- 投稿日:2020-06-26T23:30:33+09:00
Seeeduino XIAO でCircuiPythonを走らせる
はじめに
マイコン向けのPython環境であるMicroPythonを基に、Adafruit社が開発したのがCircuitPythonです。ArduinoのC言語に比べて、少ない記述で高い機能を実現できて、コンパイルの必要もなく書き込みも簡単にできます。
CircuitPython対応マイコン
https://circuitpython.org/downloadsAdafruit社の自社マイコンの他にSeeeduino XIAOにも対応しています。
このマイコンの詳しい解説
https://qiita.com/nanase/items/0fed598975c49b1d707emicro:bitもMicroPythonでプログラムできます
https://microbit.org/Seeeduino XIAOの方がmicro:bitより安価でクロック周波数も高いです。
microbit(MCU:ARM Cortex M0 + 32bit 16 MHz(Nordic nRF51822 ))
https://www.switch-science.com/catalog/5263/Seeduino XIAO(CPU:ARM Cortex-M0 + 32bit 48 MHz(SAMD21G18))
https://www.switch-science.com/catalog/6335/
Amazonでは3個セットを販売してます
https://www.amazon.co.jp/dp/B086KXY929Seeeduino XIAOのセットアップ
Seeeduino XIAO 用のCircuitPythonをダウンロードします。
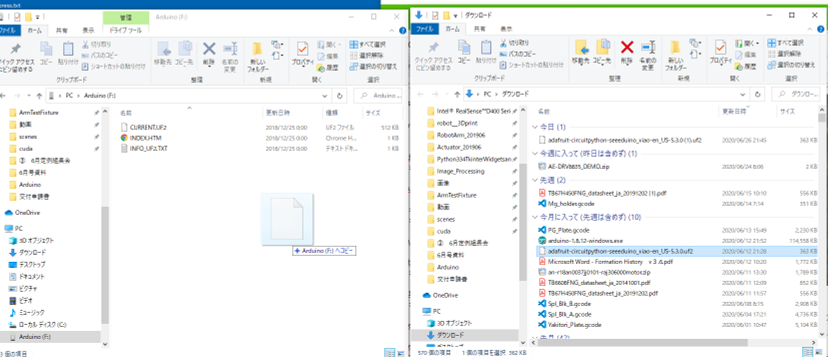
https://circuitpython.org/board/seeeduino_xiao/XIAOのRST端子を2度短絡すると橙色のLEDが点灯しArduinoドライブがPCの元に現れます。
次にダウンロードしたファイルをこのドライブにドロップしてコピーを作成します。
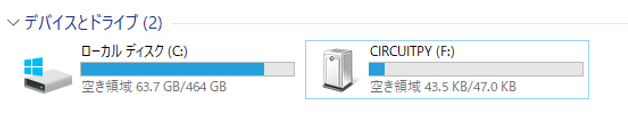
コピーが終わるとドライブ名がCIRCUITPYに変わります。
MuエディタでPythonプログラムを書き、このドライブにmain.pyとして保存すると自動的にプログラムが実行されます。
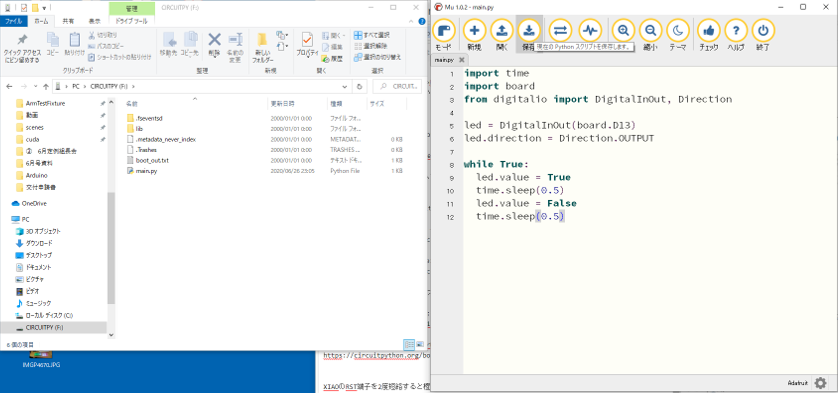
Lチカプログラム
main.pyimport time import board from digitalio import DigitalInOut, Direction led = DigitalInOut(board.D13) led.direction = Direction.OUTPUT while True: led.value = True time.sleep(0.5) led.value = False time.sleep(0.5)動画をYoutubeでご覧ください
https://youtu.be/rQwd1_cSu6cMuエディタについては、次に詳しく解説されてます。
https://qiita.com/inachi/items/8f61586cd2482987b8d0参考資料
CircuitPythonについてadafruit社が記述してるHP
https://learn.adafruit.com/welcome-to-circuitpythonCircuitPythonの解説
https://learn.adafruit.com/circuitpython-essentialsCircuitPythonの例題
https://github.com/adafruit/Adafruit_Learning_System_Guides/tree/master/CircuitPython_Essentials


- 投稿日:2020-06-26T23:25:44+09:00
Azure Functions: Python版Durable Functionsを試す
はじめに
2020/06/24、どうやらPythonのDurable FunctionsがPublic Previewになったらしい・・・
Durable Functions now supports Python
ということで、ささっとローカルで試してみました。
検証環境
ドキュメントと GitHub をもとに、以下のような検証環境を用意しました。
- Windows 10 Pro 64bit
- Visual Studio Code
- Azure Functions拡張機能
- Node.js 12.18.0
- Azure Functions Core Tools 3.0.2630
- 3.0.2630 以上が必須
- Python 3.7.7
- Python 3.6 以降が必須
- Azure Storage Emulator 5.10.0.0
- ローカルデバッグで使用
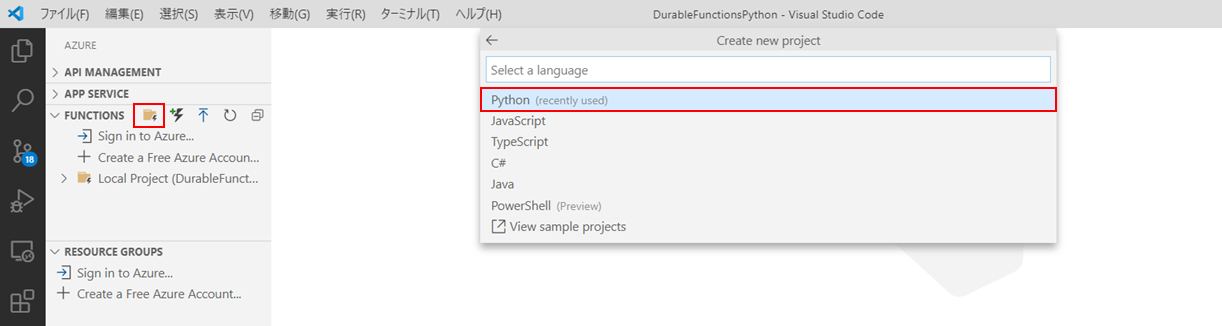
プロジェクトの作成
Azure Functions拡張機能を使ってプロジェクトを作成します。
拡張機能のプロンプトに沿ってPythonの関数プロジェクトを作成します。
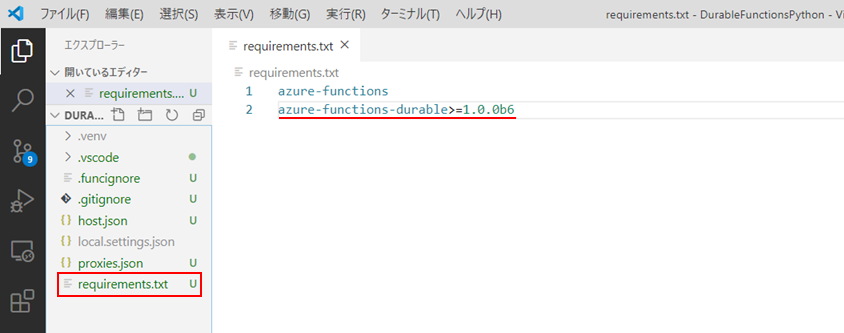
作成されたプロジェクトの「requirements.txt」を開き、Durable Functions用モジュール「azure-functions-durable>=1.0.0b6」を書き加えます。
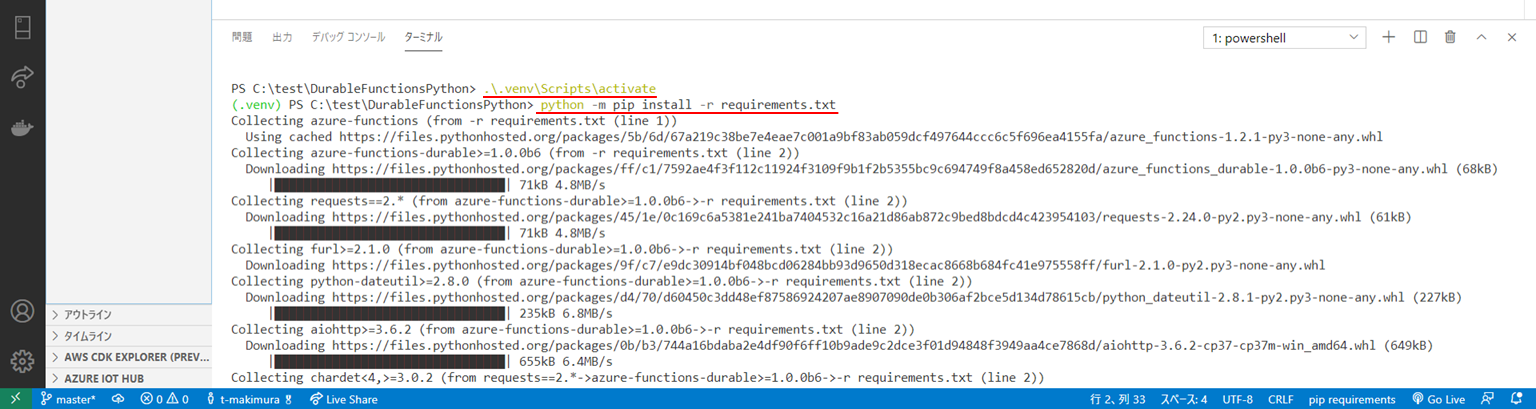
VS Codeのターミナルを開き、プロジェクト内に作成されているPython仮想環境をactivateします。
Python仮想環境に「requirements.txt」でモジュールをインストールします。> .\.venv\Scripts\activate > python -m pip install -r requirements.txt
関数の作成
プロジェクトが作成されたら、Orchestrator、Activity、Clientの関数をそれぞれ作成していきます。
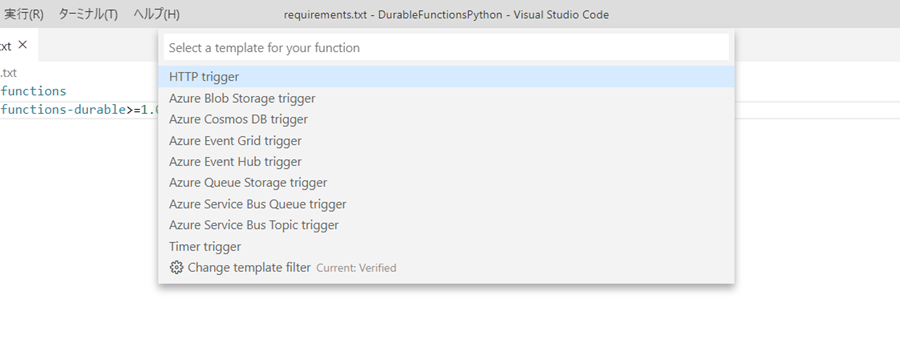
ドキュメントでは、Durable Functions用テンプレートを使用することになっていますが、現時点ではテンプレートがないため、「Http Trigger」のテンプレートで作って「_init_.py」、「functions.json」の中身を書き換えます。
Activity関数
「Http Trigger」のテンプレートで「durable-activity」の関数を作成し、「_init_.py」、「functions.json」を下記の内容で書き換えます。
内容としては、関数に渡された値の頭に「Hello」をつけて返すだけの簡単な処理です。
関数の実行状態を分かりやすくするため処理に2秒のWaitをかけ、ログに「Activity {name}」が表示されるようにしています。_init_.pyimport logging import time def main(name: str) -> str: time.sleep(2) logging.warning(f"Activity {name}") return f'Hello {name}!'functions.json{ "scriptFile": "__init__.py", "bindings": [ { "name": "name", "type": "activityTrigger", "direction": "in", "datatype": "string" } ], "disabled": false }Orchestrator関数
「Http Trigger」のテンプレートで「durable-orchestrator」の関数を作成し、「_init_.py」、「functions.json」を下記の内容で書き換えます。
先ほど作成したActivity関数に「Tokyo」、「Seattle」、「London」の値を渡し、結果を配列に格納しています。
各呼び出しにyieldをつけて関数チェーンとして動作させています。
Activity関数の呼び出し方法は、関数がスネークケースになったぐらいでJavaScriptと変わりません。_init_.pyimport azure.durable_functions as df def orchestrator_function(context: df.DurableOrchestrationContext): # Activity関数の呼び出し task1 = yield context.call_activity("durable-activity", "Tokyo") task2 = yield context.call_activity("durable-activity", "Seattle") task3 = yield context.call_activity("durable-activity", "London") outputs = [task1, task2, task3] return outputs main = df.Orchestrator.create(orchestrator_function)functions.json{ "scriptFile": "__init__.py", "bindings": [ { "name": "context", "type": "orchestrationTrigger", "direction": "in" } ], "disabled": false }Client関数
「Http Trigger」のテンプレートで「durable-client」の関数を作成し、「_init_.py」、「functions.json」を下記の内容で書き換えます。
「client.start_new」でOrchestrator関数を指定して呼び出しをしています。
こちらも呼び出し方法は、JavaScriptと変わりませんが、バインドのtypeがJavaScriptでは「durableClient」なのに対し、「orchestrationClient」と変わっているところもあります。_init_.pyimport logging from azure.durable_functions import DurableOrchestrationClient import azure.functions as func async def main(req: func.HttpRequest, starter: str, message): logging.info(starter) client = DurableOrchestrationClient(starter) # Orchestratorの開始 instance_id = await client.start_new('durable-orchestrator') response = client.create_check_status_response(req, instance_id) message.set(response)functions.json{ "scriptFile": "__init__.py", "bindings": [ { "authLevel": "anonymous", "name": "req", "type": "httpTrigger", "direction": "in", "methods": [ "post", "get" ] }, { "direction": "out", "name": "message", "type": "http" }, { "name": "starter", "type": "orchestrationClient", "direction": "in", "datatype": "string" } ] }関数のローカル実行
関数が作成できたので、ローカルで実行してみます。
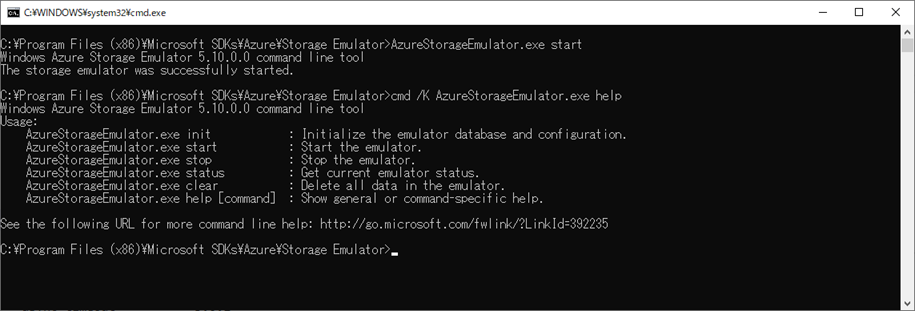
Durable Functionsは仕組上Azure Storageが必要なため、ローカルだけで実行する場合はAzure Storage Emulatorを使用します。
Emulatorを使用する場合は、プロジェクトのrootにある「local.settings.json」を開いて「AzureWebJobsStorage」に「UseDevelopmentStorage=true」を代入し、Azure Storage Emulatorを開始します。local.settings.json{ "IsEncrypted": false, "Values": { "AzureWebJobsStorage": "UseDevelopmentStorage=true", "FUNCTIONS_WORKER_RUNTIME": "python" } }
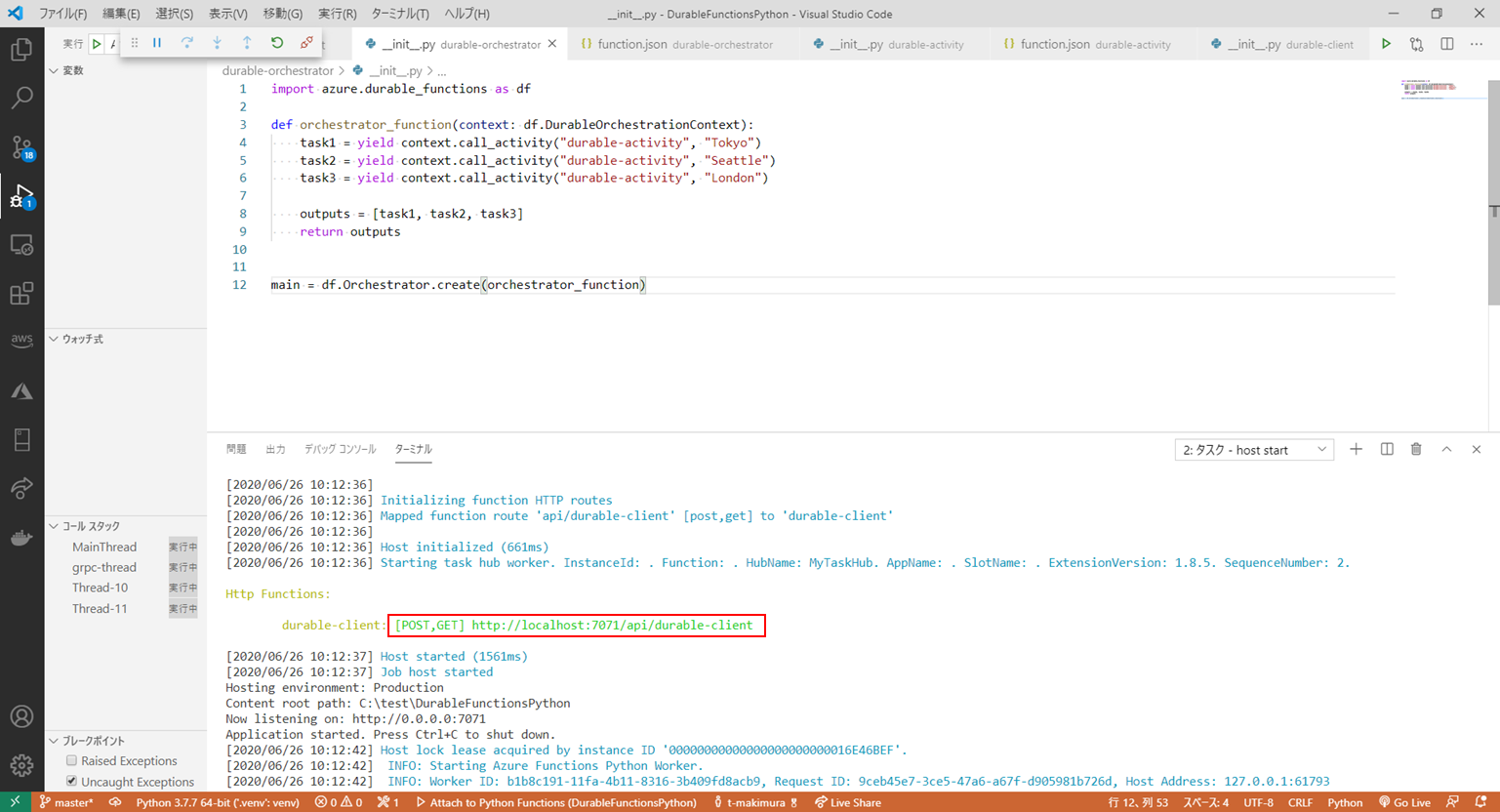
F5キーでデバッグモードを開始します。
プロセスが起動するとClient関数のURLが表示されるので、Postman等のクライアントでアクセスします。
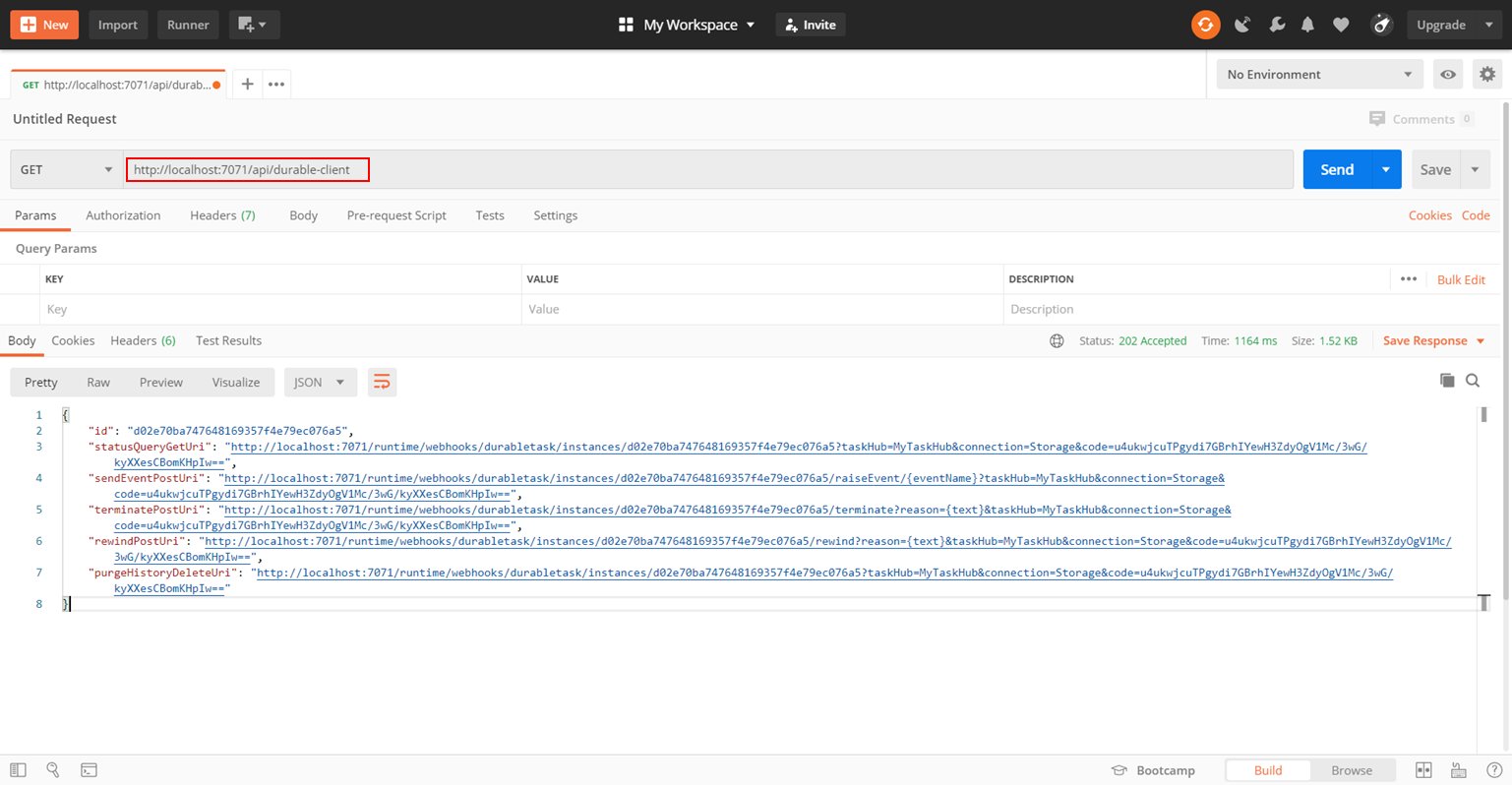
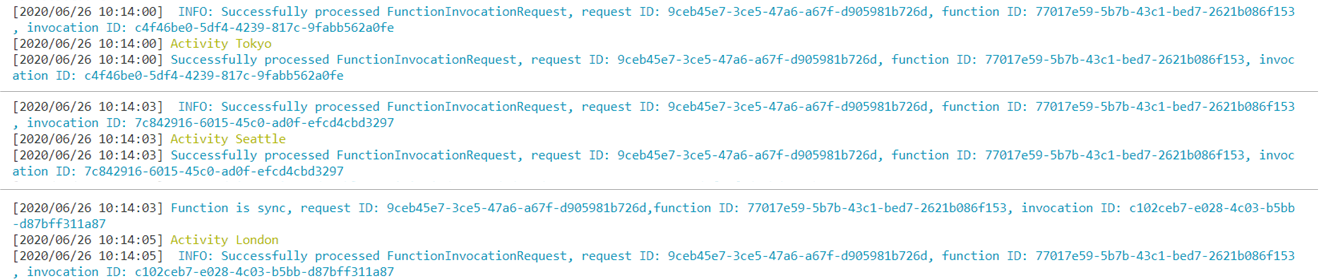
PostmanでGetリクエストをするとターミナルにログが流れ始め、レスポンスとして状態管理用URLが返されます。
表示されたログを確認するとWarningの黄文字が「Activity Tokyo」、「Activity Seattle」、「Activity London」の順でおおよそ2秒ごとに表示されていることがわかります。
関数チェーンが正しく機能していることがわかります。
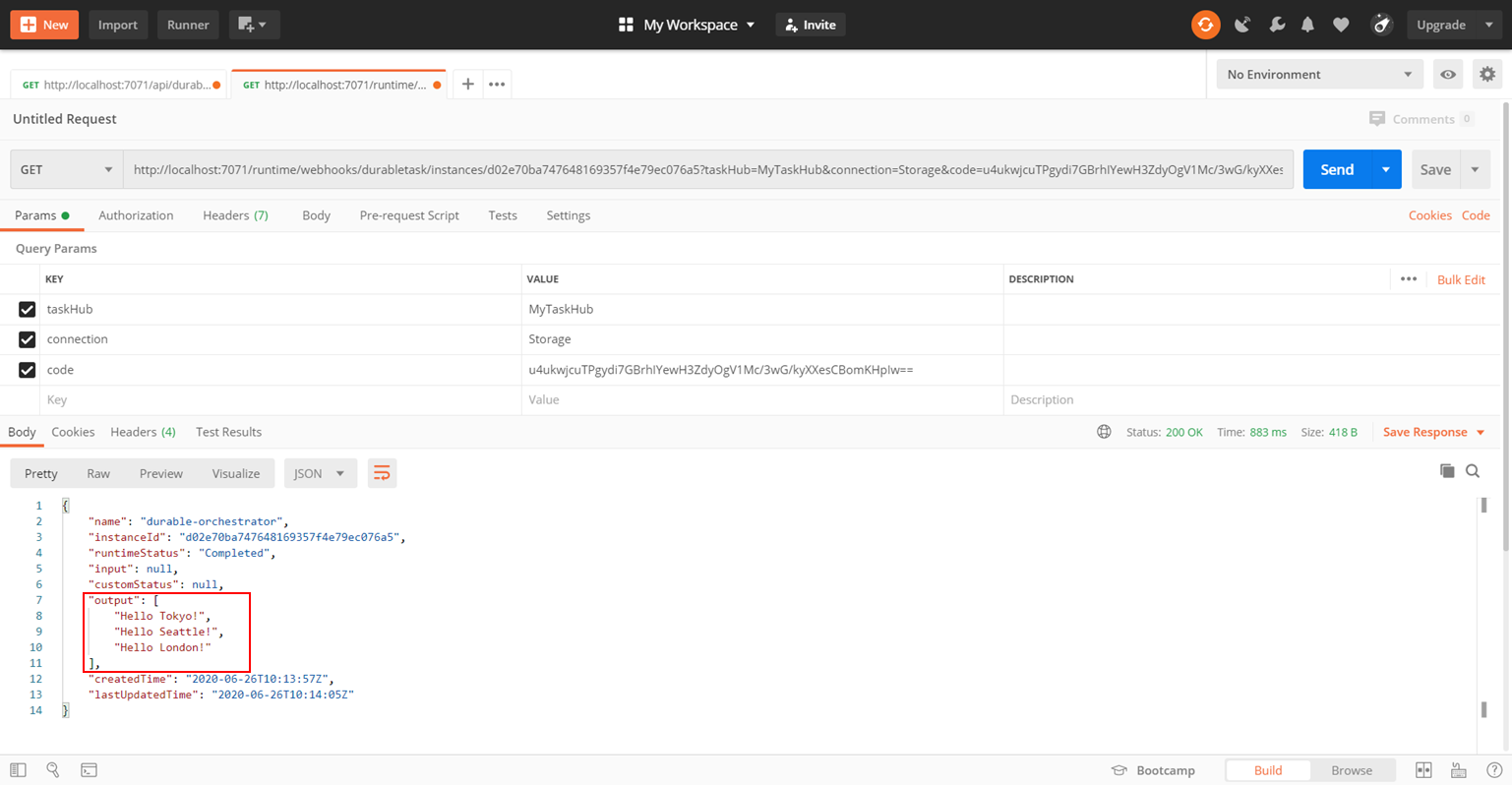
レスポンスの「statusQueryGetUri」でOrchestratorの状態を確認すると、runtimeStatusが「Completed」となっており、outputとして「Hello Tokyo!」、「Hello Seattle!」、「Hello London!」の配列が得られました。
Fan-Out/Fan-In
せっかくなのでFan-Out/Fan-Inも試してみます。
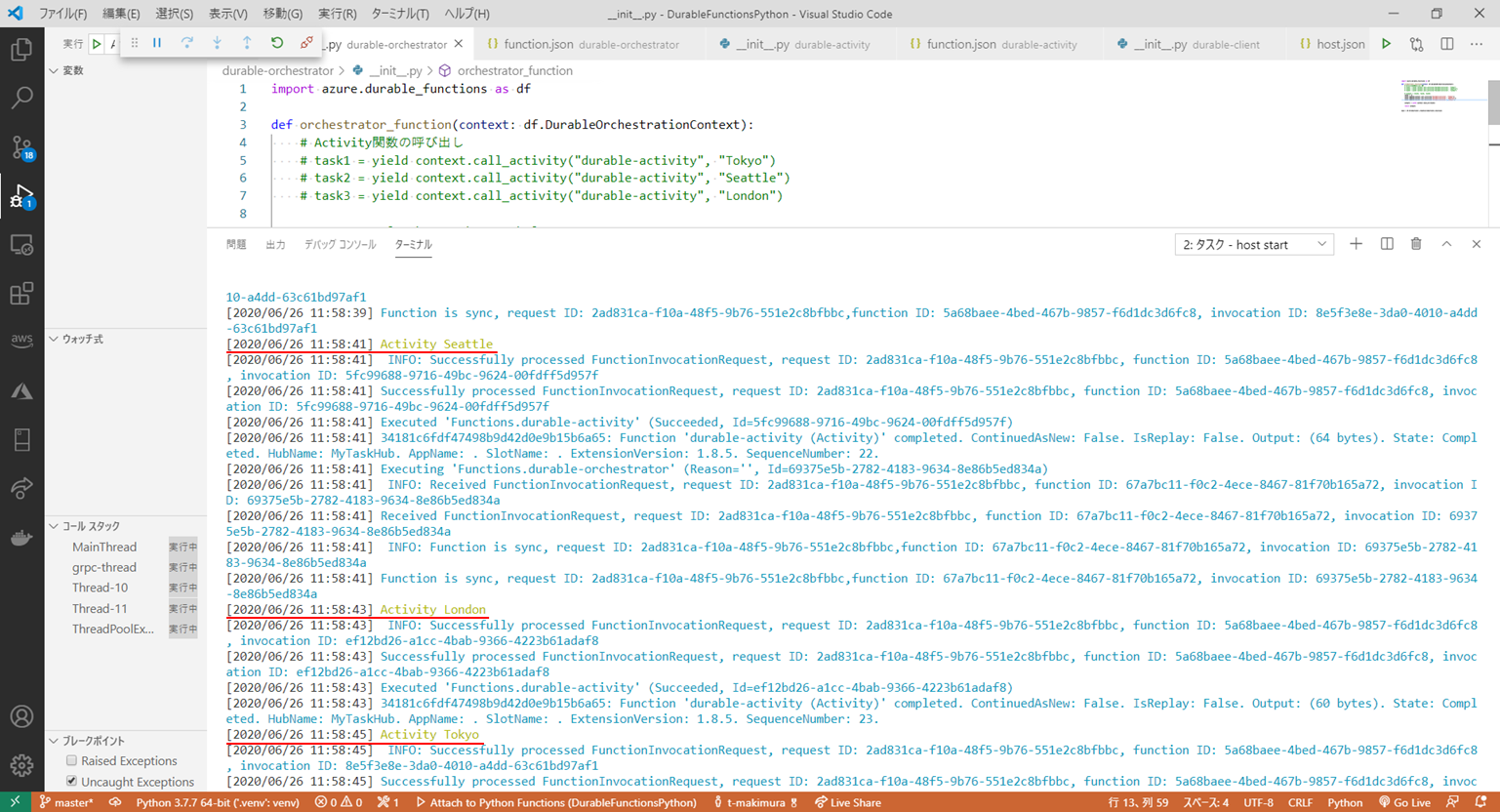
Orchestrator関数を下記のように書き換えます。_init_.pyimport azure.durable_functions as df def orchestrator_function(context: df.DurableOrchestrationContext): # Activity関数の呼び出し # task1 = yield context.call_activity("durable-activity", "Tokyo") # task2 = yield context.call_activity("durable-activity", "Seattle") # task3 = yield context.call_activity("durable-activity", "London") # outputs = [task1, task2, task3] tasks = [] tasks.append(context.call_activity("durable-activity", "Tokyo")) tasks.append(context.call_activity("durable-activity", "Seattle")) tasks.append(context.call_activity("durable-activity", "London")) outputs = yield context.task_all(tasks) return outputs main = df.Orchestrator.create(orchestrator_function)書き換えたものを実行してみました。
「Tokyo」、「Seattle」、「London」の順で登録したタスクが「Seattle」、「London」、「Tokyo」と順不同で処理されました。
ただ、処理はそれぞれ2秒ごとに発生しておりFan-Out/Fan-Inで期待される並列処理にはなっていないようでした。まだプレビュー段階なので今後に期待といったところでしょうか。
まとめ
Python版とはいえDurable Functionsなので、スクリプトのお作法はJavaScriptと変わっておらず、JavaScriptでの開発経験があれば難なく開発はできそうです。
リリースにも書かれているように、Pythonの場合は機械学習やデータ分析方面での活用が期待でき、サーバレスでデータの並列処理環境を構築するといったシナリオが新たに可能になったというのは活用方法として面白そうです。参考
- 投稿日:2020-06-26T23:01:04+09:00
HSPICEのデータをPythonで読み込んだ話
はじめに
やりたかったこと。
HSPICEの中から必要なデータを読み取って機械学習などに利用するため行列演算すること。DeCiDaライブラリ
DeCiDaというPython3上で動く回路シミュレータライブラリを発見した。
このライブラリを利用すると、DeCiDaから直接回路シミュレータの操作が可能であるが、今回はデータ変換のみに利用した。Code
import numpy as np from scipy import interpolate from decida.Data import Data d_sampling = 0.005 s_sampling = 0 e_sampling = 70 n_sampling = int((e_sampling - s_sampling)/d_sampling + 1) time_r = np.linspace(s_sampling,e_sampling,n_sampling) #read .tr0 d = Data() d.read_hspice('xxx.tr0') rows = d.nrows() cols = d.ncols() #delete unnecessary cols leave_cols = [0,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,42] n_leave_cols = len(leave_cols) for i in range( cols ): j = cols - i if not (j in leave_cols) : d.delete(j) #d.delete( tuple of col_name ) #trans to numpy array original_data = np.empty((n_leave_cols,rows)) for i in range(n_leave_cols): original_data[i] = d.get(i) #delete rows which is not change TIME k = np.zeros(rows-1) for i in range(rows-1): j = rows-i-1 if (original_data[0,j] <= original_data[0,j-1] ): original_data = np.delete(original_data,j,1) # resamp def resamp(y): f = interpolate.interp1d(original_data[0], y, kind='linear') return f(time_r) r_data = np.empty((n_leave_cols,n_sampling)) r_data[0] = time_r r_data[1:] = resamp(original_data[1:]) np.save('rData.npy',r_data)コードの説明
DeCiDaのDataクラスでHSPICEシミュレート結果をPython上で読み出すことが可能。
変数
・s_sampling, e_sampling
Spice内のシミュレートの開始時間、終了時間。
・d_sampling
読み出し時のサンプリング間隔。データ読み出し
d = Data()
d.read_hspice('xxx.xxx')でデータをdに保管できる。CSVやNGSpiceに対応したメソッドもある。必要のないデータの消去
計算上必要のないデータ配列があると思うが、
d.delete(col)
で消す操作が可能。
colは整数値orカラム名で指定可能。タプルを渡すと複数消去することができる。(今回は残す列名を持っていたので、ひとつずつ消した)d.index("zzz")でカラム名から列番号を取得することができる。
Numpy array に変換
d.get(col) で入手できます。 for文使わなくてもできそう……。上の章である必要ないデータの消去部と統合できそう……。
リサンプリング
Spiceデータの時間軸が非等間隔なので、SciPyのinterpolateでリサンプリングを行う。
しかし、時間データにかぶりがあるとリサンプリングができないため、消去を行う。そして、線形で補完を行い、Numpyデータとして保存した。
まとめ
アナログ回路シミュレータとPythonデータの変換を行うコードを解説した。
現在、Spiceは別で回してその結果からデータを読んでいるが、DeCiDa自体にSpiceを操作するメソッドもあるので、そちらの利用による効率化を検討したい。
- 投稿日:2020-06-26T22:34:31+09:00
google Colaboratoryでダークテーマでも図の目盛りとラベルを見やすくする設定
こんな人におすすめ
・google colaboratoryでダークテーマを使用しているが、図の目盛りとラベルが見えづらくて困っている人
google colaboratoryのダークテーマ
標準テーマでは味気ないですがダークテーマはクールです。
やる気も上がりますし夜でも目に優しい。
問題点
ただし、難点が一つあります。それは図の目盛りやラベルが潰れてしまうこと。
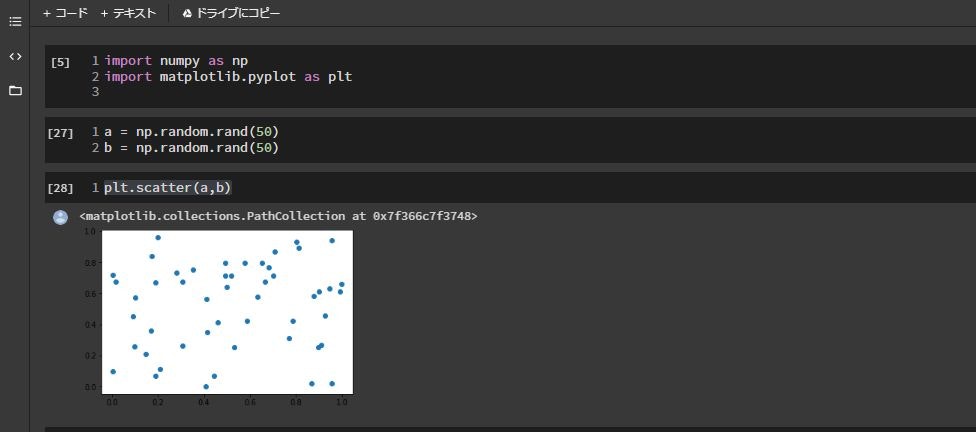
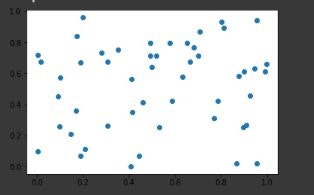
適当にランダムな50個の散布図をプロットしてみます。import numpy as np import matplotlib.pyplot as plt a = np.random.rand(50) b = np.random.rand(50) plt.scatter(a,b)
見えない...
目盛りやラベル部分の背景が透過画像となっているため背景画像と同色の文字が見えづらくなっているのが原因です。解決方法
下の文章を追加しましょう。
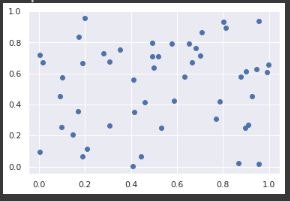
import seaborn as sns sns.set()これで同じように
plt.scatter(a,b)とすると
きれいに見えました。sns.set()をいれないと、seabornにしてもラベルと目盛り部分が透過画像となってしまうので注意しましょう。
- 投稿日:2020-06-26T20:55:13+09:00
Pandasでバージョンにより微妙に異なる動作
はじめに
Pandasは超便利なライブラリではあるが、バージョンが変わると、以前動作していたものが動作しなくなったりすることがある。今回は、0.24⇒1.0にした時のケースとして2点あげる。
その① ixが使えねー。
まずは、0.24で。'a'と'b'という列からなるデータフレームを作成し、ixで列を指定してみよう。
0.24>>>a = pd.DataFrame([[1,2],[3,4]], index=[1,2], columns=['a', 'b']) >>> a.ix[:, ['a','b']] a b 1 1 2 2 3 4普通に使える。
次に、1.0で。1.0>>> a.ix[:, ['a','b']] Traceback (most recent call last): File "<stdin>", line 1, in <module> File "C:\ProgramData\Anaconda3\envs\padnas1\lib\site-packages\pandas\core\generic.py", l ine 5273, in __getattr__ return object.__getattribute__(self, name) AttributeError: 'DataFrame' object has no attribute 'ix'使えねー。
しかし焦ることはない。
ixの代わりにlocを使えばいいのだ。その② locで存在しない列を指定するとエラー。
今度はそのまま、'c'という存在しない列を指定してみよう。
0.24の場合。0.24>>> a.loc[:, ['a','c']] a c 1 1 NaN 2 3 NaN列を自動的に作成し、'NaN'で埋めてくれるようだ。気が利きすぎ?
次1.0で。
1.0>>> a.loc[:, ['a','c']] Traceback (most recent call last): File "<stdin>", line 1, in <module> File "C:\ProgramData\Anaconda3\envs\padnas1\lib\site-packages\pandas\core\indexing.py", line 1760, in __getitem__ return self._getitem_tuple(key) File "C:\ProgramData\Anaconda3\envs\padnas1\lib\site-packages\pandas\core\indexing.py", line 1287, in _getitem_tuple retval = getattr(retval, self.name)._getitem_axis(key, axis=i) File "C:\ProgramData\Anaconda3\envs\padnas1\lib\site-packages\pandas\core\indexing.py", line 1952, in _getitem_axis return self._getitem_iterable(key, axis=axis) File "C:\ProgramData\Anaconda3\envs\padnas1\lib\site-packages\pandas\core\indexing.py", line 1593, in _getitem_iterable keyarr, indexer = self._get_listlike_indexer(key, axis, raise_missing=False) File "C:\ProgramData\Anaconda3\envs\padnas1\lib\site-packages\pandas\core\indexing.py", line 1550, in _get_listlike_indexer self._validate_read_indexer( File "C:\ProgramData\Anaconda3\envs\padnas1\lib\site-packages\pandas\core\indexing.py", line 1652, in _validate_read_indexer raise KeyError( KeyError: 'Passing list-likes to .loc or [] with any missing labels is no longer supported , see https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#deprecate-loc- reindex-listlike'キーエラーが発生。これはこれで厳密でよいかもしれない。
対応としては、事前に列にそのキーが存在しているか調べた方がよさそうだ。最後に
今回、たまたま見つかった2例を紹介したが、他にも細かいところで多々動作が変わっていると思われるので、以下などにより、網羅的に変更点を確認した方がよいだろう。
https://pandas.pydata.org/docs/whatsnew/v1.0.0.html
- 投稿日:2020-06-26T19:44:49+09:00
Anaconda Promptを使わずにPythonコマンドを実行する場合のエラー
はじめに
掲題のエラーについて対応した時のチップス。
環境
- Windows10
- Anaconda
- Python3.7
現象
Anaconda でconda activate 等をせずにDOSプロンプト上で直接 Anacondaの仮想環境のptyhonを実行した場合に以下のエラーが発生した。
During handling of the above exception, another exception occurred: Traceback (most recent call last): File "common/utils/create_project_schema.py", line 5, in <module> import numpy as np File "c:\ProgramData\Anaconda3\envs\hogehoge\lib\site-packages\numpy\__init__.py", line 142, in <module> from . import core File "c:\ProgramData\Anaconda3\envs\hogehoge\lib\site-packages\numpy\core\__init__.py", line 50, in <module> raise ImportError(msg) ImportError: IMPORTANT: PLEASE READ THIS FOR ADVICE ON HOW TO SOLVE THIS ISSUE! Importing the numpy C-extensions failed. This error can happen for many reasons, often due to issues with your setup or how NumPy was installed. We have compiled some common reasons and troubleshooting tips at: https://numpy.org/devdocs/user/troubleshooting-importerror.html Please note and check the following: * The Python version is: Python3.7 from "c:\ProgramData\Anaconda3\envs\hogehoge\python.exe" * The NumPy version is: "1.18.5" and make sure that they are the versions you expect. Please carefully study the documentation linked above for further help. Original error was: DLL load failed: 指定されたモジュールが見つかりません。原因と対応
AnacondaプロンプトとMS DOSプロンプトの環境変数PATHの違いをよーくみてみると原因は、以下パスの不足だった。
C:\ProgramData\Anaconda3\envs\<仮想環境名>\Library\bin上をシステム環境変数に設定することで解決。Python3.6では発生しなかったり、Anacondaのインストールの仕方によって変わってくる可能性はあるが、ご参考まで。
- 投稿日:2020-06-26T18:52:15+09:00
【強化学習】爆誕: DeepMind製 Experience Replay (経験再生)フレームワーク Reverb
英語で書いたブログ記事の日本語焼き直し。
1. はじめに
5月26日にDeepMindが強化学習における Experience Replay (経験再生) のためのフレームワークとして、Reverbをリリースした。(参照)
Reverb is an efficient and easy-to-use data storage and transport system designed for machine learning research. Reverb is primarily used as an experience replay system for distributed reinforcement learning algorithms but the system also supports multiple data structure representations such as FIFO, LIFO, and priority queues.
(筆者訳) Reverb は機械学習の研究のためにデザインされた効率的で簡単に利用できるデータ・ストレージ兼データ転送システムです。Reverbは主に分散強化学習アルゴリズムのための experience replay (経験再生) に利用されるが、このシステムはFIFO、LIFO、重み付きキューといったデータ構造をサポートしています。 (筆者訳ここまで)
同じくDeepMind製の強化学習フレームワーク Acme (A research framework for reinforcement learning) は、このReverbを利用している。(Acmeについてはまたの機会に)
2. インストール
記事を書いている6月26日現在、Reverbは、LinuxベースのOSのみをサポートし、 production use レベルではないと公式に記載されている。
TensorFlow の開発版が必要で、以下のコマンドで、PyPIからインストールすることができる
pip install tf-nightly==2.3.0.dev20200604 dm-reverb-nightly3. アーキテクチャ
Reverbはサーバー・クライアント方式を採用しており、その名前付けルールは他のReplay Bufferの実装よりもデータベースの用語に近いと感じる。
3.1 サーバー
サーバー側のサンプルコードは以下のようになる。
import reverb server = reverb.Server(tables=[ reverb.Table( name='my_table', sampler=reverb.selectors.Uniform(), remover=reverb.selectors.Fifo(), max_size=100, rate_limiter=reverb.rate_limiters.MinSize(1)), ], port=8000 )この例では、キャパシティ
100の 普通のReplay Buffer (一様サンプリング、古いものから順次上書き) が8000番のポートを待ち受ける。reverb.rate_limiters.MinSize(1)は最低1個のアイテムが入ってくるまでは、いかなるサンプリング要求もブロックすることを意味している。3.1.1 要素選択 (
sampler/remover)上の例でわかるように、Reverbでは要素のサンプリングと削除(上書き)のロジックをそれぞれ独立して指定することができる様になっている。
Reverbでサポートしているロジックは、
reverb.selectorsに実装してあり、次のようなものがある
Uniform: すべてのアイテムから一様分布でランダムに選択Prioritized: プライオリティに応じてランダムに選択FIFO: 最も古いデータを選択LIFO: 最も新しいデータを選択MinHeap: プライオリティが最低のデータを選択MaxHeap: プライオリティが最高のデータを選択3.1.2 制約条件指定 (
rate_limiter)
rate_limiter引数は、Replay Bufferの使用条件をを設定することができる。
Reverbでサポートされている条件はreverb.rate_limitersに実装されており、
次のようなものがある
MinSize: サンプル可能になる最低限のアイテム数を設定SampleToInsertRatio: データ挿入(更新)とデータサンプルの平均的な比率を設定
- 上書きされるまでにおよそ何回サンプルされるという利用法に役立つ(らしい)
Queue: 上書きされる前に、ちょうど1回取り出される (FIFO用)Stack: 上書きされる前に、ちょうど1回取り出される (LIFO用)ソースコードのコメントを見ると、
reverb.rate_limiters.Queueとreverb.rate_limiters.Stackは直接利用することが推奨されておらず、代わりに静的メソッドのreverb.Table.queueとreverb.Table.stackがそれぞれ、FIFOとLIFOのロジックを持つReplay Bufferになるように適切にsampler、remover、rate_limiterを設定してくれる。3.2 クライアント
クライアントプログラムのサンプルコードは以下
import reverb client = reverb.Client('localhost:8000') # サーバーとクライアントが同じマシーンの場合 # [0,1] という状態 (observation) を priority 1.0 でReplay Bufferに入れる例 client.insert([0, 1], priorities={'my_table': 1.0}) # サンプリングすると、 generator が返ってくる client.sample('my_table', num_samples=2))3.3 保存/読み込み
Reverbは、データの保存/読み込み機能に対応している。
クライアントから、以下のコードを実行することで、現在のサーバー内のデータがファイル上に保存され、保存したファイルパスが得られるcheckpoint_path = client.checkpoint()保存したデータを利用して、サーバーを作成することでもとのデータの状態を復元することができる。
注意しないといけないことは、コンストラクタのtables引数は、データを保存した元のサーバーと全く同じものを、 ユーザーの責任で 指定しないことである。checkpointer = reverb.checkpointers.DefaultCheckpointer(path=checkpoint_path) server = reverb.Server(tables=[...], checkpointer=checkpointer)最後に
DeepMindが発表したExperience Replay用の新しいフレームワークのReverbは、まだ安定版には到達していないが、柔軟で大規模な強化学習をターゲットとした将来有望なものであると感じた。
拙作のExperience Replay用ライブラリ cpprb にとっては、巨大なライバルが突然出現したわけではあるが、より小規模な強化学習の実験においては、cpprbの方が便利で使いやすい部分もあると思う。 (過去Qiita記事参照)
- 投稿日:2020-06-26T18:52:00+09:00
Linux(ubuntu)を知らない人がWindows上でLinuxコマンドを実行する方法【Rとpythonの動作確認まで】
この記事の目的
- Windowsユーザー向けだよ(Win10)

- Linux(ubuntu)とかわからなくても大丈夫だよ
- とりあえず動かせるところまで紹介するよ
記事を書くまでの経緯
新しいライブラリが出た時にgithub見に行ったらチュートリアルに
sudo,~.sh,wget
とかlinux系のコマンドが出てきて今までは
「Linux環境...VirtualBoxたてるか
ってなってたんですが、
windowsでも簡単に試したいと思って調べてたら、
windowsでもubuntuが動かせるみたいなので紹介。step-1 Windows Subsystem for Linux(WSL)の有効化
win10では標準の機能としてLinux環境をwindows上で実行することができます。
使ってみた感じHyper-VやVirtualBoxよりも使いやすいので使いやすさを味わってみてほしい
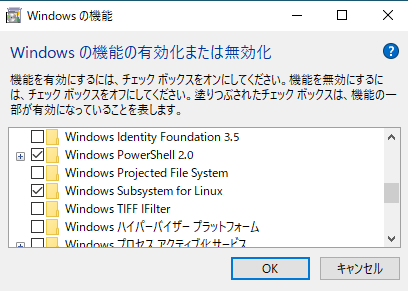
※Windows Subsystem for Linuxにチェックを付ける
step-2 Ubuntuをダウンロード
今回は18.04LTSを使いますが、各自のやりたいことによって選んでください。
2020/06/26時点では20.04までダウンロードできる。
インストールした後起動し、IDとpassを設定
passはデフォルトでは表示もされなければ、打ち込んでも*記号が出てきたりもしないので打ち間違いのないように。step-3 Ubuntuコマンドを打ち込む(アップデートとRの追加)
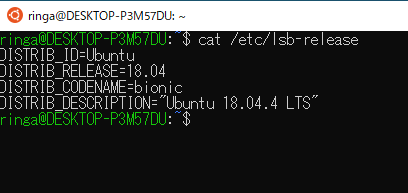
バージョン確認
cat /etc/lsb-release
アップデート
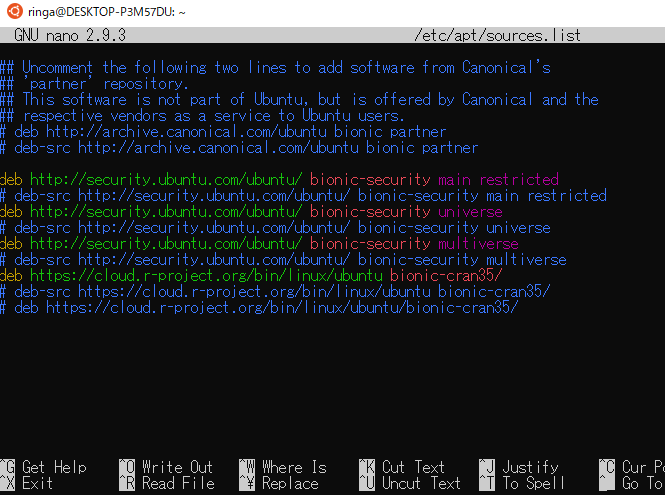
sudo apt updateRのダウンロード先を追加
echo 'deb https://cran.rstudio.com/bin/linux/ubuntu bionic-cran35/' | sudo tee -a /etc/apt/sources.listエディタで追加されていることの確認
sudo nano /etc/apt/sources.list
「Ctrl + X」でnanoを抜ける
key追加
sudo apt-key adv --keyserver keyserver.ubuntu.com --recv-keys E298A3A825C0D65DFD57CBB651716619E084DAB9コマンドに問題なければ
gpg: Total number processed: 1 gpg: imported: 1が返ってくると思う
最後に
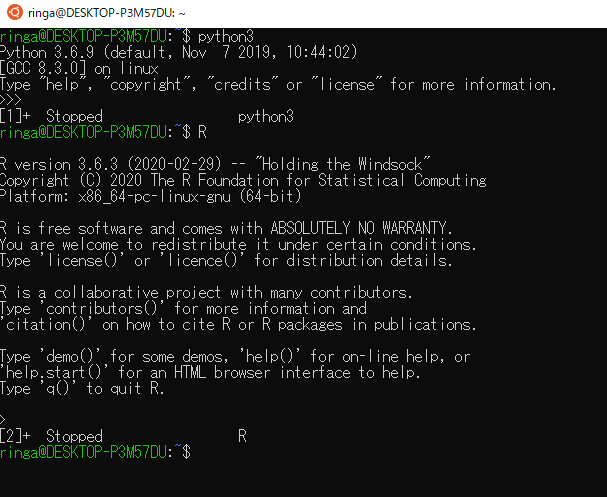
sudo apt install r-base sudo apt updatestep-4 pythonとRが起動できるかだけ確認する
pythonはデフォルトのままでpython3と打ち込むと開く
Rもpythonも抜けるときは「Ctrl + Z」
RやPython側から「パッケージが入ってない」と言われたら上記のように起動した後
install.packagesなりpip installなりを実行する。以上
これで今後Linux環境が必要な時に試せる
やったぜメモ:フォルダ移動が面倒な時
フォルダを移動するときに
cmdと同じく
cd ~~~~
で移ってもいいけど、使いたいフォルダのアドレスに「bash」と打ち込めばらくちん
参考記事
Windows Subsystem for Linux (WSL1) をインストールしてみよう!
【WSL入門】第1回 Windows 10標準Linux環境WSLを始めよう
最新のRをUbuntuにインストール




- 投稿日:2020-06-26T18:50:42+09:00
Pipenvのlockingが遅すぎる
- 投稿日:2020-06-26T17:54:10+09:00
ゼロから始めるLeetCode Day68 「709. To Lower Case」
概要
海外ではエンジニアの面接においてコーディングテストというものが行われるらしく、多くの場合、特定の関数やクラスをお題に沿って実装するという物がメインである。
どうやら多くのエンジニアはその対策としてLeetCodeなるサイトで対策を行うようだ。
早い話が本場でも行われているようなコーディングテストに耐えうるようなアルゴリズム力を鍛えるサイトであり、海外のテックカンパニーでのキャリアを積みたい方にとっては避けては通れない道である。
と、仰々しく書いてみましたが、私は今のところそういった面接を受ける予定はありません。
ただ、ITエンジニアとして人並みのアルゴリズム力くらいは持っておいた方がいいだろうということで不定期に問題を解いてその時に考えたやり方をメモ的に書いていこうかと思います。
Python3で解いています。
前回
ゼロから始めるLeetCode Day67 「1486. XOR Operation in an Array」今はTop 100 Liked QuestionsのMediumを優先的に解いています。
Easyは全て解いたので気になる方は目次の方へどうぞ。Twitterやってます。
技術ブログ始めました!!
技術はLeetCode、Django、Nuxt、あたりについて書くと思います。こちらの方が更新は早いので、よければブクマよろしくお願いいたします!問題
709. To Lower Case
難易度はEasy。問題としては文字列パラメータ str を持ち、同じ文字列を小文字で返す関数 ToLowerCase() を実装する、という問題です。
Example 1:
Input: "Hello"
Output: "hello"Example 2:
Input: "here"
Output: "here"Example 3:
Input: "LOVELY"
Output: "lovely"解法
class Solution: def toLowerCase(self, str: str) -> str: return str.lower() # Runtime: 24 ms, faster than 91.12% of Python3 online submissions for To Lower Case. # Memory Usage: 14 MB, less than 15.17% of Python3 online submissions for To Lower Case.
lowerを知っている人ならばこう書けば良いと思いますが、知らない上に調べる環境がない、もしくは組み込み関数を使わないで解いて、と実際の面接でパッと出されたらどうでしょう。そういった状況も考えてみるとEasyですが意外と頭を使いそうです。
僕がパッと思い浮かんだのは辞書で管理するやり方です。keyに大文字、valueに小文字を格納し、for文で回して仮にkeyに該当する要素があればvalueの該当する要素へと変える、というものですね。
ただ、もう一つ思い浮かんだものとしてUnicode変換を使ったものができるのかも、と思い今回はそちらを実装しました。class Solution: def toLowerCase(self, str: str) -> str: ans = '' for s in str: if ord(s) >= ord('A') and ord(s) <= ord('Z'): ans +=chr(ord(s) - (ord('A') - ord('a'))) else: ans += s return ans # Runtime: 28 ms, faster than 71.56% of Python3 online submissions for To Lower Case. # Memory Usage: 13.8 MB, less than 69.29% of Python3 online submissions for To Lower Case.
ord関数を使って一旦UnicodeのUnicodeポイントへと変換し、比較します。
仮にそちらの値が範囲内であればUnicodeポイント分引き算をしてあげて、最終的にchr関数を使って文字列に直し、ansに代入。それ以外の場合は元々小文字なのでそのまま代入してあげれば大丈夫、という考え方です。なお、補足のために貼っておきますが、Unicodeの一覧は以下のものとなります。
Unicode一覧 0000-0FFF
なかなか普段だったら考えない視点から考えられたのでとても面白かったです。
では今回はここまで。お疲れ様でした。
- 投稿日:2020-06-26T17:35:50+09:00
pythonを1行でセグフォらせる
pythonを三行でセグフォらせる、pythonを2行でセグフォらせると元ネタの流れへのリスペクトを込めて。
__import__("ctypes").cast(1, __import__("ctypes").py_object)
- 投稿日:2020-06-26T17:14:51+09:00
【EC2】seleniumでの日本語文字化けを防ぐ(noto対応)
日本語サイトの文字化けを防ぐ
環境
- Red Hat Enterprise Linux release 8.2
- google-chrome-stable-83.0.4103.116
- python3.6
- selenium 3.141.0
一行
その他諸々は既にインストール済という前提(参考情報参照)
sudo yum install google-noto* -yおしまい!
参考情報
Amazon LinuxでSelenium環境を最短で構築する - Qiita
【EC2】seleniumでキャプチャしたときの文字化けを防ぐ - Qiita参照するリポジトリの問題か、IPAフォントが入れられなかったので、yumでgoogle-noto探したらあったので解決。
- 投稿日:2020-06-26T17:00:02+09:00
Python 用 Azure SDK のログレベル変更方法
はじめに
Azure App Service のデータを CosmosDB で永続化しようと思い、pip で
azure-cosmosライブラリを追加、接続処理の実装を行いました。requirements.txtazure-cosmos==4.0.0実装後、デバッグをしていると Azure SDK のパッケージ
azure.core.pipeline.policies.http_logging_policyに関するログが大量に出力されることに気づきました。この記事では上記ロガーのログレベルを変更して、ログ出力を抑制する方法を紹介します。
ログ出力例
私の環境では、以下のログが出力されました。
2020-06-24 19:11:55,493 DEBUG urllib3.connectionpool :https://xxx.documents.azure.com:443 "POST /dbs/xxx/colls/xxx/docs/ HTTP/1.1" 200 None 2020-06-24 19:11:55,495 INFO azure.core.pipeline.policies.http_logging_policy :Response status: 200 2020-06-24 19:11:55,495 INFO azure.core.pipeline.policies.http_logging_policy :Response headers: 2020-06-24 19:11:55,495 INFO azure.core.pipeline.policies.http_logging_policy : 'Cache-Control': 'no-store, no-cache' 2020-06-24 19:11:55,495 INFO azure.core.pipeline.policies.http_logging_policy : 'Pragma': 'no-cache' 2020-06-24 19:11:55,495 INFO azure.core.pipeline.policies.http_logging_policy : 'Transfer-Encoding': 'chunked' 2020-06-24 19:11:55,495 INFO azure.core.pipeline.policies.http_logging_policy : 'Content-Type': 'application/json' 2020-06-24 19:11:55,495 INFO azure.core.pipeline.policies.http_logging_policy : 'Server': 'Microsoft-HTTPAPI/2.0' 2020-06-24 19:11:55,496 INFO azure.core.pipeline.policies.http_logging_policy : 'Strict-Transport-Security': 'REDACTED' 2020-06-24 19:11:55,496 INFO azure.core.pipeline.policies.http_logging_policy : 'x-ms-last-state-change-utc': 'REDACTED' 2020-06-24 19:11:55,496 INFO azure.core.pipeline.policies.http_logging_policy : 'x-ms-resource-quota': 'REDACTED' 2020-06-24 19:11:55,496 INFO azure.core.pipeline.policies.http_logging_policy : 'x-ms-resource-usage': 'REDACTED' 2020-06-24 19:11:55,496 INFO azure.core.pipeline.policies.http_logging_policy : 'lsn': 'REDACTED' 2020-06-24 19:11:55,496 INFO azure.core.pipeline.policies.http_logging_policy : 'x-ms-item-count': 'REDACTED' 2020-06-24 19:11:55,496 INFO azure.core.pipeline.policies.http_logging_policy : 'x-ms-schemaversion': 'REDACTED' 2020-06-24 19:11:55,496 INFO azure.core.pipeline.policies.http_logging_policy : 'x-ms-alt-content-path': 'REDACTED' 2020-06-24 19:11:55,496 INFO azure.core.pipeline.policies.http_logging_policy : 'x-ms-content-path': 'REDACTED' 2020-06-24 19:11:55,496 INFO azure.core.pipeline.policies.http_logging_policy : 'x-ms-quorum-acked-lsn': 'REDACTED' 2020-06-24 19:11:55,496 INFO azure.core.pipeline.policies.http_logging_policy : 'x-ms-current-write-quorum': 'REDACTED' 2020-06-24 19:11:55,496 INFO azure.core.pipeline.policies.http_logging_policy : 'x-ms-current-replica-set-size': 'REDACTED' 2020-06-24 19:11:55,496 INFO azure.core.pipeline.policies.http_logging_policy : 'x-ms-xp-role': 'REDACTED' 2020-06-24 19:11:55,497 INFO azure.core.pipeline.policies.http_logging_policy : 'x-ms-cosmos-query-execution-info': 'REDACTED' 2020-06-24 19:11:55,497 INFO azure.core.pipeline.policies.http_logging_policy : 'x-ms-global-Committed-lsn': 'REDACTED' 2020-06-24 19:11:55,497 INFO azure.core.pipeline.policies.http_logging_policy : 'x-ms-number-of-read-regions': 'REDACTED' 2020-06-24 19:11:55,497 INFO azure.core.pipeline.policies.http_logging_policy : 'x-ms-transport-request-id': 'REDACTED' 2020-06-24 19:11:55,497 INFO azure.core.pipeline.policies.http_logging_policy : 'x-ms-cosmos-llsn': 'REDACTED' 2020-06-24 19:11:55,497 INFO azure.core.pipeline.policies.http_logging_policy : 'x-ms-cosmos-quorum-acked-llsn': 'REDACTED' 2020-06-24 19:11:55,497 INFO azure.core.pipeline.policies.http_logging_policy : 'x-ms-session-token': 'REDACTED' 2020-06-24 19:11:55,498 INFO azure.core.pipeline.policies.http_logging_policy : 'x-ms-request-charge': 'REDACTED' 2020-06-24 19:11:55,498 INFO azure.core.pipeline.policies.http_logging_policy : 'x-ms-serviceversion': 'REDACTED' 2020-06-24 19:11:55,498 INFO azure.core.pipeline.policies.http_logging_policy : 'x-ms-activity-id': 'REDACTED' 2020-06-24 19:11:55,498 INFO azure.core.pipeline.policies.http_logging_policy : 'x-ms-gatewayversion': 'REDACTED' 2020-06-24 19:11:55,498 INFO azure.core.pipeline.policies.http_logging_policy : 'Date': 'Wed, 24 Jun 2020 10:11:55 GMT'対処方法
azure.core.pipeline.policies.http_logging_policyロガーにログレベルを設定することで不要なログを抑制できます。application.pylogging.getLogger('azure.core.pipeline.policies.http_logging_policy').setLevel('WARNING')この例ではログレベル
WARNING以上のログが出力されます。その他のログレベルを設定したければ、logging — Logging facility for Python — Python 3.8.3 documentation を参照してください。参考
- 投稿日:2020-06-26T16:21:10+09:00
トリビアからへぇを予測するAIを作り、自分の雑学を推論させた。Hee-AI(へぇあい)
Hee-AI (へぇあい)
Hee-AIを作りました.
このGoogle Colabは編集できない状態で公開しています. 自分のドライブにコピーしてからぜひ遊んでみてください! (PC環境推奨)
ソースコードも公開しておりますので, 参考までにご覧ください.
制作物語
これは全て2020年6月26日に起こった出来事です.
動機
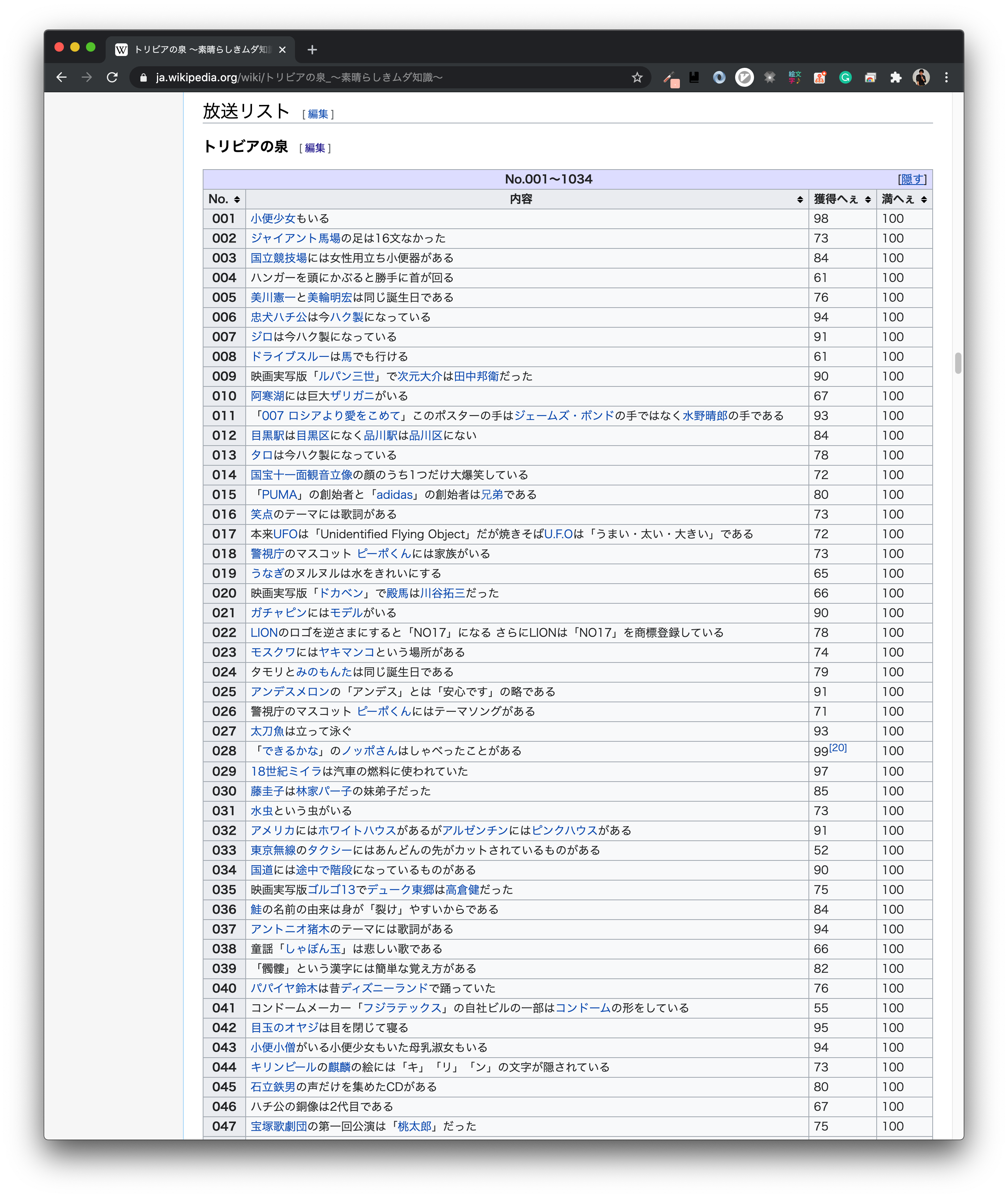
趣味がWikipedia探索の僕ですが, ある日のことトリビアの泉のページに番組で紹介された過去すべてのトリビアとそのいいねが記載されていることを知りました.
僕は迷いもなく「これは回帰問題になるじゃないか...!!!」と思いました.
早速デスクトップを立ち上げました.
計画
最終的に多くの人に遊んでもらいたいので, 最初はWebサービスにしようかと考えましたが, 1日以上研究をストップすることはしたくなかったので, それは諦めました. Google Colab上で実行可能にすることで, 個々のドライブ上にコピーしてもらえば簡単に遊べるので, その路線で計画を練って行きました.
Google Colab
Google Colab (Google Colaboratory)はGoogleが提供するサービスで, Google Drive上のJupyter NotebookをGoogleさんのマシンで実行できる代物です. GPUも使えます. ローカルで計算する必要がないためとても重宝できるものなのですが, なにせJupyter Notebookですので, 僕のように階層構造が大好きな人間にはあまり向きません.
しかし今回はそんなこと言ってられません. しかも, できれば一つのセルを実行するだけで全てが完結するようにし, できるだけユーザーの負担を減らすべきです. しかし, 学習プロセスと推論プロセスを同じセルにしてしまうと, 推論する度に学習が回ってしまいますので, そこだけは分ける必要があります. なので, 完成形としては以下のような2つのセルのみで構成されたGoogle Colabを計画しました.
- 学習のセル
- 推論のセル
そして, 省ける処理はできるだけ省いた状態で公開したいと考えました. そこで, Google Golab上ではディレクトリ構造を持つGithubリポジトリをcloneしてきたりせず, install系以外は完結したものにしようと決めました. 従って, Wikipediaのデータなどもpythonの辞書型で先に保持しておいたり, 一つのpythonファイルにするためにstickytapeというpythonパッケージを用いたり, 様々な工夫を凝らしました.
Qiita夏祭り2020
ということで, Colab上のpythonのみでAIアプリを作るという強い制約プレイになりましたので, 現在開催中のQiita夏祭り2020に応募することにもしました.
こちらの企画では, 以下の3つのお題に沿った記事を募集しています.
1. 〇〇(言語)のみを使って、今△△(アプリ)を作るとしたら
2. システム開発における過去の失敗と乗り越えた方法について共有しよう!
3. 【機械学習】"やってはいけない” アンチパターンを共有しよう!自分は1.かなぁと思って書き始めたのですが, やっているうちに3.の機械学習アンチパターンにも触れられそうかと考えたので, そちらにも話題を乗せていこうかと思います.
話がそれました.
制作物語に戻りましょう.
スクレイピング
ますはスクレイピングです. 最初はHTMLをコピペしてきてvimのマクロで自動整形とかできないかなと15分ほど格闘したのですが, いくつか異常値があり, それに対応するためにはプログラミングの方がいいかと諦めました.
実際に書いたスクレイピングのコードはこんな感じです.
scraping.pyimport urllib from bs4 import BeautifulSoup URL = "https://ja.wikipedia.org/wiki/%E3%83%88%E3%83%AA%E3%83%93%E3%82%A2%E3%81%AE%E6%B3%89_%E3%80%9C%E7%B4%A0%E6%99%B4%E3%82%89%E3%81%97%E3%81%8D%E3%83%A0%E3%83%80%E7%9F%A5%E8%AD%98%E3%80%9C" def get_text(tag): text = tag.text text = text.replace('\n', '') text = text.replace('[18]', '') text = text.replace('[19]', '') text = text.replace('[20]', '') text = text.replace('[21]', '') text = text.replace('[22]', '') return text if __name__ == "__main__": html = urllib.request.urlopen(URL) soup = BeautifulSoup(html, 'html.parser') trivia_table = soup.find('table', attrs={'class': 'sortable'}) trivias_list = [] for i, line in enumerate(trivia_table.tbody): if i < 3: continue if line == '\n': continue id = line.find('th') content, hee, man_hee = line.find_all('td') id, content, hee, man_hee = map(get_text, [id, content, hee, man_hee]) if hee == '?': continue trivias_list.append({'id': id, 'content': content, 'hee': int(hee), 'man_hee': int(man_hee)}) print(trivias_list)ざっくり説明しますと,
- BeautifulSoupの
soup.find()を用いてwikipediaのトリビアのページから全てのトリビアが乗っているtableを見つけてくる.continueのところらへんで関係のない行を飛ばす例外処理を行いながら一行一行読み込んでいく.- 所望の行を手に入れても注釈など意味のない文字列があるので
get_text関数で整形.trivial_listにidや文章やへぇの数などを格納していく.という流れです.
特徴量エンジニアリング
さて, データが揃いましたので機械学習屋さんの見せ所, 特徴量エンジニアリングです. 正直やる前からわかっていたのですが, どうせいい精度は出ません. 高々20文字程度の一文が1000ちょっとあるくらいでは絶対に無理があります. しかし, やるからには最低減やるべきことはやろうと以下のように特徴量を抽出しました.
- 文章の長さ
- 単語の数
- 平仮名の数
- カタカナの数
- 漢字の数
- 英語の数
- tfidf
- へぇの数/満へぇ
です.
最後の
へぇの数/満へぇに関してはこれを目的変数としています. へぇの数をそのまま使用してしまうと, トリビアの泉のスペシャル会では200へぇが満へぇの時もありましたので, スケールが異なってしまいます. 従って,へぇの数/満へぇという0-1に正規化された値を目的変数としました.コードはこんな感じです.
feature.pyimport re import MeCab import numpy as np import pandas as pd from sklearn.feature_extraction.text import TfidfVectorizer, CountVectorizer # Mecab tagger = MeCab.Tagger('-d /usr/local/lib/mecab/dic/mecab-ipadic-neologd') tagger.parse('') # lambda re_hira = re.compile(r'^[あ-ん]+$') re_kata = re.compile(r'[\u30A1-\u30F4]+') re_kanj = re.compile(r'^[\u4E00-\u9FD0]+$') re_eigo = re.compile(r'^[a-zA-Z]+$') is_hira = lambda word: not re_hira.fullmatch(word) is None is_kata = lambda word: not re_kata.fullmatch(word) is None is_eigo = lambda word: not re_eigo.fullmatch(word) is None is_kanj = lambda word: not re_kanj.fullmatch(word) is None # tl: trivias_list def normalize_hee(tl): for i in range(len(tl)): tl[i]['norm_hee'] = tl[i]['hee'] / tl[i]['man_hee'] return tl def wakati(text): node = tagger.parseToNode(text) l = [] while node: if node.feature.split(',')[6] != '*': l.append(node.feature.split(',')[6]) else: l.append(node.surface) node = node.next return ' '.join(l) def preprocess(tl): tl = normalize_hee(tl) for i in tqdm(range(len(tl))): tl[i]['wakati_content'] = wakati(tl[i]['content']) return tl def count_len(sentence): return len(sentence) def count_word(sentence): return len(sentence.split(' ')) def count_kata(sentence): cnt = 0; total=0 for word in sentence.split(' '): if word == '': continue total += 1 if is_kata(word): cnt += 1 return cnt/total def count_hira(sentence): cnt = 0; total=0 for word in sentence.split(' '): if word == '': continue total += 1 if is_hira(word): cnt += 1 return cnt/total def count_eigo(sentence): cnt = 0; total=0 for word in sentence.split(' '): if word == '': continue total += 1 if is_eigo(word): cnt += 1 return cnt/total def count_kanj(sentence): cnt = 0; total=0 for word in sentence.split(' '): if word == '': continue total += 1 if is_kanj(word): cnt += 1 return cnt/total def get_features(trivias_list, content=None, mode='learn'): trivias_list = preprocess(trivias_list) trivias_df = pd.DataFrame(trivias_list) wakati_contents_list = trivias_df['wakati_content'].values.tolist() word_vectorizer = TfidfVectorizer(max_features=5) word_vectorizer.fit(wakati_contents_list) if mode == 'inference': content = [{'content': content, 'wakati_content': wakati(content)}] content_df = pd.DataFrame(content) wakati_content_list = content_df['wakati_content'].values.tolist() tfidf = word_vectorizer.transform(wakati_content_list) content_df = pd.concat([ content_df, pd.DataFrame(tfidf.toarray()) ], axis=1) num_len_df = content_df['wakati_content'].map(count_len) num_word_df = content_df['wakati_content'].map(count_word) num_hira_df = content_df['wakati_content'].map(count_hira) num_kata_df = content_df['wakati_content'].map(count_kata) num_eigo_df = content_df['wakati_content'].map(count_eigo) num_kanj_df = content_df['wakati_content'].map(count_kanj) content_df['num_len'] = num_len_df.values.tolist() content_df['num_word'] = num_word_df.values.tolist() content_df['num_hira'] = num_hira_df.values.tolist() content_df['num_kata'] = num_kata_df.values.tolist() content_df['num_eigo'] = num_eigo_df.values.tolist() content_df['num_kanj'] = num_kanj_df.values.tolist() content_df = content_df.drop('content', axis=1) content_df = content_df.drop('wakati_content', axis=1) return content_df tfidf = word_vectorizer.transform(wakati_contents_list) all_df = pd.concat([ trivias_df, pd.DataFrame(tfidf.toarray()) ], axis=1) num_len_df = all_df['wakati_content'].map(count_len) num_word_df = all_df['wakati_content'].map(count_word) num_hira_df = all_df['wakati_content'].map(count_hira) num_kata_df = all_df['wakati_content'].map(count_kata) num_eigo_df = all_df['wakati_content'].map(count_eigo) num_kanj_df = all_df['wakati_content'].map(count_kanj) all_df['num_len'] = num_len_df.values.tolist() all_df['num_word'] = num_word_df.values.tolist() all_df['num_hira'] = num_hira_df.values.tolist() all_df['num_kata'] = num_kata_df.values.tolist() all_df['num_eigo'] = num_eigo_df.values.tolist() all_df['num_kanj'] = num_kanj_df.values.tolist() if mode == 'learn': all_df = all_df.drop('id', axis=1) all_df = all_df.drop('hee', axis=1) all_df = all_df.drop('man_hee', axis=1) all_df = all_df.drop('content', axis=1) all_df = all_df.drop('wakati_content', axis=1) return all_dfモデリング
モデルはlightgbmを選択しました. 理由はめんどくさかったからです.
他のモデルなら何が使えるやろ, nn使うなら正規化しないといけないし...んー、勾配ブースティング!
という思考回路です. 笑
しかし, やるからには最低限のことはしました.
- 評価指標はMSE
- KFoldで5セットのテストデータに対してMSEを計算
- 5セットのMSEの平均値を目的値として, optunaでハイパーパラメータ探索
- max_depth: 1-20
- learning_rate: 0.001-0.1
- num_leaves: 2-70
最終的なbest MSEは
0.014程度でした.つまり, 一つのトリビアに対する誤差の2乗が0.014くらいということですので, ルートを取ると0.118程度, 正規化していましたので100かけると, 11.8.
従って, 大体11.8へぇくらいの誤差となりました. (へぇ...)
コードはこんな感じです.
train_lgb.pyimport os import optuna import numpy as np import pandas as pd import lightgbm as lgb from sklearn.model_selection import KFold from data.loader import load_data from data.feature import get_features from data.trivias_list import trivias_list def objective(trial): max_depth = trial.suggest_int('max_depth', 1, 20) learning_rate = trial.suggest_uniform('learning_rate', 0.001, 0.1) params = { 'metric': 'l2', 'num_leaves': trial.suggest_int("num_leaves", 2, 70), 'max_depth': max_depth, 'learning_rate': learning_rate, 'objective': 'regression', 'verbose': 0 } mse_list = [] kfold = KFold(n_splits=5, shuffle=True, random_state=1) for train_idx, valid_idx in kfold.split(X, y): X_train = X.iloc[train_idx] y_train = y.iloc[train_idx] X_valid = X.iloc[valid_idx] y_valid = y.iloc[valid_idx] lgb_train = lgb.Dataset(X_train, y_train) lgb_valid = lgb.Dataset(X_valid, y_valid) model = lgb.train(params, lgb_train, valid_sets=lgb_valid, verbose_eval=10, early_stopping_rounds=30) # f-measure pred_y_valid = model.predict(X_valid, num_iteration=model.best_iteration) true_y_valid = np.array(y_valid.data.tolist()) mse = np.sum((pred_y_valid - true_y_valid)**2) / len(true_y_valid) mse_list.append(mse) return np.mean(mse_list) def build_model(): study = optuna.create_study() study.optimize(objective, n_trials=500) valid_split = 0.2 num_train = int((1-valid_split)*len(X)) X_train = X[:num_train] y_train = y[:num_train] X_valid = X[num_train:] y_valid = y[num_train:] lgb_train = lgb.Dataset(X_train, y_train) lgb_valid = lgb.Dataset(X_valid, y_valid) lgb_data = lgb.Dataset(X, y) params = study.best_params params['metric'] = 'l2' model = lgb.train(params, lgb_data, valid_sets=lgb_valid, verbose_eval=10, early_stopping_rounds=30) return model X, y = load_data(trivias_list) if __name__ == "__main__": model = build_model() content = 'ミツバチが一生かけて集める蜂蜜はティースプーン1杯程度。' content_df = get_features(trivias_list, content=content, mode='inference') output = model.predict(content_df) hee = int(output*100) print(f"{content}") print(f"{hee}へぇ")アンチパターン
機械学習モデル作成に当たって, 失敗したアンチパターンを記載します. 少しでも皆さん, そして未来の自分の役に立てればと思います.
失敗① スケーリング
目的変数のスケーリングとして,
へぇ数/満へぇとしました. 運よくすぐに気をつけられたのですが, 最初はへぇ数を目的変数にする気満々でした. そのままコーディングを続けていれば, 精度が出ないまま「まぁこんなもんか...」と諦めていたことでしょう.失敗② word_vectorizerのfit忘れ
すみません. めっちゃくちゃ細かい話になります...
しかし, わたくしこの失敗2回目なので書かせてください...文章からtfidfを埋め込む際に, 以下の3ステップを踏む必要があります.
# インスタンスの生成 word_vectorizer = TfidfVectorizer(max_features=max_features) # 分かち書きされた文章リストを入力し, fitさせる. word_vectorizer.fit(wakati_contents_list) # 所望の分かち書きされた文章リストを埋め込む. tfidf = word_vectorizer.transform(wakati_contents_list)tfidfは全ての文章の中から当該文章に存在する単語がどれほど珍しいかを考慮しなければならないので, 一度全ての文章をベクトライザーインスタンスに渡す必要があります. つまり, 「この文章埋め込んどいて」と一文だけを渡してもダメです.
しかし僕はいつもtfidfが決定論的な処理であることからfitさせないといけないというイメージに直結せず, 適当にtransformで埋め込もうとしてしまいます...
皆さんもお気をつけて.
失敗③ 使わない特徴量の削除
これは基本的すぎるので書くか迷ったのですが, 1分ほど詰まってしまったのは事実ですので書きます.
はいこちら。
all_df = all_df.drop('id', axis=1) all_df = all_df.drop('hee', axis=1) all_df = all_df.drop('man_hee', axis=1) all_df = all_df.drop('content', axis=1) all_df = all_df.drop('wakati_content', axis=1)
id,content(元の文字列)などなど, lightgbmに入力しない情報はpandasデータフレームからちゃんと削除しようねという話です.これ意外とやりがちかと思います.
特徴量生成していく過程で, 以下のように, pandasのデータフレームにホイホイと追加していくので, いらないのが残っていることを忘れてしまいがちです. (多分pandas初心者だからですね.ディープラーニングやりすぎました.)
all_df['num_eigo'] = num_eigo_df.values.tolist()公開
さて, 前述の通り, 完成物はGoogle Colabで公開しました.
stickytapeで単一のコードにビルドし, Google Colab上でもわかりやすいUIで遊べるように工夫を凝らしました.stickytapeについては昨日自分が書いた記事がありますので, よければご覧ください.複数pythonファイルを一つのpythonファイルにする@wataoka
実験!
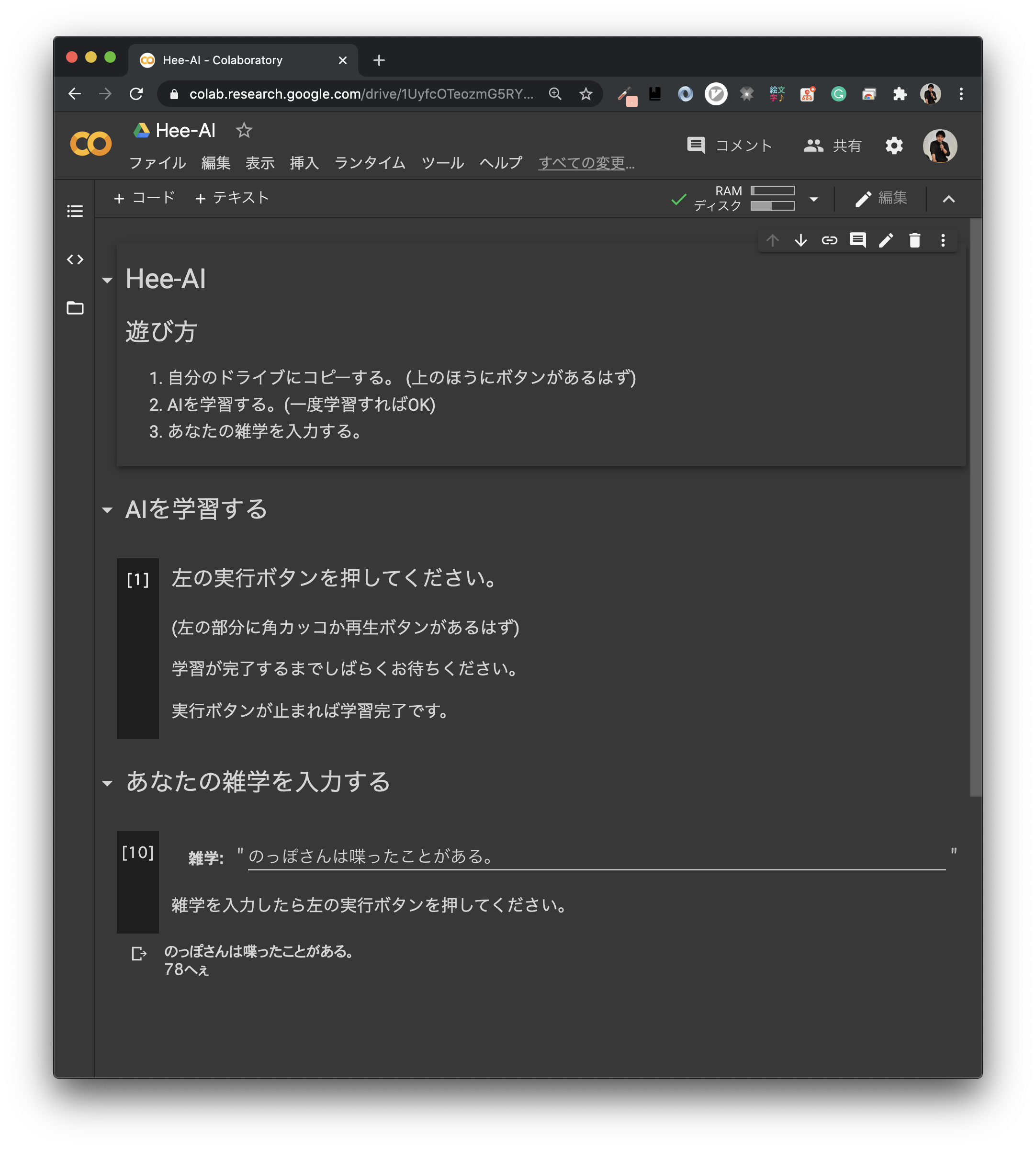
さて, せっかく作ってみたんですから自分でも遊んでみましょう. 学習させた後に, 自分の持っている雑学をHee-AIに入力し推論させます.
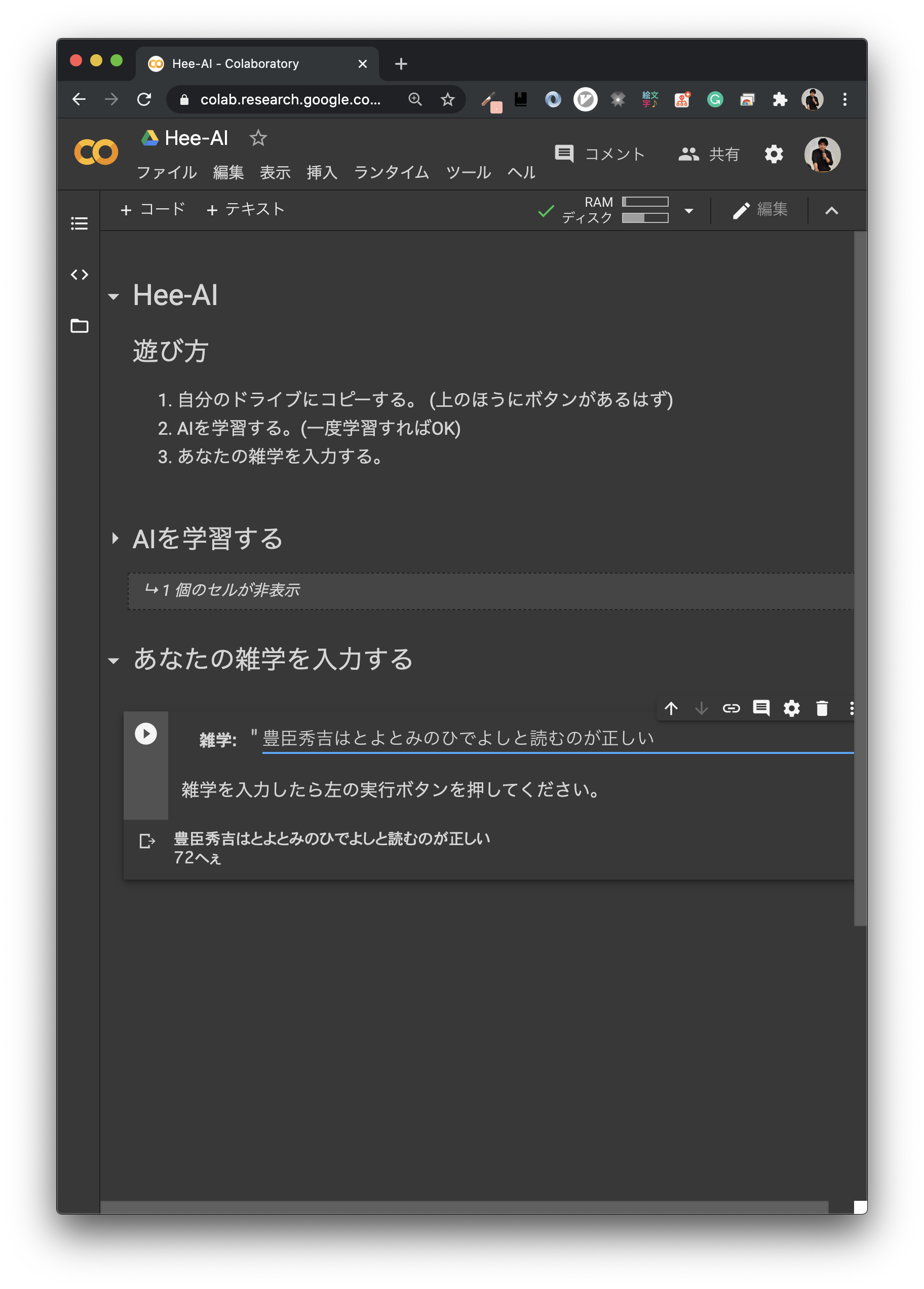
- 「豊臣秀吉はとよとみのひでよしと読むのが正しい」 72へぇ
手厳しい...
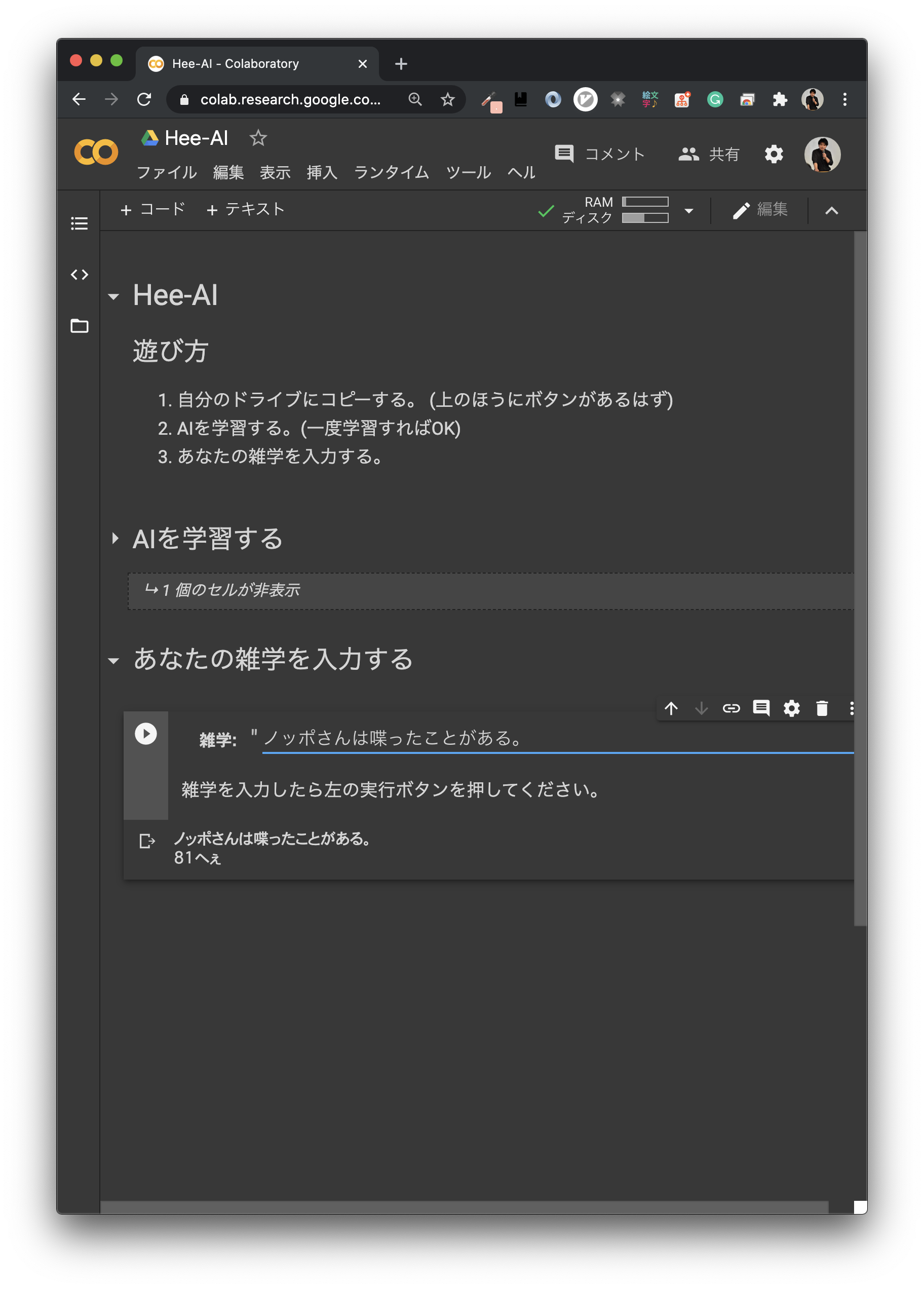
- 「ノッポさんは喋ったことがある。」 81へぇ
本家では99へぇで歴代トップなのになぁ...
- 「晴れの日は明るい」 68へぇ
当たり前な言うとちょっとは低くしてくれてるのかな?
感想
全体としては手厳しい評価ですね. 90へぇに一度も到達しませんでした. 5人中5人がタモリさんなのでしょうか.
どなたか90へぇに到達したら教えてください.
自己紹介
冒頭に書くと邪魔になるので最後にひっそりと自己紹介させてください。
名前 綿岡晃輝 学校 神戸大学大学院 学部の研究 機械学習, 音声処理 大学院の研究 機械学習, 公平性, 生成モデル, etc @Wataoka_Koki Twitterフォローしてね!

- 投稿日:2020-06-26T16:02:36+09:00
【競プロ練習】AtCoder Beginner Selectionをやってみた
つい1週間前にAtCoderを初め、そのときにAtCoder Beginners Selection をやってみました。
競技プログラミングとうものに初めて触れたので、入力方法を学ぶことから初めました。
自分なりにどう考えたのかということと、解答をまとめました。PracticeA - Welcome to AtCoder
a = int(input()) b, c = map(int, input().split()) s = input() print('{} {}'.format(a+b+c,s))入出力関連のテスト
int(input())
map(int, input().split())
後々他のコンテストを解くに連れて、この2つは多用することを知りました。ABC086A - Product
strings = ['Even','Odd'] a, b = map(int, input().split()) print(strings[(a*b)%2])奇遇を解答する問題。
ABC081A - Placing Marbles
#Placing Marbles S = list(input()) print(S.count('1'))入力数値から1である桁数を求める問題。
文字列として入力し個数を判定しました。ABC081B - Shift only
#Shift only import numpy as np N = int(input()) A = np.array(list(map(int, input().split()))) count = 0 check = A%2 while np.count_nonzero(check)==0 : count += 1 A = A/2 check = A%2 print(count)入力配列を何回2で割り切れるかとい問題。
numpy array では演算子は各要素に適用されるため、入力をnumpyに受けて解答しています。
今思うと、わざわざcheckという変数に受ける必要はなかった気がする……。ABC087B - Coins
#Coins A = int(input()) B = int(input()) C = int(input()) X = int(input()) count=0 for i in range(A+1): yo = X-i*500 if(yo>=0): for j in range(B+1): yoi = yo-j*100 if(yoi>=0): for k in range(C+1): yoii = yoi-k*50 if(yoii==0): count +=1 print(count)500円玉A枚、100円玉B枚、50円玉C枚からX円を作る組み合わせの数。
解答の方針は
500円玉を0枚に固定して、100円玉ループ。
100円玉ループでは100円玉0枚に固定して50円玉ループ。
50円玉C枚以下でX円が生成できたら、上位の100円玉ループに戻り、100円玉を1枚として……以下略
for文が多重化してるのでなんとか簡単にしたいなと思いつつこれが限界でした。ABC083B - Some Sums
#Some Sums N, A, B = list(map(int, input().split())) count = 0 for j in range(N): S = str(j+1) numN = 0 for i in range(len(S)): numN += int(S[i]) if A <= numN <= B: count += j+1 print(count)1<=x<=NかつA<=各桁の和<=Bであるすべての整数xの総和。
数字をstrになおして各桁をintで受けてfor文で総和を求めました。反省点
3入力を3変数で受けるのでlistにする必要はなかった。
range(1,N+1)で1からNを計算できたこと。
sumメソッドが活用できた(?)ABC088B - Card Game for Two
#Card Game for Two N = int(input()) a = sorted(map(int, input().split())) count = 0 for i in range(N): count += a[-i-1] * (-1)**i print(count)任意の数字が書かれたN枚のカードをAliceとBobが得点が最大となるよう交互に取得していく。最後にAliceとBobの得点差を求める問題。
N枚のカードを大きい順にソートし、奇数番目をAlice、偶数番目をBobにわたす。
↓
最終的に得点差を求めるため、奇数番目を足し、偶数番目を引くとよい。
このように考え解答しました。ABC085B - Kagami Mochi
import numpy as np N = int(input()) d = np.zeros(N) for i in range(N): d[i] = int(input()) sorted_d = np.unique(d) print(len(sorted_d))N個の円盤の直径が与えられ、それを上より下が大きい順に積んだとき最大何段積むことができるかという問題。
同じ直径の円盤は重ねることはできない。
↓
Numpyのuniqueな配列を返す関数を利用することで、重複しない配列を入手できる。その要素数を求める。
このとうに考え解答しました。ABC085C - Otoshidama
#Otoshidama N, Y = list(map(int, input().split())) y_man = Y flag = False out = [-1,-1,-1] for i in range(N+1): y_gsen = y_man for j in range(N-i+1): n_sen = int(y_gsen/1000) if N-i-j == n_sen: out = [i,j,n_sen] flag = True break y_gsen -= 5000 if flag: break y_man -= 10000 print('{} {} {}'.format(out[0],out[1],out[2])) # print(out[0]*10000+out[1]*5000+out[2]*1000)1万円札、5千円札、千円札合わせてN枚、Y円が可能かどうか。可能ならその組み合わせを解答(不可能なら-1 -1 -1)
下層のfor文から抜けた場合、上層のfor文も抜けるという方法が検索したらでてきましたが、理解が難しくflagという変数を設けることで代用しました。
ABC049C - 白昼夢
#Hakuchumu S = input() m = ['dream','dreamer','erase','eraser'] for i in range(len(m)): m[i] = m[i][::-1] lenS = len(S) revS = S[::-1] Header = 0 flag = True Ans = 'YES' while Header < lenS-1 : flag = True if Header + 6 < lenS: # print('6t') if revS[Header:Header+7]==m[1]: Header += 7 flag = False # print('6tt') if Header + 5 < lenS: # print('5t') if revS[Header:Header+6]==m[3]: Header += 6 flag = False # print('5tt') if Header + 4 < lenS: # print('4t') if revS[Header:Header+5]==m[0] or revS[Header:Header+5]==m[2]: Header += 5 flag = False # print('4tt') if flag: Ans = 'NO' # print('out') break print(Ans)文字列Sを'dream','dreamer','erase','eraser'の4を任意に並べることで完成できるか判定する問題。
文字列の先頭から判定し、一致すればその文字数分Headerを動かすという方法を考えましたが、dreameraseなどの分け方が複雑な文字列の条件分岐に敗北しました。
文字列を反転させると、一致することがないというヒントを元に完成させた解答です。ABC086C - Traveling
#Traveling import numpy as np N = int(input()) Plan = np.zeros((N+1,3)) for i in range(N): Plan[i+1] = list(map(int, input().split())) able = 'Yes' for j in range(N): t, x, y = Plan[j] t_next, x_next, y_next = Plan[j+1] distance = abs(x-x_next) + abs(y-y_next) delta = t_next - t amari = delta - distance # print(distance,delta,amari) if amari < 0 or amari%2 == 1: able = 'No' break print(able)1時刻に上下左右いずれか1マスの格子点に必ず移動するとき、時刻t_nにx_n,y_nに存在するという組み合わせが実現可能かという問題。
まず、次のx,yの距離がtより小さいことを判定します。そして、必ず移動するというのを考慮し、あまりの時刻が偶数である場合、実現可能。奇数の場合、必ず移動しなければならないため到達不可能ということを判定しました。
まとめ
今見直すと、いろいろ改善点がありました。
次のコンテストに向けて精進精進……。
- 投稿日:2020-06-26T15:43:22+09:00
乃木坂46ブログの画像を全自動保存するプログラム
はじめに
こんにちは.
坂道オタクの@tfujitaniです.
今回は乃木坂46の指定したメンバーのブログの画像を全自動で保存できるようなPythonを作成したので公開します.
ちなみにこのプログラムを作ろうと思った”きっかけ”としては,推しだった井上小百合さんが卒業する(した)ためです.(きっかけ,いい歌ですよね.)
そのために作成したプログラムを今更ですが公開します.今回やったこと
用いたもの
・Python
・BeautifulSoupスクレイピング環境のインストール
pip install requests pip install beautifulsoup4Pythonコード
Beautiful SoupとPython3を用いてスクレイピングしています.
今回は指定したいメンバーのブログURLを指定します.
秋元真夏さん( http://blog.nogizaka46.com/manatsu.akimoto/ )なら"manatsu.akimoto"
伊藤理々杏ちゃん( http://blog.nogizaka46.com/riria.itou/ )なら"riria.itou"という感じです.
さらに,保存したい期間の始点と終点も指定できます.nogiblog.py# coding:utf-8 from time import sleep import time from bs4 import BeautifulSoup import sys import requests, urllib.request, os from selenium.common.exceptions import TimeoutException domain="http://blog.nogizaka46.com/" member="manatsu.akimoto" #メンバーの指定 url=domain+member+"/" def getImages(soup,cnt,mouthtrue): member_path="./"+member #画像を保存する関数 for entry in soup.find_all("div", class_="entrybody"):# 全てのentrybodyを取得 for img in entry.find_all("img"):# 全てのimgを取得 cnt +=1 imgurl=img.attrs["src"] imgurlnon=imgurl.replace('https','http') if mouthtrue: try: urllib.request.urlretrieve(imgurlnon, member_path+ str(year)+'0'+str(mouth) + "-" + str(cnt) + ".jpeg") except: print("error",imgurlnon) else: try: urllib.request.urlretrieve(imgurlnon, member_path + str(year)+str(mouth) + "-" + str(cnt) + ".jpeg") except: print("error",imgurlnon) if(__name__ == "__main__"): #保存するブログの始まり year=2012 mouth=12 #保存するブログの終わり endyear=2020 endmouth=6 while(True): mouthtrue=True if mouth<10: BlogPageURL=url+"?d="+str(year)+"0"+str(mouth) else: BlogPageURL=url+"?d="+str(year)+str(mouth) mouthtrue=False headers = {"User-Agent": "Mozilla/5.0"} soup = BeautifulSoup(requests.get(BlogPageURL, headers=headers).content, 'html.parser')#htmlの取得 print(year,mouth) sleep(3) cnt = 0 ht=soup.find_all("div", class_="paginate") print("ht",ht) getImages(soup,cnt,mouthtrue)#画像保存関数の呼び出し if len(ht)>0:#もし同じ月に複数ページあったとき,そのページ分だけ保存 ht_url=ht[0] print(ht_url) url_all=ht_url.find_all("a") for i,hturl in enumerate(url_all): if (i+1)==len(url_all): break link = hturl.get("href") print("url",url+link) soup = BeautifulSoup(requests.get(url+link, headers=headers).content, 'html.parser') sleep(3) getImages(soup,cnt,mouthtrue)#画像保存関数の呼び出し if year==endyear and mouth==endmouth: print("Finish") sys.exit()#プログラム終了 if mouth==12: mouth=1 year=year+1 print("update",year,mouth) else: mouth=mouth+1 print("update",year,mouth)ちなみに「#もし同じ月に複数ページあったとき,そのページ分だけ保存」というのは画像で例示すると,こういうイメージです.
この画像の例でいうと,2013年1月の秋元真夏さんのブログなのですが,1ページ目の画像を保存した後に,2,3,4のリンクを取得して,それぞれのページで画像を保存するという内容になっています.実行結果
試しに秋元真夏さんのブログで実行してみたところ,以下のような形で画像の保存が確認できました.
※2013年1月の画像が欠けているのは,ブログにあげられてた元画像が欠けているためです.
ちなみに先ほどのプログラムでhtがわかりにくいかと思ったので,その部分の実行結果を表示します.
少しわかりにくいですが,このようにその月ごとのページをそれぞれスクレイピングで表示しています.
ht
[<div class="paginate"> 1 | <a href="?p=2&d=201301"> 2 </a> | <a href="?p=3&d=201301"> 3 </a> | <a href="?p=4&d=201301"> 4 </a> | <a href="?p=2&d=201301">></a></div>, <div class="paginate"> 1 | <a href="?p=2&d=201301"> 2 </a> | <a href="?p=3&d=201301"> 3 </a> | <a href="?p=4&d=201301"> 4 </a> | <a href="?p=2&d=201301">></a></div>]
その後,以下のように1ページ目をスクレイピングした後に,4ページスクレイピングしていることがわかります.
url http://blog.nogizaka46.com/manatsu.akimoto/?p=2&d=201301
url http://blog.nogizaka46.com/manatsu.akimoto/?p=3&d=201301
url http://blog.nogizaka46.com/manatsu.akimoto/?p=4&d=201301
おわりに
余談ですが,井上小百合さんのブログを保存したときは,余裕で数千枚を超えました(余計なものを消去して2385枚でした.)
さゆの努力家の部分が見えますね.参考文献
https://qiita.com/xxPowderxx/items/e9726b8b8a114655d796 の記事がめちゃくちゃ参考になりました・
- 投稿日:2020-06-26T15:26:12+09:00
Cloud pak for Dataのデプロイメントスペースを一旦きれいにする
Cloud pak for Data (以下CP4D)でのモデル開発中に、デプロイメントスペースにモデルや関数やデプロイメントを大量に作ってしまった後、それらを一旦きれいに全消ししたい時に使ってください。
あまりそんなシーンは多発しないかもしれませんが、2020年6月時点のCP4D v3.0ではモデルやデプロイメントなどのバージョン管理ができない制約があるため、複数世代のモデルを作成していくとあっという間にどんどんモデルやデプロイメントが増えていきます。
CP4Dの画面上でポチポチ1つずつ削除できるのですが、めんどくさいので一気に消すpythonコードを作りました。分析プロジェクトで適当なNotebookを立ち上げて実行します。
準備その1。WMLclientを初期化url = "https://cloudpackfordata.url.com" from watson_machine_learning_client import WatsonMachineLearningAPIClient import os token = os.environ['USER_ACCESS_TOKEN'] wml_credentials = { "token" : token, "instance_id" : "openshift", "url": url, "version": "3.0.0" } client = WatsonMachineLearningAPIClient(wml_credentials)準備その2。デプロイメントスペースIDをセット# IDは client.repository.list_spaces() で調べられる space_id = "xxxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx" client.set.default_space(space_id)全消しの順番は依存関係から、デプロイメント → モデル → 関数 の順番に行います。
全デプロイメントを削除all_deps = client.deployments.get_details()['resources'] for dep in all_deps: dep_name = dep['metadata']['name'] dep_id = dep['metadata']['guid'] client.deployments.delete(dep_id) print(dep_name +"(" + dep_id + ") is deleted")全モデルを削除all_models = client.repository.get_model_details()['resources'] for model in all_models: model_name = model['metadata']['name'] model_id = model['metadata']['guid'] client.repository.delete(model_id) print(model_name +" (" + model_id + ") is deleted")全関数を削除all_funcs = client.repository.get_function_details()['resources'] for func in all_funcs: func_name = func['metadata']['name'] func_id = func['metadata']['guid'] client.repository.delete(func_id) print(func_name +" (" + func_id + ") is deleted")削除後、CP4D画面上できれいになったデプロイメントスペースを確認して終了です。
ちなみに、デプロイメントスペース自体を削除し再作成することでも瞬時にきれいになります。その場合はデプロイメントスペースIDが変わってしまうので、各種コードの修正をお忘れなく。
あと、本番稼働開始した後はこのNotebookは削除しておいたほうが無難です。残しておくと危険です。
- 投稿日:2020-06-26T14:31:36+09:00
pythonを2行でセグフォらせる
これが一番早い
これに対抗
pythonを三行でセグフォらせるimport ctypes ctypes.cast(1, ctypes.py_object)

- 投稿日:2020-06-26T14:24:21+09:00
Python+Selenium+Chromeでスマホモードに切り替える方法
1.概要
Python+Selenium+Chromeを用いて自動テストを行っていたのですが、どうもスマホ画面にアクセスするとPC画面にリダイレクトされ、スマホ画面をテストできないことがありました。
そのため、Chromeのスマホモードを使ってうまく自動化できないか調べましたので、その方法をまとめます。
2.スマホモードで起動するプログラム
調べた結果をまとめると、以下のプログラムを実行することでスマホモードで起動できるようです。(そのままコピペしても動作します)
smp_mood.pyfrom selenium import webdriver import time def smp_mood(): url = "https://www.yahoo.co.jp/" mobile_emulation = { "deviceName": "Galaxy S5" } options = webdriver.ChromeOptions() options.add_experimental_option("mobileEmulation", mobile_emulation) driver = webdriver.Chrome(options=options) driver.get(url) time.sleep(2) smp_mood()上記はYahooのサイトに「Galaxy S5」でアクセスしています。
3.端末の切り替え方
上記プログラムの、
"Galaxy S5"を書き換えることで、利用したい端末に変更することが可能です。
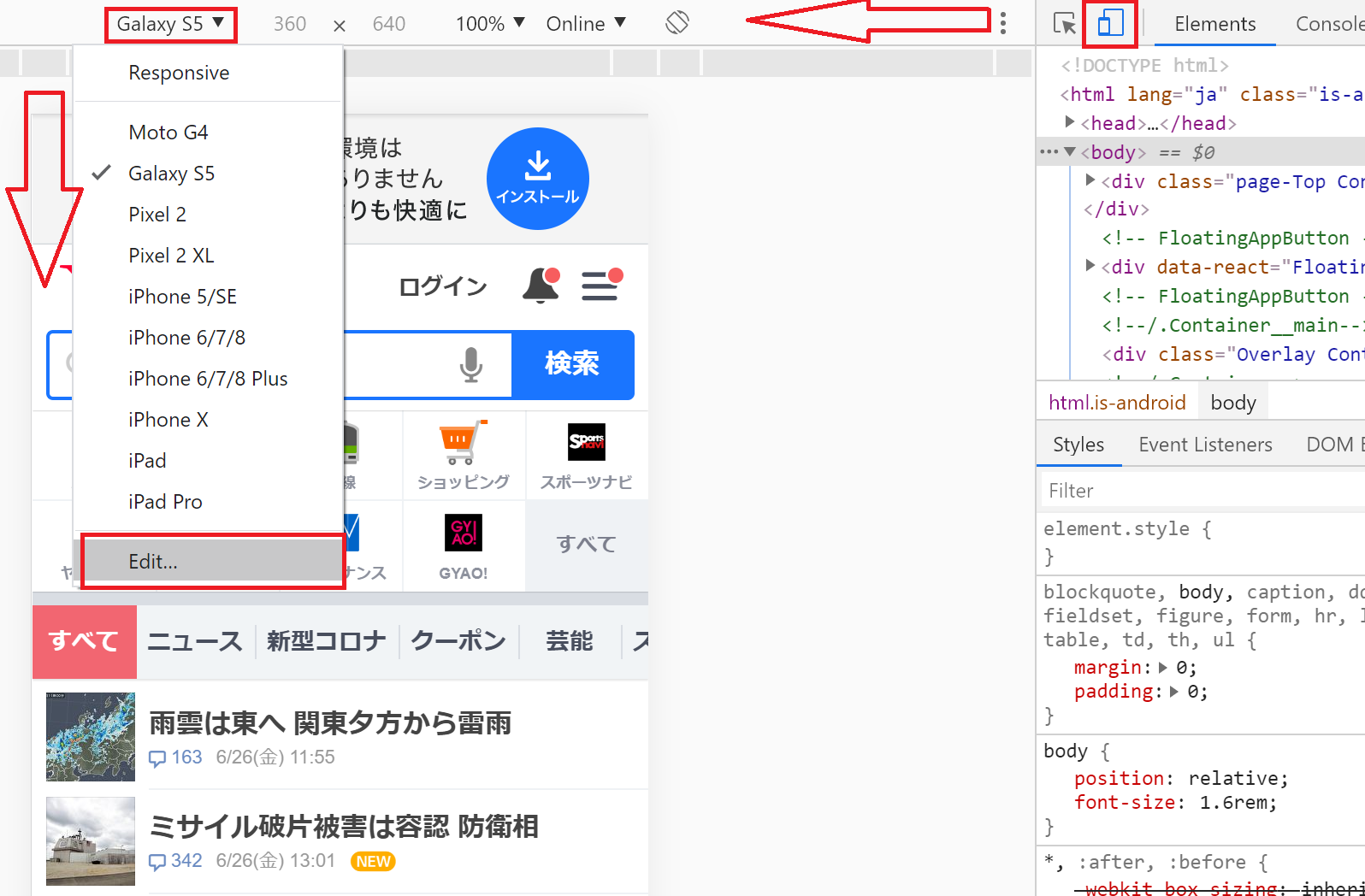
切り替えられる端末は、Chromeで右クリックを押下し、「検証」を押下。その後、画面右上のスマホマークを押下しスマホモードに変更後、画面左上に表示されている「端末名>Edut...」を押下して表示される一覧が、変更できる端末になります。
↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓
上記をもとに、
"iPhone 6"などと書き換えることで、対象の端末を変更できます。
- 投稿日:2020-06-26T14:15:50+09:00
【競プロ練習】AtCoder Beginner Contest 171をやってみた
AtCoder Beginner Contest 171に参加しました。
初めての競技プログラミングコンテスト参加です。3完、D問題は実行時間の壁に阻まれ、Eも実装しましたがTLE今見直すとなんとも言えないコードで恥ずかしい……
A - Alphabet
#Alphabet S = input() if S in 'ABCDEFGHIJKLMNOPQRSTUVWXYZ': print('A') else: print('a')アルファベット一文字の入力に対し、大文字or小文字を返す問題。
ASCIIコードなどから判定できればよかったのですが、そういうことをPythonで実装したことがなかったので、ご覧のとおり無理やり解答しました。B - Mix Juice
#Mix Juice N, K = list(map(int, input().split())) P = sorted(map(int, input().split())) print(sum(P[0:K]))N種類の果物それぞれの価格が与えられ、K種類の果物1つづつ購入したときの最低価格を求める。
↓
N種類の価格をソートし小さい方からK個の合計値として解答。C - One Quadrillion and One Dalmatians
#One Quadrillion and One Dalmatians alphabet = list('abcdefghijklmnopqrstuvwxyz') N = int(input())-1 def shin26(N): if(int(N/26)!=0): return(shin26(int(N/26)-1)+alphabet[N%26]) return alphabet[N%26] print(shin26(N))EXCELの列番号みたいに入力にたいし、A〜Z,AA〜AZ,BA~...を返す問題(答えは小文字)。
N進数を求める再帰関数をa~zの文字列を返すように変更して制作しました。
ここでもa~zのlistを作成することで、listのアドレスを与えることでアルファベットを入手できるようにしています。このあとに、Python上で切り捨て割算の演算子「//」を知りました。(int と割算演算子を組み合わせる必要はなかった)
D - Replacing
###失敗### #Replacing import numpy as np N = int(input()) A = np.array(list(map(int, input().split()))) Q = int(input()) for i in range(Q): B, C = list(map(int, input().split())) CC = A==B NC = CC==False A = A*(NC) + C*CC print(A.sum())D問題は時間内にできませんでした。ある配列Aが与えられ、BをCに置き換えることを繰り返しそのたびにAの合計値を出力する問題。
最初は愚直に置換してましたが、実行時間超過であえなく撃沈。終了直後に配列内のBの個数さえわかれば、直前の合計値と差分を求められるとアドバイスをいただきました(ありがとうございます!!)
###失敗### #Replacing import numpy as np N = int(input()) A = np.array(list(map(int, input().split()))) Q = int(input()) u, count = np.unique(A,return_counts=True) asum = A.sum() for i in range(Q): B, C = list(map(int, input().split())) if B in u: posB = np.where(u==B) asum += int(count[posB]) * (C-B) # print(u) # print(count) if not (C in u): u[posB] = C else : posC = np.where(u==C) count[posC] += count[posB] u = np.delete(u,posB) count = np.delete(count,posB) print(asum)配列Aをある数uがcount個あるという配列に変換。
BからCに変えるときはその数を変更、統合できれば統合という方針で行いました(出力は前述のように差分から求める)が、こちらもあえなく撃沈。listの検索は遅い
知ってた……。Python上でfor文回すこと遅いです(いつもはfor文回す計算があれば行列演算に置き換えてnumpyで回しています)。
さらにいうと、C++使いの知り合いも同じ方法では実行時間超過を食らっていました。B→Cの変換ツリーを作って最後に適用する案
↓
各変換ごとに出力が必要なので不可能。結局は解説をチラ見して
「入力される整数はたかだか$10^5$なので$10^5$の配列を作りアドレス番地にその数字の個数を入れる」
確かにこれは、検索が必要ない!ということで、以下の解答でACいただきました。
#Replacing import numpy as np N = int(input()) A = np.array(list(map(int, input().split()))) Q = int(input()) u, count = np.unique(A,return_counts=True) L = np.zeros(10**5,int) for i in range(len(u)): L[u[i]-1] = count[i] asum = A.sum() for i in range(Q): B, C = list(map(int, input().split())) asum += L[B-1] * (C-B) L[C-1] += L[B-1] L[B-1] = 0 print(asum)E - Red Scarf
###失敗### #Red Scarf import numpy as np N = int(input()) A = np.array(list(map(int, input().split()))) output = '' def binary(A, p): if not np.all(A==0) : return binary( (A-A%2)/2 , p+1 ) + ((A%2).sum())%2 * 2**p return ((A%2).sum())%2 * 2**p for i in range(N): ken = (np.delete(A,i)) output += str(int(binary(ken,0))) if i != N-1: output += ' ' print(output)xorの知識がなかったのでbinaryで判定しました。終
2進数の各桁の1の個数で判定できるということだけは理解したのでこうしましたが、TLE。
知り合いに、すべての数値のxorを取って、そのあと自身の数値とxorとればできるというアドバイスで以下でACをいただきました。#Red Scarf N = int(input()) A = list(map(int, input().split())) output = list() axor = A[0] for i in range(1,N): axor ^= A[i] for i in range(N): output.append(axor^A[i]) print(*output)appendのメソッドなど少し覚えた知識を加えました。
まとめ
F問題は手を付けられていません。次のABCではより多くの完答数を目指したいと過去問を解いて精進中です。いずれそのことも記事に起こしたい。。。
- 投稿日:2020-06-26T14:00:40+09:00
【Django】template上で使用できる user について
はじめに
Djangoで、現在ログインしているユーザーの名前を画面上に表示させたい時はtemplate上で
{{ user.username }}や{{ user.get_username }}とすることで実現できる。しかし、このuserという変数はviews.pyでrender関数を用いてtempletesに渡したり、get_context_data()をオーバーライドして変数を追加したりしていないのになぜ使えるのか。ここに疑問を持ったので少し調べてみた。結論
templateで使用できる変数はcontext(={<変数名>: <変数>, .....})に格納されていて、このcontextは大きく以下の2種類の変数を含む。
- views.pyでrender関数などを用いて渡された変数
- settings.py内のTEMPLATESのOPTIONに指定されている'context_processers'で指定されるファイル内で定義された変数
userは2.の説明にあたる変数であり、他にviews.pyで指定しなくても使える主な変数としてrequest,perm,messageなどがある。どこに格納されているのか
まずsetting.pyを見てみる。
config/setting.py# # 省略 # TEMPLATES = [ { 'BACKEND': 'django.template.backends.django.DjangoTemplates', 'DIRS': [os.path.join(BASE_DIR, 'templates')], 'APP_DIRS': True, 'OPTIONS': { 'context_processors': [ 'django.template.context_processors.debug', 'django.template.context_processors.request', 'django.contrib.auth.context_processors.auth', 'django.contrib.messages.context_processors.messages', ], }, }, ] # # 省略 #setting.pyにあるTEMPLATES.OPTIONS.context_processorsで指定されているファイルは、以下の4つ。
django.template.context_processors.debug
django.template.context_processors.request
django.contrib.auth.context_processors.auth・・・・・・・userの在処
django.contrib.messages.context_processors.messages
userの格納場所django.contrib.auth.context_processors# # 省略 # def auth(request): """ Return context variables required by apps that use Django's authentication system. If there is no 'user' attribute in the request, use AnonymousUser (from django.contrib.auth). """ if hasattr(request, 'user'): user = request.user else: from django.contrib.auth.models import AnonymousUser user = AnonymousUser() return { 'user': user, 'perms': PermWrapper(user), }
'user': userをreturnすることによってuserがtemplate内で使えるようになる。user.usernameとしuser内のusername属性を取り出したり、AnonymousUserクラスをインスタンス化したあと、クラス内のget_userメソッドを使用しuser.get_usernameとすることでログイン中のユーザー名が表示可能となる。(参考)
一番下にget_username関数がある。
django.contrib.auth.modelsclass AnonymousUser: id = None pk = None username = '' is_staff = False is_active = False is_superuser = False _groups = EmptyManager(Group) _user_permissions = EmptyManager(Permission) def __str__(self): return 'AnonymousUser' def __eq__(self, other): return isinstance(other, self.__class__) def __hash__(self): return 1 # instances always return the same hash value def __int__(self): raise TypeError('Cannot cast AnonymousUser to int. Are you trying to use it in place of User?') def save(self): raise NotImplementedError("Django doesn't provide a DB representation for AnonymousUser.") def delete(self): raise NotImplementedError("Django doesn't provide a DB representation for AnonymousUser.") def set_password(self, raw_password): raise NotImplementedError("Django doesn't provide a DB representation for AnonymousUser.") def check_password(self, raw_password): raise NotImplementedError("Django doesn't provide a DB representation for AnonymousUser.") @property def groups(self): return self._groups @property def user_permissions(self): return self._user_permissions def get_user_permissions(self, obj=None): return _user_get_permissions(self, obj, 'user') def get_group_permissions(self, obj=None): return set() def get_all_permissions(self, obj=None): return _user_get_permissions(self, obj, 'all') def has_perm(self, perm, obj=None): return _user_has_perm(self, perm, obj=obj) def has_perms(self, perm_list, obj=None): return all(self.has_perm(perm, obj) for perm in perm_list) def has_module_perms(self, module): return _user_has_module_perms(self, module) @property def is_anonymous(self): return True @property def is_authenticated(self): return False def get_username(self): return self.username
- 投稿日:2020-06-26T13:22:16+09:00
データサイエンス100本ノック~初心者未満の戦いpart8
これはデータサイエンティストの卵がわけもわからないまま100本ノックを行っていく奮闘録である。
完走できるか謎。途中で消えてもQiitaにあげてないだけと思ってください。ネタバレも含みますのでやろうとされている方は注意
模範解答を書き方が違いすぎて怖い
コレは見づらい!この書き方は危険!等ありましたら教えていただきたいです。
心にダメージを負いながら糧とさせていただきます。この解き方は間違っている!この解釈の仕方は違う!等もありましたらコメントください。
今回は41~44まで。
[前回]36~40
[目次付き初回]41本目
P-041: レシート明細データフレーム(df_receipt)の売上金額(amount)を日付(sales_ymd)ごとに集計し、前日からの売上金額増減を計算せよ。なお、計算結果は10件表示すればよい。
mine41.pydf_day=df_receipt.groupby('sales_ymd').agg({'amount':'sum'}).reset_index() df_Yday=pd.concat([df_day['sales_ymd']+1,df_day['amount']],axis=1).rename(columns={'amount': 'Y_amount'}) df=pd.merge(df_day.head(10),df_Yday,on='sales_ymd',how='outer') df['sa']=df['amount']-df['Y_amount'] df.head(10) '''模範解答''' df_sales_amount_by_date = df_receipt[['sales_ymd', 'amount']].groupby('sales_ymd').sum().reset_index() df_sales_amount_by_date = pd.concat([df_sales_amount_by_date, df_sales_amount_by_date.shift()], axis=1) df_sales_amount_by_date.columns = ['sales_ymd','amount','lag_ymd','lag_amount'] df_sales_amount_by_date['diff_amount'] = df_sales_amount_by_date['amount'] - df_sales_amount_by_date['lag_amount'] df_sales_amount_by_date.head(10)1日ずらしの集計です
自分の手法としては
df_Yという[(1日後の)日付 、 集計]の形の表を作成- 日付を合わせてマージ、こうすることで[日付、集計、(1日前の)集計]というデータができる
- 集計の差の列を追加する
として作りました。このやり方が間違ってるとは思わないが、「1日」ではなくテーブルの日付から引っ張ったほうがいいなとは思った。
- 例えば、土日休みのお店がある場合、日付が飛ぶから
模範解答を見てから
.shift()の使い方を調べたらすごく楽だと思ったので次の問題から活用することにした42本目
P-042: レシート明細データフレーム(df_receipt)の売上金額(amount)を日付(sales_ymd)ごとに集計し、各日付のデータに対し、1日前、2日前、3日前のデータを結合せよ。結果は10件表示すればよい。
mine42.pydf_day=df_receipt.groupby('sales_ymd').agg({'amount':'sum'}) df=df_day for i in range(1,4): df=pd.merge( df,df_day.shift(i).reset_index(),how='outer',on='sales_ymd') df.columns=['sales_ymd','amount_sum_0','amount_sum_1','amount_sum_2','amount_sum_3'] df.head(10) '''模範解答''' # コード例2:横持ちケース df_sales_amount_by_date = df_receipt[['sales_ymd', 'amount']].groupby('sales_ymd').sum().reset_index() for i in range(1, 4): if i == 1: df_lag = pd.concat([df_sales_amount_by_date, df_sales_amount_by_date.shift(i)],axis=1) else: df_lag = pd.concat([df_lag, df_sales_amount_by_date.shift(i)],axis=1) df_lag.columns = ['sales_ymd', 'amount', 'lag_ymd_1', 'lag_amount_1', 'lag_ymd_2', 'lag_amount_2', 'lag_ymd_3', 'lag_amount_3'] df_lag.dropna().sort_values(['sales_ymd']).head(10)最初はfor文で回さずに4つの表を一気に結合しようと思いましたが、どうやら
pd.merge()は二つの結合しかできないらしい
参考なので1つ元を作ってfor文でまわしてツッコミました。
個人的に最近で一番楽しかったデータの操作でした
ちなみに、.shift(0)で変わらないデータでるっぽいです
df=pd.merge( df_day.shift(0).reset_index()
, df_day.shift(1).reset_index()
, df_day.shift(2).reset_index()
, df_day.shift(3).reset_index()
,how='outer',on='sales_ymd')
こんな感じで書きたかった43本目
P-043: レシート明細データフレーム(df_receipt)と顧客データフレーム(df_customer)を結合し、性別(gender)と年代(ageから計算)ごとに売上金額(amount)を合計した売上サマリデータフレーム(df_sales_summary)を作成せよ。性別は0が男性、1が女性、9が不明を表すものとする。
ただし、項目構成は年代、女性の売上金額、男性の売上金額、性別不明の売上金額の4項目とすること(縦に年代、横に性別のクロス集計)。また、年代は10歳ごとの階級とすること。次の問題は
- 「年代」列を作成
.groupbyで2項目指定する- クロス集計の形にする
という段階を踏みました
mine43.pydf=pd.merge(df_receipt,df_customer,how='inner',on='customer_id') df_bins=pd.cut(df.age,range(0,100,10)) df=pd.concat([df[['gender_cd','amount']],df_bins],axis=1) df=df.groupby(['age','gender_cd']).agg({'amount':'sum'}).reset_index() df_cross=pd.merge( df.query("gender_cd=='0'")[['age','amount']] ,df.query("gender_cd=='1'")[['age','amount']] ,how='outer',on='age') df_cross=pd.merge( df_cross ,df.query("gender_cd=='9'")[['age','amount']] ,how='outer',on='age') df_cross.columns=['age','male','female','unkown'] df_cross '''模範解答''' df_tmp = pd.merge(df_receipt, df_customer, how ='inner', on="customer_id") df_tmp['era'] = df_tmp['age'].apply(lambda x: math.floor(x / 10) * 10) df_sales_summary = pd.pivot_table(df_tmp, index='era', columns='gender_cd', values='amount', aggfunc='sum').reset_index() df_sales_summary.columns = ['era', 'male', 'female', 'unknown'] df_sales_summaryと、思って模範解答見たらbinに分けることなく
.apply(lambda x: math.floor(x / 10) * 10)
10で割って(整数型にして)10でかけてるのかな?
lambdaの使い方がイマイチ分かっていない。
そして、ピボットテーブル化……なるほど。そういう使い方もできるのか……44本目
P-044: 前設問で作成した売上サマリデータフレーム(df_sales_summary)は性別の売上を横持ちさせたものであった。このデータフレームから性別を縦持ちさせ、年代、性別コード、売上金額の3項目に変換せよ。ただし、性別コードは男性を'00'、女性を'01'、不明を'99'とする。
今回は連続問題なので前回のまとめたdfをそのまま流用
縦持ちに変えるということなので、dfを3つに分けて縦に並べました。
というか前回縦を横に変えたので逆のが楽だった……mine44.pydf_cross_M=df_cross[['age','male']].rename(columns={'male':'sum'}) df_cross_M['gender']='00' df_cross_F=df_cross[['age','female']].rename(columns={'female':'sum'}) df_cross_F['gender']='01' df_cross_U=df_cross[['age','unkown']].rename(columns={'unkown':'sum'}) df_cross_U['gender']='99' df=pd.concat([df_cross_M,df_cross_F,df_cross_U]) df '''模範解答''' df_sales_summary = df_sales_summary.set_index('era'). \ stack().reset_index().replace({'female':'01', 'male':'00', 'unknown':'99'}).rename(columns={'level_1':'gender_cd', 0: 'amount'})超長い1文で模範解答さん終わらせています。
setindex()で年代列をインデックスに待避させてすべての列を一本化させたのかな?
.replace()で一気に名前を変えられるのはすごいと思う。ぜひとも使いこなしたい今回はここまで
いずれにしても、自分のやり方とは違うやり方が増えてきたのでとても勉強になります
この場を借りて
いつも自分のスタックしてくださる方、ありがとうございます。
もし個別記事を登録するのではなく、自分の進捗を見ていただけている方がいるのであれば、part1の目次を更新するたびに更新通知を送らせていただいております。
その為、すべての記事をストックすることなくpart1をストックすれば自分の進捗を見ることができますので、お手数かけずに済むかと思います。(思ってるだけです)いつも見ていただけてる方、今回が初の方、すべての方に感謝します。閲覧ありがとうございます。
- 投稿日:2020-06-26T13:17:04+09:00
AtCoder Beginner Contest 171 復習
今回の成績
今回の感想
早解き回は苦手なんですが、そこそこ健闘した方だと思います。
F問題を時間内で通せるようにしたいですね。考察が複雑になっても余裕を持って論理的に考えられるようにしたいです。そのためには、メモをもう少し綺麗に書くべきなのかなと思います。
最近コンテストの復習はしっかりできているのでその点は自分の中で評価したいと思います。そろそろその成果が実ってくれると嬉しいと思っています。A問題
大文字かどうかはisupper関数で判定でき、以下のようになります。
A.pya=input() print("A" if a.isupper() else "a")B問題
このパターンの問題はいくらでもAtCoderで出てきている気がします。
金額の小さい順にK個選ぶので昇順ソートして配列の1~K番目の和を考えれば良いです。B.pyn,k=map(int,input().split()) p=list(map(int,input().split())) p.sort() print(sum(p[:k]))C問題
前回の予想通り、Cで崖を作ろうとしているのがわかります。処理が面倒だと思うのですが、かなりの人数が通してるのが驚きです。
まず、犬の名前の長さを$l$とすればその犬の名前の命名の仕方は$26^l$通りあることが明らかです。また、ここから26進数として考えれば都合が良いことがわかります。名前の長さを決めればあとはn進数の桁を決めていく処理と考えることができるので、まずは名前の長さをn_len関数で求めることにしました。
ここで、与えられたNから$26,26^2,…$を0以下にならないように引いていくことで名前の長さは求めることができるので、この処理をした下では名前の長さ$l$とその長さの名前の中で(辞書順で)何番目か$N$という情報を持っています。
26進数の処理は下側の桁から決めていくと考えれば、
n%26でその桁のアルファベットが求まってn//=26でその桁を捨てることができるので、これを名前の長さ$l$について全て行えば良いです。C.pyn=int(input())-1 def n_len(): global n i=1 while n>=26**i: n-=26**i i+=1 return i l=n_len() alp=[chr(i) for i in range(97, 97+26)] ans="" for i in range(l): k=n%26 ans=alp[k]+ans n//=26 print(ans)D問題
数列を配列のまま保存してクエリの計算を行うと、全ての配列の要素をチェックする必要があり、計算量が$O(QN)$となり間に合いません。
クエリの処理は値が$B_i$の数を全て$C_i$に書き換えるというもので、辞書で数列内にそれぞれの数がいくつあるかを保存しておけばこの処理は$O(1)$で行うことができます。
したがって、要素の和を保存する用の変数を用意して、$B_i,C_i$が数列内に存在しない可能性を考慮すれば、計算量が$O(Q)$のプログラムを実装することができます。
D.pyn=int(input()) a=dict() ans=0 for i in map(int,input().split()): ans+=i if i in a: a[i]+=1 else: a[i]=1 q=int(input()) for i in range(q): b,c=map(int,input().split()) if c not in a: a[c]=0 if b not in a: a[b]=0 ans=ans-b*a[b]+c*a[b] a[c]+=a[b] a[b]=0 print(ans)E問題
hamayanhamayanさんの記事を参照すればわかるように、XORのよく使う性質には以下の3つがあります($a$は0以上の整数)。
1:交換則及び結合則
2:$a \oplus a=0$
3:$2a \oplus (2a+1)=1 \leftrightarrow 4a \oplus (4a+1) \oplus (4a+2) \oplus (4a+3)=0$
この他にも、$F=\{0,1\}$,(ビット数)=$n$として$\oplus$を線形結合とするようなベクトル空間$F^n$を考えて整数を表現し、線型独立や線形従属などの判定を行う問題(AGC045のA問題)もありますが、詳しくは先ほどのhamayanhamayanさんの記事などを参照して下さい。
この問題では主に上記の性質2を用いて、被りが生じると0なのでいい感じに消せると考察をすることで下図のようになります。(暗黙的に性質1も用いています。)
$a_1,a_2,…,a_n$のXORを考えると$b_1,b_2,…,b_n$は$n-1$回ずつ現れるのは明らかです。さらに、$b_i$を求めるために$a_i$に注目すると、$a_i$をもう一回XORすることで$b_1,…,b_{i-1},b_{i+1},…,b_n$が$n$回ずつ,$b_i$は$n-1$回ずつ出現することがわかります。したがって、問題の制約より$n$は偶数なので、$b_1,…,b_{i-1},b_{i+1},…,b_n$によるXORは全て0で、$b_i$のみが残ることがわかります。
以上より、前計算として$a_1,a_2,…,a_n$のXORを求めておき、答えとしてはその数と$a_1,a_2,…,a_n$それぞれのXORを求めればよく以下のようになります。
E.pyn=int(input()) a=list(map(int,input().split())) b=0 for i in range(n): b^=a[i] ans=[0]*n for i in range(n): ans[i]=a[i]^b print(" ".join(map(str,ans)))F問題
もう少しの頭の捻りで解けそうでした…。青diffはこのような問題が多いです…。
(以下では、元々の文字列を$S$、その長さを$N$、$i$文字目を$S_i$、最終的に生成する文字列を$S^{'}$と表します。)
まず、文字列かつ順番が関係しそうなのでDPを疑いましたが、明らかに計算量的に間に合いません。ここで、サンプルを利用した実験と問題の制約から多くの文字列が表せそうなので、組み合わせ計算によって$O(K+N)$程度に収めようと考えました。また、後から追加する文字の自由度が高いので、$S$に含まれる文字の場所を決めてから後から追加する文字の組み合わせの総数を考えるという方法を採りました。
しかし、$S$に含まれる文字を決めた後に他の文字がそれぞれ26通りずつあるとして組み合わせを求めると、$S^{'}$に重複する文字列が生じる可能性があります。したがって、先ほどの$S$に含まれる文字の位置を決める方針と合わせれば、$S$に含まれる文字の位置を決めたもとで$S^{'}$の作り方が一意に決まるような方法を求めれば良いです。また、この方法は$S^{'}$に対し$S$に含まれる文字の位置が一意に決まるような方法(✳︎)を求めれば良いと言い換えることができます。
(↑ある方法で答えが一意に定まる数え上げ$\leftrightarrow$数え上げたものからある方法が一意に定まる、ということです。一意性がテーマの問題は多いので、解けるようにしていきたいです。)
ここで、(✳︎)についてですが、前から$S^{'}$を眺めた時に$S$に含まれる文字が最初に出てくる位置とすれば一意に決めることができます。また、このもとでは、$S^{'}$の$S _{i-1} $の位置から$S _{i} $の位置までは$S_{i} $以外の全てのアルファベットを使うことができます。したがって、$S_{N} $の位置より前で$S$に含まれない文字は全て25(=26-1)通りとなります。また、$S_{N} $の位置より後の文字列についてはどのアルファベットでも良いので26通りとなります。
以上より、26通りある場合と25通りある場合の境目である$S_{N} $の位置を決めれば、残りの$S$に含まれる文字の位置が何通りあるかと26と25が何乗ずつあるかを求めることで以下のような実装になります。また、以下では整数を常にmodをとって管理するmodint構造体を使っています。
F.cc//インクルード(アルファベット順) #include<algorithm>//sort,二分探索,など #include<bitset>//固定長bit集合 #include<cmath>//pow,logなど #include<complex>//複素数 #include<deque>//両端アクセスのキュー #include<functional>//sortのgreater #include<iomanip>//setprecision(浮動小数点の出力の誤差) #include<iostream>//入出力 #include<iterator>//集合演算(積集合,和集合,差集合など) #include<map>//map(辞書) #include<numeric>//iota(整数列の生成),gcdとlcm(c++17) #include<queue>//キュー #include<set>//集合 #include<stack>//スタック #include<string>//文字列 #include<unordered_map>//イテレータあるけど順序保持しないmap #include<unordered_set>//イテレータあるけど順序保持しないset #include<utility>//pair #include<vector>//可変長配列 using namespace std; typedef long long ll; //マクロ //forループ関係 //引数は、(ループ内変数,動く範囲)か(ループ内変数,始めの数,終わりの数)、のどちらか //Dがついてないものはループ変数は1ずつインクリメントされ、Dがついてるものはループ変数は1ずつデクリメントされる #define REP(i,n) for(ll i=0;i<(ll)(n);i++) #define REPD(i,n) for(ll i=n-1;i>=0;i--) #define FOR(i,a,b) for(ll i=a;i<=(ll)(b);i++) #define FORD(i,a,b) for(ll i=a;i>=(ll)(b);i--) //xにはvectorなどのコンテナ #define ALL(x) (x).begin(),(x).end() //sortなどの引数を省略したい #define SIZE(x) ll(x.size()) //sizeをsize_tからllに直しておく //定数 #define INF 1000000000000 //10^12:極めて大きい値,∞ #define MOD 1000000007 //10^9+7:合同式の法 #define MAXR 3000000 //10^5:配列の最大のrange(素数列挙などで使用) //略記 #define PB push_back //vectorヘの挿入 #define MP make_pair //pairのコンストラクタ #define F first //pairの一つ目の要素 #define S second //pairの二つ目の要素 template<ll mod> class modint{ public: ll val=0; //コンストラクタ modint(ll x=0){while(x<0)x+=mod;val=x%mod;} //コピーコンストラクタ modint(const modint &r){val=r.val;} //算術演算子 modint operator -(){return modint(-val);} //単項 modint operator +(const modint &r){return modint(*this)+=r;} modint operator -(const modint &r){return modint(*this)-=r;} modint operator *(const modint &r){return modint(*this)*=r;} modint operator /(const modint &r){return modint(*this)/=r;} //代入演算子 modint &operator +=(const modint &r){ val+=r.val; if(val>=mod)val-=mod; return *this; } modint &operator -=(const modint &r){ if(val<r.val)val+=mod; val-=r.val; return *this; } modint &operator *=(const modint &r){ val=val*r.val%mod; return *this; } modint &operator /=(const modint &r){ ll a=r.val,b=mod,u=1,v=0; while(b){ ll t=a/b; a-=t*b;swap(a,b); u-=t*v;swap(u,v); } val=val*u%mod; if(val<0)val+=mod; return *this; } //等価比較演算子 bool operator ==(const modint& r){return this->val==r.val;} bool operator <(const modint& r){return this->val<r.val;} bool operator !=(const modint& r){return this->val!=r.val;} }; using mint = modint<MOD>; //入出力ストリーム istream &operator >>(istream &is,mint& x){//xにconst付けない ll t;is >> t; x=t; return (is); } ostream &operator <<(ostream &os,const mint& x){ return os<<x.val; } //累乗 mint modpow(const mint &a,ll n){ if(n==0)return 1; mint t=modpow(a,n/2); t=t*t; if(n&1)t=t*a; return t; } //二項係数の計算 mint fac[MAXR+1],finv[MAXR+1],inv[MAXR+1]; //テーブルの作成 void COMinit() { fac[0]=fac[1]=1; finv[0]=finv[1]=1; inv[1]=1; FOR(i,2,MAXR){ fac[i]=fac[i-1]*mint(i); inv[i]=-inv[MOD%i]*mint(MOD/i); finv[i]=finv[i-1]*inv[i]; } } //演算部分 mint COM(ll n,ll k){ if(n<k)return 0; if(n<0 || k<0)return 0; return fac[n]*finv[k]*finv[n-k]; } signed main(){ //入力の高速化用のコード //ios::sync_with_stdio(false); //cin.tie(nullptr); COMinit(); ll k,l;cin>>k; string s;cin>>s;n=SIZE(s); mint ans=0; FOR(i,n,k+n){ ans+=(modpow(25,i-n)*modpow(26,k+n-i)*COM(i-1,n-1)); } cout<<ans<<endl; }

- 投稿日:2020-06-26T12:06:01+09:00
Pythonとrepl.itを使って無料でDiscord Botを運用してみた
経緯
最近TRPGをDiscord上でやっているからか、かなりの頻度でDiscordでチャットをするようになりました。
そこで今回は、チャット内で多発する「うんこ」に自動的にうんこの絵文字を付けるようなBOTを開発しました。
今回のようにあまり難しいBotでなければ小一時間(経験なし)で実際に運用できることが分かりました。
是非みなさんも僕のように生活を豊かにする(意味のない)BOT開発を楽しみましょう!こちらの記事では、Pythonの基礎知識がある方を対象に書いています。
また、「うんこ」という言葉が数え切れないほど出てきますが、ご容赦ください。開発環境
- Repl.it
- Python 3.8
- discord.py 1.3.3
- Flask 1.1.2
- Uptime Robot
Repl.it について
- オンラインコーディングプラットフォームです
- ブラウザに表示されたIDEからコードを実行できます
- ウェブ上でアプリやウェブサイトの開発ができます
Uptime Robot について
- ネットワークを(50まで)無料で監視できるサービス
Botアカウントの作成
- Discord Developer PortalへアクセスしてDiscordのアカウントを使ってログインします
New Applicationボタンを押して、名前を付けてください
- 私の場合は
Unkoとしました
- 作成したApplicationの中に入り、
Botのタブに入ります。
Add Botボタンを押します
- Botが作成された後にBotの
Usernameを変更することができます- 私はここで
UnkoManという名前を授けました。 (Save Changesを押すのを忘れないように)- ここでプロファイル写真の変更も可能です
PUBLIC BOTがオンになっているのを確認しますTOKENをコピーしておきます
Guild(discord APIではGuild == Serverらしい)を作成します。Discord内(アプリの方)で"+"ボタンを押してサーバーを作成します
Botをサーバーへ登録します
OAuth2のタブに入りSCOPES内のbotをチェックします- 下にある
BOT PERMISSIONSからBOTの必要な権限もチェックします
- 今回はテキストに対する権限だけが必要なので
Send MessagesとAdd Reactionsのみをチェックしました
- すると認証URLが生成されるので、コピーしてブラウザで開きます
- ちなみに他の人が保有しているサーバーにBotを追加したい場合もこの認証URLを使います
- 先ほど作成したサーバーを選択して認証ボタンを押します
Botが自分のサーバーにいることを確認!
ウェブサーバー
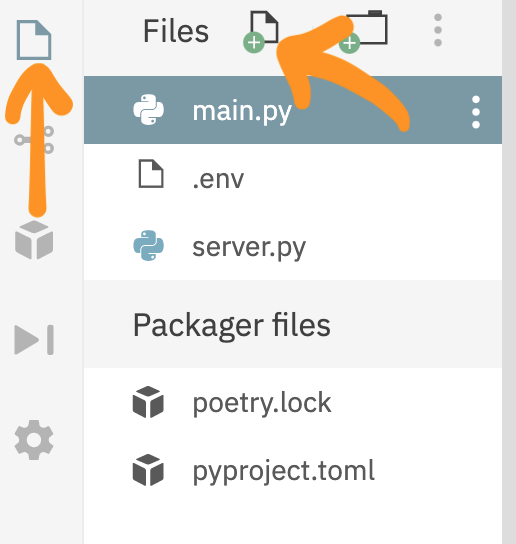
- Repl.itに行き、Python replを作成します
Packageタブを開きdependencyをインストールしていきます。下記を検索してインストールしてください
- discord.py
- Flask
server.pyという新規ファイルを作成します
- FlaskとThreadを使ってサーバーを作ります
- 後でサーバーをUptime robotにpingしてもらいます
server.pyfrom flask import Flask from threading import Thread app = Flask("") @app.route("/") def main(): return "UnkoMan is alive!" def run(): app.run("0.0.0.0", port=8080) def keep_alive(): t = Thread(target=run) t.start()Bot
.envファイルを作成しますTOKEN=先ほどコピーしておいたTOKEN
main.pyにどのようなBotにしたいかを書きます。以下コードにコメントを付けて説明します仕様
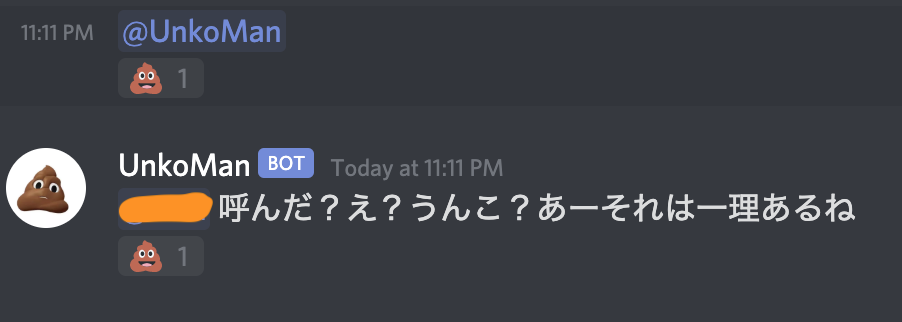
UNNKO_LISTに入っている言葉にうんこの絵文字を付ける- メンション(または、”お腹すいた”と言われたら)されたら、何かしらの返事をする
- 新しい人が入ってきたときに自己紹介をする
main.pyimport os import discord from server import keep_alive # うんこに関する言葉のリスト UNKO_LIST = ["うん", "うんこ", "poop", "うんち", "unnko", "unko", "くそ", "クソ", "糞", "大便", "排泄物", "ばば", "糞便", "crap", "feces", "manure", "shit"] # .envからTOKENを取ってくる TOKEN = os.getenv("TOKEN") # 接続するためのオブジェクト client = discord.Client() # 起動時にログする # @デコレーターを使ってイベントをハンドルします @client.event async def on_ready(): print('UnkoMan is here') @client.event async def on_message(message): message.content = message.content.lower() # メッセージの送信者がBot自身だった場合は無視 if message.author == client.user: return # メンションされたら返信 if client.user in message.mentions: await reply_unko(message) # メッセージ自体または、メッセージの中にうんこ(うん以外)が入ってたら、うんこの絵文字 if message.content in UNKO_LIST or any(s in message.content for s in UNKO_LIST[1:]): await react_unko(message) # 隠しコマンド:お腹すいたら、特別メッセージを送るよ if "お腹すいた" in message.content: await reply_unko(message, "お腹すいた") async def reply_unko(message, special=""): if special == "お腹すいた": reply = "とりあえずうんこでも食っておけ(辛辣)" else: reply = f'{message.author.mention} 呼んだ?え?うんこ?あーそれは一理あるね' # メッセージの送信と送信したメッセージにうんこを sent_msg = await message.channel.send(reply) await react_unko(message) await react_unko(sent_msg) # うんこの絵文字をメッセージに付ける async def react_unko(message): await message.add_reaction("?") # 新しい人が入ってきたとき @client.event async def on_member_join(member): # guildはdiscord内のserverのこと for channel in member.guild.channels: # generalチャンネルでの自己紹介 if str(channel) == "general": await channel.send_message(f"""初めまして {member.mention}さん うんこマンです!""") # ウェブサーバーを起動する keep_alive() # Discordへ接続 client.run(TOKEN)Repl.it内の
runボタンを押して実行!これでDiscord上のサーバーであなたのBotが動いているはずです!
気をつけなければいけないのは、repl.itではアクティビティがない状況が1時間続くとreplがオフラインになるとこです。
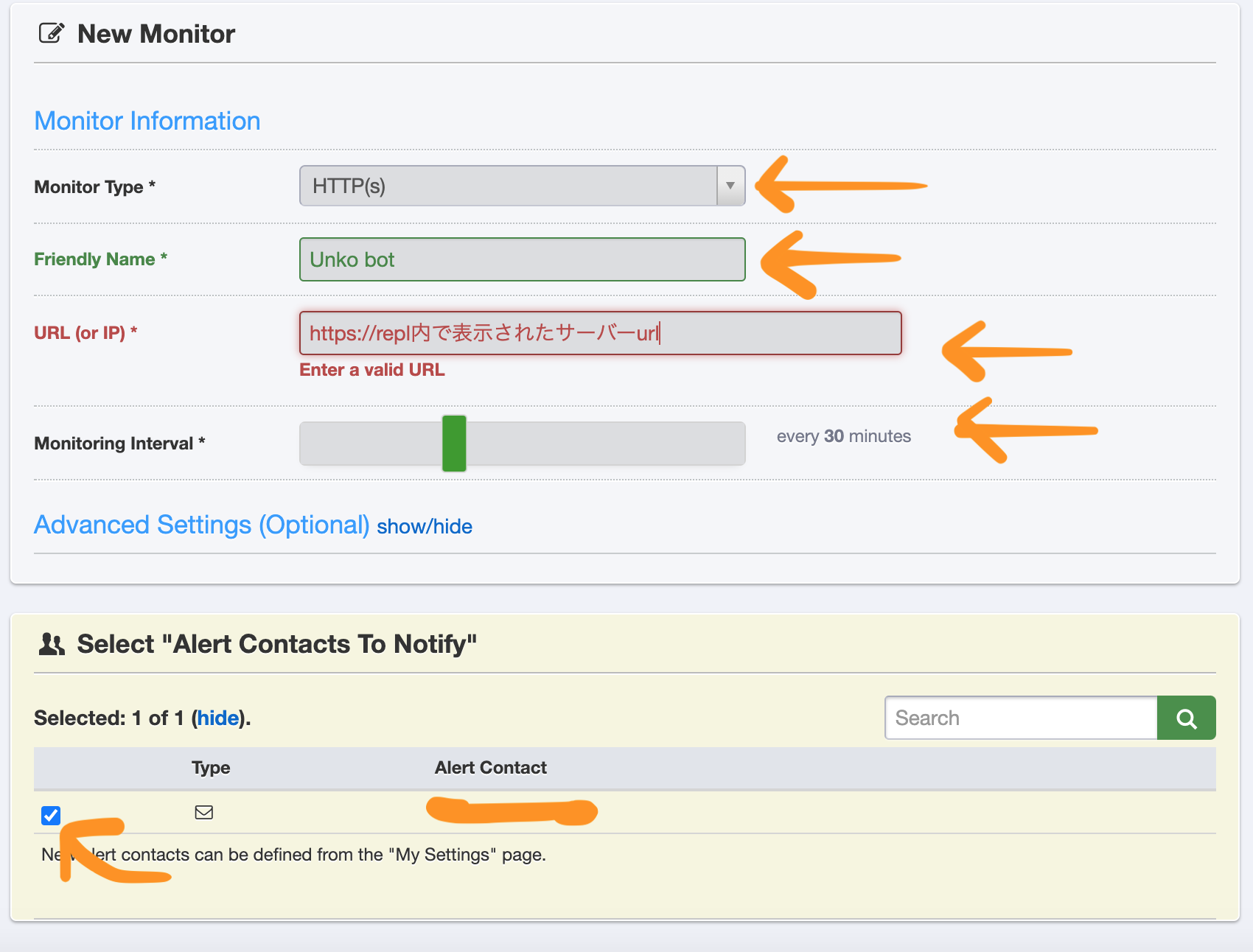
対策としてUptime Robotを使いBotを365日24時間稼働させる方法を説明しますUptime Robot
- Uptime Robotにてアカウントを作成します
+ Add New Monitorボタンを押します
Monitor TypeをHTTP(S)、Friendly Nameに好きな名前、URLをrepl.itで表示されていたものに、Monitoring Intervalをevery 30 minutesに設定してreplがオフラインにならないように設定します
- エラーが起きたときように
Alert Contacts To Notifyをチェックしておきます
Create Monitorボタンを押して完成です!
追記
- "Repl it being just another host, won't be able to host it 24/7 so it will have a downtime of a few minutes within every 24 hours" なので365日24時間は稼働できないようです。24時間中数分はダウンタイムがあるようですが、この際目を瞑りましょう...
終わりに
いかがでしたでしょうか?納得のいくBotが作れましたか?
もし、より機能を充実させてたいのであれば、ドキュメントを読むことをお勧めします。関連記事にQiitaの記事を載せているのですが、どうやらHerokuでもBotなら無料でホスティングができるようです。Herokuは、ウェブアプリでの開発でしか使ったことがなかったので、勘違いをしていましたが、どうやら"Heroku の無料プランでは30分動作しないWebアプリケーションはスリープしますが、 紹介した手順ではwebプロセスを使用していないため、問題なく常時稼働します。"とのことです。
まあ、Procfileやらなんやら他にもファイルを作らなければならないので、repl.itで実装した方が面倒くさくないなぁ...笑今回作成したBotですが、どなたか実用されたい方がいればどうぞ UnkoMan を是非よろしくお願いします。
また、
UnkoMan最高など、何かコメント・質問があれば是非お知らせください!追記
愛用されているようです
関連記事・参考にしたもの

- 投稿日:2020-06-26T12:06:01+09:00
Pythonとrepl.itを使って無料でDiscord Botを運用してみた ~?をつけまくってみる~
経緯
最近TRPGをDiscord上でやっているからか、かなりの頻度でDiscordでチャットをするようになりました。
そこで今回は、チャット内で多発する「うんこ」に自動的にうんこの絵文字を付けるようなBOTを開発しました。
今回のようにあまり難しいBotでなければ小一時間(経験なし)で実際に運用できることが分かりました。
是非みなさんも僕のように生活を豊かにする(意味のない)BOT開発を楽しみましょう!こちらの記事では、Pythonの基礎知識がある方を対象に書いています。
また、「うんこ」という言葉が数え切れないほど出てきますが、ご容赦ください。実際に開発したもの
開発環境
- Repl.it
- Python 3.8
- discord.py 1.3.3
- Flask 1.1.2
- Uptime Robot
Repl.it について
- オンラインコーディングプラットフォームです
- ブラウザに表示されたIDEからコードを実行できます
- ウェブ上でアプリやウェブサイトの開発ができます
Uptime Robot について
- ネットワークを(50まで)無料で監視できるサービス
Botアカウントの作成
- Discord Developer PortalへアクセスしてDiscordのアカウントを使ってログインします
New Applicationボタンを押して、名前を付けてください
- 私の場合は
Unkoとしました- 作成したApplicationの中に入り、
Botのタブに入ります。
Add Botボタンを押します
- Botが作成された後にBotの
Usernameを変更することができます- 私はここで
UnkoManという名前を授けました。 (Save Changesを押すのを忘れないように)- ここでプロファイル写真の変更も可能です
PUBLIC BOTがオンになっているのを確認しますTOKENをコピーしておきます
Guild(discord APIではGuild == Serverらしい)を作成します。Discord内(アプリの方)で"+"ボタンを押してサーバーを作成します
Botをサーバーへ登録します
OAuth2のタブに入りSCOPES内のbotをチェックします- 下にある
BOT PERMISSIONSからBOTの必要な権限もチェックします
- 今回はテキストに対する権限だけが必要なので
Send MessagesとAdd Reactionsのみをチェックしました- すると認証URLが生成されるので、コピーしてブラウザで開きます
- ちなみに他の人が保有しているサーバーにBotを追加したい場合もこの認証URLを使います
- 先ほど作成したサーバーを選択して認証ボタンを押します
Botが自分のサーバーにいることを確認!
ウェブサーバー
- Repl.itに行き、Python replを作成します
Packageタブを開きdependencyをインストールしていきます。下記を検索してインストールしてください
- discord.py
- Flask
server.pyという新規ファイルを作成します
- FlaskとThreadを使ってサーバーを作ります
- 後でサーバーをUptime robotにpingしてもらいます
server.pyfrom flask import Flask from threading import Thread app = Flask("") @app.route("/") def main(): return "UnkoMan is alive!" def run(): app.run("0.0.0.0", port=8080) def keep_alive(): t = Thread(target=run) t.start()Bot
.envファイルを作成しますTOKEN=先ほどコピーしておいたTOKEN
main.pyにどのようなBotにしたいかを書きます。以下コードにコメントを付けて説明します仕様
UNNKO_LISTに入っている言葉にうんこの絵文字を付ける- メンション(または、”お腹すいた”と言われたら)されたら、何かしらの返事をする
- 新しい人が入ってきたときに自己紹介をする
main.pyimport os import discord from server import keep_alive # うんこに関する言葉のリスト UNKO_LIST = ["うん", "うんこ", "poop", "うんち", "unnko", "unko", "くそ", "クソ", "糞", "大便", "排泄物", "ばば", "糞便", "crap", "feces", "manure", "shit"] # .envからTOKENを取ってくる TOKEN = os.getenv("TOKEN") # 接続するためのオブジェクト client = discord.Client() # 起動時にログする # @デコレーターを使ってイベントをハンドルします @client.event async def on_ready(): print('UnkoMan is here') @client.event async def on_message(message): message.content = message.content.lower() # メッセージの送信者がBot自身だった場合は無視 if message.author == client.user: return # メンションされたら返信 if client.user in message.mentions: await reply_unko(message) # メッセージ自体または、メッセージの中にうんこ(うん以外)が入ってたら、うんこの絵文字 if message.content in UNKO_LIST or any(s in message.content for s in UNKO_LIST[1:]): await react_unko(message) # 隠しコマンド:お腹すいたら、特別メッセージを送るよ if "お腹すいた" in message.content: await reply_unko(message, "お腹すいた") async def reply_unko(message, special=""): if special == "お腹すいた": reply = "とりあえずうんこでも食っておけ(辛辣)" else: reply = f'{message.author.mention} 呼んだ?え?うんこ?あーそれは一理あるね' # メッセージの送信と送信したメッセージにうんこを sent_msg = await message.channel.send(reply) await react_unko(message) await react_unko(sent_msg) # うんこの絵文字をメッセージに付ける async def react_unko(message): await message.add_reaction("?") # 新しい人が入ってきたとき @client.event async def on_member_join(member): # guildはdiscord内のserverのこと for channel in member.guild.channels: # generalチャンネルでの自己紹介 if str(channel) == "general": await channel.send_message(f"""初めまして {member.mention}さん うんこマンです!""") # ウェブサーバーを起動する keep_alive() # Discordへ接続 client.run(TOKEN)Repl.it内の
runボタンを押して実行!これでDiscord上のサーバーであなたのBotが動いているはずです!
気をつけなければいけないのは、repl.itではアクティビティがない状況が1時間続くとreplがオフラインになるとこです。
対策としてUptime Robotを使いBotを365日24時間稼働させる方法を説明しますUptime Robot
- Uptime Robotにてアカウントを作成します
+ Add New Monitorボタンを押します
Monitor TypeをHTTP(S)、Friendly Nameに好きな名前、URLをrepl.itで表示されていたものに、Monitoring Intervalをevery 30 minutesに設定してreplがオフラインにならないように設定します
- エラーが起きたときように
Alert Contacts To Notifyをチェックしておきます
Create Monitorボタンを押して完成です!
追記
- "Repl it being just another host, won't be able to host it 24/7 so it will have a downtime of a few minutes within every 24 hours" なので365日24時間は稼働できないようです。24時間中数分はダウンタイムがあるようですが、この際目を瞑りましょう...
終わりに
いかがでしたでしょうか?納得のいくBotが作れましたか?
もし、より機能を充実させてたいのであれば、ドキュメントを読むことをお勧めします。関連記事にQiitaの記事を載せているのですが、どうやらHerokuでもBotなら無料でホスティングができるようです。Herokuは、ウェブアプリでの開発でしか使ったことがなかったので、勘違いをしていましたが、どうやら"Heroku の無料プランでは30分動作しないWebアプリケーションはスリープしますが、 紹介した手順ではwebプロセスを使用していないため、問題なく常時稼働します。"とのことです。
まあ、Procfileやらなんやら他にもファイルを作らなければならないので、repl.itで実装した方が面倒くさくないなぁ...笑今回作成したBotですが、どなたか実用されたい方がいればどうぞ UnkoMan を是非よろしくお願いします。
また、
UnkoMan最高など、何かコメント・質問があれば是非お知らせください!関連記事・参考にしたもの
- 投稿日:2020-06-26T11:31:54+09:00
pythonを三行でセグフォらせる
多分これが一番早いと思います。
$ docker run -ti python:3.8-slim bash # pip install mysql-connector-python==8.0.20 # python >>> import random >>> import mysql.connector Segmentation fault何が起こっているのか。
前提
mysql-connector-pythonは
8.0.20からlibcrypto.so.1.1とlibssl.so.1.1をbundleするようになりました。$ pip show -f mysql-connector-python | grep lib Location: /usr/local/lib/python3.8/site-packages mysql-vendor/libcrypto.so.1.1 mysql-vendor/libssl.so.1.1解説
import random
randomをインポートするとlibcrypto.so.1.1をロードします。
この時はシステムにインストールされたlibcrypto.so.1.1をロードします。import mysql.connectorこのimport文で
libssl.so.1.1とlibcrypto.so.1.1をロードしようとします。
その際、libssl.so.1.1はバンドルされた独自のものをロードするのですが、
libcrypto.so.1.1はすでにロード済みなので、ロードしません。したがって以下のような状態になります。
libcrypto.so.1.1 --> /usr/lib/x86_64-linux-gnu/libcrypto.so.1.1 libssl.so.1.1 --> /usr/local/lib/python3.8/site-packages/mysql-vendor/libssl.so.1.1
libcrypto.so.1.1に互換性がないため、segmentation faultとなります。すでにbugとして報告されています。
https://bugs.mysql.com/bug.php?id=97220回避策
- LD_PRELOADで
/usr/local/lib/python3.8/site-packages/mysql-vendor/libssl.so.1.1等を読み込む8.0.19以前のバージョンを使う。追記
別にrandomを読み込まなくてもセグフォすることがわかりました。
>>> import mysql.connector Segmentation Fault上記の理屈だと若干説明がつかないので原因は別にあるようです。
LD_PRELOADで回避できるのでバンドルされたライブラリに読み込み順序に何か問題があることは確かだと思います。ちなみに、不思議なのですが、
python:3.8-slimイメージでは発生しますが、python:3.8イメージでは発生しません。
- 投稿日:2020-06-26T11:22:21+09:00
アンケート調査データを分析してみる【第4回:感情分析】
今回は、アンケートの回答データを使って感情分析にチャレンジしてみたいと思います。感情分析を行うことで、自由回答中の語句から、回答者の態度がポジティブかネガティブかを判定します。
今回も以下URLより、「電子版お薬手帳を使いたい理由」に関する自由回答データを使用します。
「電子版お薬手帳に関する意識調査」を行いました
https://www.nicho.co.jp/corporate/newsrelease/11633/①まずはライブラリをインポートします。今回はjanomeを使います。
import csv from janome.tokenizer import Tokenizer②次に「日本語評価極性辞書」をダウンロードし、読み込みます。これは、語句の判定に使う単語辞書のことで、例えば「誠実」はポジティブ、「弱気」はネガティブといったように、約8,500の表現に対してポジティブかネガティブかの紐付けがされています(下記URL参照)。
! curl http://www.cl.ecei.tohoku.ac.jp/resources/sent_lex/pn.csv.m3.120408.trim > pn.csv np_dic = {} fp = open("pn.csv", "rt", encoding="utf-8") reader = csv.reader(fp, delimiter='\t') for i, row in enumerate(reader): name = row[0] result = row[1] np_dic[name] = result if i % 500 == 0: print(i)③対象データについて形態素解析を実施、各語句と上記の辞書を照らし合わせます。以下のコード中、「p」はポジティブ、「n」はネガティブ、「e」はどちらでもないニュートラルな語句を指しており、それぞれをカウントして、ポジティブ度とネガティブ度を判定します。
df = open("survey3.txt", "rt", encoding="utf-8") text = df.read() tok = Tokenizer() res = {"p":0, "n":0, "e":0} for t in tok.tokenize(text): bf = t.base_form if bf in np_dic: r = np_dic[bf] if r in res: res[r] += 1 print(res) cnt = res["p"] + res["n"] + res["e"] print("Positive", res["p"] / cnt) print("Negative", res["n"] / cnt)結果は以下のようになりました。「電子版お薬手帳を使いたい理由」に関する回答なだけあって、やはりポジティブ度が高い結果になっています。
因みにこの調査では、「電子版お薬手帳を使いたくない理由」についても調べています。このデータで同様の分析をするとどうなるでしょうか。
結果はこのようになりました。「使いたくない理由」にも関わらずポジティブ度がネガティブ度を上回っています。元の回答データを見ると、「紙の手帳のほうが良い」といった回答も散見され、上記のような結果になってしまったようです。このあたりはアンケート設計にも関わってくる部分になり、テキストマイニングの実施を前提にしている場合は留意が必要になりそうです。
参考サイト
読み放題のネット小説をネガポジ判定で評価してみよう
https://news.mynavi.jp/article/zeropython-58/
- 投稿日:2020-06-26T11:04:52+09:00
[python] リストとディクショナリ 要素の取り出し方まとめ
はじめに
リストとディクショナリの要素の取り出し方の覚書- 要素の追加や削除等、他にもいろいろあるけど、ここでは要素の取り出し方だけまとめる
- 使ってるうちに便利だなと思ったのは
リストとディクショナリを組み合わせることができること- 特に
ディクショナリの中にディクショナリを入れ子にできることで、個人的に一番よく使うリスト
- 同じ型のデータを一列に並べたもの
- 各要素には0から順にインデックスが振られている
インデックスで一つづつ要素を取り出す
list.pyls = ['りんご', 'もも', 'さくらんぼ'] print(ls[0]) print(ls[1]) print(ls[2])結果りんご もも さくらんぼ
for文で一つづつ要素を取りだすlist2.pyls = ['りんご', 'もも', 'さくらんぼ'] for a in ls: print(a)結果りんご もも さくらんぼディクショナリ
- キーと要素で一つのデータの集まり
キーを指定して一つづつ要素を取り出す
dic.pydic = {'フルーツ':'りんご', '野菜':'玉ねぎ'} print(dic['フルーツ']) print(dic['野菜'])結果りんご 玉ねぎ
for文でキーを取り出す
keysを使うとkeyを取得できるdic2.pydic = {'フルーツ':'りんご', '野菜':'玉ねぎ'} for mykey in dic.keys(): print(mykey)結果フルーツ 野菜
for文で要素を取り出す
valuesを使うとvalueを取得できるdic2.pydic = {'フルーツ':'りんご', '野菜':'玉ねぎ'} for myval in dic.values(): print(myval)結果りんご 玉ねぎ
for文でキーと要素を同時に取り出す
itemsを使うとkeyとvalueの両方を取得できるdic3.pydic = {'フルーツ':'りんご', '野菜':'玉ねぎ'} for mykey, myval in dic.items(): print(mykey) print(myval)結果フルーツ りんご 野菜 玉ねぎディクショナリの中にリスト
valueをリストにする
keyとインデックスの組み合わせで要素を取り出すことができるdic_list.pydic = {'フルーツ':['りんご', 'もも'], '野菜':['玉ねぎ', '人参']} # キーから要素であるリストを取り出す for mykey in dic.keys(): for i in range(0,len(dic[mykey])): print(dic[mykey][i]) # 直接、要素であるリストを取り出す for myvalue in dic.values(): for i in range(0,len(myvalue)): print(myvalue[i])どちらも結果は同じ
結果フルーツ りんご 野菜 玉ねぎディクショナリの中にディクショナリ
valueをディクショナリにする
keyと入れ子のディクショナリのkeyの組み合わせで要素を取り出すことができるdic_dic.pydic = {'フルーツ': {'好き':'りんご', '大好き':'もも'}, '野菜': {'好き':'トマト', '嫌い':'ピーマン'}} print(dic['フルーツ']['好き']) print(dic['野菜']['嫌い'])結果りんご ピーマン
- 投稿日:2020-06-26T10:58:30+09:00
ルービックキューブを解くロボットを作ろう!3 ソフトウェア編
この記事はなに?
この記事は連載しているルービックキューブを解くロボットを作ろう!という記事集の一部です。全貌はこちら
1. 概要編
2. アルゴリズム編
3. ソフトウェア編(本記事)
4. ハードウェア編(未公開)GitHubはこちら。
プロモーションビデオはこちらです。
この記事集に関する動画集はこちらです。
今回の記事の内容
今回の記事では、私が作った2x2x2ルービックキューブを解くロボットSoltvvoのソフトウェアの解説をします。
構成
ソフトウェアの解説の前に、どのような構成でロボットを動かすのかを書いておく必要がありますね。図のような感じです。
ここで、Raspberry PiはRaspberry Pi 4(2GBRAM)というシングルボードコンピュータ(つまり普通の(?)コンピュータ)、ATMEGA328Pは有名なマイコン(マイクロコントローラ)で、Arduinoというマイコンボードに使われているものです。今回はArduino Unoとして使います。ATMEGA328Pからはそれぞれ2つずつ、ステッピングモーターとサーボモーターが生えています。これは実際にキューブを回すアームを動かすアクチュエータ(動力)です。
また、Webカメラを使ってキューブの状態を入力します。全貌
プログラムの全体像をお見せします。
Raspberry Pi側のプログラム 概略
- キューブの状態を表すクラス
- CPとCOの状態を簡単に管理できる
- キューブを動作させる記述が簡単
- アクチュエータを動かす関数
- アームを動かすコマンドを送る
- GUI
- 画面表示
- カメラを使ってパズルの状態を取得
- 画像認識
- 解を探索する
- IDA*探索
- 前計算は事前に計算してcsvファイルにしてある
- 回転記号の羅列からロボットが動くための手順を作る
- 最適な解になるようにする
- 実際にロボットを動かす
ATMEGA328P側のプログラム 概略
- コマンドを受け取る
- モーターを動かす関数
- アームでキューブを掴む関数
- アームでキューブを離す関数
Raspberry Pi側のプログラム - Python
ここではPC側のプログラムの解説をします。
プログラムは580行程度あって長いので、いくつかの部位に分割して解説します。ライブラリのインポート
使うライブラリをインポートします。
from copy import deepcopy from collections import deque from time import time, sleep import tkinter import cv2 import numpy as np import serialCubeクラス
キューブをプログラム上で一つの「モノ」として捉えると良い、ということで、Cubeのクラスを作りました。恥ずかしながら人生初のクラス作成です。
class Cube: def __init__(self): self.Co = [0, 0, 0, 0, 0, 0, 0] self.Cp = [0, 1, 2, 3, 4, 5, 6] # 回転処理 CP def move_cp(self, num): surface = [[0, 1, 2, 3], [2, 3, 4, 5], [3, 1, 5, 6]] replace = [[2, 0, 3, 1], [3, 2, 1, 0], [1, 3, 0, 2]] idx = num // 3 res = [i for i in self.Cp] for i, j in zip(surface[idx], replace[num % 3]): res[i] = self.Cp[surface[idx][j]] return res # 回転処理 CO def move_co(self, num): surface = [[0, 1, 2, 3], [2, 3, 4, 5], [3, 1, 5, 6]] replace = [[2, 0, 3, 1], [3, 2, 1, 0], [1, 3, 0, 2]] pls = [2, 1, 1, 2] idx = num // 3 res = [i for i in self.Co] for i, j in zip(surface[idx], replace[num % 3]): res[i] = self.Co[surface[idx][j]] if num // 3 != 0 and num % 3 != 1: for i in range(4): res[surface[idx][i]] += pls[i] res[surface[idx][i]] %= 3 return res # 回転番号に則って実際にパズルの状態配列を変化させる def move(self, num): res = Cube() res.Co = self.move_co(num) res.Cp = self.move_cp(num) return res # cp配列から固有の番号を作成 def cp2i(self): res = 0 marked = set([]) for i in range(7): res += fac[6 - i] * len(set(range(self.Cp[i])) - marked) marked.add(self.Cp[i]) return res # co配列から固有の番号を作成 def co2i(self): res = 0 for i in self.Co: res *= 3 res += i return res一つずつ関数の説明をします。
__init__(self)
def __init__(self): self.Co = [0, 0, 0, 0, 0, 0, 0] self.Cp = [0, 1, 2, 3, 4, 5, 6]Cubeクラスを呼んだ時に最初に実行される関数です。ここではCubeクラスにCo、Cpという2つの配列を紐付けます。これらは順に、CO(Corner Orientationの略。コーナーパーツの向きを表す)、CP(Corner Permutationの略。コーナーパーツの位置を表す)です。
なお、キューブの状態の保持にCO配列とCP配列を独自に持っておくととても効率が良いです。また、回す面はRとUとFしかないので、DLB(左下奥)のパーツは動きません。このパーツの情報を保持する必要はなく、データ数はCOとCPそれぞれにつき7つずつで済みます。
CPは図のようにパーツに番号をつけ、CP配列の要素のインデックスの場所にあるパーツがCP配列の要素となるように値を保持します。
COは白色または黄色のステッカーがU面、またはD面にあらわれているときに0、そこから時計回りに120度ずつ回転するたびに1、2となっていくようにしました。例として写真にCO番号を振っておきます。
move_cp(self, num)
# 回転処理 CP def move_cp(self, num): surface = [[0, 1, 2, 3], [2, 3, 4, 5], [3, 1, 5, 6]] replace = [[2, 0, 3, 1], [3, 2, 1, 0], [1, 3, 0, 2]] idx = num // 3 res = [i for i in self.Cp] for i, j in zip(surface[idx], replace[num % 3]): res[i] = self.Cp[surface[idx][j]] return resこの関数は実際にキューブを回転させる関数(の一部)です。配列のCPのみを回転させます。COについてはいじりません。
なお、numというのは回転記号の番号(回転番号)を表し、グローバルに置いた以下の配列のインデックスに対応します。move_candidate = ["U", "U2", "U'", "F", "F2", "F'", "R", "R2", "R'"] #回転の候補surface配列はそれぞれU面、F面、R面を動かしたときに動くパーツを示し、replace配列はそれぞれX、X2、X'を動かしたときのパーツの動き方を示します。これらの配列を使ってうまく置換してやることで、回転処理を可能にしています。
move_co(self, num)
# 回転処理 CO def move_co(self, num): surface = [[0, 1, 2, 3], [2, 3, 4, 5], [3, 1, 5, 6]] replace = [[2, 0, 3, 1], [3, 2, 1, 0], [1, 3, 0, 2]] pls = [2, 1, 1, 2] idx = num // 3 res = [i for i in self.Co] for i, j in zip(surface[idx], replace[num % 3]): res[i] = self.Co[surface[idx][j]] if num // 3 != 0 and num % 3 != 1: for i in range(4): res[surface[idx][i]] += pls[i] res[surface[idx][i]] %= 3 return resこの関数も先程のmove_cp関数と同様に、パーツを実際に動かす関数です。この関数はCOを動かします。内容はmove_cp関数と酷似していますが、U面を回す場合でなく(num % 3 != 0)、180度回転でない(num % 3 != 1)場合はCOが変わるので、適宜処理する必要があります。
move(self, num)
# 回転番号に則って実際にパズルの状態配列を変化させる def move(self, num): res = Cube() res.Co = self.move_co(num) res.Cp = self.move_cp(num) return resこの関数も実際にパーツを動かす関数です。この関数ではCOとCP両方を動かします。先程の2つの関数をただただ動かしているだけです。
cp2i(self)
# cp配列から固有の番号を作成 def cp2i(self): res = 0 marked = set([]) for i in range(7): res += fac[6 - i] * len(set(range(self.Cp[i])) - marked) marked.add(self.Cp[i]) return resこの関数はCP配列からCP配列固有の番号を生成し、返します。内容としてはCP配列の順列の番号を返しているだけです。順列の番号とは、
0: 0, 1, 2, 3, 4, 5, 6
1: 0, 1, 2, 3, 4, 6, 5
2: 0, 1, 2, 3, 5, 4, 6
3: 0, 1, 2, 3, 5, 6, 4
4: 0, 1, 2, 3, 6, 5, 4
のような順番で並べたときの番号です。
この番号の計算の仕方はこちらのサイトがわかりやすいと思います。co2i(self)
# co配列から固有の番号を作成 def co2i(self): res = 0 for i in self.Co: res *= 3 res += i return resこの関数はCO配列からCO配列固有の番号を生成し、返します。このときCO配列を3進数7桁の数とみなして計算することで固有の番号を作っています。
その他のパズルに関する関数
num2movesという、回転番号を回転記号に翻訳する関数があります。
# 回転番号を回転記号に変換 def num2moves(arr): res = '' for i in arr: res += move_candidate[i] + ' ' return resmove_candidateは
move_candidate = ["U", "U2", "U'", "F", "F2", "F'", "R", "R2", "R'"] #回転の候補です。
アクチュエータを動かす関数
全容はこちらです。
def move_actuator(num, arg1, arg2, arg3=None): if arg3 == None: com = str(arg1) + ' ' + str(arg2) else: com = str(arg1) + ' ' + str(arg2) + ' ' + str(arg3) ser_motor[num].write((com + '\n').encode()) ser_motor[num].flush() print('num:', num, 'command:', com) def grab_p(): for i in range(2): for j in range(2): move_actuator(i, j, 5) def release_p(): for i in range(2): for j in range(2): move_actuator(i, j, 6)move_actuator(num, arg1, arg2, arg3=None)
# アクチュエータを動かすコマンドを送る def move_actuator(num, arg1, arg2, arg3=None): if arg3 == None: com = str(arg1) + ' ' + str(arg2) else: com = str(arg1) + ' ' + str(arg2) + ' ' + str(arg3) ser_motor[num].write((com + '\n').encode()) ser_motor[num].flush() print('num:', num, 'command:', com)この関数はATMEGA328Pにシリアル通信でコマンドを送り、モーターを動かす関数です。ここで、numはATMEGA328Pの番号(0か1)で、arg1にはアクチュエータの番号、arg2にはアクチュエータの動作させる量、arg3にはステッピングモーターを動かす場合、モーターのスピード(rpm)を入力します。
なお、シリアル通信関係については
ser_motor[0] = serial.Serial('/dev/ttyUSB0', 9600, write_timeout=0) ser_motor[1] = serial.Serial('/dev/ttyUSB1', 9600, write_timeout=0)という定義があります。それぞれのATMEGA328Pにステッピングモーターが2つ、サーボモーターが2つずつついています。
grab_p()
# キューブを掴む def grab_p(): for i in range(2): for j in range(2): move_actuator(i, j, 1000)この関数は先程のmove_actuator関数を使って全部のアームを一気に動かし、キューブを掴む関数です。
release_p()
# キューブを離す def release_p(): for i in range(2): for j in range(2): move_actuator(i, j, 2000)この関数は全部のアームを一気に動かし、キューブを離す関数です。
GUI
GUIに関する部分はこちらです。
root = tkinter.Tk() root.title("2x2x2solver") root.geometry("300x150") grid = 20 offset = 30 entry = [[None for _ in range(8)] for _ in range(6)] for i in range(6): for j in range(8): if 1 < i < 4 or 1 < j < 4: entry[i][j] = tkinter.Entry(master=root, width=2, bg='gray') entry[i][j].place(x = j * grid + offset, y = i * grid + offset) inspection = tkinter.Button(root, text="inspection", command=inspection_p) inspection.place(x=0, y=0) start = tkinter.Button(root, text="start", command=start_p) start.place(x=0, y=40) solutionvar = tkinter.StringVar(master=root, value='') solution = tkinter.Label(textvariable=solutionvar) solution.place(x=70, y=0) solvingtimevar = tkinter.StringVar(master=root, value='') solvingtime = tkinter.Label(textvariable=solvingtimevar) solvingtime.place(x=120, y=20) grab = tkinter.Button(root, text="grab", command=grab_p) grab.place(x=0, y=120) release = tkinter.Button(root, text="release", command=release_p) release.place(x=120, y=120) root.mainloop()GUIライブラリにはtkinterを使っています。それぞれの変数が何に当たるのかを図でご説明します。
ここには出ていませんが、キューブを解くのにかかった時間を画面上に表示するsolvingtimeというラベルがあります。
なぜ色を表示するのがエントリーボックスなのかといいますと、もともとこのプログラムはエントリーボックスに色を打ち込むことでキューブの状態を入力していたからです。そんな時代は終わって今ではカメラで認識しています。パズルの色を配列に格納
全容はこちらです。
dic = {'w':'white', 'g':'green', 'r':'red', 'b':'blue', 'o':'magenta', 'y':'yellow'} parts_place = [[[0, 2], [2, 0], [2, 7]], [[0, 3], [2, 6], [2, 5]], [[1, 2], [2, 2], [2, 1]], [[1, 3], [2, 4], [2, 3]], [[4, 2], [3, 1], [3, 2]], [[4, 3], [3, 3], [3, 4]], [[5, 3], [3, 5], [3, 6]], [[5, 2], [3, 7], [3, 0]]] parts_color = [['w', 'o', 'b'], ['w', 'b', 'r'], ['w', 'g', 'o'], ['w', 'r', 'g'], ['y', 'o', 'g'], ['y', 'g', 'r'], ['y', 'r', 'b'], ['y', 'b', 'o']] # ボックスに色を反映させる def confirm_p(): global colors for i in range(6): for j in range(8): if (1 < i < 4 or 1 < j < 4) and colors[i][j] in j2color: entry[i][j]['bg'] = dic[colors[i][j]] # 埋まっていないところで色が確定するところを埋める for i in range(6): for j in range(8): if (1 < i < 4 or 1 < j < 4) and colors[i][j] == '': done = False for k in range(8): if [i, j] in parts_place[k]: for strt in range(3): if parts_place[k][strt] == [i, j]: idx = [colors[parts_place[k][l % 3][0]][parts_place[k][l % 3][1]] for l in range(strt + 1, strt + 3)] for strt2 in range(3): idx1 = strt2 idx2 = (strt2 + 1) % 3 idx3 = (strt2 + 2) % 3 for l in range(8): if parts_color[l][idx1] == idx[0] and parts_color[l][idx2] == idx[1]: colors[i][j] = parts_color[l][idx3] entry[i][j]['bg'] = dic[colors[i][j]] done = True break if done: break break if done: break # 埋まっていないところの背景色をgrayに for i in range(6): for j in range(8): if (1 < i < 4 or 1 < j < 4) and colors[i][j] == '': entry[i][j]['bg'] = 'gray'この関数は少し複雑です。パズルの状態を一意に決定するためには、2x2x2の場合、パズルの(うまく選んだ)4面(例えばこのプログラムではD、F、U、B面)だけを見ることで事足ります。そこで、見ていない面の色を推測し決定するのがこの関数です。決定した色はさきほどのエントリーボックスの背景色として反映させます。
この関数では単に、埋まっていないところの色が何になるかを全探索で求めています。ですが実装が少し重くなってしまっています。これが最善の書き方だという自信はありません。
カメラからパズルの状態を取得
全容はこちらです。
j2color = ['g', 'b', 'r', 'o', 'y', 'w'] idx = 0 colors = [['' for _ in range(8)] for _ in range(6)] # パズルの状態の取得 def detect(): global idx, colors idx = 0 while idx < 4: #color: g, b, r, o, y, w color_low = [[50, 50, 50], [90, 150, 50], [160, 150, 50], [170, 50, 50], [20, 50, 50], [0, 0, 50]] #for PC color_hgh = [[90, 255, 255], [140, 255, 255], [10, 255, 200], [20, 255, 255], [50, 255, 255], [179, 50, 255]] circlecolor = [(0, 255, 0), (255, 0, 0), (0, 0, 255), (0, 170, 255), (0, 255, 255), (255, 255, 255)] surfacenum = [[[4, 2], [4, 3], [5, 2], [5, 3]], [[2, 2], [2, 3], [3, 2], [3, 3]], [[0, 2], [0, 3], [1, 2], [1, 3]], [[3, 7], [3, 6], [2, 7], [2, 6]]] capture = cv2.VideoCapture(0) ret, frame = capture.read() capture.release() size_x = 200 size_y = 150 frame = cv2.resize(frame, (size_x, size_y)) show_frame = deepcopy(frame) d = 50 center = [size_x // 2, size_y // 2] tmp_colors = [['' for _ in range(8)] for _ in range(6)] hsv = cv2.cvtColor(frame,cv2.COLOR_BGR2HSV) dx = [-1, 1, -1, 1] dy = [1, 1, -1, -1] for i in range(4): y = center[0] + dy[i] * d x = center[1] + dx[i] * d cv2.circle(show_frame, (y, x), 5, (0, 0, 0), thickness=3, lineType=cv2.LINE_8, shift=0) val = hsv[x, y] for j in range(6): flag = True for k in range(3): if not ((color_low[j][k] < color_hgh[j][k] and color_low[j][k] <= val[k] <= color_hgh[j][k]) or (color_low[j][k] > color_hgh[j][k] and (color_low[j][k] <= val[k] or val[k] <= color_hgh[j][k]))): flag = False if flag: tmp_colors[surfacenum[idx][i][0]][surfacenum[idx][i][1]] = j2color[j] cv2.circle(show_frame, (y, x), 15, circlecolor[j], thickness=3, lineType=cv2.LINE_8, shift=0) break cv2.imshow('title',show_frame) key = cv2.waitKey(0) if key == 32: #スペースキーが押されたとき for i in range(4): colors[surfacenum[idx][i][0]][surfacenum[idx][i][1]] = tmp_colors[surfacenum[idx][i][0]][surfacenum[idx][i][1]] print(idx) idx += 1 confirm_p() if idx < 4: for i in range(2): move_actuator(i, 0, 5) move_actuator(i, 0, (-1) ** i, 50) move_actuator(i, 1, 5) move_actuator((i + 1) % 2, 1, 5) move_actuator(i, 0, 6) move_actuator(i, 0, -(-1) ** i, 50) move_actuator(i, 0, 5) move_actuator(i, 1, 6) move_actuator((i + 1) % 2, 1, 6) cv2.destroyAllWindows()この関数ではカメラで撮影した画像の中のある4つのピクセルの色がそれぞれ何であるかによってパズルの色を取得します。画面はこんな感じです。
ロボット専用手順を作る
後述するinspection関数内でIDA*を使って出力されるのは人間が読むための回転記号(回転番号)の羅列です。これを、どのモーターを、いつ、何度動かすのか、という情報を持った配列に変換します。全容はこちらです。
# 回転記号番号の配列から回すモーターを決定する def proc_motor(rot, num, direction): if num == len(ans): return rot, num, direction turn_arr = [-3, -2, -1] r_arr = [[-1, 2, 4, -1, 5, 1], [5, -1, 0, 2, -1, 3], [1, 3, -1, 4, 0, -1], [-1, 5, 1, -1, 2, 4], [2, -1, 3, 5, -1, 0], [4, 0, -1, 1, 3, -1]] f_arr = [[1, 2, 4, 5], [3, 2, 0, 5], [3, 4, 0, 1], [4, 2, 1, 5], [3, 5, 0, 2], [3, 1, 0, 4]] regrip_arr = [[21, 5, 9, 17, 20, 13, 10, 3, 4, 12, 18, 0, 23, 19, 11, 7, 8, 15, 22, 1, 16, 14, 6, 2], [4, 8, 16, 20, 12, 9, 2, 23, 15, 17, 3, 7, 18, 10, 6, 22, 14, 21, 0, 11, 13, 5, 1, 19]] regrip_rot = [[[1, -3], [3, -1]], [[0, -3], [2, -1]]] u_face = direction // 4 f_face = f_arr[u_face][direction % 4] r_face = r_arr[u_face][f_face] d_face = (u_face + 3) % 6 b_face = (f_face + 3) % 6 l_face = (r_face + 3) % 6 move_able = [r_face, b_face, l_face, f_face] move_face = ans[num] // 3 move_amount = turn_arr[ans[num] % 3] if move_face == u_face or move_face == d_face: rot_tmp = [[i for i in rot] for _ in range(2)] direction_tmp = [-1, -1] num_tmp = [num, num] for j in range(2): rot_tmp[j].extend(regrip_rot[j]) direction_tmp[j] = regrip_arr[j][direction] rot_tmp[j], num_tmp[j], direction_tmp[j] = proc_motor(rot_tmp[j], num_tmp[j], direction_tmp[j]) idx = 0 if len(rot_tmp[0]) < len(rot_tmp[1]) else 1 rot_res = rot_tmp[idx] num_res = num_tmp[idx] direction_res = direction_tmp[idx] else: tmp = move_able.index(move_face) rot_res = [i for i in rot] rot_res.append([tmp, move_amount]) rot_res, num_res, direction_res = proc_motor(rot_res, num + 1, direction) return rot_res, num_res, direction_res # ロボットの手順の最適化 def rot_optimise(): global rot i = 0 tmp_arr = [0, -3, -2, -1] while i < len(rot): if i < len(rot) - 1 and rot[i][0] == rot[i + 1][0]: tmp = tmp_arr[(rot[i][1] + rot[i + 1][1]) % 4] del rot[i + 1] if not tmp: del rot[i] i -= 1 else: rot[i][1] = tmp elif i < len(rot) - 2 and rot[i][0] == rot[i + 2][0] and rot[i][0] % 2 == rot[i + 1][0] % 2: tmp = tmp_arr[rot[i][1] + rot[i + 2][1] + 2] del rot[i + 2] if tmp == 0: del rot[i] i -= 1 else: rot[i][1] = tmp i += 1なにかとても愚直なことをしているようですね。とんでもなく長い手打ちの配列がいくつもあります。では一つずつ関数を説明しましょう。
proc_motor(rot, num, direction)
# 回転記号番号の配列から回すモーターを決定する def proc_motor(rot, num, direction): if num == len(ans): return rot, num, direction turn_arr = [-3, -2, -1] r_arr = [[-1, 2, 4, -1, 5, 1], [5, -1, 0, 2, -1, 3], [1, 3, -1, 4, 0, -1], [-1, 5, 1, -1, 2, 4], [2, -1, 3, 5, -1, 0], [4, 0, -1, 1, 3, -1]] f_arr = [[1, 2, 4, 5], [3, 2, 0, 5], [3, 4, 0, 1], [4, 2, 1, 5], [3, 5, 0, 2], [3, 1, 0, 4]] regrip_arr = [[21, 5, 9, 17, 20, 13, 10, 3, 4, 12, 18, 0, 23, 19, 11, 7, 8, 15, 22, 1, 16, 14, 6, 2], [4, 8, 16, 20, 12, 9, 2, 23, 15, 17, 3, 7, 18, 10, 6, 22, 14, 21, 0, 11, 13, 5, 1, 19]] regrip_rot = [[[1, -3], [3, -1]], [[0, -3], [2, -1]]] u_face = direction // 4 f_face = f_arr[u_face][direction % 4] r_face = r_arr[u_face][f_face] d_face = (u_face + 3) % 6 b_face = (f_face + 3) % 6 l_face = (r_face + 3) % 6 move_able = [r_face, b_face, l_face, f_face] move_face = ans[num] // 3 move_amount = turn_arr[ans[num] % 3] if move_face == u_face or move_face == d_face: rot_tmp = [[i for i in rot] for _ in range(2)] direction_tmp = [-1, -1] num_tmp = [num, num] for j in range(2): rot_tmp[j].extend(regrip_rot[j]) direction_tmp[j] = regrip_arr[j][direction] rot_tmp[j], num_tmp[j], direction_tmp[j] = proc_motor(rot_tmp[j], num_tmp[j], direction_tmp[j]) idx = 0 if len(rot_tmp[0]) < len(rot_tmp[1]) else 1 rot_res = rot_tmp[idx] num_res = num_tmp[idx] direction_res = direction_tmp[idx] else: tmp = move_able.index(move_face) rot_res = [i for i in rot] rot_res.append([tmp, move_amount]) rot_res, num_res, direction_res = proc_motor(rot_res, num + 1, direction) return rot_res, num_res, direction_res詳しくはハードウェア編でお話ししますが、ロボットにはアームが4つついており、それぞれF、R、B、L面についています。つまり、持ち替えないとU面は回せません。ここで、持ち替えるとは例えばR面とL面を同時に回すようなことです。キューブを持つ向きは$4(通り/面)\times6(面)=24通り$ありますから、それぞれの向きに番号を振っておいて、それぞれの向きからどのように持ち替えたらどのような向きになるのかを配列regrip_arrに打ち込んでおきます(この作業が大変)。なお、持ち替えの方法はRLの同時回しまたはFBの同時回しで2通りあります(時計回り、反時計回りに関してはどちらに回しても結局同値です)。
現在のキューブの向きから、次に回す手順が持ち替えなしで回せるか否か、持ち替えが必要であれば、2通りの持ち替えのどちらがより効率的かを再帰を使った全探索で探ります。
rot配列には、以下のような感じで値が格納されます。
rot = [[回すモーターの番号, 回す向きと量], [0, -90], [1, -180], [2, -270]] #モーター0を90度反時計回りに回し、モーター2を180度回し、モーター2を270度反時計回り(=90度時計回り)に回すここで反時計回りしか使わないのにはハードウェアに依存する理由があります。詳しくはハードウェア編で。
rot_optimise()
# ロボットの手順の最適化 def rot_optimise(): global rot i = 0 tmp_arr = [0, -3, -2, -1] while i < len(rot): if i < len(rot) - 1 and rot[i][0] == rot[i + 1][0]: tmp = tmp_arr[(rot[i][1] + rot[i + 1][1]) % 4] del rot[i + 1] if not tmp: del rot[i] i -= 1 else: rot[i][1] = tmp elif i < len(rot) - 2 and rot[i][0] == rot[i + 2][0] and rot[i][0] % 2 == rot[i + 1][0] % 2: tmp = tmp_arr[rot[i][1] + rot[i + 2][1] + 2] del rot[i + 2] if tmp == 0: del rot[i] i -= 1 else: rot[i][1] = tmp i += 1生成されたロボット専用手順には、例えばrot配列が
rot = [[0, -90], [0, -90], [2, -90]]のようになっていて、以下のように簡略化できる場合があります。この場合の回転記号はF' F' R'です。これはF2 R'に簡略化できますね。
rot = [[0, -180], [2, -90]]この簡略化をこの関数内で行います。
インスペクション処理
さあ、いよいよメインの処理(パズルの解法を探索する処理)です。
# インスペクション処理 def inspection_p(): global ans, rot, colors ans = [] rot = [] colors = [['' for _ in range(8)] for _ in range(6)] grab_p() for i in range(2): move_actuator(i, 1, 2000) detect() strt = time() # 色の情報からパズルの状態配列を作る confirm_p() puzzle = Cube() set_parts_color = [set(i) for i in parts_color] for i in range(7): tmp = [] for j in range(3): tmp.append(colors[parts_place[i][j][0]][parts_place[i][j][1]]) tmp1 = 'w' if 'w' in tmp else 'y' puzzle.Co[i] = tmp.index(tmp1) if not set(tmp) in set_parts_color: solutionvar.set('cannot solve!') print('cannot solve!') return puzzle.Cp[i] = set_parts_color.index(set(tmp)) tmp2 = list(set(range(7)) - set(puzzle.Cp)) if len(tmp2): tmp2 = tmp2[0] for i in range(7): if puzzle.Cp[i] > tmp2: puzzle.Cp[i] -= 1 print('scramble:') for i in range(6): print(colors[i]) print(puzzle.Cp) print(puzzle.Co) # パズルの向きから、solved状態の配列を作る solved_color = [['' for _ in range(8)] for _ in range(6)] solved_color[5][2] = colors[5][2] solved_color[3][7] = colors[3][7] solved_color[3][0] = colors[3][0] solved_color[2][2] = j2color[(j2color.index(solved_color[3][7]) // 2) * 2 - j2color.index(solved_color[3][7]) % 2 + 1] solved_color[3][4] = j2color[(j2color.index(solved_color[3][0]) // 2) * 2 - j2color.index(solved_color[3][0]) % 2 + 1] solved_color[0][2] = j2color[(j2color.index(solved_color[5][2]) // 2) * 2 - j2color.index(solved_color[5][2]) % 2 + 1] for i in range(6): for j in range(8): if (1 < i < 4 or 1 < j < 4) and solved_color[i][j] == '': if i % 2 and j % 2: dx = [0, -1, -1] dy = [-1, -1, 0] elif i % 2 and (not j % 2): dx = [0, 1, 1] dy = [-1, -1, 0] elif (not i % 2) and j % 2: dx = [-1, -1, 0] dy = [0, 1, 1] elif (not i % 2) and (not j % 2): dx = [1, 1, 0] dy = [0, 1, 1] #print(i, j, dx, dy) for k in range(3): if solved_color[i + dy[k]][j + dx[k]] != '': solved_color[i][j] = solved_color[i + dy[k]][j + dx[k]] solved = Cube() for i in range(7): tmp = [] for j in range(3): tmp.append(solved_color[parts_place[i][j][0]][parts_place[i][j][1]]) tmp1 = 'w' if 'w' in tmp else 'y' solved.Co[i] = tmp.index(tmp1) solved.Cp[i] = set_parts_color.index(set(tmp)) tmp2 = list(set(range(7)) - set(solved.Cp)) if len(tmp2): tmp2 = tmp2[0] for i in range(7): if solved.Cp[i] > tmp2: solved.Cp[i] -= 1 print('solved:') for i in range(6): print(solved_color[i]) print(solved.Cp) print(solved.Co) # 枝刈り用のco配列とcp配列 direction = -1 direction_arr = [21, 12, 15, 18, 2, 22, 20, 4, 8, 13, 23, 1, 6, 0, 3, 9, 11, 16, 14, 7, 5, 19, 17, 10] for idx, d in enumerate(direction_arr): if solved_color[5][2] == parts_color[d // 3][d % 3] and solved_color[3][7] == parts_color[d // 3][(d % 3 + 1) % 3]: direction = idx if direction == -1: solutionvar.set('cannot solve!') print('cannot solve!') return with open('cp'+ str(direction) + '.csv', mode='r') as f: cp = [int(i) for i in f.readline().replace('\n', '').split(',')] with open('co'+ str(direction) + '.csv', mode='r') as f: co = [int(i) for i in f.readline().replace('\n', '').split(',')] print('pre', time() - strt, 's') # 深さ優先探索with枝刈り def dfs(status, depth, num): global ans if num + max(cp[status.cp2i()], co[status.co2i()]) <= depth: l_mov = ans[-1] if num else -1 t = (l_mov // 3) * 3 lst = set(range(9)) - set([t, t + 1, t + 2]) for mov in lst: n_status = status.move(mov) ans.append(mov) if num + 1 == depth and n_status.Cp == solved.Cp and n_status.Co == solved.Co: return True if dfs(n_status, depth, num + 1): return True ans.pop() return False # IDA* for depth in range(1, 12): ans = [] if dfs(puzzle, depth, 0): break if ans: print('answer:', num2moves(ans)) solutionvar.set(num2moves(ans)) rot, _, _ = proc_motor(rot, 0, 4) print('before:', len(rot)) print(rot) rot_optimise() print('after:', len(rot)) print(rot) print('all', time() - strt, 's') else: solutionvar.set('cannot solve!') print('cannot solve!')長いですね。なんで関数化しなかったんでしょう。塊ごとに解説します。
色の情報からパズルの状態配列を作る
# 色の情報からパズルの状態配列を作る confirm_p() puzzle = Cube() set_parts_color = [set(i) for i in parts_color] for i in range(7): tmp = [] for j in range(3): tmp.append(colors[parts_place[i][j][0]][parts_place[i][j][1]]) tmp1 = 'w' if 'w' in tmp else 'y' puzzle.Co[i] = tmp.index(tmp1) if not set(tmp) in set_parts_color: solutionvar.set('cannot solve!') print('cannot solve!') return puzzle.Cp[i] = set_parts_color.index(set(tmp)) tmp2 = list(set(range(7)) - set(puzzle.Cp)) if len(tmp2): tmp2 = tmp2[0] for i in range(7): if puzzle.Cp[i] > tmp2: puzzle.Cp[i] -= 1 print('scramble:') for i in range(6): print(colors[i]) print(puzzle.Cp) print(puzzle.Co)この部分では色の配列colorsから、CO配列(puzzle.Co)とCP配列(puzzle.Cp)を生成します。ただただ愚直に探索していますが実装が少し重めです。
parts_colorとparts_placeは以下の配列です。parts_place = [[[0, 2], [2, 0], [2, 7]], [[0, 3], [2, 6], [2, 5]], [[1, 2], [2, 2], [2, 1]], [[1, 3], [2, 4], [2, 3]], [[4, 2], [3, 1], [3, 2]], [[4, 3], [3, 3], [3, 4]], [[5, 3], [3, 5], [3, 6]], [[5, 2], [3, 7], [3, 0]]] parts_color = [['w', 'o', 'b'], ['w', 'b', 'r'], ['w', 'g', 'o'], ['w', 'r', 'g'], ['y', 'o', 'g'], ['y', 'g', 'r'], ['y', 'r', 'b'], ['y', 'b', 'o']]パズルの向きから、solved状態の配列を作る
# パズルの向きから、solved状態の配列を作る solved_color = [['' for _ in range(8)] for _ in range(6)] solved_color[5][2] = colors[5][2] solved_color[3][7] = colors[3][7] solved_color[3][0] = colors[3][0] solved_color[2][2] = j2color[(j2color.index(solved_color[3][7]) // 2) * 2 - j2color.index(solved_color[3][7]) % 2 + 1] solved_color[3][4] = j2color[(j2color.index(solved_color[3][0]) // 2) * 2 - j2color.index(solved_color[3][0]) % 2 + 1] solved_color[0][2] = j2color[(j2color.index(solved_color[5][2]) // 2) * 2 - j2color.index(solved_color[5][2]) % 2 + 1] for i in range(6): for j in range(8): if (1 < i < 4 or 1 < j < 4) and solved_color[i][j] == '': if i % 2 and j % 2: dx = [0, -1, -1] dy = [-1, -1, 0] elif i % 2 and (not j % 2): dx = [0, 1, 1] dy = [-1, -1, 0] elif (not i % 2) and j % 2: dx = [-1, -1, 0] dy = [0, 1, 1] elif (not i % 2) and (not j % 2): dx = [1, 1, 0] dy = [0, 1, 1] #print(i, j, dx, dy) for k in range(3): if solved_color[i + dy[k]][j + dx[k]] != '': solved_color[i][j] = solved_color[i + dy[k]][j + dx[k]] solved = Cube() for i in range(7): tmp = [] for j in range(3): tmp.append(solved_color[parts_place[i][j][0]][parts_place[i][j][1]]) tmp1 = 'w' if 'w' in tmp else 'y' solved.Co[i] = tmp.index(tmp1) solved.Cp[i] = set_parts_color.index(set(tmp)) tmp2 = list(set(range(7)) - set(solved.Cp)) if len(tmp2): tmp2 = tmp2[0] for i in range(7): if solved.Cp[i] > tmp2: solved.Cp[i] -= 1 print('solved:') for i in range(6): print(solved_color[i]) print(solved.Cp) print(solved.Co)パズルの向きは決まった向きではなくランダムで色が入力されるとします。その場合にもうまく対応できるよう、まず解けた状態でのパズルの色の状態が入るsolved_color配列を作ります。ここで、j2colorはこれです。
j2color = ['g', 'b', 'r', 'o', 'y', 'w']そして、実際にsolved(Cubeクラス)を作っていきます。パズルの向きがランダムなので、solved配列が一意に決定できないのです。
IDA*で探索する
# 枝刈り用のco配列とcp配列 direction = -1 direction_arr = [21, 12, 15, 18, 2, 22, 20, 4, 8, 13, 23, 1, 6, 0, 3, 9, 11, 16, 14, 7, 5, 19, 17, 10] for idx, d in enumerate(direction_arr): if solved_color[5][2] == parts_color[d // 3][d % 3] and solved_color[3][7] == parts_color[d // 3][(d % 3 + 1) % 3]: direction = idx if direction == -1: solutionvar.set('cannot solve!') print('cannot solve!') return with open('cp'+ str(direction) + '.csv', mode='r') as f: cp = [int(i) for i in f.readline().replace('\n', '').split(',')] with open('co'+ str(direction) + '.csv', mode='r') as f: co = [int(i) for i in f.readline().replace('\n', '').split(',')] print('pre', time() - strt, 's') # 深さ優先探索with枝刈り def dfs(status, depth, num): global ans if num + max(cp[status.cp2i()], co[status.co2i()]) <= depth: l_mov = ans[-1] if num else -1 t = (l_mov // 3) * 3 lst = set(range(9)) - set([t, t + 1, t + 2]) for mov in lst: n_status = status.move(mov) ans.append(mov) if num + 1 == depth and n_status.Cp == solved.Cp and n_status.Co == solved.Co: return True if dfs(n_status, depth, num + 1): return True ans.pop() return False # IDA* for depth in range(1, 12): ans = [] if dfs(puzzle, depth, 0): breakここでやっとアルゴリズム編で出てきた探索です。ですがアルゴリズム編のプログラムと大きく違います。アルゴリズム編ではみやすさ重視のため深さ優先探索を再帰を使わずstackを使って書いていましたが、ここでは再帰を使ってうまくメモリ使用量を極限まで減らしています。また、枝刈り用の配列はたったの24個ずつ(CPとCOで2セット)のバリエーションしかないので、以下のプログラムで前計算してcsvファイルにしてあります。
import csv from collections import deque class Cube: def __init__(self): self.Co = [0, 0, 0, 0, 0, 0, 0] self.Cp = [0, 1, 2, 3, 4, 5, 6] self.Moves = [] #self.Movnum = 0 # 回転処理 CP def move_cp(self, num): surface = [[0, 1, 2, 3], [2, 3, 4, 5], [3, 1, 5, 6]] replace = [[2, 0, 3, 1], [3, 2, 1, 0], [1, 3, 0, 2]] idx = num // 3 res = Cube() res.Cp = [i for i in self.Cp] for i, j in zip(surface[idx], replace[num % 3]): res.Cp[i] = self.Cp[surface[idx][j]] res.Moves = [i for i in self.Moves] res.Moves.append(num) return res # 回転処理 CO def move_co(self, num): surface = [[0, 1, 2, 3], [2, 3, 4, 5], [3, 1, 5, 6]] replace = [[2, 0, 3, 1], [3, 2, 1, 0], [1, 3, 0, 2]] pls = [2, 1, 1, 2] idx = num // 3 res = Cube() res.Co = [i for i in self.Co] for i, j in zip(surface[idx], replace[num % 3]): res.Co[i] = self.Co[surface[idx][j]] if num // 3 != 0 and num % 3 != 1: for i in range(4): res.Co[surface[idx][i]] += pls[i] res.Co[surface[idx][i]] %= 3 res.Moves = [i for i in self.Moves] res.Moves.append(num) return res # 回転番号に則って実際にパズルの状態配列を変化させる def move(self, num): res = Cube() res = self.move_co(num) res.Cp = self.move_cp(num).Cp return res # cp配列から固有の番号を作成 def cp2i(self): res = 0 marked = set([]) for i in range(7): res += fac[6 - i] * len(set(range(self.Cp[i])) - marked) marked.add(self.Cp[i]) return res # co配列から固有の番号を作成 def co2i(self): res = 0 for i in self.Co: res *= 3 res += i return res parts_place = [[[0, 2], [2, 0], [2, 7]], [[0, 3], [2, 6], [2, 5]], [[1, 2], [2, 2], [2, 1]], [[1, 3], [2, 4], [2, 3]], [[4, 2], [3, 1], [3, 2]], [[4, 3], [3, 3], [3, 4]], [[5, 3], [3, 5], [3, 6]], [[5, 2], [3, 7], [3, 0]]] parts_color = [['w', 'o', 'b'], ['w', 'b', 'r'], ['w', 'g', 'o'], ['w', 'r', 'g'], ['y', 'o', 'g'], ['y', 'g', 'r'], ['y', 'r', 'b'], ['y', 'b', 'o']] j2color = ['g', 'b', 'r', 'o', 'y', 'w'] direction_arr = [21, 12, 15, 18, 2, 22, 20, 4, 8, 13, 23, 1, 6, 0, 3, 9, 11, 16, 14, 7, 5, 19, 17, 10] fac = [1] for i in range(1, 8): fac.append(fac[-1] * i) for idx, d in enumerate(direction_arr): set_parts_color = [set(i) for i in parts_color] solved_color = [['' for _ in range(8)] for _ in range(6)] solved_color[5][2] = parts_color[d // 3][d % 3] solved_color[3][7] = parts_color[d // 3][(d % 3 + 1) % 3] solved_color[3][0] = parts_color[d // 3][(d % 3 + 2) % 3] solved_color[2][2] = j2color[(j2color.index(solved_color[3][7]) // 2) * 2 - j2color.index(solved_color[3][7]) % 2 + 1] solved_color[3][4] = j2color[(j2color.index(solved_color[3][0]) // 2) * 2 - j2color.index(solved_color[3][0]) % 2 + 1] solved_color[0][2] = j2color[(j2color.index(solved_color[5][2]) // 2) * 2 - j2color.index(solved_color[5][2]) % 2 + 1] for i in range(6): for j in range(8): if (1 < i < 4 or 1 < j < 4) and solved_color[i][j] == '': if i % 2 and j % 2: dx = [0, -1, -1] dy = [-1, -1, 0] elif i % 2 and (not j % 2): dx = [0, 1, 1] dy = [-1, -1, 0] elif (not i % 2) and j % 2: dx = [-1, -1, 0] dy = [0, 1, 1] elif (not i % 2) and (not j % 2): dx = [1, 1, 0] dy = [0, 1, 1] #print(i, j, dx, dy) for k in range(3): if solved_color[i + dy[k]][j + dx[k]] != '': solved_color[i][j] = solved_color[i + dy[k]][j + dx[k]] solved = Cube() for i in range(7): tmp = [] for j in range(3): tmp.append(solved_color[parts_place[i][j][0]][parts_place[i][j][1]]) tmp1 = 'w' if 'w' in tmp else 'y' solved.Co[i] = tmp.index(tmp1) solved.Cp[i] = set_parts_color.index(set(tmp)) tmp2 = list(set(range(7)) - set(solved.Cp)) if len(tmp2): tmp2 = tmp2[0] for i in range(7): if solved.Cp[i] > tmp2: solved.Cp[i] -= 1 print('solved:') for i in range(6): print(solved_color[i]) print(solved.Cp) print(solved.Co) print(idx) # 枝刈り用のco配列とcp配列 inf = 100 cp = [inf for _ in range(fac[7])] cp_solved = Cube() cp_solved.Cp = solved.Cp cp[cp_solved.cp2i()] = 0 que = deque([cp_solved]) while len(que): status = que.popleft() num = len(status.Moves) l_mov = status.Moves[-1] if num else -1 t = (l_mov // 3) * 3 lst = set(range(9)) - set([t, t + 1, t + 2]) for mov in lst: n_status = status.move_cp(mov) n_idx = n_status.cp2i() if cp[n_idx] == inf: cp[n_idx] = len(n_status.Moves) #n_status.Movnum que.append(n_status) co = [inf for _ in range(3 ** 7)] co_solved = Cube() co_solved.Co = solved.Co co[co_solved.co2i()] = 0 que = deque([co_solved]) while len(que): status = que.popleft() num = len(status.Moves) l_mov = status.Moves[-1] if num else -1 t = (l_mov // 3) * 3 lst = set(range(9)) - set([t, t + 1, t + 2]) for mov in lst: n_status = status.move_co(mov) n_idx = n_status.co2i() if co[n_idx] == inf: co[n_idx] = len(n_status.Moves) #n_status.Movnum que.append(n_status) with open('cp' + str(idx) + '.csv', mode='x') as f: writer = csv.writer(f, lineterminator='\n') writer.writerow(cp) with open('co' + str(idx) + '.csv', mode='x') as f: writer = csv.writer(f, lineterminator='\n') writer.writerow(co)ちょっとクラスが前に説明したものと違うため、載せるプログラムが長くなってしまいましたが大したことはしていません。愚直に24通りの持ち方についてCOとCPのどちらかを揃えるのに必要な最短手数をまとめてcsvにしています。
ロボットを動かすための配列を生成する
if ans: print('answer:', num2moves(ans)) solutionvar.set(num2moves(ans)) rot, _, _ = proc_motor(rot, 0, 4) print('before:', len(rot)) print(rot) rot_optimise() print('after:', len(rot)) print(rot) print('all', time() - strt, 's') else: solutionvar.set('cannot solve!') print('cannot solve!')ここでは、人間が読む回転記号としての答えをロボットを動かすための配列に変換します。また、回転記号を画面に表示します。キューブが揃えられない状態のときはcannot colve!と表示します。
実際にロボットを動かす
ここでは実際にATMEGA328Pと通信してロボットを動かします。
# 実際にロボットを動かす def start_p(): print('start!') strt_solv = time() i = 0 while i < len(rot): if GPIO.input(4) == GPIO.LOW: solvingtimevar.set('emergency stop') print('emergency stop') return grab = rot[i][0] % 2 for j in range(2): move_actuator(j, grab, 1000) sleep(0.4) for j in range(2): move_actuator(j, (grab + 1) % 2, 2000) sleep(0.1) ser_num = rot[i][0] // 2 rpm = 100 offset = -5 move_actuator(ser_num, rot[i][0] % 2, rot[i][1] * 90 + offset, rpm) max_turn = abs(rot[i][1]) flag = i < len(rot) - 1 and rot[i + 1][0] % 2 == rot[i][0] % 2 if flag: move_actuator(rot[i + 1][0] // 2, rot[i + 1][0] % 2, rot[i + 1][1] * 90 + offset, rpm) max_turn = max(max_turn, abs(rot[i + 1][1])) slptim = 60 / rpm * (max_turn * 90 + offset) / 360 * 1.1 sleep(slptim) move_actuator(ser_num, rot[i][0] % 2, -offset, rpm) if flag: move_actuator(rot[i + 1][0] // 2, rot[i + 1][0] % 2, -offset, rpm) i += 1 i += 1 slptim2 = abs(60 / rpm * offset / 360) * 1.1 sleep(slptim2) print('done', i, 'sleep:', slptim, slptim2) solv_time = time() - strt_solv solvingtimevar.set(str(round(solv_time, 3)) + 's') print('solving time:', solv_time, 's')モーター0と2、または1と3はそれぞれU・B、R・Lのモーターに当たるので、同時に回すことができます。そのような場合は同時回しをすることで高速化を図っています。
また、モーターを回したら回している時間(の1.1倍)だけ待機するようにしています。
ATMEGA328P - C++
Pythonの内容はかなり重かったですね。その分ATMEGA328Pのプログラムは簡素なので、分割せずいっぺんにお見せします。
#include <Servo.h> const long turn_steps = 400; const int step_dir[2] = {3, 7}; const int step_pul[2] = {4, 8}; char buf[30]; int idx = 0; long data[3]; Servo servo0; Servo servo1; void move_motor(long num, long deg, long spd) { bool hl = true; if (deg < 0) hl = false; digitalWrite(step_dir[num], hl); long wait_time = 1000000 * 60 / turn_steps / spd; long steps = abs(deg) * turn_steps / 360; bool motor_hl = false; for (int i = 0; i < steps; i++) { motor_hl = !motor_hl; digitalWrite(step_pul[num], motor_hl); delayMicroseconds(wait_time); } } void release_arm(int num) { if (num == 0)servo0.write(120); else servo1.write(120); } void grab_arm(int num) { if (num == 0)servo0.write(60); else servo1.write(60); } void setup() { Serial.begin(9600); for (int i = 0; i < 2; i++) { pinMode(step_dir[i], OUTPUT); pinMode(step_pul[i], OUTPUT); } servo0.attach(5); servo1.attach(6); } void loop() { if (Serial.available()) { buf[idx] = Serial.read(); if (buf[idx] == '\n') { buf[idx] = '\0'; data[0] = atoi(strtok(buf, " ")); data[1] = atoi(strtok(NULL, " ")); data[2] = atoi(strtok(NULL, " ")); if (data[1] == 1000) grab_arm(data[0]); else if (data[1] == 2000) release_arm(data[0]); else move_motor(data[0], data[1], data[2]); idx = 0; } else { idx++; } } }各関数を紹介します。
turning_time(int deg, int speed_motor)
float turning_time(int deg, int speed_motor) { return abs(1000 * quarter * deg / turn_steps * 60 / speed_motor); }この関数はモーターの動く角度とスピードを入力することで、モーターを動かすのにかかる時間(ミリ秒)を返します。
move_motor(int num, int deg, int spd)
void move_motor(long num, long deg, long spd) { bool hl = true; if (deg < 0) hl = false; digitalWrite(step_dir[num], hl); long wait_time = 1000000 * 60 / turn_steps / spd; long steps = abs(deg) * turn_steps / 360; bool motor_hl = false; for (int i = 0; i < steps; i++) { motor_hl = !motor_hl; digitalWrite(step_pul[num], motor_hl); delayMicroseconds(wait_time); } }ステッピングモーターを動かす関数です。モータードライバにはA4988という(amazonで5つ1000円くらいの)ものを使いましたので、それに合わせた書き方になっています。
step_dir[num]をHIGHにすると正転、LOWで逆転です。そしてstep_pul[num]にパルスを送るたびに1ステップずつ動きます。詳しいA4988の使い方はこちらなどをご覧ください。
release_arm(int num)
void release_arm(int num) { if (num == 0)servo0.write(120); else servo1.write(120); }アームでキューブを離す関数です。サーボの角度を120度にします。
grab_arm(int num)
void grab_arm(int num) { if (num == 0)servo0.write(60); else servo1.write(60); }アームでキューブを掴む関数です。サーボの角度を60度にします。
loop()
void loop() { if (Serial.available()) { buf[idx] = Serial.read(); if (buf[idx] == '\n') { buf[idx] = '\0'; data[0] = atoi(strtok(buf, " ")); data[1] = atoi(strtok(NULL, " ")); data[2] = atoi(strtok(NULL, " ")); if (data[1] == 1000) grab_arm(data[0]); else if (data[1] == 2000) release_arm(data[0]); else move_motor(data[0], data[1], data[2]); idx = 0; } else { idx++; } } }送られてきたスペース区切りのコマンドを分割し、それをクエリとしてmove_motorまたはgrab_arm、release_armを実行します。
まとめ
ここまで読んでくださり本当にありがとうございます!全部で800行程度のそれなりの規模のプログラムで、紹介するのにも、そして読むのにも一苦労でしょう…今回は関数の機能の紹介に留め、細かい内容には触れませんでした。また、ハードウェア編をまだお読みになっていなければアーム周りの仕組みがいまいちわからないかもしれません。なにかわからないことがありましたらコメントをください。





- 投稿日:2020-06-26T10:21:43+09:00
Windows10でRTX2060を使えるようになるまで(NVIDIA DRIVER, NVIDIA CUDA ツールキット, PyTorchのインストール)
初めに
機械学習をするときに、GPUを使いたいですが、GPUを使うためには専用のソフトを入れる必要があります。具体的には以下の2つでした。
- NVIDIA DRIVER
- NVIDIA CUDA ツールキット
- PyTorch
それぞれのインストールの仕方の備忘録です。
NVIDIA DRIVER
- こちらのサイトからダウンロードします。 容量は600MBほどなのでちょっと時間がかかります。
僕の環境の場合は、これらを選択しました。
インストールオプションでは、カスタムを選択しました。
NVIDIA GeForce Experienceは既にインストールされていたのでチェックを外しました。
クリーンインストールをしました。
NVIDIA CUDA ツールキット
- こちらからCUDA Toolkitxx(xxはバージョン)をダウンロードします。
- PyTorchを使う予定の方は現時点だと10.2を使ってください。
- local版をダウンロードしました。2.5GB強あり、ダウンロードに時間がかかります。
- こちらも、カスタムでインストール。
- Visual Studioをインストールしていない場合は、確認が出ます。Visual Studioをインストールする予定がある場合は、個々の段階でインストールしたほうが良いみたいです。
PyTorch
こちらから自分の環境を選びます。
一番下に、コマンドが出るのでコピーしてコマンド プロンプトで実行しましょう。windows消して、ubuntu入れようかな...