- 投稿日:2020-07-28T23:15:25+09:00
【Python】Pyroでベイズ推定
最近確率的モデルを扱うPyroを知り、面白そうだと思ったので、お試しとして触ってみました。
本記事は、そのソースコードの共有となります。ソースコードはJupyter Notebookで書いています。
理論的な説明はほぼありませんが、ご了承ください。
環境
Windows10
Python: 3.7.7
Jupyter Notebook: 1.0.0
PyTorch: 1.5.1
Pyro: 1.4.0
scipy: 1.5.2
numpy: 1.19.1
matplotlib: 3.3.0Pyroとは?
Pyroは、Pytorchをバックエンドにした確率的モデルを扱うライブラリです。
pipからインストールできます。pip install pyro-pplこのとき、事前にPytorchのインストールが必要です。詳細は公式ページをご参照ください。
試しに動かしてみる
今回は、ベルヌーイ分布$Ber(p)$に従うデータから、そのパラメータ$p$を推定することを考えます。
まず、必要なモジュールをインポートします。from collections import Counter import numpy as np import scipy.stats as stats import matplotlib.pyplot as plt import torch import torch.distributions.constraints as constraints import pyro import pyro.distributions as dist from pyro.optim import SGD, Adam from pyro.infer import SVI, Trace_ELBO %matplotlib inline pyro.set_rng_seed(0) pyro.enable_validation(True)データの生成
乱数でデータを作成します。このとき、型をPytorchのtensorにする必要があります。
obs = stats.bernoulli.rvs(0.7, size=30, random_state=1) obs = torch.tensor(obs, dtype=torch.float32) obs> tensor([1., 0., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 0., 1., 1., 1., 1., 1., 1., 0., 0., 1., 1., 0., 0., 1., 1., 1., 0.])データ中の1の個数を確認します。
Counter(obs.numpy())> Counter({1.0: 23, 0.0: 7})よって、パラメータ$p$の最尤推定量は$23/30 \fallingdotseq 0.77$です。1
以降、$p$をベイズ推定していきます。事前分布の設定
ベイズ推定では、パラメータの事前分布を仮定し、観測したデータを合わせて事後分布を求めます。
ベルヌーイ分布$Ber(p)$のパラメータ$p$については、事前分布をベータ分布を仮定するのが一般的です 2
Pyroでは、modelメソッドで事前分布とデータのモデルを記述します。def model(data): # 事前分布を仮定 prior = dist.Beta(1, 1) # データのモデリング p = pyro.sample('p', prior) for i in range(len(data)): pyro.sample(f'obs{i}', dist.Bernoulli(p), obs=data[i])今回は$Beta(1, 1)$を仮定していますが、実はこれは一様分布と一致します。
事後分布の設定
guideメソッドで事後分布を記述します。事後分布も、事前分布と同様にベータ分布とします。
このとき、事後分布のパラメータとして適当な初期値を与えます。def guide(data): # 事後分布の定義 alpha_q = pyro.param('alpha_q', torch.tensor(15), constraint=constraints.positive) beta_q = pyro.param('beta_q', torch.tensor(15), constraint=constraints.positive) posterior = dist.Beta(alpha_q, beta_q) pyro.sample('p', posterior)この事後分布のパラメータ$\alpha, \beta$を求めることになります。
事後分布のフィッティング
事後分布のパラメータの推定方法について、今回は確率的変分推定を採用します。Pyroではこの方法を使うのが基本のようです。
今回のベルヌーイ分布の例では解析的に事後分布を求めることができるため、変分推定のような近似手法を用いるのはナンセンスですが、練習ということでこの方法を使ってみます。
(本来は、解析的に分布を求めることができない場合に使う手法ですね。)NUM_STEPS = 2000 optimizer = SGD(dict(lr=0.0001, momentum=0.9)) svi = SVI(model, guide, optimizer, loss=Trace_ELBO()) pyro.clear_param_store() history = { 'loss': [], 'alpha': [], 'beta': [] } for step in range(1, NUM_STEPS + 1): loss = svi.step(obs) history['loss'].append(loss) history['alpha'].append(pyro.param('alpha_q').item()) history['beta'].append(pyro.param('beta_q').item()) if step % 100 == 0: print(f'STEP: {step} LOSS: {loss}')> STEP: 100 LOSS: 17.461310371756554 STEP: 200 LOSS: 18.102468490600586 (中略) STEP: 1900 LOSS: 17.97793820500374 STEP: 2000 LOSS: 17.95139753818512ここで、
historyにフィッティング中のLoss、事後分布のパラメータ$\alpha, \beta$を記録しています。
ステップごとのこれらの数値をプロットすると、次のようになります。(ソースコードは省略します。)
!
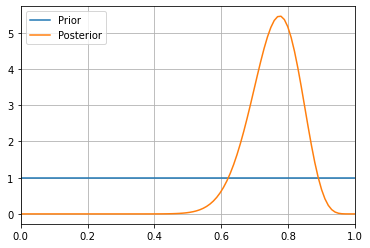
最終的に得られた$\alpha, \beta$を確認し、事後分布の期待値、分散を確認します。
infered_alpha = pyro.param('alpha_q').item() infered_beta = pyro.param('beta_q').item() posterior = stats.beta(infered_alpha_beta, infered_beta_beta) print(f'alpha: {infered_alpha}') print(f'beta: {infered_beta}') print(f'Expected: {posterior.expect()}') print(f'Variance: {posterior.var()}')> alpha: 25.764650344848633 beta: 7.556574821472168 Expected: 0.7732203787899605 Variance: 0.005109101547631603事前分布と事後分布をプロットしてみます。(ソースコードは省略します。)
うまく推定できていそうです。
まとめ
Pyroを使って簡単なベイズ推定を実行してみました。
今回は単純なベイズ推定でしたが、複雑なモデルを柔軟に、かつシンプルに記述できるのがPyroの強みかと思います。
公式ドキュメントには多くの確率的手法の例が載ってあり、これらを眺めているだけでも勉強になりそうです。
- 投稿日:2020-07-28T20:46:51+09:00
高卒工場勤務が未経験から転職するまで(Prologue)
自己紹介
はじめまして!高校卒業後→地元の工場へ就職→現在転職のため学習中
はい。こんな感じで何にも学歴も良いわけでもなく何も取り柄がないわけですが、
転職を考えております。技術で勝負するしかないのです。Qiitaになぜ投稿し始めたか。
これは単純にアウトプットする場所が欲しかったからです。
これから少しづつアウトプットしていきます。とりあえず触ってみた技術、言語
HTML,CSS,JavaScript,Python,Django,Vue.js
とざっくりこのあたりを触りましたが、エラーを吐かれすぎて挫折仕掛けていました。これからどうしていくのか
エラーを吐かれて解決できずに止まることがモチベーションが下がり気味
スクールに通うか迷いましたが、闇が深すぎて断念
様々な人に聞いたところMENTAを使ってみてはどうかということで、
メンターさんについてもらうことにしました。
これからはもう少し効率的に進めていけたらと思います。
- 投稿日:2020-07-28T20:10:46+09:00
天気図をクラスター分析してみた
はじめに
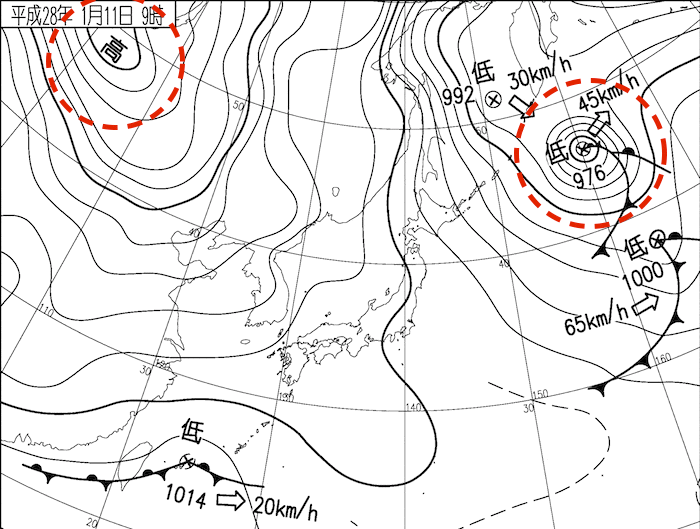
みなさん西高東低や冬型の気圧配置などという言葉を聞いたことはありませんか?日本付近の気圧配置にはいくつかのパターンがあり、西高東低とよばれる冬型の気圧配置はその中でも有名なほうでしょう(下図)。このほかにも太平洋高気圧に覆われる夏型の気圧配置などいくつかの種類があります。この記事では、このパターンを教師なし学習で分類してみようと思います。
(weather newsより)今回実行したことは以下の3つです。
- 衛星画像をスクレイピング
- エルボー法
- クラスター分析(教師無し学習)
衛星画像の取得
衛星画像の取得は江波山気象館のHPから行いました。というのも、rowデータをダウンロードするのは重く、いい感じに加工されたデータでスクレイピングしてよさそうだったのがこのサイトだったからです。
本来は 気象業務支援センターのHP から購入するのが妥当だと思われるので、ここら辺は自己判断でお願いします。ソースコードはここでは記載しませんが、 github に挙げておきます。筆者が利用した画像は日本付近の12:00(JST)の画像で、以下のような画像(854×480px)です。
前処理
import numpy as np import pandas as pd import matplotlib.pyplot as plt import seaborn as sns from PIL import Image import glob from tqdm import tqdm from os import makedirs from sklearn.cluster import KMeans from sklearn.metrics import silhouette_score, silhouette_samples x=np.empty((0,240*427)) paths=glob.glob("pictures/*.jpg") for path in tqdm(paths): img=Image.open(path) img = img.convert('L') img=img.resize((int(img.width/2), int(img.height/2))) x=np.append(x,np.array(img).reshape(1,-1),axis=0)画像を読み込んで1行になるようにreshapeしてから、numpy配列にぶち込みます。画質がいいとだいぶ時間がかかったのでグレスケにして半分の大きさにしました。
エルボー法
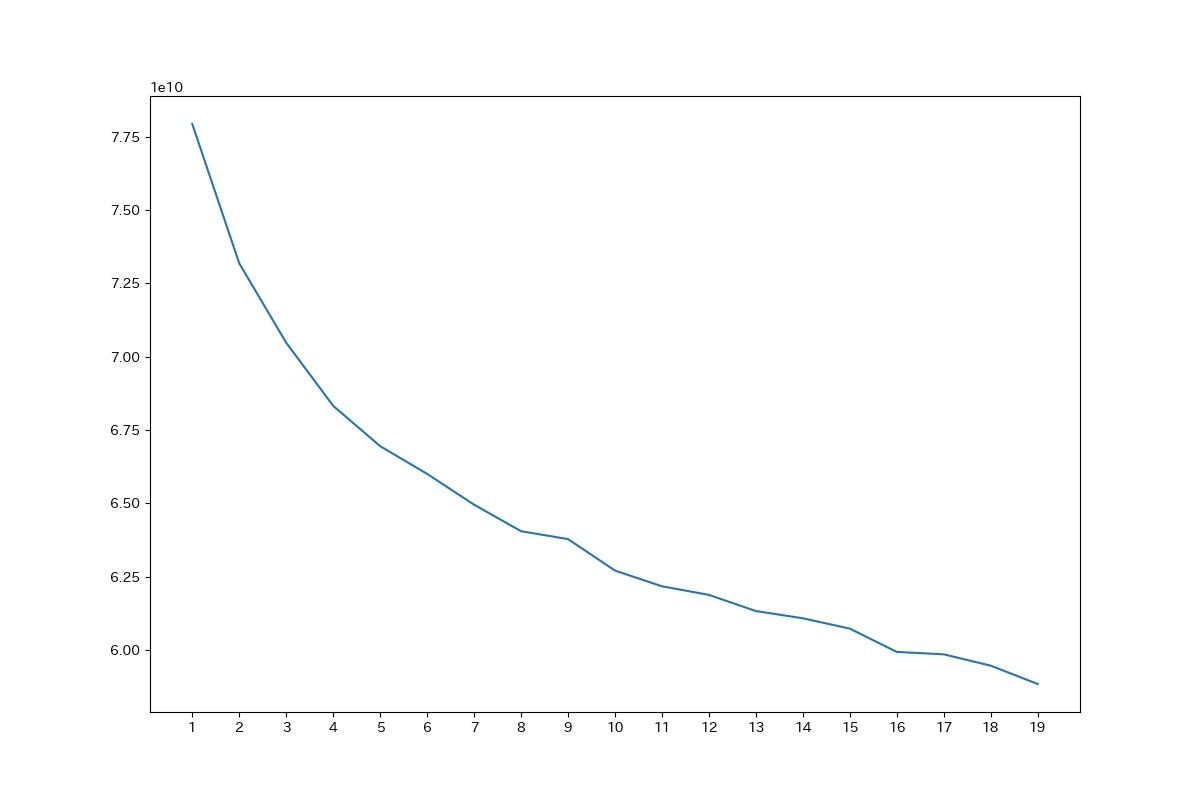
distortions = [] #エルボー法(最適なクラスター数を求める) for k in tqdm(range(1, 20)): kmeans = KMeans(n_clusters=k, n_init=10, max_iter=100) kmeans.fit(x) distortions.append(kmeans.inertia_) fig = plt.figure(figsize=(12, 8)) plt.xticks(range(1, 20)) plt.plot(range(1, 20), distortions) plt.savefig("elbow.jpg") plt.close()エルボー法により最適なクラスター数を求めました。20でやると10分ほどかかったので10ぐらいで十分かと思います。結果は以下の図のようになりました。
明確に何個がいいかは出ませんでしたが、今回は4でやることにしました。クラスター分析
k_means = KMeans(n_clusters=4).fit(x) y_pred = k_means.predict(x) print(k_means.labels_) print(pd.Series(k_means.labels_, name='cluster_number').value_counts(sort=False)) out=pd.DataFrame() out["picture"]=paths out["classnumber"]=y_pred out["date"]=pd.to_datetime(out["picture"].str.split("\\",expand=True).iloc[:,1].str.split(".",expand=True).iloc[:,0]) out.to_csv("out.csv")クラスターごとの要素数は139,61,68,98でした。いい感じに分かれたので期待できそうです。
#クラスごとに保存 for i in range(4): makedirs(str(i)+"_pictures", exist_ok=True) for i in out.itertuples(): img=Image.open(i.picture) img.save(str(i.classnumber)+"_"+i.picture) for i in range(4): out["month"]=out["date"].dt.month sns.countplot("month",data=out[out["classnumber"]==i]) plt.title(i) plt.savefig("月分布"+str(i)) plt.close()それぞれのクラスごとに分けて保存するとともに、それぞれのクラスの月の分布および具体的な画像を見てみましょう。
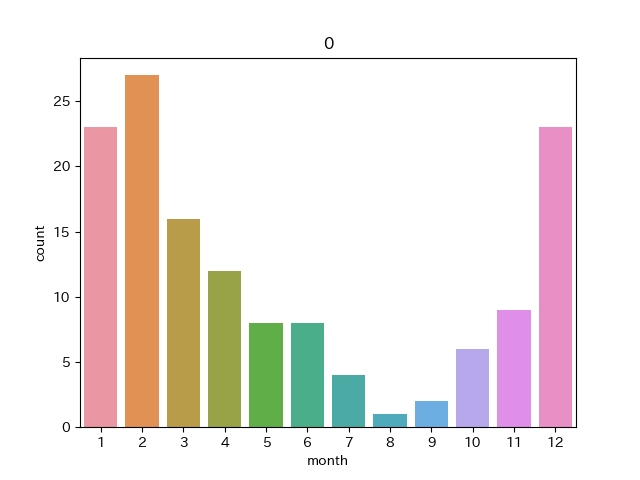
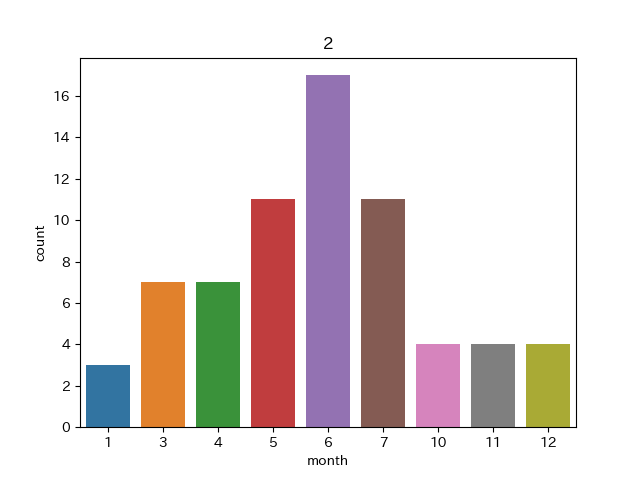
クラスターNo.0
冬に多くて夏に少ない感じですね。冬型の気圧配置といったとこでしょうか。数は少ないといっても夏にもこれがみられるのは不思議な感じがします。このクラスターに属する画像は例えば以下のようなものです。
2020/1/13 2020/1/19 これは典型的な西高東低な気圧配置で北西から冷たい風が吹くことで日本列島上空に雲がかかっているような天気図でした。
また、このクラスターに属する図で冬でない季節のものは以下の図のようなものでした。
2020/6/26 2019/10/26 雰囲気としては大陸上及び日本上空に雲があり太平洋上には雲がない感じであるということでしょうか。雲種は違えど雲の場所の雰囲気は確かに似ている気はします。
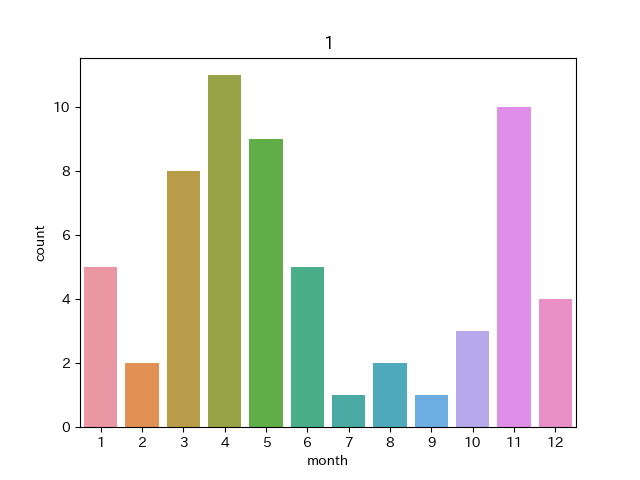
クラスターNo.1
4,11月に多くなっています。このグラフだけではどのような共通点があるのかわかりませんでした。このクラスターに属する画像は例えば以下のようなものです。
2019/11/2 2020/4/29 明確な気圧配置の特徴があるわけではないように見受けられました。画像の特徴としては日本付近は晴れており、日本の南東方向に斜めの雲が入っている画像が多かったです。このような雲は季節によっては太平洋高気圧の縁を回るようにしてできているものもありましたが、偶然似通った雲ができているだけの気がします。どちらかというとこのクラスターは他のクラスターの余りのような印象が強かったです。
クラスターNo.2
これは梅雨の時期に多い感じです。梅雨前線があるような場合の気圧配置でしょうか。なお、2,8,9月には1個も見られなかったようです。
2020/6/28 2020/7/4 このクラスターには予想通り梅雨前線を示したものが多くありました。春夏秋冬の4区分には現れない梅雨ですが、その気象学的な特徴は明確にあることが示されたのではないかと思います。
なお、このクラスターに属する他の季節の画像は以下の様なものでした。
2019/10/20 2020/3/19 日本列島上に前線によるものに近い形状の雲が広がっており、このクラスターに分類されたのが納得できます。
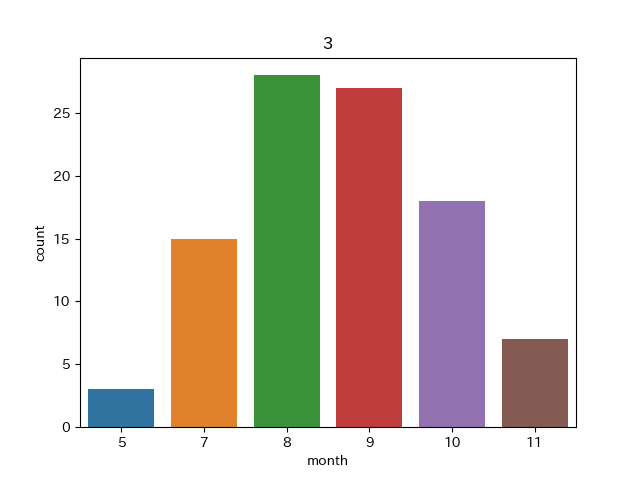
クラスターNo.3
圧倒的夏を示しています。太平洋高気圧が張りだした夏型の気圧配置を表していそうです。実際にこのクラスターに分類された画像を見てみると以下のように夏型感満載の画像でした。
2019/7/29 2019/8/21 また、他の季節の画像は晴れ間が広がった画像が多くなっていました。
2019/10/14 2019/11/1 まとめ
以上の解析結果から、クラスター分析により、大まかな気圧配置の傾向を分類し、それから外れたものも解釈することができた。ただ、衛星画像は気圧を直接表したものではないため、気圧配置を直接的に分類できるわけではなく、雲の分布状況でクラスターが分けられてしまうので、どうしても雲の形状が似ていれば誤分類されてしまう。気圧配置の分類をするためには雲だけでなく気圧を取り込む方法を検討する余地があるそうだ。
今回実行したコード(github)参考文献












- 投稿日:2020-07-28T20:05:21+09:00
Pythonビルトインの様々な文字列操作
まえおき
- この記事は執筆中のやさしくはじめるPythonプログラミングの本の特定の章の部分抜粋です。
- 入門本なので初心者の方向けです。
- ビルトインの文字列操作関係の章の内容が主になります。
- Qiita記事にマッチしていない箇所(「章」や「ページ」といった単語が使っていたり、改行数が余分だったり、リンクが対応していない等)があるという点はご留意ください。気になる方は↑のリンクの電子書籍版をご利用ください(Githubでダウンロードできます)。
- コメントなどでフィードバックいただいた場合、書籍側にも活用・反映させていただく場合があります。
文字列の各操作
前章までで基本的なPythonの操作や型・ビルトイン関数などを学んできました。本章では文字列に対して追加の操作について学んでいきます(前章までである程度操作方法について学んできましたが、他にも大切で便利な操作方法などが色々あるのでそちらを学んでいきます)。
数は多いので全ては覚えなくても、「そういえばこんなものもあった」程度で大丈夫です。必要な時に都度検索して思い出せれば問題ありません。
文字列のインデックスとスライス
リストの説明関係のセクションでスライス(リストの特定の範囲の値のみに抽出など)について学びましたが、実は文字列でも同様のスライスを行うことができます。リストの時のように、
[1:3]といったような括弧と数字・コロンを使ったインデックス範囲の指定で制御することができます。インデックスの数字は各文字ごとに割り振られます。リストの時と同じく0からスタートとなります。
例えば
Appleという文字列であれば、以下のようにインデックスが割り振られます。
- 0 → A
- 1 → p
- 2 → p
- 3 → l
- 4 → e
ある種、「文字列(string)は文字(character)を格納したリストのようなもの」とも言えるかもしれません。
実際にリスト的にインデックスへの値の参照をコードを書いて試してみましょう。
まずは特定のインデックスの内容を出力してみます(
[0]とか[1]といった指定をします)。該当する文字単体が出力されることを確認できます。str_value = 'Apple' print(str_value[0])コード実行結果の出力内容:
A
str_value = 'Apple' print(str_value[1])コード実行結果の出力内容:
p
続いて「〇〇のインデックス以降××のインデックス未満」というようにスライスで特定範囲の文字列を抽出してみます。リストと同様にコロンの左側の数字が「〇〇のインデックス以降」を表し、コロンの右側の数字が「××のインデックス未満」という条件になります。つまり
[1:4]と指定すれば、「1以降4未満」という条件(1, 2, 3のインデックスが対象)になり、Appleという文字に対して設定すればpplという部分が抽出できます。str_value = 'Apple' print(str_value[1:4])コード実行結果の出力内容:
ppl
勿論リストのスライスと同様に、コロンの左側の数字だけ指定して「〇〇以降」という条件だけ指定したり、右側の数字だけ指定して「××未満」という条件だけを指定するといった書き方もすることができます。
文字列の最初が特定の文字列になっているかどうかを調べる : startswithメソッド
文字列のstartswithメソッドでは、対象の文字列が第一引数に渡された文字列で始まっているかの真偽値を取得することができます。
「〇〇の文字列で始まる」という意味で「starts with 〇〇の文字列」といった英語で書くので、メソッド名はそちらに由来します。
プログラムでは変数名や定数名などで、同じグループの値を統一して特定の文字列から始める書き方がされることが結構あり、プレフィックス(prefix)などとも呼ばれます。
preが「前に」といった意味を持ち、「先頭に付けるもの」といったように使われます(その他にも)。例えば
ITEM_ID_というプレフィックスを使って定数にITEM_ID_〇〇といったような名前が付けられます。startswithメソッドではこのようなプレフィックスに対象の文字列がなっているかどうかを調べるのに便利です。後々の章で触れますが、プログラム内の変数名や定数名なども文字列として取得することができるので、特定のプレフィックスだったら処理を行う...といったような制御が可能になります。
使い方は第一引数にプレフィックスを指定すると、TrueかFalseかの真偽値が返却されます。
文字列が指定したプレフィックスで始まっているためTrueが返却されるケース :
str_value = 'FRUIT_ID_APPLE' print(str_value.startswith('FRUIT_ID_'))コード実行結果の出力内容:
True
文字列が指定したプレフィックスで始まっていないためFalseが返却されるケース :
str_value = 'FRUIT_ID_APPLE' print(str_value.startswith('ITEM_ID'))コード実行結果の出力内容:
False
文字列の最後が特定の文字列になっているかどうかを調べる : endswithメソッド
endswithメソッドはstartswithメソッドと似たようなメソッドとなりますが、startswithメソッドが文字列の先頭が対象なのに対してこちらは末尾が対象となります。
末尾の文字列のことはサフィックス(suffix)と言います。
startswithメソッドと同様に、endswithメソッドでも第一引数にサフィックスを指定する形で使います。結果も同様に真偽値で返ってきます。
文字列が指定したサフィックスで終わっているためTrueが返却されるケース :
str_value = 'CAT_NAME' print(str_value.endswith('_NAME'))コード実行結果の出力内容:
True
文字列が指定したサフィックスで終わっていないためFalseが返却されるケース :
str_value = 'CAT_AGE' print(str_value.endswith('_NAME'))コード実行結果の出力内容:
False
startswithとendswithメソッドはスライスでも同じようなことはできるけれども...
前のセクションで触れた通り、文字列はスライスを使って特定の範囲の文字列を抽出することができます。例えば以下のようにすると、任意の文字数のプレフィックス部分を取得することができます。
str_value = 'FRUIT_ID_APPLE' print(str_value[:6])コード実行結果の出力内容:
FRUIT_
また、後々の章で学びますが、Pythonでは
左辺の値 == 右辺の値といったように、半角のイコールの記号2つとその左右に任意の値を指定して、もし両辺の値が一致していればTrue、一致していなければFalseとなる書き方ができます。両辺の値が一致しているためTrueとなるサンプル :
int_value = 100 print(int_value == 100)コード実行結果の出力内容:
True
両辺の値が一致していないためFalseとなるサンプル :
int_value = 95 print(int_value == 100)コード実行結果の出力内容:
False
スライスとこの2つのイコールの記号を使うとstartswithメソッドやendswithメソッドででやるような判定と同じことをすることができます。例えば以下のように
[:9]とスライスで指定すれば先頭の9文字が取得できるのでその9文字を左辺、右辺に文字列で想定しているプレフィクスを指定すればstartswithメソッドを使った時と同じようにTrueもしくはFalseの真偽値を取得することができます。str_value = 'FRUIT_ID_APPLE' print(str_value[:9] == 'FRUIT_ID_')コード実行結果の出力内容:
True
ただし、この書き方は文字数を数え間違えていたり、うっかりスライスの数字の指定を間違えてしまったりすると想定した挙動になってくれません。例えば以下のようなコードは想定した判定になってくれません。
str_value = 'FRUIT_ID_APPLE' print(str_value[:9] == 'FRUIT_ID')コード実行結果の出力内容:
False
この書き方だとぱっと見で「どこが間違っているの・・・?」という点は瞬時には分かりづらいですし、コードの内容も読みづらく思えます。プレフィックス(文字の先頭)の比較はまだしもサフィックス(文字の末尾)側はもっとコードが読みづらくなります。
この辺りの間違いやすさなどはPythonのコーディング規約のPEP8でもstartswithやendswithを使うようにと定められています。
文字列に特定のプレフィックスやサフィックスがついているかをチェックするには、文字列のスライシングではなく ''.startswith() と ''.endswith() を使いましょう。
startswith() と endswith() を使うと、綺麗で間違いが起こりにくいコードになります:
Python コードのスタイルガイド他の人がコードを読んだ時に少し時間をかければしっかりと内容は把握できますが、普段の仕事で時間が限られているので極力コードは「瞬時に内容が把握できる」ものが理想です。
特に理由が無ければ、PEP8に合わせてスライスではなくstartswithなどを使って判定するようにしましょう。
文字列内に特定の文字列が含まれる位置を検索する : find, rfind, index, rindexメソッド
このセクションでは文字列のfind, rfind, index, rindexの4つのメソッドについて学びます。findメソッドは頻繁に使いますが、他の3つは比較的必要になるケースが少な目かもしれません。
findメソッドは文字列内に特定の文字列がどこに含まれているのかを調べるのに使います。
使い方は第一引数に検索したい文字列を指定します。返却値には最初に見つかった位置のインデックスが設定されます。リストなどのインデックスと同様に、インデックスの値は0から始まります(1文字目がインデックスの0、2文字目がインデックスの1というようになります)。
例えば以下のコードでは
猫という文字を検索しています。結果は3が返ってきているので、3のインデックス(4文字目)に猫という文字があるということを調べることができます。str_value = '吾輩は猫である。まだ名は無い。' print(str_value.find('猫'))コード実行結果の出力内容:
3
取得できたインデックスの整数(今回は3)を文字列に指定してみると、確かに
猫という文字と位置が一致していることが確認できます。str_value = '吾輩は猫である。まだ名は無い。' print(str_value[3])コード実行結果の出力内容:
猫
猫という文字ではなく猫であるといったような文字列を指定した場合には、その文字列がスタートするインデックスが返却されます。そのため、今回のサンプルでは猫という文字を指定した時と返っているインデックスの整数は同じ値の3となります。str_value = '吾輩は猫である。まだ名は無い。' print(str_value.find('猫である'))コード実行結果の出力内容:
3
検索に指定した文字列が見つからない場合には-1が返却されます。
str_value = '吾輩は猫である。まだ名は無い。' print(str_value.find('犬'))コード実行結果の出力内容:
-1
これを利用して、もし-1が返却されるかどうかで「特定の文字列が含まれるかどうか」の判定などにも使うことができます。
第二引数は検索するインデックス範囲の開始値です。例えば4を指定したら「4以降のインデックス範囲の文字列が検索される」挙動になります(省略した場合には先頭のインデクス0から検索が実行されます)。
以下のサンプルでは第二引数に3と4を指定しており、文字列が見つかるかどうかの結果が変わることを確認しています。
該当の文字が見つかるケースのサンプル :
str_value = '吾輩は猫である。' print(str_value.find('猫', 3))コード実行結果の出力内容:
3
開始インデックスの影響で該当の文字が見つからないケースのサンプル :
str_value = '吾輩は猫である。' print(str_value.find('猫', 4))コード実行結果の出力内容:
-1
第三引数は検索するインデックスの終了値です。省略した場合には最後の文字列まで検索が実行されます。
注意点として、ここで指定した値は「以下」の条件ではなく「未満」の条件となります。そのため3を指定した場合インデックスの3はインデックスの対象に含まれず、2までが検索対象となります。
第三引数に3を指定した結果、検索でヒットしなくなるケースのサンプル :
str_value = '吾輩は猫である。' print(str_value.find('猫', 0, 3))コード実行結果の出力内容:
-1
第三引数に4を指定した結果、範囲が4未満となるため3のインデックスの文字がヒットするケースのサンプル :
str_value = '吾輩は猫である。' print(str_value.find('猫', 0, 4))コード実行結果の出力内容:
3
findメソッドの次はrfindメソッドです。
rfindメソッドはfindメソッドとは逆に文字列の右側から検索を実施します。rは「右側から」という意味でrightのrとなっています。
例えば「吾輩は猫である。吾輩は猫ながら時々考える事がある。」という文字列に対して
猫という文字を検索した場合、右から検索して最初にヒットしたものの位置が返却値として使われるので、2番目の猫の文字の位置が対象となります。str_value = '吾輩は猫である。吾輩は猫ながら時々考える事がある。' print(str_value.rfind('猫'))コード実行結果の出力内容:
11
注意すべき点として、検索自体は右から実施されるものの、結果のインデックスの番号は左からカウントした通常のインデックスで返却されます。
以前の章のリストで触れた通り、
-1,-2,-3, ...とインデックスに指定すればそれぞれ右端の文字、右端から2番目の文字、右端から3番目の文字...といったように文字列の右端を基準としたインデックスによるアクセスもできますが、rfindメソッドでは左端の基準とした通常のインデックスの値が返却されるので通常通りにインデックスを指定すれば該当の文字を取得することができます。str_value = '吾輩は猫である。吾輩は猫ながら時々考える事がある。' index = str_value.rfind('猫') print(str_value[index])コード実行結果の出力内容:
猫
第二引数と第三引数はfindメソッドと同じく、検索するインデックス範囲の開始値と終了値(未満)となります。こちらもインデックス番号は右からではなく、通常のインデックスと同様に左からのインデックスの番号が使われます。指定したインデックスの範囲で「右側から」検索されるようになります。
str_value = '吾輩は猫である。吾輩は猫ながら時々考える事がある。' print(str_value.rfind('猫', 11))コード実行結果の出力内容:
11
str_value = '吾輩は猫である。吾輩は猫ながら時々考える事がある。' print(str_value.rfind('猫', 12))コード実行結果の出力内容:
-1
indexメソッドはほぼfindメソッドと同様の挙動をします。こちらも文字列を検索して見つかったインデックスの番号を取得する挙動となります。
ただし、findメソッドでは検索した文字列が見つからなかった時には-1が返却されていましたが、indexメソッドでは-1ではなくエラーとなります。
該当する文字列が存在するため、findと同様の挙動をするケースのサンプル :
str_value = '吾輩は猫である。' print(str_value.index('猫'))コード実行結果の出力内容:
3
該当する文字列が見つからないためエラーになるケースのサンプル :
str_value = '吾輩は猫である。' print(str_value.index('犬'))ValueError: substring not foundsubstringは特定の文字列の中の一部分の文字列という意味です。これらのメソッドでは第一引数の検索対象の文字列のことを指します。そのためエラーメッセージは「検索に指定された文字列が見つかりませんでした」といった内容になります。
最後のrindexメソッドは名前からも推測できる通り、rfindメソッドのように右から検索が実行され、且つindexメソッドのように検索に指定した文字列が見つからない場合はエラーになる挙動をします。
str_value = '吾輩は猫である。吾輩は猫ながら時々考える事がある。' print(str_value.rindex('猫'))コード実行結果の出力内容:
11
str_value = '吾輩は猫である。吾輩は猫ながら時々考える事がある。' str_value.rindex('犬')ValueError: substring not found文字列を別の文字列に置き換える : replace, translate, maketransメソッド
このセクションでは文字列の置換について学んでいきます。特定の文字列部分を別の文字列に置き換えたりといった制御が該当します。replace, translate, maketransの3つのメソッドを対象とします。特にreplaceメソッドは頻繁に利用します。
まずはreplaceメソッドについてです。replaceメソッドは特定の文字列を検索し、該当する文字列を別の文字列に置換します。
第一引数には検索する文字列、第二引数には置換後の文字列を指定します。例えば文字列の中の「猫」という部分を「犬」に置換したい場合には以下のように書きます。
str_value = '吾輩は猫である。吾輩は猫ながら時々考える事がある。' print(str_value.replace('猫', '犬'))コード実行結果の出力内容:
吾輩は犬である。吾輩は犬ながら時々考える事がある。
第三引数は置換回数の設定です。省略すると検索してヒットした文字列が全て置換されます。1を指定すると1回のみ置換、2を指定すると2回のみ置換といった挙動になります。以下のコードでは第三引数に1を指定しているため、1つ目の「猫」という文字部分のみ置換されています。
str_value = '吾輩は猫である。吾輩は猫ながら時々考える事がある。' print(str_value.replace('猫', '犬', 1))コード実行結果の出力内容:
吾輩は犬である。吾輩は猫ながら時々考える事がある。
translateとmaketransメソッドは一緒に使います。置換前の文字と置換後の文字の特定の組み合わせのものを指定して、一気に複数の文字の置換を行うことができます。
なお、対象は「1文字のもの」となります。複数の文字列のものには使えないのでreplaceメソッドの方を使いましょう。1文字同士の置換がたくさん必要な場合にはtranslateメソッドを使うことで高速に、且つシンプルなコードで置換を行うことができます。
maketransメソッドはその置換の組み合わせのデータを作るためのメソッドです。文字列のインスタンスでも使えますが、後々触れるクラスを直接指定して利用する方が一般的です(
str.maketransという書き方をします)。メソッド名はmake translation tableという英文に由来します。translationは移転や通訳という意味があり、tableは表という意味を持つので、文字と文字の変換表を作るといった感じの意味合いになります。
maketransメソッドには値の指定方法が「辞書のキーと値で指定する方法」と「第一引数と第二引数の2つのセットで指定する方法」の2つが存在します。
まずは辞書での設定の仕方を見ていきます。maketransメソッドの第一引数に辞書を指定して、キーに置換前の文字、値に置換後の文字を指定します。複数の対象がある場合には複数のキーと値のセットを指定します。
今回は以下のような組み合わせで句読点の文字を置換するコードで試してみます(左が置換前、右が置換後)。
、→,。→.trans_table = str.maketrans( { '、': ',', '。': '.', } )もしくは第一引数に置換前の文字を1文字ずつ順番に設定した文字列(今回の例では
、。という文字列)を指定し、第二引数に置換後の文字列を1文字ずつ順番に設定した文字列(今回の例では,.という文字列)を指定する方法もあります。第一引数と第二引数での文字の順番は一致するように注意してください。こちらの書き方でも辞書を使ったときと同じ挙動になります。trans_table = str.maketrans('、。', ',.')maketransメソッドで作られたデータを使ってtranslateメソッドを使ってみます。第一引数にmaketransメソッドで作られたデータを指定します。
str_value = 'ニャー、ニャーと試みにやって見たが誰も来ない。' print(str_value.translate(trans_table))コード実行結果の出力内容:
ニャー,ニャーと試みにやって見たが誰も来ない.
このセクションでは文字同士もしくは文字列同士の置換について学びました。この他にも正規表現と呼ばれるものを使って「特定のパターンにマッチするものを置換する」といった置換のやり方も存在します(且つ、便利でもあります)。
正規表現に関してはのちほど正規表現の章で詳しく触れていきます。
文字列を分割する : split, rsplit, splitlines, partition, rpartitionメソッド
このセクションでは文字列の分割について学んでいきます。split, rsplit, splitlines, partition, rpartitionの5つのメソッドが対象となります。特に一番ベーシックなsplitメソッドは多用します。
文字列の分割結果は文字列を格納したリストとなります。コンマ区切りやスペース区切り、タブ区切りなど特定の文字区切りで各値が意味を持つケースなどで利用します。
※コンマ区切りのデータはCSV(Comma Separated Valuesの略)と呼ばれ、色々な環境やツールで使われていますが、CSVの制御はこのセクションで学ぶメソッドではなく別途CSV用の機能がPythonには用意されていたり、Pandasと呼ばれるライブラリで快適に操作ができるのでそれらを使うことが多めです。CSV関係やPandasなどのライブラリは後々の章で触れます。
まずはsplitメソッドから見ていきます。splitは「分割する」といった意味を持つ単語になります。
第一引数に任意の区切り文字を指定すると、その区切り文字で分割された文字列を格納したリストが返ってきます。
以下のサンプルでは半角のコンマで文字列を分割して、1つ1つの文字列を格納したリストにしています。なお、splitメソッドでは結果のリストには分割で指定した文字列(今回のサンプルでは
,)は結果には含まれません。str_value = '100,200,300' print(str_value.split(','))コード実行結果の出力内容:
['100', '200', '300']
第二引数は分割の上限回数です。例えば2を指定したら2回分割がされ結果のリストの件数が3件になります。回数を超えた部分の文字列は分割されずにそのまま結果のリストの最後の値に残ります。
str_value = '100,200,300,400,500' print(str_value.split(',', 2))コード実行結果の出力内容:
['100', '200', '300,400,500']
第二引数を省略した場合には全ての区切り文字で分割が実施されます。
rsplitメソッドは他の先頭にrが付くメソッドと同様に、「右側から」分割処理が実行されます。ただし、第二引数を省略した場合には全ての区切り文字で分割が実行されるので、左から分割しても右から分割しても同じ結果になります。つまり、splitメソッドと同じ挙動になります。
splitと同じ結果になるrsplitのコード例 :
str_value = '100,200,300' print(str_value.rsplit(','))コード実行結果の出力内容:
['100', '200', '300']
第二引数(最大分割回数)を指定した場合には「右から」分割がされるので、リストの先頭(左端)に未分割の文字列が残ります。
str_value = '100,200,300,400,500' print(str_value.rsplit(',', 2))コード実行結果の出力内容:
['100,200,300', '400', '500']
splitlinesメソッドは文字列を改行単位で分割します。lineは行という意味も持つ単語となります。
splitメソッドで改行を指定すればいいのでは?という感じもしますが、改行の表現はOSやバージョンなどの環境で変わるうるため、全てを加味するとコードが煩雑になってしまいます。
改行は環境によって文字列中で
\nで表したり、もしくは\r\nと表されたり、\rと表されたり、もしくはクォーテーションを三つ使ってそのまま文字列内で改行を入れるということもできます。試しにWindows上のJupyterで
\nや\r\nという文字を含んだ文字列をprint関数で出力してみると、どちらも改行として表示されます。print('a\nb')コード実行結果の出力内容:
a b
print('a\r\nb')コード実行結果の出力内容:
a b
このように改行は複数の表現がありますが、ではsplitメソッドで分割しようとしたらどうなるでしょうか?たとえばsplitメソッドで改行を
\n区切りで指定していたとして、改行が\r\nで表現されているデータが来たときです。試してみると以下のように、
\r部分が結果に残ってしまって想定したものになりません。str_value = '100\r\n200\r\n300' print(str_value.split('\n'))コード実行結果の出力内容:
['100\r', '200\r', '300']
プログラムで扱う時にはその辺りの改行表現の差などを気にせずに単純に「改行で分割」としたいところです。そういったケースのために、splitlinesメソッドが用意されておりこちらを使うことで煩雑にコードを書かなくてもシンプルに改行で分割してくれます。
以下のように色々な改行を含んだ文字列に対して実行してみても、同じ結果が得られることが確認できます。
改行が
\nで表現されているケースでの分割サンプル :str_value = '100\n200\n300' print(str_value.splitlines())コード実行結果の出力内容:
['100', '200', '300']
改行が
\r\nで表現されているケースでの分割サンプル :str_value = '100\r\n200\r\n300' print(str_value.splitlines())コード実行結果の出力内容:
['100', '200', '300']
改行が
\rで表現されているケースでの分割サンプル :str_value = '100\r200\r300' print(str_value.splitlines())コード実行結果の出力内容:
['100', '200', '300']
改行が3つの連続したクォーテーションでの文字列表現で直接記述されているケースでの分割サンプル :
str_value = """100 200 300 """ print(str_value.splitlines())コード実行結果の出力内容:
['100', '200', '300']
partitionメソッドはsplitメソッドと同じように、区切り文字を指定して分割を実行します。ただし以下の点がsplitメソッドと異なります。
- 分割は1回のみ実施されます。
- 分割後の左側の文字列、区切り文字、分割後の右側の文字列の3つの値を格納したタプルが返却されます。
- splitメソッドはリストが返却され、partitionメソッドは分割結果の値が3件になるのを加味してかタプルとなります。返却値の型が異なるので注意してください。
- splitメソッドでは区切り文字は結果のリストには含まれませんが、partitionメソッドでは区切り文字も結果のタプルに含まれます。
実際にコードを書いて試してみます。サンプルとしてコロンを含んだ文字列に対して試してみると、コロンの左右の文字列で結果が分割されていることが確認できます。
str_value = '100:200' print(str_value.partition(':'))コード実行結果の出力内容:
('100', ':', '200')
文字列中に複数の区切り文字が含まれていても分割は1回しかされません。タプルの右側の値に区切り文字がそのまま残ります。
str_value = '100:200:300:400' print(str_value.partition(':'))コード実行結果の出力内容:
('100', ':', '200:300:400')
文字列中に引数で指定した区切り文字が無い場合には、タプルの最初のインデックスに元の文字列が配置され、2つ目と3つ目のインデックスには空文字が設定されます。区切り文字も含まれない形となります。タプルの値の件数は3件のままです。
str_value = '100:200' print(str_value.partition(','))コード実行結果の出力内容:
('100:200', '', '')
最後のrpartitionメソッドはメソッド名からも推測できるように、「右から」分割がされます。他の挙動はpartitionと同じです。
str_value = '100:200:300:400:500' print(str_value.rpartition(':'))コード実行結果の出力内容:
('100:200:300:400', ':', '500')
文字列内に変数などを差し込んだり、特定のフォーマットで値を挿入する : %記号, format, format_mapメソッド, f-strings
変数の値を差し込んだ文字列を作る場合、文字列同士を
+の記号で連結する方法があります。例えば以下のような書き方をします。name = 'タマ' concatenated_str = '飼っている猫の名前は' + name + 'です。' print(concatenated_str)コード実行結果の出力内容:
飼っている猫の名前はタマです。
しかし、もし変数の値が文字列以外の値、例えば整数などの場合にはこの方法だとそのままだとエラーになってしまいます。例えば以下のように
ageという整数の変数を連結しようとするとエラーになります。age = 5 concatenated_str = '飼っている猫の歳は' + age + '歳です。'TypeError: can only concatenate str (not "int") to strconcatenateは「連結する」といった意味の単語なので、エラーメッセージは「文字列と(整数ではなく)文字列のみが連結できるよ」といったような内容になります。
整数もしくは別の文字列以外の型の変数を文字列の連結に使いたい場合にはキャストと呼ばれる処理を挟んで対象の変数を文字列にする必要があります(キャストについては後々の章で触れます)。
文字列へのキャストするには対象の変数などを
str()関数の引数に渡すことで実現できます。先ほどのエラーが出てしまったコードをエラーが出ないように文字列にキャストするように書き直すと以下のようになります。age = 5 concatenated_str = '飼っている猫の歳は' + str(age) + '歳です。' print(concatenated_str)コード実行結果の出力内容:
飼っている猫の歳は5歳です。
この書き方でもやろうとしていた「文字列に変数を差し込んで連結する」という目的は達成できました。ただ、少し記述が煩雑(
+の記号やキャスト部分など)ですし、文字列の変数想定だった箇所が何かの拍子に別の型の値になってしまって、キャストを忘れていてエラーになってまう・・・みたいなケースも無いわけではありません。前置きが長くなりましたが、このセクションではそういったケースによりシンプルに・より読みやすい形に文字列へ変数を差し込む方法を学んでいきます。
まずは
%記号を使った書き方から学んでいきます。前の章で触れたように、%の記号は整数で使うと余り(剰余)の計算をすることができます。6 % 4コード実行結果の出力内容:
2
一方文字列では
%の記号を使って文字列中に変数を差し込む挙動に使われます。%記号と一緒に特定のフォーマットを表す英文字を文字列中で指定して使います。まず最初は「文字列(string)そのままのフォーマット」としてのsを付与した形の%sという表記で文字列でサンプルコードを書いていきます。文字列と差し込みたい変数の間にはさらに
%記号で間を分割し、左に文字列右に変数という形で以下のように書きます。age = 5 concatenated_str = '飼っている猫の歳は%s歳です。' % age print(concatenated_str)コード実行結果の出力内容:
飼っている猫の歳は5歳です。
変数を差し込む部分が
%sのみとなり、複数の+記号などが消えてすっきりとした記述となりました。また、対象の変数の文字列へのキャスト(str())も省略する形で書けています。
%sの他には%dや%.3f、%xといったような色々な指定があります。ビルトイン関数の章のformat関数でも色々触れましたが、それぞれ以下のような意味と挙動になります(ここで触れる以外にも色々とあります。format関数のセクションで色々説明をしたので、ここでは10進数や16進数などの説明は割愛します)。
%s-> string。文字列としてそのまま扱われます(str()関数でキャストした場合と同じような挙動)。文字列への変数の値の挿入などでは一番使う機会が多くなると思います。%d-> digit。普段の生活で使っている0~9の範囲での10進数での値で文字列内に挿入されます。%.3f-> float。浮動小数点数で文字列内に挿入されます。3といった部分は任意の数字で、小数点以下第何位まで表示するのかの指定となります。3と指定すれば0.000といったような数値で文字列に反映されます。%x-> hex。16進数で文字列内に挿入されます。一部、
%s以外も実際にコードを書いて挙動を確かめてみます。まずは%dです。%dでは10進数の整数として文字列に値が挿入されます。5.5といった小数を含んだ値を指定しても整数に変換されるので5といった値で文字列で出力されます。age = 5.5 concatenated_str = '飼っている猫の歳は%d歳です。' % age print(concatenated_str)コード実行結果の出力内容:
飼っている猫の歳は5歳です。
%dを使った場合には、指定する変数などの値は「整数に変換できる数値」である必要があります。浮動小数点数や整数などは指定できますが、それ以外の例えば文字列などを指定するとエラーになってしまいます(文字列などを挿入する必要があれば%sなどの方を使います)。name = 'タマ' concatenated_str = '飼っている猫の名前は%dです。' % nameTypeError: %d format: a number is required, not strエラーメッセージは「
%dのフォーマットでは文字列ではなく数値が必要だよ」といったようなメッセージになっています。
%.3fを使うと、指定する変数の値が小数点以下の特定の桁数の文字列で挿入されます。5.5という値の変数で%.3fとフォーマットを指定すれば5.500という値で文字列に挿入されます。%.2fとすれば小数点以下第二位まで表示され、5.50といった値で挿入されます。age = 5.5 concatenated_str = '飼っている猫の歳は%.3f歳です。' % age print(concatenated_str)コード実行結果の出力内容:
飼っている猫の歳は5.500歳です。
文字列中に複数の変数を挿入したい場合には、タプルの括弧を使って複数の変数を指定します。例えば
(name, age)といったようにタプルで書きます。name = 'タマ' age = 5 concatenated_str = \ '飼っている猫の名前は%sです。歳は%s歳です。' % (name, age) print(concatenated_str)コード実行結果の出力内容:
飼っている猫の名前はタマです。歳は5歳です。
文字列中の
%sなどの指定と、タプル内の値の件数は一致していないとエラーになります(関数の引数で数が合っていない時にエラーになるのと似たような形ですね)。以下のコードでは文字列中に
%sの指定が3つある一方で、タプル側の変数が2つしかないためエラーになっています。name = 'タマ' age = 5 concatenated_str = \ '飼っている%sの名前は%sです。歳は%s歳です。' % (name, age)TypeError: not enough arguments for format stringエラーメッセージは「文字列の整形(ここでは変数の挿入)に必要な引数(各変数)が足りていないよ」といったメッセージになります。
タプル側の件数が多くてもエラーになります。
name = 'タマ' age = 5 concatenated_str = \ '飼っている猫の名前は%sです。歳は3歳です。' % (name, age)TypeError: not all arguments converted during string formatting「文字列の整形(変数の挿入)中に、全ての引数(タプル内の各変数)が(
%sの数が足りなくて)変換(挿入)できませんでした」といったようなエラーメッセージの内容になります。また、複数の値の挿入処理にはタプルが使われるため、タプル自体を挿入したい場合にはそのままだとうまくいきません。
%sなどの表記が1つだけで且つ複数の値を格納したタプルの変数を指定した場合には前述の通り件数が一致していないと判断されてエラーになってしまいます。このようなケースではタプルの文字列へのキャストなどの制御が必要になってしまいます。それ以外にも、関数で引数の数が増えると読みづらくなってくるといったのと同様に、文字列中に
%sの記述が多くなってくると順番などの制御などでミスをしやすくなってきます。キーワード引数のような機能が欲しくなってきます。その辺りの
%による制御の問題点を改善する形で、後述のformatメソッドが%による制御よりも後のPythonバージョンで追加されています。
%記号による制御の次はformatメソッドについて学んでいきます。%記号を使った変数などの値の文字列への挿入処理と同様に使えますが、こちらの方がPythonのバージョン的に新しい機能であり、コードの記述量は少し増えますが色々と機能が増えていたり問題点などが改善されていたりします。使い方としては、まずは文字列中に
{}の括弧を変数の値を入れたいところに追加します。その後にその文字列でformatメソッドを実行し、引数として挿入したい変数を指定します。シンプルな例だと以下のようなものになります。name = 'タマ' formatted_str = '飼っている猫の名前は{}です。' formatted_str = formatted_str.format(name) print(formatted_str)コード実行結果の出力内容:
飼っている猫の名前はタマです。
複数の変数を挿入したい場合には
{}の括弧を複数文字列内に設定します。name = 'タマ' age = 5 formatted_str = '飼っている猫の名前は{}です。歳は{}歳です。' formatted_str = formatted_str.format(name, age) print(formatted_str)コード実行結果の出力内容:
飼っている猫の名前はタマです。歳は5歳です。
複数の引数を指定した際には順番に
{}部分に値が設定されていきます。例えば(name, age)と引数に指定した場合には文字列中の最初の{}部分にnameの引数の値が設定され、次の{}部分にageの引数の値が反映されます。この順番を調整したい場合には
{}の括弧の中に整数の値を設定して{0}や{1}といったような書き方をします。括弧内の整数は0から始まる引数の番号です(最初の引数が0、その次が1、その次が2...となります)。以下のように実際にコードを書いてみると、第三引数(
name)の方が文字列中で第二引数(age)の値よりも先に文字列内で設定されることを確認できます。animal = '猫' name = 'タマ' age = 5 formatted_str = '飼っている{0}の名前は{2}です。歳は{1}歳です。' formatted_str = formatted_str.format(animal, age, name) print(formatted_str)コード実行結果の出力内容:
飼っている猫の名前はタマです。歳は5歳です。
{}の括弧で一部はそのままの文字列として使うケースで、且つformatメソッドでの変数の差し込みなどもやりたい場合には{{}}と括弧を二重に記述するとその括弧はformatメソッドで無視される普通の括弧の文字列({})として扱われます(こういった制御をエスケープするなどと言われます)。以下のサンプルではformatメソッドを使ってもエスケープされた
{}の括弧の部分が出力に残っていることが確認できます。name = 'タマ' age = 5 formatted_str = '飼っている{{猫}}の名前は{}です。歳は{}歳です。' formatted_str = formatted_str.format(name, age) print(formatted_str)コード実行結果の出力内容:
飼っている{猫}の名前はタマです。歳は5歳です。
また、
{name}や{age}といったように括弧の中に引数名を書いておくことで、キーワード引数のように変数の差し込みを指定することもできます。引数の順番のミスなどを避けれますし、引数が多くなっても読みやすいコードにすることができます。cat_name = 'タマ' cat_age = 5 formatted_str = '飼っている猫の名前は{name}です。歳は{age}歳です。' formatted_str = formatted_str.format( name=cat_name, age=cat_age, ) print(formatted_str)コード実行結果の出力内容:
飼っている猫の名前はタマです。歳は5歳です。
このキーワード引数を使う書き方は仕事でも高い頻度で利用しています。シンプルな変数値の挿入であれば
%記号を使った処理を使うことも多いですが、変数の数が多くなった場合(3つ以上など)には可読性などの面からformatメソッドでキーワード引数を使って記述することが多めです。引数の数が多くなると読みづらくミスしやすくなってくるので、積極的にキーワード引数などを使っていきましょう。以下は少し発展的な書き方且つ使う機会は低めとなりますが、
{}の括弧で指定された値がリストや辞書などの場合、インデックス的に参照することができます。たとえば
{0}と書くと第一引数の変数が参照されますが、もしその第一引数の値がnameというキーを持つ辞書であれば{0[name]}と書くことで文字列中に辞書のnameキーの値を展開することができます。このサンプルでは第一引数({0})を使っていきますが、第二引数以降でも勿論使用することができます。dict_value = { 'name': 'タマ', 'age': 5, } formatted_str = \ '飼っている猫の名前は{0[name]}です。歳は{0[age]}歳です。' formatted_str = formatted_str.format(dict_value) print(formatted_str)コード実行結果の出力内容:
飼っている猫の名前はタマです。歳は5歳です。
リストでも同様なことはできます。例えば第一引数にリストの変数を指定して
{0[0]}と書けば第一引数のインデックス0の値、{0[1]}と書けば第一引数のインデックス1の値が展開されます。list_value = [ 'タマ', 5, ] formatted_str = '飼っている猫の名前は{0[0]}です。歳は{0[1]}歳です。' formatted_str = formatted_str.format(list_value) print(formatted_str)コード実行結果の出力内容:
飼っている猫の名前はタマです。歳は5歳です。
こういった書き方は、多用すると括弧やインデックスの数値などが連続するのでコードが読みづらくなるケースが起こりえます。リストや辞書などを使う場合にも、文字列中はキーワード引数の値単体で設定(例えば
{name}といった形など)して、引数指定時にインデックスなどを参照することで同じことはできるため、コードが読みづらくなってきたらキーワード引数単体での書き方などがおすすめです。以下書き換え例です。list_value = [ 'タマ', 5, ] formatted_str = '飼っている猫の名前は{name}です。歳は{age}歳です。' formatted_str = formatted_str.format( name=list_value[0], age=list_value[1], ) print(formatted_str)コード実行結果の出力内容:
飼っている猫の名前はタマです。歳は5歳です。
第一引数としての
{0}という表記をサンプルで使ってきましたが、他の書き方、例えばキーワード引数を使ったような書き方も勿論できます。例えば{name_dict[cat_name]}みたいな書き方ができます(サンプルでは文字列が長くなってきたので()の括弧と改行を使っています)。name_dict = {'cat_name': 'タマ'} age_list = [5] formatted_str = ( '飼っている猫の名前は{name_dict[cat_name]}です。' '歳は{age_list[0]}歳です。' ).format( name_dict=name_dict, age_list=age_list, ) print(formatted_str)コード実行結果の出力内容:
飼っている猫の名前はタマです。歳は5歳です。
文字列内で辞書に対して特定のキーの値に対してアクセスする方法に関して、注意点としてキーに変数などは使えません。
通常の辞書の値への参照ではキーに変数などが使えます。例えば以下のような辞書の値へのアクセス(
[name_key]といった書き方)ができます。dict_value = {'cat_name': 'タマ'} name_key = 'cat_name' print(dict_value[name_key])コード実行結果の出力内容:
タマ
一方で文字列内での辞書の値のキーの参照は
{dict_value['name']}という書き方ではなく、直接[name]といったようにクォーテーション('記号など)無しで記述します。その際にはnameという変数ではなくnameというキー名でのアクセスとなります。特定のキーに対して変数を使って文字列に値を挿入したい場合には、文字列内でキーへ変数は使えないので、以下のように文字列の外で引数で指定する箇所で(name=dict_value[name_key]といった書き方で)設定する必要があります。name_key = 'name' age_key = 'age' dict_value = { name_key: 'タマ', age_key: 5, } formatted_str = '飼っている猫の名前は{name}です。歳は{age}歳です。' formatted_str = formatted_str.format( name=dict_value[name_key], age=dict_value[age_key], ) print(formatted_str)コード実行結果の出力内容:
飼っている猫の名前はタマです。歳は5歳です。
続いて
{}の括弧内でコロンを使った書き方について学びます。括弧内で半角のコロンを設定し、コロンの左側に対象の変数(引数順に応じた{0}や{1}もしくはキーワード引数による{name}といったような書き方の部分)を記述し、コロンの右側にフォーマットの文字列(.3fなど)を指定することで、特定のフォーマットで値を挿入することができます。{0:.3f}や{name:.3f}といったようにコロンを使って書きます。
%記号を使った書き方の際の%dとか%.3fとかの%を除いた部分が該当し、機能もそれらと同じように動作します(例えば.3fと指定すれば小数点以下第三位までの文字列の形式で表示されるといった挙動は同じです)。以下のサンプルでは
ageというキーワード引数を挿入し、小数点以下第三位まで表示する指定で{age:.3f}という指定を文字列中でしています。出力結果の文字列が元の値の5.5ではなく第三位まで表示する形で5.500となっている点が確認できます。age = 5.5 formatted_str = '猫の年齢は{0:.3f}歳です。' formatted_str = formatted_str.format( age, ) print(formatted_str)コード実行結果の出力内容:
猫の年齢は5.500歳です。
このセクションの最後のメソッドはformat_mapです。
format_mapメソッドはformatメソッドとほぼ同じような挙動をします。ただし、引数には辞書を1つ指定する形になっています。引数の辞書の各キーと値のセットが、formatメソッドでキーワード引数を使った時のように展開されて文字列中に各値が展開されます。
dict_value = { 'name': 'タマ', 'age': 5, } formatted_str = '飼っている猫の名前は{name}です。歳は{age}歳です。' formatted_str = formatted_str.format_map(dict_value) print(formatted_str)コード実行結果の出力内容:
飼っている猫の名前はタマです。歳は5歳です。
関数の章でも触れましたが関数(もしくはメソッド)実行時の引数に半角のアスタリスク2個と辞書をセットで引数に指定すると辞書内のキーと値をキーワード引数として展開してくれることを学びました。そちらの書き方とformat関数を組み合わせると、実はformat_mapメソッドを使わなくても同じような挙動を実現できます。例えば以下のようにformatメソッドの引数に
**dict_valueと指定すればformat_mapメソッドを使った時と同じ結果を得ることができます。dict_value = { 'name': 'タマ', 'age': 5, } formatted_str = '飼っている猫の名前は{name}です。歳は{age}歳です。' formatted_str = formatted_str.format(**dict_value) print(formatted_str)コード実行結果の出力内容:
飼っている猫の名前はタマです。歳は5歳です。
formatメソッドでもformat_mapメソッドと同じ結果を得られるのに何故format_mapメソッドが用意されているのでしょう?理由としては以下のようなものがあります。ただし、細かい制御とかが必要になった時にformat_mapが必要になる時が稀にある・・・といった程度で、利用頻度的にはformat_mapメソッドは大分少なくなります。
- format_mapメソッドでは引数の辞書のコピーは作成されません。2個のアスタリスクと辞書をformatメソッドに指定した場合は引数に指定した辞書のコピーが作成されます。コピーされる分、メモリや処理時間が僅かに増加します。そのため大きいデータの辞書などを指定する際にはformat_mapの方がパフォーマンス的に有利になります。ただし、大抵はキーワード引数で指定するようなケースでは小さい辞書のケース(数値や文字列が数点など)が多いと思いますので、ほとんどのケースでは差は誤差の範囲です。
- 後々の章で触れますが、クラスを使った継承などの機能を使って辞書の一部の機能を書き換える(上書きする)といったコードを書くことがあります。そのような場合にアスタリスクを2個使った引数指定では「辞書としてコピーされる」ために上書きした部分が無視されてしまうといったケースが発生します。この辺りは後々の章で触れますので、今は「カスタマイズしたものがformatメソッドでは無視されてしまうケースが稀に発生する」程度にお考えください。
このセクションの最後に、f-strings(f文字列)にも触れていきます。
f-stringsとは、文字列の引用符(シングルクォーテーションなど)の前にfという文字を付与することで、文字列中に変数などを差し込んだりPythonのコードを実行することができる機能です。
変数部分やPythonのコード部分にはformatメソッドと同じように
{}の括弧で囲みます。シンプルなサンプルコードとしては以下のようになります。
猫の...という文字列部分の先頭にfという文字が付与されていることと、formatなどのメソッド無しにnameという変数が結果の文字列に含まれているという点に注目してください。name = 'タマ' txt = f'猫の名前は{name}です。' print(txt)コード実行結果の出力内容:
猫の名前はタマです。
f-stringsを使うと直接変数の挿入などが対応でき、formatメソッドなどの呼び出しも不要なのでコード量が短くて済むというメリットがあります。できることとしては書き方は結構異なるものの、formatメソッドに近い内容となっています。
f-stringsでの
{}の括弧内ではPythonでの処理などを書くこともできます。例えば以下のように文字列内で足し算をしたりすることもできます。age = 5 print(f'来年は{age + 1}歳になります。')コード実行結果の出力内容:
来年は6歳になります。
関数の実行なども文字列中で行うことができます。
def get_name(): return 'タマ' print(f'猫の名前は{get_name()}です。')コード実行結果の出力内容:
猫の名前はタマです。
%記号を使った書き方やformatメソッドで、フォーマット(例えば小数点以下第何位までの文字列にするのかなど)を指定するにはformatメソッドと同じように半角のコロンの記号(:)を挟み、右側にフォーマットを指定します。value = 123.456789 print(f'小数点以下第三位までを含んだ値は{value:.3f}です。')コード実行結果の出力内容:
小数点以下第三位までを含んだ値は123.457です。
なお、このフォーマット指定部分(コード上では
.3fとなっている部分)は書式指定子(format specifier)などと呼ばれます。Python内部のコードを読むと、引数名などがformat_specなどになっていますがこの引数名はformat specifierに由来します。f-strings中では、このフォーマット指定子部分でさらに
{}の括弧を入れる(入れ子にすると言います)と、フォーマット指定子部分にも変数を指定することができます(条件に応じてフォーマット指定子を変更したりすることができます)。format_spec = '.2f' value = 123.456789 print(f'小数点以下第二位までを含んだ値は{value:{format_spec}}です。')コード実行結果の出力内容:
小数点以下第二位までを含んだ値は123.46です。
任意の文字列でリストの値を1つの文字列に連結する : joinメソッド
joinメソッドは任意の文字列を格納したリストなどの値を、指定の文字列を間に挟んだ形で連結をします。
間に挟む文字列は変数も使えますが、直接固定の文字や文字列が指定されることが多めです。例えばコンマ区切りでリストの値を連結したい時には
','.joinといった形の書き方がされます。メソッドの第一引数に連結したいリスト(もしくはタプルなどの値)を指定します。コンマ区切りでリスト(
animalsという変数)を連結するサンプル :animals = ['猫', '犬', '兎'] print(','.join(animals))コード実行結果の出力内容:
猫,犬,兎
アンダースコア二個(
__)でリストを連結するサンプル :animals = ['猫', '犬', '兎'] print('__'.join(animals))コード実行結果の出力内容:
猫__犬__兎
リストの中身が文字列以外(数値など)になっている場合にはエラーになります。
int_list = [1, 2, 3] print(','.join(int_list))TypeError: sequence item 0: expected str instance, int foundリストやタプルのような順番を持った各値を格納したものは総括してシークエンス(sequence)とも呼ばれます。
そのためエラーメッセージは「シークエンス(リスト)のインデックス0の要素(item)で、文字列(str)のインスタンス想定のところに整数(int)の値がありました」といったよう内容になります。文字列中に出現する特定の文字列の回数を取得する : countメソッド
countメソッドは第一引数に指定した文字列が、対象の文字列中にいくつ含まれているかの件数を返します。
文字列中に「猫」という文字が4つあるため4が返却されているサンプル :
txt = ( '吾輩は猫である。' 'その後猫にもだいぶ逢ったがこんな片輪には一度も出会わした事がない。' '猫が来た猫が来たといって夜中でも何でも大きな声で泣き出すのである。' ) print(txt.count('猫'))コード実行結果の出力内容:
4
第二引数は検索範囲の開始インデックス、第三引数は検索範囲の終了インデックスから1マイナスした値となります。
0~11までのインデックスの文字列範囲を検索対象とするサンプル :
txt = ( '吾輩は猫である。' 'その後猫にもだいぶ逢ったがこんな片輪には一度も出会わした事がない。' '猫が来た猫が来たといって夜中でも何でも大きな声で泣き出すのである。' ) print(txt.count('猫', 0, 12))コード実行結果の出力内容:
2
それぞれスライスで使われるコロンの右側の整数と右側の整数の値に該当します。つまり、検索対象の範囲を確認するには以下のような文字列へのスライスをすることで対応ができます(前述のコードサンプルの第二引数の0と第三引数の12をスライスで指定しています)。
print(txt[0:12])コード実行結果の出力内容:
吾輩は猫である。その後猫
文字列の端から空白文字などの特定の文字を取り除く : strip, lstrip, rstripメソッド
stripメソッドでは文字列の先頭と末尾の特定の文字を削除します。stripは「取り除く」といった意味の単語になります。
replaceメソッドで空文字を指定(空文字で置換)しても、特定の文字列を削除することができますが、replaceメソッドと比べてstripメソッドは以下の違いがあります。
- 引数は省略することができます。
- 引数を省略した場合は、文字列両端のスペースや改行などの空白文字と呼ばれる文字が削除されます。
- 文字列ではなく文字単位で削除が実行されます。例えば引数に
猫犬という文字列を指定した場合、猫犬という文字列で削除がされるのではなく、猫と犬という文字単位で削除がされます。まずは引数を省略したケースでの挙動を確認してみます。以下のような文字列の両端にスペースや改行などの空白文字(
\nは改行1つ分を表す文字になります)を含んだ文字列で進めます。txt = ' 吾輩は猫である。\n\n' print(txt)コード実行結果の出力内容:
吾輩は猫である。
stripメソッドを通してみると、両端にあった空白文字が取り除かれていることが確認できます。
txt = ' 吾輩は猫である。\n\n' print(txt.strip())コード実行結果の出力内容:
吾輩は猫である。
第一引数に文字列を指定した場合には、その文字列で1文字ずつ両端で削除処理が実行されます。例えば引数に
猫犬という文字列を指定すれば、両端から猫もしくは犬という文字ではなくなるまで削除処理が実行されます。txt = '猫犬猫兎狼犬猫犬' print(txt.strip('猫犬'))コード実行結果の出力内容:
兎狼
lstripメソッドは、stripメソッドの左端のみ文字の削除処理が実行されるメソッドです。lはleftのlとなります。
使い方や引数などはstripメソッドと同じです。以下のコードでは右端の
猫と犬という文字が残っていることが確認できます。txt = '猫犬猫兎狼犬猫犬' print(txt.lstrip('猫犬'))コード実行結果の出力内容:
兎狼犬猫犬
rstripメソッドはlstripメソッドなどの流れから分かる通り、右端のみ文字の削除を行います。メソッド名の先頭のrはrightのrとなります。使い方はstripやlstripメソッドと同じです。
txt = '猫犬猫兎狼犬猫犬' print(txt.rstrip('猫犬'))コード実行結果の出力内容:
猫犬猫兎狼
文字列を全て大文字にする : upperメソッド
upperメソッドは文字列を全て大文字に変換します。アルファベットの文字列部分が変換対象となります。
upper caseで「大文字」という意味なので、メソッド名はそちらに由来します。
txt = 'Apple and orange' print(txt.upper())コード実行結果の出力内容:
APPLE AND ORANGE
半角文字だけでなく全角文字でも同様に変換することができます。
txt = 'Apple' print(txt.upper())コード実行結果の出力内容:
APPLE
文字列を全て小文字にする : lowerメソッド
lowerメソッドはupperメソッドとは逆に、アルファベットの大文字の文字列部分を小文字に変換します。lower caseで「小文字」という意味なので、メソッド名はそちらに由来します。
大文字と小文字の変換が逆なだけで、使い方や挙動はupperメソッドと同じです。
txt = 'Apple And Orange' print(txt.lower())コード実行結果の出力内容:
apple and orange
数字の文字列をゼロ埋めする : zfillメソッド
任意の整数を、特定の文字数になるまで左側に0を追加する処理をゼロ埋めもしくはゼロパディング(zero padding)と言います。
例えば
135という文字を5文字に揃えるゼロ埋めをすると、00135となります。zfillメソッドは、このゼロ(zero)埋め(fill)の処理をしてくれます。第一引数には結果の文字数を整数で指定します。5を指定したら5文字になるまで0が付与され、7を指定したら7文字になるまで0が付与されます。
txt = '135' print(txt.zfill(5))コード実行結果の出力内容:
00135
文字列を特定の文字数になるまで文字を追加する : rjust, ljust, centerメソッド
rjust、ljust、centerメソッドもzfillと同じように任意の文字数になるまで文字を埋める挙動をします。ただし、zfillと以下の挙動が異なります。
- 埋める文字は0ではなく任意の文字を指定することができます。
- メソッドによって、埋める文字の位置を左端、右端、もしくは両端を選択できます。
rjustメソッドは文字列は右に配置され、左端に任意の文字が埋められます。right justifyingで「右ぞろえ」という意味であり、メソッド名はそちらに由来します。
第一引数に最終的な文字数の整数、第二引数に埋める文字を指定します。
txt = '犬犬' print(txt.rjust(5, '猫'))コード実行結果の出力内容:
猫猫猫犬犬
ljustメソッドは元の文字列は左ぞろえに配置され、右側に不足している数だけ文字が埋められます。
txt = '犬犬' print(txt.ljust(5, '猫'))コード実行結果の出力内容:
犬犬猫猫猫
centerメソッドは元の文字列は中央ぞろえに配置され、左端と右端両方に腹側している数がけ文字が埋められます。
txt = '犬' print(txt.center(5, '猫'))コード実行結果の出力内容:
猫猫犬猫猫
左右に埋める文字の数が奇数の場合は、左端の方が多く埋められます。
txt = '犬' print(txt.center(5, '猫'))コード実行結果の出力内容:
猫猫犬猫猫
先頭の1文字を大文字にして他を小文字にする : capitalizeメソッド
重要度 : ★★☆☆☆(最初は知らなくてもいいかも)
※以降の文字列操作のセクションは、比較的マイナーなものが多くなります。一応一通り触れていきますが、スキップいただいても大きな問題はありません。
capitalizeメソッドはアルファベットで先頭の一文字を大文字に変換し、その他を小文字に変換します。英語の文章などで便利です。
capitalizeという単語自体は「資本化する」といったようなお金関係の意味の他にも「大文字で始める」といった意味もあり、メソッド名はそちらに由来します。
txt = 'apple and orange' print(txt.capitalize())コード実行結果の出力内容:
Apple and orange
小文字だけが変換されるというわけではなく、文字列中に大文字が含まれている場合には先頭の1文字以外は大文字から小文字へと変換されます。
txt = 'APPLE AND ORANGE' print(txt.capitalize())コード実行結果の出力内容:
Apple and orange
各英単語の最初の1文字を全て大文字にする : titleメソッド
titleメソッドはアルファベットの各単語の先頭の一文字を大文字にし、他を小文字に変換します。
英文ではタイトルや見出しなどでは「主な単語の先頭の1文字を大文字にし、残りを小文字表記にする」という書き方がされることが多くあり、このような書き方をタイトルケース(title case)と呼びます。titleメソッドの名前の由来はタイトルケースに由来します。
注意点として、通常は
andやtheなどの単語は小文字のままで、名詞などの単語は先頭を大文字にする形(例えばApple and Orangeといったような形)でタイトルケースが反映されますが、Pythonのtitleメソッドは全ての単語で最初の1文字が大文字になります。txt = 'apple and orange' print(txt.title())コード実行結果の出力内容:
Apple And Orange
大文字と小文字を入れ替える : swapcaseメソッド
swapcaseメソッドは小文字部分を大文字にし、大文字部分を小文字にします。swapは「交換する」といった意味を持ちます。
txt = 'Apple And Orange' print(txt.swapcase())コード実行結果の出力内容:
aPPLE aND oRANGE
全ての文字列が大文字かどうか調べる : isupperメソッド
isupperメソッドは文字列内のアルファベットが全て大文字の場合に真偽値のTrueを返し、それ以外の場合にはFalseを返却します。他のセクションで触れた通り、
upper caseで大文字という意味なので、「文字列 is upper case」といった意味合いで真偽値を返す形でメソッド名がisupperとなっています。txt = 'APPLE AND ORANGE' print(txt.isupper())コード実行結果の出力内容:
True
文字列中に小文字が含まれているとTrueではなくFalseが返却されます。
txt = 'Apple And Orange' print(txt.isupper())コード実行結果の出力内容:
False
全ての文字列が小文字かどうか調べる : islowerメソッド
islowerメソッドはisupperメソッドとは逆で、文字列のアルファベットが全て小文字の場合に真偽値のTrueを返します。
lower caseで小文字という意味になります。txt = 'apple and orange' print(txt.islower())コード実行結果の出力内容:
True
1文字でも大文字が含まれていればFalseとなります。
txt = 'Apple and Orange' print(txt.islower())コード実行結果の出力内容:
False
なお、isupperメソッドも同様ですが大文字のアルファベット以外の記号や日本語などが含まれていてもそれらは判定に影響しません。あくまで小文字が含まれている文字列であり且つ大文字が含まれていないという条件になります。
txt = 'apple リンゴ' print(txt.islower())コード実行結果の出力内容:
True
各単語の最初の1文字が全て大文字・他が小文字になっているかを調べる : istitleメソッド
istitleメソッドは少し前のtitleメソッドのセクションで触れた(厳密ではありませんが)タイトルケース(各単語の先頭の1文字が大文字)かどうかの真偽値を返します。
txt = 'Apple And Orange' print(txt.istitle())コード実行結果の出力内容:
True
いずれかの単語で先頭が大文字になっていない単語があると結果はFalseになります。
txt = 'Apple and orange' print(txt.istitle())コード実行結果の出力内容:
False
文字列が全て英数字などになっているかどうかを調べる : isdecimal, isdigit, isnumeric, isasciiメソッド
このセクションでは文字列の内容が特定の文字列かどうか(10進数の整数のみの文字列かどうか、アルファベットのみの文字列かどうかなど)の判定用の真偽値を取得する各メソッドについて学んでいきます。
isdecimalメソッドは文字列が10進数(普段の生活で使っている、0~9までの10個の数字での数値表現)で表すことができる整数の文字列かどうかの真偽値を返却します(
decimal numberで10進数という意味になります)。整数以外の小数(もしくは小数記号)などが含まれている場合にはFalseとなります。記号や日本語・英語などの整数以外が含まれていてもFalseとなります。たとえば150といった数値の文字列はTrueとなります。
txt = '150' print(txt.isdecimal())コード実行結果の出力内容:
True
全角であっても内容が整数のみであれば結果はTrueとなります。
txt = '150' print(txt.isdecimal())コード実行結果の出力内容:
True
整数以外の値、例えば小数点などが含まれているとFalseとなります。
txt = '3.14' print(txt.isdecimal())コード実行結果の出力内容:
False
記号や空白文字なども含まれているとFalseとなります。例えば以下のように左端にスペースなどが含まれていてもFalseとなってしまいます。もしそういった空白文字が入る可能性があるプログラムの場合には前のセクションで触れたstripメソッドなどを使って余分な空白文字の削除を行って処理すると判定で想定外の結果になったりすることを避けられます。
txt = ' 150' print(txt.isdecimal())コード実行結果の出力内容:
False
isdigitメソッドはisdecimalと近い挙動をするメソッドで、整数かどうかの真偽値を返します。ただしこちらは通常の
0~9の数字だけでなく、数値の周りを〇で囲っている①や②といった丸付き数字の文字や指数の文字(2の3乗の3部分など、上付きの小さい数字の文字)などの特殊な数字の文字が一部許容します(isdecimalメソッドよりもTrueになる条件が多くなります)。isdecimalが名前の通り10進数かどうかの判定の一方で、digitは「アラビア数字(123などの文字)」といった意味を持つので、isdigitは特殊な文字も含めてアラビア数字かどうかといった判定になります。
isdecimalと同様に通常の整数でTrueになるサンプル :
txt = '150' print(txt.isdigit())コード実行結果の出力内容:
True
isdecimalと同様に整数以外の文字が含まれているためFalseになるサンプル :
txt = '150円' print(txt.isdigit())コード実行結果の出力内容:
False
特殊な
①などの丸付き文字でもTrueになることを確認するサンプル :txt = '①②' print(txt.isdigit())コード実行結果の出力内容:
True
特殊な
²などの指数部分の文字でもTrueになることを確認するサンプル(変換などはやりづらい文字なので、コード実行の際にはコードサンプルのコピーなどをお願いします) :txt = '²³⁴' print(txt.isdigit())コード実行結果の出力内容:
True
isnumericメソッドではさらに、isdigitメソッドの「アラビア数字の文字」という制限が無くなります(isdigitよりも多くの文字が対象になります)。文字列が全て数字を表す文字であればTrueになります。
アラビア数字という制約が無くなるので、例えば
Ⅲといったローマ数字でもTrueが返ります。txt = 'ⅠⅢⅥ' print(txt.isnumeric())コード実行結果の出力内容:
True
他にも漢字の文字列でもTrueになってくれます。
txt = '七五三' print(txt.isnumeric())コード実行結果の出力内容:
True
isasciiメソッドはASCIIコードと呼ばれる文字、例えば半角の英数時や一部の記号(
@の記号など)、改行などの特殊文字のみで文字列が構成されている場合にTrueを返却します。txt = '~@abcABC123' print(txt.isascii())コード実行結果の出力内容:
True
全角文字などではFalseが返却されます。
txt = 'ABC' print(txt.isascii())コード実行結果の出力内容:
False
他にもisalphaやisalnumなどのメソッドも存在しますが、こちらは利用頻度が少ない印象なのと、名前的にアルファベット(英字)かどうか(isalpha)、英数字かどうか(isalnum)に思えますが、漢字などの全角文字も対象となる少し直観に反したものになっているためここでは説明を割愛します。
文字列が全て空白文字かどうか調べる : isspace
isspaceメソッドは、文字列が全て空白文字になっているかどうかの真偽値を返却します。空白文字は半角スペースや全角スペース・改行(文字列中では
\nと表記されることも多くあります)・タブ(こちらも文字列中では\tと表記されることも多めです)などが該当します。txt = ' \n\t' print(txt.isspace())コード実行結果の出力内容:
True
スペースなどが含まれていても、空白文字以外が文字列中に存在するとFalseになります。
txt = '猫犬 \n\t' print(txt.isspace())コード実行結果の出力内容:
False
文字コードの変換を行う : encode. decodeメソッド
encodeメソッドとdecodeメソッドは文字列の文字コードを変換します。基本的にPythonでテキストを扱う場合にはUTF-8と呼ばれる文字コードがほぼほぼですが、古いファイルや環境、ファイルフォーマットなどによっては他の文字コード(Shift_JISなど)を扱わないといけないケースがたまに発生します。
ただし、文字列のencodeやdecodeメソッドを利用するというよりかは、テキストファイルなどの読み書き時にこれらの文字コードを指定するケースが多めです。
文字列自体のメソッドはあまり使うケースが少ないとは思いますので、ここでは軽く触れる程度に抑えておきます(ファイル操作などは後々の章でしっかりと学びます)。
まずはencodeメソッドからです。encodeメソッドではPython上の通常の文字列から、特定の文字コードの値に変換します。変換後の値はbytesクラスのインスタンスとなり、たとえばShift_JISに変換すると
\x94Lといった値になり、ぱっと見では読めない値になってしまいます。encodeメソッドの第一引数には文字コードを指定します。今回はShift_JISに変換しようと思いますので、
sjisという値を指定します(他にもutf-8などの決まった値が色々あります)。txt = '猫犬' sjis_txt = txt.encode('sjis') print('テキストの内容:', sjis_txt, '\n型:', type(sjis_txt))コード実行結果の出力内容:
テキストの内容: b'\x94L\x8c\xa2' 型: <class 'bytes'>
decodeメソッドはencodeメソッドと逆の動作をします。つまりShift_JISなどの文字コードに変換された値を、再びPython上で使える普通の文字列(
猫犬といったように、人が普通に読める文字列)に戻します。第一引数には対象の値が何の文字コードなのかを指定します。txt = sjis_txt.decode('sjis') print(txt)コード実行結果の出力内容:
猫犬参考文献・サイトまとめ
- 「関数」と「メソッド」の違い
- Pythonで文字列・数値を右寄せ、中央寄せ、左寄せ
- Pythonで大文字・小文字を操作する文字列メソッド一覧
- Python, formatで書式変換(0埋め、指数表記、16進数など)
- Pythonで文字列が数字か英字か英数字か判定・確認
- Python strip・lstrip・rstrip 空白を削除する
- Pythonで文字列を置換(replace, translate, re.sub, re.subn)
- Pythonで文字列・数値をゼロ埋め(ゼロパディング)
- Python 文字を検索し値を返す(find/index)
- 文字の変換にはstr.translate()が便利
- Comma-Separated Values
- Pythonで文字列を分割(区切り文字、改行、正規表現、文字数)
- 改行の、\nと\r\nの違いは何ですか?
- Python String partition()
- プログラマが持つべき心構え (The Zen of Python)
- PEP 3101 -- Advanced String Formatting
- what is the meaning of colon in python's string format?
- What is difference between str.format_map(mapping) and str.format
- PEP 498 -- Literal String Interpolation
- string --- 一般的な文字列操作
- Definition and Examples of Title Case and Headline Style
- 文字列の中の文字が数を表す文字かどうかを判定する(isdecimal, isdigit, isnumeric)
- [Python] 文字列が数字であることを判別する(isdigit, isdecimal, isnumeric)
- 文字列の中の文字が英字を表す文字かどうかを判定する(isascii, isalpha, isalnum)
- 投稿日:2020-07-28T19:58:26+09:00
discord.pyを使ってbotを作ったときの知見
プリコネのクラバト管理botを作ったのでそのへんで気づいたことです
https://github.com/izmktr/yukarisanon_readyでのイベント
on_readyはdiscordに接続したときに呼び出されます
また、不定期にdiscordから切断されるようで、
自動的に再接続したときにも呼び出されます。ここでは内部的に持っている情報とdiscord.pyのデータを結びつけると良さそうです。
import discord from discord.ext import tasks from typing import List, Dict, Optional #guild_idと内部的なクラスとの紐付け guildhash: Optional[Dict[int, GuildData]] = None @client.event def on_ready(): global guildhash if guildhash is None: # ロード処理 guildhash = {} for g in client.guilds: gdata = guildhash.get(g.id) if gdata is None: gdata = GuildData() guildhash[g.id] = gdata gdata.guild = gメッセージに付随する処理
リアクションを付ける/外すときに発生する、
on_reaction_add,on_reaction_remove ですが、呼び出されないことがあります。
大体、投稿されて15分程度経った後のメッセージでは反応しないことがあります。
(サーバの活発度によるのではないかと考えています)
おそらく、こうなるとon_message_deleteも飛んでこない気がします。max_messagesが1000なので大きくすれば回避できるかと思いましたが、
こんな感じで100000を入れてみても回避できませんでした。
(この辺の知見求む)# 意味がない? client = discord.Client(max_messages = 100000)on_raw_reaction_add,on_raw_reaction_remove を使えば、確実に飛んできます。
on_messageでmessageの情報を保存しておき、on_raw_reaction_~を使って
処理を解決するのがいいでしょう。なお、on_raw_reaction_add → on_reaction_addの順で呼び出されます。
on_reaction_add が飛んできたらこちらで、飛んでこないならon_raw_reaction_addと考えてましたが、
順序が逆なのでこの処理は面倒そうです。プライベートチャット
botにメッセージを送ることでbotとプライベートチャットができます。
開発用のコマンドを使う場合はプライベートチャットを使えば、
周りにログが見られない形で作業が行なえます。@client.event async def on_message(message): # メッセージ送信者がBotだった場合は無視する if message.author.bot: return # 通常のメッセージ if message.channel.type == discord.ChannelType.text: return # 1:1のメッセージ if message.channel.type == discord.ChannelType.private: return問題は、通常のメッセージとmessageの型が違います
ですから、なくなっているクラス変数やクラス関数があります。また、プライベートメッセージではギルドがありませんので、
プライベートメッセージ内でギルドを指定する必要があります。この差異を吸収するような設計にして各種コマンドの処理を作っておくと
便利だっただろう、という反省点です。
- 投稿日:2020-07-28T19:57:12+09:00
Arduino UNO : USB2UARTの最大通信速度を探る(1)
Arduino UNOのUSB2UART最高速度は115200bps ??
各場所を調べてもArduinoのUART最高速度は115200で、それ以上は保証しないと書かれています。
しかし、私が試している限りでは921600bpsを設定しても普通に通信ができています。
下記サイトを見ると、500000bpsで通信速度自体は頭打ちとのオシロ上での測定結果もあります。
https://arduino.stackexchange.com/questions/296/how-high-of-a-baud-rate-can-i-go-without-errors
Arduino UNO USB2UARTで実際にはどれくらいのスピードで通信できるか測定してみます。Arduino UNO部品レベルの限界値
ここでArduinoは Arduino UNO R3(Revision3)前提となります。
外付けOSCとATmega328P、USB2UART ICの設定を見てみます。
回路図は下記よりダウンロードできます。
https://www.arduino.cc/en/uploads/Main/Arduino_Uno_Rev3-schematic.pdfATmega328Pがメインマイコンとなります。
メインクロックは16MHzの水晶が搭載されています。
この関係から、ATmega328Pに接続されるUARTは Max 2Mbpsまで可能だと思われます。
FTDIのUSB2UARTチップを外付けで使えばこのスピードで通信が可能となります。Arduinoの場合USB通信(Virtual Com Port)用に ATmega16U2が搭載されています。
このマイコンがUART⇔USB変換と、FW書き込みを担っていると思われます。
メインクロックは16MHzの水晶が搭載されています。
こちらのUART通信最高速度は2Mbpsです。ATmega328PとATmega16U2がUART接続されているため、
システム全体では2Mbpsが最高速度となっていると思われます。通信時間確認プログラムを作る
この通信速度を計測するプログラムを作成してみます。
1byteを相互に通信しあうプログラム
それぞれに対して100kbyte送信するまでの時間を測定します。100kbyte * 2(送受信) * 8(bit) / 秒数 = ??? bps
Arduino側送受信
SpeedText.ino#include <Wire.h> #define BAUDRATE 500000 char buffer[0x10]; void setup() { Wire.begin(); Serial.begin(BAUDRATE); } void loop() { if (Serial.available() > 0) { buffer[0] = Serial.read(); Serial.write('!'); } }PC側送受信 (Python)
SpeedText.pyimport sys import serial import time from StopWatch import * datasize = 1024*100 if __name__ == "__main__": print("Arduino USB Speed Test") sw1 = StopWatch("No1") ser = serial.Serial() ser.baudrate = 500000 com_str = 'COM3' ser.port = com_str ser.open() time.sleep(2) print("start") sw1.start() for i in range(datasize): ser.write(str.encode("!")) data = ser.read(1) print(sw1.name + ":" + str(sw1.stop())) print("finesh")測定結果
209.718秒
計算してみると、1024*100 * 2 * 8 / 209.718 = 7812bps
50000bpsを設定しているのになかなかの遅さです。他のボーレートでも通信速度確認してみる。
115200bpsを設定してみても、計測結果は209.7144秒とほぼ一緒。
57600bpsを設定すると、419.4265秒とほぼ倍。 約3906bps
という事で、Web情報通りにArduinoは115200bpsがUSB-UART接続を使った場合の最大速度だと思われます。Virtual COM Port Driverは2Mbps設定可能で、実際通信ができます。
ただ、どこかの通信経路がボトルネックとなるか、別途調べてみたいと思います。
- 投稿日:2020-07-28T17:45:49+09:00
【Python】AttributeError: 'list' object has no attribute 'replace'
Pythonのスクレイピングを勉強中、値の加工をしていたら
AttributeError: 'list' object has no attribute 'replace'が出たので、メモで対策を残しますエラーが出た原因
Pythonで取得したlistに、特定の文字列を削除するロジックを書こうとしていました。
しかし、str_list = ['aaabbb','article'] str_list_new = str_list.replace('a', '')出力結果
AttributeError: 'list' object has no attribute 'replace'対策
配列を一旦単独の文字列に変換してから、replace()で置換、のちに配列に戻すという処理をすればいいらしいです。
str_list = ['aaabbb','article'] string = ",".join(str_list) string_new = string.replace('a', '') str_list_new = string_new.split(",") print(string_new)
- 投稿日:2020-07-28T17:23:26+09:00
OCRエンジンのTesseract(テッセラクト)を用いて画像ファイル内のテキストを抽出してみた
背景
画像ファイル(帳票データのスキャン)から、Tesseract(テッセラクト)を用いて、テキストデータをサクッと抽出できたので、備忘録として、整理した。
- Tesseract(テッセラクト)は、日本語にも対応したOCRエンジン
- オープンソースでライセンス(関連記事1.)は「Apache License 2.0」ということで、商用利用も可能
- Tesseract 4 からは、RNN (Recurrent Neural Network) を拡張したLSTM(Long short-term memory)をベースとしたOCRエンジン(AI-OCR)も搭載されており、これを利用することで、抽出精度も期待できる(と思う)
- サポート言語は、『tesseract/doc/tesseract.1.asc』 から数えたところ、117個存在した(2020/7/25時点)
1.導入
- 最初に、『tesseract-ocr/tesseract』 を参照
- その中で、Window環境においては、参照先からリンクされている Tesseract at UB Mannheim の older versions から、最新(v5)の安定版用(tesseract-ocr-w64-setup-v5.0.0.20190623.exe)のインストーラーをダウンロード
- その後の作業は、『Tesseract OCR をWindowsにインストールする方法(関連記事2.』)を参考に実施
2.実行
- 実行においては、テストデータとして、【エクセル・マクロ】VBA+OCRで画像内のテキストを抽出するで紹介されている、テスト画像データを活用
- 実行に先立って、実行用に『PythonでOCRを実行する方法(関連記事3.)』を参考に、pythonコードを作成
- pythonからtesseractを利用するには、PyOCRパッケージが必要
- このパッケージを利用することで、よりテキストの抽出精度が向上(ゴミ削除)が可能(のようである)
- 実行結果を以下に記載
C:\Users\xxx\work>python ocr_card.py test_data_3.png 画像上に記載されている文字列をプログラムで解析し、テキストだけを文字列として取得することが可能です!今回は、間料です友に 偽え、それをりの若六は見ふめる、をんな文字認識方法を紹介しだいと思います。 画像上に記載されている文字列を プログラムで解析し、テキストだ けを文字列として取得することが 可能です! 今回は、間料です友に偽え、それ をりの若六は見ふめる、をんな文 字認識方法を紹介しだいと思いま す。
- さらに、『【Pyocr+TesseractOCR】競馬新聞の活字化;精度向上♬(関連記事4.)』を参考に、画像データのサイズを拡大
- この結果、少なくとも空白行が除去されていた
C:\Users\xxx\work>python ocr_card.py test_data_3_mod.png 画像上に記載されている文字列をプログラムで解析し、テキストだけを文字列として取得することが可能です!今回は、和科料て考醤 に偽え、それをりの若病は見人ふめる、才んな文字認識方法を紹介しだいと思います。 画像上に記載されている文字列を プログラムで解析し、テキストだ けを文字列として取得することが 可能です! 今回は、和科料て考醤に偽え、それ をりの若病は見人ふめる、才んな文 字認識方法を紹介しだいと思いま す。
- その他、Tesseract の理解には、『八谷大岳の覚え書きブログ(関連記事5.)』が参考になる
- また、PDFファイルから画像データを抽出して保存(変換)するには、『PythonでPDFを画像ファイル(JPEG、PNG)に変換する方法(関連記事6.)』 が参考になる
3.考察
- 明朝フォント、ゴシックフォントにおいては、正しく画像内のテキストが抽出できている
- その他フォントでは、誤抽出が目立っている
- このことから、他の日本語フォントでは、おそらく学習データがなくトレーニングされていないと考えられる ⇒ したがって、画像原本内で利用されているフォントを学習させることで、誤抽出の削減が期待できる
- また、画像を拡大することで、最初の実行結果である空白行(誤抽出)の削除に繋がっている ⇒ したがって、画像データを少しでも拡大することで、より誤抽出の削減に期待できる
4.精度向上
では、どうやって精度を上げていくか?
・独自に学習データを作成して学習させる
素人的に考えられる方法としては、次のとおり。しかし、こういったことができるのか、ツール(今回は、Tesseract(テッセラクト))を調べる必要がある。
(1) 手書きの場合 ⇒ 画像原本内の手書き文字の特徴(クセ)を反映した学習データを準備し学習させる。
・『Tesseract 4.1にLSTMを使って手書き文字を再学習させる(関連記事7.)』
・『【23個掲載】OCR(光学式文字認識)・手書き文字認識データセットまとめ(関連記事8.)』(2) 画像原本内で使われているフォントを学習データとして用意して、学習させる
・すぐにでもできる方法
『【SikuliX】OCRの日本語読み取り精度を上げる3つの方法(関連記事9.)』に記載されている、次の3つを試してみることで精度向上が期待できる(と思われる)
(1)適切な文字サイズに画像を拡大して読み取る
(2)できるだけ高解像度の画像を用意する
(3)ブラックリスト、ホワイトリストを設定する関連記事
1.OSSのライセンスを理解する(「使用」と「利用」の違い、知っていますか?)
2.Tesseract OCR をWindowsにインストールする方法
3.PythonでOCRを実行する方法
4.【Pyocr+TesseractOCR】競馬新聞の活字化;精度向上♬
5.八谷大岳の覚え書きブログ
6.PythonでPDFを画像ファイル(JPEG、PNG)に変換する方法
7.Tesseract 4.1にLSTMを使って手書き文字を再学習させる
8.【23個掲載】OCR(光学式文字認識)・手書き文字認識データセットまとめ
9.【SikuliX】OCRの日本語読み取り精度を上げる3つの方法
10.Documentation of Tesseract OCR
11.tesseract-ocr/tesseract
12.PythonとTesseract OCRで文字認識
13.Tesseract 4.1にLSTMを使って日本語を再学習させる
14.甲骨文字で書かれた文章をOCRで読み取れるようにしてみる
15.文字認識エンジンTesseract OCRで学習
16.jTessBoxEditorでTesseractの学習データを作成する
17.Tesseract+PyOCRで簡易OCRを試してみる
18.PyOCRでTesseractを使う
19.罫線の無い 10 行 10 列の等間隔整列した文字の画像を大きくリサイズして ocr してみる(Python + Tesseract)
20.tesseractコマンドの使い方(Tesseract OCR 4.x)
21.tesseract のオプション PSM をいじってみた
22.Pythonで書くTesseract 4の基本的な使い方。APIとCLIからOCRを実行する方法
- 投稿日:2020-07-28T17:16:12+09:00
顔認識とPCAとK-meansクラスタリングを用いた似た顔画像検出
はじめに
似た画像の検出は画像認識におけるよく利用される機能の一つです。
レコメンドシステムや検索システムでは数万、数十万という画像を利用することも少なくありません。
画像のサイズや比較方法にもよりますが、数千、数万枚のなかから似た画像を検索するのは膨大な処理時間が必要になります。
そこでk-meansとPCAを利用してデータ量や比較回数を削減して似た画像を検出する方法を考えます。Face Recognition
顔の特徴は以下のURLのライブラリで実装できる、128次元のベクトルで表されるface_landmarkを利用します。
https://github.com/ageitgey/face_recognitionPCA後の次元数は寄与率を見つつ20としました。PCAを行って次元削減をした後にk-meansによってK=10のクラスタに分類します。
各クラスタの重心から最も近いものを算出し、最も重心が近いクラスタに分類された画像のみ距離を算出して似た画像を検出します。
また、画像の特徴をPCAで削減したデータで保存することで保存容量の削減にも有効です。1000枚の画像を利用した場合、k-means方によるクラスタリングによって平均100回+10回(各クラスタの重心との比較)の比較で済むようになります。
また各ベクトルの次元数もPCAによって128次元から20次元に削減されているため、効果的に計算量を削減することができます。http://mmlab.ie.cuhk.edu.hk/projects/CelebA.html
今回はこちらのフリーの顔画像を利用したサンプルソースを下記します。プログラム
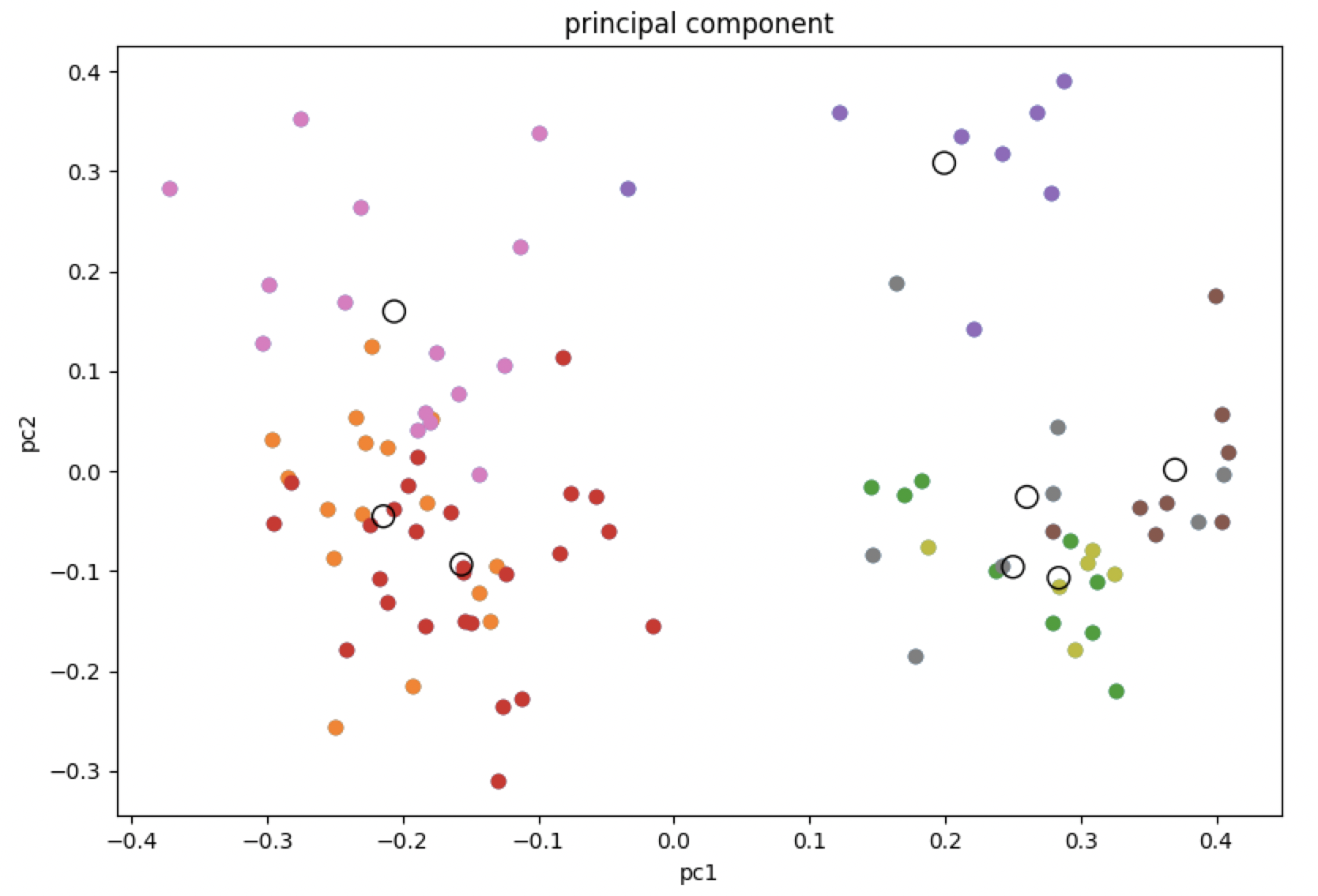
# coding:utf-8 import dlib from imutils import face_utils import cv2 import glob import face_recognition from sklearn.decomposition import PCA from sklearn.cluster import KMeans from matplotlib import pyplot as plt import numpy as np # -------------------------------- # 1.顔ランドマーク検出の前準備 # -------------------------------- # 顔検出ツールの呼び出し face_detector = dlib.get_frontal_face_detector() # 顔のランドマーク検出ツールの呼び出し predictor_path = 'shape_predictor_68_face_landmarks.dat' face_predictor = dlib.shape_predictor(predictor_path) images = glob.glob('./faces/*.jpg') images = sorted(images)[:100] face_landmarks = [] face_filepaths = [] for filepath in images: # 検出対象の画像の呼び込み img = face_recognition.load_image_file(filepath) face_encodings = face_recognition.face_encodings(img) if (len(face_encodings)>0): face_filepaths.append(filepath) face_landmarks.append(face_encodings[0]) pca = PCA(n_components=20) pca.fit(face_landmarks) # 分析結果を元にデータセットを主成分に変換する transformed = pca.fit_transform(face_landmarks) # 主成分をプロットする # plt.subplot(1, 2, 2) plt.scatter(transformed[:, 0], transformed[:, 1]) plt.title('principal component') plt.xlabel('pc1') plt.ylabel('pc2') # 主成分の次元ごとの寄与率を出力する print(pca.explained_variance_ratio_) print(sum(pca.explained_variance_ratio_)) # print(transformed[0]) # print(len(transformed[0])) # Kmeans開始 # クラスター数 K = 8 cls = KMeans(n_clusters = 8) pred = cls.fit_predict(transformed) # 各要素をラベルごとに色付けして表示する for i in range(K): labels = transformed[pred == i] plt.scatter(labels[:, 0], labels[:, 1]) # クラスタのセントロイド (重心) を描く centers = cls.cluster_centers_ plt.scatter(centers[:, 0], centers[:, 1], s=100, facecolors='none', edgecolors='black') # どの重心に一番近いかを検索 min_center_distance = -1 min_center_k = 0 # どの重心に一番遠いかを検索 max_center_distance = -1 max_center_k = 0 for center_index in range(K): distance = np.linalg.norm(transformed[0] - centers[center_index]) if ( distance < min_center_distance or min_center_distance == -1): min_center_distance = distance min_center_k = center_index if ( distance > max_center_distance or max_center_distance == -1): max_center_distance = distance max_center_k = center_index # 一番近いクラスタと一番遠いクラスタの画像名を表示 print('=========== NEAREST ==============') for i in range(len(pred)): if ( min_center_k == pred[i] ): print(face_filepaths[i]) print('=========== FARTHEST ==============') for i in range(len(pred)): if ( max_center_k == pred[i] ): print(face_filepaths[i]) print('=========================') # グラフを表示する plt.show() # ※これ以下は蛇足 # 各画像との直接的な距離を算出する distance = {} for index in range(len(transformed)): distance[face_filepaths[index]] = np.linalg.norm(transformed[0] - transformed[index]) # 距離順にソートして表示 print(sorted(distance.items(), key=lambda x:x[1]))クラスタリング結果グラフ
重心を空洞の円で各クラスタに分けられた画像の特徴を色分けして表示しています。
20次元のグラフを2次元にプロットしているので少し分かりにくいですが、主成分である程度近いもの同士をまとめてクラスタリングしていることがわかります。
分析結果
分析のベースにした画像
1.jpg 同じクラスタに含まれていた画像
10.jpg 11.jpg 19.jpg 24.jpg 重心が一番遠いクラスタに含まれていた画像
12.jpg 37.jpg 51.jpg 60.jpg 結果考察
同じクラスタに分けられた画像は長髪の女性が多く、一番遠いクラスタに分けられた画像は短髪の男性が多く、人間の感覚と似たようなクラスタリングができたと思います。
より厳密に近い画像を得たい場合は、主成分分析をせずに直接ノルムを全画像と算出をするべきですが、セレンディピティを狙ったり、より早い計算を実現するためには今回用いいたような手法を検討しても良さそうです。









- 投稿日:2020-07-28T16:29:29+09:00
PythonのCMSはWagtailが一番だ!(多分)
記事の内容
pythonのCMSとして、
なんかが挙げられると思います。
その中で、
PythonでCMS、どれ使えばいいの?
を参考に、どれを使おうかなと悩んでいた場合、参考になるのではないかと思います。経験
CMSを使わずに、djangoで開発経験がありました。
この時、使っていたのはdjango2系です。結論
django CMS は、まだ使ったことがないので
Mezzanine vs Wagtail
でやりたいと思います。結論としては、Wagtailをお勧めします。
なぜなら、(僕が知る限り)Mezzanineは、Djnago1系がベースなためです。
WordPressに慣れ親しんだ方であれば、確かに使いやすくとても便利ですが、
Django1系が2系以降とあまりにも互換性がないと感じまして、開発しずらいと思ました。その点、wagtailはdjango2系以降も対応しているため、Mezzanineよりはいいのではないかと思います。
ただし、Wagtailの日本語資料が非常に少ない点は残念ですが、Youtubeにまとめている方
がいっらしゃったので、そちらを参考に頑張ってみてください。
英語がわからなくても、ソースコードと実行画面を見るだけでやりたいことは実装できるかと思います。参考文献
- 投稿日:2020-07-28T15:50:01+09:00
プログレスバーの表示方法 (tqdm)
基本情報
tqdmを使うとfor文などの、時間のかかる処理で進捗を確認するための、プログレスバーを簡単に表示できる。
インストールが必要
$ pip install tqdm使い方
使い方はイテラブルオブジェクトをtqdmで囲むだけです。
tqdm_test.pyfrom tqdm import tqdm df = pd.read_csv("データ.csv", encoding="UTF-8") #pandasのデータをfor文処理する場面を考える #tqdmの使い方はtqdmで囲むだけ for row, item in tqdm(df.iterrows()): print(item)備忘録
手動でプログレスバーの数値を設定する方法
今まで私は上記の方法しか使ったことがありませんでした。
しかし、なぜかプログレスバーの上限が「?」になってしまう現象が発生したため、
手動で上限の数を設定する方法を調べたので、自分用の備忘録として記載しておきます。tqdm_test.pyfrom tqdm import tqdm df = pd.read_csv("データ.csv", encoding="UTF-8") #with文で囲み、for文の最後にプログレスバーを手動でupdateする方法 #total=で上限を設定。今回はdfの件数にした。増加分は.pbar.updateで指定する。 with tqdm(total=len(df)) as pbar: for row, item in tqdm(dataframe.iterrows()): print(item) pbar.update(1)jupyternotebookの場合に
from tqdm.notebookとすると簡単に見やすいプログレスバーになった。tqdm_test.pyfrom tqdm.notebook import tqdm
- 投稿日:2020-07-28T15:46:30+09:00
【Python】TypeError: 'in <string>' requires string as left operand, not list
Pythonのスクレイピングを勉強中、値の加工をしていたら
TypeError: 'in <string>' requires string as left operand, not listが出たので、メモで対策を残しますエラーが出た原因
Pythonで取得したlistに、該当する文字列がまれているかの、条件分岐をやろうとしていました。
if '該当させたい文字列' in i:そしたらこのエラーが出た
TypeError: 'in <string>' requires string as left operand, not list対策
リスト内包表記を使う
False not in [i in '該当させたい文字列' for i in 検索したい文字列の入ったリスト]参考
https://pg-chain.com/python-in
https://ai-inter1.com/python-if-in/
https://kuzunoha-ne.hateblo.jp/entry/2019/02/15/213000
- 投稿日:2020-07-28T15:24:10+09:00
Pandasメモ
Pythonの学習でPandask関連の内容があった場合は、随時更新していく予定。
インポート
import pandas as pdCSV操作
# CSV の読み込み [read_csv] csv_test_1 = pd.read_csv('hoge.csv') # データの先頭を表示 [head] csv_test_1.head()データの結合(ユニオン)
# データの縦結合 [concat] csv_test_2 = pd.read_csv('hoge_2.csv') csv_test = pd.concat([csv_test_1 , csv_test_2], ignore_index=True) csv_test.head() # データの結合 LEFT JOIN [merge] join_data = pd.merge(csv_test_1, cav_test2[["id", "date", "customer"]], on="id", how="left") join_data.head()データ列の作成
# aとbを掛け合わせた値を、追加列の new に設定する join_data["new"] = join_data["a"] * join_data["b"]
- 投稿日:2020-07-28T15:23:13+09:00
Python で CG 画質評価のメモ
背景
- モンテカルロレンダリングの結果が正しいのか(本当に収束しているのか)評価したい
- CG 画像と, 実写画像が一致するかどうか判断したい, 誤差(みたいなもの)を出したい.
Jupyter-lab + numpy/scipy とかでお手軽にぺろっとやりたい.
世の中の普通の(?)画像処理をする人向けではありません.
よくある方法
SSIM
skimage にある
https://scikit-image.org/docs/dev/auto_examples/transform/plot_ssim.html
SNR
scipy にあるようだが, 式自体は簡単なので numpy で書いたほうがよさそう
https://github.com/scipy/scipy/issues/9097
https://www.codespeedy.com/calculate-signal-to-noise-ratio-in-python/
CG 向けの方法
FLIP
ꟻLIP: A Difference Evaluator for Alternating Images
https://research.nvidia.com/publication/2020-07_FLIPHPG2020 で, できたてほやほや.
CG と実写の誤差算出などにも使えそうで我々のようなユーザによさげ.
numpy/scipy での実装含め, 各種言語での実装がある.
その他
Detecting Bias in Monte Carlo Renderers using Welch’s t-test
http://jcgt.org/published/0009/02/01/モンテカルロレンダリング向け.
こちらも python コードがありよい.
- 投稿日:2020-07-28T14:09:27+09:00
Pandasユーザーガイド「欠損データの操作」(公式ドキュメント日本語訳)
本記事は、Pandas の公式ドキュメントのUser Guide - Working with missing dataを機械翻訳した後、一部の不自然な文章を手直ししたものである。
誤訳の指摘・代訳案・質問等があればコメント欄や編集リクエストでお願いします。
欠損データの操作
このセクションでは、pandas の欠損値(NA)について説明します。
注
内部的にNaNを使用して欠落データを示すことを選択したのは、主に単純さとパフォーマンス上の理由によるものでした。pandas 1.0 以降、一部のオプションのデータ型は、マスクベースのアプローチを使用してネイティブNAスカラーを試行し始めます。詳細はこちらをご覧ください。「欠損」とみなされる値
データはさまざまな形や形式で存在するため、pandas は欠落データの処理に関して柔軟であることを目指しています。
NaNは計算速度と利便性の理由からデフォルトの欠損値マーカーですが、浮動小数点、整数、真偽値、および一般オブジェクトのさまざまなタイプのデータ型でこの値を簡単に検出できる必要があります。またしかし、多くの場合、Python のNoneも見られ、「欠落」または「利用不可」または「NA」も考慮する必要があります。
計算でinfと-infを「NA」と見なしたい場合は、pandas.options.mode.use_inf_as_na = Trueによって設定できます。In [**]: df = pd.DataFrame(np.random.randn(5, 3), index=['a', 'c', 'e', 'f', 'h'], ....: columns=['one', 'two', 'three']) ....: In [**]: df['four'] = 'bar' In [**]: df['five'] = df['one'] > 0 In [**]: df Out[**]: one two three four five a 0.469112 -0.282863 -1.509059 bar True c -1.135632 1.212112 -0.173215 bar False e 0.119209 -1.044236 -0.861849 bar True f -2.104569 -0.494929 1.071804 bar False h 0.721555 -0.706771 -1.039575 bar True In [**]: df2 = df.reindex(['a', 'b', 'c', 'd', 'e', 'f', 'g', 'h']) In [**]: df2 Out[**]: one two three four five a 0.469112 -0.282863 -1.509059 bar True b NaN NaN NaN NaN NaN c -1.135632 1.212112 -0.173215 bar False d NaN NaN NaN NaN NaN e 0.119209 -1.044236 -0.861849 bar True f -2.104569 -0.494929 1.071804 bar False g NaN NaN NaN NaN NaN h 0.721555 -0.706771 -1.039575 bar True(ときには異なるデータ型の配列を通して)欠損値の検出を容易にするために、pandasは
isna()およびnotna()関数を用意しています。これらは、Series および DataFrame オブジェクトのメソッドでもあります。In [**]: df2['one'] Out[**]: a 0.469112 b NaN c -1.135632 d NaN e 0.119209 f -2.104569 g NaN h 0.721555 Name: one, dtype: float64 In [**]: pd.isna(df2['one']) Out[**]: a False b True c False d True e False f False g True h False Name: one, dtype: bool In [**]: df2['four'].notna() Out[**]: a True b False c True d False e True f True g False h True Name: four, dtype: bool In [**]: df2.isna() Out[**]: one two three four five a False False False False False b True True True True True c False False False False False d True True True True True e False False False False False f False False False False False g True True True True True h False False False False False
警告
Python(およびNumPy)では、nanは同等ではなく、Noneは同等であることに注意する必要があります。pandas / NumPyはnp.nan != np.nanという事実を使用しながら、np.nanのようにNoneを扱うことに注意してください。In [**]: None == None # noqa: E711 Out[**]: True In [**]: np.nan == np.nan Out[**]: Falseしたがって、上記と比較して、
None/np.nanに対するスカラー等値比較は有用な情報を提供しません。In [**]: df2['one'] == np.nan Out[**]: a False b False c False d False e False f False g False h False Name: one, dtype: bool整数データ型と欠損データ
NaNは浮動小数点数であるため、欠損値が1つでもある整数の列は、浮動小数点数データ型に変換されます(詳細については、整数NAのサポートを参照してください)。pandasは、欠損値を含むことができる整数配列を提供します。これは、データ型を明示的に指定することで使用できます。In [**]: pd.Series([1, 2, np.nan, 4], dtype=pd.Int64Dtype()) Out[**]: 0 1 1 2 2 <NA> 3 4 dtype: Int64文字列エイリアス
dtype='Int64'(大文字の"I"に注意)を指定することでも使用可能です。詳しくは欠損可能整数データ型を参照してください。
時系列データ(datetime)
datetime64[ns] 型の場合、
NaTが欠損値を表します。これは、NumPyの単一のデータ型( datetime64[ns] )で表すことができる擬似ネイティブのセンチネル値です。pandasオブジェクトは、NaTとNaNの間の互換性を提供します。In [**]: df2 = df.copy() In [**]: df2['timestamp'] = pd.Timestamp('20120101') In [**]: df2 Out[**]: one two three four five timestamp a 0.469112 -0.282863 -1.509059 bar True 2012-01-01 c -1.135632 1.212112 -0.173215 bar False 2012-01-01 e 0.119209 -1.044236 -0.861849 bar True 2012-01-01 f -2.104569 -0.494929 1.071804 bar False 2012-01-01 h 0.721555 -0.706771 -1.039575 bar True 2012-01-01 In [**]: df2.loc[['a', 'c', 'h'], ['one', 'timestamp']] = np.nan In [**]: df2 Out[**]: one two three four five timestamp a NaN -0.282863 -1.509059 bar True NaT c NaN 1.212112 -0.173215 bar False NaT e 0.119209 -1.044236 -0.861849 bar True 2012-01-01 f -2.104569 -0.494929 1.071804 bar False 2012-01-01 h NaN -0.706771 -1.039575 bar True NaT In [**]: df2.dtypes.value_counts() Out[**]: float64 3 object 1 datetime64[ns] 1 bool 1 dtype: int64欠損データの挿入
コンテナに割り当てるだけで、欠損値を挿入できます。使用される実際の欠損値は、データ型に基づいて選択されます。
たとえば、与えられた欠損値の型に関係なく、数値コンテナは常に
NaNを使用します。In [**]: s = pd.Series([1, 2, 3]) In [**]: s.loc[0] = None In [**]: s Out[**]: 0 NaN 1 2.0 2 3.0 dtype: float64同様に、時系列コンテナは常に
NaTを使用します。オブジェクトコンテナの場合、pandasは与えられた値を使用します。
In [**]: s = pd.Series(["a", "b", "c"]) In [**]: s.loc[0] = None In [**]: s.loc[1] = np.nan In [**]: s Out[**]: 0 None 1 NaN 2 c dtype: object欠損データに対する計算
欠損値は、pandasオブジェクト間の算術演算を通じて自然に伝播します。
In [**]: a Out[**]: one two a NaN -0.282863 c NaN 1.212112 e 0.119209 -1.044236 f -2.104569 -0.494929 h -2.104569 -0.706771 In [**]: b Out[**]: one two three a NaN -0.282863 -1.509059 c NaN 1.212112 -0.173215 e 0.119209 -1.044236 -0.861849 f -2.104569 -0.494929 1.071804 h NaN -0.706771 -1.039575 In [**]: a + b Out[**]: one three two a NaN NaN -0.565727 c NaN NaN 2.424224 e 0.238417 NaN -2.088472 f -4.209138 NaN -0.989859 h NaN NaN -1.413542データ構造の概要(およびこちらとこちらのリスト)で説明されている記述統計と計算方法はすべて、欠損データを説明するために書かれています。例えば:
- データを合計するとき、NA(欠損)値はゼロとして扱われます。
- データがすべてNAの場合、結果は0になります。
cumsum()やcumprod()などの累積メソッドは、デフォルトではNA値を無視しますが、結果の配列には保持します。この動作をオーバーライドしてNA値を含めるには、skipna=Falseを使用します。In [**]: df Out[**]: one two three a NaN -0.282863 -1.509059 c NaN 1.212112 -0.173215 e 0.119209 -1.044236 -0.861849 f -2.104569 -0.494929 1.071804 h NaN -0.706771 -1.039575 In [**]: df['one'].sum() Out[**]: -1.9853605075978744 In [**]: df.mean(1) Out[**]: a -0.895961 c 0.519449 e -0.595625 f -0.509232 h -0.873173 dtype: float64 In [**]: df.cumsum() Out[**]: one two three a NaN -0.282863 -1.509059 c NaN 0.929249 -1.682273 e 0.119209 -0.114987 -2.544122 f -1.985361 -0.609917 -1.472318 h NaN -1.316688 -2.511893 In [**]: df.cumsum(skipna=False) Out[**]: one two three a NaN -0.282863 -1.509059 c NaN 0.929249 -1.682273 e NaN -0.114987 -2.544122 f NaN -0.609917 -1.472318 h NaN -1.316688 -2.511893空・欠損データにおける総和・総乗
この動作は v0.22.0 現在の標準であり、numpyのデフォルトと一致しています。以前は、全てNAまたは空の Series / DataFrame に対する総和・総乗は NaN を返していました。詳細については、v0.22.0 whatsnewを参照してください。空あるいは全てがNAのSeriesまたはDataFrameの列の総和は0です。
In [**]: pd.Series([np.nan]).sum() Out[**]: 0.0 In [**]: pd.Series([], dtype="float64").sum() Out[**]: 0.0空あるいは全てがNAのSeriesまたはDataFrameの列の総乗は1です。
In [**]: pd.Series([np.nan]).prod() Out[**]: 1.0 In [**]: pd.Series([], dtype="float64").prod() Out[**]: 1.0GroupBy における欠損値
GroupByではNAグループは自動的に除外されます。この動作は、Rと一致しています。例えば、
In [**]: df Out[**]: one two three a NaN -0.282863 -1.509059 c NaN 1.212112 -0.173215 e 0.119209 -1.044236 -0.861849 f -2.104569 -0.494929 1.071804 h NaN -0.706771 -1.039575 In [**]: df.groupby('one').mean() Out[**]: two three one -2.104569 -0.494929 1.071804 0.119209 -1.044236 -0.861849詳細については、こちらのgroupbyセクションをご覧ください。
欠損データの除外・穴埋め
pandasオブジェクトには、欠損データを処理するためのさまざまなデータ操作メソッドが装備されています。
欠損値の穴埋め――fillna
fillna()は、欠損値を非欠損データで「穴埋め」することができます。欠損値をスカラー値に置換
In [**]: df2 Out[**]: one two three four five timestamp a NaN -0.282863 -1.509059 bar True NaT c NaN 1.212112 -0.173215 bar False NaT e 0.119209 -1.044236 -0.861849 bar True 2012-01-01 f -2.104569 -0.494929 1.071804 bar False 2012-01-01 h NaN -0.706771 -1.039575 bar True NaT In [**]: df2.fillna(0) Out[**]: one two three four five timestamp a 0.000000 -0.282863 -1.509059 bar True 0 c 0.000000 1.212112 -0.173215 bar False 0 e 0.119209 -1.044236 -0.861849 bar True 2012-01-01 00:00:00 f -2.104569 -0.494929 1.071804 bar False 2012-01-01 00:00:00 h 0.000000 -0.706771 -1.039575 bar True 0 In [**]: df2['one'].fillna('missing') Out[**]: a missing c missing e 0.119209 f -2.10457 h missing Name: one, dtype: object前方または後方のデータによる穴埋め
リインデックスと同様の穴埋めパラメータを使用して、非欠損値を前方または後方に伝播させることができます。
In [**]: df Out[**]: one two three a NaN -0.282863 -1.509059 c NaN 1.212112 -0.173215 e 0.119209 -1.044236 -0.861849 f -2.104569 -0.494929 1.071804 h NaN -0.706771 -1.039575 In [**]: df.fillna(method='pad') Out[**]: one two three a NaN -0.282863 -1.509059 c NaN 1.212112 -0.173215 e 0.119209 -1.044236 -0.861849 f -2.104569 -0.494929 1.071804 h -2.104569 -0.706771 -1.039575穴埋め量の制限
連続したギャップを一定のデータポイントまで埋めるだけの場合は、limitキーワードを使用できます。
In [**]: df Out[**]: one two three a NaN -0.282863 -1.509059 c NaN 1.212112 -0.173215 e NaN NaN NaN f NaN NaN NaN h NaN -0.706771 -1.039575 In [**]: df.fillna(method='pad', limit=1) Out[**]: one two three a NaN -0.282863 -1.509059 c NaN 1.212112 -0.173215 e NaN 1.212112 -0.173215 f NaN NaN NaN h NaN -0.706771 -1.039575利用可能な穴埋め方法は以下のとおりです。
メソッド 動作 pad / ffill 前方へ穴埋め bfill / backfill 後方へ穴埋め 時系列データでは、pad/ffill の使用は非常に一般的であるため、「最後の既知の値」がすべての時点で利用できるようになっています。
ffill()はfillna(method='ffill')と同等であり、bfill()はfillna(method='bfill')と同等です。pandas オブジェクトによる穴埋め
整列可能な辞書またはシリーズを使用して穴埋めすることもできます。辞書のキーあるいはシリーズのインデックスは、穴埋めしたいフレームの列名と一致する必要があります。以下の例は、データフレームにその列の平均を入力しています。
In [**]: dff = pd.DataFrame(np.random.randn(10, 3), columns=list('ABC')) In [**]: dff.iloc[3:5, 0] = np.nan In [**]: dff.iloc[4:6, 1] = np.nan In [**]: dff.iloc[5:8, 2] = np.nan In [**]: dff Out[**]: A B C 0 0.271860 -0.424972 0.567020 1 0.276232 -1.087401 -0.673690 2 0.113648 -1.478427 0.524988 3 NaN 0.577046 -1.715002 4 NaN NaN -1.157892 5 -1.344312 NaN NaN 6 -0.109050 1.643563 NaN 7 0.357021 -0.674600 NaN 8 -0.968914 -1.294524 0.413738 9 0.276662 -0.472035 -0.013960 In [**]: dff.fillna(dff.mean()) Out[**]: A B C 0 0.271860 -0.424972 0.567020 1 0.276232 -1.087401 -0.673690 2 0.113648 -1.478427 0.524988 3 -0.140857 0.577046 -1.715002 4 -0.140857 -0.401419 -1.157892 5 -1.344312 -0.401419 -0.293543 6 -0.109050 1.643563 -0.293543 7 0.357021 -0.674600 -0.293543 8 -0.968914 -1.294524 0.413738 9 0.276662 -0.472035 -0.013960 In [**]: dff.fillna(dff.mean()['B':'C']) Out[**]: A B C 0 0.271860 -0.424972 0.567020 1 0.276232 -1.087401 -0.673690 2 0.113648 -1.478427 0.524988 3 NaN 0.577046 -1.715002 4 NaN -0.401419 -1.157892 5 -1.344312 -0.401419 -0.293543 6 -0.109050 1.643563 -0.293543 7 0.357021 -0.674600 -0.293543 8 -0.968914 -1.294524 0.413738 9 0.276662 -0.472035 -0.013960上記と同じ結果ですが、以下の場合はシリーズである「穴埋め」の値を揃えています。
In [**]: dff.where(pd.notna(dff), dff.mean(), axis='columns') Out[**]: A B C 0 0.271860 -0.424972 0.567020 1 0.276232 -1.087401 -0.673690 2 0.113648 -1.478427 0.524988 3 -0.140857 0.577046 -1.715002 4 -0.140857 -0.401419 -1.157892 5 -1.344312 -0.401419 -0.293543 6 -0.109050 1.643563 -0.293543 7 0.357021 -0.674600 -0.293543 8 -0.968914 -1.294524 0.413738 9 0.276662 -0.472035 -0.013960データが欠損している軸ラベルの削除――dropna
単純に、欠損データを参照しているラベルをデータセットから除外したい場合もあるでしょう。これを行うには、
dropna()を使用します。In [**]: df Out[**]: one two three a NaN -0.282863 -1.509059 c NaN 1.212112 -0.173215 e NaN 0.000000 0.000000 f NaN 0.000000 0.000000 h NaN -0.706771 -1.039575 In [**]: df.dropna(axis=0) Out[**]: Empty DataFrame Columns: [one, two, three] Index: [] In [**]: df.dropna(axis=1) Out[**]: two three a -0.282863 -1.509059 c 1.212112 -0.173215 e 0.000000 0.000000 f 0.000000 0.000000 h -0.706771 -1.039575 In [**]: df['one'].dropna() Out[**]: Series([], Name: one, dtype: float64)シリーズにも同等の
dropna()が用意されています。DataFrame.dropna には Series.dropna よりもかなり多くのオプションがあり、APIで調べることができます。補間
バージョン 0.23.0 から:キーワード引数
limit_areaが追加されました。シリーズオブジェクトとデータフレームオブジェクトの両方に
interpolate()があり、デフォルトでは、欠落しているデータポイントで線形補間を実行します。In [**]: ts Out[**]: 2000-01-31 0.469112 2000-02-29 NaN 2000-03-31 NaN 2000-04-28 NaN 2000-05-31 NaN ... 2007-12-31 -6.950267 2008-01-31 -7.904475 2008-02-29 -6.441779 2008-03-31 -8.184940 2008-04-30 -9.011531 Freq: BM, Length: 100, dtype: float64 In [**]: ts.count() Out[**]: 66 In [**]: ts.plot() Out[**]: <matplotlib.axes._subplots.AxesSubplot at 0x7fc18e5ac400>
In [**]: ts.interpolate() Out[**]: 2000-01-31 0.469112 2000-02-29 0.434469 2000-03-31 0.399826 2000-04-28 0.365184 2000-05-31 0.330541 ... 2007-12-31 -6.950267 2008-01-31 -7.904475 2008-02-29 -6.441779 2008-03-31 -8.184940 2008-04-30 -9.011531 Freq: BM, Length: 100, dtype: float64 In [**]: ts.interpolate().count() Out[**]: 100 In [**]: ts.interpolate().plot() Out[**]: <matplotlib.axes._subplots.AxesSubplot at 0x7fc18e569880>
methodキーワードを用いることで、インデックスに基づいた補間を実行できます。In [**]: ts2 Out[**]: 2000-01-31 0.469112 2000-02-29 NaN 2002-07-31 -5.785037 2005-01-31 NaN 2008-04-30 -9.011531 dtype: float64 In [**]: ts2.interpolate() Out[**]: 2000-01-31 0.469112 2000-02-29 -2.657962 2002-07-31 -5.785037 2005-01-31 -7.398284 2008-04-30 -9.011531 dtype: float64 In [**]: ts2.interpolate(method='time') Out[**]: 2000-01-31 0.469112 2000-02-29 0.270241 2002-07-31 -5.785037 2005-01-31 -7.190866 2008-04-30 -9.011531 dtype: float64浮動小数点インデックスの場合、
method='values'を使用します。In [**]: ser Out[**]: 0.0 0.0 1.0 NaN 10.0 10.0 dtype: float64 In [**]: ser.interpolate() Out[**]: 0.0 0.0 1.0 5.0 10.0 10.0 dtype: float64 In [**]: ser.interpolate(method='values') Out[**]: 0.0 0.0 1.0 1.0 10.0 10.0 dtype: float64同様に、データフレームを補間することができます。
In [**]: df = pd.DataFrame({'A': [1, 2.1, np.nan, 4.7, 5.6, 6.8], ....: 'B': [.25, np.nan, np.nan, 4, 12.2, 14.4]}) ....: In [**]: df Out[**]: A B 0 1.0 0.25 1 2.1 NaN 2 NaN NaN 3 4.7 4.00 4 5.6 12.20 5 6.8 14.40 In [**]: df.interpolate() Out[**]: A B 0 1.0 0.25 1 2.1 1.50 2 3.4 2.75 3 4.7 4.00 4 5.6 12.20 5 6.8 14.40
method引数を用いることで、より高度な補間を実行することができます。scipyがインストールされている場合は、一次元補間ルーチンの名前をmethodに渡すことができます。詳細については、scipyの補間に関するドキュメントやリファレンスガイドを参照してください。適切な補間方法は、扱うデータの種類によって異なります。
- 増加率の高い時系列を扱う場合は、
method='quadratic'が適切かもしれません。- 累積分布関数に近似した値の場合は、
method='pchip'がうまく機能するはずです。- スムーズなプロットを目指して欠損値を埋めるには、
method='akima'を検討してください。
これらのメソッドにはscipyが必要です。In [**]: df.interpolate(method='barycentric') Out[**]: A B 0 1.00 0.250 1 2.10 -7.660 2 3.53 -4.515 3 4.70 4.000 4 5.60 12.200 5 6.80 14.400 In [**]: df.interpolate(method='pchip') Out[**]: A B 0 1.00000 0.250000 1 2.10000 0.672808 2 3.43454 1.928950 3 4.70000 4.000000 4 5.60000 12.200000 5 6.80000 14.400000 In [**]: df.interpolate(method='akima') Out[**]: A B 0 1.000000 0.250000 1 2.100000 -0.873316 2 3.406667 0.320034 3 4.700000 4.000000 4 5.600000 12.200000 5 6.800000 14.400000多項式またはスプライン近似で補間する場合は、近似の次数も指定する必要があります。
In [**]: df.interpolate(method='spline', order=2) Out[**]: A B 0 1.000000 0.250000 1 2.100000 -0.428598 2 3.404545 1.206900 3 4.700000 4.000000 4 5.600000 12.200000 5 6.800000 14.400000 In [**]: df.interpolate(method='polynomial', order=2) Out[**]: A B 0 1.000000 0.250000 1 2.100000 -2.703846 2 3.451351 -1.453846 3 4.700000 4.000000 4 5.600000 12.200000 5 6.800000 14.400000いくつかの方法を比較してみましょう。
In [**]: np.random.seed(2) In [**]: ser = pd.Series(np.arange(1, 10.1, .25) ** 2 + np.random.randn(37)) In [**]: missing = np.array([4, 13, 14, 15, 16, 17, 18, 20, 29]) In [**]: ser[missing] = np.nan In [**]: methods = ['linear', 'quadratic', 'cubic'] In [**]: df = pd.DataFrame({m: ser.interpolate(method=m) for m in methods}) In [**]: df.plot() Out[**]: <matplotlib.axes._subplots.AxesSubplot at 0x7fc18e5b6c70>
もうひとつの使用例は、新しい値での補間です。ある分布から100個の観測値があるとします。そして、中央付近で何が起こっているかに特に興味があるとしましょう。pandasの
reindexとinterpolateメソッドを組み合わせることで、新しい値で補間することができます。In [**]: ser = pd.Series(np.sort(np.random.uniform(size=100))) # 新しいインデックスに対する補間 In [**]: new_index = ser.index | pd.Index([49.25, 49.5, 49.75, 50.25, 50.5, 50.75]) In [**]: interp_s = ser.reindex(new_index).interpolate(method='pchip') In [**]: interp_s[49:51] Out[**]: 49.00 0.471410 49.25 0.476841 49.50 0.481780 49.75 0.485998 50.00 0.489266 50.25 0.491814 50.50 0.493995 50.75 0.495763 51.00 0.497074 dtype: float64補間の制限
pandasの他の穴埋めメソッドと同様に、
interpolate()はキーワード引数limitを受け取ります。この引数を使用して、最後の有効な観測以降に入力された連続したNaN値の数を制限できます。In [**]: ser = pd.Series([np.nan, np.nan, 5, np.nan, np.nan, ....: np.nan, 13, np.nan, np.nan]) ....: In [**]: ser Out[**]: 0 NaN 1 NaN 2 5.0 3 NaN 4 NaN 5 NaN 6 13.0 7 NaN 8 NaN dtype: float64 # 前方へ連続するすべての値を埋める In [**]: ser.interpolate() Out[**]: 0 NaN 1 NaN 2 5.0 3 7.0 4 9.0 5 11.0 6 13.0 7 13.0 8 13.0 dtype: float64 # 前方へ1つだけ値を埋める In [**]: ser.interpolate(limit=1) Out[**]: 0 NaN 1 NaN 2 5.0 3 7.0 4 NaN 5 NaN 6 13.0 7 13.0 8 NaN dtype: float64デフォルトでは、
NaN値は順方向に穴埋めされます。後方または両方向から穴埋めするには、limit_directionパラメータを使用します。# 後方へ1つ穴埋め In [**]: ser.interpolate(limit=1, limit_direction='backward') Out[**]: 0 NaN 1 5.0 2 5.0 3 NaN 4 NaN 5 11.0 6 13.0 7 NaN 8 NaN dtype: float64 # 両方向へ1つ穴埋め In [**]: ser.interpolate(limit=1, limit_direction='both') Out[**]: 0 NaN 1 5.0 2 5.0 3 7.0 4 NaN 5 11.0 6 13.0 7 13.0 8 NaN dtype: float64 # 両方向に連続するすべての値を埋める In [**]: ser.interpolate(limit_direction='both') Out[**]: 0 5.0 1 5.0 2 5.0 3 7.0 4 9.0 5 11.0 6 13.0 7 13.0 8 13.0 dtype: float64デフォルトでは、
NaN値は、既存の有効な値の内側(囲まれている)でも、既存の有効な値の外側でも穴埋めされます。v0.23で導入されたlimit_areaパラメータは、内部または外部の値への入力を制限します。# 両方向に1つの連続する内側の値を埋める In [**]: ser.interpolate(limit_direction='both', limit_area='inside', limit=1) Out[**]: 0 NaN 1 NaN 2 5.0 3 7.0 4 NaN 5 11.0 6 13.0 7 NaN 8 NaN dtype: float64 # 連続するすべての外側の値を逆方向に埋める In [**]: ser.interpolate(limit_direction='backward', limit_area='outside') Out[**]: 0 5.0 1 5.0 2 5.0 3 NaN 4 NaN 5 NaN 6 13.0 7 NaN 8 NaN dtype: float64 # 両方向に連続するすべての外側の値を埋める In [**]: ser.interpolate(limit_direction='both', limit_area='outside') Out[**]: 0 5.0 1 5.0 2 5.0 3 NaN 4 NaN 5 NaN 6 13.0 7 13.0 8 13.0 dtype: float64一般的な値の置換
任意の値を他の値に置き換えたいと思うことはよくあります。
シリーズの
replace()およびデータフレームのreplace()によって、そのような置換を効率的かつ柔軟に実行できます。シリーズの場合、単一の値または値のリストを別の値で置き換えることができます。
In [**]: ser = pd.Series([0., 1., 2., 3., 4.]) In [**]: ser.replace(0, 5) Out[**]: 0 5.0 1 1.0 2 2.0 3 3.0 4 4.0 dtype: float64値のリストを他の値のリストで置き換えることができます。
In [**]: ser.replace([0, 1, 2, 3, 4], [4, 3, 2, 1, 0]) Out[**]: 0 4.0 1 3.0 2 2.0 3 1.0 4 0.0 dtype: float64マッピング辞書を指定することもできます。
In [**]: ser.replace({0: 10, 1: 100}) Out[**]: 0 10.0 1 100.0 2 2.0 3 3.0 4 4.0 dtype: float64データフレームの場合、列ごとに個別の値を指定できます。
In [**]: df = pd.DataFrame({'a': [0, 1, 2, 3, 4], 'b': [5, 6, 7, 8, 9]}) In [**]: df.replace({'a': 0, 'b': 5}, 100) Out[**]: a b 0 100 100 1 1 6 2 2 7 3 3 8 4 4 9指定された値で置き換える代わりに、指定されたすべての値を欠損値として扱い、それらを補間することができます。
In [**]: ser.replace([1, 2, 3], method='pad') Out[**]: 0 0.0 1 0.0 2 0.0 3 0.0 4 4.0 dtype: float64文字列・正規表現の置換
r'hello world'のようにrが前に付いたPython文字列は、いわゆる「生の(raw)」文字列です。これらは、接頭辞のない文字列とは異なるバックスラッシュに関するセマンティクスを持っています。生の文字列内のバックスラッシュは、エスケープされたバックスラッシュとして解釈されます(例:r'\' == '\\')。このことがよくわかっていない場合は、このことについて読む必要があります。「.」を
NaNに置き換えます(文字列→文字列)。In [**]: d = {'a': list(range(4)), 'b': list('ab..'), 'c': ['a', 'b', np.nan, 'd']} In [**]: df = pd.DataFrame(d) In [**]: df.replace('.', np.nan) Out[**]: a b c 0 0 a a 1 1 b b 2 2 NaN NaN 3 3 NaN d次に、正規表現で周囲の空白を削除します(正規表現→正規表現)。
In [**]: df.replace(r'\s*\.\s*', np.nan, regex=True) Out[**]: a b c 0 0 a a 1 1 b b 2 2 NaN NaN 3 3 NaN dいくつかの異なる値を置き換えます(リスト→リスト)。
In [**]: df.replace(['a', '.'], ['b', np.nan]) Out[**]: a b c 0 0 b b 1 1 b b 2 2 NaN NaN 3 3 NaN d正規表現のリスト→正規表現のリスト。
In [**]: df.replace([r'\.', r'(a)'], ['dot', r'\1stuff'], regex=True) Out[**]: a b c 0 0 astuff astuff 1 1 b b 2 2 dot NaN 3 3 dot d列
'b'のみを検索(辞書→辞書)。In [**]: df.replace({'b': '.'}, {'b': np.nan}) Out[**]: a b c 0 0 a a 1 1 b b 2 2 NaN NaN 3 3 NaN d前の例と同じですが、代わりに検索に正規表現を使用します(正規表現の辞書→辞書)。
In [**]: df.replace({'b': r'\s*\.\s*'}, {'b': np.nan}, regex=True) Out[**]: a b c 0 0 a a 1 1 b b 2 2 NaN NaN 3 3 NaN d
regex=Trueを使用して正規表現のネストされた辞書を渡すことができます。In [**]: df.replace({'b': {'b': r''}}, regex=True) Out[**]: a b c 0 0 a a 1 1 b 2 2 . NaN 3 3 . dまたは、ネストされた辞書を次のように渡すこともできます。
In [**]: df.replace(regex={'b': {r'\s*\.\s*': np.nan}}) Out[**]: a b c 0 0 a a 1 1 b b 2 2 NaN NaN 3 3 NaN d正規表現一致のグループを使用して置換することもできます(正規表現の辞書→正規表現の辞書)。これはリストでも機能します。
In [**]: df.replace({'b': r'\s*(\.)\s*'}, {'b': r'\1ty'}, regex=True) Out[**]: a b c 0 0 a a 1 1 b b 2 2 .ty NaN 3 3 .ty d正規表現のリストを渡すことができ、一致するものはスカラーに置き換えられます(正規表現のリスト→正規表現)。
In [**]: df.replace([r'\s*\.\s*', r'a|b'], np.nan, regex=True) Out[**]: a b c 0 0 NaN NaN 1 1 NaN NaN 2 2 NaN NaN 3 3 NaN d正規表現の例はすべて、
to_replace引数をregex引数として渡すこともできます。この場合、value引数は明示的に名前で渡されるか、regexはネストされた辞書である必要があります。この場合の前の例は、次のようになります。In [**]: df.replace(regex=[r'\s*\.\s*', r'a|b'], value=np.nan) Out[**]: a b c 0 0 NaN NaN 1 1 NaN NaN 2 2 NaN NaN 3 3 NaN dこれは、正規表現を使用するたびに
regex=Trueを渡したくない場合に便利です。上記の
replaceの例において、正規表現を渡すことができる場面はすべて、コンパイルされた正規表現を渡しても同様に有効です。数値の置換
In [**]: df = pd.DataFrame(np.random.randn(10, 2)) In [**]: df[np.random.rand(df.shape[0]) > 0.5] = 1.5 In [**]: df.replace(1.5, np.nan) Out[**]: 0 1 0 -0.844214 -1.021415 1 0.432396 -0.323580 2 0.423825 0.799180 3 1.262614 0.751965 4 NaN NaN 5 NaN NaN 6 -0.498174 -1.060799 7 0.591667 -0.183257 8 1.019855 -1.482465 9 NaN NaNリストを渡すことで、複数の値を置き換えることができます。
In [**]: df00 = df.iloc[0, 0] In [**]: df.replace([1.5, df00], [np.nan, 'a']) Out[**]: 0 1 0 a -1.02141 1 0.432396 -0.32358 2 0.423825 0.79918 3 1.26261 0.751965 4 NaN NaN 5 NaN NaN 6 -0.498174 -1.0608 7 0.591667 -0.183257 8 1.01985 -1.48247 9 NaN NaN In [**]: df[1].dtype Out[**]: dtype('float64')データフレームをインプレース処理することもできます。
In [**]: df.replace(1.5, np.nan, inplace=True)
複数のboolまたはdatetime64オブジェクトを置き換える場合、replaceの最初の引数(to_replace)は、置き換えられる値の型と一致する必要があります。例えば、>>> s = pd.Series([True, False, True]) >>> s.replace({'a string': 'new value', True: False}) # raises TypeError: Cannot compare types 'ndarray(dtype=bool)' and 'str'
dictのキーの1つが置換に適した型ではないため、TypeErrorが発生します。ただし、次のような単一のオブジェクトを置き換える場合、
In [**]: s = pd.Series([True, False, True]) In [**]: s.replace('a string', 'another string') Out[**]: 0 True 1 False 2 True dtype: bool元の
NDFrameオブジェクトはそのまま返されます。現在、私達はこのAPIの統合に取り組んでいますが、下位互換性の理由から、後者の動作を壊すことはできません。詳細については、GH6354を参照してください。欠損データのキャストルールとインデクシング
pandasは整数型とブール型の配列の格納をサポートしていますが、これらの型は欠損データを格納することができません。NumPyでネイティブNA型の使用に切り替えられるまでは、いくつかの「キャストルール」を確立しています。再インデックス化操作で欠損データが発生した場合、以下の表で紹介したルールに従ってシリーズがキャストされます。
データ型 キャスト先 整数 浮動小数 真偽値 オブジェクト 浮動小数 キャストしない オブジェクト キャストしない 例えば、
In [**]: s = pd.Series(np.random.randn(5), index=[0, 2, 4, 6, 7]) In [**]: s > 0 Out[**]: 0 True 2 True 4 True 6 True 7 True dtype: bool In [**]: (s > 0).dtype Out[**]: dtype('bool') In [**]: crit = (s > 0).reindex(list(range(8))) In [**]: crit Out[**]: 0 True 1 NaN 2 True 3 NaN 4 True 5 NaN 6 True 7 True dtype: object In [**]: crit.dtype Out[**]: dtype('O')通常、NumPyは、真偽値配列の代わりにオブジェクト配列を使用してndarrayから値を取得または設定しようとすると(たとえば、いくつかの基準に基づいて値を選択する)、文句を言います。真偽値ベクトルにNAが含まれている場合、例外が発生します。
In [**]: reindexed = s.reindex(list(range(8))).fillna(0) In [**]: reindexed[crit] --------------------------------------------------------------------------- ValueError Traceback (most recent call last) <ipython-input-138-0dac417a4890> in <module> ----> 1 reindexed[crit] ~/work/pandas/pandas/pandas/core/series.py in __getitem__(self, key) 901 key = list(key) 902 --> 903 if com.is_bool_indexer(key): 904 key = check_bool_indexer(self.index, key) 905 key = np.asarray(key, dtype=bool) ~/work/pandas/pandas/pandas/core/common.py in is_bool_indexer(key) 132 na_msg = "Cannot mask with non-boolean array containing NA / NaN values" 133 if isna(key).any(): --> 134 raise ValueError(na_msg) 135 return False 136 return True ValueError: Cannot mask with non-boolean array containing NA / NaN valuesただし、これらは
fillna()を使用して穴埋めすれば正常に動作します。In [**]: reindexed[crit.fillna(False)] Out[**]: 0 0.126504 2 0.696198 4 0.697416 6 0.601516 7 0.003659 dtype: float64 In [**]: reindexed[crit.fillna(True)] Out[**]: 0 0.126504 1 0.000000 2 0.696198 3 0.000000 4 0.697416 5 0.000000 6 0.601516 7 0.003659 dtype: float64pandasは欠損値を持つことができる整数データ型を提供していますが、シリーズや列を作成する際に明示的に指定する必要があります。
dtype="Int64"で大文字の「I」を使用していることに注意してください。In [**]: s = pd.Series([0, 1, np.nan, 3, 4], dtype="Int64") In [**]: s Out[**]: 0 0 1 1 2 <NA> 3 3 4 4 dtype: Int64詳しくは欠損可能整数データ型を参照してください。
欠損値を示すための試験的な
NAスカラー
試験運用:pd.NAの動作は警告なしに変更される可能性があります。バージョン 1.0.0 から
pandas 1.0 から、スカラー欠損値を表現するための試験的な値
pd.NA(シングルトン)が利用可能になりました。現時点では、nullable integer、boolean、および専用の文字列データ型で、欠損値インジケータとして使用されています。pandas 1.0 から、実験的なpd.NA値(シングルトン)を使用して、スカラー欠損値を表すことができます。現時点では、欠損可能整数、ブーリアン、および専用の文字列データ型で欠損値インジケーターとして使用されています。
pd.NAの目的は、データ型間で一貫して使用できる「欠損」値を提供することです(データタイプに応じたnp.nan・None・pd.NaTの代わりに)。たとえば、欠損可能整数データ型のシリーズに欠損値がある場合、
pd.NAが使用されます。In [**]: s = pd.Series([1, 2, None], dtype="Int64") In [**]: s Out[**]: 0 1 1 2 2 <NA> dtype: Int64 In [**]: s[2] Out[**]: <NA> In [**]: s[2] is pd.NA Out[**]: True現在のところ、(データフレームやシリーズを作成するときやデータを読み込むとき)pandasはこれらのデータ型をまだデフォルトでは使用していませんので、明示的にデータ型を指定する必要があります。これらのデータ型に変換する簡単な方法をここで説明しています。
算術演算および比較演算での伝播
一般的に、
pd.NAを含む演算では、欠損値が伝播します。オペランドの1つが不明な場合、演算の結果も不明です。例えば、
pd.NAはnp.nanと同様に算術演算で伝搬します。In [**]: pd.NA + 1 Out[**]: <NA> In [**]: "a" * pd.NA Out[**]: <NA>オペランドの片方が
NAであっても、結果がわかっている場合には、いくつかの特殊なケースがあります。In [**]: pd.NA ** 0 Out[**]: 1 In [**]: 1 ** pd.NA Out[**]: 1等値演算と比較演算では、
pd.NAも伝播します。これは、比較結果が常にFalseとなるnp.nanの挙動とは異なります。In [**]: pd.NA == 1 Out[**]: <NA> In [**]: pd.NA == pd.NA Out[**]: <NA> In [**]: pd.NA < 2.5 Out[**]: <NA>値が
pd.NAと等しいかどうかを調べるには、isna()関数を使用します。In [**]: pd.isna(pd.NA) Out[**]: Trueこの基本的な伝播ルールの例外は、(平均や最小値のような)削減で、pandasはデフォルトで欠損値をスキップします。詳細は上記を参照してください。
論理演算
論理演算については、
pd.NAは3値論理(クリーネの論理とも呼び、R・SQL・Juliaと同様の挙動)のルールに従います。この論理は、論理的に必要な場合にのみ欠落した値を伝播することを意味します。例えば、論理演算「or」(
|)の場合、オペランドの片方がTrueであれば、他の値に関係なく(つまり欠損値がTrueであってもFalseであっても)、結果はTrueになることがすでにわかっています。この場合、pd.NAは伝播しません。In [**]: True | False Out[**]: True In [**]: True | pd.NA Out[**]: True In [**]: pd.NA | True Out[**]: True一方、オペランドの片方が
Falseの場合、結果は他方のオペランドの値に依存します。したがって、この場合は、pd.NAが伝播します。In [**]: False | True Out[**]: True In [**]: False | False Out[**]: False In [**]: False | pd.NA Out[**]: <NA>論理演算「and」(
&)の動作も、同様のロジックを使用して導出することができます(この場合、オペランドの1つが既にFalseである場合には、pd.NAは伝搬しません)。In [**]: False & True Out[**]: False In [**]: False & False Out[**]: False In [**]: False & pd.NA Out[**]: FalseIn [**]: True & True Out[**]: True In [**]: True & False Out[**]: False In [**]: True & pd.NA Out[**]: <NA>ブーリアンコンテキストでの
NA欠損値は実際の値が不明なので、欠損値をブール値に変換することはできません。以下はエラーになります。
In [**]: bool(pd.NA) --------------------------------------------------------------------------- TypeError Traceback (most recent call last) <ipython-input-167-5477a57d5abb> in <module> ----> 1 bool(pd.NA) ~/work/pandas/pandas/pandas/_libs/missing.pyx in pandas._libs.missing.NAType.__bool__() TypeError: boolean value of NA is ambiguousこれはまた、
pd.NAがブール値で評価されるコンテキスト、例えばif condition: ...においてconditionがpd.NAになる可能性がある場合には、pd.NAは使用できないことを意味します。このような場合にはisna()を使用してpd.NAをチェックしたり、条件がpd.NAであることを避けるために、例えば欠落している値を事前に埋めておくことができます。同様の状況は、
if文でシリーズやデータフレームオブジェクトを使用する場合にも発生します。pandasでif/Truth文を使うを参照してください。NumPy ufunc
pandas.NAはNumPyの__array_ufunc__プロトコルを実装しています。ほとんどのufuncはNAに対して動作し、一般的にはNAを返します。In [**]: np.log(pd.NA) Out[**]: <NA> In [**]: np.add(pd.NA, 1) Out[**]: <NA>
現在のところ、ndarrayとNAを含むufuncは欠損値で埋められたオブジェクトデータ型を返します。In [**]: a = np.array([1, 2, 3]) In [**]: np.greater(a, pd.NA) Out[**]: array([<NA>, <NA>, <NA>], dtype=object)ここでの戻り値の型は、将来的には別の配列型を返すように変更される可能性があります。
ufuncの詳細については、DataFrameとNumPy関数の相互運用性を参照してください。
変換
伝統的な型を使用しているデータフレームやシリーズがあり、
np.nanを使用して表現されていないデータがある場合、シリーズにはconvert_dtypes()が、データフレームにはconvert_dtypes()があり、ここにリストされている整数、文字列、ブーリアンの新しいデータ型を使用するようにデータを変換することができます。これは、データセットを読み込んだ後にread_csv()やread_excel()などのリーダーにデフォルトのデータ型を推測させる場合に特に便利です。この例では、すべての列のデータ型が変更されていますが、最初の10列の結果を示しています。
In [**]: bb = pd.read_csv('data/baseball.csv', index_col='id') In [**]: bb[bb.columns[:10]].dtypes Out[**]: player object year int64 stint int64 team object lg object g int64 ab int64 r int64 h int64 X2b int64 dtype: objectIn [**]: bbn = bb.convert_dtypes() In [**]: bbn[bbn.columns[:10]].dtypes Out[**]: player string year Int64 stint Int64 team string lg string g Int64 ab Int64 r Int64 h Int64 X2b Int64 dtype: object
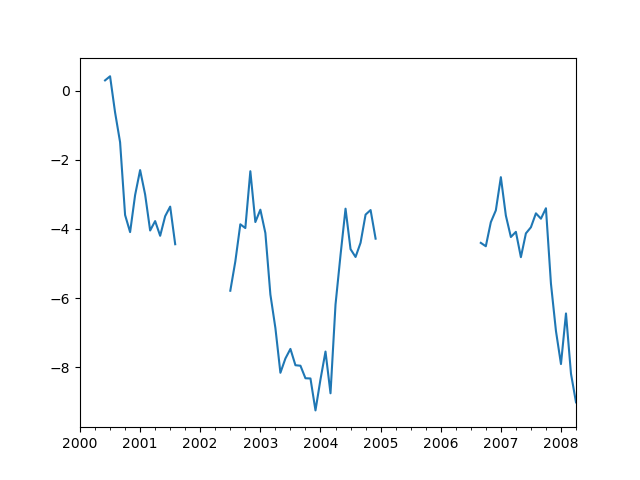
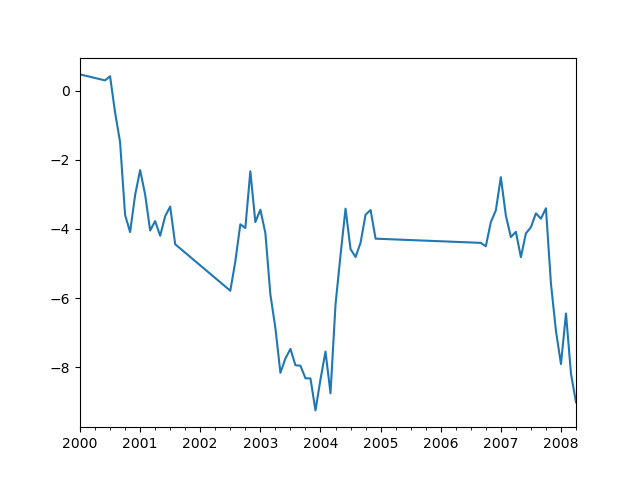
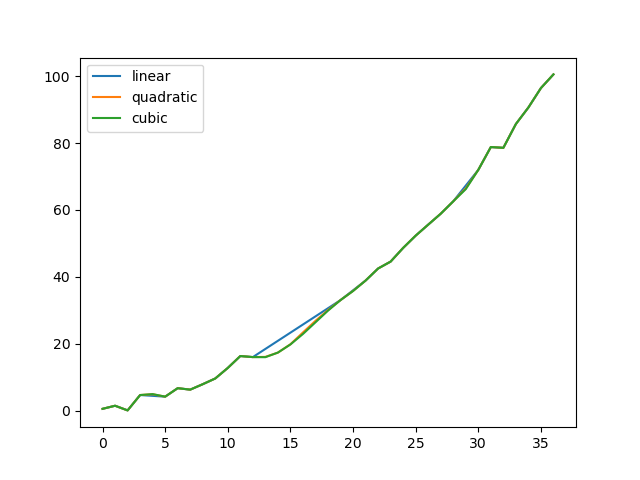
- 投稿日:2020-07-28T13:47:33+09:00
pythonでスクレイピングするための準備 【チョコレート味】
Chocolatey インストール
まず、Chocolateyが無いと面倒なことが多すぎますのでインストールします。
既にインストールしてある場合は読み飛ばしてください。powershell を管理者権限で起動します。
インストールする前に、chocoと実行してみましょう。Administrator's-Powershell$> choco choco : 用語 'choco' は、コマンドレット、関数、スクリプト ファイル、または操作可能なプログラムの名前として認識されません。名前が正しく記述されていることを確認し、パスが含まれている場合はそのパ スが正しいことを確認してから、再試行してください。 発生場所 行:1 文字:1 + choco + ~~~ + CategoryInfo : ObjectNotFound: (choco:String) [], CommandNotFoundException + FullyQualifiedErrorId : CommandNotFoundExceptionインストールされていないことが確認できます。
次に以下のインストールコマンドを実行します。
Administrator's-PowershellSet-ExecutionPolicy Bypass -Scope Process -Force; [System.Net.ServicePointManager]::SecurityProtocol = [System.Net.ServicePointManager]::SecurityProtocol -bor 3072; iex ((New-Object System.Net.WebClient).DownloadString('https://chocolatey.org/install.ps1'))Note : インストールコマンドが新しくなっていないか「Installing Chocolatey」で探しましょう。
powershellを管理者権限で開きなおします。
もう一度chocoと実行すると、バージョンとヘルプメニューの出し方が表示されます。Administrator's-Powershell$> choco Chocolatey v0.10.15 Please run 'choco -?' or 'choco <command> -?' for help menu.ここまで来たら、次に進みます。
Visual Studio Code インストール
powershellを管理者権限で起動します。
以下のコマンドを実行します。Administrator's-Powershellchoco install vscodeそのまま、
refreshenv、codeと2つコマンドを実行すれば、vscodeが開きます。Visual Studio Code Extension Pack インストール
以下の2つの拡張機能をインストールします。必須の拡張機能だけ挙げました。
オススメ拡張機能はここでは触れません。
- Japanese Language Pack for Visual Studio Code
- UIを日本語で表示するために使います。
- Python
- Python をデバッグするためにこれは必須です。
推奨拡張機能設定
.vscode/extentions.jsonを以下のように作成すれば、インストールの手間はだいぶ省けます。
そのうえ、Githubでの共有などもしやすいです。.vscode/extentions.json{ // See https://go.microsoft.com/fwlink/?LinkId=827846 to learn about workspace recommendations. // Extension identifier format: ${publisher}.${name}. Example: vscode.csharp // List of extensions which should be recommended for users of this workspace. "recommendations": [ "coenraads.bracket-pair-colorizer-2", "github.vscode-pull-request-github", "ms-python.python", "mechatroner.rainbow-csv", ], // List of extensions recommended by VS Code that should not be recommended for users of this workspace. "unwantedRecommendations": [ ] }Miniconda3 インストール
powershellを管理者権限で起動する
以下のコマンドを実行します。Administrator's-Powershellchoco install miniconda3スタートメニューに
Anaconda Powershell Prompt (miniconda3)
があれば成功です。仮想環境作成
スタートメニューに
Anaconda Powershell Prompt (miniconda3)
があるはずなので起動します。
以下のコマンドを実行して仮想環境を作成します。Anaconda-Powershell-Prompt-(miniconda3)conda create --name scraping-env-nameNote : コマンド詳細はコマンドリファレンスを参照
Note : scraping-env-nameはプレースホルダーです。この時点で、拡張子が
.pyのファイルをVSCodeにて開くと、今作った仮想環境を選択することができます。
仮想環境のアクティベーション
Anaconda-Powershell-Prompt-(miniconda3)conda activate scraping-env-nameNote : コマンド詳細はコマンドリファレンスを参照
conda-forgeをチャンネルとして追加
例えば、同じ
numpyというライブラリでも、どこのリポジトリチャンネルで公開されているnumpyを使用するのか?ということが問題になってきます。
既定では、anacondaのチャンネルからになっていますが、私はconda-forgeが好きなので、これに切り替えます。リポジトリチャンネルにconda-forgeを追加
Anaconda-Powershell-Prompt-(miniconda3)conda config --add channels conda-forge conda config --set channel_priority strictライブラリパッケージのインストール
開発に使用したい仮想環境をアクティベートした状態で以下のコマンドを実行します。
何も入っていない仮想環境にライブラリがインストールされます。Anaconda-Powershell-Prompt-(miniconda3)conda install python lxml beautifulsoup4 selenium pylint yapfpython
これがないと何も始まりません。Pythonです。3系がインストールされます。
lxml
xml や html を扱うためのパーサーライブラリです。
beautifulsoup4
beautifulsoupはパーサーをラップして使いやすくするラッパーライブラリです。
Alice in WonderlandにてMock Turtleというキャラクターが歌う
Turtle Soupにbeautiful Soup!が頻出するらしいです。selenium
Seleniumはブラウザのオートメーションツールであり、それを扱うための同一名称のライブラリです。
pylint
VScodeのリンターに注意されるので、事前に入れておきます。
yapf
VScodeの右クリックメニューから「ドキュメントのフォーマット」を行うと注意されるので、事前に入れておきます。
「autopep8っていうフォーマッターが入ってないけど、入れとく?」とか聞いてきます。
しかし、Google大好き少年なのでyapfを入れておきます。
これで決まり!最強自動コード整形ツール3選!ライブラリのインストールは順不同でも
ちなみにライブラリをインストールする順番はなんでもいいです。
ライブラリの依存関係は自動で解決してくれますので安心しましょう。WebDriver のインストール
Seleniumはブラウザを自動操作してくれます。
Chromeを自動操作したいので、Chromeドライバーをインストールします。
この時、Google Chrome をインストールする必要はありません。Administrator's-Powershellchoco install selenium-chrome-driver※その他のWebDriver の場合には、こちらのクイックリファレンスをご覧ください。
ワークスペース設定
ここまでの設定を一通り行うと、ワークスペース設定が以下のようになっていると思います。
.vscode/settings.json{ "python.pythonPath": "C:\\tools\\miniconda3\\envs\\scraping-env-name\\python.exe", "python.formatting.provider": "yapf" }先ほどフォーマッター
yapfをインストールしました。
もし後からautopep8やblackに切り替えたい場合は、こちらで切り替えができます。
minicondaのpath
chocolateyを使用してminiconda3をインストールすると、プログラム実行時に
conda: The term 'conda' is not recognized as the name of a cmdlet, function, script file, or operable program. Check the spelling of the name, or if a path was included, verify that the path is correct and try again.というメッセージが表示されます。
このままでも動作に支障はないのですが、気になるのでちゃんと設定します。先ほどの設定ファイル
.vscode/settings.jsonに"python.condaPath": "C:\\tools\\miniconda3\\Scripts"を追加して、.vscode/settings.json{ "python.pythonPath": "C:\\tools\\miniconda3\\envs\\scraping-env-name\\python.exe", "python.formatting.provider": "yapf", "python.condaPath": "C:\\tools\\miniconda3\\Scripts" }となりました。
動作確認
とりあえず、こんな感じのコードがを書きます。
F5キーを押してエラーメッセージがでなければ準備完了です。test001.pyimport lxml from bs4 import BeautifulSoup from selenium.webdriver import Chrome, ChromeOptions from selenium.webdriver.common.keys import Keys options = ChromeOptions() # options.add_argument('--headless') driver = Chrome(options=options)ファイアウォール設定
初めてPythonプログラムを実行したとき、ファイアウォールによってPythonがブロックされます。
あらかじめ、現在のインターネットへの接続設定を確認しておき、プライベートかパブリックか該当するほうを選択します。
選択したら「アクセスを許可する」をクリックしましょう。
そうすると、ファイアウォールルールが作成されるので、
この仮想環境のPythonはブロックされず正常に通信できるようになります。もし間違えても、
wf.mscで確認・変更することができます。
または「許可されたアプリ」からもできます。
「コントロール パネル\すべてのコントロール パネル項目\Windows Defender ファイアウォール\許可されたアプリ」それか、
Get-NetFirewallRuleとかNew-NetFirewallRule、Set-NetFirewallRuleを駆使すればいいと思います。それでは
ステキなスクレイピングマスターを目指しましょう
Excelsior!
参考資料
https://docs.conda.io/projects/conda/en/latest/commands.html

- 投稿日:2020-07-28T13:46:02+09:00
【Python】Lambda関数ってどう使うんだろ??【殴り書き】【続き-1】
公開理由
・前日にLambda関数のコードをqiitaに投稿してみたのだけど、PEP8違反のものでlambda関数の動作を
確認しているようでは自己成長にもつながらないと思ったから。
よくネットで転がっているmap関数とかfilter関数の使い方を理解しつつ、lambdaのありがたさを感じてみました。前回qiitaに挙げたやつ
【Python】Lambda関数ってどう使うんだろ??【殴り書き】【初投稿】
https://qiita.com/sho_cullni/items/aba9a09b30abb20cfd1amap関数
●文法
リストに対して関数の処理を実行して返り値を吐き出す処理をする関数
map(関数,リスト等)●サンプルコード
与えられたリストに対して3倍するコードを作ってみた
map_test.pynum_list = [-4, -3, -2, -1, 0, 1, 2, 3, 4] triple_num_list = map(lambda x: x * 3, num_list) print(list(triple_num_list))もしdefを使って上記コードを再現する場合は例えば以下のようになる
def triple(x): x = x * 3 return x num_list = [-4, -3, -2, -1, 0, 1, 2, 3, 4] print(list(map(triple,num_list)))上記2つのコードを実行した際の出力結果は以下になる
[-12, -9, -6, -3, 0, 3, 6, 9, 12]filter関数
●文法
リスト等に対して、関数を実行して条件に当てはまるもの(Trueになる)ものだけ返り値として吐き出す処理をする関数
filter(関数,リスト等)●サンプルコード
与えられたリストに対して3倍の倍数だけ取り出すコードを作ってみた
(世界のナベアツ感)filter_test.pynum_list = [1, 2, 3, 4, 5, 6] aho = filter(lambda x: x % 3 == 0, num_list) print(list(aho))もしdefを使って上記コードを再現する場合は例えば以下のようになる
def ahoaho(x): for i in x: if i % 3 == 0: aho.append(i) aho = [] num_list = [1, 2, 3, 4, 5, 6] ahoaho(num_list) print(list(aho))上記2つのコードを実行した際の出力結果は以下になる
[3, 6]感想
・確かに、defで関数をいちいち定義するより簡単にコードする事が出来そう。。。!
・filter関数とlambda関数の合わせ技は、Webスクレイピングで使えそう。今後良い感じに理解出来たらqiitaに挙げてみます。
- 投稿日:2020-07-28T13:46:02+09:00
【Python】lambda関数ってどう使うんだろ??【殴り書き】【続き-1】
公開理由
・前日にLambda関数のコードをqiitaに投稿してみたのだけど、PEP8違反のものでlambda関数の動作を
確認しているようでは自己成長にもつながらないと思ったから。
よくネットで転がっているmap関数とかfilter関数の使い方を理解しつつ、lambdaのありがたさを感じてみました。前回qiitaに挙げたやつ
【Python】lambda関数ってどう使うんだろ??【殴り書き】【初投稿】
https://qiita.com/sho_cullni/items/aba9a09b30abb20cfd1amap関数
●文法
リストに対して関数の処理を実行して返り値を吐き出す処理をする関数
map(関数,リスト等)●サンプルコード
与えられたリストに対して3倍するコードを作ってみた
map_test.pynum_list = [-4, -3, -2, -1, 0, 1, 2, 3, 4] triple_num_list = map(lambda x: x * 3, num_list) print(list(triple_num_list))もしdefを使って上記コードを再現する場合は例えば以下のようになる
def triple(x): x = x * 3 return x num_list = [-4, -3, -2, -1, 0, 1, 2, 3, 4] print(list(map(triple,num_list)))上記2つのコードを実行した際の出力結果は以下になる
[-12, -9, -6, -3, 0, 3, 6, 9, 12]filter関数
●文法
リスト等に対して、関数を実行して条件に当てはまるもの(Trueになる)ものだけ返り値として吐き出す処理をする関数
filter(関数,リスト等)●サンプルコード
与えられたリストに対して3の倍数だけ取り出すコードを作ってみた
(世界のナベアツ感)filter_test.pynum_list = [1, 2, 3, 4, 5, 6] aho = filter(lambda x: x % 3 == 0, num_list) print(list(aho))もしdefを使って上記コードを再現する場合は例えば以下のようになる
def ahoaho(x): for i in x: if i % 3 == 0: aho.append(i) aho = [] num_list = [1, 2, 3, 4, 5, 6] ahoaho(num_list) print(list(aho))上記2つのコードを実行した際の出力結果は以下になる
[3, 6]感想
・確かに、defで関数をいちいち定義するより簡単にコードする事が出来そう。。。!
・filter関数とlambda関数の合わせ技は、Webスクレイピングで使えそう。今後良い感じに理解出来たらqiitaに挙げてみます。
- 投稿日:2020-07-28T13:31:04+09:00
Linux上のPythonアプリからAmazon RedshiftにODBCでデータ連携
はじめに
この記事では、DataDirectドライバを利用し、Linux、UNIX上のPythonアプリケーションからAmazon RedshiftにODBCで簡単にデータ連携する方法を解説します。
unixODBCをインストールする
1、以下のコマンドで、unixODBCパッケージをインストールします。
CentOSの場合
sudo yum install unixODBC-devel unixODBCUbuntu/Debianの場合
sudo apt-get install unixODBC-dev unixODBC2、unixODBCのインストール後、
/home//Progress/DataDirect/ODBC_80_64bit/odbcinst.iniの内容を、
/etc/odbcinst.ini
に貼り付けます。
Amazon Redshift用DataDirectドライバのインストール
1、DataDirect ODBC Driver for Amazon Redshiftをダウンロードします。
2、以下のコマンドを実行し、パッケージを展開します。ar -xvf PROGRESS_DATADIRECT_ODBC_REDSHIFT_LINUX_64.tgz3、binファイルを実行し、ドライバをインストールします。
./ PROGRESS_DATADIRECT_ODBC_8.0_LINUX_64_INSTALL.bin4、インストール完了後、インストールフォルダに移動し、シェルスクリプト odbc.sh または odbc.csh を実行し、環境変数を設定します。
5、これで3つの環境変数が設定されます。正しく設定されているかどうかを確認し、先に進みましょう!
[progress@centos7264 ODBC_80_64bit]$ echo $LD_LIBRARY_PATH && echo $ODBCINI && echo $ODBCINST /home/progress/Progress/DataDirect/ODBC_80_64bit/lib:/home/progress/Progress/DataDirect/ODBC_80_64bit/jre/lib/amd64/server /home/progress/Progress/DataDirect/ODBC_80_64bit/odbc.ini /home/progress/Progress/DataDirect/ODBC_80_64bit/odbcinst.iniPythonからRedshiftに接続する
1、Linux、Unix上yPthonアプリケーションよりRedshiftにアクセスするには、pyodbcパッケージをインストールしなくてはなりません。
以下のコマンドでインストールしてください。pip install pyodbc2、以下のサンプルPythonプログラムで、Redshiftからデータにアクセスしてみましょう。
import pyodbc conn = pyodbc.connect('Driver={DataDirect 8.0 Amazon Redshift Wire Protocol}; HostName=redshift-cluster-1.cy1mp8nn6ntk.us-west-2.redshift.amazonaws.com; Database=dev; UID=awsuser; PWD=Galaxy472; Port=5439') cursor = conn.cursor() ## Create Tables cursor.execute("CREATE TABLE Track ( TrackId INT NOT NULL, Name VARCHAR(200) NOT NULL, AlbumId INT, MediaTypeId INT NOT NULL, GenreId INT, Composer VARCHAR(220), Milliseconds INT NOT NULL, Bytes INT, UnitPrice NUMERIC(10,2) NOT NULL);") cursor.execute("INSERT INTO Track (TrackId, Name, AlbumId, MediaTypeId, GenreId, Composer, Milliseconds, Bytes, UnitPrice) VALUES (1, 'For Those About To Rock (We Salute You)', 1, 1, 1, 'Angus Young, Malcolm Young, Brian Johnson', 343719, 11170334, 0.99);") conn.commit() ##Access Data using SQL cursor.execute("select * from Track") while True: row = cursor.fetchone() if not row: break print(row) ##Access Data using SQL cursor.execute("select * from Artist") while True: row = cursor.fetchone() if not row: break print(row)非常に簡単ですね。
参考記事
- 投稿日:2020-07-28T13:00:24+09:00
pythonnetを使って.NETのDLLをpythonから呼ぶときの注意点とエラー対処方法
pythonnet - Python.NETとは
Pythonから.NET向けのDLLを呼び出すことができるライブラリです.
MITライセンスとなっており,だれでも無償で使うことができます.
https://github.com/pythonnet/pythonnet使い方
使い方はこちらの記事が大変参考になりました.
Pythonから.NETを呼び出す方法とついでにその逆もここでは簡単に紹介します.
インストール方法
pip install pythonnet使用例
test.pyと同じディレクトリにあるABCLIb.dllを使いたい場合.
別のディレクトリにある場合は適宜パスを追加してください.clr.AddReference('./DEF/ABCLib')など.test.pyimport clr clr.AddReference('ABCLib') from ABCTools import ABCLib abc = ABCLib()
clrはCommon Language Runtimeの略のようです.注意点とエラーが起きたとき対処方法
私がpythonnetを使用したときにつまづいたポイントとその対象方法を紹介します.
.dllを書かない
エラー:System.IO.FileNotFoundException: Unable to find assembly 'ABCLib.dll'.
clr.AddReferenceするときに拡張子'.dll'を書いているとこのエラーが発生します。
'.dll'を消してみましょう。# エラーが発生する例 clr.AddReference('ABCLib.dll') # エラーが発生しない例 clr.AddReference('ABCLib')セキュリティを許可する
エラー:System.IO.FileNotFoundException: Unable to find assembly 'ABCLib'.
外部から取得してきたdllの場合、ファイルへのアクセスがブロックされていることがあります。
アクセスを許可する設定をしてみてください。
dllファイルで右クリック→プロパティ→全般→最下段の「許可する」にチェック→OK
DLLとPythonで64bit/32bitを合わせる
エラー:System.IO.FileNotFoundException: ファイルまたはアセンブリ 'ABCLib, Version=~~~~~~~~, Culture=neutral, PublicKeyToken=null'、またはその依存関係の 1 つが読み込めませんでした。指定されたファイルが見つかりません。
DLLとPythonのbitが合っていないと読み取ることができませんでした。
- Pythonのbitの調べ方
import sys print(sys.version)出力3.7.6 (tags/v3.7.6:43364a7ae0, Dec 19 2019, 00:42:30) [MSC v.1916 64 bit (AMD64)]
- DLLのbitの調べ方
こちらの記事を参考にさせていただきました。EXE、DLLが32bitなのか64ビットなのか確認する方法 - Qiita
- 投稿日:2020-07-28T12:30:00+09:00
PyTorchによる人工衛星画像から車の推定分布地図を作成してみる.
1. 概要.
こちらの記事を読んだとき”この内容を理解し自分で実装できたらいいな〜”と憧れていました.
Deep Learning で航空写真から自動車をカウントする
こちらを自分で実装できることをターゲットに,PyTorchを学びました.ある程度できましたので,せっかくだから公開されている人工衛星の撮影画像に構築したモデルで車の台数を推量し,同様に車のマッピングを求めてみました.
Copyright©2016DigitalGlobe.学習用および検証用の画像データの取得,PyTorchでモデル化するためのDatasetおよびDataloader処理,学習,検証と人工衛星の撮影画像によるデモンストレーションを紹介します.Pytorchによる航空画像の建物セグメンテーションの作成方法.と同様に,PyTorchや画像分類が初めての方を対象としたため,かなり細かく紹介しています.そのため長文となりましたので,PyTorchをご存知な方はポイントだけ見てください.
ここで用いたコード(Jupyter lab)はGithubに公開しています.ご自身の環境(Google Colaboratoryを含む)で試してみたい方は,下記よりダウンロードしてください.
pytorch_car_counting環境
本記事の実装環境は以下となります.
OS:Ubuntu: 18.04LTS
GPU:GeoForce GTX1070Python: 3.7
PyTorch: 1.1.02. 画像からの車のカウント方法.
画像から対象物の識別方法として,物体検知(Object detection)がはじめに思いつきます.
この技術は,はじめに画像内の物体の有無およびその位置を認識し,そして物体の分類を行うものです.例えば,以下のサイトで詳しく技術が紹介されています.今回用いる航空写真(COWC: Car Overhead With Context)においても,その学習例として物体検知の方法が紹介されています.
はじめは一般的な物体検知(SSD)の方法をPytorchで実装し,画像内の車をカウントすることも考えましたが,こちらの記事で紹介されているような,画像に写っている車の数を画像の模様(テクスチャー)として識別し,台数に応じた画像分類にて車をカウントする方法に興味を持ち,どのようなサービスやアプリケーションを作るかによりますが,画像内の車の位置情報は必要でななく,あるグリッド内の車の数を把握し,その分布が得られることで十分と考えました.また,今回は車の数をターゲットとしましたが,対象を変えることで同様の分布地図を作成することができます.
といっても難しいことを考えているわけではなく,”アノテーションコストが低減できる”に魅力とその有効性に一番関心を持ちました.面白いアイデアです.では,学習および検証用の画像データとアノテーション情報(画像内の車の台数)を準備します.
3. 学習および検証用データの準備.
COWCでのサイトから航空写真の画像データおよびアノテーションデータをダウロードし,学習用および検証用のデータを準備しようと思いましたが,すでに効果的なデータの準備がされていましたので,そちらを利用させていただきました.感謝いたします.
COWCのデータのダウンロードおよびその前処理方法について,こちらの記事をご確認ください.
ここでは,上記の前処理後のPyTorchでモデルを構築するための処理について紹介します.
なお,COWCのデータのダウロードから前処理の全般についてGithubにコードをアップしていますのでで,こちらもご参考ください.まずは,各モジュールをインポートします.
import argparse import os import shutil import math import numpy as np from PIL import Image from skimage import io from tqdm import tqdm import matplotlib.pyplot as plt import numpy as np import cv2 Image.MAX_IMAGE_PIXELS = 1000000000その後,取得した画像を確認します.
train_path = '../../data/cowc_processed/train_val/crop/train/' files =os.listdir(train_path) #ファイル名の取得 print(files[0]) #trainファイルの読み込み. im = cv2.imread(train_path + files[0]) im_rgb = cv2.cvtColor(im, cv2.COLOR_BGR2RGB) plt.imshow(im_rgb)
これより,左半分に車が写った航空写真が,右半分に車の位置がわかるアノテーション画像(白点が車の位置)で構成されているのがわかります.
次に航空写真とそれに対応する車の台数のペアのデータを準備します.
#画像サイズの確認 v_size = im_rgb.shape[0] h_size = im_rgb.shape[1] print(h_size) # 画像を左の撮像と右のアノテーション画像に分割する. clp_l = im_rgb[0:v_size, 0:h_size//2] clp_r = im_rgb[0:v_size, h_size//2:h_size] # 撮像画像の確認 plt.imshow(clp_l) #アノテーション画像の確認 plt.imshow(clp_r)
分離したアノテーション画像から車の台数を見積もります.
#アノテーション画像の積算値より車の台数を算出.(1台:765) car_count = int(np.sum(clp_r) // 765) print('車の台数: ', car_count)アノテーション画像の信号強度から台数を見積もると,以下の出力となりました.
出力車の台数: 6上記の方法で,学習用(Train)および検証用(Validation)のすべての画像に対して,分割処理およびアノテーション画像からの車の台数を算出します.
分割した航空写真は車の台数名のフォルダ(ディレクトリ)に格納します.for i in range(len(files)): train_path = '../../data/cowc_processed/train_val/crop/train/' files =os.listdir(train_path) im = cv2.imread(train_path + files[i]) im_rgb = cv2.cvtColor(im, cv2.COLOR_BGR2RGB) #画像サイズの確認 v_size = im_rgb.shape[0] h_size = im_rgb.shape[1] clp_l = im_rgb[0:v_size, 0:h_size//2] clp_r = im_rgb[0:v_size, h_size//2:h_size] car_count = int(np.sum(clp_r) // 765) car_count #rint(car_count) path_train = '../../../data/train/' #保存先のディレクトリがなければ作成 if not os.path.exists(path_train + str(car_count)): os.mkdir(path_train + str(car_count)) #分離した画像の保存 Image.fromarray(clp_l).save(path_train + str(car_count) +'/' + files[i])処理後のデータより,学習用データの車の台数分布やデータ数を確認します.
#trainデータ数 print('Trainの台数分布: ', len(os.listdir(path_train))) #trainデータ数 import glob print('Trainのデータ数: ', len(glob.glob(path_train + '/*/*')))出力
Trainの台数分布: 21 Trainのデータ数: 37981検証用データに対しても同様の処理を行い,画像の分割,および分割した画像を車の台数名のディレクトリに格納します.
ここで,検証用データの車の台数を確認したところ,最大台数が12台であったため,学習用データの12台以上の台数の画像をすべて12台として同じディレクトリに格納しました.
for i in range(13, 21, 1): move_glob('./train/12/', './train/' + str(i) + '/*.png')そして,Datasetにて分類名の文字数を固定するために,ディレクトリ名で車の台数がひと桁である場合,ふた桁に変更しました.
#ディレクトリ名を2桁に変更する. for i in range(0,10,1): os.rename('./train/'+ str(i), './train/0' + str(i)) os.rename('./val/'+ str(i), './val/0' + str(i))こちらで学習用および検証用データの前準備が終了です.
4. Pytorchでの画像分類モデルの構築.
画像分類(Image Classificaton)のモデルは,Pytorchを学ぶのに参考にした「つくりながら学ぶ!PyTorchによる発展ディープラーニング」で紹介されているモデルをベースに作りました.
書籍「つくりながら学ぶ! PyTorchによる発展ディープラーニング」(小川雄太郎、マイナビ出版 、19/07/29)
この本は,PyTorchのワークフローの考え方から,画像分類,物体検知,セグメンテーション,GAN,自然言語処理,動画分類と対象が広範囲と,自分が行いたいモデルを例として丁寧に学び構築できます.非常に参考になりました.
ここで紹介されている画像分類のなかで,VGG-16のモデルをベースとしたFine Tuningを採用しモデルを構築します.
Vgg-16や,PyTorchによるFine tuningの方法については,こちらの本をご参考ください.
また,本に記載されているコードは以下にて公開されています.どういった内容なのか関心のあるかたは,こちらもご参考ください.つくりながら学ぶ! PyTorchによる発展ディープラーニング
MIT Licenseでは,学習用および検証用データのDataset,Dataloaderの作成,およびモデルの構築と検証を実行します.
5. 画像分類による航空写真より車の分布地図を作成する.
5.1 Dataset,Dataloaderの作成
前処理にて準備した航空写真の画像データおよびそれに対応した車の台数情報による車の台数予測モデルを構築するために,PyTorchに対応したDatasetおよびDataloaderを作成します.
まずは必要なモジュールをインポートします.
# パッケージのimport import glob import os.path as osp import random import numpy as np import json from PIL import Image from tqdm import tqdm import matplotlib.pyplot as plt %matplotlib inline import torch import torch.nn as nn import torch.optim as optim import torch.utils.data as data import torchvision from torchvision import models, transforms次に乱数を固定し再現性を保ちます.
# 乱数のシードを設定 torch.manual_seed(1234) np.random.seed(1234) random.seed(1234)そして,PyTorchのバージョンを確認します.
print(torch.__version__) print(torchvision.__version__)出力
1.1.0 0.3.0私の環境は,それぞれ上記のバージョンとなります.
まずDatasetを作成します.
先に述べましたが,DatasetやFine tuningのモデルは,つくりながら学ぶ! PyTorchによる発展ディープラーニングで紹介されている設定をそのまま用いています.そのため,構築したモデルの精度を高めるにはどうしたらよいのか,など改善を考えている方は,こちらの設定をベースとしてAugmentationを変更したり,フィルターを加えたりなど色々試してみてください.
どういったパラメータが効果があるのかないのか,自分の感覚として身につくかと思います.Datasetは学習用(Train)および検証用(Val)を共通して以下の関数で設定します.
まずは,画像データのAugmentation,標準化処理やサイズの変更,そしてPyTorchで扱うためのTensor変換を下記にて行います.
class ImageTransform(): """ 画像の前処理クラス。訓練時、検証時で異なる動作をする。 画像のサイズをリサイズし、色を標準化する。 訓練時はRandomResizedCropとRandomHorizontalFlipでデータオーギュメンテーションする。 Attributes ---------- resize : int リサイズ先の画像の大きさ。 mean : (R, G, B) 各色チャネルの平均値。 std : (R, G, B) 各色チャネルの標準偏差。 """ def __init__(self, resize, mean, std): self.data_transform = { 'train': transforms.Compose([ transforms.RandomResizedCrop( resize, scale=(0.5, 1.0)), # データオーギュメンテーション transforms.RandomHorizontalFlip(), # データオーギュメンテーション transforms.RandomVerticalFlip(), # データオーギュメンテーション transforms.RandomAffine([-30, 30], scale=(0.8, 1.2)), # 回転とリサイズ #transforms.RandomErasing(p=0.5), # 確率0.5でランダムに領域を消去 transforms.ToTensor(), # テンソルに変換 transforms.Normalize(mean, std) # 標準化 ]), 'val': transforms.Compose([ transforms.Resize(resize), # リサイズ #transforms.CenterCrop(resize), # 画像中央をresize×resizeで切り取り transforms.ToTensor(), # テンソルに変換 transforms.Normalize(mean, std) # 標準化 ]) } def __call__(self, img, phase='train'): """ Parameters ---------- phase : 'train' or 'val' 前処理のモードを指定。 """ return self.data_transform[phase](img)では,この変換によって画像がどのように変化するのか.Train画像を見てみます.
# 訓練時の画像前処理の動作を確認 # 実行するたびに処理結果の画像が変わる # 1. 画像読み込み image_file_path = '../data/train/01/03553_97_597.png' img = Image.open(image_file_path) # [高さ][幅][色RGB] # 2. 元の画像の表示 plt.imshow(img) plt.show() # 3. 画像の前処理と処理済み画像の表示 size = 96 mean = (0.485, 0.456, 0.406) std = (0.229, 0.224, 0.225) transform = ImageTransform(size, mean, std) img_transformed = transform(img, phase="train") # torch.Size([3, 224, 224]) # (色、高さ、幅)を (高さ、幅、色)に変換し、0-1に値を制限して表示 img_transformed = img_transformed.numpy().transpose((1, 2, 0)) img_transformed = np.clip(img_transformed, 0, 1) plt.imshow(img_transformed) plt.show()実行結果が以下となります.
上部の元画像に対して,傾きや標準化処理が行われている(色合いが変わっている)のがわかります.
次にDatasetを作成するための学習用および検証用のファイルのリストを作成します.def make_datapath_list(phase="train"): """ データのパスを格納したリストを作成する。 Parameters ---------- phase : 'train' or 'val' 訓練データか検証データかを指定する Returns ------- path_list : list データへのパスを格納したリスト """ rootpath = "../data/" target_path = osp.join(rootpath+phase+'/**/*.png') print(target_path) path_list = [] # ここに格納する # globを利用してサブディレクトリまでファイルパスを取得する for path in glob.glob(target_path): path_list.append(path) return path_list # 実行 train_list = make_datapath_list(phase="train") val_list = make_datapath_list(phase="val")ここで準備した学習用および検証用の画像数を確認してみます.
len(train_list), len(val_list)出力
(37981, 10267)学習用画像が37981枚,検証用画像が10267枚であることが確認されました.
次にDatasetを作成します.学習用および検証用の画像の車の台数分布は0から12台(学習用は13台以上はすべて12台に移動)としたことから,以下の設定となります.
class CarCountDataset(torch.utils.data.Dataset): """ 車の数の画像のDatasetクラス。PyTorchのDatasetクラスを継承。 Attributes ---------- file_list : リスト 画像のパスを格納したリスト transform : object 前処理クラスのインスタンス phase : 'train' or 'test' 学習か訓練かを設定する。 """ def __init__(self, file_list, transform=None, phase='train'): self.file_list = file_list # ファイルパスのリスト self.transform = transform # 前処理クラスのインスタンス self.phase = phase # train or valの指定 def __len__(self): '''画像の枚数を返す''' return len(self.file_list) def __getitem__(self, index): ''' 前処理をした画像のTensor形式のデータとラベルを取得 ''' # index番目の画像をロード img_path = self.file_list[index] img = Image.open(img_path) # [高さ][幅][色RGB] # 画像の前処理を実施 img_transformed = self.transform( img, self.phase) # torch.Size([3, 224, 224]) # 画像のラベルをファイル名から抜き出す if self.phase == "train": label = img_path[14:16] #print(label) elif self.phase == "val": #print(img_path) label = img_path[12:14] #print(label) # ラベルを数値に変更する if label == "00": label = 0 elif label == "01": label = 1 elif label == "02": label = 2 elif label == "03": label = 3 elif label == "04": label = 4 elif label == "05": label = 5 elif label == "06": label = 6 elif label == "07": label = 7 elif label == "08": label = 8 elif label == "09": label = 9 elif label == "10": label = 10 elif label == "11": label = 11 elif label == "12": label = 12 #elif label == "13": #calが12までなので,trainはそれ以上を12台に含めた. # label = 13 #elif label == "14": # label = 14 #elif label == "15": # label = 15 #elif label == "16": # label = 16 #elif label == "17": # label = 17 #elif label == "18": # label = 18 #elif label == "19": # label = 19 #elif label == "20": # label = 20 #print(type(label)) return img_transformed, label # 実行 train_dataset = CarCountDataset( file_list=train_list, transform=ImageTransform(size, mean, std), phase='train') val_dataset = CarCountDataset( file_list=val_list, transform=ImageTransform(size, mean, std), phase='val') # 動作確認 index = 0 print(train_dataset.__getitem__(index)[0].size()) print(train_dataset.__getitem__(index)[1])ディレクトリ名を分類名(Class名)として扱う方法がPyTorchにありますが,今回は本で説明されている方法である,ディレクトリ名を分類名とする宣言を行っています.
上記を実行しDatasetの準備が終了しましたので,次にDataloaderを作成します.
学習用および検証のデータとして以下の処理を行います.# ミニバッチのサイズを指定 batch_size = 32 # DataLoaderを作成 train_dataloader = torch.utils.data.DataLoader( train_dataset, batch_size=batch_size, shuffle=True) val_dataloader = torch.utils.data.DataLoader( val_dataset, batch_size=batch_size, shuffle=False) # 辞書型変数にまとめる dataloaders_dict = {"train": train_dataloader, "val": val_dataloader} print(type(dataloaders_dict)) print(dataloaders_dict["train"]) print(dataloaders_dict) # 動作確認 batch_iterator = iter(dataloaders_dict["train"]) # イテレータに変換 print(type(batch_iterator)) inputs, labels = next( batch_iterator) # 1番目の要素を取り出す #print(inputs.size()) #print(labels) #print(labels.size())どういったデータ形式となるのか,Printにていくつか出力させていますが,これらは確認が目的ですので,それが終えた方はヘッドに#をつけて実行させないか,削除してください.(私の備忘録の意味でこのままとしておきます.)
これで,PyTorchを実行するためのインプイットデータの準備が終えました.次にモデルを構築します.
5.2 画像分類モデルのFine tuningの構築
ネットワークモデルはVGG-16をベースとしたFine Tuningで構築します.VGG-16をご存知の方は多いかと思いますが,「ImageNet」と呼ばれる大規模画像データセットで学習された16層からなるCNNモデルです.出力は1000クラスとなり,犬,鳥猫などの1000種類に分類された推定結果が出力されます.
まず,PyTorchでVGG16を使うためそれを呼び出します.
# 学習済みのVGG-16モデルをロード # VGG-16モデルのインスタンスを生成 use_pretrained = True # 学習済みのパラメータを使用 net = models.vgg16(pretrained=use_pretrained) print(net)PyTorchにはVGG16以外にも多くの学習済みモデルが用意されています.関心のある方は公式ドキュメントをご参考ください.
モデルは以下となります.
出力.VGG( (features): Sequential( (0): Conv2d(3, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)) (1): ReLU(inplace) (2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)) (3): ReLU(inplace) (4): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False) (5): Conv2d(64, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)) (6): ReLU(inplace) (7): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)) (8): ReLU(inplace) (9): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False) (10): Conv2d(128, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)) (11): ReLU(inplace) (12): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)) (13): ReLU(inplace) (14): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)) (15): ReLU(inplace) (16): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False) (17): Conv2d(256, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)) (18): ReLU(inplace) (19): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)) (20): ReLU(inplace) (21): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)) (22): ReLU(inplace) (23): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False) (24): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)) (25): ReLU(inplace) (26): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)) (27): ReLU(inplace) (28): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)) (29): ReLU(inplace) (30): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False) ) (avgpool): AdaptiveAvgPool2d(output_size=(7, 7)) (classifier): Sequential( (0): Linear(in_features=25088, out_features=4096, bias=True) (1): ReLU(inplace) (2): Dropout(p=0.5) (3): Linear(in_features=4096, out_features=4096, bias=True) (4): ReLU(inplace) (5): Dropout(p=0.5) (6): Linear(in_features=4096, out_features=1000, bias=True) ) )最後のout_feature=1000となっており,これはアウトプットが1000種類に分類されていることを示しています.
そのため,最後の出力層に今回の車の台数分布の出力である,0台から12台の13種類となるよう変更します.#VGG16の最後の出力層の出力ユニットを21の車の数のクラスに付け替える net.classifier[6] = nn.Linear(in_features=4096, out_features=13) # 訓練モードに設定 net.train() print('ネットワーク設定完了:学習済みの重みをロードし、訓練モードに設定しました')次にこのモデルのFine tuningを設定します.VGG16のモデルの中で,本と同じくいくつかのパラメータを学習によって更新するしないを設定します.
# ファインチューニングで学習させるパラメータを、変数params_to_updateの1~3に格納する params_to_update_1 = [] params_to_update_2 = [] params_to_update_3 = [] # 学習させる層のパラメータ名を指定 update_param_names_1 = ["features"] update_param_names_2 = ["classifier.0.weight", "classifier.0.bias", "classifier.3.weight", "classifier.3.bias"] update_param_names_3 = ["classifier.6.weight", "classifier.6.bias"] # パラメータごとに各リストに格納する for name, param in net.named_parameters(): if update_param_names_1[0] in name: param.requires_grad = True params_to_update_1.append(param) print("params_to_update_1に格納:", name) elif name in update_param_names_2: param.requires_grad = True params_to_update_2.append(param) print("params_to_update_2に格納:", name) elif name in update_param_names_3: param.requires_grad = True params_to_update_3.append(param) print("params_to_update_3に格納:", name) else: param.requires_grad = False print("勾配計算なし。学習しない:", name)次に,損失関数を定義します.損失関数は,多数分類のためクロスエントロピーとします.
# 損失関数の設定 criterion = nn.CrossEntropyLoss()そして,最適化手法を設定します.最適化手法は一般的なSGDとし,それぞれのパラメータの学習率は,本と同じ重みにしています.
# 最適化手法の設定 optimizer = optim.SGD([ {'params': params_to_update_1, 'lr': 1e-4}, {'params': params_to_update_2, 'lr': 5e-4}, {'params': params_to_update_3, 'lr': 1e-3} ], momentum=0.9)こちらも設定を変えることで結果(精度)がどのように変わるのか,実験すると理解が深まり面白いかと思います.学習に時間がかかるため,高い性能のGPUが欲しくなりますが.
では,最後に学習方法を設定します.
# モデルを学習させる関数を作成 def train_model(net, dataloaders_dict, criterion, optimizer, num_epochs): # 初期設定 # GPUが使えるかを確認 device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu") #print("使用デバイス:", device) print("device name", torch.cuda.get_device_name(0)) # ネットワークをGPUへ net.to(device) # ネットワークがある程度固定であれば、高速化させる torch.backends.cudnn.benchmark = True #train accurascy, train loss, val_accuracy, val_loss をグラフ化できるように設定. x_epoch_data=[] y_train_loss=[] y_train_accuracy=[] y_val_loss=[] y_val_accuracy=[] # epochのループ for epoch in range(num_epochs): print('Epoch {}/{}'.format(epoch+1, num_epochs)) print('-------------') x_epoch_data.append(epoch) # epochごとの訓練と検証のループ for phase in ['train', 'val']: if phase == 'train': net.train() # モデルを訓練モードに else: net.eval() # モデルを検証モードに epoch_loss = 0.0 # epochの損失和 epoch_corrects = 0 # epochの正解数 # 未学習時の検証性能を確かめるため、epoch=0の訓練は省略 if (epoch == 0) and (phase == 'train'): continue # データローダーからミニバッチを取り出すループ for inputs, labels in tqdm(dataloaders_dict[phase]): # GPUが使えるならGPUにデータを送る inputs = inputs.to(device) labels = labels.to(device) # optimizerを初期化 optimizer.zero_grad() # 順伝搬(forward)計算 with torch.set_grad_enabled(phase == 'train'): outputs = net(inputs) loss = criterion(outputs, labels) # 損失を計算 _, preds = torch.max(outputs, 1) # ラベルを予測 # 訓練時はバックプロパゲーション if phase == 'train': loss.backward() optimizer.step() # 結果の計算 epoch_loss += loss.item() * inputs.size(0) # lossの合計を更新 # 正解数の合計を更新 epoch_corrects += torch.sum(preds == labels.data) # epochごとのlossと正解率を表示 epoch_loss = epoch_loss / len(dataloaders_dict[phase].dataset) epoch_acc = epoch_corrects.double( ) / len(dataloaders_dict[phase].dataset) if phase == 'train': y_train_loss.append(epoch_loss) y_train_accuracy.append(epoch_acc) else: y_val_loss.append(epoch_loss) y_val_accuracy.append(epoch_acc) print('{} Loss: {:.4f} Acc: {:.4f}'.format( phase, epoch_loss, epoch_acc)) return x_epoch_data, y_train_loss, y_train_accuracy, y_val_loss, y_val_accuracyここでは,本と同じく1回目は学習させずに読み込んだVGG16のモデルのまま検証用データを用いて精度を求めます.学習データを用いることでどれほど向上するのか,定量的な感覚がつかめるかと思います.
また,これは本と異なりますが,学習を深めることでモデルの損失や精度がどのように向上するのかしないのか,グラフ化するためのデータを作りました.では,以下にてモデルを実行します.エポック数は50としています.
# 学習・検証を実行する num_epochs=50 train = train_model(net, dataloaders_dict, criterion, optimizer, num_epochs=num_epochs)5.3 モデルの検証
私の環境(GPU:GX 1070)で約2時間30分の学習時間となります.学習が終わりましたら,以下にて学習の評価を行います.
#Trainは1epoch目は実行していないため,対象のepochを削除する. train_epoch = train[0].copy() train_epoch.pop(0) #学習模様のグラフ化 fig = plt.figure(figsize=(14, 5)) ax1 = fig.add_subplot(1, 2, 1) line1, = ax1.plot(train_epoch,train[1],label='loss') line2, = ax1.plot(train_epoch,train[2],label='accuracy') ax1.set_title("train") ax1.set_xlabel('epoch') ax1.set_ylabel('loss, accuracy') ax1.legend(loc='upper right') ax2 = fig.add_subplot(1, 2, 2) line1, = ax2.plot(train[0],train[3],label='loss') line2, = ax2.plot(train[0],train[4],label='accuracy') ax2.set_ylim(0.5, 1.0) #y軸のスケールを固定. ax2.set_title("validation") ax2.set_xlabel('epoch') ax2.set_ylabel('loss, accuracy') ax2.legend(loc='upper right') plt.show()結果は以下となりました.
学習用データにおいては,学習回数が増える毎に損失が減少し精度が向上しています.一方,検証用データは,1エポック目のVGG16のままで精度がかなり低いですが,学習用データと同様に学習回数がふえることで精度が向上しています.ただ,その精度の向上率は学習用画像ほどではないですね.
学習用および検証用画像は同じ航空写真から準備したため,それに大きな違いはないと思います.もしかしたら,学習回数をより多くすると,学習用は精度はあがるが検証用は下がる’過学習’が現れるかもしれません.時間がある方は試してみてください.では,ここで学習したモデルのパラメータを保存します.
# PyTorchのネットワークパラメータの保存 save_path = './carcount_weights_fine_tuning.pth' torch.save(net.state_dict(), save_path)次に,ここで保存した学習モデルを再生(読み込み)ます.モデルの学習から実行まで連続して行う場合はこちらは不要ですが,過去に学習したモデルを読み込みたいとき(学習には時間がかかるため,学習後から検証やテストモデルを実装するときなど),以下から実行することとなります.
GPU環境で作成したモデルをGPU環境で使用するとき,GPU環境で作成したモデルをGPUがないCPU環境で使用するとき,などのケースによって読み込み方が異なるそうです.詳しくは,こちらをご参考にしてください.ここではGPU環境でのモデルの再生および実行例となります.
device = torch.device("cuda") load_path = './carcount_weights_fine_tuning.pth' net.load_state_dict(torch.load(load_path)) net.to(device)では,読み込んだモデルの精度を検証用データを用いて確認します.
correct = 0 total = 0 net.eval() # 評価モード for i, (x, t) in enumerate(val_dataloader): x, t = x.cuda(), t.cuda() # GPU対応 y = net(x) correct += (y.argmax(1) == t).sum().item() total += len(x) print("正解率:", str(correct/total*100) + "%")出力は,正解率: 75.05600467517289%,となりました.
次に,この正解率の意味を理解していきます.学習済みのモデルを使って検証用画像の検証結果を確認します.
例えば,以下のコードを実行してみます.test_dataloader = torch.utils.data.DataLoader( val_dataset, batch_size=batch_size, shuffle=True) dataiter = iter(test_dataloader) images, labels = dataiter.next() # サンプルを1つだけ取り出す plt.imshow(np.transpose(images[0], (1, 2, 0))) # チャンネルを一番後ろに plt.tick_params(labelbottom=False, labelleft=False, bottom=False, left=False) # ラベルとメモリを非表示に plt.show() net.eval() # 評価モード x, t = images.cuda(), labels.cuda() # GPU対応 print(x.shape) #x, t = images, labels # CPU対応 y = net(x) print("予測された車の数:", y[0].argmax().item()) print('正解の車の数:', t[0])出力は以下となります.
画像が分かり難いですが,写真には車が3台(正解の車の数)あり,モデルより予測された結果が3台と,一致しているのがわかります.
では,他の車の台数の場合はどうなのか? 車の台数分布に応じた精度を求めてみます.# ミニバッチのサイズを指定 batch_size = 32 val_dataloader = torch.utils.data.DataLoader( val_dataset, batch_size=batch_size, shuffle=False) classes = list(range(13)) class_correct = list(0. for i in range(13)) class_total = list(0. for i in range(13)) predicted_class = list(0. for i in range(13)) dataiter = iter(val_dataloader) images, labels = dataiter.next() net.eval() # 評価モード x, t = images, labels # GPU対応 for data in val_dataloader: images, labels = data x, t = images.cuda(), labels.cuda() # GPU対応 #x, t = images, labels # CPU対応 outputs = net(x) _, predicted = torch.max(outputs, 1) c = (predicted == t).squeeze() for i in range(len(c)): label = t[i] label_p = predicted[i] class_correct[label] += c[i].item() predicted_class[label_p] += 1 class_total[label] += 1 for i in range(13): print('Accuracy of %2s : %2d %%, %4d images, the number of predicted image: %4d' % ( classes[i], 100 * class_correct[i] / class_total[i], class_total[i], predicted_class[i]))出力
Accuracy of 0 : 94 %, 5773 images, the number of predicted image: 5618 Accuracy of 1 : 68 %, 1546 images, the number of predicted image: 1419 Accuracy of 2 : 52 %, 1171 images, the number of predicted image: 976 Accuracy of 3 : 47 %, 733 images, the number of predicted image: 878 Accuracy of 4 : 26 %, 465 images, the number of predicted image: 449 Accuracy of 5 : 26 %, 284 images, the number of predicted image: 370 Accuracy of 6 : 12 %, 153 images, the number of predicted image: 107 Accuracy of 7 : 21 %, 76 images, the number of predicted image: 237 Accuracy of 8 : 0 %, 40 images, the number of predicted image: 12 Accuracy of 9 : 25 %, 12 images, the number of predicted image: 106 Accuracy of 10 : 12 %, 8 images, the number of predicted image: 43 Accuracy of 11 : 0 %, 5 images, the number of predicted image: 21 Accuracy of 12 : 100 %, 1 images, the number of predicted image: 310台の車の画像に対して0台と予測した精度は94%とかなり高いことがわかります.これは,画像の多くは車が写っていない画像であり(5773枚),0台となる精度が高くなることは想像できるかと思います.(0台と予測された画像の枚数は5618枚となります.)
一方,台数が多い画像,例えば8台とすると,その精度は0%とまったく一致していません.(モデルは8台と予測された画像が12枚ありましたが,そのどれも8台の正解ラベルをもつ画像ではありませんでした.)
台数が増えることで,その精度は悪くなっているのがわかります.ただ,完全に一致していなくても,その前後である可能性は高いと思われます.記事の最初にかきましたが,今回は台数そのものを正確に求めることが目的ではなく,定性的になりますが,車の密集分布や,異なる時期の同地域の画像を比較することで,トレンドが求められればと思っています.推定された車の台数は実際の台数よりも多く推測されているのがわかりました.
ただ,精度が高いにこしたことはありませんので,モデルやパラメータの設定を変更したり,学習用画像の処理によって改善を試みたほうがよいですね.構築したモデルの精度を評価しましたので,次にこのモデルを用いて航空写真に求めた車の分布地図を作成します.
5.3 航空写真の車の分布地図の作成
検証用画像を対象に,実際の航空写真に推定された車の分布や台数を重畳します.
すでにモジュールをインポートしている方は不要ですが,念の為記載します.import argparse import os import shutil import math import numpy as np from PIL import Image from skimage import io from tqdm import tqdm import matplotlib.pyplot as plt import numpy as np import cv2 Image.MAX_IMAGE_PIXELS = 1000000000次に処理する画像のファイル名を確認します.このとき,PyTorchで処理するために分割した画像を保存するディレクトリも作っておきます.
if not os.path.exists('../data/test'): os.mkdir('../data/test') val_path = '../cowc_car_counting/data/cowc/datasets/ground_truth_sets/Utah_AGRC/' files =os.listdir(val_path) #ファイル名の取得 print(files[0])今回はUthaの航空写真を対象としました.
では,この画像を閲覧しサイズを確認します.
#opencvで検証用画像を読み込む. im = cv2.imread(val_path + files[0]) im_rgb = cv2.cvtColor(im, cv2.COLOR_BGR2RGB) #Image.fromarray(im_rgb).save('test.jpg') plt.imshow(im_rgb) #画像サイズの確認 v_size = im_rgb.shape[0] h_size = im_rgb.shape[1] print('v_size:', v_size) print('h_size:', h_size)
画像のサイズは7213 x 7226ピクセルであることが確認できました.グリッドサイズを100ピクセルとし(モデルが96ピクセルなため,それに近いサイズ),今回はその整数倍のサイズにリサイズしました.
#検証画像の分割画像の置き場所を準備する. if not os.path.exists('../data/test/val'): os.mkdir('../data/test/val') height = 100 #モデルが96ピクセルなので,それに近い100ピクセルとする. width = 100 img_size = 7200 #imageサイズで100ピクセルに近い値とする. DIR_OUTPUTS = '../data/test/val/' #画像の分割処理関数 def ImgSplit(im): # 読み込んだ画像を100*100ピクセルのサイズに分割する.のサイズで72*72枚に分割する buff = [] # 縦の分割枚数 for h1 in range(int(img_size/height)): # 横の分割枚数 for w1 in range(int(img_size/width)): w2 = w1 * height h2 = h1 * width #print(w2, h2, width + w2, height + h2) c = im.crop((w2, h2, width + w2, height + h2)) buff.append(c) return buff #画像の分割処理の実行 hi=0 for ig in ImgSplit(img_resize): hi=hi+1 #print(hi) # 保存先フォルダの指定 ig.save(DIR_OUTPUTS+str(hi)+".png")分割した画像のリストおよび変換処理を行います.今回はテスト用画像ですので,変換は画像サイズ,標準化およびPyTorchで扱うためのTensor処理のみとします.
#test_listの作成 def make_datapath_list_test(phase="test"): """ データのパスを格納したリストを作成する。 Parameters ---------- phase : 'train' or 'val' 訓練データか検証データかを指定する Returns ------- path_list : list データへのパスを格納したリスト """ rootpath = "../data/" target_path = osp.join(rootpath+phase+'/val/*.png') print(target_path) path_list = [] # ここに格納する # globを利用してサブディレクトリまでファイルパスを取得する for path in glob.glob(target_path): path_list.append(path) return path_list # 実行 test_list = make_datapath_list_test(phase="test")# test画像の前処理をするクラス # resize, normalize and totnesorを行う. class ImageTransform_test(): """ 画像の前処理クラス。訓練時、検証時で異なる動作をする。 画像のサイズをリサイズし、色を標準化する。 訓練時はRandomResizedCropとRandomHorizontalFlipでデータオーギュメンテーションする。 Attributes ---------- resize : int リサイズ先の画像の大きさ。 mean : (R, G, B) 各色チャネルの平均値。 std : (R, G, B) 各色チャネルの標準偏差。 """ def __init__(self, resize, mean, std): self.data_transform = { 'test': transforms.Compose([ transforms.Resize(resize), # リサイズ #transforms.CenterCrop(resize), # 画像中央をresize×resizeで切り取り transforms.ToTensor(), # テンソルに変換 transforms.Normalize(mean, std) # 標準化 ]) } def __call__(self, img, phase='test'): """ Parameters ---------- phase : 'train' or 'val' 前処理のモードを指定。 """ return self.data_transform[phase](img)テストファイルのリストは分割順になっていないため,natsortを用いて順番に変更します.これは,モデルにて推定された車の台数分布の行列を作成するために必要な処理になります.natsortをインストールされていない方は以下にて実行してください.
#!pip install natsort #natsoatを用いてファイルの順番をソートする from natsort import natsorted test_list = natsorted(test_list)では,作成したテスト用画像を確認します.
# 訓練時の画像前処理の動作を確認 # 実行するたびに処理結果の画像が変わる # 1. 画像読み込み image_file_path = test_list[0] img = Image.open(image_file_path).convert('RGB') # [高さ][幅][色RGB] # 2. 元の画像の表示 plt.imshow(img) plt.show() # 3. 画像の前処理と処理済み画像の表示 size = 96 mean = (0.485, 0.456, 0.406) std = (0.229, 0.224, 0.225) transform = ImageTransform(size, mean, std) img_transformed = transform(img, phase="val") # torch.Size([3, 224, 224]) # (色、高さ、幅)を (高さ、幅、色)に変換し、0-1に値を制限して表示 print(img_transformed.shape)出力
全体の航空写真の一番左上の画像になります.これを見ると車は写っていないですね.
この画像データのDatasetを作成します.# test画像のDatasetを作成する class CarCountDataset_test(torch.utils.data.Dataset): def __init__(self, file_list, transform=None, phase='train'): self.file_list = file_list # ファイルパスのリスト self.transform = transform # 前処理クラスのインスタンス self.phase = phase # train or valの指定 def __len__(self): '''画像の枚数を返す''' return len(self.file_list) def __getitem__(self, index): ''' 前処理をした画像のTensor形式のデータとラベルを取得 ''' # index番目の画像をロード img_path = self.file_list[index] img = Image.open(img_path).convert('RGB') # [高さ][幅][色RGB] # 画像の前処理を実施 img_transformed = self.transform( img, self.phase) # torch.Size([3, 224, 224]) # 画像のラベルをファイル名から抜き出す label == 0 return img_transformed, label # 実行 test_dataset = CarCountDataset_test( file_list=test_list, transform=ImageTransform(size, mean, std), phase='val') # 動作確認 index = 0 print(test_dataset.__getitem__(index)[0].size()) print(test_dataset.__getitem__(index)[1])その後,Dataloaderを作成し,先に構築したモデルにて車の台数を推定します.
batch_size =10 test_dataloader = torch.utils.data.DataLoader( test_dataset, batch_size=batch_size, shuffle=False) dataiter = iter(test_dataloader) images, labels = dataiter.next() # サンプルを1つだけ取り出す plt.imshow(np.transpose(images[0], (1, 2, 0))) # チャンネルを一番後ろに plt.tick_params(labelbottom=False, labelleft=False, bottom=False, left=False) # ラベルとメモリを非表示に plt.show() net.eval() # 評価モード x, t = images.cuda(), labels.cuda() # GPU対応 print(x.shape) #x, t = images, labels # CPU対応 y = net(x) print("予測された車の数:", y[0].argmax().item()) # 2. 元の画像の表示 print('元の画像の表示') plt.imshow(img) plt.show()
推定結果は予測どおり車がないものでした.次に,分割したすべての画像に対してモデルによる台数の推定処理を行い,その分布(行例)を求めます.
# ミニバッチのサイズを指定 batch_size = 10 #対象画像のdataloaderを作成 test_dataloader = torch.utils.data.DataLoader( test_dataset, batch_size=batch_size, shuffle=False) classes = list(range(13)) class_correct = list(0. for i in range(13)) class_total = list(0. for i in range(13)) net.eval() # 評価モード test =[] i = 0 for data in test_dataloader: images, labels = data x, t = images.cuda(), labels.cuda() # GPU対応 #x, t = images, labels # CPU対応 y = net(x) for i in range(len(y)): result = y[i].argmax().item() #GPUのtensorをnpに変換するにはargmaxを用いる必要がある. test.append(result) print('分割された画像の数: ',len(test))分割した画像数を確認すると,5184とありました.
次に,このリストを元画像のグリッド数と同じ行列に変換します.test2 = np.array(test) cars_counted =test2.reshape(72, 72) cars_counted7200サイズの画像を,100x100サイズのグリッドで分割したため,72x72の行列となり,出力は以下となります.
array([[0, 0, 1, ..., 0, 0, 0], [0, 0, 0, ..., 0, 0, 0], [0, 0, 0, ..., 0, 0, 0], ..., [0, 0, 0, ..., 0, 0, 0], [0, 0, 0, ..., 0, 0, 0], [0, 0, 0, ..., 0, 0, 0]])次に,テスト画像に推定された車の台数の分布結果を重畳する処理を行います.
はじめに画像処理に必要なモジュールをインポートします.import seaborn as sns import pandas as pd import numpy as np import matplotlib as mpl import matplotlib.pyplot as plt import itertools %matplotlib inline次にテスト画像を読み込みます.
#検証画像をベース画像として準備. image_path = val_path + files[0] mosaic_image = io.imread(image_path)[:, :, :3]それでは,元画像に推定された車の分布地図を重畳します.ここでは,この記事のきっかけとなったDeep Learning で航空写真から自動車をカウントするのコードを使わせていただきました.感謝いたします.
詳細は以下をご参照ください.
COWC Car Counting
MIT Licensedef get_color_map(sns_palette): color_map = np.empty(shape=[0, 3], dtype=np.uint8) for color in sns_palette: r = int(color[0] * 255) g = int(color[1] * 255) b = int(color[2] * 255) rgb_byte = np.array([[r, g, b]], dtype=np.uint8) color_map = np.append(color_map, rgb_byte, axis=0) return color_map def overlay_heatmap( cars, background_image, car_max, grid_size, cmap, line_rgb=[0, 0, 0], line_thickness=2, alpha=0.5, min_car_to_show=1, background_rgb=[0, 0, 0]): yi_max, xi_max = cars.shape result = background_image.copy() heatmap = background_image.copy() sns_palette = sns.color_palette(cmap, n_colors=car_max + 1) color_map = get_color_map(sns_palette) for yi in range(yi_max): for xi in range(xi_max): top, left = yi * grid_size, xi * grid_size bottom, right = top + grid_size, left + grid_size cars_counted = cars[yi, xi] if cars_counted < min_car_to_show: if background_rgb is not None: heatmap[top:bottom, left:right] = np.array(background_rgb) else: heatmap[top:bottom, left:right] = color_map[cars_counted] if line_thickness > 0: cv2.rectangle(heatmap, (left, top), (right, bottom), line_rgb, thickness=line_thickness) cv2.addWeighted(heatmap, alpha, result, 1 - alpha, 0, result) return result処理画像をresultディレクトリに保存します.
if not os.path.exists('../data/result'): os.mkdir('../data/result')heatmap_overlayed = overlay_heatmap(cars_counted, mosaic_image, car_max, grid_size, cmap='viridis', line_thickness=-1) fig = plt.figure(figsize=(15, 15)) plt.imshow(heatmap_overlayed) plt.imsave('../data/result/heatmap_' + files[0], heatmap_overlayed)出力
これでは分かり難いですね.詳しくはgithubにアップしたコードにてご確認ください.次に,テスト画像に推定された車の台数も表示させます.こちらも,提供されているコードを利用させていただきました.
heatmap_overlayed_2 = overlay_heatmap(cars_counted, mosaic_image, car_max, grid_size, cmap='Reds') def plot_counts_on_heatmap_2(heatmap_overlayed, aoi_tblr, cars, grid_size, min_car_to_show=1, figsize=(15, 15)): top, bottom, left, right = aoi_tblr yi_min, xi_min = int(math.floor(top / grid_size)), int(math.floor(left / grid_size)) yi_max, xi_max = int(math.ceil(bottom / grid_size)), int(math.ceil(right / grid_size)) top, left, bottom, right = yi_min * grid_size, xi_min * grid_size, yi_max * grid_size, xi_max * grid_size fig = plt.figure(figsize=figsize) plt.imshow(heatmap_overlayed[top:bottom, left:right]) for (yi, xi) in itertools.product(range(yi_min, yi_max), range(xi_min, xi_max)): car_num = cars[yi, xi] if car_num < min_car_to_show: continue plt.text( (xi + 0.5) * grid_size - left, (yi + 0.5) * grid_size - top, format(car_num, 'd'), horizontalalignment="center", verticalalignment="center", color="black" ) plt.show() fig.savefig('../data/result/heatmap_carcount_' + files[0])top, bottom, left, right = 1000, 4500, 2000, 4500 heatmap_carcount = plot_counts_on_heatmap_2(heatmap_overlayed_2, (top, bottom, left, right), cars_counted, grid_size)
おおよそ合っているかな.車の処理場なのか,一部に車が集中して駐車されていました.
これで,航空写真のデータから,車の台数を推定するモデルの構築,テスト画像による検証,そして元画像への重畳処理が準備できました.
長くなりましたが,次が衛星画像に同様の処理を行い,車の台数地図を作成してみます.6. 人工衛星画像の車の台数分布を求める.
6.1 人工衛星画像のダウンロード.
デモンストレーションする衛星画像を入手します.
モデルの構築で用いたい航空写真の分解能が15cmであり,その分解能になるべく近い高分解能の光学観測画像を探しました.商業衛星として画像提供がされているのは米国のDigital Globe社のWorld Viewシリーズが候補になります.この衛星の観測画像の分解能は30cmです.
高分解能の光学観測画像はかなり高価なため容易に購入することはできません.そのため,今回は公開されているサンプルデータを用いて処理を行いました.
サンプル画像は以下のサイトの画像を用いています.WorldView-3 Satellite Sensor/Satellite image corporation
では,データのダウンロードを行います.
#衛星画像を格納するディレクトリの準備 if not os.path.exists('../data/test/demo'): os.mkdir('../data/test/demo') if not os.path.exists('../data/test/demo/image'): os.mkdir('../data/test/demo/image')#衛星画像のダウンロード(ブラジル リオデジャネイロ) !wget -P ../data/test/demo https://content.satimagingcorp.com/static/galleryimages/Satellite-Image-2016-Olympics-Rio-De-Janeiro.jpgでは,取得した衛星画像を確認し前処理を行います.
6.2 人工衛星画像のデータ処理.
画像の閲覧およびサイズを確認します.
#ファイルのパスを取得する. test_path = '../data/test/demo/' files =os.listdir(test_path) #ファイル名の取得 print(files[1]) #opencvで画像のよみこみ im = cv2.imread(test_path + files[1]) im_rgb = cv2.cvtColor(im, cv2.COLOR_BGR2RGB) #Image.fromarray(im_rgb).save('test.jpg') plt.imshow(im_rgb) #画像サイズの確認 v_size = im_rgb.shape[0] h_size = im_rgb.shape[1] print('v_size:', v_size) print('h_size:', h_size)
この画像は,2016年のリオデジャネイロオリンピック時の撮像画像になります.オリンピクックの競技場が確認できますね.近くの駅の周辺に多数の車が駐車されていることも確認できました.
次にこの画像を分割し,航空写真を学習した構築したモデルで車の台数を推定します.
分割する画像のグリッドサイズは,航空写真の半分の分解能となるため,スケールを合わせる意味で50ピクセルとしました.#分割する画像サイズを50ピクセルとする. vn = v_size //50 #100pixleに分割 hn = h_size // 50 #グリッドサイズの整数倍になるように画像をリサイズする. img = Image.open(test_path + files[1]) img_size_v = vn * 50 img_size_h = hn * 50 #画像のリサイズ処理 img_resize=img.resize((img_size_h,img_size_v)) plt.imshow(img_resize)では,画像の分割処理,およびいつものDataset,Dataloaderを作成します.
#デモ画像を基準のグリッドサイズで分割する. width = 50 height = 50 DIR_OUTPUTS = '../data/test/demo/image/' #画像の分割処理関数 def ImgSplit(im): # 読み込んだ画像を100*100ピクセルのサイズに分割する.のサイズで72*72枚に分割する buff = [] # 縦の分割枚数 for h1 in range(int(vn)): # 横の分割枚数 for w1 in range(int(hn)): w2 = w1 * height h2 = h1 * width #print(w2, h2, width + w2, height + h2) c = im.crop((w2, h2, width + w2, height + h2)) buff.append(c) return buff #画像の分割処理の実行 hi=0 for ig in ImgSplit(img_resize): hi=hi+1 #print(hi) # 保存先フォルダの指定 ig.save(DIR_OUTPUTS+str(hi)+".png")#test_listの作成 def make_datapath_list_test(phase="test"): rootpath = "../data/test/demo/image" target_path = osp.join(rootpath +'/*.png') print(target_path) path_list = [] # ここに格納する # globを利用してサブディレクトリまでファイルパスを取得する for path in glob.glob(target_path): path_list.append(path) return path_list # 実行 test_list = make_datapath_list_test(phase="test")# test画像の前処理をするクラス # resize, normalize and totnesorを行う. class ImageTransform_test(): def __init__(self, resize, mean, std): self.data_transform = { 'test': transforms.Compose([ transforms.Resize(resize), # リサイズ #transforms.CenterCrop(resize), # 画像中央をresize×resizeで切り取り transforms.ToTensor(), # テンソルに変換 transforms.Normalize(mean, std) # 標準化 ]) } def __call__(self, img, phase='test'): """ Parameters ---------- phase : 'train' or 'val' 前処理のモードを指定。 """ return self.data_transform[phase](img)航空写真と同様にnatsortでファイルの順番を行列の順序にあわせてソートします.
#natsoatを用いてファイルの順番をソートする from natsort import natsorted test_list = natsorted(test_list)分割した画像を読み込んでみます.
# 訓練時の画像前処理の動作を確認 # 実行するたびに処理結果の画像が変わる # 1. 画像読み込み image_file_path = test_list[0] img = Image.open(image_file_path).convert('RGB') # [高さ][幅][色RGB] # 2. 元の画像の表示 plt.imshow(img) plt.show() # 3. 画像の前処理と処理済み画像の表示 size = 96 mean = (0.485, 0.456, 0.406) std = (0.229, 0.224, 0.225) transform = ImageTransform(size, mean, std) img_transformed = transform(img, phase="val") # torch.Size([3, 224, 224]) # (色、高さ、幅)を (高さ、幅、色)に変換し、0-1に値を制限して表示 print(img_transformed.shape)
この分割された画像は衛星画像の左上の画像で,どうみても山道で車はみあたらないですね.
では,この画像の構築したモデルで車の台数を推定してみます.
Dataset, Dataloaderを作成します.# test画像のDatasetを作成する class CarCountDataset_test(torch.utils.data.Dataset): def __init__(self, file_list, transform=None, phase='train'): self.file_list = file_list # ファイルパスのリスト self.transform = transform # 前処理クラスのインスタンス self.phase = phase # train or valの指定 def __len__(self): '''画像の枚数を返す''' return len(self.file_list) def __getitem__(self, index): ''' 前処理をした画像のTensor形式のデータとラベルを取得 ''' # index番目の画像をロード img_path = self.file_list[index] img = Image.open(img_path).convert('RGB') # [高さ][幅][色RGB] # 画像の前処理を実施 img_transformed = self.transform( img, self.phase) # torch.Size([3, 224, 224]) # 画像のラベルをファイル名から抜き出す label == 0 return img_transformed, label # 実行 test_dataset = CarCountDataset_test( file_list=test_list, transform=ImageTransform(size, mean, std), phase='val') # 動作確認 index = 0 print(test_dataset.__getitem__(index)[0].size()) print(test_dataset.__getitem__(index)[1])batch_size =10 test_dataloader = torch.utils.data.DataLoader( test_dataset, batch_size=batch_size, shuffle=False) dataiter = iter(test_dataloader) images, labels = dataiter.next() # サンプルを1つだけ取り出す plt.imshow(np.transpose(images[0], (1, 2, 0))) # チャンネルを一番後ろに plt.tick_params(labelbottom=False, labelleft=False, bottom=False, left=False) # ラベルとメモリを非表示に plt.show() net.eval() # 評価モード x, t = images.cuda(), labels.cuda() # GPU対応 print(x.shape) #x, t = images, labels # CPU対応 y = net(x) print("予測された車の数:", y[0].argmax().item()) # 2. 元の画像の表示 print('元の画像の表示') plt.imshow(img) plt.show()
モデルによる推定結果は,0台,となりました.予測通りですね.
推定処理のための画像データの準備が終わりましたので,全画像に対する推定処理,および人工衛星画像への重畳処理を航空写真と同様に行います.6.3 人工衛星画像の車の台数分布の作成.
分割した衛星画像を航空写真より構築したモデルにて推定処理を行います.
# ミニバッチのサイズを指定 batch_size = 10 #対象画像のdataloaderを作成 test_dataloader = torch.utils.data.DataLoader( test_dataset, batch_size=batch_size, shuffle=False) classes = list(range(13)) class_correct = list(0. for i in range(13)) class_total = list(0. for i in range(13)) net.eval() # 評価モード test =[] i = 0 for data in test_dataloader: images, labels = data x, t = images.cuda(), labels.cuda() # GPU対応 #x, t = images, labels # CPU対応 #outputs = net(x) #_, predicted = torch.max(outputs, 1) #print('predicted:', predicted) y = net(x) for i in range(len(y)): result = y[i].argmax().item() #GPUのtensorをnpに変換するにはargmaxを用いる必要がある. test.append(result) print('分割された画像数: ', len(test))分割した画像数は11832でした.では,この推定結果を衛星画像に重畳するための行列に変換します.
test2 = np.array(test) cars_counted =test2.reshape(int(vn), int(hn))次に,衛星画像を読み込みます.
file_path = test_path + files[1] mosaic_image = io.imread(file_path)[:, :, :3] mosaic_image=cv2.resize(mosaic_image, (img_size_h,img_size_v)) print(mosaic_image.shape)そして,航空写真と同様にこちらのコードCOWC Car Countingを利用させていただき,衛星画像への重畳処理(台数が多い地域をフォーカスしたヒートマップ)を行います.
heatmap_overlayed = overlay_heatmap(cars_counted, mosaic_image, car_max, grid_size, cmap='viridis', line_thickness=-1) fig = plt.figure(figsize=(15, 15)) plt.imshow(heatmap_overlayed) plt.imsave('../data/result/heatmap_' + files[1], heatmap_overlayed)
Copyright©2016DigitalGlobe.オリンピックの競技場の左上の駅周辺に車が多く駐車されているのがわかります.
この画像では分かり難いと思いますので,ぜひご自身でコードを実行するか,Githubのサンプル画像をご確認ください.次に,航空写真と同じく車の台数を表示させます.
heatmap_overlayed_2 = overlay_heatmap(cars_counted, mosaic_image, car_max, grid_size, cmap='Reds') def plot_counts_on_heatmap_2(heatmap_overlayed, aoi_tblr, cars, grid_size, min_car_to_show=1, figsize=(100, 100)): top, bottom, left, right = aoi_tblr yi_min, xi_min = int(math.floor(top / grid_size)), int(math.floor(left / grid_size)) yi_max, xi_max = int(math.ceil(bottom / grid_size)), int(math.ceil(right / grid_size)) top, left, bottom, right = yi_min * grid_size, xi_min * grid_size, yi_max * grid_size, xi_max * grid_size fig = plt.figure(figsize=figsize) plt.imshow(heatmap_overlayed[top:bottom, left:right]) for (yi, xi) in itertools.product(range(yi_min, yi_max), range(xi_min, xi_max)): car_num = cars[yi, xi] if car_num < min_car_to_show: continue plt.text( (xi + 0.5) * grid_size - left, (yi + 0.5) * grid_size - top, format(car_num, 'd'), horizontalalignment="center", verticalalignment="center", color="black", size=25 ) plt.show() fig.savefig('../data/result/heatmap_carcount_' + files[1]) top, bottom, left, right = 0, 1550,2000, 4000 heatmap_carcount = plot_counts_on_heatmap_2(heatmap_overlayed_2, (top, bottom, left, right), cars_counted, grid_size)
Copyright©2016DigitalGlobe.車の台数の表示数が小さくて見づらいです.フォントサイズは上記のコードのSizeを変更すれば変えられますので,試してみて下さい.こちらもgithubにサンプル画像をアップしていますので,そちらでもご確認ください.
7. まとめ
こちらの記事を参考に,PyTorchによる航空写真を用いた車の台数の推定モデルの構築,および構築したモデルを用いた衛星画像の車の台数分布地図を作成しました.
衛星画像を対象とするのであれば,学習画像も同じ性能(分解能)の画像のほうがより精度の高い結果が得られると思います.手間はかかりますが,分割した画像に写った車の台数を見て確認し,それを区分けして学習用データを作ってもいいですね.
衛星画像の利用方法としてよく紹介されている写っている車の台数を推定する方法の一例を紹介いたしました.実際に提供されているサービスは,より高精度のモデルで構築されていると思います.ここで紹介したモデルは一つの例であり,学習画像をより汎用性の高いものにするために種類を増やしたり,Augmentationの方法を工夫したり,モデルを変更したりなど,色々試してみると面白いかもしれません.
また,ここでは車の台数を対象としましたが,今回のように物体検知ではなく画像分類の方法であれば,車以外の対象物にも同じ方法が適用できますので,試してみるのもよいですね.本文にも記述しましたが,車の台数の絶対値を求めるのではなく,異なる時期の複数の画像をもちいて,時系列的な変化を求めてみるのがおもしろいかと思います.ある地域を対象として,年間でどのように分布がかわるのか,時期に依存するのか,年レベルでの長期間の傾向は,などのトレンドが把握できるかと思います.
最後になりますが,この実験および記事のきっかけとなったDeep Learning で航空写真から自動車をカウントするにあらためて感謝いたします.
こちらの記事がみなさんの活動のご参考になれば幸いです.間違いやコメントなどありましたら,いただければ幸いです.参考記事
Deep Learning で航空写真から自動車をカウントする
Pytorchによる航空画像の建物セグメンテーションの作成方法.
書籍「つくりながら学ぶ! PyTorchによる発展ディープラーニング」(小川雄太郎、マイナビ出版 、19/07/29)
ディープ・ラーニングにおける物体検出
Cars Overhead With Context
WorldView-3 Satellite Sensor/Satellite image corporation




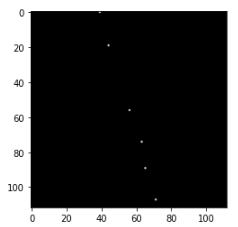


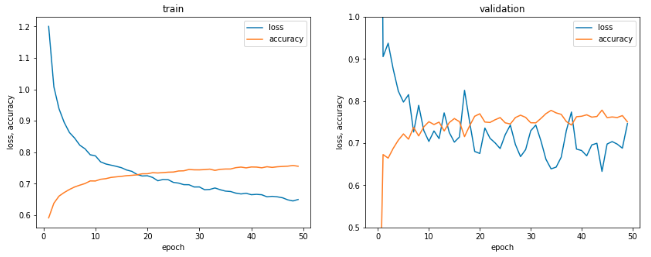

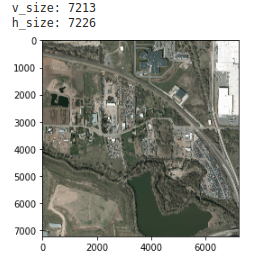




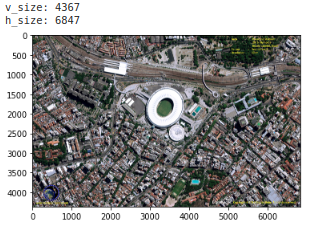


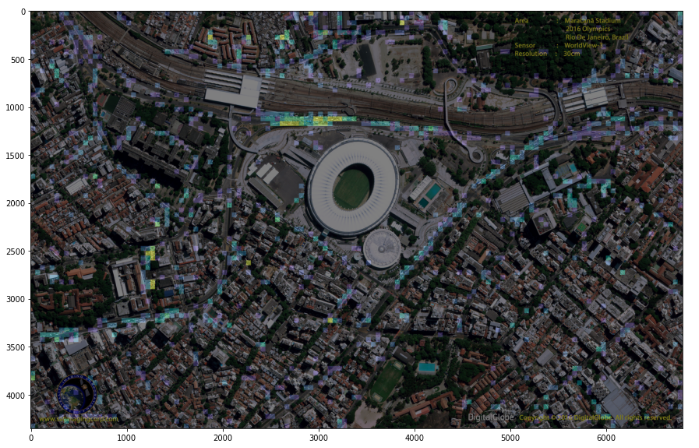

- 投稿日:2020-07-28T12:29:56+09:00
python フォルダを指定or作成してから、スクリーンショットを保存する。
結論
ディレクトリの生成は os.mkdir(path)
スクリーンショットの撮影は pyautogui.screenshot()
スクリーンショットの保存先は save("保存先")具体例
全コードimport os import pyautogui import time import datetime # 保存先path h_path = "フォルダを保存したい先をここに記入" #例えば、Macなら /Users/"username"/Downloads/ # スクショ回数(回) times = 3 # スクショ間隔(秒) span = 1 # 出力フォルダ頭文字 h_foldername = "統計分析" # 出力ファイル頭文字 h_filename = "資料" # 出力フォルダ作成(フォルダ名:頭文字_年月日時分) folder_name = h_foldername + "_" + str(datetime.datetime.now().strftime("%Y%m%d%H%M")) path = h_path + folder_name os.makedirs(path, exist_ok=True) for i in range(times): # 画像に名前を付ける filename = h_filename + '_{0:04d}.png'.format(i)+ "_" + str(datetime.datetime.now().strftime("%Y%m%d%H%M%S")) #スクリーンショットを撮る s = pyautogui.screenshot() # 保存 s.save(folder_name + '/' + filename) # スクショ間隔(秒) time.sleep(span)<補足>
画像ファイルをナンバリングする際に4桁表記にするため.format(number)を使いました。
{0:04d}'.format(number)
・ 0: 0で埋める
・04d: 4桁例(10→0010)number = 10 number_padded = '{0:04d}'.format(number) print(number_padded) # => '0010'<参考>
こちら大変勉強になりました。
【Python入門】ディレクトリを簡単に作成する|os.mkdir・os.makedirs
【Python】pyautoguiを使ってKindle書籍を自動でスクショするツールを作ってみた!
- 投稿日:2020-07-28T11:47:08+09:00
Macでopencv-python
ブログにあったちょっと前(2020/01/25)の記事を転載。
pythonで画像認識を思い、環境を構築しようとしたところ詰まったので構築メモ。
python環境はpipenvを使っています。opencvインストール
$ pipenv install opencv-python Installing opencv-python… Adding opencv-python to Pipfile's [packages]… ✔ Installation Succeeded Pipfile.lock not found, creating… Locking [dev-packages] dependencies… Locking [packages] dependencies… ✘ Locking Failed! ...(中略) [pipenv.exceptions.ResolutionFailure]: pipenv.exceptions.ResolutionFailure: ERROR: ERROR: Could not find a version that matches opencv-python [pipenv.exceptions.ResolutionFailure]: No versions found [pipenv.exceptions.ResolutionFailure]: Warning: Your dependencies could not be resolved. You likely have a mismatch in your sub-dependencies. First try clearing your dependency cache with $ pipenv lock --clear, then try the original command again. Alternatively, you can use $ pipenv install --skip-lock to bypass this mechanism, then run $ pipenv graph to inspect the situation. Hint: try $ pipenv lock --pre if it is a pre-release dependency. ERROR: ERROR: Could not find a version that matches opencv-python No versions found Was https://pypi.org/simple reachable? ...(中略) [pipenv.exceptions.ResolutionFailure]: pipenv.exceptions.ResolutionFailure: ERROR: ERROR: Could not find a version that matches opencv-python [pipenv.exceptions.ResolutionFailure]: No versions found [pipenv.exceptions.ResolutionFailure]: Warning: Your dependencies could not be resolved. You likely have a mismatch in your sub-dependencies. First try clearing your dependency cache with $ pipenv lock --clear, then try the original command again. Alternatively, you can use $ pipenv install --skip-lock to bypass this mechanism, then run $ pipenv graph to inspect the situation. Hint: try $ pipenv lock --pre if it is a pre-release dependency. ERROR: ERROR: Could not find a version that matches opencv-python No versions found Was https://pypi.org/simple reachable?大量のエラー。
メッセージに従って$ pipenv lock --clearも無意味。
別の案内に従って
$ pipenv install --skip-lock opencv-python Installing opencv-python… Adding opencv-python to Pipfile's [packages]… ✔ Installation Succeeded Installing dependencies from Pipfile… An error occurred while installing opencv-python! Will try again. ? ▉▉▉▉▉▉▉▉▉▉▉▉▉▉▉▉▉▉▉▉▉▉▉▉▉▉▉▉▉▉▉▉ 1/1 — 00:00:08 Installing initially failed dependencies… ...(中略) [pipenv.exceptions.InstallError]: ['Could not fetch URL https://pypi.org/simple/opencv-python/: There was a problem confirming the ssl certificate: HTTPSConnectionPool(host=\'pypi.org\', port=443): Max retries exceeded with url: /simple/opencv-python/ (Caused by SSLError("Can\'t connect to HTTPS URL because the SSL module is not available.")) - skipping'] ...(略)
"Can\'t connect to HTTPS URL because the SSL module is not available."
なるほどー。
ナニコレ。(参考)pip install でSSL関連のエラーが出たらこれを読め!!!
pythonを最新にしたらいいらしい。
今インストールされているのは3.7.1。
現在(2020/01/25)の最新版は3.8.1なので、入れ直そう。$ rm -rf Pipenv* .venv $ pipenv --python 3.8.1 $ pipenv shell $ pipenv install opencv-python Installing opencv-python… Adding opencv-python to Pipfile's [packages]… ✔ Installation Succeeded Pipfile.lock not found, creating… Locking [dev-packages] dependencies… Locking [packages] dependencies… ✔ Success! Updated Pipfile.lock (ee14b3)! Installing dependencies from Pipfile.lock (ee14b3)… ? ▉▉▉▉▉▉▉▉▉▉▉▉▉▉▉▉▉▉▉▉▉▉▉▉▉▉▉▉▉▉▉▉ 2/2 — 00:00:02できたわー。
- 投稿日:2020-07-28T11:46:56+09:00
【Flask+Keras】複数モデルを高速で推論させる方法
結論
テストコード
from flask import Flask import time import numpy as np import tensorflow as tf from keras.models import load_model from keras.preprocessing.image import img_to_array, load_img app = Flask(__name__) model_path1 = "mnist.h5" model1 = load_model(model_path1) label1 = ["l0", "l1", "l2", "l3", "l4", "l5", "l6", "l7", "l8", "l9"] model1._make_predict_function()#<めっちゃ重要>predictの高速化 graph1 = tf.get_default_graph() model_path2 = "mnist.h5" model2 = load_model(model_path2) label2 = ["l0", "l1", "l2", "l3", "l4", "l5", "l6", "l7", "l8", "l9"] model2._make_predict_function() graph2 = tf.get_default_graph() def model1_predict(img_path): img = img_to_array(load_img(img_path, target_size=(28, 28), grayscale=True)) img_nad = img_to_array(img) / 255 img_nad = img_nad[None, ...] global graph1 with graph1.as_default(): pred = model1.predict(img_nad, batch_size=1, verbose=0) score = np.max(pred) pred_label = label1[np.argmax(pred[0])] print("スコア:", score, "ラベル:", pred_label) def model2_predict(img_path): img = img_to_array(load_img(img_path, target_size=(28, 28), grayscale=True)) img_nad = img_to_array(img) / 255 img_nad = img_nad[None, ...] global graph2 with graph2.as_default(): pred = model2.predict(img_nad, batch_size=1, verbose=0) score = np.max(pred) pred_label = label2[np.argmax(pred[0])] print("スコア:", score, "ラベル:", pred_label) @app.route("/", methods=['GET', 'POST']) def webapp(): start1 = time.time() model1_predict("mnist_test.jpg") end1 = time.time()-start1 print("処理時間<model1>: ", end1, "秒") start2 = time.time() model2_predict("mnist_test.jpg") end2 = time.time() - start2 print("処理時間<model2>: ", end2, "秒") output = "<p>model1:"+str(round(end1, 3))+"秒</p><br><p>model2:"+str(round(end2, 3))+"秒</p>" return output if __name__ == "__main__": app.run(port=5000, debug=False)重要な部分
model1 = load_model(model_path1) model1._make_predict_function()#<めっちゃ重要>predictの高速化 graph1 = tf.get_default_graph() def model1_predict(): global graph1 with graph1.as_default(): pred = model1.predict(***, batch_size=1, verbose=0)
- 投稿日:2020-07-28T11:46:56+09:00
【Flask+Keras】サーバーで複数モデルを高速で推論させる方法
結論
keras==2.2.4
tensorflow=1.14.0
numpy==1.16.4テストコード
from flask import Flask import time import numpy as np import tensorflow as tf from keras.models import load_model from keras.preprocessing.image import img_to_array, load_img app = Flask(__name__) model_path1 = "mnist.h5" model1 = load_model(model_path1) label1 = ["l0", "l1", "l2", "l3", "l4", "l5", "l6", "l7", "l8", "l9"] model1._make_predict_function()#<めっちゃ重要>predictの高速化 graph1 = tf.get_default_graph() model_path2 = "mnist.h5" model2 = load_model(model_path2) label2 = ["l0", "l1", "l2", "l3", "l4", "l5", "l6", "l7", "l8", "l9"] model2._make_predict_function() graph2 = tf.get_default_graph() def model1_predict(img_path): img = img_to_array(load_img(img_path, target_size=(28, 28), grayscale=True)) img_nad = img_to_array(img) / 255 img_nad = img_nad[None, ...] global graph1 with graph1.as_default(): pred = model1.predict(img_nad, batch_size=1, verbose=0) score = np.max(pred) pred_label = label1[np.argmax(pred[0])] print("スコア:", score, "ラベル:", pred_label) def model2_predict(img_path): img = img_to_array(load_img(img_path, target_size=(28, 28), grayscale=True)) img_nad = img_to_array(img) / 255 img_nad = img_nad[None, ...] global graph2 with graph2.as_default(): pred = model2.predict(img_nad, batch_size=1, verbose=0) score = np.max(pred) pred_label = label2[np.argmax(pred[0])] print("スコア:", score, "ラベル:", pred_label) @app.route("/", methods=['GET', 'POST']) def webapp(): start1 = time.time() model1_predict("mnist_test.jpg") end1 = time.time()-start1 print("処理時間<model1>: ", end1, "秒") start2 = time.time() model2_predict("mnist_test.jpg") end2 = time.time() - start2 print("処理時間<model2>: ", end2, "秒") output = "<p>model1:"+str(round(end1, 3))+"秒</p><br><p>model2:"+str(round(end2, 3))+"秒</p>" return output if __name__ == "__main__": app.run(port=5000, debug=False)重要な部分
model1 = load_model(model_path1) model1._make_predict_function()#<めっちゃ重要>predictの高速化 graph1 = tf.get_default_graph() def model1_predict(): global graph1 with graph1.as_default(): pred = model1.predict(***, batch_size=1, verbose=0)
- 投稿日:2020-07-28T11:46:39+09:00
FastAPI 利用方法 ①Tutorial - User Guide
書いてあること
- FastAPIを利用した際のメモ(個人用メモのため間違っている可能性あり・・・)
- 公式サイトのドキュメント(Tutorial - User Guide)に習って実装
参考
環境
Docker環境を構築して動作確認
起動
bash# main.pyがルートディレクトリにある場合 $ uvicorn main:app --reload --host 0.0.0.0 --port 8000 # main.pyがルートディレクトリにない場合 $ uvicorn app.main:app --reload --host 0.0.0.0 --port 8000First Step
Interactive API Docs
Alternative API docs
ドキュメント自動生成前のOpenAPIを確認
単純なFastAPI機能
python.main.pyfrom fastapi import FastAPI # ① app = FastAPI() # ② @app.get("/") # ③ def read_root(): # ④ return {"message": "Hello World"} # ⑤①必要なパッケージをインポート
②FastAPIインスタンスを生成
③Path Operation Decoratorで操作、パスを指定
操作(メソッド) 説明 POST 追加 GET 取得 PUT 更新 DELETE 削除 ④Path Operation Functionでリクエスト受信の際に呼び出される関数を指定
⑤コンテンツ(JSON)を返却
Path Parameters
Basic
■
main.py@app.get("/items/{item_id}") async def get_item(item_id): return { "item_id": item_id }■Request
■Response
{ "item_id": "1" }型宣言・バリデーション
指定した型ではないパラメータが渡されると、自動でエラーを返す
■Source
main.py@app.get("/items/{item_id}") async def get_item(item_id: int): return { "item_id": item_id }■Request
■Response
{ "item_id": 1 }■Request
http://localhost:8000/items/test
■Response
{ detail: [ { loc: [ "path", "item_id" ], msg: "value is not a valid integer", type: "type_error.integer" } ] }Path Operation Decoratorの順序
他のパスパラメータよりも優先したいURLがあった場合、順序に注意。
/users/meを後に書いてしまうと、パスパラメータが優先されてしまう。■Source
main.py@app.get("/users/me") async def read_user_me(): return {"user_id": "the current user"} @app.get("/users/{user_id}") async def read_user(user_id: str): return {"user_id": user_id}■Request
http://localhost:8000/users/me
■Response
{ user_id: "the current user" }■Request
http://localhost:8000/users/user
■Response
{ user_id: "user" }パスパラメータの事前定義
Enumを利用することで有効なパスパラメータを事前定義することが可能。
■Source
main.pyfrom fastapi import FastAPI from enum import Enum app = FastAPI() class ModelName(str, Enum): alexnet = "alexnet" resnet = "resnet" lenet = "lenet" @app.get("/model/{model_name}") async def get_model(model_name: ModelName): if model_name == ModelName.alexnet: return {"model_name": model_name, "message": "Deep Learning FTW!"} if model_name.value == "lenet": return {"model_name": model_name, "message": "LeCNN all the images"} return {"model_name": model_name, "message": "Have some residuals"}```■Request
http://localhost:8000/model/alexnet
■Response
{ "model_name": "alexnet", "message": "Deep Learning FTW!" }http://localhost:8000/model/test
{ detail: [ { loc: [ "path", "model_name" ], msg: "value is not a valid enumeration member; permitted: 'alexnet', 'resnet', 'lenet'", type: "type_error.enum", ctx: { enum_values: [ "alexnet", "resnet", "lenet" ] } } ] }パスを含むパスパラメータ
パスパラメータに
pathを記載することで、パスを受け取ることが可能。■Source
main.py@app.get("/files/{file_path:path}") async def read_file(file_path: str): return {"file_path": file_path}■Request
http://localhost:8000/files/home/johndoe/myfile.txt
■Response
main.py{ "file_path": "/files/home/johndoe/myfile.txt" }Query Parameters
パスパラメータではないパラメータが渡された場合、自動的にクエリパラメータと判断される。
初期値
■Source
main.pyfrom fastapi import FastAPI app = FastAPI() fake_item_db = [ {"name": "name1"}, {"name": "name2"}, {"name": "name3"}, {"name": "name4"}, {"name": "name5"}, {"name": "name6"}, {"name": "name7"}, {"name": "name8"}, {"name": "name9"}, {"name": "name10"} ] @app.get("/items") async def read_item(skip: int = 0, limit: int = 3): return fake_item_db[skip : skip + limit]■Request
■Response
[ { name: "name1" }, { name: "name2" }, { name: "name3" } ]■Request
http://localhost:8000/items?skip=3
■Response
[ { name: "name4" }, { name: "name5" }, { name: "name6" } ]■Request
http://localhost:8000/items?limit=5
■Response
[ { name: "name1" }, { name: "name2" }, { name: "name3" }, { name: "name4" }, { name: "name5" } ]■Request
http://localhost:8000/items?skip=3&limit=4
■Response
[ { name: "name4" }, { name: "name5" }, { name: "name6" }, { name: "name7" } ]オプション
■Source
main.pyfrom typing import Optional from fastapi import FastAPI app = FastAPI() @app.get("/items/{item_id}") async def read_item(item_id: str, q: Optional[str] = None): if q: return {"item_id": item_id, "q": q} return {"item_id": item_id}■Request
http://localhost:8000/items/test
■Response
{ "item_id": "test" }■Request
http://localhost:8000/items/test?q=aaa
■Response
{ "item_id": "test", "q": "aaa" }型宣言
boolean型では
1、True、on、yesという指定もtrueと判断される。Source
main.py@app.get("/items/{item_id}") async def read_item(item_id: str, q: Optional[str] = None, short: bool = False): item = {"item_id": item_id} if q: item.update({"q": q}) if not short: item.update( {"description": "This is an amazing item that has a long description"} ) return item■Request
http://localhost:8000/items/test
■Response
{ "item_id": "test", "description": "This is an amazing item that has a long description" }■Request
http://localhost:8000/items/test?short=true
■Response
{ "item_id": "test" }複数のパスとクエリパラメータ
■Source
main.py@app.get("/users/{user_id}/items/{item_id}") async def read_item(user_id: int, item_id: str, q: Optional[str] = None, short: bool = False): item = {"item_id": item_id, "owner_id": user_id} if q: item.update({"q": q}) if not short: item.update( {"description": "This is an amazing item that has a long description"} ) return item■Request
http://localhost:8000/users/1/items/test
■Response
{ "item_id": "test", "owner_id": 1, "description": "This is an amazing item that has a long description" }必須のクエリパラメータ
■Source
main.py@app.get("/items/{item_id}") async def read_item(item_id: str, needy: str): item = {"item_id": item_id, "needy": needy} return item■Request
http://localhost:8000/items/1?needy=test
■Response
{ "item_id": "1", "needy": "test" }■Request
■Response
{ detail: [ { loc: [ "query", "needy" ], msg: "field required", type: "value_error.missing" } ] }Request Body
データモデルによるリクエストボディ生成
■Source
main.pyfrom fastapi import FastAPI from typing import Optional from pydantic import BaseModel class Item(BaseModel): name: str description: Optional[str] = None price: float tax: Optional[float] = None app = FastAPI() @app.post("/items") async def create_item(item: Item): item_dict = item.dict() if item.tax: price_with_tax = item.price + item.tax item_dict.update({"price_with_tax": price_with_tax}) return item_dict■Request
{ "name": "test", "price": 1000 }■Response
{ "name": "test", "description": null, "price": 1000, "tax": null }■Request
{ "name": "test", "description": "test test test", "price": 1000, "tax": 100 }■Response
{ "name": "test", "description": "test test test", "price": 1000, "tax": 100, "price_with_tax": 1100 }リクエスト本文+パスパラメータ
■Source
main.py@app.put("/items/{item_id}") async def create_item(item_id: int, item: Item): return {"item_id": item_id, **item.dict()}■Request
{ "name": "test", "description": "test test test", "price": 1000, "tax": 100 }■Response
{ "item_id": 1, "name": "test", "description": "test test test", "price": 1000, "tax": 100 }リクエスト本文+パスパラメータ+クエリパラメータ
■Source
main.py@app.put("/items/{item_id}") async def create_item(item_id: int, item: Item, q: Optional[str] = None): result = {"item_id": item_id, **item.dict()} if q: result.update({"q": q}) return result■Request
http://localhost:8000/items/1?q=test
{ "name": "test", "description": "test test test", "price": 1000, "tax": 100 }■Response
{ "item_id": 1, "name": "test", "description": "test test test", "price": 1000, "tax": 100, "q": "test" }Query Parameters and String Validations
クエリパラメータに検証やメタデータを設定することが可能。
検証・オプションパラメータ
■Source
main.pyfrom fastapi import FastAPI, Query from typing import Optional app = FastAPI() @app.get("/items/") async def read_items(q: Optional[str] = Query(None, min_length=5, max_length=20)): results = {"items": [{"item_id": "Foo"}, {"item_id": "Bar"}]} if q: results.update({"q": q}) return results■Request
http://localhost:8000/items/?q=0123456789
■Response
{ "items": [ { "item_id": "Foo" }, { "item_id": "Bar" } ], "q": "0123456789" }■Request
http://localhost:8000/items/?q=012345678901234567890
■Response
{ detail: [ { loc: [ "query", "q" ], msg: "ensure this value has at most 20 characters", type: "value_error.any_str.max_length", ctx: { limit_value: 20 } } ] }検証・必須パラメータ
■Source
main.py@app.get("/items/") async def read_items(q: str = Query(..., min_length=5, max_length=20)): results = {"items": [{"item_id": "Foo"}, {"item_id": "Bar"}]} results.update({"q": q}) return results■Request
http://localhost:8000/items/?q=12345
■Response
{ "items": [ { "item_id": "Foo" }, { "item_id": "Bar" } ], "q": "12345" }検証・正規表現
■Source
main.py@app.get("/items/") async def read_items(q: Optional[str] = Query(None, min_length=5, max_length=20, regex="^test")): results = {"items": [{"item_id": "Foo"}, {"item_id": "Bar"}]} if q: results.update({"q": q}) return results■Request
http://localhost:8000/items/?q=test12
■Response
{ "items": [ { "item_id": "Foo" }, { "item_id": "Bar" } ], "q": "test12" }■Request
http://localhost:8000/items/?q=tes12
■Response
{ detail: [ { loc: [ "query", "q" ], msg: "string does not match regex "^test"", type: "value_error.str.regex", ctx: { pattern: "^test" } } ] }リストのクエリパラメータ(デフォルトなし)
■Source
main.pyfrom fastapi import FastAPI, Query from typing import List, Optional app = FastAPI() @app.get("/items/") async def read_items(q: Optional[List[str]] = Query(None)): query_items = {"q": q} return query_items■Request
http://localhost:8000/items/?q=123&q=456&q=test
■Response
{ "q": [ "123", "456", "test" ] }リストのクエリパラメータ(デフォルトあり)
■Source
main.pyfrom fastapi import FastAPI, Query from typing import List, Optional app = FastAPI() @app.get("/items/") async def read_items(q: Optional[List[str]] = Query(["foo", "bar"])): query_items = {"q": q} return query_items■Request
■Response
{ "q": [ "foo", "bar" ] }メタデータの設定
設定したメタデータは自動でOpenAPIドキュメントへ反映される。
deprecatedをりようすることで非推奨であることを明示できる。
aliasを利用することでパスパラメータで受け取る際と、関数内の変数名を別にすることができる。■Source
main.py@app.get("/items/") async def read_items(q: Optional[str] = Query( None, min_length=5, max_length=20, title="metadata_title", description="metadata_description", deprecated=True, alias="alias_q" )): results = {"items": [{"item_id": "Foo"}, {"item_id": "Bar"}]} if q: results.update({"q": q}) return results
Path Parameters and Numeric Validations
メタデータの設定
パスパラメータでも同様にメタデータを設定することが可能。
■Source
main.pyfrom typing import Optional from fastapi import FastAPI, Path, Query app = FastAPI() @app.get("/items/{item_id}") async def read_items( item_id: int = Path( ..., title="metadata_title", description="metadata_description" ), q: Optional[str] = Query( None, min_length=5, max_length=20, title="metadata_title", description="metadata_description", deprecated=True, alias="alias_q" )): results = {"item_id": item_id} if q: results.update({"q": q}) return results■Request
■Response
{ "item_id": 1 }数値バリデーション
■Source
比較演算子 説明 ge 以上 gt 大きい le 以下 lt 小さい main.py@app.get("/items/{item_id}") async def read_items(*, item_id: int = Path(..., ge=1), q: str): results = {"item_id": item_id} if q: results.update({"q": q}) return results■Request
http://localhost:8000/items/1?q=test
■Response
{ "item_id": 1, "q": "test" }Body - Multiple Parameters
パスパラメータ、クエリパラメータ、リクエストボディの組み合わせ
■Source
main.pyfrom typing import Optional from fastapi import FastAPI, Path from pydantic import BaseModel app = FastAPI() class Item(BaseModel): name: str description: Optional[str] = None price: float tax: Optional[float] = None @app.put("/items/{item_id}") async def update_item( *, item_id: int = Path(..., title="The ID of the item to get", ge=0, le=1000), q: Optional[str] = None, item: Optional[Item] = None, ): results = {"item_id": item_id} if q: results.update({"q": q}) if item: results.update({"item": item}) return results■Request
{ "name": "string", "description": "string", "price": 0, "tax": 0 }■Response
{ "item_id": 1, "item": { "name": "string", "description": "string", "price": 0, "tax": 0 } }複数のリクエストボディ
■Source
main.pyfrom typing import Optional from fastapi import FastAPI from pydantic import BaseModel app = FastAPI() class Item(BaseModel): name: str description: Optional[str] = None price: float tax: Optional[float] = None class User(BaseModel): username: str full_name: Optional[str] = None @app.put("/items/{item_id}") async def update_item(item_id: int, item: Item, user: User): results = {"item_id": item_id, "item": item, "user": user} return results■Request
{ "item": { "name": "string", "description": "string", "price": 0, "tax": 0 }, "user": { "username": "string", "full_name": "string" } }■Response
{ "item_id": 1, "item": { "name": "string", "description": "string", "price": 0, "tax": 0 }, "user": { "username": "string", "full_name": "string" } }リクエストボディの明示指定
パスパラメータではないパラメータを関数で指定すると、FastAPIはクエリパラメータと見なす。
クエリパラメータではなく、リクエストボディとしたい場合は明示的に= Body(...)を記載する。■Source
main.pyfrom typing import Optional from fastapi import Body, FastAPI from pydantic import BaseModel app = FastAPI() class Item(BaseModel): name: str description: Optional[str] = None price: float tax: Optional[float] = None class User(BaseModel): username: str full_name: Optional[str] = None @app.put("/items/{item_id}") async def update_item( item_id: int, item: Item, user: User, importance: int = Body(...) ): results = {"item_id": item_id, "item": item, "user": user, "importance": importance} return results■Request
{ "item": { "name": "string", "description": "string", "price": 0, "tax": 0 }, "user": { "username": "string", "full_name": "string" }, "importance": 0 }■Response
{ "item_id": 1, "item": { "name": "string", "description": "string", "price": 0, "tax": 0 }, "user": { "username": "string", "full_name": "string" }, "importance": 0 }複数のリクエストボディとクエリパラメータ
明示的なリクエストボディに加えて、クエリパラメータも指定可能。
■Source
main.pyfrom typing import Optional from fastapi import Body, FastAPI from pydantic import BaseModel app = FastAPI() class Item(BaseModel): name: str description: Optional[str] = None price: float tax: Optional[float] = None class User(BaseModel): username: str full_name: Optional[str] = None @app.put("/items/{item_id}") async def update_item( *, item_id: int, item: Item, user: User, importance: int = Body(..., gt=0), q: Optional[str] = None ): results = {"item_id": item_id, "item": item, "user": user, "importance": importance} if q: results.update({"q": q}) return results■Request
{ "item": { "name": "string", "description": "string", "price": 0, "tax": 0 }, "user": { "username": "string", "full_name": "string" }, "importance": 1 }■Response
{ "item_id": 1, "item": { "name": "string", "description": "string", "price": 0, "tax": 0 }, "user": { "username": "string", "full_name": "string" }, "importance": 1 }Body - Fields
リクエストボディの各フィールドにメタタグを設定
スキーマにメタタグを設定することでOpenAPIへ自動反映される。
■Source
main.pyfrom typing import Optional from fastapi import Body, FastAPI from pydantic import BaseModel, Field app = FastAPI() class Item(BaseModel): name: str description: Optional[str] = Field( None, title="The description of the item", max_length=300 ) price: float = Field( ..., gt=0, description="The price must be greater than zero" ) tax: Optional[float] = None @app.put("/items/{item_id}") async def update_item(item_id: int, item: Item = Body(..., embed=True)): results = {"item_id": item_id, "item": item} return results
Body - Nested Models
リクエストボディのフィールドにリストを設定
■Source
main.pyfrom typing import List, Optional from fastapi import FastAPI from pydantic import BaseModel app = FastAPI() class Item(BaseModel): name: str description: Optional[str] = None price: float tax: Optional[float] = None tags: List[str] = [] @app.put("/items/{item_id}") async def update_item(item_id: int, item: Item): results = {"item_id": item_id, "item": item} return results■Request
{ "name": "string", "description": "string", "price": 0, "tax": 0, "tags": [ "foo", "bar" ] }■Response
{ "item_id": 1, "item": { "name": "string", "description": "string", "price": 0, "tax": 0, "tags": [ "foo", "bar" ] } }ネストされたモデル
■Source
main.pyfrom typing import Optional, Set from fastapi import FastAPI from pydantic import BaseModel app = FastAPI() class Image(BaseModel): url: str name: str class Item(BaseModel): name: str description: Optional[str] = None price: float tax: Optional[float] = None tags: Set[str] = [] image: Optional[Image] = None @app.put("/items/{item_id}") async def update_item(item_id: int, item: Item): results = {"item_id": item_id, "item": item} return results■Request
{ "name": "string", "description": "string", "price": 0, "tax": 0, "tags": [ "string" ], "image": { "url": "https://google.com", "name": "Google" } }■Response
{ "item_id": 1, "item": { "name": "string", "description": "string", "price": 0, "tax": 0, "tags": [ "string" ], "image": { "url": "https://google.com", "name": "Google" } } }サブモデルのリスト
■Source
main.pyfrom typing import List, Optional, Set from fastapi import FastAPI from pydantic import BaseModel, HttpUrl app = FastAPI() class Image(BaseModel): url: HttpUrl name: str class Item(BaseModel): name: str description: Optional[str] = None price: float tax: Optional[float] = None tags: Set[str] = [] images: Optional[List[Image]] = None @app.put("/items/{item_id}") async def update_item(item_id: int, item: Item): results = {"item_id": item_id, "item": item} return results■Request
{ "name": "string", "description": "string", "price": 0, "tax": 0, "tags": [ "string" ], "images": [ { "url": "https://google.com", "name": "Google" }, { "url": "https://yahoo.com", "name": "Yahoo" } ] }■Response
{ "item_id": 1, "item": { "name": "string", "description": "string", "price": 0, "tax": 0, "tags": [ "string" ], "images": [ { "url": "https://google.com", "name": "Google" }, { "url": "https://yahoo.com", "name": "Yahoo" } ] } }深くネストされたモデル
■Source
main.pyfrom typing import List, Optional, Set from fastapi import FastAPI from pydantic import BaseModel, HttpUrl app = FastAPI() class Image(BaseModel): url: HttpUrl name: str class Item(BaseModel): name: str description: Optional[str] = None price: float tax: Optional[float] = None tags: Set[str] = [] images: Optional[List[Image]] = None class Offer(BaseModel): name: str description: Optional[str] = None price: float items: List[Item] @app.post("/offers/") async def create_offer(offer: Offer): return offer■Request
{ "name": "string", "description": "string", "price": 0, "items": [ { "name": "string", "description": "string", "price": 0, "tax": 0, "tags": [ "string" ], "images": [ { "url": "https://google.com", "name": "Google" }, { "url": "https://yahoo.com", "name": "Yahoo" } ] }, { "name": "string", "description": "string", "price": 0, "tax": 0, "tags": [ "string" ], "images": [ { "url": "https://google.com", "name": "Google" }, { "url": "https://yahoo.com", "name": "Yahoo" } ] } ] }■Response
{ "name": "string", "description": "string", "price": 0, "items": [ { "name": "string", "description": "string", "price": 0, "tax": 0, "tags": [ "string" ], "images": [ { "url": "https://google.com", "name": "Google" }, { "url": "https://yahoo.com", "name": "Yahoo" } ] }, { "name": "string", "description": "string", "price": 0, "tax": 0, "tags": [ "string" ], "images": [ { "url": "https://google.com", "name": "Google" }, { "url": "https://yahoo.com", "name": "Yahoo" } ] } ] }モデルのリスト
■Source
main.pyfrom typing import List from fastapi import FastAPI from pydantic import BaseModel, HttpUrl app = FastAPI() class Image(BaseModel): url: HttpUrl name: str @app.post("/images/multiple/") async def create_multiple_images(images: List[Image]): return images■Request
http://localhost:8000/images/multiple/
[ { "url": "https://google.com", "name": "Google" }, { "url": "https://yahoo.com", "name": "Yahoo" } ]■Response
[ { "url": "https://google.com", "name": "Google" }, { "url": "https://yahoo.com", "name": "Yahoo" } ]Schema Extra - Example
Configでスキーマ例の設定
■Source
main.pyfrom typing import Optional from fastapi import FastAPI from pydantic import BaseModel app = FastAPI() class Item(BaseModel): name: str description: Optional[str] = None price: float tax: Optional[float] = None class Config: schema_extra = { "example": { "name": "Foo", "description": "A very nice Item", "price": 35.4, "tax": 3.2, } } @app.put("/items/{item_id}") async def update_item(item_id: int, item: Item): results = {"item_id": item_id, "item": item} return resultsモデルの各Fieldでスキーマ例の設定
■Source
main.pyfrom typing import Optional from fastapi import FastAPI from pydantic import BaseModel, Field app = FastAPI() class Item(BaseModel): name: str = Field(..., example="Foo") description: Optional[str] = Field(None, example="A very nice Item") price: float = Field(..., example=35.4) tax: Optional[float] = Field(None, example=3.2) @app.put("/items/{item_id}") async def update_item(item_id: int, item: Item): results = {"item_id": item_id, "item": item} return results関数でスキーマ例の設定
■Source
main.pyfrom typing import Optional from fastapi import Body, FastAPI from pydantic import BaseModel app = FastAPI() class Item(BaseModel): name: str description: Optional[str] = None price: float tax: Optional[float] = None @app.put("/items/{item_id}") async def update_item( item_id: int, item: Item = Body( ..., example={ "name": "Foo", "description": "A very nice Item", "price": 35.4, "tax": 3.2, }, ), ): results = {"item_id": item_id, "item": item} return results
Extra Data Types
■Source
main.pyfrom datetime import datetime, time, timedelta from typing import Optional from uuid import UUID from fastapi import Body, FastAPI app = FastAPI() @app.put("/items/{item_id}") async def read_items( item_id: UUID, start_datetime: Optional[datetime] = Body(None), end_datetime: Optional[datetime] = Body(None), repeat_at: Optional[time] = Body(None), process_after: Optional[timedelta] = Body(None), ): start_process = start_datetime + process_after duration = end_datetime - start_process return { "item_id": item_id, "start_datetime": start_datetime, "end_datetime": end_datetime, "repeat_at": repeat_at, "process_after": process_after, "start_process": start_process, "duration": duration, }■Request
http://localhost:8000/items/3fa85f64-5717-4562-b3fc-2c963f66afa6
{ "start_datetime": "2020-07-25T09:00:08.265Z", "end_datetime": "2020-07-25T09:00:08.265Z", "repeat_at": "18:20:30", "process_after": 0 }■Response
{ "item_id": "3fa85f64-5717-4562-b3fc-2c963f66afa6", "start_datetime": "2020-07-25T09:00:08.265000+00:00", "end_datetime": "2020-07-25T09:00:08.265000+00:00", "repeat_at": "18:20:30", "process_after": 0, "start_process": "2020-07-25T09:00:08.265000+00:00", "duration": 0 }Header Parameters
ヘッダーの利用
■Source
main.pyfrom typing import Optional from fastapi import FastAPI, Header app = FastAPI() @app.get("/items/") async def read_items(user_agent: Optional[str] = Header(None)): return {"User-Agent": user_agent}■Request
■Response
{ "User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.89 Safari/537.36" }ヘッダーの重複
■Source
main.pyfrom typing import List, Optional from fastapi import FastAPI, Header app = FastAPI() @app.get("/items/") async def read_items(x_token: Optional[List[str]] = Header(None)): return {"X-Token values": x_token}■Request
bashcurl -X GET "http://localhost:8000/items/" -H "accept: application/json" -H "x-token: foo,bar"■Response
{ "X-Token values": [ "foo,bar" ] }Response Model
入力と異なる出力モデルを設定
■Source
main.pyfrom typing import Optional from fastapi import FastAPI from pydantic import BaseModel app = FastAPI() class UserIn(BaseModel): username: str password: str email: str full_name: Optional[str] = None class UserOut(BaseModel): username: str email: str full_name: Optional[str] = None @app.post("/user/", response_model=UserOut) async def create_user(user: UserIn): return user■Request
{ "username": "user", "password": "pass123", "email": "user@example.com", "full_name": "aiueo" }■Response
{ "username": "user", "email": "user@example.com", "full_name": "aiueo" }デフォルト値の返却を除外
通常はモデルに指定したFieldすべてが返却される。
response_model_exclude_nusetを利用することで値が設定されたFieldのみ返却される。■Source
main.pyfrom typing import List, Optional from fastapi import FastAPI from pydantic import BaseModel app = FastAPI() class Item(BaseModel): name: str description: Optional[str] = None price: float tax: float = 10.5 tags: List[str] = [] items = { "foo": {"name": "Foo", "price": 50.2}, "bar": {"name": "Bar", "description": "The bartenders", "price": 62, "tax": 20.2}, "baz": {"name": "Baz", "description": None, "price": 50.2, "tax": 10.5, "tags": []}, } @app.get("/items/{item_id}", response_model=Item, response_model_exclude_unset=True) async def read_item(item_id: str): return items[item_id]■Request
http://localhost:8000/items/foo
■Response
{ "name": "Foo", "price": 50.2 }返却するFieldを指定
モデルから返却するFieldを指定することが可能。
■Source
main.pyfrom typing import List, Optional from fastapi import FastAPI from pydantic import BaseModel app = FastAPI() class Item(BaseModel): name: str description: Optional[str] = None price: float tax: float = 10.5 tags: List[str] = [] items = { "foo": {"name": "Foo", "price": 50.2}, "bar": {"name": "Bar", "description": "The bartenders", "price": 62, "tax": 20.2}, "baz": {"name": "Baz", "description": None, "price": 50.2, "tax": 10.5, "tags": []}, } @app.get( "/items/{item_id}", response_model=Item, response_model_include={"name", "description"} ) async def read_item(item_id: str): return items[item_id]■Request
http://localhost:8000/items/bar
■Response
{ "name": "Bar", "description": "The bartenders" }Extra Models
複数モデルの活用
■Source
main.pyfrom typing import Optional from fastapi import FastAPI from pydantic import BaseModel app = FastAPI() class UserIn(BaseModel): username: str password: str email: str full_name: Optional[str] = None class UserOut(BaseModel): username: str email: str full_name: Optional[str] = None class UserInDB(BaseModel): username: str hashed_password: str email: str full_name: Optional[str] = None def fake_password_hasher(raw_password: str): return "supersecret" + raw_password def fake_save_user(user_in: UserIn): hashed_password = fake_password_hasher(user_in.password) user_in_db = UserInDB(**user_in.dict(), hashed_password=hashed_password) print("User saved! ..not really") return user_in_db @app.post("/user/", response_model=UserOut) async def create_user(user_in: UserIn): user_saved = fake_save_user(user_in) return user_saved■Request
{ "username": "string", "password": "string", "email": "string", "full_name": "string" }■Response
{ "username": "string", "email": "string", "full_name": "string" }モデルの重複を排除
モデルの継承を利用することで重複を排除する。
■Source
main.pyfrom typing import Optional from fastapi import FastAPI from pydantic import BaseModel app = FastAPI() class UserBase(BaseModel): username: str email: str full_name: Optional[str] = None class UserIn(UserBase): password: str class UserOut(UserBase): pass class UserInDB(UserBase): hashed_password: str def fake_password_hasher(raw_password: str): return "supersecret" + raw_password def fake_save_user(user_in: UserIn): hashed_password = fake_password_hasher(user_in.password) user_in_db = UserInDB(**user_in.dict(), hashed_password=hashed_password) print("User saved! ..not really") return user_in_db @app.post("/user/", response_model=UserOut) async def create_user(user_in: UserIn): user_saved = fake_save_user(user_in) return user_saved■Request
{ "username": "string", "password": "string", "email": "string", "full_name": "string" }■Response
{ "username": "string", "email": "string", "full_name": "string" }モデルのリストを返却
■Source
main.pyfrom typing import List from fastapi import FastAPI from pydantic import BaseModel app = FastAPI() class Item(BaseModel): name: str description: str items = [ {"name": "Foo", "description": "There comes my hero"}, {"name": "Red", "description": "It's my aeroplane"}, ] @app.get("/items/", response_model=List[Item]) async def read_items(): return items■Request
http://localhost:8000/items/■Response
[ { "name": "Foo", "description": "There comes my hero" }, { "name": "Red", "description": "It's my aeroplane" } ]Response Status Code
status_codeを利用することでHTTPステータスコードを設定することが可能。ステータスコードの設定
■Source
main.pyfrom fastapi import FastAPI app = FastAPI() @app.post("/items/", status_code=201) async def create_item(name: str): return {"name": name}
ステータスコードのショートカット
■Source
main.pyfrom fastapi import FastAPI, status app = FastAPI() @app.post("/items/", status_code=status.HTTP_201_CREATED) async def create_item(name: str): return {"name": name}Form Data
フォームデータの受け取り
■Source
main.pyfrom fastapi import FastAPI, Form app = FastAPI() @app.post("/login/") async def login(username: str = Form(...), password: str = Form(...)): return {"username": username}■Request
bashcurl -X POST "http://localhost:8000/login/" -H "accept: application/json" -H "Content-Type: application/x-www-form-urlencoded" -d "username=test&password=123"Request Files
ファイルを送信
■Source
main.pyfrom fastapi import FastAPI, File, UploadFile from fastapi.responses import HTMLResponse app = FastAPI() @app.post("/files/") async def create_file(file: bytes = File(...)): return {"file_size": len(file)} @app.post("/uploadfile/") async def create_upload_file(file: UploadFile = File(...)): return {"file": file} @app.get("/") async def main(): content = """ <html> <head> <title>FastAPI Form Test</title> </head> <body> <div>files</div> <form action="/files/" enctype="multipart/form-data" method="post"> <input name="files" type="file"> <input type="submit"> </form> <div>uploadfiles</div> <form action="/uploadfiles/" enctype="multipart/form-data" method="post"> <input name="files" type="file"> <input type="submit"> </form> </body> """ return HTMLResponse(content=content)■Request
bashcurl -X POST "http://localhost:8000/files/" -H "accept: application/json" -H "Content-Type: multipart/form-data" -F "file=@img1.jpg;type=image/jpeg"■Response
{ "file_size": 386446 }■Request
bashcurl -X POST "http://localhost:8000/uploadfile/" -H "accept: application/json" -H "Content-Type: multipart/form-data" -F "file=@img2.jpg;type=image/jpeg"■Response
{ "file": { "filename": "img2.jpg", "content_type": "image/jpeg", "file": { "_file": {}, "_max_size": 1048576, "_rolled": false, "_TemporaryFileArgs": { "mode": "w+b", "buffering": -1, "suffix": null, "prefix": null, "encoding": null, "newline": null, "dir": null, "errors": null } } } }複数ファイルを送信
■Source
main.pyfrom typing import List from fastapi import FastAPI, File, UploadFile from fastapi.responses import HTMLResponse app = FastAPI() @app.post("/files/") async def create_files(files: List[bytes] = File(...)): return {"file_sizes": [len(file) for file in files]} @app.post("/uploadfiles/") async def create_upload_files(files: List[UploadFile] = File(...)): return {"filenames": [file.filename for file in files]} @app.get("/") async def main(): content = """ <html> <head> <title>FastAPI Form Test</title> </head> <body> <div>files</div> <form action="/files/" enctype="multipart/form-data" method="post"> <input name="files" type="file" multiple> <input type="submit"> </form> <div>uploadfiles</div> <form action="/uploadfiles/" enctype="multipart/form-data" method="post"> <input name="files" type="file" multiple> <input type="submit"> </form> </body> """ return HTMLResponse(content=content)■Request
bashcurl -X POST "http://localhost:8000/files/" -H "accept: application/json" -H "Content-Type: multipart/form-data" -F "files=@img1.jpg;type=image/jpeg" -F "files=@img2.jpg;type=image/jpeg"■Response
{ "file_sizes": [ 386446, 320754 ] }■Request
bashcurl -X POST "http://localhost:8000/uploadfiles/" -H "accept: application/json" -H "Content-Type: multipart/form-data" -F "files=@img1.jpg;type=image/jpeg" -F "files=@img2.jpg;type=image/jpeg"■Response
{ "filenames": [ "img1.jpg", "img2.jpg" ] }Request Forms and Files
フォームとファイルを同時に送信
■Source
main.pyfrom fastapi import FastAPI, File, Form, UploadFile app = FastAPI() @app.post("/files/") async def create_file( file: bytes = File(...), fileb: UploadFile = File(...), token: str = Form(...) ): return { "file_size": len(file), "token": token, "fileb_content_type": fileb.content_type, }■Request
bashcurl -X POST "http://localhost:8000/files/" -H "accept: application/json" -H "Content-Type: multipart/form-data" -F "token=aaa" -F "file=@img1.jpg;type=image/jpeg" -F "fileb=@img1.jpg;type=image/jpeg"■Response
{ "file_size": 386446, "token": "aaa", "fileb_content_type": "image/jpeg" }Handling Errors
指定したエラーを返却
HTTPExceptionを利用することでステータスコード、メッセージを返却することが可能。■Source
main.pyfrom fastapi import FastAPI, HTTPException app = FastAPI() items = {"foo": "The Foo Wrestlers"} @app.get("/items/{item_id}") async def read_item(item_id: str): if item_id not in items: raise HTTPException(status_code=404, detail="Item not found") return {"item": items[item_id]}■Request
http://localhost:8000/items/foo
■Response
{ "item": "The Foo Wrestlers" }■Request
http://localhost:8000/items/bar
■Response
{ "detail": "Item not found" }カスタムヘッダーを追加
■Source
main.pyfrom fastapi import FastAPI, HTTPException app = FastAPI() items = {"foo": "The Foo Wrestlers"} @app.get("/items-header/{item_id}") async def read_item_header(item_id: str): if item_id not in items: raise HTTPException( status_code=404, detail="Item not found", headers={"X-Error": "There goes my error"}, ) return {"item": items[item_id]}■Request
http://localhost:8000/items-header/bar
■Response
{ "detail": "Item not found" }content-length: 27 content-type: application/json date: Sun26 Jul 2020 02:47:20 GMT server: uvicorn x-error: There goes my errorカスタム例外ハンドラ
/unicorns/yoloにリクエストすると、raise UnicornExceptionとなる。
@app.exception_handler(UnicornException)としているため、実際にはこちらで処理が行われる。■Source
main.pyfrom fastapi import FastAPI, Request from fastapi.responses import JSONResponse class UnicornException(Exception): def __init__(self, name: str): self.name = name app = FastAPI() @app.exception_handler(UnicornException) async def unicorn_exception_handler(request: Request, exc: UnicornException): return JSONResponse( status_code=418, content={"message": f"Oops! {exc.name} did something. There goes a rainbow..."}, ) @app.get("/unicorns/{name}") async def read_unicorn(name: str): if name == "yolo": raise UnicornException(name=name) return {"unicorn_name": name}■Request
http://localhost:8000/unicorns/yolo
■Response
{ "message": "Oops! yolo did something. There goes a rainbow..." }content-length: 63 content-type: application/json date: Sun26 Jul 2020 02:52:12 GMT server: uvicorn検証エラー時のリクエストボディ表示
検証エラーがあった際のResponseに送信されたリクエストボディを追加可能。
■Source
main.pyfrom fastapi import FastAPI, Request, status from fastapi.encoders import jsonable_encoder from fastapi.exceptions import RequestValidationError from fastapi.responses import JSONResponse from pydantic import BaseModel app = FastAPI() @app.exception_handler(RequestValidationError) async def validation_exception_handler(request: Request, exc: RequestValidationError): return JSONResponse( status_code=status.HTTP_422_UNPROCESSABLE_ENTITY, content=jsonable_encoder({"detail": exc.errors(), "body": exc.body}), ) class Item(BaseModel): title: str size: int @app.post("/items/") async def create_item(item: Item): return item■Request
{ "title": "towel", "size": "XL" }■Response
{ "detail": [ { "loc": [ "body", "size" ], "msg": "value is not a valid integer", "type": "type_error.integer" } ], "body": { "title": "towel", "size": "XL" } }Path Operation Configuration
応答ステータスコードの指定
status_codeで応答ステータスコードを指定することが可能。■Source
main.pyfrom typing import Optional, Set from fastapi import FastAPI, status from pydantic import BaseModel app = FastAPI() class Item(BaseModel): name: str description: Optional[str] = None price: float tax: Optional[float] = None tags: Set[str] = [] @app.post("/items/", response_model=Item, status_code=status.HTTP_201_CREATED) async def create_item(item: Item): return item
OpenAPIドキュメントへの反映
タグ、サマリー、説明、レスポンスの説明、廃止状態を反映する。
■Source
main.pyfrom typing import Optional, Set from fastapi import FastAPI from pydantic import BaseModel app = FastAPI() class Item(BaseModel): name: str description: Optional[str] = None price: float tax: Optional[float] = None tags: Set[str] = [] @app.get( "/items/", tags=["items"], summary="summary test", description="description test", response_description="response test" ) async def read_items(): return [{"name":"Foo", "price":42}] @app.post("/items/", response_model=Item, tags=["items"]) async def create_item(item: Item): """ Create an item with all the information: - **name**: each item must have a name - **description**: a long description - **price**: required - **tax**: if the item doesn't have tax, you can omit this - **tags**: a set of unique tag strings for this item """ return item @app.get("/users/", tags=["users"], deprecated=True) async def read_users(): return [{"username": "johndoe"}]
JSON Compatible Encoder
JSON互換のデータ型に変換
JSON互換のデータ型のみ格納可能なDBに対して、例えばdatetime型を格納する場合は文字列に変換する必要がある。
jsonable_encoderを利用するとJSON互換のデータに変換することが可能。■Source
main.pyfrom datetime import datetime from typing import Optional from fastapi import FastAPI from fastapi.encoders import jsonable_encoder from pydantic import BaseModel fake_db = {} class Item(BaseModel): title: str timestamp: datetime description: Optional[str] = None app = FastAPI() @app.put("/items/{id}") def update_item(id: str, item: Item): json_compatible_item_data = jsonable_encoder(item) fake_db[id] = json_compatible_item_dataBody - Updates
PUT(置き換え)の注意
モデルが定義されたデータの置き換えを行う際に、初期値が設定されたFieldを省略すると、自動で初期値が格納される。
■Source
main.pyfrom typing import List, Optional from fastapi import FastAPI from fastapi.encoders import jsonable_encoder from pydantic import BaseModel app = FastAPI() class Item(BaseModel): name: Optional[str] = None description: Optional[str] = None price: Optional[float] = None tax: float = 10.5 tags: List[str] = [] items = { "foo": {"name": "Foo", "price": 50.2}, "bar": {"name": "Bar", "description": "The bartenders", "price": 62, "tax": 20.2}, "baz": {"name": "Baz", "description": None, "price": 50.2, "tax": 10.5, "tags": []}, } @app.get("/items/{item_id}", response_model=Item) async def read_item(item_id: str): return items[item_id] @app.put("/items/{item_id}", response_model=Item) async def update_item(item_id: str, item: Item): update_item_encoded = jsonable_encoder(item) items[item_id] = update_item_encoded return update_item_encoded■Request
http://localhost:8000/items/bar
{ "name": "Barz", "price": 3, "description": "description" }■Response
{ "name": "Barz", "description": "description", "price": 3, "tax": 10.5, "tags": [] }PATCHによる部分更新
exclude_unsetを利用することで、渡されたデータでモデルの部分更新を行う。■Source
main.pyfrom typing import List, Optional from fastapi import FastAPI from fastapi.encoders import jsonable_encoder from pydantic import BaseModel app = FastAPI() class Item(BaseModel): name: Optional[str] = None description: Optional[str] = None price: Optional[float] = None tax: float = 10.5 tags: List[str] = [] items = { "foo": {"name": "Foo", "price": 50.2}, "bar": {"name": "Bar", "description": "The bartenders", "price": 62, "tax": 20.2}, "baz": {"name": "Baz", "description": None, "price": 50.2, "tax": 10.5, "tags": []}, } @app.get("/items/{item_id}", response_model=Item) async def read_item(item_id: str): return items[item_id] @app.patch("/items/{item_id}", response_model=Item) async def update_item(item_id: str, item: Item): stored_item_data = items[item_id] stored_item_model = Item(**stored_item_data) update_data = item.dict(exclude_unset=True) updated_item = stored_item_model.copy(update=update_data) items[item_id] = jsonable_encoder(updated_item) return updated_item■Request
http://localhost:8000/items/bar
{ "name": "Barz", "price": 100, "tags": [ "test1", "test2" ] }■Response
{ "name": "Barz", "description": "The bartenders", "price": 100, "tax": 20.2, "tags": [ "test1", "test2" ] }Dependencies
共通パラメータの利用
事前に定義したパラメータを
Dependsで利用。■Source
main.pyfrom typing import Optional from fastapi import Depends, FastAPI app = FastAPI() async def common_parameters(q: Optional[str] = None, skip: int = 0, limit: int = 100): return {"q": q, "skip": skip, "limit": limit} @app.get("/items/") async def read_items(commons: dict = Depends(common_parameters)): return commons @app.get("/users/") async def read_users(commons: dict = Depends(common_parameters)): return commons■Request
http://localhost:8000/items/?limit=100
■Response
{ "q": null, "skip": 0, "limit": 100 }共通パラメータ(クラス)の利用
パラメータの型と依存関係の呼び出しが同じ場合、
Dependsのパラメータを省略可能。■Source
main.pyfrom typing import Optional from fastapi import Depends, FastAPI app = FastAPI() fake_items_db = [{"item_name": "Foo"}, {"item_name": "Bar"}, {"item_name": "Baz"}] class CommonQueryParams: def __init__(self, q: Optional[str] = None, skip: int = 0, limit: int = 100): self.q = q self.skip = skip self.limit = limit @app.get("/items/") # async def read_items(commons: CommonQueryParams = Depends(CommonQueryParams)): async def read_items(commons: CommonQueryParams = Depends()): response = {} if commons.q: response.update({"q": commons.q}) items = fake_items_db[commons.skip : commons.skip + commons.limit] response.update({"items": items}) return response依存関係の階層
■Source
main.pyfrom typing import Optional from fastapi import Cookie, Depends, FastAPI app = FastAPI() def query_extractor(q: Optional[str] = None): return q def query_or_cookie_extractor( q: str = Depends(query_extractor), last_query: Optional[str] = Cookie(None) ): if not q: return last_query return q @app.get("/items/") async def read_query(query_or_default: str = Depends(query_or_cookie_extractor)): return {"q_or_cookie": query_or_default}CORS(Cross-Origin Resource Sharning)
CORS設定
許可するオリジンのURLリストを配列に格納。
ミドルウェアを定義する際にURLリストを設定。■Source
main.pyfrom fastapi import FastAPI from fastapi.middleware.cors import CORSMiddleware app = FastAPI() origins = [ "http://localhost.tiangolo.com", "https://localhost.tiangolo.com", "http://localhost", "http://localhost:8080", ] app.add_middleware( CORSMiddleware, allow_origins=origins, allow_credentials=True, allow_methods=["*"], allow_headers=["*"], ) @app.get("/") async def main(): return {"message": "Hello World"}Bigger Applications - Multiple Files
モジュール構造によるファイル分割
分割した
users.py、items.pyで各ルートの処理を準備
include_routerでルートを紐づける。
prefixでURLのプレフィックス、tagsでOpenAPIのタグを一括で設定可能。■Source
main.pyfrom fastapi import FastAPI from routers import users, items app = FastAPI() app.include_router(users.router) app.include_router( items.router, prefix="/items", tags=["items"] )routers/users.pyfrom fastapi import APIRouter router = APIRouter() users = { "user1": {"name": "user1", "email": "user1@example.com", "age": 20}, "user2": {"name": "user2", "email": "user2@example.com", "age": 30}, "user3": {"name": "user3", "email": "user3@example.com", "age": 40}, } @router.get("/users/", tags=["users"]) async def get_users(): return {"users": users} @router.get("/users/me", tags=["users"]) async def get_user_me(): return {"name": "the current user"} @router.get("/users/{user_id}", tags=["users"]) async def get_user(user_id: str): return {"user": users[user_id]}routers/items.pyfrom fastapi import APIRouter router = APIRouter() items = { "foo": {"name": "Foo", "price": 50.2}, "bar": {"name": "Bar", "description": "The bartenders", "price": 62, "tax": 20.2}, "baz": {"name": "Baz", "description": None, "price": 50.2, "tax": 10.5, "tags": []}, } @router.get("/") async def get_items(): return {"items": items} @router.get("/{item_id}") async def get_item(item_id: str): return {"item": items[item_id]}Backgroud Tasks
バックグラウンドタスク
メール送信や長時間を要するデータ更新など、実行した処理を待たずに次の処理を行う。
■Source
main.pyfrom fastapi import BackgroundTasks, FastAPI app = FastAPI() def write_notification(email: str, message=""): with open("log.txt", mode="w") as email_file: content = f"notification for {email}: {message}" email_file.write(content) @app.post("/send-notification/{email}") async def send_notification(email: str, background_tasks: BackgroundTasks): background_tasks.add_task(write_notification, email, message="some notification") return {"message": "Notification sent in the background"}■Request
http://ubuntu18:8000/send-notification/test%40example.com?q=test%20test
■Response
{ "message": "Message sent" }log.txtfound query: test test message to test@example.comMetadata and Docs URLs
OpenAPIドキュメントのタイトル、バージョン、説明を変更
FastAPIインスタンス生成時のパラメータを設定することでOpenAPIのカスタマイズを行うことが可能。
パラメータ 説明 title タイトル description 説明 version バージョン openapi_tags タグ docs_url SwaggerのURL redoc_url ReDocのURL openapi_url OpenAPIのURL ■Source
main.pyfrom fastapi import FastAPI tags_metadata = [ { "name": "users", "description": "Operations with users. The **login** logic is also here.", }, { "name": "items", "description": "Manage items. So _fancy_ they have their own docs.", "externalDocs": { "description": "Items external docs", "url": "https://fastapi.tiangolo.com/", }, }, ] app = FastAPI( title="My Super Project", description="This is a very fancy project, with auto docs for the API and everything", version="2.5.0", openapi_tags=tags_metadata, docs_url="/api/v1/docs", # docs_url=None, redoc_url="/api/v1/redoc", # redoc_url=None, openapi_url="/api/v1/openapi.json", # openapi_url=None, ) @app.get("/users/", tags=["users"]) async def get_users(): return [{"name": "Harry"}, {"name": "Ron"}] @app.get("/items/", tags=["items"]) async def get_items(): return [{"name": "wand"}, {"name": "flying broom"}]http://localhost:8000/api/v1/docs
http://localhost:8000/api/v1/redoc
http://localhost:8000/api/v1/openapi.json
Static Files
マウント
マウントを利用することでFastAPI Routingから独立して静的ファイルを提供可能。
下記の例では/staticにアクセスすることで、staticディレクトリに配置した静的ファイルを利用することができる。■Source
main.pyfrom fastapi import FastAPI from fastapi.staticfiles import StaticFiles app = FastAPI() app.mount("/static", StaticFiles(directory="static"), name="static")http://localhost:8000/static/static_files.txt
http://localhost:8000/static/img9.pngTesting
テストファイルの分割
■Source
src/main.pyfrom fastapi import FastAPI app = FastAPI() @app.get("/") async def read_main(): return {"msg": "Hello World"}test_main.pyfrom fastapi.testclient import TestClient from src.main import app client = TestClient(app) def test_read_main(): response = client.get("/") assert response.status_code == 200 assert response.json() == {"msg": "Hello World"}兄弟階層のモジュールインポートを行うため、下記サイトを参考に
PYTHONPATH環境変数を設定してテストを実行
https://rinoguchi.hatenablog.com/entry/2019/11/29/130224bash# 環境変数を設定 $ export PYTHONPATH="..:$PYTHONPATH" # テストを実行 $ pytest
複雑なテスト
■Source
src/main.pyfrom typing import Optional from fastapi import FastAPI, Header, HTTPException from pydantic import BaseModel fake_secret_token = "coneofsilence" fake_db = { "foo": {"id": "foo", "title": "Foo", "description": "There goes my hero"}, "bar": {"id": "bar", "title": "Bar", "description": "The bartenders"}, } app = FastAPI() class Item(BaseModel): id: str title: str description: Optional[str] = None @app.get("/items/{item_id}", response_model=Item) async def read_main(item_id: str, x_token: str = Header(...)): if x_token != fake_secret_token: raise HTTPException(status_code=400, detail="Invalid X-Token header") if item_id not in fake_db: raise HTTPException(status_code=404, detail="Item not found") return fake_db[item_id] @app.post("/items/", response_model=Item) async def create_item(item: Item, x_token: str = Header(...)): if x_token != fake_secret_token: raise HTTPException(status_code=400, detail="Invalid X-Token header") if item.id in fake_db: raise HTTPException(status_code=400, detail="Item already exists") fake_db[item.id] = item return itemtests/test_main.pyfrom fastapi.testclient import TestClient from src.main import app client = TestClient(app) def test_read_item(): response = client.get("/items/foo", headers={"X-Token": "coneofsilence"}) assert response.status_code == 200 assert response.json() == { "id": "foo", "title": "Foo", "description": "There goes my hero", } def test_read_item_bad_token(): response = client.get("/items/foo", headers={"X-Token": "hailhydra"}) assert response.status_code == 400 assert response.json() == {"detail": "Invalid X-Token header"} def test_read_inexistent_item(): response = client.get("/items/baz", headers={"X-Token": "coneofsilence"}) assert response.status_code == 404 assert response.json() == {"detail": "Item not found"} def test_create_item(): response = client.post( "/items/", headers={"X-Token": "coneofsilence"}, json={"id": "foobar", "title": "Foo Bar", "description": "The Foo Barters"}, ) assert response.status_code == 200 assert response.json() == { "id": "foobar", "title": "Foo Bar", "description": "The Foo Barters", } def test_create_item_bad_token(): response = client.post( "/items/", headers={"X-Token": "hailhydra"}, json={"id": "bazz", "title": "Bazz", "description": "Drop the bazz"}, ) assert response.status_code == 400 assert response.json() == {"detail": "Invalid X-Token header"} def test_create_existing_item(): response = client.post( "/items/", headers={"X-Token": "coneofsilence"}, json={ "id": "foo", "title": "The Foo ID Stealers", "description": "There goes my stealer", }, ) assert response.status_code == 400 assert response.json() == {"detail": "Item already exists"}










- 投稿日:2020-07-28T11:42:09+09:00
【Xgboost】softmaxとsoftprobの違い
softmax vs softprob
基本的に
softmaxもsoftprobも多クラス分類に利用される。
softmaxは予測が最大確率となっている1クラスを出力する。softprobは予測しようとしているそれぞれのクラスの確率値を出力する。multi:softmax: set XGBoost to do multiclass classification using the softmax objective, you also need to set num_class(number of classes)
multi:softprob: same as softmax, but output a vector of ndata * nclass, which can be further reshaped to ndata * nclass matrix. The result contains predicted probability of each data point belonging to each class.xgboostでの使用例
param = {'max_depth': 2, 'eta': 1, 'objective': 'multi:softmax', 'num_class': 3}param = {'max_depth': 2, 'eta': 1, 'objective': 'multi:softprob', 'num_class': 3}参考
- 投稿日:2020-07-28T11:34:04+09:00
日暮れ時に夕焼け、夜には星空の壁紙を(Python)
PCの壁紙を時間とともに変えるスクリプトを作ってみた話(Windows向け)。
ポイント:
ctypes.windll.user32.SystemParametersInfoWで壁紙を変えられる。- 定期実行は無限ループ + 1秒スリープで十分。
- 実行はpythonwから実行すると、バックグラウンドで動くので良い(止めるときにtasks managerからしか止められないのは難点、しかもプロセス名がpythonwとなって分かりにくい)。
- タスクスケジューラーでスタートアップ時のタスクに登録しておけば、起動時に自動起動できる。
import ctypes import os import datetime import time image_dir = r'D:\wallpaper' current_image_name = None while True: now = datetime.datetime.now() if now.hour < 6 or 19 <= now.hour: new_image_name = 'star.png' elif 17 <= now.hour: new_image_name = 'sunset.jpeg' else: new_image_name = 'daytime.jpeg' if new_image_name != current_image_name: abs_file_name = os.path.join(image_dir , new_image_name) ctypes.windll.user32.SystemParametersInfoW(20, 0, abs_file_name, 0) current_image_name = new_image_name time.sleep(1) # check every 1 sec切り替え時にちらつくので、変更の有無をチェックして、変更があったときのみ
SystemParametersInfoWを実行している。季節ごとに変えても面白いかも。壁紙が窓のようになって、時間や季節が感じられると良いですね。
- 投稿日:2020-07-28T11:34:04+09:00
夜には星空の壁紙を(Python)
Windowsの壁紙を時刻に応じて変えるスクリプトを作ってみた話。
ポイント:
ctypes.windll.user32.SystemParametersInfoWで壁紙を変えられる。- 定期実行は無限ループ + 1秒スリープで十分。
- 実行はpythonwから実行すると、バックグラウンドで動くので良い(止めるときにtasks managerからしか止められないのは難点、しかもプロセス名がpythonwとなって分かりにくい)。
- タスクスケジューラーでスタートアップ時のタスクに登録しておけば、起動時に自動起動できる。
import ctypes import os import datetime import time image_dir = r'D:\wallpaper' current_image_name = None while True: now = datetime.datetime.now() if now.hour < 6 or 19 <= now.hour: new_image_name = 'star.png' elif 17 <= now.hour: new_image_name = 'sunset.jpeg' else: new_image_name = 'daytime.jpeg' if new_image_name != current_image_name: abs_file_name = os.path.join(image_dir , new_image_name) ctypes.windll.user32.SystemParametersInfoW(20, 0, abs_file_name, 0) current_image_name = new_image_name time.sleep(1) # check every 1 sec切り替え時にちらつくので、変更の有無をチェックして、変更があったときのみ
SystemParametersInfoWを実行する。季節ごとに変えても面白いかも。壁紙が窓のようになって、時間や季節が感じられると良いですね。
- 投稿日:2020-07-28T11:32:37+09:00
pythonのSeabornでlegendのラベルを自由に変更する
こんな人に向けた記事
- pythonでseabornを最近使い始めてboxplot, violinplotなどをやりたい人
- violinplot, boxplotで自分で決めた文字列でラベルを設定したい人
- seabornだとラベルが自動で設定されてしまって困っている人
解決方法
legendのハンドルを設定する以下の2行で簡単に解決!
handler, label = ax.get_legend_handles_labels() ax.legend(handler, ["label1", "label2"])タイタニックデータを使ったプロット例
データのダウンロード
例としてtitanicのデータを使用します。
titanicのデータセットはいろんなところで説明されています。例えば下記記事など。
参考:「Titanic:タイタニック号乗客者の生存状況(年齢や性別などの13項目)の表形式データセット」
https://www.atmarkit.co.jp/ait/articles/2007/02/news016.htmlimport pandas as pd import matplotlib.pyplot as plt import seaborn as sns sns.set("talk") df = sns.load_dataset('titanic') df.head()出力結果はこんな感じ。
旅客クラスごとの年代分布
ここではpclass(旅客クラス)ごとの年代分布をプロットしてみます。
sns.violinplot(data=df, x='pclass', y='age')
図をみるとpclass3では年代が若い層が多いことがわかります。
更に深堀りして,
「各クラスの年代分布で生死に違いがあったのか」
を見てみたいと思います。fig,ax=plt.subplots() sns.violinplot(data=df, x='pclass', y='age',hue="alive",split=True, ax=ax) ax.legend(loc='upper left',bbox_to_anchor=(1.05,1))
hueを指定することでviolinplotを2つに分けることができます。
凡例は見やすくするために図の外に配置しています。ラベルの変更(本題)
ようやく本題です。ここで気になるのは凡例のラベル。
no, yesではあとからみたときなんのことかわからないですよね。
これはdfのalive列の中身no/yesをそのままラベルに指定していることが原因です。そこで,labelのハンドルをgetして直接指定してあげます。
fig,ax=plt.subplots() sns.violinplot(data=df, x='pclass', y='age',hue="alive",split=True, ax=ax) ax.legend(loc='upper left',bbox_to_anchor=(1.05,1)) handler, label = ax.get_legend_handles_labels() ax.legend(handler, ["dead","alive"],loc='upper left',bbox_to_anchor=(1.05,1))
無事,ラベルがdead/aliveとなりあとから見ても生死に差がないかを判別することができますね。
ちなみに生死で分けることであたらしくわかったこととして
- pclass2,3のとき10代などの若い年代でaliveの割合が高い
- pclass3では30代ではdeadとaliveの割合が同程度だが,pclass2ではdeadの割合が高い
- pclass1は50代以上でdeadの割合が顕著に高くなっている。
など様々なことがわかりますね。
swarmplotの例
もちろんswarmplotでも同じことができます。
fig,ax=plt.subplots() sns.swarmplot(data=df, x='pclass', y='age',hue="alive",dodge=True, ax=ax) ax.legend(loc='upper left',bbox_to_anchor=(1.05,1)) handler, label = ax.get_legend_handles_labels() ax.legend(handler, ["dead","alive"],loc='upper left',bbox_to_anchor=(1.05,1))まとめ
- seabornでプロットすると列の中身がラベルになる
- ハンドルをgetして直接指定することでラベルを自由に編集できる
参考記事
Python: seaborn を使った可視化を試してみる https://blog.amedama.jp/entry/seaborn-plot