- 投稿日:2020-07-24T15:31:57+09:00
Spring Batchでcsvを取り込むバッチを作ってみました。
はじめに
おはようございます。先日Springを入門し、SpringBatchで小さいバッチを作ってみました。
皆にお役に立つかと思いますので、共有させていただきます。m(_ _)m日本語を勉強中ですので間違っていることがあればよろしくお願いします。
それでは始めます。
1.要件定義
csv形式で保存される販売情報をシステムに取り組むバッチを作ります。
実際、ウェブアプリでもいけますが(例えばサイトの画面でファイルを選んで、送信するとcsvを取り組むアプリなど)、SpringBatchを使ってみたいので、この場面バッチを作る必要があるとします。
それではプログラミングのInput、outputから説明してきます。
1.1.(インプット)販売情報のcsvの内容
orders.csv
customer_id,item_id,item_name,item_price,purchase_date 1,1,150000,asus notebook,2020/07/16 8:00:00 1,2,200000,macbook pro 13 inch,2020/07/16 9:00:00 2,2,200000,macbook pro 13 inch,2020/07/16 10:00:00 2,3,250000,macbook pro 15 inch,2020/07/17 10:00:00ファイルの内容はいつ、どのユーザーがどの商品、いくらで購入したかの情報です。
例えば2行目は、customerの1がitemの1のasus notebookを2020/07/16に15万円で購入したという意味を示します。
1.2.(アウトプット)テーブルの内容
上のcsvをバッチの実行で、インポートした後、該当するテーブルは下記のようになると期待します。
| id | customer_id | item_id | item_name | item_price | purchase_date | |--:|--:|--:|:--|--:|:--| | 1 | 1 | 1 | asus notebook | 150000 | 2020/07/16 | | 2 | 1 | 2 | macbook pro 13 inch | 200000 | 2020/07/16 | | 3 | 2 | 2 | macbook pro 13 inch | 200000 | 2020/07/17 | | 4 | 2 | 3 | macbook pro 15 inch | 250000 | 2020/07/17 |2.準備
自分のホストPCの情報は下記です。ご参考までと思います。
- OS : MacOS (Macbook Pro)
- Java
java version "12.0.2" 2019-07-16 Java(TM) SE Runtime Environment (build 12.0.2+10) Java HotSpot(TM) 64-Bit Server VM (build 12.0.2+10, mixed mode, sharing)
- IDE Spring Tool 4 For Eclipse https://spring.io/tools
IDEについて自分は通常VSCodeを使っていたので、最初はVSCodeでコーディングしようと思いましたが、SpringBootパッケージをインストールしてもjavaオートインポート機能がうまくいけませんでした。。。そのためこの場合VSCodeをやめました。
またIntellJも試しましたが、CommunityバージョンはSpringをサポートしなませんね・・・
という経由で、IDEはEclipseにしました。
3.実装
3.1.初期化
Spring Initialzrのおかげで簡単にボイラプレートを作れました。
https://start.spring.io/
- プロジェクト:Maven
- 現在はGradleのほうが流行している気がしますが、個人的な理由でMavenを選びます。
- 言語:Java
- 他にはできないため
- Dependence:
- SpringBatch:バッチを作りますので、Spring Batchを選びます。
- Mysql Driver:Mysqlを使いますので、そのドライバーを選びます。
- SpringDataJPA:よくわかりませんが、MysqlDriverを操作するためのライブラリようです。
選択終わった後に、Generateを押し、「demo.zip」がダウンロードされます。
3.2.DockerでMysqlのデータベースを作成
ホストにはすでにデータベースが使える状態であればこのステップをスキップしてもいいです。
3.2.1.Docker-composeで構築します
場所:
demo/ ... docker-compose.yml db/ ...
demo/docker-compose.ymlversion: '3' services: database: image: mysql:8.0 volumes: - ./db/dbdata:/var/lib/mysql command: ['--character-set-server=utf8mb4', '--collation-server=utf8mb4_unicode_ci','--default-authentication-plugin=mysql_native_password'] environment: MYSQL_DATABASE: demo MYSQL_ROOT_PASSWORD: root MYSQL_USER: demo MYSQL_PASSWORD: demo ports: - "33061:3306"ご覧になる通りにデーターベースの情報は:
- 初期で作られるデータベース名:demo
- ユーザー名:demo
- パスワード:demo
3.2.2.テーブルを作成
これでデータベースが作成できましたが、まだテーブルがないのでバッチから呼び出すとエラーが出ます。そのためテーブルを作ります。
データーベースを起動:
$ docker-compose up -d $ mysql -u demo -P 33061 -pordersというテーブルを作ります
CREATE TABLE orders ( id INT AUTO_INCREMENT PRIMARY KEY, customer_id INT(12) NOT NULL, item_id INT(12) NOT NULL, item_name VARCHAR(50), item_price INT(12) NOT NULL, purchase_date DATETIME ); Query OK, 0 rows affected, 3 warnings (0.05 sec)これでデータベースは大丈夫でした。
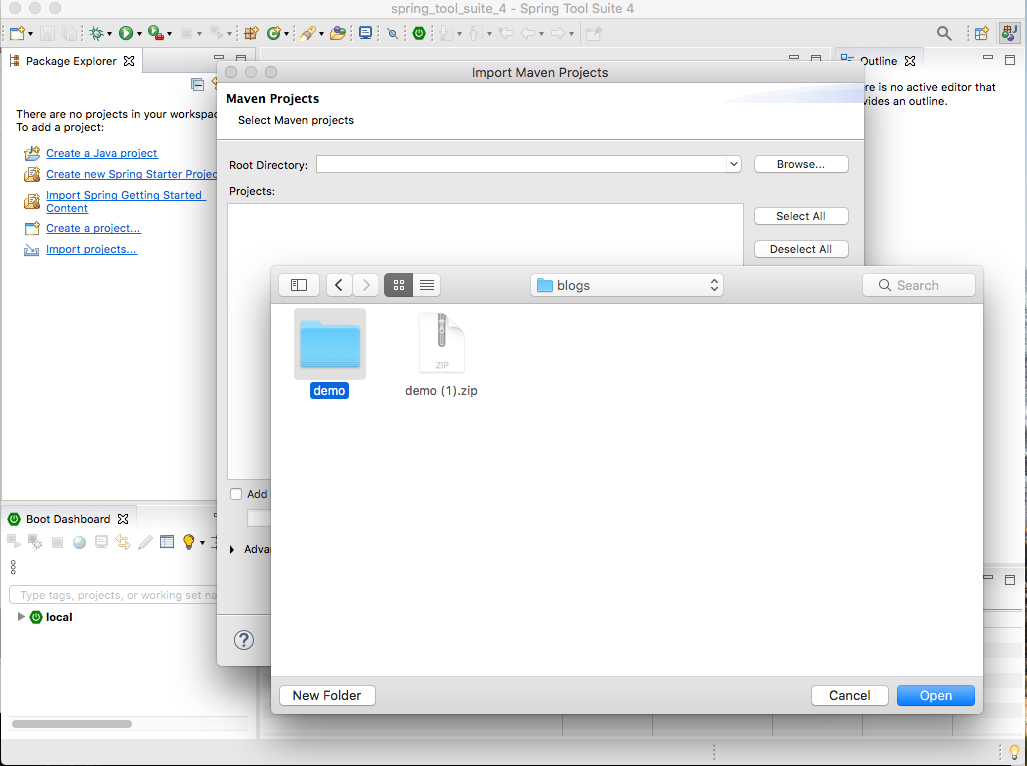
3.3.プロジェクトをインポート
3.1からzipが作られました。次はeclipseで解凍したディレクトリをインポートします。
Import > Maven > Existing Maven Project
次はバッチを設計します。
3.4.設計
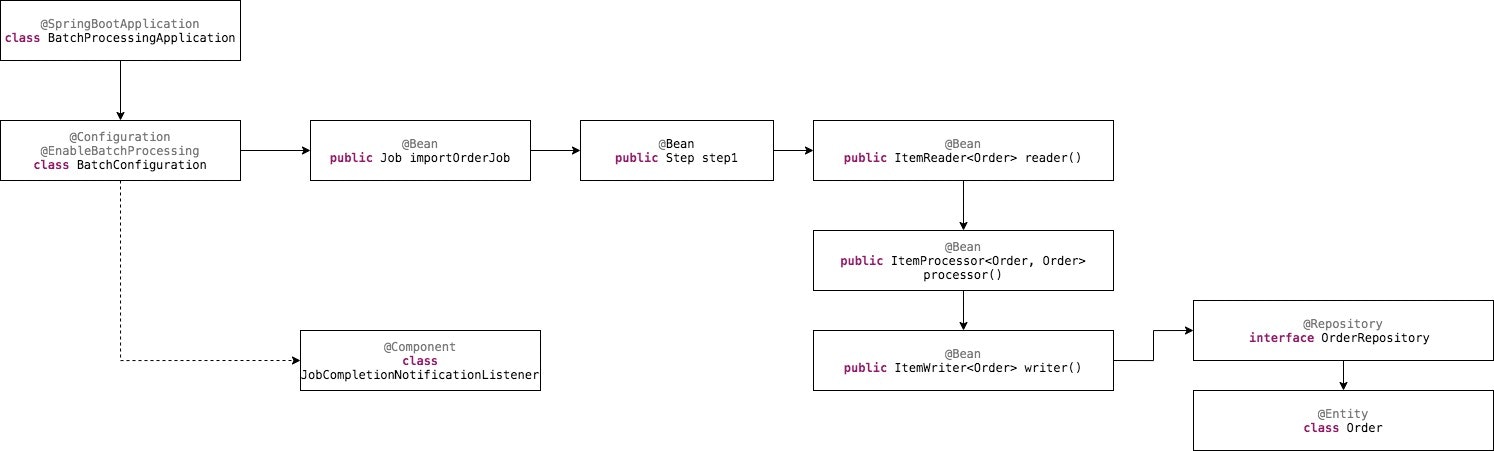
エントリーポイントから説明していきます。
- BatchProcessingApplication:アプリのエントリーポイントです。@SpringBootApplicationのAnnotationをつけたことで、自動で同じ階増にあるクラスを読み込むようフレームワークに指定することができます。
- BatchConfiguration:名前の通りに、バッチの設定はここです。
- (Job)importOrderJob:バッチにあるJobの一つです。実際のバッチには複数のJobがあるのは一般ですが、今回のプログラムは簡単ですので、このJobしか存在しません。csvを取り込む役をするJobです。
- (Step)step1():importOrderJobの最初、一つのみの実行ステップです。
- (ItemReader) reader() :step1のステップ内にあるもっと小さいな単位の最初のプロセスです。csvを取り込む役をします。
- (ItemProcessor) processor() : ステップ内に、csvを取り込んだ後に、そのデータを処理する部分です。
- (ItemWriter) writer() : csvのデータがインポート、処理された後に、それをDBに追加する部分です。
- (Repository) OrderRepository : データを保存するのをサポートするSpringが用意したクラスを継承するクラスです。
- (Entity) Order : csvの行をモデル化するクラスです。それとDBのテーブルを表現するクラスです。実際この2つの定義は違うクラスに分けたほうがいいですが、今回はcsvの行とテーブルの構成はほぼ一緒ですので、同じクラスにします。
3.5.プログラミング
3.5.1.Entityを作成
設計は上から下まで考えていましたが、コーディングはその逆です。EntityのOrderから始めます。
このクラスはcsvの構成、テーブルの構成を表現しますので、このようになります。
com.example.demo.batchprocessing.Order.java
package com.example.demo.batchprocessing; import javax.persistence.Entity; import javax.persistence.GeneratedValue; import javax.persistence.GenerationType; import javax.persistence.Id; import javax.persistence.Table; @Entity @Table(name="orders") public class Order { @Id @GeneratedValue(strategy=GenerationType.AUTO) private Integer id; private Integer customerId; private Integer itemId; private String itemName; private Integer itemPrice; private String purchaseDate; .... // Setter + Getter ... }Mysqlのドライバーが認識できるように、@EntityのAnnotationをつけます。
実際テーブルとクラス名は異なりますので、フレームワークがクラスに紐付けるテーブルが認識できるように、@Table(name="orders") をつけます。
3.5.2.レポジトリを作成
SpringではDBにデータを追加するにはEntityだけではまだいけないので、その隙間を満たすレポジトリを作成します。
com.example.demo.batchprocessing.OrderRepository
package com.example.demo.batchprocessing; import org.springframework.data.repository.CrudRepository; import org.springframework.stereotype.Repository; @Repository public interface OrderRepository extends CrudRepository<Order, Integer> { }中身にはあまりないです。ordersテーブルでCRUD操作をしたいので、CrudRepositoryを継承します。
Orderのエンティティを操作したい、またOrderのidは形はIntegerなので、合わせて<Order, Integer>を継承する構文に宣言します。3.5.3.BatchConfigurationを作成
com.example.demo.batchprocessing.BatchConfiguration
package com.example.demo.batchprocessing; import .... @Configuration @EnableBatchProcessing public class BatchConfiguration { @Autowired public JobBuilderFactory jobBuilderFactory; @Autowired public StepBuilderFactory stepBuilderFactory; @Autowired private OrderRepository orderRepository; @Bean public ItemReader<Order> reader() { return new FlatFileItemReaderBuilder<Order>() .name("orderItemReader") .resource(new ClassPathResource("orders.csv")) .delimited() .names(new String[] {"CustomerId", "ItemId", "ItemPrice", "ItemName", "PurchaseDate"}) .fieldSetMapper(new BeanWrapperFieldSetMapper<Order>() {{ setTargetType(Order.class); }}) .build(); } @Bean public ItemProcessor<Order, Order> processor() { return new ItemProcessor<Order, Order>() { @Override public Order process(final Order order) throws Exception { return order; } }; } @Bean public ItemWriter<Order> writer() { RepositoryItemWriter<Order> writer = new RepositoryItemWriter<>(); writer.setRepository(orderRepository); writer.setMethodName("save"); return writer; }
- ItemReader reader() : 普段DBから取り込む、ファイルから取り込む、取り込むために複数の既存クラスの使用の選択がありますが、今回はcsvから取り込むなので、それに当てはまるクラスのFlatFileItemReaderを選びます。
- csvの場所は「orders.csv」であることも指定する
- カラム名をnames()関数で指定する
- 読み込んだcsvの行をOrderクラスに格納するように指定する
ItemProcessor processor() : csvから読み込んだデータを処理します。今回自分は何も処理せずそのままwirterに引き渡しますが、実際はバリデーション、変換などの処理が書かれることがあるかもしれませんね。
ItemWriter writer() : processorから処理終わったデータを受け取って、DBに取り込むように処理する部分です。普段他のファイルにデータを追加、ストリームでデータを送る、などのWriterがあるかもしれませんが、この場合DBにデータを追加したいので、その該当する業務を実現するクラスのRespositoryItemWriterを使います。
次はJobとステップの処理を作成します。
@Bean public Job importOrderJob() { return jobBuilderFactory.get("importOrderJob") .incrementer(new RunIdIncrementer()) .listener(new JobCompletionNotificationListener()) .flow(step1()) .end() .build(); } @Bean public Step step1() { return stepBuilderFactory.get("step1") .<Order, Order> chunk(10) .reader(reader()) .processor(processor()) .writer(writer()) .build(); }
- 下記の設定でimportOrderJobを作成します
- Jobが実行完了というイベントを常に聞く、あればアクションするというListenerを設定:listener(new JobCompletionNotificationListener())(このクラスは後で説明します)
- step1の実行を呼び出す
- ステップのstep1を作成します
- 一回に10個を処理するというチャンクを宣言する
- reader()、processor()、writer()が順番に実行するようにそれぞれ宣言する
3.5.4.JobCompletionNotificationListenerを作成
Job実行完了のイベントが起きる時に起動されるアクションを設定します。
com.example.demo.batchprocessing.JobCompletionNotificationListener
package com.example.demo.batchprocessing; import .... @Component public class JobCompletionNotificationListener extends JobExecutionListenerSupport { private static final Logger log = LoggerFactory.getLogger(JobCompletionNotificationListener.class); @Override public void afterJob(JobExecution jobExecution) { if (jobExecution.getStatus() == BatchStatus.COMPLETED) { log.info("!!! JOB FINISHED "); } } }Jobのイベントごとにアクションをトリガーするよう、その役をするJobExecutionListenerSupportクラスを継承します。
他のイベントもあるらしいけど、実行完了のイベントのみ利用したいので、afterJob関数をオーバーライドします。
ただログに出力するようにする処理があります。3.5.5.BatchProcessingApplicationを作成
最後に、アプリのエントリーポイントを作成します。
com.example.demo.batchprocessing.BatchProcessingApplication
package com.example.demo.batchprocessing; import org.springframework.boot.SpringApplication; import org.springframework.boot.autoconfigure.SpringBootApplication; @SpringBootApplication public class BatchProcessingApplication { public static void main(String[] args) throws Exception { System.exit(SpringApplication.exit( SpringApplication.run(BatchProcessingApplication.class, args)) ); } }単にJavaのみ作成すると、複数のクラスを呼び出す、それを連携するなどの処理が必要になりますが、Springのおかげで数行だけ書いても結構です。
要は@SpringBootApplicationをクラスにつけることです。
そのため、自動的に同じパッケージの配下にあるクラスを宣言しなくても、ロードすることができます。SpringApplication.run(BatchProcessingApplication.class, args))を呼び出すだけでプログラムが実行できます。
3.5.6.要らないクラス、処理を廃棄
SpringInitializrから作成させるプロジェクトにはデフォルト処理やクラスがあります。
今回エントリーポイントを新規に作成するので、既存のエントリーポイントを削除します。
$ rm src/main/java/com/example/demo/DemoApplication.java $ rm src/main/java/com/example/demo/DemoApplicationTests.javaまた簡単にテストコードも書きます。
com.example.demo.batchprocessing.test.DemoApplicationTests.java
package com.example.demo.batchprocessing.test; import org.junit.jupiter.api.Test; import org.springframework.boot.test.context.SpringBootTest; @SpringBootTest class BatchProcessingTests { @Test void contextLoads() { } }プログラミングはこれで以上です!
4.実行
4.1.データベースを起動
dockerで起動します
$ docker-compose up -d4.2.コマンドでバッチを実行する
IDE経由で実行してもいいですが、自分が好む方法のコマンドラインで実行したいと思います。
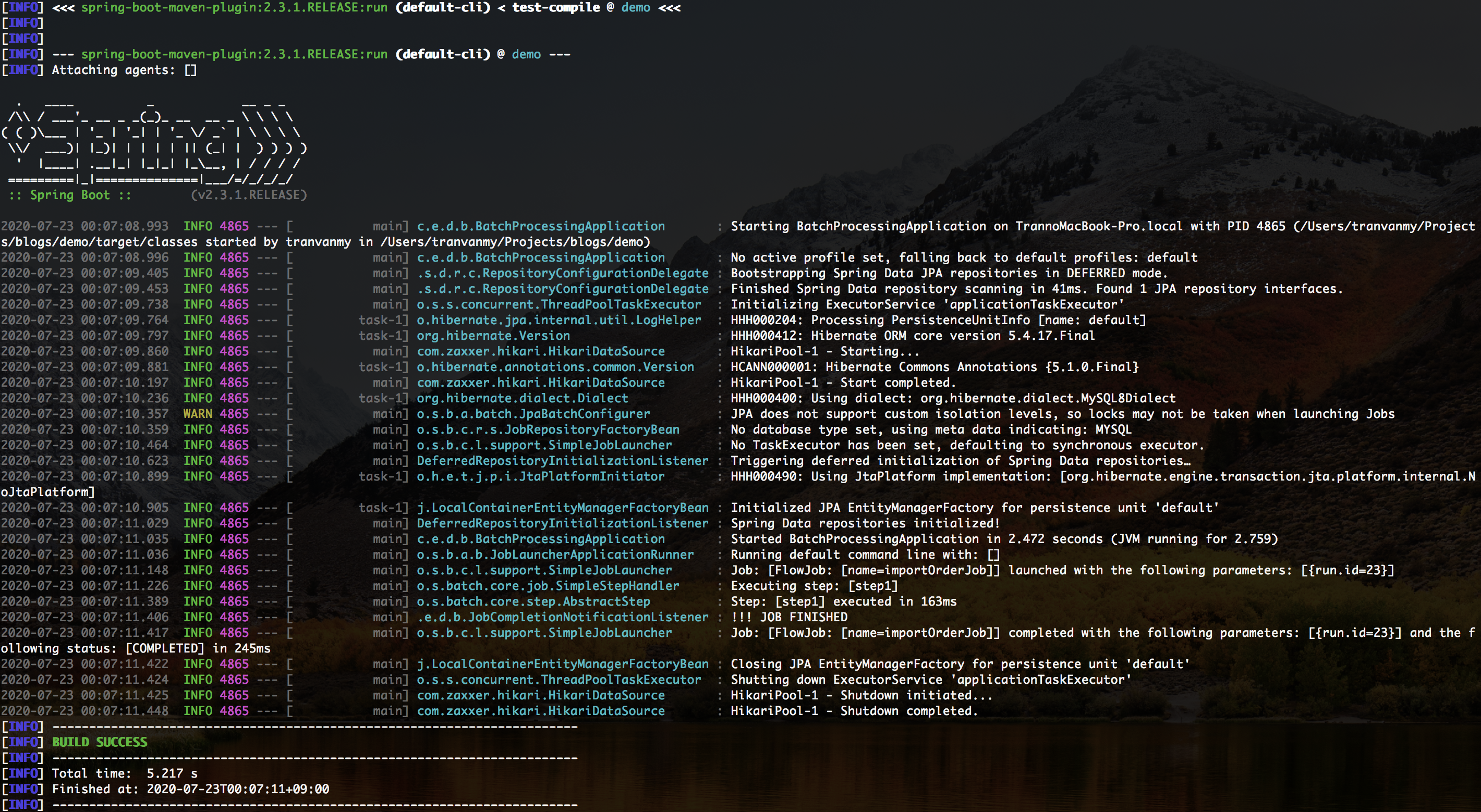
$ ./mvnw spring-boot:run最初に実行する時にライブラリをインストールする時間がかかりますが、2回めからは早いです。
実行結果はこんなイメージです。
データベースでデータがインサートされるかを確認します。
$ mysql -h 0.0.0.0 -u demo -P 33061 -p demo $ mysql> select * from orders; +----+-------------+---------+---------------------+------------+---------------------+ | id | customer_id | item_id | item_name | item_price | purchase_date | +----+-------------+---------+---------------------+------------+---------------------+ | 85 | 1 | 1 | asus notebook | 150000 | 2020-07-16 08:00:00 | | 86 | 1 | 2 | macbook pro 13 inch | 200000 | 2020-07-16 09:00:00 | | 87 | 2 | 2 | macbook pro 13 inch | 200000 | 2020-07-16 10:00:00 | | 88 | 2 | 3 | macbook pro 15 inch | 250000 | 2020-07-17 10:00:00 | +----+-------------+---------+---------------------+------------+---------------------+ 4 rows in set (0.00 sec)csvの内容通りにデータが作成されたので、バッチ作成はとりあえずOKだと思います。
5.終わりに
SpringBatchを入門する経由を共有させていただいました。
こかからSpringBatchを学びたい方々になにかお役に立てば幸いです。本文にまだ説明が足りないところがあれば失礼します。
https://github.com/mytv1/sample-spring-batchプロジェクトの処理全部は上のレポをご参考になればと思います。
6.参考
- 投稿日:2020-07-24T15:28:11+09:00
Laravelでmigatateした時にエラーが出ました。
下記のエラーが出ました。
$ php artisan migrate Illuminate\Database\QueryException : SQLSTATE[HY000] [1049] Unknown database 'laravel' (SQL: select * from information_schema.tables where table_schema = laravel and table_name = migrations and table_type = 'BASE TABLE')原因
- データベースを作成せずにコマンドを入力したこと
解決方法
- mysqlにログインしてデータベースを作成した
$ mysql -u rootmysql> create database 任意のDB名;mysql> use DB名;mysql> create user ユーザー名 IDENTIFIED BY '任意のパスワード';mysql> grant all privileges on DB名.* to 'ユーザー名';mysql> quit;- .envファイルにDB_DATABASE DB_USERNAME DB_PASSWORDをそれぞれ追記した
そして
$ php artisan config:cacheを行い設定を反映させ
再度、$ php artisan migrateで解消された。焦らず順番に行なうようにしていきたい。
- 投稿日:2020-07-24T03:56:30+09:00
初心者がDockerで開発環境構築してみた(Rails&MySQL)
はじめに
現在、就職活動中のプログラミング初学者です。
開発環境にDockerを取り入れる為、いろいろ勉強して自分用のメモとしてまとめておりましたが、折角なら同じ初学者の方の役に立てればと思い投稿させて頂きます。既に多くの方がDockerの環境構築に関する記事を書かれており、そういった記事を参考にさせて頂きながら、メモとしてまとめていましたので、内容はそんなに目新しものではありません。予めご了承ください。また、誤った表現などがありましたらご指摘頂けると幸いです。開発環境
- Ruby 2.6.3
- Rails 5.2.3
- MySQL 5.7
- MacOS 10.15.5
前提条件
- Dockerhubのアカウントを作成している。
- Docker for Macをインストールしている。
- Dockerの基礎はある程度抑えている。
Dockerの基本的なことはこちらの記事が参考になります。
いまさらだけどDockerに入門したので分かりやすくまとめてみた対象読者
今回は開発環境を構築することを目標とする為、Dockerに関する基礎的な部分はある程度抑えている方とします。
Railsの開発環境構築
DockerでRailsの開発環境を構築するには以下のファイルが必要になります。
- Dockerfile
- Gemfile
- Gemfile.lock
- docker-compose.yml
1.作成するアプリ名のディレクトリを作成する。
まずは、上記のファイルを作成するディレクトリを作成します。
#ターミナル $ mkdir my-app2.作成したディレクトリに移動する。
$ cd my-app3.Dockerfileを作成する。
1.で作成したディレクトリ内にDockerfileを作成します。
$ touch DockerfileDockerfileとは?
Dockerでは、dockerhubで公開されているimageを元にコンテナを起動することができるが、必要なパッケージや各種の設定を含んだDocker imageを自分で作成して使用したい場合が出てくる。その場合にDockerfileを用意して、それを元にDocker imageを作成することができる。
Dockerfileにはベースのimageに対して実行する内容を記述する。4.Dockerfileに記述する。
Dockerfile# ベースイメージ 今回はrubyのimage。 FROM ruby:2.6.3 # 必要なパッケージのインストール RUN apt-get update -qq && \ apt-get install -y build-essential \ libpq-dev \ nodejs # 作業ディレクトリの作成、設定 RUN mkdir /my-app #作業ディレクトリを指定している WORKDIR /my-app # ホスト側(ローカル)のGemfileを追加する(ローカルのGemfileは別途事前に作成しておく) COPY ./Gemfile /my-app/Gemfile COPY ./Gemfile.lock /my-app/Gemfile.lock # Gemfileのbundle install RUN bundle install COPY . /my-app5.Gemfileを作成する。
$ touch Gemfile6.Gemfileに記述する。
Gemfilesource 'https://rubygems.org' gem 'rails', '5.2.3'7.空のGemfile.lockを作成する。
$ touch Gemfile.lock8.docker-compose.ymlを作成する。
$ touch docker-compose.ymlDocker Composeとは?
Dockerでは1つのコンテナには、1つのアプリケーションのみを入れておき、複数のコンテナを組み合わせてサービスを構築するという方法が推奨されている。
Docker Composeは、複数のコンテナで構成されるアプリケーションについて、Docker imageのbuildや各コンテナの起動・停止などをより簡単に行えるようにするツール。docker-compose.ymlとは?
Docker Composeを使用する際に必要となるファイルのこと。
docker-compose.ymlには以下の内容を定義します。
- Docker imageをbuildするための情報(使用するDockerfile、image名など)
- コンテナ起動するための情報(ホストとの共有ディレクトリ設定やポートフォワードなどの起動オプションなど)
- 使用するDockerネットワーク など
9.docker-compose.ymlに記述する。
docker-compose.ymlversion: '3' # バージョンを指定 services: db: # データベースサーバ用のコンテナの設定を記述 image: mysql:5.7 # コンテナで使用するイメージ名を記述 environment: MYSQL_ROOT_PASSWORD: password # 任意のパスワードを設定 MYSQL_DATABASE: root # 任意のデータベース名を設定 ports: - "3306:3306" # ホストの3306ポートとコンテナの3306ポートを接続する。 volumes: - ./db/mysql/volumes:/var/lib/mysql #ホストの./db/mysql/volumesをコンテナ内の/var/lib/mysqlにマウントする。Dockerのコンテナと、ローカルを同期している。コンテナを削除してもデータは永続化する。 web: # アプリケーションサーバ用のコンテナの設定を記述 build: . # docker-compose.ymlと同じ階層にあるDockerfileを使ってimageをbuildするための記述 command: bundle exec rails s -p 3000 -b '0.0.0.0' # コンテナ立ち上げ時に起動するコマンド。railsを実行する。 volumes: - .:/my-app # 作業ディレクトリをコンテナ内の/my-appにマウントする。 ports: - "3000:3000" # ホストの3000ポートとコンテナの3000ポートを接続する。 depends_on: - db # 依存関係を表している。dbが起動してからwebが起動するという意味。10.コンテナを起動し、コンテナ内でrails newを実行する。
$ docker-compose run web rails new . --force --database=mysql --skip-bundle
runコマンドは、imageの構築から、コンテナの構築・起動まで行います。
また、runコマンドを介して引数で指定したサービスのコンテナ内でコマンドを実行できます。つまり、ここでは生成されたコンテナ内でrails newを行っています。
--forceオプションはファイルが存在する場合に上書きで作成するためのオプション。
--database=mysqlオプションは使用するデータベースの指定をするためのオプション。
--skip-bundleオプションはbundle installをスキップするためのオプション。11.database.ymlを修正する。
rails newで作成されたデータベースの接続設定ファイルにはホスト名とパスワードが設定されていません。railsアプリケーションがデータベースに接続できるようにするため、database.ymlを修正します。database.ymldefault: &default adapter: mysql2 encoding: utf8 pool: <%= ENV.fetch("RAILS_MAX_THREADS") { 5 } %> username: root password: password # docker-compose.ymlのMYSQL_ROOT_PASSWORD host: db # docker-compose.ymlのservice名12.buildを実行する。
$ docker-compose buildここでbuildを実行する理由は10.で実行したコマンドによりGemfileの内容が書き換わっている為です。
13.Dockerを起動する。
$ docker-compose up -d # docker-compose.ymlを参照してコンテナが一斉起動する。注意点としてここで実行する
docker-composeコマンドはdocker-compose.ymlを元に実行が進むので、docker-compose.ymlがあるディレクトリ上で実行する必要があります。14.データベースを作成する。
docker-compose run webをコマンドの先頭につけることでコンテナ内でコマンドを実行できるので、$ docker-compose run web rails db:createを実行すれば、データベースが作成できます。
要は、
docker-compose run webに続けていつものローカルで開発している時のコマンドが使えます。では、localhost:3000に接続してみましょう。
以下の画面が表示されれば完了です。
gemを入れてbundle installしてみる。
開発環境が整ったので試しにgemを入れてbundle installしてみます。
Gemfilegem 'devise'$ docker-compose run web bundle installそして、
$ docker-compose run web rails g devise:installしかし以下のようなエラーが出ました。
Could not find bcrypt-3.1.15 in any of the sources Run `bundle install` to install missing gems.
bundle installしたはずなのに。。。
これは12.のところと同じ現象です。つまり、ローカルで書き換えたGemfileがコンテナ内のGemfileに反映されていない。ここでは再度、docker-compose buildを行う必要があります。理由はDockerfileを見れば分かります。DockerfileCOPY ./Gemfile /my-app/Gemfile COPY ./Gemfile.lock /my-app/Gemfile.lockDockerfile内でimageをbuildする際にローカル側のGemfileをコンテナ側にコピーしていました。ですから、現状ローカルのGemfileの変更はコンテナのGemfileには反映されていない訳です。これを反映させる為に、再度
docker-compose buildを行う(imageをbuildし直す)必要があるという訳です。
では、再度docker-compose buildを実行します。$ docker-compose buildもう一度、エラーが出たコマンドを試します。
$ docker-compose run web rails g devise:install今度は上手く行きました。
しかし、gemを入れるたびに毎回
docker-compose buildするのは面倒臭い。。。という訳で、毎回
docker-compose buildをしなくてもいいようにこちらの記事を参考にさせてもらい、docker-compose.ymlを編集します。
docker-composeでRailsのGemを更新する時、docker buildするのを回避したいdocker-compose.ymlversion: '3' services: db: image: mysql:5.7 environment: MYSQL_ROOT_PASSWORD: password MYSQL_DATABASE: root ports: - "3306:3306" volumes: - ./db/mysql/volumes:/var/lib/mysql web: build: . command: bundle exec rails s -p 3000 -b '0.0.0.0' volumes: - .:/my-app - gem_data:/usr/local/bundle # ローカルのgem_dataをコンテナ内の/usr/local/bundleにマウントする。 ports: - "3000:3000" depends_on: - db volumes: # 上記のvolumesのgem_dataはローカルのものを使うことを指定している。 gem_data:これで、gemをインストールするたびに
docker-compose buildをしなくてもよくなりました。binding.pryをしたい時
docker-compose.ymlに以下を記述します。
docker-compose.ymlweb: tty: true stdin_open: trueSequelProでデータベースを可視化する。
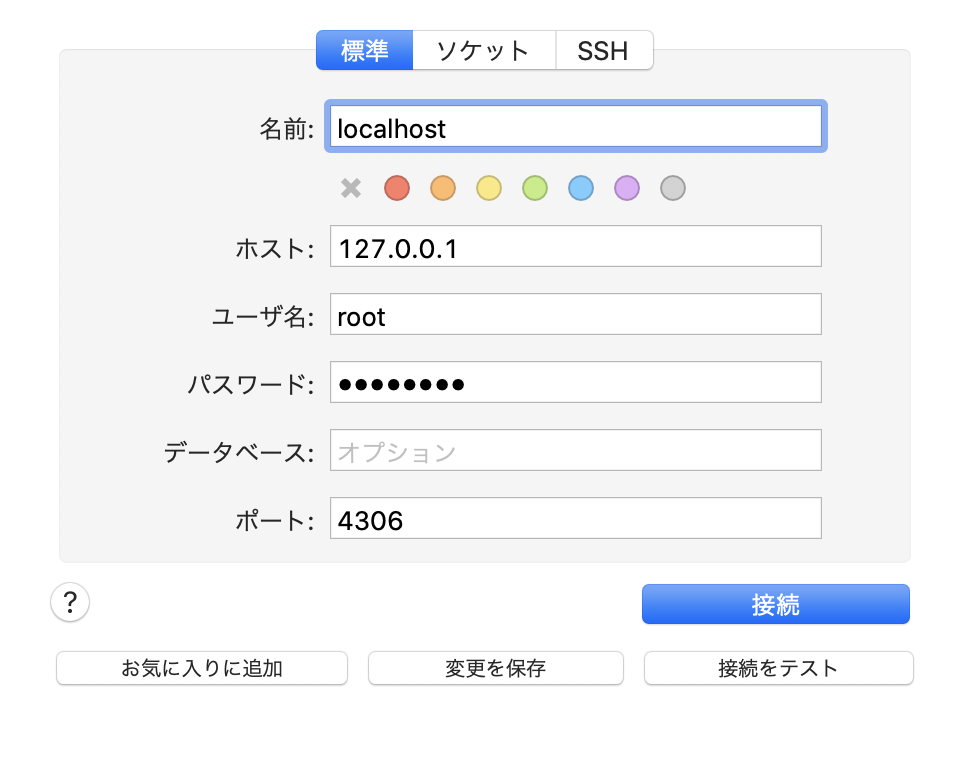
私はローカルで開発を行う際、SequelProを使用してデータベースを可視化していましたが、コンテナの仮想環境下では現状SequelProでデータベースを可視化することはできません。
docker-compose.ymlを以下の様に書き換えSequelProでデータベースを可視化できるよう設定していきます。docker-compose.ymlservices: db: image: mysql:5.7 environment: MYSQL_ROOT_PASSWORD: password MYSQL_DATABASE: root ports: - "4306:3306" # ホストの4306ポートをコンテナ内の3306ポートに接続するよう書き換える。 volumes: - ./db/mysql/volumes:/var/lib/mysql次に、sequelpro起動時のモーダル内のタブを標準タブに切り替え、下記の通りに入力します。
名前: defaultのまま ホスト: 127.0.0.1 # 自分自身を表すIPアドレス ユーザー名: root # database.ymlに記載のユーザー名 パスワード: password # database.ymlに記載のパスワード データベース: 空欄のまま ポート: 4306 # docker-compose.ymlに記載したlocal側のports番号
これでdocker環境下でもデータベースが可視化できるようになります。
参考記事・参考動画
今回Dockerを学習するにあたり、多くの方の記事を参考にさせて頂きました。
ありがとうございました。
docker-compose コマンドまとめ
docker-compose up とか build とか start とかの違いを理解できていなかったのでまとめてみた。
既存のRailsアプリをDockerコンテナで動かす方法+sequel proによるDBコンテナ可視化
Dockerを使用したRails開発①(環境構築)
【rails環境構築】docker + rails + mysql で環境構築(初心者でも30分で完了!)

- 投稿日:2020-07-24T01:13:05+09:00
Redisで100万件のデータを0.3秒で読み込む
まえがき
梅雨のせいでコインランドリーで乾燥機を回している時ふと、
「どれくらいのデータ量だとRedis(キャッシュ)導入に価値がある?
だって、一般的な処理だと早くなっても数ミリ秒の世界だし」と考え始めました。(唐突)
とりあえず100万件のデータでRedis導入にどれ程の価値があるのか、いざ検証してみます。検証環境
- ローカルPC (RAM 8GB)
- Redis 6.0.5 (maxmemory 0=無制限)
- Rails 6.0.3 (API mode)
- MySQL
※ 今回はDBに存在する100万件のレコードをそのままRedisに突っ込みます。
100万件の投稿データ作成
今回検証のアプリケーションとしてRailsを使うのでseed ※でデータ投入しても良かったんですけど、何分遅いのでストアドプロシージャでinsertしていきます。
delimiter // create procedure bulkinsert() begin SET @count = 0; SET @limit = 1000000; WHILE @limit > @count DO INSERT INTO comedians (name, created_at) VALUES ('渡部 建', now()); SET @count = @count + 1; END WHILE; end // delimiter ; call bulkinsert(); DROP PROCEDURE IF EXISTS bulkinsert;count[rails_dev_redis]> select count(*) from comedians; +----------+ | count(*) | +----------+ | 1000000 | +----------+ 1 row in set (0.26 sec)はい、100万件データがありますね。
model.to_aの実行結果をキャッシュ
キャッシュの引数にActiveRecordを渡すと、select文だけキャッシュするので、to_aで。
技術ブログによくあるパターンですね。Comedian.all.to_a計測結果
Processing by ComediansController#benchmark as HTML user system total real Rails_Cache_Fetch 38.901311 2.737989 41.639300 ( 52.607612) Completed 200 OK in 52610ms (Views: 0.7ms | ActiveRecord: 0.0ms | Allocations: 14003982)ご、52秒...。(´-`).。oO(なぜだ)
Redisのデータの読み込みが遅い問題
https://redis.io/topics/data-types
A String value can be at max 512 Megabytes in length.
Redisの公式ドキュメントにあるようにstring型は512MBまでしかサポートされていない。
ここに原因があるのではないかと考え、サイズを調べてみることに。調査結果
Processing by ComediansController#benchmark as HTML Rails_Cache_Fetch length: 2401298 Completed 200 OK in 25ms (Views: 0.9ms | ActiveRecord: 0.0ms | Allocations: 329)2.4MBしか使ってないので、sizeの問題ではなさそう。
Redis側のデータを確認してみると、バイナリ文字が入っている。
Rails.cacheがバイナリから正規化する時間分だけ、遅くなっているのかもと考え、
redis.setでjsonを突っ込んでみることに。計測結果
Processing by ComediansController#benchmark as HTML user system total real Redis_Get 7.533286 0.696594 8.229880 ( 10.452844) Redis_Get length: 86100083 Completed 200 OK in 12306ms (Views: 0.4ms | ActiveRecord: 0.0ms | Allocations: 7000593)10秒か〜。早くはなったんですけど、こういうことじゃないんですよね。
データの中身がバイナリじゃないので、8600万文字入ってます。試行錯誤の末、高速化の成功
検索しても打開策がなかったので、色々試してみることに。
key-valueを複数もつパターンもやってみましたが、結局ループするとその分だけ遅いんですよね。試行錯誤した結果、Rails.cacheでjsonを突っ込むと高速で参照できることがわかりました。
以下3パターンのRead/Writeの速度計測結果を貼ります。
オブジェクト・関数 形式 ベンチマーク上の表記 redis json Redis_Set・Redis_Get Rails.cache json Rails_Cache_Write_Json・Rails_Cache_Read_Json Rails.cache Array Rails_Cache_Write_Array・Rails_Cache_Read_Array Set時の速度計測結果
Processing by ComediansController#benchmark as */* user system total real Redis_Set Comedian Load (968.2ms) SELECT `comedians`.* FROM `comedians` ↳ app/controllers/comedians_controller.rb:9:in `block (2 levels) in benchmark' 134.868704 4.608951 139.477655 (150.200997) Rails_Cache_Write_Json CACHE Comedian Load (0.0ms) SELECT `comedians`.* FROM `comedians` ↳ app/controllers/comedians_controller.rb:12:in `block (2 levels) in benchmark' 117.643508 2.911988 120.555496 (121.557569) Rails_Cache_Write_Array CACHE Comedian Load (0.0ms) SELECT `comedians`.* FROM `comedians` ↳ app/controllers/comedians_controller.rb:15:in `block (2 levels) in benchmark' 39.717218 1.970096 41.687314 ( 41.873064)意外にもArrayが一番早いです。
Get時の速度計測結果
user system total real Redis_Get 12.294169 0.375882 12.670051 ( 12.914826) Rails_Cache_Read_Json 0.196984 0.170824 0.367808 ( 0.321568) Rails_Cache_Read_Array 24.414510 1.228965 25.643475 ( 25.746937) Get_DB CACHE Comedian Load (0.1ms) SELECT `comedians`.* FROM `comedians` ↳ app/controllers/comedians_controller.rb:30:in `block (2 levels) in benchmark' 117.189727 4.600185 121.789912 (122.321526)Rails_Cache_Read_Jsonだと0.3秒で100万件を読み込めています。
Get_DB(122秒)はDBから直接fetch allした場合の速度で、比較の為に入れてます。文字数のカウント
Redis length: 86099997 Rails_Cache_Json length: 2744225 Rails_Cache_Read_Array length: 2399348redis.setでjsonを格納した場合、8600万文字入っていたのに対し、
Rails.cacheは270万文字と驚異的な短さです。
バイナリで保存しているのは容量の面で非常に有利ということですね。あとがき
「どれくらいのデータだと導入に価値があるか」という本題でしたが、
100万未満のデータ量で参照に1秒以上かかってたら導入の価値はあるかなと思います。
たった4行のコード追加だけで、100万件読み込むのに1秒切れると思っていなかったので、ただただ脱帽しております。ありがとうサルバトーレ、ありがとうここまで読んでくれた読者。