- 投稿日:2020-07-24T23:56:53+09:00
pythonテクニック データの読み込み read_csv/sas7bdat/connect
pythonによるcsv/excel/sasデータの読み込みとデータベースの接続方法
csvの読み込みならread_csv
excelの読み込みならread_excel
SASデータセットの読み込みならsas7bdatやpandasのread_sas
DBへの接続ならsqlite3.connectなど準備
import pandas as pd import dask import dask.dataframe as dd from dask.delayed import delayed import sqlite3 from sas7bdat import SAS7BDATcsvの読み込み read_csv
Data = pd.read_csv( "パス/ファイル名.csv" ) Data = dd.read_csv( "パス/ファイル名.csv" ).compute()Daskの方が処理速度はやいので、大容量データの場合はDaskの方がいいかも
列名や型を指定する場合(データの1行目に列名あるならheader = 0で1行目無視)
FilePass = "パス/ファイル名.csv" FilePass = "./data/test.csv" name1 = "列名1", "列名2" , "列名3" , ... type1 = { "列名1":"str" , "列名2":"int" , "列名3":"float" , ... } Data = dd.read_csv( FilePass, encoding = "cp932", header = 0 ,names = ( name1 ), dtype = type1 ).compute()
excelの読み込み read_excel
Data = pd.read_excel( "パス/ファイル名.xlsx" ,sheet_name = "シート名" )csvと同様、列名の指定なども可
Daskにread_excelなかったが、無理やりやるなら
aaaaa = dask.delayed(pd.read_excel)( "パス/ファイル名.xlsx" ,sheet_name = "シート名" ) Data = dd.from_delayed( aaaaa ).compute()SASデータセットの読み込み sas7bdat/read_sas
# sas7bdat Data = SAS7BDAT( "パス/ファイル名.sas7bdat" , encoding = "cp932" ).to_data_frame()# pandasで読み込む場合(日本語入ってると、エラーにはならないが正しく読み込めない) Data = pd.read_sas( "パス/ファイル名.sas7bdat" , format = "sas7bdat" )https://qiita.com/saspy/items/2b5aeef91e87cac503e2
DB接続(SQLite3)
# データベース接続 conn = sqlite3.connect( "パス/db名.db" )# データベース閉じる conn.close()https://pandas.pydata.org/docs/user_guide/io.html#csv-text-files
https://pandas.pydata.org/docs/user_guide/io.html#excel-files
https://examples.dask.org/dataframes/01-data-access.html
https://docs.python.org/ja/3/library/sqlite3.html


- 投稿日:2020-07-24T23:41:43+09:00
【Python (PyTorch)】勾配降下法で多変数関数の最小値を求める
検索しても意外とイイ感じのがヒットしなかったので、Python(PyTorch)を使って「多変数関数の最小値と最小値を実現する点の座標を勾配降下法を用いて求める方法」についてまとめておきます。
実行環境
OS : Windows10
環境 : Anaconda(エディタ:Jupyter Notebook)
言語 : Python3
使用ライブラリ : PyTorch,numpy
※Anaconda,PyTorchのインストールについては下記を参考にしてください。勾配降下法とは
実装の前に簡単に勾配降下法について簡単に説明します。
勾配ベクトルは、以下の性質を持ちます。
『 関数の勾配ベクトルの方向は「その点から少し動いたときに(近傍のうち)関数の値を最大にする方向」となる 』
つまり、勾配ベクトルにマイナスをかけた方向は「その点から少し動いたときに(近傍のうち)関数の値を最小にする方向」になります。この性質を利用して、点を勾配方向に動かしていくことで関数の最小値を求める方法を「勾配降下法」と言います。
詳しくはこちらを参照してください。基本的な更新アルゴリズム
1 : 初期値 $x = x_0$ を決める
2 : その点での関数の勾配を求める
3 : 勾配方向に点を少し動かす (動かす幅を学習率$\eta$で指定)
4 : 2→3を繰り返す(例) ある関数$f(x)$の最小値を勾配降下法で求める場合の点の更新式 :
x ~:=~ x ~-~ \eta ~ \frac{\partial f}{\partial x} \\ただし, $x~$は$n$次元ベクトル, $\eta~$は学習率(値の更新幅)を表しているとします。
勾配降下法の実装
では、実際に勾配降下法をPyTorchを使って実装していきます。
【例題1 : 1変数関数の最小値】
$f(x) = x^2 + 1$ の最小値および最小値をとる$x$を求めよ。
当然、
【解】 最小値 : $1$, 最小値をとる$x$ : $x=0$
となるわけですが、これを勾配降下法でで求めてみます。関数の定義
$f(x) = x^2 + 1$
def func(x): return x[0]**2 + 1勾配降下法
初期値 : $x=2.0$
学習率 : $\eta = 0.01$
学習回数 : $500$
※ 初期値, 学習率, 学習回数については、問題に応じて必要があれば変更してくださいimport torch import torch.nn as nn import torch.optim as optim import numpy as np # 初期値 x = torch.tensor([2.0],requires_grad=True) # PyTorchで扱える形式に (requires_grad=True : 勾配計算可能) # 学習率 eta = 0.01 # 学習回数 n_epoch = 500 # 勾配降下法 for epoch in range(n_epoch): quad = func(x) # 関数値の計算 quad.backward() # 勾配計算 with torch.no_grad(): x = x - eta * x.grad # 点の更新 x.requires_grad = True print(f'最小値 : {func(x)}, 最小値をとる点 : {x}')出力
最小値 : 1.0, 最小値をとる点 : tensor([8.2048e-05], requires_grad=True)$x = 8.2×10^{-5} \risingdotseq0$ で最小値 $1.0$をとるという期待通りの結果が得られました。
【例題2 : 2変数関数の最小値】
$f(x_0,x_1) = {x_0}^2 - 2x_0 + {x_1}^2$ の最小値および最小値をとる$x=(x_0,x_1)$を求めよ。
平方完成すると, $f(x_0,x_1) = {(x_0-1)}^2 + {x_1}^2 - 1$となるので
【解】 最小値 : $-1$, 最小値をとる$x$ : $(1,0)$
と求まります。これを勾配降下法で求めてみます。関数の定義
$f(x_0,x_1) = {x_0}^2 - 2x_0 + {x_1}^2$
def func(x): return x[0]**2-2*x[0] + x[1]**2勾配降下法
初期値 : $x=(2.0,2.0)$
学習率 : $\eta = 0.01$
学習回数 : $500$import torch import torch.nn as nn import torch.optim as optim import numpy as np # 初期値 x = torch.tensor([2.0,2.0],requires_grad=True) # PyTorchで扱える形式に (requires_grad=True : 勾配計算可能) # 学習率 eta = 0.01 # 学習回数 n_epoch = 500 # 勾配降下法 for epoch in range(n_epoch): quad = func(x) # 関数値の計算 quad.backward() # 勾配計算 with torch.no_grad(): x = x - eta * x.grad # 点の更新 x.requires_grad = True print(f'最小値 : {func(x)}, 最小値をとる点 : {x}')出力
最小値 : -1.0, 最小値をとる点 : tensor([1.0000e+00, 8.2048e-05], requires_grad=True)最小値 : $-1.0$, 最小値をとる点 : $(1.0, ~0.0)$
※$8.2×10^{-5} \risingdotseq0.0$【例題3 : 多変数関数の最小値】
$f(x_0,x_1,x_2,x_3) = \sum_{i=1}^{5} (\sqrt{ (x_0-p_{0i})^2 + (x_1-p_{1i})^2 + (x_2-p_{2i})^2 + (x_3-p_{3i})^2} + q_i) ^2$
の最小値を求めよ。
ただし,
$~~~~ x_0,x_1,x_2,x_3,x_4$ : 変数
$~~~~p_{ji},q_i ~~(i=1,2,...,5, j=0,1,2,3)$ : 定数上のような4変数関数の最小値を勾配降下法で求めてみます。
データ点
np.random.seed(2) p = np.random.rand(5, 4) # 5行4列の正規乱数行列 q = np.random.rand(5, 1) # 5行1列の正規乱数行列 print(p) print(q)[[0.4359949 0.02592623 0.54966248 0.43532239] [0.4203678 0.33033482 0.20464863 0.61927097] [0.29965467 0.26682728 0.62113383 0.52914209] [0.13457995 0.51357812 0.18443987 0.78533515] [0.85397529 0.49423684 0.84656149 0.07964548]] [[0.50524609] [0.0652865 ] [0.42812233] [0.09653092] [0.12715997]]関数の定義
$f(x_0,x_1,x_2,x_3) = \sum_{i=1}^{5} (\sqrt{ (x_0-p_{0i})^2 + (x_1-p_{1i})^2 + (x_2-p_{2i})^2 + (x_3-p_{3i})^2} + q_i) ^2$
torchのライブラリで計算しますdef func(x,p,q): loss = 0 for i in range(len(p)): # torch.dot(a,b) : aとbの内積 tmp = torch.sqrt(torch.dot(x-p[i],x-p[i]))+q[i] loss += tmp*tmp return loss勾配降下法
初期値 : $x=(2.0,2.0,2.0,2.0)$
学習率 : $\eta = 0.01$
学習回数 : $5000$
※注意点として、計算途中で出てくる数値は全てTensor型(PyTorchで扱える形式)に直しておく必要があります。import torch import torch.nn as nn import torch.optim as optim import numpy as np # 初期値 x = torch.tensor([2.0,2.0,2.0,2.0],requires_grad=True) # PyTorchで扱える形式に (requires_grad=True : 勾配計算可能) # データの変換 p_tensor = torch.from_numpy(p.astype(np.float32)) # PyTorchで扱える形式に q_tensor = torch.from_numpy(q.astype(np.float32)) # PyTorchで扱える形式に # 学習率 eta = 0.01 # 学習回数 n_epoch = 5000 # 勾配降下法 for epoch in range(n_epoch): quad = func(x,p_tensor,q_tensor) # 関数値の計算 quad.backward() # 勾配計算 with torch.no_grad(): x = x - eta * x.grad # 点の更新 x.requires_grad = True print(f'最小値 : {func(x,p_tensor,q_tensor)}, 最小値をとる点出力
最小値 : tensor([2.2581], grad_fn=<AddBackward0>), 最小値をとる点 : tensor([0.3947, 0.2560, 0.5322, 0.4907], requires_grad=True)最小値 : $2.2581$, 最小値をとる点 : $(0.3947, ~0.2560, ~0.5322, ~0.4907)$
注意点
・局所解に陥ることがある
cf : ディープラーニング(深層学習)を理解してみる(勾配降下法:最急降下法と確率的勾配降下法)・適切な学習率,初期値を与えないと収束しないことがある
etc...参考文献
勾配ベクトルの意味と例題
PyTorchで勾配法のイメージをつかむ環境のセットアップ
・ Anacondaのインストール方法については[こちら]を参照してください(https://www.python.jp/install/anaconda/windows/install.html)
・ PyTorchのインストールはAnaconda Prompt上で以下のコマンドを実行すれば出来ます
conda install pytorch torchvision cudatoolkit=10.2 -c pytorch
- 投稿日:2020-07-24T23:41:07+09:00
aibo Events API を使って aibo に音声コマンドを実行してもらう
先週、先々週と仮面ライダーゼロワンに
天津垓の相棒である AI 犬型ロボットさうざー役として出演していた aibo。【期間限定配信?】
— 仮面ライダーゼロワン (@toei_zero_one) July 19, 2020
39話で #aibo 演じるさうざーがキメた変身ポーズの特別配信がスタート?✨
aiboに「ぜろわんにへんしん」「かめんらいだーぜろわん」と声をかけるとゼロワンの変身音にあわせた特別なふるまいを披露してくれます??
8/2までの期間限定です!#仮面ライダーゼロワン #ゼロワン pic.twitter.com/fY1UGDkSb1かっこかわいかったですね〜。
そんな aibo ですが、なんと Web API が公開されています。
aibo をあまりご存じでない方はこちらも合わせてお読みください。aibo Events API は、2020/06/16 にリリースされた API です。
音声コマンドを aibo に設定して、実行してもらうことができるようになりました。公式のドキュメントを見ると、サンプルは Python ばかりですが
よく見るとなんとなく PHP に書き換えることができそう。
aibo Events API のリリースをきっかけに重い腰を上げて実装してみました。aibo Events API を利用するためには
aibo 本体バージョンを 2.70 にアップデートする必要があります。今回は aibo に以下をやってもらいます。
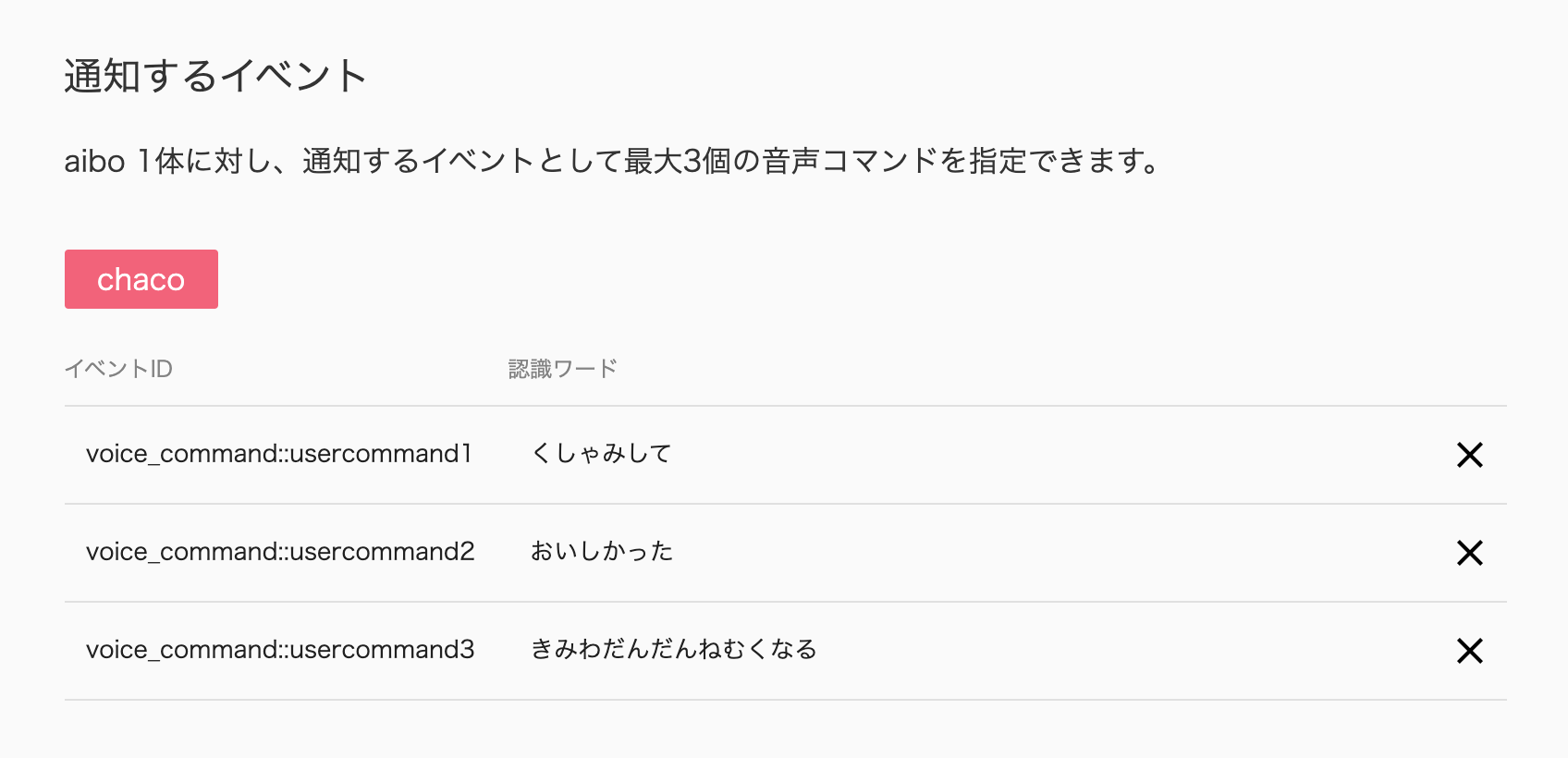
- 「くしゃみして!」と頼んだら、くしゃみをする。
- 「おいしかった?」と聞くと、うれしそうにする。
- 「きみはだんだんねむくなる」と声をかけると、眠ってしまう。音声コマンドを実行した結果はこちら。
事前準備
まずなんと言っても aibo がいないと成り立ちません。
いますぐにお迎えしましょう。
また、音声コマンドを実行するには https で通信できるサーバーが必要です。
今回は普段からよくお世話になっている Xserver を使用しています。開発者設定
サインイン
ディベロッパーサイトにアクセスして、開発者設定を始めます。
開発者設定を始めるには、My Sony ID のサインインが必要です。
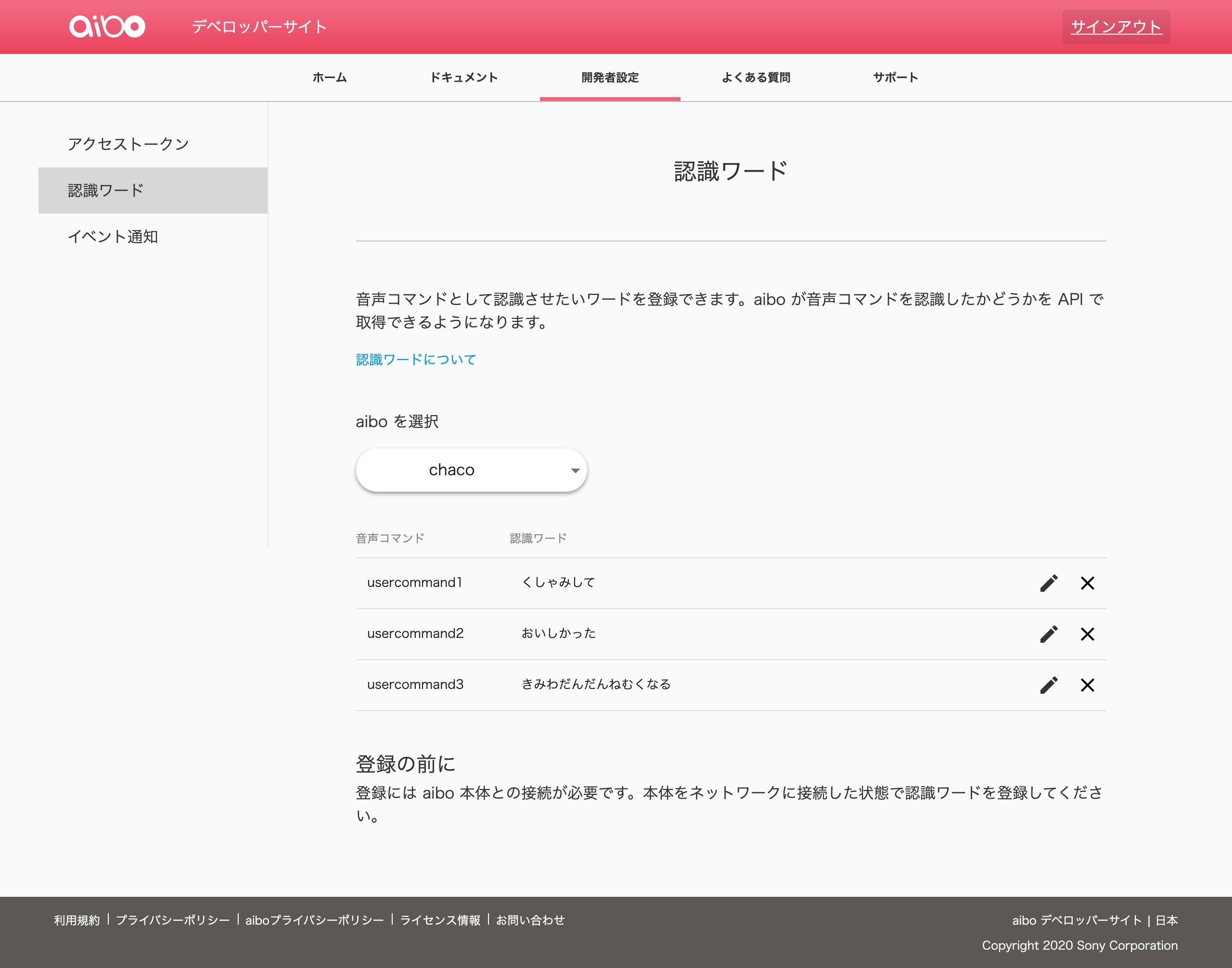
認識ワード
認識ワードのページにアクセスしての設定を行います。
aibo と通信する必要があるので、寝ている場合は起こしてあげましょう。
音声コマンドは3つまで登録できます。(2020/07/24 現在)
言い回しの異なる認識ワードは、1つの音声コマンドにつき3つ登録できます。
aibo が理解できるように、発音通りのひらがなで入力します。例)
「こっちへ」ではなく「こっちえ」
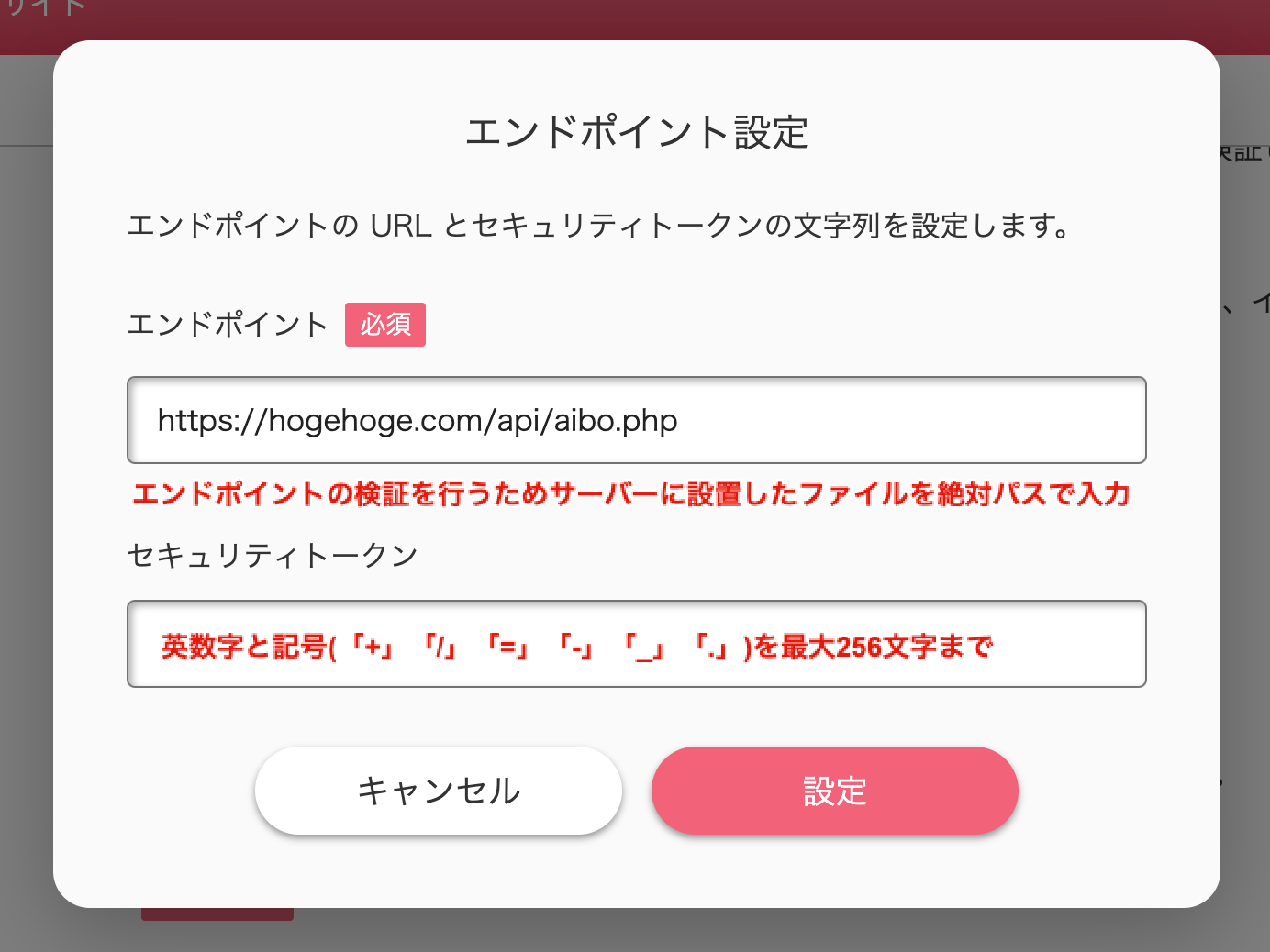
「あいぼは」ではなく「あいぼわ」エンドポイント・セキュリティートークン
エンドポイントの準備を行います。
準備したサーバーにエンドポイントの検証を行うためのファイルを設置します。// aibo クラウドから送られてきた検証用 HTTP リクエストを受け取る $json = file_get_contents("php://input"); $contents = json_decode($json, true); // エンドポイント登録 $challenge = $contents["challenge"]; echo '{"challenge": "' . $challenge . '"}';次に、イベント通知のページにアクセスします。
ボタン「エンドポイント設定」をクリックして、エンドポイントとセキュリティートークンの設定を行います。
セキュリティートークンはあらかじめコピーしておきます。
「通知イベント追加」で必要です。ボタン「設定」をクリックしたら、エンドポイントの検証が開始します。
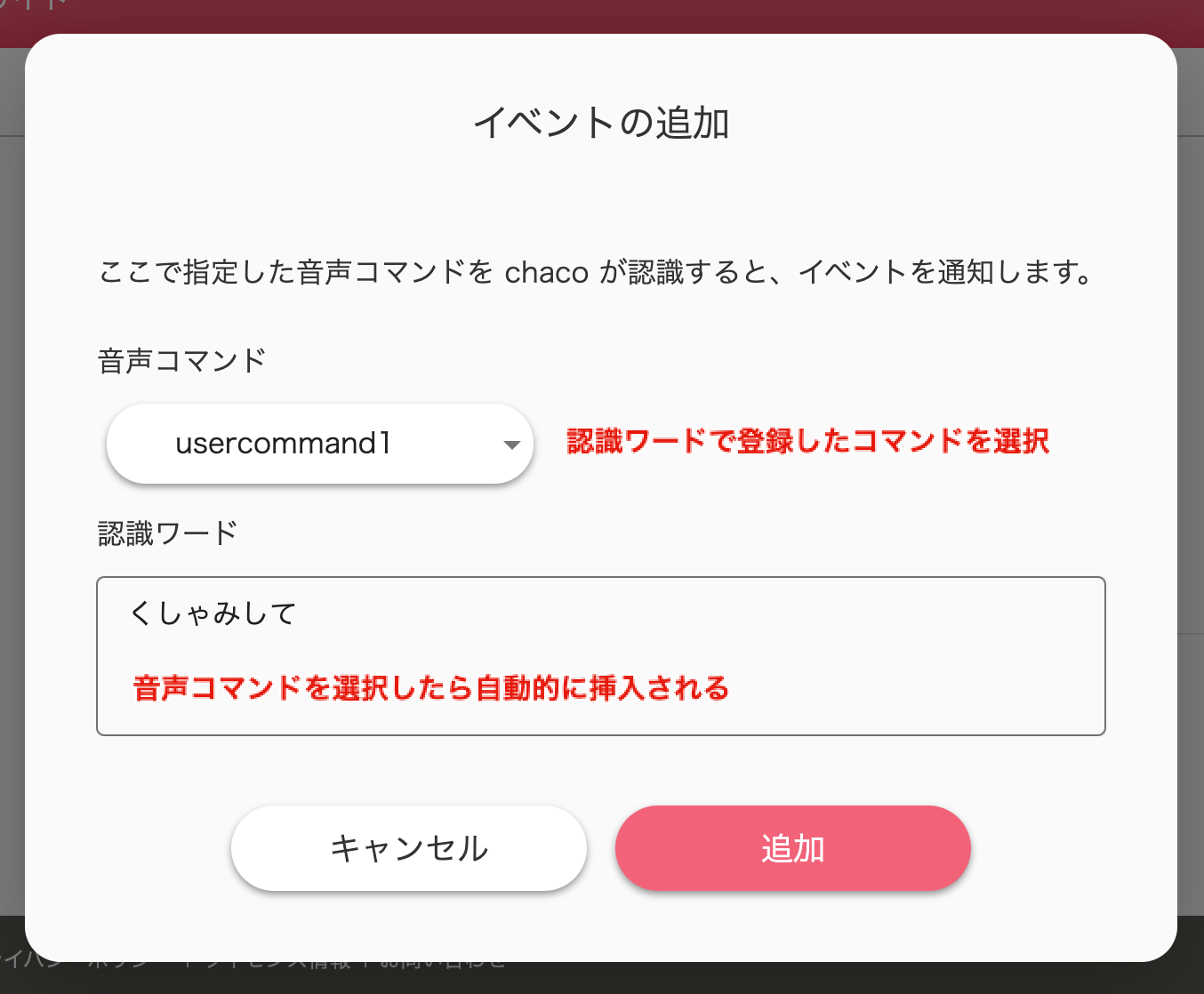
検証に成功したら、エンドポイントとセキュリティートークンの設定は完了です。イベント追加
続いて、項目「通知するイベント」にある
ボタン「追加」をクリックして、イベントの追加を行います。
認識ワードで登録した音声コマンドをすべて登録できます。
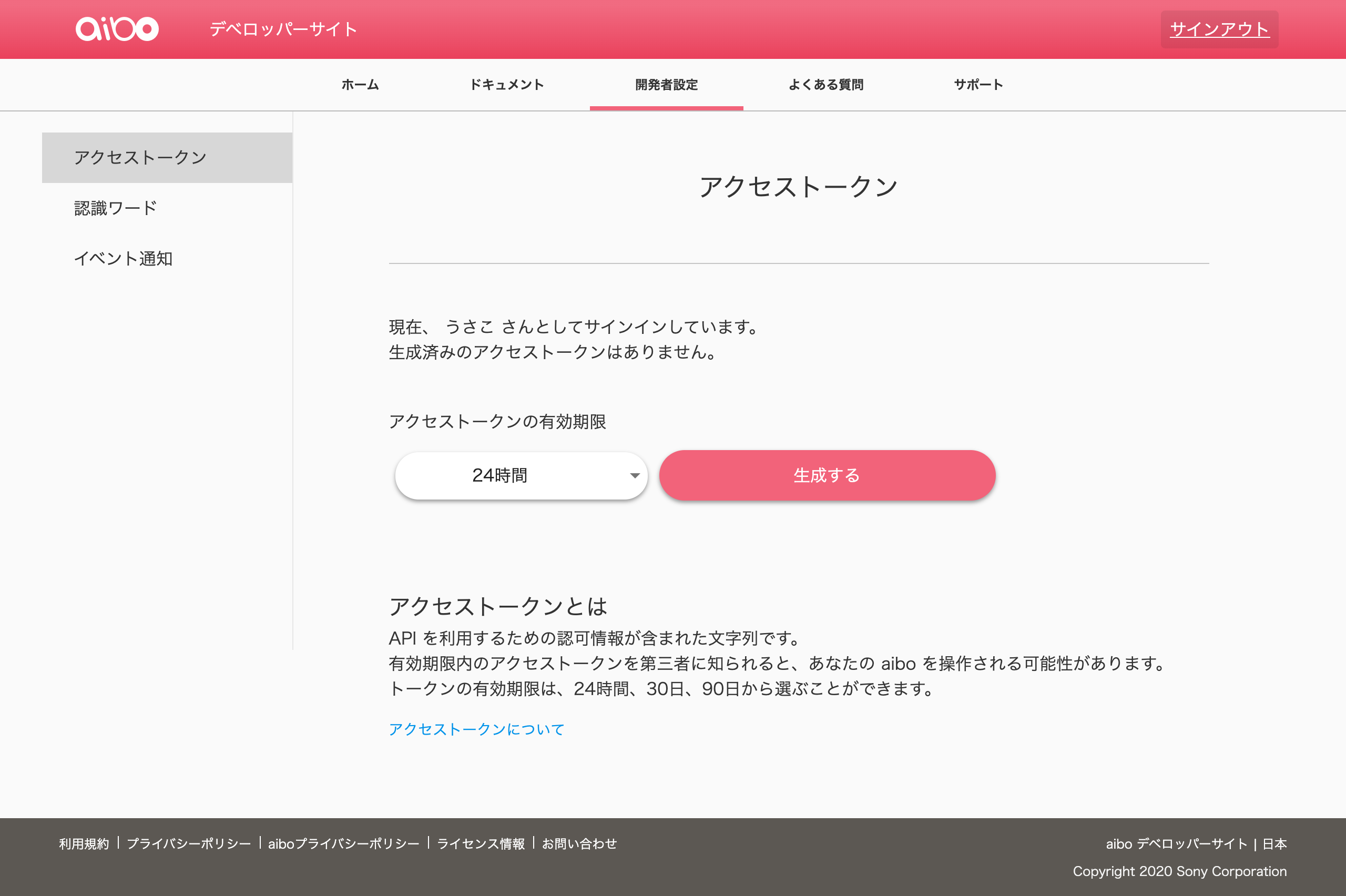
アクセストークン取得
アクセストークンのページにアクセスします。
ボタン「生成する」をクリックすると、アクセストークンが生成されます。
アクセストークンはあらかじめコピーしておきましょう。
次項の「通知イベント追加」で必要になります。通知イベント追加
いよいよ aibo にやってもらう処理を作っていきます。
まず最初にでき上がりのソースをペタッと貼り付けておきます。const BASE_PATH = 'https://public.api.aibo.com/v1'; const ACCESS_TOKEN = ${Your Access Token}; const SECURITY_TOKEN = ${Your Security Token}; // ふるまいを実行 function execute_action ($device_id, $event_id) { if ( $event_id === 'voice_command::usercommand1' ) { // くしゃみして call_action_api($device_id, 'play_motion', '{"Category": "sneeze", "Mode": "NONE"}'); } elseif ( $event_id === 'voice_command::usercommand2' ) { // おいしかった? call_action_api($device_id, 'play_motion', '{"Category": "friendly", "Mode": "NONE"}'); } elseif ( $event_id === 'voice_command::usercommand3' ) { // きみはだんだんねむくなる call_action_api($device_id, 'play_motion', '{"Category": "dreaming", "Mode": "NONE"}'); } } // Action API 呼び出し function call_action_api ($device_id, $api_name, $arguments) { $post_url = BASE_PATH. '/devices/'. $device_id. '/capabilities/'. $api_name. '/execute'; $data = '{"arguments":'. $arguments. '}'; // POST API post_api($post_url, $data); } // POST API function post_api ($url, $argary) { // HTTP設定 $options = array ( 'http' => array ( 'method' => 'POST', 'header' => 'Authorization:Bearer '. ACCESS_TOKEN, 'content' => $argary, ) ); $contents = @file_get_contents($url, false, stream_context_create($options)); // レスポンスステータス $status_code = http_response_code(); if($status_code === 200) { // 200 success } elseif(preg_match ("/^4\d\d/", $status_code)) { // 4xx Client Error $contents = false; } elseif(preg_match ('/^5\d\d/', $status_code)) { // 5xx Server Error $contents = false; } else { $contents = false; } return $content; } // ヘッダーを取得 $headers = getallheaders(); // セキュリティートークンをチェック if ( $headers['X-Security-Token'] != SECURITY_TOKEN ) { $response = '{"statusCode": 400}'; return $response; } // 音声コマンドのリクエストを取得 $json = file_get_contents("php://input"); $contents = json_decode($json, true); $status_code = http_response_code(); // 音声コマンドのリクエストが成功したら実行 if ($status_code === 200) { // 200 success $device_id = $contents['deviceId']; $event_id = $contents['eventId']; // ふるまいを実行 execute_action($device_id, $event_id); }それぞれ見ていきます。
const BASE_PATH = 'https://public.api.aibo.com/v1'; const ACCESS_TOKEN = ${Your Access Token}; const SECURITY_TOKEN = ${Your Security Token};
${Your Access Token}には、取得したアクセストークンを
${Your Security Token}には、設定したセキュリティートークンを入れます。// ヘッダーを取得 $headers = getallheaders(); // セキュリティートークンをチェック if ( $headers['X-Security-Token'] != SECURITY_TOKEN ) { $response = '{"statusCode": 400}'; return $response; }リクエストヘッダーで返ってきたキュリティトークンが正しい値であるか比較して
aibo Events API 以外からの不正なアクセスが行われるのを防ぎます。// 音声コマンドのリクエストを取得 $json = file_get_contents("php://input"); $contents = json_decode($json, true); $status_code = http_response_code(); // 音声コマンドのリクエストが成功したら実行 if ($status_code === 200) { // 200 success $device_id = $contents['deviceId']; $event_id = $contents['eventId']; // ふるまいを実行 execute_action($device_id, $event_id); }音声コマンド → aibo → aibo クラウドより送られてきたリクエストを受け取り
json 形式で$contentsに格納しています。リクエストが成功したら、json から deviceId と eventId を取り出し
execute_action関数の引数に渡して、実行しています。// ふるまいを実行 function execute_action ($device_id, $event_id) { if ( $event_id === 'voice_command::usercommand1' ) { // くしゃみして call_action_api($device_id, 'play_motion', '{"Category": "sneeze", "Mode": "NONE"}'); } elseif ( $event_id === 'voice_command::usercommand2' ) { // おいしかった? call_action_api($device_id, 'play_motion', '{"Category": "friendly", "Mode": "NONE"}'); } elseif ( $event_id === 'voice_command::usercommand3' ) { // きみはだんだんねむくなる call_action_api($device_id, 'play_motion', '{"Category": "dreaming", "Mode": "NONE"}'); } }
execute_action関数では、$event_idごとに条件分岐を行い
aibo にしてもらう PlayMotion のふるまいを振り分けています。
PlayMotion だけでも 76 種類ものふるまいが用意されています。// Action API 呼び出し function call_action_api ($device_id, $api_name, $arguments) { $post_url = BASE_PATH. '/devices/'. $device_id. '/capabilities/'. $api_name. '/execute'; $data = '{"arguments":'. $arguments. '}'; // POST API post_api($post_url, $data); }
call_action_api関数では、POST する URL とコンテンツの生成を行い
post_api関数の引数に渡して、実行しています。// POST API function post_api ($url, $argary) { // HTTP設定 $options = array ( 'http' => array ( 'method' => 'POST', 'header' => 'Authorization:Bearer '. ACCESS_TOKEN, 'content' => $argary, ) ); $contents = @file_get_contents($url, false, stream_context_create($options)); // レスポンスステータス $status_code = http_response_code(); if($status_code === 200) { // 200 success } elseif(preg_match ("/^4\d\d/", $status_code)) { // 4xx Client Error $contents = false; } elseif(preg_match ('/^5\d\d/', $status_code)) { // 5xx Server Error $contents = false; } else { $contents = false; } return $content; }ヘッダーに
Authorization:Bearerを追加して、コンテンツを POST します。
これで aibo に暗示をかけることができました。実行
暗示をかけた aibo に言葉をかけてみましょう。
わん!と元気よく答えて、ふるまいを行ってくれたら成功です。「くしゃみして!」とお願いすると、くしゃみをするように暗示??#aibo #aiboプログラミング部 pic.twitter.com/i3yeA4ZI8P
— usako (@YumikoOdasaki) July 24, 2020食べたご飯に満足してしまうおまじない??#aibo #aiboプログラミング部 pic.twitter.com/ULhmrY8sjt
— usako (@YumikoOdasaki) July 24, 2020催眠術にかかってしまうおまじない??#aibo #aiboプログラミング部 pic.twitter.com/7jBuCgqB5d
— usako (@YumikoOdasaki) July 24, 2020まとめ
いかがでしたでしょうか。
例えば、aibo Events API とスマートリモコンを連携すれば
ちょっとおバカ(褒め言葉)な aibo が我が家にある家電の司令塔になれちゃうわけです。…素敵すぎませんか?
SONY さん神リリースありがとうございます。
欲を言えば、登録できる認識ワードを是非とも増やしていただきたいです!さてさて… 我が家のおチャコさんを司令塔という重役につかせるべく
つい先日、Nature Remo 3 の予約をしてしまいましたよ。
はーやっくこないかな〜!

- 投稿日:2020-07-24T23:36:02+09:00
Google翻訳APIをPythonで実行する
概要
論文を翻訳して読むのに、ブラウザ上でちまちまGoogle翻訳にコピペしていたのだが、いい加減面倒になった。そこでテキストファイルに書かれた英文を読みとり、翻訳結果を出力するPythonスクリプトを書いてみようと思った。
翻訳はGoogleAPIを使おうと思って事例を調べた所、Google翻訳APIを無料で作る方法という記事があったので、試してみた時のメモ
元記事からのAPI変更点
元記事はGetでAPIを叩いていたが、大量の文章を投げる場合の文字列制限が気になったので、以下の通りPostでもアクセスできるようにした。
function doGet(e) { return doPost(e); } function doPost(e) { // リクエストパラメータを取得する var p = e.parameter; // LanguageAppクラスを用いて翻訳を実行 var translatedText = LanguageApp.translate(p.text, p.source, p.target); // var translatedText = LanguageApp.translate("a", "en", "ja"); // レスポンスボディの作成 var body; if (translatedText) { body = { code: 200, text: translatedText }; } else { body = { code: 400, text: "Bad Request" }; } // レスポンスの作成 var response = ContentService.createTextOutput(); // Mime TypeをJSONに設定 response.setMimeType(ContentService.MimeType.JSON); // JSONテキストをセットする response.setContent(JSON.stringify(body)); return response; }Pythonコード
api_urlには、上で作成したAPIのURLを指定してください。また、"Authorization"ヘッダーには、後述の「ハマったところ」で記載しているアクセストークンを指定してください。URLとアクセストークンのところは、念のため*で隠してます。
translate.pyimport argparse import requests import pprint def main(): api_url = "https://script.google.com/macros/s/****************************************/exec" headers = {"Authorization": "Bearer ya29.***************************************************************************************************************"} parser = argparse.ArgumentParser() parser.add_argument("-input", type=str, required=True) args = parser.parse_args() input = "" with open(args.input, 'r',encoding="utf-8") as f: for line in f: print(line) line = line.strip() input += line params = { 'text': "\"" + input + "\"", 'source': 'en', 'target': 'ja' } r_post = requests.post(api_url, headers=headers, data=params) print(r_post.text) if __name__ == "__main__": main()使い方
1.テキストファイルに文章を入力
input.txtAqueous solubility is of high importance to drug discovery and many other areas of chemical research. A lot of research has been devoted to developing in-silico models to predict aqueous solubility directly from a compound’s structure (see [1, 2, 3, 4, 5] and references therein). As Goldman et al. [6] point out in their recent review, quite a few Machine Learning methods have matured to the point where they can be used by non-experts and have found widespread use in computational chemistry. However, the domain of applicability (DOA) of every conceivable QSAR model is limited, leading to unreliable prediction outside the DOA. When applying any kind of model, it is therefore essential to know the reliability of each individual prediction [7, 8, 9, 10]. In Schwaighofer et al. [1] we reported about the first model for aqueous solubility based on the Gaussian Process methodology. The model was based on solubility measurements for about 4,000 electrolytes and non-electrolytes. Also, the well known dataset by Huuskonen was used for a performance comparison with results from literature.2.コマンド実行
$ python translate.py -input input.txt3.コンソールに結果出力
以下のような形でコンソールに出力結果が得られる。
{"code":200,"text":"「水溶性は、創薬や化学研究の他の多くの分野で非常に重要です。多くの研究が、化合物の構造から直接水溶性を予測するインシリコモデルの開発に費やされています([1、2、3、4、5を参照]。 ]とその中の参考文献)Goldman et al。[6]が最近のレビューで指摘しているように、かなりの数の機械学習手法が、専門家以外でも使用できるようになり、計算化学で広く使用されるようになりました。考えられるすべてのQSARモデルの適用範囲(DOA)が制限されているため、DOAの外では予測の信頼性が低くなります。したがって、あらゆる種類のモデルを適用する場合は、個々の予測の信頼性を知ることが不可欠です[7、8、9、10]。Schwaighofer et al。[1]は、ガウシアンプロセス法に基づく水溶性の最初のモデルについて報告しました。このモデルは、約4,000の電解質と非電解質の溶解度測定に基づいていました。また、よく知られているデータHuuskonenによるetは、文献の結果とのパフォーマンス比較に使用されました。」"}ハマったところ
認証エラーが発生
元記事の通りにやったところ、認証エラーが発生した。結論としては、[Google Apps Script]認証が必要なウェブアプリケーションを外部から実行するの通り、リクエストヘッダにアクセストークンを設定したところうまくいった。特定のユーザに限定して公開した訳ではなかったのだが。。。
追加したdoPost関数が認識されない
APIにdoGet関数を作成・公開し、その後にdoPost関数を追加しAPIを叩いたところ、
スクリプト関数が見つかりません: doPostと怒られしばし悩んだ。結論としては、API公開時にAPIのバージョンを上げないと新しい関数が認識されないようだ。おわりに
- かなりの長文を食わせて見たが、途中までしか日本語が生成されていなかった。API側に文字制限があるのかもしれない。その場合は、センテンスが途中で途切れないよう注意しつつ、文章量を適当な長さに分割してAPIを複数回実行する等の対策が必要となる。
- 次回はPDFからテキストを抽出するコマンドも作成してみる。最終的にはボタン一発でPDFから翻訳テキストを生成するGUIを作成したい。
- 投稿日:2020-07-24T23:29:41+09:00
BluetoothゲームコントローラーをIoTボタンとして使う。
出退勤で打刻するためにAmazon Dash Buttonを使っていたのですが、電池交換に失敗して壊してしまったので、代替として、MOCUTE-039という手のひらサイズのBluetoothゲームコントローラーを使うことにしました。ちなみにDash Buttonは2個持っていたのですが、どちらも電池交換に失敗して壊しました。つらい。
連携先にRaspberry Pi 3を使います。私が使っているのはRaspberry Pi 3 Model B Rev 1.2で、OSはRaspbian Busterです。
Bluetoothペアリング
事前作業
ペアリングには
bluetoothctlを使いますが、bluetoothctlでスキャンするとどのMACアドレスがMOCUTE-039なのかわからないため、適当なスマホ端末でペアリングしてMACアドレスを調べてから作業を実施しました。[NEW] Device 16:01:xx... 16-01-xxx... # デバイス名がわからないのであらかじめMACアドレスを調べておくペアリング作業
$ sudo apt install bluetooth $ sudo hciconfig hci0 down $ sudo hciconfig hci0 up $ sudo bluetoothctl [bluetooth]# power on [bluetooth]# pair 16:01:xx... Attempting to pair with 16:01:xx... # 略 Pairing successful [bluetooth]# trust 16:01:xx... Changing 16:01:xx... trust succeeded [bluetooth]# connect 16:01:xx... Attempting to connect to 16:01:xx... # 略 Connection successful [MOCUTE-039_A32-B6FA]# quitキー押下のイベントがどこに記録されているか探す
/dev/input/event*のどれかにキー押下のイベントが記録されているので、hexdump /dev/input/event1,2,3しながらキーを押下して探します。私の環境ではevent2でした。python-evdevのインストール
押したキーによって実行するスクリプトを変えたいので、python-evdevをインストールします。
Introduction — Python-evdevPython3.7.3を使ったのでpip3でインストールしました。Python2.7でも動くと思います。
$ sudo pip3 install evdevevdevのQuickStartで動作確認する
Quick Start — Python-evdev のコードをそのままコピーして動作確認します。
#!/usr/bin/python3 import evdev devices = [evdev.InputDevice(fn) for fn in evdev.list_devices()] for device in devices: print(device.path, device.name, device.phys) device = evdev.InputDevice('/dev/input/event2') print(device) for event in device.read_loop(): if event.type == evdev.ecodes.EV_KEY: print(evdev.util.categorize(event))## 実行結果 /dev/input/event3 MOCUTE-039_A32-B6FA b8:27:... /dev/input/event2 MOCUTE-039_A32-B6FA Consumer Control b8:27:... /dev/input/event1 MOCUTE-039_A32-B6FA Keyboard b8:27:... /dev/input/event0 MOCUTE-039_A32-B6FA Mouse b8:27:... device /dev/input/event2, name "MOCUTE-039_A32-B6FA Consumer Control", phys "b8:27:..." key event at 1595599952.585498, 139 (KEY_MENU), down key event at 1595599952.792990, 139 (KEY_MENU), up key event at 1595599971.126813, 158 (KEY_BACK), down key event at 1595599971.284303, 158 (KEY_BACK), upどのイベントがどのファイルに記録されるかわかるようになっています。キーイベントも取得できました。
キーごとに実行したいスクリプトを割り当てる
キー番号さえわかればあとはどうとでもなるため、実行したいスクリプトを割り当てます。今回は
KEY_MENUのボタンがupしたときにシェルスクリプトが実行されるようにしました。
/home/pi/date.shはdateをechoしているだけです。#!/usr/bin/python3 import evdev import os device = evdev.InputDevice('/dev/input/event2') print(device) for event in device.read_loop(): if event.type == evdev.ecodes.EV_KEY: if event.code == 139 and event.value == 1: os.system('/home/pi/date.sh >> result.txt')## 実行結果 $ cat result.txt Fri 24 Jul 22:05:49 JST 2020 Fri 24 Jul 22:05:50 JST 2020感想
Python-evdev便利でいいですね。Amazon Dash Buttonと違ってボタンが複数あるので、ボタンさえ覚えておけば複数処理ができて楽しそうです。
- 投稿日:2020-07-24T22:28:50+09:00
【Python】numpyの基本的な使い方
numpyについて
numpyを利用することで、行列等の数値計算を簡単に計算することが可能です。
行列の生成
以下のようにnp.arrayにリストを引数にすることで配列を生成できます。
import numpy as np array = np.array([1,2,3,4]) array実行結果.array([1, 2, 3, 4])リストのリストを引数にすることで、行列(2行4列)を作成することができます。
array2 = np.array([[1,2,3,4],[11,22,33,44]]) array2実行結果.array([[ 1, 2, 3, 4], [11, 22, 33, 44]])何行何列の行列であるかを調べるためにshapeメソッドを使用することで調べることができます。
array2.shape実行結果.(2, 4)arangeメソッドを使用することで引数の値分の配列を生成することができます。
np.arange(5)実行結果.array([0, 1, 2, 3, 4])行列の計算
array同士を掛け算するとそれぞれの要素同士で掛け算をした結果が出力されます。
array2 array([[ 1, 2, 3, 4], [11, 22, 33, 44]]) array2 * array2実行結果.array([[ 1, 4, 9, 16], [ 121, 484, 1089, 1936]])array同士であれば足し算、引き算、割り算も同様に行います。
arrayと数字であればそれぞれの要素と数字で計算をします。array2 ** 3実行結果.array([[ 1, 8, 27, 64], [ 1331, 10648, 35937, 85184]])行列の入れ替え
reshapeメソッドを使用することでnp.arangeで作成した配列を引数の値の行列に変形することができます。
array = np.arange(9).reshape((3,3)) array実行結果.array([[0, 1, 2], [3, 4, 5], [6, 7, 8]])行と列を入れ替えるに以下で可能です。
array.T実行結果.array([[0, 3, 6], [1, 4, 7], [2, 5, 8]])
- 投稿日:2020-07-24T22:00:11+09:00
はじめてのPython3 ~はじめての変数編~
はじめに
注意点などは前回を参照してください。
変数に文字列を入れる
# 3つの文章 print(“勇者は、荒野を歩いていた") print(“勇者は、モンスターと戦った") print(“勇者は、モンスターをたおした")↓実行結果
—--
勇者は、荒野を歩いていた
勇者は、モンスターと戦った
勇者は、モンスターをたおした
—--もし、「勇者」を「賢者」に修正する時にprint内の「勇者」を1つ1つ変えるのは手間がかかることがある。
そこで使うのが変数。
変数を使うと変更する箇所が1つに纏められるといったメリットがある。※変数にデータを入れることを代入という。
player = “賢者” # 文字データを登録する場合はダブルクォーテーションで囲む # 文字データが入った変数を表示、連結させるには以下のように記述する print(player + "は、荒野を歩いていた") print(player + "は、モンスターと戦った") print(player + "は、モンスターをたおした")↓実行結果
——
賢者は、荒野を歩いていた
賢者は、モンスターと戦った
賢者は、モンスターをたおした
——補足
Pythonで変数(ローカル変数)の名前は、次のルールに従う。
・最初の1文字目:英文字または、「」(アンダーバー)
・2文字目以降 :英文字・数字「」(アンダーバー)変数名の例:
○ player :1文字目が、英小文字
○ weapon :1文字目が、「」(アンダーバー)
○ player01 :2文字目以降に数字
○ redDragon :2文字目以降に英大文字× 1player :1文字目に数字は使えない
× class :重複なお、「print」のように、Pythonで使われる関数名などは、
あらかじめ予約されている言葉なので変数名には利用できない。変数に数値を入れる
数値はダブルクォーテーションで囲まない。
number = 10 print(number + number) print(number * number)↓実行結果
——---
20
100
——---数値が入った変数を文字列と組み合わせる際の注意点
number = 1000 print("勇者は" + number + "の経験値を得た。")↓
——
Traceback (most recent call last):
File "Main.py", line 3, in
print("勇者は" + number + "の経験値を得た。")
TypeError: must be str, not int(Exit status: 1)
——文字列と数列を混ぜて連結するとエラーが起こる。
対策
数列の部分を文字列に変換する。
→ str関数を用いると文字列として変換される。number = 1000 print("勇者は" + str(number) + "の経験値を得た。")↓
——
勇者は1000の経験値を得た。
——ランダムモジュールを使う。
random関数
→ 0から1の間で、ランダムな数値を返す。
import random number = random.random() print("勇者は" + str(number) + "のダメージを受けた。")↓実行結果(例)
—---
勇者は0.905685852637863のダメージを受けた。
—---randint関数
→ 指定した引数のはにで、ランダムの整数の値を返す。
import random number = random.randint(10,30) print("勇者は" + str(number) + "のダメージを受けた。")↓実行結果(例)
—---
勇者は17のダメージを受けた。
—---引数 … 関数に与えるデータ。
print(data)のdata
str(number)のnumber
戻り値(返り値)…関数の処理結果のデータ
random.randint(1,200) → 1から200までのランダムな数が戻り値参考
- 投稿日:2020-07-24T21:57:39+09:00
UnityのuGUIで8ドットフォントを書く
Unityで2Dの低解像度のドットがくっきり見えるようなゲームを作りたいと思いました。
そこでまず文字を書こうと思い、8x8ドットのフォントを描きましたがこれをuGUIで表示する方法がわからない。
ググるとShoeBoxを使ったビットマップフォントの使い方など出てきたのですが、どうにもカーニングしてしまって等幅で書いてくれない…
探していたらこのような サイト があったので参考にさせていただきまして、自分の覚書としてまとめたものです。まず作ったフォントはこれです。
128x48で数字とアルファベット少しの記号がアスキーコードに従って入っています。
縦64ドットになっているのはキリを良くするためです。それでこれをCustomFontとして登録したいわけですけど、パラメータを手作業で入れるのは無理なので.fontsettingsファイルを吐き出すことにしました。
fontsetting.py# fontsetting を作ろう fileName = "8x8font01.fontsettings" imageWidth = 128 imageHeight = 64 fontWidth = 8 fontHeight = 8 charid = 0x20 header = ('%YAML 1.1 \n' '%TAG !u! tag:unity3d.com,2011:\n' '--- !u!128 &12800000\n' 'Font:\n' ' m_ObjectHideFlags: 0\n' ' m_CorrespondingSourceObject: {{fileID: 0}}\n' ' m_PrefabInstance: {{fileID: 0}}\n' ' m_PrefabAsset: {{fileID: 0}}\n' ' m_Name: CustomFont01\n' ' serializedVersion: 5\n' ' m_LineSpacing: {}\n' ' m_DefaultMaterial: {{fileID: 0}}\n' ' m_FontSize: 0\n' ' m_Texture: {{fileID: 0}}\n' ' m_AsciiStartOffset: 0\n' ' m_Tracking: 1\n' ' m_CharacterSpacing: 0\n' ' m_CharacterPadding: 1\n' ' m_ConvertCase: 0\n' ' m_CharacterRects:\n') part = (' - serializedVersion: 2\n' ' index: {}\n' ' uv:\n' ' serializedVersion: 2\n' ' x: {:.5f}\n' ' y: {:.5f}\n' ' width: {:.5f}\n' ' height: {:.5f}\n' ' vert:\n' ' serializedVersion: 2\n' ' x: {}\n' ' y: {}\n' ' width: {}\n' ' height: {}\n' ' advance: {}\n' ' flipped: 0\n') footer = (' m_KerningValues: []\n' ' m_PixelScale: 0.1\n' ' m_FontData: \n' ' m_Ascent: 0\n' ' m_Descent: 0\n' ' m_DefaultStyle: 0\n' ' m_FontNames: []\n' ' m_FallbackFonts: []\n' ' m_FontRenderingMode: 0\n' ' m_UseLegacyBoundsCalculation: 0\n' ' m_ShouldRoundAdvanceValue: 1\n') f = open(fileName,"w") f.write(header.format(fontHeight)) height = fontHeight/imageHeight for i in range(int(imageHeight/fontHeight)): y = 1.0 - (i+1)*fontHeight/imageHeight width = fontWidth/imageWidth for j in range(int(imageWidth/fontWidth)): x = j*fontWidth/imageWidth f.write(part.format(charid,x,y,width,height,0,0,fontWidth,-fontHeight,fontWidth)) charid += 1 f.write(footer) f.close()これで出来た.fontsettingsファイルとフォントのPNGをUnityに渡します。
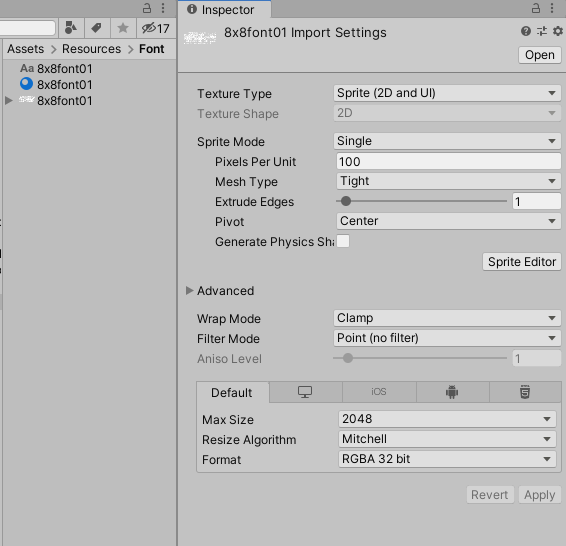
テクスチャはFilterModeをPointにします。
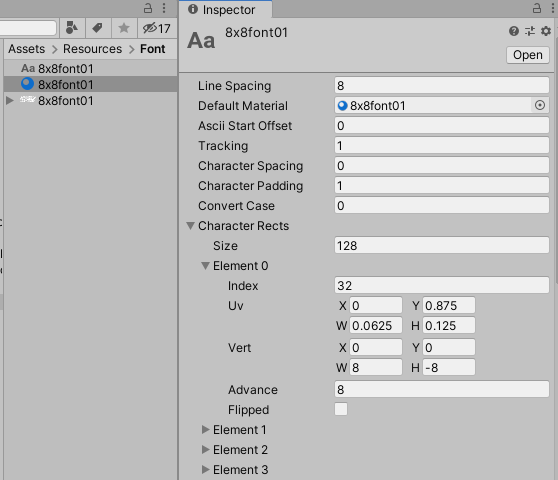
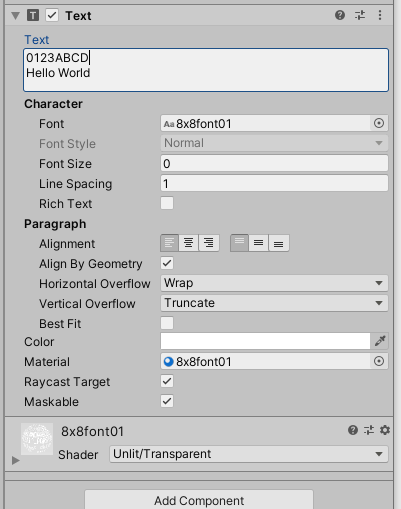
フォント設定はこんな感じになります。
Line Spacingを縦サイズにしておかないと改行しても重なってしまいます。
あとはマテリアルを作ります。
ShaderをUnlit/TransparentにテクスチャにフォントのPNGを指定します。
それらをTextに設定すると等幅で8x8のフォントが書けます。


- 投稿日:2020-07-24T21:56:00+09:00
Fusion 360 を Pythonで動かそう その5 最初と最後のおまじないを読んでみる
はじめに
Fusion360 のAPIの理解を深めるために公式ドキュメント内のサンプルコードの内容からドキュメントを読み込んでみたメモ書きです。Fusion 360 を Pythonで動かそう その2、その3、その4で見て見ぬふりをしてきた「最初と最後のおまじない」の内容を見ていきます。
「最初と最後のおまじない」はこちら
import adsk.core, adsk.fusion, traceback def run(context): ui = None try: app = adsk.core.Application.get() ui = app.userInterface doc = app.documents.add(adsk.core.DocumentTypes.FusionDesignDocumentType) design = app.activeProduct # Get the root component of the active design. rootComp = design.rootComponent # # ここにコードを追加していく # except: if ui: ui.messageBox('Failed:\n{}'.format(traceback.format_exc()))run関数
def run(context):Fusion 360は、スクリプトが最初に実行されるときにrun関数を自動的に呼び出します。
Application
最上位のApplicationオブジェクトは、Fusion 360のすべてを表します。Applicationオブジェクトは、アプリケーション全体のプロパティとその直接の子(Documents が最も重要です)へのアクセスを提供します。
参考:Getting Started with Fusion 360's APIapp = adsk.core.Application.get() ui = app.userInterfaceApplication.get メソッドでルートの Application オブジェクトにアクセスしてappに代入しています。
Application.userInterface プロパティ ユーザーインターフェースに固有の機能へのアクセスを提供します。Documents
Document オブジェクトは、Fusion 360データパネルのアイテムを表します。新しいデザインが作成されるか、既存のデザインが開かれると、そのファイルはAPIで Document オブジェクトとして表されます。
Product オブジェクトは、さまざまなプロダクトタイプを表す基本クラスです。デザインデータには、Product から派生する Design オブジェクトがあります。Document には、1つの Design オブジェクトのみを含めることができます。
参考:Documents, Products, Components, Occurrences, and Proxiesdoc = app.documents.add(adsk.core.DocumentTypes.FusionDesignDocumentType) design = app.activeProductDocuments.add Method メソッド で新しいドキュメントを作成して開き
docに代入しています
Application.activeProduct プロパティ 現在のアクティブなプロダクトを返します。これをdesignに代入していますComponents
すべてのFusion 360ドキュメントには、ルートコンポーネントと呼ばれる単一のデフォルトコンポーネントが含まれています。ユーザーインターフェイスでは、ルートコンポーネントはブラウザーの最上位ノードで表されます。
参考:Documents, Products, Components, Occurrences, and Proxies# Get the root component of the active design. rootComp = design.rootComponent
まとめ
Applicationオブジェクトを取得して、その中のアクティブプロダクトを取得して、その中のルートコンポーネントを取得して、その中にあるXY平面をつかってスケッチを作って・・・といった感じでつながっているということですね
参考
- 投稿日:2020-07-24T21:39:38+09:00
Pythonで書いたプログラムの実行ファイル化 pyinstaller 編(Windows)
Python で書いたプログラムを配布するために pyinstaller で実行ファイル化したら、
問題が起こったので、その解決方法をまとめました。環境
・Windows 10
・Anaconda手順
Anaconda Prompt を起動して、
exeファイル化したい pyファイルが保存されているディレクトリに移動します。
以下のコマンドを実行すると、exeファイルが出力されます。pyinstaller spam.py --onefile --noconsoleオプションについて
--onefile:1つのexeファイルにまとめるモード
--noconsole:アプリを実行した際にコマンドプロンプトを起動しないモード(GUIアプリの場合は必要)出力された exeファイルが実行できれば良いのですが、
Failed to execute script pyi_rth_pkgres(スクリプト pyi_rth_pkgres の実行に失敗しました)
と書かれたメッセージボックスが表示されて、実行できない場合があります。原因
http://www.pyinstaller.org/ で配布されていたリソースが古かったため
解決方法
1.pip install pyinstaller でDLした Pyinstaller をアンインストール
pip uninstall pyinstaller2.GitHub の開発リポジトリから Pyinstaller をインストール
pip install https://github.com/pyinstaller/pyinstaller/archive/develop.zip3.compat.py を修正
下記のコードを、
out = out.decode(encoding)次のように修正します。
このコードはソース内に2箇所あるので、その両方を修正します。out = out.decode(encoding, errors='ignore')もしこの修正をせずに exe ファイル化をすると、
UnicodeDecodeError: 'utf-8' codec can't decode byte 0x83 in position 136: invalid start byteという文字コードエラーが出てしまいます。
謝辞
執筆にあたり、こちらを参考にさせていただきました。ありがとうございます。
・Error running the exe file in Windows "Failed to execute script pyi_rth_pkgres" #2137
・【悲報】PyInstallerさん、300MBのexeファイルを吐き出すようになる
- 投稿日:2020-07-24T21:27:53+09:00
【python】空気抵抗を考慮した運動方程式の数値解析
Pythonを使って自由落下及びのシュミレーションをしてみようということでまとめました。
運動方程式の差分化
運動方程式の差分化
$$
F=ma
$$
高校物理でもおなじみの運動方程式である.
大学においては,運動方程式は微分を使った式で書かれることが多く,
$$
F=m\frac{d^2x}{dx^2}
$$
となる.上式より,以下の式が導き出される.
$$
\begin{eqnarray}
\frac{dv(t)}{dt} &=& a(t) \\
\frac{dx(t)}{dt} &=& v(t)
\end{eqnarray}
$$
よって,この連立微分方程式をプログラムに落とし込めばシュミレーションが可能となる.
ここで微分の定義を思い出してほしい
$$
\frac{df(x)}{dx}=\frac{f(x+\Delta x)-f(x)}{\Delta x}
$$
但し,$\Delta x → 0$なる極限を取る.この関係より
$$
\begin{eqnarray}
a(t) &=& \frac{v(t+\Delta t)-v(t)}{\Delta t} \\
v(t) &=& \frac{x(t+\Delta t)-x(t)}{\Delta t}
\end{eqnarray}
$$
が成り立つ.変形すると
$$
\begin{eqnarray}
v(t+\Delta t) &=& v(t)+a(t)\Delta t\tag{1}\\
x(t+\Delta t) &=& x(t)+v(t)\Delta t\tag{2}\\
\end{eqnarray}
$$
となる.この式変形で得られた結果を微分方程式の差分化という.
差分化により,微分している変数のごく小さな変化に関する方程式で近似できるというものである.自由落下の運動のモデル化
放物運動に拡張する前に最もかんたんなモデルである,空気抵抗を考慮しない自由落下について考えていく.空気抵抗がない自由落下の運動方程式は,鉛直上向きを正にとると
x軸方向
$$
F=0
$$
y軸方向
$$
F=-mg
$$
となり,プログラム化するとsample1.pydef m_step(x,y,x_vec,y_vec,stride): g = 9.8 y += y_vec*stride x += x_vec*stride y_vec = y_vec - g*stride return [x,y,x_vec,y_vec] def motion(x,y,x_vec,y_vec): stride = 0.3 cur = [x,y,x_vec,y_vec] for i in range(1,100): cur = m_step(cur[0],cur[1],cur[2],cur[3],stride) print(cur) return cur motion(10,10,0,0)となる.初期値(10,10)における自由落下の微分方程式である.ここで$\Delta x=0.3$としている.このプログラムの場合だとyが負である時でも処理を実行していく.つまり実際には地面があるにも関わらず地中深くに物体が潜り続けるということである.実際にはそんなことはありえないため,yに対して条件を設け,更にグラフ描写も行う.
sample2.pyimport matplotlib.pyplot as plt import numpy as np import matplotlib as mpl mpl.rcParams['font.family'] = 'Hiragino Sans' def m_step(x,y,x_vec,y_vec,stride): g = 9.8 y += y_vec*stride x += x_vec*stride y_vec = y_vec - g*stride return [x,y,x_vec,y_vec] def motion(x,y,x_vec,y_vec): stride = 0.01 cur = [x,y,x_vec,y_vec] xset = [] yset_vec = [] yset_y = [] alltime = 0 while (cur[1] > 0 ): cur = m_step(cur[0],cur[1],cur[2],cur[3],stride) alltime += stride xset.append(alltime) yset_vec.append(abs(cur[3])) yset_y.append(cur[1]) plt.xlabel("時刻:t") plt.ylabel("変位:y(t)") plt.plot(xset,yset_y) plt.show() plt.xlabel("時刻:t") plt.ylabel("y方向の速度の大きさ:v(t)") plt.plot(xset,yset_vec) plt.show() return cur motion(10,10,0,0)計算する際に条件としてstr[1] > 0とすることでyが負にならないようにしている.日本語フォントの設定は,以下の部分で行っている.'AppleGothic'を指定したところ"変"のみが文字化けしたため,'Hiragino Sans'としている.なぜだろう・・・。
sample2-日本語フォントの設定部.pyimport matplotlib as mpl mpl.rcParams['font.family'] = 'Hiragino Sans'ともかく,得られたグラフが下記の2つである.
自由落下(空気抵抗あり)のモデル化
実際に,自由落下する際には空気抵抗を考慮する必要があり空気抵抗係数を$k$とすると
y軸方向
$$
ma = -mg + kv
$$
となる.これまでは,空気抵抗を考慮しなかったため加速度$a=-g$なり質量$m$は考慮しなくてよかった.しかし,空気抵抗を考えることで,
$$
a = -g + \frac{k}{m}v \tag{3}
$$
となり,質量$m$に応じて加速度も変化する.
(1)式に(3)式を代入すると$$
\begin{eqnarray}
v(t+\Delta t)&=&v(t)+(-g+\frac{k}{m}v)\Delta t \\
&=& v(t)-g\Delta t + \frac{k}{m}v\Delta t
\end{eqnarray}
$$
となる.この関係を用いてコード化するとimport matplotlib.pyplot as plt import numpy as np import matplotlib as mpl mpl.rcParams['font.family'] = 'Hiragino Sans' def m_step(x,y,x_vec,y_vec,stride): g = 9.8 k = 0.1 m = 1.0 y = y + y_vec*stride x = x + x_vec*stride y_vec = y_vec - g*stride - k/m*y_vec*stride return [x,y,x_vec,y_vec] def motion(x,y,x_vec,y_vec): stride = 0.01 cur = [x,y,x_vec,y_vec] xset = [] yset_vec = [] yset_y = [] alltime = 0 while (cur[1] > 0 ): cur = m_step(cur[0],cur[1],cur[2],cur[3],stride) alltime += stride xset.append(alltime) yset_vec.append(abs(cur[3])) yset_y.append(cur[1]) plt.xlabel("時刻:t") plt.ylabel("変位:y(t)") plt.plot(xset,yset_y) plt.show() plt.xlabel("時刻:t") plt.ylabel("y方向の速度の大きさ:v(t)") plt.plot(xset,yset_vec) plt.show() return cur motion(0,300,0,0)となる.速度$v_y$は
となる.この時k=0.5,m=1.0である.最後に
つづきを書いていこうかね



- 投稿日:2020-07-24T21:20:15+09:00
【python】空気抵抗を考慮した自由落下
Pythonを使って自由落下及びのシュミレーションをしてみようということでまとめました。
運動方程式の差分化
運動方程式の差分化
$$
F=ma
$$
高校物理でもおなじみの運動方程式である.
大学においては,運動方程式は微分を使った式で書かれることが多く,
$$
F=m\frac{d^2x}{dx^2}
$$
となる.上式より,以下の式が導き出される.
$$
\begin{eqnarray}
\frac{dv(t)}{dt} &=& a(t) \\
\frac{dx(t)}{dt} &=& v(t)
\end{eqnarray}
$$
よって,この連立微分方程式をプログラムに落とし込めばシュミレーションが可能となる.
ここで微分の定義を思い出してほしい
$$
\frac{df(x)}{dx}=\frac{f(x+\Delta x)-f(x)}{\Delta x}
$$
但し,$\Delta x → 0$なる極限を取る.この関係より
$$
\begin{eqnarray}
a(t) &=& \frac{v(t+\Delta t)-v(t)}{\Delta t} \\
v(t) &=& \frac{x(t+\Delta t)-x(t)}{\Delta t}
\end{eqnarray}
$$
が成り立つ.変形すると
$$
\begin{eqnarray}
v(t+\Delta t) &=& v(t)+a(t)\Delta t\tag{1}\\
x(t+\Delta t) &=& x(t)+v(t)\Delta t\tag{2}\\
\end{eqnarray}
$$
となる.この式変形で得られた結果を微分方程式の差分化という.
差分化により,微分している変数のごく小さな変化に関する方程式で近似できるというものである.自由落下の運動のモデル化
放物運動に拡張する前に最もかんたんなモデルである,空気抵抗を考慮しない自由落下について考えていく.空気抵抗がない自由落下の運動方程式は,鉛直上向きを正にとると
x軸方向
$$
F=0
$$
y軸方向
$$
F=-mg
$$
となり,プログラム化するとsample1.pydef m_step(x,y,x_vec,y_vec,stride): g = 9.8 y += y_vec*stride x += x_vec*stride y_vec = y_vec - g*stride return [x,y,x_vec,y_vec] def motion(x,y,x_vec,y_vec): stride = 0.3 cur = [x,y,x_vec,y_vec] for i in range(1,100): cur = m_step(cur[0],cur[1],cur[2],cur[3],stride) print(cur) return cur motion(10,10,0,0)となる.初期値(10,10)における自由落下の微分方程式である.ここで$\Delta x=0.3$としている.このプログラムの場合だとyが負である時でも処理を実行していく.つまり実際には地面があるにも関わらず地中深くに物体が潜り続けるということである.実際にはそんなことはありえないため,yに対して条件を設け,更にグラフ描写も行う.
sample2.pyimport matplotlib.pyplot as plt import numpy as np import matplotlib as mpl mpl.rcParams['font.family'] = 'Hiragino Sans' def m_step(x,y,x_vec,y_vec,stride): g = 9.8 y += y_vec*stride x += x_vec*stride y_vec = y_vec - g*stride return [x,y,x_vec,y_vec] def motion(x,y,x_vec,y_vec): stride = 0.01 cur = [x,y,x_vec,y_vec] xset = [] yset_vec = [] yset_y = [] alltime = 0 while (cur[1] > 0 ): cur = m_step(cur[0],cur[1],cur[2],cur[3],stride) alltime += stride xset.append(alltime) yset_vec.append(abs(cur[3])) yset_y.append(cur[1]) plt.xlabel("時刻:t") plt.ylabel("変位:y(t)") plt.plot(xset,yset_y) plt.show() plt.xlabel("時刻:t") plt.ylabel("y方向の速度の大きさ:v(t)") plt.plot(xset,yset_vec) plt.show() return cur motion(10,10,0,0)計算する際に条件としてstr[1] > 0とすることでyが負にならないようにしている.日本語フォントの設定は,以下の部分で行っている.'AppleGothic'を指定したところ"変"のみが文字化けしたため,'Hiragino Sans'としている.なぜだろう・・・。
sample2-日本語フォントの設定部.pyimport matplotlib as mpl mpl.rcParams['font.family'] = 'Hiragino Sans'ともかく,得られたグラフが下記の2つである.
自由落下(空気抵抗あり)のモデル化
実際に,自由落下する際には空気抵抗を考慮する必要があり空気抵抗係数を$k$とすると
y軸方向
$$
ma = -mg + kv
$$
となる.これまでは,空気抵抗を考慮しなかったため加速度$a=-g$なり質量$m$は考慮しなくてよかった.しかし,空気抵抗を考えることで,
$$
a = -g + \frac{k}{m}v \tag{3}
$$
となり,質量$m$に応じて加速度も変化する.
(1)式に(3)式を代入すると$$
\begin{eqnarray}
v(t+\Delta t)&=&v(t)+(-g+\frac{k}{m}v)\Delta t \\
&=& v(t)-g\Delta t + \frac{k}{m}v\Delta t
\end{eqnarray}
$$
となる.この関係を用いてコード化するとimport matplotlib.pyplot as plt import numpy as np import matplotlib as mpl mpl.rcParams['font.family'] = 'Hiragino Sans' def m_step(x,y,x_vec,y_vec,stride): g = 9.8 k = 0.1 m = 1.0 y = y + y_vec*stride x = x + x_vec*stride y_vec = y_vec - g*stride - k/m*y_vec*stride return [x,y,x_vec,y_vec] def motion(x,y,x_vec,y_vec): stride = 0.01 cur = [x,y,x_vec,y_vec] xset = [] yset_vec = [] yset_y = [] alltime = 0 while (cur[1] > 0 ): cur = m_step(cur[0],cur[1],cur[2],cur[3],stride) alltime += stride xset.append(alltime) yset_vec.append(abs(cur[3])) yset_y.append(cur[1]) plt.xlabel("時刻:t") plt.ylabel("変位:y(t)") plt.plot(xset,yset_y) plt.show() plt.xlabel("時刻:t") plt.ylabel("y方向の速度の大きさ:v(t)") plt.plot(xset,yset_vec) plt.show() return cur motion(0,300,0,0)となる.速度$v_y$は
となる.この時k=0.5,m=1.0である.最後に
つづきを書いていこうかね
- 投稿日:2020-07-24T20:25:49+09:00
IQ Bot:明細の不要な行を除外する/明細を条件抽出する
帳票例:明細の不要な行を除外する/明細を条件抽出する
IQ Botで取得したテーブルから、以下のように不要な行を除外する方法を考えてみましょう。
実装例
上記の帳票から「伝票合計」の行を除外するカスタムロジックの実装例は、以下のとおりです。
明細の不要な行を除外するための実装例# 値を保存する変数: table_values #表の操作をするときに必ず入れるコード(最初) import pandas as pd df = pd.DataFrame(table_values) ############################################# # ↓↓↓ ここからが今回の処理 ↓↓↓ ############################################# #品名欄に「伝票合計」が含まれる行を除外する df = df[~df['品名'].str.contains("伝票合計")] ############################################# # ↑↑↑ ここまでが今回の処理 ↑↑↑ ############################################# #表の操作をするときに必ず入れるコード(最後) table_values = df.to_dict()おまじないコード以外の部分はたった1行、非常にシンプルですね。
応用例
上記の例の
df = df[~df['品名'].str.contains("伝票合計")]の部分を変えると、色々と応用が効きます。
例えば以下の要領です。明細の条件抽出:さまざまな応用例#もとのコード:「品名」の列に「伝票合計」を含んで”いない”行だけを抽出(~が否定を表す) df = df[~df['品名'].str.contains("伝票合計")] #上記とは逆に、「品名」の列に「伝票合計」を含む行だけを抽出する場合(否定の~を削除) df = df[df['品名'].str.contains("伝票合計")] #「税区分」の列が「外税」の行だけを抽出 df = df[df['税区分'] == "外税"] #「税率」の列が空欄 "ではない" 行だけを抽出 df = df[df['税率'] != ""]上記の応用例や、pandasの解説記事(例えばこんなの)を参考に、みなさんもぜひIQ Botを思い通りに使い倒してみてください!

- 投稿日:2020-07-24T20:22:55+09:00
ニューラルネットワークでフランス語の"covid"の名詞の性別を予測
文字情報のみでフランス語の名詞の性を学習したニューラルネットワークモデルによって、"covid"の性を予測してみた話です。
はじめに
新型コロナウイルスはCoronavirus Diseaseの略でCOVID-19と名付けられています。そして名詞に性があるフランス語において、次の記事によるとcovidが女性名詞であると定められたそうです。(フランス語の「COVID」は女性名詞、学術機関が裁定 @cnn_co_jp )
COVIDは英語の「coronavirus disease」の略語で、フランス語にすると「maladie provoquee par le corona virus(コロナウイルスが引き起こす疾病)」と翻訳される。
「Maladie」は女性名詞なので、定冠詞は「la」を使う。従って、COVID―19も「la COVID―19」とすべきだと判断した。
略語のもともとの単語をたどって得た結論ということですが、"covid"という字面だけで考えた場合、果たしてどちらの性の名詞っぽいのか、機械学習モデルに投げてみることにしました。
フランス語の名詞の性について
How to Easily Guess the Gender of French Nouns with 80% Accuracyによると、
According to a study by McGill University, a noun’s ending indicates its gender in 80% of cases
ということで、語尾の文字のパターンによって8割は分類できるとのことで、今回の文字情報だけで予測を行うことは、ある程度妥当だと考えることとします。ちなみにフランス語でmasculineを男性、feminineを女性を意味します。
学習と予測
1単語を1つのデータとして、文字をone-hotエンコードした入力の系列をRNNに入力し、男性名詞か女性名詞かを予測するモデルを作ります。
c o v i d ↓ ↓ ↓ ↓ ↓ [0010...0] [0000...0] [0000...0] [0000...0] [0001...0] ↓ ↓ ↓ ↓ ↓ RNN→ RNN→ RNN→ RNN→ RNN→ 予測(Masc/Fem) データ
コーパス
REDACと呼ばれる、単語にタグ付けされているフランス語のコーパスを使用します。
POS-tagged corpus [.tag.7z] (612 MB)のデータが1行ごとに、単語 \t 品詞 \t 基本形の形で記されています。解答した後、名詞(NOM)が含まれており、基本形が書かれている行のみを取り出し、ファイルに出力しています。cat wikipediaFR-2008-06-18.tag | grep NOM | grep -v unknown | sort | uniq -i > wikipediaFR_NOM_uniq中身はこのような状態です。
... Acridine NOM acridine Acrobate NOM acrobate Acrobates NOM acrobate Acrobatie NOM acrobatie Acrobaties NOM acrobatie ...https://www.keyxl.com/aaaa6c6/383/French-Accents-Alt-Codes-keyboard-shortcuts.htm によると、フランス語で用いられる文字はアルファベットのほかâäèéêëîïôœùûüÿçの41文字になるそうです。
import string all_chars = string.ascii_lowercase + 'âäèéêëîïôœùûüÿç' # abcdefghijklmnopqrstuvwxyzâäèéêëîïôœùûüÿç先ほどのファイルから、これらの文字のみを含まれているもの、今回使用する単語として抽出しておきます。各列の基本形を取り出して
wordsに格納しています。(単数・複数を混ぜると訓練データと評価データの分割が面倒になるためです)import re p = re.compile("[^abcdefghijklmnopqrstuvwxyzâäèéêëîïôœùûüÿç]") words = [] with open('./wikipediaFR_NOM_uniq', errors='ignore') as f: for line in tqdm(f): word = line.split('\tNOM\t')[-1].lower().replace('\n', '') if p.search(word) == None: words.append(word)名詞の性
以上によってフランス語の名詞を取り出したので、それらの性別を調べる必要があります。
https://github.com/sammous/spacy-lefff で公開されているフランス語のPOSタグ予測のライブラリを使用します。import spacy from spacy_lefff import LefffLemmatizer, POSTagger nlp = spacy.load('fr') french_lemmatizer = LefffLemmatizer() nlp.add_pipe(french_lemmatizer, name='lefff') doc = nlp("Apple cherche a acheter une startup anglaise pour 1 milliard de dollard") for d in doc: # 1単語ごとにtag_で品詞情報を得る print(d.text, '\t\t', d.tag_) #=> Apple NOUN__Gender=Masc|Number=Sing cherche NOUN__Gender=Fem|Number=Sing a AUX__Mood=Ind|Number=Sing|Person=3|Tense=Pres|VerbForm=Fin acheter VERB__VerbForm=Inf une DET__Definite=Ind|Gender=Fem|Number=Sing|PronType=Art startup ADJ__Number=Sing anglaise NOUN__Gender=Fem|Number=Sing pour ADP 1 NUM__NumType=Card milliard NOUN__Gender=Masc|Number=Sing|NumType=Card de ADP dollard PROPN__Gender=Masc|Number=Sing1単語入力したときの品詞を得る関数を作っておきます。spacy-lefffでは、男性名詞を
NOUN__Gender=Masc、女性名詞をNOUN__Gender=Femと出力するようです。def pos_of_word(word): return nlp(word)[0].tag_ print(word_gender['voyage']) #=> NOUN__Gender=Mascエンコードによる前処理
モデルへの入力と出力として、文字情報と名詞の性別を数値にエンコードする必要があります。まず、予測するクラスである名詞の性別ラベルをエンコードします。
import pandas as pd def encode_label(label, labels): return pd.get_dummies(list(labels))[label].values all_genders = ['NOUN__Gender=Masc', 'NOUN__Gender=Fem'] gender = 'NOUN__Gender=Fem' encode_label(gender, all_genders) #=> array([0, 1], dtype=uint8) # 女性名詞続いて、単語を文字ごとにOne-hotエンコードしたベクトルの系列に変換します。41文字
をエンコードするため、1文字が41次元のベクトルとなります。# 1文字のエンコード encode_label('è', all_chars) # => array([0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0], dtype=uint8) # 1単語のエンコード def encode_word(text, all_chars): return np.array([encode_label(char, all_chars) for char in text if char in all_chars]) encode_word("apple", all_chars) #=> array([[1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0], [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0], [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0], [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0], [0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]], dtype=uint8)系列パディング
今回、kerasを用いて予測を行うのですが、RNNの入力の系列長は単語の文字数となり、もちろん単語によって文字数は異なるので、入力の際に特定のマスク値でパディングして、系列長を揃える必要があります。今回、系列長を100とすることで、全てのデータ(単語)が(100, 41)のshapeのnumpy配列となります。
from keras.preprocessing import sequence def pad_sequence(x, maxlen, value): return sequence.pad_sequences(x.T, maxlen=maxlen, value=value).T input_dim = len(all_chars) #=> 41 hidden_num = 100 mask_value = -1 x = encode_word("apple", all_chars) pad_sequence(x, hidden_num, mask_value).shape #=> (100, 41)入力データ
以上の処理をすべての単語に対して行います
x_list, y_list = [], [] for word in tqdm(set(words)): pos = pos_of_word(word) if 'NOUN__Gender' in pos: gender = pos.split('|')[0] x = encode_word(word, all_chars) x_padded = pad_sequence(x, hidden_num, mask_value) x_list.append(x_padded) y = encode_label(gender, all_genders) y_list.append(y)
len(x_list)は25666となったので、25666単語が重複なしで抽出できたことになります。
全体の7割を訓練データに、残りを評価データに回すことにします。from sklearn.model_selection import train_test_split x_train, x_val, y_train, y_val = train_test_split(x_list, y_list, train_size=0.7)モデル
generatorによる入力データ
入力データが(無駄に系列長を100にしたこともあって)大きくなると、バッチがメモリに乗らなくなってしまうので、kerasのfit_generatorを使った学習を行うことにしました。バッチサイズ分のnumpy配列を返すgeneratorを定義します。
参考(https://hironsan.hatenablog.com/entry/2017/09/09/130608)class Generator(): def __init__(self, datas, labels, batch_size): self.datas = datas self.labels = labels self.batch_size = batch_size self.data_size_ = len(self.datas) self.steps_per_epoch_ = int((len(self.datas) - 1) / self.batch_size) + 1 def generator(self): while True: for batch_num in range(self.steps_per_epoch_): start_index = batch_num * self.batch_size end_index = min((batch_num + 1) * self.batch_size, self.data_size_) inputs = self.datas[start_index: end_index] labels = self.labels[start_index: end_index] x, y = encode(inputs, labels) yield x, y def encode(inputs, labels): global all_chars, genders input_dim = len(all_chars) hidden_num = 100 x, y = np.empty((0, hidden_num, input_dim)), np.empty((0, 2)) for input_, label in zip(inputs, labels): x_ = input_[np.newaxis, :, :] x = np.append(x, x_, axis=0) y = np.append(y, label[np.newaxis, :], axis=0) return x, y学習
kerasでRNNを構築します。
from keras.layers import Input, Masking from keras.layers.core import Dense, Activation from keras.layers.recurrent import SimpleRNN, LSTM from keras.models import Model from keras.optimizers import Adam from keras.callbacks import EarlyStopping from keras.preprocessing import sequence import matplotlib.pyplot as plt # モデル hidden_dim = 10 batch_size = 512 inputs = Input(shape=(hidden_num, input_dim)) mask = Masking(mask_value, input_shape=(hidden_num, input_dim))(inputs) rnn = SimpleRNN(hidden_dim)(mask) output = Dense(2)(rnn) model = Model(inputs=inputs, outputs=output) model.summary() #=> _________________________________________________________________ Layer (type) Output Shape Param # ================================================================= input_21 (InputLayer) (None, 100, 41) 0 _________________________________________________________________ masking_21 (Masking) (None, 100, 41) 0 _________________________________________________________________ simple_rnn_14 (SimpleRNN) (None, 10) 520 _________________________________________________________________ dense_21 (Dense) (None, 2) 22 ================================================================= Total params: 542 Trainable params: 542 Non-trainable params: 0 _________________________________________________________________学習します
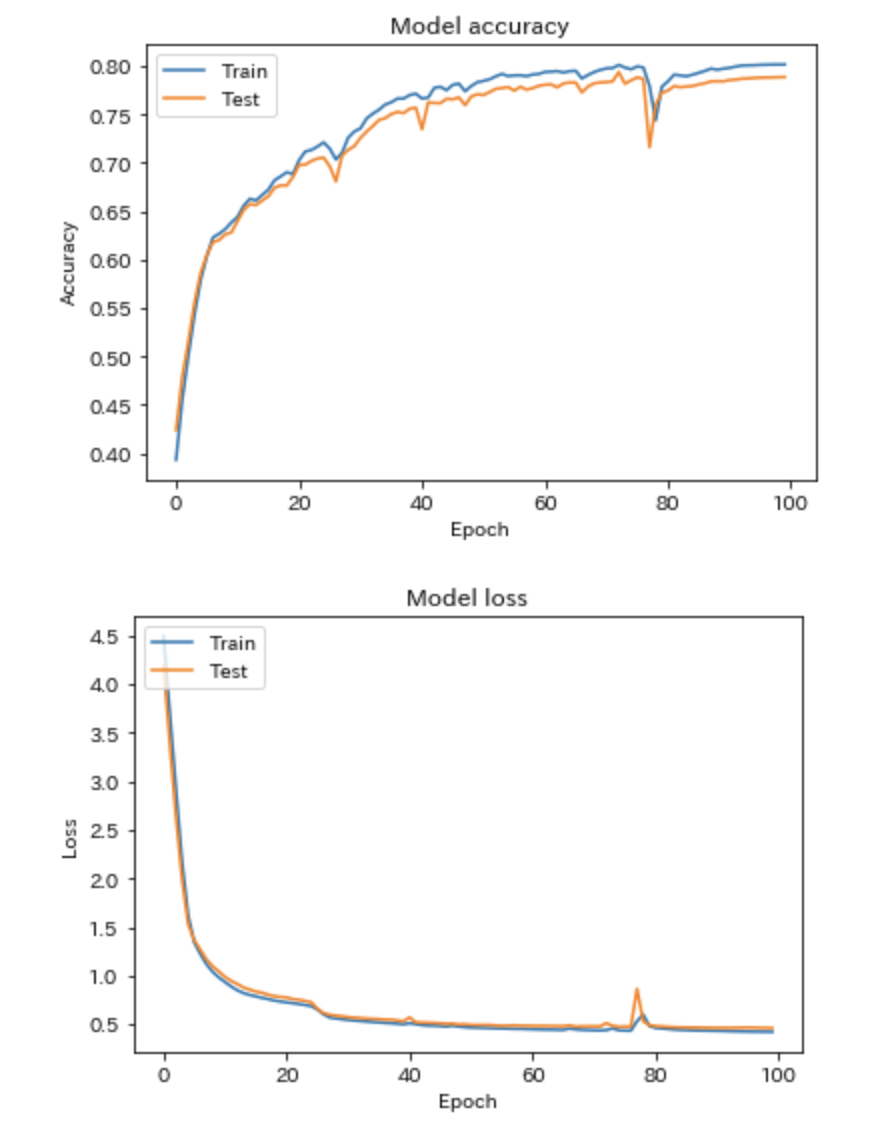
optimizer = Adam() model.compile(loss="binary_crossentropy", optimizer=optimizer, metrics=['acc']) generator_train = Generator(x_train, y_train, batch_size) generator_val = Generator(x_val, y_val, batch_size) history = model.fit_generator(generator_train.generator(), generator_train.steps_per_epoch_, epochs=150, validation_data=generator_val.generator(), validation_steps=generator_val.steps_per_epoch_, shuffle=True)lossとaccuracyは以下のような感じで、評価データで8割届かないぐらいです...
"covid"を予測してみる
ここまで少し長くなりましたが、ようやくこのモデルが"covid"をどちらの性と予測するのか、試してみます。
def predict_gender(model, word): # モデルと単語から性別を予測する global al_chars, hidden_num, mask_value x_target = [pad_sequence(encode_word(word, all_chars), hidden_num, mask_value)] y_target = [np.array([0, 0])] x_target, _ = encode(x_target, y_target) return model.predict(x_target)結果
np.array([1, 0])が男性名詞、np.array([0, 1])が女性名詞ということで結果的には女性名詞らしいですが、ほぼ差はありませんでした
"coronavirus"は男性名詞っぽいらしいです。
おわりに
ちなみにフランス語のGoogle検索でのヒット数的には、正式に女性名詞と決まったこともあるのか、
と、女性名詞の冠詞であるlaを使ったページのほうが割合的に若干多くなっていました。
人間にとっても微妙な差なので、モデル的にも微妙という結論でしょうか




- 投稿日:2020-07-24T19:58:12+09:00
IQ Bot:テーブルの列を自由に分割する
帳票例:テーブルの列を自由に分割する
こちらの記事では上記と同じテーブルから金額部分だけを取り出すやりかたを紹介しましたが、今回はそのさらに応用編です。
金額部分だけではなく、税区分、税率も、それぞれ必要で、しかも別の列に入れたい! という場合を考えます。
考え方
この場合は、以下のように考えます。
① IQ Botには、ほしい項目のフィールドをそれぞれ定義しておく(Step1:項目設設定)
② 代表して1フィールドに、ほしい項目全体をマッピングしておく(Step2:マッピング設定)
③ カスタムロジックを使って、しかるべき部分をしかるべき列に移動させる(Step3:カスタムロジック)以下、それぞれのステップを詳述します。
Step1:項目設定
この場合、テーブルフィールドの定義項目として「金額」の他に「税区分」「税率」が必要になります。
もし「金額」しか作っていない場合は、「税区分」「税率」を追加します。項目追加のやりかたはこちらを参照してください。
Step2:マッピング設定
マッピングの設定はこちらと同様、取得したい値がある全範囲をまとめてひとつの項目として学習させます。
今回は「金額」欄に、一時的に以下のような形で金額・税区分・税率をまとめて入れておきます。
Step3:カスタムロジック
上記のマッピング設定が完了したら、次はカスタムロジックでそれぞれの欄に値を取り出していきます。
カスタムロジックの組み方は、帳票の内容によって千差万別なので一般化は本当に難しいですが、上記の帳票を処理する場合の実装例は以下のとおりです。
カスタムロジック実装例
列を分割するためのカスタムロジック# 値を保存する変数: table_values #表の操作をするときに必ず入れるコード(最初) import pandas as pd df = pd.DataFrame(table_values) ############################################# # ↓↓↓ ここからが今回の処理 ↓↓↓ ############################################# #税区分を抽出する関数 def zeikubun(x): result = "" cnt = 0 kubun = ("外税","内税") for i in kubun: if i in x: result = i cnt = cnt + 1 if cnt > 1: result = "エラー" return result #税区分を抽出する関数の適用 df['税区分'] = df['金額'].apply(zeikubun) #税率を抽出する処理 def zeiritsu(x): result = "" splitter = ("外税","内税") #Point1:分割の根拠となる文字列 for i in splitter: if i in x: result = x.split(i)[1] #Point2:↑を根拠に分割した上で、分割したどの部分を取り出すかの指定 return result #金額欄に定義した関数を適用する df['税率'] = df['金額'].apply(zeiritsu) #金額を抽出する処理 def kingaku(x): result = "" splitter = ("外税","内税") #Point1:分割の根拠となる文字列 for i in splitter: if i in x: result = x.split(i)[0] #Point2:↑を根拠に分割した上で、分割したどの部分を取り出すかの指定 if result == "": result = x return result #金額欄に定義した関数を適用する df['金額'] = df['金額'].apply(kingaku) ############################################# # ↑↑↑ ここまでが今回の処理 ↑↑↑ ############################################# #表の操作をするときに必ず入れるコード(最後) table_values = df.to_dict()最後に
さすがにこの処理をpythonやプログラミング言語の素養が全然ない人が実務で実装することは考えにくいので、カスタムロジックの初心者向けの説明は省略します。
pythonなり、他の言語をやったことあれば、上記の処理で何をやっているかはだいたい想像がつくかなと思います。
が、もし何かわからなくて困ったことがあれば、この記事にコメントを投稿していただくか、twitterで @IQ_Bocchi までご連絡いただければ、可能な限りお答えします。



- 投稿日:2020-07-24T19:50:09+09:00
pythonでインターネットのspeedtestを行い、excelシートに出力する
はじめに
なんとなくウチのインターネット遅くね?って気持ちになったので、具体的にどのくらいの速度で動いてくれているのか、speedtestを使って測ってみることにしました。
ついでに結果をどこかしらに出力してくれたら嬉しいなーということで、pythonからspeedtestを実行し、speedtestを行った日付、時間帯と共にexcelに出力させてみました。やってみたこと
1. speedtestをpythonを通じて実行する
2. 結果をexcelシートに出力する。その際に、speedtestを行った日付、時間帯も併せて記載する環境
・windows10
・python3.7.2使用したspeedtestツール
使用したツールは、こちら。CLIでspeedtestを行えます。オプションでPNGファイルを生成することもできる、優れものです。
参考にしたのは、GitHubとこちらのブログ。cmdからのspeedtestで十分って気持ちにもなってきます。。speedtestをpythonを通じて実行する
参考にしたのは、このQiita投稿。9割9分写経です。。
speedtest_wifi.pyimport sys import speedtest def get_speed_test(): servers = [] stest = speedtest.Speedtest() stest.get_servers(servers) stest.get_best_server() return stest def command_line_runner(): stest = get_speed_test() down_result = stest.download() up_result = stest.upload() mbps_down_result = down_result / 1024 /1024 mbps_up_result = up_result / 1024 /1024 result = [mbps_down_result, mbps_up_result] print(result) command_line_runner()出力は、こんな感じ。
python speedtest_wifi.py [16.08899947399507, 4.28247380989742]下りが大体16Mbps、上りが大体4Mbpsみたいですね。
結果をexcelシートに出力する。その際に、speedtestを行った日付、時間帯も併せて記載する
参考にしたのがこちらとこちら。
speedtestの測定結果が、excelシート上の表の末尾に追加されるようにしています。
下に載せている私のコードからは消しましたが、そもそものexcelシートの作成も、pythonから行いました。最初の1回だけはexcelシートを作成し、2回目以降は測定結果を追記していくような書き方にできないものでしょうか。今後の課題ですね。(手を付けない気がする)appendするリストの0番目を、speedtest測定時の日付&時間帯とし、以降の要素に、speedtest測定結果を入れています。
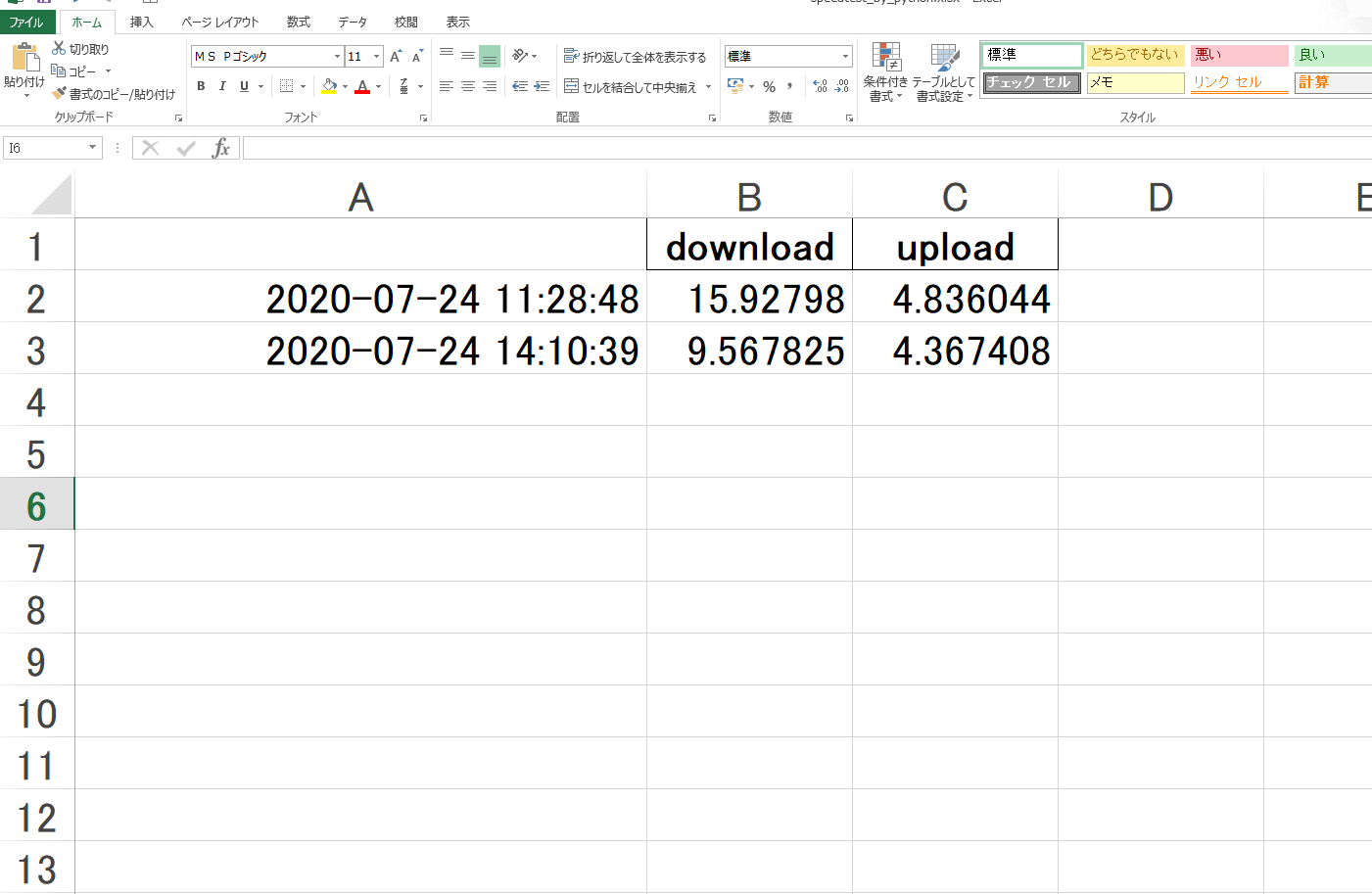
speedtest_wifi.py で、下りの測定結果と上りの測定結果をリストに格納しているので、一度バラしてリストに格納しなおしています。(上で載せたものから、excelシート出力用にちょっと手直し)speedtest_wifi.pyimport sys import speedtest def get_speed_test(): servers = [] stest = speedtest.Speedtest() stest.get_servers(servers) stest.get_best_server() return stest def command_line_runner(): stest = get_speed_test() down_result = stest.download() up_result = stest.upload() mbps_down_result = down_result / 1024 /1024 mbps_up_result = up_result / 1024 /1024 result = [mbps_down_result, mbps_up_result] return result if __name__ == '__main__': command_line_runner()sp_xlsx.pyimport speedtest_wifi as sp import xlwt import openpyxl import pandas as pd import datetime as dt wb = openpyxl.load_workbook("speedtest_by_python.xlsx") sheet = wb.worksheets[0] dt_now = dt.datetime.now() result = [dt_now] for i in range(len(sp.command_line_runner())): result.append(sp.command_line_runner()[i]) i += 1 sheet.append(result) wb.save('speedtest_by_python.xlsx')出力されたexcelシートが、以下。
狙い通り、1列目に日付&時間帯、2列目、3列目に下りと上りの測定結果が出力されています。余談
本編とは関係なく、コーディング中に行き会ったよしなきことを書きつけます。
AttributeError: module ‘xxx’ has no attribute ‘yyy’ のエラーが出まくる
importしているspeedtestモジュールには「Speedtest」というアトリビュートがあるはずなのですが、なぜか「AttributeError: module ‘xxx’ has no attribute ‘yyy’」のエラーが出てしまいます。
原因は、「ファイル名とモジュール名が同じになっている」ことでした。今でこそ「speedtest_wifi.py」というファイル名にしていますが、エラー頻発当初は「speedtest.py」というファイル名にしていました。本来読み込みたいモジュールではなく、自分自身を読み込んでいたのですね。そりゃーエラーが出るはずだ。。ありがとうございました!→[python]「AttributeError: module(object) ‘xxx’ has no attribute ‘yyy’」が起きたときの対処法5選
モジュールのアトリビュートを調べる方法
上記エラーのトラシューというか横道として、「speedtestモジュールはどのようなアトリビュートを持つのか?」と思ったので、そのようなコマンドを探してみました。
まあ最初は、このために用意したファイルの名前を「inspect.py」にしていたのでまったく同じエラーが発生してしまい、想定通りの確認をできなかったのですが。。
「inspect_speedtest.py」とかにファイル名を変更してみたら、うまいこと行きました。それはそう。ありがとうございました!→【Python】属性の一覧を取得する方法(2種類)
if __name__ == '__main__' とは
所謂「おまじない」ですね。
if __name__ == '__main__'は「該当のファイルがコマンドラインからスクリプトとして実行された場合にのみ以降の処理を実行する」という意味となる。他のファイルからインポートされたときは処理は実行されない。
こいつ自身がcmdから指定され、動くときに、「if__name__ == '__main__'」の中身が実行される。別のファイルがこいつを呼び出す際には、中身が実行されることはない。余計な処理は発生しない。なるほど。
モジュールをインポートした際には、__name__属性にそのモジュールの名前が文字列格納されている。一方モジュールをcmdから実行すると、__name__には「__main__」という文字列が格納されている。つまり、「__name__」が「"__main__"」のときとは、モジュールがcmdから直接実行されたとき。なるほど!!
ありがとうございました!&引用元→Pythonのif __name__ == '__main__'の意味と使い方
参考資料
・SPEEDTEST CLI Internet connection measurement for developers
・SpeedTest(スピードテスト)をコマンドからやりたい
・GitHub
・インターネット回線の速度計測(上り/下り)
・pandasでExcelファイル(xlsx, xls)の書き込み(to_excel)
・OpenPyXLでExcelファイルに書き込む その2
・[python]「AttributeError: module(object) ‘xxx’ has no attribute ‘yyy’」が起きたときの対処法5選
・【Python】属性の一覧を取得する方法(2種類)
・Pythonのif __name__ == '__main__'の意味と使い方
- 投稿日:2020-07-24T19:41:51+09:00
【Python】Python歴2年、野球ファン歴10年の俺がプロ野球選手を主成分分析してクラスタリングする【機械学習】
はじめに
プロ野球が開幕して早一ヶ月が立っております。皆様、贔屓球団の調子はいかがでしょうか。
え?私の贔屓球団はどうだって?最下位(7/23現在)ですけど?
...まぁシーズンも始まったばかりなのでまだわかりませんね!
野球といえば他のスポーツと比べて多くの指標があり、データ分析にはもってこいな球技です。
いわゆるセイバーメトリクスは、メジャーはもちろん日本野球においても大きな注目を受けています。
今回の記事ではこれらの指標を主成分分析してクラスタリングすれば打者の傾向を見抜くことができるのでは?と思い実際に行ってみました!できたものがこちら!
(*かなり画質を落としています)
今回は4パターンに分類しました。できたものをぐるぐる回して見ると多くの気付きがありましたので
ぜひ皆さんもやってみてほしいと思います!Webスクレイピング
まずは、指標データの取得をするためWebスクレイピングを行いました。今回はプロ野球データFreak様のデータを利用しました。
内容としてはセ・パ両リーグの打席数ランキング上位50名の成績が22項目にわたって載っています。スクレイピング用に関数をいくつか定義しています。
これはこちらのサイトを参考にしました。スクレイピング.py# Webスクレイピングのためのimport import requests from bs4 import BeautifulSoup as BS import os, csv # Webスクレイピングし、table情報を取得する関数を定義 def get_tables(content, is_talkative=True): """table要素を取得する""" bs = BS(content, "lxml") tables = bs.find_all("table") n_tables = len(tables) if n_tables == 0: emsg = "table not found." raise Exception(emsg) if is_talkative: print("%d table tags found.." % n_tables) return tables # table要素のデータを読み込んで二次元配列を返す関数を定義 def parse_table(table): """table要素のデータを読み込んで二次元配列を返す""" ##### thead 要素をパースする ##### # thead 要素を取得 (存在する場合) thead = table.find("thead") # thead が存在する場合 if thead: tr = thead.find("tr") ths = tr.find_all("th") columns = [th.text for th in ths] # pandas.DataFrame を意識 # thead が存在しない場合 else: columns = [] ##### tbody 要素をパースする ##### # tbody 要素を取得 tbody = table.find("tbody") # tr 要素を取得 trs = tbody.find_all("tr") # 出力したい行データ rows = [columns] # td (th) 要素の値を読み込む # tbody -- tr 直下に th が存在するパターンがあるので # find_all(["td", "th"]) とするのがコツ for tr in trs: row = [td.text for td in tr.find_all(["td", "th"])] rows.append(row) return rows # parse_table情報をcsvに変換する関数を定義 def table2csv(path, rows, lineterminator="\n", is_talkative=True): """二次元データをCSVファイルに書き込む""" # HTMLを取得 url = 'https://baseball-data.com/stats/hitter2-all/tpa-2.html' res = requests.get(url) content = res.text # table 要素を取得 tables = get_tables(content) table = tables[0] rows = parse_table(table) # CSV ファイルとして出力する # 出力先が Windows なら以下のようにする table2csv("./table.csv", rows, "\r\n")これで選手の「table.csv」ファイルが作られるはずです。中身を見てみましょう。
raw_data.pyimport pandas as pd url =r'table.csv' # datasetのdirectory or URLを指定 raw_data = pd.read_csv( url, thousands = ',', encoding='cp932' ) 順位 選手名 チーム 打率 試合 打席数 打数 得点 安打 ... 犠打 犠飛 四球 敬遠 死球 三振 併殺打 出塁率 長打率 0 1 西川 遥輝 日本ハム 0.275 30 137 109 23 30 ... 2 0 25 0 1 21 2 0.415 0.367 1 1 栗原 陵矢 ソフトバンク 0.234 30 137 124 13 29 ... 2 3 7 0 1 32 0 0.274 0.419 2 3 大島 洋平 中日 0.299 30 134 117 11 35 ... 2 1 12 1 2 11 2 0.371 0.342 3 4 鈴木 大地 楽天 0.316 29 133 114 22 36 ... 6 1 10 0 2 16 4 0.378 0.368 4 5 梶谷 隆幸 DeNA 0.295 29 131 112 23 33 ... 1 0 17 0 1 27 1 0.392 0.491 [5 rows x 25 columns]うまくできていますね!ではこのデータを使って主成分分析をしていきましょう!
主成分分析及びその後のFigure作成には以下のパッケージをimportします。データの標準化
文字データが入ると主成分分析できないので該当するカラムを削除し、 StandardScalerを用いてデータを標準化します。
normalize.pyfrom sklearn.preprocessing import StandardScaler raw_data_drop = raw_data.drop(columns=['選手名','順位', 'チーム'] ) # 文字が入るとPCAできないのでcolumnの削除 # StandardScalerを用いたdatasetの標準化 scaler = StandardScaler() scaler.fit(raw_data_drop) scaler.transform(raw_data_drop) raw_data_drop_normalize = pd.DataFrame(scaler.transform(raw_data_drop), columns=raw_data_drop.columns) # 標準化したdatasetをraw_data_drop_normalizeとする raw_data_drop_normalize.head() 打率 試合 打席数 打数 ... 三振 併殺打 出塁率 長打率 0 0.001746 1.148813 2.045134 0.621331 ... -0.060951 -0.201524 0.914646 -0.704579 1 -0.893094 1.148813 2.045134 2.470530 ... 1.535373 -1.262178 -1.463906 -0.247859 2 0.525555 1.148813 1.679931 1.607570 ... -1.512154 -0.201524 0.172403 -0.924156 3 0.896586 0.480899 1.558197 1.237730 ... -0.786552 0.859129 0.290487 -0.695796 4 0.438253 0.480899 1.314729 0.991171 ... 0.809771 -0.731851 0.526655 0.384523 [5 rows x 22 columns]標準化したデータを使って主成分分析を行います。scikitlearnを用いて
主成分分析
今回は3次元のプロットにしたいので、
n_components = 3としました。
主成分分析したデータはデータフレームにしています。PCA.pyfrom sklearn.decomposition import PCA # raw_data_drop_normalizeを用いたPCA pca = PCA(n_components = 3) #3軸でPCA classを作成する pca.fit(raw_data_drop_normalize) #fitting、実際のPCA処理はここ # PCAの結果はarrayで返ってくるのでをData.Frameにする pca_result = pca.transform(raw_data_drop_normalize) pca_result = pd.DataFrame(pca_result) pca_result.columns = ['PC1', 'PC2', 'PC3']これでプロ野球選手50名分のデータを用いた主成分分析ができているはずなので中身を確認してみましょう。
pca_result.pypca_result.head() PC1 PC2 PC3 0 -0.217280 4.262306 0.512089 1 -0.516226 -0.131497 4.269493 2 -0.592064 2.799863 2.578358 3 0.086469 1.690605 2.112824 4 1.128880 2.884067 0.784286 len(pca_result) 50これで、22項目のデータを3つに集約することができました!
では次にクラスタリングをしてみましょう!クラスタリング
クラスタリングは有名なk-means法を用いています。
clustering.py# PCAのためのimport from sklearn.cluster import KMeans #クラスタリング num_cluster = 4 pca_result_cluster = KMeans(n_clusters=num_cluster).fit(pca_result)できているかのチェックは、
.labels_を見ることでわかります。clustering_label.pypca_result_cluster.labels_ array([2, 0, 2, 2, 2, 3, 1, 1, 2, 0, 1, 3, 2, 2, 1, 0, 1, 0, 3, 3, 1, 1, 3, 0, 0, 1, 2, 0, 0, 0, 2, 0, 3, 0, 1, 0, 2, 0, 0, 0, 0, 3, 0, 0, 0, 3, 3, 3, 3, 3])0-3の数字が割り振られていることから4グループに分類できていることがわかります!
では実際に分類された結果を可視化していきましょう!可視化(3D plot)
まずは主成分分析の結果にクラスタリングの結果と選手名の列を追加します。
annotation.pyplayer_name = raw_data['選手名'] # annotation用に格納 pca_result["name"] = player_name pca_result["cluster"] = pca_result_cluster.labels_ pca_result.head() PC1 PC2 PC3 name cluster 0 -0.217280 4.262306 0.512089 西川 遥輝 2 1 -0.516226 -0.131497 4.269493 栗原 陵矢 0 2 -0.592064 2.799863 2.578358 大島 洋平 2 3 0.086469 1.690605 2.112824 鈴木 大地 2 4 1.128880 2.884067 0.784286 梶谷 隆幸 2さて、ここから、matplotlibを使って選手をアノテーションを付けつつ3次元にプロットするのですが、
matplotlibのAnnotationは2次元のプロットにしか対応していません。そこで、Annotationクラスを継承し新たにannotation3Dという関数を定義します。
また、アニメーションgifを作る都合上3次元にplotする関数(plot_3D)も作成しておきます。annotation3D.pyimport matplotlib.pyplot as plt from matplotlib.text import Annotation from mpl_toolkits.mplot3d.axes3d import Axes3D from PIL import Image # アニメーション用 from matplotlib import animation # アニメーション用 from io import BytesIO # アニメーション用 # クラスの継承 class Annotation3D(Annotation): '''Annotate the point xyz with text s''' def __init__(self, s, xyz, *args, **kwargs): Annotation.__init__(self,s, xy=(0,0), *args, **kwargs) self._verts3d = xyz def draw(self, renderer): xs3d, ys3d, zs3d = self._verts3d xs, ys, zs = proj_transform(xs3d, ys3d, zs3d, renderer.M) self.xy=(xs,ys) Annotation.draw(self, renderer) # annotate3Dを定義 def annotate3D(ax, s, *args, **kwargs): '''add anotation text s to to Axes3d ax''' tag = Annotation3D(s, *args, **kwargs) ax.add_artist(tag) # plot_3Dを定義 color = ["red", "blue", "green", "orange"] # クラスタリング用の色 def plot_3D(data, angle = 50): # 3d plot用Figure fig = plt.figure(num=None, figsize=(12, 12), dpi=150) #アニメーションgifを作る際はdpiを72にする ax = fig.gca(projection = '3d') for i in range(len(data.index)): ax.scatter3D(data.iloc[i,0], data.iloc[i,1],data.iloc[i,2], c=color[int(data.iloc[i,4])]) # プロットの座標を指定 annotate3D(ax, s=str(data.iloc[i,3]), xyz=(data.iloc[i,0], data.iloc[i,1],data.iloc[i,2]), fontsize=6, xytext=(-3,3), textcoords='offset points', ha='right',va='bottom', fontname="MS Gothic") # annotation ax.view_init(30, angle) ax.set_xlim(data.describe().at['min', 'PC1'], data.describe().at['max', 'PC1']) ax.set_ylim(data.describe().at['min', 'PC2'], data.describe().at['max', 'PC2']) ax.set_zlim(data.describe().at['min', 'PC3'], data.describe().at['max', 'PC3']) ax.set_xlabel('PC1 ' + str(round(pca.explained_variance_ratio_[0]*100, 1)) + "%") # 軸に寄与率を表示 ax.set_ylabel('PC2 ' + str(round(pca.explained_variance_ratio_[1]*100, 1)) + "%") ax.set_zlabel('PC3 ' + str(round(pca.explained_variance_ratio_[2]*100, 1)) + "%") buf = BytesIO() fig.savefig(buf, bbox_inches='tight', pad_inches=0.0) return Image.open(buf)ここまでこれば可視化までもう一歩です。
plot_3D.pyplot_3D(pca_result) plt.show()
できました!もし、アニメーションgifを作成したい場合は、gif.py# gif animationを作る場合 images = [plot_3D(pca_result,angle) for angle in range(180)] images[0].save('output.gif', save_all=True, append_images=images[1:], duration=100, loop=0)と書くことで一番最初に出ているようなgifアニメーションが出力されます。
ただし、dpiを大きくしすぎるとメモリ不足に陥るので注意してください。データ分析+考察
データのクラスタリング+可視化ができましたので、これを元に色々と考察をしていきたいと思います。
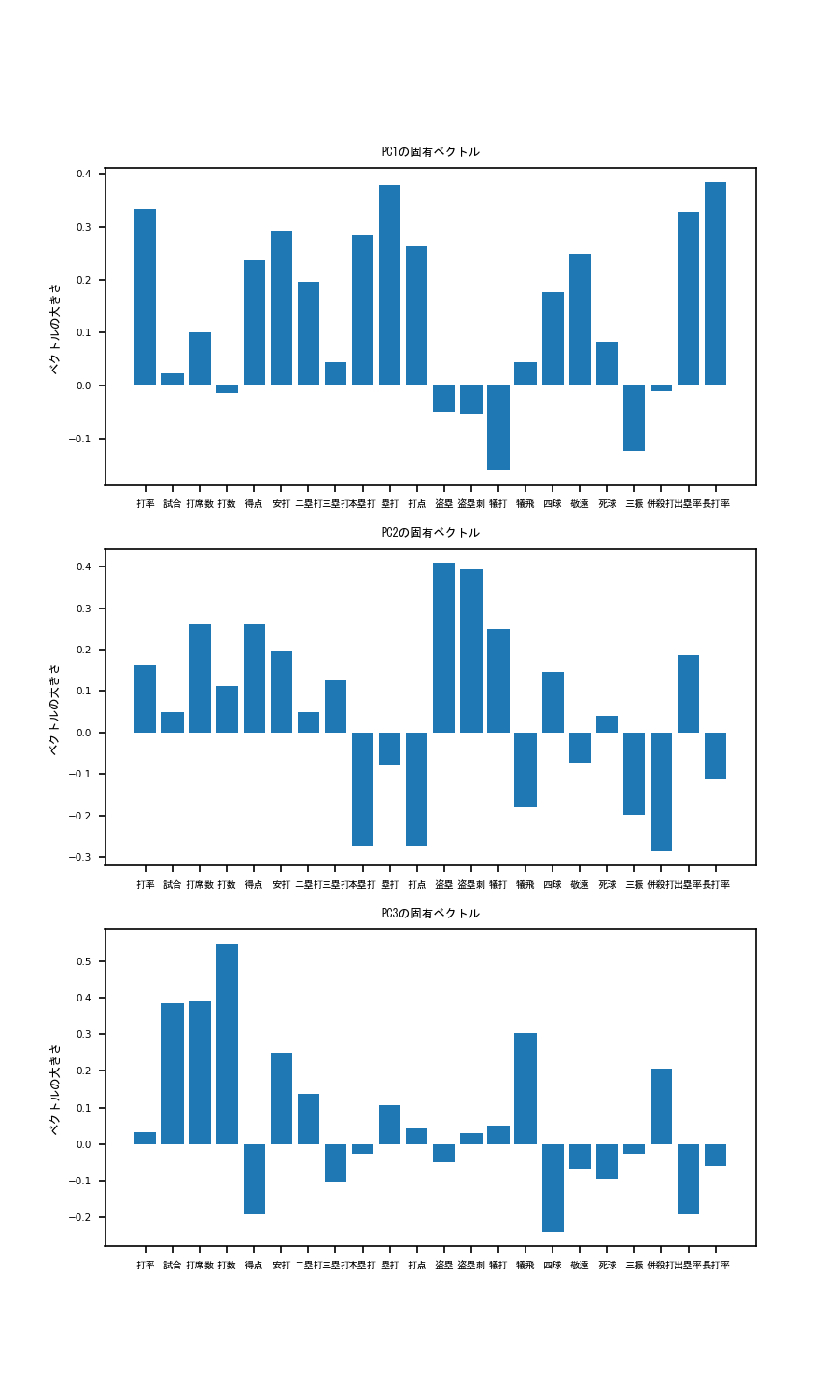
まず、各軸の固有ベクトルを出してみましょう。固有ベクトルの成分がわかることで、各軸が何を表しているかを考えることができます。component.py# PCの固有ベクトルの成分を表示 component = pd.DataFrame(pca.components_) fig = plt.figure(figsize=(12, 20)) for i in range(len(component.index)): ax = fig.add_subplot(3,1,i+1) ax.bar(raw_data_drop_normalize.columns, component.iloc[i]) ax.set_xticks(raw_data_drop_normalize.columns) ax.set_xticklabels(raw_data_drop_normalize.columns, rotation = 270, fontname="MS Gothic", fontsize=10) ax.set_title('PC' +str(i+1) + 'の固有ベクトル', fontname="MS Gothic", fontsize=10) ax.set_ylabel('ベクトルの大きさ', fontname="MS Gothic", fontsize=10) plt.xticks(rotation = '0') plt.tick_params(labelsize=10) ax.plot() plt.show()こうすることで、以下のような図が出力されます。
これを見てみると、PC1は、本塁打、塁打、打点ベクトル成分が非常に大きいことがわかります。
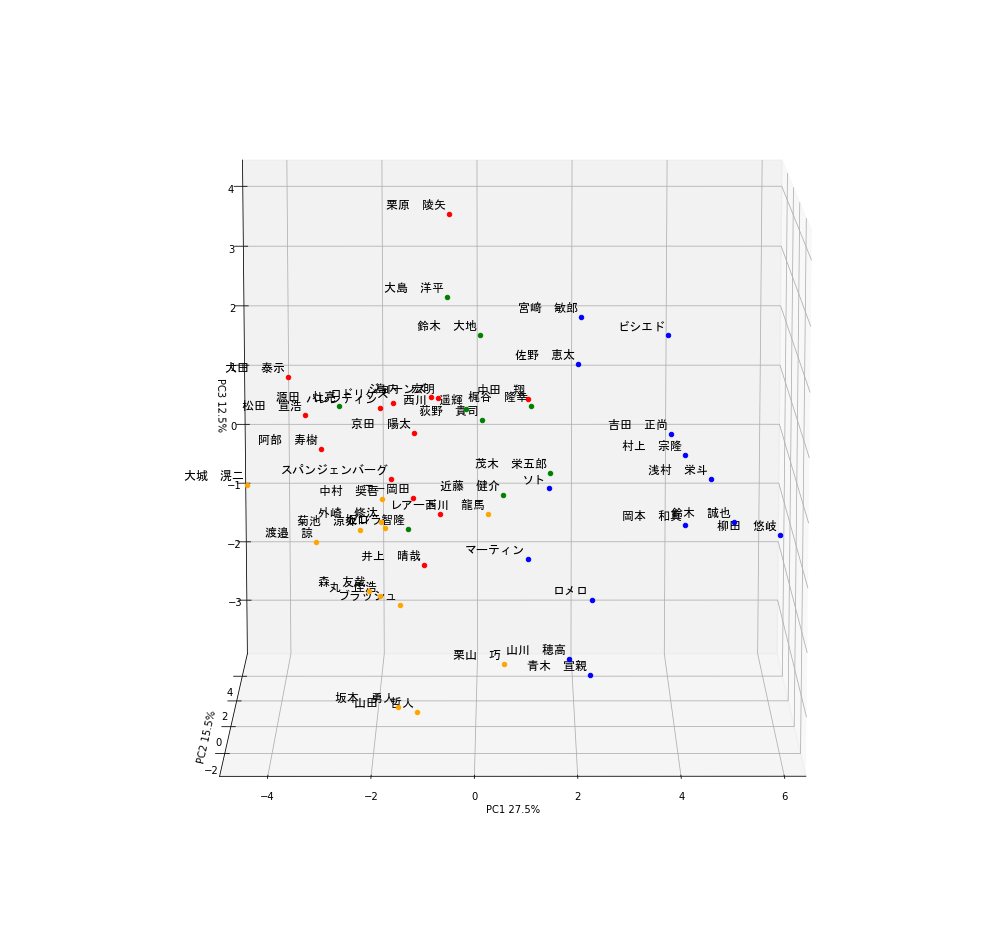
このことから、PC1の大きい選手はパワー自慢の長距離バッターであると考えられます。そこで、PC1の軸でplotを見てみると...
ギータやべぇ...もう独走しています。他にも岡本和真、鈴木誠也、吉田正向、村上宗隆など、まさにホームランバッターと呼ばれる選手の名前が散見されます。
しかもクラスタリングにおいても彼らは青色のグループに属していることがわかります。これらのことから、この青色のグループは4番バッターグループと言って良いでしょう次にPC2を見てみると、本塁打の大きさがぐっとさがり、代わりに盗塁、盗塁刺、犠打の値が大きくなっています。
すなわちPC2の高いバッターはスピードに特化したバッターであると推察されます。そこで、PC2の軸でplotを見てみると...
荻野やべぇ...もう独走(ry。他にも西川遥輝、源田壮亮、大島洋平などの名が見られており、彼らは緑色のグループに分けられています。
これらの結果を踏まえると緑色のグループはスピード特化の1,2番打者グループと言えそうです。最後にPC3の軸について考えてみましょう。打率の寄与が低いですが併殺打、犠飛のベクトル成分が大きいほか、四球の大きさが非常に低いことがわかります。
ということはPC3の高いバッターはフリースインガータイプなのでは?と考えられます。見てみましょう。
縦軸がPC3を示しています。栗原ェ...もう独(ry。他にはビシエド、宮崎敏郎、大田泰示などの名前も見られますね。
ここで大事なのはビシエド、宮崎敏郎は青グループである一方で大田泰示は赤グループであるという点です。
ビシエド、宮崎敏郎はある程度フリースインガーであるものの、本塁打や打点が高くPC1が大きいため4番バッターグループに入ったのだと考えられます。
そういったことから赤グループは典型的フリースインガー、四球拒否マンであると考えられます。
では残った黄色グループはどう考えればよいでしょうか?彼らは青グループほど長打力があるわけでもなく、
緑色グループほど走力が高いわけでもない、ある程度の選球眼も有しているバランスタイプであると考えても良いかもしれません。
また、PC1-PC3全てにおいて試合、打席数、打数のベクトル成分が大きいことも無視できません。
つまり、彼らは一時的に離脱をした結果PC1-PC3全てのスコアが伸び悩み、黄色グループに入っている可能性もあります。
そういったことから黄色グループはバランスタイプ or 今後のペナントに大きく影響しうる眠れる獅子グループと考えてみました。さいごに
いかがでしたでしょうか?まだ開幕して1ヶ月のデータで分析した結果なので、ここからどのように変化していくかはわかりません。
ですがこのようなデータを元に野球観戦をするとまた別の趣があって楽しめると思います!では素敵な野球観戦ライフを!おまけ
codeの全文をこちらに表記しておきます。
PCA.py# Webスクレイピングのためのimport import requests from bs4 import BeautifulSoup as BS import os, csv # Webスクレイピングし、table情報を取得する関数を定義 def get_tables(content, is_talkative=True): """table要素を取得する""" bs = BS(content, "lxml") tables = bs.find_all("table") n_tables = len(tables) if n_tables == 0: emsg = "table not found." raise Exception(emsg) if is_talkative: print("%d table tags found.." % n_tables) return tables # table要素のデータを読み込んで二次元配列を返す関数を定義 def parse_table(table): """table要素のデータを読み込んで二次元配列を返す""" ##### thead 要素をパースする ##### # thead 要素を取得 (存在する場合) thead = table.find("thead") # thead が存在する場合 if thead: tr = thead.find("tr") ths = tr.find_all("th") columns = [th.text for th in ths] # pandas.DataFrame を意識 # thead が存在しない場合 else: columns = [] ##### tbody 要素をパースする ##### # tbody 要素を取得 tbody = table.find("tbody") # tr 要素を取得 trs = tbody.find_all("tr") # 出力したい行データ rows = [columns] # td (th) 要素の値を読み込む # tbody -- tr 直下に th が存在するパターンがあるので # find_all(["td", "th"]) とするのがコツ for tr in trs: row = [td.text for td in tr.find_all(["td", "th"])] rows.append(row) return rows # parse_table情報をcsvに変換する関数を定義 def table2csv(path, rows, lineterminator="\n", is_talkative=True): """二次元データをCSVファイルに書き込む""" # # 安全な方に転ばせておく # if os.path.exists(path): # emsg = "%s already exists." % path # raise ValueError(emsg) # データを書き込む with open(path, "w") as f: writer = csv.writer(f, lineterminator=lineterminator) writer.writerows(rows) if is_talkative: print("%s successfully saved." % path) # HTMLを取得 url = 'https://baseball-data.com/stats/hitter2-all/tpa-2.html' res = requests.get(url) content = res.text # table 要素を取得 tables = get_tables(content) table = tables[0] rows = parse_table(table) # CSV ファイルとして出力する # 出力先が Windows なら以下のようにする table2csv("./table.csv", rows, "\r\n") # PCAのためのimport import numpy as np import pandas as pd import scipy as sp import seaborn as sns from sklearn.decomposition import PCA from sklearn.cluster import KMeans import matplotlib.pyplot as plt from matplotlib.text import Annotation from mpl_toolkits.mplot3d.proj3d import proj_transform from mpl_toolkits.mplot3d.axes3d import Axes3D from PIL import Image from sklearn.preprocessing import StandardScaler from matplotlib import animation from io import BytesIO # 3D annotationのために、Annotation classを継承 class Annotation3D(Annotation): '''Annotate the point xyz with text s''' def __init__(self, s, xyz, *args, **kwargs): Annotation.__init__(self,s, xy=(0,0), *args, **kwargs) self._verts3d = xyz def draw(self, renderer): xs3d, ys3d, zs3d = self._verts3d xs, ys, zs = proj_transform(xs3d, ys3d, zs3d, renderer.M) self.xy=(xs,ys) Annotation.draw(self, renderer) # annotate3Dを定義 def annotate3D(ax, s, *args, **kwargs): '''add anotation text s to to Axes3d ax''' tag = Annotation3D(s, *args, **kwargs) ax.add_artist(tag) url =r'table.csv' # datasetのdirectory or URLを指定 raw_data = pd.read_csv( url, thousands = ',', encoding='cp932' ) raw_data_drop = raw_data.drop(columns=['選手名','順位', 'チーム'] ) # columnのドロップ。文字型のカラムはPCAできないので削除。 player_name = raw_data['選手名'] # annotation用に格納 # StandardScalerを用いたdatasetの標準化 scaler = StandardScaler() scaler.fit(raw_data_drop) scaler.transform(raw_data_drop) raw_data_drop_normalize = pd.DataFrame(scaler.transform(raw_data_drop), columns=raw_data_drop.columns) # 標準化したdatasetをraw_data_drop_normalizeとする # raw_data_drop_normalizeを用いたPCA pca = PCA(n_components = 3) #3軸でPCA classを作成する pca.fit(raw_data_drop_normalize) #fitting、実際のPCA処理はここ # PCAの結果はarrayで返ってくるのでをData.Frameにする pca_result = pca.transform(raw_data_drop_normalize) pca_result = pd.DataFrame(pca_result) pca_result.columns = ['PC1', 'PC2', 'PC3'] # columnに #クラスタリング num_cluster = 4 color = ["red", "blue", "green", "orange"] # クラスタリング用の色 pca_result_cluster = KMeans(n_clusters=num_cluster).fit(pca_result) # annotation用 pca_result["name"] = player_name pca_result["cluster"] = pca_result_cluster.labels_ # PCの固有ベクトルの成分を表示 component = pd.DataFrame(pca.components_) fig = plt.figure(figsize=(6, 10)) for i in range(len(component.index)): ax = fig.add_subplot(3,1,i+1) ax.bar(raw_data_drop_normalize.columns, component.iloc[i]) ax.set_xticks(raw_data_drop_normalize.columns) ax.set_xticklabels(raw_data_drop_normalize.columns, rotation = 30, fontname="MS Gothic", fontsize=6) ax.set_title('PC' +str(i+1) + 'の固有ベクトル', fontname="MS Gothic", fontsize=6) ax.set_ylabel('ベクトルの大きさ', fontname="MS Gothic", fontsize=6) plt.xticks(rotation = '0') plt.tick_params(labelsize=5) ax.plot() plt.show() fig.savefig("PCA_vector.png", dpi = 150) def plot_3D(data, angle = 50): # 3d plot用Figure fig = plt.figure(num=None, figsize=(12, 12), dpi=72) ax = fig.gca(projection = '3d') for i in range(len(data.index)): ax.scatter3D(data.iloc[i,0], data.iloc[i,1],data.iloc[i,2], c=color[int(data.iloc[i,4])]) # プロットの座標を指定 annotate3D(ax, s=str(data.iloc[i,3]), xyz=(data.iloc[i,0], data.iloc[i,1],data.iloc[i,2]), fontsize=12, xytext=(-3,3), textcoords='offset points', ha='right',va='bottom', fontname="MS Gothic") # annotation ax.view_init(30, angle) ax.set_xlim(data.describe().at['min', 'PC1'], data.describe().at['max', 'PC1']) ax.set_ylim(data.describe().at['min', 'PC2'], data.describe().at['max', 'PC2']) ax.set_zlim(data.describe().at['min', 'PC3'], data.describe().at['max', 'PC3']) ax.set_xlabel('PC1 ' + str(round(pca.explained_variance_ratio_[0]*100, 1)) + "%") # 軸に寄与率を表示 ax.set_ylabel('PC2 ' + str(round(pca.explained_variance_ratio_[1]*100, 1)) + "%") ax.set_zlabel('PC3 ' + str(round(pca.explained_variance_ratio_[2]*100, 1)) + "%") buf = BytesIO() fig.savefig(buf, bbox_inches='tight', pad_inches=0.0) return Image.open(buf) plot_3D(pca_result) plt.show() # gif animationを作る場合 images = [plot_3D(pca_result,angle) for angle in range(180)] images[0].save('output.gif', save_all=True, append_images=images[1:], duration=100, loop=0)



- 投稿日:2020-07-24T19:37:58+09:00
ZeroMQ PUB-SUB REQ-RESパターンとクラス化
はじめに
ZeroMQのPUB-SUBパターンを利用していましたが、たまにメッセージの落としがあったので、(そのようなことが前提のメッセージング方式ですが)落としがないようにREQ-REPに変更しました。
その際に、PUB-SUBからREQ-REP簡単に入れ替えられるようにクラス化を行いました。その覚えとして書き留めます。環境
Windows10 Pro 64 bit
Anaconda
python 3.7クラス化
ZeroMQ(TCP/IP)通信では、通信の初期化(接続)、メッセージの送信、メッセージの受信、通信の切断があります。
まず、ひな形を親クラスで作成します。この親クラスを継承して、PUB 、SUB、REQ、REPクラスを作成します。親クラス
import zmq class ConSock(object): """ ZeroMQ Super class """ def __init__(self, kind): """ kind:継承した際にそれぞれのメッセージング方式を入れます。 ex: zmq.REP """ self.context = zmq.Context() self.sock = self.context.socket(kind) def send(self, param): if type(param) is list: """ multipart message param: [byte, byte,...] """ self.sock.send_multipart(param) else: """ param: string Pythonのユニコード文字列を、バイト列に変換して送信 """ self.sock.send_string(param) def recv(self, type='multipart'): """ type: 'multipart' or 'string' """ # print('Receive') if type == 'multipart': # recv_msg: [byte,byte...] recv_msg = self.sock.recv_multipart() elif type == 'string': # recv_msg : string recv_msg = self.sock.recv_string() return recv_msg def recv_string(self): recv_msg = self.sock.recv_string() return recv_msg def recv_multi(self): recv_msg = self.sock.recv_multipart() return recv_msg def close(self): self.sock.close() self.context.destroy()コードの説明
初期化(Constructor)でソケットを作成します。引数としてkindを入れておき、親クラスを継承して他のメッセージングパターを作るときにkindに通信方式を入力します。
sendメソッドについては、2つの方式を入れています。一つは、ただ文字列を送るString方式、もう一つは、リストの中にメッセージを入れて、リストを送るmalutipart方式です。
recvメソッドについては、送られてくるメッセージの方式が2つあるので、受ける方はそれに対応して2つ用意しています。recvメソッドの引数で送られてくるメッセージ方式を指定しています。そこを指定しないで、直接受け取る方式も念のために作っておきました。
メッセージの注意点は、stringで送るときは、そのままstringで送信しても問題ありません。(ZeroMQ側でbyteにして送信して、byteで受け取りstringに変換してくれます。)multipartでは、リスト内に入れる情報はbyteに変換しておかないとエラーになります。送信受信方式についてはこちらの記事が参考になります。
Raspberry Pi3 と ZeroMQ でフォグ・コンピューティングの雰囲気を体験(前編)Pub-Subクラス
Pub-Sub方式では、一般にPubがサーバー側、Subがリスナー側になります。また、Pubは、メッセージ送信のみ、Sub側はメッセージ受信のみになります。
class Pub(ConSock): """ Pub-Sub type Server side (bind side) """ def __init__(self, host, port): super().__init__(zmq.PUB) self.sock.bind("tcp://{}:{}".format(host, port)) class Sub(ConSock): """ Pub-Sub type listener side # Channelを指定すること """ def __init__(self, host, port, channel): super().__init__(zmq.SUB) self.channel = channel channel_name = self.channel.encode('utf-8') self.sock.setsockopt(zmq.SUBSCRIBE, channel_name) self.sock.connect("tcp://{}:{}".format(host, port))コード説明
ConSock親クラスを継承します。オーバーライドしているは、初期化のところだけです。それ以外のところは、親クラスのメソッドをそのまま使います。
初期化のところでは、 親クラスの初期化メソッドを呼んできて、足りない部分を つけ足しています。(superクラスのkindにzmq.PUB)を入れてインスタンスを作っています。)
サーバー側はbind、リスナー側はconnectになっています。リスナー側は、サーバー側のHostとPortの値が入ります。
Subクラスでは、channelの指定をしなければならないので、初期化の引数にchannelが入っています。また、channelはbyteにしなければならないので、byteに変換しています。Req-Repクラス
Req-Rep方式では、一般にRepがサーバー側、Reqがクライアント側になります。また、メーセージはRepは受信-->送信、Reqは送信-->受信を行います。
class Rep(ConSock): """ REQ-REP type Server side (bind side) """ # superクラスのkindにzmq.REPを入れてインスタンスを作っている # それ以外で足りないところをコンストラクタでインスタンス作成 def __init__(self, host, port): super().__init__(zmq.REP) self.sock.bind("tcp://{}:{}".format(host, port)) class Req(ConSock): """ REQ-Res type Client side """ def __init__(self, host, port): super().__init__(zmq.REQ) self.sock.connect("tcp://{}:{}".format(host, port))コード説明
ConSock親クラスを継承します。オーバーライドしているは、初期化のところだけです。それ以外のところは、親クラスのメソッドをそのまま使います。
初期化のところでは、 親クラスの初期化メソッドを呼んできて、足りない部分を つけ足しています。(superクラスのkindにzmq.REP)を入れてインスタンスを作っている。)
サーバー側はbind、クライアント側はconnectになっています。クライアント側は、サーバー側のHostとPortの値が入ります。全クラス化コードとテストコード
""" ZeroMQ Req-Rep, Pub-Sub class """ import json import random import time import zmq class ConSock(object): """ ZeroMQ Super class """ def __init__(self, kind): """ kind:継承した際にそれぞれのメッセージング方式を入れます。 ex: zmq.REP """ self.context = zmq.Context() self.sock = self.context.socket(kind) def send(self, param): if type(param) is list: """ multipart message param: [byte, byte,...] """ self.sock.send_multipart(param) else: """ param: string Pythonのユニコード文字列を、バイト列に変換して送信 """ self.sock.send_string(param) def recv(self, type='multipart'): """ type: 'multipart' or 'string' """ # print('Receive') if type == 'multipart': # recv_msg: [byte,byte...] recv_msg = self.sock.recv_multipart() elif type == 'string': # recv_msg : string recv_msg = self.sock.recv_string() return recv_msg def recv_string(self): recv_msg = self.sock.recv_string() return recv_msg def recv_multi(self): recv_msg = self.sock.recv_multipart() return recv_msg def close(self): self.sock.close() self.context.destroy() class Rep(ConSock): """ REQ-REP type Server side (bind side) """ # superクラスのkindにzmq.REPを入れてインスタンスを作っている # それ以外で足りないところをコンストラクタでインスタンス作成 def __init__(self, host, port): super().__init__(zmq.REP) self.sock.bind("tcp://{}:{}".format(host, port)) class Req(ConSock): """ REQ-REP type Client side """ def __init__(self, host, port): super().__init__(zmq.REQ) self.sock.connect("tcp://{}:{}".format(host, port)) class Pub(ConSock): """ Pub-Sub type Server side (bind side) """ def __init__(self, host, port): super().__init__(zmq.PUB) self.sock.bind("tcp://{}:{}".format(host, port)) class Sub(ConSock): """ Pub-Sub type listener side # Channelを指定すること """ def __init__(self, host, port, channel): super().__init__(zmq.SUB) self.channel = channel channel_name = self.channel.encode('utf-8') self.sock.setsockopt(zmq.SUBSCRIBE, channel_name) self.sock.connect("tcp://{}:{}".format(host, port)) """ Pub-Sub test code Pubはsendのみ Subはrecvのみ """ def pub(): host = '127.0.0.1' port = 5500 conn = Pub(host, port) # Sub側の受信準備を待つため time.sleep(1) id = 0 for i in range(10): random_topic = str(random.randint(1, 2)) id += 1 msg = {'num': id, 'message': 'Pub Hello'} # 送信メッセージはすべてバイト列にしなければならないので、文字列をバイト列に変換します。 topic = random_topic.encode('utf-8') jmsg = json.dumps(msg).encode('utf-8') conn.send([topic, jmsg]) print("Send:{}, {}".format(random_topic, str(msg))) time.sleep(1) print('Pub server done') def sub_1(): """ Topicが’1’の時だけ受信 """ host = '127.0.0.1' port = 5500 conn = Sub(host, port, '1') while True: [topic, jmsg] = conn.recv() # バイト列から文字列に変更してからloads msg = json.loads(jmsg.decode()) print('received topic 1 : ', msg) print(msg['num'], msg['message']) """ Req-Rep test code Req-Resともにsend,recvが必要。 """ def client(): host = '127.0.0.1' # host = 'localhost' port = 5600 conn = Req(host, port) for id in range(10): random_topic = str(random.randint(1, 2)) msg = {'num': id, 'message': 'Hello'} # 送信メッセージはすべてバイト列にしなければならないので、文字列をバイト列に変換 topic = random_topic.encode('utf-8') jmsg = json.dumps(msg).encode('utf-8') conn.send([topic, jmsg]) print("Send:{}, {}".format(random_topic, str(msg))) # Responseの受け取り msg = conn.recv('string') print('Response : ', msg) time.sleep(1) print('client done') def server(): """ Server """ host = '127.0.0.1' # host = '*' port = 5600 conn = Rep(host, port) print("Server startup.") while True: [topic, jmsg] = conn.recv('multipart') # バイト列から文字列に変更してからloads # jmsgはJSONで送信されているため msg = json.loads(jmsg.decode()) print('received topic : ', msg) print(msg['num'], msg['message']) # Responseの内容を文字列で送信 conn.send('OK') if __name__ == "__main__": """ Req-Res test、Pub-Sub testを両方同時に試しても動作しますが、 個々の動きを確かめたい場合は、 Req-Res testを行いたいときは Pub-Sub testをコメントアウトしてください。 Pub-Sub testを行いたいときは Req-Rep testをコメントアウトしてください。 """ import threading # Req-Res test thc = threading.Thread(target=client, args=()).start() time.sleep(0.5) # while loopで待ち受けている方は、daemonにしている。 ths = threading.Thread(target=server, args=(), daemon=True).start() # Pub-Sub test # while loopで待ち受けている方は、daemonにしている。 ths = threading.Thread(target=sub_1, args=(), daemon=True).start() time.sleep(0.5) thp = threading.Thread(target=pub, args=()).start()Req-Res test の結果
Send:1, {'num': 0, 'message': 'Hello'} Server startup. received topic : {'num': 0, 'message': 'Hello'} 0 Hello Response : OK Send:1, {'num': 1, 'message': 'Hello'} received topic : {'num': 1, 'message': 'Hello'} 1 Hello Response : OK Send:2, {'num': 2, 'message': 'Hello'} received topic : {'num': 2, 'message': 'Hello'} 2 Hello Response : OK Send:2, {'num': 3, 'message': 'Hello'} received topic : {'num': 3, 'message': 'Hello'} 3 Hello Response : OK Send:1, {'num': 4, 'message': 'Hello'} received topic : {'num': 4, 'message': 'Hello'} 4 Hello Response : OK Send:1, {'num': 5, 'message': 'Hello'} received topic : {'num': 5, 'message': 'Hello'} 5 Hello Response : OK Send:2, {'num': 6, 'message': 'Hello'} received topic : {'num': 6, 'message': 'Hello'} 6 Hello Response : OK Send:1, {'num': 7, 'message': 'Hello'} received topic : {'num': 7, 'message': 'Hello'} 7 Hello Response : OK Send:1, {'num': 8, 'message': 'Hello'} received topic : {'num': 8, 'message': 'Hello'} 8 Hello Response : OK Send:2, {'num': 9, 'message': 'Hello'} received topic : {'num': 9, 'message': 'Hello'} 9 Hello Response : OK client donePub-Sub testの結果
Send:2, {'num': 1, 'message': 'Pub Hello'} Send:2, {'num': 2, 'message': 'Pub Hello'} Send:1, {'num': 3, 'message': 'Pub Hello'} received topic 1 : {'num': 3, 'message': 'Pub Hello'} 3 Pub Hello Send:2, {'num': 4, 'message': 'Pub Hello'} Send:2, {'num': 5, 'message': 'Pub Hello'} Send:1, {'num': 6, 'message': 'Pub Hello'} received topic 1 : {'num': 6, 'message': 'Pub Hello'} 6 Pub Hello Send:2, {'num': 7, 'message': 'Pub Hello'} Send:2, {'num': 8, 'message': 'Pub Hello'} Send:1, {'num': 9, 'message': 'Pub Hello'} received topic 1 : {'num': 9, 'message': 'Pub Hello'} 9 Pub Hello Send:2, {'num': 10, 'message': 'Pub Hello'} Pub server done
- 投稿日:2020-07-24T18:49:13+09:00
競プロ精進日記29日目(7/23)
感想
昨日もよくがんばりました。
解説書くのが遅くなりがちなので、すぐ復習するようにします。ABC149-E Handshake
かかった時間
45分
考察
$M$はその回数シミュレートが明らかなので別の方法で考えます。ここで、パワーの高い人のペアから順に握手をするとして選んで行くことが最適なのは自明です。
また、ここではそのような最終的な幸福度の合計が最大の時を求めたく、ペアを$M$個選んである幸福度以上を達成できるかには単調性があると言えるので、ある幸福度の境界となるものを探すには二分探索を用います。ここで、幸福度の合計は考えにくいので、選んだペアのパワーがある値以上になるかを考えてから、答えとなる$M$個のペアを求めます。
よって、あるパワー以上となるペアが$M$個以上作れるようなもののうち最大のものを二分探索で探します。ここで、あるパワー$x$以上となるペアの個数を数える時、左手で握手する人(パワー$A_i$)を決めると、右手で握手する人は$x-A_i$以上のパワーがあればよく、パワーの昇順で人を並べておけばbisect_leftにより求めることができます。
ここで、通常の二分探索では〇〇が成り立つ中で最小のものを求めますが、ここでは〇〇が成り立つ中で最大のものを求めなければならないので、処理を全て逆にする必要があることに注意が必要です。この処理については自分の二分探索の解説記事を参照して、これと真逆のことを行えば良いです。
また、「〇〇が成り立つ中で最小」の場合はその値以上で全て成り立ちその値未満で全て成り立たず、「〇〇が成り立つ中で最大」の場合はその値以下で全て成り立ちその値より大きいと全て成り立たない、ということを意識して境界を考えると上記は実装しやすいと思います。
また、初期値の$l,r$について、$l$は必ず成り立つ値で$r$は必ず成り立たない値をこの問題では指定する必要があり、自分は$l=-1,r=1000000$にしました(ここで少しバグらせました、二分探索の探索範囲には気をつけましょう。)。
以上で、選ぶペアがある値$y$以上になれば良いことがわかったので、それぞれのペアのパワーの合計(幸福度)を求めます。この時も先ほどと同様にbisect_left(bisect_rightでも良い)を用いて探せば難しくありません。ただし、パワーが$y$に等しいペアが複数あって取り除かなければならない場合があるので、場合分けには注意が必要です。
Pythonのコード
abc149e.pyn,m=map(int,input().split()) a=list(map(int,input().split())) a.sort() if n==1: print(a[0]*2) exit() from bisect import bisect_left,bisect_right #幸福度がx以上がm以上か? def f(x): global n,a ret=0 for i in range(n): ret+=(n-bisect_left(a,x-a[i])) return ret #端がやはりコーナーケース(ここまじでバグらせんな) l,r=-1,10**6 while l+1<r: k=l+(r-l)//2 if f(k)>=m: l=k else: r=k co,ans=0,0 for i in range(n): co+=(n-bisect_right(a,l-a[i])) ans+=(n-bisect_right(a,l-a[i]))*a[i] print(2*ans+(m-co)*l)ABC150-E Change a Little Bit
かかった時間
1時間
考察
和を求めよと書かれてあるので、見やすいように$\Sigma$を使って簡易的に表すと、$\sum_{S,T}(\sum_{i} D \times {C_i})$となり、任意の文字列$S,T$に対して和を求めることは計算量的に難しいのでそれぞれの$C_i$がどれだけ寄与するか($D$がどれだけあるか)を考えます。
そして、数列$S,T$が与えられた時に$\sum_{i} D \times {C_i}$を最小にするには、$S,T$で異なる数列の要素のうち$C_i$が小さいものから順に変化させれば良い(✳︎)ことも問題文から読み取ることができます。
ここで、$S,T$がどちらも動くと扱いにくく、異なるビットが同じ時は違う$S,T$も場合の数では同じとみなせるので、$S$を固定して考えることにしました。また、同様の理由で$C_i$は小さい順で並んでいるものとしました。
このもとで$C_i$がどれほど寄与するかを考えるので、$S$と異なるような$T$の$i$番目の要素を考えます。ここで、(✳︎)より$i$番目の要素が選ばれた後に残る可能性があるのは$i+1$番目以降の要素です。従って、「$i$番目の要素と$i+1$番目以降の要素のうち$S$と$T$で異なる要素」の合計の個数が$D$となります。また、$i+1$番目以降の要素のうち$S$と$T$で異なる要素の個数が$k$個となるような場合の数は$_{(N-i)} C _k$通りです。従って、$k=0$~$N-i$より$D$の和は$\sum_{k=0}^{N-i} {_{(N-i)} C _k \times (k+1)}$となります。
実はこれは間違いで、$i$番目より前の要素がどうなるかを決めていません。$i$番目より前の要素は$C_i$の$D$に影響を与えないので、$T$の$i$番目より前の要素の組み合わせを考えて$2^{i-1}$通りとなります。(この間違いでWAになり焦りました。)
よって、$C_i$の和への寄与は合計で$(\sum_{k=0}^{N-i} {_{(N-i)} C _k \times (k+1)}) \times 2^{i-1} \times C_i$となりま、求めたい和は$S$の固定を外して$2^N \times \sum_{i=1}^{N}((\sum_{k=0}^{N-i} {_{(N-i)} C _k \times (k+1)}) \times C_i \times 2^{i-1})$となります。
ここで、組み合わせを前計算しても$O(N^2)$と間に合わないので、$\sum_{k=0}^{N-i} {_{(N-i)} C _k \times (k+1)}$の部分の計算がうまく省略できるのではと考え、以下のように式変形をしました。
$\sum_{k=0}^{N-i} {_{(N-i)} C _k \times (k+1)}$
$= \sum_{k=0}^{X} {_{X} C _k \times (k+1)}(\because X=N-i)$$= \sum_{k=0}^{X} {_{X} C _k }+\sum_{k=0}^{X} {_{X} C _k \times k}$
$= 2^{X} + \sum_{k=0}^{X} {_{X} C _k \times k}(\because$二項定理$)$すると、この式の変形をググったところこのサイトが見つかり、$\sum_{k=0}^{X} {_{X} C _k \times k}=X \times 2^{X-1}$となることがわかりました(二項定理と微分で示せます。このような問題では二項定理を変形して考えることを忘れないようにしたいです。)。また、高校数学では$\sum_{k=1}^{X} {_{X} C _k \times k}=X \times \sum_{k=1}^{X} {_{X-1}C_{k-1}}$という公式があるそうです。
いずれにせよ、先ほどの式は$2^{X} + X \times 2^{X-1}$となるので、求めたい和は$2^N \times \sum_{i=1}^{N}((2^{N-i}+(N-i) \times 2^{N-i-1} ) \times C_i \times 2^{i-1})$となり、$2$の累乗を$10^9+7$乗で割った余りを前計算しておくことで和の計算は$O(N)$で求めることができます。
以上より、ソートの部分がボトルネックとなって$O(N \log{N})$のプログラムを書くことができます。
Pythonのコード
abc150e.pyfrom bisect import bisect_left n=int(input()) c=sorted(list(map(int,input().split()))) mod=10**9+7 #2のx乗を前計算(mod)(0~N-1) p=[1]*(n+1) for i in range(n): p[i+1]=p[i]*2 p[i+1]%=mod ans=0 #それ以上のもの for i in range(n): x=n-i-1 ans+=(p[x]+x*p[x-1])*c[i]*p[i] ans%=mod print(ans*p[n]%mod)
- 投稿日:2020-07-24T18:35:28+09:00
IQ Bot:テーブルの列から必要な部分だけを取り出す
帳票例:テーブルの列から必要な部分だけを取り出す
以下の表では、「金額」というひとつの列の中に、金額・税区分(「外税」)・税率という3つの値が入っています。
ここでは、その中から純粋に金額部分だけを取り出したい場合に、どのように対処すればいいかを解説します。
難易度の違い:表をよく見てみよう
このケース、実は表のつくりは同じでも、OCRの取得結果によって対処の方法が違います。
以下の図の左側のように、青い枠が分割したい項目別にきっちり分かれてとれている場合は、とても簡単に対応できます。
一方、図の右側のように、青い枠が項目をまたいでくっついている場合があると、少し対処が難しくなります。このページでは両方ともやりかたを解説します。
Easyモード:青い枠がきっちり分かれている場合
この場合の対応は簡単。
列値を選択する際に、以下の動画のイメージどおり、ほしい部分の値の幅だけを選択すればOKです。
Hardモード:青い枠がくっついている場合
青い枠がくっついてしまっていると、上記のようにはいきません。
IQ Botは値を青枠のかたまりごとに取得しようとするので、部分的に取得しようとしてもうまくいかないはずです。
Hardモードへの対応方法
Hardモードに対応する場合は、①マッピングでは列全体を取得しつつ、②カスタムロジックで必要な部分だけを取り出すと良いです。
①マッピングのとりかた
②カスタムロジックで必要な部分だけを取り出す
マッピングができたら、カスタムロジックで必要な部分だけを取り出します。
この「必要な部分」がどういう条件で決まるかは帳票によって千差万別なので、一概にパターン化できないのですが、例えば今回の帳票でいえば以下のような分割のしかたが可能です。方法1:決まった文字列を根拠に分割する
考え方
今回の帳票では、金額は税区分(外税)の前に書いてあるか(パターン①)、単独で書いてあるか(パターン②)のどちらかです。
この考え方に基づいてカスタムロジックを作る場合、実装例は以下のようになります。
実装例
必要な部分だけを取り出す処理の例(決まった文字列で分割)# 値を保存する変数: table_values #表の操作をするときに必ず入れるコード(最初) import pandas as pd df = pd.DataFrame(table_values) ############################################# # ↓↓↓ ここからが今回の処理 ↓↓↓ ############################################# #金額欄を分割する処理 def bunkatsu(x): result = "" splitter = ("外税","内税") #Point1:分割の根拠となる文字列 for i in splitter: if i in x: result = x.split(i)[0] #Point2:↑を根拠に分割した上で、分割したどの部分を取り出すかの指定 if result == "": result = x return result df['金額'] = df['金額'].apply(bunkatsu) ############################################# # ↑↑↑ ここまでが今回の処理 ↑↑↑ ############################################# #表の操作をするときに必ず入れるコード(最後) table_values = df.to_dict()方法1の応用方法
例えば税区分で「外税」「内税」以外に「非課税」が考えられる場合は、上記の
splitter = ("外税","内税")をsplitter = ("外税","内税","非課税")のように変更します。上記は税区分よりも前の部分を取り出していますが、税区分よりも後の部分(税率)を取り出したい場合は、上記の
result = x.split(i)[0]の[0]を[1]に変えます。
[0]を[1]に変えると、なぜ税区分より後の部分が取り出せるのかわからない&知りたい人は、文系初心者でもわかるsplitの説明を読んでみてください。方法2:「数値以外の文字」を根拠に分割する
上記の処理をさらに一般化して、「数値以外の文字(1~複数)があれば、それを根拠に分割する」という組み方もできます。
注意:この方法は正規表現を使うので、pythonの正規表現ライブラリ(re)を使います。このライブラリは、V11系統では使用できますが、A2019系統の.14以前のバージョンでは使用できません。
必要な部分だけを取り出す処理の例(正規表現で分割)# 値を保存する変数: table_values #表の操作をするときに必ず入れるコード(最初) import pandas as pd df = pd.DataFrame(table_values) ############################################# # ↓↓↓ ここからが今回の処理 ↓↓↓ ############################################# import re #正規表現ライブラリのインポート #金額欄を分割する処理(関数) def bunkatsu(x): #結果の初期化 result = "" #分割の根拠にしたくない文字列を除外 x = x.replace(" ","") x = x.replace(",","") #対象の文字列に含まれる数字を取り除く → 数字以外の部分だけが残る (”\d"は正規表現で数字を表す) letterX = re.sub("\d","",x) if letterX != "": #数字以外の文字列が含まれていたら...(★) result = re.split("\D+", x)[0] #数字以外の文字列で分割した最初のかたまりを取り出してresultに入れる #"\D+" は正規表現で「数字以外の文字列の任意の数の繰り返し」を表す else: #★以外(=数字のみ)なら... result = x #もとの値をそのままresultに入れる return result #resultの中身を返す #↑ここまでが関数の定義 #金額欄に定義した関数を適用する df['金額'] = df['金額'].apply(bunkatsu) ############################################# # ↑↑↑ ここまでが今回の処理 ↑↑↑ ############################################# #表の操作をするときに必ず入れるコード(最後) table_values = df.to_dict()いかがでしたか?
今回はIQ Botで使うカスタムロジックにしては、そこそこ長め&中級編の内容が入ってきました。
わからない部分があった場合は、質問を投稿していただければ回答しますのでお気軽にどうぞ!それでは!





- 投稿日:2020-07-24T18:32:40+09:00
競プロ精進日記28日目(7/22)
感想
ここ2,3日はかなり頑張れてます。土曜日のABC級は一気にレートを伸ばしたいと思ってます。
あと、最近精進で上埋めをしてるので一問一問が難しく解説が長くなりがちなので、1日ごとに分けようと思います。ABC146-E Rem of Sum is Num
かかった時間
31分
考察
類題に帰着させて素早く解くことができたので良かったと思います。
連続部分列や区間はまず累積和的に考えると良いです。また、この問題では連続部分列の長さが$N$以下かつ$K$未満(①)であることが自明です。このもとで、一般化した実験を以下で行います。
ここで、連続部分列の範囲が$[L,R](1 \leqq L \leqq R \leqq N )$でその要素の和を$K$で割った余りが要素の数と等しい時、$S[X]=A_1+A_2+…+A_X$(ただし、$S[0]=0$)をすでに求めているとすれば、$(S[R]-S[L-1])\%K=R-L+1$かつ$R-L+1<K$($\because ①$)が成り立てば良いです。
ここで、$L-1$を扱いやすいように$L$に直すと、先ほどの条件は、$0 \leqq L \leqq N-1$かつ$1 \leqq R \leqq N$かつ$L < R$のもとで$(S[R]-S[L])\%K=R-L$かつ$R-L<K$と同値になります。
さらに、この条件を変形すると、$L,R$を分離することができ、$(S[R]-S[L])\%K=R-L \leftrightarrow (S[L]-L)\%K=(S[R]-R)\%K$となります。
したがって、$0 \leqq X \leqq N$のそれぞれの$X$について$(S[X]-X) \% K$を求め、$(S[X]-X) \% K$の値をkeyとしその値のインデックス$X$を含む配列をvalueとする辞書に保存し、keyの同じインデックスどうしで$0<R-L<K$を満たすような$L,R$の組を求めれば良いです($S[X]-X$の$K$についての剰余類に分けます。)。
また、インデックス$X$が$L$となるような連続部分列の$R$は$X$より大きく$X+K$未満のインデックスで同じ集合に含まれるものなので、インデックスを含む集合をインデックスの昇順で保存すればbisect_leftを使って探すことができます。よって、これを任意の$X$について求めて答えとなります。
Pythonのコード
abc146e.pyfrom itertools import accumulate n,k=map(int,input().split()) a=list(map(int,input().split())) x=[0]+list(accumulate(a)) mods=dict() for i in range(n+1): now=(x[i]-i)%k if now in mods: mods[now].append(i) else: mods[now]=[i] ans=0 from bisect import bisect_left #mods中はソート済 #K未満なら選べる for i in mods: l=len(mods[i]) for j in range(l): b=bisect_left(mods[i],mods[i][j]+k)-1 ans+=(b-j) print(ans)ABC147E Balanced Path
かかった時間
30分+30分TLE排除、解説AC
間違えた原因
方針は完璧だったのですが、unordered_setの挿入が常に$O(1)$だと思っていました…。(最悪は$O(n)$になります。)
vectorで代用可能な場合はvectorを使うということを忘れずにします。
また、unordered_setを使いたい時も最悪計算量が$O(\log{n})$であるsetをできるだけ使うようにします。
考察
まずは、できるだけ絶対値が小さくなるような貪欲法で行うことを考えますが都合の悪いパターンが発生するのは明らかなので、貪欲法はできません。
ここで、経路を辿っていく際に遷移する先が二つだけと明らかであり、あるマスにたどり着いた時にそのマスでの偏りは$-80 \times 80 \times 2$~$80 \times 80 \times 2$しかなく状態数が少ないことに注目しました。
したがって、以下のようにDPの状態を保存する配列を定義します。
$dp[i][j][k]:=$($i$行目$j$列目の偏りが$k$となるものがあるか)
したがって、$i:1 \rightarrow h,j:1 \rightarrow w$でループを回してそれぞれの状態での遷移を考えれば良いので、状態数を$x$として$O(h \times w \times x)$となり、$h \times w \times x$は高々$10^8$なので間に合うプログラムを書くことができます。
しかし、実装をサボるために状態をset(unordered_set)で保存しようとしたために計算量的に間に合わなくなりました。ここでは通常の配列を使えば間に合わせることができます。
また、DPの遷移については、$dp[i][j] \rightarrow dp[i+1][j]$または$dp[i][j] \rightarrow dp[i][j+1]$であり、その状態変化の差分は$A_{i,j}-B_{i,j}$または$B_{i,j}-A_{i,j}$で、これを実装すれば良いです。また、状態については絶対値のみがわかれば良いので、状態変化した先の状態の絶対値を取りました。
C++のコード
abc147e.cc//コンパイラ最適化用 #pragma GCC optimize("Ofast") //インクルード(アルファベット順) #include<algorithm>//sort,二分探索,など #include<bitset>//固定長bit集合 #include<chrono>//実行時間計測 #include<cmath>//pow,logなど #include<complex>//複素数 #include<deque>//両端アクセスのキュー #include<functional>//sortのgreater #include<iomanip>//setprecision(浮動小数点の出力の誤差) #include<iostream>//入出力 #include<iterator>//集合演算(積集合,和集合,差集合など) #include<map>//map(辞書) #include<numeric>//iota(整数列の生成),gcdとlcm,accumulate #include<queue>//キュー #include<set>//集合 #include<stack>//スタック #include<string>//文字列 #include<unordered_map>//順序保持しないmap #include<unordered_set>//順序保持しないset #include<utility>//pair #include<vector>//可変長配列 using namespace std; typedef long long ll; //マクロ //forループ //引数は、(ループ内変数,動く範囲)か(ループ内変数,始めの数,終わりの数)、のどちらか //Dがついてないものはループ変数は1ずつインクリメントされ、Dがついてるものはループ変数は1ずつデクリメントされる #define REP(i,n) for(ll i=0;i<ll(n);i++) #define REPD(i,n) for(ll i=n-1;i>=0;i--) #define FOR(i,a,b) for(ll i=a;i<=ll(b);i++) #define FORD(i,a,b) for(ll i=a;i>=ll(b);i--) //xにはvectorなどのコンテナ #define ALL(x) x.begin(),x.end() #define SIZE(x) ll(x.size()) //定数 #define INF 1000000000000 //10^12:∞ #define MOD 1000000007 //10^9+7:合同式の法 #define MAXR 100000 //10^5:配列の最大のrange //略記 #define PB push_back //挿入 #define MP make_pair //pairのコンストラクタ #define F first //pairの一つ目の要素 #define S second //pairの二つ目の要素 signed main(){ ll h,w;cin>>h>>w; vector<vector<ll>> ab(h,vector<ll>(w,0)); vector<vector<ll>> b(h,vector<ll>(w)); REP(i,h)REP(j,w)cin>>ab[i][j]; REP(i,h)REP(j,w){cin>>b[i][j];ab[i][j]-=b[i][j];} ll r=2*80*80+1; vector<vector<vector<bool>>> dp(h,vector<vector<bool>>(w,vector<bool>(r,false))); dp[0][0][abs(ab[0][0])]=true; REP(i,h){ REP(j,w){ REP(k,r){ if(dp[i][j][k]){ if(i!=h-1)dp[i+1][j][abs(k+ab[i+1][j])]=true; if(i!=h-1)dp[i+1][j][abs(k-ab[i+1][j])]=true; if(j!=w-1)dp[i][j+1][abs(k+ab[i][j+1])]=true; if(j!=w-1)dp[i][j+1][abs(k-ab[i][j+1])]=true; } } } } REP(k,r)if(dp[h-1][w-1][k]){cout<<k<<endl;return 0;} }
- 投稿日:2020-07-24T18:06:13+09:00
[備忘録] バッカス・ナウア記法について小メモ(Python言語リファレンス内書式)
はじめに
Pythonのリファレンスマニュアルを読もうとしたとき、初めて
BNF文法記法という概念に遭遇したので、今後のために小メモを残します。記号の説明を表にまとめただけのものです。
本編
マニュアルの解説では、随所に下記のような書式のコードが登場します。
for文の構文for_stmt ::= "for" target_list "in" expression_list ":" suite ["else" ":" suite](8.3. for 文 - 8. 複合文 (compound statement) — Python 3.8.4 ドキュメント)
Pythonの言語リファレンスには上記のような記法のコードが掲載されています。
これは、リファレンス内で説明されているように、BNF文法記法やバッカス・ナウア記法などと呼ばれるものです。定義、記法の背景は下記のリンクなどで参照できます。
バッカス・ナウア記法 - Wikipedia
SYNTAX SUMMARY - Algol-60 BNF
About BNF notation"[]" を用いた書式などは、オリジナルの記法を拡張したものです。
Pythonの言語リファレンスでも同様に"[]"が書式に含まれています。Pythonのリファレンスマニュアルで説明されている記号の用法を表にまとめます。
記号 読み 説明 備考 ::= - <左式>は<右式>で定義 - | 垂直線 選択項目の列挙
(左側セル:エスケープの都合で全角文字)演算子の優先度は最低 * アスタリスク 直前にくる要素のゼロ個以上の繰り返し 演算子の結合範囲は可能な限り狭い + プラス 直前にくる要素の一個以上の繰り返し 演算子の結合範囲は可能な限り狭い [] 角括弧 字句がゼロ個か一個出現
(要素がオプションである)- () 丸括弧 字句のグループ化 - "" クオート リテラル文字列の表記 -
- 投稿日:2020-07-24T17:59:42+09:00
Pythonのsplitについて、文系初心者にもわかるように説明してみる
Pythonでめっちゃよく使うsplitの処理ですが、初心者向けにさくっとわかる日本語の記事が意外にも見つからなかったので自分で書いてみます。
ちなみに筆者も文系卒のエンジニアです。
splitとは?
splitは英語で「分割する」という意味で、その名のとおり、文字列を分割にしてリストにします。
「文字列を分割にしてリストにする」が宇宙語に見えた人も安心してください。ちゃんと説明します。文字列とは?
「文字列」はあまり難しく考えず、「言葉」や「文章」みたいなものと思ってください。
"バナナ"も文字列、"りんご"も文字列、"バナナを2つ、りんごを3つ買いました"も文字列です。リストって何?
リストとは何かというと、何かしらの情報を入れておくための番号つきのロッカーのようなイメージです。
銭湯やスポーツジムに行くと、番号つきのロッカーが並んでいますよね? あれです。銭湯やスポーツジムのロッカーは、100番から始まっていたり1000番から始まっていたりしますが、pythonのリストの場合は番号は必ず0番から始まります。
「文字列を分割してリストに入れる」ってどういうこと?
百聞は一見にしかず、ということで、文字列を分割してリストに入れる処理を、実際にpythonでやってみます。
文字列を分割してリストに入れる例word = "りんごとバナナといちごとみかん" #←「word」という変数(箱)に入ったこの文字列を…… mylist = word.split("と") #←「と」という文字のところで切り分けてmylistに入れてね、という意味 print(mylist) #←mylistの中身を見せてね、という意味 #すると、["りんご","バナナ","いちご","みかん"] と表示されます。 # ↑この形が、pythonにおける「リスト」上記の処理の結果得られるmylistの中身は、python的に表現すると
["りんご","バナナ","いちご","みかん"]という形ですが、イメージは以下のような感じです。
「りんご」から「みかん」までが、番号つきのロッカーの中に入っていますね。
splitした結果を使う
上記の例ではsplitした結果として、「りんご」から「みかん」までをmylistという名前のリスト=番号つきロッカーに入れました。
この状態で、
リストの名前[番号]と指定すると、リストの中身を取り出すことができます。たとえばこんなかんじ。
リストから値を取り出す方法print(mylist[0]) # mylistの0番の中身を見せてね、という意味 → 「りんご」が表示される print(mylist[1]) # mylistの1番の中身を見せてね、という意味 → 「バナナ」が表示される print(mylist[2]) # mylistの2番の中身を見せてね、という意味 → 「いちご」が表示される print(mylist[3]) # mylistの3番の中身を見せてね、という意味 → 「みかん」が表示されるまた、pythonならではのおもしろい文法で、「最後から●番目」という指定のしかたもできます。
「最後から●番目」という指定をしたいときは、番号を表す[]の中にマイナスの数字を指定します。リストから値を取り出す方法(後ろから)print(mylist[-1]) # mylistの最後から1番目(=最後)の中身を見せてね、という意味 → 「みかん」が表示される print(mylist[-2]) # mylistの最後から2番目の中身を見せてね、という意味 → 「いちご」が表示される print(mylist[-3]) # mylistの最後から3番目の中身を見せてね、という意味 → 「バナナ」が表示される print(mylist[-4]) # mylistの最後から4番目の中身を見せてね、という意味 → 「りんご」が表示されるいかがでしたか?
splitの仕組みと、結果を取り出す方法について、イメージをつかんでいただけたでしょうか。
この内容が理解できていれば、例えば口座情報から銀行名だけ・支店名だけを取り出す処理でどうしてsplitが使われるのかも理解できると思います。


- 投稿日:2020-07-24T17:43:19+09:00
探索的データ分析の第一歩に便利なpandas-profilingの導入と概要
はじめに
機械学習のデータの前処理工程において、pandas等を用いて、いろいろとデータを眺めながら探索的データ分析をすると思いますが、データの可視化を1コマンドで簡単にやってくれるツール「pandas-profiling」というものがあるので、それを紹介します。
導入
ターミナル$ pip install pandas-profilingライブラリインポート
import pandas as pd import pandas_profiling as pdp仕様
タイタニックのデータで試してみます。タイタニックがわからない人は「kaggle タイタニック」で調べて下さい。
dataframe = pd.read_csv('train.csv')コマンドは1文のみです。
pdp.ProfileReport(dataframe)出力結果は結構なボリュームなのでhtmlファイルに落とす方が見やすいです。
html = pdp.ProfileReport(dataframe) html.to_file(output_file='dump.html')アウトプット
Overview
データの概要を教えてくれます。列数(Number of variables)、行数(Number of observations)、欠損値数(Missing cells)、重複列(Duplicate rows)
Variables
各項目(列)毎のデータ概要を教えてくれます。年齢(Age)のアウトプット例です。
Interactions
列と列の関係を教えてくれます。年齢と運賃のアウトプット例です
Correlations
列と列との相関を教えてくれます。
Missing values
欠損値の情報を教えてくれます。
最後に
初心者にもわかるように、Pythonで機械学習を実施する際の必要な知識を簡便に記事としてまとめております。
目次はこちらになりますので、他の記事も参考にして頂けると幸いです。




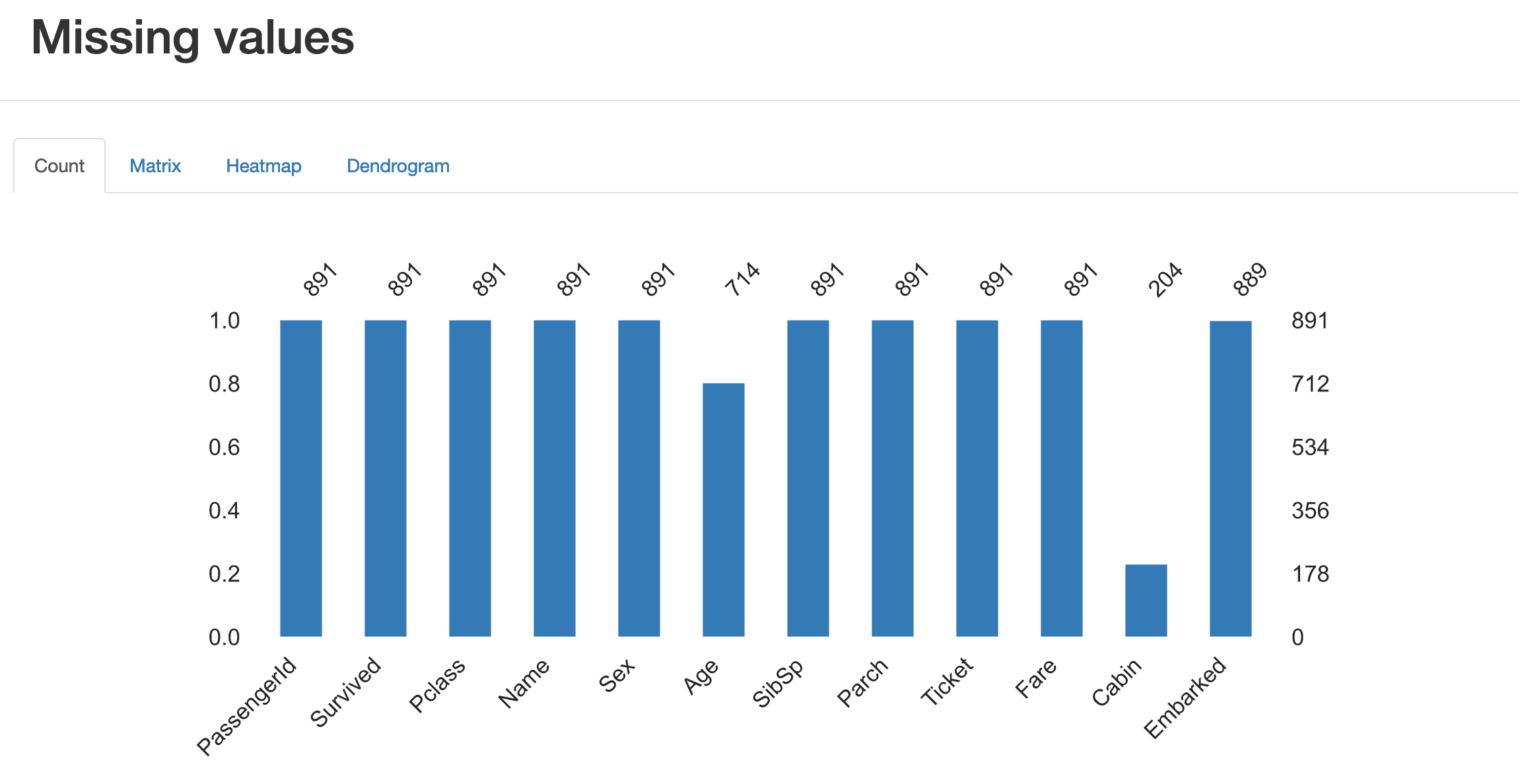
- 投稿日:2020-07-24T17:42:02+09:00
pyplotで中学数学のグラフを書く(その2)
前書き
投稿済みの記事pyplotで中学数学のグラフを書くの続き。
前回の最後の時点から再開します。
コードの再掲
figure3.pyimport matplotlib import matplotlib.pyplot as plt import numpy as np # 日本語化 matplotlib.rc('font', family='BIZ UDGothic') # データの作成 # 横軸(X軸) x = np.arange(-10., 10., 0.01) # 縦軸(Y軸) y1 = 2 * x y2 = 3 * x + 10 # データの描画 plt.plot(x, y1, x, y2) # 軸のラベル plt.xlabel('X軸') plt.ylabel('Y軸') # 格子の表示 plt.grid(True) # 表示 plt.show()実行結果がこちら。
今回は以下の内容を作っていきます。
- 縦横比が1:1になっていない。
- 始点、終点でグラフが切れている。(そのようなグラフもあるのですが、-∞<x<∞のグラフを最初に学ぶので、そのように「見える」方が良い。)
- 原点(座標[0,0])がわかりにくい。
環境
- Windows10 build 18363.959
- Python 3.8.5
- matplotlib 3.3.0
- numpy 1.19.1
原点をわかりやすくする
ともあれ、原点がわかりやすい方がグラフとしては見やすいと思います。
figure4.py# 横軸(horizon)ゼロの太線化 plt.axhline(0, linewidth=2, color="gray") # 縦軸(Vertical)ゼロの太線化 plt.axvline(0, linewidth=2, color="gray")
- 今回は
plt.gridの下に追加します。axhlineは水平線(Horizon)を、指定した値の位置に描く処理です。今回は、"0"の位置に太さ"2"、色"gray"で設定しています。axvlineは垂直線(Vertical)を、指定した値の位置に描く処理です。今回は、"0"の位置に太さ"2"、色"gray"で設定しています。実行すると、
と、いい感じで原点(座標(0, 0))が見やすくなったと思います。原点を中央にする(描画範囲を設定する)
引き続き、次は原点を中央にしたいと思いますが、単純に「上下左右の描画範囲(大きさ)が同じなら、原点は中央になる」という考えで、
plt.axisを使用して設定してみます。figure5.py# 表示範囲の設定 plt.axis([-22, 22, -22, 22])
- 今回は
plt.xlabelの上に追加します。- 描画範囲はX軸の左端"-22"から右端"22"とY軸の下端"-22"から上端"22"としています。今回似たような値を使って分かりにくいので、ちょっとずつ値を変えて、描画がどのように変わるのか試してみるのも良いと思います。
- 設定値は切りのいい値でも良いと思いますが、描画の端と格子が重なるのも個人的に好みでない為、格子線が描かれる(と考えられる)値より少し大きい値を指定しています。
いい感じで、原点が中央に来たと思います。さて、この状態でオレンジのグラフは上端が途切れているように見えますが、描画ウインドウの下端にあるアイコン
をオンにしてグラフ内をドラッグすると描画範囲を動かせるので、少し上の方まで見えるようにずらしてみます。
データの端まできちんと描画されています。
つまり、「データ上では描画していても描画範囲を指定したことで見えない部分がでてくる」という事なので、逆に「描画範囲外までデータを設定すれば、見かけ上-∞<x<∞のグラフが描けそう」と言えます。で、あれば元のデータを増やせば良さそうなので、
xを設定しているところでデータの範囲を広げます。figure6.py# 横軸(X軸) # x = np.arange(-10., 10., 0.01) x = np.arange(-25., 25., 0.01)
青いグラフも描画範囲内の端から端まで表示されるようになりました。
先ほどの様に、
縦横比を1:1にする
軸の表示範囲を
plt.axisで設定した際に、格子が正方形からやや長方形になってしまったので、手当てしていきます。figure7.py# 表示の縦横比を揃える ax = plt.axes(label='xxx') ax.set_aspect('equal')
plt.axisの上に記述します。set_aspectでは数値の指定もできます。(y/x)
- 例えば"3/4"だと横4、縦3(昔のブラウン管テレビ)の比率、"9/16"だと横16、縦9(最近のワイド画面)の比率になります。
四隅の部分を見る限りでは、縦横比が1:1になりました。
ただ、X軸の目盛りが減ってしまい、格子としては長方形になってしまっています。
そこで、目盛りをX,Y両方の軸に対して設定します。figure7.pyplt.xticks(np.arange(-25, 25, 5)) plt.yticks(np.arange(-25, 25, 5))
plt.axisより上に記述します。今回はax.set_aspectとplt.plotの間に記述します。-25 <= x < 25、-25 <= y < 25で両軸とも5刻みで目盛りを設定しています。
なお、
xticks、yticksを使うと、指定箇所以外の目盛りが消えてしまうので、注意が必要です。
二次関数グラフを追加する
さて、中学数学らしく、二次関数と三角関数からsin(正弦)のグラフをそれぞれ追加してみます。
figure8.pyy3 = x ** 2 y4 = np.sin(x)
- sin関数はnumpyにあるものを使います。
作成したデータを
plt.plotに、追加します。figure8.pyplt.plot(x, y1, x, y2, x, y3, x, y4)
最初のグラフと比べるとたいぶ「いい感じ」になりました。後書き
ここまでできれば、見栄えがだいぶ整うので、あとはy1~y4に与える式をいろいろと変えたり、xの刻み幅を変えたりして、どんなグラフになるか試すのも面白いと思います。
※matplotlib.pyplotは今回の使い方では、座標データを順にプロットし、点と点の間を直線で補間しています。
また、グラフが増えたので「凡例」があっても良さそうです。私が学生の頃(?年前)は、グラフと言えば手書きが基本だったので、こういったツールで「自分でいろいろ試せる」環境が整っている昨今がうらやましい限りですが、昔を思い出しつつ、今になっていろいろやってみるのもいい感じに思いました。
最後に、最終版のコードを手直し(前半に体裁の設定、後半にグラフの描画)したものを掲載しておきます。
figure.pyimport matplotlib import matplotlib.pyplot as plt import numpy as np import math # 日本語化 matplotlib.rc('font', family='BIZ UDGothic') # グラフの体裁を整える。 # 表示の縦横比を揃える ax = plt.axes(label='xxx') ax.set_aspect('equal') # 目盛りを整える # X軸 plt.xticks(np.arange(-25, 25, 5)) # Y軸 plt.yticks(np.arange(-25, 25, 5)) # 表示範囲の設定 plt.axis([-22, 22, -22, 22]) # 軸のラベル plt.xlabel('X軸') plt.ylabel('Y軸') # 格子の表示 plt.grid(True) # 横軸(horizon)ゼロの太線化 plt.axhline(0, linewidth=2, color="gray") # 縦軸(Vertical)ゼロの太線化 plt.axvline(0, linewidth=2, color="gray") # データの作成 # 横軸(X軸) x = np.arange(-25., 25., 0.01) # 縦軸(Y軸) y1 = 2 * x y2 = 3 * x + 10 y3 = x ** 2 y4 = np.sin(x) # データの描画 plt.plot(x, y1, x, y2, x, y3, x, y4) # 表示 plt.show()









- 投稿日:2020-07-24T17:25:00+09:00
Fusion 360 を Pythonで動かそう その3 スケッチに3つの接線で円を描く
はじめに
Fusion360 のAPIの理解を深めるために公式ドキュメント内のサンプルコード Create circle by 3 tangents API Sample (3つの接線で円を作る APIサンプル) の内容からドキュメントを読み込んでみたメモ書きです
スクリプトの内容を確認する
最初と最後のおまじないとスケッチの作成まで
最初と最後のこの辺りはFusion360 APIのお決まりのパターンのようです。スケッチの作成については前回も触れたので今回は説明を省略します。
import adsk.core, adsk.fusion, traceback def run(context): ui = None try: app = adsk.core.Application.get() ui = app.userInterface doc = app.documents.add(adsk.core.DocumentTypes.FusionDesignDocumentType) design = app.activeProduct # Get the root component of the active design. rootComp = design.rootComponent # Create a new sketch on the xy plane. sketches = rootComp.sketches; xyPlane = rootComp.xYConstructionPlane sketch = sketches.add(xyPlane) # # ここにコードを追加していく # except: if ui: ui.messageBox('Failed:\n{}'.format(traceback.format_exc()))線を3本描く
# Draw three lines. lines = sketch.sketchCurves.sketchLines; line1 = lines.addByTwoPoints(adsk.core.Point3D.create(0, 0, 0), adsk.core.Point3D.create(3, 1, 0)) line2 = lines.addByTwoPoints(adsk.core.Point3D.create(4, 3, 0), adsk.core.Point3D.create(2, 4, 0)) line3 = lines.addByTwoPoints(adsk.core.Point3D.create(-1, 0, 0), adsk.core.Point3D.create(0, 4, 0))
linesという名前で sketchLines オブジェクトを作成する
Point3D.create メソッドでXYZ座標を指定してポイントを作成し、SketchLines.addByTwoPoints メソッドで始点・終点を指定して線を3本描いている
3本の線に接する円を描く
# Draw circle tangent to the lines. circles = sketch.sketchCurves.sketchCircles circle1 = circles.addByThreeTangents(line1, line2, line3, adsk.core.Point3D.create(0,0,0))
circlesという名前で sketchCircles オブジェクトを作成する
SketchCircles.addByThreeTangents メソッドで3本の線とhintPointの座標値を指定して円を描いている
スケッチ拘束を作成
# Apply tangent contstraints to maintain the relationship. constraints = sketch.geometricConstraints constraints.addTangent(circle1, line1) constraints.addTangent(circle1, line2) constraints.addTangent(circle1, line3)
constraintsという名前で sketch.geometricConstraints オブジェクトを作成?
あるいはconstraintsという変数に sketch.geometricConstraints プロパティを代入?どっちだろう?
GeometricConstraints.addTangent メソッドで circle1 と line1, line2, line3 に接線拘束を作成
まとめ
これぐらいの内容なら読んで理解するのは問題ないけど、サンプルにはないものを作りたいときにドキュメントから必要な情報を探すのに苦労しそうな気がするなー
参考

- 投稿日:2020-07-24T16:57:14+09:00
Pygameを使ってフラクタルツリー(FractalTree)を作る方法
0.はじめに
今回作るものがどういう感じで動くのか見てみたい、この記事を読むのが面倒くさい方はこちら(Youtubeの動画)をご覧ください。
1.実装
fractal_tree.pyimport pygame import math import random pygame.init() win = pygame.display.set_mode((750, 650)) def drawTree(a, b, pos, deepness): if deepness: branch1 = random.randint(1,10) branch2 = random.randint(1,10) c = a + int(math.cos(math.radians(pos)) * deepness * branch1) d = b + int(math.sin(math.radians(pos)) * deepness * branch2) pygame.draw.line(win, (255,255,255), (a, b), (c, d), 1) drawTree(c, d, pos - 20, deepness - 1) drawTree(c, d, pos + 20, deepness- 1) else: pygame.draw.circle(win,(0,255,0),(a,b),2,0) drawTree(370, 650, -90,10) pygame.display.flip() while True: for event in pygame.event.get(): if event.type == pygame.QUIT: pygame.quit()ここでは、まず棒を描き、そこから一定の角度を引いたり足したりして三角関数を使って次の棒まで距離を縦横求め元の棒にそれを足してというのを繰り返しています。pygameでは下に行くほどyの値が大きくなり、木は上に伸ばしたいので角度はマイナスからスタートしています。また、ここではリアルな感じにするためにランダムにbranch1とbranch2を作っていますがそこを両方10にすると普通のフラクタルツリーになります。
2.OpenCVを使って木の形を変えてみる
FractalTree.pyimport cv2 import math import numpy as np def nothing(x): pass def drawTree(a, b, pos, deepness,angle,img): if deepness: c = a + int(math.cos(math.radians(pos)) * deepness * 10.0) d = b + int(math.sin(math.radians(pos)) * deepness * 10.0) cv2.line(img,(a, b), (c, d),(255,255,255),1) drawTree(c, d, pos - angle, deepness - 1,angle,img) drawTree(c, d, pos + angle, deepness- 1,angle,img) def draw(event,x,y,flags,param): global img img = np.zeros((800,800,3),np.uint8) b = cv2.getTrackbarPos('bar','image') drawTree(370, 650, -90,10,angle=b,img=img) img = np.zeros((800,800,3),np.uint8) cv2.namedWindow('image') cv2.createTrackbar('bar','image',0,360,nothing) cv2.setMouseCallback('image',draw) while True: k = cv2.waitKey(1) & 0xFF if k == ord('q'): break cv2.imshow('image',img) cv2.destroyAllWindows()細かい説明はしませんが、ここでは、OpenCVを使ってトラックバーを作り、最初から引いたり足したりする角度を変えることで色々な木の形を作れるようにしています。動作が重くなってしまいましたが、なんとかできました。
最後に
今回作ったものはYoutubeでも解説しているのでそちらも良かったらご覧ください。質問等がございましたらその動画のコメント欄もしくは、この記事のコメント欄でどうぞ。また、いいなと思ったらチャンネル登録お願いします。
- 投稿日:2020-07-24T16:55:18+09:00
neovimでjedi-language-serverをnvim-lspのデフォルト以外の設定で使う
まえがき
最近vimからneovimに移行するにあたってPythonの開発環境を整えているのですが,jedi-language-serverの設定に関する情報が少なかったので,備忘録がてらまとめます.
LSPを使うのが初めてということもあり,「とりあえずは補完が出てくれればいいや,リンターやフォーマッタなどはあとからにしよう」という感じで今回は補完オンリーをターゲットにして環境を開発構築していきます.
環境
今回セットアップした環境は以下の通りです.
- OS: macOS 10.14 (Mojave)
- neovim: 0.5.0 (HomebrewのHEAD 1ca67a7)
- Python: 3.8.5 (Homebrewでインストールしたやつ)
- LSPクライアント: neovim0.5.0から標準のクライアント + nvim-lsp
- LSPサーバ: jedi-language-server
- 補完: deoplete.nvim
巷ではpython-language-serverを使用している例が多いのですが,私の環境では補完候補が出てくるのがものすごく遅かったのでjedi-language-serverを採用しています.
Luaの設定
jedi-language-serverをnvim-lspのデフォルト設定で使うのは簡単です.以下の設定を
init.vimに入れておけば使えるようにはなります.lua <<END local nvim_lsp = require 'nvim_lsp' nvim_lsp.jedi_language_server.setup{} ENDが,デフォルトだとリンターの反応が早い & 張り切りすぎてうるさい.タイプ途中に構文エラーで怒られても...という感じなので,リンターをオフにします.
lua << END local nvim_lsp = require 'nvim_lsp' nvim_lsp.jedi_language_server.setup{ init_options = { diagnostics = { enable = false, }, completion = { disableSnippets = true, }, jediSettings = { autoImportModules = {'numpy', 'pandas'}, }, }, } END設定可能な項目は,GitHubのREADMEを参照ください.
pylsの場合はsettings.pyls.pluginsなんかに記載するのですが,jedi-language-serverはinit_optionsのようです.このへんの設定のお作法?がよく分かっていないのがつらいところ.補完をした際にtextEditのエラーが発生する
上記の設定を行い,構文エラーで怒られないことを確認した後,意気揚々と
np.と打ったところ,以下のエラーが発生しました.Error executing vim.schedule lua callback: ...vim/HEAD-1ca67a7/share/nvim/runtime/lua/vim/lsp/util.lua:277: attempt to index field 'textEdit' (a userdata value)どうやらLuaの
nilとvim.NILの違いが原因のエラーのようです.既にバグは報告されており,近いうちに修正されるとは思うのですが,今のところは以下の変更を加えることで使えるようになります.diff --git a/runtime/lua/vim/lsp/util.lua b/runtime/lua/vim/lsp/util.lua index 52a6fe89f..fc619c8a8 100644 --- a/runtime/lua/vim/lsp/util.lua +++ b/runtime/lua/vim/lsp/util.lua @@ -274,13 +274,13 @@ end -- textEdit.newText > insertText > label -- https://microsoft.github.io/language-server-protocol/specifications/specification-current/#textDocument_completion local function get_completion_word(item) - if item.textEdit ~= nil and item.textEdit.newText ~= nil then + if item.textEdit ~= vim.NIL and item.textEdit.newText ~= vim.NIL then if protocol.InsertTextFormat[item.insertTextFormat] == "PlainText" then return item.textEdit.newText else return M.parse_snippet(item.textEdit.newText) end - elseif item.insertText ~= nil then + elseif item.insertText ~= vim.NIL then if protocol.InsertTextFormat[item.insertTextFormat] == "PlainText" then return item.insertText elseこの修正を行うことで,ようやく補完が出てくるようになりました.それなりに早くて快適.
ちなみに,ROS2のrclpyもさくさく補完できるようになりました.これは便利.
これは本当にPyCharmがいらなくなる日がくるかもしれない.
おまけ1
最終的には使いませんでしたが,pylsを使ってリンターの出力を消したときの設定も載せておきます.
nvim_lsp.pyls.setup{ settings = { pyls = { plugins = { pyflakes = {enabled = false}, pycodestyle = {enabled = false}, pydocstyle = {enabled = false}, } } } }おまけ2
jedi-language-serverでどんな設定が最終的にされているのかを確認するために使ったコードです.
参考: https://stackoverflow.com/a/27028488
function dump_impl(o, level) if type(o) == 'table' then local s = '{\n' for k, v in pairs(o) do if type(k) ~= 'number' then k = '"' .. k .. '"' end local indent = string.rep(' ', level + 1) s = s .. indent .. '['..k..'] = ' .. dump_impl(v, level + 1) .. ',\n' end local indent = string.rep(' ', level) return s .. indent .. '}' else return tostring(o) end end function dump(o) return dump_impl(o, 0) end local c = nvim_lsp.jedi_language_server.make_config() print(dump(c))


- 投稿日:2020-07-24T16:25:17+09:00
Fusion 360 を Pythonで動かそう その2 スケッチに円を描いてみる
はじめに
Fusion360 のAPIの理解を深めるために公式ドキュメント内のサンプルコード Create circle by center and radius API Sample の内容からドキュメントを読み込んでみたメモ書きです
スクリプトの内容を確認する
最初と最後のおまじない
最初と最後のこの辺りはFusion360 APIのお決まりのパターンのようです。今回はあまり気にせずに進むことにします。
import adsk.core, adsk.fusion, traceback def run(context): ui = None try: app = adsk.core.Application.get() ui = app.userInterface doc = app.documents.add(adsk.core.DocumentTypes.FusionDesignDocumentType) design = app.activeProduct # Get the root component of the active design. rootComp = design.rootComponent # # ここにコードを追加していく # except: if ui: ui.messageBox('Failed:\n{}'.format(traceback.format_exc()))スケッチの作成
# Create a new sketch on the xy plane. sketches = rootComp.sketches; xyPlane = rootComp.xYConstructionPlane sketch = sketches.add(xyPlane)
sketchesにルートコンポーネントのスケッチを代入?
xyPlaneにルートコンポーネントのXY平面を代入?
sketchという名前でSketches.add メソッドでルートコンポーネントのスケッチに新しいスケッチを作成ここまでの内容を実行すると新しいスケッチが作成された
円を何個か描いてみる
# Draw some circles. circles = sketch.sketchCurves.sketchCircles circle1 = circles.addByCenterRadius(adsk.core.Point3D.create(0, 0, 0), 2) circle2 = circles.addByCenterRadius(adsk.core.Point3D.create(8, 3, 0), 3)
circlesという名前で sketchCirclesオブジェクトを作成する
Point3D.create メソッドでXYZ座標を指定してポイントを作成し、SketchCircles.addByCenterRadius メソッドで中心点と半径を指定して円を描いている
既存の円の中心に円を追加する
# Add a circle at the center of one of the existing circles. circle3 = circles.addByCenterRadius(circle2.centerSketchPoint, 4)circle2 の centerSketchPoint プロパティ で中心点を取得し、その点を中心点として circle3 を描いている
まとめ
これぐらいの内容なら読んで理解するのは問題ないけど、サンプルにはないものを作りたいときにドキュメントから必要な情報を探すのに苦労しそうな気がするなー
参考

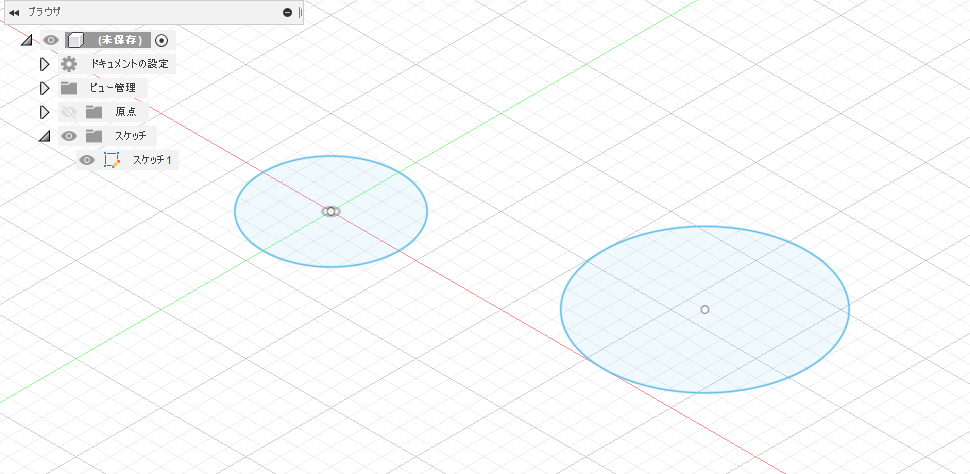

- 投稿日:2020-07-24T16:08:45+09:00
TRPO実装のためのTips
はじめに
TRPOを実装する際に詰まったところがあったのでそのメモです。あくまでメモですが、実装したいなーと思っている方の手助けとなればと思います。
Step1: TRPOの実装はいろいろ種類があることを知ろう
TRPOのオリジナルは2015年に提案されたこちら
Trust Region Policy Optimization
GAE (Generalized Advantage Estimation)の論文内で言及されているもの
High-Dimensional Continuous Control Using Generalized Advantage Estimation
PPO内で言及されているもの
Proximal Policy Optimization Algorithms
RL that Mattersで言及されているもの
Deep Reinforcement Learning that Matters
です。ただ、実装例を見ていくと、Chainerrl、著者の実装、Open AI gym baselineの実装はどれもGAEをQ値(下記式のQです。)の推定に使ってそうです。ネットワーク構造やパラメータは各実装でばらつきがあり、パラメータに敏感すぎる深層強化学習手法においてこれだけいろいろとあると、ちょっと弱ってしまいますが、GAEを使う実装が普及していることを知っておいた方が良さそうです。何もしらずにTRPOのオリジナルだけ読んで、実装しようとすると、参考になる実装例があまりないかと思います。chainerrlはRL that mattersのパラメータで再現されていますのでそれを信頼するのが一番良さそうです。
Step2: Appendix Cをちゃんと読もう、そのほかの説明記事を参考にしよう
深層強化学習論文のあるあるですが、TRPOの論文はAppendixC(特にAppendixC.1)を読まないと実装ができないようになっています。重要な理論パートを全部飛ばすとTRPOがやっているのは
- 下記式のold方策と更新後の方策のkl divergenceのパラメータに関するヘッシアンと近似収益のパラメータに関する勾配を算出
- 算出したヘッシアンと勾配を使い、共役勾配法でパラメータの更新値を算出
- そのパラメータ更新値が制約を満たすか、性能向上するかを確認しながら、直線探索
の3手順です。オリジナルの論文内でいうと重要な式は以下です。(muupanさんの記事より引用)
\text{maximize}_\theta ~ L_{\theta_\text{old}}(\theta)\\ \text{subject to} ~ \bar{D}_\text{KL}(\theta_\text{old},\theta) \le \delta,\\ \text{where} ~ L_{\theta_\text{old}}(\theta) = \mathbb{E}_{s \sim \rho_{\theta_\text{old}}, a \sim \pi_{\theta_\text{old}}} \Big[ \frac{\pi_\theta(a|s)}{\pi_{\theta_{old}}(a|s)} A_{\theta_\text{old}}(s,a) \Big],\\ \bar{D}_\text{KL}(\theta_\text{old},\theta) = \mathbb{E}_{s \sim \rho_{\theta_\text{old}}} [ D_\text{KL}(\pi_{\theta_{old}}(\cdot|s)||\pi_\theta(\cdot|s))].もっと詳しい内容は、muupanさんの記事やスライドSonyのYu Ishiharaさんの記事が分かりやすいです。
https://qiita.com/muupan/items/34f3c89c100d414e9afc
https://www.slideshare.net/mooopan/trust-region-policy-optimization
https://speakerdeck.com/yuishihara/model-based-reinforcement-learning-for-atari
Open AIの記事も英語が読める方にとっては良いかと思います。
https://spinningup.openai.com/en/latest/algorithms/trpo.html
Step3: Hessianを自動微分ライブラリで計算できるようにしよう、パラメータの持つ勾配の抜き出し方などを把握しよう
TRPOは語弊を恐れずに言うならパラメータの勾配に関する扱い方が普通の強化学習手法と異なります。通常のPytorchやtensorflow、nnablaなどに実装されているSolver(Optimizer)を用いる場合、パラメータやネットワークをSolverに渡してあげてこちらは、lossを計算し、backwardして、solverをupdateすればSolverが勝手にパラメータを更新してくれるので良いですが、TRPOの場合、各パラメータの勾配やヘッシアンを実際に抜き出し、こちらで更新量を計算する必要があります。
そのため各パラメータが保持している、勾配を抜き出すなどの処理を行う必要があります。ヘッシアンを計算するためには、Pytorchであれば、grad.autograd.grad、nnablaであればgradなどを使ってパラメータの勾配を計算し、その勾配を使ってさらに、backwardしてまたパラメータの勾配を算出することが必要です。そのためにも、grad関数(通常、引数はloss、パラメータで構成されているはず)の使い方を理解しましょう。
Step4: Hessianとxの掛け算の結果を高速に計算できることを知って、実装しよう
パラメータに関するヘッシアンをナイーブに計算するとなると、時間もメモリも消費します(ネットワークのパラメータ数×ネットワークのパラメータ数)。そこで、それを工夫するための手法というかテクニックがあります。
https://www.telesens.co/2018/06/09/efficiently-computing-the-fisher-vector-product-in-trpo/
の記事のみていただくと分かりますが、テクニック次第で効率よく計算することができます。なお、この記事の内容は一応Appendix C.1に書かれていますが、分かりにくいので上記の記事がとっても参考になりました。
Step5: 共役勾配法を理解しよう
TRPOはパラメータの更新量をもとめる際に共役勾配法を使います。なので、まず共役勾配法の実装が必要になります。なお、共役勾配法は、以下式を解くために使われます。$\boldsymbol{s}$は更新量を計算するために必要なパラメータのベクトルです。(なので、shape=パラメータ数です。よって、$\boldsymbol{g}$もそうです。)
\boldsymbol{s} = \boldsymbol{H}^{-1}\boldsymbol{g}ナイーブに計算するなら、ヘッシアンの算出+ヘッシアンの逆行列が必要になりますが、共役勾配法を使うことで、$\boldsymbol{H}\boldsymbol{s}$の計算できる関数と、$\boldsymbol{g}$(近似の期待収益のパラメータに関する勾配)があれば良く、上記の式を計算できます。よってナイーブなヘッシアンの計算がいらないというメリットがあります。Appendix中に記述がありますが、共役勾配法で10回反復したものを近似解とすることで、計算量や時間、メモリなどを節約しています。(RL that mattersでは20回になっています。)共役勾配法については、Wikipediaの解説が分かりやすいです。共役勾配法は最適化のための手法ですが、$x = A^{-1}b$のような連立方程式を解法することに使えます。
実装例をみていくと、著者実装参考
def cg(f_Ax, b, cg_iters=10, callback=None, verbose=False, residual_tol=1e-10): p = b.copy() r = b.copy() x = np.zeros_like(b) rdotr = r.dot(r) fmtstr = "%10i %10.3g %10.3g" titlestr = "%10s %10s %10s" if verbose: print titlestr % ("iter", "residual norm", "soln norm") for i in xrange(cg_iters): if callback is not None: callback(x) if verbose: print fmtstr % (i, rdotr, np.linalg.norm(x)) z = f_Ax(p) v = rdotr / p.dot(z) x += v*p r -= v*z newrdotr = r.dot(r) mu = newrdotr/rdotr p = r + mu*p rdotr = newrdotr if rdotr < residual_tol: break if callback is not None: callback(x) if verbose: print fmtstr % (i+1, rdotr, np.linalg.norm(x)) # pylint: disable=W0631 return xこの共役勾配法の関数の引数になっているAxがヘッシアンとベクトルの積を計算する関数になります。(多くの実装でHessian(fisher)-vector-productと名前が付けられています。)
ヘッシアンとベクトルの積は実際の実装例を見ていただければわかると思いますが、多くが、vectorを受け取り、そのvectorを使ってパラメータの勾配との積を計算し、その勾配を求めることでパラメータのヘッシアンを算出しています。chainerrlの実装を参考
def _hessian_vector_product(flat_grads, params, vec): """Compute hessian vector product efficiently by backprop.""" grads = chainer.grad([F.sum(flat_grads * vec)], params) assert all(grad is not None for grad in grads),\ "The Hessian-vector product contains None." grads_data = [grad.array for grad in grads] return _flatten_and_concat_ndarrays(grads_data)なお、実際にこの関数を使うときに、
def fisher_vector_product_func(vec): fvp = _hessian_vector_product(flat_kl_grads, policy_params, vec) return fvp + self.conjugate_gradient_damping * vecというようにdampingが存在していますが、
http://www2.maths.lth.se/matematiklth/vision/publdb/reports/pdf/byrod-eccv-10.pdf
の3pの6式に書かれているように、これは正則化項で計算を安定させるためのものです。
Step6: ここまでで必ずテストを書こう
ここまで理解できれば、様々な方の実装例を参考にしながらTRPOのコアな部分は実装ができるかと思います。しかし、要素が多いのでテストを書くことをお勧めします。各要素が比較的独立しているのでtrpoはテストしやすいかと思います。
- 共役勾配法が正しく実装できているのか確認、$x = A^{-1}b$を正しく計算できるか(numpyのinvやpinvを使えばすぐ計算できるのでそれと比較する。)
- ヘッシアンの計算が正しく理解できているのか、適当な関数($x^2 + y^3 + ...$)を用いて手で計算したヘッシアンと比較し、自分が正しくライブラリを扱えているのかテスト。不安な場合は、自分の使っているライブラリと異なるライブラリで計算して比較する。
- ヘッシアンとベクトルの積を計算する関数があっているのかをmuupanさんの記事のようにテストしてみる、または、実際の使われ方のように、共役勾配法を含めて$x = A^{-1}b$を本当に正しく計算できるのかテスト。不安な場合は、自分の使っているライブラリと異なるライブラリで計算して比較する。
- 計算グラフを一応表示できるなにかのツールを使って目視で確認する、shapeのテストを行う。
STEP8: GAEやモンテカルロ推定を実装しよう
本記事では触れませんが、TRPOはQ値の推定が必要なので、その値を推定するアルゴリズムを実装しましょう。こちらもテストすることをおすすめします。
最後に
学習が上手くいくことを祈りましょう。。。