item)] struct Book { #[dynomite(partition_key)] id: i32, title: String, price: i32, }すると先ほどのコードはこのように簡潔に書けます。
new_item.into()でBook構造体をHashMap<String, AttributeValue>に変換してくれます。dynomite.rslet new_item = Book { id: 101, title: "Book 101 Title".to_string(), price: 2, }; let input = PutItemInput { table_name: "Books".to_string(), item: new_item.into(), ..PutItemInput::default() };このとき、
Book::from_attrs(hm)でHashMap<String, AttributeValue>->Book構造体の変換もサポートしています。
項目を取得したときに大活躍します。参考
rusoto_dynamodb - Rust
softprops/dynomite: ⚡? ? make your rust types fit DynamoDB and visa versa
- 投稿日:2020-09-09T17:32:22+09:00
AWS Global Acceleratorを使ってAWS ECSのIP固定をやってみた
背景
大人の事情に伴い、とある環境においてはアクセス先(AWSの各種リソース)のIPを予め固定しておく必要があった。
今回の対象はAWS ECS(Fargate)とAPI Gatewayであり、超簡略化して書くと以下のような感じである。
「AWSへのアクセス元を絞る」といったケースはよく聞くが、「AWSリソースのIPを固定する」というケースは初めてだったので、その調査結果をまとめる。
結論
結論から言うと、AWS Global Acceleratorを使って固定IPをApplication Load Balancerにくっつけることで対処が可能だった。
調べたこと
1. ECS(Fargate)
ECS(Fargate)を使用する際、
(1)public subnetに配置してpublic IPをつけ、それを使って外部とアクセスするor(2)private subnetに配置してNAT Gateway(or NAT Instance)経由で外部とアクセスするの2択になる。
(1)の方法だとIPは露出できるが、これは固定IPではないので要件を満たさない。
以下、(2)に関して少し調べてみた。1-1. NAT Gateway
「NAT Gatewayのおかげでprivate/public subnetの連携ができているのなら、そこで使ってるElastic IPに相乗りすれば良いのでは?」と考えた。
そこで手始めにNAT Gayeway用のIPにアクセスしてみたがレスポンスが返ってこなかった。調べてみた所、公式のNAT ゲートウェイのトラブルシューティングに答えが書いてあった。
なるほど...そもそもそういう用途ではないのか。
1-2. NAT Instance
NAT Gatewayがダメならインスタンスならどうだ!?と思って試したが結果は同じだった...。
ここでようやく、
NAT Gatewa/Instanceはあくまでもprivate subnetからpublic subnetにアクセスする際に使用するものであり、外部のインターネットからコレに対してアクセスするためのものではないということに気づいた...。1-3. リバースプロキシ・サーバーを建てる
「Nginxなどのリバースプロキシ用のサーバーを建てて、ソイツを経由するのはどうだろう?」と思いついた。
雰囲気としては以下のような構成だ。
ELBでALBの代わりにNetwork Load Balancerを使っているのは、Network Load Balancerを使うと固定IPをアタッチできるためである。
*詳細はこちら:Elastic Load Balancing の特徴
この構成でのメリット/デメリットは以下の感じ。
メリット
- 既存のリソースに対する変更なし
デメリット
- 管理するインスタンスが増える
- リバースプロキシ・サーバーの運用知見が薄い
- アクセス負荷は低いが、落としちゃいけない類のものなので、トラブルシューティングがつらそう
トラブった時に大変そうだなぁという印象..。
2. API Gateway
API GatewayのIPが固定できるか(そもそも固定かどうかも含め)を調べてみたが、基本的にはできないっぽい感じだった...。
AWS Global Accelerator現る
ここまであまり良い情報が無かったので、「AWSで固定IPを使う手段はないか」を調べた所、AWS Global Acceleratorというのがあることを知った。
公式の説明は以下の通り
AWS Global Accelerator は、ローカルまたは世界中のユーザーに提供するアプリケーションの可用性とパフォーマンスを改善するサービスです。Application Load Balancer、Network Load Balancer、Amazon EC2 インスタンスなど、単一または複数の AWS リージョンのアプリケーションエンドポイントへの固定エントリポイントとして機能するスタティック IP アドレスを提供します。
AWS Global Accelerator は、AWS グローバルネットワークを使用してユーザーからアプリケーションへのパスを最適化し、トラフィックのパフォーマンスを 60% も改善します。速度比較ツールを使用することで、お客様のロケーションからどのようなパフォーマンスの利点があるかをテストできます。AWS Global Accelerator は、アプリケーションエンドポイントの状態を継続的にモニタリングし、30 秒以内に正常なエンドポイントにトラフィックをリダイレクトします。
なるほど、ALBにもアタッチ可能な固定IP!
ほしかったのはまさしくコレだ!軽く触ったところでは、Global Accelerator経由で固定IPを生成してALBにアタッチし、外部からそのIPでアクセスできた。
API Gatewayに対してGlobal Acceleratorをアタッチすることはできないが、ALBに対してLambdaを登録できるようになったらしいので、API Gatewayに紐付いたLambdaへのアクセスもALBを使えば良さそう。
*詳細はこちら:アプリケーションロードバランサー(ALB)のターゲットにAWS Lambdaが選択可能になりました構成としては以下のような感じ。
この構成でのメリット/デメリットは以下の感じ。
メリット
- 既存のリソースに対する変更なし
- 自分で管理しないといけないリソースの追加はない(マネージドのものが追加されるだけ)
デメリット
- ぱっと思いつかない
もうコレでいいじゃん!
というわけでGlobal Acceleratorを使って実装していこうと思う。所感
クラウドインフラ関連の力は、知っているサービスの数(どのような用途に向いているのかなどを理解している前提)に左右されると言っても過言ではないのかもしれないと思った。
参考




- 投稿日:2020-09-09T17:10:44+09:00
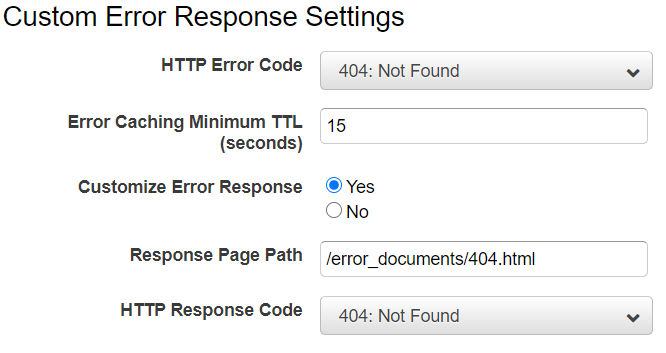
CloudFront 運用で覚えておきたいこと
CloudFront でコンテンツをキャッシュし、システム負荷の軽減・レスポンス速度の向上を図ることも多いと思います。
私自身も最近、CloudFront で CDN 環境を構築したばかりです。
運用フェーズに入り、構築時には気付けなかった CloudFront の設定・仕様を今後の為にまとめました。覚えておきたいこと
- オブジェクトのキャッシュ設定
- カスタムエラーページのキャッシュ設定
- オリジンとの通信でhttpとhttpsを有効にするときの注意
- s3オリジンでオブジェクトが存在しないとき403エラーが返ってくる
- デフォルトのルートオブジェクトの指定
- アクセスログのステータスがゼロ
オブジェクトのキャッシュ設定
ラジオボタン選択形式であることから勝手に誤った解釈をしてしまいました
どのように誤った解釈をしてしまったか
- Use Origin Cache Headers
- オリジンの Cache-Control、Expires のみでキャッシュされる
- Customize
- カスタマイズ設定で指定した TTL 値でキャッシュされる = オリジンの Cache-Control、Expires を無視する
指定した TTL 値でキャッシュされないケースが発生した為、調査したが原因不明。あらためて公式ドキュメントを読み返すとCloudFront がキャッシュにオブジェクトを保持する期間の指定の解釈に誤りがあることに気付きました。
現在はどちらか片方の設定のみが有効ということはなく、「オリジンが指定するキャッシュ制御を基準としてTTL値をカスタマイズできる」と解釈しています。詳しくは、公式ドキュメントをご確認ください
「ディストリビューションを作成または更新する場合に指定する値」ページ
https://docs.aws.amazon.com/ja_jp/AmazonCloudFront/latest/DeveloperGuide/distribution-web-values-specify.html「コンテンツがエッジキャッシュに保持される期間の管理 (有効期限)」ページ
https://docs.aws.amazon.com/ja_jp/AmazonCloudFront/latest/DeveloperGuide/Expiration.htmlカスタムエラーページのキャッシュ設定
エラーに対するキャッシュ時間は、オブジェクトが正常になったときを考慮して短めに設定していますが、先の「オブジェクトのキャッシュ設定」に続き、こちらも誤った解釈をしておりました
どのように誤った解釈をしてしまったか
「Error Caching Minimum TTL (seconds)」で設定した TTL 値でキャッシュされる = オリジンの Cache-Control、Expires を無視すると解釈してしまいました
エラーのキャッシュが長すぎる展開になってしまいました。
このケースでも公式ドキュメントを読み返し間違いに気付きました。
オリジンの Cache-Control が優先されるので「Error Caching Minimum TTL (seconds)」で設定した値でキャッシュさせてたい場合、オリジンのCache-Control を調整しています動作について公式ドキュメントから抜粋します
「CloudFront がエラーをキャッシュする時間を制御する」ページ
https://docs.aws.amazon.com/ja_jp/AmazonCloudFront/latest/DeveloperGuide/custom-error-pages-expiration.htmlオリジンが Cache-Control max-age または Cache-Control s-maxage ディレクティブ、あるいは Expires ヘッダーを追加する場合: CloudFront は、ヘッダーの値と [Error Caching Minimum TTL (エラーキャッシュ最小 TTL)] の値のどちらか大きい方の値の期間、エラーレスポンスをキャッシュします。
オリジンとの通信でhttpとhttpsを有効にするときの注意
オリジンポリシーを「Match Viewer (ビューワーに合わせる)」に設定しているケースになります。
この場合、オリジンからのレスポンスがプロトコル毎に異なっていたら注意ください!例えば、http リクエストを https に301リダイレクトしてるケース
パターン1. 先に https リクエストされる
-> コンテンツがキャッシュされる
-> 後に http リクエストされる
-> コンテンツがキャッシュされているのでコンテンツを正常表示パターン2. 先に http リクエストされる
-> 301 リダイレクトがキャッシュされる
-> 後に https リクエストされた
-> 301 リダイレクトがキャッシュされているのでリダイレクトループパターン2では、リダイレクトループに陥るケースとなりました。
対応として「リクエストのプロトコルに基づいてキャッシュを設定する」必要があります。
公式ドキュメントから抜粋します。「リクエストヘッダーに基づくコンテンツのキャッシュ」ページ
https://docs.aws.amazon.com/ja_jp/AmazonCloudFront/latest/DeveloperGuide/header-caching.htmlリクエストのプロトコル (HTTP または HTTPS) に基づいて、オブジェクトの異なるバージョンを CloudFront でキャッシュするには、CloudFront-Forwarded-Proto ヘッダーをオリジンに転送するように CloudFront を設定します。
この動作は、オリジンポリシーの「Match Viewer (ビューワーに合わせる)」の仕様に起因します。
「ディストリビューションを作成または更新する場合に指定する値」のページから抜粋します。
https://docs.aws.amazon.com/ja_jp/AmazonCloudFront/latest/DeveloperGuide/distribution-web-values-specify.htmlCloudFront は、ビューワーリクエストのプロトコルに応じて HTTP または HTTPS を使用してオリジンと通信します。ビューワーが HTTP と HTTPS の両方のプロトコルを使用してリクエストを行った場合でも、CloudFront がオブジェクトをキャッシュするのは 1 回だけです。
s3オリジンでオブジェクトが存在しないとき403エラーが返ってくる
CloudFront のオリジンとして S3バケットを OAI 接続するケースもあるかと思います。
S3 バケットポリシーに "s3:ListBucket" の許可がないことでオブジェクトが存在しない URL にアクセスしたとき 403 エラーが返ってしまいます。404 を返したいですよね。公式ドキュメントから抜粋します。
「Amazon S3 から HTTP 403: Access Denied エラーをトラブルシューティングする方法」ページ
https://aws.amazon.com/jp/premiumsupport/knowledge-center/s3-troubleshoot-403/
ページ内「存在しないオブジェクト」を参照くださいリクエストされたオブジェクトがバケット内に存在することを確認します。ユーザーに s3:ListBucket のアクセス許可がない場合、ユーザーには「404 Not Found」エラーの代わりに、存在しないオブジェクトに対し、アクセス拒否エラーが表示されます。
デフォルトのルートオブジェクトの指定
オリジンが S3 の場合、注意が必要でした。
https://hogehoge.jp のリクエストに対してあらかじめ設定したオブジェクトを返すものです。
あくまでもルートに対する設定となりサブディレクトリには有効でないことに注意ください。
https://hogehoge.jp/hoge/ とアクセスしてコンテンツのダウンロードが開始されたときは「なぜ?」となってしまいました。公式ドキュメントから抜粋します。
「デフォルトのルートオブジェクトの指定」ページ
https://docs.aws.amazon.com/ja_jp/AmazonCloudFront/latest/DeveloperGuide/DefaultRootObject.html
ページ内「ヘッダーとデフォルトのルートオブジェクトの連携方法」を参照くださいただし、デフォルトルートオブジェクトを定義しても、ディストリビューションのサブディレクトリに対するエンドユーザーリクエストはデフォルトルートオブジェクトを返しません。たとえば、index.html がデフォルトルートオブジェクトであり、CloudFront が CloudFront ディストリビューション下の install ディレクトリに対するエンドユーザーリクエストを受け取ったと仮定します。
http://d111111abcdef8.cloudfront.net/install/
index.html のコピーが install ディレクトリ内にあっても、CloudFront はデフォルトルートオブジェクトを返しません。
アクセスログのステータスがゼロ
運用中にアクセスログをチェックしたところ status = 0 のアクセスログが存在していました。
公式ドキュメントを確認するとビューワーはリクエスト送信後にレスポンスを受信することなく接続が終了したときの値とのこと。公式ドキュメントから抜粋します。
「アクセスログの設定および使用」ページ
https://docs.aws.amazon.com/ja_jp/AmazonCloudFront/latest/DeveloperGuide/AccessLogs.html
ページ内「ウェブディストリビューションのログファイル形式」セクションの表を参照ください。000。CloudFront がリクエストに応答する前に、ビューワーが接続をクローズしたこと (ブラウザタブを閉じたなど) を示します。CloudFront でレスポンスの送信を開始した後でビューワーで接続を終了すると、該当する HTTP ステータスコードがログに記録されます。
あとがき
いろいろと誤認識してしまったと反省。
同じ過ちを繰り返さない為の「CloudFront 運用で覚えておきたいこと」でした。

- 投稿日:2020-09-09T16:34:30+09:00
CircleCI + Capistrano + AWS(EC2) + Railsで自動デプロイしてみた
はじめに
先日、Capistranoを使って自作のポートフォリオをAWSにデプロイしたので、CircleCIと組み合わせて自動デプロイしてみました。
筆者はプログラミング学習を始めて4ヶ月ぐらいですが、一週間ほどで実装できました。
ポートフォリオにCircleCI/CDを組み込んでみたい!という方の参考になれば嬉しいです。
ご指摘等あれば、コメントいただければ幸いです。
前提
- Railsアプリ作成済
- CIrcleCIによる自動テストを導入済
- Capistranoを使ってAWSにデプロイ済
CircleCIとCapistranoに関しては別の記事でまとめています。
CircleCIでSystemSpec(RSpec)とRubocopを走らせる)
Capistrano + AWS(EC2) + Rails で簡単デプロイ手順
複数の設定をする必要があるので、順を追ってやっていきましょう。
- CircleCIにssh秘密鍵を登録して、AWSのEC2インスタンスにアクセスできるようにする
- CircleCIのコンソール上で環境変数を設定する
- .circleci/config.ymlを編集して、SSH接続できることを確認する
- GithubへpushしたときにCapistranoデプロイを走らせる
- Githubのブランチがmasterの時にだけCapistranoデプロイを走らせるように設定する
1.CircleCIにSSH秘密鍵を登録
CIrcleCIのGUI上で使用するプロジェクトを選択した後に"Project settings >> SSH KEYS >> Add SSH key" を選択して
Host NameとPrivate Keyを記入します。
Host Nameはドメイン、またはIPを記述します。
筆者は独自ドメインを取得していたのでappname.comを記述しました。
Private Keyは秘密鍵の中身を記述します、
ただ、ここで注意点が2点があるので説明します。(筆者はここで2〜3日詰まりました...)秘密鍵を登録する時の注意点
1. ローカルからEC2にログインする際に使用する秘密鍵の中身を記述する
自作アプリを作成してAWSにデプロイまでやっていると、AWSアクセスキーやGithubとの紐付けのための秘密鍵など、複数の秘密鍵があるはずです。
そのため、どの秘密鍵を使用すればいいのかが迷うかもしれません。(筆者は迷いました...)必要な鍵はローカルからEC2にログインする際に使用する秘密鍵です。
もし、秘密鍵を~/.sshに格納している場合、秘密鍵は以下のコマンドで一覧が確認します。
(local)[~]$ cd ~/.ssh [.ssh]$ ls筆者の場合はローカルからEC2にログインする際に以下のコマンドを使用します。
(local)[~]$ ssh appname_rsaその場合、ターミナル上で以下のコマンドを打ち、秘密鍵の中身をコピーできます。
(local)[~]$ pbcopy < ~/.ssh/appname_rsaコピーした中身を
Private Keyにペーストしましょう。そして、記述内容の冒頭が
-----BEGIN RSA PRIVATE KEY-----であればOK
です。もし、
-----BEGIN OPENSSH PRIVATE KEY-----であれば次の注意点に進みましょう。2. 秘密鍵のファイル形式はPEM形式でなければならない
SSH Keyのファイル形式は
OPENSSHとPEMがあり、CircleCIに設定するSSH Keyのファイル形式はPEMに指定されています。ファイル形式の見分け方は秘密鍵の中身の冒頭部分でわかります。
OPENSSHの場合:-----BEGIN OPENSSH PRIVATE KEY-----
PEMの場合:-----BEGIN RSA PRIVATE KEY-----もし、ローカルからEC2にログインする際に使用する秘密鍵が
OPENSSH形式だった場合は、PEM形式の秘密鍵を作成し、EC2にログインできるように設定する必要があります。筆者は
OPENSSH形式で作成していたので、次の手順で秘密鍵を作成しなおしました。PEM形式の秘密鍵の作成・ログイン設定方法
まずローカルで鍵の生成を行います。
(local)[~]$ cd .ssh [.ssh]$ ssh-keygen -m pem (#公開鍵を作成) ----------------------------- Enter file in which to save the key ():appname_rsa (#ここでファイルの名前を記述して、エンター) Enter passphrase (empty for no passphrase): (#何もせずそのままエンター) Enter same passphrase again: (#何もせずそのままエンター) ----------------------------- [.ssh]$ ls #「appname_rsa」と「appname_rsa.pub」が生成されたことを確認 [.ssh]$ cat appname_rsa.pub (#鍵の中身をターミナル上に出力→ssh-rsa~~~~localまでをコピーしておく)次にサーバー側(EC2)で先ほど作成した公開鍵を設定します。
(server)[yuki|~]$ mkdir .ssh [yuki|~]$ chmod 700 .ssh [yuki|~]$ cd .ssh [yuki|.ssh]$ vim authorized_keys (#vimが開く) ----------------------------- ssh-rsa sdfjerijgviodsjcIKJKJSDFJWIRJGIUVSDJFKCNZKXVNJSKDNVMJKNSFUIEJSDFNCJSKDNVJKDSNVJNVJKDSNVJKNXCMXCNMXNVMDSXCKLMKDLSMVKSDLMVKDSLMVKLCA -------@--------no-MacBook-Air.local (#先ほどコピーした鍵の中身を貼り付け) ----------------------------- [yuki|.ssh]$ chmod 600 authorized_keys [yuki|.ssh]$ exit [ec2-user|~]$ exit完了したら、ローカルに戻って鍵をどの通信の認証時に使用するか等を設定します。
(local)[~]$ cd .ssh [.ssh]$ vim config (#Vimを起動し、設定ファイルを編集する) # 以下を追記 Host appname_rsa Hostname EC2のElastic IP (#自分の設定に合わせて) Port 22 User yuki (#EC2のユーザー名) IdentityFile ~/.ssh/appname_rsa (#秘密鍵の設定) -----------------------------これで
PEM形式の秘密鍵を使ったSSH通信が可能になります。
ローカルで下記コマンドを入力し、実際にログインできるか試してみましょう。(local)ssh appname_rsaログインできれば、設定完了です。
ここまでできたら、注意点1を参考にしてCircleCIの
Private Keyに秘密鍵の中身を記述して登録しましょう。2. CircleCIのコンソール上で環境変数を設定する
CircleCIはGithubのソースコードをベースにデプロイを行います。
そのため、gitignoreに記述されているようなGithub上にpushされていないファイルは認識できません。そしてCircleCIではコンソール上で環境変数として設定することで、そういったファイルを管理する機能があるのでそれを利用します。
CircleCIのプロジェクトの設定から
Environment Variablesのページへ行き、Add Variableを選択します。そして、二つの環境変数を設定します。
Name:'RAILS_MASTER_KEY' Value: ローカルにある'master.key'の中身を記述。 Name:'PRODUCTION_SSH_KEY' Value:'~/.ssh/appname_rsa_xxxxxxxxxxxxxxx~'
PRODUCTION_SSH_KEYのValueのappname_rsa_の後ろには、先ほど登録したSSH KeyのHost Nameの隣に記述されているFingerprintsの:抜きの文字列を記述してください。次に本番環境でのCapistranoのSSH接続設定を行います。
ここでは、PRODUCTION_SSH_KEYを使ってconfig/deploy/production.rbを記述しましょう。config/deploy/production.rbserver 'EC2のElastic IPを記述', user: 'yuki', roles: %w[app db web] # CircleCIのGUIで設定した環境変数を使ってSSH接続 set :ssh_options, { keys: [ENV.fetch('PRODUCTION_SSH_KEY').to_s], forward_agent: true, auth_methods: %w[publickey] }3. SSH通信できることを確認する
.circleci/config.ymlに以下の記述を追加しましょう。
Fingerprintsには先ほど登録したSSH KeyのHost Nameの隣に記述されているのでコピペしてください。.circleci/config.yml- add_ssh_keys: fingerprints: - "XX:XX:XX:XX:XX:XX:XX:XX:XX:XX:XX:XX:XX:XX:XX:XX"そしてgithubへpushしてみましょう。
実行できていれば、CircleCI側のコンソールで、
Installing additional ssh keysという処理に対してInstalled key XX:XX:XX:XX:XX:XX:XX:XX:XX:XX:XX:XX:XX:XX:XX:XXと表示されるはずです。
4. GithubへpushしたときにCapistranoを走らせる
.circleci/config.ymlに以下の記述をします。.circleci/config.yml- add_ssh_keys: fingerprints: - "XX:XX:XX:XX:XX:XX:XX:XX:XX:XX:XX:XX:XX:XX:XX:XX" - deploy: name: Capistrano deploy command: bundle exec cap production deployGithubにpushしてみましょう。
自動デプロイできるはず!...です。5. Githubのブランチがmasterの時にだけCapistranoデプロイを走らせるように設定する
circleci/config.ymlのworkflowsの最後にfilters追記します。.circleci/config.yml# build,test,deployを記述。 ・ ・ ・ workflows: version: 2 build_accept_deploy: jobs: - build - test: requires: - build - deploy: requires: - test filters: branches: only: masterこれでGithubのブランチがmasterの時にだけCapistranoデプロイが走るようになります!
まとめ
筆者はSSH認証の部分でかなりつまずきました笑。
同じようにつまづいている方の手助けになれば嬉しいです☺️
最後にCircleCIとCapistranoのソースコードと参考記事を載せておくのでご参考までに。
ソースコード
.circleci/config.ymlversion: 2.1 orbs: ruby: circleci/ruby@1.1.0 jobs: build: docker: - image: circleci/ruby:2.5.1-node-browsers environment: BUNDLER_VERSION: 2.1.4 steps: - checkout - ruby/install-deps test: parallelism: 3 docker: - image: circleci/ruby:2.5.1-node-browsers environment: DB_HOST: 127.0.0.1 RAILS_ENV: test BUNDLER_VERSION: 2.1.4 - image: circleci/mysql:8.0 command: --default-authentication-plugin=mysql_native_password environment: MYSQL_ALLOW_EMPTY_PASSWORD: 'true' MYSQL_ROOT_HOST: '%' steps: - checkout - ruby/install-deps - run: mv config/database.yml.ci config/database.yml - run: name: Wait for DB command: dockerize -wait tcp://localhost:3306 -timeout 1m - run: bundle exec rake db:create - run: bundle exec rake db:schema:load # Run rspec in parallel - ruby/rspec-test - ruby/rubocop-check deploy: docker: - image: circleci/ruby:2.5.1-node-browsers environment: BUNDLER_VERSION: 2.1.4 steps: - checkout - ruby/install-deps - add_ssh_keys: fingerprints: "XX:XX:XX:XX:XX:XX:XX:XX:XX:XX:XX:XX:XX:XX:XX:XX" - deploy: name: Capistrano deploy command: bundle exec cap production deploy workflows: version: 2 build_accept_deploy: jobs: - build - test: requires: - build - deploy: requires: - test filters: branches: only: masterconfig/deploy.rb# capistranoのバージョン固定 lock '3.14.1' # デプロイするアプリケーション名 set :application, 'golfour' # cloneするgitのレポジトリ set :repo_url, 'git@github.com:xxxxxx/xxxxxx.git' # deployするブランチ。デフォルトはmasterなのでなくても可。 set :branch, 'master' # deploy先のディレクトリ。 set :deploy_to, '/var/www/rails/appname' # secret_base_keyを読み込ませるため追記 set :linked_files, %w[config/master.key] # シンボリックリンクをはるファイル。 set :linked_files, fetch(:linked_files, []).push('config/database.yml', 'config/settings.yml', '.env') # シンボリックリンクをはるフォルダ。 set :linked_dirs, fetch(:linked_dirs, []).push('log', 'tmp/pids', 'tmp/cache', 'tmp/sockets', 'vendor/bundle', 'public/system') # 保持するバージョンの個数。過去5つまで履歴を保存。 set :keep_releases, 5 # rubyのバージョン set :rbenv_ruby, '2.5.1' # 出力するログのレベル。 set :log_level, :debug namespace :deploy do desc 'Restart application' task :restart do invoke 'unicorn:restart' end desc 'Create database' task :db_create do on roles(:db) do |_host| with rails_env: fetch(:rails_env) do within current_path do execute :bundle, :exec, :rake, 'db:create' end end end end desc 'Run seed' task :seed do on roles(:app) do with rails_env: fetch(:rails_env) do within current_path do execute :bundle, :exec, :rake, 'db:seed' end end end end after :publishing, :restart after :restart, :clear_cache do on roles(:web), in: :groups, limit: 3, wait: 10 do end end endconfig/deploy/production.rbserver 'EC2のElastic IP', user: 'yuki', roles: %w[app db web] # CircleCIのGUIで設定した環境変数を使ってSSH接続 set :ssh_options, { keys: [ENV.fetch('PRODUCTION_SSH_KEY').to_s], forward_agent: true, auth_methods: %w[publickey] }参考記事
【circleCI】rails5.2/Capistrano/CICD環境によるAWSへの自動デプロイ
CircleCIでデプロイを自動化
- 投稿日:2020-09-09T14:01:59+09:00
ウサギでもできるWindows上のAWS CLIによるSnapShot取得(マルチボリューム)
前回はWindows OS上で動作するツールからVSS Snapshotの取得を実行するところまで実施してみました。
今回はVSSではなく、通常のSnapShotを取得するところを、おさらいしてみたいと思います。また、複数のドライブ(ボリューム)にまたがってDBのデータなどを同時に保存している場合は、同時にSnapShotを取得しないと、整合性が取れないバックアップとなってしまいます。そのため、一回のAPIコールで複数のボリュームのSnapShotを取得することができる機能を利用することになります。
それはマルチボリュームスナップショットという機能です。
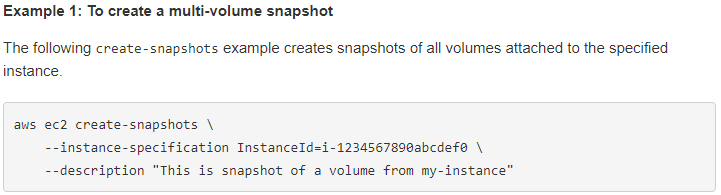
Windows OSが動作するインスタンスからSnapShotを取得するには、AWS APIの操作が必要になるため、当然ですがAWS CLIを利用することになります。
AWS CLIによるスナップショットの作成はcreate-snapshotsに詳しく記載がありますので、このページを参照しながら実施してみたいと思います。
その際は当然ながら、インスタンスにロールを適用し、ポリシーを当てる必要がありますので、どのようなポリシーが必要になるかも調べてみます。取り合ず何も考えずにSnapShotを取得してみる
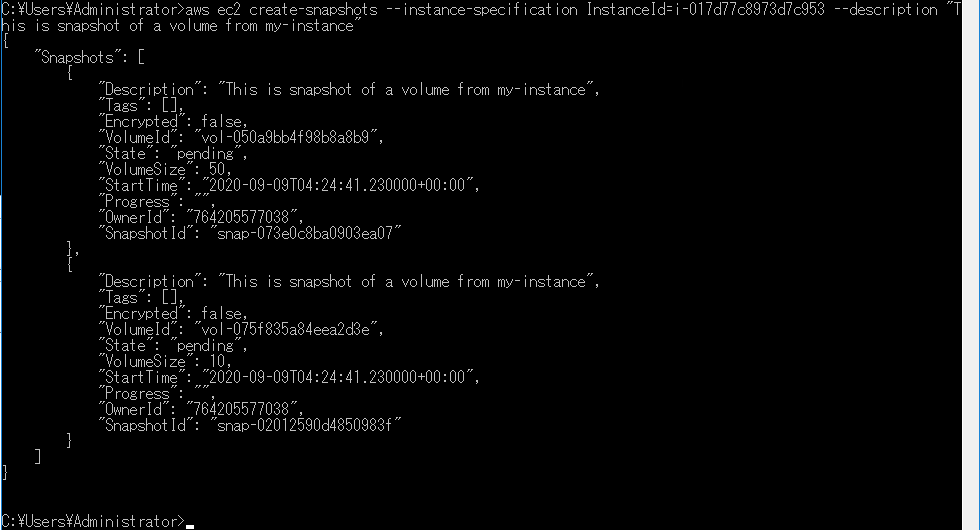
おもむろにコマンドプロンプトを起動して、実行してみましょう。
まず実行するのはサンプル1つ目。
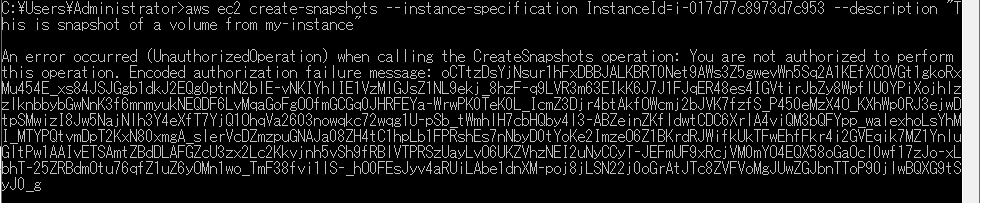
以下の一行です。aws ec2 create-snapshots --instance-specification InstanceId=i-017d77c8973d7c953 --description "This is snapshot of a volume from my-instance"えいっ!
はい!ブッブー!怒られましたーっ!
そりゃそうですよね。
権限がないといわれました。当たり前です。
とりあえずロールを作って、それらしいポリシーを当ててみましょう。ポリシーを適用する
実行した文をもう一度見てみましょう。
aws ec2 create-snapshots --instance-specification InstanceId=i-017d77c8973d7c953 --description "This is snapshot of a volume from my-instance"要素を一つ一つ見ていきます。
1.「aws ec2 create-snapshots」とりあえずSnapshotを作成するので、作成の権限は絶対に必要になりますね。
2.「--instance-specification InstanceId=i-017d77c8973d7c953」ここでインスタンスIDを指定しています。特に何かを読んだりするわけではないので不要に見えます。
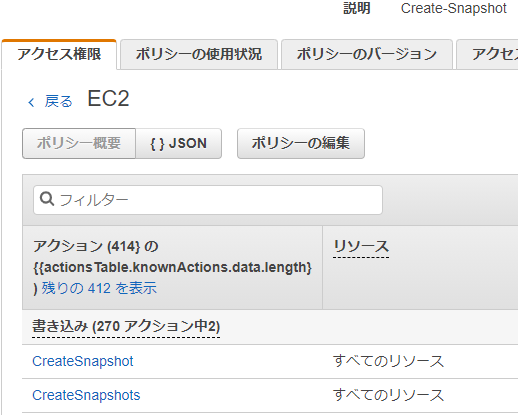
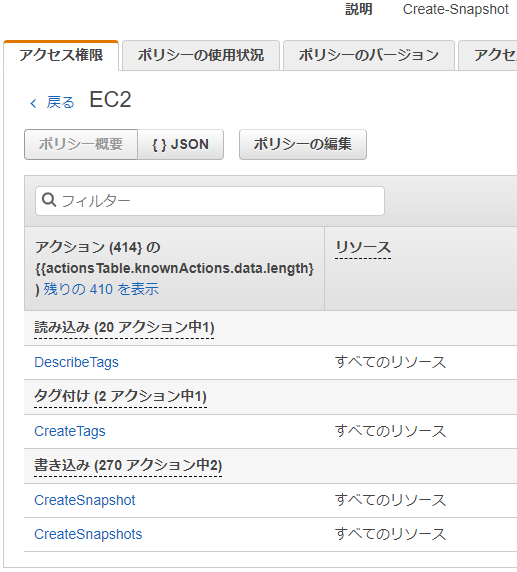
3.「--description "This is snapshot of a volume from my-instance"」と記載があります。これは取得するスナップショットの詳細情報を追加するものですね。スナップショットの作成と同時なので特に不要でしょうか。そこで、CLIを実行するEC2インスタンスに以下の様なポリシーを適用したロールを設定してみます。
以下の2つのアクションのみを許可します。
- CreateSnapshot
- CreateSnapshots
ここで、複数形のものも指定しているのは、マルチボリュームで複数一度に取得する際には必要になるからです。これで実行してみましょう。
ポリシーを付けて実行
aws ec2 create-snapshots --instance-specification InstanceId=i-017d77c8973d7c953 --description "This is snapshot of a volume from my-instance"
おぉ!動きましたね。
Snapshotも無事に取得できています!
タグをボリュームからコピーしてみよう
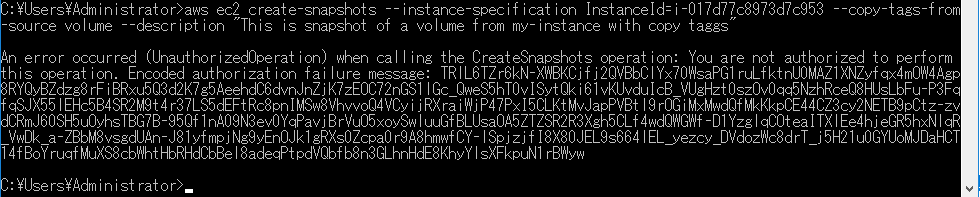
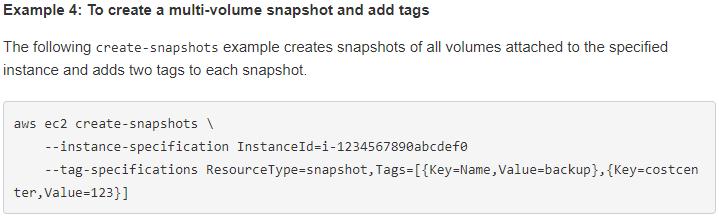
次のサンプルです。
実際に動かした文はこちらです。aws ec2 create-snapshots --instance-specification InstanceId=i-017d77c8973d7c953 --description "This is snapshot of a volume from my-instance"
はい!また怒られましたーっ!
さて、どんな権限が不足しているのでしょうか?
さっきと異なるのは、EBSからタグをコピーしてくる部分ですね。
そのため、以下の様にポリシーを追加してみます。
以下の2つのアクションのみを許可します。
- DescribeTags
- CreateTags
タグを読み込んで作成するので当たり前ですね。ポリシーを付けて実行
やってみます。
おー!動きました!
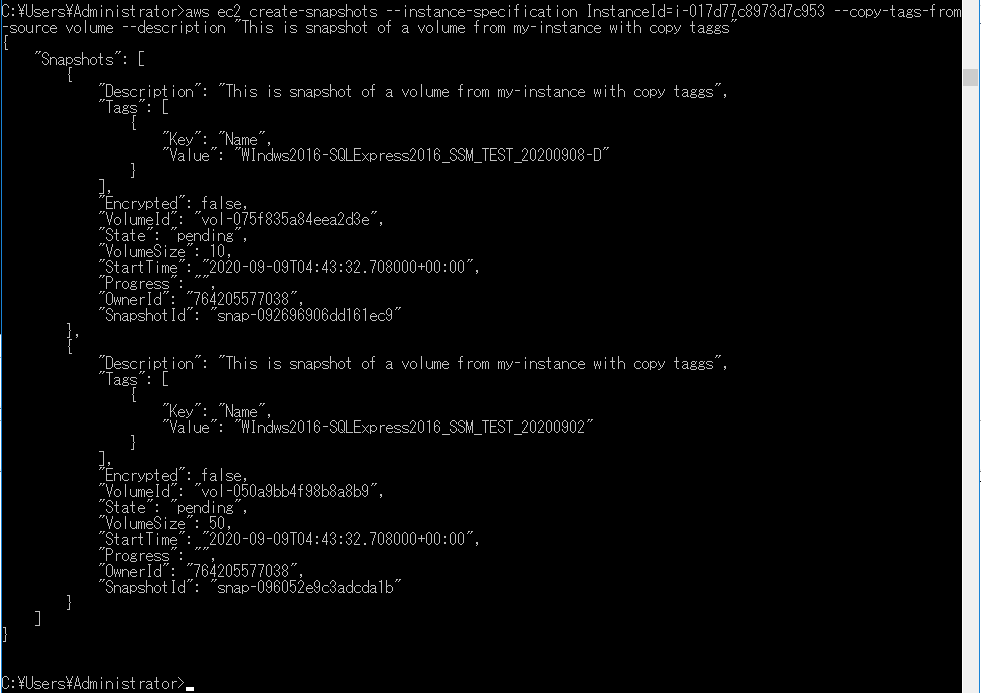
次に進んでみましょう。さらに新規タグを付加してみよう
次のサンプルはルートボリュームを除いてコピーなのですが、特に必要性を感じないので、一つ飛ばして任意のタグをさらに付与してみます。
実際に動かした文はこちらです。「Backupedby」タグに「AWSCLI_snapshot」という文言を付けて目印にしてみます。aws ec2 create-snapshots --instance-specification InstanceId=i-017d77c8973d7c953 --copy-tags-from-source volume --tag-specifications ResourceType=snapshot,Tags=[{Key=Backupedby,Value=AWSCLI_snapshot}]
今度はそのまま問題なく動きました。タグの付与はポリシーですでに許可しているからですね。次回は、取得したSnapshotを消す方法を模索したいと思います。


- 投稿日:2020-09-09T14:00:33+09:00
AWS CloudFrontのキャッシュ設定が新しくなっていた
概要
- 以前は CloudFront ではキャッシュ設定を個別のパスに対する Behavior でTTL設定などを毎回設定する必要があった
- 設定に
Use a cache policy and origin request policyの選択肢が現れ、cache policy を作って使い回せるようになった
もっともベーシックなCache Policy と Origin Request Policy
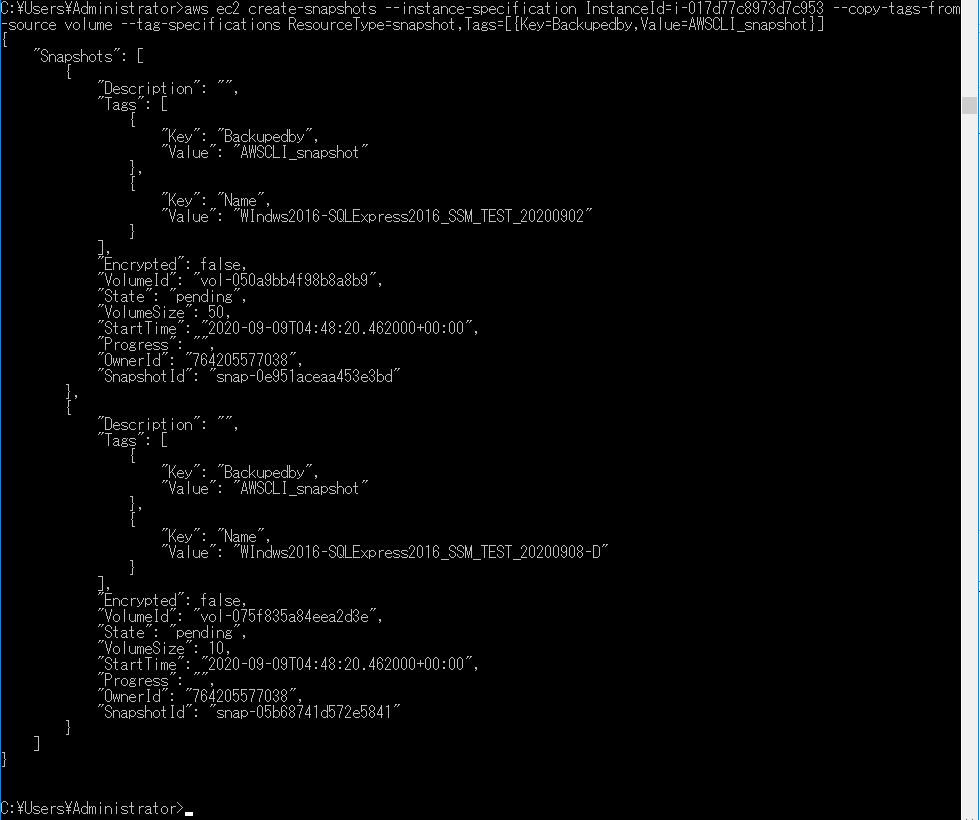
以下のようにすでに組み込み(Managed)な Cache Policy が利用可能です。
既存の Policy の設定を見ることで、どういう設定ができるかみていきます。
Cache Policy
- Managed-CachingOptimized
- TTL Settings
- 設定値
- Minimum TTL => 1
- Maximum TTL => 31536000
- Default TTL => 86400
- 意味
- サーバサイドから返しているキャッシュ関連ヘッダ(Cache-Control max-age など)とTTLの関係についてはこちらが参考になります
Cache-Control max-ageがサーバサイドから帰ってきているケースだと、TTLのレンジに収まっていればそれが使われ、収まっていなければTTLが優先されるようです- CloudFrontがレスポンスヘッダを書き換えるわけではないので、クライアントから見える
Cache-Control max-ageが書き換わっているわけではないので、実際に設定したTTLが適用されているかは確認できませんでした- Cache key contents (The cache key includes the headers, cookies, and query strings in the cache policy, as follows)
- 設定値
- Headers => None
- Cookies => None
- Query strings => None
- 意味
- CachingOptimizedという名前がついている通り、上記の設定が一番最適化されたものです
- レスポンスヘッダ、クッキー、クエリストリングの特定のものが入っているかどうかでキャッシュを分岐することができますが、それを設定しないということは、全てのリクエストが同じパスであれば同じキャッシュを見ることを意味します
- ファイルを差し替えるとき、ファイル名を変更しないでクエリストリングだけ変更してキャッシュ揮発させることを期待している場合には、
Query Stringsの設定はNoneではダメで、All設定をいれておかなければいけないと思いますOrigin Request Policy
- Managed-AllViewer
- Origin request contents
- 設定値
- Headers => All viewer headers
- Cookies => All
- Query strings => All
- 意味
- オリジンサーバに対してCloudFrontからどの情報を流すかを示しているようです
HeadersのAll viewer headersは、クライアントが送ってきたヘッダをそのままオリジンに渡す設定です。Origin Request Policy を新たに作成すれば、CloudFrontが後から付与するヘッダなどもオリジンに流せるようですキャッシュ設定の反映確認
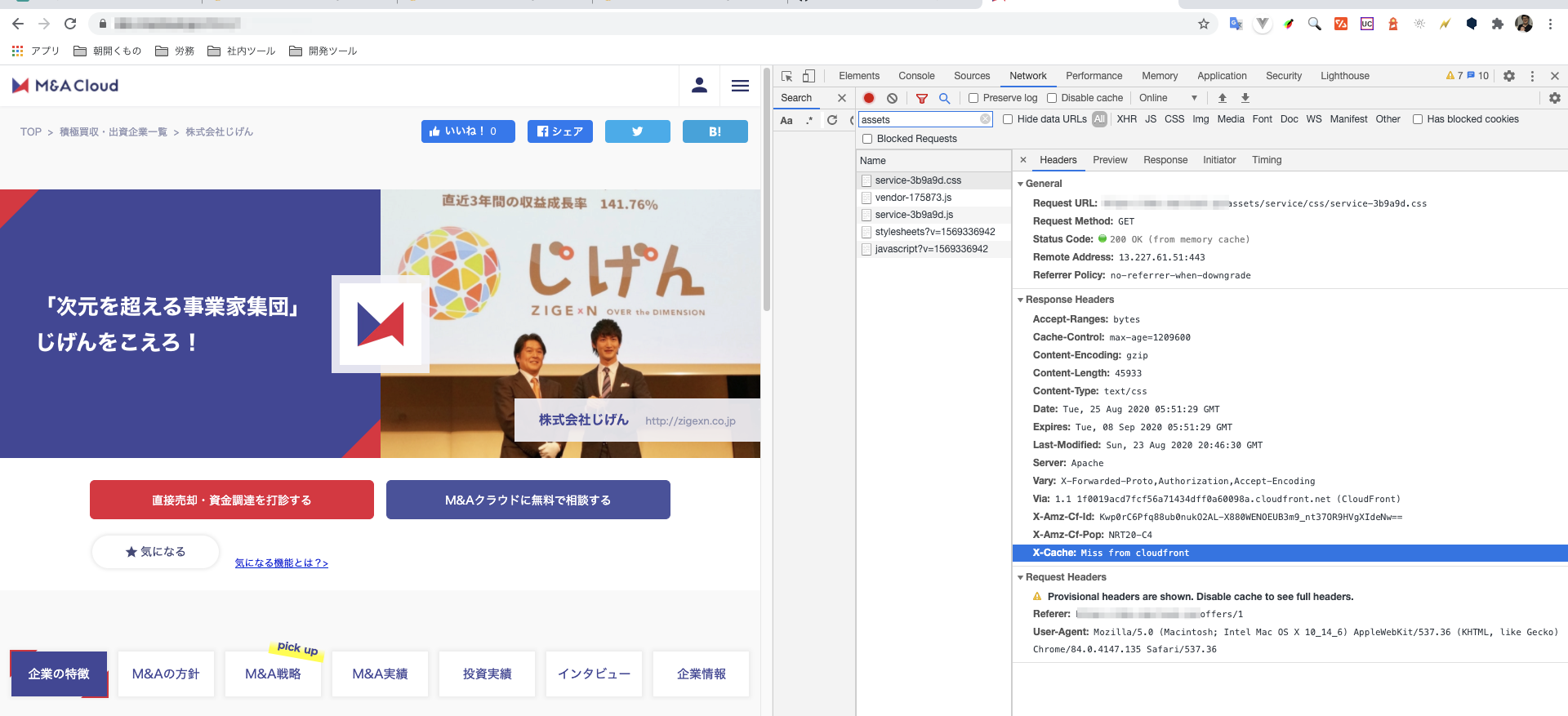
キャッシュ設定をする前は以下のように Miss From cloudfront になっていると思います。
Hit from CloudFront になります。

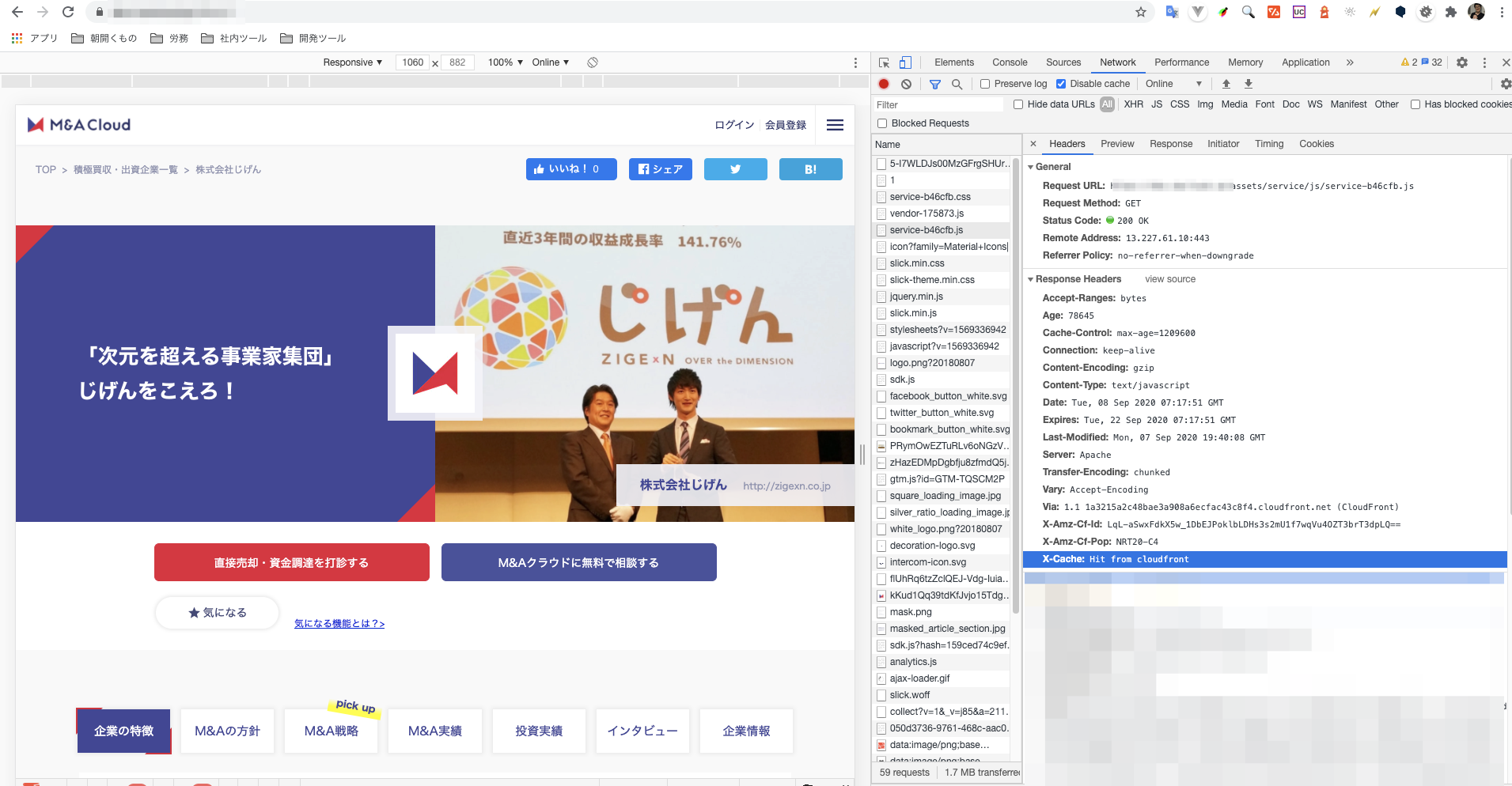
- 投稿日:2020-09-09T09:31:29+09:00
OSの基本設定 ~複数バーチャルホストの設定まで~
はじめに
AWSのEC2にてインスタンス(サーバー)を建てた際にOSの基本設定をしたので、その手順を記録します。ほぼ確実にサーバー建てるたびに設定すると思うので、
ターミナルでコマンド手打ちするのがめんどくせー!と思ったらコピペでがんがん使って下さい。
(インスタンス再作成しまくってたとき手打ちするのがだるすぎた)1.時間の変更 2.言語変更 3.コマンド履歴の表示変更 おまけ.複数バーチャルホストの設定
以上の4つを行います。開発環境
Amazon Linux 2 AMI (HVM), SSD Volume Type (AWSアカウント登録済み)
どのサーバーでも設定方法はそれほど変わらないと思いますが、設定ファイルやディレクトリがなければ、ググって確認してみてください。1.時間の変更
サーバー作成後、作成したキーペアに権限を与えてssh接続します。
//自分に読込・書込みの権限を与える chmod 600 ~/Desktop/[キーの名前] ssh -i ~/Desktop/作成したキーペア名 ec2-user@インスタンスと紐付けたElastic IP //Elastic IPはRoute 53で紐付けた名前でも可一般ユーザーでは権限を持たないので、(viコマンドなどが使えない)
全権限を持つrootユーザーに変更後、タイムゾーンを変更します。//全権限を与える sudo su vi /etc/sysconfig/clock //書き換え前 ZONE="UTC" //協定世界時間 //書き換え後 ZONE="Asia/Tokyo" //日本時間シンポリックリンク(ショートカット)の作成をします。
ln -sf /usr/share/zoneinfo/Asia/Tokyo /etc/localtime //紐付いてるか確認 ls -l /etc/localtimelocaltime->~Asia/Tokyoなら成功です。
2.言語変更
vi /etc/sysconfig/i18nLANG="ja_JP.UTF-8"に変更。
こちらだけでは、サーバー復元時に自動でen_US.UTF-8に戻ってしまうので下記も変更。vi /etc/cloud/cloud.cfg //最後の行に追加 locale: ja_JP.UTF-8 //catコマンドで確認 cat /etc/cloud/cloud.cfglocale: ja_JP.UTF-8が追加されていたら成功です。
3.コマンド履歴の表示変更
vi /etc/bashrc //最後の行に2行追加 HISTTIMEFORMAT='%F %T ' //コマンド操作日時表示 HISTFILESSIZE=2000 . //履歴の上限2000 //追加した2行の確認 tail -2 /etc/bashrc1~3終了後再起動します。
reboot1~2分後、sshで再接続。設定がうまくできてるか最終確認します。
date //日時表示が日本時間・日本語化 history //表示数・コマンド操作日時の表示以上がうまく出来ていれば、OSの基本設定完了です!
おまけ.複数バーチャルホストの設定
今回設定したのはApacheサーバーです。
使用するサーバーによって設定ファイルは異なるので注意しましょう。Apacheサーバーの大本となる設定ファイルは
/etc/httpd/conf/httpd.confなので
tailコマンドで最後の5行だけ確認します。tails -5 /etc/httpd/conf/httpd.conf //最後の行 InclodeOptional conf.d/*.conf //conf.d/*.confを取り込んでるのがわかる //conf.d/*.confより上のディレクトリを確認 grep "^ServerRoot" /etc/httpd/conf/httd.conf ServerRoot "/etc/httpd" // "/etc/httpd"直下にあることがわかる
/etc/httpd/conf.d/*.confで設定したらいいとわかったので、
サブドメインを作り、バーチャルホストを複数作成します。
今回作成したのが下記になります。start-aws-virtualhost.conf//PHPファイルのバーチャルホスト作成 <VirtualHost *:80> ServerName attendance.www.startdns.tokyo //Route53で設定したドメイン名 ServerAdmin webmaster@localhost DocumentRoot /var/www/main_attendance/public //画面表示するパスを指定 //ディレクトリにアクセス許可を与える <Directory /var/www/main_attendance> Options Indexes FollowSymLinks AllowOverride All Require all granted </Directory> </VirtualHost> //HTMLファイルのバーチャルホスト作成 2つ目以降の作成方法も同様 <VirtualHost *:80> ServerName introduction.startdns.tokyo //Route53で設定したドメイン名 DocumentRoot /var/www/introduction //画面表示するパスを指定 ErrorLog "logs/introduction-error.log" //エラーログの出力 CustomLog "logs/introduction-access.log" combined //アクセスログの出力 //ディレクトリにアクセス許可を与える <Directory /var/www/introduction> Options Indexes FollowSymLinks AllowOverride All Require all granted </Directory> </VirtualHost>2つ目以降も同様に作成すれば、サブドメインをいくつでも作成できます。
アクセスが集中しすぎるとサーバーダウンするので、
オートスケーリングを設定するか、別でサーバーを作成しましょう。参考文献・参考記事
・AWSをはじめよう ハンズオン形式。本はハンズオン形式のものをおすすめする。
・バーチャルホストの例 - Apache HTTP サーバ バージョン 2.2 バーチャルホストに関する様々な作成方法が書いてある。
- 投稿日:2020-09-09T02:32:29+09:00
AWSを使ってアプリケーションを公開する手順(4)データベースの作成
はじめに
AWSを使ってアプリケーションを公開する手順を記載していく。
この記事ではデータベースの作成を行う。データベースを作成する
WEBアプリケーションのデータを保存するためにデータベースを作成する。
データベースの種類
データベースの種類には以下のようなものがある。
- 階層型データベース
- ネットワーク型データベース
- リレーショナルデータベースこの中で最も利用されているのがリレーショナルデータベースである。
リレーショナルデータベースを管理するソフトウェアをリレーショナルデータベースマネジメントシステム(RDBMS)という。
RDBMSの一つにMySQLがある。
MySQLはOracle社が開発・提供をしているRDBMSで、データベースの作成、編集、削除などを行うことができる。
オープンソースソフトウェアとして公開されており、誰でも無償で利用することができます。
Ruby on Railsと併せて利用することができるため、本稿ではMySQLを用いてデータベースを作成していく。MySQLをインストールする
以下のコマンドを実行し、MySQLをインストールする。
今回はバージョン5.6をインストールする。sudo yum -y install mysql56-server mysql56-devel mysql56MySQLを起動する
以下のコマンドを実行し、MySQLを起動する。
sudo service mysqld start以下のコマンドを実行し、「running」と表示されれば無事起動できている。
sudo service mysqld statusserviceコマンドとは
UNIX系(LinuxやMacなど)で使えるコマンドで、サービスを起動したり停止したりできる。
mysqldとは
上記のコマンドはmysqlではなくmysqldとなっていて、末尾に「d」がついている。
このdはLinuxの用語「デーモン(daemon)」の略で、「サーバ」を意味する。MySQLのパスワード設定
インストールしたMySQLにはデフォルトでrootユーザーでアクセス出来るようになっているが、
パスワードが設定されていないので、パスワードを設定する。
例えば'AbCdEf1234'というパスワードにするときは以下のコマンドを実行する。sudo /usr/libexec/mysql56/mysqladmin -u root password 'AbCdEf1234'MySQLの接続確認
以下のコマンドを実行し、MySQLに接続できるか確認する。
パスワードの入力を求められるので先ほど設定したパスワードを入力する。
エラーが出なければOK。mysql -u root -pMySQLコマンドのオプションについて
上記MySQLコマンドのオプションは次のような意味である。
-u. ユーザ名指定 -p. パスワード指定
- 投稿日:2020-09-09T01:20:28+09:00
【AWS】CDKでECS Clusterを構築しよう
【AWS】CDKでECRを構築しようのECS Clusterバージョンです
前提などは省きますので前回の記事を参照してください環境


インストール
pipenv install aws_cdk.aws_ec2 aws_cdk.aws_ecs実装
props/ecs_cluster.py
ECS Clusterを作成する時に既存のVPCを利用したい場合は、VPC IDをもとにルックアップして既存VPCをStack内で利用できるようにする必要があります。そのためVpcForEcsClusterというクラスでパラメータ管理をします。
あとはAPI Referenceを参照しながら、設定可能なパラメータを定義しています。Container Insightsは有効化しておいた方が監視で役に立つので、デフォルトでTrueにしてあります。
props/ecs_cluster.pyfrom dataclasses import dataclass from typing import Optional from aws_cdk.aws_ecs import CloudMapNamespaceOptions from src.props.base import Base @dataclass(frozen=True) class VpcForEcsCluster(Base): id: str vpc_id: str @dataclass(frozen=True) class EcsCluster(Base): id: str cluster_name: str container_insights: bool = True default_cloud_map_namespace: Optional[CloudMapNamespaceOptions] = Noneentity/ecs_cluster.py
ECS Clusterの場合は環境によってパラメータが違う、具体的にいうとVPC IDが異なるので環境ごとのentityを作成します。今回はステージングだけを書いていますが、本番の場合は同じファイルにProdEcsClusterクラスを定義すればいいでしょう。
entity/ecs_cluster.pyfrom src.entity.base import Base from src.props.ecs_cluster import EcsCluster, VpcForEcsCluster class EcsClusterBase(Base): vpc: VpcForEcsCluster cluster: EcsCluster class StgEcsCluster(EcsClusterBase): id = 'StgEcsCluster' vpc = VpcForEcsCluster( id='StgVpc', vpc_id='vpc-xxxxxxxx' ) cluster = EcsCluster( id='StgEcsCluster', cluster_name='sample' )stack/ecs_cluster.py
stackはどの環境でも使いまわせるようになっています。
Clusterでは、既存VPCを利用したい場合は引数に
vpcの指定が必要なのでVpc.from_lookupというクラスメソッドを利用して、VPC IDをもとに取得しています。stack/ecs_cluster.pyfrom typing import Any, Type from aws_cdk.aws_ec2 import Vpc from aws_cdk.aws_ecs import Cluster from aws_cdk.core import Construct, Stack from src.entity.ecs_cluster import EcsClusterBase class EcsClusterStack(Stack): def __init__( self, scope: Construct, entity: Type[EcsClusterBase], **kwargs: Any) -> None: super().__init__(scope, entity.id, **kwargs) vpc = Vpc.from_lookup(self, **entity.vpc.to_dict()) Cluster(self, **entity.cluster.to_dict(), vpc=vpc)app.py
それではapp.pyに構築したいリソースのスタックを追加しましょう。
既存VPCを利用してECS Clusterを構築したい場合は、region/accountの環境設定もEcsClusterStackに渡してあげます。CDKが自動でContextを作成して、デプロイ時に変更されるとまずいデータ(今回は既存VPC)を保持してくれます。キャッシュ的な意味もあります。app.py#!/usr/bin/env python3 from aws_cdk import core from src.entity.ecr import SampleEcr from src.entity.ecs_cluster import StgEcsCluster from src.stack.ecr import EcrStack from src.stack.ecs_cluster import EcsClusterStack app = core.App() # 全てのリソースに設定するタグ tags = {'CreatedBy': 'iscream'} # 環境設定 (既存VPCを利用するために必須) env_stg = {'region': 'ap-northeast-1', 'account': 'xxxxxxxx'} # 前回作成したECR EcrStack(app, entity=SampleEcr, tags=tags) # ECS Cluster EcsClusterStack(app, StgEcsCluster, tags=tags, env=env_stg) app.synth(skip_validation=False)デプロイ
いざ、デプロイ!!!
pipenv run cdk deploy StgEcsClusterReference
