- 投稿日:2020-06-26T21:01:00+09:00
【元不合格者の合格体験記】新版のAWS認定ソリューションアーキテクト-アソシエイト-(SAA-C02)試験勉強まとめ
0.はじめに
こんにちは。都内でエンジニアをしている、@gkzvoiceです。
新版のAWS認定ソリューションアーキテクト-アソシエイト-(SAA-C02)に合格しました(英語受験)。
そこで、今回はその合格体験記を書いていきます。I've passed AWS Certified Solutions Architect – Associate(SAA-C02):)
— gakuji tamaki@July Tech Festa 2020運営スタッフ (@gkzvoice) June 24, 2020
AWS 認定ソリューションアーキテクト アソシエイト(英語)合格しましたっ! https://t.co/3L19ue7G6F実は、私、元不合格者です
一度負けて敗者復活戦から這い上がった者にしか書けない合格体験記を世に放ちます(書かないという退路を自ら絶っていくスタイル)
— gakuji tamaki@July Tech Festa 2020運営スタッフ (@gkzvoice) June 24, 2020実は、私、昨年秋に
旧版のSAA-C01を英語で受験して落ちています。
本記事では、合格体験記でよく書かれている勉強したことだけではなく、落ちたからこそ、分かる合格の決め手も書いていきます。
みなさんには、本記事を読んでいただき、ぜひ一発で合格してほしいと思います!!!1.どんな奴が受けたの?
開発エンジニア@オンプレミス
AWS実務経験無し
- プライベートでLambdaでBotは作った。
- EC2上でコンテナ立てた。
勉強期間は4ヶ月
- 勉強ペースはゆるめ。(コロナということで受験するタイミングを伺っていたので。)
- 受験日は2週間ほど前に決め、そこからガッツリ。
2.やったこと
2-0. 大まかな流れ
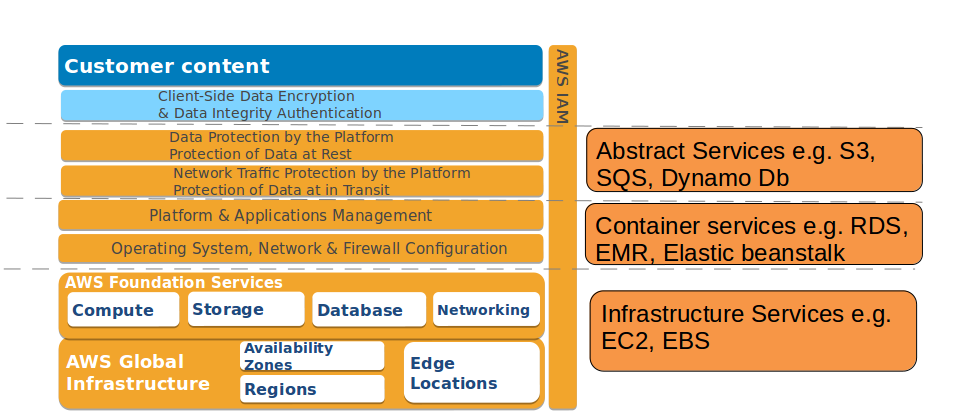
出題傾向を把握 ↓ 最も重要な概念といってもいい「責任共有モデル」を確認 ※EC2とLambda、Elastic BeanstalkとFargateなどサービス間の違いを抑えるときは必ずこの図に立ち返るほどよく見ていた ↓ 基礎固めとしてudemyの講座と書籍を通読 ↓ 模擬試験の演習と復習 ↓ 買った模擬試験のうち、いずれかを半分ほど消化したらBlack Beltを通読 ↓ 模擬試験の演習と復習を再開 ※braincertは2〜3回解いた ※udemyは問題が週1〜隔週ペースで更新されていくので、braincertより多く3〜4回解いた ※模擬試験の復習にて疑問点は社内英会話レッスン時に講師に質問して解消していた ※読み物として、classmethod社のre:invent2019のレポートを読んでいたが、 サービスの概要を理解しやすいレポートばかりでよかった https://dev.classmethod.jp/series/aws-reinvent-2019/2-1.最も重要な概念といってもいい「責任共有モデル」を確認
こちらの図は
サービスが責任共有モデルではどこに位置づけられるか紹介されていてめちゃくちゃオススメです。
参考:Shared Responsibility Model for AWS cloud Security2-2.出題傾向の把握に使った参考資料
- AWSが公開する試験ガイド
udemyでAWS試験対策講座の講師を務める方の記事Q.新旧(SAA-C02とSAA-C01)の違いは?
- 下記のとおり出題される問題のカテゴリー別の問題数に違いがみられますが、「こういう問題多いな」なんて思わなかった汗。
- 新旧両方の試験を解いた私からすれば、新版のほうがAWSの新しいサービスや機能を多く扱っているくらいしか分からず。。。
- それに比べて、上述した↑
udemyでAWS試験対策講座の講師を務める方の記事はより具体的に試験の出題傾向について言及されていて、どのサービスのBlack Beltを読めばいいか助かった。
参考:THE NEW 2020 AWS CERTIFIED SOLUTIONS ARCHITECT ASSOCIATE EXAM (SAA-C02)2-3. 基礎固めとして使ったudemyの講座と書籍
- udemyの講座
- 書籍
- 後述する模擬試験の演習やblackbeltの資料の通読の際に不明点や、概要をおさらいする際には↑udemyの講座や書籍に立ち戻った。
2-4. 模擬試験の演習
- 使った模擬試験はudemyとbraincert
- 【udemy】 AWS Certified Solutions Architect Associate Practice Exams
- 【braincert】 AWS Solutions Architect – Associate (SAA-C01) Practice Exams
- braincertはSAA-C01対応のようだが、模擬試験と本試験を解いた感じでは、十分対策として使えたと思う。
Q. udemyとbraincertのうち、どちらから解いたか?
- どちらから先に始めてもよいと思うが私は
braincertから解いた。
- 理由は、それぞれ1セットずつ解いた結果、braincertのほうが簡単に感じたので。
- また、文章量に慣れたかったので、文章が短いbraincertから先に解いた。
Q. 1回目と2回目以降でそれぞれ解いていくうえで意識したことは?
- 初回
- 時間オーバーになるかもしれないが、解き切ることを目標とした。
- 2回目以降
- 試験時間140分のうち2/3(90分)程度を目指して解いた。
選択肢を選ぶ際はひとつずつ、正解の根拠と不正解の根拠を考えた。
- 初回と2回目以降共通
- 模擬試験の解説は問題を解き終わってから読むようにした。
2-5. 模擬試験の復習方法
模擬試験の解説を読み込むだけではなく、以下の点を考えながらメモアプリに書きなぐっていた。
- 問題文から優先度が高い点は何か理解して解答していたか?
(安さ、冗長化、耐障害性?AZレベル、リージョン間?)- サービス間の類似点や相違点、どちらが安いか、それぞれどういうユースケースで使うか?
- 責任共有モデルでいうとサービスはどこまでカバーしているか?
- サービスはAZ/リージョン/グローバルのうちどこまでカバーしているか?
並行して、
英英辞典で技術用語の意味や例文、類義語を調べて書いた。買った模擬試験教材のうち片方を半分ほど消化したら、Black Beltを読んでいたような気がする。
Q. オススメのメモアプリは?
scrapboxがオススメ。
- 理由はデバイス問わず読み書きでき、ちょっとしたスキマ時間も勉強に充てることができるので。
- また、ページに画像を貼ったり、文字の色を変えたりや太字にすることも簡単。
- 私が書いていたメモのスクリーンショットです↓
2-6. Black Beltを通読
- Black Beltは相当量かつちょくちょく更新あり(T_T)
- クラスメソッドさんの記事にて
SAA対策に必要な資料として紹介されているものから手を付けた`- 初回
初めて読んだときには不明点が出ても立ち止まらず、一気に読んだ。- 「模試を解いていくなかで見たことがある単語だと思えるくらいでよい」と考えて。
- 2回目以降
- 模擬試験中に出会った気になったサービスを都度辞書のように使ってサービスの勘所をメモアプリ(私の場合はscrapbox)に書きなぐった。
3.元不合格者が考える合格の決め手
第1位:以下の記事で紹介されているSAA-C02試験の出題傾向について熟読
- What’s new for AWS Certified Solutions Architect Associate SAA-C02?
- ソリューションアーキテクト-アソシエイトはリニューアルされてからまだ2ヶ月しか経っていないので、試験の傾向に関する情報が少なく貴重。
- 出題されるサービスやその問われ方も紹介されているので、一目散に読むべき。
第2位:調べても分からない不明点を聞ける人の存在
- 私の場合は社内英会話も務めている英語ネイティブのエンジニアに聞いていたが、彼がいなかったら、間違いなく合格できなかった。
- 試験当日は不明点がない状態で臨みたいので、頼れる人は失礼のないように頼りましょう。
第3位:腑に落ちない箇所は図にしてみる
- 理解度がグッと深まる。
- 図を作った後は見返すだけで復習できるようになり、復習がラク。
- 第4位:自分のレベルに合った問題から解いた
- 上述したが、私の場合、braincertの問題の難易度がちょうどよく、問題を解いていくうちにサービスの理解度が上がっていると感じた。
- 第5位:模擬試験の反復演習と復習
- 実務未経験者にとって試験に合格するためには、試験での聞かれ方を抑えることによってひとつひとつのサービスの勘所を知っていくしかないと思う。
4. 私が文字に起こしたものまとめ
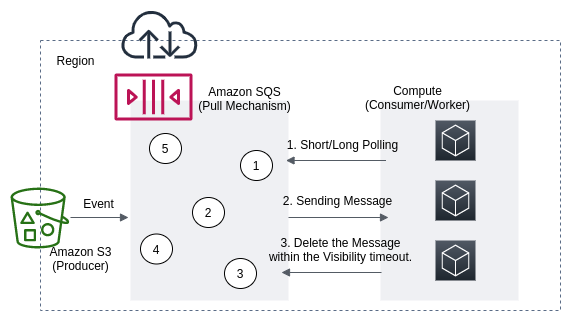
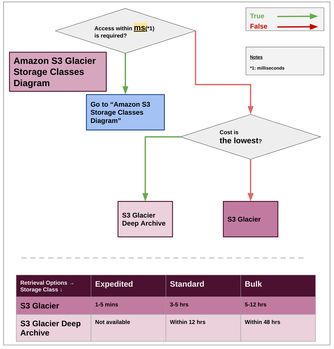
SQSの
long/short pollingとvisibility timeoutの違い
- ブログ未執筆のため、リンクは無いです。。
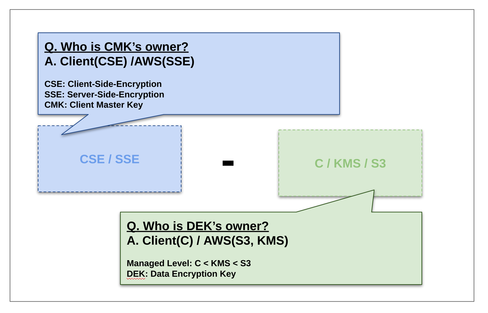
暗号化周りの違い
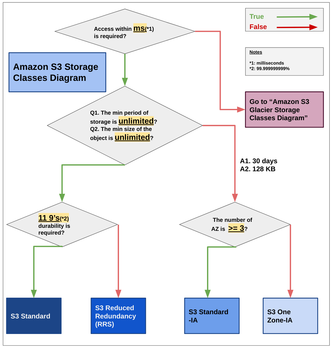
- S3/Glacierのストレージクラスの違い
5. AWS認定ソリューションアーキテクト-アソシエイト-(SAA-C02)を受験して思うこと
- 資格試験を受ける意義のひとつに、
「学習の指針となる」というものがありますが、これはそのとおり
- とりわけ、実務ではAWSを触っていない私にとって、本試験の受験はAWSサービスを体系的に知る絶好の機会だった。
- なので、
「インフラ系の知識を身に付けたいけど何やればいいか分からない」という方は受験を検討してもいいかも。- ただし、試験は丸暗記ではとてもじゃないが難しいので、しっかり試験勉強の時間を取って試験に臨む必要はあると思う。
- 「FAIL」の烙印を押されてから現実を直視できず、模擬試験のスコアも伸び悩み、再受験を諦めようと何度も思った
- それでも私がリベンジマッチを果たすことが出来たのは、社内英会話講師の丁寧なレクチャーあってこそだと確信している。ありがとうございました!!
補足1. 私が読んだBlack Belt一覧
参考までに私が読んだBlack Beltを貼っておきます。
P.S. Twitterもやってるのでフォローしていただけると泣いて喜びます:)
- Mediumでは技術に限らず、雑多に書き起こしています。
- 「4. 私が文字に起こしたものまとめ」で使った資料はこちらのブログに置いてあります。



- 投稿日:2020-06-26T17:33:41+09:00
AWSでデプロイしちゃおうってわけ(AWS登録補足編)
どうもこんにちは。
今日は暑いですね。
そろそろ転職の準備をしなければいけない段階に入りました。個人アプリ実装って難しいですね。
何作りたいとか無いですが、自分のスキルを示すには必要なもの。
でもありきたりなもの作っても意味ないし、複雑すぎても間に合わないし。
うーん悩みどころですね。話がそれました。
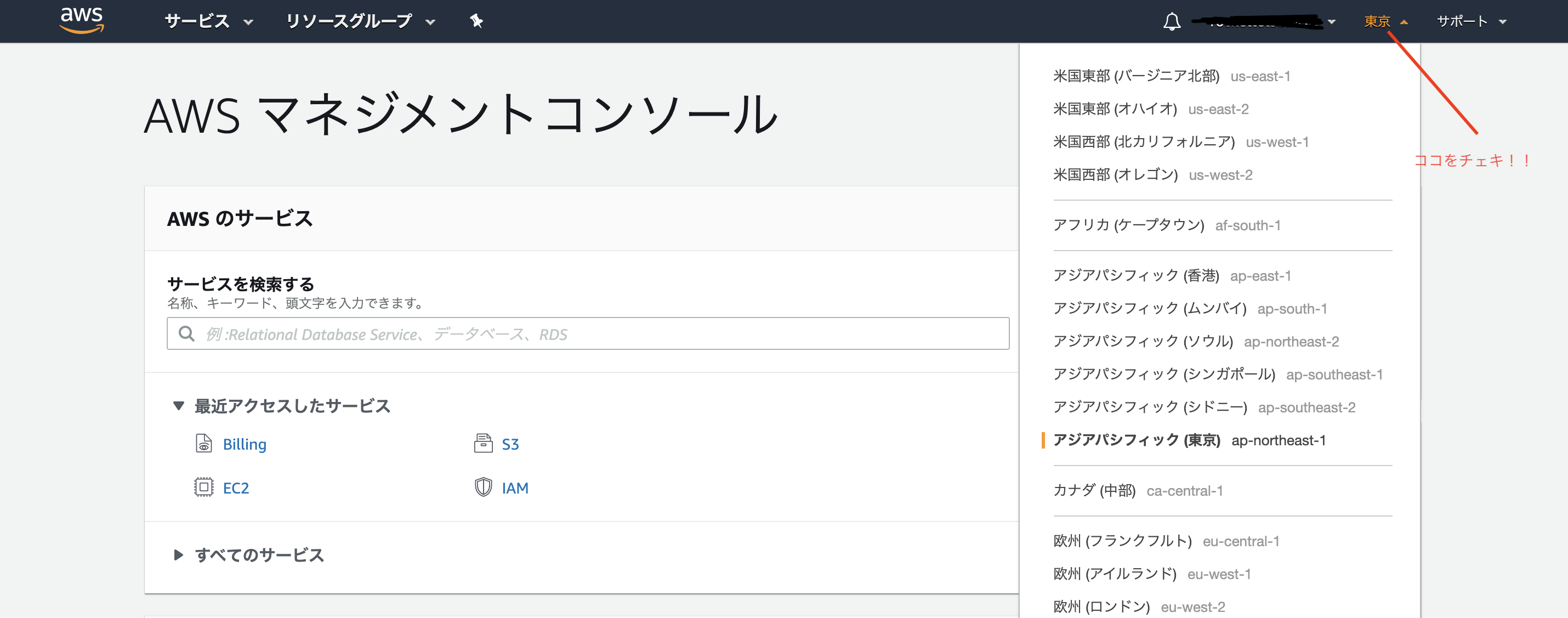
今回はAWSの登録が済んだということでリージョンの編集です。
1そもそもリージョンってなんぞや
そうですよね。
カタカナって難しいですよね。リージョンとは== データセンターが存在する独立した地域
わかりませんねぇ。
うーん。カリキュラムによると
AWSの物理的なサーバの場所を指定するものです
こっちのがなんとなくピンとくるな!!
リージョンは世界各地に10箇所以上あるらしく、そのうちの一つが東京にあるとのこと。
なのでこのリージョンを東京に設定すれば良いのです。
※おそらく最初はシンガポールとかになっているはず。
ここでちゃんと東京に設定しておかないとこの後のEC2に影響が出るので意外と大事なとこなのよっ!!
- 投稿日:2020-06-26T17:15:16+09:00
Bitrise の接続先を、AWS CodeCommit から GitHub に変更する
0.はじめに
iOS や Android アプリについて、
ビルドやデプロイに Bitrise を、
コードのバージョン管理に AWS CodeCommit を、
利用させて頂いてたんですが…、
この度、バージョン管理を GitHub へ移行することとなりまして…、
せっかくなので、手順をシェアしておこうかなと。
1. Bitrise から GitHub へ接続用の SSH 公開鍵と秘密鍵を作成する。
- 以下のコマンドを実行します。
ssh-keygen -m PEM -t rsa -b 4096 -P '' -f ./bitrise-ssh- 作成された公開鍵と秘密鍵を確認します。
- 秘密鍵 :
./bitrise-ssh- 公開鍵 :
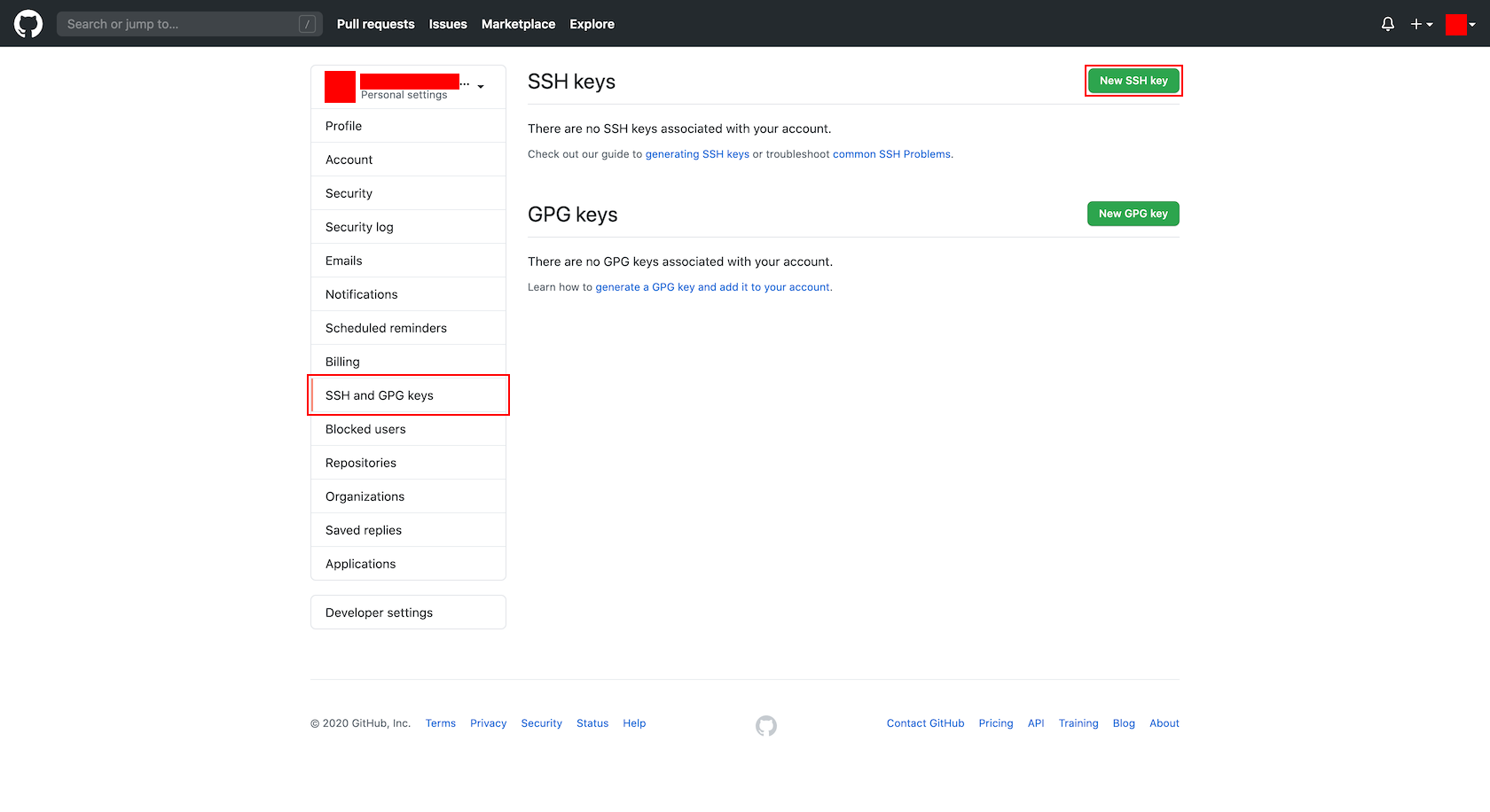
./bitrise-ssh.pub2. 作成した SSH 公開鍵を GitHub へ登録する。
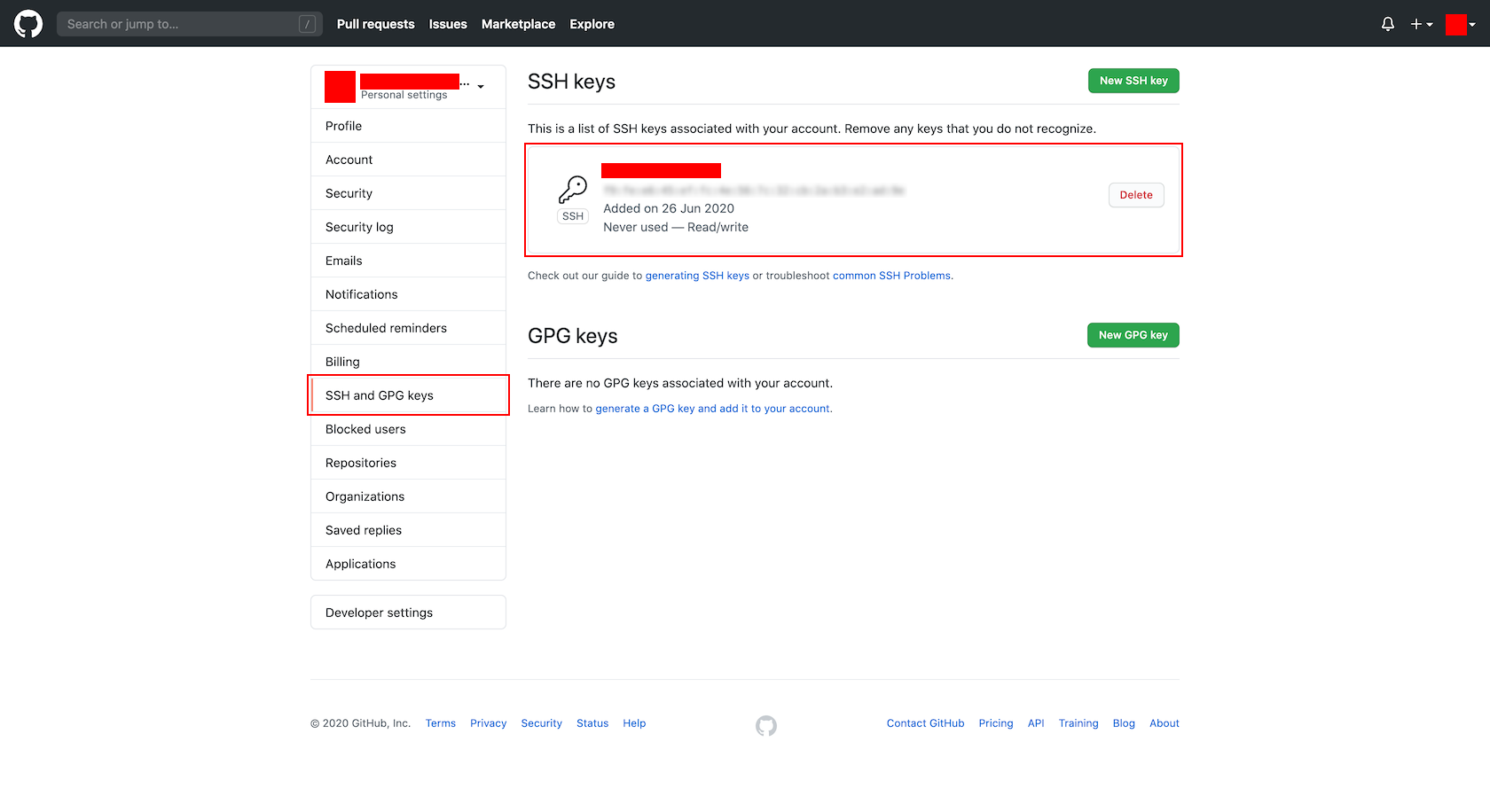
- Bitrise に接続する GitHub アカウントの「SSH and GPG keys」画面を開きます。
- 「SSH keys」欄の「New SSH key」ボタンを押下します。
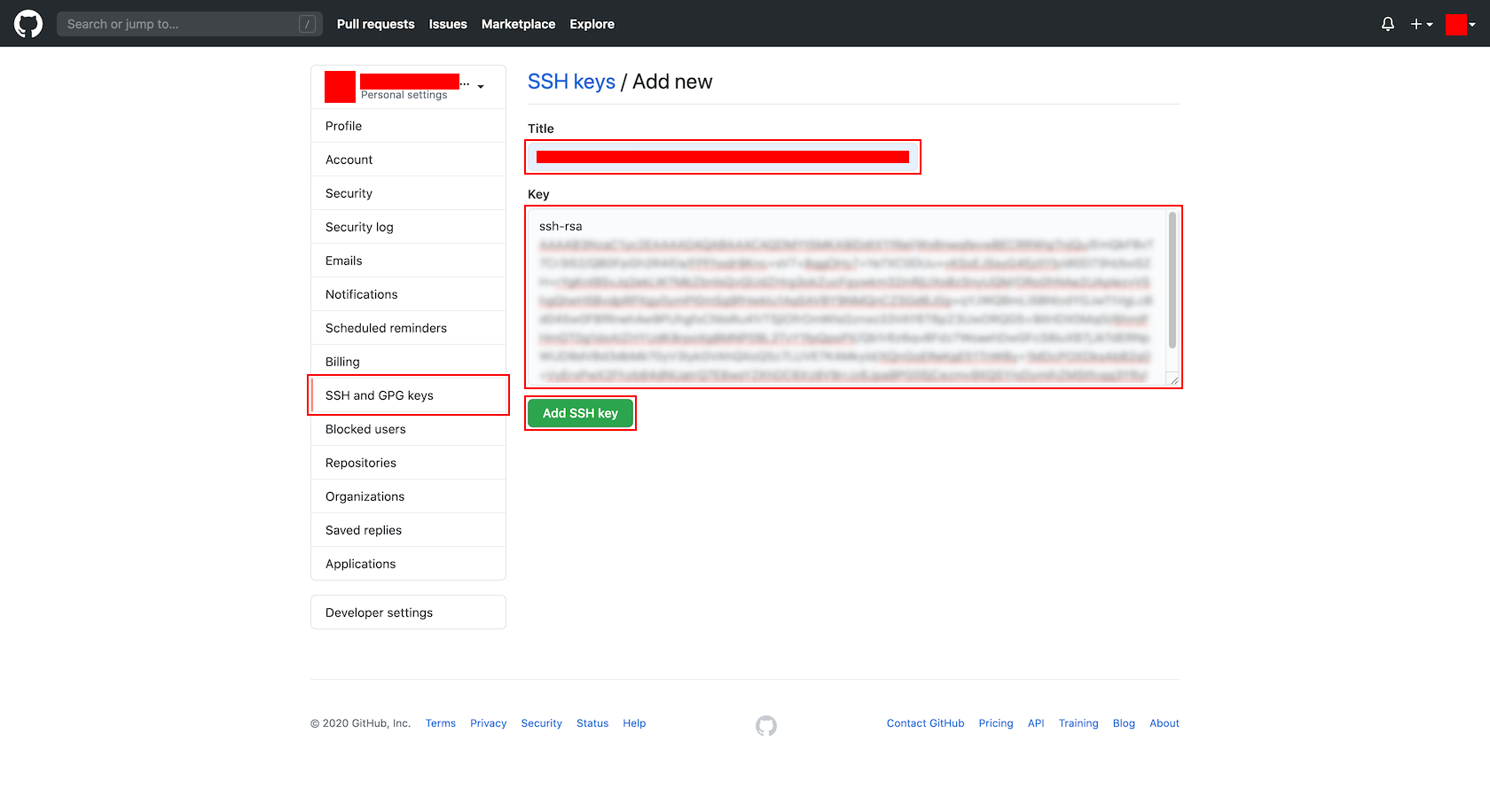
- 「SSH keys / Add new」画面で、以下の項目を設定し、「Add SSH key」ボタンを押下します。
- Title : ※任意
- Key : ※作成しておいた公開鍵の内容
- 登録された内容を確認します。
3. 作成した SSH 秘密鍵を Bitrise へ登録する。
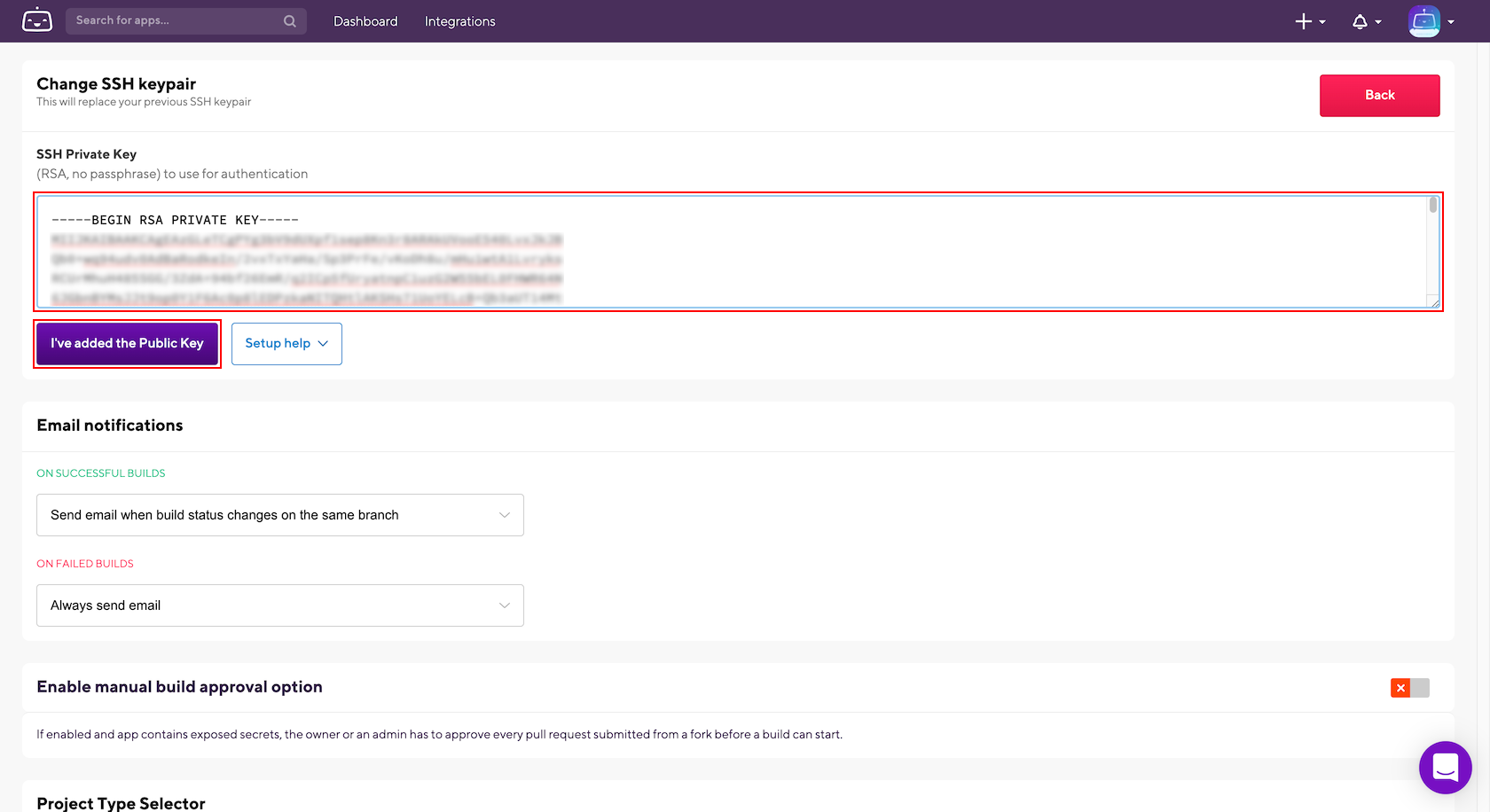
- Bitrise の対象となる APP の設定画面を開きます。
- 設定画面の 「Change SSH keypair」欄で、以下の項目を設定し、「I've added the Public Key」ボタンを押下します。
- SSH Private Key : ※作成しておいた秘密鍵の内容
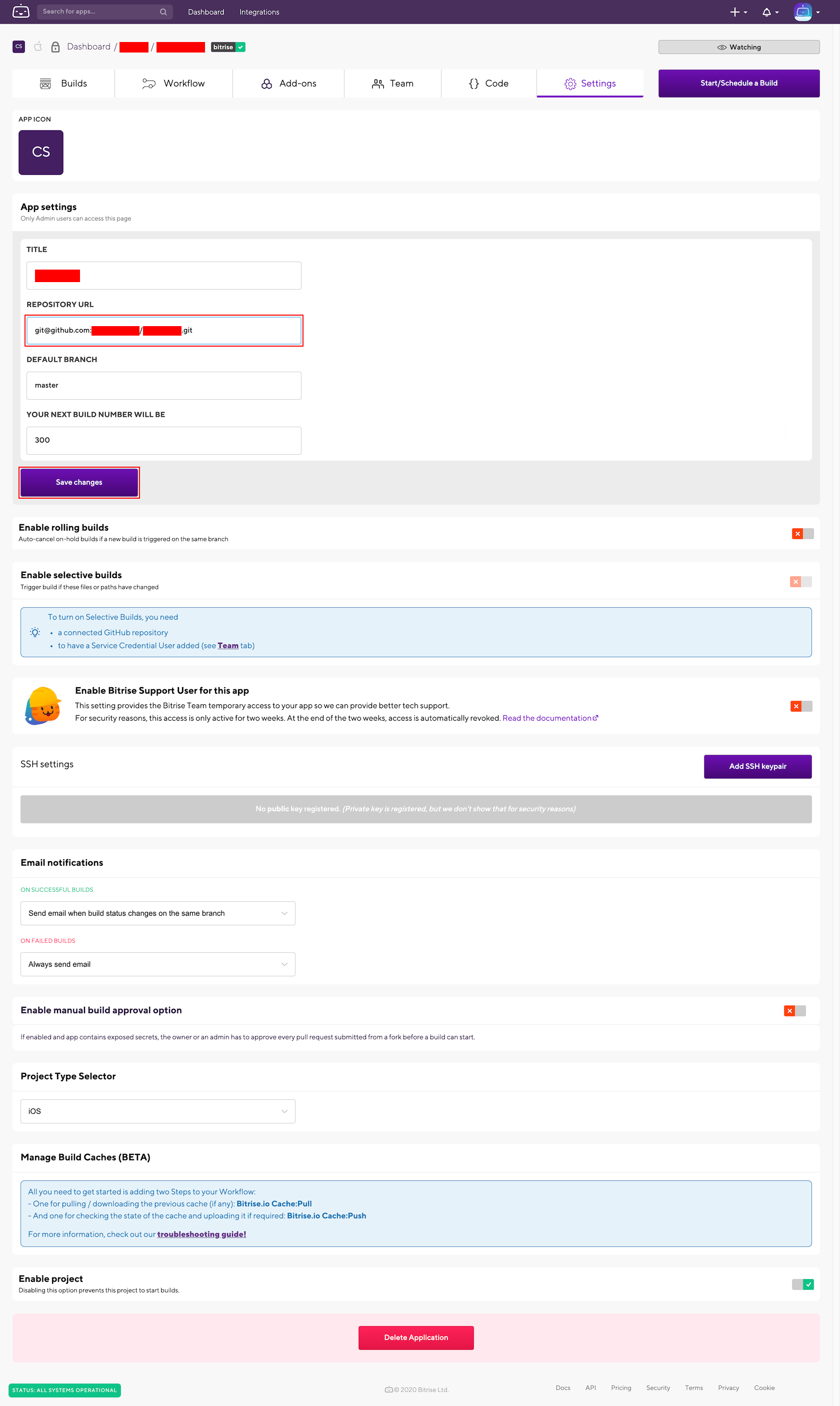
4. Bitrise に設定されている接続先リポジトリの URL を、 AWS CodeCommit から GitHub へ変更する。
- 設定画面の 「App settings」欄で、以下の項目を設定し、「Save changes」ボタンを押下します。
- REPOSITORY URL : ※GitHubのリポジトリ
- 例 :
git@github.com:genbasupport[Organization 名]/[リポジトリ名].git
- 元 :
ssh://[SSH キー ID]@git-codecommit.ap-northeast-1.amazonaws.com/v1/repos/[リポジトリ名]99.ハマりポイント
今回は、ちょっとハマるぐらいでした。
やっぱり Bitrise のノウハウは少なめな気がする…。
XX.まとめ
以上、ご参考になれば ♪♪♪
???
- 投稿日:2020-06-26T17:14:51+09:00
【EC2】seleniumでの日本語文字化けを防ぐ(noto対応)
日本語サイトの文字化けを防ぐ
環境
- Red Hat Enterprise Linux release 8.2
- google-chrome-stable-83.0.4103.116
- python3.6
- selenium 3.141.0
一行
その他諸々は既にインストール済という前提(参考情報参照)
sudo yum install google-noto* -yおしまい!
参考情報
Amazon LinuxでSelenium環境を最短で構築する - Qiita
【EC2】seleniumでキャプチャしたときの文字化けを防ぐ - Qiita参照するリポジトリの問題か、IPAフォントが入れられなかったので、yumでgoogle-noto探したらあったので解決。
- 投稿日:2020-06-26T16:34:58+09:00
【AWS EC2】Amazon Linux2でやっておきたい設定
概要
EC2を起動したらまずはやっておきたい設定周り
環境
- AWS EC2
- OS: Amazon Linux 2
- AMI ID: amzn2-ami-hvm-2.0.20200520.1-x86_64-gp2
- セキュリティグループ: SSH 22 を開けておく
1. サーバーの時刻をJSTにする
- デフォルトはUTCになっている
- timezoneをAsia/Tokyoに変更してJSTにしておく
- timezoneを変更したらcrondも再起動しておく
$ timedatectl status Local time: Fri 2020-06-26 06:10:18 UTC Universal time: Fri 2020-06-26 06:10:18 UTC RTC time: Fri 2020-06-26 06:10:18 Time zone: n/a (UTC, +0000) NTP enabled: yes NTP synchronized: no RTC in local TZ: no DST active: n/a $ sudo timedatectl set-timezone Asia/Tokyo $ timedatectl status Local time: Fri 2020-06-26 15:50:10 JST Universal time: Fri 2020-06-26 06:50:10 UTC RTC time: Fri 2020-06-26 06:50:09 Time zone: Asia/Tokyo (JST, +0900) NTP enabled: yes NTP synchronized: no RTC in local TZ: no DST active: n/a $ sudo systemctl restart crond $ date Fri Jun 26 16:03:47 JST 20202. プロンプトの変更
- デフォルトだと情報が少ないので変更する
- 変更前:
[ec2-user@ip-XX-XX-XX-XX ~]$- 変更後:
[16:17:47 ec2-user@ip-XX-XX-XX-XX ~]$.bashrcにexport PS1を追記する
- 全体に反映したい場合は
/etc/bashrcの$PS1を編集する- sourceコマンドで反映するのをお忘れなく
$ vi .bashrc # User specific aliases and functions export PS1='\[\033[37m\][\t \[\033[36m\]\u\[\033[37m\]@\h \[\033[32m\]\W\[\033[37m\]]$ ' $ source .bashrc3. ロケールの変更
- やらなくても良いが、日本語環境にしたいのであればやる
$ localectl status System Locale: LANG=en_US.UTF-8 VC Keymap: n/a X11 Layout: n/a $ sudo localectl set-locale LANG=ja_JP.UTF-8 $ sudo localectl set-keymap jp106 $ localectl status System Locale: LANG=ja_JP.UTF-8 VC Keymap: jp106 X11 Layout: jp X11 Model: jp106 X11 Options: terminate:ctrl_alt_bksp参考
- 投稿日:2020-06-26T15:53:41+09:00
seeds.rbのデータを本番環境に反映させるのは実は簡単!!!
はじめに
seedファイルを作成したが、本番環境に反映されなかったため、調べ以下を実行したら上手くいきました!
メモとして、記事を投稿します!
問題
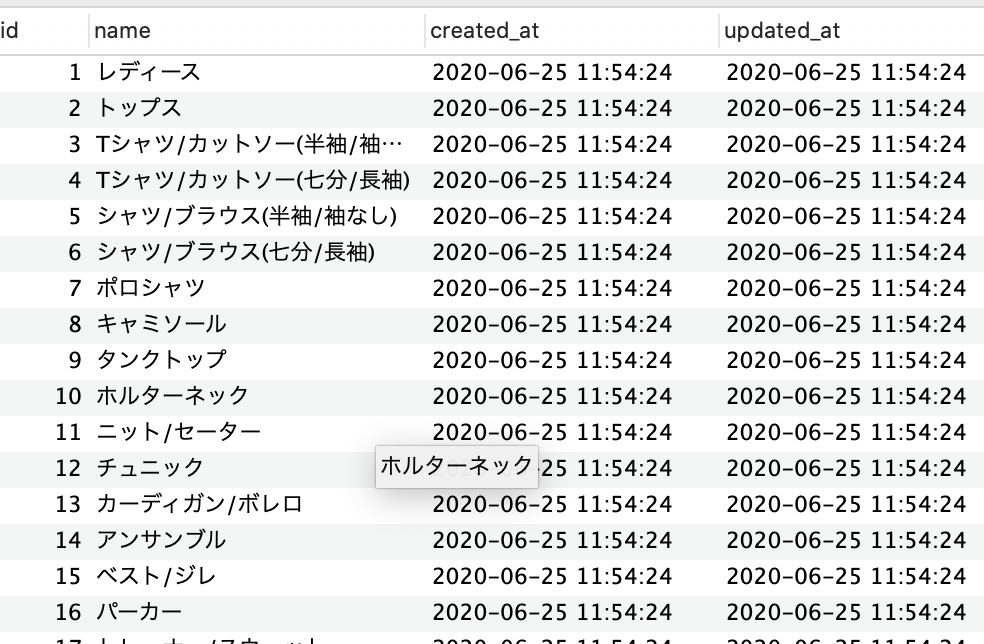
seedファイルが本番環境に反映されない
<seedファイル> lady = Category.create(name: "レディース") lady_1 = lady.children.create(name: "トップス") lady_1.children.create([{name: "Tシャツ/カットソー(半袖/袖なし)"},{name: "Tシャツ/カットソー(七分/長袖)"},{name: "シャツ/ブラウス(半袖/袖なし)"},{name: "シャツ/ブラウス(七分/長袖)"},{name: "ポロシャツ"},{name: "キャミソール"},{name: "タンクトップ"},{name: "ホルターネック"},{name: "ニット/セーター"},{name: "チュニック"},{name: "カーディガン/ボレロ"},{name: "アンサンブル"},{name: "ベスト/ジレ"},{name: "パーカー"},{name: "トレーナー/スウェット"},{name: "ベアトップ/チューブトップ"},{name: "ジャージ"},{name: "その他"}]) lady_2 = lady.children.create(name: "ジャケット/アウター") lady_2.children.create([{name: "テーラードジャケット"},{name: "ノーカラージャケット"},{name: "Gジャン/デニムジャケット"},{name: "レザージャケット"},{name: "ダウンジャケット"},{name: "ライダースジャケット"},{name: "ミリタリージャケット"},{name: "ダウンベスト"},{name: "ジャンパー/ブルゾン"},{name: "ポンチョ"},{name: "ロングコート"},{name: "トレンチコート"},{name: "ダッフルコート"},{name: "ピーコート"},{name: "チェスターコート"},{name: "モッズコート"},{name: "スタジャン"},{name: "毛皮/ファーコート"},{name: "スプリングコート"},{name: "スカジャン"},{name: "その他"}]) ~以下省略~開発環境でDBに反映させる(ステップ①)
以下を実行します
rails db:seedすると、DBに反映されます。
テスト環境で反映させる(ステップ②)
ターミナルに以下を実行させます。
rails db:seed RAILS_ENV=test本番環境で反映させる(ステップ③)
まず、本番環境で以下のディレクトリに移動してください。
cd /var/www/アプリ名/current
移動しましたら、以下を実します。
rake db:seed RAILS_ENV=production最後に
最後に以下を実装し、unicornを止め、自動デプロイを実行
bundle exec cap production unicorn:stop bundle exec cap production deployこれで上手く行きました。
終わりに
本番環境で反映させる際に、currentのディレクトリにいせずコマンドを実行したら上手く行きませんでした。
cd /var/www/アプリ名/currentのディレクトリまで移動するのは、必須の様です。
- 投稿日:2020-06-26T14:01:00+09:00
S3のバケットポリシーで気をつけること
概要
ECSのDockerコンテナ内でaws s3 cpコマンドを実行させようとした時にエラーが出たのでその対処法メモ。
エラー内容
fatal error: An error occurred (AccessDenied) when calling the ListObjectsV2 operation: Access Deniedこれは
s3:ListBucketが権限なくて実行できないよというエラー。
https://aws.amazon.com/jp/premiumsupport/knowledge-center/s3-access-denied-listobjects-sync/指示通り実行できるように権限を追加する必要がある。
今回はECSのタスクロールとS3バケットの実行Userが同じなのでS3バケットのアクセスポリシーにのみ追加すれば良い。S3のバケットポリシー
AWS -> S3 -> ポリシー追加したいバケット -> アクセス権限
の順で遷移するとパケットポリシーの追加画面が現れる。{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Principal": { "AWS": "ECSタスクロールのarn" }, "Action": [ "s3:ListBucket", "s3:GetObject" ], "Resource": [ "arn:aws:s3:::バケット名", "arn:aws:s3:::バケット名/*" ] } ] }ここで気をつけるべきは、
s3:ListBucketはバケットに付与する権限で、s3:GetObjectはバケット配下にあるオブジェクトに付与されるというところ。
だからResourceにある"arn:aws:s3:::バケット名"はバケットに対して、"arn:aws:s3:::バケット名/*"はバケット配下のオブジェクトに対して、ということで両方書く必要がある。(どっちかが不足しているとパケットポリシー作成の保存時にAction does not apply to any resource(s) in statementというエラーが出る)
- 投稿日:2020-06-26T13:47:02+09:00
【初心者向け】AWSとは?
AWSとは?
正式名称:Amazon Web Services
GCPやAzureに並ぶ、3大クラウドプラットフォームの名称のこと。
元々は、Amazonの社内のビジネス課題を解決するために誕生した。
2020年6月4日の時点で、世界シェアの約3割を占めている。AWSの特徴
Design for Failure(故障に備えた設計)がされているため、耐故障性に優れたクラウドという特徴がある。この点が利用者が多い理由の一つ。
WEB上からの操作だけで、世界中にサーバーを立てられるようになっており、個人がクラウドサーバを用意することも容易にできます。AWSをこれから使おうとされている方へ、ちょっとした情報をご提供
・アカウント作成は無料
・料金は従量課金制 (アカウント開設時には無料枠が適用されます。)
詳しくは以下のURLを参照
https://aws.amazon.com/jp/free/?all-free-tier.sort-by=item.additionalFields.SortRank&all-free-tier.sort-order=asc
・AWS認定資格あり
・国内のイベントやセミナーが豊富
・東京に「AWS Loft Tokyo」という場所がある。
ここでAWSの相談もできる。
(おしゃれなオフィスで一日中滞在可能!私も行ってみたい!)有名なサービスの例
・Amazon S3 (最強のファイル置き場!と言われている)
(Simple Strage Serviceの略)
最初はこれだけだったそうです。・Amazon EC2 (仮想サーバ)
(Elastic Compute Cluodの略)
Elasticには、弾力のある、伸縮自在な、という意味があります。
※仮想サーバを後から増やしたり、減らしたりすることが容易にできるから。他にも100種類以上のサービスがあります。
AWSのURL:https://aws.amazon.com/jp簡単にですが、AWSについて書かせていただきました。
- 投稿日:2020-06-26T12:54:42+09:00
[AWS RDS][Rails]環境構築
これは何
Railsでアプリを作成中、データベースをRDSに切り替えました。
Qiitaの記事などでRDSの作成手順はあるのですが、その後のRailsのデータベースとして設定していくのにハマったので備忘録として残します。バージョン
Rails 5.2.4.2
MySQL 5.6.4RDS構築
私はUdemyの教材を参考に作成しましたが、
こちらの記事を参考にすれば問題ないかなと思います。
(DB・サーバー構築編)世界一丁寧なAWS解説。EC2を利用して、RailsアプリをAWSにあげるまで設定
database.ymlの記述を変えていくのですが、そこにパスワード などを直接記入することはセキュリティ上問題なので、credentials.ymlを使っていきます。
credentials.ymlrds: DATABASE_USERNAME: ***** DATABASE_PASSWORD: ターミナルからRDSに接続するときのパスワード DATABASE_HOST: RDSのエンドポイントRDSのエンドポイントは、AWSコンソールのRDSのデータベースをクリックして、下にスクロールするとあります。
続いて、database.ymlの変更
database.ymlproduction: <<: *default database: アプリ名_production username: <%= Rails.application.credentials.rds[:DATABASE_USERNAME] %> password: <%= Rails.application.credentials.rds[:DATABASE_PASSWORD] %> host: <%= Rails.application.credentials.rds[:DATABASE_HOST] %> socket: /var/lib/mysql/mysql.sock終わったら、プッシュアンドデプロイ。
ターミナルからRDSに接続し、
mysql> show tables from アプリ名_production; mysql> select * from アプリ名.users;などで中身を確認してみましょう!
反映されていますかね〜。私はRDSに切り替えるのにずっと検索し続け、1日かかりました、、、
何はともあれ以上です!
ありがとうございました!
- 投稿日:2020-06-26T12:52:55+09:00
Qiita の記事を自動投稿するシステムをサーバーレスで組んだ
サーバーレスの勉強と実益を兼ねて、自分のQiitaの記事を自動でサマリして簡単なポートフォリオ代わりに使える記事を出してみようと思いました。
※ソースコードは現在整備中なので、追って公開します。
成果物
こちらの記事です。
Qiita Contributions Portfolio (Auto Generated)
自分の投稿記事について、使用したタグと Like数が多いものを表示します。
要件
- 自分が投稿したすべての記事を集計して、その集計結果を報告する記事を自動生成したい
- 自動生成する記事は、定期的に集計結果の更新を行い、その結果が自動的に反映されるようにしたい
構成図
全体的な構成は以下の図の通りです。
記事の作成/更新の機能と、記事の投稿内容となる変数の部分を計算するジョブの2つの部分からなります。
事前に Jinja2 をベースにした記事のテンプレートを作成しておきます。記事のタイトルやタグ、テンプレート変数を動的に DynamoDB から取得して本文をレンダリングし、投稿します。 Qiita への投稿部分は Step Functions で実装しています。
テンプレート変数部分は定期的に再計算して記事更新したいので、テンプレート変数の値を求めるための lambda を別で動かしています。集計処理と記事投稿は密結合したくない要素なので、自動投稿との間に SQS を挟んでいます。
SQS のコンシューマ側にあたる lambda でテンプレート変数を DynamoDB に永続化し、続いて Step Functions を起動します。
DynamoDB では 記事ID をハッシュキーとして記事情報を保持します。次のような情報を持っています。
- タイトル、タグ
- テンプレート変数(本文のレンダリングに使用)
- レンダリング時に使用すべきテンプレートの名前
- Qiita の記事公開状態のステート(公開済みである場合は、Qiita側が持っている記事IDも保持)
Step Functions の中身は次のような内容になっています。
このステートマシンは入力として記事ID(QiitaのItem IDではなく、このシステム内部でのみ使用する管理用変数)を受け取ります。
記事ID を指定して、 DynamoDB から投稿内容等の情報を取得します。見つからなければ記事投稿の情報が存在しないということなので、その時点で Fail させます。
次に、公開状態のステートを評価します。公開済みステートの場合は Qiita API を呼び出し、その記事が実際に存在しているかどうかを確認します。
その後、公開状態のステートを評価し、記事を新規作成すべきか、更新すべきかを判定します。新規作成の場合は最後に公開状態のステートを更新して終了です。
設計ポイント
記事更新に必要な構成要素はほぼ集計側から分離している点が設計上のメリットとなります。集計側としては結果を dict にしてキューイングするだけでよく、後続に存在する DynamoDB や Step Functions などの詳細は知る必要がありません。
今回は1つの記事だけ自動生成していますが、別の記事を同じ仕組みに乗せることも簡単です。任意の記事IDを決めてあげて、
- 記事のテンプレート (Jinja2) を作成
- DynamoDB に記事の投稿情報を Put しておく
- タイトル、タグ
- 作成したテンプレートの名前
- テンプレート変数の値を計算するための仕組み (今回の例ではlambda を使用) を開発する
- 計算したテンプレート変数は SQS にキューイングする
Qiita の投稿部分に Step Functions を使用したことで、中で行うロジックの見通しが良くなっています。雑に lambda を書いていると1本の function に多くの仕事をさせてしまいがちですが、Step Functions であれば各ステップの実装だけを綺麗にやれば後は繋ぎ込みを Serverless Framework のリソース定義で用意するだけです。
function 1本あたりでやっていることがシンプルなので、自然とコードは本質的なロジックのみをそれぞれ関数化しただけの、すっきりした構造になります。 また、Step Functions では分岐の制御構造を No Code で実装できるので、(今回の例では微々たる量ではあるものの)コードの記述量もより少なく済みます。
改善点
いくつかありますが、目につくのは次のポイントです。
- Jinja2 テンプレートがソースコードに直接含まれている
- S3 に置けるようにしたい
- 初投稿を行うためには、予め DynamoDB に記事投稿の情報を Put しておく必要がある
- 単純に面倒くさい
- 他の人に横展開しづらい構成になっている
- 私が作成したい記事の集計ロジックと jinja2 テンプレートが投稿システムと同じソースに含まれてしまっている
他の人にも使ってもらおうと考えたとき、私が使っている Jinja2 のテンプレートがソースに含まれている状態はあまりよろしくない感じがします。また、テンプレートは Static Contents なので、置き場はできれば外部化したいです。
Jinja2 + S3 なら誰かが拡張機能を作ってそうな気はするので、既存パッケージを使って実現可能ならサクッとやりたいです。ローカルか S3 か、データソースを選択できるようになってるとよりよいのではないか、という気もします。


- 投稿日:2020-06-26T12:39:35+09:00
QRadarでAmazon VPC Flow Logsを取得し監視する
はじめに
みなさまこんにちは。IBM QRadarを活用されていらっしゃいますか?
これまでAWS環境にIBM QRadar SIEMを構築、導入する手順を投稿してきましたが、今回はAmazon VPC Flow Logsの取得にチャレンジしたいと思います。背景
IBM QRadarは元々フローログの分析を主体とする製品から誕生しており、NetFlow/IPFIX/sFlowなどのトラフィックモニタリングが得意なSIEM製品です。AWS環境ではVPC内の通信監視機能としてVPCフローログを生成することが出来るのですが、フローログの分析を行うためにはAmazon CloudWatch LogsやAmazon Elasticsearch Serviceなどの分析基盤を活用する必要があります。
IBM QRadarにAWS VPCフローログを取り込むことで、従来IBM QRadarで培ってきたフロー情報の異常検知、監視がQRadar側のSIEMルールで判定できるようになるため、取り込みを行なってみました。Amazon VPCフローログとは?
公式ドキュメントはこちら。VPCフローログは、VPC のネットワークインターフェイスとの間で行き来する IPトラフィックに関する情報をキャプチャできるようにする機能で、フローログデータを Amazon CloudWatch Logs または Amazon S3 に発行できます。
AWSを触っている方は、Amazon CloudWatch Logsに出力されている方も多いのではと思います。
以下のようなフォーマットで出力されます。<version> <account-id> <interface-id> <srcaddr> <dstaddr> <srcport> <dstport> <protocol> <packets> <bytes> <start> <end> <action> <log-status>IPFIX規格と異なる点として、AWSアカウントIDやVPC内取得元のインターフェース情報などが付加されています。
2 634148078504 eni-0d88826XXXX11111 10.0.4.114 10.0.1.190 443 52737 6 31 9135 1593139499 1593139510 ACCEPT OK 2 634148078504 eni-0d88826XXXX11111 10.0.4.114 10.0.1.190 443 52729 6 33 9215 1593139499 1593139510 ACCEPT OKIBM QRadar DSMによる設定方法 〜 Amazon S3/SQS経由の取得 〜
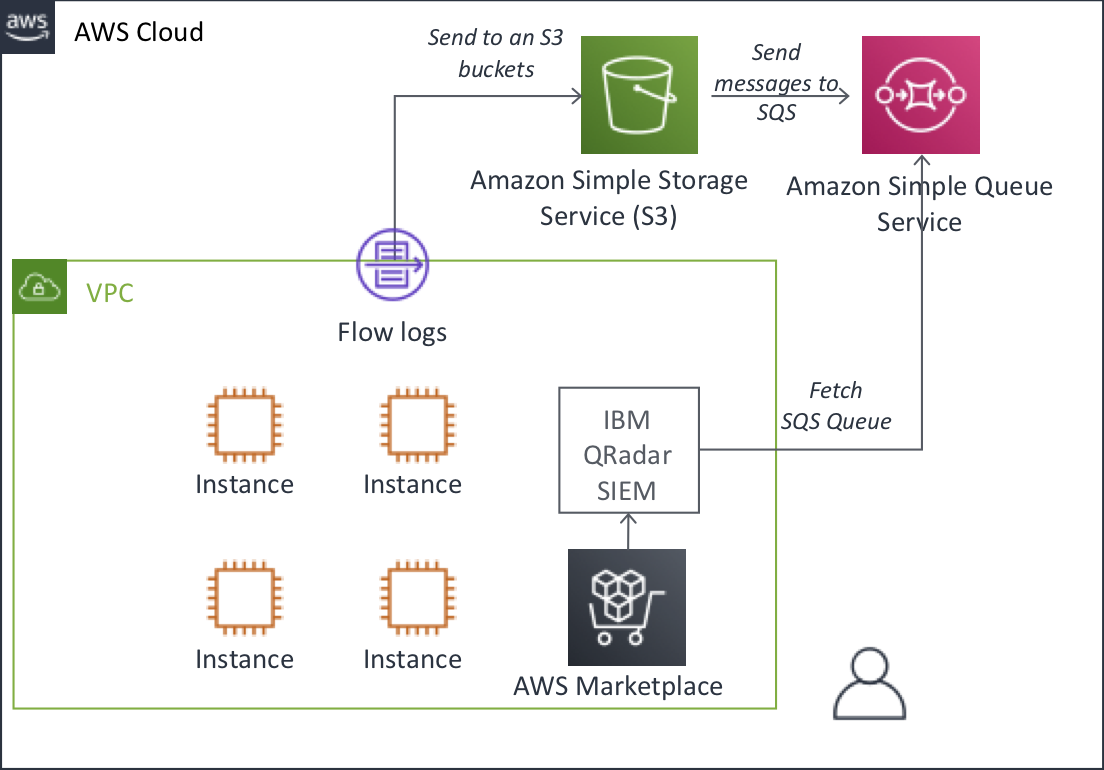
それでは設定してみましょう。
IBM QRadarのDSMドキュメントを見ると、VPCフローログの収集はAmazon SQS経由による接続であることが分かります。
DSMガイドの記載が文字しか無いため、分かり難いので図に起こしてみました。
手順をまとめると、以下のようになります。
- AWS側設定
- AWS環境側でVPC Flow Logsを有効にする(VPC)
- VPC Flow Logs用のSQSキューを作成する(SQS)
- VPC Flow Logsが保管されているS3 BucketからSQSに発行する
- IBM QRadar側設定
- DSMモジュール (Protocol Common / Amazon RESTAPIなど)の更新(※本記事では省略)
- Flow設定の有効化(Default_NetFlowが動いていればOK)
- DSM設定(DSM接続ガイドの通りに記載し、SQSキューを指定する)
AWS側設定
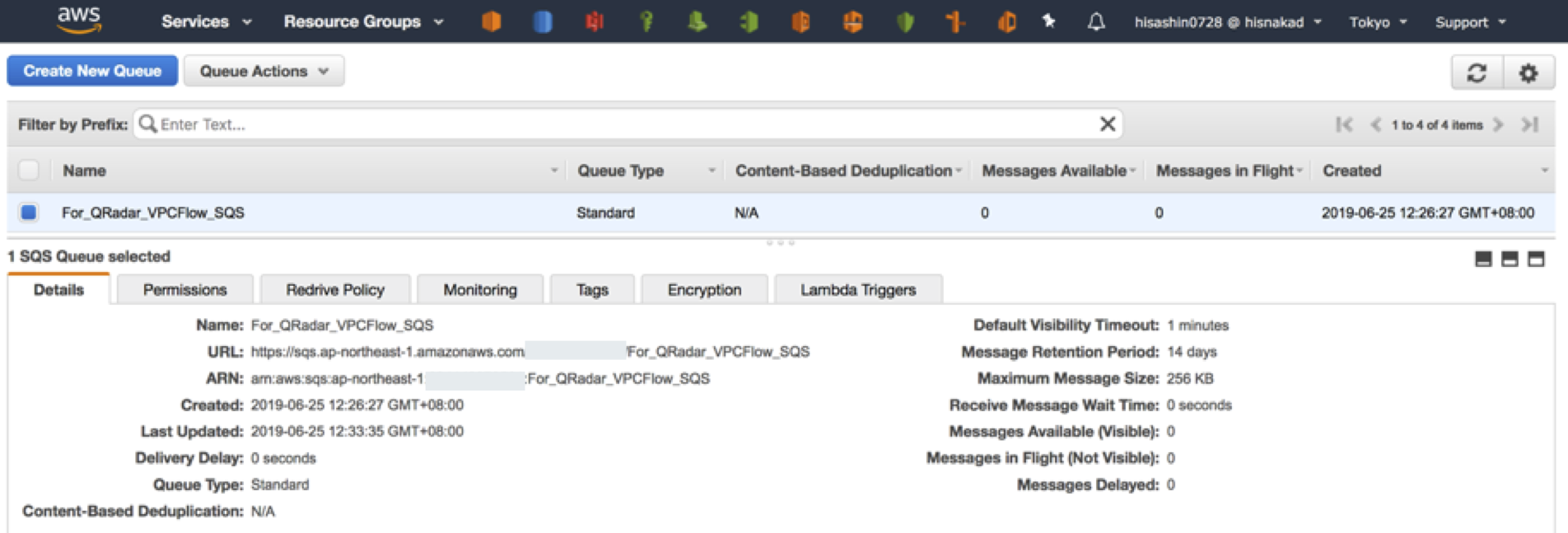
1. Amazon SQSキューの作成
Amazon SQSの画面に入り、VPC Flow Logsを一次受けするキューを作成します。
ここで、SQSキューに対して許可ポリシーを適用するのですが、公式のドキュメントがPrincipalを全許可してCondition条件で対象元を絞るポリシーになっており、表現上適切ではない様に思えましたので、筆者は以下のように設定しました。SQSのリソースベースのポリシー側で、IBM QRadarのEC2から受ける許可ポリシーと、S3 BucketからSendを受ける許可ポリシーを二つ記載しています。{ "Version": "2012-10-17", "Id": "arn:aws:sqs:ap-northeast-1:[AWSアカウントID]:For_QRadar_VPCFlow_SQS/SQSDefaultPolicy", "Statement": [ { "Sid": "AllowQRadarEC2", "Effect": "Allow", "Principal": { "AWS": "arn:aws:iam::[AWSアカウントID]:root" }, "Action": "SQS:*", "Resource": "arn:aws:sqs:ap-northeast-1:[AWSアカウントID]:For_QRadar_VPCFlow_SQS" }, { "Sid": "AllowS3", "Effect": "Allow", "Principal": { "Service": "s3.amazonaws.com" }, "Action": "SQS:SendMessage", "Resource": "arn:aws:sqs:ap-northeast-1:[AWSアカウントID]:For_QRadar_VPCFlow_SQS", "Condition": { "ArnLike": { "aws:SourceArn": "arn:aws:s3:::[VPCフローログ保管Bucket]" } } } ] }2. S3Bucket設定
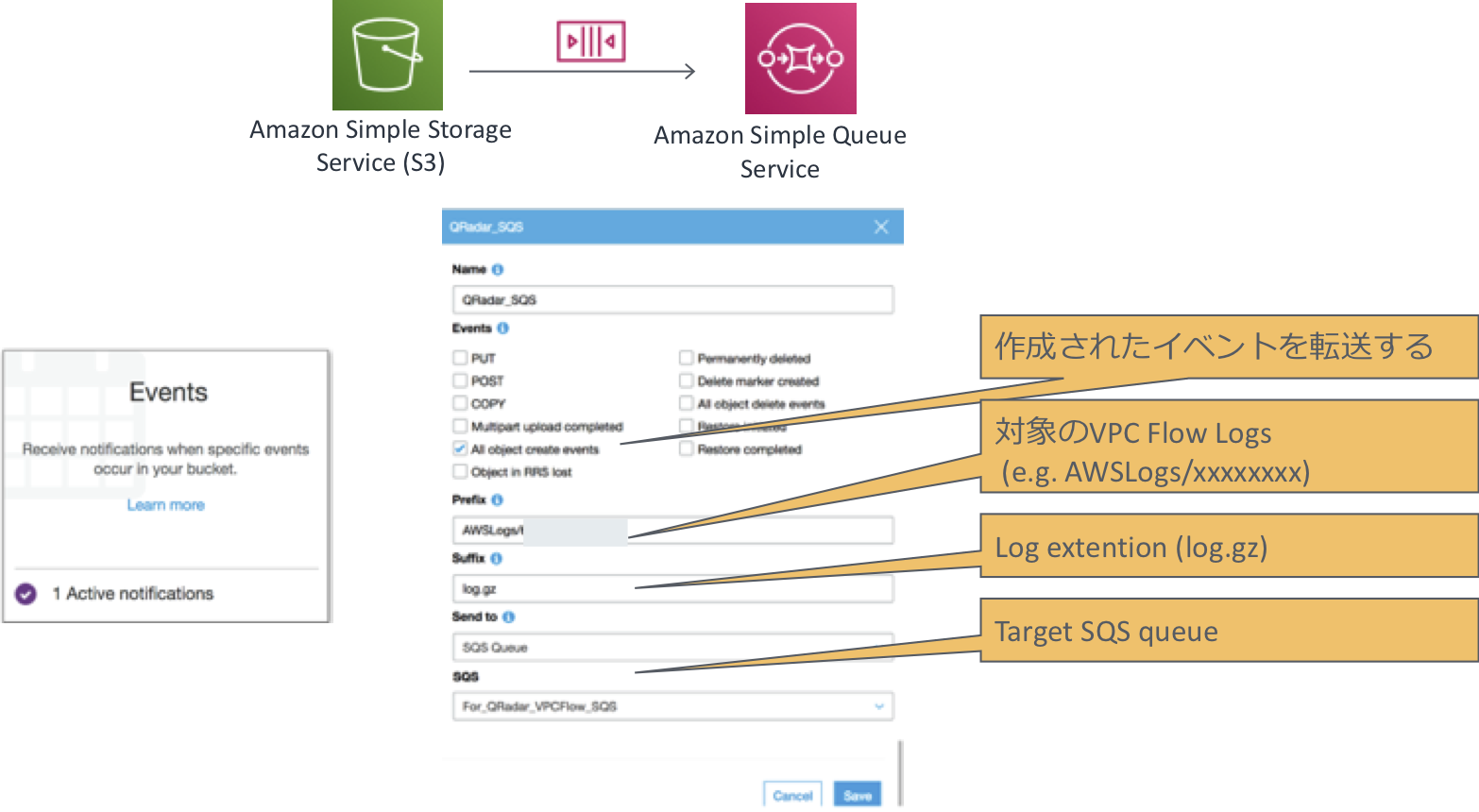
Amazon VPC Flow Logsが保管されるS3 Bucket側でSQSキューに転送する設定を行います。
設定後、Amazon SQS側でキューが溜まることを確認できればOKです。IBM QRadar DSM設定
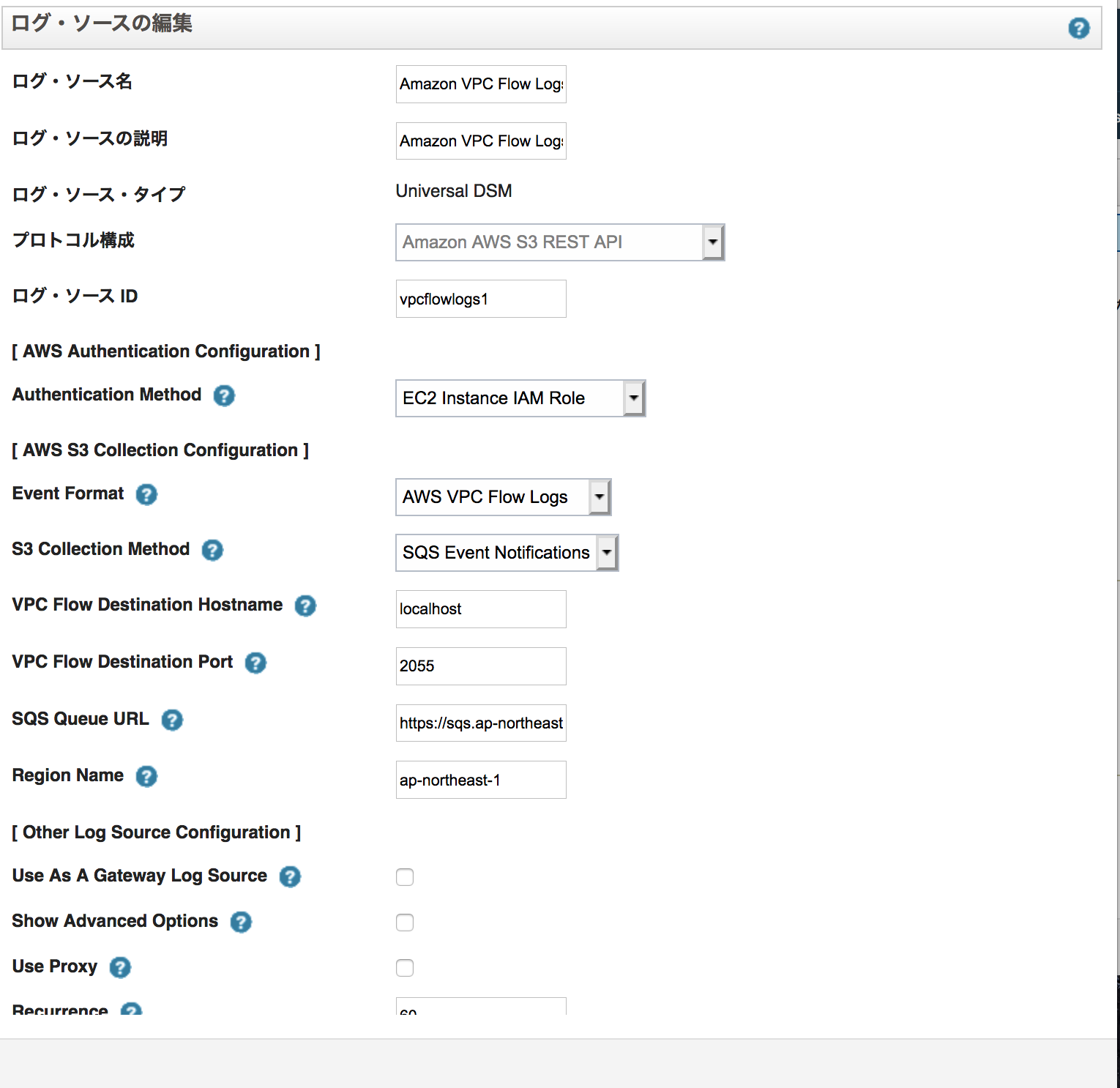
IBM QRadarのDSMガイドの通り、設定を行います。
注意点としては、Universal DSMを用いる特殊なDSM設定になるのでご注意ください。
ここでは、認証方式としてVPC内にIBM QRadar (Community Edition)を構築しているため、IAMロールによるセキュアな接続方式を用いています。
「SQS Queue URL」の部分が、https://から始まるSQSキューのURLを指定することになります。動作確認
設定が反映されて、QRadarがDSMを用いてSQSにポーリングし、Flow情報として展開できているかどうか、QRadarのログ(/var/log/qradar.log)から確認ができます。
Jun 26 11:29:14 ::ffff:127.0.0.1 [ecs-ec-ingress.ecs-ec-ingress] [Amazon AWS S3 REST API Protocol Provider Thread: class com.q1labs.semsources.sources.amazonawsrest.AmazonAWSRESTProvider59] com.q1labs.semsources.sources.amazonawsrest.utils.web.SQSEventProcessor: [INFO] [NOT:0000006000][10.0.2.4/- -] [-/- -]Processed [0] records from S3 File [/store/tmp/59/AWSLogs-634148078504-vpcflowlogs-ap-northeast-1-2020-06-26-XXXXXXXXXXXX_vpcflowlogs_ap-northeast-1_fl-081519e90b2edcb30_20200626T0215Z_a96f8084.log.gz] Jun 26 11:29:14 ::ffff:127.0.0.1 [tomcat.tomcat] [configservices@10.0.2.4 (1314) /console/JSON-RPC/System.addAliases System.addAliases] com.q1labs.configservices.capabilities.CapabilitiesHandler: [INFO] [NOT:0000006000][127.0.0.1/- -] [-/- -]adding autodetected flowsource alias: 127.0.0.1:localhost_localdomain Jun 26 11:29:14 ::ffff:127.0.0.1 [ecs-ec-ingress.ecs-ec-ingress] [Amazon AWS S3 REST API Protocol Provider Thread: class com.q1labs.semsources.sources.amazonawsrest.AmazonAWSRESTProvider59] com.q1labs.semsources.sources.amazonawsrest.utils.web.SQSEventProcessor: [INFO] [NOT:0000006000][10.0.2.4/- -] [-/- -]Processing S3 File: [AWSLogs-XXXXXXXXXXXX-vpcflowlogs-ap-northeast-1-2020-06-26-XXXXXXXXXXXX_vpcflowlogs_ap-northeast-1_fl-081519e90b2edcb30_20200626T0225Z_3729e216.log.gz] Jun 26 11:29:14 ::ffff:127.0.0.1 [ecs-ec-ingress.ecs-ec-ingress] [Amazon AWS S3 REST API Protocol Provider Thread: class com.q1labs.semsources.sources.amazonawsrest.AmazonAWSRESTProvider59] com.q1labs.semsources.sources.amazonawsrest.utils.file.VPCFlowLogHandler: [INFO] [NOT:0000006000][10.0.2.4/- -] [-/- -]Processed [161] VPC Flow records from [AWSLogs-XXXXXXXXXXXX-vpcflowlogs-ap-northeast-1-2020-06-26-XXXXXXXXXXXX_vpcflowlogs_ap-northeast-1_fl-081519e90b2edcb30_20200626T0225Z_3729e216.log.gz] Jun 26 11:29:14 ::ffff:127.0.0.1 [ecs-ec-ingress.ecs-ec-ingress] [Amazon AWS S3 REST API Protocol Provider Thread: class com.q1labs.semsources.sources.amazonawsrest.AmazonAWSRESTProvider59] com.q1labs.semsources.sources.amazonawsrest.utils.web.SQSEventProcessor: [INFO] [NOT:0000006000][10.0.2.4/- -] [-/- -]Processed [0] records from S3 File [/store/tmp/59/AWSLogs-XXXXXXXXXXXX-vpcflowlogs-ap-northeast-1-2020-06-26-XXXXXXXXXXXX_vpcflowlogs_ap-northeast-1_fl-081519e90b2edcb30_20200626T0225Z_3729e216.log.gz] Jun 26 11:29:14 ::ffff:127.0.0.1 [ecs-ec-ingress.ecs-ec-ingress] [Amazon AWS S3 REST API Protocol Provider Thread: class com.q1labs.semsources.sources.amazonawsrest.AmazonAWSRESTProvider59] com.q1labs.semsources.sources.amazonawsrest.utils.web.SQSEventProcessor: [INFO] [NOT:0000006000][10.0.2.4/- -] [-/- -]Processing S3 File: [AWSLogs-XXXXXXXXXXXX-vpcflowlogs-ap-northeast-1-2020-06-26-XXXXXXXXXXXX_vpcflowlogs_ap-northeast-1_fl-081519e90b2edcb30_20200626T0220Z_c3db12b5.log.gz] Jun 26 11:29:14 ::ffff:127.0.0.1 [ecs-ec-ingress.ecs-ec-ingress] [Amazon AWS S3 REST API Protocol Provider Thread: class com.q1labs.semsources.sources.amazonawsrest.AmazonAWSRESTProvider59] com.q1labs.semsources.sources.amazonawsrest.utils.file.VPCFlowLogHandler: [INFO] [NOT:0000006000][10.0.2.4/- -] [-/- -]Processed [1167] VPC Flow records from [AWSLogs-XXXXXXXXXXXX-vpcflowlogs-ap-northeast-1-2020-06-26-XXXXXXXXXXXX_vpcflowlogs_ap-northeast-1_fl-081519e90b2edcb30_20200626T0220Z_c3db12b5.log.gz] Jun 26 11:29:14 ::ffff:127.0.0.1 [ecs-ec-ingress.ecs-ec-ingress] [Amazon AWS S3 REST API Protocol Provider Thread: class com.q1labs.semsources.sources.amazonawsrest.AmazonAWSRESTProvider59] com.q1labs.semsources.sources.amazonawsrest.utils.web.SQSEventProcessor: [INFO] [NOT:0000006000][10.0.2.4/- -] [-/- -]Processed [0] records from S3 File [/store/tmp/59/AWSLogs-XXXXXXXXXXXX-vpcflowlogs-ap-northeast-1-2020-06-26-XXXXXXXXXXXX_vpcflowlogs_ap-northeast-1_fl-081519e90b2edcb30_20200626T0220Z_c3db12b5.log.gz] Jun 26 11:29:14 ::ffff:127.0.0.1 [ecs-ec-ingress.ecs-ec-ingress] [Amazon AWS S3 REST API Protocol Provider Thread: class com.q1labs.semsources.sources.amazonawsrest.AmazonAWSRESTProvider59] com.q1labs.semsources.sources.amazonawsrest.utils.web.SQSEventProcessor: [INFO] [NOT:0000006000][10.0.2.4/- -] [-/- -]Processing S3 File: [AWSLogs-XXXXXXXXXXXX-vpcflowlogs-ap-northeast-1-2020-06-26-XXXXXXXXXXXX_vpcflowlogs_ap-northeast-1_fl-081519e90b2edcb30_20200626T0210Z_5168a8cc.log.gz] Jun 26 11:29:14 ::ffff:127.0.0.1 [ecs-ec-ingress.ecs-ec-ingress] [Amazon AWS S3 REST API Protocol Provider Thread: class com.q1labs.semsources.sources.amazonawsrest.AmazonAWSRESTProvider59] com.q1labs.semsources.sources.amazonawsrest.utils.file.VPCFlowLogHandler: [INFO] [NOT:0000006000][10.0.2.4/- -] [-/- -]Processed [902] VPC Flow records from [AWSLogs-XXXXXXXXXXXX-vpcflowlogs-ap-northeast-1-2020-06-26-XXXXXXXXXXXX_vpcflowlogs_ap-northeast-1_fl-081519e90b2edcb30_20200626T0210Z_5168a8cc.log.gz] Jun 26 11:29:14 ::ffff:127.0.0.1 [ecs-ec-ingress.ecs-ec-ingress] [Amazon AWS S3 REST API Protocol Provider Thread: class com.q1labs.semsources.sources.amazonawsrest.AmazonAWSRESTProvider59] com.q1labs.semsources.sources.amazonawsrest.utils.web.SQSEventProcessor: [INFO] [NOT:0000006000][10.0.2.4/- -] [-/- -]Processed [0] records from S3 File [/store/tmp/59/AWSLogs-XXXXXXXXXXXX-vpcflowlogs-ap-northeast-1-2020-06-26-XXXXXXXXXXXX_vpcflowlogs_ap-northeast-1_fl-081519e90b2edcb30_20200626T0210Z_5168a8cc.log.gz] Jun 26 11:29:29 ::ffff:127.0.0.1 [tomcat.tomcat] [admin@27.0.3.146 (1394) /console/JSON-RPC/QRadar.getUndeployedChanges QRadar.getUndeployedChanges] com.q1labs.configservices.deployment.DeploymentHandler: [INFO] [NOT:0000006000][10.0.2.4/- -] [-/- -]DETECTED: 1 flowsource aliases need deploying Jun 26 11:29:53 ::ffff:10.0.2.4 [masterdaemon.masterdaemon] [SourceMonitorTimerTask] com.q1labs.sem.monitors.SourceMonitor: [INFO] [NOT:0000006000][10.0.2.4/- -] [-/- -]Incoming flow rate [5s: (0.00):(0.00) fps], [10s: (0.00):(0.00) fps], [15s: (0.00):(0.00) fps], [30s: (0.00):(0.00) fps], [60s: (0.00):(0.00) fps], [300s: (0.00):(0.00) fps], [900s: (0.00):(0.00) fps]. Peak in the last 60s: (0.00):(0.00) fps. Max Seen (0.00):(0.00) fps.License Threshold: 0.00 Jun 26 11:29:59 localhost [QRADAR] [21607] qflow: [INFO] [1593138540] IPFIX Flow Source Stats for default_Netflow: received and processed 188 packets. Jun 26 11:29:59 localhost [QRADAR] [21607] qflow: [INFO] [1593138540] Sent 0 flows on transport connection to 10.0.2.4:32010 Jun 26 11:29:59 localhost [QRADAR] [21607] qflow: [INFO] [1593138540] Flows held over for the next reporting interval: 0 Jun 26 11:29:59 localhost [QRADAR] [21607] qflow: [INFO] [1593138600] Current interval starting input flow count: 0 Jun 26 11:29:59 localhost [QRADAR] [21607] qflow: [INFO] [1593138600] Number offlows that should be reported in the interval: 1655 Jun 26 11:29:59 localhost [QRADAR] [21607] qflow: [INFO] [1593138600] Total number of aggregatable flows received from all flow sources: 3528 Jun 26 11:29:59 localhost [QRADAR] [21607] qflow: [INFO] [1593138600] Total number of non-aggregatable flows received from all flow sources: 0 Jun 26 11:29:59 localhost [QRADAR] [21607] qflow: [INFO] [1593138600] Byte count: 18364323 Jun 26 11:29:59 localhost [QRADAR] [21607] qflow: [INFO] [1593138600] Packet count: 50524 Jun 26 11:29:59 localhost [QRADAR] [21607] qflow: [INFO] [1593138600] Overflow count: 0 (Compressed: 0) Jun 26 11:29:59 localhost [QRADAR] [21607] qflow: [INFO] [1593138600] Superflow count: 0 (Compressed: 0) Jun 26 11:29:59 localhost [QRADAR] [21607] qflow: [INFO] [1593138600] New input interval started Jun 26 11:30:00 localhost [QRADAR] [21607] qflow: [INFO] Successfully connected to 10.0.2.4:32010設定が無事できているようであれば、IBM QRadar側からトラフィック情報が確認できるはずです。
ダブルクリックして、フロー情報の詳細を見てみましょう。
AWS固有の情報である Interface名、Action、ENI IDなども取り込まれていることが分かります。これで分析やQRadarの相関ルールも判定できそうですね。
まとめ
本記事では、AWS VPC FlowLogsをIBM QRadarに取り込んで、分析を行うための接続方法について記載しました。次回からは、取り込んだ分析の異常検知に取り組んでみたいと思います。

- 投稿日:2020-06-26T11:55:41+09:00
【AWS CloudWatch】基本の紹介から、実際にセッティングまでしてみる
目次
- はじめに
- CloudWatchアラーム
- CloudWatchイベント
- CloudWatchログ
- CloudWatchメトリクス
- まとめ:より可観測性なシステムの構築するためには
Amazon Web Services(AWS)が提供する100を超えるサービスの中で、Amazon CloudWatchはAWSが提供する最も初期のサービスの1つでした。 CloudWatchは2009年5月17日に発表され、S3、SQS、SimpleDB、EBS、EC2、EMRの後にリリースされた7番目のサービスでした。
AWS CloudWatchは、ログやメトリックの収集など、幅広いクラウドリソースを網羅するツールスイートです。 モニタリング; 視覚化とアラート; 運用状態の変化に応じた自動化されたアクション。 CloudWatchは、監視を超えて可観測性を実現できる優れたツールです。
AWS CloudWatchのデータをMetricFireのダッシュボードに直接繋げることができ、実はUIの向上や経済的な面からみてもMetricFireを使用する価値があるはずです。 無料トライアルで確認し、是非MetricFireでデータを視覚化してみてください。
1. はじめに
しばらくの間、可観測性はクラウドコンピューティングと最新のソフトウェアエンジニアリングエコシステムにおいて不可欠な位置を占めてきました。この言葉はもはや単なる流行語ではありません。Amazonは、予防的な監視を行うためのツールと手段を追加することで、これに適応してきました。
実際、多くの監視を行うことができますが、監視可能なシステムがない場合もあります。
可観測性が聞きなれない方は、システムの内部出力が外部出力の知識からどれだけ適切に推測できるかを示す尺度と考えてください。簡単に言うと、監視は問題の症状に関するものであり、可観測性は問題の(考えられる)根本原因に関するものです。
可観測性は、「ホワイトボックスモニタリング」と考えることもできます。このタイプの監視では、ログ、メトリック、およびトレースが可観測性の柱です。
このブログ投稿では、CloudWatchの基本を紹介し、そのユースケースをいくつか見て、重要なコンセプトについて詳しく説明していきます。今回は、CloudWatchが提供する以下の4つの主な機能に焦点を当てます。
- アラート
- イベント
- ログ
- メトリック
2. CloudWatchアラーム
事前設定されたしきい値に達した時や、条件が満たされた時にアクションを開始するようにアラームを設定できます。 これをよりよく理解するために、Elastic Computing Cloud(EC2)マシンを作成してみましょう。 ナノインスタンスまたはマイクロインスタンスを使用できるため、本番インスタンスは必要ありません。
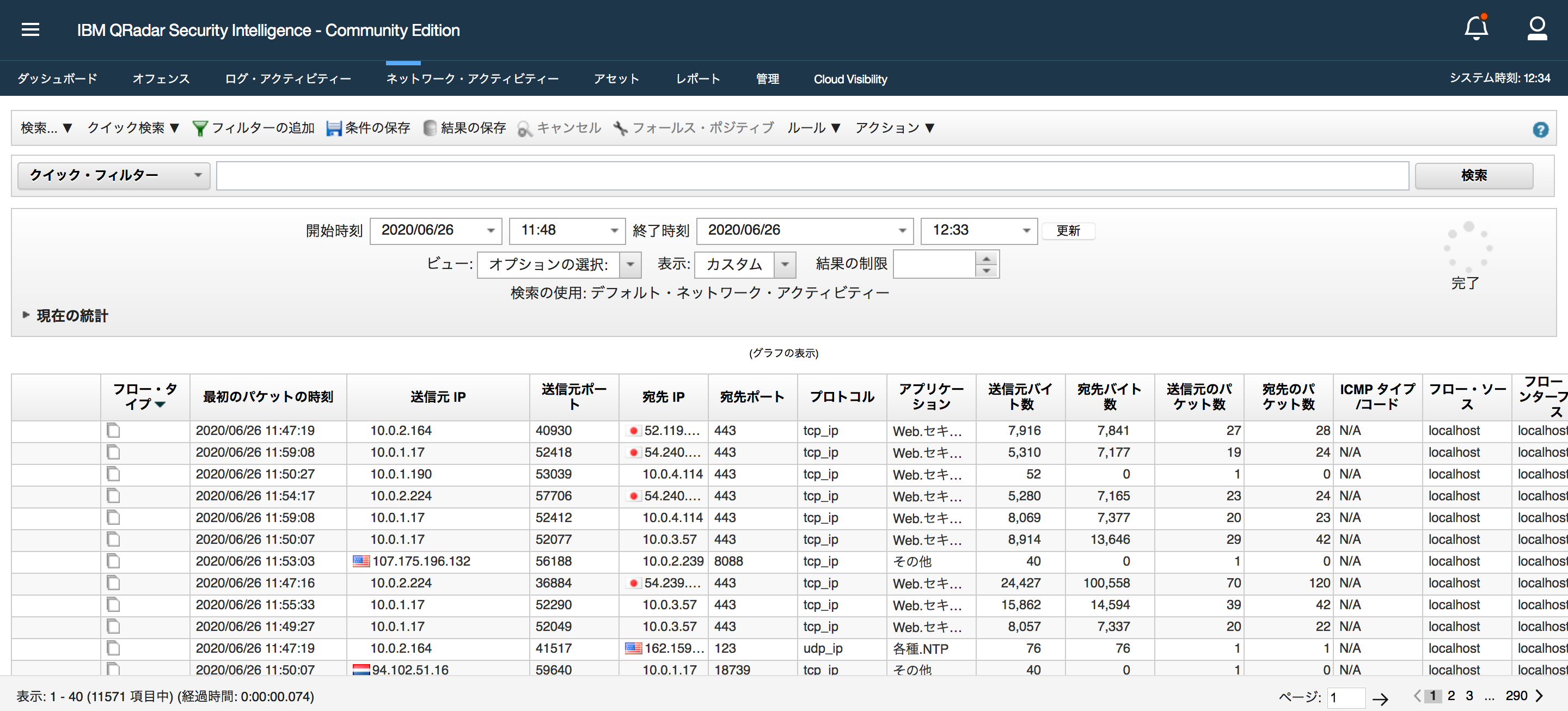
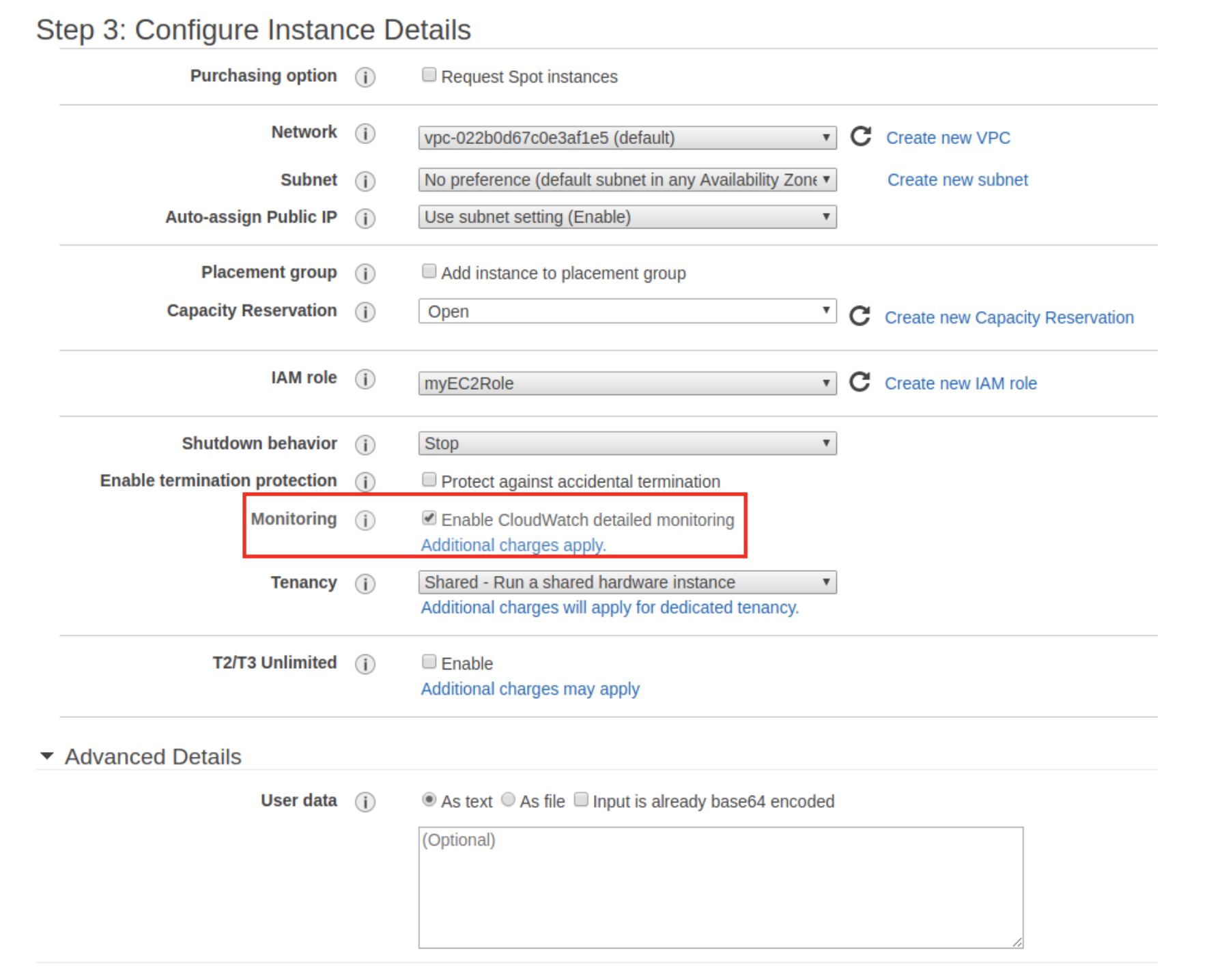
このインスタンスを作成するときは、必ずCloudWatch detailed monitoringを有効にしてください。これにより、追加コストで1分間隔でデータを利用できるようになります。 標準モニタリングは無料ですが、CloudWatchにデータを配信するのに5分かかります。
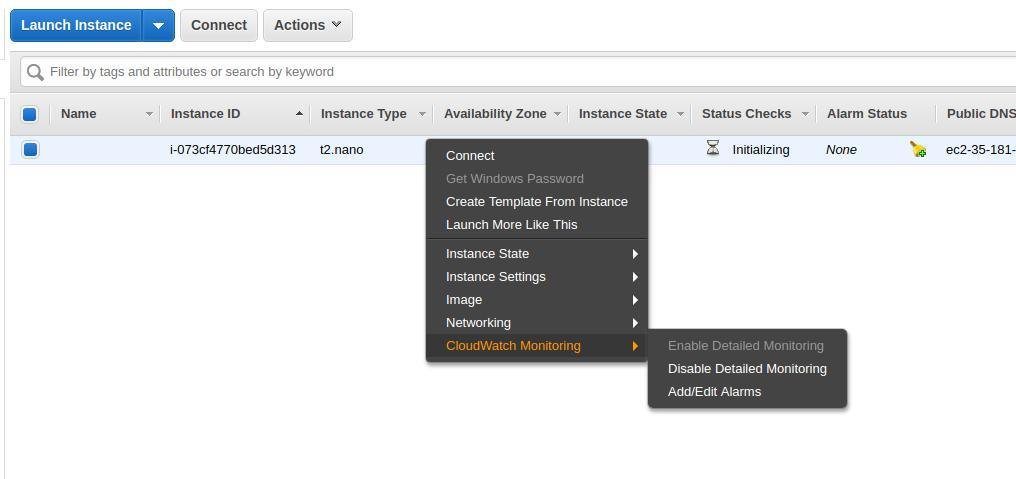
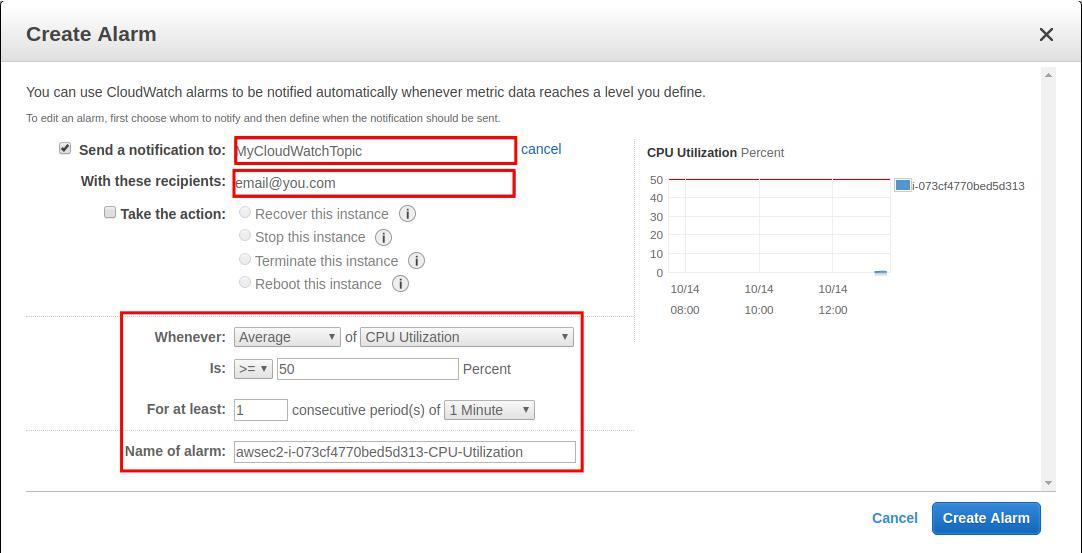
EC2インスタンスを作成したら、EC2マシンを使用してアラームを設定できます。 まず[Edit]をクリックし、次に[Add alarms]をクリックします。
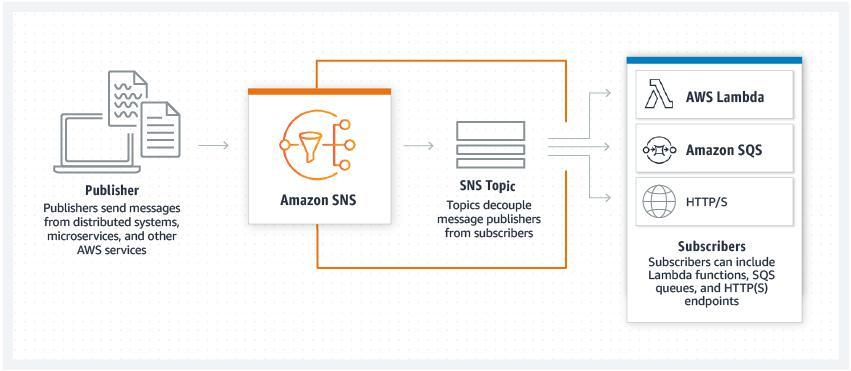
このステップでは、理解すべき重要なコンセプトがあります。アラームはAWS CloudWatchによって管理されますが、ほとんどのユースケースでは、アラームがアクティブになるとメールなどで通知されるように設定されています。 この機能は、AWS Simple Notification ServiceまたはSNSによって管理されており、 SNSは、低コストのメッセージングおよび通知サービスであり、パブリッシャーをサブスクライバーから切り離すことができます。 私たちの場合、SNSはCloudWatchアラームをリッスンし、アラームがアクティブになったときにメールを送信するために使用されます。
EC2アラーム設定ウィンドウからSNSトピックを作成するか、SNS管理ダッシュボードを使用できます。今回は、EC2インスタンスの平均CPU使用率が少なくとも1分間50%以上に達したときに、CloudWatchからメールを送信するとします。 これはEC2コンソールから簡単に設定できま、同じ条件が満たされたときにトリガーされるアクションを設定することもできます。 ここで、トピックへのメール購読を確認することを忘れないでください。
これをテストするために、EC2 CPUに負荷をかけ、CloudWatchからの結果のアラームと通知を確認します。 ここで使用するツールはstressと呼ばれます。 タイムアウトが600秒のsqrt()で500ワーカーをスピンさせるには、次のコマンドを使用できます。
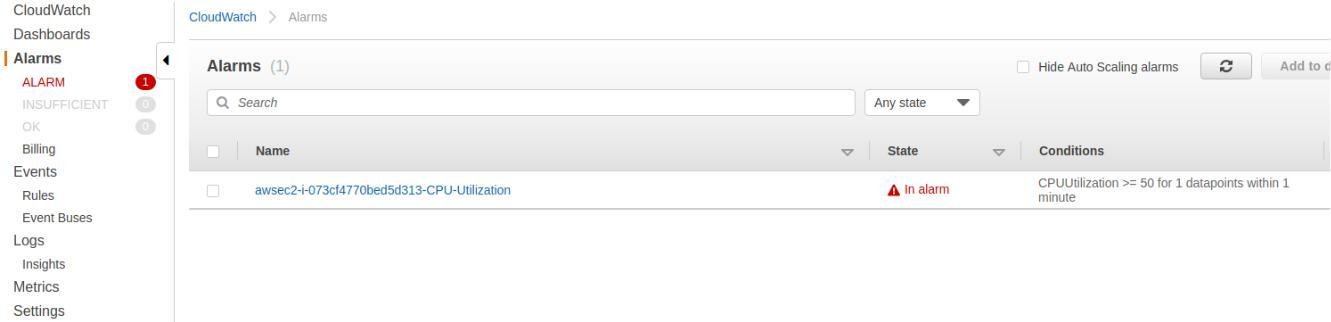
stress --cpu 500 --timeout 600数分後、アラームがアクティブであることを確認できます。また、上記で作成したトピックへのサブスクリプションを確認した場合は、メールも届きます。
条件が満たされたときにメール通知をプッシュする方法を確認しましたが、補足として、自動スケーリングなどのメソッドをトリガーする他のアクションを設定することもできます。
You are receiving this email because your Amazon CloudWatch Alarm "awsec2-i-073cf4770bed5d313-CPU-Utilization" in the EU (Paris) region has entered the ALARM state, because "Threshold Crossed: 1 datapoint [71.6666666666667 (14/10/19 14:00:00)] was greater than or equal to the threshold (50.0)." at "Monday 14 October, 2019 14:01:56 UTC".
3. CloudWatchイベント
AWSリソースの変更を説明するほぼリアルタイムのストリームが必要な場合、探しているのはイベントです。 イベントにより、CloudWatchは操作上の変更が発生したときにそれを認識し、アクションを実行することによって応答します。
3.1 イベントとアラーム
使用するAWSリソースのいずれかにアラームを作成でき、しきい値に達すると通知が届きます。 イベントは時間の経過とともに継続的に記録されます。 この継続性は、イベントとアラームの主な違いです。
CloudWatchイベントはシステムイベントのストリームであり、システムの全体像を提供します。 一方、アラームは通常、測定しているメトリックがわかっている場合に使用されます。
例を挙げるとすれば、Netflixのようなストリーミングサービスを実行していて、世界中で何百万人もの視聴者がいるとします。 アラームのみを使用している場合、システムの負荷と運用上の変更が発生するため、それらを完全に把握することはできません。
3.2 CloudWatchイベントの基本
CloudWatchイベントストリームを設定するときに理解しておくべき3つの概念があります。
1. イベント
各リソースには、状態が変化したときにAWSによって生成されたイベントのリストがあります。 この例では、EC2インスタンスの状態が変化したときにイベントをトリガーする方法を学びました。
2. ターゲット
イベントがトリガーされると、ターゲットはイベントを(JSON形式で)受け取ります。
3. ルール
イベントがトリガーされたとき、または状態が変化したとき(この変化が、ユーザーが事前構成したルールと一致したときのみ)、イベントはイベントソースからターゲットに送信されて処理されます。
以下は、AWS CloudWatchが提供するターゲットサービスの一部です。
- Amazon EC2インスタンス
- Amazon CloudWatch Logsのロググループ
- AWS Batchジョブ
- AWS Lambda関数
- Amazon ECSタスク
- Amazon SNSトピック
- Amazon SQSキュー
- Amazon Kinesisデータストリーム
別のAWSアカウントのデフォルトのイベントバスをターゲットとして設定することもできます。
3.3イベントとルールの作成
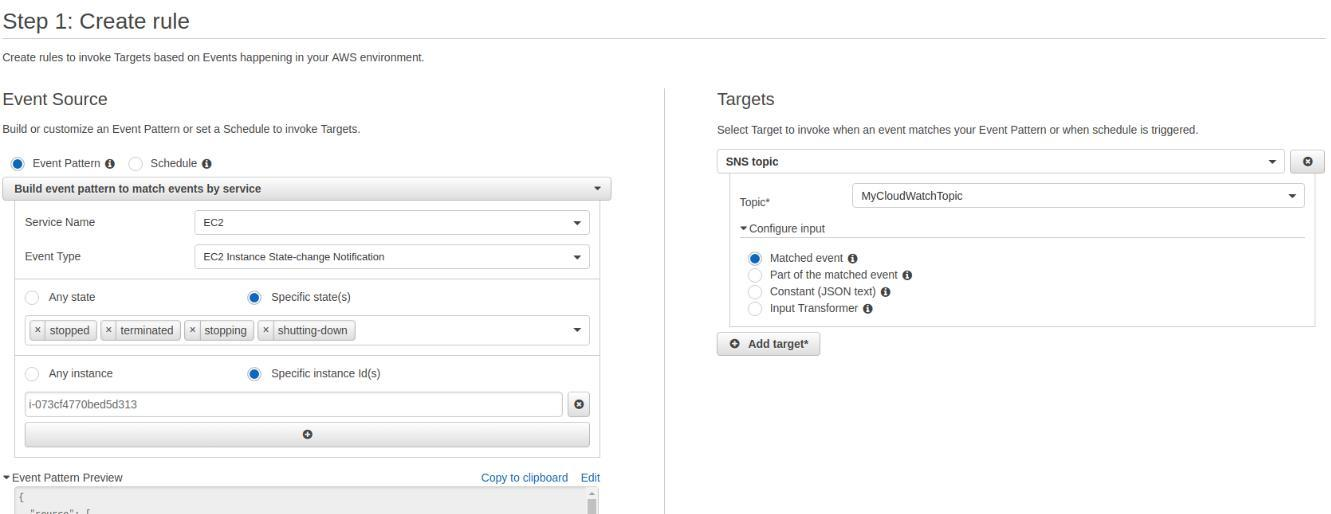
このブログ投稿の最初の部分では、EC2マシンを作成しました。 これを使用して、インスタンスの状態に関するデータを含みながら、イベントを継続的にストリーミングする方法と、変更が発生するとすぐにイベントがターゲットを呼び出す方法を説明していきます。
AWS CloudWatchコンソールに移動し、[Events]をクリックして、新しいルールを作成します。
EC2サービスの状態変化に一致するようにイベントパターンを構成し、(IDを使用して)単一のインスタンスを指定できます。 ターゲットには、すでにメールで購読しているのと同じSNSトピックを設定できます。 これにより、インスタンスの状態が"stopped", "terminated", "stopping", または "shutting-down"になると、メールが送信されることが保証されます。
インスタンスを停止してイベントをトリガーしてみましょう:
aws ec2 stop-instances --instance-ids <instance_id>インスタンスが停止すると、2つの電子メールを受信するはずです。 1つは「stopping」状態で、もう1つはインスタンスが完全に停止したときのメールです。
{ } "version":"0", "id":"2d2fa149-b1b6-23ad-27cd-15fdc00d4ff2", "detail-type":"EC2 Instance State-change Notification", "source":"aws.ec2", "account":"998335703874", "time":"2019-10-14T14:06:15Z", "region":"eu-west-3", "resources":[ "arn:aws:ec2:eu-west-3:998335703874:instance/i-073cf4770bed5d313" ], "detail":{ "instance-id":"i-073cf4770bed5d313", "state":"stopped" }CloudWatchが提供するさまざまな構成を使用して、いくつかのユースケースを実装できます。 たとえば、AWS Lambda関数を追加して、変更が発生したときに送信されるデータを処理、変換、分析し、これにより、カスタムアクションを指定してトリガーできます。 SNSをSlackチームチャットに接続して、同じSNSにアラームを公開することもできます。
4. CloudWatchログ
メトリクスと同様に、システムの制御性と可観測性を高めたい場合、ログは重要です。 CloudWatchを使用して、ログを監視、保存、アクセス、クエリ、分析、視覚化できます。 CloudWatchは、スケーラブルなサービスで使用するすべてのリソースとAWSサービスからのログを一元化しています。 たとえば、Webアプリケーションのアクセスログを保存して、保持期間を10年に調整できたり、システムログを保存することもできます。これは、ホストマシンにログを保持したくない場合や、インフラストラクチャが不変である場合に最適です。
4.1 Twelve Factor-AppとCloudWatch
ログをイベントストリームとして扱うということは、Herokuによって開発された12要素アプリの原則の1つです。
Logs are the stream of aggregated, time-ordered events collected from the output streams of all running processes and backing services. Logs in their raw form are typically a text format with one event per line (though backtraces from exceptions may span multiple lines). Logs have no fixed beginning or end, but flow continuously as long as the app is operating.
AWS CloudWatch Logsの哲学を受け入れ、この原則を実装していくと、ログをイベントストリームとして扱うと役立ちます。
4.2 4.2 CloudWatch Logsエージェントの使用
CloudWatch Logsを使用してシステムログ(syslog)のストリームを作成したいので、EC2マシンにエージェントをインストールして設定する必要があります。
curl https://s3.amazonaws.com/aws-cloudwatch/downloads/latest/awslogs-agent-setup.py -O sudo python ./awslogs-agent-setup.py --region eu-west-3インストールが完了すると、インタラクティブなセットアップが開始されます。
Step 3 of 5: Configuring AWS CLI ... AWS Access Key ID [None]: xxxxxxxxxxxxxx AWS Secret Access Key [None]: xxxxxxxxxxxxxxxxxxxxxxxxxx Default region name [eu-west-3]: Default output format [None]: Step 4 of 5: Configuring the CloudWatch Logs Agent ... Path of log file to upload [/var/log/syslog]: Destination Log Group name [/var/log/syslog]:少なくともこれらのアクションを実行する機能を持つIAM認証情報を設定してください。
- logs:CreateLogGroup
- logs:CreateLogStream
- logs:PutLogEvents
- logs:DescribeLogStreams
または、このポリシーを使用するロールに添付します。
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": [ "logs:CreateLogGroup", "logs:CreateLogStream", "logs:PutLogEvents", "logs:DescribeLogStreams" ], "Resource": [ "arn:aws:logs:*:*:*" ] } ] }上記の設定を完了して数秒すると、syslogが表示されます。
5. CloudWatchインサイト
Insights Explorerを使用すると、ログストリームをクエリできます。 下記はいくつかの有用な例です:
最近追加された25個のログイベント:
fields @timestamp, @message sort @timestamp desc limit 205分ごとに記録されるログの例外の数:
filter @message like /Exception/ stats count(*) as exceptionCount by bin(5m) sort exceptionCount desc例外ではないログイベントのリスト:
fields @message filter @message not like /Exception/Lambdaレイテンシ統計を5分間隔で表示:
filter @type = "REPORT" stats avg(@duration), max(@duration), min(@duration) by bin(5m)送信元および宛先IPアドレス別のVPC上位10バイト転送:
stats sum(bytes) as bytesTransferred by srcAddr, dstAddr sort bytesTransferred desc limit 105.1 CloudWatch Logsサブスクリプション
この機能により、AWS Lambdaなどの別のサービスにサブスクライブできます。 AWS CloudWatchから別のデータストアにログデータをETL(抽出、変換、ロード)する必要がある場合は、良いユースケースです。 全文検索エンジンを使用する必要がある場合もあります。これは、サブスクリプションを使用してログをAmazon Elasticsearch Service(AES)に送信できる場合です。
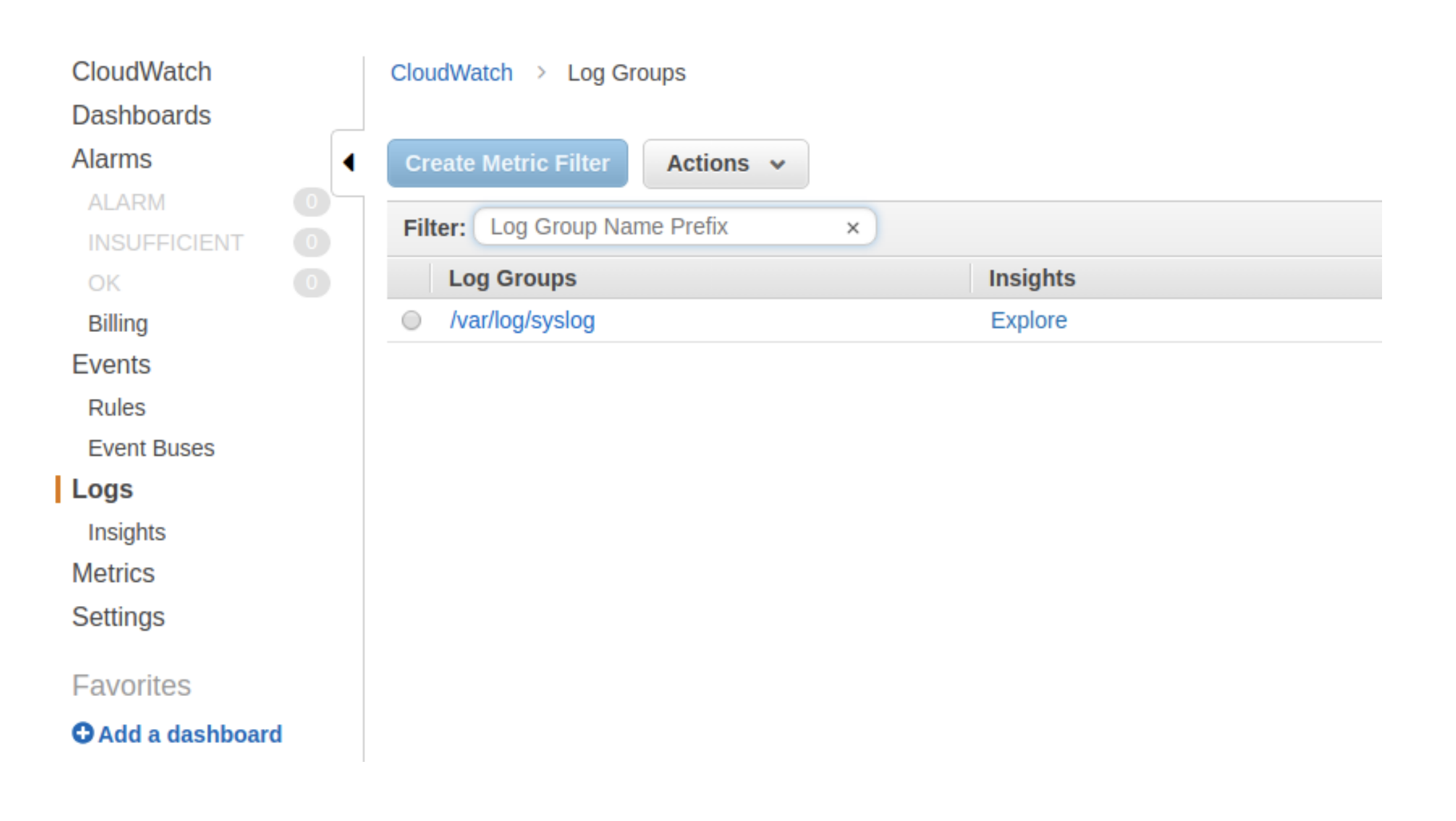
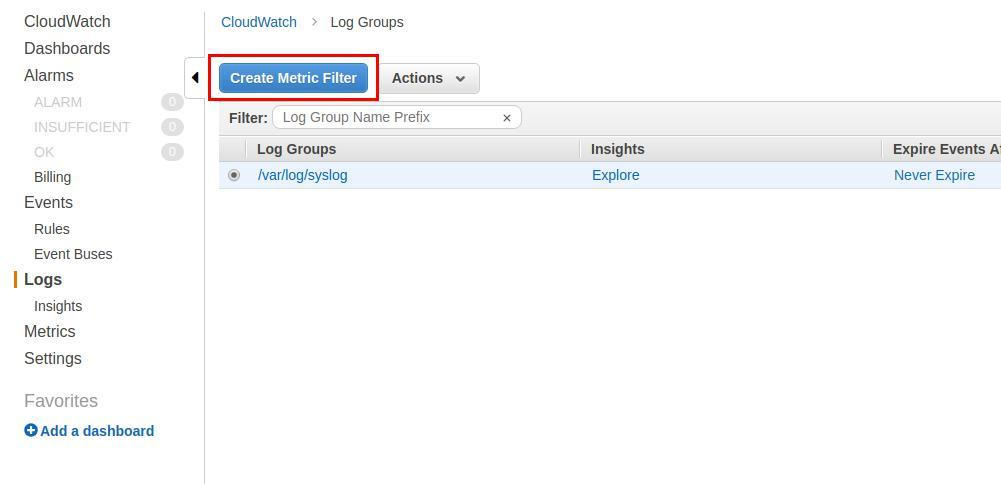
CloudWatchメトリックフィルター
CloudWatchコンソールを使用して、次のセクションに示すように、ログからカスタムテキストを抽出するフィルターを作成することもできます。
5.2 CloudWatchメトリクス
メトリクスは、CloudWatchに公開される時間順に並べられたデータポイントのセットです。 カスタム指標の作成を順を追って説明し、AWSで可観測性なメトリックについて説明します。
5.3カスタムメトリック
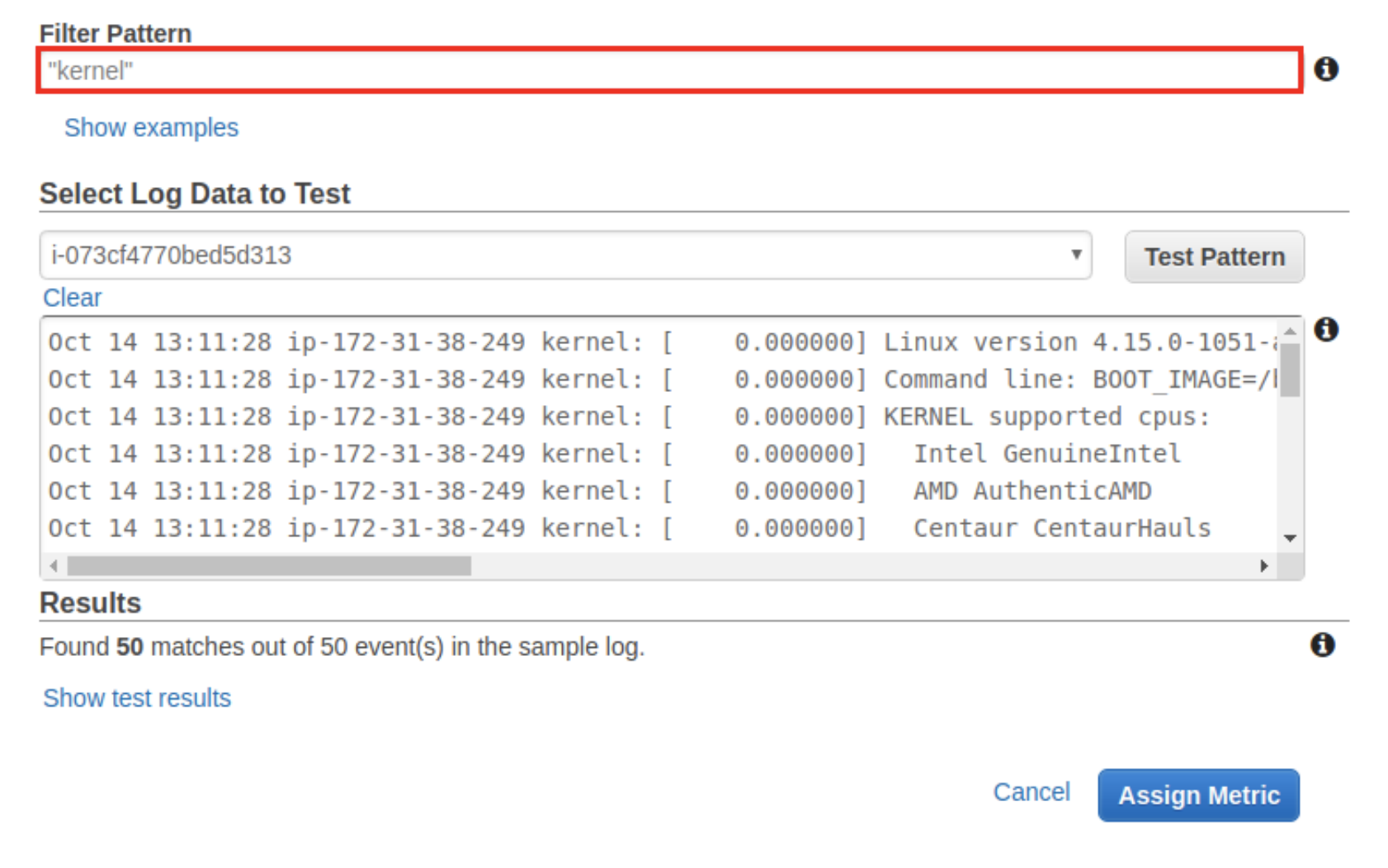
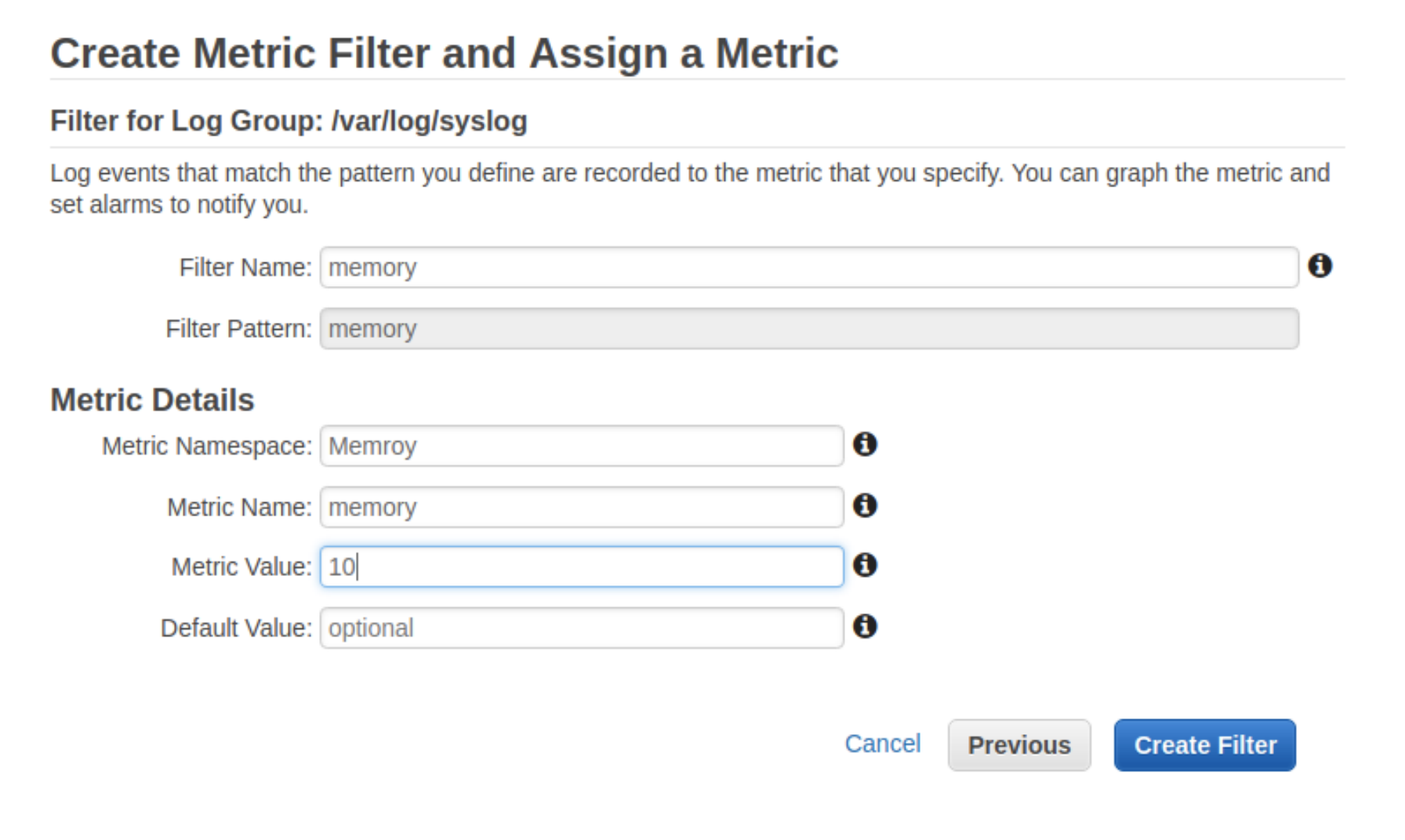
最後の例に加えて、「kernel」という単語を含むすべてのログ行をグループ化するか、「memory」という単語をグループ化したいとします。 以前から「Create metric filter」を使用してこれを実行してみましょう。
注:この例では単純なパターンを使用していますが、AWSでは複雑なユースケースでより高度なパターンを使用できます。 パターンが複雑か単純かに関係なく、パターンを割り当てて、選択したら視覚化できます。
この実際的な例では、前に設定したsyslogストリームから「Memory」という単語をフィルタリングします。 すべてが正常に機能していることを確認するために、メモリの負荷テストを行います。
stress --vm 10 --timeout 200 --- stress: info: [12302] dispatching hogs: 0 cpu, 0 io, 10 vm, 0 hdd stress: FAIL: [12306] (494) hogvm malloc failed: Cannot allocate memorynanoマシンを使用しているので、メモリがこの種のストレステストをサポートしていないことは明らかですが、これはログをチェックして視覚化するための良い練習です。 まず、ここでメモリ障害を確認できます。
同時に、適切な構成で、ログストリーム内の「memory」ワード数を視覚化し、EC2インスタンスメモリの状態を監視できます。
5.4 AWS標準メトリクス
AWSは、デフォルトで設定されたメトリックスも公開します。メトリクスダッシュボードにアクセスすると、AWS名前空間の一部である使用可能なメトリクスを確認できます。カスタムメトリックには異なる名前空間を作成できます。メトリックを別のコンテナに分離する場合は、これをお勧めします。同時に多くのアプリケーションを管理している場合、同じフィードに集約されたさまざまなアプリのメトリックを表示したくないでしょう。
ほとんどのAWSサービスがメトリックスを公開しているという事実を考えると、CloudWatchを効果的に使用するための多くの可能性があります。これらはいくつかの一般的な例です:
IntegrationLatency、Latency、CacheHitCount、およびCacheMissCountメトリックスを集約することにより、Amazon CloudWatchでAPI実行をモニタリングする
ビルドの試行、成功、失敗の数をカウントし、BuildDuration、FailedBuilds、QueuedDurationなどのメトリクスを使用してAWS CodeBuildをモニタリングする
Amazon DocumentDBメトリクスのモニタリング(ディスク使用量、レプリケーションラグ、CPU使用量、ディスクキュー深度など)。 DocumentDBは、BackupRetentionPeriodStorageUsed、Bu ff erCacheHitRatio、CPUUtilization、DatabaseConnections、DBInstanceReplicaLag、DBClusterReplicaLagMaximumなどの多くのメトリックを公開します。
6. まとめ:より良い可観測性なシステムの構築
アラーム、イベント、ログ、およびメトリックス(他のAWSサービスと組み合わせて)は、効率的な監視および監視システムを構築するために必要な柔軟性を提供します。 システムを完全に把握するには、収集および分析する必要のある情報やデータのソースが異なる場合があり、そんな時はAWS CloudWatchが役に立ちます。 CloudWatchの組み込み機能を使用して、最大のデータを収集および集約し、CloudWatchが提供するさまざまなツールを使用してデータを整理および視覚化できます。
AWS CloudWatchを使用してインフラストラクチャのメトリックを収集しているが、よりカスタマイズ可能なアラートと集計データの監視プラットフォームを探している方は、MetricFireの無料トライアルをチェックしてください。 AWSとMetricFireの互換性の詳細については、ドキュメントをご覧ください。 また、AWS CloudWatchをMetricFireと互換性のあるものにする方法について、デモを予約して直接MetricFireに相談することもできます。是非、お試しを。
それでは、またの記事で!

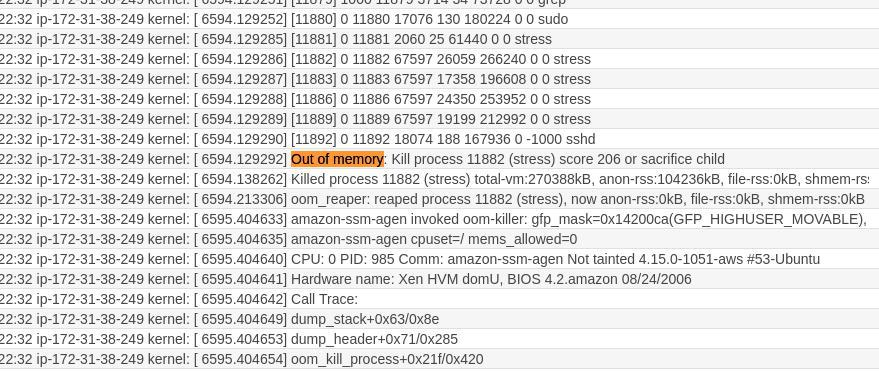
- 投稿日:2020-06-26T05:47:21+09:00
(自分用)AWS_1(Linux仮想マシンとインスタンスの起動/インスタンス周りを整理)
項目
- Linux仮想マシンの起動と整理
1.Linux仮想マシンの起動
1-1.AWSコンソールにアクセス
- AWSにサインアップ後、ページからコンソールにアクセスする
- ルートユーザとIWA?ユーザが有るけど多分
ルートで良いと思う...1-2.インスタンスを作成(仮想マシンを起動)
- コンソールから
EC2を選択- 先に右上の所から東京リージョンを選択しとく
インスタンスを作成を選択Amazon Linux AMIかAmazon Linux2 AMIを選択、取り敢えず無印を選択で良いはず- インスタンスタイプは
t2 microってやつが無料枠なので取り敢えずそれ選択- インスタンス作成の確認→
作成- キーペアを作成みたいなポップアップが出る、上のメニューバーから
新しいキーペアを云々を選択、キーペア名は適当にキーペアのダウンロードをし、後生大事に保存1-3.パブリックIPアドレスを作成
- このままだと見るたびにIPアドレスが変わってなんかめんどくさい
- なのでIPアドレスを固定する
- 左側のメニューから
Elastic IPを選択- 青いそれっぽいボタンを押す
- 指示に従い取り敢えずIPアドレスを作成
アクションを選択し、作成したIPアドレスの関連付けをクリック- インスタンスのテキストバーをクリックすると下になんか出てくる、選択
関連付けるを選択- 完了
1-4.HTTPで接続できる様にする
- SSHだけじゃ色々不都合
- インスタンスのリストから右にスクロールして、
セキリュティグループのリンクをクリック- 上の方にある
アクションを選択インバウンドルールの編集を選択ルールの追加クリックHTTPか任意のそれを選択- 多分保存を押してもエラーが出る
- 送信元みたいなところでエラーが出てるので、そこをクリックしSSHと同じ奴を選択
- 保存
2.終わりに
- 次はリモートコントロールだったり
- 明後日ぐらいまでに
phpMyAdminを接続していよいよ開発へ
- 投稿日:2020-06-26T05:38:31+09:00
[エラー]自動デプロイ実行時のrbenv: ruby 2.5.1 is not installedot〜に関して
はじめに
今回の投稿は私が自動デプロイを実行した時にエラーにハマったので、その内容を共有させていただきます。
エラー内容
[Deprecation Notice] Future versions of Capistrano will not load the Git SCM plugin by default. To silence this deprecation warning, add the following to your Capfile after `require "capistrano/deploy"`: require "capistrano/scm/git" install_plugin Capistrano::SCM::Git 00:00 rbenv:validate WARN rbenv: ruby 2.5.1 is not installed or not found in $HOME/.rbenv/versions/ruby 2.5.1 on 54.95.87.53仮説を立てる
1. require "capistrano/scm/git"
require〜という記述からCapfileに異常があると仮説。2. WARN rbenv: ruby 2.5.1 is not installed〜
ruby 2.5.1 is not installedという記述からruby2.5.1のインストールがされていない、またローカル環境とのverに差異があると仮説。怪しいのはdeploy.rbか...?仮設検証 Capfile
require "capistrano/setup" require "capistrano/deploy" require 'capistrano/rbenv' require 'capistrano/bundler' require 'capistrano/rails/assets' require 'capistrano/rails/migrations' require 'capistrano3/unicorn' require "capistrano/scm/git" install_plugin Capistrano::SCM::Git Dir.glob("lib/capistrano/tasks/*.rake").each { |r| import r }特に異常なし。
仮設検証 ver確認
ローカル開発環境と本番環境(EC2)内でruby -vを実行したが問題なし。
仮設検証 deploy.rb
deploy.rb# config valid only for current version of Capistrano # capistranoのバージョンを記載。固定のバージョンを利用し続け、バージョン変更によるトラブルを防止する lock '3.14.1' # Capistranoのログの表示に利用する set :application, 'chat-space' # どのリポジトリからアプリをpullするかを指定する set :repo_url, 'git@github.com:ken-sasaki-222/chat-space.git' # バージョンが変わっても共通で参照するディレクトリを指定 set :linked_dirs, fetch(:linked_dirs, []).push('log', 'tmp/pids', 'tmp/cache', 'tmp/sockets', 'vendor/bundle', 'public/system', 'public/uploads') set :rbenv_type, :user set :rbenv_ruby, 'ruby2.5.1' #ここに注目 # どの公開鍵を利用してデプロイするか set :ssh_options, auth_methods: ['publickey'], keys: ['~/.ssh/test_key.pem'] # プロセス番号を記載したファイルの場所 set :unicorn_pid, -> { "#{shared_path}/tmp/pids/unicorn.pid" } # Unicornの設定ファイルの場所 set :unicorn_config_path, -> { "#{current_path}/config/unicorn.rb" } set :keep_releases, 5 # デプロイ処理が終わった後、Unicornを再起動するための記述 after 'deploy:publishing', 'deploy:restart' namespace :deploy do task :restart do invoke 'unicorn:restart' end endrubyのverに問題はなさそう。と思いきや...
ver指定の箇所が'ruby 2.5.1'になっている!正しくは'2.5.1'でOK!
修正すると。deploy.rb#省略 set :rbenv_type, :user set :rbenv_ruby, '2.5.1' #ここに注目 #省略これでローカル環境のターミナルにてbndle exec cap production deployを実行すると
無事自動デプロイが走りました。
- 投稿日:2020-06-26T02:43:16+09:00
laravel web.phpで解決 データベース項目追加できなかった件
課題で入力フォームを増やすというものがあったが、どれだけフォームを変更してもデータベースが更新されず常におなじ値になっていた。
原因は、以下の// Eloquent モデルが定数になっていたこと
use App\Book; use Illuminate\Http\Request; /** * 本のダッシュボード表示(books.blade.php) */ Route::get('/', function () { $books = Book::orderBy('created_at', 'asc')->get(); return view('books', [ 'books' => $books ]); //return view('books',compact('books')); //も同じ意味 }); /** * 新「本」を追加 */ Route::post('/books', function (Request $request) { //バリデーション $validator = Validator::make($request->all(), [ 'item_name' => 'required|max:255', 'item_number' => 'required|min:1|max:3', 'item_amount' => 'required|max:6', 'published' => 'required|min:7', ]); //バリデーション:エラー if ($validator->fails()) { return redirect('/') ->withInput() ->withErrors($validator); } //以下に登録処理を記述(Eloquentモデル) // Eloquent モデル $books = new Book; $books->item_name = $request->item_name; $books->item_number = $request->item_number; $books->item_amount = $request->item_amount; $books->published = $request->published; $books->save(); return redirect('/'); }); /** * 本を削除 */ Route::delete('/book/{book}', function (Book $book) { $book->delete(); //追加 return redirect('/'); //追加 }); Auth::routes(); Route::get('/home', 'HomeController@index')->name('home');
- 投稿日:2020-06-26T01:14:44+09:00
【AWS】CloudFormationでRoute53 Private Hosted Zoneを構築してみる
皆さんはEC2インスタンスなどAWS上のリソースの名前解決はどのようにしているでしょうか?
オンプレだとInternal DNS構築して管理すると思います
AWS上で管理するならマネージドの方がいいですよね
そこで今回はRoute53 Private Hosted Zoneを利用してマネージドで内部向けのDNS管理してみます
手ポチやawscliで地道に構築するより、CloudFormation (以下CFnと略) で構築した方が早いですしレコードの管理もしやすいので、CFnを使用した構築方法をご紹介しますCloudFormation
今回はシンプルルーティングポリシーという極一般的なDNSを構築していきます
テンプレート
Private Hosted Zoneの作成には
AWS::Route53::HostedZoneのVPCsでVPCオブジェクトを指定するだけですAWSTemplateFormatVersion: "2010-09-09" Parameters: HostedZoneName: Type: String HostedZoneVPCId: Type: AWS::EC2::VPC::Id FirstServerFQDN: Type: String FirstServerIPAddress: Type: CommaDelimitedList SecondServerFQDN: Type: String SecondServerIPAddress: Type: CommaDelimitedList Resources: MyPrivateHostedZone: Type: AWS::Route53::HostedZone Properties: Name: Ref: HostedZoneName HostedZoneConfig: Comment: My Private Domain VPCs: - VPCId: Ref: HostedZoneVPCId VPCRegion: Fn::Sub: "${AWS::Region}" FirstServerRecordSet: Type: AWS::Route53::RecordSet Properties: Name: Ref: FirstServerFQDN Comment: FirstServer Type: A TTL: "300" HostedZoneId: Ref: MyPrivateHostedZone ResourceRecords: Ref: FirstServerIPAddress SecondServerRecordSet: Type: AWS::Route53::RecordSet Properties: Name: Ref: SecondServerFQDN Comment: SecondServer Type: A TTL: "300" HostedZoneId: Ref: MyPrivateHostedZone ResourceRecords: Ref: SecondServerIPAddress注意点
VPCの関連付け
Private Hosted ZoneをCFnで構築する際に関連付けられるのは1つのVPCだけです
追加で関連付けを行いたい場合はマネジメントコンソールやawscliなどから操作を行ってください
このようなにCFnでできないことがあるので、実運用ではPrivate Hosted ZoneとRecord setでCFnテンプレートを分けた方がいいかもしれませんまた異なるAWSアカウントのVPCを関連付けしたい場合は、awscliやAPIからでしかできないので注意が必要です
手順は作成済みの Amazon VPC と、別の AWS アカウントで作成したプライベートホストゾーンを関連付けるを参考にしてください工夫点
複数IPアドレスの設定
AWS::Route53::RecordSetで複数のIPアドレスを設定できるように、FirstServerIPAddress / SecondServerIPAddressのパラメータタイプでCommaDelimitedListを指定します
これで冗長構成でも使えるCFnテンプレートになります参考
- 投稿日:2020-06-26T00:53:19+09:00
Amazon Honeycode 上でのデータの扱いとAWS上のデータを扱うためには
Amazon Honeycodeの概要や操作感は公式ブログやレビュー記事があるので、実際のアプリケーション開発に必要となるデータの扱いについて調べました。
[6/24 9:40 追記]
IoT デバイスからのデータを AWS Lambda を通じて Amazon Honeycode で表示している様子が掲載されています。
"Amazon HoneycodeにIoTデバイスからデータを送ろう": https://blog.soracom.jp/blog/2020/06/26/send-data-to-amazon-honeycode/Amazon Honeycode は自前でDBを持っている
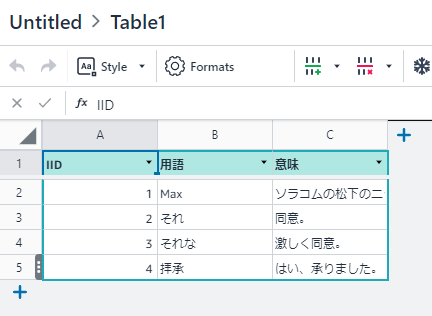
Amazon Honeycode(以下、Honeycode)は、Honeycode自身にストレージを持っています。管理単位はTablesと呼ばれ、RDBのテーブルと同等と考えて良いです。
ただしリレーションシップは作れません(2020年6月時点)。なので、スプレッドシートに近い感じです。
Amazon HoneycodeのアプリケーションからAWSサービス上のDBなどは参照することができない
Honeycodeで作るアプリケーションのデータソースに例えばAmazon DynamoDBといったAWSサービス上のDBサービスを参照する事はできません。(2020年6月時点)
じゃあAWS上で作られたデータをどうやってHoneycodeで扱えるようにするかというと、Honeycode APIを経由してTablesに入れることになります。
※ 個人的にはきっとダイレクトにRead/Writeできるようになるアップデートがあると信じている。
Amazon HoneycodeのAPIを呼ぶためにはPlus以上のプランが必要です
Freeプランでは呼び出せません。そうやって書いてある。
https://honeycodecommunity.aws/t/getting-started-with-honeycode-apis/790Upgrading to a Plus or Pro plan is a prerequisite to accessing developer tools and Honeycode APIs.
Plus 以上へのアップグレードは、HoneycodeのTeamsメニューからAWS accountを接続する必要があります。
課金はそこから支払われるようです(ごめん、ここは未確認だけど多分そう)。Amazon HoneycodeのAPIを経由したデータ操作の呼び出し方
APIの呼び出し方自体は https://honeycodecommunity.aws/t/getting-started-with-honeycode-apis/790 に書いてある通りですが、ここで「Honeycodeのアプリケーション構造」を理解しておくとスムーズです。
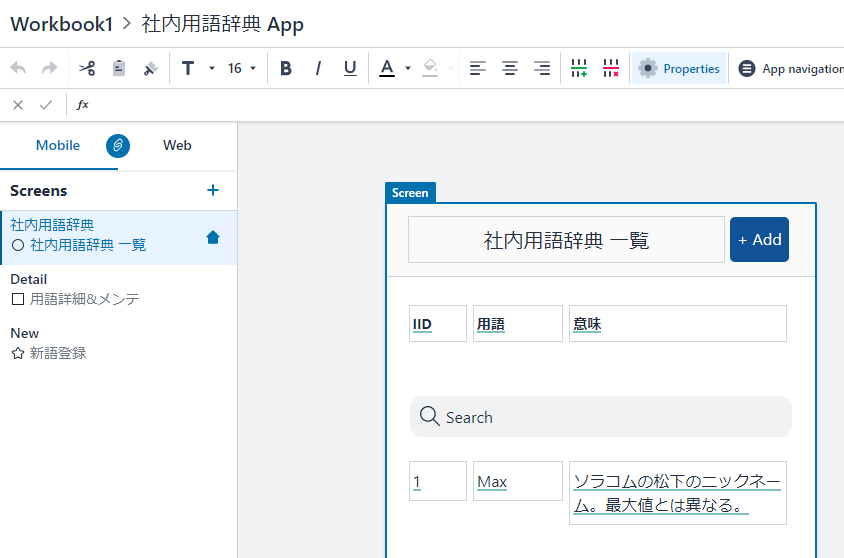
Amazon Honeycodeのアプリケーション構造
Honeycodeはworkbookを頂点に階層構造となっています。APIの呼び出しもこの階層構造を追う形です。
Workbook +-- (Tables) +-- App +-- Screen +-- Screen Automation
- WorkbookはHoneycodeのアプリケーション開発スペースとなります。この中にAppを作っていくわけです。
- TablesはWorkbookの配下ですので、Tablesは複数のAppで共有できるという事です。カッコ書きな理由は、TablesにはIDが無いのです。このIDが何者かは後述します。
- Appは名前の通りアプリケーションです。配布の単位にもなります。
- ScreenはWebアプリで言えばページです。データを表示するページ、データを入力するページ、、、といった単位で作るのが一般的になりそうです。
- Screen Automationはイベントハンドラです。「ボタンをクリックしたときに~を実行する」というアクションになります。
Amazon HoneycodeのAPIを経由したデータ操作の呼び出し方
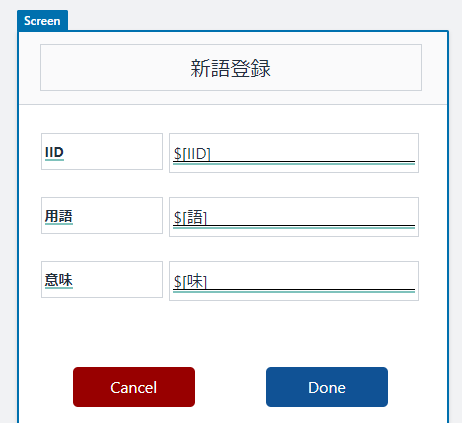
データの操作をどうやってやるのかというと、例えばデータを追加するには...
- データを追加するScreen Automationを作って
- それをScreen上に配置してから
InvokeScreenAutomationでScreen Automationを実行するという仕組みです。追加したいデータの引き渡しはAWS CLIであれば
--variablesでScreen上のテキストボックスを指定して値を設定します。要するに「テキストボックスにパラメータの値を入れて、ボタンを押す」ことでデータの操作を行うわけです。1
そのため「どのWorkbookの、どのAppの、どのScreenの、どのScreen Automation」と階層的に指定していくことになります。
上の例だと「Done」を狙い撃つわけです。削除や更新も同様に、そのアクションに対応したScreen Automationを作成し、ボタンをScreenに配置して、そのボタンを
InvokeScreenAutomationで狙い撃ちします。
データ取得はGetScreenDataになりますが、これもお察しの通り「Screenに表示されている内容がJSONで取得できる」というものです。Tablesを直接いじりたい気持ちはとてもわかりますが、APIで呼び出すために必要なIDが割り当てられてなく(見えないだけかな?)、また、Tablesを直接操作するAPI自体も存在しない事から現時点では無理の様です。(2020年6月時点)
AWSからはLambda 関数を使うことになる
Python3のSDKがリリース済みのようですので、Lambda関数からも
invoke_screen_automationを呼ぶことができます。
そのためAWS側からHoneycodeへLambda 関数を経由してデータを送る形になります。Honeycode Community は入っておいた方がいい
スタートしたばかりのAmazon Honeycodeですので最新情報のキャッチアップが必要となりますが、それもHoneycode Communityを見ておけば大丈夫そうです。Getting StartやAnnouncementもあるので、入っておきましょう。
あとがき
公式ブログの出だしに「VisiCalc」を持ってくるあたり、さすがJeff Barr。そういう大人になりたい。
EoT
スクレイピングかよ!wwww ↩