- 投稿日:2020-05-25T23:03:38+09:00
【学習メモ】AWS(EC2インスタンスの設置)
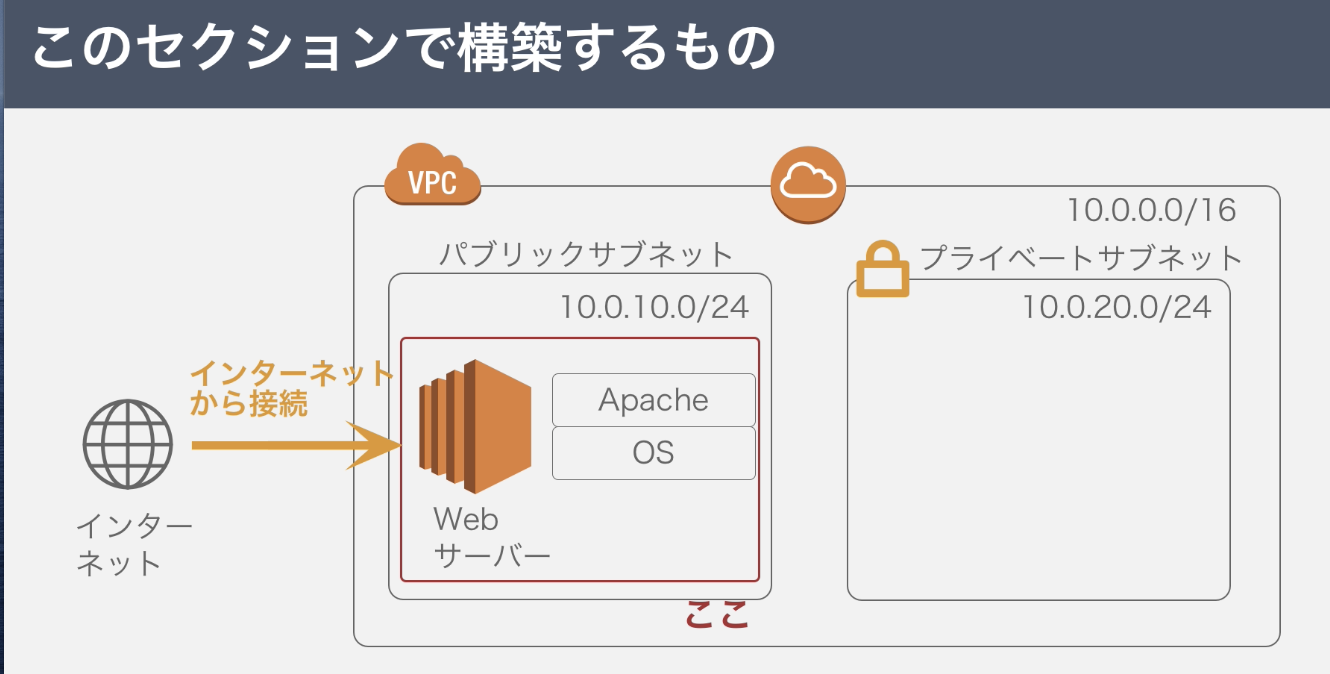
1.目標成果物
EC2とは?
Elastic Compute Cloud、AWSクラウド上の仮想サーバーのこと。EC2インスタンスとも。
特徴
数分で起動し、1時間または秒単位で従量課金
サーバーの追加・削除、マシンスペック変更も数分で可能
OSより上のレイヤーについて自由に設定可能2.サーバー構築の作業手順
1.EC2インスタンスを設置する←今回はここ
2.Apacheをインストールする
- SSHでサーバーにログイン
- Apacheをインストール
3.ファイアウォールを設定する3.EC2インスタンス設置手順の確認
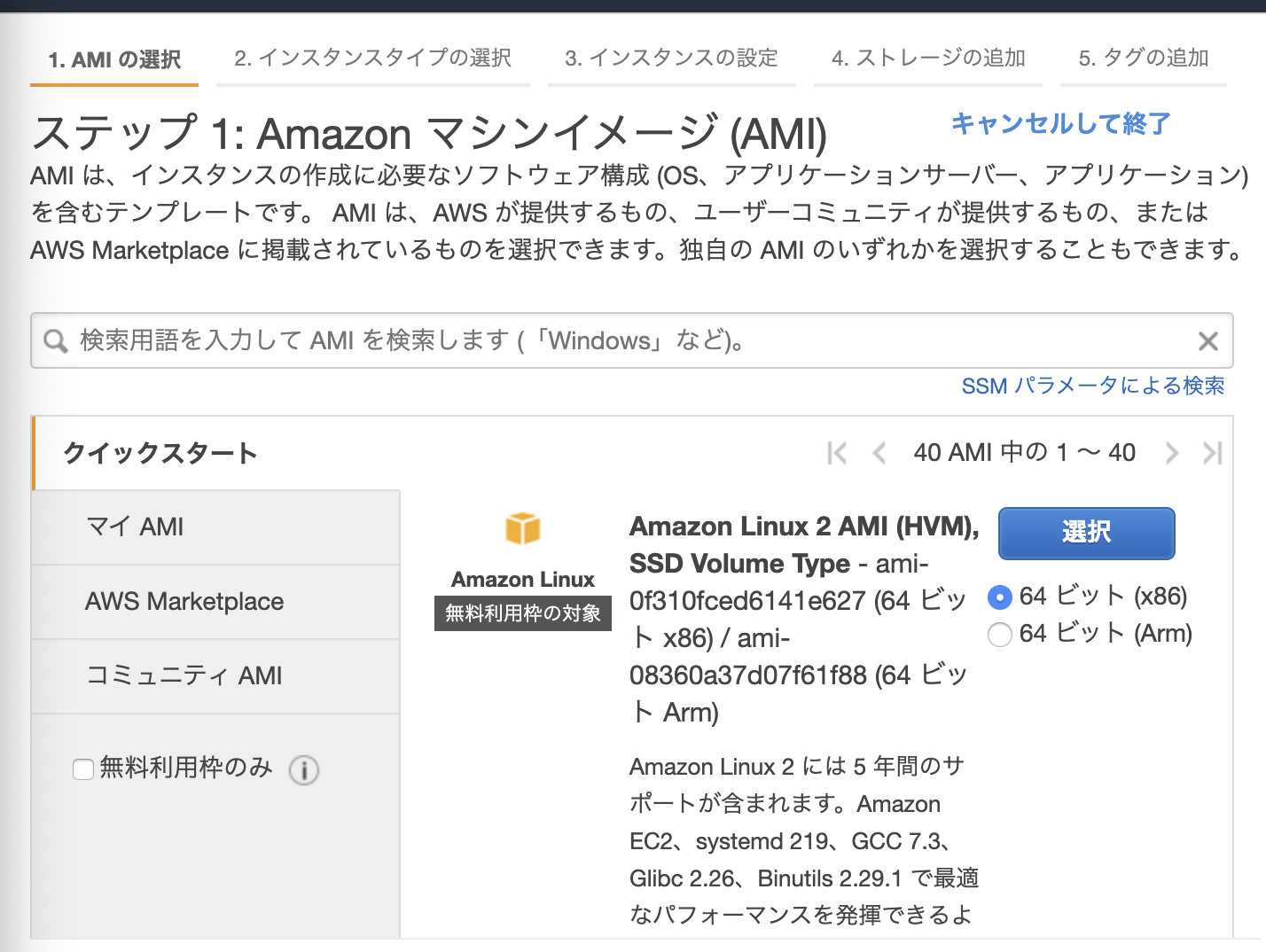
1.AMIの選択
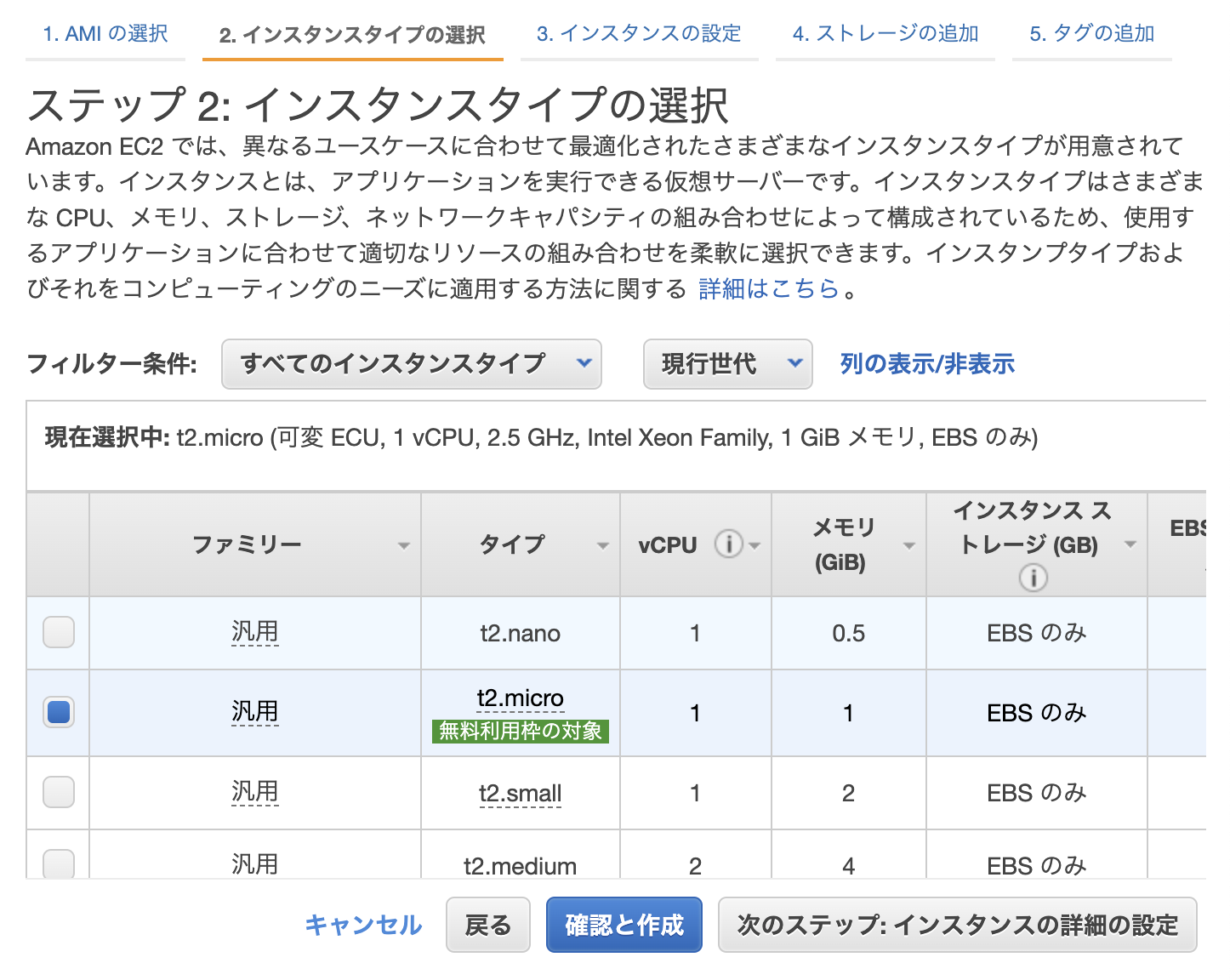
2.インスタンスタイプの選択
3.インスタンスの詳細の設定
4.ストレージの追加
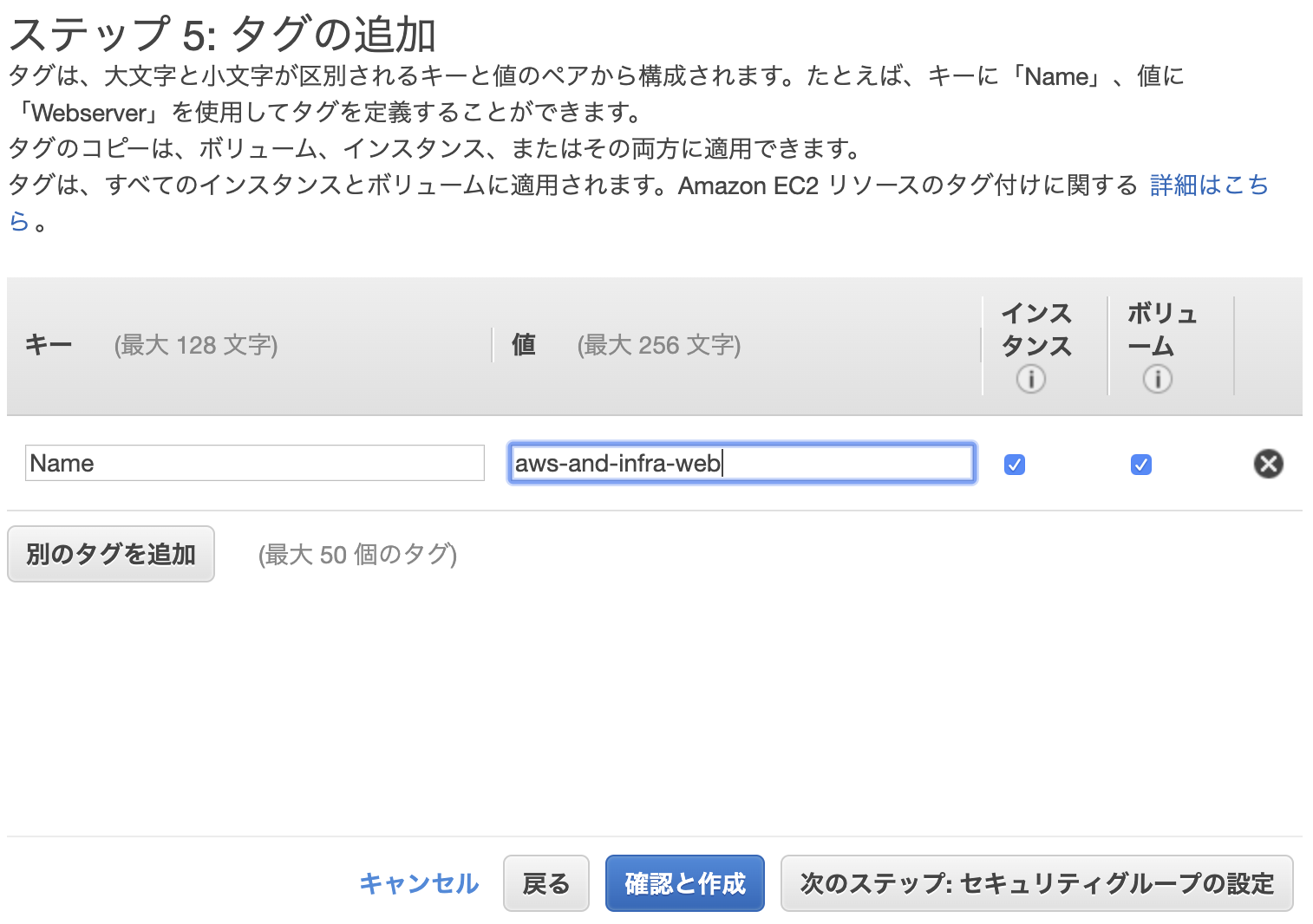
5.タグの追加
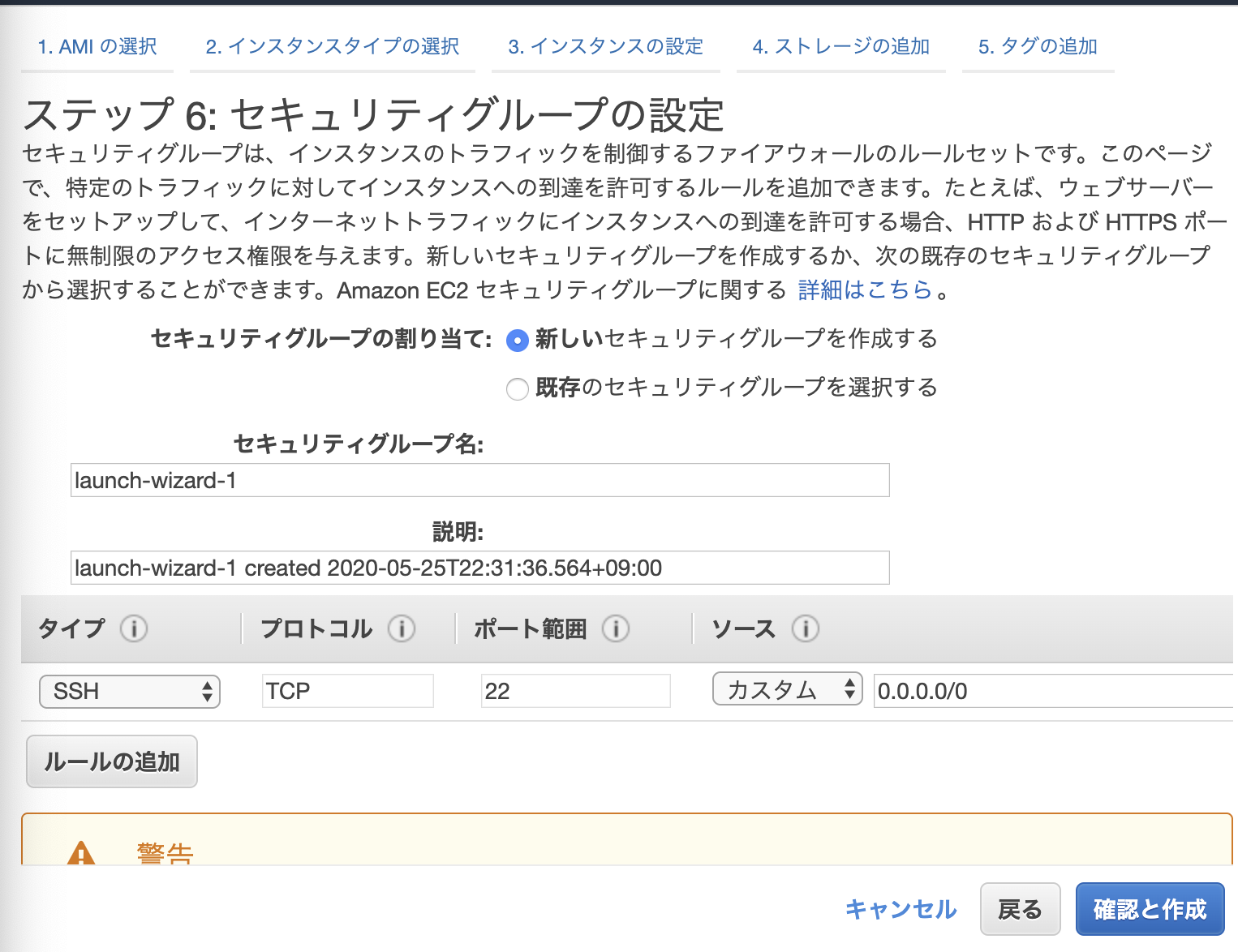
6.セキュリティグループの設定
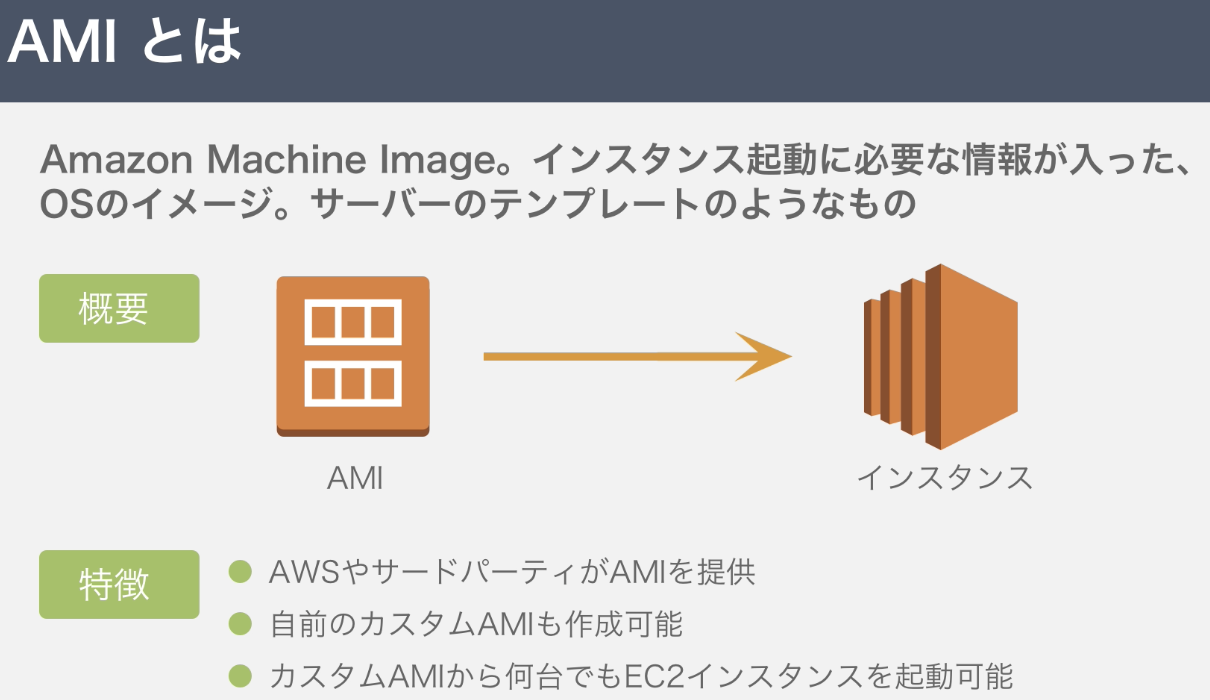
7.SSHキーペアの設定AMI
インスタンス起動に必要な情報が入ったOSのイメージ。サーバーのテンプレのようなもの
インスタンスタイプとは
サーバーのスペックを定義したものm5.xlarge
m:インスタンスファミリー
5:インスタンス世代(バージョン的な)
xlarge:インスタンスサイズストレージとは
サーバーにくっつけるデータの保存場所。EC2のストレージには2種類ある。
4.いざ、構築へ
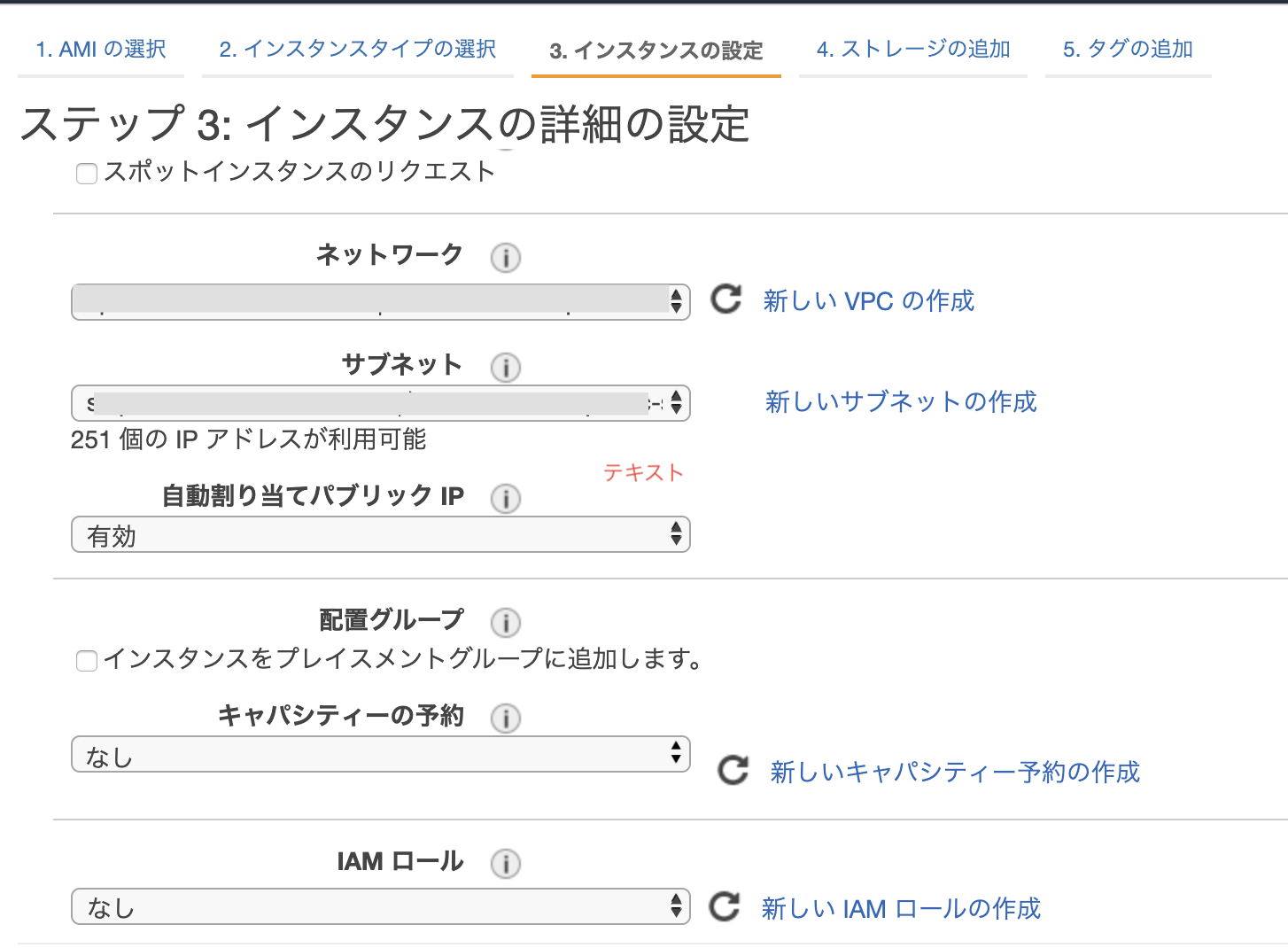
自動割り当て
インターネット経由でアクセスできるグローバルIPアドレスをつけるかどうか選べる
→インターネットからアクセスできる状態にしたいので、「有効」を選択配置グループ
複数のEC2インスタンス間の通信を高速化するためのグループ
→1つしかしないのでチェックなしでOK順に進めていく。
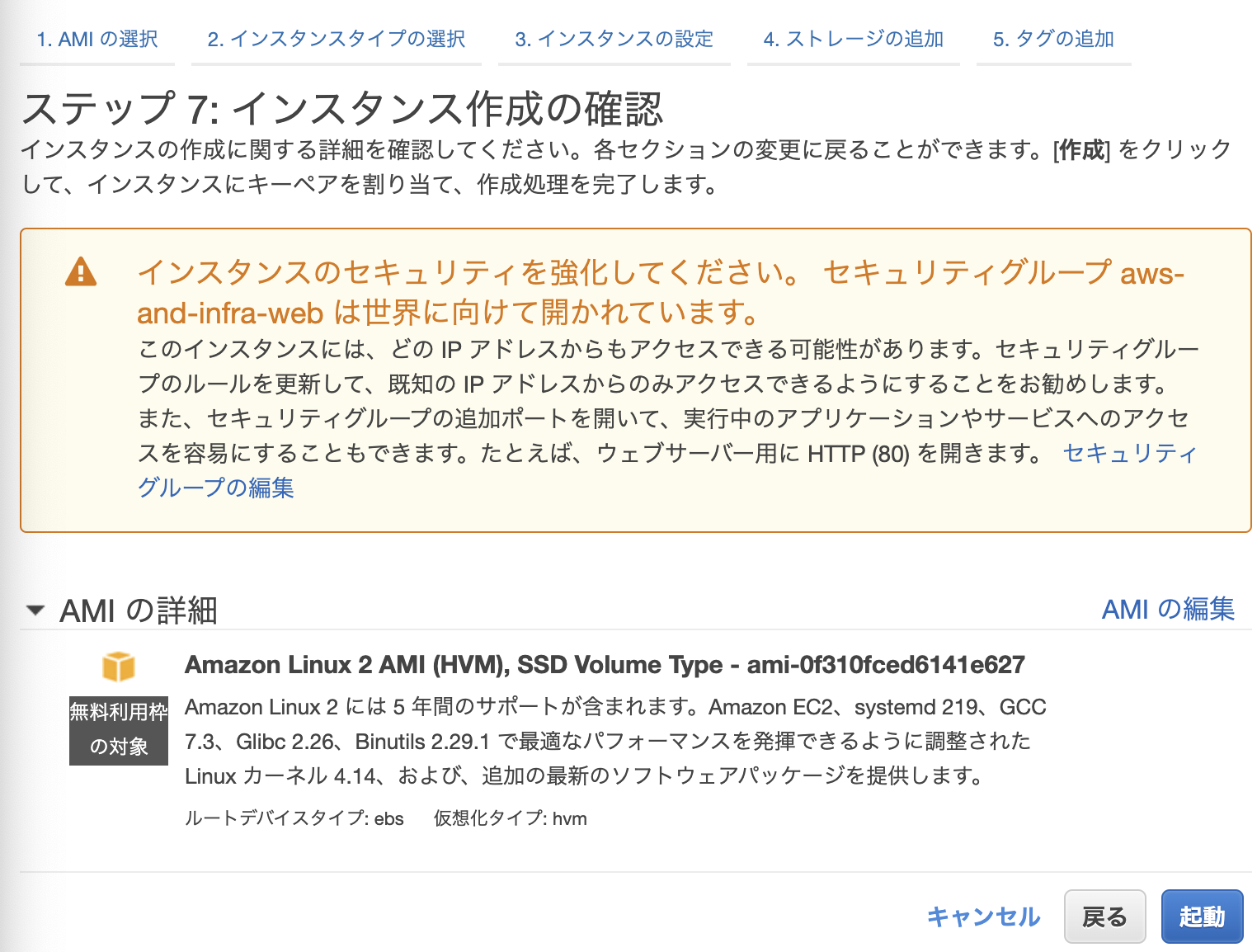
起動を押すと、キー作成の画面が出るので、キーを新規作成する。SSHの作業になるのだが、そこは次回に回す。
次回は、
サーバー構築の作業手順
1.EC2インスタンスを設置する
2.Apacheをインストールする
- SSHでサーバーにログイン
- Apacheをインストール
3.ファイアウォールを設定する

- 投稿日:2020-05-25T22:23:31+09:00
ECS Cluster Auto Scalingについて調べたこと
使うと何が嬉しいのか
- 今まではECSのタスクとEC2のコンテナインスタンスを別々に管理しないといけなかった
- ECS Cluster Auto Scaling(CAS)を設定すると、ECSでタスクに合わせてASGをスケールイン/アウトしてくれる
- ASGを使うことが前提
デモ環境構築メモ
参考: https://dev.classmethod.jp/articles/aws-ecs-cluster-auto-scaling/
- ECSで空のクラスタを作成
- ASGを作成
- 起動テンプレートも必要に応じて
- 「スケールインからのインスタンス保護」を有効にすること
- ECSクラスターでキャパシティプロバイダを作成する
- 設定項目について
マネージドスケーリング: 有効になっているとECSがASGのスケールを行ってくれるターゲットキャパシティー(%): ASG内のインスタンスをどのくらい使うか。(20%くらいは空けておきたいという人は80を記入)マネージドターミネーション保護: インスタンスがスケールインするときにタスクが終了するのを防いでくれる。→タスクが終了するまでインスタンスは終了せずに待っていてくれる
- ASGの設定で「スケールインからのインスタンス保護」が有効になっていること
- クラスター更新でデフォルトのキャパシティープロバイダー戦略にて↑で作ったキャパシティプロバイダを設定する
- サービスを作ってタスクを起動させる
- 「キャパシティープロバイダー戦略」欄が表示される
ベース: 指定されたキャパシティープロバイダーで実行するタスクの最小限の数を指定できる。(指定できるのは複数あったら1つのみ)ウェイト: 起動済みタスクの総数に対する、それぞれのキャパシティプロバイダで起動するタスク数の相対的な割合を指定できる動かしてみたメモ
- インスタンス0の状態でタスクがrunningになるまでの時間
- 何回かやったけど、早い時で1分半、遅い時で10分以上とまちまちだった
- ASGのキャパシティを直接変更した時の挙動
- キャパシティプロバイダの方に設定が反映された。が、しばらくするとまた別の数字に上書きされた
- → ECSのマネージドスケーリングによって値が上書きされたもの。この値がどのように決められているのかは後述
- タスクを0にしてもなぜか2か3台くらい稼働し続けた
- → キャパシティプロバイダのターゲットキャパシティの設定を80%にしていたので、タスクがないのに2,3台稼働し続けていた分は20%に当たる余剰分だったと思われる。
- 同じ理由でASGの「希望するキャパシティ」を0にしても、しばらくすると2,3台に上書かれてインスタンスが起動してくる。ただしASGの「インスタンスの最大値」以上の数にはならないので、ここを0にするとインスタンスは0になる
疑問
?CASがどのようにインスタンスのキャパシティを決めているのか
本家のブログに記事があった
Amazon ECS クラスターの Auto Scaling を深く探る
長いのと難しいのとであまり理解できなかった。
とりあえず読み取れたこととしては、
- タスク配置の最適値を求めるアルゴリズムの開発は難しい
- ECSの配置戦略や配置制約、ASGのインスタンスの設定、タスク定義で指定しているcpuやmemoryなど変数が多いため
- 理想の状態は「全てのインスタンスがタスクを1つ以上実行している」としている
- この状態にあるとインスタンスはスケールをする必要がないと判断する
- CAS は追加すべきインスタンス数の最適値の下限を見積る
- 流れとしては、
- すべてのプロビジョニングタスクを、リソース要件が正確に等しくなるようにグループ化する
- ASG に最も新しく追加されたインスタンスのインスタンスタイプと属性を取得
- 配置戦略と制約を踏まえて、グループ化したタスクを配置するのに必要なインスタンス数を求める
- 上記を全てのグループに対して計算し、その最大値を必要なインスタンス数と定義し、スケールする
インスタンス数を決める主な変数としては、「希望されているインスタンス数(稼働中のもの+これから稼働される予定のもの)」と「現在稼働しているインスタンス数」があり、スケールしてインスタンス数が変動することで計算され直しているそう。なので1度のスケールで適切な値にならないこともある。何回か繰り返しスケールされるけど、必ずしも無駄なこととも限らないよ...とのこと
タスクの配置の完全な最適化は難しい。
(インスタンスサイズとか固定にすればある程度はいけるかもだけど、スポットインスタンスを使う場合はいろんなサイズのを混ぜて使うことになるのでやっぱり難しいと思う)
タスクが乗らないことはないけど、「詰めればもっと乗るはずなのにな?」ということはあるかもしれない。その他のブログメモ
- CWのメトリクス
CapacityProviderReservationでスケーリングポリシーの指標となる数字が見れる
CapacityProviderReservation = CASが必要であると判断したインスタンス数 / 稼働中のインスタンス数 * 100- 100だとちょうどよくて、100以上だとインスタンスが余っているのでスケールインされる、100より少なければ足りていないので増える方向に働く
- 以前はタスクが起動するときは利用可能なキャパシティに基づいて実行されるか否だったが、CASを導入すると、利用可能なキャパシティの有無に限らずプロビジョニング状態に入る → 空きリソースを探す → あれば起動、見つからなければ失敗 のようになる
- 最大100までプロビジョニング状態にできる
- プロビジョニング状態のタスクは15minでタイムアウトする
?キャパシティプロバイダの設定変更はできないのか
現段階では新しいものを作り直すしかないみたい。
ASGとキャパシティプロバイダは1:1なので、ASGも合わせて作り直す必要がある。
既存のとは別に新しいリソースを作成し、クラスタやサービスで設定している箇所を変更し、古い方を無効にする。ちなみにコンソールからだとキャパシティプロバイダの設定内容をすべて見ることができず不便さを感じた。(
describe-capacity-providersコマンドを使うことになる)無効にするときはコンソールからだと対象を選択して無効ボタンを押すのだが、確認画面も出ずあっさり消えるので間違えないように注意する必要がありそう。
※あとで調べてわかったことだが、無効にされただけで削除されるわけではないらしい。describeコマンドからは存在が確認できる。名前やASGの設定が被って作れなくなるといったこともあるらしいので注意参考: Auto Scaling Capacity Providerの再作成時にASGが既に使用されているというエラーが発生した時のメモ
作り直しをするときは注意が要りそう
追加で検証したいこと
- サービス稼働時にプロバイダーを変更したらタスクに影響はあるか、あるとしたら影響が出ないように設定を更新する方法
- 投稿日:2020-05-25T21:50:43+09:00
AWS Elemental MediaPackage とは
- 投稿日:2020-05-25T21:36:55+09:00
AWS Elemental MediaLive とは
AWS Elemental MediaLive とは
AWS Elemental MediaLive はリアルタイムの動画サービスで、ブロードキャストおよびストリーミング配信用のライブ出力を簡単に作成できます。
AWS Elemental MediaLive の詳細
AWS Elemental MediaLive では、MediaLive を含むライブストリーミングワークフローには 3 つのシステムが含まれています。
- ソースコンテンツの取り込みと変換を行う MediaLive チャネル。
- MediaLive にソースコンテンツ (動画) を提供する 1 つ以上のアップストリームシステム。
- MediaLive が生成する出力の送信先となる 1 つ以上のダウンストリームシステム。
コンテンツの処理を開始するには、チャネルを開始します。チャネルが実行中の場合、入力によって識別されたアップストリームシステムからソースコンテンツを取り込みます。次に、チャネルはその動画 (および関連するオーディオ、字幕、メタデータ) を変換し、出力を作成します。MediaLive は、指定されたダウンストリームシステムに出力を送信します。
AWS Elemental MediaLive 用語
- CDN
- コンテンツ配信ネットワーク (CDN) は、オリジンサーバーまたはパッケージャのダウンストリームにあるサーバーのネットワークです。CDN は、コンテンツをオリジンサーバーから数十または数百のネットワークサーバーに配信し、視聴ユーザーにコンテンツを提供します。この分散ネットワークにより、コンテンツを数千人または数百万人の視聴ユーザーに同時に配信できます。
- チャネル
- MediaLive チャネルは、そのチャネルにアタッチされた入力からソースコンテンツを取り込み、変換 (デコードおよびエンコード) し、新しいコンテンツを出力にパッケージ化します。
- チャネルクラス
- 各チャネルは、次のいずれかのクラスに属します。
- 標準クラス – 2 つの処理パイプラインがあるチャネル
- 単一パイプラインクラス – 1 つの処理パイプラインがあるチャネル
- チャネル設定
- MediaLive チャネル設定には、チャネルがコンテンツを取り込み、変換して出力にパッケージ化する方法についての情報が含まれています。
- ダウンストリームシステム
- ダウンストリームシステムは、ワークフローの MediaLive の後に配置される 1 つ以上のサーバーのセットです。ダウンストリームシステムは、MediaLive から出力されるコンテンツを処理します。
- エンコード
- エンコードは、出力内に存在します。エンコードには、動画、オーディオ、字幕の 3 種類があります。各エンコードには、変換プロセスで作成される 1 つの動画ストリーム、1 つのオーディオストリーム、または 1 つの字幕トラックの指示が含まれています。エンコードによってその特徴は異なります。たとえば、入力から生成される動画エンコードは高解像度のものもあれば、低解像度のものもあります。
- Input
- MediaLive 入力は、アップストリームシステムと MediaLive チャネルの接続方法について記述された情報を保持します。入力は、MediaLive のエンドポイント (IP アドレス) (アップストリームシステムが MediaLive にプッシュするプッシュ入力の場合)、またはアップストリームシステムのソース IP アドレス (MediaLive がアップストリームシステムからプルするプル入力の場合) を識別します。MediaLive には、ソースコンテンツの形式とプロトコルごとに異なる入力タイプがあります。たとえば、HLS 入力と RTMP プッシュ入力です。
- 入力セキュリティグループ
- MediaLive 入力セキュリティグループは、許可リストを定義する 1 つ以上の IP アドレスの範囲のセットです。入力に対してコンテンツのプッシュが許可されている IP アドレスの範囲を識別するために、1 つ以上の入力セキュリティグループをプッシュ入力に関連付けます。
- 出力
- 出力は、出力グループ内に存在します。これは、1 つのセットとして処理するエンコードのコレクションです。
- オリジンサービス
- オリジンサービスは、ワークフローの MediaLive の後に配置されるダウンストリームシステムの一部である場合があります。MediaLive からの動画出力を受け入れます。
- 出力グループ
- 出力グループは、MediaLive チャネル内の出力のコレクションです。
- パッケージャ
- パッケージャは、ダウンストリームシステムの一部である場合があります。MediaLive からの動画出力を受け取り、再パッケージ化します。AWS Elemental MediaPackage はパッケージャです。
- パイプライン
- MediaLive には、MediaLive 入力と MediaLive チャネル内で処理を実行する 1 つまたは 2 つの独立したパイプラインがあります。
- 再生デバイス
- 再生デバイスは、ダウンストリームシステムの最終コンポーネントです。これは、視聴者であるユーザーが動画を表示するために使用するデバイスです。
- スケジュール
- 各 MediaLive チャネルには、関連付けられたスケジュールがあります。スケジュールには、特定の時間にチャネルで実行するアクションのリストが含まれます。
- ソースコンテンツ
- MediaLive が変換する動画コンテンツ。コンテンツは通常、動画、オーディオ、字幕、メタデータで構成されています。
- アップストリームシステム
- ワークフローの MediaLive の前にあり、ソースコンテンツを保持するシステム。アップストリームシステムの例としては、インターネットに直接接続されているストリーミングカメラまたはアプライアンス、またはスポーツイベントでスタジアムに配置されるコントリビューションエンコーダーが挙げられます。

- 投稿日:2020-05-25T21:35:48+09:00
CodePipelineを使ってLambdaに自動デプロイ
概要
Lambdaの関数が増えてくると修正のたびにコンソールで修正したり、ローカルのPCで修正したソースをzipに固めてコンソールでアップする作業って結構大変ですよね!!
ってことでCodePipelineを使ってgitにpush(merge)されたタイミングでLmabdaにデプロイしたときの話を書いていきます。処理の流れ
- Lambdaに関数を登録(Hello World)
- GithubにLambda用のコードをpush
- CodePipelineのSourceでソースの取得
- CodePipelineのBuildでテストの実行など(今回はテストの実行はしない)
- CodePipelineのDeployでLambdaにデプロイ
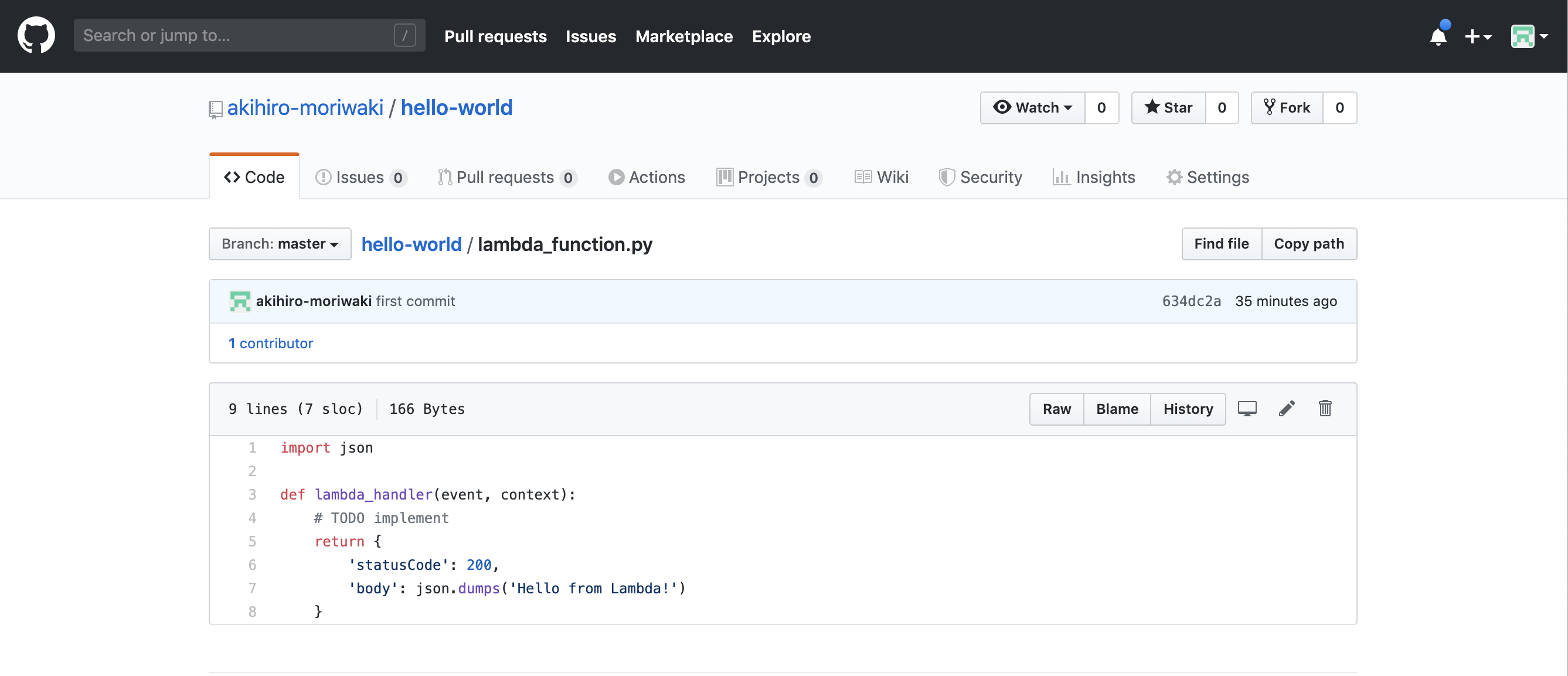
Lambdaに関数を登録
LambdaにHello Worldの関数を登録
関数の作成ボタンから関数の作成
今回はpython3.8
こんな感じ
Githubにリポジトリを作成とソースのpush
Githubに適当なリポジトリを作成しHello Worldを登録
先ほど作ったLambdaのコードをどうにかしてGitに登録
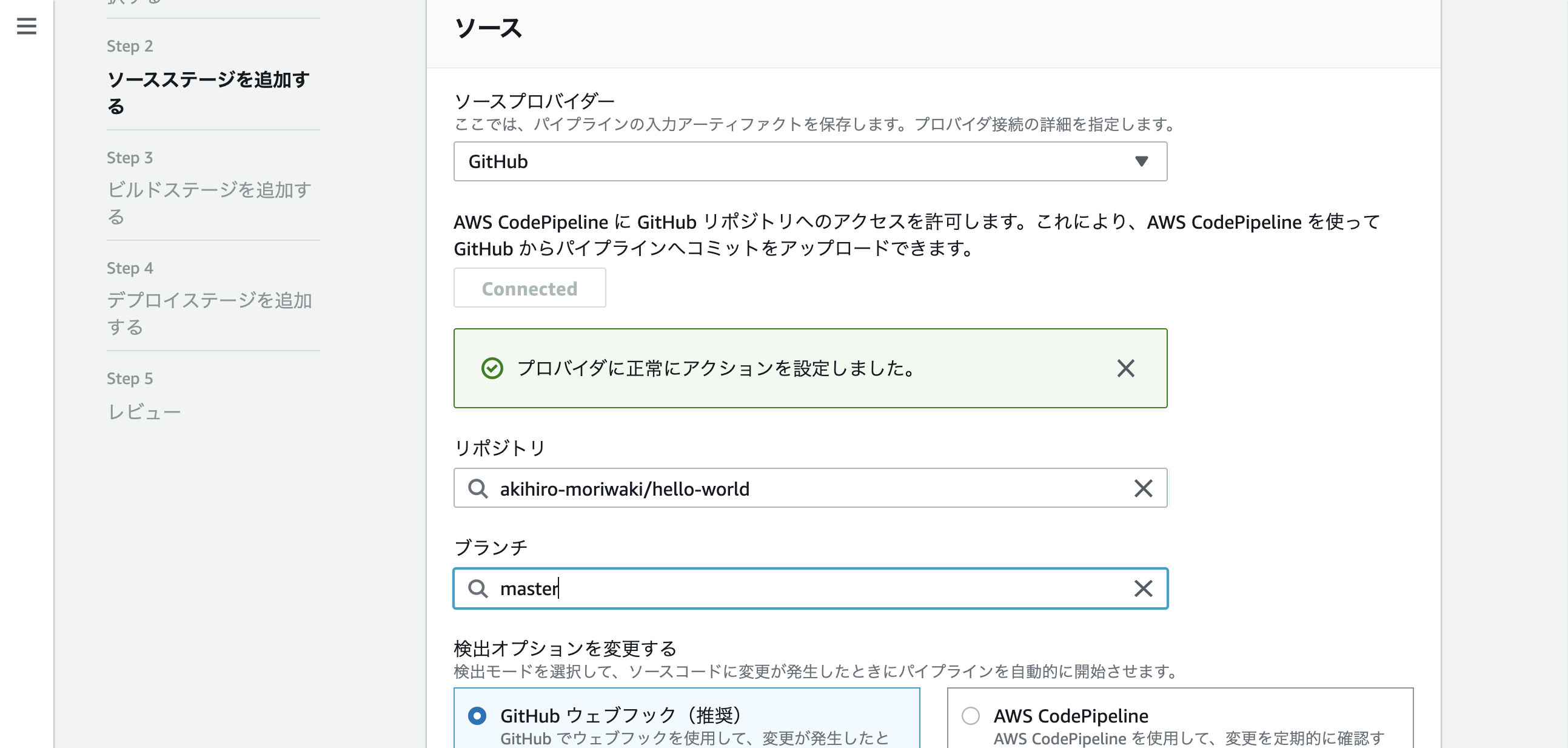
CodePipelineのSourceでソースの取得
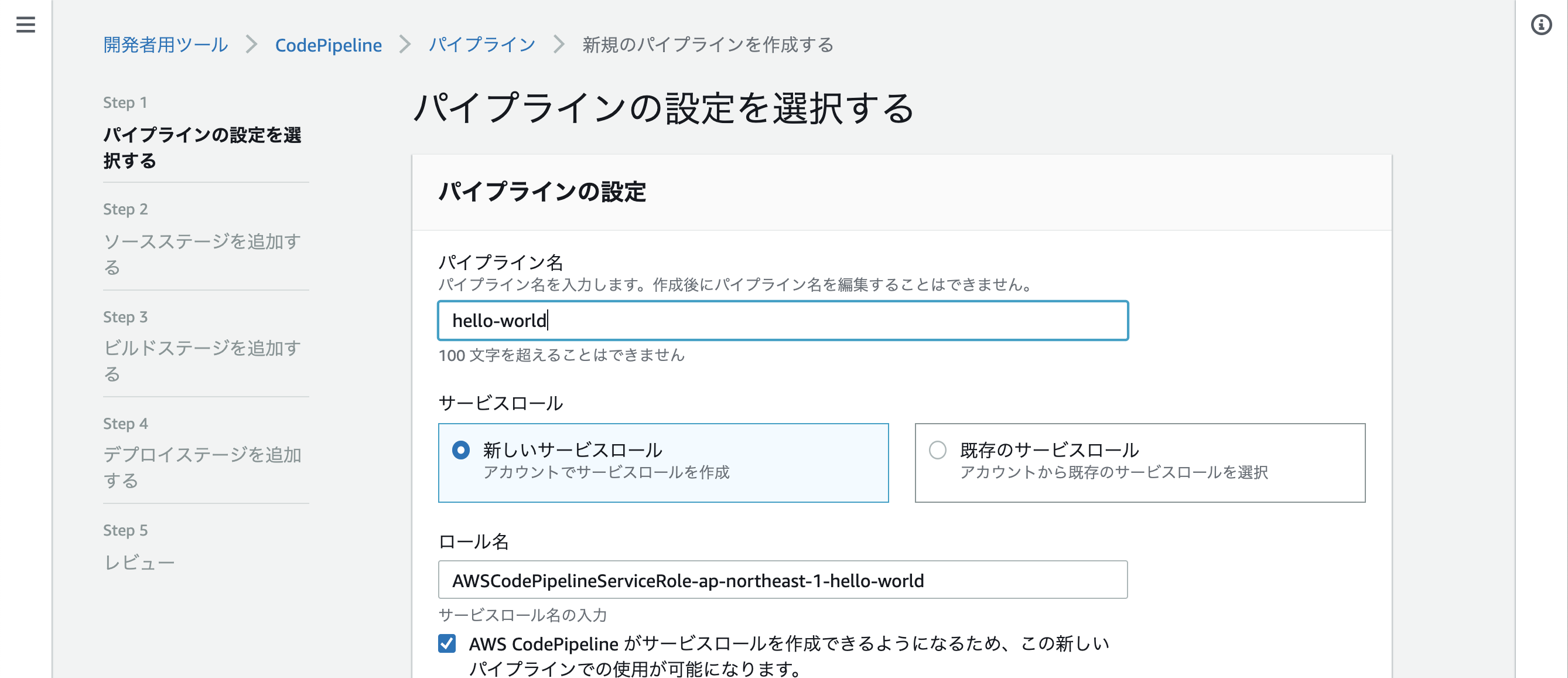
CodePipelineでパイプラインを作成する
パイプライン名を入力しあとはデフォルト
次にソースの追加
Githubを選んで接続後、リポジトリとブランチを選択
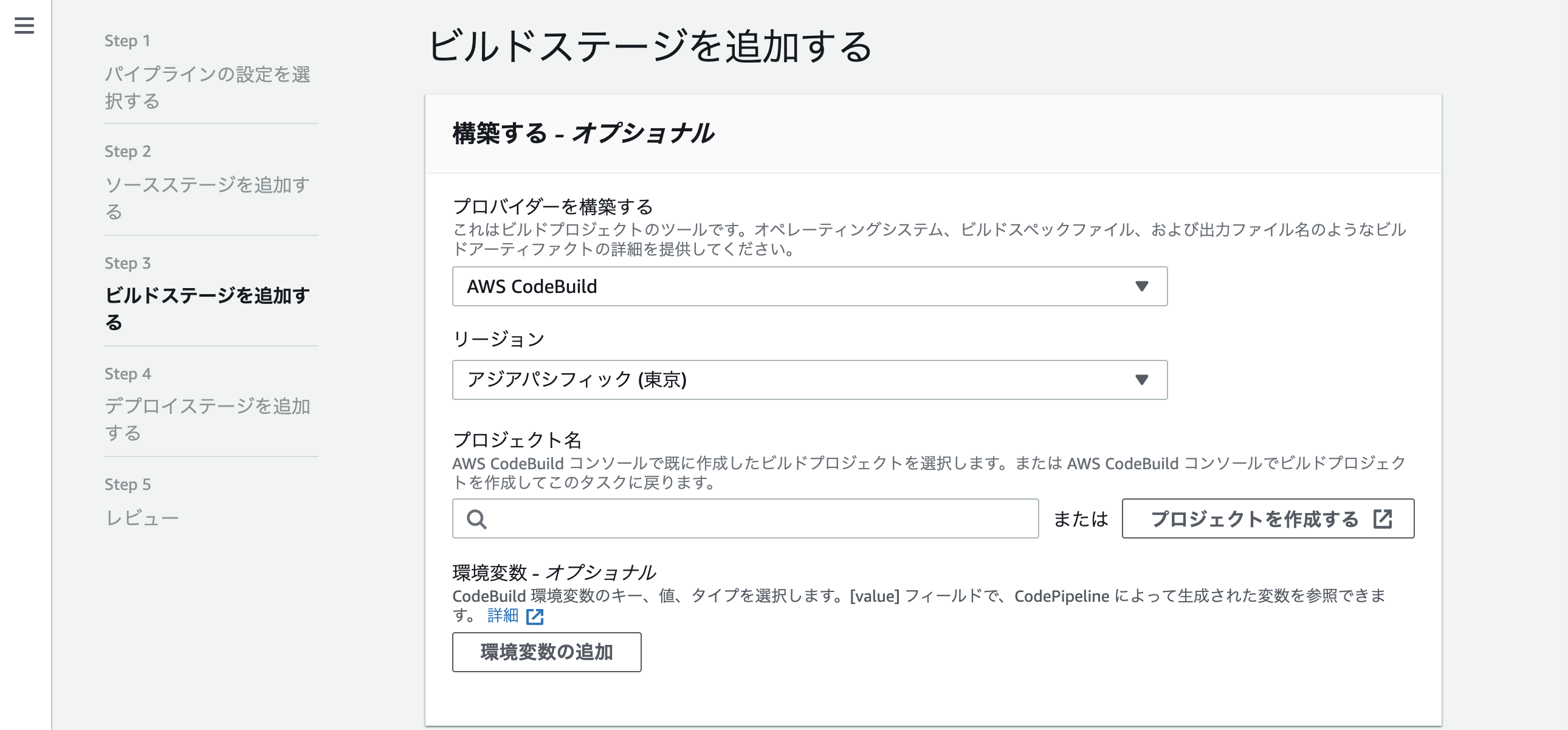
次はビルド
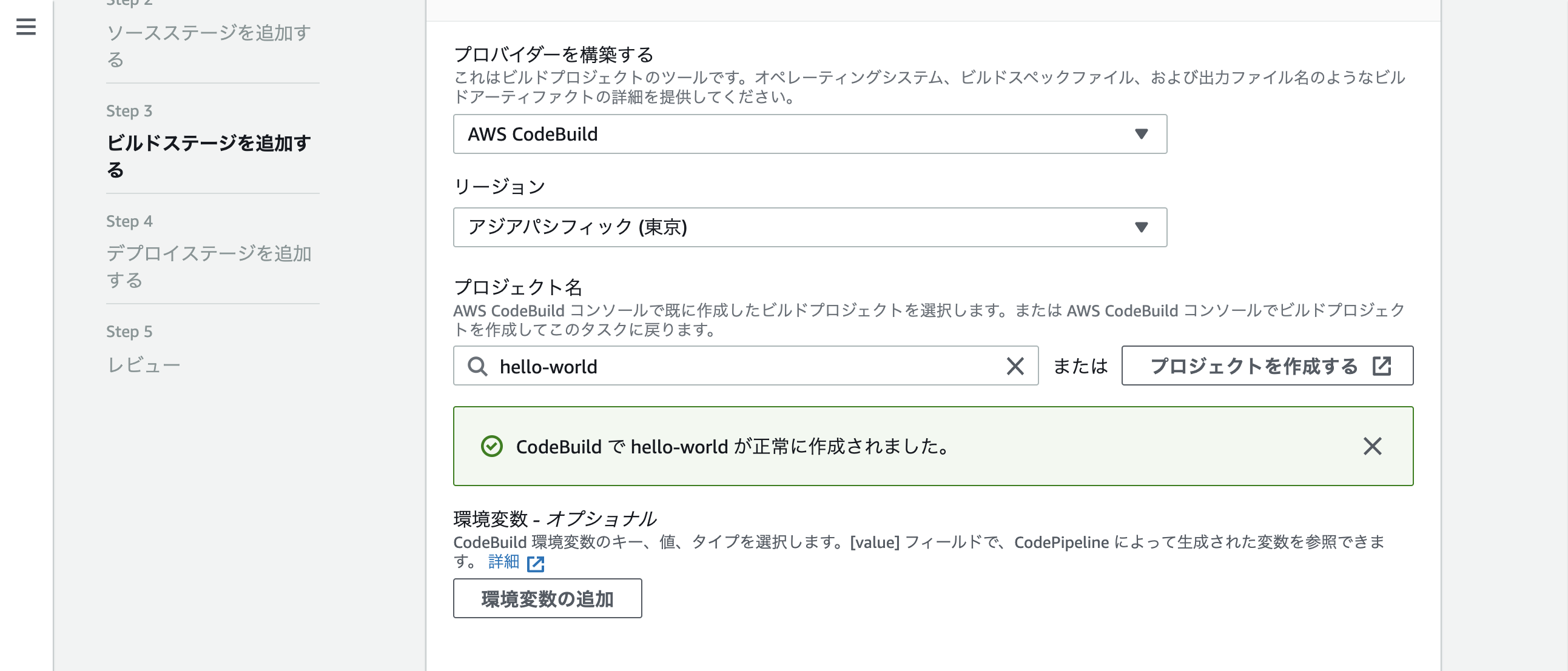
CodeBuildを選択、ビルド用のプロジェクトを作ってないので「プロジェクトの作成」をクリック
ポップアップが開くので、色々入力
完了すると、プロジェクト名のところに勝手に入力される
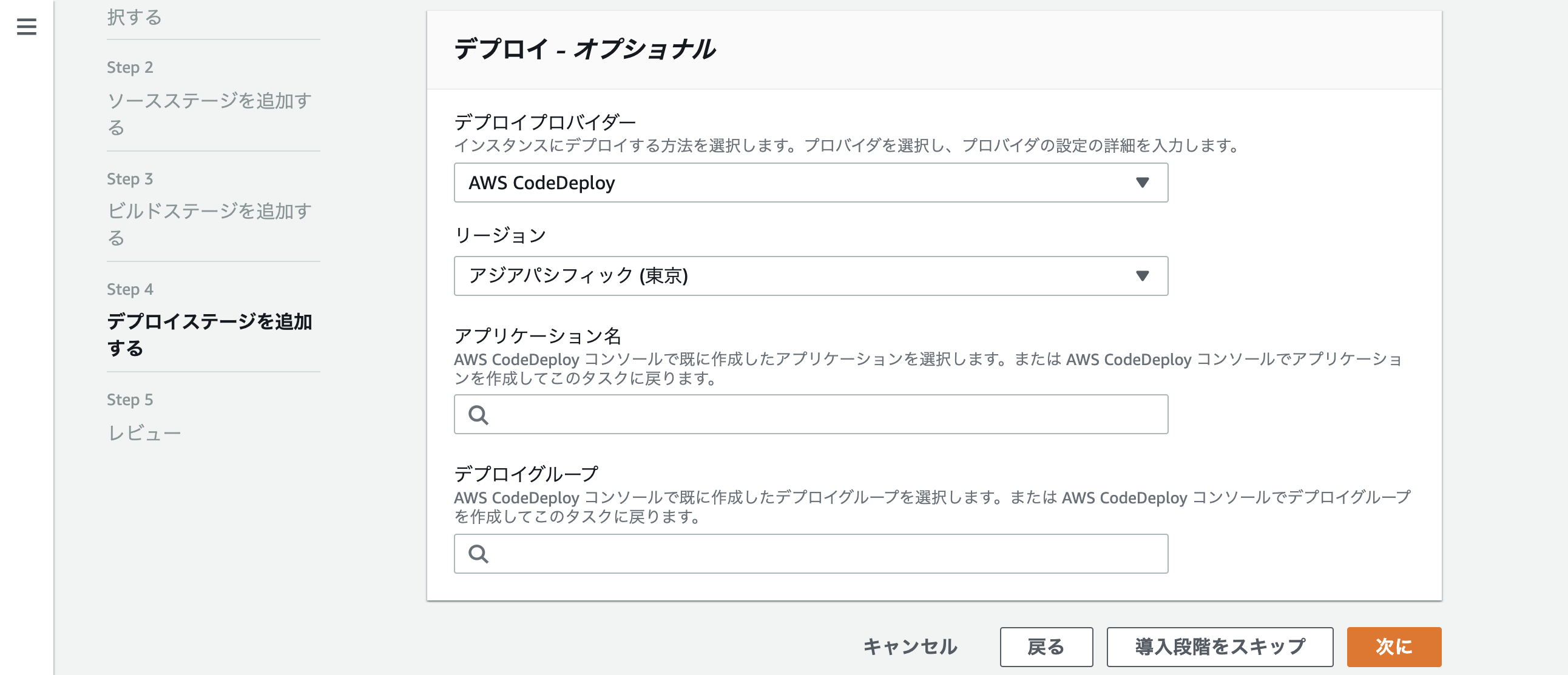
最後デプロイですが、アプリケーションを作ってないので、一旦スキップする
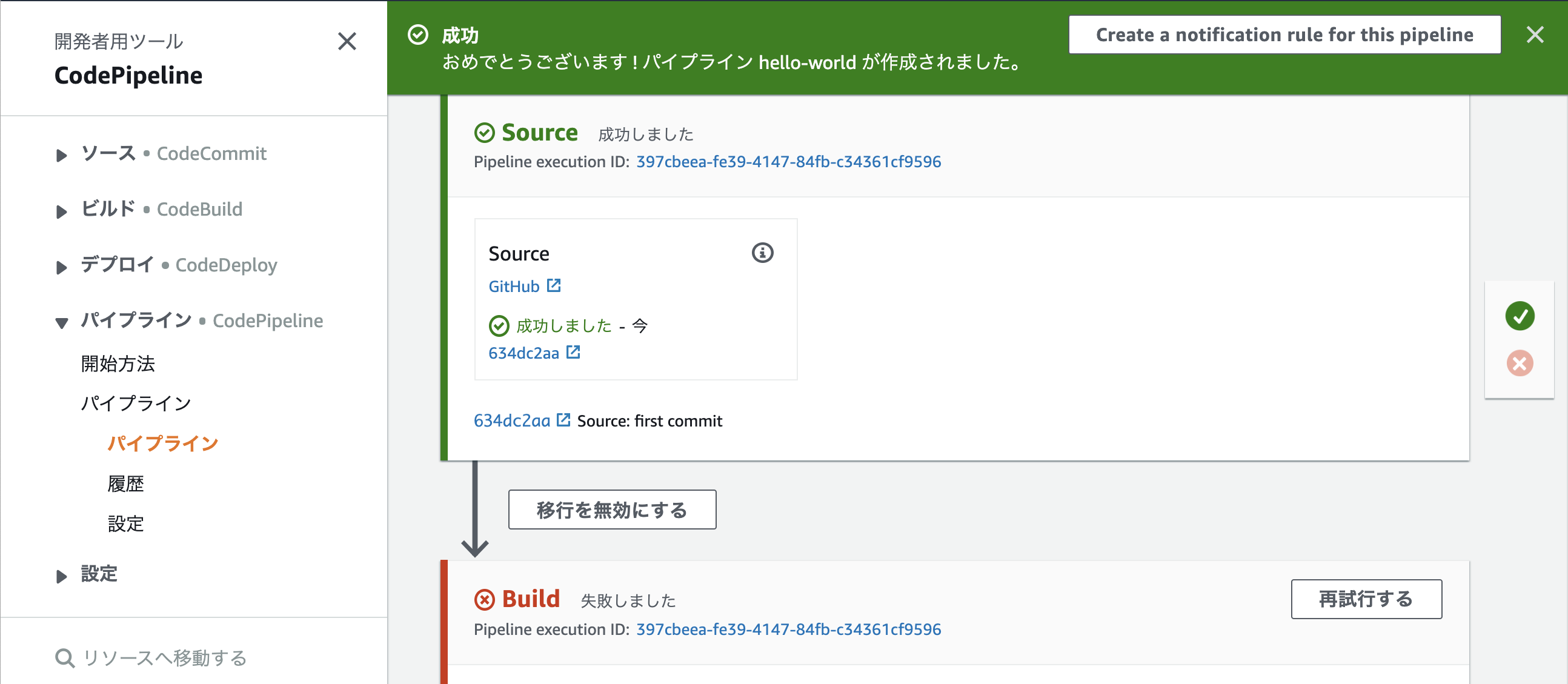
パイプラインが実行される
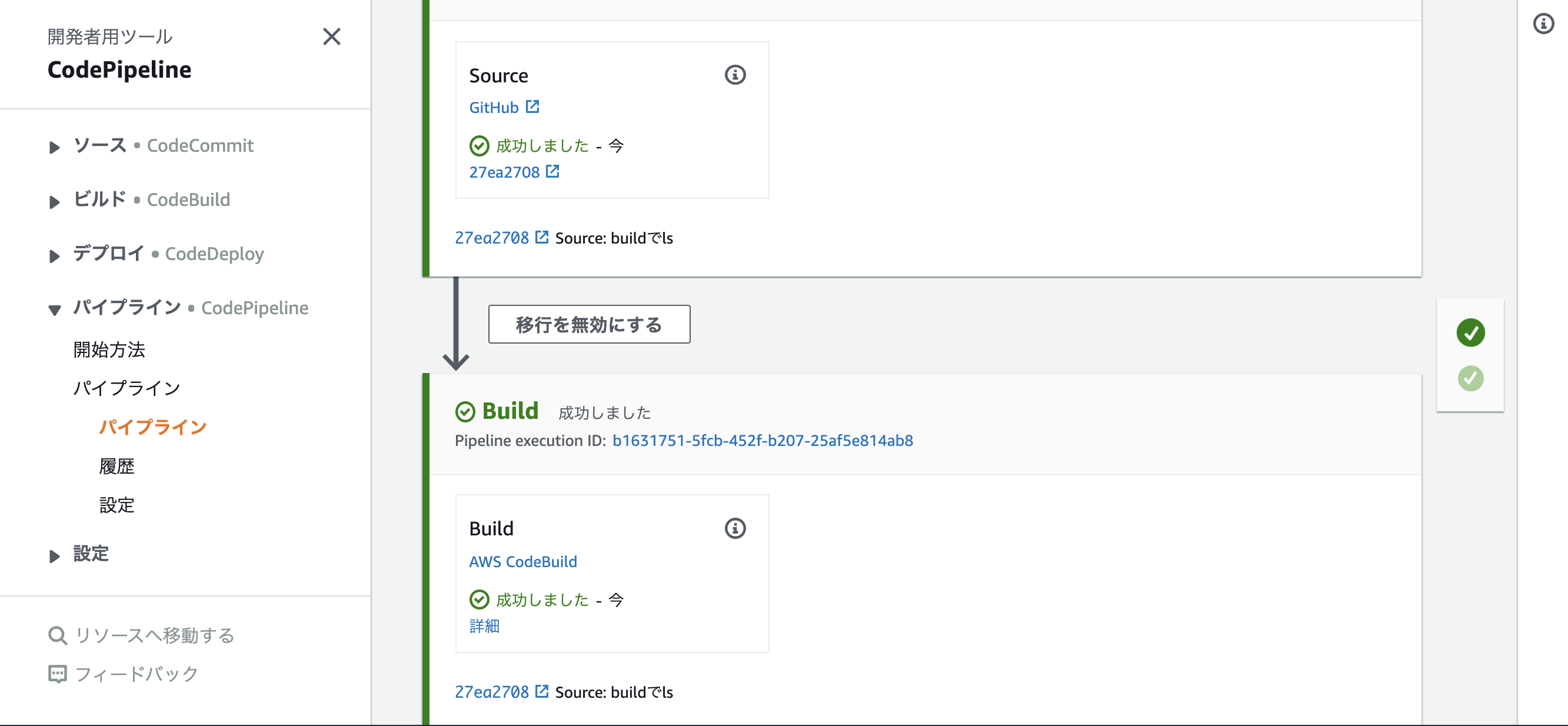
Gitにbuildspec.ymlをあげてないので、Buildは失敗する、改めてbuildspec.ymlを作ってGitにpushするbuildspec.ymlversion: 0.2 phases: build: commands: - ls artifacts: files: - "**/*"ビルドも成功しました。コードテストも実行したいが今回は割愛
CodePipelineのDeployでLambdaにデプロイ
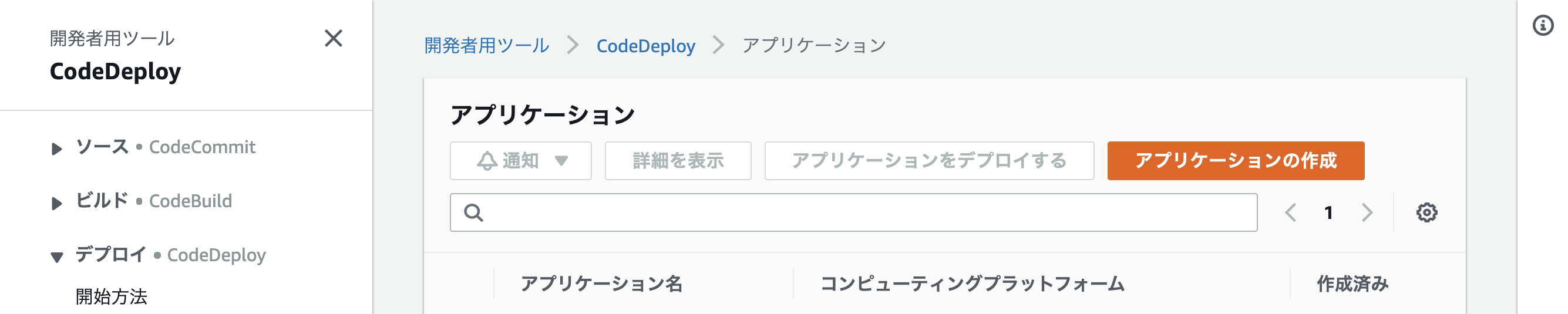
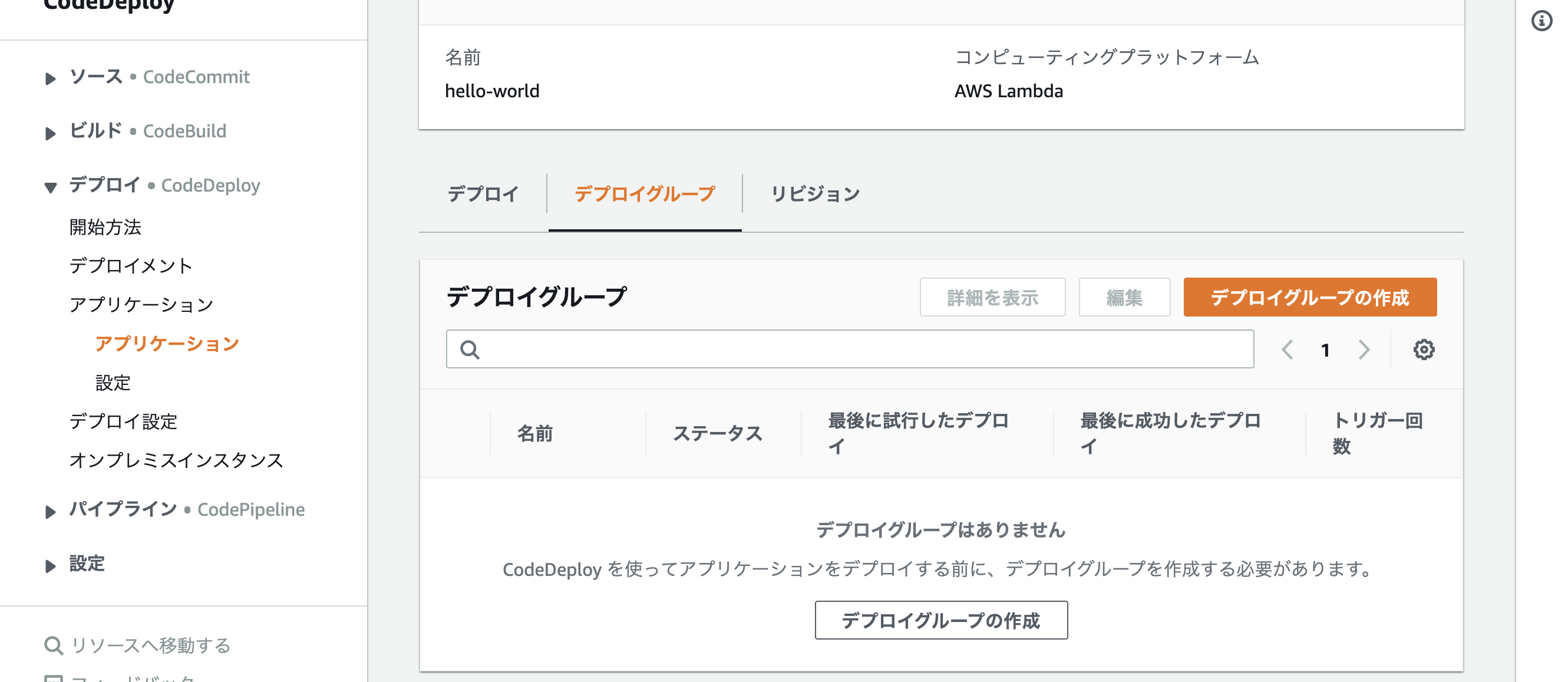
CodeDeployでアプリケーションを設定する
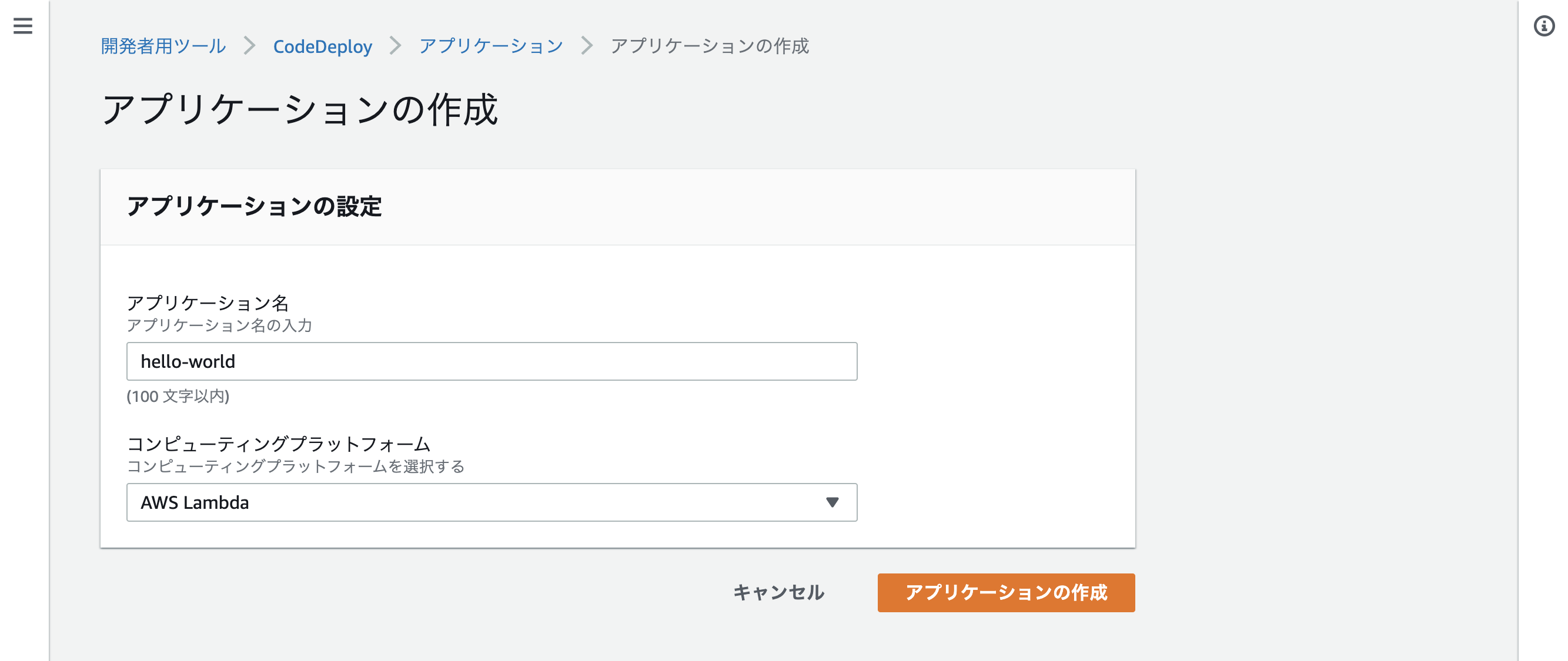
アプリケーションの作成をクリック
コンピューティングプラットフォームを「Lambda」にする
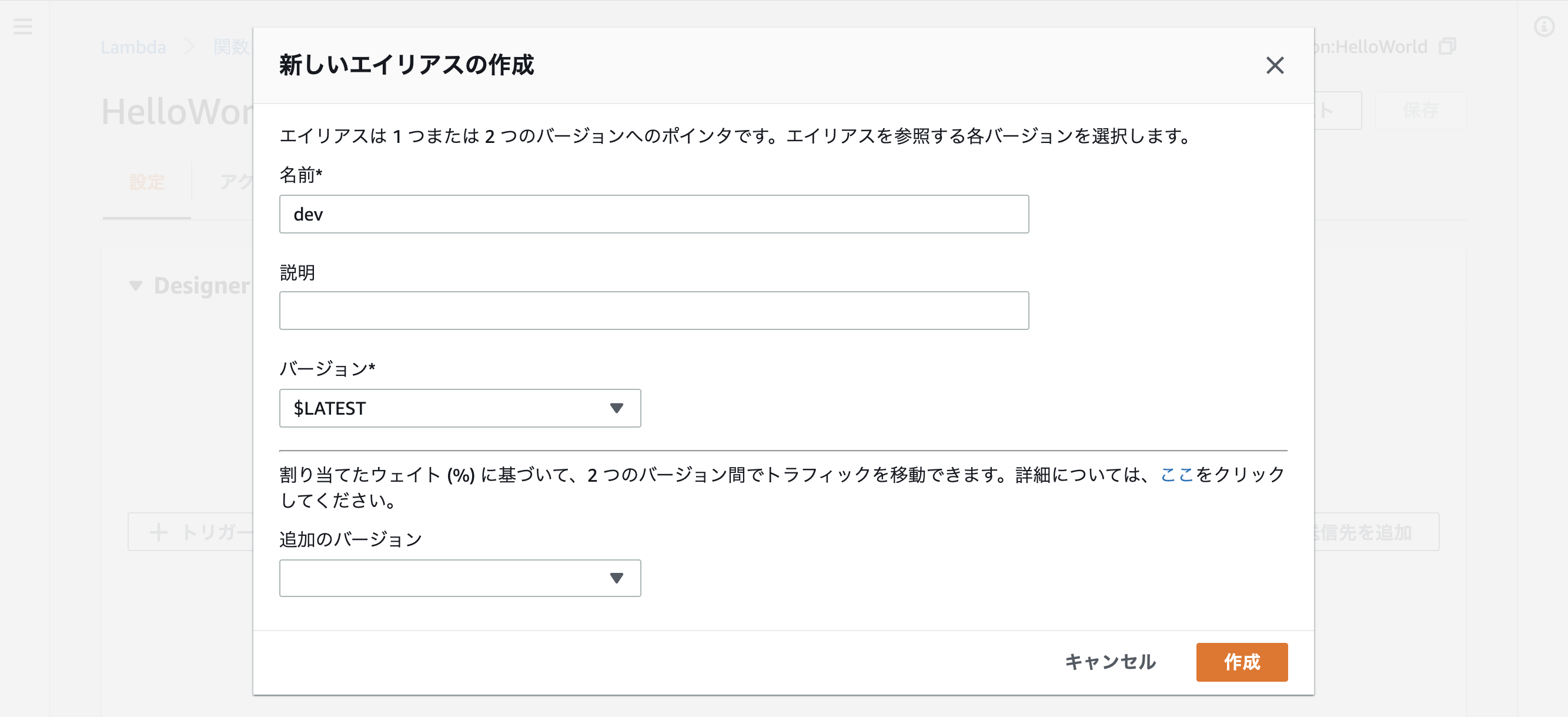
先ほど作ったアプリケーションでデプロイグループを作成する今回は「dev」としています
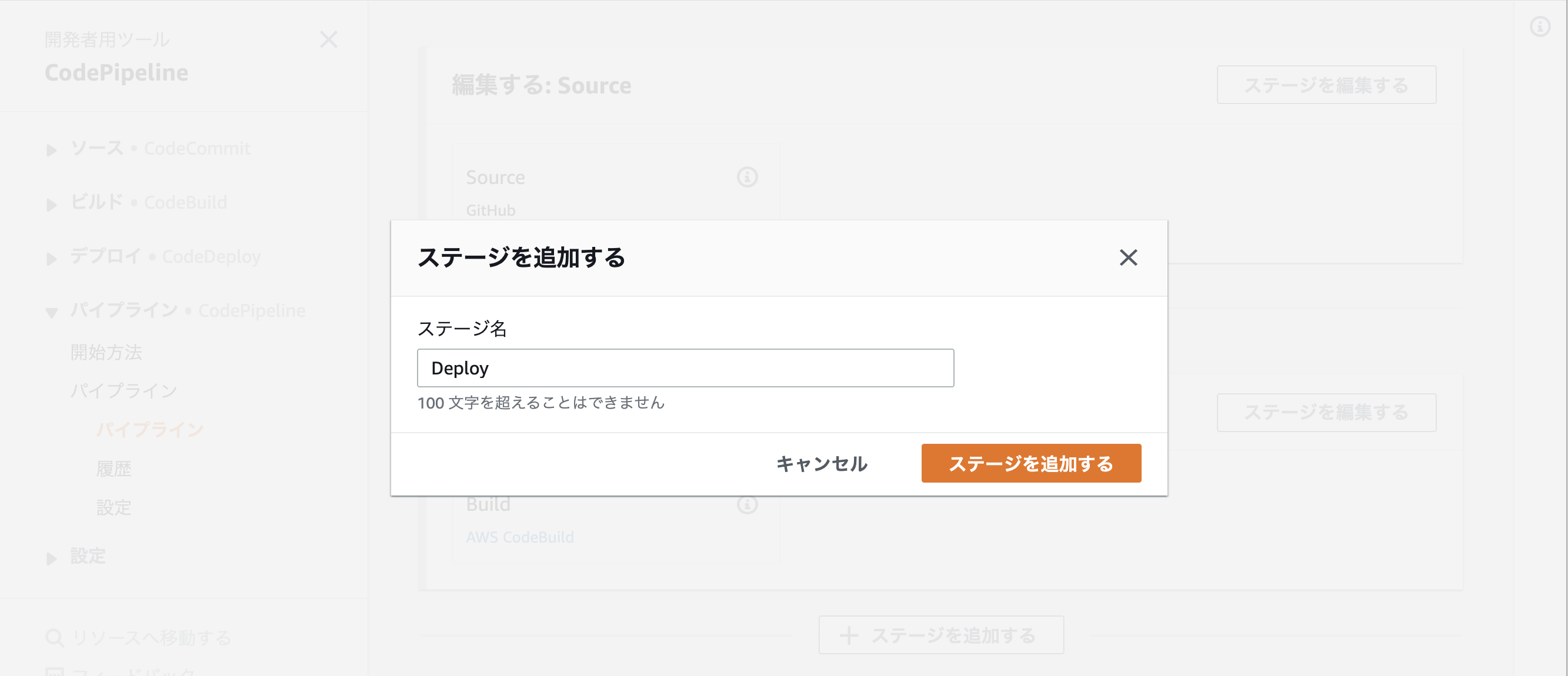
今後はパイプラインに戻ってステージを追加する
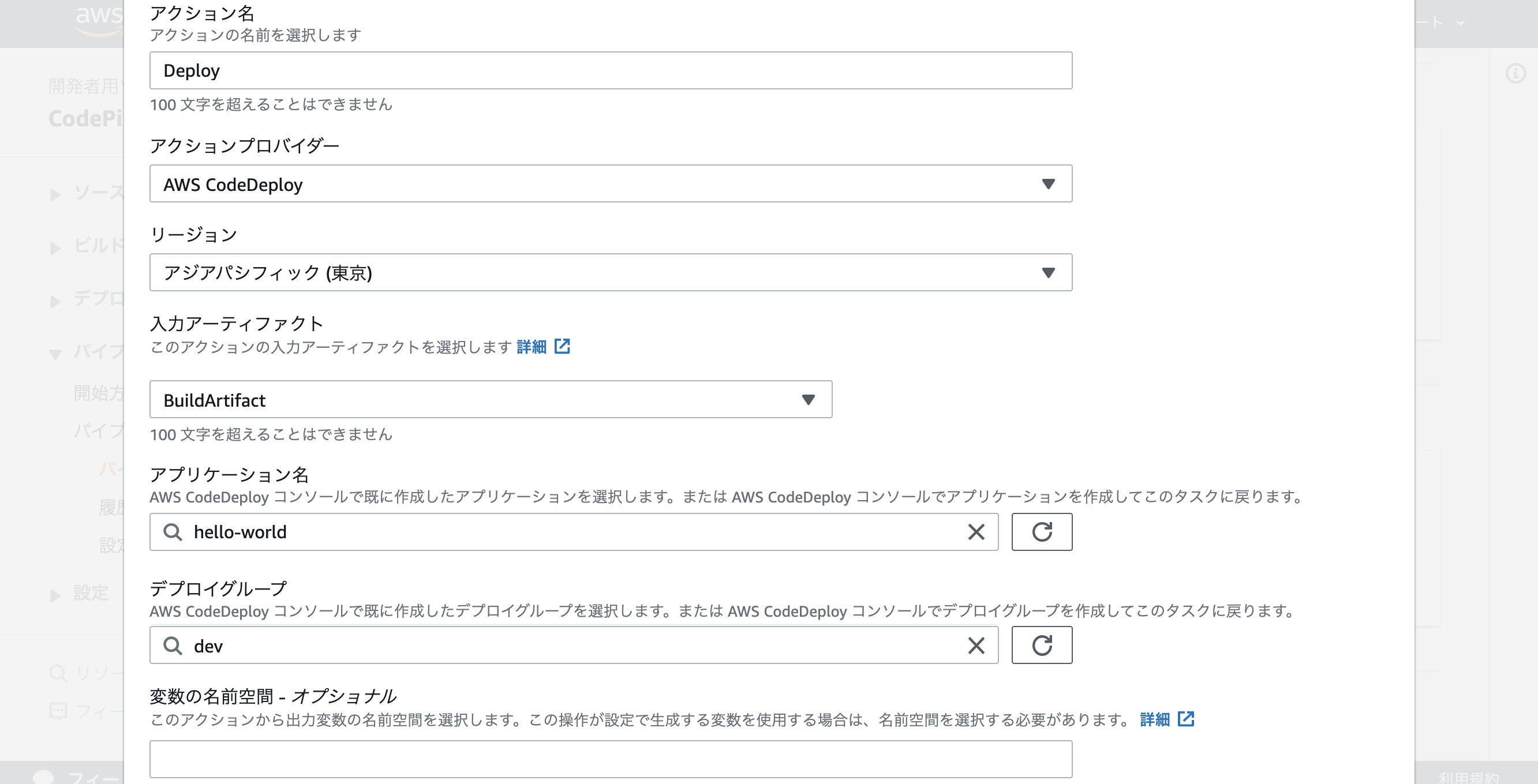
デプロイ用のアクションお追加を行う、アプリケーション名とデプロイグループのところはCodeDeployで作った物を選択する
appspec.ymlを追加する、ビルド時に動的に生成するため{{xxxx}}のように記載します
appspec.ymlversion: 0.0 Resources: - HelloWorld: Type: AWS::Lambda::Function Properties: Name: "HelloWorld" Alias: "dev" CurrentVersion: "{{CurrentVersion}}" TargetVersion: "{{TargetVersion}}"buildspec.ymlの変更を行う
buildspec.ymlversion: 0.2 phases: build: commands: - CurrentVersion=$(echo $(aws lambda get-alias --function-name HelloWorld --name dev | grep FunctionVersion | tail -1 |tr -cd "[0-9]")) post_build: commands: - ls - aws lambda publish-version --function-name HelloWorld - TargetVersion=$(echo $(aws lambda list-versions-by-function --function-name HelloWorld | grep Version | tail -1 | tr -cd "[0-9]")) - echo $CurrentVersion - echo $TargetVersion - sed -i -e "s/{{CurrentVersion}}/$CurrentVersion/g" appspec.yml - sed -i -e "s/{{TargetVersion}}/$TargetVersion/g" appspec.yml artifacts: files: - "**/*"buildspec.yml内でaws lambdaコマンドを実行するので、CodeBuildで使うロールにポリシーを追加する
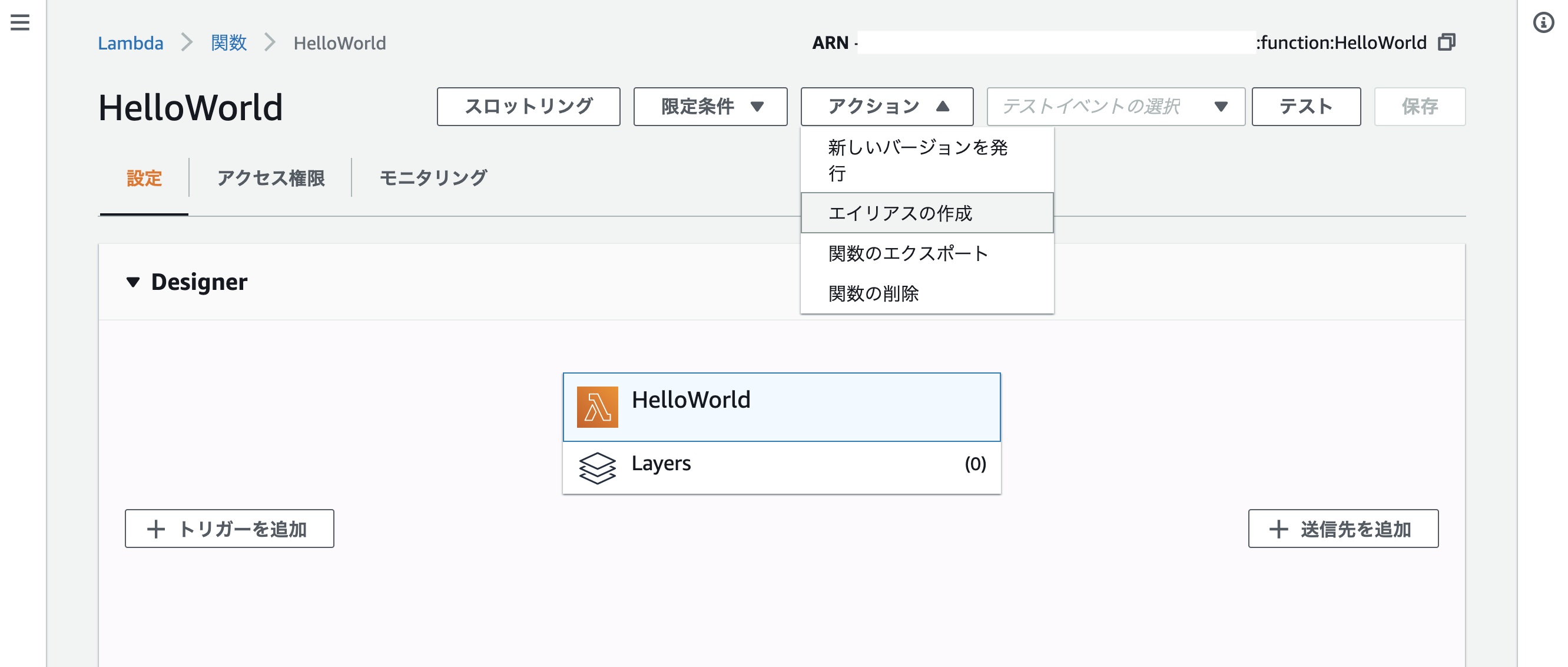
iam"lambda:PublishVersion" "lambda:GetAlias"Lambdaのaliasを作る
変更をリリースするをクリックしてパイプラインを実行する
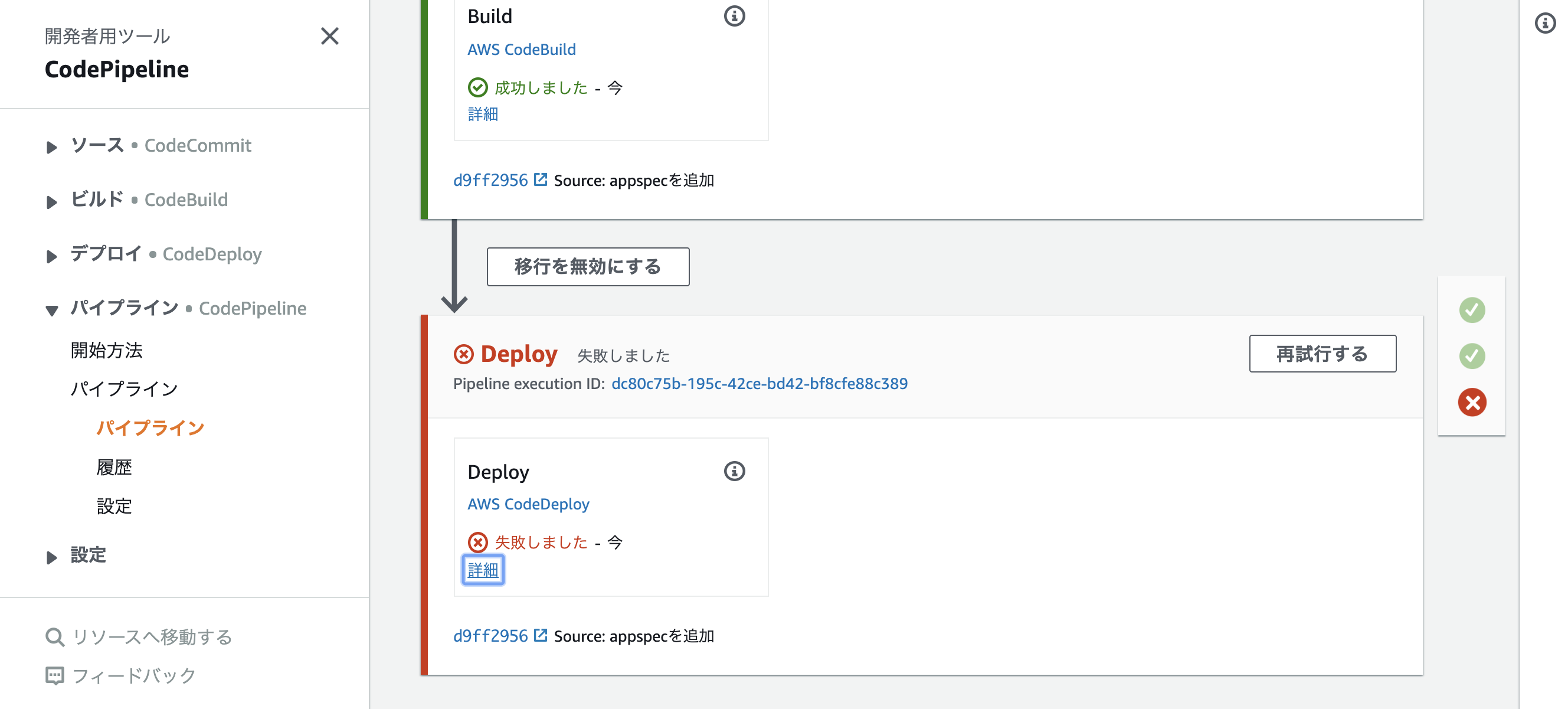
実行結果
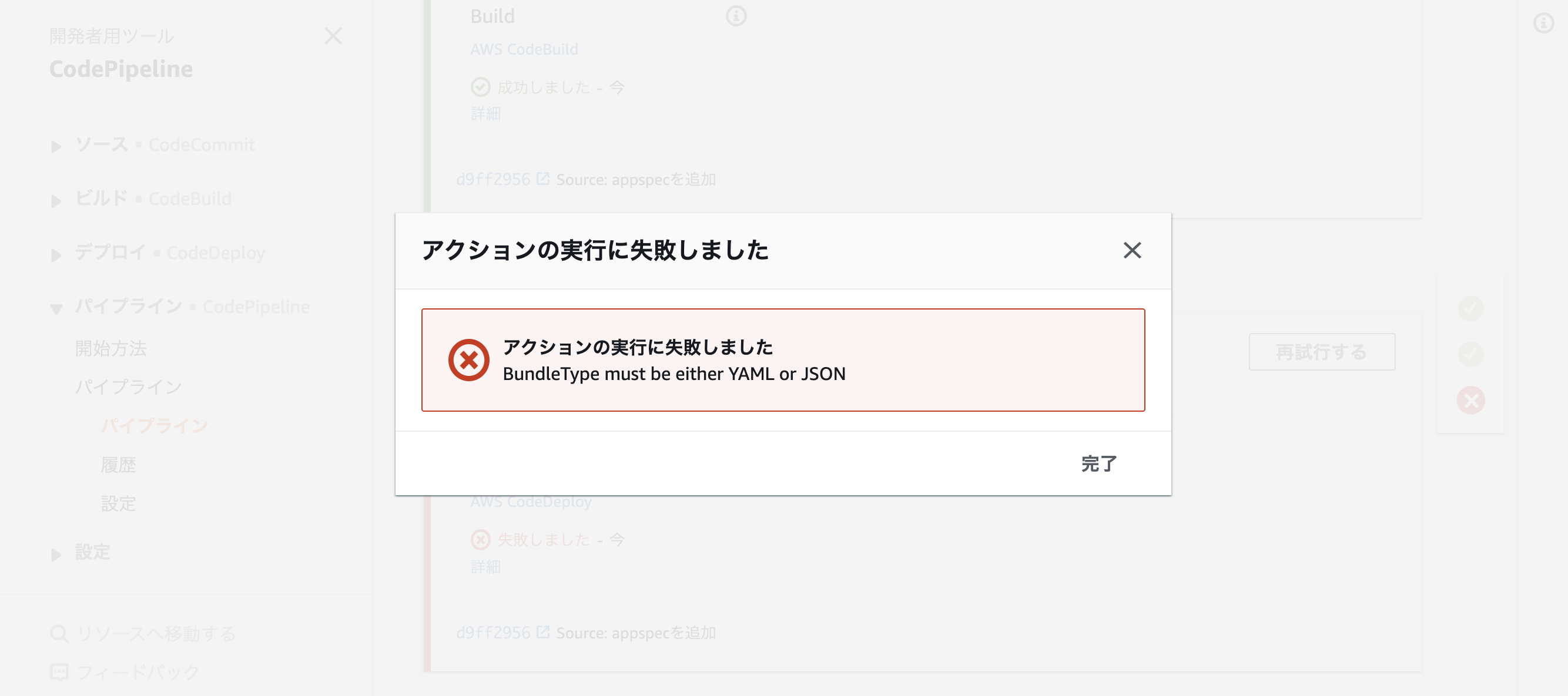
失敗!!!!
BundleType must be either yaml or json????
artifactの中にあるし、色々試したけど解決せずサポートに問い合わせると、artifactで保存されるファイルはzipで圧縮されるので、そうするとappspec.ymlが参照できないらしい
って無理じゃん!!!
現時点ではデプロイでCloudFormationを使うしかないということです、無駄足でした。最後に
ここまでみて頂いた方ありがとうございます
ただデプロイしたいだけで、3日も溶かしてしまった、どうしてもこのやり方でやりたい方は
https://github.com/aws-samples/aws-serverless-workshop-greater-china-region/tree/master/Lab8A-CICD-CodePipeline
ここを参考にどうぞ、デプロイはCodeDeployじゃなくてLambdaを実行しているけどね・・・




- 投稿日:2020-05-25T21:10:47+09:00
AWS Media connect
AWS Elemental MediaConnectとは何ですか?
AWS Elemental MediaConnectは、放送局やその他のプレミアムビデオプロバイダーがAWSクラウドにライブビデオを確実に取り込み、AWSクラウドの内部または外部の複数の宛先に配信することを容易にするサービス
AWS Elemental MediaConnectの概念と用語
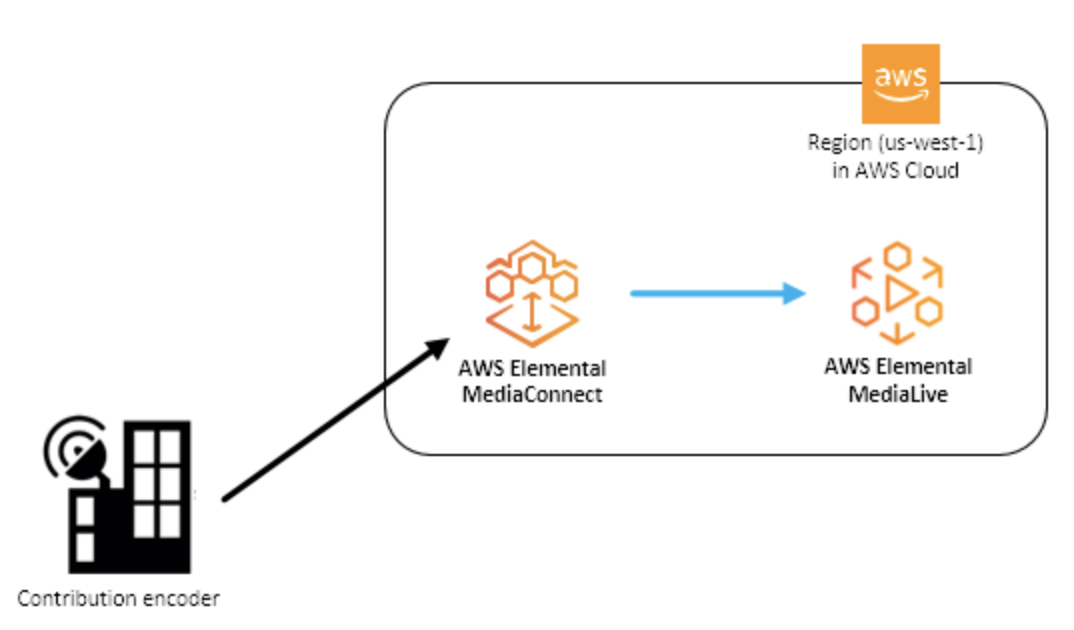
- Contribution encoder
- ライブビデオフィードを受信し、トランスポートまたはアダプティブビットレート(ABR)ストリームへのさらなる処理のために、ストリームを単一の高品質メザニンストリームにエンコードするエンコーダー。
- Distribution
- 地理的に異なる場所にコンテンツを配信する目的で、他のAWSリージョンのAWS Elemental MediaConnectフローを指す出力を作成した結果。
- Entitlement
- AWSアカウントが特定のAWS Elemental MediaConnectフローのコンテンツにアクセスできるようにするために付与されるアクセス許可。コンテンツの作成者は、特定のAWSアカウント(サブスクライバー)に資格を付与します。資格が付与されると、サブスクライバーは、発信元のフローをソースとして使用してフローを作成できます。各フローには最大50の資格を含めることができます。
- Flow
- 1つ以上のビデオソースと1つ以上の出力間の接続。フローごとに、使用するトランスポートプロトコル、暗号化情報、および必要な出力または資格の詳細を指定します。AWS Elemental MediaConnectは、単一のユニキャストストリームとしてライブビデオを送信できる取り込みエンドポイントを返します。サービスは、AWSクラウドの内外を問わず、指定したすべての出力にビデオを複製して配信します。
- Mezzanine stream
- フル解像度の非圧縮ストリームよりも占有スペースが少ない、軽く圧縮されたビデオストリーム。
- Originator account
- 少なくとも1つのエンタイトルメントを持つフローを作成するために使用されたAWSアカウント。
- Output
- AWS Elemental MediaConnectが取り込んだビデオを送信する宛先アドレス、プロトコル、およびポート。各フローには最大50個の出力を含めることができます。出力には、ソースと同じプロトコルまたは異なるプロトコルを使用できます。
- Protocol
- ファイル送信に使用される一連のルール。AWS Elemental MediaConnectは、サービスがメザニン品質のライブビデオで動作できるようにするためのサービス品質(QoS)レイヤーを実装するプロトコルオプション(Zixi、RTP、RTP-FECなど)を提供します。
- Receiver
- AWS Elemental MediaConnectからのストリームの受信者。レシーバーは、RTPまたはZixiストリームを受信できるAWSクラウドの内部または外部のエンティティです。これは、アフィリエイト、クラウドエンコーダー、または別のMediaConnectフローである可能性があります。
- Replication
- 複数の出力を持つフローを作成した結果。ソースは複製され、複数の出力が生成されます。レプリケーションは、自分のアカウント内の複数のワークフローにビデオストリームを配布したり、コンテンツを他のAWSアカウントと共有したりする場合に役立ちます。
- Resource
- Sharing
- 別のAWSアカウントにフローのコンテンツへのアクセスを許可します。コンテンツを共有するには、あなた(オリジネーター)が別のAWSアカウント(サブスクライバー)にライセンスを付与します。
- Source
- 構成情報(暗号化とソースの種類)とネットワークアドレスを含む外部ビデオコンテンツ。各フローには少なくとも1つのソースがあります。標準ソースは、オンプレミスエンコーダーなど、別のAWS Elemental MediaConnectフロー以外のソースから取得されます。資格のあるソースは、別のAWSアカウントによって所有され、アカウントに資格を付与したAWS Elemental MediaConnectフローからのものです。
- Subscriber account
- 別のAWSアカウント(オリジネーターアカウント)が所有するAWS Elemental MediaConnectフローからコンテンツへのアクセスが許可されたAWSアカウント。この許可は、発信者がサブスクライバーの資格をセットアップするときに付与されます。資格により、サブスクライバーは、発信元のコンテンツをソースとして使用するフローを作成できます。
- Whitelisting
- クラスレスドメイン間ルーティング(CIDR)IPアドレスのブロックがAWS Elemental MediaConnectフローのソースとして機能できるようにします。
AWS Elemental MediaConnectの使用例
- AWSクラウドにオンプレミスエンコーダからのインジェストコンテンツにAWSエレメンタルMediaConnectを使用しています。
- 異なる地理的領域にコンテンツを配信するためにAWSエレメンタルMediaConnectを使用
- 資格については、AWS Elemental MediaConnectを使用してコンテンツを他のAWSアカウントと共有
Contribution encoder
Distribution
Entitlement
AWS Elemental MediaConnectのソース
- オンプレミスエンコーダ
- 別のAWS Elemental MediaConnectフロー
- AWS Elemental MediaLive出力
- プレイアウトシステム(クラウドベースまたはオンプレミス)
VPCインターフェース
Amazon Virtual Private Cloudサービスに基づく仮想プライベートクラウド(VPC)は、AWSクラウド内の論理的に分離されたプライベートネットワークです。VPCインターフェイスをセットアップして、AWS Elemental MediaConnectフローとVPC間の接続を確立できます。
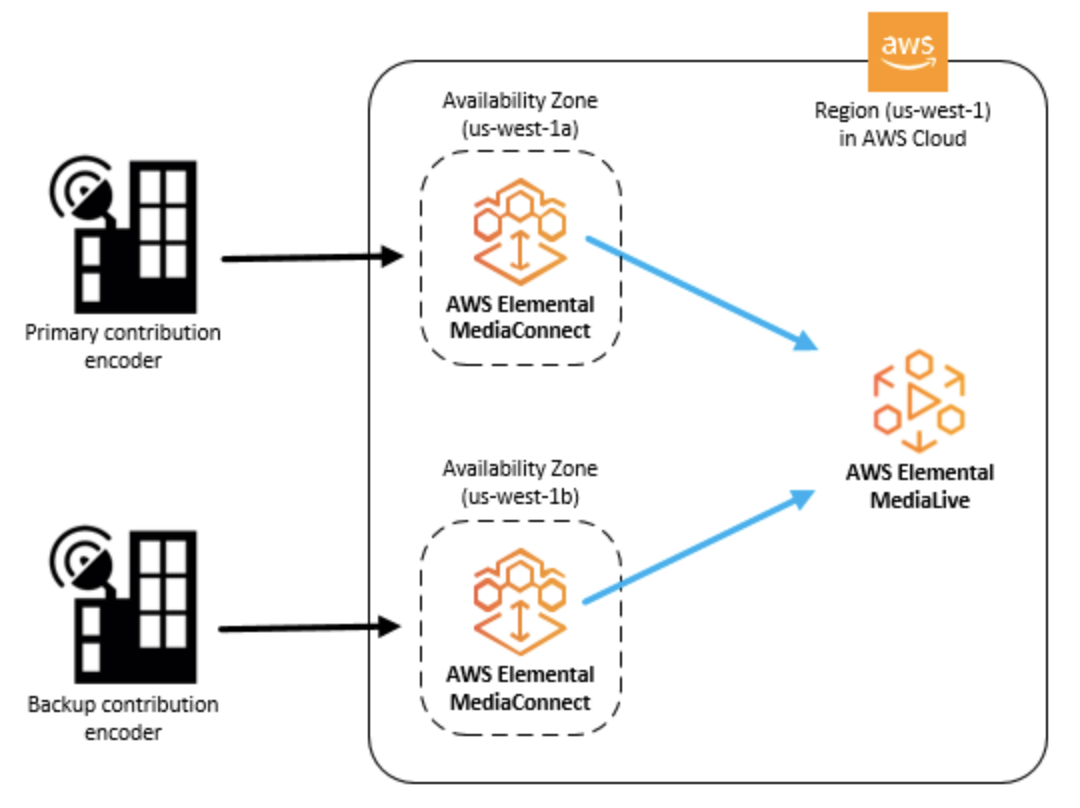
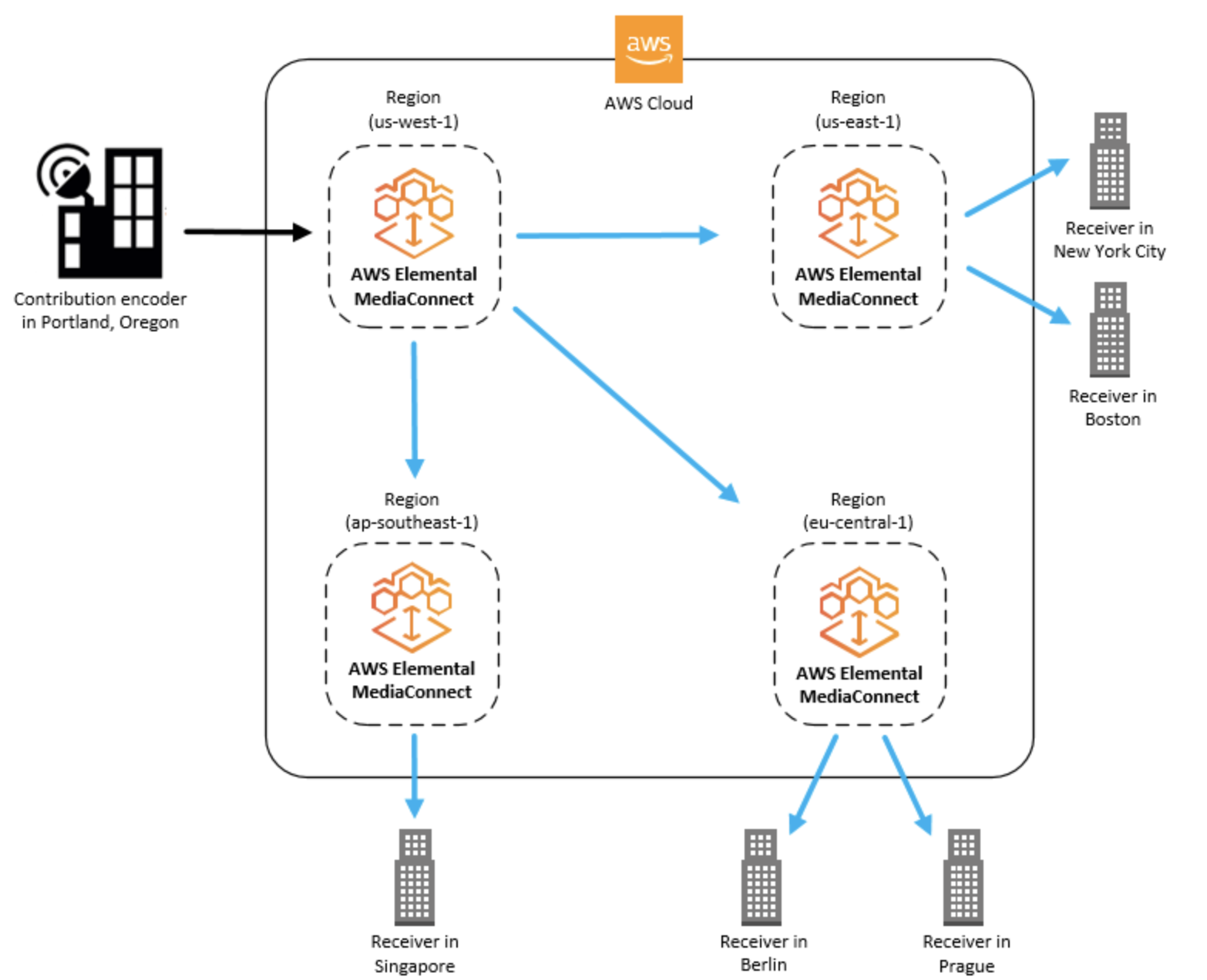
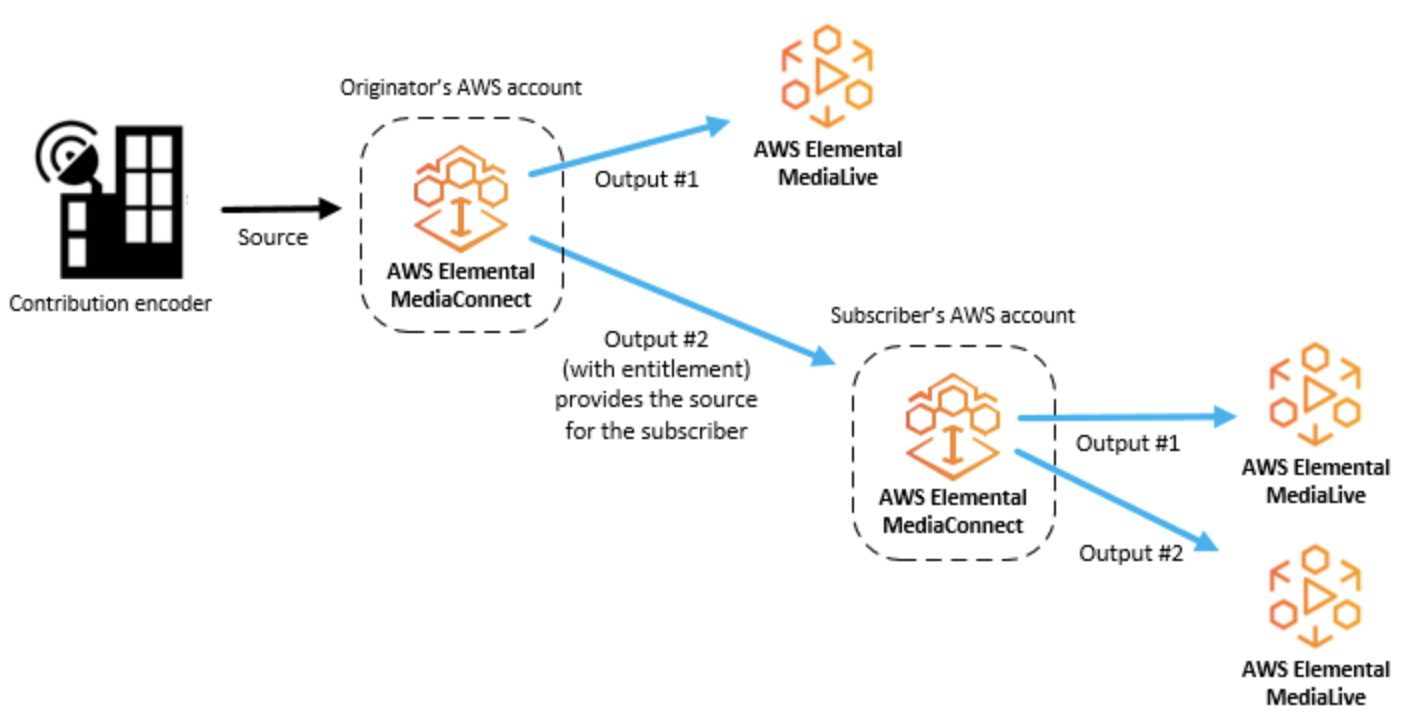
- 投稿日:2020-05-25T20:42:42+09:00
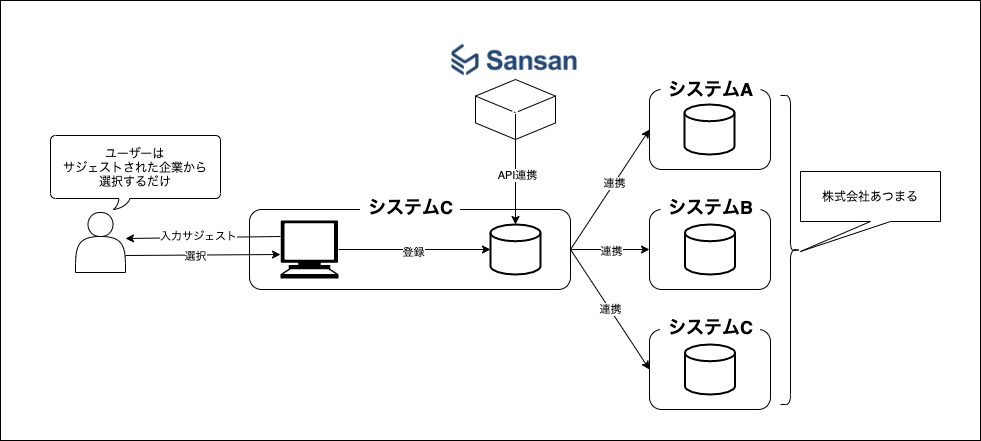
Sansan API + AWSで企業情報のマスターDBを構築する
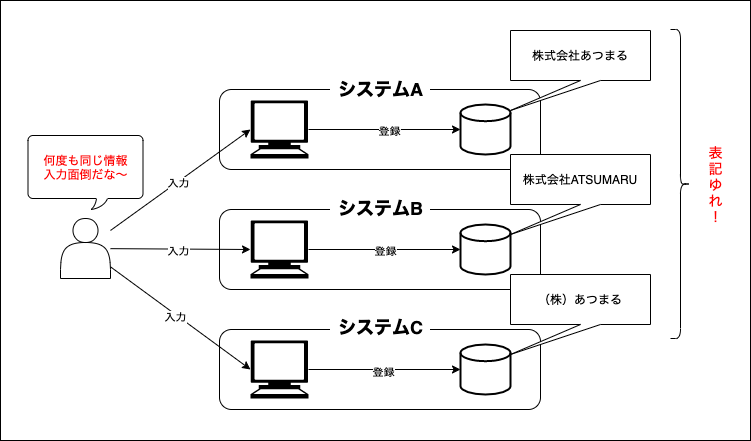
1. 経緯
社内には数多くのシステムがあります。CRM、ERP、経費精算、、、etc...
そして、その各システムには、企業を登録するUIがあり、それぞれのシステムに企業登録を行います。
そこで課題に上がってくることが以下の2点!社内の課題?
①それぞれのツールに何度も同じような情報を入力しなければならない。
※CRMやERPなど各システムに企業名や担当者など共通する情報を何度も入力。。。②色々な人が入力するので、同じ企業の登録でも表記ゆれをする。
※「株式会社あつまる」「株式会社ATSUMARU」、「(株)あつまる」、「あつまる」、半角や全角、など考え出したらキリがないレベルで表記ゆれがあります。一番の絶叫は、半角カタカナですね。?特に、②に関しては、今後、各システム同士を連携する際にもかなりネックになってきますね。?
※イメージ図
2. 実現したいこと
①一つのUIに企業を登録すると全てのシステムに同じ企業情報が登録される。
②企業情報に関しては、ユーザーに入力させるのではなく、クラウド名刺管理Sansanから企業データを引っ張ってきて、選択させる方式で企業を登録。
【流れ】
名刺を写真にとり、Sansanに登録 → システムに企業登録する際は企業一覧が表示されるので選択するだけ
企業名だけではなく、名刺に含まれる企業情報も同時にデータベースに登録されます。
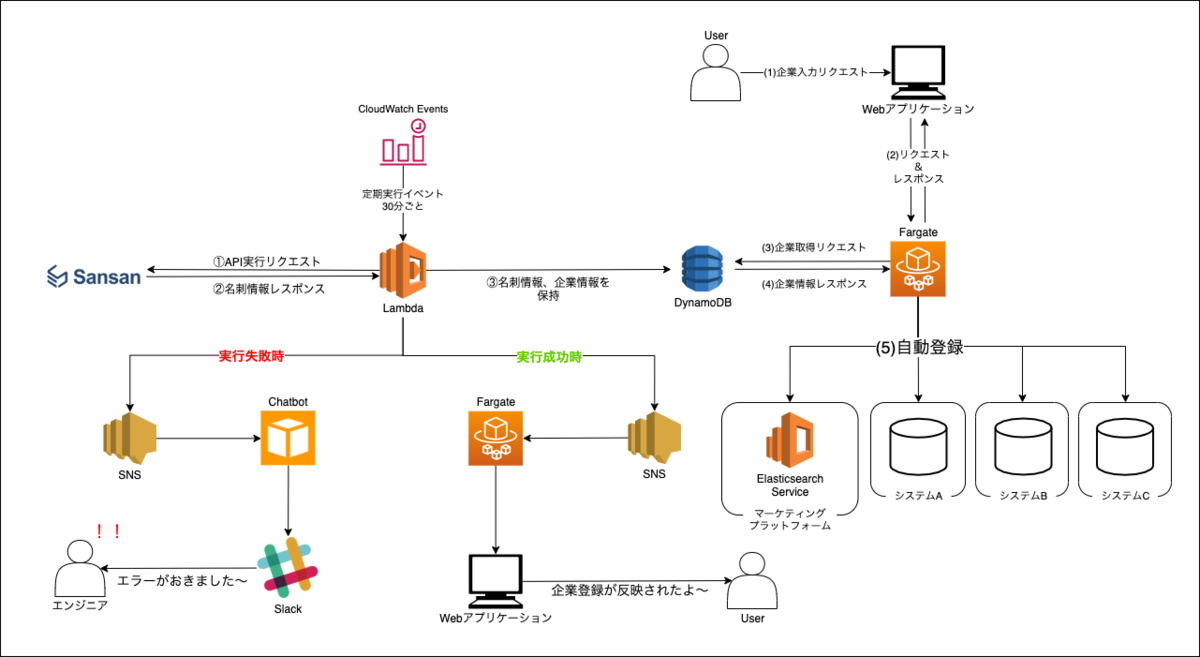
2-1. Sansan APIについて
クラウド名刺管理Sansanを契約している企業向けにAPIが公開されています。
APIドキュメント自体は一般公開されています。
非常にわかりやすく、そして、APIリクエストからのレスポンスも早い!!!
色々なパラメータで条件を絞れたり、あらゆる角度から欲しい情報が引っ張れるので、
社内のシステム連携には非常にやりやすく、とても嬉しい!?2-2. アーキテクト
3. 開発のポイント
- Sansan APIは名刺 Set 取得(期間指定)で12時間前から現在時刻までの取得、Lambdaの実行は30分ごと。
- LambdaからDynamoDBに企業登録する際は、一度、企業検索をかけて、ないことを確認して、登録している。既に登録されている企業データに関しては、登録処理を行わない。
3-1. 企業入力に関して
名刺登録されている膨大な選択肢から企業を探すのは、非常に困難なため、企業名の入力サジェストで選択できる形にしています。
Vue-Multiselect | Vue Select Library.
4. 今後の展望
社内システムとの連携に関して、システムA、システムB、システムCと書いていますが、まだ実は連携ができていません。そこで、以下の2点を実現できる基盤と仕組みを創っていきたいと思っています。
- 正しい情報の整理
- データ登録業務の効率化
記事を読んでいただきありがとうございます!
今後も、定期的にアウトプットしていこうと思います!?

- 投稿日:2020-05-25T20:36:12+09:00
【前編】日本語対応!Amazon Transcribeを使用してみた 〜サービス編〜
Amazon Transcribeってなに?
端的にいうと、音声情報をテキスト情報に変えるサービスです。
Amazon Transcribe を使用すると、開発者は音声をテキストに変換する機能をアプリケーションに簡単に追加できます。コンピュータでは、音声データを検索および分析することは事実上不可能です。したがって、録音された音声は、アプリケーションで使用する前にテキストに変換する必要があります。
https://aws.amazon.com/jp/transcribe/背景
会社の中の人?「ミーティングや勉強会の議事録(発言録)を作成するのが大変!なんとかならないかな(涙)」
僕? 「そういえば、Amazon Transcribeが最近、日本語対応したって聞いたな。試してみるか!」
サービス内容(2020年1月30日時点)
1. 機能について
(1) 動画、音声データの文字起こしが可能
当たり前ではあるのですが、動画ファイルも文字起こしができるっていうところが味噌ですね〜。
mp3,mp4,wav,flacの拡張子が可能。(2) スピーカーの識別ができる
最大10人までのスピーカーの識別が可能。
会議やMTG時に有効な機能かも。(3) 特定の単語、語彙の削除機能(フィルタリング)
使用者が定義した単語、語彙のフィルタリング設定に基づいて、
特定の単語を削除または、***(アスタリスク)に置き換えるなどの設定が可能。(4) 固有の単語やフレーズを登録して認識するように設定が可能
会社独自の単語や固有名詞を登録して、発音を学習させることで、認識可能にすることができる。
2. 音声データを変換する時間について
20分ほどの動画の場合(1.33GB)、ダウンロード〜文字起こしまで約5分程度
3. 価格について
GoogleやAzure(Microsoft)にも似たようなサービスがあり、クラウドサービス内では、平均的な価格。
文字起こし業者と比較すると圧倒的に安い(約1万円〜3万円/時間)
ただ、文字起こし業者は整文、要約までしてくれるのは魅力的。Amazon Transcribeの料金
▼【公式】Amazon Transcribeの料金▼
[https://aws.amazon.com/jp/transcribe/pricing/:embed:cite]| 例 | 音声の長さ | 料金(ドル) | 料金(円) |
| --- | --- | --- |
| ソーシャルメディアビデオ | ~10秒 | 0.006 USD | ¥0.66 |
| ラジオのコマーシャル | ~15秒 | 0.006 USD | ¥0.66 |
| ビデオ トレイラー | ~2分30秒 | 0.06 USD | ¥6.6 |
| 録画版ウェビナー | ~30分 | 0.72 USD | ¥79.2 |
| 'The Marvelous Mrs. Maisel'の1話 | ~60分 | 1.44 USD | ¥158.4 |
| 平均的な長さの経営会議の録音 | ~120分 | 2.88 USD | ¥316.8 |※$1=¥110で計算
4. 正確性について
実際、どのくらい音声を正しく、テキストに起こすことができるの?という誰もが気になるこのテーマについては、最後に明らかになるので、ここでは省略します!!
ここからは実際に使用方法についてのお話
はじめに、今回良いなと思ったことが、一つありまして。
それは、GUIのみで音声をテキスト化する目的を果たせるということ。
つまり、エンジニアではない方にも簡単に使用できます!繰り返し同じことを言います!
1行もコードを書かず、マウス操作だけで音声をテキスト化できます!
使用方法については2つのセクションに分けて、書いていきます!
① GUIからの使用方法
② CLIを用いて、自動音声認識システム構築 → 後日、後編も書きます!①はエンジニアではない方向け、②はエンジニア向けの内容になります。
① GUIからの使用方法(エンジニアではない方向け)
【STEP 1】S3へ音声データを準備
AWSコンソールにサインイン
S3に音声(動画)データをアップロード
S3内に音声データをアップロードするフォルダを作成し、データを格納。
※細かい部分は割愛
【STEP 2】Amazon Transcribeでテキスト化実行
サービスから「Amazon Transcribe」を選択
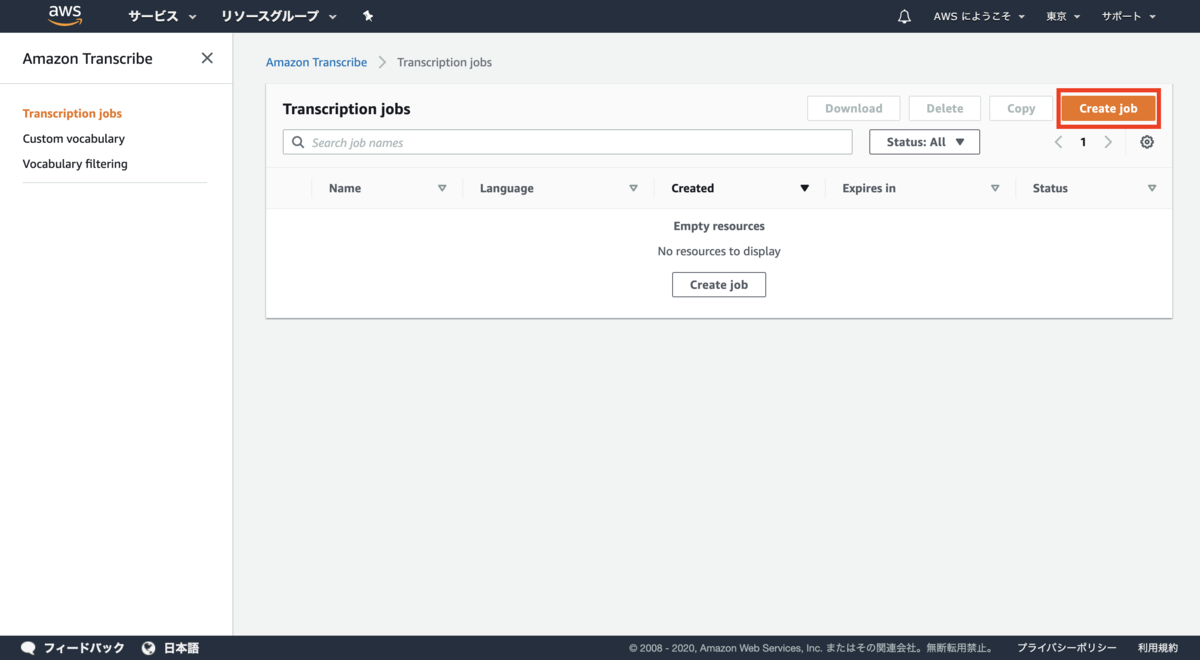
「Create Job」からジョブを作成
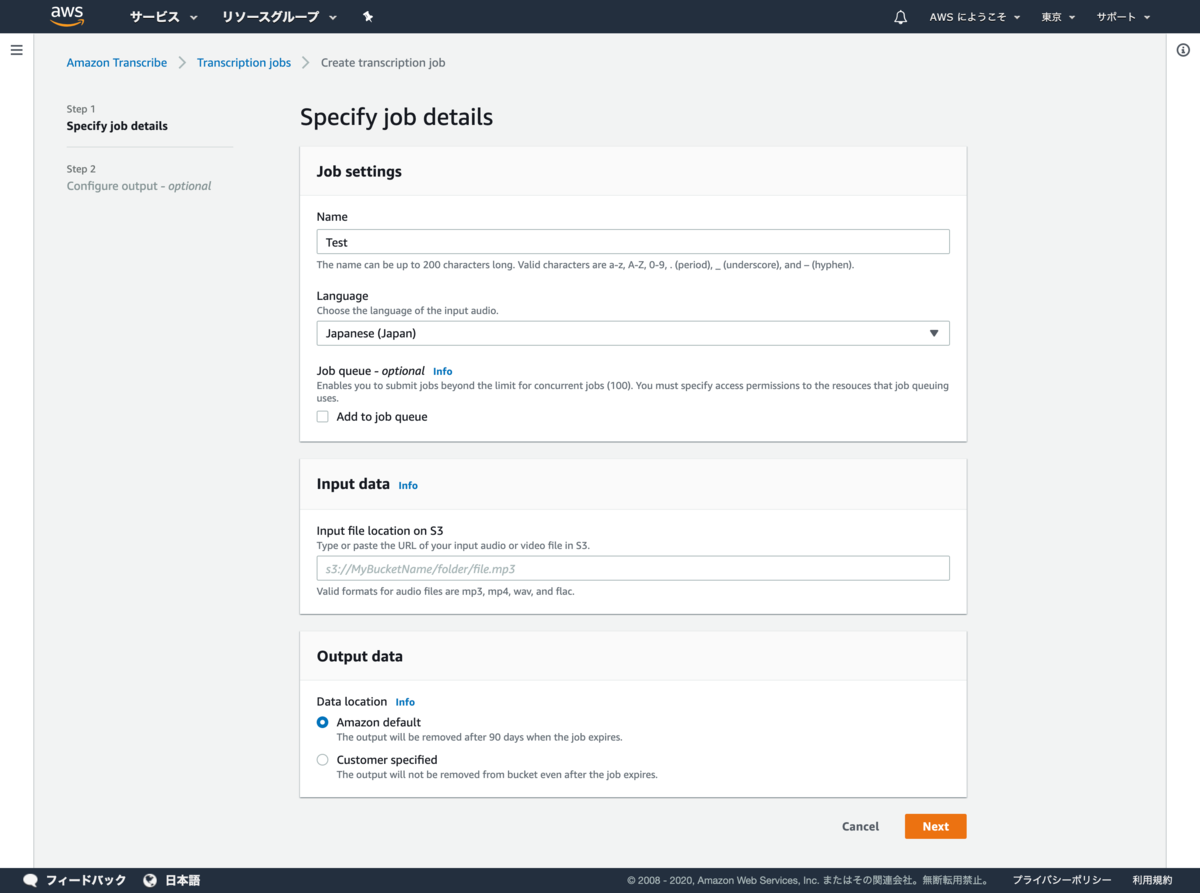
ジョブの情報を入力
ラベル 入力値 内容 Name Test(今回はテストのため)ジョブ名 Language Japanese (Japan) 音声データの言語 Job queue - optional チェックなし ジョブキューイングのアクセス許可 Input file location on S3 s3://[Bucketフォルダ名] S3のパス Data location Amazon defaultにチェック実行後の結果データを保管する場所
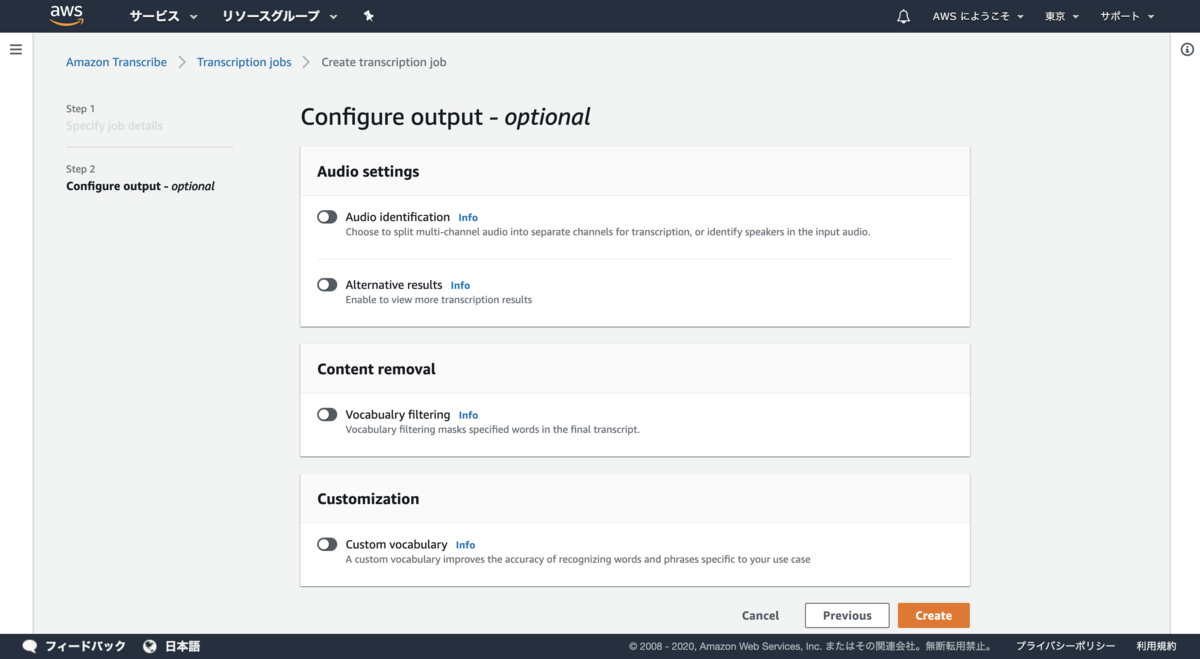
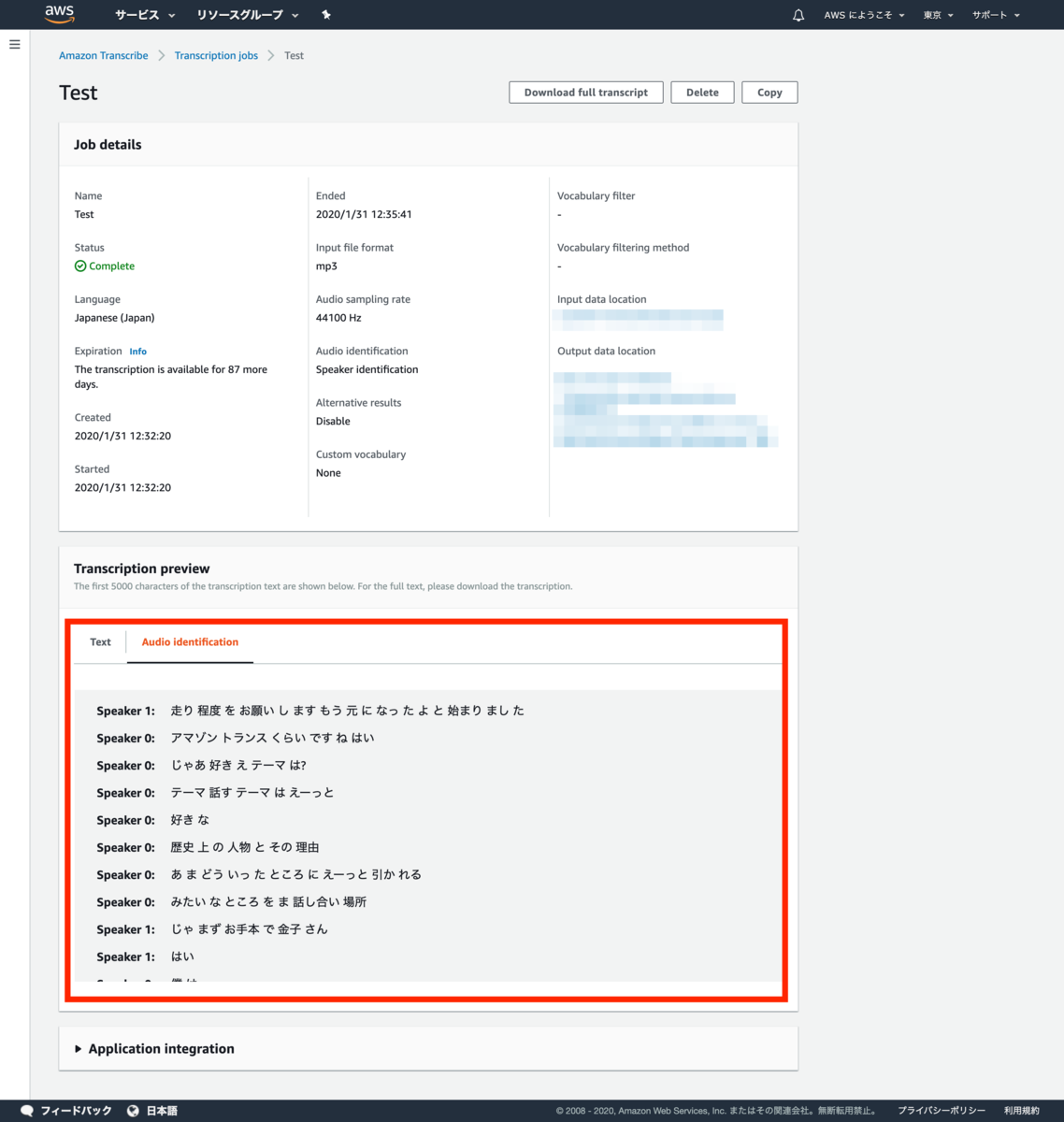
ラベル 設定値 内容 Audio identification OFF 話者の識別(個別のチャネルに分割するか、入力オーディオのスピーカーを識別するか) Alternative results OFF 文字起こしの信頼レベルに基づいて、代替文字起こしの数指定が可能 Vocabualry filtering OFF 語彙フィルタリング Custom vocabulary OFF ユースケースにあった固有名詞や固有単語の設定 Audio identificationについては以下の記事がわかりやすい。
[https://dev.classmethod.jp/cloud/aws/amazon_transcribe_can_now_identify_and_label_transcripts_based_on_audio_channels/:embed:cite]ジョブ作成
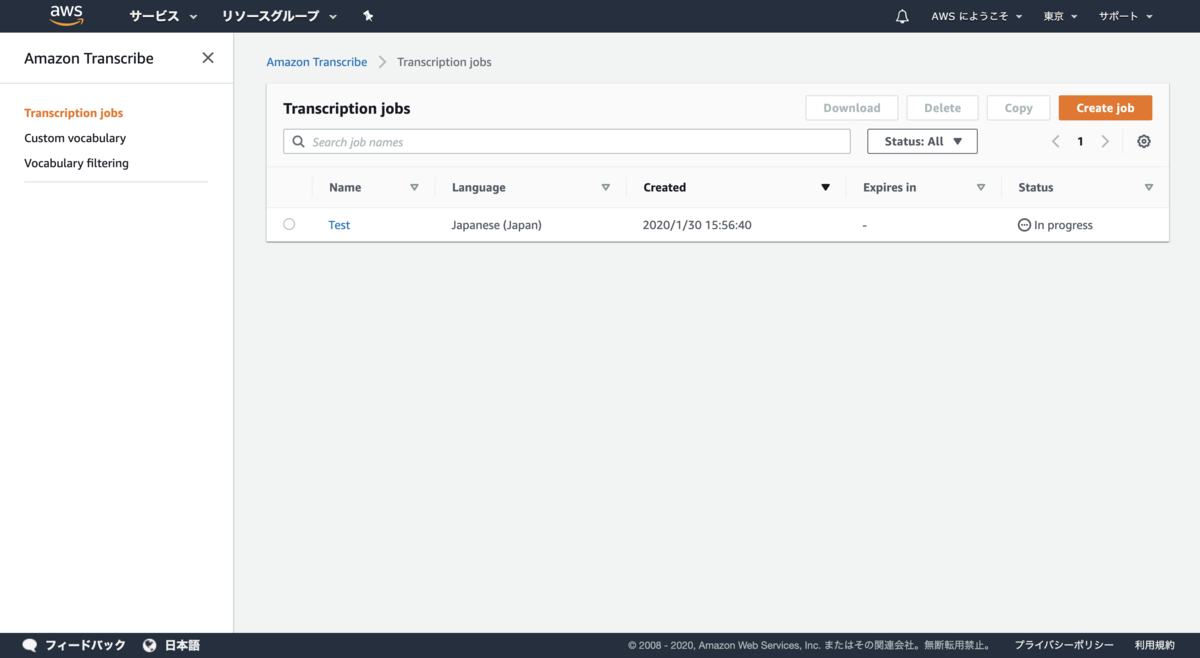
ジョブを作成後、すぐにテキスト化が実行されます。
数分後・・・
Nameの
Testを選択すると簡易的にテキスト化した内容をみることができます。
※長いテキストは全文表示されません。【STEP 3】結果表示
気になる正確性については?
よりリアルな正確性をお伝えするため、あえてハキハキと話した音声ではなく、普段の話し口調で試してみました。
私(金子)と近くにいたエンジニアのメンバー渡邊と対話形式で、10分間、好きな歴史上の人物について話した内容になります。Speaker 1(渡邊): 走り 程度 を お願い し ます もう 元 に なっ た よ と 始まり まし た (渡邊)[ファシリテートをお願いしますよ お、もう始まりましたよ] Speaker 0(金子): アマゾン トランス くらい です ね はい じゃあ 好き え テーマ は? テーマ 話す テーマ は えーっと好き な歴史 上 の 人物 と その 理由 あ ま どう いっ た ところ に えーっと 引か れるみたい な ところ を ま 話し合い 場所 (金子)[アマゾン トランスクライブのテストですね。](渡邊)[はい、じゃあ好き、え、テーマは?](金子)[テーマ、、話すテーマはえっとー好きな歴史上の人物とその理由。ま、どういったところにえっとー惹かれるのかみたいなところをまぁ話し合いましょうか。] Speaker 1(渡邊): じゃ まず お手本 で 金子 さん はい (渡邊)[じゃあまず お手本で金子さん はい] Speaker 0(金子): 僕 は ちょっと 分かる 人 が いる か どう か 分から ない ん です けど 犬 ちょっと マイナー な とか 言っ てる と 三国志 の 教員 (金子)[僕は、わかる人がいるかどうかわからないんですけど](渡邊)[え、マイナー?](金子)[ちょっと、マイナーなところをいくと三国志の姜維(きょうい)] Speaker 1(渡邊): ああ (渡邊)[はぁ〜〜またちょっと] Speaker 0(金子): なるほど そう 甘い な の? ところ 教員 が めちゃめちゃ えっ と ま 脅威 を 簡単 に 説明 する と えーっと ま 物凄く この 三 区 時代 って いう ので 戯号 色 に 別れ て で 色 の 流儀 先頭 を 切っ て たら 類 義 が ま 亡くなっ た 後に ま る ぜ って いう その 子供 が ま 校庭 に なる ん です けど ま そこ まで 以前 は 結構 遊び人 で なかなか そう な 後 面 だ って 活躍 する よう な 人 で は なかっ た ん です けど ま 教員 が ま そこ を ま 持っ て た 感覚 な ん です ね で ま 所轄 量 の 教え を いただき ながら その 部位 と 地 の 両方 を 兼ね備え て あと は 豆 はい な ところ です か ね? です なんか 最後 まで そこ を 戦い 抜く っていう の が すごく 僕 の 中 で は 聞か れる ので ま その 一番 は やっぱり 豆 誠実 と いう か? そういった ところ が 教員 の 魅力 から (渡邊)[マイナーなところですね](金子)[姜維がめちゃめちゃ好きでえっとーま、姜維を簡単に説明するとえっとまぁものすごく三国時代っていうところで魏呉蜀に分かれて、で、蜀の劉備、先頭を切っていた劉備がなくなった後に劉禅っていうその子供が皇帝になるんですけど、そこぉ〜劉禅は結構、遊び人でだからなんかなんていうんだろうな、表立って活躍するような人ではなかったんですけど、姜維がそこを守っていた感覚なんですね。で、諸葛亮の教え もいただきながら、その武勇と知能の両方を兼ね備えて、とあとは忠実なところですかね。で、最後までそこを戦い抜くっていうのが、すごく僕の中では惹かれる。ので、まぁその、一番は忠実、誠実みたいなそういったところが姜維の魅力かなと思っています。] Speaker 1(渡邊): 脅威 さん 組み そう だっ たら めっちゃ イケ 麺 の 人 です ね そう じゃ 若林 って (渡邊)[おぉ〜姜維。三國無双やったらめっちゃイケメンの人ですね?](金子)[そうですね](渡邊)[めちゃめちゃ若々しくて] Speaker 0(金子): 実際 は どう な の か? わかん ない です けど ね (金子)[実際どうなのか、わかんないですけどね] Speaker 1(渡邊): 実際 で も あの 色 が 滅ぶ 辺り で で もう 六 十 歳 ぐらい です よ (渡邊)[実際、でもあの蜀が滅ぶ辺りでもう六十歳ぐらいですよ] Speaker 0(金子): ね あんな 若く ない です ね しかも (渡邊)[あんな若くないですね、しかも] Speaker 1(渡邊): 結構 最後 も 無残 じゃ ない です か (渡邊)[結構、最後も無残じゃないですか] Speaker 0(金子): そう です ね (金子)[そうですね] Speaker 1(渡邊): うん なんか 反乱 放送 と し て きょう い 私 達 は 三沢 括弧 です よ ね カッコ 入れ て 言う も ある 知略 も ある 両方 持っ てる そう です よ 教員 教員 ちょっと 分かっ てる 人 も 居る だろ (渡邊)[なんか反乱起こそうとして姜維、確かにその忠実さはかっこいいですよね。まぁ武勇もある、知略もある、両方持ってる。姜維、姜維、ちょっとわからん人もおるだろうな〜] Speaker 0(金子): あと なら さ (金子)[渡邊さんは?] Speaker 1(渡邊): 私 は です ね もう これ 昔 から です よ 小学 三 年 生 から 方 十 歳 臭い 方 から もう ずっと 好き です もう 二 十 年間 凄い です ね 幕末 の 志士 吉田 松陰 です (渡邊)[私はですねもうこれ昔からですよ。小学3年生から、だから十歳。九歳か。からもうずっと好きです。もう二十年間。](金子)[凄いですね](渡邊)[幕末の志士 吉田松陰ですよ] Speaker 0(金子): 俺 (金子)[おぉ〜] Speaker 1(渡邊): は もう 事 ある ごと に ずっと 言っ て (渡邊)[これはもうことあるごとにずっと言ってます] Speaker 0(金子): ます そう な (金子)[そうなんですね] Speaker 1(渡邊): ん です ね 吉田 松陰 な ん です よ で 最初 に ご存知 (渡邊)[吉田松陰なんですよ。吉田松陰、ご存知?] Speaker 0(金子): もちろん 山口 岡山 だっ た の です ね はい まさに (金子)[もちろんです。僕、山口県出身なので。はい、まさにですね。] Speaker 1(渡邊): です ね ドクター じゃ ない です けど えっ と 僕 は 週内 主 な ん です けど 萩 はぎ です よ ね そう 背景 です よ あのー 小学 三 年 生 の 時 に 家族 旅行 で 山口 県 って (渡邊)[どちらでしたっけ?](金子)[えっと、僕は周南市なんですけど、萩ですよね?](渡邊)[そうです、そうです。萩ですよ。あのー小学三年生の時に家族旅行で山口県いって] Speaker 0(金子): そう です よ (金子)[あ、そうなんですね。] Speaker 1(渡邊): ね はぎ に 行っ て 城下 町 (渡邊)[で、萩に行って、城下町] Speaker 0(金子): はい はい はい はい (金子)[はい はい はい はい] Speaker 1(渡邊): 歩い て て 吉田 松陰 の その 消化 遜色 入れる ところ で ま 色々 資料 館 と か 言っ て 勉強 し て き た ん? です けど 何 だろ う? 一言 で 言う と アホ みたい な 強靭 な ん です よ はい はい 私 も 行っ て 何 が 他 なんか すごい の か って その 来る ほど の 熱量 自分 の 中 で は こう だ と 思っ た 理想 に 思想 に対して も とことん 突き詰める (渡邊)[歩いて、で吉田松陰のその松下村塾っていうところに行ってまぁ色々資料館とか行って勉強してきたんですけど、何だろうな、んー、一言で言うと、アホみたいな狂人何ですよ。](金子)[はい、はい](渡邊)[吉田松陰って。何が僕は凄いのかってその狂うほどの熱量。自分の中でこうだと思った理想に、思想に対して、とことん突き詰めるみたいな] Speaker 0(金子): ある 外国 に そう ね ドリンク って いう の も (金子)[あの外国に行くっていうのも] Speaker 1(渡邊): 当時 ま バック 江戸 幕府 は 鎖国 体制 を 取っ て た ん です よ ね で も 当然 海外 に 行く の も 禁止 し て た 訳 です よ で そこ に ペリー が 来航 し て って こんな まだ 日本 が 受理 さ れ て しまう と 吉田 松陰 は 危機 感 を 覚え られ ない で 吉田 松陰 は その 上位 船 です けど 他 の 上位 版 の 人 と 違う ところ って 他 の 人 は? 外国 は 岸 から だ から 今 すぐ 殺す べき だ って いう 議論 だっ た です よ 吉田 証人 は そっ えーっと 彼 って 元々 軍略 か な ん です よ 軍 の そういう 平方 とか を その 君主 の モー リー 氏 高知 か に 教える 人 だっ たり し ます よ で その 日 吉田 松陰 は 戦略 課 として 軍略 か として じゃ 外国 を どう 内原 う か? っていう ところ を 考え て 分から ない と 敵 の 戦力 が わから のに 戦略 の 立て よ なんか を 立て られる わけ ない じゃ ない か って いう 穴 に その ロジック から じゃ 適応 知る に は アメリカ 行く しか なく ない (渡邊)[当時、幕府、江戸幕府は鎖国体制を取ってたんですよね。でも当然、海外に行くのも禁止していたわけですよ。でそこにペリーが来航して、でこのままだったら、えー日本が蹂躙されてしまうと吉田松陰は危機感を覚えたわけですね。で吉田松陰はその攘夷派何ですけど他の攘夷派の人と違うところって他の人は、外国はけしからんだから今すぐ殺すべきだっていう議論だったんですよ。吉田松陰は、彼って元々軍略家だったんですよ。軍のその兵法とかを君主の毛利氏、敬親に教える人だったんですね。でその、吉田松陰は、戦略家として軍略家としてじゃあ外国をどう打ち払うかっていうところを考えてて、わからんと、敵の戦力がわからんのに戦略の立てようなんかたてられるわけないじゃないかっていう結、そのロジックからじゃあ敵を知るには?アメリカ行くしかなくね?ってなったんですよ。] Speaker 0(金子): 子 だっ た ん です よ Speaker 1(渡邊): ま 彼 に とっ て は 当時 そんな 日本 にとって の 外国 って 別 に 今 って なんか 外国 イコール アメリカ の イメージ が あり ます けど 当時 は もっと オランダ とか 中国 と か ロシア と か の 方 が どっち か って いう と 身近 で ただ 最初 分かり 吉田 松陰 は ロシア に 行っ た ん です よ で も ロシア の 船 に 乗り込む と 長崎 に 行っ たら もう その ロシア の 頭 に い なく なっ ちゃっ て だ から ま 過ごす 事 帰っ て いっ た ん? です けど それで 今度 ちょっと 東京 じゃ ない です ね 江戸 に 行っ て 浦賀 に 行っ て あ ベイリオル は 構成 って その 一 コンフェデ ちっちゃい その 熱狂 っぷり だ 末 同じ ソレ バレ たら 殺さ れる 訳 です よ (渡邊)[ま、彼にとっては、当時そんな日本にとっての外国って別に今ってなんか外国=アメリカのイメージがありますけど、当時はもっとオランダとか中国とかロシアとかの方がどっちかっていうと身近でだから彼、吉田松陰はロシアに行こうとしたんですよ。でも、ロシアの船に乗り込もうと長崎に言ったら、もうそのロシアの船、いなくなっちゃってだからまぁすごすごと帰っていったんですけど、それで今度とう、東京じゃないですね、江戸に行って、浦賀に行って、あ、ペリーおるわ、行こうぜってなって、その行こうぜで行っちゃえる、その熱狂っぷりが凄い。当時それがバレたら殺されるわけですよ。] Speaker 0(金子): ね 命懸け 命がけ の 優れ た (金子)[そうですね、命懸けのまさに] Speaker 1(渡邊): ソレ を やっ ちゃ う (渡邊)[それをやっちゃう] Speaker 0(金子): 東京 に 行く 間 エド 行く だけ で も もう 物凄い てる よう です けど 当時 は 浸透 で ある 訳 じゃ ない です ね 一 か月 ぐらい あり ます よ ね かなり そこ まで に 行く に し て も 覚悟 決め て 行っ てる なんか (金子)[東京に行く、ま、江戸に行くだけでももう物凄い熱量ですけど当時は新幹線があるわけでもないからですね](渡邊)[2ヶ月ぐらいかかりますよね](金子)[かなりそこまでに行くにしても、覚悟決めて行ってる中] Speaker 1(渡邊): フリー さ も です ね 当時 は 版 て いう 萩 藩 です か ね の 中 の ま 反応 起き て として 多種 (渡邊)[クレイジーさも当時は、藩っていう萩藩ですかね?の中の藩の掟として](金子)[長州藩では](渡邊)[あ、長州藩] Speaker 0(金子): ファン で は (渡邊)[長州藩ですね] Speaker 1(渡邊): ない 気持ち は 調子 外れ た 上質 な ん です ね ええ 掟 として 脱藩 は 罪 だっ た 訳 です よ 脱藩 版 を 付ける こと は やっぱり ロシア も だから 殺さ れ て も 文句 だ よ って 言わ れ ない 言え ない ところで 彼 は 簡単 に 脱藩 し チャウ です よ ね この 話 ご存知 です よ ね もう その 理由 は 何 だ? って 言っ たら 友達 と 旅行 する 約束 を し て しまう た から でも ぞ 版 が 許し て くれ ない じゃあ 止める って (渡邊)[で、掟として脱藩は罪だったわけですよ。脱藩、藩を抜けることは脱藩浪士はもう殺されても文句言えないところで、彼は簡単に脱藩しちゃうんですよ。この話ご存知です?](金子)[はい](渡邊)[その理由は何だっていったら、友達と旅行をする約束をしてしまったから、でもそれを藩が許してくれない、じゃあやめる] Speaker 0(金子): いう と やっぱり し ちゃっ た ね そう で (渡邊)[っていう理由で脱藩しちゃうんです] Speaker 1(渡邊): 純粋 さ 自分 の 思想 なんか 理想 思い に対する 純粋 さ が す 圧倒的 な 結論 に なっ て その 結果 消化 村塾 で 学ん だ 例えば 高杉 晋作 だっ たり と いろいろ みんな 明治維新 を 作っ て いく って いう の を 考える と その 熱量 です (渡邊)[その純粋さ、自分の思想なんか理想、想いに対する純粋さが圧倒的な熱量になって、その結果、松下村塾で学んだ例えば高杉晋作だったり、伊藤博文が明治維新を作っていくっていうのを考えるとその熱量って凄い。] Speaker 0(金子): まだ 本当 に 色んな 人 に 影響 を 与え て ます よ ね そう いう こと 坂本 遼 前 もう 吉田 調印 の 影響 を 受け て です ね (金子)[本当にいろんな人に影響を与えてますよね。それこそ坂本龍馬も吉田松蔭の影響をかなり受けてるみたいですね。] Speaker 1(渡邊): そう です よ ね 例えば その 人 に 有名 な 人 久坂 玄 ずい って いう ね 高杉 晋作 と 僧兵 強打 し た ま 塾 の 姿勢 の 一 人 な ん? です けど 彼 が もし その 明治 明治維新 で です ね その 前 の 何 だろ? う ま 幕末 でも 生き抜い て い たら あのー 西郷 隆盛 で さえ も 彼 の 久坂 玄 髄 が 生き て い たら 自分 は これ ほど なんか 幅 を 利か せ られ なかっ た だろ う って 言っ てる ぐらい すごい 人 だっ た ん です よ ね でも そういう ホント すごい 人材 を たくさん 生み出し た 紹介 層 から ソレ を 作っ た 吉田 松陰 って いう の は うん すごい な と 確か って いう の が ま 僕 が 尊敬 する 人 の 歴史 上 の 人物 です ね (渡邊)[そうですよね。例えばその〜一人有名な人で久坂玄瑞っていう人ですね。高杉晋作と双璧を成した、ま、塾の出生の一人何ですけど。彼がもし、明治〜明治維新じゃないですね。その前のま、何だろう、幕末を生き抜いていたら、あの西郷隆盛でさえもかの久坂玄瑞が生きていたら自分はこれほど幅をきかせられなかっただろうって言ってるぐらい凄い人がいたんですよ。そういう本当凄い人材をたくさん生み出した松下村塾。それを作った吉田松陰っていうのは本当凄いなと](金子)[確かに](渡邊)[っていうのが、僕が尊敬する人、歴史上の人物ですね。] Speaker 0(金子): 確か に 白 勝因 と か もう 何 か 名前 だけ は 聞い て て その 生きざま で あっ たり と か って いう の は 結構 意外 と 習わ ない なら ない 学校 で 習わ ない こと って 結構 ある と 思う ん です よ ね あの 辺 なんか さら っと 行く じゃ ない です か でも 何 か あ そっ こう 生き た 人 たち って 本当 に こう 覚悟 で あっ たり ね 対 で あっ たり って の は 色々 こう 何 です か 本質 じゃ ない なるほど カネ ミ 瓶 と いう か もの が ある 中 で の もう 活躍 な まで 凄い な って 思い ます よ ね ホント に (金子)[確かに吉田松陰とかも、なんか名前だけは聞いてて、その生き様であったりとかっていうのは結構意外と習わない、学校で習わないことって結構あると思うんですよね。あの辺、結構サラーッといくじゃないですか。でもなんかあそこ生きた人たちって本当に覚悟であったり、熱意であったり、っていうのは、色々こうなんていうんですか、本質じゃない壁というか、ものがある中でのもう活躍なので、凄いなって思いますよね。本当に。] Speaker 1(渡邊): ある 意味 そう いう 壁 が ある から なんか かっこよく 見える の か な と 思っ て い て 例えば 新選 組 も も 投じ て いく と 思う ま 無事 あろ う でし た 時代遅れ 無事 で あろ う と し た し その 江戸 幕府 中性 を 誓い 続け た って いう ところ も やっぱ 何 年 も 制約 が ある 中 で でも 自分 の 理想 を 追い求め た って いう の は やっぱ カッコ いい もん だ な って 思い ます 確か に そう です ね でも 新鮮 も 言う たら 多分 人殺し 集団 です から ね でも それだけ やっぱ あれ だけ かっこいい って の は やっぱ その 生きざま 何 か たくさん の 壁 が ある ので 頑張っ て 自分 の 理想 を 追求 する から 姿 って いう の は やっぱり かっこよく 見える そう です (渡邊)[ある意味そういう壁があるからなんかカッコよく見えるのかなとも思っていて、例えば、新撰組も、何だろう、当時でいくともう武士であろうとした。時代遅れの武士であろうとしたし、江戸幕府に忠誠を誓い続けた。っていうところもやっぱ何かしらの制約がある中ででも自分の理想を追い求めたっていのがなんかカッコよく映るのかなって思います。](金子)[確かにそうですね。](渡邊)[新撰組もいうたらただの人殺し集団ですからね。元も子もないこというと。でも、それだけ、あれだけかっこいいっていうのはその生き様、なんかたくさんの壁がある中でも頑張って自分の理想を追求する方ていうのはカッコよく見えるのかな。](金子)[そうですね] Speaker 0(金子): ね ま なんか も どっち に しろ かっこいい です よ ね 坂本 竜馬 に し て も 恐れ こそ 新選 組 の 立場 に し て も 両方 とも カッコ よく 戻っ た 違い です よ ね ソレ は 本当 に 生きざま を 貫い て いる と いう か そこ が やっぱ 違い ます よ (金子)[なんかもどっちにしろかっこいいですよね、坂本龍馬にしてもそれこそ、新撰組の立場にしても両方ともがカッコ良い時代ですよね、それは本当に生き様を貫いているというかそこがやっぱ違いますよね。] Speaker 1(渡邊): ね 確か 確か 面白い です ね 歴史 上 の 人物 だ けど 僕 も 参画 し て 大好き な ので 脅威 と か (渡邊)[面白いですね。歴史上の人物だけど僕も三国志大好きなので姜維とかいいですね。] Speaker 0(金子): そう です ね いや 選び 選ぶ の は 結構 大変 で は ある ん です けど そういう 所轄 よう お願い し てる し た ん です けど まあ 教員 キャロル ま これ は ね 是非 あれ です よ ね お 茶 分から ない ま 僕 も ちょっと 吉田 松陰 について ちょっと 知り たい な って 思い ます し (金子)[そうですね。選び、選ぶのは結構大変ではあるんですけどそれこそ諸葛亮も大好きですし、とかあるんですけど、まぁ姜維になるのかな〜。これはぜひあれですよね、わからない、僕もちょっと吉田松陰についてちょっと知りたいなって思いますし。] Speaker 1(渡邊): 驚異 の 小説 が あっ た ん です よ (渡邊)[姜維の小説があったんですよ] Speaker 0(金子): 驚異 の 小説 が ある (金子)[姜維の小説があるんですか?] Speaker 1(渡邊): 教員 の 小説 が 脅威 と いう か? その さん 牧師 が 終わっ た 後 の 省察 はい はい 何で 所轄 量 が 五 上限 で 死ん だ (渡邊)[姜維というかその三国志が終わった後の小説。なので、諸葛亮が五丈原で死んだ後。] Speaker 0(金子): ん だ (金子)[ん〜] Speaker 1(渡邊): から その 脅威 昔 死ぬ まで の (渡邊)[から、その姜維が死ぬまでの] Speaker 0(金子): 小説 を あのー 結構 こう マイナー (渡邊)[小説。](金子)[へー、結構、コアな。](渡邊)[結構、コア、マイナー] Speaker 1(渡邊): な ところ が あっ て でも そう 面白かっ た です (渡邊)[なところがあってでもそれ面白かったですよ] Speaker 0(金子): よ Speaker 1(渡邊): 脅威 が 当該 東大 たち が 当該 障害 か 障害 と じゃ どう いう 風 な 話 を し て 体 を 起こす よう に 思っ た の か? はい そこ の ストーリー が 凄い (渡邊)[姜維が鄧艾、頭蓋と、あ、違う鄧艾じゃないか、鍾会か。鍾会とじゃどういう風な話をして反乱を起こすように思ったのか。そこのストーリーが凄い面白い] ...これが普通の会話のリアルな精度です。
※僕の滑舌が悪いだけかもしれないですが、、、(汗)
② CLIを用いて、自動音声認識システム構築(エンジニア向け)
エンジニアの方々お待たせしました!いよいよ開発!!!といったところですが、
長くなったので、後編の記事で書きます!前編のまとめ
精度には不安が残りますが、なんといってもこの手軽さが素晴らしい!
エンジニアではない方でも使用でき、日本語にも対応して、この安さ!!
一度、使ってみる価値はあると思います!また、時間を見つけて、Google Cloudの
Speech-to-TextやAzureのSpeech to Textも試して、サービス比較表を作りたいな〜と思っています?・Google Cloud Speech-to-Text
・Azure Speech to Text気になる正確性については後編へ!!
※後編まだかけていないですが、気が向いたらかきます。。。?


- 投稿日:2020-05-25T19:17:32+09:00
AWS SAA資格取得~EBSとEFS編~
はじめに
SAA対策のWEB問題集で「EBS」と「EFS」の違いについて理解できていなかったため、
少しまとめたいと思います。EBSとは
永続可能なブロックストレージサービス。EC2インスタンスにアタッチすることで利用できる。
※ブロックストレージとはデータを「ブロック」と呼ばれる細かい単位で分割して保管する方式。EBS特徴的機能
複数のストレージタイプ
汎用SSD(General Purpose SSD:gp2)
デフォルトで提供されているストレージタイプ。SSDを安価に利用することができる。
確保した容量に応じてIOPSが設定されており、OSのルート領域や、高性能なI/Oを
要求されないデータ領域で利用される。プロビジョンドIOPS SSD(PIOPS:io1)
高パフォーマンスを実現できるストレージタイプ。
SSDをベースにユーザが自由にIOPSを設定して利用することができる。
汎用SSDより高いパフォーマンスが求められる場合にも利用され、ストレージ容量に加えて、
指定したIOPSに対しても課金される。スループット最適化HDD(st1)
HDDタイプのストレージタイプで大容量のストレージを安価に利用することができる。
SSDのストレージタイプと比べて契約できる最低の容量が多くなっている。高可用性
EBSはS3のAZ間での複製とは異なり、AZ内で自動的に複製される仕組みを備えている。
単一のディスク障害を回避することができる。スナップショットによるバックアップ
EBSではスナップショットを用いてバックアップを取得することができる。
スナップショットは自動的にS3に保管される。⇨高い耐久性が備えられている。
オンプレミス環境のストレージではバックアップを取得完了するまで待たなくてはならない。
しかしEBSの場合取得を実行した時点で保管される。
初回はフルバックアップで取得し、以後は増分で取得する特徴がある。EFS(Amazon Elastic File System)とは
スケーラブルな共有ストレージサービスで、複数のEC2インスタンスから
共有ファイルストレージとして利用することができる。
標準的なファイルシステムかでアクセスすることが可能。
そのためEC2だけでなくオンプレミスサーバーからも
利用することが可能。ストレージ容量や、パフォーマンスを自動的にスケーリングする機能も備えている。価格は高いが、可用性や拡張性に優れている。
またEBSでは不可能であった複数EC2インスタンスとの共有ディスクとして利用でき、
データベースサーバーやファイルサーバのストレージとして利用用途が多い。スナップショットのようなバックアップ機能を提供していないため、
別途バックアップを行う仕組みを組む必要がある。EBSとEFSの違いについて
簡単に
・接続台数
EBS:1台のEC2インスタンスと接続可能
EFS:複数のEC2インスタンスと接続可能
・耐久性
EBS:単一のAZ内で冗長化
EFS:複数のAZで冗長化
・拡張性
EBS:手動でボリューム拡張可能
EFS:自動でボリューム拡張可能
・料金体系
EBS:Gバイトあたりの従量課金(安)
EFS:Gバイトあたりの従量課金(高)共通項としては
・接続:EC2インスタンスとネットワーク接続
・データ永続性:永続化可能
・パフォーマンス:高速コストを許容できるならEFSがおすすめ(高パフォーマンス・高可用性で自動で拡張される。楽)
コストが積めない。パフォーマンス重視なら⇨EBS最後に
それぞれの特徴と、ユースケースを踏まえ理解を深めます。
あぁ〜〜〜〜先は長いなぁ〜
- 投稿日:2020-05-25T18:49:38+09:00
AWS MediaServicesについて
AWS Elemetnalとは
まずは一読
[初心者向け] AWS MediaServices の役割をライブ配信ワークフローと照らし合わせながら理解する
https://dev.classmethod.jp/articles/aws-mediaservices-role-with-live/
AWS MediaServices は、主に AWS 上で動画配信を行うために使用されるサービス
- AWS Elemental MediaConnect
- 信頼性と柔軟性が高く、安全なライブビデオの転送
- AWSElemental MediaLive
- ブロードキャストとマルチスクリーンビデオ配信のために入力をライブ出力に変換する
- AWS Elemental MediaPackage
- ライブおよびオンデマンドのビデオコンテンツの作成とパッケージ化
- AWS Elemental MediaStore
- ライブやオンデマンドのメディアワークフロー向けにビデオアセットを作成および保存する
- AWS Elemental MediaTailor
- サーバー側の広告挿入を使って、ビデオコンテンツをパーソナライズし、収益化する
- AWS Elemental MediaConvert
- オンデマンドブロードキャストとマルチスクリーン配信のためのファイルベースのビデオアセットを準備する
OTT(Over-The-Top)
インターネット経由で動画コンテンツ等のサービスを提供する企業の事を OTT(Over-The-Top)
動画配信ワークフローとは
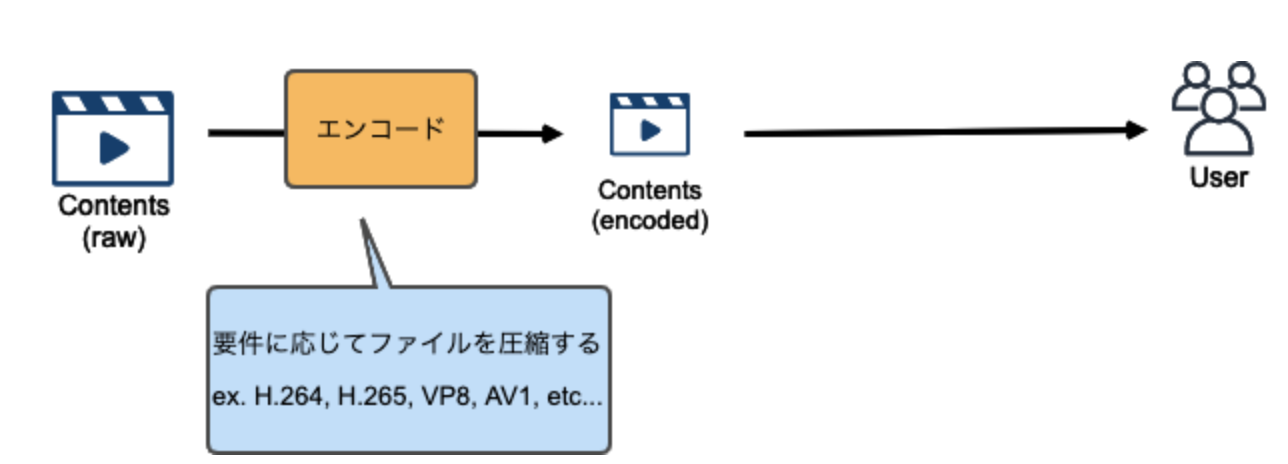
1 エンコード
撮影された生の動画ファイルはサイズが膨大であるため、それをユーザに届けるにはファイルサイズを適切に小さくする圧縮する際のアルゴリズムの事をコーデックと呼びます。
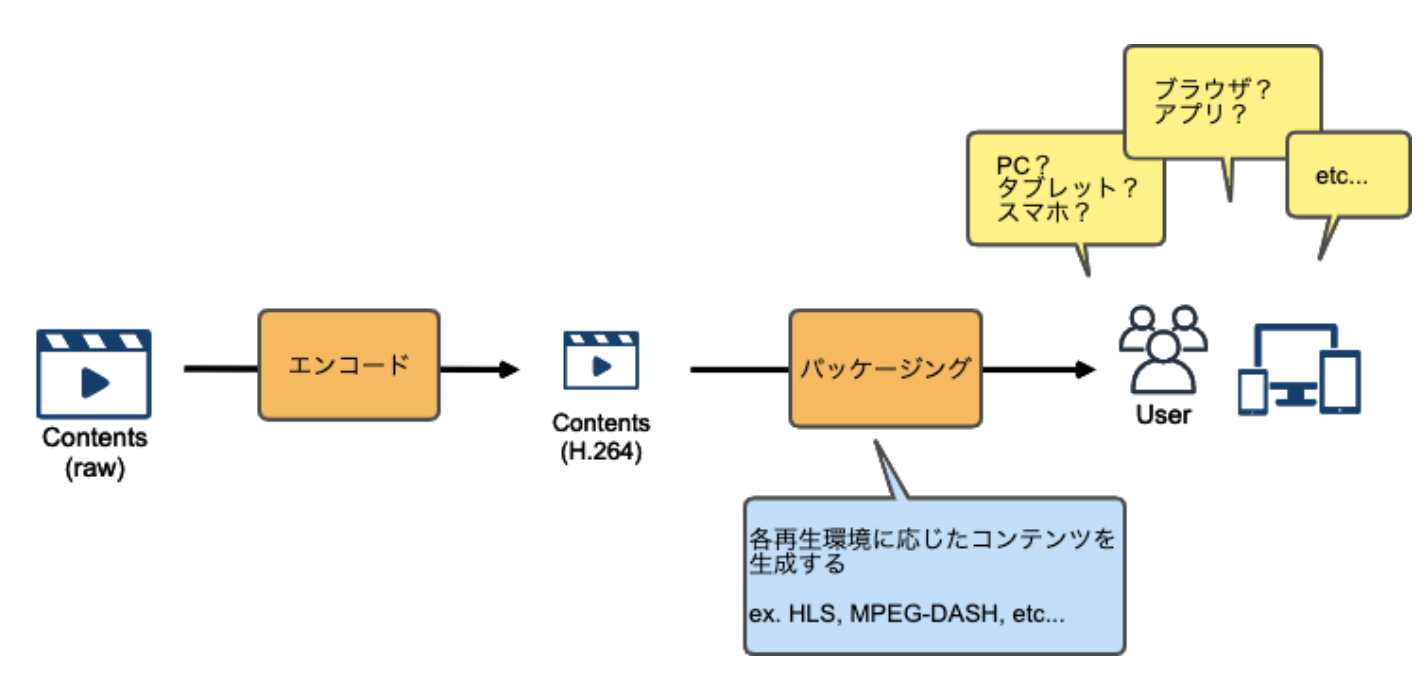
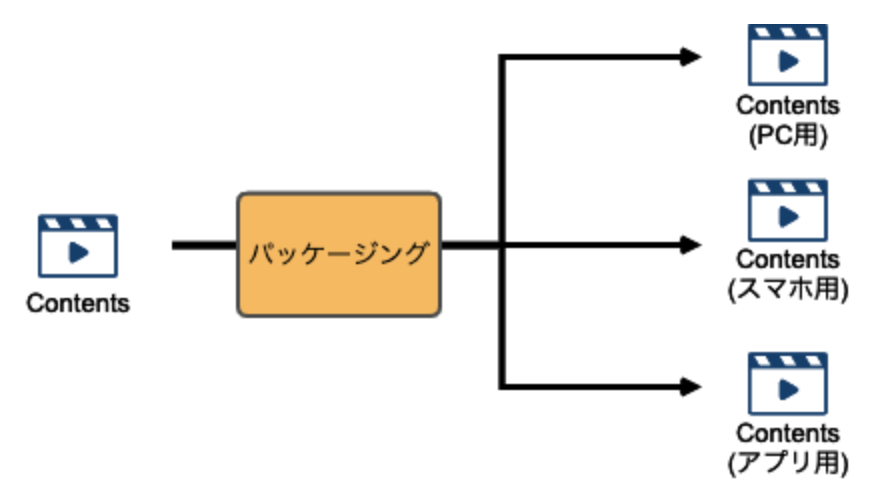
また、ユーザがコンテンツを再生する環境は様々であるため、各環境に対応したコンテンツを生成する必要があります。
これをパッケージングと呼ぶことが多いです。
パッケージングには、各環境に対応する為のコンテンツ生成だけではなく、コンテンツを保護する為にDRMの仕組みを入れたり、広告のメタデータを埋め込むなど、様々な役割が内包されます。
- DRM(Digital Rights Management, DRM)
- デジタル著作権管理
ユーザからのリクエストに素早く応える為に、コンテンツを保管しておく場所も必要になってきます。これをオリジンと呼びます。
AWS MediaServices は、上記における各仕組みを AWS 上で提供し、動画配信ワークフローを実現するためのサービスとなります。
AWS 上でのライブ配信ワークフロー
動画配信のソースとしては、大きく分けてライブと VOD(Video on Demand)が挙げられる
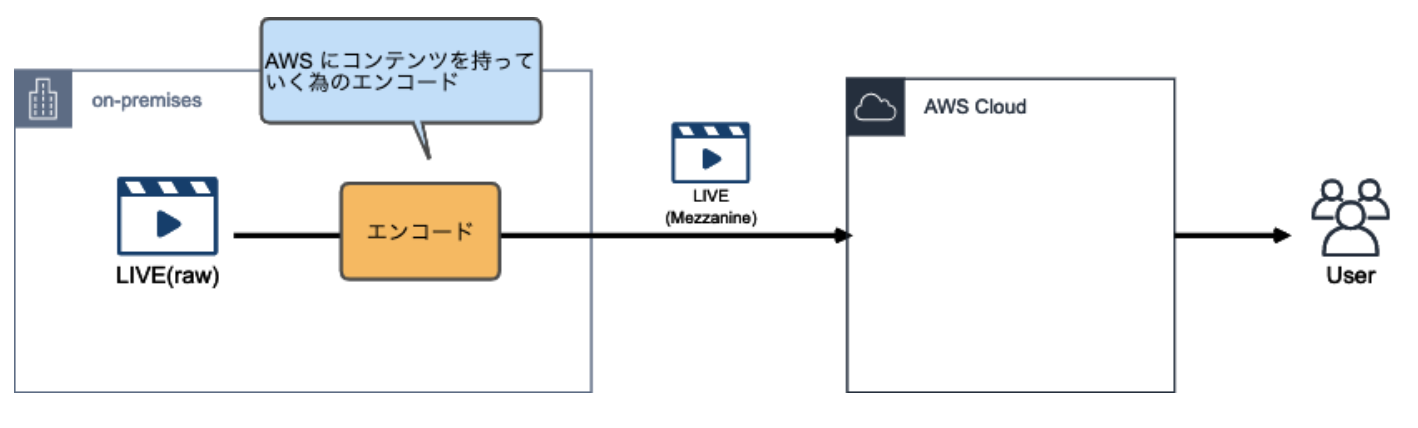
コンテンツを AWS に転送
大抵のケースで生の撮影データはサイズが膨大な為、AWS にコンテンツを転送する前にオンプレミス側で圧縮(エンコード)する必要があります。
AWS に転送される前にオンプレでエンコードされたコンテンツについて、AWS ドキュメント上では Mezzanine Stream(メザニンストリーム)と表現される
Mezzanine」には「中間」といった意味合いがある
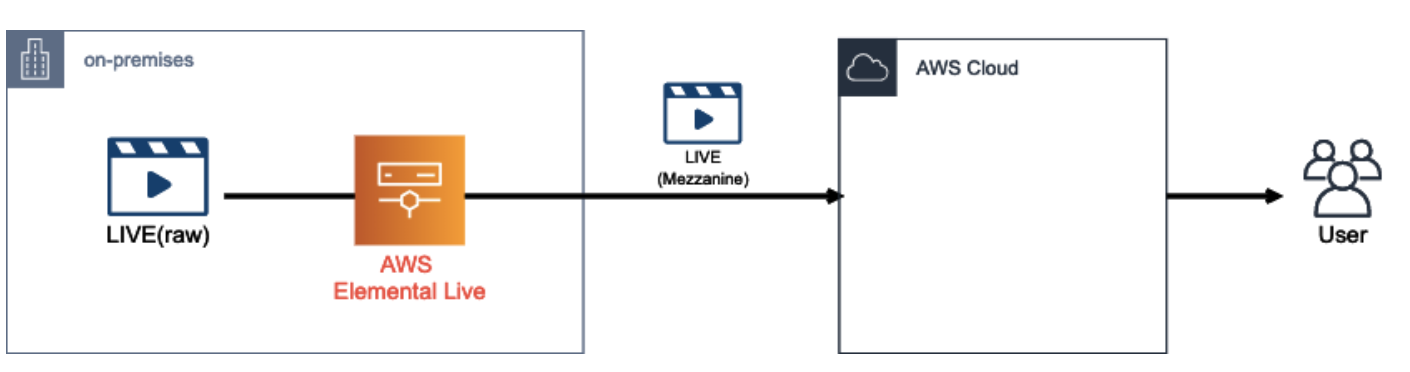
また、オンプレ側で使用するエンコーダーとして、AWS は Elemental Live と呼ばれる物理エンコーダーを提供しています。
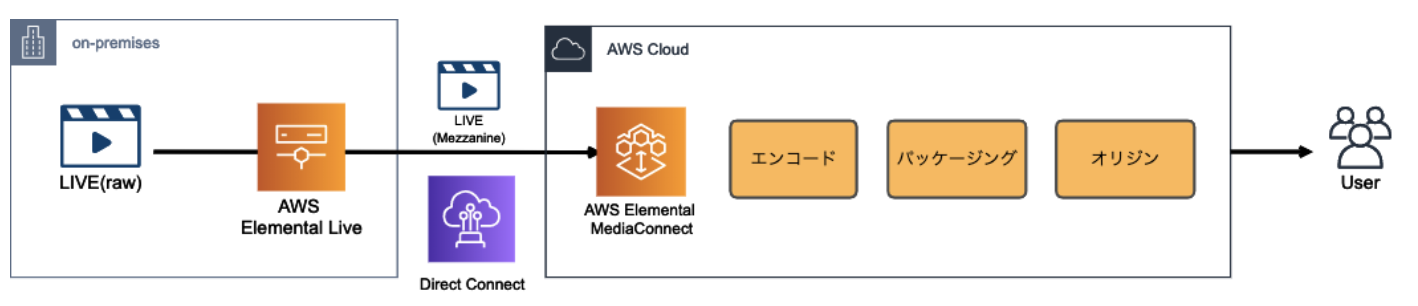
ここで、オンプレから転送されて来る Mezzanine Stream を AWS 側で受ける際に使用できるサービスが AWS Elemental MediaConnect
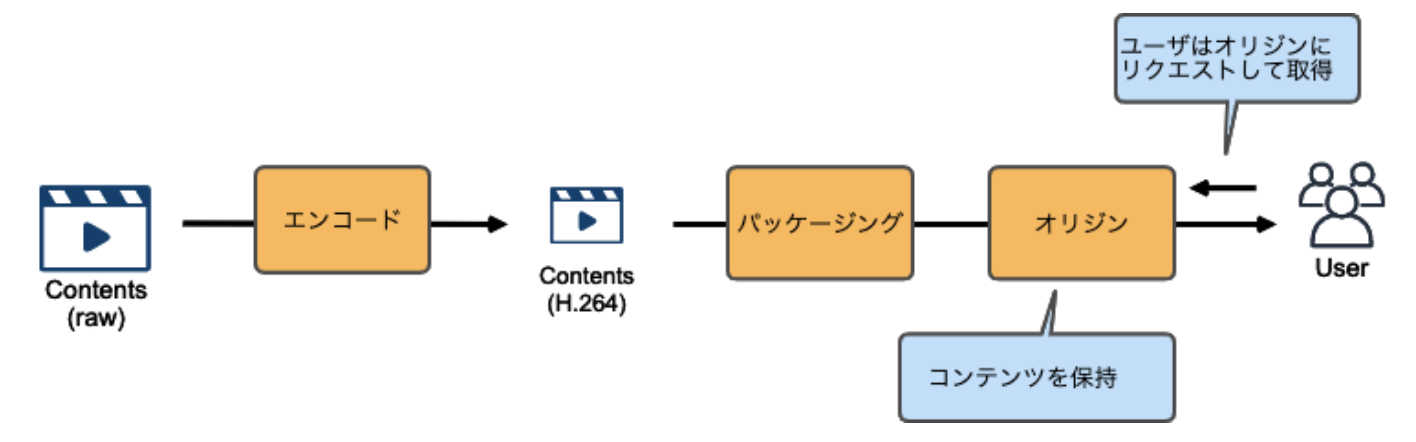
エンコード〜パッケージング〜オリジン
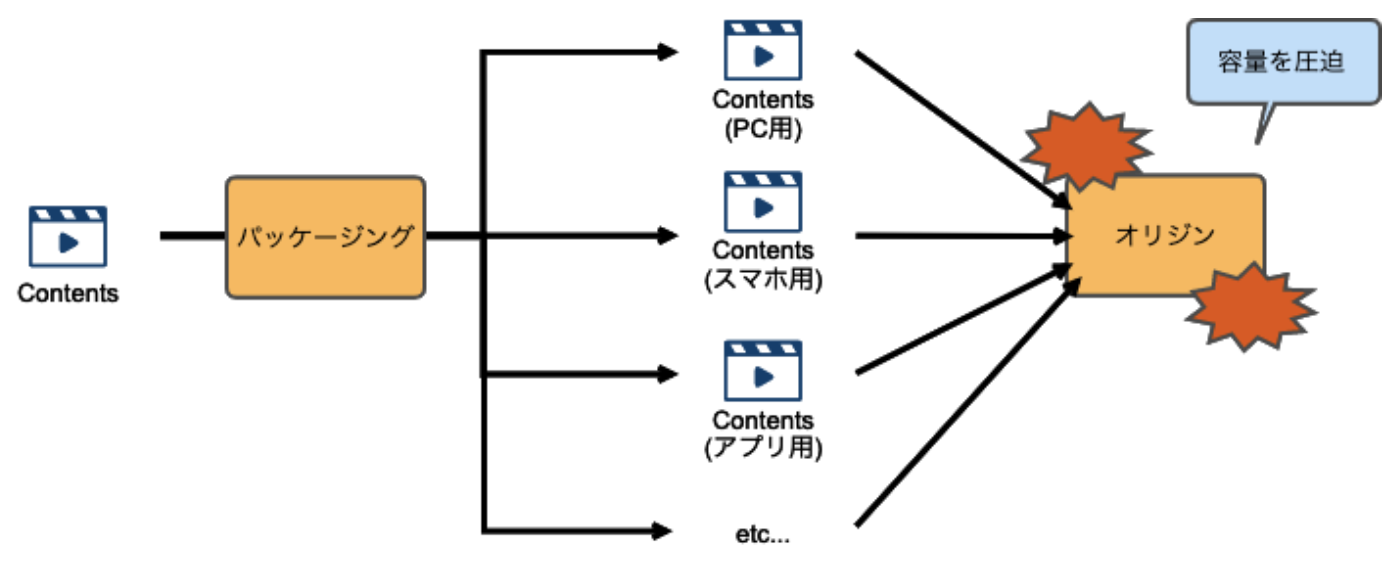
AWS に動画を取り込んだら、ファイルを圧縮(エンコード)し、各再生環境に応じてコンテンツを変換(パッケージング)し、一連の処理が完了したコンテンツをオリジンに格納
AWS Elemental MediaLive
MediaLive によって、オンプレから来た動画ファイルが、私たちがよく目にする H.264 などのコーデックに変換されます。
また、MediaLive の主な役割はエンコードですが、HLS 形式で出力するなど、パッケージングも行う事が出来ます。
AWS Elemental MediaPackage
基本的に、MediaLive でエンコードされたファイルを受け取り、パッケージング処理を行います。
MediaPackage パッケージング処理
- ジャストインタイム(JIT)パッケージング
- DRM や 広告挿入との連携
ジャストインタイム(JIT)パッケージング
パッケージングによって、様々な再生環境に対応するコンテンツが生成
ただし、複数の再生環境に対応するパッケージングファイルを用意してしまうと、オリジンサーバーの容量を圧迫してしまいます。
そこで、パッケージング前のコンテンツのみを保持しておき、リクエストに応じて都度パッケージング処理をする事によってオリジンの負荷を下げる仕組みがジャストインタイムパッケージングです。
DRM や 広告挿入との連携
他にも、デジタル著作権保護(DRM)や、広告挿入なども MediaPackage はサポートしています。
今回は記事ボリュームの都合上取り上げていませんが、MediaTailor と連携する事で広告挿入の仕組みを実現できます
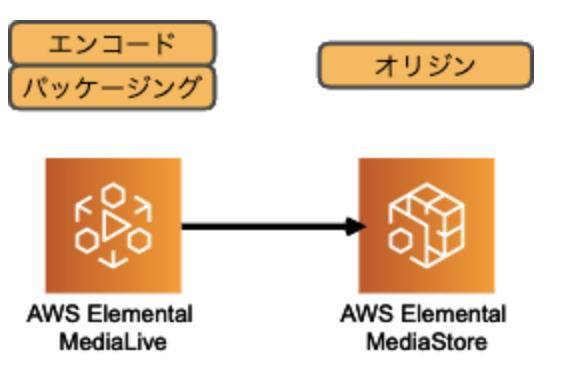
MediaStore は、ライブ動画の様に頻繁に更新&参照されるコンテンツに特化したオブジェクトストレージです。
AWS Elemental MediaStore
AWS 上でライブコンテンツのオリジン機能を提供するサービスが、AWS Elemental MediaStore です。
MediaStoreをS3よりも整合性の強いストレージとして理解する
https://dev.classmethod.jp/articles/aws-elemental-mediastore-mediastore-immediate-consistency/MediaLive / MediaPackage / MediaStore 使い分け
MediaLive + MediaStore
ユースケースとしては、DRM や広告挿入などパッケージングに不要で、かつコンテンツの再生環境も限られている(HLSだけとか)場合にはこの構成で十分
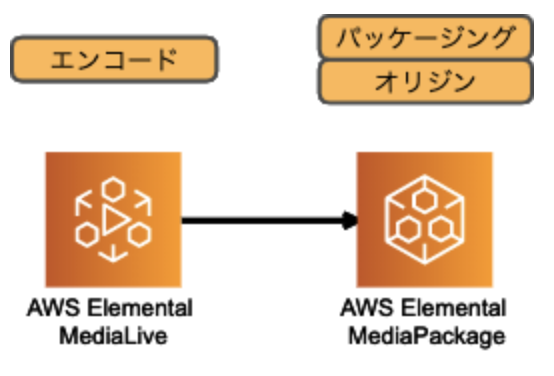
MediaLive + MediaPackage
MediaLive にてエンコードのみを行い、パッケージングとオリジンの機能は MediaPackage で実現する構成
基本的には、MediaLive + MediaStore の構成をベース検討し、やりたい事(複数デバイス対応、DRM、広告挿入、etc)が達成出来ない場合には MediaPackage の使用を検討する、という流れが良いのではないでしょうか。
CDN
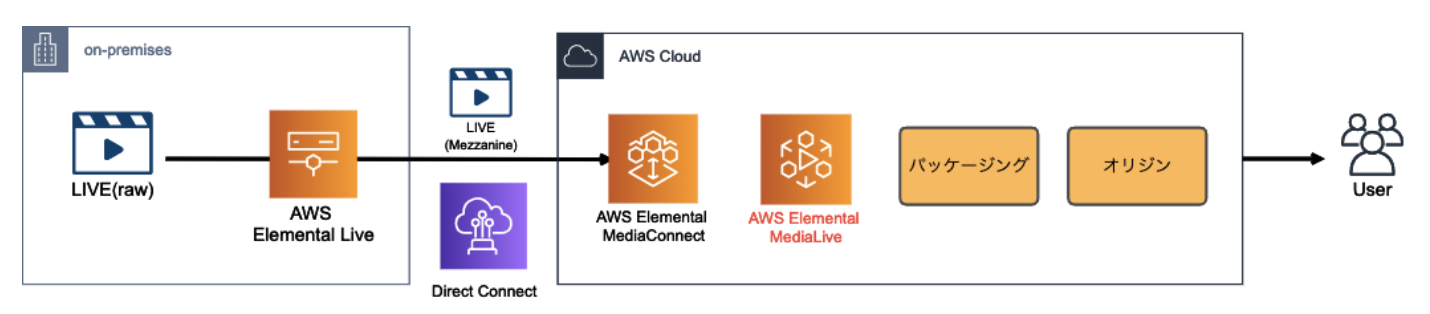
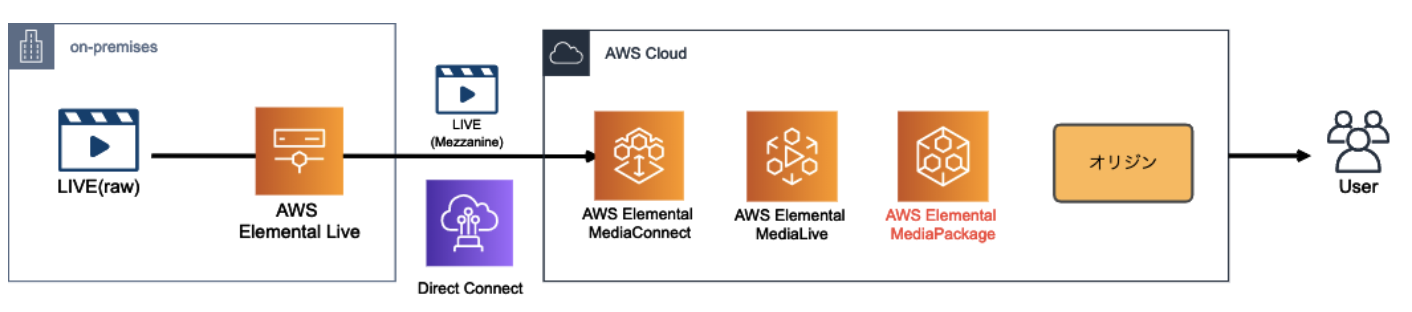
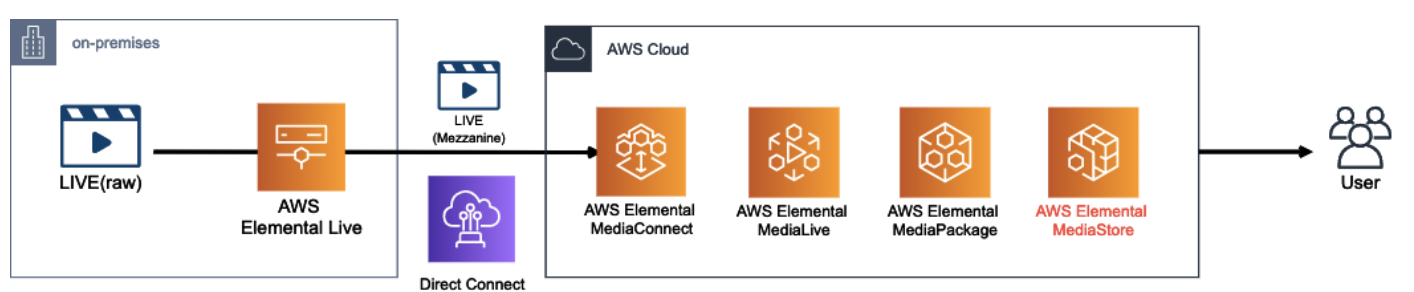

- 投稿日:2020-05-25T18:25:29+09:00
S3 Glacier Deep Archiveを使ってみる
S3 Glacier Deep Archiveとは
S3 Glacier Deep Archiveとは、
AWS S3のストレージクラスの1つで、データの取り出しに12時間くらいかかるけど、ストレージ費用(データ保管費用)がめっちゃ安いというものです。ストレージ費用は、2020年5月現在最安のリージョン(オハイオなど)では、
「0.00099USD/GB/月≒1GBを1か月あたり約0.11円」なので、
- 1TBのデータを1年間保管した場合
- 11.88USD≒1300円程度
となります。
取り出しには別途費用がかかりますが、めちゃくちゃ安いです。ビジネス上の帳簿データから個人的なデータまで、あらゆるバックアップに活用できます。
今回は、これをブラウザから簡単に使ってみる方法を紹介します。
※AWSのCLIから利用する方法については、公式ドキュメントをご参照ください。この記事の対象読者
本記事は、
- 安くて安全な、長期保管データの保存場所が欲しい
- AWSやS3をほぼ触ったことがない
- ブラウザから使いたい
という人を想定して作成しています。
ブラウザからの使い方
S3バケットのセットアップ
公式ドキュメントを参考に、
- 開始方法
- Amazon S3 のセットアップ
- バケットの作成
までを実施します。(既にバケットがある場合は、それを使っても大丈夫です。)
なお、リージョンによって利用料金が違う点にご注意ください。
利用料金は、S3の料金表から確認できます。バケットへのオブジェクトのアップロード
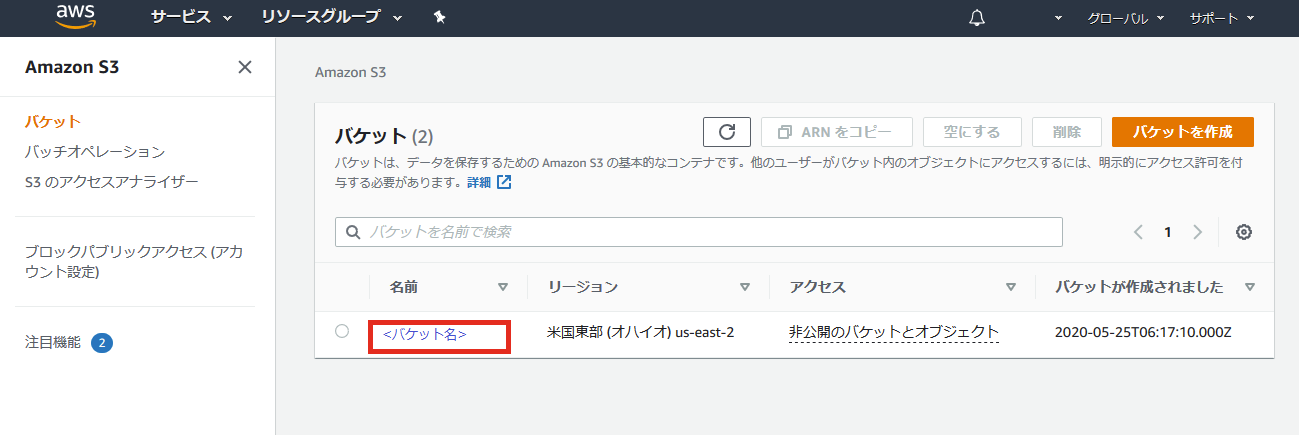
- バケット一覧 を開くと、さきほど作ったバケットが表示されているので、それを開きます。
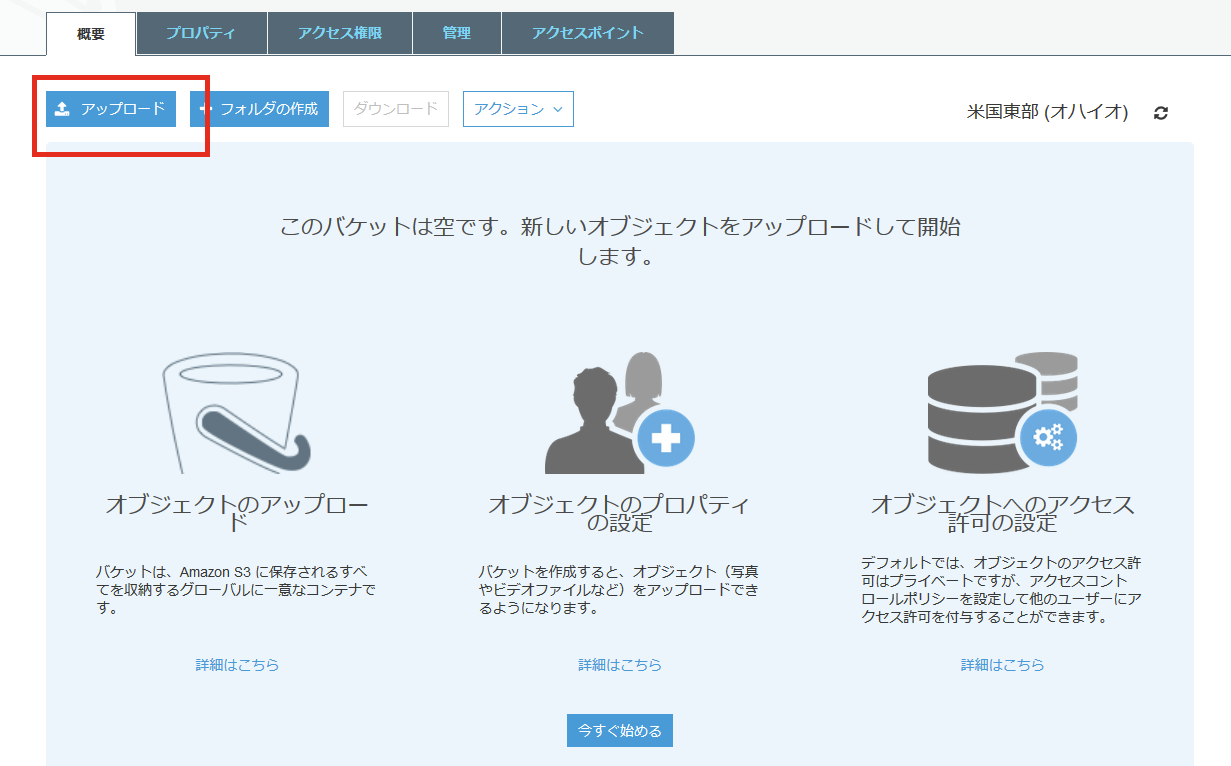
- 「アップロード」ボタンがあるので、クリックします。
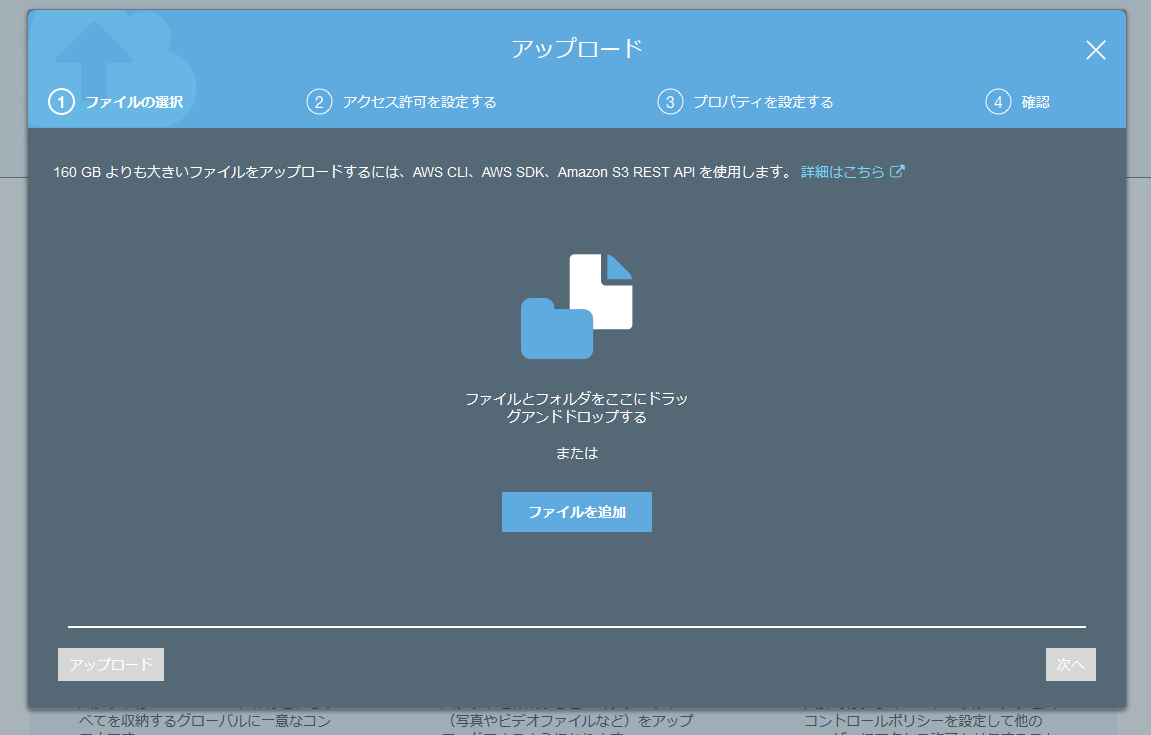
- アップロードするファイルを選択し、選択し終わったら「次へ」をクリックします。
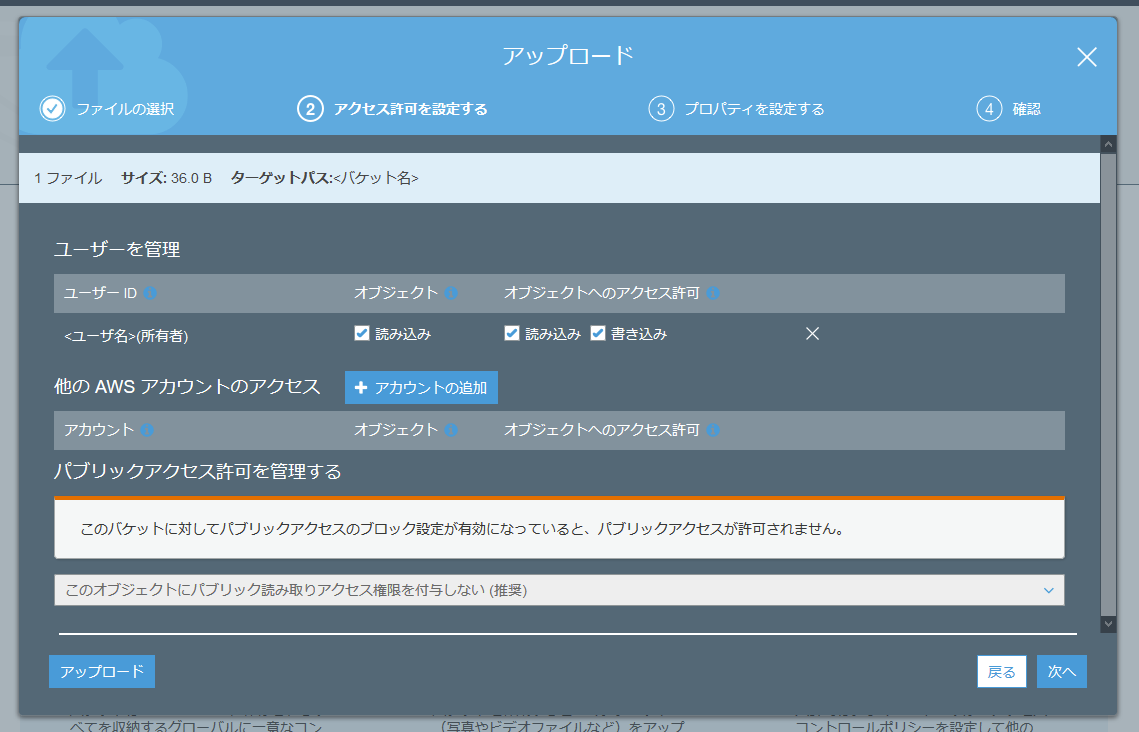
- 「アクセス許可の設定」が開きます。アップロードしたデータの公開範囲の設定なので、不用意に公開してしまわないよう注意してください。
公開したくないデータの場合は、「このバケットに対してパブリックアクセスのブロック設定が有効になっていると、パブリックアクセスが許可されません。」と表示されている場合は、公開しない設定となっているので大丈夫です。
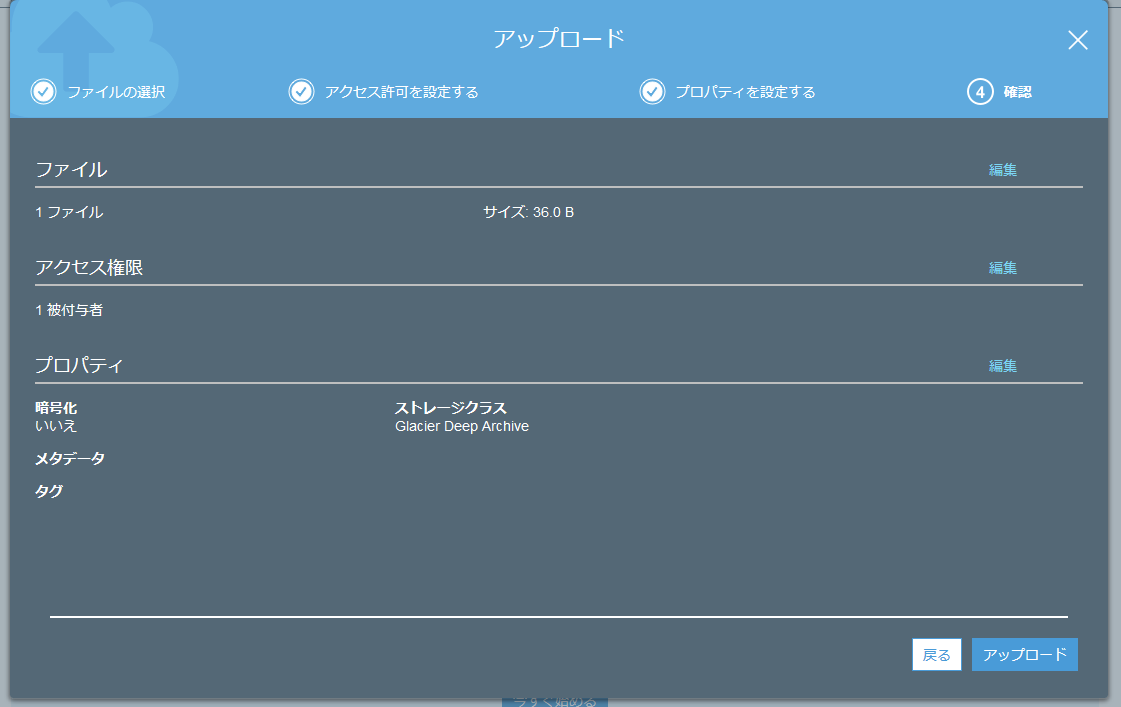
- ストレージクラスを「Glacier Deep Archive」に設定し、「次へ」をクリックします。
ここが一番重要です。
これを指定することで、ストレージ料金の安い「S3 Glacier Deep Archive」を利用できます。「暗号化」は「なし」でも構いませんが、設定するとAmazonのデータセンターから媒体が盗まれた時などの安全性が高まります。
- 設定を確認し、「アップロード」をクリックするとアップロードが始まります。
ちょっと(ファイルサイズによる)待つと、アップロード完了です。
アップロードしたオブジェクトの確認
アップロードしたオブジェクトについては、メタデータを確認することはできますが、
内容を確認したい・ダウンロードしたいといった場合には「復元」のリクエストを行ったうえで取り出す必要があります。詳細については、公式マニュアル: アーカイブされた S3 オブジェクトを復元する方法を参照してください。
まとめ
S3の「Glacier Deep Archive」は、保管費用がめっちゃ安いので、
使わないけど取っておきたいデータ用にぜひ使ってみてください!ご拝読ありがとうございました。
間違っている点等あれば、ぜひご指摘ください!

- 投稿日:2020-05-25T18:25:29+09:00
AWS S3 Glacier Deep Archive - 世界一安いストレージの試し方
S3 Glacier Deep Archiveとは
S3 Glacier Deep Archiveとは、
AWS S3のストレージクラスの1つで、データの取り出しに12時間くらいかかるけど、ストレージ費用(データ保管費用)がめっちゃ安いというものです。ストレージ費用は、2020年5月現在最安のリージョン(オハイオなど)では、
「0.00099USD/GB/月≒1GBを1か月あたり約0.11円」なので、
- 1TBのデータを1年間保管した場合
- 11.88USD≒1300円程度
となります。
取り出しには別途費用がかかりますが、めちゃくちゃ安いです。ビジネス上の帳簿データから個人的なデータまで、あらゆるバックアップに活用できます。
今回は、これをブラウザから簡単に使ってみる方法を紹介します。
※AWSのCLIから利用する方法については、公式ドキュメントをご参照ください。この記事の対象読者
本記事は、
- 安くて安全な、長期保管データの保存場所が欲しい
- AWSやS3をほぼ触ったことがない
- ブラウザから使いたい
という人を想定して作成しています。
ブラウザからの使い方
S3バケットのセットアップ
公式ドキュメントを参考に、
- 開始方法
- Amazon S3 のセットアップ
- バケットの作成
までを実施します。(既にバケットがある場合は、それを使っても大丈夫です。)
なお、リージョンによって利用料金が違う点にご注意ください。
利用料金は、S3の料金表から確認できます。バケットへのオブジェクトのアップロード
- バケット一覧 を開くと、さきほど作ったバケットが表示されているので、それを開きます。
- 「アップロード」ボタンがあるので、クリックします。
- アップロードするファイルを選択し、選択し終わったら「次へ」をクリックします。
- 「アクセス許可の設定」が開きます。アップロードしたデータの公開範囲の設定なので、不用意に公開してしまわないよう注意してください。
公開したくないデータの場合は、「このバケットに対してパブリックアクセスのブロック設定が有効になっていると、パブリックアクセスが許可されません。」と表示されている場合は、公開しない設定となっているので大丈夫です。
- ストレージクラスを「Glacier Deep Archive」に設定し、「次へ」をクリックします。
ここが一番重要です。
これを指定することで、ストレージ料金の安い「S3 Glacier Deep Archive」を利用できます。「暗号化」は「なし」でも構いませんが、設定するとAmazonのデータセンターから媒体が盗まれた時などの安全性が高まります。
- 設定を確認し、「アップロード」をクリックするとアップロードが始まります。
ちょっと(ファイルサイズによる)待つと、アップロード完了です。
アップロードしたオブジェクトの確認
アップロードしたオブジェクトについては、メタデータを確認することはできますが、
内容を確認したい・ダウンロードしたいといった場合には「復元」のリクエストを行ったうえで取り出す必要があります。詳細については、公式マニュアル: アーカイブされた S3 オブジェクトを復元する方法を参照してください。
まとめ
S3の「Glacier Deep Archive」は、保管費用がめっちゃ安いので、
使わないけど取っておきたいデータ用にぜひ使ってみてください!ご拝読ありがとうございました。
間違っている点等あれば、ぜひご指摘ください!
- 投稿日:2020-05-25T18:25:29+09:00
AWS S3 Glacier Deep Archive - AWSで一番安いストレージの試し方
S3 Glacier Deep Archiveとは
S3 Glacier Deep Archiveとは、
AWS S3のストレージクラスの1つで、データの取り出しに12時間くらいかかるけど、ストレージ費用(データ保管費用)がめっちゃ安いというものです。ストレージ費用は、2020年5月現在最安のリージョン(オハイオなど)では、
「0.00099USD/GB/月≒1GBを1か月あたり約0.11円」なので、
- 1TBのデータを1年間保管した場合
- 11.88USD≒1300円程度
となります。
取り出しには別途費用がかかりますが、めちゃくちゃ安いです。ビジネス上の帳簿データから個人的なデータまで、あらゆるバックアップに活用できます。
今回は、これをブラウザから簡単に使ってみる方法を紹介します。
※AWSのCLIから利用する方法については、公式ドキュメントをご参照ください。この記事の対象読者
本記事は、
- 安くて安全な、全く使わないけど長期保管するデータの保存場所が欲しい
- AWSやS3をほぼ触ったことがない
- ブラウザから使いたい
という人を想定して作成しています。
注意点
S3 Glacier Deep Archiveには、オブジェクトごとに180日間の最低利用期間があります。
https://aws.amazon.com/jp/s3/pricing/
S3 Glacier と S3 Glacier Deep Archive にアーカイブされるオブジェクトには、それぞれ最小 90 日間と 180 日間のストレージがあります。90 日間および 180 日間が経過する前にオブジェクトが削除された場合、残りのストレージ料金が日割りで請求されます。最小ストレージ期間が経過する前にオブジェクトが削除されたり、上書きされたり、別のストレージクラスに移行されたりした場合、通常のストレージ利用料金に加えて、その最小ストレージ期間の残りのリクエスト料金が日割りで請求されます。
180日以内にアップロードしたオブジェクトを削除すると、その時点で半年分の金額からいままで払った分を引いた額が請求されるのでご注意ください。
ブラウザからの使い方
S3バケットのセットアップ
公式ドキュメントを参考に、
- 開始方法
- Amazon S3 のセットアップ
- バケットの作成
までを実施します。(既にバケットがある場合は、それを使っても大丈夫です。)
なお、リージョンによって利用料金が違う点にご注意ください。
利用料金は、S3の料金表から確認できます。バケットへのオブジェクトのアップロード
- バケット一覧 を開くと、さきほど作ったバケットが表示されているので、それを開きます。
- 「アップロード」ボタンがあるので、クリックします。
- アップロードするファイルを選択し、選択し終わったら「次へ」をクリックします。
- 「アクセス許可の設定」が開きます。アップロードしたデータの公開範囲の設定なので、不用意に公開してしまわないよう注意してください。
公開したくないデータの場合は、「このバケットに対してパブリックアクセスのブロック設定が有効になっていると、パブリックアクセスが許可されません。」と表示されている場合は、公開しない設定となっているので大丈夫です。
- ストレージクラスを「Glacier Deep Archive」に設定し、「次へ」をクリックします。
ここが一番重要です。
これを指定することで、ストレージ料金の安い「S3 Glacier Deep Archive」を利用できます。「暗号化」は「なし」でも構いませんが、設定するとAmazonのデータセンターから媒体が盗まれた時などの安全性が高まります。
- 設定を確認し、「アップロード」をクリックするとアップロードが始まります。
ちょっと(ファイルサイズによる)待つと、アップロード完了です。
アップロードしたオブジェクトの確認
アップロードしたオブジェクトについては、メタデータを確認することはできますが、
内容を確認したい・ダウンロードしたいといった場合には「復元」のリクエストを行ったうえで取り出す必要があります。詳細については、公式マニュアル: アーカイブされた S3 オブジェクトを復元する方法を参照してください。
まとめ
S3の「Glacier Deep Archive」は、保管費用がめっちゃ安いので、
使わないけど取っておきたいデータ用にぜひ使ってみてください!ご拝読ありがとうございました。
間違っている点等あれば、ぜひご指摘ください!更新履歴
- 2020-05-26
- @netebakari さんのご指摘を受け、「注意点」として最低利用期間の記述を追加
- 投稿日:2020-05-25T17:11:51+09:00
AWS EC2にHTMLをアップロードする
AWS EC2にHTMLをアップロードする
びっくりするほどハマったのでノウハウをシェアします。
AWSの練習というよりはリナックスの練習のようでした。
SESで仕事をしているといきなりリナックスも使うときは使うのでいい練習になりました。No1 EC2にSSH接続を行う。
ssh -i "/Users/gina/.ssh/flash-card.pem" ec2-user@9.999.999.999
No2 入ってない場合はApacheをインストールし、スタートする。
sudo -i (ルート権限に変更する)
yum -y install httpd
service httpd start
systemctl status httpdNo3 ブラウザでWebサーバーのIPアドレスを入力する。
ブラウザでWebサーバーのIPアドレスを入力し、画面が見えたら正解。
↓ ここまでは下記の記事が参考になります。【Amazon3時間クッキング】材料費500円でAWSにWordPress環境を構築するレシピ
https://qiita.com/blackriver/items/9ef870b1624373d18dfaNo4 exitを行う。
exit
No5 SCPのコマンドでEC2上に一時的にアップロード
scp -i /Users/gina/.ssh/flash-card.pem -r /Users/gina/Documents/itFlash/flashCard.html ec2-user@9.999.999.999:/home/ec2-user/
注 移動するファイルは絶対パスでないとうまく行かないようです。No6 EC2にSSH接続を行い、ルート権限に変更し、Apacheが見ている場所へファイルの移動を行う。
ssh -i "/Users/gina/.ssh/flash-card.pem" ec2-user@9.999.999.999
sudo -i (ルート権限に変更する)
cp /home/ec2-user/flashCard.html /var/www/htmlNo7画面を確認する。
- 投稿日:2020-05-25T16:30:51+09:00
Amazon CloudWatch Synthetics の動作を確認する
Amazon CloudWatch Synthetics では、Canary を作成してエンドポイントと API を監視できます。
ただやってみる。
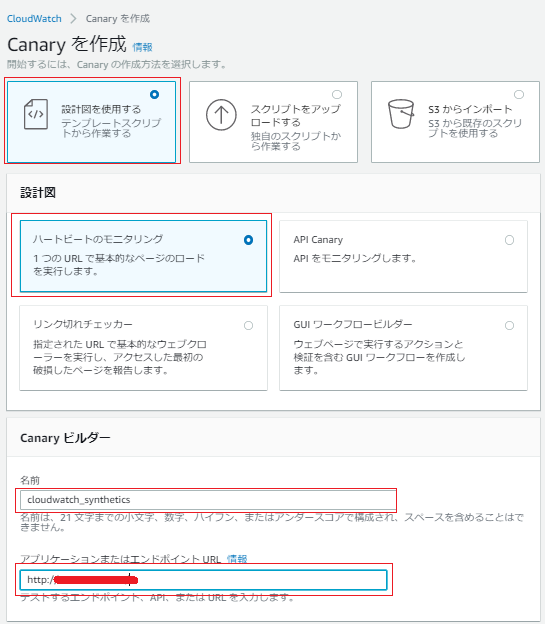
今回は基本的な動作を確認したいだけなので、「設計図を使用する」とし「ハートビートのモニタリング」を試す。
「名前」は適当に入力し、「アプリケーションまたはエンドポイント」は適当に作成しておいたWEBサーバのアドレスを指定しておいた。
「スクリプトエディタ」では以下のとおり、Node JS 10.x で作成され、
const URL = "http://*.*.*.*/";に先程のWEBサーバのアドレスが入る。var synthetics = require('Synthetics'); const log = require('SyntheticsLogger'); const pageLoadBlueprint = async function () { // INSERT URL here const URL = "http://*.*.*.*/"; let page = await synthetics.getPage(); const response = await page.goto(URL, {waitUntil: 'domcontentloaded', timeout: 30000}); //Wait for page to render. //Increase or decrease wait time based on endpoint being monitored. await page.waitFor(15000); await synthetics.takeScreenshot('loaded', 'loaded'); let pageTitle = await page.title(); log.info('Page title: ' + pageTitle); if (response.status() !== 200) { throw "Failed to load page!"; } }; exports.handler = async () => { return await pageLoadBlueprint(); };「スケジュール」「データ保持」はデフォルトにしておきます。
データを保存するS3バケット「データストレージ」を選択。
アーティファクトを S3 に配置し、ログを保存して Cloudwatch にメトリクスを発行する権限が必要なIAM ロールを作成します。ここでは「新しいロールを作成」。
ちなみに作成されるIAMロールは以下のとおり。
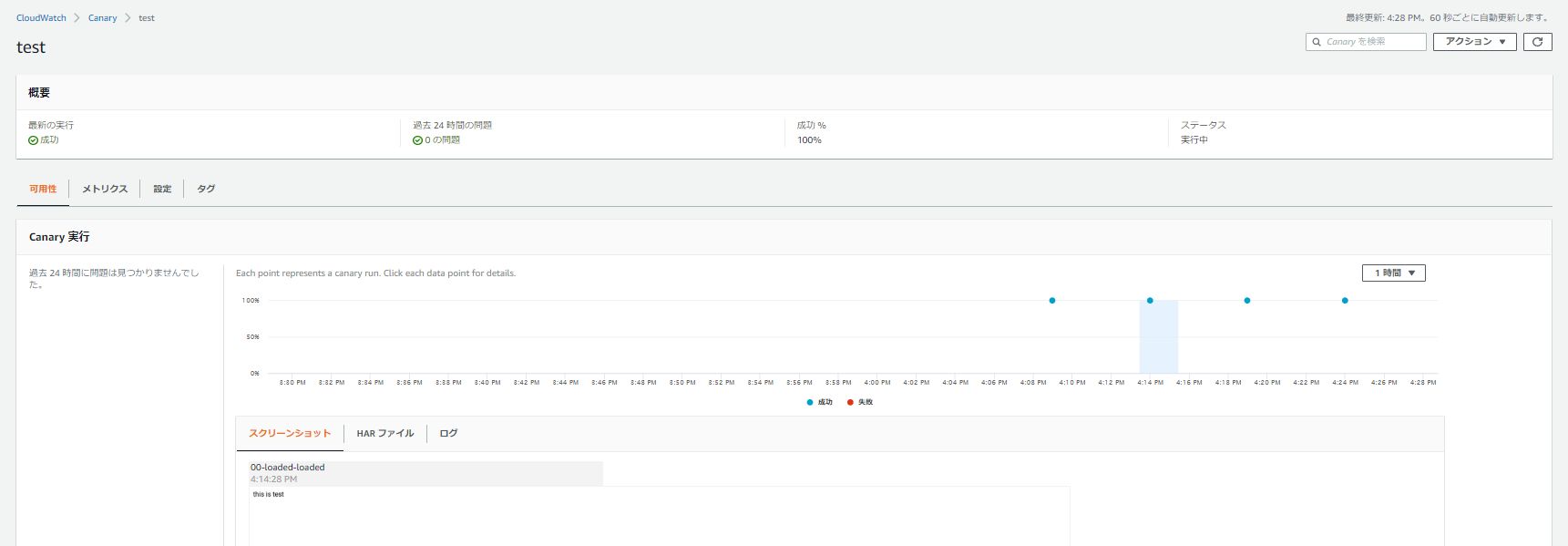
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": [ "s3:PutObject", "s3:GetBucketLocation" ], "Resource": [ "arn:aws:s3:::cw-syn-results-000000000000-ap-northeast-1/canary/test-fa5-8ddfac9762db/*" ] }, { "Effect": "Allow", "Action": [ "logs:CreateLogStream", "logs:PutLogEvents", "logs:CreateLogGroup" ], "Resource": [ "arn:aws:logs:ap-northeast-1:000000000000:log-group:/aws/lambda/cwsyn-test-*" ] }, { "Effect": "Allow", "Action": [ "s3:ListAllMyBuckets" ], "Resource": [ "*" ] }, { "Effect": "Allow", "Resource": "*", "Action": "cloudwatch:PutMetricData", "Condition": { "StringEquals": { "cloudwatch:namespace": "CloudWatchSynthetics" } } } ] }このようにデフォルト5分おきに設定したため、ハートビートのモニタリングに成功していることが確認できる。

- 投稿日:2020-05-25T16:11:03+09:00
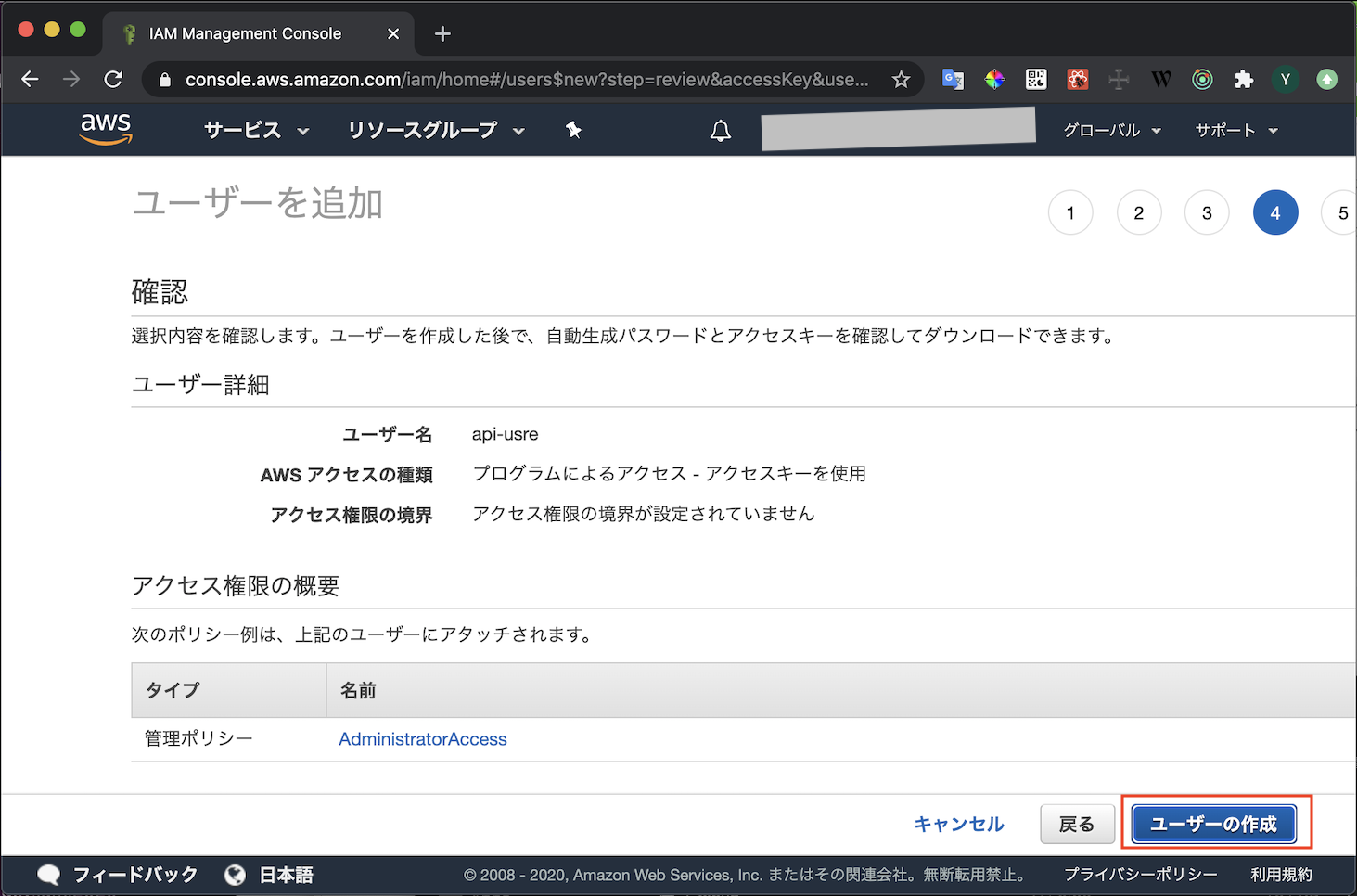
【AWS】アクセスキーの作成/登録
概要
- CLIなどからAWSにアクセスするためのアクセスキーの発行手順です
アクセスキーの発行
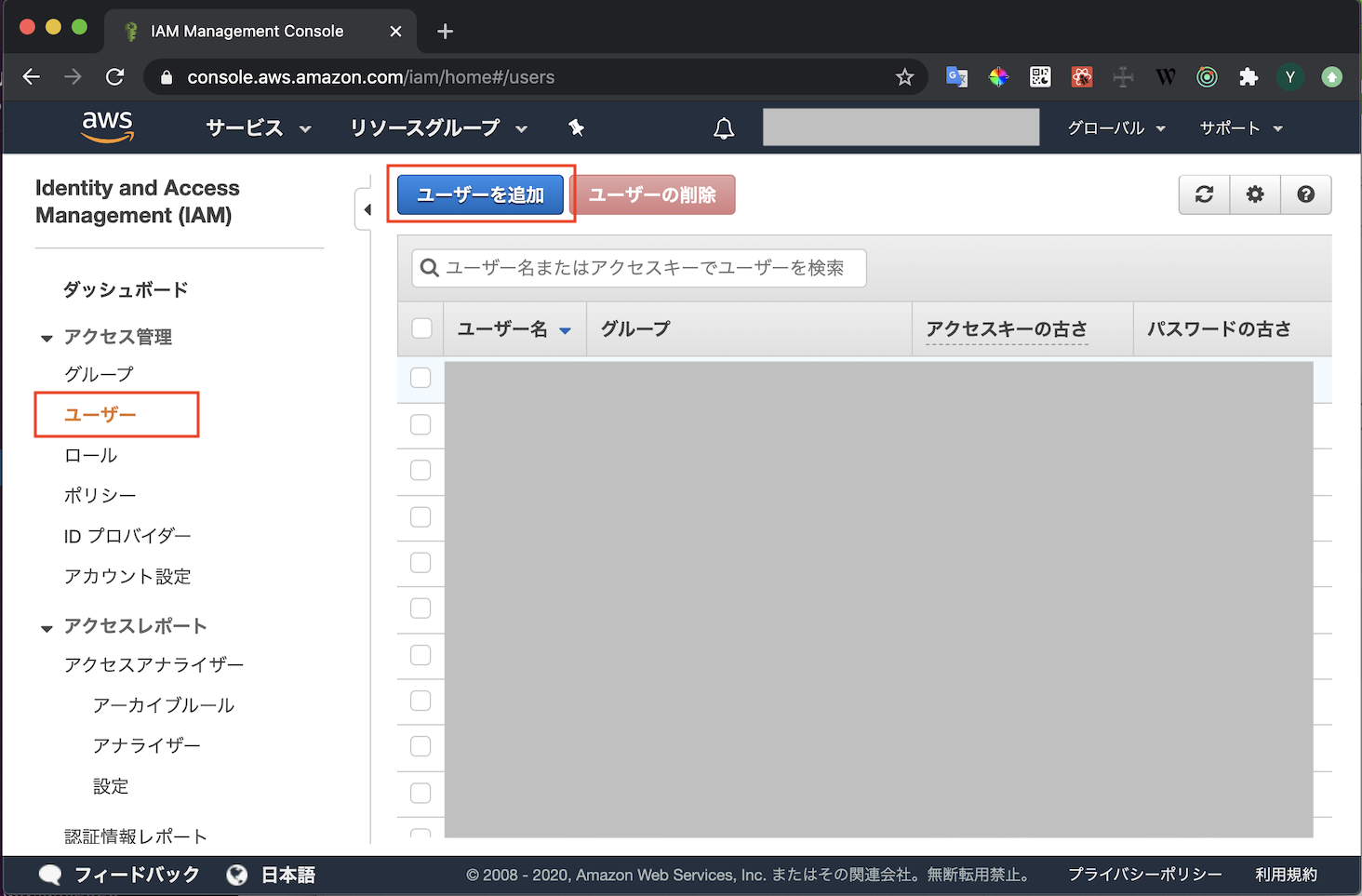
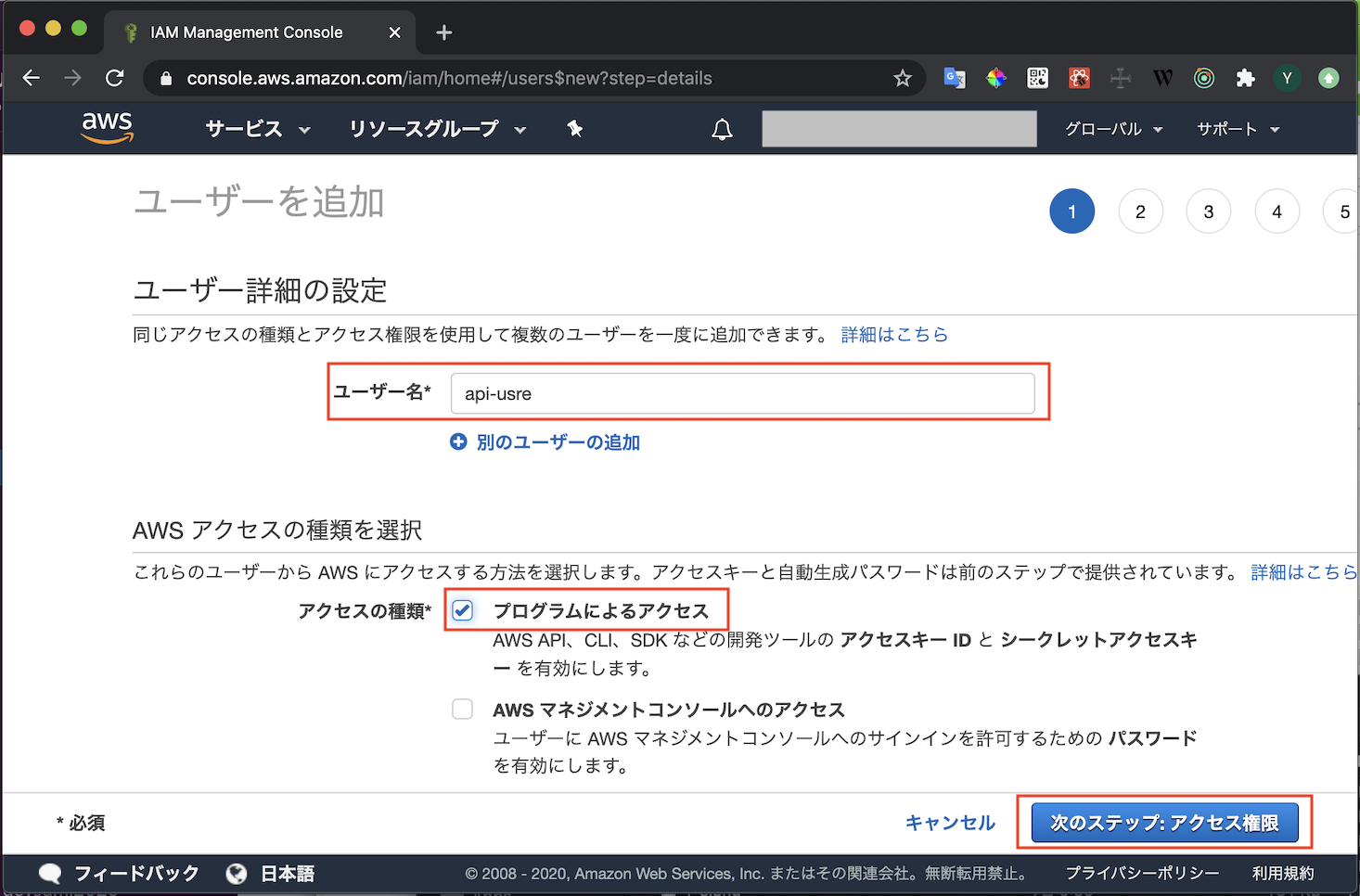
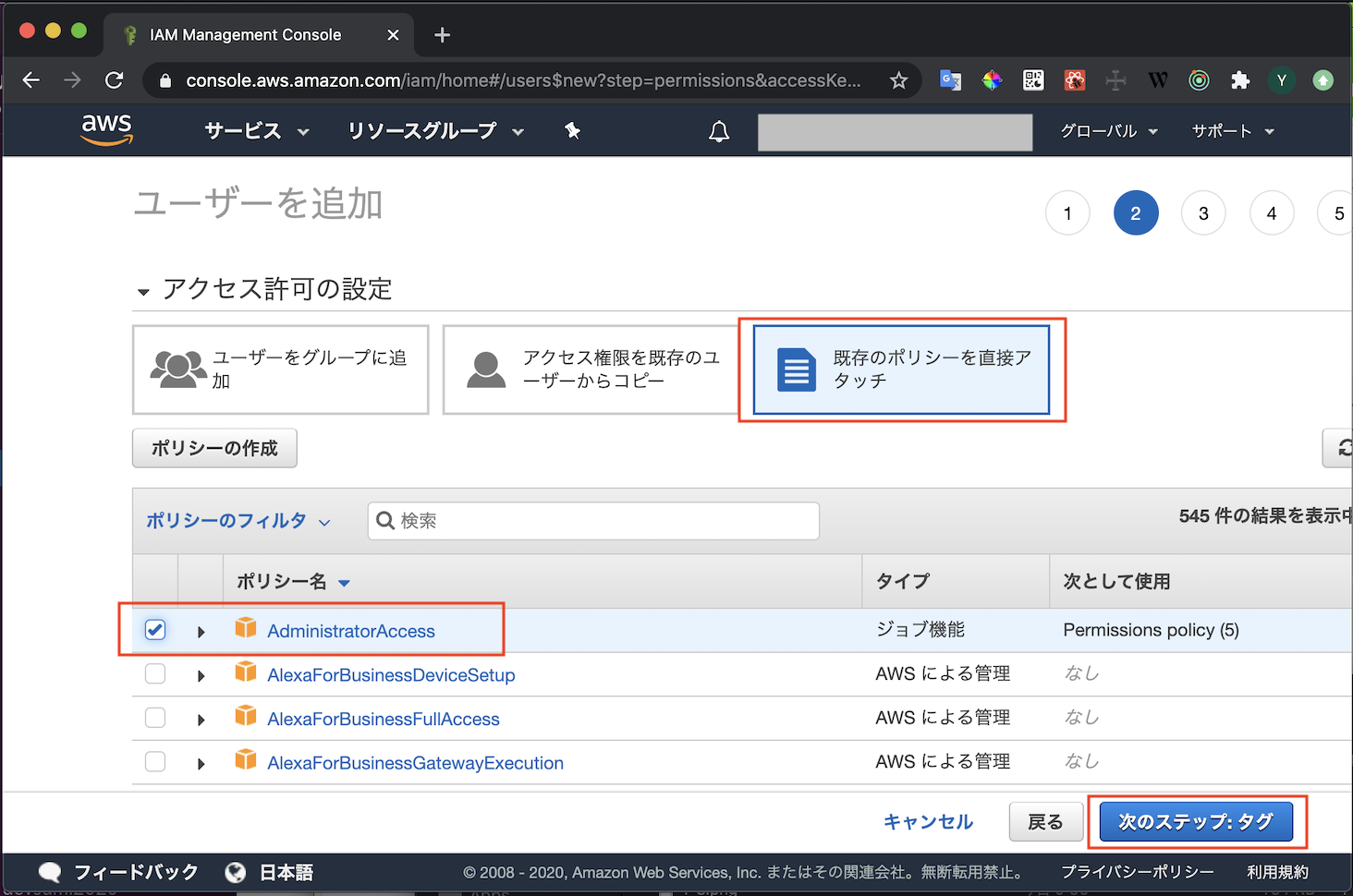
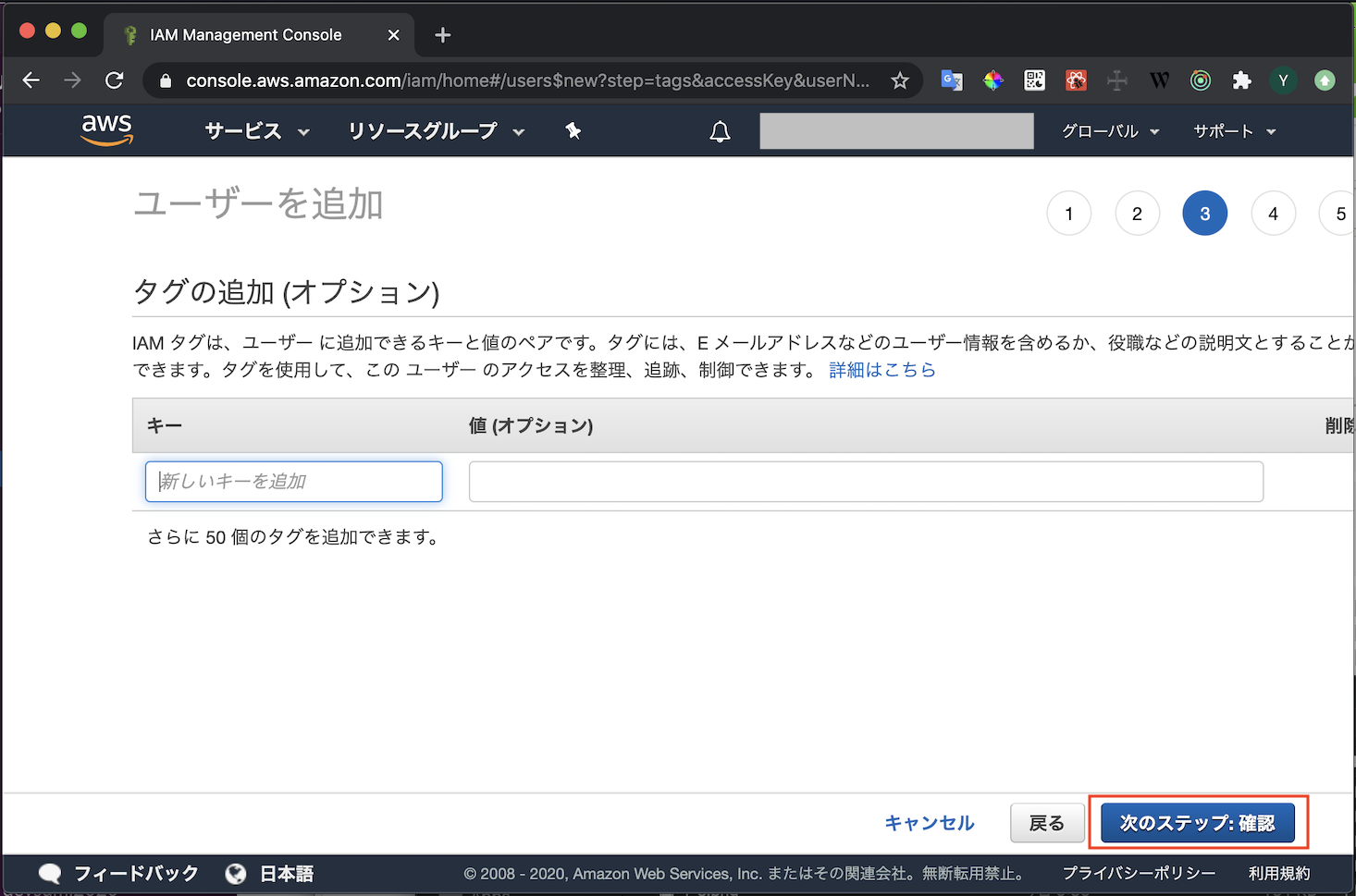
- AWSにログインしキャプチャの通り進めていきます
- ユーザ作成の権限があるユーザで実行してください
- IAMのメニューを開く
- ユーザタブからユーザ追加を選択
- 適当なユーザ名を入れます
- プログラムによるアクセスのみチェックを入れます
- AWSマネジメントコンソールへのアクセスにチェックを入れるとWebコンソールにログインできるユーザになってしまいます
- 権限を設定します
- ここではAdmin権限を付与しています
- タグは何も設定しなくて大丈夫です
- ユーザーの作成ボタンを押して送信します
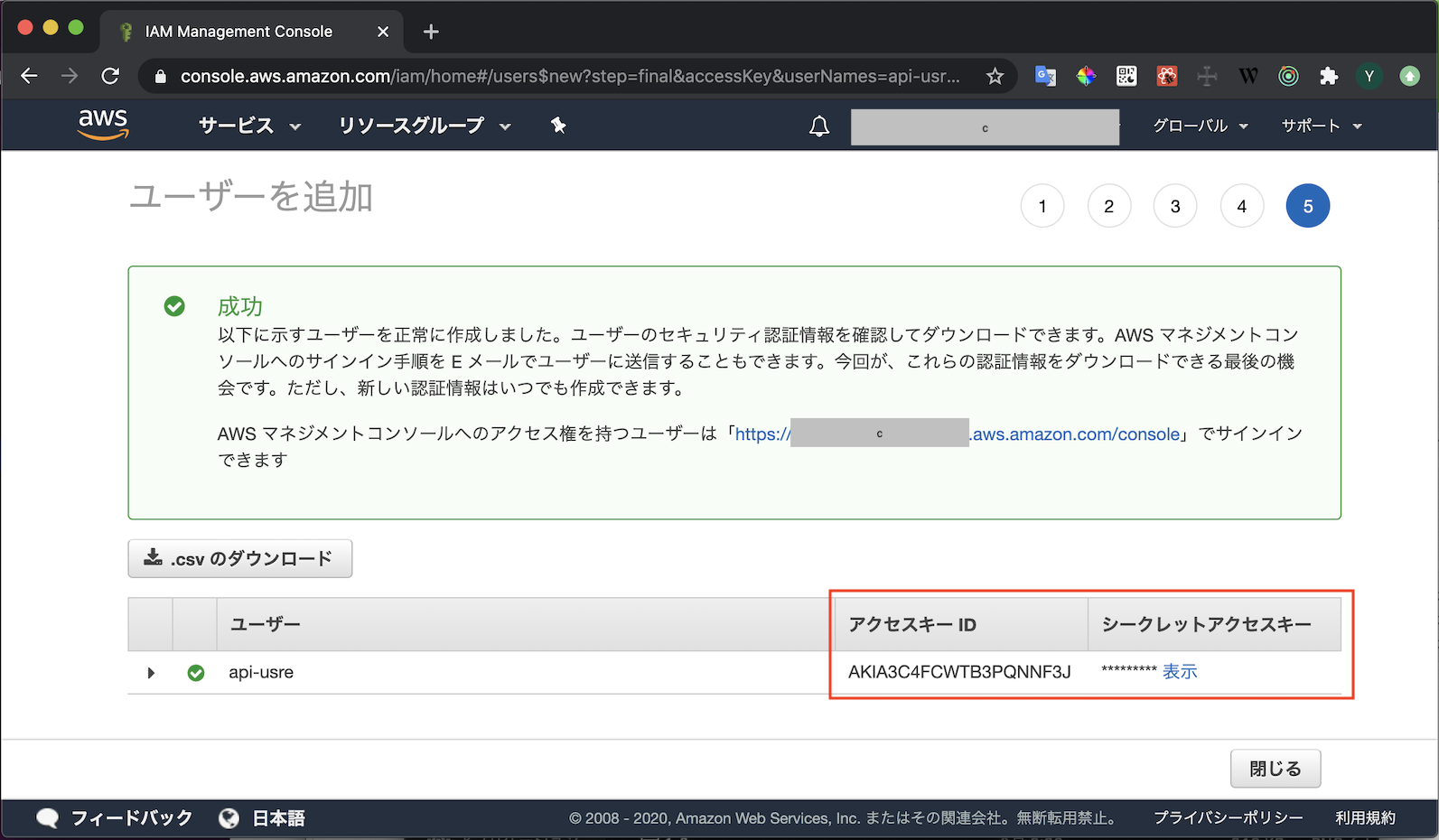
- アクセスキーIDとシークレットアクセスキーが表示されます
- 漏洩することがないよう厳重に管理しましょう
アクセスキーの登録
- ローカル端末上にアクセスキーを登録します
- ホームディレクトリ直下に
.awsフォルダを作成しその中にcredentialsという名前のファイルを作成します- 発行したアクセスキーとシークレットキーを登録します
~/.aws/credentials[default] aws_access_key_id=XXXXXXXXXXXXXXXXXXXX aws_secret_access_key=XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX region=ap-northeast-1 output=json
- 複数のキーを登録したい場合は
[default]の部分を他の名前にして登録します~/.aws/credentials[default] aws_access_key_id=XXXXXXXXXXXXXXXXXXXX aws_secret_access_key=XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX region=ap-northeast-1 output=json [my-account] aws_access_key_id=XXXXXXXXXXXXXXXXXXXX aws_secret_access_key=XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX region=ap-northeast-1 output=json
- 投稿日:2020-05-25T15:25:20+09:00
Node.js, npm, yarn, gitの環境構築+コマンド解説
EC2にフロントエンド開発ができる環境構築をしていくぞ〜〜
あわせてコマンドが色々わからなかったので解説もしてみる
ところどころ間違えてそうなので直してほしい別にAWSじゃなくても、ローカルPCに環境構築するのでも同じだと後から気が付きました
なので、ローカルに環境構築したい人の参考にもなるはず環境: AWS Linux
(WindowsとかMacOSの人はこの記事は参考にならないよ)
コメント大歓迎
EC2インスタンスの立ち上げ & 接続
インスタンスを作ってなかったらこっちの記事の1-4を見てね
ここから先は、ターミナルからインスタンスにSSHで接続してる前提でいきますgitのインストール
sudo yum install git
yumはAWS Linuxのパッケージマネージャーで、macOSのbrewみたいなやつ
Linux系だとapt-getとかもあるけど、このインスタンスではyumを使ってパッケージをインストールするNode.js & npm のインストール
AWSの公式の手順でやっていく
流れ: nvmインストール
Nodeインストール(npmも一緒に入る)
curl -o- https://raw.githubusercontent.com/nvm-sh/nvm/v0.34.0/install.sh | bash
nvmのバージョンに応じて
v0.34.0のとこは変えてね
執筆時点だと、nvmの最新バージョンはv0.35.3だったんだけど、AWSのdocsがv0.34.0だったので、とりあえずそっちに従ってみた
curl: ネットワーク上でデータを転送するためのコマンド (Wikipediaより翻訳)-oオプション: 出力先を指定する-引数: stdout (標準出力)を意味する引数(argument)|(「パイプ」と読む): パイプの前にあるやつをパイプの後にあるやつに流す。つまりパイプbash: このターミナル/シェル/黒い画面のことを指す
-oの使い方は、例えばcurl -o "filename.txt" http://www.hoge.com/hogehoge.shだったら、hogehoge.shをfilename.txtに出力するこのコマンドでやってることは、
nvmのインスールスクリプトをインストールするためのシェルスクリプトをhttps://raw.githubusercontent.com/nvm-sh/nvm/v0.34.0/install.shからダウンロードする
nvm.shが入る. ~/.nvm/nvm.sh
nvm.shが入ったのでこのシェルスクリプトを実行して、nvmをインストール
.はsourceと同じで、シェルスクリプトを実行するコマンド
ここでは~/.nvm/nvm.shにあるファイルを実行しているnvm install nodenvmでnodeをインストールする
(npmとかyarnと同じ構文)npm i -g yarnnpmが入ったので、npmを使ってyarnを入れる
※yarn公式では非推奨のやり方。今回は力尽きたのでこの方法でやったVSCodeで開発
Remote-SSHプラグインを入れる
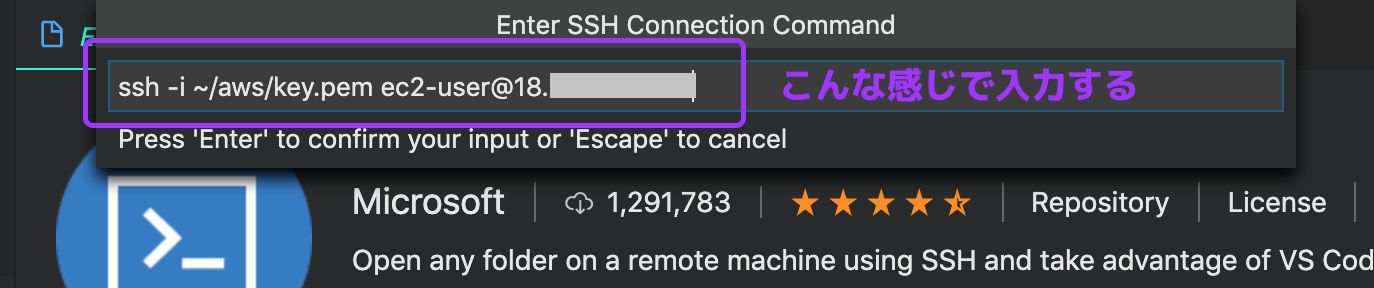
VSCodeのExtensionsから探すか、[ここ]((https://code.visualstudio.com/docs/remote/ssh)からダウンロードするSSH接続は公式に書いてあるとおりにやります
- F1キーを押して Remote-SSH: Add New SSH Hostを選択
ssh -i <.pemファイルへのパス> ec2-user@<インスタンスのIP>を入力- config fileを聞かれるので、適当に選ぶ(わたしは/etc/ssh/ssh_configがドロップダウンの中にあったので、それにした)
- 左のタブのファイル > 「Open Folder」ボタンで、リモートのフォルダを開く
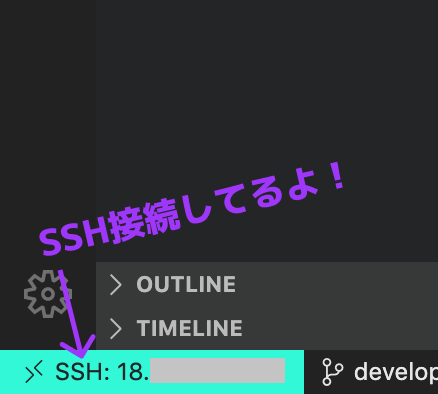
参考までのスクショたち
SSH接続してると、左下に接続先が表示される
おわり
あとは、
git cloneとかでソースコードをリモートにおいて、リモートにSSHしたVSCodeで開発すればokおまけ
yarnしようとしたらこんなエラーが出たmake: g++: コマンドが見つかりませんでしたくわしく調べなかったけど、C++コンパイラがインストールされてなかったせいらしい
この記事を参考にこのコマンドを叩いたら治ったsudo yum -y install gcc-c++
- 投稿日:2020-05-25T15:25:20+09:00
AWSのEC2インスタンスにNode.js, npm, yarn, gitを入れる
EC2にフロントエンド開発ができる環境構築をしていくぞ〜〜
あわせてコマンドが色々わからなかったので解説もしてみる
ところどころ間違えてそうなので直してほしい別にAWSじゃなくても、ローカルPCに環境構築するのでも同じだと後から気が付きました
なので、ローカルに環境構築したい人の参考にもなるはず
EC2インスタンスの立ち上げ & 接続
インスタンスを作ってなかったらこっちの記事の1-4を見てね
ここから先は、ターミナルからインスタンスにSSHで接続してる前提でいきますgitのインストール
sudo yum install git
yumはAWS Linuxのパッケージマネージャーで、macOSのbrewみたいなやつ
Linux系だとapt-getとかもあるけど、このインスタンスではyumを使ってパッケージをインストールするNode.js & npm のインストール
AWSの公式の手順でやっていく
流れ: nvmインストール
curl -o- https://raw.githubusercontent.com/nvm-sh/nvm/v0.34.0/install.sh | bash
v0.34.0のとこは変えてね
執筆時点だと、nvmの最新バージョンはv0.35.3だったんだけど、AWSのdocsがv0.34.0だったので、とりあえずそっちに従ってみた
curl: ネットワーク上でデータを転送するためのコマンド (Wikipediaより翻訳)-oオプション: 出力先を指定する-引数: stdout (標準出力)を意味する引数(argument)|(「パイプ」と読む): パイプの前にあるやつをパイプの後にあるやつに流す。つまりパイプbash: このターミナル/シェル/黒い画面のことを指す
-oの使い方は、例えばcurl -o "filename.txt" http://www.hoge.com/hogehoge.shだったら、hogehoge.shをfilename.txtに出力するこのコマンドでやってることは、
nvmのインスールスクリプトをインストールするためのシェルスクリプトをhttps://raw.githubusercontent.com/nvm-sh/nvm/v0.34.0/install.shからダウンロードする
nvm.shが入る. ~/.nvm/nvm.sh
nvm.shが入ったのでこのシェルスクリプトを実行して、nvmをインストール
.はsourceと同じで、シェルスクリプトを実行するコマンド
ここでは~/.nvm/nvm.shにあるファイルを実行しているnvm install nodenvmでnodeをインストールする
(npmとかyarnと同じ構文)npm i -g yarnnpmが入ったので、npmを使ってyarnを入れる
※yarn公式では非推奨のやり方。今回は力尽きたのでこの方法でやったVSCodeで開発
Remote-SSHプラグインを入れる
VSCodeのExtensionsから探すか、[ここ]((https://code.visualstudio.com/docs/remote/ssh)からダウンロードするSSH接続は公式に書いてあるとおりにやります
- F1キーを押して Remote-SSH: Add New SSH Hostを選択
ssh -i <.pemファイルへのパス> ec2-user@<インスタンスのIP>を入力- config fileを聞かれるので、適当に選ぶ(わたしは/etc/ssh/ssh_configがドロップダウンの中にあったので、それにした)
- 左のタブのファイル > 「Open Folder」ボタンで、リモートのフォルダを開く
参考までのスクショたち
SSH接続してると、左下に接続先が表示される
おわり
あとは、
git cloneとかでソースコードをリモートにおいて、リモートにSSHしたVSCodeで開発すればokおまけ
yarnしようとしたらこんなエラーが出たmake: g++: コマンドが見つかりませんでしたくわしく調べなかったけど、C++コンパイラがインストールされてなかったせいらしい
この記事を参考にこのコマンドを叩いたら治ったsudo yum -y install gcc-c++
- 投稿日:2020-05-25T14:03:17+09:00
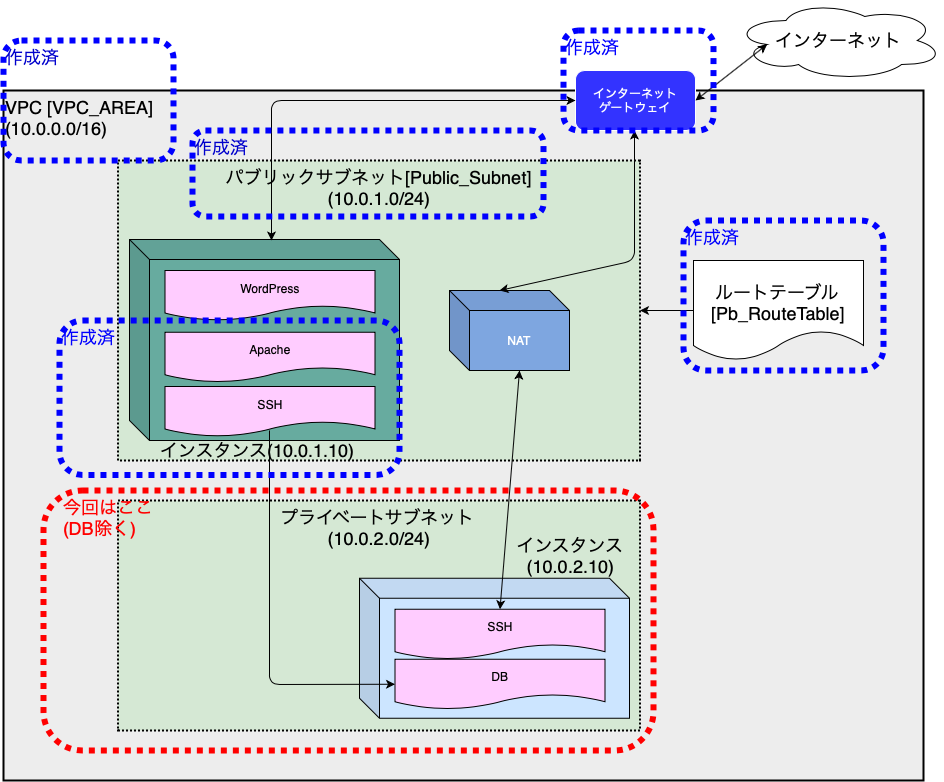
クラウド初心者のAWS入門(第8回)
第8回 プライベートサブネットの構築
今回はインターネットとは直接的に接続しない、プライベートサブネットの構築を行います。
以下の順番にて進めていきますので、よろしくお願いします!
プライベートサブネットの構築
パブリックサブネットと同じアベイラビリティゾーンに、プライベートサブネットを構築します。
異なるリージョンに配置した場合、課金されてしまうとのことです。
(料金についても勉強しないと・・ソリューションアーキテクト資格の勉強で出てきますかね?)
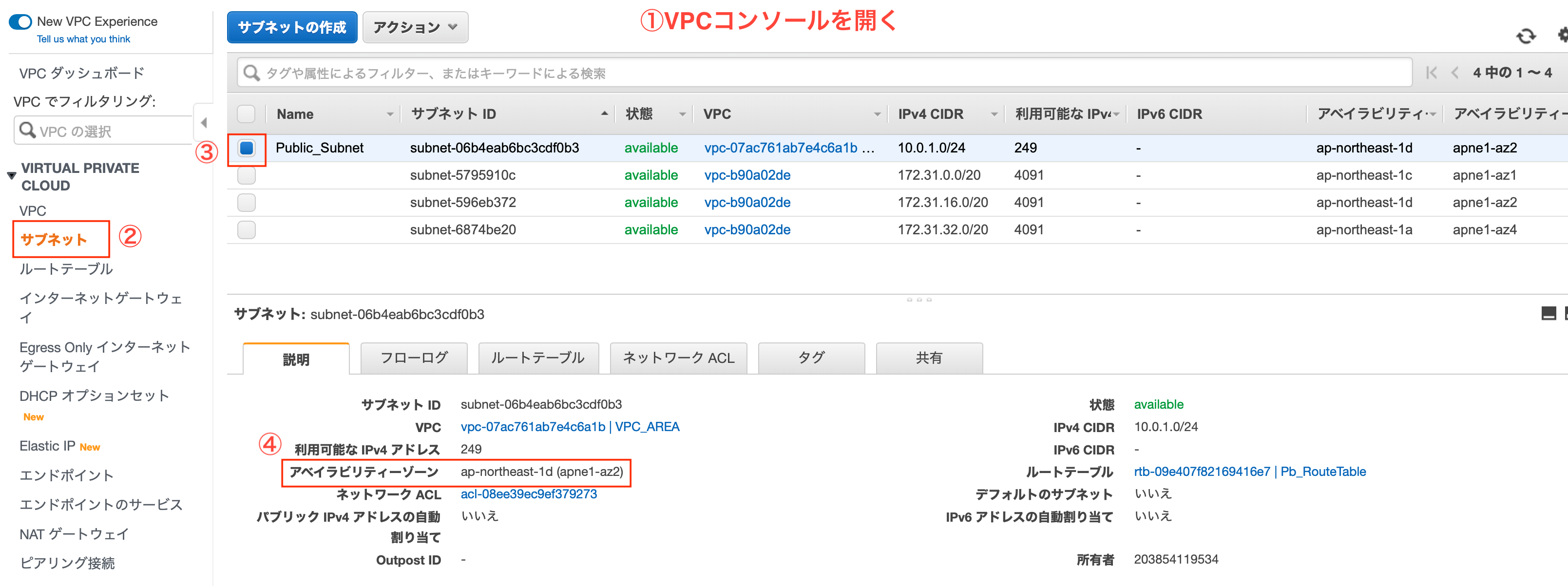
アベイラビリティゾーンの確認
「VPCマネジメントコンソール」から、「サブネット」を選択し、パブリックサブネットのゾーンを確認します。
アベイラビリティゾーンは「ap-northeast-1d(apne1-az2)」でした。
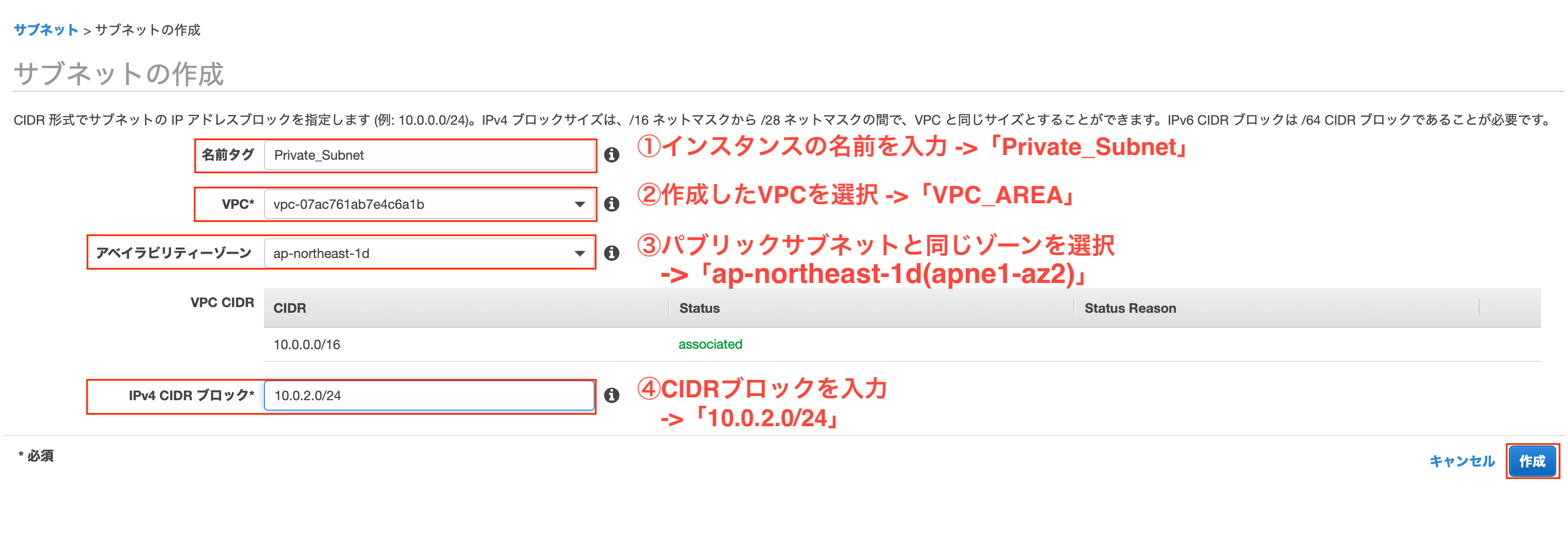
プライベートサブネットの作成
上記で確認したアベイラビリティゾーンと同じ場所に、プライベートサブネットを構築していきます。
できました!
ルートテーブルの確認
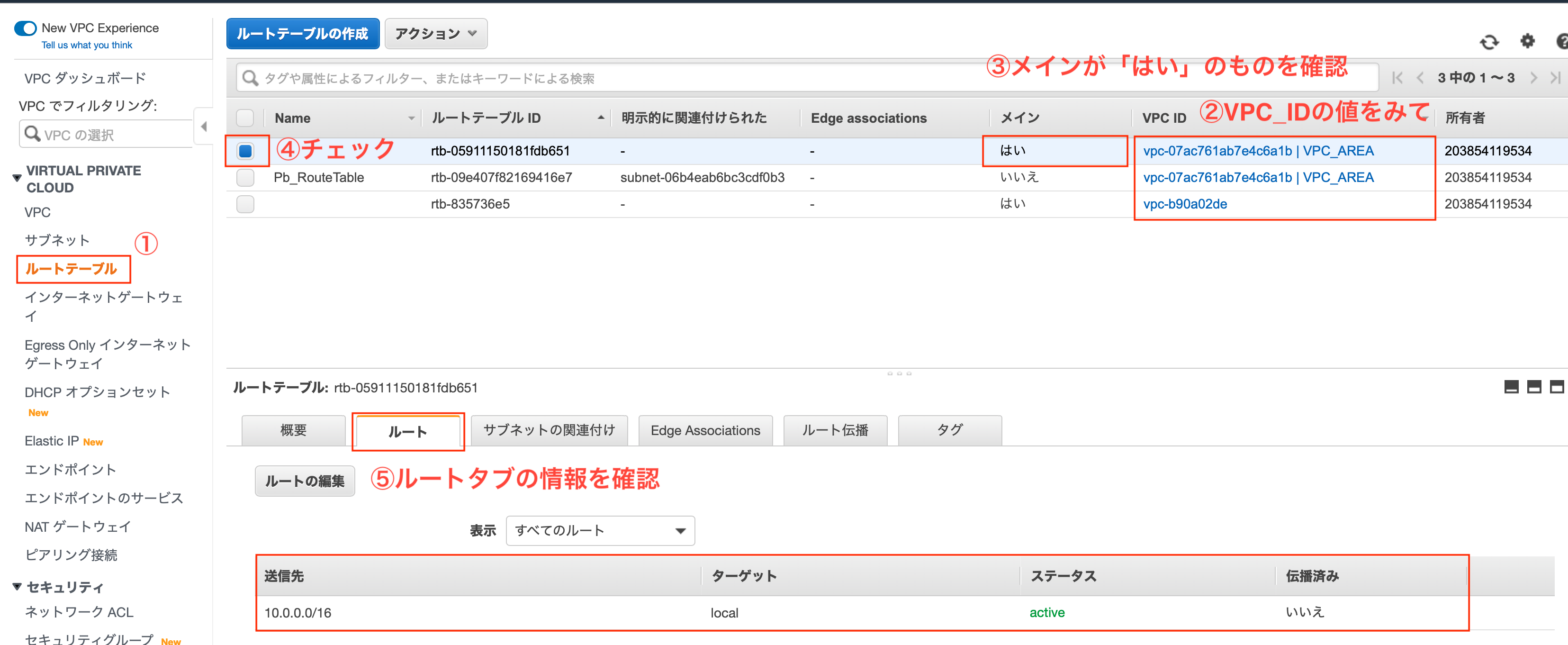
サブネットを作成した直後には、VPCに対して設定されている「メインルートテーブル」が適用されています。
出典:Amazon Web Services 基礎からのネットワーク&サーバー構築
とのことですので、メインルートテーブルを見て、必要に応じて設定を変更します。
いくつかあるルートテーブルの中で、どれがメインなのかは以下の2項目を確認することで判定可能です。
「VPC ID」列を確認
- 「vpc-xxxxx | VPC_AREA」のように、"|"(パイプ区切り)で「VPC名」が表示されているものを選別する。VPC名が表示されていないルートはデフォルトルート
「メイン」列が「はい」
メインのルートテーブルを確認した結果、下表のようになっていました。
(これが作成したプライベートサブネットに割り当てられたルートテーブル)
送信先 ターゲット 10.0.0.0/16 local このルートテーブルは、プライベートサブネットに必要な以下の条件を満たすため、特に設定をいじることはしません。
インターネットには繋がない
- インターネットゲートウェイがルートテーブルの宛先に入っていないこと。
内部通信だけできれば良い
- パブリックサブネット(10.0.1.0/24)とプライベートサブネット(10.0.2.0/24)間で通信できればOK。
ということで、確認だけして次に進みます。
補足
デフォルトルートとはなんぞやと調べたところ、とてもわかりやすい解説がありましたため、リンクを掲載させていただきます。
大変参考にさせていただきました。ありがとうございます。
tkj06さんの記事
インスタンスの作成
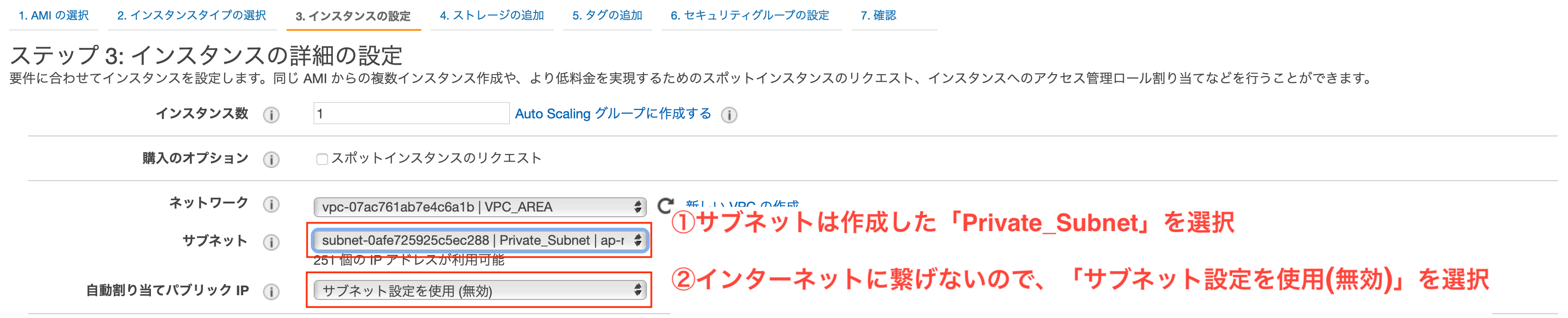
作成したプライベートサブネット内にインスタンスを作成します。
基本は前回作成したインスタンスと同様に進めていきますので、差異がある点のみ記載します。
インスタンスの設定
「インスタンスタイプの選択」までは前回同様です。
- サブネット
- 先ほど作成した「Private_Subnet」を選択
- 自動割り当てパブリックIP
- 「サブネット設定を使用(無効)」を選択(「無効」でも良い)
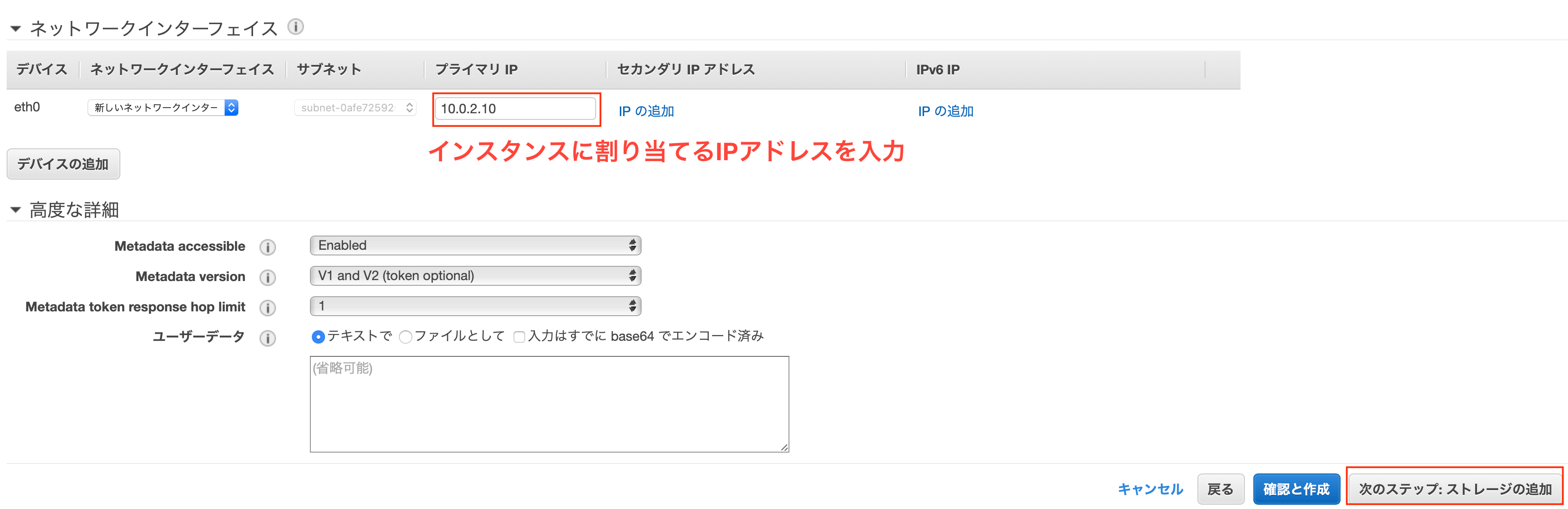
- プライマリIP
- 「10.0.2.10」を入力
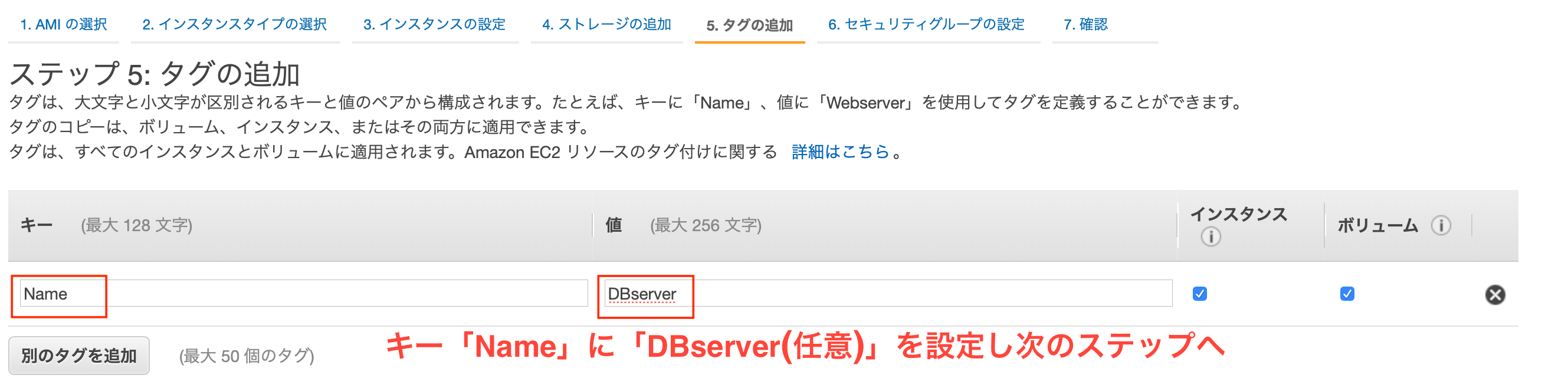
ストレージの設定をおえたら(デフォルトですが)、インスタンスの名前を設定します。
- キー
- 「Name」を入力(固定)
- 値
- 「DBserver」を入力(任意)
セキュリティグループの作成
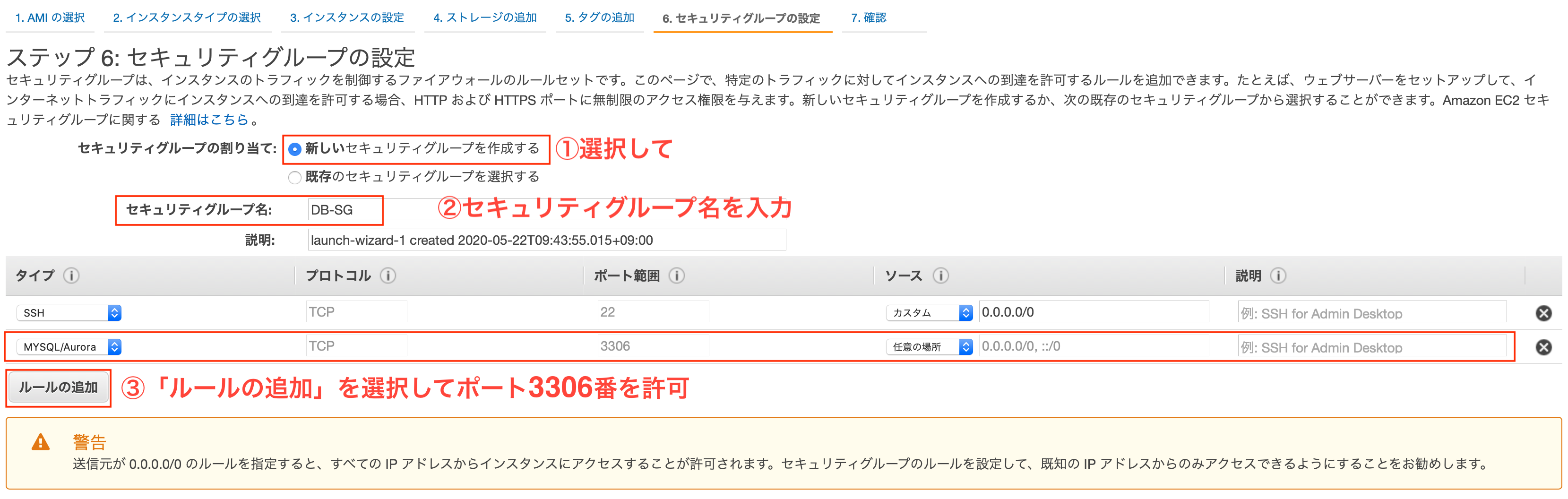
今後、プライベートサブネットにはDBを配置するので事前準備をしておきます。
具体的には、DBサーバが使用するポート3306番を、セキュリティグループに許可設定します。セキュリティグループを新しく作成したら、3306番の許可設定をします。(図中③)
- タイプ
- 「MySQL/Aurora」を選択
- プロトコル
- 「TCP」を選択(固定)
- ポート範囲
- 「3306」(固定)
- ソース -- 「任意の場所」
ソースとして選択した「任意の場所」ですが、設定を行うと以下の2つが許可されます。
- 「0.0.0.0/0」・・IPv4の許可
- 「::/0」・・IPv6の許可
画面に従いインスタンスの作成を終えます。
キーファイル紛失注意です!!動作確認
プライベートサブネット内にインスタンスの作成を行なったので、pingによる応答確認を実施していきたいと思います。
なお、今回確認するルートは下表となります。
送信元 送信先 パブリックサブネット内のインスタンス(10.0.1.10) プライベートサブネット内のインスタンス(10.0.2.10) 内部通信として「10.0.0.0/16」の通信を「local」へ通信させるルートは存在しているため、セキュリティグループの設定だけでOKです!!
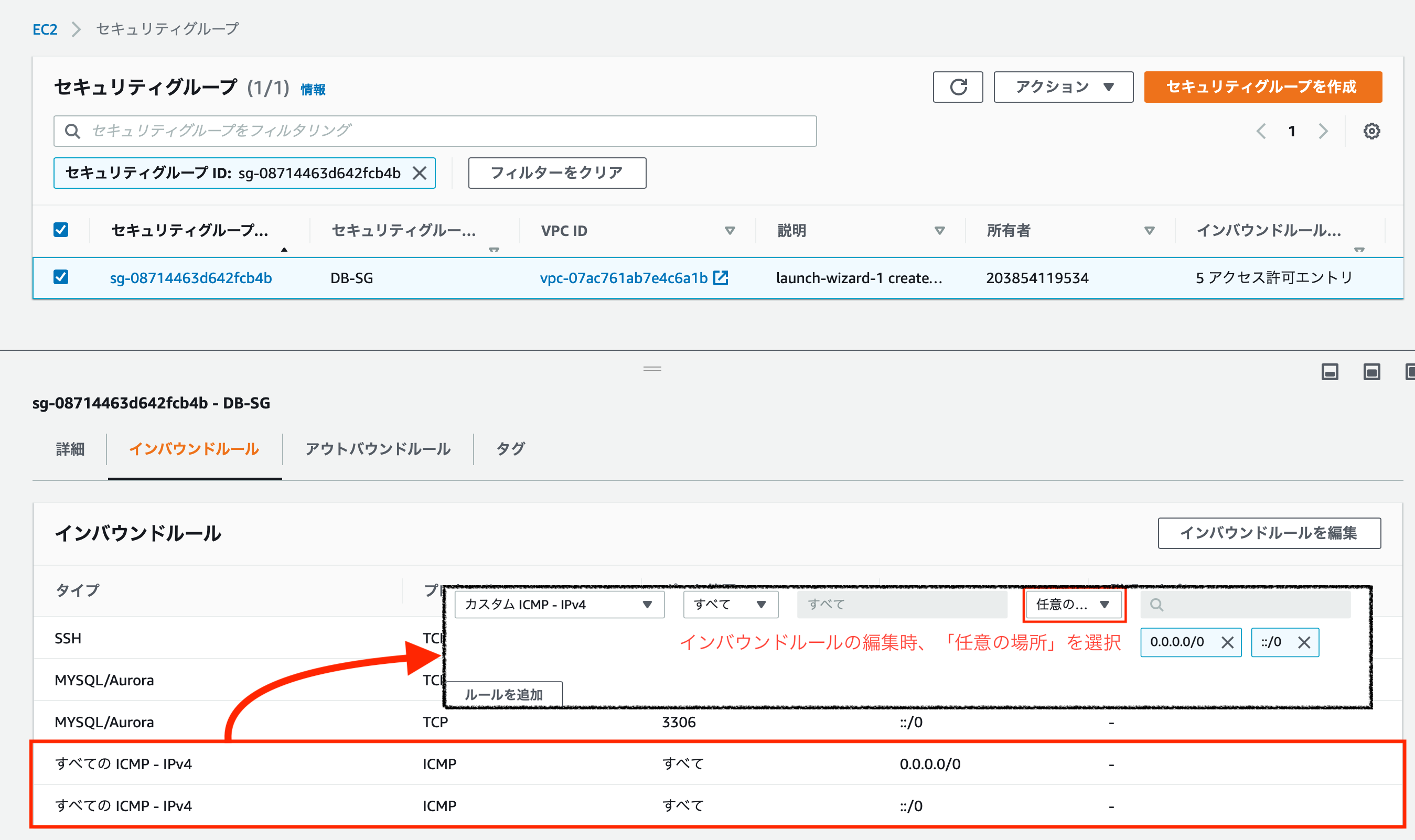
ルートテーブルの確認
セキュリティグループの設定変更
セキュリティグループでは、デフォルトではping通信が許可されてません。
そのため、ping通信(ICMP)を許可設定してあげます。
具体的には下図の設定を加えます。
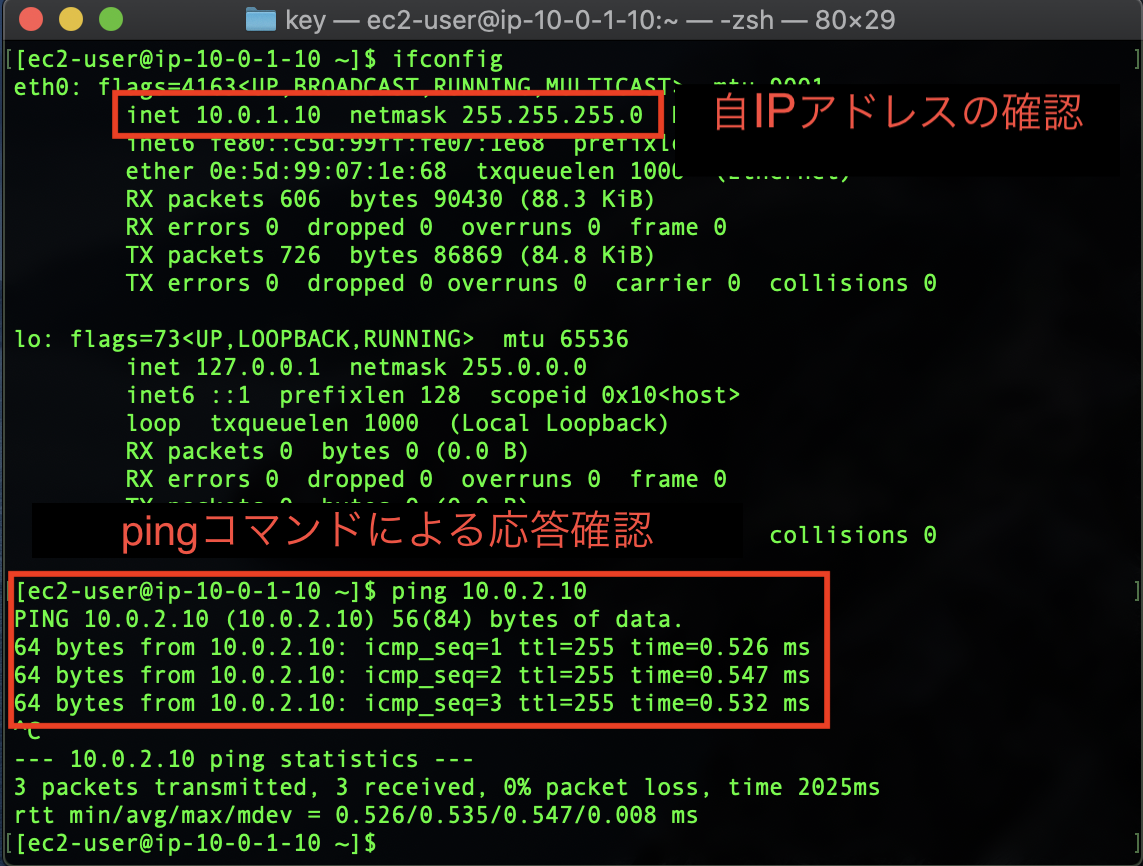
pingによる疎通確認
パブリックサブネット内のインスタンス(10.0.1.10)にSSHで接続し、
プライベートサブネット内のインスタンス(10.0.2.10)へpingによる疎通確認を行います。
画面はmacなのですが、TeraTerm等のターミナルで接続しても同じです。
設定変更手順はこちら->TeraTermでインスタンスへログイン無事に疎通が取れることが確認できました。
今回は以上となります、長々とお付き合いいただきありがとうございました。参考文献
- 投稿日:2020-05-25T13:07:20+09:00
AWS Update 5/22
AWS Systems Managerパラメータストアを使用してAWSアベイラビリティーゾーンとローカルゾーンをクエリする
お客様は、AWSリージョン、サービス、エンドポイントに関する情報に加えて、AWSアベイラビリティーゾーンとローカルゾーンに関する情報にプログラムでアクセスできるようになりました。AWSのお客様は、AWSアベイラビリティーゾーン、ローカルゾーンの完全なリストに簡単にアクセスし、AWS Systems Managerパラメーターストアにクエリを実行することで、リージョン内で利用可能なサービスを見つけることができます。
パラメータストアはSystems Managerの機能で、アプリケーション構成データ用の安全な集中ストレージを提供します。AWSサービスは、AMI IDやリージョンなどの一般的なアーティファクトに関する情報を公開パラメーターとして公開します。利用可能なパブリックパラメータを検索して、スクリプトとコードから呼び出すことができます。今回のリリースにより、AWSアベイラビリティーゾーンとローカルゾーンをクエリできるようになりました。パブリックパラメータには、AWSコマンドラインインターフェイス(CLI)、AWS Tools for Windows PowerShell、または任意のAWS SDKを使用してアクセスできます。
AWS のサービス、リージョン、エンドポイント、アベイラビリティーゾーン、ローカルゾーンのパブリックパラメータの呼び出し
以前より便利になったのかな?
AWSソリューション:Spark Streamingを使用したリアルタイム分析で、Spark SQL、データフレームなどがサポートされるようになりました
AWSは、Apache Spark StreamingとAmazon Kinesisを活用するAWSクラウドに高可用性で費用効果の高いバッチおよびリアルタイムデータ分析アーキテクチャを自動的にデプロイするAWSソリューションであるSpark Streamingを使用したリアルタイム分析を更新しました。このソリューションは、カスタムApache Sparkストリーミングアプリケーションをサポートするように設計されており、動的にスケーラブルなAmazon Elastic Compute Cloud(Amazon EC2)インスタンス全体で膨大な量のデータを処理するためにAmazon EMRを活用します。
このソリューションには、最新バージョンのSparkを使用する更新されたコンシューマーアプリケーションが含まれ、最新の機能(Spark SQLやDataFramesなど)、きめ細かなカスタムIAMポリシー、保存時の暗号化(デフォルト)、VPCへのフローログ、サンプルSparkストリーミングアプリケーションの移植Java(Scalaから)、およびPythonのバージョン3.8への更新、Amazon EMRのバージョン5.29.0への更新など、いくつかのメンテナンスアップグレード。AWSでのSpark Streamingによるリアルタイム分析の詳細については、ソリューションのWebページを参照してください。
Spark Streaming を用いたリアルタイム分析
https://aws.amazon.com/jp/solutions/real-time-analytics-spark-streaming/
AWS CodeBuildテストレポートが一般提供になりました
AWS CodeBuildのテストレポートのサポートが、本番環境での一般提供を開始しました。テストレポートは、CodeBuildでのテスト実行の詳細で実用的なビューを提供し、テストの失敗を簡単に調査できるようにします。
テストのレポートには、過去の傾向、集約メトリック、またはAWS CodeBuild上で実行されたテストのためのテスト失敗の詳細を表示することができます。これらの機能は、JUnit、Cucumber、TestNG、またはTRXのファイルを出力するすべてのテストフレームワークでサポートされています。2019年11月に発表されたテストレポートベータ版以降、レポートグループのタグ付けのサポートと2つの追加のテストフレームワーク(TestNGおよびTRX)が導入されました。あなたは、あなたへの参照が含まれ、「レポート」セクション追加してbuildspecファイルを更新することで始めることができレポート・グループとテスト結果ファイルのパスを。
AWS CodeBuild でのテストレポートの使用
https://docs.aws.amazon.com/ja_jp/codebuild/latest/userguide/test-reporting.html
ビルド時に実行したテストの詳細を含むレポートを AWS CodeBuild で作成できます。単体テスト、設定テスト、機能テストなどのテストを作成できます。テストファイル形式は、JUnit XML または Cucumber JSON にすることができます。これらの形式 (たとえば、Surefire JUnit プラグイン、TestNG、Cucumber) のいずれかでファイルを作成することができる任意のテストフレームワークを使用してテストケースを作成します。
テストレポートを作成するには、ビルドプロジェクトの buildspec ファイルにテストケースに関する情報を含むレポートグループ名を追加します。ビルドプロジェクトを実行すると、テストケースが実行され、テストレポートが作成されます。テストを実行する前にレポートグループを作成する必要はありません。レポートグループ名を指定すると、CodeBuild はレポートの実行時に自動的にレポートグループを作成します。既に存在するレポートグループを使用する場合は、buildspec ファイルでその ARN を指定します。
テストレポートを使用すると、ビルドの実行中に問題をトラブルシューティングできます。ビルドプロジェクトの複数のビルドから多数のテストレポートがある場合、テストレポートを使用してトレンドやテストと失敗率を表示し、ビルドを最適化できます。
レポートは、作成から 30 日後に有効期限が切れます。期限切れのテストレポートは表示できません。30 日以上テストレポートを保持する場合は、テスト結果の生データファイルを S3 バケットにエクスポートできます。エクスポートされたテストファイルは期限切れになりません。S3 バケットに関する情報は、レポートグループを作成するときに指定します。
- 投稿日:2020-05-25T12:48:41+09:00
CloudFrontのSSL Certificate項目がグレーアウトで選択不可?原因はSSL証明書(ACM)をバージニア北部で発行していないから
AWSのCloudFront+S3+Route53で静的WEBサイトをSSLで公開しようと思ったところ、CroudFrontと独自ドメインの紐付けでハマった話です。
概要/環境
HTMLのファイルをS3で公開するように構築します。
- CloudFront
- S3
- Route53
- ACM(AWS Certificate Manager)
まずは、S3バケットを作って公開設定。次にCloudFrontを使ってS3とドメインを紐付け……
というところでハマりました。
S3でのHTMLファイルの公開方法等は下記サイトを参考にしてみてください。本記事では割愛します。
* Amazon S3 で静的なウェブページを公開してみた。
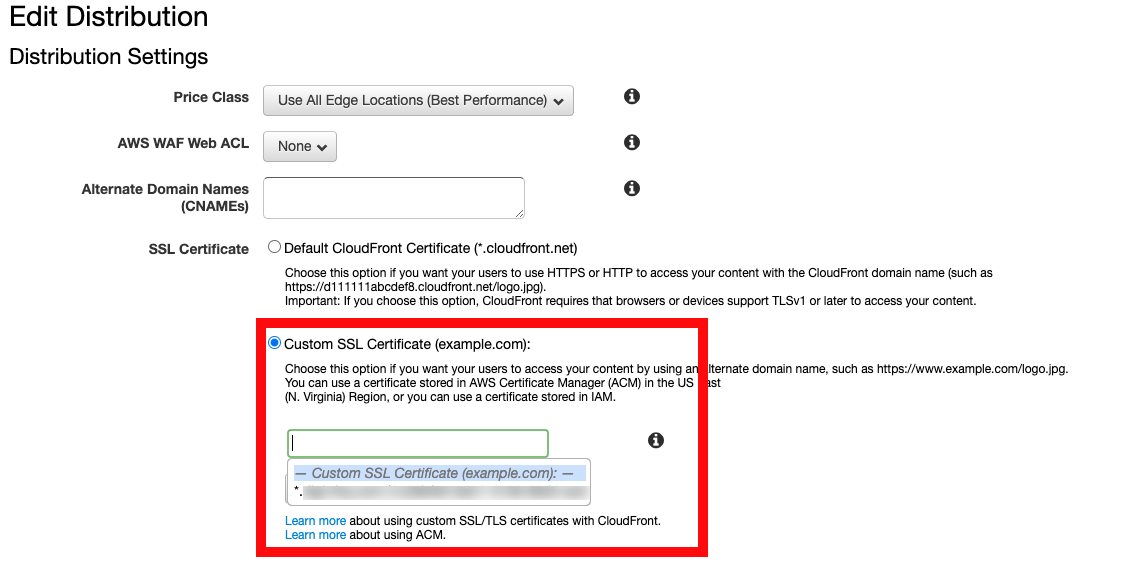
* CloudFront で S3 静的ウェブサイトホスティングを SSL/TLS に対応させるCloudFrontのSSL Certificate項目がグレーアウトしてた
さてS3の公開設定も終わり、CloudFrontの設定をしていると「SSL Certificate」という項目がグレーアウトしているんです。ここでCloudFrontとRoute53の独自ドメインを紐付けるはずなのに…。
んんん??
ACMを確認しても、ちゃんとワイルドカード(*.hogehoge.com)で設定済み。
いろいろ検索した結果、リージョンが間違っていたことが発覚。
CloudFrontでACMを利用する場合はバージニア北部でないといけない
いろいろ検索をしていたところ、AWSの公式で下記の文言を見つけました。
Amazon CloudFront で ACM 証明書を使用するには、米国東部(バージニア北部) リージョンで証明書をリクエストまたはインポートする必要があります。CloudFront ディストリビューションに関連づけられたこのリージョンの ACM 証明書は、このディストリビューションに設定されたすべての地域に分配されます。
参考:AWS Certificate Manager (ACM)-サポートされているリージョン
要は「CloudFrontでSSL証明書を使いたいなら、ACMのリージョンはバージニア北部で設定してね」ってこと。
先ほど「ワイルドカード(*.hogehoge.com)で設定済みだった」と書きましたが、たしかにACMは東京リージョンで設定されていました。
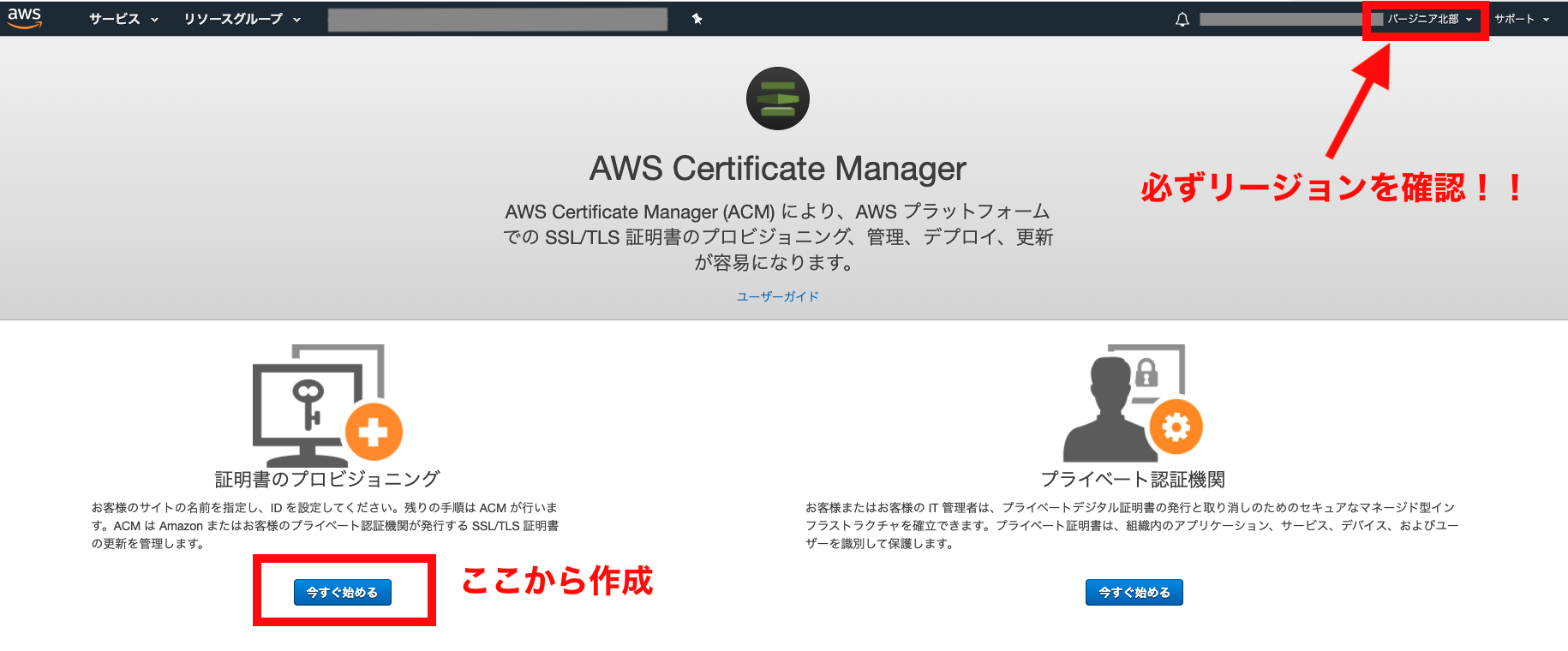
ACMをバージニア北部リージョンで設定してみる
コンソール画面からAWS Certificate Managerページを開く。
リージョンが「バージニア北部」になっていることを必ず確認してから、作成します。
ドメインの設定は*(ワイルドカード)でOKです。
画像は*.hogehoge.comでセットしています。
あとは特に設定せずに次へ次へでOKです。
少し待てば状況が「発行済」になるので次に進みます。
CloudFrontで設定できた!
ACM設定後にCloudFrontの設定に戻ったところ、「SSL Certificate」のグレーアウトが解除されて設定可能に!
あとは選択肢に出てるものをクリックして保存でOK。
これでSSLドメインでS3へのアクセスが可能になります!
まとめ
CloudFrontを使用する場合、ACMをバージニア北部で設定しなければならない。というのは盲点でした。
CloudFront自体はリージョンという概念はないのになーとちょっとしっくりこ部分もありますが、解決したのでヨシ!



- 投稿日:2020-05-25T09:12:46+09:00
AWS Sesstion Manager で Fargate に SSH 接続する
AWS Session Manager
AWS Session Manager は AWS Systems Manager の機能で、AWS CLI を経由して EC2 インスタンス、オンプレミスインスタンス、仮想マシン (VM) にログインできるようにしてるというものです。
IAMベースで認証するのでセキュリティーグループを神経質に設定してインバウンドポートを開いたり、パブリックIPアドレスを開放する必要がなくなるというメリットがあります。
また、ハイブリットアクティベーション機能を利用することで Fargate のようなマネージドインスタンスに SSM ログインしターミナルセッションを開くことができます。面倒な SSH 鍵の登録などは不要です。
とはいえSSHしたいときもある
とはいえ、運用の都合でSSHしたいこともあります。ということで、AWS Sesstion Manager を経由してFargate コンテナへのSSH 接続を試してみました。
Dockerコンテナの準備
まず大前提として Fargate に SSH するにはデプロイするコンテナに SSH できる必要があります。それに加えて、SSMエージェントをインストールインストールしハイブリットアクティベーション可能なコンテナを作ります。
FROM ubuntu:18.04 COPY run.sh /run.sh RUN apt-get update \ && apt-get -y install curl openssh-server \ && curl https://s3.ap-northeast-1.amazonaws.com/amazon-ssm-ap-northeast-1/latest/debian_amd64/amazon-ssm-agent.deb -o /tmp/amazon-ssm-agent.deb \ && dpkg -i /tmp/amazon-ssm-agent.deb \ && cp /etc/amazon/ssm/seelog.xml.template /etc/amazon/ssm/seelog.xml RUN mkdir /var/run/sshd RUN sed -i 's/#\?PermitRootLogin prohibit-password/PermitRootLogin yes/' /etc/ssh/sshd_config RUN sed 's@session\s*required\s*pam_loginuid.so@session optional pam_loginuid.so@g' -i /etc/pam.d/sshd ENV NOTVISIBLE "in users profile" RUN echo "export VISIBLE=now" >> /etc/profile COPY path/to/id_rsa.pub /root/authorized_keys RUN mkdir ~/.ssh && \ mv ~/authorized_keys ~/.ssh/authorized_keys && \ chmod 0600 ~/.ssh/authorized_keys EXPOSE 22 CMD ["bash", "run.sh"]run.sh#!/bin/bash /usr/sbin/sshd & amazon-ssm-agent -register -code "${SSM_AGENT_CODE}" -id "${SSM_AGENT_ID}" -region "${AWS_DEFAULT_REGION}" amazon-ssm-agent作成した Docker Image は ECR に登録して利用しますが詳細は端折ってます。
ハイブリットアクティベーションのセットアップ
ハイブリッド環境の IAM サービスロールを作成する
作成するハイブリットアクティベーションにアタッチするロールを作成します。インスタンスと System Manager の通信を許可する設定が入ってます。
ssm-trust.json{ "Version": "2012-10-17", "Statement": { "Effect": "Allow", "Principal": {"Service": "ssm.amazonaws.com"}, "Action": "sts:AssumeRole" } }aws iam create-role \ --role-name SSMServiceRole \ --assume-role-policy-document file://ssm-trust.json aws iam attach-role-policy \ --role-name SSMServiceRole \ --policy-arn arn:aws:iam::aws:policy/AmazonSSMManagedInstanceCoreSSM アクティベーションを作成する
aws ssm create-activation --description my-fargate-task \ --iam-role "SSMServiceRole" \ --registration-limit 1000 \ --default-instance-name my-fargate-task { "ActivationId": "xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx", "ActivationCode": "yyyyyyyyyyyyyyyyyyyy" }
Activation ID, Code は後の工程で利用するのでメモしておきます。
パラメータストアに登録
作成した ActivationId, ActivationCode をパラメータストアに登録します。これらの情報は Fargate Task 起動時に読み込まれます。
aws ssm put-parameter --overwrite --name "my-activation-id" \ --value "xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx" \ --type "SecureString" aws ssm put-parameter --overwrite --name "my-activation-code" \ --value "yyyyyyyyyyyyyyyyyyyy" \ --type "SecureString"
Task Definition 作成
起動タイプに Fargate を選択して、コンテナの定義を下記の通り設定します。
環境変数
Task Definition 起動時に ssm-agent を起動するのでパラメータストアから先程登録した ActivationId, ActivationCode を環境変数に読み込ませます。
ポートマッピング
SSHログインするのでポートは 22 をマッピングしておきます。
Fargate Task 起動
Task Role に SSMの読み込みポリシーをアタッチ
タスク起動時にパラメータストアから ssm-agent 起動のための値を読み込む必要があるので、以下のようなポリシーを作成し、
ecsTaskExecutionRole等にアタッチしておきます。{ "Version": "2012-10-17", "Statement": [ { "Sid": "DescribeSSMParameter", "Effect": "Allow", "Action": [ "ssm:GetParameters", "secretsmanager:GetSecretValue", "kms:Decrypt" ], "Resource": "*" } ] }Fargate Task 起動
Fargate Task を起動します。
起動していることが確認できました。
セキュリティグループは インバウンドトラフィックはVPC内部での通信のみ許可、アウトバウンドはVPC内部のトラフィックに加えて 443 ポートのトラフィックを許可しました。
また、ECR からの Image 取得、Fargate と System Manager との通信許可のため Private Link を設定しています。
Cloud Watch からログを確認してみると ssm-agent の起動が確認できます。
mi-*となっているのがインスタンスIDで 、後に SSM および SSH ログインする際に利用します。
また、
aws ssm describe-instance-informationで ssm-agent が起動しているインスタンスの情報を閲覧することができます。aws ssm describe-instance-information { "InstanceInformationList": [ { "InstanceId": "mi-0abfaba2ca9885629", "PingStatus": "Online", "LastPingDateTime": "2020-05-24T17:55:55.927000+09:00", "AgentVersion": "2.3.978.0", "IsLatestVersion": false, "PlatformType": "Linux", "PlatformName": "Ubuntu", "PlatformVersion": "18.04", "ActivationId": "63dd7755-c64b-477c-b2ad-25e46a964363", "IamRole": "SSMServiceRole", "RegistrationDate": "2020-05-24T17:23:55.481000+09:00", "ResourceType": "ManagedInstance", "Name": "my-fargate-task", "IPAddress": "169.254.172.42", "ComputerName": "ip-10-0-1-86.ap-northeast-1.compute.internal" } ] }SSMログインする
SSMログインできるか試してみます。
Fargaet にSSMログインするには System Manager → マネージドインスタンス → 設定 → インスタンス枠 が 「高度なインスタンス枠を使用する」設定になっている必要があるので事前に設定を変更しておきます。
以下のようにして SSM ログインすることができます。
aws ssm start-session --target mi-0abfaba2ca9885629 Starting session with SessionId: me-0c78ed24d7770a19c $ whoami ssm-userSSHログインする
ssh_config を修正します。proxy command で start-session コマンドを経由して SSH するような設定になっています。
host i-* mi-* ProxyCommand sh -c "aws ssm start-session --target %h --document-name AWS-StartSSHSession --parameters 'portNumber=%p'" IdentityFile path/to/id_rsa UseKeychain yes AddKeysToAgent yesSSH 接続してみましょう。
ssh root@mi-0abfaba2ca9885629 Welcome to Ubuntu 18.04.4 LTS (GNU/Linux 4.14.158-129.185.amzn2.x86_64 x86_64) * Documentation: https://help.ubuntu.com * Management: https://landscape.canonical.com * Support: https://ubuntu.com/advantage This system has been minimized by removing packages and content that are not required on a system that users do not log into. To restore this content, you can run the 'unminimize' command. Last login: Sun May 24 15:10:15 2020 from 127.0.0.1 root@ip-10-0-1-86:~#Sesstion Manager を使って Fargate に SSH できるようになりました。
所感
そもそも Session Manager を使うと IAM で認証できるから、SSH する必要もなくて SSH 鍵の管理もしなくていいというのがメリットなはずなのに、開発してると結局 SSH しなきゃいけないタイミングが出てきてしまうのがモヤッとしてます。
System Manager 側で SSH をサポートするもっと便利な機能を提供してくれないかなーと感じています。
とはいうものの Public なインスタンスを作らなくて良いのはセキュリティの面ではメリットではないかと思います。
参考










- 投稿日:2020-05-25T09:04:35+09:00
じっくり読みたい資料48選
日々情報をキャッチアップする中で、後でじっくり読みたいと思った記事や資料をまとめました。
詳細は各資料をご確認ください。Index
- AWSに関するスキルアップ方法と一度は読むべきブログの紹介
- 「Infrastructure as Codeに疲れたので、僕たちが本来やりたかったことを整理する」を1年掛けて整理した
- Infrastructure as Dataとは何か
- Eric Evans Says Domain-Driven Design (DDD) Isn't Done
- API 設計: gRPC、OpenAPI、REST の概要と、それらを使用するタイミングを理解する
- gRPC Internal - gRPC の設計と内部実装から見えてくる世界
- サーバーレスアーキテクチャ再考
- Pattern: Backends For Frontends
- BFF @ SoundCloud
- Dockerが注目されている理由を探る
- Why Discord is switching from Go to Rust
- LinuxコミュニティはRustを受け入れた
- Linux memory management at scale
- アニメーションで感覚的にハッシュ関数「SHA-256」の算出過程を理解できる「SHA-256 Animation」
- bash の危険な算術式
- LOGGING BEST PRACTICES: THE 13 YOU SHOULD KNOW
- 機械学習アプリケーションにおけるテストについて
- Node.js徹底攻略 ─ ヤフーのノウハウに学ぶ、パフォーマンス劣化やコールバック地獄との戦い方
- ?⚙️ JavaScript Visualized: the JavaScript Engine
- Things nobody ever taught me about CSS.
- Cookie 概説
- Brilliant Jerks in Engineering
- The Importance of Fun in the Workplace
- How to Debug Your Team: QCon London Q&A
- High-Performing Teams Need Psychological Safety. Here’s How to Create It
- 技術系イベントにおけるアンチハラスメントポリシーの効果について
- Netflix Culture
- Levels of Seniority
- Advice From A 19 Year Old Girl & Software Developer
- How To Stay Motivated as a Developer
- The Secret to Being a Top Developer Is Building Things! Here’s a List of Fun Apps to Build!
- OSSへの貢献ノウハウ
- あなたはなぜ英語ができないのか — プロジェクトベース英語学習法のススメ
- AWS Summit Berlin セッション資料・動画一覧
- AWSのNoSQL入門
- AWS サービス別資料
- 53サービス・アプリのクラウドやフレームワーク・言語など聞いてみた! アーキテクチャ大調査2020
- アルゴリズムビジュアル大辞典 図解でよくわかるアルゴリズムとデータ構造
- プログラミング演習 Python 2019
- systemd エッセンシャル
- 古典プログラマ向け量子プログラミング入門 [フル版]
- Introduction to Kubernetes
- マネージャー
- 研修資料まとめ.md
- [Object-Oriented Conference] 資料まとめ
- Developers Summit 2020 資料リンクまとめ
- SRE Books
- Developer Roadmaps
記事
AWSに関するスキルアップ方法と一度は読むべきブログの紹介
- AWS のスキルアップを図る上で読んでおきたい
「Infrastructure as Codeに疲れたので、僕たちが本来やりたかったことを整理する」を1年掛けて整理した
- IaC の発端、どのように導入すれば良いか
Infrastructure as Dataとは何か
- Infrastructure as Data とは何か、 IaC とは何が違うのか
Eric Evans Says Domain-Driven Design (DDD) Isn't Done
- DDD はこれからどうあるべきか
API 設計: gRPC、OpenAPI、REST の概要と、それらを使用するタイミングを理解する
- gRPC, OpenAPI, REST の概要と使い所
gRPC Internal - gRPC の設計と内部実装から見えてくる世界
- gRPC の発端、特徴、仕組みを手を動かしながら学べる
サーバーレスアーキテクチャ再考
- サーバーレスの定義と制約
Pattern: Backends For Frontends
- Backends for Frontends の発端、メリット、今までの汎用 API バックエンドとは何が違うのか
BFF @ SoundCloud
- SoundCloud 社の BFF の使い方、 monolithic なアプリケーションから microservice に移行する上で、 Backends for Frontends がうまく機能したという話
Dockerが注目されている理由を探る
- 仮想化方式の比較、 Docker の特徴や使い所
Why Discord is switching from Go to Rust
- Discord 社がサービスを Rust で実装し直すことがなぜ理にかなっていたのか、どうやって成し遂げられたのか、パフォーマンスの改善結果
LinuxコミュニティはRustを受け入れた
- 2014年に Rust が Linux コミュニティにどうやって受け入れられ始めたのか
Linux memory management at scale
- Linux のメモリ管理についての誤解、信頼性がありスケーラブルなシステムの構築方法、 Facebook でどのようにシステムを管理してきたか
アニメーションで感覚的にハッシュ関数「SHA-256」の算出過程を理解できる「SHA-256 Animation」
- SHA-256 の具体的な算出過程について
bash の危険な算術式
- 算術式の何が危険なのか、どういう時に危険なのか
LOGGING BEST PRACTICES: THE 13 YOU SHOULD KNOW
- 現在のロギングのベストプラクティス
機械学習アプリケーションにおけるテストについて
- 機械学習モデルの「何を、どこを、どうやって」テストするかの指針
- 機械学習のテストについて無知だったので、非常に勉強になった
Node.js徹底攻略 ─ ヤフーのノウハウに学ぶ、パフォーマンス劣化やコールバック地獄との戦い方
- Node.js を使ったアプリケーションのパフォーマンスを高める方法、コールバック地獄の対処方法
?⚙️ JavaScript Visualized: the JavaScript Engine
- JavaScript Engine がどのように JS のコードをバイトコードに変換しているかの仕組み
Things nobody ever taught me about CSS.
- CSS の仕組み、パフォーマンスを高める方法、 CSS の順番について
Cookie 概説
- Cookie の仕組みについて、手を動かしながら学べる
Brilliant Jerks in Engineering
- Brilliant Jerks とは何か、その特徴、どのように対処するか
The Importance of Fun in the Workplace
- 職場において「楽しさ」がなぜ重要なのか、どのように高めていくか
How to Debug Your Team: QCon London Q&A
- チームをどのように成功に導くか、またそのテクニックを具体的に学べる
High-Performing Teams Need Psychological Safety. Here’s How to Create It
- 心理的安全性とは何か、そのメリット、それを高める方法を具体的に学べる
技術系イベントにおけるアンチハラスメントポリシーの効果について
- アンチハラスメントポリシーを掲げることによるメリット、副次的効果
Netflix Culture
- Netflix が brilliant jerks をどのように考えているか
Levels of Seniority
- Developer のジョブレベル毎の主要なファクターについて
Advice From A 19 Year Old Girl & Software Developer
- 19歳の Software Developer が日々行っていること
How To Stay Motivated as a Developer
- 自分を動機付け、品質の高いコードを書くために自分自身を訓練するために使うTips
The Secret to Being a Top Developer Is Building Things! Here’s a List of Fun Apps to Build!
- コーディングスキルを鍛える八つのプロジェクト
OSSへの貢献ノウハウ
- OSS に貢献することのメリット、貢献の仕方、貢献における課題
あなたはなぜ英語ができないのか — プロジェクトベース英語学習法のススメ
- なぜ英語ができないのか、どうすればできるようになるのか、効率よく学習する方法
資料
AWS Summit Berlin セッション資料・動画一覧
- AWS Summit 2019 ( Tokyo / Osaka ) のセッションの資料と動画、 EXPO 会場の展示ブースにて配布された資料が公開されている
AWSのNoSQL入門
- NoSQL の特徴や使い所、 AWS の NoSQL サービスについて
AWS サービス別資料
- AWS の各サービスの資料がまとめられている
- スライドや発表( Youtube )を見るだけでも勉強になる
53サービス・アプリのクラウドやフレームワーク・言語など聞いてみた! アーキテクチャ大調査2020
- 各社のサービスやアプリを開発しているプログラミング言語やアーキテクチャ、またインフラを構成するミドルウェアやデータベース等がまとめられている
アルゴリズムビジュアル大辞典 図解でよくわかるアルゴリズムとデータ構造
- マイナビ出版発行の書籍「アルゴリズムビジュアル大事典」のアニメーションや疑似コードが公開されている
プログラミング演習 Python 2019
- 京都大学の全学共通科目として実施されるプログラミング演習( Python )の教科書が公開されている
- 1が演習編、2がコラム編となっている
systemd エッセンシャル
- systemd の概要と仕組み
古典プログラマ向け量子プログラミング入門 [フル版]
- 量子プログラミングの概念や計算方法、今後の予想など
Introduction to Kubernetes
- Kubernetes の基本を手を動かしながら学べる
マネージャー
- Google はマネージャーの存在をどのように考えているか、マネージメントスキルを伸ばす方法
研修資料まとめ.md
- 各社新卒研修資料をまとめてくださっている
- 自分のスキルチェックや、自社で研修資料を作成する際に大いに参考となるはず
[Object-Oriented Conference] 資料まとめ
- Object-Oriented Conference 2020 の資料をまとめてくださっている
Developers Summit 2020 資料リンクまとめ
- Developers Summit 2020 の資料をまとめてくださっている
SRE Books
- 以下の技術書がオンラインで読める
- 『Building Secure & Reliable Systems』
- 『The Site Reliability Workbook』
- 『Site Reliability Engineering』
Developer Roadmaps
- このロードマップの目的は「次に何を学ぶかを迷った際の指針となること」であり、「トレンドを追うこと」ではない
- トレンドがその仕事に最も適しているということでは決してない
- Programming Guides も良い
- 投稿日:2020-05-25T08:08:26+09:00
【Laravel】 ネストしたEagerLoadを書いてみる
やりたいこと
以下のテーブル構成があったときに、
マンションテーブルの情報から郵便番号テーブルの住所名を取得したいときに、
ネストしたEagerLoadを使用することができたので、残します。マンションテーブル(apartments)
項目名 カラム名 外部キー id マンションID マンションの基本情報テーブル(apartment_infos)
項目名 カラム名 外部キー id マンションの基本情報のID apartment_id マンションテーブルのID apartments.id postal_code 郵便番号 postal_codes.postal_code 郵便番号テーブル(postal_codes)
項目名 カラム名 外部キー postal_code 郵便番号 name 住所名(愛媛県松山市...) 公式の説明
初歩の初歩なのか、あっさりと書かれていて、
私はぱっと見ただけでは理解出来ませんでした。実際のコード
モデル//マンションモデル class Apartment extends Model{ public function apartmentInfo() { //マンションの基本情報テーブルとの関係を明示 return $this->hasOne(ApartmentInfo::class,"id" , "id")->withDefault(); } } //マンションの基本情報モデル class ApartmentInfo extends Model{ public function postalCode() { //郵便番号テーブルとの関係を明示 return $this->hasOne(PostalCode::class,"postal_code" , "postal_code")->withDefault(); } } //郵便番号のモデル class PostalCode extends Model{ }コントローラpublic function sample(){ $apartments = Apartment::with( ["apartmentInfo", "apartmentInfo.postalCode"])->get(); var_dump($apartments->ApartmentInfo->PostalCode->name); }感想
最初は、郵便番号のモデルに、findするようなメソッドを用意していたが、
N+1クエリ問題が発生してしまうので、どうにかならないかなあと思っていたところ、改善できてよかった。
- 投稿日:2020-05-25T07:46:02+09:00
Mac/Linuxのaliasでaws ssmによるパスワード管理を直感的にする
公私共にお世話になっているSSMですが、都度コマンドは何だっけと苦労してたのでaliasにしました。
正確には、引数を使う必要があったので、aliasではなくfunctionとして実装しました。以下のように利用できます。$ setssm TEST_KEY test_val #登録して $ getssm TEST_KEY #参照する test_val #出力 $ setssm TEST_KEY2 "test space日本語" #スペース、日本語の処理も可 $ echo HOGE$(getssm TEST_KEY2)FUGA #コマンド上で展開し変数としても扱える HOGEtest space日本語FUGA $ listssm | grep TEST #一覧の出力からgrepで検索し、TESTを含むキーと値を出力 TEST_KEY test_val TEST_KEY2 test space日本語実装は
~/.bash_profileの終わりに以下を追加し、source ~/.bash_profileで更新するだけです。~/.bash_profilefunction setssm() { command aws ssm put-parameter --name $1 --type "String" --overwrite --value "$2"; } function getssm() { command aws ssm get-parameter --name $1 --query 'Parameter.Value' --output text; } function listssm() { command aws ssm get-parameters-by-path --path "/" --query "Parameters[].[Name,Value]" --output text }個人的に最も捗るのはコマンドを会社用と自分用に分けてしまうことです。
setssm_privateとsetssm_corpなどコマンドを2パターン用意し、--profile引数をそれぞれに付与するとパーソナルな情報を会社のssmにアップしたりその逆を避けれます。最近は認証情報もSSM経由で取り扱えるフレームワークが増えてきて、レポジトリに認証情報をアップするリスクや心配が無くなってきていいですね。皆様も良いAWSライフを。
参考
https://github.com/aws/aws-cli/issues/1961
https://hacknote.jp/archives/8043/
https://dev.classmethod.jp/articles/aws-cli-all-ssm-parameter-get/
https://qiita.com/tomoya_oka/items/a3dd44879eea0d1e3ef5
- 投稿日:2020-05-25T02:33:11+09:00
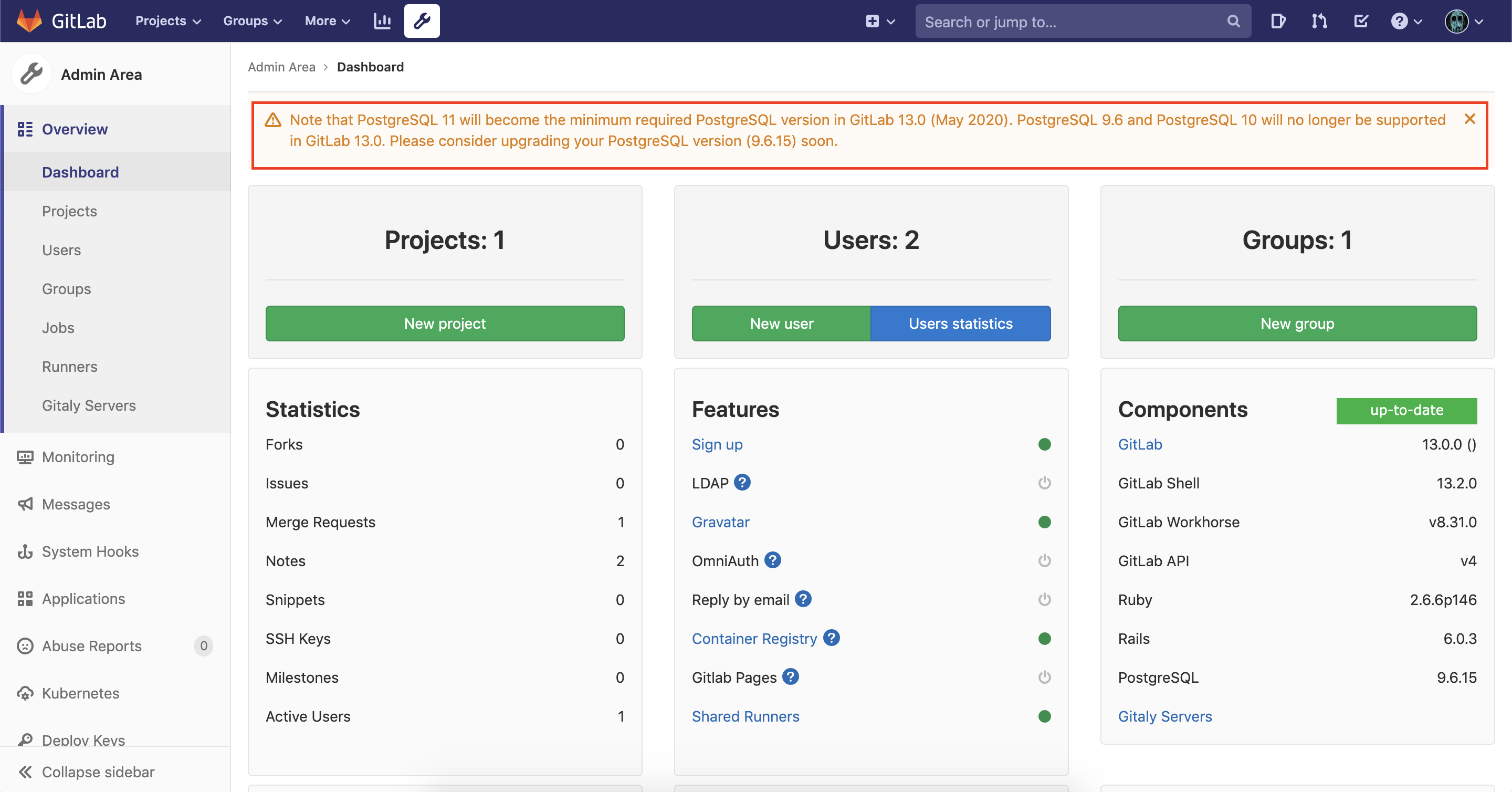
EKSにデプロイしたGitLabのバージョンを12から13にアップデートする
はじめに
GitLab 13.0.0が2020/05/22にリリースされました。
そこで今回はEKSにHelmでデプロイしたGitLab 12.3.5を13.0.0にバージョンアップデートする方法を説明します。まずはGitLab Helm Chartのアプリバージョンとのマッピングを見てみましょう。
詳細はこちらのページにあります。
Chart Version GitLab Version 2.3.7 12.3.5 2.6.9 (2系の最新) 12.6.8 3.0.0 12.7.0 3.3.5 (3系の最新) 12.10.6 4.0.0 13.0.0 表から分かるようにアプリのメジャーバージョンが変わる前にChartのメジャーバージョンが変わっているので少し変則的にバージョンを上げていく必要があります。
Chartのメジャーアップデートを2回行うため、2.3.7 → 2.6.9 → 3.0.0 → 3.3.5 → 4.0.0と段階的にバージョンを上げていきます。環境情報
macOS Mojabe 10.14.6
Helm 3.2.1
EKS 1.13
RDS PostgreSQL 9.6.15
ALB Ingress Controller Helm Chart 0.1.11
kube2iam Helm Chart 2.0.1
GitLab Helm Chart 2.3.7, 2.6.9, 3.0.0, 3.3.5, 4.0.0前準備
ALBを使用するために
ALB Ingress Controller、IAM RoleをPodに付与するためにkube2iamをデプロイしておきます。GitLabがS3を使うためにはS3バケット情報をSecretとして作る必要があります。
こちらの記事に詳しく書いてあるので参考にしてください。
今回はgitlab-rails-storage、storage-config、registry-storageの名前で3つのSecretを作成します。RDSへのアクセス情報のSecretは次のコマンドで作成します。namespaceは
update-testにします。$ kubectl create secret generic gitlab-postgresql \ --from-literal password=<PASSWORD> \ --namespace update-test
my-values.yamlを作成してHelmコマンドでGitLabをデプロイします。
s3-full-access-roleはPodがS3にアクセスするためのものです。my-values.yamlglobal: edition: ce hosts: https: false gitlab: name: 1ec885a2-updatetest-albing-6622-1089076412.ap-northeast-1.elb.amazonaws.com https: false ingress: configureCertmanager: false enabled: false tls: enabled: false psql: password: secret: gitlab-postgresql key: password host: update-test-gitlab.crdjlj5j7v3p.ap-northeast-1.rds.amazonaws.com port: 5432 username: gitlab database: gitlabhq_production minio: enabled: false appConfig: lfs: bucket: update-test-gitlab-lfs connection: secret: gitlab-rails-storage key: connection artifacts: bucket: update-test-gitlab-artifacts connection: secret: gitlab-rails-storage key: connection uploads: bucket: update-test-gitlab-uploads connection: secret: gitlab-rails-storage key: connection packages: bucket: update-test-gitlab-packages connection: secret: gitlab-rails-storage key: connection externalDiffs: enabled: true bucket: update-test-gitlab-mr-diffs connection: secret: gitlab-rails-storage key: connection pseudonymizer: configMap: bucket: update-test-gitlab-pseudo connection: secret: gitlab-rails-storage key: connection backups: bucket: update-test-gitlab-backups tmpBucket: update-test-gitlab-tmp time_zone: Tokyo upgradeCheck: enabled: false certmanager: install: false nginx-ingress: enabled: false prometheus: install: false postgresql: install: false gitlab-runner: install: false registry: minReplicas: 1 storage: secret: registry-storage key: config annotations: iam.amazonaws.com/role: s3-full-access-role ingress: enabled: false gitlab: gitlab-shell: enabled: false gitlab-exporter: enabled: false unicorn: annotations: iam.amazonaws.com/role: s3-full-access-role ingress: enabled: false service: type: NodePort sidekiq: annotations: iam.amazonaws.com/role: s3-full-access-role task-runner: annotations: iam.amazonaws.com/role: s3-full-access-role backups: objectStorage: config: secret: storage-config key: config$ helm install \ --namespace update-test \ --values my-values.yaml \ --version 2.3.7 \ update-test-gitlab \ gitlab/gitlabALBはIngressをデプロイすることで自動で作成されます。
GitLab Helm Chartに同梱されているIngressはNGINX Ingress Controller用のため、template内のIngressのannotationsを編集することになります。Helm Chartのtemplateはできる限り編集しないほうが良いです。
values.yamlのようにバージョン跨ぎで再利用できないためバージョンアップのたびに作業が増えるからです。そこで今回は自分でIngressを作成してデプロイします。
spec.rules[].hostはALBのDNS名を入れます。alb-ingress.yamlapiVersion: extensions/v1beta1 kind: Ingress metadata: annotations: alb.ingress.kubernetes.io/scheme: internet-facing kubernetes.io/ingress.class: alb name: alb-ingress namespace: update-test spec: rules: - host: 1ec885a2-updatetest-albing-6622-1089076412.ap-northeast-1.elb.amazonaws.com http: paths: - backend: serviceName: update-test-gitlab-unicorn servicePort: 8181 - backend: serviceName: update-test-gitlab-unicorn servicePort: 8080 path: /admin/sidekiq$ kubectl apply -f alb-ingress.yaml以上で検証環境構築は完了です。
バージョンアップ手順
2.3.7 → 2.6.9
GitLab Helm Chart 2系の最新である2.6.9にアップデートします。
my-values.yamlに変更点はありません。$ helm upgrade \ --namespace update-test \ --values my-values.yaml \ --version 2.6.9 \ update-test-gitlab \ gitlab/gitlab2.6.9 → 3.0.0
GitLab Helm Chart 3.0.0にアップデートします。
ここでもmy-values.yamlに変更点はありません。$ helm upgrade \ --namespace update-test \ --values my-values.yaml \ --version 3.0.0 \ update-test-gitlab \ gitlab/gitlab3.0.0 → 3.3.5
GitLab Helm Chart 3系の最新である3.3.5にアップデートします。
ここでもmy-values.yamlに変更点はありません。$ helm upgrade \ --namespace update-test \ --values my-values.yaml \ --version 3.3.5 \ update-test-gitlab \ gitlab/gitlab3.3.5 → 4.0.0
GitLab Helm Chart 4.0.0からwebサーバにunicornだけでなくpumaを使用できるようになっています。(デフォルトではpumaを使用)
それに伴い、今までHelm Chart内のコードはunicornがwebserviceという名前に変わっています。
my-values.yamlの中身を変更してからアップデートします。$ sed -i -e "s/unicorn/webservice/g" my-values.yaml$ helm upgrade \ --namespace update-test \ --values my-values.yaml \ --version 4.0.0 \ update-test-gitlab \ gitlab/gitlabアクセスしてみると502画面になってしまいます。
アクセスできない原因はIngressです。Helm Chartのtemplateに含めなかったことの弊害がここで現れました。
宛先のService名を変更して再デプロイします。$ sed -i -e "s/unicorn/webservice/g" alb-ingress.yaml$ kubectl apply -f alb-ingress.yamlアクセスできるようになり、アプリバージョンも13.0.0になっています。
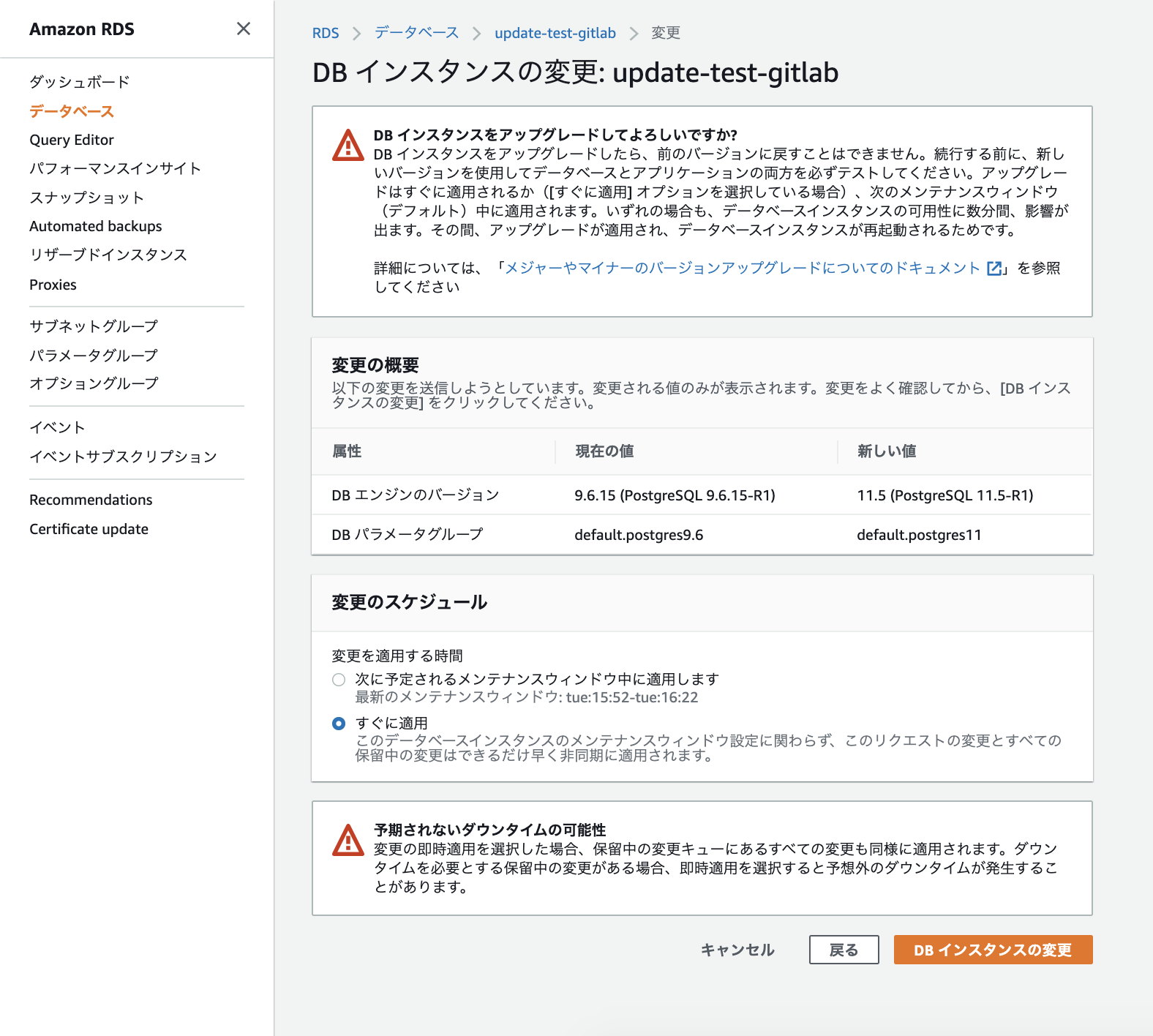
ただ、PostgreSQL 9.6が古いと怒られています。
PostgreSQLコンテナを使っていると色々と面倒な作業が生じますが、今回はRDSを使用しているのでAWSコンソールからさっとPostgreSQL 11にアップデートします。
PostgreSQLアップデートは15分ほどで終わりました。
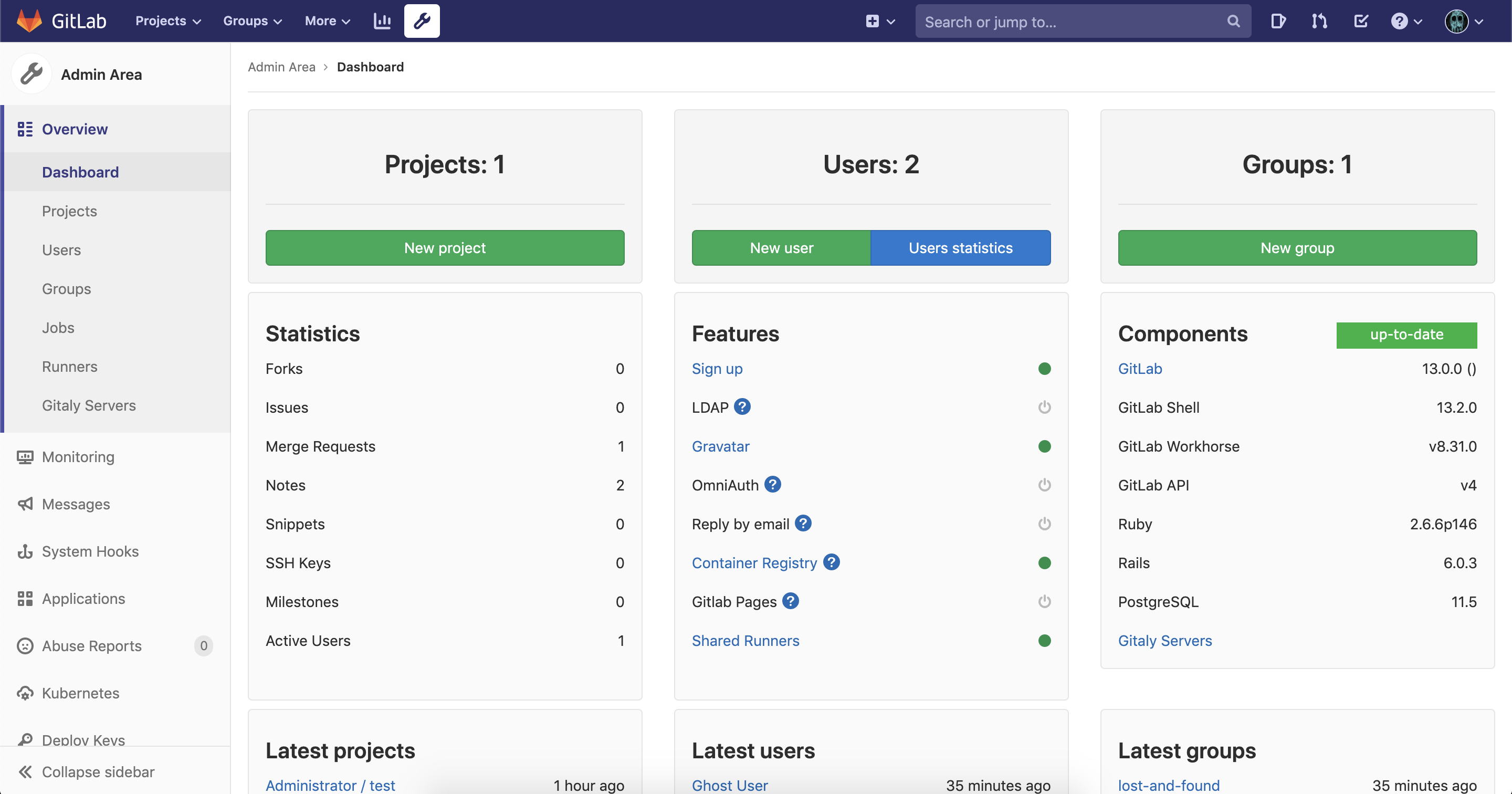
次にDBマイグレーション処理を行うためにhelm upgradeします。$ helm upgrade \ --namespace update-test \ --values my-values.yaml \ --version 4.0.0 \ update-test-gitlab \ gitlab/gitlabadminページに警告が現れることがなくなりました。
バージョンアップ前のコミットなどを見てデータの整合性を確認しましょう。
問題はなさそうです。
おわりに
EKSにデプロイしたGitLabを12から13にメジャーアップデートする方法を説明しました。
今回はHelm 3.2.1を使用しましたが、Helm 2.14.3でも同様に成功することを確認済みです。
ですが今後のことを考えるとHelm 3の方が良いと思います。

- 投稿日:2020-05-25T01:58:28+09:00
Netflixのパフォーマンスエンジニアも使っているsarコマンドについてまとめた
https://twitter.com/go_vargo/status/1215281798948642817?s=20
上記Tweetで紹介されていた内で、
sarコマンドに馴染みがなかったので少し調査してみました。sarコマンドとは
sar(System Activity Reporter)はLinuxのモニタリングツールの1つです。
メモリ、CPU使用率、ディスクIO、ネットワーク、ロードアベレージ等の統計情報を表示するコマンドで、sysstatパッケージに含まれています。
リアルタイムの統計情報だけでなく、過去の統計情報を表示することが可能で、
過去にさかのぼって情報を見ることができるため、障害対応時の原因調査に役立ちます。表示する統計情報の種類は、オプションで指定します。
基本的な使い方
オプション
sar [...options][...options]に、どのリソースの情報を表示するか指定します。
オプションを指定しない場合、当日のリソース情報が取得されます。
情報取得間隔は、デフォルトは10分です。過去データの保存先
Amazon Linux 2だと、
/var/log/sa配下に過去データが保存されていきます。[ec2-user@xxx ~]$ ls -la /var/log/sa 合計 2652 drwxr-xr-x 2 root root 167 5月 24 05:14 . drwxr-xr-x 8 root root 4096 5月 24 05:14 .. -rw-r--r-- 1 root root 91760 10月 12 2019 sa12 -rw-r--r-- 1 root root 336992 10月 13 2019 sa13 -rw-r--r-- 1 root root 336992 10月 14 2019 sa14 -rw-r--r-- 1 root root 238880 10月 15 2019 sa15 -rw-r--r-- 1 root root 290320 10月 17 2019 sa17 -rw-r--r-- 1 root root 336992 10月 18 2019 sa18 -rw-r--r-- 1 root root 16960 10月 19 2019 sa19 -rw-r--r-- 1 root root 5328 5月 24 05:30 sa24 -rw-r--r-- 1 root root 68488 10月 12 2019 sar12 -rw-r--r-- 1 root root 249044 10月 13 2019 sar13 -rw-r--r-- 1 root root 249044 10月 14 2019 sar14 -rw-r--r-- 1 root root 214675 10月 17 2019 sar17 -rw-r--r-- 1 root root 249044 10月 18 2019 sar18
sar**のあとの数字は、直近何日分かを表しています。ファイル自体はバイナリで保存されていますが、
sar経由でファイルの中身を表示できます。[ec2-user@xxx ~]$ sar -r -f /var/log/sa/sa12 Linux 4.14.123-111.109.amzn2.x86_64 (localhost) 2019年10月12日 _x86_64_ (1 CPU) 17時23分29秒 LINUX RESTART 17時30分01秒 kbmemfree kbmemused %memused kbbuffers kbcached kbcommit %commit kbactive kbinact kbdirty 17時40分01秒 493536 513796 51.01 2088 390136 593996 58.97 166828 253464 252 17時50分01秒 493540 513792 51.01 2088 390300 593996 58.97 166892 253532 252 18時00分01秒 493004 514328 51.06 2088 390636 593988 58.97 167000 253844 216リアルタイムの情報を、特定間隔に絞って表示する場合
コマンドのあと
[取得間隔] [取得回数]でリアルタイムで表示するデータを制限できます。1秒おきに3回情報を習得する場合は、下記の通りです。
[ec2-user@xxx ~]$ sar -r 1 3 Linux 4.14.146-119.123.amzn2.x86_64 2020年05月24日 _x86_64_ (1 CPU) 05時37分41秒 kbmemfree kbmemused %memused kbbuffers kbcached kbcommit %commit kbactive kbinact kbdirty 05時37分42秒 585824 421468 41.84 2088 323892 531260 52.74 154588 198628 128 05時37分43秒 584948 422344 41.93 2088 323892 531260 52.74 155608 198628 128 05時37分44秒 584568 422724 41.97 2088 323892 531260 52.74 155884 198628 128 平均値: 585113 422179 41.91 2088 323892 531260 52.74 155360 198628 128統計情報を別ファイルに保存する
## memというファイルにメモリのリアルタイム情報を1秒間隔で3回保存する [ec2-user@xxx ~]$ sar -r 1 3 -o mem ## memファイルに保存した統計情報を表示する [ec2-user@xxx ~]$ sar -r -f mem表示するリソースを指定する
オプションを変えることで、表示するリソースを指定できる
- CPU使用率
[ec2-user@xxx ~]$ sar -P ALL 1 Linux 4.14.146-119.123.amzn2.x86_64 2020年05月24日 _x86_64_ (1 CPU) 05時39分43秒 CPU %user %nice %system %iowait %steal %idle 05時39分44秒 all 0.00 0.00 0.00 0.00 0.00 100.00 05時39分44秒 0 0.00 0.00 0.00 0.00 0.00 100.00
- メモリ使用率
[ec2-user@xxx ~]$ sar -r 1 Linux 4.14.146-119.123.amzn2.x86_64 2020年05月24日 _x86_64_ (1 CPU) 05時41分24秒 kbmemfree kbmemused %memused kbbuffers kbcached kbcommit %commit kbactive kbinact kbdirty 05時41分25秒 586180 421112 41.81 2088 323940 526944 52.31 154808 198444 0 05時41分26秒 586180 421112 41.81 2088 323940 526944 52.31 154808 198444 0 05時41分27秒 586180 421112 41.81 2088 323940 526944 52.31 154808 198444 0
- ネットワーク
受信/送信パケット数[ec2-user@xxx ~]$ sar -n DEV 1 Linux 4.14.146-119.123.amzn2.x86_64 (ip-172-31-63-105.ap-northeast-1.compute.internal) 2020年05月24日 _x86_64_ (1 CPU) 05時42分33秒 IFACE rxpck/s txpck/s rxkB/s txkB/s rxcmp/s txcmp/s rxmcst/s 05時42分34秒 eth0 2.00 0.00 0.10 0.00 0.00 0.00 0.00 05時42分34秒 lo 0.00 0.00 0.00 0.00 0.00 0.00 0.00 05時42分34秒 IFACE rxpck/s txpck/s rxkB/s txkB/s rxcmp/s txcmp/s rxmcst/s 05時42分35秒 eth0 1.01 1.01 0.05 0.39 0.00 0.00 0.00 05時42分35秒 lo 0.00 0.00 0.00 0.00 0.00 0.00 0.00
- 投稿日:2020-05-25T01:02:16+09:00
aws-sdkでSTSを利用してDynamoDBにputItemする時の注意点
はじめに
Lambdaを使って別アカウントのDynamoDBにputItemする際にハマったことをメモ。
DynamoDBにputItemするのは初めてだったので、
事前に同一アカウントのDynamoDBにputItemをした。やったこと
- Lambdaから同一アカウントのDynamoDBにputItem
- LambdaからSTSを使って別アカウントのDynamoDBにputItem
Lambdaから同一アカウントのDynamoDBにputItem
AWS.DynamoDBクラスを使用
index.jsconst AWS = require('aws-sdk'); exports.handler = async (event, context) => { const dynamodb new AWS.DynamoDB() const param = { TableName: "テーブル名", Item: { "name": { S: "tuaaasa" }, "age": { N: 23 } } }; await dynamodb.putItem(param, (err, data) => { if(err) console.log(err); else console.log(data); }); };問題なく送信されました。
LambdaからSTSを使って別アカウントのDynamoDBにputItem
今回は別アカウントのため、STSを使い別アカウントから許可されたロールを利用する。
AWS.DynamoDB.DocumentClientクラスを使用して、こんな感じで実装。
index.jsconst AWS = require('aws-sdk'); const arn = "別アカウントから許可されたロールARN"; const myAccountId = '自分のアカウントID'; exports.handler = async (event, context) => {l; const sts = new AWS.STS(); const role = await sts.assumeRole({ RoleArn: '別アカウントから許可されたロールARN', RoleSessionName: 'test' }); const credentials = new AWS.Credentials( role.Credentials.AccessKeyId, role.Credentials.SecretAccessKey, role.Credentials.SessionToken ); const dynamodb new AWS.DynamoDB.DocumentClient({ credentials }); const param = { TableName: "テーブル名", Item: { "name": { S: "tuaaasa" }, "age": { N: 23 } } }; await dynamodb.putItem(param, (err, data) => { if(err) console.log(err); else console.log(data); }); };
TypeError: dynamodb.putItem is not a functionで怒られた。ドキュメントをよくみてみると、
DocumentClientの場合はputメソッドのようだ。index.js... const param = { TableName: "テーブル名", Item: { "name": { S: "tuaaasa" }, "age": { N: 23 } } }; await dynamodb.put(param, (err, data) => { // putに修正 if(err) console.log(err); else console.log(data); });今度はこんなエラーで怒られた。
"One or more parameter values were invalid: Type mismatch for key id expected: S actual: M","code":"ValidationException"Itemの型が合っていない模様。
しかしnameは文字列型でageは数値型で間違っているはずがない...ハマりポイント
AWS.DynamoDB.DocumentClientクラスをよく見ると、
paramで指定するItemのJSON構造が違った。// AWS.DynamoDBクラスの場合 const param = { TableName: "テーブル名", Item: { "name": { S: "tuaaasa" }, "age": { N: 23 } } }; // AWS.DynamoDB.DocumentClientクラスの場合 const param = { TableName: "テーブル名", Item: { "name": "tuaaasa", "age": 23 } };
AWS.DynamoDB.DocumentClientクラスを扱う場合はItemに型と値のオブジェクトにしないことです。おわりに
ちゃんとドキュメントは読みましょう(自戒)。
- 投稿日:2020-05-25T00:42:21+09:00
Go言語でAWS SNSにメッセージを送信する
概要
Amazon Simple Notification Service(SNS)で、Go言語のSDKを使ってトピックに対してメッセージを送信します。
環境
- Go : 1.14.3
- Mac OS X : 10.15.4
- AWS SDK for Go
シンプルな実装
シンプルなメッセージ送信package main import ( "fmt" "github.com/aws/aws-sdk-go/aws" "github.com/aws/aws-sdk-go/aws/session" "github.com/aws/aws-sdk-go/service/sns" ) // TopicARNとRegionは環境に合わせます const ( TopicARN = "arn:aws:sns:XXXXXXXXXXXXXXXXX" AwsRegion = "XXXXXX" ) func main() { // SNSクライアントの作成 mySession := session.Must(session.NewSession()) svc := sns.New(mySession, aws.NewConfig().WithRegion(AwsRegion)) message := "This is sample message." // メッセージを送信するための構造体を作成 inputPublish := &sns.PublishInput{ Message: aws.String(message), TopicArn: aws.String(TopicARN), } // メッセージの送信(Publish) MessageId, err := svc.Publish(inputPublish) if err != nil { fmt.Println("Publish Error: ", err) } fmt.Println(MessageId) }シンプルにメッセージを送る場合の実装です。登録されたサブスクリプションに対してメッセージが送信されます。例として、SQSをサブスクリプションにした場合、以下の通り確認できます。
サブスクリプションごとにメッセージを変える場合
サブスクライブするプロトコルごとのメッセージpackage main import ( "encoding/json" "fmt" "github.com/aws/aws-sdk-go/aws" "github.com/aws/aws-sdk-go/aws/session" "github.com/aws/aws-sdk-go/service/sns" ) const ( TopicARN = "arn:aws:sns:XXXXXXXXXXXXXXXXX" AwsRegion = "XXXXXX" ) func main() { mySession := session.Must(session.NewSession()) svc := sns.New(mySession, aws.NewConfig().WithRegion(AwsRegion)) message := "This is sample message." // サブスクリプションのプロトコルごとにメッセージを指定 messageJson := map[string]string{ "default": message, "sqs": "This is sample message for sqs.", } // メッセージ構造体はJSON文字列にする bytes, err := json.Marshal(messageJson) if err != nil { fmt.Println("JSON marshal Error: ", err) } messageForSQS := string(bytes) inputPublish := &sns.PublishInput{ Message: aws.String(messageForSQS), MessageStructure: aws.String("json"), // MessageStructureにjsonを指定 TopicArn: aws.String(TopicARN), } MessageId, err := svc.Publish(inputPublish) if err != nil { fmt.Println("Publish Error: ", err) } fmt.Println(MessageId) }このソースの実行結果は以下の通りです。SQS用に設定したメッセージが送信されています。
このようにサブスクリプションのプロトコルごとに異なるメッセージを送る場合、
MessageStructureにjsonを設定します。また、メッセージはJSON文字列として、トップレベルにプロトコル(今回の例ではsqs)を指定します。トップレベルにdefaultは必須です。
プロトコルとして指定する値はCLIのリファレンスを参照。
subscribe - Optionsなお、メッセージ属性を設定する場合は
MessageAttributesを使います。詳細は以下の公式ドキュメントを参照。
type PublishInput参考

