- 投稿日:2020-07-27T23:01:54+09:00
S3 アクセスを特定IPアドレスのみに制限する
アクセス権限→バケットポリシーに以下を設定。※アクションは用途に合わせて変更してください
{ "Version": "2012-10-17", "Statement": [ { "Sid": "AccessControl-From-IPaddress-001", "Effect": "Allow", "Principal": { "AWS": "*" }, "Action": [ "s3:GetObjectVersion", "s3:GetObject" ], "Resource": "arn:aws:s3:::{バケットネーム}/*", "Condition": { "IpAddress": { "aws:SourceIp": [ "{IPアドレス}" ] } } } ] }
- 投稿日:2020-07-27T21:51:53+09:00
SSMドキュメントでCloudFormation Stackを作成してみた
背景
AWS環境にて一時サーバー用のEC2インスタンスを定期的に起動/削除する作業があり、手順を自動化したいというニーズがありました。
CodePipelineによるEC2インスタンス用のCloudFormation(CFn) Stack作成も検討したのですが、一時サーバー上で実行する処理を既にSSMドキュメント化していたため、CFn Stack作成自体もSSMドキュメントによる実行という方針に決まりました。
筆者はSSMドキュメント作成自体が初めてだったため、試した際の手順や注意点をメモしておきます。事前準備
S3バケットにCFn Templateのyamlファイルを配置します。
※SSMドキュメント作成時にyamlファイルの内容を直接記載することもできます。SSMドキュメント作成手順
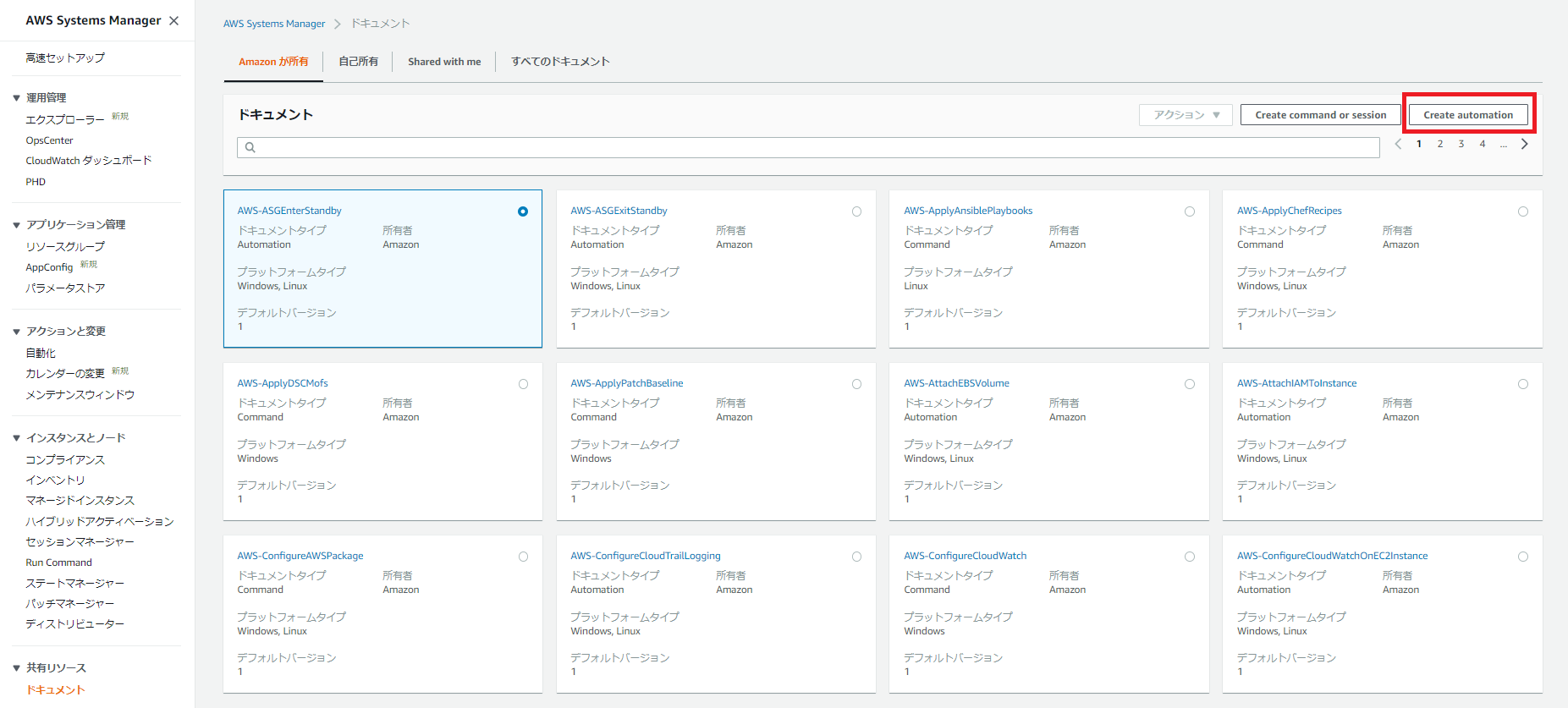
1.AWS Systems Managerのコンソールのドキュメントから「Create automation」をクリックします。
2.「Document Attributes」を設定します。
ドキュメントの名前の指定は必須です。
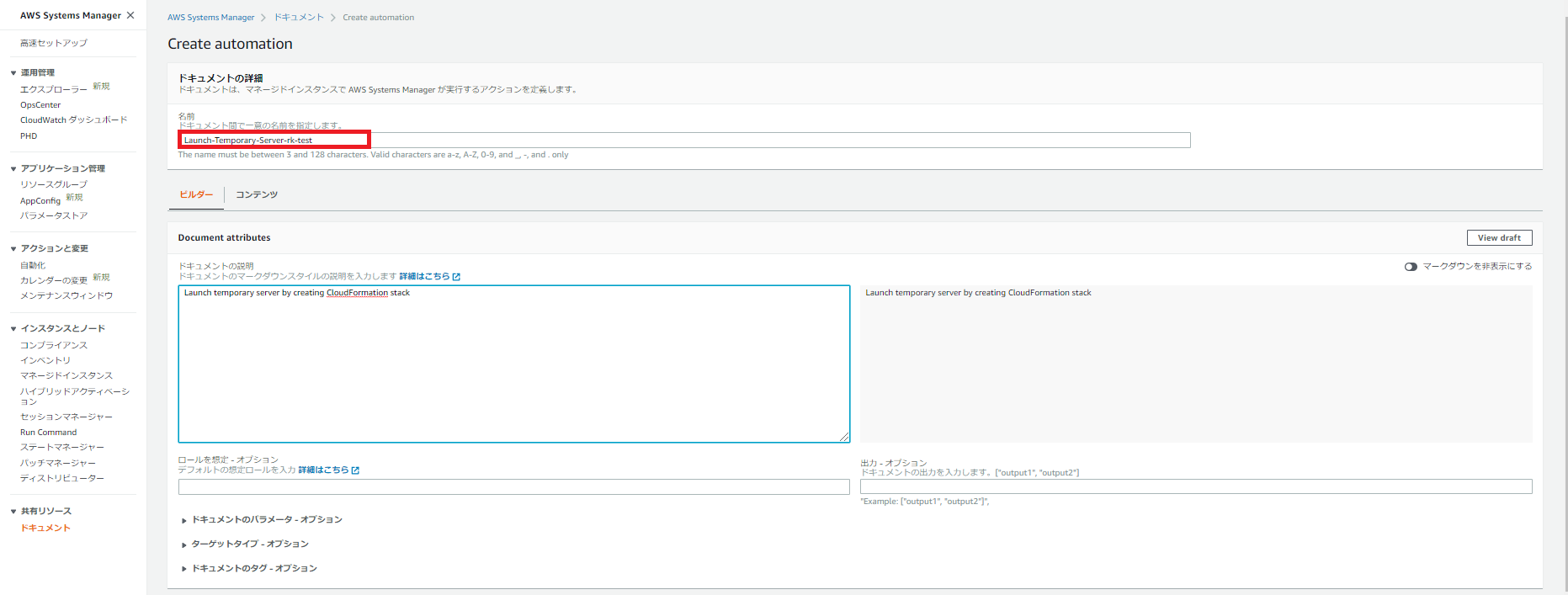
3.ステップの詳細を設定します。
指定する項目は「ステップ名」、「アクションタイプ」、「Stack name」、「Template URL」、「Additional inputs」の「Input name」と「値」です。
事前にCFn TemplateをS3バケットに配置せずyamlファイルの内容を直接記載する場合は「Template URL」は未指定のまま「Template body」に記載します。
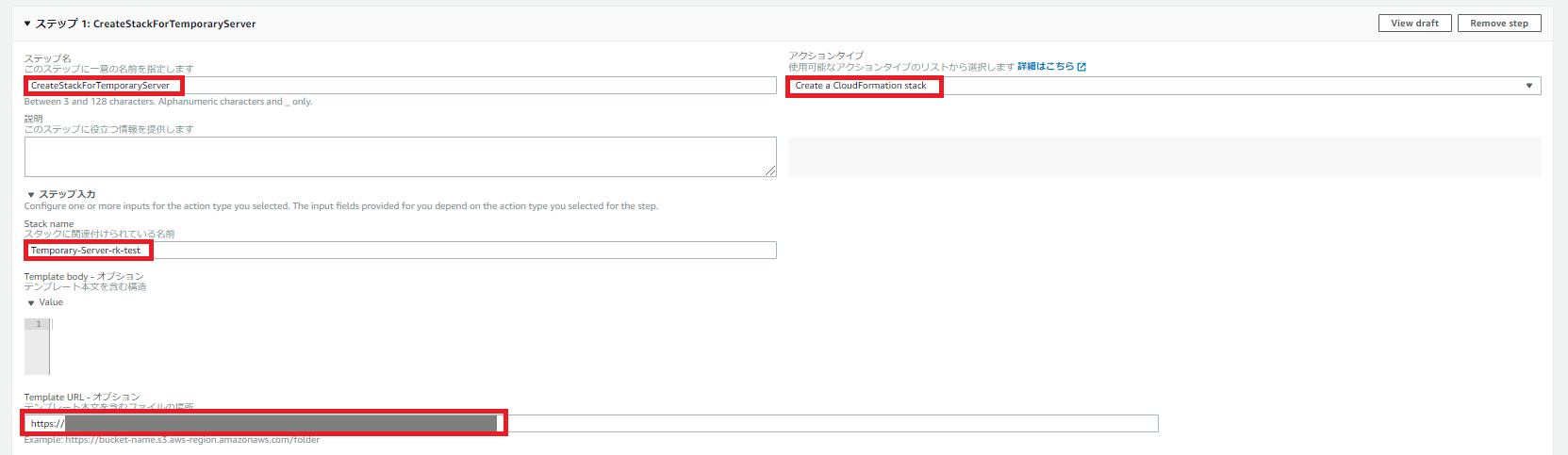
ハマったポイント①
「Template URL」はs3://bucket-name/folder/xxxxx.yamlのような指定でもSSMドキュメント自体は作成できますが、ドキュメント実行時に以下のメッセージが出てエラーになりました。Exception Message from CreateStack API: [S3 error: Domain name specified in bucket-name is not a valid S3 domain (Service: AmazonCloudFormation; Status Code: 400; Error Code: ValidationError; Request ID: 48c6c446-06e5-4200-8008-e3e5d7dea160; Proxy: null)].
URL形式で指定するようご注意ください。
ハマったポイント②
「Additional inputs」は最初未指定でSSMドキュメントを作成したのですが、以下のエラーが出ました。Exception Message from CreateStack API: [Requires capabilities : [CAPABILITY_IAM] (Service: AmazonCloudFormation; Status Code: 400; Error Code: InsufficientCapabilitiesException; Request ID: 3914e8fa-bf73-4d74-b77b-020266bc8a2d; Proxy: null)].
アクセス許可に影響するリソース作成が含まれるためにアクション実行時にその機能を明示的に認識するために
CAPABILITY_IAMの指定が必要とのことです。
参考:https://docs.aws.amazon.com/ja_jp/systems-manager/latest/userguide/automation-action-createstack.htmlCFn Templateで作成予定のリソースは正確には一時サーバ用のEC2インスタンス自体でなく一時サーバ用のAutoScalingGroupおよび起動テンプレートですが、指定がないとだめでした。
この
CAPABILITY_IAMの指定をするのが「Additional inputs」です。
ただし、「Input name」にCapabilities、「値」にCAPABILITY_IAMを指定してもだめで、以下のようなエラーが出ます。
CAPABILITY_IAMはStringList formatでないとだめだそうで、[CAPABILITY_IAM]と指定すれば通ります。4.「Create automation」をクリックします。
これでSSMドキュメント完成です。
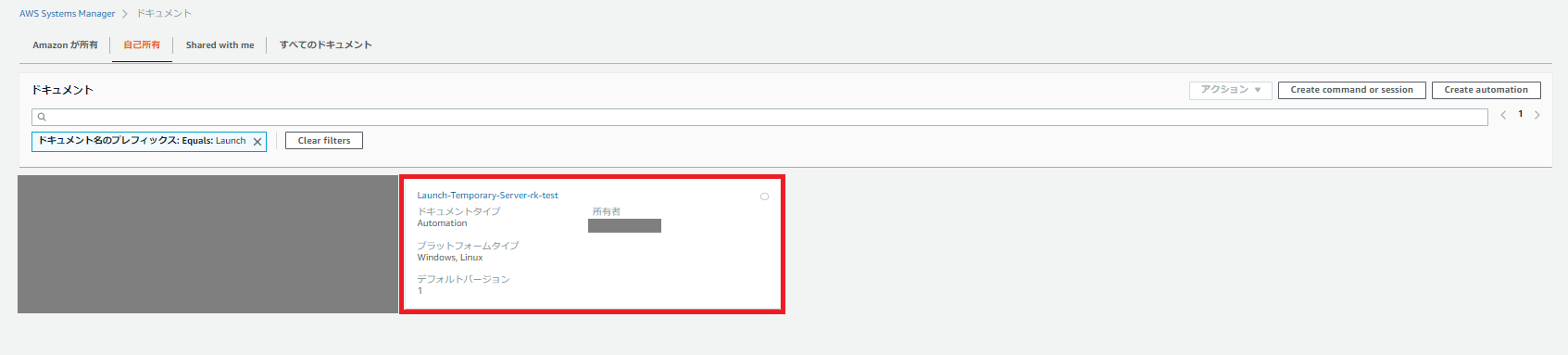
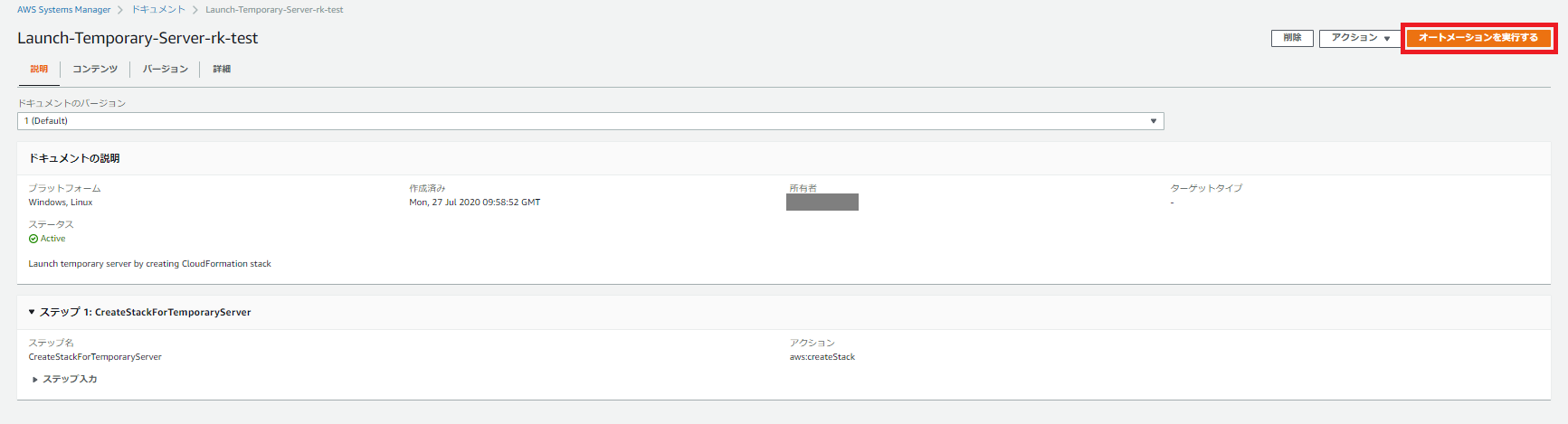
SSMドキュメント実行手順
「自己所有」タブから先ほど作成したドキュメントを見つけてクリックします。
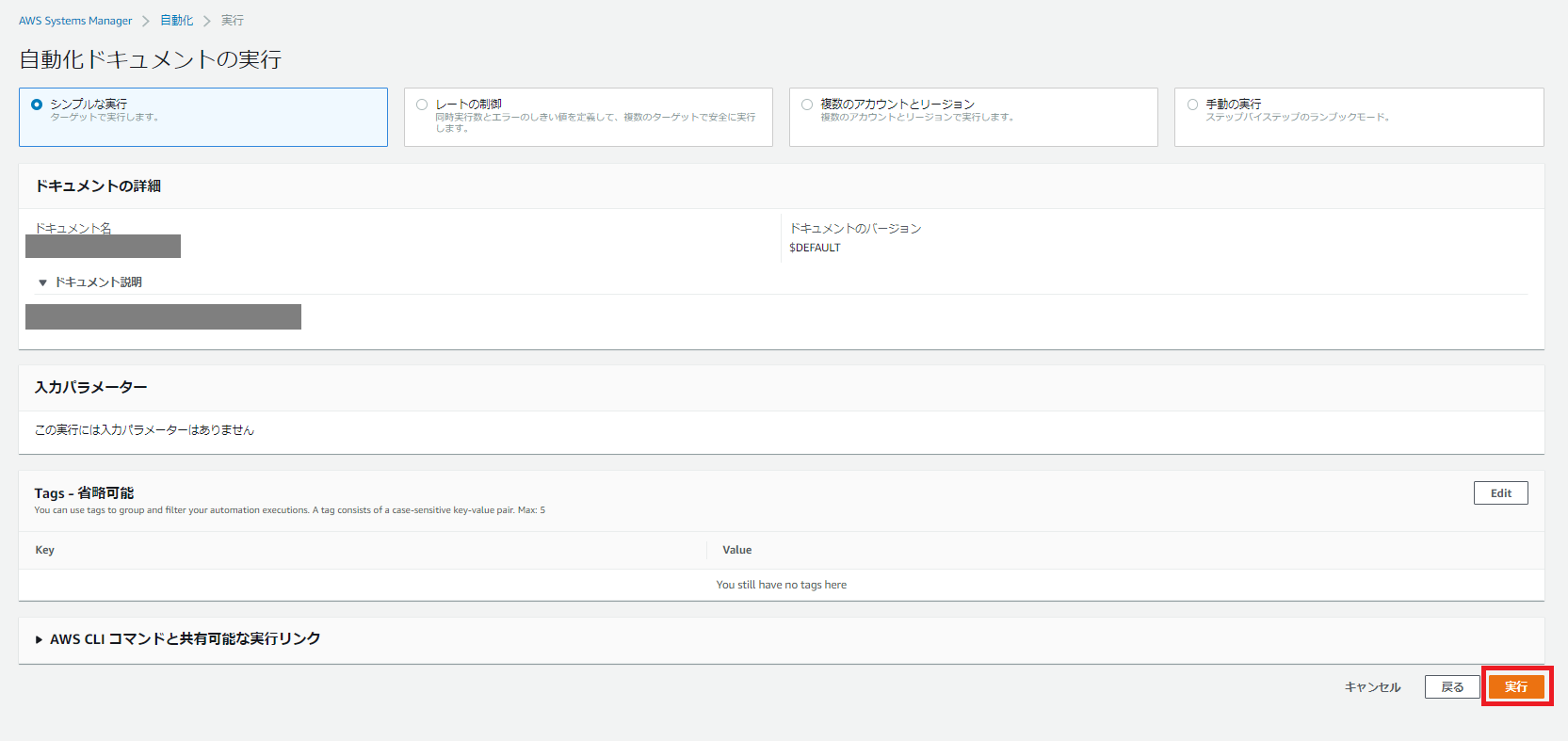
「オートメーションを実行する」をクリックします。
「実行」をクリックします。
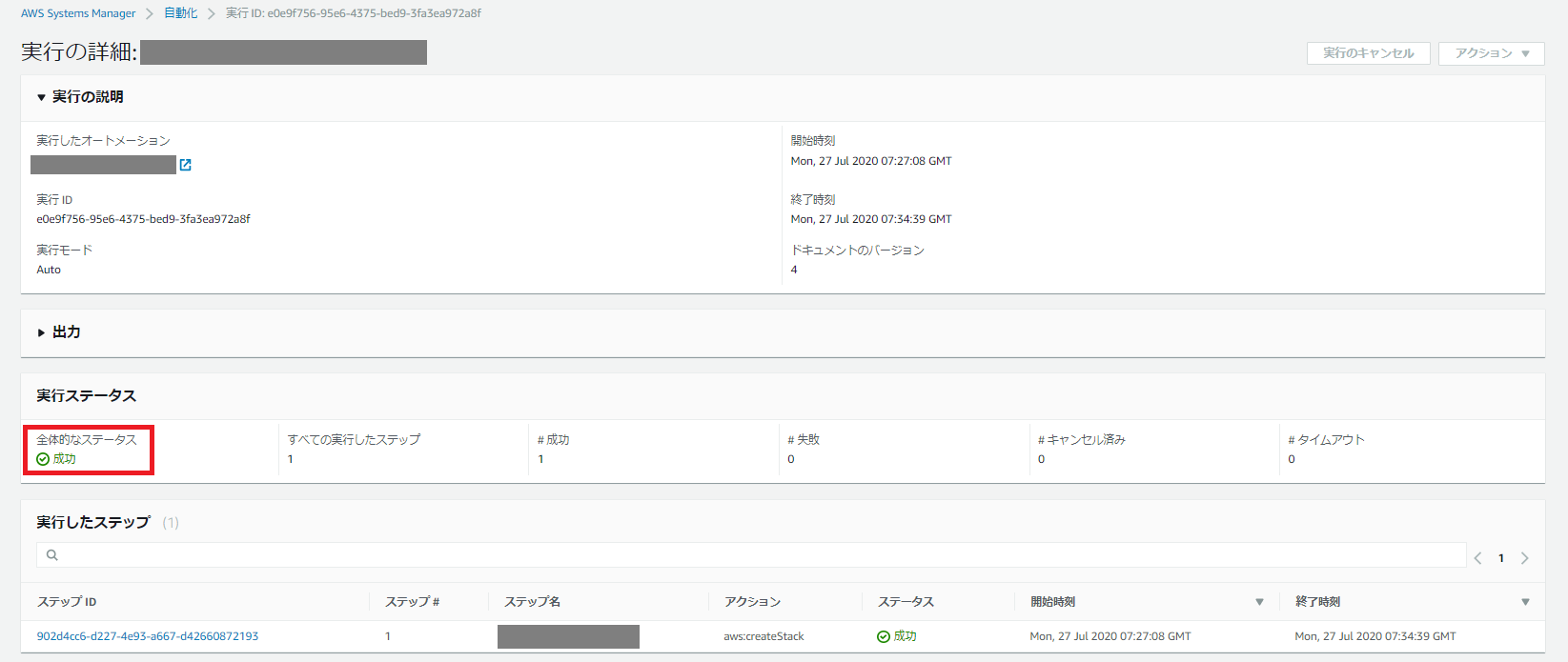
「全体的なステータス」が「成功」になるのを確認します。
CFn Stackが作成されたかやEC2インスタンスが起動しているかどうかも確認します。
SSMドキュメント修正&再実行する場合の注意点
実行するバージョンが修正後のバージョンになるよう明示指定が必要になります。
未指定の場合、実行バージョンはバージョン1のままとなります。
筆者は最初のうちこれに気づかずドキュメントを更新しても挙動が変わらず戸惑いました。。
ドキュメント修正時に指定、ドキュメント修正後に指定、実行時に指定するのいずれかが必要です。ドキュメント修正時に実行バージョンを指定する場合
新しいバージョンを作成する際に「Set new version as default」にチェックを入れます。
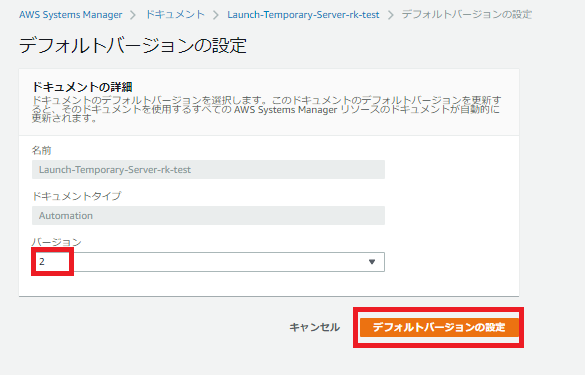
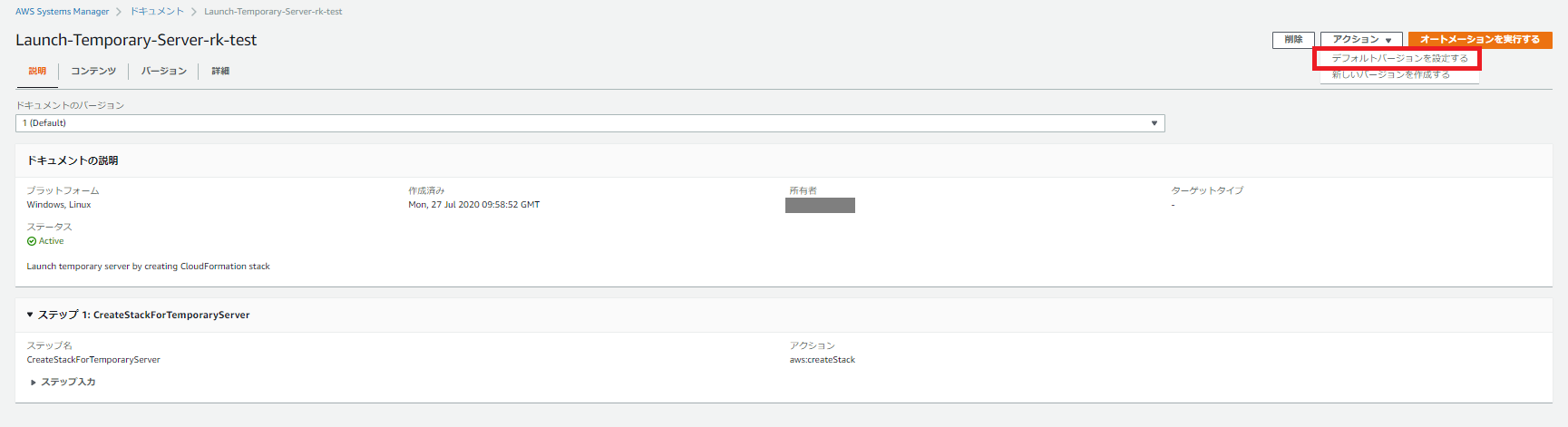
ドキュメント修正後に実行バージョンを指定する場合
「アクション」で「デフォルトバージョン」を指定し、バージョンを更新します。
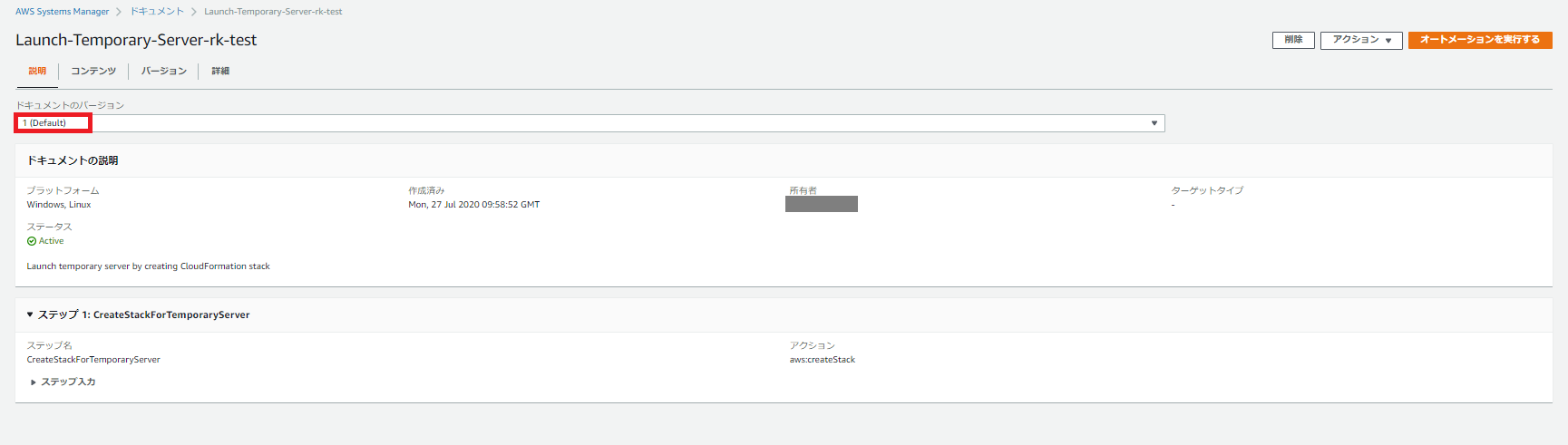
ドキュメント実行時に実行バージョンを指定する場合
ドキュメントのバージョンをデフォルトから更新して実行します。




- 投稿日:2020-07-27T21:07:02+09:00
【AWS】ロードバランサーでHTTPリクエスト(80ポート)をHTTPS(443ポート)にリダイレクトする
はじめに
作成したWEBアプリをHTTPでもHTTPSでも通信できるように設定していたが、よく考えてみればHTTPSのみで通信するべきでした。
よって、HTTPをHTTPSにリダイレクトできるようにします。環境(2020/07/27現在)
ブラウザ : Google Chrome バージョン 84.0.4147.89(Official Build)(64 ビット)
OS : Windows 10 Home 2004
※AWSはときどきUIが変わるので、注意してください。手順
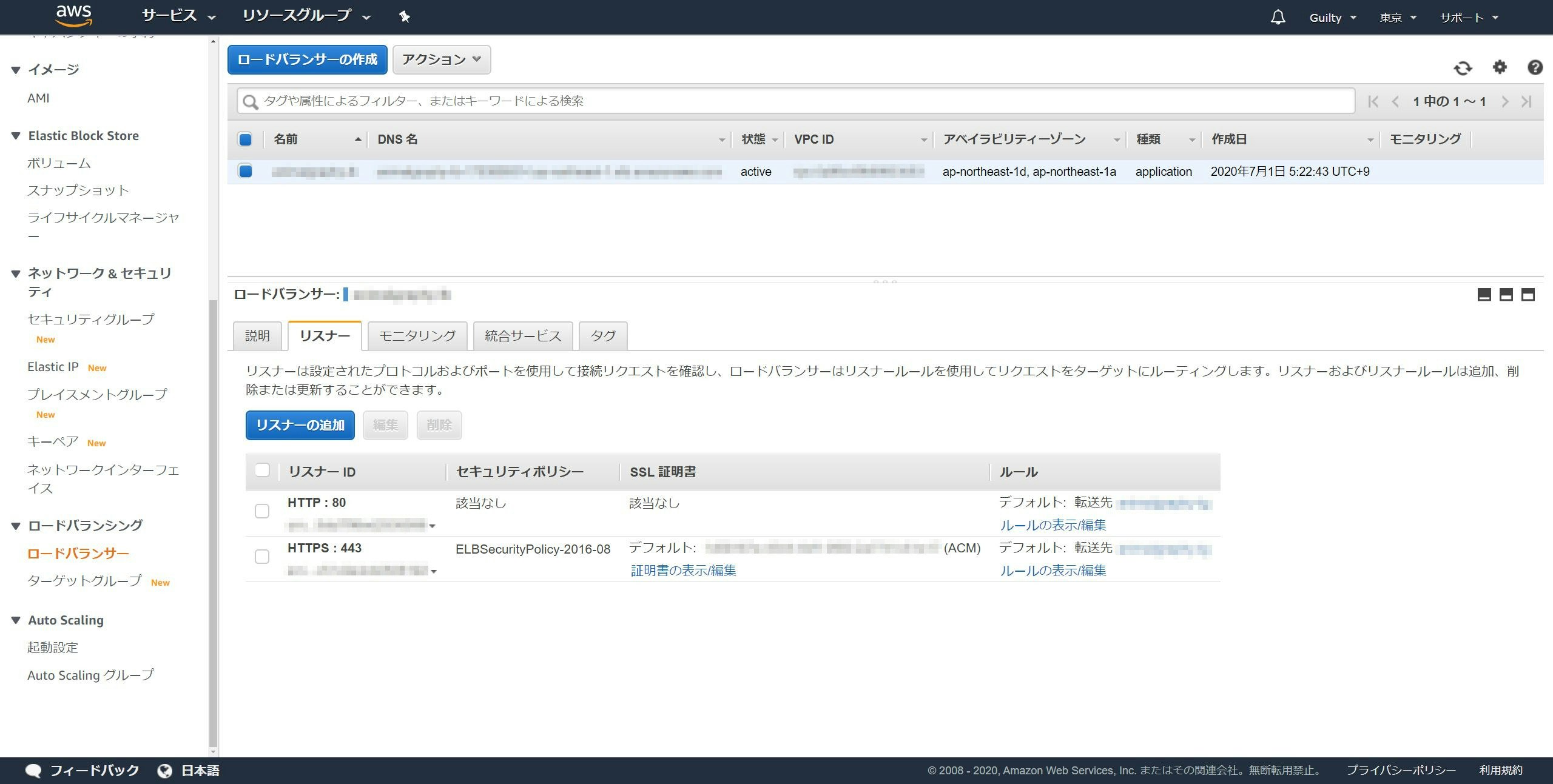
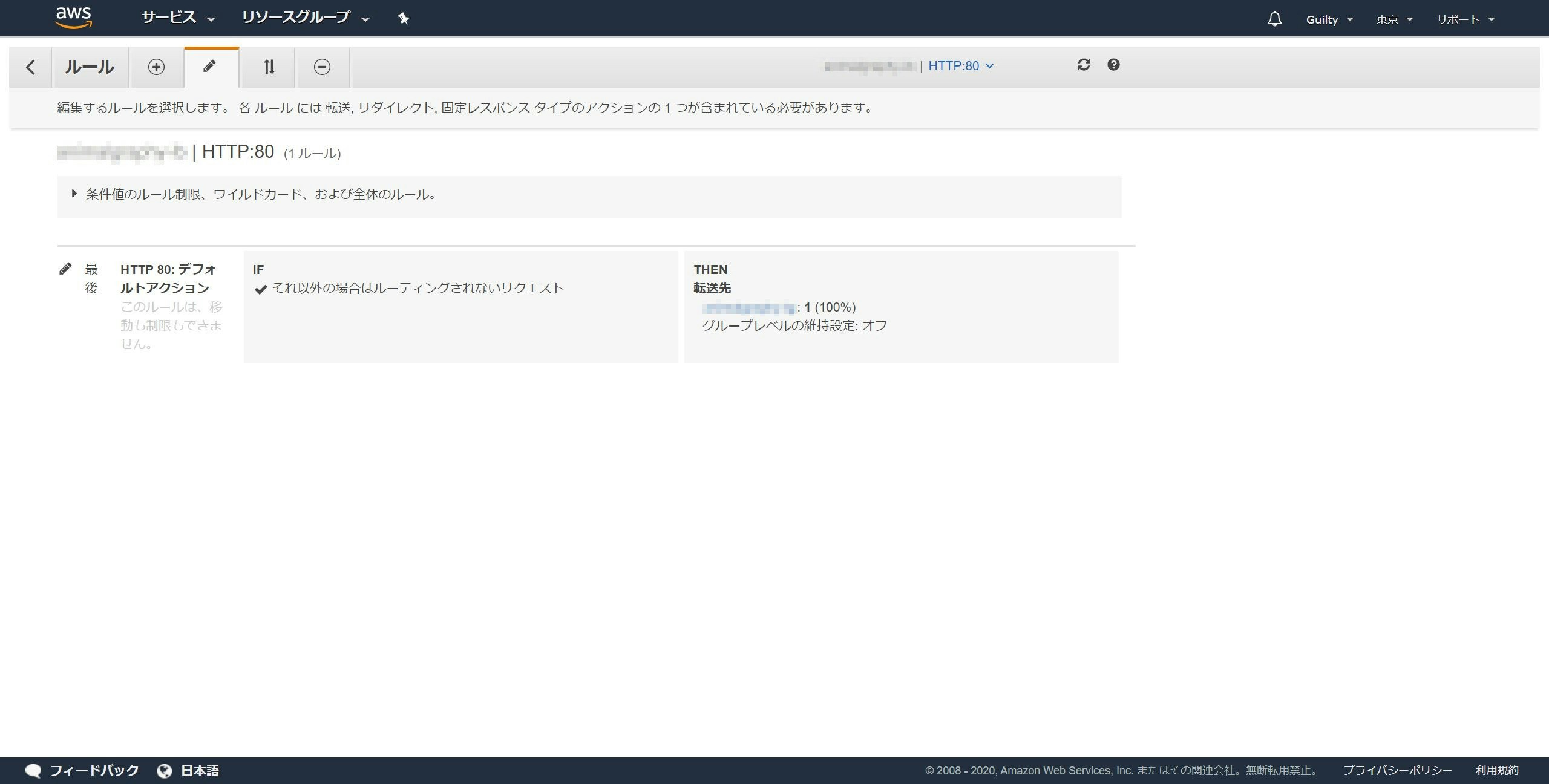
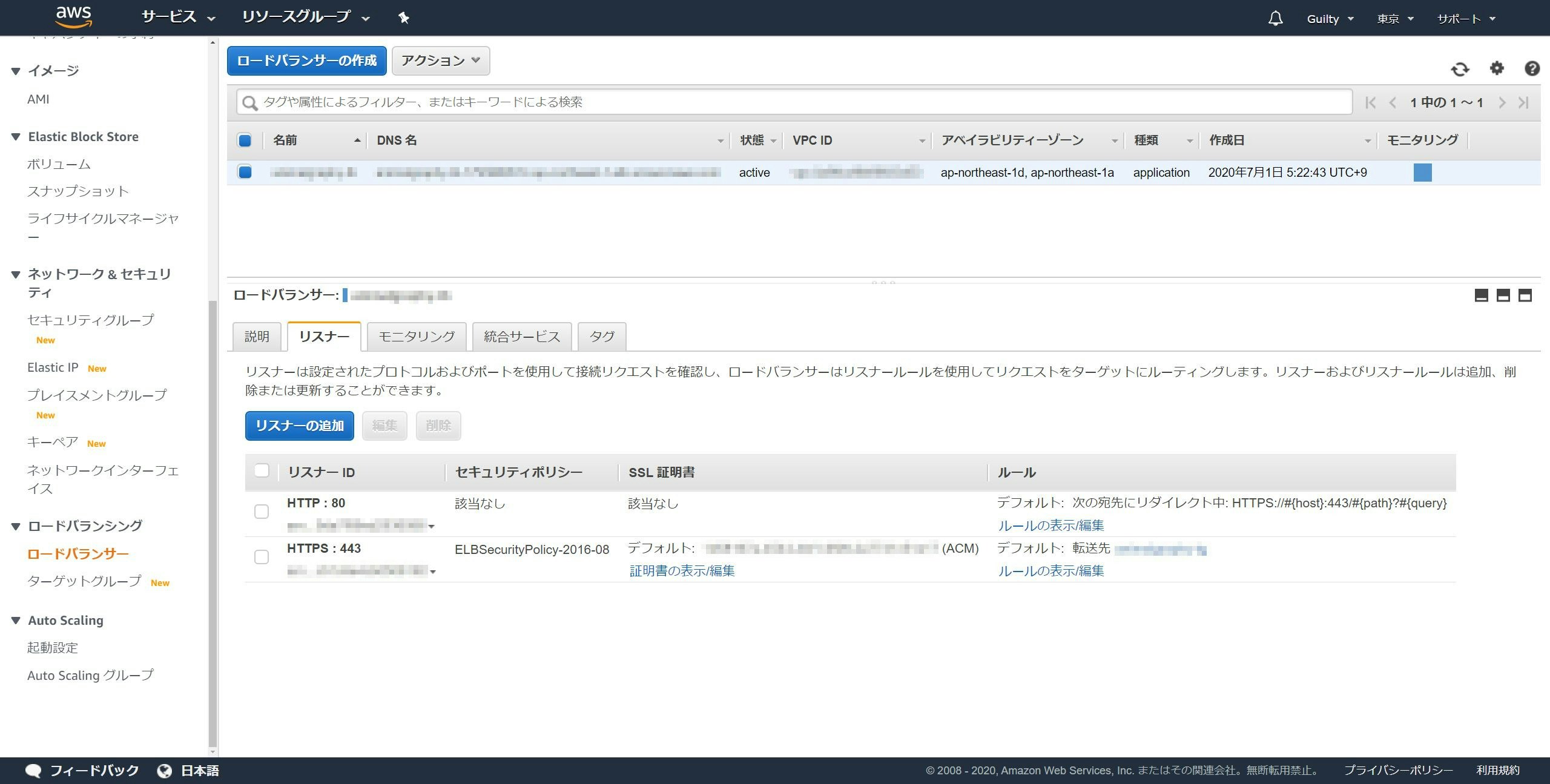
左のメニューからロードバランサーを開き、リスナータブを開きます。
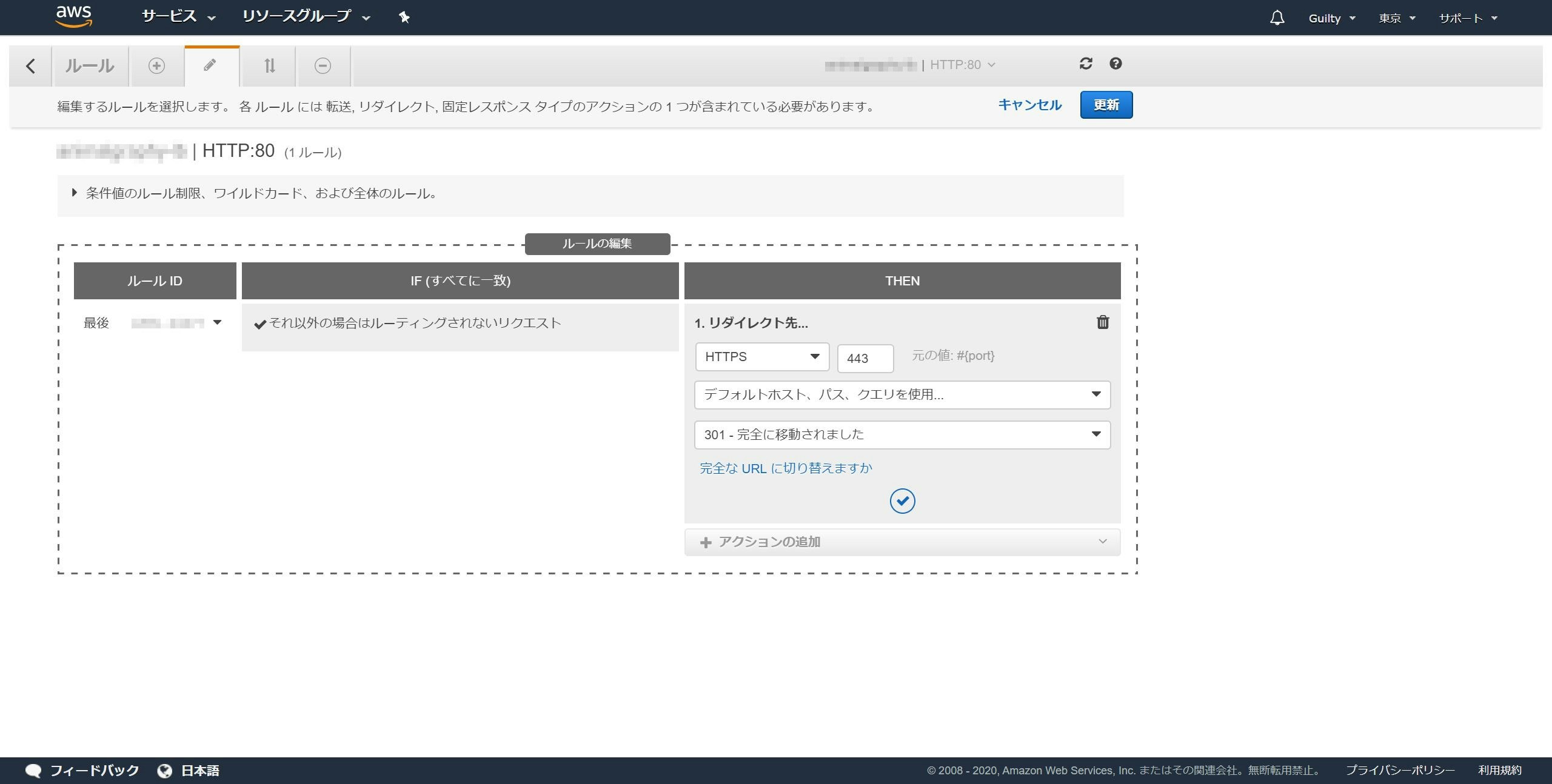
HTTP : 80のルールの表示/編集をクリックします。
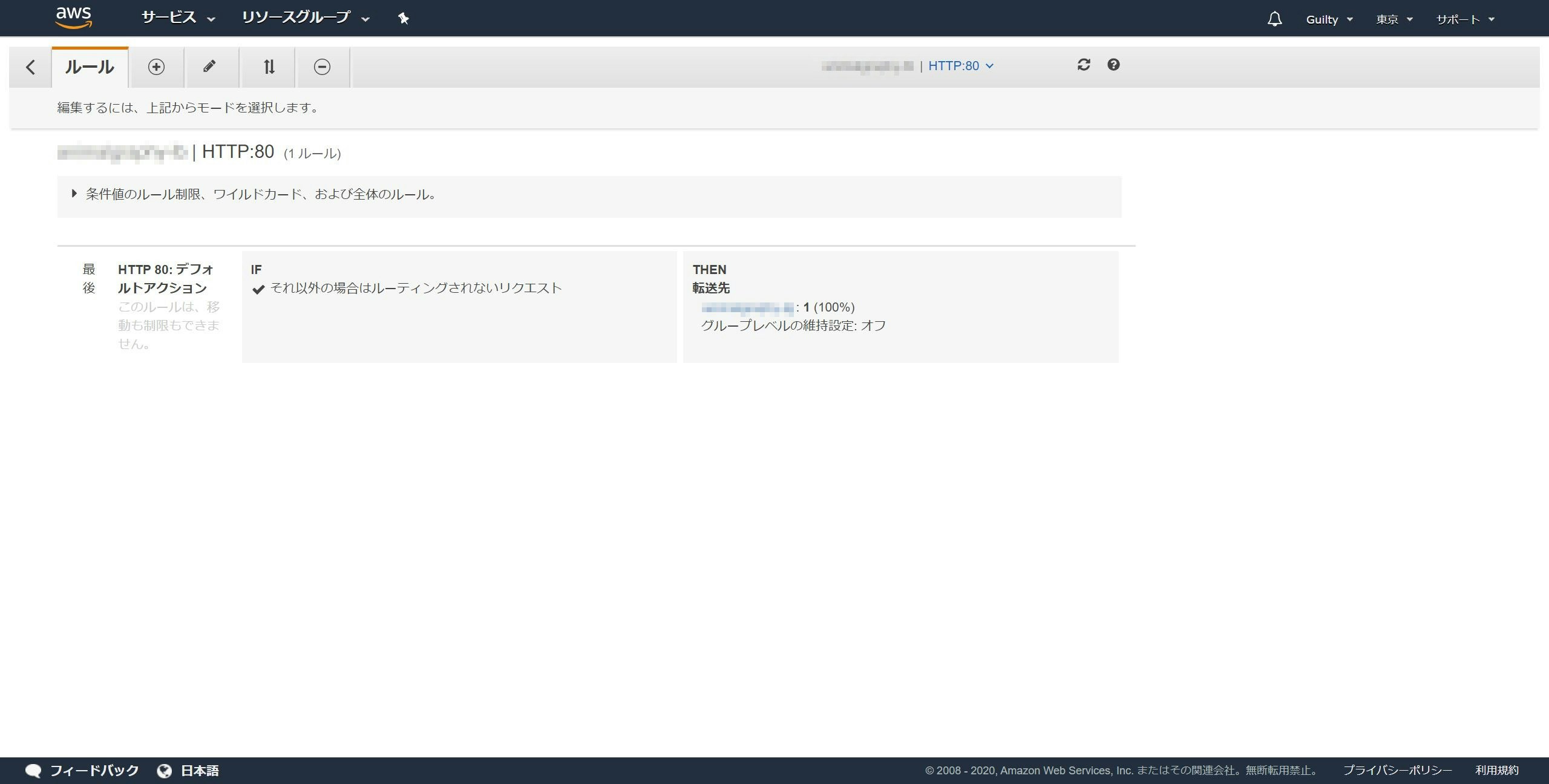
鉛筆マークのタブを開きます。
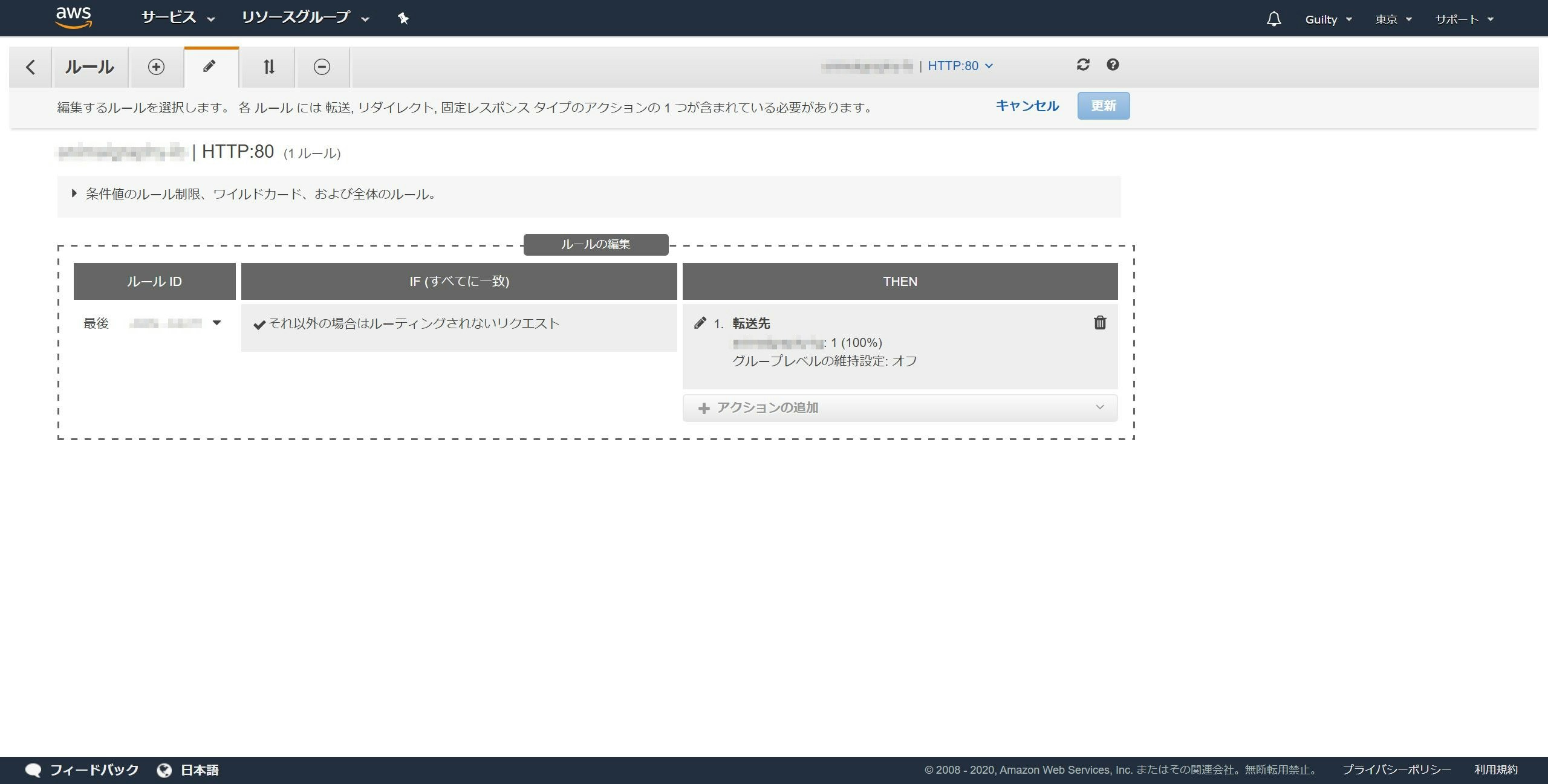
「最後」の左隣の鉛筆マークをクリックします。
ゴミ箱マークをクリックします。
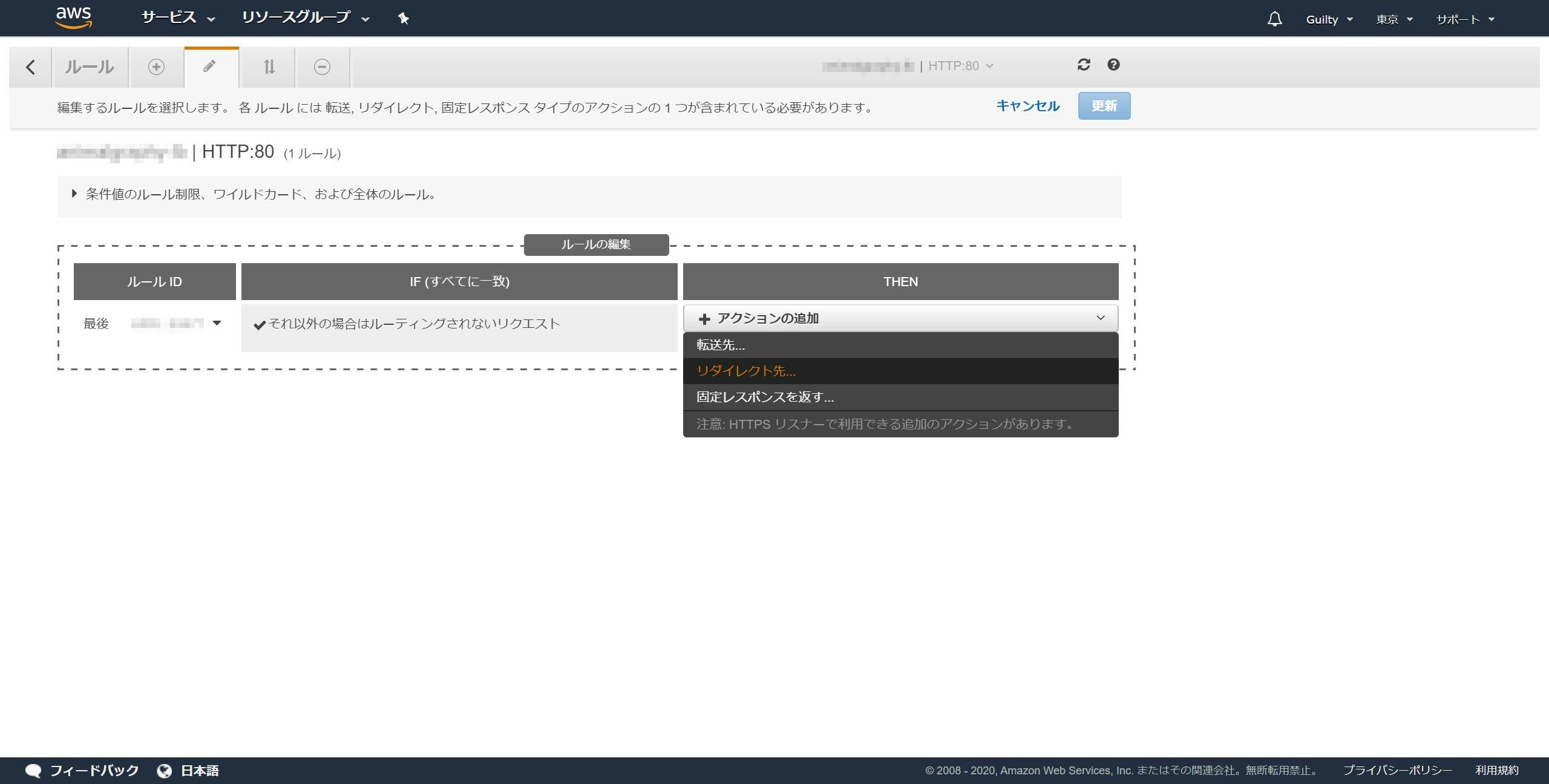
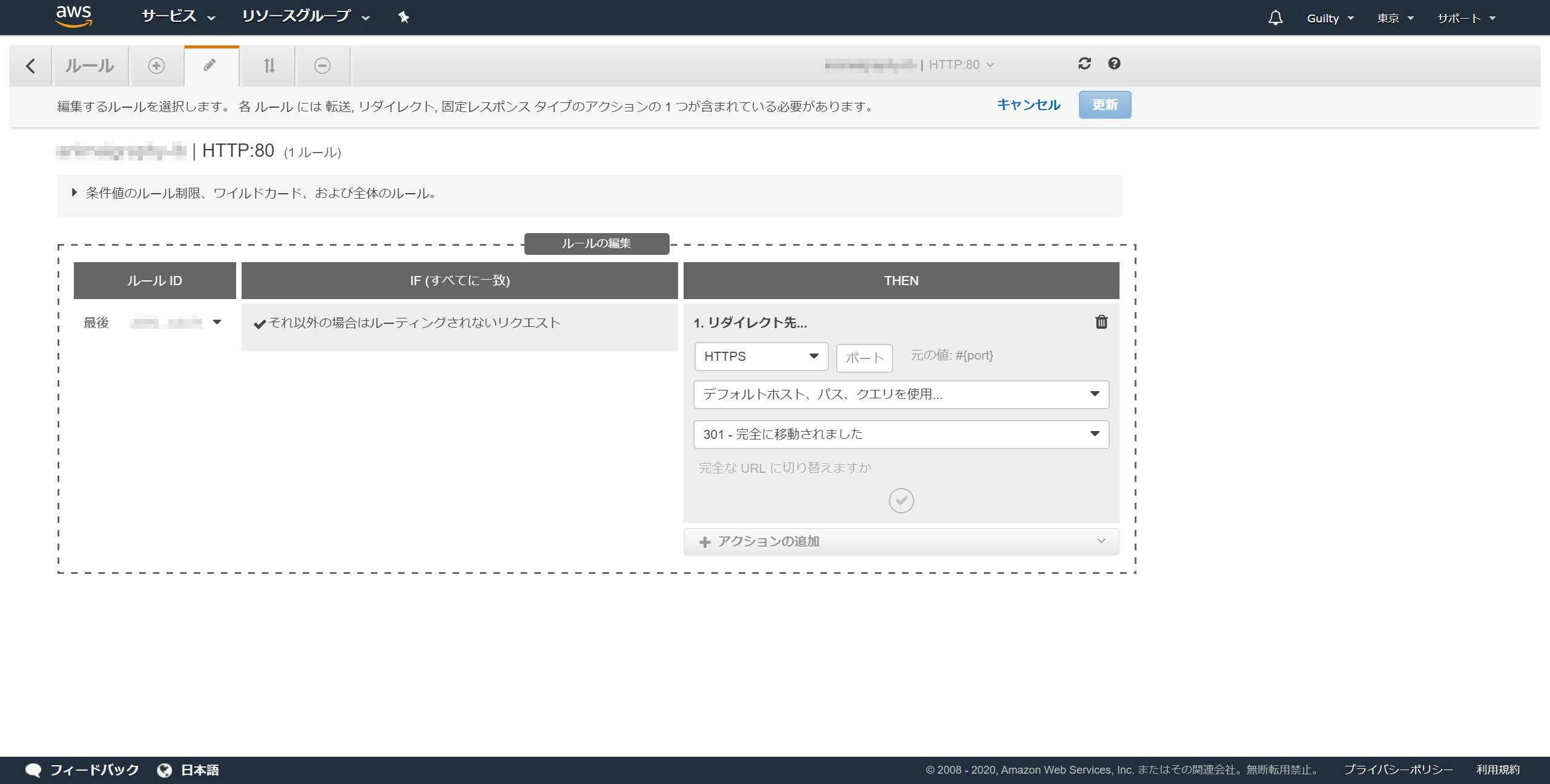
アクションの追加をクリックし、リダイレクト先をクリックします。
ポートに443を入力します。
✔ボタンをクリックします。
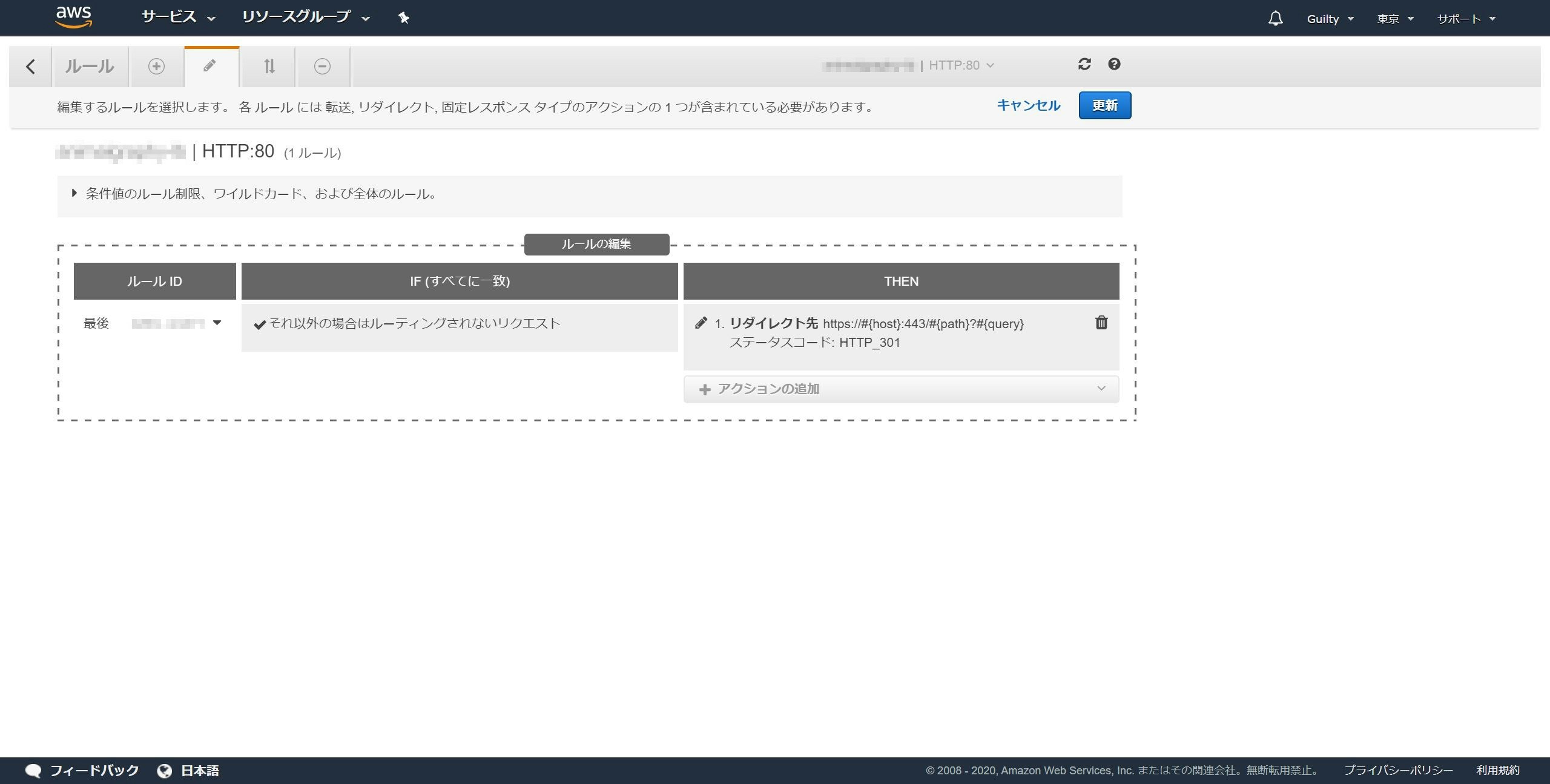
更新ボタンをクリックします。
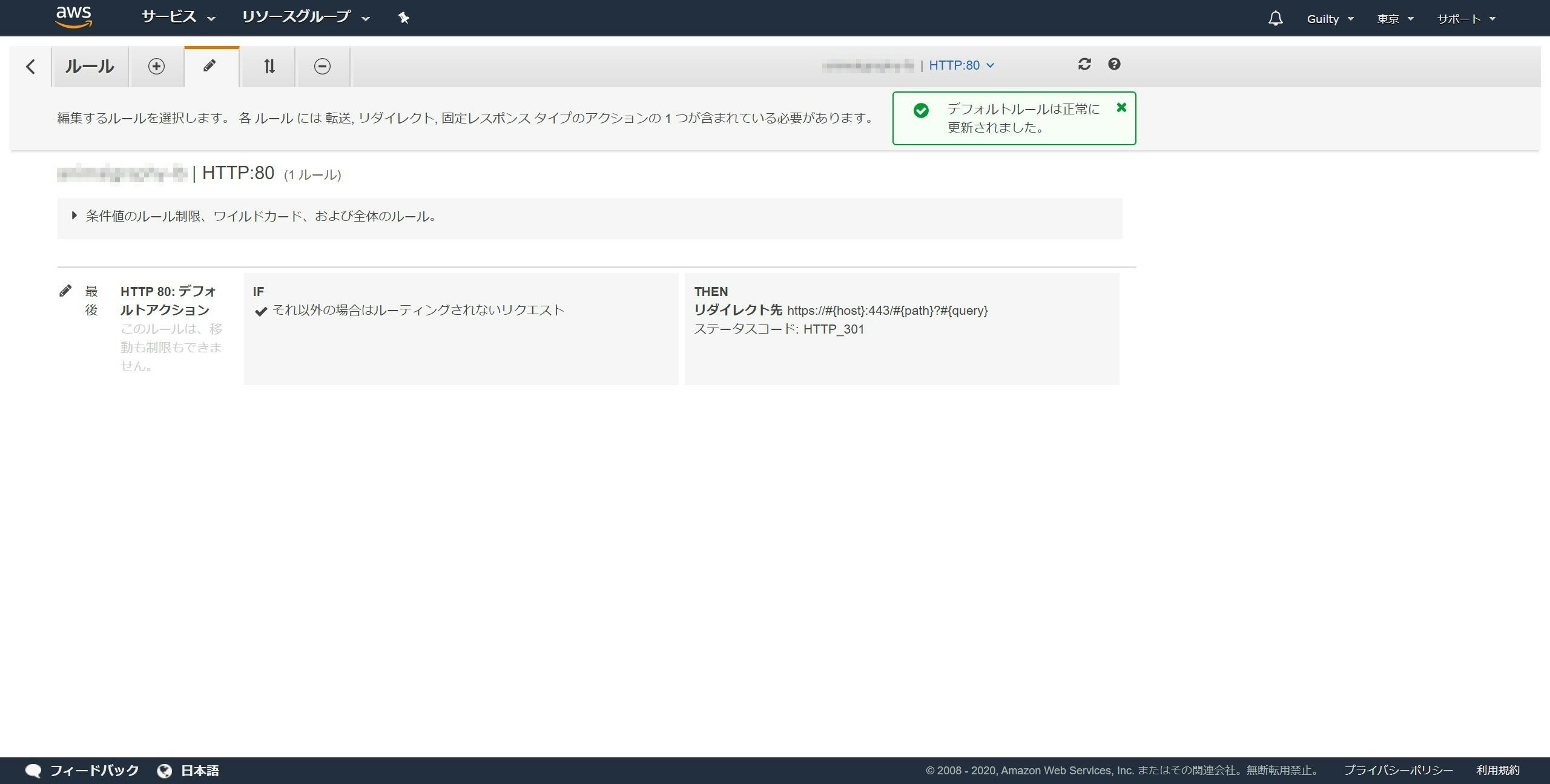
「デフォルトルールは正常に変更されました。」と表示され、リダイレクト先がhttpsはじまりになっていれば成功です。
HTTP : 80のルールがHTTPSにリダイレクトされるようになっていれば完了です。
お疲れさまでした!最後に
http://example.comにアクセスして、https://example.comにリダイレクトされることが確認できました。
※example.comの部分は当然自分のWEBサイトのドメイン名に変えてください。パブリックIPアドレスでもいいと思います。
- 投稿日:2020-07-27T19:58:15+09:00
VSCodeでAWSのLightsailインスタンス上のソースコードを編集する
はじめに
WordPress用のインスタンスを簡単に作成できるAWSのサービス「Lightsail」を触っていて、サーバ上のソースコードを編集したくなりました。
Vimを使うのもいいのですが、使い慣れているVSCodeで作業したくなりました。VSCodeに拡張機能を入れる
VSCodeでLightsailサーバにアクセスするには、SSH接続が出来るようにする必要があります。
そこで、Microsoftがリリースしている「Remote - SSH」を使用します。
SSH接続をする
拡張機能が入ったら、ウィンドウ左側のサイドメニューに新たなアイコンが表示されるので、クリックします。
SSH TARGETSの右側に+ボタンがあるので、クリックします。
SSH接続のコマンドを入力します。
"ssh -i "[秘密鍵]" [ユーザ]@[ホスト]"
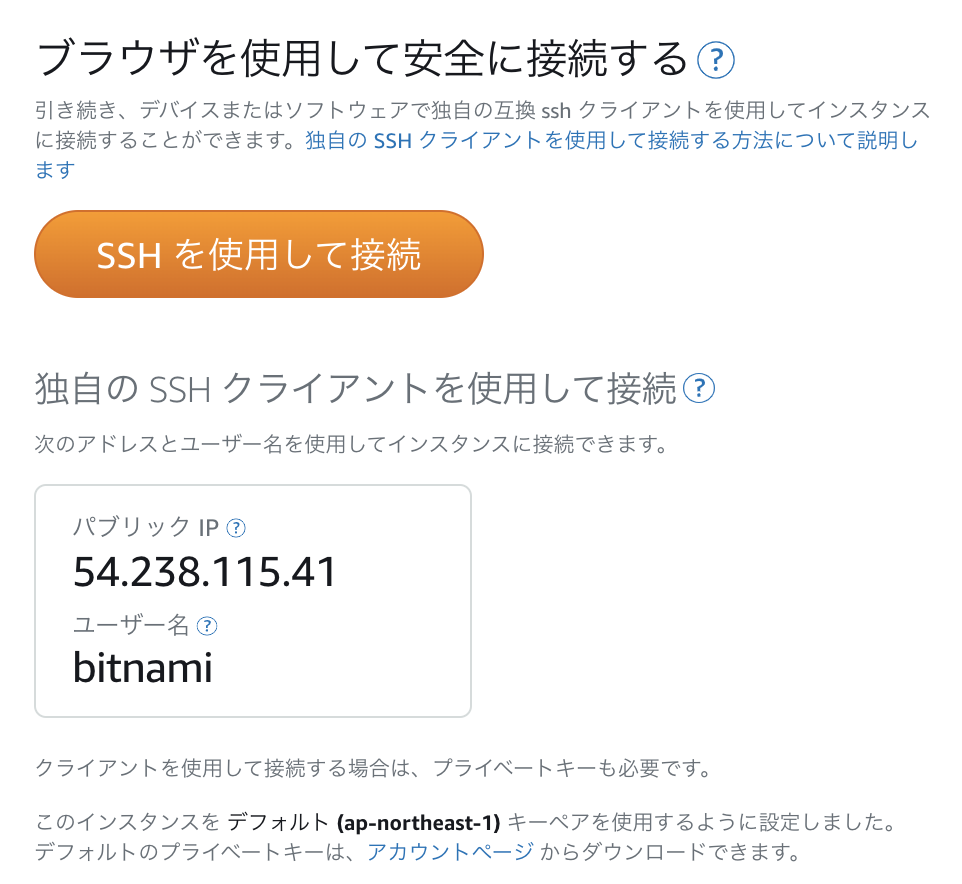
ユーザはbitnami(デフォルト)、ホストはパブリックIPです。
※パブリックIPを固定にしています。方法は「Lightsail 静的IP」などで調べてください。
秘密鍵は、Lightsailインスタンス管理画面、アカウントページからダウンロードできます。
接続完了したら、SSH TARGETSの下に接続先サーバが表示されるので、右クリックをして、現在のウィンドウで接続します。
完了
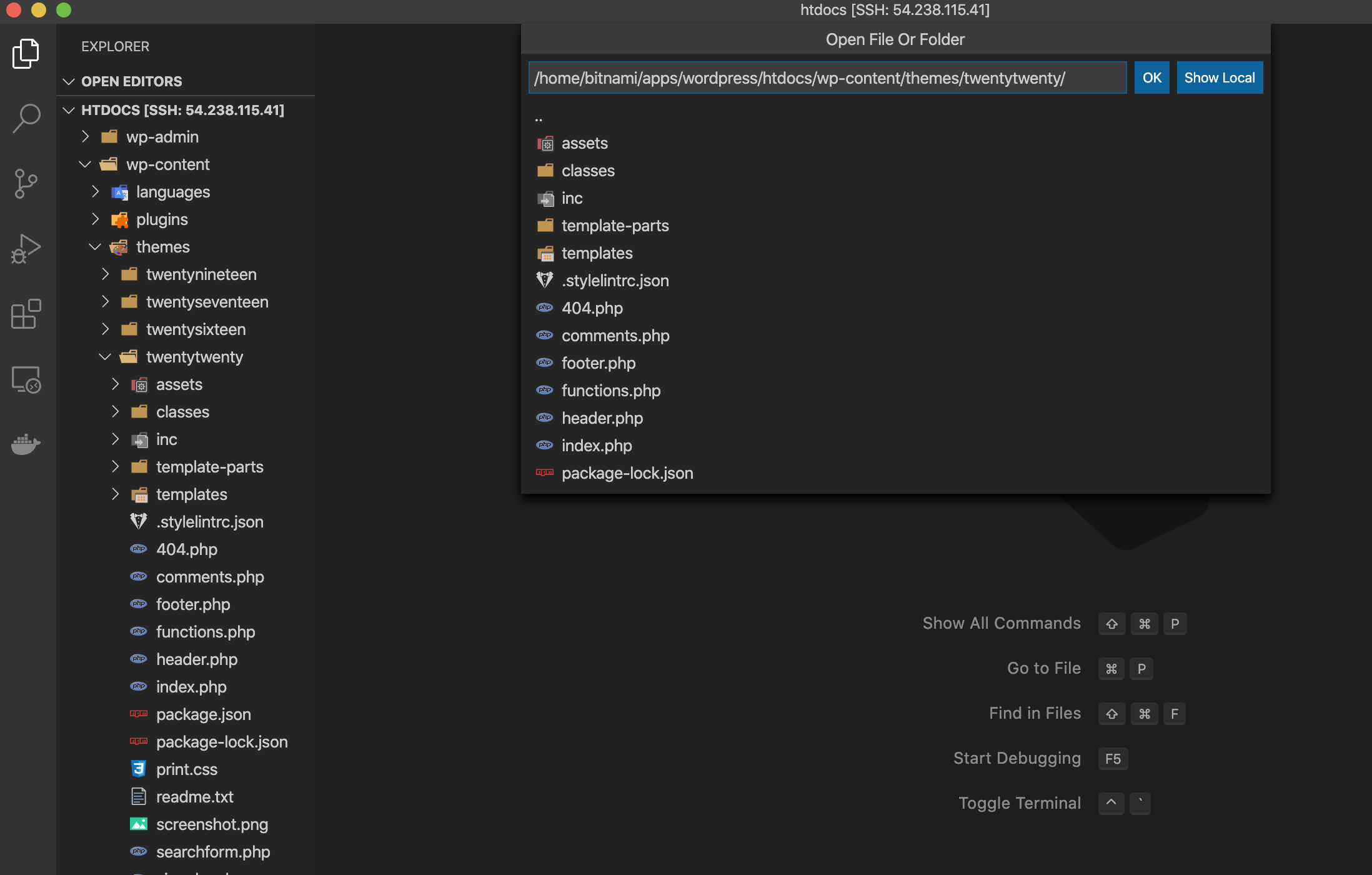
あとは、Open Folderをクリックしてフォルダを開けば、VSCodeで編集可能です。

- 投稿日:2020-07-27T19:53:49+09:00
AWS Lightsail でWordPress環境構築
はじめに
この記事では、WordPressでHP作成をするにあたって、簡単に環境構築ができる AWSのサービス「Lightsail」を使った手順を記載します。
PCはMacを使用しています。AWSアカウントは作成済みです。
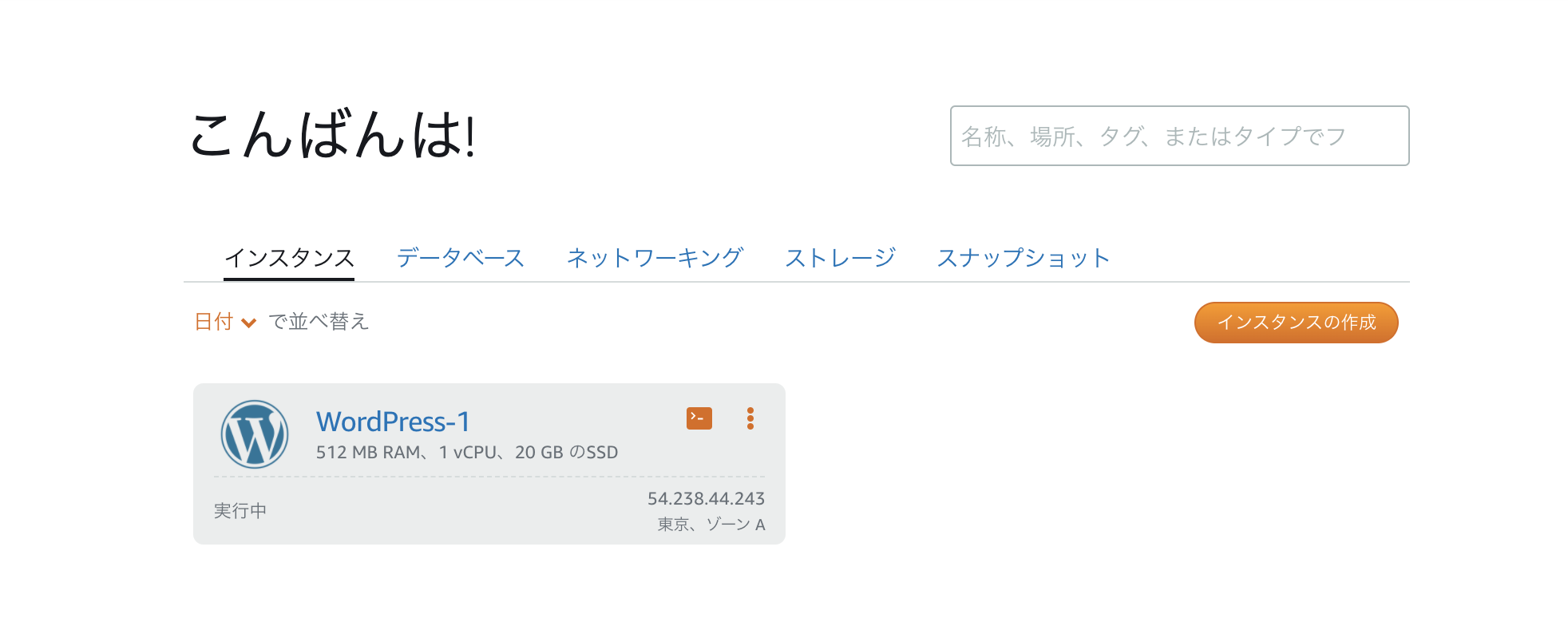
インスタンスの作成
Lightsailを利用開始すると、デフォルトで Linux/Unix + WordPress のインスタンスが選択されています。
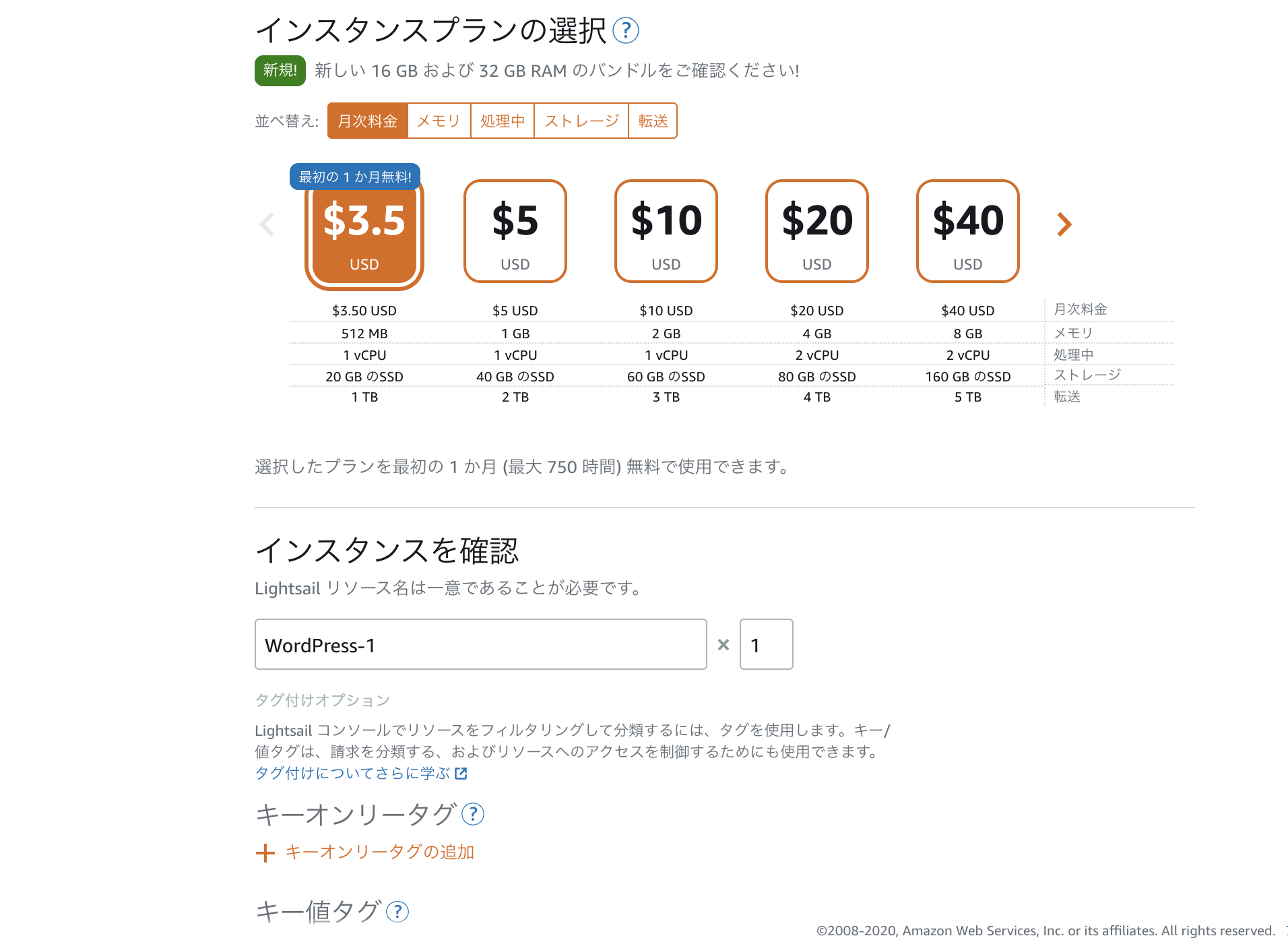
プランとインスタンス名もデフォルトのままでいきます。
数分待つと色がついて保留中から実行中に変わり、以下のような画面になりインスタンスが作成されます。
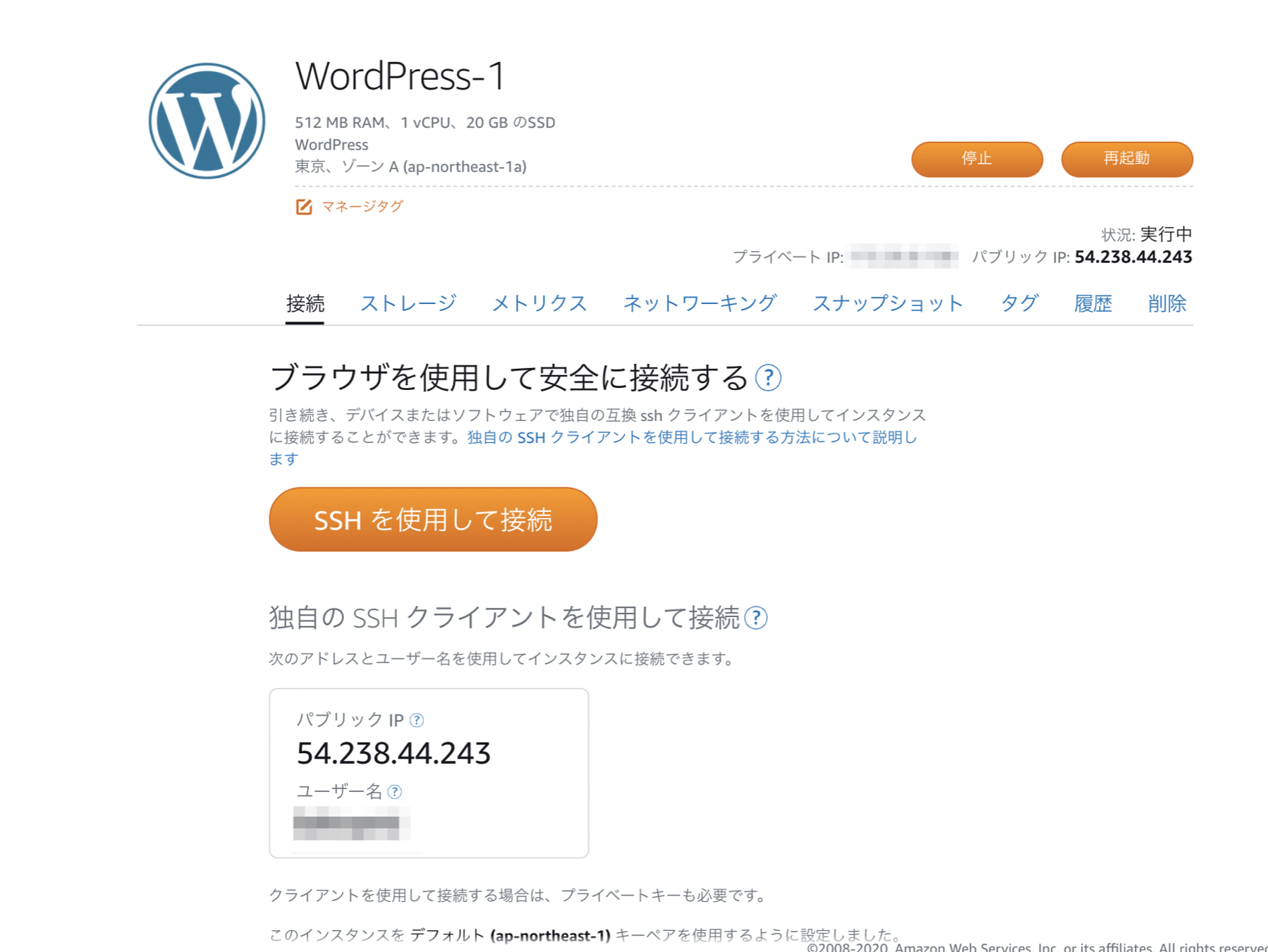
WordPressにログインする
「SSHを使用して接続」を押すと、自動でターミナルが起動しインスタンスに接続されます。
ターミナルで以下のコマンドを入力すると表示されるパスワードをどこかに記録しておきます(WordPressにログインするときに使います)。
cat bitnami_application_passwordexitでターミナルを抜けます。
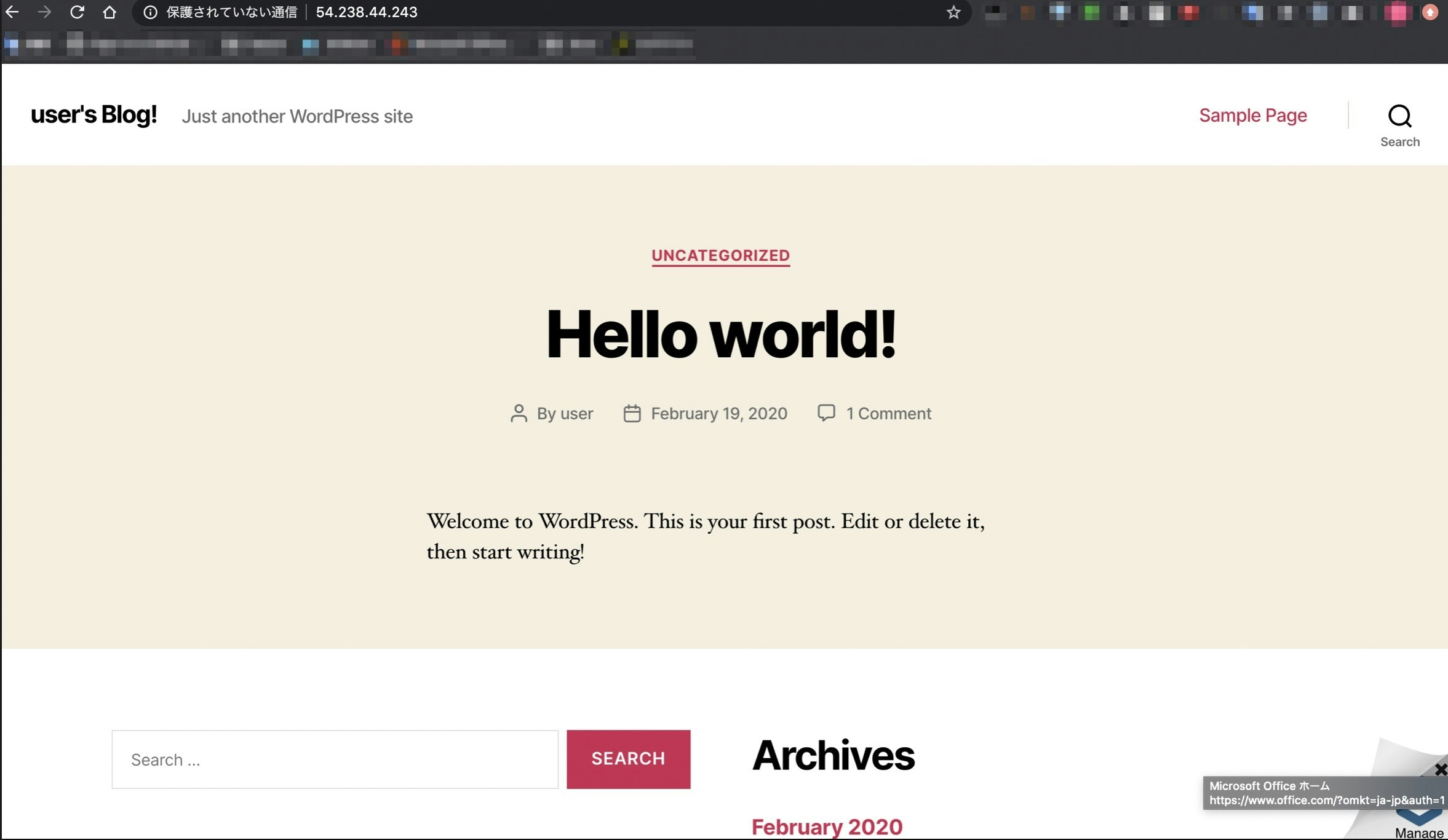
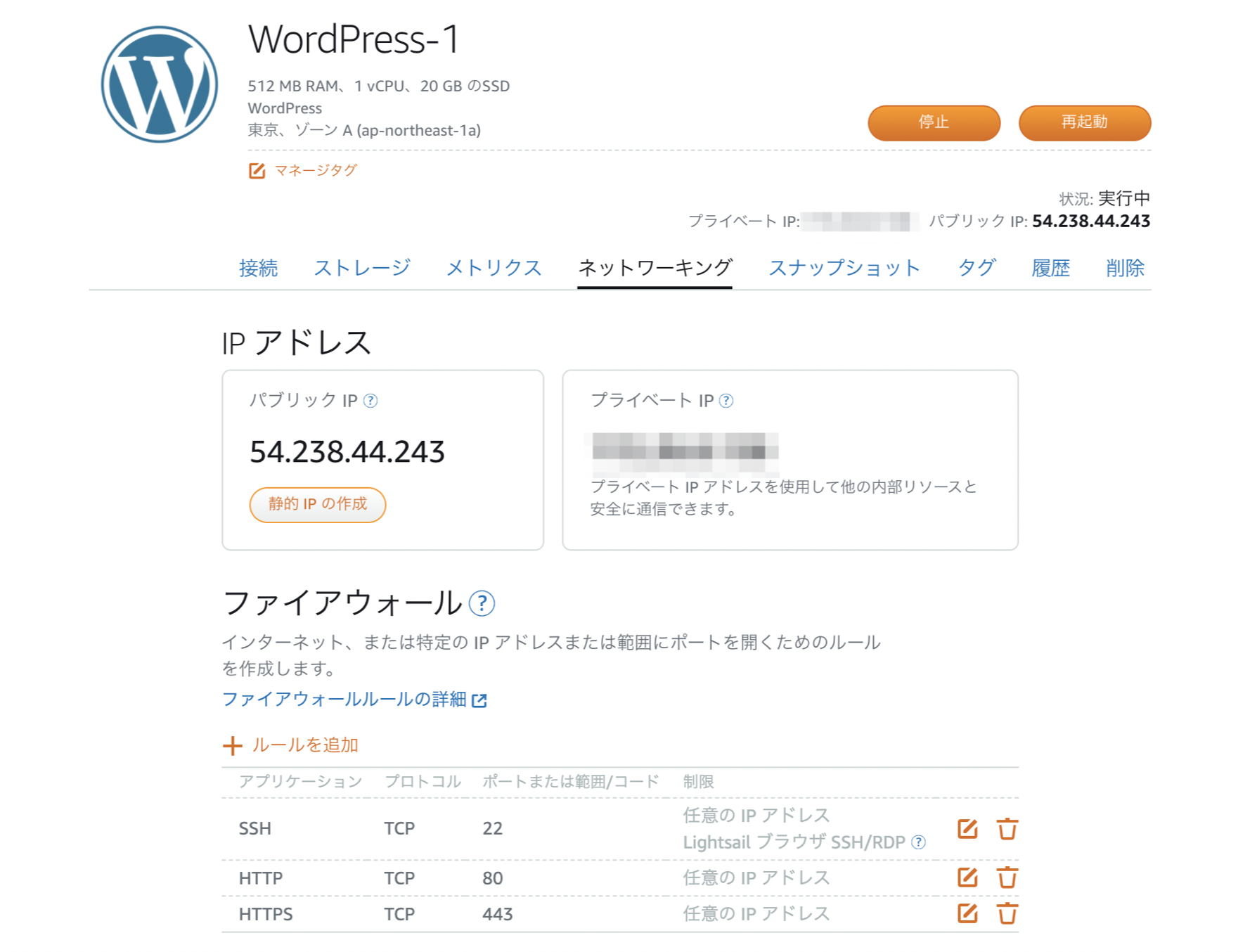
exitawsの画面に戻り、パブリックIPをブラウザのURLに入力すると、WordPressのトップページが表示されるはずなので確認しましょう。
現時点ではパブリックIPは変動してしまうので、後ほど固定します。独自ドメインへの紐付けは今回は行いません。
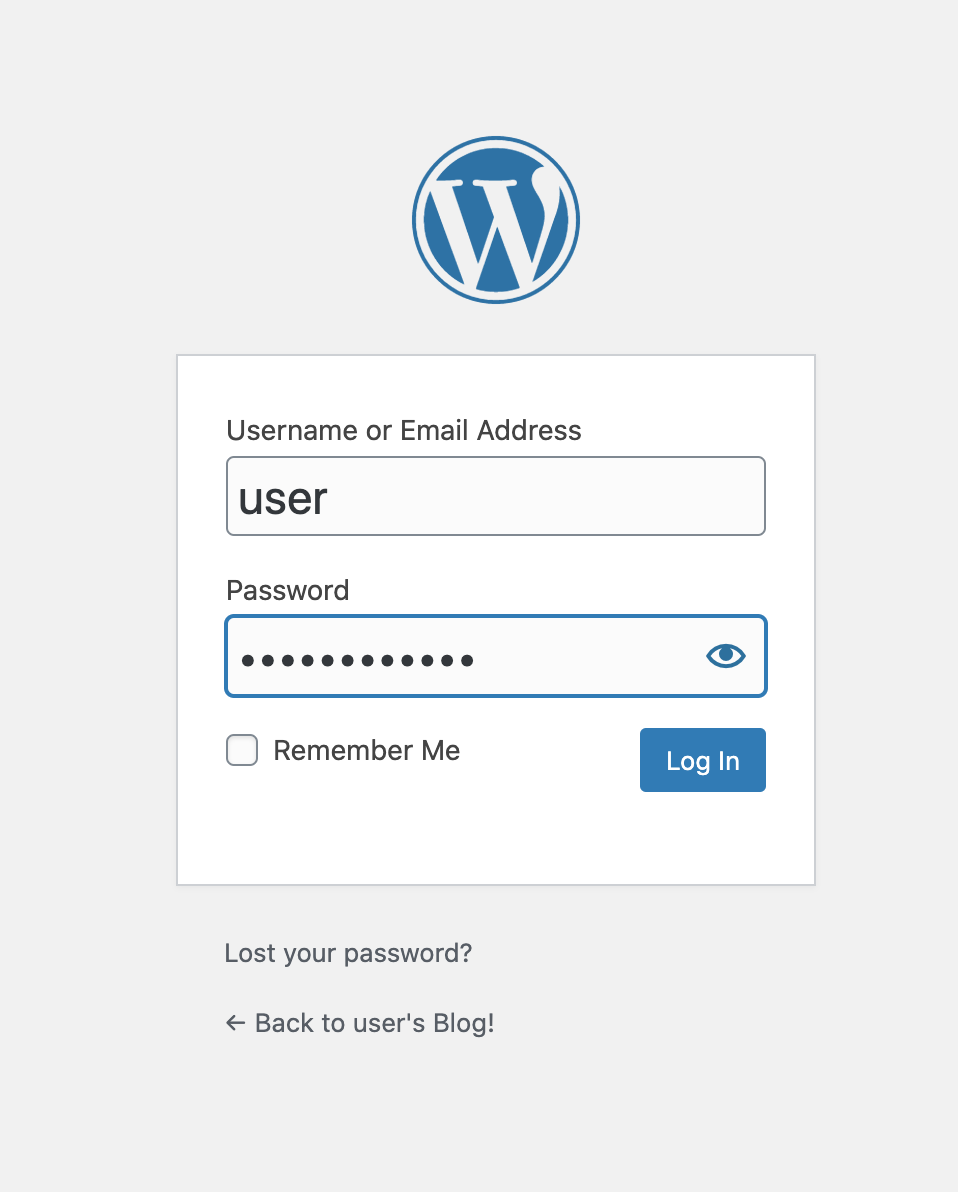
ブラウザURLのパブリックIPの後ろに/wp-loginを加えアクセスすると、ログイン画面が表示されます。
以下を入力して、ログインします。
ユーザー名:user
パスワード:先ほど記録したパスワード
WordPressにログイン完了です。ここでページの編集などを行えます。
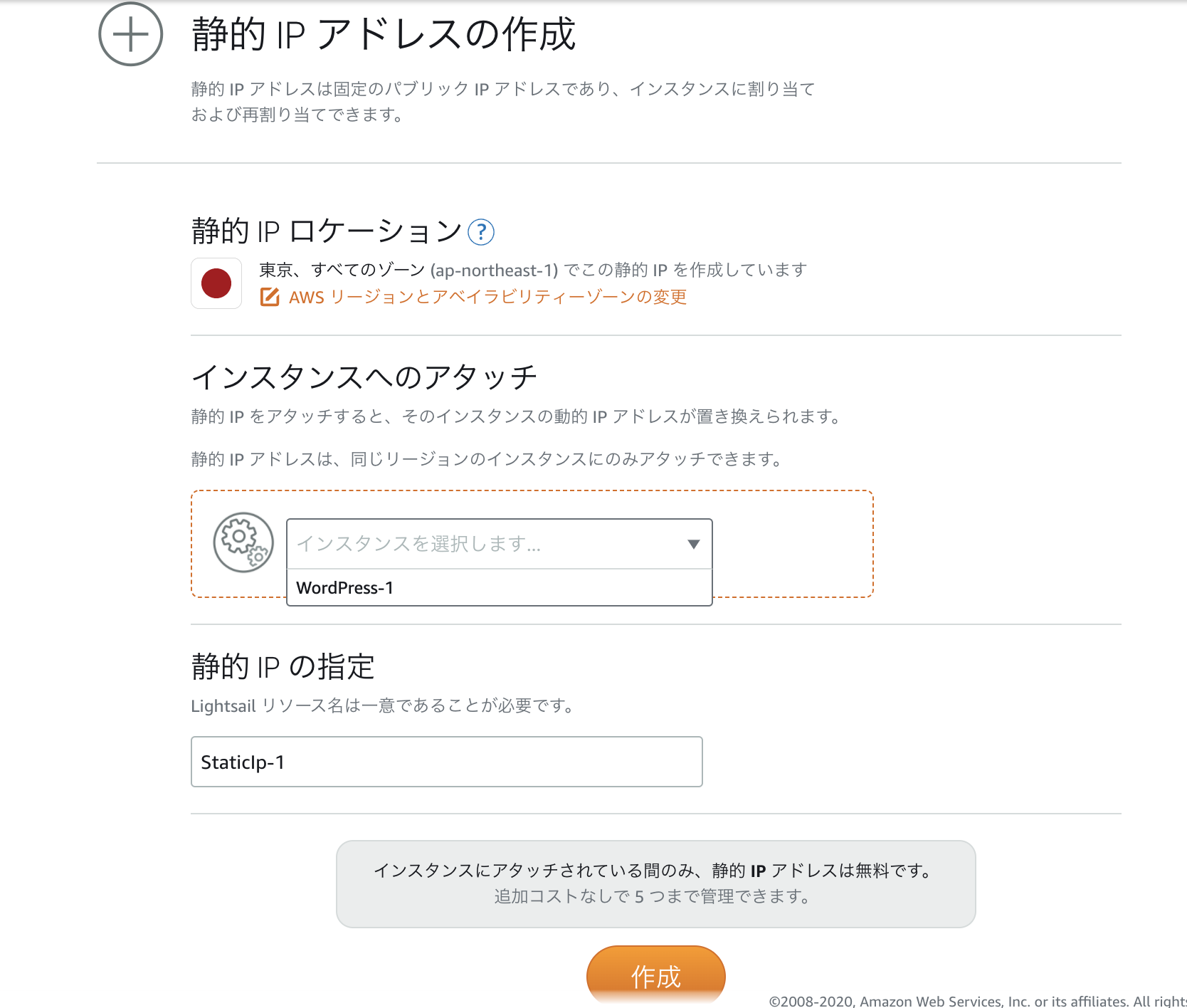
IPの固定
aws画面で、ネットワーキングタブを選択し、「静的IPの作成」をします。
先ほど作成したインスタンスを選択し、作成します。
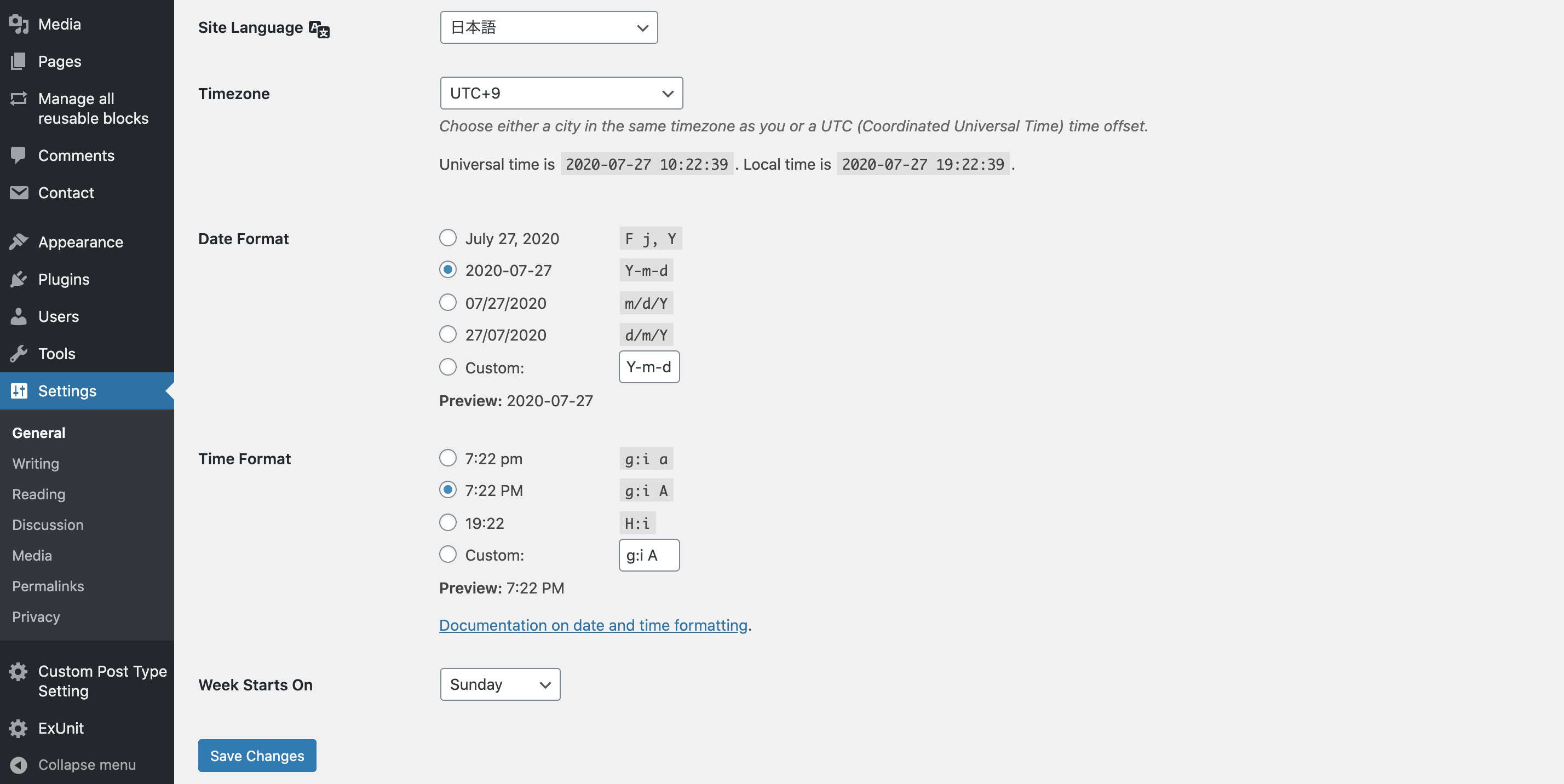
WordPressの設定について
ちなみに、Settingsより、管理画面の日本語化や、タイムゾーンの設定、日時表示形式の設定などができます。
デフォルトのタイムゾーンは海外仕様になっていたので、日本時間にしたいなら「UTC+9」に設定しましょう。
おわりに
LightsailはWordPressでHPを作成したいユーザーをターゲットにしているサービスなだけあって、細かな設定をすることなくサイトの立ち上げまでスイスイ進むことができました。
ページのデザインや、独自ドメインの紐付けなどはまた改めて投稿します。
- 投稿日:2020-07-27T19:43:11+09:00
EKSにKubeFlow1.0.2を構築する
はじめに
Installing Kubeflowページにある「Cloud deployment」をやってみます。全体の手順はこちらに従っています。
※ Q.なぜGCPを使わないのか A.会社でAWSを使うからです。
k8sを使うだけならGCPが圧倒的に使いやすいです。比較記事を参照してください。環境
- 開発PC(macOS Catalina 10.15.6(19G73))
- AWS
手順
AWS CLI のインストール
AWS CLIをインストールします。手順はこちらを参考にしてください。
AWS CLIのコンフィグレーションを実行しておきます。手順はこちらを参考にしてください。$ aws --version aws-cli/1.18.105 Python/3.6.5 Darwin/19.6.0 botocore/1.17.28kubectl のインストール
開発PCにkubectlをインストールします手順はこちらを参考にしてください。Homebrewを使ってインストールできます。
$ kubectl version Client Version: version.Info{Major:"1", Minor:"18", GitVersion:"v1.18.4", GitCommit:"c96aede7b5205121079932896c4ad89bb93260af", GitTreeState:"clean", BuildDate:"2020-06-18T02:59:13Z", GoVersion:"go1.14.3", Compiler:"gc", Platform:"darwin/amd64"}eksctl (version 0.1.31 or newer)と aws-iam-authenticator のインストール
eksctlをインストールします手順はこちらを参考にしてください。Homebrewを使ってインストールできます。
$ eksctl version 0.24.0AWS IAM Authenticator for Kubernetes のインストールですが、AWS CLI のバージョン 1.16.156 以降をインストールしている場合はAWS CLIに内包されているのでインストールは不要です。代わりに
aws eks get-tokenコマンドを使用します。今回はAWS CLIを使用します。
インストールする場合の手順はこちらを参考にしてください。EKS クラスタ作成
EKSの解説はこちらの記事がとてもわかり易いので、事前に一読しておくことを推奨します。
eksctlを使用してクラスタを作成します。Overview of Deployment on Existing Clustersによると、2020年7月現在、Kubeflow 1.0 はKubernetesのバージョン1.14または1.15のみ動作確認が行われています。一方でAWSのユーザーガイドによると、eksctlがサポートしているKubernetesのバージョンは1.15、1.16、1.17です。したがって今回は両方を満たすバージョン1.15を使用します。
ワーカーノードの要件はMinimum system requirementsに記載があります。
- 4 CPU
- 50 GB storage
- 12 GB memory
これを満たすインスタンスとして
m5.largeを使用します。インスタンスのスペックはこちらから確認できます。ボリュームサイズはクラスタ作成時のコマンドで指定します。次のコマンドでクラスタを作成します。今回は
kubeflowという名前のクラスタを作成します。リージョンは東京を選択しました(使用可能なリージョンはこちら)。ワーカーノード数は3、ボリュームのサイズは70GBとしています(ワーカーノード数が少ないとセカンダリIPが足りなくてPendingしてしまいますので3以上推奨です。)。また、ワーカーノードはEC2を使用するので、--managedオプションを使用します。
コマンドの詳細はEKS解説記事が分かりやすいです。またはeksctlの公式ドキュメントを参照してください。$ eksctl create cluster \ --name kubeflow \ --version 1.15 \ --region ap-northeast-1 \ --nodegroup-name standard-workers \ --node-type m5.large \ --nodes 3 \ --nodes-min 2 \ --nodes-max 3 \ --node-volume-size 70 \ --managedeksctlは、AWSの複数のリソースを作成してkubernetesを使用するための環境を作成します。eksctlが具体的に何をやっているのかはクラスメソッドさんの記事が分かりやすいです。
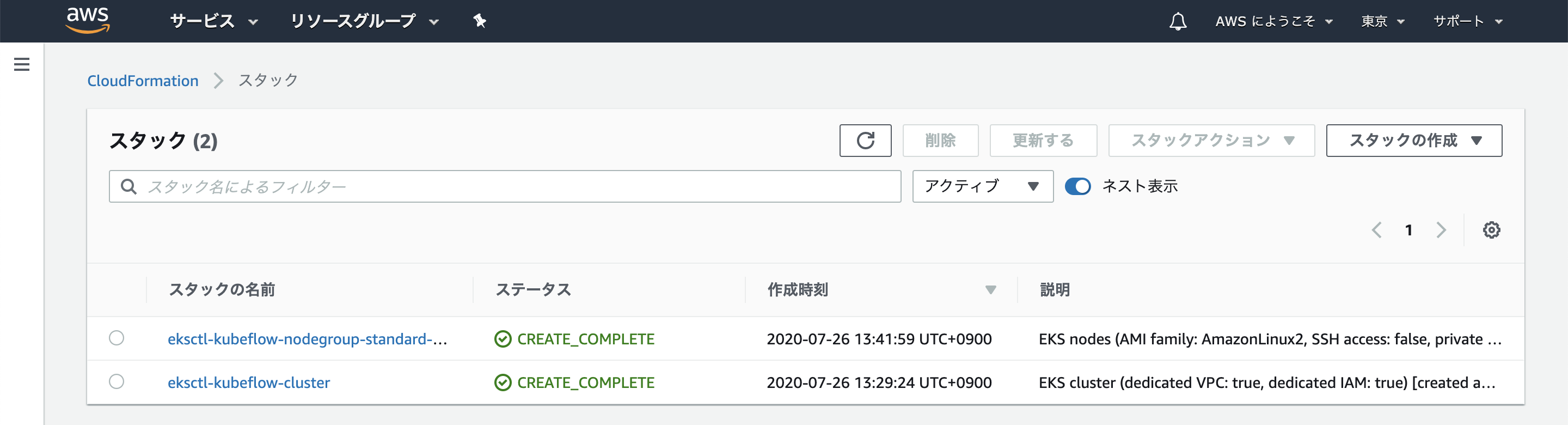
次のようなログが標準出力に出力され、クラスタが作成され始めます。クラスターのプロビジョニングには通常、10 ~ 15 分かかります。
[ℹ] eksctl version 0.24.0 [ℹ] using region ap-northeast-1 [ℹ] setting availability zones to [ap-northeast-1a ap-northeast-1c ap-northeast-1d] [ℹ] subnets for ap-northeast-1a - public:192.168.0.0/19 private:192.168.96.0/19 [ℹ] subnets for ap-northeast-1c - public:192.168.32.0/19 private:192.168.128.0/19 [ℹ] subnets for ap-northeast-1d - public:192.168.64.0/19 private:192.168.160.0/19 [ℹ] nodegroup "standard-workers" will use "ami-0bb8387c124770444" [AmazonLinux2/1.15] [ℹ] using Kubernetes version 1.15 [ℹ] creating EKS cluster "kubeflow" in "ap-northeast-1" region with un-managed nodes [ℹ] will create 2 separate CloudFormation stacks for cluster itself and the initial nodegroup [ℹ] if you encounter any issues, check CloudFormation console or try 'eksctl utils describe-stacks --region=ap-northeast-1 --cluster=kubeflow' [ℹ] CloudWatch logging will not be enabled for cluster "kubeflow" in "ap-northeast-1" [ℹ] you can enable it with 'eksctl utils update-cluster-logging --region=ap-northeast-1 --cluster=kubeflow' [ℹ] Kubernetes API endpoint access will use default of {publicAccess=true, privateAccess=false} for cluster "kubeflow" in "ap-northeast-1" [ℹ] 2 sequential tasks: { create cluster control plane "kubeflow", 2 sequential sub-tasks: { no tasks, create nodegroup "standard-workers" } } [ℹ] building cluster stack "eksctl-kubeflow-cluster" [ℹ] deploying stack "eksctl-kubeflow-cluster"作成されたら次のコマンドで応答が返ってくるか確認します。
$ kubectl get svc NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE kubernetes ClusterIP 10.100.0.1 <none> 443/TCP 19m $ kubectl version Client Version: version.Info{Major:"1", Minor:"18", GitVersion:"v1.18.6", GitCommit:"dff82dc0de47299ab66c83c626e08b245ab19037", GitTreeState:"clean", BuildDate:"2020-07-16T00:04:31Z", GoVersion:"go1.14.4", Compiler:"gc", Platform:"darwin/amd64"} Server Version: version.Info{Major:"1", Minor:"15+", GitVersion:"v1.15.11-eks-14f01f", GitCommit:"14f01fe8f04411d5e187b220034ca2117d79f7de", GitTreeState:"clean", BuildDate:"2020-05-23T21:32:47Z", GoVersion:"go1.12.17", Compiler:"gc", Platform:"linux/amd64"}コンソールで作成されたリソースを確認することが出来ます。
EKSが使えるか、少し試してみましょう。
$ kubectl create deployment hello-node --image=k8s.gcr.io/echoserver:1.4 deployment.apps/hello-node created $ kubectl get deployments NAME READY UP-TO-DATE AVAILABLE AGE hello-node 1/1 1 1 72s $ kubectl get replicasets NAME DESIRED CURRENT READY AGE hello-node-bcbcd7f76 1 1 1 2m17s $ kubectl get pods NAME READY STATUS RESTARTS AGE hello-node-bcbcd7f76-skspt 1/1 Running 0 8sこれでサンプルデプロイメントが作成されました。
次にkubectl expose コマンドを使用してPodをインターネットに公開します。$ kubectl expose deployment hello-node --type=LoadBalancer --port=8080 service/hello-node exposed $ kubectl get services NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE hello-node LoadBalancer 10.100.115.107 xxxxx.ap-northeast-1.elb.amazonaws.com 8080:30979/TCP 31s kubernetes ClusterIP 10.100.0.1 <none> 443/TCP 40m
xxxxx.ap-northeast-1.elb.amazonaws.com:8080にアクセスすると次のレスポンスが返ってきてサーバが公開されていることがわかります。CLIENT VALUES: client_address=xx.xx.xx.xx command=GET real path=/ query=nil request_version=1.1 request_uri=http://xxxxx.ap-northeast-1.elb.amazonaws.com:8080/ SERVER VALUES: server_version=nginx: 1.10.0 - lua: 10001 HEADERS RECEIVED: accept=text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9 accept-encoding=gzip, deflate accept-language=ja-JP,ja;q=0.9,en-US;q=0.8,en;q=0.7 cache-control=max-age=0 connection=keep-alive host=xxxxx.ap-northeast-1.elb.amazonaws.com:8080 upgrade-insecure-requests=1 user-agent=Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.89 Safari/537.36 BODY: -no body in request-確認できたらリソースを削除します。
$ kubectl delete service hello-node service "hello-node" deleted $ kubectl delete deployment hello-node deployment.extensions "hello-node" deletedこのHelloWorldはこちらで確認できます。
以上でkubernetesクラスタの準備が完了しました。
KubeFlow構築
こちらの手順に従ってインストールしていきます。
まずkfctlをインストールします。Macなのでplatformはdarwinです。
$ wget https://github.com/kubeflow/kfctl/releases/download/v1.0.2/kfctl_v1.0.2-0-ga476281_darwin.tar.gz $ tar -xvf kfctl_v1.0.2-0-ga476281_darwin.tar.gz $ mv kfctl /usr/local/bin/kfctl $ rm kfctl_v1.0.2-0-ga476281_darwin.tar.gzパスが通っているかの確認ついでにバージョンを確認します。
$ kfctl version kfctl v1.0.2-0-ga476281インストールに必要な変数をセットします。
$ export CONFIG_URI="https://raw.githubusercontent.com/kubeflow/manifests/v1.0-branch/kfdef/kfctl_aws.v1.0.2.yaml" $ export AWS_CLUSTER_NAME=kubeflow $ export KF_NAME=${AWS_CLUSTER_NAME} $ export BASE_DIR=~/kubeflow $ export KF_DIR=${BASE_DIR}/${KF_NAME}コンフィグファイルをダウンロードします。
$ mkdir -p ${KF_DIR} $ cd ${KF_DIR} $ wget -O kfctl_aws.yaml $CONFIG_URI $ export CONFIG_FILE=${KF_DIR}/kfctl_aws.yamlコンフィグを編集します。KubeFlowではv1.0.1からKubeFlowのServiceAccountにAWS IAM Roleが使用できるようなのですが、v1.0.2でやってみたところ、Roleが作成できないというエラーが発生してしまい、うまくいきませんでした。そこで従来のUse Node Group Roleの方法でRoleを設定します。
コンフィグ中の
kubeflow-awsを${AWS_CLUSTER_NAME}に置き換えます。$ sed -i'.bak' -e 's/kubeflow-aws/'"$AWS_CLUSTER_NAME"'/' ${CONFIG_FILE} $ aws iam list-roles \ | jq -r ".Roles[] \ | select(.RoleName \ | startswith(\"eksctl-$AWS_CLUSTER_NAME\") and contains(\"NodeInstanceRole\")) \ .RoleName" eksctl-kubeflow-nodegroup-standar-NodeInstanceRole-1X5H1J5YPHLPC標準出力に出力されたRole名をコピーし、コンフィグの
.spec.plugins.spec.rolesに設定します。plugins: - kind: KfAwsPlugin metadata: name: aws spec: auth: basicAuth: password: name: password username: admin region: ap-northeast-1 roles: - eksctl-kubeflow-nodegroup-standar-NodeInstanceRole-1X5H1J5YPHLPCKubeFlowをデプロイします。
$ cd ${KF_DIR} $ kfctl apply -V -f ${CONFIG_FILE}全てのリソースがreadyになるのを待ちます。次のコマンドで確認できます。
$ kubectl -n kubeflow get allSTATUSを見て
RunningまたはCompletedになっていれば問題ないと思います。nvidia-device-plugin-daemonsetがPendingのままなのですが、GPUインスタンスを使っていないからだと思います(多分)。なので今回はスルーします。NAME READY STATUS RESTARTS AGE pod/admission-webhook-bootstrap-stateful-set-0 1/1 Running 0 19h pod/admission-webhook-deployment-569558c8b6-dbwqc 1/1 Running 0 19h pod/alb-ingress-controller-7c4f854447-d2pwk 1/1 Running 0 19h pod/application-controller-stateful-set-0 1/1 Running 0 19h pod/argo-ui-7ffb9b6577-5rkzb 1/1 Running 0 19h pod/centraldashboard-659bd78c-j5zqs 1/1 Running 0 19h pod/jupyter-web-app-deployment-679d5f5dc4-2xwn2 1/1 Running 0 19h pod/katib-controller-7f58569f7d-dsb92 1/1 Running 1 19h pod/katib-db-manager-54b66f9f9d-g6pxr 1/1 Running 1 19h pod/katib-mysql-dcf7dcbd5-mvq42 1/1 Running 0 19h pod/katib-ui-6f97756598-5fc7k 1/1 Running 0 19h pod/kfserving-controller-manager-0 2/2 Running 1 19h pod/metacontroller-0 1/1 Running 0 19h pod/metadata-db-65fb5b695d-442jv 1/1 Running 0 19h pod/metadata-deployment-65ccddfd4c-xn7cp 1/1 Running 0 19h pod/metadata-envoy-deployment-7754f56bff-fjcck 1/1 Running 0 19h pod/metadata-grpc-deployment-5c6db9749-pb752 1/1 Running 4 19h pod/metadata-ui-7c85545947-nl8h4 1/1 Running 0 19h pod/minio-6b67f98977-jcz5j 1/1 Running 0 19h pod/ml-pipeline-6cf777c7bc-d7dlc 1/1 Running 0 19h pod/ml-pipeline-ml-pipeline-visualizationserver-6d744dd449-rr8df 1/1 Running 0 19h pod/ml-pipeline-persistenceagent-5c549847fd-4c5bb 1/1 Running 0 19h pod/ml-pipeline-scheduledworkflow-674777d89c-rvrtc 1/1 Running 0 19h pod/ml-pipeline-ui-549b5b6744-hkv7d 1/1 Running 0 19h pod/ml-pipeline-viewer-controller-deployment-fc7f7cb65-thjm5 1/1 Running 0 19h pod/mpi-operator-548d8cdbbd-ndwkc 1/1 Running 0 19h pod/mysql-85bc64f5c4-gvwph 1/1 Running 0 19h pod/notebook-controller-deployment-5c55f5845b-n9xgn 1/1 Running 0 19h pod/nvidia-device-plugin-daemonset-5rmbb 0/1 Pending 0 19h pod/nvidia-device-plugin-daemonset-7pqv2 0/1 Pending 0 19h pod/nvidia-device-plugin-daemonset-j4jc7 1/1 Running 0 18m pod/profiles-deployment-57d44f597d-mhl87 2/2 Running 0 19h pod/pytorch-operator-cf8c5c497-gbt6z 1/1 Running 0 19h pod/seldon-controller-manager-6b4b969447-5vzqx 1/1 Running 0 19h pod/spark-operatorcrd-cleanup-h8454 0/2 Completed 0 19h pod/spark-operatorsparkoperator-76dd5f5688-7d4fv 1/1 Running 0 19h pod/spartakus-volunteer-57d9875c96-sr8lj 1/1 Running 0 19h pod/tensorboard-5f685f9d79-745tf 1/1 Running 0 19h pod/tf-job-operator-5fb85c5fb7-79hn9 1/1 Running 0 19h pod/workflow-controller-689d6c8846-t2wvp 1/1 Running 0 19h NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE service/admission-webhook-service ClusterIP 10.100.51.140 <none> 443/TCP 19h service/application-controller-service ClusterIP 10.100.15.143 <none> 443/TCP 19h service/argo-ui NodePort 10.100.18.201 <none> 80:31463/TCP 19h service/centraldashboard ClusterIP 10.100.16.227 <none> 80/TCP 19h service/jupyter-web-app-service ClusterIP 10.100.60.58 <none> 80/TCP 19h service/katib-controller ClusterIP 10.100.11.97 <none> 443/TCP,8080/TCP 19h service/katib-db-manager ClusterIP 10.100.250.190 <none> 6789/TCP 19h service/katib-mysql ClusterIP 10.100.27.243 <none> 3306/TCP 19h service/katib-ui ClusterIP 10.100.215.210 <none> 80/TCP 19h service/kfserving-controller-manager-metrics-service ClusterIP 10.100.40.10 <none> 8443/TCP 19h service/kfserving-controller-manager-service ClusterIP 10.100.41.230 <none> 443/TCP 19h service/kfserving-webhook-server-service ClusterIP 10.100.124.190 <none> 443/TCP 19h service/metadata-db ClusterIP 10.100.174.250 <none> 3306/TCP 19h service/metadata-envoy-service ClusterIP 10.100.80.246 <none> 9090/TCP 19h service/metadata-grpc-service ClusterIP 10.100.247.63 <none> 8080/TCP 19h service/metadata-service ClusterIP 10.100.59.187 <none> 8080/TCP 19h service/metadata-ui ClusterIP 10.100.234.158 <none> 80/TCP 19h service/minio-service ClusterIP 10.100.78.186 <none> 9000/TCP 19h service/ml-pipeline ClusterIP 10.100.0.209 <none> 8888/TCP,8887/TCP 19h service/ml-pipeline-ml-pipeline-visualizationserver ClusterIP 10.100.115.213 <none> 8888/TCP 19h service/ml-pipeline-tensorboard-ui ClusterIP 10.100.148.88 <none> 80/TCP 19h service/ml-pipeline-ui ClusterIP 10.100.112.177 <none> 80/TCP 19h service/mysql ClusterIP 10.100.92.26 <none> 3306/TCP 19h service/notebook-controller-service ClusterIP 10.100.107.0 <none> 443/TCP 19h service/profiles-kfam ClusterIP 10.100.176.124 <none> 8081/TCP 19h service/pytorch-operator ClusterIP 10.100.53.116 <none> 8443/TCP 19h service/seldon-webhook-service ClusterIP 10.100.11.184 <none> 443/TCP 19h service/tensorboard ClusterIP 10.100.165.203 <none> 9000/TCP 19h service/tf-job-operator ClusterIP 10.100.7.225 <none> 8443/TCP 19h NAME DESIRED CURRENT READY UP-TO-DATE AVAILABLE NODE SELECTOR AGE daemonset.apps/nvidia-device-plugin-daemonset 3 3 1 3 1 <none> 19h NAME READY UP-TO-DATE AVAILABLE AGE deployment.apps/admission-webhook-deployment 1/1 1 1 19h deployment.apps/alb-ingress-controller 1/1 1 1 19h deployment.apps/argo-ui 1/1 1 1 19h deployment.apps/centraldashboard 1/1 1 1 19h deployment.apps/jupyter-web-app-deployment 1/1 1 1 19h deployment.apps/katib-controller 1/1 1 1 19h deployment.apps/katib-db-manager 1/1 1 1 19h deployment.apps/katib-mysql 1/1 1 1 19h deployment.apps/katib-ui 1/1 1 1 19h deployment.apps/metadata-db 1/1 1 1 19h deployment.apps/metadata-deployment 1/1 1 1 19h deployment.apps/metadata-envoy-deployment 1/1 1 1 19h deployment.apps/metadata-grpc-deployment 1/1 1 1 19h deployment.apps/metadata-ui 1/1 1 1 19h deployment.apps/minio 1/1 1 1 19h deployment.apps/ml-pipeline 1/1 1 1 19h deployment.apps/ml-pipeline-ml-pipeline-visualizationserver 1/1 1 1 19h deployment.apps/ml-pipeline-persistenceagent 1/1 1 1 19h deployment.apps/ml-pipeline-scheduledworkflow 1/1 1 1 19h deployment.apps/ml-pipeline-ui 1/1 1 1 19h deployment.apps/ml-pipeline-viewer-controller-deployment 1/1 1 1 19h deployment.apps/mpi-operator 1/1 1 1 19h deployment.apps/mysql 1/1 1 1 19h deployment.apps/notebook-controller-deployment 1/1 1 1 19h deployment.apps/profiles-deployment 1/1 1 1 19h deployment.apps/pytorch-operator 1/1 1 1 19h deployment.apps/seldon-controller-manager 1/1 1 1 19h deployment.apps/spark-operatorsparkoperator 1/1 1 1 19h deployment.apps/spartakus-volunteer 1/1 1 1 19h deployment.apps/tensorboard 1/1 1 1 19h deployment.apps/tf-job-operator 1/1 1 1 19h deployment.apps/workflow-controller 1/1 1 1 19h NAME DESIRED CURRENT READY AGE replicaset.apps/admission-webhook-deployment-569558c8b6 1 1 1 19h replicaset.apps/alb-ingress-controller-7c4f854447 1 1 1 19h replicaset.apps/argo-ui-7ffb9b6577 1 1 1 19h replicaset.apps/centraldashboard-659bd78c 1 1 1 19h replicaset.apps/jupyter-web-app-deployment-679d5f5dc4 1 1 1 19h replicaset.apps/katib-controller-7f58569f7d 1 1 1 19h replicaset.apps/katib-db-manager-54b66f9f9d 1 1 1 19h replicaset.apps/katib-mysql-dcf7dcbd5 1 1 1 19h replicaset.apps/katib-ui-6f97756598 1 1 1 19h replicaset.apps/metadata-db-65fb5b695d 1 1 1 19h replicaset.apps/metadata-deployment-65ccddfd4c 1 1 1 19h replicaset.apps/metadata-envoy-deployment-7754f56bff 1 1 1 19h replicaset.apps/metadata-grpc-deployment-5c6db9749 1 1 1 19h replicaset.apps/metadata-ui-7c85545947 1 1 1 19h replicaset.apps/minio-6b67f98977 1 1 1 19h replicaset.apps/ml-pipeline-6cf777c7bc 1 1 1 19h replicaset.apps/ml-pipeline-ml-pipeline-visualizationserver-6d744dd449 1 1 1 19h replicaset.apps/ml-pipeline-persistenceagent-5c549847fd 1 1 1 19h replicaset.apps/ml-pipeline-scheduledworkflow-674777d89c 1 1 1 19h replicaset.apps/ml-pipeline-ui-549b5b6744 1 1 1 19h replicaset.apps/ml-pipeline-viewer-controller-deployment-fc7f7cb65 1 1 1 19h replicaset.apps/mpi-operator-548d8cdbbd 1 1 1 19h replicaset.apps/mysql-85bc64f5c4 1 1 1 19h replicaset.apps/notebook-controller-deployment-5c55f5845b 1 1 1 19h replicaset.apps/profiles-deployment-57d44f597d 1 1 1 19h replicaset.apps/pytorch-operator-cf8c5c497 1 1 1 19h replicaset.apps/seldon-controller-manager-6b4b969447 1 1 1 19h replicaset.apps/spark-operatorsparkoperator-76dd5f5688 1 1 1 19h replicaset.apps/spartakus-volunteer-57d9875c96 1 1 1 19h replicaset.apps/tensorboard-5f685f9d79 1 1 1 19h replicaset.apps/tf-job-operator-5fb85c5fb7 1 1 1 19h replicaset.apps/workflow-controller-689d6c8846 1 1 1 19h NAME READY AGE statefulset.apps/admission-webhook-bootstrap-stateful-set 1/1 19h statefulset.apps/application-controller-stateful-set 1/1 19h statefulset.apps/kfserving-controller-manager 1/1 19h statefulset.apps/metacontroller 1/1 19h NAME COMPLETIONS DURATION AGE job.batch/spark-operatorcrd-cleanup 1/1 69s 19histio-ingressgatewayを使用してポートフォワードします。
$ kubectl port-forward svc/istio-ingressgateway -n istio-system 8080:80 Forwarding from 127.0.0.1:8080 -> 80 Forwarding from [::1]:8080 -> 80
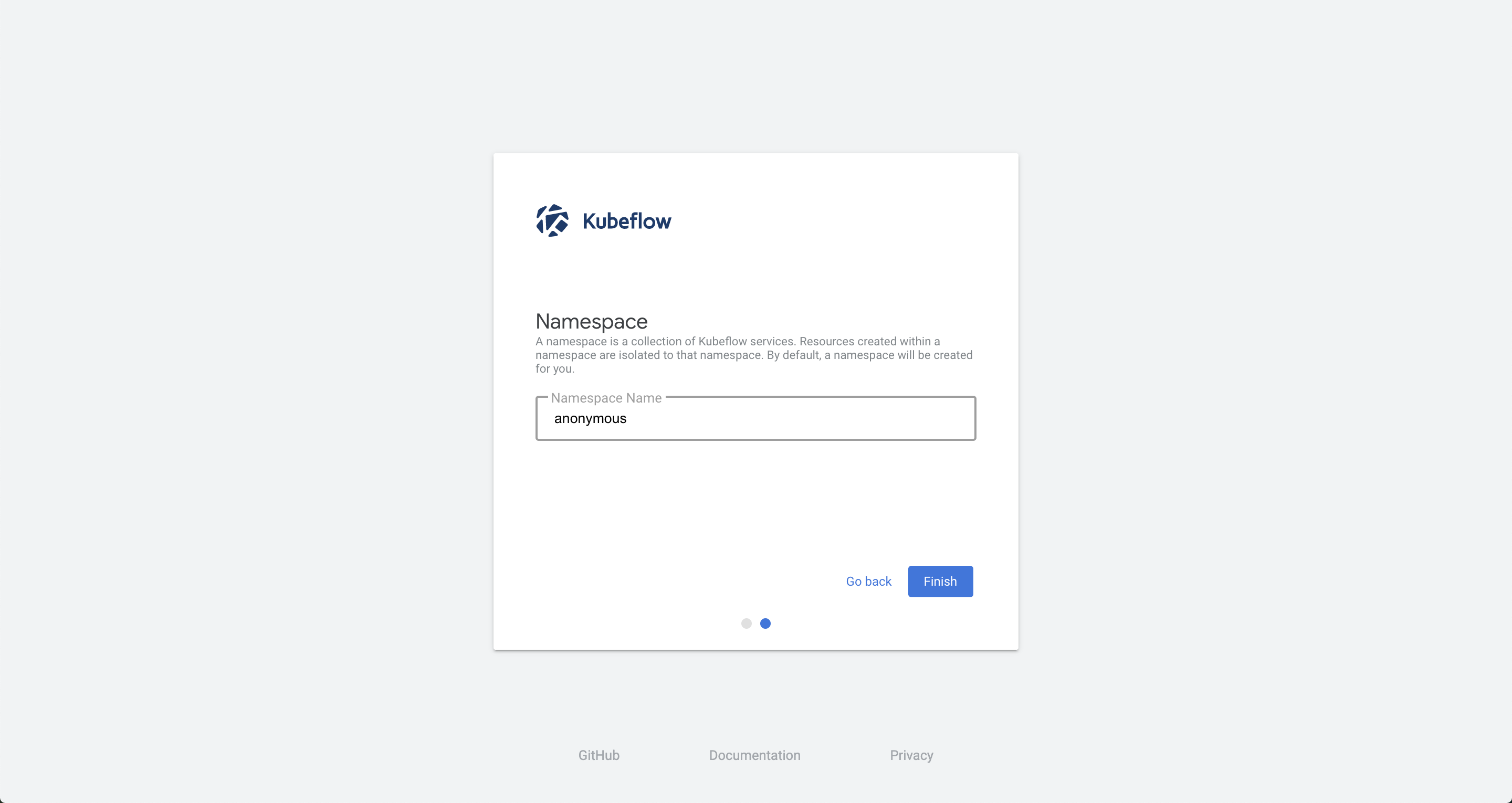
127.0.0.1:8080にアクセスするとダッシュボードが開きます。
「Start Setup」をクリックします。
namespaceを設定します。今回はデフォルトの
anonymousとしました。
これでKubeFlowを使う準備が整いました。
構築の次へ
KubeFlowの準備ができたら次は下記のようなことを試してみてください。
また、今のままだとKubeFlowに認証がないので、Cognitoを使って認証の仕組みを用意する必要があります。ロードバランサを作成して外部からアクセスできるようにした方が便利です。また、クラスター作成時に設定をオプションで与えていましたが、コンフィグファイル
cluster.yamlを作成したほうが便利です。おまけ
クラスターのスケール
notebookのpodを作ろうと思ったらInsufficient podsになってしまったので増強させます。
クラスターのスケールは下記のように行います。eksctl scale nodegroup --cluster=kubeflow --nodes=5 standard-workers --nodes-max 5リソース削除
KubeFlowを削除します。
cd ${KF_DIR} kfctl delete -f ${CONFIG_FILE}kubernetesを削除します。
$ eksctl delete cluster kubeflowクラスター削除時に次のようなエラーが出るかもしれません。
[ℹ] eksctl version 0.24.0 [ℹ] using region ap-northeast-1 [ℹ] deleting EKS cluster "kubeflow" [ℹ] deleted 0 Fargate profile(s) [✔] kubeconfig has been updated [ℹ] cleaning up LoadBalancer services [ℹ] 2 sequential tasks: { delete nodegroup "standard-workers", delete cluster control plane "kubeflow" [async] } [ℹ] will delete stack "eksctl-kubeflow-nodegroup-standard-workers" [ℹ] waiting for stack "eksctl-kubeflow-nodegroup-standard-workers" to get deleted [✖] unexpected status "DELETE_FAILED" while waiting for CloudFormation stack "eksctl-kubeflow-nodegroup-standard-workers" [ℹ] fetching stack events in attempt to troubleshoot the root cause of the failure [✖] AWS::CloudFormation::Stack/eksctl-kubeflow-nodegroup-standard-workers: DELETE_FAILED – "The following resource(s) failed to delete: [NodeInstanceRole]. " [✖] AWS::IAM::Role/NodeInstanceRole: DELETE_FAILED – "Cannot delete entity, must delete policies first. (Service: AmazonIdentityManagement; Status Code: 409; Error Code: DeleteConflict; Request ID: 238db5e1-9d5e-4698-9d3e-eecfe5b229aa)" [ℹ] 1 error(s) occurred while deleting cluster with nodegroup(s) [✖] waiting for CloudFormation stack "eksctl-kubeflow-nodegroup-standard-workers": ResourceNotReady: failed waiting for successful resource state Error: failed to delete cluster with nodegroup(s)そのときはIAMのコンソールから
Nodeで検索してロールを削除し、もう一度実行します。



- 投稿日:2020-07-27T19:33:57+09:00
yps並走備忘録 Task1 EC2インスタンス作成~SSH接続~環境設定@Win環境
Twitterで無料で公開されているカリキュラムypsに今月より並走を開始しました。
備忘録がてら一通り書き残しておこうと思います。ちなみに自分の環境は少数であろうWin環境なので、マイナーが故に困った人の役に立てばと思います。
用語や理解は適当なので間違ってたら教えてくださいまし…事前準備
- Task0をまず読みルールを理解する
- amazon AWSのアカウント
- GitHubのアカウント(task3までは不要)推奨
- Linux標準教科書 *無料のPDF、Linuxコマンドで迷ったら読む
- TeraTerm *yotaro氏は推奨,個人的にはVS Code x コマンドプロンプトでもいいかもしれないと思います
Task1 クラウド環境の準備
事前にやること
- AWSのアカウント開設
- コマンドプロンプトをすぐ使えるようにしておく(自分はタスクバーに固定しています)Task1 手順
参考:https://github.com/yotaro-ok/yps/blob/master/task_1.md
Step1. EC2でCentOSインスタンスを作成(クラウドに仮想サーバーをセットアップ)
ザックリとした流れ
EC2 ⇒ インスタンス ⇒ インスタンス作成 ⇒ 無料枠のCentOS7選択 ⇒ 料金表を確認、t2.micro(無料枠)を選択 ⇒ ストレージを30GiBに変更 ⇒ インスタンスの作成&起動 ⇒ キーペアを作成 ⇒ インスタンスの表示ステップ詳細
1. AWSマネジメントコンソールで「EC2」を選択
2. 左側のメニューから「インスタンス」を選択
3. 青い「インスタンスの作成」ボタンを押す
4. 左側の「無料枠のみ」にチェックを入れ、「AWS Marketplace」をクリック
5. 上部の検索バーに「CentOS7」と入力してEnter
5. 無料枠終了後の料金表が出てくるので右下のContinueをクリック
6. インスタンスタイプの選択画面で上から2番目、「無料利用枠の対象」と緑色で表示されている「t2.micro」をにチェックを入れる
7. 右下の「次のステップ:インスタンス詳細の設定」をクリック
7. 詳細設定は特に設定するところなしなので、そのまま右下の「次のステップ:ストレージの追加」をクリック
8. 真ん中らへんにサイズ(GiB)と書いたボックスがあるので30と入力(※初期はおそらく8になってます)
9. 「次のステップ:タグの追加」をクリック
10. タグは特に追加しなくてもOKなので、追加しなければ「次のステップ:セキュリティグループの設定」をクリック
11. 「確認と作成」をクリック
12. 「起動」をクリックすると「既存のキーペアを選択するか、新しいキーペアを作成します。」と表示されるので、「新しいキーペアの作成」を選択、適当な名前をつけ、ダウンロードします(これのファイルが後ほどパスワードの代わりなります)
13. 請求が不安な方は「請求アラートの作成」からメールを設定しておけば無料枠を使い切りそうな時に通知が来ます。
14. 「インスタンスの表示」をクリック
15. インスタンスの状態が「running」になっていれば作成完了
(このウインドウは環境設定などでもそのまま使うので閉じずに残しておきましょう)Step.2 SSH接続(クラウドに作成したインスタンスに自分のパソコンから接続)
- ダウンロードした秘密鍵ファイル(.pemファイル)をデスクトップに移す
- 作成したインスタンスを選択し、IPv4パブリックIPと書いてあるものをコピー(※右側にコピーアイコンが出るので使うことを推奨)
- コマンドプロンプトを開いて下記3 ~ 5のコマンドを順番に打つ
mkdir .ssh(解説:.sshという隠しフォルダを作成)copy Desktop\xxxx.pem .ssh(解説:デスクトップの秘密鍵ファイルを先ほど作成した.sshファイルにコピー)ssh centos@xx.xx.xx.xx -i .ssh/xxx.pem(解説: centosユーザーとしてxx.xx.xx.xxのIPアドレスにssh接続 -i の後ろの秘密鍵ファイルを使いますよ)whoamiと打ってcentosと表示されれば接続完了Step.3 環境設定(色々いじれるようにしていく&悪意のある接続がされないように設定変更)
上記SSHで接続した状態で以下のコマンドを入力してSELinuxを無効化し、設定をいじれるようにする
sudo setenforce 0(解説:sudoは管理者権限を利用できるようにするコマンド、SELinuxを一時的に無効化)sudo vi /etc/selinux/config(解説:SELinuxのファイルを編集)- 画面に表示された中から 「SELINUX = enforcing」と書いてあるところを見つけて「SELINUX=disabled」に変更
- *iキーで編集モード、wqで保存して終了
getenforceと打ってPermissiveと返ってくれば一先ずOK- AWSのマネジメントコンソール画面に戻って右下のセキュリティグループと書いてある横の「CentOs 7」から始まる青文字のリンクをクリック
- 下の方にある「インバウンドルール」をクリックして、「インバウンドルールを編集」ボタンをクリック
- 左側にある「ルールを追加」をクリック
- タイプは「カスタムTCP」を選択
- ポート範囲に「49152~65536内の任意の番号」を入力(ポート≒サーバーに入るためのドア番号)
- ソースは「カスタム」ですぐ横の虫眼鏡のところに0.0.0.0/0を入力
- 右下の「ルールを保存」をクリック
- コマンドプロンプトで下記のコマンドを入力
sudo cp /etc/ssh/sshd_config /etc/ssh/sshd_config.org(解説: sshd_configの元のファイルをsshd_config.orgというファイル名でバックアップ)sudo vi /etc/ssh/sshd_config(解説: sshd_configファイルを編集して、サーバーコンピューターのアクセス周りの設定をする)- sshd_config ファイル変更点(ルートユーザーのログインを禁止して、自分で設定したポートからしか入れないようにする操作)
- 「#Port 22」と書いてあるところの22という数字を10.で設定したポート番号へ変更(#はコメントアウトの意なので外す)
- 「#PermitRootLogin Yes」と書いてあるところを「PermitRootLogin No」へ変更(#はコメントアウトの意なので外す)
- i で編集モードを終了し、:wqで変更を保存してターミナルへ戻る 15. 変更が正しいかを確認
sudo sshd -tと打って何も表示されなければ設定はOKsudo systemctl restart sshdでサーバーを再起動して設定を反映する- 以下のコマンドを打ってスワップ領域(サーバーのメインメモリ足りなくなった際に使うsshdの領域)を作成
sudo -s /bin/dd if=/dev/zero of=/var/swap.1 bs=1M count=1024sudo -s /sbin/mkswap /var/swap.1sudo -s /sbin/swapon /var/swap.1Step.4 環境設定完了の確認
- ログインしているターミナル画面で
exitと打って、一度ログアウト- コマンドプロンプトで下記のコマンドを打ってログインできるか確認
ssh -p xxxxxx(設定したポート番号) centos@xx.xx.xx.xx(EC2のIPアドレス) -i .ssh/xxx(秘密鍵のファイル名).pem- ログインできていればポートの設定は問題なくできているので
- AWSのマネジメントコンソールへ戻り
- インバウンドルールの編集から 6.SSH (ポート22)を削除、ルールを保存
なお、インスタンスが1つ以上稼働しているとAWSは課金されるので、使用しているインスタンス以外は停止もしくは終了させること
ここまでできたら一先ずクラウドにサーバーができたのでTask1終了
- 投稿日:2020-07-27T17:38:28+09:00
AWS RDSについてのメモ
- 特徴
- AWSのフルマネージドなRDBサービス。
- 従来のDBの構築よりすごく楽に運用構築できる。
- オンプレミスのDBサーバ構築の場合、物理サーバの設置、OSインストール、アップデート、スケーリング、アプリ最適化などが必要になってくるが、RDSはアプリ最適化以外は自動でやってくれる。
- ちなみにEC2でDBサーバを立てることもできるが、この場合はアップデート、スケーリング、アプリ最適化などは自分でやらなければならない。
- 高い可用性をもち、マルチAZ(アベイラビリティゾーン)のマスタースレイブ構成でDBを簡単に構築できる。
- 高パフォーマンスの実現が簡単(例えば複数のRDSインスタンスを立ち上げ、レプリケーションされた読み取り専用のリードDBを起動することができる。)
利用可能なDBエンジン
- MySQL
- PostgreSQL
- Microsoft SQL server
- AmazonAurora
- MariaDB
設定できる項目
フルマネージドなサービスのため、SSHで接続で設定するのではなく、設定グループのパラメータ値で設定する。
- DBパラメータグループ: DB設定値を制御
- DBオプショングループ: RDSの機能追加を制御
- DBサブネットグループ: RDSを起動させるサブネットを制御運用負荷の軽減
- 自動的なバックアップ
- 1日1回自動的にバックアップを自動で取ってくれる (スナップショット)
- そのスナップショットを元にDBインスタンス再作成できる(リストア)
- 自動的なソフトウェアメンテナンス
- メンテナンスウィンドウで指定した曜日・時間帯にアップデートを自動的にしてくれる。
- 監視
- 各種メトリクスを60秒間隔で取得、確認可能
セキュリティグループの作成
RDSのセキュリティグループは「EC2」の「セキュリティグループ」の項目ででアクセスに関する制御を設定する
サブネットグループ
RDSのサブネットグループで作成できる。
DBを構築するサブネットを指定する。DBパラメータグループ
RDSのパラメータグループで作成できる。
DBの各種値をここで設定する。DBオプショングループ
RDSのオプショングループで作成できる。
例えばプラグインを使いたいときなど注意
・基本的に外部インターネットからのアクセスを防ぐためのプライベートサブネット内に構築する。
・自動バックアップ以外にも手動でその時のスナップショットを取得できるが、手動スナップショットはRDSインスタンスを消しても存在し続け、料金がかかり続ける。
・RDSインスタンスを削除するときは同時に手動スナップショットも削除する
- 投稿日:2020-07-27T17:12:29+09:00
S3バケットポリシーであるユーザーを特定のバケットにしかアクセスできないように設定する
バケットポリシー全然わからん
S3のバケットにアクセスする際の権限設定をIAM、S3のバケットポリシーで設定するのはわかるのだが、どのように設定すれば良いのか全然わかっていませんでした。
許可または拒否の決定の仕方
あるユーザーがあるバケットにアクセスしようとした際に許可されるか拒否されるかは以下のように決まっています。
1. 拒否設定があるか(ある場合必ず拒否)
2. 1がない場合許可設定があるか(ある場合許可)
3. 記述がないか(デフォルト拒否)初期状態のバケットを作り、ユーザーを作成しただけの状態では当然そのユーザーはどのバケットにもアクセスできません。これは3のデフォルト拒否が働いているからです。
アクセスするために許可設定を行って、IAMユーザーにAmazonS3FullAccessのような権限を与えるとこれでS3のどのバケットにもアクセスできます。
ただ、このあと拒否設定をバケットポリシーなどで設定するとS3にアクセスできなくなります。拒否設定があると他で許可を取っていても必ず拒否となります。実際はもっと細かい話がありますが、最初はこの程度わかっていればOKだと思います
参考:ポリシーの評価論理許可設定で勘違いしていたこと
S3にアクセスする際に勘違いしていたのは
IAMユーザーにS3へのアクセス権限を与えることが必須ということでした。
実際にはIAMユーザー自体にポリシーを与えなくてもバケットポリシーで権限を付与することが可能です。むしろIAMに必ずアクセス権限を与えると設定に困ることが必ず出てくると思います。
単純に特定のバケットのみアクセスさせたい場合はIAMユーザーにポリシーを与えず、バケットポリシーに許可設定を与えればOKです。S3バケットポリシーであるユーザーを特定のバケットにしかアクセスできないように設定する
ようやくタイトルの回答になるのですが、以下のようなバケットポリシーを設定します。バケット名・ユーザー名は適宜変更が必要です。
ActionにS3:*としているのでS3へのフル権限が与えられます。必要に応じて変更が必要です。ワイルドカードが使えるのでS3:Put*などで特定の権限を一括設定も可能です。
このバケットポリシーだけ設定して、このexample-userには他のポリシーを設定しなければこのバケットのみアクセスできるユーザーとなります。{ "Version": "2012-10-17", "Id": "123", "Statement": [ { "Sid": "", "Effect": "Allow", "Principal": { "AWS": "arn:aws:iam::123456789:user/example-user" }, "Action": "s3:*", "Resource": [ "arn:aws:s3:::examplebucket/*", "arn:aws:s3:::examplebucket" ] } ] }json形式での記入なのでユーザーや権限を増やしたい場合は配列に値を増やしていけばOKです。
また今回はAllowの記述ですがDenyで拒否設定もできます。上述しましたが、Denyが一番優先となるので絶対にアクセスさせたくない部分に関しては記述をしないのではなく、Deny設定をしておくことが安心です。
- 投稿日:2020-07-27T17:05:39+09:00
SageMaker上のnotebookでログが出力されなくなった際の対処法
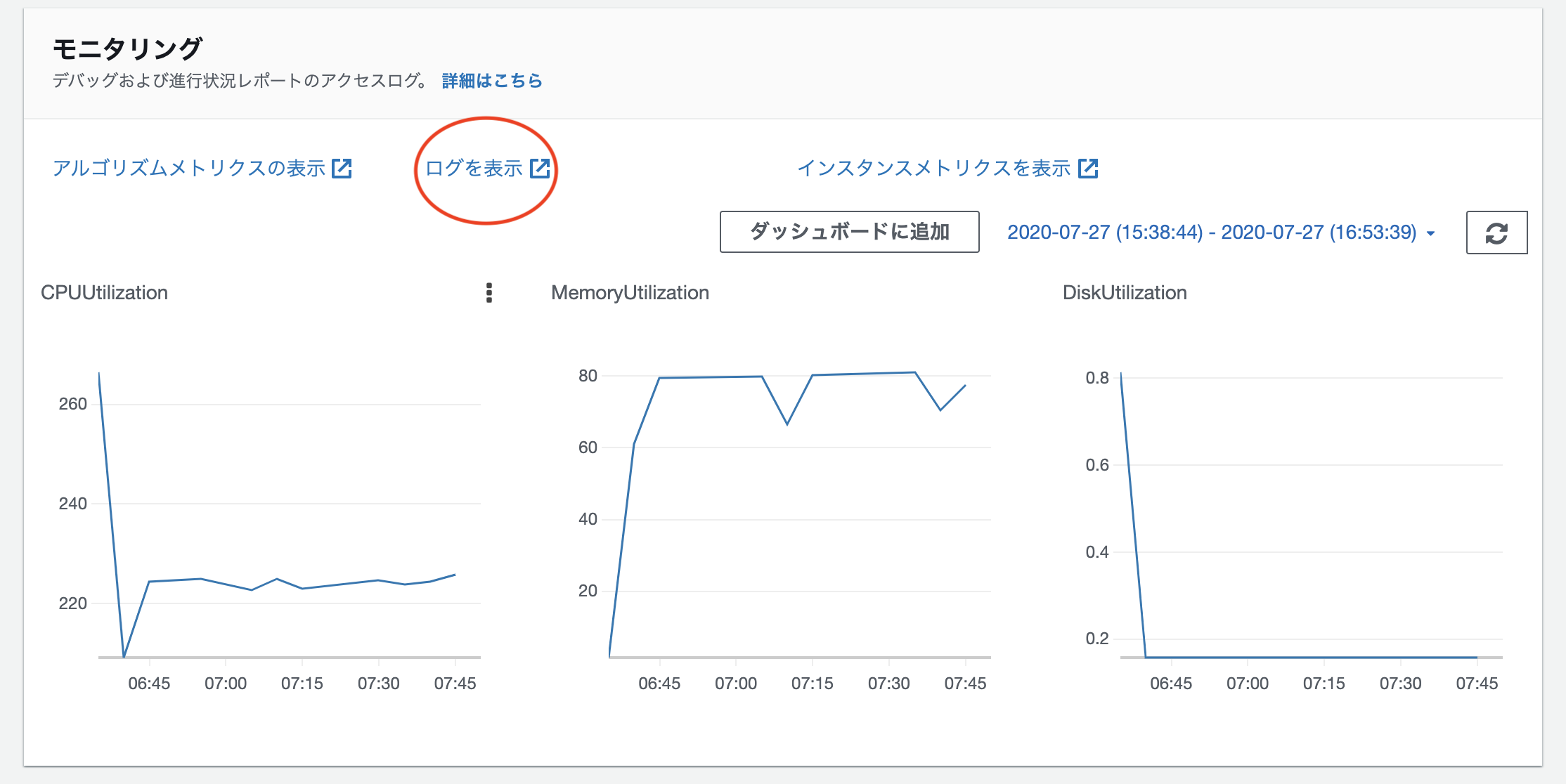

- 投稿日:2020-07-27T16:58:33+09:00
RDSProxyを使ってもDB接続は速くならないという話
結論
特別、速くはならない。
速さを求めるのであれば自分でプールするしかないっぽい。
※とはいえ、接続数管理してくれるのは魅力。。以下、AWSサポートとのやり取り。
AWSサポートへの質問
本文の最後に記載している "実行しているLambda" を実行しています。
(1) RDSProxyのエンドポイントを指定した場合、DB接続にかかる時間は下記になります。
connect:0.754[sec] ※Lambdaのコールドスタート
connect:0.420[sec] ※以降、同じコンテナで再実行
connect:0.322[sec]
connect:0.551[sec](2) RDSのエンドポイント&コネクションプール無しで設定した場合、DB接続にかかる時間は下記になります。
connect:0.640[sec] ※Lambdaのコールドスタート
connect:0.442[sec] ※以降、同じコンテナで再実行
connect:0.419[sec]
connect:0.410[sec](3) RDSのエンドポイント&コネクションプール有りで設定した場合、DB接続にかかる時間は下記になります。
※ pool_size=1 のコメントアウトを外す
connect:0.729[sec] ※Lambdaのコールドスタート
connect:0.002[sec] ※プールが効いているので接続にほぼ時間がかからない
connect:0.003[sec]
connect:0.002[sec](1)のRDSProxyをエンドポイントに指定した場合の結果に関して、RDS⇔RDSProxy間でコネクションプールが張られるので、
(3)結果と等しくなることを期待していました。こちらの結果に関して、そういうものなのか、実装or設定方法に何かしら誤りがあるのか判断したいための問い合わせとなります。
ご確認いただけますでしょうか。※
RDSのmax_connectionsを超えるようにLambda同時実行した場合、(1)の場合、正常に終了しますが、(2)の場合、too many connectionsが出るので
RDSProxyへのアクセス自体は正常に行えていると思います。※
実行しているLambda(DB接続はmysql-connector-pythonを使用)from mysql import connector import os import time def lambda_handler(event, context): # 接続にかかった時間 start = time.time() con = connector.connect( host=os.environ['DB_HOST'], user=os.environ['DB_USER'], password=os.environ['DB_PASSWORD'], database=os.environ['DB_DATABASE'], # pool_name="mypool", # pool_size=1, ) elapsed_time = time.time() - start print ("connect:{0}".format(elapsed_time) + "[sec]") ~SQL( "select sleep(3), 2" )を実行して結果を取得する処理~ # 切断 con.close()AWSサポートの回答
(1)のRDSProxyをエンドポイントに指定した場合の結果に関して、RDS⇔RDSProxy間でコネクションプールが張られるので、(3)結果と等しくなることを期待していました。
こちらの結果に関して、そういうものなのか、実装or設定方法に何かしら誤りがあるのか判断したいための問い合わせとなります。ご確認いただけますでしょうか。いいえ、恐れ入りますが、クライアント側でConnection Poolingを使用した場合と等しくはなりえません。
クライアント側で各Driverにて実施できるConnection Poolingと、RDS ProxyなどDatabase ProxyのConnection Poolingでは立ち位置が異なり、例えば、前者ではクライアント/DBサーバー間のコネクションを再利用できますが、後者では再利用されうるコネクションはあくまでProxy/DBサーバー間ですのでクライアント/Proxyの接続は必要であり、クライアントから見た接続時の所要時間としてはややオーバーヘッドになります。
また、ProxyのConnection Poolingのコネクションは常に必ず再利用されるというものではなく、必要に応じて、ピン留めが発生したり、ProxyやDB側で接続が切断されることもございます。基本的には、例えば、「コネクションが再利用できる場合、DBでの新規コネクション作成の負荷軽減につなげることができる」、「接続の多重化としてDBへの実際のConnection数をおさえることができる」、「IAM認証をDB側で実施するのではなくProxy側で実施できる」などの特徴の観点で、ご想定されている運用方法などを踏まえ、ご検討・ご検証いただけますと幸いでございます。
[+] Amazon RDS Proxy による接続の管理 - RDS Proxy の概念
https://docs.aws.amazon.com/ja_jp/AmazonRDS/latest/UserGuide/rds-proxy.html#rds-proxy-overview
- 投稿日:2020-07-27T15:45:07+09:00
【AWS】【CircleCI】【Terraform】【Rails】CircleCIでECSに自動デプロイをする時にハマったとこ
状況
config.ymlversion: 2.1 orbs: aws-ecr: circleci/aws-ecr@6.11.0 aws-ecs: circleci/aws-ecs@1.2.0Orbsを使用してデプロイを実行しようとすると以下のエラーが発生
An error occurred (ClientException) when calling the DescribeTaskDefinition operation: Unable to describe task definition.
エラー内容と対処
調べると、
aws ecs describe-task-definitionコマンドを叩いて、うまくいかなかった時のエラーであるとわかるcircleciのlogから、awsコマンドを叩いてる部分を探すと以下の記述に出会う
circleciPREVIOUS_TASK_DEFINITION=$(aws ecs describe-task-definition --task-definition ${MY_APP_PREFIX}-service --include TAGS)注意するのは、引っ張りたいタスク定義の
familyの末尾は-serviceである必要があるということなので、Terraformでは
task_definition.tfresource "aws_ecs_task_definition" "manabi-app" { family = "app名" #これをapp名-serviceに変更 container_definitions = file("./container_definitions/service.json") task_role_arn = data.terraform_remote_state.iam.outputs.ecs_task_role_arn execution_role_arn = data.terraform_remote_state.iam.outputs.ecs_task_role_arn network_mode = "bridge" }うまくデプロイできた!

- 投稿日:2020-07-27T15:18:30+09:00
[AWS] Serverless Application Model (SAM) の基本まとめ
SAM
SAMとは
サーバレスアプリケーションを構築するためのオープンソースなフレームワークです。
SAMは、簡単な記述により
- 関数
- API
- データベース
- イベントソースマッピング
を表現することができます。
対応言語
SAMでは、Lambdaがサポートされている任意のランタイムを使用するサーバレスアプリケーションを構築することができます。
ユーザが任意で追加するランタイム以外で、Lambdaが標準でサポートされている言語は、下記の通り(2020年7月時点)です。
- Node.js (12/10)
- Python (3.8/3.7/3.6/2.7)
- Ruby (2.7/2.5)
- Java (11/8)
- Go (1.x)
- .NET (3.1/2.1)
対応リージョン
SAMでは、Lambdaがサポートされているリージョンで利用することができます。利用可能なリージョンは、下記の通り(2020年7月時点)です。
- バージニア北部(us-east-1)
- オハイオ(us-east-2)
- 北カリフォルニア(us-west-1)
- オレゴン(us-west-2)
- ケープタウン(af-south-1)
- 香港(ap-east-1)
- ムンバイ(ap-south-1)
- ソウル(ap-northeast-2)
- シンガポール(ap-southeast-1)
- シドニー(ap-southeast-2)
- 東京(ap-northeast-1)
- カナダ中部(ca-central-1)
- フランクフルト(eu-central-1)
- アイルランド(eu-west-1)
- ロンドン(eu-west-2)
- ミラノ(eu-south-1)
- パリ(eu-west-3)
- ストックホルム(eu-north-1)
- バーレーン(me-south-1)
- サンパウロ(sa-east-1)
デプロイ
SAM自体は、もともとCloud Formationを拡張したものであるため、SAMの中でCloud Formationのリソースを定義することができるとともに、デプロイの中でリソースのプロビジョニングを行うこともできます。
そのため、関連するコンポーネントの定義も含めて一元的に管理できるようになります。料金
SAM自体は追加料金なしで使用することができます。
デプロイしたアプリケーションや、プロビジョニングされたリソースについてのみ、それぞれの利用に応じた料金が請求されます。SAM CLI
SAMを操作するためのコマンドラインで、SAMの本体とともに、オープンソースとして公開されています。
SAM CLIは、ローカルにLambdaに似た実行環境を構築することができ、ローカル環境でテストやデバッグすることが可能となります。SAM CLIインストール手順
ローカル環境でテスト・デバッグするために、Dockerの環境が必要となります。
Mac
- Docker Desktopをインストールする
- Homebrewをインストールする
SAM CLIをインストール
brew tap aws/tap brew install aws-sam-cliWindows(64bit)
- Dockerをインストールする
- SAM CLIのインストーラをダウンロードし、インストールする
Linux
- Dockerをインストールする
pipをインストールする
curl -kL https://bootstrap.pypa.io/get-pip.py | pythonSAM CLIをインストール
pip install -U aws-sam-cliSAM CLIコマンドリファレンス
ローカルでの開発・テスト
sam init
SAM テンプレートを使用してサーバーレスアプリケーションを初期化します。テンプレートはLambda関数のフォルダ構造を提供し、API、S3バケット、DynamoDBテーブルなどのイベントソースに接続できます。
このアプリケーションには、使用を開始し、最終的には本番規模のアプリケーションに拡張するために必要なものがすべて含まれています。構文
sam init [OPTIONS]オプション
Option Description --no-interactive initパラメータの対話型プロンプトを無効にし、必要な値がない場合は失敗します。-l, --location TEXT テンプレートまたはアプリケーションの場所 (Git、Mercurial、HTTP/HTTPS、ZIP、パス)。このパラメータは、 --no-interactiveが指定され、--runtime、--name、--app-templateが指定されていない場合に必要です。Gitリポジトリの場合は、リポジトリのルートの場所を使用する必要があります。-r, --runtime [python2.7 / nodejs6.10 / ruby2.5 / java8 / python3.7 / nodejs8.10 / dotnetcore2.0 / nodejs10.x / dotnetcore2.1 / dotnetcore1.0 / python3.6 / go1.x] アプリケーションのLambdaランタイム。このパラメータは、 --no-interactiveが指定され、--locationが指定されていない場合に必要です。-d, --dependency-manager [gradle / mod / maven / bundler / npm / cli-package / pip] Lambdaランタイムの依存関係マネージャ -o, --output-dir PATH 初期化されたアプリケーションが出力される場所。 -n, --name TEXT フォルダとして生成されるプロジェクトの名前。このパラメータは、 --no-interactiveが指定され、--locationが指定されていない場合に必要です。--app-template TEXT 使用するマネージドアプリケーションテンプレートの識別子。不明な場合は、対話型ワークフローのオプションを指定せずに「 sam init」を呼び出します。このパラメータは、--no-interactiveが指定され、--locationが指定されていない場合に必要です。このパラメータは、SAM CLIバージョン0.30.0以降でのみ使用できます。以前のバージョンでこのパラメータを指定すると、エラーが発生します。--no-input Cookiecutterのプロンプトを無効にし、テンプレート設定で定義されているデフォルト値を受け入れます。 sam build
このコマンドを使用して、Lambdaソースコードを構築し、Lambdaの実行環境をターゲットとするデプロイアーティファクトを生成します。これにより、ローカルで構築する関数は、AWSクラウド内の同様の環境で実行されます。
sam buildコマンドは、アプリケーション内の関数を反復処理し、依存関係を含むマニフェストファイル (requirements.txtなど) を検索し、sam packageおよびsam deployコマンドを使用してLambdaにデプロイできるデプロイアーティファクトを自動的に作成します。
またsam buildをsam local invokeのような他のコマンドと組み合わせて使用して、アプリケーションをローカルでテストすることができます。構文
sam build [OPTIONS] [RESOURCE_LOGICAL_ID]オプション
Option Description -b, --build-dir DIRECTORY 構築されたアーティファクトが格納されるフォルダへのパス。このオプションを使用すると、このディレクトリとそのすべてのコンテンツが削除されます。 -s, --base-dir DIRECTORY このフォルダに関する関数のソースコードへの相対パスを解決します。AWS SAM テンプレートとソースコードが同じ囲みフォルダにない場合は、これを使用します。デフォルトでは、相対パスはテンプレートの場所に関して解決されます。 -u, --use-container 関数がネイティブにコンパイルされた依存関係を持つパッケージに依存する場合、このフラグを使用してLambdaに似たDockerコンテナ内で関数を構築します。 -m, --manifest PATH デフォルトの依存関係マニフェストの代わりに使用するカスタム依存関係マニフェスト (例: package.json) へのパス。-t, --template PATH SAM テンプレートファイル [デフォルト: template.[yaml / yml]]。 --parameter-overrides 省略可能。キーと値のペアとしてエンコードされた、AWS CloudFormation パラメータオーバーライドを含む文字列。AWS CLI と同じ形式を使用します — 例:「ParameterKey=KeyPairName、ParameterValue=MyKey ParameterKey=InstanceType、ParameterValue=t1.micro」。 --skip-pull-image コマンドがLambdaランタイムの最新のDockerイメージのプルダウンをスキップするかどうかを指定します。 --docker-network TEXT Lambda Dockerコンテナに接続する既存のDockerネットワークの名前またはIDを、デフォルトのブリッジネットワークとともに指定します。指定しない場合、Lambdaコンテナはデフォルトのブリッジ Docker ネットワークにのみ接続します。 --profile TEXT 認証情報ファイルから特定のプロファイルを選択して、AWS認証情報を取得します。 --region TEXT サービスのAWSリージョン( us-east-1など)を設定します。sam local invoke
ローカル Lambda 関数を一度呼び出し、呼び出しが完了した後に終了します。
これは、非同期イベント(S3またはKinesisイベントなど)を処理するサーバーレス関数を開発する場合に便利で、テストケースのスクリプトを作成する場合にも便利です。
イベント本体は、stdin(デフォルト)によって、または--eventパラメータを使用して渡すことができます。ランタイム出力 (ログなど)はstderrに出力され、Lambda関数の結果はstdoutに出力されます。構文
sam local invoke [OPTIONS] [FUNCTION_IDENTIFIER]オプション
Option Description -e, --event PATH 呼び出されたときにLambda関数に渡されるイベントデータを含むJSONファイル。このオプションを指定しない場合、イベントは想定されません。stdinからJSONを入力するには、値「-」を渡す必要があります。 --no-event 空のイベントを使用して関数を呼び出します。 -t, --template PATH SAM テンプレートファイル [デフォルト: template.[yaml / yml]]。 -n, --env-vars PATH Lambda関数の環境変数の値を含むJSONファイル。環境変数ファイルの詳細については、「環境変数ファイル」を参照してください。 --parameter-overrides 省略可能。キーと値のペアとしてエンコードされたCloudFormation パラメータオーバーライドを含む文字列。AWS CLIと同じ形式を使用します — 例: 「ParameterKey=KeyPairName, ParameterValue=MyKey ParameterKey=InstanceType,ParameterValue=t1.micro」。 -d, --debug-port TEXT 指定すると、Lambda関数コンテナをデバッグモードで起動し、このポートをローカルホストに公開します。 --debugger-path TEXT Lambdaコンテナにマウントされるデバッガーへのホストパス。 --debug-args TEXT デバッガーに渡される追加の引数。 -v, --docker-volume-basedir TEXT SAMファイルが存在するベースディレクトリの場所。Dockerがリモートマシンで実行されている場合は、Dockerマシン上に AWS SAMファイルが存在するパスをマウントし、この値をリモートマシンと一致するように変更する必要があります。 --docker-network TEXT Lambda Dockerコンテナが接続する必要のある既存のDockerネットワークの名前またはID、およびデフォルトのブリッジネットワークです。これを指定しない場合、LambdaコンテナはデフォルトのブリッジDockerネットワークにのみ接続します。 -l, --log-file TEXT ランタイムログを送信するログファイル。 --layer-cache-basedir DIRECTORY テンプレートで使用するレイヤーがダウンロードされる場所 basedirを指定します。 --skip-pull-image CLIがLambdaランタイムの最新のDockerイメージのプルダウンをスキップするかどうかを指定します。 --force-image-build CLIがレイヤーを使用して関数を呼び出すために使用されるイメージを再構築するかどうかを指定します。 --profile TEXT 使用するAWS認証情報プロファイル。 --region TEXT サービスのAWSリージョン( us-east-1など)を設定します。sam local generate-event
S3、API Gateway、SNS などのさまざまなイベントソースからサンプルペイロードを生成します。
これらのペイロードには、イベントソースがLambda関数に送信する情報が含まれています。構文
sam local generate-event COMMAND [ARGS]...COMMANDに指定できるものは以下の通りです。
- alexa-skills-kit
- alexa-smart-home
- apigateway
- batch
- cloudformation
- cloudfront
- cloudwatch
- codecommit
- codepipeline
- cognito
- config
- dynamodb
- kinesis
- lex
- rekognition
- s3
- ses
- sns
- sqs
- stepfunctions
sam local start-lambda
AWS CLIまたはSDKを使用して、プログラムでLambda関数をローカルで呼び出すことができます。
このコマンドは、Lambdaをエミュレートするローカルエンドポイントを起動します。
このローカルLambdaエンドポイントに対して自動テストを実行できます。
AWS CLIまたはSDKを使用してこのエンドポイントに呼び出しを送信すると、リクエストで指定された Lambda関数がローカルで実行されます。構文
sam local start-lambda [OPTIONS]オプション
Option Description --host TEXT バインド先のローカルホスト名または IPアドレス(デフォルト:「127.0.0.1」)。 -p, --port INTEGER リッスンするローカルポート番号(デフォルト:「3001」)。 -t, --template PATH SAMテンプレートファイル [デフォルト: template.[yaml / yml]]。 -n, --env-vars PATH Lambda関数の環境変数の値を含むJSONファイル。 --parameter-overrides 省略可能。キーと値のペアとしてエンコードされたCloudFormation パラメータオーバーライドを含む文字列。AWS CLIと同じ形式を使用します — 例: 「ParameterKey=KeyPairName、ParameterValue=MyKey ParameterKey=InstanceType、ParameterValue=t1.micro」。 -d, --debug-port TEXT 指定すると、Lambda関数コンテナをデバッグモードで起動し、このポートをローカルホストに公開します。 --debugger-path TEXT Lambdaコンテナにマウントされるデバッガーへのホストパス。 --debug-args TEXT デバッガーに渡される追加の引数。 -v, --docker-volume-basedir TEXT SAMファイルが存在するベースディレクトリの場所。Dockerがリモートマシンで実行されている場合は、Dockerマシン上にSAMファイルが存在するパスをマウントし、この値をリモートマシンと一致するように変更する必要があります。 --docker-network TEXT Lambda Dockerコンテナが接続する必要のある既存のDockerネットワークの名前またはID、およびデフォルトのブリッジネットワークです。これを指定しない場合、LambdaコンテナはデフォルトのブリッジDockerネットワークにのみ接続します。 -l, --log-file TEXT ランタイムログを送信するログファイル。 --layer-cache-basedir DIRECTORY テンプレートが使用するレイヤーがダウンロードされる場所basedirを指定します。 --skip-pull-image CLIがLambdaランタイムの最新のDockerイメージのプルダウンをスキップするかどうかを指定します。 --force-image-build CLIがレイヤーを使用して関数を呼び出すために使用されるイメージを再構築するかどうかを指定します。 --profile TEXT 使用するAWS認証情報プロファイル。 --region TEXT サービスのAWSリージョン( us-east-1など)を設定します。sam local start-api
サーバーレスアプリケーションをローカルで実行して、開発とテストを迅速に行うことができます。
サーバーレス関数とSAMテンプレートを含むディレクトリでこのコマンドを実行すると、すべての関数をホストするローカルHTTPサーバーが作成されます。
(ブラウザ、CLIなどを介して)アクセスされると、Dockerコンテナをローカルで起動して関数を呼び出します。AWS::Serverless::FunctionリソースのCodeUriプロパティを読み取り、Lambda関数コードを含むファイルシステム内のパスを検索します。これは、Node.jsやPythonなどの解釈された言語用のプロジェクトのルートディレクトリ、またはコンパイルされたアーティファクトやJavaアーカイブ(JAR)ファイルを格納するビルドディレクトリです。
解釈された言語を使用している場合は、すべての呼び出しでローカルの変更をDockerコンテナですぐに使用できます。さらにコンパイルされた言語や複雑なパッキングサポートを必要とするプロジェクトについては、独自のビルドソリューションを実行し、SAMをポイントして、ビルドアーティファクトを含むディレクトリまたはファイルを指定することを推奨しています。構文
sam local start-api [OPTIONS]オプション
Option Description --host TEXT バインド先のローカルホスト名または IPアドレス(デフォルト:「127.0.0.1」)。 -p, --port INTEGER リッスンするローカルポート番号(デフォルト:「3000」)。 -s, --static-dir TEXT このディレクトリにある静的アセット(CSS / JavaScript / HTML など)ファイルは、/ に表示されます。 -t, --template PATH SAM テンプレートファイル [デフォルト: template.[yaml / yml]]。 -n, --env-vars PATH Lambda関数の環境変数の値を含むJSONファイル。 --parameter-overrides 省略可能。キーと値のペアとしてエンコードされたCloudFormation パラメータオーバーライドを含む文字列。AWS CLIと同じ形式を使用します — 例: 「ParameterKey=KeyPairName、ParameterValue=MyKey ParameterKey=InstanceType、ParameterValue=t1.micro」。 -d, --debug-port TEXT 指定すると、Lambda関数コンテナをデバッグモードで起動し、このポートをローカルホストに公開します。 --debugger-path TEXT Lambdaコンテナにマウントされるデバッガーへのホストパス。 --debug-args TEXT デバッガーに渡される追加の引数。 -v, --docker-volume-basedir TEXT SAMファイルが存在するベースディレクトリの場所。Dockerがリモートマシンで実行されている場合は、Dockerマシン上にSAMファイルが存在するパスをマウントし、この値をリモートマシンと一致するように変更する必要があります。 --docker-network TEXT Lambda Dockerコンテナが接続する必要のある既存のDockerネットワークの名前またはID、およびデフォルトのブリッジネットワークです。これを指定しない場合、LambdaコンテナはデフォルトのブリッジDockerネットワークにのみ接続します。 -l, --log-file TEXT ランタイムログを送信するログファイル。 --layer-cache-basedir DIRECTORY テンプレートが使用するレイヤーがダウンロードされる場所basedirを指定します。 --skip-pull-image CLIがLambdaランタイムの最新のDockerイメージのプルダウンをスキップするかどうかを指定します。 --force-image-build CLIがレイヤーを使用して関数を呼び出すために使用されるイメージを再構築するかどうかを指定します。 --profile TEXT 使用するAWS認証情報プロファイル。 --region TEXT サービスのAWS リージョン( us-east-1など)を設定します。sam validate
SAMテンプレートを検証します。
構文
sam validate [OPTIONS]オプション
Option Description -t, --template PATH SAMテンプレートファイル [デフォルト: template.[yaml / yml]]。 --profile TEXT 認証情報ファイルから特定のプロファイルを選択して、AWS認証情報を取得します。 --region TEXT サービスのAWSリージョン( us-east-1など)を設定します。デプロイ
sam deploy
AWS SAMアプリケーションをデプロイします。
ガイド付きインタラクティブモード(--guidedパラメータを指定することで有効にできる)では、デプロイに必要なパラメータが順番に示され、デフォルトのオプションが提供され、これらのオプションがプロジェクトフォルダの設定ファイルに保存されます。
sam deployを実行するだけで、アプリケーションの後続のデプロイを実行でき、必要なパラメータが SAM CLI設定ファイルから取得されます。
CloudFormationを使用してLambda関数をデプロイするには、Lambdaデプロイパッケージ用のS3バケットが必要です。SAM CLIは、このS3バケットを作成して管理します。構文
sam deploy [OPTIONS] [ARGS]...オプション
Option Description -g, --guided このフラグを指定して、SAMでガイド付きプロンプトを使用してデプロイをガイドできるようにします。このパラメータの指定時に、必要に応じて保存される設定の詳細については、「SAM CLI設定」を参照してください。 --template-file PATH SAM テンプレートが配置されているパス。デフォルト: template.[yaml / yml]。 --stack-name TEXT デプロイ先のCloudFormation スタックの名前。既存のスタックを指定すると、コマンドはスタックを更新します。新しいスタックを指定すると、コマンドはスタックを作成します。必須。 --s3-bucket TEXT テンプレートで参照されるアーティファクトがある S3バケットの名前。これは、51,200バイトを超えるサイズのテンプレートをデプロイする場合に必要です。 --s3-prefix TEXT S3バケットにアップロードされるアーティファクト名に追加されたプレフィックス。プレフィックス名は、S3バケットのパス名 (フォルダ名) です。 --capabilities LIST CloudFormationが特定のスタックを作成できるように指定する必要がある機能の一覧。一部のスタックテンプレートには、新しいIAMユーザーを作成する場合などで、AWSアカウントのアクセス権限に影響を与える可能性のあるリソースが含まれている場合があります。このようなスタックの場合は、このパラメータを指定して、それらの機能を明示的に認識する必要があります。有効な値は、CAPABILITY_IAMとCAPABILITY_NAMED_IAMのみです。IAMリソースがある場合、どちらの機能でも指定できます。カスタム名を持つIAMリソースがある場合は、CAPABILITY_NAMED_IAMを指定する必要があります。このパラメータを指定しない場合、このアクションはInsufficientCapabilitiesエラーを返します。 --region TEXT デプロイ先の AWS リージョン( us-east-1など)。--profile TEXT 認証情報ファイルから特定のプロファイルを選択して、AWS認証情報を取得します。 --kms-key-id TEXT S3バケットに保存されているアーティファクトを暗号化するために使用される AWS KMSキーのID。 --force-upload S3バケット内の既存のファイルを上書きします。S3バケット内の既存のアーティファクトと一致する場合でも、アーティファクトをアップロードするには、このフラグを指定します。 --no-execute-changeset 変更セットを実行するかどうかを示します。変更セットを実行する前にスタックの変更を表示する場合は、このフラグを指定します。このコマンドは、CloudFormation変更セットを作成し、変更セットを実行せずに終了します。変更セットを実行する場合は、このフラグを指定せずに同じコマンドを実行することで、スタックの変更を行うことができます。 --role-arn TEXT 変更セットの実行時にCloudFormationが引き受けるIAMロールのAmazon リソースネーム (ARN)。 --fail-on-empty-changeset / --no-fail-on-empty-changeset スタックに変更を加えていない場合に0以外の終了コードを返すかどうかを指定します。デフォルトの動作では、ゼロ以外の終了コードが返されます。 --confirm-changeset 計算された変更セットをデプロイする前に確認を求めます。 --use-json CloudFormationテンプレートのJSONを出力します。デフォルトでYAMLが使用されます。 --metadata テンプレートで参照されているすべてのアーティファクトに添付するメタデータのマップ。省略可能。 --notification-arns LIST CloudFormationがスタックに関連付けるSNSトピックAmazon リソースネーム (ARN)。 --tags 作成または更新されたスタックに関連付けるタグの一覧。CloudFormationでは、リソースがスタックをサポートしている場合、これらのタグをスタックのリソースにも伝達します。 --parameter-overrides key=value のペアとしてエンコードされたCloudFormationパラメータオーバーライドを含む文字列。AWS CLIと同じ形式を使用します。たとえば、ParameterKey=KeyPairName, ParameterValue=MyKey ParameterKey=InstanceTy pe,ParameterValue=t1.microと指定します。 sam package
SAMアプリケーションをパッケージします。
コードと依存関係のZIPファイルを作成し、S3にアップロードを行います。
次に、SAMテンプレートのコピーを返し、ローカルのアーティファクトへの参照を、コマンドがアーティファクトをアップロードしたS3の場所に置き換えます。
sam deployを実行する場合は、暗黙的にsam packageが呼びだされます。構文
sam package [OPTIONS] [ARGS]...オプション
Option Description --template-file PATH SAM テンプレートが置かれているパス。デフォルト: template.[yaml / yml]。 --s3-bucket TEXT このコマンドがテンプレートで参照されるアーティファクトをアップロードするS3バケットの名前。必須。 --s3-prefix TEXT S3バケットにアップロードされるアーティファクト名に追加されたプレフィックス。プレフィックス名は、S3バケットのパス名 (フォルダ名) です。 --kms-key-id TEXT S3バケットに保管されているアーティファクトを暗号化するために使用される AWS KMSキーのID。 --output-template-file PATH コマンドがパッケージ化されたテンプレートを書き込むファイルへのパス。パスを指定しない場合、コマンドはテンプレートを標準出力に書き込みます。 --use-json CloudFormationテンプレートのJSONを出力します。デフォルトでは、YAMLが使用されます。 --force-upload S3バケット内の既存のファイルを上書きします。S3バケット内の既存のアーティファクトと一致する場合でも、アーティファクトをアップロードするには、このフラグを指定します。 --metadata テンプレートで参照されているすべてのアーティファクトにアタッチするメタデータのマップ。省略可能。 --profile TEXT 認証情報ファイルから特定のプロファイルを選択して、AWS認証情報を取得します。 --region TEXT サービスのAWSリージョン( us-east-1など)を設定します。sam publish
SAMアプリケーションServerless Application Repositoryに公開します。
このコマンドは、パッケージ化されたSAMテンプレートを受け取り、指定されたリージョンにアプリケーションの公開を行います。
このコマンドは、SAMテンプレートに、公開に必要なアプリケーションメタデータを含むMetadataが含まれていることを想定してます。さらに、これらのプロパティには、LicenseUrlおよびReadmeUrlの値のS3バケットへのリファレンスを含め、ローカルファイルへのリファレンスは含まれていない必要があります。
SAMテンプレートのMetadataセクションの詳細については、「AWS SAM CLI を使用してサーバーレスアプリケーションを公開する」を参照してください。構文
sam publish [OPTIONS]オプション
Option Description -t, --template PATH SAM テンプレートファイル [デフォルト: template.[yaml / yml]]。 --semantic-version TEXT 省略可能。このパラメータによって提供されるアプリケーションのセマンティックバージョンは、テンプレートファイルのMetadataセクションのSemanticVersionをオーバーライドします。 --profile TEXT 認証情報ファイルから特定のプロファイルを選択して、AWS認証情報を取得します。 --region TEXT サービスのAWSリージョン( us-east-1など) を設定します。その他
sam logs
Lambda関数によって生成されたログを取得します。
関数がCloudFormationスタックの一部である場合、スタック名を指定するときに、関数の論理IDを使用してログを取得することができます。構文
sam logs [OPTIONS]オプション
Option Description -n、--name TEXT Lambda関数の名前。この関数がCloudFormationスタックの一部である場合、CloudFormation/SAMテンプレート内の関数リソースの論理IDになります。[必須] --stack-name TEXT 関数が一部であるCloudFormation スタックの名前。 --filter TEXT 式を指定して、ログイベントの用語、フレーズ、または値に一致するログをすばやく検索できます。これは、単純なキーワード (「error」など) またはCloudWatch Logsでサポートされるパターンです。構文については、「CloudWatch Logsのドキュメント」を参照してください。 -s、--start-time TEXT この時刻からログを取得します。時刻には、「5分前」、「昨日」などの相対的な値、または「2018-01-01 10:10:10」のような形式のタイムスタンプを指定できます。デフォルトは「10分前」です。 -e、--end-time TEXT この時刻までのログを取得します。時刻には、「5分前」、「明日」などの相対的な値、または「2018-01-01 10:10:10」のような形式のタイムスタンプを指定できます。 -t、--tail ログ出力の末尾を表示します。これにより、終了時間引数は無視され、ログが使用可能になった時点で引き続き取得されます。 --profile TEXT 認証情報ファイルから特定のプロファイルを選択して、AWS認証情報を取得します。 --region TEXT サービスのAWSリージョン( us-east-1など)を設定します。まとめ
今回は、機能の説明や、コマンドラインのリファレンスなどまでとします。
実際にコマンドを使ってのサンプルの解説は、別の投稿にてまとめたいと思います。
- 投稿日:2020-07-27T13:57:00+09:00
ionicの始め方&S3簡単デプロイ
はじめに
ionicを使ってどうやってプロジェクト作るのー?
作ったは良いけどどうやってS3にデプロイするのー?
って人向けの記事です。ionicの始め方
まずはじめにterminalでionicCLI、native-run、cordova-resをインストールします。
$ npm install -g @ionic/cli native-run cordova-resあとはionic startを使ってプロジェクトを作成していきます。
ですがここで結構決めておかないと後々困る事があるので説明していきます。
まず下記がionic startコマンドです。$ ionic start <name> <template> [options]nameの部分ですがこれはプロジェクト名です。
わかりやすい名前をつけましょう。templateに関しては今回作成するプロジェクトに対してionicが用意してくれているテンプレートをつけるか否かです。
--listでどういったテンプレートがあるか見れます。
例:blank, tabs等optionsですがこれは名前の通り色々なオプションがつけれます。
ここでangularをベースにするのかreactをベースにするのか等選べます。
--listでどういったオプションがあるか見れます。
例:--type=angular, --type=react等nameをhogeにしtemplateをつないのでblankにしoptionsでangularをベースにする場合は下記のようになります。
$ ionic start hoge blank --type=angular作成されたファイルの確認
では作成されたを確認していきましょう。
今回はhogeというプロジェクト名にしたのでhogeをサンプルとして書いていきます。
まず作成した対象のファルダに移動して下記のコマンドを叩いてみてください。$ ionic serveこれでhttp://localhost:8100/home の画面が勝手に表示されたと思います。
まずhomeが作成されているのでhoge/src/app/homeに確認しにいきましょう。
home配下にhtml,ts,scss等が作成されているのが確認出来ると思います。
基本となるhome.page.htmlを見ていきましょう。home.page.html<ion-header [translucent]="true"> <ion-toolbar> <ion-title> Blank </ion-title> </ion-toolbar> </ion-header> <ion-content [fullscreen]="true"> <ion-header collapse="condense"> <ion-toolbar> <ion-title size="large">Blank</ion-title> </ion-toolbar> </ion-header> <div id="container"> <strong>Ready to create an app?</strong> <p>Start with Ionic <a target="_blank" rel="noopener noreferrer" href="https://ionicframework.com/docs/components">UI Components</a></p> </div> </ion-content>ion-header
まずion-headerですがこれがheaderです
ion-titleの中にタイトルを書き込むと反映されます。ion-content
ion-contentはbodyの部分にあたります。
デフォルトだとion-contentの中にion-headerが書いてありますが,
これは画面上には反映されていません。
よく見るとion-headerの中にcollapse="condense"というのがありますね。
collapse="condense"はiosに対して表示されるheaderのオプションになります。
気になる人は後ほどデプロイするのでデプロイ先をiphoneで確認してみてください。build
terminalで下記コマンドを実行します。
$ ionic buildそしたらhoge配下にwwwというフォルダが作成されたかと思います。
この中にbuildされたファイルが入っています。S3へデプロイ
自身のAWSアカウントへログインしAWSマネジメントコンソールにてS3を検索しS3へ移動します。
新しいバゲットを作成するをクリックし任意の名前やリージョンを指定しバゲットを作成してください。
作成したらバゲット一覧の中に新しく作ったバゲットがあるのでクリックします。
次にアップロードボタンがあるのでクリックするとアップロード画面が表示されますのでwww配下のファイルを全てアップロードします。
あとはバゲットポリシーを設定し完了です。
とりあえず下記のものがパブリックですが設定すると見れます。
セキュアにしたい場合はipアドレスの設定をしてください。{ "Version": "2008-10-17", "Id": "PolicyAccessCtrl", "Statement": [ { "Sid": "StmtAccessCtrl", "Effect": "Allow", "Principal": { "AWS": "*" }, "Action": "s3:GetObject", "Resource": "arn:aws:s3:::作成したバケット名/*" } ] }最後に
ionicの基本的な始め方を書きましたがこれがモバイルアプリ作成の第一歩です!
ionicを使うとiosアプリやandroidアプリをデプロイ出来ます。
DeployGateを使い簡単にデバックも出来ますので今度はDeployGateを使った記事を書いてみようと思います。参考
- 投稿日:2020-07-27T13:30:47+09:00
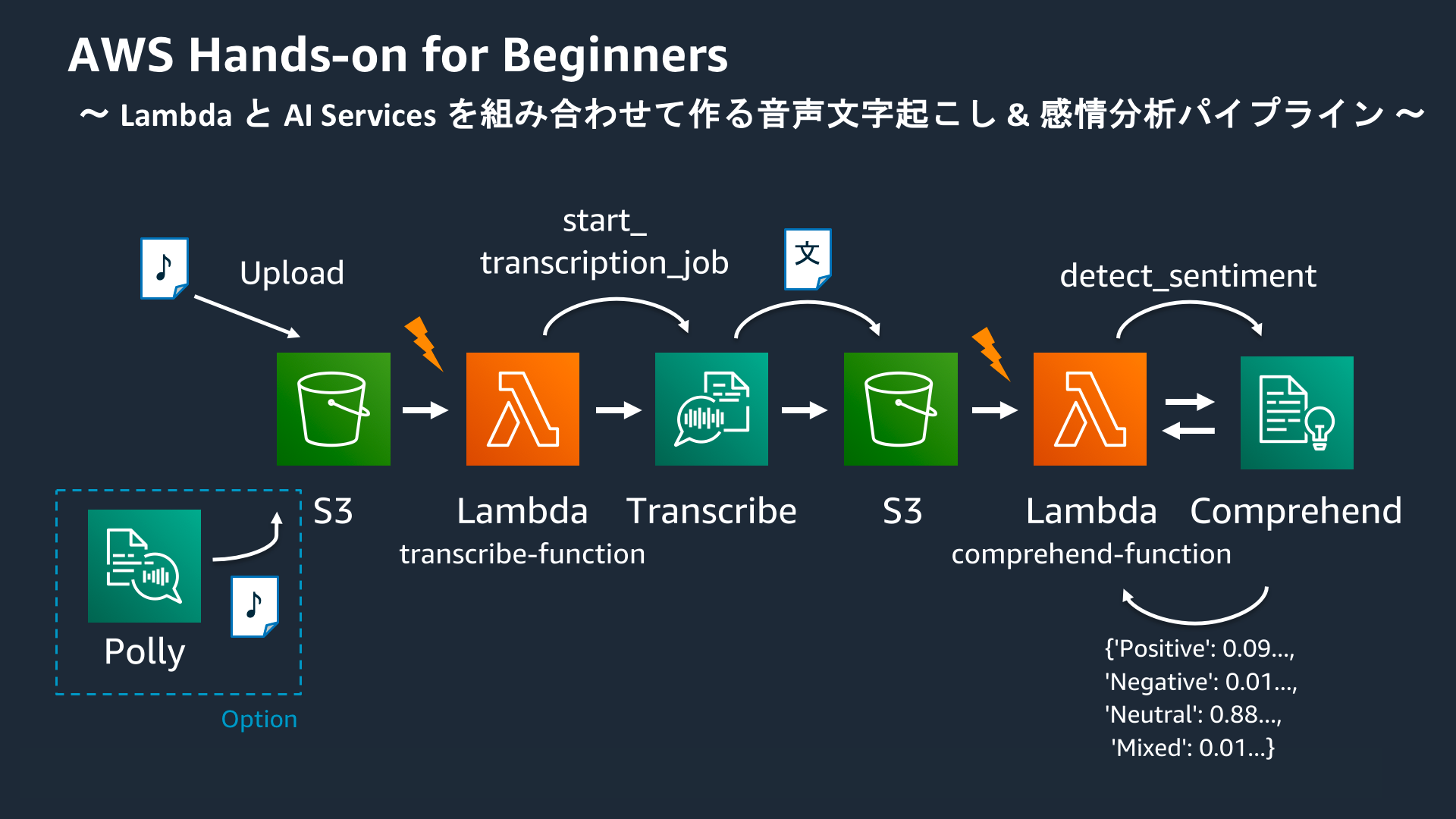
AWSハンズオン実践メモ 〜AWS Lambda と AWS AI Services を組み合わせて作る音声文字起こし & 感情分析パイプライン〜
はじめに
AWS公式のハンズオンシリーズの中から、AWS Lambda と AWS の各種 AI サービスを組み合わせて、“音声ファイルがアップロードされると文字起こしと感情分析を自動的に行う” パイプラインを構築するハンズオンを実施しました。
本記事は自身のハンズオン学習メモとして投稿します。
目次
ハンズオンの目的
- 音声の文字起こし、およびその感情分析を行うパイプラインをサーバーレスアーキテクチャで構築する
- S3トリガーでLambdaを非同期に呼び出す方法を理解する
- AWSのAI Servicesの特徴と使い方を理解する
AWS Hands-on for Beginners - AWS Lambda と AWS AI Services を組み合わせて作る音声文字起こし & 感情分析パイプライン では、AWS Lambda と AWS の各種 AI サービスを組み合わせて、“音声ファイルがアップロードされると文字起こしと感情分析を自動的に行う” パイプラインを構築していきます。これまでのハンズオンでは、Amazon API Gateway と AWS Lambda との組み合わせを試してきましたが、AWS Lambda は他にも多くの AWS サービスと連携できます。このハンズオンでは、Amazon S3 へのファイルアップロードをトリガーに Lambda Function を実行する機能を利用し、パイプラインを構築します。また、AWS には多くの AI サービスがあり、このハンズオンをきっかけに、皆様のプロダクト開発に活かせる AI サービス群を知っていただければと考えています。
(https://aws.amazon.com/jp/aws-jp-introduction/aws-jp-webinar-hands-on/ より引用)
本編
S3 トリガーで Lambda ファンクションを起動する
- S3作成
- Lambda関数作成
- S3にファイルをアップロードし、Lambdaが処理をする事を確認
Amazon Transcribe を使って文字起こしを試してみる
Amazon Transcribeとは
音声をテキストに変換する文字起こしサービス。
- S3作成(結果出力用)
- Amazon TranscribeでJobを作成し、Inputデータをアップロード
- S3に結果出力
Test-Job.json{"jobName":"Test-Job","accountId":"996770387061","results":{"transcripts":[{"transcript":"ハンズオン 順調 です か 手 を 動かす の 楽しい です よ ね"}],"items":[{"start_time":"0.04","end_time":"0.71","alternatives":[{"confidence":"0.9967","content":"ハンズオン"}],"type":"pronunciation"},{"start_time":"0.71","end_time":"1.23","alternatives":[{"confidence":"1.0","content":"順調"}],"type":"pronunciation"},{"start_time":"1.23","end_time":"1.5","alternatives":[{"confidence":"1.0","content":"です"}],"type":"pronunciation"},{"start_time":"1.5","end_time":"1.74","alternatives":[{"confidence":"0.9985","content":"か"}],"type":"pronunciation"},{"start_time":"2.16","end_time":"2.32","alternatives":[{"confidence":"0.9958","content":"手"}],"type":"pronunciation"},{"start_time":"2.32","end_time":"2.51","alternatives":[{"confidence":"1.0","content":"を"}],"type":"pronunciation"},{"start_time":"2.51","end_time":"3.02","alternatives":[{"confidence":"1.0","content":"動かす"}],"type":"pronunciation"},{"start_time":"3.02","end_time":"3.21","alternatives":[{"confidence":"1.0","content":"の"}],"type":"pronunciation"},{"start_time":"3.4","end_time":"3.94","alternatives":[{"confidence":"0.999","content":"楽しい"}],"type":"pronunciation"},{"start_time":"3.94","end_time":"4.22","alternatives":[{"confidence":"1.0","content":"です"}],"type":"pronunciation"},{"start_time":"4.22","end_time":"4.39","alternatives":[{"confidence":"1.0","content":"よ"}],"type":"pronunciation"},{"start_time":"4.39","end_time":"4.64","alternatives":[{"confidence":"1.0","content":"ね"}],"type":"pronunciation"}]},"status":"COMPLETED"}S3 への音声ファイルアップロードをトリガに Lambda を起動し Transcribe するパイプラインを作る
- LambdaにアタッチされているIAMロールのポリシーを修正(TranscribeとS3への権限を追加)
- Lambda関数を修正
lambda_function.pyimport json import urllib.parse import boto3 import datetime s3 = boto3.client('s3') transcribe = boto3.client('transcribe') def lambda_handler(event, context): bucket = event['Records'][0]['s3']['bucket']['name'] key = urllib.parse.unquote_plus(event['Records'][0]['s3']['object']['key'], encoding='utf-8') try: transcribe.start_transcription_job( TranscriptionJobName= datetime.datetime.now().strftime("%Y%m%d%H%M%S") + '_Transcription', LanguageCode='ja-JP', Media={ 'MediaFileUri': 'https://s3.ap-northeast-1.amazonaws.com/' + bucket + '/' + key }, OutputBucketName='handson-serverless-3-072518-output' ) except Exception as e: print(e) print('Error getting object {} from bucket {}. Make sure they exist and your bucket is in the same region as this function.'.format(key, bucket)) raise e以下のような流れで処理が実行される。
- S3にファイルをアップロード
- Lamndaに連携
- Transcribeのジョブ作成・実行
- ジョブ実行結果をLambdaに返却
- OutputのjsonをS3にアップロード
パイプラインで文字起こししたテキストを Comprehend で感情分析する
Amozon Comprehendとは
Amozon Comprehendは、機械学習を利用した自然言語処理サービス。
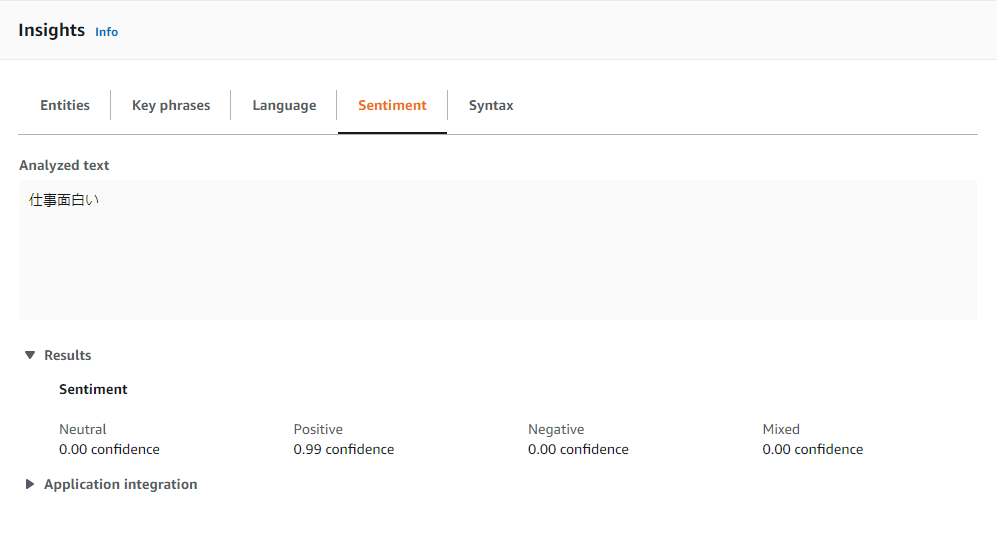
テキストの中の有用な情報を発見・分析したり、キーフレーズやエンティティの取得、感情分析をする事が出来るサービスである。以下は、感情分析の例。
- Lambda関数を作成
lambda_function_2.pyimport json import urllib.parse import boto3 s3 = boto3.client('s3') comprehend = boto3.client('comprehend') def lambda_handler(event, context): bucket = event['Records'][0]['s3']['bucket']['name'] key = urllib.parse.unquote_plus(event['Records'][0]['s3']['object']['key'], encoding='utf-8') try: response = s3.get_object(Bucket=bucket, Key=key) body = json.load(response['Body']) transcript = body['results']['transcripts'][0]['transcript'] sentiment_response = comprehend.detect_sentiment( Text=transcript, LanguageCode='ja' ) sentiment_score = sentiment_response.get('SentimentScore') print(sentiment_score) except Exception as e: print(e) print('Error getting object {} from bucket {}. Make sure they exist and your bucket is in the same region as this function.'.format(key, bucket)) raise e実行すると、以下のように感情分析がCloudWatch Logsに表示される。
まとめると、以下のような流れになる。
- S3にファイルをアップロード
- Lamnda(Transcribe用)に連携
- Transcribeのジョブが作成・実行され、文字起こしが行われる
- 結果をLambdaに返却
- 文字起こし結果のjsonをS3にアップロード
- Lamnda(Comprehend用)に連携
- Comprehendを呼び出し、感情分析を実行
- 感情分析結果を出力
Amazon Pollyを試してみる
Amazon Pollyとは
テキストを音声に変換するサービス。
作成した AWS リソースの削除
粛々と削除。特筆すべき事はなし。
おわりに
今回はAWSのAIサービスを利用したハンズオンを実施した。
実際に触ってみると、想像以上に簡単に各種サービスを使う事ができた。
また今回利用したサービスは全てマネージドサービスであり、サーバーをたてる事なく手軽に利用でき、かつ料金も使った分だけであるのが有難いと感じた。AWS以外のパブリッククラウドに同様の機能はあるのか、もしくは同じような事をしようとしたらどのように実装する必要があるのか、等を学習する事で理解を深めていきたい。
また、今回AIサービスに触れたが、AWSのSageMakerはまだ触った事がないので、実際に動かす機会を設けたいと思う。
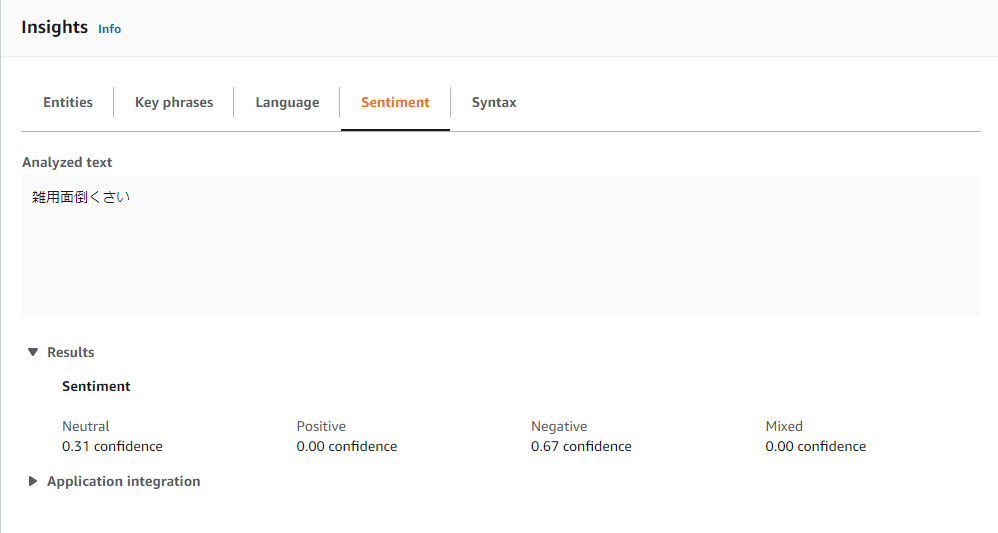

- 投稿日:2020-07-27T10:25:39+09:00
RDSのMariaDBにてロールを使って権限管理
はじめに
AWSのRDSにて、MariaDBを使ってみました。
サービスごとに権限を分けてロールで管理して使うようにしたのですが、
そのような例がネット上にあまり見つからなかったので、
記録として残しておきます。実行したMariaDBのバージョンは10.4です。
ロール機能は10.0.5からですが、
実質的にはデフォルトロールが使える10.1からが
ロール対応バージョンということのようです。ちなみにMySQLでは8.0からロール機能が使えます。
構成
サービスごとにDB(スキーマ)をservice01_db, service02_dbの2つ作ります。
service01_roleに属しているservice01_userはservice01_dbにのみアクセス可能にします。
service02についても同様です。どちらのDBにもアクセス可能なpoweruser_roleとそのユーザ(poweruser_user)を作ります。
これらのユーザには管理者権限は与えません。また、最初に作成したマスターユーザー(admin)と同じ権限を持つ、
admin_roleとadmin_userを作ります。WebコンソールでのRDS構築
初期DBとしてservice01_dbを作り、
adminという管理者ユーザを作ります。
最初のRDSの構築についてはここでは省略。以下、service01_dbにadminユーザで接続して作業します。
なお、接続する際のクライアントとしてはRedshiftの接続クライアントツールの比較でも紹介したDBeaverが使えます。
接続先設定としてMariaDBがデフォルトで用意されているのがいい感じです。データベース
サービスごとにデータベースを分けて作ります。
サービス1用のDBとして初期構築したservice01_dbを使い、
サービス2用のDBとして新たにservice02_dbを作ります。作成
create database service02_db;確認
show databases;ロール
以下のようにロール、ユーザを作っていきます。
ロール名 権限タイプ 範囲 ユーザ admin_role すべての権限 すべて admin_user poweruser_role 権限管理以外 すべて poweruser_user service01_role 権限管理以外 service01_db service01_user service02_role 権限管理以外 service02_db service02_user 作成
----- admin_role ----- create role admin_role; grant SELECT, INSERT, UPDATE, DELETE, CREATE, DROP, RELOAD, PROCESS, REFERENCES, INDEX, ALTER, SHOW DATABASES, CREATE TEMPORARY TABLES, LOCK TABLES, EXECUTE, REPLICATION SLAVE, REPLICATION CLIENT, CREATE VIEW, SHOW VIEW, CREATE ROUTINE, ALTER ROUTINE, CREATE USER, EVENT, TRIGGER ON *.* TO admin_role WITH GRANT OPTION; ----- poweruser_role ----- create role poweruser_role; grant SELECT, INSERT, UPDATE, DELETE, CREATE, DROP, RELOAD, PROCESS, REFERENCES, INDEX, ALTER, SHOW DATABASES, CREATE TEMPORARY TABLES, LOCK TABLES, EXECUTE, REPLICATION SLAVE, REPLICATION CLIENT, CREATE VIEW, SHOW VIEW, CREATE ROUTINE, ALTER ROUTINE, EVENT, TRIGGER ON *.* TO poweruser_role; ----- service01_role ----- create role service01_role; -- グローバル単位 grant RELOAD, PROCESS, SHOW DATABASES, REPLICATION SLAVE, REPLICATION CLIENT ON *.* TO service01_role; -- DB単位 grant SELECT, INSERT, UPDATE, DELETE, CREATE, DROP, REFERENCES, INDEX, ALTER, CREATE TEMPORARY TABLES, LOCK TABLES, EXECUTE, CREATE VIEW, SHOW VIEW, CREATE ROUTINE, ALTER ROUTINE, EVENT, TRIGGER ON service01_db.* TO service01_role; ----- service02_role ----- create role service02_role; -- グローバル単位 grant RELOAD, PROCESS, SHOW DATABASES, REPLICATION SLAVE, REPLICATION CLIENT ON *.* TO service02_role; -- DB単位 grant SELECT, INSERT, UPDATE, DELETE, CREATE, DROP, REFERENCES, INDEX, ALTER, CREATE TEMPORARY TABLES, LOCK TABLES, EXECUTE, CREATE VIEW, SHOW VIEW, CREATE ROUTINE, ALTER ROUTINE, EVENT, TRIGGER ON service02_db.* TO service02_role;admin_role はALLで作ってしまえばいい気がしますが、
RDSではALLが使えないので以下のSQLで得られた結果の権限をずらずらと並べています。-- 管理者ユーザの権限一覧 show grants for admin;参考:MySQL を実行している Amazon RDS DB インスタンス用に別のマスターユーザーを作成する方法を教えてください
service01_role, service02_roleについては、
権限によってグローバル単位のものとDB単位のものがあるので
2回に分けて権限を付与しています。今回それぞれに与えた権限を表にすると以下のようになります。
権限の付与単位にはDB単位以外にもテーブル単位などもありますので、
詳細はMariaDB公式のGRANTの説明を参照してください。確認
-- 作成されたロールの確認 select * from mysql.user u where is_role = 'Y'; -- データベースとロールの関連を確認 select db, user from mysql.db order by db, user;作成したロールは
mysql.userに入ります。
テーブル名通り、ユーザもこのテーブルに格納されるのですが、
ロールかどうかはis_role = 'Y'で判別します。
なお、このis_roleカラムはMySQLにはありません。ユーザ
ユーザを作成します。
パスワードはダミーで入れています。作成
create user admin_user identified by 'PASSWORD_AAA'; create user poweruser_user identified by 'PASSWORD_BBB'; create user service01_user identified by 'PASSWORD_XXX'; create user service02_user identified by 'PASSWORD_YYY';確認
select user from mysql.user where is_role = 'N' order by user;ユーザへのデフォルトロール割り当て
ログイン時にロールが割り当たるように
デフォルトロールとして設定します。作成
-- admin_user grant admin_role to admin_user; set default role admin_role for admin_user; -- poweruser_user grant poweruser_role to poweruser_user; set default role poweruser_role for poweruser_user; -- service01_user grant service01_role to service01_user; set default role service01_role for service01_user; -- service02_user grant service02_role to service02_user; set default role service02_role for service02_user;確認
-- ユーザにロールが割り当たっているかを確認 select * from mysql.roles_mapping rm order by User; -- それぞれのユーザのデフォルトロールを確認 select user, default_role from mysql.user u where is_role = 'N' order by user;なお、MySQLではmysql.role_edges、mysql.default_rolesで確認するようです。
おわりに
MariaDBとMySQL、内部的には違っていても人間が触る部分は一緒と思っていたのですが、
確認に使うシステム系のテーブルなど
違っているところもあり、いろいろと注意点がありそうです。


- 投稿日:2020-07-27T10:20:30+09:00
AWS初心者がSQSでキューを作成してみる
どうも!最近ソリューションアーキテクトアソシエイトを無事取得することができましたがまだまだサービスに慣れていないのでAWS初心者を名乗って行こうかと思っているSATO論外です!
今回はAWSのキューイングサービスであるSQSを触って実際に動かして行こうかと思いますSQSとは?
Amazon Simple Queue Serviceの略です。
完全マネージド型のメッセージキューイングサービスでマイクロサービス・分散システム・サーバレスアプリケーションの切り離しとスケーリングが可能です。
主に送信側のアプリケーションと受信側のアプリケーションのポーリング処理の中継役(キューをため込んでポーリング処理を実施)として使用するサービスとなります。
疎結合化を進めるためにSAAの試験でも結構な確率で出てくる項目となりますので是非覚えていて損はありません実際に触ってみる
SQSの作成
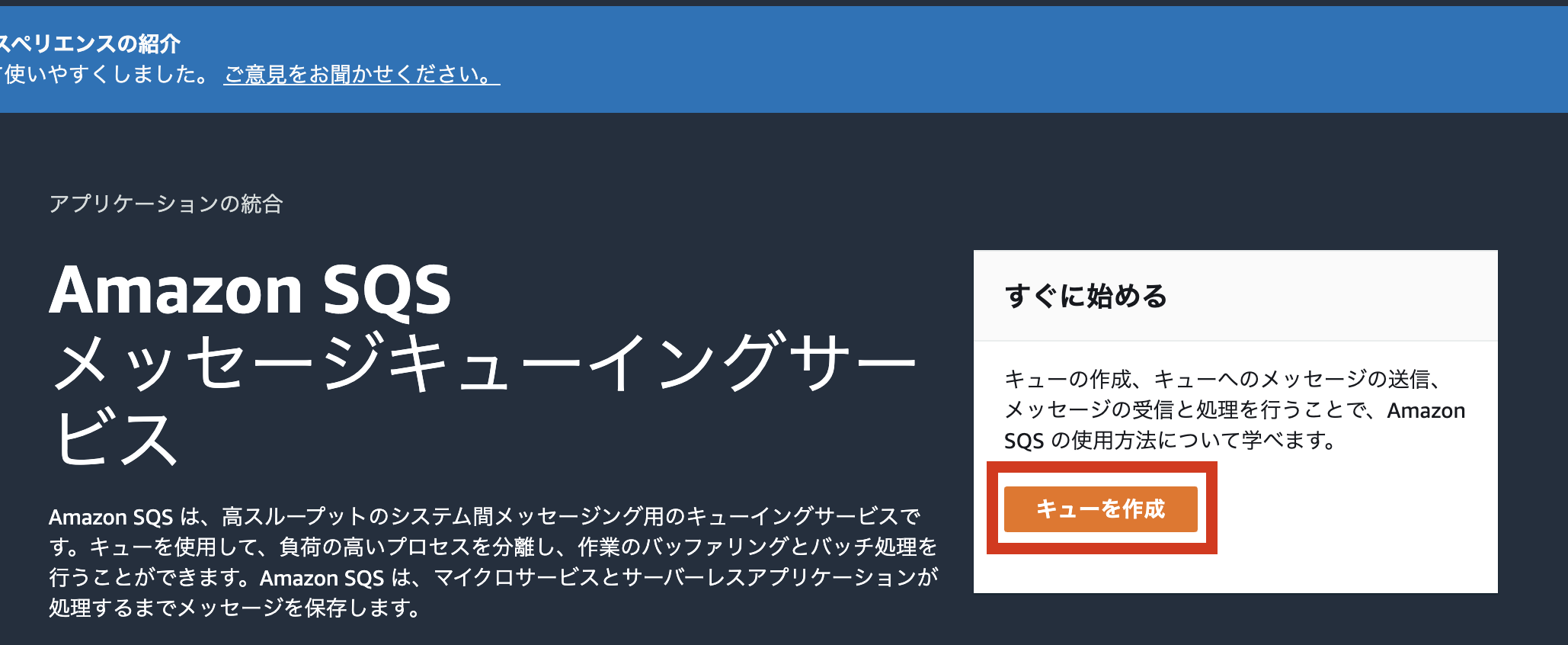
- AWS マネジメントコンソールからSQSを検索して移動、キューを作成をクリック
- 作成画面に移動するのでキューのタイプを選択して名前を入力
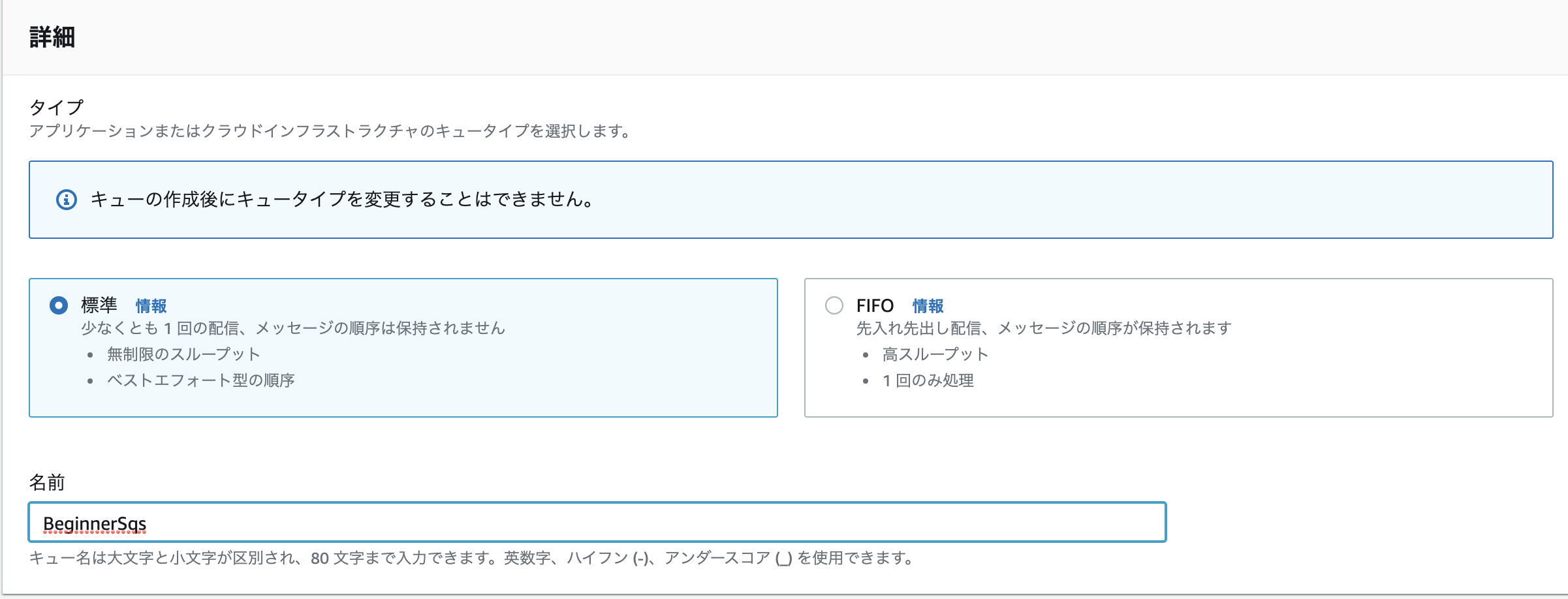
- SQSには標準キューとFIFOキューの2つのタイプがあります(今回は標準キューを使用します)
- 標準キュー:基本的には順番通り処理するが場合によっては順番が変わる可能性がある(またメッセージを複数回受信する可能性もある)
- FIFOキュー:最初に入った順にキューを処理する(順番を確実に保証したい場合に使用する)
- 詳細の設定(可視生タイムアウト(いつまで見れるか)・メッセージ保持期間など)を行っていきます
※今回は可視性タイムアウトとメッセージ受信待機時間をそれぞれ10秒に設定してその他の項目はデフォルト
- その他アクセスポリシー・暗号化・デットレターキュー・タグについてはこの度はデフォルト設定のまま作成します
- デットレターキュー:残されたままのメッセージを別キューに移動し正常に処理できなかったメッセージを隔離できる
- 作成を押すとキューの完成です
作成したキューを操作してみる
- 先ほど作成したキューをクリック
- メッセージを送受信をクリック
- メッセージと配信遅延を入力してメッセージの送信をクリック
- キューの一覧画面に戻ると利用可能なメッセージに1件追加されていることがわかります
- キューの名前をクリックして詳細画面に移動
- メッセージを送受信をクリック
- 下にあるメッセージを受信からメッセージをポーリングをクリックするとポーリング処理が実行されます
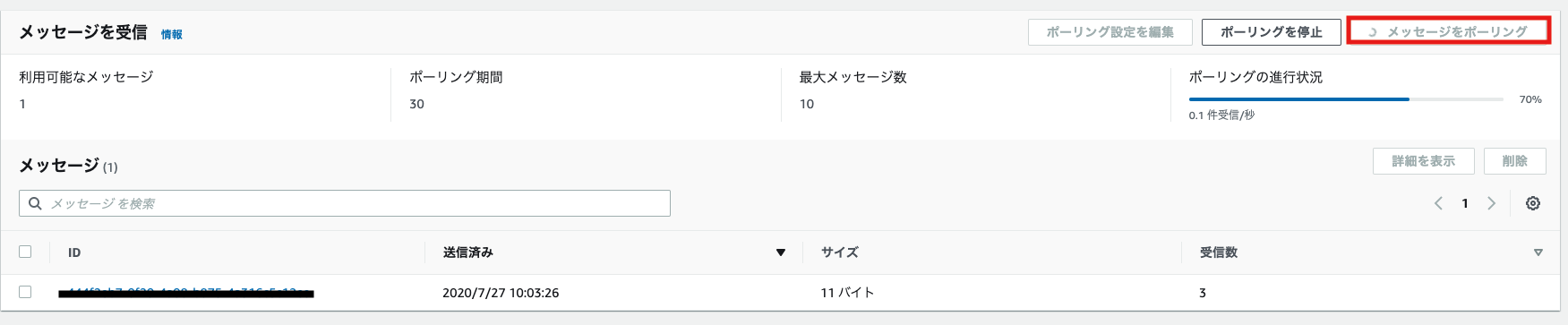
- ポーリングが完了するとメッセージ欄に先ほど送信したメッセージが届いていることが確認できます
※今回は管理画面にて簡易的に行っておりますが実際はEC2インスタンスなどを利用してメッセージの受け渡しなどを行っていきます
- 投稿日:2020-07-27T09:54:55+09:00
AWS Copilot Pipelineを触ってみた
きっかけ
前回AWS Copilotを触ってみましたが、その時はpipelineをうまく動かせませんでした。
しかし、その後うまく動いたので今回はcopilot pipelineの話を書こうと思います。動かなかった原因
なぜ動くようになったのかは不明です...
とりあえずcopilotに新バージョンが出ていたのでバージョンを上げて色々試していたら動きました...$ copilot --version copilot version: v0.2.0Copilotのセットアップ
まずはCopilotをセットアップします。セットアップに使うファイルややり方は前回記事同様です。
# 必要なファイル . ├── Dockerfile └── index.html 0 directories, 2 files# Dockerfile FROM nginx EXPOSE 80 COPY index.html /usr/share/nginx/html
copilot initでCopilotのセットアップを開始します。
選択肢の詳細等の詳しいセットアップ方法は前回記事を確認してください。$ copilot init (省略) Application name: qiita-copilot-pipeline-app # 今回設定したアプリ名 Service type: Load Balanced Web Service Service name: qiita-copilot-pipeline-service # 今回設定したサービス名 Dockerfile: ./Dockerfile (省略) ✔ Wrote the manifest for service qiita-copilot-pipeline-service at copilot/qiita-copilot-pipeline-service/manifest.yml Your manifest contains configurations like your container size and port (:80). (省略) All right, you're all set for local development. Deploy: Yes (省略)git管理しているフォルダで
copilot initを行うと、Copilotセットアップ中に自動で作成されたAmazon ECRのImageタグにcommit番号?(7桁の英数字)が入ります。
git管理していない場合は以下のメッセージが表示され、Imageタグを入力するように求められます。fatal: not a git repository (or any of the parent directories): .git Note: Failed to default tag, are you in a git repository? Input an image tag value:設定がすべて終わるとアクセス先URLが表示されるのでブラウザで確認してみましょう。
index.htmlの内容が表示されているはずです。✔ Deployed qiita-copilot-pipeline-service, you can access it at http://.....Copilotのセットアップが終わったファイル構成は以下の通りです。
# ファイル構成 . ├── .git │ └── (省略) ├── Dockerfile ├── README.md ├── copilot # 今回のcopilot initで作成されたフォルダ │ ├── .workspace # 今回のcopilot initで作成された隠しファイル │ └── qiita-copilot-pipeline-service # 今回のcopilot initで作成されたフォルダ │ └── manifest.yml # 今回のcopilot initで作成されたファイル └── index.html
copilot initで作成されたファイルをGitHubにプッシュしましょう。
./copilot/.workspaceファイルも忘れずにGitHubプッシュをしてください。
.workspaceファイルがないとPipeline実行時にbuildでエラーが発生します。(気づかずにハマった...)Copilot Pipelineのセットアップ
続いて今回のメインディッシュのCopilot Pipelineのセットアップを行います。
copilot pipeline initで対話形式のセットアップが始まります。$ copilot pipeline init Would you like to add an environment to your pipeline? [? for help] (y/N)
Would you like to add an environment to your pipeline?でNoにすると、後ほど聞かれるGitHubのPersonal Access Tokenの設定のみ行われ、Pipelineの設定は行われません。(下の環境に関する質問がスキップされる)
何に使うんだろ...Which environment would you like to add to your pipeline? [Use arrows to move, type to filter, ? for more help] > testpipelineを追加する環境を選択します。
ここでは自動で作成されるテスト環境以外の環境は作っていないので、表示されているテスト環境を選択します。Which GitHub repository would you like to use for your service? [Use arrows to move, type to filter, ? for more help] > git@github.com:『アカウント名』/『リポジトリ名』 Please enter your GitHub Personal Access Token for your repository copilot-test: [? for help]接続するGitHubリポジトリを選択し、GitHubの
Personal Access Tokenを入力します。
Personal Access TokenはGitHubサイトで以下の操作で生成します。
1. GitHubアカウントのSettingsをクリック
2. 左メニューの一番下のDeveloper settingsをクリック
3. 左メニューの一番下のPersonal access tokensをクリック
4. Personal access tokens画面のGenerate new tokenをクリック
詳しくはGitHub「Personal access tokens」の設定方法 - Qiitaが参考になります。(省略) ✔ Wrote the pipeline manifest for qiita-copilot-pipeline at 'copilot/pipeline.yml' The manifest contains configurations for your CodePipeline resources, such as your pipeline stages and build steps. ✔ Wrote the buildspec for the pipeline's build stage at 'copilot/buildspec.yml' The buildspec contains the commands to build and push your container images to your ECR repositories.セットアップが終わると
copilot/pipeline.ymlとcopilot/buildspec.ymlが作成されます。# ファイル構成 . ├── .git │ └── (省略) ├── Dockerfile ├── README.md ├── copilot │ ├── .workspace │ ├── buildspec.yml # 今回のcopilot pipeline initで作成されたファイル │ ├── pipeline.yml # 今回のcopilot pipeline initで作成されたファイル │ └── qiita-copilot-pipeline-service │ └── manifest.yml └── index.htmlまたセットアップ完了後に以下のように推奨手順が表示されます。
Recommended follow-up actions: - Commit and push the generated buildspec and manifest file. - Update the build phase of your buildspec to unit test your services before pushing the images. - Update your pipeline manifest to add additional stages. - Run `copilot pipeline update` to deploy your pipeline for the repository.が、今回作成されたbuildspec(buildspec.yml)とPipelineマニフェスト(pipeline.yml)はPipelines · aws/copilot-cli Wikiの
Setting up a Pipeline, step by stepでオプションになっており、以下の通り同ページのシンプルな手順でも触れられていないため、推奨手順に書かれている- Update the build phase of your buildspec to unit test your services before pushing the images.と- Update your pipeline manifest to add additional stages.は無視することにします。# Pipelines · aws/copilot-cli Wikiに書かれているシンプルな手順 $ copilot pipeline init $ git add copilot/buildspec.yml && git commit -m "Adding Pipeline Buildspec" && git push $ copilot pipeline updateということで、Pipelines · aws/copilot-cli Wikiに書かれているシンプルな手順に従います。
$ git add copilot/buildspec.yml && git commit -m "Adding Pipeline Buildspec" && git push $ copilot pipeline updateCodePipelineが作成されます。
AWSマネジメントコンソールで確認するとしばらくステータスが進行中なので成功しましたになるまで待ちます。
以下のコマンドでも確認できます。$ copilot pipeline status Pipeline Status Stage Transition Status ----- ---------- ------ Source ENABLED Succeeded └── SourceCodeFor-qiita-app Succeeded Build ENABLED InProgress └── Build InProgress DeployTo-test ENABLED - Last Deployment Updated At 8 minutes agoステータスが
成功しましたになったらpipelineの設定が完了しているので試しにローカルのindex.htmlを編集してGitHubにプッシュしてみましょう。
5、6分待つと公開サイトに反映されているはずですその他のCopilot Pipelineのコマンド
Pipelineの詳細情報表示
$ copilot pipeline showPipelineの削除
$ copilot pipeline deletePipelineマニフェスト(pipeline.yml)
このファイルは以下の3要素で構成されています。
このファイルを更新した場合はcopilot pipeline updateを実行する必要があります。
- name: Pipelineの名前
- source: 追跡するGitHubリポジトリとブランチ
- stages: デプロイする環境
まとめ
奥が深そうなので今回は
buildspec.ymlには触れませんでした。
が、テストも関係してきてテスト担当者としては見逃せないので、日を改めて研究したいと思います。We're hiring!
AIチャットボットを開発しています。
ご興味ある方は Wantedlyページ からお気軽にご連絡ください!参考記事
Pipelines · aws/copilot-cli Wiki
AWS CopilotでAmazon ECSの環境とCI/CDの超簡単構築を試してみた - SMARTCAMP Engineer Blog
GitHub「Personal access tokens」の設定方法 - Qiita
- 投稿日:2020-07-27T09:21:07+09:00
Chromebook(ASUS C101PA)でAWS CodeDeployチュートリアルやってみた
概要
CodeDeployが気になっていたのでAWS公式のチュートリアルをやってみた。
何もしないと忘れそうなので、作業メモとして残す。作業環境・使用サービス
- 作業端末
- chromebook (ASUS C101PA)
- Secure Shell App (SSH接続用)
- AWSサービス(東京リージョン)
- EC2(Amazon Linux 2 AMI (HVM), SSD Volume Type)
- AWS CodeDeploy
- AWS CodePipeline
- github
1. IAM準備
EC2用とCodeDeploy用のIAMロールを準備する。
・EC2用
IAMロール作成画面でAWSサービス > EC2を選択。
↓
ポリシーに”AmazonEC2RoleforAWSCodeDeploy”を指定。
↓
タグは飛ばす。
↓
任意のロール名を入力し、ロールの作成。・CodeDeploy用
IAMロール作成画面でAWSサービス > CodeDeployを選択。
↓
ユースケースの選択でCodeDeployを指定。
↓
ポリシーにAWSCodeDeployRoleが表示される。(変更なし)
↓
任意のロール名を入力し、ロールの作成。2. EC2準備
EC2インスタンスの作成のクイックスタートで、
Amazon Linux 2 AMI (HVM), SSD Volume Type - ami-06ad9296e6cf1e3cf (64 ビット x86)
を選択し、下記以外は適当な設定で作成。(すべて無料枠で作成した。)
・「ステップ3:インスタンスの詳細の設定」のIAMロールに1で作成したEC2用ロールを割り当てる。
・同画面最下部のユーザーデータに下記記入
sudo yum install ruby
sudo yum install aws-cli
aws s3 cp s3://aws-codedeploy-ap-northeast-1/latest/install . --region ap-northeast-1
chmod +x ./install
sudo ./install auto
↓
・タグはあとで使用するのでメモ残しておくこと。
↓
起動
↓
Secure Shell Appで接続
↓
・AWS CLIインストール??(←不要?要確認)
・gitインストール
$ sudo yum update
$ sudo yum install git
$ git version4. github準備
GitHubの自分のアカウントで下記設定でニューレポジトリ作成。
[レポジトリ名] CodeDeployGitHubDemo
[Public]
[Initialize this repository with a README] チェックボックスをオフ
↓
ターミナルで下記コマンドを1行ずつ実行
$ mkdir /tmp/CodeDeployGitHubDemo
$ cd /tmp/CodeDeployGitHubDemo
$ touch README.md
$ git init
$ git add README.md
$ git commit -m "My first commit"
$ git remote add origin https://github.com/user-name/CodeDeployGitHubDemo.git
$ git push -u origin master
$ aws s3 cp s3://aws-codedeploy-ap-northeast-1/samples/latest/SampleApp_Linux.zip . --region ap-northeast-1
$ unzip SampleApp_Linux.zip
$ rm SampleApp_Linux.zip
$ git add .
$ git commit -m "Added sample app"
$ git push5. CodeDeploy準備
・アプリケーションおよびデプロイグループの作成
$ aws deploy create-application --application-name CodeDeployGitHubDemo-App
$ aws deploy create-deployment-group --application-name CodeDeployGitHubDemo-App --ec2-tag-filters Key=ec2-tag-key,Type=KEY_AND_VALUE,Value=ec2-tag-value --deployment-group-name CodeDeployGitHubDemo-DepGrp --service-role-arn service-role-arnec2-tag-key:作成したEC2インスタンスのタグ
ec2-tag-value:作成したEC2インスタンスのタグ値
service-role-arn:CodeDeploy用のIAMロールのARN6. アプリケーションをデプロイ
GitHubへの権限付与にコンソールを使用するのでそのままコンソールで設定しきる。
サービスからCodeDeploy画面へ移動
↓
アプリケーション>作成したデプロイグループ>[デプロイの作成]
↓
[リビジョンタイプ] で [GitHub] を選択
リビジョンの場所:自分のGitHubアカウント名
リポジトリ名:アカウント名/リポジトリ名
Commit ID:コミット(基本的に最新のID)
↓
デプロイの作成7.CodePipeline設定
サービスからCodePipeline画面へ移動。
↓
パイプラインを作成する
↓
パイプライン名:適当
サービスロール:自動
↓
ソース:GitHub
リポジトリ:紐付けたリポジトリ
を選択
ブランチ:master
↓
ビルドステージをスキップする。
↓
デプロイプロバイダー:AWS CodeDeploy
リージョン:アジアパシフィック(東京)
アプリケーション名:作成したアプリケーション
デプロイグループ:作成したデプロイグループ
↓
パイプラインを作成するインスタンスのパブリックIPをブラウザ入力すると、水色の画面が表示されるはず。
GitHubのリポジトリのhtmlファイルのカラーコードを「#000000」に変更して、画面が黒色に変わることを確認する。所感
CodeDeploy用のIAMロール作成が抜けていて、解決までに時間がかかった。
また、awsconfigの設定等、基本的なところで詰まってしまったので、スムーズに
設定できるように作成で順などまとめるようにしようと思う。
- 投稿日:2020-07-27T07:47:40+09:00
CPUバーストUnlimitedのEC2さんに乱暴したら課金された
秘密鍵を10億個作ろうとして遊休サーバーを使い始めたら、CPUバーストがUnlimitedであることに気づきました。危ない危ない。
以下のコマンドでEC2が自分の望む状態になるようコントロールしましょう。
# 一覧を出す。 $ aws ec2 describe-instance-credit-specifications { "InstanceCreditSpecifications": [ { "InstanceId": "i-1234567890abcdef0", "CpuCredits": "unlimited" }, { "InstanceId": "i-1234567890abcdef0", "CpuCredits": "unlimited" } ] } # インスタンスIDを指定してstandardにする $ aws ec2 modify-instance-credit-specification --instance-credit-specification "InstanceId=i-1234567890abcdef0,CpuCredits=standard" { "SuccessfulInstanceCreditSpecifications": [ { "InstanceId": "i-1234567890abcdef0" } ], "UnsuccessfulInstanceCreditSpecifications": [] } # インスタンスIDを指定してunlimitedにする $ aws ec2 modify-instance-credit-specification --instance-credit-specification "InstanceId=i-1234567890abcdef0,CpuCredits=unlimited" { "SuccessfulInstanceCreditSpecifications": [ { "InstanceId": "i-1234567890abcdef0" } ], "UnsuccessfulInstanceCreditSpecifications": [] }参考
- https://docs.aws.amazon.com/ja_jp/AWSEC2/latest/UserGuide/burstable-performance-instances-unlimited-mode.html
- https://docs.aws.amazon.com/cli/latest/reference/ec2/modify-instance-credit-specification.html
- https://docs.aws.amazon.com/ja_jp/AWSEC2/latest/UserGuide/burstable-performance-instances-unlimited-mode-concepts.html#how-burstable-performance-instances-unlimited-works
- https://qiita.com/digitalpeak/items/420732dfed1a6416711b
- https://qiita.com/kter/items/45c19119c170e52135df
- https://tech.smartcamp.co.jp/entry/aws-ec2-t2-unlimited
- https://dev.classmethod.jp/articles/notes-on-using-t2-unlimited/#toc-t2-unlimited2
- https://thr3a.hatenablog.com/entry/20180831/1535674868
- 投稿日:2020-07-27T06:47:59+09:00
AWS EC2 Konga導入
環境
Amazon Linux AMI release 2018.03
インストールコマンド
$ curl -sL https://rpm.nodesource.com/setup_14.x | sudo bash - $ sudo yum install -y nodejs $ sudo npm install bower gulp sails -g $ sudo yum install git $ git clone https://github.com/pantsel/konga.git $ cd konga $ npm install $ cd konga $ cd config $ cp -pr local_example.js local.js $ npm start起動すると、1338番ポートでGUIサービスが起動します。
セキュリティグループで外部(自分のIP)からTCP/1338番ポートに繋がるようにして、ブラウザからアクセスしましょう。設定
- NEW CONNECTION
Name: (任意でユニークな名前) Kong Admin URL: http://127.0.0.1:8001参考
aws linuxにnpmを導入する
Error: UNABLE_TO_GET_ISSUER_CERT_LOCALLYエラーで詰まった際に、参考にさせていただきました。
- 投稿日:2020-07-27T02:23:07+09:00
ELB (ALB) のヘルスチェックが Request timed out になって悩んだ
ぜんぜん大した話ではないのですが、検索しても答えが見つからず、しばらく悩んだので。
ロードバランサのアウトバウンドルールが閉じていた
リクエストが通るには、
- ロードバランサに設定したセキュリティグループのアウトバウンドルール
- インスタンスに設定したセキュリティグループのインバウンドルール
の双方で接続を許可する必要があります。
インスタンスのインバウンドルールばかり見ていて、ロードバランサのアウトバウンドルールが閉じていることになかなか気づきませんでした。。

その他
ALB のセキュリティグループの推奨設定が以下にあります。
https://docs.aws.amazon.com/ja_jp/elasticloadbalancing/latest/application/load-balancer-update-security-groups.html
アウトバウンドを絞るのは、ALB のルールを間違えて、変なサーバにリクエストを送るのを防ぐためでしょうか。今回は特に関係ありませんでしたが、ヘルスチェックのリクエストは以下のような内容になるそうです。Host ヘッダは IP になるとのこと。
https://aws.amazon.com/jp/premiumsupport/knowledge-center/elb-fix-failing-health-checks-alb/GET / HTTP/1.1 Host: 10.0.0.1:80 Connection: close User-Agent: ELB-HealthChecker/2.0 Accept-Encoding: gzip, compressed

- 投稿日:2020-07-27T02:10:03+09:00
2020年のAWSでいい感じWordpressインフラを組んでみる
これまでちょこちょこAWS関連の記事を書いてきたのですが、
そういえば一般的な1システム全体のことを書いたものが無いなと気付きました。じゃあせっかくなので1システムをキッチリ組んで思考メモをまとめよう、ということでやってみました。
題材と前提
オーソドックスな題材がいいなということで、RailsかWordpressあたりかと思ったのですが、
最近Fargate+EFSが実装されたときに
「Fargateで冗長化Wordpressやってみたいな」と思っていたところだったためWordpressにしました。
※実際にはFargateではなくEC2になりましたが...その他前提としては、
- 可能な限り実運用を意識する
- 冗長化を行う
- 開発環境・本番環境はAWSアカウントレベルで分離し、それぞれ関係ないリソースは原則置かない
- Infrastructure as Codeを意識する
としています。
なお成果物はこちらです: https://github.com/cumet04/awsed-wordpress-infra
できあがった全体構成
そんな複雑でもなく、EFSがあることを除けばAWSのごく一般的な構成です。
Network
冗長化のため2AZをベースにし、サブネットを3組(Ingress, App, Data)用意しています。
ここでの構成ではApp, Dataはともにprivate subnetになっており分離する必然性は無いのですが、Appの部分は要件によってpublicになったりNATゲートウェイが刺さったりする可能性があるため分離しています。
なおEC2があるApp部分がprivateなため、いくつかのAWSサービス利用のためVPCエンドポイントが設定されています:
- Cloudwatch Agent用; ec2, monitoring, logs 参考
- SSM SSH用; ec2messages, ssm, ssmmessages, s3 参考
yum update用; s3 参考AmazonLinux系のyumリポジトリがS3にありprivateサブネットでも使えるのは今回始めて知りました。便利ですね。
なおAmazonLinux2であれば時刻同期もAmazon Time Sync Serviceがデフォルトで有効なため、こちらは何も心配する必要がありません。Ingress (Cloudfront, WAF, ALB)
一般ユーザのリクエストはCloudfrontで、管理画面アクセスはALB直(別ドメイン割当)で行います。
対象となるサイトには特にユーザごとやリクエストごとに動的なコンテンツは無い想定をしており、通常の閲覧リクエストを全てCloudfrontで受ける(キャッシュする)ことでComputing系の負荷を下げます。
もし一部ページにお問い合わせフォームが存在するなどする場合にはCloudfrontのBehaviorで別途設定するなどします。ここのセキュリティもやっておこうということで、AWS WAFをALBに紐付ける(ALBに前段に入る)ようにしています。
ここではお安く使えるAWSのマネージドルールを使っています。またALBへのアクセス制限として
- 所定IPからのリクエストは無条件許可
/wp-adminへのアクセスは(上記より一段下がる優先度で)拒否- Cloudfront以外からのアクセス(ALB直)は拒否 参考
というルールを設定しており、AWSマネージドのセキュリティ系ルールは優先度的にこれらの下に並ぶかたちです。
これらの条件により、管理画面は所定IPからALB直アクセスのみ可能としています。ちなみにWAFが不要な場合であっても、上記手動アクセス制御は全てALBのリクエストルーティングで可能です。
WAFありでもこれらだけALBでやる、という選択肢もあるのですが、その場合管理画面アクセスにWAFのセキュリティルールが反映されてしまい操作に悪影響が発生する恐れがあるため避けています。Computing (EC2, AutoscalingGroup)
コンピューティングはEC2を2台(冗長化目的)並べています。
AutoscalingGroupにしていますが自動スケールアウトは設定しておらず、インスタンス/ホスト異常からの自動復旧やCDKでの管理の都合上の目的で使っています。障害復帰はEC2のステータスチェックもありますが、最初から特定インスタンス(EBS)に依存しない状態にしておいたほうがいざというときにも比較的安心ですし、取りうる選択肢が広くなります。
またCDK上で「特定インスタンス」を管理すると手動オペレーションが発生した際に整合性を気にする必要やモニタリング対象の設定などがややこしくなり、AutoscalingGroupにしたほうがわかりやすくなります。負荷はCloudfrontで吸収する想定で自動スケールアウトは設定していませんが、CDNがある場合でもWordpressに負荷が集中する場合もあるにはある(大量の過去記事をクローリングされた場合など)ため、サイトによっては有効にしたほうがよいかと思います。
なおメトリクスやログはCloudwatch agentで送信し、webコンテンツ(ドキュメントルート配下)は全てEFSに置くことでEC2にステートを持たせないようにしています。
EC2インスタンスに入ってのメンテ系作業、いわゆるssh作業したい場合はSSM経由でsshする想定です。
Fargateの夢
計画当初はFargateを使おうと思っていたのですが、執筆時点ではFargate+EFSがCDK(Cloudformation)未対応でした。
EFS紐付けだけ手動で行いそれ以外をCDKにすることもできますが、この場合後からCDKでタスク定義を変更&反映した場合にEFS紐付け設定が消えてしまいます。
※タスク定義は変更ではなくリビジョンの新規作成のためこの挙動は運用上リスキーなため採用を見送ることとしました。残念ではありますが、ここはAWSさんの頑張りに期待ですね。
まぁEC2にしておくとEFS上のファイルを直接いじったりDBにCLIアクセス(mysqldumpやリストア含む)できたりして便利なので良しとしておきます。ちなみにCDKではなくTerraformを使えば実現できるようです。
Data Store (RDS, EFS)
DBはスタンダードにRDSのMySQLです。特にひねりはありません。
強いて言えば、DBを参照するアプリケーションがEFS上(IaC管理外)にあるため、あえてパスワードなどをコード上で管理していない(する必要がない)という点があります。ディスクストレージにはEFSを使い、ドキュメントルート以下をまるっと格納しています。EC2の
/var/www/html/に直接マウントしています。
パフォーマンスが気になるところではありますが、そこは負荷テストしつつ必要に応じてプロビジョンするなり対応できます。Monitoring & Alarm
モニタリング系はCloudwatchに集約されているため、ここらにアラームを設置していきます。
通知先として適当なSNS Topicを用意しておき、実際の通知先は運用者の好みで決められるようにしています。
メール通知もよし、Lambdaを発火してslackに流してもよし、AWS Chatbotを紐付けてもよし。またRoute53を利用するのであればWeb外部監視も実行できますね。
Infrastructure as Code
インフラ構成はごく一部を除きAWS CDKおよびansibleで管理しています。
実運用を考えた場合、設定変更などはまずステージング環境(開発環境)で行った後に本番反映を行う流れになりますが、設定群をコード化しておくことで「本番反映する変更点がステージングで行ったものと同一であること」を(ほぼ)保証できるためです。手順書&手作業はつらいし怖いですよね。
以下、リポジトリのコードを参照することを前提としています。
EC2の構成 (ansible)
playbookディレクトリ配下です。
本記事はAWSインフラが主眼なこと・そもそもこのEC2にはWordpressを動かす以外のことをほとんどさせていないことから、ここはポイントだけ抑えて軽めに流します。
site.ymlより、実行している処理は
- common; EC2サーバ一般。タイムゾーンやswap、メンテ用ツールなどをとりあえず入れる
- cloudwatch_agent; cloudwatch_agentおよびその設定を入れる
- httpd; apacheサーバと設定。アクセス制御などはWAF/ALBで実施するため、ごくごく最低限の設定のみ。LogFormatに
X-Forwarded-For入れたくらい。- php;
phpとphp-mysqlndいれるだけ。amazon-linux-extrasよりphp7.4を入れる。- efs; efsマウントヘルパー入れるだけ
- mysql_client; メンテ用にmysqlクライアントを入れる。Wordpressの動作に必須ではない。
amazon-linux-extrasを使うとphpのバージョンがややこしいので使わない。かなり古いのが入るがWordpressレベルなら多分大丈夫...?となっています。基本的に入れるだけです。
ポイントとしては、cloudwatchのメトリクス設定にてaggregation_dimensionsを設定することです。config.json{ ... "metrics": { "append_dimensions": { "AutoScalingGroupName": "${aws:AutoScalingGroupName}", "ImageId": "${aws:ImageId}", "InstanceId": "${aws:InstanceId}", "InstanceType": "${aws:InstanceType}" }, "aggregation_dimensions": [["AutoScalingGroupName"]], "metrics_collected": { ...こうしておくことでcloudwatchに記録される際にAutoScalingGroup名で一つにまとまったメトリクスができます。
そうしないと監視対象のメトリクスが一つに定まらず、EC2全体に対してアラートを設定することができません。またEFSについて、ansibleで実行するのはヘルパーを入れるだけです。
マウントするにはEFSインスタンスのIDが必要になるため、CDKからユーザデータ経由で実施します。AWSリソース (CDK)
インフラ全体はCDKの1スタックにまとめました。
cdk/lib/cdk-stack.ts
コード上ではリソースセットごとにcreateXXXメソッドとしてまとめ、スタックのコンストラクタからそれらを順に呼ぶかたちにしています。この構造にして必要な値を引数として指定することで
- 個々のリソース作成が依存しているパラメータが何なのかが明示できる
- 実プロジェクト依存・チューニングで変わりそうなパラメータたち(DB名やインスタンスサイズなど)を一部分(コンストラクタ)に集約できる1
- CDK作成に試行錯誤している段階で「今はALBとWAFの繋がりが確認できればいいので時間のかかるRDSはコメントアウト」というような融通がききやすい
というメリットがあります。
CDKに与えるパラメータ・CDK管理外リソース
可能な限り外部から指定するパラメータは減らしましたが、それでもいくつかはCDK外で作成・指定するものがあります。
- EC2のAMI
- 各種証明書 (Cloudfront, ALB(管理画面), ALB(Cloudfrontから受けるドメイン))
- Cloudfrontのオリジンに指定するALBのドメイン名
- Cloudfront -> ALBの通信制限に使うヘッダ名・値
- Cloudfrontの閲覧を指定IPに制限するか(要するに開発環境かどうか)
- 管理者として扱うIP
ここでは
面倒なので環境変数で指定していますが、どれも間違えて更新するとダメなものなので、実運用上はソースコードに直接書き込む or 手動でSSMパラメータストアに値を入れておいて参照するのが安全です。EC2のAMI自体はCDK外で作成しますが、ARNを指定する必要は無いようにしています。
構築対象のAWSアカウントにはこのWordpress環境1セットのみ存在する想定なので、イメージ名を指定&アカウント内から検索することで必要なAMIをCDK内で特定できます。createVpc
createVpcメソッドを定義し、VPCまわり(VPC, Subnet, SecurityGroup, VPC Endpoint)を作成します。VPCとサブネットについては
const vpc = new ec2.Vpc(this, "VPC", { cidr: "10.0.0.0/24", maxAzs: 2, subnetConfiguration: [ { name: "Ingress", subnetType: ec2.SubnetType.PUBLIC, }, { name: "Data", subnetType: ec2.SubnetType.ISOLATED, }, { name: "App", subnetType: ec2.SubnetType.ISOLATED, }, ], });だけでいい感じに出来上がります2。CDKは便利ですね。
サブネットもこれで生成されていますが、ここでselectSubnetsしておくことでその後の取り回しを良くしています。次にセキュリティグループもここで作成します。(以下は抜粋)
const sgALB = new ec2.SecurityGroup(this, "sgALB", { vpc }); ... const sgApp = new ec2.SecurityGroup(this, "sgApp", { vpc }); sgApp.addIngressRule(sgALB, ec2.Port.tcp(80));セキュリティグループの内容は個々のリソース依存が強いため、リソース生成時にそのメソッド内で一緒に作るほうがスッキリしそうですが、
addIngressRuleにてアクセス元の指定で他のグループを使う(上記ではsgAppの生成にsgALBの依存がある)ため、ここでまとめて作成しています。最後にVPCエンドポイントですが、愚直に全部並べると少々長いので、対象サブネットが全部同じであることを利用してforEachでまとめています。
createRDS
長いので割愛しますが、必要なパラメータを地道に入れていくだけです。
なお本要件はアプリケーションがWordpressであること・その実態はEFSに手動でいれる(インフラコードで管理しない)ことから、DBのパスワードは全く管理せず自動生成(SecretManagerが使われます)に任せています。
(DBパスを必要とするのはwp-config.phpのみで、それはEC2->EFSに手動で設置するため)その他CDK tipsとして、CDKのコードを作っている(試行錯誤している)最中は
multiAzおよびdeletionProtectionをfalseにしておくことで、AWS料金の節約・スタック削除やロールバックの際に楽ができます。createEFS
ファイルストレージなのでデータストア系かなと思いDataサブネットに置いたのですが、執筆時に調べたところ、どうもEC2と同じところに置くのがよさそうです。
Q. 作成時のsubnet指定は、EFSをマウントするEC2インスタンスが所属しているsubnetを選択すればよいですか?
A. はい。 EC2 インスタンスが属するサブネットに EFS マウントターゲットを作成することができます。この場合、ネットワーク的にもアクセス効率の良い構成になります。createInstances
EC2関連一式を含むAutoScalingGroupを作成します。
ポイントは以下です:
- 前述の通り、AMIはARN指定ではなく検索にしている
- UserDataを使ってパッケージのパッチを実施している(パッチ作業の半自動化のため)
- UserDataを使ってEFSのマウントを実施している(EFSのIDが必要なためansibleで完結できない)
- ScalingEventの通知を設定している
AMIを検索にした場合、検索結果がCDK実行ディレクトリの
cdk.context.jsonにキャッシュされます。
試行錯誤の段階で同名のAMIを作り直した場合はこのファイルを消す or 編集する必要があります。またAMIについてはEC2 Image Builderを使うのもよいと思います。今回は題材がWordpressなのでそんなに頻繁にEC2の設定・構成変更は発生しないだろうという想定で手動にしています。
createCloudwatchAlarms
CloudWatchのメトリクスに対しアラームをセット・通知先を設定しています。
最初に設定を作る段階では、まずアラームなしでインフラを作成 -> AWSコンソールからCloudWatchのメトリクス名を実際に見ながら作っていくのが確実です。
ここのコードは冗長な感じになっていますが、案外共通化できる要素が少ないため愚直にコピペで並べています(SNSトピックの設定だけまとめた)。
createALB
ALBを作り、ターゲットグループ(AutoScalingGroup)および証明書を割り当てます。
通信許可などの設定はWAFで行う構成なのでシンプルですが、WAFなしの場合はここでリスナールールを設定することになりそうです。
createWAF
WAFのルールおよびACLを作りますが、執筆時点でWAFにはLow Level Construct (CdnXXXのようなリソース。CDKでいい感じになっていないもの) しかなく3、コードがかなり冗長になっています。
仕方ないので型定義を見ながら愚直にコードを書いていきます。ここではIPSet, RuleGroup(カスタムルール), WebACLを定義しています。
RuleGroupにしていするcapacityの値は推測ができない(推測方法がわからない)ため、同じルールをAWSコンソールで作成し、そこに表示されるCapacityをそのまま使っています。なおWebACLを作成する際の
rulesの指定にはoverrideAction(もしくはaction)を指定する必要があり忘れるとエラーが発生するのですが、そのエラーメッセージから上記原因を全く推測できないので注意が必要です。
CDKでのWAF作成にハマった際にはこれを思い出し、エラーメッセージを無視して上記の点を確認することをオススメします。参考createCloudfront
CloudfrontのDistributionを作成します。
型定義に従って作成すればよいのですが、(多くの場合)priceClassは明示的に指定する必要がある点に注意が必要です。デフォルトにしておくと欧米でしか使えなくなります。
また本記事の内容では正規の証明書を使っていないためCNAMEを指定していない(できない)ですが、あらかじめ正規の証明書が使えるのであればコードの時点でCNAMEsを指定できるはずです。
...はずなのですが、CNAMEを指定するにはaliasConfiguration属性を指定する必要があり、このパラメータはdeprecatedとなっています。推奨手段(リポジトリで使っているviewerCertificate)で証明書は指定できますがCNAMEsを指定する手段は見当たらないため、警告に沿うのであればいずれにせよCNAMEsは手動指定が必要かもしれません。初期構築手順
詳しくはリポジトリのREADMEにあるので割愛しますが、ざっくりまとめると
- AmazonLinux2インスタンスにplaybookを投入したAMIを用意する
- ACMで証明書を用意する
- 上記を環境変数にセットし、CDKを投入する
- EC2経由でEFSにWordpressを設置する
- DNS設定(とCloudfrontのCNAMEsの設定)をする
となります。
まとめ
インフラ一式の構築を全て集約したのでかなり長くなりましたが、思考メモくらいにはなったと思います。
実用的にはコンテンツバックアップをやりたい(EFSのデータ・DBダンプをS3に日次で吐き出したい)と思っていますが、ひとまずここまでとなります。
一部分でも何かの参考になれば。
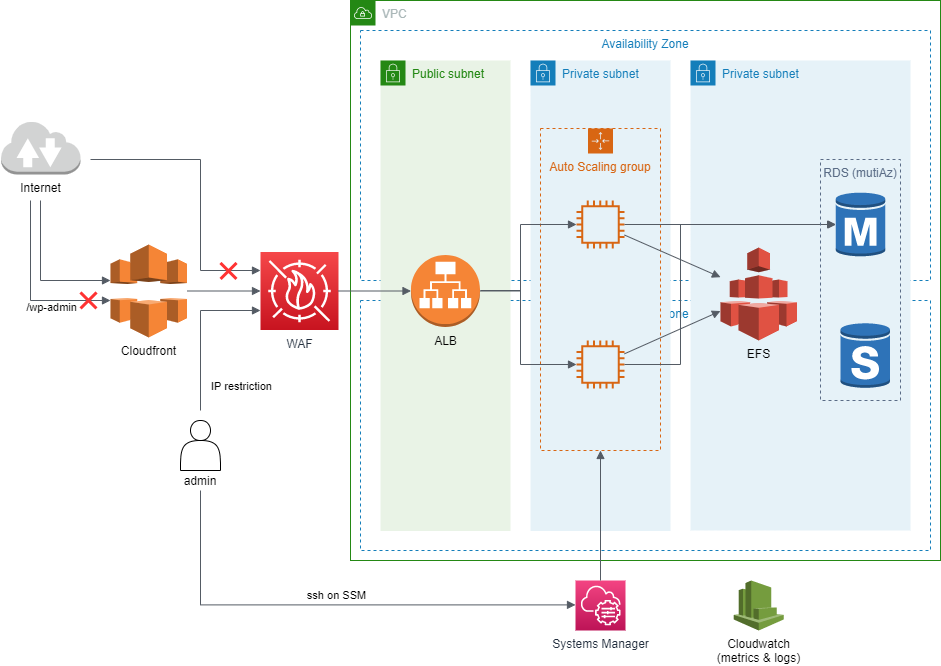
- 投稿日:2020-07-27T01:40:05+09:00
Railsアプリで画像の保存先をS3に変更する。その2
はじめに
前回の記事からの続きです。
安全にAWSのキーを扱えるようにする
AWSキーの漏洩を防ぐため、キーの内容は環境変数に設定します。
環境変数が分からない人はググって調べてみましょう!AWSのキーの設定
carrierwave.rbのなかに[:access_key_id]や[:secret_access_key]といった記載がありました。
ここには予め設定したキーが入り、Rails5.2では「credentials.yml.enc」というファイルで管理されます。それではcredentials.yml.encをエディタで開いてみましょう。
以下のように暗号化された文字列が表示されると思います。
これをターミナルからVSCodeを起動できるよう設定を行います。
VSCodeで、「Command + Shift + P」を同時に押してコマンドパレットを開きます。
続いて、「shell」と入力しましょう。
メニューに「PATH内に'code'コマンドをインストールします」という項目が表示されるので、それをクリックします。
この操作を行うことで、ターミナルから「code」と打つことでVSCodeを起動できるようになります。それではターミナルから以下のコマンドを実行しましょう。
復号化されたcredentials.yml.encがVSCodeで表示され、編集可能となるはずです。% EDITOR='code --wait' rails credentials:editAWSのaccess_key_idとsecret_access_keyを以下のように編集しましょう。
master.keyの設定
credentials.yml.encはmaster.keyというファイルで復号化を行います。
しかし、本番環境にmaster.keyを配置することはセキュリティ上問題があります。
そのため、本番環境の環境変数にmaster.keyの中身を設定しましょう。EC2インスタンスにログインし、環境変数の設定を行うファイルを開きます。
sudo vim /etc/environmentローカル開発環境で「config/master.key」の値をコピーして、本番環境のRAILS_MASTER_KEYに設定します。
RAILS_MASTER_KEY='master.keyの値'これで環境変数が設定できたはずなので、EC2インスタンスにログインし直して以下のコマンドで環境変数を確認しましょう。
env | grep RAILS_MASTER_KEYまとめ
環境変数を参照する流れをまとめますと以下のようになります。
1.credentials.yml.encをローカル環境のmaster.keyで復号する
2.credentials.yml.encを編集し、access_key_idとsecret_access_keyを設定する。
3.本番環境にデプロイする
4.master.keyの内容を本番環境の環境変数に設定する。
5.本番環境のcredentials.yml.encが環境変数を用いて復号可能となる。前回の記事と上記の設定を行えば、S3に画像をアップロード出来るようになるはずです!多分!以上!

- 投稿日:2020-07-27T00:30:41+09:00
Serverlessフレームワークで${aws:username}を使う
Serverlessフレームワークで
${aws:username}のようなIAM ポリシーエレメント(IAM Policy Elements)を使用するとエラーとなります。Invalid variable reference syntax for variable aws:username. You can only reference env vars, options, & files. You can check our docs for more info.ServerlessのValuablesと記法が被っているからですね。
対処法
以下のように
providerにvariableSyntaxを設定して、ServerlessのValuablesの記法を変更する必要があります。provider: name: aws runtime: python3.8 region: ap-northeast-1 variableSyntax: "\\${{([ ~:a-zA-Z0-9._\\'\",\\-\\/\\(\\)]+?)}}"これにより、ServerlessのValuablesは
${{xxx}}という記法に変わります。これでIAMの ポリシーエレメントが${...}の記法で使えるようになりました。
が、これだけでは今度はCloudFormationでエラーとなります。Error: The CloudFormation template is invalid: Template format error: Unresolved resource dependencies [aws:username] in the Resources block of the templateこの場合は↓のようにエスケープする必要があります。
${aws:username}->${!aws:username}以上で無事、IAM ポリシーエレメントが使用可能となりました。
2重に対応しないといけないのは厄介ですね。Serverless側でどうにかできないかというissueも立っていますね。環境
- Serverless: 1.76.1