- 投稿日:2020-05-26T23:55:12+09:00
bashでevalを使って変数内の文字列を評価・連結して実行する
目的
- bashでevalを使って変数内の文字列を評価して実行する
- bashでevalを使って変数内の文字列を連結して実行する
環境
- bash
evalの使用例
同ディレクトリ内に、以下2つのtxtファイルを格納した状態とします。
hoge.txthoge hogefuga.txtfuga fugaevalを使って、単純な文字列ではなく、文字列を評価・連結します。
evalの基本的な機能の説明は割愛します。example.sh#!/bin/bash value='hoge' #文字列としてコマンドを変数に格納 #bash内の関数に文字列としてコマンドを与えるケースや、 #ファイルから文字列としてコマンドを読み込むケースを想定 cmd='grep $value hoge.txt' echo $cmd #出力 -> grep $value hoge.txt #echoの場合、コマンドは実行されない. 変数は展開されずに、文字列として出力される eval $cmd #出力 -> hoge hoge #evalの場合、変数が展開され、コマンド実行される実行結果$ ./example.sh grep $value hoge.txt hoge hoge文字列内の変数を評価してechoで出力
success.sh#!/bin/bash #同ディレクトリ内のtxtファイルにgrepを実行し,検索パターンが見つかった場合,メッセージを出力する関数. #第一引数に検索パターン,第二引数に出力するメッセージを渡す grep_text() { for txt_file in $(ls . | grep ".txt$"); do grep_result=$(grep $1 $txt_file) if [ $? -eq 0 ]; then eval echo $2 fi done } query='hoge' #関数内で使用している変数を出力メッセージに含める message='検索対象が見つかりました. 見つかったファイル名:$txt_file' grep_text $query "${message}" query='fuga' message='検索対象が見つかりました. 見つかった文:$grep_result' grep_text $query "${message}"実行結果$ ./success.sh 検索対象が見つかりました. 見つかったファイル名:hoge.txt 検索対象が見つかりました. 見つかった文:fuga fuga以下のように、evalを使わない場合、文字列内の変数が評価されません。
failed.sh#!/bin/bash grep_text() { for txt_file in $(ls . | grep ".txt$"); do grep_result=$(grep $1 $txt_file) if [ $? -eq 0 ]; then #evalを使わない場合 echo $2 fi done } query='hoge' message='検索対象が見つかりました. 見つかったファイル名:$txt_file' grep_text $query "${message}" query='fuga' message='検索対象が見つかりました. 見つかった文:$grep_result' grep_text $query "${message}"実行結果$ ./fail.sh 検索対象が見つかりました. 見つかったファイル名:$txt_file 検索対象が見つかりました. 見つかった文:$grep_result文字列内のコマンドを評価して実行
cmd.sh#!/bin/bash grep_text() { for txt_file in $(ls | grep ".txt$"); do #引数で渡されたgrepを実行 grep_result=$(eval $1) #検索パターンが見つかった場合,メッセージを出力 if [ -n "$grep_result" ]; then echo "検索対象が見つかりました. 見つかった文:$grep_result" fi done } cmd='grep "hoge" $txt_file' echo $cmd grep_text "$cmd" cmd='grep "fuga" $txt_file' echo $cmd grep_text "$cmd"実行結果$ ./cmd.sh grep "hoge" $txt_file 検索対象が見つかりました. 見つかった文:hoge hoge grep "fuga" $txt_file 検索対象が見つかりました. 見つかった文:fuga fuga
- 投稿日:2020-05-26T23:50:36+09:00
MBDynの使い方(コマンド設定)
雑談
MBDynをインストール後どのように扱うかの備忘録です。
環境はUbuntuを想定。
MBDynというツールを使う人がもしかしたら日本にもいるかもしれないので公開しておきます。ちなみに他の記事のようにコードもかっこよく書きたかったので今回からちゃんと書こうと思います。
パスを通す
まずMBDynをどの場所でも使うには環境変数を設定してパスを通す必要があります。
そこで環境変数を設定する必要があります。
デフォルトで'MBDyn'コマンドは'/usr/local/mbdyn/bin'にあります。
そのため以下のコマンドでシェルがコマンドを実行する際にコマンドを検索する場所に上の場所を追加しておきます。PATH.rbexport PATH=$PATH:/usr/local/mbdyn/binbashの設定ファイル変更
しかしこれでは一時的な変更にしかならずbashを終了するとすべての設定は消えてしまいます。
そのためbashの設定ファイルを変更します。PATHvim.rbvim ~/.bashrc開いたファイルに上のexportコマンドを追加しておきます。
以上でおそらく次から'MBDyn'を使えるようになっています。
- 投稿日:2020-05-26T22:25:20+09:00
LVMでボリューム同士をまとめる方法
ホームディレクトリにでかい容量割り当てられていて、ルートボリュームとまとめてしまいたい時とかに!
現在の状況を確認
[root@cmst301 ~]# lvdisplay -C LV VG Attr LSize Pool Origin Data% Meta% Move Log Cpy%Sync Convert lv_home vg_cmst301 -wi-ao---- 197.68g lv_root vg_cmst301 -wi-ao---- 50.00g lv_swap vg_cmst301 -wi-ao---- 7.83g対象ディレクトリのバックアップ
[root@cmst301 ~]# cp -rp /home /home_bkfstabの以下の行をコメントアウト
/dev/mapper/vg_cmst301-lv_home /home ext4 defaults 1 2homeディレクトリのマウントを解除
現在の状況[root@cmst301 ~]# df -h Filesystem Size Used Avail Use% Mounted on /dev/mapper/vg_cmst301-lv_root 50G 6.0G 41G 13% / tmpfs 3.9G 0 3.9G 0% /dev/shm /dev/sda1 477M 78M 374M 18% /boot /dev/mapper/vg_cmst301-lv_home 195G 416M 185G 1% /homeマウント解除[root@cmst301 ~]# umount /home確認[root@cmst301 ~]# df -h Filesystem Size Used Avail Use% Mounted on /dev/mapper/vg_cmst301-lv_root 50G 5.0G 42G 11% / tmpfs 3.9G 0 3.9G 0% /dev/shm /dev/sda1 477M 78M 374M 18% /boot論理ボリュームの削除
[root@cmst301 ~]# lvremove /dev/vg_cmst301/lv_home Do you really want to remove active logical volume lv_home? [y/n]: y Logical volume "lv_home" successfully removed論理ボリュームの拡張
[root@cmst301 ~]# lvextend -L +200G /dev/mapper/vg_cmst301-lv_root Size of logical volume vg_cmst301/lv_root changed from 247.49 GiB (63357 extents) to 247.59 GiB (63382 extents). Logical volume lv_root successfully resized.ファイルシステムの拡張
[root@cmst301 ~]# resize2fs /dev/mapper/vg_cmst301-lv_root resize2fs 1.41.12 (17-May-2010) Filesystem at /dev/mapper/vg_cmst301-lv_root is mounted on /; on-line resizing required old desc_blocks = 4, new_desc_blocks = 16 Performing an on-line resize of /dev/mapper/vg_cmst301-lv_root to 64903168 (4k) blocks. The filesystem on /dev/mapper/vg_cmst301-lv_root is now 64903168 blocks long.拡張結果の確認
[root@cmst301 ~]# df -h Filesystem Size Used Avail Use% Mounted on /dev/mapper/vg_cmst301-lv_root 244G 5.0G 227G 3% / tmpfs 3.9G 0 3.9G 0% /dev/shm /dev/sda1 477M 78M 374M 18% /boot
- 投稿日:2020-05-26T21:59:47+09:00
Boot time memory management
https://www.kernel.org/doc/html/latest/core-api/boot-time-mm.html
Boot time memory management
Early system initialization cannot use “normal” memory management simply because it is not set up yet. But there is still need to allocate memory for various data structures, for instance for the physical page allocator.
システムの初期化を開始した直後では、通常のメモリマネージャーは単純に利用できません、なぜならばそれの準備はまだできていないからです。しかしながら、例えば、physical page allocatorのように、さまざまなデータ構造に対するメモリを割り当てる必要があります。
A specialized allocator called memblock performs the boot time memory management. The architecture specific initialization must set it up in setup_arch() and tear it down in mem_init() functions.
memblockと呼ばれる特別なallocatorは、起動時のmemory managementを実行します。アーキテクチャ固有の初期化処理では、setup_arch()で設定を行い、mem_init()関数でそれを破棄する必要があります。
Once the early memory management is available it offers a variety of functions and macros for memory allocations. The allocation request may be directed to the first (and probably the only) node or to a particular node in a NUMA system. There are API variants that panic when an allocation fails and those that don’t.
early memory managementは有効になったら、memory allocationsのための様々な関数やマクロが有効になります。allocationは、NUMA systemにおいて最初の(そしておそらく唯一の)nodeや特定nodeに送信されます。割り当てに失敗した時に、panicになるAPIと、そうではないAPIがあります。
Memblock also offers a variety of APIs that control its own behaviour.
Memblockはまた、自信の振る舞いを制御するための様々なAPIも提供しています。
Memblock Overview
Memblock is a method of managing memory regions during the early boot period when the usual kernel memory allocators are not up and running.
Memblockは、通常、kernel memory allocatiorがまた起動も動作もしていないであろうearly boot periodにおけるmemory regionの管理する方法です。
Memblock views the system memory as collections of contiguous regions. There are several types of these collections:
Memblockはsystem memroy を連続したregionの集合として捉えます。これらの集合にはいくつかのタイプがあります。
・memory - describes the physical memory available to the kernel; this may differ from the actual physical memory installed in the system, for instance when the memory is restricted with mem= command line parameter
・reserved - describes the regions that were allocated
・physmap - describes the actual physical memory regardless of the possible restrictions; the physmap type is only available on some architectures.・memory - カーネルに対して、物理的なメモリを記述する;これは実際にシステムに装着されている物理メモリと異なる場合があります。例えば、mem= command line parameterによって、制限がなされている場合。
・reserved -すでにallocatedされているregion を記述する。
・physmap - 可能な制限に関係なく、実際の物理メモリを記述します。physmap typeは一部のアーキテクチャだけで利用できます。Each region is represented by struct memblock_region that defines the region extents, its attributes and NUMA node id on NUMA systems. Every memory type is described by the struct memblock_type which contains an array of memory regions along with the allocator metadata. The memory types are nicely wrapped with struct memblock. This structure is statically initialzed at build time.
それぞれのregionは、region 範囲、その属性、NUMA systemではNUMA node idを定義する、構造体memblock_regionで表現されます。すべてのmemory typeは、struct memblock_typeで記述されます。それは、allocator metadataと共に、memory regionの配列を含みます。memory typeは、構造体memblockを上手く包み込みます。この構造体は、起動時に静的に初期化されます。
The region arrays for the “memory” and “reserved” types are initially sized to INIT_MEMBLOCK_REGIONS and for the “physmap” type to INIT_PHYSMEM_REGIONS. The memblock_allow_resize() enables automatic resizing of the region arrays during addition of new regions. This feature should be used with care so that memory allocated for the region array will not overlap with areas that should be reserved, for example initrd.
"memory"と"reserved" typeであるregion arrayは、INIT_MEMBLOCK_REGIONSのサイズで初期化され、"physmap" typeでは、INIT_PHYSMEM_REGIONSです。memblock_allow_resize()は、新しいregionが追加される間、自動的にregion arrayのサイズを変更します。この機能は、region arrayに割り当てられたmemoryが例えばinitrdなどの予約する必要があるregionと重複しないように、気を付ける必要があります。
The early architecture setup should tell memblock what the physical memory layout is by using memblock_add() or memblock_add_node() functions. The first function does not assign the region to a NUMA node and it is appropriate for UMA systems. Yet, it is possible to use it on NUMA systems as well and assign the region to a NUMA node later in the setup process using memblock_set_node(). The memblock_add_node() performs such an assignment directly.
初期のアーキテクチャーセットアップでは、memblock_add() or memblock_add_node() functionsを利用して、物理メモリレイアウトを、memblockへ通知する必要があります、最初の関数は領域をNUMA nodeに割り当てないので、UMAシステムに適しています。ただし、NUMAシステムでも利用可能です。memblock_set_node()を使ってセットアッププロセスを実行した後、NUMA nodeを割り当ててください。The memblock_add_node()は直接このような割り当てを実行します。
Once memblock is setup the memory can be allocated using one of the API variants:
memblockでメモリがセットアップされると 、API variantsの1つを使ってメモリを割り当てることができます。
・memblock_phys_alloc*() - these functions return the physical address of the allocated memory
・memblock_alloc*() - these functions return the virtual address of the allocated memory.・memblock_phys_alloc*() - これらの関数では、物理アドレスの確保されたメモリを戻値として返します。
・memblock_alloc*() - これらの関数では確保済みメモリの仮想アドレスを返します。Note, that both API variants use implict assumptions about allowed memory ranges and the fallback methods. Consult the documentation of memblock_alloc_internal() and memblock_alloc_range_nid() functions for more elaborate description.
どちらのAPI variantsでも許可されたメモリ範囲とfallback手段について、暗黙の過程を利用することに注意してください。より詳細な説明については、memblock_alloc_internal)およびmemblock_alloc_range_nid)関数のドキュメントを参照してください。
As the system boot progresses, the architecture specific mem_init() function frees all the memory to the buddy page allocator.
system boot progressの時に、アーキテクチャ固有のmem_init()関数で、buddy page allocatorのメモリはすべて解放されます。
Unless an architecture enables CONFIG_ARCH_KEEP_MEMBLOCK, the memblock data structures will be discarded after the system initialization completes.
アーキテクチャがCONFIG_ARCH_KEEP_MEMBLOCKを有効にしない限り、memblockデータ構造はシステムの初期化が完了した後に破棄されます。
- 投稿日:2020-05-26T21:38:18+09:00
マンションのNATを気合と技術で超える(NAT超えWake on LAN)[2]
はじめに
前回の続きです.
とりあえずやりたいことはこんなんです.
今回は「GCPにSoftether Serverを立てる(iPhone/ラズパイから接続)」です.
- [1]GCPとMyDNSを使って,ドメインを取得する
- [2]GCPにSoftether Serverを立てる(iPhone/ラズパイから接続)
- [3]GCP上のApacheからローカルのラズパイApacheにリバースプロキシする
- [4]ラズパイをルーター化する
- [5]Wake on LAN用のPythonスクリプトを作成する.
Softether Client
GCPにSoftether Clientをインストール
まず,Softether Clientをインストールします.(※もしかしたら,必要ないかもです.)
GCPにSSH接続し,必要なモジュールをインストールします.sudo apt update sudo apt-get install -y gcc make wget tzdata git libreadline-dev libncurses-dev libssl-dev bridge-utilsSoftherで指定するCPUのためにCPU情報を取得します.
$ lscpu Architecture: x86_64 <<< bit info CPU op-mode(s): 32-bit, 64-bit <<< which bit cpu can handle Byte Order: Little Endian CPU(s): 1 On-line CPU(s) list: 0 Thread(s) per core: 1 Core(s) per socket: 1 Socket(s): 1 NUMA node(s): 1 Vendor ID: GenuineIntel CPU family: 6 Model: 79 Model name: Intel(R) Xeon(R) CPU @ 2.20GHz Stepping: 0 CPU MHz: 2200.000上記情報を元に公式サイトからClientのダウンロード用URLを取得します.
# Download and Install mkdir tmp cd /tmp wget https://github.com/SoftEtherVPN/SoftEtherVPN_Stable/releases/download/v4.34-9745-beta/~~~~.tar.gz tar -xvf ~~~.tar.gz cd vpnclient make # >> Enter 1 # move to usr/local cd ../ sudo mv vpnclient/ /usr/local/ # set permission cd /usr/local/vpnclient/ sudo chmod 600 * sudo chmod 700 vpncmd vpnclient再起動した時にSoftether Clientが起動するようにサービスを作成します.
sudo vi /etc/systemd/system/vpnclient.service/etc/systemd/system/vpnclient.service[Unit] Description=SoftEther VPN Client After=network.target network-online.target [Service] ExecStart=/usr/local/vpnclient/vpnclient start ExecStop=/usr/local/vpnclient/vpnclient stop Type=forking RestartSec=3s [Install] WantedBy=multi-user.target先ほど作成したサービスを有効にします.
sudo systemctl daemon-reload sudo systemctl start vpnclient sudo systemctl enable vpnclientSoftether Server
GCPにSoftether Serverを立てる
Client同様に公式サイトからServerのダウンロード用URLを取得します.※GCPにはClientとServerの両方インストールします.
# Download and Install mkdir tmp cd /tmp wget https://github.com/SoftEtherVPN/SoftEtherVPN_Stable/releases/download/v4.34-9745-beta/~~~~.tar.gz #取得したURLをここで貼り付け tar -xvf ~~~.tar.gz cd vpnserver make # >> Enter 1 # move to usr/local cd ../ sudo mv vpnserver/ /usr/local/ # set permission cd /usr/local/vpnserver/ sudo chmod 600 * sudo chmod 700 vpncmd vpnserver再起動した時にSoftether serverが起動するようにサービスを作成します.
sudo vi /etc/systemd/system/vpnserver.service/etc/systemd/system/vpnserver.service[Unit] Description=SoftEther VPN Server After=network.target network-online.target [Service] ExecStart=/usr/local/vpnserver/vpnserver start ExecStop=/usr/local/vpnserver/vpnserver stop Type=forking RestartSec=3s [Install] WantedBy=multi-user.target先ほど作成したサービスを有効にします.
# read service sudo systemctl daemon-reload # enable and start sudo systemctl enable vpnserver.service sudo systemctl start vpnserver.serviceserver用のポートを解放する
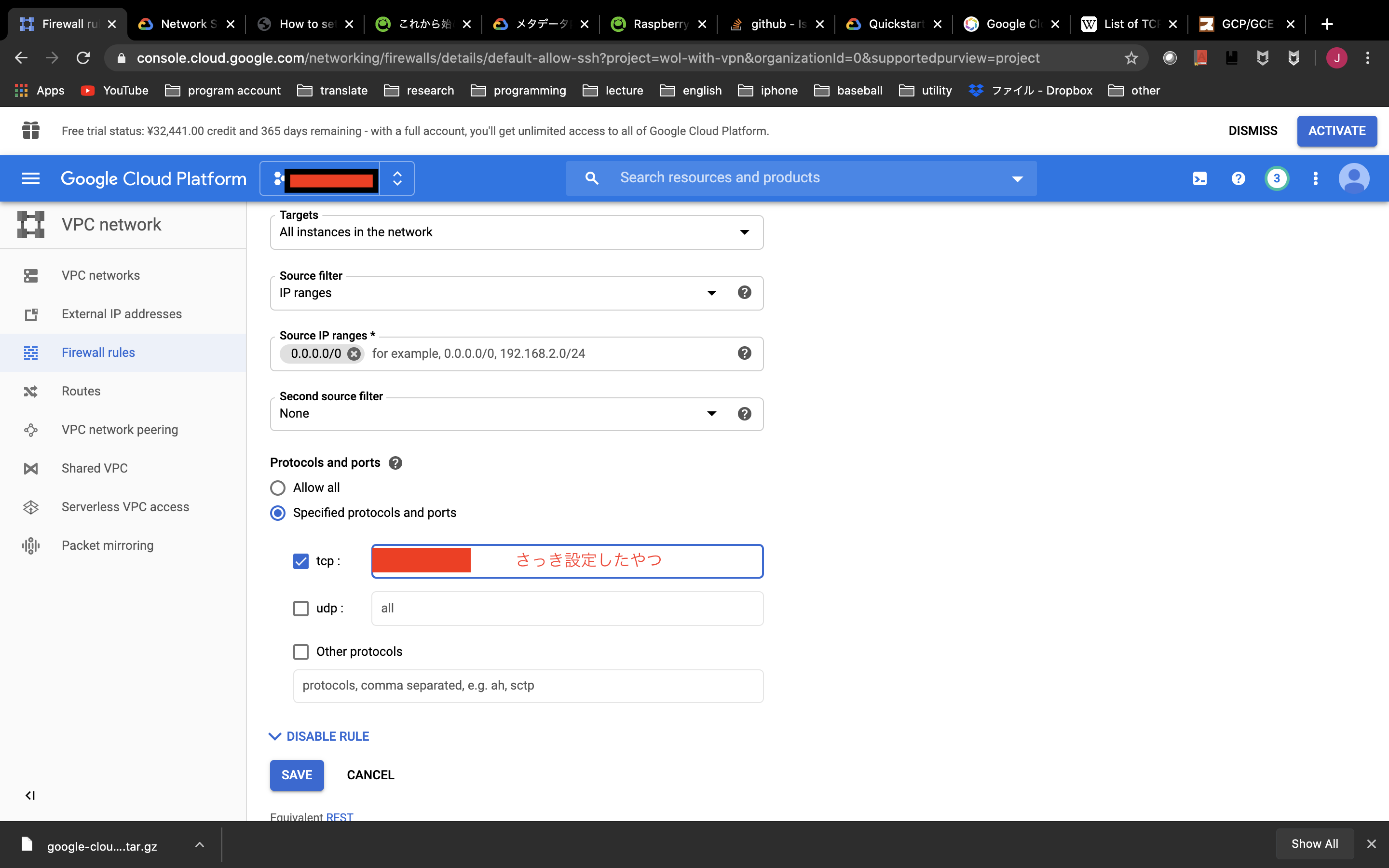
VPN接続用にGCPのポート(TCP992,1194,5555のいずれか,UDP500,4500,1701)を開放する必要があります.
手順はSSH用にポート開放した手順と同様です.
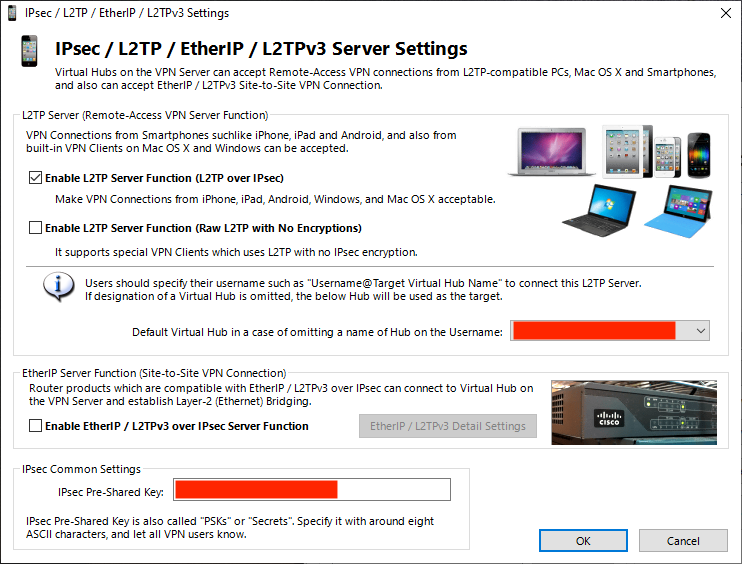
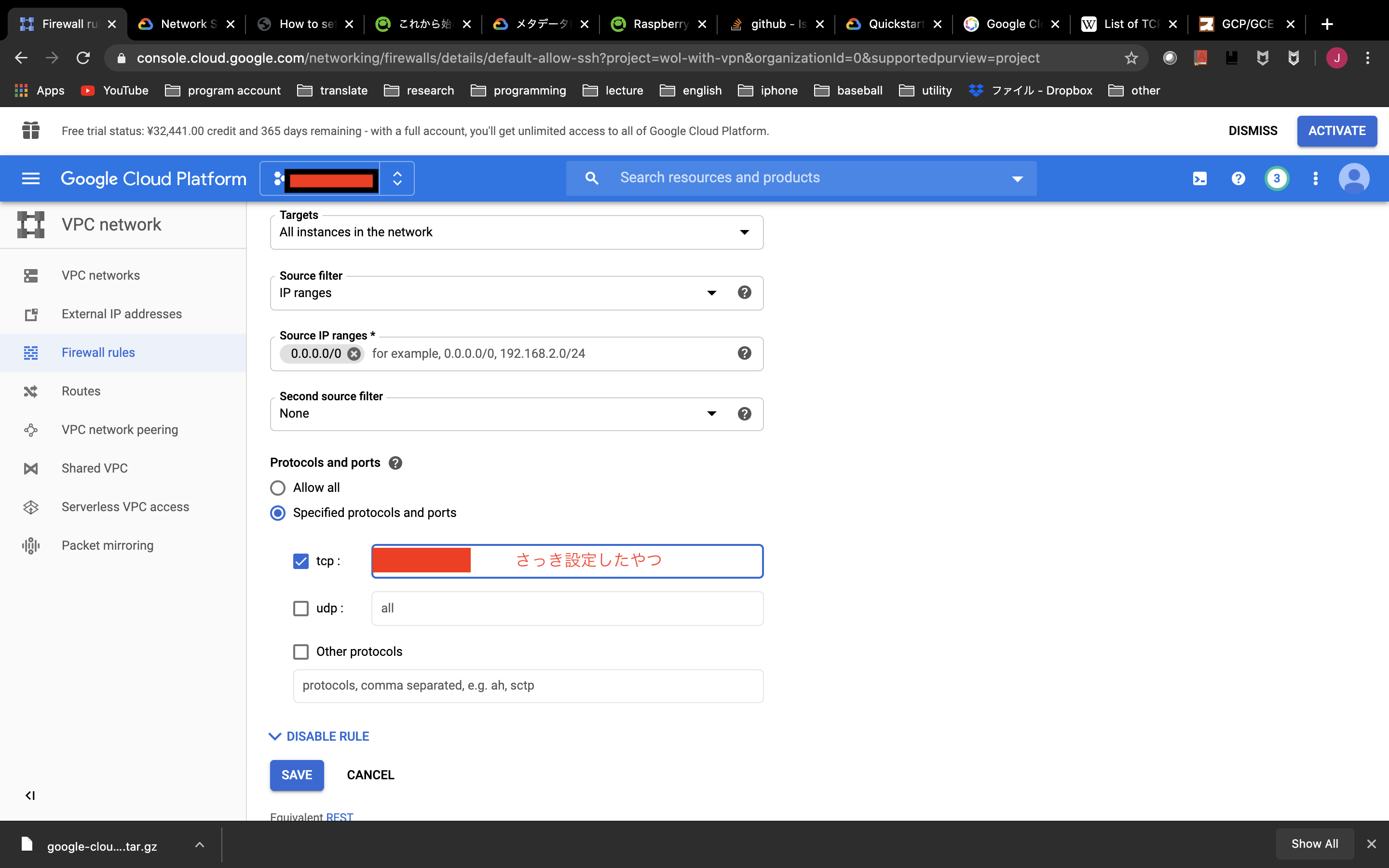
画像の「さっき設定したやつ」のところに適宜,「TCP992,1194,5555のいずれか」と「UDP500,4500,1701(iPhoneのL2TP用)」入力して保存します.
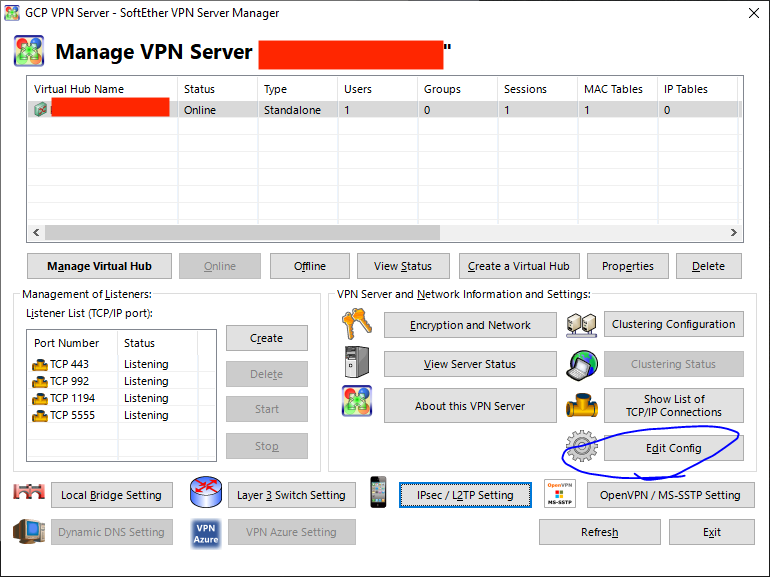
softether serverの詳細な設定を行う
WindowsまたはMacの方は公式サイトからGUIツールが配布されているので,それをインストールします.
インストールが完了し,実行します.
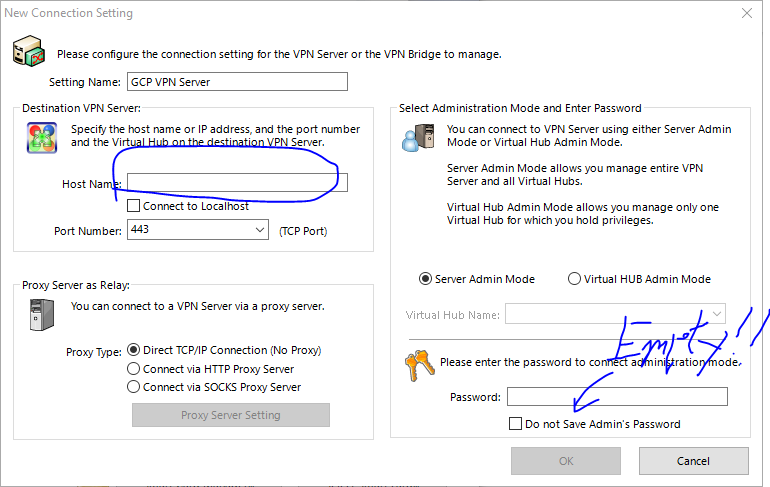
初期画面>New Setting から新しくホストを作成します.ホストネームに先ほどDDNSで取得したドメインを入力します.この時のパスワードは空で良いです.
OKを選択し,作成したホストをクリックすると,パスワード設定するように言われるので設定します.
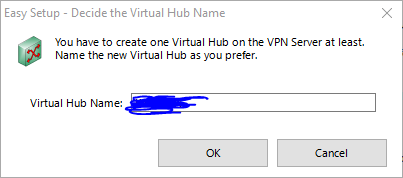
仮想ハブを作成します.
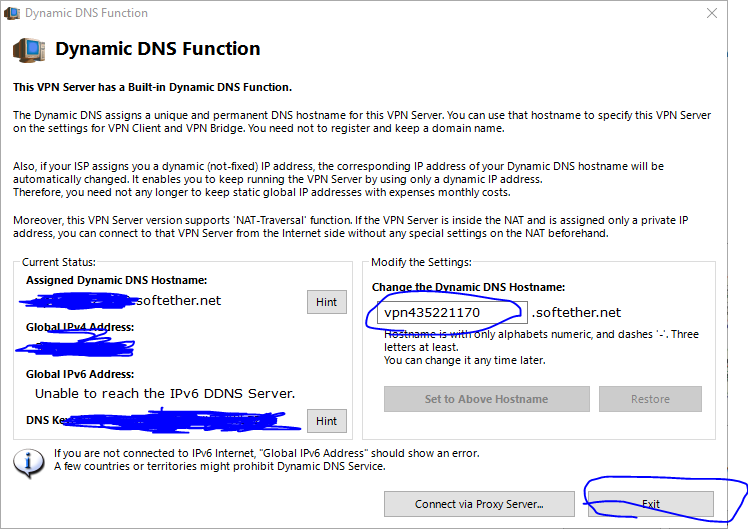
DDNSは既に設定しているので,青丸部分はテキトーでいいです.(あとで無効にします.)
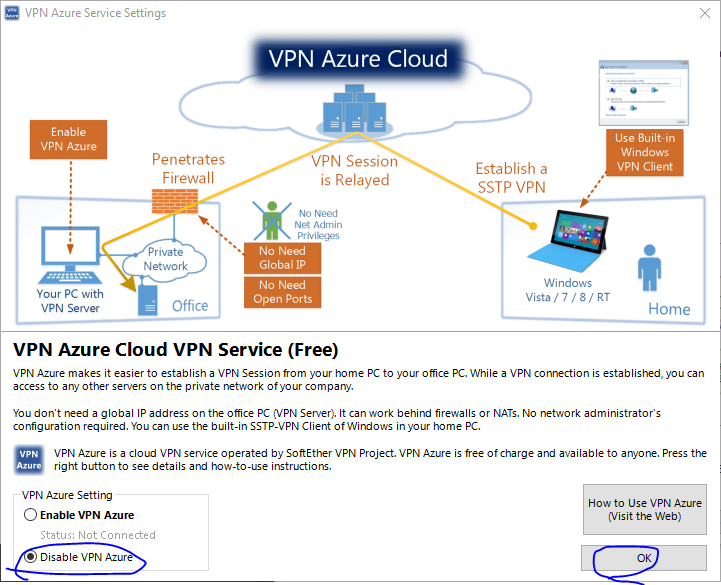
VPN Azureは使いません.
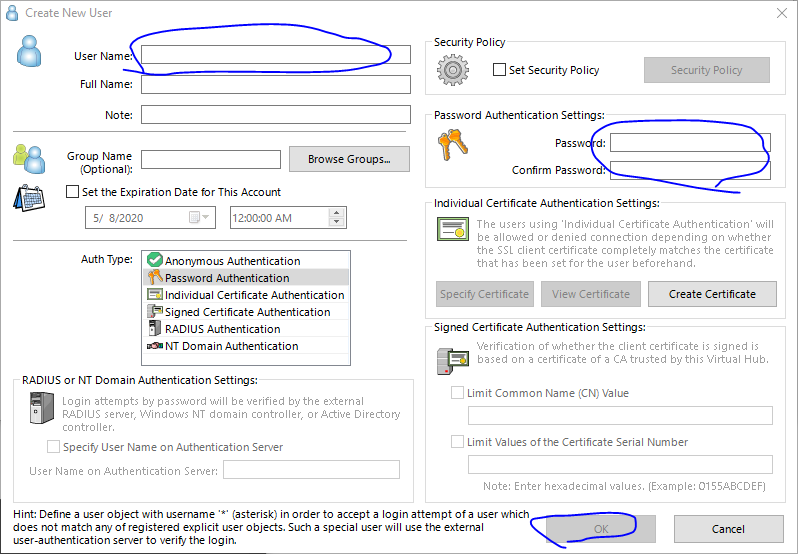
Create Userを選択し,ユーザーを作成します.
ユーザーネームとパスワードを設定します.
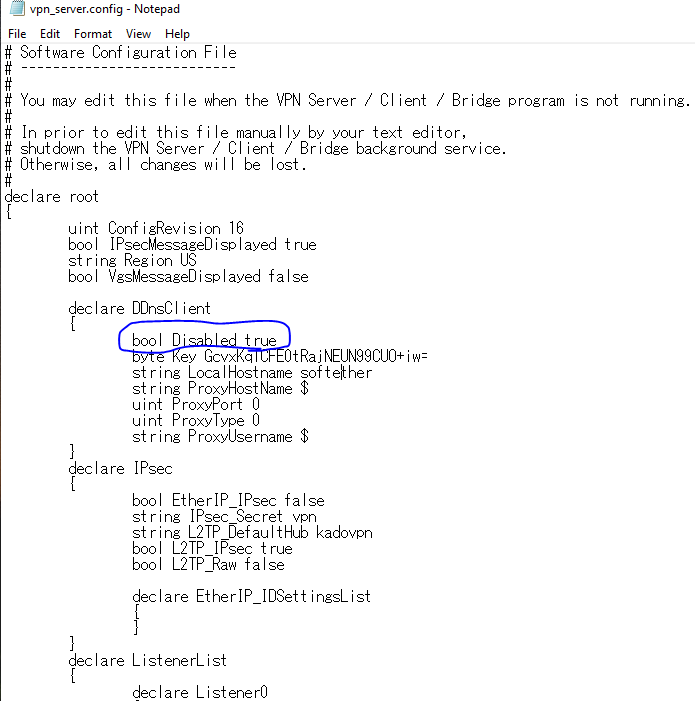
次にDDNSを無効にします.
設定ファイルを出力し,そのファイルを以下にようにfalseからtrueに編集し保存します.
先ほど編集したファイルを読み込み,適用すればOKです.
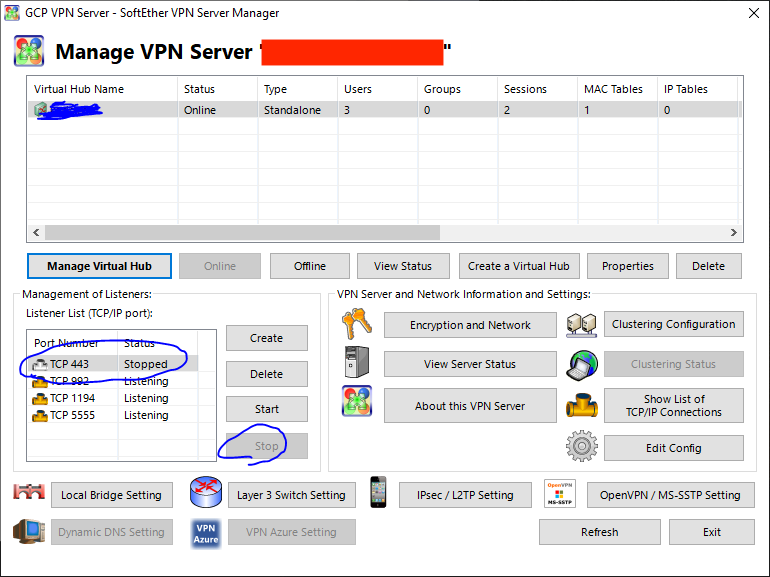
⚠️また,443ポートはApacheサーバー用にしたいので,Listener Listから443をStopさせます.
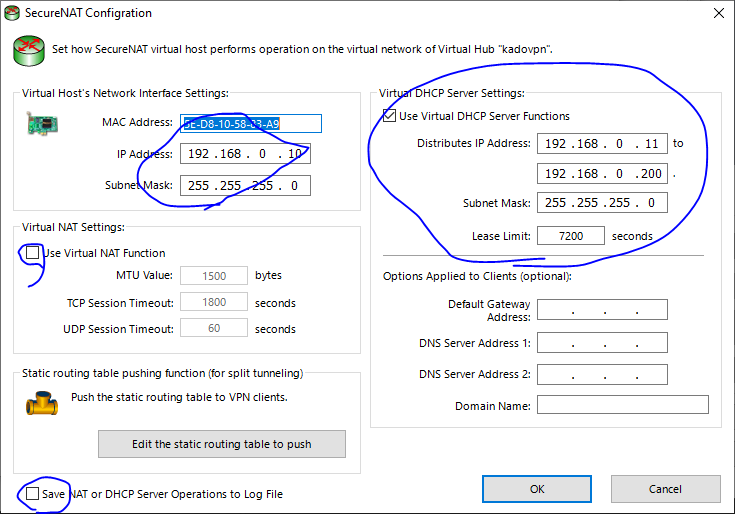
Secure NATの設定
Manage Virtual Hub > Virtual NAT and Virtual DHCP Server (Secure NAT) > Secure NAT Configurationから好きなプライベートアドレスを割り当てます.
今回は最初に載せた上図のような構成にしたいので,192.168.0.0/24のネットワークを構築します.
ClientからServerに接続する
Clientの設定
ClientにはGUIツールがないので,コマンドで操作します.
cd /usr/local/vpnclient/ ./vpncmd仮想NICを作成します.今回は
vpn_nicという名前にします.
bash
NicCreate {name}
アカウントを作成します.今回は
testとします.AccountCreate test > host and port: {ip address or host name}:{port number} # 前回取得したドメイン:ポート番号は992か1194か5555 > virtual hub name: {server's hub name} # Server Managerで設定したハブ名 > username: {username} # Server Managerで設定したユーザーネーム > LAN card name: vpn_nic # さっき作成したやつ AccountPassword test (AccountCreateで作成した名前) > Password: ***** > standard or radius: standard AccountConnect test以下で接続済と出ればOKです.
# check connection status AccountListまた,再起動時に自動で接続するように設定します.
AccountStartupSet testこれでClientの設定は終わりです.
ルーティングテーブルの設定
先ほど作成した仮想NICにIPアドレスを振るようにします.恐らく,
ip aコマンドを打ってもまだ割り当てられていないと思います.sudo vi /etc/sysctl.conf/etc/sysctl.confnet.ipv4.ip_forward=1sudo sysctl -p sudo dhclient vpn_{name} # 今回は{name}=vpn_nic ip aでIPが割り当てられたらOK
最後にスタートアップ時にDHCPが動くようにします.
sudo vi /home/{user}/vpn/dhcp.sh/home/{user}/vpn/dhcp.shdhclient vpn_{name}iPhoneから接続する
本題とは逸れますが,一応行います.
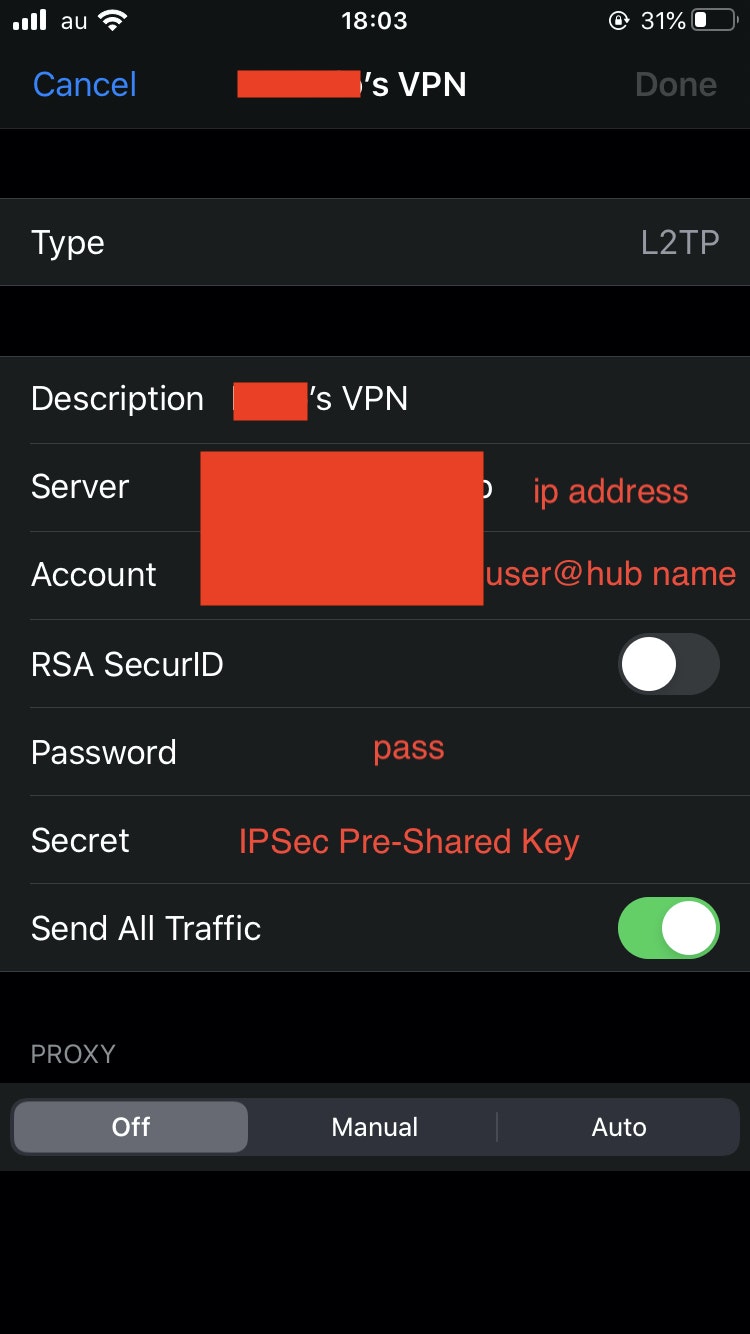
まず,iPhone用にL2TPの設定を行います.最初の画面>IPSec/L2TP Settingというのがあるのでそれをクリックします.そして,下図の画面のようにします.
ip addressの部分はDDNSのドメイン名にしてください.
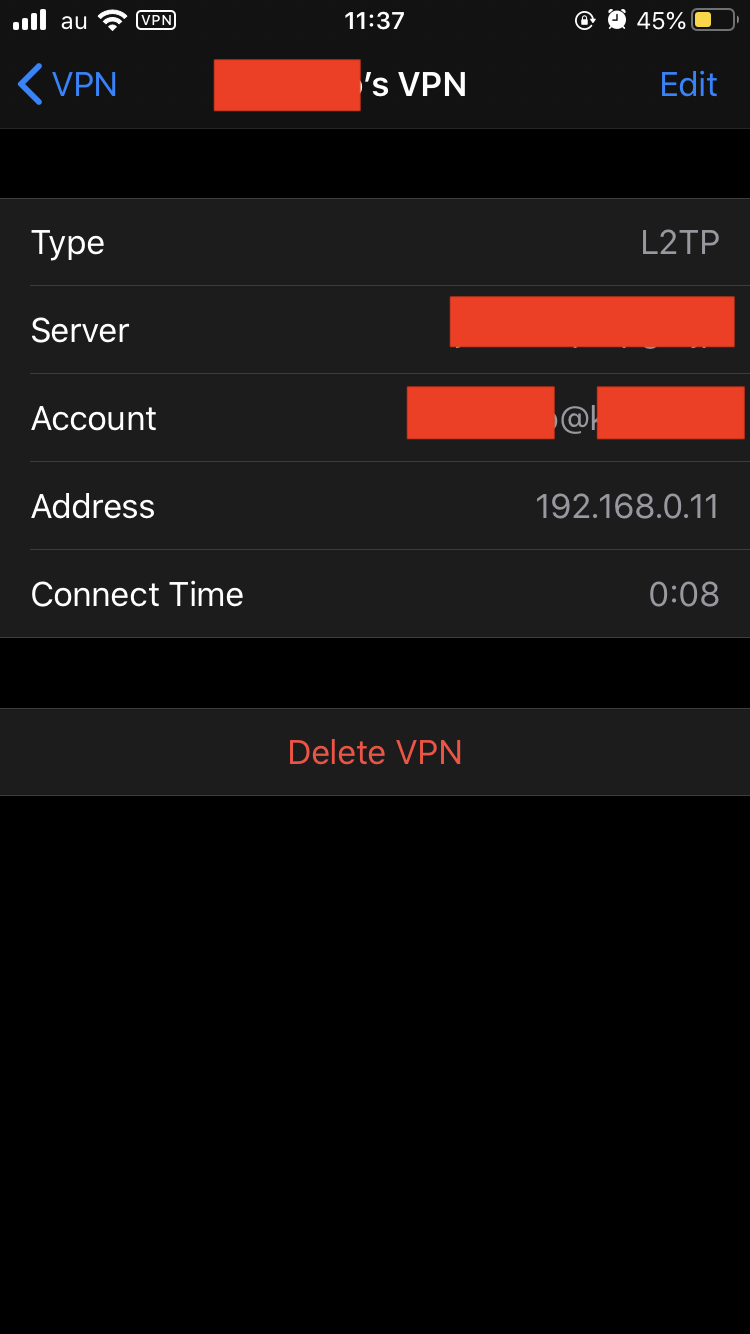
で接続できればOKです.
192.168.0.11が割り当てられていて,ちゃんと接続できていますね!
ラズパイから接続する
softether client
基本的には,GCPにSoftether ClientをインストールとClientの設定と同じことをラズパイでします.
IPの固定
ラズパイはIPを固定した方が使い勝手がいい(∵GCP→ラズパイにリバースプロキシしたい)ので,固定します.
/etc/dhcpcd.confに以下を追記します.{name}には,作成した仮想NICの名前が入ります./etc/dhcpcd.confinterface {name} static ip_address=*.*.*.*/~再起動して,ホスト(GCPのsoftether serverのインターフェース)に
pingが通ればOKです!
※今回は,Secure NATの設定で指定した192.168.0.10にpingを送っていいます.sudo reboot ping 192.168.0.10 # check host's interfaceおわりに
とりあえず,長いのでここで終了です.
参考

- 投稿日:2020-05-26T21:38:18+09:00
GCPにSoftether Serverを立てる(iPhone/ラズパイから接続)(NAT超えWake on LAN[2])
はじめに
前回の続きです.
とりあえずやりたいことはこんなんです.
今回は「GCPにSoftether Serverを立てる(iPhone/ラズパイから接続)」です.
- [1]GCPとMyDNSを使って,ドメインを取得する
- [2]GCPにSoftether Serverを立てる(iPhone/ラズパイから接続)
- [3]GCP上のApacheからローカルのラズパイApacheにリバースプロキシする
- [4]ラズパイをルーター化する
- [5]Wake on LAN用のPythonスクリプトを作成する.
Softether Client
GCPにSoftether Clientをインストール
まず,Softether Clientをインストールします.(※もしかしたら,必要ないかもです.)
GCPにSSH接続し,必要なモジュールをインストールします.sudo apt update sudo apt-get install -y gcc make wget tzdata git libreadline-dev libncurses-dev libssl-dev bridge-utilsSoftherで指定するCPUのためにCPU情報を取得します.
$ lscpu Architecture: x86_64 <<< bit info CPU op-mode(s): 32-bit, 64-bit <<< which bit cpu can handle Byte Order: Little Endian CPU(s): 1 On-line CPU(s) list: 0 Thread(s) per core: 1 Core(s) per socket: 1 Socket(s): 1 NUMA node(s): 1 Vendor ID: GenuineIntel CPU family: 6 Model: 79 Model name: Intel(R) Xeon(R) CPU @ 2.20GHz Stepping: 0 CPU MHz: 2200.000上記情報を元に公式サイトからClientのダウンロード用URLを取得します.
# Download and Install mkdir tmp cd /tmp wget https://github.com/SoftEtherVPN/SoftEtherVPN_Stable/releases/download/v4.34-9745-beta/~~~~.tar.gz tar -xvf ~~~.tar.gz cd vpnclient make # >> Enter 1 # move to usr/local cd ../ sudo mv vpnclient/ /usr/local/ # set permission cd /usr/local/vpnclient/ sudo chmod 600 * sudo chmod 700 vpncmd vpnclient再起動した時にSoftether Clientが起動するようにサービスを作成します.
sudo vi /etc/systemd/system/vpnclient.service/etc/systemd/system/vpnclient.service[Unit] Description=SoftEther VPN Client After=network.target network-online.target [Service] ExecStart=/usr/local/vpnclient/vpnclient start ExecStop=/usr/local/vpnclient/vpnclient stop Type=forking RestartSec=3s [Install] WantedBy=multi-user.target先ほど作成したサービスを有効にします.
sudo systemctl daemon-reload sudo systemctl start vpnclient sudo systemctl enable vpnclientSoftether Server
GCPにSoftether Serverを立てる
Client同様に公式サイトからServerのダウンロード用URLを取得します.※GCPにはClientとServerの両方インストールします.
# Download and Install mkdir tmp cd /tmp wget https://github.com/SoftEtherVPN/SoftEtherVPN_Stable/releases/download/v4.34-9745-beta/~~~~.tar.gz #取得したURLをここで貼り付け tar -xvf ~~~.tar.gz cd vpnserver make # >> Enter 1 # move to usr/local cd ../ sudo mv vpnserver/ /usr/local/ # set permission cd /usr/local/vpnserver/ sudo chmod 600 * sudo chmod 700 vpncmd vpnserver再起動した時にSoftether serverが起動するようにサービスを作成します.
sudo vi /etc/systemd/system/vpnserver.service/etc/systemd/system/vpnserver.service[Unit] Description=SoftEther VPN Server After=network.target network-online.target [Service] ExecStart=/usr/local/vpnserver/vpnserver start ExecStop=/usr/local/vpnserver/vpnserver stop Type=forking RestartSec=3s [Install] WantedBy=multi-user.target先ほど作成したサービスを有効にします.
# read service sudo systemctl daemon-reload # enable and start sudo systemctl enable vpnserver.service sudo systemctl start vpnserver.serviceserver用のポートを解放する
VPN接続用にGCPのポート(TCP992,1194,5555のいずれか,UDP500,4500,1701)を開放する必要があります.
手順はSSH用にポート開放した手順と同様です.
画像の「さっき設定したやつ」のところに適宜,「TCP992,1194,5555のいずれか」と「UDP500,4500,1701(iPhoneのL2TP用)」入力して保存します.
softether serverの詳細な設定を行う
WindowsまたはMacの方は公式サイトからGUIツールが配布されているので,それをインストールします.
インストールが完了し,実行します.
初期画面>New Setting から新しくホストを作成します.ホストネームに先ほどDDNSで取得したドメインを入力します.この時のパスワードは空で良いです.
OKを選択し,作成したホストをクリックすると,パスワード設定するように言われるので設定します.
仮想ハブを作成します.
DDNSは既に設定しているので,青丸部分はテキトーでいいです.(あとで無効にします.)
VPN Azureは使いません.
Create Userを選択し,ユーザーを作成します.
ユーザーネームとパスワードを設定します.
次にDDNSを無効にします.
設定ファイルを出力し,そのファイルを以下にようにfalseからtrueに編集し保存します.
先ほど編集したファイルを読み込み,適用すればOKです.
⚠️また,443ポートはApacheサーバー用にしたいので,Listener Listから443をStopさせます.
Secure NATの設定
Manage Virtual Hub > Virtual NAT and Virtual DHCP Server (Secure NAT) > Secure NAT Configurationから好きなプライベートアドレスを割り当てます.
今回は最初に載せた上図のような構成にしたいので,192.168.0.0/24のネットワークを構築します.
ClientからServerに接続する
Clientの設定
ClientにはGUIツールがないので,コマンドで操作します.
cd /usr/local/vpnclient/ ./vpncmd仮想NICを作成します.今回は
vpn_nicという名前にします.
bash
NicCreate {name}
アカウントを作成します.今回は
testとします.AccountCreate test > host and port: {ip address or host name}:{port number} # 前回取得したドメイン:ポート番号は992か1194か5555 > virtual hub name: {server's hub name} # Server Managerで設定したハブ名 > username: {username} # Server Managerで設定したユーザーネーム > LAN card name: vpn_nic # さっき作成したやつ AccountPassword test (AccountCreateで作成した名前) > Password: ***** > standard or radius: standard AccountConnect test以下で接続済と出ればOKです.
# check connection status AccountListまた,再起動時に自動で接続するように設定します.
AccountStartupSet testこれでClientの設定は終わりです.
ルーティングテーブルの設定
先ほど作成した仮想NICにIPアドレスを振るようにします.恐らく,
ip aコマンドを打ってもまだ割り当てられていないと思います.sudo vi /etc/sysctl.conf/etc/sysctl.confnet.ipv4.ip_forward=1sudo sysctl -p sudo dhclient vpn_{name} # 今回は{name}=vpn_nic ip aでIPが割り当てられたらOK
最後にスタートアップ時にDHCPが動くようにします.
sudo vi /home/{user}/vpn/dhcp.sh/home/{user}/vpn/dhcp.shdhclient vpn_{name}iPhoneから接続する
本題とは逸れますが,一応行います.
まず,iPhone用にL2TPの設定を行います.最初の画面>IPSec/L2TP Settingというのがあるのでそれをクリックします.そして,下図の画面のようにします.
ip addressの部分はDDNSのドメイン名にしてください.
で接続できればOKです.
192.168.0.11が割り当てられていて,ちゃんと接続できていますね!
ラズパイから接続する
softether client
基本的には,GCPにSoftether ClientをインストールとClientの設定と同じことをラズパイでします.
IPの固定
ラズパイはIPを固定した方が使い勝手がいい(∵GCP→ラズパイにリバースプロキシしたい)ので,固定します.
/etc/dhcpcd.confに以下を追記します.{name}には,作成した仮想NICの名前が入ります./etc/dhcpcd.confinterface {name} static ip_address=*.*.*.*/~再起動して,ホスト(GCPのsoftether serverのインターフェース)に
pingが通ればOKです!
※今回は,Secure NATの設定で指定した192.168.0.10にpingを送っていいます.sudo reboot ping 192.168.0.10 # check host's interfaceおわりに
とりあえず,長いのでここで終了です.
参考
- 投稿日:2020-05-26T21:35:28+09:00
マンションのNATを気合と技術で超える(NAT超えWake on LAN)[1]
はじめに
これもタイトルの通りなのですが,長年の夢だったマンションのNATを超えたWake on LAN(正しい言い回しなのか?)が遂に実現できました.
かなり長いので分けて書きます.備忘録的に書きますが,どれかが役に立てれば幸いです.
今回は,「GCPとMyDNSを使って,ドメインを取得する」について書きます.
- [1]GCPとMyDNSを使って,ドメインを取得する
- [2]GCPにSoftether Serverを立てる(iPhone/ラズパイから接続)
- [3]GCP上のApacheからローカルのラズパイApacheにリバースプロキシする
- [4]ラズパイをルーター化する
- [5]Wake on LAN用のPythonスクリプトを作成する.
目的
目的は単純でこんな感じで外からWake on LAN(WOL)で自宅のデスクトップPCを起動させたいだけです.
問題点
ポート解放ができない
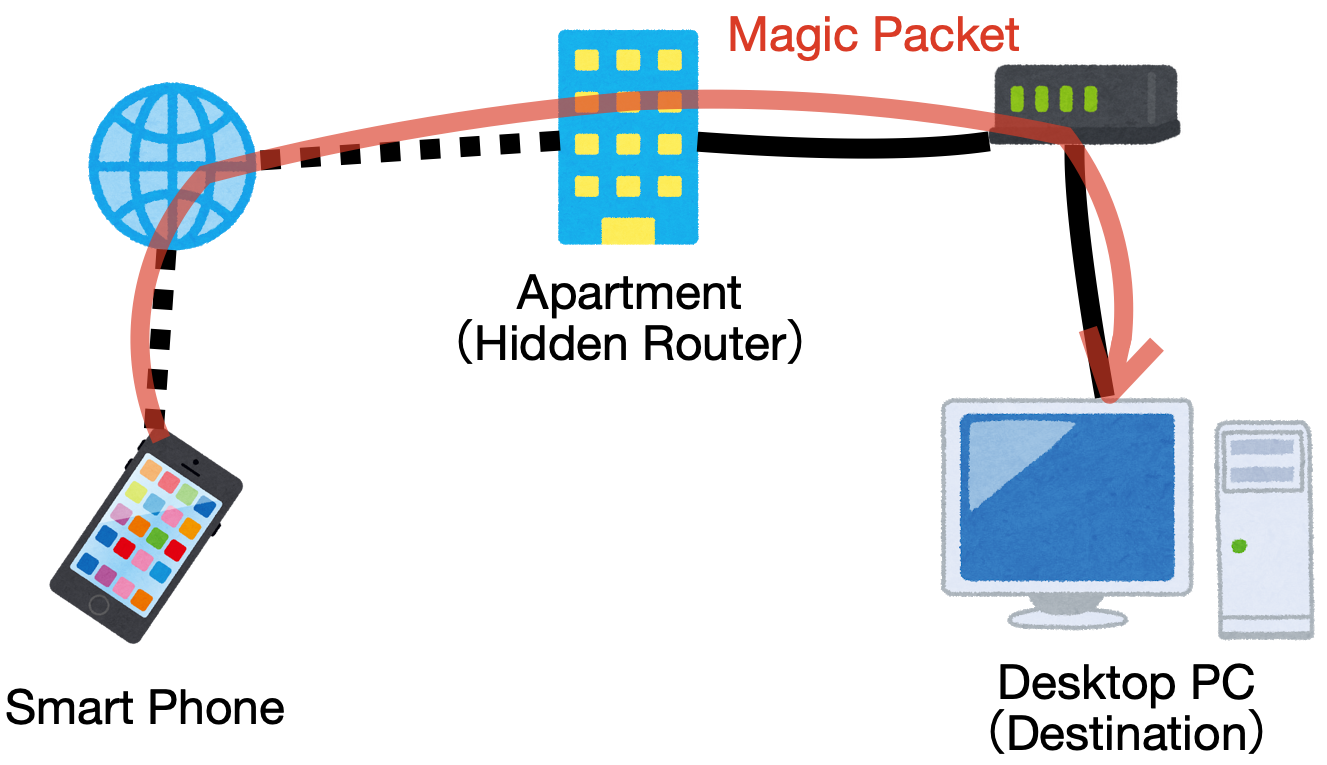
まず,マンションのセキュリティからかポート解放ができません.恐らく,図のようにルーターがマンション内にあり,管理人でないかぎりポート開放の設定はできないようになっているのでしょう.自前のルーターがブロードキャスト対応していない
マンションのLANケーブルの差込口は1つのため,元々から持っていたルーターをアクセスポイントモードで使用していました.しかし,そのルーターがブロードキャスト対応していませんでした.Magic Packetを送るときは,ルーターからブロードキャスト宛てに送らないとデスクトップには届かないらしいです.解決策
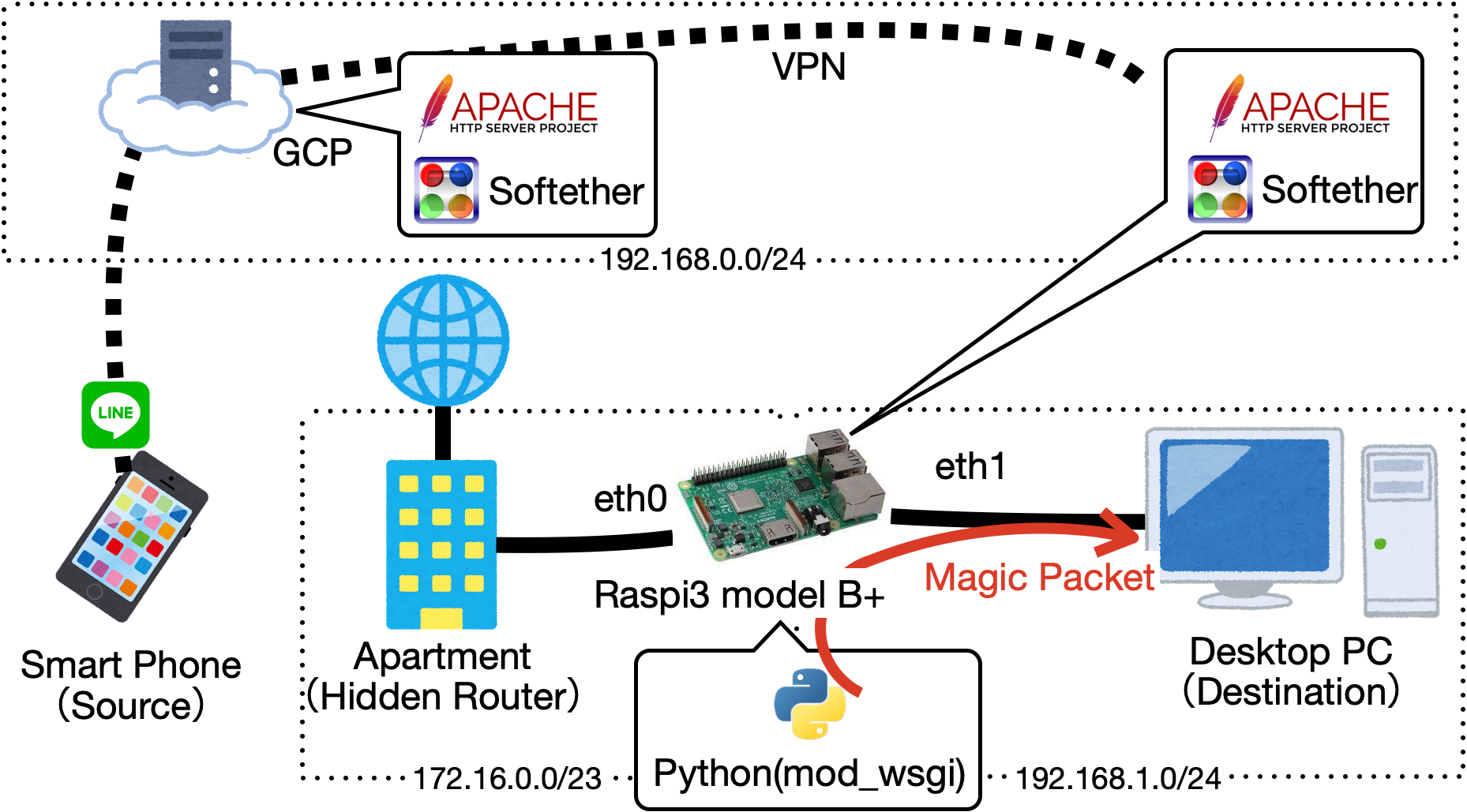
と,上記の問題点に直面したのですが,幸いにも手元にラズパイを持っていたので,これを使って以下のように接続すると解決できました.
- ネットワークの完成イメージ図
つまり,
- Magic Packetをブロードキャスト宛てに送るために,ラズパイをルーターにする
- ラズパイからPythonでMagic Packetを送る
- 外にいるスマホからアクセスできるようにクラウドサービスのGoogle cloud platform(GCP)を使う
- GCPからラズパイにリダイレクトできるようにGCPとラズパイをVPN接続する
- 使いやすさのためにLINEからGCPにアクセスする
主に使ったもの
- サービス
- Google Cloud Platform
- Softether
- MyDNS
- mod_wsgi
- apache
- LINE bot
- もの
- ラズパイ
GCPとMyDNSを使って,ドメインを取得する
備忘録的に順を追って書いていきます.上記を達成するために,まずは「GCPとMyDNSを使って,ドメインを取得」します.
GCP
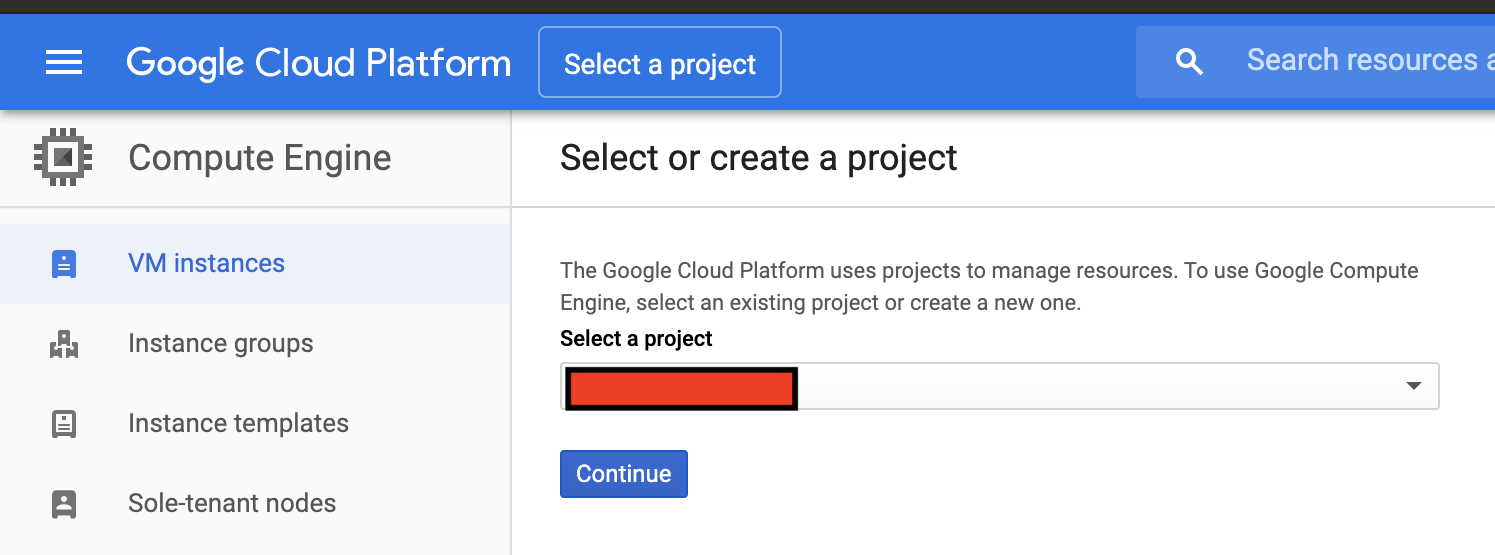
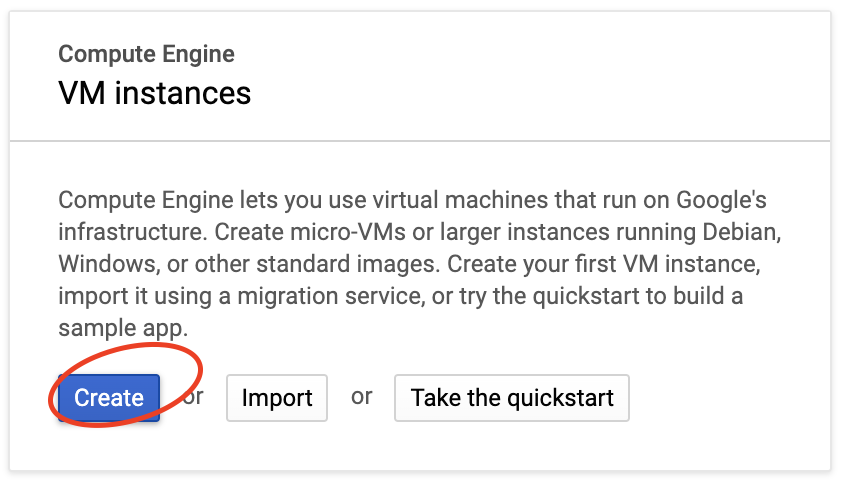
VMインスタンスの作成
まずはGCPを利用し,サーバーを構築します.公式サイトからこれから始めるGCP(GCE) 安全に無料枠を使い倒せを参考に作成します.
まずプロジェクトを作成します.
Organizationはなしにしました.
プロジェクトを作成したら,VMインスタンスを作成します.
先ほど作成したらプロジェクトを選択します.
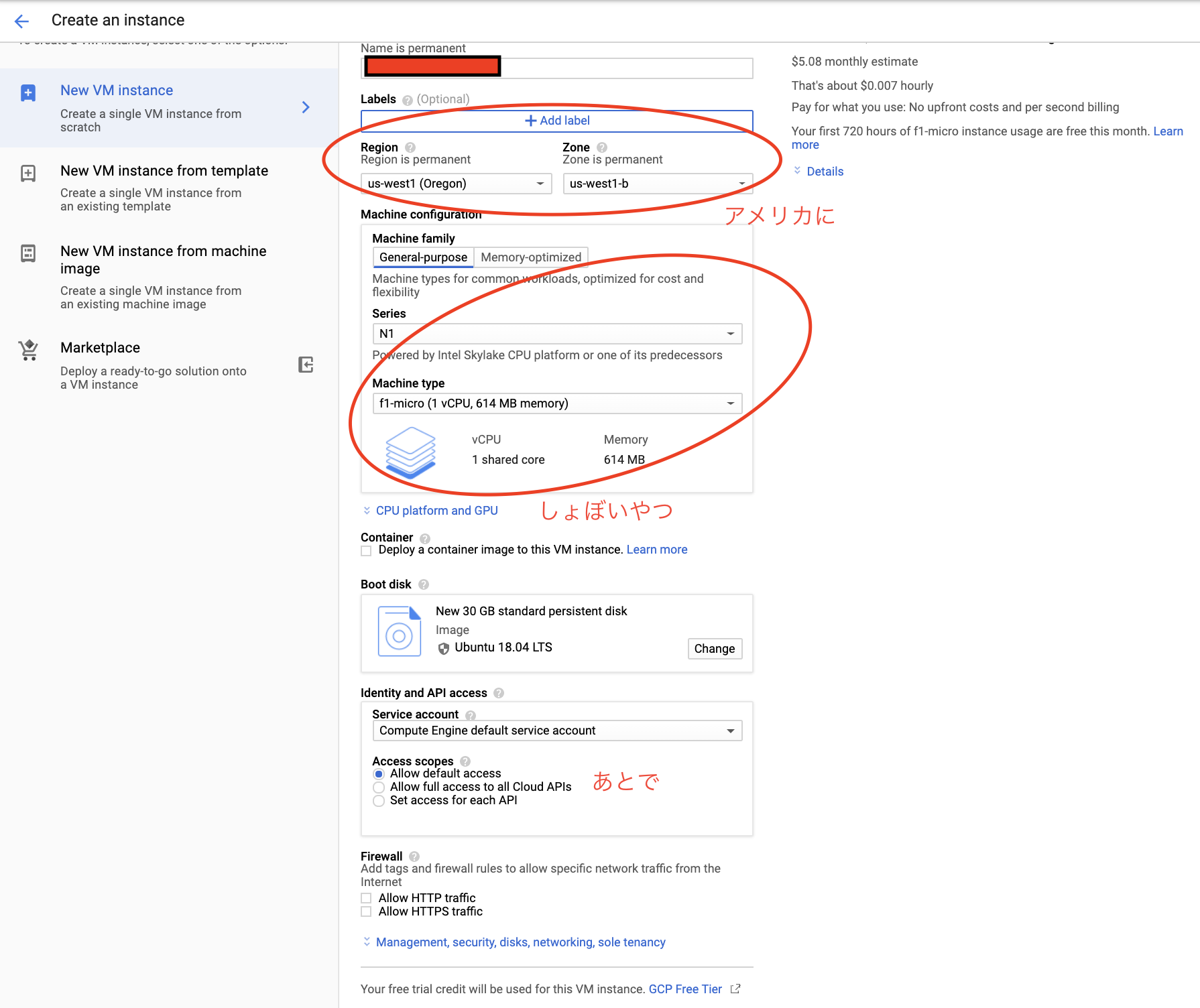
無料なのは,Regionはアメリカ,マシンタイプはしょぼいやつにします.(無料枠)
図中であとでと書いているところはファイアウォールの設定です.あとで設定できるのでそのままでいいと思います.
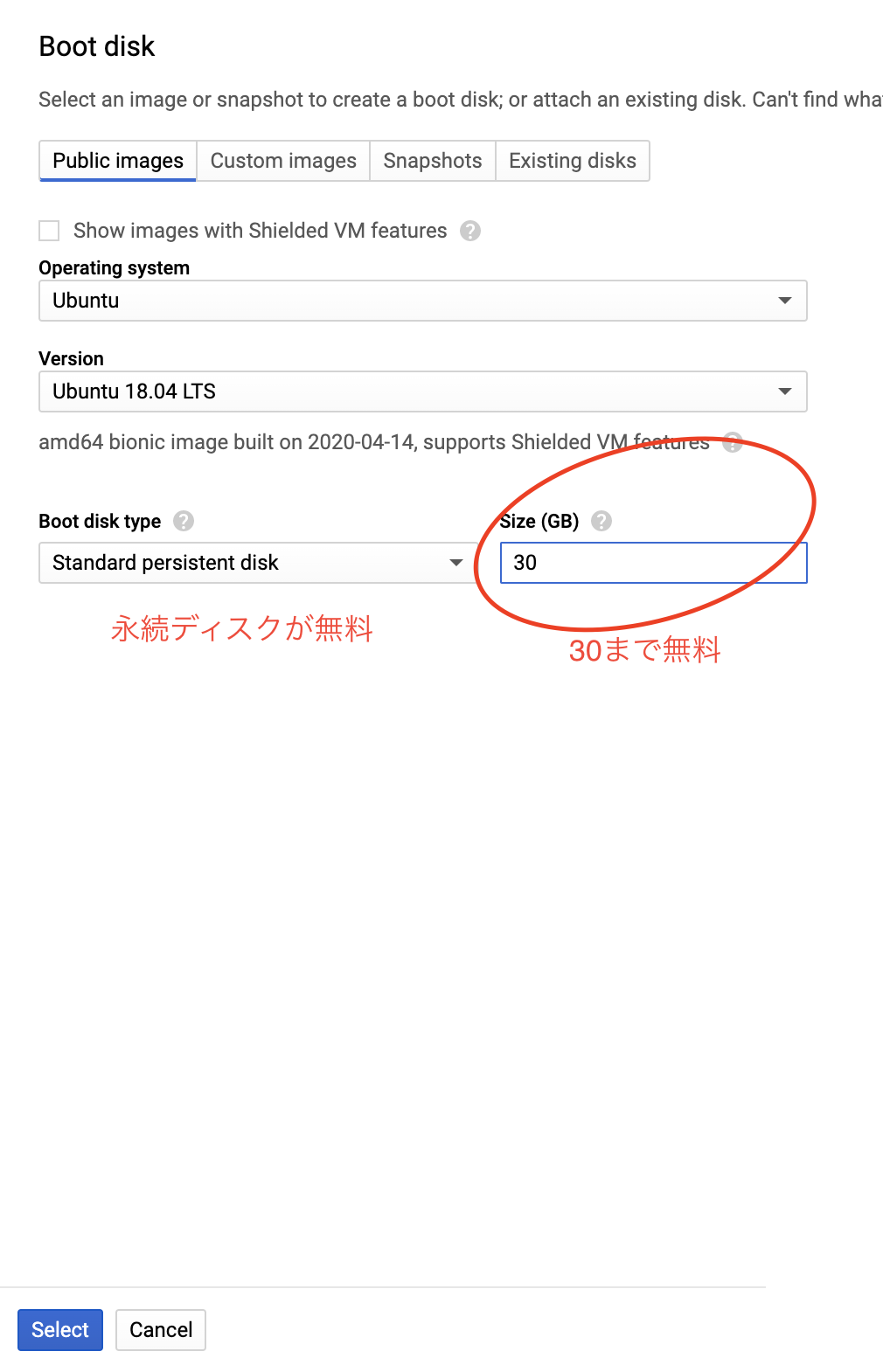
Boot Diskは慣れているUbuntuを選びました.容量は30GBまで無料なので,デフォルト値の10GBから変更しておきます.
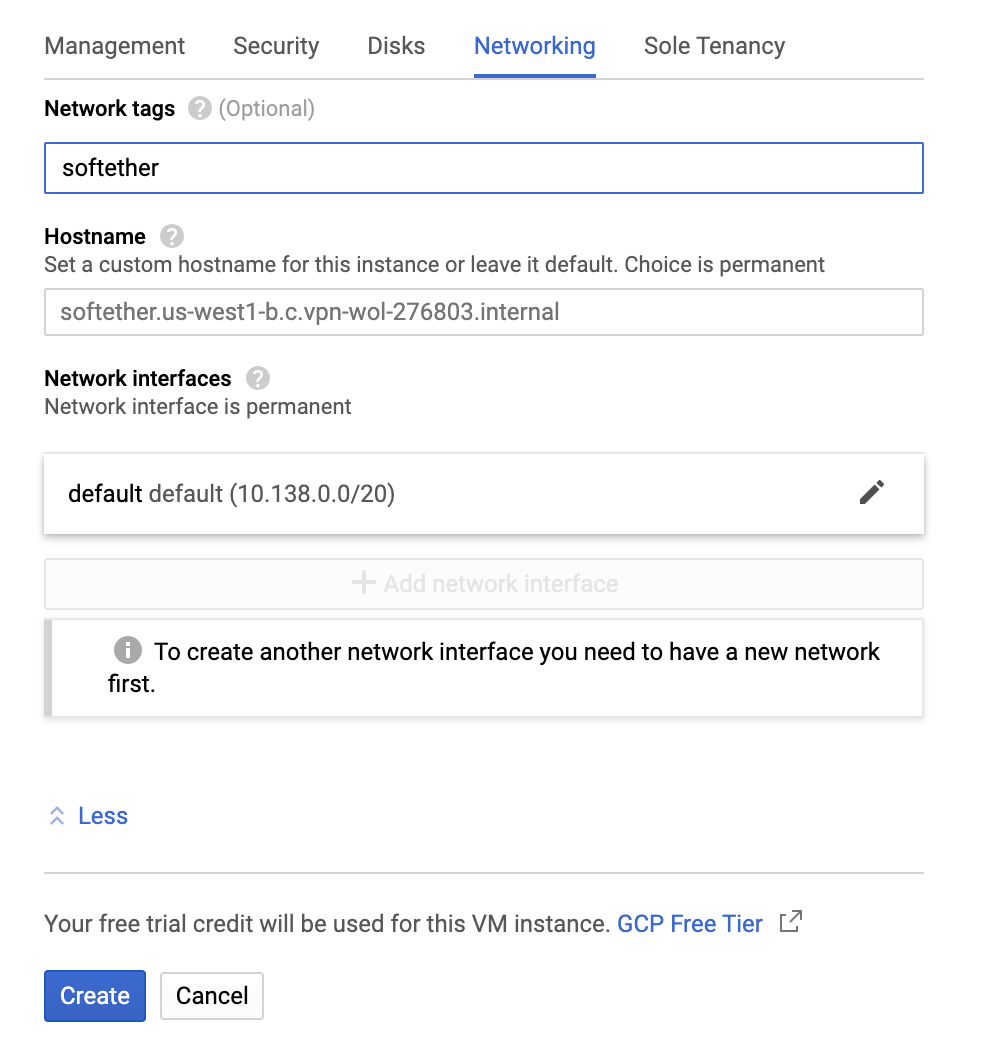
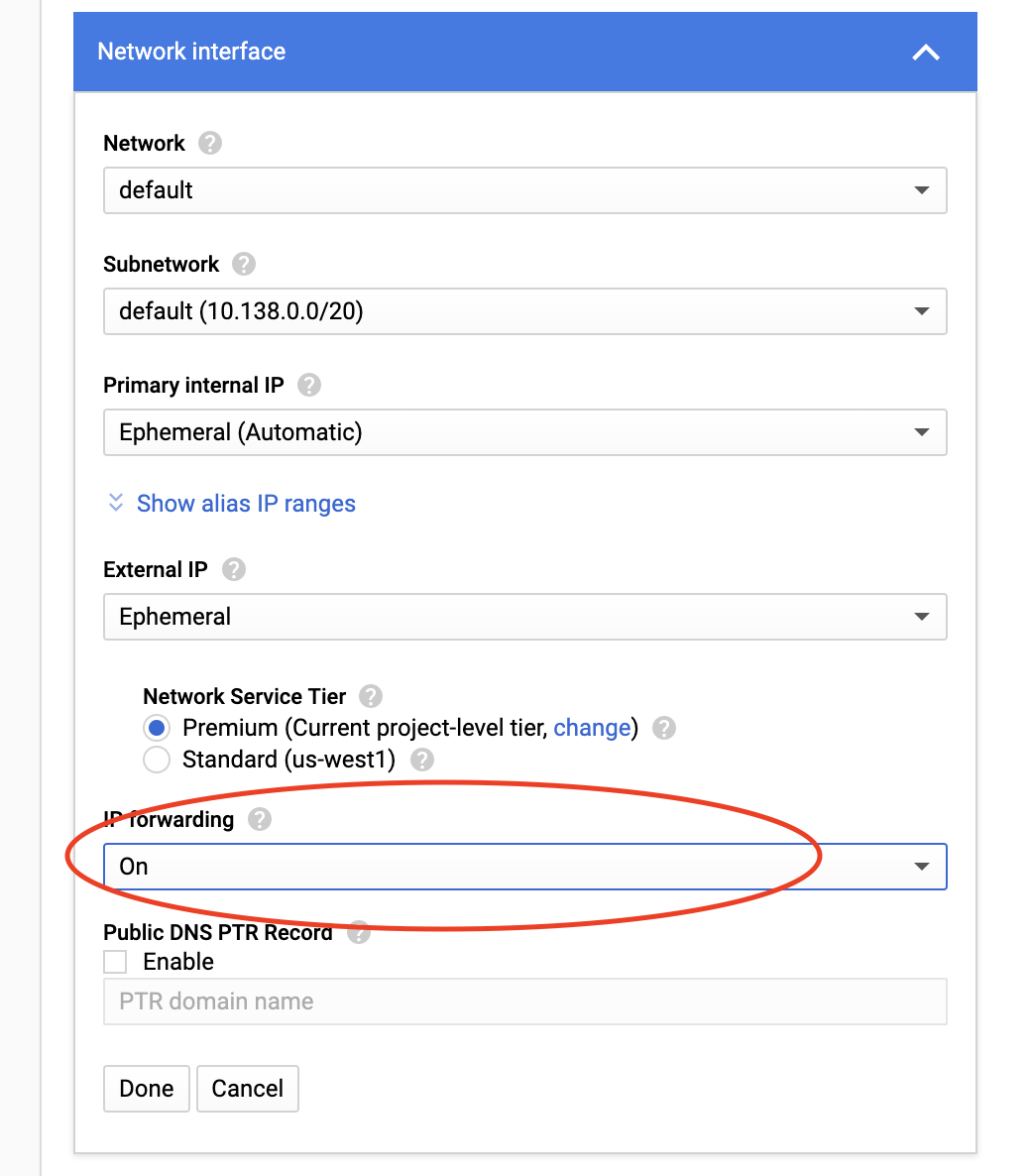
※重要 IPフォワーディングを有効にします.これは後から変更できません!
あとは「作成」を押して,VMインスタンスの作成は完了です.
GCloudのインストール
SSHで作成したVMインスタンスに接続できるようにするために,
gcloudをインストールします.mkdir ~/gcloud cd ~/gcloudここのクイックスタート>自身のOSに合わせて
tar.gzファイルをダウンロードし,先ほど作成したディレクトリに入れます.
そしてそのファイルを以下のように解凍し,インストールします.tar xvzf gcloud.tar.gz ./google-cloud-sdk/install.shターミナルを再起動し,以下コマンドを打てば
gloudのインストールは完了です.gcloud initgcloudからSSH接続できるか確認
インストールが完了したら,先ほど作成したGCPのプロジェクトと紐付けします.
gcloud config set project {my-project or id}次に,VMインスタンスにSSH接続します.
gcloud compute ssh {instance name or id} #--ssh-flag="-p {port number}"※ポートはこの後変えるので,今後はコメントを消して,自身が設定したポートを指定する必要があります.
接続できればOKです.SSH用のファイアウォールの設定
後回しにしていたファイアウォールを設定します.
デフォルトのポート番号は使わない方が良いらしいです.
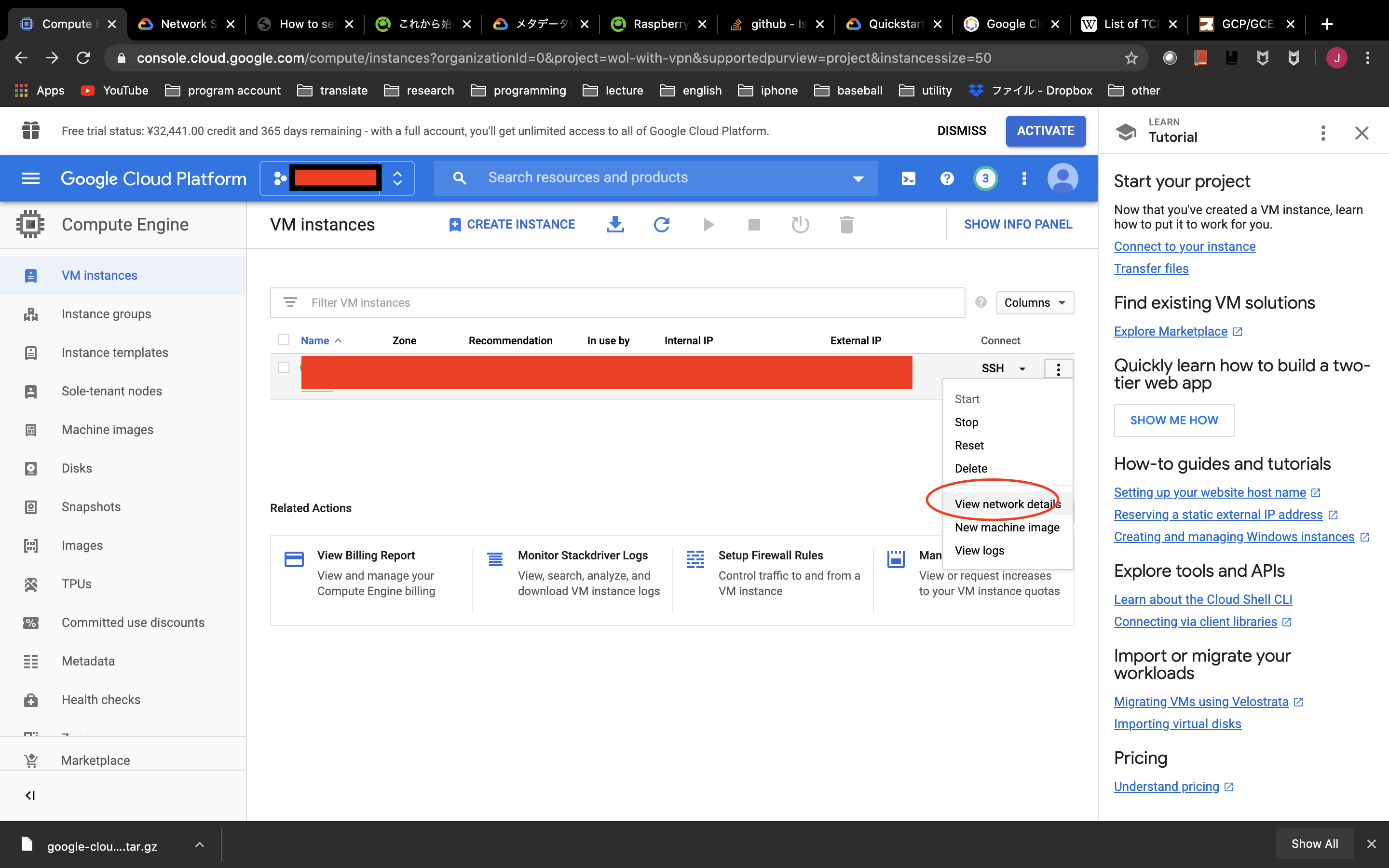
まず,VMインスタンスにSSH接続し,SSHの設定を変更します.gcloud compute ssh {instance name or id} sudo cp -p /etc/ssh/sshd_config /etc/ssh/sshd_config.bak sudo sed -i -e "s/#Port 22/Port {port number}/g" /etc/ssh/sshd_config sudo service ssh restartその後,Webの方から
Compute Engine>VM Instances> View Network details で先ほど設定した{port number}をルールとして設定します.
保存して,再度以下で接続できればOKです.
gcloud compute ssh {instance name or id} --ssh-flag="-p {port number}"時間の設定
デフォルトでは,日本時間に設定されていないので,変更しておきます.
SSH接続して,sudo apt-get install dbus sudo timedatectl set-timezone Asia/Tokyo以上でGCPの基本設定は終わりです.その他,セキュリティのために2ファクタ認証もやっておいた方が良いですが,ここでは割愛します.
DDNS
設定
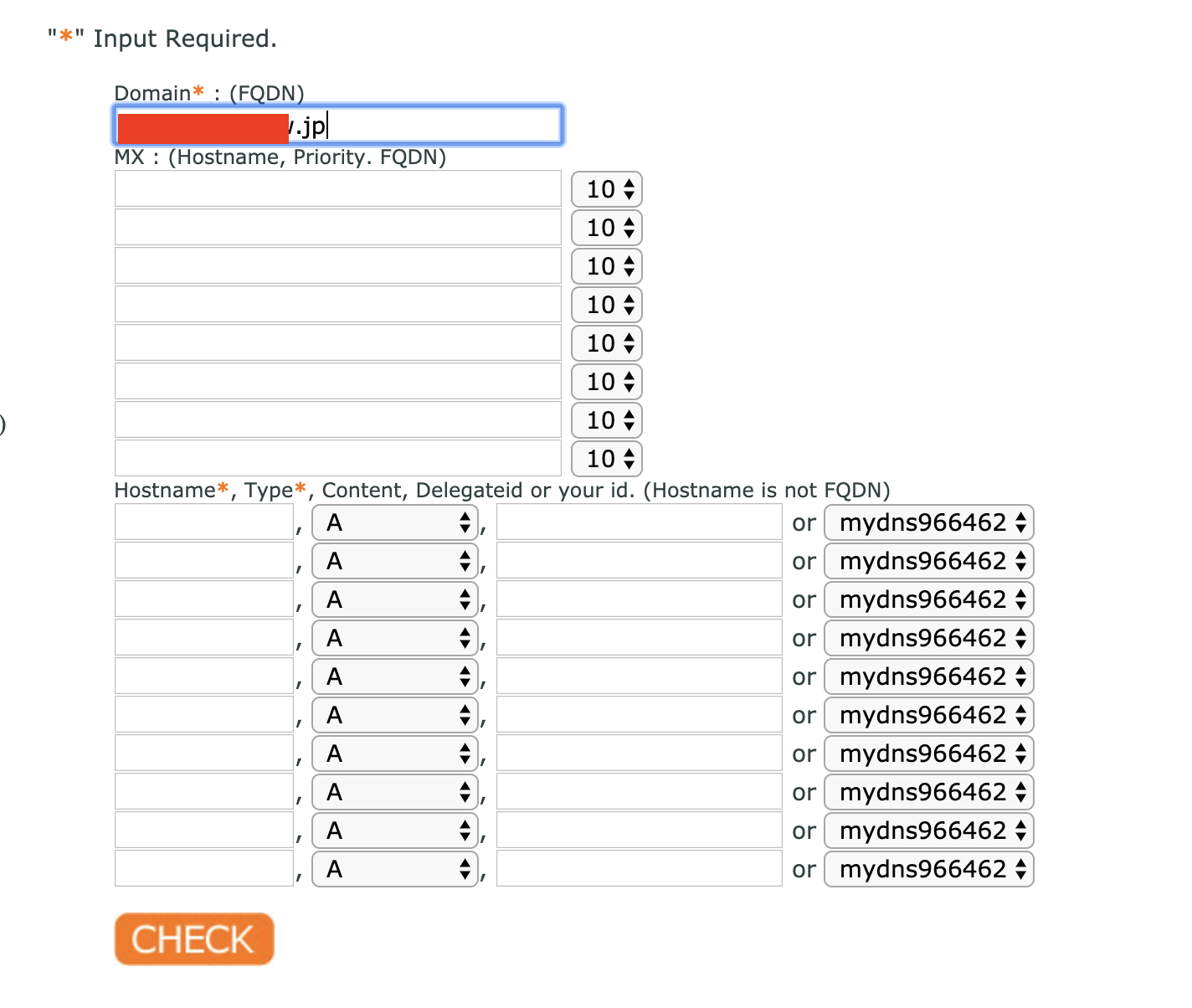
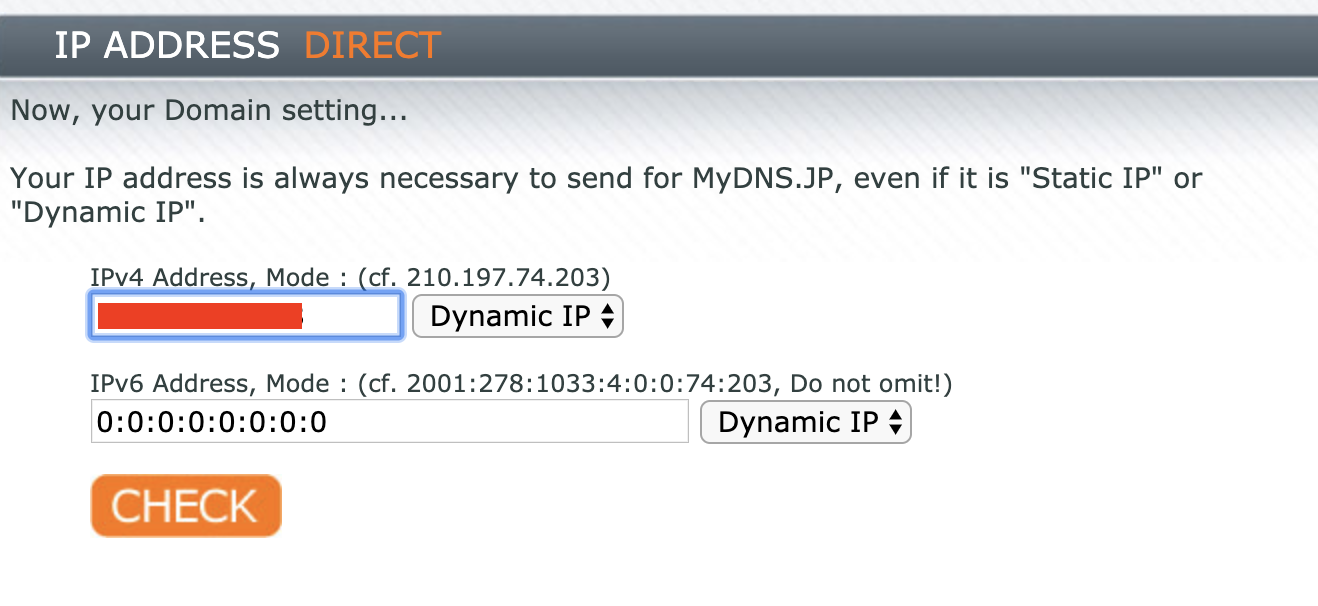
お金を払えば,固定IPが得られますが,ドメインの取得がてらmydnsを使って,DDNSします.
myDNSからJoin us>Sign UPでアカウントを作成したら,DOMAIN INFO > OKから,ドメインを設定します.
CHECK > OKで完了です.
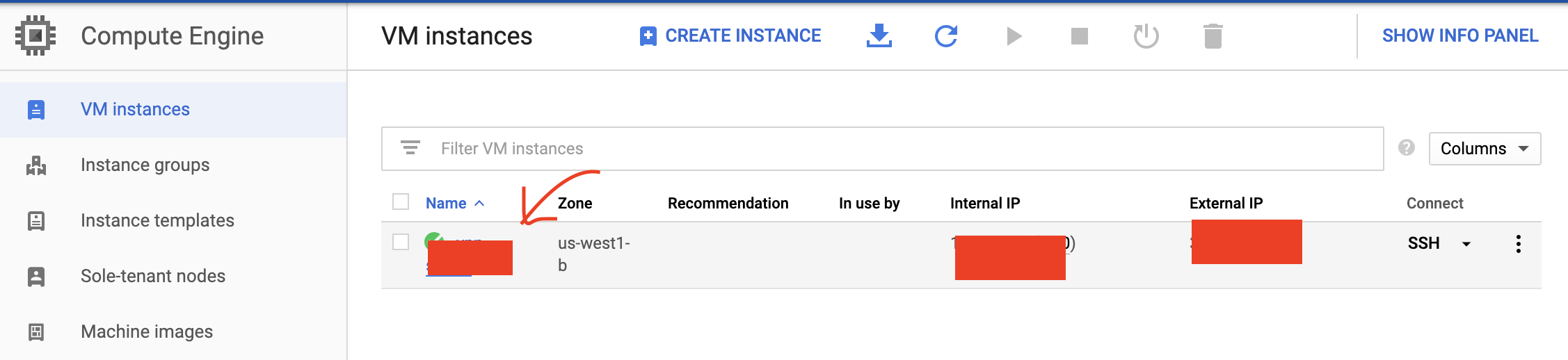
次にIP ADDR DIRECTから,DDNSの設定をします.GCPのサイトに戻り,
上図のように赤四角で隠している部分に現在のGCPのExternal IPがあるので,それをメモし,入力します.(矢印は無視してください)
CHECK > OKで完了です.
IPの通知
IPを再起動時と1時間起きに通知するようにします.
まず,GCPにSSH接続し,アップデート用のシェルスクリプトを作成します.mkdir ~/vpn cd ~/vpn vi update_ip.shupdate_ip.sh#! /bin/bash wget --http-user=mydnsxxxxx --http-password=~~~~~~~ http://www.mydns.jp/login.html -O /dev/nullパーミッションを変更します.
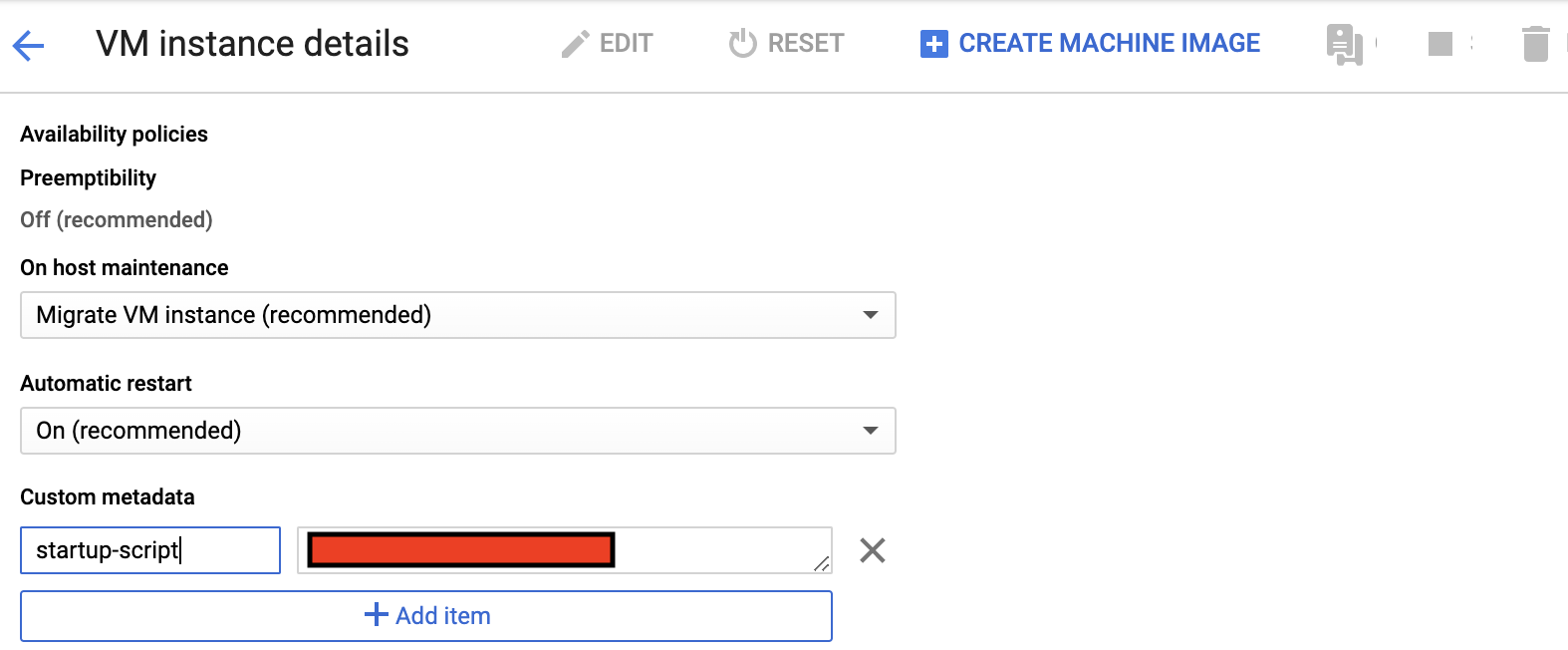
chmod +x ~/vpn/update_ip.sh次に,再度GCPのサイトから,
EDIT > custom metadata で,以下の赤四角部分に以下を入力します.
#! /bin/bash bash /home/{name}/vpn/update_ip.sh
これで,再起動時の通知設定は完了です.
最後に念のため,1時間置きに通知するように設定します.
crontab -e# update ip * */1 * * * /home/{name}/vpn/update_ip.sh以上でDDNSの設定は完了です.
おわりに
とりあえず,長いのでここで終了です.
参考

- 投稿日:2020-05-26T21:35:28+09:00
GCPとMyDNSを使って,ドメインを取得する(NAT超えWake on LAN[1])
はじめに
長年の夢だったマンションのNATを超えたWake on LAN(正しい言い回しなのか?)が遂に実現できました.
かなり長いので分けて書きます.備忘録的に書きますが,どれかが役に立てれば幸いです.
今回は,「GCPとMyDNSを使って,ドメインを取得する」について書きます.
- [1]GCPとMyDNSを使って,ドメインを取得する
- [2]GCPにSoftether Serverを立てる(iPhone/ラズパイから接続)
- [3]GCP上のApacheからローカルのラズパイApacheにリバースプロキシする
- [4]ラズパイをルーター化する
- [5]Wake on LAN用のPythonスクリプトを作成する.
目的
目的は単純でこんな感じで外からWake on LAN(WOL)で自宅のデスクトップPCを起動させたいだけです.
問題点
ポート解放ができない
まず,マンションのセキュリティからかポート解放ができません.恐らく,図のようにルーターがマンション内にあり,管理人でないかぎりポート開放の設定はできないようになっているのでしょう.自前のルーターがブロードキャスト対応していない
マンションのLANケーブルの差込口は1つのため,元々から持っていたルーターをアクセスポイントモードで使用していました.しかし,そのルーターがブロードキャスト対応していませんでした.Magic Packetを送るときは,ルーターからブロードキャスト宛てに送らないとデスクトップには届かないらしいです.解決策
と,上記の問題点に直面したのですが,幸いにも手元にラズパイを持っていたので,これを使って以下のように接続すると解決できました.
- ネットワークの完成イメージ図
つまり,
- Magic Packetをブロードキャスト宛てに送るために,ラズパイをルーターにする
- ラズパイからPythonでMagic Packetを送る
- 外にいるスマホからアクセスできるようにクラウドサービスのGoogle cloud platform(GCP)を使う
- GCPからラズパイにリダイレクトできるようにGCPとラズパイをVPN接続する
- 使いやすさのためにLINEからGCPにアクセスする
主に使ったもの
- サービス
- Google Cloud Platform
- Softether
- MyDNS
- mod_wsgi
- apache
- LINE bot
- もの
- ラズパイ
GCPとMyDNSを使って,ドメインを取得する
備忘録的に順を追って書いていきます.上記を達成するために,まずは「GCPとMyDNSを使って,ドメインを取得」します.
GCP
VMインスタンスの作成
まずはGCPを利用し,サーバーを構築します.公式サイトからこれから始めるGCP(GCE) 安全に無料枠を使い倒せを参考に作成します.
まずプロジェクトを作成します.
Organizationはなしにしました.
プロジェクトを作成したら,VMインスタンスを作成します.
先ほど作成したらプロジェクトを選択します.
無料なのは,Regionはアメリカ,マシンタイプはしょぼいやつにします.(無料枠)
図中であとでと書いているところはファイアウォールの設定です.あとで設定できるのでそのままでいいと思います.
Boot Diskは慣れているUbuntuを選びました.容量は30GBまで無料なので,デフォルト値の10GBから変更しておきます.
※重要 IPフォワーディングを有効にします.これは後から変更できません!
あとは「作成」を押して,VMインスタンスの作成は完了です.
GCloudのインストール
SSHで作成したVMインスタンスに接続できるようにするために,
gcloudをインストールします.mkdir ~/gcloud cd ~/gcloudここのクイックスタート>自身のOSに合わせて
tar.gzファイルをダウンロードし,先ほど作成したディレクトリに入れます.
そしてそのファイルを以下のように解凍し,インストールします.tar xvzf gcloud.tar.gz ./google-cloud-sdk/install.shターミナルを再起動し,以下コマンドを打てば
gloudのインストールは完了です.gcloud initgcloudからSSH接続できるか確認
インストールが完了したら,先ほど作成したGCPのプロジェクトと紐付けします.
gcloud config set project {my-project or id}次に,VMインスタンスにSSH接続します.
gcloud compute ssh {instance name or id} #--ssh-flag="-p {port number}"※ポートはこの後変えるので,今後はコメントを消して,自身が設定したポートを指定する必要があります.
接続できればOKです.SSH用のファイアウォールの設定
後回しにしていたファイアウォールを設定します.
デフォルトのポート番号は使わない方が良いらしいです.
まず,VMインスタンスにSSH接続し,SSHの設定を変更します.gcloud compute ssh {instance name or id} sudo cp -p /etc/ssh/sshd_config /etc/ssh/sshd_config.bak sudo sed -i -e "s/#Port 22/Port {port number}/g" /etc/ssh/sshd_config sudo service ssh restartその後,Webの方から
Compute Engine>VM Instances> View Network details で先ほど設定した{port number}をルールとして設定します.
保存して,再度以下で接続できればOKです.
gcloud compute ssh {instance name or id} --ssh-flag="-p {port number}"時間の設定
デフォルトでは,日本時間に設定されていないので,変更しておきます.
SSH接続して,sudo apt-get install dbus sudo timedatectl set-timezone Asia/Tokyo以上でGCPの基本設定は終わりです.その他,セキュリティのために2ファクタ認証もやっておいた方が良いですが,ここでは割愛します.
DDNS
設定
お金を払えば,固定IPが得られますが,ドメインの取得がてらmydnsを使って,DDNSします.
myDNSからJoin us>Sign UPでアカウントを作成したら,DOMAIN INFO > OKから,ドメインを設定します.
CHECK > OKで完了です.
次にIP ADDR DIRECTから,DDNSの設定をします.GCPのサイトに戻り,
上図のように赤四角で隠している部分に現在のGCPのExternal IPがあるので,それをメモし,入力します.(矢印は無視してください)
CHECK > OKで完了です.
IPの通知
IPを再起動時と1時間起きに通知するようにします.
まず,GCPにSSH接続し,アップデート用のシェルスクリプトを作成します.mkdir ~/vpn cd ~/vpn vi update_ip.shupdate_ip.sh#! /bin/bash wget --http-user=mydnsxxxxx --http-password=~~~~~~~ http://www.mydns.jp/login.html -O /dev/nullパーミッションを変更します.
chmod +x ~/vpn/update_ip.sh次に,再度GCPのサイトから,
EDIT > custom metadata で,以下の赤四角部分に以下を入力します.
#! /bin/bash bash /home/{name}/vpn/update_ip.sh
これで,再起動時の通知設定は完了です.
最後に念のため,1時間置きに通知するように設定します.
crontab -e# update ip * */1 * * * /home/{name}/vpn/update_ip.sh以上でDDNSの設定は完了です.
おわりに
とりあえず,長いのでここで終了です.
参考
- 投稿日:2020-05-26T18:46:10+09:00
VirtualBox上のLinuxにコンパクトにオラクルデータベース(19c)を構築
VirtualBox上にコンパクトにオラクルデータベース(19c)を構築
VirtualBoxに複数の仮想マシンを構築すると、自端末のパソコンのリソースを結構食います。
仮想マシンを作る目的が「動作確認」であり、データを沢山格納しない、重い処理を流さないのであれば、あまりリソース掛けたくないですよね。ということで手順に起こしてみました。とはいえ、DBの物理設計ではなく、論理設計やSQLの動作確認を中心ということであれば、
以下を参考にVirtualBoxイメージから手軽にDBを作ることをお勧めします。
- OTN の VirtualBoxイメージ で Oracle DB 19c環境 を 楽々構築
https://qiita.com/ora_gonsuke777/items/b41f37637e59319796b4
※上記の方法は、物理設計を色々試したい場合には、勝手に名前が決まってたり、足りないライブラリがあったりと個人的には使いずらさを感じました。マルチテナント・アーキテクチャになっているのも、ローカル環境としてはちょっとリッチに感じました。ローカルはシンプルな構成が好き。
だけど、SQLの動作確認とかに使うのであれば、最高な気がします('ω')!!構成
ホストOS 仮想化ソフト ゲストOS DB DB備考 Windows10 Pro VirtualBox6.1 Oracle Linux 7.8 Oracle Database 19c 非CDB、Enterprise Edition Oracle Linuxをダウンロード
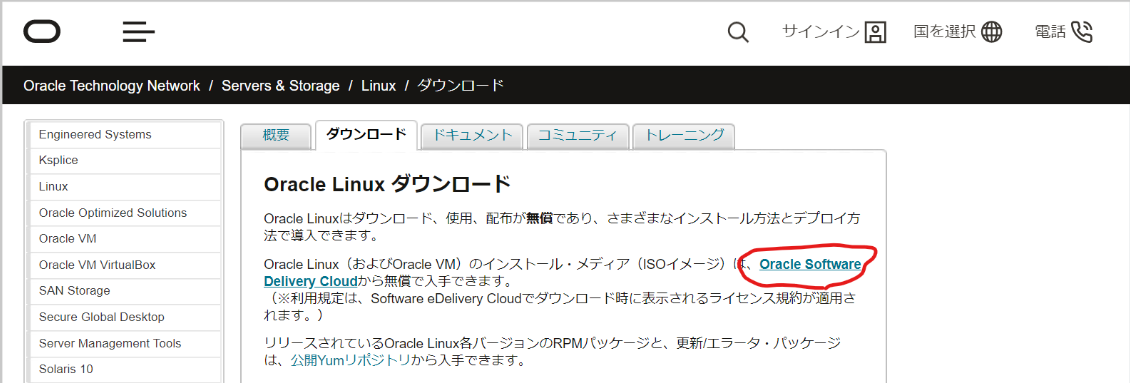
- ダウンロードページにアクセス、次のページでサイイン
https://www.oracle.com/technetwork/jp/server-storage/linux/downloads/index.html
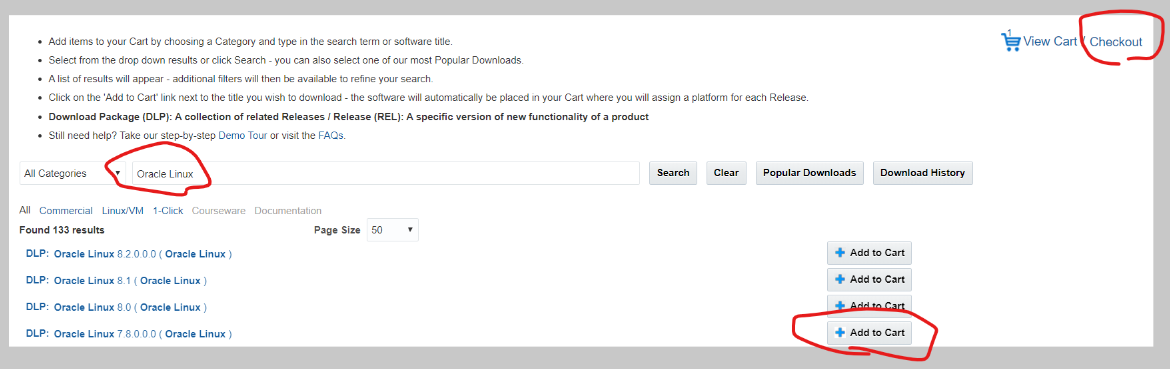
- 「Oracle Linux」の文言で検索し、カートに追加、そしてチェックアウトを押下
- 64bitを選択し、コンティニューを押下、次のページでライセンスに同意
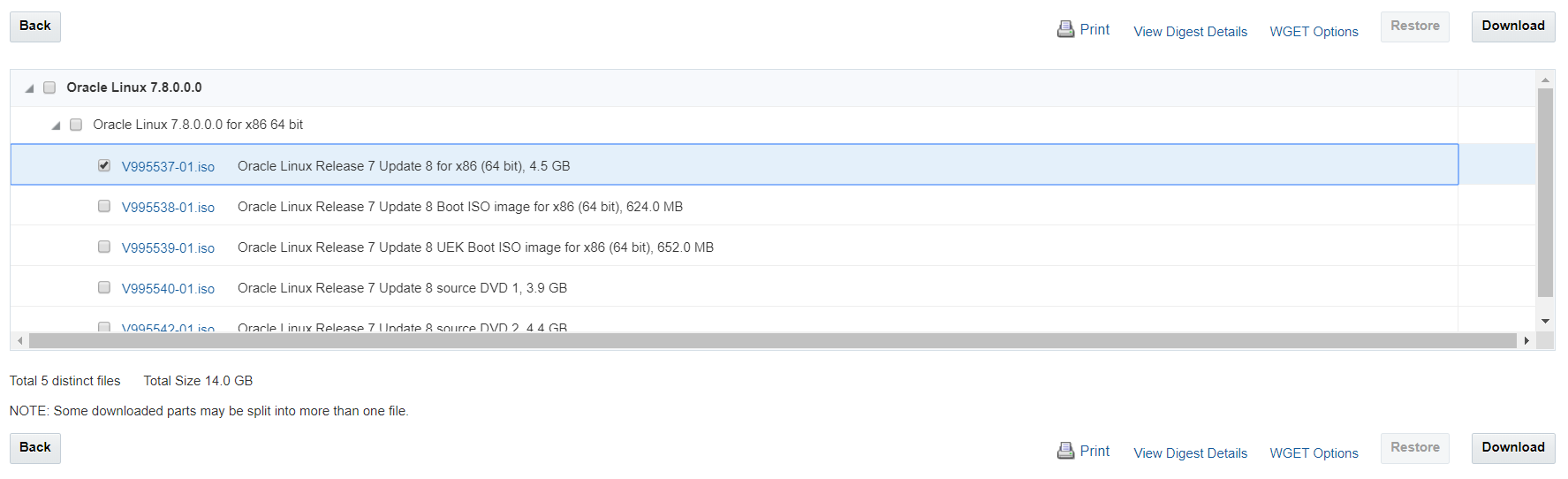
- 「V995537-01.iso」のみを選択し、ダウンロードボタンを押下、そうすると、ダウンロードマネージャー(exe)がダウンロードされるので実行する。その結果、「V995537-01.iso」がダウンロードされる。
Oracle Linuxを構築(仮想マシンの作成)
- VirtualBoxを立ち上げ後、新規ボタン押下、任意(例:dev)の名前を入力、タイプはLinux、バージョンはOracle(64bit)を選択
※マシンフォルダは任意でOK。環境設定でデフォルト設定できます。
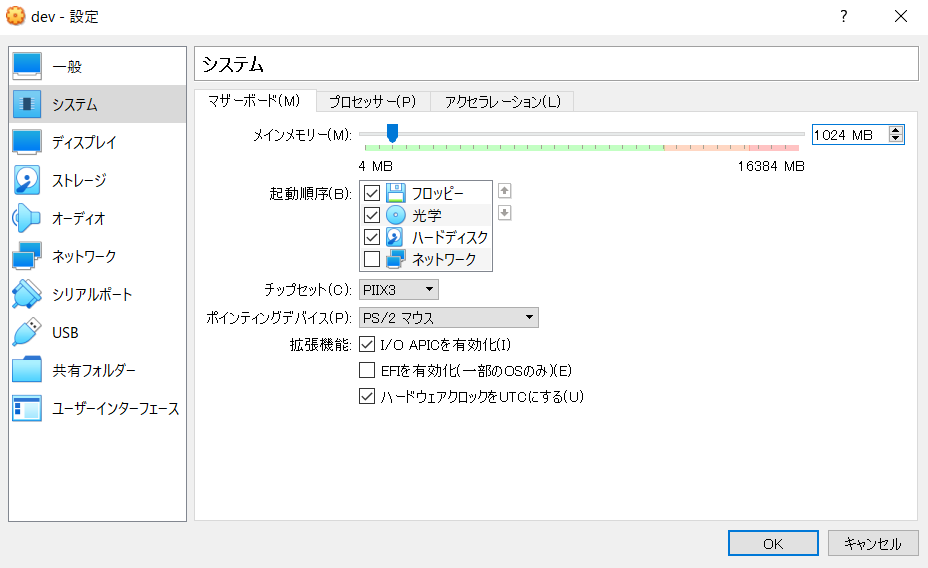
- メモリ「2048MB」に設定。※構築後、節約の為、1024MBにする。
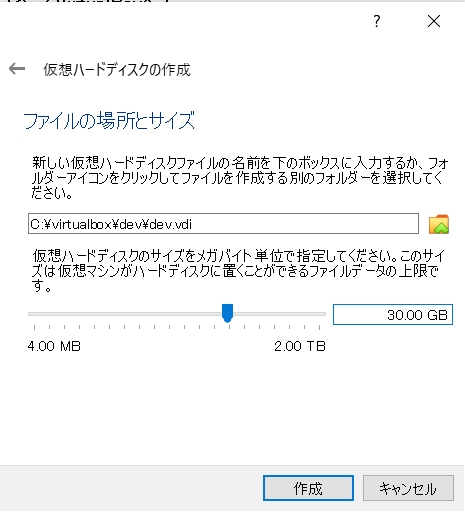
- 「仮想ハードディスクを作成する」を選択
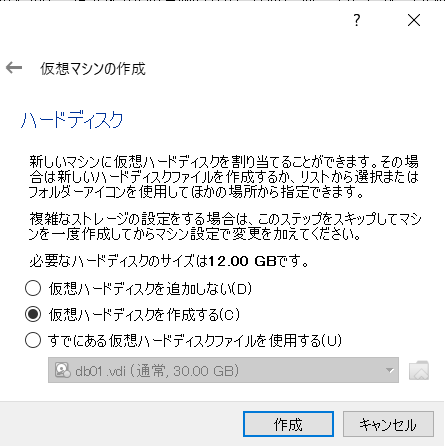
- 「VDI」を選択
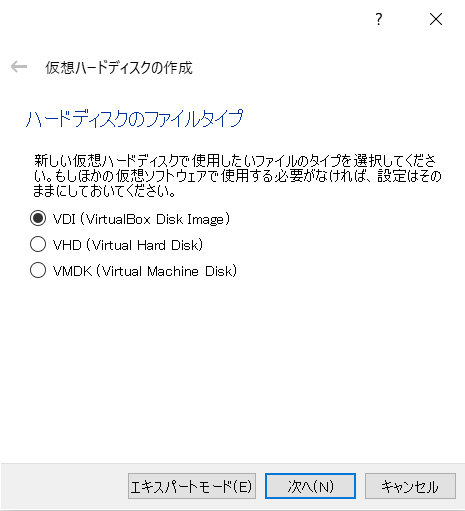
- 「可変サイズ」を選択
- ちょっと多めに「30G」。※デフォルトの「12G」だと私の場合DB構築中にディスク不足になりました。
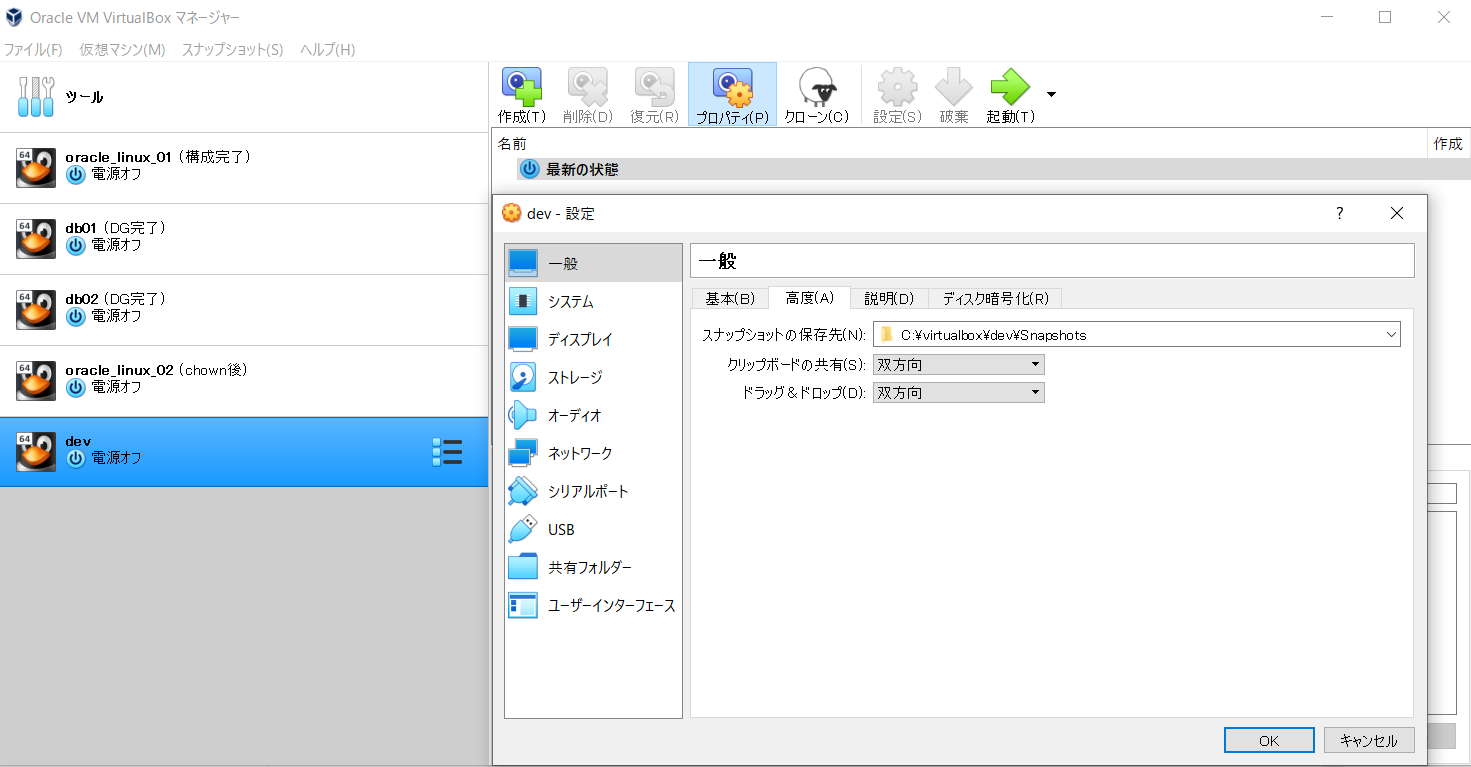
- 作成した仮想マシンを選択しながら、設定ボタンを押下、その後、「高度」タブを選択し、「クリップボードの共有」と「ドラッグ&ドロップ」に「双方向」を設定
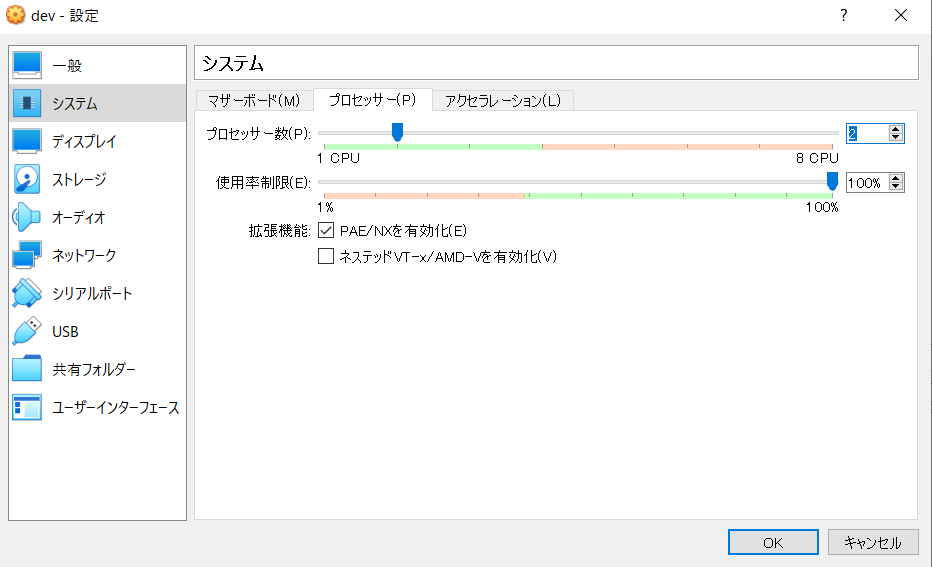
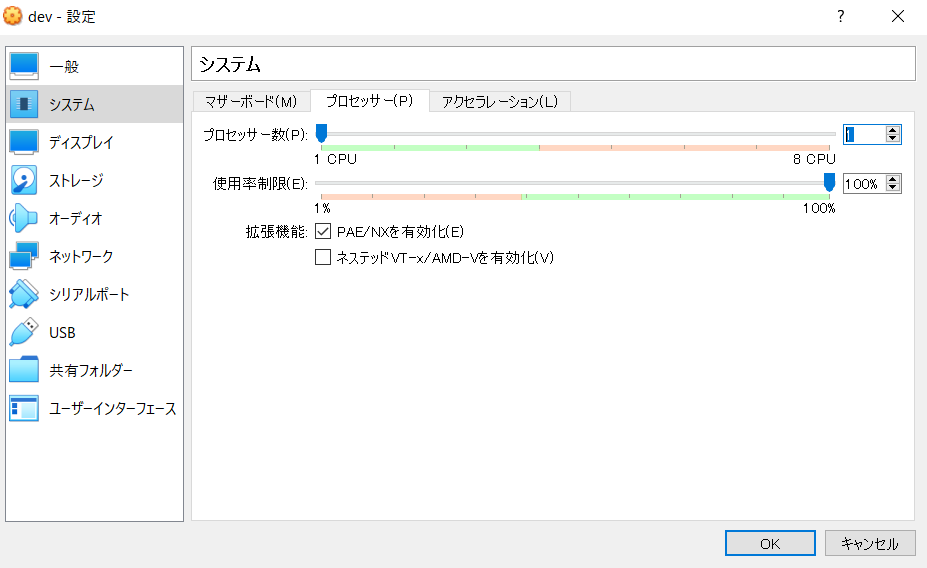
- プロセッサー数を「2」に。※構築後、節約の為、「1」にする。
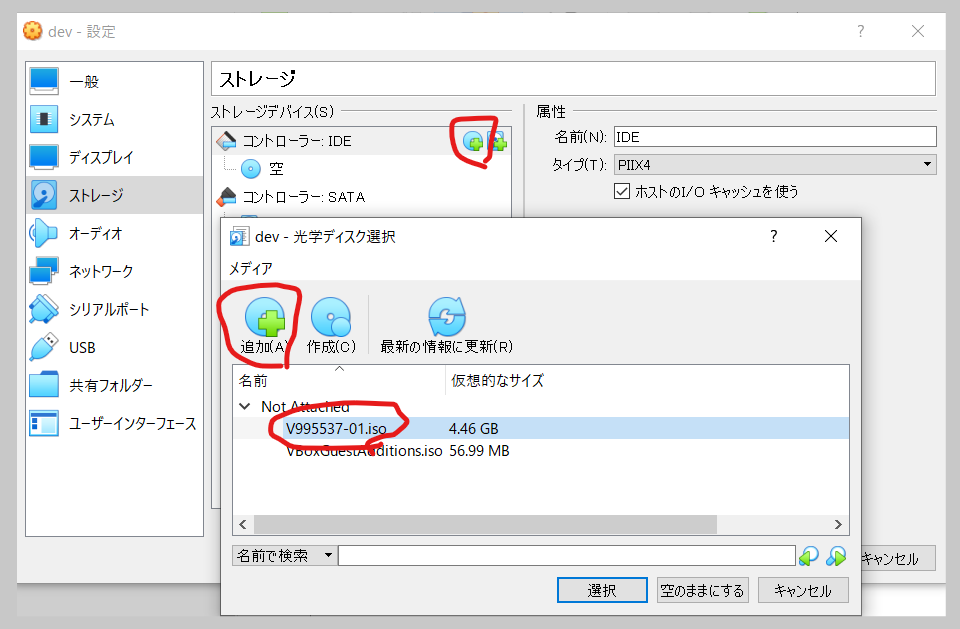
- オラクルのページからダウンロードしたisoファイルを光学ドライバに追加
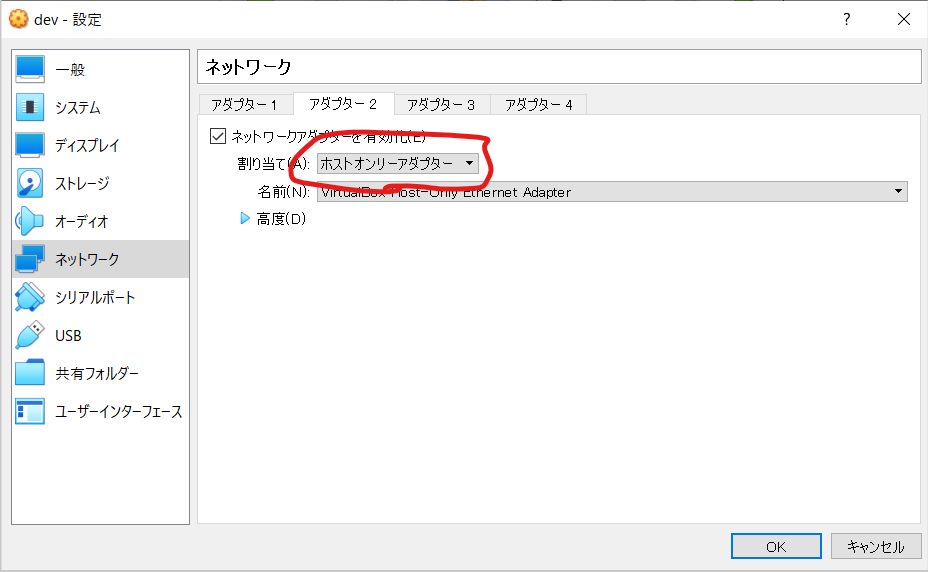
- アダプター2に「ホストオンリーアダプター」を選択。アダプター1はデフォルトの「NAT」でOK
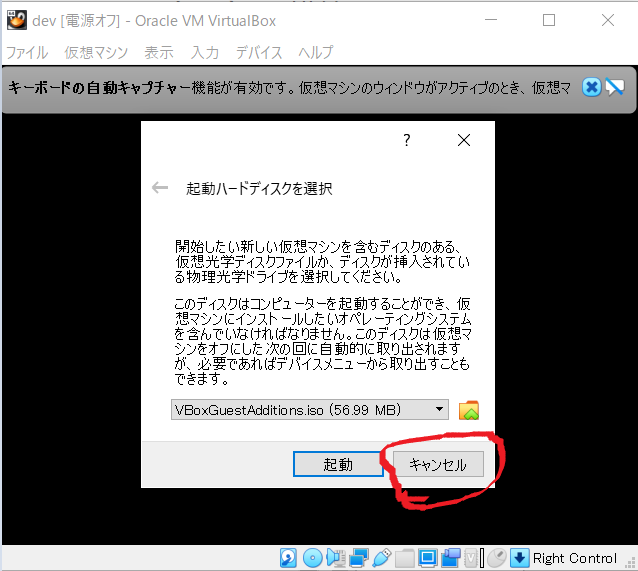
- 「起動」ボタン押下、「起動ハードディスクの選択」ダイアログが出た場合(初回は出ないはず)は、キャンセルでOK。
- 赤い画面が出てきたら、矢印キーで「Install Oracle Linux 7.8」を選択後、「Enter」ボタンを押下
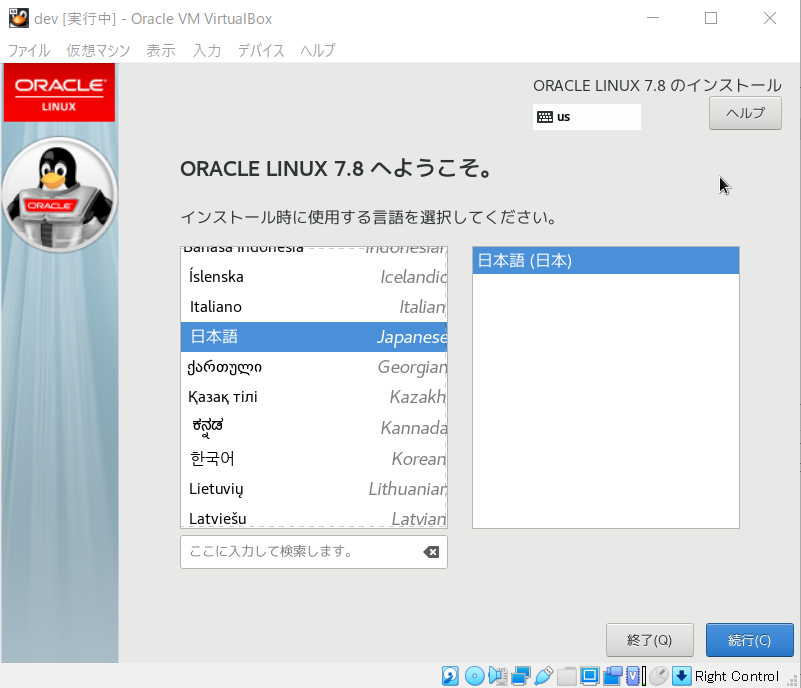
- 「日本語」を選択し、「続行」ボタン押下
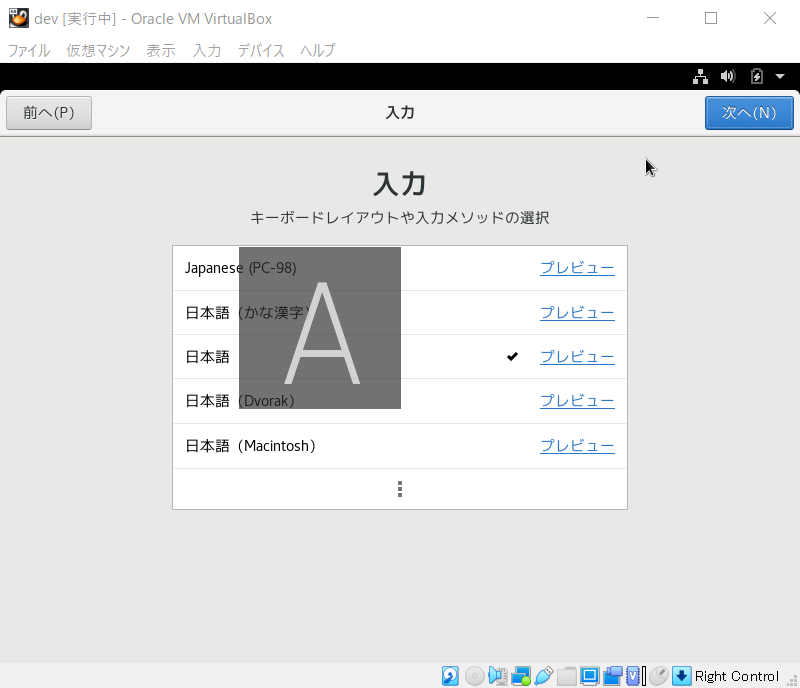
ゲストOSとホストOSのマウスカーソルを切り替えるには、「Ctrl」(二つある方の右側)ボタンを押下
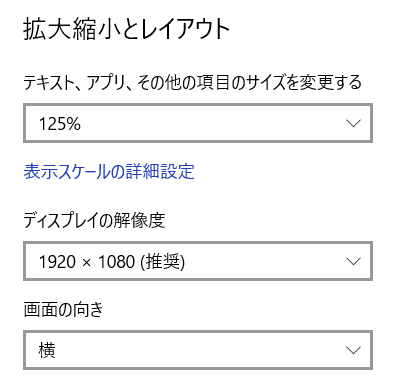
ボタンが見切れる場合は、ホストOSのディスプレイの設定を見直す。私の場合以下のように設定。
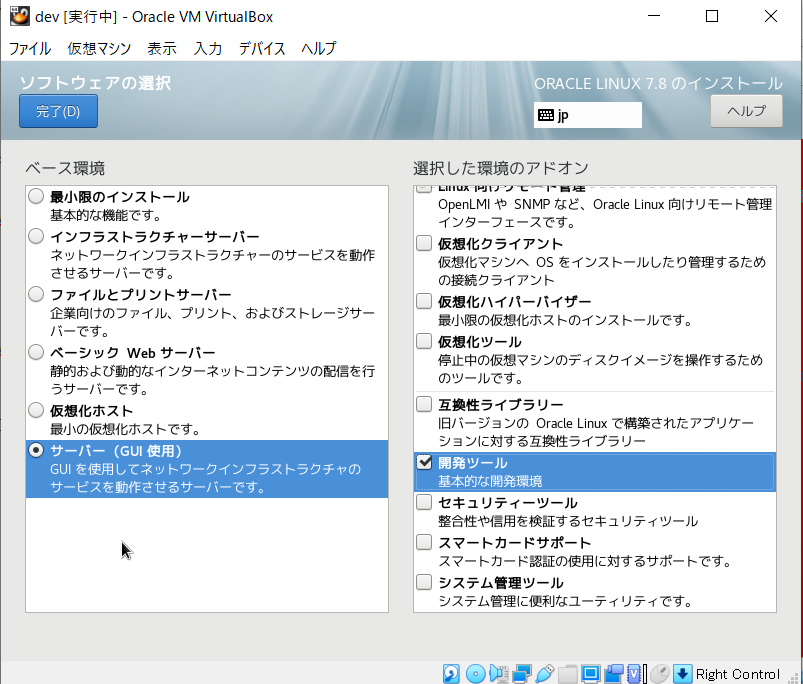
- 「ソフトウェアの選択」を押下し、以下の画像のように設定し、「完了」ボタンを押下
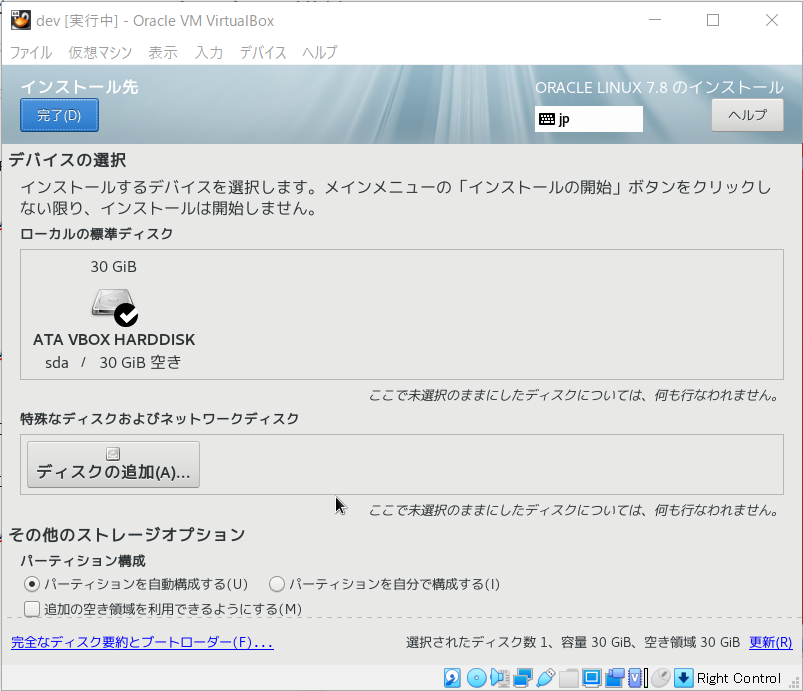
- 「インストール先」を押下し、デフォルトのまま、「完了」ボタンを押下
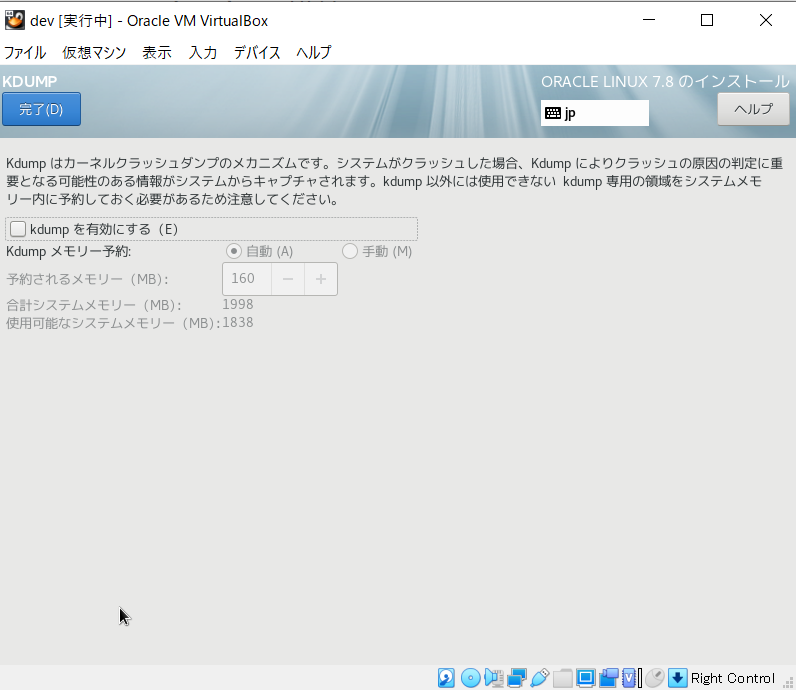
- 「KDUMP」を押下し、チェックを外し、KDUMPを無効にし、「完了」ボタンを押下
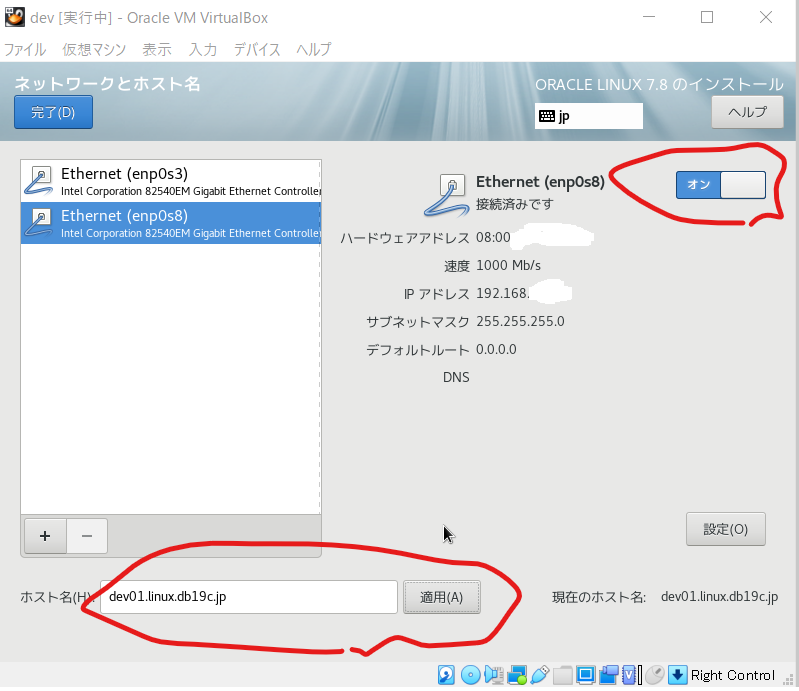
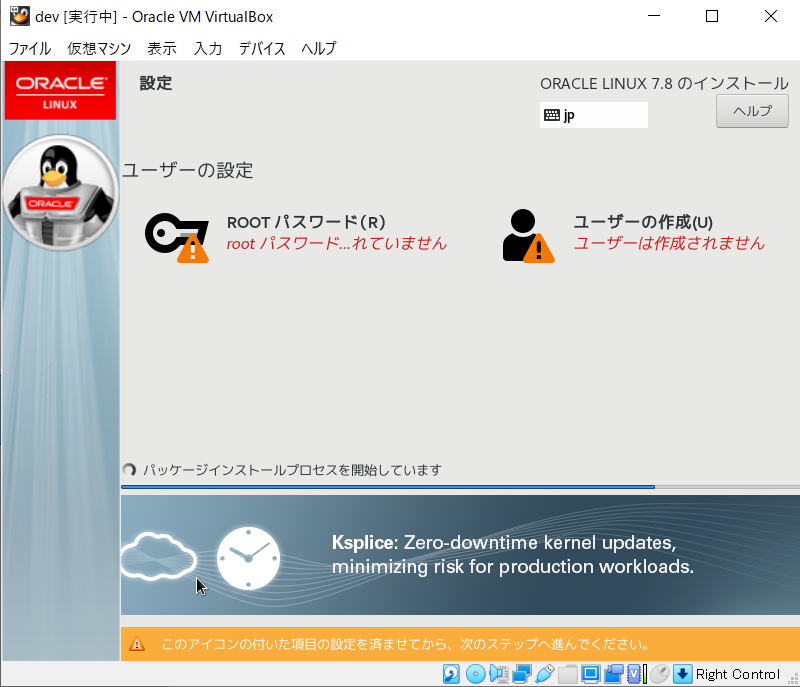
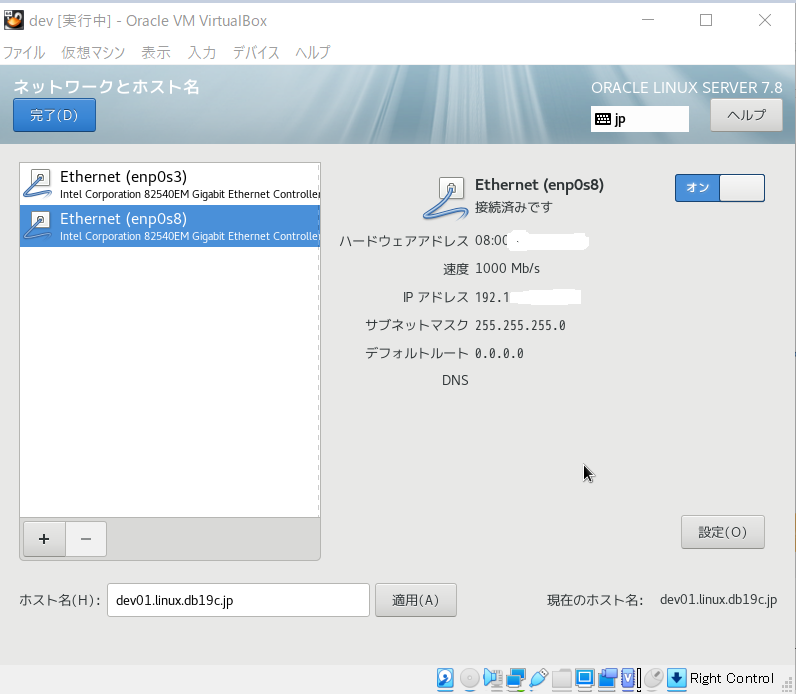
- 「ネットワークとホスト名」を押下し、二つのイーサネットを接続済みに、またホスト名を任意の名前にし、「完了」ボタンを押下
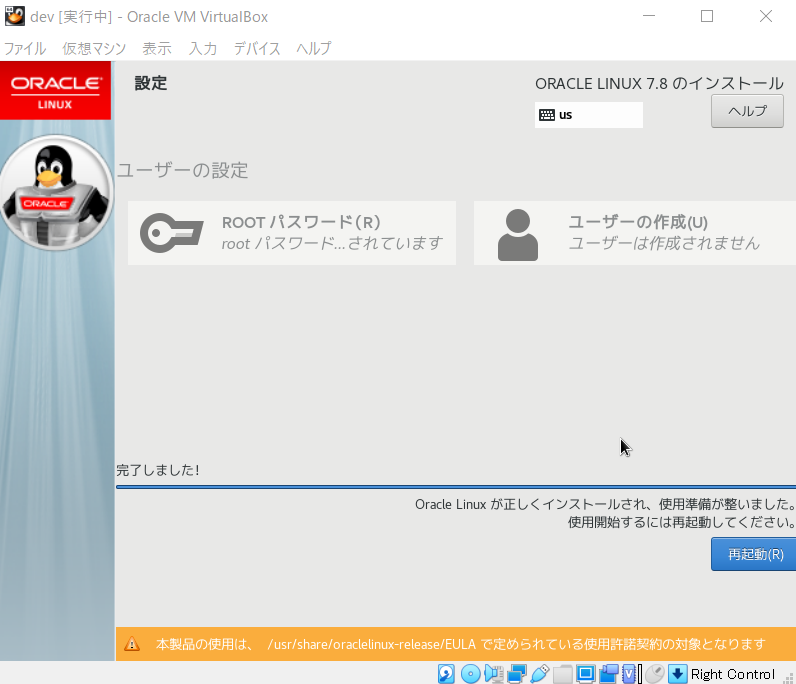
- インストール開始ボタンを押下、インストール中にrootのパスワードを設定 ※パスワードが簡単すぎると、完了ボタンを2回押すことになります。
- 再起動
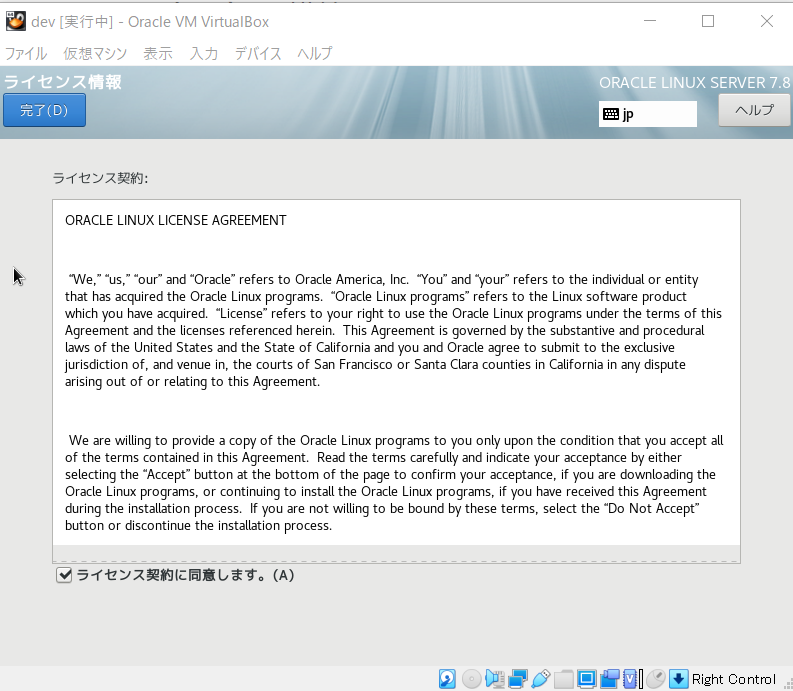
- ライセンス情報を押下し、同意にチェックし、「完了」ボタンを押下
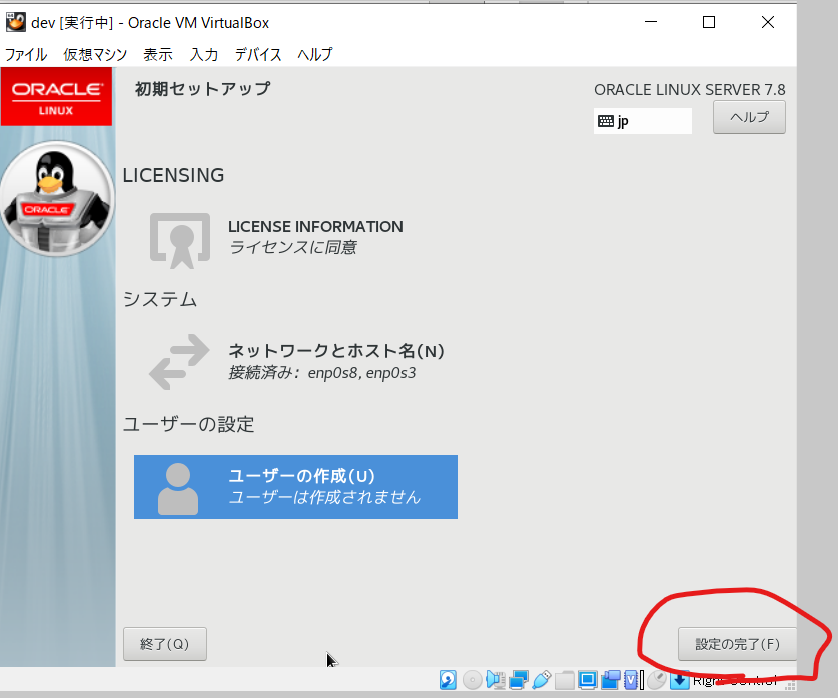
- 「ネットワークとホスト名」を押下し、二つのイーサネットを接続済みし、「完了」ボタンを押下
- ユーザーの作成はいったん不要、設定完了を押下
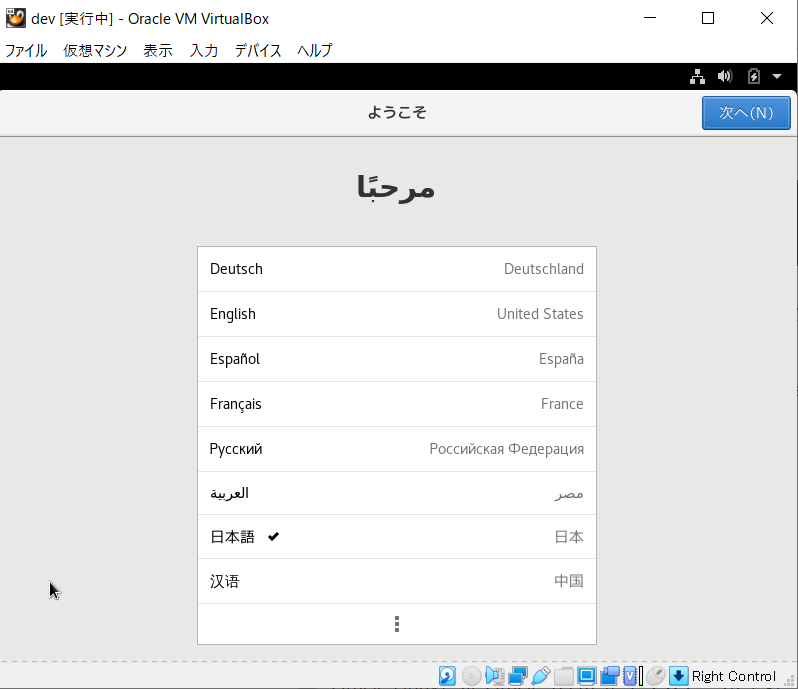
- 日本語を選択し、次へ
- 「日本語」を選択し、次へ
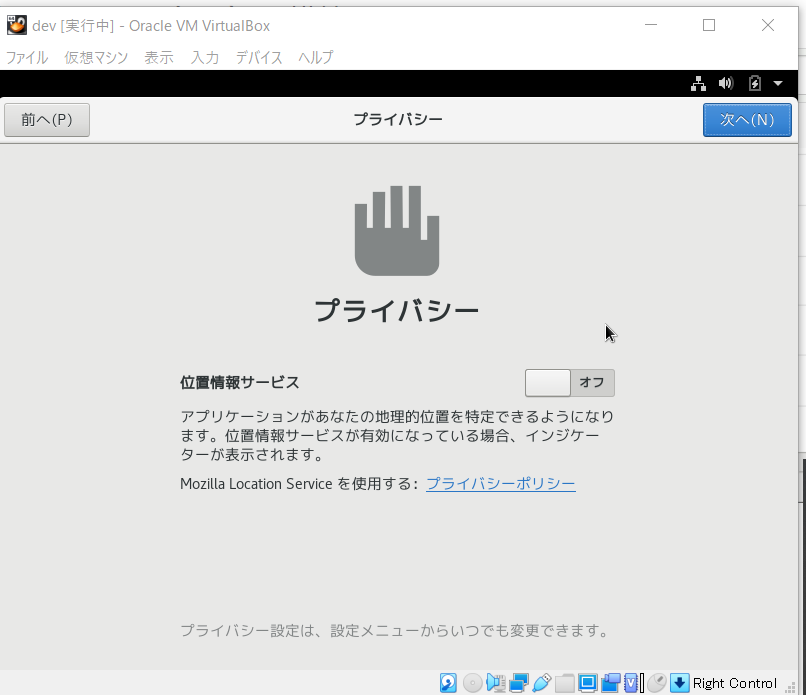
- 位置情報はOFFにし、次へ
- タイムゾーンは、「東京、日本」で、次へ
- オンラインアカウントへの接続は行わず、スキップボタンを押下
- 任意のユーザー名を入力
- 任意のパスワードを設定
- ヘルプは、「×」ボタン押下で閉じる
- ログアウト ※パッケージをアップデートする為。
- 「アカウントが見つかりませんか?」をクリックし、rootでログイン
- 端末をクリック
- アップデート実行
yum -y update
- 完了したら、再起動(reboot)
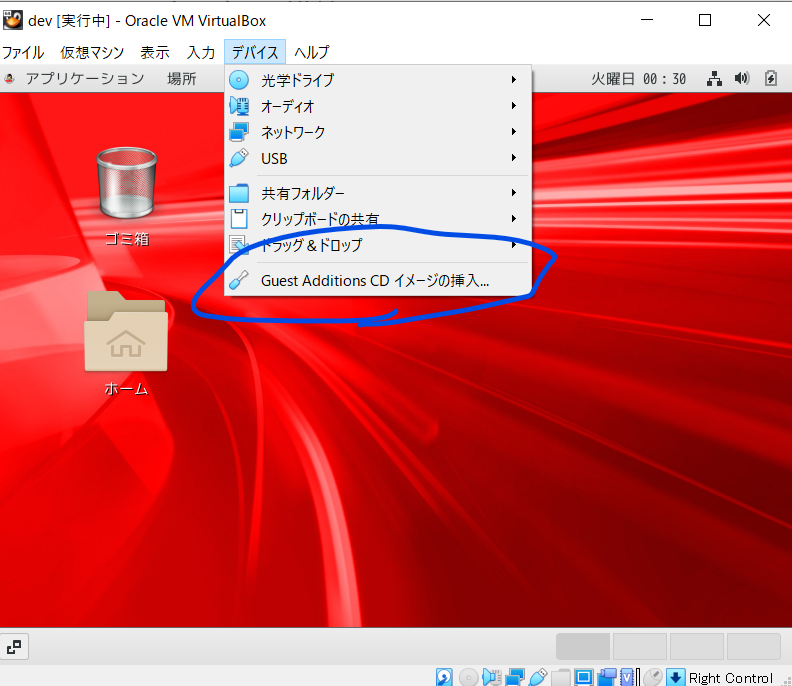
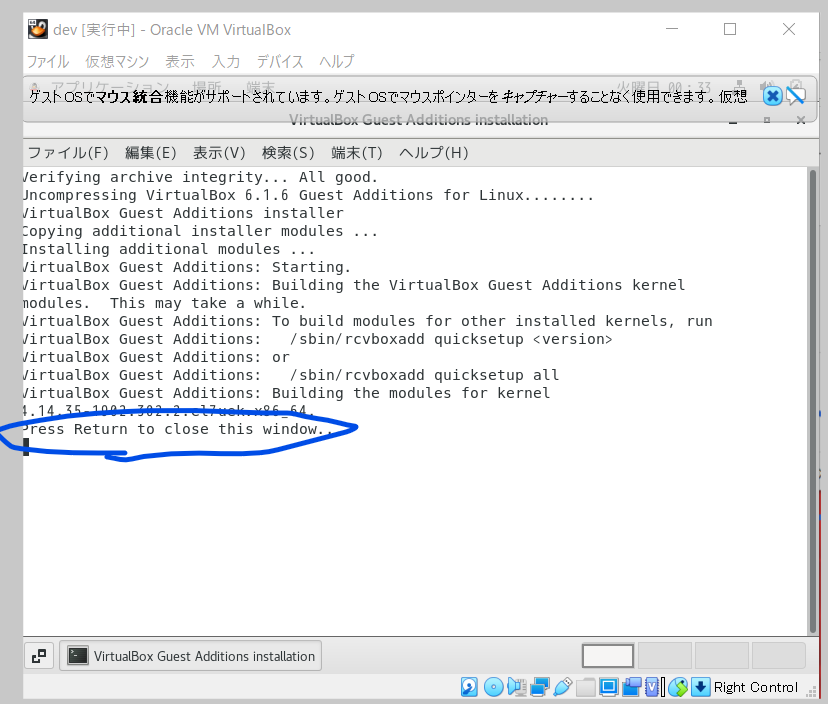
- Guest Additionsをインストールする ※ctrlボタン押さなくても、マウスカーソルが自動的に切り替わる
- 完了したら、「enter」押下
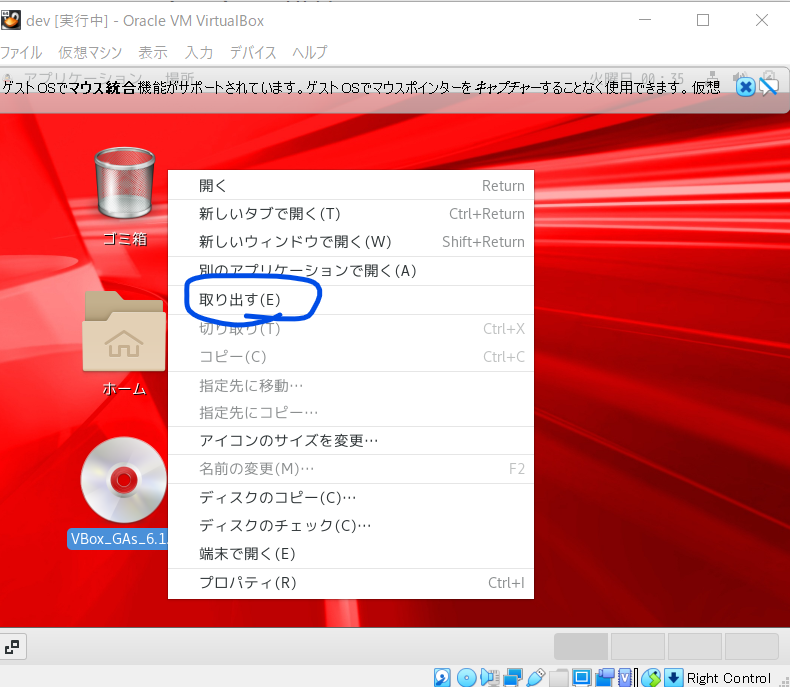
- メディア取り出し ※ctrlボタン押さなくても、マウスカーソルが自動的に切り替わっているはず
これより先は、随時スナップショット(Vritual Boxの機能)を取っていくと、やり直しがきくので便利
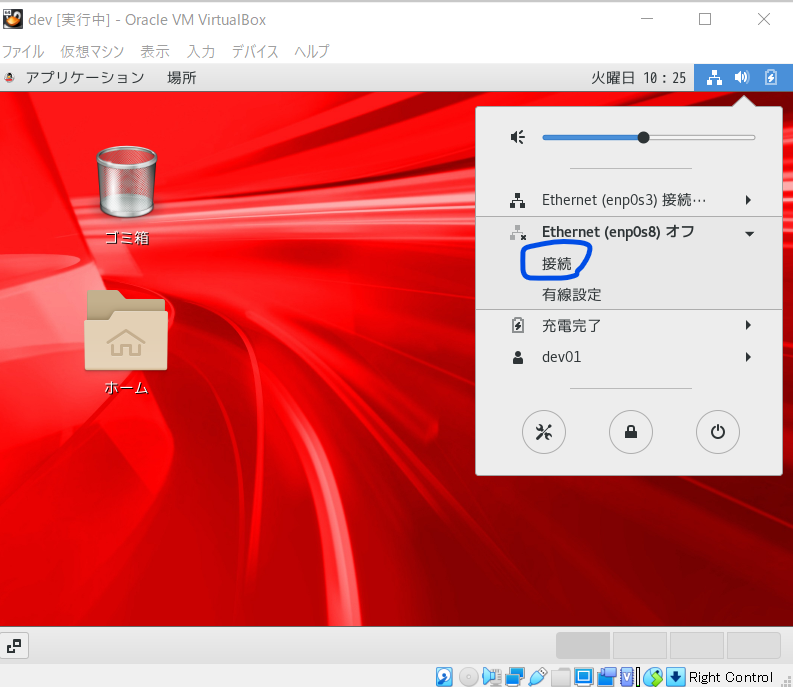
ネットワークの再接続
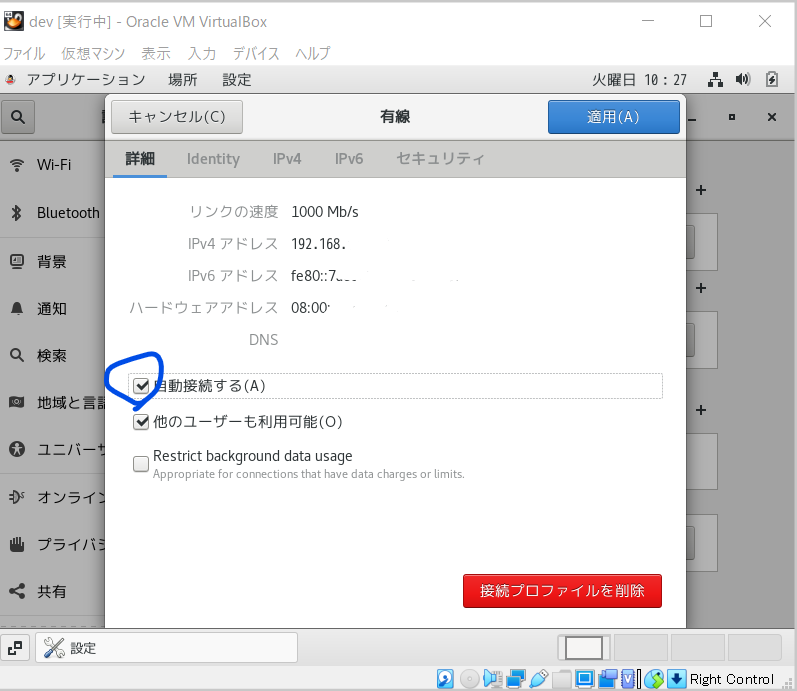
- ネットワークの有線設定を自動接続へ
- ホストOSから、ポート22以外でも接続できるように、ファイヤーウォールを止める
# 停止 systemctl stop firewalld # ステータス確認 systemctl status firewalld# 自動起動停止 systemctl disable firewalld # 設定確認 systemctl is-enabled firewalld
ホストOSからTeraTermでSSH接続 ※接続IPは、ifconfig等で確認すること
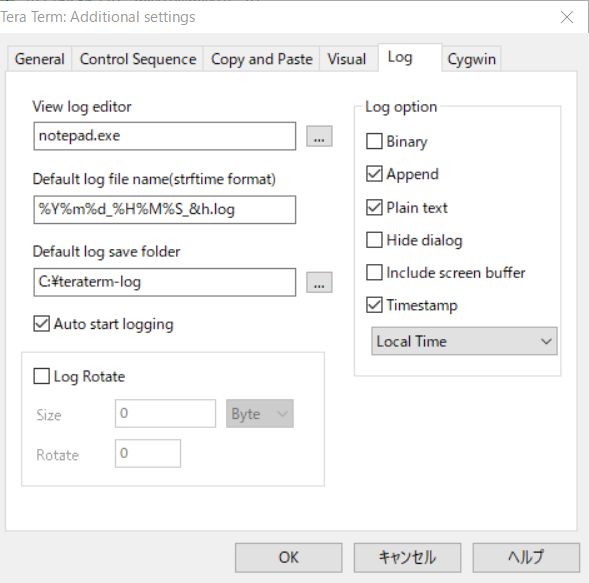
TeraTermは自動ログ設定しておくと証跡が残るので便利 ※設定後、「Save setup」するのを忘れないように
Oracle Databaseをダウンロード
- ダウンロードページにアクセスし、「Oracle Database 19c (19.3)」の「Linux x86-64」のzip(LINUX.X64_193000_db_home.zip)を取得 ※オラクルのIDが必要
https://www.oracle.com/technetwork/jp/database/enterprise-edition/downloads/index.html
事前作業
- oracle-database-preinstall-19cの実行 ※oracleユーザーとかを作ってくれたりする
# インストール sudo yum -y install oracle-database-preinstall-19c # 実行 export LANG=C sudo oracle-database-preinstall-19c-verify
- oracleユーザーのパスワード設定
sudo passwd oracle
- ディレクトリ作成 ※「su root」後、実行
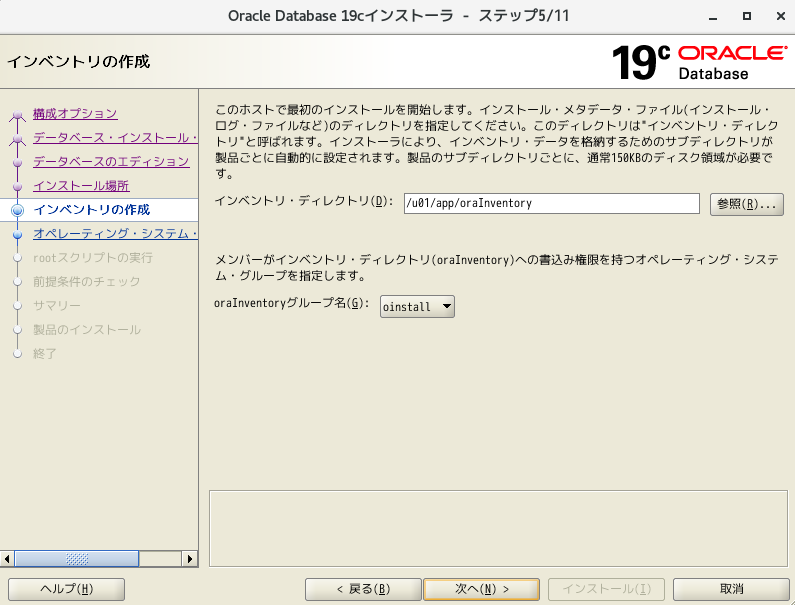
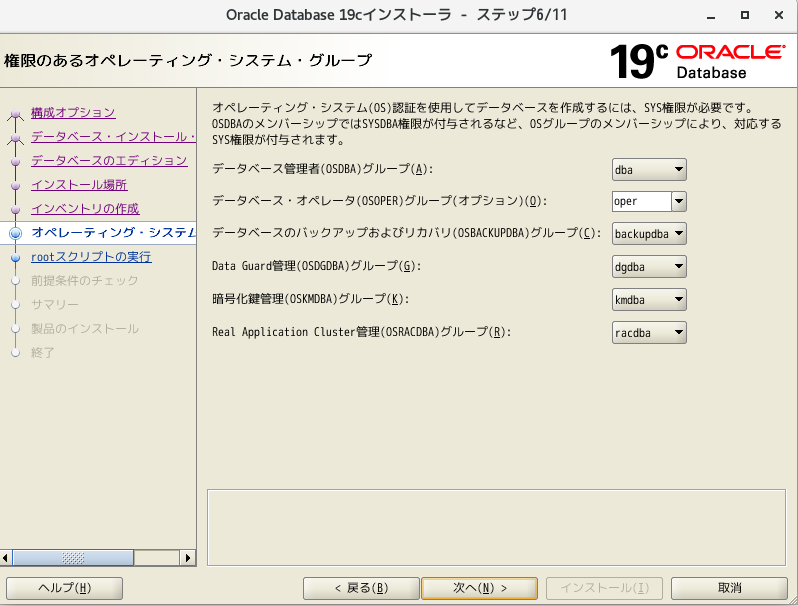
mkdir -p /u01/app/oracle/product/19.3.0/dbhome_1 chown -R oracle:oinstall /u01 chmod -R 775 /u01 mkdir -p /u01/app/oraInventory chown -R oracle:oinstall /u01/app/oraInventory chmod -R 775 /u01/app/oraInventoryOracle Databaseのインストール
- ダウンロードしたoracle databaseをtmp配下に配置
# 権限付けとく chmod 777 LINUX.X64_193000_db_home.zip
- oracleユーザーに切替、zip解凍
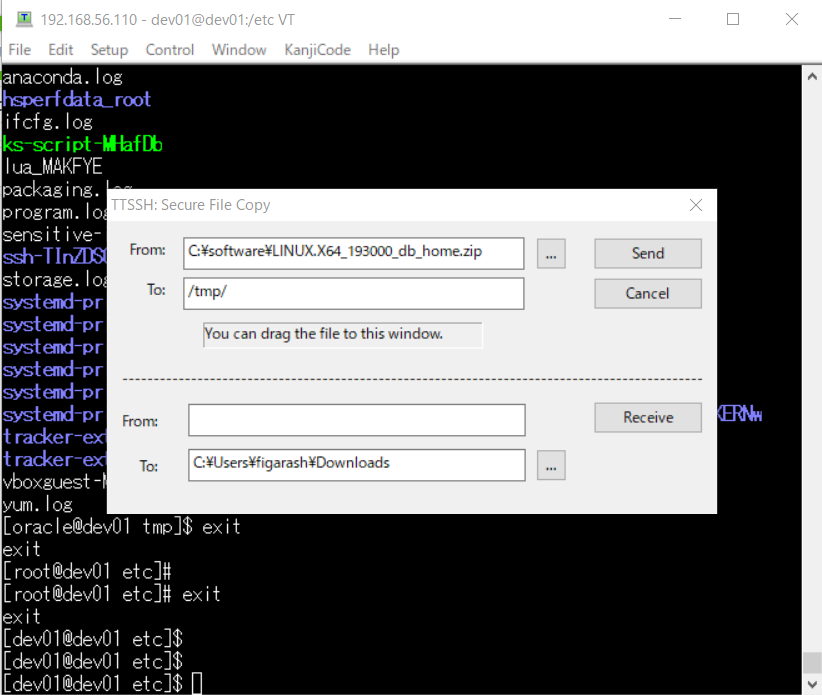
su oracle unzip -d /u01/app/oracle/product/19.3.0/dbhome_1/ LINUX.X64_193000_db_home.zip
ゲストOSにSSH接続ではなく、oracleユーザーで直接ログイン
インストーラー実行
cd /u01/app/oracle/product/19.3.0/dbhome_1/ ./runInstaller
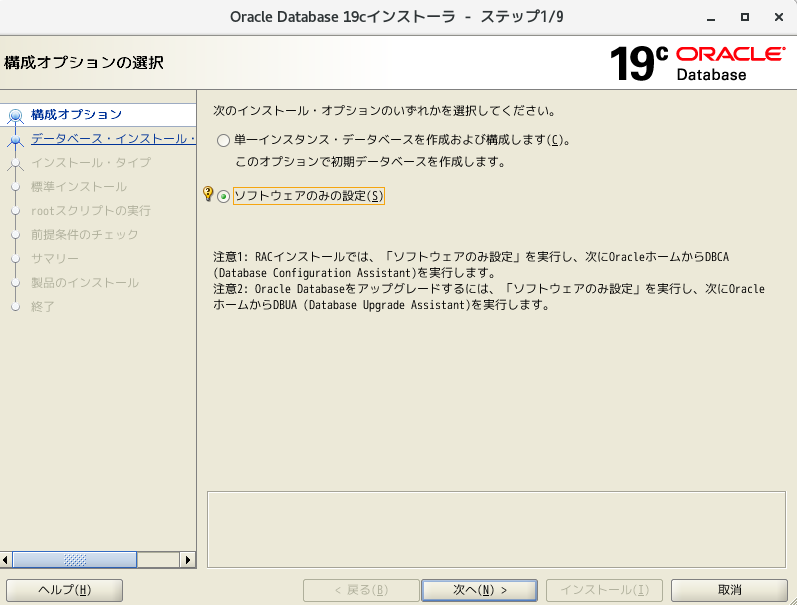
- 「ソフトウェアのみの設定」を選択し、次へ
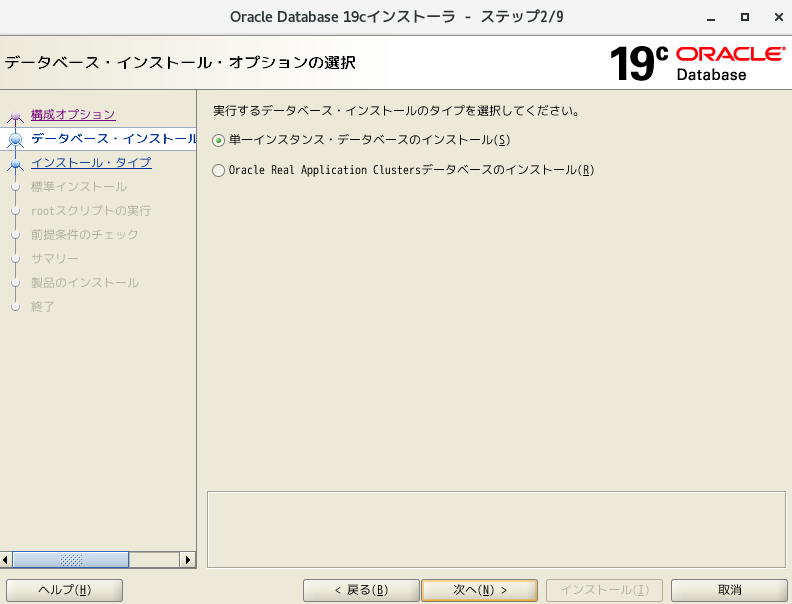
- 「単一インスタンス・データベースのインストール」を選択し、次へ
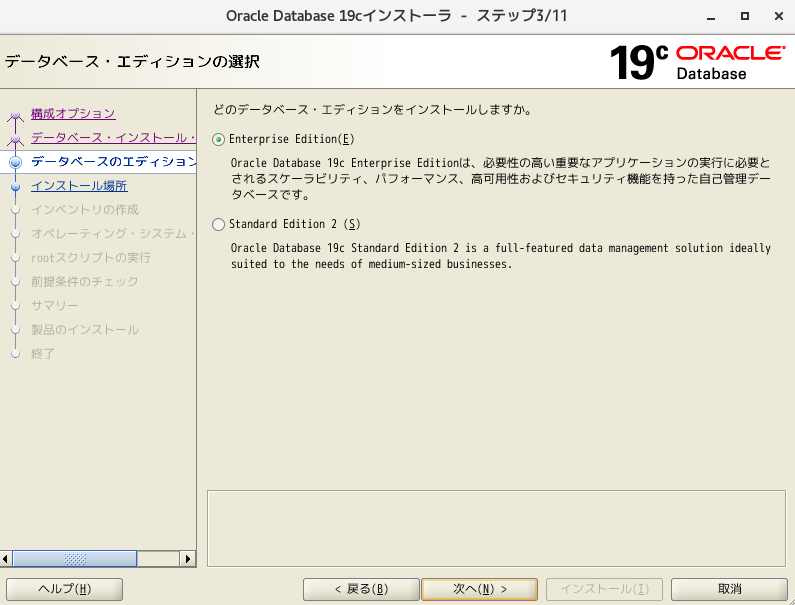
- 「Enterprise Edition」を選択し、次へ
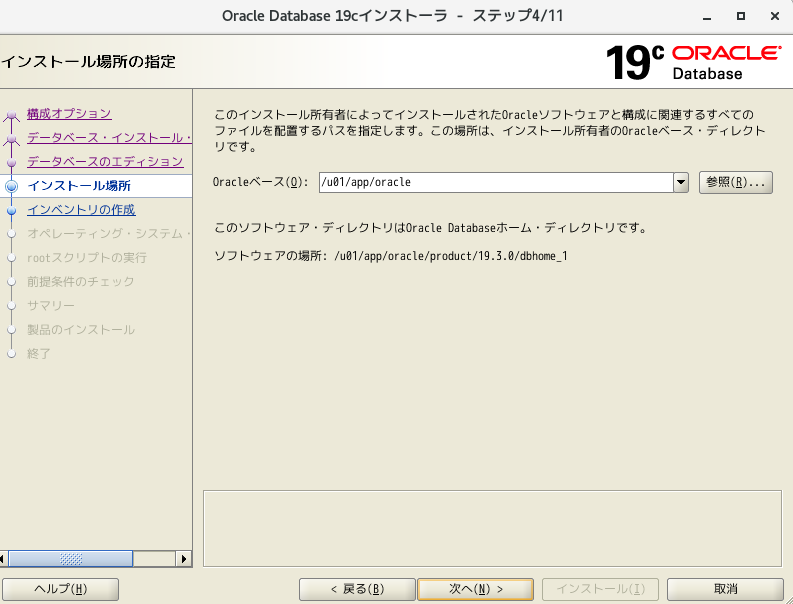
- そのまま、次へ
- そのまま、次へ
- そのまま、次へ
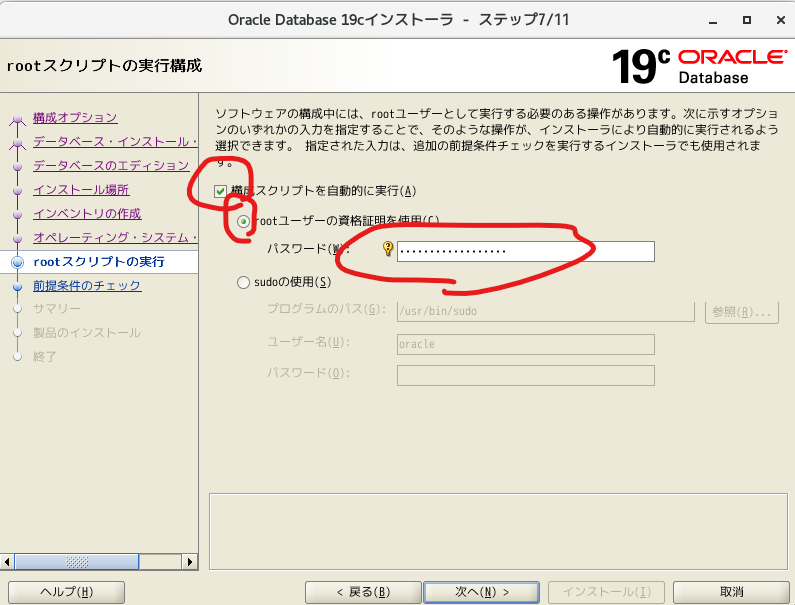
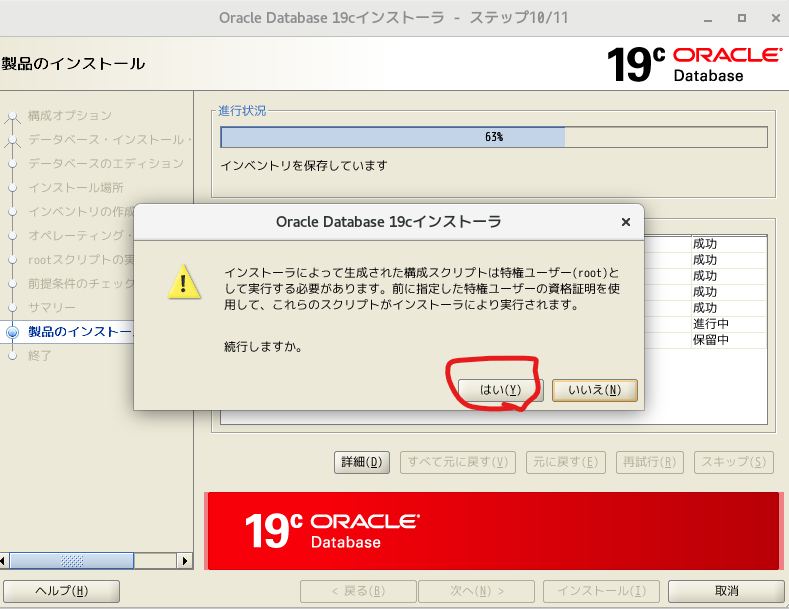
- 構成スクリプトの実行にチェックを入れ、認証情報を入力
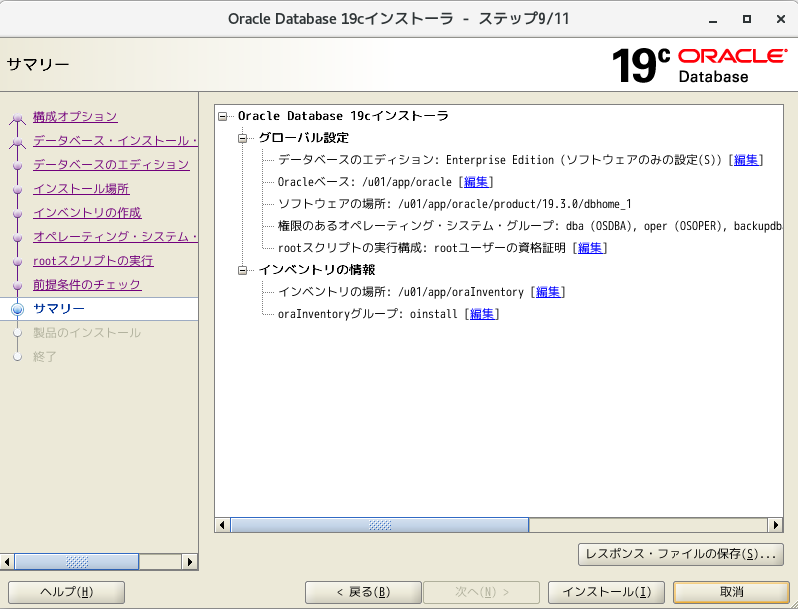
- インストール
- 構成スクリプト実行
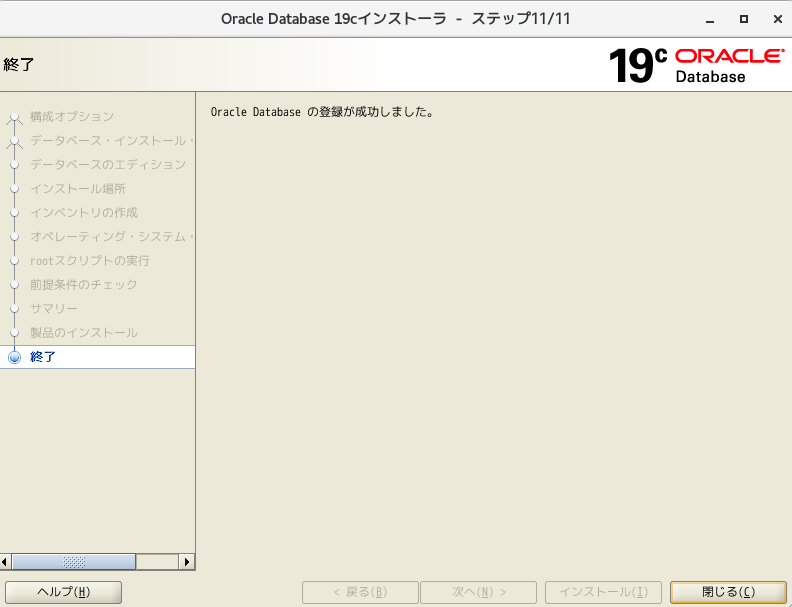
- インストール完了
データベース作成(dbca利用)※oracleユーザーで実行
- 環境変数を設定 ※データベース名は、「ora01」を設定
export ORACLE_BASE=/u01/app/oracle export ORACLE_HOME=/u01/app/oracle/product/19.3.0/dbhome_1 export PATH=$ORACLE_HOME/bin:$ORACLE_HOME/jdk/bin:${PATH} export LD_LIBRARY_PATH=$ORACLE_HOME/lib export NLS_LANG=JAPANESE_JAPAN.UTF8 export LANG=ja_JP.UTF-8 export ORACLE_SID=ora01
- 再起動しても環境変数が反映されるように「.bash_profile」に上記export文を書き込み
vi $HOME/.bash_profile
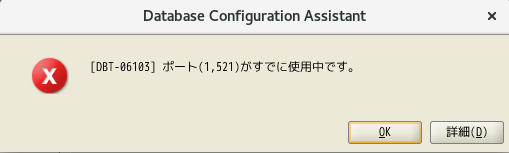
- hostsの設定 ※設定していないと、リスナーの設定でポートが空いているにも関わらず、以下のエラーが発生することになります。
vi /etc/hosts # 一応reboot reboot # 設定例 # 192.168.XX.XXX dev01 dev01.XXX.XXX.XX
- dbca起動
$ORACLE_HOME/bin/dbca
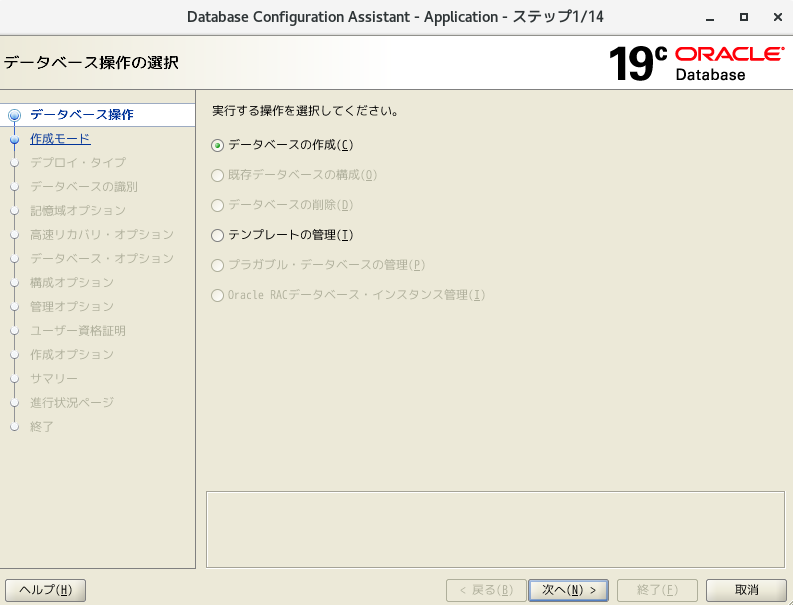
- 「データベースの作成」を選択
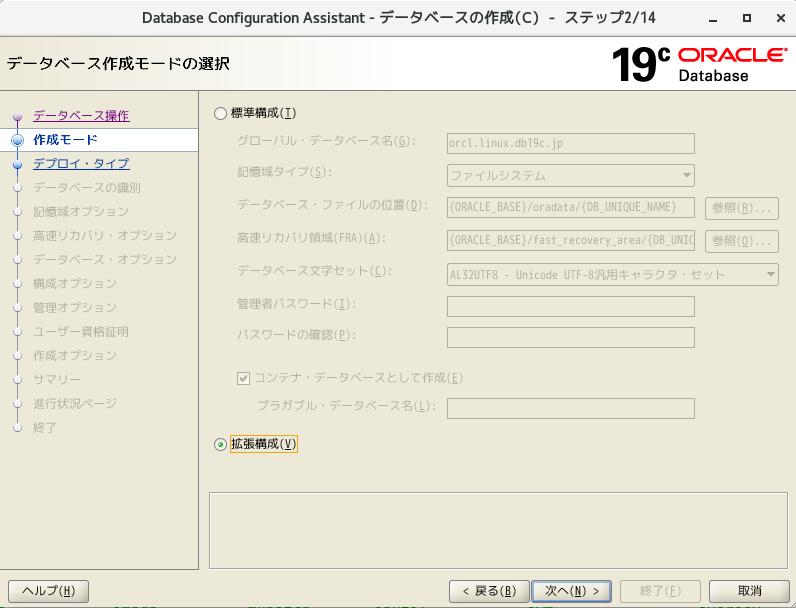
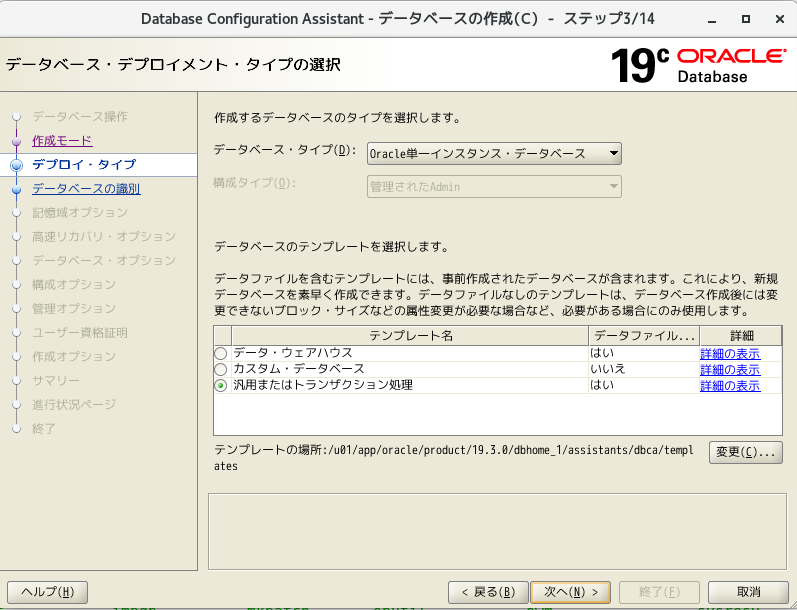
- 「拡張性構成」を選択
- そのまま次へ
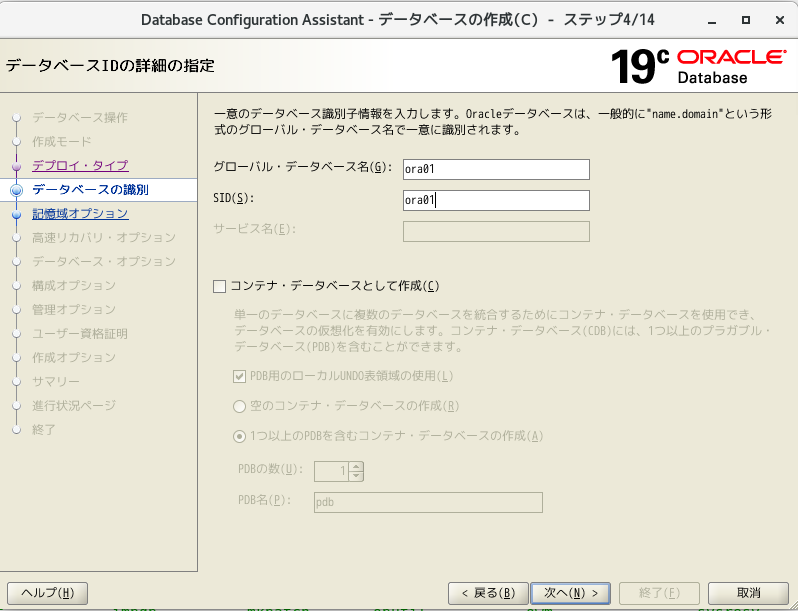
- グローバルデータベース名とSIDに「ora01」を指定。「コンテナデータベースとして作成」のチェック外して、次へ
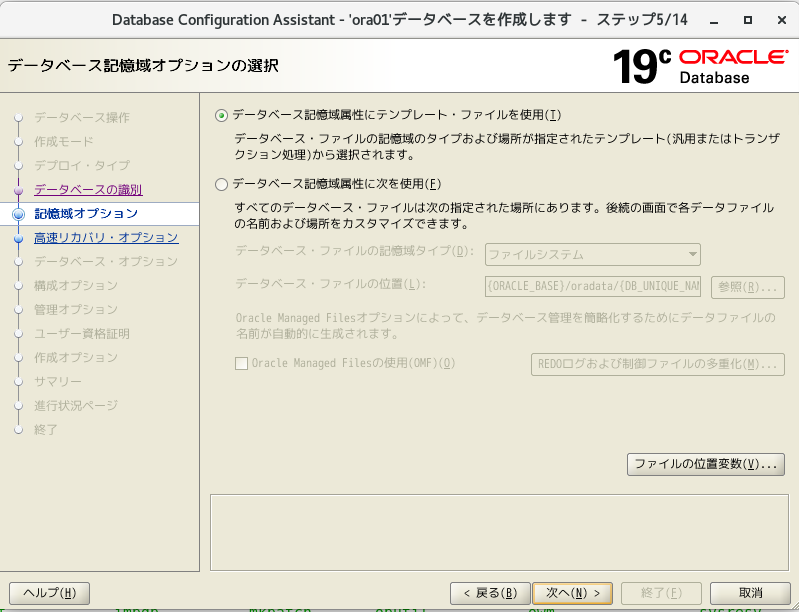
- そのまま次へ
- そのまま次へ
- 「新規リスナーの作成」を選択し、任意のリスナー名&ポート名を指定し、次へ
- そのまま次へ
- そのまま次へ ※後でメモリの設定変更します
- そのまま次へ
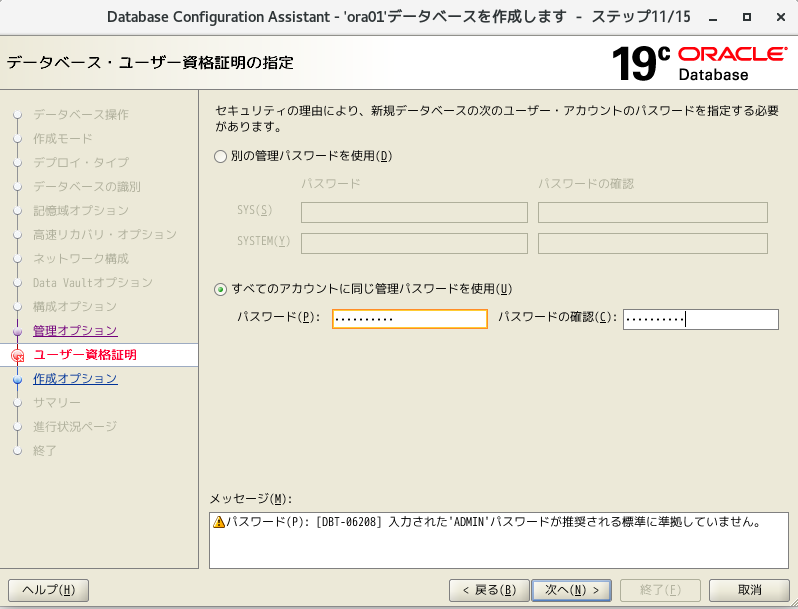
- 「同じ管理パスワードを使用」を選択し、任意のパスワードを入力
- そのまま次へ
- 「終了」ボタン押下
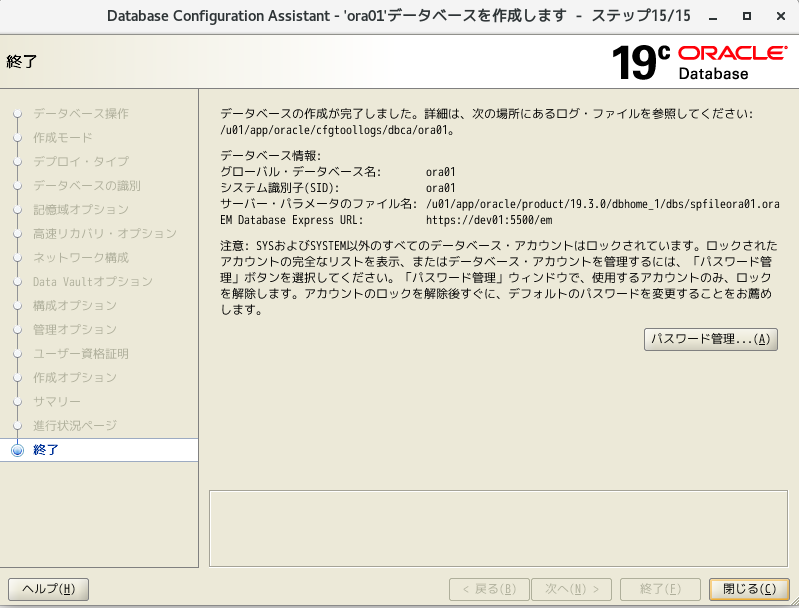
- データベース作成完了!!閉じるボタン押下
- ゲストOSのsqlplusで接続
sqlplus / as sysdba # linuxを再起動後であればDB起動する # startup # systemユーザーで接続 connect system/XXXX # SQL実行 SELECT INSTANCE_NAME FROM V$INSTANCE;
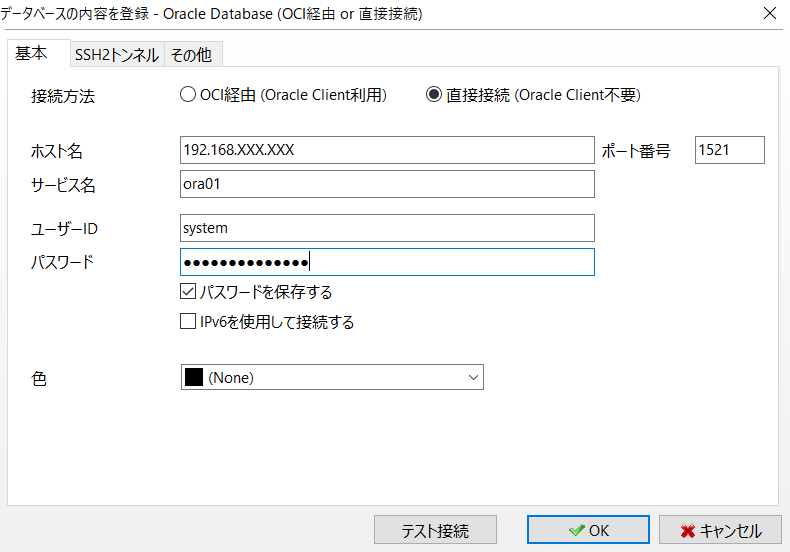
- ホストOSのSQLクライアント(a5m2)から接続
# リスナーのステータス確認 # 動いてなければ、startさせる lsnrctl status
- 節約の為、メモリの設定を変更
# 接続 sqlplus / as sysdba # 現状確認 show parameter memory show parameter sga # メモリサイズ変更 alter system set memory_target = 0 scope = spfile; alter system set memory_max_target = 0 scope = spfile; alter system set sga_target = 512m scope = spfile; alter system set pga_aggregate_target = 128m scope = spfile; # DB再起動(設定反映) shutdown immediate startup # 現状確認 show parameter memory show parameter sga # 今度はLinuxの設定を変更する為、DB停止 shutdown immediate # sqlplusからexit後、リスナー停止 lsnrctl stop # linux停止 ※su root後 shutdown now
- メモリを1024Mに変更
- プロセッサーを1に変更
Linux起動&DB起動&リスナー起動
DBに接続し、動作確認(SQL実行)し、問題なければデータベース構築完了。
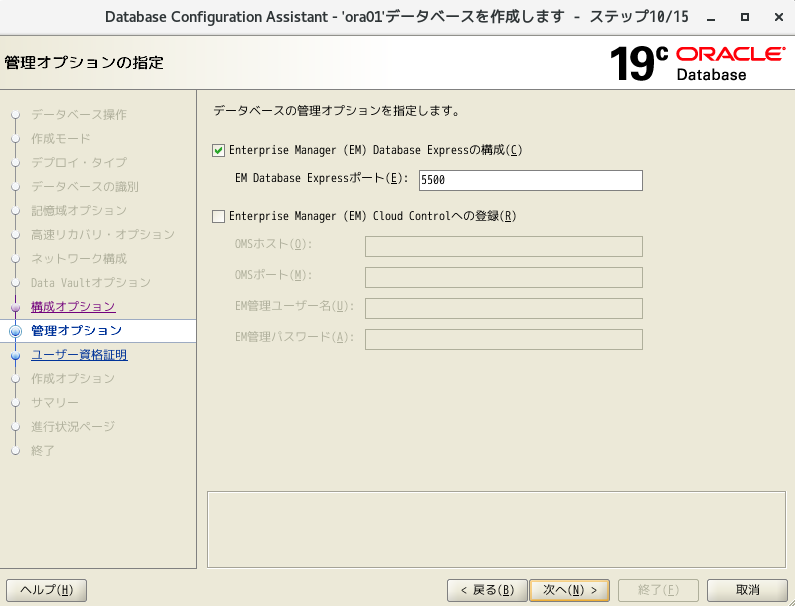
EM Expressへの接続
- 以下のURLで接続 ※sysとかsystemユーザー使用で動作確認可能
https://[OracleサーバのIPアドレス]:5500/em/login
ユーザー作成 ※スキーマも同時に作成される
- 「ユーザーとスキーマ」は「人とカバン」という関係性
-- ユーザーが、デフォルトでどこの表領域を使用するか確認 select property_value from database_properties where property_name ='DEFAULT_PERMANENT_TABLESPACE'; -- ユーザー表領域に作られることを確認 -- ユーザー作成 create user test identified by test; -- 作成されたか確認 -- 名前は大文字で管理される。 select username,default_tablespace,created from dba_users where username = 'TEST';権限付与 ※ユーザー作成しただけじゃ、接続する権限さえない
-- DBA権限付与 grant DBA to test; -- 権限確認 select * from dba_role_privs;参考URL
VirtualBoxの仮想マシンにOracle Linuxをインストールする
https://dbalone.com/oracle-linux-installOracle Linux7.5にOracle 12cR2をインストールする
https://qiita.com/mkyz08/items/945cdf72597b0e044b14Oracle DB 19cオンプレ版をインストールする
https://infrasenavi.com/gijutsuroku/2266CentOS7 ファイアウォール停止方法
https://www.server-memo.net/centos-settings/centos7/firewalld-stop.htmlOracleのスキーマとユーザーの違いとは?
https://sql-oracle.com/?p=110


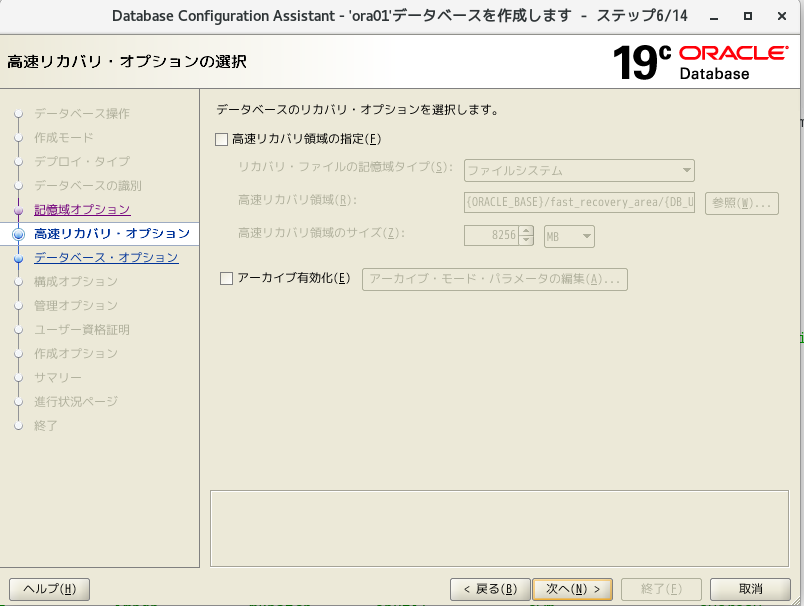
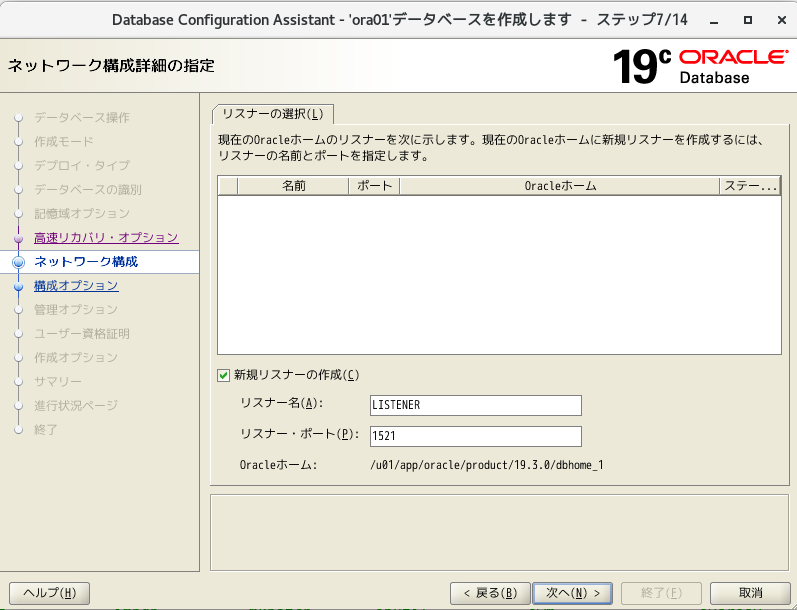
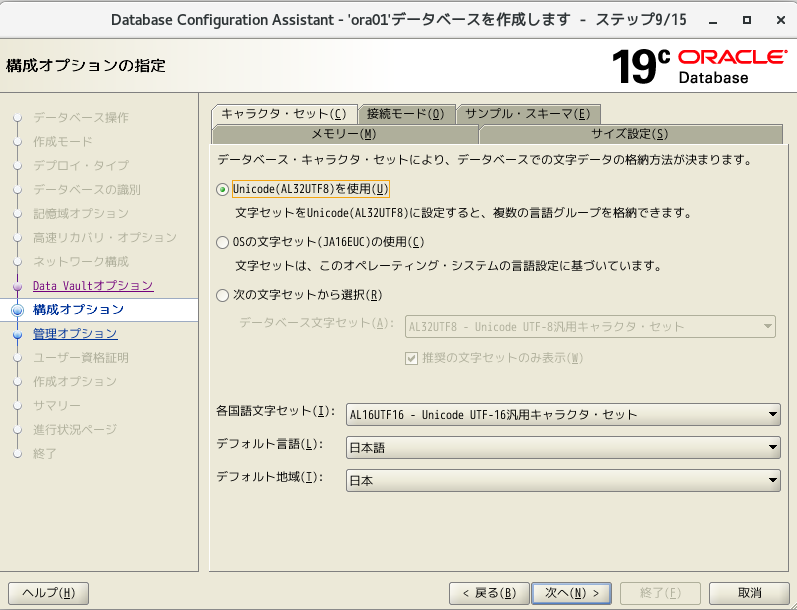
- 投稿日:2020-05-26T14:54:57+09:00
Linux基礎9 - プロセスとジョブ-
はじめに
今回は、実行中のプログラムを操作する方法や、シェルから複数のプログラムを並行して実行したり停止するといった、マルチタスクを活かした使い方を紹介します。
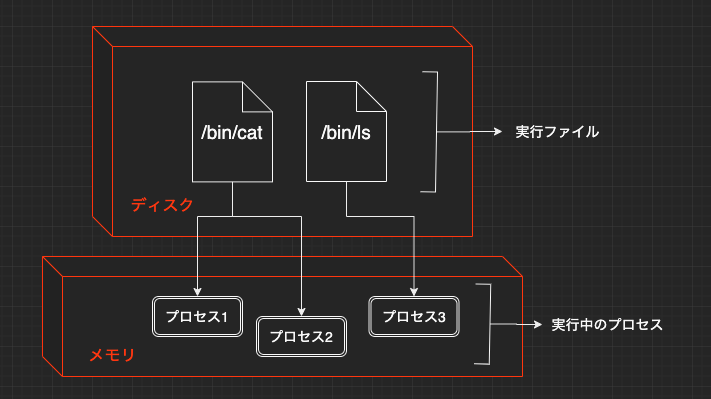
プロセスとは
これまでたくさんのコマンドを紹介してきましたが、これらのコマンドの実体はディスク上に保存されたファイルです。シェルからコマンドを実行すると、Linuxカーネルはディスクから実行ファイルを読み出してメモリに格納し、そのメモリ内容に従ってCPUがプログラムを実行します。ここで
メモリ上で実行状態にあるプログラムのことをプロセスと呼びます。
プロセスは同一のコマンドから実行されていても、それぞれ別個のメモリ領域を持ちます。そのため、同一コマンドが多数実行されても、その中身がお互いに混ざってしまったりはしません。また、プロセスには、ファイルのオーナー同様に実行ユーザが設定されており、他人のプロセスを勝手に操作することができないようになっています。これは、Linuxカーネルが1つ1つのプロセスに
プロセスIDという一意の番号を割り振り、適切に管理してくれているからです。なお、Linuxでプロセスが新しく作成されるときには、むから発生するのではなく、すでに存在しているプロセスを元に作成されるというモデルをとっています。これを
親子関係で表現し、作成するプロセスを親プロセス、作成されるプロセスを子プロセスと呼びます。psコマンドでプロセスの表示
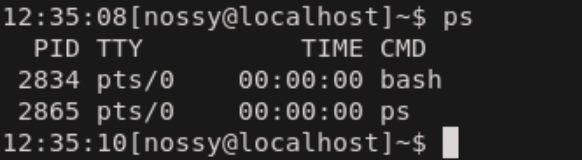
現在動作しているプロセスを表示するには、
psコマンドを使用します。引数なしでpsコマンドを実行すると、現在のターミナルで実行しているプロセスだけを表示します。
それぞれの表示が意味するものは次の表の通りです。
表示 内容 PID プロセスID TTY ターミナル TIME プロセスがCPUを使った時間 CMD 実行されているコマンド "psコマンドで表示される内容について調べた"に詳しく書いてありますので参考にしてみてください。
PIDはプロセスが終わるまで変化しません。そのためプロセスを操作するときはPIDをを使ってプロセスを特定することができます。現在のターミナル以外のプロセスも表示する
別のターミナルで実行しているコマンドや、デーモン(daemon)と呼ばれるターミナルに接続していないプロセスを表示する場合には、
xオプションを指定します。これにより、現在のユーザが実行している全てのプロセスを表示できます
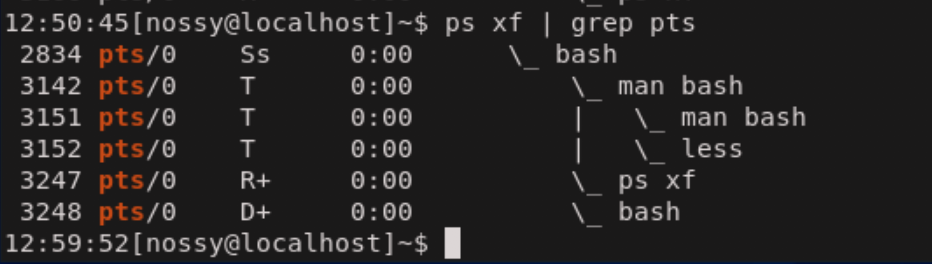
次の例ではプロセスの親子関係を表示するfオプションも合わせて指定しています。
bashが起動されて、そこからman bashが実行されている様子がわかります。manコマンドは内部でlessコマンドを起動するため、さらにlessの子プロセスを引き連れています。これが前述したプロセスの親子関係です。
TTYのカラムからpts/0というターミナルでログインしていることがわかります。TTYに?と表示されている場合は、ターミナルに接続していないプロセス(デーモン)であることを意味しています。オプション形式
先ほどpsコマンドを実行した際に、オプションの指定に
ps xfと入力し、-(ハイフン)が不要であったことに注意しましょう。Linuxのpsコマンドは、歴史的な理由から以下の2種類のオプション形式があります。
- UNIXオプション --- ハイフン付きでオプションを指定する。 ps -aefなど
- BSDオプション --- ハイフンなしでオプションを指定する。 ps xfなど
この
2種類はそれぞれ、オプションの意味も異なるため、別物として覚える必要があります。
今回は現在主流である、BSDオプションでの例を紹介します。UNIXオプションはpsコマンドのマニュアルを参照してみましょう。全てのプロセスの表示
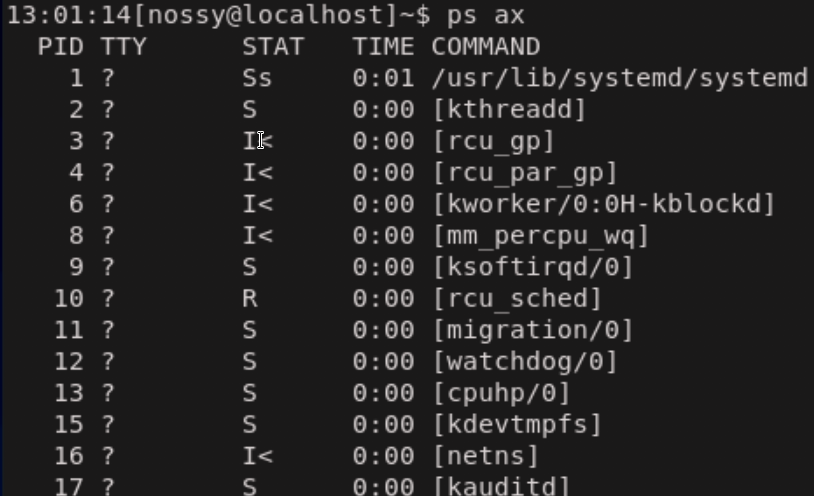
Linuxでは、ログイン中のユーザが実行しているプロセス以外にも、スーパーユーザの権限で実行されているシステムを管理するためのプロセスが最初から動いています。システムで動いている全体のプロセスを表示するには、
xオプションに加えてaオプションを指定します。
環境にもよりますが、ログイン直後の何もしていない状態でも数十個以上のプロセスが実行されています。
Linuxでは、マルチタスク機能によって、さまざまなプロセスが並行して動作していることを覚えておきましょう。よく使われるオプション
psコマンドには多数のオプションがありますが、その中でも頻繁に使われるものを紹介します。
オプション 意味 x psコマンドを実行したユーザのプロセス全てを表示 ux psコマンドを実行したユーザのプロセスの全てを、詳細情報を合わせて表示 ax 全てのユーザのプロセスを表示 aux 全てのユーザのプロセスを、詳細情報をを合わせて表示 auxww arxオプションで、コマンドラインが長くターミナルの右端で切れてしまう際に、表示幅を制限せず全て表示 psコマンドのオプションについて詳しくは
man psをしてマニュアルを読んでみてください。ジョブとは
プロセスはLinuxカーネルから見た処理の単位でした。これに対して、
シェルから見た処理の単位をジョブと呼びます。
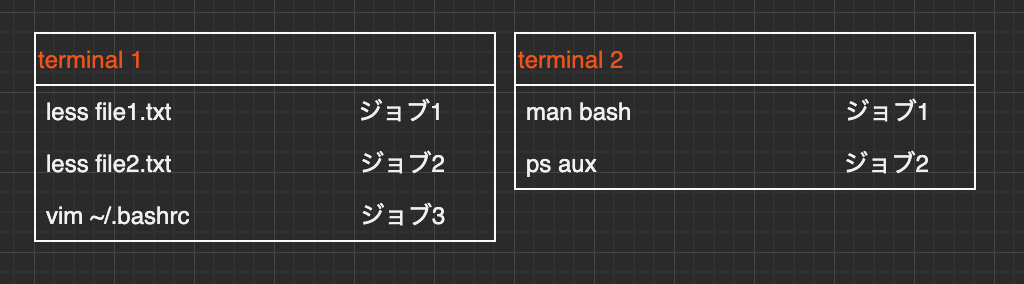
コマンドラインに入力している1つの行が1つのジョブになります。例えば、コマンドを|(パイプ)で繋いだ場合には、プロセスはコマンドごとに生成されるのに対して、ジョブはコマンドライン全体で1つとなります。プロセスは3つ、ジョブは1つ$ ls -l | cat -n | lessプロセスはシステム全体で一意のPIDを持ちますが、
ジョブはシェルごとにジョブ番号を持つため、複数のターミナルエミュレータを起動して2つ以上のセルを同時に使っている場合、ジョブ番号は重複します。
シェルの機能を使うと、ジョブを一時停止させたり、バックグラウンドで実行させたりといった、ジョブの制御が可能になります。コマンドを一時停止する
ここでは、
man bashページを読みながら、エディタで~/.bashrcファイルを編集するという作業を行っていきます。
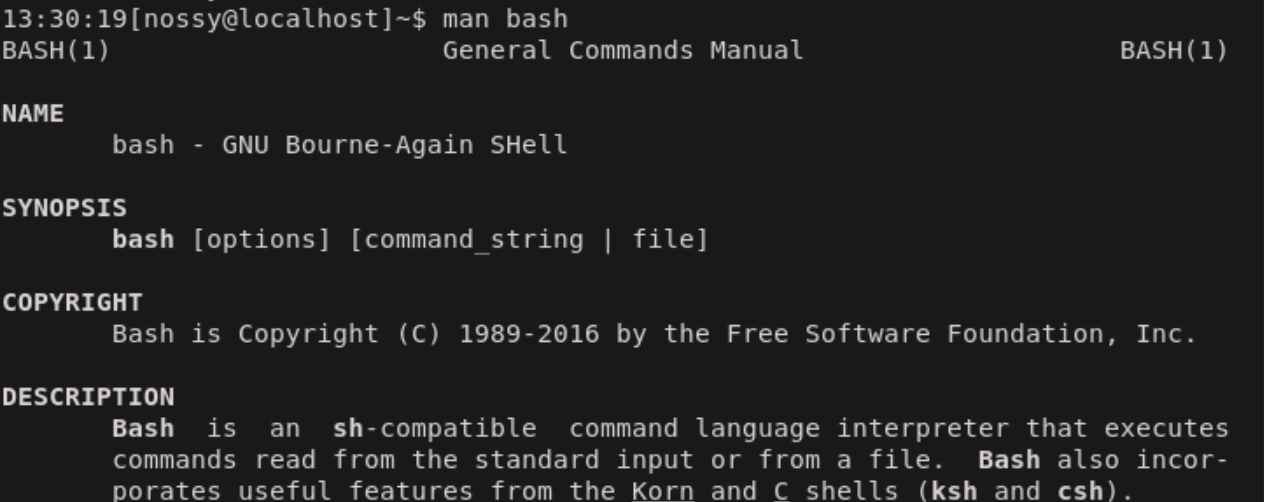
まずは、man bashを起動します。
ここでマニュアル閲覧中に~/.bashrcファイルを編集したくなったとしましょう。
Ctrl+zでman bashを一時停止することができます。
これでman bashというジョブが停止状態に移行しました。
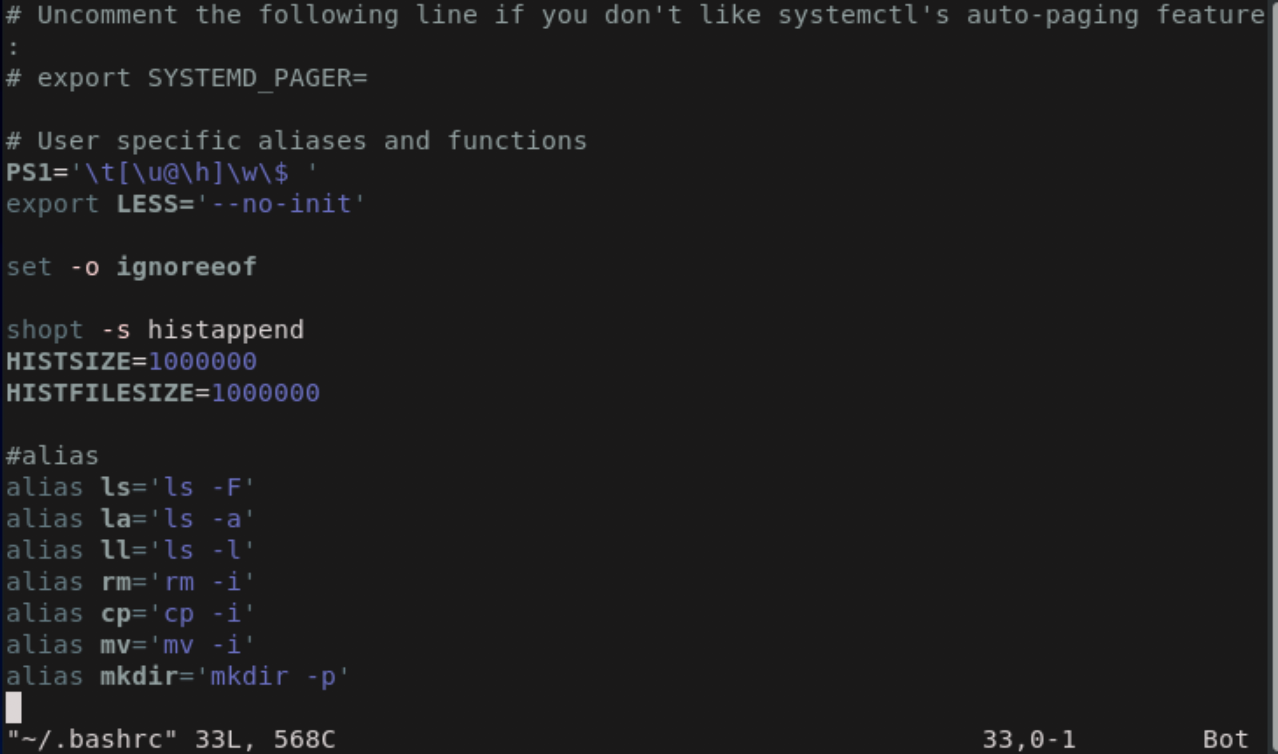
では、vimを起動して、~/.bashrcファイルの編集作業にうつりましょう。$ vim ~/.bashrc
編集中に先ほど表示していた、man bashが見たくなりました。まだファイルは編集中なので、Ctrl+zで一時停止します。
ここで、現在のジョブ状況を確認しましょう。jobsコマンドでジョブ一覧を表示できます。
停止中のジョブが2つ確認できました。先頭の[1]や[2]はジョブ番号を表しています。なおジョブ番号だけではなくPIDを確認したい場合には-lをつけます。
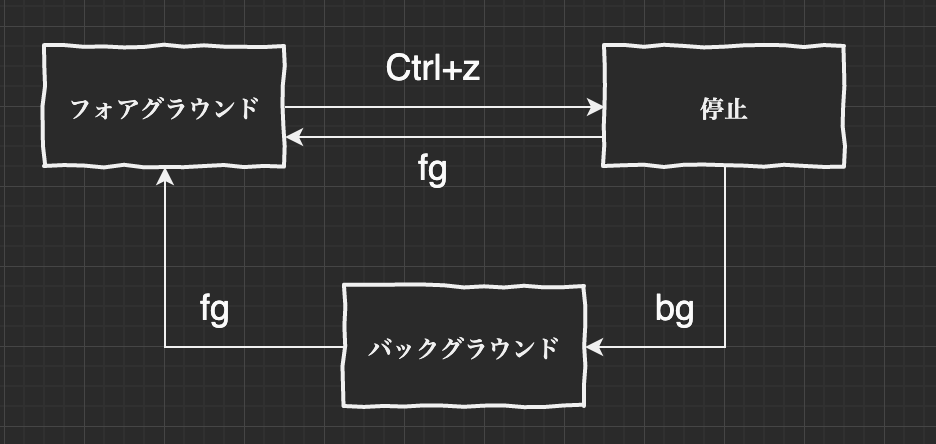
fgコマンドでジョブをフォアグラウンドにする
フォアグラウンドとはユーザからの入力を受け付けるジョブの状態を意味します。ジョブをフォアグラウンドにするにはfgコマンドを使用します。ジョブをフォアグラウンドにする$ fg %<ジョブ番号>今回はジョブ番号1番の
man bashが対象なので、%1で実行します。
すると停止状態にする前の状態に復元されました。このようにジョブを一時停止状態にしておくことで効率よく作業が可能になります。
なお、fgでジョブ番号を省略するとカレントジョブがフォアグラウンドになります。jobsコマンドで+のついているものがカレントジョブです。bgコマンドでジョブをバックグラウンドにする
Ctrl+zでジョブを停止すると、そのジョブは動作を止めてしまいます。このため、例えばcpコマンドでファイルをコピー中にCtrl+zを押すと、コピー処理は停止してしまい、いつまでも完了しません。
このようなときは、処理を続行したままシェルへと戻ってくるようにコマンドを実行できると便利です。そのようにユーザが対話的に操作できないジョブの状態を、バックグラウンドと呼びます。ジョブをバックグラウンドにするには、bgコマンドを使用します。ジョブをバックグラウンドにするbg %<ジョブ番号>これは先ほどの
fgコマンド同様、Ctrl+zで一時停止にしたジョブに対してバックグラウンド操作を行う手順です。このとき、jobsコマンドを実行すると実行中と表示され、そのジョブが完了すると終了と表示されます。なお、
はじめからジョブをバックグラウンドで実行したい場合には、コマンドラインの末尾に&を追加します。ジョブをバックグラウンドで実行する$ cp file1 file2 &ジョブの状態遷移
ここまでに登場したジョブの状態を表にまとめます。
状態 内容 フォアグラウンド ユーザが対話的に操作しながら処理が実行されている状態 バックグラウンド ユーザが対話的に操作せずに処理が実行されている状態 停止 処理を一時的に中断している状態 これらの状態は、次の図のように遷移させることが可能です。
なお、
jobs、fg、bgはすべてシェルの組み込みコマンドです。
ジョブ・プロセスの終了
コマンドを誤って実行してしまったり、プログラムの不具合などによってコマンドが操作を受け付けなくなった場合には、シェルからコマンドを終了させる必要があります。ここではそれらの操作方法を紹介します。
ジョブの終了
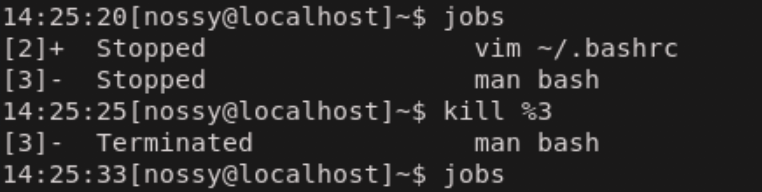
ジョブを終了させる方法は、そのジョブの状態によって変わってきます。
状態 終了の操作 フォアグラウンド Ctrl+c バックグラウンド $ kill %<ジョブ番号> 停止 $ kill %<ジョブ番号>
フォアグラウンドの場合は、キー入力を受け付けている状態なので、Ctrl+cで終了させます。
バックグラウンドや停止の状態は、キー入力を受け付けていないので、killコマンドを使用する必要があります。
下の図は停止中のman bashのジョブを終了した例です。
プロセスの終了
プロセスを終了するには、バックグラウンドジョブと同様に
killコマンドを用います。プロセスの終了$ kill <プロセスID> #プロセスの場合は%をつけずにプロセス番号を記入する
他人のプロセスを勝手に終了させることができないように、プロセスを終了できるのはその実行ユーザのみとなっています。しかし、スーパーユーザだけは例外です。
スーパーユーザは全てのプロセスを終了する権限を持っています。killコマンド シグナルを送信する
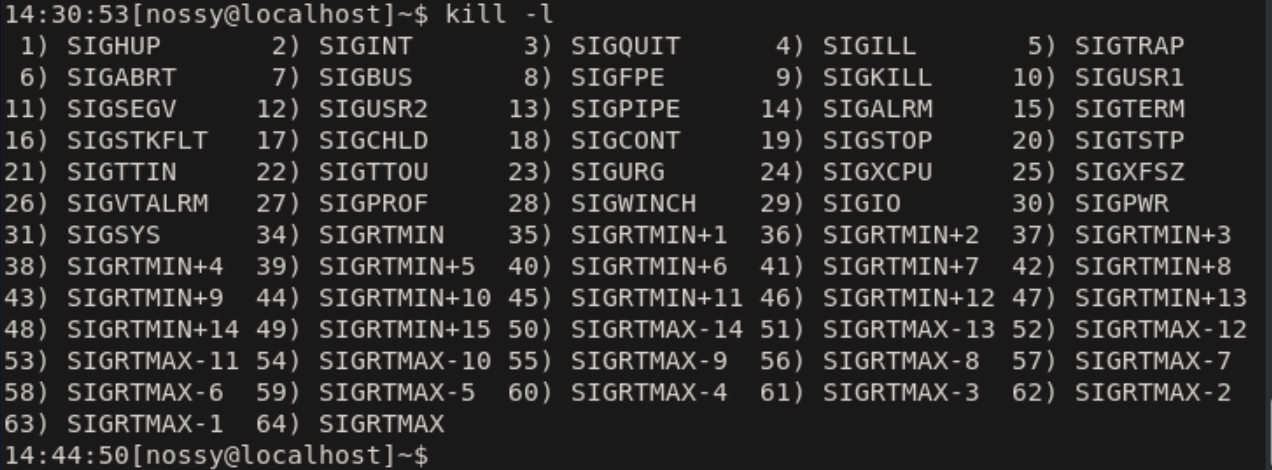
先ほど紹介したkillコマンドは、ジョブやプロセスを終了させるコマンドではなく、正確には
シグナルを送信するコマンドです。
シグナルとは、その名の通りプロセスに送信される信号です。プロセスは受け取った信号の種類に応じて、終了・停止・再起動などの振る舞いをします。killコマンドで送信するシグナルの種類は、
kill -<シグナル名>という形で指定できます。シグナル名を省略すると、デフォルト値としてTERMというシグナルを送信します。また、それぞれのシグナルには番号がついており、TERMのシグナル番号は15なので、次の3つは同じ意味です。killコマンドでシグナルの送信$ kill 4565 $ kill -TERM 4565 $ kill -15 4565
TERMというシグナルはTerminateで、終了を指示します。そのため、シグナルを指定せずkillコマンドを実行すると、デフォルトのTERMシグナルが送信されて、ジョブ・プロセスは終了したわけです。また、フォアグラウンドジョブに対する、
Ctrl+zやCtrl+cもシグナルを送信するための操作です。
システムで利用可能なシグナル一覧は、killコマンドに-lをつけて実行することで確認できます。
この中で、SIGKILLは例外的なシグナルです。
このシグナルだけは、プロセスに渡されずに、直接Linuxカーネルが処理します。指定されたプロセスを強制的に終了させるシグナルです。通常はTERMを受け付けなくなった異常プロセスを終了させるときに用います。
プログラムの設定によっては、TERMのシグナルを受信したときに、現在の情報を保存したりといった、最後に必要な処理を行ってから終了するものもあるため、TERMシグナルを試して、うまく終了できない場合にのみ使用するようにしましょう。参考資料




- 投稿日:2020-05-26T14:38:18+09:00
FHS (Filesystem Hierarchy Standard)
TL;DR
覚えておきたいものだけメモします。
関わりの深いもの順にメモします。/bin
システム管理者(root)と一般ユーザーの両方が使う基本的なコマンド
/sbin は、システム管理者(root)が使用するコマンド/etc
設定ファイル
システムに関する設定ファイル、アプリケーションに関する設定ファイル/tmp
一時的にファイルを保存
再起動すると、ディレクトリ内のファイルは削除される/var
一時的にファイルを保存
再起動しても、ディレクトリ内のファイルは削除されない
ログファイルなどが置かれる/usr
ユーザー向けのディレクトリで、たくさんのサブディレクトリを持つ
/usr/bin ユーザーが一般的に使用するコマンド
/usr/lib プログラムに必要な共有ライブラリ
/usr/local ローカルシステムで必要とされるコマンドやライブラリ/mnt
リムーバブルメディア
/lib
「/bin」や「/sbin」ディレクトリにあるコマンドを実行するのに必要なライブラリ
/home
各ユーザーのホームディレクトリ
/boot
システム起動時に必要なファイル
/dev
デバイスファイル
/opt
dpkgでインストールする時に使用する
/proc
カーネル内部の情報
CPU、メモリの使用状況、ネットワーク情報など
- 投稿日:2020-05-26T13:25:19+09:00
[個人メモ]いまさらbashの自動補完
概要
Linuxのコマンドが長くなると入力するのがめんどくさくなり、効率が悪い
なので、いまさらだがコマンドの自動補完の設定手順を残す導入方法
bash-completionをインストール
> yum install -y bash-completionロード&確認
> source /usr/share/bash-completion/bash_completion # エラーがなければOK > type _init_completion例としてyumコマンドの入力補完設定
> source /usr/share/bash-completion/completions/yum # yum入力後にtabキーで以下の様に入力補完が表示されればOK > yum check deplist groups info load-transaction reinstall search upgrade check-update distro-sync help install makecache remove shell version clean downgrade history list provides repolist update※
/usr/share/bash-completion/completions/配下に様々な入力補完用のスクリプトが導入されるので、必要に合わせてロードしてください。
/usr/share/bash-completion/completions/にない場合は?
モノによってはコマンドにビルドインしているものもあります。例えば、kubectlの場合はkubectl completion bashで補完機能を提供しています。またdocker-composeの場合は、こちらの手順に従って自動補完スクリプトを導入し、同じようにロードすればOK。なので補完したいものを探してロードしてあげてください。自動ロード登録
> echo 'source /usr/share/bash-completion/bash_completion' >> ~/.bashrc > echo 'source /usr/share/bash-completion/yum' >> ~/.bashrc_get_comp_words_by_ref command not foundが表示されたら
以下の2つを試す
bash_completionがロードされていない
上記の「2. ロード&確認」を実行
bash_completionがインストールされていない
パッケージマネージャーからbash-completionをインストール
上記の「1. bash-completionをインストール」を実行
```
- 投稿日:2020-05-26T11:49:23+09:00
ubuntuメモ
そもそも何?
公式参照
要するにlinuxとお友達なOSのイメージ
今回はver18.04の設定でcmd
基本はlinux系のだと思う備忘録兼ねて
説明 cmd($省略) シャットダウン shutdown -h now ファイルをエクスプローラーで開く xdg-open filename OS info cat /etc/os-release パッケージチェック sudo apt-get check パッケージ依存関係修復 sudo apt-get -f install 絶対パス取得 readlink -f hoge.sam 環境パス確認 printenv インストールしたもの確認 dpkg --get-selections パスワード変更 sudo passwd <username>パスワード変更 sudo passwd <username>画面録画 Alt+Ctrl+Shift+R Extension
手間がかかったもの、使えそうなものをメモ
slack
Ubuntuのversionが18.04だと脳死でインストールすると日本語打てないらしいので
公式から圧縮ファイルとって
こちらの記事を参考にインストールすれば
解決したAlbert
エンジニアさんに教えてもらったツール
便利。使いこなすためにまずはインストールから
この記事がわかりやすくておすすめでした。Tweaks
ubuntuの見た目が結構お手軽に変更できる拡張機能
この記事から読んで色々設定しました。
- 投稿日:2020-05-26T09:49:56+09:00
CentOS 6でTorqueのセットアップ
ジョブスケジューラとしてtorqueを使用します。
torqueをyumから利用するにはEPELレポジトリの追加が必要です。
下記のようにインストール、設定します。$ su - $ rpm -Uvh http://ftp.riken.jp/Linux/fedora/epel/6/x86_64/epel-release-6-8.noarch.rpm $ yum install --enablerepo=epel torque-server torque-client torque-mom torque-scheduler $ /usr/sbin/create-munge-key $ hostname > /etc/torque/server_name $ pbs_server -t createこの後、qmgr.txtを次のように編集します。
create queue L0 queue_type = execution set queue L0 enabled = true set queue L0 started = true set server default_queue = L0 set server scheduling = true set queue L0 resources_max.ncpus = 12 # ←12コアの場合 set queue L0 resources_max.nodes = 1続けて、以下のように操作します。
$ service trqauthd start $ qmgr < qmgr.txt $ echo `hostname` "np=12 num_node_boards=1" > /var/lib/torque/server_priv/nodes $ sed -i.bak s/localhost/`hostname`/g /var/lib/torque/mom_priv/config $ echo "nodes=1" > /var/lib/torque/mom_priv/mom.layout $ service pbs_server restart $ service pbs_mom restart $ service pbs_sched restart $ chkconfig pbs_mom on $ chkconfig pbs_sched on $ chkconfig pbs_server on $ chkconfig munge on $ chkconfig trqauthd on
- 投稿日:2020-05-26T02:23:48+09:00
開発環境の負荷計測メモ
- 投稿日:2020-05-26T01:27:03+09:00
【備忘録】特定のプロセスのCPU使用率をwhileループで確認するシェルスクリプト
0.はじめに
プロセス監視をtopコマンドで定期的に行うために作ったシェルスクリプトを共有します。
具体的には、topコマンドの実行結果をlogファイルにwhileループで出力し続けるという、シンプルなものです。1.検証環境など
- ローカルpc
- ubuntu20.04
2.topコマンドの実行結果
まず、シェルスクリプトにするtopコマンドの実行結果をサンプルとして共有します。
$ top -n 1 top - 00:58:08 up 55 min, 1 user, load average: 0.67, 0.58, 0.64 Tasks: 329 total, 1 running, 328 sleeping, 0 stopped, 0 zombie %Cpu(s): 4.6 us, 0.8 sy, 0.0 ni, 93.1 id, 0.0 wa, 0.0 hi, 1.5 si, 0.0 st MiB Mem : 15662.8 total, 9716.0 free, 2467.8 used, 3478.9 buff/cache MiB Swap: 2048.0 total, 2048.0 free, 0.0 used. 11582.7 avail Mem PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND 9095 gkz 20 0 4616108 107196 70536 S 25.0 0.7 0:00.37 chrome 2487 gkz 20 0 4730532 335940 156620 S 6.2 2.1 2:42.61 gnome-shell 4102 gkz 20 0 321656 12708 11268 S 6.2 0.1 0:05.56 ibus-engine-moz 7243 gkz 20 0 961388 52248 37448 S 6.2 0.3 0:05.53 gnome-terminal- 1 root 20 0 168164 11936 8272 S 0.0 0.1 0:10.67 systemdtopコマンドはnオプションを使うことで画面(フレーム?)の更新回数を制限することが可能です。
本記事では任意のプロセスのCPU使用率を定期的に監視するため、パイプでtopコマンドの結果を渡し、grepで特定のプロセスの出力結果のみ絞ることとします。3.ソースコード
toploop.sh#!/bin/bash # debug mode # bash -x toploop.sh $process # your monitored process, e.g. dockerd process=$1 starttime=`date +"%Y%m%d_%H%M%S"` filename=`echo "log/top.log.$process.$starttime"` while true do sleep 5 output=`top -n 1| grep $process` val=`echo $output | awk '{print $13}'` if [ "$val" == "$process" ]; then num=`echo "$output" | grep -oP "[S|R]\s+[0-9]*[.]?[0-9]" | awk '{print $2}'` date +"%Y%m%d_%H%M%S" >> $filename echo "$process: $num%" >> $filename else date +"%Y%m%d_%H%M%S" >> $filename echo "$process: notfound" >> $filename fi done4.実行方法
4-1.コマンドの末尾に
&をつけてバッググラウンドでコマンドを実行$ . toploop.sh chrome& [1] 111754-2.シェルスクリプトを実行した後、tailコマンドでログファイルの更新を追う
※シェルスクリプトではlogファイル名のフォーマットを
top.log.${process}.${starttime}としています。$ tail -f log/top.log.chrome.20200526_011531 20200526_011602 chrome: notfound 20200526_011608 chrome: 6.2%※プロセス監視が終わったら、4-1で実行したシェルスクリプトの実行プロセスを忘れずに
kill ${bashのPID}しておきましょう。5. 参考
P.S. Twitterもやってるのでフォローしていただけると泣いて喜びます:)