- 投稿日:2020-06-23T23:59:05+09:00
[光-Hikari-のPython]07章-02 例外処理(例外処理によるプログラムの継続実行)
[Python]07章-02 例外処理によるプログラムの継続実行
07章-01では2つの例の例外について取り扱いました。
しかし、前節でも見た通り、例外が発生すると、その場でブログラムが終了してしまいます。このプログラムを継続して処理したり、または継続できなくても画面に例外が発生した旨を通知したりする必要があります。
今回は、例外が発生した際の例外処理について説明していきます。例外処理の記載
前述した通り、例外が発生すると処理がそのまま中断してしまいます。そのため、中断をさせないために、別の個所に記載されたプログラムでの処理を実行していく必要があります。こういった処理を例外処理と言います。
例外処理はおおよそ以下のように記述します。
try: 例外処理を行いたい場所 except: 例外を処理する場所実際に、例外処理を記述してみましょう。chap07の中にsamp07-02-01.pyというファイル名でファイルを作成し、以下のコードを書いてください。
samp07-02-01.pyprint('割り算a÷bを求めます。') try: a = int(input('aの値を入力してください:')) b = int(input('bの値を入力してください:')) print(a / b) except: print('0による除算がおこなわれましたので、処理を終了します。')【実行結果】
割り算a÷bを求めます。
aの値を入力してください:10
bの値を入力してください:0
0による除算がおこなわれましたので、処理を終了します。今回、try:のブロックにおいて、0による除算が行われたため、例外処理が発生します。すると、except:ブロックへ飛び、そのブロック内での処理が行われます。
なお、07章-01のときにはtry~catchを記載していなかったため、処理が強制的に中断して赤文字でエラーメッセージが出ていましたが、今回は例外処理が発生しているため、エラーメッセージは出ておりません。
このように、except内では、例外が発生した際の処理を書きます。今回はprint関数による出力でしたが、「監視端末への通知を行う」、「再度処理を促す」などといったことに使用したりします。
特定の例外
先ほどはexceptと記載していました。今回は「bに0が代入されるかもしれない」という前提でexcept内には「0による除算がおこなわれましたので、処理を終了します。」と出力していました。
しかし、例外にはほかにもあります。exceptにしてしまうと、0による除算以外での例外も発生する可能性があります。
例えば、入力の際に数値でなく誤って文字を入力してしまうと以下のエラーが出力されます。先ほどのプログラムsamp07-02-01.pyの実行結果です。【実行結果】
割り算a÷bを求めます。
aの値を入力してください:10
bの値を入力してください:z
0による除算がおこなわれましたので、処理を終了します。これを見てみると、bの個所に'z'という文字が入っています。これは0による除算の例外ではありません。本来は数値を入力しなければならないところに文字を入れたことによる例外です。
したがって、exceptとしてしまうと、どのような例外でも例外処理を実行させてしまいます。
この場合、「0による除算の例外処理」と「文字を入力した際の例外処理」2つ準備する必要があります。これらはそれぞれ特定の例外となり、それぞれに対しての例外処理を実行させる必要があります。以下のURLを見てみるとわかるのですが、特定の例外がかなりの種類があります。
https://docs.python.org/ja/3/library/exceptions.html#concrete-exceptions
上記のサイトにも記載がありますが、今回はこの中で、「0による除算の例外処理」がZeroDivisionError、「文字を入力した際の例外処理」が「文字を入力した際の例外処理」を使用します。
chap07の中にsamp07-02-02.pyというファイル名でファイルを作成し、以下のコードを書いてください。samp07-02-02.pyprint('割り算a÷bを求めます。') try: a = int(input('aの値を入力してください:')) b = int(input('bの値を入力してください:')) print(a / b) except ZeroDivisionError: #bの値が0出会ったときに行う例外処理 print('0による除算がおこなわれましたので、処理を終了します。') except ValueError: #aまたはbが数値でなかった際に行う例外処理 print('数値でないデータが入力されましたので処理を終了します。')【実行結果1】
割り算a÷bを求めます。
aの値を入力してください:10
bの値を入力してください:0
0による除算がおこなわれましたので、処理を終了します。【実行結果2】
割り算a÷bを求めます。
aの値を入力してください:10
bの値を入力してください:z
数値でないデータが入力されましたので処理を終了します。順に処理を追ってみます。
まず、0による除算の場合の例外について、上記のURLには以下の記載があります。exception ZeroDivisionError
除算や剰余演算の第二引数が 0 であった場合に送出されます。関連値は文字列で、その演算における被演算子と演算子の型を示します。最初の【実行結果1】では、bの値として0が代入されたため、例外が発生し、ZeroDivisionError側の例外処理が行われます。
exception ValueError
演算子や関数が、正しい型だが適切でない値を持つ引数を受け取ったときや、 IndexError のようなより詳細な例外では記述できない状況で送出されます。【実行結果2】では、bの値として'z'が代入され、除算ができないために例外が発生し、ValueError側の例外処理が行われます。
演習問題
演習問題を用意しました。ぜひ解いてみてください。プログラムはchap07内に作成してください。使用する変数名は好きな変数名を指定してかまいません。
【1】07章-01で書いた以下のプログラム、ls = [1, 3, 5, 7, 9] print(ls) i = int(input('上記のリストの要素番号を指定してください:')) print(ls[i])について、例外処理を発生させるプログラムを作成してください。なお、特定の例外を使った方法で作成してください。特定の例外は先ほどの上記あるURLで調べてみましょう。
【実行結果】
[1, 3, 5, 7, 9]
上記のリストの要素番号を指定してください:5
リストの要素を超えて指定しています。最後に
例外処理はエラーに強いプログラムを作る方法の1つであることを留めておいてください。例外処理によりプログラムがエラーにならないため、重大なインシデントも防ぐ意味でも、ぜひ身に着けておきましょう。今後もよく登場します。
【目次リンク】へ戻る
- 投稿日:2020-06-23T23:50:32+09:00
Python のインストール 2020(macOS)
Python は標準機能だと以下の仕様です。
- ローカルマシンに 1 つのバージョンしか動かせない
- プロジェクトごとに実行される Python のバージョンを変えられない
依存ライブラリ(pip でインストールするライブラリ)がローカルマシン共通でインストールされる
- プロジェクトごとに依存ライブラリのバージョンを変えられない
- どのプロジェクトの依存ライブラリかわからなくなる
個人的なスクレイピング程度のことをする場合は、あまり問題になりません。しかし、複数人での開発、複数プロジェクトの開発を行う場合は、これらが問題となります。
これらは「バージョン管理」「依存ライブラリ管理」するためのツールを使用することで解決することができます。
今回は、macOS にインストールする方法になります。
今回使用するツール
- pyenv
- バージョン管理ツール
- poetry
- 依存ライブラリ管理ツール
- pipx
- 依存ライブラリを共通して使用できるツール
pyenv のインストール
バージョンを切り替えるツールとして「pyenv」が人気です。
pyenv
pyenv は、Python の複数バージョンを切り替えることができるツールです。ローカルマシンのバージョンを切り替えることができるのはもちろん、特定のディレクトリ配下で動作する Python のバージョンを指定することもできます。
インストール
brew からインストールします。(brew 自体のインストール方法は省きます)
brew install pyenvインストール後パスを通す必要があります。shell に zsh を使用している例です。
bash を使用している場合は、「~/.zshrc」を「~/.bashrc」に修正して実行してください。echo 'export PYENV_ROOT="$HOME/.pyenv"' >> ~/.zshrc echo 'export PATH="$PYENV_ROOT/bin:$PATH"' >> ~/.zshrc echo 'eval "$(pyenv init -)"' >> ~/.zshrcバージョン切り替え
pyenv でインストールとバージョンの切り替えができます。
pyenv install 3.8.3 ## python3.8.3を取得します pyenv global 3.8.3 ## ローカルマシンで使用するバージョンを切り替えますpipx のインストール
プロジェクト間の依存回避のためには、必要ないツールなのですが、共通して使用する依存ライブラリをインストールする際に便利です。
pipx
poetry でプロジェクトごとに依存ライブラリをインストールすると、共通して使用するライブラリ(「aws cli」などの、Python のコードから使用するのではなく、OS から直接使用するツール)をプロジェクトごとに毎回インストールしなければいけません。pipx コマンドで依存ライブラリをインストールすると、どのプロジェクトからでも共通して使用できます。
インストール
brew install pipxインストール後はパスを通します。
echo 'export PATH=$PATH:~/.local/bin' >> ~/.zshrcpoetry のインストール
依存ライブラリ管理ツールとして poetry を使用します。
poetry
poetry は依存ライブラリを通常のインストール先とは隔離された場所にインストールしてくれるツールです。隔離された環境のことは仮想環境と呼ばれています。
また、配布用にライブラリを作成する際のパッケージングまで行うことができます。インストール
pipx を使用してインストールします。
pipx install poetrypipx を使用していない場合は、インストーラースクリプトからインストールします。
curl -sSL https://raw.githubusercontent.com/sdispater/poetry/master/get-poetry.py | python python get-poetry.py仮想環境のインストール先は各プロジェクト内に作成された方が自分好みなので設定を変更します。
poetry config virtualenvs.in-project trueこの設定をすると、プロジェクト内の venv フォルダに仮想環境が作成されるようになります。
プロジェクトの作成方法
実際にプロジェクトを作成してみます。
Python バージョンの指定
ルートディレクトリをプロジェクトのディレクトリに指定し Pyenv で Python のバージョンを指定します。
pyenv local 3.8.3pyproject.toml 作成
このファイルにプロジェクトで使用する依存ライブラリが記載されていきます。
poetry initpoetry 仮想環境内の Python を実行できることを確認します。
poetry run python -Vバージョンが表示されれば正常にインストールできています。
依存ライブラリ追加
プロジェクトの依存ライブラリを追加します。
poetry add {パッケージ名} ## プロジェクトに依存ライブラリを追加 protry add --dev {パッケージ名} ## 開発用の依存ライブラリを追加コマンドから実行
poetry から追加した依存ライブラリは poetry コマンドから実行できます。
poetry run {パッケージ名}小ネタ
Python を使用するにあたりちょっと便利な小ネタです。
依存ライブラリを全て削除
pip freeze > requirements.txt sudo pip uninstall -r requirements.txt依存パッケージのインストール場所を調べる
pip も Python の依存ライブラリなので、pip のインストール場所を調べることでわかります。
pip show pipLocation にインストール場所が表示されます。
- 投稿日:2020-06-23T23:50:32+09:00
Python のインストール界隈 2020(macOS)
Python は標準機能だと以下の仕様です。
- ローカルマシンに 1 つのバージョンしか動かせない
- プロジェクトごとに実行される Python のバージョンを変えられない
依存ライブラリ(pip でインストールするライブラリ)がローカルマシン共通でインストールされる
- プロジェクトごとに依存ライブラリのバージョンを変えられない
- どのプロジェクトの依存ライブラリかわからなくなる
個人的なスクレイピング程度のことをする場合は、あまり問題になりません。しかし、複数人での開発、複数プロジェクトの開発を行う場合は、これらが問題となります。
これらは「バージョン管理」「依存ライブラリ管理」するためのツールを使用することで解決することができます。
今回は、macOS にインストールする方法になります。
今回使用するツール
- pyenv
- バージョン管理ツール
- poetry
- 依存ライブラリ管理ツール
- pipx
- 依存ライブラリを共通して使用できるツール
pyenv のインストール
バージョンを切り替えるツールとして「pyenv」が人気です。
pyenv
pyenv は、Python の複数バージョンを切り替えることができるツールです。ローカルマシンのバージョンを切り替えることができるのはもちろん、特定のディレクトリ配下で動作する Python のバージョンを指定することもできます。
インストール
brew からインストールします。(brew 自体のインストール方法は省きます)
brew install pyenvインストール後パスを通す必要があります。shell に zsh を使用している例です。
bash を使用している場合は、「~/.zshrc」を「~/.bashrc」に修正して実行してください。echo 'export PYENV_ROOT="$HOME/.pyenv"' >> ~/.zshrc echo 'export PATH="$PYENV_ROOT/bin:$PATH"' >> ~/.zshrc echo 'eval "$(pyenv init -)"' >> ~/.zshrcバージョン切り替え
pyenv でインストールとバージョンの切り替えができます。
pyenv install 3.8.3 ## python3.8.3を取得します pyenv global 3.8.3 ## ローカルマシンで使用するバージョンを切り替えますpipx のインストール
プロジェクト間の依存回避のためには、必要ないツールなのですが、共通して使用する依存ライブラリをインストールする際に便利です。
pipx
poetry でプロジェクトごとに依存ライブラリをインストールすると、共通して使用するライブラリ(「aws cli」などの、Python のコードから使用するのではなく、OS から直接使用するツール)をプロジェクトごとに毎回インストールしなければいけません。pipx コマンドで依存ライブラリをインストールすると、どのプロジェクトからでも共通して使用できます。
インストール
brew install pipxインストール後はパスを通します。
echo 'export PATH=$PATH:~/.local/bin' >> ~/.zshrcpoetry のインストール
依存ライブラリ管理ツールとして poetry を使用します。
poetry
poetry は依存ライブラリを通常のインストール先とは隔離された場所にインストールしてくれるツールです。隔離された環境のことは仮想環境と呼ばれています。
また、配布用にライブラリを作成する際のパッケージングまで行うことができます。インストール
pipx を使用してインストールします。
pipx install poetrypipx を使用していない場合は、インストーラースクリプトからインストールします。
curl -sSL https://raw.githubusercontent.com/sdispater/poetry/master/get-poetry.py | python python get-poetry.py仮想環境のインストール先は各プロジェクト内に作成された方が自分好みなので設定を変更します。
poetry config virtualenvs.in-project trueこの設定をすると、プロジェクト内の venv フォルダに仮想環境が作成されるようになります。
プロジェクトの作成方法
実際にプロジェクトを作成してみます。
Python バージョンの指定
ルートディレクトリをプロジェクトのディレクトリに指定し Pyenv で Python のバージョンを指定します。
pyenv local 3.8.3pyproject.toml 作成
このファイルにプロジェクトで使用する依存ライブラリが記載されていきます。
poetry initpoetry 仮想環境内の Python を実行できることを確認します。
poetry run python -Vバージョンが表示されれば正常にインストールできています。
依存ライブラリ追加
プロジェクトの依存ライブラリを追加します。
poetry add {パッケージ名} ## プロジェクトに依存ライブラリを追加 protry add --dev {パッケージ名} ## 開発用の依存ライブラリを追加コマンドから実行
poetry から追加した依存ライブラリは poetry コマンドから実行できます。
poetry run {パッケージ名}小ネタ
Python を使用するにあたりちょっと便利な小ネタです。
依存ライブラリを全て削除
pip freeze > requirements.txt sudo pip uninstall -r requirements.txt依存パッケージのインストール場所を調べる
pip も Python の依存ライブラリなので、pip のインストール場所を調べることでわかります。
pip show pipLocation にインストール場所が表示されます。
- 投稿日:2020-06-23T23:24:55+09:00
音楽データからボーカルと楽器を分離できる「spleeter」について
開発環境
OS:Windows10
コマンド:Git Bushを使用spletterとは
ボーカルや複数の楽器で構成された音楽データを、機械学習を用いてそれぞれの音に分類したファイルとして出力できるものらしい
詳細書いてある通りにするとうまくいかない

この通りにすると、「conda env create -f spleeter/conda/spleeter-cpu.yaml」を実行した段階でエラーが起きる
原因
そもそもgit cloneしたリンクに
conda/spleeter-cpu.yamlというパスが存在しないため解決策
spletterのgitHubの修正リンクがあった!
しかし、 README.mdのQuick startに書かれている内容ではうまくいかないため
下に修正版を乗せるhttps://github.com/sigsep/spleeter-musdb conda env create -f spleeter-musdb/conda/spleeter-cpu.yaml conda activate spleeter-cpu spleeter separate -i spleeter-musdb/audio_example.mp3 -p spleeter:2stems -o output4つ目の「spleeter separate -i spleeter-musdb/audio_example.mp3 -p spleeter:2stems -o output」では、-i 音源のパス -o 出力先のパス -p spleeter:2(ボーカルと伴奏の分離)という意味
詳しくはこちら
なお、windowsでの、コマンドプロンプトやPowerShellでは4つ目のsepleenerが使えないので、python -m spleeter separate~ と書くとうまくいくはず、、たぶん
だいぶ端折った説明になっているので、間違いや質問があれば、下のコメント欄からよろしくお願いしまーす

- 投稿日:2020-06-23T23:05:00+09:00
Enum
import enum #@enum.unique class Status(enum.Enum): ACTIVE = 1 RENAME_ACTIVE = 1 #デコレーターをつけている場合はエラー出る #ACTIVE = 2 エラー出る INACTIVE =2 RUNNING = 3 print(Status.ACTIVE) #print(Status.STOPPING) エラー出る print(Status.RENAME_ACTIVE) #ACTIVEが返ってくる print(repr(Status.ACTIVE)) print(Status.ACTIVE.name) #ACTIVE print(Status.ACTIVE.value) #1 for s in Status: print(s) print(type(s)) print(Status(1)) #Status.ACTIVE実行結果:
Status.ACTIVE Status.ACTIVE <Status.ACTIVE: 1> ACTIVE 1 Status.ACTIVE <enum 'Status'> Status.INACTIVE <enum 'Status'> Status.RUNNING <enum 'Status'> Status.ACTIVEimport enum class Status(enum.IntEnum): ACTIVE = 1 INACTIVE =2 RUNNING = 3 print(Status.ACTIVE) # Status.ACTIVE print(type(Status.ACTIVE)) # <enum 'Status'> print(Status.ACTIVE == 1) # True 判定の時だけ数値に置き換えてくれるimport enum class Perm(enum.IntFlag): R = 4 W = 2 X = 1 print(Perm.R | Perm.W) # Perm.R|W print(repr(Perm.R | Perm.W | Perm.X)) # <Perm.R|W|X: 7> RWX = Perm.R | Perm.W | Perm.X print(Perm.W in RWX) # True
- 投稿日:2020-06-23T22:59:17+09:00
Tello eduで編隊飛行入門(Python)
はじめに
時代に乗り遅れた感ありますが、telloで編隊飛行やってみました。いろんな人がやっていますが、Pythonでやったのまとめてる人あんま見なかったんで、半分自分用でまとめときます。
参考サイト
以下の記事/サイトに大変お世話になりました。
ありがとうございます。
Tello Eduを子機にしてwifiアクセスポイントに接続する【python】
DJI の教育用トイドローン TELLO EDU で編隊飛行に挑戦(2)Telloの設定
前項で提示したTello Eduを子機にしてwifiアクセスポイントに接続する【python】様を参考にさせていただきました。
皆さんもこちらをご覧ください。ipアドレスの確認
自分だけかもしれませんがipに対する理解が浅くここではまりました。自分は192.168.10.1にとりあえず命令投げ解けばいいだろとか思ってましたが違いました。
まず、telloの接続先を自分のPCのホットスポットにします。そうすると
みたいな感じでIPアドレスが表示されるので、確認しておきましょう。winキー押してMobileHotspotで調べれば出てきます。実際のプログラム
import socket import time drone1 = '192.168.137.125' drone2 = '192.168.137.17' tello_port = 8889 #udpソケット socket = socket.socket(socket.AF_INET, socket.SOCK_DGRAM) drone1_address = (drone1 , tello_port) drone2_address = (drone2 , tello_port) #コマンドモードに入る socket.sendto('command'.encode('utf-8'),drone1_address) socket.sendto('command'.encode('utf-8'),drone2_address) time.sleep(3) #離陸 socket.sendto('takeoff'.encode('utf-8'),drone1_address) socket.sendto('takeoff'.encode('utf-8'),drone2_address) time.sleep(0.1) #着陸 socket.sendto('land'.encode('utf-8'),drone1_address) socket.sendto('land'.encode('utf-8'),drone2_address)非常にシンプルな形に落ち着きます。
これなら任意の数のドローンに対応することができます。
注意点として先ほども申し上げましたが、ドローンのipは皆さん異なると思うので(違ったらすみません)きちんとご自分でお調べください。お願いします。
課題として、ドローンの数が増えるとコードがきもくなってしまいます。今後の課題として、ブロードキャストでできたらかっこいいかな??なんて思っています。

- 投稿日:2020-06-23T22:54:52+09:00
アルファチャンネルつき png を透過画像で貼り付ける with Python/OpenCV
TL; DR
bg.jpgの左上に、png_image.png(アルファチャンネルつき画像)を重ねる場合のコードです。import cv2 frame = cv2.imread("bg.jpg") png_image = cv2.imread("alpha.png", cv2.IMREAD_UNCHANGED) # アルファチャンネル込みで読み込む # 貼り付け先座標の設定。とりあえず左上に x1, y1, x2, y2 = 0, 0, png_image.shape[1], png_image.shape[0] # 合成! frame[y1:y2, x1:x2] = frame[y1:y2, x1:x2] * (1 - png_image[:, :, 3:] / 255) + \ png_image[:, :, :3] * (png_image[:, :, 3:] / 255)簡単な解説
PNG ファイルには「アルファチャンネル」という各ピクセルの透明度を表すデータが入っています。値域は RGB と同じく 0-255 です。255 のときに 100% 有効で、0 のときに 0% (完全に透明)になります。
png_image = cv2.imread("alpha.png", cv2.IMREAD_UNCHANGED) # アルファチャンネル込みで読み込む通常の
cv2.imread()では、[h, w, 3]のnumpy.ndarrayの形になりますが、cv2.IMREAD_UNCHANGEDを指定してcv2.imread()を呼び出すと、[h, w, 4]の形になります。BGRがBGRAと、最後にアルファチャンネルがつきます。画像を読み込めたら、合成します。といっても、NuPy の通常の行列演算で合成可能です。やっていることは、元々の背景画像・描画する画像を、それぞれアルファチャンネルの数値で配分して、足し合わせています。
frame[y1:y2, x1:x2] = frame[y1:y2, x1:x2] * (1 - png_image[:, :, 3:] / 255) + \ png_image[:, :, :3] * (png_image[:, :, 3:] / 255)
png_image[:, :, 3:]がアルファチャンネルの取り出しです。アルファチャンネルの値域は 0-255 なので、255 で割って 0-1 の比率にします。描画する画像には計算した比率を掛け、背景のほうには比率の "残り" を掛け、足し合わせることで、最終的な画像を得ることが出来ます。ちなみに、
png_image[:, :, 3]と書くと、行列のサイズが合わないと怒られるので注意してください(間違えた)。例
bg.jpg
alpha.png
cv2.imwrite("result.jpg", frame)した結果
余録
色々参考になるサイトはありつつ、そのものズバリなコードをうまく検索できなかったので、記事を作ってみました。(当たり前すぎてかえって書かなかったりするのかもしれませんね)
参考にさせてもらったサイト
画像は かわいいフリー素材集 いらすとや の素材を使わせてもらいました。



- 投稿日:2020-06-23T22:44:53+09:00
ブログの目的
はじめに
初めまして。
大学生をしております。
Qiitaは技術ブログとしてはじめました。
2020年4月からプログラミングの学習を始めました。取り組んでいること
主に競プロ、機械学習に取り組んでおります。
一応HTML, CSS, WordPressにも取り組んでみましたが触った程度です。Progateに毛がはえたくらいしかかけません。
今年の10月に基本情報技術者を取得するために勉強しております。
Pythonが得意です。 PHP,jsは文法を知っている程度です。このブログに書くこと
主に競プロ、機械学習、またはスクレイピングなどの実務関係のことで学んだことをまとめてアウトプットする目的で書いていこうと思います。
アルゴリズムの解説、参考になったコード、ライブラリの使い方等です。最後に
まだまだ未熟者ですが、私の記事をご覧になっている方がいらっしゃれば遠慮なくご意見等いただければ幸いです。
- 投稿日:2020-06-23T22:43:50+09:00
vscodeにblackを導入したけど、自動フォーマットされない
はじめに
全然効かないblack。
何でだろう?チェックポイント
- pythonは3.6以降ですか?
- 適切な設定をしていますか?
- オプションの付け方が間違っていませんか?
私は3番にハマりました。
いきなり色々変更するのはやっぱりよくないですね...settings.json"[python]": { "editor.tabSize": 4, "editor.detectIndentation": false, "editor.formatOnSave": true, }, "python.linting.enabled":true, "python.linting.pylintEnabled": false, "python.linting.flake8Enabled": true, "python.linting.lintOnSave":true, "python.formatting.provider": "black", "python.linting.flake8Args": [ "--max-line-length=120", "--ignore=E203,W503,W504" ], "python.formatting.blackArgs": [ "--line-length=120" ],自動フォーマットが効かない問題は、1行における最大文字数の指定方法でした。
- flake8→max-line-length
- black →line-length
まじか
以上。
- 投稿日:2020-06-23T22:12:59+09:00
【AWS;Lambda入門】第二弾;jsonファイルから文章抽出してS3保存♬
前回は、以下のコードでs3://バケットに配置されたmp3ファイルをtranscribeしてテキストに変換して、jsonファイルをOutputBucketNameのS3;バケットに配置した。
今回は、このjsonファイルを呼び出して、テキスト変換された文章を抽出しようと思います。わざわざ前回コードを出したのは、今回もコードが似ているからです。s3 = boto3.client('s3') transcribe = boto3.client('transcribe') def lambda_handler(event, context): bucket = event['Records'][0]['s3']['bucket']['name'] key = urllib.parse.unquote_plus(event['Records'][0]['s3']['object']['key'], encoding='utf-8') try: transcribe.start_transcription_job( TranscriptionJobName= datetime.datetime.now().strftime('%Y%m%d%H%M%S') + '_Transcription', LanguageCode='ja-JP', Media={ 'MediaFileUri': 'https://s3.ap-northeast-1.amazonaws.com/' + bucket + '/' + key }, OutputBucketName='lamoutput' ) ... raise eということで、以下のコードで実施できました。
S3;バケットに保存する方法は参考のとおりにしています。
【参考】
①【AWS Lambdaの基本コードその2】 S3へのファイル保存
②Boto3 で S3 のオブジェクトを操作する(高レベルAPIと低レベルAPI)
参考①のコメントを残しています。ほぼまんまなコードで動きました。
異なるのは、先日のjsonファイルの取り扱い方を取り入れている部分です。
まず、Libは以下のとおり、# ①ライブラリのimport import boto3 import urllib.parse from datetime import datetime import json以下は、参考②から真似してclientを定義しています。
print('Loading function') # ②Functionのロードをログに出力 s3 = boto3.resource('s3') # ③S3オブジェクトを取得 client = s3.meta.clientlambda_handlerの入りのbucket, keyの取得は、上記のtranscribeのコードと全く同一です(当然ですが。。)。
# ④Lambdaのメイン関数 def lambda_handler(event, context): bucket = event['Records'][0]['s3']['bucket']['name'] key = urllib.parse.unquote_plus(event['Records'][0]['s3']['object']['key'], encoding='utf-8')以下は、参考②と同じコードでjsonファイルから、response['Body']を読込ます。
ところが、ここで躓きました。
つまり、このbody.decode('utf-8')とすれば日本語の文章が表れると思っておりました。が、現実は結構なjson likeな(文字列)が出現。
当初は、これは文字列と気づかず、jsonファイルだと思いました。
ということで、文字列と気づき、さらにjson.loadsでjsonファイルに変換できることが分かり、...やっと以下のコードにたどり着きました。
つまり、bodyは文字列です。response = client.get_object(Bucket=bucket, Key=key) body = response['Body'].read()文字列をjsonファイルに変換します。
dec = json.loads(body)そして、jsonファイルなるがゆえに以下のように日本語文章が簡単に抽出できました。
con_el=dec["results"]["transcripts"][0]["transcript"] print('contents=',con_el)
contents= こんにちは 東京 横浜 も 少し 曇り です 声 は 水木 さん です
最後に以下のように指定したs3;バケットにkeyのような時刻入りの.txtとして保存できます。bucket = 'muauanpub' # ⑤バケット名を指定 key = 'test_' + datetime.now().strftime('%Y-%m-%d-%H-%M-%S') + '.txt' # ⑥オブジェクトのキー情報を指定 file_contents = con_el # 'Lambda test' # ⑦ファイルの内容 obj = s3.Object(bucket,key) # ⑧バケット名とパスを指定 obj.put( Body=file_contents ) # ⑨バケットにファイルを出力 returnまとめ
・音声ファイルを変換したjsonファイルから文章抽出してs3バケットに保管できた
・これで二段階になっていますが、mp3ファイルをs3バケットに置くと、自動的にそのテキスト変換された文章そのものがs3バケットに保存されるようになりました。
・一応、Teraterm→ec2→s3バケット転送...s3バケットからダウンロード⇒表示は出来ました・あと、このs3バケットに音声ファイルを転送するアプリとs3バケットのテキストファイルを表示するアプリが出来るとより使いやすい音声ファイル-テキスト変換アプリが出来そうです(Web化)
・変換時間が長くともどちらのLambda関数も非同期起動なので、お金にも時間にも優しいアプリになりそうです
- 投稿日:2020-06-23T22:00:42+09:00
zipline Beginner Tutorial
1.この記事は
ziplineのBeginner Tutorial(リンクはこちら)に載っているバックテストを動かすまでの手順を説明します。
2.内容
2-1 準備
下記リンク記事の2-1,2-2,2-3を終わらせてください。
2-1 python3.5をjupyter仮想環境上にインストールする。
2-2 仮想環境上にziplineをインストールする。
2-3 benchmarks.pyとloaders.pyの修正2-2 銘柄データの取得
Quandle APIを使って株価データを取得します。(無料アカウントの場合2018年以降のデータは取得できないようです。) 使用するには、https://www.quandl.com/にアクセスし、APIキーの取得をまず行ってください。
(0)https://www.quandl.com/よりAPIキーを入手する。
入手したキーを"xxx123"とします。(1)anaconda3プロンプトを立ち上げます。
(2)QUANDLのAPIキーをセットします。
windowsの場合は下記のとおりset ***でAPIキーをセットする必要があります。(python355) C:\Users\***\anaconda3>set QUANDL_API_KEY=xxx123(3)QUANDLから株価データを入手します。
(python355) C:\Users\***\anaconda3>zipline ingest(4)データセット「quandl」が作成されていることが確認できます。
(python355) C:\Users\fdfpy\anaconda3>zipline bundles quandl 2020-06-23 11:59:39.4784492-3 Beginner Tutorialの実行(コンソールで実行)
コンソールで実行する場合、C:/Users/fdfpy/anaconda3/envs/python355/Lib/site-packages/zipline/examples/buyapple.py を実行します。
(1)anaconda3プロンプトを立ち上げます。
(2)C:/Users/fdfpy/anaconda3/envs/python355/Lib/site-packages/zipline/examples/に移動します。
(3)buyapple.pyを実行し、バックテストを行います。
(python355) C:\Users\fdfpy\anaconda3\envs\python355\Lib\site-packages\zipline\examples>zipline run -f buyapple.py --start 2016-1-1 --end 2018-1-1 -o buyapple_out.pickle(4)実行結果が表示されます。
2-4 Beginner Tutorialの実行(Jupyter上で実行)
jupyter上で下記コードを実行してください。
%load_ext ziplinefrom zipline.api import symbol, order, record def initialize(context): pass def handle_data(context, data): order(symbol('AAPL'), 10) record(AAPL=data[symbol('AAPL')].price)%zipline --bundle quandl --start 2016-1-1 --end 2017-1-1 -o start.pickle下記が出力結果です。バックテストの結果が出力されます。


- 投稿日:2020-06-23T21:25:02+09:00
ゼロから始めるLeetCode Day65「560. Subarray Sum Equals K」
概要
海外ではエンジニアの面接においてコーディングテストというものが行われるらしく、多くの場合、特定の関数やクラスをお題に沿って実装するという物がメインである。
どうやら多くのエンジニアはその対策としてLeetCodeなるサイトで対策を行うようだ。
早い話が本場でも行われているようなコーディングテストに耐えうるようなアルゴリズム力を鍛えるサイトであり、海外のテックカンパニーでのキャリアを積みたい方にとっては避けては通れない道である。
と、仰々しく書いてみましたが、私は今のところそういった面接を受ける予定はありません。
ただ、ITエンジニアとして人並みのアルゴリズム力くらいは持っておいた方がいいだろうということで不定期に問題を解いてその時に考えたやり方をメモ的に書いていこうかと思います。
Python3で解いています。
前回
ゼロから始めるLeetCode Day64「287. Find the Duplicate Number」今はTop 100 Liked QuestionsのMediumを優先的に解いています。
Easyは全て解いたので気になる方は目次の方へどうぞ。Twitterやってます。
技術ブログ始めました!!
技術はLeetCode、Django、Nuxt、あたりについて書くと思います。こちらの方が更新は早いので、よければブクマよろしくお願いいたします!問題
560. Subarray Sum Equals K
難易度はMedium。
Top 100 Liked Questionsからの抜粋です。整数の配列と整数 k が与えられたとき,和が k に等しい連続部分配列の総数を求めよ、という問題です。
Example 1:
Input:nums = [1,1,1], k = 2
Output: 2Constraints:
The length of the array is in range [1, 20,000].
The range of numbers in the array is [-1000, 1000] and the range of the integer k is [-1e7, 1e7].解法
import collections class Solution: def subarraySum(self, nums: List[int], k: int) -> int: dic = defaultdict(int) dic[0] = 1 count = calc = 0 for n in nums: calc += n dic[calc],count = dic[calc] + 1,count + dic[calc-k], return count # Runtime: 144 ms, faster than 44.41% of Python3 online submissions for Subarray Sum Equals K. # Memory Usage: 17.9 MB, less than 10.96% of Python3 online submissions for Subarray Sum Equals K.
defaultdictを使って書きました。制約についてはそこまで意識せず、ひとまず解くにはどうやったら良いかを考えました。
calcで累積和を保持し、辞書を使ってkeyの部分で値を保持し、valueの部分で連続で同値が出現した回数を保存し、そして和に遭遇した回数も差し引いたものdic[calc-k]で保持することにより、countに要求に沿った値が加算されていく、というものです。ヒントをSolutionからもらって書きましたがすごくしっくりきますね。
そういえば専門的なアルゴリズムの講義を受けたことがないのですが、思えば他の人がどうやってアルゴリズムを書いているのかをよく知らないんですよね。
僕の考え方は
一旦プログラミングのことを考えずにどうやって書くかをぼんやり考える ↓ 良さそうな考え方がつかめたら適当に紙とかに書いてちゃんと正しいフローになっているかを考える ↓ Pythonでそのフローを実現するために良さげなライブラリや組み込み関数があるか調べて書く ↓ 完成という流れです。
上手くいかない場合はフローを見直して手直ししたりざっくり新しいパターンを書いたり、といった風にしていて、僕の課題はフローを考えるところにあるのかなぁと思ったりしています。(もちろん典型的なアルゴリズムやデータ構造に関してもまだまだ勉強不足ですが)
高校生の時に真剣に受験数学というものに取り組んでこなかったですし、整数や確率、場合の数などについて聞かれると面食らう場合が多いんですよね。割とそこについての課題を克服するために数学の問題をコツコツ解いたりしているのですが、やはりやりたいことがあってその過程で学ぶ数学はやってて楽しいものがありますね。
学生時代は数学で何かをやりたいと思っていなかったので新鮮な気持ちで取り組めています。では今回はここまで、お疲れ様でした。
- 投稿日:2020-06-23T20:08:48+09:00
機械学習で使われる評価関数まとめ
はじめに
評価関数(評価指標)についてあやふやな理解だったので、代表的な評価関数をまとめてみました。
評価関数とはそもそもどんなものなのか、それぞれの評価関数はどんな意味を持つのか、実際に使う時のサンプルコードを簡単にまとめています。評価関数とは
評価関数とは学習させたモデルの良さを測る指標を指します。
目的関数との違い
機械学習を勉強していると、目的関数や損失関数、コスト関数などいろいろな名前を目にします。
まずは、目的関数との違いについて確認します。
- 目的関数
- モデルの学習で最適化される関数
- 微分できる必要がある
つまり、学習中に最適化されるのが目的関数、学習後に良さを確認するための指標が評価関数ということになります。
損失関数、コスト関数、誤差関数は目的関数の一部になるそうです。
(いくつか議論がありそうなのですが、ほとんど同じものと考えても良さそうです。)回帰
まずは、回帰問題の評価関数について、まとめていきます。
MAE(Mean Absolute Error)
平均絶対誤差。
真の値と予測の値の差の絶対値の平均を表します。
- 外れ値の影響を小さく評価
\textrm{MAE} = \frac{1}{N}\sum_{i=1}^{N}|y_{i}-\hat{y}_{i}|N : レコード数 \\ y_{i} : i番目のレコードの真の値 \\ \hat{y}_{i} : i番目のレコードの予測値from sklearn.metrics import mean_absolute_error mean_absolute_error(y_true, y_pred)MSE(Mean Squared Error)
平均二乗誤差。
真の値と予測の値の差を二乗した平均を表します。
- 外れ値の影響を大きく評価
- 単位が目的変数の二乗
\textrm{MSE} = \frac{1}{N}\sum_{i=1}^{N}(y_{i}-\hat{y}_{i})^{2}from sklearn.metrics import mean_squared_error mean_squared_error(y_true, y_pred)RMSE(Root Mean Squared Error)
平均平方二乗誤差。
真の値と予測の値の差を二乗した平均を表します。
- 外れ値の影響を大きく評価
- 単位が目的変数と同じ
\textrm{RMSE} = \sqrt{\frac{1}{N}\sum_{i=1}^{N}(y_{i}-\hat{y}_{i})^{2}}scikit-learnのモジュールでは直接計算できないため、
mean_squared_errorから計算する必要があります。from sklearn.metrics import mean_squared_error from numpy as np np.sqrt(mean_squared_error(y_true, y_pred))RMSLE(Root Mean Squared Logarithmic Error)
真の値と予測の値の対数をそれぞれとったあとの差を二乗した平均を表します。
- 目的変数のとりうる値の範囲が広いデータに利用
- 差を比率として表現
\textrm{RMSLE} = \sqrt{\frac{1}{N}\sum_{i=1}^{N}(\log (1+y_{i})-\log (1+\hat{y}_{i}))^{2}}from sklearn.metrics import mean_squared_log_error from numpy as np np.sqrt(mean_squared_log_error(y_true, y_pred))決定係数
$\textrm{R}^{2}$。
回帰分析の当てはまりの良さを表します。
- 目的変数のスケールに依存せず評価可能
- 0から1の値をとる
\textrm{R}^{2} = 1 - \frac{\sum_{i=1}^{N}(y_{i}-\hat{y_{i}})^{2}}{\sum_{i=1}^{N}(y_{i}-\bar{y_{i}})^{2}}\bar{y} = \frac{1}{N}\sum_{i=1}^{N}y_{i}from sklearn.metrics import r2_score r2_score(y_true, y_pred)二値分類(正例か負例を予測する場合)
分類問題で、正例か負例かを予測する問題で扱う評価関数について、まとめていきます。
混合行列
評価指標ではないですが、正例と負例を予測する評価指標で利用されるため、最初に説明します。
混合行列は、以下の分類結果を表形式で表します。
- TP(True Positive) : 正例を正しく予測
- TN(True Negative) : 負例を正しく予測
- FP(False Positive) : 正例と誤って予測
- FN(False Negative) : 負例と誤って予測
from sklearn.metrics import confusion_matrix confusion_matrix(y_true, y_pred)以下の形式で出力されます。
真の値が正例 真の値が負例 予測値が正例 TN FP 予測値が負例 FN FP Accuracy
正解率。
予測結果全体に対して、予測が正しい割合を表します。正解率(\textrm{Accuracy}) = \frac{TP + TN}{TP + TN + FP + FN}from sklearn.metrics import accuracy_score accuracy_score(y_true, y_pred)Precision
適合率。
正例と予測したなかで正しく予測できた割合を表します。適合率(\textrm{Precision}) = \frac{TP}{TP + FP}from sklearn.metrics import precision_score precision_score(y_true, y_pred)Recall
再現率。
正例を予測したなかで正しく予測できた割合を表します。再現率(\textrm{Recall}) = \frac{TP}{TP + FN}from sklearn.metrics import recall_score recall_score(y_true, y_pred)F1-score
F値。
precisionとrecallのバランスをとった指標を表します。precisionとrecallの調和平均で計算されます。
\textrm{F1-score} = \frac{2 \times \textrm{recall} \times \textrm{precision}}{\textrm{recall} + \textrm{precision}}from sklearn.metrics import f1_score f1_score(y_true, y_pred)二値分類(正例である確率を予測する場合)
次に、分類問題で正例である確率を予測する問題で扱う評価関数についてまとめます。
logloss
cross entropyとも呼ばれることもあります。
予測した確率分布と正解となる確率分布がどのくらい同じかを表します。
- 0から1の値をとる
- 正しく予測できているときに小さくなる
\begin{align} \textrm{logloss} &= -\frac{1}{N}\sum_{i=1}^{N}(y_{i}\log p_{i} + (1 - y_{i} \log (1 - p_{i}))) \\ &=-\frac{1}{N}\sum_{i=1}^{N} \log \acute{p}_{i} \end{align}y_{i} : 正例かどうか表すラベル \\ p_{i} : 正例である予測確率 \\ \acute{p}_{i} : 真の値を予測している確率from sklearn.metrics import log_loss log_loss(y_true, y_prob)AUC
ROC曲線の下部の面積を表します。
- ランダムな予測は0.5
- 全て正しく予測すると1.0
- 不均衡データでの分類に利用
- 予測確率と正解となる値(1か0か)の関係から評価
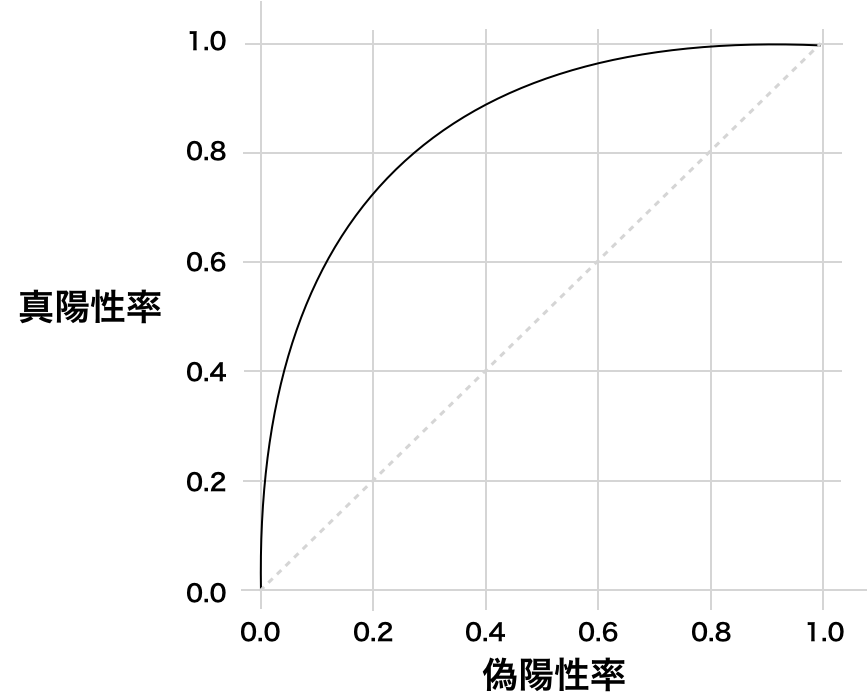
from sklearn.metrics import roc_auc_score roc_acu_score(y_true, y_prob)ROC曲線とは
予測値を正例とする閾値を0から1に動かした時の真陽性率と偽陽性率の関係をプロットしたグラフです。
閾値を変化させると真陽性率と偽陽性率がどのように変化するかを表します。
- 真陽性率:全体の正例のうち正例と予測した割合
- 偽陽性率:全体の負例のうち正例と予測した割合
- (1.0, 1.0)は全て正例と予測
- (0.0, 0.0)は全て負例と予測
- (0.0, 1.0)上は全て正しく予測
- 直線はランダムな予測(AUC=0.5)
多クラス分類
Multi-class accuracy
二値分類のAccuracyを多クラス分類に拡張した指標となります。
正しく予測がされているレコード数の割合を表します。from sklearn.metrics import accuracy_score accuracy_score(y_true, y_pred)mean-F1/macro-F1/micro-F1
F1-scoreを多クラス分類に拡張した指標となります。
- mean-F1:レコードごとのF1-scoreの平均
- macro-F1:クラスごとのF1-scoreの平均
- micro-F1:レコード×クラスのペアごとにTP/TN/FP/FNを計算してF1-scoreを算出
from sklearn.metrics import f1_score f1_score(y_true, y_pred, average='samples') f1_score(y_true, y_pred, average='macro') f1_score(y_true, y_pred, average='micro')Multi-class logloss
二値分類のloglossを多クラス分類に拡張した指標となります。
\textrm{multiclass logloss} = -\frac{1}{N}\sum_{i=1}^{N}\sum_{m=1}^{M}y_{i,m}\log p_{i,m}M : クラス数 \\ y_{i,m} : レコードiがクラスmに属するか表すラベル \\ p_{i,m} : レコードiがクラスmに属する予測確率 \\from sklearn.metrics import log_loss log_loss(y_true, y_prob)参照
- 投稿日:2020-06-23T19:23:26+09:00
GANの生成画像を自分好みで質の高いものに変える方法
1.はじめに
通常、学習済みGANモデルの生成画像は、好みの画像、嫌いな画像、破綻した画像が混在していて、そのままでは鑑賞に耐えません。そこで、今回は手軽にGANの生成画像を自分好みで質の高いものに変える方法をご紹介します。
今回使うGANの学習済みモデルは、TF-Hub Progressive GAN です。コードは Goole colab で作成し Github に上げてあります(リンクはこちら)ので、良かったら一杯やりながらでも、いじってみて下さい。
2.どうやるの?
学習済みのGANモデルは、入力するベクトルと出力画像は1対1で既に決まっているので、改造できません。ではどうするか。入力するベクトルの方を変えます。
GANモデルにランダムベクトルを入力して画像生成した時に、破綻した画像や自分が嫌いな画像がある場合は該当するベクトルをマイナスベクトルに蓄積し、自分の好みの画像がある場合は該当するベクトルをプラスベクトルに蓄積します。
そして、GANモデルに入力する次のベクトルは、ランダムベクトル+プラスベクトルの平均ーマイナスベクトルの平均とします。これを繰り返すことで、あーら不思議、GANの生成画像は自分好みで質の高いものに変身して行きます。
3.実装します
最初に、ライブラリーのインストール及びインポート、関数定義、モデルのダウンロードを行います。詳細は、google colab を参照下さい。
まず、初期化します。
# 学習の初期化 tf.random.set_seed(80) vectors = tf.zeros([5,512]) plus_vector = tf.zeros([1,512]) minus_vector = tf.zeros([1,512])google colab の Form機能を使っていますので、初期状態ではコードが見えませんが、UIをクリックするとコードを見ることが出来ます。操作をするには、初期状態の方がやりやすいです。
#@title please, you change the selected action if you need. vec_0 = 'nothing' #@param ['plus', 'nothing', 'minus'] vec_1 = 'nothing' #@param ['plus', 'nothing', 'minus'] vec_2 = 'nothing' #@param ['plus', 'nothing', 'minus'] vec_3 = 'nothing' #@param ['plus', 'nothing', 'minus'] vec_4 = 'nothing' #@param ['plus', 'nothing', 'minus'] vec = [vec_0, vec_1, vec_2, vec_3, vec_4] for i in range(len(vectors)): if vec[i] == 'plus': plus_vector = tf.concat([plus_vector, tf.reshape(vectors[i],[1,512])],axis=0) if vec[i] == 'minus': minus_vector = tf.concat([minus_vector, tf.reshape(vectors[i],[1,512])], axis=0) print('number of plus_vector = ', len(plus_vector)-1) print('number of minus_vector = ', len(minus_vector)-1) plus_vector_mean = tf.reduce_mean(plus_vector, axis=0) # plus_vectorの平均をとる minus_vector_mean = tf.reduce_mean(minus_vector, axis=0) # minus_vectorの平均をとる vectors = tf.random.normal([5, 512]) # ランダムベクトル取得 vectors = vectors + plus_vector_mean - minus_vector_mean # ベクトルの補正 display_images(vectors)Form機能によって、変数 vec_0〜vec_4 には UIで選択した文字列 ('plus', 'nothing', 'minus')が入ります。その文字列が 'plus' ならば該当するベクトルをplus_vectorに蓄積し、'minus' ならば該当するベクトルを minus_vector に蓄積します。後は、
tf.reduce_mean()で平均を取り、ランダムベクトルに足したり引いたりするだけです。初回は何も設定をいじらずコードを実行します。2回目以降、生成した5つの画像を見て、自分の判断でマイナスベクトルに入れるのか(minus)、プラスベクトルに入れるのか(plus)、何もしないのか(nothing)を決めて、設定を変更してからコードを実行します。これを何回も繰り返します。
表示しているのは、十数回ほどやってみた結果です。UIは初期状態のまま実行しています。プラスベクトルを5つ(自分の好みの女性)、マイナスベクトルを8つ(破綻した画像)選んだ結果の画像です。確かに、割りと自分好みの女性ばかりになっていますね(笑)。

- 投稿日:2020-06-23T18:56:24+09:00
効果検証入門 1章をPythonで書く
はじめに
効果検証入門 ~正しい比較のための因果推論/計量経済学の基礎内のソースコードをPythonで再現します。
既に素晴らしい先人の実装例がありますが、自分の勉強用のメモとして残しておきます。
この記事では、1章について記載します。
なお、変数名や処理内容は、基本的に書籍内に寄せて実装します。データの準備
データの準備import pandas as pd # 元データ読込 email_data = pd.read_csv('http://www.minethatdata.com/Kevin_Hillstrom_MineThatData_E-MailAnalytics_DataMiningChallenge_2008.03.20.csv') # 女性向けメール配信データの削除と介入変数の追加 male_df = email_data.copy() # SettingWithCoppyWarningを回避するためにコピーしているが、本質的に意味はない male_df = male_df[male_df['segment'] != 'Womens E-Mail'] male_df['treatment'] = male_df['segment'].apply(lambda x: 1 if x == 'Mens E-Mail' else 0)RCTの集計
集計summary_by_segment = ( male_df .groupby('treatment') .agg( conversion_rate=('conversion', 'mean'), spend_mean=('spend', 'mean'), count=('recency', 'size'), ) )ここでの件数については
countでもsizeでもいいのだが、欠損値含む場合でも数えたいのでsizeにしている。(このデータは欠損を含まない)有意差の検定
有意差の検定from scipy import stats mens_mail = male_df[male_df['treatment'] == 1]['spend'] no_mail = male_df[male_df['treatment'] == 0]['spend'] stats.ttest_ind(mens_mail, no_mail, equal_var=True)元のソースコードで分散が等しいと仮定してスチューデントのt検定を使っているので、同様に
equal_var=Trueを設定する(デフォルト値でなっているが)。バイアスデータの作成
バイアスデータの作成import numpy as np np.random.seed(529) obs_rate_c = 0.5 obs_rate_t = 0.5 biased_data = male_df.copy() biased_data = male_df.copy() biase_rule = (biased_data['history'] > 300) | (biased_data['recency'] < 6) | (biased_data['channel'] == 'Multichannel') biased_data['obs_rate_c'] = biase_rule.apply(lambda x: obs_rate_c if x else 1) biased_data['obs_rate_t'] = biase_rule.apply(lambda x: 1 if x else obs_rate_t) biased_data['random_number'] = np.random.uniform(size=biased_data.shape[0]) biased_data = ( biased_data[ ((biased_data['treatment'] == 0) & (biased_data['random_number'] < biased_data['obs_rate_c'])) | ((biased_data['treatment'] == 1) & (biased_data['random_number'] < biased_data['obs_rate_t'])) ] )乱数処理が含まれているため、、同一結果にはならないがこれでおおよそ一致する。
この結果だと、若干介入なしの群の平均購入額が多くなるが、元々全体のうち購入者(conversion=1)が少ないこともあり、乱数シードによって値が結構ぶれる。filter条件が少しややこしく、元のソースコードで変数名と列名で同じobs_rate_c/obs_rate_tを指定してるため、間違えないように注意。
関連
- 投稿日:2020-06-23T17:25:22+09:00
Anaconda (conda)の簡単な使い方メモ
はじめに
Anaconda (condaコマンド)の使い方に関して程よい資料 (情報が多すぎず少なすぎず)が見つからなかったのでまとめてみました。
本記事は、Anacondaがインストールされていることを前提としています。
インストールの確認は下記コマンドで行えます。
$ conda --version conda 4.8.2※Jupyter notebookの場合は、Pythonセル上で
!conda --versionとコマンド冒頭に!を付けてセルを実行すれば同様に確認できます。Anacondaとは
データサイエンス向けのPythonパッケージ集合体
- 1,500以上のパッケージに対応
- GUIとコマンドラインの両方に対応
-condaコマンドを使って操作できるAnacondaを使うことでライブラリのインストール等に時間を取られることなく簡単に開発環境の構築や切り替えを行うことが可能です。
参考:https://www.creativevillage.ne.jp/72837
Anaconda (condaコマンド)の使い方メモ
1. condaによる仮想環境の構築
$ conda create --name my_notebook_env python=3.7 -y
-name my_notebook_env:仮想環境の名前. 好きなものを設定できる
python=3.7:仮想環境で使用するPythonバージョン
-y:確認項目に自動的にyesで応答する2. 仮想環境の有効化
仮想環境の有効化
$ conda activate my_notebook_env仮想環境の無効化
$ conda deactivate仮想環境の削除
$ conda remove --name my_notebook_env --all3. 仮想環境内でのライブラリのインストール
pandasをインストールするには
$ conda install pandasjupyterをインストールするには
$ conda install jupyterインストールされているライブラリの一覧を表示
$ conda list例:仮想環境内でjupyter notebooksを起動する
仮想環境の有効化し、jupyter notebooksを起動する
$ conda activate my_notebook_env $ jupyter notebookまとめ
Anacondaを使うことで簡単に開発環境の構築や切り替えを行えます!また環境が壊れてしまった場合も容易に再構築可能なので安心です!
参考
- 投稿日:2020-06-23T17:19:22+09:00
CPLEXをPythonから呼ぶ(DOcplex)
1. はじめに
Qiita初投稿です。本記事は備忘録として記録し誤った箇所があるかもしれません。
IBM ILOGの提供する最適化ソリューションとしての開発環境はIBM ILOG CPLEX Optimization Studioと呼ばれています。
CPLEXの開発言語としてC/C++/Java/Python などがあげられ、他にもEclipseのPluginを用いたOPL言語を用いて最適化問題を記述することができます。
CPLEX Studioの統合開発環境(IDE)では、基本的にOPL言語を用いた開発とインタラクティブに最適化問題を解くことができる一方で、多目的最適化問題を解いたり、CPLEXで得た解をさらに別の問題に適用したりするような場面においては若干の使いづらさが見られるように思えます。
そこで今回はPython APIによる開発環境の構築を備忘録的に記録する意味を込めて、記事を書くに至ります。
ここで、CPLEX Python APIには大きく DOCplex[1]とPython-API(Legacy)[2]との2つが存在しますが、レガシー版は遠くない将来に廃止される予定らしいので、ここではDOCplexを用いた開発環境の構築を行います。2. 動作環境
動作確認は
・Ubuntu 18.04 Bionic (64bit, 8GB, on VMWare)
・CPLEX Optimization Studio 12.9
・Python 3.7.3
にて行いました。
- 前提として、Pythonはインストール済とします。 なお、Pythonは Python2*(≧Python2.7.9) もしくは Python3*(≧ Python3.6) とします。 (ただし、Python3.8以上は対応していないようです)
- 本記事ではpipやcondaを使用せずに環境を構築します。pip/condaでのインストールは既出なのでここでは触れません。
3. CPLEX Studio 12.9 のインストール手順
まずはCPLEXStudioをDLします。
サイト[3]から.binをダウンロードしておきます (~/Downloadsに置くとします)。
ダウンロードの方法ですが、[3]を読めば簡単にダウンロードできるのでここでは省略します。ダウンロードが終わったら、インストールを開始していきましょう。
~/Downloadsに移動して作業することにします。$cd ~/Downloadsまずは.binファイルに実行権限を与えます。
$chmod +x CPLEX_OPT_STUD_129_LNX_X86-64.bin次に、.binファイルを実行します。
$sudo ./CPLEX_OPT_STUD_129_LNX_X86-64.bin何らかの言語で、インストーラが立ち上がっていくつか質問をされます。
以下にまとめておきます。もし嫌になった場合は quit と叩けば止まります。
1. ローカルの選択: --> 1. English or 2. 日本語
2. インストール前に全てのプログラムを終了することをお勧めします: --> ENTER or back
3. インストールパスの指定: /opt/ibm/ILOG/CPLEX_Studio129がデフォルト
4. インストールするにはENTERキーを押してください: --> ENTER
5. ディスク容量の確認 (約2GB程度): --> ENTER
6. 正常にインストールが完了しました: --> ENTERいくつかパスを通す必要があります。
CPLEXにはMathematical Programming (MP)と Constraint Programming (CP)の2種類の最適化エンジンが備わっており、それぞれバイナリパスが異なります。
シェルの設定ファイル(~/.bashrc)を開いて、最終行に続けて以下のexportを記述します。$echo "export LD_LIBRARY_PATH="/opt/ibm/ILOG/CPLEX_Studio129/opl/bin/x86-64_linux:$LD_LIBRARY_PATH" $echo "export PATH="/opt/ibm/ILOG/CPLEX_Studio129/opl/bin/x86-64_linux:$PATH" $echo "export PATH="/opt/ibm/ILOG/CPLEX_Studio129/cplex/bin/x86-64_linux:$PATH" $echo "export PATH="/opt/ibm/ILOG/CPLEX_Studio129/cpoptimizer/bin/x86-64_linux:$PATH"追記したら、反映しておきます。
$source ~/.bashrcここで、コマンドが動くかを確認してみましょう。
$cplex Welcome to IBM(R) ILOG(R) CPLEX(R) Interactive Optimizer 12.9.0.0 with Simplex, Mixed Integer & Barrier Optimizers 5725-A06 5725-A29 5724-Y48 5724-Y49 5724-Y54 5724-Y55 5655-Y21 Copyright IBM Corp. 1988, 2019. All Rights Reserved. Type 'help' for a list of available commands. Type 'help' followed by a command name for more information on commands.制約プログラミングの最適化エンジンも起動して確認してみましょう。
$cpoptimizer Welcome to IBM(R) ILOG(R) CP Interactive Optimizer 12.9.0.0 with Simplex, Mixed Integer & Barrier Optimizers 5724-Y48 5724-Y49 5724-Y54 5724-Y55 5724-A06 5724-A29 Copyright IBM Corp. 1990, 2019. All Rights Reserved. Type 'help' for a list of available commands. Type 'help' followed by a command name for more information on commands.また、パスが通っていれば以下のコマンドも通るはず。
ズラズラっとhelpの内容が表示されれば問題なくパスが通っています。$oplrun【もしこれで command not found が出たりなどしてうまく起動しなかったら】
LD_LIBRARY_PATHの設定が反映されない場合があるようです (OS依存でしょうか..?)。
共有ライブラリにパスを登録することで回避できます (この辺はあまりよくわかっていません...)。
/etc/ld.so.conf.d 以下にhogehoge.confというファイルを作成し、LD_LIBRARY_PATHを追記しておけば大丈夫そうです。$sudo vim /etc/ld.so.conf.d/oplrun.conf以下を中に書いておきます。
/opt/ibm/ILOG/CPLEX_Studio129/opl/bin/x86-64_linux/ /opt/ibm/ILOG/CPLEX_Studio129/cplex/bin/x86-64_linux/ /opt/ibm/ILOG/CPLEX_Studio129/cpoptimizer/bin/x86-64_linux/ファイルを保存し、cacheを再構築しておきます。
$sudo ldconfig4. DOCplexのセットアップ
本記事ではCPLEXを /opt/ibm/ILOG/CPLEX_Studio129/...にインストールしてきました。
以下、 /opt/ibm/ILOG/CPLEX_129 を (CPLEX_DIR) と置くことにします。
自身で任意のパスを設定した場合はCPLEX_DIRは別パスのはずです。注意してください。(CPLEX_DIR)/python/docplex/ に移動するとsetup.pyというファイルがあるので、これを実行します。
$cd (CPLEX_DIR)/python/docplex $sudo python3 setup.py installセットアップが開始し、数秒のうちに終了します。
これでDOCplexの環境構築は終わりです。5. 例題を解く
ここからは公式リファレンスのサンプル[4]を用いて簡単に書き方についても触れようと思います。
筆者自身が勉強中の身なのであやふやな箇所もありますが、何かしら貢献できれば幸いです。ここでは、[4]の最初の例題 The Transportation Problem を取り上げようと思います。
これは、2拠点に置かれた物資を3拠点へと輸送する際のコストを最小化する問題です。
図は非負整数重み付きの有向非循環グラフ(DAG)です。
左側のOut-goingノードが示すのは物資を運び出すことができる拠点を示しています。
また、赤字で書かれた数は各ノードの重みであり、輸送可能な物資の総量を示します。
右側のIn-comingノードの横に緑字の数が示すのは拠点が要求する必要物資の総量です。
ノード間のアークが示すのは輸送可能な経路であり、アーク上の重みは物資1つあたりの輸送コストを示しますこの問題において輸送コストを算出する上での組合せとしては、いくつか存在します。
これは単純な例題ですので、最適解は以下のように簡単に求まります。ノード3はノード1からの物資以外は受け取れず,物資を7つを必要とします。
したがってノード1の物資15から物資7だけノード3へと送られるためノード1の残量は8となり、このとき物資7をノード3へ輸送コスト2で送るので2×7=14の輸送コストを要します。同様にノード4はノード2からしか物資を受け取れないのでノード2の残物資量は20-10=10となり、このときの輸送コストは10×5=50となるので、ノード1残物資量は8、ノード2残物資量は10で、あとはノード5が15の物資を必要としている状態になります。
このとき、ノード2からノード5に対するの輸送コストが低いのでノード2から優先的に物資を運ぶことにすると,ノード2は10を全て運びきり残量が0,一方ノード5の必要物資は5となります。
最後にノード1から物資を5だけノード5へ送ることで全ての要求を満たせます。
ここでの過程で、ノード2が輸送コスト3で10運ぶので 10×3=30輸送コスト、ノード1が輸送コスト4で5だけ運ぶので5×4=20輸送コストを要する。以上から、最終的に14+50+30+20=114だけの輸送コストが必要となります。
この問題を最適化問題として成立させるために目的関数と制約条件を整理し、決定変数を定義する必要があります。
- 目的関数: 総輸送コストを最小化する
- 制約条件1: 左側各ノードの輸出量が重みと等しいか、それより小さい
- 制約条件2: 右側各ノードの輸入量が重みをと等しいか、それより大きい
以上を踏まえると決定変数は以下にすると良さそうです。
- 決定変数: x (i , j): ノードiからノードjへ輸送する物資の量
以下でプログラムを書いていくことにします。
sample.py#URL/Keyを書くとクラウドで問題を解くことができます。 #ここではローカル実行を想定しているのでNoneとします。 url=None key=None #Preparation of data #ノード1は15, ノード2は20だけ物資を有する capacities = {1:15, 2:20} #ノード3は7, ノード4は10, ノード5は15の要求がある demands = {3:7, 4:10, 5:15} #このときアークにおけるコストは (1,3)=2, (1,5)=4, (2,4)=5, (2,5)=3なので costs = {(1,3):2, (1,5):4, (2,4):5, (2,5):3} source = range(1,3) #pythonでは range(i,j)は i...j-1まで target = range(3,6) #description of a problem #docplexをインポートする from docplex.mp.model import Model tm = Model(name='transportation') #decision (continuous) variable #変数x(i,j)を問題tmの中に定義する.xは連続変数でiはsource,jはtargetを参照する.ただしこれはcostsに存在する (アークが繋がっている者同士) 場合に限る. x = {(i,j): tm.continuous_var(name='x_{0}_{1}'.format(i,j)) for i in source for j in target if (i,j) in costs} tm.print_information() #add constraints # (1,3), (1,5) を運ぶ物資の総量がcapacities[1] (=15)を超えない # (2,4), (2,5) を運ぶ物資の総量がcapacities[2] (=20)を超えない for i in source: tm.add_constraint(tm.sum(x[i,j] for j in target if (i,j) in costs) <= capacities[i] ) for j in target: tm.add_constraint(tm.sum(x[i,j] for i in source if (i,j) in costs) >= demands[j] ) #Objective function #目的関数はアーク(i,j)間に係る輸送コストの総量の最小化 tm.minimize(tm.sum(x[i,j]*costs[i,j] for i in source for j in target if (i,j) in costs)) #Solve #問題を解く tms = tm.solve(url=url,key=key) #Display and exceptions #解を表示 assert tms tms.display()実行すると以下を得ます。
Model: transportation - number of variables: 4 - binary=0, integer=0, continuous=4 - number of constraints: 0 - linear=0 - parameters: defaults solution for: transportation objective: 114.000 x_1_3 = 7.000 x_1_5 = 5.000 x_2_4 = 10.000 x_2_5 = 10.000DOCplex (Python-API) の導入はここまでです。
参考リンク
1: DOCplex公式リファレンス
2: Python-API(Legacy)
3: CPLEXダウンロード
4: DOCplex公式リファレンス - 例題

- 投稿日:2020-06-23T16:54:49+09:00
機械学習による株価予測 さがそうNumerai Signals
はじめに
前回記事はこちら。本記事はNumerai Tournamentに参加したことがある方を対象読者として想定しており、予備知識があるものとして説明を行う。
前回記事で説明したNumerai Tournamentは、運営が予め用意したデータセットで予測性能を競うものだった。これに対してNumerai Signalsはさらに実戦的で広大なバトルフィールドだ。ユーザーは予測に使うデータセットを自ら用意しなければならない。それどころか、ユニバースの選択でさえ自身の手に委ねられている。
現在はまだベータ版であるが、参加者は将来的にTournament同様とてつもなく大きな恩恵を享受できるようになると考えている。以下にSignalsの仕様、参加するインセンティブ、そしてSignals構築における留意点について解説を進める。Numerai Signalsの仕様
Signals概要
Signalsのドキュメントはこちら。Signalsは世界中の市場における株価の騰落の予測を提出するものである。以下のサンプルのように騰落の予測を0~1の数値(一般的な機械学習におけるProbability)として提出する。参加者の最終的な目標は、提出したSignalをNumeraiのようなデータドリブンなヘッジファンドに「購入してもらう」ことだ。世界中の様々なデータソースにアクセスし、たっぷりとアルファを含んだ特徴量を見つけ出し、そこから予測性能が高く且つオリジナリティのあるSignalを抽出する。そして自らがヘッジファンドのブレインの一部として置き換わる。何ともエキサイティングな試みだろう。
それでは以下にSignalsの仕様について説明していこう。
対象アセット
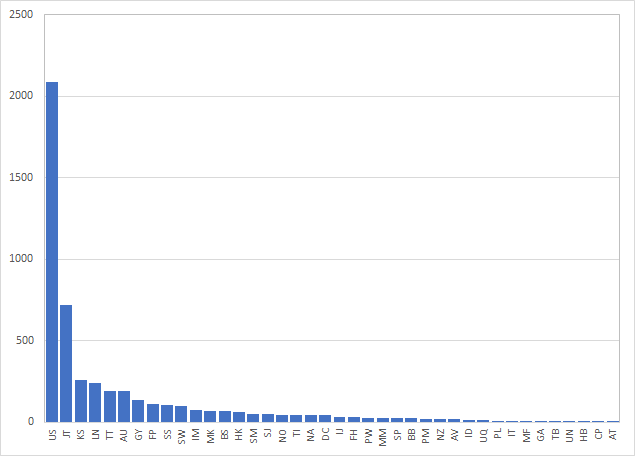
Numerai Signalsは世界中の市場における株式銘柄を対象としており、現時点でその総数はおよそ5200銘柄である。このリストには毎日変更が入るが、流動性不足の銘柄が入れ替わったりするだけで殆どの銘柄は据え置きとなる。最新のリストはこちらから入手することができる。
参考までにどの市場の銘柄がどれだけあるか集計した。最も多いのはUS市場でありおよそ2000銘柄超である。続いて日本市場、韓国市場、ロンドン市場と続いている。
参加者はこの全ての銘柄について予測を提出する必要はない。5000を超える銘柄の中から自身で好きなようにユニバースを作ることができるのだ(ただし最低100銘柄以上が必要となる)。これは自由度が高い反面、ユニバースの選択方法も重要な判断が必要となる。
データの取得について
これらの銘柄について、予測に必要なデータは参加者自身が収集する必要がある。Numerai Signalsは、既に自身の予測システムを構築済みで市場データにアクセスできるユーザー向けのプラットホームなのだ。
参加者の予測性能を評価するために運営が公式で使っているデータソースはQuandlである。その他のデータソースとしてQuantopianやAlpacaなどが挙げられる。NumeraiのForumでは安価なデータソースのリストが共有されているので、そちらを是非参考にすべきだろう。なお筆者は現時点ではYahoo Financeを使っている。Submissionについて
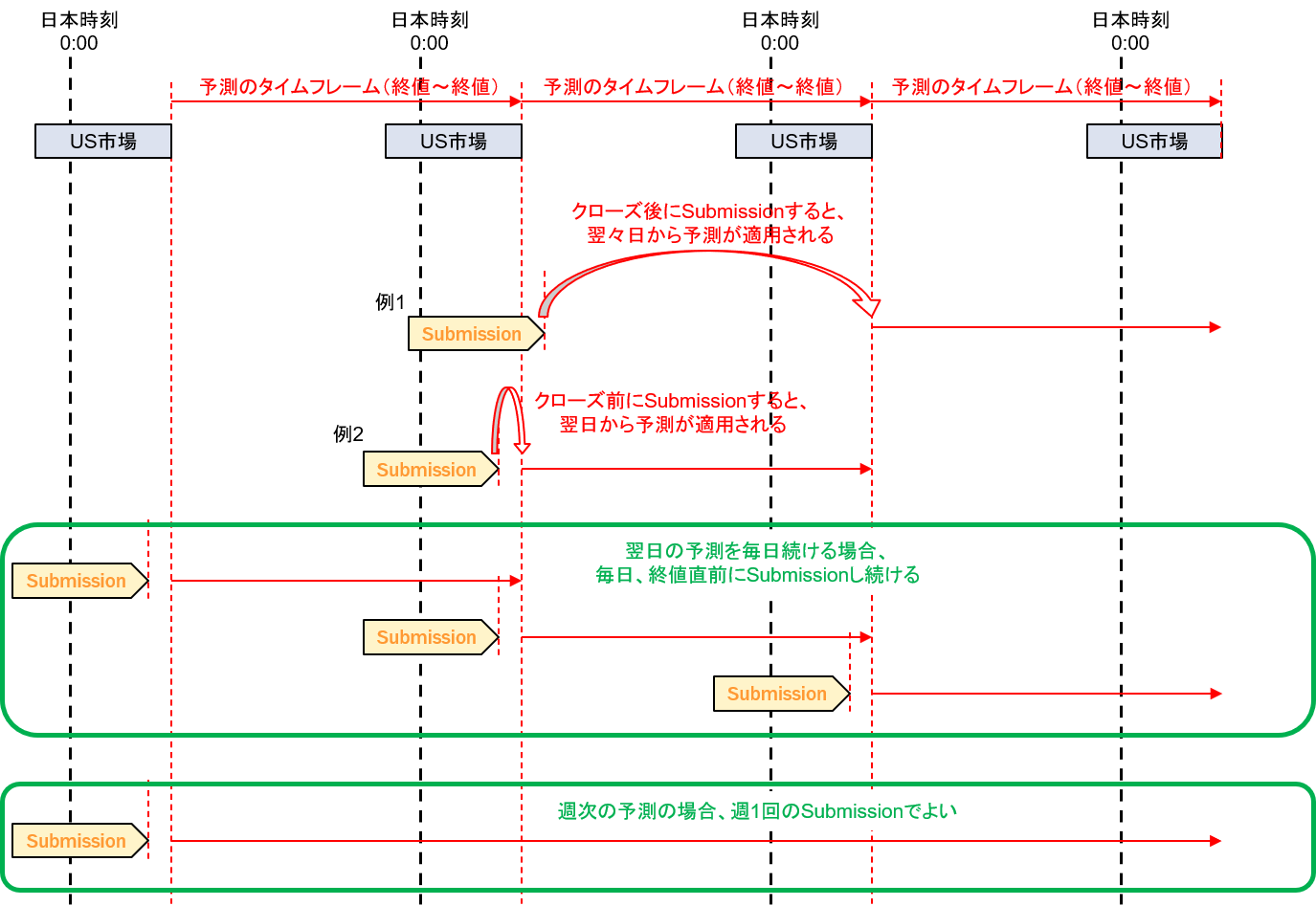
参加者は任意の時刻に予測結果をSubmissionできる。次のSubmissionが行われるまで、参加者の予測は最終Submissionの内容が保持されることになる。つまり参加者は予測結果をSubmissionすることでポートフォリオをリバランスすることができると思えばよい。週次の予測モデルであれば週一回のSubmissionでもよいのだ。なお後述するリーダーボードの評価におけるタイムフレームは日次であり、終値が基準となっている(Close to Closeでの予測)。
1点注意しておきたいことは、予測結果が反映されるのは最終Submissionの次の終値時刻だということだ。つまり翌日の日次を予測するためには、市場がクローズする前にSubmissionを行う必要がある。予測結果の評価は毎日行われる。一度提出した予測結果は60日後まで有効であるため、60日以内に次のSubmission(リバランス)を行う必要がある。
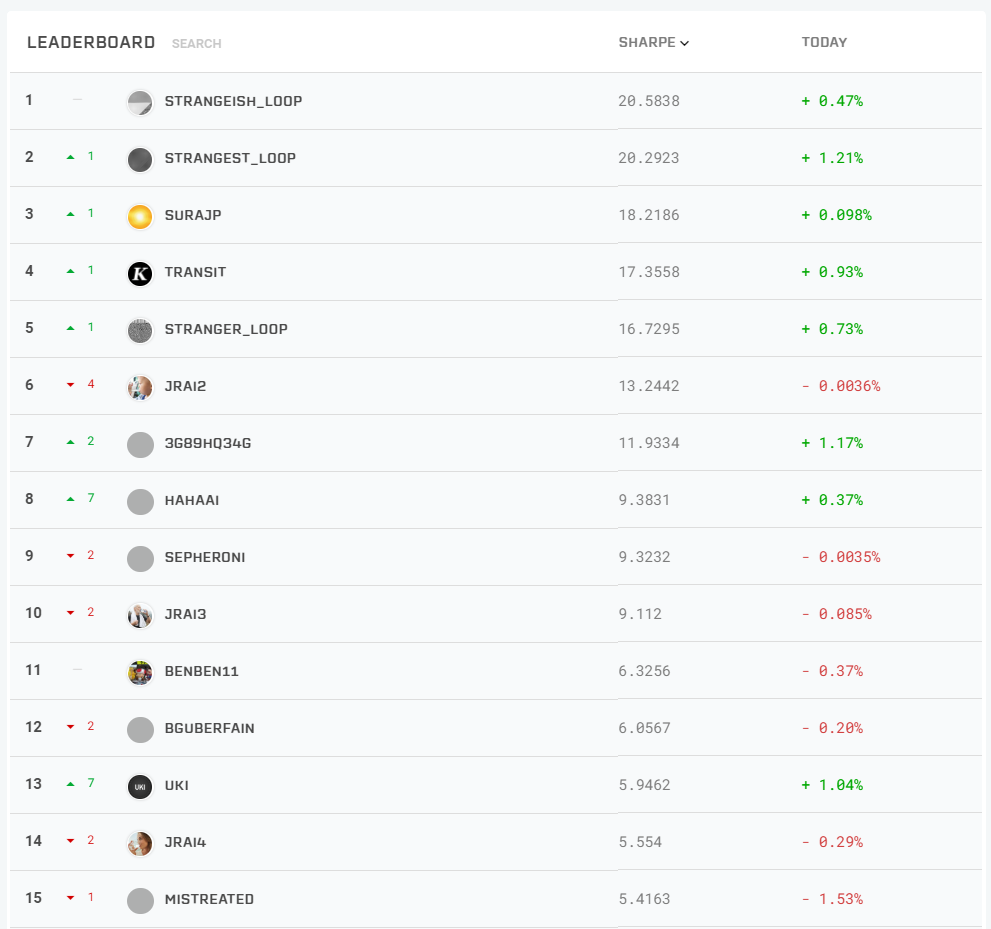
リーダーボード
形式的であるが、リーダーボードが存在する。ランキングの基準は現時点では日次リターンのシャープレシオである。
シャープレシオの計算方法は以下による。ここで、$r_{long}$は予測結果の上位半数に含まれる銘柄の日次リターン、$r_{short}$は下位半数に含まれる銘柄の日次リターンである(銘柄数が奇数の場合、真ん中の銘柄はロングに含まれる)。この式はあまり見掛けない形かもしれないが、計算結果は$ave(r_{long})-ave(r_{short})$とほぼ一致する。Sharpeは日次から年次へと換算したシャープレシオである。ここで$r_{daily}$は、ユーザーがSubmissionを開始した後の全ての結果が含まれる。試験的にHigh Varianceな予測結果をSubmissionしてしまうと生涯反映され続けるので、ある程度モデルが決まってからSubmissionを開始したほうがよいかもしれない。
r_{daily}=\frac{1+ave(r_{long})}{1+ave(r_{short})}-1\\ Sharpe=\sqrt{365} \times \frac{ave(r_{daily})}{stdev(r_{daily})}なお、リーダーボードに載るには最低でも直近20日のデータが必要である。ただし今はベータ版であるため、Submission直後(厳密には結果が集計される3営業日程度後)からリーダーボードに載るようだ。
報酬体系
ステイクに対する報酬(もしくは徴収)
記事執筆の現時点(6/23)において、ステイクの仕様は未決定である。ユーザーは自身の予測結果を裏付けるためにNMRをステイクしなければならない(当然ステイクしなくても参加できるが、報酬や評価対象には含まれない)。これは試験的な予測結果を提出したり、ラッキーパンチを狙って提出するユーザーがいるため当然の仕様である。
ステイクは早ければ近日中に実装される見込みである。ステイクの仕様が決まり次第、本章は更新する予定である。Singalの買い取り
ステイクに対する報酬とは別に、NumeraiがSignalを購入する場合がある。しかし、この購入基準や報酬額については公開されることはない。唯一分かることは、Numeraiが求めているものは、ロバストで長期間安定しており且つ他の一般的なファクターとの相関が低いSignalであることだ。Signalは予測性能にも増してそのオリジナリティが重要であり、当然ながらリーダーボードの順位に基づいて購入されるわけではない。
Signalsに参加するインセンティブ
本章はステイク仕様が決定し次第更新するが、Tournamentにおける知見からSignalsにおいても以下のようなインセンティブが存在すると考えられる。これらはシステムトレーダーにとって驚くほど大きな恩恵だ。米国個別株の運用を視野に入れていた筆者もこれらの恩恵を最大限に授かろうと目論んでいる。
- 参加者のSharpeを元に報酬が付与徴収される場合、実際の株式リターンよりもハイレバレッジとなりマーケットニュートラルの資金効率を劇的に改善できる可能性がある。
- Numerai SignalsではTournament同様に参加者は実際に株式を購入するわけではなく、予測そのものにベットできる。このためポートフォリオ構築に要する執行コストを無視することができ、理想的なリターンを享受することができる。
- 現実的に個人投資家が構築できないような分散されたポートフォリオにベットすることでき、運用成績の安定に繋がる
- Numerai SignalsではTournament同様に予測モデルを提出する必要はない。このため参加者の知的財産は全て保護される。
Signals構築における留意点
ユニバースの選定
ユニバースの選定はSignalsにおいて最も重要な項目だと考えている。予測力が同じ場合、ユニバースが広いほうがシャープレシオは改善する。予測力を一定と仮定した場合、ユニバースの銘柄数の1/2乗に比例してシャープレシオは向上する。下図は理想的なシミュレーション結果である。
一方であまりに多数の銘柄を取り込みすぎると、極端にボラティリティの高い銘柄が含まれていたり、少数のユニバースでは見えていた特性が逆に見えなくなって全体としての予測性能が劣化する可能性もある。従ってユニバースを逆に狭く限定することで、値動きの安定した銘柄に絞りつつユニバース内の説明力を向上させるという選択肢もあるわけだ。
ユニバースというハイパーパラメータのチューニングがパフォーマンスの優劣を分けるカギだと考えている。またそのチューニングを網羅的に行うために、できるかぎり多くの銘柄について正確なデータベースを構築する能力が求められる。
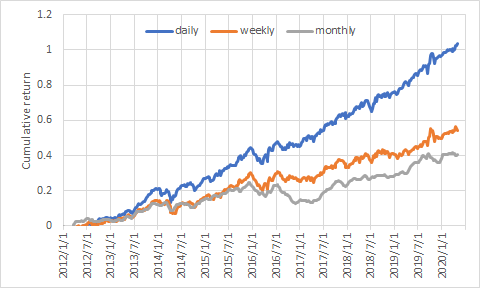
タイムフレーム(リバランス頻度)の最適化
基本的にリバランスは短いほど予測力は向上し成績は安定する。これはフィナンシャルデータの予測力には大きなタイムディケイが発生するからだ。以下に日次、週次、月次リバランス時の損益曲線の一例を示す。
ただし、現実の世界では執行コストが発生してしまうため、頻繁にリバランスできないことが多い。Numerai Signalsでは現時点ではSubmissionの頻度に対するペナルティは発生しない。しかし実際に予測が頻繁に変化すると運用額の大きなファンドには好ましくないため、Submissionあたりに一定のステイクを徴収する、などという対応が取られる可能性がある。この辺りの事情を加味して予測のタイムフレームもユーザー自身が最適化することになる。
おわりに
本記事ではNumerai Signalsの仕様、参加するインセンティブ、そしてSignals構築における留意点について解説した。Numerai Signalsは自由度が高く、戦略の殆どが参加者に委ねられており、参加者は自身の知見を存分に活用することでこれに挑戦することができる。そしてその行く末にヘッジファンドがあなたの力を借りるという未来があれば、それはとても名誉なことではないか。ヘッジファンドが投資判断のために個人投資家を力を借りる時代が、今まさにそこまで来ているのだ。ワクワクしてきただろう。
さあ君もたっぷりとアルファを含んだ、とびっきりのSignalをさがしてみよう。

- 投稿日:2020-06-23T15:38:36+09:00
AtCoderBeginnerContest171復習&まとめ(後半)
AtCoder ABC171
2020-06-21(日)に行われたAtCoderBeginnerContest171の問題をA問題から順に考察も踏まえてまとめたものとなります.
後半ではDEの問題を扱います.前半はこちら.
問題は引用して記載していますが,詳しくはコンテストページの方で確認してください.
コンテストページはこちら
公式解説PDFD問題 Replacing
問題文
あなたは、$N$個の正整数$A_1,A_2,⋯,A_N$からなる数列$A$を持っています。
あなたは、これから以下の操作を$Q$回、続けて行います。
・$i$回目の操作では、値が$B_i$である要素すべてを$C_i$に置き換えます。
すべての$i(1 \leq i \leq Q)$に対して、$i$回目の操作が行われた後の数列$A$のすべての要素の和、$S_i$を求めてください。毎回,和の計算をしていると時間が足りなくなってしまうと思ったので,操作ごとに差分を計算するようにしました.
数列$A$はdictで管理するようにしました.abc171d.pyn = int(input()) a_list = list(map(int, input().split())) a_dict = {} total = 0 for a in a_list: if a in a_dict: a_dict[a] += 1 else: a_dict[a] = 1 total += a q = int(input()) for i in range(q): b, c = map(int, input().split()) if b in a_dict: if c in a_dict: a_dict[c] += a_dict[b] else: a_dict[c] = a_dict[b] total -= a_dict[b] * b total += a_dict[b] * c a_dict[b] = 0 print(total)D問題までは順調に解けました.
しかし,次のE問題に躓き解けませんでした.E問題 Red Scarf
問題文
猫のすぬけくんが$N$(偶数)匹います。
各すぬけくんには$1,2,…,N$の番号が振られています。
各すぬけくんは首に赤いスカーフを巻いており、スカーフにはそのすぬけくんが一番好きな非負整数が$1$つ書き込まれています。
すぬけくんたちは最近、整数の xor(排他的論理和)と呼ばれる演算を覚えました。
早速この演算を使いたくなったすぬけくんたちは、自分以外のすぬけくんのスカーフに書かれた整数の xor を計算することにしました。
番号$i$が振られたすぬけくんが計算した、自分以外のすぬけくんのスカーフに書かれた整数の xor が$a_i$であることが分かっています。 この情報を元に、各すぬけくんのスカーフに書かれた整数を特定してください。4264人もE問題が解けてて,D解けた段階で2000位くらいだったのに,最終的に順位が目も当てられない結果になってしまいました.
偶数がポイントになってたんですね.
自分もノートにいろいろ式を計算したりしてみたのですが,答えを求めるための式を出せませんでした.
次はもう解けると思うので,勉強になったと割り切りたいと思います.abc171e.pyn = int(input()) a_list = list(map(int, input().split())) y = 0 for a in a_list: y = y ^ a for a in a_list: x = y ^ a print(x, end=" ")F問題は,今週も忙しいので時間ができたときにでも追記できたらいいなと思ってます.
後半も最後まで読んでいただきありがとうございました.
- 投稿日:2020-06-23T15:38:12+09:00
AtCoderBeginnerContest171復習&まとめ(前半)
AtCoder ABC171
2020-06-21(日)に行われたAtCoderBeginnerContest171の問題をA問題から順に考察も踏まえてまとめたものとなります.
前半ではABCまでの問題を扱います.
問題は引用して記載していますが,詳しくはコンテストページの方で確認してください.
コンテストページはこちら
公式解説PDFA問題 αlphabet
問題文
英大文字か英小文字のいずれか$1$文字$α$が入力されます。$α$が英大文字なら"A"、英小文字なら"a"と出力してください。大文字か小文字か判定する方法はたくさんあるのですが,今回は
str.istitle()を使って判定しました.abc171a.pyn = input() if n.istitle(): print("A") else: print("a")B問題 Mix Juice
問題文
ある店で$N$種類の果物、果物$1,…,N$が売られており、それぞれの価格は一個あたり$p_1,…,p_N$円です。
この店で$K$種類の果物を一個ずつ買うとき、それらの合計価格として考えられる最小の金額を求めてください。安いものから$k$種類の果物を購入すればいいので,価格をsortすれば簡単に解けました.
abc171b.pyn, k = map(int, input().split()) p_list = list(map(int, input().split())) p_list = sorted(p_list) print(sum(p_list[:k]))C問題 One Quadrillion and One Dalmatians
問題文
ロジャーは、彼のもとに突如現れた$1000000000000001$匹の犬をすべて飼うことを決意しました。犬たちにはもともと$1$から $1000000000000001$までの番号がふられていましたが、ロジャーは彼らに以下のルールで名前を授けました。
・$1,2,⋯,26$番の番号がついた犬はその順に a,b,...,z と命名されます。
・$27,28,29,⋯,701,702$番の番号がついた犬はその順に aa,ab,ac,...,zy,zz と命名されます。
・$703,704,705,⋯,18277,18278$番の番号がついた犬はその順に aaa,aab,aac,...,zzy,zzz と命名されます。
・$18279,18280,18281,⋯,475253,475254$番の番号がついた犬はその順に aaaa,aaab,aaac,...,zzzy,zzzz と命名されます。
・$475255,475256,⋯$番の番号がついた犬はその順に aaaaa,aaaab,... と命名されます。
・(以下省略)
つまり、ロジャーが授けた名前を番号順に並べると:
a,b,...,z,aa,ab,...,az,ba,bb,...,bz,...,za,zb,...,zz,aaa,aab,...,aaz,aba,abb,...,abz,...,zzz,aaaa,... のようになります。
ロジャーはあなたに問題を出しました。
「番号$N$の犬の名前を答えよ。」26進数的な考え方で解けると思って,実装したら通りました.
abc171c.pyn = int(input()) n = n - 1 mozi_list = [] while True: k = n % 26 n = n // 26 - 1 chr_s = chr(97 + k) mozi_list.append(chr_s) if n == -1: break for i in range(len(mozi_list)): print(mozi_list[len(mozi_list)-i-1], end="")前半はここまでとなります.
今回,解説がとても丁寧に記述してあったので,詳しい解法はそちらを参考にしてもらえたらと思います.
前半の最後まで読んでいただきありがとうございました.後半はDEF問題の解説となります.
後半に続く.
- 投稿日:2020-06-23T15:24:36+09:00
【Django】1対多の関係( related_name, _set.all() )について
はじめに
Djangoにてモデル同士を紐づける際に用いるmodels.ForeignKey()の引数の中でrelated_nameというパラメータがあるが、いつ使われるのかが分からなかったので調べてみた。
前提
今回は以下のように、CategoryモデルとPostモデルを作成して考える。
apps/models.pyclass Category(models.Model): name = models.CharField(max_length=100) slug = models.SlugField(unique=True) def __str__(self): return self.name class Post(models.Model): category = models.ForeignKey(to=Category, on_delete=models.CASCADE) author = models.ForeignKey(settings.AUTH_USER_MODEL, on_delete=models.CASCADE) title = models.CharField(max_length=100) content = models.TextField() def __str__(self): return self.title上のコードでcategoryを3つ、ポストを6つ生成し、次の図の様な関係をもつとする。
以下2つの場合分けを行いそれぞれの方法を考える。
- 二次関数(post.id=1)に紐づくcategoryを取得したい時《多→1の参照》
- 社会(category.id=3)に紐づくpostをすべて取得したい時《1→多の参照》
多 → 1 への参照方法
オブジェクト.フィールド名で取得可能>>> post1 = Post.object.get(id=1) >>> post1 <Post: 二次関数> >>> post1.category <Category: 数学>1 → 多 への参照方法 【 _set.all() 】
オブジェクト.モデル名(小文字)_set.all()で取得可能>>> category3 = Category.object.get(id=3) >>> category3 <Category: 社会> >>> category3.post_set.all() <QuerySet [<Post: 坂本龍馬>, <Post: 鎌倉幕府>]>※ .all()の他に.filter()や.count()などを使って絞り込みやオブジェクト数をカウントしたりもできる。
related_nameとは
- models.ForeignKeyの引数の一つで別になくても良い。
- related_nameを指定すると
モデル名(小文字)_setに置き換えて使用可能となる。- related_name=’posts’とすると先ほどの例では、
category3.post_set.all()→→category3.posts.all()
となり、より直感的に分かるようになる。引数としてrelated_nameを追加
apps/models.pyclass Category(models.Model): name = models.CharField(max_length=100) slug = models.SlugField(unique=True) class Post(models.Model): category = models.ForeignKey(to=Category, on_delete=models.CASCADE, related_name='posts') #追加 author = models.ForeignKey(settings.AUTH_USER_MODEL, on_delete=models.CASCADE) title = models.CharField(max_length=100) content = models.TextField()related_nameを活用する
>>> category3 = Category.object.get(id=3) >>> category3 <Category: 社会> >>> category3.posts.all() #変更 <QuerySet [<Post: 坂本龍馬>, <Post: 鎌倉幕府>]> # ←結果は同じ

- 投稿日:2020-06-23T15:07:00+09:00
LinuxでもDeepLアプリのようなショートカット翻訳を使いたい
はじめに
WindowsやMacで使えるDeepLのアプリでは
ctrl-c ctrl-c
で簡単にコピーしたものが翻訳できて英文読むのが捗ります.同じようなことをLinuxでもしたいと思いました.
調べて見るとdeepl cliのようなものがいくつかあり,これを使って簡単なアプリを作ろうかなと思いましたが, 現在はpro版の公式のapiを利用しないと翻訳結果にアクセスできないみたいです.なので, ブラウザからアクセスすることにしました.同じようなことをしているものとして, @masan4444さんのLinuxでDeepL翻訳というものがありました.ショートカットにシェルスクリプトを登録するだけで簡単に利用できます.(参考にさせて頂きました.ありがとうございます.)
ただ, 個人的に,
- 翻訳の度にタブを開かずに同一タブで翻訳して欲しい.
- 翻訳元,翻訳先の言語を簡単に切り替えたい.
- 閲覧用ブラウザとは別ブラウザで翻訳したい.
ということをしたかったので作ってみました.
clip-translator
https://github.com/kosuke55/clip-translator
Install
google chromeのバージョンを確認.
google-chrome --version Google Chrome 81.0.4044.113調べたバージョンに最も近いchromedriver_binaryをインストール.
sudo pip install chromedriver_binary==81.0.4044.138.0以下のバッケージをインストール(PyPI登録はしてないです)
git clone https://github.com/kosuke55/clip-translator.git cd clip-translator sudo pip install -e .Setting
keyboardと検索して,shorcuts, custom shortcutsの欄を選択.
+ボタンを押して以下の画像のようにショートカットを登録する.
(例ではctrl-alt-cを設定しています.)

.
Run
ターミナルから
clip_translatate_sとするとブラウザが立ち上がる.
ブラウザが立ち上がった後にctrl-cでtextをコピーしてctrl-alt-cを押すと,自動的にdeeplに送られて翻訳ができる.
Options
clip_translate_s -h usage: clip_translate_s [-h] [--source SOURCE] [--target TARGET] [--mode MODE] optional arguments: -h, --help show this help message and exit --source SOURCE, -s SOURCE source language (default: en) --target TARGET, -t TARGET target language (default: ja) --mode MODE, -m MODE Translation site (deepl or google) (default: deepl)DeepLの代わりにgoogle翻訳を使いたければ
clip_translatate_s -m googleとする.
おわりに
とりあえずやりたいことはできた気がします. 公式アプリが出るまでこれで我慢します.



- 投稿日:2020-06-23T15:02:50+09:00
Google ColabでBigQueryを使う際によく使うコードスニペット
前提: 認証
from google.colab import auth auth.authenticate_user()ColabからBigQueryを利用するには、最初に認証を行う必要がある。
短いコードなのでわざわざ覚えるほどでもないが、コードスニペットが用意されているのでそれを使うと素早く追加できる。
クエリーの結果をDataFrameに格納する
google.cloud.bigqueryのMagicコマンドを使うと、一発でクエリーの結果をPandasのDataFrameとして取得できる。%%bigquery --project myproject df SELECT * FROM `myproject.foo.logs`Magicコマンドの最後の引数で指定した名前でDataFrameが作られ、Python側から参照できるようになっている。
df.head(5)パラメータを渡す
%%bigquery --project myproject df --params {"user_id": 123} SELECT * FROM `myproject.foo.logs` WHERE user_id = @user_id
--paramsで辞書型のパラメータを渡すこともできる。渡されたパラメータは@パラメータ名で参照できる。結果をCSVとして保存する
import os df.to_csv(os.path.join("output.csv"), index=False)取得したDataFrameは
to_csvでCSVファイルに書き出せる。Google Driveをマウントしておけば、Google Drive上に書き出すことができて便利。クエリーの結果からテーブルを作る
分析の内容によっては、中間テーブルを作ることで計算量を節約できたり、中間結果の可視化/チェックをできて効率を改善できる。
最新のgoogle-cloud-bigqueryでは、
--destination_tableを指定することで、クエリーの実行結果からそのままテーブルを作ることができるが、2020年6月現在Google Colabでデフォルトで入っているgoogle-cloud-bigqueryのバージョンではこのオプションが利用できないため、Magicコマンドを使わずにジョブを作成するコードを書く。from google.cloud import bigquery client = bigquery.Client(project="myproject") table_id = "myproject.foo.purchase_logs" job_config = bigquery.QueryJobConfig(destination=table_id) sql = r''' SELECT transaction_id, user_id, transaction_date, product_id FROM `myproject.foo.transactions` WHERE action = "purchase" ''' query_job = client.query(sql, job_config=job_config) query_job.result()公式ドキュメント: https://cloud.google.com/bigquery/docs/writing-results?hl=ja
テーブルが存在する時に上書きする
QueryJobConfigのWriteDispositionで
WRITE_TRUNCATEを指定すると、すでにテーブルが存在した場合に内容を破棄した上で作り直すことができる。(元のテーブルのデータは破棄されるため注意)job_config = bigquery.QueryJobConfig(destination=table_id, write_disposition=bigquery.WriteDisposition.WRITE_TRUNCATE)
WRITE_APPENDを指定した場合は既存のテーブルにさらにデータが追加される。CSVファイルの中身からテーブルを作る
CSVファイルからテーブルを作りたい場合は、
bqコマンドのbg loadを使ってアップロードする。!bq load --project_id=myproject --autodetect --source_format=CSV myproject:foo.products sample.csv指定するパラメータの内容は、読み込むCSVの内容によって適宜変更する。
--replaceを指定すると、すでにテーブルがあった場合にその内容を破棄した上で、作り直すことができる。https://cloud.google.com/bigquery/docs/loading-data-cloud-storage-csv?hl=ja
参考

- 投稿日:2020-06-23T14:36:52+09:00
Pythonで salesforce API(Bulk API)経由でデータ取得しBigQueryにロードする
背景
Pythonを使ってSalesforceからデータを取得したい。
今回は simple_salesforce というライブラリを使用し、Salsesorce APIのBulkAPI を使ってデータを取得し、それをBigQueryにロードする。認証周り
以下の3つを用意する
- username
- password
- security_token
- security_tokenは管理画面の [私のセキュリティトークンのリセット] で発行されるものを用意する
実装例
from google.cloud import bigquery from simple_salesforce import Salesforce import json import os class SalesforceAPI: def __init__(self, job_type): self.sf = Salesforce( username='USERNAME', password='PASSWORD', security_token='SECURITY_TOKEN' ) def execute(self): self.dl_file() self.load_to_bq() def dl_file(self): res = self.sf.bulk.TABLE_NAME.query('SELECT column1, column2 FROM TABLE_NAME') with open('dl_file_name', mode='w') as f: for d in res: f.write(json.dumps(d, ensure_ascii=False) + "\n") # 日本語の文字化け対応 def load_to_bq(self): client = bigquery.Client('project') filename = 'file_name' dataset_id = 'dataset' dataset_ref = client.dataset(dataset_id) table_id = 'table_name' table_ref = dataset_ref.table(table_id) job_config = bigquery.LoadJobConfig() job_config.source_format = bigquery.SourceFormat.NEWLINE_DELIMITED_JSON job_config.autodetect = True # 必要ならばschemaを指定 with open(filename, "rb") as source_file: job = client.load_table_from_file( source_file, table_ref, job_config=job_config ) job.result() print("Loaded {} rows into {}:{}.".format( job.output_rows, dataset_id, table_id))参考
- ここで紹介されているSOQL実行ツールが便利
- DL用のSOQLの作成はこれを使うといい
- 投稿日:2020-06-23T13:52:50+09:00
データサイエンス100本ノック~初心者未満の戦いpart3
これはデータサイエンティストの卵がわけもわからないまま100本ノックを行っていく奮闘録である。
完走できるか謎。途中で消えてもQiitaにあげてないだけと思ってください。ネタバレも含みますのでやろうとされている方は注意
記事を書く時点で27本目まで終わっていますが、知らなかった書き方も多く、また「自分はこう書いたけど答えはこうだった」というものも多くあったのでメモ代わりに置いておきます。
コレは見づらい!この書き方は危険!等ありましたら教えていただきたいです。
心にダメージを負いながら糧とさせていただきます。今回は19~2まで。
[前回]10~18
part11~9まで戦いはここから始まる
19本目
P-19: レシート明細データフレーム(df_receipt)に対し、1件あたりの売上金額(amount)が高い順にランクを付与し、先頭10件を抽出せよ。項目は顧客ID(customer_id)、売上金額(amount)、付与したランクを表示させること。なお、売上金額(amount)が等しい場合は同一順位を付与するものとする。
今回の要件は
id amo rank A00 100 1 B00 70 2 C00 80 2 D00 70 4 みたいな形の表を作る、ということらしい
SQLでいうならrei.sqlSELECT id,amo amo, (SELECT count(amo) FROM df b WHERE a.amo < b.amo)+1 rank FROM df a ORDER BY rankといったところか(久々にSQL打った)
一応解説するとamoとa.amoが今見ている売上で、その見ている売上よりも高い売上b.amoの数をカウントして(一番大きいと0になるから)+1する。と、いうrankを作りその列を追加するという内容。
注意:とても計算に時間がかかる書き方です。10本ノックのSQLで試しましたが、数分単位でかかりました。Dataframeでも同じように
df_receipt[['customer_id', 'amount']]
とランク列を作り、(横に)結合すると表ができる
ランク列の作り方は
df_receipt['amount'].rank(method='min', ascending=False)
※[参考]
ascending=Falseで降順(多いほうが優先)データ。method='min'は少ない数(最小値)が順位データとして返る。横結合をするには
pd.concat([['列A'],['列B']], axis=1)
pd.concatはaxisがデフォルトだと縦結合(表の下に表がくっつく)が、axis=1をつけると横結合されるらしい最後に列名を変え、rank昇順に並び替えると
mine19.pydf_tmp = pd.concat([df_receipt[['customer_id', 'amount']] ,df_receipt['amount'].rank(method='min', ascending=False)], axis=1) df_tmp.columns = ['customer_id', 'amount', 'ranking'] df_tmp.sort_values('ranking', ascending=True).head(10)こうなる
もちろん分からなくてカンニングである
20本目
mine20.pydf=df_receipt df=pd.concat([df[['customer_id','amount']] ,df['amount'].rank(method='first',ascending=False) ],axis=1) df.columns=['customer_id','amount','ranking'] df.sort_values('ranking',ascending=True).head(10)19本目と内容が一部被るので割愛
変わる部分はなお、売上金額(amount)が等しい場合でも別順位を付与すること。
の部分。つまり、表示として
id amo rank A00 100 1 B00 70 2 C00 80 3 D00 70 4 という形をとりたい。
method='min'は少ない数(最小値)が順位データとして返る。ここを変更すればよく、降順データにした後に
'min'を'first'とすることで出現順にナンバリングされる。21,22本目
mine21.pylen(df_receipt)mine22.pylen(df_receipt['customer_id'].unique())
解説いる?
22本目をSQLに直すと
SELECT COUNT(DISTINCT customer_id) FROM receipt
でいけます。どっちが楽?今回はここまで
実際ランクをつけるのをSQLとPythonで比較してPythonのほうが早いと感じたので、ようやくpandasを使うことに意義を見出し始めました。
LIKEとかSQLのが楽やろ
問題を解いているだけだとあまり頭に入ってこないので、また問題を解いてから整理をするをしていきたいと思います。
- 投稿日:2020-06-23T13:02:05+09:00
【随時更新】データ分析によく使うPythonメモ【N分割等】
リストのデータをN分割する
from matplotlib import pyplot as plt import numpy as np import random #任意の数の分割する(分割数, データリスト) def division_datas(division_length, datas): sort_data = sorted(datas) datas = [sort_data[i:i+division_length] for i in range(0, len(datas), division_length)] return datas #0~100のランダムな数値を100個生成する my_data = [random.randint(0, 100) for i in range(100)] #データを15分割してみる division_data_ls = division_datas(15, my_data) print(division_data_ls)
- 投稿日:2020-06-23T12:41:59+09:00
Pythonで信号処理(1):フーリエ変換
はじめに
Pythonで行う信号処理の勉強資料。
使用するライブラリー
numpy, matplotlib
scipyのfftpack実行内容
- 特定周波数の正弦波を生成する。(numpy)
- FFTを実行する。(scipy)
- 実行結果をプロットする。(matplotlib)
プログラムコード
1.正弦波の生成部分
N = 2**20 # data number dt = 0.0001 # data step [s] f1 = 5 # frequency[Hz] A1 = 1 # Amplitude p1 = 90*pi/180 # phase [rad] #波形形成 t = np.arange(0, N*dt, dt) # time freq = np.linspace(0, 1.0/dt, N) # frequency step y = A1*np.sin(2*np.pi*f1*t + p1)2.フーリエ変換部分
# 離散フーリエ変換&規格化 yf = fft(y)/(N/2) # y : numpy 配列 # N : サンプリング数全体コード
fft.pyimport numpy as np from scipy.fftpack import fft import matplotlib.pyplot as plt #円周率π pi = np.pi # parameters N = 2**20 # data number dt = 0.0001 # data step [s] f1 = 5 # frequency[Hz] A1 = 1 # Amplitude p1 = 90*pi/180 # phase #波形形成 t = np.arange(0, N*dt, dt) # time freq = np.linspace(0, 1.0/dt, N) # frequency step y = A1*np.sin(2*np.pi*f1*t + p1) #フーリエ変換 yf = fft(y)/(N/2) # 離散フーリエ変換&規格化 #プロット plt.figure(2) plt.subplot(211) plt.plot(t, y) plt.xlim(0, 1) plt.xlabel("time") plt.ylabel("amplitude") plt.subplot(212) plt.plot(freq, np.abs(yf)) plt.xlim(0, 10) plt.xlabel("frequency") plt.ylabel("amplitude") plt.tight_layout() plt.savefig("01") plt.show()3.実行結果
上:時間領域のグラフ:位相が90度ずれていることを確認。
下:周波数領域のグラフ:5Hzの周波数が確認。
まとめ
1.PythonでFFTを実行した。
感想
これまで信号処理には、matlabを使ってきたが、pythonのscipyのほうも簡単。
参考資料

- 投稿日:2020-06-23T12:08:21+09:00
アリババクラウドにDjangoアプリケーションをデプロイする方法
この記事では、Alibaba Cloud上でDjangoアプリケーションを起動してデプロイする方法を説明します。
本ブログは英語版からの翻訳です。オリジナルはこちらからご確認いただけます。一部機械翻訳を使用しております。翻訳の間違いがありましたら、ご指摘いただけると幸いです。
前提条件
最初の前提条件として、Python ベースのアプリケーションに virtualenv と virtualenv wrapperをインストールして、Python プロジェクトに分離された環境を作成する必要があります。そのためには、以下の手順で行うことができます。
pipをインストールするsudo apt-get install python-pip
virtualenvのインストールsudo pip install virtualenv
- virtualenvs を格納する
dirを作成します。mkdir ~/.virtualenvs
virtualenvwrapperのインストールsudo pip install virtualenvwrapper
- virtualenv のディレクトリに
WORKON_HOMEを設置するexport WORKON_HOME=~/.virtualenvs
virtualenvwrapper.shを.bashrcに追加します。 この行を~/.bashrcの最後に追加し、virtualenvwrapperコマンドが読み込まれるようにします。/usr/local/bin/virtualenvwrapper.shシェルを終了して再度開くか、
.bashrcまたはsource ~/.bashrcコマンドで.bashrcをリロードすれば準備は完了です。
- gitをインストールします。
apt-get install git
- ウェブサーバとしてNginxをインストールし、その背後でアプリケーションを実行できるようにします。
Sudo apt-get install nginx手順
それでは、Alibaba Cloud ECSインスタンスのセットアップと起動に取り掛かりましょう。
最初のLinuxインスタンスの起動
Alibaba Cloud Management Consoleを使用してECSインスタンスを実行する手順を簡単に見てみましょう。
- アカウントにログインし、Product & ServicesセクションのElastic Compute Serviceに移動します。サイドバーメニューの[概要]をクリックします。すでに実行中のインスタンスのリストが表示されます。Buy Instanceをクリックして、任意のリージョンからインスタンスを購入するか、次のステップに進んで新しいインスタンスを作成します。
2.サイドバーメニューの[Instances]をクリックします。インスタンス一覧で必要なリージョンを選択し、右上のバーでCreate Instanceをクリックします。
3.製品購入コンソールにリダイレクトされますので、ご希望のパッケージを選択する必要がありますが、クイック起動オプション(ECSインスタンスとデータ転送の特別価格を提供しています)、またはカスタム起動オプション(2つの異なる価格モデルを備えています)のいずれかを選択することができます。具体的には、月額または年単位で支払うサブスクリプション課金、またはニーズに応じて従量課金のいずれかを選択することができます。このチュートリアルでは、課金方法としてPay-As-You-Goを選択しました。
4.このウィンドウで、ECS インスタンスを起動する Datacenter Region と Zone を選択します。Region を選択して Zone を選択しない場合は、ランダムゾーンにインスタンスが配置されます。
5.ここで、作成するインスタンスの種類を選択する必要があります。要件に基づいて、Generationタブからインスタンスのジェネレーションのタイプを選択します。ジェネレーション タイプは、使用する構成と計算能力に基づいて異なるインスタンスの種類を表します。
6.次に、Network Type を選択して ECS インスタンスを起動します。ニーズに応じて、Classic Network または VPC のいずれかにすることができます。Classic Networkでは、アリババクラウドがIPアドレスを分散的に割り当てます。シンプルで高速なECSの利用を必要とするユーザーに適しています。VPCは、論理的に分離されたプライベートネットワークで、専用の接続に対応しています。より複雑なネットワーク管理プロセスに慣れているユーザーに適しています。
7.ここで、Operating Systemを選択する必要があります。各オプションの下には、異なるOSのバージョンのリストが用意されています。Ubuntuオプションを選択します。
8.必要に応じてドロップダウンメニューからシステムディスクの種類を選択します。また、[Add a disk] をクリックして、このリストにディスクを追加することもできます。
9.セキュリティ設定セクションでは、セキュリティを強化するためのパスワードを作成することができます。
10.Purchase Plan セクションで、インスタンスの名前を入力し、起動するインスタンスの数を設定します。
11.Overviewセクションで構成の詳細と合計価格を確認し、Buy Nowをクリックします。
12.Activateをクリックして注文を確定し、インスタンスを起動します。
13.インスタンスが起動したら、コンソールのInstancesタブで確認できます。
Djangoアプリケーションのインストールとデプロイ
Alibaba Cloud Management Consoleを使用してECSインスタンスを作成して起動したので、Djangoアプリケーションをインストールしてデプロイする方法を見てみましょう。
1.SSHコマンドを使ってサーバーにログインします。
2.パスワードを入力します。
3.新しい virtualenv を作成して、Django アプリケーションをデプロイするための環境を設定します。
mkvirtualenv DjangoApp新しい virtualenv を終了するには、deactivate を使用します。これで、workon で環境を切り替えることができるようになりました。virtualenv をロードしたり切り替えたりするには workon コマンドを使用します。
workon DjangoApp4.現在の環境にDjangoをインストールします。
pip install Django5.django-adminコマンドでSample Projectを作成し、ディレクトリをプロジェクトフォルダに変更します。
django-admin startproject todoAppcd todoApp/6.データベースを移行またはブートストラップします。
python manage.py migrate7.管理パネルにアクセスするためのスーパーユーザーを作成します。
python manage.py createsuperuser8.ユーザーを設定したら、manage.pyで処理されるrunerverコマンドを実行してアプリケーションをテストします。
python manage.py runserver 0.0.0.0:80008000番ポートで以下のように実行されていることがわかります。
あなたの管理パネルである/adminに移動して、アプリケーションを管理することができます。
ここで、Nginx を使用してアプリケーションを Web サーバーの後ろに配置します。
9.データベーススキーマを作成し、Python環境を有効化します。以下の手順で行うことができます。
- ディレクトリを Django Project ディレクトリに変更する
- 次のコマンドを実行する
python manage.py migrate10.CSSやJSファイルを含むすべての静的ファイルを収集します。以下の手順で行うことができます。
- 次のコマンドを実行して、特定の場所にあるすべての静的ファイルを収集します。
Python manage.py collectstatic --noinput
- 開発者は、すべての静的ファイルが収集される場所への
STATIC_URLパスを設定する責任を負います。- これらの変数は、Project ディレクトリ内の
setting.pyで定義されています。1、
STATIC_URL
2、STATICFILES_DIRS
3、STATIC_ROOT
11.uwsgiライブラリをインストールし、uwsgi serverを使用してサーバを起動します。以下の手順を実行することで実行できます。
pip install uWSGdjango アプリケーションのデプロイに使用する ini ファイルを作成します。
vim uwsgi.ini
application dirのuwsgi.iniに保存します。iniファイルの書き方については、Python/WSGIアプリケーションのクイックスタートを参照してください。以下のコマンドを実行してアプリケーションを起動します。uwsgi uwsgi.ini (your ini file)12.アプリケーションを提供するnginxの設定ファイルを変更します。
server { listen 80 default_server; listen [::]:80 default_server ipv6only=on; server_name localhost; location /static/ { include uwsgi_params; alias /root/todoApp/public/; } location / { include uwsgi_params; uwsgi_pass unix:/tmp/uwsgi.sock; } }13.nginxを再起動すると、アプリケーションはポート80でnginxの後ろで稼働しています。
結論
この記事では、Alibaba Cloud上にDjangoアプリケーションをデプロイする方法について説明しました。要約すると、これに関わる最初のステップは、UbuntuをOSとしてECSインスタンスを起動して実行すること、次に、このインスタンスに Django アプリケーションをインストールしてデプロイすることでした。このチュートリアルの前提条件の一部として、デプロイを完了し、有効な Alibaba Cloud のアカウントを持っている必要があることを覚えておいてください。
以下は、このチュートリアルに関連する製品のリストで、実運用のシナリオで Django アプリケーションをデプロイする際に役立つでしょう。
- Alibaba Cloud Elastic Compute Service (ECS)
- Alibaba Cloud CloudMonitor
- Alibaba Cloud Web Application Firewall (WAF)
- Alibaba Cloud Domain Name Service (DNS)
- Alibaba Cloud ApsaraDB for RDS
アリババクラウドは日本に2つのデータセンターを有し、世界で60を超えるアベラビリティーゾーンを有するアジア太平洋地域No.1(2019ガートナー)のクラウドインフラ事業者です。
アリババクラウドの詳細は、こちらからご覧ください。
アリババクラウドジャパン公式ページ

















- 投稿日:2020-06-23T11:55:52+09:00
データサイエンス100本ノック~初心者未満の戦いpart2
これはデータサイエンティストの卵がわけもわからないまま100本ノックを行っていく奮闘録である。
完走できるか謎。途中で消えてもQiitaにあげてないだけと思ってください。ネタバレも含みますのでやろうとされている方は注意
今回は10~18まで
part11~9まで今回から、自分で書いたモノが成功してるとは限らず、答えを見ながら書いていたり、失敗例も書いてあります。
10本目
mine10.pydf=df_store df[df['store_cd'].str.contains('S14')].head() '''模範解答''' df_store.query("store_cd.str.startswith('S14')", engine='python').head(10) '''失敗例''' import re df=df_store df[None != re.match(r'S14.*',str(df['store_cd']))] #>(中略)KeyError: False一目見て「SQLでLIKE使えば一発じゃねぇか!?」と思いました。
とりあえず、心の友reマッチングに突っ込んで解決しようとする。が、文字列型じゃないことに気づいたり、この書き方だと頭1文字マッチングしてもNoneで帰らなかったりそもそもKeyErrorを起こし続けたので別の手段を模索。すると、
df.str.containsというものを見つけて感動。
内部も正規表現で書けるので無敵感を覚えながら使用したが、模範解答は更にワケノワカラナイメソッドを使用。
engine='python'はおまじないのようなものらしい[参考]11本目
mine11.pydf=df_customer df[df['customer_id'].str.contains('1$')].head() '''模範解答''' df_customer.query("customer_id.str.endswith('1')", engine='python').head(10)引き続きSQLのありがたさを教えてくれる問題。
記事をある程度書いて復習が終わったらリファレンスを読み直してdf.str以下のメソッドも調べてみます。12~15本目
mine12.pydf= df_store df=df[df['address'].str.contains('横浜市')] df '''模範解答''' df_store.query("address.str.contains('横浜市')", engine='python')mine13.pydf=df_customer df=df[df['status_cd'].str.contains('^[A-F]')] df.head(10) '''模範解答''' df_customer.query("status_cd.str.contains('^[A-F]', regex=True)", engine='python').head(10)mine14.pydf=df_customer df=df[df['status_cd'].str.contains('[0-9]$')] df.head(10) '''模範解答''' df_customer.query("status_cd.str.contains('[1-9]$', regex=True)", engine='python').head(10)mine15.pydf=df_customer df=df[df['status_cd'].str.contains('^[A-F].*[0-9]$')] df.head(10) '''模範解答''' df_customer.query("status_cd.str.contains('^[A-F].*[1-9]$', regex=True)", engine='python').head(10)mine16.pydf=df_store df=df[df['tel_no'].str.contains('[0-9]{3}-[0-9]{3}-[0-9]{4}')] df.head(10) '''模範解答''' df_store.query("tel_no.str.contains('[0-9]{3}-[0-9]{3}-[0-9]{4}', regex=True)", engine='python')感想が無くてすいません。query使わなくてすいません。
お前書きながらエラー吐かないから怖いんだよ尚、
regex=Trueは「正規表現を利用する」ということらいしい[参考]17本目
mine17.pydf_customer.sort_values('birth_day', ascending=True).head(10)唐突に来る別パターン
これに関しては
忘れていたので調べながら記述しました。
ascendingはSQLのORDER BY ASCと同じ意味かな?18本目
mine17.pydf_customer.sort_values('birth_day', ascending=False).head(10)SQLと違うのは
DESCを使うのではなくascending=Falseとする部分。ここまではよかったんだ。ここまでは。
1,2は消化試合感もある復習でしたが、ここからは知識を組み合わせられるかが試される問題が増えてきます。
知識が足りてない自分には難しい問題が多かったので、少しゆっくりとしたペースで進みたいです。飛ばす部分もありますが(21,22とか)。
- 投稿日:2020-06-23T10:40:39+09:00
データサイエンス100本ノック~初心者未満の戦いpart1
これはデータサイエンティストの卵子(卵になる前。
♂だと垢BANくらいそうなので)がわけもわからないまま100本ノックを行っていく奮闘録である。
完走できるかすら謎。途中で消えてもQiitaにあげてないだけと思ってください。ネタバレも含みますのでやろうとされている方は注意
記事を書く時点で25本目まで終わっていますが、知らなかった書き方も多く、また「自分はこう書いたけど答えはこうだった」というものも多くあったのでメモ代わりに置いておきます。
コレは見づらい!この書き方は危険!等ありましたら教えていただきたいです。
心にダメージを負いながら糧とさせていただきます。今回は1~9まで。
[part2]10~181本目
さすがにこれは書ける。
予習しても頭に入らない鳥頭でもコレが書けないと支障をきたすので。mine01.pydf_receipt.head(10)2本目
いきなりエラーをかます
そうだった。複数列を射影するときは[['列A','列B']]と書くんだった。エラーを吐くのは日常茶飯事です。mine02.pydf_receipt[['sales_ymd','customer_id','product_cd','amount']].head(10)3本目
早くも答えと違う回答をする。
自分が書いたのがmine03.pydf=df_receipt[['sales_ymd','customer_id','product_cd','amount']] df.columns=['sales_date','customer_id','product_cd','amount'] df.head(10)こんな簡単なことに3行使うのはバカらしいのかもしれないが、頭の中を整理しながら解いていたのでこうなった。
というか、{ }とかpythonやりはじめてからほぼ使わないので、単純にrenameを知らなかった。模範解答
df_receipt[['sales_ymd', 'customer_id', 'product_cd', 'amount']].rename(columns={'sales_ymd': 'sales_date'}).head(10)4本目
ここも違う回答をしました。
mine04.pydf=df_receipt[['sales_ymd','customer_id','product_cd','amount']] df=df[df['customer_id']=='CS018205000001'] df模範解答
df_receipt[['sales_ymd', 'customer_id', 'product_cd', 'amount']].query('customer_id == "CS018205000001"')
queryが文字列として書くという部分に抵抗を覚えるのは自分だけでしょうか。文字列……WAF……正規表現マッチング……うっ頭が
文字列型入力だと内部で入力ミスしてもエラーが分からないんですよね。queryのほうが動作が早かったりするのでしょうか?5本目
mine05.py#df=df_receipt[['sales_ymd','customer_id','product_cd','amount']] #df=df[df['customer_id']=='CS018205000001'] df[df['amount']>=1000]模範解答
df_receipt[['sales_ymd', 'customer_id', 'product_cd', 'amount']] \
.query('customer_id == "CS018205000001" & amount >= 1000')4本目と前提条件が同じだったのでそのまま
dfを流用しました。
ここでも模範解答はquery。書きながら思ったのですが、ixみたいな非推奨な書き方だったりするのかな?余談
df=df[df['customer_id']=='CS018205000001']
df[df['amount']>=1000]
の二行をつなげて
df=df[df['customer_id']=='CS018205000001'][df['amount']>=1000]としても同じ結果は出ますが、
/opt/conda/lib/python3.7/site-packages/ipykernel_launcher.py:2: UserWarning: Boolean Series key will be reindexed to match DataFrame index.
というWarningをします。
df=df[条件]でdfになるのだからdf[条件1][条件2]も行けるだろうと思ったら怒られました。6本目
mine06.pydf=df_receipt[['sales_ymd','customer_id','product_cd','quantity','amount']] df=df[df['customer_id']=='CS018205000001'] df=df[(1000<=df['amount'])|(5<=df['quantity'])] df模範解答
df_receipt[['sales_ymd', 'customer_id', 'product_cd', 'quantity', 'amount']].query('customer_id == "CS018205000001" & (amount >= 1000 | quantity >=5)')条件が長くなってきたので更に分割。特にAND条件は分割したほうが分かりやすいと思い。レスポンスは下がるのか?
7本目
mine07.pydf=df_receipt[['sales_ymd','customer_id','product_cd','amount']] df=df[df['customer_id']=='CS018205000001'] df=df[(1000<=df['amount'])&(df['amount']<=2000)] df模範解答
df_receipt[['sales_ymd', 'customer_id', 'product_cd', 'amount']] \
.query('customer_id == "CS018205000001" & 1000 <= amount <= 2000')Between条件を一言で書けるのは魅力的である。ちなみにこれくらいからひたすらに「SQLで書きてぇ……」って思ってました。
8本目
mine08.pydf=df_receipt[['sales_ymd','customer_id','product_cd','amount']] df=df[df['customer_id']=='CS018205000001'] df=df[df['product_cd'] != 'P071401019'] df模範解答
df_receipt[['sales_ymd', 'customer_id', 'product_cd', 'amount']] \
.query('customer_id == "CS018205000001" & product_cd != "P071401019"')これくらいの条件なら中で条件を結ぶべきか迷うところ。
9本目
mine09.pydf_store.query('prefecture_cd != "13" & not (floor_area > 900)')模範解答
df_store.query('prefecture_cd != "13" & floor_area <= 900')ついにqueryに
屈する
ではなく、書き換え問題なので。notを使う必要性があったかは不明。というか、ない。今回はここまで
正直、自分が調べずにいけたのはココまで。次回からは分からないことを無理やり書こうとして玉砕する図を書いていこうと思う。