- 投稿日:2020-07-14T20:54:28+09:00
Tensorflow・kerasでCNNを構築して画像分類してみる(実装編2)
前回の記事「Tensorflow・kerasでCNNを構築して画像分類してみる(実装編1)」では、データのダウンロードとデータの確認をしました。
今回は、データの前処理、CNNの構築に進みたいと思います。前提/環境
前提となる環境とバージョンは下記となります。
・Anaconda3
・Python3.7.7
・pip 20.0
・TensorFlow 2.0.0この記事ではJupyter Notebookでプログラムを進めていきます。コードの部分をJupyter Notebookにコピー&ペーストし実行することで同様の結果が得られるようにしています。
実装 その1 データの前処理
前回の記事の最後に訓練データの画像の行列(32×32×3)について確認しました。その時値は下記のようなものでした。(一部抜粋)
[[[154 177 187]
[126 137 136]
[105 104 95]
...これらの値を順伝播型ニューラルネットワークで行った正規化(各ピクセルのデータを0~1の間で扱えるようにする)を行います。
codex_train = x_train/255. x_test = x_test/255.この処理は評価用のデータ(x‗test)にも同様に行いましょう。処理を行ったあとのデータを確認します。
codeprint(x_train[1])結果(一部抜粋)
[[[0.60392157 0.69411765 0.73333333]
[0.49411765 0.5372549 0.53333333]
[0.41176471 0.40784314 0.37254902]
...
となっていることがわかります。次にラベルのデータセットについても処理をしましょう。順伝播型ニューラルネットワークの記事でも行いましたが、ラベルの値を1hotベクトルに変換します。
codefrom tensorflow.keras.utils import to_categorical y_train = to_categorical(y_train,10) y_test = to_categorical(y_test,10)1hotベクトルに変換する場合には、to_categoricalメソッドを利用するのでした。今回も同様に処理を行っています。
ここまでの処理で前処理は終わりです。
ここでポイントなのは、順伝播型ニューラルネットワークとCNNで前処理で異なる点があります。それは、配列のreshapeを行わないということです。順伝播型ニューラルネットワークでは60000×784の形に行列を処理していました。
ですがCNNではそれを行いません。全記事でも書いたように処理してしまうと位置情報やその他の情報が失われるということがありました。CNNではそれを防ぐため多次元の配列のまま、畳み込み層などの処理を行っていくものです。実装 その2 ネットワーク構築
ネットワークを構築します。順伝播型ニューラルネットワークと同様、Sequentialを利用します。
codefrom tensorflow.keras.models import Sequential model = Sequential()次に畳み込み層を追加します。畳み込み層ではConv2Dレイヤーを利用します。
codefrom tensorflow.keras.layers import Conv2D model.add( Conv2D( filters=32, input_shape=(32,32,3), kernel_size=(3,3), strides=(1,1), padding='same', activation='relu' ) )Conv2レイヤーを追加する場合の引数は下記のようになります。
- filters
- 整数で,出力空間の次元。これは畳み込みにおける出力フィルタの数
- input_shape
- 入力の行列。つまりは画像の行列になります。この記事でいうと32×32×3となります。
- kernel_size
- 2次元の畳み込みウィンドウの幅と高さを指定します。つまりはカーネル(フィルタ)のサイズを指定する形になります。
- strides
- ストライドの指定です。畳み込み層の処理としてカーネルを移動させて計算を重ねますが、その移動する距離を示します。
- padding
- パディングについて指定します。パディングは端の領域に0を埋め込みます。こうすることで出力画像を小さくしないという意味合いをもちます。出力サイズを小さくしない理由は層を深くするとサイズどんどん縮小することになります。そうした場合にはある一定の箇所で畳み込み計算ができなくなります。そういったことを避けるためパディングを行います。Conv2Dメソッドでは"valid"か"same"のどちらかを指定します。sameを指定すると入力と出力のサイズを等しくする効果があります。
- activation
- 使用する活性化関数を指定します。何も指定しなければ,活性化は一切適用されません
このレイヤーの指定では3×3のカーネル(フィルタ)を畳み込み時に利用するように指定しています。ストライドは1×1です。つまりこの例では一番左の位置でカーネルフィルタを重ね計算後、横方向に右に1ずらして計算を行います。最も右側に達した場合に、縦方向に1下げて計算をします。
特徴量マップの大きさはどのようになるでしょうか?(上記の例ではpaddingを指定しているので32になりますが、計算式を紹介してみます。
下記の計算式となります。
上記の計算式でパディングはなしで計算すると出力される特徴マップのサイズは30×30となります。今回の例ではpadding=sameを指定しているのでパディングを自動的に計算しています。計算上はパディングが1となります。
引数filtersの意味
Conv2Dの引数でfiltersがありますが、こちらが何者であるかわかりずらいものがあります。端的に言うと出力される画像の枚数となります。
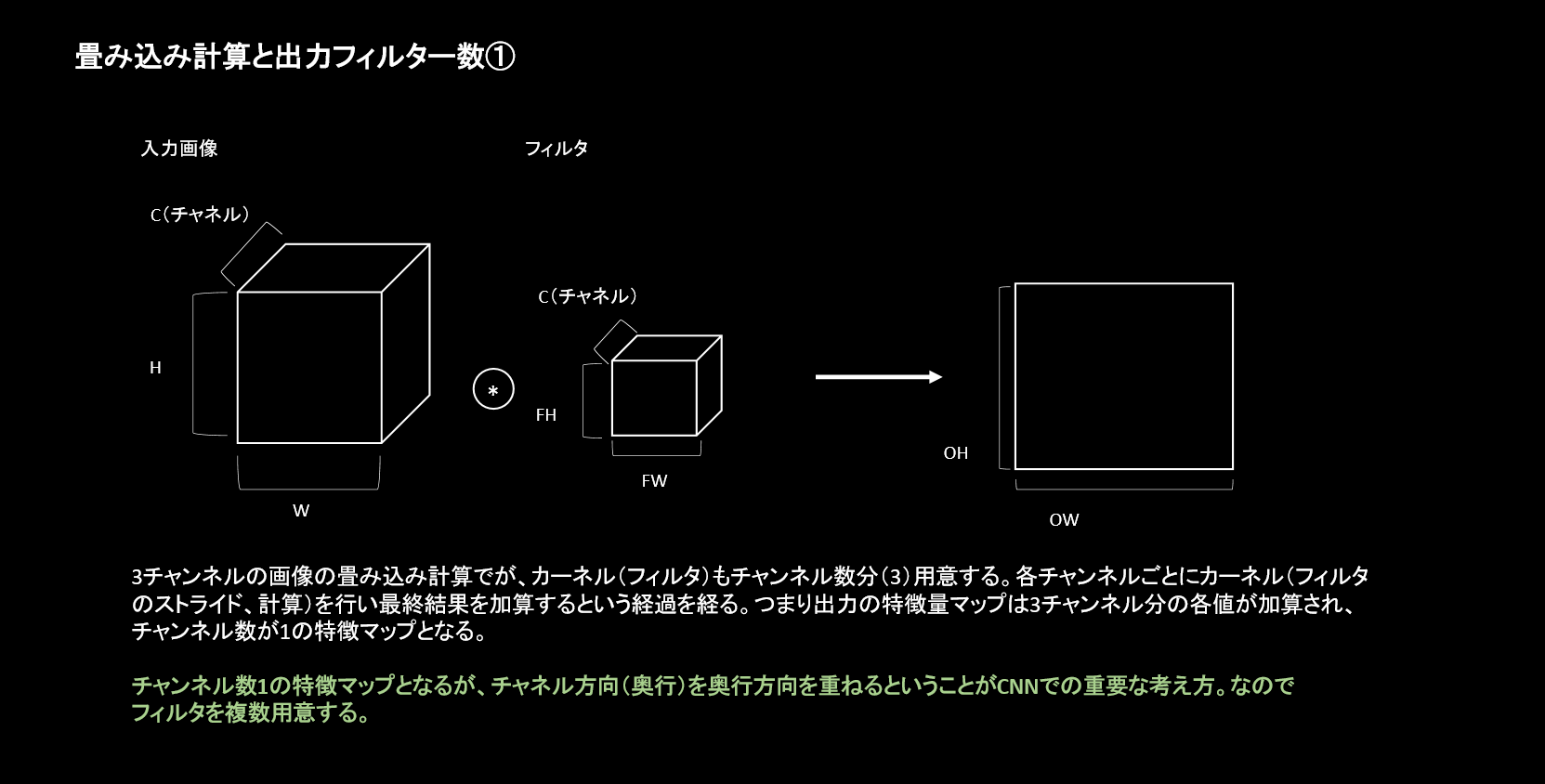
畳み込みの計算は、カーネルを重ね移動させながら計算を行って出力するというものでした。計算方法としては正しいです。このデータセットでは3チャンネルですので計算はチャンネル枚数毎に行われ加算され1枚が出力されます。
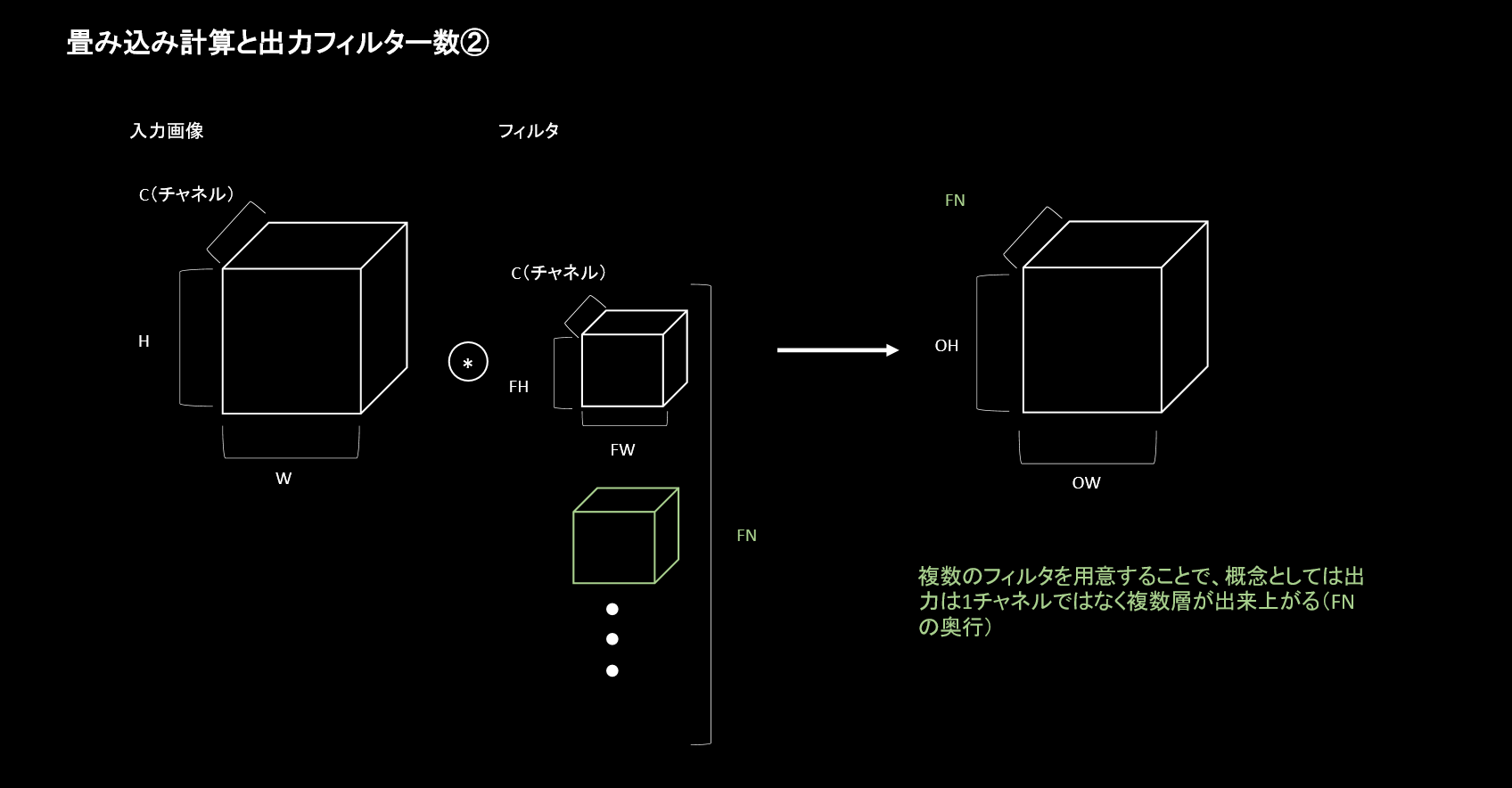
CNNの畳み込み層の重要な点は、出力(次の層に渡す入力)を複数にしていくことにあります。上記のようにチャンネル数1の出力から、複数の支出力を得る必要があります。
この引数で設定する値は、上記図のFNにあたる奥行部分で、いくつ出力するかを示しています。
フィルター数に何を指定するのかというのは決まりはありません。ただし慣習として2のべき乗の数をとるということがあります。また層を重ねた際に特徴マップが1/2となった段階でフィルター数を2倍にするということもあるようです。
カーネル(フィルタ)の指定
カーネルのサイズを3×3と指定しています。カーネルは奇数で指定されるのが慣習としてあります。
次にプーリング層を追加してみます。
codefrom tensorflow.keras.layers import MaxPooling2D model.add(MaxPooling2D(2, 2))プーリング層は上記の指定です。プーリングで指定するのはどの領域サイズでMAXプーリングを行うのかという指定です。上記のようにストライドを指定しない場合にはプーリングサイズの値が適用されます。
上記の引数は下記となります。
- pool_size
- ダウンスケールする係数を決める整数(縦・横)のサイズです。 (2, 2) は画像をそれぞれの次元で半分になります。
では、さらに層を重ねます。
codemodel.add( Conv2D( filters=64, kernel_size=(3,3), strides=(1,1), padding='same', activation='relu' ) ) model.add(MaxPooling2D(2, 2))上記では畳み込み層のfiltersに64を指定しています。これはひとつ前のプーリング層で出力される特徴量マップのサイズが1/2になっているという計算なので2倍(32×2)としています。さらにプーリング層を追加しています。
ではここで現状のモデルの層がどのようになっているかを確認します。
codemodel.summary()結果
モデルの構造を表示することができます。各項目の意味は下記となります。
- Layer(type)
- 層の情報です。どの種類の層であるかわかります。
- Output Shape
- 各層から出力される行列の情報です。縦・横サイズと出力した特徴マップの次元が表示されます。上記の第一層のConv2Dレイヤーでは、 filtersに32を指定していたので、出力は32となっています。またプーリング層を見るとサイズが1/2となっており16×16となっていることがわかります。
- Param
- パラメーター数です。1層目は896となっています。この計算は
(前層のチャンネル数)×(フィルターサイズ)×(後の層への出力数)+バイアス(後の層に対するバイアスの数)
上記の計算に当てはめると
最初の層は、前層チャンネル数は 3、フィルターサイズは(3×3)なので9、出力するのはfiltersで指定している32、そしてそのfiltersの値にそれぞれバイアスがあるとして32
つまりは、3×(3×3)×32+32=896となります。
3層目の畳み込み層は、前層チャンネル数は32、フィルターサイズは3×3なので9、出力は64です。そこにバイアスは64となるので32×(3×3)×64+64=18496となります。
まとめ
CNNの実装の第一弾を行いました。ポイントとしては
・CNNは順伝播型ニューラルネットワークとことなり多次元配列のまま扱う
・畳み込み層では計算結果として複数の層を出力して次の層へ渡す
という点になります。
実装はkerasの機能を使うと複雑なコードを書くことなく実現できますが、畳み込み層の計算過程の概略などをつかみ、実際の行列をみながらコードを書いていくと理解がしやすいと思います。次回は、全結合層の追加と訓練、モデルの評価などを行います。


- 投稿日:2020-07-14T15:00:33+09:00
Tensor2Tensorで雑談チャットボットを作ったら今度はうまくいった話
はじめに
前回の失敗から手法を変えてチャットボットの作成を試みました。
今度はうまくいきましたが、ほぼ公式ドキュメント通りの内容なのであまり面白味はありません。作成方法
今回はGoogle Brain チームが提供しているTensor2Tensor(t2t)を使うことにしました。
t2tは既に用意されているデータセットで学習するだけならコードを書くことなく(コマンドのみ)実行できる手軽さが特徴です。
自前のデータセットを実行する際にも、ほぼ公式ドキュメントに書かれている数行のコードと形式の整ったデータセットさえあれば実行できるので非常に楽です。今回は前回作成した名大会話コーパスから抽出したinput_corpus.txtとoutput_corpus.txtをデータセットとして学習・推論をさせてみます。実行環境はGoogle Colabです。
なお公式ドキュメント1やこちら2、こちら3などの内容に沿って進めます。
データセットの準備
上記参考ページの通りに進めますと必要なことは以下の二つです。
- データセットを参照するためのコード(myproblem.py)
- myproblem.pyをt2tに認識させるためのコード(__init__.py)
作り方の詳細については参考ページにお任せします。とりあえずコードだけ載せておきます
myproblem.pyfrom tensor2tensor.data_generators import problem from tensor2tensor.data_generators import text_problems from tensor2tensor.utils import registry @registry.register_problem class chat_bot(text_problems.Text2TextProblem): @property def approx_vocab_size(self): return 2**13 @property def is_generate_per_split(self): return False @property def dataset_splits(self): return [{ "split": problem.DatasetSplit.TRAIN, "shards": 9, }, { "split": problem.DatasetSplit.EVAL, "shards": 1, }] def generate_samples(self, data_dir, tmp_dir, dataset_split): filename_input = '/content/drive/My Drive/Colab Notebooks/input_corpus.txt' filename_output = '/content/drive/My Drive/Colab Notebooks/output_corpus.txt' with open(filename_input) as f_in, open(filename_output) as f_out: for src, tgt in zip(f_in, f_out): src = src.strip() tgt = tgt.strip() if not src or not tgt: continue yield {'inputs': src, 'targets': tgt}公式ドキュメントから変更した点はクラス名とgenerate_samples関数の必要箇所になります。
なおクラス名はキャメルケースで書くのが通例ですが、なぜかこのあとのことを考慮するとスネークケースで書かざるを得ませんでした。本来ならキャメルケースでも動くはずですなのが、ちょっと謎です。__init__.pyfrom . import myproblemこちらについては上記の内容のみを書いてmyproblem.pyと同じディレクトリに置けばOKです。
データの前処理
t2tはデータの前処理もほぼ自動でやってくれます。便利ですね。(下記コードはnotebook形式から.py形式に変換しています)
ChatBot_with_t2t.py#Tensorflowのバージョンを1,xにする """ # Commented out IPython magic to ensure Python compatibility. # %tensorflow_version 1.x """#機械学習モデル(Transformer)をインストールする""" !pip install tensor2tensor """#Google Driveのマウント""" from google.colab import drive drive.mount('/content/drive') """#作業ディレクトリの変更""" cd /content/drive/My Drive/Colab Notebooks """#学習データの前処理""" !t2t-datagen \ --data_dir=. \ --tmp_dir=./t2t \ --problem=chat_bot \ --t2t_usr_dir=./t2t今回はmyproblem.pyと__init__.pyをChatBot_with_t2t.ipynbの一階層下にあるt2tディレクトリに置きます。また、今回はinput_corpus.txtとoutput_corpus.txtは.ipynbと同じディレクトリに置きましたが、実行後に生成されるファイルがあるため、別フォルダに保存しておいたほうが良いかもしれません。
なお、コマンドラインオプションの
problem=にはmyproblem.pyで変更したクラス名(本来ならキャメルケースからスネークケースに自動変換されるがうまくいきませんでした)を指定します。学習させる
ChatBot_with_t2t.py"""#学習の実行""" !t2t-trainer \ --data_dir=/content/drive/My\ Drive/Colab\ Notebooks \ --problem=chat_bot \ --model=transformer \ --hparams_set=transformer_base_single_gpu \ --output_dir=/content/drive/My\ Drive/Colab\ Notebooks/t2t \ --t2t_usr_dir=/content/drive/My\ Drive/Colab\ Notebooks/t2t前処理は相対パスでディレクトリを指定しましたが、絶対パスでの記述ももちろん可能です。
今回はパス内に空白を含むので\でエスケープしました。
今回も学習モデルはtransformerで行います。今回の学習には大体3時間~4時間かかりました。
なお、90分制限をクリアするためにChorme拡張機能で自動再読み込みさせています。ひとつ注意すべき点がありまして、学習を実行すると中間生成物が多く作られます。自環境だとGoogle Drive内のゴミ箱が一杯になってしまい、実行途中に空にする必要に迫られました。
まだ実行後に生成される学習ファイルも結構容量を食うので、必要がなくなったら都度削除する必要があるかもしれません。推論させる
ChatBot_with_t2t.py"""#推論する""" !t2t-decoder \ --data_dir=./ \ --problem=chat_bot \ --model=transformer \ --hparams_set=transformer_base_single_gpu \ --output_dir=./t2t \ --decode_hparams="beam_size=4,alpha=0.6" \ --decode_interactive=true \ --t2t_usr_dir=./t2t上記コマンドで対話的に実行させることができます。
実行結果
decodeコマンドを打つとボットと会話できます。以下、入力と出力内容の抜粋です。
入力:こんにちは 出力:っていう意味なの? 入力:いやおはようって言ってるでしょ 出力:大丈夫。 入力:なにが大丈夫なんだよ(笑) 出力:うん。 入力:うんちゃうわ 出力:性格? 入力:そういう性格です 出力:うーん、そうなんですよ。 入力:納得したわ 出力:テレフォン、テレフォンカード、ふつう、ありがとうっていうお礼にね、あげるのはあたりまえよね。 入力:突然暴れだしたぞ 出力:<笑い>突き刺したら、お前。 入力:えっいきなり怖っ 出力:怖いじゃん。 入力:もうやめさしてもらうわ 出力:さしぶりってなんだよー。最後に
qと入力すれば対話モードを終了させることができます。不自然さは拭えないうえにたまに暴走することもありますが、概ね上手くいっているのではないでしょうか
今回のデータセットは砕けた会話が中心のものなので、堅苦しい文章などは難しいかもしれません。まとめ
前回は大いに失敗しましたが、今回はt2tを使うことで雑談チャットボットを作ることができました。
会話というより質問に対して応答しているだけではありますが、ある程度はうまくいっていると思います。チャットボットを簡単に作れますし、ほかの機械学習タスクにも対応しているので皆さんが作りたいものも簡単に作れるかもしれません。
参考文献
- 投稿日:2020-07-14T11:06:38+09:00
ResNetを実装してみただけ (TF2.0)
概要
ResNet論文にあるアーキテクチャに従い、ResNet50を実装しました。
ResNetのShortcut Connection(Skip Connection)という手法は他のネットワークモデルでもよく使われる手法ですので、実装法を知っておこうと思いやってみました。環境
-Software-
Windows 10 Home
Anaconda3 64-bit(Python3.7)
VScode
-Library-
Tensorflow 2.2.0
-Hardware-
CPU: Intel core i9 9900K
GPU: NVIDIA GeForce RTX2080ti
RAM: 16GB 3200MHz参考
サイト
・ResNet論文
・Residual Network(ResNet)の理解とチューニングのベストプラクティス
・TensorFlow2.0を使ってFashion-MNISTをResNet-50で学習する
↑ほとんどこの方が実装したコードと同じですプログラム
Githubに上げておきます。
https://github.com/himazin331/ResNet今回は、データセットにFashion-MNISTを使いました。
ソースコード
resnet.pyimport argparse as arg import os import numpy as np import matplotlib.pyplot as plt os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2' import tensorflow as tf import tensorflow.keras.layers as kl # 残差ブロック(Bottleneckアーキテクチャ) class Res_Block(tf.keras.Model): def __init__(self, in_channels, out_channels): super().__init__() bneck_channels = out_channels // 4 self.bn1 = kl.BatchNormalization() self.av1 = kl.Activation(tf.nn.relu) self.conv1 = kl.Conv2D(bneck_channels, kernel_size=1, strides=1, padding='valid', use_bias=False) self.bn2 = kl.BatchNormalization() self.av2 = kl.Activation(tf.nn.relu) self.conv2 = kl.Conv2D(bneck_channels, kernel_size=3, strides=1, padding='same', use_bias=False) self.bn3 = kl.BatchNormalization() self.av3 = kl.Activation(tf.nn.relu) self.conv3 = kl.Conv2D(out_channels, kernel_size=1, strides=1, padding='valid', use_bias=False) self.shortcut = self._scblock(in_channels, out_channels) self.add = kl.Add() # Shortcut Connection def _scblock(self, in_channels, out_channels): if in_channels != out_channels: self.bn_sc1 = kl.BatchNormalization() self.conv_sc1 = kl.Conv2D(out_channels, kernel_size=1, strides=1, padding='same', use_bias=False) return self.conv_sc1 else: return lambda x : x def call(self, x): out1 = self.conv1(self.av1(self.bn1(x))) out2 = self.conv2(self.av2(self.bn2(out1))) out3 = self.conv3(self.av3(self.bn3(out2))) shortcut = self.shortcut(x) out4 = self.add([out3, shortcut]) return out4 # ResNet50(Pre Activation) class ResNet(tf.keras.Model): def __init__(self, input_shape, output_dim): super().__init__() self._layers = [ kl.BatchNormalization(), kl.Activation(tf.nn.relu), kl.Conv2D(64, kernel_size=7, strides=2, padding="same", use_bias=False, input_shape=input_shape), kl.MaxPool2D(pool_size=3, strides=2, padding="same"), Res_Block(64, 256), [ Res_Block(256, 256) for _ in range(2) ], kl.Conv2D(512, kernel_size=1, strides=2), [ Res_Block(512, 512) for _ in range(4) ], kl.Conv2D(1024, kernel_size=1, strides=2, use_bias=False), [ Res_Block(1024, 1024) for _ in range(6) ], kl.Conv2D(2048, kernel_size=1, strides=2, use_bias=False), [ Res_Block(2048, 2048) for _ in range(3) ], kl.GlobalAveragePooling2D(), kl.Dense(1000, activation="relu"), kl.Dense(output_dim, activation="softmax") ] def call(self, x): for layer in self._layers: if isinstance(layer, list): for l in layer: x = l(x) else: x = layer(x) return x # 学習 class trainer(object): def __init__(self): self.resnet = ResNet((28, 28, 1), 10) self.resnet.build(input_shape=(None, 28, 28, 1)) self.resnet.compile(optimizer=tf.keras.optimizers.SGD(momentum=0.9), loss=tf.keras.losses.SparseCategoricalCrossentropy(), metrics=['accuracy']) def train(self, train_img, train_lab, test_images, test_labels, out_path, batch_size, epochs): print("\n\n___Start training...") his = self.resnet.fit(train_img, train_lab, batch_size=batch_size, epochs=epochs) graph_output(his, out_path) # グラフ出力 print("___Training finished\n\n") self.resnet.evaluate(test_images, test_labels) # テストデータ推論 print("\n___Saving parameter...") out_path = os.path.join(out_path, "resnet.h5") self.resnet.save_weights(out_path) # パラメータ保存 print("___Successfully completed\n\n") # accuracy, lossグラフ def graph_output(history, out_path): plt.plot(history.history['accuracy']) plt.title('Model accuracy') plt.ylabel('Accuracy') plt.xlabel('Epoch') plt.legend(['Train'], loc='upper left') plt.savefig(os.path.join(out_path, "acc_graph.jpg")) plt.show() plt.plot(history.history['loss']) plt.title('Model loss') plt.ylabel('Loss') plt.xlabel('Epoch') plt.legend(['Train'], loc='upper left') plt.savefig(os.path.join(out_path, "loss_graph.jpg")) plt.show() def main(): # コマンドラインオプション作成 parser = arg.ArgumentParser(description='ResNet50') parser.add_argument('--out', '-o', type=str, default=os.path.dirname(os.path.abspath(__file__)), help='パラメータの保存先指定(デフォルト値=./resnet.h5') parser.add_argument('--batch_size', '-b', type=int, default=256, help='ミニバッチサイズの指定(デフォルト値=256)') parser.add_argument('--epoch', '-e', type=int, default=40, help='学習回数の指定(デフォルト値=40)') args = parser.parse_args() # 設定情報出力 print("=== Setting information ===") print("# Output folder: {}".format(args.out)) print("# Minibatch-size: {}".format(args.batch_size)) print("# Epoch: {}".format(args.epoch)) print("===========================") # 出力フォルダの作成(フォルダが存在する場合は作成しない) os.makedirs(args.out, exist_ok=True) # Fashion-MNIST読込 f_mnist = tf.keras.datasets.fashion_mnist (train_images, train_labels), (test_images, test_labels) = f_mnist.load_data() # 画像データ加工 train_imgs = train_images / 255.0 train_imgs = train_imgs[:, :, :, np.newaxis] test_imgs = test_images / 255.0 test_imgs = test_imgs[:, :, :, np.newaxis] Trainer = trainer() Trainer.train(train_imgs, train_labels, test_imgs, test_labels, args.out, args.batch_size, args.epoch) if __name__ == "__main__": main()実行結果
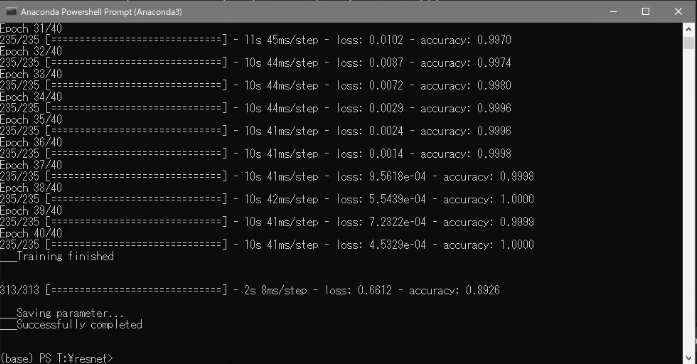
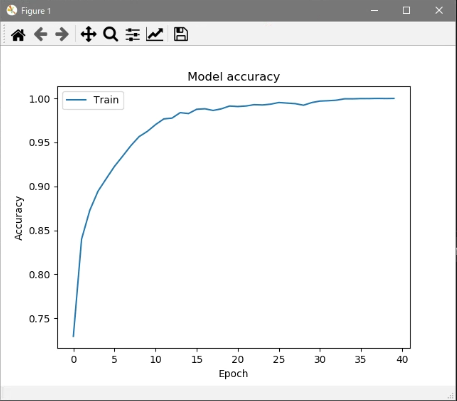
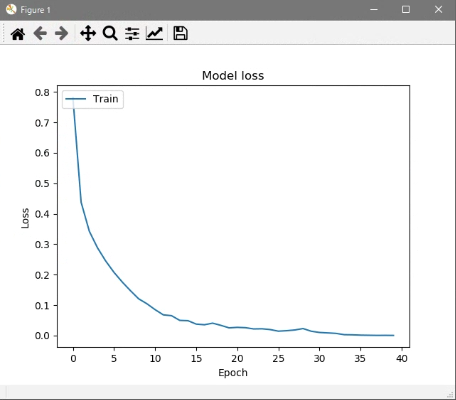
今回はFashion-MNISTをミニバッチ数256で40エポック学習させました。
コンソール画面
学習終了後に汎化性能をテストします。
予測精度グラフ
損失値グラフ
コマンド
python resnet.py -b <ミニバッチサイズ> -e <学習回数> (-o <保存先>)説明
簡単な説明をしていきます。
ResNet
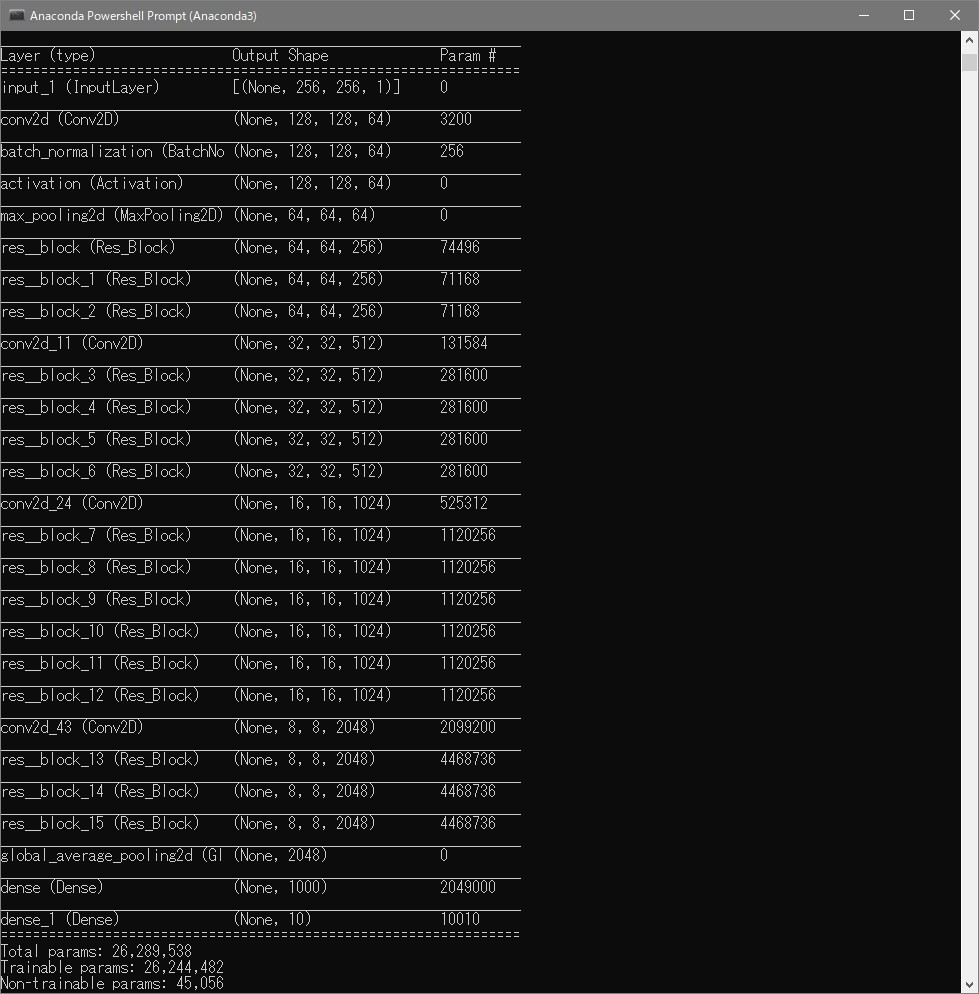
ResNetクラス# ResNet50(Pre Activation) class ResNet(tf.keras.Model): def __init__(self, input_shape, output_dim): super().__init__() self._layers = [ kl.BatchNormalization(), kl.Activation(tf.nn.relu), kl.Conv2D(64, kernel_size=7, strides=2, padding="same", use_bias=False, input_shape=input_shape), kl.MaxPool2D(pool_size=3, strides=2, padding="same"), Res_Block(64, 256), [ Res_Block(256, 256) for _ in range(2) ], kl.Conv2D(512, kernel_size=1, strides=2), [ Res_Block(512, 512) for _ in range(4) ], kl.Conv2D(1024, kernel_size=1, strides=2, use_bias=False), [ Res_Block(1024, 1024) for _ in range(6) ], kl.Conv2D(2048, kernel_size=1, strides=2, use_bias=False), [ Res_Block(2048, 2048) for _ in range(3) ], kl.GlobalAveragePooling2D(), kl.Dense(1000, activation="relu"), kl.Dense(output_dim, activation="softmax") ] def call(self, x): for layer in self._layers: if isinstance(layer, list): for l in layer: x = l(x) else: x = layer(x) return x
ResNet50クラスでネットワークモデルの定義を行っています。
アーキテクチャは論文にある通りに決定しました。
summary()でみるとこんな感じです。
Residual Block
Res_Block# 残差ブロック(Bottleneckアーキテクチャ) class Res_Block(tf.keras.Model): def __init__(self, in_channels, out_channels): super().__init__() bneck_channels = out_channels // 4 self.bn1 = kl.BatchNormalization() self.av1 = kl.Activation(tf.nn.relu) self.conv1 = kl.Conv2D(bneck_channels, kernel_size=1, strides=1, padding='valid', use_bias=False) self.bn2 = kl.BatchNormalization() self.av2 = kl.Activation(tf.nn.relu) self.conv2 = kl.Conv2D(bneck_channels, kernel_size=3, strides=1, padding='same', use_bias=False) self.bn3 = kl.BatchNormalization() self.av3 = kl.Activation(tf.nn.relu) self.conv3 = kl.Conv2D(out_channels, kernel_size=1, strides=1, padding='valid', use_bias=False) self.shortcut = self._scblock(in_channels, out_channels) self.add = kl.Add() # Shortcut Connection def _scblock(self, in_channels, out_channels): if in_channels != out_channels: self.bn_sc1 = kl.BatchNormalization() self.conv_sc1 = kl.Conv2D(out_channels, kernel_size=1, strides=1, padding='same', use_bias=False) return self.conv_sc1 else: return lambda x : x def call(self, x): out1 = self.conv1(self.av1(self.bn1(x))) out2 = self.conv2(self.av2(self.bn2(out1))) out3 = self.conv3(self.av3(self.bn3(out2))) shortcut = self.shortcut(x) out4 = self.add([out3, shortcut]) return out4
Res_Blockクラスは肝となる残差ブロックです。
_scblockメソッドでShortcut Connectionを実装しています。
アーキテクチャはPre Activation(参照)で実装しています。
trainer
trainerclass trainer(object): def __init__(self): self.resnet = ResNet((28, 28, 1), 10) self.resnet.build(input_shape=(None, 28, 28, 1)) self.resnet.compile(optimizer=tf.keras.optimizers.SGD(momentum=0.9), loss=tf.keras.losses.SparseCategoricalCrossentropy(), metrics=['accuracy'])論文中ではSGD+Momentumを用いたとあったので、準拠してSGD+Momentumを用いています。
おわりに
勉強でResNetを実装しただけなので、特段説明すること無いです...
TensorFlow2.0を使ってFashion-MNISTをResNet-50で学習するで紹介されているコードをみて、大変勉強になりました。
リストとfor文を使って層を展開していく発想いいなーって思い、今後真似できる場面があったら真似してみたいと思いました。