- 投稿日:2020-07-28T23:01:42+09:00
RSpecの自動的にロードされるバスについて
要約
RSpec実行時に自動的にロードされるバスがあります。(下記の2つです)
./lib./specRailsプロジェクトを触っていると、
そもそもRSpecの自動的にロードされるバスを気にする必要はあまりないのですが、
Rubyのみのプロジェクト + RSpecで動作を確認する時は知っておきたい情報ですね。これがgem内のどこで設定されているのかを調べました。
ついでに default_path についても記載しています。対象のバージョン
- rspec-core:
3.9.2ロードの設定箇所
では、実際にgem内のどこでパスをロードしているのかを確認します。
$LOAD_PATHに パスを追加するメソッド$LOAD_PATH に、指定したパスを追加するメソッドは下記のファイルにあります。
lib/rspec/core/ruby_project.rbdef add_to_load_path(*dirs) dirs.each { |dir| add_dir_to_load_path(File.join(root, dir)) } end def add_dir_to_load_path(dir) $LOAD_PATH.unshift(dir) unless $LOAD_PATH.include?(dir) end
add_to_load_pathメソッドを実行している箇所
add_to_load_pathメソッドは、下記のメソッド内で呼び出されています。
['lib', default_path]がadd_to_load_pathメソッドの引数になっています。「
default_pathが指定するディレクトリ」と 「'lib'」が$LOAD_PATHに追加されることになります。lib/rspec/core/configuration.rbdef requires=(paths) directories = ['lib', default_path].select { |p| File.directory? p } RSpec::Core::RubyProject.add_to_load_path(*directories) paths.each { |path| load_file_handling_errors(:require, path) } @requires += paths end
default_pathの初期値は、下記の箇所で設定されています。lib/rspec/core/configuration.rb@default_path = 'spec'上記の
requires=メソッドが、
テスト実行時、事前に呼び出されるようになっているので、
libディレクトリとspecディレクトリは
rspec実行時の$LOAD_PATHに追加されるようになっています。
default_pathを変更する方法
default_pathを変更する場合はどうすればよいのでしょうか?
(必要がなければやらない方がいいとは思いますが・・・。)例えば、テストファイルを
specではなくbehaviorというディレクトリに置いている場合、
どうすればdefault_pathを変更できるでしょうか。方法1: 実行時にオプションを渡す
テスト実行時にオプションを渡すことで、
default_pathを指定できます。$ rspec --default_path behavior方法2:
.rspecを修正
.rspecを下記のどちらかの内容に変更することで、
default_pathを指定できます。
実行時、毎回オプションを指定したくない場合はこちらの方法がよいでしょう。.rspec- --require spec_helper + RSpec.configure do |config| + config.default_path = 'behavior' + end.rspec- --require spec_helper + --default_path behaviorあとがき
普段はコマンドを実行すればとりあえずテストが流れるので、
中身まで見ることはあまりないです。
調べる過程でいろんなオプションとかを知れて面白かったです。
- 投稿日:2020-07-28T23:01:42+09:00
RSpecの自動的にロードされるパスについて
要約
RSpec実行時に自動的にロードされるパスがあります。(下記の2つです)
./lib./specRailsプロジェクトを触っていると、
そもそもRSpecの自動的にロードされるパスを気にする必要はあまりないのですが、
Rubyのみのプロジェクト + RSpecで動作を確認する時は知っておきたい情報ですね。これがgem内のどこで設定されているのかを調べました。
ついでに default_path についても記載しています。対象のバージョン
- rspec-core:
3.9.2ロードの設定箇所
では、実際にgem内のどこでパスをロードしているのかを確認します。
$LOAD_PATHに パスを追加するメソッド$LOAD_PATH に、指定したパスを追加するメソッドは下記のファイルにあります。
lib/rspec/core/ruby_project.rbdef add_to_load_path(*dirs) dirs.each { |dir| add_dir_to_load_path(File.join(root, dir)) } end def add_dir_to_load_path(dir) $LOAD_PATH.unshift(dir) unless $LOAD_PATH.include?(dir) end
add_to_load_pathメソッドを実行している箇所
add_to_load_pathメソッドは、下記のメソッド内で呼び出されています。
['lib', default_path]がadd_to_load_pathメソッドの引数になっています。「
default_pathが指定するディレクトリ」と 「'lib'」が$LOAD_PATHに追加されることになります。lib/rspec/core/configuration.rbdef requires=(paths) directories = ['lib', default_path].select { |p| File.directory? p } RSpec::Core::RubyProject.add_to_load_path(*directories) paths.each { |path| load_file_handling_errors(:require, path) } @requires += paths end
default_pathの初期値は、下記の箇所で設定されています。lib/rspec/core/configuration.rb@default_path = 'spec'上記の
requires=メソッドが、
テスト実行時、事前に呼び出されるようになっているので、
libディレクトリとspecディレクトリは
rspec実行時の$LOAD_PATHに追加されるようになっています。
default_pathを変更する方法
default_pathを変更する場合はどうすればよいのでしょうか?
(必要がなければやらない方がいいとは思いますが・・・。)例えば、テストファイルを
specではなくbehaviorというディレクトリに置いている場合、
どうすればdefault_pathを変更できるでしょうか。方法1: 実行時にオプションを渡す
テスト実行時にオプションを渡すことで、
default_pathを指定できます。$ rspec --default_path behavior方法2:
.rspecを修正
.rspecを下記のどちらかの内容に変更することで、
default_pathを指定できます。
実行時、毎回オプションを指定したくない場合はこちらの方法がよいでしょう。.rspec- --require spec_helper + RSpec.configure do |config| + config.default_path = 'behavior' + end.rspec- --require spec_helper + --default_path behaviorあとがき
普段はコマンドを実行すればとりあえずテストが流れるので、
中身まで見ることはあまりないです。
調べる過程でいろんなオプションとかを知れて面白かったです。
- 投稿日:2020-07-28T22:20:24+09:00
自作ログイン機能
事前情報
セッション
「サーバ側に用意された一つのブラウザから連続しておくれらている一連のリクエスト間で「状態」を共有できる仕組み」のことを言う
セッションがなければ、同じユーザから送られた一つ目のリクエストから二つ目のリクエストに情報を受け渡すことができないcontroller#セッションにアクセス session[:user_id] = @user.id #セッションの値の取り出し @user.id = session[:user_id]Cookie
ブラウザとwebサーバの間での情報の受け渡し。
「複数のリクエストの間で共有したい「状態」をブラウザ側に保存する仕組み」Userモデルを作る
rails g model user name:string email:string password_digest:string #同じパスワードから生成すると同じだが、それ自体は無意味な文字列migrationfileclass CreateUsers < ActiveRecord::Migration[5.2] def change create_table :users do |t| t.string :name, null: false t.string :email, null: false t.string :password_digest, null: false t.timestamps t.index :email, unique: true end end endrails db:migrateパスワードをdigestに変換する仕組みを作る
has_secure_passwordを使用し、パスワードをハッシュ化するためbcryptと言うハッシュ関数を提供するgemをインストールする
Gemfilegem 'bcrypt' #記述あるはずなのでコメントアウトをするbundle installmodelclass User < ApplicationRecord has_secure_password end #この一行で「password」「password_confirmation」 カラム が追加されるadminフラグのカラムをuserモデルに追加する
rails g migration add_admin_to_usersmigrationfileclass AddAdminToUsers < ActiveRecord::Migration[5.2] def change add_column :user, :admin, :boolean, default: false, null: false end endrails db:migrateコントローラの作成
rails g controller Admin::Users new edit show index #Adminと言うモジュールの名前空間の中にUsersControllerクラスを定義するルーティングの設定
routesRails.application.routes.draw do namespace :admin do resources :users end root to: 'task#index' resources :tasks endコントローラの中身を定義
controllerclass Admin::UsersController < ApplicationController def index @users = User.all end def show @user = User.find(params[:id]) end def new @user = User.new end def edit @user = User.find(params[:id]) end def create @user = User.new(user_params) if @user.save redirect_to admin_user_url(@user), notice:"ユーザー「#{@user.name}」を登録しました。" else render :new end end def update @user = User.find(params[:id]) if @user.update(user_params) redirect_to admin_user_url(@user), notice:"ユーザー「#{@user.name}」を更新しました。" else render :edit end end def destroy @user = User.find(params[:id]) @user.destroy redirect_to admin_user_url(@user), notice:"ユーザー「#{@user.name}」を削除しました。" end private def user_params params.require(:user).permit(:name, :email, :admin, :password, :password_confirmation) end endモデルの中身を定義
modelclass User < ApplicationRecord has_secure_password validates :name, presence: true validates :email, presence: true, uniqueness: true endビューの中身を定義
indexh1 ユーザー一覧 = link_to '新規登録', new_admin_user_path, class: 'btn btn-primary' .mb-3 table.table.table-hover thead.thead-default tr th= User.human_attribute_name(:name) th= User.human_attribute_name(:email) th= User.human_attribute_name(:admin) th= User.human_attribute_name(:created_at) th= User.human_attribute_name(:updated_at) th tbody - @users.each do |user| tr td= link_to user.name, [:admin, user] td= user.email td= user.admin? ? 'あり' : 'なし' td= user.created_at td= user.updated_at td = link_to '編集', edit_admin_user_path(user), class:'btn btn-primary mr-3' = link_to '削除', [:admin, user], method: :delete, date:{confirm:ユーザー「#{user.name}」を削除します。よろしいですか?”}, class:'btn btn-danger'newh1 ユーザー登録 .navjustify-content-end = link_to '一覧', admin_users_path, class: 'nav-link' = render partial: 'form', locals:{user: @user}edith1 ユーザー編集 .navjustify-content-end = link_to '一覧', admin_users_path, class: 'nav-link' = render partial: 'form', locals:{user: @user}_form- if user.errors.present? ul#error_explanation - user.errors.full_messages.each do |message| li = message = form_with model:[:admin, user], local: true do |f| .form-group = f.label :name, '名前' = f.text_field :name, class: 'form-control' .form-group = f.label :email, 'メールアドレス' = f.text_field :email, class: 'form-control' .form-check = f.label :admin, class: 'form-check-label' do = f.check_box :admin, class: 'form-check-input' | 管理者権限 .form-group = f.label :password, 'パスワード' = f.text_field :password, class: 'form-control' .form-group = f.label :password_confirmation, 'パスワード(確認)' = f.text_field :password_confirmation, class: 'form-control' = f.submit '登録する', class: 'btn btn-primary'showh1 ユーザーの詳細 .nav.justify-content-end = link_to '一覧', admin_users_path, class: 'nav-link' table.table.table-hover tbody tr th= User.human_attribute_name(:id) td= @user.id tr th= User.human_attribute_name(:name) td= @user.name tr th= User.human_attribute_name(:email) td= @user.email tr th= User.human_attribute_name(:admin) td= @user.admin? ? 'あり' : 'なし' tr th= User.human_attribute_name(:created_at) td= @user.created_at tr th= User.human_attribute_name(:updated_at) td= @user.updated_at = link_to '編集', edit_admin_user_path, class:'btn btn-primary mr-3' = link_to '削除', [:admin, user], method: :delete, date:{confirm:ユーザー「#{user.name}」を削除します。よろしいですか?”}, class:'btn btn-danger'ja.ymlja: activerecord: attributes: task: user: name: 名前 email: メールアドレス admin: 管理者権限 password: パスワード password_confirmation: パスワード(確認) created_at: 登録日時 updated_at: 更新日時ログインフォームの表示
rails g controller Sessions newroutesRails.application.routes.draw do get '/login', to:'sessions#new' endnewh1 ログイン = form_with scope: :session, local: true do |f| .form-group = f.label :email, 'メールアドレス' = f.text_field :email, class: 'form-control', id: 'session_email' .form-group = f.label :password, 'パスワード' = f.text_field :password, class: 'form-control', id: 'session_password' = f.submit 'ログインする', class: 'btn btn-primary'ログインの実装
routesRails.application.routes.draw do get '/login', to:'sessions#new' post '/login', to:'sessions#create' endsessions_controllerclass SessionsController < ApplicationController def new end def create user = User.find_by(email: session_params[:email]) #メールアドレスで検索 if user&.authenticate(session_params[:password]) #パスワード認証 見つからなかった場合はnilで返したいから&. session[:user_id] = user.id #セッションにuser_idを格納 redirect_to root_url, notice: 'ログインしました。' else render :new end end private def session_params params.require(:session).permit(:email, :password) end endログイン後、ユーザーを取得したい場合、、
以下でコードで取得できるが、ヘルパーメソッドを定義する方が良い
User.find_by(id: session[:user_id)application_controllerclass ApplicationController < ActionController::Base helper_method :current_user private def current_user @current_user ||= User.find_by(id: session[:user_id]) if session[:user_id] end endログアウトを実装
routesRails.application.routes.draw do get '/login', to:'sessions#new' post '/login', to:'sessions#create' delete '/logout', to:'sessions#destroy' endsessions_controllerclass SessionsController < ApplicationController def new end def create ・・・ end def destroy reset_session redirect_to root_url, notice: 'ログアウトしました。' end private ・・・ endapplicationul.navbar-nav.ml-auto - if current_user li.nav-item= link_to 'タスク一覧', tasks_path, class:'nav-link' li.nav-item= link_to 'ユーザー一覧', admin_users_path, class:'nav-link' li.nav-item= link_to 'ログアウト', logout_path, method: :delete, class:'nav-link' - else li.nav-item= link_to 'ログイン', login_path, class:'nav-link各アクションの実行前に毎回ユーザーがログインしているか調べる
application_controllerclass ApplicationController < ActionController::Base helper_method :current_user before_action :login_required private def current_user @current_user ||= User.find_by(id: session[:user_id]) if session[:user_id] end def login_required redirect_to login_url unless current_user end endログイン画面のときは、「before_action :login_required」がスキップされるように
sessions_controllerclass SessionsController < ApplicationController skip_before_action :login_required endUserとTaskを紐付ける
rails g migration AddUserIdTasksmigrationfileclass AddUserIdToTasks < ActiveRecord::Migration[5.2] def up execute 'DELETE FROM tasks;' #外部キーのついていない今までのtaskが削除される add_reference :tasks, :user, null: false, index: true end def down remove_reference :tasks, :user, index:true end endアソシエーションを定義する
user.rbclass User < ApplicationRecord validates :email, presence: true has_many :tasks endtask.rbclass Task < ApplicationRecord validates :name, presence: true validate :validate_name_not_including_comma belongs_to :user end紐付け後コントローラーの修正
tasks_controllerdef index @tasks = Task.all #を①または②に変更 @tasks = current_user.tasks #① @tasks = Task.where(user_id: current_user.id) #② end def create @task = Task.new(task_param)#を①または②に変更 @task = Task.new(task_param.merge(user_id: current_user.id)) #① @task = current_user.tasks.new(task_params) #② if @task.save redirect_to @task, notice: "タスク「#{@task.name}」を登録しました。" else render :new: end Task.find(params[:id])#を以下に変更 current_user.tasks.find(params[:id]) end管理者だけに管理機能を表示させる
applicationul.navbar-nav.ml-auto - if current_user li.nav-item= link_to 'タスク一覧', tasks_path, class:'nav-link' - if current_user.admin? li.nav-item= link_to 'ユーザー一覧', admin_users_path, class:'nav-link' li.nav-item= link_to 'ログアウト', logout_path, method: :delete, class:'nav-link' - else li.nav-item= link_to 'ログイン', login_path, class:'nav-linkusers_controllerclass Admin::UsersController < ApplicationController before_action :require_admin private def require_admin redirect_to root_url unless current_user.admin? end end
- 投稿日:2020-07-28T20:34:24+09:00
Bootstrap導入手順をまとめてみた(RubyonRails)
初めまして!
弱弱駆け出しエンジニアのてしまと申します。初投稿です!
今回はRubyonRailsでのBootStrapの導入手順についてまとめてみました。
導入自体は簡単です!
もし僕のような初学者でBootstrapに興味がある方は参考になればと思います。
実際に使った例も載せているため後半は長くなっております。内容
①RubyonRailsにBootstrapを導入
②Bootstrapを使ってテーブルとボタンの装飾対象者
・RubyonRailsで簡単なアプリケーションを立ち上げたことがある
・Bootstrapを知らないor使ってみたいと考えている
・Scaffoldを使ったことがある(無くても導入はできます)Bootstrapとは
CSSの「フレームワーク」
通常CSSを書く場合、全てのスタイルを自分で作っていく必要がありますが
このフレームワークにはよく使われるスタイルがあらかじめ定義してあるので
ルールに沿って利用するだけで整ったデザインのページを作成できます。
(引用:https://techacademy.jp/magazine/6270)色々調べているとBootstrapをダウンロードすると出てきましたが
今回、Gemを使ったので特にダウンロードせずに使えました。前提条件
今回はBootstrapの導入と一部使用例をまとめています。
予めscaffoldを使ってtasksテーブルを作成。titleカラム、textカラムを追加しております。
今回使いませんがdeviseも入れてます。では早速本題の導入手順です。
RubyonRailsでBootstrapを使えるようにする
①Gemの導入
まずはGemfileにgemを導入します。
Gemfile.gem 'bootstrap', '~> 4.1.1' gem 'jquery-rails'jqueryは今回使っていませんが、いつか使うと思われるので入ってなければ記述。
ターミナル.bundle installbundle installも忘れずに。
②SCSSファイルにimport
application.cssをapplication.scssに名前を変更。
そして以下の文を追記application.scss@import "bootstrap";一応application.jsにも追記
application.js//= require bootstrapはい!以上で準備完了です!
これだけでBootstrapが使えるようになります!
肝心の使い方があまり載ってなかったので
実際にコードを入れて装飾してみたいと思います。Bootstrapのコードを実際に入れてみる
では実際にBootstrapを使って装飾をしていきます。
装飾前がこんな感じです。
Scaffoldで生成してるのである程度形は整ってます。
①まずはHPにアクセス
「Bootstrap HP」
https://getbootstrap.com/
ヘッダー左2番目のDocumentationをクリックして参考コードを検索しに行きます。
②作りたいCSSを検索
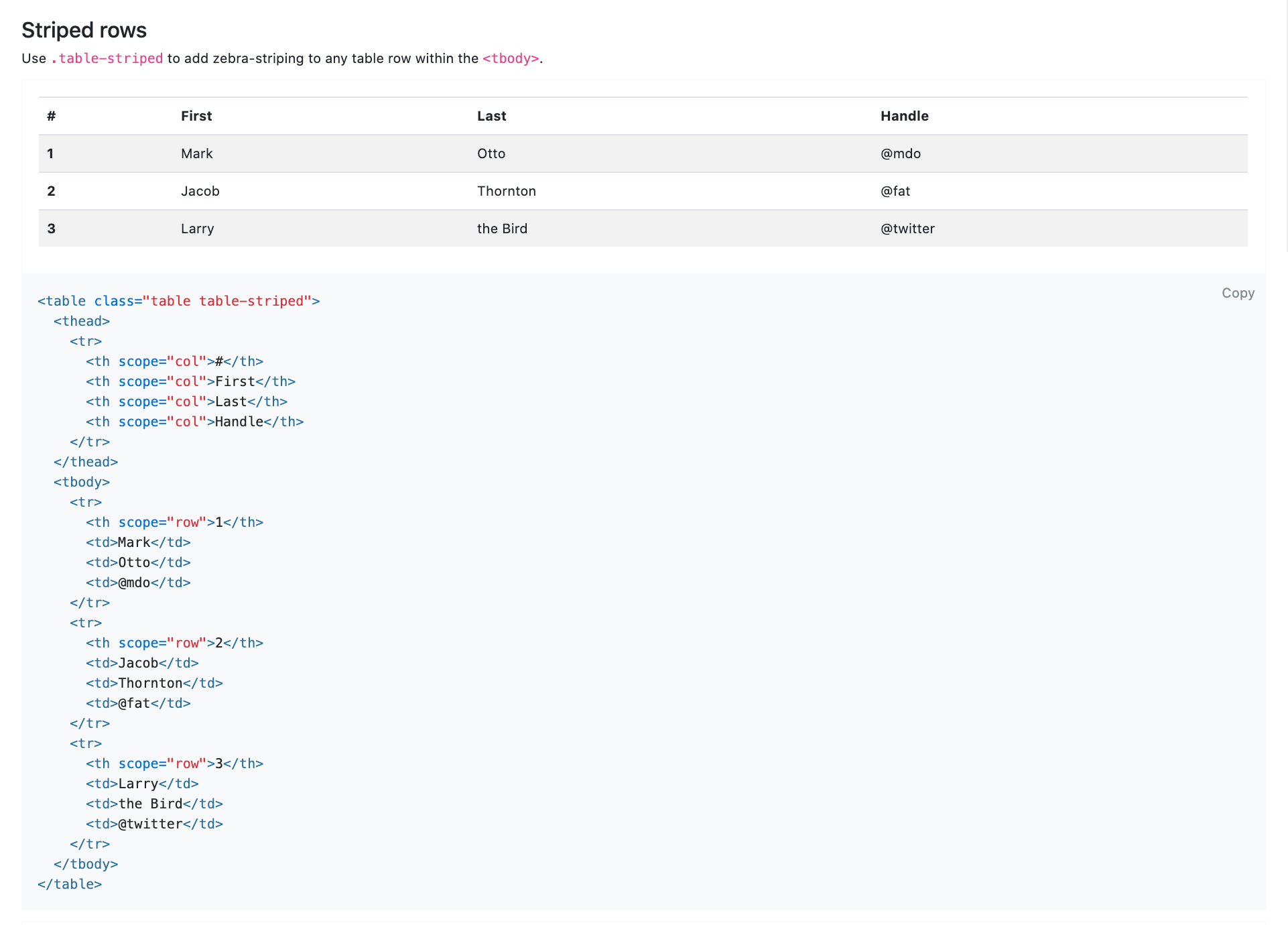
今回はテーブルを作るので「table」で検索
するとサンプル画像とそのコード一覧が出てくるので使いたいものを選びコピペするだけです!③使いたいコードをコピー
一覧は画面の大きさの都合上、割愛してます。
今回は以下の画像サンプルのコードを使って実装していきます。
③エディタに貼り付け
先ほどコピーしたコードをエディタの対象ファイルに貼り付けます。
今回はviews/tasks(ご自身のファイル名)/index.html.erb
一旦、一番下などに貼り付けしてしっかり反映するか確かめてみると良いです。
下記はコピーして貼り付けただけです。
このテーブルタグの中身の記述(白テキスト部分)を自分のデータに置き換えていきましょう!<table class="table table-striped"> <thead> <tr> <th scope="col">#</th> <th scope="col">First</th> <th scope="col">Last</th> <th scope="col">Handle</th> </tr> </thead> <tbody> <tr> <th scope="row">1</th> <td>Mark</td> <td>Otto</td> <td>@mdo</td> </tr> <tr> <th scope="row">2</th> <td>Jacob</td> <td>Thornton</td> <td>@fat</td> </tr> <tr> <th scope="row">3</th> <td>Larry</td> <td>the Bird</td> <td>@twitter</td> </tr> </tbody> </table>④記述場所にデータを置き換え(index.html.erbファイル)
貼り付け前のファイルの記述がこちらです。(参考までに)
views/tasks/index.html.erb<p id="notice"><%= notice %></p> <h1>Tasks</h1> <table> <thead> <tr> <th>Title</th> <th>Text</th> <th colspan="3"></th> </tr> </thead> <tbody> <% @tasks.each do |task| %> <tr> | <td><%= task.title %></td> <td><%= task.text %></td> <td><%= link_to 'Show', task %></td> <td><%= link_to 'Edit', edit_task_path(task) %></td> <td><%= link_to 'Destroy', task, method: :delete, data: { confirm: 'Are you sure?' } %></td> </tr> <% end %> </tbody> </table> <br> <%= link_to 'New Task', new_task_path %>Bootstrapのサンプルに余計なテーブルがあるので削除。
先ほどコピペしたコードのテーブルタグの中身を表示したいデータの記述に置き換えます。
バーっと作ったのでインデントなど細かいところはすみません?
変更場所は見比べていただければと思います。
貼り付けがうまくいったら元々あった記述は消しちゃいましょう。
以下が変更後の記述です。<h1>Tasks</h1> <% if user_signed_in?%> <%= link_to "ログアウト", destroy_user_session_path, method: :delete %> <% else %> <%= link_to "新規登録", new_user_registration_path %> <%= link_to "ログイン", new_user_session_path %> <% end %> <%# ----------以下がBootstrapのテーブル---------- %> <table class="table table-striped"> <thead> <tr> <th scope="col">No</th> <th scope="col">Title</th> <th scope="col">Text</th> <th scope="col">Date</th> <th scope="col">Show</th> <th scope="col">Edit</th> <th scope="col">Destroy</th> </tr> </thead> <tbody> <% @tasks.each.with_index do |task, no| %> <tr> <td><%= no++1 %></td> <td><%= task.title %></td> <td><%= task.text %></td> <td><%= task.created_at.strftime('%Y/%m/%d %H:%M') %></td> <td><%= link_to 'Show', task %></td> <td><%= link_to 'Edit', edit_task_path(task) %></td> <td><%= link_to 'Destroy', task, method: :delete, data: { confirm: 'Are you sure?' } %></td> </tr> <% end %> </tbody> </table> <%# ----------以上がBootstrapのテーブル---------- %> <br> <%= link_to 'New Task', new_task_path %>完成図と相違があると困惑するため
deviseで使っている上の部分の記述があります。
気になさらずに。
コメントアウトで区切っている中身のみをご確認ください。⑤ボタンも作成
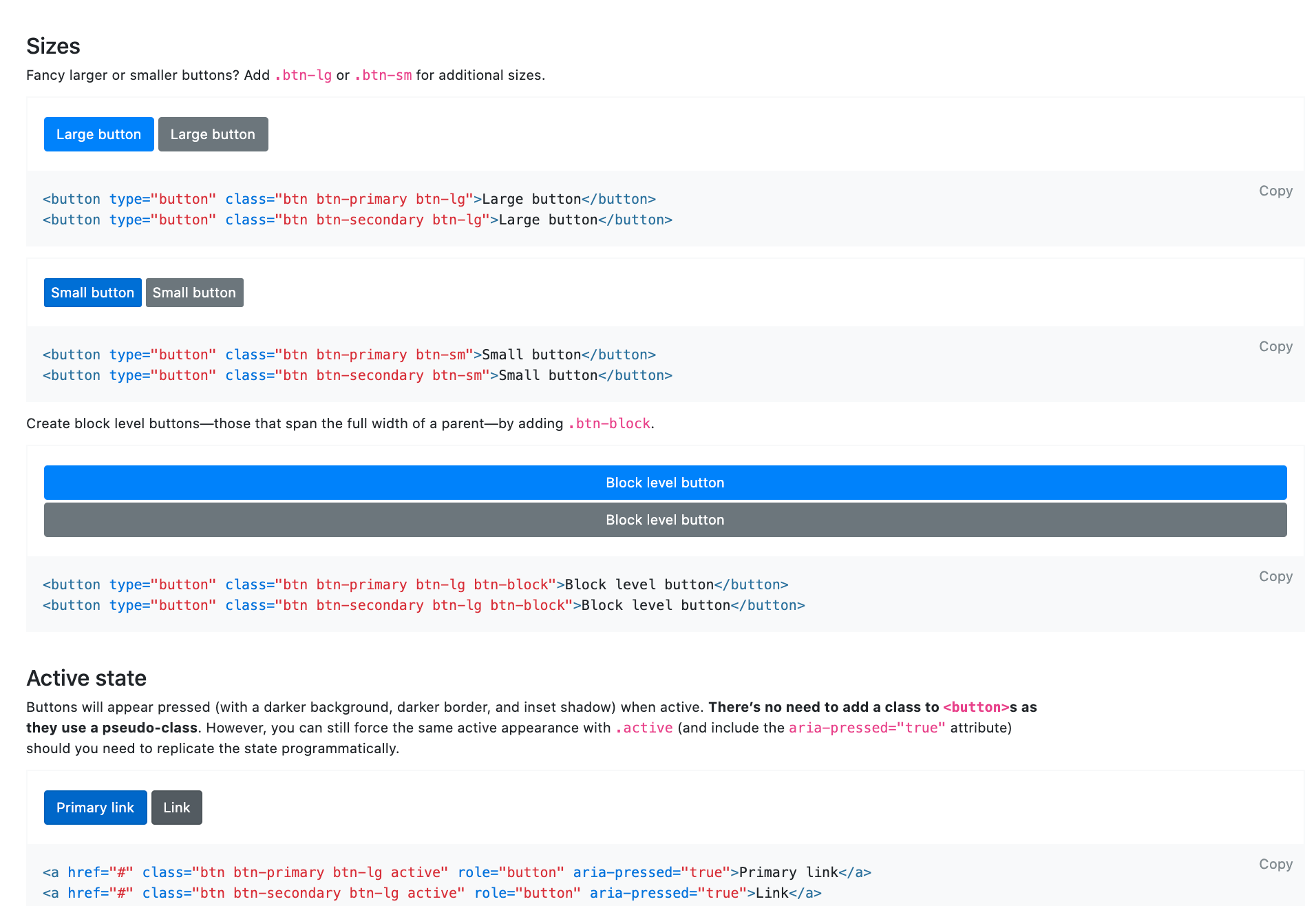
せっかくなのでボタンも入れてみましょう!
今度は「btn」で検索して(検索方法は色々あると思います)
以上のように色々出てきました。
今回は新規投稿ページにリンクさせたいので画像最下部のaタグのCSSを拝借。まずは以下のリンクの記述を削除し
<%# ----------以上がBootstrapのテーブル---------- %> <br> <%= link_to 'New Task', new_task_path %>以下のように書き換え
※引用元のa href=後ろのリンク先の記述とタグ内の文字を変更しただけ
引用元に合わせてPrefixからURIパターンに書き換えてます。<br> <a href="tasks/new" class="btn btn-primary btn-lg active" role="button" aria-pressed="true">New Task</a>完成画像
HTMLの記述だけでサンプル画像と同じ見た目の装飾ができました!
(CSSのクラス名がBootstrapによって決められているため)
この高さの揃った綺麗なテーブルを作るのが意外と大変•••
きっと初学者の方なら共感いただけるかと思います。Bootstrapを使えば決まったレイアウトにデータを置き換えるだけなので
このように簡単にCSSを作成可能!
アイコンなどもたくさんあったのでFontawsome派の方もぜひみる価値はありそうです!
今後はJSなども色々試してみてみたいと思います!参考資料
初めてのRuby on rails Bootstrap導入編 [Memo for neko]
https://qiita.com/Matteneko3/items/4dae9e55054e4a4affb4参考資料の方の記事を長く書いただけの記事です、、、
画像もつけて結構丁寧に書いたつもりですが
初投稿なのでもし間違っている点、ご意見などございましたら
コメントに残していただけると勉強、励みになります?♂️?
よろしくお願いいたします。


- 投稿日:2020-07-28T18:46:35+09:00
コールバック(モデルの状態を自動的に制御)
イベントの前後に任意の処理を挟むことをコールバックと言う
主に、イベントの前(before)、イベントの後(after)、イベントを挟む(around)のタイミングで書くことができる。※トランザクション
一連の複数の処理によるデータベースの整合性を保つための機能。
コーツバックの一つで例外が発生した場合、ロールバックと言う取り消し作業が発生し、その後のコールバックが実行されない仕組みになっている。
コールバックの種類 使い道 before_validation 検証前の値の正規化 after_validation 検証結果(エラーメッセージ)の加工 before_save, before_create, before_update saveのために裏側で行いたいデータ準備を行う after_save, after_create, after_update そのモデルの状態に応じてほかのモデルの状態をカエルなど、連動した挙動を実現する。検証エラーを出してもユーザーにはどうすることもできない状態異常を防ぐために例外を出す before_destroy 削除してOKかチェックし、ダメなら例外を出すなどして防ぐ after_destroy そのモデルの削除に応じてほかのモデルの状態をかえるといった連動した挙動を実現する
- 投稿日:2020-07-28T18:19:07+09:00
Couldn't find ModelName with 'id'=batch_action
- 投稿日:2020-07-28T17:57:53+09:00
指定文字数の文字列出力 絶対値の出力
- 投稿日:2020-07-28T14:32:54+09:00
letを使用することで、通るはずのテストが通らないfalse Alarmを生じる可能性がある
先日RSpecのテストコードにレビューを頂いたので、
なるべく多くを学びたいと思い、その内容を咀嚼する過程での気付きを書きたいと思います
元記事
RSpecのEmail一意性テストで"Email has already been taken"問題と回避策 - Qiita
なるべく小さいscope?(contextの中など)を見ただけでテストの内容が把握できるような書き方のほうが、読み手に理解しやすい、想定外の挙動を防ぐことができる。
letを使って書くことはこれを実現するために有効
letの遅延評価によって、テストによっては必要のないインスタンス変数を毎回beforeで定義するような冗長性を回避できるが、この遅延評価を理解せずに、なんとなく変数代入の感覚で使用していたために以下のようなエラーに遭遇しました
letを使用することで、通るはずのテストが通らないfalse Alarmを生じる可能性がある
letとlet!の使い分けが重要になりそうなケース
- テストを実施する時点と、前提となる条件の間に時間的なずれがある場合
- すでに完了しているものと、現在の比較が必要な場合
- モデルのテストの場合なら、一意性のテスト
遅延評価されるletが、実際にテストの失敗を招いたケース
レビューの内容を参考に、
属性の一意性についてのテストを書いてみた。User modelの属性
usernameの一意性についてのテストを以下のうように書くとdescribe "username" do ... context "usernameが重複している場合" do let(:existing_user) { FactoryBot.create(:user, username: "alice") } subject { FactoryBot.build(:user, username: "alice" ) } it { is_expected.to be_invalid } end ... endモデルで
username属性についてのvalidationが記述されているにもかかわらずclass User < ApplicationRecord validates :username, presence: true, uniqueness: true, length: { maximum: 12 } ... endvalidationがinvalidにならない
1) User#create username usernameが重複している場合 is expected to be invalid Failure/Error: it { is_expected.to be_invalid } expected `#<User id: nil, email: "test_user_5@example.com", created_at: nil, updated_at: nil, username: "alice">.invalid?` to return true, got falseテストの記述を変更する
(実際にレビューコードではこの書き方を提示してくれていました)
let>>let!describe "username" do ... context "usernameが重複している場合" do let!(:existing_user) { FactoryBot.create(:user, username: "alice") } #let!に変更 subject { FactoryBot.build(:user, username: "alice" ) } it { is_expected.to be_invalid } end ... endこのようにすると、想定通りテストがパスするようになる。
letとlet!の違い
- letは、itやexampleが実行されるまで評価されない
- let!は即座に実行される
it { is_expected.to be_invalid }の時点で、existing_userは存在完了していないといけない
英文でいうところletは現在完了的な振る舞いをして、let!は過去完了の状態をつくってくれると考えると個人的にはしっくりきた。参考
- 投稿日:2020-07-28T14:32:54+09:00
letを使用することで、通るはずのテストが通らないFalse Alarmを生じる可能性がある
先日RSpecのテストコードにレビューを頂いたので、
なるべく多くを学びたいと思い、その内容を咀嚼する過程での気付きを書きたいと思います
元記事
RSpecのEmail一意性テストで"Email has already been taken"問題と回避策 - Qiita
なるべく小さいscope?(contextの中など)を見ただけでテストの内容が把握できるような書き方のほうが、読み手に理解しやすい、想定外の挙動を防ぐことができる。
letを使って書くことはこれを実現するために有効
letの遅延評価によって、テストによっては必要のないインスタンス変数を毎回beforeで定義するような冗長性を回避できるが、この遅延評価を理解せずに、なんとなく変数代入の感覚で使用していたために以下のようなエラーに遭遇しました
letを使用することで、通るはずのテストが通らないfalse Alarmを生じる可能性がある
letとlet!の使い分けが重要になりそうなケース
- テストを実施する時点と、前提となる条件の間に時間的なずれがある場合
- すでに完了しているものと、現在の比較が必要な場合
- モデルのテストの場合なら、一意性のテスト
遅延評価されるletが、実際にテストの失敗を招いたケース
レビューの内容を参考に、
属性の一意性についてのテストを書いてみた。User modelの属性
usernameの一意性についてのテストを以下のうように書くとdescribe "username" do ... context "usernameが重複している場合" do let(:existing_user) { FactoryBot.create(:user, username: "alice") } subject { FactoryBot.build(:user, username: "alice" ) } it { is_expected.to be_invalid } end ... endモデルで
username属性についてのvalidationが記述されているにもかかわらずclass User < ApplicationRecord validates :username, presence: true, uniqueness: true, length: { maximum: 12 } ... endvalidationがinvalidにならない
1) User#create username usernameが重複している場合 is expected to be invalid Failure/Error: it { is_expected.to be_invalid } expected `#<User id: nil, email: "test_user_5@example.com", created_at: nil, updated_at: nil, username: "alice">.invalid?` to return true, got falseテストの記述を変更する
(実際にレビューコードではこの書き方を提示してくれていました)
let>>let!describe "username" do ... context "usernameが重複している場合" do let!(:existing_user) { FactoryBot.create(:user, username: "alice") } #let!に変更 subject { FactoryBot.build(:user, username: "alice" ) } it { is_expected.to be_invalid } end ... endこのようにすると、想定通りテストがパスするようになる。
letとlet!の違い
- letは、itやexampleが実行されるまで評価されない
- let!は即座に実行される
it { is_expected.to be_invalid }の時点で、existing_userは存在完了していないといけない
英文でいうところletは現在完了的な振る舞いをして、let!は過去完了の状態をつくってくれると考えると個人的にはしっくりきた。参考
- 投稿日:2020-07-28T13:26:57+09:00
[Ruby]return,break,next それぞれの処理の終わらせ方
初めに
paizaで競プロみたいなことできるやん!!ってなってとりあえず朝の勉強初めはやる気出すために遊んでいるのですが。
その中でreturn等、処理を終わらせる記述の挙動についてわかってなかったな〜ってことがあったので書き留めておきます(正直まだ理解しきってはいない)環境
Ruby 2.6.5
遭遇したこと
以下の様なコードを書いていました。(数値とかは問題の公表につながらない様書き換えています)
test.rbarray = [1,2,3] ans = [] array.each do |a| if a >= 1 ans << a return end end p ans簡略化した処理をしていますが、僕がやりたかったのは以下の様なことでした。
配列の要素について条件を検証し、該当するものが見つかった時点でその値を空配列に入れ、繰り返し処理を終える
上記のコードで言えば一番目の1の時点でifに該当しているので、ans = [1]となり処理が終わってくれれば良いのでした。
そして上記コードを実行した結果が以下の通り。
何も反応しねえ。
何もpされてこない訳です。
僕は最初これを、ansにaが入っていないから表示されていないと思い、returnでスコープが変わる・・・!?とか動揺してたんですが。
よく考えたらその場合でも p ansしたら []って感じで空の配列は表示されるはずなんですよね。そう思って上記コードの最後に 「p array」と追記しても何も表示されなかったので、「ああーー処理が終わってんのか!」とたどり着くことができた訳です。
上記の様なケースに遭遇したため、処理を終わらせる方法について調べて出てきた3つについてまとめておこうと思います(return,break,next)
returnについて
returnはメソッドそのものを終わらせます
上記が答えです。
それについては知っていたのですが、今回の場合defでメソッドを作っていた訳じゃないので以降の処理が終了するという状況が同じであると気付けませんでした。ここ、正直あやふやですが、今回の様に何も定義しないでやってる場合は「そのプログラム全体を範囲として終了させる」ということでしょうか。
ちなみにメソッドを終わらせるとはどういうことか例を使ってもう少し説明すると
test.rbarray = [1,2,3] ans = [] def check array.each do |a| if a >= 1 ans << a return end puts "Hello" end上記の様なケースでcheckメソッドを実行した場合、returnが終わらせるのはeach処理ではなくcheck全てです。
なので、returnでeachの処理が終わった後、puts "Hello"されるわけではありません、ということです。
何か処理の中で使われていても、その処理だけを終わらせるのではなく、メソッドそのものを終わらせるのがreturn ですよ、ということですね。breakについて
breakはその繰り返し処理のみを終わらせます。
今回の場合これが僕のやりたかったことですね。
test.rbarray = [1,2,3] ans = [] array.each do |a| if a >= 1 ans << a break end end p ansこの様にreturnではなくbreakに書き換えてあげると
望んでいた[1]がえられました。
条件に該当した時点で、each処理のみを終わらせてくれた、という期待していた挙動になっています。nextについて
実行されてる処理内で、以降の処理を行わず終わらせますが、繰り返し処理自体は続きます
ちょっとわかりづらいので、以下の様にコードを書き換えて実験して見ます。
test.rbarray = [3,2,1] ans = [] sum = 0 array.each do |a| if a >= 2 ans << a end sum += 1 end p sumif内の条件をa >= 2にしたので、array[2]は1であるためそれのみ条件に非該当になります。
カウンター用にsumを用意しました。これを実行すると以下の結果になります。
sum += 1はif外かつeach内の処理なので、ifに該当してようとしてなかろうと、要素の数だけ繰り替えされます。
今回は要素が3個あるので、「3」と出力されるわけです。これにnextを追記します。
test.rbarray = [3,2,1] ans = [] sum = 0 array.each do |a| if a >= 2 ans << a next end sum += 1 end p sum結果は以下の通りです。
ifに該当した場合、nextによって以降の処理を無視します。
なので3、2の場合はsum += 1が行われません。ただし、繰り返し処理自体は継続されます。
なので、array[2]が1であり、ifに非該当であった場合はsum += 1が実行されており、結果として1が出力されているわけです。終わりに
頭でわかってることをプログラムにやってもらう時の指示の出し方についてまだまだ知らないことが多いな〜という印象です。
機械語を理解するのは大事だなと思うわけで、半分趣味にはなってますがアルゴリズムの勉強もしたくてたまんないなという最近です。実際こういう気づきあるし笑※かなりざっくりした理解で書いているので、間違い等あれば指摘いただけるとありがたいです。




- 投稿日:2020-07-28T12:32:39+09:00
rails console環境下で気軽にスクリプトを実行をする。
経緯
rails console環境下でbenchmarkを取りたい場面があった。rails console環境下で以下のように1行ずつ実行するのも手間で、ファイルのスクリプトを読み込む手法が個人的によかったので記録に残す。Loading development environment (Rails 6.0.3.2) [1] pry(main)> require 'benchmark' => false [2] pry(main)> def benchmark(try_num:) [2] pry(main)*手順
1、
rails consoleコマンドをターミナル上で実行。$ rails c Loading development environment (Rails 6.0.3.2) [1] pry(main)>2、
load "[ファイル名]"でファイルに記載されたスクリプトを読み込んで実行することができる。
スクリプトが実行されるので、ファイル内に定義した変数やメソッドをコンソール上で利用できる。[1] pry(main)> load "benchmark_script.rb" => trueちなみに、
benchmark_script.rbの中身としては以下の通り。オブジェクト型の配列のサイズが大きいregionsと小さいcountriesでsampleメソッドのパフォーマンスを分析する。rails console環境下であるので、railsアプリケーション内で定義したRegionやCountryのモデルを利用できる。benchmark_script.rbdef benchmark(try_num:) # SQL 出力制御をする。 old_logger = ActiveRecord::Base.logger ActiveRecord::Base.logger = nil regions = Region.all countries = Country.all Benchmark.bm(10) do |x| x.report('region'){ try_num.times { regions.sample } } x.report('country'){ try_num.times { countries.sample } } end # SQL 出力抑制を元に戻す ActiveRecord::Base.logger = old_logger nil end3、
benchmark_script.rbて定義したbenchmarkメソッドを実行。結果として、sampleメソッドは配列のサイズは速度に影響しないことがわかる。[2] pry(main)> benchmark try_num:10000 user system total real region 0.003220 0.000101 0.003321 ( 0.003317) country 0.002791 0.000147 0.002938 ( 0.002952) => nil備考
Railsアプリケーション内の修正(モデル内コードを一部書き換えた etc..)があった場合には、その修正分を反映させるために
rails consoleを再起動しないといけない。その際には、以下のreload!コマンドが便利です。(今まで、exitしてからrails consoleを立ち上げていた・・・)[11] pry(main)> reload! Reloading... => true [12] pry(main)>
- 投稿日:2020-07-28T12:32:39+09:00
rails console環境下でスクリプトを実行をする。
経緯
rails console環境下でbenchmarkを取りたい場面があった。rails console環境下で以下のように1行ずつ実行するのも手間で、ファイルのスクリプトを読み込む手法が個人的によかったので記録に残す。Loading development environment (Rails 6.0.3.2) [1] pry(main)> require 'benchmark' => false [2] pry(main)> def benchmark(try_num:) [2] pry(main)*手順
1、
rails consoleコマンドをターミナル上で実行。$ rails c Loading development environment (Rails 6.0.3.2) [1] pry(main)>2、
load "[ファイル名]"でファイルに記載されたスクリプトを読み込んで実行することができる。
スクリプトが実行されるので、ファイル内に定義した変数やメソッドをコンソール上で利用できる。[1] pry(main)> load "benchmark_script.rb" => trueちなみに、
benchmark_script.rbの中身としては以下の通り。オブジェクト型の配列のサイズが大きいregionsと小さいcountriesでsampleメソッドのパフォーマンスを分析する。rails console環境下であるので、railsアプリケーション内で定義したモデルなども利用できる。benchmark_script.rbdef benchmark(try_num:) # SQL 出力制御をする。 old_logger = ActiveRecord::Base.logger ActiveRecord::Base.logger = nil regions = Region.all countries = Country.all Benchmark.bm(10) do |x| x.report('region'){ try_num.times { regions.sample } } x.report('country'){ try_num.times { countries.sample } } end # SQL 出力抑制を元に戻す ActiveRecord::Base.logger = old_logger nil end3、
benchmark_script.rbて定義したbenchmarkメソッドを実行。結果として、sampleメソッドは配列のサイズは速度に影響しないことがわかる。[2] pry(main)> benchmark try_num:10000 user system total real region 0.003220 0.000101 0.003321 ( 0.003317) country 0.002791 0.000147 0.002938 ( 0.002952) => nil備考
Railsアプリケーション内の修正(モデル内コードを一部書き換えた etc..)があった場合には、その修正分を反映させるために
rails consoleを再起動しないといけない。その際には、以下のreload!コマンドが便利です。(今まで、exitしてからrails consoleを立ち上げていた・・・)[11] pry(main)> reload! Reloading... => true [12] pry(main)>
- 投稿日:2020-07-28T12:31:25+09:00
Ruby on Rails から Open Distro for Elasticsearch に接続する
この記事について
Ruby on Rails から Docker 上の Open Distro for Elasticsearch に接続する方法を記載します。
Open Distro for Elasticsearch とは
Open Distro for Elasticsearch は Elasticsearch のディストリビューションで、 Amazon Elasticsearch Service で使われているものです。
Docker
公式のドキュメントを参考に docker-compose で Open Distro for Elasticsearch を立ち上げます。
今回はシングルノードで立ち上げています。docker-compose.ymlversion: "3" services: elasticsearch_open_distro: image: amazon/opendistro-for-elasticsearch:1.9.0 environment: - discovery.type=single-node - cluster.name=elasticsearch - bootstrap.memory_lock=true - "ES_JAVA_OPTS=-Xms512m -Xmx512m" ulimits: memlock: soft: -1 hard: -1 ports: - 9200:9200Ruby on Rails から接続
elasticsearch-rails と elasticsearch-model を使います。
Gemfilegem 'elasticsearch-model' gem 'elasticsearch-rails'素の Elasticsearch と違い Open Distro for Elasticsearch は localhost の場合も https で接続しなければなりません。
よって initializer は以下のように書きます。
localhost の場合はtransport_optionsで ssl の verify を false にしています。
ELASTICSEARCH_USERとELASTICSEARCH_PASSWORDはデフォルトでは両方 admin を使うと接続することはできます。config/initializers/elasticsearch.rbElasticsearch::Model.client = Elasticsearch::Client.new( host: 'localhost', port: 9200, user: ENV['ELASTICSEARCH_USER'], password: ENV['ELASTICSEARCH_PASSWORD'], scheme: 'https', transport_options: { ssl: { verify: false, }, }, )これで接続することができました。
elasticsearch-rails の Usage の手順で接続を確認することができます。
- 投稿日:2020-07-28T12:07:24+09:00
【初心者向け?】SQL超マスター〜複雑なテーブルにへこたれない編〜【Railsとの比較あり】
はじめに
Railsを利用していると、普通に使っている分にはどんなSQLが発行されるんだろう?ということを考えずとも、欲しいレコードが簡単に取得できますよね。Railsを学び始めた頃からすごいな〜と思っていましたが、今になってもやはり凄いなと思います。ただ1つ、便利だからこそ生じる弊害があります。それは
>>>SQLが書けなくなる<<<
別に、「SQLが書けなくても
ActiveRecordとかが頑張ってくれるから困らないじゃん」と思っている方もいらっしゃるかもしれません。私もそう思っていました。
しかし、例えRailsであっても、テーブル構造が複雑になってくると、どんなSQLを発行したいのか?という部分が分からないと、Railsでどう書いたらデータが取れるのか?というのが分からなくなります。業務中に、そういった場面と直面する機会が最近格段に増え物凄く困った、危機感を持った、というのが私の体験談であり、結果として「やばい、SQL勉強し直そう」と思うきっかけとなりました。
なんとなくでRailsでレコードを取得している方は、この記事で一緒に学び直しましょう!環境
- Docker for Mac 2.3.0.3
- Ruby 2.6.6
- Rails 6.0.3
- MySQL 8.0
- DBeaver 7.1.0
環境構築
- こちらからリポジトリをcloneする
$ docker-compose buildを実行$ docker-compose up -dを実行$ docker-compose exec web rails db:createを実行$ docker-compose exec web rails db:migrateを実行$ docker-compose exec web rails db:seedを実行- こちらの記事を参考に、
MySQLとDBeaverを接続するDBeaverとの接続後、studentsテーブルにレコードが 6 件登録されていることを確認できればOK※DBeaver との接続時、MySQL の
rootパスワードを要求されると思います。
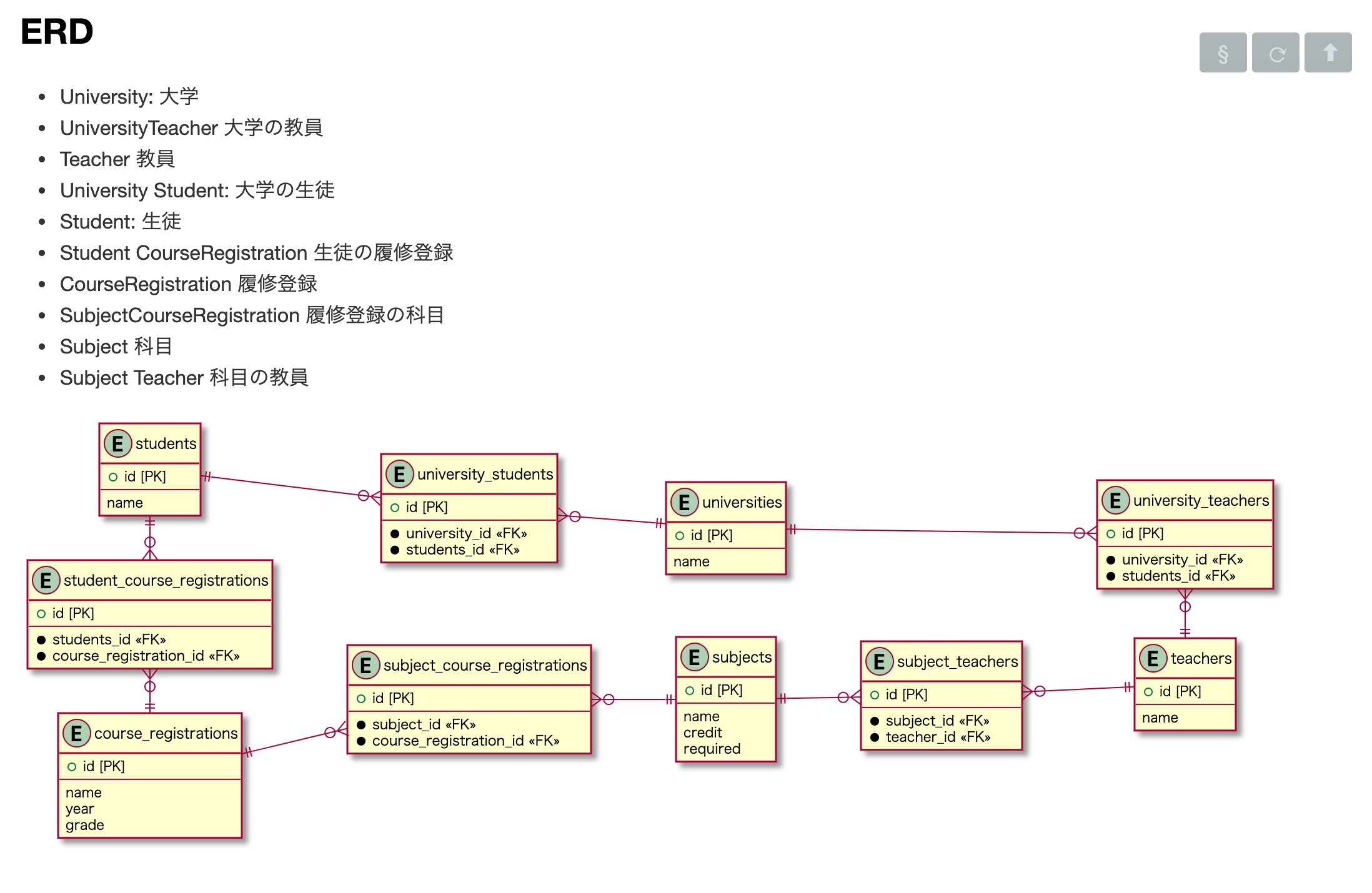
パスワードはdocker-compose.ymlのMYSQL_ROOT_PASSWORDに指定した値を入力してください。(未設定の場合はpasswordが設定されます。)今回使用するテーブル
初級編〜SELECTの基礎を学ぶ〜
※ここからは
DBeaverのSQLコンソールを使用していきます。sql_master_developmentがデフォルト選択されるよう設定を行って下さい。
universitiesテーブルのレコードを全件取得する手始めに
universitiesテーブルのレコードを全件取得してみましょう。これは簡単ですね!
universitiesテーブルのレコードを全件取得する
select * from universities;これは
Railsだと以下のようになります。University.all特定のUniversityのレコードを取得する
では、次は
nameがUniversityAのレコードを全件取得しましょう。
nameがUniversityAのレコードを全件取得するselect * from universities where name = 'UniversityA';これは
Railsだと以下のようなイメージです。University.where(name: 'UniversityA')
whereが出て来たので、find_byもSQLで書いてみましょう。
※1件のみ取得したい時はlimitを使用します。
nameがUniversityAのレコードを1件取得するselect * from universities where name = 'UniversityA' limit 1;中級編 テーブルを結合して、欲しいレコードを取得する
UniversityAに紐づいたstudentsレコードを全件取得するテーブル結合について(簡易版)
≈
universitiesテーブルとstudentsテーブルはuniversity_studentsという中間テーブルによって紐づけられています。そのため、該当レコードを取得するためにはテーブル同士の結合が必要になります。
テーブル結合には内部結合(JOIN/INNER JOIN)と外部結合(LEFT JOIN)があります。
- 内部結合・・・あるカラムの値が一致しているレコードを取得し、結合して表示する
- 外部結合・・・あるカラムの値が一致していない場合でもテーブルを結合し、全件表示する
今回のような場合は
内部結合か外部結合か考えながら、まずは最終的に欲しい情報であるstudentsテーブルと中間テーブルであるuniversity_studentsテーブルを結合して、studentsレコードを全件取得してみましょう。※結合の構文は
inner join(left join)結合するテーブル名on結合先テーブル名.カラム名=結合するテーブル名.カラム名
nameがUniversityAのレコードを1件取得するselect students.* from students inner join university_students on students.id = university_students.student_id;取得できましたか?
これはRailsだと以下のようになります。Student.joins(:university_student)結合したテーブルを使って、
UniversityAに紐づいたstudentsレコードを全件取得するでは、次は本題である
UniversityAに紐付いたstudentsレコードを全件取得していきましょう。
先ほどstudentsテーブルとuniversity_studentsテーブルを結合したので、今回は追加でuniversity_studentsテーブルとuniversitiesテーブルを結合します。そして、
universitiesレコードのnameカラムがUniversityAであるものを特定すると、UniversityAに紐づいたstudentsレコードを全件取得することができます。
StudentA〜StudentFまで取得できていたらOKです
UniversityAに紐づいたstudentsレコードを全件取得するselect students.* from students inner join university_students on students.id = university_students.student_id inner join universities on university_students.university_id = universities.id where universities.name = 'UniversityA';これを
Railsで書くと以下のようになります。Student.joins(:university).where(universities: { name: 'UniversityA' })この辺りから「
Railsスゲー!!」という気持ちが大きくなってくるのではないでしょうか?
joinsが:universityのみの記述で良いのは、Model(Student)でhas_one :university, through: :university_studentを定義しているからです。Railsは関連付けさえ綺麗に定義できれば上記のように記述をどんどん簡略化できるのでよいですね
UniversityAに所属しているStudentAのcourse_registrationsレコードを全件取得するこの辺から関連するテーブルが増えてきてごちゃごちゃします。
一つずつ紐解いて考えていきましょう。ここでは
UniversityA大学に所属しているStudentAさんのcourse_registrationレコード、つまり履修登録情報を取得します。ここで簡単に仕様を説明します。
course_registrationsレコードは年度毎に作成されます。
StudentAさんは、2020年度の時点で2回生です。
そのため、course_registrationsレコードは2レコード作成されています。
studentsテーブルとcourse_registrationsテーブルはstudent_course_registrationsという中間テーブルを持っています。
UniversityA大学に所属しているStudentAさんのcourse_registrationレコードを全件取得するselect course_registrations.* from course_registrations inner join student_course_registrations on course_registrations.id = student_course_registrations.course_registration_id inner join students on student_course_registrations.student_id = students.id inner join university_students on students.id = university_students.student_id inner join universities on university_students.university_id = universities.id where universities.name = 'UniversityA' and students.name = 'StudentA';これを
Railsで書くとこうなります。CourseRegistration.joins(student: :university) .where( students: { name: 'StudentA' }, universities: { name: 'UniversityA' } )ここまで書いた私「Railsやばい」
自分で生のSQLを全部書く時間と比較してどうでしょう?
Rails凄い。さて、まだこれはテーブル結合として「まだ」優しいです。
この時点ではまだ、全て年度の履修を登録したという情報しか取得できていません。
最初のER図を見た時に少し嫌な予感がした、という方。正しい判断です。
次はある年度に履修した全ての科目を取得してみましょう!
UniversityAに所属しているStudentAの2020年度のCourseRegistration(履修登録情報)に紐付いたsubjectsレコードを全件取得する見出しがカオスになってきました。
ただ、ここまでの知識を活かせばそう難しくないと思います。
subjectsテーブルとcourse_registrationsテーブルにも、例によってsubject_course_registrationsという中間テーブルがいます。
では、今までの知識を活かして取得してみましょう!
UniversityAに所属しているStudentAの2020年度のCourseRegistration(履修登録情報)に紐付いたsubjectsレコードを全件取得するselect subjects.* from subjects inner join subject_course_registrations on subjects.id = subject_course_registrations.subject_id inner join course_registrations on subject_course_registrations.course_registration_id = course_registrations.id inner join student_course_registrations on course_registrations.id = student_course_registrations.course_registration_id inner join students on student_course_registrations.student_id = students.id inner join university_students on students.id = university_students.student_id inner join universities on university_students.university_id = universities.id where universities.name = 'UniversityA' and students.name = 'StudentA' and course_registrations.year = '2020';これを
Railsで書くと以下のようになります。Subject.joins(course_registration: { student: :university }) .where( universities: { name: 'UniversityA' }, students: { name: 'StudentA' }, course_registrations: { year: '2020' } )やっぱり
Railsって凄いですね。。。
UniversityAに所属するTeacherAが受け持っている科目基礎英語を2020年度に受講する生徒を全件取得する
subjectsレコードを取得したから、今度はどうせteachersレコードでも取得するんでしょうと思われた方もいるかもしれません。
ですが、恐らくワンパターンすぎて飽きてきたという方もいるでしょう。
私も流石に(ちょっともういいかな……)と思えてきたため、teachersレコードを追加するのは各自で試してみていただければ、と思います。今度は生徒ではなく、教員側がデータベースに登録された情報を参照したい場合を考えてみます。
表題のようなレコードが欲しい、というケースですが、例えば
教員が 「今年度の出席簿を作りたいな……」と思った時に、履修対象者を全件取得したい、といった時に起こり得そうですね。
UniversityAに所属するTeacherAが受け持っている科目基礎英語を2020年度に受講する生徒を全件取得するselect distinct students.* from students inner join student_course_registrations on student_course_registrations.student_id = students.id inner join course_registrations on course_registrations.id = student_course_registrations.course_registration_id inner join subject_course_registrations on subject_course_registrations.course_registration_id = course_registrations.id inner join subjects on subjects.id = subject_course_registrations.subject_id inner join subject_teachers on subject_teachers.subject_id = subjects.id inner join teachers on teachers.id = subject_teachers.teacher_id inner join university_teachers on university_teachers.university_id = teachers.id inner join universities on university_teachers.university_id = universities.id where universities.name = 'UniversityA' and teachers.name = 'TeacherA' and subjects.name = '基礎英語' and course_registrations.year = '2020';これを
Railsで書くと以下のようになります。Student.joins(course_registrations: { subjects: { teachers: :university } }) .where( course_registrations:{ subjects: { name: '基礎英語' }, teachers: { name: 'TeacherA' }, universities: { name: 'UniversityA' }, course_registrations: { year: '2020' } } )上級(?)編 結合したテーブルを使って合計値を出す
各生徒ごとの総取得単位を取得する
ただレコードをとるだけでは面白くないので、次は生徒の名前と、総取得単位を取得し閲覧したいと思います。
取得するのは以下のようなデータです。
student_name total_credit StudentA 13 StudentB 13 StudentC 8 StudentD 7 ・・・ ・・・ 今回は
生徒ごとの単位の合計を出すので、studentsテーブルとsubjectsテーブルの情報が必要になります。1人の生徒には年度ごとに
履修登録情報が紐づいていて、履修登録情報に各科目の情報が紐づいている、というのは一度SQLを書いたので問題ないと思います。キモとなるのは、
1人ずつ単位の合計値をまとめたいという点だと思います。
情報をまとめたい場合はGROUP BYを使います。group by (カラム名)また、カラムの合計値を出す時は
SUM関数を使います。sum(カラム)そして、先程の表を見ると、少しヘッダーの表示がカラム名と異なっていたと思います。
ASでエイリアスをつける必要がありそうですね。上記のことを踏まえて、SQLを書いてみましょう!
各生徒ごとの総取得単位を取得する
select students.name as student_name, sum(subjects.credit) as sum_credit FROM students inner join student_course_registrations ON student_course_registrations.student_id = students.id inner join course_registrations ON course_registrations.id = student_course_registrations.course_registration_id inner join subject_course_registrations ON subject_course_registrations.course_registration_id = course_registrations.id inner join subjects ON subjects.id = subject_course_registrations.subject_id group by students.nameこれはRailsで書くと以下のようになります。
Student.joins(course_registrations: :subjects) .group('students.name') .sum(:credit)
書く量が全然違いますよね。
ただ、これを書こうと思った時に、結局どんな感じのSQLが発行されて欲しいのか?というところがわからないと、「???」となると思います。(私は毎回そうなっていました)また、「上みたいな場合だと
Rubyでなんとかできそうだから、mapとかeach_with_object使ってなんとかしちゃお」と私は思いがちだったのですが、純粋に値が必要なだけであればデータベースから直接取得できるので、Rubyでゴリ押すのではなく、いい感じのSQLを発行して必要な値を取得する、というのも必要なスキルだなと思いました最後に
親子関係のあるテーブルならまだ良いのですが、親子孫曽孫……のような構成のテーブルがあった時に、「親から曽孫ってどうやってとるんだ!?!?」と混乱することが多かったのですが、「どのテーブルのレコードが主人公になっているのか?」を意識しながら書いていくとそんなに複雑ではないということが分かったと思います。
また、Railsでレコードを取得する時も少し混乱してしまいがちですが、SQLのテーブル結合を意識するとシンプルに書いていくことができるので、
こんなSQLが発行されて欲しい!というのを意識しながら書いていくと良いですねRailsでシンプルに書いていこうと思うと、Modelに定義する
関連付けが大事だという話を少ししました。テーブルが複雑になればなるほど、この関連付けの定義も難しくなります(ここ最近私が頭を抱えているところです。)次はRailsで条件付きの
has_one・has_manyの定義の仕方を学べるようなQiitaが書けたらと思っています
- 投稿日:2020-07-28T10:05:15+09:00
RailsでIPベースでBasic認証をかける
社内システムでかつ、外部公開をする場合に社内なら認証なし+社外からは認証かけたい場合のIPベースでの解決方法
RailsでのBasic認証
https://api.rubyonrails.org/classes/ActionController/HttpAuthentication/Basic.html
まずは公式参照ほぼこの内容なので、条件をローカルネットワークなら認証必要に変える。
ちなみにこの公式の内容だと通常のログイン認証と併用できたりする。管理者アクセスとかに使えるかも。application_controller.rbclass ApplicationController < ActionController::Base protect_from_forgery with: :exception http_basic_authenticate_with name: "user", password: "pass" endIPベースの判定
CIDRベースで指定したい。
IPAddrかnetaddrでいけるみたい。今回はnetaddrの方を使う。github
https://github.com/dspinhirne/netaddr-rb
readmeに使い方はないので、テストケースを参照。サブネットで判定
https://github.com/dspinhirne/netaddr-rb/blob/master/test/ipv4net_test.rb
ここにいろいろあるテストケースから抜粋def test_contains net = NetAddr::IPv4Net.parse("1.0.0.8/29") ip1 = NetAddr::IPv4.parse("1.0.0.15") ip2 = NetAddr::IPv4.parse("1.0.0.16") ip3 = NetAddr::IPv4.parse("1.0.0.7") assert_equal(true, net.contains(ip1)) assert_equal(false, net.contains(ip2)) assert_equal(false, net.contains(ip3)) endこのへんですね。
実際に書くとdef is_local_access? return NetAddr::IPv4Net.parse('192.168.1.0/24').contains(NetAddr::IPv4.parse(request.ip)) endこんな感じでしょうか。
これで192.168.1.0/24のネットワークが判定できる。
(nginxとかリバースプロキシ挟んでるときはrequest.ipかrequest.remote_ip、nginxの設定によるかも)もうちょっとやるならlocalリクエストも判定しておいたほうがいい。
request.local?application_controller
application_controller.rbrequire 'netaddr' class ApplicationController < ActionController::Base protect_from_forgery with: :exception http_basic_authenticate_with name: "user", password: "pass", unless: : is_local_access? private def is_local_access? return NetAddr::IPv4Net.parse('192.168.1.0/24').contains(NetAddr::IPv4.parse(request.ip)) end end
- 投稿日:2020-07-28T04:42:29+09:00
parallel_test が並列数を決定する仕組み
Rubyのテストは、素のままですと直列実行なので、テストケース数が増えると実行時間も増えていきます。
CIの実行環境は、マルチプロセッサを選択できることがあるため、テストも並列実行できると、時間短縮を狙うことができます。
Rubyでは parallel_tests というgem越しに、めぼしいテストフレームワークを並列実行することができます。
ところで
bin/parallel_test -n 4のように並列数を指定すると4並列で動かしてくれますが、指定しなかった場合は、どうやら実行環境のプロセッサの数を、どこかから取ってきて動いているようです。README.md を眺めてもよくわからなかったので、ソースを読んでみました。手元に持ってくる
この記事を書いてる時点の最新版 v3.1.0 を読んでみます。
- https://github.com/grosser/parallel_tests/releases/tag/v3.1.0
- https://github.com/grosser/parallel_tests/tree/v3.1.0
ghq get git@github.com:grosser/parallel_tests.git cd parallel_tests git checkout -b tag3.1.0 refs/tags/v3.1.0rake 越しの実行の場合
このように実行することで、テスト用に
create databaseと、RSpecを実行してくれます。そのときの並列数は、実行環境のプロセッサの数らしいです。4コアなら4並列です。bundle exec rake parallel:setup bundle exec rake parallel:spec
[]に数字を入れると、実行環境のプロセッサ数のことは忘れて、指定した並列数で実行してくれます。bundle exec rake parallel:setup[6] bundle exec rake parallel:spec[6]これが
parallel_testsのソースコードでは、:countというパラメータを取るRakeタスクとして定義されています。
- https://github.com/grosser/parallel_tests/blob/v3.1.0/lib/parallel_tests/tasks.rb#L99-L102
- https://github.com/grosser/parallel_tests/blob/v3.1.0/lib/parallel_tests/tasks.rb#L180-L208
parallel:setupはさらにrun_in_parallelに渡して、bin/parallel_testを呼ぶコマンドライン文字列を組み立てています。このとき
:countを渡していれば、-nを付けるようにしています。しかし-nを付けなかった場合に、どのように決まるかは不明です。
parallel:specも同様で、なんなら:countを渡していようがいまいが、-nを付けています。:countを渡さなかった場合は-n ""となりそうですし、-nを付けなかった場合に、どのように決まるかは不明です。Rakeタスクは、パラメータとして並列数を受けとっていればその数を
bin/parallel_testに渡し、受けとっていなければbin/parallel_testに判断させているようです。bin/parallel_test
CLI に丸投げしていますね
実体はこれで、並列数に関心を集中して読むと、
コマンドライン引数が最も強く、環境変数
$PARALLEL_TEST_PROCESSORS、Parallel.processor_countの順に、並列数の取得元としているようです。
-n ""と渡ってきても、以下でイイかんじに対処できてそうに読めます。Parallel.processor_count
Parallel.processor_countは、parallel_testsを漁っても存在しておらず、parallelに定義されているようです。gem parallel を漁ると、環境変数
$PARALLEL_TEST_PROCESSORS、Etc.nprocessorsの順に、並列数の取得元としているようです。Etc.nprocessors
Etc.nprocessorsはetcというライブラリに定義されてそう。
Etc.nprocessorsでググると、Rubyの標準ライブラリのひとつとして実装されていることがわかります。
- https://www.google.com/search?q=Etc.nprocessors
- https://docs.ruby-lang.org/ja/latest/method/Etc/m/nprocessors.html
- https://www.rubydoc.info/stdlib/etc/Etc.nprocessors
2.7.0 で読んでみます。
ghq get git@github.com:ruby/ruby.git cd ruby git checkout -b tag2_7_0 refs/tags/v2_7_0どこに実装があるのか何もわからねえな...とりあえず ripgrep で漁ってみます。
rg nprocessors doc/ChangeLog-2.2.0 2564: * ext/etc/etc.c (etc_nprocessors_affin): maximum "n" should be 16384. 2568: * ext/etc/etc.c (etc_nprocessors_affin): minor spell fix. 2572: * ext/etc/etc.c (etc_nprocessors_affin): optimize memory usage a 2924: * ext/etc/etc.c (etc_nprocessors_affin): Test CPU_ALLOC availability. 2929: * ext/etc/etc.c (etc_nprocessors_affinity): use sched_getaffinity 2932: * ext/etc/etc.c (etc_nprocessors): use etc_nprocessors_affinity if 2935: [Feature #10267] etc-nprocessors-kosaki2.patch 3539: * ext/etc/etc.c (etc_nprocessors): Windows support. 3544: * ext/etc/etc.c (etc_nprocessors): New method. test/etc/test_etc.rb 167: def test_nprocessors 168: n = Etc.nprocessors ext/etc/etc.c 927:etc_nprocessors_affin(void) 992: * p Etc.nprocessors #=> 4 1000: * linux$ taskset 0x3 ./ruby -retc -e "p Etc.nprocessors" #=> 2 1004:etc_nprocessors(VALUE obj) 1013: ncpus = etc_nprocessors_affin(); 1033:#define etc_nprocessors rb_f_notimplement 1092: rb_define_module_function(mEtc, "nprocessors", etc_nprocessors, 0); doc/NEWS-2.2.0 162: * Etc.nprocessors lib/bundler/installer.rb 223: Etc.nprocessors spec/ruby/library/etc/nprocessors_spec.rb 4:describe "Etc.nprocessors" do 6: Etc.nprocessors.should be_kind_of(Integer) 7: Etc.nprocessors.should >= 1 spec/mspec/lib/mspec/utils/script.rb 256: [Etc.nprocessors, max].minhttps://github.com/ruby/ruby/tree/v2_7_0/ext/etc に転がっているものを眺めてみます。
- https://github.com/ruby/ruby/blob/v2_7_0/ext/etc/etc.c#L1092 で、Rubyコード内で
Etc.nprocessorsとしてetc_nprocessorsを利用できるよう定義されている。- https://github.com/ruby/ruby/blob/v2_7_0/ext/etc/etc.c#L979-L1034 が
etc_nprocessorsの実体
- Winwos なら
GetSystemInfo()https://github.com/ruby/ruby/blob/v2_7_0/ext/etc/etc.c#L1027-L1028 から取得している- Linuxなら
sched_getaffinity()https://github.com/ruby/ruby/blob/v2_7_0/ext/etc/etc.c#L961 から取得している- Linuxで
sched_getaffinity()が使えなければsysconf(_SC_NPROCESSORS_ONLN)https://github.com/ruby/ruby/blob/v2_7_0/ext/etc/etc.c#L1021 から取得している
parallel_testは Linux な CodeBuild で動かしているので、 Linux に関心を絞ります。sched_getaffinity
これは Linux のシステムコールで、C関数として利用できるよう定義されています。テキトーなLinuxディストリビューションで
man sched_getaffinityするとカーネルのマニュアルが出てきます。
- https://man7.org/linux/man-pages/man2/sched_getaffinity.2.html
- http://manpages.ubuntu.com/manpages/bionic/ja/man2/sched_setaffinity.2.html
たいへんありがたいことに解説記事があります。
- https://qiita.com/kubo39/items/dec96d7c93a50a310d7e#ruby-1
- https://qiita.com/masami256/items/47163fefed7c1e337dec
まとめ
parallel_testは、単独では実行環境のCPU数を取得していない。Parallel.processor_countから取得しているParallel.processor_countは Ruby 標準ライブラリ etc のEtc.nprocessorsから取得しているEtc.nprocessorsは、Linux ならシステムコールsched_getaffinity()が使えなければsysconf(_SC_NPROCESSORS_ONLN)から取得している
- 投稿日:2020-07-28T04:42:29+09:00
parallel_tests が並列数を決定する仕組み
Rubyのテストは、素のままですと直列実行なので、テストケース数が増えると実行時間も増えていきます。
CIの実行環境は、マルチプロセッサを選択できることがあるため、テストも並列実行できると、時間短縮を狙うことができます。
Rubyでは parallel_tests というgem越しに、めぼしいテストフレームワークを並列実行することができます。
ところで
bin/parallel_test -n 4のように並列数を指定すると4並列で動かしてくれますが、指定しなかった場合は、どうやら実行環境のプロセッサの数を、どこかから取ってきて動いているようです。README.md を眺めてもよくわからなかったので、ソースを読んでみました。手元に持ってくる
この記事を書いてる時点の最新版 v3.1.0 を読んでみます。
- https://github.com/grosser/parallel_tests/releases/tag/v3.1.0
- https://github.com/grosser/parallel_tests/tree/v3.1.0
ghq get git@github.com:grosser/parallel_tests.git cd parallel_tests git checkout -b tag3.1.0 refs/tags/v3.1.0rake 越しの実行の場合
このように実行することで、テスト用に
create databaseと、RSpecを実行してくれます。そのときの並列数は、実行環境のプロセッサの数らしいです。4コアなら4並列です。bundle exec rake parallel:setup bundle exec rake parallel:spec
[]に数字を入れると、実行環境のプロセッサ数のことは忘れて、指定した並列数で実行してくれます。bundle exec rake parallel:setup[6] bundle exec rake parallel:spec[6]これが
parallel_testsのソースコードでは、:countというパラメータを取るRakeタスクとして定義されています。
- https://github.com/grosser/parallel_tests/blob/v3.1.0/lib/parallel_tests/tasks.rb#L99-L102
- https://github.com/grosser/parallel_tests/blob/v3.1.0/lib/parallel_tests/tasks.rb#L180-L208
parallel:setupはさらにrun_in_parallelに渡して、bin/parallel_testを呼ぶコマンドライン文字列を組み立てています。このとき
:countを渡していれば、-nを付けるようにしています。しかし-nを付けなかった場合に、どのように決まるかは不明です。
parallel:specも同様で、なんなら:countを渡していようがいまいが、-nを付けています。:countを渡さなかった場合は-n ""となりそうですし、-nを付けなかった場合に、どのように決まるかは不明です。Rakeタスクは、パラメータとして並列数を受けとっていればその数を
bin/parallel_testに渡し、受けとっていなければbin/parallel_testに判断させているようです。bin/parallel_test
CLI に丸投げしていますね
実体はこれで、並列数に関心を集中して読むと、
コマンドライン引数が最も強く、環境変数
$PARALLEL_TEST_PROCESSORS、Parallel.processor_countの順に、並列数の取得元としているようです。
-n ""と渡ってきても、以下でイイかんじに対処できてそうに読めます。Parallel.processor_count
Parallel.processor_countは、parallel_testsを漁っても存在しておらず、parallelに定義されているようです。gem parallel を漁ると、環境変数
$PARALLEL_TEST_PROCESSORS、Etc.nprocessorsの順に、並列数の取得元としているようです。Etc.nprocessors
Etc.nprocessorsはetcというライブラリに定義されてそう。
Etc.nprocessorsでググると、Rubyの標準ライブラリのひとつとして実装されていることがわかります。
- https://www.google.com/search?q=Etc.nprocessors
- https://docs.ruby-lang.org/ja/latest/method/Etc/m/nprocessors.html
- https://www.rubydoc.info/stdlib/etc/Etc.nprocessors
2.7.0 で読んでみます。
ghq get git@github.com:ruby/ruby.git cd ruby git checkout -b tag2_7_0 refs/tags/v2_7_0どこに実装があるのか何もわからねえな...とりあえず ripgrep で漁ってみます。
rg nprocessors doc/ChangeLog-2.2.0 2564: * ext/etc/etc.c (etc_nprocessors_affin): maximum "n" should be 16384. 2568: * ext/etc/etc.c (etc_nprocessors_affin): minor spell fix. 2572: * ext/etc/etc.c (etc_nprocessors_affin): optimize memory usage a 2924: * ext/etc/etc.c (etc_nprocessors_affin): Test CPU_ALLOC availability. 2929: * ext/etc/etc.c (etc_nprocessors_affinity): use sched_getaffinity 2932: * ext/etc/etc.c (etc_nprocessors): use etc_nprocessors_affinity if 2935: [Feature #10267] etc-nprocessors-kosaki2.patch 3539: * ext/etc/etc.c (etc_nprocessors): Windows support. 3544: * ext/etc/etc.c (etc_nprocessors): New method. test/etc/test_etc.rb 167: def test_nprocessors 168: n = Etc.nprocessors ext/etc/etc.c 927:etc_nprocessors_affin(void) 992: * p Etc.nprocessors #=> 4 1000: * linux$ taskset 0x3 ./ruby -retc -e "p Etc.nprocessors" #=> 2 1004:etc_nprocessors(VALUE obj) 1013: ncpus = etc_nprocessors_affin(); 1033:#define etc_nprocessors rb_f_notimplement 1092: rb_define_module_function(mEtc, "nprocessors", etc_nprocessors, 0); doc/NEWS-2.2.0 162: * Etc.nprocessors lib/bundler/installer.rb 223: Etc.nprocessors spec/ruby/library/etc/nprocessors_spec.rb 4:describe "Etc.nprocessors" do 6: Etc.nprocessors.should be_kind_of(Integer) 7: Etc.nprocessors.should >= 1 spec/mspec/lib/mspec/utils/script.rb 256: [Etc.nprocessors, max].minhttps://github.com/ruby/ruby/tree/v2_7_0/ext/etc に転がっているものを眺めてみます。
- https://github.com/ruby/ruby/blob/v2_7_0/ext/etc/etc.c#L1092 で、Rubyコード内で
Etc.nprocessorsとしてetc_nprocessorsを利用できるよう定義されている。- https://github.com/ruby/ruby/blob/v2_7_0/ext/etc/etc.c#L979-L1034 が
etc_nprocessorsの実体
- Winwos なら
GetSystemInfo()https://github.com/ruby/ruby/blob/v2_7_0/ext/etc/etc.c#L1027-L1028 から取得している- Linuxなら
sched_getaffinity()https://github.com/ruby/ruby/blob/v2_7_0/ext/etc/etc.c#L961 から取得している- Linuxで
sched_getaffinity()が使えなければsysconf(_SC_NPROCESSORS_ONLN)https://github.com/ruby/ruby/blob/v2_7_0/ext/etc/etc.c#L1021 から取得している
parallel_testは Linux な CodeBuild で動かしているので、 Linux に関心を絞ります。sched_getaffinity
これは Linux のシステムコールで、C関数として利用できるよう定義されています。テキトーなLinuxディストリビューションで
man sched_getaffinityするとカーネルのマニュアルが出てきます。
- https://man7.org/linux/man-pages/man2/sched_getaffinity.2.html
- http://manpages.ubuntu.com/manpages/bionic/ja/man2/sched_setaffinity.2.html
たいへんありがたいことに解説記事があります。
- https://qiita.com/kubo39/items/dec96d7c93a50a310d7e#ruby-1
- https://qiita.com/masami256/items/47163fefed7c1e337dec
まとめ
parallel_testは、単独では実行環境のCPU数を取得していない。Parallel.processor_countから取得しているParallel.processor_countは Ruby 標準ライブラリ etc のEtc.nprocessorsから取得しているEtc.nprocessorsは、Linux ならシステムコールsched_getaffinity()が使えなければsysconf(_SC_NPROCESSORS_ONLN)から取得している
- 投稿日:2020-07-28T00:55:38+09:00
renderメソッドとredirect_toの違い
※この記事は私の勘違いが含まれています。正確な内容はコメント欄でご指摘頂いている通りです。
ツイッターのようなツイートアプリを作成中なのですが、表題の通りrenderとredirect_toの違いってなんや?
と思い私なりの結論が出たのでアウトプットのため、記事にしています。結論
- renderは同じコントローラー内のファイルしか基本読み込まないため、同じコントローラーのビューファイルを表示されることに向いている。
- redirect_toはurlを指定できるので、別のコントローラーのindexのビューファイルを表示させたい場合に向いている。
この結論に至った経緯は以下の通りです。
まずは以下のコードを見てください。app/controllers/users_controller.rbclass UsersController < ApplicationController def edit end def update if current_user.update(user_params) redirect_to root_path else render :edit end end private def user_params params.require(:user).permit(:name, :email) end endこれはユーザー管理用のusersコントローラーの記述です。
updeteアクションで、ユーザーアカウントの編集ができた場合はroot_path(messageコントローラーのindexアクション)へリダイレクトする。
できなかった場合はrender :editで再度編集画面(usersコントローラーのeditのビューファイル)へ戻すというものです。では
redirectをrenderに変えた場合どうなるのか考えてみました。def update if current_user.update(user_params) render template : "messages/index" else render :editこれで同じになったやろ!
と思ったらエラーになりました。
原因はmessage/indexのビューファイルは部分テンプレートを使用していたからでした。app/views/messages/index.html.erb<div class="wrapper"> <div class="side-ber"> <%= render "side_bar" %> </div> <div class="chat"> <%= render "main_chat" %> </div> </div>ここでmessagesフォルダ内にある部分テンプレート
side_bar,main_chatを読み込むという記述があります。
試しに部分テンプレートをapp/views/usersフォルダの直下に入れたら正常に表示されました。以上のことからわかったこと
usersコントローラーからmessages/indexのビューファイルだけを呼び出した。- ビューファイル内に部分テンプレートを呼び出すコードがあったため
usersのビューファイル内で部分テンプレートを呼び出そうとしたが部分テンプレートがないためエラーになった。まとめ
- 同じコントローラーのビューファイルを指定する場合は
renderの方が早い- redirect_toはリクエストがルーティングに戻されるので別コントローラーのビューファイルを表示させる時に使う。