- 投稿日:2020-05-26T23:43:29+09:00
【前編】Mask R-CNNで発生したエラー「UserWarning: An input could not be retrieved. It could be because a worker has died」を解決してみた。
Mask R-CNNのnucleus検出デモを練習中
Deep learning初心者の私が、google colaboratoryを使ってMask R-CNNに試行錯誤している挑戦の続きです。
今回は以下を活用して、細胞の検出に挑戦しています。https://github.com/matterport/Mask_RCNN/tree/master/samples/nucleus
おなじみ、Matterport社のものです。
このデモでは、Mask R-CNNの検出の裏側である、ROIやAnchorなどを表示してくれるとともに、Detectionの際にもStep by stepでやってくれるものです。
初心者にとって、どうやって学習&認識してくれているのか理解することができるので、とても勉強になります。トレーニングのipynbがない
_dataと_modelの2つipynbファイルがあり特につまずくことなくデモを実行できたのですが、detectionで使うweightをトレーニングするipynbがないのです。
そこで、自分で作ってみようと思い、ヒントが隠されているnucleus.pyの中身を見てみました。10~25行目に、トレーニングするために実行するコマンドが書かれていました。
nucleus_train.py#Train a new model starting from ImageNet weights python3 nucleus.py train --dataset=/path/to/dataset --subset=train --weights=imagenet #Train a new model starting from specific weights file python3 nucleus.py train --dataset=/path/to/dataset --subset=train --weights=/path/to/weights.h5 #Resume training a model that you had trained earlier python3 nucleus.py train --dataset=/path/to/dataset --subset=train --weights=last #Generate submission file python3 nucleus.py detect --dataset=/path/to/dataset --subset=train --weights=<last or /path/to/weights.h5>なるほど、0から学習させるためには一番目のコマンドを実行すればいいんですね。
実行してみよう
ステップ①:とりあえず実行
--dataset=/path/to/datasetの部分を
nucleus_train.py--dataset=/content/drive/My drive/.../datasetに変更して実行します。
※utils.Dataset.add_imageの中で、
dataset_dir(上記)とsubset_dir(stage1_train)を合体させるので、stage1_trainまで指定する必要はなさそうです。ステップ②:重みDownload
これで実行してみると出力にURLが出現するので、
resnet50_weights_tf_dim_ordering_tf_kernels_notop.h5
をダウンロードします。ステップ③:学習開始
この後、--weights=/path/toの部分を
nucleus_train.py--weights=/content/.../resnet50_weights_tf_dim_ordering_tf_kernels_notop.h5に同様に変更します。
Pathも指定できたので、成功かと思いきや…!?トラブル発生
nucleus_train.pyEpoch 1/20と表示されたまま固まってしまいました。
そこに出ているエラーは、nucleus_train.pyUserWarning: An input could not be retrieved. It could be because a worker has died??なので、そのままgoogleにコピペして調査します。
最初に参考にしたのは以下の記事です。参考記事①
Colabolatoryで UserWarning: An input could not be retrieved. It could be because a worker has died
どうやら、「Colabolatoryのファイルストリームが学習速度に追いついていない。」ことが原因らしい。
google driveから画像を読み込むところがボトルネックになっていったぽい。参考記事②
うーん、pathをcolaboratory内にコピーすればよいことしかわかりませんね…
参考記事③
【秒速で無料GPUを使う】深層学習実践Tips on Colaboratory
nucleus_train.py!cp drive/My Drive/<指定フォルダ>/<指定ファイル等>大きなデータセットなどはzipのままGoogle Driveに保存しておき、Colabを起動都度、Colabローカルに解凍して持ってくると良い。
nucleus_train.py!unzip -q drive/My Drive/<指定フォルダ>/<指定ファイル>.zip-q は解凍時のメッセージを出さないオプション。2GB程度、数千ファイルを含むアーカイブでも、1分程度でGoogle Driveからの取得と解凍が終わる。
なるほど、大きなデータを使う時はcolaboratoryの中にデータを移せばいいんですね!
※この記事はcolaboratoryを活用するのに役立つ情報がわんさかです!参考記事④
ただのコマンド紹介ですが、zipの解凍先はこのように指定できるっぽいです。
nucleus_train.py% unzip dataset.zip -d /content/dataset実装してみた
長くなってしまったので、次の記事で実装例を紹介します!
【
今記事を書いています。乞うご期待!】
【記事書き終わりました。】
- 投稿日:2020-05-26T23:27:39+09:00
【Python】業務効率化ツールを配布するためのexe化手段について検討してみた
やりたいこと
pythonで作った業務効率化ツールを社内で配布したい。メンバーにはPCに疎い人も多いので、exeファイルとして配布する。
exe化は何通りかのやり方がある。「起動時間」「ファイルサイズ」「配布・導入のし易さ」などの観点で、どの方法でやれば良いか、自分なりに考えてみる。先に結論
pyinstallでonefile化 + 仮想環境で必要最低限のライブラリをインストールした状態でexe化するのが無難と思った。
起動時間が求められる状況では、onefile化は諦めるのも必要かもしれない。環境
Windows10 Home
Python3.8.2(32bit)
Visual Studio Code 1.45.1
PyInstaller3.6勉強・検証した内容
0.検証するコード
1.PyInstallerによるexe化
1-1.onefileにしない(デフォルト)
1-2.onefileにする
2.PyInstaller以外の方法
3.仮想環境下でexe化する0.検証するコード
超簡単なtest.pyを作成し、このファイルを各方法でexe化した。
importしているpyautoguiに特に意味はない(外部ライブラリが一つもないのも寂しいと思ったので)test.pyimport pyautogui print("Hello,World!")尚、起動時間の測定は本稿末尾に記載したツールで測定した。
1.PyInstallerによるexe化
現在一番メジャーと思われるexe化の手段。標準ライブラリではないのでpipでインストールする。
ターミナルから> pip install pyinstallerでインストール。
その後、ターミナルから> pyinstaller <変換するファイル.py> <-オプション>を実行すると、exe化が始まる。
オプションで後述するワンファイル化や、exeファイルの名前の変更、起動したときにコンソール(黒い画面)を表示させなくする等を設定できる。オプションの「-」(ハイフン)は一本だったり二本だったりするので注意。> pyinstaller test.py --name test2 --noconsole --onefile
~INFO: Building EXE from EXE-00.toc completed successfully.と表示されたら完了。exe化したファイルはカレントディレクトリの中の「dist」というフォルダ内に生成される。オプションで名前を指定しなかった場合、変換するファイル名.exeのファイルが生成される。1-1.onefileにしない(デフォルト)
オプションに--onefileを指定しない(=デフォルト)と、distフォルダにファイル名のフォルダが生成されており、その中にexeファイルが格納されている。メリットは起動時間の早さ。後述のワンファイル化する方法だと起動に5秒以上かかってしまうのに対し、ワンファイル化しないと1秒未満で起動できる。ただし、ディレクトリ内はこんな感じ。
うちの職場の場合、このフォルダを「この中にある〇〇〇.exeをクリックして起動してくださいね」と言って配布しても、しばらくして使われなくなることが容易に想像できる。(ショートカットを作成してもらえればワンチャンあるかも)1-2.onefileにする
やはりツールは配布したあとにシンプルに使ってもらうため、一つのファイルにまとめたい。
そのやり方は簡単。pyinstallerを実行する際に--onefile(もしくは-F)のオプションを追加するだけ。これでdistフォルダにexeのみの単一のファイルが追加されるようになる。
デメリットは起動時間。何も対策をしないと、test.pyみたいな超単純なコードでも起動に5秒以上かかってしまうプログラムとなる。2.PyInstaller以外の方法
Windows対応だと「cx-Freeze」「py2ex」が有名っぽい。
py2exはPython3.4までしか対応していないとのこと。(一応、直接GithubからダウンロードすればPython3.7まで対応できるらしい。トライしてみたけどPythonのバージョン切替が良くわからなくて諦めた)
ということでcx-Freezeの方を試してみた。導入及びexe化の仕方は下記のサイトが参考になったので割愛。
cx_FreezeでPythonをexeにしてみた
変換するスクリプトとは別にsetup.pyという設定用ファイルを作成する必要あるため、ひと手間かかるのが気になる。(py2exも同様らしい)
起動時間はそこそこ早い(0.6秒程度)が、onefile化できないみたいで、ファイルサイズも大して変わらないので、PyInstallerと比較してメリットは少ないと感じた。3.仮想環境下でexe化する
PyInstaller + onefile化でtest.pyを変換すると、ただ「Hello,World!」と表示するだけのファイルが36M程度になった。これはまだマシな方で、環境によっては100MBを超すことも多々あるらしい。
どうやらPyInstallerはファイルが肥大化しやすく、その原因は、使用しているPythonにインストールされているライブラリ等をすべてパッケージングしてしまうことにある模様。
そこで、対策として何もインストールされていないまっさらな仮想環境を構築し、そこに必要最低限のライブラリをいれてpyinstallerでexe化してあげればよい、と以下の記事で勉強させていただいた。
【悲報】PyInstallerさん、300MBのexeファイルを吐き出すようになる仮想環境構築について、自分なりにやり方を整理したので、備忘録も兼ねて記しておく。
3-1.仮想環境を作成する
総合ターミナルから「venv」コマンドを実行して仮想環境を構築する(Vertial ENVironmentの略?)
> py -m venv <任意の仮想環境名(ここではpyautogui_only)>⇒ カレントディレクトリに任意の仮想環境名のフォルダが作成される
3-2.作成した仮想環境をアクティブにする。
先ほど作成されたフォルダの「Scripts」フォルダから「Activate.ps1」を右クリック ⇒ パスとしてコピー ⇒ 総合ターミナルに貼り付け ⇒前後の"(ダブルクォーテーション)を削除 ⇒ ENTERで実行(cdで移動してして実行でもOK)
> C:\Users\aaa\Desktop\python\pyautogui_only\Scripts\Activate.ps1ここで「このシステムではスクリプトの実行が無効になっているため~」というエラーが出る人は、多分セキュリティの設定上スクリプトが実行できない状態になっている。なので、総合ターミナル上でまず以下コマンドを実行する。
> Set-ExecutionPolicy RemoteSigned -Scope Processその後、もう一度Activate.ps1を実行すると多分アクティブ化できるはず。
この設定はターミナルを立ち下げるたびに再度設定が必要。参考ページ↓にはVSCode恒久的に設定を変えるやり方も書いてあった。
Windows版VisualStudioCodeで、スムーズvenvを使うための設定まとめ
アクティブ化に成功するとハイパーターミナルのカレントディレクトリの左側に仮想環境名が表示される。(pyautogui_only) PS C:Users\~\ > _3-3.pipコマンドで必要なライブラリのみをインストール。
今回のtest.pyの場合はpyautoguiのみインストール。PyInstallerも忘れずインストールしておく。
(ちなみになぜか最新のpyautoguiのインストールでエラー出る場合はこちらも見てみてください)3-4.PyInstallerを実行
仮想環境でないときと同じようにでOK。
(pyautogui_only) PS C:Users\~\ > pyinstaller test.py --onefile⇒ distフォルダ内にexeファイルが出力される。
(ちなみに仮想環境を抜け出すには総合ターミナルでdeactivateコマンドを実行する)結果、自分の場合、そのままだと36MB程度だったファイルサイズが10MB程度まで抑制できた。
起動時間も6秒程度かかっていたのが2.3秒程度まで短縮できた。まとめ
今回検証した数値を並べると以下のような感じ。
前述したとおり、業務改善ツールの配布目的だったらPyInstaller + onefile化 + 仮想環境での最低限ライブラリインストールで良いかな、と思います。(数秒程度の起動なら、毎回でもそこまで苦にはならないはず)
いちいち仮想環境作るのはやや面倒ですが、exe化はそこまで頻発する作業でもなさそうですし。
もちろん、この結果はtest.pyみたいな超簡単なプログラムのケース。使用する外部ライブラリが増えてきたりすると状況が変わる可能性もあるので、都度判断が必要ですね。おまけ:起動時間を測定するため作ったプログラム
import time import subprocess import sys import csv import pyautogui import os if len(sys.argv) >= 2: start_time = time.time() subprocess.run(sys.argv[1]) # ←ドラッグ&ドロップしたファイルのパスを受け取り、実行 end_time = time.time() process_time = end_time - start_time pyautogui.alert(str(sys.argv[1]) + " " + str(process_time)) # ただの結果表示 # 結果をこのファイルと同じディレクトリ内にcsvで出力 file_name = os.path.join(os.path.dirname(sys.argv[0]), "check_time.csv") with open(file_name, "a", newline="") as fo: csv_file = csv.writer(fo) csv_file.writerow([sys.argv[1], process_time])↑これをexeファイルにして、ドラッグ&ドロップでプログラムを起動し、終了するまでかかった時間を測定⇒出力。

- 投稿日:2020-05-26T22:58:21+09:00
GAE & GCS & Django で image URL が Blank な件
概要
Django を動かしている インフラを GKE から GAE に載せ替えた時に発狂したメモ
django-storages というモジュールを使って、imageField 経由でGCSへのアップロード・URLの取得を行っていた
https://django-storages.readthedocs.io/en/latest/backends/gcloud.html?highlight=GS_DEFAULT_ACL#settingsしかし、GAEに移行したら imageField が空白で返ってくる様になった
upload は上手くいくし、Django を localhost や GKE で動かすときは上手くいく結論
URLの有効期間とかが不要なのであれば
settings に下記を追記すれば良いだけDEFAULT_FILE_STORAGE = 'storages.backends.gcloud.GoogleCloudStorage' GS_BUCKET_NAME = 'yourbacketname' GS_DEFAULT_ACL = 'publicRead' <= 追加追跡経路 / 原因
GAE はスタックドライバーにエラーログも吐かなかった
ステータス自体は 200だったからだ認証系は、GAEなのでデフォルトサービスアカウントにストレージの管理者権限を付与して 問題無いと思っていた
でも動かない仕方がないので django-storage のソースを追った
python3.6/site-packages/storages/backends/gcloud.pydef url(self, name): """ Return public url or a signed url for the Blob. This DOES NOT check for existance of Blob - that makes codes too slow for many use cases. """ name = self._normalize_name(clean_name(name)) blob = self.bucket.blob(self._encode_name(name)) if not self.custom_endpoint and self.default_acl == 'publicRead': return blob.public_url elif self.default_acl == 'publicRead': return '{storage_base_url}/{quoted_name}'.format( storage_base_url=self.custom_endpoint, quoted_name=_quote(name, safe=b"/~"), ) elif not self.custom_endpoint: return blob.generate_signed_url(self.expiration) else: return blob.generate_signed_url( expiration=self.expiration, api_access_endpoint=self.custom_endpoint, )GAEのデバック機能を使用して、デプロイ&ブラウザでのチマチマデバッグを繰り返したら
blob.generate_signed_url(self.expiration)この関数が悪人らしい
実際はエラーを吐いていたが、握り潰されていたのでGAEデバッグで try except でやっと原因が判明
"you need a private key to sign credentials.the credentials you are currently using <class 'google.auth.compute_engine.credentials.Credentials'> just contains a token.認証系のエラーでした
※ ちなみに、self に入ってる _service_account_email はキッチリGAEのやつでした
めんどいので、URLに認証情報なんていらないということで
self.default_acl == 'publicRead': の分岐に入れるために、settings に定数を追加した感じです疲れた・・・
後で代表に聞いたら
「バケットの作り直しでもイケるで」って言われた泣いた
- 投稿日:2020-05-26T22:40:40+09:00
競馬予想 機械学習(LightGBM)で回収率100%超えた話
はじめに
最近データ分析にはまっています。
データ分析コンペのKaggleをやっていて、私がよく思うのは「売上予測?もっと面白いテーマはないのかい?」です。
そんなわけで、勉強も兼ねて一から競馬予測モデルを作ることにしました。上手くいけば金儲けもできるし、競馬好きの私にとっては最高の分析テーマです。
ほぼ初心者ですが、結果として回収率が安定して100%を超えるようなモデルが作成できたので、この記事では、競馬モデル作成までのおおざっぱな流れと、シュミレーション結果の詳細について記載していきます。考え方でおかしなところがあればご指導お願いします。
条件設定
出走馬の走破タイムを予測し、最も速いタイムの馬に単勝掛けします。
巷では、1着の馬の的中率を挙げるようなモデルが多かったですが、回収率が思うように伸びてないようなものが多かったように思います。それならば、純粋にタイムを予測してから賭けると、いい感じになるかも?(暴論)と思い、この設定にしました。
本当は他にも理由がありまして.....
競馬では、人気馬は能力値以上に多くの人が賭けてしまうそうです。(参考:人気馬を軸にしたら勝てない理論)
つまり、1着的中率を追求するより、オッズにも目を向けて予想することで回収率を上げれるのかもしれません。
ただ、私は余裕をもって馬券を買いたいので、レース直前に確定するオッズを特徴量に組み込みたくないのです。どうしようかな...
競馬は様々な要因が絡むので、純粋に走破タイムを予測するのは困難です。困難だからこそ、人が賭けないような期待値の高い馬を予測してくれるのではないか?(暴論)。よし、走破タイムで行こう。
学習対象とシュミレーション対象
京都に住んでいるので、京都競馬のみを対象としました。データは、2009年から2019年までのほぼ全レース(データの前処理の項で説明します)とします。
それらを学習用データとテスト用データに分けて、テストデータに対してシュミレーションを行いました。合計で7年分のシュミレーションです。以下はデータ分割の内容です。
学習用データ テスト用データ 2009~2018 2019 2009~2017 2018 2009~2016 2017 2009~2015 2016 2009~2014 2015 2009~2013 2014 2009~2012 2013 万が一リークする場合も考え、学習データはテストデータより前の年にしています。
扱った特徴量の詳細は以下で説明します。
モデル作成までの流れ
- データの取得(webスクレイピング)
- データの前処理
- モデル作成
1. データの取得
お金を払えばデータを簡単に取得できそうですが、勉強も兼ねてwebスクレイピングでデータを取得しました。
まずはHTML・CSSをProgateで簡単に勉強です。最低限知識がないとどこに欲しいデータがあるかわからなかったからです。
WEBスクレイピングに関しては、以下の記事を参考に作成しました。正直ここが一番大変だった気がします。(例外処理が多すぎる!)
スクレイピング対象のサイトは https://www.netkeiba.com/ です。
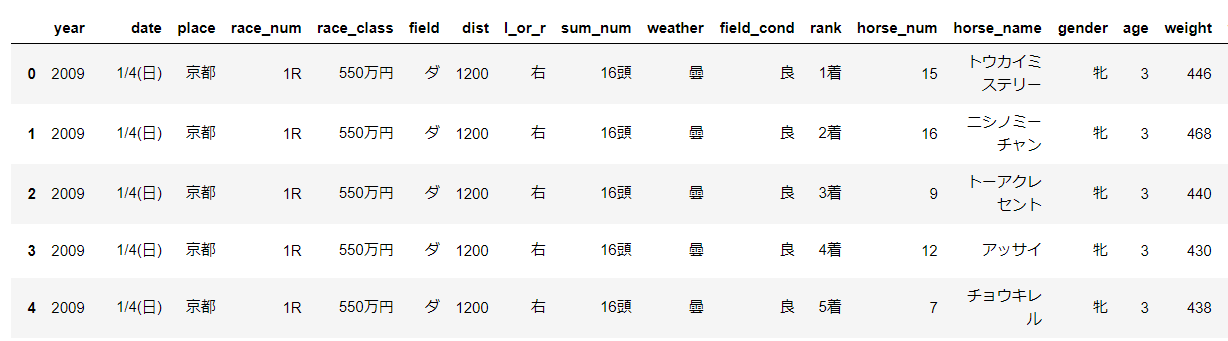
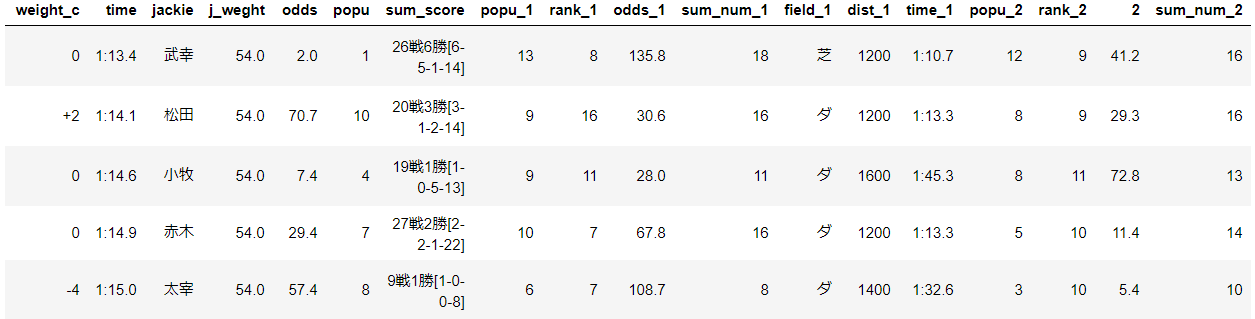
以下は実際にスクレイピングして得たデータです。コードは付録に載せています。
取得したデータは以下の通りです
feature 説明 feature 説明 race_num 第何レース field 芝かダートか dist 距離 l_or_r 右回りor左回り sum_num 頭数 weather 天候 field_cond 馬場状態 rank 着順 horse_num 馬番 horse_name 馬名 gender 性別 age 年齢 weight 馬の体重 weight_c 騎手の体重 time 走破タイム sum_score 通算成績 odds 単勝オッズ popu 人気 +で前走3レース分のデータを得ています。
この中で、走破タイム、着順、オッズ、人気の特徴量は学習データとして使っていません。
また、前走3レース分ない馬については情報を削除しています。しかし、各レースで一頭でも情報が残っていれば、その中で一番早い馬を予測します。当然、消し去ったデータに一着馬がいれば予想は外れることになります。
一年あたり大体450レース分のデータが残ります。(ほぼ全レース)
2. データの前処理
得られたデータを機械学習モデルに入れられるように変換します。といっても、カテゴリ変数をラベルエンコーディングしたり、文字型を数値型に変化しただけです。
今回扱うモデルのアルゴリズム木モデルの一種なので、標準化などは行っていません。
また、取得した特徴量を使って、新たな特徴量を何個か作っています。(距離とタイムから速さなど)
3. モデル作成
勾配ブースティング決定木アルゴリズムのLightGBMライブラリを使用して実装しました。Kaggleなんかで最近よく使われているあれです。
以下は実装コードです。
lgb_train = lgb.Dataset(X_train, y_train) lgb_eval = lgb.Dataset(X_valid, y_valid, reference=lgb_train) params = {'objective': 'regression', 'metric': 'rmse', } model = lgb.train( params, lgb_train, valid_sets=[lgb_train, lgb_eval], verbose_eval=10, num_boost_round=1000, early_stopping_rounds=10)御覧の通り何の工夫も行っていません(笑)
Optunaなどを使ってパラメータチューニングを行ってみたのですが、いかんせん評価関数と回収率は別ものなので、回収率向上にはそれほどつながりませんでした。
シュミレーション
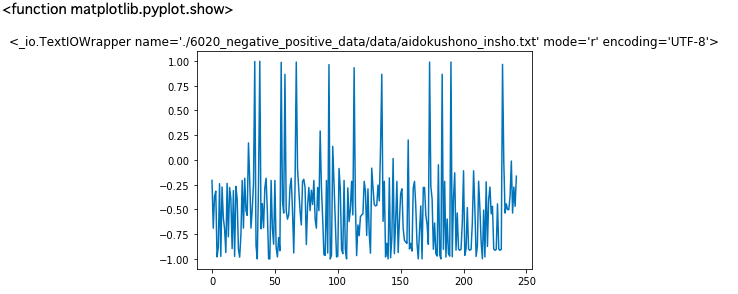
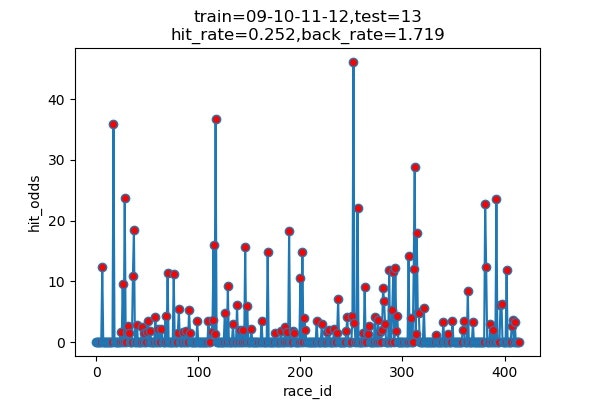
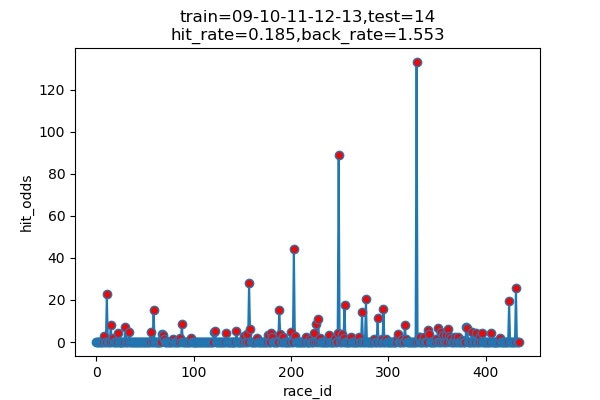
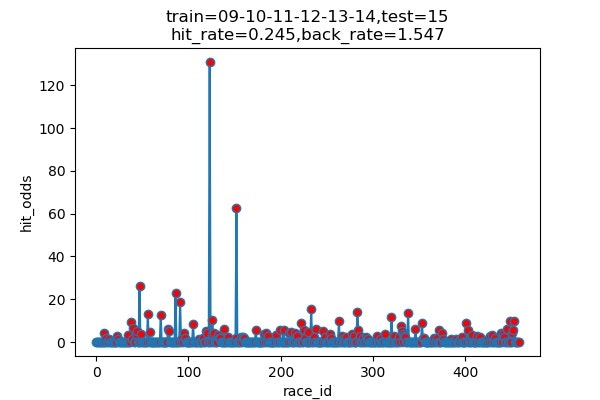
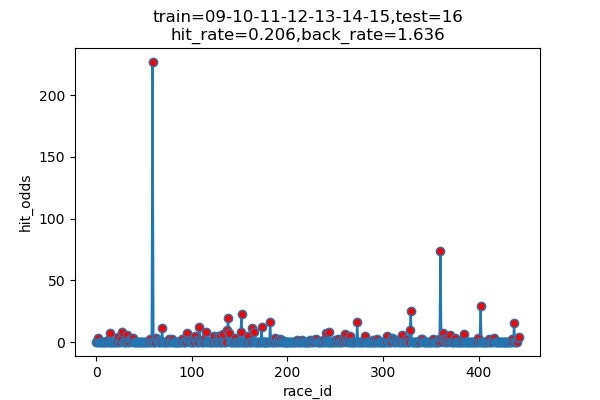
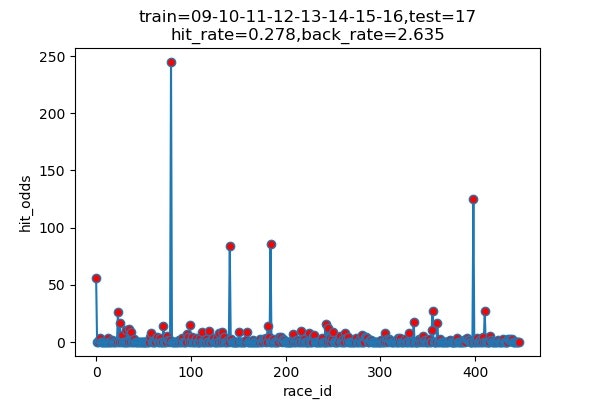
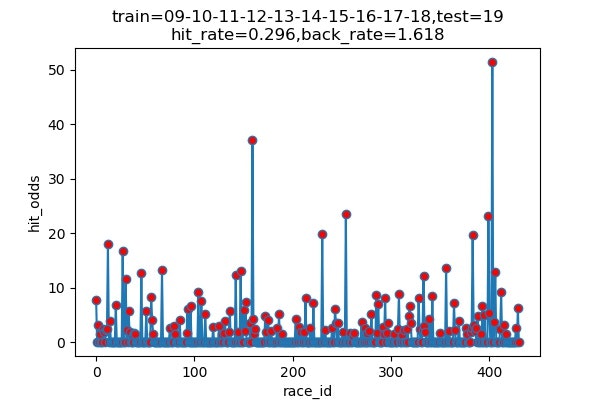
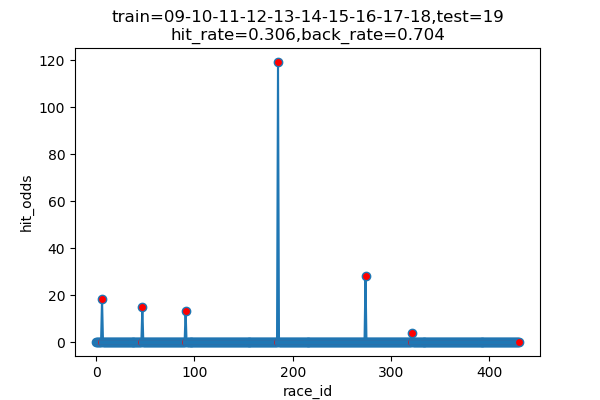
以下は7年分のシュミレーション結果です
横軸 : 何レース目か
縦軸 : 的中した場合の単勝オッズ(外れた場合は0)
hit_rate : 的中率
back_rate : 回収率
titleのtrainとtestはそれぞれに使ったデータの期間を表しています。(09は2009年)
以下に結果をまとめます
シュミレーション年度 的中回数 的中率 回収率 2013 116/460 25.2% 171.9% 2014 89/489 18.5% 155.3% 2015 120/489 24.5% 154.7% 2016 101/491 20.6% 163.6% 2017 131/472 27.8% 263.5% 2018 145/451 32.2% 191.8% 2019 136/459 29.6% 161.7% 平均 ------ 25.5% 180.4% 上出来すぎです。
的中率はまあまあですが、驚いたのは、オッズの高い馬をちょくちょく当ててきていることです。
2017年には、250倍の馬当ててるし!
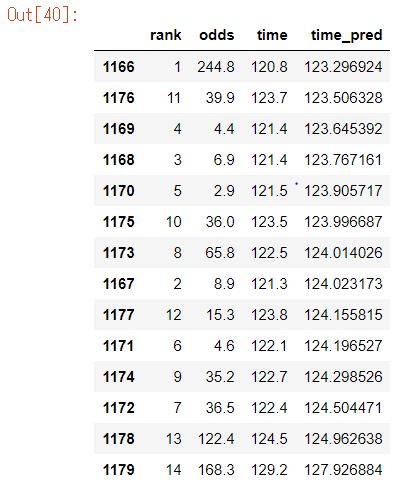
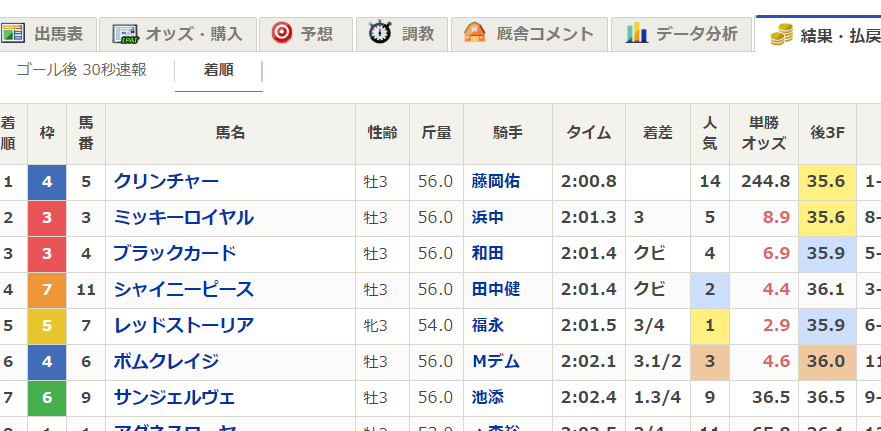
気になるので、中身を見てみましょう
以下はその日のレースの内容です。(time_pred順にsortしています)
マジで当ててる。
何か間違っているのではないかと怖くなってきました。そもそもこんな簡単に100%を超えてしまっていいのでしょうか。
こういう時は何を調べたら、正しいといえるのでしょうか.....
リアルでやってみるしかないですね!
以下は一応探ってみたことです。
・当日に使える特徴量だけを使っているか
・回収率の計算式は合っているか
・ネットの情報と齟齬はないか?
・予想タイムが最も早い者を選択できているか
・作成モデルを様々な方向から遊んでみる
モデルで遊んでみた
折角なのでいろいろ検証してみます。
1 一番遅いと予測した馬をかけてみる
6回だけ当てています。
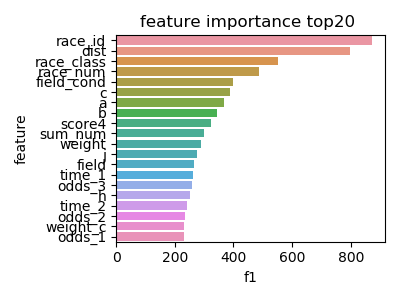
2 特徴量の重要度
以下はlightGBMのfeature-importannces(2019)です。
a,b,cはそれぞれ前走、前々走、前前々走の馬の速さ(dist/time)です。
タイムを予測しているので
dist(レース距離)が重要なのはわかりますが、race_id(その年の何レース目か)が重要なのははて?季節をタイムを予測するのに重要なのでしょうか。
他にも
race_cond(馬場状態),race_num(その日第何レース)など、環境が大きな重要度を占めています。3 n番人気をかけ続けるとどうなるか?
作成したモデルとは一切関係ありません(笑)
以下は2019年度の結果です
n番人気 的中率 回収率 1番人気 30.9% 71.1% 2番人気 17.3% 77.2% 3番人気 15.3% 90.3% 4番人気 10.1% 81.3% 5番人気 8.4% 100.5% 6番人気 6.2% 92.4% 7番人気 3.2% 64.2% 8番人気 2.4% 52.1% 9番人気 1.5% 48.2% 10番人気 1.3% 59.1% 11番人気 1.5% 127.6% 12番人気 1.3% 113.9% 13番人気 1.5% 138.6% 14番人気 0.4% 77.8% とても面白い結果です
回収率を狙うなら不人気馬を買い続けるのもありですね。
ほとんど当たらないので見ていても楽しくなさそうですが(笑)面白いので2013~2019年の平均で見てみました。
n番人気 的中率 回収率 1番人気 31.7% 73.4% 2番人気 20.0% 83.7% 3番人気 13.2% 80.2% 4番人気 9.9% 81.9% 5番人気 7.8% 89.1% 6番人気 5.5% 89.8% 7番人気 4.2% 86.0% 8番人気 2.4% 64.8% 9番人気 2.1% 64.8% 10番人気 1.7% 80.9% 11番人気 1.1% 98.2% 12番人気 1.0% 69.4% 13番人気 1.1% 113.2% 14番人気 0.2% 35.4% ※取得できたデータのみで行った検証なので注意
面白い
まとめ
ほぼ工夫無しで、回収率100%超えられる
lightGBMすごい付録
汚いコードですがご了承ください。
・スクレイピング(レース情報と各馬のURLの取得)
def url_to_soup(url): time.sleep(1) html = requests.get(url) html.encoding = 'EUC-JP' return BeautifulSoup(html.text, 'html.parser') def race_info_df(url): df1 = pd.DataFrame() HorseLink = [] try: # year = '2018' # url = 'https://race.sp.netkeiba.com/?pid=race_result&race_id=201108030409&rf=rs' soup = url_to_soup(url) if soup.find_all('li',class_='NoData') != []: return df1,HorseLink else: race_cols = ['year', 'date', 'place', 'race_num' ,'race_class', 'field', 'dist', 'l_or_r',\ 'sum_num','weather', 'field_cond', 'rank', 'horse_num', 'horse_name', 'gender', 'age',\ 'weight', 'weight_c', 'time', 'jackie', 'j_weght', 'odds', 'popu'] # 共通項目 # # Year = year Date = soup.find_all('div', class_='Change_Btn Day')[0].text.split()[0] Place = soup.find_all('div', class_="Change_Btn Course")[0].text.split()[0] RaceClass = soup.find_all('div', class_="RaceDetail fc")[0].text.split()[0][-6:].replace('、','') RaceNum = soup.find('span', id= re.compile("kaisaiDate")).text RaceData = soup.find_all('dd', class_="Race_Data")[0].contents Field = RaceData[2].text[0] Dist = RaceData[2].text[1:5] l_index = RaceData[3].find('(') r_index = RaceData[3].find(')') LOrR = RaceData[3][l_index+1:r_index] RD = RaceData[3][r_index+1:] SumNum = RD.split()[0] Weather = RD.split()[1] FieldCond = soup.find_all('span',class_= re.compile("Item"))[0].text # Not 共通 # HorseLink = [] for m in range(int(SumNum[:-1])): HN = soup.find_all('dt',class_='Horse_Name')[m].contents[1].text HL = soup.find_all('dt',class_='Horse_Name')[m].contents[1].get('href') HorseLink.append(HL if HN!='' else soup.find_all('dt',class_='Horse_Name')[m].contents[3].get('href')) HorseName = [] for m in range(int(SumNum[:-1])): HN = soup.find_all('dt',class_='Horse_Name')[m].contents[1].text HorseName.append(HN if HN!='' else soup.find_all('dt',class_='Horse_Name')[m].contents[3].text) # print(soup.find_all('dt',class_='Horse_Name')[m].contents[3]) Rank = [soup.find_all('div',class_='Rank')[m].text for m in range(int(SumNum[:-1]))] # ここから得られる情報も獲得 HorseNum = [soup.find_all('td', class_ = re.compile('Num Waku'))[m].text.strip() for m in range(1,int(SumNum[:-1])*2+1,2)] Detail_Left = soup.find_all('span',class_='Detail_Left') Gender = [Detail_Left[m].text.split()[0][0] for m in range(int(SumNum[:-1]))] Age = [Detail_Left[m].text.split()[0][1] for m in range(int(SumNum[:-1]))] Weight = [Detail_Left[m].text.split()[1][0:3] for m in range(int(SumNum[:-1]))] WeightC = [Detail_Left[m].text.split()[1][3:].replace('(','').replace(')','') for m in range(int(SumNum[:-1]))] Time = [soup.find_all('td', class_="Time")[m].contents[1].text.split('\n')[1] for m in range(int(SumNum[:-1]))] Detail_Right = soup.find_all('span',class_='Detail_Right') Jackie = [Detail_Right[m].text.split()[0] for m in range(int(SumNum[:-1]))] JWeight = [Detail_Right[m].text.split()[1].replace('(','').replace(')','')for m in range(int(SumNum[:-1]))] Odds = [soup.find_all('td', class_="Odds")[m].contents[1].text.split('\n')[1][:-1] for m in range(int(SumNum[:-1]))] Popu = [soup.find_all('td', class_="Odds")[m].contents[1].text.split('\n')[2][:-2] for m in range(int(SumNum[:-1]))] Year = [year for a in range(int(SumNum[:-1]))] RaceCols = [Year, Date, Place, RaceNum ,RaceClass, Field, Dist, LOrR,\ SumNum,Weather, FieldCond, Rank, HorseNum, HorseName, Gender, Age,\ Weight, WeightC, Time, Jackie, JWeight, Odds, Popu] for race_col,RaceCol in zip(race_cols,RaceCols): df1[race_col] = RaceCol return df1,HorseLink except: return df1,HorseLink・スクレイピング(各馬の今までのレース情報)
def horse_info_df(HorseLink, df1): df2 = pd.DataFrame() # print(HorseLink) for n,url2 in enumerate(HorseLink): try: soup2 = url_to_soup(url2) horse_cols = ['sum_score',\ 'popu_1','rank_1','odds_1','sum_num_1','field_1','dist_1','time_1',\ 'popu_2','rank_2','2','sum_num_2','field_2','dist2','time_2',\ 'popu_3','rank_3','odds_3','sum_num_3','field_3','dist_3','time_3'] sec = 1 ya = soup2.find_all('section',class_="RaceResults Sire") #ya = soup.find_all('div',class_="Title_Sec") if ya !=[]: sec = 2 tbody1 = soup2.find_all('tbody')[sec] SomeScore = tbody1.find_all('td')[0].text # print(SomeScore) tbody3 = soup2.find_all('tbody')[2+sec] HorseCols = [SomeScore] for late in range(1,4): HorseCols.append(tbody3.contents[late].find_all('td')[2].text) # Popu HorseCols.append(tbody3.contents[late].find_all('td')[3].text) # Rank HorseCols.append(tbody3.contents[late].find_all('td')[6].text) # Odds HorseCols.append(tbody3.contents[late].find_all('td')[7].text) # SumNum HorseCols.append(tbody3.contents[late].find_all('td')[10].text[0]) # Field HorseCols.append(tbody3.contents[late].find_all('td')[10].text[1:5]) # Dist HorseCols.append(tbody3.contents[late].find_all('td')[14].text) # Time dfplus = pd.DataFrame([HorseCols], columns=horse_cols) dfplus['horse_name'] = df1['horse_name'][n] df2 = pd.concat([df2,dfplus]) except: pass return df2

- 投稿日:2020-05-26T22:23:20+09:00
Brian2で神経活動をシミュレーションする
神経活動をコンピュータ上でシミュレーションする研究は以前から行われています。
シミュレータとしてはイェール大学のNEURONが有名ですが、他にも様々なソフトがあります。今回は、去年(2019年)にeLifeで論文発表されたBrian2というソフトを使ってみます。
*間違えやすいですが、名前はBrain(脳)ではなくてBrian(ブライアン)ですね。ホームページ:https://briansimulator.org/
GitHub:https://github.com/brian-team/brian2
論文:https://elifesciences.org/articles/47314
開発元はフランスのソルボンヌ大学などです。インストール
環境は
Ubuntu 16.04
Anaconda
Python 3.6
です。インストールはcondaでもpipでも出来るようです。
pip install brian2これでインストールできました。
バージョンはbrian2-2.3.0.2でした。次項からドキュメントのチュートリアルを参考にしながら基本的なところをやってみます。
動かしてみる
まずは単純な膜電位シミュレーションをやってみます。
インポートします。
(この項ではどれがモジュールかを分かりやすくするために、あえてマニュアル通りのfrom brian2 import *ではなく普通にインポートします。)import brian2Brian2には物理単位がモジュールになっていて、
Hzやmsなどをそのまま定義することができます。
これを使うことで、パラメータや定数を簡潔に記述できます。
また、計算時に物理単位が揃わないとエラーになるようになっているので設定ミスを防ぐことができます。v0 = -10 * brian2.mV tau = 10 * brian2.msシミュレーションを始めるときにはまず
start_scope()を入れます。brian2.start_scope()微分方程式(膜電位の変化を定義する)はString型で定義するようです。
eqs = 'dv/dt = (v0-v)/tau : volt (unless refractory)'上記のvoltは変数の物理単位です。SI単位で表します。
ここでは膜電位が変数になります。
(unless refractory)は不応期を使う場合に必要です。神経細胞は
NeuronGroupモジュールで定義します。G = brian2.NeuronGroup(1, eqs, threshold='v > -40*mV', reset='v = -60*mV', refractory=5*brian2.ms, method='exact')第一引数は神経細胞の数です。今回は1個で設定しました。
第二引数は膜電位の微分方程式です。
他の引数は
thresholdはスパイクになる閾値電位
resetはスパイク後のリセット電位
refractoryは不応期
methodは数値計算の方法
を設定しています。膜電位の初期値を設定します。
G.v = -70 * brian2.mV
StateMonitorによってモニタリングができます。M = brian2.StateMonitor(G, 'v', record=True)シミュレーションは
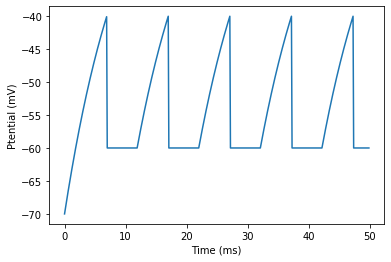
run(<時間>)によって開始されます。brian2.run(50*brian2.ms)これでシミュレーションできました。
結果をプロットします。
brian2.plot(M.t/brian2.ms, M.v[0]/brian2.mV) brian2.xlabel('Time (ms)') brian2.ylabel('Ptential (mV)');
この結果はLIFモデルのニューロンのスパイクをシミュレーションした結果になります。(ピーク電位がありませんが。)
これでシミュレーションの流れが分かりました。
発展として、
xi(標準正規分布の確率変数)を使うことで、ノイズを含んだ確率微分方程式を扱うこともできるようです。複数の神経細胞のスパイクシミュレーション
次に複数の神経細胞のスパイクをシミュレーションします。
今回は各細胞に異なる入力電位(I)を与えてみます。インポートからやっていきます。
from brian2 import * start_scope() N = 100 #細胞の数 tau = 10*ms #膜時定数 v0 = -50*mV #静止膜電位 eqs = ''' dv/dt = (v0-v+I)/tau : volt (unless refractory) I : volt ''' G = NeuronGroup(N, eqs, threshold='v>-40*mV', reset='v=-60*mV', refractory=1*ms, method='exact') G.v = -70*mV膜電位変化ではなくスパイクのみを見たいときは
SpikeMonitorを使います。M = SpikeMonitor(G)各細胞に異なる入力を定義します。
I_max = 40*mV G.I = 'i*I_max/(N-1)'iは細胞のインデックスになります。これで異なる入力を定義できました。
runします。
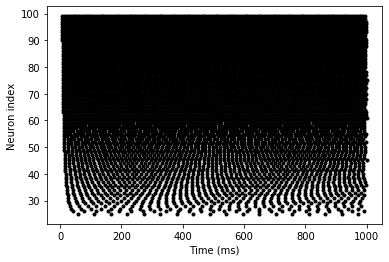
duration = 1000*ms run(duration)ラスタープロットを作成します。
plot(M.t/ms, M.i, '.k') xlabel('Time (ms)') ylabel('Neuron index');
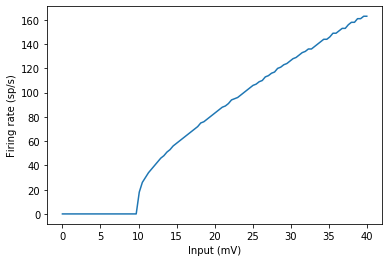
細胞のインデックスが上がるごとに入力電位が上がるので、スパイクが多くなりました。
よく見るF-Iカーブも作ってみます。
plot(G.I/mV, M.count/duration) xlabel('Input (mV)') ylabel('Firing rate (sp/s)');
出来ました。
これがReLU関数に似ていると言われますね。神経回路をシミュレーションするには
詳細は割愛しますが、神経回路のシミュレーションも簡単に出来るようです。
シナプスは
Synapsesモジュールで定義できます。
connectメソッドで細胞の結合が行われます。(どの細胞からどの細胞へつなげるか)シナプスの強度に微分方程式を定義することもできて、STDPモデルも作れるようです。
他にも
Networkでネットワークの定義ができたりするようです。感想
シミュレーションのための機能が充実していて、使いやすいと思いました。
ドキュメントには他にも様々な例が載っています。
https://brian2.readthedocs.io/en/stable/examples/index.html
コンパートメントモデルの例もありました。
これらも試してみたいですね。*追記
今年の1月にBrian2GeNNというものが発表されていました。
https://www.nature.com/articles/s41598-019-54957-7
これでGPUも活用できるようになったみたいです。
- 投稿日:2020-05-26T22:23:20+09:00
Brian2で神経活動シミュレーション
神経活動をコンピュータ上でシミュレーションする研究は以前から行われていています。
シミュレータとしてはYale大学のNEURONが有名ですが、他にも様々なソフトがあります。今回は、去年(2019年)にeLifeで論文発表されたBrian2というソフトを使ってみます。
*「Br ai n2」ではなくて「Br ia n2」です。ホームページ:https://briansimulator.org/
GitHub:https://github.com/brian-team/brian2
論文:https://elifesciences.org/articles/47314
開発元はフランスのソルボンヌ大学などです。インストール
環境は
Ubuntu 16.04
Anaconda
Python 3.6
です。インストールはcondaでもpipでも出来るようです。
pip install brian2これでインストールできました。
バージョンはbrian2-2.3.0.2でした。次項からドキュメントのチュートリアルを参考にしながら基本的なところをやってみます。
動かしてみる
まずは単純な膜電位シミュレーションをやってみます。
インポートします。
(この項ではどれがモジュールかを分かりやすくするために、あえてマニュアル通りのfrom brian2 import *ではなく普通にインポートします。)import brian2Brian2には物理単位がモジュールになっていて、
Hzやmsなどをそのまま定義することができます。
これを使うことで、パラメータや定数を簡潔に記述できます。
また、計算時に物理単位が揃わないとエラーになるようになっているので設定ミスを防ぐことができます。v0 = -10 * brian2.mV tau = 10 * brian2.msシミュレーションを始めるときにはまず
start_scope()を入れます。brian2.start_scope()微分方程式(膜電位の変化を定義する)はString型で定義するようです。
eqs = 'dv/dt = (v0-v)/tau : volt (unless refractory)'上記のvoltは変数の物理単位です。SI単位で表します。
ここでは膜電位が変数になります。
(unless refractory)は不応期を使う場合に必要です。神経細胞は
NeuronGroupモジュールで定義します。G = brian2.NeuronGroup(1, eqs, threshold='v > -40*mV', reset='v = -60*mV', refractory=5*brian2.ms, method='exact')第一引数は神経細胞の数です。今回は1個で設定しました。
第二引数は膜電位の微分方程式です。
他の引数は
thresholdはスパイクになる閾値電位
resetはスパイク後のリセット電位
refractoryは不応期
methodは数値計算の方法
を設定しています。膜電位の初期値を設定します。
G.v = -70 * brian2.mV
StateMonitorによってモニタリングができます。M = brian2.StateMonitor(G, 'v', record=True)シミュレーションは
run(<時間>)によって開始されます。brian2.run(50*brian2.ms)これでシミュレーションできました。
結果をプロットします。
brian2.plot(M.t/brian2.ms, M.v[0]/brian2.mV) brian2.xlabel('Time (ms)') brian2.ylabel('Ptential (mV)');
この結果はLIFモデルのニューロンのスパイクをシミュレーションした結果になります。(ピーク電位がありませんが。)
これでシミュレーションの流れが分かりました。
発展として、xi(標準正規分布の確率変数)を使うことで、ノイズを含んだ確率微分方程式を扱うこともできるようです。複数の神経細胞のスパイクシミュレーション
次に複数の神経細胞のスパイクをシミュレーションします。
今回は各細胞に異なる入力電位(I)を与えてみます。from brian2 import * start_scope() N = 100 #細胞の数 tau = 10*ms #膜時定数 v0 = -50*mV #静止膜電位 eqs = ''' dv/dt = (v0-v+I)/tau : volt (unless refractory) I : volt ''' G = NeuronGroup(N, eqs, threshold='v>-40*mV', reset='v=-60*mV', refractory=1*ms, method='exact') G.v = -70*mV膜電位変化ではなくスパイクのみを見たいときは
SpikeMonitorを使います。M = SpikeMonitor(G)各細胞に異なる入力を定義します。
I_max = 40*mV G.I = 'i*I_max/(N-1)'iは細胞のインデックスになります。これで異なる入力を定義できました。
runします。
duration = 1000*ms run(duration)ラスタープロットを作成します。
plot(M.t/ms, M.i, '.k') xlabel('Time (ms)') ylabel('Neuron index');
細胞のインデックスが上がるごとに入力電位が上がるので、スパイクが多くなりました。
よく見るF-Iカーブも作ってみます。
plot(G.I/mV, M.count/duration) xlabel('Input (mV)') ylabel('Firing rate (sp/s)');
これがReLU関数に似ていると言われますね。
神経回路をシミュレーションするには
神経回路のシミュレーションも簡単に出来るようです。(試したら更新します。)
シナプスは
Synapsesモジュールで定義できます。
connectメソッドで細胞の結合が行われます。(どの細胞からどの細胞へつなげるか)シナプスの強度に微分方程式を定義することもできて、STDPモデルも作れるようです。
他にも
Networkでネットワークの定義ができたりするようです。感想
シミュレーションのための機能が充実していて、使いやすいと思いました。
ドキュメントには他にも様々な例が載っています。
https://brian2.readthedocs.io/en/stable/examples/index.html
コンパートメントモデルの例もありました。
これらも試してみたいですね。*追記
今年の1月にBrian2GeNNというものが発表されていました。
https://www.nature.com/articles/s41598-019-54957-7
これでGPUも活用できるようになったみたいです。
- 投稿日:2020-05-26T22:00:26+09:00
im2col徹底理解
対象者
CNNを用いた画像認識で登場する
im2col関数について詳しく知りたい方へ
初期の実装から改良版、バッチ・チャンネル対応版、ストライド・パディング対応版までgifや画像を用いて徹底解説します。目次
im2colとは
im2colは、画像認識において用いられている関数です。動作としては多次元配列を2次元配列へ、可逆的に変換します。
これの最大のメリットは高速な行列演算ができるnumpyの恩恵を最大限に受けられることでしょう。
これなくして今日の画像認識の発展はなかったと言っても過言ではありません(たぶん)。なぜ必要か
画像はもともと2次元のデータ構造をしていると思いますよね?
見た目は確かに2次元ですが、実際に機械学習する際はRGBに分解した(これをチャンネルといいます)画像を用いることが多いです。
つまり、カラー画像は3次元のデータ構造をしていることになります。
また、白黒画像はチャンネル数が1ですが、一度の伝播で複数の画像を流す(これをバッチといいます)ので、3次元のデータ構造となります。
実用上、わざわざ白黒画像だけ3次元にして実装するのは効率が悪いので、白黒画像はチャンネル数1としてカラー画像と揃え、合計で4次元のデータ構造をしています。
二重ループを用いれば1枚ずつ画像に処理をかけていくことができますが、それではnumpyの利点を消してしまいます(numpyはforループなどで回すと遅いという性質があります)。
そのため4次元のデータを2次元にすることでnumpyの利点を最大限活かすことができるim2colという関数が必要となるのです。CNNとは
CNNとは、Convolutional Neural Network: 畳み込みニューラルネットワークの略で、ある座標点とその周囲の座標点に深い関係があるデータに対して用いられます。簡単な例で言えば画像や動画ですね。
CNN登場以前は画像などのデータ構造をニューラルネットワークを用いて学習する場合、2次元のデータを平滑化して1次元のデータとして扱っており、2次元のデータが持つ重要な相関関係を無視していました。
CNNは画像という2次元のデータ構造を保ったまま特徴量を抜き出していくことで画像認識にブレークスルーを引き起こしました。
網膜から視神経への情報伝達の際に行われている処理から着想を得ている技術であり、より人間の認識に近い処理を行うことが可能となりました。フィルタリング
CNNの処理の内容は主にフィルタリング(畳み込み層)とプーリング(プーリング層)と呼ばれる処理です。
フィルタリングとは、画像データから例えば縦線などの特徴を検出する処理を行うものです。
これは人間の網膜細胞が行っている処理と似ています(人間の網膜細胞では特定のパターンに反応し電気信号を発して情報を視神経に伝える細胞があります)。
プーリングとはフィルタリングで抜き出した特徴量のうち、より特徴的な物を抜き出す処理を行うものです。
これは人間の視神経で行われている処理と似ています(視神経から脳へ情報が伝達される時点で神経細胞の数が減っている→情報が圧縮されている)。
データ量削減の観点からこれは非常に優秀な処理で、特徴量をうまく残しながらメモリ節約および計算量を削減することができます。
プーリングの実装にもim2colと別の記事で紹介する予定のcol2imが活躍しますが、今回は特にフィルタリングに注目します。
上のgifはフィルタリングのイメージを表したものです。
im2colの動作と初期の実装
im2colの実装を理解するために、その動作を数式と画像とgifを用いて徹底的に解剖します。
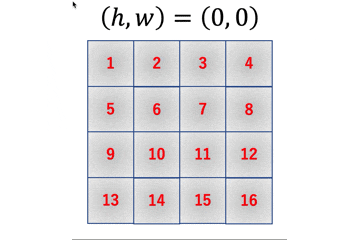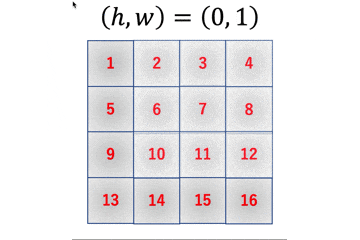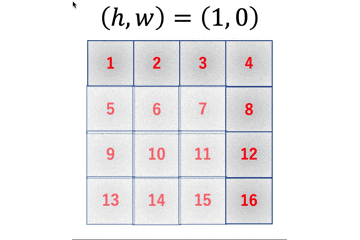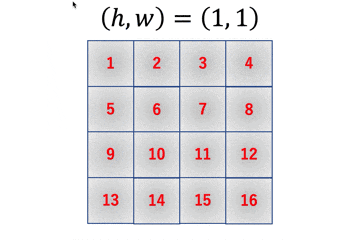
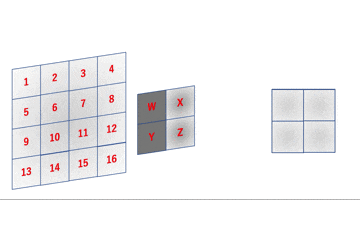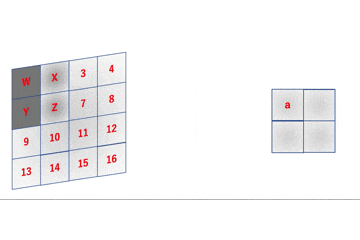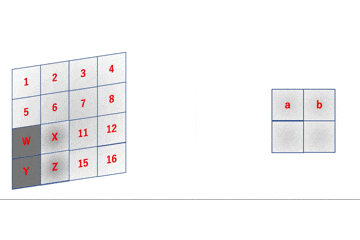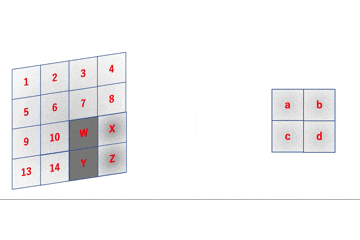
im2colの動作先のgifは数式的には
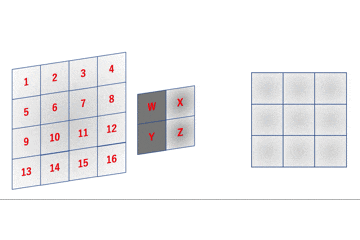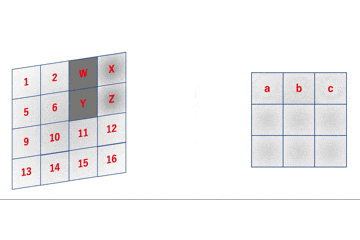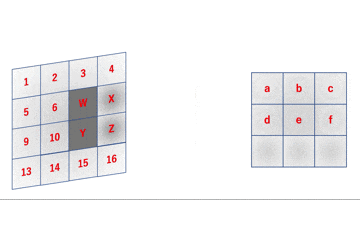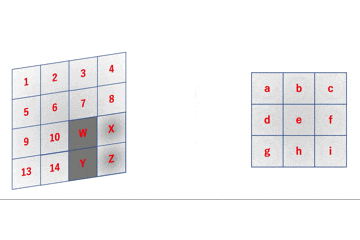
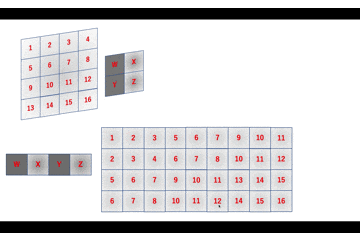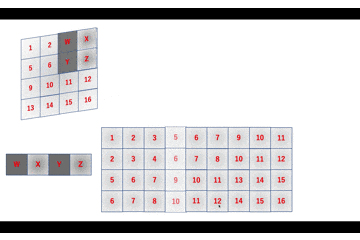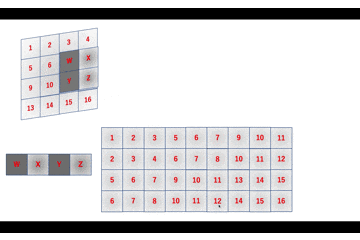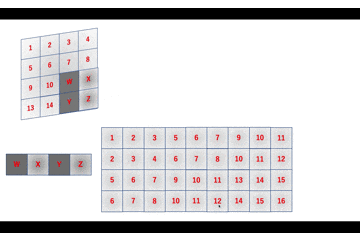
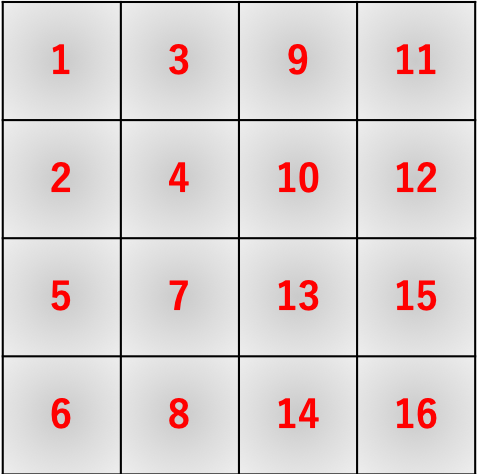
a = 1W + 2X + 5Y + 6Z \\ b = 2W + 3X + 6Y + 7Z \\ c = 3W + 4X + 7Y + 8Z \\ d = 5W + 6X + 9Y + 10Z \\ e = 6W + 7X + 10Y + 11Z \\ f = 7W + 8X + 11Y + 12Z \\ g = 9W + 10X + 13Y + 14Z \\ h = 10W + 11X + 14Y + 15Z \\ i = 11W + 12X + 15Y + 16Zのようになります。
im2colはこれを行列積演算で実現するためにいい感じに画像データを変形します。
数式でも確認します。\begin{align} \left( \begin{array}{c} a \\ b \\ c \\ d \\ e \\ f \\ g \\ h \\ i \end{array} \right)^{\top} &= \left( \begin{array}{cccc} W & X & Y & Z \end{array} \right) \left( \begin{array}{ccccccccc} 1 & 2 & 3 & 5 & 6 & 7 & 9 & 10 & 11 \\ 2 & 3 & 4 & 6 & 7 & 8 & 10 & 11 & 12 \\ 5 & 6 & 7 & 9 & 10 & 11 & 13 & 14 & 15 \\ 6 & 7 & 8 & 10 & 11 & 12 & 14 & 15 & 16 \end{array} \right) \\ &= \left( \begin{array}{c} 1W + 2X + 5Y + 6Z \\ 2W + 3X + 6Y + 7Z \\ 3W + 4X + 7Y + 8Z \\ 5W + 6X + 9Y + 10Z \\ 6W + 7X + 10Y + 11Z \\ 7W + 8X + 11Y + 12Z \\ 8W + 9X + 12Y + 13Z \\ 10W + 11X + 14Y + 15Z \\ 11W + 12X + 15Y + 16Z \end{array} \right)^{\top} \end{align}
im2colの初期の実装ということで、まずはこれを愚直に実装してみます。
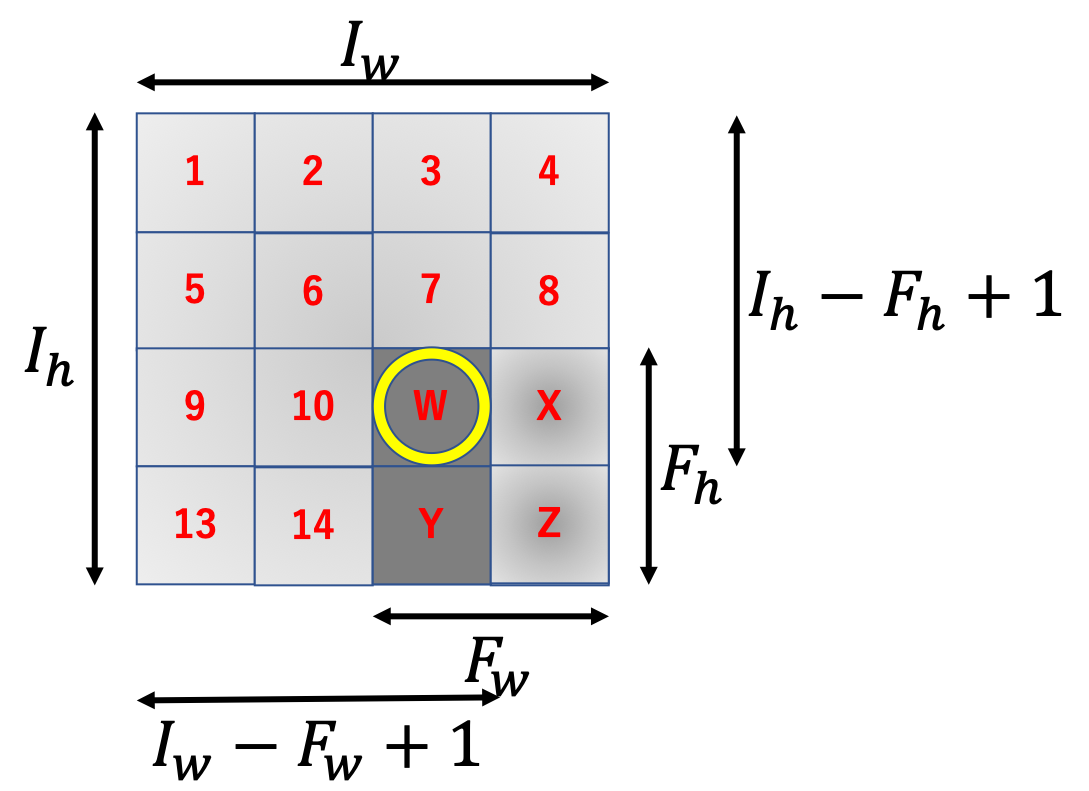
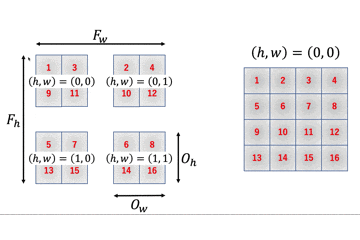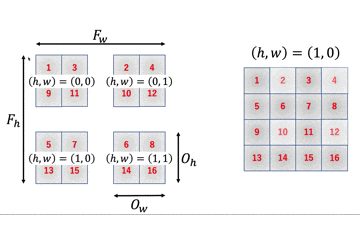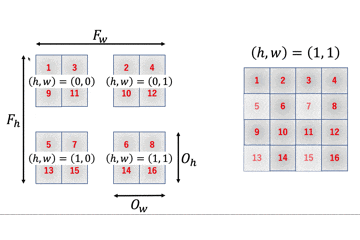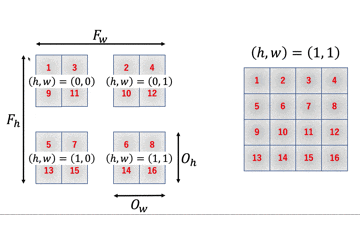
$4 \times 4$の行列に$2 \times 2$のフィルタをかけると$3 \times 3$の行列が出力されます。これを一般化しましょう。
$I_h \times I_w$の行列に$F_h \times F_w$のフィルタをかけることを考えます。
この時、一番最後にフィルタをかけた時の、フィルタの一番左上のインデックスが出力行列のサイズと一致します。フィルタをかける回数と出力行列のサイズが一致するからですね。
画像から、出力行列のサイズは$(I_h - F_h + 1) \times (I_w - F_w + 1) = O_h \times O_w$のように計算することができます。
つまり、$O_h O_w$個の要素が必要となるため、im2colの列数は$O_h O_w$となります。
一方で、行数はフィルタのサイズに比例しますので$F_hF_w$となるため、$I_h \times I_w$の入力行列に$F_h \times F_w$のフィルタをかける時、im2colの出力行列は$F_h F_w \times O_h O_w$となります。
以上をプログラムに落とし込むと次のようになります。
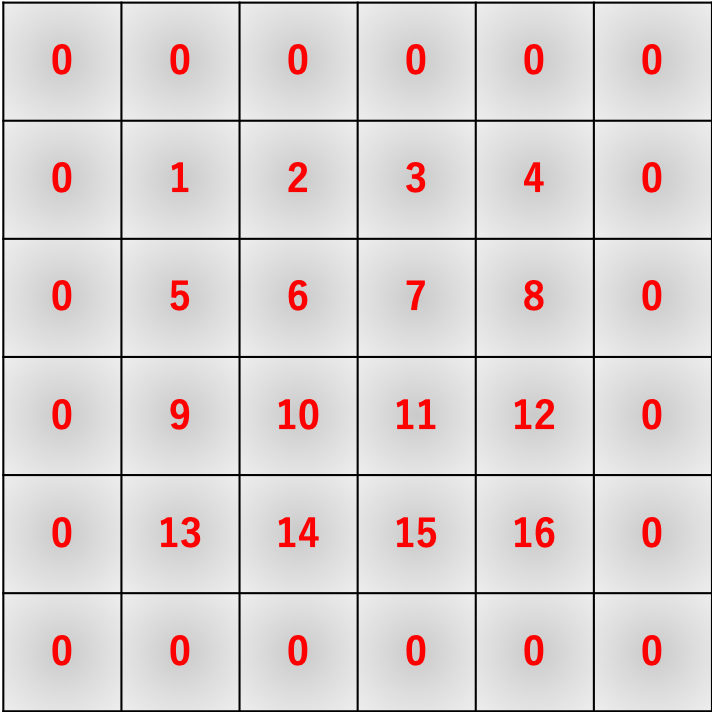
初期のim2col
early_im2col.pyimport time import numpy as np def im2col(image, F_h, F_w): I_h, I_w = image.shape O_h = I_h - F_h + 1 O_w = I_w - F_w + 1 col = np.empty((F_h*F_w, O_h*O_w)) for h in range(O_h): for w in range(O_w): col[:, w + h*O_w] = image[h : h+F_h, w : w+F_w].reshape(-1) return col x = np.arange(1, 17).reshape(4, 4) f = np.arange(-4, 0).reshape(2, 2) print(im2col(x, 2, 2)) print(im2col(f, 2, 2).T) print(im2col(f, 2, 2).T @ im2col(x, 2, 2))
行列のサイズに関しての計算は上記の通りです。
以下では実際に変形しているところの実装を見てみます。early_im2col.pyfor h in range(O_h): for w in range(O_w): col[:, w + h*O_w] = image[h : h+F_h, w : w+F_w].reshape(-1)各
h, wに対応する出力行列への書き込み場所は以下の通りです。
col[:, w + h*O_w]で指定されている書き込み場所ですね。ここに入力行列の該当箇所image[h : h+F_h, w : w+F_w]を.reshape(-1)で平滑化して代入しています。
まだ簡単ですね。初期の
im2colの問題点さて、early_im2col.pyには重大な欠点が存在します。
その欠点とは、先にも述べた通りnumpyはforなどのループ処理でアクセスすると遅くなるという欠点に由来するものです。
一般に、early_im2dol.pyで動作例として紹介している入力配列xはもっとずっと大きいものです(例えばすごく画像サイズの小さいデータセットであるMNISTの手書き数字画像は$28 \times 28$の行列です)。
処理時間を計測してみましょう。early_im2col.pyy = np.zeros((28, 28)) start = time.time() for i in range(1000): im2col(y, 2, 2) end = time.time() print("time: {}".format(end - start))
高々$28 \times 28$の行列に対して1000回処理を行っただけで1.5秒もの時間がかかってしまいます。
MNISTデータベースは実に6万枚もの手書き数字データベースですので、単純計算で全ての画像に1回ずつフィルタリングするだけで900秒かかる計算になります。
実際の機械学習では複数のフィルタを数多の回数かけるため、これでは実用的ではありません。改良版
im2col(初期ver)問題点を復習すると、つまり
forループでnumpy配列にアクセスする回数が多いことが問題であることがわかります。ということはアクセス回数を減らせば良いわけです。
early_im2col.pyでは、numpy配列であるimageに$O_h O_w$回アクセスしており、$28 \times 28$の入力行列に$2 \times 2$のフィルタをかける処理ではアクセス回数は実に$27 \times 27 = 729$回となります。
ところで、一般に出力行列よりもフィルタの方が圧倒的にサイズが小さいため、これを利用すると等価な処理でnumpy配列へのアクセス回数を劇的に減らすことができます。
それが改良版im2col(初期ver)です。
なかなかトリッキーなことをしています。
改良版
im2col(初期ver)
improved_early_im2col.pyimport time import numpy as np def im2col(image, F_h, F_w): I_h, I_w = image.shape O_h = I_h - F_h + 1 O_w = I_w - F_w + 1 col = np.empty((F_h, F_w, O_h, O_w)) for h in range(F_h): for w in range(F_w): col[h, w, :, :] = image[h : h+O_h, w : w+O_w] return col.reshape(F_h*F_w, O_h*O_w) x = np.arange(1, 17).reshape(4, 4) f = np.arange(-4, 0).reshape(2, 2) print(im2col(x, 2, 2)) print(im2col(f, 2, 2).T) print(im2col(f, 2, 2).T @ im2col(x, 2, 2)) y = np.zeros((28, 28)) start = time.time() for i in range(1000): im2col(y, 2, 2) end = time.time() print("time: {}".format(end - start))
結果はご覧の通り、150倍もの高速化に成功しました!
これなら6万枚に1回ずつ処理を行っても6秒で済むため(先ほどよりは)実用的になりました。
では、具体的に何がどう変わったのかを追っていきます。変更点1
まず最初の変更点としては、出力行列のメモリ確保部分ですね。
improved_early_im2col.pycol = np.empty((F_h, F_w, O_h, O_w))
こんな感じで4次元のデータ構造でメモリを確保しています。変更点2
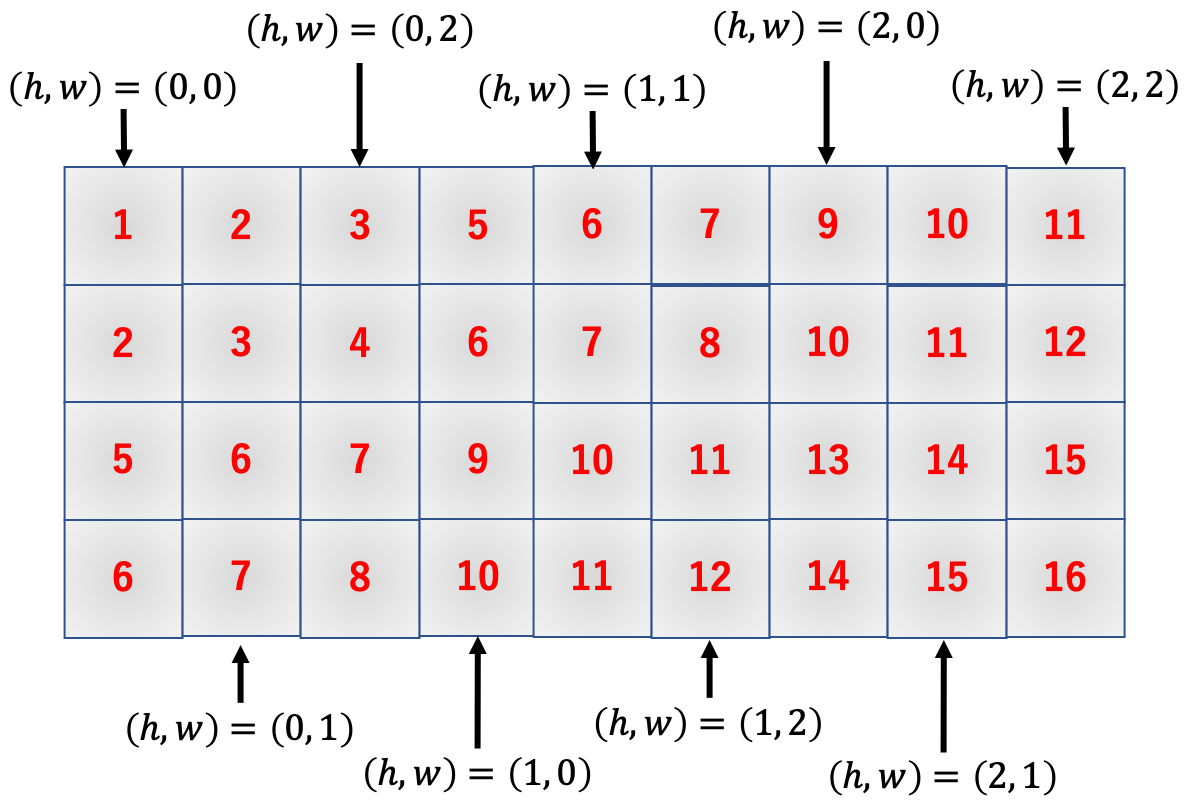
続いての変更点は、アクセス回数を減らすためにループ回数を$O_h O_w$から$F_h F_w$にしているところですね。
improved_early_im2col.pyfor h in range(F_h): for w in range(F_w): col[h, w, :, :] = image[h : h+O_h, w : w+O_w]これにより、MNIST画像一枚あたりのnumpy配列アクセス回数が729回からなんと4回にまで減少します!
また、各ループでの出力配列へのアクセス場所と入力配列へのアクセス場所は以下のようになっています。
このようにアクセスすると以下のような出力配列ができます。
変更点3
最後に出力時に求める形状に整形します。
improved_early_im2col.pyreturn col.reshape(F_h*F_w, O_h*O_w)numpyの動作的には$(F_h, F_w, O_h, O_w)$を平滑化した$(F_h F_w O_h O_w, )$の1次元データを$(F_h F_w, O_h O_w)$の2次元データに変形している感じです。
もっと噛み砕いて言うと、図の一つ一つの2次元データを1次元に平滑化して下に積んでいく感じです。
上手いこと考えますよね〜多次元配列への拡張
さて、
im2colとはで述べたように、本来この関数の対象の行列は4次元のデータ構造をしています。
フィルタも入力行列のチャンネル数分はまず確保し、それに加えてそのセットを$M$個用意した4次元のデータ構造をしています。
これを加味してimproved_early_im2col.pyを修正していきます。数式で追いかける
まずは数学的にどのような形状に変形する必要があるかを考えましょう。
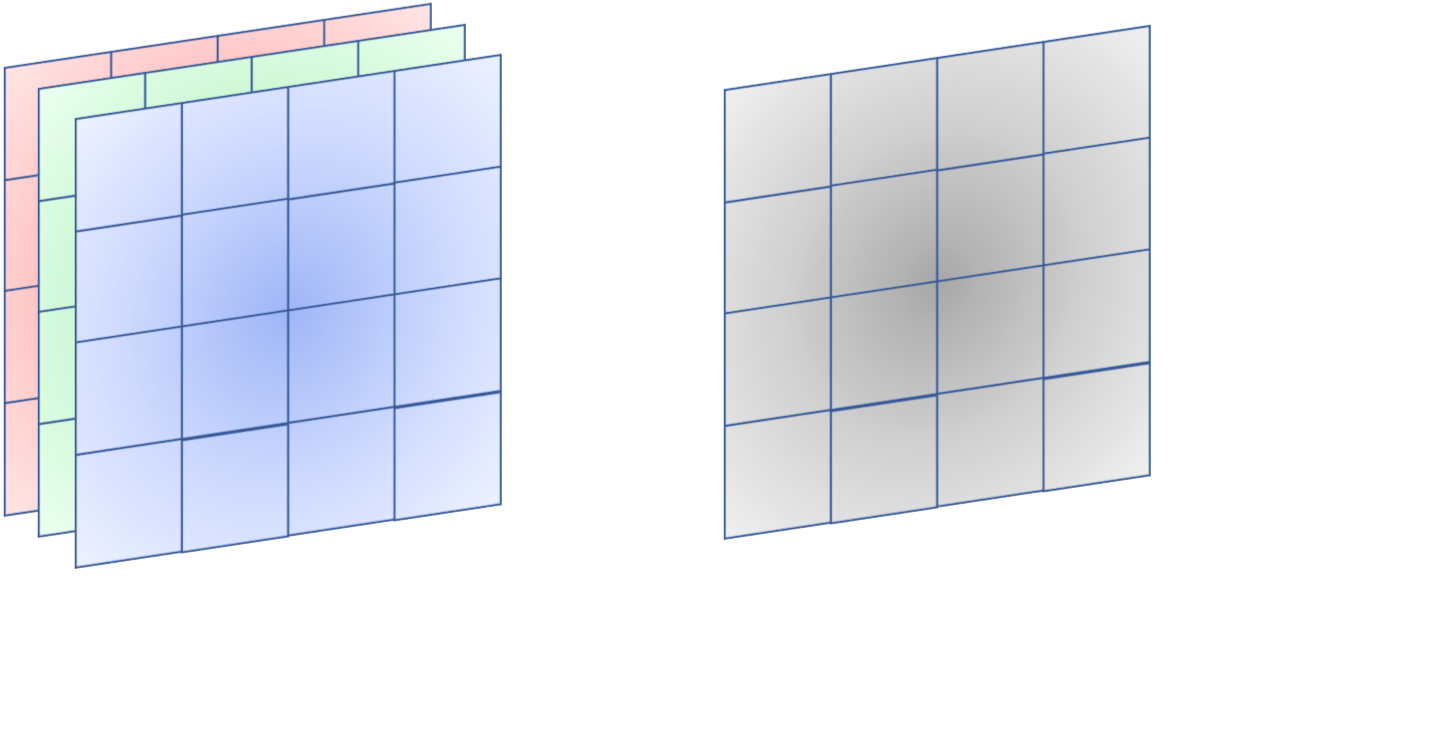
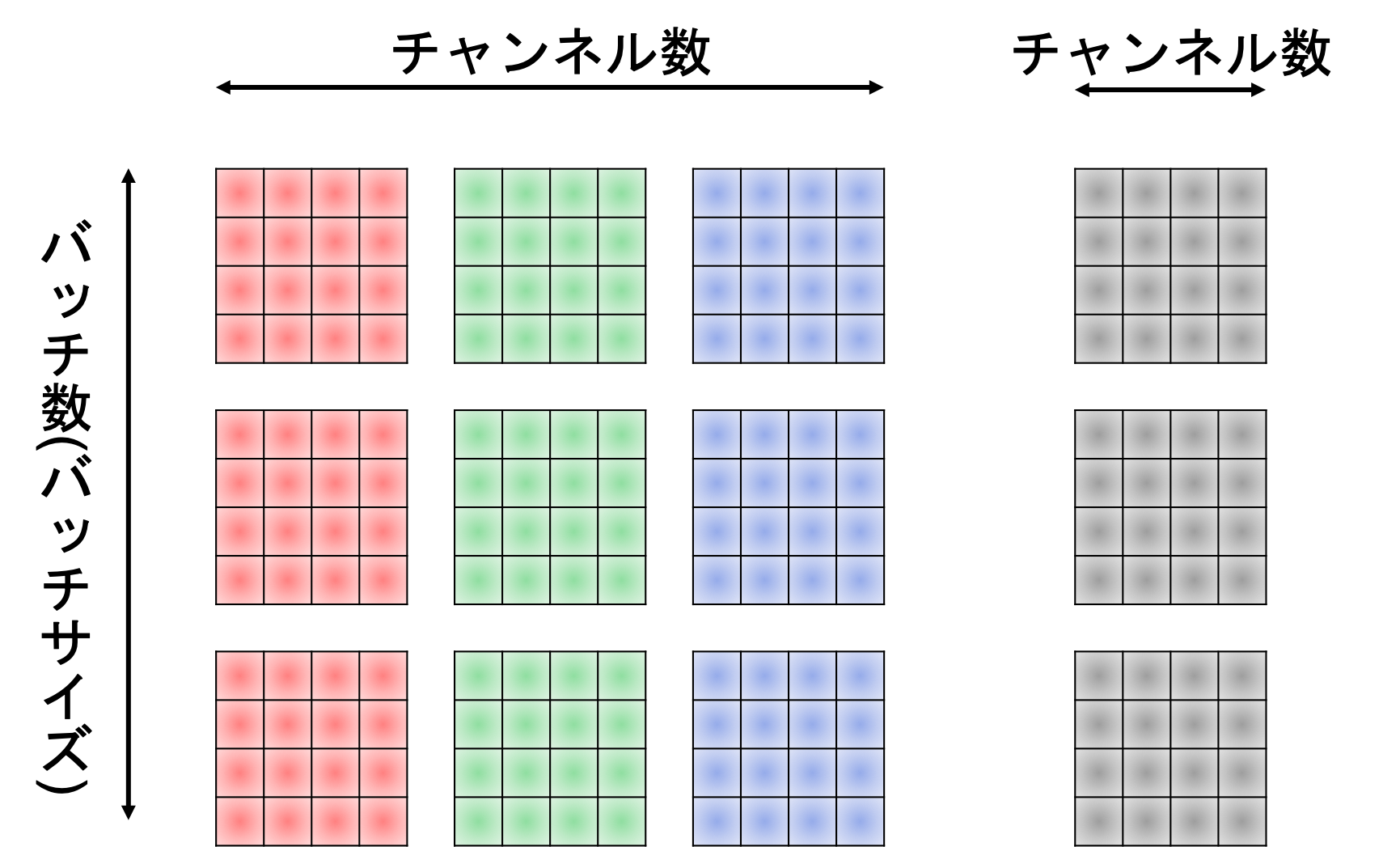
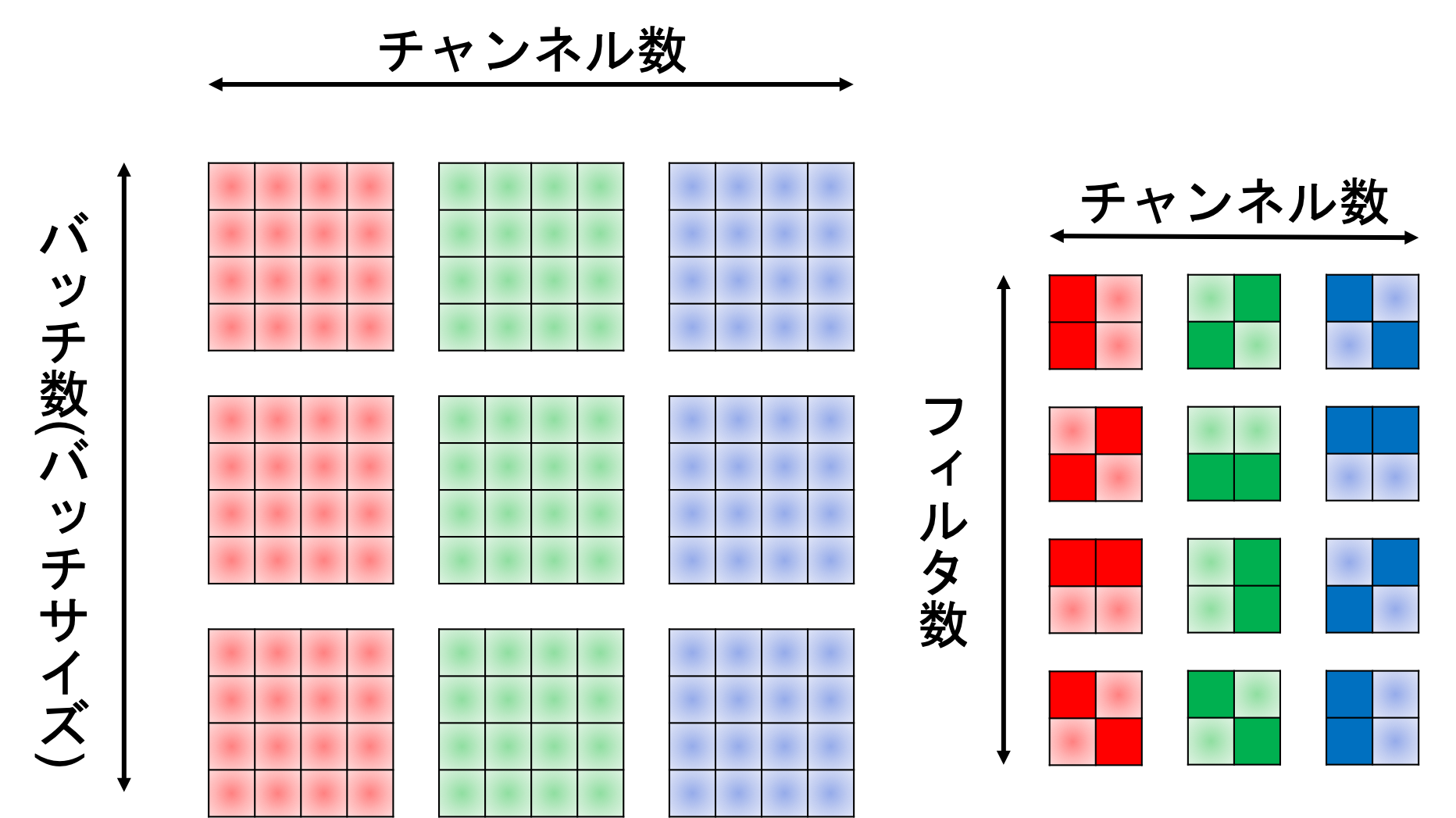
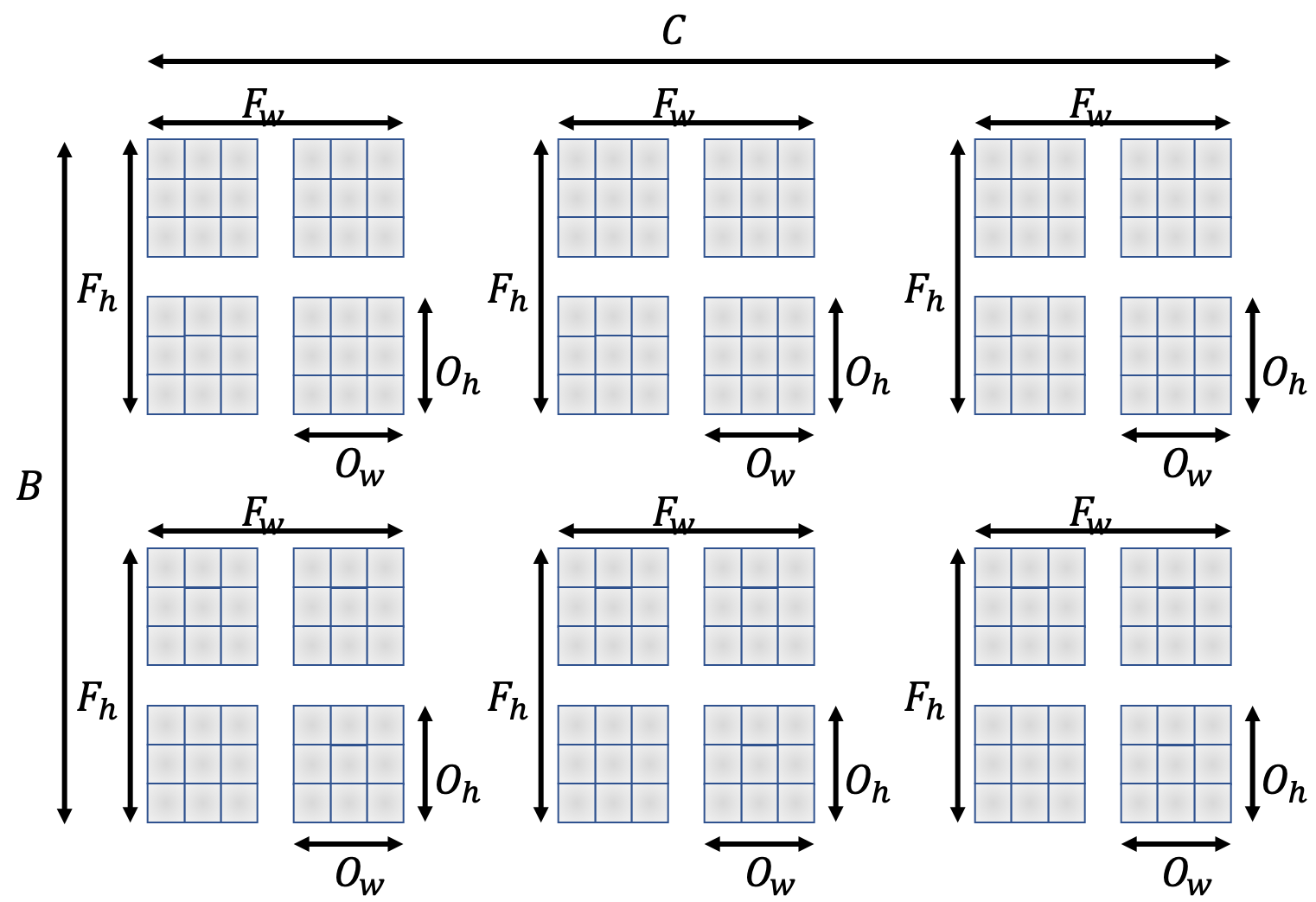
カラー画像の構造は、チャンネル数を$C$、バッチサイズを$B$とすると$(B, C, I_h, I_w)$という構造をしています。
一方でフィルタは$(M, C, F_h, F_w)$という構造をしています。
improved_early_im2col.pyでは$(I_h, I_w)$の行列に$(F_h, F_w)$のフィルタをかける場合出力される行列が$(F_h F_w, O_h O_w)$および$(1, F_h F_w)$でしたね。
$B=1$と$M=1$を仮定すると、フィルタリングを行列積で計算させるためには、im2colで変形された入力データとフィルタの形状のそれぞれの行と列が一致していなければならないため、$(C F_h F_w, O_h O_w)$および$(1, C F_h F_w)$となります。
また、一般的に$B \ne M$であるから、これらは$C F_h F_w$とは関係ない方に組み合わせる必要があります。
これらの事実を組み合わせると、im2colで出力されるべき配列の形状は$(C F_h F_w, B O_h O_w)$および$(M, C F_h F_w)$となります。
ついでに、フィルタリングの計算結果としては$(M, C F_h F_w) \times (C F_h F_w, B O_h O_w) = (M, B O_h O_w)$となり、これをreshapeして次元を入れ替えた$(B, M, O_h, O_w):=(B, C', I_h', I_w')$が次の層への入力として伝播していきます。実装してみる
実装内容はほとんどimproved_early_im2col.pyと変わりません。上位にバッチとチャンネルの次元を追加しただけです。
バッチ・チャンネル対応
im2col
BC_support_im2col.pyimport time import numpy as np def im2col(images, F_h, F_w): B, C, I_h, I_w = images.shape O_h = I_h - F_h + 1 O_w = I_w - F_w + 1 cols = np.empty((B, C, F_h, F_w, O_h, O_w)) for h in range(F_h): for w in range(F_w): cols[:, :, h, w, :, :] = images[:, :, h : h+O_h, w : w+O_w] return cols.transpose(1, 2, 3, 0, 4, 5).reshape(C*F_h*F_w, B*O_h*O_w) x = np.arange(1, 3*3*4*4+1).reshape(3, 3, 4, 4) f = np.arange(-3*3*2*2, 0).reshape(3, 3, 2, 2) print(im2col(x, 2, 2)) print(im2col(f, 2, 2).T) print(np.dot(im2col(f, 2, 2).T, im2col(x, 2, 2))) y = np.zeros((100, 3, 28, 28)) start = time.time() for i in range(10): im2col(y, 2, 2) end = time.time() print("time: {}".format(end - start))
最大の変化は返り値の部分ですね。BC_support_im2col.pyreturn cols.transpose(1, 2, 3, 0, 4, 5).reshape(C*F_h*F_w, B*O_h*O_w)ここでは、numpyの
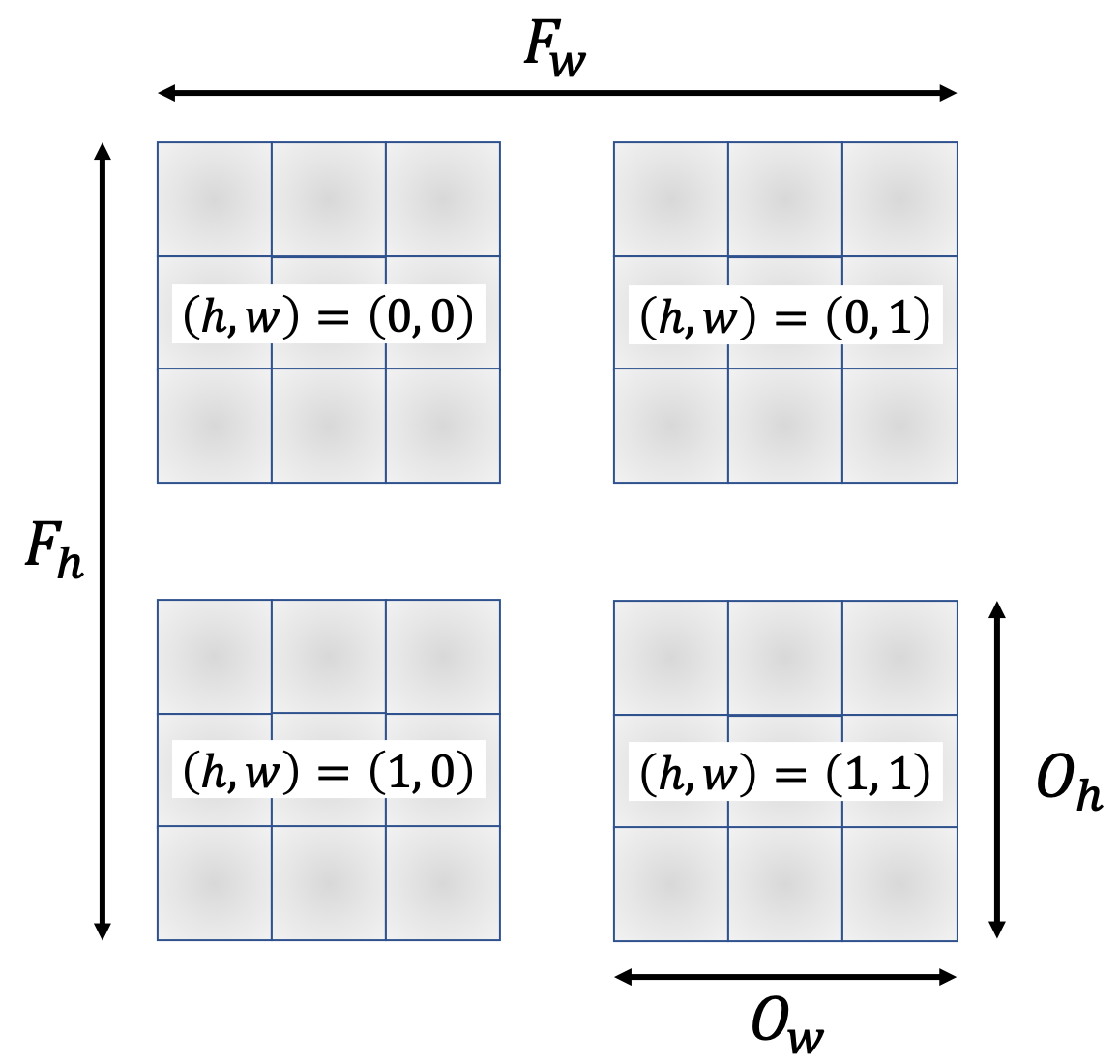
transpose関数を用いて次元の順番を入れ替えています。
それぞれ以下のように対応しており、順番を入れ替えてからreshapeすることで正しい出力を返します。\begin{array}{ccccccc} (&0, &1, &2, &3, &4, &5) \\ (&B, &C, &F_h, &F_w, &O_h, &O_w) \end{array}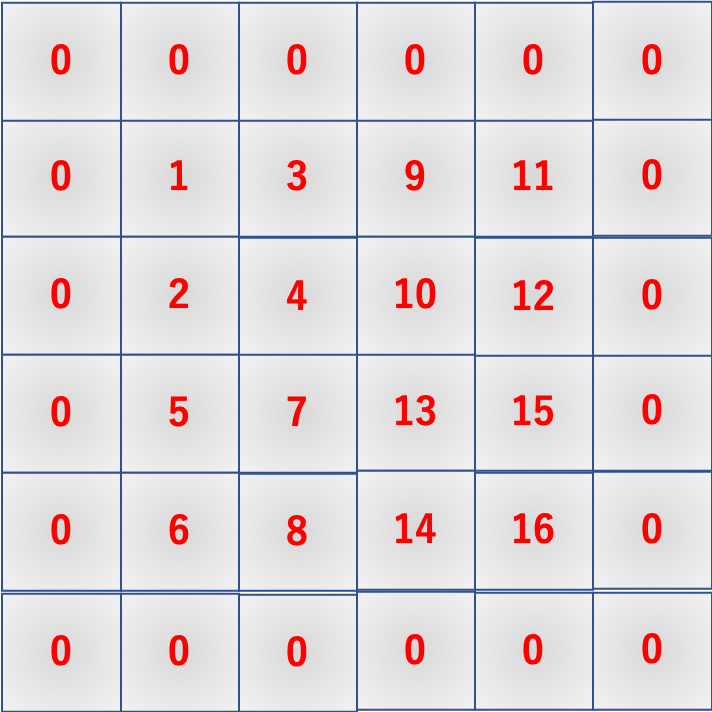 \xrightarrow[\textrm{transpose}]{入れ替え} \begin{array}{ccccccc} (&1, &2, &3, &0, &4, &5) \\ (&C, &F_h, &F_w, &B, &O_h, &O_w) \end{array} \xrightarrow[\textrm{reshape}]{変形} (C F_h F_w, B O_h O_w)これでバッチ・チャンネルにも対応した
im2colが完成です!ストライドとパディング
さて、これで終わりかと思いきやそうでもなかったりします。最後に紹介するのはストライドとパディングと呼ばれる処理です。
いずれもより効率的で効果的なCNNの実装には不可欠な要素です。ストライド
これまでの実装では、当たり前のようにフィルタは1マスずつズレていましたよね?
このズレる量のことをストライドといいますが、これは何も1マスずつでなければならないという決まりはありません。
実際の画像はわずか1ピクセルズレるだけで情報が大きく変わるような場面の方が少ないため、大抵の場合ストライドは1ではないでしょう。パディング
ストライドと違ってパディングはこれまでの実装で一切触れられていません。
その主な役目はフィルタリングによって出力画像のサイズが変わらないようにすることと、画像の端の方の情報を余さず得ることです。
具体的には入力画像の周囲を$0$で埋めることでフィルタが動く範囲を広げています。
ストライドとパディングの実装
ではそれぞれの実装について見ていきます。
ストライドの実装
ストライドの実装はそんなに難しくないですね。これまでのストライド移動幅を1から変更できるようにするだけです。
今までBC_support_im2col.pycols[:, :, h, w, :, :] = images[:, :, h : h+O_h, w : w+O_w]のようにしていましたが、これを
im2col.pycols[:, :, h, w, :, :] = images[:, :, h : h + stride*O_h : stride, w : w + stride*O_w : stride]のように変更します。
初期版の動きはこんな感じで
数式ではa = 1W + 2X + 5Y + 6Z \\ b = 3W + 4X + 7Y + 8Z \\ c = 9W + 10X + 13Y + 14Z \\ d = 11W + 12X + 15Y + 16Z \\ \Leftrightarrow \left( \begin{array}{c} a \\ b \\ c \\ d \end{array} \right)^{\top} = \left( \begin{array}{cccc} W & X & Y & Z \end{array} \right) \left( \begin{array}{cccc} 1 & 3 & 9 & 11 \\ 2 & 4 & 10 & 12 \\ 5 & 7 & 13 & 15 \\ 6 & 8 & 14 & 16 \end{array} \right)こんな感じで、改良版だとこんな感じですね。
やっぱりトリッキーですね...これ考えた人凄すぎです。パディングの実装
一方パディングの処理の実装は至ってシンプルです。
numpyにあるpad関数を用いてim2col.pyimages = np.pad(images, [(0, 0), (0, 0), (pad, pad), (pad, pad)], "constant")とすればOK。
pad関数の動作は結構ややこしいので(後日紹介します)、とりあえず上記の解説をしておきます。
padの第一引数は対象の配列です。これは大丈夫でしょう。
問題は第二引数です。im2col.py[(0, 0), (0, 0), (pad, pad), (pad, pad)]
pad関数にこのように入力すると、
- 1次元目は
(0, 0)、つまりパディングなし- 2次元目は
(0, 0)、つまりパディングなし- 3次元目は
(pad, pad)、つまり上下の増量幅padで0埋め("constant")- 4次元目は
(pad, pad)、つまり左右の増量幅padで0埋め("constant")第三引数はいくつか指定できるものがありますが、今回は0埋めしたいので
"constant"を指定しています。
詳しくは公式ドキュメントを見てください。出力次元の計算
さて、上記の変更を施して実行してもまだエラーが出て動きませんね。はい。
理由はお察しの通り、ストライドとパディングの実装とともに出力次元が変わるからです。どのように変わるのか考えて見ましょう。ストライドの影響
ストライド幅を増やすとフィルタをかける回数が反比例的に減少します。
フィルタを1マスごとにかけるか2マスごとにかけるかで回数が半減することは察しがつくでしょう。
数式で表すとO_h = \cfrac{I_h - F_h}{\textrm{stride}} + 1\\ O_w = \cfrac{I_w - F_w}{\textrm{stride}} + 1という感じになります。
$I_h = 4, F_h = 2, \textrm{stride} = 1$の場合は
$O_h = \cfrac{4 - 2}{1} + 1 = 3$
となり、$I_h = 4, F_h = 2, \textrm{stride} = 2$の場合は
$O_h = \cfrac{4 - 2}{2} + 1 = 2$
となり、これまでの画像と一致することが確認できますね。パディングの影響
パディングの影響はすごくシンプルです。入力画像1枚ごとのサイズが上下$+ \textrm{pad}_{ud}$、左右$+ \textrm{pad}_{lr}$されるため、
I_h \leftarrow I_h + 2\textrm{pad}_{ud} \\ I_w \leftarrow I_w + 2\textrm{pad}_{lr}と置き換えればよく、つまり
O_h = \cfrac{I_h - F_h + 2\textrm{pad}_{ud}}{\textrm{stride}} + 1 \\ O_w = \cfrac{I_w - F_w + 2\textrm{pad}_{lr}}{\textrm{stride}} + 1となります。
また逆に、出力画像のサイズを入力画像のサイズに揃えたい場合は$O_h = I_h$および$O_w = I_w$なので\textrm{pad}_{ud} = \cfrac{1}{2}\left\{(I_h - 1) \textrm{stride} - I_h + F_h\right\} \\ \textrm{pad}_{lr} = \cfrac{1}{2}\left\{(I_w - 1) \textrm{stride} - I_w + F_w\right\}のように計算できます。
ついでにストライドも自由度を上げておきましょう。O_h = \cfrac{I_h - F_h + 2\textrm{pad}_{ud}}{\textrm{stride}_{ud}} + 1 \\ O_w = \cfrac{I_w - F_w + 2\textrm{pad}_{lr}}{\textrm{stride}_{lr}} + 1 \\ \textrm{pad}_{ud} = \cfrac{1}{2}\left\{(I_h - 1) \textrm{stride}_{ud} - I_h + F_h\right\} \\ \textrm{pad}_{lr} = \cfrac{1}{2}\left\{(I_w - 1) \textrm{stride}_{lr} - I_w + F_w\right\}完成版
im2colストライドとパディングを加味して自由度を上げた
im2colは次のようになります。
ついでにいくつかカスタマイズも施しておきます。
im2col.py
im2col.pyimport numpy as np def im2col(images, filters, stride=1, pad=0, get_out_size=True): if images.ndim == 2: images = images.reshape(1, 1, *images.shape) elif images.ndim == 3: B, I_h, I_w = images.shape images = images.reshape(B, 1, I_h, I_w) if filters.ndim == 2: filters = filters.reshape(1, 1, *filters.shape) elif images.ndim == 3: M, F_h, F_w = filters.shape filters = filters.reshape(M, 1, F_h, F_w) B, C, I_h, I_w = images.shape _, _, F_h, F_w = filters.shape if isinstance(stride, tuple): stride_ud, stride_lr = stride else: stride_ud = stride stride_lr = stride if isinstance(pad, tuple): pad_ud, pad_lr = pad elif isinstance(pad, int): pad_ud = pad pad_lr = pad elif pad == "same": pad_ud = 0.5*((I_h - 1)*stride_ud - I_h + F_h) pad_lr = 0.5*((I_w - 1)*stride_lr - I_w + F_w) pad_zero = (0, 0) O_h = int(np.ceil((I_h - F_h + 2*pad_ud)/stride_ud) + 1) O_w = int(np.ceil((I_w - F_w + 2*pad_lr)/stride_lr) + 1) pad_ud = int(np.ceil(pad_ud)) pad_lr = int(np.ceil(pad_lr)) pad_ud = (pad_ud, pad_ud) pad_lr = (pad_lr, pad_lr) images = np.pad(images, [pad_zero, pad_zero, pad_ud, pad_lr], \ "constant") cols = np.empty((B, C, F_h, F_w, O_h, O_w)) for h in range(F_h): h_lim = h + stride_ud*O_h for w in range(F_w): w_lim = w + stride_lr*O_w cols[:, :, h, w, :, :] \ = images[:, :, h:h_lim:stride_ud, w:w_lim:stride_lr] if get_out_size: return cols.transpose(1, 2, 3, 0, 4, 5).reshape(C*F_h*F_w, B*O_h*O_w), (O_h, O_w) else: return cols.transpose(1, 2, 3, 0, 4, 5).reshape(C*F_h*F_w, B*O_h*O_w)簡単に解説していきます。
整形など
im2col.pydef im2col(images, filters, stride=1, pad=0, get_out_size=True): if images.ndim == 2: images = images.reshape(1, 1, *images.shape) elif images.ndim == 3: B, I_h, I_w = images.shape images = images.reshape(B, 1, I_h, I_w) if filters.ndim == 2: filters = filters.reshape(1, 1, *filters.shape) elif images.ndim == 3: M, F_h, F_w = filters.shape filters = filters.reshape(M, 1, F_h, F_w) B, C, I_h, I_w = images.shape _, _, F_h, F_w = filters.shape if isinstance(stride, tuple): stride_ud, stride_lr = stride else: stride_ud = stride stride_lr = stride if isinstance(pad, tuple): pad_ud, pad_lr = pad elif isinstance(pad, int): pad_ud = pad pad_lr = pad elif pad == "same": pad_ud = 0.5*((I_h - 1)*stride_ud - I_h + F_h) pad_lr = 0.5*((I_w - 1)*stride_lr - I_w + F_w) pad_zero = (0, 0)
この部分では
- 引数の数を削減するためにフィルタそのものを引数に取るように変更
- 入力画像が4次元でなければ4次元に変換
- フィルタが4次元でなければ4次元に変換
- バッチサイズ、チャンネル数、入力画像一枚のサイズを取得
- フィルタの数とフィルタのチャンネル数は不要なため捨てて(
_, _, ...の部分)、フィルタ一枚のサイズを取得strideがtupleなら上下と左右のストライド幅を個別に指定しているとみなし、そうでなければ同じ値を用いるpadがtupleなら上下と左右のパディング幅を個別に指定しているとみなし、そうでなければ同じ値を用いるpad == "same"と指定された場合は、入力画像のサイズを維持するパディング幅をfloatで計算(後の出力サイズ計算のため)という感じの処理をしています。
準備
im2col.pyO_h = int(np.ceil((I_h - F_h + 2*pad_ud)/stride_ud) + 1) O_w = int(np.ceil((I_w - F_w + 2*pad_lr)/stride_lr) + 1) pad_ud = int(np.ceil(pad_ud)) pad_lr = int(np.ceil(pad_lr)) pad_ud = (pad_ud, pad_ud) pad_lr = (pad_lr, pad_lr) images = np.pad(images, [pad_zero, pad_zero, pad_ud, pad_lr], \ "constant") cols = np.empty((B, C, F_h, F_w, O_h, O_w))ここでは
- 出力画像のサイズを計算
- 可読性の向上のためにパディングをタプルに変更する
- 入力画像にパディングを施す
- 出力用配列のメモリ確保
を行っています。
処理本体と返り値
im2col.pyfor h in range(F_h): h_lim = h + stride_ud*O_h for w in range(F_w): w_lim = w + stride_lr*O_w cols[:, :, h, w, :, :] \ = images[:, :, h:h_lim:stride_ud, w:w_lim:stride_lr] if get_out_size: return cols.transpose(1, 2, 3, 0, 4, 5).reshape(C*F_h*F_w, B*O_h*O_w), (O_h, O_w) else: return cols.transpose(1, 2, 3, 0, 4, 5).reshape(C*F_h*F_w, B*O_h*O_w)最後に、処理本体と返り値についてです。
- 可読性の向上のため、
h_limとw_limという変数を新たに用意し、フィルタリング処理の右端と下端を定義- ストライド幅ごとに入力画像から値を取得し出力用配列
colsに格納- 次元を入れ替えて変形して返す
MNISTで実験
KerasのデータセットからMNISTのデータをダウンロードして実験してみます。
mnist_test.py
mnist_test.py#%pip install tensorflow #%pip install keras #from PIL import Image from keras.datasets import mnist import matplotlib.pyplot as plt # 取得する枚数を指定 B = 3 # データセット取得 (x_train, _), (_, _) = mnist.load_data() x_train = x_train[:B] # 表示してみる fig, ax = plt.subplots(1, B) for i, x in enumerate(x_train): ax[i].imshow(x, cmap="gray") fig.tight_layout() plt.savefig("mnist_data.png") plt.show() # 縦線を検出してみる M = 1 C = 1 F_h = 7 F_w = 7 _, I_h, I_w = x_train.shape f = np.zeros((F_h, F_w)) f[:, int(F_w / 2)] = 1 no_pad, (O_h, O_w) = im2col(x_train, f, stride=2, pad="same") filters = im2col(f, f, get_out_size=False) y = np.dot(filters.T, no_pad).reshape(M, B, O_h, O_w).transpose(1, 0, 2, 3).reshape(B, O_h, O_w) fig2, ax2 = plt.subplots(1, B) for i, x in enumerate(y): ax2[i].imshow(x[F_h : I_h-F_h, F_w : I_w-F_w], cmap="gray") fig2.tight_layout() plt.savefig("filtering.png") plt.show()
出力結果
元となるデータ
縦線検出結果
横線検出結果
右下がり検出結果
右上がり検出結果
最初の2行はtensorflowとkerasをインストールしておく必要があるため入れています。
必要ならコメントの#だけを削除して実行してください。
一度実行すればあとはまたコメントアウトして大丈夫です。
出力結果を見れば分かる通り、それぞれのフィルタをかけた結果、対象の線だけが色濃く残っていますね。
これが特徴量検出です。おわりに
以上で
im2colについての説明は終了となります。
もしバグやもっとスマートな書き方があればコメントなどでご教授いただけると幸いです。参考

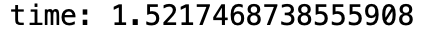





- 投稿日:2020-05-26T21:59:33+09:00
2変数、4分岐の if 文について
変数 min_value, max_value が存在するとき、それぞれの条件で処理を変えたい
例えば…
min_value max_value 処理 null null なにもしない null not null 上限より小さいことを検証 not null null 下限より大きいことを検証 not null not null 範囲内にあることを検証 普通はこんな感じ
Main.javaclass Main { public static void main(String[] args) { } private static String hoge(int value, Integer min_value, Integer max_value) { if (min_value == null && max_value == null) { // なにもしない return ""; } if (min_value == null) { // 上限チェック return ""; } if (max_value == null) { // 下限チェック return ""; } // 範囲チェック return ""; } }
- パッと見、分かりづらい
- 比較が一つの場合と、四つの場合が存在し、データによっては速度に違いが出る
- 見た目が悪い
これをなんとか解消したい…
main.swiftfunc hoge(_ value: Int, _ min_value: Int?, _ max_value: Int?) -> String { // Optional が外れない switch(min_value != nil, max_value != nil) { case (true, true): return "" // 範囲チェック case (true, false): return "" // 上限チェック case (false, true): return "" // 下限チェック case (false, false): return "" // 何もしない } }Pytyon3 の場合
main.pydef hoge(value, min_value, max_value): command = { (True, True): lambda: "", # 範囲チェック (True, False): lambda: "", # 下限チェック (False, True): lambda: "", # 上限チェック (False, False): lambda: "", # なにもしない } return command[(min_value is not None, max_value is not None)]()
もっと良い方法がありましたら、教えていただきたいです。
- 投稿日:2020-05-26T21:56:49+09:00
コード規約、メソッド対応表
#python--sqlコード規約
python
#python df_used_method1_used_method2\ = df.copy()\ .used_method1()\ .used_method2()\SQL
--sql select datamart1.column1 , datamart1.column2 , datamart2.column3 from datamart1 left join datamart2 on = column2 where datamart1.column1 > 10 ; select column1 , column2 , sum(column3) , avg(column4) from datamart1 group by column1 , column2 ;SQLルール
- すべて、小文字
- インデントは上記のとおり
メソッド対応表_データ分析関連
テーブルデータのデータ理解/データ準備
キーでユニークになるかの検証
#python--sqlレコードに重複が無いかの検証
#python--sqlカラムの抽出
#python #シリーズ形式で抽出 df.loc[:,'column'] df['column'] df.column #データフレーム形式で抽出 df.loc[:,['column1','column2']] df[['column1','column2']]--sql select column1 from datamart ; select * from datamart ;一部のレコードを抽出
#python df.head(10)--sql select top(10) column1 from datamart ; select column1 from datamart limit 10 ;重複なくカラムを抽出
#python df.drop_duplicates()--sql select unique * from datamart ;カラムの追加
#python df_assign\ = df.copy()\ .assign(column = 10) df['column'] = 10--sql select 10 as column1 from dataframe ;条件に一致するレコードを抽出
#python df_query_loc\ = df.copy()\ .query('column1 == 10')\ .loc[:,['column1','column2']] df[df.column1 == 10, ['column1','column2']]--sql select column1 from datamart1 where column1 == 10 ; select column1 , count(column1) from datamart1 group by column1 having count(column1) == 10 ;カラム名の変更
#python df.rename(columns = {'column1':'new_column1','column2':'new_column2'}) pd.DataFrame(df.values, columns = ['new_column1','new_column2']) df.columns = ['new_column1','new_column2'] df.columns = 'new_' + df.columns--sql select column1 as new_column1 from datamart1 ;dfを結合
#python pd.merge( df1, df2, on = ['column1','column2'], how = 'left') pd.merge( df1, df2, left_on = ['column1','column2'], right_on = ['column3','column4'], how = 'left') df1.merge( df2, on = 'column1', how = 'left')--sql select datamart1.column1 , datamart1.column2 , datamart2.column3 from datamart1 left join datamart2 on = column2複数のデータを一つのデータにする、concat
#python_pandas #縦 pd.concat([df1,df2],axis=0) df1.append(df2) #横 pd.concat([df1,df2],axis=1)#python_numpy #縦 np.concatenate([nparray1,nparray2], axis=0) #横 np.concatenate([nparray1,nparray2], axis=1)--sql select column1 from datamart1 union -- union all / intersect / except select column2 from datamart2行数のカウント
#python len(df)--sql select count(*) from datamart1 ;データの性質をチェック
#python #形状のチェック np.array().shape並び変え
#python df.sort_values()--sql select * from datamart1 order by column1ウィンドウ関数の処理
#python--sqlデータを生成する
#python #すべて同じ値のnparrayを生成 #例、3次元 np.tile(数字, (n, n, n))リスト内包表記
[i for i in range(100)] #if文を使う場合 [i for i in range(100) if i > 50]集約
#python df\ .groupby(['column1','column2'])\ .agg({'column3':'sum', 'column4':'mean'})\ .reset_index()-- sql select column1 , column2 , sum(column3) , avg(column4) from datamart1 group by column1 , column2 ;集約時に、特定の要素だけをカウント
df_tmp\ .groupby('column1')\ .agg({'column2':'nunique'})集約時に、1つのカラムに対して複数の演算を行う
df_tmp\ .groupby('column1')\ .agg({'column2':['sum', 'min', 'max']})演算をする
#python #平均 np.average(nparray, axis = n) #2次元以上のデータの場合、平均の次元によって結果が異なる np.array().mean() #割り算 np.array(nparray1, nparray2)文字列を特定の記号で分割
#リスト形式で取得 str_data.split('特定の文字列')文字列の末尾n字を抽出
str_data[-n]文字列の末尾n字を削除
str_data[:-n]画像データの処理
画像データの読み込み
#python import cv2 cv2.imread('filename.png')#python import PIL PIL.image.open('filename.png')画像データの表示
#python cv2.imshow("image_name", cv2.imread('filename.png')) #"image_name"は任意で設定#python PIL.image.open('filename.png').show()画像データの変換
#python #画像データのnp化 image = PIL.image.open('filename.png') np.array(image)画像の一部の抽出
#python np.array(image)[上ピクセル:下ピクセル, 左ピクセル:右ピクセル]画像に書き加える
#python #四角を書き加える plt.figure() plt.grid(false) cv2.rectangle(np.array(image), (右ピクセル, 上ピクセル), (左ピクセル, 下ピクセル), (255, 255, 255), 4) plt.imshow(np.array(image),cmap='gray',vmin=0,vmax=65555)画像の変換
signal.convolve2DTIF形式の対応
#最後の数字で、何番目の画像を抽出するのかを変える Image.open('~.tif').seek(0)可視化の処理
表示する画像のサイズ
#python plt.figure(figsize = (6,4))表示するグラフの範囲の指定
#python plt.x_lim([右, 左]) plt.y_lim([上, 下])表示する画像を正方形にする
#python aspect = (ax.get_x_lim()[1] - ax.get_xlim()[1]) / (ax.get_y_lim()[1] - ax.get_y_lim()[0]) ax.set_aspect(aspect)背景を透明にする
#python fig.patch.set_alpha(0) #figのみ対応グリッド線の対応
#python #グリッド線を表示させない複数画像の表示
#python #1、subplot、を使う plt.subplot(縦,横,1) plt.plot(~) plt.subplot(縦,横,2) plt.plot(~) ↓ plt.subplot(縦,横,縦×横) plt.show(~) #2、add_subplot、を使う ax1 = plt.figure().add_subplot(縦,横,1) ax1 = plot(~) ↓ plt.show() #3、subplots、を使う fig, axes = plt.subplots(~, figsize=(6,4)) #fig、は使わない axes[1].plot日本語を表示する
#python #ライブラリを使って処理モデリング
メソッド対応表_コーディング一般
時間データの処理
処理時間の計算
#python import time #処理の初め time_start = time.time() #処理の終わり time_end = time.time() print(time_end-time_start)日時データを、文字型から時間型に変換
import datetime from dateutil.relativedelta import relativedelta date_datetime = datetime.datetime.strptime('2020-05-24', '%Y-%m-%d')日時データを、文字型から時間型に変換
import datetime from dateutil.relativedelta import relativedelta datetime.datetime.strftime(date_datetime, '%Y-%m-%d')日時データの差分
date_datetime + datetime.timedelta(days=7) date_datetime + relativedelta(weeks = 1)曜日の情報を日時データから取得
datetime.weekday(date_datetime)パスの処理
pyファイルから関数の読み込み
#python #ディレクトリ"src"以下のファイルから関数を読み込む import sys sys.path.append('src/') from filename.py import func_nameWindowsサーバー上のデータを読む
#python import pathlib filepath = r'パス_ファイル名.csv' read_file = pathlib.WindowPath()特定のディレクトリのファイルを抽出
import glob glob.glob('path/*')ファイルの読み込み、保存
ファイルの読み込み
#python_pandas #dfの読み込み pd.DataFrame(data,columns=[column1,column2]) pd.read_csv('filename')#python_numpy #npz の読み込み np.load(filename)ファイルの保存
#python_pandas #dfの読み込み pd.DataFrame().to_csv('filename', index=False)#python_numpy #npz の保存 np.savez(pathname, filename1 = np.array('1'), filename2 = np.array('2'))#python_matplotlib #画像の保存 plt.savefig('filename')#python_sklearn #モデルの保存 import sklearn import pickle reg = sklearn.LinearRegression().fit(x,y) with open('filename.pickle', mode = 'wb', as f pickle.dump(reg, f)イテレーションの処理
複数要素のイテレーション
#zip for i_column1, i_column2 in zip(df_tmp.column1, df_tmp.column2): #itertools for i,j in permutations(i,j): 順列 combinations(i,j): 組み合わせ products(i,j): 直積イテレーションの番号を入れる
for i in enumerate(df_tmp.column):関数・クラスについて
関数
#def、を使用 def_func_name(parameter1, parameter2): 処理 return 戻り値 #lambda、を使用 lambda parameter: 戻り値の式(parameter) #lambda、を使用_一行で表現 (lambda parameter: 戻り値の式(parameter))(parameter_instance)クラス
- 投稿日:2020-05-26T21:55:16+09:00
ゼロから始めるLeetCode Day37「105. Construct Binary Tree from Preorder and Inorder Traversal」
概要
海外ではエンジニアの面接においてコーディングテストというものが行われるらしく、多くの場合、特定の関数やクラスをお題に沿って実装するという物がメインである。
その対策としてLeetCodeなるサイトで対策を行うようだ。
早い話が本場でも行われているようなコーディングテストに耐えうるようなアルゴリズム力を鍛えるサイト。
せっかくだし人並みのアルゴリズム力くらいは持っておいた方がいいだろうということで不定期に問題を解いてその時に考えたやり方をメモ的に書いていこうかと思います。
前回
ゼロから始めるLeetCode Day36「155. Min Stack」今はTop 100 Liked QuestionsのMediumを解いています。
Easyは全て解いたので気になる方は目次の方へどうぞ。Twitterやってます。
問題
105. Construct Binary Tree from Preorder and Inorder Traversal
難易度はMedium。
Top 100 Liked Questionsからの抜粋です。
前回でEasyが全て解き終わったので今回からはMediumを解いていきます。問題としては、木の構造として、
inorderとpreorderが引数として与えられるので、それらを元に二分木を構築するようなアルゴリズムを書いてください、というものです。preorder = [3,9,20,15,7]
inorder = [9,3,15,20,7]
Return the following binary tree:3 / \ 9 20 / \ 15 7解法
# Definition for a binary tree node. # class TreeNode: # def __init__(self, val=0, left=None, right=None): # self.val = val # self.left = left # self.right = right class Solution: def buildTree(self, preorder: List[int], inorder: List[int]) -> TreeNode: if not preorder or not inorder: return None preordersIndex = preorder[0] Tree = TreeNode(preordersIndex) inordersIndex = inorder.index(preordersIndex) Tree.left = self.buildTree(preorder[1:inordersIndex+1],inorder[:inordersIndex]) Tree.right = self.buildTree(preorder[inordersIndex+1:],inorder[inordersIndex+1:]) return Tree # Runtime: 216 ms, faster than 33.07% of Python3 online submissions for Construct Binary Tree from Preorder and Inorder Traversal. # Memory Usage: 87.7 MB, less than 13.16% of Python3 online submissions for Construct Binary Tree from Preorder and Inorder Traversal.再帰で解きました。TreeNodeのroot部分は固定になるので先に代入しておき、あとは
Treeを左と右に分けて再帰で代入し続けました。ちなみに、こうやって書くよりも短く書かれていたのがdiscussにあったのでこちらも載せておきます。
# Definition for a binary tree node. # class TreeNode: # def __init__(self, val=0, left=None, right=None): # self.val = val # self.left = left # self.right = right class Solution: def buildTree(self, preorder: List[int], inorder: List[int]) -> TreeNode: if inorder: ind = inorder.index(preorder.pop(0)) root = TreeNode(inorder[ind]) root.left = self.buildTree(preorder, inorder[0:ind]) root.right = self.buildTree(preorder, inorder[ind+1:]) return root # Runtime: 164 ms, faster than 49.71% of Python3 online submissions for Construct Binary Tree from Preorder and Inorder Traversal. # Memory Usage: 52.2 MB, less than 60.53% of Python3 online submissions for Construct Binary Tree from Preorder and Inorder Traversal.読みやすい上に速い・・・!
この解答を載せている人はどの問題でも大体簡潔なコードをPythonで書いているのでとても参考になります。Easyまでは一つの要素についての処理ができれば大体解けていたのですが、Mediumだと二つ以上の要素を上手く処理することを求められるイメージですね。
もっと精進せねば。他にもdiscussをもうちょっと読み込んでみようと思います、お疲れ様でした。
- 投稿日:2020-05-26T21:53:32+09:00
【Python】平衡二分木が必要な時に代わりに何とかするテク【競プロ】
※この記事は説明の都合上AtCoderで出題された問題に関するネタバレが含まれています。ご了承ください。
はじめに
平衡二分(探索)木というデータ構造があります。(Wikipedia)
名前 操作 計算量 insert(x)要素 $x$ の挿入 $O(\log N)$ erase(x)要素 $x$ の削除 $O(\log N)$ find(x)要素 $x$ の検索 $O(\log N)$ などの操作が可能で、C++では
std::setやstd::map等の連想配列の実装に用いられています。
このstd::set,std::mapというのは優れもので、標準ライブラリ中のデータ構造でありながら
lower_bound(x): $x$ 以上の最小の要素upper_bound(x): $x$ 以下の最大の要素を$O(\log N)$で検索することができます。内部的に常にソートされているので二分探索ができる、と考えると分かりやすいかと思います。この手軽さゆえに、競技プログラミングの問題の解説に
「……よって、平衡二分木(C++ではsetなど)を使うことで解くことができます。」
と書かれていることがしばしばあります。
残念ながら、Pythonにはそのような組み込みのデータ構造が存在しないため、解説の通りにコードを組むことができません。そこで本記事では、平衡二分木が欲しい場面で代用できる(ある程度汎用的な)手法をいくつか紹介したいと思います。
扱う問題
ABC128-E Roadwork を題材として使用します。(問題リンク)
解説にも書かれているように、この問題は
クエリ 操作 insert(x)集合に要素 $x$ を追加 erase(x)集合から要素 $x$ を削除 minimum()集合内の最小の要素を検索 というクエリをこなす問題です。最小の要素は、充分小さな数を
-INFとしてlower_bound(-INF)を計算すればよいので、まさに平衡二分木の出番、という問題です。解決法1: 平衡二分木を作る
身も蓋もないですが、平衡二分木がないなら自分で作ればよいのです。
幸いにも自作の平衡二分木ライブラリを公開してくれている方が何人もいらっしゃるので、自力で実装するのは難しい……という方でも簡単に使うことができます。大感謝ですね。ただし、自作の複雑なデータ構造は往々にして最適化が働きづらく、定数倍はかなり重くなります。そのため、せっかく平衡二分木を用意したのにTLE、となってしまうことが少なくありません。
平衡二分木を使わずに、平衡二分木と同じ操作はできないでしょうか?補足:
AVL木、実はedamatさん(@edamat1 )がPypy用に書き直してくれた(再帰をなくしたりしてくれた)のがあり、そちらだと割と通るそう
— じゅっぴー (@juppyjappy) May 26, 2020
解決法2: BIT(またはセグメント木)
おそらくこれが一番汎用的な手法かと思います。それぞれのデータ構造を知らない人は調べてください。実装は大差がないため、ここではBITを用いることとします。BITの配列を $B[0], B[1], ..., B[i], ...,$ という形で表します。
先述した平衡二分木に対する操作を、以下のように対応付けて考えます。
クエリ 操作 insert(x)$B[x]$ に $1$ を加算 erase(x)$B[x]$ に $-1$ を加算 minimum()$\sum_{i=0}^x B[x] - \sum_{i=0}^{x-1} B[x]$ lower_bound(x)$s = \sum_{i=0}^{x-1} B[x]$ とし、累積和が初めて $s$ を超える位置を二分探索 こうすると、平衡二分木と同様にこれらの操作をすべて$O(\log N)$で行うことができます。二分探索は単純に実装すると $O(\log^2 N)$ となってしまいますが、セグ木上の二分探索と同じ手法により$O(\log N)$に落とすことができます。(参考リンク)
挿入する要素 $x$ の範囲が $0 \leqq x \leqq 10^6$ 程度であれば、このサイズのBITを構築すればそれでOKですが、今回は挿入する最大の要素が $10^9$ 程度であるので、圧倒的にMLEします。
解決策2.5: 座標圧縮 + BIT(またはセグメント木)
今回の問題はオフラインクエリであり、最初の段階で将来挿入する値がすべてわかります。そこで、これらの値を全てまとめて昇順にソートし、新たに $0, 1, 2, ...$ と番号を振りなおします。(詳しくは「座標圧縮」と検索してください )要素の個数は最大で $2×10^5$ 個であるので、新たに割り振った番号の最大値も $2×10^5$ です。よってこのサイズのBITを用意すれば、MLEすることなく解くことができます。
提出コード(手持ちのライブラリでは
lower_bound(x)の定義が「累積和が $x$ 以上になる最小のindex」だったのでそれに合わせて実装しています。)TLEしてしまいました……
解決法3: 優先度付きキュー
ところで、
eraseクエリがない場合を考えてみましょう。
クエリ 操作 insert(x)集合に要素 $x$ を追加 minimum()集合内の最小の要素を検索 これならば、Pythonにある優先度付きキューのライブラリを用いることで実現できます。
しかし、eraseクエリを行うには、先頭から線形探索して削除する必要があり、 $O(N)$ かかってしまいます。これを解決するために、優先度付きキューを二本使った以下のようなテクニックが使えます。
まず、$p, q$ という二つの優先度付きキューを用意して、以下のように対応付けます。import heapq p = list() q = list() def insert(x): heapq.heappush(p, x) return def erase(x): heapq.heappush(q, x) return def minimum(): while q and p[0] == q[0]: heapq.heappop(p) heapq.heappop(q) return p[0](これは疑似コードであり、変数のスコープの関係でこのままでは動作しません。)
このアイデアの核は、「現時点での最小値を削除するのでないかぎり、
eraseを後回しにしてもminimumの結果には影響しない」ということです。そこで、eraseクエリは後回し用の優先度付きキュー $q$ に突っ込んでおきます。
minimumの結果を返す際、現時点での最小値 $x$ が削除する必要のあるものかどうかを確かめます。 $x$ が $q$ の中に存在しているとしたら、先頭にあるはずです。よって、 $p$ と $q$ の先頭の要素が等しい場合は、後回しにしていたeraseを行う必要があります。こうして更新された最小値もまた削除する必要があるかもしれないので、削除されていない本当の最小値が確定するまでこれを繰り返します。
一見この操作には $O(N\log N)$ かかるようにも思えますが、各要素は最大1回しか削除されないため、償却 $O(\log N)$ で計算可能です。(償却計算量についてはこちらをご覧ください)
ちなみに $q$ は優先度付きキューではなくsetでも大丈夫です。また、以上の議論では不当な
erase(そもそも存在しない要素を削除しようとすること)が存在しないと暗に仮定していましたが、別途「現時点で各要素 $x$ がいくつあるか」を格納した辞書を用意することで、クエリが来た時点でそれが不当かどうか判断することもできます。今回は問題の性質上不当なクエリは存在しません。提出コード
間に合いました!無事ACです。解決法4: setでゴリ押し
要素の追加、削除はsetを使えば $O(1)$ で行えます。ただし、
minimumには $O(N)$ かかってしまいます。
そこで、各クエリあたりの計算量を抑えるのではなく、クエリ計算する回数自体をを減らすことを考えてみます。発想としては先ほどの「後回しにしてもよい」に近いです。以下の疑似コードをご覧ください。S = set() curmin = 10**18 # 現時点での最小値 flag = False # 更新が必要か def insert(x): S.add(x) if x <= curmin: curmin = x flag = False return def erase(x): S.remove(x) if x == curmin: flag = True return def minimum(): if flag: curmin = min(S) flag = False return curminコードを見てもらえばなんとなく分かるとは思いますが、なるべく結果を保存しようとしています。このように無駄な
minimumの計算を最大限抑えることで、クエリ一回当たりの平均計算量をなるべく抑えることができます(計算回数はテストケースに依存します)。意地悪なケースではほとんど改善されませんが、完全にランダムなケースでは実行時間が大幅に短くなることもあります。提出コード
優先度付きキューの解法より速くなりました!驚き番外編: 別の解法を考える
視点を変えることで別の解法が適用できる場合があります。この問題では二分探索を上手に使う解法があったりします。
おわりに
紹介した各手法は、平衡二分木の代用としてだけではなく、他の問題を解くうえで計算量を削減するヒントにもなるテクニックです。なんとなく覚えておくと役に立つときが来るかもしれません。
- 投稿日:2020-05-26T21:40:31+09:00
Auteoencoderによる,MNISTを用いた異常検知 (PyTorch)
概要
皆様,こんにちは.
漸く緊急事態宣言が解除されましたが,まだまだ予断を許さない状況が続いていますね..
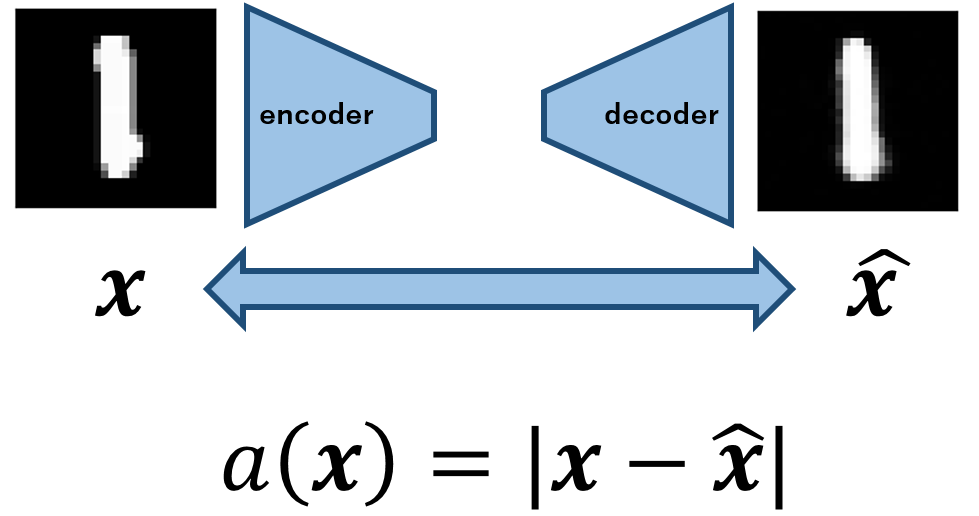
まだまだ私も,家にこもりっぱなしの生活が続きそうです.さて,今回は,シンプルなAutoencoderを用いてMNISTに対する異常検知プログラムを実装し,検証していきたいと思います.具体的には,以下のようなモデルとなります.
(当記事でご理解いただけるのは,Autoencoderと異常検知の基本的な流れ,PyTorchを用いたMNISTの異常検知の流れとその検証結果です.)
QiitaにはすでにMNISTを使った異常検知の記事が何件か掲載されております.
なので,じゃあこの記事の需要はどこに?って話になるのですが,実はPyTorchで実装している点が他と違う点と考えています.ググると良くでてくるのはKerasを使った実装例なんですが,僕は最近PyTorchに乗り換えた身なので,PyTorchの実装ないかなーとあさっていたんですが,見つからなかったので自分で実装した次第です.それでは解説に参ります.
なお,今回の実装したコードはすべてこちらで公開しております.
Autoencoderと異常検知
Autoencoderがどのように異常検知タスクに応用されるのか,簡単に振り返ります.(ご存じの方は実装以降の章をご覧ください)
Autoencoderについて
モデルの構造を以下に示します.
Autoencoderの発想はいたってシンプルで,画像などが存在する高次元データをencoderを用いて潜在変数へと符号し,decoderを用いて画像を復号するモデルです.
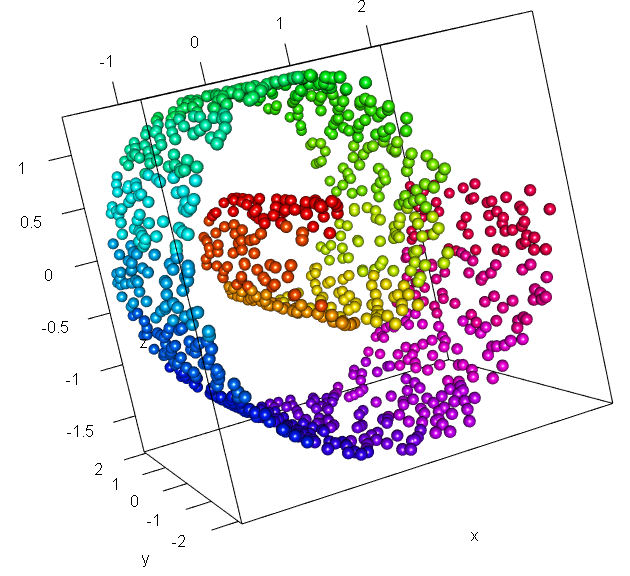
潜在空間へと写像するメリットは何?となってくるわけですが,これは多様体仮説に基づいています.以下の分布をご覧ください.
引用元:こちら
上記はスイスロール分布と呼ばれるものです.画像では三次元ですが,高次元データの例だとお考え下さい.よく見ると,かなりデータが疎な部分が存在しているのがわかるかと思います.これを二次元に写像する(平面に引き延ばすようなイメージ)ことができれば,元の分布を低次元空間で表現可能と推測できます.より一般的に言えば,高次元空間に存在するデータは低次元多様体としてとらえられる,これを多様体仮説と呼びます.
Autoencoderの話に戻ると,encoderによって,高次元空間から低次元の潜在空間へと写像されるのでした.つまり,画像のような高次元のデータの「特徴」なるものを抽出し,潜在変数として扱っていることになります.
この低次元の「特徴」から,元のデータを復号するのです.異常検知への応用
このAutoencoderの枠組みは,異常検知でしばしば応用されます[1].
異常検知の目的は,入力データに対してモデルが「正常」か「異常」かどうかを認識することにあります.この問題設定は,よく用いられる教師あり学習でのパターン認識の枠組みですが,残念ながら異常検知が実際に応用される工場など(外観検査)の多くは,異常データが集まらないのが普通です.
そのため,パターン認識のような教師ありのアプローチは適用できません.
しかし,一般に工場などの現場では,大量に「正常」なデータが取得できます.これを活用して,「異常検知」に落とし込むために,Autoencoderが登場します.
上記までで説明した通り,Autoencoderでは高次元のデータの分布から,特徴を抽出して低次元の潜在空間へと写像することができます.つまり,大量の正常データを用いてモデルを学習することで,正常なデータの特徴を獲得できます.このことから,「正常」なデータをモデルに入力すれば,もちろんdecoderは元の入力を復号できるでしょう.しかし「異常」なデータが入力されたとき,これは異常なデータを表現できる特徴を獲得していないので,うまく復号することができません.
このトリックを用いて異常検知が行われます.具体的には,入出力間で差分をとり,それを異常度として計算することで異常が検知できます.
なお,実際の異常検知への応用事例は,大半が「教師なし」もしくはわずかな異常データを活用する「半教師あり」の二つが用いられます.次に,実際にMNISTの実装と実験を確認することで,より理解を深めていただければと思います.
実装・MNISTのロード部分
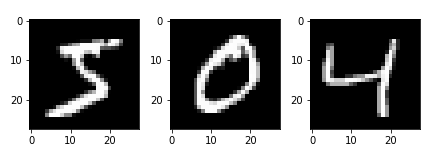
MNIST(手書き数字のデータセット)を用いて異常検知をさせます.今回は,MNISTの有する0~9のうち,「1」のラベルがついたものを正常データとして学習します.
そして,「9」のラベルがついたものを異常データとして,これを検知できるかどうかを検証していきます.まず,PyTorchのdatasetクラスのMNISTモジュールを用いることで,簡単にMNISTデータをロードできます.
しかしこのままでは,0~9すべてのデータが存在していますので,これを任意のラベルのものにのみ絞る作業が必要です.以下のようなクラスを定義しました.main.pyclass Mnisttox(Dataset): def __init__(self, datasets ,labels:list): self.dataset = [datasets[i][0] for i in range(len(datasets)) if datasets[i][1] in labels ] self.labels = labels self.len_oneclass = int(len(self.dataset)/10) def __len__(self): return int(len(self.dataset)) def __getitem__(self, index): img = self.dataset[index] return img,[]初期化メソッドでは,引数として与えた任意のラベルのlistに該当するデータのみを,クラス内の変数として渡しています.後は通常のDatasetクラスと同じ挙動ですね.
肝心のAutoencoderは,以下のように定義しています.
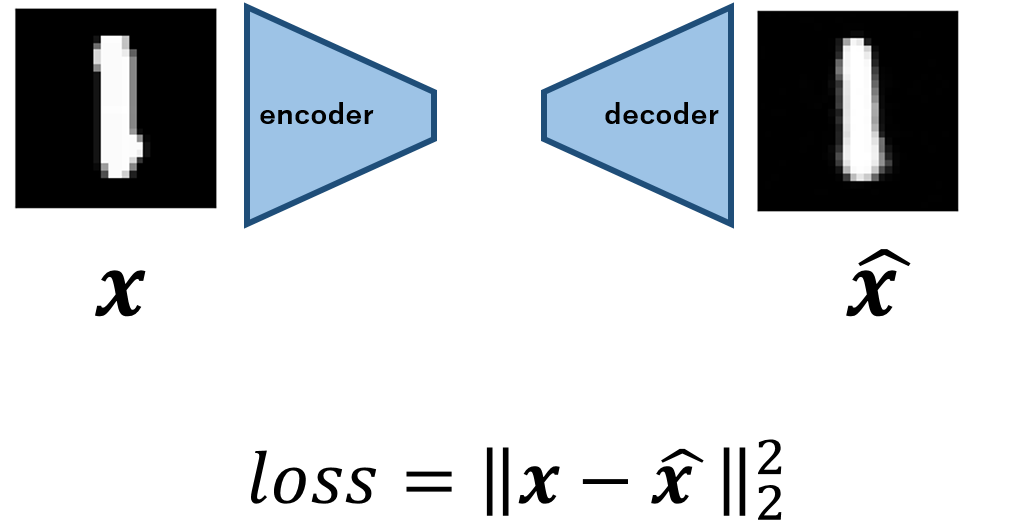
main.pyclass Autoencoder(nn.Module): def __init__(self,z_dim): super(Autoencoder, self).__init__() self.encoder = nn.Sequential( nn.Linear(28 * 28, 256), nn.ReLU(True), nn.Linear(256, 128), nn.ReLU(True), nn.Linear(128, z_dim)) self.decoder = nn.Sequential( nn.Linear(z_dim, 128), nn.ReLU(True), nn.Linear(128, 256), nn.ReLU(True), nn.Linear(256, 28 * 28), nn.Tanh() ) def forward(self, x): z = self.encoder(x) xhat = self.decoder(z) return xhatそれぞれ三層のシンプルなものです.
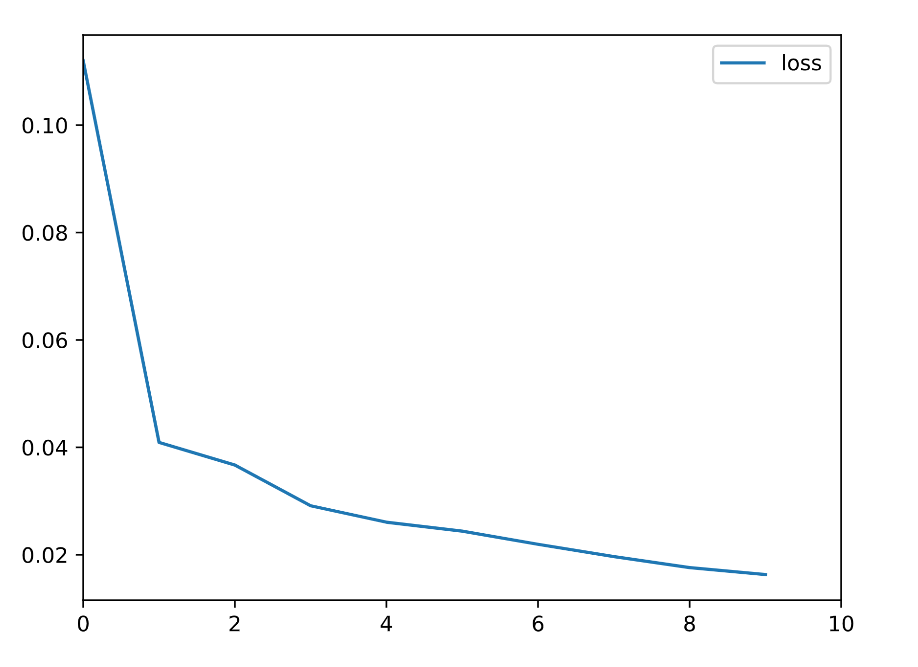
学習は入出力間のMSEをとり,これを最小化することで入力を再構成するように学習されます.
では,実験に入ります.実験・考察
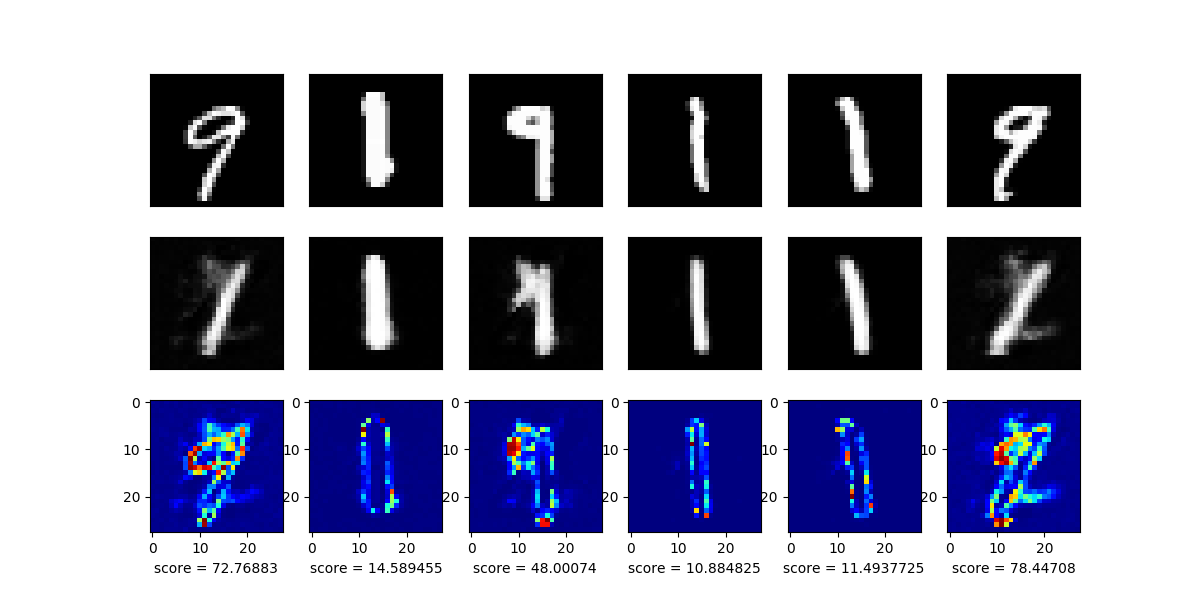
上記のように,学習データは「1」の画像のみで,約6,000枚の画像データを学習します.
テストデータは「1」と「9」のデータを混ぜ,「9」を正しく異常と判別できるかを確認します.
なお,異常度の定義は入出力間の差の絶対値を用います.lossの推移をを以下に示します.
モデルの入力(上段)と,その出力(中段),さらにその差分画像(下段)を以下に示します.
目論見通り,学習した「1」の画像はうまく再構成できているのがわかりますが,異常データとして混ぜた「9」のデータはうまく再構成できていないのがわかりますね.
今回はシンプルな全結合層のみのモデルでしたが,うまくいった印象です.また,下段のscoreに着目すると,異常データが入力された際には値が大きくなっていることがわかります.
実際には異常度に閾値を設けることで,異常検知を行います.閾値の設け方は,専門家による設計だよりであることがほとんどです.まとめ
今回は,PyTorchを用いてMNISTによる教師なし異常検知を実装し,検証しました.
また,Autoencoderを用いた異常検知の基本的な流れについても解説しました.
今回の記事は,技術的な新規性という観点では微妙になってしまいましたが,PyTorchによるMNISTの異常検知という意味では需要があるかと思ってます(そう思っているのは僕だけかもしれませんが(笑))
記事が冗長になるのを恐れて,異常検知性能の定量的評価(AUROCなど)までは手をつけませんでしたが,近いうちにまとめたいと思います.
同時に,GANによる異常検知のframeworkの検証も行いたいところです.
最近では,Autoencoderからさらに発展して,AnoGAN,EfficientGAN,AnoVAEGANなど,多様なGANを活用した異常検知のframeworkが登場し,次々にSOTAを獲得しています.
今後の動向にさらに期待できますね.参考文献
- 投稿日:2020-05-26T21:31:48+09:00
【EC2】seleniumを使ってサックっとスクレイピング入門(テキスト抽出と画面キャプチャ)
【EC2】seleniumを使ってサックっとスクレイピング入門
EC2上でpythonのseleniumを使って指定したURLの要素を抜き出すまでの流れまとめ。
やること
- chromeドライバーのインストール
- chromeのインストール
- seleniumのインストール
- 日本語フォントのインストール
- 指定したURLのテキストを抜き出す(text.py)
- 指定したURLの画面キャプチャを取得(capture.py)
前提
・sshを使ってEC2インスタンスに接続済み。
・python3インストール済み。1.chromeドライバーのインストール
①ChromeDriverのオフィシャルページからDLしたいバージョンのDLページに移動。
②linux64用のリンクのアドレスをコピー。
③DLし解凍
#tmpディレクトリに移動 $ cd/tmp/ #chromedriverをダウンロード(URLはコピペ) $ wget https://chromedriver.storage.googleapis.com/83.0.4103.39/chromedriver_linux64.zip #解凍 $ unzip chromedriver_linux64.zip #解凍したファイルを /user/bin配下に移動 $ sudo mv chromedriver /usr/bin/chromedriver2.chromeのインストール
#1文でchromeインストール完了 $ curl https://intoli.com/install-google-chrome.sh | bash Complete! <-インストール成功 Successfully installed Google Chrome! #ファイル名を変更 $ sudo mv /usr/bin/google-chrome-stable /usr/bin/google-chrome #バージョンの確認 $ google-chrome --version && which google-chrome Google Chrome 83.0.4103.61 <- --versionの実行結果 /usr/bin/google-chrome <- whichの実行結果3.seleniumのインストール
$ pip3 install selenium
4.日本語フォントのインストール
$ sudo yum install ipa-gothic-fonts ipa-mincho-fonts ipa-pgothic-fonts ipa-pmincho-fontsインストールしておかないと、画面キャプチャした際に文字化けする。
5.指定したURLのテキストを抜き出す(text.py)
①ユーザーフォルダにtext.pyファイルを作成
$ cd ~ $ touch text.py $ vi text.py②vimエディタが立ち上がるので以下をコピペ。
└ 「i」キーで挿入モードに入る。
└ コピペは「shift+ins」(もしくは右クリックでpasteを選択)#-*- coding: utf-8 -*- from selenium import webdriver from selenium.webdriver.chrome.options import Options options = Options() options.headless = True driver = webdriver.Chrome(options=options) #URLの指定 driver.get("https://www.google.co.jp/") #スクレイピングする要素を指定 element_text = driver.find_element_by_id("hptl").text print(element_text) driver.quit()③貼り付けが終わったら下記でvimエディタを保存し終了。
esc + :wq + Enter④作成したファイルを実行
$ python3 text.py #下記が表示されれば成功 Googleについて ストア
googleトップの右上のテキストをスクレイピング完了。
指定したURLの画面キャプチャを取得(capture.py)
①ユーザーフォルダにcaputure.pyファイルを作成
$ cd ~ $ touch capture.py $ vi capture.py②vimエディタが立ち上がるので以下をコピペ。
└ 「i」キーで挿入モードに入る。
└ コピペは「shift+ins」(もしくは右クリックでpasteを選択)#-*- coding: utf-8 -*- from selenium import webdriver from selenium.webdriver.chrome.options import Options options = Options() options.headless = True #キャプチャする画面サイズを指定 options.add_argument('--window-size=1280,1024') driver = webdriver.Chrome(options=options) #URLを指定 driver.get("https://www.google.co.jp/") #キャプチャのファイル名と拡張子を指定 driver.save_screenshot('googletop.png') driver.quit()③貼り付けが終わったら下記でvimエディタを保存し終了。
esc + :wq + Enter④作成したファイルを実行
$ python3 capture.py #同一ディレクトリに下記ファイルができていれば成功 $ ls googletop.png
割とシンプルにスクレイピングができる。
あとはURL変えたり、抜き出す要素を変更したりカスタマイズ。
- 投稿日:2020-05-26T21:29:20+09:00
[Python] TkinterでYoutube Downloaderを作ってみた。
1.はじめに
TkinterとPytubeを用いて、Youtubeの動画をダウンロードするGUIプロるグラムを作ってみました。
2.1.pytyube
Pytubeの設置方法、使い方は下記のリンクを参考にしてください。
https://python-pytube.readthedocs.io/en/latest/
2.2.Threading導入
GUIの応答性を維持しながら、Freezeするために、Multi-threadingを導入します。
2.2.1. 生成順番
下記の順番で、Threadを設計します。
StartボタンのCall Back関数 → Thread生成メソッド → 実行メソッドfrom threading import Thread #Call Back関数 def click_me(self): self.create_thread() #Thread生成メソッド def create_thread(self): self.run_thread = Thread( target=self.method_in_a_thread ) self.run_thread.start() print(self.run_thread) #実行メソッド def method_in_a_thread(self): print('New Thread is Running.') self.get_youtube( self.URL_name.get(), self.Folder_name.get())2.2.2. 呼び出し
self.btn_Start = tk.Button(self.frame_form, text = 'Start') self.btn_Start.configure( font= self.font02 ) self.btn_Start.grid( column=1, row=2, padx=20, pady=20, sticky= tk.W + tk.E ) self.btn_Start.configure( command = self.click_me)3.使い方
ダウンロードするYoutube動画のURLを入力し、ダウンロードするフォルダーを指定します。
そして、Startボタンを押します。
最近、NHK大河ドラマ「麒麟がくる」の解説動画で躍進中のMr.武士道さんの動画を例として挙げます。
https://www.youtube.com/watch?v=NYUYYMs-5UY
ダウンロードした後、プレーヤーで再生する様子です。
4.まとめ
- YoutubeダウンロードにPytubeというモジュールを利用。
- Tkinterを利用し、GUI化する。
- GUIの応答性を維持するため、Multi-threadingを導入。
5.コード
GUI_youtube.pyfrom pytube import YouTube import tkinter as tk from tkinter import Menu from tkinter import messagebox as msg from tkinter import font from tkinter import filedialog from tkinter import ttk import os from time import sleep from threading import Thread class Application(tk.Frame): def __init__(self,master): super().__init__(master) self.pack() self.master.geometry("800x500") self.master.title("Youtube Downloader") self.master.resizable(False, False) # --------------------------------------- # Favicon # --------------------------------------- self.iconfile = "./favicon.ico" self.master.iconbitmap(default=self.iconfile) self.create_widgets() def create_widgets(self): # --------------------------------------- # font # --------------------------------------- self.font01 = font.Font(family="Helvetica", size=15, weight="normal") self.font02 = font.Font(family='Helvetica', size=15, weight='bold') self.font03 = font.Font(family='Helvetica', size=30, weight='bold') # --------------------------------------- # Menu # --------------------------------------- self.menu_bar = Menu( self.master ) self.master.config( menu=self.menu_bar ) self.file_menu = Menu( self.menu_bar, tearoff=0 ) self.file_menu.add_command( label='Exit', command=self._quit ) self.menu_bar.add_cascade( label='File', menu=self.file_menu ) # Add another help menu self.help_menu = Menu( self.menu_bar, tearoff=0 ) self.help_menu.add_command( label='About', command=self._msgBox ) # Display messagebox when clicked self.menu_bar.add_cascade( label='Help', menu=self.help_menu ) # --------------------------------------- # Main Label # --------------------------------------- self.lbl_main = ttk.Label(self.master, text = 'Youtube Downloader', font=self.font03) self.lbl_main.place(relx = 0.25, rely = 0.02) # --------------------------------------- # Frame : URL Input Form, Downloader Folder # --------------------------------------- self.frame_form = tk.Label(self.master) self.frame_form.place(relx = 0.01 , rely = 0.25, height = 400 , width= 780 ) # --------------------------------------- # URL Input Form # --------------------------------------- self.lbl_URL = ttk.Label(self.frame_form, text = 'URL') self.lbl_URL.configure(font=self.font01) self.lbl_URL.grid(column=0, row=0, padx = 20, pady= 20) self.URL_name = tk.StringVar() self.ent_URL = ttk.Entry(self.frame_form, textvariable = self.URL_name) self.ent_URL.configure(width = 35, font= self.font01) self.ent_URL.grid(column=1, row=0, padx = 20, pady= 20) self.ent_URL.focus() # --------------------------------------- # Download Folder # --------------------------------------- self.Folder_name = tk.StringVar() self.lbl_folder = ttk.Label( self.frame_form, text='Download\n Folder' ) self.lbl_folder.configure( font=self.font01 ) self.lbl_folder.grid( column=0, row=1, padx=20, pady=20 ) self.ent_Folder = ttk.Entry(self.frame_form,textvariable = self.Folder_name) self.ent_Folder.configure(width =35,font= self.font01) self.ent_Folder.grid(column=1, row=1, padx=20, pady=20) self.btn_Folder = tk.Button( self.frame_form, text = 'Set Folder Path') self.btn_Folder.configure(font = self.font02) self.btn_Folder.grid(column=2, row=1, padx=20, pady=20, sticky=tk.W + tk.E ) self.btn_Folder.configure( command= self._get_Folder_Path) # --------------------------------------- # Start Button # --------------------------------------- self.btn_Start = tk.Button(self.frame_form, text = 'Start') self.btn_Start.configure( font= self.font02 ) self.btn_Start.grid( column=1, row=2, padx=20, pady=20, sticky= tk.W + tk.E ) self.btn_Start.configure( command = self.click_me) # # --------------------------------------- # Progress Bar # --------------------------------------- self.progress_bar = ttk.Progressbar(self.frame_form, orient='horizontal', length=286, mode = 'determinate') self.progress_bar.grid(column=1, row=3, padx=20, pady=12,sticky=tk.W + tk.E) # --------------------------------------- # Create Callback Functions # --------------------------------------- #Python Treading to prevent GUI freezing. def click_me(self): self.create_thread() def create_thread(self): self.run_thread = Thread( target=self.method_in_a_thread ) self.run_thread.start() print(self.run_thread) def method_in_a_thread(self): print('New Thread is Running.') self.get_youtube( self.URL_name.get(), self.Folder_name.get()) # Display a Message Box def _msgBox(self): msg.showinfo('Program Information', 'Youtube Downloader with Tkinter \n (c) 2020 Tomomi Research Inc.') # Youtube Download Function def get_youtube(self, y_url, download_folder): #Youtube Instance yt = YouTube(y_url) yt.streams.filter(progressive=True ,subtype='mp4' ).get_highest_resolution().download( download_folder ) #progress bar self.progress_bar["maximum"] = 100 for i in range(101): sleep(0.05) self.progress_bar["value"]= i self.progress_bar.update() # Exit GUI cleanly def _quit(self): self.master.quit() self.master.destroy() exit() # Get Folder Path def _get_Folder_Path(self): iDir = os.path.abspath(os.path.dirname(__file__)) folder_Path = filedialog.askdirectory(initialdir = iDir) self.Folder_name.set(folder_Path) def main(): root = tk.Tk() app = Application(master=root)#Inherit app.mainloop() if __name__ == "__main__": main()参考資料
1.pytubeを使ってみよう
2.YouTubeから動画をダウンロードしてくるGUIツール(Python)
3.Threading in Tkinter python improve the performance
- 投稿日:2020-05-26T21:26:19+09:00
Biopython Tutorial and Cookbook和訳(4.1)
Biopythonのチュートリアルを訳する目的と理由:
- 生物の学習
- Biopythonの勉強
- 英語の復習
- 少しでもこの分野に貢献したい
どっちも全くの初心者なので、意味を通じない部分があればぜひご指摘ください。
2日で1節のペースで訳して行きます。
間違いを発見しやすいように英文も一緒に載せます。
一章を終えたら一つの記事にまとめます。Chapter 4 Sequence annotation objects
Chapter 3 introduced the sequence classes.
chp3はシーケンスクラスを紹介しました。Immediately “above” the Seq class is the Sequence Record or SeqRecord class, defined in the Bio.SeqRecord module.
Seq classの真上(継承の意味?)はSequence Record、あるいはSeqRecordクラス、Bio.SeqRecordモジュール内に定義されています。This class allows higher level features such as identifiers and features (as SeqFeature objects) to be associated with the sequence, and is used throughout the sequence input/output interface Bio.SeqIO described fully in Chapter 5.
このクラスはidentifiersやfeature(SeqFeatureオブジェクト)のようなハイレベルの特徴をシーケンスと結びつける、そしてchap5に紹介するシーケンスのinput/outputインタフェース - Bio.SeqIOに広く使われています。If you are only going to be working with simple data like FASTA files, you can probably(おそらく) skip this chapter for now.
もしあなたがFASTAのようなシンプルなデータしか扱わないなら、この章を飛ばしてもたぶん問題ないでしょう。While this chapter should cover most things to do with the SeqRecord and SeqFeature objects in this chapter,
you may also want to read the SeqRecord wiki page (http://biopython.org/wiki/SeqRecord), and the built in documentation (also online – SeqRecord and SeqFeature):
この章ではSeqRecord や SeqFeature objectsを使って多くのことをこなす必要があり、
SeqRecord wiki pageや関数のドキュメンテーションも参照したほうがいいかもしれないです。>>> from Bio.SeqRecord import SeqRecord >>> help(SeqRecord)4.1 The SeqRecord object
The SeqRecord (Sequence Record) class is defined in the Bio.SeqRecord module.
SeqRecord (Sequence Record)クラスはBio.SeqRecordモジュール内に定義されています。This class allows higher level features such as identifiers and features to be associated with a sequence (see Chapter 3),
and is the basic data type for the Bio.SeqIO sequence input/output interface (see Chapter 5).
このクラスはシーケンスに高いレベルの特徴と修飾子を付ける機能を提供しています。
そして、それはBio.SeqIOシーケンスinput/outputインタフェースの基本のデータとなります(chap5を参照)The SeqRecord class itself is quite simple, and offers the following information as attributes:
SeqRecordクラス自体はとてもシンプルで、以下の情報を属性として使います。.seq
– The sequence itself, typically a Seq object.
.id
– The primary ID used to identify the sequence – a string. In most cases this is something like an accession number.
.name
– A “common” name/id for the sequence – a string. In some cases this will be the same as the accession number, but it could also be a clone name. I think of this as being analogous to the LOCUS id in a GenBank record.
.description
– A human readable description or expressive name for the sequence – a string.
.letter_annotations
– Holds per-letter-annotations using a (restricted) dictionary of additional information about the letters in the sequence. The keys are the name of the information, and the information is contained in the value as a Python sequence (i.e. a list, tuple or string) with the same length as the sequence itself. This is often used for quality scores (e.g. Section 20.1.6) or secondary structure information (e.g. from Stockholm/PFAM alignment files).
.annotations
– A dictionary of additional information about the sequence. The keys are the name of the information, and the information is contained in the value. This allows the addition of more “unstructured” information to the sequence.
.features
– A list of SeqFeature objects with more structured information about the features on a sequence (e.g. position of genes on a genome, or domains on a protein sequence). The structure of sequence features is described below in Section 4.3.
.dbxrefs
- A list of database cross-references as strings..seq
– シーケンス自分自身, 一般的にSeqオブジェクト.
.id
– シーケンスを識別するためのID – 文字列. 多くの場合はアクセッション番号.
.name
– シーケンスの通称 – 文字列. たまにはアクセッション番号かクローンネームとなります('Clone name'が'IR'で始まるクローンが完全長クローンです). GenBank recordの遺伝子座IDに似ています.
.description
– 人間が可読な情報 あるいはシーケンスの意味を表す名前 – 文字列.
.letter_annotations
– (制限された)シーケンスの文字に関する付加情報(辞書型)を利用することで文字ごとのアノテーションを保持します. キーは情報の名前で, 情報は値に含まれます (i.e. リスト、タプルあるいは文字列) シーケンスと同じ長さになります. 品質スコア (e.g. Section 20.1.6) あるいは二次構造情報によく使われます (e.g. from Stockholm/PFAM alignment files).
.annotations
– シーケンス付加情報(辞書型). キーは情報の名前, 値は情報. シーケンスにより多くの付加情報を追加することができます.
.features
– SeqFeature objectsのリスト型でより多くの構造化情報が含まれるシーケンスの特徴データ (e.g. ゲノム上の遺伝子位置情報, あるいはたんぱく質シーケンスのドメイン). Section 4.3では構造化したシーケンスの特徴を言及します.
.dbxrefs
– データベースの相互参照リスト(文字列).
- 投稿日:2020-05-26T21:24:30+09:00
Pythonでドラクエのポーカーを実装してみた
はじめに
今回は前の記事にある山札を利用してドラクエのポーカーを実装してみたいと思います。
通常のポーカーは基本的にplayer同士で行われますが、
- player同士のリアルタイム対戦機能が大変
- ブラフ(はったり)が一切なくなる
- 強いカードと思わせ、相手を降ろして勝つ
- 弱いカードと思わせ、相手により多くのお金を賭けさせる
こういった理由からplayer同士のポーカーではなく、
ドラクエのポーカーのような一人用のゲームを実装していこうと思います。ゲームの流れ
ポーカーで役を作る → ダブルアップゲームでスコアを倍にしていく
というのが基本的な流れです。機能要件
基本
- デッキはポーカー、ダブルアップゲーム共に毎回リセット
- プレイヤーの初期スコアは0
- ポーカー終了後、1ペア以上の役があればダブルアップゲームスタート
- ジョーカーはなし
ポーカー
- 5枚のカードが配られる
- 1枚ずつ 変える or 残す を選択
- 変える を選択したカードを交換
- 交換後の5枚で役の計算
- 役の判定を行い、役に応じてスコア決定
ダブルアップゲーム
- 5枚のカードが配られる(1枚は表向き、4枚は裏向き)
- 4枚の裏向きのカードから表向きのカードよりも強いと思うカードを選択
- 強い場合はスコアが倍、再度ダブルアップゲームに挑戦できる
- 弱い場合はスコアが0、ポーカーから再スタート
役・スコアについて
役名 カードの状態 手札の例 スコア 1ペア 同じ数字のペアが1つ [♣️-4, ♠︎-4, ♦︎-Q, ♠︎-K, ❤︎-5] 50 2ペア 同じ数字のペアが2つ [♣️-4, ♠︎-4, ♦︎-Q, ♠︎-Q, ❤︎-5] 100 3カード 同じ数字3枚 [♣️-4, ♠︎-4, ♦︎-4, ♠︎-Q, ❤︎-5] 200 ストレート 数字が連続している [♣️-3, ♠︎-4, ♦︎-5, ♠︎-6, ❤︎-7] 300 フラッシュ マークが全て同じ [♠︎-3, ♠︎-4, ♠︎-5, ♠︎-Q, ♠︎-9] 400 フルハウス 同じ数字3枚 + 1ペア [♠︎-3, ♠︎-4, ♠︎-5, ♠︎-Q, ♠︎-9] 500 フォーカード 同じ数字4枚 [♠︎-4, ♦︎-4, ♠︎-4, ♣️-4, ❤︎-9] 1000 ストレートフラッシュ フラッシュ かつ ストレート [♠︎-4, ♠︎-5, ♠︎-6, ♠︎-7, ♠︎-8] 2000 ロイヤルストレートフラッシュ フラッシュ かつ ストレート [♠︎-10, ♠︎-J, ♠︎-Q, ♠︎-K, ♠︎-A] 10000 ※ 今回はジョーカーなしで実装するのでファイブカード、
ドラクエだと一番上のロイヤルストレートスライム(マークがスライム)はなしです!実装
下記のクラスを用意しました。他にも良い方法はあると思います。。
Cardクラス・Deckクラス
こちらの記事で作成したものをそのまま利用しました。
Playerクラス
class Player: """ プレイヤーのスコア・手札・ポーカー勝利フラグ """ def __init__(self): self.score = 0 self.hands = [] self.is_poker_win = True def draw_card(self, deck, num=1): """ カードをデッキからドローし手札に加える ※異なる枚数がドローされてもok Parameters ---------- num : int, default 1 カードをドローする回数 Examples -------- >>> player.draw_card(2) # 2枚ドロー [♠︎-J, ♠︎-10] >>> player.draw_card(3) # [♦︎-9, ♣️-10, ♠︎-2] >>> print(player.hands) [♠︎-J, ♠︎-10, ♦︎-9, ♣️-10, ♠︎-2] """ self.hands_store = deck.pick_card(num) self.hands.extend(self.hands_store)Gameクラス
class Game: """ メインゲーム Examples -------- >>> game = Game() >>> game.main() # ゲームスタート(下記の初期フェーズが表示) """ RANKS = (*"23456789", "10", *"JQKA") VALUES = (range(2, 14 + 1)) # 表示マークとスコアを紐づける RANK_TO_VALUES = dict(zip(RANKS, VALUES)) def main(self): """ ゲーム全体(ポーカー + ダブルアップチャンス) """ can_play_game = True while can_play_game: # ゲームごとにplayer情報リセット player = Player() # 山札セット(セット数を決める) = ゲームごとに山札再構築 deck = stock.Deck() poker = Poker(deck, player) poker.main_game() # 役ありはダブルアップチャンス print(player.is_poker_win) if player.is_poker_win: bonus_game = DoubleUp(player) bonus_game.main_game() # ゲームリスタート restart_msg = "Qでゲーム終了、それ以外でゲームスタート:" start_res = input(restart_msg) if start_res == 'Q': can_play_game = False if __name__ == '__main__': game = Game() game.main()Pokerクラス
役判定について
役判定については下記のフローチャートのようになってます。
class Poker: RANKS = (*"23456789", "10", *"JQKA") VALUES = (range(2, 14 + 1)) # 表示マークとスコアを紐づける RANK_TO_VALUES = dict(zip(RANKS, VALUES)) def __init__(self, deck, player): self.deck = deck self.player = player def change_hands(self, player_hands): """ カードを1枚ずつ交換選択させ、交換後の手札を返す Parameters ---------- player_hands : list カード交換する前のplayerの山札 Returns -------- changed_hands : list カード交換した後のplayerの山札 """ changed_hands = [] # それぞれのカードを「のこす」か「かえる」のどちらかを選択 print("Enter \"y\" to replace the card.") for card_idx, change_card in enumerate(player_hands): change_card_msg = f"{change_card}:" change_card_res = input(change_card_msg) # 変える場合は山札からドローしてカードを交換 if change_card_res == "y": # デッキからドローして上書き change_card = self.deck.pick_card(1)[0] self.player.hands[card_idx] = change_card # 連想配列に追加 check_card_set = str(change_card).split("-") # ❤︎ card_mark = check_card_set[0] # K card_rank = check_card_set[1] # 13 card_number = self.RANK_TO_VALUES[card_rank] # チェック用の辞書に追加 changed_hands.append({ "mark": card_mark, "rank": card_rank, "number": card_number }) return changed_hands def calc_hand(self, check_hands): """ 手札から役の計算 Parameters ---------- check_hands : list カード交換した後のplayerの山札 Returns -------- hand_results : dict playerの山札のそれぞれの役の状態 """ # フラッシュ(マークが同じ) is_flash = True # ストレート(数字が連番) is_straight = True # 同じ数字のカウント same_number_count = 0 same_number = 0 # ペア数(1ペアや2ペア) match_pair_count = 0 # 手札からカードの数字をもとに昇順に並べ替え check_hands_sorted = sorted(check_hands, key=lambda x: x["number"]) # カード5枚から1枚ずつチェック for check_idx, check_card in enumerate(check_hands_sorted): # 1枚目は前のカードがないのでスキップ if check_idx == 0: continue # 前のカード {'mark': '♠︎', 'rank': '4', 'number': 4} prev_card = check_hands_sorted[check_idx - 1] # 前後のマーク違う場合はフラッシュ判定をFalse if is_flash and check_card["mark"] != prev_card["mark"]: is_flash = False # 前後で数字が連続していない場合はストレート判定をFalse if is_straight and check_card["number"] != prev_card["number"] + 1: is_straight = False # 前後で数字が一致してる場合は 同じ数字のカウント を+1 if check_card["number"] == prev_card["number"]: # マッチ数 + 1 same_number_count += 1 # 最後のカード if check_idx == 4: if same_number_count == 1: # ペア数 + 1 match_pair_count += 1 else: # 3カードや4カード same_number = same_number_count + 1 # 違う数字の場合 else: if same_number_count == 1: # ペア数 + 1 match_pair_count += 1 elif same_number_count > 1: # 3カードや4カード same_number = same_number_count + 1 # 違う数字なのでリセット same_number_count = 0 # 手札のそれぞれの役の状態 hand_results = { "is_flash": is_flash, "is_straight": is_straight, "same_number_count": same_number_count, "same_number": same_number, "match_pair_count": match_pair_count } return hand_results def showdown_hand(self, hand_status, check_hands): """ 役の状態から役の決定、スコア計算 Parameters ---------- hand_status : dict カード交換した後のplayerの役の状態 check_hands : list playerの手札 Returns -------- hand_result_msg : str 役の判定文 """ # 結果 hand_result_msg = "" # フラッシュかつストレート if hand_status["is_flash"] and hand_status["is_straight"]: # 最小のカードが10,最大のカードが14(A) if check_hands[0]["number"] == 10 and \ check_hands[4]["number"] == 14: hand_result_msg = "ロイヤルストレートフラッシュ" self.player.score = 10000 else: hand_result_msg = "ストレートフラッシュ" self.player.score = 2000 # 4カード elif hand_status["same_number"] == 4: hand_result_msg = "4カード" self.player.score = 1000 # 3カード, フルハウス判定 elif hand_status["same_number"] == 3: # 3カードかつペアが1 if hand_status["match_pair_count"] == 1: hand_result_msg = "フルハウス" self.player.score = 500 else: hand_result_msg = "3カード" self.player.score = 250 # フラッシュ elif hand_status["is_flash"]: hand_result_msg = "フラッシュ" self.player.score = 400 # ストレート elif hand_status["is_straight"]: hand_result_msg = "ストレート" self.player.score = 300 # 2ペア elif hand_status["match_pair_count"] == 2: hand_result_msg = "2ペア" self.player.score = 200 # 1ペア elif hand_status["match_pair_count"] == 1: hand_result_msg = "1ペア" self.player.score = 150 return hand_result_msg def main_game(self): """ ポーカーのメインゲーム """ print("Poker Game start") # 最初は5枚ドロー self.player.draw_card(self.deck, 5) # 初期カード表示 print(f"player's hands:{self.player.hands}") # カード交換フェイズ check_hands = self.change_hands(self.player.hands) # 交換後のカード表示 print(f"player's hands:{self.player.hands}") # 手札の数字をもとに昇順にソート check_hands_sorted = sorted(check_hands, key=lambda x: x["number"]) # 手札から役の計算 hand_results = self.calc_hand(check_hands_sorted) print(hand_results) # 役判定 hand_result_msg = self.showdown_hand(hand_results, check_hands_sorted) # 何もない場合は負け if hand_result_msg == "": hand_result_msg = "役はありませんでした..." self.player.is_poker_win = False # 結果出力 print(hand_result_msg)DoubleUpクラス
import re from deck import stock class DoubleUp: RANKS = (*"23456789", "10", *"JQKA") VALUES = (range(2, 14 + 1)) # 表示マークとスコアを紐づける RANK_TO_VALUES = dict(zip(RANKS, VALUES)) def __init__(self, player): self.player = player self.is_game_win = True def add_check_hands(self, player_hands): """ カードを1枚ずつ表示して番号を割り振る Parameters ---------- player_hands : list 手札5枚 Returns -------- check_hands : list playerの手札 """ check_hands = [] for card_idx, card_val in enumerate(player_hands): # 連想配列に追加 check_card_set = str(card_val).split("-") # ❤︎ card_mark = check_card_set[0] # K card_rank = check_card_set[1] # 13 card_number = self.RANK_TO_VALUES[card_rank] # チェック用の辞書に追加 check_hands.append({ "mark": card_mark, "rank": card_rank, "number": card_number }) # 1番目は選択できない if card_idx >= 1: # 隠す # print(f"{card_idx}:*-*") print(f"{card_idx}:{card_val}") return check_hands def win_judge_selected_card(self, input_res, check_hands): """ ゲームの勝利判定(選択したカードと表向きのカードを比較) Parameters ---------- input_res : str コマンドに入力された数字 check_hands : list playerの手札 """ if re.compile(r'^[1-4]+$').match(input_res) is not None: # 選んだ番号のカードと表向きのカードの数字の大きさ比較 if check_hands[int(input_res)]["number"] >= check_hands[0]["number"]: # 大きければスコア2倍 print("win!") self.player.score *= 2 else: # 小さい場合, スコアは0になり、再度ポーカーからスタート print("lose..") self.player.score = 0 self.is_game_win = False else: print("ダメです") def main_game(self): """ ダブルアップのメインゲーム """ while self.is_game_win: # 山札再構築 self.deck = stock.Deck() print("double-Up Chance Game start") print(f"Now, your score is {self.player.score} points.") self.player.hands = [] # デッキから5枚のカードを配る self.player.draw_card(self.deck, 5) # 5枚中1枚が表、4枚は裏向きでセット print(f"player's hands:{self.player.hands[0]}, *-*, *-*, *-*, *-*") # カードを1枚ずつ表示して番号を割り振る check_hands = self.add_check_hands(self.player.hands) # 4枚の裏向きカードの中から、表向きのカードの数字より強いものを1枚選ぶ card_select_msg = f"Enter a card number that is stronger than {self.player.hands[0]}:" card_select_res = input(card_select_msg) # 1〜4までの数字から1つ選ぶ self.win_judge_selected_card(card_select_res, check_hands) print(self.player.score)動作
$ python main.py Poker Game start player's hands:[❤︎-4, ♠︎-9, ♣️-4, ♠︎-3, ♠︎-2] Enter "y" to replace the card. ❤︎-4: ♠︎-9: y ♣️-4: ♠︎-3: y ♠︎-2: y player's hands:[❤︎-4, ❤︎-K, ♣️-4, ♠︎-K, ♣️-6] 2ペア double-Up Chance Game start Now, your score is 100 points. player's hands:♠︎-6, *-*, *-*, *-*, *-* 1:*-* 2:*-* 3:*-* 4:*-* Enter a card number that is stronger than ♠︎-6: 2 Selected card is ❤︎-12 win! 200 double-Up Chance Game start Now, your score is 200 points. player's hands:♠︎-K, *-*, *-*, *-*, *-* 1:*-* 2:*-* 3:*-* 4:*-* Enter a card number that is stronger than ♠︎-K: 3 Selected card is ♦︎-2 lose.. 0 Qでゲーム終了、それ以外でゲームスタート:Q※今回作成した全ファイルはこちらに載せております。
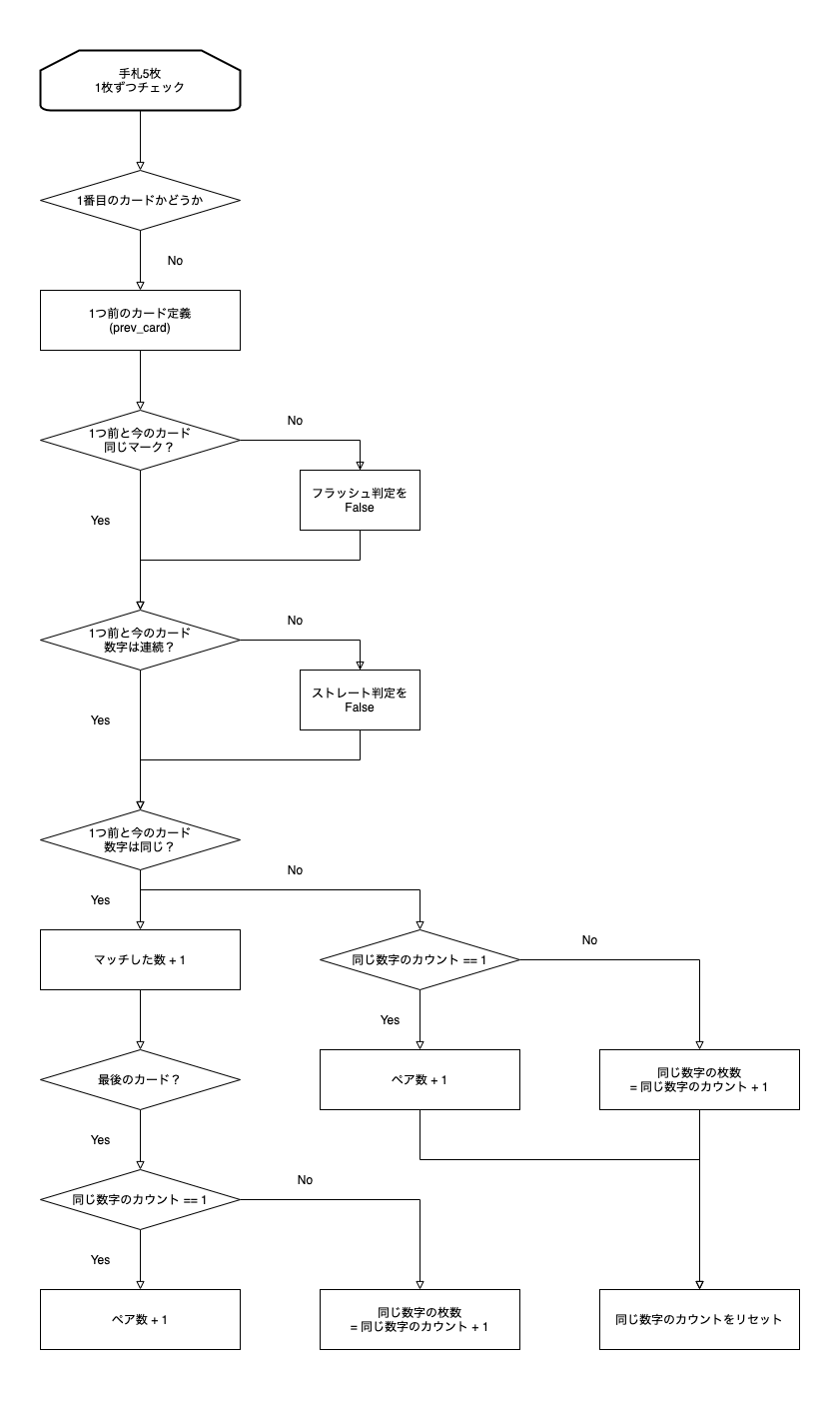
- 投稿日:2020-05-26T21:22:49+09:00
【EC2】seleniumでキャプチャしたときの文字化けを防ぐ
【EC2】seleniumでキャプチャしたときの文字化けを防ぐ
pythonのseleniumで指定したURLの画面キャプチャを取得した際に文字化けが発生した。。
▼chrome(日本語)トップをキャプチャするプログラム
screenshot.pyfrom selenium import webdriver from selenium.webdriver.chrome.options import Options options = Options() options.headless = True options.add_argument('--window-size=1280,1024') driver = webdriver.Chrome(options=options) driver.get("https://www.google.co.jp/") driver.save_screenshot('test.png') driver.quit()文字化け
文字化け(とうふ)が並んだ状態に、、
*上記はwindowsize指定してない対処法
sudo yum install ipa-gothic-fonts ipa-mincho-fonts ipa-pgothic-fonts ipa-pmincho-fonts日本語用のフォントパッケージをインストール。
途中でインストールしてもいいか?と聞かれるので「y」にする。
文字化けが無事解消。
notoフォント
下記記事でnotoフォントを入れることで文字化けが解消するとの記事があったのですが、ワークしませんでした、、
https://qiita.com/onorioriori/items/4fa271daa3621e8f6fd9#zipダウンロード用にtmpディレクトリに移動 cd /tmp/ #notoフォントのフルパッケージをインストール wget https://noto-website-2.storage.googleapis.com/pkgs/Noto-hinted.zip #解凍 unzip Noto-hinted.zip #/usr/share/fonts配下にディレクトリを作成 mkdir -p /usr/share/fonts/opentype/noto #該当するファイルを移動 cp *otf *ttf /usr/share/fonts/opentype/noto #フォントキャッシュの更新(やらなくてもいい) fc-cache -f -v指定ディレクトリ内にファイルを置いたのに文字化けがなおならい。
どなたかnotoを使う方法がわかる方がいたら教えてください。。
補足:notoフォントとは
GoogleとAdobeとイワタが共同で開発した言語パッケージ。すべての言語に対応。
文字化けすると豆腐のような□がたくさん表示されるので、no tofu を略してnotoフォント。
フォント毎にパッケージをDLすることもできるし、フルパッケージでDLすることもできる。▼フルパッケージのURL
https://noto-website-2.storage.googleapis.com/pkgs/Noto-hinted.zip▼notoSansのURL
https://noto-website-2.storage.googleapis.com/pkgs/NotoSans-hinted.zip
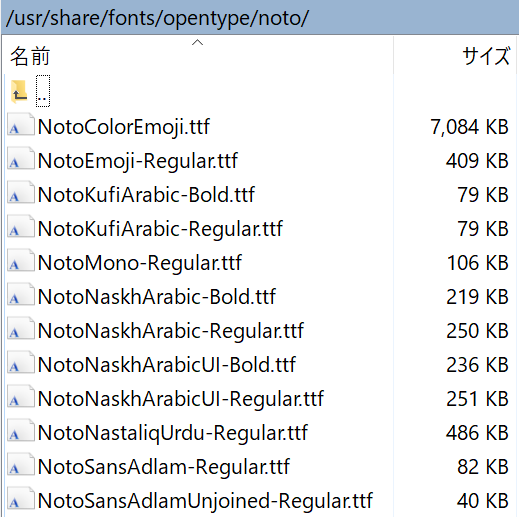
- 投稿日:2020-05-26T21:21:54+09:00
【EC2】seleniumがスタックして処理が進まないときの対処法
【EC2】seleniumがスタックして処理が進まないときの対処法
- EC2でseleniumを使っているときに、データ取得までにとても時間がかかる。
- 最初はスムーズにいっていたのに、実行を繰り返すうちに処理が重くなっていく。
- ずーっと待っていると、最終的にchromeにたどり着けないエラーが表示される。
エラー$ python3 ファイル名.py selenium.common.exceptions.WebDriverException: Message: chrome not reachable原因
chromeブラウザの複数プロセスやドライバーが何個も立ち上がってしまっている。(headlessなので目視で確認できない、、)
対処法
・立ち上がっているchromeブラウザ&ドライバーを停止する。
・ファイル末尾にオブジェクト.quit()を記述。対処手順
1.chromeドライバーが複数立ち上がっていないか確認する。
#「chrome」を含む実行中のプロセスをすべて表示 $ ps aux | grep chrome #以下のような記述がたくさん表示された場合、複数のwebdriverが起動している。 ユーザー名 pts/0 Sl 04:09 0:00 chromedriver --port=49671 #以下のような記述がたくさん表示された場合、複数のブラウザのプロセスが起動している。 ユーザー名 pts/0 S 04:32 0:00 /opt/google/chrome/chrome --type=broker*Chromeはブラウザを1つ表示した場合でも、複数のプロセスを実行している。
ps aux
- psコマンド:実行中のコマンドを表示する
- auxはオプション
- a:すべてのユーザーのプロセス
- u:ユーザー名と開始時刻を表示
- x:制御端末のないプロセスも表示
- Process Status
- |grepとセットで使うことが多い
|grep テキスト
- 「|(パイプ)」:コマンドを追加
- grep テキスト:テキストを含む処理のみ表示
- Global Regular Expression Print
2.chromeブラウザ&webdriverを終了する
killall chrome killall webdriver再度実行中のファイルを確認。
$ ps aux | grep chrome #以下だけ残り他は終了できた。 ユーザー名 pts/0 S+ 04:35 0:00 grep --color=auto chrome
3.処理にquit()を追記
.pyファイルの末尾でquit()を実行しすべてのブラウザを閉じる。
#下記記述がある前提で browser = webdriver.Chrome(options=options) browser.quit()webdriver起動の変数をdriverなど他の記述にしている場合は、合わせる。
例:driver.quit()
以上で、
・pyファイルの実行がぐっと早くなる。
・処理後の実行中プロセスもなくなる。補足
別記事でsandboxを停止したり、オプションで--no-sandboxをつけるようなものがありましたが、私の場合、sandboxは立ち上がっておらず不要でした。
もし実行中プロセスでsandboxが表示された方は下記も試してみると効果あるかもです。
killall chrome-sandboxchrome_options.add_argument("--no-sandbox") chrome_options.add_argument("--disable-setuid-sandbox")元記事はこちら
ちなみにsandboxというのは、外のプログラムに影響のない隔離された環境だそうです。(ウイルスが含まれてそうなプログラムを実行するのに使うなど)
- 投稿日:2020-05-26T21:01:58+09:00
ziplineをインストールしてHello worldまで(on Windows)
1 この記事は
株式投資のバックテストを行うクラウドサービスとしてQuantopianがあり高機能ですが、メインは米国株です。(日本株の銘柄データを読み込むことができますが、最新の株価は読み込むことはできません。)
ライブラリZiplineをjupyterにインストールし、日本株のバックテストを行うことを考えましたが、Ziplineの環境設定は簡単ではなく試行錯誤が必要でした。この記事では、Ziplineを使うための環境設定の方法を書きたいと思います。2 本文
前提条件
Windows10, Jupyter, Anacondaはインストール済み2-1 python3.5をjupyter仮想環境上にインストールする。
ライブラリziplineは、pythonのversionが3.5以下でないと動作しません。よって、python ver3.5を入手うることが必要です。
JupyterをインストールするとPythonのversionは最新のものがインストールされます(2020年6月現在Python ver3.7がインストールされます)。違うversionのpython (ver3.5)をjupyter上に同居させる場合、仮想環境を構築し、仮想環境上にpython ver3.5をインストールする方法をとりました。仮想環境の構築の方法はこちらの記事をご覧ください。2-2 仮想環境上にziplineをインストールする
(1)anaconda3プロンプトを立ち上げます。
(2)仮想環境python355に切り替えを行います。
(base) C:\Users\***\anaconda3>activate python355 #仮想環境python355に切り替え(3)仮想環境上でziplineをインストールします。pipよりもcondaを使用した方がインストールが楽です。
(python355) C:\Users\***\anaconda3>>conda install -c Quantopian zipline2-3 benchmarks.pyとloaders.pyの修正
ziplineはバックテスト実施時にベンチマークデータ(S&P500)を取得しに行きますが、デフォルトのコードでは、2020年6月現在ではすでに使われいないAPI(IEX API)をbenchmarks.pyの中でたたきにいくため、コード実行時にエラーJSONDecodeError: Expecting value: line 1 column 1 (char 0)が発生します。
出現するエラーの詳細内容 ・・・リンク先参照
そのため、benchmarks.pyとloaders.pyを修正する必要があります。benchmarks.pyとloaders.pyを下記のとおり書き直してください。
下記のコードをコピペしてbenchmarks.pyに貼り付けてください。
/anaconda3/pkgs/zipline-1.3.0-np114py35_0/Lib/site-packages/zipline/data/benchmarks.pyimport pandas as pd from trading_calendars import get_calendar def get_benchmark_returns(symbol, first_date, last_date): cal = get_calendar('NYSE') dates = cal.sessions_in_range(first_date, last_date) data = pd.DataFrame(0.0, index=dates, columns=['close']) data = data['close'] return data.sort_index().iloc[1:]下記のコードをコピペしてloaders.pyに貼り付けてください。
/anaconda3/pkgs/zipline-1.3.0-np114py35_0/Lib/site-packages/zipline/data/loader.py# # Copyright 2016 Quantopian, Inc. # # Licensed under the Apache License, Version 2.0 (the "License"); # you may not use this file except in compliance with the License. # You may obtain a copy of the License at # # http://www.apache.org/licenses/LICENSE-2.0 # # Unless required by applicable law or agreed to in writing, software # distributed under the License is distributed on an "AS IS" BASIS, # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. # See the License for the specific language governing permissions and # limitations under the License. import os import logbook import pandas as pd from six.moves.urllib_error import HTTPError from trading_calendars import get_calendar from .benchmarks import get_benchmark_returns from . import treasuries, treasuries_can from ..utils.paths import ( cache_root, data_root, ) logger = logbook.Logger('Loader') # Mapping from index symbol to appropriate bond data INDEX_MAPPING = { 'SPY': (treasuries, 'treasury_curves.csv', 'www.federalreserve.gov'), '^GSPTSE': (treasuries_can, 'treasury_curves_can.csv', 'bankofcanada.ca'), '^FTSE': # use US treasuries until UK bonds implemented (treasuries, 'treasury_curves.csv', 'www.federalreserve.gov'), } ONE_HOUR = pd.Timedelta(hours=1) def last_modified_time(path): """ Get the last modified time of path as a Timestamp. """ return pd.Timestamp(os.path.getmtime(path), unit='s', tz='UTC') def get_data_filepath(name, environ=None): """ Returns a handle to data file. Creates containing directory, if needed. """ dr = data_root(environ) if not os.path.exists(dr): os.makedirs(dr) return os.path.join(dr, name) def get_cache_filepath(name): cr = cache_root() if not os.path.exists(cr): os.makedirs(cr) return os.path.join(cr, name) def get_benchmark_filename(symbol): return "%s_benchmark.csv" % symbol def has_data_for_dates(series_or_df, first_date, last_date): """ Does `series_or_df` have data on or before first_date and on or after last_date? """ dts = series_or_df.index if not isinstance(dts, pd.DatetimeIndex): raise TypeError("Expected a DatetimeIndex, but got %s." % type(dts)) first, last = dts[[0, -1]] return (first <= first_date) and (last >= last_date) def load_market_data(trading_day=None, trading_days=None, bm_symbol='SPY', environ=None): """ Load benchmark returns and treasury yield curves for the given calendar and benchmark symbol. Benchmarks are downloaded as a Series from IEX Trading. Treasury curves are US Treasury Bond rates and are downloaded from 'www.federalreserve.gov' by default. For Canadian exchanges, a loader for Canadian bonds from the Bank of Canada is also available. Results downloaded from the internet are cached in ~/.zipline/data. Subsequent loads will attempt to read from the cached files before falling back to redownload. Parameters ---------- trading_day : pandas.CustomBusinessDay, optional A trading_day used to determine the latest day for which we expect to have data. Defaults to an NYSE trading day. trading_days : pd.DatetimeIndex, optional A calendar of trading days. Also used for determining what cached dates we should expect to have cached. Defaults to the NYSE calendar. bm_symbol : str, optional Symbol for the benchmark index to load. Defaults to 'SPY', the ticker for the S&P 500, provided by IEX Trading. Returns ------- (benchmark_returns, treasury_curves) : (pd.Series, pd.DataFrame) Notes ----- Both return values are DatetimeIndexed with values dated to midnight in UTC of each stored date. The columns of `treasury_curves` are: '1month', '3month', '6month', '1year','2year','3year','5year','7year','10year','20year','30year' """ if trading_day is None: trading_day = get_calendar('NYSE').trading_day if trading_days is None: trading_days = get_calendar('NYSE').all_sessions first_date = trading_days[0] now = pd.Timestamp.utcnow() # we will fill missing benchmark data through latest trading date last_date = trading_days[trading_days.get_loc(now, method='ffill')] br = ensure_benchmark_data( bm_symbol, first_date, last_date, now, # We need the trading_day to figure out the close prior to the first # date so that we can compute returns for the first date. trading_day, environ, ) tc = ensure_treasury_data( bm_symbol, first_date, last_date, now, environ, ) # combine dt indices and reindex using ffill then bfill all_dt = br.index.union(tc.index) br = br.reindex(all_dt, method='ffill').fillna(method='bfill') tc = tc.reindex(all_dt, method='ffill').fillna(method='bfill') benchmark_returns = br[br.index.slice_indexer(first_date, last_date)] treasury_curves = tc[tc.index.slice_indexer(first_date, last_date)] return benchmark_returns, treasury_curves def ensure_benchmark_data(symbol, first_date, last_date, now, trading_day, environ=None): """ Ensure we have benchmark data for `symbol` from `first_date` to `last_date` Parameters ---------- symbol : str The symbol for the benchmark to load. first_date : pd.Timestamp First required date for the cache. last_date : pd.Timestamp Last required date for the cache. now : pd.Timestamp The current time. This is used to prevent repeated attempts to re-download data that isn't available due to scheduling quirks or other failures. trading_day : pd.CustomBusinessDay A trading day delta. Used to find the day before first_date so we can get the close of the day prior to first_date. We attempt to download data unless we already have data stored at the data cache for `symbol` whose first entry is before or on `first_date` and whose last entry is on or after `last_date`. If we perform a download and the cache criteria are not satisfied, we wait at least one hour before attempting a redownload. This is determined by comparing the current time to the result of os.path.getmtime on the cache path. """ filename = get_benchmark_filename(symbol) data = _load_cached_data(filename, first_date, last_date, now, 'benchmark', environ) if data is not None: return data # If no cached data was found or it was missing any dates then download the # necessary data. logger.info( ('Downloading benchmark data for {symbol!r} ' 'from {first_date} to {last_date}'), symbol=symbol, first_date=first_date - trading_day, last_date=last_date ) try: data = data = get_benchmark_returns(symbol, first_date, last_date) data.to_csv(get_data_filepath(filename, environ)) except (OSError, IOError, HTTPError): logger.exception('Failed to cache the new benchmark returns') raise if not has_data_for_dates(data, first_date, last_date): logger.warn( ("Still don't have expected benchmark data for {symbol!r} " "from {first_date} to {last_date} after redownload!"), symbol=symbol, first_date=first_date - trading_day, last_date=last_date ) return data def ensure_treasury_data(symbol, first_date, last_date, now, environ=None): """ Ensure we have treasury data from treasury module associated with `symbol`. Parameters ---------- symbol : str Benchmark symbol for which we're loading associated treasury curves. first_date : pd.Timestamp First date required to be in the cache. last_date : pd.Timestamp Last date required to be in the cache. now : pd.Timestamp The current time. This is used to prevent repeated attempts to re-download data that isn't available due to scheduling quirks or other failures. We attempt to download data unless we already have data stored in the cache for `module_name` whose first entry is before or on `first_date` and whose last entry is on or after `last_date`. If we perform a download and the cache criteria are not satisfied, we wait at least one hour before attempting a redownload. This is determined by comparing the current time to the result of os.path.getmtime on the cache path. """ loader_module, filename, source = INDEX_MAPPING.get( symbol, INDEX_MAPPING['SPY'], ) first_date = max(first_date, loader_module.earliest_possible_date()) data = _load_cached_data(filename, first_date, last_date, now, 'treasury', environ) if data is not None: return data # If no cached data was found or it was missing any dates then download the # necessary data. logger.info( ('Downloading treasury data for {symbol!r} ' 'from {first_date} to {last_date}'), symbol=symbol, first_date=first_date, last_date=last_date ) try: data = loader_module.get_treasury_data(first_date, last_date) data.to_csv(get_data_filepath(filename, environ)) except (OSError, IOError, HTTPError): logger.exception('failed to cache treasury data') if not has_data_for_dates(data, first_date, last_date): logger.warn( ("Still don't have expected treasury data for {symbol!r} " "from {first_date} to {last_date} after redownload!"), symbol=symbol, first_date=first_date, last_date=last_date ) return data def _load_cached_data(filename, first_date, last_date, now, resource_name, environ=None): if resource_name == 'benchmark': def from_csv(path): return pd.read_csv( path, parse_dates=[0], index_col=0, header=None, # Pass squeeze=True so that we get a series instead of a frame. squeeze=True, ).tz_localize('UTC') else: def from_csv(path): return pd.read_csv( path, parse_dates=[0], index_col=0, ).tz_localize('UTC') # Path for the cache. path = get_data_filepath(filename, environ) # If the path does not exist, it means the first download has not happened # yet, so don't try to read from 'path'. if os.path.exists(path): try: data = from_csv(path) if has_data_for_dates(data, first_date, last_date): return data # Don't re-download if we've successfully downloaded and written a # file in the last hour. last_download_time = last_modified_time(path) if (now - last_download_time) <= ONE_HOUR: logger.warn( "Refusing to download new {resource} data because a " "download succeeded at {time}.", resource=resource_name, time=last_download_time, ) return data except (OSError, IOError, ValueError) as e: # These can all be raised by various versions of pandas on various # classes of malformed input. Treat them all as cache misses. logger.info( "Loading data for {path} failed with error [{error}].", path=path, error=e, ) logger.info( "Cache at {path} does not have data from {start} to {end}.\n", start=first_date, end=last_date, path=path, ) return None def load_prices_from_csv(filepath, identifier_col, tz='UTC'): data = pd.read_csv(filepath, index_col=identifier_col) data.index = pd.DatetimeIndex(data.index, tz=tz) data.sort_index(inplace=True) return data def load_prices_from_csv_folder(folderpath, identifier_col, tz='UTC'): data = None for file in os.listdir(folderpath): if '.csv' not in file: continue raw = load_prices_from_csv(os.path.join(folderpath, file), identifier_col, tz) if data is None: data = raw else: data = pd.concat([data, raw], axis=1) return data上記情報の出典先はこちらを参照くださいです。
2-4 銘柄データの取得
バックテストを実施するには銘柄データが必要です。ziplineのDocumentではQuandle APIを使って株価データを取得しておりますが、無料アカウントの場合2018年以降のデータは取得できないようです。よって、ziplineを使う上で銘柄データは自分で用意するのがベストであると思われます。ziplineでは、「bundle」で銘柄データを管理しております。「bundle」にデータセットが登録されていないとバックテスト時に銘柄データを読み出すことができませんので、「bundle」へのデータ登録は必須です。
(python355) C:\Users\xxxxx\anaconda3>zipline bundles #ziplineが管理するbundle csvdir <no ingestions> custom-csvdir-bundle 2020-06-13 11:56:14.025797 custom-csvdir-bundle 2020-06-13 11:50:49.932352 custom-csvdir-bundle 2020-06-13 11:47:58.074644 quandl 2020-06-13 03:54:52.594770 quandl 2020-05-26 11:58:22.253861 quantopian-quandl 2020-06-13 07:46:19.699674(1)銘柄データをcsv形式で用意する。
/.zipline/dataの下にフォルダを作り、銘柄データ(csvデータ形式)を入れます。date,open,high,low,close,volume,dividend,splitの順番の列名を持つデータ構造であることが必要です。
銘柄番号1570(日経レバ,期間:2020/6/1-2020/6/5)を登録bundleに登録してみます。
下記が期間:2020/6/1-2020/6/5における銘柄番号1570(日経レバ)の銘柄データです。../.zipline/data/test/n1570.csvdate,open,high,low,close,volume,dividend,split 2020/6/1,18490,18870,18440,18700,11776152,0,1 2020/6/2,18880,19280,18790,19170,12187992,0,1 2020/6/3,19900,20000,19370,19650,15643729,0,1 2020/6/4,20100,20120,19440,19760,15125070,0,1 2020/6/5,19660,20070,19510,20060,9999219,0,1(2)extension.pyの書き換え
./ziplineの下のextension.pyを下記ソースコードのように書き換えてください。
../.zipline/extension.pyimport pandas as pd from zipline.data.bundles import register from zipline.data.bundles.csvdir import csvdir_equities register( 'custom-csvdir-bundle', #bundle名を書く csvdir_equities( ['test'], #銘柄データcsv形式が格納されているフォルダ名 'C:/Users/fdfpy/.zipline/data/', #「銘柄データcsv形式が格納されているフォルダ名」の上位パス ), calendar_name='NYSE', # US equities #ここは'NYSE'のままにしておく )(3)bundleの登録
上記の銘柄株価を'custom-csvdir-bundle'に登録します。銘柄番号1570日経レバはsid番号0と採番されたことが分かります。
(python355) C:\Users\fdfpy\anaconda3>zipline ingest -b custom-csvdir-bundle | n1570: sid 0 #銘柄番号1570日経レバ | test: sid 13 バックテストを行ってみる
バックテストというほどではありませんが、毎日大引けで日経レバを1株買うというコードを書いて実際にrunさせてみたいと思います。
jupyter_notebook上に記入%reload_ext zipline #ziplineコマンドを読み込みます(%はマジックコマンドを示す)jupyter_notebook上に記入from zipline.api import order, record, symbol def initialize(context): pass def handle_data(context, data): order(symbol('n1570'), 1) #毎日大引けで日経レバを1株買う。 record(N1570=data[symbol('n1570')].price) #銘柄名n1570の株価情報等を書き出す。jupyter_notebook上に記入#実際に上記のコードを走らせる(%はマジックコマンドを示す) %zipline --bundle custom-csvdir-bundle --start 2020-6-1 --end 2020-6-5 -o start.pickle下記に上記コードの出力結果を張り付けています。毎日大引けで1株ずつ購入していることが分かります。
ziplineをインストールしてHello worldができるまでいろいろとカットアンドトライしながらやってみましたが、やっとHello worldまでたどり着けました。今からはもっと複雑なバックテスト等を試すことができそうで楽しみです。
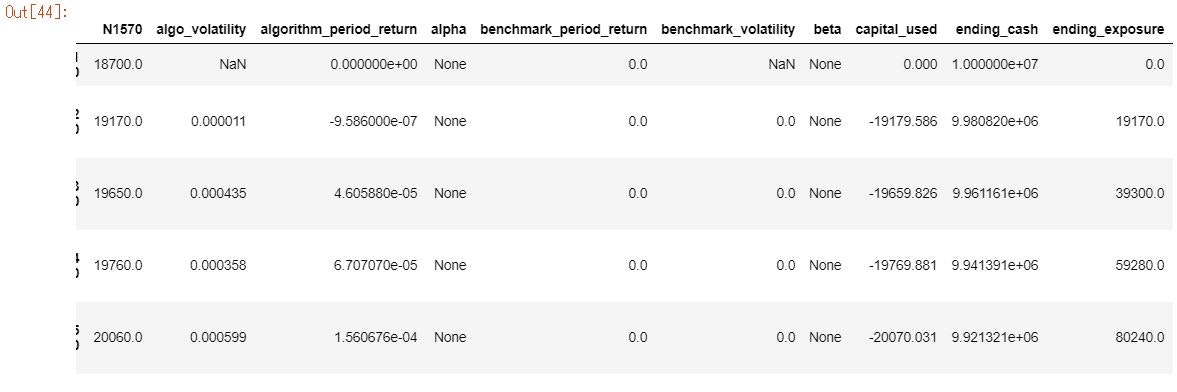
- 投稿日:2020-05-26T20:18:21+09:00
Pythonで使える 線形計画(LP)ソルバー と モデラー 一覧
Pythonには使線形計画問題(LP)を扱える最適化アプリケーションがいくつかあります.
アプリケーションは大きく以下の2種類に分類されます.
- Solver (ソルバー); 問題を解くアルゴリズムを内包したアプリケーション
- Modeler (モデラー); 最適化問題をプログラムしやすくするアプリケーション. ユーザーとSolverの橋渡しを行う
使用可能なSolverとModelerの組み合わせと, Modelerの簡単な実装例をまとめました.
LP (Modeling & Solver summary)
LP Solver / Modeler PuLP Scipy CVXOPT PICOS Pyomo GLPK ok ok ok ok CBC ok ok SCIP ok? ok ok CPLEX ok ok ok MOSEK ok ok GUROBI ok ok ok CVXOPT ok ok SCIPY ok Solver Install
mac環境を想定.
- glpk
非商用
brew install glpk pip install swiglpk
- mosek
商用, アカデミックライセンスあり.
pip install mosekand get academic license from https://www.mosek.com/products/academic-licenses/ if you can.
Modeler Install
- PuLp, Scipy, CVXOPT, PICOS, Pyomo
pip install pulp scipy cvxopt picos pyomoLP (Modeling)
以下の問題をそれぞれのモデラーを使って解いてみます.
min -x+4y s.t. -3x + y ≤ 6 -x - 2y ≥ -4 y ≥ -3PuLP
from pulp import LpVariable, LpProblem, value x = LpVariable('x') y = LpVariable('y', lowBound=-3) # y ≥ -3 prob = LpProblem() prob += -x + 4*y # 目的関数 prob += -3*x + y <= 6 prob += -x - 2*y >= -4 prob.solve() print(value(prob.objective), value(x), value(y))Available Solvers
CBC, CPLEX, GLPK, GUROBI, XPRESS, (CHOCO)
使用可能なソルバーの表示.
(参考; http://www.logopt.com/download/OptForPuzzle.pdf)from pulp import LpSolver def AvailableSolver(cls): for c in cls.__subclasses__(): try: AvailableSolver(c) if c().available(): print(c) except: pass AvailableSolver(LpSolver)from pulp import PULP_CBC_CMD # GLPK, SCIP solver = PULP_CBC_CMD() # solver=GLPK(), solver=SCIP() prob.solve(solver=solver)Scipy
min c^T x, s.t. Ax <= b
定式化を以下の形に変更
min -x+4y s.t. -3x + y ≤ 6 x + 2y ≤ 4 -y ≤ 3from scipy.optimize import linprog c = [-1, 4] A = [[-3, 1], [1, 2]] b = [6, 4] bounds =[ (None, None), # -∞ ≤ x ≤ ∞ (-3, None) # -s ≤ y ≤ ∞ ] res = linprog(c, A_ub=A, b_ub=b, bounds=bounds) print(res)CVXOPT
min c^T x s.t. Gx <= h, Ax = b
定式化を以下の形に変更
min -x+4y s.t. -3x + y ≤ 6 x + 2y ≤ 4 0x + -y ≤ 3from cvxopt import matrix, solvers c = matrix([-1., 4.]) G = matrix([[-3., 1., 0.], [1., 2., -1.]]) h = matrix([6., 4., 3.]) sol = solvers.lp(c, G, h) print(sol['primal objective'], sol['x'])Available Solvers
conelp(CVXOPT), glpk, mosek
https://cvxopt.org/userguide/coneprog.html#s-lpsolver
sol = solvers.lp(c, G, h, solver='mosek') # solver='glpk' print(sol['primal objective'], sol['x'])CVXOPT (modeling)
from cvxopt import matrix from cvxopt.modeling import variable, op x = variable() y = variable() c1 = ( -3*x + y <= 6 ) c2 = ( -x - 2*y >= -4 ) c3 = ( y >= -3 ) lp = op(-x+4*y, [c1,c2,c3]) lp.solve() print(lp.objective.value(), x.value, y.value)Available Solvers
conelp(CVXOPT), glpk, mosek
sol = solvers.lp(c, G, h, solver='mosek') # solver='glpk' print(sol['primal objective'], sol['x'])PICOS (solver CVXOPT)
import picos as pic prob = pic.Problem() x = prob.add_variable('x') y = prob.add_variable('y') prob.set_objective('min', -x+4*y) prob.add_constraint(-3*x + y <= 6) prob.add_constraint(-x - 2*y >= -4) prob.add_constraint(y >= -3) sol = prob.solve() print(sol.value, x.value, y.value)/usr/local/lib/python3.7/site-packages/ipykernel_launcher.py:5: DeprecationWarning: Problem.add_variable is deprecated: Variables can now be created independent of problems, and do not need to be added to any problem explicitly. """ /usr/local/lib/python3.7/site-packages/ipykernel_launcher.py:6: DeprecationWarning: Problem.add_variable is deprecated: Variables can now be created independent of problems, and do not need to be added to any problem explicitly.Available Solvers
- None to let PICOS choose.
- "cplex" for CPLEXSolver.
- "cvxopt" for CVXOPTSolver.
- "ecos" for ECOSSolver.
- "glpk" for GLPKSolver.
- "gurobi" for GurobiSolver.
- "mosek" for MOSEKSolver.
- "mskfsn" for MOSEKFusionSolver.
- "scip" for SCIPSolver.
- "smcp" for SMCPSolver.
https://picos-api.gitlab.io/picos/api/picos.modeling.options.html#option-solver
sol = prob.solve(solver='glpk') print(sol.value, x.value, y.value)Pyomo
import pyomo.environ as pyo model = pyo.ConcreteModel() model.x = pyo.Var() model.y = pyo.Var() model.OBJ = pyo.Objective(expr=-model.x + 4*model.y) # add constraints model.Constraint1 = pyo.Constraint(expr=-3*model.x+model.y <= 6) model.Constraint2 = pyo.Constraint(expr=-model.x-2*model.y >= -4) model.Constraint3 = pyo.Constraint(expr=model.y >= -3) # add constraints # def rule(model, i): # A = [[-3, 1], [1, 2], [0, -1]] # b = [6, 4, 3] # return A[i][0]*model.x + A[i][1]*model.y <= b[i] # model.const_set = pyo.Set(initialize=[0, 1, 2]) # model.CONSTRAINTS = pyo.Constraint(model.const_set, rule=rule) opt = pyo.SolverFactory('glpk') res = opt.solve(model) print(model.OBJ(), model.x(), model.y())Available Solvers
Serial Solver Interfaces ------------------------ The serial, pyro and phpyro solver managers support the following solver interfaces: asl + Interface for solvers using the AMPL Solver Library baron The BARON MINLP solver bilevel_blp_global + Global solver for continuous bilevel linear problems bilevel_blp_local + Local solver for continuous bilevel linear problems bilevel_bqp + Global solver for bilevel quadratic problems bilevel_ld + Solver for bilevel problems using linear duality cbc The CBC LP/MIP solver conopt The CONOPT NLP solver contrib.gjh Interface to the AMPL GJH "solver" cplex The CPLEX LP/MIP solver cplex_direct Direct python interface to CPLEX cplex_persistent Persistent python interface to CPLEX gams The GAMS modeling language gdpbb * Branch and Bound based GDP Solver gdpopt * The GDPopt decomposition-based Generalized Disjunctive Programming (GDP) solver glpk * The GLPK LP/MIP solver gurobi The GUROBI LP/MIP solver gurobi_direct Direct python interface to Gurobi gurobi_persistent Persistent python interface to Gurobi ipopt The Ipopt NLP solver mindtpy * MindtPy: Mixed-Integer Nonlinear Decomposition Toolbox in Pyomo mosek * Direct python interface to Mosek mpec_minlp + MPEC solver transforms to a MINLP mpec_nlp + MPEC solver that optimizes a nonlinear transformation multistart * MultiStart solver for NLPs path Nonlinear MCP solver pico The PICO LP/MIP solver ps * Pyomo's simple pattern search optimizer py + Direct python solver interfaces scip The SCIP LP/MIP solver trustregion * Trust region filter method for black box/glass box optimization xpress The XPRESS LP/MIP solverhttps://pyomo.readthedocs.io/en/stable/solving_pyomo_models.html
その他とまとめ
- Scipy は 制約行列の形で入力しないといけないので手間です.
- PuLPとCVXOPTはSolverも一緒にinstallされるのですぐに問題を解くことができます.
- CVXOPTとPICOSは線形計画以外の問題(二次計画など, CVXOPTはそちらがメイン)を解くことができるので, 汎用性が高い.
- Pyomoの実装はクセが強い.
- 投稿日:2020-05-26T20:11:41+09:00
anacondaなしでVSCodeとSpyderを使いたい!!!
anacondaを使わず、初心者の頃から慣れ親しんだSpyderを使いたい。その備忘録です
これでSpyder 5.0.0.dev0(Python 3.8.2)が使えます。
テスト環境(前提として入っているもの)
Windows 10(64bit)
version:1909
OS build:18363.836VisualStudioCode
version:1.45.1Python 3.8.2
https://github.com/spyder-ide/spyder
zipを任意の場所に解凍するかcloneします必要なモジュールをインストールしていきます。自環境での必要だったものを纏めました。
requirements.txtPyQt5 qtpy chardet atomicwrites psutil zmq pickleshare qtawesome pygments qtconsole docutils jinja2 sphinx qdarkstyle diff_match_patch intervaltree cloudpickle watchdog PyQtWebEngine jedi==0.15.2 parso==0.5.2ファイルを作成した場所で
cmd.exepip install -r requirements.txt起動テストをしてみます。
cmd.execd "解凍 or Cloneしたフォルダ内のbootstrap.pyのあるフォルダ" python bootstrap.py起動したのなら、それでOKです
もし何かが足りないと出てきたら、pipでインストールしてください。
任意の場所で、新規作成→ショートカット
"%LOCALAPPDATA%\Programs\Python\Python38\pythonw.exe" "(解凍した場所)\bootstrap.py"pythonw.exeにすることで、コンソール画面なしで起動するようにします。
ショートカット名 Spyder
ショートカット右クリック→プロパティ
ショートカットタブの"アイコンの変更(C)…"
spyder-master\img_src\spyder.ico起動しました。まるで実家のような安心感のSpyder
あとは、作ったショートカットを
"C:\ProgramData\Microsoft\Windows\Start Menu\Programs"に置くと、それっぽくなります。
初記事の為、不慣れなところがあると思いますがご了承ください。
- 投稿日:2020-05-26T20:02:30+09:00
TeslaのAPIを触ってみた
やりたいこと
TeslaのAPIが非公式ながら使えるとのことで,早速触ってみた
車両情報を取得できるので,とりあえずPythonで取得してSlackに通知してみる準備
APIについてのドキュメント(非公式)は以下を参照
https://tesla-api.timdorr.com/api-basics/authentication認証IDは下記に記載されている通り
https://pastebin.com/pS7Z6yyP認証IDTESLA_CLIENT_ID=81527cff06843c8634fdc09e8ac0abefb46ac849f38fe1e431c2ef2106796384 TESLA_CLIENT_SECRET=c7257eb71a564034f9419ee651c7d0e5f7aa6bfbd18bafb5c5c033b093bb2fa3動作環境など
- Python 3.7系で確認(Windows)
- 一応,GAEを使って動作もさせてみた
概要
- 認証は
OAuth2Service- ID/PASSを埋め込みたくないので別ファイルにして
configparserで取得- データの構造はrespの中身を見ればだいたい分かる
- 車両を起こす処理を入れていないので予めアプリ等で起動させておいてからスクリプトを実行(リトライ等も入れていないのでそうしないと失敗して終了)
スクリプト
teslaapi_test.pydef access_vehicle(): import json from rauth import OAuth2Service # TESLA API用 import configparser config = configparser.ConfigParser() config.read('config.conf') section = 'development' teslaID = config.get(section,'teslaID') password = config.get(section,'password') tesla = OAuth2Service( client_id = config.get(section,'client_id'), client_secret = config.get(section,'client_secret'), access_token_url = "https://owner-api.teslamotors.com/oauth/token", authorize_url = "https://owner-api.teslamotors.com/oauth/token", base_url = "https://owner-api.teslamotors.com/", ) data = {"grant_type": "password", "client_id": config.get(section,'client_id'), "client_secret": config.get(section,'client_secret'), "email": teslaID, "password": password} session = tesla.get_auth_session(data=data, decoder=json.loads) access_token = session.access_token my_session = tesla.get_session(token=access_token) url = 'https://owner-api.teslamotors.com/api/1/vehicles/' vehicles = my_session.get(url).json()['response'][0] mycar = vehicles['id_s'] return mycar,my_session def get_vehicle_status(): import json import datetime from rauth import OAuth2Service # TESLA API用 mycar,my_session = access_vehicle() url_vehicle_state = "https://owner-api.teslamotors.com/api/1/vehicles/{:}/vehicle_data".format(mycar) resp = my_session.get(url_vehicle_state).json() return resp設定ファイルとして以下を作成
config.conf[development] #tesla teslaID = 'ユーザID' password = 'パスワード' client_id = '81527cff06843c8634fdc09e8ac0abefb46ac849f38fe1e431c2ef2106796384' client_secret = 'c7257eb71a564034f9419ee651c7d0e5f7aa6bfbd18bafb5c5c033b093bb2fa3'Slack通知
通知はIncoming-webhookを使って簡単に.
https://api.slack.com/messaging/webhooks#posting_with_webhooksslack通知import slackweb slack = slackweb.Slack(url="WebhookのURL") slack.notify(text="航続距離 : {}[km]".format(resp['response']['battery_range'] * 1.60934))※ 距離単位が[mi]なので[Km]に換算
結果はこんな感じ
その後
定期的にステータスを取得して通知を送信するため,GAEにデプロイしてcronでトリガしたり,車両がSleepの場合でも取得できるようにWake-Up処理を入れたりしてみるつもり.
- 投稿日:2020-05-26T19:08:54+09:00
100日後にエンジニアになるキミ - 67日目 - プログラミング - 形態素解析について
昨日までのはこちら
100日後にエンジニアになるキミ - 66日目 - プログラミング - 自然言語処理について
100日後にエンジニアになるキミ - 63日目 - プログラミング - 確率について1
100日後にエンジニアになるキミ - 59日目 - プログラミング - アルゴリズムについて
100日後にエンジニアになるキミ - 53日目 - Git - Gitについて
100日後にエンジニアになるキミ - 42日目 - クラウド - クラウドサービスについて
100日後にエンジニアになるキミ - 36日目 - データベース - データベースについて
100日後にエンジニアになるキミ - 24日目 - Python - Python言語の基礎1
100日後にエンジニアになるキミ - 18日目 - Javascript - JavaScriptの基礎1
100日後にエンジニアになるキミ - 14日目 - CSS - CSSの基礎1
100日後にエンジニアになるキミ - 6日目 - HTML - HTMLの基礎1
今回からは自然言語処理についてです。
形態素解析とは
形態素解析は形態素と呼ばれる最小単位の語句に文章を分かち書きし
それぞれの形態素の品詞等を判別する手法のことを言います。分かち書き
英語のように言葉の区切りに空白を入れる書き方です。
ワタシ ガ ヘンタイ デス ワタシ ハ ド スケベ デス英語の形態素解析
英語のように単語と単語の間がスペースで区切られる言語においては非常に簡単であり
英語の形態素解析の手順をまとめると以下のようになります。1.文全体を小文字化し単語の位置により単語が区別されてしまうことを防ぐ 2.it's や don't 等の省略形を分割する(it's → it 's 、 don't → do n't) 3.文末のピリオドを前の単語と切り離す(Mr. などに使われる文末とは関係ないピリオドは切り離さない) 4.スペースで分割する日本語の形態素解析
日本語は英語の場合と異なり、空白は余りなく、単語の切れ目が分かりません。
そのため専用の辞書を用いて辞書ベースで規則による分割を考える必要があります。自前で形態素解析を行うのであれば、この分割のルールを自分で定めて実装する必要があります。
日本語の形態素解析に関してはいくつかの
ライブラリが開発されており
これを用いて形態素解析を行うのが一般的になっています。代表的なライブラリだと
MeCab(めかぶ)と言うものがあります。https://ja.wikipedia.org/wiki/MeCab
Python言語では
janomeと言うライブラリもあります。https://mocobeta.github.io/janome/
こういったライブラリを用いて実装すれば、比較的簡単に形態素解析を主なうことができます。
本日は
janomeライブラリを用いた形態素解析を行います。形態素とは
英:morpheme
言語学の用語で、意味をもつ表現要素の最小単位
それ以上分解したら意味をなさなくなる語句です。例:
どこまで分かち書きすれば良いか行うは「動詞」であるが、それをさらに分けてしまうと
意味をなさなくなってしまう。
行う ⇒ 動詞 〇行 ⇒ 名詞 ×
う ⇒ 感動詞 ×そのため適切な所で分解をとどめておかないといけません。
日本語の品詞
日本語の品詞は以下のようなものがあります。
日本語の形態素解析における問題点
日本語を形態素解析する際においては、以下のような問題があります。
・単語の境界判別の問題
・品詞判別の問題
・未知語の問題
・ルーズな文法の問題
・修飾語の有無で意味が変わる問題単語の境界判別の問題
例えば
うらにわにはにわとりがいるという文には、文法的に正しい異なる読み方がいくつか存在しています。・裏庭 / には / 鶏 / が / いる
・裏庭 / には / 二 / 羽 / トリ / が / いる
・裏 / に / ワニ / は / 鶏 / が / いる
・裏庭 / に / 埴輪 / 取り / が / いる
すもももももももものうちにおいても、どこで区切るかが問題となりますが
完璧な正解を得るにはその文がおかれている文脈や、書き手の意図等の背景をくみとらねばなりません。品詞判別の問題
たとえば単語 「time」 は「時間」という名詞としての意味のほかにも
「 - 倍する」という動詞としての意味もあるため、これをどちらの意味にとるかによって
文の文法的構造や導かれる意味がまったく違うものになってしまいます。品詞の種類は文の構造と密接に関連しているため、合わせて検討しないといけません。
未知語の問題
形態素解析は普通、その言語の単語を収めた辞書を用いておこなわれるため
解析対象の文中の辞書に含まれない単語は未知語と呼ばれています。未知語をどう扱うかによっては、その後の解析の結果に大きく影響されます。
そのため、辞書は定期的に更新を行う必要があります。。
(特に固有名詞:人名、施設名、商品名、ギャグなど)ルーズな文法の問題
SNSやメール、トークアプリなどの会話の内容は、ある特定のモデル化された日本語の文法からかけ離れたものも多いです。
こういった内容を解析するには文章や単語の表記ゆれ、校正の仕方を根本から検討しないといけません。修飾語の有無で意味が変わる問題
修飾語は動詞や形容詞の意味を変えるように働くが、形態素解析をしてしまうと
単語では分かれてしまう。複数の単語の組み合わせで解釈しないと、意味が全く異なってしまうことになる。janomeを用いた形態素解析
pythonの
janomeライブラリを用いて形態素解析を行いましょう。インストールしていないと使うことはできないため、もしインストールしていなければ
下記のコマンドでインストールしてください。
pip install janome簡単な形態素解析の例です。
from janome.tokenizer import Tokenizer t = Tokenizer() tokens = t.tokenize('甘からず辛からず旨からず') for token in tokens: print(token)甘から 形容詞,自立,,,形容詞・アウオ段,未然ヌ接続,甘い,アマカラ,アマカラ
ず 助動詞,,,,特殊・ヌ,連用ニ接続,ぬ,ズ,ズ
辛から 形容詞,自立,,,形容詞・アウオ段,未然ヌ接続,辛い,カラカラ,カラカラ
ず 助動詞,,,,特殊・ヌ,連用ニ接続,ぬ,ズ,ズ
旨から 形容詞,自立,,,形容詞・アウオ段,未然ヌ接続,旨い,ウマカラ,ウマカラ
ず 助動詞,,,*,特殊・ヌ,連用ニ接続,ぬ,ズ,ズ
janomeのTokenizerを呼び出しインスタンス化しておきます。from janome.tokenizer import Tokenizer 変数名 = Tokenizer()
変数名.tokenize('文章')で文章を形態素解析した結果を返す事ができます。形態素解析の結果は
・単語
・品詞
・読み
に分かれています。単語で分割された結果が返ってくるので1つ1つ処理したい場合は
for文などを用いて処理を繰り返します。文章を変えてみます。
words = 'すもももももももものうち' tokens = t.tokenize(words) for token in tokens: print(token)すもも 名詞,一般,,,,,すもも,スモモ,スモモ
も 助詞,係助詞,,,,,も,モ,モ
もも 名詞,一般,,,,,もも,モモ,モモ
も 助詞,係助詞,,,,,も,モ,モ
もも 名詞,一般,,,,,もも,モモ,モモ
の 助詞,連体化,,,,,の,ノ,ノ
うち 名詞,非自立,副詞可能,,,*,うち,ウチ,ウチ次の文章を形態素解析した場合はどうなるでしょうか?
日本テレビ東京tokens = t.tokenize('日本テレビ東京') for token in tokens: print(token)日本テレビ 名詞,固有名詞,組織,,,,日本テレビ,ニホンテレビ,ニホンテレビ
東京 名詞,固有名詞,地域,一般,,*,東京,トウキョウ,トーキョーこれは形態素解析用の辞書データに格納されている
コストで算出した結果
より知名度のある方やより繋がりやすい単語の区切りでコストが小さいものが
選ばれる仕組みのため、こう言った結果になります。最近できた
固有名詞などは辞書が対応していないことの方が多いため
望ましくない結果になってしまうことがあります。tokens = t.tokenize(u'とうきょうスカイツリー駅で魚を見てきました') for token in tokens: print(token)とう 副詞,助詞類接続,,,,,とう,トウ,トウ
きょう 名詞,副詞可能,,,,,きょう,キョウ,キョー
スカイ 名詞,一般,,,,,スカイ,スカイ,スカイ
ツリー 名詞,一般,,,,,ツリー,ツリー,ツリー
駅 名詞,接尾,地域,,,,駅,エキ,エキ
で 助詞,格助詞,一般,,,,で,デ,デ
魚 名詞,一般,,,,,魚,サカナ,サカナ
を 助詞,格助詞,一般,,,,を,ヲ,ヲ
見 動詞,自立,,,一段,連用形,見る,ミ,ミ
て 助詞,接続助詞,,,,,て,テ,テ
き 動詞,非自立,,,カ変・クル,連用形,くる,キ,キ
まし 助動詞,,,,特殊・マス,連用形,ます,マシ,マシ
た 助動詞,,,*,特殊・タ,基本形,た,タ,タ本来は
とうきょうスカイツリー駅としたかったのですが、辞書にはこのような単語はありませんので、適切な単語に分割されてしまいます。このような場合は
ユーザー辞書を用いて対応します。
辞書ファイルを作成しておいて読み込みします。
変数名 = Tokenizer('辞書ファイル名', udic_enc='文字コード')userdic.csv東京スカイツリー,1288,1288,4569,名詞,固有名詞,一般,*,*,*,東京スカイツリー,トウキョウスカイツリー,トウキョウスカイツリー 東京スカイツリー駅,1288,1288,4143,名詞,固有名詞,一般,*,*,*,東京スカイツリー駅,トウキョウスカイツリーエキ,トウキョウスカイツリーエキ 東武スカイツリーライン,1288,1288,4700,名詞,固有名詞,一般,*,*,*,東武スカイツリーライン,トウブスカイツリーライン,トウブスカイツリーライン とうきょうスカイツリー駅,1288,1288,4143,名詞,固有名詞,一般,*,*,*,とうきょうスカイツリー駅,トウキョウスカイツリーエキ,トウキョウスカイツリーエキt = Tokenizer("userdic.csv", udic_enc="utf8") tokens = t.tokenize(u'とうきょうスカイツリー駅で魚を見てきました') for token in tokens: print(token)とうきょうスカイツリー駅 名詞,固有名詞,一般,,,,とうきょうスカイツリー駅,トウキョウスカイツリーエキ,トウキョウスカイツリーエキ
で 助詞,格助詞,一般,,,,で,デ,デ
魚 名詞,一般,,,,,魚,サカナ,サカナ
を 助詞,格助詞,一般,,,,を,ヲ,ヲ
見 動詞,自立,,,一段,連用形,見る,ミ,ミ
て 助詞,接続助詞,,,,,て,テ,テ
き 動詞,非自立,,,カ変・クル,連用形,くる,キ,キ
まし 助動詞,,,,特殊・マス,連用形,ます,マシ,マシ
た 助動詞,,,*,特殊・タ,基本形,た,タ,タ
userdic.csvに登録してある固有名詞が反映されるようになりました。
未知語は辞書を作成して対応を行います。
token.surfaceで単語部分が取得できます。for token in tokens: print(token.surface)とうきょうスカイツリー駅
で
魚
を
見
て
き
まし
た
token.part_of_speechで品詞部分だけを抽出できます。
品詞部分は,区切りで細分化されているため
細分化したものを取得する際は,で分割して取り出します。for token in tokens: print(token.part_of_speech)名詞,固有名詞,一般,*
助詞,格助詞,一般,*
名詞,名詞,一般,*
助詞,格助詞,一般,*
動詞,自立,,
助詞,接続助詞,,
動詞,非自立,,
助動詞,,,*
助動詞,,,*
token.readingで読みが確認できます。for token in tokens: print(token.reading)トウキョウスカイツリーエキ
デ
サカナ
ヲ
ミ
テ
キ
マシ
タ
for文の中で品詞や読みなどを使い分け、後続の処理を行います。まとめ
形態素解析は言語の解析の中でも基本になります。
ライブラリも多数あるので、いろいろ試してみると良いでしょう。新しい単語に対応するには辞書を作成するしか無いので
形態素解析を正しく行いたい場合は未知語のための辞書の整備が不可欠です。君がエンジニアになるまであと33日
作者の情報
乙pyのHP:
http://www.otupy.net/Youtube:
https://www.youtube.com/channel/UCaT7xpeq8n1G_HcJKKSOXMwTwitter:
https://twitter.com/otupython
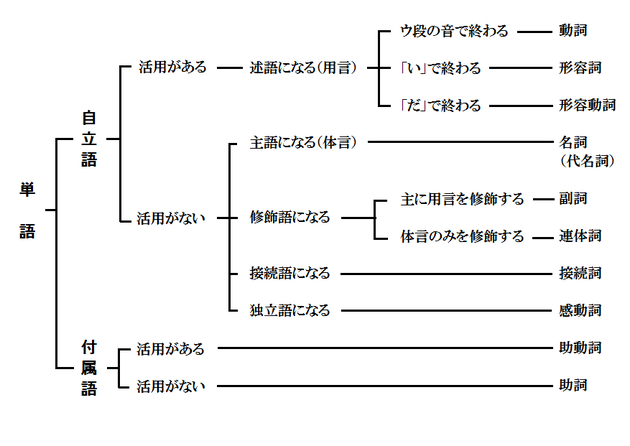
- 投稿日:2020-05-26T19:05:04+09:00
機械学習アルゴリズムの分類と実装まとめ
はじめに
機械学習の分類とそれらのアルゴリズムのライブラリを用いた簡単な実装をまとめました。
各アルゴリズムのコードはサンプルデータまで含めているので、そのまま実行することができます。
必要最低限のパラメータしか設定していないので、細かい設定は公式ドキュメントなど参照して設定してください。それぞれのアルゴリズムについては、簡単な説明は載せてますが、詳しい説明はしていません。
対象読者
- 機械学習アルゴリズムの分類を知りたい
- 機械学習アルゴリズムを実装して動かしたい
ゴール
- 機械学習のアルゴリズムの分類がわかる
- 機械学習アルゴリズムの実装ができる
機械学習の分類
機械学習は以下のように分類されます。
- 教師あり学習
- 回帰
- 分類
- 教師なし学習
- 強化学習
今回は、強化学習の実装は扱いません。教師あり学習
教師あり学習は、特徴を表すデータ(特徴量、説明変数)と答えとなるデータ(ラベル、目的変数)から問題の答えを学習させる手法です。
教師あり学習は、以下の2つに分類されます。
- 回帰:連続した数値を予測
- 身長の予測など
- 分類:順番のないラベルを予測
- 性別の予測など
利用データ
実装で利用するデータについて、簡単に説明します。
ここでは、scikit-learnのサンプルデータを利用します。
利用するデータは、回帰と分類で以下の通りです。アルゴリズム
教師あり学習のアルゴリズムについて、紹介していきます。
それぞれのアルゴリズムで、回帰と分類どちらに適用できるか記載しています。線形回帰
- 回帰
特徴量が大きくなるほど、目的変数が大きく(小さく)なる関係をモデル化する手法。
from sklearn.datasets import load_boston from sklearn.model_selection import train_test_split from sklearn.linear_model import LinearRegression # データの読み込み boston = load_boston() X = boston['data'] y = boston['target'] X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=0) model = LinearRegression() model.fit(X_train, y_train) score = model.score(X_test, y_test) print('score is', score)ロジスティック回帰
- 分類
ある事象が起こる確率を学習する手法。
from sklearn.datasets import load_wine from sklearn.model_selection import train_test_split from sklearn.linear_model import LogisticRegression # データの読み込み wine = load_wine() X = wine['data'] y = wine['target'] X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=0) model = LogisticRegression() model.fit(X_train, y_train) score = model.score(X_test, y_test) print('score is', score)ランダムフォレスト
- 回帰
- 分類
複数の決定木から多数決で予測する手法。
回帰版
from sklearn.datasets import load_boston from sklearn.model_selection import train_test_split from sklearn.ensemble import RandomForestRegressor # データの読み込み boston = load_boston() X = boston['data'] y = boston['target'] X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=0) model = RandomForestRegressor(random_state=0) model.fit(X_train, y_train) score = model.score(X_test, y_test) print('score is', score)分類版
from sklearn.datasets import load_wine from sklearn.model_selection import train_test_split from sklearn.ensemble import RandomForestClassifier # データの読み込み wine = load_wine() X = wine['data'] y = wine['target'] X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=0) model = RandomForestClassifier(random_state=0) model.fit(X_train, y_train) score = model.score(X_test, y_test) print('score is', score)サポートベクターマシン
マージンを最大化することでより良い決定境界を得る手法。
- 回帰
- 分類
回帰版
from sklearn.datasets import load_boston from sklearn.model_selection import train_test_split from sklearn.svm import SVR # データの読み込み boston = load_boston() X = boston['data'] y = boston['target'] X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=0) model = SVR(kernel='linear', gamma='auto') model.fit(X_train, y_train) score = model.score(X_test, y_test) print('score is', score)分類版
from sklearn.datasets import load_wine from sklearn.model_selection import train_test_split from sklearn.svm import SVC # データの読み込み wine = load_wine() X = wine['data'] y = wine['target'] X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=0) model = SVC(gamma='auto') model.fit(X_train, y_train) score = model.score(X_test, y_test) print('score is', score)kNN
学習データを全て覚えて、予測したいデータと距離の近いk個のデータから多数決をする手法。
- 回帰
- 分類
回帰版
from sklearn.datasets import load_boston from sklearn.model_selection import train_test_split from sklearn.neighbors import KNeighborsRegressor # データの読み込み boston = load_boston() X = boston['data'] y = boston['target'] X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=0) model = KNeighborsRegressor(n_neighbors=3) model.fit(X_train, y_train) score = model.score(X_test, y_test) print('score is', score)分類版
from sklearn.datasets import load_wine from sklearn.model_selection import train_test_split from sklearn.neighbors import KNeighborsClassifier # データの読み込み wine = load_wine() X = wine['data'] y = wine['target'] X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=0) model = KNeighborsClassifier(n_neighbors=3) model.fit(X_train, y_train) score = model.score(X_test, y_test) print('score is', score)ニューラルネットワーク
入力層、隠れ層、出力層からなる構造をもつ人間の脳の神経回路を模倣した手法。
- 回帰
- 分類
回帰版
from sklearn.datasets import load_boston from sklearn.model_selection import train_test_split from tensorflow.keras import models from tensorflow.keras import layers # データの読み込み boston = load_boston() X = boston['data'] y = boston['target'] X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=0) model = models.Sequential() model.add(layers.Dense(64, activation='relu', input_shape=(X_train.shape[1],))) model.add(layers.Dense(64, activation='relu')) model.add(layers.Dense(1)) model.compile(optimizer='rmsprop', loss='mse', metrics=['mae']) model.fit(X_train, y_train) mse, mae = model.evaluate(X_test, y_test) print('MSE is', mse) print('MAE is', mae)分類版
from sklearn.datasets import load_wine from sklearn.model_selection import train_test_split from tensorflow.keras import models from tensorflow.keras import layers from tensorflow.keras import utils # データの読み込み boston = load_wine() X = boston['data'] y = utils.to_categorical(boston['target']) X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=0) model = models.Sequential() model.add(layers.Dense(64, activation='relu', input_shape=(X_train.shape[1],))) model.add(layers.Dense(64, activation='relu')) model.add(layers.Dense(3, activation='softmax')) model.compile(optimizer='rmsprop', loss='categorical_crossentropy', metrics=['accuracy']) model.fit(X_train, y_train) crossentropy, acc = model.evaluate(X_test, y_test) print('Categorical Crossentropy is', crossentropy) print('Accuracy is', acc)勾配ブースティング
複数のモデルを学習させるアンサンブル学習の1つ。
一部のデータを繰り返し抽出し、逐次的に複数の決定木モデルを学習させる手法。
- 回帰
- 分類
回帰版
from sklearn.datasets import load_boston from sklearn.model_selection import train_test_split from sklearn.metrics import mean_squared_error import lightgbm as lgb import numpy as np # データの読み込み wine = load_boston() X = wine['data'] y = wine['target'] X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=0) lgb_train = lgb.Dataset(X_train, y_train) lgb_eval = lgb.Dataset(X_test, y_test) params = { 'objective': 'regression', 'metric': 'mse', } num_round = 100 model = lgb.train( params, lgb_train, valid_sets=lgb_eval, num_boost_round=num_round, ) y_pred = model.predict(X_test) score = mean_squared_error(y_test, y_pred) print('score is', score)分類版
from sklearn.datasets import load_wine from sklearn.model_selection import train_test_split from sklearn.metrics import accuracy_score import lightgbm as lgb import numpy as np # データの読み込み wine = load_wine() X = wine['data'] y = wine['target'] X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=0) lgb_train = lgb.Dataset(X_train, y_train) lgb_eval = lgb.Dataset(X_test, y_test) params = { 'objective': 'multiclass', 'num_class': 3, } num_round = 100 model = lgb.train( params, lgb_train, valid_sets=lgb_eval, num_boost_round=num_round, ) pred = model.predict(X_test) y_pred = [] for p in pred: y_pred.append(np.argmax(p)) score = accuracy_score(y_test, y_pred) print('score is', score)教師なし学習
教師なし学習は、答えとなるデータがなく、特徴を表すデータのみから学習させる手法です。
利用データ
教師なし学習の利用では、教師あり学習で使用したワインの品質のデータです。
- ワインの品質
- 特徴量は13個
- 分類するクラスは3
アルゴリズム
教師なし学習のアルゴリズムについて、紹介していきます。
K-means
クラスタリング手法の1つ。
k個のクラスにデータをまとめる手法。from sklearn.datasets import load_wine from sklearn.cluster import KMeans # データの読み込み wine = load_wine() X = wine['data'] model = KMeans(n_clusters=3, random_state=0) model.fit(X) print("labels: \n", model.labels_) print("cluster centers: \n", model.cluster_centers_) print("predict result: \n", model.predict(X))混合ガウス分布
クラスタリング手法の1つ。
データが複数のガウス分布から生成されたとみなし、どのガウス分布に属するかで分類する手法。from sklearn.datasets import load_wine from sklearn.mixture import GaussianMixture # データの読み込み wine = load_wine() X = wine['data'] model = GaussianMixture(n_components=4) model.fit(X) print("means: \n", model.means_) print("predict result: \n", model.predict(X))主成分分析
次元削減手法の1つ。
多数の変数から、データの特徴を保ちながらより少ない変数(主成分)でデータを表現する手法。from sklearn.datasets import load_wine from sklearn.decomposition import PCA # データの読み込み wine = load_wine() X = wine['data'] model = PCA(n_components=4) model.fit(X) print('Before Transform:', X.shape[1]) print('After Transform:', model.transform(X).shape[1])まとめ
- 教師あり学習は回帰と分類に分けられる
- 教師なし学習はいくつか種類がある
- 試すぐらいであれば少しのコードで機械学習ができる
- パラメータはいくつかあるため必要に応じて公式ドキュメントを参照する
教師なし学習、強化学習についてはまだまだ勉強不足だったので、これから勉強していきます。
参考文献
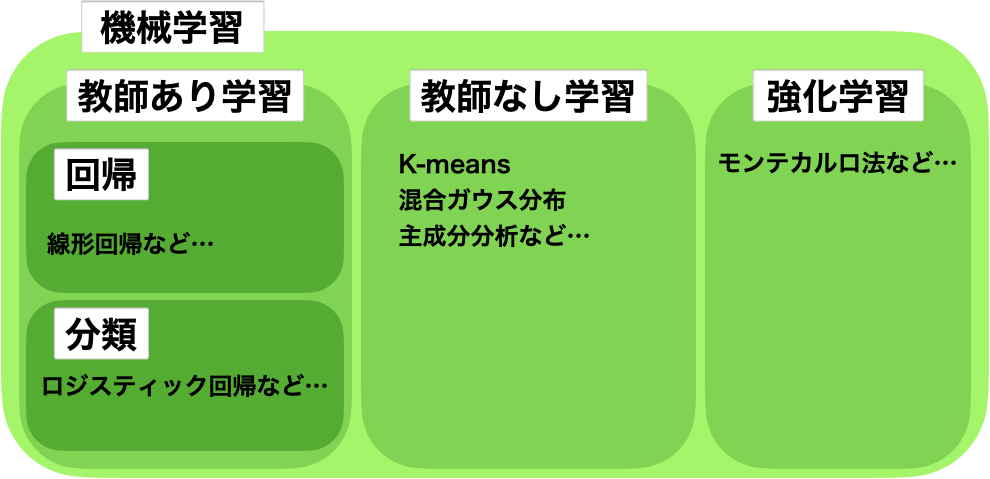
- 投稿日:2020-05-26T17:53:54+09:00
深層学習/ゼロから作るディープラーニング2 第7章メモ
1.はじめに
名著、「ゼロから作るディープラーニング2」を読んでいます。今回は7章のメモ。
コードの実行はGithubからコード全体をダウンロードし、ch07の中で jupyter notebook にて行っています。2.文章生成
まず、6章の
train_rnnlm.pyで学習した重みファイル Rnnlm.pkl を読み込んで文章生成を行うコードrnnlm_gen.pyを実行してみます。import sys sys.path.append('..') from rnnlm_gen import RnnlmGen from dataset import ptb # PTBデータセットを読み込む corpus, word_to_id, id_to_word = ptb.load_data('train') vocab_size = len(word_to_id) corpus_size = len(corpus) model = RnnlmGen() # モデル生成 model.load_params('../ch06/Rnnlm.pkl') # 学習済みの重みをロード # start文字とskip文字の設定 start_word = 'you' start_id = word_to_id[start_word] skip_words = ['N', '<unk>', '$'] skip_ids = [word_to_id[w] for w in skip_words] # 文章生成 word_ids = model.generate(start_id, skip_ids) txt = ' '.join([id_to_word[i] for i in word_ids]) txt = txt.replace(' <eos>', '.\n') print(txt)
なにやら、それらしい英文が生成されました。理屈は簡単で、最初の単語を決めたら次の単語の予測を行い、その予測結果を元にまた次の単語を予測するということを繰り返すというものです。ポイントは、モデル生成のところに出て来るRnnlmGen()ですので、それを見て行きます。3.class RnnlmGen
文章生成を行うクラスをゼロから作ることも出来ますが、6章の学習の時に使った
class Rnnlmに機能を追加する方が簡単です。下記の様にコードの冒頭で、
class RnnlmGen(Rnnlm):と宣言することによって、class Rnnlmにあったメソッドは全てclass RnnlmGenにビルトインされることになります。これを「継承」と言います。class RnnlmGen(Rnnlm): def generate(self, start_id, skip_ids=None, sample_size=100): word_ids = [start_id] x = start_id # 文章生成の単語idを指定 # word_ids が sample_size に達するまで続ける while len(word_ids) < sample_size: x = np.array(x).reshape(1, 1) # 2次元配列に(ミニバッチ対応) score = self.predict(x) # 予測結果を取得 p = softmax(score.flatten()) # ソフトマックスで確率分布を正規化 # 長さ10000、サイズ1で、pの確率分布に従ってランダムチョイス sampled = np.random.choice(len(p), size=1, p=p) # skip_ids がないか、サンプルした単語がskip_idsになければ if (skip_ids is None) or (sampled not in skip_ids): x = sampled word_ids.append(int(x)) # word_idsにアペンド return word_ids def get_state(self): return self.lstm_layer.h, self.lstm_layer.c def set_state(self, state): self.lstm_layer.set_state(*state)ここにあるのは、
class Rnnlmに追加するメソッドです。predict(x)でxの次の単語の出現度合いを予測しsoftmaxで正規化すると、語彙数分の確率分布pが得られます。
sampled = np.random.choice(len(p), size=1, p=p)は0〜語彙数-1の整数から1つ、確率分布pに従って、ランダムサンプリングするということになります。ちなみに、
class Rnnlmを見ておくと、class Rnnlm(BaseModel): def __init__(self, vocab_size=10000, wordvec_size=100, hidden_size=100): V, D, H = vocab_size, wordvec_size, hidden_size rn = np.random.randn # 重みの初期化 embed_W = (rn(V, D) / 100).astype('f') lstm_Wx = (rn(D, 4 * H) / np.sqrt(D)).astype('f') lstm_Wh = (rn(H, 4 * H) / np.sqrt(H)).astype('f') lstm_b = np.zeros(4 * H).astype('f') affine_W = (rn(H, V) / np.sqrt(H)).astype('f') affine_b = np.zeros(V).astype('f') # レイヤの生成 self.layers = [ TimeEmbedding(embed_W), TimeLSTM(lstm_Wx, lstm_Wh, lstm_b, stateful=True), TimeAffine(affine_W, affine_b) ] self.loss_layer = TimeSoftmaxWithLoss() self.lstm_layer = self.layers[1] # すべての重みと勾配をリストにまとめる self.params, self.grads = [], [] for layer in self.layers: self.params += layer.params self.grads += layer.grads def predict(self, xs): for layer in self.layers: xs = layer.forward(xs) return xs def forward(self, xs, ts): score = self.predict(xs) loss = self.loss_layer.forward(score, ts) return loss def backward(self, dout=1): dout = self.loss_layer.backward(dout) for layer in reversed(self.layers): dout = layer.backward(dout) return dout def reset_state(self): self.lstm_layer.reset_state()こんな内容です。今回はこのクラスを「継承」しましたので、これらのメソッドは自動的に
class RnnlmGenにビルトインされます。これは便利ですよね。4.日本語データセット
私は、英語の文章生成では、うまく出来ているのかどうか実感できないので、日本語でもやってみます。但し、予測方法は単語単位ではなく文字単位とします。
今回は、青空文庫から夏目漱石の「吾輩は猫である」のテキストファイル(ルビあり)をダウンロードして使います。ダウンロードしたら解凍し、wagahaiwa_nekodearu.txt という名称でch07に保存します。
import sys import re path = './wagahaiwa_nekodearu.txt' bindata = open(path, "rb") lines = bindata.readlines() for line in lines: text = line.decode('Shift_JIS') # Shift_JISで読み込み text = re.split(r'\r',text)[0] # 改行削除 text = text.replace('|','') # ルビ前記号削除 text = re.sub(r'《.+?》','',text) # ルビ削除 text = re.sub(r'[#.+?]','',text) # 入力者注削除 print(text) file = open('data_neko.txt','a',encoding='utf-8').write(text) # UTF-8に変換前処理用のコードです。実行すると、テキストファイルの形式(Shift-JIS)で読み込み、改行、ルビ、入力者注などを削除してから、UTF-8に変換し、data_neko.txt という名前で保存します。後は、エディターを使って手動で、文章の前後にある余分な部分を削除します。
次に、data_neko.txt から corpus, word_to_id, id_to_word を取得する関数
load_data()を定義します。import numpy as np import io def load_data(): # file_name をUTF-8 形式で textに読み込み file_name = './data_neko.txt' with io.open(file_name, encoding='utf-8') as f: text = f.read().lower() # word_to_id, id_to_ward の作成 word_to_id, id_to_word = {}, {} for word in text: if word not in word_to_id: new_id = len(word_to_id) word_to_id[word] = new_id id_to_word[new_id] = word # corpus の作成 corpus = np.array([word_to_id[W] for W in text]) corpus_test = corpus[300000:] # テストデータ corpus = corpus[:300000] # 学習データ return corpus_test, corpus, word_to_id, id_to_word今回作成した corpus 全体は318,800語なので、300,000語より後の18,800語をcorpus_test とし、前の300,000語を corpus にしています。
5.学習
それでは、ch06で使った学習コードをGPUを使って実行します。
import sys sys.path.append('..') from common import config # GPUで実行する場合は下記のコメントアウトを消去(要cupy) # ============================================== config.GPU = True # ============================================== from common.optimizer import SGD from common.trainer import RnnlmTrainer from common.util import eval_perplexity, to_gpu from dataset import ptb from ch06.better_rnnlm import BetterRnnlm # ハイパーパラメータの設定 batch_size = 20 wordvec_size = 650 hidden_size = 650 time_size = 35 lr = 20.0 max_epoch = 40 max_grad = 0.25 dropout = 0.5 # 学習データの読み込み corpus_test, corpus, word_to_id, id_to_word = load_data() corpus_val = corpus_test # 簡略化のため、valとtestは同じに if config.GPU: corpus = to_gpu(corpus) corpus_val = to_gpu(corpus_val) corpus_test = to_gpu(corpus_test) vocab_size = len(word_to_id) xs = corpus[:-1] ts = corpus[1:] model = BetterRnnlm(vocab_size, wordvec_size, hidden_size, dropout) optimizer = SGD(lr) trainer = RnnlmTrainer(model, optimizer) best_ppl = float('inf') for epoch in range(max_epoch): trainer.fit(xs, ts, max_epoch=1, batch_size=batch_size, time_size=time_size, max_grad=max_grad) model.reset_state() ppl = eval_perplexity(model, corpus_val) print('valid perplexity: ', ppl) if best_ppl > ppl: best_ppl = ppl model.save_params() else: lr /= 4.0 optimizer.lr = lr model.reset_state() print('-' * 50) # テストデータでの評価 model.reset_state() ppl_test = eval_perplexity(model, corpus_test) print('test perplexity: ', ppl_test)
windowsマシン(GTX1060)を使って約40分で学習が完了しました。完了すると、ch07フォルダー内に学習済みの重みパラメータが BetterRnnlm.pkl という名前で保存されます。
6.class BetterRnnlmGen
次に、
class BetterRnnlmGenを定義します。基本的に、6章のclass BetterRnnlmを継承しますが、「吾輩は猫である」の vocab_size は PTB とは異なるので、関連するdef __init___()の部分を追加して上書きします(これをオーバーライドと言います)。import sys sys.path.append('..') import numpy as np from common.functions import softmax from ch06.rnnlm import Rnnlm from ch06.better_rnnlm import BetterRnnlm from common.time_layers import * # def __init__ で必要なファイルをインポート class BetterRnnlmGen(BetterRnnlm): def __init__(self, vocab_size=3038, wordvec_size=650, hidden_size=650, dropout_ratio=0.5): V, D, H = vocab_size, wordvec_size, hidden_size rn = np.random.randn embed_W = (rn(V, D) / 100).astype('f') lstm_Wx1 = (rn(D, 4 * H) / np.sqrt(D)).astype('f') lstm_Wh1 = (rn(H, 4 * H) / np.sqrt(H)).astype('f') lstm_b1 = np.zeros(4 * H).astype('f') lstm_Wx2 = (rn(H, 4 * H) / np.sqrt(H)).astype('f') lstm_Wh2 = (rn(H, 4 * H) / np.sqrt(H)).astype('f') lstm_b2 = np.zeros(4 * H).astype('f') affine_b = np.zeros(V).astype('f') self.layers = [ TimeEmbedding(embed_W), TimeDropout(dropout_ratio), TimeLSTM(lstm_Wx1, lstm_Wh1, lstm_b1, stateful=True), TimeDropout(dropout_ratio), TimeLSTM(lstm_Wx2, lstm_Wh2, lstm_b2, stateful=True), TimeDropout(dropout_ratio), TimeAffine(embed_W.T, affine_b) # weight tying!! ] self.loss_layer = TimeSoftmaxWithLoss() self.lstm_layers = [self.layers[2], self.layers[4]] self.drop_layers = [self.layers[1], self.layers[3], self.layers[5]] self.params, self.grads = [], [] for layer in self.layers: self.params += layer.params self.grads += layer.grads def generate(self, start_id, skip_ids=None, sample_size=100): word_ids = [start_id] x = start_id while len(word_ids) < sample_size: x = np.array(x).reshape(1, 1) score = self.predict(x).flatten() p = softmax(score).flatten() sampled = np.random.choice(len(p), size=1, p=p) #sampled = np.argmax(p) if (skip_ids is None) or (sampled not in skip_ids): x = sampled word_ids.append(int(x)) return word_ids def get_state(self): states = [] for layer in self.lstm_layers: states.append((layer.h, layer.c)) return states def set_state(self, states): for layer, state in zip(self.lstm_layers, states): layer.set_state(*state)7.文章生成(日本語版)
最後に、文章生成を行う下記のコードを実行します。
import sys sys.path.append('..') from common.np import * corpus_test, corpus, word_to_id, id_to_word = load_data() vocab_size = len(word_to_id) corpus_size = len(corpus) model = BetterRnnlmGen() model.load_params('./BetterRnnlm.pkl') # start文字とskip文字の設定 start_word = '吾' start_id = word_to_id[start_word] skip_words = ['〇'] skip_ids = [word_to_id[w] for w in skip_words] # 文章生成(最初の1単語から) word_ids = model.generate(start_id, skip_ids) txt = ''.join([id_to_word[i] for i in word_ids]) print(txt) # 文章生成(フレーズから) model.reset_state() # モデルをリセット start_words = '吾 輩 は 猫 で あ る 。' start_ids = [word_to_id[w] for w in start_words.split(' ')] # 単語idに変換 # フレーズの最後の単語idの前までを予測(予測結果は使わない) for x in start_ids[:-1]: x = np.array(x).reshape(1, 1) model.predict(x) word_ids = model.generate(start_ids[-1], skip_ids) # フレーズの最後の単語idから予測を実行 ord_ids = start_ids[:-1] + word_ids # フレーズと予測結果を連結 txt = ''.join([id_to_word[i] for i in word_ids]) # 文に変換 print('-' * 50) print(txt)
文章生成のパターンは2通りあります。1つは1単語から後を予測する方法、もう1つは1フレーズから後を予測する方法です。全体としては意味は全く分かりませんが、文節くらいでみると「なんとなく分からないでもない」という感じでしょうか。
8.足し算モデル
import sys sys.path.append('..') import numpy as np import matplotlib.pyplot as plt from dataset import sequence from common.optimizer import Adam from common.trainer import Trainer from common.util import eval_seq2seq from seq2seq import Seq2seq from peeky_seq2seq import PeekySeq2seq # データセットの読み込み (x_train, t_train), (x_test, t_test) = sequence.load_data('addition.txt') char_to_id, id_to_char = sequence.get_vocab() # Reverse input? ================================================= is_reverse = False # True if is_reverse: # [::-1]で逆順で並べ替え、2次元なので[:, ::-1] x_train, x_test = x_train[:, ::-1], x_test[:, ::-1] # ================================================================ # ハイパーパラメータの設定 vocab_size = len(char_to_id) wordvec_size = 16 hidden_size = 128 batch_size = 128 max_epoch = 25 max_grad = 5.0 # Normal or Peeky? ============================================== model = Seq2seq(vocab_size, wordvec_size, hidden_size) # model = PeekySeq2seq(vocab_size, wordvec_size, hidden_size) # ================================================================ optimizer = Adam() trainer = Trainer(model, optimizer) acc_list = [] for epoch in range(max_epoch): trainer.fit(x_train, t_train, max_epoch=1, batch_size=batch_size, max_grad=max_grad) correct_num = 0 for i in range(len(x_test)): question, correct = x_test[[i]], t_test[[i]] verbose = i < 10 correct_num += eval_seq2seq(model, question, correct, id_to_char, verbose, is_reverse) acc = float(correct_num) / len(x_test) acc_list.append(acc) print('val acc %.3f%%' % (acc * 100)) # グラフの描画 x = np.arange(len(acc_list)) plt.plot(x, acc_list, marker='o') plt.xlabel('epochs') plt.ylabel('accuracy') plt.ylim(0, 1.0) plt.show()
足し算を覚えさせる地味なコードです。まず、class Seq2seqを見てみましょう。9.class Seq2seq
class Seq2seq(BaseModel): def __init__(self, vocab_size, wordvec_size, hidden_size): V, D, H = vocab_size, wordvec_size, hidden_size self.encoder = Encoder(V, D, H) self.decoder = Decoder(V, D, H) self.softmax = TimeSoftmaxWithLoss() self.params = self.encoder.params + self.decoder.params self.grads = self.encoder.grads + self.decoder.grads def forward(self, xs, ts): decoder_xs, decoder_ts = ts[:, :-1], ts[:, 1:] h = self.encoder.forward(xs) score = self.decoder.forward(decoder_xs, h) loss = self.softmax.forward(score, decoder_ts) return loss def backward(self, dout=1): dout = self.softmax.backward(dout) dh = self.decoder.backward(dout) dout = self.encoder.backward(dh) return dout def generate(self, xs, start_id, sample_size): h = self.encoder.forward(xs) sampled = self.decoder.generate(h, start_id, sample_size) return sampledclass Encoder, class Decoder のクラスを組み合わせているだけなので、まず class Encoder を見てみます。
class Encoder: def __init__(self, vocab_size, wordvec_size, hidden_size): V, D, H = vocab_size, wordvec_size, hidden_size rn = np.random.randn embed_W = (rn(V, D) / 100).astype('f') lstm_Wx = (rn(D, 4 * H) / np.sqrt(D)).astype('f') lstm_Wh = (rn(H, 4 * H) / np.sqrt(H)).astype('f') lstm_b = np.zeros(4 * H).astype('f') self.embed = TimeEmbedding(embed_W) self.lstm = TimeLSTM(lstm_Wx, lstm_Wh, lstm_b, stateful=False) self.params = self.embed.params + self.lstm.params self.grads = self.embed.grads + self.lstm.grads self.hs = None def forward(self, xs): xs = self.embed.forward(xs) hs = self.lstm.forward(xs) self.hs = hs return hs[:, -1, :] def backward(self, dh): dhs = np.zeros_like(self.hs) dhs[:, -1, :] = dh dout = self.lstm.backward(dhs) dout = self.embed.backward(dout) return dout
Encoder の模式図です。学習データを順次入力し、最終段のLSTMの出力hを、Decoderへ渡します。class Decoder: def __init__(self, vocab_size, wordvec_size, hidden_size): V, D, H = vocab_size, wordvec_size, hidden_size rn = np.random.randn embed_W = (rn(V, D) / 100).astype('f') lstm_Wx = (rn(D, 4 * H) / np.sqrt(D)).astype('f') lstm_Wh = (rn(H, 4 * H) / np.sqrt(H)).astype('f') lstm_b = np.zeros(4 * H).astype('f') affine_W = (rn(H, V) / np.sqrt(H)).astype('f') affine_b = np.zeros(V).astype('f') self.embed = TimeEmbedding(embed_W) self.lstm = TimeLSTM(lstm_Wx, lstm_Wh, lstm_b, stateful=True) self.affine = TimeAffine(affine_W, affine_b) self.params, self.grads = [], [] for layer in (self.embed, self.lstm, self.affine): self.params += layer.params self.grads += layer.grads def forward(self, xs, h): self.lstm.set_state(h) out = self.embed.forward(xs) out = self.lstm.forward(out) score = self.affine.forward(out) return score def backward(self, dscore): dout = self.affine.backward(dscore) dout = self.lstm.backward(dout) dout = self.embed.backward(dout) dh = self.lstm.dh return dh def generate(self, h, start_id, sample_size): sampled = [] sample_id = start_id self.lstm.set_state(h) for _ in range(sample_size): x = np.array(sample_id).reshape((1, 1)) out = self.embed.forward(x) out = self.lstm.forward(out) score = self.affine.forward(out) sample_id = np.argmax(score.flatten()) sampled.append(int(sample_id)) return sampled
Decoder の模式図です。Decoder は、この後のSoftmax with Lossレイヤの扱いが学習時と生成時で変わるので、Softmax with LossレイヤはSeq2seqクラスで対応します。9.入力データの反転
入力データを反転させると、学習の進みが早くなり、最終的な精度も高くなります。先程の足し算モデルのコードを、
is_reverse = Trueで実行します。
なんと反転するだけで、正答率が10%台から50%台にジャンプアップしてしまいました。各入力要素とその出力要素のタイムラグが近い方が精度が良いということです。なるほど。10.PeekyDecoder
Encoder から出力されるベクトルh は大変重要な情報ですが、Decoderの最初の時刻にしか入力されません。そこで、ベクトルhの情報を全ての時刻のLSTMレイヤとAffineレイヤへ入力させたらどうかという発想が生まれます。この方法をPeeky(覗き見)と言います。
class PeekyDecoderを見てみましょう。class PeekyDecoder: def __init__(self, vocab_size, wordvec_size, hidden_size): V, D, H = vocab_size, wordvec_size, hidden_size rn = np.random.randn embed_W = (rn(V, D) / 100).astype('f') lstm_Wx = (rn(H + D, 4 * H) / np.sqrt(H + D)).astype('f') lstm_Wh = (rn(H, 4 * H) / np.sqrt(H)).astype('f') lstm_b = np.zeros(4 * H).astype('f') affine_W = (rn(H + H, V) / np.sqrt(H + H)).astype('f') affine_b = np.zeros(V).astype('f') self.embed = TimeEmbedding(embed_W) self.lstm = TimeLSTM(lstm_Wx, lstm_Wh, lstm_b, stateful=True) self.affine = TimeAffine(affine_W, affine_b) self.params, self.grads = [], [] for layer in (self.embed, self.lstm, self.affine): self.params += layer.params self.grads += layer.grads self.cache = None def forward(self, xs, h): N, T = xs.shape N, H = h.shape self.lstm.set_state(h) out = self.embed.forward(xs) hs = np.repeat(h, T, axis=0).reshape(N, T, H) out = np.concatenate((hs, out), axis=2) out = self.lstm.forward(out) out = np.concatenate((hs, out), axis=2) score = self.affine.forward(out) self.cache = H return score def backward(self, dscore): H = self.cache dout = self.affine.backward(dscore) dout, dhs0 = dout[:, :, H:], dout[:, :, :H] dout = self.lstm.backward(dout) dembed, dhs1 = dout[:, :, H:], dout[:, :, :H] self.embed.backward(dembed) dhs = dhs0 + dhs1 dh = self.lstm.dh + np.sum(dhs, axis=1) return dh def generate(self, h, start_id, sample_size): sampled = [] char_id = start_id self.lstm.set_state(h) H = h.shape[1] peeky_h = h.reshape(1, 1, H) for _ in range(sample_size): x = np.array([char_id]).reshape((1, 1)) out = self.embed.forward(x) out = np.concatenate((peeky_h, out), axis=2) out = self.lstm.forward(out) out = np.concatenate((peeky_h, out), axis=2) score = self.affine.forward(out) char_id = np.argmax(score.flatten()) sampled.append(char_id) return sampledそれでは、先程の足し算モデルのモデル生成のところで、
model = PeekySeq2seq(vocab_size, wordvec_size, hidden_size)の方を有効にして、実行します。
劇的な効果です!正答率は99.1%となりました。


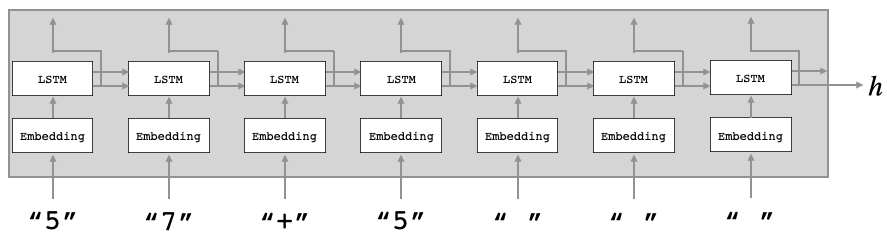
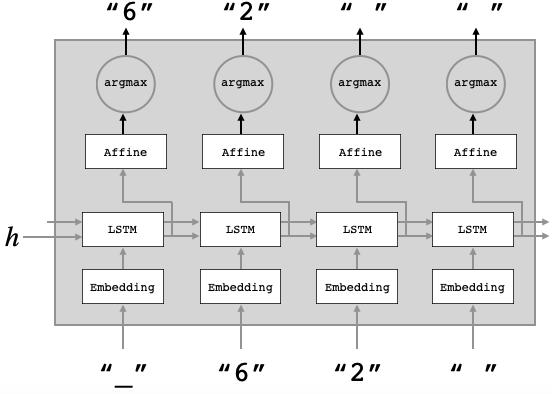
- 投稿日:2020-05-26T17:22:35+09:00
Python: ネガポジ分析:RNNを使ったTwitterのネガ・ポジ分析-前編
RNNを使ったTwitterのネガ・ポジ分析-前編
RNNとは
極性辞書では文章の文脈を読んでネガ・ポジを判断することが難しく
適切な分析ができないことがあります。ここでは再帰型ニューラルネットワーク(RNN)を使って文章の流れから
ネガ・ポジ分析を行う手法について学びます。RNNは以前に計算された情報を記憶して学習することができるので
文章の次に来る単語を予測したり
単語の出現確率などから機械翻訳に使われています。もちろん日本語でもできますが、データの関係性から今回は英語で分析をさせてもらいます。
Twitterのネガ・ポジ分析
Twitterでは140文字という文字制限があるので
短い文章でユーザーが発信しています。大量のデータを手に入れることができるので
ネガ・ポジ分析を始め様々な自然言語処理の分析に使われています。今回はUSAirlineに関するTwitterのデータを使って学習します。
データは米Figure Eightが配布しているAirline Twitter sentimentを使います。ライセンスについてはこちら
import pandas as pd Tweet = pd.read_csv('./6020_negative_positive_data/data/Airline-Sentiment-2-w-AA.csv', encoding='cp932') tweetData = Tweet.loc[:,['text', 'airline_sentiment']] print(tweetData)
データベースの作成
頻出単語の削除
RNNでは単語の関連性を分析するので、頻出する単語を削除する必要があります。
Iやwhatなどの頻出する単語をストップワードと呼びます。
Googleの検索エンジンではストップワードを検索対象外にすることで他の単語同士の関連度を高めています。また、Twitterで返信を意味する@やflightという単語が頻出しているので
それらの単語を削除したデータを作成します。import nltk import numpy as np import pandas as pd import re from nltk.corpus import stopwords #stopwordsでエラーが出たら↓を実行してください # #nltk.download('stopwords') # Tweetデータの読み込みます Tweet = pd.read_csv('./6020_negative_positive_data/data/Airline-Sentiment-2-w-AA.csv', encoding='cp932') tweetData = Tweet.loc[:,['text','airline_sentiment']] # 英語Tweetの形態素解析を行います def tweet_to_words(raw_tweet): # a~zまで始まる単語を空白ごとに区切ったリストをつくります letters_only = re.sub("[^a-zA-Z@]", " ",raw_tweet) words = letters_only.lower().split() # '@'と'flight'が含まれる文字とストップワードを削除します stops = set(stopwords.words("english")) meaningful_words = [w for w in words if not w in stops and not re.match("^[@]", w) and not re.match("flight",w)] return( " ".join( meaningful_words )) cleanTweet = tweetData['text'].apply(lambda x: tweet_to_words(x)) print(cleanTweet)
単語のデータベースを作成
どの単語がネガ・ポジに影響を与えるか調べるために
一度全ての単語のデータベースを作成します。このデータベースを使って、単語の出現頻度やネガ・ポジのタグづけを行います。
import nltk import numpy as np import pandas as pd import re from nltk.corpus import stopwords Tweet = pd.read_csv('./6020_negative_positive_data/data/Airline-Sentiment-2-w-AA.csv', encoding='cp932') tweetData = Tweet.loc[:,['text','airline_sentiment']] def tweet_to_words(raw_tweet): # a~zまで始まる単語を空白ごとに区切ったリストをつくります letters_only = re.sub("[^a-zA-Z@]", " ",raw_tweet) words = letters_only.lower().split() # '@'と'flight'が含まれる文字とストップワードを削除します stops = set(stopwords.words("english")) meaningful_words = [w for w in words if not w in stops and not re.match("^[@]", w) and not re.match("flight",w)] return( " ".join( meaningful_words )) cleanTweet = tweetData['text'].apply(lambda x: tweet_to_words(x)) #データベースを作成します all_text = ' '.join(cleanTweet) words = all_text.split() print(words)
単語の数値化
単語の出現回数をベースにそれぞれの単語に数値のタグづけを行います。
また今回学習に使うcleanTweetの文字列を数値化して新しいリストを作成します。import nltk import numpy as np import pandas as pd import re from nltk.corpus import stopwords from collections import Counter Tweet = pd.read_csv('./6020_negative_positive_data/data/Airline-Sentiment-2-w-AA.csv', encoding='cp932') tweetData = Tweet.loc[:,['text','airline_sentiment']] def tweet_to_words(raw_tweet): # a~zまで始まる単語を空白ごとに区切ったリストをつくります letters_only = re.sub("[^a-zA-Z@]", " ",raw_tweet) words = letters_only.lower().split() # '@'と'flight'が含まれる文字とストップワードを削除します stops = set(stopwords.words("english")) meaningful_words = [w for w in words if not w in stops and not re.match("^[@]", w) and not re.match("flight",w)] return( " ".join( meaningful_words )) cleanTweet = tweetData['text'].apply(lambda x: tweet_to_words(x)) #データベースを作成します all_text = ' '.join(cleanTweet) words = all_text.split() # 単語の出現回数をカウントします counts = Counter(words) # 降順に並べ替えます vocab = sorted(counts, key=counts.get, reverse=True) vocab_to_int = {word: ii for ii, word in enumerate(vocab, 1)} #print(vocab_to_int) # 新しいリストに文字列を数値化したものを格納します tweet_ints = [] for each in cleanTweet: tweet_ints.append([vocab_to_int[word] for word in each.split()]) print(tweet_ints)
ネガ・ポジの数値化
文章ごとに与えられたネガ・ポジの評価を数値化します。
今回はネガティブ=0, ポジティブ=1, ニュートラル=2に変換します。このネガ・ポジ数値は単語から生成された文章を学習する際に使用します。
import numpy as np import pandas as pd # Tweetデータの読み込みます Tweet = pd.read_csv('./6020_negative_positive_data/data/Airline-Sentiment-2-w-AA.csv', encoding='cp932') tweetData = Tweet.loc[:,['text','airline_sentiment']] # Tweetのnegative/positiveの文字列を数字に変換します labels = np.array([0 if each == 'negative' else 1 if each == 'positive' else 2 for each in tweetData['airline_sentiment'][:]]) print(labels)列の数を揃える
作成したtweet_intsではtweetごとにバラバラな単語数が格納されています。
学習する際にリストの列を揃える必要があります。
またcleanTweetの処理により単語数が0になってしまった行をそれぞれのリストから削除します。from collections import Counter # 前節のコード内容です------------------------- import numpy as np import pandas as pd # Tweetデータの読み込みます Tweet = pd.read_csv('./6020_negative_positive_data/data/Airline-Sentiment-2-w-AA.csv', encoding='cp932') tweetData = Tweet.loc[:,['text','airline_sentiment']] # Tweetのnegative/positiveの文字列を数字に変換します labels = np.array([0 if each == 'negative' else 1 if each == 'positive' else 2 for each in tweetData['airline_sentiment'][:]]) # ---------------------------------------- # 新しいリストに文字列を数値化したものを格納します tweet_ints = [] for each in cleanTweet: tweet_ints.append([vocab_to_int[word] for word in each.split()]) # Tweetの単語数を調べます tweet_len = Counter([len(x) for x in tweet_ints]) print(tweet_len) seq_len = max(tweet_len) print("Zero-length reviews: {}".format(tweet_len[0])) print("Maximum review length: {}".format(max(tweet_len))) # cleanTweetで単語数が0になってしまった行をそれぞれのリストから削除します tweet_idx = [idx for idx,tweet in enumerate(tweet_ints) if len(tweet) > 0] labels = labels[tweet_idx] tweetData = tweetData.iloc[tweet_idx] tweet_ints = [tweet for tweet in tweet_ints if len(tweet) > 0] # 列数を揃えるためにi行ごとの数値化した単語を右から書いたフレームワークを作ります features = np.zeros((len(tweet_ints), seq_len), dtype=int) for i, row in enumerate(tweet_ints): features[i, -len(row):] = np.array(row)[:seq_len] print(features)
まとめ
Tweetのデータからデータセットの作成
1,Tweetデータの読み込み 2,Tweetデータの形態素解析 3,単語のデータベース化 4,フィーチャー(データベース)の作成import nltk import numpy as np import pandas as pd import re from collections import Counter from nltk.corpus import stopwords # Tweetデータを読み込みます Tweet = pd.read_csv('./6020_negative_positive_data/data/Airline-Sentiment-2-w-AA.csv', encoding='cp932') tweetData = Tweet.loc[:,['text','airline_sentiment']] # 英語Tweetの形態素解析を行います def tweet_to_words(raw_tweet): # a~zまで始まる単語を空白ごとに区切ったリストをつくります letters_only = re.sub("[^a-zA-Z@]", " ",raw_tweet) words = letters_only.lower().split() # '@'と'flight'が含まれる文字とストップワードを削除します stops = set(stopwords.words("english")) meaningful_words = [w for w in words if not w in stops and not re.match("^[@]", w) and not re.match("flight",w)] return( " ".join(meaningful_words)) cleanTweet = tweetData['text'].apply(lambda x: tweet_to_words(x)) # データベースを作成します all_text = ' '.join(cleanTweet) words = all_text.split() # 単語の出現回数をカウントします counts = Counter(words) # 降順に並べ替えます vocab = sorted(counts, key=counts.get, reverse=True) vocab_to_int = {word: ii for ii, word in enumerate(vocab, 1)} # 新しいリストに文字列を数値化したものを格納します tweet_ints = [] for each in cleanTweet: tweet_ints.append([vocab_to_int[word] for word in each.split()]) # Tweetの単語数を調べます tweet_len = Counter([len(x) for x in tweet_ints]) seq_len = max(tweet_len) print("Zero-length reviews: {}".format(tweet_len[0])) print("Maximum review length: {}".format(max(tweet_len))) # cleanTweetで単語数が0になってしまった行をそれぞれのリストから削除します tweet_idx = [idx for idx,tweet in enumerate(tweet_ints) if len(tweet) > 0] tweet_ints = [tweet for tweet in tweet_ints if len(tweet) > 0] # 列数を揃えるためにi行ごとの数値化した単語を右から書いたフレームワークを作ります features = np.zeros((len(tweet_ints), seq_len), dtype=int) for i, row in enumerate(tweet_ints): features[i, -len(row):] = np.array(row)[:seq_len] print(features)





- 投稿日:2020-05-26T17:15:34+09:00
DeepRunning
Level1.間違いじゃないよ
Qiitaを利用することになり、登録してみました。
主にAI関連の勉強をするのに活用してみようと思っています。
継続がチカラとなるように、少しずつ頑張ってみよう。1-1.G検定との出会い
昨年、ひょんなことからAIの勉強に興味を持ち、1週間がんばってG検定に合格しました。
10月末でした。
上司と面接した際に、AIの勉強してみようと思っていると話をした後、
「そうだ、G検定って12月にあったよな。やってみようかな。」・・・なーんて勘違いに気が付かず、受験を宣言しちゃった。。。
さてさて、余裕をもって申し込んでみよう。
JDLAのホームページを開き、そうそう。11月だったね。OK~!!・・・
・・・
・・・え?11月?
そう。2019年11月9日(土)だったんです。
あと1週間しかない。たまたま、Amazonで参考書は買ってあったので、すぐに申し込み。
それから、1週間は必死に頑張りました。
でも、楽しかったんですね。
AI関係の勉強って。勉強というより遊び感覚でした。1-2.E資格もやってみようじゃないか
楽しくなっちゃったんです。
勉強するために、それまで持っていた非力なVAIOじゃダメで、
PCを購入までしちゃいました。
やるならちゃんと勉強しよう。
E資格へのスタートでした。1-3.DeepLearningとDeepRunning
タイトルどうしようかなって考えていて、
DeepLearningの勉強するので少し遊んでつけました。
勉強より楽しんで継続しようと思って。少し運動不足も気にしながら、レッツE資格!!
1-4.運命的なStudy-AIさんとの出会い?
E資格に向けて勉強していたところ、実装師A級のお誘いを受けて、
またまた、勉強のうえで合格できました。
E資格と比べると安く受験できるので、軽い気持ちでした。合格後、ラビットチャレンジに参加させていただけるというありがたいご連絡が。
会社にJDLA認定の研修を受けさせてもらおうか悩んでいたところで、
個人申し込みなら安く(それでも高いですけれど。。。)、
余計な買い物をしないと決めて申し込みました。今は、ラビットチャレンジを頑張ろう。
Qiitaの投稿はこうして幕を上げました。どうぞ、よろしくお願いいたします。
3ヵ月で現場で潰しが効くディープラーニング講座とは

- 投稿日:2020-05-26T17:15:34+09:00
DeepRunning ~Level1~
Level1.間違いじゃないよ
Qiitaを利用することになり、登録してみました。
主にAI関連の勉強をするのに活用してみようと思っています。
継続がチカラとなるように、少しずつ頑張ってみよう。1-1.G検定との出会い
昨年、ひょんなことからAIの勉強に興味を持ち、1週間がんばってG検定に合格しました。
10月末でした。
上司と面接した際に、AIの勉強してみようと思っていると話をした後、
「そうだ、G検定って12月にあったよな。やってみようかな。」・・・なーんて勘違いに気が付かず、受験を宣言しちゃった。。。
さてさて、余裕をもって申し込んでみよう。
JDLAのホームページを開き、そうそう。11月だったね。OK~!!・・・
・・・
・・・え?11月?
そう。2019年11月9日(土)だったんです。
あと1週間しかない。たまたま、Amazonで参考書は買ってあったので、すぐに申し込み。
それから、1週間は必死に頑張りました。
でも、楽しかったんですね。
AI関係の勉強って。勉強というより遊び感覚でした。1-2.E資格もやってみようじゃないか
楽しくなっちゃったんです。
勉強するために、それまで持っていた非力なVAIOじゃダメで、
PCを購入までしちゃいました。
やるならちゃんと勉強しよう。
E資格へのスタートでした。1-3.DeepLearningとDeepRunning
タイトルどうしようかなって考えていて、
DeepLearningの勉強するので少し遊んでつけました。
勉強より楽しんで継続しようと思って。少し運動不足も気にしながら、レッツE資格!!
1-4.運命的なStudy-AIさんとの出会い?
E資格に向けて勉強していたところ、実装師A級のお誘いを受けて、
またまた、勉強のうえで合格できました。
E資格と比べると安く受験できるので、軽い気持ちでした。合格後、ラビットチャレンジに参加させていただけるというありがたいご連絡が。
会社にJDLA認定の研修を受けさせてもらおうか悩んでいたところで、
個人申し込みなら安く(それでも高いですけれど。。。)、
余計な買い物をしないと決めて申し込みました。今は、ラビットチャレンジを頑張ろう。
Qiitaの投稿はこうして幕を上げました。どうぞ、よろしくお願いいたします。
3ヵ月で現場で潰しが効くディープラーニング講座とは
- 投稿日:2020-05-26T16:26:37+09:00
Python: ネガポジ分析:テキスト分析応用
ネガ・ポジ分析とは
概要
心理学を始め、人間は自分たちの感情を分析してきました。
その中でもネガ・ポジ分析では主に人の発言や発想などが
前向き(ポジティブ)か後ろ向き(ネガティブ)かを分析します。ネガ・ポジ分析は「感情分析」(Sentiment Analysis)と呼ばれる技術の一種であるということができます。
これは、文章などに含まれる評価・感情に関する表現を抽出して
文章中の感情を解析する技術などを指します。ネガ・ポジ分析の手法として、極性辞書を使った単語ごとの分類や、ディープラーニングを使ったものもあります。
極性辞書
ネガ/ポジのことを「極性」と呼び 極性辞書とは単語ごとに極性を付けてまとめたものを指します。PN Tableという極性辞書は人力で大量の単語に極性を当てたわけではなく
少量の極性情報をもつ単語をベースに関連度の高い単語に-1~+1までの点数を割り振ることで作られています。他には東北大の乾・岡崎研究室のページで公開されている「日本語評価極性辞書」というものがあります。
こちらはネガ・ポジ以外にニュートラルというタグをつけることで
辞書に含まれている単語の極性バランスを取っています。また、Yahoo!JAPAN研究所が作った「Polar Phrase Dictionary」があります。
# PNTableを出力します。 import pandas as pd pn_df = pd.read_csv('./6020_negative_positive_data/data/pn_ja.dic',\ sep=':', encoding='utf-8', names=('Word','Reading','POS', 'PN') ) print (pn_df)
極性辞書を用いたネガ・ポジ分析
形態素解析
形態素解析とは文章の中から最小の単位となる単語に分割する作業です。
形態素解析を行うことで、極性辞書に対応する単語を見つけることができます。
今回はMeCabを使った形態素解析を行い、文章を読み込みやすい形に変えますimport MeCab mecab = MeCab.Tagger('') title = open('./6020_negative_positive_data/data/aidokushono_insho.txt') file = title.read() title.close() print(mecab.parse(file))
形態素解析のリスト化
まずは解析結果をリスト化することで他の処理をしやすい形にします。
MeCabで形態素解析を行うと、最後の行が"空白"、最後から2番目の行が"EOS"となっています。
その2行は使わないので削除する処理を行います。解析結果のそれぞれの行では単語の後にタブ、他の情報はカンマで区切っています。
import MeCab import pandas as pd import re mecab = MeCab.Tagger('') title = open('./6020_negative_positive_data/data/aidokushono_insho.txt') file = title.read() title.close() def get_diclist(file): parsed = mecab.parse(file) # 解析結果を改行ごとに区切ります lines = parsed.split('\n') # 後ろ2行を削除した新しいリストを作ります lines = lines[0:-2] #解析結果のリストを作成します diclist = [] for word in lines: # タブとカンマで区切ったデータを作成します data = re.split('\t|,',word) datalist = {'BaseForm':data[7]} diclist.append(datalist) return(diclist) wordlist = get_diclist(file) print(wordlist)
解析結果にネガ・ポジ判定を行う
極性辞書(PNTable)を読み込み
解析結果のリストと照らし合わせることで出現した単語に極性を与えることができます。PNTableから単語と極性値のみの辞書を作成します。
新しくなったPNTableに存在している単語、極性値の新しいリストを作成します。import pandas as pd # 辞書を読み込みます pn_df = pd.read_csv('./6020_negative_positive_data/data/pn_ja.dic',\ sep=':', encoding='utf-8', names=('Word','Reading','POS', 'PN') ) # PNTableを単語と極性値のみのdict型に変更します word_list = list(pn_df['Word']) pn_list = list(pn_df['PN']) pn_dict = dict(zip(word_list, pn_list)) # 解析結果のリストからPNTableに存在する単語を抽出します def add_pnvalue(diclist_old): diclist_new = [] for word in diclist_old: baseword = word['BaseForm'] if baseword in pn_dict: # PNTableに存在していれば極性値とその単語を追加します pn = float(pn_dict[baseword]) else: # 存在していなければnotfoundを明記します pn = 'notfound' word['PN'] = pn diclist_new.append(word) return(diclist_new) wordlist = get_diclist(file) #1.2.3で使った関数です pn_list = add_pnvalue(wordlist) print(pn_list)
ネガ・ポジ分析実装
import re import csv import time import pandas as pd import matplotlib.pyplot as plt import MeCab import random %matplotlib inline # ファイルの読み込み title = open('./6020_negative_positive_data/data/aidokushono_insho.txt') file = title.read() title.close() # MeCabインスタンス作成 mecab = MeCab.Tagger('') # 辞書の読み込み pn_df = pd.read_csv('./6020_negative_positive_data/data/pn_ja.dic',\ sep=':', encoding='utf-8', names=('Word','Reading','POS', 'PN') ) def get_diclist(file): parsed = mecab.parse(file) lines = parsed.split('\n') lines = lines[0:-2] diclist = [] for word in lines: l = re.split('\t|,',word) d = {'BaseForm':l[7]} diclist.append(d) return(diclist) word_list = list(pn_df['Word']) pn_list = list(pn_df['PN']) pn_dict = dict(zip(word_list, pn_list)) def add_pnvalue(diclist_old): diclist_new = [] for word in diclist_old: base = word['BaseForm'] if base in pn_dict: pn = float(pn_dict[base]) else: pn = 'notfound' word['PN'] = pn diclist_new.append(word) pn_point = [] for word in diclist_new: pn = word['PN'] if pn != 'notfound': pn_point.append(pn) return(pn_point) wordlist = get_diclist(file) pn_list = add_pnvalue(wordlist) plt.plot(pn_list) plt.title(title) plt.show