- 投稿日:2020-06-23T23:03:05+09:00
【Go】並行処理の「拘束」で安全に並行処理を扱う
オライリーの「Go言語による並行処理」を参考に、
実務で使ってみてなるほどと思った内容です。
今日初めて並行処理を書いたのでまだまだ浅い理解ですがメモとしてまとめてみます。拘束とは
拘束は、チャネルの読み書きを制限することにより、安全にチャネルを扱えるようにするという考え方です。
チャネルの扱いには注意が必要で、例えばチャネルに対する不適切な書き込みや、
チャネルを閉じる作業の漏れや重複により、デッドロックやpanicが起きてしまう可能性があります。
そうしたことを防ぐために、並行処理を関数にまとめてチャネルに対する権限を制限し、
関数の呼び出し側が安全に並行処理を扱えるようにするという考え方です。コード
「拘束」を使わない場合
package main import ( "fmt" "time" ) type processAResult struct { Message string Error error } type processBResult struct { Message string Error error } func main() { start := time.Now() channelA := make(chan processAResult, 1) // 関数の外でchannelを定義 go func() { time.Sleep(time.Second * 5) channelA <- processAResult{ Message: "AAAAA", Error: nil, } }() channelB := make(chan processBResult, 1) go func() { time.Sleep(time.Second * 3) channelB <- processBResult{ Message: "BBBBB", Error: nil, } }() // 関数の外でchannelの受信 resultA := <-channelA resultB := <-channelB // channelを閉じる close(channelA) close(channelB) if resultA.Error != nil { fmt.Println(resultA.Error.Error()) } fmt.Println(resultA.Message) if resultA.Error != nil { fmt.Println(resultB.Error.Error()) } fmt.Println(resultB.Message) fmt.Println(time.Since(start)) }ちょっと誇張した書き方かもしれませんが、関数の外側でチャネルを定義し、
関数の呼び出し側が自分でchannelを受け取って、自分でchannelを受け取らなければなりません。
デッドロックやpanicなど思わぬ結果になりやすい構造と言えます。
次に、「拘束」を使ってみます。「拘束」を使った場合
package main import ( "fmt" "time" ) type processAResult struct { Message string Error error } type processBResult struct { Message string Error error } func main() { start := time.Now() processA := func() <-chan processAResult { // 読み込み専用のチャネルを返す channelA := make(chan processAResult, 1) // チャネルの初期化 go func() { defer close(channelA) // チャネルを閉じる time.Sleep(time.Second * 5) channelA <- processAResult{ Message: "AAAAA", Error: nil, } }() return channelA } processB := func() <-chan processBResult { channelB := make(chan processBResult, 1) go func() { defer close(channelB) time.Sleep(time.Second * 5) channelB <- processBResult{ Message: "BBBBB", Error: nil, } }() return channelB } // 読み込み専用のチャネルを引数に取る getProcessAFinalResult := func(resultA <-chan processAResult) processAResult { var result processAResult for v := range resultA { result = v } return result } getProcessBFinalResult := func(resultB <-chan processBResult) processBResult { var result processBResult for v := range resultB { result = v } return result } processAResult := processA() processBResult := processB() finalResultA := getProcessAFinalResult(processAResult) finalResultB := getProcessBFinalResult(processBResult) if finalResultA.Error != nil { fmt.Println(finalResultA.Error.Error()) } fmt.Println(finalResultA.Message) if finalResultB.Error != nil { fmt.Println(finalResultB.Error.Error()) } fmt.Println(finalResultB.Message) fmt.Println(time.Since(start)) }先ほどの「拘束」を使わない例とほぼ同じ処理を、「拘束」を使って書き直してみました。
以下のチャネルに対する4つの操作が関数に閉じ込められ、関数の呼び出し側はチャネルに対する操作をしていません。
(1) チャネルの生成
(2) チャネルの書き込み
(3) チャネルのクローズ
(4) チャネルの読み込み(1) チャネルの生成、(2) チャネルの書き込み、(3) チャネルのクローズ はprocessA, processBという関数に閉じ込められました。
processA := func() <-chan processAResult { // 読み込み専用のチャネルを返す channelA := make(chan processAResult, 1) // (1) チャネルの生成 go func() { defer close(channelA) // (3) チャネルのクローズ time.Sleep(time.Second * 5) channelA <- processAResult{ // (2) チャネルの書き込み Message: "AAAAA", Error: nil, } }() return channelA }(4) チャネルの読み込みはgetProcessAFinalResult, getProcessBFinalResultという関数に閉じ込められました。
getProcessAFinalResult := func(resultA <-chan processAResult) processAResult { var result processAResult for v := range resultA { // (4) チャネルの読み込み result = v } return result }チャネルに対する操作が関数に閉じ込められたことは、「拘束」、すなわちチャネルに対する権限の制限です。
これにより、関数の呼び出し側は一切チャネルを操作する必要がなくなります。具体的には以下のような権限の制限となります。
- 関数processA, processBの中でチャネルの初期化を行うことで、チャネルへの書き込み権限を制限、
他のgo routineが意図せずチャネルへの書き込みをしてしまうことを防いでいる
- 関数processA, processBは読み込み専用のチャネルを返すことで、呼び出し側はチャネルの呼び出ししかできない
- 関数getProcessAFinalResult, getProcessBFinalResultは読み込み専用のチャネルを引数に取るので、
チャネルに対しては読み込みしかしないことが明示的になるこのように、「拘束」を使うことで一定程度安全に並行処理を扱うことができます。
- 投稿日:2020-06-23T21:48:05+09:00
gRPC: メソッドの呼び出しと HTTP/2 フレームの関係
この記事について
この記事では gRPC の Go言語実装である grpc-go を元に、 gRPC のメソッド呼び出しが HTTP/2 を使ってどう実現されているかをまとめる。
- 環境情報
- Go 言語のバージョン : 1.14.4
- grpc-go のバージョン : 1.29.1
はじめに
この記事では、以下のようなシンプルな protobuf の定義(*.protoファイル)を用いて確認をしている。
syntax = "proto3"; package helloworld; service Greeter { // Unary RPC rpc SayHello (HelloRequest) returns (HelloResponse) {} // Server streaming RPC rpc SayHello_SS (HelloRequest) returns (stream HelloResponse) {} // Client streaming RPC rpc SayHello_CS (stream HelloRequest) returns (HelloResponse) {} // Bidirectional streaming RPC rpc SayHello_BI (stream HelloRequest) returns (stream HelloResponse) {} } message HelloRequest { string name = 1; } message HelloResponse { string message = 1; }メソッド呼び出しと応答のフレーム
概要
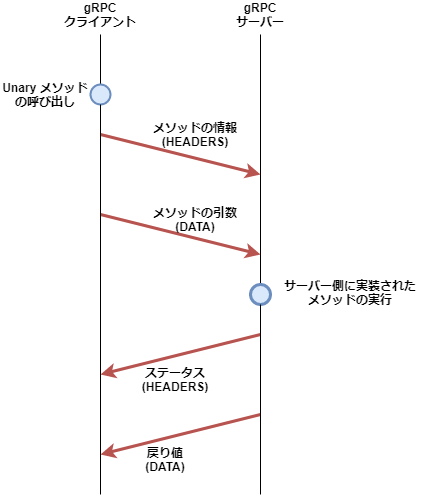
クライアントのプログラム内で gRPC のメソッドが呼ばれると、そのメソッドの情報や引数、戻り値などが HTTP/2 フレームで送受信される。以下は Unary のメソッドを呼び出した場合の例。
- メソッドの情報
- 呼び出されたメソッドの情報(サービス名、メソッド名など)は HTTP/2 の HEADERS フレームでサーバーに送られる
- サーバーはこれによりどのメソッドが呼ばれたかを判断して必要な初期化処理などを行う
- メソッドの引数
- メソッドの引数は DATA フレームでサーバーに送られて、サーバー側に実装されたメソッドに渡される
- ステータス
- サーバー側に実装されたメソッド呼び出しの成否、失敗した場合のエラーメッセージなどを HEADERS フレームでクライアントへ返す
- 戻り値
- メソッドの戻り値を DATA フレームで返す
詳細
メソッドの情報
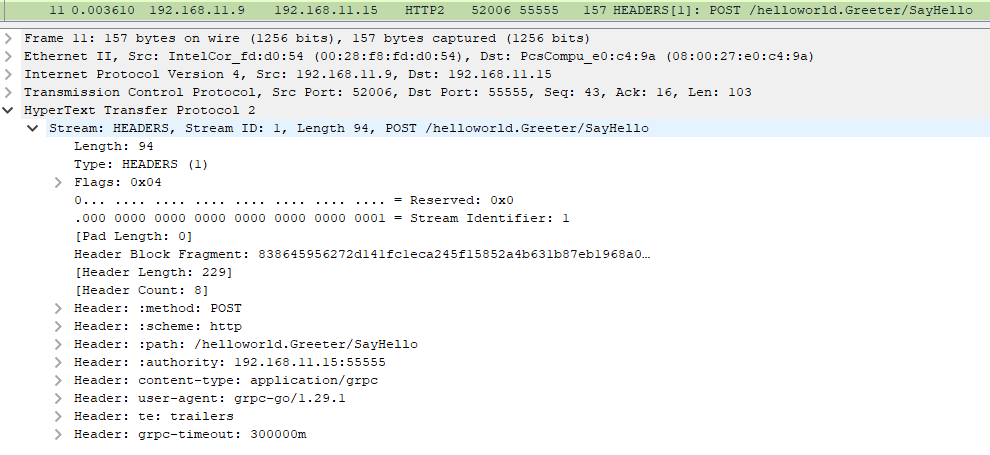
クライアントで呼び出したメソッドの情報は、以下のような HEADERS フレームでサーバーに送信される。
- HTTP メソッド :
POST- パス:
/サービス名/メソッド名(例: /helloworld.Greeter/SayHello)- その他の HTTP ヘッダー (content-type や gRPC 固有のヘッダーなど)
それぞれをもう少し詳しく見ると次のようになる。
HTTPメソッド
gRPC メソッドの種類(Unary, Server-Streaming, Client-Streaming, Bidirectional-Streaming) によらず、HTTPリクエストのPOSTが使われるパス
protobuf(*.proto ファイル)での定義に従い/サービス名/メソッド名という形式になる。サービス名はpackageとserviceで指定された名前。(例) helloworld.GreeterHTTP ヘッダー
標準的な HTTP ヘッダーだけでなく gRPC 固有のヘッダーも複数用いるが、以下によく使われるものだけ記載。
- content-type
- 必須のヘッダー
- 値は
application/grpc、または、その後ろに+か;に続けてサブタイプを付けたもの
- 例)
application/grpc+proto、application/grpc+json- サブタイプはペイロードのエンコーディング方式を表す
- 省略された場合のデフォルト値は
proto(protobuf の意味)content-typeが無い、または値がapplication/grpcで始まってない場合は、エラーになる[メソッド情報を送信してる HEADERS フレームの例]
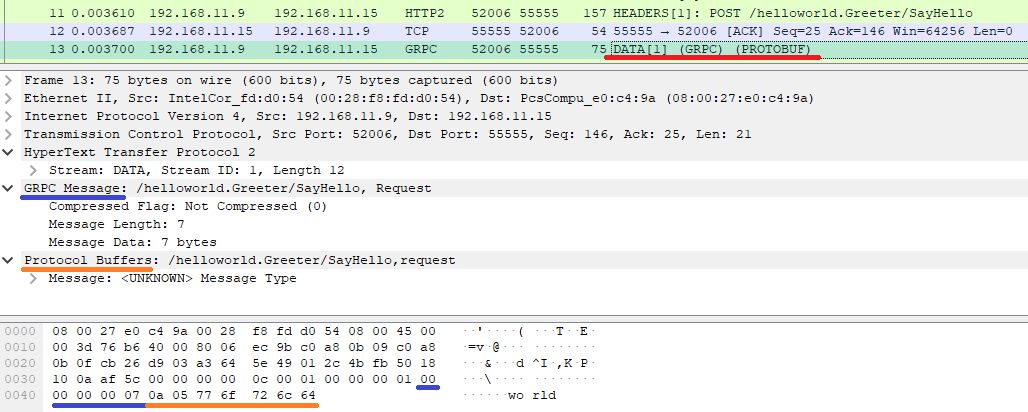
メソッドの引数
メソッドの引数は DATA フレームのペイロードに乗せてサーバーに送られる。ペイロードは gRPC の「固定長ヘッダー」と「メッセージ」から構成される。
[メソッドの引数を送信してる DATA フレームの例]
以下にペイロードの構造を記載。
- 固定長ヘッダー(5バイト) ※青色の部分
- ペイロードを圧縮してるかどうかのフラグ (1バイト)
- 0 は未圧縮の意味
- メッセージ部分の長さ(4バイト)
- この場合、メッセージは7バイト
- メッセージ ※オレンジ色の部分
- この場合は protobuf でエンコードされていて "0a 05 77 6f 72 6c 64" は、以下を意味する
- メッセージのフィールド番号が 1、型は Length-delimited、データ長は 5バイト、データは "world"
- 見方は、 Protocol Buffers: バイナリフォーマット(Wire Format)の中身 を参照
ステータス
サーバー側でのメソッドの呼び出し成否やエラーメッセージを HEADERS フレームで返す。
- 呼び出し自体が成功すれば、そのメソッドがエラーを返したとしても HTTP のステータスコードは 200 がクライアントに送られる
- メソッドが返したエラーメッセージ(error.Error())は
grpc-messageヘッダーとしてクライアントに送られる- メソッド呼び出し自体が失敗した場合(例:クライアントから送られた
content-typeヘッダーがapplication/grpcから始まってない) 200 以外が返る。この例では 415 になる。戻り値
戻り値は DATA フレームで引数と同様のペイロード形式でクライアントに送られる。
gRPC ストリーミングの場合
Server-Streaming, Client-Streaming, Bidirectional-Streaming のいずれかのストリーミングの場合、メソッド情報は HEADERS フレームで送られるが、gRPC のストリームに対して Send したメッセージは全て DATA フレームで送られる。
HTTP/2 ストリームとの関係
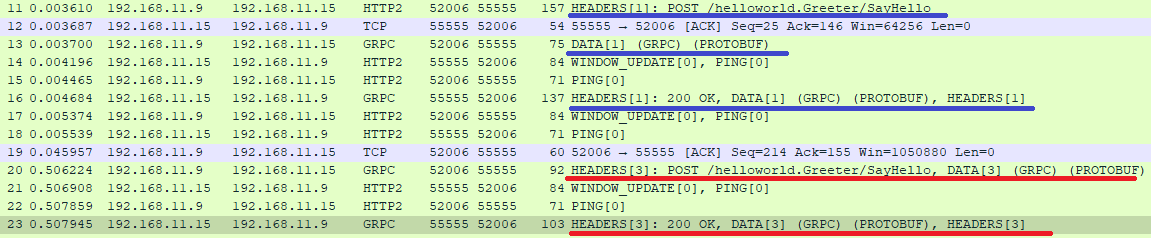
Unary の場合
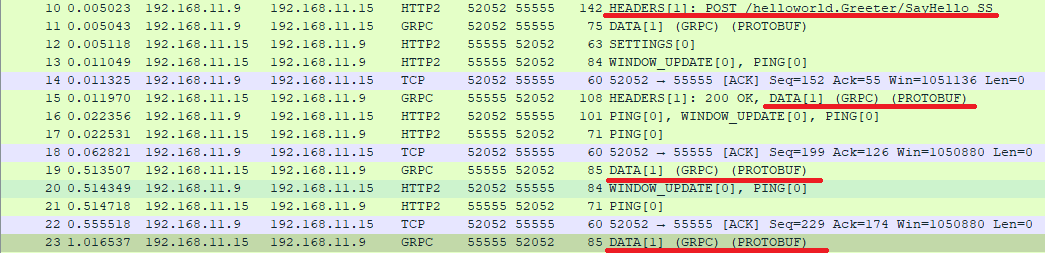
1回の Unary メソッドの呼び出し/引数/戻り値は、同一の HTTP/2 ストリームで送受信される。
続けて同じメソッドを呼んだとしても別のストリームが使われる。以下は同じ Unary のメソッドを2回続けて呼んだ例。1回目(青)は Stream ID 1、2回目(赤)は Stream ID 3 を用いていることが分かる。
ストリーミングの場合
メソッド呼び出し(HEADERS フレーム)、および、その呼び出しで取得した同一の gRPC ストリームに Send するメッセージ(DATA フレーム)は、全て同じ HTTP/2 ストリームで送受信される。
以下は Server-Streaming の例。メソッド情報送信に使われた Stream ID 1 が、サーバーからのストリーミングデータ送信にずっと使われていることが分かる。
参考
- 投稿日:2020-06-23T19:48:41+09:00
GraphQLについてまとめてみた
GraphQLとは
Facebookにより開発された、APIのためのクエリ言語であり、既存のデータを使用しクエリを実行するためのランタイム
GraphQLは、API内のデータの完全で理解可能な説明を提供し、クライアントに必要なものだけを正確に要求する力を与え、APIの長期的な発展を容易にし、強力な開発者ツールを有効にする (翻訳)
GraphQLクエリ言語とスキーマ言語
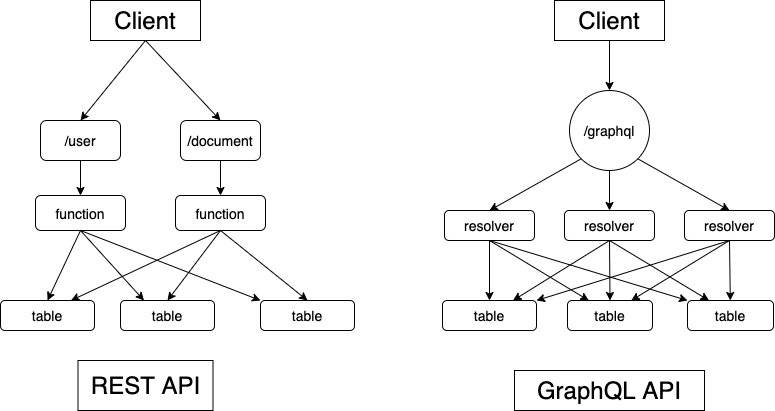
GraphQLは、一般的にクエリ言語とスキーマ言語から構成される
クエリ言語(フロント側)は、GraphQL APIのリクエストのための言語であり、データ取得に関連するquery、データ更新に関連するmutation、サーバサイドからのイベント通知を行うsubscriptionの3種類がある
一般的にはqueryとmutationを利用するスキーマ言語(サーバー側)は、GraphQL API の仕様を記述するための言語であり、記述したスキーマに従ってレスポンスを生成する
REST GraphQL 取得 GET Query 作成 POST Mutation 更新 PUT Mutation 削除 DELETE Mutation (GraphQLはQueryもMutationもPostでやりとりをしているが、わかりやすいようにRESTに合わせている)
フィールド
クエリで取得できるフィールドとして、スカラタイプとオブジェクトタイプの2種類が存在する
GraphQLでは、以下の5種類に対応している
- Int
- Float
- String
- Boolean
- ID (String)また、オブジェクト対応は1つ以上のフィールドを含んだグループで、JSON
の入れ子として表現されるエンドポイント
GraphQLのサーバー側の処理の流れ
- スキーマ等の設定
- query/mutationの判別
- variables(input)が必要ならそれの判定
- query/mutationの各リクエストに対するresolverの割り当て
- resolverで、細かい処理、値の返却
- 要求返却値に対しての処理
などなど、全て実装する必要がある
→ 手動での実装は辛い
→ gqlgenなど利用して、ボイラープレートコードを自動生成簡単な例
schematype Query { docs: [Document!]! } type Document { id: ID! title: String! description: String! file: String! }このスキーマに対して、クエリを書くとすると、
queryquery { docs { id title } }となる。これは、docsのidとtitleを取得するという意味になる。これにdescriptionやfileなどの情報が欲しい場合は、そのように記述することでデータを取得することができる。
また複数のschemaに対しては、schematype Query { user(username: String!): User! } type User { id: ID! username: String! password: String! email: String! }queryquery { user(username:"your name") { id username email } docs { id title description } }のように、複数のresolverに対してqueryを投げることができ、リクエストの回数を減らすこともできる
メリット
- 必要な情報しか通信が行われない
- エンドポイントが1つですむ
- リクエストの回数を減らすことができるかも
- 型の検証を行いながらリクエストできる
- バックエンド側の調整なしに、フロント側で情報を選択し、取得することができる
デメリット
- サーバー側の処理の実装が難しい
- スキーマの全てのパターンの実装が必要とになってくる
- スキーマを元に、自動で枠組みを生成してくれるライブラリなどを利用する場合もある
- gqlgenやgraphql-goなど
- データのキャッシュがめんどくさい
- RESTのキャッシュは、エンドポイントに応じてキャッシュの処理を行う
- GraphQLの場合、一意のIDを定義し、正規化されたキャッシュを構築する。クライアントが構築されたオブジェクトを参照するクエリを発したら、キャッシュを返すという仕組みになっている
備考
間違っている内容や追加指摘など、ございましたら教えていただけると幸いです。
- 投稿日:2020-06-23T18:20:13+09:00
sqlxのNamedQueryをIN句に適用する方法(名前付きクエリ)
1. はじめに
GoのsqlxでSQLを書く際に、IN句にNamedQueryを使おうとしてハマったので簡単な例文を書きます。
例はPostgreSQLで書いてます。2. 例文
コネクション生成
db, err := sqlx("postgres","接続情報") if err != nil { log.Fatal(err) }NamedQuery→PreparedStatementまでの変換
baseQuery := `SELECT * FROM users WHERE id IN (:userID) AND name = :userName` bindParams := make(map[string]interface{}) bindParams["userID"] = []int{1, 2} bindParam["userName"] = "Taro" users := &User{} query, params, err := sqlx.Named(baseQuery, bindParams) if err != nil { log.Fatal(err) } fmt.Println(query) // SELECT * FROM users WHERE user_id IN (?) AND name = ? fmt.Println(params) // [[1 2] Taro]sqlxのIn関数で、IN句の展開
query, params, err = sqlx.In(query, params...) if err != nil { log.Fatal(err) } fmt.Println(query) // SELECT * FROM users WHERE user_id IN (?, ?) AND name = ? fmt.Println(params) // [1 2 Taro]DBドライバーに合わせてバインドし直す
query = db.Rebind(query) fmt.Println(query) // SELECT * FROM users WHERE user_id IN ($1, $2) AND name = $3 fmt.Println(params) // [1 2 Taro]SQLを実行し、結果をUser構造体にバインド
err = db.Select(&users, query, params...) if err != nil { log.Fatal(err) }
- 投稿日:2020-06-23T08:27:04+09:00
【Go言語 GitHubActions】linterで特定のファイルを無視する方法
調べてもあまりでてこなかったのでメモ用に残す
on: pull_request: paths: - '**.go' jobs: lint: name: runner / lint runs-on: ubuntu-latest steps: - uses: actions/checkout@v2 - uses: reviewdog/action-golangci-lint@v1 with: github_token: ${{ secrets.github_token }} tool_name: golint # ここに--skipをつけて指定する golangci_lint_flags: "--disable-all -E golint --skip pkg/" level: warning filter_mode: nofilter fail_on_error: true reporter: github-pr-review
- 投稿日:2020-06-23T07:18:10+09:00
Hyperledger Fabricで個人情報をクエリする(RDB連携)
Hyperledger Fabricのchaincodeで個人情報を検索します
Hyperledger Fabric(以下HF。HLFが正式な略称なのだろうか?)の
queryメソッドで個人情報を問い合わせます。前に投稿しましたが、HFのState DBに個人情報を持つのはよろしくないので、個人情報はRDB(PostgreSQL)から引き当てることにします。
// 最近はHFでもchaincodeをSmart contractと呼ぶようになっている気がします。環境について
動作環境については次の通りです。前回の投稿と(ry
Ubuntu 18.04.4 LTS
docker-compose 1.26.0
docker 19.03.11
HF 2.1.1
go 1.14.4
PostgreSQL(Dockerイメージ) 12.3(latest)下準備
下準備をします。
RDBのテーブル定義
新しく個人情報用のテーブルを定義しました。DB
asset内にownerテーブルを定義しました。asset=# \d owner Table "public.owner" Column | Type | Collation | Nullable | Default ---------+-------------------+-----------+----------+--------- id | character(17) | | not null | name | character varying | | not null | country | character varying | | not null | city | character varying | | not null | addr | character varying | | not null | Indexes: "owner_pkey" PRIMARY KEY, btree (id) asset=#名前と住所が入っているので危ないですね。idは車体番号(VIN)を利用して、同じくVINをKeyにしている
State DBと紐付けることにします。何はなくともダミーデータ
とりあえず1件だけ、マイカー「Mira Qiita」のオーナー情報を登録しました。
asset=# SELECT * FROM owner WHERE id = 'JMYMIRAGINO200302'; id | name | country | city | addr -------------------+-----------------+---------+-----------+----------- JMYMIRAGINO200302 | ニ・キータ | 日本 | 東京都 | 足立区 (1 row) asset=#「ニ・キータ」さんの個人情報が入っています;-)
ニ・キータさんは足立区に住んでいるんですね。足立区は「修羅の国」と揶揄されることがあるのですが、同じ足立区民として心が痛いです…chaincodeを書く
さっそくコーディングしましょう。
データ構造の定義
新しいデータを扱うので、新しいデータ構造を定義しました。
// データ構造の定義 type Asset struct { Year string `json:"year"` // 初度登録年 Month string `json:"month"` // 初度登録月 Mileage int `json:"mileage"` // 走行距離(km) Battery int `json:"battery"` // バッテリーライフ(%) Location string `jasn:"location"` // 位置 } type AssetWithOwner struct { Name string // 名前 Country string // 国 City string // 都道府県 Addr string // 市区町村 Record *Asset }構造体
AssetWithOwnerを追加しています。実装しましょう
asset.goから抜粋func (s *SmartContract) QueryAssetWithOwner(ctx contractapi.TransactionContextInterface, key string) (*AssetWithOwner, error) { fmt.Println("QueryAssetWithOwner") assetAsBytes, err := ctx.GetStub().GetState(key) if err != nil { return nil, fmt.Errorf("Failed to read from world state. %s", err.Error()) } if assetAsBytes == nil { return nil, fmt.Errorf("%s does not exist", key) } asset := new(Asset) _ = json.Unmarshal(assetAsBytes, asset) db, err := sql.Open("postgres", "host=pgsql port=5432 user=postgres password=secret dbname=asset sslmode=disable") defer db.Close() if err != nil { return nil, fmt.Errorf("sql.Open: %s", err.Error()) } sql := "SELECT * FROM owner WHERE id = '" + key + "';" rows, err := db.Query(sql) if err != nil { return nil, fmt.Errorf("db.Query: %s", err.Error()) } var id string awo := new(AssetWithOwner) for rows.Next() { rows.Scan(&id, &awo.Name, &awo.Country, &awo.City, &awo.Addr) awo.Record = asset } return awo, nil }新規メソッド
QueryAssetWithOwnerを実装しました。通常のqueryメソッドと同じく、GetStateでState DBから情報をGETした後、RDBから個人情報を検索してAssetWithOwner構造体へ両方を合体セットしています。
SQL文は文字列を整形して作っています。VINはユニークなidなので、1件しか検索できない前提で書いてあります。2件以上見つかったら後勝ちになるでしょう:-(
当初、何も考えず文字列変数Keyを使っていたのですが上手くいかず。PostgresSQLのコンテナに入って手打ちでSQL文を叩いても上手くいかず…なぜか問い合わせたKey文字列が小文字になってしまうんです:-(asset=# SELECT * FROM owner WHERE id = JMYMIRAGINO200302; ERROR: column "jmymiragino200302" does not exist LINE 1: SELECT * FROM owner WHERE id = JMYMIRAGINO200302; ^ asset=#数時間ハマった挙げ句、シングルクォーテーションで挟めば良いことが分かりました。RDBなんて普段使わないから、そんなローカルルールは知らないよ!
「なぜ小文字になる!!」「なぜ小文字になる!」「なぜ小文字になるのよ(涙)」「ワケワカメ」(数時間経過)
論理的な仕様ではないと思うのですが。大昔のDOSも大文字と小文字を区別しなかったけど、レガシーなソリューションにはそういう名残があるのかしら:-|動作確認
実際にQueryしてみましょう!
# ./QueryAssetWithOwner.sh | jq { "Name": "ニ・キータ", "Country": "日本", "City": "東京都", "Addr": "足立区", "Record": { "year": "2003", "month": "02", "mileage": 43871, "battery": 100, "Location": "QIITA東京販売" } } #ちゃんとRDBから情報が取れています。前の投稿では、車がニ・キータさんのところにあっても
LocationはOwnerでした。逆にオーナーがニ・キータさんでもLocationが別の場所だと誰が真のオーナーかは分からなかったのです。
個人情報を加えることで、
「オーナーがニ・キータさんの車がQIITA東京販売に存在する」ということが分かるようになります。
履歴情報も見てみましょう。# ./GetHistoryOfAsset.sh | jq [ { "TxId": "9b99263e5b75378af40e8466d28dd85654e3b8e427572a6ae038501a8dfebe97", "Timestamp": "2020-06-22 21:52:52 +0000 UTC", "IsDelete": false, "Record": { "year": "2003", "month": "02", "mileage": 43871, "battery": 100, "Location": "QIITA東京販売" } } ] #履歴情報には個人情報が残っていないですね。個人情報保護法対策もバッチリ(?)です。
最後に
ブロックチェーンの主キーをマスターにして、レガシーRDB含め色んな周辺システムと連携が取れそうです。ブロックチェーンをシステム間のハブの位置付けで利用するのも面白いと思いました。
ちなみに、ニ・キータさんは架空の人物です;-)
念の為。