- 投稿日:2020-07-27T23:58:59+09:00
マイグレーションファイルやテーブルの削除手順書
Railsを使い始めた頃に、マイグレーションファイルの扱いに苦戦していた時がありました。
手順や状態の確認もしないまま「いらないマイグレーションだから消してしまえ!」とか...部分的なコマンドだけではなく、「実際の流れ」や「意図」を交えて書いていきます。
スクショも使ってあるので、見難かったらすみません...汗
$は入力しなくても大丈夫です!はじめにマイグレーションファイルの状態を確認します
プロジェクト内のターミナルで下記を実行
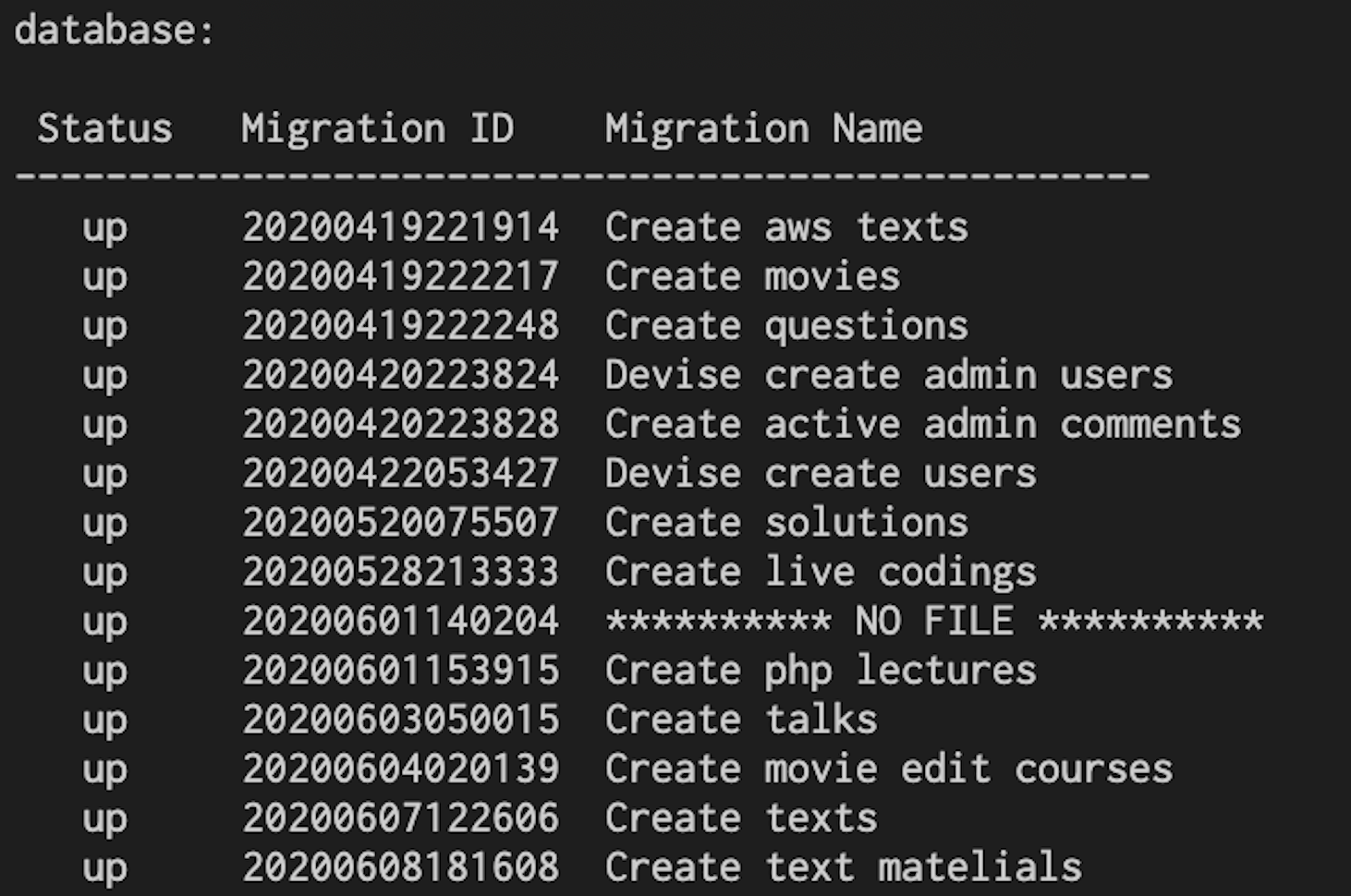
$ rails db:migrate:statusすると、現在実行されているマイグレーションファイルの状態が分かります。
※ 行いたい事:
一番下にあるCreate text matelialsのマイグレーションファイルで作成したテーブルを削除してからマイグレーションファイルも削除したい時の説明です。
1: Statusの状態を確認する
左側のStatusは全て
upになっています。upになっているということはデータベースは、このマイグレーションファイルの構造を取り入れている(マイグレーションファイルはすでに実行済みのファイル)ということです。
up状態のマイグレーションファイルは削除したり編集したりしてはいけません。状態がわかったので次は、
2: upをdownを切り替える方法
ここで必要な情報は Migration ID の数字!!
今回で言うと20200608181608です。プロジェクト内のターミナルで下記を実行
$ rails db:migrate:down VERSION= "Migration ID"今回だと下記になります。
$ rails db:migrate:down VERSION=20200608181608すると、こんな画面になる。
エラーが出なければOKです!
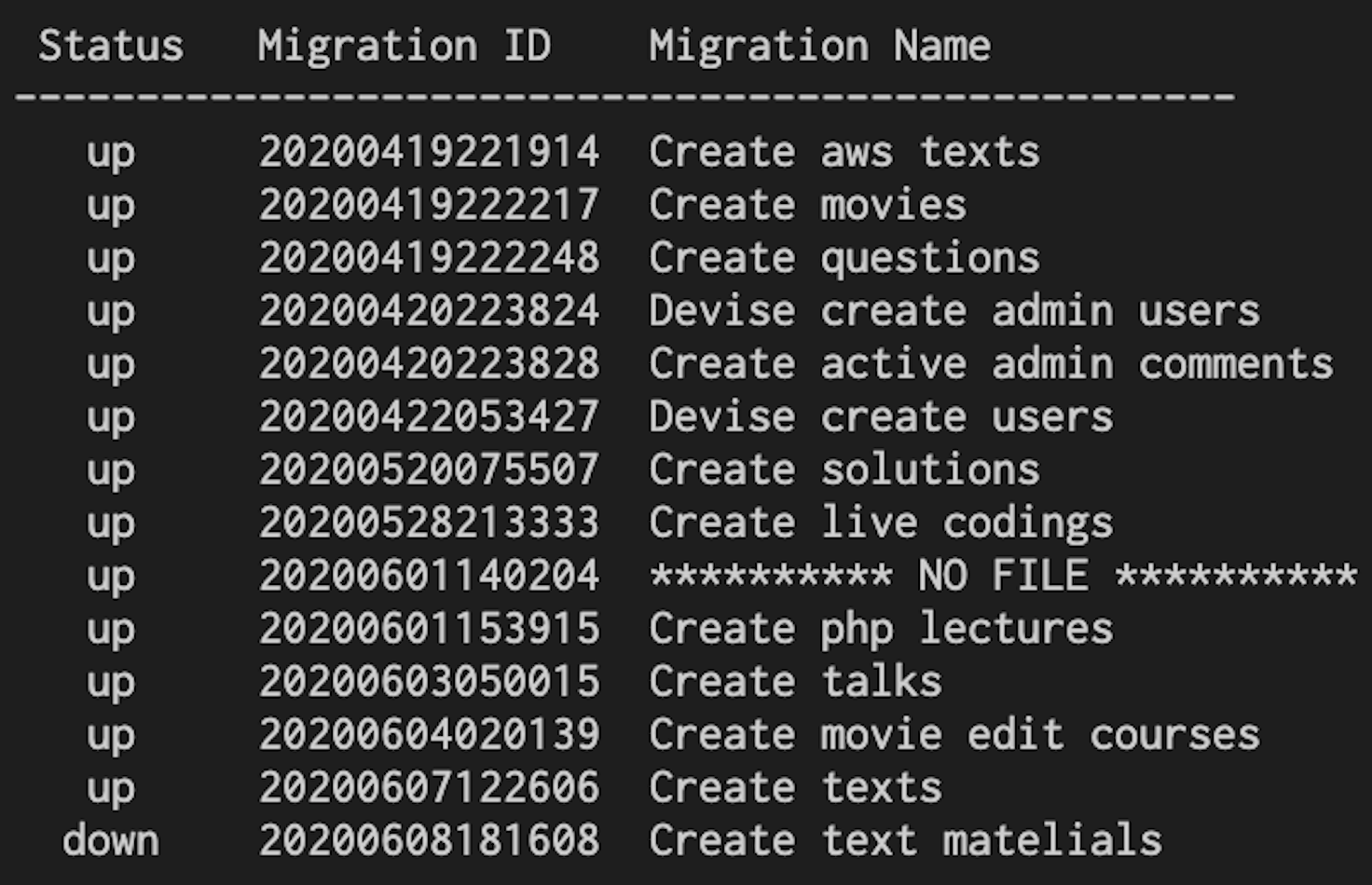
もう一度Statusを確認します
rails db:migrate:statusを実行
ちゃんとdownになっています。
down状態なので編集と削除ができます。3: テーブルを編集、削除する手順
"db/maigrate"内にあるマイグレーションファイルを開いて追記します。
(↑ は後に重要なことなので、太めに書いておきました)
今回は、"db/maigrate"内にある
20200608181608_create_text_matelials.rbファイルを開きます。中のコードが下記の時
class CreateTextMatelials < ActiveRecord::Migration[6.0] def change end endこの中へ
drop_table :削除したいテーブル名を追記します。
※自身のテーブル名を確認したい場合はdb/schema.rbの中を確認してください。
※注意:ActiveRecord::Migration [6.0] の部分は自身のRailsのバージョンに指定してください。(例) [5.1]等「Railsのバージョンがわからない...」場合は
ターミナルでrails -vを実行するとわかりますよ。追記後は下記です。
class CreateTextMatelials < ActiveRecord::Migration[6.0] def change drop_table :text_matelials end end削除する追記が完了したら
rails db:migrateを実行します。
これでテーブルの削除ができました。
db/schema.rbの中を確認すると指定したテーブルは削除されているはずです。【何が起きていたのか文章で言うと..】
drop_table :text_matelialsとしてtext_matelialsテーブルを削除する内容を記述したファイルを実行したのでテーブルを削除できたというわけです。
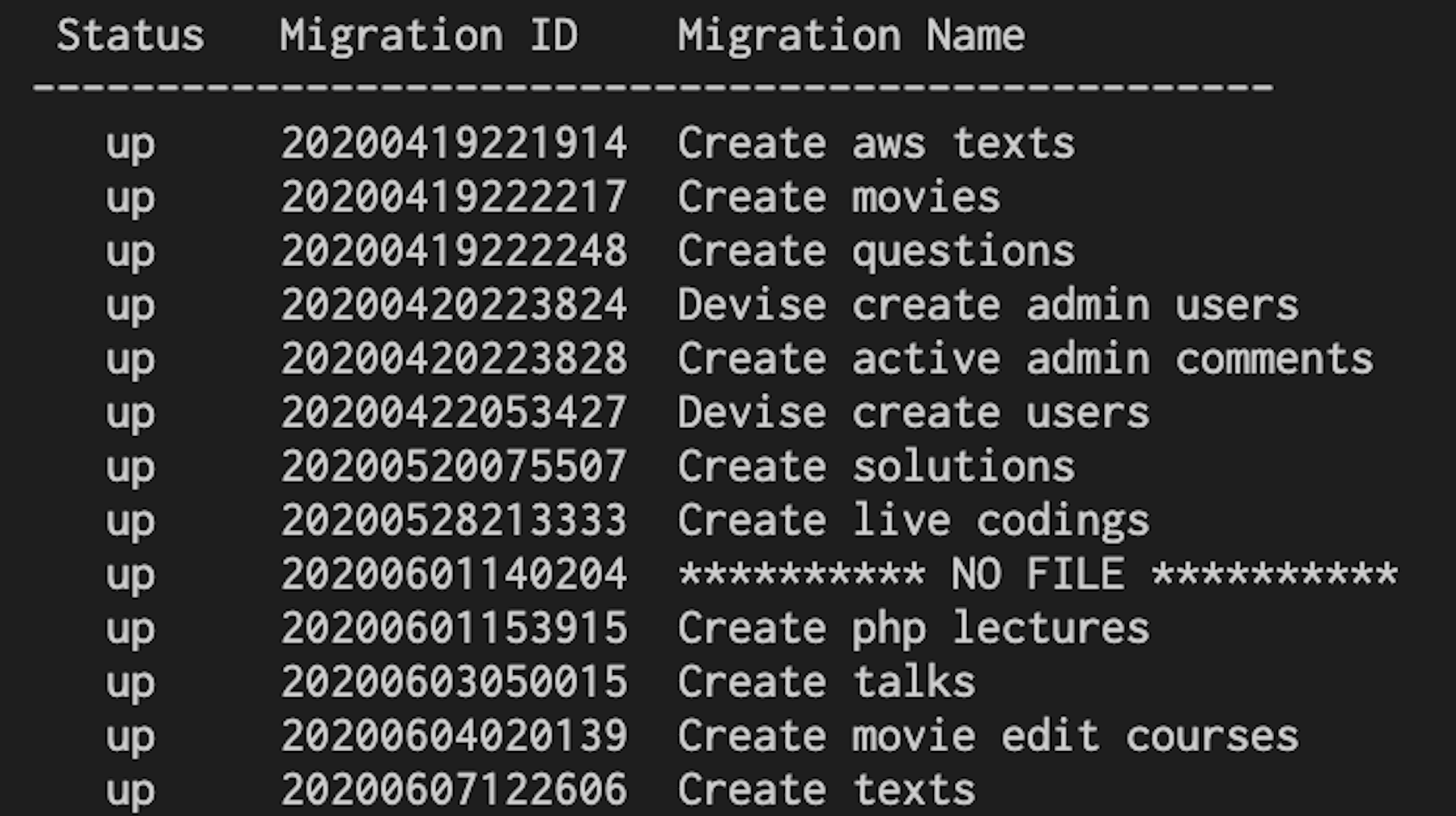
rails db:migrate:statusでステータスを確認してみると
rails db:migrateを実行したのでStatusの状態はupになっています。
こんな感じでしょうか..引き続き"マイグレーションファイルの削除"を説明します。
4: マイグレーションファイルを削除する手順
今は、
"db/maigrate"内にある
20200608181608_create_text_matelials.rbファイルをこのまま削除する方法です。プロジェクト内のターミナルで下記を実行
$ rm -rf db/migrate/20200608181608_create_text_matelials.rb
rails db:migrate:statusを実行して、ステータスを確認してください。
削除されていることがわかると思います。5: マイグレーションを間違って削除してしまった場合
データベースに反映したマイグレーションファイルを不要だと思い、誤って削除した時に
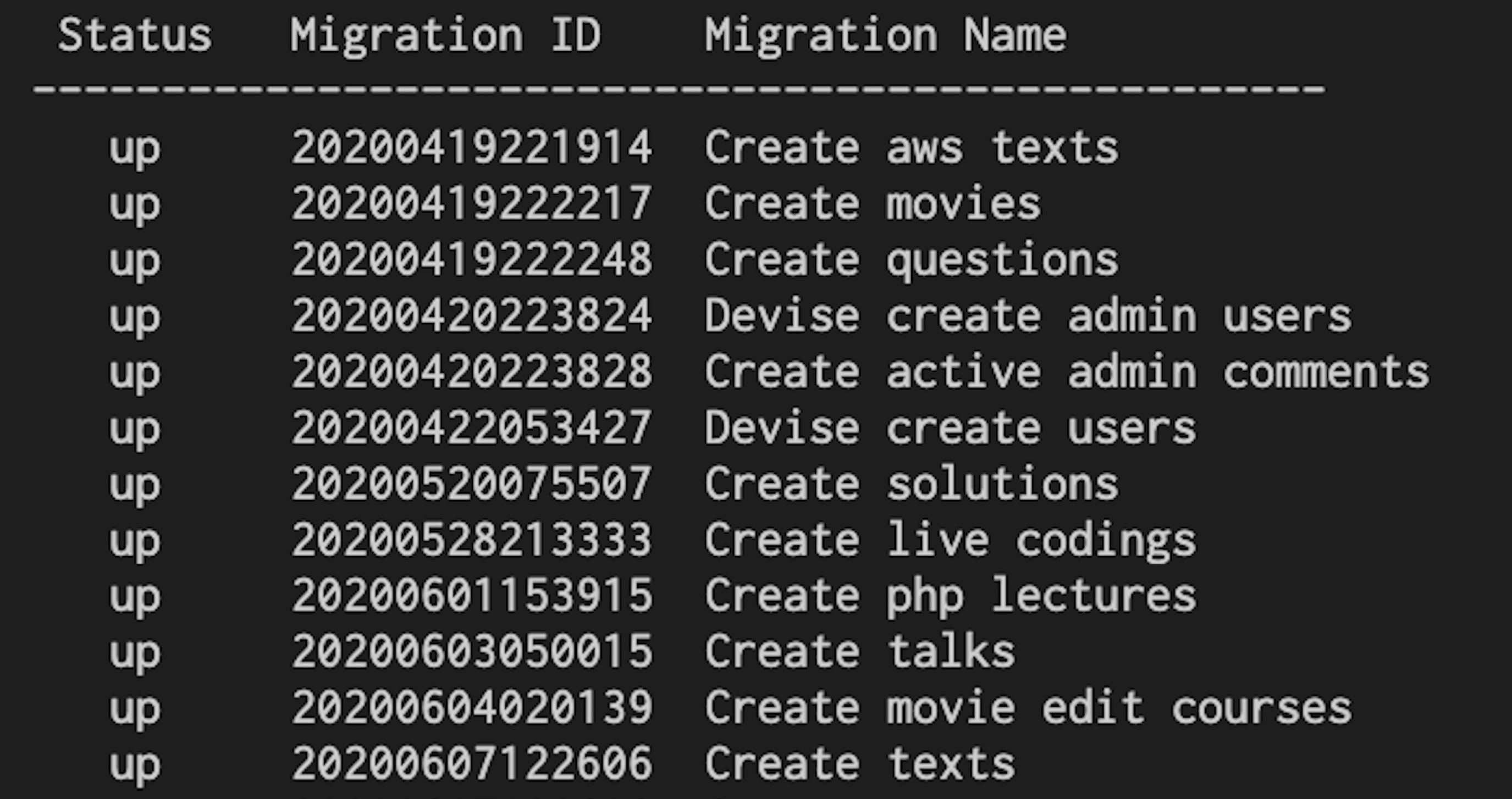
rails db:migrate:statusを実行してステータスを確認すると下のように"NO FILE"と出てきてしまった時の対処です。
手順に入る前になぜNO FILE になっているのか状況を説明します。
【 NO FILE になっている状況の説明 】
上の画面から分かることはStatusが NO FILE となっているマイグレーションがupになっている!
ということはデータベースはこのマイグレーションファイルの構造を取り入れているということですね。up状態のマイグレーションファイルを手動でカラムの削除したり、カラムを使っていないということでマイグレーションファイルを削除したのかもしれません。
NO FILE になるのは、
マイグレーションファイルを削除してもdb/migration内のschema_migrationsテーブルにバージョンが保存されているためです。schema_migrationsテーブルから削除してしまったマイグレーションファイルのバージョンが保存されているレコードを削除すればこの表示は消えます。
※ 単にdb/migration/schema.rbの内部を削除しただけでは
rails db:migrateするとまた復活してしまいます。6: NO FILE状態のschema.rb内のテーブルとNO FILEを削除する手順
[3: テーブルを編集、削除する手順]で説明したように
"db/maigrate"内にあるマイグレーションファイルを開いて追記が必要
ですが、今回の場合はマイグレーションファイルが無いので、マイグレーションファイルを作成するところからはじめます。
はじめに
rails db:migrate:statusを実行してMigration ID を確認しましょう。
今回だと
20200601140204になります。マイグレーションファイルを作成する
rails プロジェクトの db/migrateに移動
プロジェクト内のターミナルで下記を実行$ cd db/migrateマイグレーションファイルを作成します。
db/schema.rbの中でテーブルを確認した時に、
今回はconversationsテーブルを削除したい。とすると
touch マイグレーションID_ファイル名.rb
(※最終的に削除します。一時的な使用なのでのでファイル名はなんでも構いません)
(※もしテーブルを使いたい場合は、適した名前にしてください)今回は下記のようにしました
プロジェクト内のターミナルで実行$ touch 20200601140204_tmp.rbこれで
tmp.rbというマイグレーションファイルができました。
次に
[3: テーブルを編集、削除する手順]
[4: マイグレーションファイルを削除する手順]
を行います。...と省略されると不安に思う人(自分..)もいると思うので、ダブりますが続きも書いておきますね。
テーブルを編集、削除する
エディタから
db/migrate内の
20200601140204_tmp.rbファイルを開いて下記を記述
※注意:ActiveRecord::Migration [6.0] の部分は自身のRailsのバージョンに指定します。(例) [5.1]等
「Railsのバージョンがわからない...」場合は
ターミナルでrails -vを実行するとわかります。class Tmp < ActiveRecord::Migration[6.0] def change end endschema.rb内にテーブルを作成していないファイルならこのまま削除しますが今回は先ほど作成したマイグレーションファイルを使ってschema.rb内のテーブルを削除したいので更に
drop_table :削除したいテーブル名を追記します。※テーブル名を確認したい場合は
db/schema.rbの中を確認。今回は
conversationsテーブルを削除したいとします。class CreateConversations < ActiveRecord::Migration[6.0] def change drop_table :conversations end end編集が終了したので
rails db:migrateをしてテーブルを削除します。
db/schema.rbの中を確認すると指定したテーブルが削除されていると思います。マイグレーションファイルを削除する
残るは先ほどNOFILE状態だったファイル(現在の 20200601140204_tmp.rb)ですね。
まずはup状態をdown状態にします!!...と
その前にdrop_table :conversationsがあるとdownできないので削除しておきましょう。down状態にするのに必要な情報は Migration ID の数字です。
今回で言うと20200601140204ですね。プロジェクト内のターミナルで下記を実行
$ rails db:migrate:down VERSION=20200601140204
rails db:migrate:statusを実行してステータスを確認。
downになっていればOKです!"db/maigrate"内にある
20200601140204_tmp.rbファイルをこのまま削除します。プロジェクト内のターミナルで下記を実行
$ rm -rf db/migrate/20200601140204_tmp.rbステータスを確認
rails db:migrate:statusを実行
するとはじめにNOFILEだったものも削除されていることがわかるります!
自分も経験した勘違い
サーバーにアップされた時に、マイグレーションファイルは全てdown状態なので
rails db:migrateコマンドを実行します。例えばusersテーブルを作成するマイグレーションファイルを削除してしまって、その後にusersテーブルにカラムを追加するマイグレーションファイルがあった時、存在しないusersテーブルにカラムを追加することはできないのでエラーが出てしまいます。
ローカルではエラーは出ないのに、サーバーにアップしたらなぜかエラーになる...
こんな状況になるときがありました。ローカル環境ではusersテーブルが削除される前に
rails db:migrateで実行してありマイグレーションファイルによって既に作成されているので、マイグレーションファイルを誤って削除してしまった場合でもエラーが出ない。
ただ、
サーバーにアップされた時は、マイグレーションファイルは全てdown状態になっているのでrails db:migrateコマンドを実行することになります。でも、usersテーブルを作成するマイグレーションファイルを削除してしまっている状態では存在しないusersテーブルにカラムを追加することはできないぞ!とエラーが出てしまう。
「ローカルとサーバーにアップした時で上記のような齟齬がないようにするため」と、
「チーム開発している場合に、他の開発者を混乱させる要員になる」ので注意して行う。
マイグレーションファイルを削除する際は必ずdown状態になっているのを確認してから編集や削除する!ということを忘れないようにしたいですね。手動で削除してしまえばいいだろ!とはいかないのです。
最後に
意味がわからない..と焦りますよね。
私もそうです。(現在進行形)笑
今回は長くなってしまいましたが、「コマンドだけ」とか「ここを参考」とかをあえて使わず、内容ダブってもいいから書こう!その方が流れが分かりやすいと思い書きました。初学者目線だと「流れ」が分かれば、理解は早いと感じてます。
少しでも参考になれば嬉しいです!間違い等ございましたら、勉強して修正させて頂きますのでご指摘ください!
以上です。おつかれさまでした!


- 投稿日:2020-07-27T23:13:19+09:00
RubyとRailsの勉強録0
Railでいろんなアプリ作りたいんや!
っと意気込んで、プログラミングを始めてみました。
これまで、プログラミングはMQLという超マイナーな言語を軽くしか触ってないので、本格的に勉強するのは始めてです。
会社では、プログラミングとは無関係な仕事をしています。
そのため、モチベーションが下がらいないようにするため、また、分からないことやこれまで何を考えて勉強してきたかを記録する意味でもブログを開始しようと思います。ちなみ、ブログを書くのも初心者ですし、Qiitaの使い方もよく理解していないので、ブログを書きながら勉強していこうと思います。
なぜRubyを勉強しようと思ったか
クラウドソーシングのサイトを作ってみたかったからです。
他にも、ツイッターとかインスタグラムもどきを簡単に作れるってすごくない!?という安直な理由からです。
他の言語でも作れるんでしょうけど、なんとなく自分の作りたいものを一番表現しやすい言語なのかなと思いました。今までやってきたこと
- 本(なお買っただけの模様)
- プロを目指すためのRuby入門
- 現場で使えるRuby on Rails5速習実践ガイド
- ドットインストール(やった順)
- Ruby入門 (全26回)
- Ruby on Rails 5入門 (全28回)
- はじめてのRuby (全9回)
- UNIXコマンド入門 (全24回)
- Active Record入門 (全19回)
以上のことをやってきたのですが、、、
全くわからん!!
なんとなくブログっぽいものができたけど、なぜできたのか一切理解できていない!!
と、危機感を覚えたのもブログを開始した理由の一つです。
これからやること
HTML、CSS、JavaScriptは必須!と色々書かれていますが、モチベが上がらないので、必要になったらやろうと思います。
だって早くアプリ作りたいじゃん?
ということで、とりあえずrailsを中心にやりながら、必要になったものを必要になった時だけ勉強しようと思います。
これで良いのか分かりませんが、これが一番モチベ上がります!w
ということで、次回から早速railsの勉強を記録していこうと思います。
- 投稿日:2020-07-27T22:50:25+09:00
アウトプット
- 投稿日:2020-07-27T21:21:48+09:00
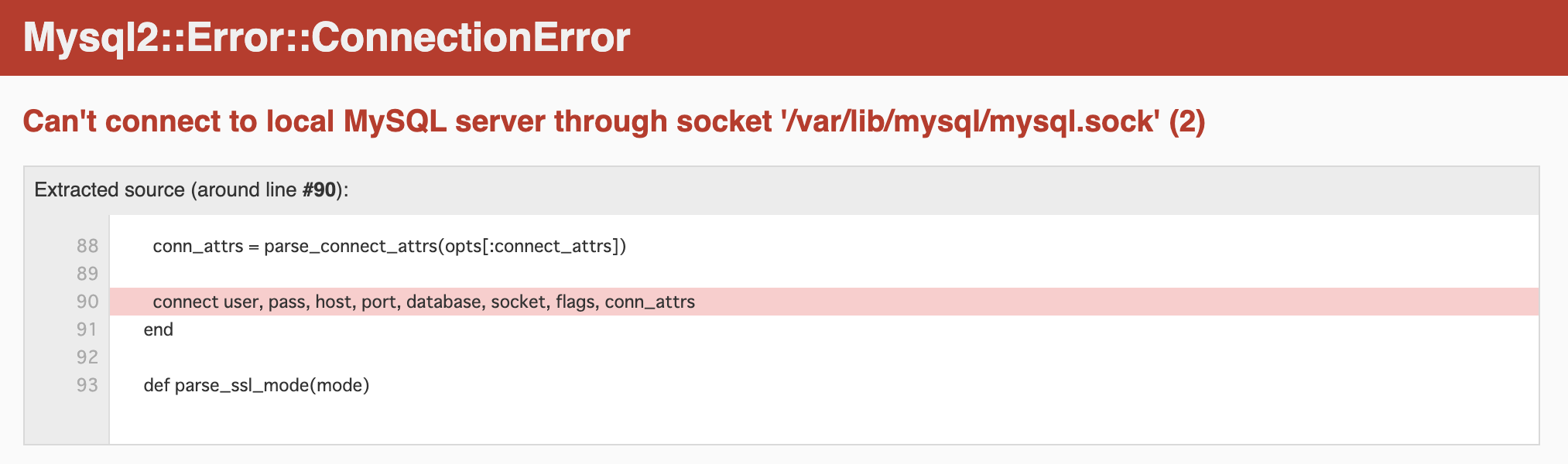
Mysql2::Error::ConnectionErrorが出た場合
localhost:3000で出たエラーを解決させました
自作アプリの開発中に起きたエラーを紹介します。
環境
・macOS
・Rails 5.2.4.3
・Ruby 2.5.1今日(投稿日)はエンゼルスの大谷投手が693日ぶりに登板と言う事で、めちゃくちゃテレビを見たい気持ちを抑えて、いつも通りの朝活を行う事に。。。
そして、自作アプリを開くとこんな画面に遭遇しました。
へ?
何だこれは??
一瞬頭が真っ白になってしまいました。
なかなか自作アプリ開発が思う様に進まない中で、もはや自分でアプリを見ることすら出来ないのかと愕然。
5分くらい絶望した後に、取り敢えずエラーの解析から始めました。
Can't connect to local MySQL server through socket '/var/lib/mysql/mysql.sock' (2)って何??
エラーの内容を調べていると結構同じ様なエラーに遭遇されている方が多かったので、その記事を見ていくと、
クライアント(自分のPC) → /var/lib/mysql/mysql.sock にデータを見に行こうとしたら、そんな場所ないじゃん。って感じのエラーなんだと理解。
socketとは
プログラムとネットワークを結ぶ接続口。仲介役。仲介業者。仲人。合コンで言う幹事。
って事で正しい出入り口(ソケット)を探す旅に
socketってどこにあんの??
他の記事を読み漁り、socketの存在を調べました
特に参考にさせてもらった記事
Can't connect to local MySQL server through socket '/tmp/mysql.sock'記事を読み比べる中で
'/tmp/mysql.sock' '/var/lib/mysql/mysql.sock'と言う2つのソケットを見比べて、
「自分のエラーの場合は'/var/lib/mysql/mysql.sock'に行こうとしたが、そんな場所はないと言われているので、そこを見つけて修正すれば良いのか!!」と推測。
で、どこに書いてあんの?
解決法
この記事を読んで私も解決しました
【Rails】ローカル環境におけるmysql接続エラー対処法【Can't connect to local MySQL server through socket】database.yml#修正前 development: <<: *default database: データベース名_development username: root password: <%= ENV['DATABASE_PASSWORD'] %> socket: /var/lib/mysql/mysql.sock #修正後 development: <<: *default database: データベース名_development username: root password: <%= ENV['DATABASE_PASSWORD'] %> socket: /tmp/mysql.sock /var/lib/mysql/mysql.sock → /tmp/mysql.sock に変更してますコードの修正を行ったので、再起動させます。
rails sこれでソケット名が正しくなったので、無事に閲覧が出来ました!!
原因
database.ymlですが、特に自分で何かを記述した訳ではなくて、何かしらの教材や記事を
コピペしてしまう事で、起きやすい事象なのかと思いました。
その分、最初はすごく焦りましたが、今まで気にしなかった所を考えたり、エラー文を調べていく中で、同じ様なエラーに遭遇されている方が多かった事も、自分の中では収穫でした。ymlを一度見てもらうのも良いかも知れません。最後にsocketの
'/tmp/mysql.sock' '/var/lib/mysql/mysql.sock'の箇所ですが、使われている方によっては、
/tmp/mysql.sock → /var/lib/mysql/mysql.sockが正解のパターンも多くあると思いますので、まずは自身のsocketの所在を確認してみてください!!

- 投稿日:2020-07-27T21:17:05+09:00
2020.7.27
qiita.rbdef greeting(&block) puts "Hello" block.call("Goodbye") end greeting do |text| puts text end # ターミナル出力結果 # Hello # Goodbye上記のコードの詳しい説明
qiita.rbgreeting do |text| puts text endまずは上記のコードが実行される。
上記のコードはgreetingというメソッドを実行し、その際に、下記のコードを引数としている。qiita.rbdo |text| puts text endつまり、
qiita.rb&block = do |text| puts text endとなってる。
このとき、仮引数(今回はgreeting(&block)のblockのこと)に&(アンパサンド)を前置すると&blockとなり、これは「ブロック引数」となる。
最初のコードにもどるとqiita.rbblock.call("Goodbye")のところで、&blockが呼び出されており、その時の引数は"Goodbye"である。
つまり、qiita.rbdo |"Goodbye"| puts "Goodbye" endとなっている。ターミナルで表示されるのは、下記の部分になる。
qiita.rbputs "Hello" puts "Goodbye"
- 投稿日:2020-07-27T21:04:29+09:00
累乗、剰余の計算
ただの備忘録です。
累乗 3**2 3の2乗
剰余 7%3 2あまり1
関数使うなら n**s みたいな。
- 投稿日:2020-07-27T11:54:22+09:00
Rails環境下でjqueryにて画面のバリデーションを設定する
背景
現在、自分が作成しているポートフォリオについて、データの更新、新規登録時にバリデーションをかけたい項目がある。個人的には、Vue.jsを学習中のため、こちらで実施したかったが、いろいろ試した結果について次のとおりにまとめる。
環境
項目 内容 OS.Catalina v10.15.4 Ruby v2.5.1 Ruby On Rails v5.2.4.3 MySQL v5.6 対応手順
【手順1】
1)公式サイトからバリデーションを実行してくれるJSファイルをダウンロードする
jquery-validation-1.19.1/dist/jquery.validate.js
jquery-validation-1.19.1/src/localization/messages_ja.js2)以下に格納する
app/assets/javascripts/jquery.validate.js
app/assets/javascripts/messages_ja.js3)JSファイルの設定
①対象となるフォームオブジェクトのIDを設定する(2行目)
②rulesオブジェクトに対象となるテキストボックスのオブジェクトIDを設定する(4行目)
→ここで、正確なオブジェクトidはデベロッパーツールを使用すること
③対象オブジェクトにバリデーションに引っかかった場合の出力メッセージを設定する(9行目)app/assets/javascripts/genre_edit_vaidate.js1 $(function(){ 2 $("#new_genre").validate({ 3 rules : { 4 "genre[in_genre]": { 5 required: true 6 } 7 }, 8 messages: { 9 "genre[in_genre]": { 10 required: "必須入力です", 11 } 12 } 13 }); 14 });4)htmlファイルの設定
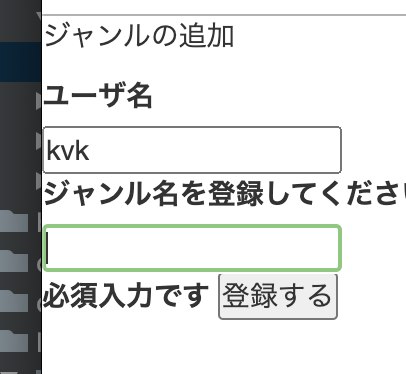
今回例では、ジャンル名の登録テキストボックスに必須バリデーションを設定した。new.html.erb<title>メモのカテゴリを登録</title> <p>ジャンルの追加<br></p> <%= form_for (@genre), url: genres_path(:id), method: :post do |f| %> <%= f.label :id,"ユーザ名" ,class: "com-box" %> <%= f.text_field :user_id ,class: "com-box" ,value: current_user.name, readonly:true %> <%= f.hidden_field :user_id ,value: current_user.id%> <%= f.label :id,"ジャンル名を登録してください" ,class: "com-box" %> <%= f.text_field :in_genre ,class: "com-box" %> <%= f.submit "登録する" %> <% end %>
→「必須入力です」と出力されています。あとはスタイルシートで加工すればOKです。簡単にできました!以上です。
参考文献
【jQuery】RailsでValidation Pluginを使った動的なバリデーションチェックの実装 〜導入編〜
- 投稿日:2020-07-27T10:21:18+09:00
devise_token_auth ログアウトのテストコード実装時に苦戦したことをまとめる
devise_token_auth でログアウトのテストコード作成時、エラー解決の情報が少なかったのでまとめます。
※ user の新規登録、ログイン、ログアウト機能を実装しているものとします。
※ FactoryBot を導入してます。headers にログインに必要な情報が入っていないため、エラー発生
エラー発生時のコード
describe "DELETE /v1/auth/user/sign_out" do subject { delete(destroy_v1_user_session_path) } context "トレーナーログアウト時" do let(:user) { create(:user) } it "トークンを無くし、ログアウトできる" do subject expect(response).to have_http_status(200) end end endエラー内容
Failure/Error: expect(response).to have_http_status(200) expected the response to have status code 200 but it was 404正常なレスポンス(200)ではなく、リクエストが存在しない(404)エラーが出てます。との内容。
subject の下に binding.pry を入れ、デバック画面にしuserを実行#<Trainer id: 532, provider: "email", uid: "6_hannah@emmerich.name", allow_password_change: false, name: "松本 七海", nickname: nil, email: "6_hannah@emmerich.name", address: nil, birthday: nil, created_at: "2020-07-26 06:10:35", updated_at: "2020-07-26 06:10:35">user の中にデータがあることを確認できました。
次に headers 情報を確認するため、response.headersを実行。{"X-Frame-Options"=>"SAMEORIGIN", "X-XSS-Protection"=>"1; mode=block", "X-Content-Type-Options"=>"nosniff", "X-Download-Options"=>"noopen", "X-Permitted-Cross-Domain-Policies"=>"none", "Referrer-Policy"=>"strict-origin-when-cross-origin", "Content-Type"=>"application/json; charset=utf-8", "Cache-Control"=>"no-cache", "X-Request-Id"=>"a2ad39e6-d2b2-4ae8-93c1-5ddcd2ea22d1", "X-Runtime"=>"0.010570", "Content-Length"=>"71"}headers の情報は返ってきましたが、ログアウトに必要な情報
access-token、client、uidが入ってないことが分かります。
headers にログアウトに必要な情報が入ってないから、404の異常系のエラーが発生している。
新規作成時、ログイン時にトークン情報が発行され、その情報をもとにログアウトの処理を行うのですが、現状のコードでは user の情報は作成されても、トークン情報は作成されていない状況です。
なので、トークン情報を入れてあげましょう。describe "DELETE /v1/auth/user/sign_out" do subject { delete(destroy_v1_user_session_path, headers: headers) } context "トレーナーログアウト時" do let(:user) { create(:user) } let(:headers) { user.create_new_auth_token } it "トークンを無くし、ログアウトできる" do subject expect(response).to have_http_status(200) end end end
create_new_auth_tokenメソッドで、必要なメタデータ全てを含む新しい認証トークンを作成します。
subject の下に binding.pry を入れheadersを実行し、データが入っていればオッケーです。ログアウト時にトークン情報が残ったままのため、エラー発生
ログアウトは、「有効なトークン情報がなくなる」なので、先ほどのコードにトークン情報の有無を確認するテストコードを追記しました。
describe "DELETE /v1/auth/user/sign_out" do subject { delete(destroy_v1_user_session_path, headers: headers) } context "トレーナーログアウト時" do let(:user) { create(:user) } let(:headers) { user.create_new_auth_token } it "トークンを無くし、ログアウトできる" do subject + expect(user.tokens).to be_blank expect(response).to have_http_status(200) end end endエラー内容
Failure/Error: expect(trainer.tokens).to be_blank expected `{"LT4SdlN2czyzNnwTfLGjTw"=>{"expiry"=>1596957557, "token"=>"$2a$10$BgZ4YItos1hQRTp4y1JvZ.mIsreaIxD1NC3ckRk0euxsk8IBkoM7K", "updated_at"=>"2020-07-26 07:19:17 UTC"}}.blank?` to return true, got falseトークン情報が残ったままとのエラーです。
ログアウトに必要な情報を user に入れ、ログアウトの処理はできても、user の値は更新されないので残ったままになっています。
user の値を更新するためには、user.reload.tokenと記述してあげる必要があります。describe "DELETE /v1/auth/user/sign_out" do subject { delete(destroy_v1_user_session_path, headers: headers) } context "トレーナーログアウト時" do let(:user) { create(:user) } let(:headers) { user.create_new_auth_token } it "トークンを無くし、ログアウトできる" do subject expect(user.reload.tokens).to be_blank expect(response).to have_http_status(200) end end end以上の内容にすれば、ログアウト後の user の値が更新されるため、user にトークン情報がなくなります。
- 投稿日:2020-07-27T08:46:31+09:00
[Rails]find_eachが無限ループして本番環境のメモリを食いつぶした話
ActiveRecordにある便利メソッド
find_each
実装の仕方が良くなくて無限ループしてしまい、本番環境でOOM killerによって強制停止させられるという事象が発生したのでその話について書きます。
※ この記事に登場するテーブルや実装などはすべて記事用にカスタマイズしています
find_eachとは
find_eachは何をしてくれるかというと、大量のデータを一度に取得してループするのではなく決まった単位(デフォルト1,000件)ごとに取得してループしてくれます。
大量データを扱うときに一括で取得してしまうと大量のメモリを使っていしまうのですが、find_eachを使って分割して取得することで少ないメモリで処理することができます。言葉で書いてもわかりづらいですね。下記が実行例です。
# userが1万人いる場合 pry(main)> User.all.count (1.1ms) SELECT COUNT(*) FROM `users` => 10000 # eachを使うと一括で1万件取得される pry(main)> User.all.each {|user| p user.id} User Load (4.5ms) SELECT `users`.* FROM `users` 1 2 3 ... 10000 # find_eachを使うと1,000件ずつ取得される [8] pry(main)> User.all.find_each {|user| p user.id} User Load (3.9ms) SELECT `users`.* FROM `users` ORDER BY `users`.`id` ASC LIMIT 1000 1 2 3 ... 1000 User Load (0.8ms) SELECT `users`.* FROM `users` WHERE `users`.`id` > 1000 ORDER BY `users`.`id` ASC LIMIT 1000 1001 1002 1003 ... 2000 User Load (0.8ms) SELECT `users`.* FROM `users` WHERE `users`.`id` > 2000 ORDER BY `users`.`id` ASC LIMIT 1000 2001 ... 10000詳細はRailsガイドをご覧ください。
https://railsguides.jp/active_record_querying.html#find-eachfind_eachが無限ループ!!
便利メソッドfind_eachですが、最初に書いたとおり実装をミスって無限ループさせてしまいました。
無限ループになった実装を説明する前に、そもそもfind_eachはどのような仕組みで動いているのか確認します。find_eachの仕組み
最初に載せた実行例を使ってどのように動いているのか確認します。
一番最初に発行されるSQLを見てみましょう。
SELECT `users`.* FROM `users` ORDER BY `users`.`id` ASC LIMIT 1000limit 1000を指定して1000件取得しています。
ここで注目すべきはPRIMARY KEY(id)の昇順に並べているところです。それでは次の1000件はどのように取得しているのでしょうか?
SELECT `users`.* FROM `users` WHERE `users`.`id` > 1000 ORDER BY `users`.`id` ASC LIMIT 1000SQLを使って次の1000件を取得する場合はLIMITとOFFSETを使う事がよくありますが、今回のSQLにはOFFSETは使われていません。
代わりにwhere句にusers.id > 1000という条件が増えていることがわかります。
users.id > 1000の1000は最初に取得した1000件の最後のidが指定されています。
今回のデータはidの昇順に並んでいるため、最後のidより大きいデータを取得するという意味のusers.id > 1000を条件に指定することでOFFSETを使わずに次の1000件を取得しています。無限ループになる実装
無限ループが発生したfind_eachは下記のように実装されていました。
何が起きるのでしょうか?# users.idとbooks.titleしか使わないのでselectで必要なデータのみ取得する Book.joins(:user).select('users.id, books.title').find_each do |book| p "user_id: #{book.id}, title: #{book.title}" end最初は下記のSQLが発行されます。
SELECT users.id, books.title FROM `books` INNER JOIN `users` ON `users`.`id` = `books`.`user_id` ORDER BY `books`.`id` ASC LIMIT 10001件目のSQLは特に問題ありません。
それでは次の1000件を取得するSQLはどうなるのでしょうか?SELECT users.id, books.title FROM `books` INNER JOIN `users` ON `users`.`id` = `books`.`user_id` WHERE `books`.`id` > 1000 ORDER BY `books`.`id` ASC LIMIT 1000
books.id > 1000とい条件が追加されています。条件の1000は最初に取得した1000件の最後のデータのidです。
SQLだけを見ていると気づきづらいですが、今回のSQLで取得しているidはbooks.idではなくusers.idです。
そのため、books.id > 1000に設定されている1000は最後のデータのusers.idが指定されています。このSQLではbooks.idの昇順になっており、users.idの順序は特に制御されていません。
そのため、次の1000件目の最後のデータがbooks.id: 2000, users.id: 1ということもありえます。
この場合、次に発行されるSQLは下記のようになります。SELECT users.id, books.title FROM `books` INNER JOIN `users` ON `users`.`id` = `books`.`user_id` WHERE `books`.`id` > 1 ORDER BY `books`.`id` ASC LIMIT 1000条件が
books.id > 1となってしまい、1つ前のSQL(books.id > 1000)より前のデータを取得してしまいます。
このようにbooks.idの条件に順序が制御されていないusers.idが入ることで、取得するデータが前後してしまい、最悪の場合何度も同じデータを取得してしまい無限ループしてしまいます。この問題の厄介なところは常に無限ループになるわけではなく、データによっては
books.id > #{最後のusers.id}がたまたまいい感じに指定されてそれっぽく完了してしまうこともあることです。
その場合、エラーにはならないけどデータが微妙におかしいという気づきづらいバグになってしまうので、無限ループになってくれたほうがマシかもしれません。修正方法
上記の例の場合であれば、selectで取得カラムを絞らなくするとbooks.idも取得するようになるので正しく動作するようになります。
selectで取得カラムを絞る場合でも下記のようにbooks.idもきちんと取得するようにすれば正しく動作します。Book.joins(:user).select('books.id AS id, users.id AS user_id, books.title').find_each do |book| p "user_id: #{book.user_id}, title: #{book.title}" end上記の通り修正すれば修正完了ですが、今回の問題は自動テストがなかったことだと思っています。
該当の処理を通るテストはあったのですが、find_eachを2ループ以上するテストは書いていませんでした。
テストがあれば、無限ループするか結果がおかしくなるのでバグに気づけていた可能性が高いです。
これをきっかけにfind_eachが2ループ以上するテストも追加しました。まとめ
今回のバグはfind_eachの仕組みを正しく理解していたとしても、コードレビューなど机上確認だけで気づくのは難しいと思います。
また、1000件以上になることが稀な処理であり、1000件という単位もただのプログラム上の都合なので、ブラックボックスな動作テストでも気づかれずにしばらく潜在バグとして潜んでいました。これに事前に気づくにはどうすればよかったのかと考えると、ホワイトボックステストでfind_eachが2ループするテストをするしかないと思いました。
ホワイトボックステストを手動でワンタイム実行してももったいないので、きちんと自動テストを書いて継続的に検証できるようにしておくとよいですね。
- 投稿日:2020-07-27T02:13:37+09:00
【rails】activehashについて
Active Hashとは
ハッシュ形式の値をActive Recordと同じように操作できるようにするgem
Relationも貼れるので便利基本的な使い方
以下のような書き方ができる
app/models/plan.rbclass Plan < ActiveHash::Base self.data = [ {id: 1, name: "free"}, {id: 2, name: "silver"}, {id: 3, name: "gold"}, ] end class Plan < ActiveHash::Base self.data = [ {id => 1, name => "free"}, {id => 2, name => "silver"}, {id => 3, name => "gold"}, ] end class Plan < ActiveHash::Base fields :name add id: 1, name: "free" add id: 2, name: "silver" add id: 3, name: "gold" endターミナルpry(main)>Plan.first => #<Plan:0x00007ffd3d2c43f8 @attributes={:id=>1, :name=>"free"}>
relationを貼りたいモデルに以下を記載すればアソシエーションを利用してデータを操作できる。
ActiveHashのモデル側には特に追記することはないextend ActiveHash::Associations::ActiveRecordExtensions belongs_to_active_hash :ActiveHashのモデル名参考
https://qiita.com/DON4024/items/78edb7a309ee96766952
https://qiita.com/Toman1223/items/8633142312bfa886d50b
- 投稿日:2020-07-27T01:40:05+09:00
Railsアプリで画像の保存先をS3に変更する。その2
はじめに
前回の記事からの続きです。
安全にAWSのキーを扱えるようにする
AWSキーの漏洩を防ぐため、キーの内容は環境変数に設定します。
環境変数が分からない人はググって調べてみましょう!AWSのキーの設定
carrierwave.rbのなかに[:access_key_id]や[:secret_access_key]といった記載がありました。
ここには予め設定したキーが入り、Rails5.2では「credentials.yml.enc」というファイルで管理されます。それではcredentials.yml.encをエディタで開いてみましょう。
以下のように暗号化された文字列が表示されると思います。
これをターミナルからVSCodeを起動できるよう設定を行います。
VSCodeで、「Command + Shift + P」を同時に押してコマンドパレットを開きます。
続いて、「shell」と入力しましょう。
メニューに「PATH内に'code'コマンドをインストールします」という項目が表示されるので、それをクリックします。
この操作を行うことで、ターミナルから「code」と打つことでVSCodeを起動できるようになります。それではターミナルから以下のコマンドを実行しましょう。
復号化されたcredentials.yml.encがVSCodeで表示され、編集可能となるはずです。% EDITOR='code --wait' rails credentials:editAWSのaccess_key_idとsecret_access_keyを以下のように編集しましょう。
master.keyの設定
credentials.yml.encはmaster.keyというファイルで復号化を行います。
しかし、本番環境にmaster.keyを配置することはセキュリティ上問題があります。
そのため、本番環境の環境変数にmaster.keyの中身を設定しましょう。EC2インスタンスにログインし、環境変数の設定を行うファイルを開きます。
sudo vim /etc/environmentローカル開発環境で「config/master.key」の値をコピーして、本番環境のRAILS_MASTER_KEYに設定します。
RAILS_MASTER_KEY='master.keyの値'これで環境変数が設定できたはずなので、EC2インスタンスにログインし直して以下のコマンドで環境変数を確認しましょう。
env | grep RAILS_MASTER_KEYまとめ
環境変数を参照する流れをまとめますと以下のようになります。
1.credentials.yml.encをローカル環境のmaster.keyで復号する
2.credentials.yml.encを編集し、access_key_idとsecret_access_keyを設定する。
3.本番環境にデプロイする
4.master.keyの内容を本番環境の環境変数に設定する。
5.本番環境のcredentials.yml.encが環境変数を用いて復号可能となる。前回の記事と上記の設定を行えば、S3に画像をアップロード出来るようになるはずです!多分!以上!

- 投稿日:2020-07-27T01:12:16+09:00
【Ruby】シンプルなPingクライアントを作ってみた
概要
ICMP Echo Requestの送信・受信を1回だけ実行するシンプルなクライアントを作ってみたので、忘れないうちに実装時に学習したことや、気をつけたこと等をつらつらとメモ。
成果物リンク
https://rubygems.org/gems/simple_ping
https://github.com/kuredev/simple_ping目的
- ネットワークプログラミングの練習
- gem パッケージ公開の練習
- 気晴らし
どんなものか/使い方
できること
- ping(ICMP)した結果の成否をtrue/falseで返却する
- 宛先の指定はIPアドレス
できないこと
- FQDNでの宛先指定
- リトライ
- 送信データのカスタマイズ(ID指定やデータ部の指定等)
- 等など
使い方サンプル
ping.rbrequire "simple_ping" ping_client = SimplePing::Client.new(src_ip_addr: "192.168.1.100") puts ping_client.exec(dest_ip_addr: "192.168.1.101") ? "Success!" : "Failed.."※実行時にはroot権限が必須
console> sudo ruby ping.rb Success!実装メモ
- ソケットプログラミングを行うこととなるが、 ドキュメントを見るといくつかソケットにも種類があるが、今回はICMPヘッダを直に触るので、
SOCK_RAW(Rawソケット)を用いる。- 最終的にデータを送信(send)するときはデータを文字列で指定する必要がある。用意したICMPヘッダのデータ列を1ByteずつASCIIコードに従って文字列に変換する必要がある。
- 受信する際は
recvfromメソッドによって受信し、データは文字列で取得できる
- 取得したデータはIPヘッダも含んだ形でのデータとなっている。
- IPヘッダのサイズは基本的に20Byteなので(違う場合もあるようだが今回は実装上は想定していない)ICMPヘッダのデータは21Byte目から順番に取得できる
- 例えばICMPヘッダ先頭の「タイプ」であれば以下のように取得できる
bytesメソッドで文字列をASCIIコードに変換できるmesg, _ = socket.recvfrom(1500) mesg[21].bytes[0] #=> 0
- 受信時には受信したパケットが送信した物の帰りのパケットかを判定する必要があるが、「ID」と「シーケンス番号」と「タイプ」を照合して、送信・受信の対応を確認する(以下RFCの通り)
受信したエコーメッセージに含まれるデータは、エコーリプライメッセージのデータとして返されなければならない。
識別子とシーケンス番号は、エコー送信者がエコー要求とそのリプライとを対応させるのに使用される。例えば TCP や UDP がセッションを特定するために使用するポート番号のように識別子を使用してもよいし、エコー要求のたびにシーケンス番号を増加させてもよい。エコーを返す側は、エコーリプライの中で同じ値を返す。
http://srgia.com/docs/rfc792j.html参考
RubyでいろいろなSocket作って遊んでみた。 - Qiita https://qiita.com/MikuriyaHiroshi/items/b0a40f5e7b7be1ef327c
【Ruby】RawSocketを使ったネットワークプログラム – Euniclus https://euniclus.com/article/ruby-port-scan/
BasicSocket#send (Ruby 2.7.0 リファレンスマニュアル) https://docs.ruby-lang.org/ja/latest/method/BasicSocket/i/send.html
Internet Control Message Protocol - Wikipedia https://ja.wikipedia.org/wiki/Internet_Control_Message_Protocol#ICMP%E3%83%98%E3%83%83%E3%83%80
ASCII コードと文字を変換する (ord, chr, bytes, unpack, codepoints) | まくまくRubyノート https://maku77.github.io/ruby/number/ascii-char.html
RFC792(INTERNET CONTROL MESASAGE PROTOCOL) http://srgia.com/docs/rfc792j.html
- 投稿日:2020-07-27T01:04:57+09:00
[備忘録] CircleCI / Ruby(公式doc.の最小構成)について各設定項目の概要と参照先リンク
はじめに
Language Guide: Ruby - CircleCIにて、設定ファイルの各項目について調べた備忘録メモです。
解釈した範囲で短い説明を試みましたが、全体的として参照先のリンク集に近い形になりました。本投稿の目的
/.circleci/config.ymlの構造の把握- 類似の調査の効率化準備
- 投稿の経験値
本編
各所で下記のリファレンスの該当タグへのリンクを貼っています。
各設定項目のリファレンス
CircleCI を設定する - CircleCI/.circleci/config.yml
/.circleci/config.ymlversion: 2.1 # Use 2.1 to enable using orbs and other features. # Declare the orbs that we'll use in our config. # read more about orbs: https://circleci.com/docs/2.0/using-orbs/ orbs: ruby: circleci/ruby@1.0 node: circleci/node@2 jobs: build: # our first job, named "build" docker: - image: cimg/ruby:2.7-node # use a tailored CircleCI docker image. steps: - checkout # pull down our git code. - ruby/install-deps # use the ruby orb to install dependencies # use the node orb to install our packages # specifying that we use `yarn` and to cache dependencies with `yarn.lock` # learn more: https://circleci.com/docs/2.0/caching/ - node/install-packages: pkg-manager: yarn cache-key: "yarn.lock" test: # our next job, called "test" # we run "parallel job containers" to enable speeding up our tests; # this splits our tests across multiple containers. parallelism: 3 # here we set TWO docker images. docker: - image: cimg/ruby:2.7-node # this is our primary docker image, where step commands run. - image: circleci/postgres:9.5-alpine environment: # add POSTGRES environment variables. POSTGRES_USER: circleci-demo-ruby POSTGRES_DB: rails_blog_test POSTGRES_PASSWORD: "" # environment variables specific to Ruby/Rails, applied to the primary container. environment: BUNDLE_JOBS: "3" BUNDLE_RETRY: "3" PGHOST: 127.0.0.1 PGUSER: circleci-demo-ruby PGPASSWORD: "" RAILS_ENV: test # A series of steps to run, some are similar to those in "build". steps: - checkout - ruby/install-deps - node/install-packages: pkg-manager: yarn cache-key: "yarn.lock" # Here we make sure that the secondary container boots # up before we run operations on the database. - run: name: Wait for DB command: dockerize -wait tcp://localhost:5432 -timeout 1m - run: name: Database setup command: bundle exec rails db:schema:load --trace # Run rspec in parallel - ruby/rspec-test # We use workflows to orchestrate the jobs that we declared above. workflows: version: 2 build_and_test: # The name of our workflow is "build_and_test" jobs: # The list of jobs we run as part of this workflow. - build # Run build first. - test: # Then run test, requires: # Test requires that build passes for it to run. - build # Finally, run the build job.各設定項目の概要について
Orbs、ジョブ、ステップ、ワークフロー - CircleCIversion:
version: 2.1 # Use 2.1 to enable using orbs and other features.version - CircleCI を設定する - CircleCI
CircleCIのバージョンを指定します。orbs:
orbs: ruby: circleci/ruby@1.0 node: circleci/node@2Orbについてのドキュメント
Orbs とは - CircleCI
Orbs を使う - CircleCI
orbs - CircleCI を設定する - CircleCIOrbとは、ジョブやコマンドなどの設定要素をまとめた共有可能なパッケージのことです。
この設定項目では、CircleCI Orb RegistryにあるOrbsからインポートするものを記載します。今回使用するOrbのレジストリページ
Ruby : CircleCI Orb Registry - circleci/ruby
Node : CircleCI Orb Registry - circleci/node( Orbレジストリのドキュメントにある
Orb Sourceは、あくまでドキュメントページを生成するためのソースコードです。
(ファイル階層も含めた)Orb自体のソース情報を確認する場合はGitHubのリポジトリを参照する必要があります。 )jobs:
jobs - CircleCI を設定する - CircleCI
今回におけるjobsは、2つのパラレルジョブ、buildとtestから構成されます。build:
build: # our first job, named "build" docker: - image: cimg/ruby:2.7-node # use a tailored CircleCI docker image. steps: - checkout # pull down our git code. - ruby/install-deps # use the ruby orb to install dependencies # use the node orb to install our packages # specifying that we use `yarn` and to cache dependencies with `yarn.lock` # learn more: https://circleci.com/docs/2.0/caching/ - node/install-packages: pkg-manager: yarn cache-key: "yarn.lock"docker:
docker: - image: cimg/ruby:2.7-node # use a tailored CircleCI docker image.docker - CircleCI を設定する - CircleCI
Dockerのイメージや、エントリーポイント、コマンドなどを設定します。
docker-composeの設定項目と似ています。steps:
steps: - checkout # pull down our git code. - ruby/install-deps # use the ruby orb to install dependencies # use the node orb to install our packages # specifying that we use `yarn` and to cache dependencies with `yarn.lock` # learn more: https://circleci.com/docs/2.0/caching/ - node/install-packages: pkg-manager: yarn cache-key: "yarn.lock"steps - CircleCI を設定する - CircleCI
checkout
checkout - CircleCI を設定する - CircleCI
チェックアウトディレクトリを指定します。
デフォルトではworking_directory裏ではBourne shellのスクリプトが実行されてGitHubのソースコードをチェックアウトしているようです。
SSH周りの勉強にもなりそうなので、また機会を改めて調べてみます。ruby/install-deps
Orb - circleci/rubyで定義されるコマンドです。
description: Install gems with Bundler.
(引用:ソースから)Bundlerを使用してGemをインストールします。
test:
test: # our next job, called "test" # we run "parallel job containers" to enable speeding up our tests; # this splits our tests across multiple containers. parallelism: 3 # here we set TWO docker images. docker: - image: cimg/ruby:2.7-node # this is our primary docker image, where step commands run. - image: circleci/postgres:9.5-alpine environment: # add POSTGRES environment variables. POSTGRES_USER: circleci-demo-ruby POSTGRES_DB: rails_blog_test POSTGRES_PASSWORD: "" # environment variables specific to Ruby/Rails, applied to the primary container. environment: BUNDLE_JOBS: "3" BUNDLE_RETRY: "3" PGHOST: 127.0.0.1 PGUSER: circleci-demo-ruby PGPASSWORD: "" RAILS_ENV: test # A series of steps to run, some are similar to those in "build". steps: - checkout - ruby/install-deps - node/install-packages: pkg-manager: yarn cache-key: "yarn.lock" # Here we make sure that the secondary container boots # up before we run operations on the database. - run: name: Wait for DB command: dockerize -wait tcp://localhost:5432 -timeout 1m - run: name: Database setup command: bundle exec rails db:schema:load --trace # Run rspec in parallel - ruby/rspec-testparallelism:
parallelism: 3parallelism - CircleCI を設定する - CircleCI
ジョブのステップを並列処理するための設定です。CircleCIには、プロジェクトのテストに掛かる時間を短縮するために、テストを複数のマシンに分散して並列に実行するための仕組みがあり、
parallelismのキーに並列マシンの個数を指定します。
パラレルジョブについて:テストの並列実行 - CircleCIdocker:
docker: - image: cimg/ruby:2.7-node # this is our primary docker image, where step commands run. - image: circleci/postgres:9.5-alpine environment: # add POSTGRES environment variables. POSTGRES_USER: circleci-demo-ruby POSTGRES_DB: rails_blog_test POSTGRES_PASSWORD: ""テスト環境を構築します。
environment:
environment: BUNDLE_JOBS: "3" BUNDLE_RETRY: "3" PGHOST: 127.0.0.1 PGUSER: circleci-demo-ruby PGPASSWORD: "" RAILS_ENV: testenvironment - CircleCI を設定する - CircleCI
Rails + PostgreSQLのための環境変数を設定します。steps:
# A series of steps to run, some are similar to those in "build". steps: - checkout - ruby/install-deps - node/install-packages: pkg-manager: yarn cache-key: "yarn.lock" # Here we make sure that the secondary container boots # up before we run operations on the database. - run: name: Wait for DB command: dockerize -wait tcp://localhost:5432 -timeout 1m - run: name: Database setup command: bundle exec rails db:schema:load --trace # Run rspec in parallel - ruby/rspec-testrun
- run: name: Wait for DB command: dockerize -wait tcp://localhost:5432 -timeout 1m - run: name: Database setup command: bundle exec rails db:schema:load --tracerun - CircleCI を設定する - CircleCI
コマンドラインプログラムを呼び出すための項目です。
dockerize -wait tcp://localhost:5432 -timeout 1m
DBサービスの立ち上がりを待機します。
#Dockerize を使用した依存関係の待機 - データベースの設定 - CircleCI
dockerizeの公式リポジトリ:jwilder/dockerize: Utility to simplify running applications in docker containers
bundle exec rails db:schema:load --trace
マイグレーションファイルは扱わず、db/schema.rbからデータベースを作成します。
スキーマファイルでデータベースを作成 - Rake - Railsドキュメント
6.1 スキーマファイルの意味について - Active Record マイグレーション - Railsガイドworkflows:
# We use workflows to orchestrate the jobs that we declared above. workflows: version: 2 build_and_test: # The name of our workflow is "build_and_test" jobs: # The list of jobs we run as part of this workflow. - build # Run build first. - test: # Then run test, requires: # Test requires that build passes for it to run. - build # Finally, run the build job.workflows - CircleCI を設定する - CircleCI
ジョブを自動化するための設定です。version:
version - CircleCI を設定する - CircleCIbuild_and_test:
workflow_name - CircleCI を設定する - CircleCIjobs:
jobs - workflow_name - CircleCI を設定する - CircleCI
requiresでジョブの依存関係を明確化し、このジョブが実行されるまでに完了されるべきジョブを指定します。
即ち、buildが実行され完了した後にtestは実行されます。
- 投稿日:2020-07-27T00:05:15+09:00
[Rails]Railsのバージョンを5.0→5.2に上げてみた
やりたいこと
Rails5.0系からRails5.2系にバージョンを上げたい。(Rails5.2から使えるようになったActive Storageを使いたかった。)
この記事の趣旨は、Rails5.0系からRails5.2系にバージョンを上げるために必要な手順とその際に発生したエラー対応をご紹介したい(そしてActive Storage使いたい)というものです。
修正(2020/07/27)
伊藤さんご本人からコメントいただき、
bootsnap gemを追加する方法に変更いたしました。
詳しくはこの記事のコメントをご確認ください?♂️環境
Ruby 2.5.1
Rails 5.0.7.2手順
伊藤さんのQiita記事を大いに参考にさせていただきました。
永久保存版!?伊藤さん式・Railsアプリのアップグレード手順基本的には伊藤さんの記事を見ていただくのがわかりやすいです(この記事の意味)。
ただ、「とりあえず早いとこバージョン上げたい!!」という方も少なからずいらっしゃるかと思うので、邪道的な形で見ていただけると幸いです。また、本来はテストまでカバーすべきですが、今回は目的がActive Storageを使うことなので、そちらに関しては割愛します。
1. Rails以外のgemをバージョンアップする
Rails本体のバージョンを先に上げてしまうと、DeviseやCarrierwaveのような周辺のgemが最新のRailsに対応しておらず、思いがけないエラーが起きるかもしれません。
はい。まさに起きました。笑
1-1. developmentとtestグループのgemを先にアップデートする
terminal# 該当のアプリのディレクトリで実行 $ bundle update -g development -g test1-2. トラブルが起きやすそうなgemを1つずつアップデートする
bundle outdatedコマンドを実行すると、最新でないgemが一覧表示されます。
ただ、そこまでgemの数が多くない場合は、一気にアップデートしてしまってもいいかもしれません。1つずつアップデートする場合は、
bundle updateの後ろにgem名を指定します。terminal# deviseだけをアップデートしたい時 $ bundle update devise1-3. その他のgemをまとめてアップデートする
gem名を指定せず、
bundle updateです。
※なお、このタイミングではRailsのバージョンは変えないでください(元のバージョン指定のままにしておく)。Railsのバージョンアップは別途行います。Gemfile# Railsのバージョン指定は元のままにしておく gem 'rails', '~> 5.0.7', '>= 5.0.7.2'Railsのバージョン指定がされていることを確認したら、
bundle updateterminal# gemをまとめてアップデートする $ bundle update2. Railsのバージョンを上げる
GemfileでRailsのバージョン指定を変更して、
bundle update railsです。Gemfile# gem 'rails', '~> 5.0.7', '>= 5.0.7.2' gem 'rails', '~> 5.2.4', '>= 5.2.4.2'terminal$ bundle update rails3. rails app:updateタスクを実行する
次にrails app:updateタスクを実行します。
このタスクを実行すると、新しいバージョンで必要になる新しいファイル作成や、既存ファイルの変更を対話形式で行うことができます。terminal$ rails app:update conflict config/boot.rb Overwrite config/boot.rb? (enter "h" for help) [Ynaqdhm]上記のように、コンフリクトが起きるファイルの扱いをどうするかを一つずつ確認していく作業です。
Y/n/a/q/d/hのいずれかのキーで回答します。Y - Yes。上書き実行 n - No。上書きしない a - All。このファイル以降の全ファイルを上書き q - Quit。処理中断 d - Diff。新旧ファイルのdiffを表示 h - Help。入力する各キーの意味を表示「これ一個ずつ確認するの面倒…まとめてやっていいんじゃ?」
はい、僕もそう思って、
a= allを実行しました。
するとroutes.rbがまっさらに生まれ変わりました(白日か)。
routes.rbだけはしっかり確認しましょう!というよりnにしましょう!!伊藤さんもこうおっしゃっています。
僕はd = diffを確認した上で、Yかnを入力することが多いです。
(でも、routes.rb以外はほとんどYを入力しているかもしれない)4. 動作確認(
rails sが起動するか)他にもテストコードや自分の目で見て確認も必要ですが、今回は
rails s(とりあえず開発環境でサーバー起動させる)を目指します。4-1. エラー①
意気揚々と
rails sしたところまずはこちらのエラーから。
require': cannot load such file -- bootsnap/setup (LoadError)とのエラーが。terminal$ rails s Traceback (most recent call last): 3: from bin/rails:3:in `<main>' 2: from bin/rails:3:in `require_relative' 1: from /myapp/config/boot.rb:4:in `<top (required)>' ~~~config/boot.rb:4:in `require': cannot load such file -- bootsnap/setup (LoadError)こちらの方法で対応できました。変更箇所は2箇所(ファイル)。
Gemfile# 全部の環境に適用させたいので、グループの中には入れない gem 'bootsnap', require: falseconfig/initializers/new_framework_defaults.rb~ # この行↓をコメントアウト # ActiveSupport.halt_callback_chains_on_return_false = false ~4-2. エラー②
「さあ、今度こそサーバー起動だ!」と思って
rails sしたらまたもエラーが。
<top (required)>': undefined method `halt_callback_chains_on_return_false=' for ActiveSupport:Module (NoMethodError)terminal=> Booting Puma => Rails 5.2.4.3 application starting in development => Run `rails server -h` for more startup options Exiting Traceback (most recent call last): ~~~/config/initializers/new_framework_defaults.rb:23:in `<top (required)>': undefined method `halt_callback_chains_on_return_false=' for ActiveSupport:Module (NoMethodError)こちらで対応できました。
config/initializers/new_framework_defaults.rb~ # この行↓コメントアウト # Rails.application.config.action_controller.raise_on_unfiltered_parameters = true ~必読の記事
今回僕が遭遇したエラーは、伊藤さんがまさにおっしゃっている部分なので、この記事は読んで理解しておくと今後に役立つと思います。
Railsのバージョンが上がると、従来の挙動とは異なる、新しい挙動が導入される場合があります。
バージョンアップ後はすべて新しい挙動に合わせられるのが理想的ですが、場合によっては一部の挙動を古いRailsに合わせないといけないかもしれません。こうした挙動の変更はload_defaultsやnew_framework_defaults_x_x.rbで行います。
load_defaultsとnew_framework_defaults_x_x.rbの関係については以下の記事で詳しく説明しているので、こちらを読んで適切に設定を変更してください。
config.load_defaultsとnew_framework_defaults_x_x.rbの関係を詳しく調べてみた - Qiita
Railsのバージョンアップは完了
これでRailsのバージョンアップは完了です。
上記手順で実行してもうまくいかない時は、サーバーの再起動(ctrl + cで終了、rails sで起動)を試してみてください。5. 環境変数周りのファイルってどうなるの?
環境変数を定義するファイルは、Rails5.0系では
secrets.ymlでしたが、Rails5.2系以降はcredentials.yml.encとmaster.keyを使用するのが一般的です。5-0. 「あれ?credentialsもmasterキーもなくない??」
Railsのバージョンアップをすれば勝手に作られるものだと思っていましたが、そんな美味しい話はありませんでした。
そもそもmaster.keyはrails new時に作成されるもののはずなので、当たり前といえば当たり前ですが…5-1. 結論:
secrets.ymlのままで良い特に環境変数ファイルはいじることなく動作しました。笑