- 投稿日:2020-07-28T18:47:27+09:00
【RHEL】サブスクリプション適用
RHELでめんどくさいのがサブスクリプション関係です。
適用しないとyumとかできないのではじめにやっておく必要があります。
さくっと手順載せておきます。※前提:カスタマーポータルのアカウント
https://access.redhat.com/management/
に利用可能なサブスクリプションが紐づいていること。外部接続できる場合
OS上からそのまま登録・適用できます。
ターミナルコピペゆるちて[root@host01 /]# [root@host01 /]# subscription-manager register 登録中: subscription.rhsm.redhat.com:443/subscription ユーザー名: dango パスワード: このシステムは、次の ID で登録されました: 943908a1-d1bf-4d75-b7c6-f2513122fbe4 登録したシステム名: host01 [root@host01 /]# [root@host01 /]# subscription-manager list +-------------------------------------------+ インストール済み製品のステータス +-------------------------------------------+ 製品名: Red Hat Enterprise Linux Server 製品 ID: 69 バージョン: 7.5 アーキテクチャー: x86_64 状態: サブスクライブしていません 状態の詳細: 有効なサブスクリプションでサポートされていません。 開始: 終了: [root@host01 /]# [root@host01 /]# subscription-manager list --available +-------------------------------------------+ 利用可能なサブスクリプション +-------------------------------------------+ サブスクリプション名: 30 Day Red Hat Enterprise Linux Server Self-Supported Evaluation 提供: Red Hat Beta Oracle Java (for RHEL Server) Red Hat Enterprise Linux Server Red Hat Ansible Engine Red Hat Container Images Beta Red Hat Enterprise Linux Atomic Host Beta Red Hat Enterprise Linux Atomic Host Red Hat Container Images SKU: RH00065 契約: 11833975 プール ID: 8a85f99a67cdc3e701682adea40e3295 管理の提供: いいえ 数量: 1 推奨: 1 サービスレベル: Self-Support サービスタイプ: L1-L3 サブスクリプションタイプ: Instance Based 終了: 2019年02月06日 システムタイプ: 物理 [root@host01 /]# [root@host01 /]# subscription-manager subscribe --pool=8a85f99a67cdc3e701682adea40e3295 サブスクリプションが正しく割り当てられました: 30 Day Red Hat Enterprise Linux Server Self-Supported Evaluation [root@host01 /]# [root@host01 /]# subscription-manager list +-------------------------------------------+ インストール済み製品のステータス +-------------------------------------------+ 製品名: Red Hat Enterprise Linux Server 製品 ID: 69 バージョン: 7.5 アーキテクチャー: x86_64 状態: サブスクライブ済み 状態の詳細: 開始: 2019年01月07日 終了: 2019年02月06日 [root@host01 /]#ユーザー名・パスワードは管理ポータルのものを使用します。
ここでは評価版のライセンスを適用しています。
subscription-manager list --availableで利用できるサブスクリプションのプールIDを確認し、
subscription-manager subscribe --pool=xxxxxxxxxxで適用します。
上記完了後、WEBポータルにも反映されます。
https://access.redhat.com/management/
オフラインの場合
はじめに外部に繋がる端末のWEBでいろいろやる必要があります。
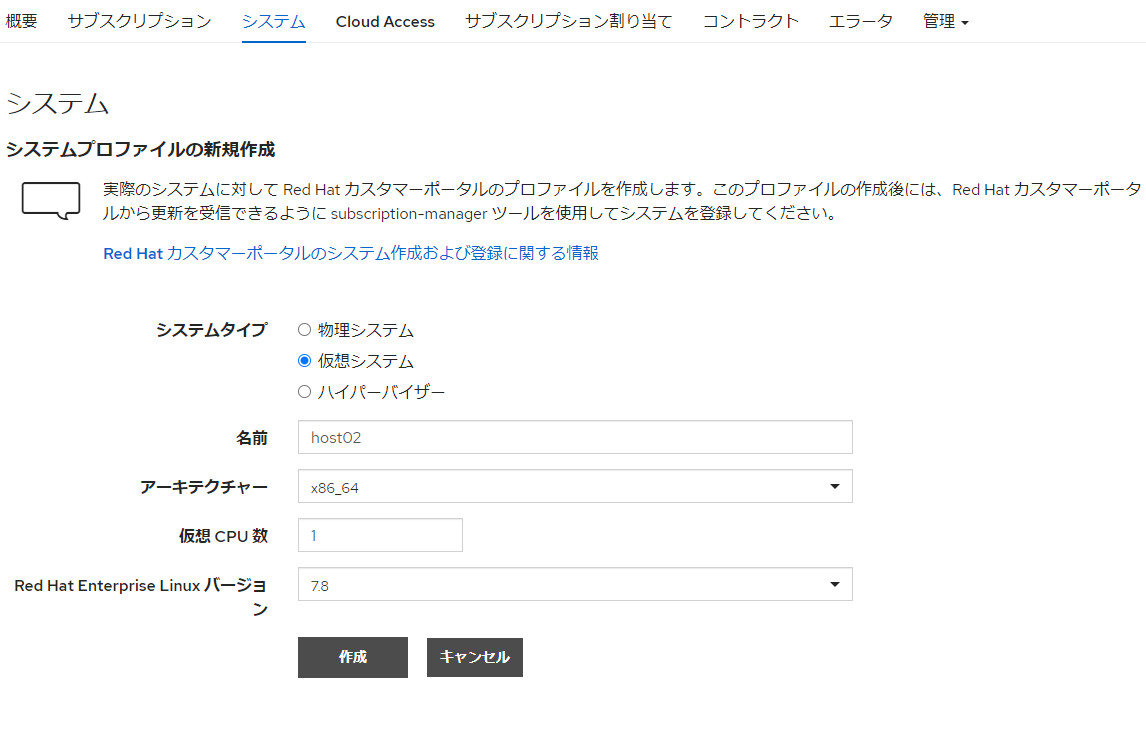
①システム登録
https://access.redhat.com/management/
にアクセスし、[システム]タブの「システムプロファイルの新規作成」
から適用するシステムを手動で登録します。
どうせ繋がらないのでなんでもいいのですが、システム名やバージョンなどを入力します。
②サブスクリプションのアタッチ
登録したシステムの[サブスクリプション]タブから、
「サブスクリプションのアタッチ」をクリックします。適用可能なサブスクリプションが出てくるのでアタッチします。
③証明書のダウンロード
適用後、横に「証明書のダウンロード」が出てくるのでクリックしてダウンロードします。
(zipでダウンロードされます)
④適用
ダウンロードしたzipを解凍し、中にあるpemファイルを適用するコンピューター上に配置します。
/tmpに配置したとして、以下コマンドを実行します。subscription-manager import --certificate=/tmp/Name_Of_Downloaded_Entitlement_Cert.pem
証明書 Name_Of_Downloaded_Entitlement_Cert.pem は正常にインポートされました
と表示されればOK 。確認
# subscription-manager list +-------------------------------------------+ インストール済み製品のステータス +-------------------------------------------+ 製品名: Red Hat Enterprise Linux Server 製品 ID: 69 バージョン: 7.8 アーキテクチャー: x86_64 状態: 不明 状態の詳細: 開始: 終了:オフラインなのでステータス情報はみえませんが、これでyum実行できるようになります。
以上オオン。

- 投稿日:2020-07-28T17:37:06+09:00
新規ファイル作成【BashとPowerShellの比較】
コマンドの比較
シェル コマンド コマンドの短縮形 Bash touch- PowerShell New-ItemniBash
コマンド形式
$ touch 新規ファイル名使用例
例えば
sample_bash.txtというファイルを作るには、下のようにします。$ touch sample_bash.txtPowerShell
コマンド形式
> New-Item -Type File 新規ファイル名または
> ni -Type File 新規ファイル名使用例
例えば
sample_powershell.txtというファイルを作るには、下のようにします。> New-Item -Type File sample_powershell.txtまたは
> ni -Type File sample_powershell.txt
- 投稿日:2020-07-28T17:27:37+09:00
Linux(Bash)とWindows(PowerShell)のコマンド対応表
とりあえずメモ。
私が必要と感じた時、またはリクエストがあった時に随時追加。BashとPowerShellのコマンド対応表 (50音順)
したいこと Bashコマンド PowerShellコマンド 使い方(URLリンク) エイリアスの作成 aliasSet-AliasまたはsalComing Soon. エイリアスの作成(引数が複数ある場合) alias存在しない(自作関数を作成する) Coming Soon. エイリアスの詳細の表示 aliasGet-AliasまたはgalComing Soon. コマンドのマニュアルの表示 manGet-HelpまたはmanComing Soon. 再起動 shutdownまたはrebootRestart-ComputerComing Soon. シャットダウン shutdownStop-ComputerComing Soon. 設定の反映 sourceまたは..Coming Soon. ファイル権限の変更 chmodicaclsComing Soon. ファイルの削除 rmRemove-ItemまたはrmComing Soon. ファイル所有者の変更 chowntakeownComing Soon. ファイル新規作成 touchNew-Itemまたはni新規ファイル作成【BashとPowerShellの比較】 ファイル内の文字列検索 grepSelect-StringまたはslsComing Soon. ファイル名検索 findGet-ChildItemまたはdirまたはlsComing Soon. プロセスの起動(アプリの起動) xdg-openまたは./Start-Processまたはstartまたは./Coming Soon. プロセスの表示 psGet-ProcessComing Soon. 何かあったら、追加していきます `` `` Coming Soon.
- 投稿日:2020-07-28T17:27:37+09:00
BashとPowerShellのコマンド対応表
とりあえずメモ。
私が必要と感じた時、またはリクエストがあった時に随時追加。BashとPowerShellのコマンド対応表 (50音順)
したいこと Bashコマンド PowerShellコマンド 使い方(URLリンク) エイリアスの作成 aliasSet-AliasまたはsalComing Soon. エイリアスの作成(引数が複数ある場合) alias存在しない(自作関数を作成する) Coming Soon. エイリアスの詳細の表示 aliasGet-AliasまたはgalComing Soon. コマンドのマニュアルの表示 manGet-HelpまたはmanComing Soon. 設定の反映 sourceまたは..Coming Soon. ファイル権限の変更 chmodicaclsComing Soon. ファイルの削除 rmRemove-ItemまたはrmComing Soon. ファイル所有者の変更 chowntakeownComing Soon. ファイル新規作成 touchNew-Itemまたはni新規ファイル作成【BashとPowerShellの比較】 ファイル内の文字列検索 grepSelect-StringまたはslsComing Soon. ファイル名検索 findGet-ChildItemまたはdirまたはlsComing Soon. 何かあったら、追加していきます `` `` Coming Soon.
- 投稿日:2020-07-28T13:31:04+09:00
Linux上のPythonアプリからAmazon RedshiftにODBCでデータ連携
はじめに
この記事では、DataDirectドライバを利用し、Linux、UNIX上のPythonアプリケーションからAmazon RedshiftにODBCで簡単にデータ連携する方法を解説します。
unixODBCをインストールする
1、以下のコマンドで、unixODBCパッケージをインストールします。
CentOSの場合
sudo yum install unixODBC-devel unixODBCUbuntu/Debianの場合
sudo apt-get install unixODBC-dev unixODBC2、unixODBCのインストール後、
/home//Progress/DataDirect/ODBC_80_64bit/odbcinst.iniの内容を、
/etc/odbcinst.ini
に貼り付けます。
Amazon Redshift用DataDirectドライバのインストール
1、DataDirect ODBC Driver for Amazon Redshiftをダウンロードします。
2、以下のコマンドを実行し、パッケージを展開します。ar -xvf PROGRESS_DATADIRECT_ODBC_REDSHIFT_LINUX_64.tgz3、binファイルを実行し、ドライバをインストールします。
./ PROGRESS_DATADIRECT_ODBC_8.0_LINUX_64_INSTALL.bin4、インストール完了後、インストールフォルダに移動し、シェルスクリプト odbc.sh または odbc.csh を実行し、環境変数を設定します。
5、これで3つの環境変数が設定されます。正しく設定されているかどうかを確認し、先に進みましょう!
[progress@centos7264 ODBC_80_64bit]$ echo $LD_LIBRARY_PATH && echo $ODBCINI && echo $ODBCINST /home/progress/Progress/DataDirect/ODBC_80_64bit/lib:/home/progress/Progress/DataDirect/ODBC_80_64bit/jre/lib/amd64/server /home/progress/Progress/DataDirect/ODBC_80_64bit/odbc.ini /home/progress/Progress/DataDirect/ODBC_80_64bit/odbcinst.iniPythonからRedshiftに接続する
1、Linux、Unix上yPthonアプリケーションよりRedshiftにアクセスするには、pyodbcパッケージをインストールしなくてはなりません。
以下のコマンドでインストールしてください。pip install pyodbc2、以下のサンプルPythonプログラムで、Redshiftからデータにアクセスしてみましょう。
import pyodbc conn = pyodbc.connect('Driver={DataDirect 8.0 Amazon Redshift Wire Protocol}; HostName=redshift-cluster-1.cy1mp8nn6ntk.us-west-2.redshift.amazonaws.com; Database=dev; UID=awsuser; PWD=Galaxy472; Port=5439') cursor = conn.cursor() ## Create Tables cursor.execute("CREATE TABLE Track ( TrackId INT NOT NULL, Name VARCHAR(200) NOT NULL, AlbumId INT, MediaTypeId INT NOT NULL, GenreId INT, Composer VARCHAR(220), Milliseconds INT NOT NULL, Bytes INT, UnitPrice NUMERIC(10,2) NOT NULL);") cursor.execute("INSERT INTO Track (TrackId, Name, AlbumId, MediaTypeId, GenreId, Composer, Milliseconds, Bytes, UnitPrice) VALUES (1, 'For Those About To Rock (We Salute You)', 1, 1, 1, 'Angus Young, Malcolm Young, Brian Johnson', 343719, 11170334, 0.99);") conn.commit() ##Access Data using SQL cursor.execute("select * from Track") while True: row = cursor.fetchone() if not row: break print(row) ##Access Data using SQL cursor.execute("select * from Artist") while True: row = cursor.fetchone() if not row: break print(row)非常に簡単ですね。
参考記事
- 投稿日:2020-07-28T08:01:19+09:00
mmap(2)したファイルは、いつ更新されるのか (2)
前回は、概要を述べて、mmap域への書き込みの検出方式として大きく2通り、細かくは3通り (1a ページテーブルスキャン方式、1b 物理ページスキャン方式、2 write fault捕捉方式) を予測した。本稿では、広く使われているOSSのOSのコードを調べて、どの方式を取っているか、あるいは他の方式を取っているのか調べてみる。
Linuxの場合
Linuxの仮想メモリ関連コードは、ソースツリーのmmというディレクトリにあり、ページ置換コードはvmscan.cにある。
Linuxのmmコードの特徴として、機種非依存部が直接ページテーブルを操作する点が挙げられる。もちろん、ページテーブルの構造は機種によって様々であるが、機種依存部で定義されたマクロを介して操作している。多段ページテーブルの構造までが機種非依存部に現れているのは、あまり見かけない特徴だと思う。これは、Linuxが元々x86専用のカーネルであったこと、比較的新しいためエキセントリックなMMUが淘汰され、似通った構成のMMUばかりになった後で開発されていることなどが影響していると考えられる。
ページテーブルのスキャン
x86のMMU操作マクロは、arch/x86/include/asm/pgtable.hなどで定義されている。あるページのD bitが立っているかどうかを調べるマクロは、pte_dirty()。
vmscanは大変複雑なコードである。ページ入れ替えが動くのは2通りの場合があり、一つはkswapdというカーネル内で動作するバックグラウンドプロセス (kthread) が実行する場合、もう一つはLinuxないでメモリを獲得しようとしたときに、空きメモリがなかった (非常に少なかった) 場合にフォアグラウンドで実行される場合 (direct reclaim) である。どちらも、最終的にはshrink_node()という所にくる。
この先を追いかけても (それなりに骨が折れる)、直接・間接にpte_dirty()を呼んでいるところは存在しない。したがって、Linuxはwrite fault捕捉方式らしいことがわかる。
write faultとページ書き出し
念のため、write faultのコードと、ダーティページの書き出しの部分を見てみる。Linuxのページフォルトコードは、機種依存部にあるページフォルトルーチンを経てhandle_mm_fault()にくる。このとき、write faultのときはflags引数 (ビットマップ) でFAULT_FLAG_WRITEが指定されている。この後__handle_mm_fault()→handle_pte_fault()と来る (途中HugePagesとか多段ページテーブルの上位部分の処理などは気にしない)。FAULT_FLAG_WRITEかつページが書き込み禁止 (!pte_write(entry)) のときは、do_wp_page()に飛ぶ。ファイルをMAP_SHAREDでマップしている場合はwp_page_shared()だ。
vma->vm_ops->page_mkwriteは、filemap_page_mkwrite()を指しているはずで、この中でファイルのタイムスタンプを更新し、またページをダーティにしている (このダーティは、PTEのD bitのダーティとは異なりページ属性である。あるページが複数プロセスからマップされている場合、対応するPTEは複数あり、書き込みが行われた仮想空間に対応するページテーブルの中のPTEのD bitがセットされる。write(2)などのシステムコールでダーティとなるのはカーネル空間のページテーブルの中のPTEであり、vmscanの対象にはならないが、これはいつダーティとなるかが明白であるためシステムコールの時点でページ属性のダーティをセットできる。またset_page_dirty()では、ページをダーティページを管理するリストにつなぐ処理も行っている)。
このダーティなページを書き出すのは、bdi flusherという人である。bdi flusherによる書き出しは、sysctl変数vm.dirty_expire_centisecsなどで制御され、ある程度のメモリ書き込みを貯めてからストレージに書き出すようになっている。現在はworkqueueを利用して実装されている。データをキューに登録すると、後からコールバック関数を実行してくれる仕組みで、この場合データはブロックデバイスごとに作られる (正確にはmemcgごとにも) struct bdi_writeback (wb)、コールバック関数はwb_workfnである。
この先は煩雑なので省略するが、ページキャッシュの書き出しは、do_writepages()でファイルシステム毎に用意されたwritepagesメソッド (ext4ならext4_writepages()、XFSならxfs_vm_writepages()など) の先で行われるようだ。ここでは、汎用 (ファイルシステムごとのwritepagesメソッドが登録されていないときに呼ばれ、またテンプレート的なコードでもある) のgeneric_writepages()を追ってみる。本体は、write_cache_pages()だ。指定のファイルのダーティページキャッシュを書き出す。
whileループの中で、pagevec_lookup_range_tag()で、ダーティなキャッシュページを探してくる。結果が収められるstruct pagevecは、物理ページを表すstruct pageの固定長配列 (長さ15) で、forループはpagevecの要素毎のもの。pagevec_lookup_range_tag()ではダーティページのみを探すようになっているが、他のCPUなどでフラッシュが行われたりした場合はスキップするなどの処理後、
if (!clear_page_dirty_for_io(page)) goto continue_unlock; trace_wbc_writepage(wbc, inode_to_bdi(mapping->host)); error = (*writepage)(page, wbc, data);この部分がミソである。clear_page_dirty_for_io()は後で見るが、これから書き出すのでダーティマークを外す、といった名前になっている。writepageはファイルシステム依存のwritepageメソッドで、その名の通りページを書き出す。
clear_page_dirty_for_io()は、同じファイルの少し後ろにある。以下がキモだ。
if (page_mkclean(page)) set_page_dirty(page);page_mkclean()はrmap.cの中にある。rmapとは、reverse mapの略で、物理ページからPTEを得るための構造である。物理ページは複数のPTEから参照される可能性があるので、その一つ一つについてpage_mkclean_one()を呼び出す。というわけで、ようやく
entry = ptep_clear_flush(vma, address, pte); entry = pte_wrprotect(entry); entry = pte_mkclean(entry); set_pte_at(vma->vm_mm, address, pte, entry);にたどり着いた。D bitを落とすと同時にR/W bitをクリアしてwrite protectしている。これで、ページキャッシュの書き出しを始める前にread onlyにしていることがわかった。
NetBSDの場合
NetBSDは、4.4BSDをベースとしたOSである。4.4BSDは、仮想メモリシステムをCMUのマイクロカーネルMach (マーク) から移植したようだが、要件の異なるMachの仮想メモリシステムを使い続けるのは無理があったのか、NetBSDは仮想メモリシステムを独自のものに置き換えた。このコードをUVMとよび、The NetBSD Projectの文書のページからリンクされているCharles D. Cranorの学位論文に詳しく説明されている (20年以上前の論文であり、現状とは異なる点には注意が必要)。
NetBSDのUVMでは、機種依存部 (NetBSD用語でMD: Machine Dependent) はpmapレイヤと呼ぶ。機種非依存部 (MI: Machine Independent) に登場するのは、Linuxのようなページテーブルそのものではなくstruct pmapというopaque構造体 (MDのpmapレイヤで実装される) と、仮想アドレス (VA)、物理アドレス (PA) などである。ページテーブルの多段構造などは、pmapレイヤに隠蔽されている。UVMは、Mach仮想メモリシステムとpmapレイヤとのインターフェイスを保つ形で実装された。
NetBSDのソースコードに慣れている人はさほどいないと思われるため、簡単に用語解説をしておく。
- struct vm_map: 仮想メモリ空間を表す。Linuxのstruct mm_structに相当。
- struct vm_map_entry/entry: 仮想メモリ空間の一部で、実行ファイルのテキスト領域、データ領域、スタックなどに、それぞれ1つずつが割り当てられる。Linuxのstruct vm_area_structに相当。
- struct vnode/vnode: ファイルを表す。Linuxのstruct inodeに相当する。inode operationsに相当するメソッド群をvnode operations (vnops) と呼ぶ。
- pager: ページング動作を行う人で、ページング先によってvnode pager (通常ファイル)、aobj pager (swap域。なお、通常の匿名メモリはaobjではなく、aobj pagerはtmpfsなどの少々特殊な目的)、device pager (キャラクタデバイス) などがある (他にread(2)/write(2)などのための特殊なpagerであるUBCなど)。実体はPGO (Pager Operations) とよばれる関数ポインタ群で、ページ読み込みのためのpgo_get、ページ書き出しのためのpgo_putなどがある。
- struct uvm_object/uobj: ファイルやデバイスなどをさす。それぞれ、pager一つと関連づけられている。vnode pagerと結びついたvnode object (uvn)、デバイスと結びついたdevice object (udv)、aobj pagerと結びついたaobjなどがある。
- upper layer/lower layer: 各vm_map_entryのlower layerはuobj、upper layerは匿名メモリを管理する構造 (aobjではない) である。たとえばプロセスのテキスト域は、通常vnode objectのlower layerのみをもつ。データ域は当初はvnode objectのlower layerのみを持つが、そこに書き込みが発生すると、Copy on Writeによりupper layerに匿名メモリが確保される (この動作をpromoteと呼ぶ)。ヒープやスタックはupper layerのみを持つ。
- wired page/wire/unwire: mlock(2)やI/Oの最中などで、一時的にページアウトの対象とならないページのことをwired pageとよび、あるページをそのような状態にする操作をwire、wired pageをページング対象に戻す操作をunwireと呼ぶ。
- protection: 仮想メモリのパーミッション (R/W/X) のこと。各entryには、mmap(2)の引数で示されるprotectionの他に、max_protectionが定義されており、これはmmap時のopen(2)のフラグ (O_RDONLYなど) などによって決まる。たとえば、MAP_PRIVATEでmmapされた領域では、常にmax_protectionでは書き込みが許されている。プロセスのテキスト域は通常r-xでmmapされている (protectionがr-x) が、gdbなどからブレークポイントを仕掛けると、指定アドレスの命令をブレークポイント命令に書き換える。こうした特殊な場合にmax_protection (常に書き込みが許可されているのでrwx) が適用される。
- pv mapping/pv: Physical to Virtual mapping。物理アドレスから仮想空間 (struct pmap)/仮想アドレスを引く仕組みで、Linuxのrmapに相当するが、pmapレイヤで実装されている。同一物理ページが複数の仮想アドレスにマップされることがあるので、リスト構造になっている。
- loan: 仮想メモリ空間の間でページを貸し借りするUVMの機能で、プロセス間通信 (pipeなど) の実装に使われている。
NetBSDのソースコードは、CVSで管理されているが、特定の行にリンクするため、以下ではGithubのミラーを参照する。
ページテーブルのスキャン
pmapインターフェイスで、あるページのD bitが立っているかどうかを調べるのは、pmap_is_modified()である。引数は物理ページであるため、これを指すPTEは複数ある可能性があり、その場合は1つでもD bitがセットされているPTEがあれば真を返す。他にpmap_clear_modify()が、あるページを指すPTE (複数ある可能性) のD bitをクリアすると同時に、セットされているPTEがあったかどうかを返す (Linuxのpage_mkclean()相当)。UVMでページ解放を担うのは、page daemon (pdaemon) というカーネルスレッドであるが、この先どころか、実は、UVMのソースコード全体をgrepでさらってみても、pmap_is_modified() (やpmap_clear_modify()) を呼んでいる箇所はない。したがって、NetBSDもwrite fault捕捉方式らしいとわかる。
興味深いことに、NetBSDではページ置換アルゴリズムがpluggableになっていて、実際にClock、Clock Proの2種類から選択することができる。
write faultとページの書き出し
念のため、write faultのコードと、ダーティページの書き出しの部分を見てみる。NetBSDのページフォルト処理は、uvm/uvm_fault.cにある。write faultの場合、引数access_typeに、VM_PROT_WRITEが入っていて、これはstruct uvm_faultctx flt.access_typeに保存される。上の方にあるコメントによると、mmapでMAP_SHAREDでファイルを貼った部分へのwrite faultは、CASE 2Aという分類だ。uvm_fault_lower()というところで処理される。uobjは、mmapされているファイルをあらわしている。
通常ファイルの場合、uobj->pgops->pgo_faultはNULL、uobj->pgops->pgo_getはuvn_get()、またファイルシステムがBSD FFSの場合のvop_getpagesがgenfs_getpages()である、ということに留意してコードを追いかけると、uvm_fault_lower()→uvm_fault_lower_lookup()→uvm_get()→VOP_GETPAGES()→genfs_getpages()と進む。genfs_getpages()は、ページキャッシュにストレージからデータを読み込んでくるところだ。access_typeのVM_PROT_WRITEは、変数memwriteに反映される。またタイムスタンプが更新されている。そして261行目。
if (error == 0 && memwrite) { genfs_markdirty(vp); }ここでvnodeをダーティとし、後述のsyncerによるライトバック対象のリストに登録している。ページをダーティとしている (ページのflagsからPG_CLEANフラグを落とす) 部分はないようだ (以下のダーティページを書き出す処理を読むと、確かに不要に思える)。どこかでダーティにしているのであれば、誰か教えてください。
次に、ダーティページを書き出す処理。これは、syncerというカーネルスレッドが行う。syncerの本体は、sched_sync()である。ここからlazy_sync_vnode()→VOP_FSYNC()→ffs_fsync()→ffs_full_fsync()→vflushbuf()→VOP_PUTPAGES()→genfs_putpages()で書き出される。wapblというのは、ext3/4のjournalに相当するが、ここではないものとしよう。vflushbuf()でPGO_CLEANITをセットしているので、その流れを追うと、まずfstransという仕組みでtransactionを開始してretryにもどり、whileループに入る。whileループでは、オンメモリのページの粗密により、by_list (ページのリストを辿る) かページを順々に見ていくか切り替えているようだ。いずれにしても、現在の対象ページはstruct vm_page *pgに入っている。
この先少々自信がない。1112行目
if (flags & PGO_CLEANIT) { needs_clean = pmap_clear_modify(pg) || (pg->flags & PG_CLEAN) == 0; pg->flags |= PG_CLEAN; } else {pmap_clear_modify()で、pgを指す各PTEのD bitを落とすとともに、落とす前のD bitがneeds_cleanに反映される。
またread onlyにしているのはその少し前のようだ。
if (cleanall && wasclean && gp->g_dirtygen == dirtygen) { /* * uobj pages get wired only by uvm_fault * where uobj is locked. */ if (pg->wire_count == 0) { pmap_page_protect(pg, VM_PROT_READ|VM_PROT_EXECUTE); } else { cleanall = false; } }wascleanは、vnodeのvp_numoutputという属性が0のときセットされている。このメンバー、この先のページの書き出しを開始するところで増やされているが、ここに来る時点で必ず0なのだろうか。dirtygenは、genfs_do_putpages()の最初のところでvnodeの同名の属性からコピーしている。この属性は、genfs_markdirty()というところで増やされている。dirty generationと思われ、ページを書き出している裏で同一ファイルの別なページでwrite faultが発生したりすると、gp->g_dirtygen == dirtygenの条件が外れる。この場合、後の処理でこのvnodeをsyncerの対象から外す処理がなされないので、確かにこれで良さそうだ。
怪しいながら、NetBSDもwrite fault時にページの書き込みを許可すると同時にこれをダーティとし、これを書き出す際に再度read onlyにしているらしいことがわかった。ただ、あるファイルのページキャッシュのうち、具体的にどのページがダーティなのかを判断するのに、D bitを活用している。
長くなったので、本稿はここまで。次稿では、あと2つ見て最終回の予定。LinuxとNetBSDという出自の異なる2つのOSが、同じ方式を取っていた。これが主流ということなのか、他の方式のOSもあるのか、お楽しみに。
- 投稿日:2020-07-28T05:42:28+09:00
How Linux Works読書メモ
Table of Contents
はじめに
Linuxがどのように起動するかについて書かれている書籍として、それほど
マニアでない一般エンジニア向けに書かれているHow Linux Worksは貴重です
(表紙に若干クセがありますが)。私が以前、VirtualBoxに入れたLinuxで動作を
確認しつつこの本を読んだときに書いたメモを発掘したので公開します。
一部の物好きな人にはそれなりに有用なコンテンツになっていると思います。
この記事は、私のブログからの転載です。https://achiwa912.github.io/デバイス
デバイスファイル
- Unixシステムでは、デバイスI/Oインタフェースをカーネルがファイルとしてユーザースペースに見せているため、多くのデバイスを扱うことが容易である。これらのデバイスファイルはデバイスノードと呼ばれることもある。デバイスファイルは/devにある。
ls -lをしたときに属性の最初のバイトがb(block), c(character), p(pipe) or s(socket)であれば、それはデバイスファイルである。
brw-rw---- 1 root disk 8, 0 Jan 23 21:44 sda
crw--w---- 1 Debian-gdm tty 4, 1 Jan 23 21:44 tty1プログラムはブロックデバイスのデータを固定長のチャンクとしてアクセスする。
キャラクターデバイスはデータストリームを扱う。リード、ライトしかできずサイズを持たない。カーネルはデバイスやプロセスにデータを渡した後では、データストリームをバックアップしたり内容の確認をしたりすることはできない。
名前付きパイプ(named pipes)はキャラクターデバイスに似ている。I/Oストリームの行き先にカーネルドライバーがいる代わりに他のプロセスがいる。
ソケットはプロセス間通信でよく使われる、特別な用途のインタフェース。これらは通常/devの外にある。
上記例の日付の前の2つの数字はメジャー及びマイナーデバイス番号で、カーネルがデバイスを特定するのに使う。sda1やsda3のような類似のデバイスは同じメジャー番号を持つ。
sysfsデバイスパス
- トラディショナルなUnixの/devディレクトリは簡単であるが問題もある。名前からどのようなデバイスかわからないし、カーネルは見つかった順にデバイス名を付けるので、リブートで異なるデバイス名が付く可能性がある。
デバイスの実際のハードウエア属性に基づいた、一貫したビューを提供するために、Linuxカーネルはシステムファイルやディレクトリを通じたsysfsインタフェースを提供する。デバイスのベースパスは/sys/devicesである。
$ udevadm info --name=/dev/sda
P: /devices/pci0000:00/0000:00:0d.0/ata1/host0/target0:0:0/0:0:0:0/block/sda/devファイルはユーザープロセスがデバイスを使うためのもので、こちらはデバイスの情報を見たり管理するためのもの。これはディレクトリになっていて、プログラムがアクセスするためのファイルやサブディレクトリを持つ。
/sysディレクトリにいくつかのショートカットを持つ。これらはシンボリックリンクである。
$ ls -l /sys/block
total 0
lrwxrwxrwx 1 root root 0 Jan 23 21:44 sda -> ../devices/pci0000:00/0000:00:0d.0/ata1/host0/target0:0:0/0:0:0:0/block/sda
lrwxrwxrwx 1 root root 0 Jan 23 21:44 sr0 -> ../devices/pci0000:00/0000:00:01.1/ata3/host2/target2:0:0/2:0:0:0/block/sr0udev (from wiki)
- udev (userspace /dev)はLinux kernel用のデバイスマネージャー。/devディレクトリ内のデバイスノードを管理すると共に、ハードウエアデバイスが接続されたり抜かれたりしたときに上がるユーザースペースイベントを扱う。
- udevはジェネリックなデバイスマネージャーで、Linuxシステム上でデーモンとして動き、新たなデバイスが初期化されたり抜かれたりしたときにカーネルが(netlinkソケット経由で)送るueventsをリッスンする。
- udevは以下の部分からなる。
- ライブラリ - デバイス情報へのアクセスを許す
- ユーザースペースデーモン(udevd) - 仮想的な/devを管理する
- udevadm - 管理コマンドラインユーティリティ
- udevパッケージは広範なルールのセットを持つ。ルールはイベントのエキスポートされた値とディスカバリしたデバイスの属性値を結びつける。
- udevはメッセージをカーネルから受け取り、Network Managerのようなサブシステムデーモンに渡す。アプリケーションはD-Bus上でNetwork Managerと話す。
- カーネル → udev → Network Manager ↔ D-Bus ↔ Firefox
udevadm
udevadmはudevd用の管理ツール
achiwa@dach:/tmp/myinitrd$ udevadm info --name=/dev/sda
P: /devices/pci0000:00/0000:00:0d.0/ata1/host0/target0:0:0/0:0:0:0/block/sda
N: sda
S: disk/by-id/ata-VBOX_HARDDISK_VB65997552-f7e41c5c
S: disk/by-path/pci-0000:00:0d.0-ata-1
E: DEVLINKS=/dev/disk/by-id/ata-VBOX_HARDDISK_VB65997552-f7e41c5c /dev/disk/by-path/pci-0000:00:0d.0-ata-1
E: DEVNAME=/dev/sda
E: DEVPATH=/devices/pci0000:00/0000:00:0d.0/ata1/host0/target0:0:0/0:0:0:0/block/sda
E: DEVTYPE=disk
E: ID_ATA=1
E: ID_ATA_FEATURE_SET_PM=1
P:はsysfsのデバイスパス、N:はデバイスノード、S:はudevdが作成したシンボリックリンク、E:はudevd rulesからのadditionalデバイス情報
カーネルのブート
- カーネルのブートメッセージの見方は2つ
- /var/log/kern.log
- dmesgコマンド
- カーネル初期化の流れ
- CPUチェック
- メモリチェック
- デバイスバスディスカバリー
- デバイスディスカバリー
- 補助的なカーネルサブシステム設定(ネットワーク等)
- ルートファイルシステムマウント
- ユーザースペーススタート
カーネルパラメータ
- Note: roオプションはノーマル。fsckが終わったらrwとしてリマウントする。
$ cat /proc/cmdline
BOOT_IMAGE=/boot/vmlinuz-4.9.0-8-amd64 root=UUID=bea739b9-5c56-4e5a-8c00-c84af6ae59d1 ro quietカーネルは理解できないオプションが指定されたら、initの引数として渡す。
ブートローダー
- ブートローダーは、カーネルをメモリ上に読み込み、カーネルパラメーターを指定してカーネルを起動する
- PCでは、ブートローダーはBIOS又はUnified Extensible Firmware Interface (UEFI)を使ってディスクにアクセスする。最近のブートローダーはパーティションテーブルを読み、ファイルシステムへのリードオンリーアクセスができる。
- MBRは441バイトの小さな領域で、MBRと最初のパーティションの間にある、残りのブートローダーを読むためのコードが入る。GPTでパーティションされたディスクとは互換性がない。
- UEFIはビルトインシェルを持ち、パーティションテーブルが読め、ファイルシステムをナビゲートできる。GPTパーティショニングスキームはUEFI standardの一部。ファイルシステム外のブートコードを実行する代わりに、EFI System Partition (ESP)という特殊なファイルシステムを持つ。ESPには efi というディレクトリがあり、各ブートローダーはそれぞれのIDと対応するサブディレクトリを持つ。efi/microsoft, efi/apple, efi/grubのように。ブートローダーは、.efi拡張子を持ち、これらのサブディレクトリの一つにある。UEFIにはセキュアブートの問題がある。
GRUBの挙動
- GRUPは以下のように動く。
- PC BIOS又はfirmwareがハードウエアを初期化し、ブートオーダーストレージ内のブートコードを探す
- ブートコードが見つかったら、BIOS/firmwareはロードして実行する。ここからGRUBが始まる。
- GRUBコアをロードする
- コアを初期化する。この時点ではGRUBはディスクやファイルシステムにアクセスできるようになる。
- GRUBはブートパーティションを見つけ、設定を読み込む。
- GRUBはユーザーに設定を変えるチャンスを与える。
- タイムアウトまたはユーザーアクションの後、GRUBは設定を実行する。
- 設定を実行する間に、GRUBはブートパーティション内の追加モジュールをロードするかも。
- GRUBはbootコマンドを実行し、設定のlinuxコマンドで指定されたカーネルをロードして実行する。
- ステップ3と4は複雑。ESPパーティションがある場合はそこからGRUBコアを一つのファイルとして読み込む。それ以外はPC BIOSがMBRから512Bをロードして実行し、コアをロード、実行する。
- ブートローダーは、カーネルをロード・実行する前に、initial RAM filesystemをメモリ上にロードする必要があるかもしれない。これはinitrd設定パラメータで指定する。
ユーザースペースの開始
- ユーザースペースは次のように始まる。
- init
- udevd, syslogdのような必要不可欠な低レベルサービス
- ネットワーク設定
- 中〜高レベルサービス(cron, printing等)
- ログインプロンプト, GUI他の高レベルアプリケーション
init
initはLinux上の他のプログラム同様のユーザースペースプログラムで、他のシステムバイナリと同様に/sbinにある。
$ ls -l /sbin/init
lrwxrwxrwx 1 root root 20 Jan 15 18:59 /sbin/init -> /lib/systemd/systemdinitの主な目的は、システム上で必要不可欠なサービスプロセスをstart, stopすること。主に3種類の実装がある。
- System V init. 伝統的なinit。Red Hat Enterprise Linuxは他のいくつかのディストリビューションがこのバージョンを使っている。
- systemd. 標準になりつつあるinit。多くのディストリビューションがsystemdに移行し、まだしていないものも移行を計画中。
- Upstart. Ubuntuが使っているが、systemdに移行予定。
System V initや他の古いバージョンは一度に一つのスタートアップタスクをすることしかできない。dependenciesの解決は比較的楽だが性能がよくない。systemdとUpstartは複数のサービスを並行して起動することで性能問題を軽減する。
systemdはゴール指向。達成したいターゲットを、依存関係とともに、いつそのターゲットを達成したいかを定義する。systemdはサービスの開始を、絶対に必要になるまで遅らせることができる。
systemd
- systemdのブート時の動き
- systemdが設定を読む
- systemdはブートゴールを決める。これは通常 default.target
- systemdはデフォルトのブートゴールの依存関係やそれらに対するさらなる依存関係を全て把握する
- systemdはその依存関係とブートゴールをactivateする
- ブート後、systemdはueventsのようなシステムイベントに反応して追加コンポーネントをactivateできる。
- 複数サービスを起動する時、systemdは厳密なシーケンス(順番)に従わない。他のモダンなinitシステム同様に、systemdブートアッププロセスにはかなりの自由度がある。
ユニットとユニットタイプ
- systemdはプロセスやサービスを操作するだけでなく、ファイルシステムをマウントし、ネットワークソケットをモニターし、タイマーを走らせ、といった多くのことを行う。各capabilityのタイプをユニットタイプと呼び、具体的なcapabilityをユニットと呼ぶ。
- 全てのUnixシステムで必要なブート時のタスクを実行するユニットタイプ:
- サービスユニット. Unixシステムにおけるトラディショナルなサービスデーモンを制御する
- マウントユニット. Unixシステムへのファイルシステムのマウントを制御する
- ターゲットユニット. 他のユニットを、通常グループ化して制御する
- デフォルトのブートゴールは通常、複数のサービスとマウントユニット(複数)をdependenciesとしてグループ化したターゲットユニット。
systemdの依存関係
- systemdには多くの依存関係タイプとスタイルがある。
- Requires - 厳密な依存関係。もし依存されるユニットがfailすると、依存するユニットをfailさせる
- Wants - Dependencies for activation only. systemdはユニットのWants dependenciesを有効化しようとするが、failしても気にしない
- Requisite - 既にアクティブでなくてはいけないユニット。Requisite dependencyのユニットを有効化する前に、systemdはそのdependencyのチェックを行う。もしそのdependencyが有効になっていなければ、systemdはそのユニットの有効化に失敗する
- Conflicts - Negative dependencies. Conflict dependencyのユニットを有効化する際に、systemdはそのdependencyのユニットがアクティブであれば自動的に無効化する。2つのコンフリクトするユニットの有効化は失敗させる。
- Note: Wants dependencyは強力で、失敗が他のユニットに影響しない。systemdのドキュメントによると、可能な限りWantsを使うべきと書いてある。
- dependenciesを逆順に付けることもできる。Wants -> WantedBy, Requires -> RequiredBy
- ユニットの起動を順序付けするために、以下のdependency modifiresを使うことができる。
- Before. 並べられたユニットよりも早くこのユニットを有効化する。
- After. その逆
- Conditional dependencyキーワードが、systemdユニットではなく様々なoperation system statesに対して存在する。
- ConditionPathExists=p: (ファイル)パスpが存在すればTrue
- ConditionPathIsDrectory=p: 略
- ConditionFileNotEmpty=p: 略
- Conditional dependencyキーワードがfalseだった場合、systemdはそのユニットを有効化しない。しかしこれはそのキーワードが現れたユニットに対してだけ適用される。このため、condition dependencyを持つユニットを有効化しようとしたとき、それが他のユニットdependenciesを持っていたら、systemdは条件がtrue/falseによらず、そのユニットdependenciesを有効化しようとする。
systemd Configuration
systemdの構成ファイルは多くのディレクトリに散らばっているが、2つの主なディレクトリがある: システムユニットディレクトリ(/usr/lib/systemd/system)とシステム構成ディレクトリ(/etc/systemd/system)。システムユニットディレクトリはディストリビューションが管理するため、システム構成ディレクトリにローカルな変更を入れるべき(/usrではなく/etc)。
$ pkg-config systemd --variable=systemdsystemunitdir
/lib/systemd/system
$ pkg-config systemd --variable=systemdsystemconfdir
/etc/systemd/systemユニットファイルはXDG Desktop Entry Specificationから来ており、セクション名をブラケット([])で囲み、各セクションで変数=値の設定を行う。/lib/systemd/system/keyboard-setup.serviceの例:
[Unit]
Description=Set the console keyboard layout
DefaultDependencies=no
Before=local-fs-pre.target
Wants=local-fs-pre.target
ConditionPathExists=/bin/setupcon[Service]
Type=oneshot
ExecStart=/lib/console-setup/keyboard-setup.sh
RemainAfterExit=yes[Install]
WantedBy=sysinit.target[Install]セクションのWantedByやRequiredByは、構成ファイルに手を付けずにユニットを有効化するメカニズムとして使える。通常systemdは[Install]セクションを無視するが、このサービスをdisableしてまたenableする時にsystemdは[Install]セクションを見る。WantedByを見たら、systemdはこのサービス(依存する側のユニット)に対するシンボリックリンクを構成ディレクトリ(のサブディレクトリ)内に作成する。
ln -s '/lib/systemd/system/keyboard-setup.service' '/etc/systemd/system/sysinit.target.wants/keyboard-serup.service'
[Install]セクションは通常、システム構成ディレクトリ内に.wantsや.requiresサブディレクトリを作る犯人である。[Install]セクションに対応しないリンクを手動で作成することもできる。これは、構成ファイルを変えずにdependencyを追加する簡単な方法。
Note: ユニットをenableにすることは、activate(有効化)とは異なる。ユニットをenableにする時、systemdの構成にそれをインストールすることで、リブートをsurviveする準永続する変更を加える。あるユニットが[Install]セクションを持つ場合、systemctl enableでenableする必要があるが、そうでなければそのファイルがあるだけでenableされる。systemctl startでactivateすることは、現在のランタイム環境内で使えるようにしているだけ。なお、ユニットをenableしても自動でactivateされない。
ユニットファイルにおいて、変数(eg, $MAINPID: サービスをトラックするプロセス)やSpecifies(eg, %n: 現在のユニット名)が使える。tty1, tty2などで動くgettyプロセスのような場合、getty@tty1, getty@tty2のインスタンスのためにgetty@.serviceという名のユニットファイルが作られる。
systemdに対する操作
- 基本的に、systemctlコマンドを使ってsystemdとやりとりする。
ユニットの一覧表示
$ systemctl list-units | head -3
UNIT LOAD ACTIVE SUB DESCRIPTION
proc-sys-fs-binfmt_misc.automount loaded active waiting Arbitrary Executable File Formats File System Automount Point
sys-devices-pci0000:00-0000:00:01.1-ata3-host2-target2:0:0-2:0:0:0-block-sr0.device loaded active plugged VBOX_CD-ROM VBox_GAs_5.2.18ステータス表示
$ systemctl status NetworkManager.service
● NetworkManager.service - Network Manager
Loaded: loaded (/lib/systemd/system/NetworkManager.service; enabled; vendor p
Active: active (running) since Tue 2019-01-22 12:39:39 JST; 3h 21min ago
Docs: man:NetworkManager(8)
Main PID: 377 (NetworkManager)
Tasks: 4 (limit: 4915)
CGroup: /system.slice/NetworkManager.service
├─377 /usr/sbin/NetworkManager --no-daemon
└─496 /sbin/dhclient -d -q -sf /usr/lib/NetworkManager/nm-dhcp-helperその他のコマンド
- systemctl start, stop, restart
- systemctl reload unit ユニットのconfigのみをリロードする
- systemctl daemon-reload 全てのユニットのconfigをリロードする
- systemctl list-jobs (まだ)残っているジョブ一覧を表示する
systemdにユニットを追加する
- systemdにユニットを追加することは、ユニットファイルを作成し、activateしてenable化すること。通常は、ディストリビューションの設定と干渉しないように、/etc/systemd/systemにユニットファイルを置く。
ユニット追加
(ユニットファイルを置く)
systemctl enable
systemctl startユニット削除
systemctl stop
systemctl disable
(ユニットファイルを消す)systemdのプロセストラッキングと同期
- サービスのユニットファイルでスタートアップ時の挙動を示すのにTypeオプションを使う。
- Type=simple - このサービスプロセスはforkしない
- Type=forking - このサービスはforiし、systemdは元のサービスプロセスがterminateすることを期待する。terminateすると、systemdはサービスの準備完了を知る。
- Type=notify - このサービスがreadyになったら、systemdにsd_notify()を使って通知を送る。
- Type=dbus - このサービスはreadyになるとD-bus (Desktop Bus)に自身を登録する。
- Type=oneshot - 完了したらterminateする。サービスがactiveであることをsystemdが把握できるように、RemainAfterExit=yesオプションを追加必要。
- Type=idle - 他にactiveなジョブがなくなるまでスタートしない。システム負荷を下げたり、サービスの出力が混ざることを防ぐために使う。
補助ユニットによるブート最適化
- systemdのユニット有効化の一般的なスタイルは、依存関係を単純化し、ブート時間を短くする。これは、サービスユニットと、それが提供するリソースを表す補助ユニットによるオンデマンドなスタートアップに似ているが、このケースでは、補助ユニットが有効化されると、systemdがすぐにサービスユニットを開始する。
- このスキームにする理由は、syslogやdbugといったブート時に必要なサービスがスタートするのに時間がかかり、他の多くのユニットがそれらに依存するため。systemdはあるユニットに必要な、ソケットユニットのようなリソースをすぐに用意でき、必須リソースを示すユニットだけでなく、それに依存する全てのユニットをすぐに有効化できる。
System V init
- System V initのコアとなる考えは、注意深く並べられたプロセス開始による、異なるランレベルへの順序だったブートアップをサポートすること。
- System V initのインストールには、中央設定ファイル/etc/inittabと、シンボリックリンクfarmによってaugmentされた巨大なブートスクリプト群の2つのメジャーなコンポーネントがある。(以下略)
Initial RAM Filesystem
- Linuxカーネルはドライバーサポートがなければrootファイルシステムをマウントすることができない。サポートすべきストレージの種類が多すぎるのでカーネルに全てのドライバーを組み込んでおくことはできず、ドライバーは通常loadable modulesとして提供される。しかしこれらはファイルである。
- workaroundとして、カーネルドライバーモジュールの小さなコレクションといくつかの他のユーティリティーをアーカイブとして集めておき、ブートローダーがカーネルを起動する前にこのアーカイブをメモリに読み込む。カーネルは起動時に、このアーカイブの中身をテンポラリのRAMファイルシステム(initramfs)に読み、/(ルート)にマウントし、initramfs内のユーティリティーによって、カーネルは必要なドライバーモジュールをロードしてinitramfs内のinitにハンドオフする。最後にユーティリティーが本物のルートファイルシステムをマウントして本物のinitを開始する。
initramfsは以下のようにして見ることができる。
achiwa@dach:/tmp/myinitrd$ zcat /boot/initrd.img-4.9.0-8-amd64 | cpio -i --no-absolute-filenames
113317 blocks
achiwa@dach:/tmp/myinitrd$ ls
bin conf etc init lib lib64 run sbin scriptsintelのigbドライバーも入っている。
achiwa@dach:/tmp/myinitrd/lib/modules/4.9.0-8-amd64/kernel/drivers/net/ethernet/intel$ ls -F
e1000/ e1000e/ e100.ko i40e/ i40evf/ igb/ igbvf/ ixgb/ ixgbe/ ixgbevf/
achiwa@dach:/tmp/myinitrd/lib/modules/4.9.0-8-amd64/kernel/drivers/net/ethernet/intel$ ls -lF igb
total 352
-rw-r--r-- 1 achiwa achiwa 357784 Feb 8 14:45 igb.koinitramfsを作るツールに、dracutとmkinitfamfsがある。VSP-Nにおいては、stretch標準のdracutに移行するのは大変なので、initramfs-toolsを採用する。
initramfs-tools
- http://gihyo.jp/admin/serial/01/ubuntu-recipe/0384?page=2
- initramfs-toolsパッケージはupdate-initramfsやmkinitramfs、lsinitramfsコマンドを提供する。
update-initramfsはinitfamfsイメージ(/boot/initrd-img*)の更新を行う。/etc/kernel/postinst.d/initramfs-toolsから呼び出す。
achiwa@dach:/etc/kernel/postinst.d$ head /etc/kernel/postinst.d/initramfs-tools
we're good - create initramfs. update runs do_bootloader
INITRAMFS_TOOLS_KERNEL_HOOK=1 update-initramfs -c -t -k "${version}" ${bootopt} >&2
initramfs起動の流れ
initramfs内の/initが起動される。
achiwa@dach:/tmp/myinitrd$ ls -l ./init
-rwxr-xr-x 1 achiwa achiwa 5960 Feb 12 13:16 ./init
achiwa@dach:/tmp/myinitrd$ file ./init
./init: POSIX shell script, ASCII text executable