- 投稿日:2020-07-24T22:46:33+09:00
【AWS-SAA】選択肢でたまに出題されるAWSサービス
はじめに
教材ではあまり触れられないが、問題集などの選択肢でたまに出題されるサービスについて備忘録を兼ねて、AWSのサイトの内容を中心に簡単にまとめていきたい。(たまに出題されると思ったのは私の主観での判断なので、その点ご了承ください。)
サービス一覧
API Gateway
簡単にAPIの作成、公開、保守、モニタリング、保護を行えるフルマネーフド型サービス。トラフィック管理、CORS サポート、認可とアクセスコントロール、スロットリング、モニタリング、API バージョン管理など、最大数十万規模の同時 API コールの受け入れと処理に伴うすべてのタスクを取り扱う。
Athena
Amazon S3 内のデータを標準SQLを使用して簡単に分析するサービス。即時にデータのクエリを実行し、数秒で結果取得。料金は実行したクエリに対してのみ。
Cognito
ウェブアプリケーションおよびモバイルアプリに簡単にユーザーのサインアップ/サインインおよびアクセスコントロールの機能を追加できる。Facebook、Google、AmazonなどのソーシャルIDプロバイダー、およびSAML2.0によるエンタープライズIDプロバイダーを使用したサインインが可能。
Shield
マネージド型の分散サービス妨害 (DDoS) に対する保護サービス。AWS で実行しているアプリケーションを保護する。
AWS SDK
AWSサービスをプログラムから操作できるサービス。各サービスで提供されているAPIをwrapしたもの。
※SDKとは、あるシステムに対応したソフトウェアを開発するために必要なプログラムや文書などをひとまとめにしたパッケージのこと。参考
- 投稿日:2020-07-24T21:39:00+09:00
Golangはじめて物語(第3話: CodePipeline+SAM+LambdaでCI/CD編)
はじめに
前回というか第一話の続編。
第一話ではServerless Frameworkを使ったが、今回はCodePipelineを使って自動起動するパイプラインを使ってみようと思う。となると、セオリー(だと思ってるの)はSAMをCloudFormationで起動するパターンだろう。golangのアプリケーションそのものの話は薄めというか、ほぼ入っていないのであしからず。
前提条件
・golangのアプリケーションは第一話のものをほぼ流用するので、読んでいる前提
・別の記事で書いたTerraformのサブモジュールをほぼ流用するので、読んでいる前提
・というかここまでやったら何を書くんだっけ?という感じではあるけど、一応今回は、buildspec.ymlとSAMテンプレートのコツを書いておく全体構成
golang-lambdapipeline ├── buildspec.yml ├── .gitignore ├── .gitmodules ├── Makefile ├── src │ ├── go.mod │ ├── main.go │ └── main_test.go ├── template.yml └── terraform ├── 01_prepare │ └── main.tf └── 02_pipeline ├── main.tf └── modules ├── 01_variables.tf ├── 02_iam.tf ├── 03_s3.tf ├── 04_cloudwatchlogs.tf ├── 05_codepipeline.tf └── 06_cloudformation_parameter.jsonアプリケーション中で、
users-tableというDynamoDBを触るので、予め作っておく必要がある。
terraform/01_prepare は、上記DynamoDBテーブルを作成するtfファイルを入れてている。terraform/01_prepare/main.tf###################################################################### # Provider # ###################################################################### provider "aws" { region = "ap-northeast-1" } ###################################################################### # DynamoDB # ###################################################################### resource "aws_dynamodb_table" "users" { name = "users-table" billing_mode = "PROVISIONED" read_capacity = 1 write_capacity = 1 hash_key = "id" attribute { name = "id" type = "S" } }アプリケーション
アプリケーションは、上記の通り第一話のほぼ流用である。モジュール化するのが面倒だったので、ちょっとまとめたくらいだ。
src/main.go
src/main.gopackage main import ( "errors" "context" "encoding/json" "log" "github.com/aws/aws-lambda-go/events" "github.com/aws/aws-lambda-go/lambda" "github.com/aws/aws-lambda-go/lambdacontext" "github.com/aws/aws-sdk-go/aws" "github.com/aws/aws-sdk-go/aws/session" "github.com/aws/aws-sdk-go/service/dynamodb" "github.com/aws/aws-sdk-go/service/dynamodb/dynamodbattribute" ) var () const () type item struct { Id string `dynamodbav:"id"` Name string `dynamodbav:"name"` } func init() { } func main() { lambda.Start(handler) } func handler(ctx context.Context, request events.APIGatewayProxyRequest) (events.APIGatewayProxyResponse, error) { var ( statusCode int id string idIsNotNull bool record item returnbody string err error ) if lc, ok := lambdacontext.FromContext(ctx); ok { log.Printf("AwsRequestID: %s", lc.AwsRequestID) } statusCode = 200 if len(request.QueryStringParameters) == 0 { log.Println("QueryStringParameters is not specified.") statusCode = 400 } else { if id, idIsNotNull = request.QueryStringParameters["id"]; !idIsNotNull { log.Println("[QueryStringParameters]id is not specified") statusCode = 400 } if id == "99999" { statusCode = 500 } } if statusCode == 200 { record, err = getUser(id) if err != nil { if err.Error() == "Not Found" { statusCode = 404 } else { statusCode = 500 } } else { jsonBytes, _ := json.Marshal(record) returnbody = string(jsonBytes) } } response := events.APIGatewayProxyResponse{ StatusCode: statusCode, IsBase64Encoded: false, Body: returnbody, Headers: map[string]string{ "Content-Type": "application/json", }, } return response, nil } func getUser(id string) (item, error) { var ( item item ) sess := session.Must(session.NewSessionWithOptions(session.Options{ SharedConfigState: session.SharedConfigEnable, })) svc := dynamodb.New(sess) result, err := svc.GetItem(&dynamodb.GetItemInput{ TableName: aws.String("users-table"), Key: map[string]*dynamodb.AttributeValue{ "id": { S: aws.String(id), }, }, }) if err != nil { log.Println("Got error calling GetItem:") log.Println(err.Error()) return item, errors.New("Library Error") } err = dynamodbattribute.UnmarshalMap(result.Item, &item) if err != nil { log.Println("Failed to unmarshal Record", err) log.Println(err.Error()) return item, errors.New("Library Error") } if item.Id == "" { log.Printf("Could not find id: %s", id) return item, errors.New("Not Found") } return item, nil }
src/main_test.go
src/main_test.gopackage main import ( "context" "os" "testing" "log" "github.com/pkg/errors" "github.com/aws/aws-lambda-go/events" "github.com/aws/aws-lambda-go/lambdacontext" "github.com/aws/aws-sdk-go/aws" "github.com/aws/aws-sdk-go/aws/session" "github.com/aws/aws-sdk-go/service/dynamodb" "github.com/aws/aws-sdk-go/service/dynamodb/dynamodbattribute" ) var ( items = []struct { Id string `dynamodbav:"id"` Name string `dynamodbav:"name"` }{ {"test11111", "Tanaka Ichiro"}, {"test22222", "Sato Jiro"}, } ) const () func setup() error { sess := session.Must(session.NewSessionWithOptions(session.Options{ SharedConfigState: session.SharedConfigEnable, })) svc := dynamodb.New(sess) for _, item := range items { av, err := dynamodbattribute.MarshalMap(item) if err != nil { return errors.Wrap(err, "Got error marshalling new item") } log.Println(av) _, err = svc.PutItem(&dynamodb.PutItemInput{ Item: av, TableName: aws.String("users-table"), }) if err != nil { return errors.Wrap(err, "Got error calling PutItem") } } return nil } func teardown() error { sess := session.Must(session.NewSessionWithOptions(session.Options{ SharedConfigState: session.SharedConfigEnable, })) svc := dynamodb.New(sess) for _, item := range items { _, err := svc.DeleteItem(&dynamodb.DeleteItemInput{ TableName: aws.String("users-table"), Key: map[string]*dynamodb.AttributeValue{ "id": { S: aws.String(item.Id), }, }, }) if err != nil { return errors.Wrap(err, "Got error calling DeleteItem") } } return nil } func TestHandler(t *testing.T) { tests := []struct { testid string queryStringParameters map[string]string expected int }{ {testid: "001", queryStringParameters: map[string]string{"id": "test11111"}, expected: 200}, {testid: "002", queryStringParameters: map[string]string{"id": "test22222"}, expected: 200}, {testid: "003", queryStringParameters: map[string]string{"id": "test33333"}, expected: 404}, } lc := &lambdacontext.LambdaContext{ AwsRequestID: "test request", } ctx := lambdacontext.NewContext(context.Background(), lc) for _, te := range tests { res, _ := handler(ctx, events.APIGatewayProxyRequest{ QueryStringParameters: te.queryStringParameters, }) if res.StatusCode != te.expected { t.Errorf("Test-ID%s: StatusCode=%d, Expected %d", te.testid, res.StatusCode, te.expected) } } } func TestMain(m *testing.M) { err := setup() if( err != nil){ log.Println(err) } ret := m.Run() teardown() os.Exit(ret) }ちゃんと、
go mod initしてgo.modを作ってバージョンを固定化しておこう。
go.sumはリポジトリに入れなくても良いので.gitignoreに書いておく。CI/CDパイプライン
Terraform
これはもう別の記事そのままのTerraformを使っているので、これを見てもらえれば。
ディレクトリ内に.gitmodulesがあるのも、この中でGitのサブモジュール機能を使っているためである。Buildspec
BuildSpecについては、以下のポイントを気にしておけば特に難しいところはない。
- ランタイムは
golang: 1.1x(xは適切な値を選択)- 今回の構成では、トップディレクトリにsrcがあるもののビルド自体はsrcフォルダ内で実行する必要があるため、
pre_buildでcdしている。後述のMakefileを使っても良いかと思いつつ、ビルドスクリプト内で別のビルドスクリプトを動かすのには抵抗があったので、一旦は保留。- Lambdaで動作させるためには
GOARCH=amd64 GOOS=linuxの変数設定が必要あと、今回はテストコード中で本物のDynamoDBに繋いでしまったため、通常のCodePipelineのロールにDynamoDBアクセスのポリシを追加する必要があって面倒なので割愛した。本当はテストコードをモックにするのが良いのかな……。
buildspec.ymlversion: 0.2 phases: install: runtime-versions: golang: 1.13 pre_build: commands: cd src build: commands: - echo Build started on `date` - GOARCH=amd64 GOOS=linux go build -o ../artifact/gopipeline-test - echo Build ended on `date` post_build: commands: # - echo Test started on `date` # - go test ./... # - echo Test ended on `date` - cd ../ - echo CloudFormation Package started on `date` - aws cloudformation package --template-file template.yml --output-template-file output-template.yml --s3-bucket ${CF_BUCKET_NAME} - echo CloudFormation Package ended on `date` artifacts: type: zip files: - output-template.yml cache: paths: - '/root/.m2/**/*'SAMテンプレート
SAMテンプレートも以下のポイントを抑えておけば、あとは普通のテンプレートである。
AWS::Serverless::FunctionのRuntimeはgo1.xを指定(ここは、適切な値に変えてね、ではなくて本当にxを書いておけば良い)AWS::Serverless::FunctionのCodeUriはCloudFormationを実行するディレクトリから見た、実行コマンドのある相対パスを指定AWS::Serverless::FunctionのHandlerはビルドターゲットのファイル名template.ymlAWSTemplateFormatVersion: 2010-09-09 Transform: AWS::Serverless-2016-10-31 Description: Test for golang Lambda CI/CD Pipeline Parameters: LambdaFunctionName: Description: "Lambda Function Name" Type: "String" Default: "LambdaFunctionName" LambdaExecutionRoleName: Description: "Lambda Execution Role Name" Type: "String" Default: "LambdaExecutionRoleName" Globals: Function: Timeout: 60 Resources: # ------------------------------------------------------------# # IAM Role # ------------------------------------------------------------# LambdaExecutionRole: Type: AWS::IAM::Role Properties: RoleName: !Sub ${LambdaExecutionRoleName} AssumeRolePolicyDocument: Version: 2012-10-17 Statement: - Effect: Allow Principal: Service: - lambda.amazonaws.com Action: sts:AssumeRole ManagedPolicyArns: - arn:aws:iam::aws:policy/service-role/AWSLambdaBasicExecutionRole # ------------------------------------------------------------# # Lambda # ------------------------------------------------------------# LambdaTest: Type: AWS::Serverless::Function Properties: FunctionName: !Sub ${LambdaFunctionName} Handler: gopipeline-test Runtime: go1.x MemorySize: 128 Role: !GetAtt LambdaExecutionRole.Arn CodeUri: artifact AutoPublishAlias: Prod DeploymentPreference: Type: AllAtOnceMakefile
今回のリポジトリは、やりたいことに対していろいろと
cdしないといけなくて面倒なので、その辺はMakefileに任せる。
Terraformなんかも、いちいちディレクトリに移動なんてしないで、make terraform-pipeline ARG=applyとかやって、ディレクトリしないようにする。build: cd src; \ GOARCH=amd64 GOOS=linux go build -o ../artifact/gopipeline-test .PHONY: build test: cd src; \ go test ./... .PHONY: test terraform-prepare: cd terraform/01_prepare; \ terraform $(ARG) terraform-pipeline: cd terraform/02_pipeline; \ terraform $(ARG) clean: rm -rf artifact .PHONY: cleanこれでGolangのCI/CDパイプラインを作ることができる。簡単!
- 投稿日:2020-07-24T20:54:30+09:00
QuickSight ネームスペース(マルチテナンシー)
QuickSightのネームスペースとは
ネームスペースを複数作ることでQuickSight上の最上位の空間を分割することができます。
例えばSaaS事業者の方がお客様である会社A、会社Bごとにネームスペース(空間)を分けて様々な干渉を無くすことができます。いわゆるマルチテナンシーの機能になります。わかりやすくスッキリしてマルチテナンシーできますね。aws cli v2を最新にする
まずは新しい機能が使えるようにaws cliをアップデートしておく。今回はaws cli v2を使っています。
Macにインストールの場合、手順は公式通り以下を実施します。これによって20200724段階での最新(?)のv2.0.34となりました。curl "https://awscli.amazonaws.com/AWSCLIV2.pkg" -o "AWSCLIV2.pkg" sudo installer -pkg ./AWSCLIV2.pkg -target /バージョンの確認
aws --version aws-cli/2.0.34 Python/3.7.4 Darwin/18.7.0 botocore/2.0.0dev38ネームスペース確認
ここからが本題です。QuickSightには実は元々DefaultのみでしたがNameSpaceという表記(概念)がされていました。手元の環境で新しいAPIのlist-namespacesをしてみます。以下のように既存の環境にはnamespace/defaultとなっているように、defaultという名前のネームスペースになっています。
aws quicksight list-namespaces --aws-account-id xxxxxxxxxxxx { "Status": 200, "Namespaces": [ { "Name": "default", "Arn": "arn:aws:quicksight:us-east-1:xxxxxxxxxxxx:namespace/default", "CapacityRegion": "us-east-1", "CreationStatus": "CREATED", "IdentityStore": "QUICKSIGHT" } ], "RequestId": "9b2a27f8-0515-4a0f-93db-275beea8731b" }describe-namespaceで確認
aws quicksight describe-namespace --aws-account-id xxxxxxxxxxxx --namespace default { "Status": 200, "Namespace": { "Name": "default", "Arn": "arn:aws:quicksight:us-east-1:xxxxxxxxxxxx:namespace/default", "CapacityRegion": "us-east-1", "CreationStatus": "CREATED", "IdentityStore": "QUICKSIGHT" }, "RequestId": "6f4ace7d-4465-410d-b8ad-5da6552cebc5" }新しいネームスペース作成
新しくcompany-aという名前のネームスペースを作成します。SaaS事業者からしてお客様となる会社(company-a)様と思ってください。お客さんが増えていけばこの単位で増やしていけばしっかりアイソレーションできます。
aws quicksight create-namespace --aws-account-id xxxxxxxxxxxx --namespace company-a --identity-store QUICKSIGHT { "Status": 202, "Name": "company-a", "CapacityRegion": "us-east-1", "CreationStatus": "CREATING", "IdentityStore": "QUICKSIGHT", "RequestId": "1b23f19f-d7f6-4626-ab13-ddba7db43ceb" }新しいネームスペースの確認(list, describe)
company-aのネームスペースが出来ていることが確認できます。
aws quicksight list-namespaces --aws-account-id xxxxxxxxxxxx { "Status": 200, "Namespaces": [ { "Name": "company-a", "Arn": "arn:aws:quicksight:us-east-1:xxxxxxxxxxxx:namespace/company-a", "CapacityRegion": "us-east-1", "CreationStatus": "CREATED", "IdentityStore": "QUICKSIGHT" }, { "Name": "default", "Arn": "arn:aws:quicksight:us-east-1:xxxxxxxxxxxx:namespace/default", "CapacityRegion": "us-east-1", "CreationStatus": "CREATED", "IdentityStore": "QUICKSIGHT" } ], "RequestId": "99536eb6-8ea8-46e6-abc1-ad241fd57f53" }aws quicksight describe-namespace --aws-account-id xxxxxxxxxxxx --namespace company-a { "Status": 200, "Namespace": { "Name": "company-a", "Arn": "arn:aws:quicksight:us-east-1:xxxxxxxxxxxx:namespace/company-a", "CapacityRegion": "us-east-1", "CreationStatus": "CREATED", "IdentityStore": "QUICKSIGHT" }, "RequestId": "6928b871-5c8c-4a1d-8ff2-c318d63c2919" }company-aのネームスペースにユーザー追加
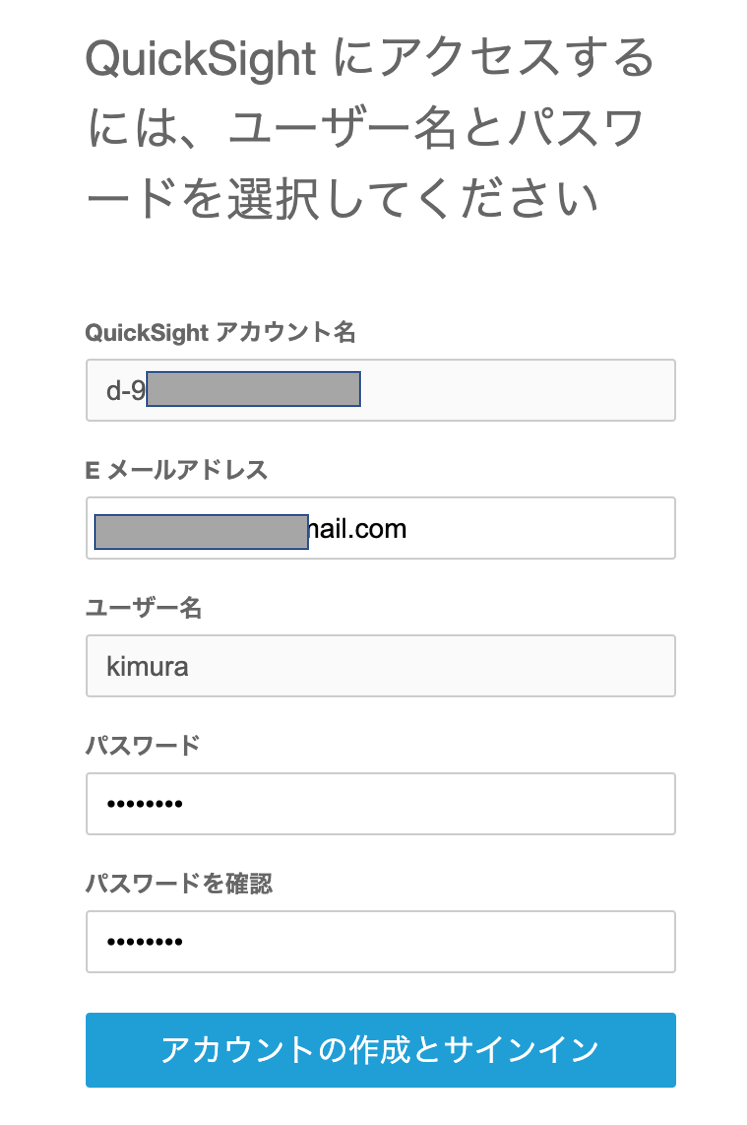
以下のファイル作成します。これを読み込みregister-userでユーザーを作成します。
ここでネームスペースにcompany-aを指定しています。comnpany-aのネームスペースにユーザーが作成され、既存のdefaultのネームスペースにはなんら操作は出来ないユーザーです。company-aの会社にも管理者(ADMIN)、グラフを作る人(AUTHOR)、グラフを見る人(READER)がいると思うのでそれぞれ作れます。今回はまず管理者(ADMIN)を作ります。vim register-reader1.json{ "IdentityType": "QUICKSIGHT", "Email": "xxxx@gmail.com", "UserRole": "ADMIN", "AwsAccountId": "xxxxxxxxxxxx", "Namespace":"company-a", "UserName": "kimura" }register-userで実際にユーザー作成
ここではkimuraというユーザーを作成しています。company-aの会社の管理者となるkimuraさんと思ってもらえたらと。aws quicksight register-user --cli-input-json file://register-reader1.json { "Status": 201, "User": { "Arn": "arn:aws:quicksight:us-east-1:xxxxxxxxxxxx:user/company-a/kimura", "UserName": "kimura", "Email": "xxxx@gmail.com", "Role": "ADMIN", "Active": false, "PrincipalId": "user/d-90677c1ab6/d17bed3d-e17e-4474-b9b3-0994713217c6" }, "UserInvitationUrl": "https://signin.aws.amazon.com/inviteuser?token=yyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyy", "RequestId": "f1606c12-1cfb-4d87-8177-6b26c516d813" }セキュリティ上、kimuraさんはこの登録を自身で承認しパスワード登録しなければいけません。
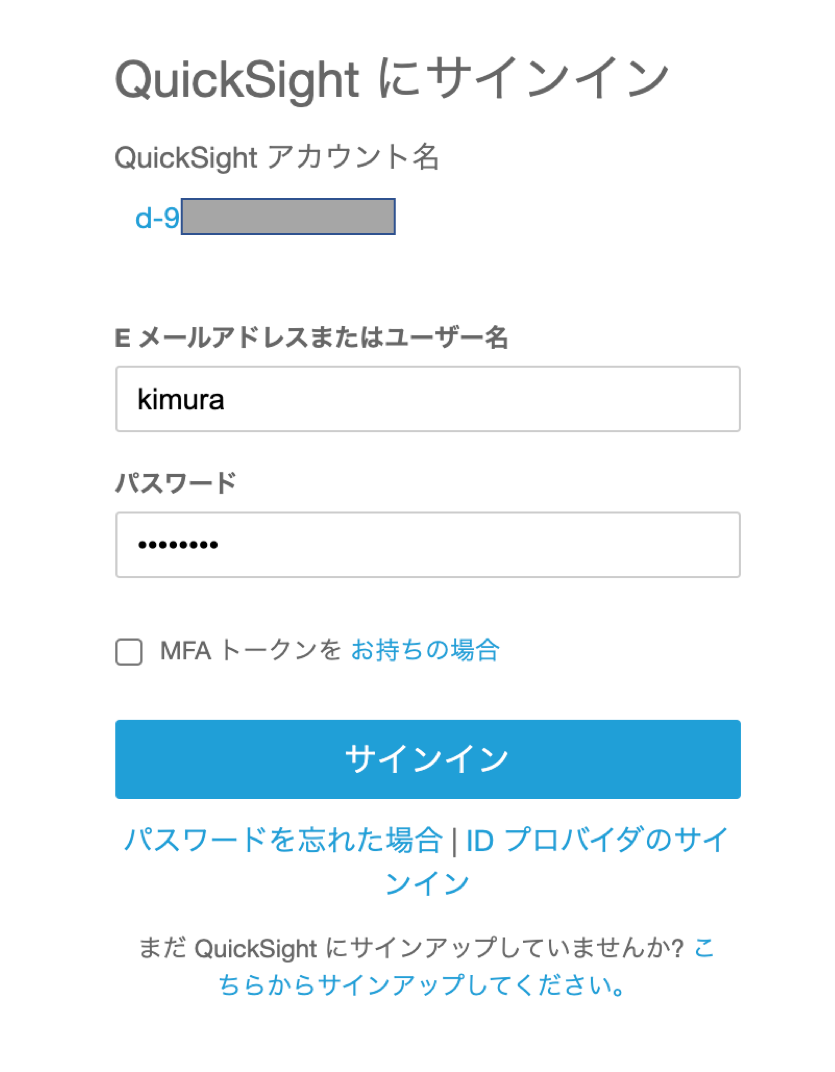
このUserInvitationURLをブラウザで開くとサインアップ画面です。パスワードを設定し登録します。
登録したkimuraでサインインします。
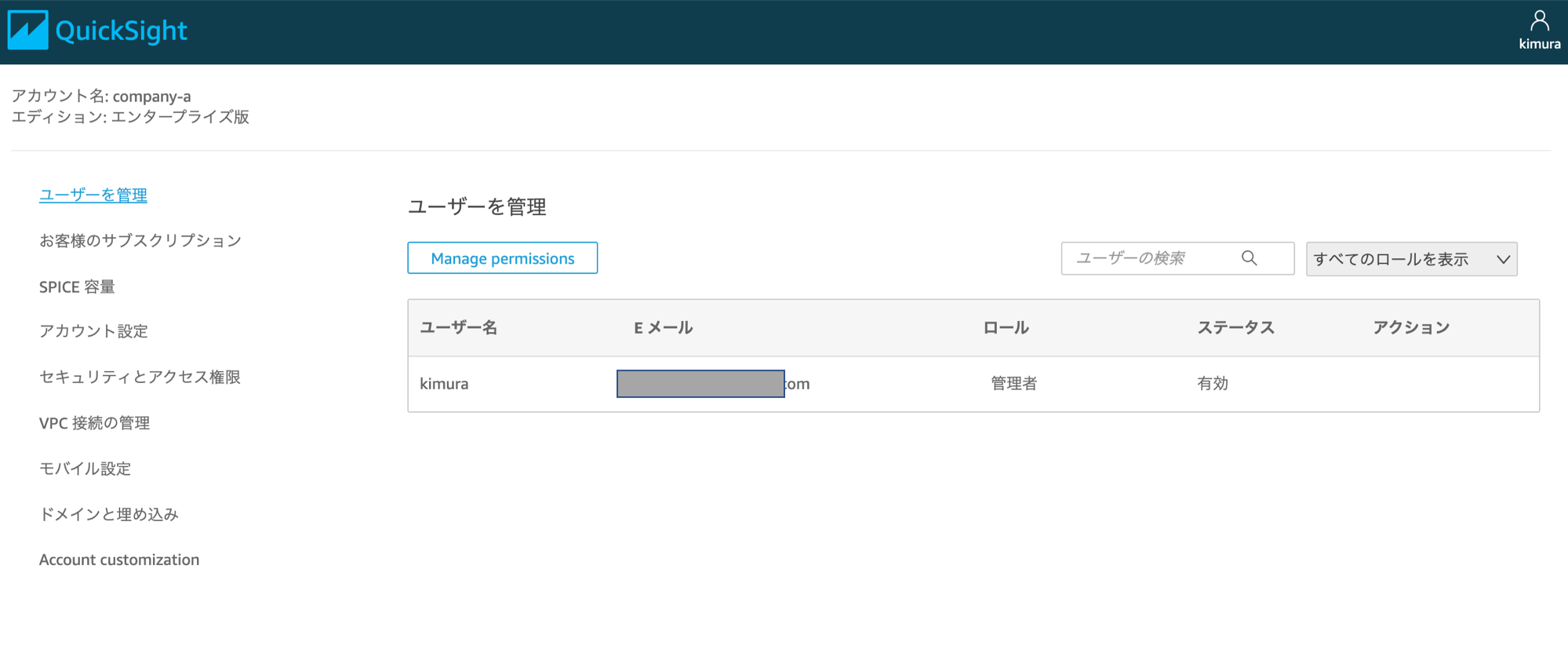
サインインし、QuickSightの初期画面が表示されます。画面キャプチャを取り忘れましたが普通に分析(グラフやダッシュボード)を作れました。
右上のユーザー名のアイコンをクリックし、"QuickSightの管理"をクリックするとQuickSightの管理画面になります。この画面の左上のアカウント名が"compay-a"となっています。これがネームスペースっぽいですね。
ちなみにdefault(元からあるネームスペース)のQuickSightの画面を確認すると、company-aで作成した分析やデータセットは見えていません。company-aで作った画面をキャプチャ取り忘れて確認をお見せできてないですが、しっかりアイソレーションされてます。
GUIで出来たらいいよねこれ
参考資料
Supporting Multitenancy with Isolated Namespaces
QuickSight API create namespace
https://docs.aws.amazon.com/quicksight/latest/APIReference/API_CreateNamespace.html
AWS CLI QuickSight

- 投稿日:2020-07-24T17:32:50+09:00
GitHubActions+S3+CloudFrontでキャッシュクリアしてSPAをデプロイする
はじめに
ここでやってること
- 前回はDockerでsvelteの開発環境を作成しました
- 今回は、svelteをGitHubにpushしたら、GitHubActionsがbuildしてS3にアップロード & CloudFrontのキャッシュ消去して配信します(svelteでなくても設定自体は可能です)
AWSの設定
1. S3にアップロード用のバケットを作成
今回はCloudFrontで配信するので「パブリックアクセスをすべてブロック」して作成します。
この記事ではsvelte-spaというバケット名で作成しています。
(よくこのシンプルな名前で取れたな...2. CloudFrontを設定
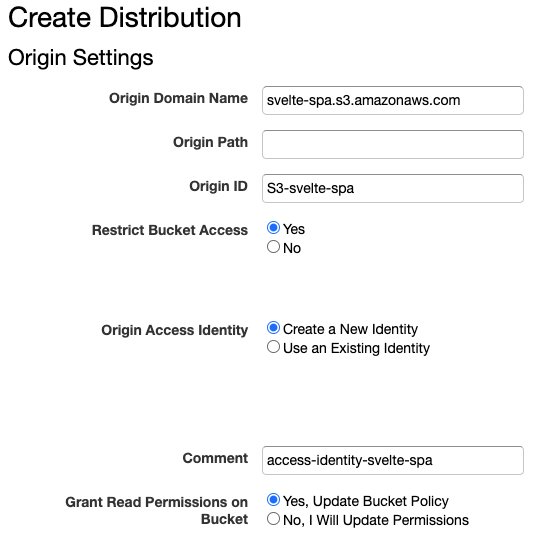
Create Distribution > Web(Get Startedボタンクリック)
Restrict Bucket Access: S3へのアクセスを不可にするためYesを選択Grant Read Permissions on Bucket: CloudFrontからS3バケットへの読み取りを許可する権限設定をしてもらうためYesを選択
3. デプロイ用のIAMポリシーを作成
- Action
s3:PutObject: S3にbuildした成果物をアップロードするためs3:ListBucket: アップロード先のバケットを取得するためcloudfront:CreateInvalidation: キャッシュクリアするため。Invalidationは無効化という意味- Resource
arn:aws:cloudfront: 先に設定したCloudFrontの詳細でARNを確認できますarn:aws:s3: 先に作成したバケットそのものとその配下すべてIAMポリシー{ "Version": "2012-10-17", "Statement": [ { "Sid": "VisualEditor0", "Effect": "Allow", "Action": [ "s3:PutObject", "s3:ListBucket", "cloudfront:CreateInvalidation" ], "Resource": [ "arn:aws:cloudfront::123456789012:distribution/EDFDVBD6EXAMPLE", "arn:aws:s3:::<INPUT-YOUR-BUCKET>/*", "arn:aws:s3:::<INPUT-YOUR-BUCKET>" ] } ] }4. デプロイ用のIAMユーザーを作成
- 先に作成したIAMポリシーをアタッチしたグループを作成(ここでは
svelte-deployグループとする)- 先のグループに属するIAMユーザーを作成(ここでは
svelte-deployerユーザーとする)
- 作成時に表示される
AWS_ACCESS_KEY_IDとAWS_SECRET_ACCESS_KEYは後で使うのでメモしておいてください5. GitHubに設定するSecrets情報をメモ
- デプロイ用のIAMユーザー
svelte-deployerのAWS_ACCESS_KEY_IDとAWS_SECRET_ACCESS_KEY- CloufFrontの
Distribution ID- 上記のAWSリソースを作成したAWSリージョン
GitHubのの設定
Secrets情報の設定
Settings > Secrets から追加
AWS_ACCESS_KEY_ID: IAMユーザー作成時に取得した値AWS_SECRET_ACCESS_KEY: IAMユーザー作成時に取得した値DISTRIBUTION: CloudFrontの詳細画面から取得したDistribution IDの値AWS_REGION:
Actionsの設定
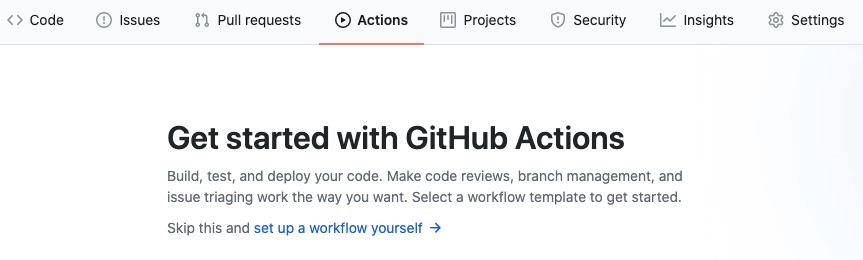
ついに来ました...
Github Actions > set up a workflow yourself をクリック
ymlに下記の設定をします。
.github/workflows/main.ymlname: CI # トリガーの設定 on: push: branches: [ master ] # ジョブの設定(直列に動かしたり並行に動かしたり指定できる) # 今回はbuildジョブとdeployジョブの2つを設定します jobs: build: runs-on: ubuntu-latest strategy: matrix: node-version: [14.5.0] steps: # masterブランチをチェックアウト - uses: actions/checkout@v2 # nodeでパッケージをインストール&ビルド - name: Use Node.js ${{ matrix.node-version }} uses: actions/setup-node@v1 with: node-version: ${{ matrix.node-version }} - run: npm install - run: npm run build # ビルド結果をdeployジョブに渡すためにアップロード - name: Upload build result uses: actions/upload-artifact@v1 with: name: build path: public/ deploy: # ジョブは並行で動くので前後関係の指定が必要 needs: build runs-on: ubuntu-latest steps: # ビルド結果をダウンロード - name: Download build result uses: actions/download-artifact@v2 with: name: build path: public/ # S3にアップロード - name: Publish to AWS S3 uses: opspresso/action-s3-sync@master env: AWS_ACCESS_KEY_ID: ${{ secrets.AWS_ACCESS_KEY_ID }} AWS_SECRET_ACCESS_KEY: ${{ secrets.AWS_SECRET_ACCESS_KEY }} AWS_REGION: ${{ secrets.AWS_REGION }} FROM_PATH: "public/" DEST_PATH: "s3://svelte-spa" # CloudFrontのキャッシュクリア - name: Clear cache in CloudFront uses: chetan/invalidate-cloudfront-action@v1.2 env: DISTRIBUTION: ${{ secrets.DISTRIBUTION }} PATHS: "/*" AWS_REGION: ${{ secrets.AWS_REGION }} AWS_ACCESS_KEY_ID: ${{ secrets.AWS_ACCESS_KEY_ID }} AWS_SECRET_ACCESS_KEY: ${{ secrets.AWS_SECRET_ACCESS_KEY }}動作確認
何かしらmasterに変更を加えてプッシュしてみます。
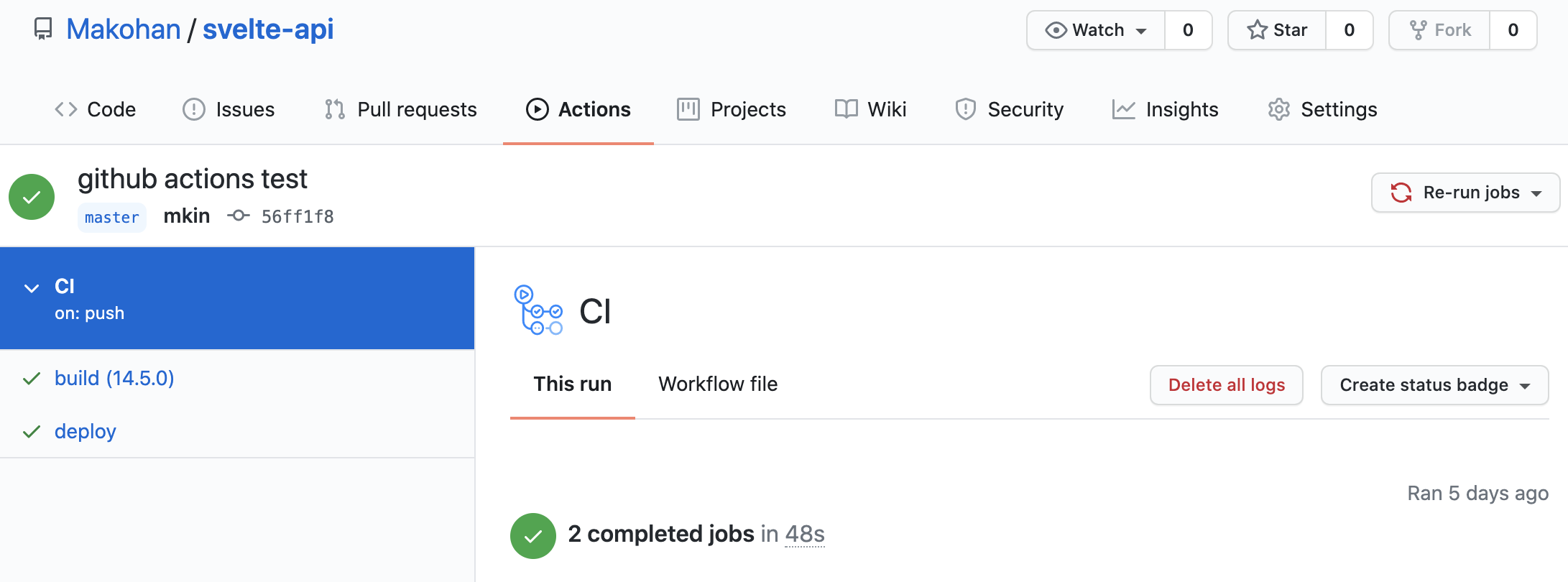
GitHub Actionsのページを確認
- 成功したことを確認できます
- 失敗した場合、ログを確認しながら調整してください
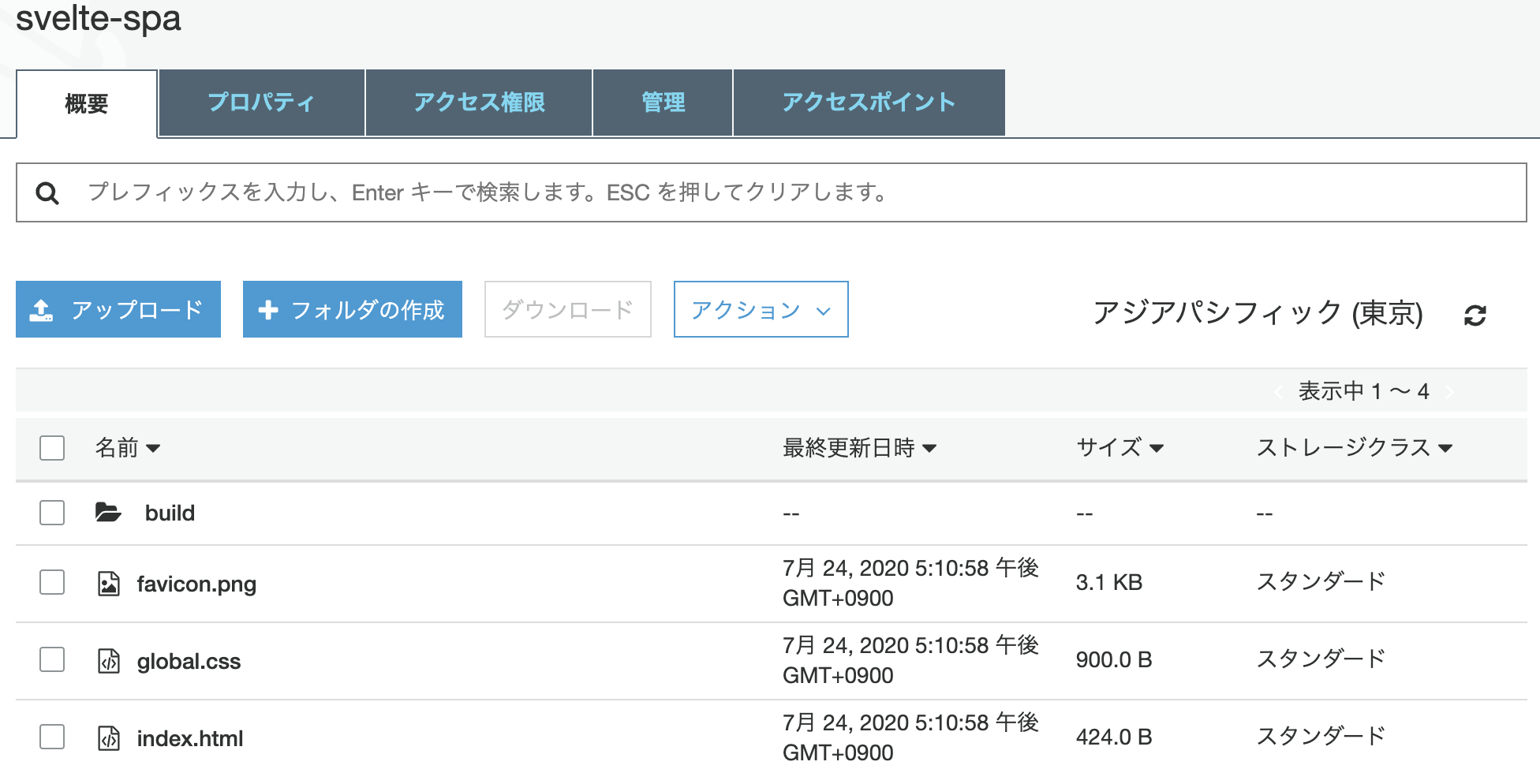
S3にビルド結果が保存されていることを確認
CloudFrontのエンドポイントにブラウザからアクセス
CloudFrontのドメイン名+index.htmlでアクセス
- 成功です!
- 再度、masterに変更を加えても自動デプロイされてることが確認できました!!
結びの言葉
何でこれしたの?
技術を触れるにつけて、ただやってみたい!という想いだけだと、現場の推進力にはなれないなと、自分の中で最近思うようになりました。やはり、どうやって導入するの?とかリリース作業はどうするの?とか、、、技術単体で完結しない難しさがあります。
じゃあ、自分にそのスキルがあるか?と自問すると、、、無かった。
なので、まずはミニマムでもリリースするまでの感覚を養いたいなと思い着手しました。後日、テストのジョブを組み込んで、エラーならチャット通知をして、CI/CDのレベルアップが必要だなと思います。
参考


- 投稿日:2020-07-24T16:28:41+09:00
【AWS】git pushでEC2にも自動デプロイ(CodeDeploy / CodePipeline)
この記事では、
・ローカルのソースコードを更新してコミット
↓
・Githubにプッシュ
↓
・EC2上のソースコードも自動更新する設定法を備忘録としてまとめておきます。
ローカル環境を更新して、さらにそこから手動でEC2にデプロイするのが面倒だったので
自動デプロイ化を取り入れてみたのですが、だいぶ作業が効率化されて楽になってように感じます。今回利用するAWSリソースについて
自動デプロイを実現するために、今回は以下のAWSリソースを利用します。
①VPC(パブリックサブネット)/InternetGateway
②IAM
③EC2
④CodeDeploy
⑤CodePipeline※別途Githubアカウントも必要になります
設定の手順について
①IAMロールの作成
②EC2を作成し、CodeDeployエージェントをインストール
③ローカル環境とGithub上での設定
④CodeDeployの設定
⑤CodePipelineの設定
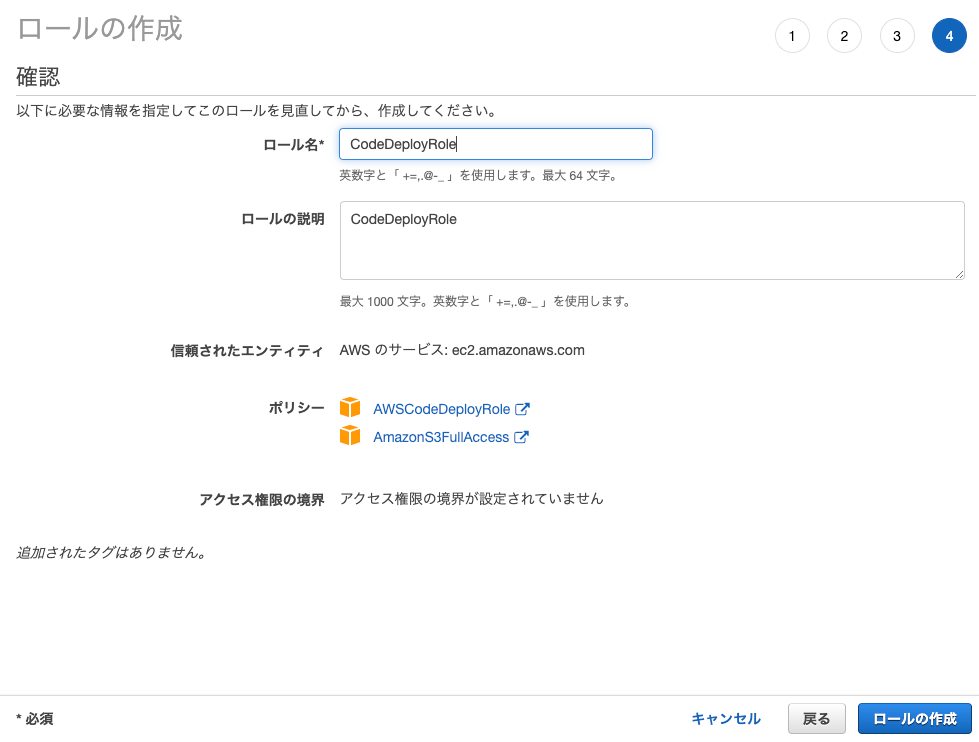
①IAMロールの作成
EC2用に、
以下の2種類のポリシーがアタッチされたIAMロールを作成します。①AmazonS3FullAccess (CodePipelineの仕様で、S3にアクセスする必要があるため)
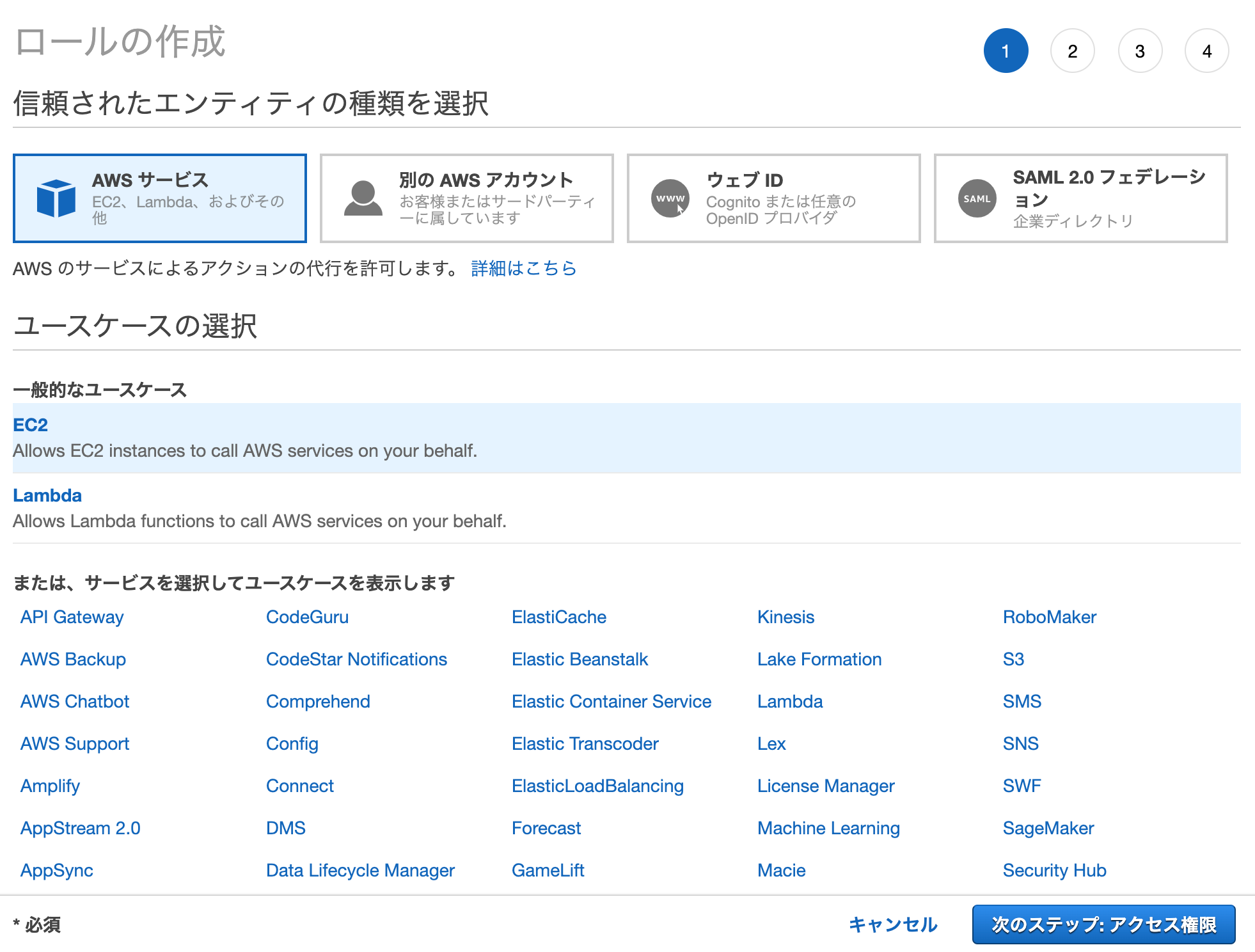
②AWSCodeDeployRole (CodeDeployと連携するため)IAMロール作成画面にて、
以下のように選択して次に進みます。
項目 選択する値 信頼されたエンティティの種類を選択 AWS サービス ユースケースの選択 EC2
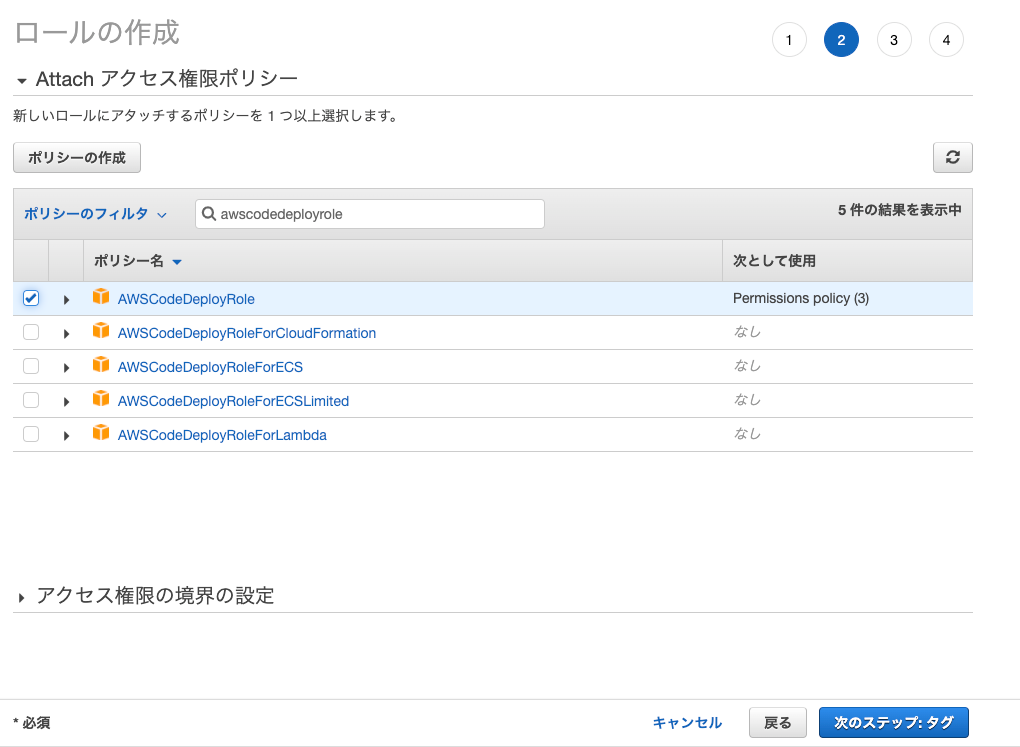
次に、「awscodedeployrole」で検索して、ヒットした
AWSCodeDeployRole のポリシーを選択します。
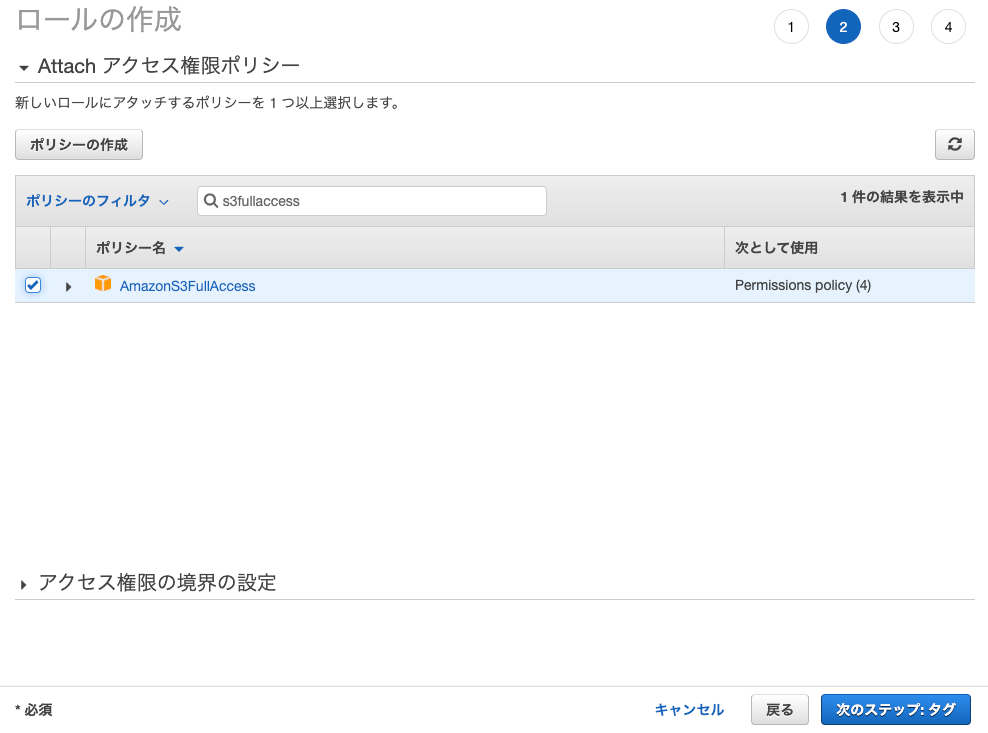
続けて「AmazonS3FullAccess」で検索して、
AmazonS3FullAccess のポリシーを選択して次に進みます。
次に、タグの選択画面に進みますが、こちらはつけてもつけなくてもOKです。
ロール名/ロールの説明は任意のものでOKです。
(今回はどちらも「CodeDeployRole」としました)
そして「ロールの作成」をクリックすると、ロールが作成されます。
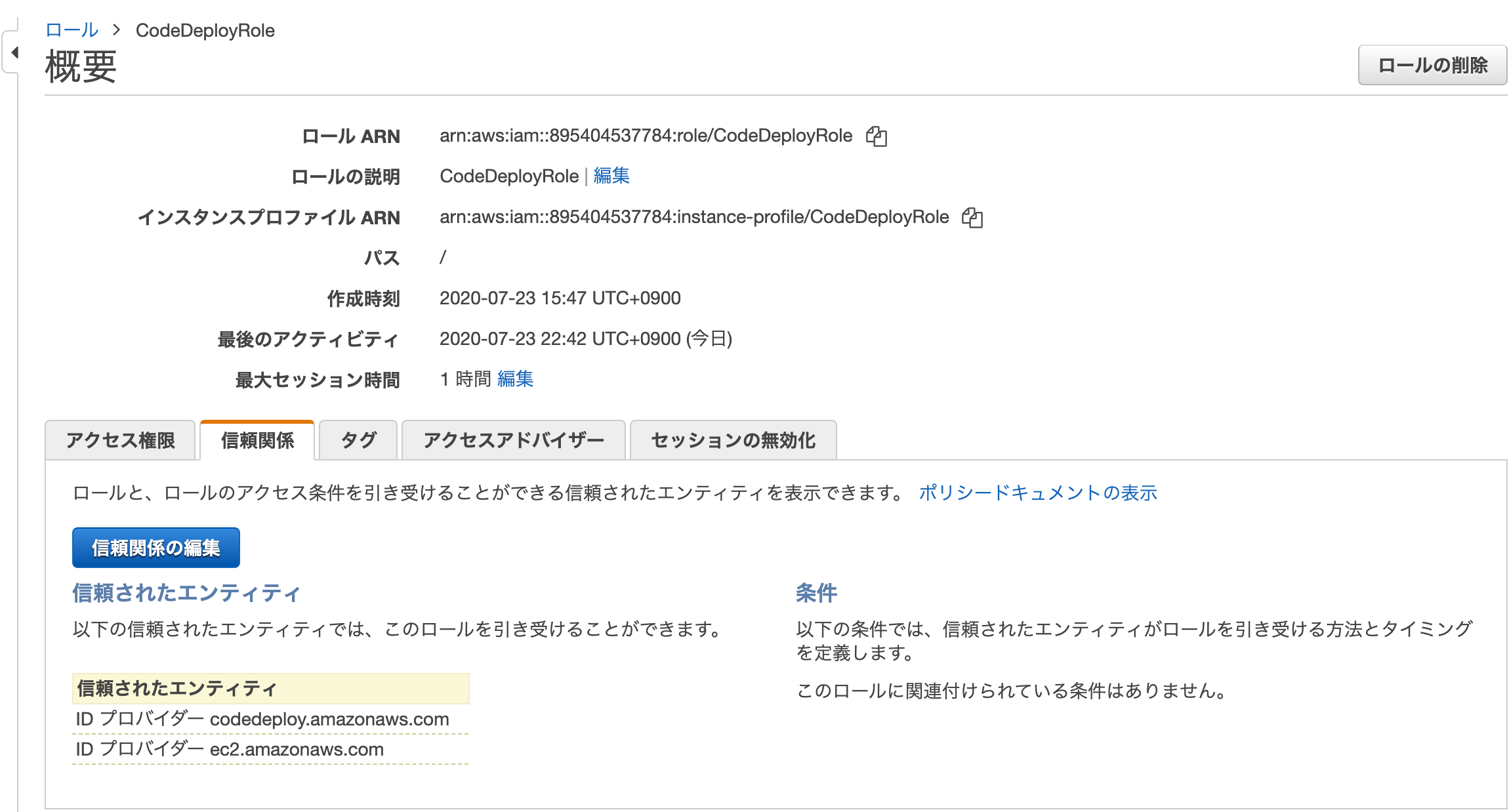
最後に、作成されたIAMロールを少し編集します。
今作成したロールの概要ページに移動して、信頼関係のタブをクリックし、
青色の信頼関係の編集ボタンをクリックします。
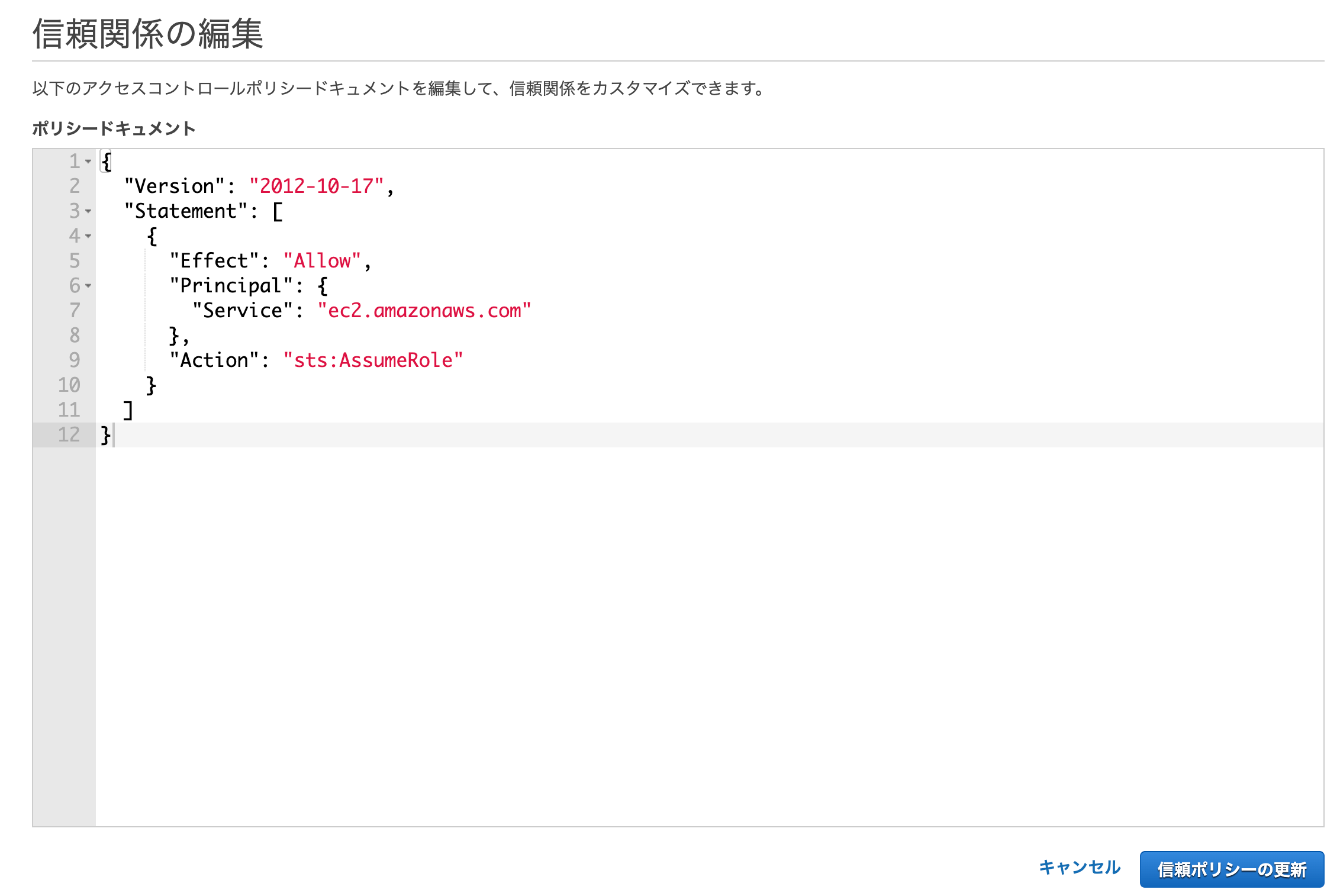
するとポリシードキュメントの編集画面が開くので、これを編集していきます。
"Service": "ec2.amazonaws.com"この部分に、
"codedeploy.amazonaws.com"を追加して、以下のように編集します。{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Principal": { "Service": [ "codedeploy.amazonaws.com", "ec2.amazonaws.com" ] }, "Action": "sts:AssumeRole" } ] }信頼ポリシーの更新ボタンをクリックすると、これでIAMロールの設定は完了です。
②EC2を作成し、CodeDeployエージェントをインストール
自動デプロイ用のEC2の作成していきます。
EC2のマネジメントコンソールに移動して、「インスタンスの作成」をクリックします。ステップ1:AMIの選択
今回は、無料枠対象のAmazon Linux 2 AMI (HVM), SSD Volume Typeを選択していきます。
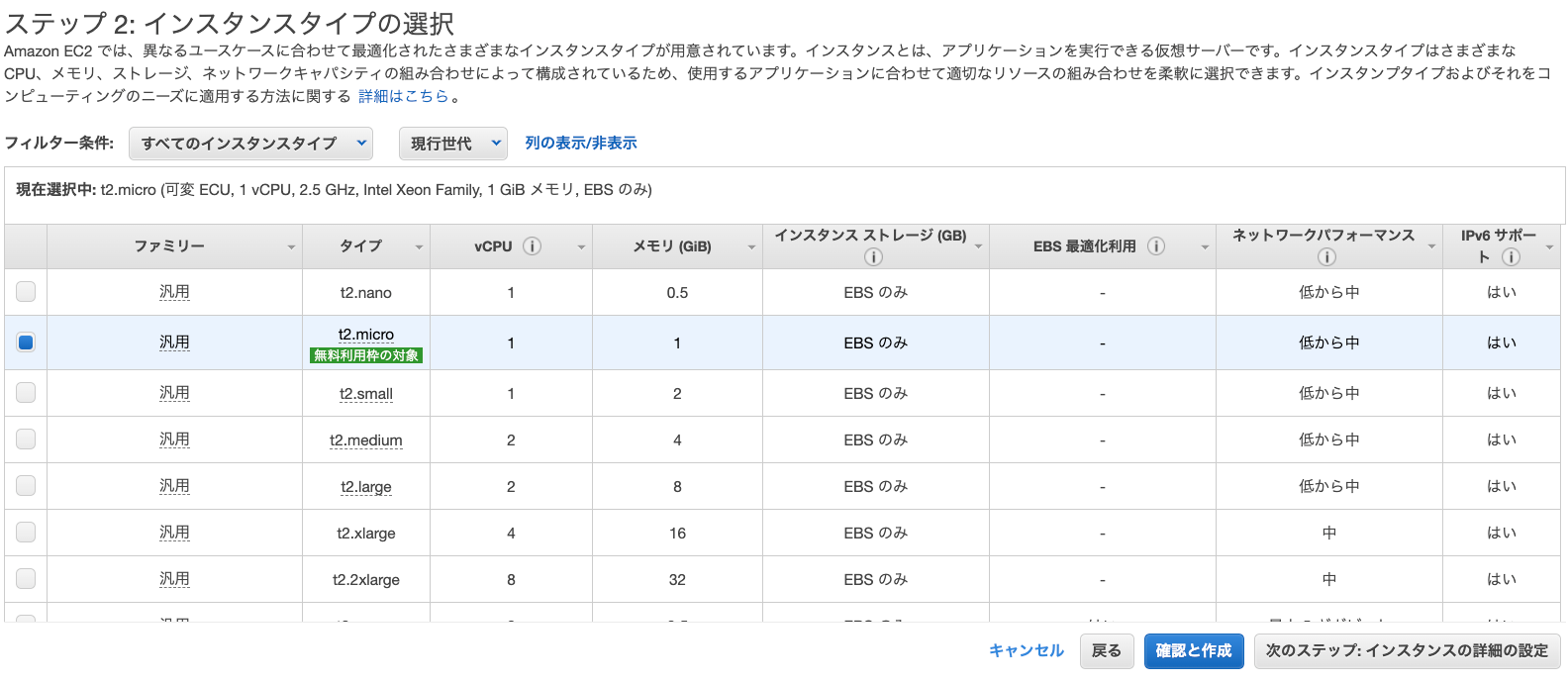
ステップ2:インスタンスタイプの選択
こちらも自由ですが、今回は無料枠のt2.microを選択します。
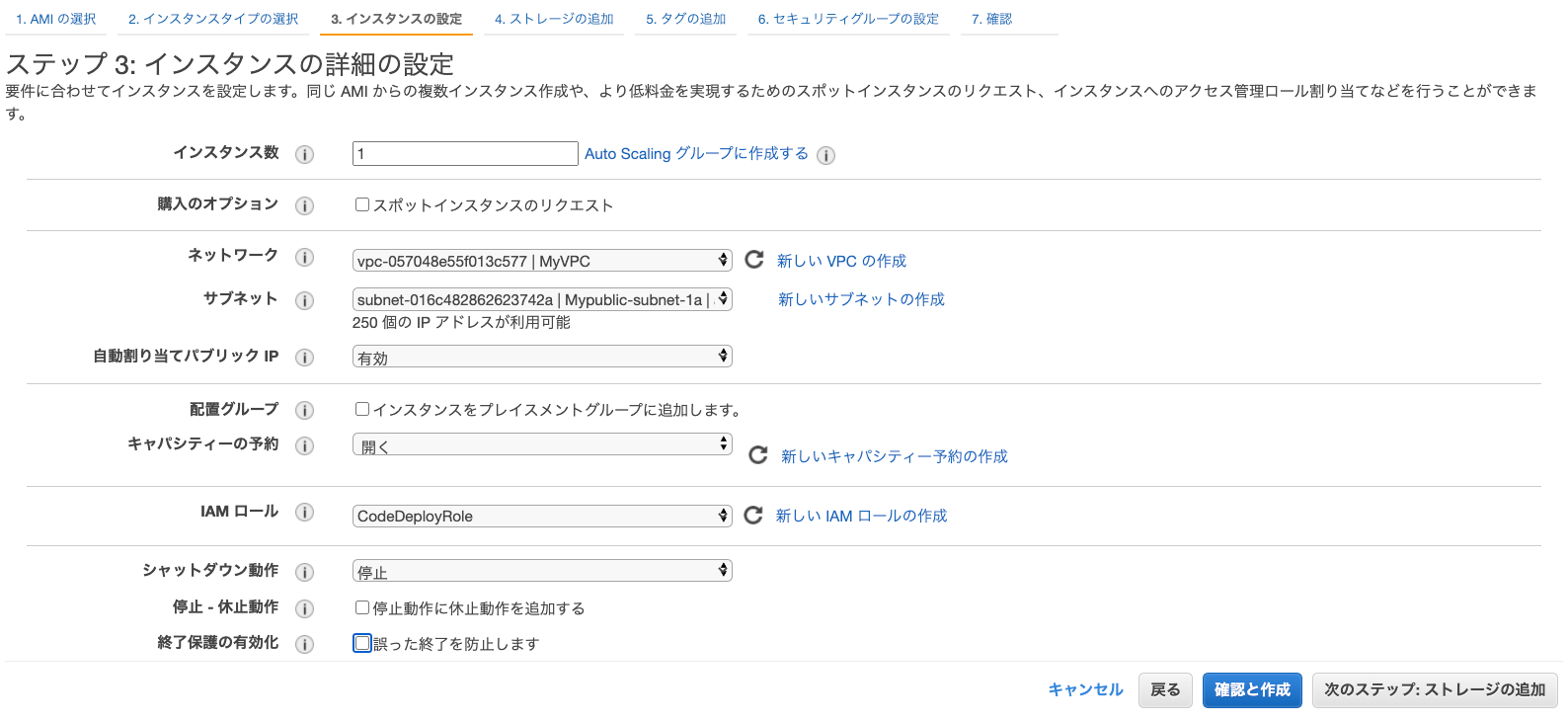
ステップ3:インスタンスの詳細の設定
以下のように項目を選択して、それ以外はデフォルトでOKです。
項目 選択する値 ネットワーク InternetGatewayがアタッチされたVPCを選択 サブネット インターネットからアクセスできるパブリックサブネットを選択 自動割り当てパブリック IP 有効 IAMロール 先ほど作成したロールを選択 例)
また、この設定ページの一番下「高度な詳細」という項目内に、ユーザーデータを入力する箇所があるので、
以下のコードを入力します。#!/bin/bash # CodeDeployAgentのインストール yum install -y ruby cd /home/ec2-user curl -O https://aws-codedeploy-ap-northeast-1.s3.amazonaws.com/latest/install chmod +x ./install ./install auto ====
このユーザーデータとは、EC2が新規作成されて起動した時に自動で実行されるスクリプトです。(コマンドの集まり)
これにより、EC2にCodeDeployエージェントがインストールされます。なお、CodeDeployエージェントのインストールコマンドについて、こちらは東京リージョンで
利用する場合限定になります。
CodeDeployエージェントのダウンロードリンクはリージョンによって異なるため、
もし違うリージョンで利用したい場合は、AWSの公式ドキュメントを参考にして、コマンド内の
ダウンロードリンクを適切なものに設定します。
https://docs.aws.amazon.com/ja_jp/codedeploy/latest/userguide/codedeploy-user.pdf#codedeploy-agent-operations-install(427p辺り)
# CodeDeployAgentのインストール yum install -y ruby cd /home/ec2-user # ↓ この部分に、リージョン毎のバケットネームをいれる curl -O https://<< bucket-name >>.s3.amazonaws.com/latest/install chmod +x ./install ./install autoユーザーデータの入力が終わったら、「次のステップ:ストレージの追加」をクリックして進みます。
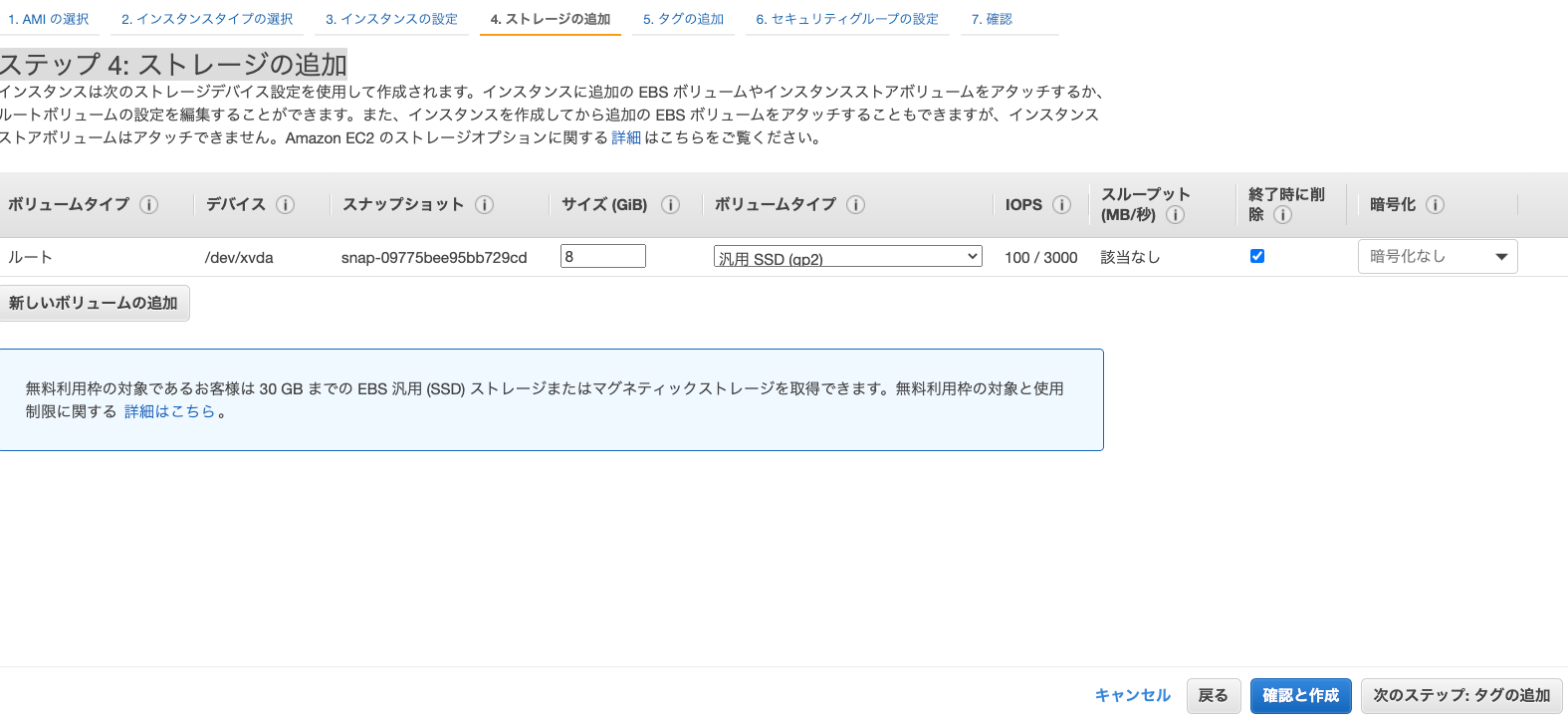
ステップ 4: ストレージの追加
こちらはデフォルトのままで、次に進みます。
ステップ 5: タグの追加
タグは以下のように追加します。
Nameの他にもう一組、CodeDeploy用のキーと値を設定しておくことで、
そのタグを持つ複数のインスタンスに一斉に自動デプロイすることが可能になります。
キー 値 Name 任意の値(インスタンス名) 任意のキー
(自動デプロイ先の識別用)任意の値
(自動デプロイ先の識別用)例)
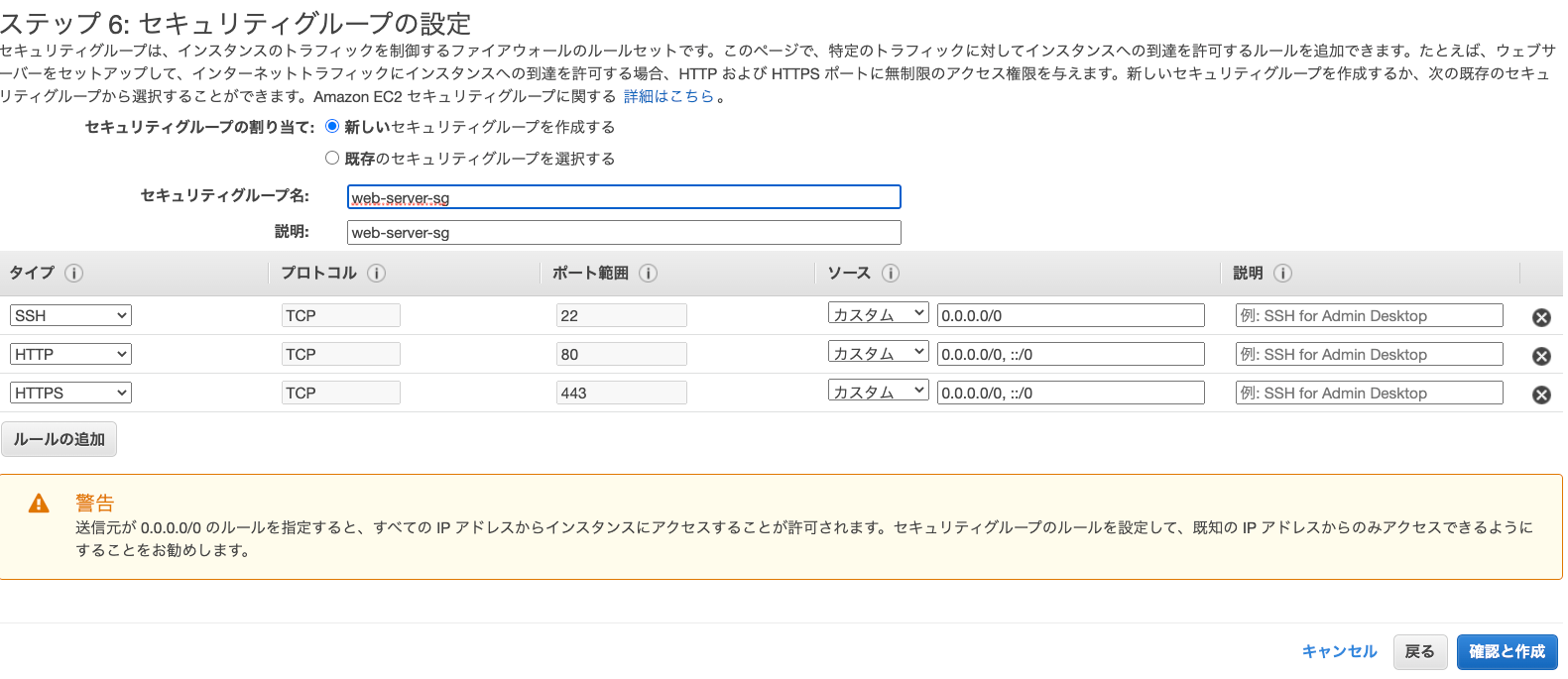
ステップ 6: セキュリティグループの設定
セキュリティグループは、インスタンスにHTTPアクセスできる(ポート80)ものが既にあればそれを設定し、
もしなければ新しいセキュリティグループを以下のような設定で作成します。
ステップ 7: インスタンス作成
最後に、キーペアを設定してインスタンスを作成します。
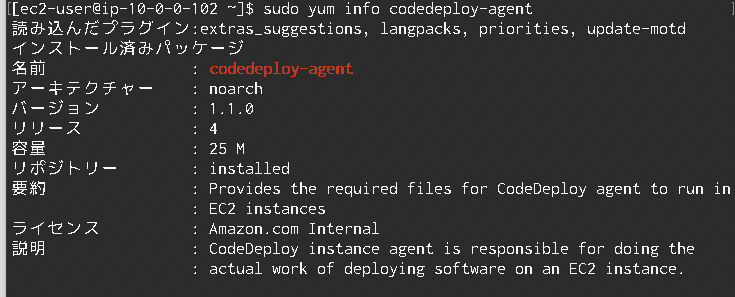
これで、EC2の設定と作成は完了です。なお、CodeDeployエージェントがちゃんとインストールできているかは、EC2インスタンスに
ログインした後、以下のコマンドを打つことで確認することができます。sudo yum info codedeploy-agent
③ローカル環境とGithub上での設定
appspec.ymlの作成
CodeDeployでの自動デプロイをする際には、デプロイ元のソースのルートに、
appspec.ymlという設定ファイルを作成する必要があります。
なお、この設定ファイルはAWS公式サンプルスクリプトとして公開されているので、こちらのリンクからダウンロードすることができます。
https://github.com/aws-samples/aws-codedeploy-samples/tree/master/applications/SampleApp_Linuxまた、上記のリポジトリにはappspec.ymlの他にも、scriptというディレクトリがありますが、こちらも一緒にダウンロードします。
このディレクトリの中には、Apacheの起動に関するスクリプトファイルが3つ格納されています。
scriptディレクトリも、asspec.ymlと一緒にソースのルートに配置しておきます。ダウンロードしたappspec.ymlの中身を見てみると、以下のようになっています。
version: 0.0 os: linux files: - source: /index.html destination: /var/www/html/ hooks: BeforeInstall: - location: scripts/install_dependencies timeout: 300 runas: root - location: scripts/start_server timeout: 300 runas: root ApplicationStop: - location: scripts/stop_server timeout: 300 runas: root各項目の詳細については割愛しますが、主に重要なのは以下の項目です。
項目 説明 os デプロイ先のEC2インスタンスのOS files: source デプロイ元のソースのパス
→全ファイル指定の場合は、「/」と記入
(同期元)files: destination ソースをEC2のどこにデプロイするか、パスを設定(同期先) 上記の設定では、files: sourceの項目に注目すると、これは
ローカルのソースのルートにあるindex.htmlという名前のファイルが更新されたら、EC2上の
/www/html配下のindex.htmlが更新されますよという内容になります。
もし、ローカルのindex.html以外のファイル全部を同期させたい場合は、以下のように「/」のみを指定します。files: - source: /Githubへプッシュ
appspec.ymlとscriptディレクトリが用意できたら、コミットして同期させたいソースと一緒に
Githubのリモートリポジトリにプッシュします。
これで、ローカル環境とGithub上の設定は完了です。④CodeDeployの設定
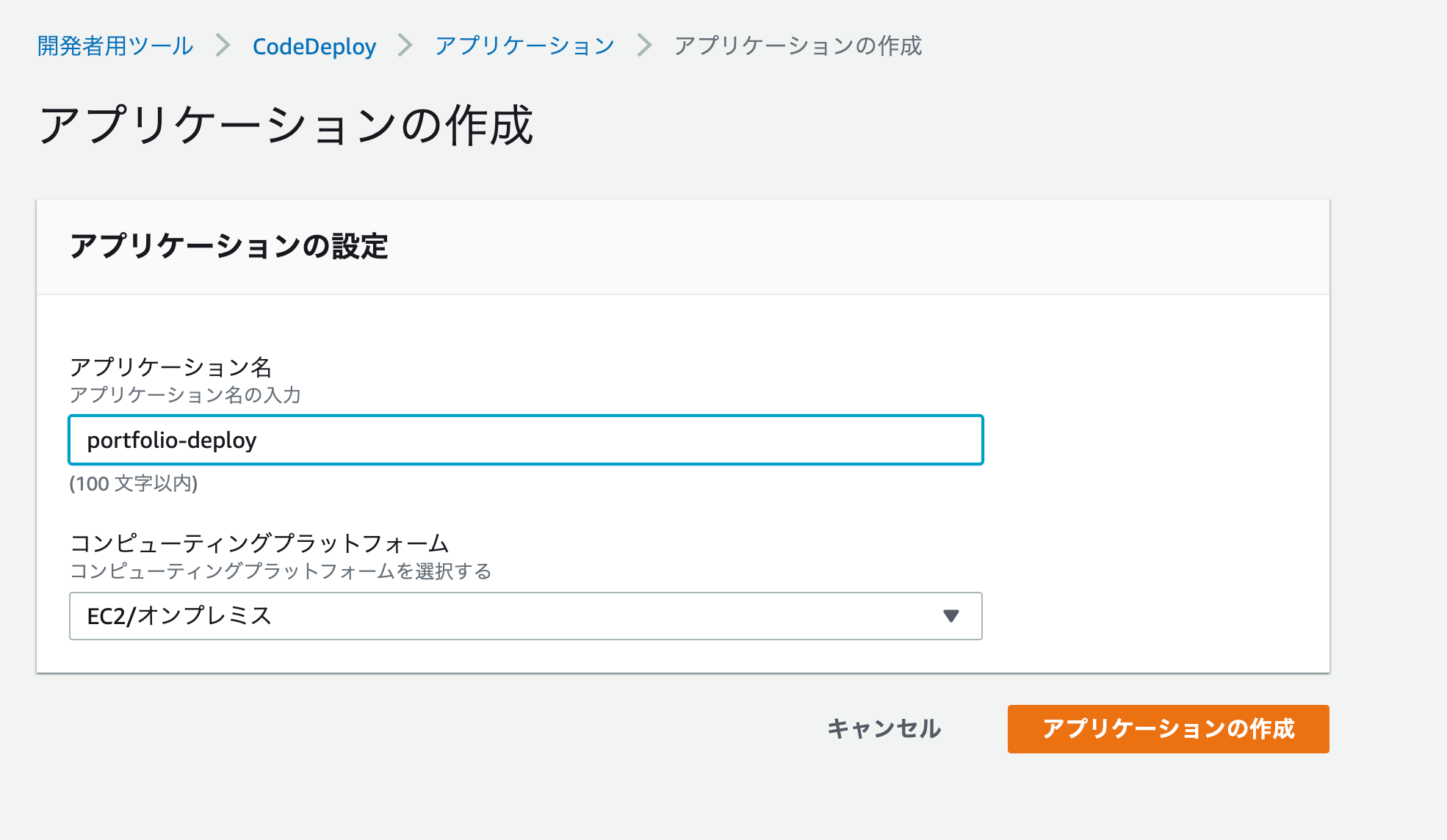
次に、CodeDeployのマネジメントコンソールに移動し、「アプリケーションの作成」をクリックします。
アプリケーションの作成
項目 設定値 アプリケーション名 任意の名前を設定 コンピューティングプラットフォーム EC2/オンプレミス 例)
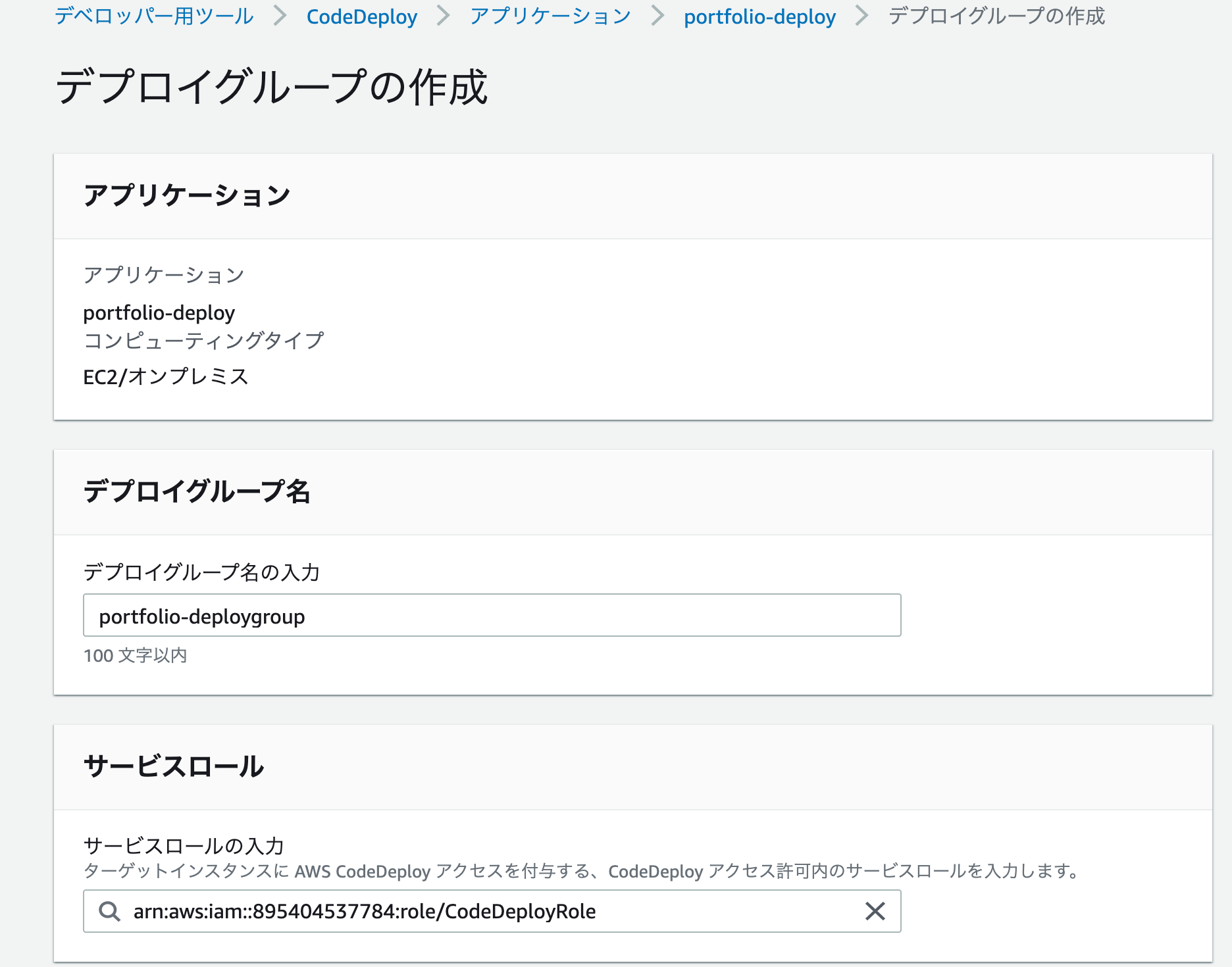
デプロイグループの作成
今回は以下の表のように設定し、それ以外はデフォルトでOKです。
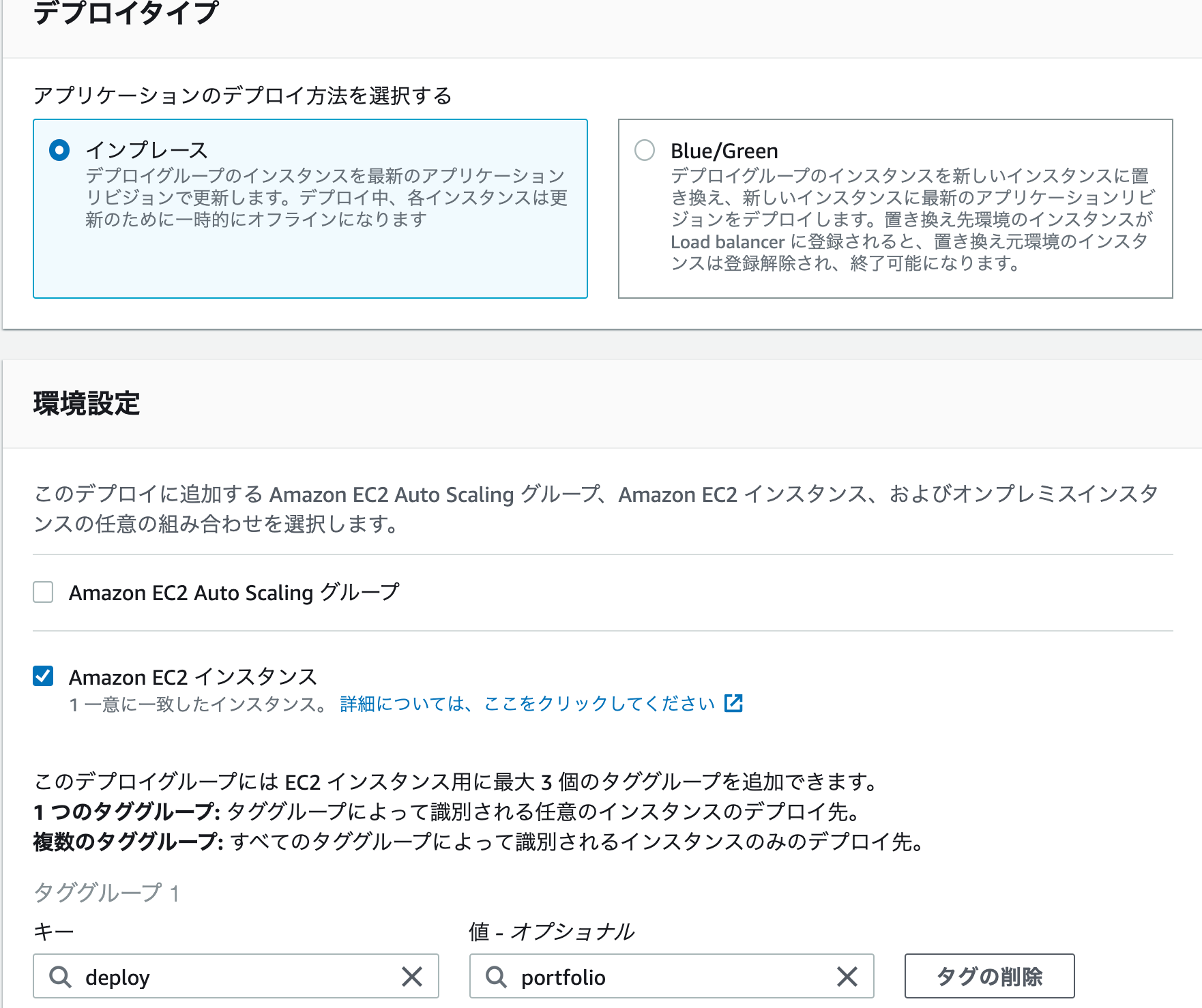
項目 設定値 デプロイグループ名 任意の名前 サービスロール 手順①で作成したIAMロールを選択
(入力欄のテキストボックスをクリックすると、候補一覧が表示されます。)デプロイタイプ インプレース 環境設定 Amazon EC2 インスタンスにチェックをいれる キー/値 手順②のステップ5でEC2に追加した、
CodeDeploy用のキー/値を入力Load balancer チェックを外す
(今回はELBを使用しないため)例)
最後に画面右下のデプロイメントグループの作成ボタンを押して次に進みます。
デプロイの作成
デプロイメントグループが作成できたら、次はデプロイの作成ボタンをクリックして設定画面に移り、以下のように設定していきます。
項目 設定値 デプロイグループ 先ほど作成したデプロイグループを選択 リビジョンタイプ アプリケーションは GitHub に格納されています を選択 GitHub トークン名 Githubアカウント名を入力 リポジトリ名 Githubのリポジトリ名を入力
→ アカウント名/リポジトリ名 の形式コミットID 最新のコミットIDを入力(ハッシュ値) Githubgとの連携も完了したら、画面下のデプロイの作成をクリックします。
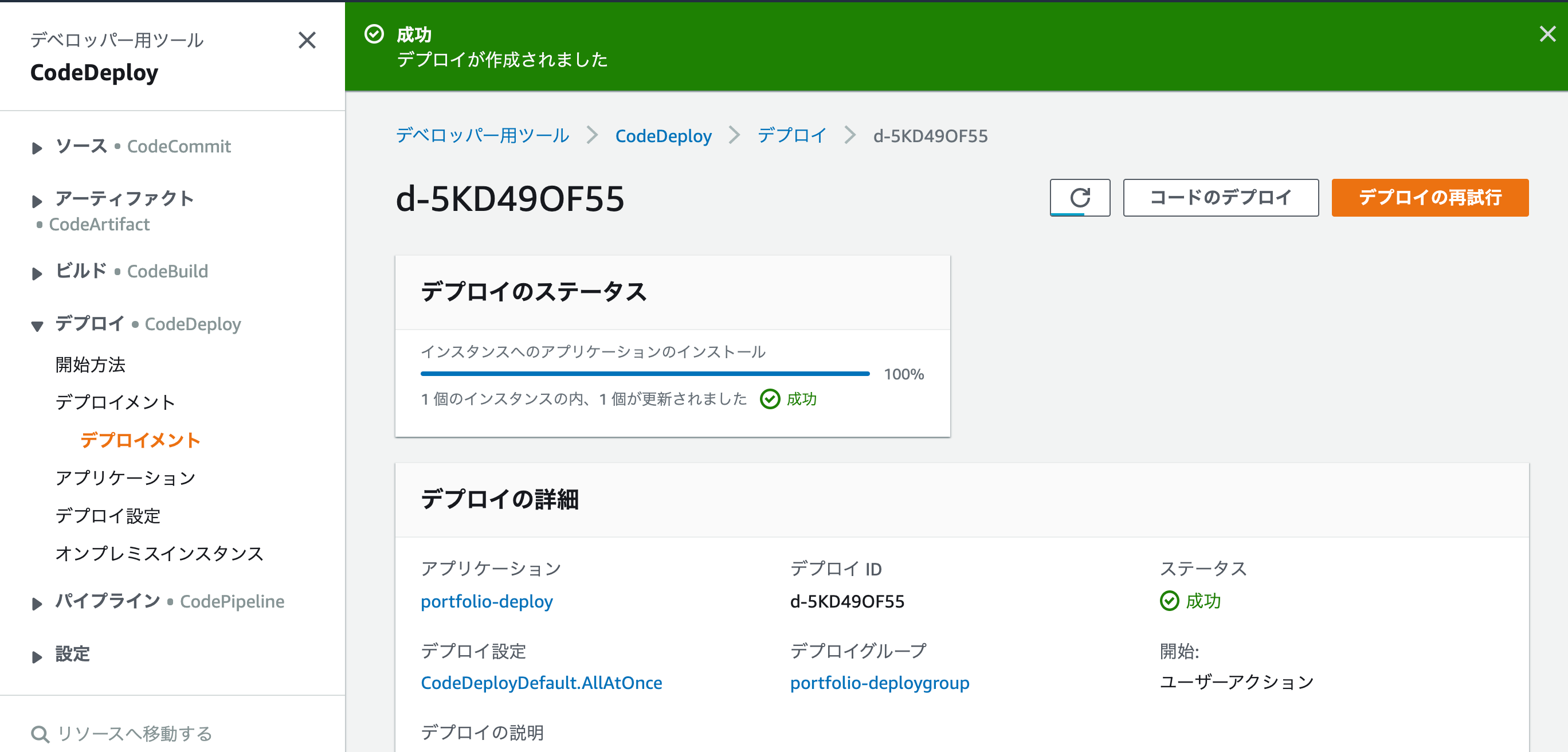
するとデプロイの作成が開始され、やや時間がかかります。ここでエラーが発生せずに無事に「成功」と出れば無事にデプロイ完了です。
EC2インスタンスのIPアドレスを、ブラウザのアドレスバーに入れてエンターキーを押すと、ソースコードの中身が表示されます。
(デプロイ元のソースのルートにindex.htmlという名前のファイルがある場合)ここで、ローカルのソースに変更を加えてコミットし、Githubへプッシュしてみます。
そしてCodeDeployのマネジメントコンソールからコードのデプロイボタンを押すとデプロイ作成画面に移り、
コミットIDの入力欄に最新のコミットIDを入れてデプロイの作成を実行すると、Githubにプッシュした内容がEC2上にも反映されて、同期します。
Githubにプッシュする度にコミットIDを書き換えてデプロイの作成を行うのは面倒なので、プッシュと同時に自動デプロイされるように、最後にCodePipelineの設定をします。⑤CodePipelineの設定
CodeDeployのマネジメントコンソールの左側に、パイプラインという項目があるのでこちらをクリックするとCodePipelineのマネジメントコンソールに移動します。
そうしたらパイプラインを作成するボタンをクリックして設定画面に進みます。
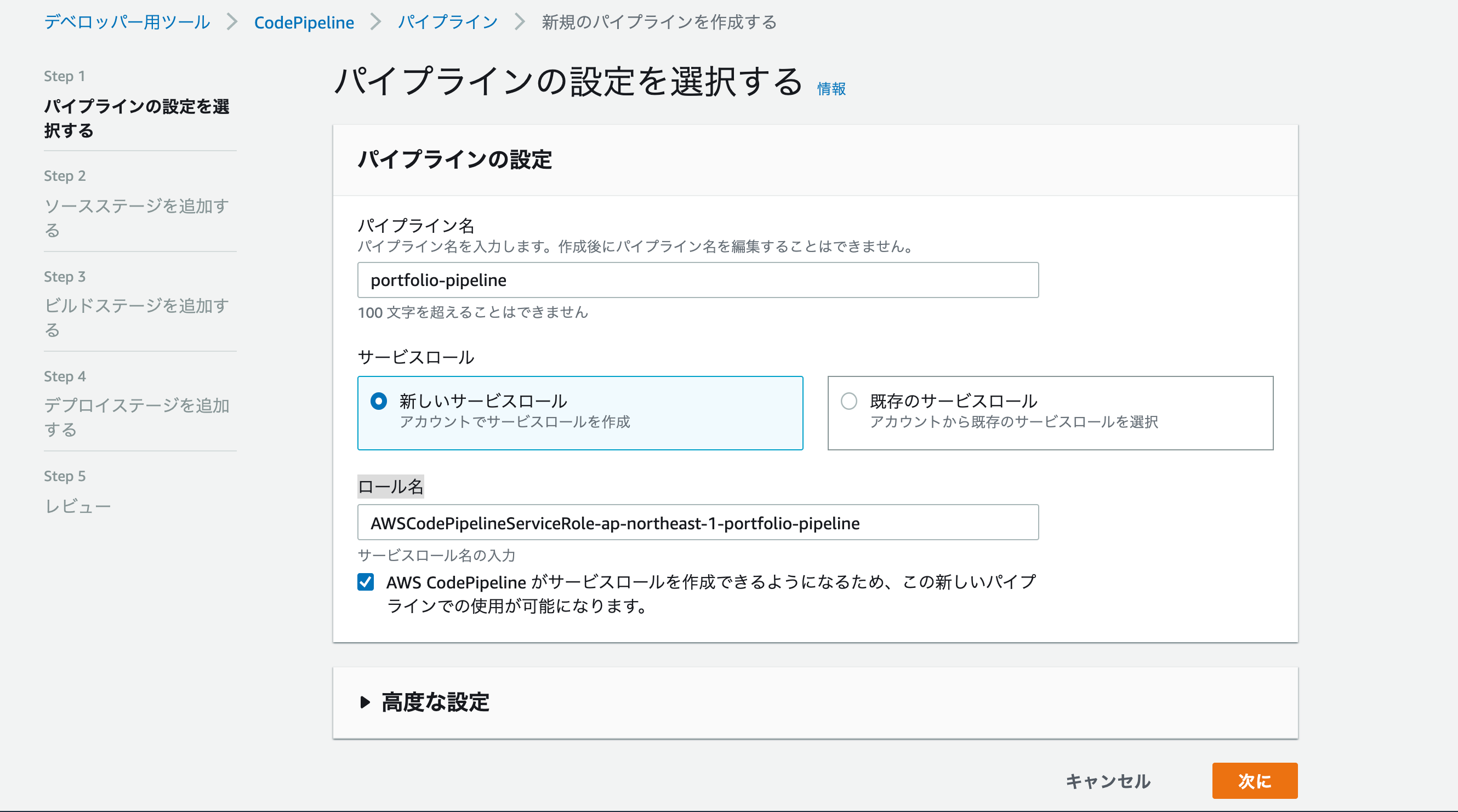
設定画面では、以下のように設定します。
項目 設定値 パイプライン名 任意の名前 サービスロール 新しいサービスロール ロール名 ロールが自動入力されるので、そのままでOK 例)
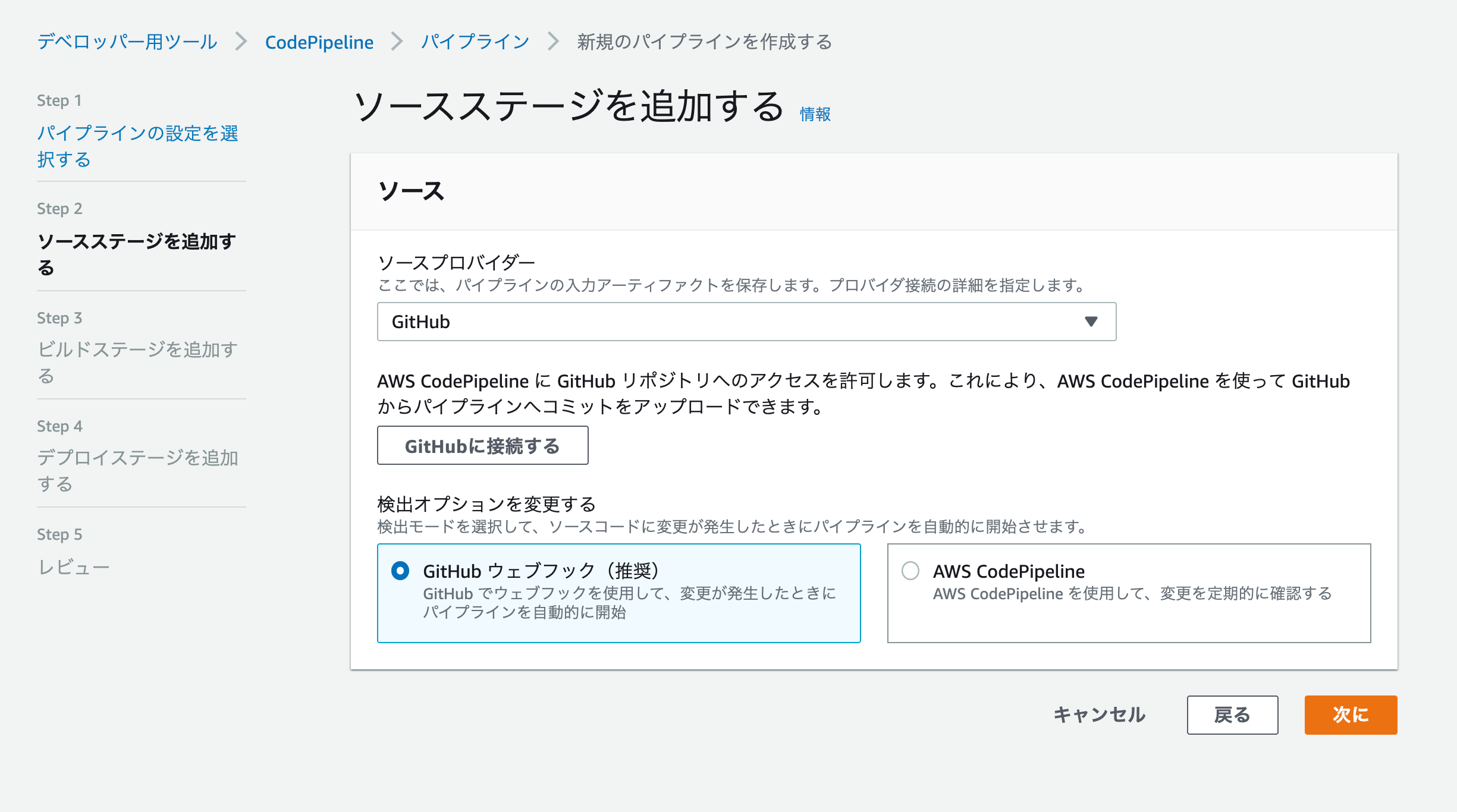
ソースプロバイダーはGitHubを選択「GitHubに接続する」をクリック
リポジトリとブランチの入力欄が表示されるのでそれぞれを入力して次に進みます。
項目 設定値 リポジトリ CodeDeployで設定したリポジトリ
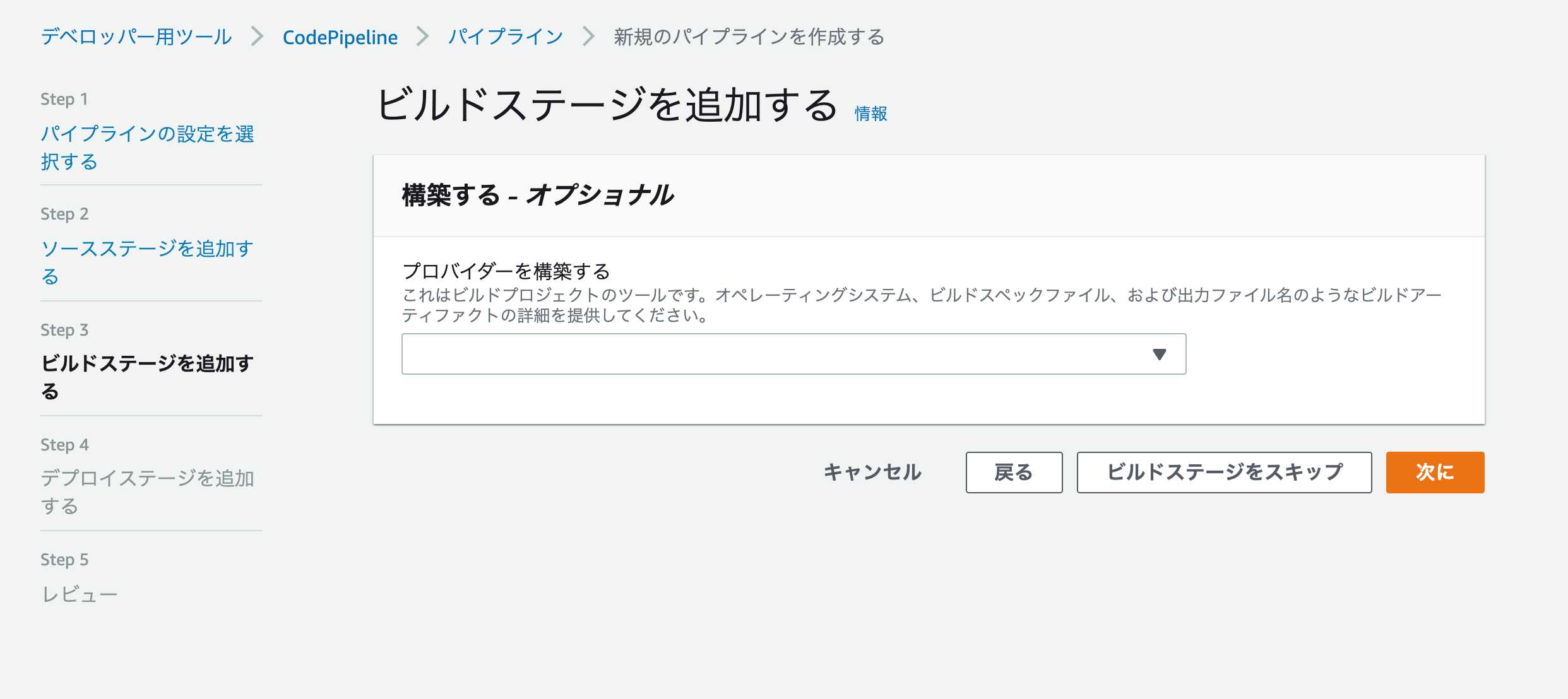
ブランチ master 今回は、ビルドステージの追加をスキップします。
※もしソースにJavaやC#等、コンパイルの必要な言語を使用している場合はビルドの設定が必要になります。
次に、デプロイステージの追加画面では、以下のように設定して次に進みます。
項目 設定値 デプロイプロバイダー AWS CodeDeploy リージョン 利用するリージョンを選択 アプリケーション名 CodeDeployで作成したアプリケーションを選択 デプロイグループ CodeDeployで作成したデプロイグループを選択 例)
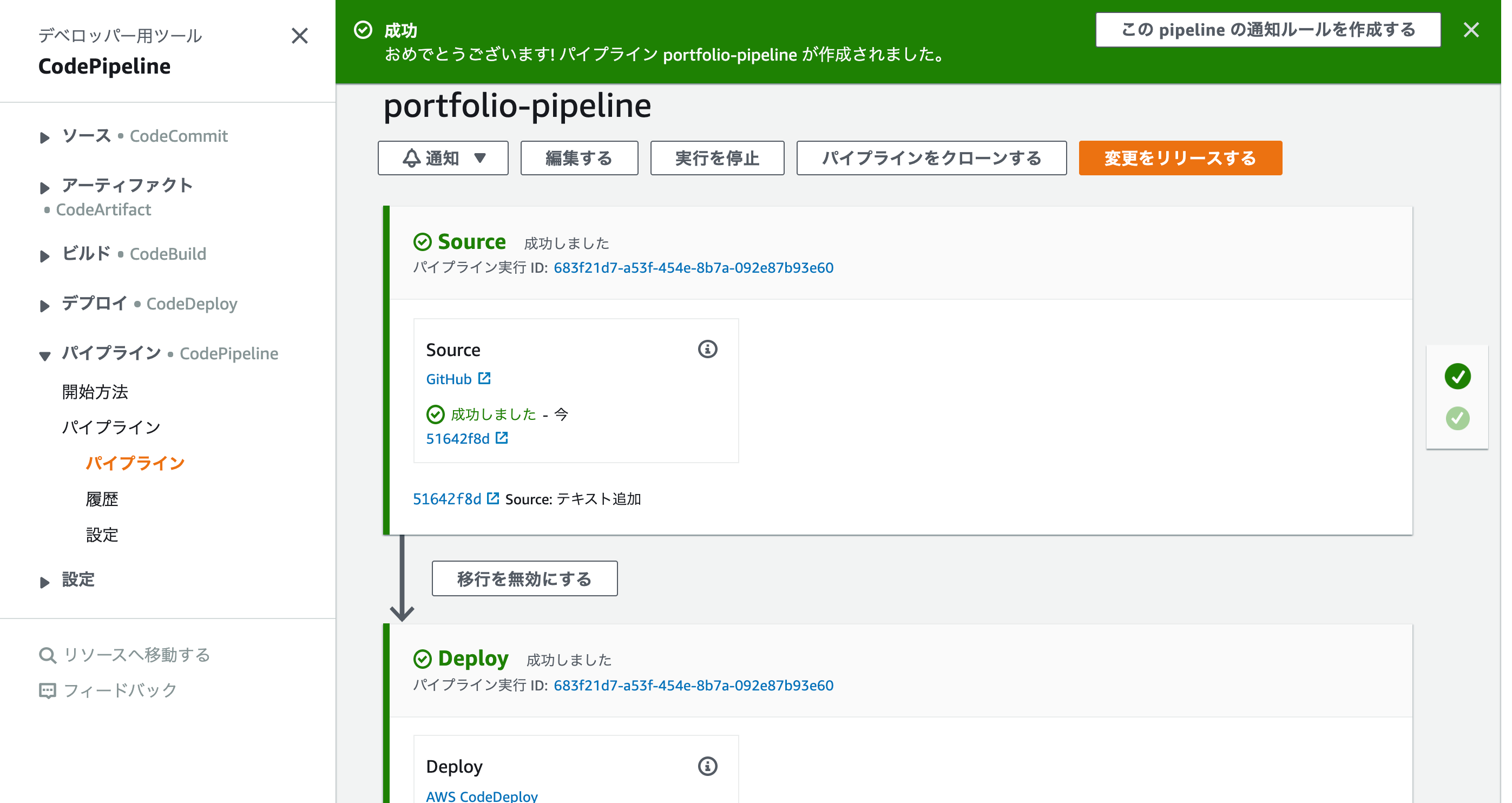
確認画面で内容の確認が終わったら、パイプラインの作成を実行します。
そうすると以下のような画面が表示され、無事に成功したら、これで全ての設定は終了です!
ここまできたら、もうローカルのソースを更新してGitHubにプッシュするだけで、自動でEC2にも更新が反映されるようになります。






- 投稿日:2020-07-24T16:20:03+09:00
AWSガチで何もわかってない人がECSでWordPressをデプロイするまで
AWSはネットワークが独学難しく、半ば挫折気味でした。
AWSだと「Hello World!」を出すまでが非常に難しく(VPC、サブネット、ルーティングetc)まずは手を動かしてみるのにいい題材はないだろうか?
...と考えていたところ、ECSでWordPressをデプロイしてみるのが非常に簡単でオススメだということで、実際にやってみました。
必要なもの
- docker for mac
https://docs.docker.com/docker-for-mac/install/
- docker-compose
docker for macに同梱- AWSアカウント
https://aws.amazon.com/jp/?nc2=h_lg- ecs cli
https://docs.aws.amazon.com/ja_jp/AmazonECS/latest/developerguide/ECS_CLI_installation.html
少し複雑なので、Homebrew(https://brew.sh/) を使って下記のようにインストール可能です。(AWSの認証情報必須です)dockerコンテナをローカルで立ち上げてみる
1. CLI上でdocker-composeファイル作成
(とりあえずディレクトリ直下にdocker-compose.yml作成いただければOKです)
cd path/to/your/directoryプロジェクトを作成するディレクトリへ移動してくださいmkdir {フォルダ名} && cd {フォルダ名}フォルダを作成し、そのディレクトリへ移動しますtouch docker-compose.ymldoccker-composeという複数コンテナからなるサービスを実行するための手順書(のようなもの)を作成します。vi docker-compose.ymliインサートモード起動
- ▼をコピペ
docker-compose.ymlversion: '2' services: wordpress: image: wordpress mem_limit: 268435456 ports: - "80:80" links: - mysql mysql: image: mysql:5.7.25 mem_limit: 268435456 environment: MYSQL_ROOT_PASSWORD: password
escインサートモード終了:wqを押してEnter
これでファイルを保存しviを終了します2. docker-composeファイルのビルド
docker-compose up -d先ほど作成したファイルがあるディレクトリ直下で実行しますdocker psmysql:5.7.25とwordpressというイメージが作成されているのを確認します。ブラウザでhttp://localhostへアクセス自動的に次のような画面にリダイレクトされると成功です。
AWS ECS上でdockerコンテナを実行する
(参考) Homebrewによるecs-cliのインストール
- パッケージのインストール
brew install amazon-ecs-cli
- 初回インストールなのでリージョン/クラスター設定
ecs-cli configure --region ap-northeast-1 --cluster {好きなクラスター名}
リージョンは日本を示すap-northeast-1を。
クラスターとはかなりざっくり言えば、dockerコンテナをひとまとめにした大きな括りです。ここでは「wordpress-example」とかで大丈夫です。実際にECS上にコンテナをデプロイする
先ほどのdocker-compose.ymlの存在するルートディレクトリから実行します。
- 新規AWS ECSクラスターを作成する
ecs-cli up --capability-iam --size 2 --instance-type t2.micro
インスタンスタイプはお好みですが、最小限のt2.microを選択推奨です。
--capability-iamは、新規でIAMロールを作成することを示唆します。 (https://docs.aws.amazon.com/AmazonECS/latest/developerguide/cmd-ecs-cli-up.html)
このコマンドを実行することで、新規CloudFormationスタックが作成されます。- 成功したら...
ecs-cli psこちらのコマンドをどうぞ。
すると下記のような出力がされるはず。
Name State Ports TaskDefinition HealthこちらのPorts欄にある({IPアドレス}->80/tcpの){IPアドレス}をコピペして、ブラウザで開けると、ローカルと同じような画面が出てきます。
お疲れ様でした!
学んだことなど
AWSコンソールから、ECSクラスターを作成してみても、いっこうにうまくいかなかったのですが、CLIだとここまで簡単にデプロイできるのか!と思いました。
このデプロイをやるだけでも、AWS全くわかってない勢としては、非常に苦戦しましたので、ぜひ参考にしてみていただけますと!

- 投稿日:2020-07-24T15:35:25+09:00
ElasticBeanstalkのアプリケーションログをCloudWatchで捕捉したい
サーバのログ問題ってあると思いますが、皆さんはどうされていますか?
よくあるパターンはfluentdで特定のログ保存用サーバに送るパターンだと思います。
他にもDatadogやInsight7でトラッキングする方法などありますが、いずれも設定が大変でエージェント仕掛けたりとかCloudFormation仕掛けたりとか挫折しやすいです(実際今回の記事書くときにもやってみたけど正直何度もサポートに聞く羽目になったし、仮に設定できても有料なのも痛い)。あとdmsgとかアクセスログとかの保存は簡単だけど、アプリケーションログに関しては保存していないケースも多くて情報探すのにも苦労しました。
ElasticBeansTalkで作成したサーバのアプリケーションログは1時間とかでローテーションしてしかも消えてしまったり、AWSの管理画面でログのダウンロードしても出てこなかったりという問題があります。
ローカルでテストしているときはエラーのハンドリングは難しくないけど、本番じゃないと発生しない問題にはどう対処すればいいのか悩ましいところです。エラーのトラッキングはSentryも仕掛けているけど例外発生のときくらいしか拾わないのでなかなか使いにくいというのもあります。
長々すみません。ということでAWSでEC2(ElasticBeranstalk)使っているならCloudWatchでアプリケーションログ管理しようってことでチャレンジした内容になります。非常に簡単なので似たような環境をお持ちでしたらぜひご検討ください。
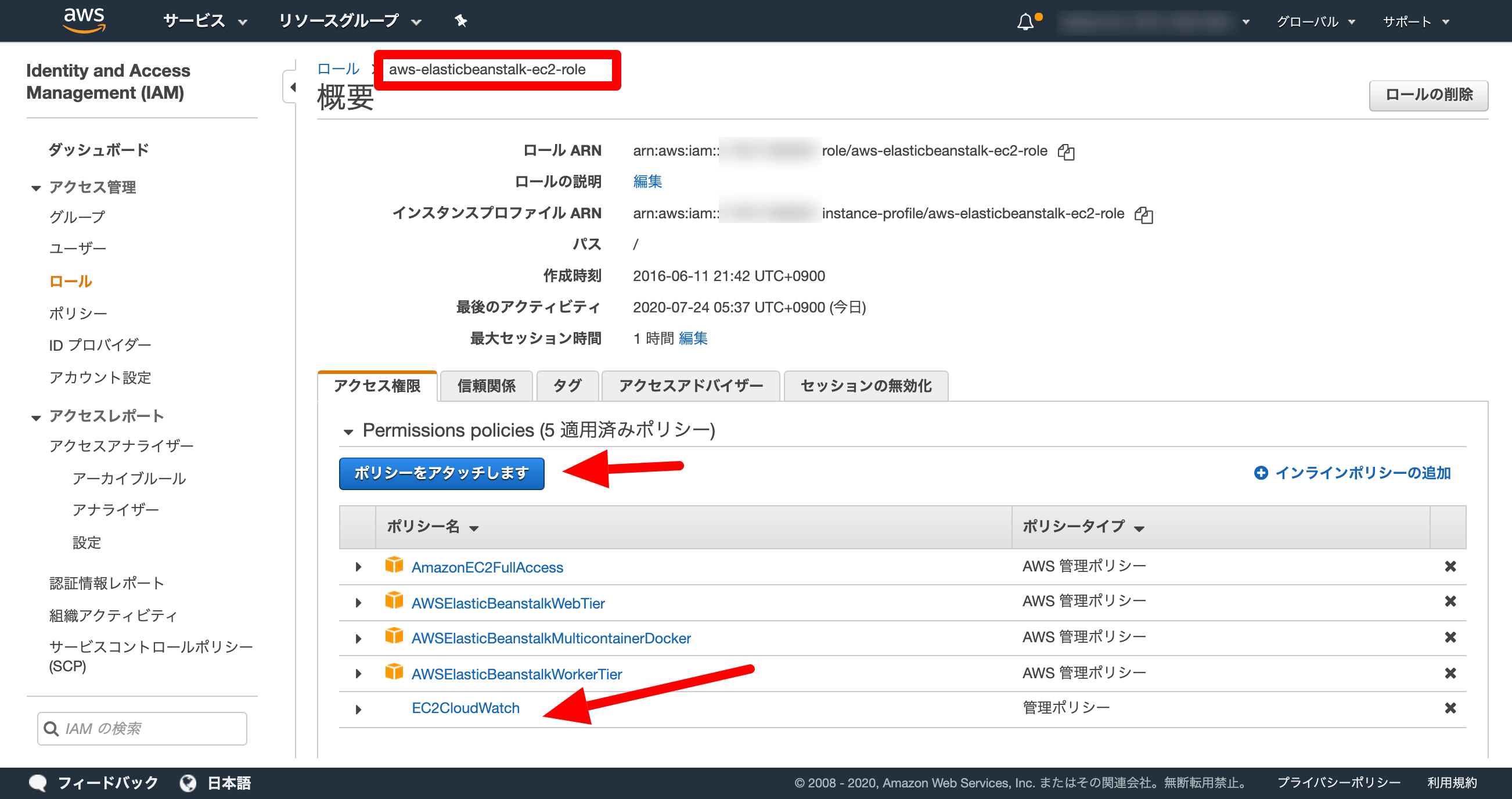
IAMにポリシーを追加
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": [ "logs:CreateLogGroup", "logs:CreateLogStream", "logs:GetLogEvents", "logs:PutLogEvents", "logs:DescribeLogGroups", "logs:DescribeLogStreams", "logs:PutRetentionPolicy" ], "Resource": [ "*" ] } ] }.ebextensionsにawslogsエージェントをインストール&設定する記述を追加
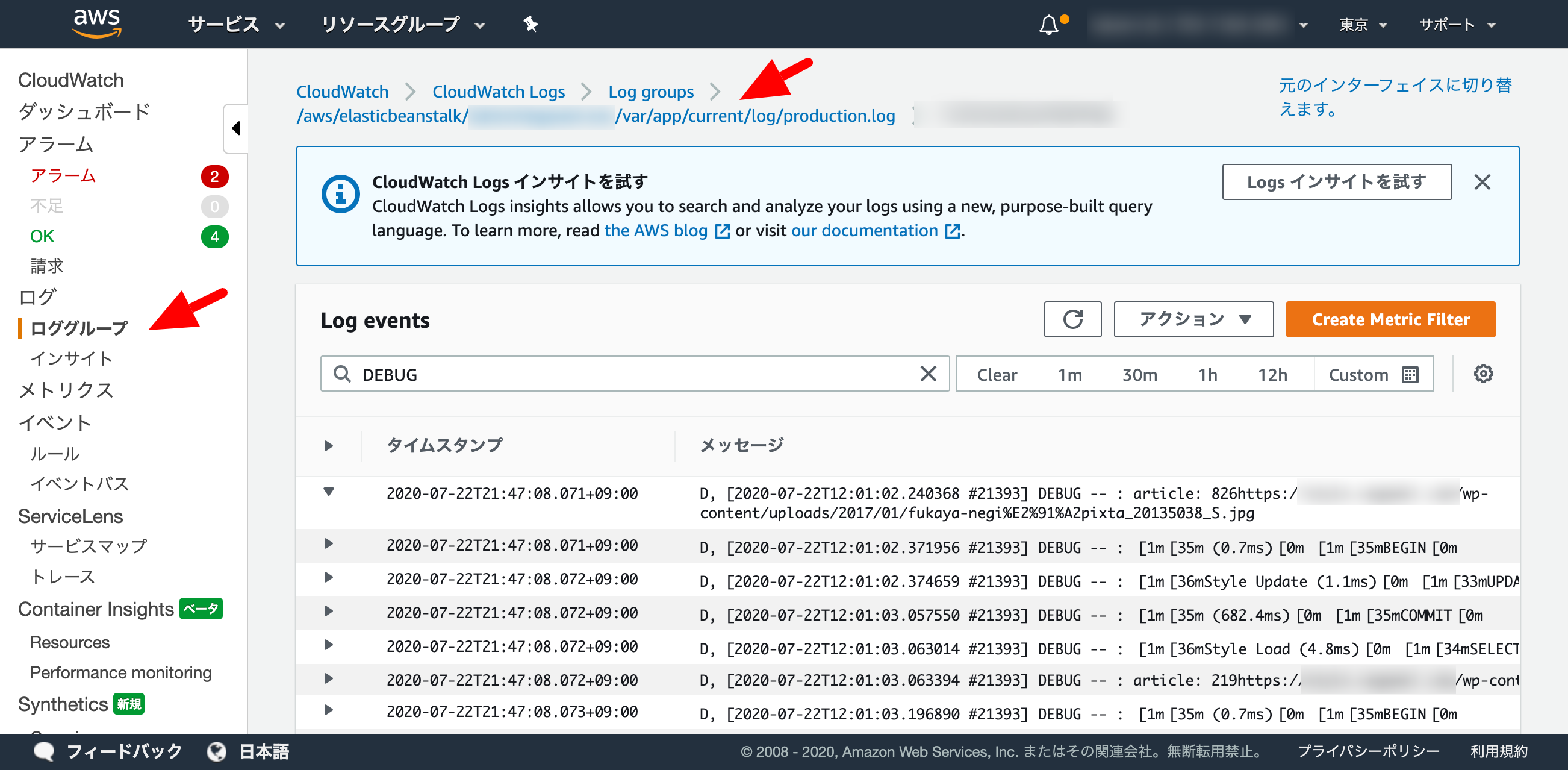
packages: yum: awslogs: [] files: "/etc/awslogs/awscli.conf" : mode: "000600" owner: root group: root content: | [plugins] cwlogs = cwlogs [default] region = `{"Ref":"AWS::Region"}` "/etc/awslogs/awslogs.conf" : mode: "000600" owner: root group: root content: | [general] state_file = /var/lib/awslogs/agent-state "/etc/awslogs/config/logs.conf" : mode: "000600" owner: root group: root content: | [/var/log/messages] log_group_name = `{"Fn::Join":["/", ["/aws/elasticbeanstalk", { "Ref":"AWSEBEnvironmentName" }, "var/log/messages"]]}` log_stream_name = {instance_id} file = /var/log/messages [/var/log/dmesg] log_group_name = `{"Fn::Join":["/", ["/aws/elasticbeanstalk", { "Ref":"AWSEBEnvironmentName" }, "var/log/dmesg"]]}` log_stream_name = {instance_id} file = /var/log/dmesg [/var/app/current/log/production.log] log_group_name = `{"Fn::Join":["/", ["/aws/elasticbeanstalk", { "Ref":"AWSEBEnvironmentName" }, "var/app/current/log/production.log"]]}` log_stream_name = {instance_id} file = /var/app/current/log/production.log commands: "01": command: chkconfig awslogs on "02": command: service awslogs restartCloudWatchのロググループで確認
なんとこれだけ、検索もできるしRails.loggerで仕掛けたログも引っ掛けやすい。是非試してみてください。
- 投稿日:2020-07-24T12:13:43+09:00
AWS Honeycodeで役に立ちそうなTips
いつも忘れないように、コンセプトから。
コンセプト
・お金かけてまでやりたくないのでほぼ無料でAWSを勉強する
→ちょっとしたサービスを起動すると結構高額になりやすい。
・高いレベルのセキュリティ確保を目指す
→アカウントを不正に使われるととんでもない額を請求されるので防ぐ今回はAWSのHoneycodeをもうちょっと勉強してみました。何かを作るというよりは、コミュニティサイトを眺めて学習する感じです。自分の疑問を解決する記事を探してみました。
スプレッドシートにデータを入れるけど、Excelみたいな関数は何が使えるの?
ちょっと古い記事なのでもっと増えているかもしれませんが、ある程度まとまってました。これなら英語が苦手でも感覚的にわかりそうです。
https://honeycodecommunity.aws/t/honeycode-functions/90複数のTablesを組み合わせるのはどうするの?
SQLでいう結合というかリレーションに関する疑問です。ここは以下の「Tasks-to-Project」の部分を見るとわかりやすいです。Formatsを選んでからRowlinkを選択していますね。こうやって他のTablesと関連付けています。
https://honeycodecommunity.aws/t/data-modeling-101/87Automationsでできることって何?
概要としては
- Add, edit, and delete data in tables(Tablesへの挿入・変更・削除)
- Send notifications and reminders(通知の送信)
- Change screens and navigate users through your app(画面遷移とナビゲート)
- Set variables in current or target screens(変数のセット)
のようです。大きく、Workbook Automationsと、Builder Automationsに分かれていて、それぞれでできることが違います。スプレッドシートでできることと、アプリ(画面)でできることのイメージに近いので、できることが違って当然という気もします。簡単な比較表もリンクにあるのでわかりやすいです。
https://honeycodecommunity.aws/t/automations-overview/96AWSアカウントに接続するには?
Teamsのタブからセットしますが、リンク先のスクリーンショットを見たほうが早いです。
https://honeycodecommunity.aws/t/connecting-honeycode-to-an-aws-account/98学習メニューはある?
現状リンク先の3つみたいです。英語なんで読めないとちょっと辛いかも。動画や簡単なテストもあります。
https://honeycodecommunity.aws/c/Courses/17モバイルでカメラアクセスできないの?
現状ではできないみたいですね。でもニーズはありそうなので前向きに検討されそうです。確かにメンバー限定アプリで写真の情報をシェアできると面白そうです。
https://honeycodecommunity.aws/t/access-camera-on-mobile/1827/4消してしまったアプリ(Workbook)を復元するには?
現状ではできないみたいですね。さすがに正式版にはリリースされる機能でしょうね。単にアプリのバックアップというだけじゃなくて、Gitとかのバージョン管理も出ると思いますがそこは今後に期待ですね。
https://honeycodecommunity.aws/t/how-do-i-recover-my-deleted-app/5212アプリをパブリック公開できますか?
自分で調べろよって言っている人もいますが、、、
https://honeycodecommunity.aws/t/create-a-public-site/1387
現状では以下の方法でシェアすることになりそうです。App Userで使う人を登録する感じですね。
https://honeycodecommunity.aws/t/sharing-workbooks-apps/911
いろいろ意見交換されているので、ここも早々に実装・改善されてくるでしょうね。Googleのフォームみたいになると便利ですね。HoneyCodeでS3アクセスするにはどうすればいいですか?
API経由でのアクセスになります。Read、Writeの方法が書いてあります。以下の引用の部分、詳しくはリンク先のドキュメントを見たほうがいいですね。
https://honeycodecommunity.aws/t/aws-platform-integration/5082-- How much integration is there to the AWS services ?
Today Honeycode offers an API to read and write data. This gives you the ability
to integrate with external services.-- What is the best documentation to follow ?
For APIs, the same link as previous response. Getting Started with Honeycode
APIs . For general getting started Honeycode docs,
https://honeycodecommunity.aws/c/get-started/9 .今日はここまで。またいい感じのものを見つけて蓄積していこうと思います。
- 投稿日:2020-07-24T11:56:16+09:00
AWS; Amazon workbook って何だ?
AWSはついにOfficeアプリまで浸食しに行くのか、Microsoft Excel や Google Spreadsheet的なやつ。
AWS Honeycode はローコード・ノーコードつまり、プログラミング言語を書かなくてもスマホアプリやWEBアプリを開発できる開発環境のサービス。現在AWSからプレビュー提供中(2020/6月~, 7月現在)。Honeycodeで開発するアプリのデータを保存したり取り出したりするデータベースとしてExcelみたいな Amazon workbook が使える。
ならば Amazon workbook を調べてみよう
何ができるのか?
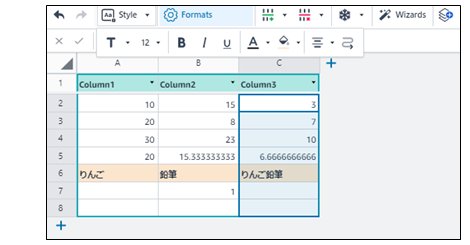
- 【保存】オンラインストレージ(Amazon Drive)に作成した「表データ(amazon workbook)」を扱える。アップロードやダウンロードの機能は見つからなかった。
- 【データ追加/削除】レコードの入出力ができる(データをworkbookに入力、データをworkbookで表示)。
- 【表計算】表計算としても機能する。表形式で印刷もできる。
表計算できるのかな?
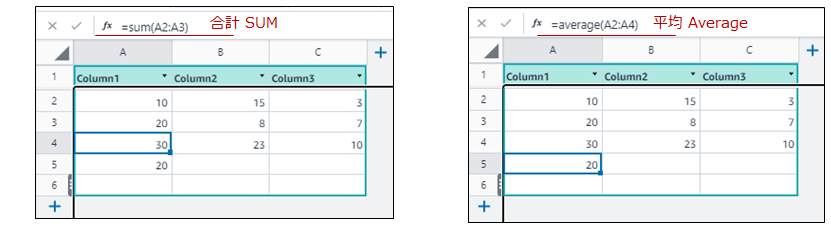
Excelと同じ関数 合計Sum や 平均Average 他 が同じ書式で使える。
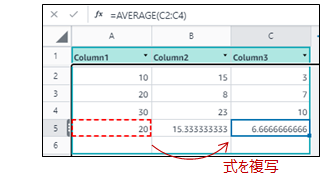
セルの式を、コピー&ペーストで複製できる。
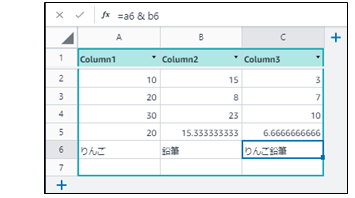
日本語データも扱える。セル[A6]とセル[B6]の文字列連結ができる。
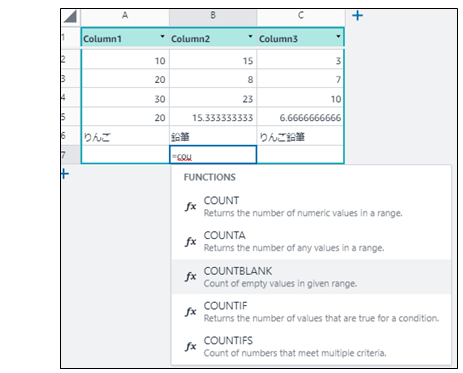
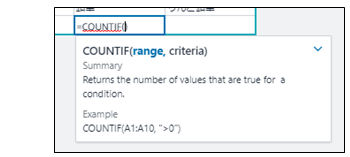
利用できる関数はExcelとほぼ同じ。前方一致検索してくれるので、例えば"cou"..と入力すれば関数の候補一覧が表示される。
関数の書式(使い方)も表示される。
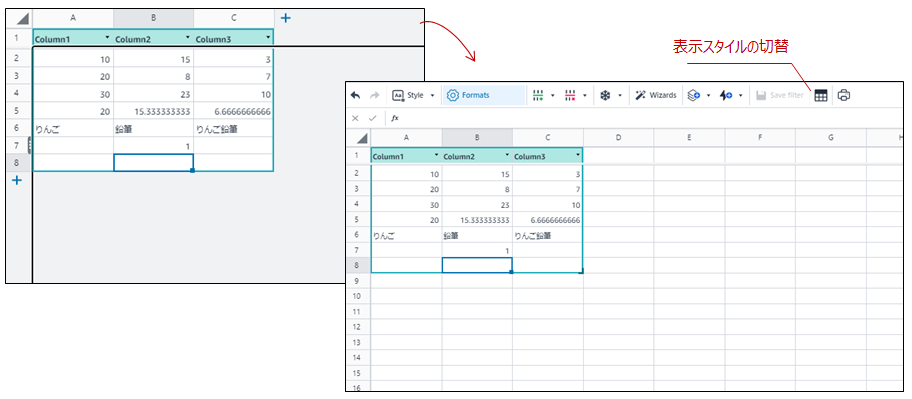
workbookのメニュー
表示スタイル
データを都度、[追加/削除]するスタイルか、Excelワークシートみたいな表示スタイルか切替ができる。
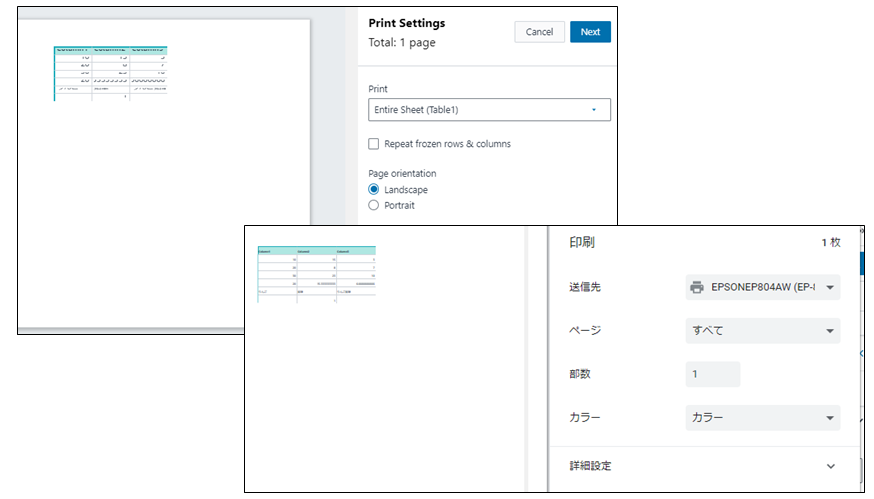
印刷
表示スタイルがワークスタイルの場合、[印刷]アイコンが表示される。
(1)印刷プレビューが表示されて、
(2)パソコン標準の印刷ダイアログに連携、プリンターに出力できる。
文字修飾、セル修飾
表の見た目(文字/セル修飾)は、[Style]アイコンで文字の大きさ、太文字、下線、色などを選べる。
ファイル操作
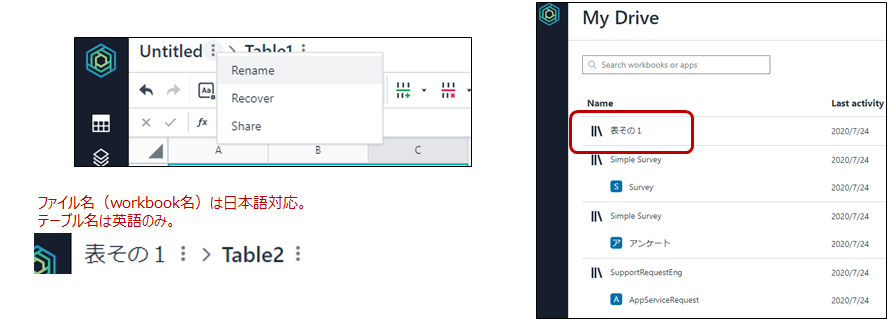
ファイル名の変更:例えば、表データの名前を「表その1」に変更して保存する。
テーブル名の変更:日本語にできなかった。英語なら変更可能。
まとめ
AWSがOfficeアプリも提供するというよりは、スマホやWEBアプリのデータとしてExcel形式のデータベースとして扱うためのworkbookの様です、今のところ。そしてプログラミング言語を書かなくてもアプリを開発する手法として、最初にWorkbookでデータを作成し、そのデータを基にウイザード形式でアプリを自動作成するのが AWS Honeycode 。
本記事の通り表計算としても機能するので、アプリ側で合計やら平均やらをプログラミングで計算しなくてもアプリに表示できるので、業務でExcel得意なEUC担当者など、サーバーネットワークインフラを知らなくても、アプリ開発の経験がなくても、アプリを作成できる時代が到来したのですね。
- 投稿日:2020-07-24T10:47:32+09:00
LambdaとDjangoの相性ってどうなの??
忙しい人へ
結論とまとめを最初にのせときます
結論
Djangoのようなフルスタックフレームワークではあまり良いとは言えない
フルスタックフレームワーク使うならECSを使った方が良いらしいまとめ
Lambdaのコールドスタートで時間かかるのでは?
結構かかります
DjangoのプロジェクトをLambdaにアップロードしたら、Lambdaのアップロードサイズ制限に引っかかるのでは?
かかる可能性はあります
ただよほど入れなければ大丈夫なはずREST APIを作る時に、DjangoのルーティングとAPI Gatewayの組み合わせって相性悪くね?
実害はないと思うけど悪いと思います
Django使うってことはサーバーレスなのにサーバー立ち上げるってこと?
その通りです
前置き
この記事はあくまでも私見です
これが絶対正しいということではないのでご了承ください前提
zappaというデプロイツールを用いての検証
本題
LambdaとDjangoの組み合わせにした時の疑問点がいくつかあった
その疑問点をひとつづつ考えてみた疑問点
- Lambdaのコールドスタートで時間かかるのでは?
- DjangoのプロジェクトをLambdaにアップロードしたら、Lambdaのアップロードサイズ制限に引っかかるのでは?
- REST APIを作る時に、DjangoのルーティングとAPI Gatewayの組み合わせって相性悪くね?
- Django使うってことはサーバーレスなのにサーバー立ち上げるってこと?
Lambdaのコールドスタートで時間かかるのでは?
Lambdaのコールドスタート
- ENIの作成(LambdaにVPC設定した時に限る)
- 実行コンテキストの起動
- デプロイパッケージの読み込み
- デプロイパッケージの展開
- ランタイムの起動と初期化
- 関数の実行
調査
今回はVPC設定なしで、コールドスタートの時間を調べたいので2~5までの時間を調べる
Djangoのプロジェクトと生のPythonのプロジェクトを用意
※DjangoのプロジェクトではzappaとDRFを導入
プログラムの内容はLambda実行時に「Hello world」をJSONで返す
これらをマネージドコンソールから実行してCloudWatchで処理時間を確認する
Djangoのパッケージサイズは42.2MB
生Pythonのパッケージサイズは129B
Lambdaに割り当てたメモリはどちらも512MB結果
(msで表記)
回数 Django 生Python 差分 1 3073 4 3069 2 3159 3 3156 3 3173 3 3170 4 3190 3 3187 5 3196 4 3192 デプロイパッケージのサイズによってコールドスタートにかなり影響があることが分かった
Lambdaはなるべく最小限のパッケージをアップロードすることが好ましいのでフルスタックフレームワークを使用するのは相性が悪そうDjangoのプロジェクトをLambdaにアップロードしたら、Lambdaのアップロードサイズ制限に引っかかるのでは?
Lambdaのパッケージサイズの上限
50 MB (zip 圧縮済み、直接アップロード)
250 MB (解凍、レイヤーを含む)いろいろライブラリを突っ込んでたら制限にかかりそう
REST APIを作る時に、DjangoのルーティングとAPI Gatewayの組み合わせって相性悪くないか?
実際にプログラムを動かす上で実害はない
だが、あまり筋の良いやり方だとは思えなかった
本来APIGateway + LambdaでREST APIを作成した時の処理の流れは
1. APIGatewayでURLを指定
2. 指定したURLと紐づくLambdaを呼び出す
3. 処理
になると思うDjangoを使用するとなると、Djangoで設定したURLに合わせることになる
処理の流れとしては
1. APIGatewayはどんなURLが来ても同じLambdaを呼び出す
2. Lambdaが起動したらまずDjangoのサーバーを立ち上げる
3. DjangoのサーバーがURLを受け取りルーティングする
4. URLに紐づいたDjangoのViewを実行
という流れになるため非常に筋が悪いなのであまり相性が良いとは言えない
Django使うってことはサーバーレスなのにサーバー立ち上げるってこと?
そういうことになる
GitHubでzappaのLambda処理を見てみると
- Django動かす準備
- URLの取得
- Djangoのサーバー起動
みたいな感じだった
サーバーレスなのにサーバー立ち上げる処理が入るから違和感を感じた
その他
検証中に思ったこととかをここに書いときます
- RDSとLambdaって相性よくなかった気がする
- ただ2020年7月にRDS Proxyがリリースされたからかなり解消されてるかも?
- LambdaとDjangoの事例がなさすぎる
- 開発で詰まった時に調べても、ドキュメントがないから解決にかなり時間かかりそう
- zappaでRDS使おうと思ってmysqlclient入れてzappaのコマンドでマイグレーションしたら死ぬほどエラー出た
- zappaのコマンド使わずにマイグレーションしたら普通に通ったからzappaの問題?
- ライブラリによって使えないものがあると困るので結構致命的
- そもそもLambdaの実行時間制限15分・パッケージサイズ250MBまでなど、制限があるので一つのLambdaにいろんな処理をさせるのは不向きなのでは?
結論
Djangoのようなフルスタックフレームワークではあまり良いとは言えない
フルスタックフレームワーク使うならECSを使った方が良いらしいまとめ
Lambdaのコールドスタートで時間かかるのでは?
結構かかります
DjangoのプロジェクトをLambdaにアップロードしたら、Lambdaのアップロードサイズ制限に引っかかるのでは?
かかる可能性はあります
ただよほど入れなければ大丈夫なはずREST APIを作る時に、DjangoのルーティングとAPI Gatewayの組み合わせって相性悪くね?
実害はないと思うけど悪いと思います
Django使うってことはサーバーレスなのにサーバー立ち上げるってこと?
その通りです
- 投稿日:2020-07-24T02:24:44+09:00
AWS Copilot
AWS Copilot?
- ”Amazon ECS が AWS でコンテナをデプロイして操作するための新しい CLI ”とのこと
- Copilot(そのまま英訳を検索すると副操縦士)
- AWS Copilot CLI (preview)
- この辺りを参考にサンプルを触ってみようと思います
作業環境
- macOS Catalina(10.15.5)
- 以下の通りCopilotはAWS CLIの認証情報を参照するため、設定は事前に実施しておきます
- Copilot uses the same credentials as the AWS CLI (引用元)
インストール
インストール方法
・MacとLinuxのInstall方法が記載されています
・Windows環境は手元にないため確認できていないですが
バイナリの配置で使用できそうなのでWSLとかであれば使えるかもしれませんが…わかりません。brew install aws/tap/copilot-cli一旦オプション等何も確認せず、サンプルを動かしてみます
git clone https://github.com/aws-samples/aws-copilot-sample-service.git demo-appcd cd demo-app copilot init --app demo \ --svc api \ --svc-type 'Load Balanced Web Service' \ --dockerfile './Dockerfile' \ --deploy
- 以下の通り、実行に失敗したようです(exit status 1)
- 実行状況を見るとAWSのリソースは作られているようです
- copilotを導入後、個別でAWSの認証情報は設定していないので、やはりAWSCLIの認証情報を使用している
- 実行に際しCloudFormationにスタックが追加されていたので、環境構築のベースはCloudFormation
- 異常終了の原因はローカルのPCでDockerプロセスを起動していなかったため、Buildができずにコンテナイメージが作れなかったようです
Note: It's best to run this command in the root of your Git repository. Welcome to the Copilot CLI! We're going to walk you through some questions to help you get set up with an application on ECS. An application is a collection of containerized services that operate together. Ok great, we'll set up a Load Balanced Web Service named api in application demo listening on port 80. ✔ Created the infrastructure to manage services under application demo. ✔ Wrote the manifest for service api at copilot/api/manifest.yml Your manifest contains configurations like your container size and port (:80). ✔ Created ECR repositories for service api. ✔ Created the infrastructure for the test environment. - Virtual private cloud on 2 availability zones to hold your services [Complete] - Virtual private cloud on 2 availability zones to hold your services [Complete] - Internet gateway to connect the network to the internet [Complete] - Public subnets for internet facing services [Complete] - Private subnets for services that can't be reached from the internet [Complete] - Routing tables for services to talk with each other [Complete] - ECS Cluster to hold your services [Complete] - Application load balancer to distribute traffic [Complete] ✔ Linked account xxxxxxx and region ap-northeast-1 to application demo. ✔ Created environment test in region ap-northeast-1 under application demo. Cannot connect to the Docker daemon at unix:///var/run/docker.sock. Is the docker daemon running? ✘ build Dockerfile at ./Dockerfile with tag f8d65d4: building image: exit status 1DockerDesktopプロセスを起動して再度実行してみます
- アカウント情報やエンドポイント等マスクが必要な情報が増えてしまったので、実行内容を要約します
- 1回目にCloudFromationで作成されたAWSリソースは"already exists"と表示され作成はスキップされていました(スタックのテンプレートに変更は生じていないので)
- DockerImageのビルド処理が実行され、ビルド後ECRにPushされていました
- Push後、デプロイが行われたようでALBのエンドポイントが表示されました
✔ Deployed api, you can access it at http://demo-Publi-xxxxxx.ap-northeast-1.elb.amazonaws.com.・ALBのエンドポイントにアクセスすると以下のような画面が表示されました
作られたリソース
- Sampleのreadmeに記載されていましたが今回のinitコマンドは動作確認向け(チュートリアル向け)にある程度定められた構成をCloudFormationで作成しているようです
Copilot will set up the following resources in your account: * A VPC * Subnets/Security Groups * Application Load Balancer * Amazon ECR Repositories * ECS Cluster & Service running on AWS Fargate環境の掃除
copilot app delete所感・感想
- 今回使用したinitコマンドはチュートリアル目的と思われるためcopilotの実力を確認するためには十分ではないことはわかった。もっと触らないといけない
- 「便利なものを使う」ことは「どのような課題が解消されたかを言語化できる」ことと「便利さに隠蔽された短所とのトレードオフを把握した上で使用する判断ができている」ことが大前提だと改めて感じた。そうでないと使っている気でいるツールに置いてけぼりを食らうように思います
- 置行堀は本所(東京都墨田区)を舞台とした本所七不思議と呼ばれる奇談・怪談の1つ

- 投稿日:2020-07-24T02:06:58+09:00
isucon9 の portal を Amazon Linux2 で動かすメモ
MEMO: 必要あれば ports を適宜変更すること
sudo yum -y update sudo timedatectl set-timezone Asia/Tokyo sudo yum -y install docker sudo systemctl start docker sudo systemctl enable docker sudo curl -L "https://github.com/docker/compose/releases/download/1.26.2/docker-compose-$(uname -s)-$(uname -m)" -o /usr/local/bin/docker-compose sudo chmod +x /usr/local/bin/docker-compose sudo yum -y install git sudo reboot git clone git@github.com:chibiegg/isucon9-portal.git cd isucon9-portal docker-compose build docker-compose up docker-compose exec discard_forever python manage.py manufacture -t 300
- 投稿日:2020-07-24T00:17:35+09:00
同一リージョンS3バケット間で大きなサイズのファイルをコピーする
概要
- 東京リージョンのs3バケットにあるサイズの大きなファイルを、リージョン内の別のバケットに効率よくコピーする方法を検討した。
課題
- 対象ファイルは、4Kの動画ファイル(.MOVまたは.MXF)でサイズは 大きいものだと数ギガから数十ギガバイトである。このサイズだと、Multipart Uploadの利用が前提である。
- 時間と費用を最小限にしたい。
仮説
- boto3 s3 clientに、copyという関数が用意されていて、
This is a managed transfer which will perform a multipart copy in multiple threads if necessary.
と記載されいるので、これを使えばよさそうである。しかし、The transfer configuration に何を設定すればよいのかわからない。
参考 : https://boto3.amazonaws.com/v1/documentation/api/latest/reference/services/s3.html#S3.Client.copy試したこと
- 東京リージョンにバケットを2つ用意。デフォルト設定。
- コピーに用いたファイルは 5.09GB (5,471,004,718 バイト)の動画ファイル
- Lambda関数のランタイムは Pyathon3.8
- 実験で使うLambda関数
lambda_function.pyimport json import boto3 def copy(src_bucket,src_key,dest_bucket,dest_key): s3client = boto3.client('s3') response = s3client.copy( {"Bucket":src_bucket,"Key":src_key}, dest_bucket,dest_key ) return def lambda_handler(event, context): src_bucket=event['src_bucket'] src_key=event['src_key'] dest_bucket=event['dest_bucket'] dest_key=event['dest_key'] copy(src_bucket,src_key,dest_bucket,dest_key) return "OK"
- Lambda関数の入力値はソースをみればわかると思うが、コピー元のバケット、キー、コピー先のバケット、キーである。
{ "src_bucket": "コピー元バケット", "src_key": "test_4k.mov", "dest_bucket": "コピー先バケット", "dest_key": "test_4k.mov" }Config指定なしの結果
REPORT RequestId: d5f00753-aae0-41a5-8e1a-e6c18747b114 Duration: 36905.20 ms Billed Duration: 37000 ms Memory Size: 128 MB Max Memory Used: 91 MB
- 課金実行時間が37秒かかっている。
Config{max_concurrency=20}の結果
- max_concurrencyとは、thread数のことらしい。単純に増やせばどうかと思い、デフォルト10のところを20にかえてみた。
- コピー関数部分を次のように変更して実行
def copy(src_bucket,src_key,dest_bucket,dest_key): s3client = boto3.client('s3') TransferConfig = boto3.s3.transfer.TransferConfig( multipart_threshold=8388608, max_concurrency=20, multipart_chunksize=8388608, num_download_attempts=5, max_io_queue=100, io_chunksize=262144, use_threads=True ) response = s3client.copy( {"Bucket":src_bucket,"Key":src_key}, dest_bucket,dest_key,Config=TransferConfig ) return
- 実行結果
[WARNING] Connection pool is full, discarding connectionが大量に発生。REPORT RequestId: 655f0859-0599-4231-923a-480cb47fcef8 Duration: 43544.81 ms Billed Duration: 43600 ms Memory Size: 128 MB Max Memory Used: 98 MB Init Duration: 251.39 ms
- コネクションプールがあふれ? 43秒に増えてしまった。
- スレッド数20だと不安定のようだ。ここは、デフォルトの10に固定し、ほかのパラメータを変更してみる
Config{multipart_chunksize=64MB}の結果
- 転送のブロックを大きくすればどうか、ということでデフォルト8MBから64MBに増やしてみる
def copy(src_bucket,src_key,dest_bucket,dest_key): s3client = boto3.client('s3') TransferConfig = boto3.s3.transfer.TransferConfig( multipart_threshold=64*1024*1024, max_concurrency=10, multipart_chunksize=64*1024*1024, num_download_attempts=5, max_io_queue=100, io_chunksize=262144, use_threads=True ) response = s3client.copy( {"Bucket":src_bucket,"Key":src_key}, dest_bucket,dest_key,Config=TransferConfig ) return
- 実行結果
REPORT RequestId: 45c89f9b-47b9-4a26-a7f0-59149f9b3e6a Duration: 13235.39 ms Billed Duration: 13300 ms Memory Size: 128 MB Max Memory Used: 87 MB Init Duration: 254.25 ms
- 13秒まで減った。メモリサイズも減っている。いい感じである。
Config{multipart_chunksize=128MB}の結果
REPORT RequestId: f6d1bec9-7c0f-4c2e-ae56-04ddd6f8d929 Duration: 11707.85 ms Billed Duration: 11800 ms Memory Size: 128 MB Max Memory Used: 86 MB Init Duration: 255.65 ms
- 12秒弱である。まだまだいけそうだ。
Config{multipart_chunksize=256MB}の結果
REPORT RequestId: 1ba387d6-0da3-4f7f-8893-6a98b63c9368 Duration: 11088.25 ms Billed Duration: 11100 ms Memory Size: 128 MB Max Memory Used: 88 MB Init Duration: 236.17 ms
- 11秒。
Config{multipart_chunksize=512MB}の結果
REPORT RequestId: b6eacb3d-fe1c-4abd-9bd6-eedd9ee69aa7 Duration: 11371.11 ms Billed Duration: 11400 ms Memory Size: 128 MB Max Memory Used: 87 MB Init Duration: 257.59 ms
- 11.4秒。multipart_chunksize=256MBよりも時間が増えている。
まとめ
結論
実行タイミングや環境で差がでる可能性はあるが、今回の実験結果によると、boto3 s3 clientのcopy関数で、5GBのファイルを東京リージョンのバケット間でコピーする場合、max_concurrency=10,multipart_chunksize=256*1024*1024 が最小のBilled Durationであった。
def copy(src_bucket,src_key,dest_bucket,dest_key): s3client = boto3.client('s3') TransferConfig = boto3.s3.transfer.TransferConfig( multipart_threshold=256*1024*1024, max_concurrency=10, multipart_chunksize=256*1024*1024, num_download_attempts=5, max_io_queue=100, io_chunksize=262144, use_threads=True ) response = s3client.copy( {"Bucket":src_bucket,"Key":src_key}, dest_bucket,dest_key,Config=TransferConfig ) return考察
- 今回の評価は およそ5GB というファイルで行ったが、5GBより大きなファイルにおいても、本実験の結果は参考になると考える。しかし、5GBよりも十分小さいファイルでは別の最適解である可能性がある。
- 今回の実験では、max_concurrency増加は結果がよくなかったので深掘りしなかった。エラーの内容から、S3の書き込みでコネクションプールを制限していることが想定されるが、 これについて記述したドキュメントは発見できなかった。S3の書き込み特性が理解できれば、チューニングの可能性は残されていると考える。