- 投稿日:2020-07-14T22:43:11+09:00
psycopg2 メモ
ローカルにあったメモ書きをQiitaで供養します。
書いたのが去年なので古い情報もあるかもしれませんです。。psycopg2 について
psycopg2はPythonでPostgreSQLを扱うライブラリです。
Refs.: 1, 2psycopg2 で PostgreSQL DB に接続する
conn = psycopg2.connect({DB_URL(str)})でDBコネクションを作成できます。
{DB_URL}はpostgresql://{username}:{pass}@{IP Address or hostname}:{port}/{DB name}で指定されます。または、
conn = psycopg2.connect(host={IP Address or hostname(str)}, port={port number(int)}, dbname={DB name(str)}, user={username(str)}, password={pass(str)})でも指定できます。コネクションは不要になったら
close()しますが、with構文が使えるので使うといいと思います。import psycopg2 with psycopg2.connect({DB URL}) as conn: # Processes you want to doクエリを投げる
投げるために、カーソルを作ります。
カーソルは、conn.cursor()で作れます。これも不要になったらclose()しますが、wi(以下略)。
cursor.execute({query string})でクエリを実行できます。
引数を与えたいときは、cursor.execute('SELECT * FROM EXAMPLE_TABLE WHERE FOO = %s', (fooval, ))といったように第二引数にタプル(またはリスト)で与えます。また、引数を辞書(Dictionary型)で与えることもできます。その際は
%(key)sといったようにプレースホルダにキーを与えます。cur.execute(""" INSERT INTO some_table (an_int, a_date, another_date, a_string) VALUES (%(int)s, %(date)s, %(date)s, %(str)s); """, {'int': 10, 'str': "O'Reilly", 'date': datetime.date(2005, 11, 18)})import psycopg2 with psycopg2.connect({DB URL}) as conn: with conn.cursor() as cur: cur.execute({query})クエリの結果を受け取る
SELECTとかの結果をPythonオブジェクトで受け取ります。
cursor.fetchone(),cursor.fetchall(),cursor.fetchmany(size)で受け取れます。cursor.fetchone()
結果(クエリのresultset)の次の行から1件だけ受け取ります。結果はタプルで返ってきます。
cursorが終端を指しているときに実行すると、Noneが返ってきます。cursor.fetchall()
結果(クエリのresultset)の次の行から全件受け取ります。結果はタプルのリストで返ってきます。
cursorが終端を指しているときに実行すると、空のリストが返ってきます。cursor.fetchmany(size)
結果(クエリのresultset)の次の行から
size件受け取ります。結果はタプルのリストで返ってきます。
cursorが終端を指しているときに実行すると、空のリストが返ってきます。コミットする
デフォルトでトランザクションが有効になっているため、コミットしないと変更が反映されません。
connect.commit()でコミットしましょう。
connect.autocommit = Trueを設定するとトランザクションが無効になります。ロールバックする
connect.rollback()です。
コネクションをwith構文で作成している場合、withブロック内で例外が起きると自動的にロールバックされるようです。便利だね1。
- 投稿日:2020-07-14T22:06:48+09:00
Neural ODEのODE Blockを実装するライブラリ "torchdiffeq"の使い方
1.はじめに
すごく今更ですが,Neural ODE実装ライブラリの使い方を紹介します.ちなみに,Neural ODE はNeurIPS 2018のbest paperに輝いた論文です.
このNeural ODE,著者らによってtorchdiffeqというライブラリ化された公式レポジトリが公開されています.
Neural ODEは理論や解釈を説明した記事は数多くあっても、このライブラリの実際の使い方を記述している日本語記事が少ないように思ったので、この記事で基礎的な使い方をまとめました.
ちなみにtorchdiffeqはPyTorch用のライブラリです.この記事を読むことで、以下のことができるようになります.
- 一階常微分方程式の初期値問題をtorchdiffeqで解ける
- 二階常微分方程式の初期値問題をtorchdiffeqで解ける
- Neural ODEを構成する層であるODE Block層が実装できる
2.前提知識
torchdiffeqを使うに当たっての前提知識をおさらいします.
2.1 常微分方程式とは
微分方程式のうち,未知変数が本質的にただ一つのものを常微分方程式といいます.例えば,$\frac{dz}{dt}=f(z(t), t)$や,$m\ddot{x} = -kx$などの微分方程式は複数の変数が出てきますが,$z$や$x$は$t$の関数となるので,本質的に未知変数が$t$のただ一つしか存在せず,常微分方程式だと言えます.
2.2 Neural ODEとは
Neural ODEに関してはわかりやすい記事が他にたくさんあるので,そちらを参照していただきたいです.
一応,概要だけを簡単に説明すると,Neural ODEとは,「連続的な層をもつニューラルネットワーク」だと言えます.
「常微分方程式」というニューラルネット界隈では聞きなれない言葉があるせいでコンセプトが掴みにくくなっている説がありますが,重要な点は,「層を連続化した」したという点だと思っています.これにより従来のモデルでは不可能だった,例えば「0.5層目の出力を取り出す」といったことができるようになりました.
以下参考リンク:
- 連続ダイナミクスを表現可能なニューラルネットワーク
- 【NIPS 2018最優秀賞論文】トロント大学発 : 中間層を微分可能な連続空間で連結させる、まったく新しいNeural Networkモデル3. torchdiffeqの使い方
それでは早速,torchdiffeqの使い方を見ていきましょう.
3.1 インストール
インストールするには以下のコマンドを実行します.
pip install torchdiffeq3.2 例:一階微分方程式
実際にNeural ODEの実装に入る前に,簡単な一階常微分方程式を例にして,torchdiffeqの簡単な使い方を見ていきましょう.
以下の式微分方程式を考えます.
$$
z(0) = 0, \\
\frac{dz(t)}{dt} = f(t) = t
$$この解は$C$を積分定数として
$$
\int dz = \int tdt+C \\
z(t) = \frac{t^2}{2} + C
$$と書く下すことができ、$z(0) = 0$なので, この微分方程式の解は以下のようになることがわかります.
$$
z(t) = \frac{t^2}{2}
$$torchdiffeqによる実装
この問題をtorchdiffeqで解くための最もシンプルな実装が以下になります.
first_order.pyfrom torchdiffeq import odeint def func(t, z): return t z0 = torch.Tensor([0]) t = torch.linspace(0,2,100) out = odeint(func, z0, t)以下,ポイントを箇条書きにします.
- 関数
funcは上の微分方程式$\frac{dz}{dt}=f(t, z)$の$f$にあたります.引数は(t, z)の順番です.出力の次元はzに一致する必要があります.z,tのどちらかを用いなくても大丈夫です.- 変数
z0はダイナミクスの初期値になります.変数
tは時間を表し,tensor([0., 0.1, 0.2, ..., 0.9, 1.0])のように1次元テンソルである必要があります.t[0]は初期値に対応する時刻になります.注意すべきは,tの要素は狭義単調増加(減少)する列でなくてはならないということです.
t=tensor([0, 0, 1])のように,同じ値が含まれていてもエラーになります.
odeint(func, z0, t)で微分方程式を解きます.引数は順番に関数func, 初期値y0,時刻tです.ソルバーは
tで指定されている時刻でのzの値を返します.つまり,t=tensor([t0, t1, ..., tn])のとき,out = tensor([z0, z1,..., zn])となります.t[0]は初期時刻なので,出力out[0]は必ずz0に一致しています.以上の結果をプロットします.
from matplotlib.pyplot as plt plt.plot(t, out) plt.axes().set_aspect('equal', 'datalim') # 縦横比を1:1にする plt.grid() plt.xlim(0,2) plt.show()
手計算で求めた微分方程式の解$z = \frac{t^2}{2}$と一致していることがわかります.
3.3 (参考)例2:二階微分方程式を解く
torchdiffeqを使うと二階微分方程式も解けてしまいます.例として,理系には馴染み深い(?)単振動の微分方程式をtorchdiffeqで解きます.単振動の微分方程式は以下になります.
$$
m\ddot{x} = -kx
$$
初期状態として,$t=0$のとき,$x=1$, $\dot{x}=\frac{dx}{dt}=0$とします.
二階微分方程式を解くコツは,二階微分方程式を2つの一階微分方程式に分解することです.具体的には,以下のようにします.$$
\left[
\begin{array}{c}
\dot{x} \\
\ddot{x} \\
\end{array}
\right] =
\left[
\begin{array}{cc}
0 & 1\\
-\frac{k}{m} & 0\\
\end{array}
\right]
\left[
\begin{array}{c}
x \\
\dot{x} \\
\end{array}
\right]
$$ここで,$\boldsymbol{y}= \left[
\begin{array}{c}
x \\
\dot{x} \\
\end{array}
\right]$とおけば,この二階微分方程式は以下の一階微分方程式に帰着します.$$
\frac{d\boldsymbol{y}}{dt} = f(\boldsymbol{y})
$$実装は以下になります.$k=1, m=1$としています.
oscillation.pyclass Oscillation: def __init__(self, km): self.mat = torch.Tensor([[0, 1], [-km, 0]]) def solve(self, t, x0, dx0): y0 = torch.cat([x0, dx0]) out = odeint(self.func, y0, t) return out def func(self, t, y): # print(t) out = y @ self.mat # @は行列積 return out if __name__=="__main__": x0 = torch.Tensor([1]) dx0 = torch.Tensor([0]) import numpy as np t = torch.linspace(0, 4 * np.pi, 1000) solver = Oscillation(1) out = solver.solve(t, x0, dx0)描画すると,きちんと単振動の解が求まっていることがわかります.
4.ODE Blockの実装
torchdiffeqの使い方に慣れてきたところで,実際のODE Blockの実装の仕方について見ていきましょう.ODE Blockとは,$\frac{dz}{dt} = f(t, z)$のダイナミクスを形成する一つのモジュールです.実際のNeural ODEは,通常のFull-Connect層や畳み込み層と共にODE Blockが使われて構成されています.
以下の実装は簡潔さを重視したものであり,あくまで一例です.
from torchdiffeq import odeint_adjoint as odeint class ODEfunc(nn.Module): def __init__(self, dim): super(ODEfunc, self).__init__() self.seq = nn.Sequential(nn.Linear(dim, 124), nn.ReLU(), nn.Linear(124, 124), nn.ReLU(), nn.Linear(124, dim), nn.Tanh()) def forward(self, t, x): out = self.seq(x) return out class ODEBlock(nn.Module): def __init__(self, odefunc): super(ODEBlock, self).__init__() self.odefunc = odefunc self.integration_time = torch.tensor([0, 1]).float() def forward(self, x): self.integration_time = self.integration_time.type_as(x) out = odeint(self.odefunc, x, self.integration_time) return out[1] # out[0]には初期値が入っているので.簡単に解説をすると,
- ODE Blockは受け取った入力
xを微分方程式の初期値として扱います.ODEfuncが系のダイナミクスを記述する$f$となっています.- ODE Blockの積分区間は0~1で固定となっています.そして$t=1$での層の出力を返します.
こうすることで,以下のように,ニューラルネットの一つのモジュールとしてODE Blockを使うことができます.
class ODEnet(nn.Module): def __init__(self, in_dim, mid_dim, out_dim): super(ODEnet, self).__init__() odefunc = ODEfunc(dim=mid_dim) self.fc1 = nn.Linear(in_dim, mid_dim) self.relu1 = nn.ReLU(inplace=True) self.norm1 = nn.BatchNorm1d(mid_dim) self.ode_block = ODEBlock(odefunc) # ODE Blockを使用 self.norm2 = nn.BatchNorm1d(mid_dim) self.fc2 = nn.Linear(mid_dim, out_dim) def forward(self, x): batch_size = x.shape[0] x = x.view(batch_size, -1) out = self.fc1(x) out = self.relu1(out) out = self.norm1(out) out = self.ode_block(out) out = self.norm2(out) out = self.fc2(out) return outこのモデルは計算速度が遅かったです.
しかし,torchdiffeqを使えば必ず遅くなるわけでもないようで,自分が試した限りでは公式レポジトリのNeural ODEモデルでは通常のニューラルネットワークと遜色ない速度が出ていました.(こっちのほうがモデル小さいはずなのに...)5. まとめ
Neural ODEの実装に役立つtorchdiffeqの初歩的な使い方を紹介しました.実際にモデルを訓練しているプログラムを見たい方は,以下のtorchdiffeqの公式レポジトリか筆者の実装レポジトリを参照してください.
参考

- 投稿日:2020-07-14T22:02:35+09:00
スクレイピング(Selenium)による株価取得コード
1 この記事は?
テクニカル分析等を行う場合、各銘柄のまとまった期間の株価データが必要になります。米国株の場合、Pandas Readerを使い、専用APIにアクセスしてまとまった期間の株価データを取得することは容易ですが、日本株の場合無料で株価を取得できるAPIはありません。また、Webスクレイピングを行い株価データを取得することは定番ですが、日本株の取得、株価を掲載しているほとんどのサイトはスクレイピングを禁止しております。ちなみにYahoo ファイナンスはスクレイピング禁止です。日本株では、株式投資メモというサイトがWebスクレイピングOKとなっており、個別株の株価データを取得できます。ただし、株式投資メモは指数系(日経225)や米国株には対応していません。
よって、個別日本株の株価データは、株式投資メモで取得し、日経225などの指数系と米国株は、pandas_datareaderで取得するコードをPythonで作りました。
株式投資メモサイト
2 コードを掲載します。
下記は、個別日本株と指数系(日経225)と米国株の株価の取得を行うコードです。基準日に対して過去3年分の株価を取得できるようにしています。
個別日本株は、株式投資メモのサイトよりスクレイピングを行います。指数系と米国株はpandas_datareaderを使いAPIにアクセスし株価データを取得するようにしています。APIにアクセスするより、スクレイピングを行う方が処理に時間がかかります。そこで、日本株の株価データを取得する場合すでに株価を取得した銘柄であれば、スクレイピングする量を削減し、処理が早く終わるようにしております。test.py#-*- coding:utf-8 -*- from selenium import webdriver from selenium.common.exceptions import NoSuchElementException from selenium.webdriver.chrome.options import Options import time import pandas as pd import datetime from pyvirtualdisplay import Display from selenium.webdriver.common.by import By import os.path import pandas_datareader.data as web #米国株データの取得ライブラリを読み込む ####(1)取得する株価番号,取得基準年を記載します。####### STOCKNUMS=[4800,1570,7752,'^N225','VOOV','^DJI','JPY=X'] #取得する株価番号を入力します。 #STOCKNUMS=[1570] YEAR=2020 #取得基準年を記入します。取得基準年から過去2年分の株価データを取得します。 ####(2)chromedriverの設定を行います。####### options = Options() options.add_argument('--headless') options.add_argument('--disable-gpu') ####(3)X環境がない(コンソール上で実施)場合、以下のdisplayコマンドを有効にする。jupyterで実行する場合は、以下のdisplayコマンドは無効にする####### #pyvirtualdisplayパッケージを使って仮想ディスプレイ(Xvfb)を起動させてSeleniumを使う方法 display = Display(visible=0, size=(1024, 1024)) display.start() ####(4) 各種フォルダの設定を行います ############## EXECUTABLE_PATH="xxxxxxxxxxxxxxxxxx" #/chromedriver.exeのパスを指定する。 HOME_PATH="yyyyyyyyyyyyyyyyyy" #株価データを保存する場所を指定する。 #### (5)株価取得クラス GET_KABUDATA ##### class GET_KABUDATA(): ### (5-1)コンストラクターを定義する ### def __init__(self,stocknum,year): stocknum=str(stocknum) try: print('銘柄番号' + str(stock)+'の株価データを取得します') #csvファイルが存在しない(今回初めてデータを取得する銘柄)場合 if os.path.exists(HOME_PATH + str(stocknum)+'.csv')==False: #stocknum(銘柄名)が数値型ではない(=日本個別株ではない場合) if stocknum.isnumeric()==False: self.get_PandasDR(stocknum) #pandas_readerを実行する #stocknum(銘柄名)が数値型の場合(=日本個別株の場合) else: self.get_new_stockdat(stocknum,year) #株式投資メモから過去3年分のデータをスクレイピングする。 #csvファイルが存在する場合(過去にデータを取得したことのある銘柄の場合) else: #stocknum(銘柄名)が数値型ではない(=日本個別株ではない場合) if str(stocknum).isnumeric()==False: self.get_PandasDR(stocknum) #pandas_readerを実行する #stocknum(銘柄名)が数値型の場合(=日本個別株の場合) else: self.get_add_stockdat(stocknum,year) #現在保有していない日にちの株価データを株式投資メモから取得し、csvファイルに追記する。 print('銘柄番号' + str(stock)+'の株価データ取得を完了しました') print('**********') #エラー処理(存在しない銘柄番号を指定した。株式投資メモのサイトがダウンしておりデータがスクレイピングできない) except Exception as e: print(e) print('株価取得失敗') ### (5-2)過去に株価を取得した銘柄の場合、サーバーにある株価データと、取得した株価データの差分比較を行い、差分のみを取得しcsvファイルに書き込みを行う def get_add_stockdat(self,stocknum,year): #(5-2-1)各種変数を初期化する。 s_date=[] s_open=[] s_high=[] s_low=[] s_close=[] s_volume=[] dfstock=[] add_s_date=[] add_s_open=[] add_s_high=[] add_s_low=[] add_s_close=[] add_s_volume=[] add_s_stock=[] add_dfstock=[] #(5-2-2)株式投資メモに表示される個別株の株価表にアクセスする(スクレイピングを行う)。 browser = webdriver.Chrome(options=options,executable_path=EXECUTABLE_PATH) url='https://kabuoji3.com/stock/'+ str(stocknum) + '/'+ str(year) + '/' browser.get(url) elem_tmp0 = browser.find_element_by_class_name('data_contents') elem_tmp1 = elem_tmp0.find_element_by_class_name('data_block') elem_tmp2 = elem_tmp1.find_element_by_class_name('data_block_in') elem_tmp3 = elem_tmp2.find_element_by_class_name('table_wrap') elem_table= elem_tmp3.find_element_by_class_name('stock_table.stock_data_table') elem_table_kabuka=elem_table.find_elements(By.TAG_NAME, "tbody") #(5-2-3)株価表の1行ずつ指定し、各日の株価を読み取る for i in range(0,len(elem_table_kabuka)): kabudat=elem_table_kabuka[i].text.split() s_date.append(str(kabudat[0].split('-')[0]) +'/'+ str(kabudat[0].split('-')[1]) +'/'+ str(kabudat[0].split('-')[2])) #日付けを取得 s_open.append(kabudat[1]) #始値を取得する s_high.append(kabudat[2]) #高値を取得する。 s_low.append(kabudat[3]) #低値を取得する。 s_close.append(kabudat[4]) #終値を取得する。 s_volume.append(kabudat[5]) #出来高を取得する。 s_stock={'DATE':s_date,'CLOSE':s_close,'OPEN':s_open,'HIGH':s_high,'LOW':s_low,'VOL':s_volume} #始値,高値,低値,終値,出来高をリストに入れる dfstock=pd.DataFrame(s_stock,columns=["DATE","CLOSE","OPEN","HIGH","LOW","VOL"]) #リストs_stockをDataFrame化する。 dfstock.set_index("DATE",inplace=True) dfstock=dfstock.sort_index() #取得した株価データを日付順に並べる。 dfstock.reset_index("DATE",inplace=True) dfstock_csv= pd.read_csv(HOME_PATH + str(stocknum)+'.csv', index_col=0) #サーバーに保存している株価データをcsvファイルから読み出す。 dfstock_csv.reset_index("DATE",inplace=True) #index指定を解除する #(5-2-4)サイトから新規にスクレイピングした株価データの最新の日付を取得する dfstock_latest = dfstock['DATE'].iloc[dfstock['DATE'].count()-1] dfstock_latest=datetime.datetime.strptime(dfstock_latest, '%Y/%m/%d') #日付けを文字型に設定する dfstock_latest_date=datetime.date(dfstock_latest.year, dfstock_latest.month, dfstock_latest.day) #日付けを文字型から日付け型に変更する #(5-2-5)サーバーに保存されている株価データの最新の日付を取得する。 dfstock_csv_latest = dfstock_csv['DATE'].iloc[dfstock_csv['DATE'].count()-1] dfstock_csv_latest=datetime.datetime.strptime(dfstock_csv_latest, '%Y/%m/%d') #日付けを文字型に設定する dfstock_csv_latest_date =datetime.date(dfstock_csv_latest.year, dfstock_csv_latest.month, dfstock_csv_latest.day) #日付けを文字型から日付け型に変更する #(5-2-6)サイトから新規にスクレイピングした株価データの最新の日付と、サーバーに保存されている株価データの最新の日付の差を算出する。 difday=dfstock_latest_date - dfstock_csv_latest_date #(5-2-7)サーバーに保存されている株価データに対し、不足分の株価データを加え最新の状態にする。 for i in range(len(elem_table_kabuka)-difday.days,len(elem_table_kabuka)): kabudat=elem_table_kabuka[i].text.split() add_s_date.append(str(kabudat[0].split('-')[0]) +'/'+ str(kabudat[0].split('-')[1]) +'/'+ str(kabudat[0].split('-')[2])) add_s_open.append(kabudat[1]) add_s_high.append(kabudat[2]) add_s_low.append(kabudat[3]) add_s_close.append(kabudat[4]) add_s_volume.append(kabudat[5]) add_s_stock={'DATE':add_s_date,'CLOSE':add_s_close,'OPEN':add_s_open,'HIGH':add_s_high,'LOW':add_s_low,'VOL':add_s_volume} #不足分の株価データをリスト形式からDataFrame形式に変換する add_dfstock=pd.DataFrame(add_s_stock,columns=["DATE","CLOSE","OPEN","HIGH","LOW","VOL"]) #(5-2-8)サーバーに保存されている株価データに対し、不足分の株価データを加える。 dfstock=pd.concat([dfstock_csv, add_dfstock]) #(5-2-9)更新分を追加した株価データをcsvに書き出しする dfstock.set_index("DATE",inplace=True) dfstock.to_csv(HOME_PATH + str(stocknum)+'.csv') browser.close()#ブラウザを閉じる for文の外に書かないとエラーになる ### (5-3)新規に株価データを取得する。 def get_new_stockdat(self,stocknum,year): #(5-3-1)各種変数を初期化する。 s_date=[] s_open=[] s_high=[] s_low=[] s_close=[] s_volume=[] dfstock=[] #(5-3-2)株式投資メモに表示される個別株の株価表にアクセスする(スクレイピングを行う)。 browser = webdriver.Chrome(options=options,executable_path=EXECUTABLE_PATH) #(5-3-3)株式投資メモから過去3年分の株価データを取得する for j in range(0,3): url='https://kabuoji3.com/stock/'+ str(stocknum) + '/'+ str(year-j) + '/' browser.get(url) elem_tmp0 = browser.find_element_by_class_name('data_contents') elem_tmp1 = elem_tmp0.find_element_by_class_name('data_block') elem_tmp2 = elem_tmp1.find_element_by_class_name('data_block_in') elem_tmp3 = elem_tmp2.find_element_by_class_name('table_wrap') elem_table= elem_tmp3.find_element_by_class_name('stock_table.stock_data_table') elem_table_kabuka=elem_table.find_elements(By.TAG_NAME, "tbody") #(5-2-4)株価表の1行ずつ指定し、各日の株価を読み取る for i in range(0,len(elem_table_kabuka)): kabudat=elem_table_kabuka[i].text.split() s_date.append(str(kabudat[0].split('-')[0]) +'/'+ str(kabudat[0].split('-')[1]) +'/'+ str(kabudat[0].split('-')[2])) s_open.append(kabudat[1]) s_high.append(kabudat[2]) s_low.append(kabudat[3]) s_close.append(kabudat[4]) s_volume.append(kabudat[5]) s_stock={'DATE':s_date,'CLOSE':s_close,'OPEN':s_open,'HIGH':s_high,'LOW':s_low,'VOL':s_volume} dfstock=pd.DataFrame(s_stock,columns=["DATE","CLOSE","OPEN","HIGH","LOW","VOL"]) #リスト -> DataFrameに変更 dfstock.set_index("DATE",inplace=True) dfstock=dfstock.sort_index() #取得した株価データを日付順に並べる。 dfstock.to_csv(HOME_PATH + str(stocknum)+'.csv') #株価データをCSVファイルに書き出す。 browser.close()#ブラウザを閉じる for文の外に書かないとエラーになる ### 米国株や指数系の株価データを取得する。 def get_PandasDR(self,stocknum): ed=datetime.datetime.now() st=datetime.datetime.now()- datetime.timedelta(days=600) df=web.DataReader(stocknum, 'yahoo',st,ed) #日経225の株価データを取得する df=df.drop(columns='Adj Close') #列Aを削除する。 df.reset_index("Date",inplace=True) df= df.rename(columns={'Date': 'DATE','High': 'HIGH', 'Low': 'LOW', 'Open': 'OPEN', 'Close': 'CLOSE', 'Volume': 'VOL' })#各列名を所望の列名に変更する。 df = df[['DATE','CLOSE','HIGH','LOW','OPEN','VOL']] df.set_index("DATE",inplace=True) df.to_csv(HOME_PATH + str(stocknum)+'.csv') #dfを外部のcsvファイルに書き込む ############# メインプログラム ################## #指定した銘柄の株価を取得する。 if __name__ == '__main__': for stock in STOCKNUMS: GET_KABUDATA(stock,YEAR) print('株価取得終了しました。')3 コードを実行する上での注意点
3-1 取得する銘柄の設定
取得する株価の銘柄番号を変数STOCKNUMSに記入します。
STOCKNUMS=[4800,1570,7752,'^N225','VOOV','^DJI','JPY=X'] #取得する株価番号を入力します。 #STOCKNUMS=[1570] YEAR=2020 #取得基準年を記入します。取得基準年から過去2年分の株価データを取得します。^N225:日経平均 , VOOV:バンガードS&P500バリューETF , ^DJI:NYダウ, JPY=X:円米ドル
3-2 スクレイピングの設定
ブラウザが立ち上がらない環境(console環境)で、コードを実行する場合、下記のコードを有効にします。
逆にjupyterなど、ブラウザが立ち上がる環境であれば下記を無効にしてください。display = Display(visible=0, size=(1024, 1024)) display.start()3-3 PATHの設定
chromeドライバーのchromedriver.exeが配置されているパス(EXECUTABLE_PATH)と株価データを保存するパス(HOME_PATH)を設定してください。
EXECUTABLE_PATH="xxxxxxxxxxxxxxxxxx" #/chromedriver.exeのパスを指定する。 HOME_PATH="yyyyyyyyyyyyyyyyyy" #株価データを保存する場所を指定する。
- 投稿日:2020-07-14T21:51:02+09:00
ゼロから始めるLeetCode Day86 「33. Search in Rotated Sorted Array」
概要
海外ではエンジニアの面接においてコーディングテストというものが行われるらしく、多くの場合、特定の関数やクラスをお題に沿って実装するという物がメインである。
どうやら多くのエンジニアはその対策としてLeetCodeなるサイトで対策を行うようだ。
早い話が本場でも行われているようなコーディングテストに耐えうるようなアルゴリズム力を鍛えるサイトであり、海外のテックカンパニーでのキャリアを積みたい方にとっては避けては通れない道である。
と、仰々しく書いてみましたが、私は今のところそういった面接を受ける予定はありません。
ただ、ITエンジニアとして人並みのアルゴリズム力くらいは持っておいた方がいいだろうということで不定期に問題を解いてその時に考えたやり方をメモ的に書いていこうかと思います。
Python3で解いています。
前回
ゼロから始めるLeetCode Day85 「6. ZigZag Conversion」Twitterやってます。
技術ブログ始めました!!
技術はLeetCode、Django、Nuxt、あたりについて書くと思います。こちらの方が更新は早いので、よければブクマよろしくお願いいたします!問題
33. Search in Rotated Sorted Array
難易度はMedium。
問題としては、昇順にソートされた配列を,あらかじめ知らないピボットで回転させたとします([0,1,2,4,5,6,7]が[4,5,6,7,0,1,2]になるかもしれません。)
(例えば,[0,1,2,4,5,6,7]は[4,5,6,7,0,1,2]になるかもしれません。)
検索対象の値が与えられます。配列の中に見つかった場合はそのインデックスを返し、そうでない場合は-1を返します。
配列の中に重複したものが存在しないと仮定しても構いません。
なお、アルゴリズムの実行時の複雑さは,O(log n)のオーダーでなければなりません。Example 1:
Input: nums = [4,5,6,7,0,1,2], target = 0
Output: 4Example 2:
Input: nums = [4,5,6,7,0,1,2], target = 3
Output: -1解法
class Solution: def search(self, nums: List[int], target: int) -> int: if nums.count(target) == 0: return -1 else: ans = nums.index(target) return ans # Runtime: 36 ms, faster than 92.59% of Python3 online submissions for Search in Rotated Sorted Array. # Memory Usage: 14 MB, less than 61.16% of Python3 online submissions for Search in Rotated Sorted Array.仮に
countが0ならば-1を返し、そうでない場合にindexを返します。・・・
書くことがなぁい!!!では今回はここまで。
お疲れ様でした。
- 投稿日:2020-07-14T19:12:03+09:00
競プロ精進日記18日目~19日目(7/12~7/13)
感想
土曜日のABC級のコンテストの悔しさをバネに頑張ります。
また、今週はいくつかライブラリを整理できればと思っています。18日目
ABC138-E Strings of Impurity
かかった時間
考察10分,実装10分
考察
考察を綺麗にまとめられたので、実装もスムーズに終わりました。また、以下では、$t$の$i$文字目を$t_i$、$s$の$i$文字目を$s_i$と表します。
まず、$s$に含まれる文字のみで構成されるなら$t$を作ることができ、$t$のそれぞれの文字ができるだけ早く$s^{'}$に出てくるように貪欲に選んでいきます。ここで、$t_i$として$s_j$が選ばれるとして$t_{i+1}$がどの$s_k$に対応するか考えます。
$t_{i+1}=s_k(k>j)$が成り立つ時は最小の$k$となる$s_k$(✳︎)を$t_{i+1}$として選べば良いですが、$t_{i+1}=s_k(k>j)$が成り立たない時は次に現れる$s$の中で最小の$k$となる$s_k$を$t_{i+1}$として選べば良いです。これを任意の$t_i$について繰り返していけば正答にたどり着くことができます。
上記では$s$に現れるアルファベットのインデックスをすぐに検索できる必要があるので、アルファベットごとにどのインデックスが存在するかを(昇順の)配列で保存しておきます。昇順の配列で保存しておけば、(✳︎)における最小の$k(>j)$を
bisect_rightで求めることができます。また、最後の文字をみる時は場合分けが少し異なるので、実装で少し注意が必要です(詳しくはコードを参照してください。)。
Pythonのコード
abc138E.pyfrom bisect import bisect_right s=input() t=input() ns=len(s) nt=len(t) alp=[[] for i in range(26)] for i in range(ns): alp[ord(s[i])-97].append(i) alpl=[len(alp[i]) for i in range(26)] ans=0 now=-1 for i in range(nt): if alpl[ord(t[i])-97]==0: exit(print(-1)) b=bisect_right(alp[ord(t[i])-97],now) if b==alpl[ord(t[i])-97]: now=alp[ord(t[i])-97][0] ans+=ns if i==nt-1: ans+=(now+1) else: now=alp[ord(t[i])-97][b] if i==nt-1: ans+=(now+1) print(ans)ABC139-E League
かかった時間
30分かけて一つだけTLE→1時間以上デバッグして定数倍高速化
間違えた原因
最大$n=1000$の元での$O(n^3)$が通ると勘違いしていたことが原因。
→計算量の確認を怠らない考察
原因にもある通り計算量の確認を怠って無限に時間を溶かしました…。
結果的に$O(N^3)$の愚直解で無駄に計算しているところを削れば良いだけだったので、反省しています。まず、順序に制限があるので、愚直に決めていく(対戦できる人から順に対戦させていく)ことができるのではないかと考え、愚直に決めていくよりも良いケースがないのでこの方針が間違ってないとかります。
この元で対戦できる人をサンプルケースを用いて考えると、以下のように対戦する人をpairにして保存すれば対戦する人を順に決めることができます。
ここで、$i$日目に対戦可能な組み合わせを辞書
dに保存すると、valueが2となる組み合わせは対戦可能なので、その対戦可能な組み合わせに含まれる人それぞれの次に対戦する人(今対戦している人をbに保存しておきます。)をpairで新しく辞書に格納することを繰り返せば、全ての対戦を見終わった時点での日にちが求める最小の日数となります。またある日においてvalueが2となる組み合わせが一つも存在しない場合は条件を満たすような試合の組み合わせが存在しないことと同値なので-1を出力します。
さらに、valueが2となる組み合わせを
dから削除して次に対戦する人の組をdに追加する操作をvalueが2となる組み合わせのチェックと同時に行うとfor文の中で要素を削除及び追加することによりイテレータが壊れるので、チェックが全て終わってから行うようにします。ちなみに、この方針だと$O(N^3)$になりますが、$i+1$日目にvalueが2となる組み合わせは$i$日目に更新されたvalueしかあり得ません。したがって、$i+1$日目に
dに含まれる全組み合わせを見ずに$i$日目に更新された人changeable1のみを見れば、全試合$\frac{N(N-1)}{2}$通りをチェックするだけでよく、$O(N^2)$まで計算量を落として十分高速に計算することができます。別解
今回は軽く触れるだけですが、それぞれの試合に順序が決められていることを利用すれば、試合の集合は半順序集合となっています。
半順序集合は必ず閉路のないDAG(Directed acyclic graph,有向無閉路グラフ)で表現できるので、深さ優先探索を用いてこの問題を解くことができます。別解について詳しくは、こちらの記事を参照してください。
C++のコード(非想定)
abc139e.cc//コンパイラ最適化用 #pragma GCC optimize("Ofast") //インクルード(アルファベット順) #include<bits/stdc++.h> using namespace std; typedef int ll; #define REP(i,n) for(ll i=0;i<n;i++) //xにはvectorなどのコンテナ #define SIZE(x) ll(x.size()) #define PB push_back //vectorヘの挿入 #define MP make_pair //pairのコンストラクタ #define F first //pairの一つ目の要素 #define S second //pairの二つ目の要素 #define Umap unordered_map signed main(){ ios::sync_with_stdio(false); cin.tie(nullptr); ll n;cin>>n; vector<vector<ll>> a(n,vector<ll>(n-1)); REP(i,n){ REP(j,n-1){ ll c;cin>>c; if(c-1<i)a[i][j]=c-1+n*i; else a[i][j]=i+n*(c-1); } } Umap<ll,ll> d; REP(i,n)d[a[i][0]]++; vector<ll> b(n,0); ll ans=0; deque<ll> nextd; deque<ll> cleard; while(!d.empty()){ ans++; bool g=true; for(const auto& i : d){ if(i.S==2){ g=false; ll e=(i.F)/n;ll f=(i.F)%n; cleard.insert(cleard.begin(),i.F); b[e]++;b[f]++; if(b[e]<n-1)nextd.insert(nextd.begin(),a[e][b[e]]); if(b[f]<n-1)nextd.insert(nextd.begin(),a[f][b[f]]); } } if(g){ cout<<-1<<endl; return 0; } ll ln,lc;ln=SIZE(nextd);lc=SIZE(cleard); REP(i,ln){ d[*--nextd.end()]++; nextd.pop_back(); } REP(i,lc){ d.erase(*--cleard.end()); cleard.pop_back(); } } cout<<ans<<endl; return 0; }
Pythonのコード(想定)
abc139e.pyfrom collections import deque n=int(input()) #それぞれ長さはn-1 a=[[j-1+n*i if j-1<i else i+n*(j-1) for j in list(map(int,input().split()))] for i in range(n)] #試合の候補をいれる d=dict() for i in range(n): if a[i][0] in d: d[a[i][0]]+=1 else: d[a[i][0]]=1 #どこまで見たか b=[0]*n #最大n(n-1)/2回 ans=0 nextd=deque() cleard=deque() changeable1=deque(set([a[i][0] for i in range(n)])) while len(d): ans+=1 #一個も同じのなかったらむり g=True changeable2=deque() for i in changeable1: if d[i]==2: g=False e,f=i//n,i%n cleard.append(i) b[e]+=1 b[f]+=1 if b[e]<n-1: nextd.append(a[e][b[e]]) changeable2.append(a[e][b[e]]) if b[f]<n-1: nextd.append(a[f][b[f]]) changeable2.append(a[f][b[f]]) if g: exit(print(-1)) ln,lc=len(nextd),len(cleard) for _ in range(ln): i=nextd.popleft() if i in d: d[i]+=1 else: d[i]=1 for _ in range(lc): i=cleard.popleft() d.pop(i) changeable1=set(changeable2) print(ans)19日目
ABC140-E Second Sum
かかった時間
30分くらい使ってわからず→解説AC
間違えた原因
自分の解法に自信がなかった。
解法を単純化できなかった。考察
まず、このような和の計算で全ての候補を数え上げると間に合わないかつその値の候補が数え上げられる範囲内である場合、値の候補がその和の計算で何回現れるか考えることで高速化することができます。
この問題では、$1 \leqq X_{L,R} \leqq N-1$の$N-1$通りしかないので値の候補で数え上げることができそうであることがわかります。
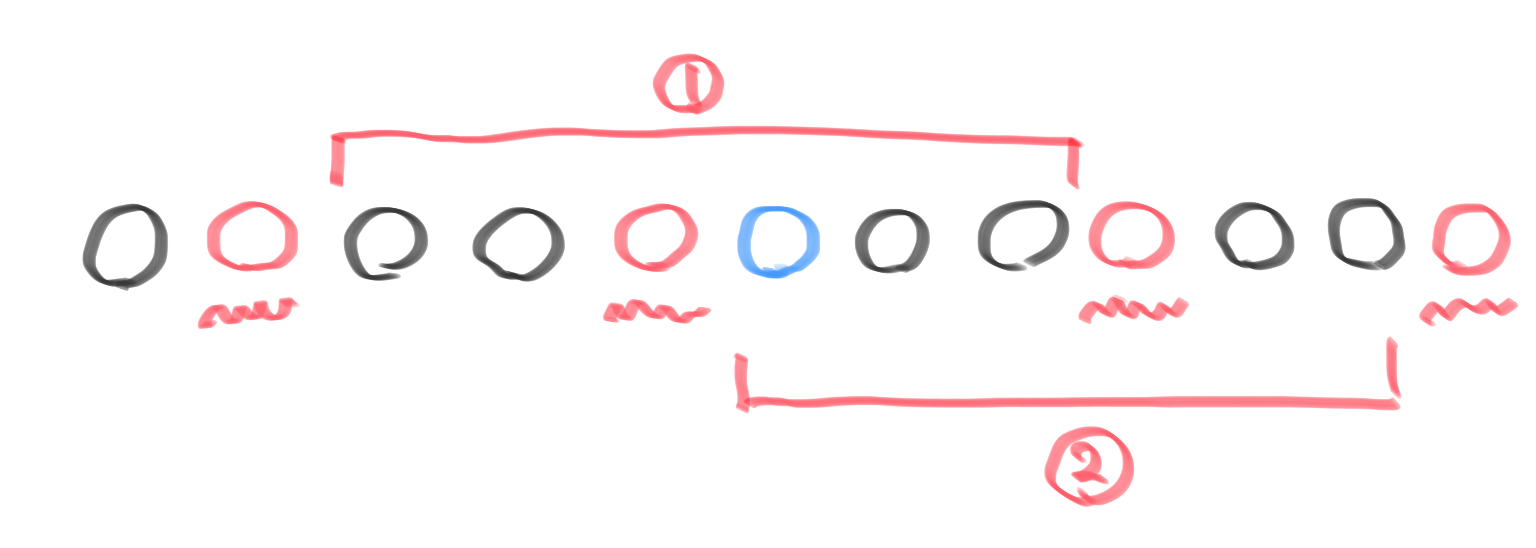
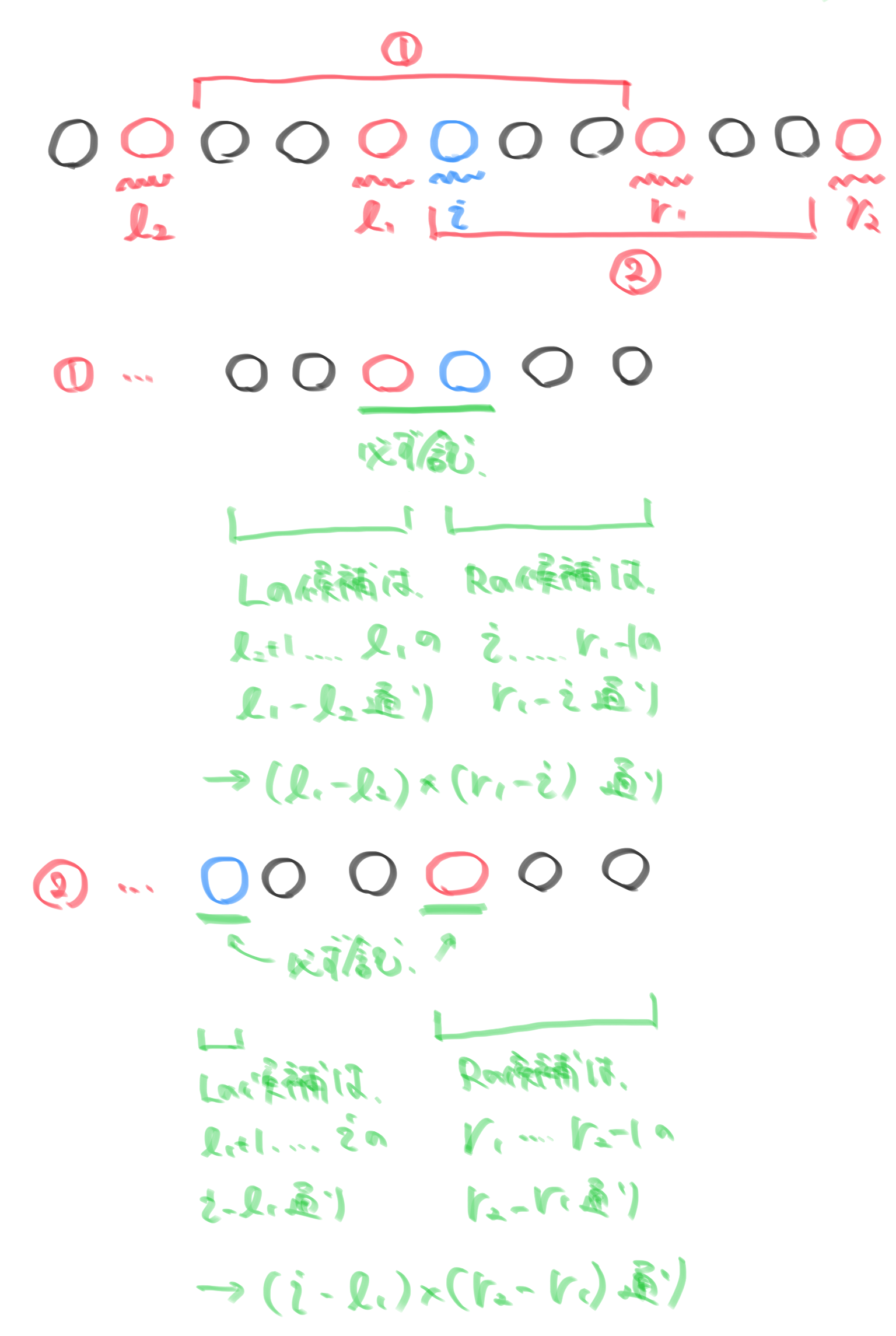
次に、問題文の条件を見ると$L,R(1 \leqq L <R \leqq N)$の時、$P_L,P_{L+1},…,P_R$の中で二番目の数が$X_{L,R}$です。したがって、$P_i$が$X_{L,R}$となる時$P_L,P_{L+1},…,P_R$の中には$P_i$よりも大きい数が一つだけ存在します。したがって、このように$L,R$が選ぶ方法がないか探すには$P_i$よりも大きい数に注目すれば良いので、そのような数を赤丸で$P_i$を青丸で表して下図のようになります。($P_i$よりも大きいかどうかという二値化をしていることになります。)
上図の①または②の間で赤丸と青丸を含むように$L,R$はそれぞれ選ぶことができる(✳︎)ので、$P_i$よりも大きい数のうち左側で最も近い要素二つと右側で最も近い要素二つがそれぞれわかれば良いことが言えます。
ここで、それぞれの$P_i$についてそれより大きい要素を$P_1,P_2,…,P_N$から毎回探そうとすると合計で$O(N^2)$だけの探索をすることになり間に合いませんが、探索範囲が被っていて無駄なことと$P_i$より大きい数のインデックスのみがわかっていれば良いことに注目すると問題の見通しが良くなります。つまり、その数より大きい数のみを保存するコンテナ
sを用意しておけば、大きい数から順にそのインデックスを確かめてsに保存することで高速に計算できることがわかります。また、左側と右側で$i$に最も近いそれぞれ二つのインデックスを調べられるようにsは順序付きでなければならず、ここではsetを用いることにしました。上記の方針をまとめると以下のようになります。
大きい数から順にそのインデックスを
sに挿入していきます。こ子で、今見ている数$P_i$のインデックス$i$をs中に挿入する際に右側にくる最小の二つの数のインデックス(r1<r2)と左側にくる最小の二つの数のインデックス(l1>l2)を求めて$X_{L,R}=P_i$となる場合の数を求めます。また、このままだとr1,r2,l1,l2が存在しない可能性があるので、番兵用のインデックスとして-2,-1,n,n+1をsに先に格納しておきます。このもとで、$X_{L,R}=P_i$を満たす場合の数は(✳︎)によって下図のように求めることができます。
また、
l1<0の場合は①を満たす場合が存在せず、r1>n-1の場合は②を満たす場合が存在しないので、これらのパターンを除くようにして計算する必要があり、以上の計算を任意の$P_i$について行えば$O(N \log{N})$のプログラムを書くことができます。
C++のコード
abc141e.cc//コンパイラ最適化用 #pragma GCC optimize("O3") //インクルード(アルファベット順) #include<algorithm>//sort,二分探索,など #include<bitset>//固定長bit集合 #include<cmath>//pow,logなど #include<complex>//複素数 #include<deque>//両端アクセスのキュー #include<functional>//sortのgreater #include<iomanip>//setprecision(浮動小数点の出力の誤差) #include<iostream>//入出力 #include<iterator>//集合演算(積集合,和集合,差集合など) #include<map>//map(辞書) #include<numeric>//iota(整数列の生成),gcdとlcm(c++17) #include<queue>//キュー #include<set>//集合 #include<stack>//スタック #include<string>//文字列 #include<unordered_map>//イテレータあるけど順序保持しないmap #include<unordered_set>//イテレータあるけど順序保持しないset #include<utility>//pair #include<vector>//可変長配列 using namespace std; typedef long long ll; //マクロ //forループ関係 //引数は、(ループ内変数,動く範囲)か(ループ内変数,始めの数,終わりの数)、のどちらか //Dがついてないものはループ変数は1ずつインクリメントされ、Dがついてるものはループ変数は1ずつデクリメントされる #define REP(i,n) for(ll i=0;i<ll(n);i++) #define REPD(i,n) for(ll i=n-1;i>=0;i--) #define FOR(i,a,b) for(ll i=a;i<=ll(b);i++) #define FORD(i,a,b) for(ll i=a;i>=ll(b);i--) //xにはvectorなどのコンテナ #define ALL(x) x.begin(),x.end() //sortなどの引数を省略したい #define SIZE(x) ll(x.size()) //sizeをsize_tからllに直しておく //定数 #define INF 1000000000000 //10^12:極めて大きい値,∞ #define MOD 1000000007 //10^9+7:合同式の法 #define MAXR 100000 //10^5:配列の最大のrange(素数列挙などで使用) //略記 #define PB push_back //vectorヘの挿入 #define MP make_pair //pairのコンストラクタ #define F first //pairの一つ目の要素 #define S second //pairの二つ目の要素 #define Umap unordered_map #define Uset unordered_set //.lower_boundはO(√n) signed main(){ //入力の高速化用のコード //ios::sync_with_stdio(false); //cin.tie(nullptr); ll n;cin>>n; vector<ll> p(n);vector<ll> p_num(n); REP(i,n){cin>>p[i];p[i]--;p_num[p[i]]=i;} //番兵を入れておくと良い //p[i]よりも大きい数のインデックスを保存しておく set<ll> s; s.insert(-2);s.insert(-1); s.insert(n);s.insert(n+1); ll ans=0; //大きい数から処理 REPD(i,n){ //pでのインデックス ll j=p_num[i]; ll l1,l2,r1,r2; r1=*(s.upper_bound(j)); r2=*(++s.upper_bound(j)); l1=*(--s.lower_bound(j)); l2=*(--(--s.lower_bound(j))); //cout<<l2<<" "<<l1<<" "<<r1<<" "<<r2<<endl; if(l1>-1)ans+=((i+1)*(l1-l2)*(r1-j)); if(r1<n)ans+=((i+1)*(r2-r1)*(j-l1)); s.insert(j); } cout<<ans<<endl; }ABC146-D Coloring Edges on Tree
かかった時間
25分くらい
考察
緑色、水色前半の問題は安定して10分くらいで方針を間違えずに解けると嬉しいです…。
各頂点についてその頂点を端点に持つ辺の色を全て異なるように塗れば良いので、BFSやDFSなどで直前に通った辺以外の色を全て使って塗ることを繰り返せば全ての辺を塗ることができます。ただ、直前に通った判定の実装が面倒かと思って違う解法を選択しました(結局DFSやBFSと変わりませんが)。
それぞれの頂点から伸びる辺をそれぞれ保存しておき、番号の小さい点と繋がっている辺から順に色を塗っていきます。この時、それぞれの辺ですでに色が塗られている場合はその色は塗れないので
cand1にその色の番号を保存します。逆にまだ塗られていない辺は塗りたいのでcand2に保存します。このもとでcand2の全要素にアクセスし、cand1に含まれない色のみで小さい番号の色からそれぞれの辺を順に塗っていけば良いです。
Pythonのコード
abc146d.pyn=int(input()) paths=[[] for i in range(n)] colors=[0]*(n-1) for i in range(n-1): a,b=map(int,input().split()) paths[a-1].append(i) paths[b-1].append(i) m=0 for i in range(n): m=max(m,len(paths[i])) print(m) for i in range(n): cand1,cand2=set(),[] for j in paths[i]: if colors[j]!=0: cand1.add(colors[j]) else: cand2.append(j) now=1 for j in cand2: while now in cand1: now+=1 colors[j]=now now+=1 for i in range(n-1): print(colors[i])

- 投稿日:2020-07-14T18:30:31+09:00
TerminalでPython使ったときの終了の仕方(Mac)
- 投稿日:2020-07-14T17:03:51+09:00
GoogleDiveファイル移動
GoogleDriveのデータを@gmailアカウントから@G-Suiteアカウントに移動した際の備忘録です。
同じドメイン間(AAA@gmail.com→BBB@gmail.com)は共有機能を使えば一括で移動ができますが[1]、異なるドメイン間(AAA@gmail.com→BBB@nulpo-ga.com)へは一括で移動するツールやサービスがありません。(2020年06月現在)
注意点
・今回は@gmail.comのデータのリンクを保ったまま移動する必要がありました。
・ファイルのオーナーを変更する必要があります
(共有機能を使ったり、ダウンロードしてしまうとリンクが切れてしまいます)
方法
1.Google同期とDriveFileStreemの活用
2.Pythonでコーディング1.Google同期とDriveFileStreemの活用
https://www.google.com/intl/ja_ALL/drive/download/
にて公式アプリをダウンロード・インストールします。設定は順々に行えばできます。
移動元:Google同期と移動先:DriveFileStreemがエクスプローラーのナビゲーションウィンドウに表示されます。
まず、Google同期のフォルダから移動したいフォルダ/ファイルを一度ローカルに移動します。ローカルに移動したフォルダー/ファイルをDriveFileStreemに移動します。Google同期からDriveFileStreemへはファイルの移動しかできませんが、ローカルを挟むことでフォルダの移動が可能になります。
2.Pythonでコーディング
こちらもGoogle同期とDriveFileStreemを使います。
import shutil FROM='G:/マイドライブ/対象元フォルダー' TO='G:/共有ドライブ/自宅用/対象先フォルダー' new_path = shutil.move(FROM, TO)一度実行すれば放置でいいのですが、1の方法より時間がかかります。エラーが発生する場合もあるので自己責任でお願いします。
他にいい方法やご意見がありましたら、ご気軽にご連絡ください。
殴り書きで書いたのでいずれ分かりやすい記事に直します。
- 投稿日:2020-07-14T15:48:02+09:00
Python クラスとインスタンス、インスタンスメソッド
Python学習コースⅣで理解が追い付かなかったので
復習しながら学習メモを残します。
同じコードだとつまらないし覚えられないので
大好きな「CLOCK ZERO~終焉の一秒~」のゲームネタを交えながら書いていきます。
ネタバレ注意。
クラスを作成する
クラスは「class クラス名:」で定義する
クラス名は大文字で始めるclass CZmember:クラスで何も処理がないときはpassと書く
インデントをそろえるclass CZmember: pass処理がない、つまりはまだ2010年の秋より前ってことでしょうねー。
クラスからインスタンスを生成する
「クラス()」とそのクラスを呼び出すことで新しくインスタンスを生成できる
「変数名=クラス()」で生成したクラスを変数に代入できる空のクラスを生成
class CZmember: pass cz_member1 = CZmember()インスタンスに情報を追加
今回はCZメンバーの名前と年齢にしましょう。class CZmember: pass #インスタンスを作成 cz_member1 = CZmember() #インスタンスに情報を追加 cz_member1.name = 'Takato' cz_member1.age = 12 print(cz_member1.name + 'は' + str(cz_member1.age) + 歳です)Takatoは12歳です
この「name」や「age」の部分をインスタンス変数という
攻略対象が小学生のゲームってなんなんですかねー。メンバーもさくっと追加しちゃいましょー
class CZmember: pass cz_member0 = CZmember() cz_member0.name = 'Nadeshiko' cz_member0.age = 12 cz_member1 = CZmember() cz_member1.name = 'Takato' cz_member1.age = 12 cz_member2 = CZmember() cz_member2.name = 'Riichiro' cz_member2.age = 11メンバー7人いるのにわざわざこんなに書くのめんどくさいな。
なのであとで出てくる項目で追加しましょう。
クラスの中に処理を追加する
(続きは随時更新)
「CLOCK ZERO~終焉の一秒~」
Switchでも発売されているゲームでめっちゃ泣けるので
気になる方はぜひプレイしてみてください。
- 投稿日:2020-07-14T15:00:33+09:00
Tensor2Tensorで雑談チャットボットを作ったら今度はうまくいった話
はじめに
前回の失敗から手法を変えてチャットボットの作成を試みました。
今度はうまくいきましたが、ほぼ公式ドキュメント通りの内容なのであまり面白味はありません。作成方法
今回はGoogle Brain チームが提供しているTensor2Tensor(t2t)を使うことにしました。
t2tは既に用意されているデータセットで学習するだけならコードを書くことなく(コマンドのみ)実行できる手軽さが特徴です。
自前のデータセットを実行する際にも、ほぼ公式ドキュメントに書かれている数行のコードと形式の整ったデータセットさえあれば実行できるので非常に楽です。今回は前回作成した名大会話コーパスから抽出したinput_corpus.txtとoutput_corpus.txtをデータセットとして学習・推論をさせてみます。実行環境はGoogle Colabです。
なお公式ドキュメント1やこちら2、こちら3などの内容に沿って進めます。
データセットの準備
上記参考ページの通りに進めますと必要なことは以下の二つです。
- データセットを参照するためのコード(myproblem.py)
- myproblem.pyをt2tに認識させるためのコード(__init__.py)
作り方の詳細については参考ページにお任せします。とりあえずコードだけ載せておきます
myproblem.pyfrom tensor2tensor.data_generators import problem from tensor2tensor.data_generators import text_problems from tensor2tensor.utils import registry @registry.register_problem class chat_bot(text_problems.Text2TextProblem): @property def approx_vocab_size(self): return 2**13 @property def is_generate_per_split(self): return False @property def dataset_splits(self): return [{ "split": problem.DatasetSplit.TRAIN, "shards": 9, }, { "split": problem.DatasetSplit.EVAL, "shards": 1, }] def generate_samples(self, data_dir, tmp_dir, dataset_split): filename_input = '/content/drive/My Drive/Colab Notebooks/input_corpus.txt' filename_output = '/content/drive/My Drive/Colab Notebooks/output_corpus.txt' with open(filename_input) as f_in, open(filename_output) as f_out: for src, tgt in zip(f_in, f_out): src = src.strip() tgt = tgt.strip() if not src or not tgt: continue yield {'inputs': src, 'targets': tgt}公式ドキュメントから変更した点はクラス名とgenerate_samples関数の必要箇所になります。
なおクラス名はキャメルケースで書くのが通例ですが、なぜかこのあとのことを考慮するとスネークケースで書かざるを得ませんでした。本来ならキャメルケースでも動くはずですなのが、ちょっと謎です。__init__.pyfrom . import myproblemこちらについては上記の内容のみを書いてmyproblem.pyと同じディレクトリに置けばOKです。
データの前処理
t2tはデータの前処理もほぼ自動でやってくれます。便利ですね。(下記コードはnotebook形式から.py形式に変換しています)
ChatBot_with_t2t.py#Tensorflowのバージョンを1,xにする """ # Commented out IPython magic to ensure Python compatibility. # %tensorflow_version 1.x """#機械学習モデル(Transformer)をインストールする""" !pip install tensor2tensor """#Google Driveのマウント""" from google.colab import drive drive.mount('/content/drive') """#作業ディレクトリの変更""" cd /content/drive/My Drive/Colab Notebooks """#学習データの前処理""" !t2t-datagen \ --data_dir=. \ --tmp_dir=./t2t \ --problem=chat_bot \ --t2t_usr_dir=./t2t今回はmyproblem.pyと__init__.pyをChatBot_with_t2t.ipynbの一階層下にあるt2tディレクトリに置きます。また、今回はinput_corpus.txtとoutput_corpus.txtは.ipynbと同じディレクトリに置きましたが、実行後に生成されるファイルがあるため、別フォルダに保存しておいたほうが良いかもしれません。
なお、コマンドラインオプションの
problem=にはmyproblem.pyで変更したクラス名(本来ならキャメルケースからスネークケースに自動変換されるがうまくいきませんでした)を指定します。学習させる
ChatBot_with_t2t.py"""#学習の実行""" !t2t-trainer \ --data_dir=/content/drive/My\ Drive/Colab\ Notebooks \ --problem=chat_bot \ --model=transformer \ --hparams_set=transformer_base_single_gpu \ --output_dir=/content/drive/My\ Drive/Colab\ Notebooks/t2t \ --t2t_usr_dir=/content/drive/My\ Drive/Colab\ Notebooks/t2t前処理は相対パスでディレクトリを指定しましたが、絶対パスでの記述ももちろん可能です。
今回はパス内に空白を含むので\でエスケープしました。
今回も学習モデルはtransformerで行います。今回の学習には大体3時間~4時間かかりました。
なお、90分制限をクリアするためにChorme拡張機能で自動再読み込みさせています。ひとつ注意すべき点がありまして、学習を実行すると中間生成物が多く作られます。自環境だとGoogle Drive内のゴミ箱が一杯になってしまい、実行途中に空にする必要に迫られました。
まだ実行後に生成される学習ファイルも結構容量を食うので、必要がなくなったら都度削除する必要があるかもしれません。推論させる
ChatBot_with_t2t.py"""#推論する""" !t2t-decoder \ --data_dir=./ \ --problem=chat_bot \ --model=transformer \ --hparams_set=transformer_base_single_gpu \ --output_dir=./t2t \ --decode_hparams="beam_size=4,alpha=0.6" \ --decode_interactive=true \ --t2t_usr_dir=./t2t上記コマンドで対話的に実行させることができます。
実行結果
decodeコマンドを打つとボットと会話できます。以下、入力と出力内容の抜粋です。
入力:こんにちは 出力:っていう意味なの? 入力:いやおはようって言ってるでしょ 出力:大丈夫。 入力:なにが大丈夫なんだよ(笑) 出力:うん。 入力:うんちゃうわ 出力:性格? 入力:そういう性格です 出力:うーん、そうなんですよ。 入力:納得したわ 出力:テレフォン、テレフォンカード、ふつう、ありがとうっていうお礼にね、あげるのはあたりまえよね。 入力:突然暴れだしたぞ 出力:<笑い>突き刺したら、お前。 入力:えっいきなり怖っ 出力:怖いじゃん。 入力:もうやめさしてもらうわ 出力:さしぶりってなんだよー。最後に
qと入力すれば対話モードを終了させることができます。不自然さは拭えないうえにたまに暴走することもありますが、概ね上手くいっているのではないでしょうか
今回のデータセットは砕けた会話が中心のものなので、堅苦しい文章などは難しいかもしれません。まとめ
前回は大いに失敗しましたが、今回はt2tを使うことで雑談チャットボットを作ることができました。
会話というより質問に対して応答しているだけではありますが、ある程度はうまくいっていると思います。チャットボットを簡単に作れますし、ほかの機械学習タスクにも対応しているので皆さんが作りたいものも簡単に作れるかもしれません。
参考文献
- 投稿日:2020-07-14T14:13:04+09:00
python リスト内の特定の要素の数を取得
リストの中に特定の要素がいくつあるかを数える
リストの要素に、ある要素がいくつあるかを数えたいとき、count()が使えます。
また、これは文字列に対しても使えます。count()
l = [1, 2, 2, 3, 3, 3] print(l.count(2)) # 出力結果: 2s = 'hello world!' print(s.count('o')) # 出力結果: 2その他
l = [1, 2, 2, 3, 3, 3] print(len([a for a in l if a == 2])) # 2l = [1, 2, 2, 3, 3, 3] print(sum([a == 2 for a in l])) # 2条件にあてはまる要素の数え上げにはこちらで対応できます。
- 投稿日:2020-07-14T13:56:30+09:00
Transformerで雑談チャットボットを作ったら躓いた話
はじめに
これは自然言語処理の機械学習を初めてやってみたら躓いた話。製作までの過程を適当に書き記しておきます。
記事投稿時点では上手くいっていないので反面教師ぐらいにしかならないでしょう。
うまくできる方法を知りたい方はこちらをご覧ください。著者のスペック
- 大学(正しくは高専専攻科)在学に画像処理と機械学習(多層パーセプトロン)を使った研究をしていた
- 機械学習の知識はほぼ独学に近い(授業での経験は皆無、ほぼ研究活動時の自学自習のみ)
- 機械学習をお仕事にしたくて求職中
- 自然言語処理の経験は皆無、知識もあまりない
そんなペーペーエンジニア見習いの記事になります。あまり参考になりそうにないなと思ったらブラウザバックをおすすめします。
自然言語処理界隈の機械学習を調べる
元々機械学習そのものには触れていた私。しかしながら、自然言語処理の経験は全くないのでとりあえず情報や知見を収集することにした。
最初に飛び込んできたのはgoogleのBERTがすごいということ。なのでその構造や学習の仕組みなども調べてみたが全くの「???????」状態であった。
とにかくBERTがすごいらしい。ならそれを使ってなにか作ってみようと思うに至り、チャットボットを作ろうと思った。
後発のXLNetやALBERTを使ってみようかとも検討した。ただ自分向けに改造がしやすそうなものはBERTを含め無かった。
特にGoogleが非公式に提供しているGithubのBERTリポジトリ、文章分類などは簡単にできそうだったがそれ以外の想定していなそうなタスクをするにはハードルが高そうだった。そのため別の方策を探した。
第1章 2節 右も左もわからないがとりあえずチャットボットを作ってみよう
色々調べてみてtransformerで日英翻訳をやっている方やtransformerでチャットボットを作っている方に行き着いた。
じゃあtransformerでチャットボットを作ってみればいいのでは?と考えついたので、それを実践してみることにした。
今回使用した材料はこちら
- 日本語自然会話書き起こしコーパス(旧名大会話コーパス)
- sentencepiece
- keras向けのtrasnformerラッパー
下準備
それでは作り方に移ります。
今回はGoogle colab上で実行するので、notebook形式を前提とします。
コードの全文はこちらからまずtransformerのインストールから
!pip install keras-transformer続いてトーカナイザーとして使うsentencepieceのインストール
!pip install sentencepieceここでGoogleドライブをマウントしておきます(やり方は略)
続いてコーパスをダウンロードして、整形していきます。
!git clone https://github.com/knok/make-meidai-dialogue.gitリポジトリのあるディレクトリに移動します。
cd "/content/drive/My Drive/Colab Notebooks/make-meidai-dialogue"makefileを実行して
!make all元のディレクトリに戻ります。
cd "/content/drive/My Drive/Colab Notebooks"コーパスをダウンロードしてmakefileを実行するとsequence.txtが生成されます。
この中には
input:~~~~
output:~~~~
の形式で会話文が書かれているので、今後使いやすいように整形していきます。input_corpus = [] output_corpus = [] for_spm_corpus = [] with open('/content/drive/My Drive/Colab Notebooks/make-meidai-dialogue/sequence.txt') as f: for s_line in f: if s_line.startswith('input: '): input_corpus.append(s_line[6:]) for_spm_corpus.append(s_line[6:]) elif s_line.startswith('output: '): output_corpus.append(s_line[7:]) for_spm_corpus.append(s_line[7:]) with open('/content/drive/My Drive/Colab Notebooks/input_corpus.txt', 'w') as f: f.writelines(input_corpus) with open('/content/drive/My Drive/Colab Notebooks/output_corpus.txt', 'w') as f: f.writelines(output_corpus) with open('/content/drive/My Drive/Colab Notebooks/spm_corpus.txt', 'w') as f: f.writelines(for_spm_corpus)transformerに入力するためのテキストと出力用テキスト、sentencepieceに学習させるためにinput:とoutput:部分を除した学習用テキストに分割しました。
前準備
続いてsentencepieceで会話文を分かち書きにします。
spm_corpus.txtを使って学習させてみましょう。import sentencepiece as spm # train sentence piece spm.SentencePieceTrainer.Train("--input=spm_corpus.txt --model_prefix=trained_model --vocab_size=8000 --bos_id=1 --eos_id=2 --pad_id=0 --unk_id=5")詳細はsentencepieceの公式リポジトリにやり方が書かれているので省略します。
それでは一度sentencepieceで文章を分かち書きしてみます。
sp = spm.SentencePieceProcessor() sp.Load("trained_model.model") #test print(sp.EncodeAsPieces("ああそういうことね")) print(sp.EncodeAsPieces("なるほどわかった")) print(sp.EncodeAsPieces("つまり、そのあなたの言いたいことはそういうことですか?")) print(sp.DecodeIds([0,1,2,3,4,5]))実行結果です。
['▁ああ', 'そういうこと', 'ね'] ['▁なるほど', 'わかった'] ['▁', 'つまり', '、', 'その', 'あなた', 'の', '言い', 'たい', 'ことは', 'そういうこと', 'ですか', '?'] 、。 ⁇以上のように分割されることがわかりました。
ここからの内容はKeras TransformerのREADME.mdに書かれている内容を一部改変したものになります。
それではパディングとtransformerに適した形式にコーパスを整形させていきます。
import numpy as np # Generate toy data encoder_inputs_no_padding = [] encoder_inputs, decoder_inputs, decoder_outputs = [], [], [] max_token_size = 168 with open('/content/drive/My Drive/Colab Notebooks/input_corpus.txt') as input_tokens, open('/content/drive/My Drive/Colab Notebooks/output_corpus.txt') as output_tokens: #コーパスから一行ずつ読み込む input_tokens = input_tokens.readlines() output_tokens = output_tokens.readlines() for input_token, output_token in zip(input_tokens, output_tokens): if input_token or output_token: encode_tokens, decode_tokens = sp.EncodeAsPieces(input_token), sp.EncodeAsPieces(output_token) #パディングする encode_tokens = ['<s>'] + encode_tokens + ['</s>'] + ['<pad>'] * (max_token_size - len(encode_tokens)) output_tokens = decode_tokens + ['</s>', '<pad>'] + ['<pad>'] * (max_token_size - len(decode_tokens)) decode_tokens = ['<s>'] + decode_tokens + ['</s>'] + ['<pad>'] * (max_token_size - len(decode_tokens)) encode_tokens = list(map(lambda x: sp.piece_to_id(x), encode_tokens)) decode_tokens = list(map(lambda x: sp.piece_to_id(x), decode_tokens)) output_tokens = list(map(lambda x: [sp.piece_to_id(x)], output_tokens)) encoder_inputs_no_padding.append(input_token) encoder_inputs.append(encode_tokens) decoder_inputs.append(decode_tokens) decoder_outputs.append(output_tokens) else: break #学習モデルへの入力用に変換する X = [np.asarray(encoder_inputs), np.asarray(decoder_inputs)] Y = np.asarray(decoder_outputs)学習させる
それではtransformerに学習させていきます。
from keras_transformer import get_model # Build the model model = get_model( token_num=sp.GetPieceSize(), embed_dim=32, encoder_num=2, decoder_num=2, head_num=4, hidden_dim=128, dropout_rate=0.05, use_same_embed=True, # Use different embeddings for different languages ) model.compile( optimizer='adam', loss='sparse_categorical_crossentropy', ) model.summary() # Train the model model.fit( x=X, y=Y, epochs=10, batch_size=32, )実行結果です。
Epoch 1/10 33361/33361 [==============================] - 68s 2ms/step - loss: 0.2818 Epoch 2/10 33361/33361 [==============================] - 66s 2ms/step - loss: 0.2410 Epoch 3/10 33361/33361 [==============================] - 66s 2ms/step - loss: 0.2331 Epoch 4/10 33361/33361 [==============================] - 66s 2ms/step - loss: 0.2274 Epoch 5/10 33361/33361 [==============================] - 66s 2ms/step - loss: 0.2230 Epoch 6/10 33361/33361 [==============================] - 66s 2ms/step - loss: 0.2193 Epoch 7/10 33361/33361 [==============================] - 66s 2ms/step - loss: 0.2163 Epoch 8/10 33361/33361 [==============================] - 66s 2ms/step - loss: 0.2137 Epoch 9/10 33361/33361 [==============================] - 66s 2ms/step - loss: 0.2114 Epoch 10/10 33361/33361 [==============================] - 66s 2ms/step - loss: 0.2094損失は悪くなさそうですね。
推論させる
学習したモデルで推論を行ってみます。
from keras_transformer import decode input = "今日はいい天気ですね" encode = sp.EncodeAsIds(input) decoded = decode( model, encode, start_token=sp.bos_id(), end_token=sp.eos_id(), pad_token=sp.pad_id(), max_len=170 ) decoded = np.array(decoded,dtype=int) decoded = decoded.tolist() print(sp.decode(decoded))実行結果です。
ね、でも、あの、あの、あの、あの、あの、あの、あの、あの、あの、あのあれ…全然結果が芳しくありません。これじゃコミュ障です。
ここまでの考察
うまくいかなかった原因はなんでしょうか?
- 一文の長さが長すぎてうまく学習できていない?
- コーパスが足りない(今回は質問と回答それぞれ3万文ずつ)
- パラメータの設定がよくない
などが最初にあげられるでしょうか?
モデルの性能改善に向けて
そこでOptunaを使ってチューニングをしようと試みましたが次の理由でうまくいきませんでした。
- チューニングにかかる時間が長すぎる(最後までやっていませんが1日は余裕でかかりそう)
- 上記の理由からColabでの実行は難しい(12時間制限に引っかかるため)
- Colabではできないので自分のPC内の環境で試す(GPUは使えない)がもっと時間がかかるので断念
- ではクラウド上ではやるかと考えAWSを試すもGPU付きインスタンスの作成が許可されない(次記事の方法を試している間に許可されましたが…)
- そもそも途中までやってみた結果もあまり芳しくない(ほぼ精度に変化なしか)
ということで別の方法を試すことにしました。
うまくいった方法はこちら
- 投稿日:2020-07-14T13:07:02+09:00
Wikipediaダンプからリダイレクトを抽出する
個人的な備忘録として残します。
手早くファイルを得られるよう、なるべく簡潔に書きたいと思います。完成予想図
Wikipediaのリダイレクトを収集して以下のようなファイルを作ります。
redirects.json{"src": "COVID-19", "dst": "新型コロナウイルス感染症_(2019年)"} {"src": "COVID-2019", "dst": "新型コロナウイルス感染症_(2019年)"} {"src": "Covid-19", "dst": "新型コロナウイルス感染症_(2019年)"} {"src": "Covid-2019", "dst": "新型コロナウイルス感染症_(2019年)"} {"src": "新型コロナウイルス感染症", "dst": "新型コロナウイルス感染症_(2019年)"} {"src": "コビッド19", "dst": "新型コロナウイルス感染症_(2019年)"} {"src": "COVID19", "dst": "新型コロナウイルス感染症_(2019年)"} {"src": "2019新型コロナウイルス感染症", "dst": "新型コロナウイルス感染症_(2019年)"}リダイレクトとは
以下参照
Wikipedia:リダイレクトリダイレクト例
https://ja.wikipedia.org/wiki/COVID-19 にアクセスしようとすると、
自動的にhttps://ja.wikipedia.org/wiki/新型コロナウイルス感染症_(2019年) に飛ばされます。実装等
0. 必要な色々
- MySQL
- Python3
- mysqlclient
pip install mysqlclient1. Wikidumpのリストア
必要データのダウンロード
以下から必要なデータをダウンロードしてください。
https://dumps.wikimedia.org/jawiki/
jawiki-[dump取得日]-redirect.sql.gzjawiki-[dump取得日]-page.sql.gz解凍
$ gunzip jawiki-[dump取得日]-redirect.sql.gz $ gunzip jawiki-[dump取得日]-page.sql.gzMySQLデータベースへリストア
$ mysql -u [ユーザー名] -p [DB名] < jawiki-[dump取得日]-page.sql $ mysql -u [ユーザー名] -p [DB名] < jawiki-[dump取得日]-redirect.sql2. リダイレクト抽出
Pythonコード
データベースを叩いてリダイレクトを抽出しJSONで保存するコードです。
extract_redirects.pyimport json import MySQLdb USERNAME = "[MySQLユーザー名]" PASSWORD = "[パスワード]" DB_NAME = "[DB名]" OUTPUT = "./redirects.json" def save_jsonl(file_path, data): json_dumps = lambda d:json.dumps(d, ensure_ascii=False) dumps = map(json_dumps, data) with open(file_path, "w") as f: f.write("\n".join(dumps)) if __name__ == '__main__': # データベースに接続 conn = MySQLdb.connect( user=USERNAME, passwd=PASSWORD, host='localhost', db=DB_NAME ) # Cursorを作成しクエリを実行 cur = conn.cursor(MySQLdb.cursors.DictCursor) sql = "select page.page_title, redirect.rd_title from page, redirect where redirect.rd_from=page.page_id" cur.execute(sql) rows = cur.fetchall() # 実行結果を整理 redirects = [] for row in rows: row = {key:cell.decode() if type(cell) is bytes else cell for key, cell in row.items()} redirects.append({ "src":row["page_title"], "dst":row["rd_title"] }) # 保存 save_jsonl(OUTPUT, redirects) cur.close() conn.close()実行
python extract_redirects.py以上です!
α. 軽い解説等
※事前知識:Wikipediaのページには
titleの他にpage_idが個別に割り振られています。
jawiki-[dump取得日]-redirect.sql.gzでは、リダイレクト元のpage_idとリダイレクト先のtitleがレコードで紐づけられています。
jawiki-[dump取得日]-page.sql.gzでは、page_idとtitleがレコードで紐づけられています。この2つのダンプを組み合わせることで、リダイレクト元
titleとリダイレクト先titleを紐づけています。
- 投稿日:2020-07-14T11:49:00+09:00
列挙型に値が存在するか確認する方法
特定の事柄に対して値を持たせる場合に、定数って使いたいじゃないですか。
Pythonで定数を扱う場合って個人的にはEnum(列挙型)を使うのがいいと思うんです。そもそもPythonって定数なくない?
そうなんです。
どんな値でもやりようによっては上書きできてしまうので、厳密な意味での定数は存在しません。
でも公式ドキュメント にそう書いてあるんだもん。列挙型の記法
from enum import Enum class Hoge(Enum): ONE = 1 TWO = 2 THREE = 3列挙型とループ処理
列挙型は識別子の集合なので、識別子に持たせた値そのものに意味があるケースが少ないのではないかなと。
リスト型であればfor文で簡単に出力できるのですが、列挙型では書き方に工夫が要ります。リスト型>>> lst = [1, 2, 3] >>> [l for l in lst] [1, 2, 3]列挙型>>> from enum import Enum >>> class Hoge(Enum): ... ONE = 1 ... TWO = 2 ... THREE = 3 ... >>> [v.value for n, v in Hoge.__members__.items()] [1, 2, 3]ここまで来れば書けそう
>>> from enum import Enum >>> class Hoge(Enum): ... ONE = 1 ... TWO = 2 ... THREE = 3 ... >>> [v.value for n, v in Hoge.__members__.items()] [1, 2, 3] >>> 1 in [v.value for n, v in Hoge.__members__.items()] Trueできました。使い所は知りません。
おまけ
列挙型の
__members__の中身ってどうなっているんだろう?>>> Hoge.__members__ mappingproxy({ 'ONE': <Hoge.ONE: 1>, 'TWO': <Hoge.TWO: 2>, 'THREE': <Hoge.THREE: 3> })
MappingProxyTypeってなんだろう?
公式ドキュメントによると読み出し専用のマッピングのプロキシです。マッピングのエントリーに関する動的なビューを提供します。
つまり、マッピングが変わった場合にビューがこれらの変更を反映するということです。なるほど(?)
このプロキシの中にitems()があるわけですね。
さらっと見た感じだと辞書型にも似てますね。追記
@shiracamus様よりもっと簡素的な書き方があると教えていただきました。
>>> 1 in [e.value for e in Hoge] Trueあるいは
>>> any(e.value == 1 for e in Hoge) Trueと書けるようです。ありがとうございます!!
一つ目の方はなぜ気付かなかったのだろうかというレベルです・・・記事を書くことでアドバイスをいただけるので、やはりアウトプットって大切だなぁと思いました。
- 投稿日:2020-07-14T11:25:53+09:00
3次元座標データ群に関し、”ほぼ一致する”点が存在するかをひたすら確認する
はじめに
もっといい方法はないだろうか..と模索しつつも、ひとまずこの方法でまとめておく。(もっといい方法ご存知の方、教えてください!!)
やりたいこと
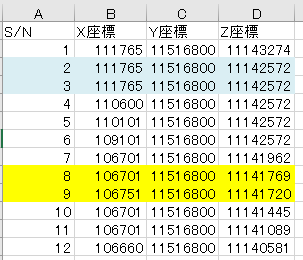
①基本
下図のように3次元の座標点が格納されているエクセルがあり、同じ座標を持つ番号をリンクさせたい。下図の例ではS/N-2の座標とS/N-3の座標(水色でハイライトした箇所)は完全一致しているので、これらは「同じ座標です!」と判定させる。②応用
私が今回取り組んでいる対象の仕様として、完全に座標が一致することはなかなか起こらない。そのため、ある程度のMarginをもって一致していると判定したい。例えば、S/N-8の座標とS/N-9の座標(黄色でハイライトした箇所)は概ね一致しているので、これらも「同じ座標です」と判定して欲しい。
今回、この”応用”のグッドアイデアが今一つ思い浮かばなかった。。
完全一致のみを抽出する場合はX座標、Y座標、Z座標を文字列として結合して、一致するか判断していけばいいのかなと思いました。できたコードがこのような感じ
まずはmarginを含んで判定できるような関数を作成。以下の場合誤差±100は無視され、3つの座標がmargin込みで一致した場合、Trueが返ります。
def coordinates_check(ax,ay,az,bx,by,bz): margin=100 flag = 0 result=False if ax-margin < bx < ax+margin: flag = flag +1 if ay-margin < by < ay+margin: flag = flag +1 if az-margin < bz < az+margin: flag = flag +1 if flag >2: result = True return resultこの関数を使用して、エクセルファイルの行を上から読み取っていきます。
読み取りが重複しないように、2つ目のfor文の開始番号を工夫しています。df_test = pd.read_excel('sample.xlsx') for i in range(len(df_test)): ax= df_test.loc[i,"X座標"] ay= df_test.loc[i,"Y座標"] az= df_test.loc[i,"Z座標"] k = i+1 for j in range(k,len(df_test)): bx = df_test.loc[j,"X座標"] by = df_test.loc[j,"Y座標"] bz = df_test.loc[j,"Z座標"] if coordinates_check(ax,ay,az,bx,by,bz): print("一致しました:",df_test.loc[i,"S/N"],"-->",df_test.loc[j,"S/N"])結果、うまくできている。
少ないデータならいいのだけど..
私が今回使いたいデータは1万行超えで、上記のコードを実行すると3時間くらいかかってしまったんですよね..。もっといい方法があるはずだよなぁと思った今日この頃でした。いい方法をご存知の方、助けてください!

- 投稿日:2020-07-14T11:18:52+09:00
テキスト画像の文字の背景を白飛びさせて読みやすくする
スマホで書類を撮影して使うことが多くなった。手軽だけどスキャナで取り込んだものより鮮明さに欠ける。スマホで撮影したようなコントラストの鈍い画像を読みやすくするには、文字を黒く残したまま背景の明度を上げるのがいいだろう。背景を白く飛ばす処理の都合で、画像の文字部分とただの白地部分を区別する必要がでてきたが、画像の局所ごとの画素の統計をとり画素値の標準偏差の大小で判定するとうまくいった。
例として次の画像を加工して行くことにする。各画像をクリックすると拡大して見ることができるはず。
波田野 直樹 著「多良間島幻視行」p.36ヒストグラム平坦化
画像の鮮明化をするときによく行われるのはヒストグラムの平坦化処理である。画像の画素の明度が狭い範囲に収まっているとき、それを画像フォーマットのレンジ全体、グレースケール画像なら0~255の範囲に広げてやれば、画素同士の違いが大きくなり画像がはっきりする。OpenCVには専用の関数が用意されており、以下のリンク先に詳しい説明がある。
OpenCVでのヒストグラム>ヒストグラム その2: ヒストグラム平坦化
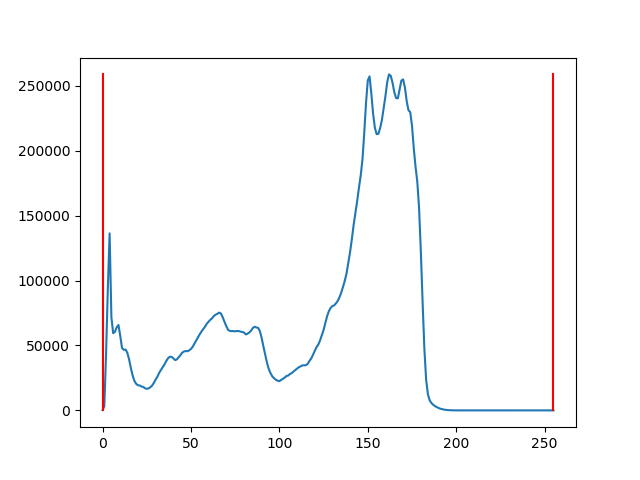
これを利用して元画像をグレースケール化してからヒストグラム平坦化したのが以下の画像である。プログラムとともに示す。bookimg = cv2.imread('tarama36p.jpg') img_gray = cv2.cvtColor(bookimg, cv2.COLOR_BGR2GRAY) equ = cv2.equalizeHist(img_gray) cv2.imwrite('tarama36pcv2.jpg', equ )
結果は特に文字が鮮明になった感じはしない。元画像では分からなかったが、左より右ページの方が明るいようだ。上部の金属片の反射が強調されている。実はこの画像のヒストグラムは以下のようになっていて、赤線が画素の明るさの最大最小値を表しているが、既に最大最小値が画像レンジいっぱいまで広がっているので、単純なヒストグラム平坦化の効果は少ない。
OpenCVには適用的ヒストグラム平坦化という、画像を細かいブロックに分けブロックごとにヒストグラム平坦化するという関数も用意されている。それによる処理結果が以下の画像である。bookimg = cv2.imread('tarama36p.jpg') img_gray = cv2.cvtColor(bookimg, cv2.COLOR_BGR2GRAY) equ = cv2.equalizeHist(img_gray) cv2.imwrite('tarama36pcv2.jpg', equ )
cv2.equalizeHist()よりは見やすくなったがスキャナほどではない。白画素をすべて真っ白に
汎用のコントラスト強化処理は、白い部分の画素値の違いもある程度残そうとする。テキスト画像の場合、背景白地の細かな情報は不要なので、ある閾値より上の画素はは全部真っ白、画素値としてすべて255に書き換えてもいいだろう。黒い方は文字形状の情報が入っているので、元の画素値に1より小さい値をかけて、値としては黒い方に寄せるが元の傾向は残すようにした。閾値はヒストグラムの中央値あたりの値から、仮に140としてみた。プログラムと処理結果は以下のとおり。
for y in range(img_gray.shape[0]): for x in range(img_gray.shape[1]): if img_gray[y][x] > 140: img_gray[y][x] = 255 else: img_gray[y][x] = img_gray[y][x] * 0.5 cv2.imwrite('tarama36p140.jpg', img_gray )
右側は狙い通り背景が白くつぶれ文字がクッキリとした。金属片の余計な映り込みも消えている。しかしながら左下は全体として暗めだったので、背景部分まで黒と認識されて強調されてしまった。かといって左下に閾値を合わせると、今度は右側で文字部分が白く飛んでしまう。つまり適切な閾値は画像の場所によって違う。画像をブロックに分けて処理する
適用的ヒストグラム平坦化同様、元画像を縦横64ドットのブロックに分け、それぞれ適切な閾値を求め処理する。閾値をどう決めるかが重要だが、ここでは閾値の値は各ブロックの画素の中央値の下半分のさらに中央値、つまりブロック画素全体の1/4を黒とみなすような値とした。ブロック画像imgを引数として閾値を返す関数をPythonで書くと、以下のようになる。使ってみると大雑把だがまあまあ適切な値を返してくれるようだ。ただし黒字に白のテキストだとうまくいかないだろう。
import numpy as np def getBWThrsh(img): med = np.median(img) fild = img[img < med] return np.median(fild)処理した結果が以下の画像である。なお、各ブロックごとにヒストグラム平均化処理も合わせて行い、白く飛ばすところは単純に255を代入するのではなく、元の画素に大多数の背景が256を越えるような係数をかけて代入している。ほとんどは白く飛ばすが、それよりちょっと暗い文字の部分は残すためだ。
文字部分はうまく背景が白く抜けているが、改行して文字のないただの白地の部分は、薄っすらと裏のページの文字が透けている。拡大したのが以下の画像である。
裏ページが透けた部分には非常に微かな濃淡の差しかないが、ヒストグラム平均化処理をすることで、見事に裏文字が浮き上がってきたわけである。文字と白地の区別をつける
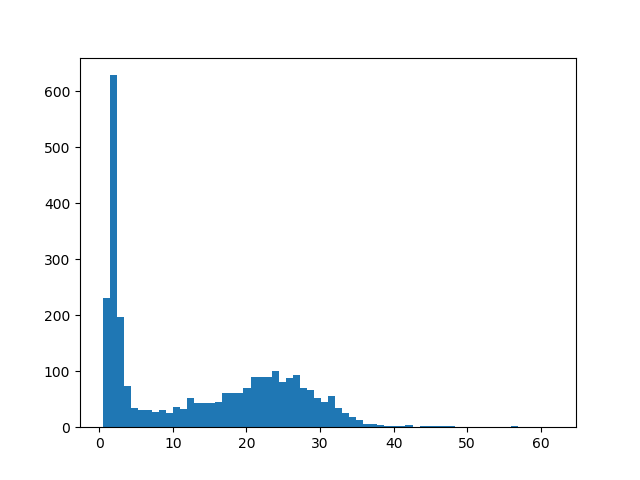
裏ページが透けるので白地部分はヒストグラム平均化処理をしないようにしたい。文字部分と白地部分を見分けるにはどうすればいいだろうか。これまでブロックごとにnumpyで統計処理を行い画素の中央値などを求めてきたが、文字と白地の区別に画素値の標準偏差が使えるのではないかと思いついた。白地は画素値のバラツキが少なく標準偏差が小さい、文字部分はそれより大きい値になるだろう。ともかく各ブロックの画素の標準偏差を求め、どういう値が多いのかヒストグラムを作成して傾向を調べてみた。
左側の小さい値に突出してピークになっているところがあるが、これか白地のブロックだろう。このピークを含むような値に標準偏差の閾値を設定すれば白地を判定できる。閾値をあまり小さくすると白地のゴミが残るし、大きくすると白地に小さい文字の一部が含まれていても白地とみなされて欠けてしまうので、適切な閾値を設定するのは実は難しいのだが、ともかくこれで文字と白地の区別をつけ、白地は完全に白く飛ばす処理を行ったのが以下の画像である。
周辺のテキストでないところに、いろいろとゴミが残ったが、テキスト部分は綺麗に処理できたと思う。ブロック単位で白地とそうでない部分の区別がつくようになったので、白地ブロックが連続していると周りの余白部分であるとか、余白部にぽつりと文字が入ってるとノンブルだろうとか、いろいろな判定に応用ができるような気がする。以上のソースは以下のとおり。一番下の行にあるsharpenImg()の引数に変換したいファイル名を書くと背景を白飛びさせたファイルを作成する。今のところ変換に数十秒の時間がかかるが、Cなどで書き換えれば実用な処理速度になると思う。
import cv2 from matplotlib import pyplot as plt import numpy as np def getStdThrsh(img, Blocksize): stds = [] for y in range( 0, img.shape[0], Blocksize ): for x in range( 0, img.shape[0], Blocksize ): pimg = img[y:y+Blocksize, x:x+Blocksize] std = np.std( pimg ) minv = np.min( pimg ) maxv = np.max( pimg ) stds.append(std) hist = np.histogram( stds, bins=64 ) peaki = np.argmax(hist[0]) #plt.hist( stds, bins=64 ) #plt.show() slim = 6.0 for n in range(peaki,len(hist[0])-1): if hist[0][n] < hist[0][n+1]: slim = hist[1][n+1] break if slim > 6.0: slim = 6.0 return slim def getBWThrsh(img): med = np.median(img) fild = img[img < med] return np.median(fild) def getWbias( img, bwthr ): wimg = img[ img > bwthr ] hist = np.histogram( wimg, bins=16 ) agm = np.argmax(hist[0]) return hist[1][agm] def getOutputName( title, slim ): return title + "_s{:04.2f}.jpg".format( slim ) def sharpenImg(imgfile): Testimagefile = imgfile TestimageTitle = Testimagefile.split('.')[0] Blocksize = 64 Bbias = 0.2 bookimg = cv2.imread( Testimagefile ) img_gray = cv2.cvtColor(bookimg, cv2.COLOR_BGR2GRAY) slim = getStdThrsh(img_gray, Blocksize) for y in range( 0, img_gray.shape[0], Blocksize ): s = "" for x in range( 0, img_gray.shape[1], Blocksize ): pimg = img_gray[y:y+Blocksize, x:x+Blocksize] std = np.std( pimg ) minv = np.min( pimg ) maxv = np.max( pimg ) pimg -= minv cimg = pimg.copy() if maxv != minv: for sy in range (cimg.shape[0]): for sx in range( cimg.shape[1] ): cimg[sy][sx] = (cimg[sy][sx]*255.0)/(maxv - minv) bwthrsh = getBWThrsh( pimg ) wb = getWbias( cimg, bwthrsh ) wbias = 256 / wb if std < slim: s = s + "B" for sy in range (pimg.shape[0]): for sx in range( pimg.shape[1] ): img_gray[y+sy][x+sx] = 255 else: s = s + "_" for sy in range (cimg.shape[0]): for sx in range( cimg.shape[1] ): if maxv != minv: img_gray[y+sy][x+sx] = (img_gray[y+sy][x+sx]*255.0)/(maxv - minv) if pimg[sy][sx] > bwthrsh: v = img_gray[y+sy][x+sx] v = v * wbias if v > 255: v = 255 img_gray[y+sy][x+sx] = v else: img_gray[y+sy][x+sx] = pimg[sy][sx] * Bbias print( "{:4d} {:s}".format( y, s ) ) cv2.imwrite(getOutputName(TestimageTitle, slim), img_gray ) if __name__ =='__main__': sharpenImg('tarama36p.jpg')







- 投稿日:2020-07-14T11:07:11+09:00
pandas_profilingを使ってデータの状態を確認する
概要
データエンジニアやデータ整備をやっている方はデータの不整合見るときにいろいろなツールを使って調べたり、SQLで叩いて調べたりすると思います。
最近自分もそのようなことをすることが多いです。特に新しいデータの連携とかが始まった時などはデータの内容を見ることが多いです。そんな時にpandas_profilingは役に立ちます。インストール方法
pip install pandas-profiling[notebook]使い方
import pandas_profiling as pdp from sklearn.datasets import load_boston data = load_boston() df = pd.DataFrame(data.data, columns=data.feature_names) profile = pdp.ProfileReport(df, {'correlations': None}) profile.to_file("profile.html")私は単純にデータの分布が知りたいことが多いので相関の計算などはしないようにオプションを追加しています。
また他の方への共有などをするためにhtmlに出力しています。結果
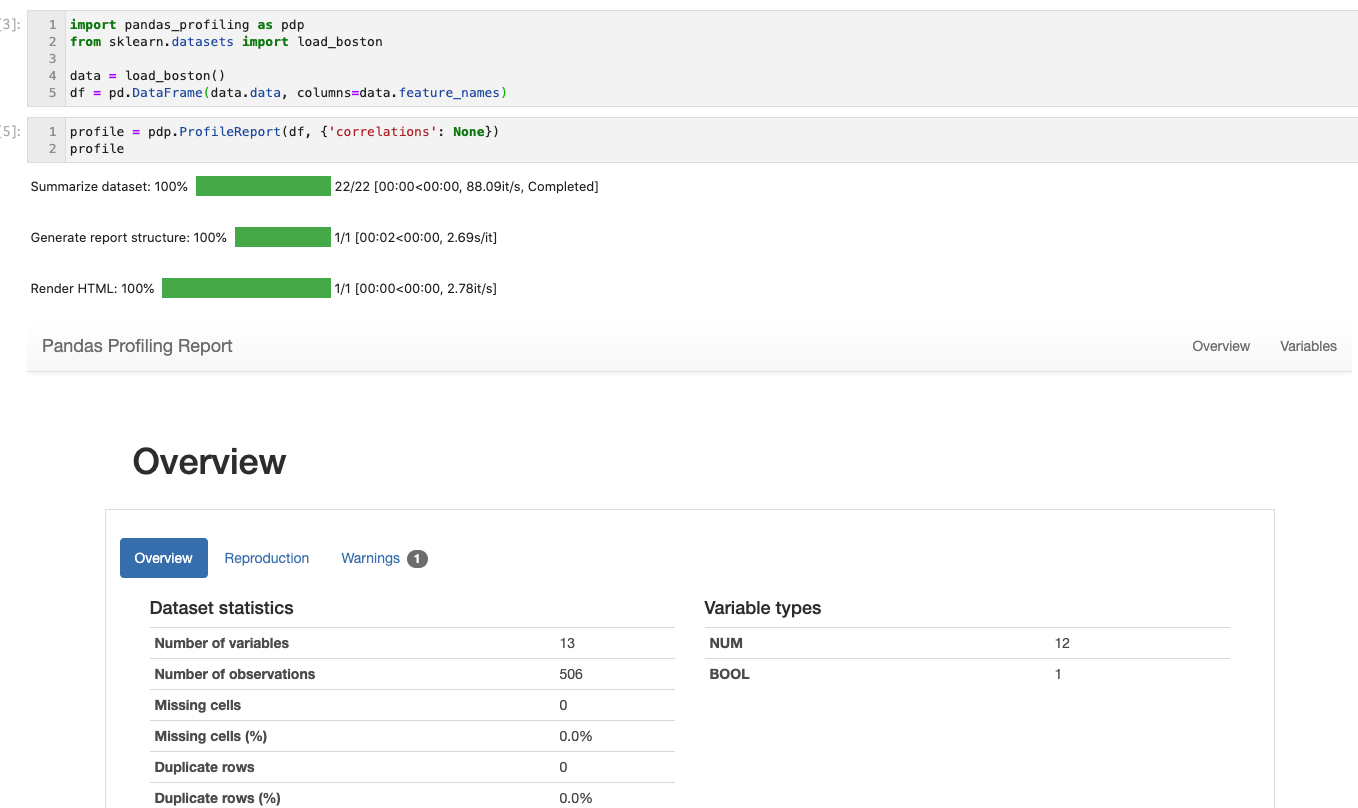
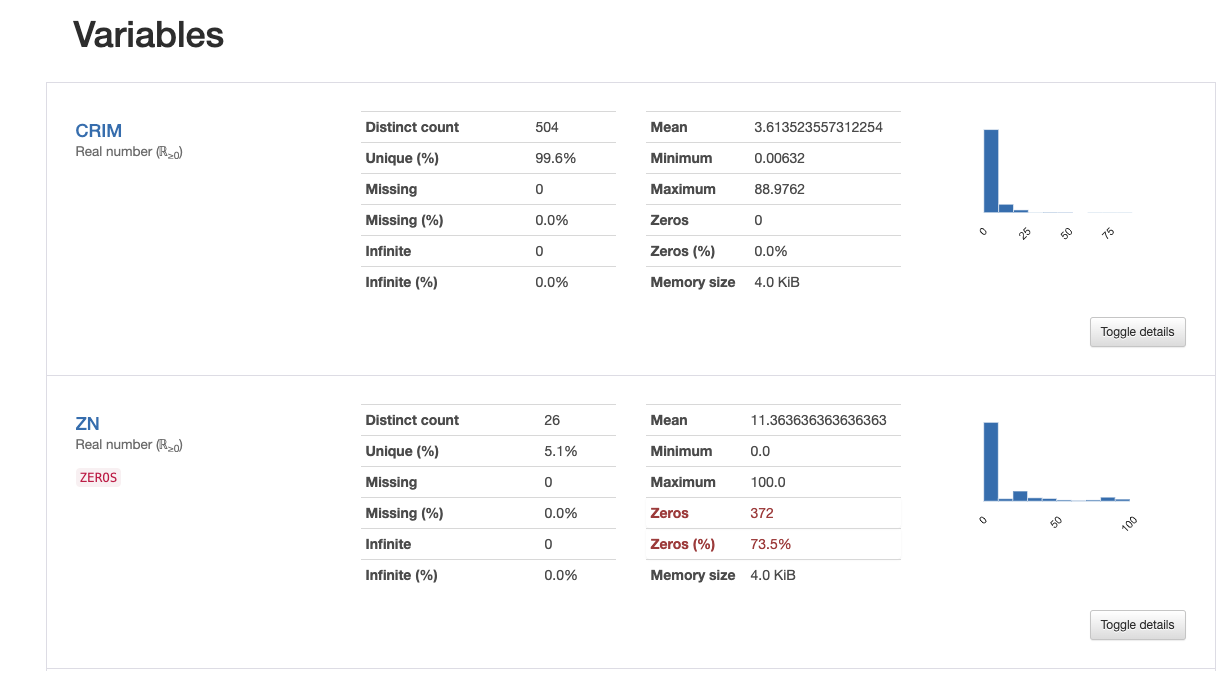
Jupyter notebook上で実行すると下図のようにプロセスバーが表示され、処理されている状態がわかります。
各項目のデータの状態がわかります。特に私が気にかけているのは欠損値で、欠損値の数や割合が表示されるのでとても便利です。
- 投稿日:2020-07-14T11:06:38+09:00
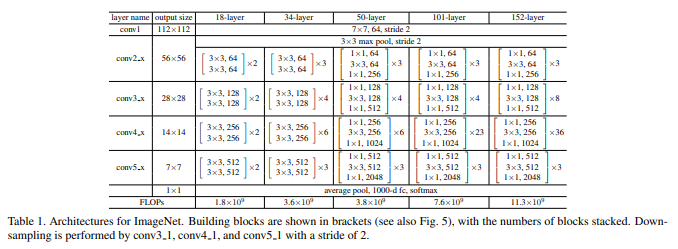
ResNetを実装してみただけ (TF2.0)
概要
ResNet論文にあるアーキテクチャに従い、ResNet50を実装しました。
ResNetのShortcut Connection(Skip Connection)という手法は他のネットワークモデルでもよく使われる手法ですので、実装法を知っておこうと思いやってみました。環境
-Software-
Windows 10 Home
Anaconda3 64-bit(Python3.7)
VScode
-Library-
Tensorflow 2.2.0
-Hardware-
CPU: Intel core i9 9900K
GPU: NVIDIA GeForce RTX2080ti
RAM: 16GB 3200MHz参考
サイト
・ResNet論文
・Residual Network(ResNet)の理解とチューニングのベストプラクティス
・TensorFlow2.0を使ってFashion-MNISTをResNet-50で学習する
↑ほとんどこの方が実装したコードと同じですプログラム
Githubに上げておきます。
https://github.com/himazin331/ResNet今回は、データセットにFashion-MNISTを使いました。
ソースコード
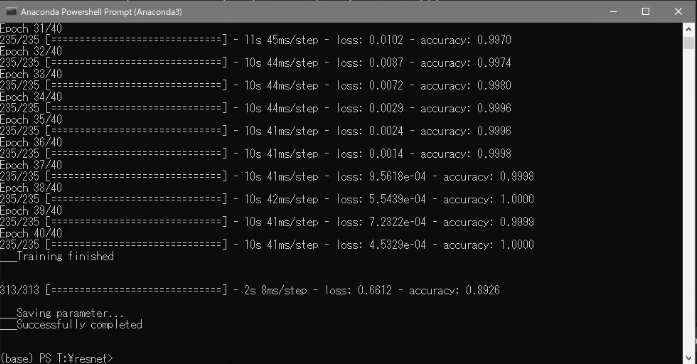
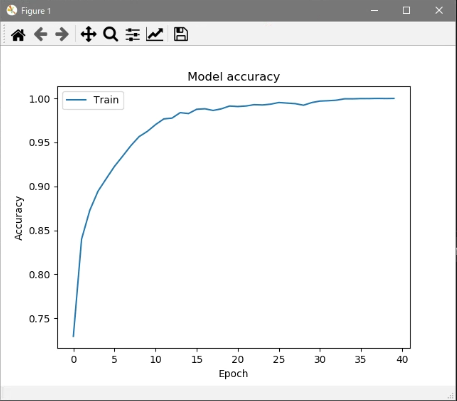
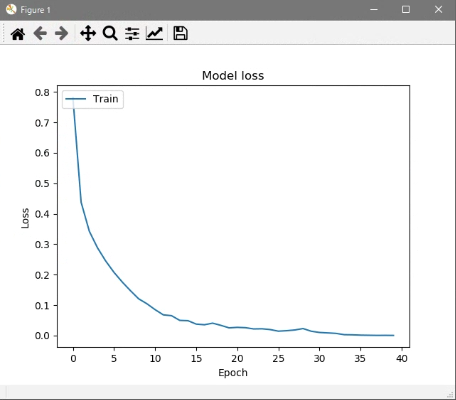
resnet.pyimport argparse as arg import os import numpy as np import matplotlib.pyplot as plt os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2' import tensorflow as tf import tensorflow.keras.layers as kl # 残差ブロック(Bottleneckアーキテクチャ) class Res_Block(tf.keras.Model): def __init__(self, in_channels, out_channels): super().__init__() bneck_channels = out_channels // 4 self.bn1 = kl.BatchNormalization() self.av1 = kl.Activation(tf.nn.relu) self.conv1 = kl.Conv2D(bneck_channels, kernel_size=1, strides=1, padding='valid', use_bias=False) self.bn2 = kl.BatchNormalization() self.av2 = kl.Activation(tf.nn.relu) self.conv2 = kl.Conv2D(bneck_channels, kernel_size=3, strides=1, padding='same', use_bias=False) self.bn3 = kl.BatchNormalization() self.av3 = kl.Activation(tf.nn.relu) self.conv3 = kl.Conv2D(out_channels, kernel_size=1, strides=1, padding='valid', use_bias=False) self.shortcut = self._scblock(in_channels, out_channels) self.add = kl.Add() # Shortcut Connection def _scblock(self, in_channels, out_channels): if in_channels != out_channels: self.bn_sc1 = kl.BatchNormalization() self.conv_sc1 = kl.Conv2D(out_channels, kernel_size=1, strides=1, padding='same', use_bias=False) return self.conv_sc1 else: return lambda x : x def call(self, x): out1 = self.conv1(self.av1(self.bn1(x))) out2 = self.conv2(self.av2(self.bn2(out1))) out3 = self.conv3(self.av3(self.bn3(out2))) shortcut = self.shortcut(x) out4 = self.add([out3, shortcut]) return out4 # ResNet50(Pre Activation) class ResNet(tf.keras.Model): def __init__(self, input_shape, output_dim): super().__init__() self._layers = [ kl.BatchNormalization(), kl.Activation(tf.nn.relu), kl.Conv2D(64, kernel_size=7, strides=2, padding="same", use_bias=False, input_shape=input_shape), kl.MaxPool2D(pool_size=3, strides=2, padding="same"), Res_Block(64, 256), [ Res_Block(256, 256) for _ in range(2) ], kl.Conv2D(512, kernel_size=1, strides=2), [ Res_Block(512, 512) for _ in range(4) ], kl.Conv2D(1024, kernel_size=1, strides=2, use_bias=False), [ Res_Block(1024, 1024) for _ in range(6) ], kl.Conv2D(2048, kernel_size=1, strides=2, use_bias=False), [ Res_Block(2048, 2048) for _ in range(3) ], kl.GlobalAveragePooling2D(), kl.Dense(1000, activation="relu"), kl.Dense(output_dim, activation="softmax") ] def call(self, x): for layer in self._layers: if isinstance(layer, list): for l in layer: x = l(x) else: x = layer(x) return x # 学習 class trainer(object): def __init__(self): self.resnet = ResNet((28, 28, 1), 10) self.resnet.build(input_shape=(None, 28, 28, 1)) self.resnet.compile(optimizer=tf.keras.optimizers.SGD(momentum=0.9), loss=tf.keras.losses.SparseCategoricalCrossentropy(), metrics=['accuracy']) def train(self, train_img, train_lab, test_images, test_labels, out_path, batch_size, epochs): print("\n\n___Start training...") his = self.resnet.fit(train_img, train_lab, batch_size=batch_size, epochs=epochs) graph_output(his, out_path) # グラフ出力 print("___Training finished\n\n") self.resnet.evaluate(test_images, test_labels) # テストデータ推論 print("\n___Saving parameter...") out_path = os.path.join(out_path, "resnet.h5") self.resnet.save_weights(out_path) # パラメータ保存 print("___Successfully completed\n\n") # accuracy, lossグラフ def graph_output(history, out_path): plt.plot(history.history['accuracy']) plt.title('Model accuracy') plt.ylabel('Accuracy') plt.xlabel('Epoch') plt.legend(['Train'], loc='upper left') plt.savefig(os.path.join(out_path, "acc_graph.jpg")) plt.show() plt.plot(history.history['loss']) plt.title('Model loss') plt.ylabel('Loss') plt.xlabel('Epoch') plt.legend(['Train'], loc='upper left') plt.savefig(os.path.join(out_path, "loss_graph.jpg")) plt.show() def main(): # コマンドラインオプション作成 parser = arg.ArgumentParser(description='ResNet50') parser.add_argument('--out', '-o', type=str, default=os.path.dirname(os.path.abspath(__file__)), help='パラメータの保存先指定(デフォルト値=./resnet.h5') parser.add_argument('--batch_size', '-b', type=int, default=256, help='ミニバッチサイズの指定(デフォルト値=256)') parser.add_argument('--epoch', '-e', type=int, default=40, help='学習回数の指定(デフォルト値=40)') args = parser.parse_args() # 設定情報出力 print("=== Setting information ===") print("# Output folder: {}".format(args.out)) print("# Minibatch-size: {}".format(args.batch_size)) print("# Epoch: {}".format(args.epoch)) print("===========================") # 出力フォルダの作成(フォルダが存在する場合は作成しない) os.makedirs(args.out, exist_ok=True) # Fashion-MNIST読込 f_mnist = tf.keras.datasets.fashion_mnist (train_images, train_labels), (test_images, test_labels) = f_mnist.load_data() # 画像データ加工 train_imgs = train_images / 255.0 train_imgs = train_imgs[:, :, :, np.newaxis] test_imgs = test_images / 255.0 test_imgs = test_imgs[:, :, :, np.newaxis] Trainer = trainer() Trainer.train(train_imgs, train_labels, test_imgs, test_labels, args.out, args.batch_size, args.epoch) if __name__ == "__main__": main()実行結果
今回はFashion-MNISTをミニバッチ数256で40エポック学習させました。
コンソール画面
学習終了後に汎化性能をテストします。
予測精度グラフ
損失値グラフ
コマンド
python resnet.py -b <ミニバッチサイズ> -e <学習回数> (-o <保存先>)説明
簡単な説明をしていきます。
ResNet
ResNetクラス# ResNet50(Pre Activation) class ResNet(tf.keras.Model): def __init__(self, input_shape, output_dim): super().__init__() self._layers = [ kl.BatchNormalization(), kl.Activation(tf.nn.relu), kl.Conv2D(64, kernel_size=7, strides=2, padding="same", use_bias=False, input_shape=input_shape), kl.MaxPool2D(pool_size=3, strides=2, padding="same"), Res_Block(64, 256), [ Res_Block(256, 256) for _ in range(2) ], kl.Conv2D(512, kernel_size=1, strides=2), [ Res_Block(512, 512) for _ in range(4) ], kl.Conv2D(1024, kernel_size=1, strides=2, use_bias=False), [ Res_Block(1024, 1024) for _ in range(6) ], kl.Conv2D(2048, kernel_size=1, strides=2, use_bias=False), [ Res_Block(2048, 2048) for _ in range(3) ], kl.GlobalAveragePooling2D(), kl.Dense(1000, activation="relu"), kl.Dense(output_dim, activation="softmax") ] def call(self, x): for layer in self._layers: if isinstance(layer, list): for l in layer: x = l(x) else: x = layer(x) return x
ResNet50クラスでネットワークモデルの定義を行っています。
アーキテクチャは論文にある通りに決定しました。
summary()でみるとこんな感じです。
Residual Block
Res_Block# 残差ブロック(Bottleneckアーキテクチャ) class Res_Block(tf.keras.Model): def __init__(self, in_channels, out_channels): super().__init__() bneck_channels = out_channels // 4 self.bn1 = kl.BatchNormalization() self.av1 = kl.Activation(tf.nn.relu) self.conv1 = kl.Conv2D(bneck_channels, kernel_size=1, strides=1, padding='valid', use_bias=False) self.bn2 = kl.BatchNormalization() self.av2 = kl.Activation(tf.nn.relu) self.conv2 = kl.Conv2D(bneck_channels, kernel_size=3, strides=1, padding='same', use_bias=False) self.bn3 = kl.BatchNormalization() self.av3 = kl.Activation(tf.nn.relu) self.conv3 = kl.Conv2D(out_channels, kernel_size=1, strides=1, padding='valid', use_bias=False) self.shortcut = self._scblock(in_channels, out_channels) self.add = kl.Add() # Shortcut Connection def _scblock(self, in_channels, out_channels): if in_channels != out_channels: self.bn_sc1 = kl.BatchNormalization() self.conv_sc1 = kl.Conv2D(out_channels, kernel_size=1, strides=1, padding='same', use_bias=False) return self.conv_sc1 else: return lambda x : x def call(self, x): out1 = self.conv1(self.av1(self.bn1(x))) out2 = self.conv2(self.av2(self.bn2(out1))) out3 = self.conv3(self.av3(self.bn3(out2))) shortcut = self.shortcut(x) out4 = self.add([out3, shortcut]) return out4
Res_Blockクラスは肝となる残差ブロックです。
_scblockメソッドでShortcut Connectionを実装しています。
アーキテクチャはPre Activation(参照)で実装しています。
trainer
trainerclass trainer(object): def __init__(self): self.resnet = ResNet((28, 28, 1), 10) self.resnet.build(input_shape=(None, 28, 28, 1)) self.resnet.compile(optimizer=tf.keras.optimizers.SGD(momentum=0.9), loss=tf.keras.losses.SparseCategoricalCrossentropy(), metrics=['accuracy'])論文中ではSGD+Momentumを用いたとあったので、準拠してSGD+Momentumを用いています。
おわりに
勉強でResNetを実装しただけなので、特段説明すること無いです...
TensorFlow2.0を使ってFashion-MNISTをResNet-50で学習するで紹介されているコードをみて、大変勉強になりました。
リストとfor文を使って層を展開していく発想いいなーって思い、今後真似できる場面があったら真似してみたいと思いました。
- 投稿日:2020-07-14T10:50:01+09:00
progate Python 学習メモ(随時更新)
実務でPythonやNumpy、Pandas、その他のライブラリを使うことはありましたが、
自分の知識が歯抜けなのを自覚していたので、
今回Progateで1から復習しようと思いました。progateの学習コースの上級の知識は知っているのに
初級のある部分が抜けていたりと、本当に歯抜けの知識です。抜けている部分をメモしていこうと思います。(随時更新)
辞書
※注意 ゲーム「CLOCK ZERO~終焉の一秒~」のネタバレを含みます
script01.py#Chara = {'King':'Takato', 'Wonderer':'Riichiro', 'Bishop':'Madoka', 'Traitor':'Toranosuke', 'Philosopher':'Syuya'} #長い辞書を見やすくする Chara = {'King':'Takato', 'Wonderer':'Riichiro', 'Bishop':'Madoka', 'Traitor':'Toranosuke', 'Philosopher':'Shuya'} print('攻略対象は以下の5人です。') for target in Chara : print (Chara[target]) #辞書要素の追加 Chara['Journalist'] = 'Nakaba' print(Chara) print('2015年発売のExtimeから' + Chara['Journalist'] + 'が攻略対象に追加されました。')
ループ処理のスキップ continue
script02.pynumbers = [1, 2, 3, 4, 5, 6] for number in numbers : if number % 3 == 0 ; #変数numberが3の倍数の時 continue #ループ処理をスキップ print (number)
私の経歴について
プログラミング歴は1~6年ちょい??
OA事務として仕事していたときに
Windowsのバッチスクリプトをゴリゴリ書いて業務を自動化したり、
Excel VBAで数値計算用のデータを整理したりしていました。
ある数値計算プログラムを動かすのにシェルが必要だったので
WindowsにCygwinを入れてシェルのコードを書いたり
fortranのコードを書き直したり。
(当時は77と90の違いが分からなかった!)
ソフト上でデータベースを扱っていたので
SQLの仕組みも知っているけどコードは分からない。
本当に変な経歴です。
- 投稿日:2020-07-14T10:34:46+09:00
Pycharmの日本語化
環境 windows7 32bit
公式サイトから日本語化zipファイルをダウンロードして解凍先から.exeを実行しても~.dllがありませんと
日本語化出来ずにハマりました。少しだけのコツであっさり日本語化出来ました。
Pycharm日本語化
1,まずは日本語化のプラグイン本体をダウンロード
2,解凍先にPycharmのフォルダを選択
3,解凍先から.exeを実行する
4,Pycharmを立ち上げる
これだけでした。
ちなみに私のPycharmのインストール先は
C:\Program Files\JetBrains\PyCharm Community Edition 2018.3.7\bin
にありました。fin

- 投稿日:2020-07-14T10:18:19+09:00
python よく忘れるlistの中から条件抽出
自分がpandasの列名から条件で列を抽出する方法をよく忘れるのでメモ
new_list.pynew_list = [x for x in data.columns if 'liquid_' in x] display(df[new_list])
- 投稿日:2020-07-14T09:43:42+09:00
【技術書】Pythonによるデータ分析入門 -1章 はじめに-
本書で使うデータファイルや関連する素材は下記のGitHubレポジトリ
https://github.com/wesm/pydata-book
要点をまとめた備忘録目次
- 覚えておくとよいこと
- 必須のPythonライブラリ
- 専門用語等
- 感想等
覚えておくとよいこと
- 優秀なデータ分析者になることを目的に書かれており、データ分析のために必要なプログラミングをPythonによって行うための知識を学ぶ本。
- PythonはDjnagoなどのウェブフレームワークを使って、ウェブサイトの構築によく利用されている。データサイエンス、機械学習、一般的なソフトウェア開発において、最も重要な言語の1つ。
- pandasやscikit-learnといったライブラリのサポートの改善により、Pythonはデータ分析における有力な選択肢になった。
- Pythonはインタプリタ型言語なので、実行速度が遅い。待ち時間が短いことが求められるアプリケーションや、リソースの有効利用を要求するようなアプリケーション(例えば高頻度の取引システム)などでは、C++のような低レベル言語で性能を極限までに高める方が、有効な時間の使い方になる。
- Pythonは、並列でマルチスレッドなアプリケーションを開発する言語としては難易度が高い(GILという機構による)
必須のPythonライブラリ
Numpy
Pythonにおける数値計算の基盤で、データ構造やアルゴリズムを提供
高速で効率的な多次元配列オブジェクトndarrayや数学的演算が代表的。pandas
2010年に登場。
主要なオブジェクトはDataFrame = テーブル形式で列指向のデータ構造
numpyの高性能な配列計算機能と、スプレッドシートやリレーショナルデータベースのデータを(SQLのように)柔軟に操作する機能を併せ持つ。
pandasはこの本で主に扱うものの1つ。
データの操作や準備、クリーニング等行える。Matplotlab
グラフなどの2次元形式の可視化に用いる最も一般的なPythonのライブラリ。
デフォルトで使う可視化ツールとして安全な選択肢IpythonとJupyter
IPythonは、編集して実行して試行錯誤する状況での利用を推奨
2014年に、IPython web notebookはJupyter Notebookに変わり、今では40以上のプログラミング言語をサポートしている。Ipythonは、JupyterでPythonを使うためのカーネルとして使われている。
Jupyter Notebookは、ウェブベースでコードを書くための「ノート」である。
MarkdownやHTMLで内容を編集できるため、コードと文章が混在したリッチなドキュメントを作ることができる。SciPy
科学計算の領域における一般的な問題を扱うパッケージを集めたもの。
NumpyとSciPyを一緒に用いることで、それらを合理的で成熟した計算基盤として使うことができ、多くの伝統的な科学計算に適用できる。scikit-learn
一般的な「機械学習ツール」のトップに立つ。
分類、回帰、クラスタリングを始めとするサブモジュールや、交差検証、前処理などstatsmodels
scikit-learnと比べ古典的な統計分析用パッケージ。専門用語等
- Python 2.xは「レガシー Python」、Python 3.xを単に「Python」と呼ぶ
- マンジング、ラングリング … 構造化されていなかったり、乱雑なデータを構造化されたきれいな形式に操作するプロセス全体のこと。
- 疑似コード … アルゴリズムやプロセスを説明するため、ソースコードに似た形式で説明するもの。
- シンタックスシュガー … 新機能を追加するわけではないが、入力を便利にするようなプログラミング言語の文法のこと。
感想等
初めてのqiita投稿は技術書の備忘録
復習に応じて編集したりしよう
qiitaで技術発信、人に見てもらいたいことを載せたりする
プラス、pythonで機械学習・AIのwebアプリケーション作ってみたい
なるべく自分の言葉で書く。完璧を求めすぎず。
人に見てもらうというのは大変良いモチベーション、かつ勉強が効率的に進む。
全ては書けない、覚えておきたいことや理解に頑張ったこと、興味を持ったことをまとめる
- 投稿日:2020-07-14T09:25:59+09:00
正規表現re
import re m = re.match('a.c', 'abc') print(m.group()) m = re.search('a.c', 'test abc test abc') print(m) print(m.span()) print(m.group()) m = re.findall('a.c', 'test abc test abc') print(m) m = re.finditer('a.c', 'test abc test abc') print([w.group() for w in m]) # 0または1の繰り返し m = re.match('ab?', 'a') print(m) # 0回以上の繰り返し m = re.match('ab*', 'abb') print(m) # 1回以上の繰り返し m = re.match('ab+', 'abbb') print(m) # 3回以上の繰り返し m = re.match('a{3}', 'aaaa') print(m) # 2-4回の繰り返し m = re.match('a{2,4}', 'aaaa') print(m) # 英数字とアンダースコアー m = re.match('[a-zA-Z0-9_]', '1') # m = re.match('\w', '1') print(m) # 英数字とアンダースコアー以外 m = re.match('[^a-zA-Z0-9_]', '@') # m = re.match('\W', '1') print(m) # 任意の数字 m = re.match('[0-9]', '1') # m = re.match('\d', '1') print(m) # 任意の数字以外 m = re.match('[^0-9]', '@') # m = re.match('\D', '1') print(m) # aまたはb m = re.match('a|b', 'b') print(m) m = re.match('(abc)+', 'abcabc') print(m) # スペース m = re.match('\s', ' ') print(m) # スペース以外 m = re.match('\S', '1') print(m) # エスケープ m = re.match('\*', '*') print(m) m = re.match('\?', '?') print(m) # 先頭一致 m = re.search('^abc', 'abctest abc') print(m) # 末尾 m = re.search('abc$', 'test abc') print(m)abc <re.Match object; span=(5, 8), match='abc'> (5, 8) abc ['abc', 'abc'] ['abc', 'abc'] <re.Match object; span=(0, 1), match='a'> <re.Match object; span=(0, 3), match='abb'> <re.Match object; span=(0, 4), match='abbb'> <re.Match object; span=(0, 3), match='aaa'> <re.Match object; span=(0, 4), match='aaaa'> <re.Match object; span=(0, 1), match='1'> <re.Match object; span=(0, 1), match='@'> <re.Match object; span=(0, 1), match='1'> <re.Match object; span=(0, 1), match='@'> <re.Match object; span=(0, 1), match='b'> <re.Match object; span=(0, 6), match='abcabc'> <re.Match object; span=(0, 1), match=' '> <re.Match object; span=(0, 1), match='1'> <re.Match object; span=(0, 1), match='*'> <re.Match object; span=(0, 1), match='?'> <re.Match object; span=(0, 3), match='abc'> <re.Match object; span=(5, 8), match='abc'>
- 投稿日:2020-07-14T06:45:44+09:00
CloudFormationコード(yaml)からパラメータ一覧を作りたい
はじめに
CloudFormationのyamlファイルから、パラメータに関する情報のみ抜き出して、一覧を作れるか挑戦しました。yamlの書き方によってはエラーになる未完成品ですが、個人的には及第点をとれたのでここに残します。
参考
今回のスクリプト作成にあたり、参考にさせて頂いたサイトです。
スクリプト(Python3)
早速ですが、スクリプトを紹介します。
- スクリプトの流れ
- (1)CloudFormationコード(yaml)をテキストファイルとして読み込む
- (2)短縮構文を拡張する(例:
!Sub->Fn::Sub,!Ref->Fn::Ref)- (3)短縮構文がない状態でyamlとして読み込む
- (4)yamlの中身を確認し、Parameters配下の情報をリスト表示する
paramlist.py## command sample ## python paramlist.py test.yml # yamlモジュールインストール `$ pip install pyyaml` import yaml import sys import re # 深堀りしない exclusionStr = "|AWSTemplateFormatVersion|Description|Type|TemplateURL|DependsOn|Mappings|Outputs|" args = sys.argv path = args[1] #(1)CloudFormationコード(yaml)をテキストファイルとして読み込む f = open(path) s0 = f.read() f.close() # (2)短縮構文を拡張する(例: `!Sub` -> `Fn::Sub` , `!Ref` -> `Fn::Ref`) s1 = re.sub("!((Sub|Ref|Join|GetAtt|FindInMap))\s", r'Fn::\1 ', s0) #(3)短縮構文がない状態でyamlとして読み込む obj = yaml.safe_load(s1) #(4)yamlの中身を確認し、Parameters配下の情報をリスト表示する def readYaml( curObj, pathStr , exeFlg): try: if exeFlg == 0: for key in curObj: # 次の階層に進む curFlg = key in exclusionStr if not curFlg: if key == "Parameters": nxtFlg = 1 else: nxtFlg = 0 pathStr += "/" + key readYaml( curObj[key] , pathStr , nxtFlg) else: print("---- {0} ----".format( pathStr ) ) # パラメータの項目と値を表示 for key in curObj: print( "\t{0} - {1}".format(key , curObj[key] ) ) except Exception as e: print("ERROR curObj = {0}, pathStr = {1}, exeFlg = {2}".format( curObj, pathStr, exeFlg ) ) print(e) ############################# ## -------- START -------- ## print("---- Parameter List ----" ) readYaml( obj , "" , 0 )実行結果
以下のCloudFormationコードに対してスクリプトを実行します。
test.ymlAWSTemplateFormatVersion: "2010-09-09" Description: cloudformation yaml sample Parameters: hogePrefix: { Type: String , Default: hogefuga123 } BucketUrl: { Type: String , Default: "https://hogefuga123.s3.amazonaws.com/" } AZName001: { Type: String , Default: ap-northeast-1a } AZName002: { Type: String , Default: ap-northeast-1c } VPCName: { Type: String , Default: vhoge01 } Resources: VPC: Type: AWS::CloudFormation::Stack Properties: TemplateURL: !Sub "${BucketUrl}${VPCTemplate}" Parameters: hogePrefix: !Ref hogePrefix BucketUrl: !Ref BucketUrl VPCName: !Ref VPCName実行結果
$ python paramlist.py test.yml ---- Parameter List ---- ---- /Parameters ---- hogePrefix - {'Type': 'String', 'Default': 'hogefuga123'} BucketUrl - {'Type': 'String', 'Default': 'https://hogefuga123.s3.amazonaws.com/'} AZName001 - {'Type': 'String', 'Default': 'ap-northeast-1a'} AZName002 - {'Type': 'String', 'Default': 'ap-northeast-1c'} VPCName - {'Type': 'String', 'Default': 'vhoge01'} ---- /Parameters/Resources/VPC/Properties/Parameters ---- hogePrefix - Fn::Ref hogePrefix BucketUrl - Fn::Ref BucketUrl VPCName - Fn::Ref VPCNameおまけ
[おまけ1] Cloud9 のセットアップ
本スクリプトを AWS Cloud9 で使うときの環境設定です。
# デフォルトを Python 2 -> Python 3 に切り替える $ sudo alternatives --config python $ pip -V $ sudo pip install --upgrade pip $ pip -V # yamlモジュールをインストール $ pip install pyyaml[おまけ2] そのままyamlロードするとエラーになる
上のサイトで紹介されている通り、短縮系の構文を含むCloudFormationコードをyamlとしてロードするとエラーになります。
$ python sample.py test.yml test.yaml Exception occurred while loading YAML... could not determine a constructor for the tag '!Sub' in "test.yaml", line 72, column 20
作ったスクリプトは未完成、どんなyaml形式でもエラーがでないようにしたい。

- 投稿日:2020-07-14T06:39:46+09:00
島根県の公開している河川の水位データを可視化してみる
はじめに
昨日に引き続き、島根県さんの公開されているデータを使って何かできないかと考えていて、河川の水位データが広い範囲にわたって公開されているようなので、これを可視化してみました。
手順確認
公開ページの構成を見る
カタログページ
まず、カタログページがあります。
https://shimane-opendata.jp/db/organization/main
河川水位ページ
カタログページの中に「河川水位データ」のページがあります。
https://shimane-opendata.jp/db/dataset/010010
日別のデータページ
日別で10分おきに保存された河川水位のデータがCSVで保存されているようです。
例えば、6月30日のデータをダウンロードしようと思うと以下のURLにアクセスします。https://shimane-opendata.jp/db/dataset/010010/resource/88f86c3b-b609-45a2-b3b9-1949c459aeae
7月1日は...
https://shimane-opendata.jp/db/dataset/010010/resource/2db49bb8-1e87-4f7d-9bc3-3e3c5d188044
あれ?
日別にURLが大きく異なります。日別のCSV
さらにCSVのURLは...
はい、使いにく〜い!
手順
ということで、以下の手順で可視化作業を行ってみることにします。
- 河川水位データのページから日別ページのURLを取得
- 日別のURLページからCSVのURLを取得
- 取得したCSVのURLからデータを取得
- データの加工
- 可視化
ちなみに、今回もColaboratoryを使用して実行します。
日別ページのURLを取得
以下のスクリプトで日別ページのURLを取得します。
import requests from bs4 import BeautifulSoup urlBase = "https://shimane-opendata.jp" urlName = urlBase + "/db/dataset/010010" def get_tag_from_html(urlName, tag): url = requests.get(urlName) soup = BeautifulSoup(url.content, "html.parser") return soup.find_all(tag) def get_page_urls_from_catalogpage(urlName): urlNames = [] elems = get_tag_from_html(urlName, "a") for elem in elems: try: string = elem.get("class")[0] if string in "heading": href = elem.get("href") if href.find("resource") > 0: urlNames.append(urlBase + href) except: pass return urlNames urlNames = get_page_urls_from_catalogpage(urlName) print(urlNames)CSVのURLを取得
以下のスクリプトでCSVのURLを取得します。
def get_csv_urls_from_url(urlName): urlNames = [] elems = get_tag_from_html(urlName, "a") for elem in elems: try: href = elem.get("href") if href.find(".csv") > 0: urlNames.append(href) except: pass return urlNames[0] urls = [] for urlName in urlNames: urls.append(get_csv_urls_from_url(urlName)) print(urls)URLからデータを取得してデータフレームを作成
上記で取得したURLからデータを直接読み込みます。
ちなみに、文字コードがShift JISになっていることと、最初の5行にデータ以外の情報が入っているのでそれは除きます。import pandas as pd df = pd.DataFrame() for url in urls: df = pd.concat([df, pd.read_csv(url, encoding="Shift_JIS").iloc[6:]]) df.shapeデータの確認と加工
df.info()上記を実行すると列の情報が取得できます。
<class 'pandas.core.frame.DataFrame'> Int64Index: 2016 entries, 6 to 149 Data columns (total 97 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 観測所 2016 non-null object 1 岩崎橋 2016 non-null object 2 大谷 2016 non-null object 3 玉湯川 2016 non-null object 4 鹿島 2016 non-null object 5 馬橋川 2016 non-null object 6 比津川水門上流 2016 non-null object 7 比津川水門下流 2016 non-null object 8 北田川水門上流 2016 non-null object 9 北田川水門下流 2016 non-null object 10 京橋川 2016 non-null object 11 京橋川水門上流 2016 non-null object 12 京橋川水門下流 2016 non-null object 13 手貝水門上流 2016 non-null object 14 手貝水門下流 2016 non-null object 15 神納橋 2016 non-null object 16 出雲郷 2016 non-null object 17 布部 2016 non-null object 18 大渡 2016 non-null object 19 矢田 2016 non-null object 20 飯梨橋 2016 non-null object 21 下山佐 2016 non-null object 22 祖父谷川 2016 non-null object 23 弘鶴橋 2016 non-null object 24 安来大橋 2016 non-null object 25 吉田橋 2016 non-null object 26 日の出橋 2016 non-null object 27 掛合大橋 2016 non-null object 28 坂山橋 2016 non-null object 29 神田橋1 2016 non-null object 30 八口橋 2016 non-null object 31 八神 2016 non-null object 32 横田新大橋 2016 non-null object 33 三成大橋 2016 non-null object 34 新橋 2016 non-null object 35 高瀬川 2016 non-null object 36 五右衛門橋 2016 non-null object 37 論田川 2016 non-null object 38 湯谷川 2016 non-null object 39 西平田 2016 non-null object 40 一文橋 2016 non-null object 41 仁江 2016 non-null object 42 佐田 2016 non-null object 43 木村橋 2016 non-null object 44 新内藤川 2016 non-null object 45 赤川 2016 non-null object 46 流下橋 2016 non-null object 47 十間川 2016 non-null object 48 神西湖 2016 non-null object 49 因原 2016 non-null object 50 下口羽 2016 non-null object 51 川合橋 2016 non-null object 52 八日市橋 2016 non-null object 53 正原橋 2016 non-null object 54 出口 2016 non-null object 55 日の出 2016 non-null object 56 神田橋2 2016 non-null object 57 長久 2016 non-null object 58 久手 2016 non-null object 59 刺鹿 2016 non-null object 60 宅野 2016 non-null object 61 善興寺橋 2016 non-null object 62 古市橋 2016 non-null object 63 江尾 2016 non-null object 64 栃谷 2016 non-null object 65 近原 2016 non-null object 66 日貫 2016 non-null object 67 勝地 2016 non-null object 68 都治 2016 non-null object 69 府中橋 2016 non-null object 70 下来原 2016 non-null object 71 砂子 2016 non-null object 72 三宮橋 2016 non-null object 73 中芝橋 2016 non-null object 74 浜田大橋 2016 non-null object 75 浜田 2016 non-null object 76 中場 2016 non-null object 77 三隅 2016 non-null object 78 西河内 2016 non-null object 79 敬川橋 2016 non-null object 80 大道橋 2016 non-null object 81 昭和橋 2016 non-null object 82 染羽 2016 non-null object 83 朝倉 2016 non-null object 84 喜阿弥川 2016 non-null object 85 塔尾橋 2016 non-null object 86 相生橋 2016 non-null object 87 旭橋 2016 non-null object 88 町田 2016 non-null object 89 中条 2016 non-null object 90 八尾川 2016 non-null object 91 八田橋 2016 non-null object 92 新堤橋 2016 non-null object 93 清見橋 2016 non-null object 94 五箇大橋 2016 non-null object 95 都万川 2016 non-null object 96 美田 2016 non-null object dtypes: object(97) memory usage: 1.5+ MBみんなDtypeがobjectになっているから、数値データが文字列になっているみたい...
また、少し中を見てみると「未収集」「欠測」「保守」という文字列が入っているようです。
それらの文字情報を取り除いた上で実数値に変換します。
日時のデータも文字列なので、これもシリアル値に変換しないといけないですね。ということで、以下のスクリプトを実行。
df.index = df["観測所"].map(lambda _: pd.to_datetime(_)) df = df.replace('未収集', '-1') df = df.replace('欠測', '-1') df = df.replace('保守', '-1') cols = df.columns[1:] for col in cols: df[col] = df[col].astype("float")可視化
日本語表示がおかしくならないよう環境設定をしてからグラフを描画してみます。
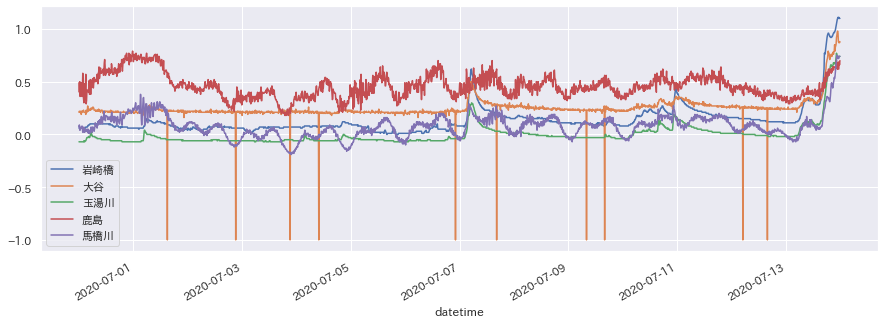
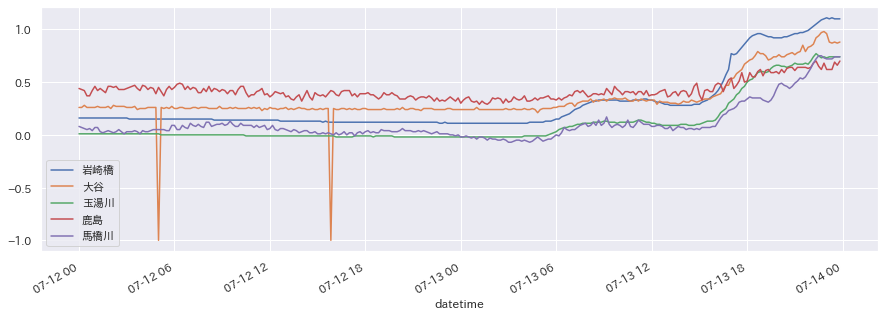
!pip install japanize_matplotlib import matplotlib.pyplot as plt import japanize_matplotlib import seaborn as sns sns.set(font="IPAexGothic") df[cols[:5]].plot(figsize=(15,5)) plt.show() df["2020-07-12":"2020-07-13"][cols[:5]].plot(figsize=(15,5)) plt.show()
先日から雨が続いているので、水位が上がっている様子が一目瞭然ですね。
さて、これから何をするかな〜。
- 投稿日:2020-07-14T02:30:36+09:00
白黒画像をカラー画像に変換するネットワークを作ってみた(pix2pix)
1. はじめに
GAN(敵対的生成ネットワーク)を用いて、グレースケール画像に自動彩色をしていきたいと思います。
技術的には「pix2pix」と呼ぶらしいです。このグレースケール画像が
自動で以下のように彩色できました!!
ところどころ、おかしなところもあったり、うまくいかない画像もあったりしますが、結構自然な着色になっています。ちなみに元画像を一番下の段だけ示すと、
こんな感じ。電車やベッドの色は違ったりしますが、全体的には同じような色合いで塗れている気がします。2.ざっくりとした今回の学習のイメージ
ざっくりとした今回の学習のイメージは以下のようになります。
GANなのでGenerator, Discriminatorの2つのネットワークを用いてます。
(1)(2)
(3)
(4)
(5)
(6)
このようにGeneratorとDiscriminator、 2つのネットワークを交互にだまし合うように学習させます。
3.学習のネットワークについて
今回はpytorch 1.1, torchvision 0.30を用いてます。とりあえず、使用するライブラリをimport
import glob import os import pickle import torch import torch.nn.functional as F import torchvision import torch.utils.data as data import torchvision.transforms as transforms import numpy as np #1.16.4 import matplotlib.pyplot as plt from PIL import Image from torch import nn from skimage import io環境は
windows10, Anaconda1.9.7,
core-i3 8100, RAN 16.0 GB
GEFORCE GTX 1060結構、学習時間がかかるのでGPU推奨です。
3-1.Generator
Generatorにはセマンティックセグメンテーションに用いられているU-netを用いています。
Encoder-Decoderのネットワークで、入力画像と同じ形状の出力画像を得ることができます。
入力画像はGray画像,出力画像はカラー画像(Fake画像)です。
このU-netの特徴はCopy and Cropの部分になります。
入力層に近い出力を出力層に近い層にも加えて、元画像の形を崩さないようにする工夫(らしい)です。このCopy and Cropをpytorchで実現するのは結構簡単で、
・torch.catを用いて、入力を結合する。
・Conv2dやBatchNorm2dの入力のチャンネル数を倍にする。
だけです。初めて見たときは結構感動しました。ただしtorch.catで結合するtensorの形状を合わせておく必要があります。
このU-netをそのまま用いると、かなり巨大なネットワークになります。
(CNNが18個ぐらいあるように見える)
そのため、ネットワークを小さくして、入出力画像のサイズも3×128×128まで小さくします。class Generator(nn.Module): def __init__(self): super().__init__() self.conv1 = nn.Conv2d(3, 32, kernel_size=5, stride=1, padding=2) self.bn1 = nn.BatchNorm2d(32) self.av2 = nn.AvgPool2d(kernel_size=4) self.conv2 = nn.Conv2d(32, 64, kernel_size=3, stride=1, padding=1) self.bn2 = nn.BatchNorm2d(64) self.av3 = nn.AvgPool2d(kernel_size=2) self.conv3 = nn.Conv2d(64, 128, kernel_size=3, stride=1, padding=1) self.bn3 = nn.BatchNorm2d(128) self.av4 = nn.AvgPool2d(kernel_size=2) self.conv4 = nn.Conv2d(128, 256, kernel_size=3, stride=1, padding=1) self.bn4 = nn.BatchNorm2d(256) self.av5 = nn.AvgPool2d(kernel_size=2) self.conv5 = nn.Conv2d(256, 256, kernel_size=3, stride=1, padding=1) self.bn5 = nn.BatchNorm2d(256) self.un6 = nn.UpsamplingNearest2d(scale_factor=2) self.conv6 = nn.Conv2d(256, 256, kernel_size=3, stride=1, padding=1) self.bn6 = nn.BatchNorm2d(256) #conv7にはconv6の出力とconv4の出力を流す, input channelが2倍 self.un7 = nn.UpsamplingNearest2d(scale_factor=2) self.conv7 = nn.Conv2d(256 * 2, 128, kernel_size=3, stride=1, padding=1) self.bn7 = nn.BatchNorm2d(128) #conv8にはconv7の出力とconv3の出力を流す, input channelが2倍 self.un8 = nn.UpsamplingNearest2d(scale_factor=2) self.conv8 = nn.Conv2d(128 * 2, 64, kernel_size=3, stride=1, padding=1) self.bn8 = nn.BatchNorm2d(64) #conv9にはconv8の出力とconv2の出力を流す, input channelが2倍 self.un9 = nn.UpsamplingNearest2d(scale_factor=4) self.conv9 = nn.Conv2d(64 * 2, 32, kernel_size=3, stride=1, padding=1) self.bn9 = nn.BatchNorm2d(32) self.conv10 = nn.Conv2d(32 * 2, 3, kernel_size=5, stride=1, padding=2) self.tanh = nn.Tanh() def forward(self, x): #x1-x4はtorch.catする必要があるので,残しておく x1 = F.relu(self.bn1(self.conv1(x)), inplace=True) x2 = F.relu(self.bn2(self.conv2(self.av2(x1))), inplace=True) x3 = F.relu(self.bn3(self.conv3(self.av3(x2))), inplace=True) x4 = F.relu(self.bn4(self.conv4(self.av4(x3))), inplace=True) x = F.relu(self.bn5(self.conv5(self.av5(x4))), inplace=True) x = F.relu(self.bn6(self.conv6(self.un6(x))), inplace=True) x = torch.cat([x, x4], dim=1) x = F.relu(self.bn7(self.conv7(self.un7(x))), inplace=True) x = torch.cat([x, x3], dim=1) x = F.relu(self.bn8(self.conv8(self.un8(x))), inplace=True) x = torch.cat([x, x2], dim=1) x = F.relu(self.bn9(self.conv9(self.un9(x))), inplace=True) x = torch.cat([x, x1], dim=1) x = self.tanh(self.conv10(x)) return x3-2.Discriminator
Discriminatorは普通の画像識別ネットワークに近い構成です。
ただし、出力は1次元ではなく、n×n個の数字になります。
この分割された領域毎にTrue or Falseを出力します。下の画像の場合は4×4ですね。
このテクニックはpatch GANと呼ぶそうです。後は活性化関数にGANの定番のLeakly Relu、
BatchNorm2dの代わりにInstanceNorm2dを用いています。InstanceNorm2dとBatchNorm2d,両方試しましたが、実はあまり結果に差を感じられませんでした。
Pix2PixではInstanceNorm2dがよいときいたので、今回はこちらを採用しています。class Discriminator(nn.Module): def __init__(self): super().__init__() self.conv1 = nn.Conv2d(3, 16, kernel_size=5, stride=1, padding=2) self.in1 = nn.InstanceNorm2d(16) self.av2 = nn.AvgPool2d(kernel_size=2) self.conv2_1 = nn.Conv2d(16, 32, kernel_size=3, stride=1, padding=1) self.in2_1 = nn.InstanceNorm2d(32) self.conv2_2 = nn.Conv2d(32, 32, kernel_size=3, stride=1, padding=1) self.in2_2 = nn.InstanceNorm2d(32) self.av3 = nn.AvgPool2d(kernel_size=2) self.conv3_1 = nn.Conv2d(32, 64, kernel_size=3, stride=1, padding=1) self.in3_1 = nn.InstanceNorm2d(64) self.conv3_2 = nn.Conv2d(64, 64, kernel_size=3, stride=1, padding=1) self.in3_2 = nn.InstanceNorm2d(64) self.av4 = nn.AvgPool2d(kernel_size=2) self.conv4_1 = nn.Conv2d(64, 128, kernel_size=3, stride=1, padding=1) self.in4_1 = nn.InstanceNorm2d(128) self.conv4_2 = nn.Conv2d(128, 128, kernel_size=3, stride=1, padding=1) self.in4_2 = nn.InstanceNorm2d(128) self.av5 = nn.AvgPool2d(kernel_size=2) self.conv5_1 = nn.Conv2d(128, 256, kernel_size=3, stride=1, padding=1) self.in5_1 = nn.InstanceNorm2d(256) self.conv5_2 = nn.Conv2d(256, 256, kernel_size=3, stride=1, padding=1) self.in5_2 = nn.InstanceNorm2d(256) self.av6 = nn.AvgPool2d(kernel_size=2) self.conv6 = nn.Conv2d(256, 512, kernel_size=3, stride=1, padding=1) self.in6 = nn.InstanceNorm2d(512) self.conv7 = nn.Conv2d(512, 1, kernel_size=1) def forward(self, x): x = F.leaky_relu(self.in1(self.conv1(x)), 0.2, inplace=True) x = F.leaky_relu(self.in2_1(self.conv2_1(self.av2(x))), 0.2, inplace=True) x = F.leaky_relu(self.in2_2(self.conv2_2(x)), 0.2, inplace=True) x = F.leaky_relu(self.in3_1(self.conv3_1(self.av3(x))), 0.2, inplace=True) x = F.leaky_relu(self.in3_2(self.conv3_2(x)), 0.2, inplace=True) x = F.leaky_relu(self.in4_1(self.conv4_1(self.av4(x))), 0.2, inplace=True) x = F.leaky_relu(self.in4_2(self.conv4_2(x)), 0.2, inplace=True) x = F.leaky_relu(self.in5_1(self.conv5_1(self.av5(x))), 0.2, inplace=True) x = F.leaky_relu(self.in5_2(self.conv5_2(x)), 0.2, inplace=True) x = F.leaky_relu(self.in6(self.conv6(self.av6(x))), 0.2, inplace=True) x = self.conv7(x) return x3-3.確認
torch.randnを用いて擬似的な画像を生成し、
Generator, Discriminatorの出力サイズを確認します。ここでは3×128×128のサイズの画像を2枚生成、Generator、Discriminatorの2つに入力しています。
g, d = Generator(), Discriminator() #乱数による疑似画像 test_imgs = torch.randn([2, 3, 128, 128]) test_imgs = g(test_imgs) test_res = d(test_imgs) print("Generator_output", test_imgs.size()) print("Discriminator_output",test_res.size())出力は以下のようになりました。
Generator_output torch.Size([2, 3, 128, 128])
Discriminator_output torch.Size([2, 1, 4, 4])Generatorのアウトプットサイズが、入力と同じです。
Discriminatorのアウトプットサイズが 4×4になっています。4. データローダーについて
今回は以下のような流れで、データを取得します。
b.の部分のデータ拡張
class DataAugment(): #PIL imageをデータオーギュメンテーション, PILをreturn def __init__(self, resize): self.data_transform = transforms.Compose([ transforms.RandomResizedCrop(resize, scale=(0.9, 1.0)), transforms.RandomHorizontalFlip(), transforms.RandomVerticalFlip()]) def __call__(self, img): return self.data_transform(img)dのtensorに変換する部分では,データの正規化も同時に行います。
class ImgTransform(): #PILのimageをresize,正規化してtensorをreturn def __init__(self, resize, mean, std): self.data_transform = transforms.Compose([ transforms.Resize(resize), transforms.ToTensor(), transforms.Normalize(mean, std)]) def __call__(self, img): return self.data_transform(img)
PytorchのDatasetクラスを継承をしたクラスで、a-dまでのフローは getitemの場所に書きます。
getitemの部分に1画像の入力と出力のフローを作ることで、簡単にデータローダーを作成できます。class MonoColorDataset(data.Dataset): """ PytorchのDatasetクラスを継承 """ def __init__(self, file_list, transform_tensor, augment=None): self.file_list = file_list self.augment = augment #PIL to PIL self.transform_tensor = transform_tensor #PIL to Tensor def __len__(self): return len(self.file_list) def __getitem__(self, index): #index番号のファイルパスを取得 img_path = self.file_list[index] img = Image.open(img_path) img = img.convert("RGB") if self.augment is not None: img = self.augment(img) #モノクロ画像用のコピー img_gray = img.copy() #カラー画像をモノクロ画像に変換 img_gray = transforms.functional.to_grayscale(img_gray, num_output_channels=3) #PILをtensorに変換 img = self.transform_tensor(img) img_gray = self.transform_tensor(img_gray) return img, img_grayaugment=Noneとすることで、データ拡張をしない、すなわちテストデータ用のデータセットになります。
データローダを作る関数は以下のようにしました。def load_train_dataloader(file_path, batch_size): """ Input file_path 取得したい画像のファイルパスのリスト batch_size データローダのバッチサイズ return train_loader, RGB_images and Gray_images """ size = 128 #画像の1辺のサイズ mean = (0.5, 0.5, 0.5) #画像の正規化した際のチャンネル毎の平均値 std = (0.5, 0.5, 0.5) #画像の正規化した際のチャンネル毎の標準偏差 #データセット train_dataset = MonoColorDataset(file_path_train, transform=ImgTransform(size, mean, std), augment=DataAugment(size)) #データローダー train_dataloader = data.DataLoader(train_dataset, batch_size=batch_size, shuffle=True) return train_dataloader5.可視化方法
5.1 可視化する関数
複数の画像をタイル状に並べるには「torchvision.utils.make_grid」を使うと便利です。
tensorでタイル状の画像を生成した後にnumpyに変換して、matplotlibで描画します。def mat_grid_imgs(imgs, nrow, save_path = None): """ pytorchのtensor(imgs)をタイル状に描画する関数 nrowでタイルの1辺の数を決定 """ imgs = torchvision.utils.make_grid( imgs[0:(nrow**2), :, :, :], nrow=nrow, padding=5) imgs = imgs.numpy().transpose([1,2,0]) imgs -= np.min(imgs) #最小値を0 imgs /= np.max(imgs) #最大値を1 plt.imshow(imgs) plt.xticks([]) plt.yticks([]) plt.show() if save_path is not None: io.imsave(save_path, imgs)テスト画像をロードして、gray画像とfake画像をタイル状に描画する関数です。
def evaluate_test(file_path_test, model_G, device="cuda:0", nrow=4): """ test画像をロード,gray画像とfake画像をタイル状に描画 """ model_G = model_G.to(device) size = 128 mean = (0.5, 0.5, 0.5) std = (0.5, 0.5, 0.5) test_dataset = MonoColorDataset(file_path_test, transform=ImgTransform(size, mean, std), augment=None) test_dataloader = data.DataLoader(test_dataset, batch_size=nrow**2, shuffle=False) #データローダーごとに画像を描画 for img, img_gray in test_dataloader: mat_grid_imgs(img_gray, nrow=nrow) img = img.to(device) img_gray = img_gray.to(device) #img_grayからGeneratorを用いて,FakeのRGB画像 img_fake = model_G(img_gray) img_fake = img_fake.to("cpu") img_fake = img_fake.detach() mat_grid_imgs(img_fake, nrow=nrow)5.2 可視化結果(学習前)
g = Generator() file_path_test = glob.glob("test/*") evaluate_test(file_path_test, g)
学習前の結果ですが、ぼんやりと入力画像の形状が分かります。6.学習データの取得方法
今回はとりあえず、大量の画像データを集めればよいということで、COCO2014, PASCAL Voc2007, Labeled Faces in the Wild etc.をちゃんぽんで入力しています。
これらのデータにはGray画像が結構な割合で含まれています。今回は白黒画像をカラーにしたいのに、お手本となるべき画像がGray画像では示しがつきません(?)。なので、Gray画像は除去したいと思います。
Gray画像の場合,R channelとG channelとB channelの色が等しいはずなので、それを利用して除去したいと思います。
同時に白すぎる画像、暗すぎる画像、あまり色の濃淡がない画像(標準偏差が小さい)画像も抜きました。from skimage import io, color, transform def color_mono(image, threshold=150): #3chnnelの入力画像がカラーか否かを判別 #thresholdを大きく設定すると微妙にカラーが混じっている写真もMonoに設定できる image_size = image.shape[0] * image.shape[1] #channelの組み合わせは(0, 1),(0, 2),(1, 2)の3通り,チャネル毎の差分を見る diff = np.abs(np.sum(image[:,:, 0] - image[:,:, 1])) / image_size diff += np.abs(np.sum(image[:,:, 0] - image[:,:, 2])) / image_size diff += np.abs(np.sum(image[:,:, 1] - image[:,:, 2])) / image_size if diff > threshold: return "color" else: return "mono" def bright_check(image, ave_thres = 0.15, std_thres = 0.1): try: #明るすぎる画像,暗すぎる画像,同じような明るさばかりの画像 False #白黒に変換 image = color.rgb2gray(image) if image.shape[0] < 144: return False #明るすぎる画像の場合 if np.average(image) > (1.-ave_thres): return False #暗すぎる画像の場合 if np.average(image) < ave_thres: return False #同じような明るさばかりの場合 if np.std(image) < std_thres: return False return True except: return False paths = glob.glob("./test2014/*") for i, path in enumerate(paths): image = io.imread(path) save_name = "./trans\\mscoco_" + str(i) +".png" x = image.shape[0] #x軸方向のピクセル数 y = image.shape[1] #y軸方向のピクセル数 try: #xとy軸の内、短い方の1/2 clip_half = min(x, y)/2 #画像の正方形の切り出し image = image[int(x/2 -clip_half): int(x/2 + clip_half), int(y/2 -clip_half): int(y/2 + clip_half), :] if color_mono(image) == "color": if bright_check(image): image = transform.resize(image, (144, 144, 3), anti_aliasing = True) image = np.uint8(image*255) io.imsave(save_name, image) except: pass正方形に画像を切り取って全部、一つのフォルダに画像をいれました。
データ拡張できるように128×128でなく,144×144の画像になっています。これで大体okなのですが、なぜか除去漏れやセピア色の画像などもあったりしたので、それは手動で削除しました。
大体11万枚画像を「trans」のフォルダに突っ込みました。
globを用いて、画像のパスのリストを作成して、ロードします。7.学習
7.1 学習の関数
学習は大体1 epochが20分ぐらいかかりました。
Generatorの学習,Discriminatorの学習の両方させているので、コードが長くなっています。注意点はlossを計算するためのラベルで、先ほど4.の確認でDiscriminatorのアウトプットのサイズが
[batch_size, 1, 4, 4]になることを確認しましたので、それに合わせて
true_labelsと false_labelsを生成します。def train(model_G, model_D, epoch, epoch_plus): device = "cuda:0" batch_size = 32 model_G = model_G.to(device) model_D = model_D.to(device) params_G = torch.optim.Adam(model_G.parameters(), lr=0.0002, betas=(0.5, 0.999)) params_D = torch.optim.Adam(model_D.parameters(), lr=0.0002, betas=(0.5, 0.999)) #lossを計算するためのラベル, Discriminatorのsizeに注意 true_labels = torch.ones(batch_size, 1, 4, 4).to(device) #True false_labels = torch.zeros(batch_size, 1, 4, 4).to(device) #False #loss_function bce_loss = nn.BCEWithLogitsLoss() mae_loss = nn.L1Loss() #エラーの推移を記録 log_loss_G_sum, log_loss_G_bce, log_loss_G_mae = list(), list(), list() log_loss_D = list() for i in range(epoch): #temporaryのエラーを記録 loss_G_sum, loss_G_bce, loss_G_mae = list(), list(), list() loss_D = list() train_dataloader = load_train_dataloader(file_path_train, batch_size) for real_color, input_gray in train_dataloader: batch_len = len(real_color) real_color = real_color.to(device) input_gray = input_gray.to(device) #Generatorの訓練 #偽のカラー画像を生成 fake_color = model_G(input_gray) #偽画像を一時保存 fake_color_tensor = fake_color.detach() # 偽画像を本物と騙せるようにロスを計算 LAMBD = 100.0 # BCEとMAEの係数 #fake画像を識別器に入れたときのout, Dは0に近づけようとする. out = model_D(fake_color) #Dの出力に対するLoss, Gを本物に近づけたいのでtargetはtrue_labels loss_G_bce_tmp = bce_loss(out, true_labels[:batch_len]) #Gの出力に対するLoss loss_G_mae_tmp = LAMBD * mae_loss(fake_color, real_color) loss_G_sum_tmp = loss_G_bce_tmp + loss_G_mae_tmp loss_G_bce.append(loss_G_bce_tmp.item()) loss_G_mae.append(loss_G_mae_tmp.item()) loss_G_sum.append(loss_G_sum_tmp.item()) #勾配を計算,Gの重みの更新 params_D.zero_grad() params_G.zero_grad() loss_G_sum_tmp.backward() params_G.step() #Discriminatorの訓練 real_out = model_D(real_color) fake_out = model_D(fake_color_tensor) #損失関数の計算 loss_D_real = bce_loss(real_out, true_labels[:batch_len]) loss_D_fake = bce_loss(fake_out, false_labels[:batch_len]) loss_D_tmp = loss_D_real + loss_D_fake loss_D.append(loss_D_tmp.item()) #勾配を計算,Dの重みの更新 params_D.zero_grad() params_G.zero_grad() loss_D_tmp.backward() params_D.step() i = i + epoch_plus print(i, "loss_G", np.mean(loss_G_sum), "loss_D", np.mean(loss_D)) log_loss_G_sum.append(np.mean(loss_G_sum)) log_loss_G_bce.append(np.mean(loss_G_bce)) log_loss_G_mae.append(np.mean(loss_G_mae)) log_loss_D.append(np.mean(loss_D)) file_path_test = glob.glob("test/*") evaluate_test(file_path_test, model_G, device) return model_G, model_D, [log_loss_G_sum, log_loss_G_bce, log_loss_G_mae, log_loss_D]学習を実行します。
file_path_train = glob.glob("trans/*") model_G = Generator() model_D = Discriminator() model_G, model_D, logs = train(model_G, model_D, 40)
7.2 学習結果
学習データのLossはこんな感じです。
2epoch終了後
あれ?
飛行機画像が全く塗れていない以外、結構良い感じ??11 epoch終了後
21 epoch終了後
40 epoch終了後(はじめにで示した画像)
案外、2 epoch終了後の画像が良いような気がしてきた…
他の画像も載せてみます。
11 epoch終了後です。失敗気味の画像を多めに選んでいます。
ひどい画像は本当にひどくて、色がほとんど塗れていないとか、
野球の画像みたいに、境界線無視で塗っていたりします。
草とか木の緑系、空とかの青系は得意な気がします。
これは元のデータセットの偏りや、塗りやすさ(認識しやすさ)に依存してそうです。8.マトメ、感想
pix2pixを用いてGray画像のカラー化を行いました。
今回は何でもかんでも手当たり次第、画像を入れてみてカラー画像を作るということをしましたが、
さすがにネットワークが浅い分、表現力が低いので、
画像の種類を絞りこんだほうが上手くいくような気がします。参考文献
正直、こちらのほう自分が書いたものより、分かりやすくまとまっている気もします。
U-Net: Convolutional Networks for Biomedical Image Segmentation
https://lmb.informatik.uni-freiburg.de/people/ronneber/u-net/pix2pixを1から実装して白黒画像をカラー化してみた(PyTorch)
https://blog.shikoan.com/pytorch_pix2pix_colorization/pix2pixを理解したい
https://qiita.com/mine820/items/36ffc3c0aea0b98027fd画像
CoCo https://cocodataset.org/#home
Labeled Faces in the Wild http://vis-www.cs.umass.edu/lfw/
The PASCAL Visual Object Classes Homepage http://host.robots.ox.ac.uk/pascal/VOC/












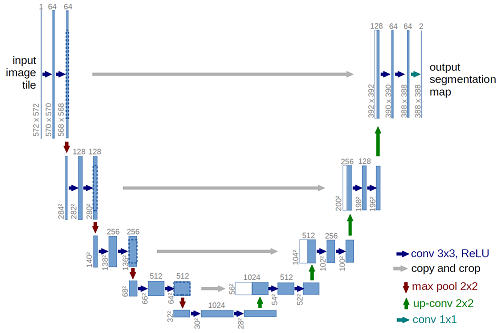









- 投稿日:2020-07-14T01:59:44+09:00
あつ森でカブ価の最高値と最低値が出る確率
概要
『あつまれ どうぶつの森』におけるカブの売値(たぬき商店での平日の値段)は9~660ベルの間で変動するとされ、特に最高値660ベル、最安値9ベルが出るのは非常に珍しいとされている。
そこで、ある週において、最高値および最安値が出現する確率を計算してみる。前提
- 求める確率は、ゲームプレイ週数を無限大に近づけた際に収束する値とする。
- 以下のカブ価決定アルゴリズムの解析結果(2020年7月13日時点)が正しいものとする。
https://gist.github.com/Treeki/85be14d297c80c8b3c0a76375743325b- ゲーム内の時刻を現実のものから変える行為(いわゆる時間操作)は行わないものとする。
- 擬似乱数に規則性を見いだし、特定の値になるように調整する行為(いわゆる乱数調整)は行わないものとする。
カブ価変動パターン
カブ価の変動パターンは大きく以下の4種類に分けられる。
- 減少型: 単調減少し、買値を超えることはない。
- 波型: 何度か上下を繰り返し、買値の近辺の値をとり続ける。
- 跳ね大型: 単調減少ののち増加に転じ、大きなピークを迎え、減少する。
- 跳ね小型: 単調減少ののち増加に転じ、小さなピークを迎え、減少する。
最高値は「3. 跳ね大型」でのみ、最安値は「4. 跳ね小型」でのみ発生する。
そのため、まずは各型の確率を求めてみる。各型になる確率は、一つ前の週の型によってのみ決定され(マルコフ連鎖)、以下の表のようになっている。(解析結果のコード135~209行目)
前週\今週 減少型 波型 跳ね大型 跳ね小型 減少型 5% 25% 45% 25% 波型 15% 20% 30% 35% 跳ね大型 20% 50% 5% 25% 跳ね小型 15% 45% 25% 15% この表から、下記のサイトの方法で、ゲームプレイ週数を無限大に近づけた際に各型が収束する確率(定常分布)を求めてみる。
(本当は収束することの証明が必要であるが、ここでは省略する。)
https://withcation.com/2020/01/23/%E3%83%9E%E3%83%AB%E3%82%B3%E3%83%95%E9%80%A3%E9%8E%96%E3%81%AE%E5%AE%9A%E5%B8%B8%E5%88%86%E5%B8%83%E3%82%92%E8%A7%A3%E3%81%8F/減少型、波型、跳ね大型、跳ね小型の確率がそれぞれ $a, b, c, d$ になるとすると、以下の方程式が成り立つ。
\begin{pmatrix} a & b & c & d \end{pmatrix} \begin{pmatrix} 0.05 & 0.25 & 0.45 & 0.25 \\ 0.15 & 0.20 & 0.30 & 0.35 \\ 0.20 & 0.50 & 0.05 & 0.25 \\ 0.15 & 0.45 & 0.25 & 0.15 \\ \end{pmatrix} = \begin{pmatrix} a & b & c & d \end{pmatrix}移項して、
\begin{pmatrix} a & b & c & d \end{pmatrix} \begin{pmatrix} -0.95 & 0.25 & 0.45 & 0.25 \\ 0.15 & -0.80 & 0.30 & 0.35 \\ 0.20 & 0.50 & -0.95 & 0.25 \\ 0.15 & 0.45 & 0.25 & -0.85 \\ \end{pmatrix} = \begin{pmatrix} 0 & 0 & 0 & 0 \end{pmatrix}一見、4種の文字を使った4式の連立方程式を行列表記したようにみえるが、実は任意の3式を変形すると残り1式になってしまうため、式が一つ足りない(4x4の行列の行列式は0になり、逆行列が求められない)。
そのため、 $ a+b+c+d=1 $ を任意の列(ここでは1列目)に埋め込む。\begin{pmatrix} a & b & c & d \end{pmatrix} \begin{pmatrix} 1 & 0.25 & 0.45 & 0.25 \\ 1 & -0.80 & 0.30 & 0.35 \\ 1 & 0.50 & -0.95 & 0.25 \\ 1 & 0.45 & 0.25 & -0.85 \\ \end{pmatrix} = \begin{pmatrix} 1 & 0 & 0 & 0 \end{pmatrix} \\ \begin{pmatrix} a & b & c & d \end{pmatrix} = \begin{pmatrix} 1 & 0 & 0 & 0 \end{pmatrix} \begin{pmatrix} 1 & 0.25 & 0.45 & 0.25 \\ 1 & -0.80 & 0.30 & 0.35 \\ 1 & 0.50 & -0.95 & 0.25 \\ 1 & 0.45 & 0.25 & -0.85 \\ \end{pmatrix}^{-1} = \begin{pmatrix} 0.1476 & 0.3463 & 0.2474 & 0.2588 \end{pmatrix}各型の確率が求められた。Pythonのコードを以下に示す。
import numpy as np A = np.array( [[0.05, 0.25, 0.45, 0.25], [0.15, 0.20, 0.30, 0.35], [0.20, 0.50, 0.05, 0.25], [0.15, 0.45, 0.25, 0.15]] ) A -= np.identity(4) # 移項 A[:, 0] = 1 # 条件a+b+c+d=1を入れる B = np.array([1, 0, 0, 0]) print(B @ np.linalg.inv(A)) # [0.1476074 0.34627733 0.24736279 0.25875248]最高値(660ベル)となる確率
最高値(660ベル)になるためには、「3. 跳ね大型」になること(確率0.2474)に加え、以下の条件が必要である。
A: その島の買値(日曜午前にウリから買える値段)は90~110ベルであるが、これが110ベルである。
B: ピーク時には買値の2~6倍になるが、これが6倍になる。Aについてはランダムであり(コード123行目のrandint)、確率は$\frac{1}{21}$である。
Bについては、まず倍率として2.0~6.0のfloat型の数値を生成するが、ピーク時の値段は(買値)×(倍率)の結果の小数点以下を切り上げたものであるため、ちょうど6.0倍でなくてもよい可能性がある。
倍率は、uint32_t型( $0$ ~ $2^{32}$ の整数値をとる)の乱数をもとに決められ、乱数の値が大きいほど大きくなる。
そこで、ピーク時の値段が660ベルになるuint32_t型乱数のボーダーを二分探索を用いて調べることで、条件Bを満たす確率を求める。#include <bits/stdc++.h> using namespace std; // uint32_t型の乱数をもとに、float型の数を返す関数。乱数が大きいほどbに近い数となる。 float randfloat(float a, float b, uint32_t u32) { uint32_t val = 0x3F800000 | (u32 >> 9); float fval = *(float *)(&val); return a + ((fval - 1.0f) * (b - a)); } // 小数点以下を切り上げる関数 int intceil(float val) { return (int)(val + 0.99999f); } int main() { uint32_t ll = 0; //uint32_tの下限値 uint32_t rr = pow(2, 32) - 1; //uint32_tの上限値 int32_t basePrice = 110; // 買値 uint64_t l, r, m; int32_t peakPrice; l = 0; r = pow(2, 32) - 1; m = (l + r) / 2; // 二分探索 while (r - l > 1) { peakPrice = intceil(randfloat(2.0, 6.0, m) * basePrice); // ピーク時の値段 if (peakPrice < 660) {l = m;} else {r = m;} m = (l + r) / 2; } cout << 0 << " から " << rr << " の値をとる乱数が " << m << " より大きい場合、最高値となる。" << endl; cout << "その確率は " << (double)(rr - m) / (double)(rr) << " である。" << endl; }出力
0 から 4294967295 の値をとる乱数が 4285206015 より大きい場合、最高値となる。 その確率は 0.00227273 である。求めた確率すべてを掛け合わせると、 $0.2474 \times \frac{1}{21} \times 0.002272 = 2.68 \times 10^{-5}$ となる。
0.00268%と低い確率だが、ゲームの販売本数は2020年5月7日時点で1177万本であるため、カブ価をチェックしているのがそのうち1%だったとしても、毎週世界中で3人くらいは最高値660ベルを確認している計算になる。それでは、次に最安値の確率も計算してみる。
最安値(9ベル)となる確率
最安値(9ベル)になるためには、「4. 跳ね小型」になること(確率0.2588)に加え、以下の条件が必要である。
A: その島の買値(日曜午前にウリから買える値段)は90~110ベルであるが、これが90ベルである。
B: 「初めて増加に転じる時期」が {月曜午前, 月曜午後, ... , 木曜午後} の8つのうち、月曜午前または木曜午後である。
※なお、Bで月曜午前の場合と木曜午後の場合の確率は等しく、プログラムもほぼ同じであるため、以降のC,Dの条件は木曜午後の場合で説明する。
C: 以上の条件の下で、月曜午前のカブ価は36~81ベルの可能性があるが、これが36ベルである。
D: 以上の条件の下で、木曜午後のカブ価は9~65ベルの可能性があるが、これが9ベルである。A, Bについては整数の乱数で選ばれるため、それぞれ $\frac{1}{21}, \frac{1}{4}$ の確率となる。
Cについては、まず倍率として0.4~0.9のfloat型の数値を生成し、買値の90ベルに掛けた結果が月曜午前のカブ価となる。
小数点以下は切り上げであるため、36ベルとなるためには、倍率は0.4(誤差の関係上、わずかに上回る分には問題ない)でなければならない。
前述したように倍率は、uint32_t型( $0$ ~ $2^{32}$ の整数値をとる)の乱数をもとに決められるが、ここでは乱数の値が小さいほど倍率が大きくなるプログラムとなっている(コード317行目)。
やはり、カブ価が36ベルとなる乱数のボーダーを二分探索を用いて調べることで、条件Cを満たす確率を求めるのがよさそうだ。#include <bits/stdc++.h> using namespace std; // uint32_t型の乱数をもとに、float型の数を返す関数。乱数が大きいほどbに近い数となる。 float randfloat(float a, float b, uint32_t u32) { uint32_t val = 0x3F800000 | (u32 >> 9); float fval = *(float *)(&val); return a + ((fval - 1.0f) * (b - a)); } // 小数点以下を切り上げる関数 int intceil(float val) { return (int)(val + 0.99999f); } int main() { uint32_t ll = 0; //uint32_tの下限値 uint32_t rr = pow(2, 32) - 1; //uint32_tの上限値 int32_t basePrice = 90; // 買値 uint64_t l, r, m; int32_t monAmPrice; l = 0; r = pow(2, 32) - 1; m = (l + r) / 2; // 二分探索 while (r - l > 1) { monAmPrice = intceil(randfloat(0.9, 0.4, m) * basePrice); // 月曜午前の値段 if (monAmPrice > 36) {l = m;} else {r = m;} m = (l + r) / 2; } cout << ll << " から " << rr << " の値をとる乱数が " << m << " より大きい場合、条件Cが満たされる。" << endl; cout << "その確率は " << (double)(rr - m) / (double)(rr) << " である。" << endl; }出力
0 から 4294967295 の値をとる乱数が 4294966783 より大きい場合、条件Cが満たされる。 その確率は 1.19209e-07 である。小数点以下を切り上げるという性質上、最高値のときの条件Bより、今回のほうが確率は大幅に低くなっている。
最後に、条件「D: 木曜午後のカブ価は9~65ベルの可能性があるが、これが9ベルである。」を満たす確率を考えてみる。
月曜午前時点で0.4である倍率は、月曜午後~木曜午後までの6期間において単調減少する。
この際、各期間において、倍率の下落幅が0.03~0.05の中から決められ、更新される。
90ベルが9ベルになるためには、倍率は $0.1 = 0.4 - 0.05 \times 6$ とならなければならず、6期間連続で下落幅がほぼ最大(0.05)になる場合を考えることになる。
しかし、カブ価の小数点以下切り上げ時に「0.99999を足してから小数を切り捨てる」という処理を行っているため、例えば9.0001ベルは10ベルに切り上げられるが、9.0000001ベルは9ベルとなる、という現象が発生する。そのため、下落幅は6回すべてが最大値でなくてもよい可能性がある。
それでも条件Cでは二分探索をすることで乱数の閾値を求められたが、それは乱数発生が1回だけであったからできたことであり、今回は6回の乱数が関係してくるため単純にはできない。
そこで、以下のような方法で確率を求める。D-1. 乱数が最高値の $2^{32}-1$ である場合の倍率下落幅(0.03に最も近い(注))を $A$ とする。6回中5回の下落幅が $A$ であるという条件の下で、残り1回の下落幅がいくつ以上であったら9ベルになるか、という閾値を求める。その閾値を $B$ とする。
D-2. $B$ から $A$ の下落幅について、乱数がどの範囲であった場合その下落幅になるか、を求める。
D-3. 6回の下落幅それぞれを $B$ から $A$ の間で全探索し、9ベルになるものについては、そうなる場合の数(D-2で求めた幅を6つ掛け合わせたもの)を足し合わせる。
D-4. その値を $(2^{32})^6$ で割ったものが、条件Dを満たす確率である。(注)0.05ではなく0.03であるのは、解析では「0.02を引いてから、0~0.03を引く」という操作をしており、それに倣ったため。
下落幅については10進数で小数点以下を表示するより、float型の仮数部を見たほうが扱いやすいので、そう表記する。
仮数部の16進数表現を得るのに、以下の記事を参考にした。
https://qiita.com/nia_tn1012/items/d26f0fc993895a09b30b
また、今までは10進数表記していた乱数の値も、これからは16進数表記することとする。まずはD-1を二分探索で行う。
#include <bits/stdc++.h> using namespace std; // uint32_t型の乱数をもとに、float型の数を返す関数。乱数が大きいほどbに近い数となる。 float randfloat(float a, float b, uint32_t u32) { uint32_t val = 0x3F800000 | (u32 >> 9); float fval = *(float *)(&val); return a + ((fval - 1.0f) * (b - a)); } // 小数点以下を切り上げる関数 int intceil(float val) { return (int)(val + 0.99999f); } // float型の仮数部を返す関数 int printb(float ff) { union { float f; int i; } a; int i; a.f = ff; return a.i & 0x7FFFFF; } int main() { uint32_t ll = 0; //uint32_tの下限値 uint32_t rr = pow(2, 32) - 1; //uint32_tの上限値 int32_t basePrice = 90; // 買値 uint64_t l, r, m; float declineRate; int32_t thuPmPrice; l = 0; r = pow(2, 32) - 1; m = (l + r) / 2; // 二分探索 while (r - l > 1) { declineRate = (0.4 - 0.03 * 6 - randfloat(0, 0.02, rr) * 5 - randfloat(0, 0.02, m)); thuPmPrice = intceil(declineRate * basePrice); // 木曜午後の値段 if (thuPmPrice > 9) {l = m;} else {r = m;} m = (l + r) / 2; } cout << hex << "下落率Bの仮数部は " << printb(randfloat(0, 0.02, m+1)) \ << " であり、その下落率になる中で最小の乱数の値は " << m+1 << " である。" << endl; cout << hex << "下落率Aの仮数部は " << printb(randfloat(0, 0.02, rr)) << " である。" << endl; }出力
下落率Bの仮数部は 23d6db であり、その下落率になる中で最小の乱数の値は ffffb600 である。 下落率Aの仮数部は 23d709 である。よって、 23d6db ~ 23d709 を探索すればよいが、念のため 23d6da ~ 23d709 の48通りを調べる。(計算順序によっては、丸め誤差の関係で仮数部が 23d6da の下落率でも9ベルになる可能性があるため)
次に、D-2からD-4を一気に行った。計算時間は10分ほどかかった。
#include <bits/stdc++.h> using namespace std; // uint32_t型の乱数をもとに、float型の数を返す関数。乱数が大きいほどbに近い数となる。 float randfloat(float a, float b, uint32_t u32) { uint32_t val = 0x3F800000 | (u32 >> 9); float fval = *(float *)(&val); return a + ((fval - 1.0f) * (b - a)); } // 小数点以下を切り上げる関数 int intceil(float val) { return (int)(val + 0.99999f); } // float型の仮数部を返す関数 int printb(float ff) { union { float f; int i; } a; int i; a.f = ff; return a.i & 0x7FFFFF; } // 倍率の下落のしかたを全探索する再帰関数 int64_t fullSearch(float declineRateNow, int step, int basePrice, vector<float> declineRates, int c) { int64_t ans = 0; int32_t thuPmPrice; if (step == 6) { thuPmPrice = intceil(declineRateNow * basePrice); // 木曜午後の値段が9ベルかを確認 if (thuPmPrice == 9) {return 1;} else {return 0;} } else { declineRateNow -= 0.03; for (int i=0; i<c; i++) { ans += fullSearch(declineRateNow - declineRates.at(i), step + 1, basePrice, declineRates, c); } } return ans; } int main() { uint32_t m = pow(2, 32) - 1; float declineRate = randfloat(0, 0.02, m); float declineRate_b = randfloat(0, 0.02, m); uint32_t l, r; int c = 0; vector<float> declineRates(50); // D-2 r = m; cout << "No. | 乱数下限 | 乱数上限 | 幅 | 下落率の仮数部" << endl; while (true) { declineRate_b = declineRate; declineRate = randfloat(0, 0.02, m); if (printb(declineRate) < printb(declineRate_b)) { l = m + 1; cout << hex << setfill('0') << setw(2) << c << " | " << l << " | " << r << " | " \ << r-l+1 << " | " << printb(declineRate_b) << endl; declineRates.at(c) = declineRate_b; r = m; c++; if (printb(declineRate) < 0x23d6da) {break;} } m--; } // D-3 int32_t basePrice = 90; int64_t count9bell = fullSearch(0.4, 0, basePrice, declineRates, c); // D-4 // (2^9)^6を掛けてから(2^32)^6で割る代わりに、2で23*6回割っている double prob_d = count9bell; for (int i=0; i<23*6; i++) { prob_d /= 2; } cout << dec << "37^6 通りある「倍率の下落のしかた」のうち、カブ価が9ベルとなるのは " << count9bell << " 通りである。" << endl; cout << "その場合、条件Dが満たされ、その確率は " << prob_d << " である。" << endl; }最初に、D-2として、仮数部が 23d6da ~ 23d709 の48通りである下落幅について、乱数がどの範囲であった場合その下落幅になるか、を求めた。以下の出力が得られた。
No. | 乱数下限 | 乱数上限 | 幅 | 下落率の仮数部 00 | fffffe00 | ffffffff | 200 | 23d709 01 | fffffc00 | fffffdff | 200 | 23d707 02 | fffffa00 | fffffbff | 200 | 23d706 03 | fffff800 | fffff9ff | 200 | 23d705 04 | fffff600 | fffff7ff | 200 | 23d704 05 | fffff400 | fffff5ff | 200 | 23d702 06 | fffff200 | fffff3ff | 200 | 23d701 07 | fffff000 | fffff1ff | 200 | 23d700 08 | ffffee00 | ffffefff | 200 | 23d6fe 09 | ffffec00 | ffffedff | 200 | 23d6fd 0a | ffffea00 | ffffebff | 200 | 23d6fc 0b | ffffe800 | ffffe9ff | 200 | 23d6fb 0c | ffffe600 | ffffe7ff | 200 | 23d6f9 0d | ffffe400 | ffffe5ff | 200 | 23d6f8 0e | ffffe200 | ffffe3ff | 200 | 23d6f7 0f | ffffe000 | ffffe1ff | 200 | 23d6f6 10 | ffffde00 | ffffdfff | 200 | 23d6f4 11 | ffffdc00 | ffffddff | 200 | 23d6f3 12 | ffffda00 | ffffdbff | 200 | 23d6f2 13 | ffffd800 | ffffd9ff | 200 | 23d6f0 14 | ffffd600 | ffffd7ff | 200 | 23d6ef 15 | ffffd400 | ffffd5ff | 200 | 23d6ee 16 | ffffd200 | ffffd3ff | 200 | 23d6ed 17 | ffffd000 | ffffd1ff | 200 | 23d6eb 18 | ffffce00 | ffffcfff | 200 | 23d6ea 19 | ffffcc00 | ffffcdff | 200 | 23d6e9 1a | ffffca00 | ffffcbff | 200 | 23d6e7 1b | ffffc800 | ffffc9ff | 200 | 23d6e6 1c | ffffc600 | ffffc7ff | 200 | 23d6e5 1d | ffffc400 | ffffc5ff | 200 | 23d6e4 1e | ffffc200 | ffffc3ff | 200 | 23d6e2 1f | ffffc000 | ffffc1ff | 200 | 23d6e1 20 | ffffbe00 | ffffbfff | 200 | 23d6e0 21 | ffffbc00 | ffffbdff | 200 | 23d6de 22 | ffffba00 | ffffbbff | 200 | 23d6dd 23 | ffffb800 | ffffb9ff | 200 | 23d6dc 24 | ffffb600 | ffffb7ff | 200 | 23d6db表の数値はすべて16進数である。
例えば、最後の行を見ると、( 00000000 ~ ffffffff の値をとる乱数が) ffffb600 から ffffb7ff までの 0x200 通りの値をとった場合、下落幅の仮数部は 23d6db になる、ということである。
この表より、以下のことがわかる。
- 乱数がどんな値であっても、下落幅が 23d708, 23d703,... などの仮数部になることはない。(48通り調べているのに、表の行数が 0x25 すなわち37行なので、そのような下落幅が11通りあることがわかる。)
- なりうる下落幅について、乱数の範囲の幅はすべて 0x200 すなわち $2^9 = 512$ である。(実はこれはrandfloat関数のコードからもわかる)
よって、D-3, D-4については、6回の下落幅それぞれをこの37通りで全探索し、下落のしかた $37^6$ パターンにおいてカブ価が9ベルとなった回数を数え、その回数に $(2^9)^6$ を掛けてから $(2^{32})^6$ で割ったものが、条件「D: 木曜午後のカブ価は9~65ベルの可能性があるが、これが9ベルである。」を満たす確率、ということになる。
これを計算した結果、以下の出力が得られた。37^6 通りある「倍率の下落のしかた」のうち、カブ価が9ベルとなるのは 8689156 通りである。 その場合、条件Dが満たされ、その確率は 2.49367e-035 である。変動パターン(跳ね小型)の確率と条件A~Dの確率すべてを掛け合わせると、
$0.2588 \times \frac{1}{21} \times \frac{1}{4} \times (1.192 \times 10^{-7}) \times (2.494 \times 10^{-35}) = 9.16 \times 10^{-45}$ となる。
これは天文学的な低確率である。
仮に、地球に住む77億人全員がこのゲームを持ち、138億年前の宇宙誕生から今に至るまで毎週カブ価を確認したとしても、1回でも「1カブ9ベル」を見られる確率は $5.08 \times 10^{-23}$ なのである。
なお、これは「前提」に記載したカブ価決定アルゴリズムの解析結果のソースコードが、完全にゲーム内部のものと同じである場合の確率である。小数点以下を切り上げるintceil関数で足す値が0.99999でなく0.999999であれば最安値の確率はもっと低くなるわけであり、またfloat型をdouble型にするだけでも確率は変わるだろう。まとめ
- カブ価が最高値の660ベルとなる確率は $2.68 \times 10^{-5}$ であり、毎週世界のどこかでは出ているといえる。
- カブ価が最安値の9ベルとなる確率は $9.16 \times 10^{-45}$ であり、まず起こり得ない。
参考
あつまれどうぶつの森 カブ価予測ツール | hyperWiki
カブの買値や売値を入力すると、カブ価の予測値や、カブ価が各変動パターンである確率が表示される。AtCoder コードテスト
競技プログラミングのサイトAtCoderのコードテストページ。C++の標準出力に日本語を使用しても、文字化けされずに出力される。更新履歴
- 2020/07/14 最安値の確率を修正
- 投稿日:2020-07-14T01:33:34+09:00
Pythonのsqlite3で自動で閉じるCursurを使う
これはなに
Python標準ライブラリのsqlite3でwith構文を使って自動で閉じるCursurオブジェクトを生成する方法です。
普通に使うと、毎回例外処理をしながらcur.close()を書く必要があり大変面倒です。
またこれを使うことで、似たAPI形式を持つ
psycopg2とのコードの共通化ができます。実装
import sqlite3 class AutoCloseCursur(sqlite3.Cursor): def __init__(self, connection): super().__init__(connection) def __enter__(self): return self def __exit__(self, *args): self.close()どう変わるのか
このような実装をせずに書くと、以下のようなコードになります
with sqlite3.connect(DATABASE) as conn: cur = conn.cursur() cur.execute(SQL_QUERY) cur.close() conn.commit()これには以下の問題点があります
1. 読みづらい
2. curを明示的に閉じる必要がある
3. 2.より、例外が発生したときにファイルを開いたままになってしまう上で示したような自作クラスを使うことで、この3つ全てを解決することができます。
使用例
with sqlite3.connect(DATABASE) as conn: with AutoCloseCursur(conn) cur.execute(SQL_QUERY) conn.commit()上手く組み合わせることで、PostgreSQLとSQLiteのDBを同じコードで扱うことができるようになります
- 投稿日:2020-07-14T00:43:35+09:00
【Python】格子ボルツマン法でカルマン渦を観察しよう。【流体シミュレーション】
はじめに
今回は格子ボルツマン法を用いて上のgifのような流体シミュレーションをしてみたいと思います。
格子ボルツマン法とは
格子ボルツマン法(こうしボルツマンほう)とは、流体を多数の仮想粒子の集合体(格子気体モデル)で近似し、各粒子の衝突と並進とを粒子の速度分布関数を用いて逐次発展させることにより、そのモーメントを計算することによって、流体の熱流動場を求めるシミュレーション法のことである。 -Wikipedia
また、今回もできるだけ短くなるように書いたところ、案の定参考サイト(記事の最後にリンクあります)に載っているサンプルコードより遅くなりました。行列計算が早いNumpyといえど頼り過ぎはだめみたいです。
方法
ここでは詳しい理論は省略して、実装に必要な内容を解説します。
計算する式を始めに示しておきます。
n_i'(r,t+1)=n_i(r+e_i,t)\tag{1}\\n_i(r,t+1) = (1-\omega)n_i'(r,t+1)+\omega\bigg[\rho w_i(1+3\vec{e_i}\cdot\vec{u}+\frac{9}{2}(\vec{e_i}\cdot\vec{u})^2-\frac{3}{2}|\vec{u}|^2)\bigg] \tag{2}ここで、\\ n_i は粒子分布関数の i 成分、\\ \vec{e_i} は i 番目の位置ベクトル、\\ w_i=\begin{cases} \frac{4}{9} & ( i = 0 ) \\ \frac{1}{9} & ( 1\le i \le 4 )\\ \frac{1}{36} & (5 \le i \le 8) \end{cases}\\ \rho =\sum_{i} n_i(t)\\ \vec{u} は二次元の場合 x, y 2方向の速度ベクトル、\\ \omega = 1/\tau , \tau は単一時間緩和係数です。これを各 $i$ 、各地点について計算します。
まず、 $\vec e_i$ ですがこれは自分のマスを原点としたときの自分のマス+隣接する8マスに向かう位置ベクトルで、
$i=0$ が自分のマス $\vec e_0=(0, 0)$、
$1\le i\le 4$ が上下左右 $\vec e_{1...4}=(0,1),(0,-1),(1,0),(-1,0)$、
$5\le i\le 8$ がナナメに隣り合っているマス $\vec e_{5...8}=(1,1),(-1,-1),(1,-1),(-1,1)$
を表します。
ですので、$(1)$式は隣接マスからの流入を表していると解釈できますね。次に $\vec e_i \cdot \vec u$ です。
$\vec u=(u_x,u_y)$ ですので、例えば $i=7$ であれば、
$\vec e_7 \cdot \vec u = (1,-1)\cdot (u_x,u_y) = u_x-u_y$
となります。最後に $|u|^2$ 、
これは$\vec u$ の長さの2乗ですので、
$|u|^2=u_x^2+u_y^2$ です。障害物の処理
ただ流れるだけではあまり面白くない上、本題のカルマン渦が発生しないので、障害物を設置した際の処理についても考えましょう。
ただ、これについては格子ボルツマン法の場合簡単で(ナヴィエ・ストークス方程式を近似計算したときは少し面倒だった気がする)、
もともと流入方向ごとに分けて計算しているので、障害物に当たったら流入方向と逆の成分に流してやれば済みます。ではそろそろ実装と行きましょう。
実装
関数の定義
Lattice_Boltzmann_Method.pyimport numpy as np import matplotlib.pyplot as plt from matplotlib.animation import FuncAnimation from ipywidgets import interact w = np.array([4 / 9, 1 / 9, 1 / 9, 1 / 9, 1 / 9, 1 / 36, 1 / 36, 1 / 36, 1 / 36]) e = np.array([[0, 0], [0, 1], [0, -1], [1, 0], [-1, 0], [1, 1], [-1, -1],[1, -1], [-1, 1]]) def stream(): #(1)式+障害物との衝突処理 global n for i, axis in zip(range(1, 5),[[1, 1, 0, 1], [1, -1, 0, -1], [0, 1, 1, -1], [0, -1, 1, 1]]): #(1)式 n[:, :, i] = np.roll(n[:, :, i], axis[1], axis=axis[0]) n[:, :, i + 4] = np.roll(np.roll(n[:, :, i + 4], axis[1],axis=axis[0]),axis[3],axis=axis[2]) for i in range(1, 9): n[:, :, i][barrier[:, :, i]] = n[:, :, i - (-1)**i][barrier[:, :, 0]] #衝突した分を逆向きの成分に流してます。 def collide(): #(2)式+左端からの流入 global n, u, u9 rho = n.sum(axis=2).reshape(H, W, 1) #ρの計算 u = (n @ e) / rho #(ux,uy)の計算 n = (1 - om) * n + om * w * rho * (1 - 1.5 *(u**2).sum(axis=2).reshape(H, W, 1) +3 * (u @ e.T) + 4.5 * (u @ e.T)**2) #(2)式 n[:, 0] = w * (1 - 1.5 * (u_o**2).sum(axis=1).reshape(H, 1) + 3 *(u_o @ e.T) + 4.5 * (u_o @ e.T)**2) #左端からの流入 def curl(): #プロットする際の色に関係してる関数 return np.roll(u[:, :, 0], -1, axis=1) - np.roll(u[:, :, 0], 1, axis=1) - np.roll(u[:, :, 1], -1, axis=0) + np.roll(u[:, :, 1], 1, axis=0) def mk_barrier(arr): #障害物を表現した配列を渡すと衝突時の跳ね返り先の対応関係などを計算してくれる子 global barrier barrier = np.zeros((H, W, 9), bool) barrier[:, :, 0] = arr for i, axis in zip(range(1, 5),[[1, 1, 0, 1], [1, -1, 0, -1], [0, 1, 1, -1], [0, -1, 1, 1]]): barrier[:, :, i] = np.roll(barrier[:, :, 0], axis[1], axis=axis[0]) barrier[:, :, i + 4] = np.roll(barrier[:, :, i], axis[3], axis=axis[2])パラメータの定義、初期化
Lattice_Boltzmann_Method.pyH, W = 40, 100 #タテ・ヨコ viscosity = .005 #粘度 om = 1 / (3 * viscosity + 0.5) #参考サイトに倣ってこの計算になっています。粘度とωの関係式らしい。 u0 = [0, .12] #初速兼左端からの流入の速度ベクトル(-uy,ux)に対応 u = np.ones((H, W, 2)) * u0 u_o = np.ones((H, 2)) * u0 n = w * (1 - 1.5 * (u**2).sum(axis=2).reshape(H, W, 1) + 3 * (u @ e.T) + 4.5 * (u @ e.T)**2)障害物
Lattice_Boltzmann_Method.pyr = 3 #壁の長さとか円の半径とか #壁 wall = np.zeros((H, W), bool) wall[H // 2 - r:H // 2 + r, H // 2] = True #円 x, y = np.meshgrid(np.arange(W), np.arange(H)) circle = ((x - H / 2)**2 + (y - H / 2)**2 <= r**2) mk_barrier(circle)プロット
Lattice_Boltzmann_Method.pydef update(i): for t in range(10): stream() collide() im.set_array(curl() - barrier[:, :, 0]) return im, """Jupyter用 インタラクティブになる @interact(Viscosity=(0.05, 2.0, 0.01),v0=(0, 0.12, 0.01),Barrier=["circle", "wall"]) def a(Viscosity, v0, Barrier): global viscosity, om, u0, u_o viscosity = Viscosity * .1 om = 1 / (3 * viscosity + 0.5) u0 = [0, v0] u_o = np.ones((H, 2)) * u0 mk_barrier(eval(Barrier)) """ fig = plt.figure() stream() collide() im = plt.imshow(curl() - barrier[:, :, 0],cmap="jet",norm=plt.Normalize(-.1, .1)) anim = FuncAnimation(fig, update, interval=1, blit=True) plt.show()結果
冒頭に示したものと同じですが、
まとめ
自然現象を自分で書いたコードで再現できると感動しますよね。
皆さんも是非試してみてください。
全コードツナゲターノ
Lattice_Boltzmann_Method.pyimport numpy as np import matplotlib.pyplot as plt from matplotlib.animation import FuncAnimation from ipywidgets import interact w = np.array([4 / 9, 1 / 9, 1 / 9, 1 / 9, 1 / 9, 1 / 36, 1 / 36, 1 / 36, 1 / 36]) e = np.array([[0, 0], [0, 1], [0, -1], [1, 0], [-1, 0], [1, 1], [-1, -1],[1, -1], [-1, 1]]) def stream(): #(1)式+障害物との衝突処理 global n for i, axis in zip(range(1, 5),[[1, 1, 0, 1], [1, -1, 0, -1], [0, 1, 1, -1], [0, -1, 1, 1]]): #(1)式 n[:, :, i] = np.roll(n[:, :, i], axis[1], axis=axis[0]) n[:, :, i + 4] = np.roll(np.roll(n[:, :, i + 4], axis[1],axis=axis[0]),axis[3],axis=axis[2]) for i in range(1, 9): n[:, :, i][barrier[:, :, i]] = n[:, :, i - (-1)**i][barrier[:, :, 0]] #衝突した分を逆向きの成分に流してます。 def collide(): #(2)式+左端からの流入 global n, u, u9 rho = n.sum(axis=2).reshape(H, W, 1) #ρの計算 u = (n @ e) / rho #(ux,uy)の計算 n = (1 - om) * n + om * w * rho * (1 - 1.5 *(u**2).sum(axis=2).reshape(H, W, 1) +3 * (u @ e.T) + 4.5 * (u @ e.T)**2) #(2)式 n[:, 0] = w * (1 - 1.5 * (u_o**2).sum(axis=1).reshape(H, 1) + 3 *(u_o @ e.T) + 4.5 * (u_o @ e.T)**2) #左端からの流入 def curl(): #プロットする際の色に関係してる関数 return np.roll(u[:, :, 0], -1, axis=1) - np.roll(u[:, :, 0], 1, axis=1) - np.roll(u[:, :, 1], -1, axis=0) + np.roll(u[:, :, 1], 1, axis=0) def mk_barrier(arr): #障害物を表現した配列を渡すと衝突時の跳ね返り先の対応関係などを計算してくれる子 global barrier barrier = np.zeros((H, W, 9), bool) barrier[:, :, 0] = arr for i, axis in zip(range(1, 5),[[1, 1, 0, 1], [1, -1, 0, -1], [0, 1, 1, -1], [0, -1, 1, 1]]): barrier[:, :, i] = np.roll(barrier[:, :, 0], axis[1], axis=axis[0]) barrier[:, :, i + 4] = np.roll(barrier[:, :, i], axis[3], axis=axis[2]) H, W = 40, 100 #タテ・ヨコ viscosity = .005 #粘度 om = 1 / (3 * viscosity + 0.5) #参考サイトに倣ってこの計算になっています。粘度とωの関係式らしい。 u0 = [0, .12] #初速兼左端からの流入の速度ベクトル(-uy,ux)に対応 u = np.ones((H, W, 2)) * u0 u_o = np.ones((H, 2)) * u0 n = w * (1 - 1.5 * (u**2).sum(axis=2).reshape(H, W, 1) + 3 * (u @ e.T) + 4.5 * (u @ e.T)**2) r = 3 #壁の長さとか円の半径とか #壁 wall = np.zeros((H, W), bool) wall[H // 2 - r:H // 2 + r, H // 2] = True #円 x, y = np.meshgrid(np.arange(W), np.arange(H)) circle = ((x - H / 2)**2 + (y - H / 2)**2 <= r**2) mk_barrier(circle) def update(i): for t in range(10): stream() collide() im.set_array(curl() - barrier[:, :, 0]) return im, """Jupyter用 インタラクティブになる @interact(Viscosity=(0.05, 2.0, 0.01),v0=(0, 0.12, 0.01),Barrier=["circle", "wall"]) def a(Viscosity, v0, Barrier): global viscosity, om, u0, u_o viscosity = Viscosity * .1 om = 1 / (3 * viscosity + 0.5) u0 = [0, v0] u_o = np.ones((H, 2)) * u0 mk_barrier(eval(Barrier)) """ fig = plt.figure() stream() collide() im = plt.imshow(curl() - barrier[:, :, 0],cmap="jet",norm=plt.Normalize(-.1, .1)) anim = FuncAnimation(fig, update, interval=1, blit=True) plt.show()参考
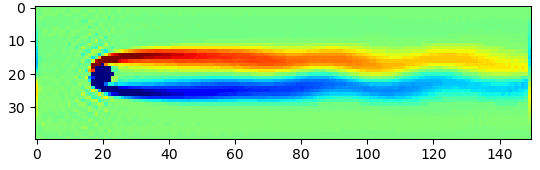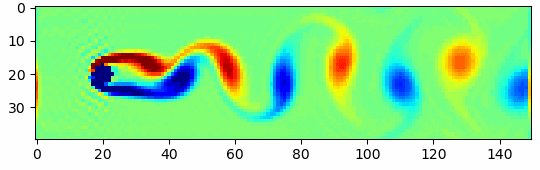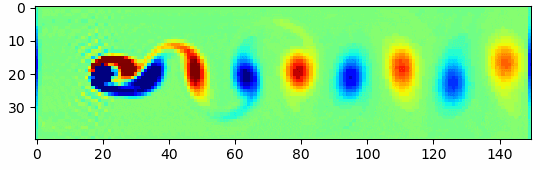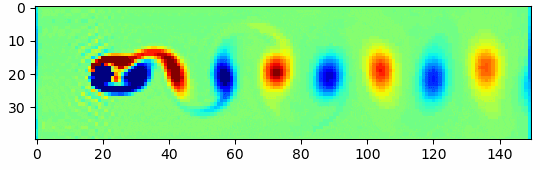
- 投稿日:2020-07-14T00:30:04+09:00
Raspberry Piでオシロスコープを操作する
1. はじめに
Raspberry PiのGPIOにタクタイルスイッチを接続し、スイッチが押されたらSCPIコマンドの「:RUN」「:STOP」をオシロスコープへ送信します。SCPIコマンドの送信はpyVISAを使用します。
2. 結線
BCM Physical I/O 機能 2 3 IN RUNコマンド(:RUN)発行 3 5 IN STOPコマンド(:STOP)発行 17 11 OUT LED点灯 LEDは3kΩの電流制限抵抗を介して接続します。
3. プログラム
- あらかじめpyUSB、pyVISA、pyVISA-pyをpipコマンドでラズパイにインストールしてください
- VISAアドレスはハードコーディングしています(VISAアドレスの調べ方は付録をご参照ください)
- sudo python scpi-commander.py で実行します(sudo重要!)
scpi-commander.pyimport RPi.GPIO as GPIO import time import visa PORT_RUN = 2 PORT_STOP = 3 PORT_LED = 17 VISA_ADDR = "USB0::6833::1230::DS1Zxxxxxxxxxx::0::INSTR" GPIO.setmode(GPIO.BCM) GPIO.setup(PORT_LED, GPIO.OUT) GPIO.setup(PORT_RUN, GPIO.IN) GPIO.setup(PORT_STOP,GPIO.IN) def open_dso(): rm = visa.ResourceManager() resources = rm.list_resources() #print(resources) try: dso = rm.open_resource(VISA_ADDR) except: print("Not Found:", resources) else: pass #print("Detected") return dso def main(): try: dso = open_dso() except: print("DSO Open Failed, exit.") exit(1) else: print("DSO Open Success.") try: while True: port_run = GPIO.input(PORT_RUN) port_stop = GPIO.input(PORT_STOP) if port_run == GPIO.LOW: GPIO.output(PORT_LED,GPIO.HIGH) #print(dso.query("*IDN?")) print(":RUN") dso.write(":RUN") while(GPIO.input(PORT_RUN)==GPIO.LOW): #print("pressing...") time.sleep(0.1) if port_stop == GPIO.LOW: GPIO.output(PORT_LED,GPIO.HIGH) print(":STOP") dso.write(":STOP") while(GPIO.input(PORT_STOP)==GPIO.LOW): #print("pressing...") time.sleep(0.1) GPIO.output(PORT_LED,GPIO.LOW) time.sleep(0.1) except KeyboardInterrupt: GPIO.cleanup() main()4. おわりに
- フットスイッチを使うと両手がふさがっていても足で操作できそうです。
5. 参考資料
この記事を作成するにあたって参考にさせていただいた記事です。
X. 付録 VISAアドレスの調べ方
あらかじめオシロとラズパイ(またはPC)をUSBで接続します。
> sudo python >>> import visa >>> rm = visa.ResourceManager() >>> print(rm.list_resources()) ('USB0::0x1AB1::0x04CE::DS1Zxxxxxxxxxx::0::INSTR')

- 投稿日:2020-07-14T00:01:20+09:00
networkxでバージョン問題が出たのでメモ
networkxでバージョン問題が出たのでメモ
・networkは環境依存しているモジュールがあり、バージョンにより関数が見つからずエラーを吐いてしまうので、解決方法を書いておくことにしました。
環境
python 3.7.7
anaconda 4.8.3
os1 windows10
os2 ubuntu 18.04
networkx 2.4
問題となった関数
nx.connected_component_subgraphs(G)
nx.draw(SG)自分は、今回この二つの関数でエラーが出てしまった。
解決方法
コマンドプロンプトもしくは、ターミナルから
pip install networkx==2.3を実行しバージョンを下げることでエラーを回避することができた。
ubuntuとwindow両方で動作を確認できたため、networkx側の問題だと考えられる。
考察
networkxのstable版が公開されたのが約半年前のため、大きな問題があればstable版を2.3に戻していると考えられるので、
代替えになる関数が用意されていると考えたが特に見つけることができなかった。