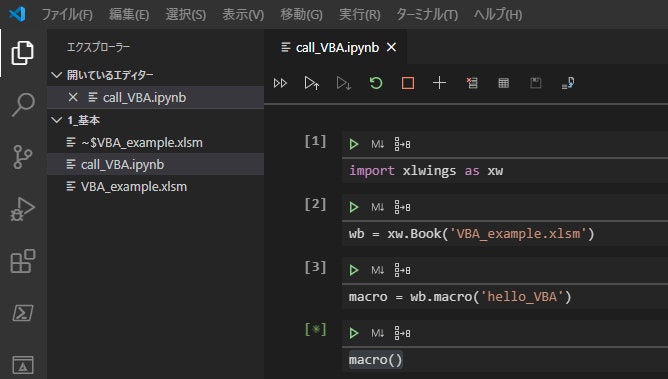
- 投稿日:2020-05-25T23:54:55+09:00
Poetry入門 インストールから実行、バージョン管理まで
はじめに
備忘録としてPoetryの使い方を残します。
インストール
$ curl -sSL https://raw.githubusercontent.com/python-poetry/poetry/master/get-poetry.py | pythonコマンド一覧
個人的に使いそうなコマンドを載せます。
Poetryのアップデート
$ poetry self updateプロジェクトの作成
$ poetry new <project-name>パッケージのインストール
$ poetry add <package-name>パッケージのアンインストール
$ poetry remove <package-name>パッケージ一覧を表示
$ poetry show仮想環境内でのコマンドの実行
$ poetry run <commands...>
pythonでファイルを実行$ poetry run python <file-name>仮想環境内でシェルを立ち上げる
$ poetry shell
$SHELLに従ってシェルを立ち上げますインストール後の始め方
プロジェクト内に、仮想環境が作られるようにします
$ poetry config virtualenvs.in-project trueこのコマンドはインストール後に、1回すればOK
サンプルプロジェクトを作成します
$ poetry new poetry-sampleプロジェクトディレクトリに移動
$ cd poetry-sample追加したいパッケージをインストール
ここでは、numpyをインストール$ poetry add numpy
poetry-sampleディレクトリで、sample.pyを作成sample.pyimport numpy as np x = np.array([1, 2, 3]) print(x)仮想環境内でシェルを立ち上げます
$ poetry shellスクリプトを実行
$ python sample.pyまたは仮想環境でシェルを立ち上げずに、直接コマンドを実行して実行できます
poetry run python sample.py以上のような流れで、プロジェクトの作成、パッケージの追加、プログラムの実行を行えます
スクリプトは
poetry-sample内になくても実行はできますPythonのバージョンの管理
pyenvを併用して行う方法ですPython3.7.0を例とします
まず
pyenvで3.7.0がインストールされていなければインストールします$ pyenv install 3.7.0プロジェクト内のローカルのバージョンを変更します
$ pyenv local 3.7.0コマンドで仮想環境を構築します
$ poetry env use 3.7.0これでプロジェクト内のPythonのバージョンは3.7.0になります
最後に
とても便利なのでこれから使っていきたいです。
- 投稿日:2020-05-25T23:47:48+09:00
韻を扱いたいpart5
内容
前回グラフを作れたので、クラスタリング等を行ってみる。
また、韻の捉え方を拡張する。「eい」→「ee」,「oう」→「oo」と変換し、変換後に母音が一致したものも「韻」と捉える。これはカタカナ英語や子供の間違えやすい日本語を参考にした。「ei」と表記しないのは「えき」が「ええ」にはならないということだ。「い」と「う」は母音単体ではないといけない。(「れいぞうこ」が「れえぞおこ」)グラフの操作
import networkx as nx import matplotlib.pyplot as plt import community G = nx.Graph() G.add_weighted_edges_from(edge_list) #クラスタリング partition = community.best_partition(G, weight="weight") #コミュニティごとにノードを分けてリストにする。[[コミュニティ0のノードリスト],[コミュニティ1のノードリスト]…] part_sub = [[] for _ in set(list(partition.values()))] for key in partition.keys(): part_sub[partition[key]].append(key) #各コミュニティで固有ベクトル中心性が最大となるノードをリストに格納 max_betw_cent_node = [] for part in part_sub: G_part = nx.Graph() for edge in edge_list: if edge[0] in part and edge[1] in part: G_part.add_weighted_edges_from([edge]) max_betw_cent_node.append(max(G_part.nodes(), key=lambda val: nx.eigenvector_centrality_numpy(G_part, weight="weight")[val])) print([dic[i] for i in max_betw_cent_node]) #モジュラリティ指標 print(community.modularity(partition,G))クラスタリングし、コミュニティ毎に固有ベクトル中心性が最大となるものを求めた。良い分割が出来ていれば、それぞれをtarget_wordとした時に、良い結果が得られると思われる。エッジの重みに使っている部分に閾値を設けることで重みに差が付くようにしてみる等を検討する。
韻の捉え方の拡張
from pykakasi import kakasi import re with open("./gennama.txt","r", encoding="utf-8") as f: data = f.read() kakasi = kakasi() kakasi.setMode('J', 'K') kakasi.setMode('H', 'K') conv = kakasi.getConverter() text_data = conv.do(data) #eイ→ee,oウ→ooのように変換したテキストを得る def expansion(text_data): #最後の文字次第だが、i,uの余分が出ることを長さを合わせることで解決 text_data_len = len(text_data) #いい椅子や、そういう噂のような「い、う」の連続への対処。 text_data = text_data.replace("イイ", "イi").replace("ウウ","ウu") text_data = text_data.split("イ") new_text_data = [] kakasi.setMode('K', 'a') conv = kakasi.getConverter() for i in range(text_data_len): if len(text_data[i]) > 0: if ("e" in conv.do(text_data[i][-1])): new_text_data.append(text_data[i] + "e") else: new_text_data.append(text_data[i] + "i") text_data = "".join(new_text_data).split("ウ") new_text_data = [] for i in range(text_data_len): if len(text_data[i]) > 0: if ("o" in conv.do(text_data[i][-1])): new_text_data.append(text_data[i] + "o") else: new_text_data.append(text_data[i] + "u") return "".join(new_text_data)[:text_data_len] print(expansion(text_data))まず、データをカタカナへ変換し、「イ、ウ」で分割、直前の文字の母音によって処理を変更する、という方針でやっていたがなかなか苦労した。データの最後が「イ、ウ」の場合や、それ以外の時は「iu」が残る。引数のデータと長さが変わらないようにすることで対処したが、
今後の方針
(カタカナ変換データ、母音だけ残したデータ、拡張したデータ)それぞれで一致部分をスコア化し、(子音の一致、母音の一致、響きの一致)を捉えようと思う。長音、撥音、促音の一致を見ることは不要と判断した。
つまり、これまでのことを一度まとめてみる。N-gramもスペース分割部分も考慮すべきと思うし、一致部分の見方にも問題有りと思っている。現状最良の方法をまとめ、入力データをなにかしら用意して検証していきたい。
- 投稿日:2020-05-25T23:44:49+09:00
ゼロから始めるLeetCode Day36「155. Min Stack」
概要
海外ではエンジニアの面接においてコーディングテストというものが行われるらしく、多くの場合、特定の関数やクラスをお題に沿って実装するという物がメインである。
その対策としてLeetCodeなるサイトで対策を行うようだ。
早い話が本場でも行われているようなコーディングテストに耐えうるようなアルゴリズム力を鍛えるサイト。
せっかくだし人並みのアルゴリズム力くらいは持っておいた方がいいだろうということで不定期に問題を解いてその時に考えたやり方をメモ的に書いていこうかと思います。
前回
[ゼロから始めるLeetCode Day35「160. Intersection of Two Linked Lists」(https://qiita.com/KueharX/items/f9c01184085586fbe491)基本的にeasyのacceptanceが高い順から解いていこうかと思います。
Twitterやってます。
問題
難易度はeasy。
Top 100 Liked Questionsのeasyはこれが最後の問題になります。問題としては、push,pop,top,getMinという関数を持つMinStackクラスを実装してくださいというものです。
なお、それぞれの関数の仕様は以下の通り。
push(x) -- Push element x onto stack.
pop() -- Removes the element on top of the stack.
top() -- Get the top element.
getMin() -- Retrieve the minimum element in the stack.Input
["MinStack","push","push","push","getMin","pop","top","getMin"]
[[],[-2],[0],[-3],[],[],[],[]]Output
[null,null,null,null,-3,null,0,-2]Explanation
MinStack minStack = new MinStack();
minStack.push(-2);
minStack.push(0);
minStack.push(-3);
minStack.getMin(); // return -3
minStack.pop();
minStack.top(); // return 0
minStack.getMin(); // return -2使用例は以上です。
Stackについては多くのプログラマーが知っていると思うのでここでは触れません。解法
class MinStack: def __init__(self): """ initialize your data structure here. """ self.stack = [] def push(self, x: int) -> None: minElement = self.getMin() if minElement == None or x < minElement: minElement = x self.stack.append((x,minElement)) def pop(self) -> None: self.stack.pop() def top(self) -> int: if len(self.stack) == 0: return None else: return self.stack[len(self.stack) - 1][0] def getMin(self) -> int: if len(self.stack) == 0: return None else: return self.stack[len(self.stack) - 1][1] # Your MinStack object will be instantiated and called as such: # obj = MinStack() # obj.push(x) # obj.pop() # param_3 = obj.top() # param_4 = obj.getMin() # Runtime: 72 ms, faster than 38.62% of Python3 online submissions for Min Stack. # Memory Usage: 17.9 MB, less than 5.36% of Python3 online submissions for Min Stack.スライスが便利、かと思いきや普通に他の言語でも普通に似たような実装になりそうですね・・・
何にせよstackを実装してみるのは面白いので書いてみることをお勧めします。今回はこんな感じで。お疲れ様でした。
- 投稿日:2020-05-25T23:14:07+09:00
バブルソートでソートされる様子を可視化する
概要
バブルソートでソートされる様子を
matplotlibを使って描画してみました
※jupyter notebook上に貼り付けて実行してくださいbubble_sort.pyimport numpy as np import matplotlib.pyplot as plt %matplotlib inline list_a = [5,7,4,5,1,2,3,2,9,1,4] left = np.arange(1, len(list_a) + 1) height = list_a plt.bar(left, height) plt.show() for i in range(len(list_a)): for j in range(0, len(list_a) - i - 1): if list_a[j] > list_a[j + 1]: list_a[j], list_a[j + 1] = list_a[j + 1], list_a[j] height = np.array(list_a) plt.bar(left, height) plt.show()
- 投稿日:2020-05-25T23:12:36+09:00
【1日1写経】Predict employee attrition【Daily_Coding_001】
初めに
- 本記事は、python・機械学習等々を独学している小生の備忘録的な記事になります。
- 「自身が気になったコードを写経しながら勉強していく」という、きわめてシンプルなものになります。
- 建設的なコメントを頂けますと幸いです(気に入ったら
LGTM&ストックしてください)。お題:IBM HR Analytics Employee Attrition & Performance
- 今回のお題は、IBM HR Analytics Employee Attrition & Performanceです。kaggleに記載のあった説明によると、「従業員の退職理由」を探る問題のようです。
- 今回、以下のyoutubeの動画を見つつ写経していきました。
Link:Predict Employee Attrition Using Machine Learning & Python
データはkaggleから取ってきました。
Link:IBM HR Analytics Employee Attrition & Performance
分析はyoutubeの動画にある通り、Google Colaboratryを使用しました(便利な時代になったものです)。
Step 1:データ読み込み~内容確認
それではやっていきたいと思います。
1.1: ライブラリのインポート
# ライブラリの読み込み import numpy as np import pandas as pd import seaborn as sns基本となるライブラリを読み込みます。必要なライブラリはこの後も適宜追加していく感じになります。
次にデータの読み込みですが、kaggleのサイトからダウンロードしたcsvファイルをgoogle colabで読み込みます。
1.2: Google Colabへのファイルのアップロード
# データのアップロード from google.colab import files uploaded = files.upload()これをすることによって、ローカルに保存してあるファイルをgoogle colab上に取り込むことができます。
普段はGoogle Driveにファイルのアップロードしてから、Google Driveを連携させて読み込んでいたので、こっちのほうが楽でいいですね。1.3: pandasでの読み込み
アップロードしたデータを読み込んでいきます。
# データの読み込み df = pd.read_csv('WA_Fn-UseC_-HR-Employee-Attrition.csv') # データの確認 df.head(7)おなじみのコードですね。次からはデータの中身を確認していきます。
データの中身の確認
以下のコードは(実際には)それぞれ別々に実行していますが、ここでは纏めて書いておきます。
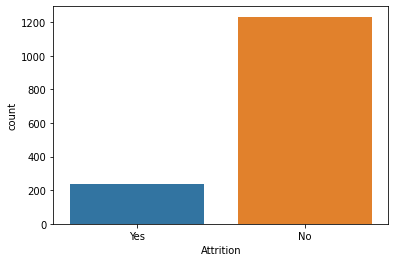
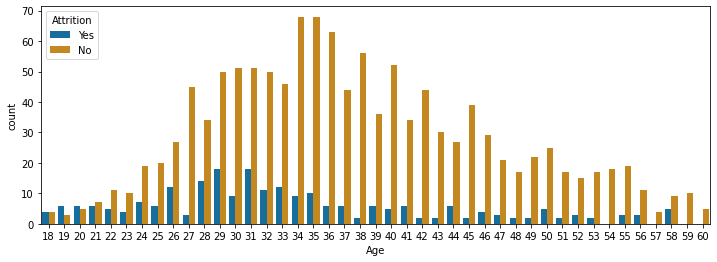
# データフレームの行・列の数確認 df.shape # それぞれの列の中身のデータ型を確認 df.dtypes # 欠損値の確認 df.isna().sum() df.isnull().values.any() #基礎統計量の確認 df.describe() # 退職者と在籍者数の数の確認(被説明変数の数の把握) df['Attrition'].values_counts() #図1 # 退職者と在籍者数の可視化 sns.countplot(df['Attrition']) # 年齢別の退職者数と在籍者数の可視化 import matplotlib.pyplot as plt plt.subplots(figsize=(12,4)) sns.countplot(x='Age', hue='Attrition', data=df, palette='colorblind') #図2【図1】
【図2】
ここまではいつもやるようなデータの確認です。まずしっかりデータの中身を確認することはやはり必要だと思います。
1.4: object型のユニーク値の確認
次に、先ほど確認したデータ型のうちobject型の列のユニーク値を確認します。
for column in df.columns: if df[column].dtype == object: print(str(column) + ':' + str(df[column].unique())) print(df[column].value_counts()) print('___________________________________________')
- 1行目:forループでそれぞれの列を繰り返しとってくる
- 2行目:取ってきた列がobject型か判定
- 3行目:カラム名 + そのカラムのユニーク値を出力
- 4行目:各ユニーク値の個数を出力
1.5: 不要行の削除
.drop()で予測するのに意味をなさない列を削除します。df = df.drop('Over18', axis=1) df = df.drop('EmployeeNumber', axis=1) df = df.drop('StandardHours', axis=1) df = df.drop('EmployeeCount', axis=1)これは説明不要ですね。退職する理由にならないものをdfの中から外します。
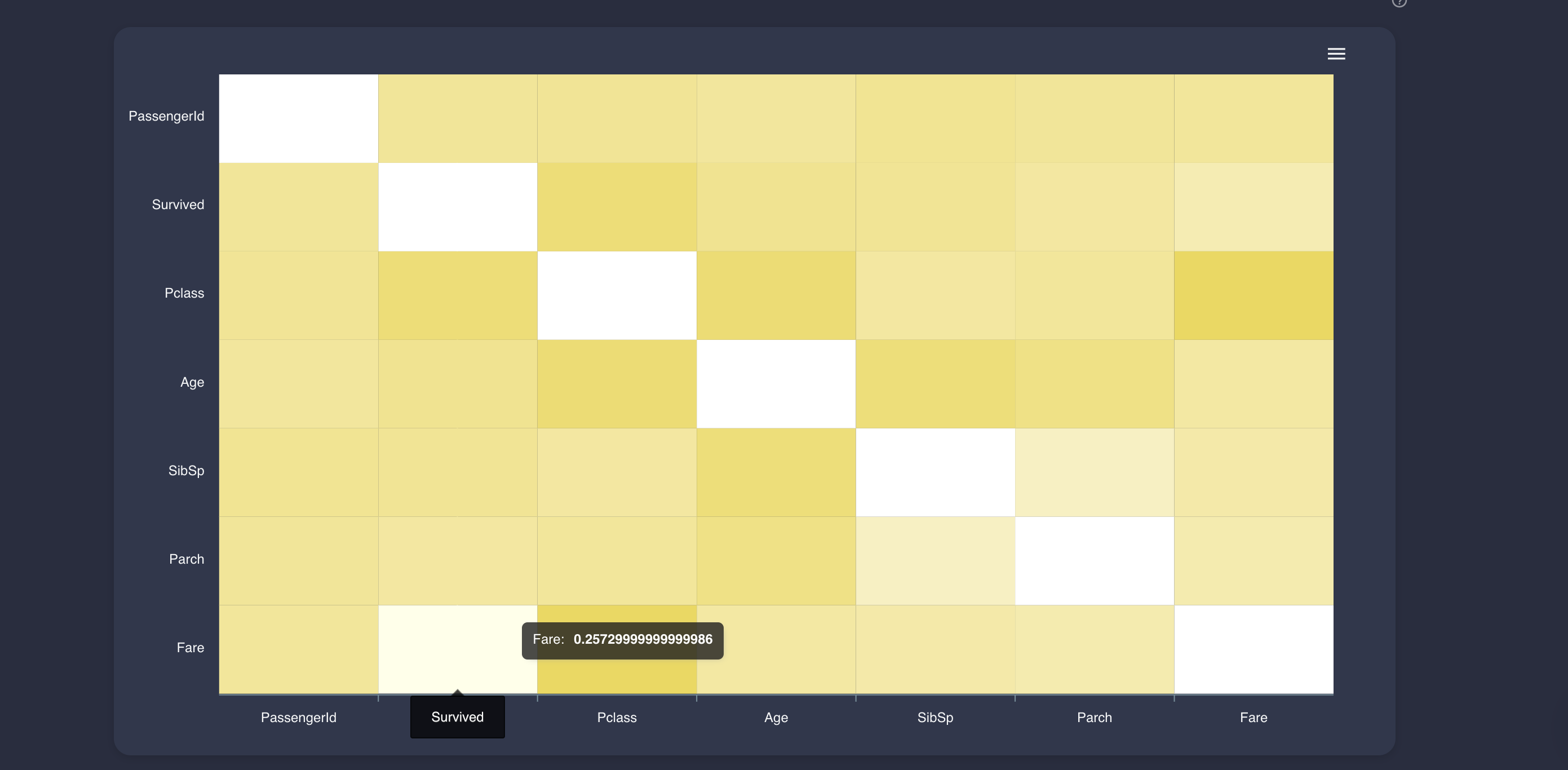
1.6: 列間の相関の確認
これもお馴染みの処理だと思います。各列間の相関(
correlation)を確認し、heatmap可視化します。df.corr() plt.figure(figsize=(14, 14)) sns.heatmap(df.corr(), annot=True, fmt='.0%')今回、heatmapを作成する際に指定しているのは以下の2つです。
Item Description annot True に設定すると、セルに値を出力します。 fmt annot=True に設定した場合、またはデータセットを指定した場合の出力フォーマットを文字列で指定 1.7: sklearnでカテゴリカル(non numerical)データにラベリング
from sklearn.preprocessing import LabelEncoder for column in df.columns: if df[columen].dtype == np.number: continue df[column] = LabelEncoder().fit_transform(df[column])ここでは、sklearnのLabelEncoderを使ってobject型だったデータに数値データに置き換える(「分類器にかける前に文字データを離散値(0, 1, ・・・)に変換」)。
置き換えが終わったら、dfの列の順番を入れ替え分析しやすい形にします。
# Ageを新しい列に複製 df['Age_Years'] = df['Age'] # Age列を落とす df = df.drop('Age', axis=1)Step2: sklearnで分析
ここからが本番ですね(前処理が重要なのは言うまでもないですが)。
# dfをデータを説明変数と被説明変数に分割 X = df.iloc[:, 1:df.shape[1]].values Y = df.iloc[:, 0].values # 訓練データ、教師データのテストデータサイズ(25%)で分割 from sklearn.model_selection import train_test_split X_train, X_test, Y_train, Y_test = train_test_split(X, Y, test_size=0.25, ramdom_state = 0) # ランダムフォレストによる分類 from sklearn.ensemble import RandomForestClassifier forest = RandomForestClassifier(n_estimators = 10, criterion = 'entropy', random_state = 0) forest.fit(X_train, Y_train)上から見ていきましょう。
iloc[]を使って説明変数と被説明変数を分離します。- sklearnの
train_test_splitを使って訓練データとテストデータの分割。 train_test_splitの引数は以下の通りです。
Item Description arrays 分割対象の同じ長さを持った複数のリスト、Numpy の array, matrix, Pandasのデータフレームを指定。 test_size 小数もしくは整数を指定。小数で指定した場合、テストデータの割合を 0.0 〜 1.0 の間で指定します。整数を指定した場合は、テストデータに必ず含めるレコード件数を整数で指定します。指定しなかった場合や None を設定した場合は、train_size のサイズを補うように設定します。train_size を設定していない場合、デフォルト値として 0.25 を用います。 train_size 小数もしくは整数を指定。小数で指定した場合、トレーニングデータの割合を 0.0 〜 1.0 の間で指定します。整数を指定した場合は、トレーニングデータに必ず含めるレコード件数を整数で指定します。指定しなかった場合や None を設定した場合は、データセット全体から test_size を引いた分のサイズとします。 random_state 乱数生成のシードとなる整数または、RandomState インスタンスを設定します。指定しなかった場合は、Numpy のnp.random を用いて乱数をセットします。 (参照: scikit-learn でトレーニングデータとテストデータを作成する)
- ランファムフォレストを使って分類をします。ここでの引数は、
n_estimators: 木の数の指定(デフォルトは100)
criterion:giniorentropyを指定(デフォルトはgini)この後、
forest.fit(...)でモデルを学習させます。それでは精度を見ていきましょう。
forest.score(X_train, Y_train)この後、
confusion_matrix(混合行列)を使ってAccuracyを計算してます。from sklearn.metrics import confusion_matrix cm = confusion_matrix(Y_test, forest.predict(X_test)) #cm: confusion_matrix TN = cm[0][0] TP = cm[1][1] FN = cm[1][0] FP = cm[0][1] print(cm) print('Model Testing Accuracy = {}'.format( (TP + TN) / (TP + TN + FN + FP)))以上で、簡単ではありますがskleanを使って二値分類の写経になります。
最後に
内容的にはそこまで難しいものではないにせよ、まだまだ理解していない箇所があることが認識できましたので、引き続き勉強していきたいと思います。
以上。
- 投稿日:2020-05-25T23:08:38+09:00
python xlwingsを用いたExcelグラフ作成
コメント
xlwingsを使ったグラフ作成の参考にしてください。
こうする方がベターだよというご指摘あればうれしいです。
apiを使うとvbaのコードが使える→ わからないことはExcelにて「マクロの記録」で調べられる。
test.xlsxは白紙のワークブックです。環境
python 3.7
xlwings 0.18.0サンプルコード
import xlwings as xw from xlwings.constants import AxisType DATA_NUM = 10 # エクセルワークブックの読み込み wb = xw.Book('test.xlsx') # データの挿入 data_x = list(x for x in range(DATA_NUM)) data_y1 = list(x*2 for x in range(DATA_NUM)) data_y2 = list(x*10-50 for x in range(DATA_NUM)) xw.Range('A1').value = 'x' xw.Range('B1').value = 'y1' xw.Range('C1').value = 'y2' cell_x = xw.Range('A2') cell_y1 = xw.Range('B2') cell_y2 = xw.Range('C2') for cnt in range(DATA_NUM): cell_x.value = data_x[cnt] cell_y1.value = data_y1[cnt] cell_y2.value = data_y2[cnt] cell_x = cell_x.offset(1, 0) cell_y1 = cell_y1.offset(1, 0) cell_y2 = cell_y2.offset(1, 0) # グラフの挿入 chart = xw.Chart() # グラフ位置・サイズの調整 chart.left = 200 chart.top = 10 chart.width = 300 chart.height = 200 # グラフ種類の設定 chart.chart_type = 'xy_scatter_lines_no_markers' # データ範囲の設定 chart.set_source_data(xw.Range('A1:C11')) # x軸の位置を下端に変更(xlminimum=4 ←VBAの定数を読み込む方法わかる方教えてください) # api[1]の1の意味がわかる方教えてください。とりあえず1にしておけば動作するのですが・・・。 chart.api[1].Axes(AxisType.xlValue).Crosses = 4 # 軸目盛りを内向きに変更(xlInside=2) chart.api[1].Axes(AxisType.xlCategory).MajorTickMark = 2 chart.api[1].Axes(AxisType.xlValue).MajorTickMark = 2
- 投稿日:2020-05-25T23:08:20+09:00
JSON日本語を表示する
- 投稿日:2020-05-25T23:08:20+09:00
JSONファイルの日本語を表示する
- 投稿日:2020-05-25T23:06:47+09:00
EC2にpython仮想環境構築する際のエラー(No such file or directory)の対処法
EC2にpython仮想環境構築する際のエラー(No such file or directory)の対処法
AWSの公式ページに従ってEC2インスタンスにpython3の仮想環境を構築する際に出たエラーの対応方法。(boto3インストールの事前準備)
仮想環境の構築は
venvを使用。エラー内容
エラーコード#仮想環境を起動する [ec2@~]$ source ~/my_app/env/bin/activatesource #エラー -bash: /home/ec2-user/my_app/env/bin/activatesource: No such file or directory指定ディレクトリに「activatesource」が存在しない。
対処法
「activatesource」→「activate」にする。
対処法#activateに修正し仮想環境を有効化 [ec2@ip- ~]$ source ~/my_app/env/bin/activate #仮想環境(env)に入れた (env) [ec2~]$要因
チュートリアルどおりに仮想環境用のフォルダを作成したが、作成されたのはactivatesourceではなくactivateだった。
▼仮想環境用の作成
[ec2~]$ python3 -m venv my_app/env▼作成したフォルダ内のリスト(~/my_app/env/bin/配下)
[ec2~ bin]$ ls activate activate.fish easy_install-3.7 pip3 python activate.csh easy_install pip pip3.7 python3
- 投稿日:2020-05-25T22:54:46+09:00
kaggleで使えるツールVARISTAの機能まとめ
VARISTAって??
クラウド上で機械学習を行えるSaaSサービスです。
https://www.varista.ai/
DataRobotやGCPのAutoML Tableのかっこいい版といった感じです。
しかも基本無料で使えるため、誰でもすぐに利用可能です。さっそく⭐️
Kaggle、Signateなどのデータサイエンスコンペサイトでは通常、
カーネルやjupyter、自前のpythonコードなどを利用して参加していると思います。そこで今回はそれらのコンペに参加する上でVARISTAをつかうことで、どんなことができるのかを試してみました。
データは住宅価格予測(回帰)とタイタニック(分類)を利用して確認します。1. データの確認?
VARISTAでは、ドラッグアンドドロップでデータをアップロードするだけで
データの自動解析が行われ、ある程度の情報を一瞬で確認することができます。
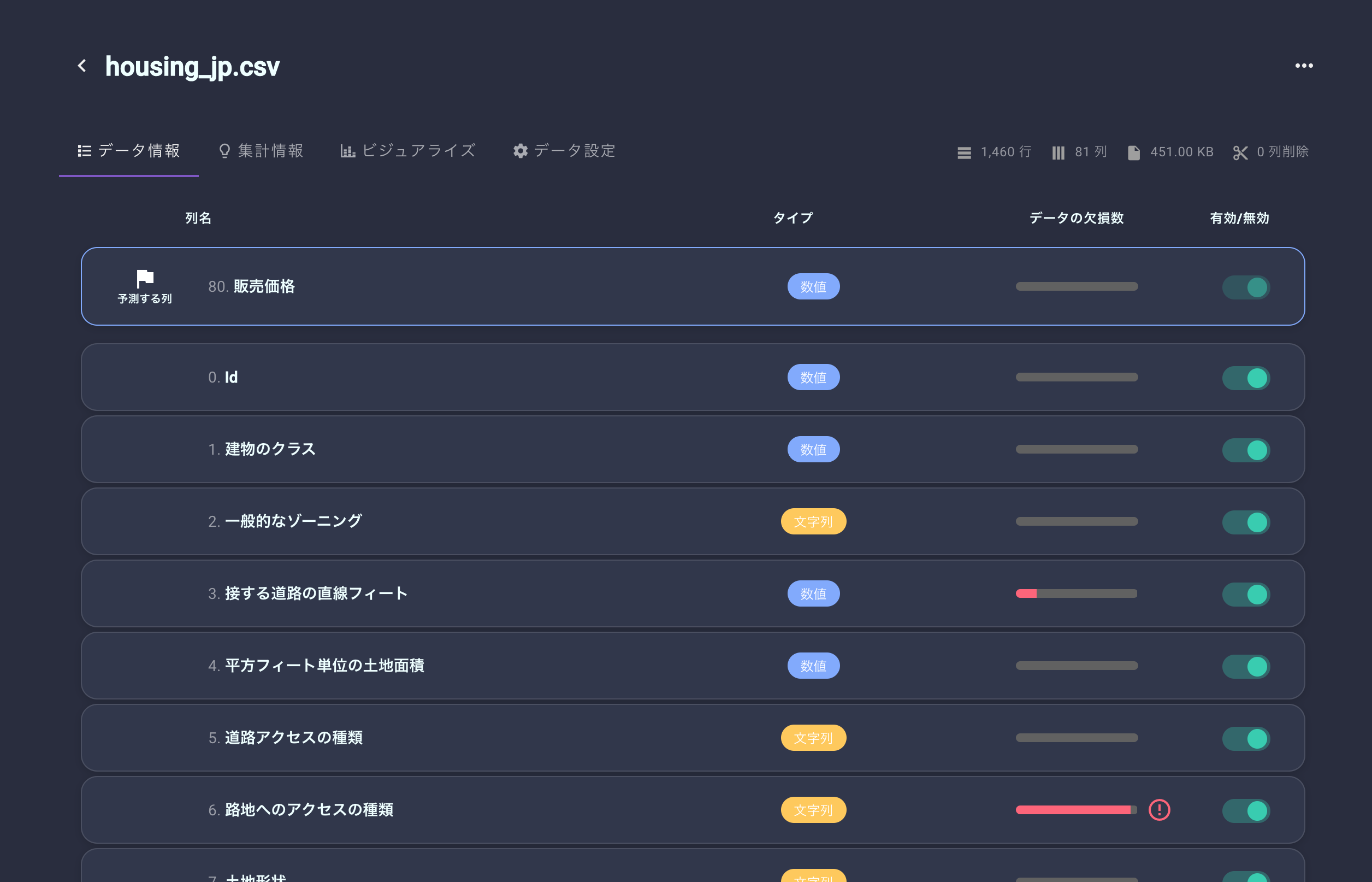
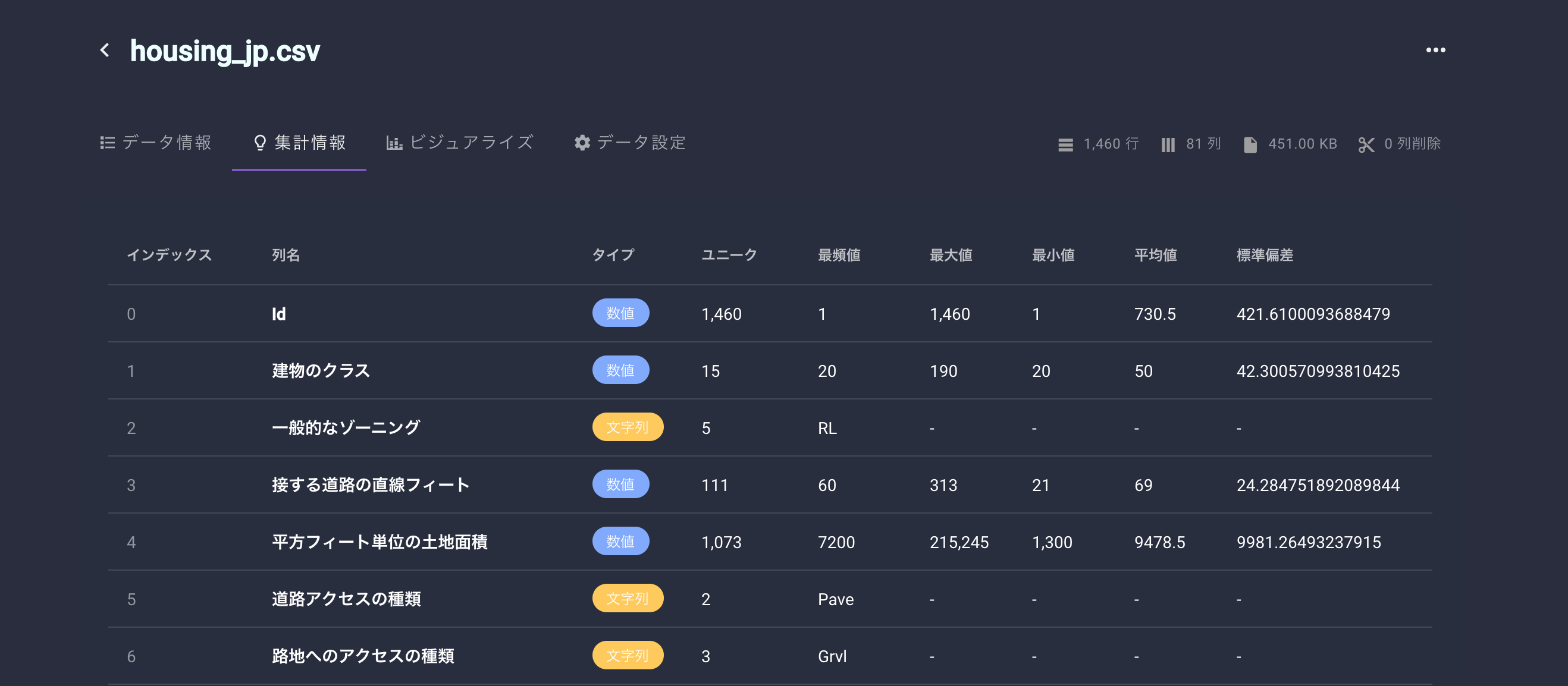
アップロードが完了すると、データの情報が表示されます。
ここでチェックするのは、各列の欠損数や、列のタイプくらいですかね。
IDなどの学習に利用しない列はトグルでOFFにしておきます。また、となりのタブにある「集計情報」からは、各列の統計情報を確認することができます。
pandas. describe()の結果をGUIで確認できる感じです。
ちょっとデータを確認したいだけなのに、わざわざ数行のスクリプト用意するのめんどくさいとき結構ありますよね。
2. データの可視化?
KaggleなどでVARISTAを利用する上で最も重宝するのが、このビジュアライズ機能です!
pythonライブラリでもmatplotlibやseabornなど、データを可視化するライブラリはいろいろあると思います。
それらと比較して、何がいいか。
それは勝手にクールなグラフを生成してくれることです!
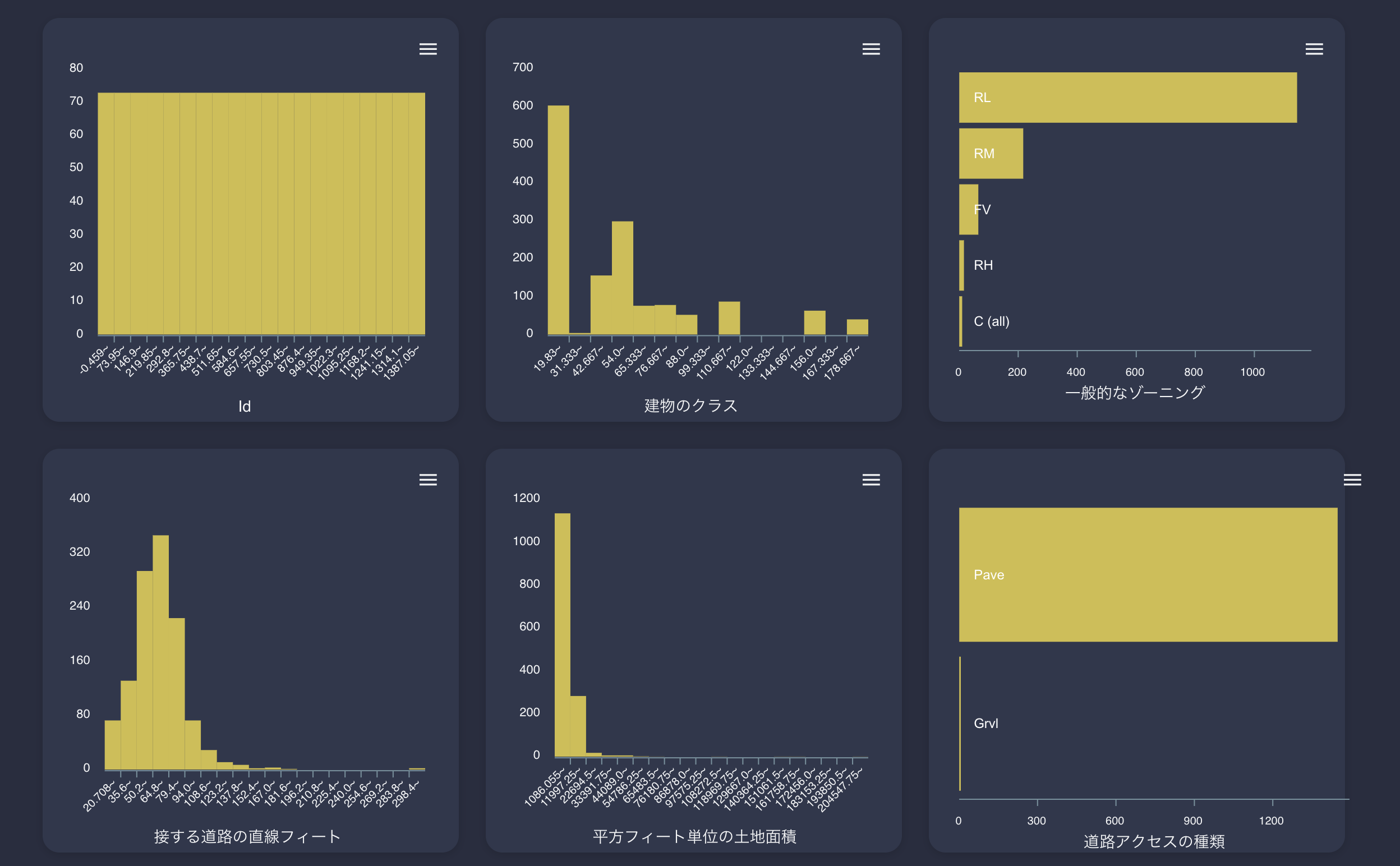
これからVARISTAが自動生成してくれる、各グラフをご紹介します。まずはヒストグラム
こんな感じで各列ごとのヒストグラムを確認することができます。
もう一度言いますが、全自動です。なにもしてません。つぎに相関図
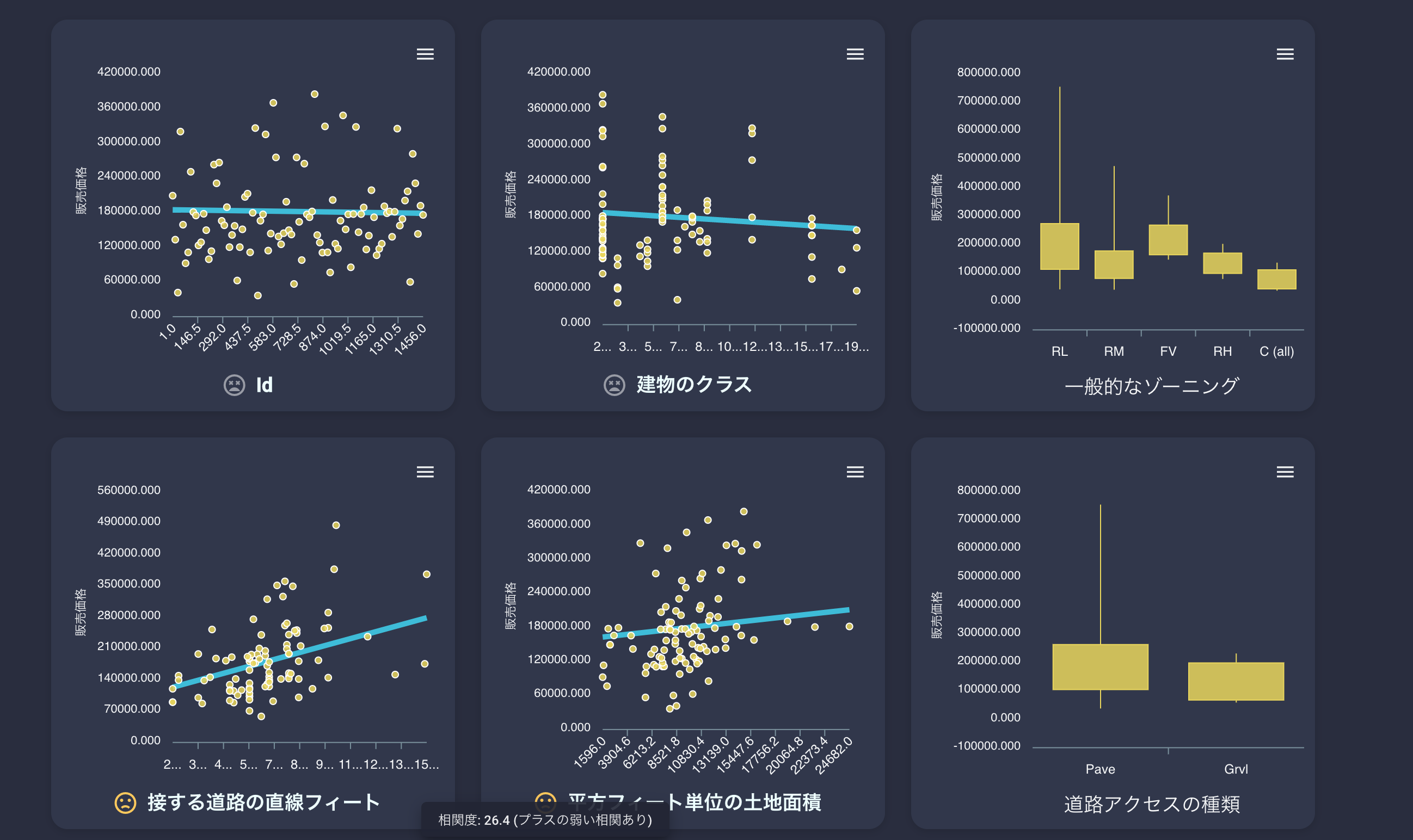
各列と予測する列との相関関係が一眼でわかります。
数値列の場合、近似一時式の直線が表示されていたり、相関度が顔文字で表現されていたりします。
カテゴリ列の場合、最大、最小などのボックスチャートとなり表示されています。
自動でこれらの表示を分けて生成してくれるのがすばらしいですね。また、これらのグラフは回帰データのもので分類問題だと以下のように表示が変わります。
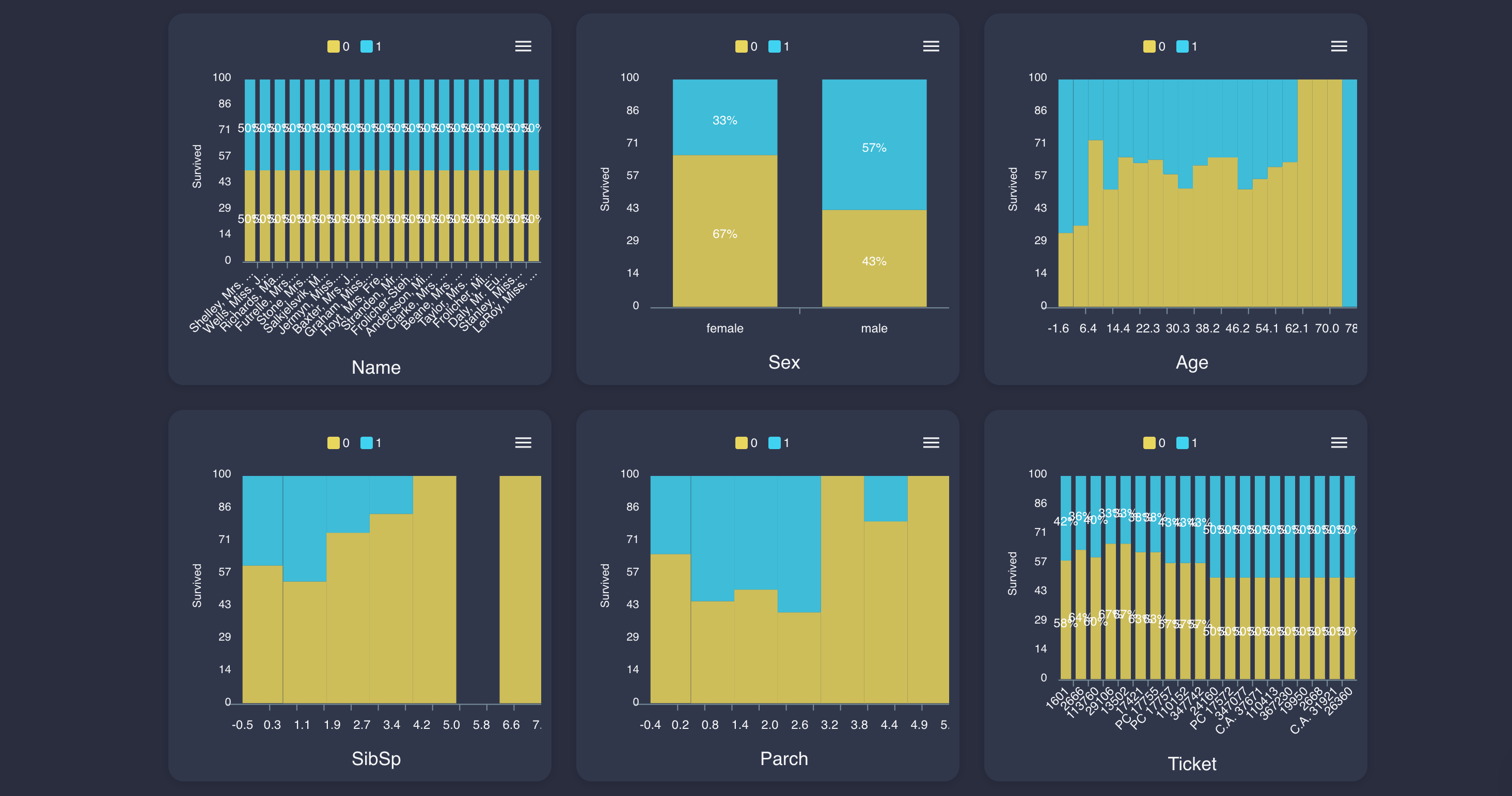
タイタニックのデータでは、各数値、カテゴリごとの生存率が可視化されています。
これにより、「年齢が若ければ若いほど生存率が高い」などが一目瞭然です。
未知のデータに対しても、この機能だけでわかるインサイトは結構あるとおもいます。ヒートマップ
おなじみのヒートマップです。
正直あまりみないですが、とりあえず可視化しますよね(自分だけか)3. オート学習機能?
VARISTAはAutoMLツールなので、もちろん学習も可能です。
ですが、Kagglerの皆さんはもちろん精度を求めて、自分なりのパイプラインで学習を行うと思います。
だからといってVARISTAの学習は無駄か?というとそういうわけでもありません。
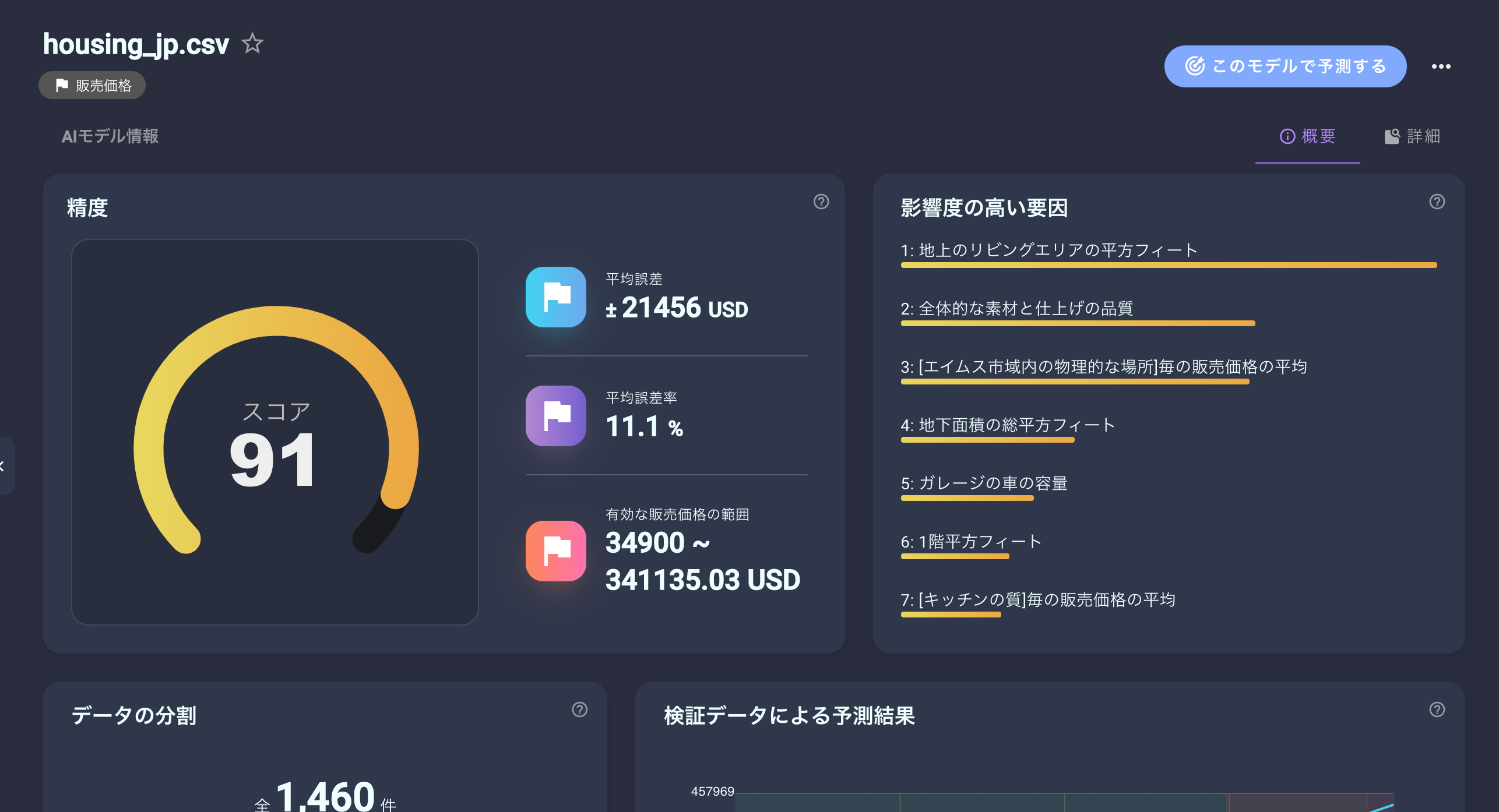
学習結果から得られるインサイトが結構あるのです。学習が完了すると、このような結果画面が確認できます。
右側にあるFeature Importanceをみれば重要な変数が確認できます。
また、詳細タブを開くとより細かい学習結果が確認可能です。
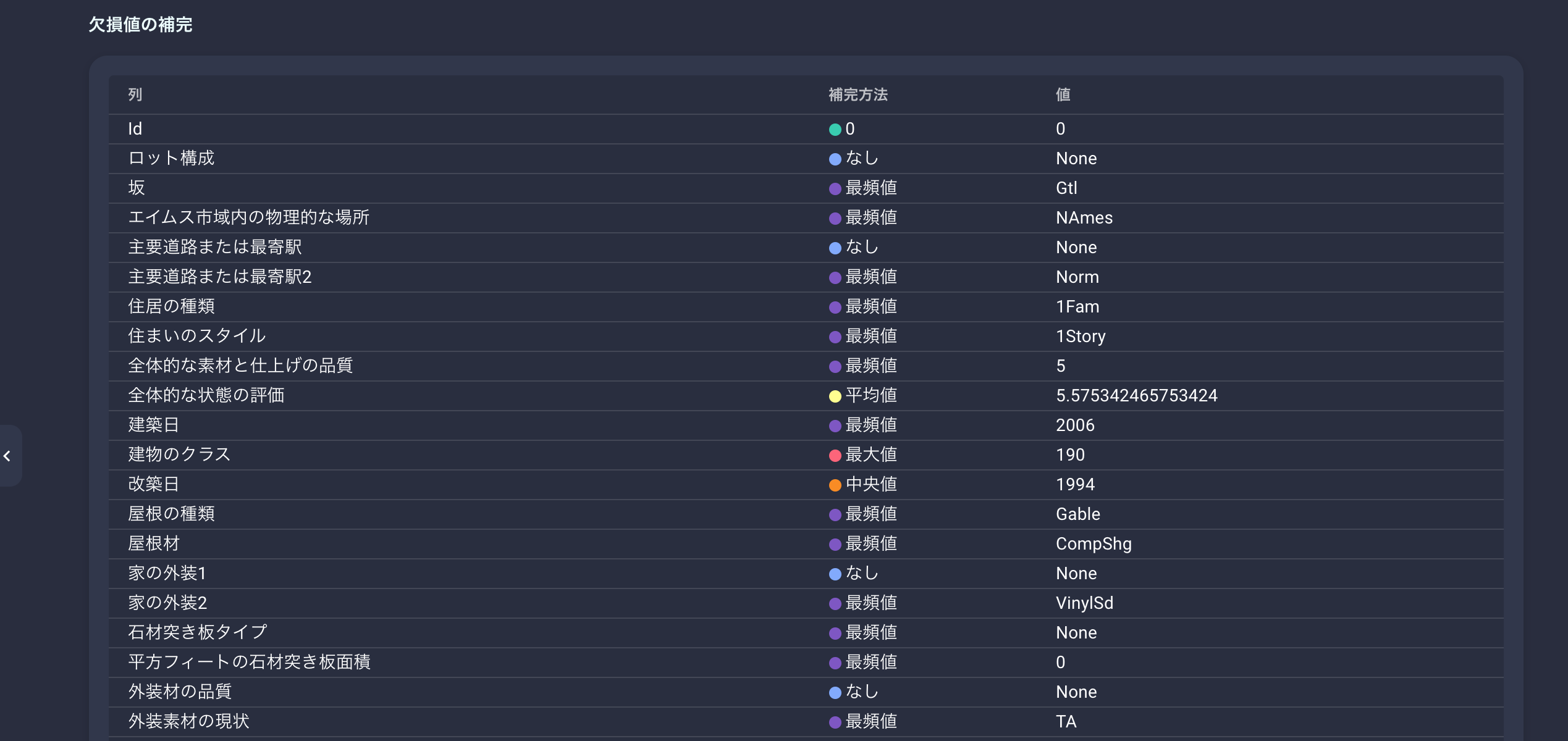
VARISTAでは欠損値の補完も自動的に探索するのですが、その結果が一覧で表示されています。
データの欠損値補完を悩んでる場合は、ここを参考にしてもいいと思います。
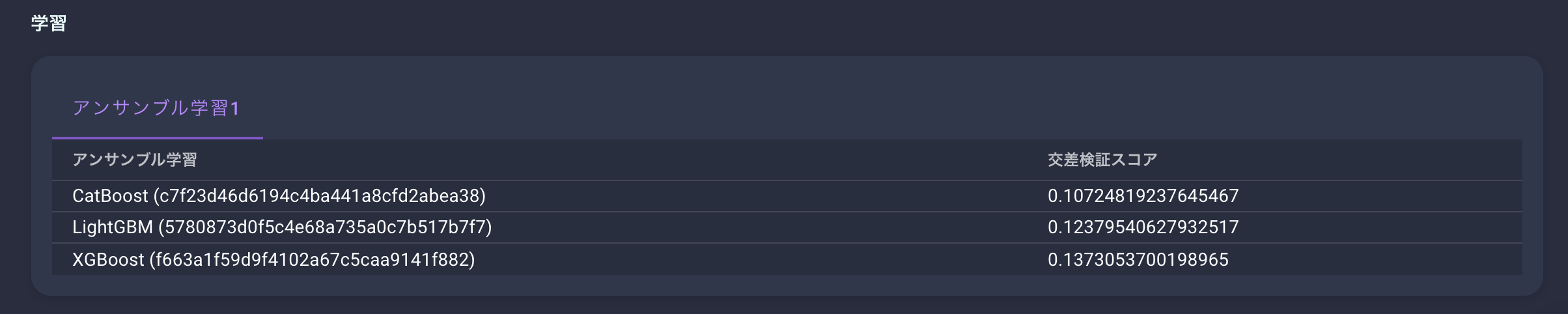
さらにVARISTAではアンサンブル学習に対応しているため、いくつかのアルゴリズムで学習させた結果も残っています。
これを確認することで、どのアルゴリズムで最もスコアが出たのかを確認することができます。
おわり?
VARISTAではこれらの機能が無料で利用可能です。
スクリプトを書いてもいいけど、とりあえずデータを確認したいってときに使えるツールであることがわかるかと思います。
みなさんも是非お試しください?
- 投稿日:2020-05-25T22:45:35+09:00
TensorFlow 2.X の様々な書き方を VGG16/ResNet50 の実装を通して理解する
はじめに
TensorFlow は Google が開発しているディープラーニングのフレームワークです。
2019年の10月1日のメジャーアップデートを経て 2 系となり、 2020年5月23日現在のバージョンは 2.2.0 です。TensorFlow は OSS 開発の過程で異なるフレームワーク(Keras)との統合や開発者の趣向反映(Define and Run → Define by Run)を経ている背景もあり、モデルの構築や訓練を様々な書き方で実現できます。
これは便利である反面、初学者にとっては理解を妨げる要因になり得ます。
今回は 2 系の TensorFlow で推奨されている記法を網羅的に紹介し、画像認識の分野で著名なモデルである VGG16 と ResNet50 を実装することで以下の達成レベルを目指します。
- 2 系の TensorFlow で記述されたソースコードからモデルの形状を把握できる
- 2 系の TensorFlow を利用して VGG シリーズ、 ResNet シリーズを独力で実装できる
対象読者
- TensorFlow のチュートリアルを試したが、自力でモデルを構築できない人
- TensorFlow で書かれたソースコードを読むと、見慣れない書き方があると感じる人
- Chainer、PyTorch でモデルを書くことができるが TensorFlow でモデルを書けない人
対象でない読者
- TensorFlow の Subclass API / Functional API / Sequential API について理解している人
- TensorFlow の built-in 訓練とカスタム訓練について理解している人
流れ
まず、 TensorFlow の 4 つのモデル構築 API について説明します。
その後、 2 つの訓練手法について説明します。
最後にこれらの手法を利用して VGG16 と ResNet50 の実装を行います。TensorFlow における 4 つのモデル構築 API
TensorFlow ではモデルを構築するために、大きく分けて 2 つ、細かく分けると 4 つの API が用意されています。
- シンボリック(宣言型)API
- Sequential API
- Functional API
- Primitive API(1.X 系の書き方。現在は非推奨)
- 命令型(モデル サブクラス化)API
- Subclassing API
まず大きな分類について簡単に紹介します。
シンボリック(宣言型) API
モデルの形状を学習実行前に宣言(定義)する書き方です。
宣言とはコンパイルのようなものだと思ってください。この記法で書かれたモデルは学習中に形状を変更することはできません。
そのため、一部の動的に形が変わるモデル(Tree-RNN など)は実装することができません。
その代わりに、学習を実行しなくてもモデル形状の確認ができるようになります。命令型(モデル サブクラス化)API
シンボリック API とは異なり、宣言をしない命令的(≒直感的)な書き方です。
日本(Preferred Networks)発祥のディープラーニングフレームワークである Chainer が最初に採用した記法で、PyTorch もこの記法を採用しています。
Python でクラスを書くようにモデルを実装することができるため、層の変更や拡張などカスタマイズが容易です。
その代わりに、一度モデルにデータを与えるまでモデルがどのような形状なのかをプログラム側からは認識することができません。続いて、具体的な書き方について簡単な例を交えて紹介します。
Sequential API
その名の通り、Sequential(連続的)に層を追加してモデルを実装する API です。
Keras や TensorFlow のチュートリアルでもこの書き方が使われることが多いため、一度は見たことがあるのではないでしょうか。以下のように、空の
tensorflow.keras.Sequentialクラスをインスタンス化した後にaddメソッドで層を追加していく方法と、tensorflow.keras.Sequentialクラスの引数にリストとして層を与えてインスタンス化する方法が一般的です。import tensorflow as tf from tensorflow.keras import layers def sequential_vgg16_a(input_shape, output_size): model = tf.keras.Sequential() model.add(layers.Conv2D(64, 3, 1, padding="same", batch_input_shape=input_shape)) model.add(layers.BatchNormalization()) # ...(中略)... model.add(layers.Dense(output_size, activation="softmax")) return model def sequential_vgg16_b(input_shape, output_size): model = tf.keras.Sequential([ layers.Conv2D(64, 3, 1, padding="same", batch_input_shape=input_shape), layers.BatchNormalization(), # ...(中略)... layers.Dense(output_size, activation="softmax") ] return modelレイヤーを追加するメソッドのみをサポートしているため、入力、中間特徴、出力が複数になる、あるいは条件分岐が存在するような複雑なネットワークを記述することはできません。
層を順番に通していくだけの(VGG のような)シンプルなネットワークを実装する際にこの記法を利用できます。Functional API
Sequential API では記述できない複雑なモデルを実装する API です。
まず
tensorflow.keras.layers.Inputをインスタンス化し、最初の層に渡します。
その後、ある層の出力を次の層へと渡していくことでモデルのデータフローを定義していきます。
最後に、得られた出力と最初の入力をtensorflow.keras.Modelの引数として与えることでモデルを構築できます。from tensorflow.keras import layers, Model def functional_vgg16(input_shape, output_size, batch_norm=False): inputs = layers.Input(batch_input_shape=input_shape) x = layers.Conv2D(64, 3, 1, padding="same")(x) if batch_norm: x = layers.BatchNormalization()(x) x = layers.ReLU()(x) # ...(中略)... outputs = layers.Dense(output_size, activation="softmax")(x) return Model(inputs=inputs, outputs=outputs)上述の例では変数
batch_normの値によって Batch Normalization 層の有無を切り替えています。
このように条件によってモデルの形状を変えるような柔軟な定義が必要な場合は Sequential API ではなく Functional API が必要になります。なお、カッコの後にカッコが続く一見奇妙な書き方が登場しますが、これは TensorFlow 特有ではなく Python で一般的に利用できる書き方で、以下の 2 つは同じ処理を表します。
# 書き方 1 x = layers.BatchNormalization()(x) # 書き方 2 layer = layers.BatchNormalization() x = layer(x)Primitive API
TensorFlow 1.X 系で主に利用されていた記法です。
2.X 系の現在は非推奨となっています。上述の Sequential API と Functional API はモデルを通るデータのフローを記述していくことでモデルを定義することができましたが、 Primitive API ではその他の計算処理を含む全体の処理フローを宣言的に記述します。
今からこの書き方を覚えるメリットはあまりないので説明は省きますが、
tensorflow.Sessionを利用して訓練を行っている場合はこの書き方に該当します。import tensorflow as tf sess = tf.Session()Subclassing API
TensorFlow 2 系へのアップデートと共に利用可能になった API です。
Chainer や PyTorch とほとんど同じ書き方であり、Python でクラスを書くようにモデルを実装することができるので直感的でカスタマイズが容易です。まず
tensorflow.keras.Modelを継承してクラスを作ります。
その後、__init__メソッドとcallメソッドを実装することでモデルを構築します。クラス内の
__init__メソッドでは親クラスの__init__メソッド呼び出しと学習したいレイヤーの登録を行います。ここに記載していないレイヤーの重みはデフォルトでは学習対象になりません。クラス内の
callメソッドではレイヤーの順伝播を記載します。(Chainer の__call__、PyTorch のforwardと同じようなものです。)from tensorflow.keras import layers, Model class VGG16(Model): def __init__(self, output_size=1000): super().__init__() self.layers_ = [ layers.Conv2D(64, 3, 1, padding="same") layers.BatchNormalization(), # ...(中略)... layers.Dense(output_size, activation="softmax") ] def call(self, inputs): for layer in self.layers_: inputs = layer(inputs) return inputs他の書き方と比べると少々冗長にも見えますが、普通にクラスを書くようにモデルを実装できることがわかります。
なお、親クラスの初期化を行う
superメソッドには引数を与えるパターンもありますが、これは 2 系の Python を考慮した書き方であり、 3 系の Python では引数なしでも同じ処理になります。from tensorflow.keras import Model # Python 3 系の書き方 class VGG16(Model): def __init__(self, output_size=1000): super().__init__() # Python 2 系の書き方 class VGG16(Model): def __init__(self, output_size=1000): super().__init__(VGG16, self)モデル構築 API 振り返り
モデル構築方法の説明は以上になります。
まとめると、以下のような使い分けができるかと思います。
- 層を一方的に通るだけのモデルを簡単に書きたい場合は Sequential API
- 複雑なモデルを学習実行前にきちんと形状確認できるように書きたい場合は Functional API
- Chainer や PyTorch 流の書き方で書きたい、あるいは動的なモデルを書きたい場合は Subclassing API
TensorFlow における 2 つの訓練方法
訓練を行う方法としては以下の 2 つが存在します。
- built-in 訓練
- カスタム訓練
※ 正式な名称があるわけではなさそうなので、本記事では便宜的に上記の名称を利用しています。
built-in 訓練
tensorflow.keras.Modelの built-in function を利用して訓練を行う方法です。Keras、 TensorFlow のチュートリアルでも利用されているためご存知の方が多いかと思います。
また、異なるライブラリですが scikit-learn でもこの方法が採用されています。まず、上述の API で実装したモデル(
tensorflow.keras.Model、あるいはこれを継承したオブジェクト)をインスタンス化します。このインスタンスは built-in function として
compileメソッドとfitメソッドを持っています。この
compileメソッドを実行して損失関数、最適化関数、評価指標を登録します。
その後fitメソッドを実行することで訓練を行います。import tensorflow as tf (train_images, train_labels), _ = tf.keras.datasets.cifar10.load_data() # 例示のため学習済みのモデルを使っています model = tf.keras.applications.VGG16() model.compile( optimizer=tf.keras.optimizers.Adam(), loss="sparse_categorical_crossentropy", metrics=["accuracy"], ) model.fit(train_images, train_labels)これで訓練が実行できます。
バッチサイズの指定、エポック数、コールバック関数の登録、バリデーションデータでの評価などは、
fitメソッドのキーワード引数として登録することができるため、ある程度のカスタマイズも可能です。多くの場合はこれで十分対応できるかと思いますが、この枠にハマらないケース(例えば GAN など複数のモデルを同時に訓練するケース)は後述するカスタム訓練で記述する必要があります。
カスタム訓練
これは特別 API が用意されているというわけではなく、普通に Python の for ループで訓練する方法です。
まず、上述の API で実装したモデル(
tensorflow.keras.Model、あるいはこれを継承したオブジェクト)をインスタンス化します。次に、損失関数、最適化関数の定義に加えてデータセットのバッチ化を行います。
その後、for ループでエポック、バッチを回していきます。for ループ内ではまず
tf.GradientTapeスコープの中に順伝搬の処理を記述します。
その後gradientメソッドを呼び出して勾配を計算し、apply_gradientsメソッドで最適化関数に従って重みを更新しています。import tensorflow as tf batch_size = 32 epochs = 10 (train_images, train_labels), _ = tf.keras.datasets.cifar10.load_data() # 例示のため学習済みのモデルを使っています model = tf.keras.applications.VGG16() buffer_size = len(train_images) train_ds = tf.data.Dataset.from_tensor_slices((train_images, train_labels)) train_ds = train_ds.shuffle(buffer_size=buffer_size).batch(batch_size) criterion = tf.keras.losses.SparseCategoricalCrossentropy() optimizer = tf.keras.optimizers.Adam() for epoch in range(epochs): for x, y_true in train_ds: with tf.GradientTape() as tape: y_pred = model(x, training=True) loss = criterion(y_true=y_true, y_pred=y_pred) gradients = tape.gradient(loss, model.trainable_variables) optimizer.apply_gradients(zip(gradients, model.trainable_variables))これで訓練が実行できます。
上記の例ではバリデーションデータでの評価や TensorBoard への出力等を一切行っていませんが、普通に for ループを回しているだけなので、好きなように処理を追加していくことができます。
一方で記述量はどうしても多くなるためソースコードの品質担保がやや大変になります。
なお Chainer、PyTorch も(細かい違いはありますが)ほぼ同じ書き方ができます。訓練方法振り返り
訓練方法の説明は以上になります。
まとめると、以下のような使い分けができるかと思います。
- 訓練中に特殊な処理を実行する必要がない場合、一般的な訓練手法の場合は built-in 訓練
- built-in の枠にハマらない場合、訓練中にいろいろな処理を追加して試行錯誤したい場合、手なりで書きたい場合は カスタム訓練
VGG16/ResNet 50 の概要
説明だけではよく分からない部分もあると思うので、実装を通して理解を深めていきます。
まず簡単に 2 つのモデルについて紹介します。
VGG16 とは
3x3 Convolution を 13 層、全結合層を 3 層持つ非常にシンプルな構造でありながら高性能なモデルです。
様々な画像認識タスクで画像特徴の抽出に利用されます。原論文は 37,000 を超える被引用数を持っており、とても有名です。Sequential API、 Functional API、 Subclassing API で実装が可能です。
なお、原論文はこちらです。
https://arxiv.org/abs/1409.1556ResNet50 とは
Residual 機構を持つ多層(Convolution を 49 層、全結合層を 1 層)モデルです。2020 年現在でもこの ResNet の亜種が画像分類の精度においてはトップクラスとなっており、こちらも高性能なモデルです。
VGG16 と同様に様々な画像認識タスクで画像特徴の抽出に利用されます。原論文は 45,000 を超える被引用数(BERT の約 10 倍)を持っており、こちらも非常に有名です。Sequential API 単体では実装できません。Functional API、 Subclassing API で実装が可能です。
なお、原論文はこちらです。
https://arxiv.org/abs/1512.03385VGG16 の実装
ではそれぞれの書き方で実装してみます。
VGG16 Sequential API
特に考えることもないので普通に書きます。
from tensorflow.keras import layers, Sequential def sequential_vgg16(input_shape, output_size): params = { "padding": "same", "use_bias": True, "kernel_initializer": "he_normal", } model = Sequential() model.add(layers.Conv2D(64, 3, 1, **params, batch_input_shape=input_shape)) model.add(layers.BatchNormalization()) model.add(layers.ReLU()) model.add(layers.Conv2D(64, 3, 1, **params)) model.add(layers.BatchNormalization()) model.add(layers.ReLU()) model.add(layers.MaxPool2D(2, padding="same")) model.add(layers.Conv2D(128, 3, 1, **params)) model.add(layers.BatchNormalization()) model.add(layers.ReLU()) model.add(layers.Conv2D(128, 3, 1, **params)) model.add(layers.BatchNormalization()) model.add(layers.ReLU()) model.add(layers.MaxPool2D(2, padding="same")) model.add(layers.Conv2D(256, 3, 1, **params)) model.add(layers.BatchNormalization()) model.add(layers.ReLU()) model.add(layers.Conv2D(256, 3, 1, **params)) model.add(layers.BatchNormalization()) model.add(layers.ReLU()) model.add(layers.Conv2D(256, 3, 1, **params)) model.add(layers.BatchNormalization()) model.add(layers.ReLU()) model.add(layers.MaxPool2D(2, padding="same")) model.add(layers.Conv2D(512, 3, 1, **params)) model.add(layers.BatchNormalization()) model.add(layers.ReLU()) model.add(layers.Conv2D(512, 3, 1, **params)) model.add(layers.BatchNormalization()) model.add(layers.ReLU()) model.add(layers.Conv2D(512, 3, 1, **params)) model.add(layers.BatchNormalization()) model.add(layers.ReLU()) model.add(layers.MaxPool2D(2, padding="same")) model.add(layers.Conv2D(512, 3, 1, **params)) model.add(layers.BatchNormalization()) model.add(layers.ReLU()) model.add(layers.Conv2D(512, 3, 1, **params)) model.add(layers.BatchNormalization()) model.add(layers.ReLU()) model.add(layers.Conv2D(512, 3, 1, **params)) model.add(layers.BatchNormalization()) model.add(layers.ReLU()) model.add(layers.MaxPool2D(2, padding="same")) model.add(layers.Flatten()) model.add(layers.Dense(4096)) model.add(layers.Dense(4096)) model.add(layers.Dense(output_size, activation="softmax")) return modelかなり単純に書くことができますが、層が多いので見るのが辛いことがわかります。
例えば、どこかでReLUが抜けてても気付かなそうです。
また、例えばBatch Normalizationを無くしたい、と思った場合は 1 行ずつコメントアウトしていく必要があり、再利用生やカスタマイズ性に乏しいです。VGG16 Functional API
Sequential API と比べて柔軟に書くことができます。
今回は再利用される層のまとまり(Convolution - BatchNormalization - ReLU)を関数にしてみます。from tensorflow.keras import layers, Model def functional_cbr(x, filters, kernel_size, strides): params = { "filters": filters, "kernel_size": kernel_size, "strides": strides, "padding": "same", "use_bias": True, "kernel_initializer": "he_normal", } x = layers.Conv2D(**params)(x) x = layers.BatchNormalization()(x) x = layers.ReLU()(x) return x def functional_vgg16(input_shape, output_size): inputs = layers.Input(batch_input_shape=input_shape) x = functional_cbr(inputs, 64, 3, 1) x = functional_cbr(x, 64, 3, 1) x = layers.MaxPool2D(2, padding="same")(x) x = functional_cbr(x, 128, 3, 1) x = functional_cbr(x, 128, 3, 1) x = layers.MaxPool2D(2, padding="same").__call__(x) # こう書いても良い x = functional_cbr(x, 256, 3, 1) x = functional_cbr(x, 256, 3, 1) x = functional_cbr(x, 256, 3, 1) x = layers.MaxPool2D(2, padding="same").call(x) # こう書いても良い x = functional_cbr(x, 512, 3, 1) x = functional_cbr(x, 512, 3, 1) x = functional_cbr(x, 512, 3, 1) x = layers.MaxPool2D(2, padding="same")(x) x = functional_cbr(x, 512, 3, 1) x = functional_cbr(x, 512, 3, 1) x = functional_cbr(x, 512, 3, 1) x = layers.MaxPool2D(2, padding="same")(x) x = layers.Flatten()(x) x = layers.Dense(4096)(x) x = layers.Dense(4096)(x) outputs = layers.Dense(output_size, activation="softmax")(x) return Model(inputs=inputs, outputs=outputs)だいぶスッキリ書くことができました。
BatchNormalizationを無くしたくなっても、ReLUをLeaklyReLUに変えたくなっても数行の改修で済みます。VGG16 Subclassing API
Functional API と同様に再利用される層のまとまり(Convolution - BatchNormalization - ReLU)をクラスにして書いてみます。
from tensorflow.keras import layers, Model class CBR(Model): def __init__(self, filters, kernel_size, strides): super().__init__() params = { "filters": filters, "kernel_size": kernel_size, "strides": strides, "padding": "same", "use_bias": True, "kernel_initializer": "he_normal", } self.layers_ = [ layers.Conv2D(**params), layers.BatchNormalization(), layers.ReLU() ] def call(self, inputs): for layer in self.layers_: inputs = layer(inputs) return inputs class VGG16(Model): def __init__(self, output_size=1000): super().__init__() self.layers_ = [ CBR(64, 3, 1), CBR(64, 3, 1), layers.MaxPool2D(2, padding="same"), CBR(128, 3, 1), CBR(128, 3, 1), layers.MaxPool2D(2, padding="same"), CBR(256, 3, 1), CBR(256, 3, 1), CBR(256, 3, 1), layers.MaxPool2D(2, padding="same"), CBR(512, 3, 1), CBR(512, 3, 1), CBR(512, 3, 1), layers.MaxPool2D(2, padding="same"), CBR(512, 3, 1), CBR(512, 3, 1), CBR(512, 3, 1), layers.MaxPool2D(2, padding="same"), layers.Flatten(), layers.Dense(4096), layers.Dense(4096), layers.Dense(output_size, activation="softmax"), ] def call(self, inputs): for layer in self.layers_: inputs = layer(inputs) return inputs
__init__でモデルの定義、callでモデルの呼び出しを担当しているため、Functional API よりも直感的に理解しやすいですが、コードは長めになります。
また命令型である Subclassing API はモデル生成時に入力の形状が必要ない(引数にinput_shapeが必要ない)こともポイントです。VGG16 実装 振り返り
なるべく比較しやすいように書いたつもりですがいかがだったでしょうか。
今回の実装は Batch Normalization を Convolution 層の間に挟んでいるのと重みの初期化に He の初期化を利用していますが、原論文が提出された時はこれらのテクニックは未だ発表されていなかったので Batch Normalization 層はなく、重みの初期化には Grolot の初期化が使われていました。そのため、原論文では勾配消失を回避するために 7 層のモデルを学習してから層を徐々に付け足していくといった転移学習ライクな学習方法が採用されています。
上記の実装をより深く理解するために Batch Normalization 層をなくすと何が起きるのか、重みの初期化手法を変えると何が起きるのか、などを試してみるのも面白いと思います。
ResNet50 の実装
続いて ResNet50 を実装します。
Sequential API 単体では書けないので Functional API、 Subclassing API で書きます。ResNet50 Functional API
再利用される Residual 機構を関数化して実装します。
from tensorflow.keras import layers, Model def functional_bottleneck_residual(x, in_ch, out_ch, strides=1): params = { "padding": "same", "kernel_initializer": "he_normal", "use_bias": True, } inter_ch = out_ch // 4 h1 = layers.Conv2D(inter_ch, kernel_size=1, strides=strides, **params)(x) h1 = layers.BatchNormalization()(h1) h1 = layers.ReLU()(h1) h1 = layers.Conv2D(inter_ch, kernel_size=3, strides=1, **params)(h1) h1 = layers.BatchNormalization()(h1) h1 = layers.ReLU()(h1) h1 = layers.Conv2D(out_ch, kernel_size=1, strides=1, **params)(h1) h1 = layers.BatchNormalization()(h1) if in_ch != out_ch: h2 = layers.Conv2D(out_ch, kernel_size=1, strides=strides, **params)(x) h2 = layers.BatchNormalization()(h2) else: h2 = x h = layers.Add()([h1, h2]) h = layers.ReLU()(h) return h def functional_resnet50(input_shape, output_size): inputs = layers.Input(batch_input_shape=input_shape) x = layers.Conv2D(64, 7, 2, padding="same", kernel_initializer="he_normal")(inputs) x = layers.BatchNormalization()(x) x = layers.MaxPool2D(pool_size=3, strides=2, padding="same")(x) x = functional_bottleneck_residual(x, 64, 256) x = functional_bottleneck_residual(x, 256, 256) x = functional_bottleneck_residual(x, 256, 256) x = functional_bottleneck_residual(x, 256, 512, 2) x = functional_bottleneck_residual(x, 512, 512) x = functional_bottleneck_residual(x, 512, 512) x = functional_bottleneck_residual(x, 512, 512) x = functional_bottleneck_residual(x, 512, 1024, 2) x = functional_bottleneck_residual(x, 1024, 1024) x = functional_bottleneck_residual(x, 1024, 1024) x = functional_bottleneck_residual(x, 1024, 1024) x = functional_bottleneck_residual(x, 1024, 1024) x = functional_bottleneck_residual(x, 1024, 1024) x = functional_bottleneck_residual(x, 1024, 2048, 2) x = functional_bottleneck_residual(x, 2048, 2048) x = functional_bottleneck_residual(x, 2048, 2048) x = layers.GlobalAveragePooling2D()(x) outputs = layers.Dense( output_size, activation="softmax", kernel_initializer="he_normal" )(x) return Model(inputs=inputs, outputs=outputs)
functional_bottleneck_residualメソッド内ではh1、h2、hが登場します。
このように、データのフローが途中で分岐するモデルは Sequential API では記述できません。また、
h2は入出力のチャネル数が同じ場合は何もせず、異なる場合はチャネル数を調整する処理(Projection)を行います。このような条件分岐も Sequential API では記述できません。このメソッドを作ってしまえば、あとは順々に記述していくだけです。
ResNet50 Subclassing API
Functional API と同様に再利用される Residual 機構をクラス化して実装します。
class BottleneckResidual(Model): """ResNet の Bottleneck Residual Module です. 1 層目の 1x1 conv で ch 次元を削減することで 2 層目の 3x3 conv の計算量を減らし 3 層目の 1x1 conv で ch 出力の次元を復元します. 計算量の多い 2 層目 3x3 conv の次元を小さくすることから bottleneck と呼ばれます. """ def __init__(self, in_ch, out_ch, strides=1): super().__init__() self.projection = in_ch != out_ch inter_ch = out_ch // 4 params = { "padding": "same", "kernel_initializer": "he_normal", "use_bias": True, } self.common_layers = [ layers.Conv2D(inter_ch, kernel_size=1, strides=strides, **params), layers.BatchNormalization(), layers.ReLU(), layers.Conv2D(inter_ch, kernel_size=3, strides=1, **params), layers.BatchNormalization(), layers.ReLU(), layers.Conv2D(out_ch, kernel_size=1, strides=1, **params), layers.BatchNormalization(), ] if self.projection: self.projection_layers = [ layers.Conv2D(out_ch, kernel_size=1, strides=strides, **params), layers.BatchNormalization(), ] self.concat_layers = [layers.Add(), layers.ReLU()] def call(self, inputs): h1 = inputs h2 = inputs for layer in self.common_layers: h1 = layer(h1) if self.projection: for layer in self.projection_layers: h2 = layer(h2) outputs = [h1, h2] for layer in self.concat_layers: outputs = layer(outputs) return outputs class ResNet50(Model): """ResNet50 です. 要素は conv * 1 resblock(conv * 3) * 3 resblock(conv * 3) * 4 resblock(conv * 3) * 6 resblock(conv * 3) * 3 dense * 1 から構成されていて, conv * 49 + dense * 1 の 50 層です. """ def __init__(self, output_size=1000): super().__init__() self.layers_ = [ layers.Conv2D(64, 7, 2, padding="same", kernel_initializer="he_normal"), layers.BatchNormalization(), layers.MaxPool2D(pool_size=3, strides=2, padding="same"), BottleneckResidual(64, 256), BottleneckResidual(256, 256), BottleneckResidual(256, 256), BottleneckResidual(256, 512, 2), BottleneckResidual(512, 512), BottleneckResidual(512, 512), BottleneckResidual(512, 512), BottleneckResidual(512, 1024, 2), BottleneckResidual(1024, 1024), BottleneckResidual(1024, 1024), BottleneckResidual(1024, 1024), BottleneckResidual(1024, 1024), BottleneckResidual(1024, 1024), BottleneckResidual(1024, 2048, 2), BottleneckResidual(2048, 2048), BottleneckResidual(2048, 2048), layers.GlobalAveragePooling2D(), layers.Dense( output_size, activation="softmax", kernel_initializer="he_normal" ), ] def call(self, inputs): for layer in self.layers_: inputs = layer(inputs) return inputsFunctional API とそこまで大きな違いはありません。
__init__レイヤーでリストに層をまとめるような書き方をしていますが、クラスの変数に登録されていれば良いのでこの辺は自由に書くことができます。ResNet50 実装 振り返り
Sequential API 単体では実装できないモデルとして ResNet50 を紹介しました。
正直大きな違いはないので Functional API、 Subclassing API は好みで使い分けても問題ないかと思います。訓練の実装
最後に訓練ループの実装を比較してみます。
全てのソースコードを載せるとかなり長くなるため部分的にメソッドを
src.utilsに切り出しています。
そこまで複雑なことをしているわけではないので補完しながら読んでいただければ助かります。一応全てのソースは以下のリポジトリにあるので気になる方はご覧ください。
https://github.com/Anieca/deep-learning-modelsbuilt-in 訓練 実装
テストデータの精度算出、TensorBoard 用のログ出力などいくつかオプションを指定してみます。
import os import tensorflow as tf from src.utils import load_dataset, load_model, get_args, get_current_time def builtin_train(args): # 1. load dataset and model (train_images, train_labels), (test_images, test_labels) = load_dataset(args.data) input_shape = train_images[: args.batch_size, :, :, :].shape output_size = max(train_labels) + 1 model = load_model(args.arch, input_shape=input_shape, output_size=output_size) model.summary() # 2. set tensorboard cofigs logdir = os.path.join(args.logdir, get_current_time()) tensorboard_callback = tf.keras.callbacks.TensorBoard(log_dir=logdir) # 3. loss, optimizer, metrics setting model.compile( optimizer=tf.keras.optimizers.Adam(), loss="sparse_categorical_crossentropy", metrics=["accuracy"], ) # 4. dataset config (and validation, callback config) fit_params = {} fit_params["batch_size"] = args.batch_size fit_params["epochs"] = args.max_epoch if args.steps_per_epoch: fit_params["steps_per_epoch"] = args.steps_per_epoch fit_params["verbose"] = 1 fit_params["callbacks"] = [tensorboard_callback] fit_params["validation_data"] = (test_images, test_labels) # 5. start train and test model.fit(train_images, train_labels, **fit_params)かなりシンプルに書けます。
コールバック関数は他にも色々あるので興味がある方はドキュメントを読んでみてください。
https://www.tensorflow.org/api_docs/python/tf/keras/callbacksカスタム訓練 実装
上記の built-in 訓練と同じ処理を自分で実装してみます。
import os import tensorflow as tf from src.utils import load_dataset, load_model, get_args, get_current_time def custom_train(args): # 1. load dataset and model (train_images, train_labels), (test_images, test_labels) = load_dataset(args.data) input_shape = train_images[: args.batch_size, :, :, :].shape output_size = max(train_labels) + 1 model = load_model(args.arch, input_shape=input_shape, output_size=output_size) model.summary() # 2. set tensorboard configs logdir = os.path.join(args.logdir, get_current_time()) train_writer = tf.summary.create_file_writer(os.path.join(logdir, "train")) test_writer = tf.summary.create_file_writer(os.path.join(logdir, "test")) # 3. loss, optimizer, metrics setting criterion = tf.keras.losses.SparseCategoricalCrossentropy() optimizer = tf.keras.optimizers.Adam() train_loss_avg = tf.keras.metrics.Mean() train_accuracy = tf.keras.metrics.SparseCategoricalAccuracy() test_loss_avg = tf.keras.metrics.Mean() test_accuracy = tf.keras.metrics.SparseCategoricalAccuracy() # 4. dataset config buffer_size = len(train_images) train_ds = tf.data.Dataset.from_tensor_slices((train_images, train_labels)) train_ds = train_ds.shuffle(buffer_size=buffer_size).batch(args.batch_size) test_ds = tf.data.Dataset.from_tensor_slices((test_images, test_labels)) test_ds = test_ds.batch(args.batch_size) # 5. start train and test for epoch in range(args.max_epoch): # 5.1. initialize metrics train_loss_avg.reset_states() train_accuracy.reset_states() test_loss_avg.reset_states() test_loss_avg.reset_states() # 5.2. initialize progress bar train_pbar = tf.keras.utils.Progbar(args.steps_per_epoch) test_pbar = tf.keras.utils.Progbar(args.steps_per_epoch) # 5.3. start train for i, (x, y_true) in enumerate(train_ds): if args.steps_per_epoch and i >= args.steps_per_epoch: break # 5.3.1. forward with tf.GradientTape() as tape: y_pred = model(x, training=True) loss = criterion(y_true=y_true, y_pred=y_pred) # 5.3.2. calculate gradients from `tape` and backward gradients = tape.gradient(loss, model.trainable_variables) optimizer.apply_gradients(zip(gradients, model.trainable_variables)) # 5.3.3. update metrics and progress bar train_loss_avg(loss) train_accuracy(y_true, y_pred) train_pbar.update( i + 1, [ ("avg_loss", train_loss_avg.result()), ("accuracy", train_accuracy.result()), ], ) # 5.4. start test for i, (x, y_true) in enumerate(test_ds): if args.steps_per_epoch and i >= args.steps_per_epoch: break # 5.4.1. forward y_pred = model(x) loss = criterion(y_true, y_pred) # 5.4.2. update metrics and progress bar test_loss_avg(loss) test_accuracy(y_true, y_pred) test_pbar.update( i + 1, [ ("avg_test_loss", test_loss_avg.result()), ("test_accuracy", test_accuracy.result()), ], ) # 5.5. write metrics to tensorboard with train_writer.as_default(): tf.summary.scalar("Loss", train_loss_avg.result(), step=epoch) tf.summary.scalar("Acc", train_accuracy.result(), step=epoch) with test_writer.as_default(): tf.summary.scalar("Loss", test_loss_avg.result(), step=epoch) tf.summary.scalar("Acc", test_accuracy.result(), step=epoch)訓練開始まではそこまで変わらないですが、訓練ループ内(コメントの 5. )の記述量がかなり多くなります。
訓練実装 振り返り
自分で TensorBoard 出力の管理やプログレスバーの作成と言ったユーティリティを管理するのはそれなりにコストがかかりますが、 built-in はかなり楽に使うことができます。
built-in に用意されていない処理を記述したい場合はカスタム訓練で書く必要がありますが、そうでなければ built-in を使った方が良さそうです。
終わりに
以上です。お疲れ様でした。
TensorFlow 2 系の色々な書き方について実装を交えて紹介しました。
あまりそれぞれの書き方について優劣はつけずにフラットに書いたつもりです。
自分で書くときは状況や好みに合わせて書けば良いと思いますが、ソースコードを探していると色々な書き方に出会うので、なんとなく全ての書き方を理解していると良いかと思います。
皆様のお役に立てれば幸いです。
- 投稿日:2020-05-25T22:45:35+09:00
TensorFlow 2.X の使い方を VGG16/ResNet50 の実装と共に解説
はじめに
Google が開発している 深層学習ライブラリである TensorFlow はモデルの構築や訓練ループを様々な書き方で実現できます。これは有識者にとっては便利ですが、初学者にとっては理解を妨げる要因になり得ます。
今回は TensorFlow 2.X で推奨されている書き方を網羅的に紹介し、画像認識の分野で著名なモデルである VGG16 と ResNet50 を実装しながら使い方を解説します。
※ TensorFlow 2.X とはメジャーバージョンが 2 以上の TensorFlow を指すものとします。
対象読者
- TensorFlow のチュートリアルを試したが、自力でモデルを構築できない人
- TensorFlow で書かれたソースコードを読むと、見慣れない書き方があると感じる人
- Chainer、PyTorch でモデルを書くことができるが TensorFlow でモデルを書けない人
流れ
まず、 TensorFlow の 4 つのモデル構築 API について説明します。
その後、 2 つの訓練手法について説明します。
最後にこれらの書き方を利用して VGG16 と ResNet50 の実装を行います。検証環境
- macOS Catalina 10.15.3
- Python 3.7.7
- tensorflow 2.2.0
>>> import sys >>> sys.version '3.7.7 (default, Mar 10 2020, 15:43:33) \n[Clang 11.0.0 (clang-1100.0.33.17)]'pip list | grep tensorflow tensorflow 2.2.0 tensorflow-estimator 2.2.0TensorFlow における 4 つのモデル構築 API
TensorFlow にはモデルを構築するために大きく分けて 2 つ、細かく分けると 4 つの API が用意されています。
- シンボリック(宣言型)API
- Sequential API
- Functional API
- Primitive API(1.X 系の書き方。非推奨)
- 命令型(モデル サブクラス化)API
- Subclassing API
まず大きな分類について簡単に紹介します。
シンボリック(宣言型) API
モデルの形状を学習実行前に宣言(≒コンパイル)する書き方です。
この API で書かれたモデルは学習中に形状を変更できません。
そのため、一部の動的に形が変わるモデル(Tree-RNN など)は実装できません。
その代わりに、データをモデルに与える前からモデル形状の確認ができます。命令型(モデル サブクラス化)API
シンボリック API とは異なり、宣言をしない命令的(≒直感的)な書き方です。
日本(Preferred Networks)発祥の深層学習ライブラリである Chainer が最初に採用した書き方で、PyTorch もこの書き方を採用しています。
Python でクラスを書くようにモデルを実装することができるため、層の変更や拡張などのカスタマイズが容易です。
その代わりに、一度データを与えるまでモデルがどのような形状なのかをプログラム側からは認識することができません。続いて、具体的な書き方について簡単な例を交えて紹介します。
Sequential API
その名の通り、Sequential(連続的)に層を追加してモデルを実装する API です。
Keras や TensorFlow のチュートリアルでもこの書き方が使われることが多いため、一度は見たことがあるのではないでしょうか。以下のように、空の
tensorflow.keras.Sequentialクラスをインスタンス化した後にaddメソッドで層を追加していく方法と、tensorflow.keras.Sequentialクラスの引数にリストとして層を与えてインスタンス化する方法が一般的です。import tensorflow as tf from tensorflow.keras import layers def sequential_vgg16_a(input_shape, output_size): model = tf.keras.Sequential() model.add(layers.Conv2D(64, 3, 1, padding="same", batch_input_shape=input_shape)) model.add(layers.BatchNormalization()) # ...(中略)... model.add(layers.Dense(output_size, activation="softmax")) return model def sequential_vgg16_b(input_shape, output_size): model = tf.keras.Sequential([ layers.Conv2D(64, 3, 1, padding="same", batch_input_shape=input_shape), layers.BatchNormalization(), # ...(中略)... layers.Dense(output_size, activation="softmax") ] return modelレイヤーを追加するメソッドのみをサポートしているため、入力、中間特徴、出力が複数になる、あるいは条件分岐が存在するような複雑なネットワークを記述することはできません。
層を順番に通していくだけの(VGG のような)シンプルなネットワークを実装する際にこの API を利用できます。Functional API
Sequential API では記述できない複雑なモデルを実装する API です。
まず
tensorflow.keras.layers.Inputをインスタンス化し、最初の層に渡します。
その後、ある層の出力を次の層へと渡していくことでモデルのデータフローを定義していきます。
最後に、得られた出力と最初の入力をtensorflow.keras.Modelの引数として与えることでモデルを構築できます。from tensorflow.keras import layers, Model def functional_vgg16(input_shape, output_size, batch_norm=False): inputs = layers.Input(batch_input_shape=input_shape) x = layers.Conv2D(64, 3, 1, padding="same")(inputs) if batch_norm: x = layers.BatchNormalization()(x) x = layers.ReLU()(x) # ...(中略)... outputs = layers.Dense(output_size, activation="softmax")(x) return Model(inputs=inputs, outputs=outputs)上述の例では変数
batch_normの値によって Batch Normalization 層の有無を切り替えています。
このように条件によってモデルの形状を変えるような柔軟な定義が必要な場合は Sequential API ではなく Functional API が必要になります。なお、カッコの後にカッコが続く一見奇妙な書き方が登場しますが、これは TensorFlow 特有ではなく Python で一般的に利用できる書き方で、以下の 2 つは同じ処理を表します。
# 書き方 1 x = layers.BatchNormalization()(x) # 書き方 2 layer = layers.BatchNormalization() x = layer(x)Primitive API
TensorFlow 1.X 系で主に利用されていた API です。
2.X 系の現在は非推奨となっています。上述の Sequential API と Functional API はモデルを通るデータのフローを記述していくことでモデルを定義することができましたが、 Primitive API ではその他の計算処理を含む全体の処理フローを宣言的に記述します。
今からこの書き方を覚えるメリットはあまりないので説明は省きますが、
tensorflow.Sessionを利用して訓練を行っている場合はこの書き方に該当します。import tensorflow as tf sess = tf.Session()Subclassing API
TensorFlow 2.X へのアップデートと共に利用可能になった API です。
Chainer や PyTorch とほとんど同じ書き方であり、Python でクラスを書くようにモデルを実装することができるので直感的でカスタマイズが容易です。まず
tensorflow.keras.Modelを継承してクラスを作ります。
その後、__init__メソッドとcallメソッドを実装することでモデルを構築します。クラス内の
__init__メソッドでは親クラスの__init__メソッド呼び出しと学習したいレイヤーの登録を行います。ここに記載していないレイヤーの重みはデフォルトでは学習対象になりません。クラス内の
callメソッドではレイヤーの順伝播を記載します。(Chainer の__call__、PyTorch のforwardと同じようなものです。)from tensorflow.keras import layers, Model class VGG16(Model): def __init__(self, output_size=1000): super().__init__() self.layers_ = [ layers.Conv2D(64, 3, 1, padding="same"), layers.BatchNormalization(), # ...(中略)... layers.Dense(output_size, activation="softmax"), ] def call(self, inputs): for layer in self.layers_: inputs = layer(inputs) return inputs他の書き方と比べると少々冗長にも見えますが、普通にクラスを書くようにモデルを実装できることがわかります。
なお、親クラスの初期化を行う
superメソッドには引数を与えるパターンもありますが、これは 2 系の Python を考慮した書き方であり、 3 系の Python では引数なしでも同じ処理になります。from tensorflow.keras import Model # Python 3 系の書き方 class VGG16_PY3(Model): def __init__(self, output_size=1000): super().__init__() # Python 2 系の書き方 class VGG16_PY2(Model): def __init__(self, output_size=1000): super().__init__(VGG16_PY2, self)モデル構築 API 振り返り
モデル構築方法の説明は以上になります。
まとめると、以下のような使い分けができるかと思います。
- 層を一方的に通るだけのモデルを簡単に書きたい場合は Sequential API
- 複雑なモデルを学習実行前にきちんと形状確認できるように書きたい場合は Functional API
- Chainer や PyTorch 流の書き方で書きたい、あるいは動的なモデルを書きたい場合は Subclassing API
TensorFlow における 2 つの訓練方法
訓練を行う方法としては以下の 2 つが存在します。
- built-in 訓練
- カスタム訓練
※ 正式な名称があるわけではなさそうなので、本記事では便宜的に上記の名称を利用しています。
built-in 訓練
tensorflow.keras.Modelの built-in function を利用して訓練を行う方法です。Keras、 TensorFlow のチュートリアルでも利用されているためご存知の方が多いかと思います。
また、異なるライブラリですが scikit-learn でもこの方法が採用されています。まず、上述の API で実装したモデル(
tensorflow.keras.Model、あるいはこれを継承したオブジェクト)をインスタンス化します。このインスタンスは built-in function として
compileメソッドとfitメソッドを持っています。この
compileメソッドを実行して損失関数、最適化関数、評価指標を登録します。
その後fitメソッドを実行することで訓練を行います。import tensorflow as tf (train_images, train_labels), _ = tf.keras.datasets.cifar10.load_data() # 例示のため学習済みのモデルを使っています model = tf.keras.applications.VGG16() model.compile( optimizer=tf.keras.optimizers.Adam(), loss="sparse_categorical_crossentropy", metrics=["accuracy"], ) model.fit(train_images, train_labels)これで訓練が実行できます。
バッチサイズの指定、エポック数、コールバック関数の登録、バリデーションデータでの評価などは、
fitメソッドのキーワード引数として登録することができるため、ある程度のカスタマイズも可能です。多くの場合はこれで十分対応できるかと思いますが、この枠にハマらないケース(例えば GAN など複数のモデルを同時に訓練するケース)は後述するカスタム訓練で記述する必要があります。
カスタム訓練
これは特別 API が用意されているというわけではなく、普通に Python の for ループで訓練する方法です。
まず、上述の API で実装したモデル(
tensorflow.keras.Model、あるいはこれを継承したオブジェクト)をインスタンス化します。次に、損失関数、最適化関数の定義に加えてデータセットのバッチ化を行います。
その後、for ループでエポック、バッチを回していきます。for ループ内ではまず
tf.GradientTapeスコープの中に順伝搬の処理を記述します。
その後gradientメソッドを呼び出して勾配を計算し、apply_gradientsメソッドで最適化関数に従って重みを更新しています。import tensorflow as tf batch_size = 32 epochs = 10 (train_images, train_labels), _ = tf.keras.datasets.cifar10.load_data() # 例示のため学習済みのモデルを使っています model = tf.keras.applications.VGG16() buffer_size = len(train_images) train_ds = tf.data.Dataset.from_tensor_slices((train_images, train_labels)) train_ds = train_ds.shuffle(buffer_size=buffer_size).batch(batch_size) criterion = tf.keras.losses.SparseCategoricalCrossentropy() optimizer = tf.keras.optimizers.Adam() for epoch in range(epochs): for x, y_true in train_ds: with tf.GradientTape() as tape: y_pred = model(x, training=True) loss = criterion(y_true=y_true, y_pred=y_pred) gradients = tape.gradient(loss, model.trainable_variables) optimizer.apply_gradients(zip(gradients, model.trainable_variables))これで訓練が実行できます。
上記の例ではバリデーションデータでの評価や TensorBoard への出力等を一切行っていませんが、普通に for ループを回しているだけなので、好きなように処理を追加していくことができます。
一方で記述量はどうしても多くなるためソースコードの品質担保がやや大変になります。
なお Chainer、PyTorch も(細かい違いはありますが)ほぼ同じ書き方ができます。訓練方法振り返り
訓練方法の説明は以上になります。
まとめると、以下のような使い分けができるかと思います。
- 訓練中に特殊な処理を実行する必要がない場合、一般的な訓練手法の場合は built-in 訓練
- built-in の枠にハマらない場合、訓練中にいろいろな処理を追加して試行錯誤したい場合、手なりで書きたい場合は カスタム訓練
VGG16/ResNet 50 の概要
説明だけではよく分からない部分もあると思うので、実装を通して理解を深めていきます。
まず簡単に 2 つのモデルについて紹介します。
VGG16 とは
3x3 Convolution を 13 層、全結合層を 3 層持つ非常にシンプルな構造でありながら高性能なモデルです。
様々な画像認識タスクで画像特徴の抽出に利用されます。原論文は 37,000 を超える被引用数を持っており、とても有名です。Sequential API、 Functional API、 Subclassing API で実装が可能です。
なお、原論文はこちらです。
https://arxiv.org/abs/1409.1556ResNet50 とは
Residual 機構を持つ多層(Convolution を 49 層、全結合層を 1 層)モデルです。2020 年現在でもこの ResNet の亜種が画像分類の精度においてはトップクラスとなっており、こちらも高性能なモデルです。
VGG16 と同様に様々な画像認識タスクで画像特徴の抽出に利用されます。原論文は 45,000 を超える被引用数(BERT の約 10 倍)を持っており、こちらも非常に有名です。Sequential API 単体では実装できません。Functional API、 Subclassing API で実装が可能です。
なお、原論文はこちらです。
https://arxiv.org/abs/1512.03385VGG16 の実装
ではそれぞれの書き方で実装してみます。
VGG16 Sequential API
特に考えることもないので普通に書きます。
from tensorflow.keras import layers, Sequential def sequential_vgg16(input_shape, output_size): params = { "padding": "same", "use_bias": True, "kernel_initializer": "he_normal", } model = Sequential() model.add(layers.Conv2D(64, 3, 1, **params, batch_input_shape=input_shape)) model.add(layers.BatchNormalization()) model.add(layers.ReLU()) model.add(layers.Conv2D(64, 3, 1, **params)) model.add(layers.BatchNormalization()) model.add(layers.ReLU()) model.add(layers.MaxPool2D(2, padding="same")) model.add(layers.Conv2D(128, 3, 1, **params)) model.add(layers.BatchNormalization()) model.add(layers.ReLU()) model.add(layers.Conv2D(128, 3, 1, **params)) model.add(layers.BatchNormalization()) model.add(layers.ReLU()) model.add(layers.MaxPool2D(2, padding="same")) model.add(layers.Conv2D(256, 3, 1, **params)) model.add(layers.BatchNormalization()) model.add(layers.ReLU()) model.add(layers.Conv2D(256, 3, 1, **params)) model.add(layers.BatchNormalization()) model.add(layers.ReLU()) model.add(layers.Conv2D(256, 3, 1, **params)) model.add(layers.BatchNormalization()) model.add(layers.ReLU()) model.add(layers.MaxPool2D(2, padding="same")) model.add(layers.Conv2D(512, 3, 1, **params)) model.add(layers.BatchNormalization()) model.add(layers.ReLU()) model.add(layers.Conv2D(512, 3, 1, **params)) model.add(layers.BatchNormalization()) model.add(layers.ReLU()) model.add(layers.Conv2D(512, 3, 1, **params)) model.add(layers.BatchNormalization()) model.add(layers.ReLU()) model.add(layers.MaxPool2D(2, padding="same")) model.add(layers.Conv2D(512, 3, 1, **params)) model.add(layers.BatchNormalization()) model.add(layers.ReLU()) model.add(layers.Conv2D(512, 3, 1, **params)) model.add(layers.BatchNormalization()) model.add(layers.ReLU()) model.add(layers.Conv2D(512, 3, 1, **params)) model.add(layers.BatchNormalization()) model.add(layers.ReLU()) model.add(layers.MaxPool2D(2, padding="same")) model.add(layers.Flatten()) model.add(layers.Dense(4096)) model.add(layers.Dense(4096)) model.add(layers.Dense(output_size, activation="softmax")) return modelかなり単純に書くことができますが、層が多いので見るのが辛いことがわかります。
例えば、どこかでReLUが抜けてても気付かなそうです。
また、例えばBatch Normalizationを無くしたい、と思った場合は 1 行ずつコメントアウトしていく必要があり、再利用生やカスタマイズ性に乏しいです。VGG16 Functional API
Sequential API と比べて柔軟に書くことができます。
今回は再利用される層のまとまり(Convolution - BatchNormalization - ReLU)を関数にしてみます。from tensorflow.keras import layers, Model def functional_cbr(x, filters, kernel_size, strides): params = { "filters": filters, "kernel_size": kernel_size, "strides": strides, "padding": "same", "use_bias": True, "kernel_initializer": "he_normal", } x = layers.Conv2D(**params)(x) x = layers.BatchNormalization()(x) x = layers.ReLU()(x) return x def functional_vgg16(input_shape, output_size): inputs = layers.Input(batch_input_shape=input_shape) x = functional_cbr(inputs, 64, 3, 1) x = functional_cbr(x, 64, 3, 1) x = layers.MaxPool2D(2, padding="same")(x) x = functional_cbr(x, 128, 3, 1) x = functional_cbr(x, 128, 3, 1) x = layers.MaxPool2D(2, padding="same").__call__(x) # こう書いても良い x = functional_cbr(x, 256, 3, 1) x = functional_cbr(x, 256, 3, 1) x = functional_cbr(x, 256, 3, 1) x = layers.MaxPool2D(2, padding="same").call(x) # こう書いても良い x = functional_cbr(x, 512, 3, 1) x = functional_cbr(x, 512, 3, 1) x = functional_cbr(x, 512, 3, 1) x = layers.MaxPool2D(2, padding="same")(x) x = functional_cbr(x, 512, 3, 1) x = functional_cbr(x, 512, 3, 1) x = functional_cbr(x, 512, 3, 1) x = layers.MaxPool2D(2, padding="same")(x) x = layers.Flatten()(x) x = layers.Dense(4096)(x) x = layers.Dense(4096)(x) outputs = layers.Dense(output_size, activation="softmax")(x) return Model(inputs=inputs, outputs=outputs)だいぶスッキリ書くことができました。
BatchNormalizationを無くしたくなっても、ReLUをLeaklyReLUに変えたくなっても数行の改修で済みます。VGG16 Subclassing API
Functional API と同様に再利用される層のまとまり(Convolution - BatchNormalization - ReLU)をクラスにして書いてみます。
from tensorflow.keras import layers, Model class CBR(Model): def __init__(self, filters, kernel_size, strides): super().__init__() params = { "filters": filters, "kernel_size": kernel_size, "strides": strides, "padding": "same", "use_bias": True, "kernel_initializer": "he_normal", } self.layers_ = [ layers.Conv2D(**params), layers.BatchNormalization(), layers.ReLU() ] def call(self, inputs): for layer in self.layers_: inputs = layer(inputs) return inputs class VGG16(Model): def __init__(self, output_size=1000): super().__init__() self.layers_ = [ CBR(64, 3, 1), CBR(64, 3, 1), layers.MaxPool2D(2, padding="same"), CBR(128, 3, 1), CBR(128, 3, 1), layers.MaxPool2D(2, padding="same"), CBR(256, 3, 1), CBR(256, 3, 1), CBR(256, 3, 1), layers.MaxPool2D(2, padding="same"), CBR(512, 3, 1), CBR(512, 3, 1), CBR(512, 3, 1), layers.MaxPool2D(2, padding="same"), CBR(512, 3, 1), CBR(512, 3, 1), CBR(512, 3, 1), layers.MaxPool2D(2, padding="same"), layers.Flatten(), layers.Dense(4096), layers.Dense(4096), layers.Dense(output_size, activation="softmax"), ] def call(self, inputs): for layer in self.layers_: inputs = layer(inputs) return inputs
__init__でモデルの定義、callでモデルの呼び出しを担当しているため、Functional API よりも直感的に理解しやすいですが、コードは長めになります。
また命令型である Subclassing API はモデル生成時に入力の形状が必要ない(引数にinput_shapeが必要ない)こともポイントです。VGG16 実装 振り返り
なるべく比較しやすいように書いたつもりですがいかがだったでしょうか。
今回の実装は Batch Normalization を Convolution 層の間に挟んでいるのと重みの初期化に He の初期化を利用していますが、原論文が提出された時はこれらのテクニックは未だ発表されていなかったので Batch Normalization 層はなく、重みの初期化には Grolot の初期化が使われていました。そのため、原論文では勾配消失を回避するために 7 層のモデルを学習してから層を徐々に付け足していくといった転移学習ライクな学習方法が採用されています。
上記の実装をより深く理解するために Batch Normalization 層をなくすと何が起きるのか、重みの初期化手法を変えると何が起きるのか、などを試してみるのも面白いと思います。
ResNet50 の実装
続いて ResNet50 を実装します。
Sequential API 単体では書けないので Functional API、 Subclassing API で書きます。ResNet50 Functional API
再利用される Residual 機構を関数化して実装します。
from tensorflow.keras import layers, Model def functional_bottleneck_residual(x, in_ch, out_ch, strides=1): params = { "padding": "same", "kernel_initializer": "he_normal", "use_bias": True, } inter_ch = out_ch // 4 h1 = layers.Conv2D(inter_ch, kernel_size=1, strides=strides, **params)(x) h1 = layers.BatchNormalization()(h1) h1 = layers.ReLU()(h1) h1 = layers.Conv2D(inter_ch, kernel_size=3, strides=1, **params)(h1) h1 = layers.BatchNormalization()(h1) h1 = layers.ReLU()(h1) h1 = layers.Conv2D(out_ch, kernel_size=1, strides=1, **params)(h1) h1 = layers.BatchNormalization()(h1) if in_ch != out_ch: h2 = layers.Conv2D(out_ch, kernel_size=1, strides=strides, **params)(x) h2 = layers.BatchNormalization()(h2) else: h2 = x h = layers.Add()([h1, h2]) h = layers.ReLU()(h) return h def functional_resnet50(input_shape, output_size): inputs = layers.Input(batch_input_shape=input_shape) x = layers.Conv2D(64, 7, 2, padding="same", kernel_initializer="he_normal")(inputs) x = layers.BatchNormalization()(x) x = layers.MaxPool2D(pool_size=3, strides=2, padding="same")(x) x = functional_bottleneck_residual(x, 64, 256) x = functional_bottleneck_residual(x, 256, 256) x = functional_bottleneck_residual(x, 256, 256) x = functional_bottleneck_residual(x, 256, 512, 2) x = functional_bottleneck_residual(x, 512, 512) x = functional_bottleneck_residual(x, 512, 512) x = functional_bottleneck_residual(x, 512, 512) x = functional_bottleneck_residual(x, 512, 1024, 2) x = functional_bottleneck_residual(x, 1024, 1024) x = functional_bottleneck_residual(x, 1024, 1024) x = functional_bottleneck_residual(x, 1024, 1024) x = functional_bottleneck_residual(x, 1024, 1024) x = functional_bottleneck_residual(x, 1024, 1024) x = functional_bottleneck_residual(x, 1024, 2048, 2) x = functional_bottleneck_residual(x, 2048, 2048) x = functional_bottleneck_residual(x, 2048, 2048) x = layers.GlobalAveragePooling2D()(x) outputs = layers.Dense( output_size, activation="softmax", kernel_initializer="he_normal" )(x) return Model(inputs=inputs, outputs=outputs)
functional_bottleneck_residualメソッド内ではh1、h2、hが登場します。
このように、データのフローが途中で分岐するモデルは Sequential API では記述できません。また、
h2は入出力のチャネル数が同じ場合は何もせず、異なる場合はチャネル数を調整する処理(Projection)を行います。このような条件分岐も Sequential API では記述できません。このメソッドを作ってしまえば、あとは順々に記述していくだけです。
ResNet50 Subclassing API
Functional API と同様に再利用される Residual 機構をクラス化して実装します。
from tensorflow import layers, Model class BottleneckResidual(Model): """ResNet の Bottleneck Residual Module です. 1 層目の 1x1 conv で ch 次元を削減することで 2 層目の 3x3 conv の計算量を減らし 3 層目の 1x1 conv で ch 出力の次元を復元します. 計算量の多い 2 層目 3x3 conv の次元を小さくすることから bottleneck と呼ばれます. """ def __init__(self, in_ch, out_ch, strides=1): super().__init__() self.projection = in_ch != out_ch inter_ch = out_ch // 4 params = { "padding": "same", "kernel_initializer": "he_normal", "use_bias": True, } self.common_layers = [ layers.Conv2D(inter_ch, kernel_size=1, strides=strides, **params), layers.BatchNormalization(), layers.ReLU(), layers.Conv2D(inter_ch, kernel_size=3, strides=1, **params), layers.BatchNormalization(), layers.ReLU(), layers.Conv2D(out_ch, kernel_size=1, strides=1, **params), layers.BatchNormalization(), ] if self.projection: self.projection_layers = [ layers.Conv2D(out_ch, kernel_size=1, strides=strides, **params), layers.BatchNormalization(), ] self.concat_layers = [layers.Add(), layers.ReLU()] def call(self, inputs): h1 = inputs h2 = inputs for layer in self.common_layers: h1 = layer(h1) if self.projection: for layer in self.projection_layers: h2 = layer(h2) outputs = [h1, h2] for layer in self.concat_layers: outputs = layer(outputs) return outputs class ResNet50(Model): """ResNet50 です. 要素は conv * 1 resblock(conv * 3) * 3 resblock(conv * 3) * 4 resblock(conv * 3) * 6 resblock(conv * 3) * 3 dense * 1 から構成されていて, conv * 49 + dense * 1 の 50 層です. """ def __init__(self, output_size=1000): super().__init__() self.layers_ = [ layers.Conv2D(64, 7, 2, padding="same", kernel_initializer="he_normal"), layers.BatchNormalization(), layers.MaxPool2D(pool_size=3, strides=2, padding="same"), BottleneckResidual(64, 256), BottleneckResidual(256, 256), BottleneckResidual(256, 256), BottleneckResidual(256, 512, 2), BottleneckResidual(512, 512), BottleneckResidual(512, 512), BottleneckResidual(512, 512), BottleneckResidual(512, 1024, 2), BottleneckResidual(1024, 1024), BottleneckResidual(1024, 1024), BottleneckResidual(1024, 1024), BottleneckResidual(1024, 1024), BottleneckResidual(1024, 1024), BottleneckResidual(1024, 2048, 2), BottleneckResidual(2048, 2048), BottleneckResidual(2048, 2048), layers.GlobalAveragePooling2D(), layers.Dense( output_size, activation="softmax", kernel_initializer="he_normal" ), ] def call(self, inputs): for layer in self.layers_: inputs = layer(inputs) return inputsFunctional API とそこまで大きな違いはありません。
__init__レイヤーでリストに層をまとめるような書き方をしていますが、クラスの変数に登録されていれば良いのでこの辺は自由に書くことができます。ResNet50 実装 振り返り
Sequential API 単体では実装できないモデルとして ResNet50 を紹介しました。
正直大きな違いはないので Functional API、 Subclassing API は好みで使い分けても問題ないかと思います。訓練の実装
最後に訓練ループの実装を比較してみます。
全てのソースコードを載せるとかなり長くなるため部分的にメソッドを
src.utilsに切り出しています。
そこまで複雑なことをしているわけではないので補完しながら読んでいただければ助かります。一応全てのソースは以下のリポジトリにあるので気になる方はご覧ください。
https://github.com/Anieca/deep-learning-modelsbuilt-in 訓練 実装
テストデータの精度算出、TensorBoard 用のログ出力などいくつかオプションを指定してみます。
import os import tensorflow as tf from src.utils import load_dataset, load_model, get_args, get_current_time def builtin_train(args): # 1. load dataset and model (train_images, train_labels), (test_images, test_labels) = load_dataset(args.data) input_shape = train_images[: args.batch_size, :, :, :].shape output_size = max(train_labels) + 1 model = load_model(args.arch, input_shape=input_shape, output_size=output_size) model.summary() # 2. set tensorboard cofigs logdir = os.path.join(args.logdir, get_current_time()) tensorboard_callback = tf.keras.callbacks.TensorBoard(log_dir=logdir) # 3. loss, optimizer, metrics setting model.compile( optimizer=tf.keras.optimizers.Adam(), loss="sparse_categorical_crossentropy", metrics=["accuracy"], ) # 4. dataset config (and validation, callback config) fit_params = {} fit_params["batch_size"] = args.batch_size fit_params["epochs"] = args.max_epoch if args.steps_per_epoch: fit_params["steps_per_epoch"] = args.steps_per_epoch fit_params["verbose"] = 1 fit_params["callbacks"] = [tensorboard_callback] fit_params["validation_data"] = (test_images, test_labels) # 5. start train and test model.fit(train_images, train_labels, **fit_params)かなりシンプルに書けます。
コールバック関数は他にも色々あるので興味がある方はドキュメントを読んでみてください。
https://www.tensorflow.org/api_docs/python/tf/keras/callbacksカスタム訓練 実装
上記の built-in 訓練と同じ処理を自分で実装してみます。
import os import tensorflow as tf from src.utils import load_dataset, load_model, get_args, get_current_time def custom_train(args): # 1. load dataset and model (train_images, train_labels), (test_images, test_labels) = load_dataset(args.data) input_shape = train_images[: args.batch_size, :, :, :].shape output_size = max(train_labels) + 1 model = load_model(args.arch, input_shape=input_shape, output_size=output_size) model.summary() # 2. set tensorboard configs logdir = os.path.join(args.logdir, get_current_time()) train_writer = tf.summary.create_file_writer(os.path.join(logdir, "train")) test_writer = tf.summary.create_file_writer(os.path.join(logdir, "test")) # 3. loss, optimizer, metrics setting criterion = tf.keras.losses.SparseCategoricalCrossentropy() optimizer = tf.keras.optimizers.Adam() train_loss_avg = tf.keras.metrics.Mean() train_accuracy = tf.keras.metrics.SparseCategoricalAccuracy() test_loss_avg = tf.keras.metrics.Mean() test_accuracy = tf.keras.metrics.SparseCategoricalAccuracy() # 4. dataset config buffer_size = len(train_images) train_ds = tf.data.Dataset.from_tensor_slices((train_images, train_labels)) train_ds = train_ds.shuffle(buffer_size=buffer_size).batch(args.batch_size) test_ds = tf.data.Dataset.from_tensor_slices((test_images, test_labels)) test_ds = test_ds.batch(args.batch_size) # 5. start train and test for epoch in range(args.max_epoch): # 5.1. initialize metrics train_loss_avg.reset_states() train_accuracy.reset_states() test_loss_avg.reset_states() test_loss_avg.reset_states() # 5.2. initialize progress bar train_pbar = tf.keras.utils.Progbar(args.steps_per_epoch) test_pbar = tf.keras.utils.Progbar(args.steps_per_epoch) # 5.3. start train for i, (x, y_true) in enumerate(train_ds): if args.steps_per_epoch and i >= args.steps_per_epoch: break # 5.3.1. forward with tf.GradientTape() as tape: y_pred = model(x, training=True) loss = criterion(y_true=y_true, y_pred=y_pred) # 5.3.2. calculate gradients from `tape` and backward gradients = tape.gradient(loss, model.trainable_variables) optimizer.apply_gradients(zip(gradients, model.trainable_variables)) # 5.3.3. update metrics and progress bar train_loss_avg(loss) train_accuracy(y_true, y_pred) train_pbar.update( i + 1, [ ("avg_loss", train_loss_avg.result()), ("accuracy", train_accuracy.result()), ], ) # 5.4. start test for i, (x, y_true) in enumerate(test_ds): if args.steps_per_epoch and i >= args.steps_per_epoch: break # 5.4.1. forward y_pred = model(x) loss = criterion(y_true, y_pred) # 5.4.2. update metrics and progress bar test_loss_avg(loss) test_accuracy(y_true, y_pred) test_pbar.update( i + 1, [ ("avg_test_loss", test_loss_avg.result()), ("test_accuracy", test_accuracy.result()), ], ) # 5.5. write metrics to tensorboard with train_writer.as_default(): tf.summary.scalar("Loss", train_loss_avg.result(), step=epoch) tf.summary.scalar("Acc", train_accuracy.result(), step=epoch) with test_writer.as_default(): tf.summary.scalar("Loss", test_loss_avg.result(), step=epoch) tf.summary.scalar("Acc", test_accuracy.result(), step=epoch)訓練開始まではそこまで変わらないですが、訓練ループ内(コメントの 5. )の記述量がかなり多くなります。
訓練実装 振り返り
自分で TensorBoard 出力の管理やプログレスバーの作成と言ったユーティリティを管理するのはそれなりにコストがかかりますが、 built-in はかなり楽に使うことができます。
built-in に用意されていない処理を記述したい場合はカスタム訓練で書く必要がありますが、そうでなければ built-in を使った方が良さそうです。
終わりに
以上です。お疲れ様でした。
TensorFlow 2 系の色々な書き方について実装を交えて紹介しました。
あまりそれぞれの書き方について優劣はつけずにフラットに書いたつもりです。
自分で書くときは状況や好みに合わせて書けば良いと思いますが、ソースコードを探していると色々な書き方に出会うので、なんとなく全ての書き方を理解していると良いかと思います。
皆様のお役に立てれば幸いです。
- 投稿日:2020-05-25T22:44:36+09:00
【自然言語処理100本ノック 2020】第4章: 形態素解析
はじめに
自然言語処理の問題集として有名な自然言語処理100本ノックの2020年版が公開されました。
この記事では、以下の第1章から第10章のうち、第4章: 形態素解析を解いてみた結果をまとめています。
- 第1章: 準備運動
- 第2章: UNIXコマンド
- 第3章: 正規表現
- 第4章: 形態素解析
- 第5章: 係り受け解析
- 第6章: 機械学習
- 第7章: 単語ベクトル
- 第8章: ニューラルネット
- 第9章: RNN, CNN
- 第10章: 機械翻訳
事前準備
回答にはGoogle Colaboratoryを利用しています。
Google Colaboratoryのセットアップ方法や基本的な使い方は、こちらの記事が詳しいです。
なお、以降の回答の実行結果を含むノートブックはgithubにて公開しています。第4章: 形態素解析
夏目漱石の小説『吾輩は猫である』の文章(neko.txt)をMeCabを使って形態素解析し,その結果をneko.txt.mecabというファイルに保存せよ.このファイルを用いて,以下の問に対応するプログラムを実装せよ.
まずは指定のデータをダウンロードします。
Google Colaboratoryのセル上で下記のコマンドを実行すると、カレントディレクトリに対象のファイルがダウンロードされます。!wget https://nlp100.github.io/data/neko.txt【 wget 】コマンド――URLを指定してファイルをダウンロードする
続いて、MeCabをインストールします。
!apt install mecab libmecab-dev mecab-ipadic-utf8インストールが完了したら、早速形態素解析を行います。
以下のコマンドを実行することにより、neko.txtを形態素解析した結果が、neko.txt.mecabとして出力されます。!mecab -o ./neko.txt.mecab ./neko.txt形態素解析 (Wikipedia)
MeCabのコマンドライン引数一覧とその実行例30. 形態素解析結果の読み込み
形態素解析結果(neko.txt.mecab)を読み込むプログラムを実装せよ.ただし,各形態素は表層形(surface),基本形(base),品詞(pos),品詞細分類1(pos1)をキーとするマッピング型に格納し,1文を形態素(マッピング型)のリストとして表現せよ.第4章の残りの問題では,ここで作ったプログラムを活用せよ.
filename = './neko.txt.mecab' # 文章単位に分割して読込 with open(filename, mode='r', encoding='utf-8') as f: text = f.read().split('EOS\n') # 空白文の削除 text = list(filter(lambda x: x != '', text)) # 確認 for i in range(3): print(text[i]) # 指定フォーマットに整形 result = [] for sentence in text: result_sentence = [] for line in sentence.split('\n'): if line == '': continue else: (surface, attr) = line.split('\t') attr = attr.split(',') d = {'surface': surface, 'base': attr[6], 'pos': attr[0], 'pos1': attr[1]} result_sentence.append(d) result.append(result_sentence) # 確認 for i in range(3): print(result[i])Pythonでファイルの読み込み、書き込み
Pythonで文字列を分割
Pythonのlambda(ラムダ式、無名関数)の使い方
Pythonのfor文によるループ処理
Pythonのif文による条件分岐の書き方
Pythonで辞書を作成するdict()と波括弧、辞書内包表記
Pythonでリスト(配列)に要素を追加する31. 動詞
動詞の表層形をすべて抽出せよ.
以降、30で作成した
resultに対して処理を行っていきます。
ここでは、filter関数で動詞を抽出し、その表層形をリスト化しています。ans = [] for sentence in result: extraction = list(filter(lambda x: x['pos'] == '動詞', sentence)) extraction = [e['surface'] for e in extraction] ans.append(extraction) # 確認 for i in range(5): print(list(filter(lambda x: x != [], ans))[i])32. 動詞の原形
動詞の原形をすべて抽出せよ.
31の表層形を原形に変えてリスト化しています。
ans = [] for sentence in result: extraction = list(filter(lambda x: x['pos'] == '動詞', sentence)) extraction = [e['base'] for e in extraction] ans.append(extraction) # 確認 for i in range(5): print(list(filter(lambda x: x != [], ans))[i])33. 「AのB」
2つの名詞が「の」で連結されている名詞句を抽出せよ.
ans = [] for sentence in result: extraction = [] for i in range(1, len(sentence) - 1): if sentence[i - 1]['pos'] == '名詞' and sentence[i]['surface'] == 'の' and sentence[i + 1]['pos'] == '名詞': extraction.append(sentence[i - 1]['surface'] + sentence[i]['surface'] + sentence[i + 1]['surface']) ans.append(extraction) # 確認 for i in range(5): print(list(filter(lambda x: x != [], ans))[i])Pythonのlen関数で様々な型のオブジェクトのサイズを取得
Pythonで文字列を連結・結合34. 名詞の連接
名詞の連接(連続して出現する名詞)を最長一致で抽出せよ.
文章ごとに、最初の形態素から順に以下のルールを適用し、名詞の連接を最長一致で抽出しています。
- 名詞であれば
nounsに連結し、連結数(num)をカウント- 名詞以外の場合、ここまでの連結数が2以上であれば出力し、
nounsとnumを初期化- それ以外の場合、
nounsとnumを初期化ans = [] for sentence in result: extraction = [] nouns = '' num = 0 for i in range(len(sentence)): if sentence[i]['pos'] == '名詞': nouns = nouns + sentence[i]['surface'] num += 1 elif num >= 2: extraction.append(nouns) nouns = '' num = 0 else: nouns = '' num = 0 ans.append(extraction) # 確認 for i in range(5): print(list(filter(lambda x: x != [], ans))[i])35. 単語の出現頻度
文章中に出現する単語とその出現頻度を求め,出現頻度の高い順に並べよ.
ans = {} for sentence in result: for i in range(len(sentence)): ans[sentence[i]['base']] = ans.get(sentence[i]['base'], 0) + 1 # 単語数の更新(初登場の単語であれば1をセット) ans = sorted(ans.items(), key=lambda x: x[1], reverse=True) # 確認 for i in range(5): print(ans[i])Pythonで辞書のリストを特定のキーの値に従ってソート
Pythonの辞書のgetメソッドでキーから値を取得36. 頻度上位10語
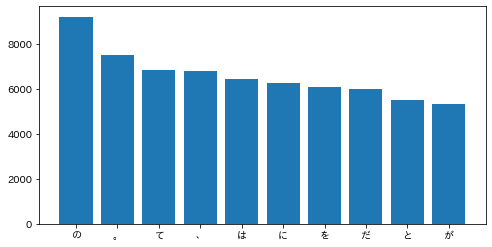
出現頻度が高い10語とその出現頻度をグラフ(例えば棒グラフなど)で表示せよ.
matplotlibで日本語を表示させるため、
japanize_matplotlibをインストールしておきます。!pip install japanize_matplotlib【超簡単】たったの2ステップで matplotlib の日本語表記を対応させる方法
そして、35と同様に出現頻度を集計し、棒グラフで視覚化します。
import matplotlib.pyplot as plt import japanize_matplotlib ans = {} for sentence in result: for i in range(len(sentence)): ans[sentence[i]['base']] = ans.get(sentence[i]['base'], 0) + 1 ans = sorted(ans.items(), key=lambda x: x[1], reverse=True) keys = [a[0] for a in ans[0:10]] values = [a[1] for a in ans[0:10]] plt.figure(figsize=(8, 4)) plt.bar(keys, values) plt.show()
Pythonのグラフ描画ライブラリMatplotlibの基礎37. 「猫」と共起頻度の高い上位10語
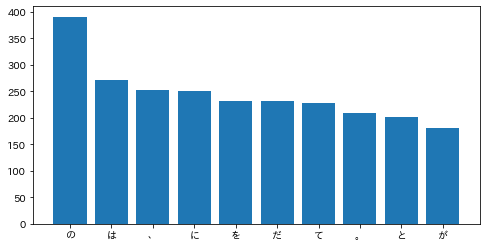
「猫」とよく共起する(共起頻度が高い)10語とその出現頻度をグラフ(例えば棒グラフなど)で表示せよ.
ans = {} for sentence in result: sentence_base = [s['base'] for s in sentence] if '猫' in sentence_base: # 「猫」が含まれる文章中の単語のみを集計 for i in range(len(sentence_base)): ans[sentence_base[i]] = ans.get(sentence_base[i], 0) + 1 del ans['猫'] ans = sorted(ans.items(), key=lambda x: x[1], reverse=True) keys = [a[0] for a in ans[0:10]] values = [a[1] for a in ans[0:10]] plt.figure(figsize=(8, 4)) plt.bar(keys, values) plt.show()38. ヒストグラム
単語の出現頻度のヒストグラム(横軸に出現頻度,縦軸に出現頻度をとる単語の種類数を棒グラフで表したもの)を描け.
ans = {} for sentence in result: for i in range(len(sentence)): ans[sentence[i]['base']] = ans.get(sentence[i]['base'], 0) + 1 ans = ans.values() plt.figure(figsize=(8, 4)) plt.hist(ans, bins=100) plt.show()39. Zipfの法則
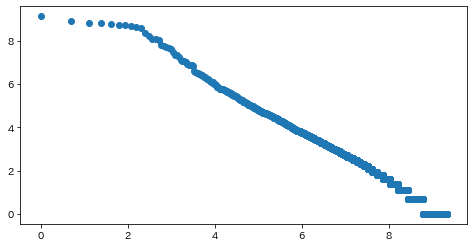
単語の出現頻度順位を横軸,その出現頻度を縦軸として,両対数グラフをプロットせよ.
import math ans = {} for sentence in result: for i in range(len(sentence)): ans[sentence[i]['base']] = ans.get(sentence[i]['base'], 0) + 1 ans = sorted(ans.items(), key=lambda x: x[1], reverse=True) ranks = [math.log(r + 1) for r in range(len(ans))] values = [math.log(a[1]) for a in ans] plt.figure(figsize=(8, 4)) plt.scatter(ranks, values) plt.show()
ジップの法則 (Wikipedia)
Pythonで指数関数・対数関数を計算おわりに
自然言語処理100本ノックは自然言語処理そのものだけでなく、基本的なデータ処理や汎用的な機械学習についてもしっかり学ぶことができるように作られています。
オンラインコースなどで機械学習を勉強中の方も、とても良いアウトプットの練習になると思いますので、ぜひ挑戦してみてください。

- 投稿日:2020-05-25T22:11:50+09:00
リアルタイムで音声認識して字幕をオーバーレイしてみた【Python】
TLを眺めていたら @1heisuzuki 氏が音声認識からWebカメラ映像への字幕合成までをChromeだけで実行するWebページの紹介をしているツイートが流れてきた.
以前こんなものを作っていた自分は,これを少しいじればより汎用的なシステムを作れるのではないか?と思い,卒研を放り投げてスパゲッティを茹で始めた.実行例
リアルタイム音声認識で字幕を付けるシステムhttps://t.co/B04xm7yjZQ
— teahat (@T3ahat) May 24, 2020
に影響されて,ウィンドウに認識結果をオーバーレイするアプリケーションを作りました
字幕をつけながらPCを操作できるので,共有画面に自分を映したカメラと別アプリを同時に表示することもできますhttps://t.co/tYS7ET4zc0 pic.twitter.com/1Ud3BmV7k0
- 投稿日:2020-05-25T22:11:50+09:00
リアルタイムに音声認識して字幕をオーバーレイしてみた【Python】
TLを眺めていたら @1heisuzuki 氏が音声認識からWebカメラ映像への字幕合成までをChromeだけで実行するWebページの紹介をしているツイートが流れてきた.
以前こんなものを作っていた自分は,これを少しいじればより汎用的なシステムを作れるのではないか?と思い,雰囲気で再現してみました.実行例
リアルタイム音声認識で字幕を付けるシステムhttps://t.co/B04xm7yjZQ
— teahat (@T3ahat) May 24, 2020
に影響されて,ウィンドウに認識結果をオーバーレイするアプリケーションを作りました
字幕をつけながらPCを操作できるので,共有画面に自分を映したカメラと別アプリを同時に表示することもできますhttps://t.co/tYS7ET4zc0 pic.twitter.com/1Ud3BmV7k0ソースコード
TranScriptoWindowにあります.
環境
- Windows10
tkinterの-transparentcolorがかなり環境依存なため,windows環境以外では動作しません.
- Python 3.7
- pyaudio 0.2.11
- Google Cloud SDK
使用方法
$python transcriptowindow.pyを実行し,startボタンを押してPCに向かって話しかけるのみです.機能及び変数紹介
リアルタイムに音声認識した結果を字幕としてウィンドウにオーバーレイします.
起動したまま別のタブを操作でき,あらゆるコンテンツに字幕をつけたまま画面共有できるので,画面共有するオンライン会議に有効です.
見せたいウィンドウの横に自分のWebカメラのウィンドウを小さく表示すれば,顔と画面を同時に見せながら字幕も大きく表示することが可能です.
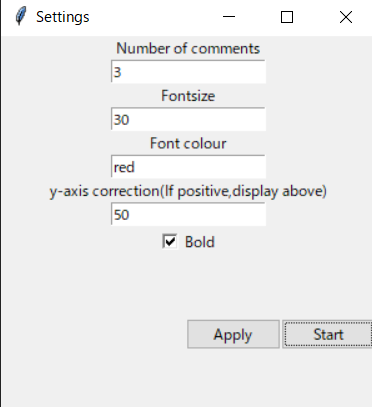
Number of comments
表示される認識結果の行数.num_commentに相当.Fontsize
フォントサイズ.fontsizeに相当.Font colour
フォントカラー.fontcolourに相当.y-axis correction
y軸補正.下にタスクバーを表示している場合,一番下の字幕がタスクバーに重なってしまうのを避けるため.
正の整数なら字幕が全体的に下に移動する.bold
チェックで太字になる.個人的にこれをオンにした方が見やすくてオススメ.環境構築
Python環境の構築は各自お願いします.
Google Cloud Speech API
基本的に
Google Cloud Speech APIのリアルタイム音声認識は使い物になる精度なのか?
の通りに進めれば構築できますが一応.(1)
GoogleCloudPlatformにログインしてプロジェクトを適当に作成.
コンソール上部の"プロダクトとリソースの検索"からCloud Speech-to-Text APIを有効化.
Cloud Speech-to-Text APIは一定量無料で利用でき,自分で設定しない限り請求されることはない(Google曰く)ですが,クレジットカード情報の登録が必要な点に注意!(2)
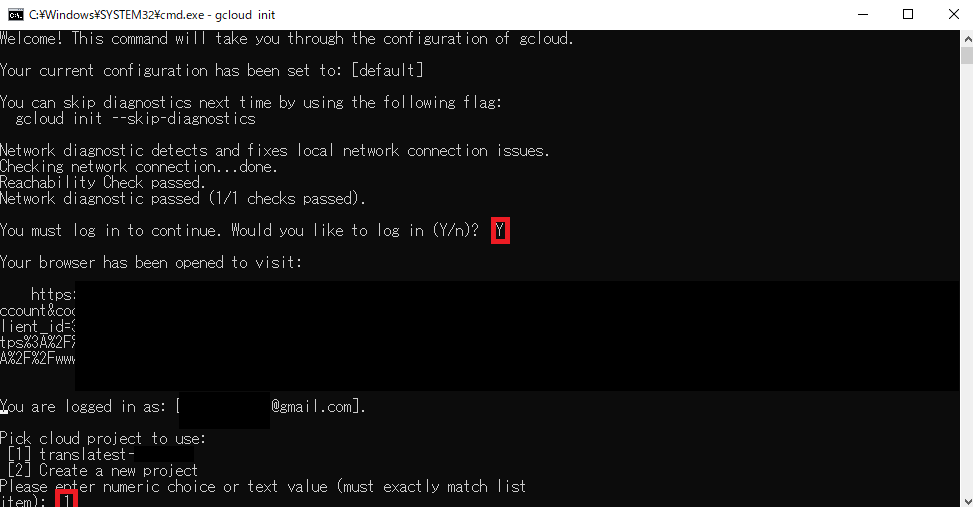
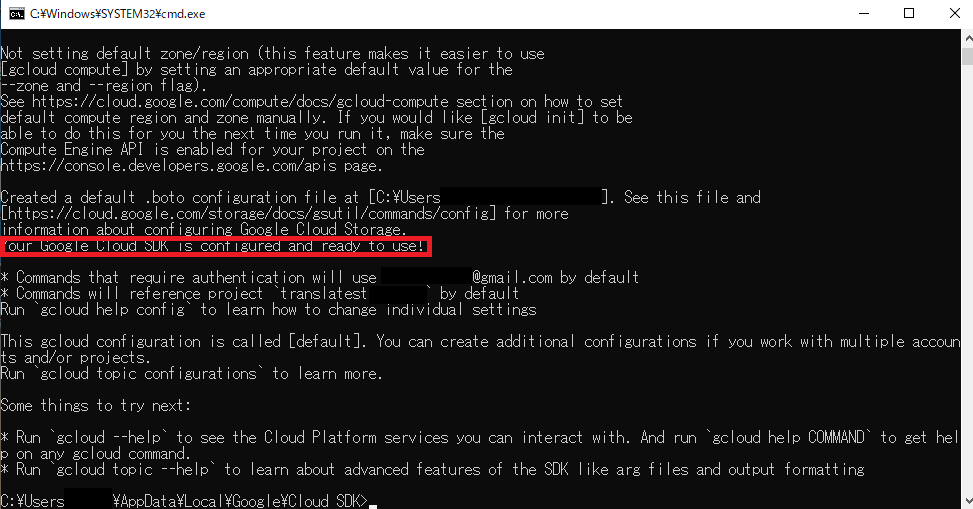
GCPのページより"Google Cloud SDK のインストーラ"をDL&起動.何も変更せずにSDKをインストールします.exeファイルを実行するとコマンドプロンプトが立ち上がるので,誘導に従って設定します.
設定が終わったらC:\Users\Username\AppData\Local\Google\Cloud SDK>gcloud auth application-default loginによりデフォルト認証設定を行います.
設定を誤った場合や,変更したい場合はgcloud initで再設定可能です.
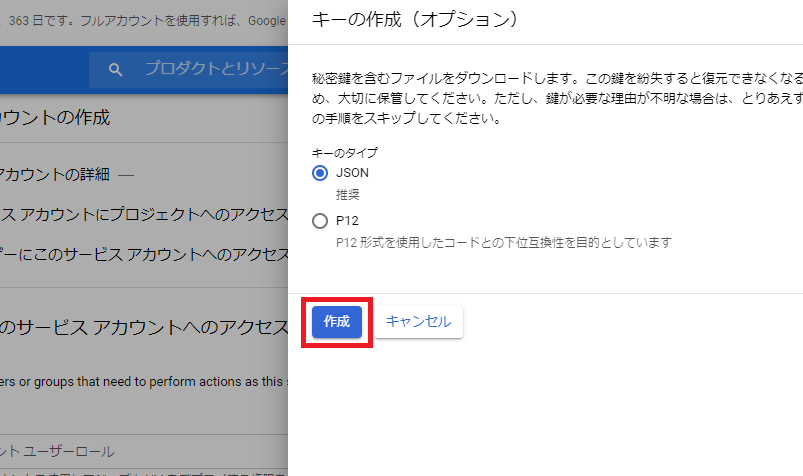
サービスアカウントキーの取得
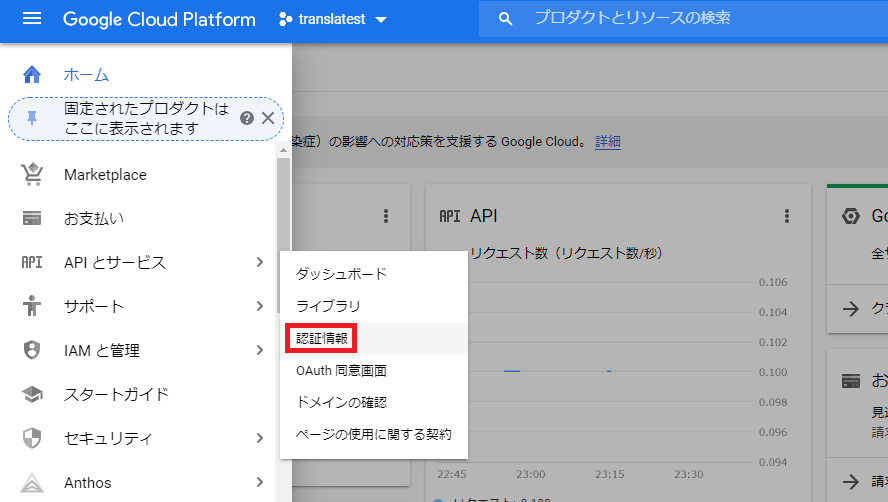
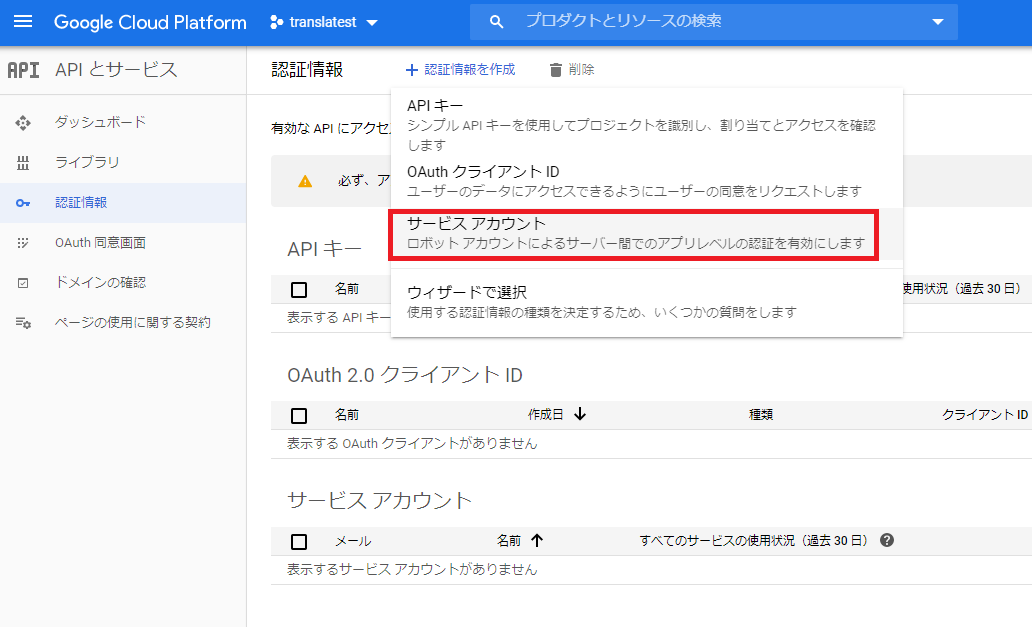
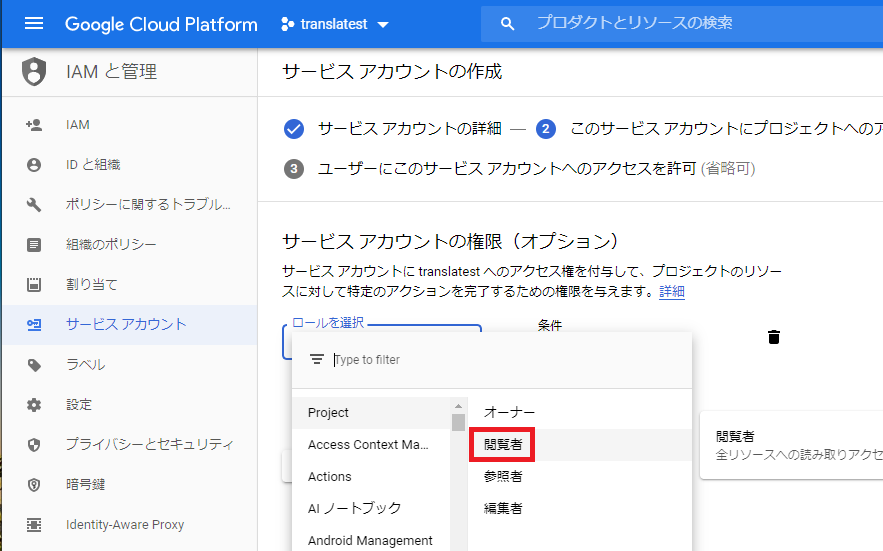
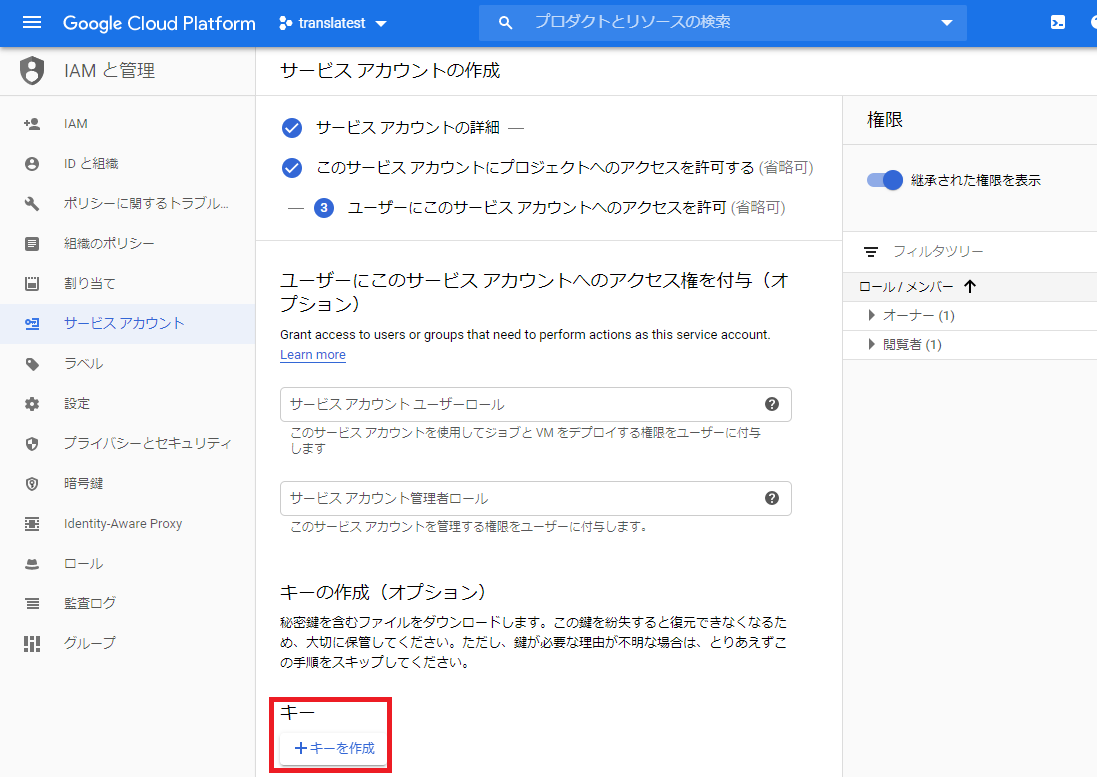
GCPコンソールの「APIとサービス > 認証情報」からサービスアカウントキーを作成します.
jsonファイルをダウンロードしたら,コマンドプロンプトでこのjsonファイルを環境変数として定義.set GOOGLE_APPLICATION_CREDENTIALS=C:\path\to\credential.jsonこれでGCPに関する設定は終了です.
ライブラリのインストール
pip install google gcloud google-auth google-cloud-speech grpc-google-cloud-speech-v1beta1 pip install pyaudioただし,Windows環境ではpyaudioの依存ライブラリの関係で
pip install pyaudioではエラーを起こす場合があります.$ pip install pyaudio Collecting pyaudio Downloading PyAudio-0.2.11.tar.gz (37 kB) Using legacy setup.py install for pyaudio, since package 'wheel' is not installed. Installing collected packages: pyaudio Running setup.py install for pyaudio ... error ERROR: Command errored out with exit status 1: command: (中略) Complete output (9 lines): running install running build running build_py creating build creating build\lib.win-amd64-3.7 copying src\pyaudio.py -> build\lib.win-amd64-3.7 running build_ext building '_portaudio' extension error: Microsoft Visual C++ 14.0 is required. Get it with "Build Tools for Visual Studio": https://visualstudio.microsoft.com/downloads/ ---------------------------------------- ERROR: Command errored out with exit status 1: 'c:\users\Username\appdata\local\programs\python\python37\python.exe' -u -c 'import sys, setuptools, tokenize; sys.argv[0] = '"'"'C:\\Users\\Username\\AppData\\Local\\Temp\\pip-install-5i7rg8qb\\pyaudio\\setup.py'"'"'; __file__='"'"'C:\\Users\\Username\\AppData\\Local\\Temp\\pip-install-5i7rg8qb\\pyaudio\\setup.py'"'"';f=getattr(tokenize, '"'"'open'"'"', open)(__file__);code=f.read().replace('"'"'\r\n'"'"', '"'"'\n'"'"');f.close();exec(compile(code, __file__, '"'"'exec'"'"'))' install --record 'C:\Users\Username\AppData\Local\Temp\pip-record-9jxqfhqn\install-record.txt' --single-version-externally-managed --compile --install-headers 'c:\users\Username\appdata\local\programs\python\python37\Include\pyaudio' Check the logs for full command output.これを解決するため,https://www.lfd.uci.edu/~gohlke/pythonlibs/#pyaudio より自分の環境にあったバージョンの.whlファイルをダウンロードしてインストール.
$ pip install c:\Users\Username\Downloads\PyAudio-0.2.11-cp37-cp37m-win_amd64.whl Processing c:\users\Username\downloads\pyaudio-0.2.11-cp37-cp37m-win_amd64.whl Installing collected packages: PyAudio以上で環境構築は終了です.transcriptowindow.pyを実行できるはずです.お疲れさまでした.
エラーが出る場合は, PCがマイク入力を正常に認識し,Pythonがアクセスできているか確認するなどしてみてください.先行事例と比較
(1)
@1heisuzuki 氏が音声認識からWebカメラ映像への字幕合成までをChromeだけで実行するWebページ https://1heisuzuki.github.io/speech-to-text-webcam-overlay/
は,ユーザは面倒な設定一切なしにGoogleChromeからアクセスするだけでWebカメラからの出力に字幕をオーバーレイできるほか,透明度,フォントサイズといった各種変数の変更,ログのダウンロード,翻訳機能を備えていて非常に多機能です(執筆当時).(2)
PC+Android+無料のツールだけで自動音声認識による字幕付き配信(ウェブ会議)をおこなう方法を紹介してみました。広く普及して常識になって欲しい(すべてのウェブ会議システムがデフォルトで対応してくれてこの動画が無駄になることを希望)。 #xdiversity pic.twitter.com/yhuT5HISxW
— Yoshiki NAGATANI (@nagataniyoshiki) May 18, 2020
動画内ではリップリードに関する言及がありました.若干用意するものが多いですが,非常に見やすいです.(3)
#xdiversity @xdiversity_org #stayhometokyo #音声文字変換 pic.twitter.com/VNKQcZONsR
— 落合陽一 (@ochyai) May 13, 2020
今回作成したシステムは, 環境構築編を見ていただければわかるように,上と比較して圧倒的に面倒で,導入難度が高いです.本格的に使用する場合,APIの無料枠を超えて料金が発生する可能性もあります.
また,これは自分ではどうもできなかったのですが,このような問題を抱えています.
現時点での問題点として,途中でWindowsやAndroid,OBSといった英字が含まれるとAPIからのレスポンスが非常に遅くなって更新されなくなる
— teahat (@T3ahat) May 25, 2020
入力音声はhttps://t.co/KlaSt5kbxC
をお借りしました pic.twitter.com/GOJY00oypk
しかし,一度環境構築してしまえば(2)と同程度かそれ以上に綺麗に字幕を表示でき,(ログの保存や,翻訳機能は実装していませんが)操作上の自由度は一番高くなっている(のではないかと思いたい...).
導入の難しささえどうにかなれば割と使いやすいシステムになったかなとは思います.まとめ
ねとらぼの記事によると,iPhoneとmacで同じような機能を再現した方もいるようです.
使いやすいものを導入してオンラインチャットしてみてはいかがでしょうか.
私はチャット相手がいないので使いませんが()
- 投稿日:2020-05-25T22:06:59+09:00
【xlsxwriter】pandas+xlsxwriterで条件付き書式Excelシート作成【pandas】メモ
概要
- 客先がExcelシートでヒートマップを見たがっていた。
- openpyxlだと、実装できなかった。(やり方が悪かった?)
- xlsxwriterをpandasのto_excelのengineとして使用
- 条件付き書式設定をxlsxwriterで行う
- セル指定は、
xl_rangeを用いる。(セルを数値で指定)ソースコード
全体# xl_rangeを使えば、"B2:C3"をxl_range(2,2,3,3)と表現できる。 from xlsxwriter.utility import xl_range import xlsxwriter import pandas as pd import numpy as np # test用データフレーム df = pd.DataFrame(np.arange(0,9,1).reshape(3,3)) # workbook生成 workbook = xlsxwriter.Workbook(r'./output_storage/hoge.xlsx') # xlsxwriterでは、mode='a'は使えない。 writer = pd.ExcelWriter(r'./output_storage/hoge.xlsx',mode='w',engine='xlsxwriter') sheet_name = 'hoge' # データフレームをシートに書き込む df.to_excel(writer,sheet_name=sheet_name,startrow=0,index_label='huga') # 条件付き書式の設定 ws = writer.sheets[sheet_name] ws.conditional_format(xl_range(2,2,3,3), {'type': '3_color_scale', 'min_color': "#44c242", 'mid_color': "#ebeb44", 'max_color': "#eb4444"}) writer.close()
- こんな感じで、エクセルに条件付き書式設定を行うことができる。
まとめ
- Excelでほしがるお客さんがまだまだ多いため、勉強する必要があるかもしれない。
- pandasとの親和性もよく、比較的柔軟に対応できそうだった。
- 投稿日:2020-05-25T21:57:19+09:00
【質問】学習済みモデルの読み込みができません/h5ファイル
MacOSでkerasの学習済みモデルVGG19の読み込みができず、下記のエラーが出てしまいます。
「vgg19_weights_tf_dim_ordering_tf_kernels_notop.h5」のファイルをダウンロードしても、どうやってVGG19に認識させればよいかわかりません。どなたか分かる方、ご教授いただけないでしょうか?
▼バージョン
Python 3.7.4
Keras 2.3.1
Keras-Applications 1.0.8
Keras-Preprocessing 1.1.2Downloading data from https://github.com/fchollet/deep-learning-models/releases/download/v0.1/vgg19_weights_tf_dim_ordering_tf_kernels_notop.h5 --------------------------------------------------------------------------- SSLCertVerificationError Traceback (most recent call last) /Library/Frameworks/Python.framework/Versions/3.7/lib/python3.7/urllib/request.py in do_open(self, http_class, req, **http_conn_args) 1316 h.request(req.get_method(), req.selector, req.data, headers, -> 1317 encode_chunked=req.has_header('Transfer-encoding')) 1318 except OSError as err: # timeout error /Library/Frameworks/Python.framework/Versions/3.7/lib/python3.7/http/client.py in request(self, method, url, body, headers, encode_chunked) 1243 """Send a complete request to the server.""" -> 1244 self._send_request(method, url, body, headers, encode_chunked) 1245 /Library/Frameworks/Python.framework/Versions/3.7/lib/python3.7/http/client.py in _send_request(self, method, url, body, headers, encode_chunked) 1289 body = _encode(body, 'body') -> 1290 self.endheaders(body, encode_chunked=encode_chunked) 1291 /Library/Frameworks/Python.framework/Versions/3.7/lib/python3.7/http/client.py in endheaders(self, message_body, encode_chunked) 1238 raise CannotSendHeader() -> 1239 self._send_output(message_body, encode_chunked=encode_chunked) 1240 /Library/Frameworks/Python.framework/Versions/3.7/lib/python3.7/http/client.py in _send_output(self, message_body, encode_chunked) 1025 del self._buffer[:] -> 1026 self.send(msg) 1027 /Library/Frameworks/Python.framework/Versions/3.7/lib/python3.7/http/client.py in send(self, data) 965 if self.auto_open: --> 966 self.connect() 967 else: /Library/Frameworks/Python.framework/Versions/3.7/lib/python3.7/http/client.py in connect(self) 1413 self.sock = self._context.wrap_socket(self.sock, -> 1414 server_hostname=server_hostname) 1415 /Library/Frameworks/Python.framework/Versions/3.7/lib/python3.7/ssl.py in wrap_socket(self, sock, server_side, do_handshake_on_connect, suppress_ragged_eofs, server_hostname, session) 422 context=self, --> 423 session=session 424 ) /Library/Frameworks/Python.framework/Versions/3.7/lib/python3.7/ssl.py in _create(cls, sock, server_side, do_handshake_on_connect, suppress_ragged_eofs, server_hostname, context, session) 869 raise ValueError("do_handshake_on_connect should not be specified for non-blocking sockets") --> 870 self.do_handshake() 871 except (OSError, ValueError): /Library/Frameworks/Python.framework/Versions/3.7/lib/python3.7/ssl.py in do_handshake(self, block) 1138 self.settimeout(None) -> 1139 self._sslobj.do_handshake() 1140 finally: SSLCertVerificationError: [SSL: CERTIFICATE_VERIFY_FAILED] certificate verify failed: unable to get local issuer certificate (_ssl.c:1076) During handling of the above exception, another exception occurred: URLError Traceback (most recent call last) ~/pyworks/env/lib/python3.7/site-packages/keras/utils/data_utils.py in get_file(fname, origin, untar, md5_hash, file_hash, cache_subdir, hash_algorithm, extract, archive_format, cache_dir) 224 try: --> 225 urlretrieve(origin, fpath, dl_progress) 226 except HTTPError as e: /Library/Frameworks/Python.framework/Versions/3.7/lib/python3.7/urllib/request.py in urlretrieve(url, filename, reporthook, data) 246 --> 247 with contextlib.closing(urlopen(url, data)) as fp: 248 headers = fp.info() /Library/Frameworks/Python.framework/Versions/3.7/lib/python3.7/urllib/request.py in urlopen(url, data, timeout, cafile, capath, cadefault, context) 221 opener = _opener --> 222 return opener.open(url, data, timeout) 223 /Library/Frameworks/Python.framework/Versions/3.7/lib/python3.7/urllib/request.py in open(self, fullurl, data, timeout) 524 --> 525 response = self._open(req, data) 526 /Library/Frameworks/Python.framework/Versions/3.7/lib/python3.7/urllib/request.py in _open(self, req, data) 542 result = self._call_chain(self.handle_open, protocol, protocol + --> 543 '_open', req) 544 if result: /Library/Frameworks/Python.framework/Versions/3.7/lib/python3.7/urllib/request.py in _call_chain(self, chain, kind, meth_name, *args) 502 func = getattr(handler, meth_name) --> 503 result = func(*args) 504 if result is not None: /Library/Frameworks/Python.framework/Versions/3.7/lib/python3.7/urllib/request.py in https_open(self, req) 1359 return self.do_open(http.client.HTTPSConnection, req, -> 1360 context=self._context, check_hostname=self._check_hostname) 1361 /Library/Frameworks/Python.framework/Versions/3.7/lib/python3.7/urllib/request.py in do_open(self, http_class, req, **http_conn_args) 1318 except OSError as err: # timeout error -> 1319 raise URLError(err) 1320 r = h.getresponse() URLError: <urlopen error [SSL: CERTIFICATE_VERIFY_FAILED] certificate verify failed: unable to get local issuer certificate (_ssl.c:1076)> During handling of the above exception, another exception occurred: Exception Traceback (most recent call last) <ipython-input-8-f66739fe150a> in <module> 12 #imagenetで学習済みのモデルを指定 13 weights="imagenet", ---> 14 input_tensor=input_tensor 15 ) 16 #.load_weights('vgg19_weights_tf_dim_ordering_tf_kernels_notop.h5', compile=False) ~/pyworks/env/lib/python3.7/site-packages/keras/applications/__init__.py in wrapper(*args, **kwargs) 18 kwargs['models'] = models 19 kwargs['utils'] = utils ---> 20 return base_fun(*args, **kwargs) 21 22 return wrapper ~/pyworks/env/lib/python3.7/site-packages/keras/applications/vgg19.py in VGG19(*args, **kwargs) 9 @keras_modules_injection 10 def VGG19(*args, **kwargs): ---> 11 return vgg19.VGG19(*args, **kwargs) 12 13 ~/pyworks/env/lib/python3.7/site-packages/keras_applications/vgg19.py in VGG19(include_top, weights, input_tensor, input_shape, pooling, classes, **kwargs) 219 WEIGHTS_PATH_NO_TOP, 220 cache_subdir='models', --> 221 file_hash='253f8cb515780f3b799900260a226db6') 222 model.load_weights(weights_path) 223 if backend.backend() == 'theano': ~/pyworks/env/lib/python3.7/site-packages/keras/utils/data_utils.py in get_file(fname, origin, untar, md5_hash, file_hash, cache_subdir, hash_algorithm, extract, archive_format, cache_dir) 227 raise Exception(error_msg.format(origin, e.code, e.msg)) 228 except URLError as e: --> 229 raise Exception(error_msg.format(origin, e.errno, e.reason)) 230 except (Exception, KeyboardInterrupt): 231 if os.path.exists(fpath): Exception: URL fetch failure on https://github.com/fchollet/deep-learning-models/releases/download/v0.1/vgg19_weights_tf_dim_ordering_tf_kernels_notop.h5 : None -- [SSL: CERTIFICATE_VERIFY_FAILED] certificate verify failed: unable to get local issuer certificate (_ssl.c:1076)▼こちらのコードを、jupyternotebookで実行しています。
train.pyimport os from keras.applications.vgg19 import VGG19 from keras.preprocessing.image import ImageDataGenerator from keras.models import Sequential, Model from keras.layers import Input, Activation, Dropout, Dense, BatchNormalization from keras.layers.pooling import GlobalAveragePooling2D from keras import optimizers from keras import regularizers import numpy as np img_width, img_height = 200, 150 train_data_dir = "train_data" validation_data_dir = "validation_data_dir" nb_train_steps = 1000 nb_validation_samples = 500 nb_epoch = 10 result_dir = "results" train_datagen = ImageDataGenerator( #画素の値を255階調から0〜1にrescale rescale = 1.0 / 255, #45度範囲で画像をランダムに回転 rotation_range = 45, #画像を20%まで、上下左右にずらす width_shift_range = 0.2, height_shift_range = 0.2, #画像をひずませる shear_range = 0.2, #画像をズームアウト zoom_range = 0.2, #空白の画像の位置に最も近い画素の値を埋める処理 fill_mode = "nearest", #ランダムに水平方向に反転 horizontal_flip = True ) test_dategen = ImageDataGenerator(rescale = 1.0 / 255) input_tensor = Input(shape=(img_height, img_width, 3)) base_model = VGG19( include_top=False, weights="imagenet", input_tensor=input_tensor )
- 投稿日:2020-05-25T20:51:47+09:00
筑波大学の機械学習講座:課題のPythonスクリプト部分を作りながらsklearnを勉強する (5)
筑波大学の機械学習講座:課題のPythonスクリプト部分を作りながらsklearnを勉強する (4)
https://github.com/legacyworld/sklearn-basic4.1 リッジ回帰とラッソの比較
リッジ回帰とラッソ回帰の比較である。
Youtubeの解説は第5回(1) 12分50秒あたり
プログラムとしてはさして変わらないのだが、結果が回答と合わない。
いろいろ試しては見たものの諦めた。
今回は最初の課題のワインのデータに戻る。Homework_4.1.pyimport pandas as pd import numpy as np import matplotlib.pyplot as plt from sklearn import linear_model from sklearn.metrics import mean_squared_error from sklearn import preprocessing from sklearn.model_selection import cross_val_score #scikit-leanよりワインのデータをインポートする df= pd.read_csv('winequality-red.csv',sep=';') # 目標値であるqualityが入っているので落としたdataframeを作る df1 = df.drop(columns='quality') y = df['quality'].values.reshape(-1,1) scaler = preprocessing.StandardScaler() # 正則化パラメータ alpha = 2 ** (-16) X = df1.values X_fit = scaler.fit_transform(X) # 結果格納用のDataFrame df_ridge_coeff = pd.DataFrame(columns=df1.columns) df_ridge_result = pd.DataFrame(columns=['alpha','TrainErr','TestErr']) df_lasso_coeff = pd.DataFrame(columns=df1.columns) df_lasso_result = pd.DataFrame(columns=['alpha','TrainErr','TestErr']) while alpha <= 2 ** 12: # リッジ回帰 model_ridge = linear_model.Ridge(alpha=alpha) model_ridge.fit(X_fit,y) mse_ridge = mean_squared_error(model_ridge.predict(X_fit),y) scores_ridge = cross_val_score(model_ridge,X_fit,y,scoring="neg_mean_squared_error",cv=10) df_ridge_coeff = df_ridge_coeff.append(pd.Series(model_ridge.coef_[0],index=df_ridge_coeff.columns),ignore_index=True) df_ridge_result = df_ridge_result.append(pd.Series([alpha,mse_ridge,-scores_ridge.mean()],index=df_ridge_result.columns),ignore_index=True) # ラッソ回帰 model_lasso = linear_model.Lasso(alpha=alpha) model_lasso.fit(X_fit,y) mse_lasso = mean_squared_error(model_lasso.predict(X_fit),y) scores_lasso = cross_val_score(model_lasso,X_fit,y,scoring="neg_mean_squared_error",cv=10) df_lasso_coeff = df_lasso_coeff.append(pd.Series(model_lasso.coef_,index=df_lasso_coeff.columns),ignore_index=True) df_lasso_result = df_lasso_result.append(pd.Series([alpha,mse_lasso,-scores_lasso.mean()],index=df_lasso_result.columns),ignore_index=True) alpha = alpha * 2 for index, row in df_ridge_coeff.iterrows(): print(row.sort_values()) print(df_ridge_result.iloc[index]) print(df_ridge_result.sort_values('TestErr')) for index, row in df_lasso_coeff.iterrows(): print(row.sort_values()) print(df_lasso_result.iloc[index]) print(df_lasso_result.sort_values('TestErr'))解説と同様に求められた係数を低い順に並べ、訓練誤差とテスト誤差も併せて出力している。
本来の回答は以下のようになっている。
- リッジ回帰における最小の訓練誤差とテスト誤差を与える正則化パラメータ
- 訓練誤差:$2^{-16}$
- テスト誤差:0.0625 (TestErr = 0.43394)
- ラッソ回帰における最小の訓練誤差とテスト誤差を与える正則化パラメータ
- 訓練誤差:$2^{-16}$
- テスト誤差:0.000244 (TestErr = 0.43404)
訓練誤差は当然正則化パラメータが一番小さいものになるのだが、テスト誤差がかなり違う。
このプログラムの結果では以下のようになる。リッジ回帰 alpha TrainErr TestErr 23 128.000000 0.417864 0.433617 22 64.000000 0.417102 0.433799 21 32.000000 0.416863 0.434265 20 16.000000 0.416793 0.434649 24 256.000000 0.420109 0.434870 19 8.000000 0.416774 0.434894 18 4.000000 0.416769 0.435033 17 2.000000 0.416768 0.435107 16 1.000000 0.416767 0.435146 15 0.500000 0.416767 0.435165 14 0.250000 0.416767 0.435175 13 0.125000 0.416767 0.435180 12 0.062500 0.416767 0.435182 11 0.031250 0.416767 0.435184 10 0.015625 0.416767 0.435184 9 0.007812 0.416767 0.435185 8 0.003906 0.416767 0.435185 7 0.001953 0.416767 0.435185 6 0.000977 0.416767 0.435185 5 0.000488 0.416767 0.435185 4 0.000244 0.416767 0.435185 3 0.000122 0.416767 0.435185 2 0.000061 0.416767 0.435185 1 0.000031 0.416767 0.435185 0 0.000015 0.416767 0.435185 25 512.000000 0.426075 0.440302 26 1024.000000 0.439988 0.454846 27 2048.000000 0.467023 0.483752 28 4096.000000 0.507750 0.526141 ラッソ回帰 alpha TrainErr TestErr 9 0.007812 0.418124 0.434068 10 0.015625 0.420260 0.434252 8 0.003906 0.417211 0.434764 7 0.001953 0.416878 0.435060 6 0.000977 0.416795 0.435161 0 0.000015 0.416767 0.435185 1 0.000031 0.416767 0.435185 2 0.000061 0.416767 0.435186 5 0.000488 0.416774 0.435186 3 0.000122 0.416768 0.435186 4 0.000244 0.416769 0.435189 11 0.031250 0.424774 0.438609 12 0.062500 0.439039 0.451202 13 0.125000 0.467179 0.478006 14 0.250000 0.549119 0.562292 15 0.500000 0.651761 0.663803 16 1.000000 0.651761 0.663803 17 2.000000 0.651761 0.663803 18 4.000000 0.651761 0.663803 19 8.000000 0.651761 0.663803 20 16.000000 0.651761 0.663803 21 32.000000 0.651761 0.663803 22 64.000000 0.651761 0.663803 23 128.000000 0.651761 0.663803 24 256.000000 0.651761 0.663803 25 512.000000 0.651761 0.663803 26 1024.000000 0.651761 0.663803 27 2048.000000 0.651761 0.663803 28 4096.000000 0.651761 0.663803
- リッジ回帰:128 (TestErr = 0.43362)
- ラッソ回帰:0.007812 (TestErr = 0.43407)
交差検証の方法をstratifiedkfoldにしてみても、K-Foldの分割数を変えても残念ながらダメだった。
ただ傾向としては正しいのでプログラムとして大きく間違ってはいないと思う。この課題をやってみるとリッジとラッソの違いがよくわかる。
リッジ回帰は全ての係数が徐々に影響が小さくなっていくのに対して、ラッソは影響が小さいものはすぐに0になってしまう。ラッソ回帰の途中経過 volatile acidity -0.183183 total sulfur dioxide -0.090231 chlorides -0.081657 pH -0.060154 fixed acidity 0.000000 citric acid -0.000000 density -0.000000 residual sugar 0.002591 free sulfur dioxide 0.027684 sulphates 0.139798 alcohol 0.304033 alpha 0.007812 TrainErr 0.418124 TestErr 0.434068ワインの品質に大きな影響を与えるvolatile acidityやalcoholはきちんと残っているが、それ以外は軒並み小さくなっている。
同じ正則化パラメータ(=0.007812)でのリッジ回帰の結果はこれ。volatile acidity -0.193965 total sulfur dioxide -0.107355 chlorides -0.088183 pH -0.063840 citric acid -0.035550 density -0.033741 residual sugar 0.023020 fixed acidity 0.043500 free sulfur dioxide 0.045605 sulphates 0.155276 alcohol 0.294240 alpha 0.007812 TrainErr 0.416767 TestErr 0.435185citrix acidやdensity等は殆ど品質に影響がないので、無視して単純化してしまえばよい、というラッソ回帰の結果は面白い。
過去の投稿
筑波大学の機械学習講座:課題のPythonスクリプト部分を作りながらsklearnを勉強する (1)
筑波大学の機械学習講座:課題のPythonスクリプト部分を作りながらsklearnを勉強する (2)
筑波大学の機械学習講座:課題のPythonスクリプト部分を作りながらsklearnを勉強する (3)
- 投稿日:2020-05-25T20:44:51+09:00
Pythonで文字列を逆順にする
- 投稿日:2020-05-25T19:10:32+09:00
100日後にエンジニアになるキミ - 66日目 - プログラミング - 自然言語処理について
昨日までのはこちら
100日後にエンジニアになるキミ - 63日目 - プログラミング - 確率について1
100日後にエンジニアになるキミ - 59日目 - プログラミング - アルゴリズムについて
100日後にエンジニアになるキミ - 53日目 - Git - Gitについて
100日後にエンジニアになるキミ - 42日目 - クラウド - クラウドサービスについて
100日後にエンジニアになるキミ - 36日目 - データベース - データベースについて
100日後にエンジニアになるキミ - 24日目 - Python - Python言語の基礎1
100日後にエンジニアになるキミ - 18日目 - Javascript - JavaScriptの基礎1
100日後にエンジニアになるキミ - 14日目 - CSS - CSSの基礎1
100日後にエンジニアになるキミ - 6日目 - HTML - HTMLの基礎1
今回からは自然言語処理についてです。
自然言語処理とは
英語、日本語のように人間が自然発生的に使って来た言語を
自然言語と言います。これに対し
プログラミング言語等の規則に基づく人工言語を形式言語と呼んで区別しています。
自然言語処理とは人間が日常的に使っている自然言語をコンピュータに処理させる
一連の技術のことを言います。
自然言語処理には沢山の技術が内包される形になります。主な自然言語処理の技術
自然言語処理の中の技術体系は、このようなものがあります。
名称 内容 形態素解析 形態素に分割し、それぞれの形態素の品詞等を判別する手法 構文解析 形態素に切分けさらにその間の関連や、構文論的な関係を図式化するなどして明確にする手法 意味解析 概念辞書等を用いて文章の意味を解釈する手法 文脈解析 複数の文のつながりをチェックする手法 日本語をコンピュータで処理する場合、基本となる技術に形態素解析がありますが
言語は日々刻々と変化し続けているのでコンピューターが対応するのは大変です。人間は言語情報を完全に処理している訳ではなく、多数の解釈の中から
妥当な解釈を行っているため
その妥当性をコンピュータに実装するのが難しいところになります。意味解析以上のものになるとなかなか難しく、今後の研究が待たれるところです。
形態素解析について
形態素解析は形態素と呼ばれる最小単位の語句に文章を分かち書きし
それぞれの形態素の品詞等を判別する手法のことを言います。分かち書き
英語のように言葉の区切りに空白を入れる書き方です。
ワタシ ガ ヘンタイ デス ワタシ ハ ド スケベ デス英語の形態素解析
英語のように単語と単語の間がスペースで区切られる言語においては非常に簡単であり
英語の形態素解析の手順をまとめると以下のようになります。1.文全体を小文字化し単語の位置により単語が区別されてしまうことを防ぐ 2.it's や don't 等の省略形を分割する(it's → it 's 、 don't → do n't) 3.文末のピリオドを前の単語と切り離す(Mr. などに使われる文末とは関係ないピリオドは切り離さない) 4.スペースで分割する日本語の形態素解析
日本語は英語の場合と異なり、空白は余りなく、単語の切れ目が分かりません。
そのため専用の辞書を用いて辞書ベースで規則による分割を考える必要があります。自前で形態素解析を行うのであれば、この分割のルールを自分で定めて実装する必要があります。
日本語の形態素解析に関してはいくつかの
ライブラリが開発されており
これを用いて形態素解析を行うのが一般的になっています。代表的なライブラリだと
MeCab(めかぶ)と言うものがあります。https://ja.wikipedia.org/wiki/MeCab
Python言語では
janomeと言うライブラリもあります。https://mocobeta.github.io/janome/
こういったライブラリを用いて実装すれば、比較的簡単に形態素解析を主なうことができます。
ここら辺のライブラリの仕組みはこちらの記事で解説されています。
日本語形態素解析の裏側を覗く!MeCab はどのように形態素解析しているか基本的な考えとしては
ラティスを構築して最適なパスを選択すると言う考え方です。
ラティスとは考えられうる単語分割の解のことです。下記がわかりやすい例かと思いますので参照させていただきます。
参考:https://techlife.cookpad.com/entry/2016/05/11/170000
これが
ラティスでこの中からコストを元に最適なパスを選んでいきます。
コストは形態素解析に用いられる辞書によって変わります。一般的な形態素解析では
NAIST辞書と言うものが使われますが
この中に計算された生起コスト,連接コストの値が記載されており
そこからコーパス用のコスト値が計算されているようです。この
コスト値が一番低いパスを形態素解析の結果としているようです。当然、この辞書に存在しなければ固有名詞などは通常の単語で分割されていく形になるため
正しく形態素解析を行うためには辞書の整備が不可欠になっています。新しく作られた言葉のことを
未知語と言ったりしますが、形態素解析を行う業務の中では
こう言った未知語への対応や辞書の整備が開発作業の工数の大半を占める形になってきます。自然言語処理を扱う企業であれば、自前で大量の単語を登録した
データベースを構築して未知語への対応をしています。構文解析について
構文解析とは係り受け解析とも言い、自然言語処理の技術の中の一種です。
文章を形態素に分けた後に、単語間の修飾関係を解析することになります。有名なライブラリとして
CaboChaと言うものがあります。https://taku910.github.io/cabocha/
余り長い文章を解析させるのには向いておらず、短めの文章で考えてあげる必要があります。
解析の結果はこんな感じになります。
一郎は二郎が作った穴に、北海道で購入したジャガイモを詰めた 一郎は-------------D 二郎が-D | 作った-D | 穴に、-------D 北海道で-D | 購入した-D | ジャガイモを-D 詰めた係り受け解析は文章の意味を解析したいときに使える技術で
文法的な構造を解析して文章の意味を解明していく際に使えるかなと思います。自然言語処理でよく出てくる言葉
正規表現
いくつかの文字列を一つの形式で表現するための表現方法です。
大量の文章の中から、一定のルールに沿った処理を行う際によく用います。詳しくはこちら
100日後にエンジニアになるキミ - 46日目 - プログラミング - 正規表現についてN-Gram
任意の文字列や文書を連続した
n個の文字で分割するテキスト分割方法のことで
nが1の場合をユニグラム(uni-gram)2の場合をバイグラム(bi-gram)
3の場合をトライグラム(tri-gram)と呼んでいます。文字ベースだと
# unigram '今', '日', 'は', 'い', 'い', '天', '気' # bigram '今日', '日は', 'はい', 'いい', 'い天', '天気' # trigram '今日は', '日はい', 'はいい', 'いい天', 'い天気'単語ベースだと、形態素解析した単語を
n個連結した形になります。# unigram '今日', 'は', 'いい', '天気' # bigram '今日は', 'はいい', 'いい天気' # trigram '今日はいい', 'はいい天気'単語ベクトル
文章を単語に分割した後に、表の列に単語を割り当ててデータ化したものです。
単語があれば1 , なければ0と言ったようなデータになります。[1,0,0,0,0,0,1,1,1], [1,0,0,0,0,0,1,1,0], ...TF-IDF
tf-idfは文書中の単語に関する重みの一種で、情報検索や文章要約などの分野で利用されます。
単語ベクトルを元に計算が行われ、単語の希少性などを判断するのに使われます。まとめ
自然言語処理はかなり難しい研究分野の一つですが研究が進んでいない分野は
逆にチャンスの多い分野でもあります。日本語の研究は特に難しく、意味を解析したりする部分を実装するところは
非常に困難であるのでじっくりと腰を据えて研究に取り組む必要があります。興味があれば自然言語処理を学んでみましょう。
君がエンジニアになるまであと34日
作者の情報
乙pyのHP:
http://www.otupy.net/Youtube:
https://www.youtube.com/channel/UCaT7xpeq8n1G_HcJKKSOXMwTwitter:
https://twitter.com/otupython
- 投稿日:2020-05-25T18:35:46+09:00
Deep Learning Specialization (Coursera) 自習記録 (C2W3)
はじめに
Deep Learning Specialization の Course 2, Week 3 (C2W3) の内容です。
(C2W3L01) Tuning process
内容
- Hyperparameter のチューニング方法の説明
Hyperparameter の重要度は,下記の通り
- 1 番大事
- $\alpha$
- 2 番目に大事
- $\beta$ ($\sim 0.9$)
- #hidden_units
- mini-batch size
- 3 番目に大事
- #layers
- learning rate decay
- チューニングしない
- Adam optimization algorithm の $\beta_1$,$\beta_2$,$\epsilon$
Hyperparameter を試すときは,try random values, don't use a grid
Coarse to Fine ; 良さそうな値が見つかったら,その近傍で細かく (fine) 調べる
(C2W3L02) Using an appropriate scale to pich hyperparameter
内容
参考
- 投稿日:2020-05-25T18:25:30+09:00
PythonファイルをWindows10のコマンドプロンプトで実行する方法
はじめに
Pythonのインストールがまだの人は、こちらの記事が分かりやすく手短に書かれていてオススメです。
ちなみに、筆者のPythonのバージョンは3.8.0ですが、Python3系であれば問題ないです。Pythonファイルの作成
まず、以下のスクリプトをテキストエディタなどにコピペして拡張子を.pyにして保存してください。ここでは、ファイル名をsample.py、保存先をDesktopフォルダの中とします。
sample.pyprint("Hello World!!")Python3系では、print()と書くと、かっこの中のものを出力してくれます。文字列を出力したい場合はダブルクォーテーション""で囲みます。
コマンドプロンプトの起動
Windows10では、画面左下にあるこの虫眼鏡を押してcmと検索すると、かんたんにコマンドプロンプトが見つかります。cmはコマンドの頭文字ですね。
虫眼鏡が画面左下にない場合は、タスクバーの上で右クリックして、検索アイコンを表示させてください。Pythonファイルの実行
コマンドプロンプトを起動できましたか?起動したら次のような画面が表示されていると思います。青色で隠してあるのは、筆者の名前です。
起動できていたら、ここでcd desktopというコマンドを打って、Pythonファイルがあるフォルダへ移動します。
Pythonファイルがあるフォルダへ移動できたら、python sample.pyというコマンドを打ってください。
このようにHello World!!と表示されていたら、成功です!終わりに
実は、Pythonファイルは直接ダブルクリックすることでも実行することが可能です。
しかし、この方法だとプログラムの処理が最後の行まで実行された後、ウィンドウが閉じられます。出力内容を確認するには、プログラムの最後の行に
input()と書く必要があります。また、
input()と書いた場合でもプログラムに誤りがあった場合、その時点で強制的にウィンドウが閉じられるため、エラー内容が分かりません(コマンドプロンプトでは、エラーの内容と場所を教えてくれます)。したがって、デバッグを楽にするためにも、Pythonファイルはコマンドプロンプトで実行するようにしましょう。


- 投稿日:2020-05-25T18:09:22+09:00
深さ優先探索と幅優先探索についてPythonで考える
こんにちは
今回は迷路を使って深さ優先探索と幅優先探索について考える。
今回使用する迷路
入力
入力はn行行われる。
- 1行目は迷路のスタート地点とゴール地点
- 2行目は迷路の縦の長さと横の長さ
- 3~n行目は迷路の情報
n-2は迷路の縦の長さ、マスの無いところは#で与えられる。
ex.)S G 3 5 # B E F G S A C H # # D # # #出力
出力は3行行われる。
1行目はスタート地点とゴール地点の距離
2行目は探索の回数
3行目はスタート地点からゴール地点へのルート
ex.)スタート地点とゴール地点の距離:5 探索回数:10 ルート:G <= F <= H <= C <= A <= S深さ優先探索
コードの流れ
1.入力される情報を読み込む
2.スタートを各種リストに追加
3.スタックから取り出す
4.ゴール判定
5.隣接している地点をスタックに追加
6.チェック済リストに入れ3に戻る実装
stack# cording = utf-8 start, goal = input().split() # スタート地点とゴール地点 height, width = map(int, input().split()) # 迷路縦と横の長さ maze, stack, checked, route = [], [], [], {} num_of_t = 0 # 探索の回数 for i in range(height): x = input().split() maze.append(x) # 迷路 if start in maze[i]: now_height, now_width = i, maze[i].index(start) start_height, start_width = now_height, now_width # スタート地点の座標を保存 stack += start checked += start route[maze[now_height][now_width]] = "Start" def search(h, w, x = maze, y = stack, z = checked): if x[h][w] != "#" and x[h][w] not in z: y += x[h][w] z += x[h][w] while stack[-1] != goal: stack.pop() if now_height < height-1: search(now_height+1, now_width) if now_width < width-1: search(now_height, now_width+1) if now_height > 0: search(now_height-1, now_width) if now_width > 0: search(now_height, now_width-1) num_of_t += 1 for j in range(height): if stack[-1] in maze[j]: route[stack[-1]] = maze[now_height][now_width] now_height, now_width = j, maze[j].index(stack[-1]) print("スタート地点とゴール地点の距離:" + str(abs(now_height - start_height) + abs(now_width - start_width))) print("探索回数:" + str(num_of_t)) print("ルート:", end = "") while route[goal] != "Start": print(goal + " <= ", end="") goal = route[goal] print(goal)出力結果
スタート地点とゴール地点の距離:5 探索回数:5 ルート:G <= F <= E <= B <= A <= S幅優先探索
コードの流れ
深さ優先探索のstackをqueueに変更
実装
queue# cording = utf-8 start, goal = input().split() # スタート地点とゴール地点を入力 height, width = map(int, input().split()) # 迷路の縦と横の長さ maze, queue, checked, route = [], [], [], {} num_of_t = 0 # 探索の回数 for i in range(height): x = input().split() maze.append(x) # 迷路 if "A" in maze[i]: now_height, now_width = i, maze[i].index(start) start_height, start_width = now_height, now_width # スタート地点の座標を保存 queue += start checked += start route[maze[now_height][now_width]] = "Start" def search(h, w, x = maze, y = queue, z = checked): if x[h][w] != "#" and x[h][w] not in z: y += x[h][w] z += x[h][w] while queue[0] != goal: place = queue.pop(0) tmp = len(queue) if now_height < height-1: search(now_height+1, now_width) if now_width < width-1: search(now_height, now_width+1) if now_height > 0: search(now_height-1, now_width) if now_width > 0: search(now_height, now_width-1) num_of_t += 1 if tmp < len(queue): for i in range(1, len(queue) - tmp+1): route[queue[-i]] = place for j in range(height): if queue[0] in maze[j]: now_height, now_width = j, maze[j].index(queue[0]) print("スタート地点とゴール地点の距離:" + str(abs(now_height - start_height) + abs(now_width - start_width))) print("探索回数:" + str(num_of_t)) print("ルート:", end = "") while route[goal] != "Start": print(goal + " <= ", end="") goal = route[goal] print(goal)出力結果
スタート地点とゴール地点の距離:5 探索回数:8 ルート:G <= F <= H <= C <= A <= S考察
アルゴリズムに関する知識は十分に深められた。
もっと短く書ける人もいるだろうが、現状の自分ではこの様になった。
- 投稿日:2020-05-25T18:09:22+09:00
深さ優先探索と幅優先探索についてPythonで考える。
こんにちは
今回は迷路を使って深さ優先探索と幅優先探索について考える。
今回使用する迷路
入力
入力はn行行われる。
- 1行目は迷路のスタート地点とゴール地点
- 2行目は迷路の縦の長さと横の長さ
- 3~n行目は迷路の情報
n-2は迷路の縦の長さ、マスの無いところは#で与えられる。
ex.)S G 3 5 # B E F G S A C H # # D # # #出力
出力は3行行われる。
1行目はスタート地点とゴール地点の距離
2行目は探索の回数
3行目はスタート地点からゴール地点へのルート
ex.)スタート地点とゴール地点の距離:5 探索回数:10 ルートはG<=F<=H<=C<=A<=S深さ優先探索
コードの流れ
1.入力される情報を読み込む
2.スタートを各種リストに追加
3.スタックから取り出す
4.ゴール判定
5.隣接している地点をスタックに追加
6.チェック済リストに入れ3に戻る実装
stack# cording = utf-8 start, goal = input().split() # スタート地点とゴール地点 height, width = map(int, input().split()) # 迷路縦と横の長さ maze, stack, checked, route = [], [], [], {} num_of_t = 0 # 探索の回数 for i in range(height): x = input().split() maze.append(x) # 迷路 if start in maze[i]: now_height, now_width = i, maze[i].index(start) start_height, start_width = now_height, now_width # スタート地点の座標を保存 stack += start checked += start route[maze[now_height][now_width]] = "Start" def search(h, w, x=maze, y=stack, z=checked): if x[h][w] != "#" and x[h][w] not in z: y += x[h][w] z += x[h][w] while stack[-1] != goal: stack.pop() if now_height < height-1: search(now_height+1, now_width) if now_width < width-1: search(now_height, now_width+1) if now_height > 0: search(now_height-1, now_width) if now_width > 0: search(now_height, now_width-1) num_of_t += 1 for j in range(height): if stack[-1] in maze[j]: route[stack[-1]] = maze[now_height][now_width] now_height, now_width = j, maze[j].index(stack[-1]) print("スタート地点とゴール地点の距離:"+str(abs(now_height - start_height) + abs(now_width - start_width))) print("探索回数:"+str(num_of_t)) print("ルート:", end="") while route[goal] != "Start": print(goal + " <= ", end="") goal = route[goal] print(goal)出力結果
スタート地点とゴール地点の距離:5 探索回数:5 ルート:G <= F <= E <= B <= A <= S幅優先探索
コードの流れ
深さ優先探索のstackをqueueに変更
実装
queue# cording = utf-8 start, goal = input().split() # スタート地点とゴール地点を入力 height, width = map(int, input().split()) # 迷路の縦と横の長さ maze, queue, checked, route = [], [], [], {} num_of_t = 0 # 探索の回数 for i in range(height): x = input().split() maze.append(x) # 迷路 if "A" in maze[i]: now_height, now_width = i, maze[i].index(start) start_height, start_width = now_height, now_width # スタート地点の座標を保存 queue += start checked += start route[maze[now_height][now_width]] = "Start" def search(h, w, x=maze, y=queue, z=checked): if x[h][w] != "#" and x[h][w] not in z: y += x[h][w] z += x[h][w] while queue[0] != goal: place = queue.pop(0) tmp = len(queue) if now_height < height-1: search(now_height+1, now_width) if now_width < width-1: search(now_height, now_width+1) if now_height > 0: search(now_height-1, now_width) if now_width > 0: search(now_height, now_width-1) num_of_t += 1 if tmp < len(queue): for i in range(1,len(queue)-tmp+1): route[queue[-i]] = place for j in range(height): if queue[0] in maze[j]: now_height, now_width = j, maze[j].index(queue[0]) print("スタート地点とゴール地点の距離:"+str(abs(now_height - start_height) + abs(now_width - start_width))) print("探索回数:"+str(num_of_t)) print("ルートは", end="") while route[goal] != "Start": print(goal + "<=", end="") goal = route[goal] print(goal)出力結果
スタート地点とゴール地点の距離:5 探索回数:8 ルートはG<=F<=H<=C<=A<=S考察
アルゴリズムに関する知識は十分に深められた。もっと短く書ける人もいるだろうが、現状の自分ではこの様になった。
- 投稿日:2020-05-25T17:58:04+09:00
ヤフオクで過去に買った商品を自動でPDFに保存するツール[Python]
課題
ヤフオクで商品を買った場合、基本的には、領収書は発行されません。そのため、証明するものがない場合、経費として落ちないことがあります。この対処法として、取引画面のキャプチャという方法があります。しかし、一個一個を手作業でやるのは、かなりの苦行です?
今回は、ChromeDriverを使って、自動化していきたいと思います。
動作環境
Mac OS Mojave
Python 3.7.6
VSCode
ChromeDriver処理の流れ
①【ヤフオクに自動ログイン】
↓
②【商品毎の落札の取引画面を開く】
↓
③【PDFに変換】
↓
④【指定のファイルに保存】処理後の例
ソースコードはこちら
from selenium import webdriver from selenium.webdriver.chrome.options import Options import time import json import sys username= "ユーザー名" password="パスワード" def main(): #ヤフオクのURL driver.get('https://login.yahoo.co.jp/config/login?.src=auc&.done=https%3A%2F%2Fauctions.yahoo.co.jp%2F' ) #自動ログイン driver.find_element_by_id("username").send_keys(username) driver.find_element_by_id("btnNext").click() time.sleep(1) driver.find_element_by_id("passwd").send_keys(password) driver.find_element_by_id("btnSubmit").click() #driver.find_element_by_id("").click() *ポップアップ広告が出た時 driver.find_element_by_xpath('//*[@id="yjMain"]/div/div[2]/div[2]/div/div[2]/table/tbody/tr[3]/td[1]/a').click() time.sleep(1) #次へのボタンがなくなるまでループ while True: try: if len(driver.find_elements_by_xpath("//img[@src='https://s.yimg.jp/images/auct/template/ui/search/arrow_next.gif']")) > -1: print("start PDF") item_list= [] for item in driver.find_elements_by_css_selector('p.decTxt01'): try: link = item.find_element_by_tag_name("a").get_attribute("href") except: link = "skip" item_list.append(link) for link in item_list: try: driver.get(link) time.sleep(2) driver.find_element_by_class_name('decIcoArw').click() time.sleep(2) driver.execute_script('return window.print()') driver.back() except : print("None") btn = driver.find_element_by_link_text("次の50件").get_attribute("href") print(btn) print("next url:{}".format(btn)) driver.get(btn) print("Next page") #強制的に終了 except: sys.exit() #印刷を無理やりPDF保存する設定 chopt=webdriver.ChromeOptions() appState = { "recentDestinations": [ { "id": "Save as PDF", "origin": "local", "account":"" #Chrome (78.0.3904.108)は、必要 } ], "selectedDestinationId": "Save as PDF", "version": 2 } prefs = {'printing.print_preview_sticky_settings.appState': json.dumps(appState)} chopt.add_experimental_option('prefs', prefs) chopt.add_argument('--kiosk-printing') driver = webdriver.Chrome(executable_path='chromedriverのディレクトリ ',options=chopt) #処理実行 if __name__ == '__main__': main() #*注意点 掲示板にて、取引をしている場合のみは、手作業でのPDF保存になります。まず最初に、selenium, time, json,sysをインポートします。
from selenium import webdriver from selenium.webdriver.chrome.options import Options import time import json import sysヤフオクのログイン画面から自動的にログインしてくれます。サーバーに負荷をかけないようにtime.sleep(1)で1秒間だけ時間を置いてます。
def main(): #ヤフオクのURL driver.get('https://login.yahoo.co.jp/config/login?.src=auc&.done=https%3A%2F%2Fauctions.yahoo.co.jp%2F' ) #自動ログイン driver.find_element_by_id("username").send_keys(username) driver.find_element_by_id("btnNext").click() time.sleep(1) driver.find_element_by_id("passwd").send_keys(password) driver.find_element_by_id("btnSubmit").click() #driver.find_element_by_id("記入").click() *ポップアップ広告が出た時 driver.find_element_by_xpath('//*[@id="yjMain"]/div/div[2]/div[2]/div/div[2]/table/tbody/tr[3]/td[1]/a').click() time.sleep(1)次のページがなくなるまで、自動でページ遷移するようにループします。
#次へのボタンがなくなるまでループ while True: try: if len(driver.find_elements_by_xpath("//img[@src='https://s.yimg.jp/images/auct/template/ui/search/arrow_next.gif']")) > -1: print("start PDF") item_list= [] for item in driver.find_elements_by_css_selector('p.decTxt01'): try: link = item.find_element_by_tag_name("a").get_attribute("href") except: link = "skip" item_list.append(link) for link in item_list: try: driver.get(link) time.sleep(2) driver.find_element_by_class_name('decIcoArw').click() time.sleep(2) driver.execute_script('return window.print()') driver.back() except : print("None") btn = driver.find_element_by_link_text("次の50件").get_attribute("href") print(btn) print("next url:{}".format(btn)) driver.get(btn) print("Next page") #強制的に終了 except: sys.exit()ChromeOptionsによって、印刷を強制的に停止させて、PDF保存を自動的にするようにしてます。
#印刷を無理やりPDF保存する設定 chopt=webdriver.ChromeOptions() appState = { "recentDestinations": [ { "id": "Save as PDF", "origin": "local", "account":"" #Chrome (78.0.3904.108)は、必要 } ], "selectedDestinationId": "Save as PDF", "version": 2 } prefs = {'printing.print_preview_sticky_settings.appState': json.dumps(appState)} chopt.add_experimental_option('prefs', prefs) chopt.add_argument('--kiosk-printing') driver = webdriver.Chrome(executable_path='chromedriverのディレクトリ ',options=chopt) #処理実行 if __name__ == '__main__': main()おわりに
ヤフオクのデータは90日で、更新されてまうので、3ヶ月毎にこのツールを使っていきたいと思います。Xpathで要素を指定している箇所は、次に使う時に変わっているかもしれませんが…?(2020/5/25 動作確認済み)
- 投稿日:2020-05-25T17:35:50+09:00
AtCoderなどで使えるPythonの便利な知識
まえがき
AtCoderでよく使うなと思いながらも書き方を忘れたりする知識をメモとして残す意味合いもあって書いていこうと思います。説明が浅いので詳しく知りたい場合は他の記事なども見てください。
受け取るものがリストかどうかわからないとき
結果から言うとinput().strip()で解決します。
こんなことがあるのかと思いますがABC158_Dなどで用いますね。qiita.py#入力例 2 1 p 1 2 2 c 1上記のように入力されるものがあった場合listにするかしないかの判定ができないので受け取り方がわからなくなりますが、
qiita.pyfor i in range(n): #ダメな例 box = list(map(str,input().split())) #一個しか入力されないときバグる for i in range(n): #よい例 box=input().strip() #文字列としてスペースも受け取る list(box)#listにしてあげましょう print(box) #box[0] = ['2', ' ', '1', ' ', 'p']のように書くと解決します。
int(box[0])などで取り出せますね。
strip自体の説明は省きます。多次元リストにてkeyを複数指定してsortする
見出しの言い方はとても難しいですが簡単に言えば多次元listをsortするときの優先順位を決めれるよって感じです。これでも難しいとは思いますが...
box = [[1,1,8], [8,6,4], [5,9,8]]このような多次元リストがあった場合にふと、こう思うときがあると思います。
「昇順に並べたいけど3番目の数字、1番目の数字、2番目の数字の順番で昇順にしてほしいんだよなー」
こうなったときにlambdaが活躍します。qiita2.pybox = [[1,1,8], [8,6,4], [5,9,8]] box_sort = sorted(box) print(box_sort) #[[1, 1, 8], [5, 9, 8], [8, 6, 4]] box_sort = sorted(box, key=lambda box_i:(box_i[2], box_i[0], box_i[1])) print(box_sort) #[[8, 6, 4], [1, 1, 8], [5, 9, 8]]こうするとできます。sortするときの優先順位が書く順番でsortするので結果も変わってきます
下の見出しにて類題がありますのでそちらもご覧ください。
lambdaについての説明は省きます。
参考文献([Python] 多次元リストを複数キーでソートする)多次元リストにてkeyを複数指定して昇順、降順どっちもしたいとき
box=[[1,1,8], [8,6,4], [5,9,8]]このような多次元リストがあった場合にふと、こう思うときがあると思います。
「3番目の数字、1番目の数字、2番目の数字の順番で昇順、降順、昇順にしてほしいんだよなー」
こうなったときは上の見出しではできないんじゃないの??と思いますがqiita3.pybox = [[1,1,8], [8,6,4], [5,9,8]] box_sort = sorted(box, key=lambda box_i:(box_i[2], box_i[0], box_i[1])) print(box_sort) #[[8, 6, 4], [1, 1, 8], [5, 9, 8]] box_sort = sorted(box, key=lambda box_i:(box_i[2], -box_i[0], box_i[1])) print(box_sort) #[[8, 6, 4], [5, 9, 8], [1, 1, 8]]このように
-をつけることで値に-1をかけるので大きい値ほど小さくなります。これを利用して降順昇順を合わせて使用することができます。ABC128_Bの問題ではこのlambda式を使って解くと勉強になる良い例題になるかと思います。辞書型を操りたい
Counterなどを使って辞書型を作った後その辞書型の処理の仕方にしばらく苦戦した覚えがあるので簡単に書こうと思います
keys():要素ごとのkeyだけ取り出せる
values():要素ごとの値だけ取り出せる
items():要素ごとのkey、値の両方を取り出せる
この三つを使って取り出したりforで回す場合に用いられたりします参考文献( Pythonの辞書(dict)のforループ処理(keys, values, items) )
最後に
最初なので丁寧な言葉遣いをしましたが次からは雑だと思います
初めて投稿するので間違った情報やらマナーの悪いところがありましたらご連絡ください
メモの意味もあるので雑な説明はご了承ください
- 投稿日:2020-05-25T17:35:50+09:00
AtCoderで使えるPython知識のメモ
まえがき
AtCoderでよく使うなと思いながらも書き方を忘れたりする知識をメモとして残す意味合いもあって書いていこうと思います。説明が浅いので詳しく知りたい場合は他の記事なども見てください。
listの中にある要素が何番目にあるか検索
if a in dataなどで変数aはdataのlistに含まれているかどうかの確認をすることがよくあります。ですが何番目に入っているか、というものを簡単に書いて返せるものがあればなと思っていたらあって感動したので紹介します。qiita1.pybox = [4, 2, 1, 0, 3] print(box.index(3)) #4このように
index()を用いることで3という値は4番目にあるよという答えを返してくれます。多次元リストにてkeyを複数指定してsortする
見出しの言い方はとても難しいですが簡単に言えば多次元listをsortするときの優先順位を決めれるよって感じです。これでも難しいとは思いますが...
box = [[1,1,8], [8,6,4], [5,9,8]]このような多次元リストがあった場合にふと、こう思うときがあると思います。
「昇順に並べたいけど3番目の数字、1番目の数字、2番目の数字の順番で昇順にしてほしいんだよなー」
こうなったときにlambda式が活躍します。qiita2.pybox = [[1,1,8], [8,6,4], [5,9,8]] box_sort = sorted(box) print(box_sort) #[[1, 1, 8], [5, 9, 8], [8, 6, 4]] box_sort = sorted(box, key=lambda box_i:(box_i[2], box_i[0], box_i[1])) print(box_sort) #[[8, 6, 4], [1, 1, 8], [5, 9, 8]]こうするとできます。sortするときの優先順位が書く順番でsortするので結果も変わってきます
下の見出しにて類題がありますのでそちらもご覧ください。
lambda式についての説明は省きます。
参考文献([Python] 多次元リストを複数キーでソートする)多次元リストにてkeyを複数指定して昇順、降順どっちもしたいとき
box=[[1,1,8], [8,6,4], [5,9,8]]このような多次元リストがあった場合にふと、こう思うときがあると思います。
「3番目の数字、1番目の数字、2番目の数字の順番で昇順、降順、昇順にしてほしいんだよなー」
こうなったときは上の見出しではできないんじゃないの??と思いますがqiita3.pybox = [[1,1,8], [8,6,4], [5,9,8]] box_sort = sorted(box, key=lambda box_i:(box_i[2], box_i[0], box_i[1])) print(box_sort) #[[8, 6, 4], [1, 1, 8], [5, 9, 8]] box_sort = sorted(box, key=lambda box_i:(box_i[2], -box_i[0], box_i[1])) print(box_sort) #[[8, 6, 4], [5, 9, 8], [1, 1, 8]]このように
-をつけることで値に-1をかけるので大きい値ほど小さくなります。これを利用して降順昇順を合わせて使用することができます。ABC128_Bの問題ではこのlambda式を使って解くと勉強になる良い例題になるかと思います。辞書型を操りたい
Counterなどを使って辞書型を作った後その辞書型の処理の仕方にしばらく苦戦した覚えがあるので簡単に書こうと思います。
keys():要素ごとのkeyだけ取り出せる。
values():要素ごとの値だけ取り出せる。
items():要素ごとのkey、値の両方を取り出せる。
この三つを使って取り出したりforで回す場合に用いられたりします。参考文献( Pythonの辞書(dict)のforループ処理(keys, values, items) )
最後に
最初なので丁寧な言葉遣いをしましたが次からは雑だと思います。
初めて投稿するので間違った情報やらマナーの悪いところがありましたらご連絡ください。
メモの意味もあるので雑な説明はご了承ください。追記
strip()の内容に対する間違いがありました、前の記述ではエラーが出ると書かれているところには実際にはエラーが出ずわざわざstrip()を使う必要性もないことが判明しました
よってそこの記述は削除いたしました
不確かな情報の発信誠に申し訳ありません
- 投稿日:2020-05-25T16:59:32+09:00
[Python] DFS(深さ優先探索) ABC157D
ABC157D
UnionFind Treeが定石だが、初学者はまずDFSを習熟するべきと考える。単純な操作なら再帰関数を使わない。
サンプルコードN, M, K = map(int, input().split()) F = [[] for _ in range(N)] B = [[] for _ in range(N)] # フレンドの隣接リスト for _ in range(M): a, b = map(int, input().split()) a, b = a - 1, b - 1 F[a].append(b) F[b].append(a) # ブロックの隣接リスト for _ in range(K): c, d = map(int, input().split()) c, d = c - 1, d - 1 B[c].append(d) B[d].append(c) # 交友関係グループ(辞書型) D = {} # グループの親 parent = [-1] * N # 訪問管理 visited = [False] * N for root in range(N): if visited[root]: continue D[root] = set([root]) # 訪問先のスタック stack = [root] # 訪問先が無くなるまで while stack: # 訪問者をポップアップ n = stack.pop() # 訪問者を訪問済み visited[n] = True # 訪問者のグループの親を設定 parent[n] = root # root のフレンドをグループと訪問先に追加 for to in F[n]: if visited[to]: continue D[root].add(to) stack.append(to) ans = [0] * N for iam in range(N): # 自分の交友関係グループを設定 group = D[parent[iam]] # グループからフレンドと自分を除く tmp_ans = len(group) - len(F[iam]) - 1 # グループからブロックを除く for block in B[iam]: if block in group: tmp_ans -= 1 ans[iam] = tmp_ans print(*ans, sep=' ')
- 投稿日:2020-05-25T16:24:13+09:00
自動因数分解装置を作成してみよう/中学数学編 vol.1
プログラミングを利用して因数分解できないか
※改善あればWelcomeですので、宜しくお願い致します。
勉強がてら自動因数分解装置を作ってみようと思い始めてみたが、ソースコードが美しくない。。。
ところどころ無理やり感満載ではあるが、中学基本数学レベルであれば因数分解できるソースは完成した。因数定理から因数分解したほうが良いかもしれないが。おいおい分数が出ると困るので、地道にやるしかないのだろうか。
以下のソースコードを利用すれば、中学数学レベルであればコンピュータがやってくれるので、宿題がはかどるかも!?
おいおいは以下のような因数分解できるようになればなと思う。
STEP1はそんなに時間かからなそうではあるが、今日は疲れたので中学数学まで。STEP1 : (a+c)x**2 + (ad+bc)x + bd = (ax+b)(cx+d)
STEP2 : 因数定理を活用した3次式の因数分解
STEP3:その他大学入試で出題されるレベルのものを網羅的に以下のコードに入力値を渡せば因数分解の式が出力される。
【inputのルール】
①符号と式の間はスペースをあける
②1*x の場合は、通常は1を省略するが、1x と記載する(例)
input
x**2 - 20x + 96
output
(x - 12)(x - 8)input
x**2 - 9
output
(x + 3)(x - 3)input
x**2 - 4x + 4
output
(x - 2)**2import math a = 0 b = 0 jud1 = "+" jud2 = "+" nums = input().split() if len(nums) <= 3: a = int(math.sqrt(int(nums[2]))) print("(x + " + str(a) + ")(x - " + str(a) + ")") else: if nums[3] == "-": nums[4] = int(nums[4])*(-1) li = list(nums[2].split("x")) if nums[1] == "-": li[0] = int(li[0])*(-1) for i in range(-100,100): if (i * (int(li[0]) - i)) == int(nums[4]): a = i b = int(li[0]) - i if a < 0: jud1 = "-" if b < 0: jud2 = "-" if a == b: print("(x " + jud1 , str(abs(a)) + ")**2") else: print("(X " + jud1 , str(abs(a)) + ")(x " + jud2 , str(abs(b)) + ")")改善したいポイント
初学者が故に実は簡単な求め方があるかもしれないが、各項の係数を簡単に取り出したい(できれば符号含め)というのができればよりスマートに書けそうだなと思う。
また、x**2 - 9のように項が2つしかないパターンを無理やりif len(nums) <= 3: a = int(math.sqrt(int(nums[2]))) print("(x + " + str(a) + ")(x - " + str(a) + ")")としているところが一番気持ち悪い。
今のところは通過できているが、例えばおいおいx**3 - 8 みたいのが出たときに困るのでどうしたものかと考え中。
- 投稿日:2020-05-25T16:00:39+09:00
xlwingsを使ってPythonからExcel VBAマクロを呼び出す
xlwingsのUDFの実用的な使い方として、PythonからExcel VBAマクロを呼び出す方法を説明します。「xlwingsとは何ぞや?」という方には、PythonのインストールからxlwingsのUDFの基本的な使い方までを以下で投稿していますので、そちらをご覧ください。
VBAユーザーのためのPython入門 ~xlwingsでExcelからPythonを呼び出す~1. 背景
脱Excel VBAを目指してPythonで社内EUCツールを作り始めたとしても、社内には先人たちが作ったExcel VBAツールが山のようにあり、それらも使用しなければならないということがあると思います。VBAが嫌いだからと言って捨てる訳にも行かず、いっそのことPythonで書き直そうかと思っても忙しいし量が多くてそれもできず。結局はVBAからは逃れられないのかと頭を抱えます。
そして、一連の作業で複数のExcel VBAツールを使う場合は、たいてい都度ファイルを開きマクロを実行して、終わったら次のファイルという流れになるかと。じゃあ、自動的にVBAマクロを次々と実行するプログラムをVBAで作ればいいじゃんとなるかもしれません。
いや、やっぱり止めましょうVBA。それ、Pythonでできますから。
本記事では、PythonからExcel VBAマクロを実行する方法を説明します。この方法なら、既存のVBA資産を活かしつつ、Pythonで快適にコーディングできるようになります。
2. 環境
以下の環境で試しています。
- OS: Windows 10 version 1909
- Python: version 3.7.5
- xlwings: version 0.18.0
- エディター: VSCode version 1.45.1 & Python拡張機能 version 2020.5.80290
3. 基本
公式ドキュメント(Python API)を参考に、PythonからExcel VBAマクロを呼び出してみましょう。
適当なフォルダーで、
VBA_example.xlsmというファイルを作成し、Alt+F11でVBAエディターを開きます。適当なモジュール(とりあえずModule1とします)を追加し、以下を記述します。VBA_example.xlsm!Module1Sub hello_VBA() MsgBox "Hello VBA from Python." End Sub次に、同じフォルダーをVisual Studio Codeで開き、
call_VBA.ipynbというファイルを作成します。call_VBA.ipynbで以下を(できれば一行ずつ)実行します。call_VBA.ipynbimport xlwings as xw # 1. xlwingsをインポート wb = xw.Book('VBA_example.xlsm') # 2. ブックを開く macro = wb.macro('hello_VBA') # 3. マクロを取得 macro() # 4. マクロを実行コードの説明すると、
- xlwingsをインポートします。
as xwとしていますので、以下xwでxlwingsを呼び出します。- 同じフォルダーにあるブックなら
xw.Bookで開けます。- ブック内のマクロ
hello_VBAを変数macroに格納します。VBAユーザーだとここで??となるかもしれませんが、Pythonは関数も変数に格納することができます。macroを実行します。VBAだとCall macroとかになるかもしれませんが、Callは不要です。引数が必要なマクロの場合は、括弧内に引数を入れます。となります。
これをVSCodeで実行中の画面は以下のとおりです:
最後のセルを実行したとき止まりますが、Excelのウィンドウをアクティブにすると、次の画面が表示されます:
ちゃんとVBAマクロが実行されてますね。
4. 応用(VBAマクロの連続実行)
UDFを使った実用的な例です。あるExcelファイルのボタンから、他のExcelファイルのVBAマクロを連続で実行できるようにしてみます。
適当なフォルダーで
VBA_caller.xlsmを作成します。ワークシートの内容は次のようにします:
- シート名は
VBA_caller- テーブル
T.VBA_callerを作成(ホームタブのテーブルとして書式設定から。場所はどこでもOK。)- テーブルには列
フォルダー、ファイル、マクロを含むこと。
Alt+F11でVBAエディターの画面を開き、参照設定でxlwingにチェックを入れます。Module1を作成し、以下を貼り付けます:VBA_caller.xlsm!Module1Sub main() Dim rg_target As Range Set rg_target = Worksheets("VBA_caller").ListObjects("T.VBA_caller").Range Application.DisplayAlerts = False var_log = xlwings_udfs.call_vba(rg_target) Application.DisplayAlerts = True End SubPythonのスクリプトを準備します。同じフォルダーに以下の内容のファイル
マクロ連続実行.pyを作成します。VBA_caller.pyimport os from pathlib import Path import numpy as np import pandas as pd import xlwings as xw os.chdir(Path(__file__).parent.absolute().resolve()) @xw.sub @xw.arg('df_target', pd.DataFrame, index=False, header=True) def call_vba(df_target: pd.DataFrame): def call_vba_single(row): #設定読み込み wb_path, wb_name, macro_name = row['フォルダー'], row['ファイル'], row['マクロ'] #マクロ実行用Excelインスタンス生成し、ブックを開く app = xw.apps.add() xl_path = (Path() / wb_path / wb_name).resolve() wb = app.books.open(str(xl_path)) #マクロ実行 app.display_alerts = False #マクロ実行中に、Excelから「別のプログラムでOLEの操作が完了するまで待機します。」というメッセージが表示され、実行が止まるため wb.macro(macro_name)() app.display_alerts = False #呼び出し先でTrueに戻されることがあるので、再びFalseに設定 #ブックを保存し、マクロ実行用ExcelインスタンスをKill wb.save() wb.close() app.kill() for _, row in df_target.iterrows(): call_vba_single(row) @xw.sub def kill_excel(): os.system('taskkill /f /im excel.exe') #デバッグ用 if __name__ == '__main__': xw.serve()
VBA_caller.py作成後、VBA_caller.xlsmに戻り、xlwingsタブのImport Functionsボタンを押し、VBA_caller.pyの内容をUDFとして取り込みます。これで、呼び出し元の準備は終了です。実験用に、呼び出し先のExcelファイルも準備してみましょう。
フォルダー構成┌example1 │ └example1.xlsm ├example2 │ ├example2.xlsm │ └example3 │ └example3.xlsm ├VBA_caller.py └VBA_caller.xlsm
example1.xlsm~example3.xlsmには標準モジュールに以下を保存しておきます:example1.slsm~example3.xlsm!Module1'プロシージャ‐名とMsgBoxの文字列は適宜変更 Sub example1() MsgBox "example1" End Subこれで準備ができました。
実行してみます。
VBA_caller.xlsmでAlt+F8を押し、mainを選択し、実行ボタンを押します。新しいExcelインスタンスでexample1.xlsmが開き、メッセージボックスにexample1と表示されれば成功です。OKボタンを押すと、example2.xlsm、example3.xlsmのマクロが次々実行されます。5. さらに応用(VBAマクロの同時連続実行)
ここまでの内容なら、VBAでもほぼ同じことができます。しかし、
VBA_caller.pyを少し書き換えると、複数マクロの同時実行もできるようになります。修正その1: imoprt文の最後に以下を追加します。
VBA_caller.pyimport joblib修正その2: 以下のforループを削除し、
VBA_caller.pyfor _, row in df_target.iterrows(): execute_vba_single(row)joblibを使った呼び出しに変更します。
VBA_caller.pyjoblib.Parallel(n_jobs=-1, verbose=10)([ joblib.delayed(execute_vba_single)(row) for _, row in df_target.iterrows() ])修正(?)その3: (2までで上手く行かなかったら試してください)xlwingsタブの
Interpreterにpython.exeのパスを入力します。Anacondaをデフォルト設定でインストールしていれば、C:\ProgramData\Anaconda3\python.exeになります。
VBA_caller.xlsmに戻り、再度Alt+F8からmainを実行してみましょう。今度は複数のExcelが同時に立ち上がり、マクロが同時実行されます。これはVBAには(たぶん)できないことであり、複数のマクロを同時実行することで、全体の処理時間を短くすることができます。joblibはPythonで簡単に並列処理をできるようにするためのライブラリーで、詳しい説明はこちらなどをご覧ください。
おわりに
最後まで読んでいただき、ありがとうございます。
今回は基本的な使い方ということで、引数が必要になるようなVBAマクロの呼び出しについては書きませんでしたが、必要でしたらその旨コメントいただければと思います。参考