- 投稿日:2020-07-14T23:38:57+09:00
AWSをゼロから勉強する。vol.2
7/11~13
体に結構な怪我を負い、勉強に気が回りませんでした。
ギプスをしながら生活するのは大変です。7/14
久々の勉強。結構忘れてしまっている。
しかし、進まなければ新しいことを覚えられないのでどんどん先に進もうと思う。
今日は少なめ。[EC2(Elastic Compute Cloud)]
仮想サーバーを構築できる"環境"の事。[インスタンス]
仮想サーバーの事。
EC2の中にインスタンスを複数作る。というようなイメージ。
インスタンスごとにセキュリティグループを定義することもでき、
公開範囲をコントロールすることもできる。
(プロトコル、ポート番号などを定義)[AMI(Amazon machine images)]
仮想マシンのパッケージ、テンプレのこと。
初期設定も含めたものも多数存在して、
それらをインストールすることでセットアップの時短になる。[EBS(Elastic Block Store)]
仮想ディスクのイメージ。(ストレージではない)
- 投稿日:2020-07-14T22:46:30+09:00
【AWS】それぞれのDBの特徴を簡単にまとめました(備忘録)
はじめに
現在、AWSSAAの学習をしております。
DBに関する問題が出題されるのですが、特徴がごっちゃになりがちなので備忘録としてアウトプットします。それぞれのDBの特徴
※AWSSAAの問題集に載っているもののみに抜粋しております。
RDS DynamoDB ElastiCache Redshift 概要 リレーショナルデータベース 高速なNoSQL インメモリデータストア ペタバイト規模に拡張できるデータウェアハウス 特徴 ・管理が簡単
・高いスケーラビリティ
・可用性と耐久性
・高速
・セキュア
・安価・連続した高速なデータ蓄積
・大規模
・サーバー管理が不要
・スケールに応じたパフォーマンス
・整合性モデルを採用・メモリをストレージとする最も高速なアクセス
・フルマネージド型
・スケーラブル・複雑なSQLを並列処理で高速に処理(列検索)
・利用可能なクラウドデータウェアハウスの中で最も高速
・大量のデータを短時間で読み出し・分析することが可能データ量 小~大 特大(無制限)
自動的にスケールアップ/ダウン小~中 特大(無制限)
サイジングと拡張操作が必要アクセス速度 中 高速 超高速 高速 トランザクション処理 可能 - - - ※トランザクション処理とは、「商品を渡して、代金を受け取る」のように「ここからここまでワンセット」になっている処理のこと
詳しくはこちらAmazon Auroraの特徴
Amazon Auroraについて
- AWSが提供するデータベースエンジン
- 高度なMulti-AZ構成/自動復旧による高可用性/大容量ストレージのサポートを提供
- 他のRDSと比較して高いスループットを提供
「Aurora」と「RDS for MySQL」との比較
特徴 Aurora RDS for MySQL Multi-AZ構成 3つのAZに2つずつのレプリケーションを構成
※明示的にMulti-AZを指定しなくても自動構成する2つのAZを使用 データベースストレージサイズ 最大64TiB 最大32TiB 最大リードレプリカ数 最大15 最大5 レプリケーションタイプ 非同期的(ミリ秒単位) Multi-AZ構成:同期
リードレプリカ:非同期リードレプリカのフェイルオーバーターゲットとして機能 はい(データ損失なし) はい(数分間データ損失の可能性) 自動フェイルオーバー はい いいえ それぞれのDBの用途
データベースのタイプ ユースケース AWSのサービス リレーショナル ・従来のアプリケーション
・ERP
・CRM
・eコマース・Amazon Aurora
・Amazon RDS
・Amazon RedShiftキー値 ・トラフィックの多いウェブアプリ
・eコマースシステム
・ゲームアプリケーション・Amazon DynamoDB インメモリ ・キャッシュ
・セッション管理
・一時データ保存
・キューイング・Amazon ElastiCache for Memcached
・Amazon ElastiCache for Redisドキュメント ・コンテンツ管理
・カタログ
・ユーザープロファイル・Amazon DocumentDB(MongoDB互換) ワイドカラム ・高スケールの業界アプリ
・ログファイルのエントリ
・チャットアプリケーションのメッセージ履歴
・大量の時系列データ・Amazon Keyspaces グラフ ・不正検出
・ソーシャルネットワーク
・レコメンデーションエンジンAmazon Neptune 時系列 ・IoTアプリケーション
・DevOps
・アプリケーションのモニタリングAmazon Timestream 台帳 ・記録システム
・サプライチェーン
・銀行トランザクションAmazon QLDB 参考
データベースサービス
この1冊で合格! AWS認定ソリューションアーキテクト - アソシエイト テキスト&問題集 Kindle版
- 投稿日:2020-07-14T22:24:13+09:00
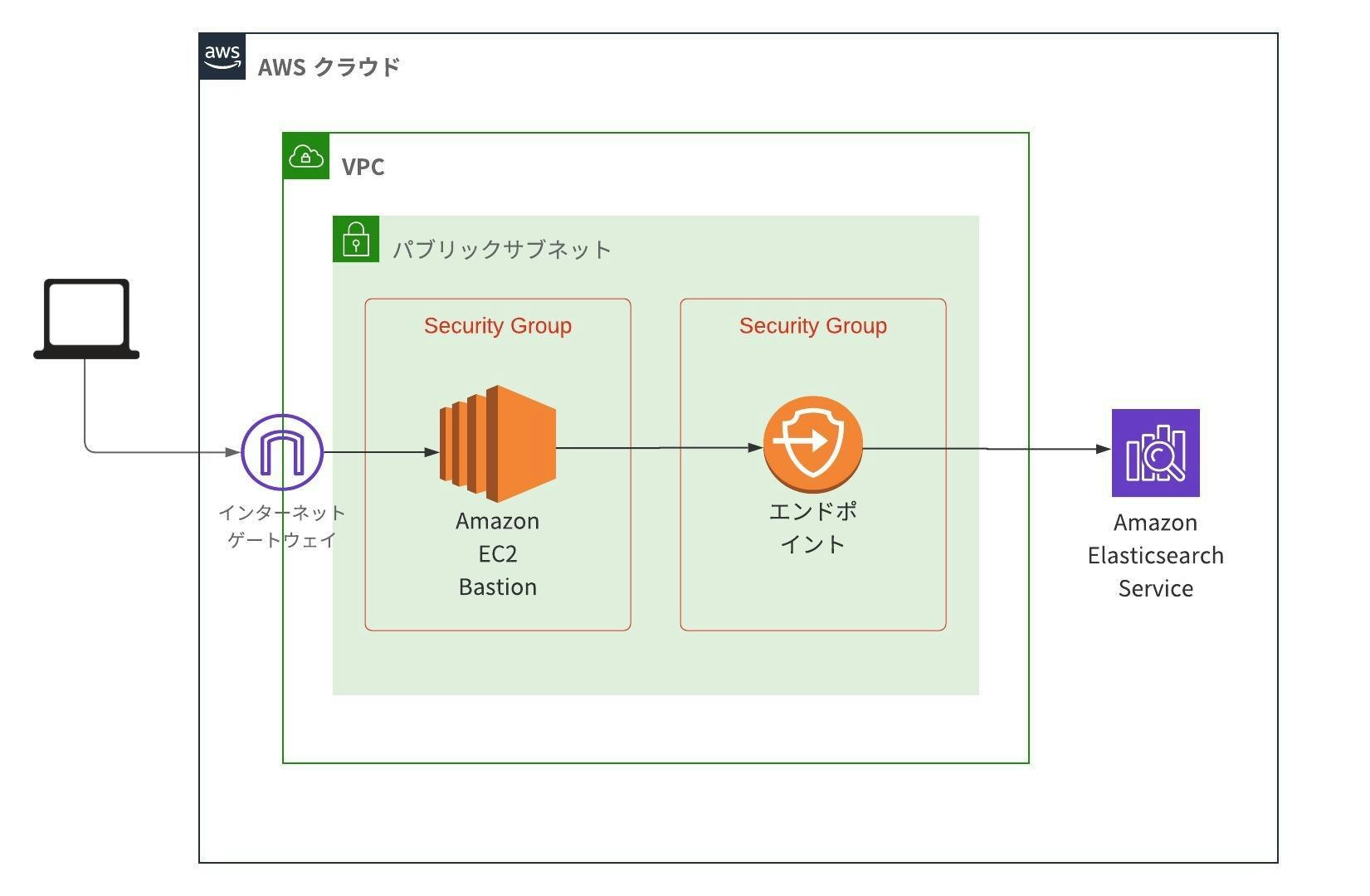
【Go】踏み台サーバー経由 (ssh) で VPC エンドポイントの Elasticsearch Service にローカルから接続する【AWS】
やりたいこと
踏み台サーバー経由 (ssh) でプライベートサブネット内の RDS (MySQL) へ接続するのと同様にして、VPC エンドポイントの Elasticsearch Service にも踏み台サーバー経由で接続することが目標です。
ssh コマンドと curl コマンドを利用すれば次のように簡単にローカルから接続できますが、今回は Go プログラムで接続することを目標とします。
ssh -i <path/to/private-key> <username>@<hostname> curl -s '<ES_ENDPOINT>/_cat/indices?format=json&pretty'前提
次のようなアーキテクチャを想定します。セキュリティグループはいい感じに設定されているものとします。
実装
Elasticsearch のクライアント用ライブラリとしては Elastic 社公式の elastic/go-elasticsearch を利用します。
実装のポイントは
http.RoundTripper (http.Transport)の Dial に SSH Client の Dial を利用することです。package main import ( "context" "encoding/json" "fmt" "io" "io/ioutil" "log" "net" "net/http" "os" "time" "github.com/elastic/go-elasticsearch/v8" "github.com/elastic/go-elasticsearch/v8/esapi" "golang.org/x/crypto/ssh" ) func main() { log.SetFlags(log.LstdFlags | log.Lshortfile) var ( sshUser = os.Getenv("SSH_USER") sshHost = os.Getenv("SSH_HOST") sshPort = os.Getenv("SSH_PORT") sshPrivateKey = os.Getenv("SSH_PRIVATE_KEY") esEndpoint = os.Getenv("ES_ENDPOINT") ) // ------------------------------ // 秘密鍵ファイルの読み込み // ------------------------------ b, err := ioutil.ReadFile(sshPrivateKey) if err != nil { log.Fatal(err) } signer, err := ssh.ParsePrivateKey(b) if err != nil { log.Fatal(err) } // ------------------------------ // SSH クライアントの生成 // ------------------------------ sshConf := ssh.ClientConfig{ User: sshUser, Auth: []ssh.AuthMethod{ ssh.PublicKeys(signer), }, HostKeyCallback: func(hostname string, remote net.Addr, key ssh.PublicKey) error { return nil }, Timeout: 10 * time.Second, } sshClient, err := ssh.Dial("tcp", net.JoinHostPort(sshHost, sshPort), &sshConf) if err != nil { log.Fatal(err) } defer sshClient.Close() // ------------------------------ // Elasticsearch クライアントの生成 // ------------------------------ esConf := elasticsearch.Config{ Addresses: []string{esEndpoint}, Transport: &http.Transport{ Proxy: http.ProxyFromEnvironment, Dial: sshClient.Dial, // ここで SSH Client を利用 TLSHandshakeTimeout: 10 * time.Second, }, } es, err := elasticsearch.NewClient(esConf) if err != nil { log.Fatal(err) } // ------------------------------ // リクエストを実行 (/_cat/indices) // ------------------------------ req := esapi.CatIndicesRequest{ Format: "json", Pretty: true, } ctx := context.Background() resp, err := req.Do(ctx, es) if err != nil { log.Fatal(err) } defer resp.Body.Close() // ------------------------------ // レスポンスを解析 // ------------------------------ if resp.IsError() { log.Fatal(resp.String()) } body := io.TeeReader(resp.Body, os.Stdout) // debug var r []map[string]interface{} if err := json.NewDecoder(body).Decode(&r); err != nil { log.Fatal(err) } for i, obj := range r { fmt.Printf("\n[#%d]\n", i) for k, v := range obj { fmt.Println(k, v) } } }
- 投稿日:2020-07-14T22:15:22+09:00
Ruby on RailsのポートフォリオにDockerを組み込む!
現在の状態
みなさんこんにちわ今回Qiita初投稿を行います!
間違っているところがあると思いますがその時は優しく教えてください(笑)
今回、AwsとDockerを用いて既に作成済のRailsのポートフォリオをデプロイしています。
現在の状態は、railsとAws用いてポートフォリオを作成したのですが、環境構築が大変だと思い、環境周りをコードで管理しやすいDockerを用いてポートフォリオを際デプロイしたいと思います。構成図
デプロイの際の構成図は以下の通りです。
めちゃくちゃ簡単に説明するとクライアントから通信リクエストが来るとNginxに行き動的な処理が必要な際はpumaに通信を行いその際にpumaとmysqlも通信する流れとなっています。
今回はこの構成をDockerを用いて作成していきたいと思います。必要な物
今回デプロイする際はAwsのEC2とRDSをを使用します。
Dockerで環境構築を行いますが、データの永続化の観点から今回データベースはDockerではなくRDSのMysqlをしようします。
以下作業に必要な準備と作業です。・AwsでEC2、RDSを用いてデプロイする際に必要な準備を行う(ネットワーク構成など...)
・local環境とEc2にDokcerをインストール
・local環境とEc2にDocker-composeをインストール参考にした記事
・EC2上でRailsアプリケーションにDockerを導入する(Rails、Nginx、RDS)
・Rails On DockerでのAWSデプロイができたので,中身を整理します。作業
まずはじめにDockerファイルを作成します。
ここではDockerfileを用いてRuby周りの環境を構築するコードを書きます。FROM ruby:2.5.7 RUN apt-get update -qq && \ apt-get install -y build-essential \ libpq-dev \ nodejs \ vim RUN mkdir /アプリの名前 WORKDIR /アプリの名前 ADD Gemfile /アプリの名前/Gemfile ADD Gemfile.lock /アプリの名前/Gemfile.lock RUN gem install bundler RUN bundle install ADD . /アプリの名前 RUN mkdir -p tmp/sockets RUN mkdir -p tmp/pids次にDocker-composeを作成します。
ここではDockerコンテナの管理やマントする箇所の指定を行っていきます!Docker-compose.ymlversion: '3' services: app: build: . command: bundle exec puma -C config/puma.rb -e production volumes: - .:/アプリの名前:cached - public-data:/アプリの名前/public - tmp-data:/アプリの名前/tmp - log-data:/アプリの名前/log web: build: context: containers/nginx volumes: - public-data:/アプリの名前/public - tmp-data:/アプリの名前/tmp ports: - 80:80 volumes: public-data: tmp-data: log-data:次に以下のファイルを作成します。
ここではNginxコンテナの設定を行っていきます。FROM nginx:1.15.8 RUN rm -f /etc/nginx/conf.d/* ADD nginx.conf /etc/nginx/conf.d/アプリの名前.conf CMD /usr/sbin/nginx -g 'daemon off;' -c /etc/nginx/nginx.confcontainers/nginx/nginx.confupstream FashionInformation_app { server unix:///アプリの名前/tmp/sockets/puma.sock; } server { listen 8000; server_name ドメイン名; access_log /var/log/nginx/access.log; error_log /var/log/nginx/error.log; root /アプリの名前/public; client_max_body_size 100m; error_page 404 /404.html; error_page 505 502 503 504 /500.html; try_files $uri/index.html $uri @アプリの名前; keepalive_timeout 5; location @アプリの名前 { proxy_set_header X-Real-IP $remote_addr; proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for; proxy_set_header Host $http_host; proxy_pass http://アプリの名前; } }Railsアプリケーションをデプロイする
ここまできたらEC2にgitをクローンします!
ec2-user@ip-xxx-xx-xx-xxx ~]$ git clone GitHubのリポジトリのURLイメージのビルド
ec2-user@ip-xxx-xx-xx-xxx]$ cd myapp [ec2-user@ip-xxx-xx-xx-xxx myapp]$ docker-compose buildサーバー起動前の準備
[ec2-user@ip-xxx-xx-xx-xxx myapp]$ docker-compose run app rails assets:precompile RAILS_ENV=productionサーバー起動前の準備
[ec2-user@ip-xxx-xx-xx-xxx myapp]$ docker-compose up -dデータベースの作成、マイグレーションファイルの読み込み
[ec2-user@ip-xxx-xx-xx-xxx myapp]$ docker-compose exec app rails db:create db:migrate RAILS_ENV=productionパブリックIPにアクセスして、正しく表示されれば成功です!

- 投稿日:2020-07-14T21:49:58+09:00
【AWS】EBSのボリュームタイプの特徴とは?(備忘録)
はじめに
現在、AWSSAAの学習をしています。
EBSのボリュームタイプの問題に戸惑うことが多いので、備忘録としてアウトプットします。EBSボリュームタイプ
ボリュームタイプの種類 ディスクタイプ 説明 汎用SSD(gp2) SSD 特徴
・1GB当たり3IOPSのベースラインパフォーマンスが設定されている。
・ベースラインパフォーマンスを下回る利用の場合
→性能がクレジットとして貯蓄され、突発的なピーク時にそのクレジットが使われてベースラインパフォーマンスを超えるI/Oパフォーマンスを発揮できる。
用途
・ほとんどのワークロードに使用される
・システムブートボリューム
・仮想デスクトップ
・中小規模のデータベース
・開発・テスト環境プロビジョンドIOPS SSD(io1) SSD 特徴
・汎用SSDでは処理しきれないI/O性能が要求される場合に利用。
用途
・主に大規模なデータベースで使用される。
例)MongoDB、MySQL、PostgreSQLスループット最適化HDD(st1) HDD 特徴
高いスループットを必要とするアクセス頻度の高いワークロード向けの低コストのHDDボリューム
用途
ビッグデータ、データウェアハウス、ログ処理に使用される。
※ブートボリュームには使用できないコールドHDD(sc1) HDD 特徴
・アクセス頻度の低いワークロード用に設計された低コストのHDDボリューム
・高い性能が不要な場合に使用
用途
・ログファイルやバックアップのアーカイブ先
・アクセス頻度の低い大量データ用のスループット指向ストレージ
※ブートボリュームには使用できないマグネティック(standard) HDD 特徴
・旧世代のボリュームタイプ
・データのアクセス頻度が低い場合やコストを最重要視する場合に利用
用途
データへのアクセス頻度が低いワークロード
備考
※スループットとは、「処理能力」のことです。
詳しくはこちら※ワークロードとは、「仕事量、作業負荷」のことです。
詳しくはこちら実際のEC2インスタンスの作成ではどうなっている??
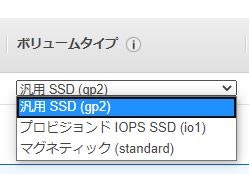
EC2インスタンスの作成画面より調べてみました。
確かに、下記ボリュームのみ存在しますね。
- 汎用SSD(gp2)
- プロビジョンドIOPS SSD(io1)
- マグネティック(standard)
参考
Amazon EBS ボリュームの種類
この1冊で合格! AWS認定ソリューションアーキテクト - アソシエイト テキスト&問題集 Kindle版
- 投稿日:2020-07-14T21:35:55+09:00
MySQL: Heroku ClearDB と AWS RDS どちらにすべきか
Heroku でアプリをデプロイする場合、デフォルトのデータベースは PostgreSQL ですが、MySQL を使うこともできます。
MySQL の一般的な導入方法は次の2つです:
Heroku で MySQL を使う場合、これら2つのうち、どちらを採用すべきか検討してみました。
検討の前提
- 新規開発のDBとして利用
- 初めは少人数開発・低予算
- 求められるストレージ容量はそこまで大きくない(はず)
- 将来的に拡張する可能性有
結論
結論から言うと、今回は Amazon RDS を使うことにしました。
その理由は、ざっと次のとおりです。
- 将来的にウェブサーバを Heroku で運用し続けるか未定
- 容量が1GBを超えた場合に固定料金を49.99ドルも払いたくない
- 設定は必要だが、それなりの作業量で導入可能
詳細は以下の「Heroku ClearDB と Amazon RDS の比較」をご参照ください。
Heroku ClearDB と Amazon RDS の比較
次の4点について比較検討します。
- 導入コスト
- ランニングコスト
- セキュリティ
- 拡張性
導入コスト
Heroku アプリに導入するためのコストを検討します。
ClearDB
Heroku のアドオンなので、コマンド1つで導入できます。
RDS
参考記事にある通り、Heroku から RDS に接続するための設定が必要です。設定の全体的な流れは、次の通りです。
- AWS: CA証明書のダウンロード
- RDS:
REQIRE SSLの設定- AWS: セキュリティーグループの調整
- Heroku:
DATABASE_URLの設定ランニングコスト
月々の利用料金について検討します。
ストレージ容量の調べ方
MySQLでのストレージ容量の調べ方はこちらの記事をご参照ください。
既存プロジェクトのストレージ容量は、新規プロジェクトの見積もり時に参考になります。
ClearDB
プランごとの固定料金が課金されます。
無料プランの Ignite だと容量が5MBしかないので、Punch (1GB, 月$9.99)ぐらいから利用することになりそうです。
Punch の次のプランは Drift (5GB, 月$49.99) なので、容量が1GBを超えた場合、利用料がいきなり40ドル/月も上がってしまいます。
RDS
DBサーバの稼働時間とストレージ容量、バックアップなどについて、利用した分だけ課金されます。従量課金なので「損」はありませんが、ClearDB の固定料金と比較すると少し分かりづらいです。
稼働時間単価は、DBサーバのスペックごとに異なります。
最安の「db.t3.micro」の場合、時間単価は「$0.017」なので(シングルAZ・バージニア北部)、月ごとの稼働料金は最低でも12.65ドルかかります。
※ バージニア北部を選んでいるのは、Heroku-RDS 間のレイテンシーを最小限にするため。
これに加えて、ストレージ料金「毎月 0.138USD/GB」やデータ転送などのコストも発生しますが、ざっくり見積もっても「月15-30ドル」では利用できるでしょう。
セキュリティ
データベースのセキュリティ面について検討します。
ClearDB
手元で確認したところ、発行される CLEARDB_DATABASE_URL の情報で、どのIPからでもデータベースにリモート接続できます。
またデフォルトではSSL接続していないので、必要な場合は自分で証明書の設定をしなくてはいけません(詳細はこちら)。
RDS
Heroku から RDS に接続する場合、その RDS が属する VPC のアクセスIP制限を一部開かないといけません。
Herokuの記事 では、すべてのIPを許可する
0.0.0.0/0が例示されています。この設定だと、ClearDB のデフォルトと同様、どのIPからでもデータベースにリモート接続できます。アクセスできるIPは制限した方が望ましいですが、そのためには Heroku のアドオン(Fixie など)でアプリ側のIPアドレスを固定しないといけなさそうです。この場合、リクエスト数に応じてアドオンの課金が発生します。
なのでコストを抑えたいなら、ClearDB と同じようにすべてのIPを許可するしかないです。(最低限、ユーザ名・パスワードは複雑なものにしましょう。)
なお、SSL接続については、Heroku から RDS に接続する場合は必須です。
拡張性
データベースやサービスの拡張性を検討します。
ClearDB
スペック・容量に応じたプランが用意されているので、サービスの拡大に伴いアップグレードしていけます。
ただし Heroku のアドオンなので、Heroku アプリと合わせて使っていくことになるでしょう。(Heroku 以外のサーバで利用できるかは不明です。)
したがって、AWSなどの他サービスへの移行は、DBのせいでフットワークが重たくなってしまう可能性があります。
RDS
こちらもサービスの拡大に伴い、スペックをアップグレードしていけます。
ClearDB と比較すると、Heroku 以外のサービスとの連携など、柔軟性はより高いでしょう。
まとめ
Heroku ClearDB Amazon RDS 導入コスト 1コマンドのみ 設定が必要 ランニングコスト(月) 9.99-49.99ドル(固定) 15-30ドル(?) セキュリティ IP制限なし IP制限可 拡張性 Heroku限定 Heroku以外も可 References
- 投稿日:2020-07-14T20:48:01+09:00
[Rails]EC2にデプロイ後、jQuery/JavaScriptが動かない
前提
Rails 6.0.3.1
ruby 2.6.3
unicorn-5.5.5
nginx/1.16.1EC2にデプロイしたら、jQueryがお仕事をサボっていた
デプロイ後に、ブラウザでトップページを確認すると
jQueryが動いておらず、トップページのfade inがいつまでたってもなされない状態でした。結論
app/views/layouts/_default.html.erb<%= csrf_meta_tags %> <%= csp_meta_tag %> <%= stylesheet_link_tag 'application', media: 'all', 'data-turbolinks-track': 'reload' %> <%= javascript_pack_tag 'application', 'data-turbolinks-track': 'reload' %> <%= stylesheet_pack_tag 'application', 'data-turbolinks-track': 'reload' %> #以下を追加 <script src="https://ajax.googleapis.com/ajax/libs/jquery/1.9.1/jquery.min.js"></script>ローカルでは、
<script src="https://ajax.googleapis.com/ajax/libs/jquery/1.9.1/jquery.min.js"></script>なしでも動いていましたが、どうやら本番環境では追加しないとうまく動かない場合があるみたいです。
ちなみに
httpsではなく、httpでも動くようですが、SSL化したアプリケーションでは大体のアプリケーションは、セキュリティの面でSSL化すると思うので、httpsでしてあげた方が良さそうです。
- 投稿日:2020-07-14T20:28:46+09:00
【NATインスタンス(AWS)】基本構築(iptables利用)
目標
AWSネットワーク上にNATインスタンスを構築し、プライベートインスタンスからのインターネット接続を可能にする。
NATインスタンス構築時のツールはiptablesを利用する。前提
・パブリックサブネット及びプライベートサブネットにEC2インスタンスが構築済みであること。
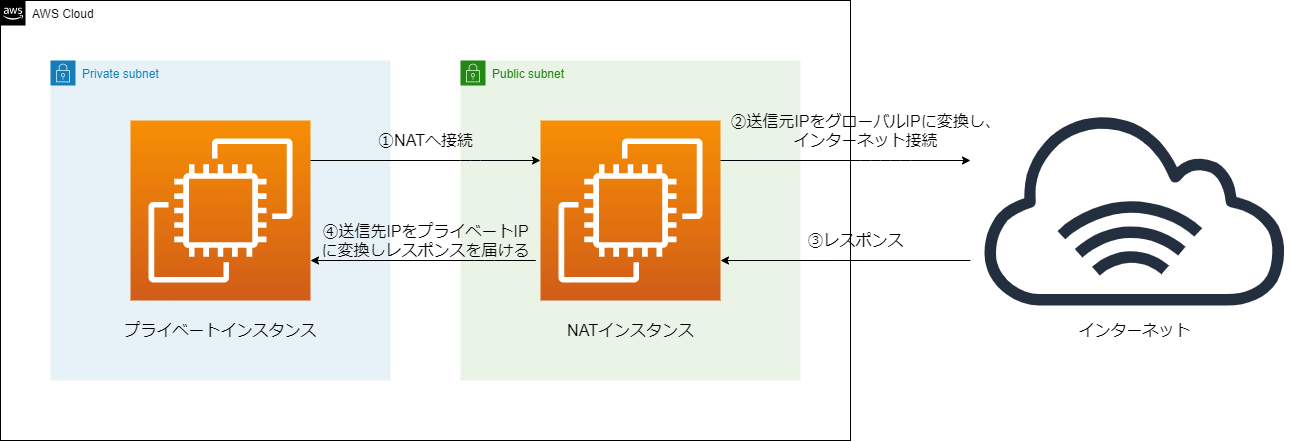
・プライベートインスタンス接続用の踏み台サーバが構築済みであること。完成フロー
①プライベートインスタンスからNATインスタンスへ接続する。
②NATインスタンスが送信元IPアドレスをグローバルIPアドレスへNAT変換し、インターネット接続する。
③インターネット側からのレスポンスがNATインスタンスへ返る。
④送信先IPアドレスをプライベートインスタンスのIPアドレスにNAT変換しレスポンスを届ける。
作業の流れ
項番 タイトル 1 NATインスタンスのセットアップ 2 プライベートサブネットのルートテーブル修正 3 接続検証 手順
1.NATインスタンスのセットアップ
パブリックサブネットに作成済みのEC2インスタンスをNATインスタンス化させます。
①NATインスタンスのセキュリティグループ確認
22番ポートに加え、443番ポート(https)が開いていることを確認します。
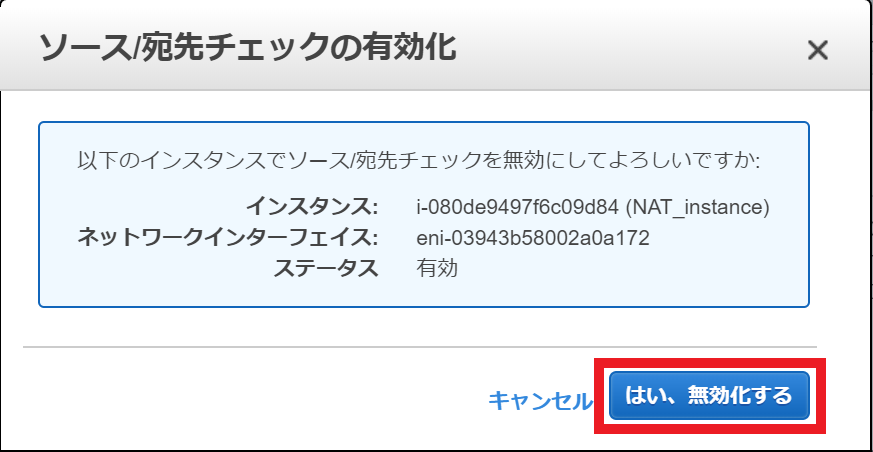
②送信元/送信先の変更チェック無効化(※)
EC2コンソールのアクション⇒ネットワーキング⇒送信元/送信先の変更チェック⇒はい、無効化するをクリック※送信元/送信先の変更チェック無効化とは
EC2インスタンスはデフォルトで送信元/送信先チェックを有効化しています。つまり、対象のEC2インスタンス宛てでないパケットはデフォルトで弾く仕様ということです。
今回はインターネット宛てのパケットをEC2で経由させる必要があるためこの機能を無効化し、パケットを弾かせないように変更する必要があります。
③OSログインし、ルートユーザへスイッチ
sudo su -④ip_forwardの有効化
異なるネットワークへのパケット転送を有効化するため、ip_forwardを有効化させます。vi /etc/sysctl.conf # 以下のエントリを追加する net.ipv4.ip_forward=1ネットワークを再起動してsysctl.confでの編集を有効化させます。
systemctl restart network⑤NAT(IPマスカレード)の有効化
iptablesを利用してNAT(IPマスカレード)を有効化させます。iptables -t nat -A POSTROUTING -o eth0 -j MASQUERADE2プライベートサブネットのルートテーブル修正
デフォルトデートウェイをNATインスタンスに向けるようにプライベートサブネットのルートテーブルを修正します。
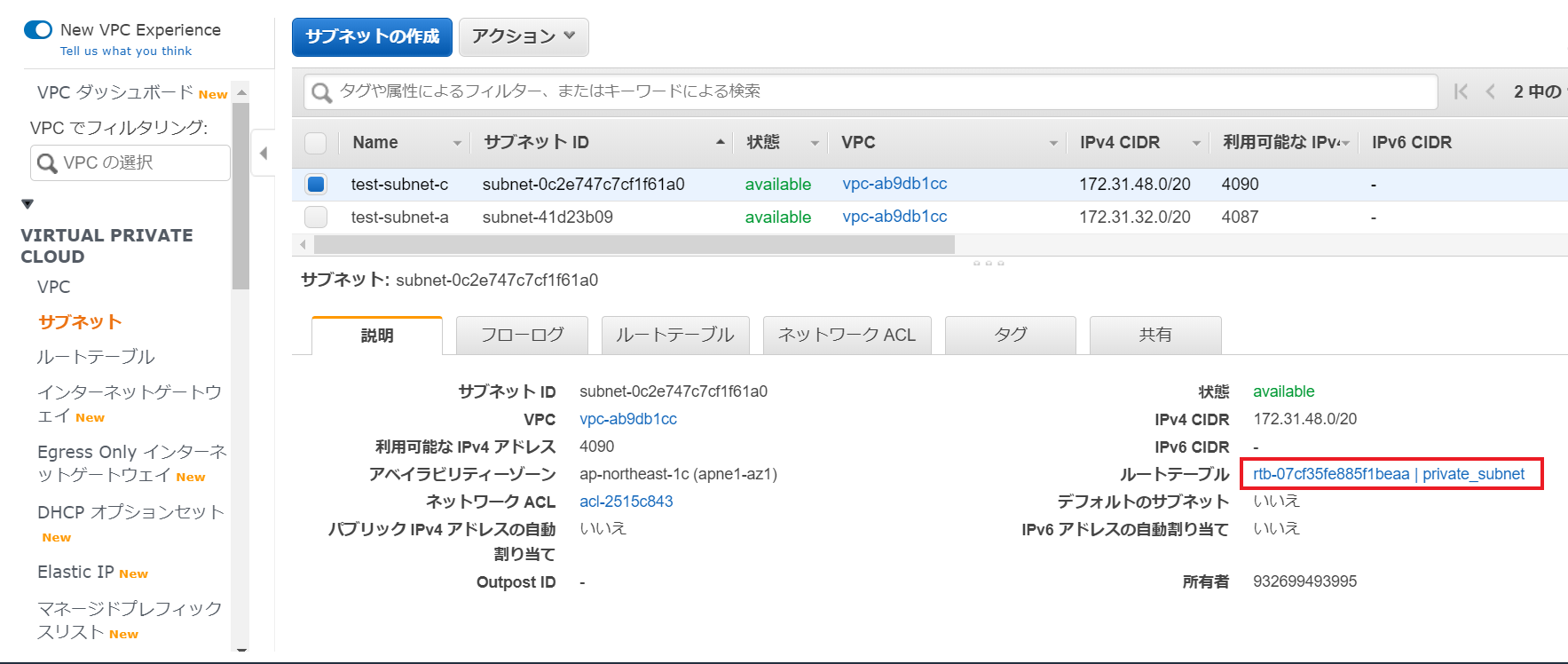
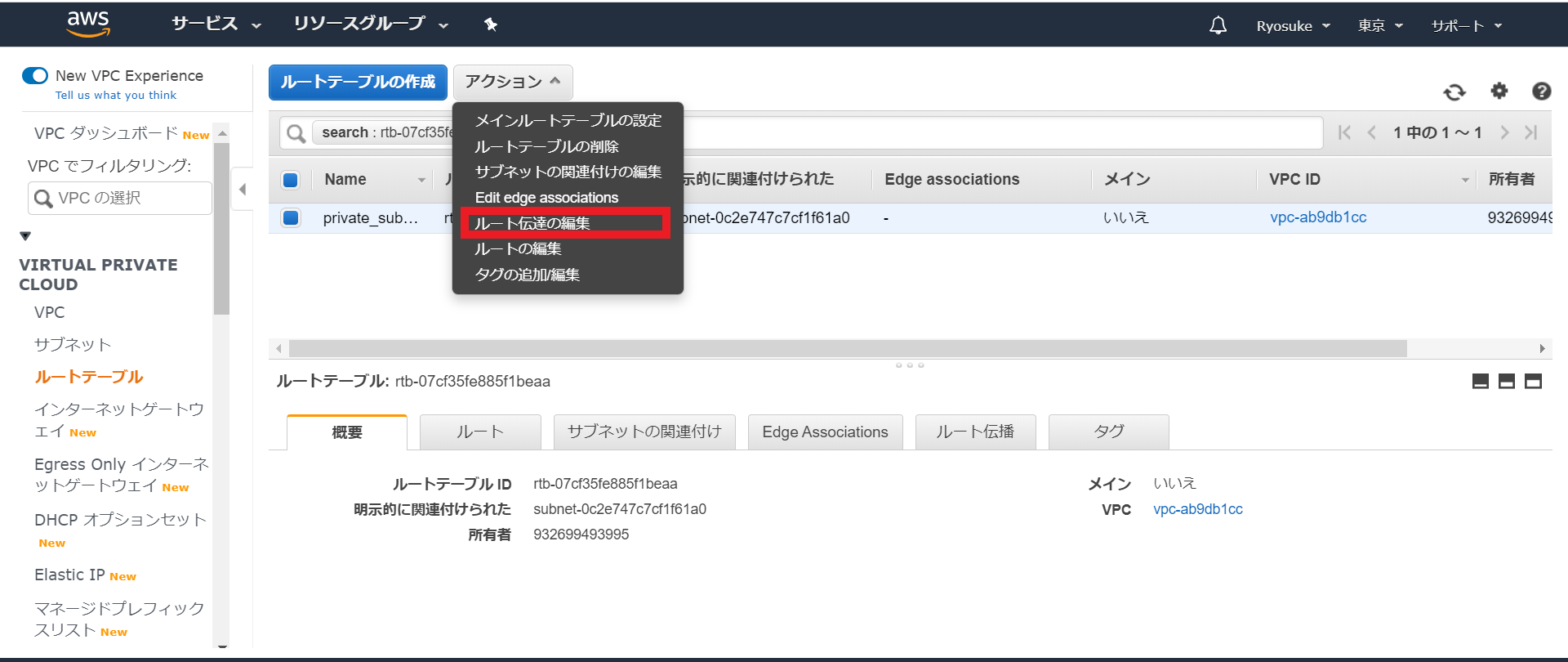
まず、VPCコンソールから対象のプライベートサブネットにアタッチされているルートテーブルを確認します。
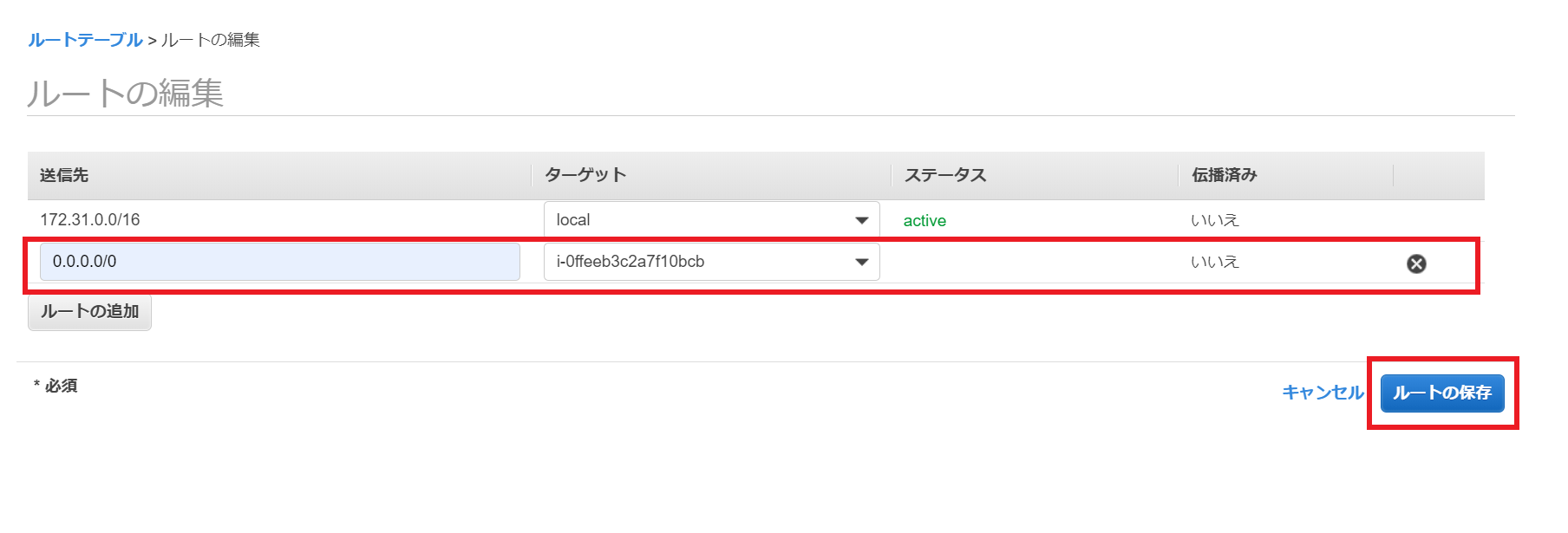
ルートの編集をクリック
デフォルトゲートウェイをNATインスタンスに向けるようにルートを追加します。
3.接続検証
①踏み台サーバから手順2でセットアップしたプライベートインスタンスへ接続
ssh -i <keypairfile_pass> <private_ip>②任意のインターネットサイトへcurl接続
接続先サイトからレスポンスが返ってきたらOKです!curl "<URL>"

- 投稿日:2020-07-14T17:59:05+09:00
AWS Budget でアラームの設定方法について(Amazon SageMakerの例)
背景
AWSでBudget・予算作成時にアラート設定ができます。これで予算がしきい値を超えた時、アラートを発信するようになる。
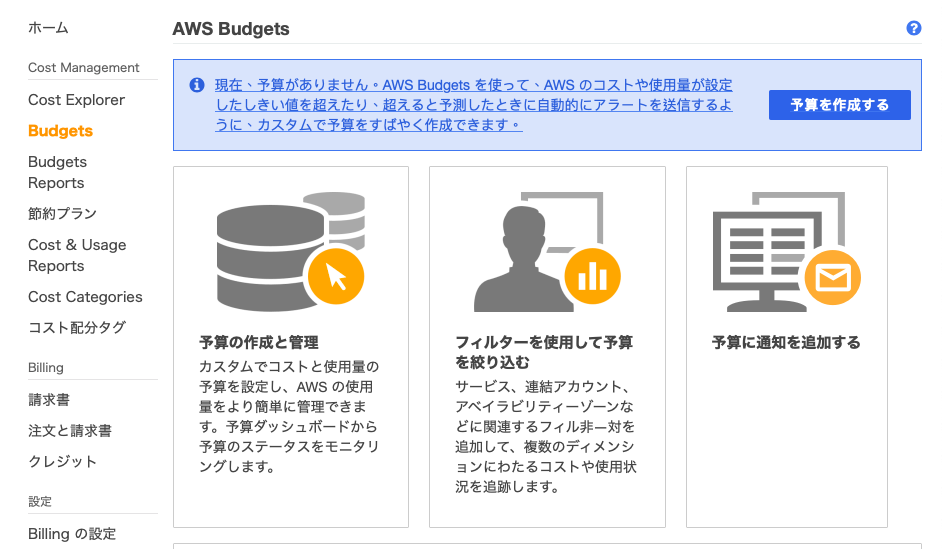
今回は「特定のMLプラットフォームサービスAmazon SageMakerに対して、プロジェクト(pjt)毎のコストを観察・アラートする」を目的にして、AWS Budget でのアラーム設定方法を説明。予算作成方法
まずは、AWS Console ホームページでBudgets選択し、「予算を作成する」をクリックする。これで、「予算作成」画面に飛んで行く。
予算作成には主に以下4つのステップがある。
ステップ1:予算タイプの選択
ステップ2:予算の設定
ステップ3:アラート設定
ステップ4:予算の確認ステップ1:予算タイプの選択
予算タイプの選択のために、各予算タイプの特徴を以下にまとめた。
コスト予算:サービスとタグでフィルタリングし、アラート設定できる
使用量予算: EC2、RDS、S3についての使用単位数を観察対象となる。全てのサービスに対してフィルタリングはできない
予約予算:RIタイプのEC2インスタンスを対象とする
Savings Planの予算:Saving Plansの使用率とカバレッジ2つのSavings Planタイプに分かれて、更にSavings Planタイプ、関連アカウント、リージョンなどのパラメータでフィルタリングできる。サービスとタグでのフィルタリングはできない「特定のサービスSageMakerに対して、PJT毎のコストを観察・アラートする」という目的に対して、コスト予算のみ使えますので、「コスト予算」を選択する
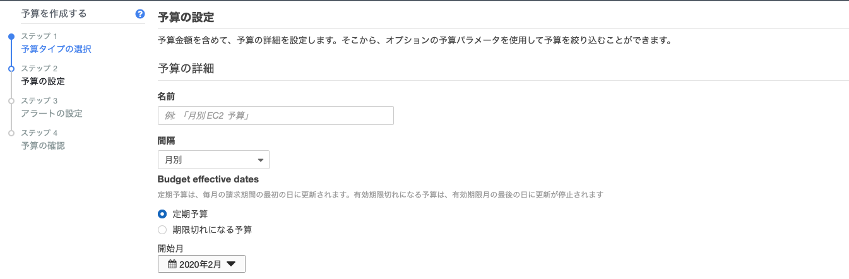
ステップ2:予算の設定
続いて予算の名前、開始日などを設定する
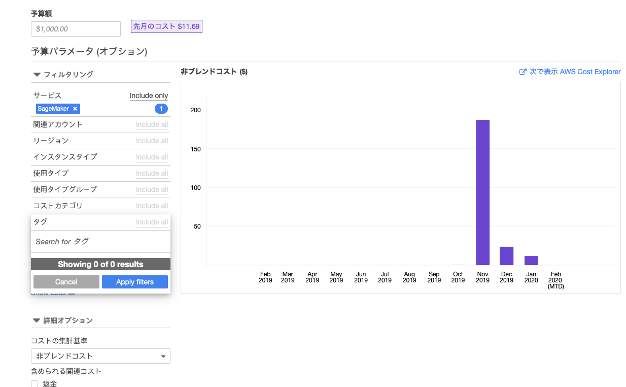
予算パラメータ(オプション)内、サービスとタグに基づいたフィルタリングができる。ここでサービスをSageMakerを選択し、タグにSageMakerリソースを作成時に設定したタグを選択することで、フィルタリングできる
※ 今回はタグ作成していないため、空白にした。タグの作成方法は以下「SageMakerのリソースのタグ付け」をご参照ください。
SageMakerのリソースのタグ付け
SageMakerが使用されるリソースを、タグ付けでpjt単位で分けれる
例えば、pjt1のNotebook Instanceにタグ「pjt1」を付けるSageMakerのタグ付けができるリソース対象は、ノートブックインスタンス、トレーニングジョブ、モデルになる。
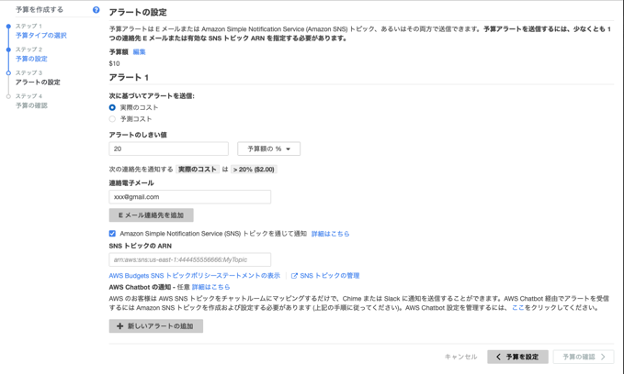
ステップ3:アラートの設定
以下「次に基づいてアラート送信」に実際のコストまたは予測のコストを選択し、アラート閾値を設定する。AWSよりメール通知できるため、連絡メールを入力。SNSトピックを通じて通知することが要る時、SNSトピックのARNを入力してください。
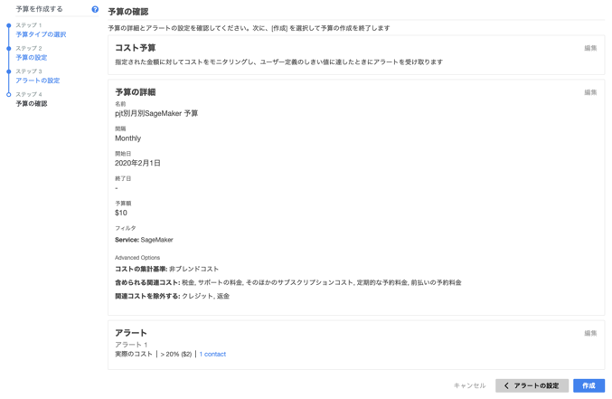
ステップ4:予算の確認
最後、予算の確認画面で設定した情報を確認ください。
ここの例では、「SageMaker」でフィルタリングし、「メール通知」には1Contactと設定している

- 投稿日:2020-07-14T17:44:38+09:00
LambdaからAuthFlow=USER_SRP_AUTHでCognitoの認証を通す
目的
Lambdaから
InitiateAuthのAuthFlowをUSER_SRP_AUTHでCognitoの認証を通す。※
AdminInitiateAuthのADMIN_USER_PASSWORD_AUTHを使って良いならそっち推奨
(boto3のadmin_initiate_auth使ってID/PWだけで簡単に実装できる。)方法
自力でやろうとすると、
initiate_auth、respond_to_auth_challengeを実行する必要があるが、
respond_to_auth_challengeの方のPASSWORD_CLAIM_SIGNATUREの計算で挫折してしまうため、
こちらを拝借する。。
※pip installできる(はず)だが、ファイル数が少ないので直接ダウンロードして使う。
__init__.pyが居ると、色々インストールしないといけなくなるため、削除してしまってOK。
(↓になるように)
Lambdaに下記を実装する。
from warrant.aws_srp import AWSSRP u = AWSSRP(pool_id='ユーザプールID', client_id='クライアントID', username='ID', password='PW') res = u.authenticate_user() id_token = res['AuthenticationResult']['IdToken']スペシャルサンクス
- 投稿日:2020-07-14T17:00:23+09:00
AWSハンズオン実践メモ 〜AWS SAM を使ってテンプレートからサーバーレスな環境を構築する〜
はじめに
前回、AWS公式のハンズオンシリーズの中から、翻訳 Web API の構築を通して、サーバーレスアーキテクチャの基本を学ぶハンズオンを実施しました。
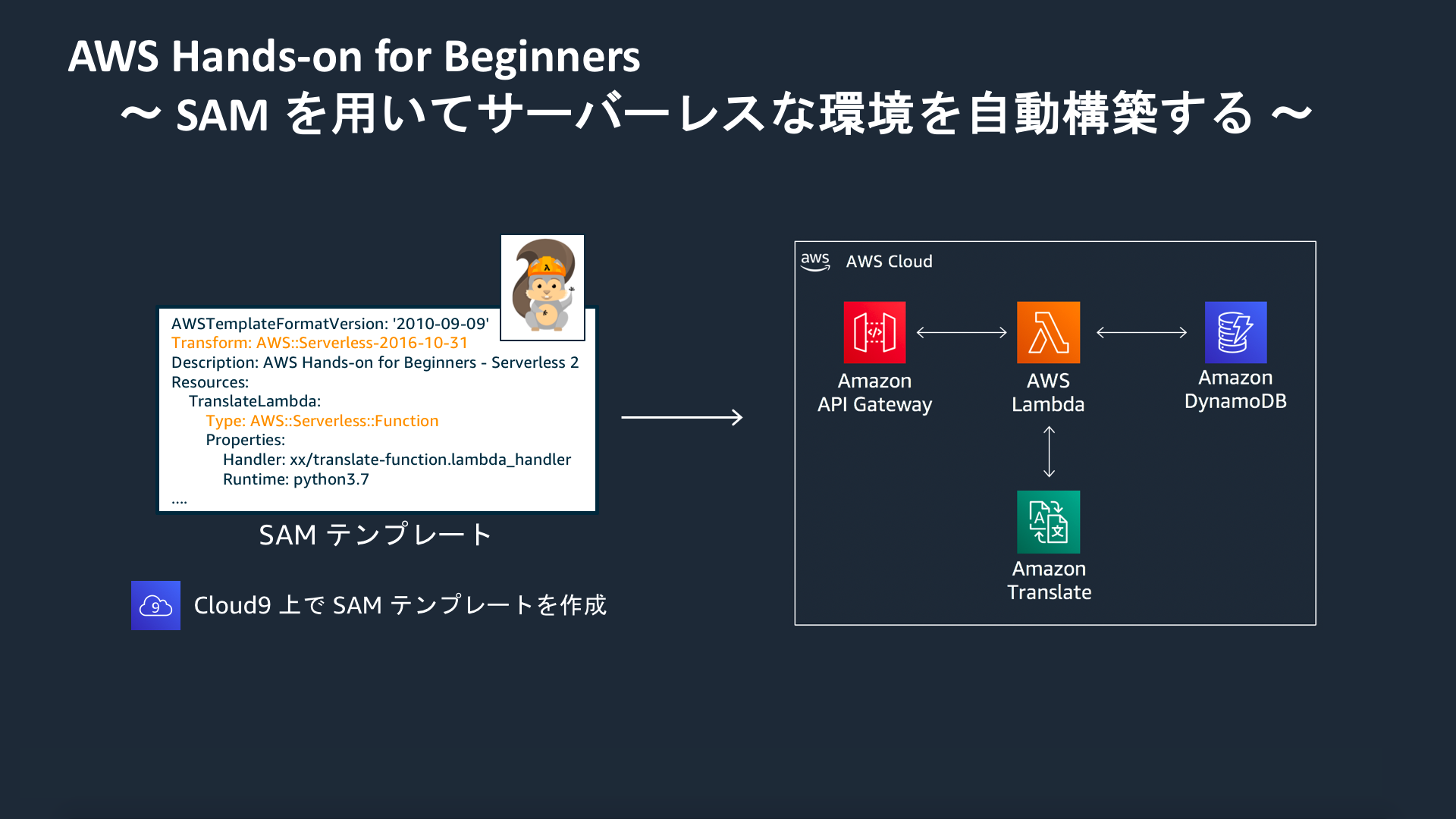
参考:AWSハンズオン実践メモ 〜サーバーレスアーキテクチャで翻訳 Web API を構築する〜今回は、前回のハンズオンで構築した翻訳 Web API をAWS Serverless Application Model (AWS SAM)を用いてテンプレートから構築します。
AWS Serverless Application Model (AWS SAM)とは、サーバーレスアプリケーション構築用のオープンソースフレームワークです。簡単に言うと、サーバレスな構成を作ることに特化した Cloudformation のテンプレートになります。
本記事は自身のハンズオン学習メモとして投稿します。
目次
ハンズオンの目的
- AWS Serverless Application Model (AWS SAM)を用いて、サーバーレス構成を自動構築する
前回の Serverless #1 で構築した翻訳 Web API を AWS Serverless Application Model (AWS SAM) を用いてテンプレートから構築します。前回のハンズオンでは全ての工程を手作業で(マネージメントコンソール上で)構築していきました。今回のハンズオンではこの構築作業をテンプレート化し、作成したテンプレートから AWS リソースを構築していきます。テンプレート化することで、そのテンプレートをバージョン管理できるようになる、チーム内でレビューがしやすくなる、といった利点があり、プロダクト開発をより効率的に進めることができます。
(https://aws.amazon.com/jp/aws-jp-introduction/aws-jp-webinar-hands-on/ より引用)本編
Cloud9 のセットアップ+Cloud9 で簡単な Lambda 関数を作成する
- Cloud9で環境を作成
- Cloud9からLambdaを作成&編集
SAM で Lambda 関数を作成する①
AM を利用するための事前準備を行い、Lambda 関数の設定情報を SAM テンプレートに記載していく。
- translate-function.pyを作成
translate-function.pyimport json import logging logger = logging.getLogger() logger.setLevel(logging.INFO) def lambda_handler(event, context): logger.info(event) return { 'statusCode': 200, 'body': json.dumps('Hello Hands on world!') }
- template.yamlを作成
template.yamlAWSTemplateFormatVersion: '2010-09-09' Transform: AWS::Serverless-2016-10-31 Description: AWS Hands-on for Beginners - Serverless 2 Resources: TranslateLambda: Type: AWS::Serverless::Function Properties: FunctionName: translate-function-2 CodeUri: ./translate-function Handler: translate-function.lambda_handler Runtime: python3.7 Timeout: 5 MemorySize: 256
- 作成したファイルをパッケージング
aws cloudformation package \ --template-file template.yaml \ --s3-bucket 20200714handsonserverless \ --output-template-file packaged-template.yamlこのコマンドで、S3 にファイルがアップロードされ、そのファイルのUri が --template-file で指定したテンプレートに書き足され、--output-template-file で指定したファイル名で出力される。
- デプロイ
aws cloudformation deploy \ --template-file ./packaged-template.yaml \ --stack-name hands-on-serverless-2 \ --capabilities CAPABILITY_IAMパッケージで書き出したテンプレートファイルを元に、AWS CLI の CloudFormation の deployコマンドを叩く。これで、テンプレートに記述されている通りのリソースが構築される。
SAM で Lambda 関数を作成する②
SAM テンプレートファイルをアップデートし、Lambda 関数から別の AWS サービスを呼び出せるよう IAM 設定を修正。
- translate-function.pyを編集
translate-function.pyimport json import boto3 translate = boto3.client('translate') def lambda_handler(event, context): input_text = "こんにちは" response = translate.translate_text( Text=input_text, SourceLanguageCode='ja', TargetLanguageCode='en' ) output_text = response.get('TranslatedText') return { 'statusCode': 200, 'body': json.dumps({ 'output_text': output_text }) }
- template.yamlを編集(Policies: - TranslateFullAccessを追加)
- 作成したファイルをパッケージング(先程と同様)
- デプロイ(先程と同様)
SAM で API Gateway のリソースを作成し、Lambda 関数と連携させる
API Gateway リソースを作成する際の設定を SAM テンプレートに記載し、外部からリクエストを受け付けられる Web API を構築する。
- translate-function.pyを編集
translate-function.pyimport json import boto3 translate = boto3.client(service_name='translate') def lambda_handler(event, context): input_text = event['queryStringParameters']['input_text'] response = translate.translate_text( Text=input_text, SourceLanguageCode="ja", TargetLanguageCode="en" ) output_text = response.get('TranslatedText') return { 'statusCode': 200, 'body': json.dumps({ 'output_text': output_text }), 'isBase64Encoded': False, 'headers': {} }
- template.yamlを編集
template.yamlAWSTemplateFormatVersion: '2010-09-09' Transform: AWS::Serverless-2016-10-31 Description: AWS Hands-on for Beginners - Serverless 2 Resources: TranslateLambda: Type: AWS::Serverless::Function Properties: FunctionName: translate-function-2 CodeUri: ./translate-function Handler: translate-function.lambda_handler Runtime: python3.7 Timeout: 5 MemorySize: 256 Policies: - TranslateFullAccess Events: GetApi: Type: Api Properties: Path: /translate Method: get RestApiId: !Ref TranslateAPI TranslateAPI: Type: AWS::Serverless::Api Properties: Name: translate-api-2 StageName: dev EndpointConfiguration: REGIONAL
- 作成したファイルをパッケージング(先程と同様)
- デプロイ(先程と同様)
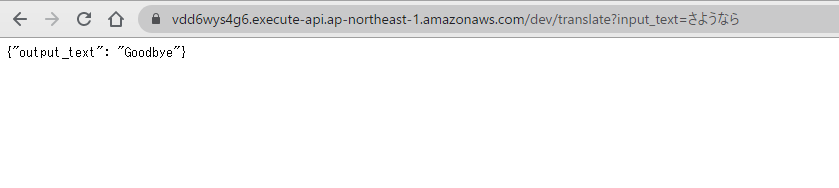
以下のようにクエリ部分にリクエストを入力し送信すると、翻訳結果が返却される。
SAM で DynamoDB TBL を作成し、Lambda 関数を連携させる
DynamoDB テーブルを作成する際の設定情報を SAM テンプレートに記載する。また、Lambda 関数側の記載も修正し、DynamoDB に翻訳リクエストの履歴情報を書き込めるようにする。
- translate-function.pyを編集
translate-function.pyimport json import boto3 import datetime translate = boto3.client(service_name='translate') dynamodb_translate_history_tbl = boto3.resource('dynamodb').Table('translate-history-2') def lambda_handler(event, context): input_text = event['queryStringParameters']['input_text'] response = translate.translate_text( Text=input_text, SourceLanguageCode="ja", TargetLanguageCode="en" ) output_text = response.get('TranslatedText') dynamodb_translate_history_tbl.put_item( Item = { "timestamp": datetime.datetime.now().strftime("%Y%m%d%H%M%S"), "input": input_text, "output": output_text } ) return { 'statusCode': 200, 'body': json.dumps({ 'output_text': output_text }), 'isBase64Encoded': False, 'headers': {} }
- template.yamlを編集
template.yamlAWSTemplateFormatVersion: '2010-09-09' Transform: AWS::Serverless-2016-10-31 Description: AWS Hands-on for Beginners - Serverless 2 Resources: TranslateLambda: Type: AWS::Serverless::Function Properties: FunctionName: translate-function-2 CodeUri: ./translate-function Handler: translate-function.lambda_handler Runtime: python3.7 Timeout: 5 MemorySize: 256 Policies: - TranslateFullAccess - AmazonDynamoDBFullAccess Events: GetApi: Type: Api Properties: Path: /translate Method: get RestApiId: !Ref TranslateAPI TranslateAPI: Type: AWS::Serverless::Api Properties: Name: translate-api-2 StageName: dev EndpointConfiguration: REGIONAL TranslateDynamoDbTbl: Type: AWS::Serverless::SimpleTable Properties: TableName: translate-history-2 PrimaryKey: Name: timestamp Type: String ProvisionedThroughput: ReadCapacityUnits: 1 WriteCapacityUnits: 1
- 作成したファイルをパッケージング(先程と同様)
- デプロイ(先程と同様)
以下のように翻訳結果がdynamoDBに蓄積される。
作成した AWS リソースの削除
CloudFormationのスタックを削除すると関連するリソースが全て削除される。
おわりに
今回はSAMを利用し、IaaCでサーバーレスアーキテクチャを構築した。
プロジェクトにおいてAWSで設計・構築する際はCloudFormationを使っていく事になると思うので、記法や管理方法についても学習したい。参考
[新ツール] AWS Serverless Application Model (AWS SAM) を使ってサーバーレスアプリケーションを構築する

- 投稿日:2020-07-14T16:47:21+09:00
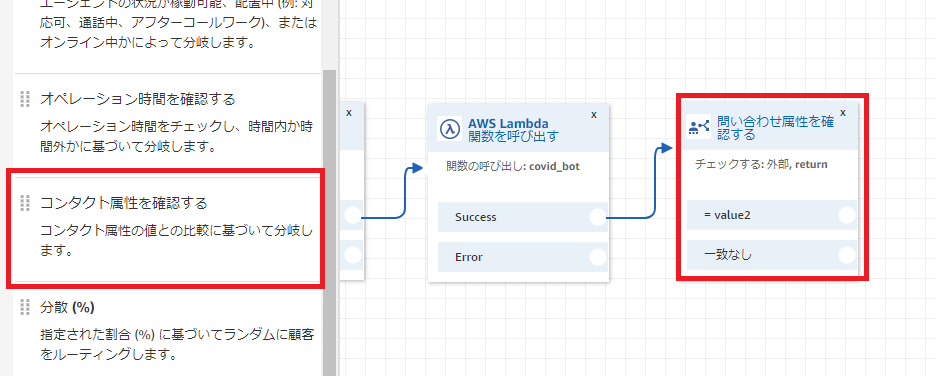
【AmazonConnect】問い合わせフロー内でのLambda呼び出し
概要
AmazonConnectでは問い合わせフロー内でLambda関数を呼び出すことができます。
また、Lambda関数を呼び出す際にはJSONリクエストをやり取りしており、これを利用することで条件分岐などが可能になります。紐づけ
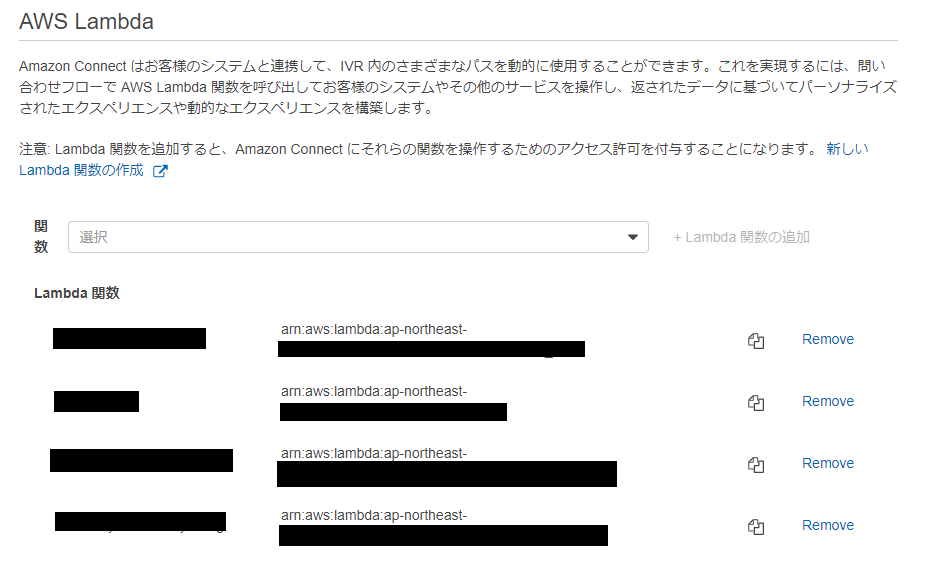
問い合わせフローから直接ARNを指定して呼び出すことも可能ですが、前もってマネジメントコンソールからインスタンス情報にアクセスし、「問い合わせフロー」からLambda関数を登録できます。
こうすれば、Lambda関数を呼び出す際、プルダウンで登録した関数が一覧で出てくるので選びやすいです。
以下、問い合わせフロー内におけるLambda関数の設定画面
問い合わせフロー内での操作
AmazonConnectからLambda関数を呼び出す際、以下のようなJSONリクエストがLambda関数に引き渡されます。
Lambda関数の戻り値は"Attributes"にJSON形式で格納され、AmazonConnectに渡されます。{ "Details": { "ContactData": { "Attributes": {"ここに":"Lambda関数の値"}, "Channel": "VOICE", "ContactId": "4a573372-1f28-4e26-b97b-XXXXXXXXXXX", "CustomerEndpoint": { "Address": "+1234567890", "Type": "TELEPHONE_NUMBER" }, "InitialContactId": "4a573372-1f28-4e26-b97b-XXXXXXXXXXX", "InitiationMethod": "INBOUND | OUTBOUND | TRANSFER | CALLBACK", "InstanceARN": "arn:aws:connect:aws-region:1234567890:instance/c8c0e68d-2200-4265-82c0-XXXXXXXXXX", "PreviousContactId": "4a573372-1f28-4e26-b97b-XXXXXXXXXXX", "Queue": "QueueName", "SystemEndpoint": { "Address": "+1234567890", "Type": "TELEPHONE_NUMBER" } }, "Parameters": { "sentAttributeKey": "sentAttributeValue" } }, "Name": "ContactFlowEvent" }Lambda関数に値を渡すとき
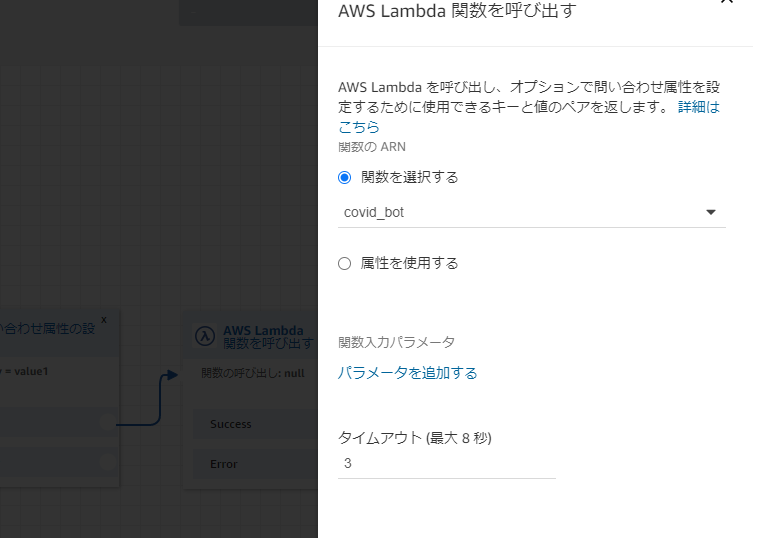
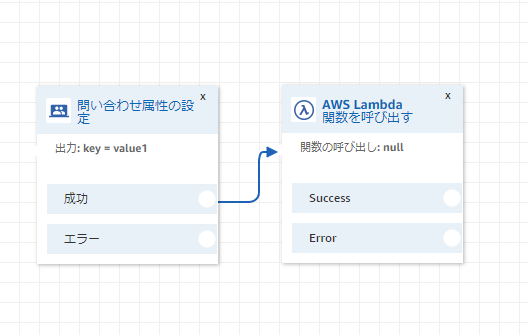
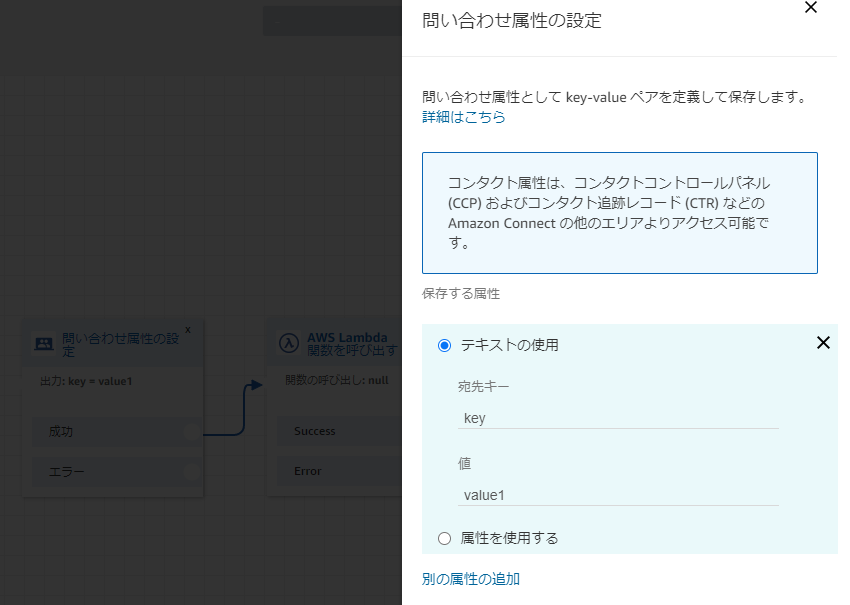
Lambda関数に値を渡すときは以下の順でブロックを並べます。
ここで設定した属性はLambda関数で
event["Details"]["ContactData"]["Attributes"]["key"]
で参照できます。Lambda関数から値を受け取るとき
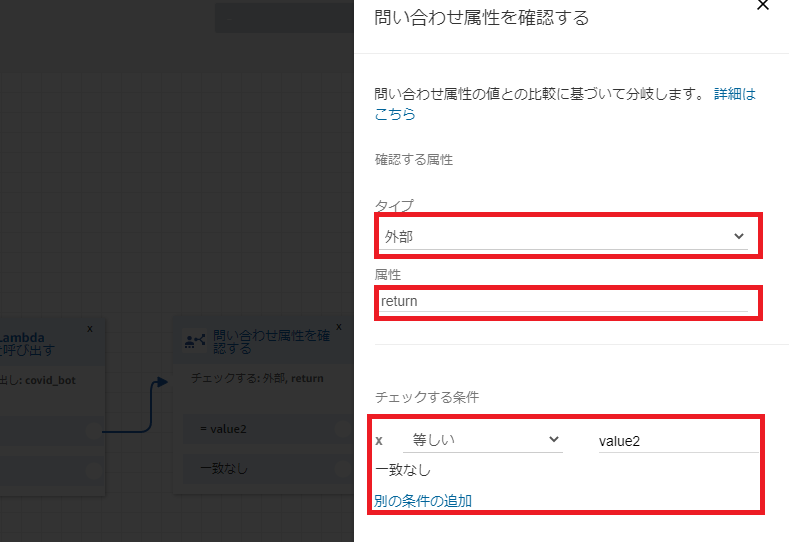
Lambda関数の戻り値は問い合わせフロー内で「属性」として扱われます。また、タイプは「外部」として扱われます。
問い合わせフロー内で、属性を確認することで分岐ができます。
チェックする条件は、「別の条件の追加」から追加可能であり、「等しい」以外でも不等号などを選択できます。
- 投稿日:2020-07-14T15:52:26+09:00
OOUI(オブジェクト指向ユーザーインターフェース)のビジネスロジックにOODAループを適用する
フロントエンドに最適なアルゴリズムモデルを提供
2020年6月、「オブジェクト指向UIデザイン──使いやすいソフトウェアの原理」が販売されたことによって、フロントエンド設計にオブジェクト指向を適用するという設計手法が確立した。
OOUIについては以下のリンク参照
・ソシオメディアHP
https://www.sociomedia.co.jp/8740フロントエンドの画面はオブジェクト単位で構成されるということで結論づけられたので、問題なのはオブジェクトに変換されるまでの過程である。
下記の記事でフロントエンドのパッケージ構成やクラス内容について記載したが、フロントエンドのビジネスロジックについてはブラックボックスのままになっている。
https://qiita.com/aLtrh3IpQEnXKN7/items/880baf26da6fcf7d96dc今回の記事では、フロントエンドのビジネスロジックにOODAループを適用し、フロントエンドのビジネスロジックがオブジェクトの母数となるデータを取得し、オブジェクトへ変換するまでの過程について明確化したいと思う。
OODAループ
OODAループとは、アメリカの航空戦略家であるジョンボイドが朝鮮戦争の航空戦、ナチスの電撃戦を研究し、人間の意識決定のスピードが勝敗が分けたと結論づけた。
人間の意識決定のプロセスを可視化したのが以下のOODAループである。
OODAループは、観察(Observe)- 情勢への適応(Orient)- 意思決定(Decide)- 行動(Act)の順番で構成されている。
フロントエンドのビジネスロジックにOODAループの意識決定モデルを採用し、フロントエンドのビジネスロジックを明確化したいと思う。フロントエンドのパッケージ構成
OOUI(オブジェクト指向ユーザーインターフェース)のOVIDモデルをベースとして、以下の5つの層にレイヤーを分割
Controller層
Interaction層
Model層
View層
Infra層・各レイヤーの細かい詳細については以下の記事を参照
https://qiita.com/aLtrh3IpQEnXKN7/items/880baf26da6fcf7d96dcInteraction層のビジネスロジックにOODAループを適用する
Interaction層のビジネスロジック
Interaction層の全体図
Interaction層のビジネスロジックを以下の4つのカテゴリに分割
観察(Observe)
情勢への適応(Orient)
意思決定(Decide)
行動(Act)ビジネスロジックの実行順番として以下を想定
1.観察(Observe)
2.情勢への適応(Orient)
3.意思決定(Decide)
4.行動(Act)観察(Observe)
Observeでは情報の収集をメインのロジックとする。
RestAPIを使用し、現実世界のリアルタイムな外部情報を収集する。
<例>
IPアドレスを使用した現在の位置情報の取得
センサーを使用した体内温度の取得
ユーザーのパーソナルデータの取得情勢への適応(Orient)
OrientとはObserveで収集したデータの統合->分析->情勢判断の順番で実行される。
OODAループ内のビッグオーと呼ばれ、最も重要な要素とされている。
Orientはパーソナル情報と収集した外部情報を統合、分析し、情勢を判断する。パーソナル状況を以下の順番で分析する
1.地理・・・現在の場所、移動手段
2.文化・・・宗教、民族の内容に応じた行動パターン
3.職業・・・職業の違いによって発生する価値観に焦点をあてる
4.コミュニティ・・・家族、友人、所属している団体
5.経済・・・年収、決済手段
パーソナル情報は本人のプロフィール情報に依存している。
プロフィール情報を設定、カスタマイズすることによって、本人の好みに応じたアルゴリズムを設定することができる。外部情報に関しては以下のような情報を取得し、分析を行う
・アプリがユーザーへ提供するサービスのレベル
・天気
・サービスを提供する地点とユーザーの位置
・サービス側で使用できる決済手段パーソナル状況を解析したユーザーの好み、傾向に合わせたサービスの選択、
外部情報を照合し、サービスを提供することができるか状況か判断を行う。意思決定(Decide)
Orientによって出力された状況判断に応じて手段を選択し、実行する。
状況判断の内容によってはObserveへ戻るものも存在する。
意識決定は以下の種類に分類される。
・手段の選択
・手段を選択不可能のため、以降の処理を中止
・代替手段を選択するため、観察(Observe)から処理をやり直し行動(Act)
Orientで選択された手段を実行する。
実行する処理の内容として以下の処理を順番に実行する
1.バックエンドのAPIと通信するか判定
2.通信する場合、RestApiへ引き渡すパラメータを設定
3.バックエンドのApiと通信を実行
4.通信結果を取得し、結果に応じて画面に表示する文字列を生成。

- 投稿日:2020-07-14T13:04:26+09:00
Webサーバーの立ち上げからアプリケーションの作成まで全て一人でやってみた件
初めに
今まで書籍でLaravelについて勉強したり、Laravelの仕組み(バインドについてなど)を調べて記事を書くことなどをしてきたのですが、最近それらが飽きてきてしまったのでLaravelを使用したWebアプリケーションをAWSのツールを用いて作成してみました。そして、このアプリを作成した経験を記事にすれば自分と同じような境遇の人の助けとなったり、このアプリケーションの宣伝になるかもと思ったので、このアプリケーションの作成やAWSのツールを使用した際に個人的に苦労したこと・気を付けたことをここへ書いてみました。
この記事は大きく分けて四章あるのですが、章ごとの内容は独立しているので気になるところを好きなように読んでください。Webアプリ宣伝編
今回私が作成したWebアプリケーションはデンデンデン・・・・バーン!!
「ロッテンポテト」です!(トマト?何のことですか?)
このアプリは映画レビューサイトです。もっと詳しく言うと、管理する人(僕です)が最近見た映画を紹介するので、それに対しレビュワーたちが気ままにレビューをする感じです。
このサイトのトップページはこんな感じです。
ほかのページはこんな感じです。
画像を見てみると新規登録とか、満足度とかありますが気になる方はトップページを見てみて下さい。また、このWebアプリに関する疑問やこんな映画をみんなとレビューしてみたいな、などの要望がありましたら、このアプリ用のtwitterアカウントへDMを送ってください!
twitterアカウントはこちら
【映画レビューサイト解説しました!!】
— ロッテンポテト (@RottemPotato) July 7, 2020
本日より映画レビューサイト「ロッテンポテト」を開設しました!
本サイトは管理する人が最近見た映画を紹介し、その映画に対してレビューを書くものとなっています。
暇つぶしがてらぜひ遊びに来てください~
(質問等はDMでお願いします。)AWS編
※インフラ、ネットワーク、Webサーバーに関する知識が全くない中で自分なりに調べてこの章を作成しました。なので間違いがあるかもしれません。もし間違い等がありましたら、指摘していただけるとありがたいです。
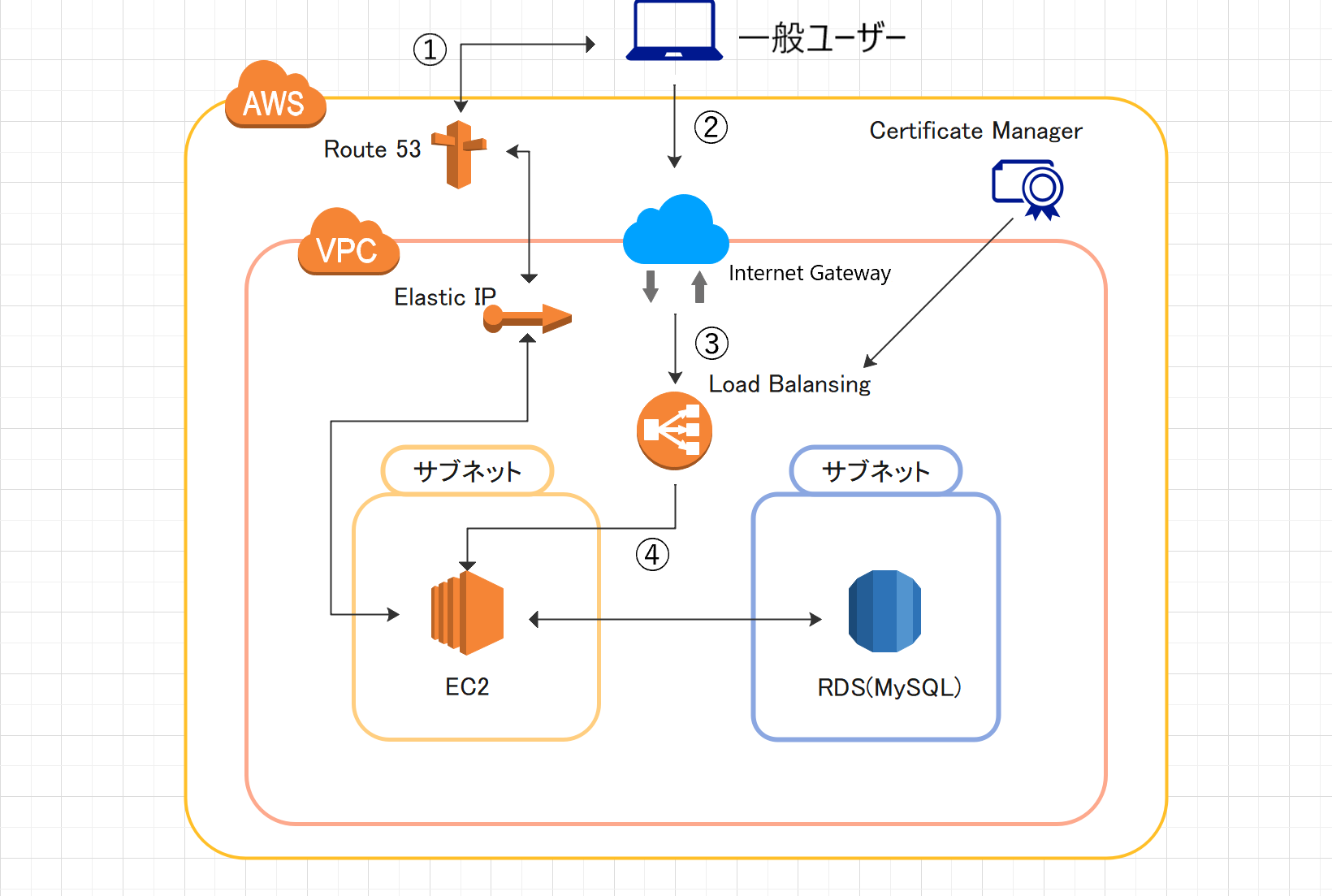
今回自分が使用したAWSのツールの関係を図にするとこんな感じです。
この図に書いてある丸付きの番号は一般ユーザーがWebサーバー(今回はEC2)へリクエストを送るまでの道順を表しています。この番号通りにそれぞれのツールのやっていることを説明すると、
- 一般ユーザーがブラウザなどからドメインを通してWebサーバーへアクセスする際まずはユーザーからAWSのDNSサーバーであるRoute53へ、ドメインに紐づいたWebサーバーのグローバルIPアドレスを教えるようにという命令が出される。そしてRoute53はElastic IPで管理しているWebサーバーのグローバルIPアドレスをユーザーへ教える。
- グローバルIPアドレスを取得したユーザーはVPC(ネットワーク空間のこと。ここにWebアプリを構成するツールを置く。)の入り口であるインターネットゲートウェイを通る。
- インターネットゲートウェイからロードバランサーまではhttps通信(http通信より安全に通信が行える通信)でリクエストの内容が伝えられ、そのリクエストはルートテーブル(VPCの外からリクエストが来た際の宛先を設定する)で設定されたサブネット内のEC2へ送られる。
- ロードバランサーから送られたリクエストはセキュリティグループにてEC2へ通すか否かの判断が下され、許可が出ればそのリクエストはEC2へ行きその結果がWebアプリへ反映される。
補足事項
グローバルIPアドレスとは?
AWSでサーバーを作成するにあたり二つのIPアドレスが使用されます。一つがグローバルIPアドレスでもう一つがプライベートIPアドレスです。グローバルIPアドレスはElastic Ipなどで後から割り当てる、VPC外からみたサーバーのアドレスを示すもので、プライベートIPアドレスはサーバーの作成時に自動的に割り当てられる、VPC内からみたサーバーのアドレスです。もしVPC内のみ(ローカルの環境)で通信を行う際はプライベートIPアドレスのみで大丈夫です。しかしVPCの外から通信を送る場合(例:第三者が利用者となるWebアプリケーションを運用する場合)はグローバルIPアドレスがなくてはサーバーへアクセスできません。Certificate Manager とは
ユーザーに対し、このWebアプリはhttps通信(SSL通信)を行っていることを証明する働きをしています。この証明をしているWebアプリはブラウザで見る際にURLの左側に鍵マークがあります。このマークがないWebアプリはユーザーのデータが漏洩する可能性が高いので、注意してください。参考にした記事
AWS初心者 入門編 脱・知ってるつもり!AWSのネットワーク関連用語を基礎からおさらい
ウィキペディア HTTPS
AWS ルートテーブル自分が使用したAWSのツールの概要は以上です。今度は導入の際に自分が行ったことや参考にした記事をツールごとに紹介していきます。
AWSのツールを使う前に
AWSアカウントを作成する際の注意点やAWSの料金管理の仕方は以下の記事から教わりました。AWSを初めて使うけどどうすれば良いかよくわからないという方はこの記事を参考にしてみてください。
Qita AWSアカウントを取得したら速攻でやっておくべき初期設定まとめVPC&EC2&RDS
AWSでのVPCの立ち上げからEC2、RDSの作成は以下の記事を参考にしました。各章ごとの内容がわかりやすく書いてありますので、自分の知りたいことをこの記事から探すような活用の仕方が良いと思います。
(下準備編)世界一丁寧なAWS解説。EC2を利用して、RailsアプリをAWSにあげるまでroute53
ドメインの作成からドメインとグローバルIPアドレスの結びつけをroute53で行いました。
参考にした記事は以下の二つです。
Route 53 でドメインを取得・購入する(2019版
AWS Amazon Route 53 の開始方法https通信(SSL通信)
EC2を作成し、Elastic IPでグローバルIPアドレスを設定しただけだと、http通信でユーザーとサーバーの通信が行われるため安全な通信とは言えません。(通信に関する知識が全くないため、どこが危険なのかはわかりません。)そこでhttp通信をhttps通信に切り替える必要があります。
自分がhttp通信をより安全なhttps通信に切り替える時やhttps通信(SSL通信)を行っていることに対する証明書を発行する時に参考にした記事はこちらです。
ナレコムAWSレシピ AWSでWebサイトをHTTPS化 その1:ELB(+ACM発行証明書)→EC2編Webサーバーソフトウェア編
自分のOS、Apacheのバージョンはこちらです。
ツール バージョン Ubuntu 18.04.4 LTS Apache 2.4.29 LAMPの導入などはいろんな方が記事を書いてくれているので、それぞれの環境に合うものを参考にしていただければと思います。この章では自分が今までWebアプリケーションをデプロイした経験がないゆえにはまったことがあったので、それを紹介します。
ちなみに自分がLAMPを導入する際に参考にした記事はこちらです。
Install PHP 7.4 on Ubuntu 18.04Apacheではまったこと
自分がはまったことは、ブラウザでドメインを入力したときに自動的に
自分のプロジェクト/public/index.phpを表示するようにApacheを設定するにはどうすれば良いのかということです。自分が見つけたこの問題に対する解決策は、Apacheの設定ファイル(/etc/apache2/apache.confなど)内のhttp通信(port80を使用)のときに表示するファイルのパスを設定する部分(<VirtualHost *:80>から</VirtualHost>にかけて)にDocmentRoot /var/www/html/自分のプロジェクト/public/を加えるというものでした。しかし自分の環境の場合それだけではうまくいきませんでした。なぜなら、自分のようにUbuntuをOSとしている場合のApacheの設定ファイルは一つにまとまっているわけではなく、いくつかの設定ファイルに分裂していたからです。
ではDocmentRoot ~をどこへ加えたのかというと、/etc/apache2/sites-available/000-default.confに加えることでうまくいきました。
(自分のWebアプリケーションの通信はインターネットゲートウェイからロードバランサーまではhttps通信ですが、EC2からロードバランサーまではhttp通信のためhttp通信の設定を行う/etc/apache2/sites-available/000-default.confを書き換えました。もしEC2からロードバランサーまでをhttps通信で行う場合はおそらくhttps通信の設定を行う/etc/apache2/sites-available/default-ssl.confを書き換える必要があるかと思います。)この問題に対する解決策は下の記事を参考にさせていただきました。
index意外のページにアクセスすると404エラーが発生するアプリケーション編
このWebアプリケーションに使用した各ツールのバージョンは以下の通りです。
ツール バージョン php 7.4 Laravel 7.12.0 Vue 2.6.11 Laravel(バックエンドorサーバーサイド)
Laravelのインストール時にはまったこと
メモリの小さいEC2を使用したがゆえにLaravelの一部しかインストールされないという問題にはまり、そのとき自分がteratailで質問したときに得た回答と参考にした記事は以下の通りです。間違えてメモリを1GBにしてしまった時などにはぜひ参考にしてみて下さい。
AWSのEC2上でのLaravelとAWSでのRDS(MySQL)の環境で"php artisan migrate"を実行した時のエラー
Life with IT swap領域拡張手順(ファイル割当)コードを書く上で気を付けたこと
Laravelを使用しコードを書く上で気を付けたことは3つです。
- 設計パターンに
MVC(Model View Controller)を用いる- MVCのうちのControllerの内容はなるべく分かり易いものにする
- phpとRDBとの手続きやOAut認証の手続きはModel内に収める
1の理由はADR(Action Domain Response)など設計パターンには様々なものがありますが、初めてFWに触れる自分にとって単純なものを選ぶ方がやりやすいと思ったからです。
2にある「分かり易い」の基準は二つあります。一つ目はController内のメソッドの引数と返り値には必ず型の指定を行う、二つ目はController内のすべてのコードの質を一定の状態に保つというものです。二つ目のコードの質を判断するために自分はPHPStanという静的解析ツールを使用しました。このツールはレベル別にコードの間違いを指摘してくれます。レベルの一番低いものだと、コード内に宣言されていない変数やメソッドが使用されていないかを確認してくれ、レベルが上がるにつれてメソッドの引数の型が指定されているかや返り値の型の指定がされているかなどを確認してくれます。コードの質のチェックだけではなく、コードのデバックにも使用できて便利です。
2,3を気を付けるようになった理由は自分が他の方が以前書いたコードの修正を行った時の経験から来ています。私が修正依頼を受けたコードはGoogleAppScript(JavaScriptにGoogleカレンダーなどのGoogleのツールと簡単に連携が取れるライブラリが付け加えられた言語)で書かれたものでした。GASにはTypeScriptのような型の指定をする機能はありませんし、修正を行うコード自体にLaravelにおけるpublic/index.phpのような処理の全体が分かり易く書かれたコードはありませんでした。そのため個々のメソッドの役割や処理全体の把握にとても時間がかかりました。今回のWebアプリケーションは自分単独で開発・運用するもので自分以外の人が関わることはありませんが、未来の自分は他人と同じような理解力しかないので、そんな自分でもすんなり理解できるにはどうすれば良いのか考えた結果、今回のWebアプリケーションのコードを書く際も2,3を気を付けるようにしました。機能を実装する上で気を付けたこと
機能を作成する際に気を付けたことは
小さく作り、小さく試し、小さく実装するということです。例えばこのような要件の機能を付けることになったとします。
ユーザの入力事項を指定のデータベースへ登録する。
この機能を作成するには以下の手順で作成するとします。
- 登録するデータベースの作成
- 入力値をデータベースへ登録する機能の作成(Model)
- 入力値をModelへ伝え、Modelの結果によって動作を変える機能の作成(Controller)
- 入力値のバリデーションの作成
- 入力ホームの作成
- フォームとデータベースの登録の機能を結びつけるためのルーティング
この機能が正常に作成・実装できたかどうかを判断する方法の一つとして、これらの機能を一気に作成・実装し、Laravelのもとからあるデバック機能を使用してエラーの有無をブラウザ上で確認する方法があります。この方法はスピーディーに実装できる反面、本番用のデータベースへ値を入れなくてはならなかったり、複数のパターンで複数回テストするのに手間がかかったりします。そこで自分が行った方法は、手順を一つ進めるごとにその手順で行ったことが要件を満たすものかテストを行うという方法です。例えば、1が完了したらLaravelのテスト機能を使用して要件に合致するレコードが作成できたのか確認し、2が完了したら作成した機能にテスト機能を使用して入力値を入れることで指定のレコードへ登録できたかを確認するという感じです。この方法は、一つ一つ手順を進めるごとにテストを作成しなくてはいけないので実装のスピードは遅くなる反面、Laravelのテスト機能のおかげで本番のデータベースへ値を入れる必要がなかったり、
factory()などのヘルパ関数を使用して様々なパターンで100件単位のテストを一瞬で行えたり、個別にテストを行うことによりエラーの原因を絞って考える(例えば、もし手順3の段階でエラーが出た場合、2までは正常だったため原因は手順3で行ったことにあると違いないと推測できる)ことができます。
Laravelのテスト機能をはじめから使用するのは大変かもしれませんが、Laravelの公式ドキュメントでもたくさんのテスト機能の紹介がされているので、Laravelを使用するのならばぜひ使ってみて下さい。Vue(フロントエンド)
LaravelとVueの両方で開発経験がなくてLaravelでアプリケーションを開発する方へ
これは自分の質問に答えてくれたエンジニアの方が言ってくれたことであり、自分もLaravelとVueを組み合わせて開発していて思ったことなのですが、もしLaravelとVueのどちらも今まで触ったことがない場合はLaravelのみでWebアプリケーション開発を行う方が良いということです。なぜならWebアプリケーション開発で二つのFWを組み合わせて使用しようと思うと、考えることがFWが一つのときの倍ぐらいに増えてデプロイまでが長くなってしまうからです。デプロイまでが長くなると気力が一気に落ちると思うので、最初のうちはなるべく単純なものの方が良いかなと思います。
LaravelにおけるVueの実装
LaravelでのVueの実装は以下の記事を参考にしました。
Laravel7からVue.jsを使う最短レシピ自分がドはまりしたところ
自分がLaravelとVueの組み合わせたときに一番悩んだのはVueのコンポーネントにフォームを作成した際、そのフォームの値をどうやってCSRF(ユーザーになりすますことで他のサイトから不正にリクエストを送ること)対策をしたうえでバックエンドへ伝えるかということです。LaravelのViewの役割をもつ
blade.phpでのLaravel7に対するCSRF対策はこんな感じです。//省略 <form action="バックエンドまでのパス" method="post"> @csrf <input name="name" type="text"> </form>これをVueのコンポーネントのフォームでも同じようなことをしようとすると
@csrfの部分が無効となり419エラーで怒られてしまいます。この問題は、コンポーネントにCSRF対策を書くのではなく、コンポーネントを表示しているblade.phpにjQueryでこのように付け加えることで解決できます。$('body').on('submit', 'form', function () { $(this).append('@csrf') });このコードで書いてあることは、body要素の中のform要素にsubmitというイベント(
<input type="submit">を実行する)が発生した時にform要素に@csrfを加えるということです。解決方法は他にもいろいろあると思います。この解決方法は自分がteratailで質問した際に教えて頂きました。その時の質問と回答はこちらです。
Laravelを使用したVueのcomponent内のformのpostリクエストで419エラーLaravelとVueにおけるこの他のCSRF対策を紹介した記事はたくさんありました。また、Laravelの公式ドキュメントではCSRF対策をしているミドルウェアを無効にする方法が紹介されていました。しかし、CSRF対策が書かれた記事に書いてある内容が自分にとって複雑に感じるものが多かったり、CSRF対策を無効にしてWebアプリケーションの安全性を下げるのは良くないと思いjQueryを使用した方法を選びました。
終わりに
Webアプリケーションを作成しただけではなく、それらを運用する環境まで整えたのでたくさんの時間(3か月くらい)がかかりました。Webアプリケーションを作成しようと思わなかったら感じる必要のないストレスを感じました。しかしこの経験を通し、自分の頭の中でふわふわ浮いていたネットや書籍で知った言葉たちが、ようやく実感のある言葉になったなーという感覚を持てるようになりました。
このWebアプリケーションのデプロイまでに自分がAWSに対して払った料金はドメイン取得時の千円ぐらいです。またEC2で初めに入れたOSが気に食わなければ何回も無料で作り直せます。(現に自分はAmazon Linux ⇒ Ubuntuへ変更しました。)AWSのEC2などのサービスは初めの12年は無料で使用できるので、初めてのWebアプリケーションのデプロイは年間で料金を払うようなレンタルサーバーよりもAWSを使用した方が良いと個人的に思っています。(BillingなどでAWSのコスト管理はしっかり行ってください。)
なにも知らなかった自分がWebアプリケーションを作成できるようになったのは、無償でteratail・コミュニティなどで自分の質問を答えていただいた方々や分かり易いLaravelの公式ドキュメントを書いてくれた方々、書籍(PHPフレームワーク Laravel Webアプリケーション開発)に携わった方々、ネットで分かり易い記事を書いてくれた方々、お金がない日本人学生でもAWSを使いやすいようにしてくれた方々のおかげです。今後自分と同じような部分で悩んでいる人へ解決策を伝えたり、OSSへの貢献(できるかなー?)するなどで恩返しできれば良いなと思います。

- 投稿日:2020-07-14T06:45:44+09:00
CloudFormationコード(yaml)からパラメータ一覧を作りたい
はじめに
CloudFormationのyamlファイルから、パラメータに関する情報のみ抜き出して、一覧を作れるか挑戦しました。yamlの書き方によってはエラーになる未完成品ですが、個人的には及第点をとれたのでここに残します。
参考
今回のスクリプト作成にあたり、参考にさせて頂いたサイトです。
スクリプト(Python3)
早速ですが、スクリプトを紹介します。
- スクリプトの流れ
- (1)CloudFormationコード(yaml)をテキストファイルとして読み込む
- (2)短縮構文を拡張する(例:
!Sub->Fn::Sub,!Ref->Fn::Ref)- (3)短縮構文がない状態でyamlとして読み込む
- (4)yamlの中身を確認し、Parameters配下の情報をリスト表示する
paramlist.py## command sample ## python paramlist.py test.yml # yamlモジュールインストール `$ pip install pyyaml` import yaml import sys import re # 深堀りしない exclusionStr = "|AWSTemplateFormatVersion|Description|Type|TemplateURL|DependsOn|Mappings|Outputs|" args = sys.argv path = args[1] #(1)CloudFormationコード(yaml)をテキストファイルとして読み込む f = open(path) s0 = f.read() f.close() # (2)短縮構文を拡張する(例: `!Sub` -> `Fn::Sub` , `!Ref` -> `Fn::Ref`) s1 = re.sub("!((Sub|Ref|Join|GetAtt|FindInMap))\s", r'Fn::\1 ', s0) #(3)短縮構文がない状態でyamlとして読み込む obj = yaml.safe_load(s1) #(4)yamlの中身を確認し、Parameters配下の情報をリスト表示する def readYaml( curObj, pathStr , exeFlg): try: if exeFlg == 0: for key in curObj: # 次の階層に進む curFlg = key in exclusionStr if not curFlg: if key == "Parameters": nxtFlg = 1 else: nxtFlg = 0 pathStr += "/" + key readYaml( curObj[key] , pathStr , nxtFlg) else: print("---- {0} ----".format( pathStr ) ) # パラメータの項目と値を表示 for key in curObj: print( "\t{0} - {1}".format(key , curObj[key] ) ) except Exception as e: print("ERROR curObj = {0}, pathStr = {1}, exeFlg = {2}".format( curObj, pathStr, exeFlg ) ) print(e) ############################# ## -------- START -------- ## print("---- Parameter List ----" ) readYaml( obj , "" , 0 )実行結果
以下のCloudFormationコードに対してスクリプトを実行します。
test.ymlAWSTemplateFormatVersion: "2010-09-09" Description: cloudformation yaml sample Parameters: hogePrefix: { Type: String , Default: hogefuga123 } BucketUrl: { Type: String , Default: "https://hogefuga123.s3.amazonaws.com/" } AZName001: { Type: String , Default: ap-northeast-1a } AZName002: { Type: String , Default: ap-northeast-1c } VPCName: { Type: String , Default: vhoge01 } Resources: VPC: Type: AWS::CloudFormation::Stack Properties: TemplateURL: !Sub "${BucketUrl}${VPCTemplate}" Parameters: hogePrefix: !Ref hogePrefix BucketUrl: !Ref BucketUrl VPCName: !Ref VPCName実行結果
$ python paramlist.py test.yml ---- Parameter List ---- ---- /Parameters ---- hogePrefix - {'Type': 'String', 'Default': 'hogefuga123'} BucketUrl - {'Type': 'String', 'Default': 'https://hogefuga123.s3.amazonaws.com/'} AZName001 - {'Type': 'String', 'Default': 'ap-northeast-1a'} AZName002 - {'Type': 'String', 'Default': 'ap-northeast-1c'} VPCName - {'Type': 'String', 'Default': 'vhoge01'} ---- /Parameters/Resources/VPC/Properties/Parameters ---- hogePrefix - Fn::Ref hogePrefix BucketUrl - Fn::Ref BucketUrl VPCName - Fn::Ref VPCNameおまけ
[おまけ1] Cloud9 のセットアップ
本スクリプトを AWS Cloud9 で使うときの環境設定です。
# デフォルトを Python 2 -> Python 3 に切り替える $ sudo alternatives --config python $ pip -V $ sudo pip install --upgrade pip $ pip -V # yamlモジュールをインストール $ pip install pyyaml[おまけ2] そのままyamlロードするとエラーになる
上のサイトで紹介されている通り、短縮系の構文を含むCloudFormationコードをyamlとしてロードするとエラーになります。
$ python sample.py test.yml test.yaml Exception occurred while loading YAML... could not determine a constructor for the tag '!Sub' in "test.yaml", line 72, column 20
作ったスクリプトは未完成、どんなyaml形式でもエラーがでないようにしたい。

- 投稿日:2020-07-14T02:09:06+09:00
AWSとか知識ゼロのクライアントエンジニアがAWSとかの勉強を始めてみる
きっかけ
今までずっとゲーム案件でUnityのクライアントエンジニアとしてお仕事してきた私。
最近初めて非ゲーム案件に携わることに。非ゲームだけど、そちらでもUnityを使うアプリなので
自分のポジションとしては今までと同様にクライアントエンジニアなんですが
現場の方々がやたらとAWSとかそちら方面に詳しい...(汗)EC2、ってなんですか?
ELB...とは?
GCP、Cloud Spanner、k8s...
はあ...なるほどまったく分からんです。あまりにも知らなすぎることに恥ずかしくなってきた。。
今回の仕事をする上ではポジション的にとくに知らなくても大丈夫だよとは言われているものの、なんだか悔しい。なので
仕事では必要ないかもですが、少しでも話についていけるようになりたいので
ちょっとAWSとか(「とか」っていう程、他に何がどう違うのか分からない)のことを
これから勉強してみることにした。もちろんインプットだけだときっと身につかないし三日坊主になると思うから
手を動かして何かを作ろう。・・・
。。。
でも、何から手をつけたらいいんだろう...?
本当に、で分からない。。
・・・ので、
とりあえずYoutubeで検索していたら
くろかわこうへいさんのAWS講座の動画に辿り着いたので、
まずは概念まわりの学習から入ってみることに。クライアントの人でも、かじってる人はかじってるんだよなー。
「自分には関係ない」と思って今までなんとなく避けていた部分があるので、
これは良いきっかけになるのかも。
ちゃんと続けばいいな。
- 投稿日:2020-07-14T02:09:06+09:00
AWSとか知識ゼロのクライアントエンジニアがAWSとかの勉強を始めてみる 1
きっかけ
今までずっとゲーム案件でUnityのクライアントエンジニアとしてお仕事してきた私。
最近初めて非ゲーム案件に携わることに。非ゲームだけど、そちらでもUnityを使うアプリなので
自分のポジションとしては今までと同様にクライアントエンジニアなんですが
現場の方々がやたらとAWSとかそちら方面に詳しい...(汗)EC2、ってなんですか?
ELB...とは?
GCP、Cloud Spanner、k8s...
はあ...なるほどまったく分からんです。あまりにも知らなすぎることに恥ずかしくなってきた。。
今回の仕事をする上ではポジション的にとくに知らなくても大丈夫だよとは言われているものの、なんだか悔しい。なので
仕事では必要ないかもですが、少しでも話についていけるようになりたいので
ちょっとAWSとか(「とか」っていう程、他に何がどう違うのか分からない)のことを
これから勉強してみることにした。もちろんインプットだけだときっと身につかないし三日坊主になると思うから
手を動かして何かを作ろう。・・・
。。。
でも、何から手をつけたらいいんだろう...?
本当に、で分からない。。
・・・ので、
とりあえずYoutubeで検索していたら
くろかわこうへいさんのAWS講座の動画に辿り着いたので、
まずは概念まわりの学習から入ってみることに。クライアントの人でも、かじってる人はかじってるんだよなー。
「自分には関係ない」と思って今までなんとなく避けていた部分があるので、
これは良いきっかけになるのかも。
ちゃんと続けばいいな。
- 投稿日:2020-07-14T02:01:22+09:00
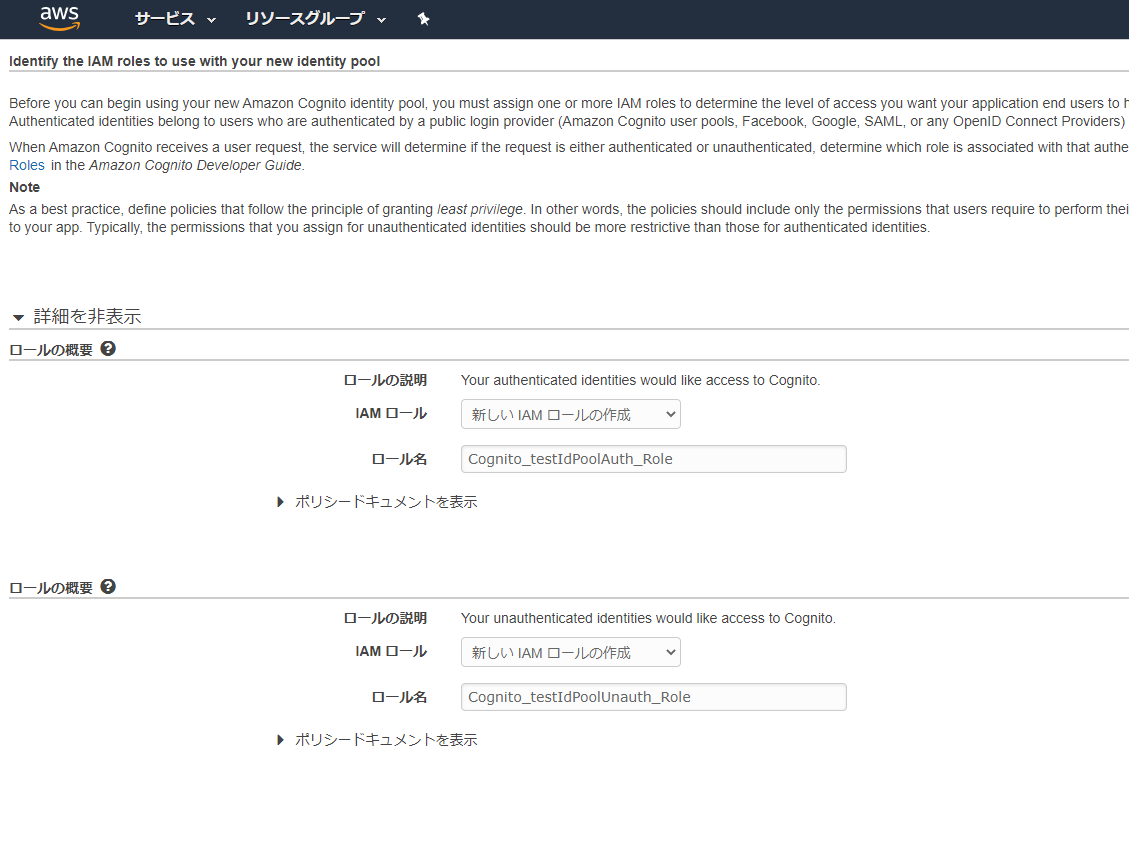
Cognito ID Poolで指定するロールに、そのID Poolの作成時に生成したもの以外を指定する場合にはロールに信頼関係を追加する
初めに
Cognitoを用いてWebアプリケーションのログイン機構を作る場合、大体の場合はログインユーザーに対してAWSリソースの実行権限を与えるために、IDプールをセットで利用すると思います。
複数のIDプールを利用する必要があるものの、それぞれのIDプールから払い出す権限は同一でよい場合、紐づける「認証されていないロール」「認証されたロール」に、複数のIDプールで同一のIAMロールを指定することになると思います。
IDプールで使うIAMロールは、IDプール作成時に自動生成したロールをそのまま使い、別のIDプールを追加した時に既存のIDプール生成時に作られたロールを紐づけて使う、というやり方を取ることが考えられますが、この時に気を付けないと引っかかる権限問題がありましたのでご紹介します。前提
- 2つのIDプールを利用するとする
- testIdPool
- testIdPool2
- 一方のIDプール作成時に作成したIAMロールを、もう一方のIDプールの「認証されたロール」「認証されていないロール」にそれぞれ設定
問題
前提の通りにIDプールとロールを作成/設定します。
testIdPoolの作成時に新しいIAMロールを作成します。
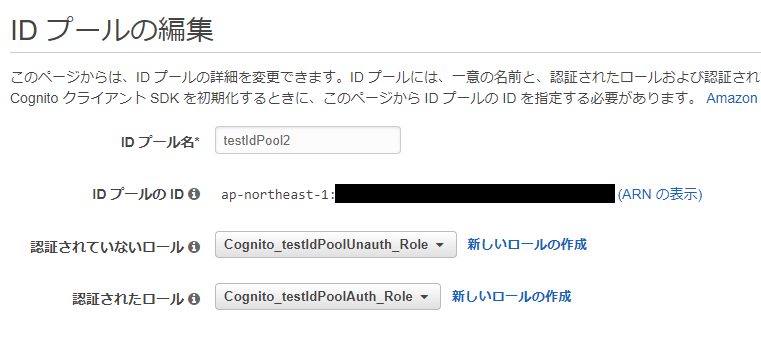
testIdPool2を作成後、「IDプールの編集」から編集画面を開き、testIdPoolの作成時に作成したIAMロールを設定します。
この状態でIDプールからcredentialsを発行しようとすると、
testIdPoolでは問題なく可能ですが、testIdPool2では以下のエラーが発生します。InvalidIdentityPoolConfigurationException: Invalid identity pool configuration. Check assigned IAM roles for this pool.解決
信頼関係タブを開き、「信頼関係の編集」からJSONの信頼関係ドキュメントを見てみると、以下のようになっていることが分かります。
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Principal": { "Federated": "cognito-identity.amazonaws.com" }, "Action": "sts:AssumeRoleWithWebIdentity", "Condition": { "StringEquals": { "cognito-identity.amazonaws.com:aud": "ap-northeast-1:1d394b04-1f10-41dc-a277-71b5c953794f" }, "ForAnyValue:StringLike": { "cognito-identity.amazonaws.com:amr": "authenticated" } } } ] }ここで、Conditionに
ap-northeast-1:1d394b04-1f10-41dc-a277-71b5c953794fというIDが指定されていることが分かりますが、これはこのロールを生成する元になった、testIdPoolのIDが設定されています。
該当のIDプールの「ID プールの編集」を開き、「ID プールの ID」を確認してみてください。つまり、Conditionにこのロールをアタッチした
testIdPool2のIDが指定されていないために、
InvalidIdentityPoolConfigurationException: Invalid identity pool configuration. Check assigned IAM roles for this pool.
が発生しました。解消には信頼関係ドキュメントのConditionに、紐づけるIDプールのIDを追加してやればいい、ということになります。
配列の形式にして、追加してやります。{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Principal": { "Federated": "cognito-identity.amazonaws.com" }, "Action": "sts:AssumeRoleWithWebIdentity", "Condition": { "StringEquals": { "cognito-identity.amazonaws.com:aud": [ "ap-northeast-1:1d394b04-1f10-41dc-a277-71b5c953794f", "ap-northeast-1:8e7a8af9-4a66-4987-b0f0-4be1473895e8" ] }, "ForAnyValue:StringLike": { "cognito-identity.amazonaws.com:amr": "authenticated" } } } ] }これで
InvalidIdentityPoolConfigurationExceptionが発生することはなくなったと思います。参考
https://stackoverflow.com/questions/30425942/aws-cognito-invalid-identity-pool-configuration
- 投稿日:2020-07-14T00:57:09+09:00
AWS VPC作成手順
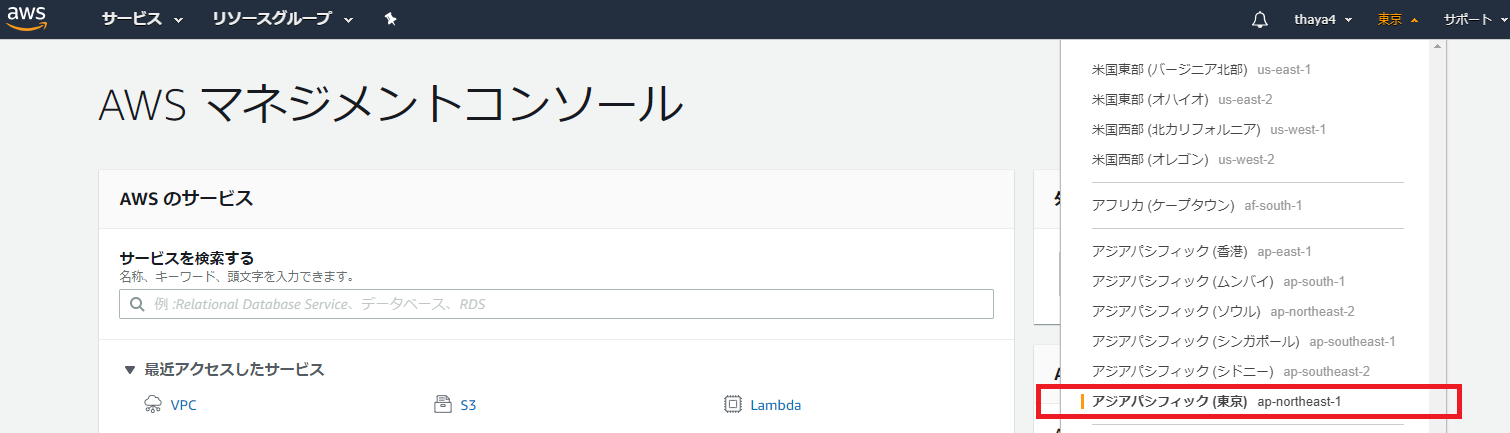
AZを東京リージョンに
- アベイラビリティゾーン(AZ)として東京リージョンを利用する。右上のリージョンのリストから「アジアパシフィック (東京)」を選択して東京リージョンに切り替える
VPCを作成する
AWS マネジメントコンソールから「VPC」を押下
遷移した画面の「VPC」を押下
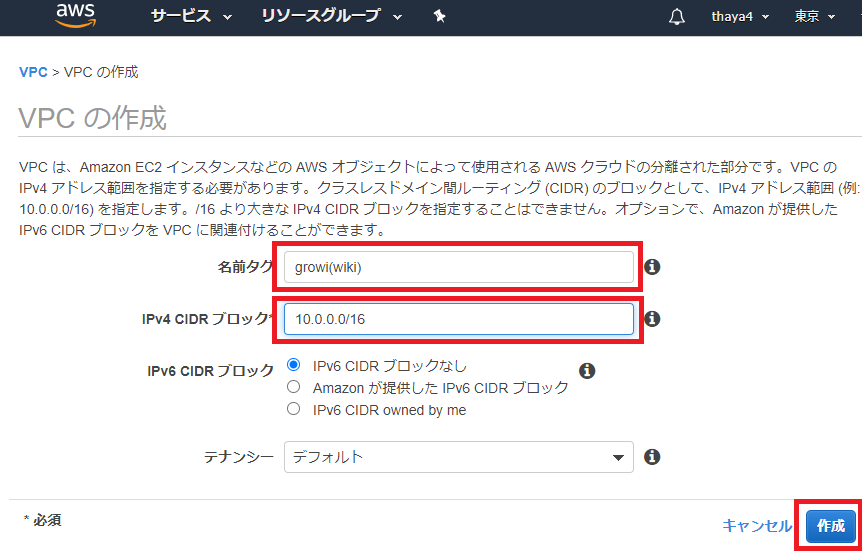
遷移した画面の「VPCの作成」を押下
VPCの作成画面が出たら、 「名前タグ」に区別しやすいVPCの名称(AWSで構築するシステム名など)を入力
「IPv4 CIDR ブロック」に今回「10.0.0.0/16」を割り当てて最大65,536個のIPアドレスが割り当て可能なVPCを作成
VPCにサブネットを作成
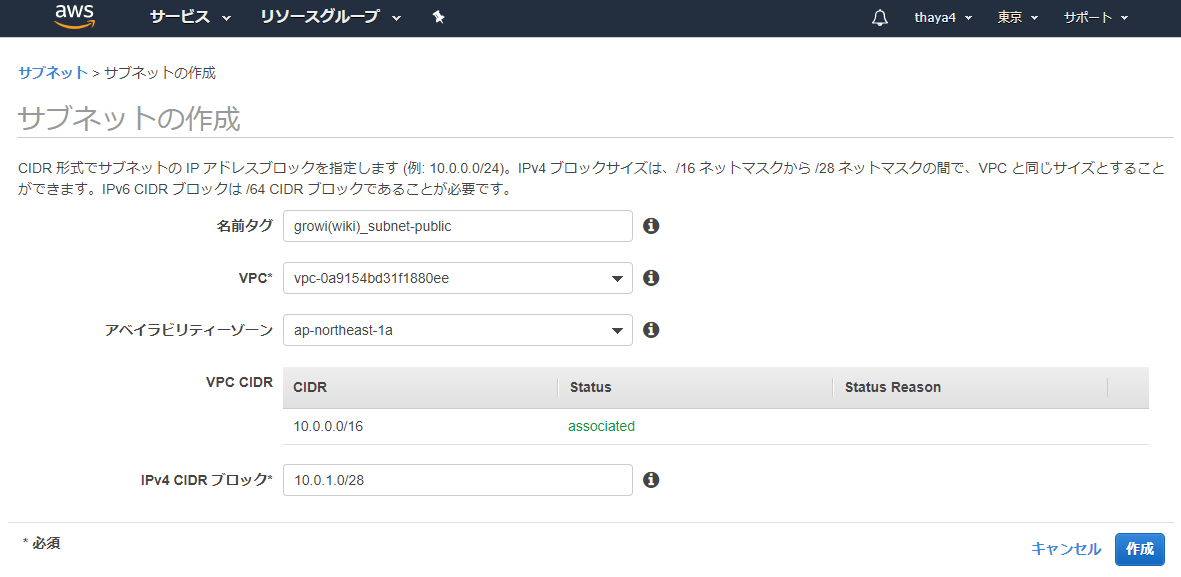
- VPCにそのままではEC2インスタンスを起動は出来ないので、次はサブネットを作成する。今回はインターネットへの通信が可能なパブリックサブネットとして作成。 「VPC」の画面の左ペインでサブネットを押下し、「サブネットの作成」を押下する

- 「名前タグ」に区別しやすいサブネット名
- VPCには先ほど作成したVPC
- アベイラビリティーゾーンは「ap-northeast-1a」を選択
- 「IPv4 CIDR ブロック」には、先ほどVPCに割り当てたCIDRブロックの範囲〜/28の範囲内でサブネットを作成することができ、今回は「10.0.1.0/28」に設定
- 「作成」ボタンを押下
IGWを作成して、VPCにアタッチ
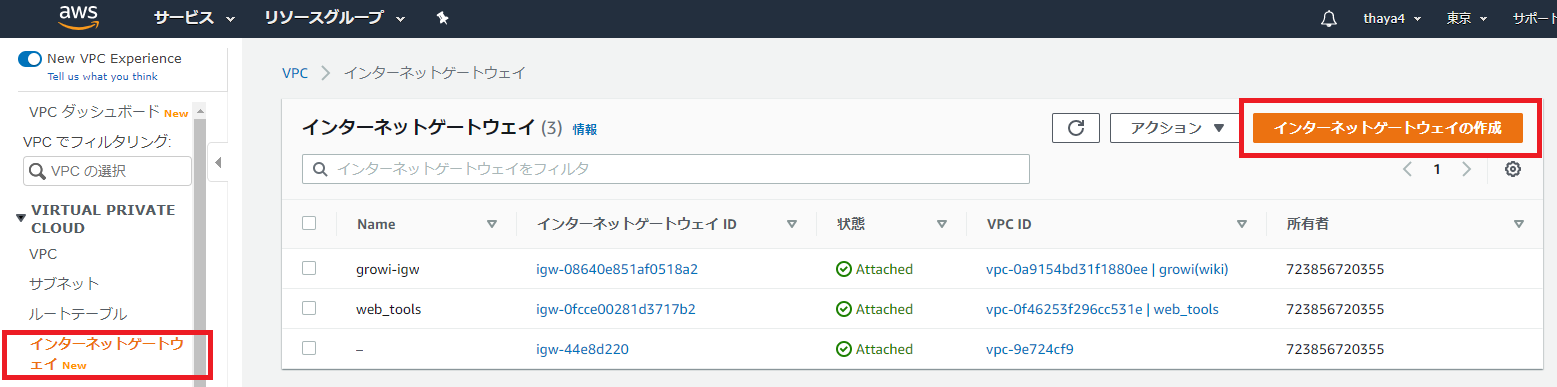
- VPCとVPC内にサブネット、ルートテーブルの作成が完了たが、インターネットへの出入り口となる「インターネットゲートウェイ」がまだのため、それを作成する
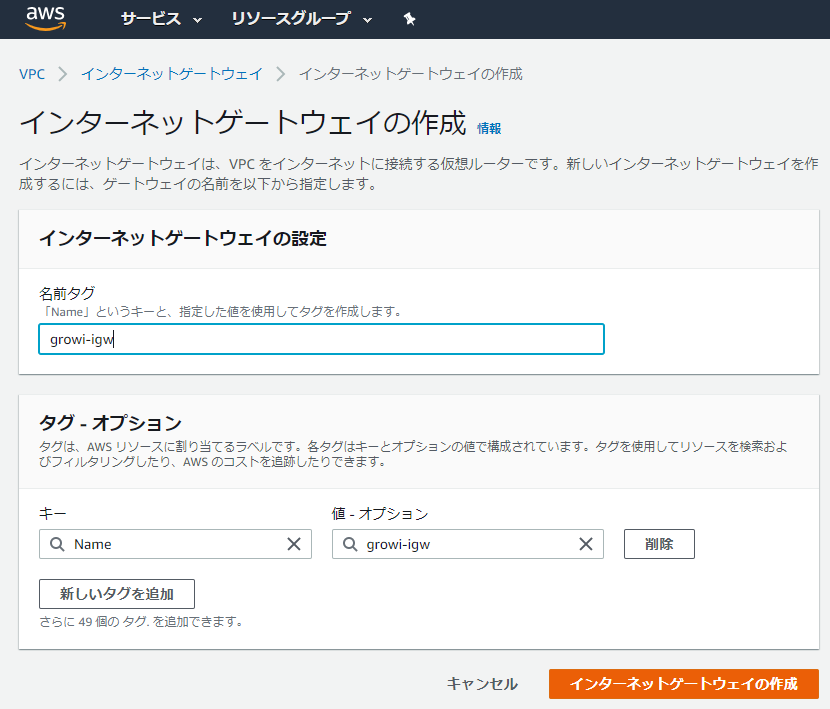
- 「VPC」の画面の左ペインでインターネットゲートウェイをクリックし、「インターネットゲートウェイの作成」を押下する
「名前タグ」にわかりやすい名前を入力して作成を押下
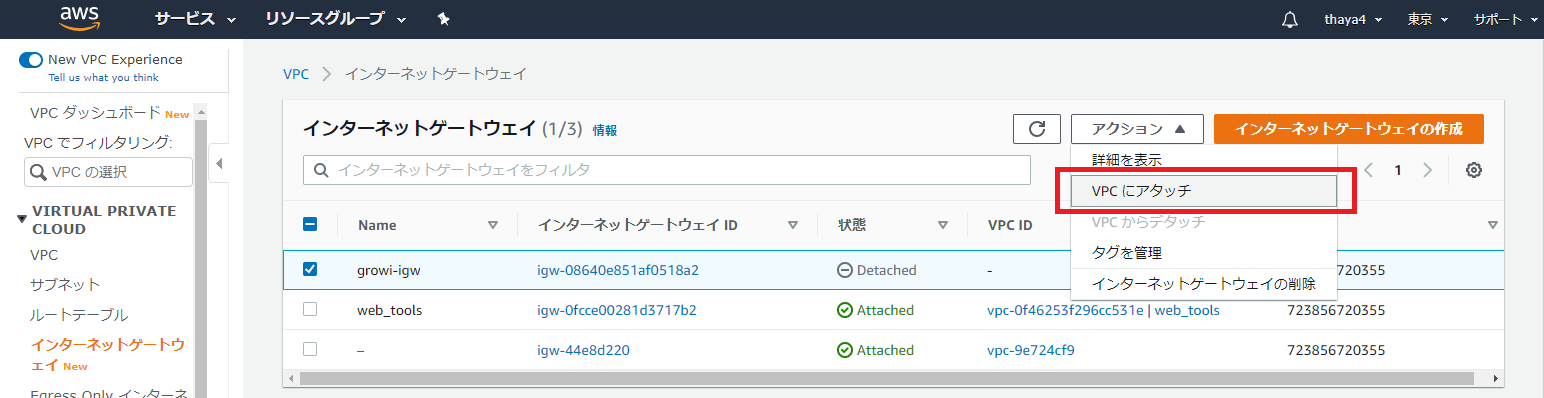
作成したインターネットゲートウェイをクリックして、アクションから「VPC にアタッチ」を選択
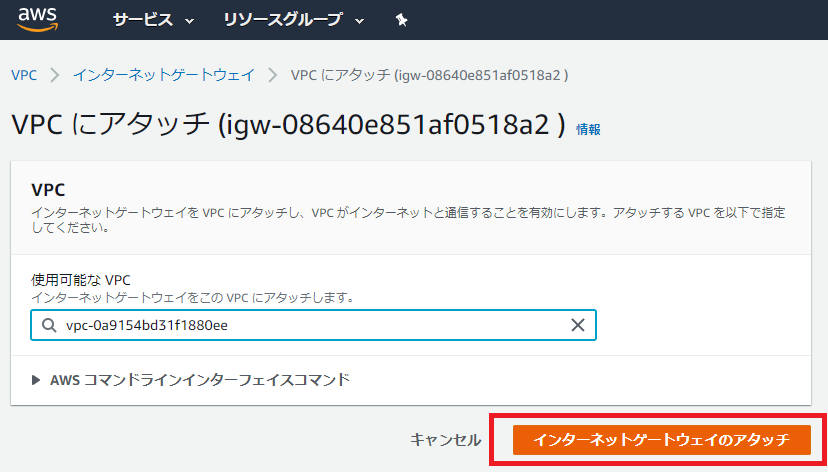
インターネットゲートウェイをアタッチするVPCを選択し「アタッチ」を押下
ルートテーブル作成
- インターネットゲートウェイを作成したことで、インターネットへの出入り口は確保できたが、どのIPアドレス宛の通信をインターネットゲートウェイへ向ければ良いか判断がつかない。 このルーティング情報「ルート」をルートテーブルに登録する
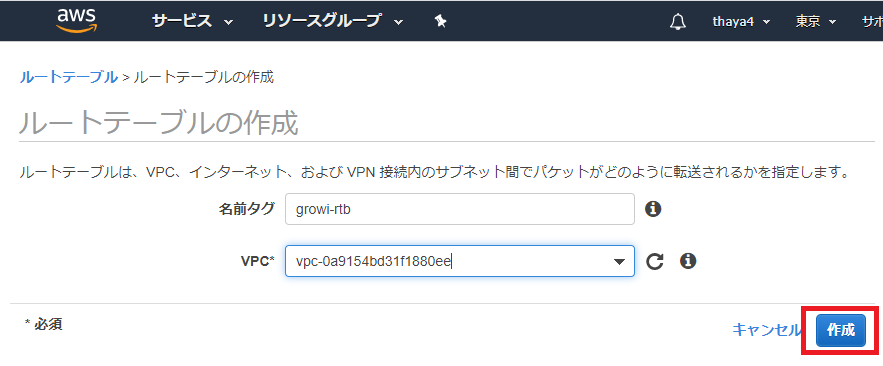
「VPC」の画面の左ペインで「ルートテーブル」を押下し、遷移したページの「ルートテーブルの作成」を押下する
「名前タグ」とVPCには先ほど作成したVPCを選択し、「作成」ボタンを押下
ルートテーブルにIGWへのルートを登録
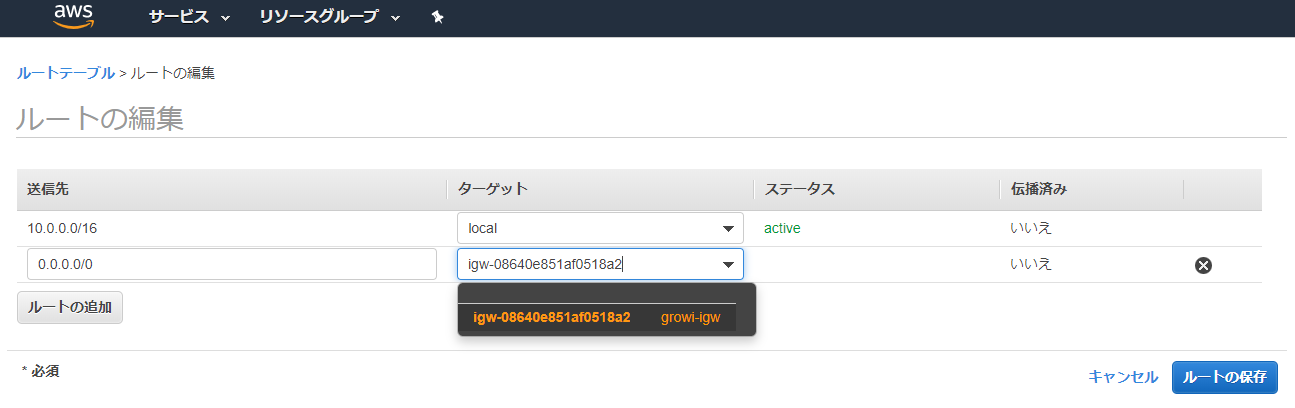
- 今の段階ではデフォルトのルートテーブルと同じく、VPC内宛の通信のルートしか登録されていないため、インターネットゲートウェイ宛の通信を登録する
- 作成したルートテーブルを選択し、「ルート」タブを選択、「ルートの編集」を押下
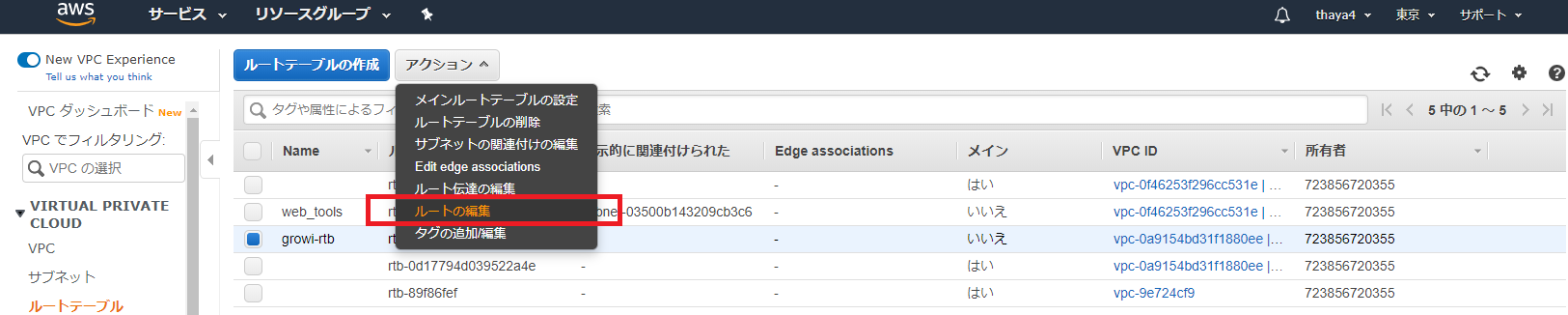
1.「ルートの追加」をクリックし、送信先に「0.0.0.0/0」(デフォルトルート)
2.ターゲットに「igw-」から始まるインターネットゲートウェイのID
3.「ルートの保存」ボタンを押下
ルートテーブルにサブネットを関連付け
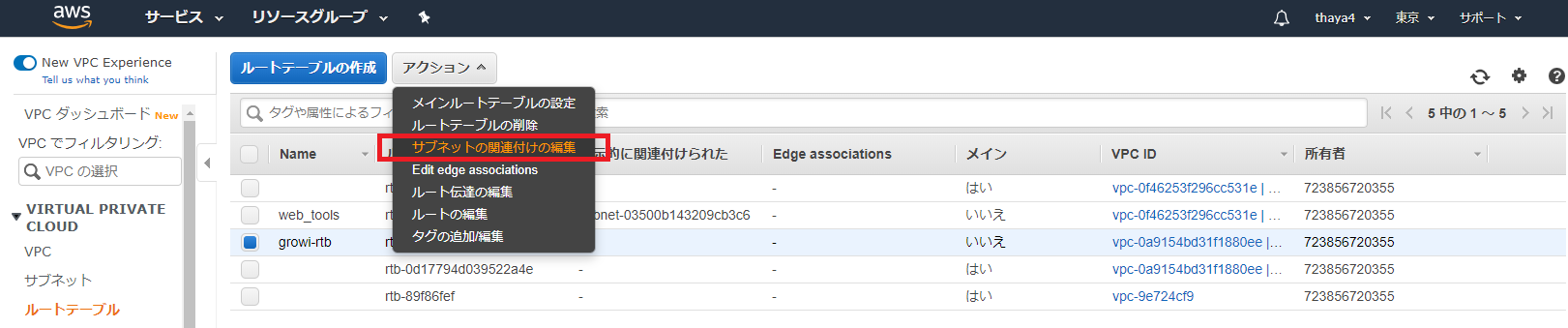
- インターネット通信用のルートテーブルを作成したが、サブネットは関連付いていないので紐づける
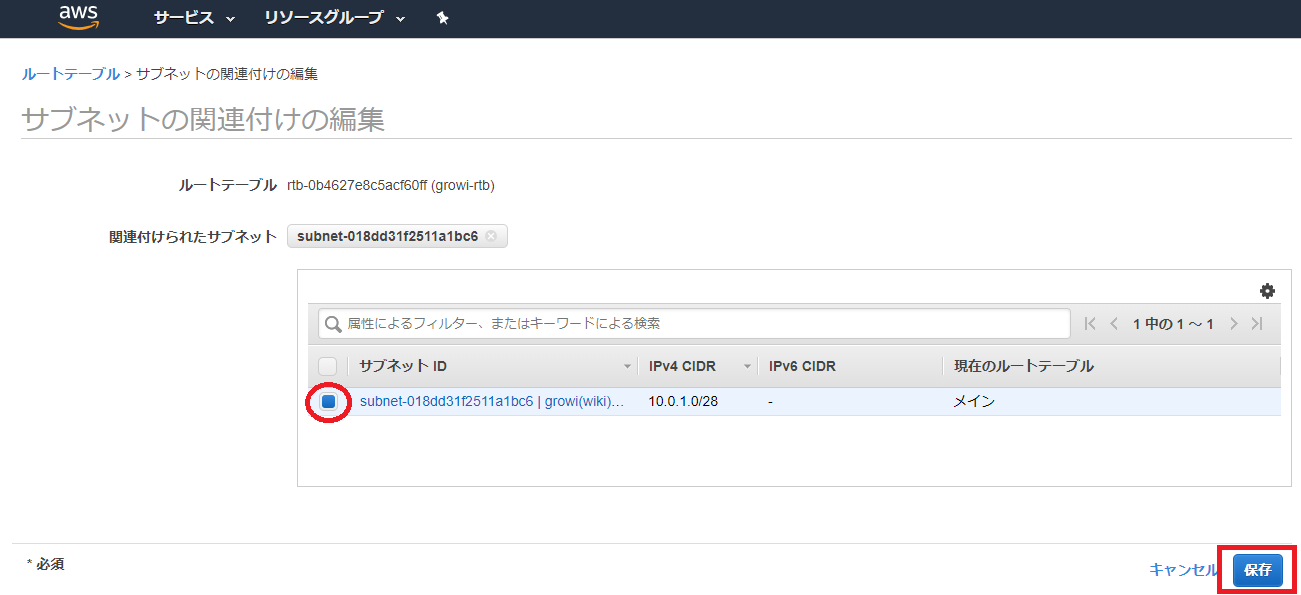
作成したルートテーブルを選択し、「サブネットの関連付けの編集」を選択
先ほど作成したサブネットを選択し、「保存」を押下
以上、お疲れ様でした


- 投稿日:2020-07-14T00:10:13+09:00
【AWS】AWS Storage Gatewayとは?(備忘録)
はじめに
現在、AWSSAAの勉強をしています。
AWSSAAの学習をする中で「AWS Storage Gateway」について間違いやすかったので、知識としてこちらにアウトプットします。
※完全に備忘録(記録)です。AWS Storage Gatewayとは?
オンプレミスからAWSのストレージサービスへのアクセスを可能とする仮想アプライアンス
(オンプレミスに設置して使用)Storage Gatewayのタイプ
Storage Gatewayのサービスを紹介していきます。
ファイルゲートウェイ
- S3をオンプレミスのNFS共有ファイルシステムのバックエンドストレージとして利用
- EC2イメージを使用して作成することも可能
- クラウドのワークロードのS3への取り込み、バックアップとアーカイブの実行、AWSクラウドへのストレージデータの階層化と移行などのタスクを行うことができる
テープゲートウェイ
- 物理テープライブラリ装置の代替として利用
- 仮想テープライブラリ対応バックアップソフトウェアを利用
- Storage Gateway軽油でS3を利用
保管型ゲートウェイ
- データのプライマリコピーはオンプレミスに存在
- ボリュームストレージをオンプレミスのデータセンターに維持
- オンプレミスのディスクデータをStorage Gateway経由でスナップショットとしてS3に保存
- iSCSIでブロックストレージとしてインターフェースを提供
- EBSディスクへのリストアも可能
- データを非同期にAWSにバックアップ(EBSスナップショットとしてS3に非同期でバックアップ)
- 最大32個のボリュームがサポート(合計ボリュームストレージは最大512TiB)
キャッシュ型ゲートウェイ
- スナップショットはS3に存在
- データのプライマリコピーはS3に存在
- よく使われるデータのみキャッシュがオンプレミスに存在
- 頻繁にアクセスするデータへの低レイテンシーなアクセスが可能
- 作成できるボリュームの最大サイズは32TiB
- 作成したボリュームをiSCSIデバイスとしてオンプレミスのアプリケーションサーバーにアタッチすることができる
特に大事だと思うところ
種類 プライマリコピー iSCSI 備考 保管型ゲートウェイ オンプレミス ブロックストレージとして提供 EBSのリストアも可能 キャッシュ型ゲートウェイ S3 オンプレミスのアプリケーションサーバーへアタッチできる よく使われるデータのみキャッシュがオンプレミスに存在 参考
AWS Storage Gateway の仕組み (アーキテクチャ)
この1冊で合格! AWS認定ソリューションアーキテクト - アソシエイト テキスト&問題集 Kindle版