devise_token_auth でログアウトのテストコード作成時、エラー解決の情報が少なかったのでまとめます。
※ user の新規登録、ログイン、ログアウト機能を実装しているものとします。
※ FactoryBot を導入してます。
headers にログインに必要な情報が入っていないため、エラー発生
エラー発生時のコード
describe "DELETE /v1/auth/user/sign_out" do
subject { delete(destroy_v1_user_session_path) }
context "トレーナーログアウト時" do
let(:user) { create(:user) }
it "トークンを無くし、ログアウトできる" do
subject
expect(response).to have_http_status(200)
end
end
end
エラー内容
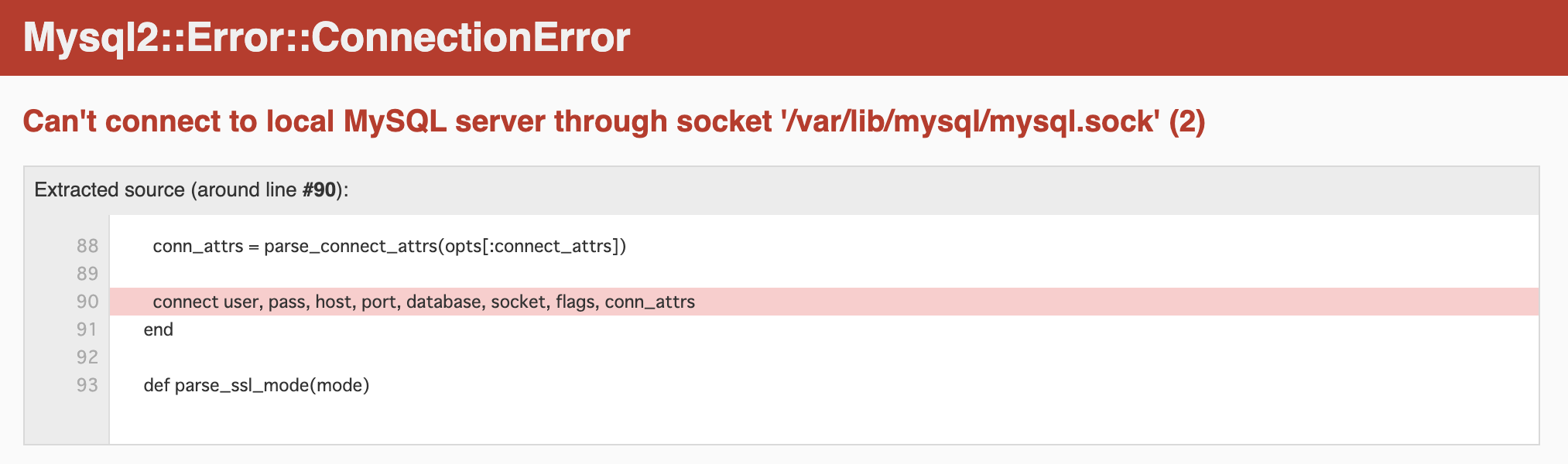
Failure/Error: expect(response).to have_http_status(200)
expected the response to have status code 200 but it was 404
headers の情報は返ってきましたが、ログアウトに必要な情報 access-token、client、uid が入ってないことが分かります。
headers にログアウトに必要な情報が入ってないから、404の異常系のエラーが発生している。
新規作成時、ログイン時にトークン情報が発行され、その情報をもとにログアウトの処理を行うのですが、現状のコードでは user の情報は作成されても、トークン情報は作成されていない状況です。
なので、トークン情報を入れてあげましょう。
describe "DELETE /v1/auth/user/sign_out" do
subject { delete(destroy_v1_user_session_path, headers: headers) }
context "トレーナーログアウト時" do
let(:user) { create(:user) }
let(:headers) { user.create_new_auth_token }
it "トークンを無くし、ログアウトできる" do
subject
expect(response).to have_http_status(200)
end
end
end
describe "DELETE /v1/auth/user/sign_out" do
subject { delete(destroy_v1_user_session_path, headers: headers) }
context "トレーナーログアウト時" do
let(:user) { create(:user) }
let(:headers) { user.create_new_auth_token }
it "トークンを無くし、ログアウトできる" do
subject
+ expect(user.tokens).to be_blank
expect(response).to have_http_status(200)
end
end
end
トークン情報が残ったままとのエラーです。
ログアウトに必要な情報を user に入れ、ログアウトの処理はできても、user の値は更新されないので残ったままになっています。
user の値を更新するためには、user.reload.tokenと記述してあげる必要があります。
describe "DELETE /v1/auth/user/sign_out" do
subject { delete(destroy_v1_user_session_path, headers: headers) }
context "トレーナーログアウト時" do
let(:user) { create(:user) }
let(:headers) { user.create_new_auth_token }
it "トークンを無くし、ログアウトできる" do
subject
expect(user.reload.tokens).to be_blank
expect(response).to have_http_status(200)
end
end
end
以上の内容にすれば、ログアウト後の user の値が更新されるため、user にトークン情報がなくなります。