- 投稿日:2020-05-25T22:42:46+09:00
Node.js 12+なら標準入力が超簡単に読める
process.stdinはfor await...ofでループできるNode.js 12から
stream.Readableが非同期反復オブジェクト(Async Iterable)になりました。当然
process.stdinもAsync Iterableなので、for await...of文でループできます。nl.js(async () => { const buffers = []; for await (const chunk of process.stdin) buffers.push(chunk); const buffer = Buffer.concat(buffers); const text = buffer.toString(); const lines = text.split(/\r?\n/); lines.forEach((line, index) => console.log('%d: %s', index + 1, line)); })();補足ですが、文字エンコーディングを指定したい場合は、事前に
setEncoding(encoding)で設定します。(async () => { process.stdin.setEncoding('utf8'); let text = ''; for await (const chunk of process.stdin) text += chunk; console.log('%s', text); })();
@moneyforward/stream-utilを使えば、さらに簡潔に
@moneyforward/stream-utilを使うと、さらに簡潔になります。まずは、インストールを。
npm install @moneyforward/stream-utilテキストとして一括取得するなら
stringify
@moneyforward/stream-utilのstringifyを使えば、ごく簡潔に文字列にできます。const { stringify } = require('@moneyforward/stream-util'); const text = stringify(process.stdin); console.lot('%s', text);行ごとに逐次処理するなら
transform.Lines
@moneyforward/stream-utilのtransform.Linesを使えば、行ごとにループして逐次処理が簡潔にできます。const { transform } = require('@moneyforward/stream-util'); let count = 0; for await (const line of process.stdin.pipe(new transform.Lines()) { console.log('%d: %s', count++, line); }参考
- 投稿日:2020-05-25T22:36:45+09:00
Node.jsでjsの非同期処理でつまづいたところ
概要
以前の記事で、イベントループ方式の理解に苦しんだことについて記事にあげましたが、今回は、非同期処理についてつまづいたところを忘れないように記事にしてみようと思います。
つまづいた経緯としては、Node.jsでローカルサーバーを構築し、リクエストを受け付けられるようになったところで、「リクエストごとに処理を変えたいなぁ」、と思ったことが全ての始まりでした。
環境
自分が実際につまづいた時の環境は、以下となります。
- OS:Windows10
- ブラウザ:Chrome
やりたかったこと
- データを取得して、それをページに表示する。
最初はMVCモデルに基づいてプログラムを組もうと考えていましたが、少しめんどくさくなりそうだったので、簡単にデータを取得・反映させるページを作ろうと思いました。
つまづいたところ
最初に記述したコードになります。
sample_node.js// モジュールの取り込み const http = require('http'); const fs = require('fs'); const path = require('path'); const ejs = require('ejs'); const mime = require('mime-types'); const qs = require('querystring'); const setting = require('./setting'); const db = require('./db'); // 本ファイルの親フォルダを取得(htmlファイル等を取得するため) const parentDir = path.dirname(__dirname); // webサーバーの作成 const server = http.createServer(); // リクエストの受付を検知する server.on('request', AppController); server.listen(setting.port, setting.host); console.log('server listeneing...'); // URLのマッピング処理を振り分ける async function AppController(req, res) { let filePath = req.url; if(filePath === '/favicon.ico'){ res.end(); return; } let parseData; if(req.method === "POST"){ req.data = ""; req.on("data", function(chunk){ req.data += chunk; }); req.on("end", function(){ parseData = qs.parse(req.data); try{ const resultData = selectAllItem(); // // 結果を取得して色々処理... // buildPage(res, "/public/index.html", resultData); }catch(e){ console.log(e.stack); buildPage(res, "err.html", ""); } }); }else if(req.method === "GET"){ try{ buildPage(res, "/public/index.html", ""); }catch(e){ console.log(e.stack); buildPage(res, "err.html", ""); } } }; // ページ遷移処理 const buildPage = function (res, filePath, postData){ try{ res.writeHead(200, {"Content-Type": mime.lookup(path.basename(filePath)) }); const content = fs.readFileSync(parentDir + filePath, 'utf-8'); const data = ejs.render(content,{form:postData}); res.write(data); res.end(); }catch(e){ console.log(e.stack); throw e; } } // DBに接続して、データを取得する const selectAllItem = async function(){ let item1 = {}; let item2 = {}; let item3 = {}; try{ item1 = db.selectItem1("*"); item2 = db.selectItem2("*"); item3 = db.selectItem3("*"); }catch(e){ console.log(e.stack); throw e; } return {"item1":item1, "item2":item2, "item3":item3}; }この状態で実行すると、selectAllItem()メソッド実行後の、resultDataに何も入っていませんでした。
これは、処理が非同期処理であるため、selectの実行をする前に、ページ遷移が先に実行されてしまったようです。
これを解決するためには、
selectの実行 → データの編集処理 → ページ遷移
という順番を守ってもらわなければなりません。解決策(Promise / async / await)
Node.jsでは、基本的にイベントループ方式のため、関数の終了を待ってはくれないみたいです。
そこで必要な知識となるのが、Promiseオブジェクトとasync/awaitの記述でした。
Promiseとasync/awaitは、書き方が違うだけで、実装できる内容はほぼほぼ同じです。
詳しい違いについては、以下の記事を参考にしてみてください。
https://qiita.com/h1guchi/items/0434f1295226cdd19a53今回の解決策には、async / awaitを使用しました。
まずメイン処理から修正していきます。メイン処理の修正
async_await_sample.js// URLのマッピング処理を振り分ける async function AppController(req, res) { ...//省略 if(req.method === "POST"){ req.data = ""; req.on("data", function(chunk){ req.data += chunk; }); req.on("end", async function(){ parseData = qs.parse(req.data); try{ // 1・・・ const resultData = await selectAllItem(); // 2・・・ // 結果を取得して色々処理... // // 3・・・ buildPage(res, "/public/index.html", resultData); }catch(e){ console.log(e.stack); buildPage(res, "err.html", ""); } }); }else if(req.method === "GET"){ try{ buildPage(res, "/public/index.html", ""); }catch(e){ console.log(e.stack); buildPage(res, "err.html", ""); } } };メイン処理で修正することは、下記の流れを守ってもらうことです。
1. データを取得する
2. データを編集する
3. ページ遷移処理を実行する
非同期処理の場合は、この1・2・3が同時に実行されてしまったために問題が起きてしまいましたが、これを解決するために、awaitを使用します。awaitを実行したいasyncな処理の前に記述することで、その処理の終了を待つことができます。
ただし、このawaitを使用する場合は、その使用しているメソッドをasyncにする必要があるみたいです。(このために下層の関数はほとんどasyncをつけなくてはいけなくなりました。。。)今回のメイン処理では、
selectAllItem()メソッドの前に、awaitを記載しました。次は、
selectAllItemメソッド内の処理を修正していきます。データ取得処理の修正
async_await_sample.jsconst selectAllItem = async function(){ let item1; let item2; let item3; return await Promise.all([ db.selectItem1("*"), db.selectItem2("*"), db.selectItem3("*") ]) .then((values) => { item1 = values[0]; item2 = values[1]; item3 = values[2]; return {"item1":item1, "item2":item2, "item3":item3}; }) .catch((err) => { console.log(err.stack);throw err; }); }ここでの処理は、
Promise.all()という処理を使用しています。
最初修正した際は、1つ1つのselect処理にawaitをかけていたのですが、それぞれのselectの順番は気にしなくてもよいため、Promise.allとしています。
Promise.all()の中で定義されたasyncな関数は、全て非同期で実行されますが、その全ての関数の終了を待ってから次に進むため、一括でデータを取得したい時とかには向いているかもしれません。まとめ
普段非同期処理などを意識することがあまりないため、かなり戸惑いましたが、とても勉強になりました。
普段はバックエンド側なので、javascriptを仕事で触ることは稀にしかないのですが、最近調べてみるとjavascriptでARの開発やサーバーの構築やフレームワーク使って簡単にリッチなWEBページを作ったり。。。すごいですねぇ
これから勉強して、またここにアウトプットしていこうと思います。補足(参考リンク)
Promiseとasync/await
https://qiita.com/suin/items/97041d3e0691c12f4974
https://qiita.com/toshihirock/items/e49b66f8685a8510bd76#comments
- 投稿日:2020-05-25T22:36:45+09:00
Node.jsの非同期処理でつまづいたところ
概要
以前の記事で、イベントループ方式の理解に苦しんだことについて記事にあげましたが、今回は、非同期処理についてつまづいたところを忘れないように記事にしてみようと思います。
つまづいた経緯としては、Node.jsでローカルサーバーを構築し、リクエストを受け付けられるようになったところで、「リクエストごとに処理を変えたいなぁ」、と思ったことが全ての始まりでした。
環境
自分が実際につまづいた時の環境は、以下となります。
- OS:Windows10
- ブラウザ:Chrome
やりたかったこと
- データを取得して、それをページに表示する。
最初はMVCモデルに基づいてプログラムを組もうと考えていましたが、少しめんどくさくなりそうだったので、簡単にデータを取得・反映させるページを作ろうと思いました。
つまづいたところ
最初に記述したコードになります。
sample_node.js// モジュールの取り込み const http = require('http'); const fs = require('fs'); const path = require('path'); const ejs = require('ejs'); const mime = require('mime-types'); const qs = require('querystring'); const setting = require('./setting'); const db = require('./db'); // 本ファイルの親フォルダを取得(htmlファイル等を取得するため) const parentDir = path.dirname(__dirname); // webサーバーの作成 const server = http.createServer(); // リクエストの受付を検知する server.on('request', AppController); server.listen(setting.port, setting.host); console.log('server listeneing...'); // URLのマッピング処理を振り分ける async function AppController(req, res) { let filePath = req.url; if(filePath === '/favicon.ico'){ res.end(); return; } let parseData; if(req.method === "POST"){ req.data = ""; req.on("data", function(chunk){ req.data += chunk; }); req.on("end", function(){ parseData = qs.parse(req.data); try{ const resultData = selectAllItem(); // // 結果を取得して色々処理... // buildPage(res, "/public/index.html", resultData); }catch(e){ console.log(e.stack); buildPage(res, "err.html", ""); } }); }else if(req.method === "GET"){ try{ buildPage(res, "/public/index.html", ""); }catch(e){ console.log(e.stack); buildPage(res, "err.html", ""); } } }; // ページ遷移処理 const buildPage = function (res, filePath, postData){ try{ res.writeHead(200, {"Content-Type": mime.lookup(path.basename(filePath)) }); const content = fs.readFileSync(parentDir + filePath, 'utf-8'); const data = ejs.render(content,{form:postData}); res.write(data); res.end(); }catch(e){ console.log(e.stack); throw e; } } // DBに接続して、データを取得する const selectAllItem = async function(){ let item1 = {}; let item2 = {}; let item3 = {}; try{ item1 = db.selectItem1("*"); item2 = db.selectItem2("*"); item3 = db.selectItem3("*"); }catch(e){ console.log(e.stack); throw e; } return {"item1":item1, "item2":item2, "item3":item3}; }この状態で実行すると、selectAllItem()メソッド実行後の、resultDataに何も入っていませんでした。
これは、処理が非同期処理であるため、selectの実行をする前に、ページ遷移が先に実行されてしまったようです。
これを解決するためには、
selectの実行 → データの編集処理 → ページ遷移
という順番を守ってもらわなければなりません。解決策(Promise / async / await)
Node.jsでは、基本的にイベントループ方式のため、関数の終了を待ってはくれないみたいです。
そこで必要な知識となるのが、Promiseオブジェクトとasync/awaitの記述でした。
Promiseとasync/awaitは、書き方が違うだけで、実装できる内容はほぼほぼ同じです。
詳しい違いについては、以下の記事を参考にしてみてください。
https://qiita.com/h1guchi/items/0434f1295226cdd19a53今回の解決策には、async / awaitを使用しました。
まずメイン処理から修正していきます。メイン処理の修正
async_await_sample.js// URLのマッピング処理を振り分ける async function AppController(req, res) { ...//省略 if(req.method === "POST"){ req.data = ""; req.on("data", function(chunk){ req.data += chunk; }); req.on("end", async function(){ parseData = qs.parse(req.data); try{ // 1・・・ const resultData = await selectAllItem(); // 2・・・ // 結果を取得して色々処理... // // 3・・・ buildPage(res, "/public/index.html", resultData); }catch(e){ console.log(e.stack); buildPage(res, "err.html", ""); } }); }else if(req.method === "GET"){ try{ buildPage(res, "/public/index.html", ""); }catch(e){ console.log(e.stack); buildPage(res, "err.html", ""); } } };メイン処理で修正することは、下記の流れを守ってもらうことです。
1. データを取得する
2. データを編集する
3. ページ遷移処理を実行する
非同期処理の場合は、この1・2・3が同時に実行されてしまったために問題が起きてしまいましたが、これを解決するために、awaitを使用します。awaitを実行したいasyncな処理の前に記述することで、その処理の終了を待つことができます。
ただし、このawaitを使用する場合は、その使用しているメソッドをasyncにする必要があるみたいです。(このために下層の関数はほとんどasyncをつけなくてはいけなくなりました。。。)今回のメイン処理では、
selectAllItem()メソッドの前に、awaitを記載しました。次は、
selectAllItemメソッド内の処理を修正していきます。データ取得処理の修正
async_await_sample.jsconst selectAllItem = async function(){ let item1; let item2; let item3; return await Promise.all([ db.selectItem1("*"), db.selectItem2("*"), db.selectItem3("*") ]) .then((values) => { item1 = values[0]; item2 = values[1]; item3 = values[2]; return {"item1":item1, "item2":item2, "item3":item3}; }) .catch((err) => { console.log(err.stack);throw err; }); }ここでの処理は、
Promise.all()という処理を使用しています。
最初修正した際は、1つ1つのselect処理にawaitをかけていたのですが、それぞれのselectの順番は気にしなくてもよいため、Promise.allとしています。
Promise.all()の中で定義されたasyncな関数は、全て非同期で実行されますが、その全ての関数の終了を待ってから次に進むため、一括でデータを取得したい時とかには向いているかもしれません。まとめ
普段非同期処理などを意識することがあまりないため、かなり戸惑いましたが、とても勉強になりました。
普段はバックエンド側なので、javascriptを仕事で触ることは稀にしかないのですが、最近調べてみるとjavascriptでARの開発やサーバーの構築やフレームワーク使って簡単にリッチなWEBページを作ったり。。。すごいですねぇ
これから勉強して、またここにアウトプットしていこうと思います。補足(参考リンク)
Promiseとasync/await
https://qiita.com/suin/items/97041d3e0691c12f4974
https://qiita.com/toshihirock/items/e49b66f8685a8510bd76#comments
- 投稿日:2020-05-25T15:25:20+09:00
Node.js, npm, yarn, gitの環境構築+コマンド解説
EC2にフロントエンド開発ができる環境構築をしていくぞ〜〜
あわせてコマンドが色々わからなかったので解説もしてみる
ところどころ間違えてそうなので直してほしい別にAWSじゃなくても、ローカルPCに環境構築するのでも同じだと後から気が付きました
なので、ローカルに環境構築したい人の参考にもなるはず環境: AWS Linux
(WindowsとかMacOSの人はこの記事は参考にならないよ)
コメント大歓迎
EC2インスタンスの立ち上げ & 接続
インスタンスを作ってなかったらこっちの記事の1-4を見てね
ここから先は、ターミナルからインスタンスにSSHで接続してる前提でいきますgitのインストール
sudo yum install git
yumはAWS Linuxのパッケージマネージャーで、macOSのbrewみたいなやつ
Linux系だとapt-getとかもあるけど、このインスタンスではyumを使ってパッケージをインストールするNode.js & npm のインストール
AWSの公式の手順でやっていく
流れ: nvmインストール
Nodeインストール(npmも一緒に入る)
curl -o- https://raw.githubusercontent.com/nvm-sh/nvm/v0.34.0/install.sh | bash
nvmのバージョンに応じて
v0.34.0のとこは変えてね
執筆時点だと、nvmの最新バージョンはv0.35.3だったんだけど、AWSのdocsがv0.34.0だったので、とりあえずそっちに従ってみた
curl: ネットワーク上でデータを転送するためのコマンド (Wikipediaより翻訳)-oオプション: 出力先を指定する-引数: stdout (標準出力)を意味する引数(argument)|(「パイプ」と読む): パイプの前にあるやつをパイプの後にあるやつに流す。つまりパイプbash: このターミナル/シェル/黒い画面のことを指す
-oの使い方は、例えばcurl -o "filename.txt" http://www.hoge.com/hogehoge.shだったら、hogehoge.shをfilename.txtに出力するこのコマンドでやってることは、
nvmのインスールスクリプトをインストールするためのシェルスクリプトをhttps://raw.githubusercontent.com/nvm-sh/nvm/v0.34.0/install.shからダウンロードする
nvm.shが入る. ~/.nvm/nvm.sh
nvm.shが入ったのでこのシェルスクリプトを実行して、nvmをインストール
.はsourceと同じで、シェルスクリプトを実行するコマンド
ここでは~/.nvm/nvm.shにあるファイルを実行しているnvm install nodenvmでnodeをインストールする
(npmとかyarnと同じ構文)npm i -g yarnnpmが入ったので、npmを使ってyarnを入れる
※yarn公式では非推奨のやり方。今回は力尽きたのでこの方法でやったVSCodeで開発
Remote-SSHプラグインを入れる
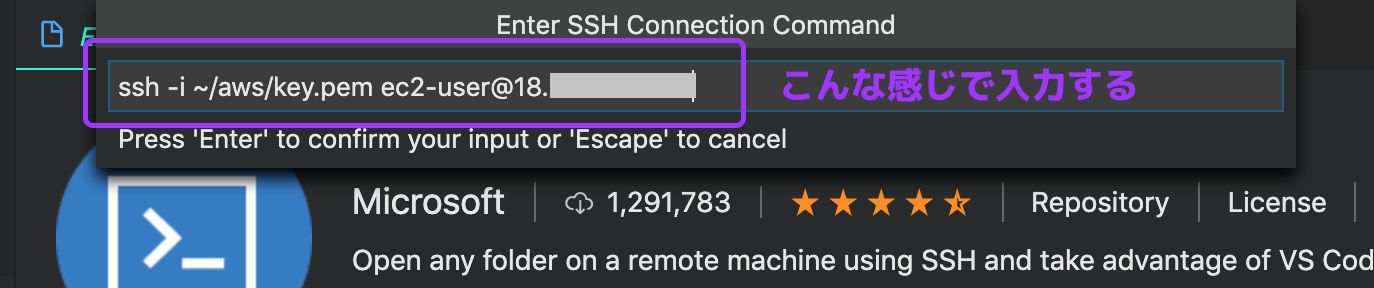
VSCodeのExtensionsから探すか、[ここ]((https://code.visualstudio.com/docs/remote/ssh)からダウンロードするSSH接続は公式に書いてあるとおりにやります
- F1キーを押して Remote-SSH: Add New SSH Hostを選択
ssh -i <.pemファイルへのパス> ec2-user@<インスタンスのIP>を入力- config fileを聞かれるので、適当に選ぶ(わたしは/etc/ssh/ssh_configがドロップダウンの中にあったので、それにした)
- 左のタブのファイル > 「Open Folder」ボタンで、リモートのフォルダを開く
参考までのスクショたち
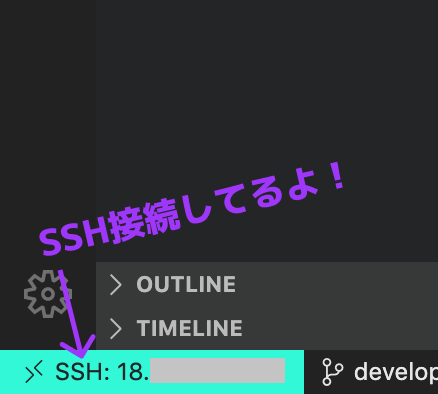
SSH接続してると、左下に接続先が表示される
おわり
あとは、
git cloneとかでソースコードをリモートにおいて、リモートにSSHしたVSCodeで開発すればokおまけ
yarnしようとしたらこんなエラーが出たmake: g++: コマンドが見つかりませんでしたくわしく調べなかったけど、C++コンパイラがインストールされてなかったせいらしい
この記事を参考にこのコマンドを叩いたら治ったsudo yum -y install gcc-c++
- 投稿日:2020-05-25T15:25:20+09:00
AWSのEC2インスタンスにNode.js, npm, yarn, gitを入れる
EC2にフロントエンド開発ができる環境構築をしていくぞ〜〜
あわせてコマンドが色々わからなかったので解説もしてみる
ところどころ間違えてそうなので直してほしい別にAWSじゃなくても、ローカルPCに環境構築するのでも同じだと後から気が付きました
なので、ローカルに環境構築したい人の参考にもなるはず
EC2インスタンスの立ち上げ & 接続
インスタンスを作ってなかったらこっちの記事の1-4を見てね
ここから先は、ターミナルからインスタンスにSSHで接続してる前提でいきますgitのインストール
sudo yum install git
yumはAWS Linuxのパッケージマネージャーで、macOSのbrewみたいなやつ
Linux系だとapt-getとかもあるけど、このインスタンスではyumを使ってパッケージをインストールするNode.js & npm のインストール
AWSの公式の手順でやっていく
流れ: nvmインストール
curl -o- https://raw.githubusercontent.com/nvm-sh/nvm/v0.34.0/install.sh | bash
v0.34.0のとこは変えてね
執筆時点だと、nvmの最新バージョンはv0.35.3だったんだけど、AWSのdocsがv0.34.0だったので、とりあえずそっちに従ってみた
curl: ネットワーク上でデータを転送するためのコマンド (Wikipediaより翻訳)-oオプション: 出力先を指定する-引数: stdout (標準出力)を意味する引数(argument)|(「パイプ」と読む): パイプの前にあるやつをパイプの後にあるやつに流す。つまりパイプbash: このターミナル/シェル/黒い画面のことを指す
-oの使い方は、例えばcurl -o "filename.txt" http://www.hoge.com/hogehoge.shだったら、hogehoge.shをfilename.txtに出力するこのコマンドでやってることは、
nvmのインスールスクリプトをインストールするためのシェルスクリプトをhttps://raw.githubusercontent.com/nvm-sh/nvm/v0.34.0/install.shからダウンロードする
nvm.shが入る. ~/.nvm/nvm.sh
nvm.shが入ったのでこのシェルスクリプトを実行して、nvmをインストール
.はsourceと同じで、シェルスクリプトを実行するコマンド
ここでは~/.nvm/nvm.shにあるファイルを実行しているnvm install nodenvmでnodeをインストールする
(npmとかyarnと同じ構文)npm i -g yarnnpmが入ったので、npmを使ってyarnを入れる
※yarn公式では非推奨のやり方。今回は力尽きたのでこの方法でやったVSCodeで開発
Remote-SSHプラグインを入れる
VSCodeのExtensionsから探すか、[ここ]((https://code.visualstudio.com/docs/remote/ssh)からダウンロードするSSH接続は公式に書いてあるとおりにやります
- F1キーを押して Remote-SSH: Add New SSH Hostを選択
ssh -i <.pemファイルへのパス> ec2-user@<インスタンスのIP>を入力- config fileを聞かれるので、適当に選ぶ(わたしは/etc/ssh/ssh_configがドロップダウンの中にあったので、それにした)
- 左のタブのファイル > 「Open Folder」ボタンで、リモートのフォルダを開く
参考までのスクショたち
SSH接続してると、左下に接続先が表示される
おわり
あとは、
git cloneとかでソースコードをリモートにおいて、リモートにSSHしたVSCodeで開発すればokおまけ
yarnしようとしたらこんなエラーが出たmake: g++: コマンドが見つかりませんでしたくわしく調べなかったけど、C++コンパイラがインストールされてなかったせいらしい
この記事を参考にこのコマンドを叩いたら治ったsudo yum -y install gcc-c++
- 投稿日:2020-05-25T13:46:13+09:00
ESLint v7.1.0
前 v7.0.0 | 次 (2020-06-05 JST)
ESLint v7.1.0 has been released! ?https://t.co/r2Dk1UBQoy
— ESLint (@geteslint) May 23, 2020ESLint
7.1.0がリリースされました。小さな機能追加とバグ修正が含まれています。また、公式のサポートチャット (英語) が Gitter から Discord に移動しました。日本語の方も移動予定です。
質問やバグ報告等ありましたら、お気軽にこちらまでお寄せください。
[PR] ESLint は開発リソースを確保するための寄付を募っています。
応援してくださると嬉しいです。
✨ 本体への機能追加
特になし
? 新しいルール
no-loss-of-precision
? #12747
number型 (IEEE 754: 64bit 浮動小数点数) で表現できない桁数の数値リテラルを警告するルールです。例/*eslint no-loss-of-precision: error */ //✘ BAD const a = 9007199254740993 const b = 5123000000000000000000000000001 const c = 1230000000000000000000000.0 const d = .1230000000000000000000000 const e = 0X20000000000001? オプションが追加されたルール
特になし
- 投稿日:2020-05-25T13:45:12+09:00
console.logからの脱却 - node.jsでデバッグするには(Visual Studio Code編)
前回のおはなし
若き開発者ヒロロはNode.jsでバックエンド開発を任されたがデバッグ方法がわからず、苦戦。
自力で調査しChrome DevToolでデバッグする方法を見つけ出し、なんとかconsole.log地獄は免れた。
しかし、普段利用しているVSCodeのデバッグツールを活用してより快適なデバッグ環境を作ろうと決意する。前回の詳細「console.logからの脱却 - node.jsでデバッグするには(Chrome DevTool編)」はこちら
VSCodeでのデバッグ環境構築
公式ドキュメント(https://code.visualstudio.com/docs/editor/debugging) によればVSCodeでデバッグを有効にするにはあらかじめ設定ファイルに情報を記載する必要があるそうです。
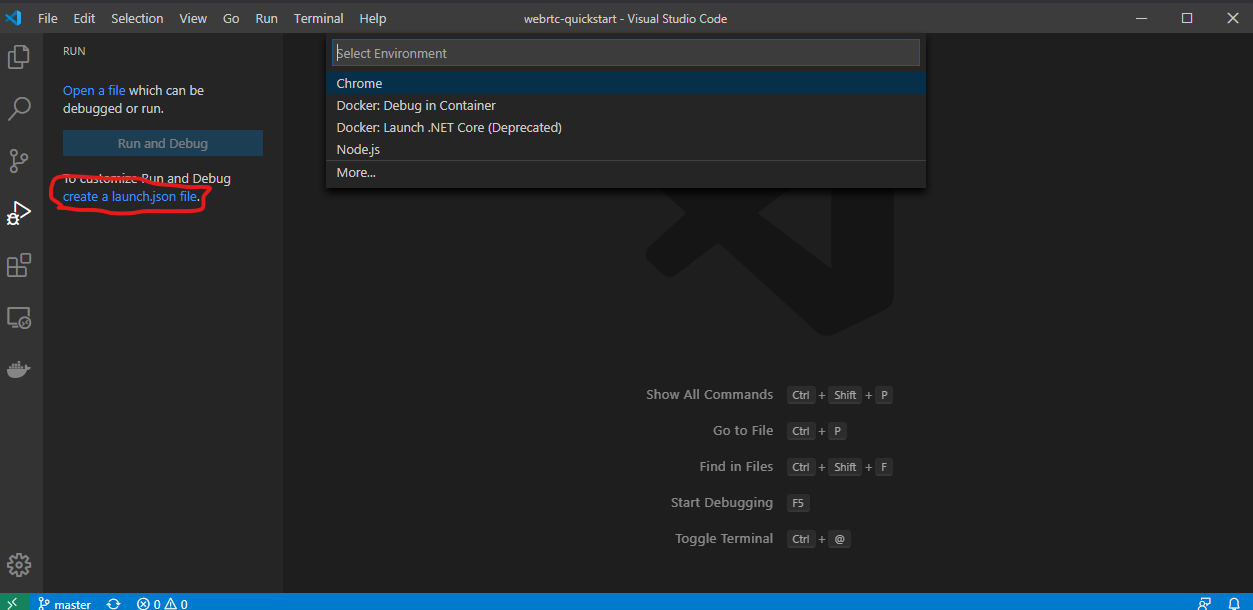
VSCodeを起動してデバッグメニューを開き、「create a launch.json file.」をクリックします。
その後、「Node.js」の項目が出てくるので選択します。
すると、以下のようなファイルが生成されます。
launch.json{ // Use IntelliSense to learn about possible attributes. // Hover to view descriptions of existing attributes. // For more information, visit: https://go.microsoft.com/fwlink/?linkid=830387 "version": "0.2.0", "configurations": [ { "type": "node", "request": "launch", "name": "Launch Program", "skipFiles": [ "<node_internals>/**" ], "program": "${file}" } ] }requestの項目について
ここからこのファイルにデバッグ設定を記載していきますが今回の記事で重要な
requestについて。
ここにはLaunchかAttachのいずれかが入ります。
Launchに設定すると、デバッグを実行したときに指定したコマンドを実行して即座にプログラムのデバッグをすることができます。一方
Aattachに設定すると、指定したポートを監視し、コマンドプロンプトやターミナルからデバッグモードでプログラムを実行することでデバッグすることができます。いずれかの方法でないとデバッグできないというわけではなくどちらを使っても問題はありません。
どのように設定していくかは実際にあった私の事例をもとに取り上げていきます。A. AWS Lambdaのコードをコマンドで実行したときにデバッグしたい
serverless frameworkでサーバーレスアプリケーションを開発していた時、TDD(テスト駆動開発)を採用していたので実装したらmochaで必ずテストをする必要がありました。
その際に失敗することがありますが、原因が何なのか特定しづらいときがありました。
その時はAttachパターンを使ってデバッグを行いました。
launch.jsonを開き、画面右下に出てくる「Add Configuration...」ボタンを押し、「Node.js:Attach」を選択する。もしくは直接以下の設定を記載する。launch.json{ // Use IntelliSense to learn about possible attributes. // Hover to view descriptions of existing attributes. // For more information, visit: https://go.microsoft.com/fwlink/?linkid=830387 "version": "0.2.0", "configurations": [ { "type": "node", "request": "attach", "name": "Attach", "port": 9229, "skipFiles": [ "<node_internals>/**" ] } ] }
- ターミナルを開き、デバッグモードでmochaを実行する。
mocha test.js --inspectmochaを実行すると指定したテストに紐づくコードが実行されるのでこれによって対象のコードにbreakpointを打って止めることができるようになりました。
Node.jsはデバッグポートはデフォルトで9229に設定されるので、変更する際はlaunch.jsonのポート番号もそれに合わせることを忘れずに。B. Electronのmain processをデバッグしたい
Electronでの開発では
main processと呼ばれるWebアプリでいうサーバーサイド的な部分があるのですが、ここでの開発では開始ボタンを押すと自動でプログラムが起動し、デバッグできるようにしたかったという背景があります。また、スムーズに開発できるようファイルを変更するとすぐさまリロードされるよう(ホットリロード)にもしたいという要望がありました。
その時はLaunchパターンを使うように設定しました。
1.事前にElectronとElectromonをDevDependancyでインストールする。npm install -D electron electromon
Electromonはホットリロードを実現するためのライブラリ。nodemonのElectronバージョンとでも考えてればわかりやすいと思う。2.先と同じく
Add Configuration...ボタンからNode.js : Electron Mainを選択する。その後、"runtimeExecutable":"${workspaceFolder}/node_modules/.bin/electromon"
"args": ["--inspect=5858"]"port": 5858"restart": true
のプロパティを追加する。
最終的に以下のようになる。launch.json{ // Use IntelliSense to learn about possible attributes. // Hover to view descriptions of existing attributes. // For more information, visit: https://go.microsoft.com/fwlink/?linkid=830387 // Debug settings for electron with 'electromon' so that it can be live reloaded on saving files. // For more information about setting, visit: https://code.visualstudio.com/docs/nodejs/nodejs-debugging#_restarting-debug-sessions-automatically-when-source-is-edited // "version": "0.2.0", "configurations": [ { "type": "node", "request": "launch", "name": "Electron Main", "runtimeExecutable": "${workspaceFolder}/node_modules/.bin/electromon", "program": "${workspaceFolder}/main.js", "args": ["--inspect=5858"], "port": 5858, "restart": true, "skipFiles": ["<node_internals>/**"], } ] }3.VSCode上でデバッグ画面から
Runを押す。するとruntimeExecutable,program,argsの設定によりelectromon --inspect=5858 main.jsが起動する。さらにファイルを編集して保存すると
"restart": trueにより再度デバッグが行われる。プロセスが終了しない
ひとまずこれで設定が終わったので開発を進めていると、Electronが同時に複数起動する問題に遭遇しました。
アプリケーション終了時の挙動を確認したかったのですが、終了するとデバッグも終了してしまうため、何度も終了→デバッグ起動を繰り返しているとそのようなことになってしまいました。ps -ef | grep electronでプロセスを確認すると、まだプロセスが残っていたことがわかりました。どうやらアプリケーションを閉じるとデバッグも終了するがelectromonは生き続けるみたいです。
VSCode公式サイトにもこのような記載がありました。Tip: Pressing the Stop button stops the debug session and disconnects from Node.js, but nodemon (and Node.js) will continue to run. To stop nodemon, you will have to kill it from the command line (which is easily possible if you use the integratedTerminal as shown above).
ちゃんと「デバッグは終了しますがnodemonは走り続けます」と書かれてますね...(こちらはnodemonですがelectromonと置き換えても問題ありません)
・electronを終了するとデバッグも終了してしまう
・デバッグが終了してもelectromonは走り続ける
ということからアプリを終了するたびに手動でelectromonも止めないといけないということですね。ご親切に
integrationTerminalを設定すると簡単にプロセスの終了ができますと書いてくれてましたのでそれに合わせてlaunch.jsonに
"console" : "integrationTerminal"を追記してみました。
起動すると、VSCodeのターミナルにelectromonのコンソールが立ち上がるようになりました。
プロセスを終了する際はこのターミナルを終了してくださいということですね。まとめ
これでVSCodeを使ってNode.jsをデバッグできるようになり、しかもそれぞれの利用シーンに応じて
AttachパターンとLaunchパターンを使い分けることができるようになりました。あれからしばらく経ちましたがもうデバッグで悩むことがほとんどなくなりました。もうNode.jsでもconsole.log地獄に悩まされなくてすみそうです。
- 投稿日:2020-05-25T12:49:32+09:00
Node.jsとFirebaseを使ってRedmineチケットの更新を通知してくれるSlack Appのバックエンドメモ
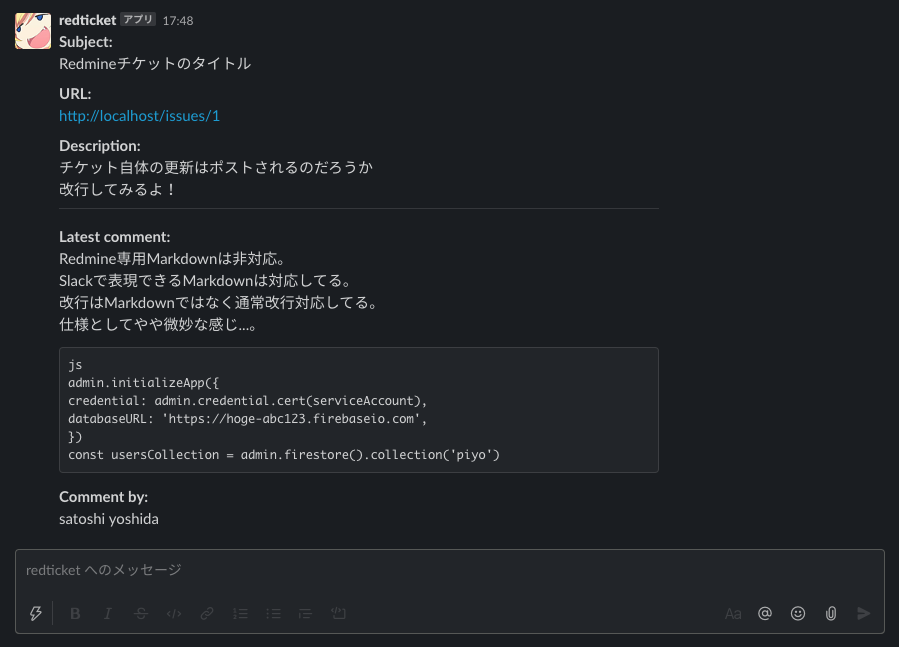
通知イメージ
root
package.json
{ "name": "redticket", "version": "1.0.0", "description": "", "main": "index.js", "scripts": { "serve": "firebase emulators:start", "deploy": "firebase deploy", "logs": "firebase functions:log" }, "keywords": [], "author": "", "license": "ISC", "devDependencies": { "babel-eslint": "^10.1.0", "eslint": "^7.0.0", "eslint-plugin-promise": "^4.2.1", "firebase-tools": "^8.2.0", "prettier": "^2.0.5" } }firebase.json
{ "hosting": { "public": "public", "ignore": ["firebase.json", "**/.*", "**/node_modules/**"], "rewrites": [ { "source": "**", "function": "api" } ] } }.prettierrc
{ "trailingComma": "es5", "tabWidth": 2, "semi": false, "singleQuote": true, "printWidth": 100, "arrowParens": "avoid" }.eslintrc
{ "extends": ["eslint:recommended"], "plugins": [], "parser": "babel-eslint", "parserOptions": {}, "env": { "es6": true, "node": true }, "globals": {}, "rules": { "semi": ["error", "never"], "arrow-parens": "off" } }functions
package,json
{ "name": "functions", "description": "Cloud Functions for Firebase", "scripts": {}, "engines": { "node": "8" }, "dependencies": { "@slack/web-api": "^5.8.1", "axios": "^0.19.2", "express": "^4.17.1", "firebase-admin": "^8.10.0", "firebase-functions": "^3.6.1" }, "devDependencies": { "firebase-functions-test": "^0.2.0" }, "private": true }index.js
const admin = require('firebase-admin') const axios = require('axios') const serviceAccount = require('./serviceAccount.json') // Firestoreの秘密鍵 const Express = require('express') const functions = require('firebase-functions') const { WebClient } = require('@slack/web-api') const client = new WebClient('[Bot User OAuth Access Token]') admin.initializeApp({ credential: admin.credential.cert(serviceAccount), databaseURL: 'https://xxxxxxx-xxxxx.firebaseio.com', }) const usersCollection = admin.firestore().collection('users') const redmineBaseURL = 'http://redmine.url' const api = Express() api.use(Express.json()) api.use(Express.urlencoded({ extended: true })) api.post('/redmine', async (req, res) => { try { const ticketUrl = req.body.payload.url const ticket = req.body.payload.issue const comment = req.body.payload.journal const watchers = [...ticket.watchers] const query = usersCollection.where( 'redmine_mail', 'in', watchers.map(watcher => watcher.mail) ) query.get().then(querySnapshot => { if (!querySnapshot.empty) { querySnapshot.docs.forEach(doc => { client.chat.postMessage({ channel: doc.data().channel_id, text: ``, blocks: [ { type: 'section', text: { type: 'mrkdwn', text: `*Subject:*\n${ticket.subject}\n\n*URL:*\n${ticketUrl}\n\n*Description:*\n${ticket.description}`, }, }, { type: 'divider', }, { type: 'section', text: { type: 'mrkdwn', text: `*Latest comment:*\n${comment.notes}\n\n*Comment by:*\n${comment.author.firstname} ${comment.author.lastname}`, }, }, ], }) }) } }) } catch (err) { console.error(err) } finally { res.status(200).send() } }) api.post('/redticket', async (req, res) => { try { res.send('') // Error avoid await client.chat.postMessage({ channel: req.body.channel_id, text: `?: Start /redticket ${req.body.text}`, }) const mode = req.body.text.trim() !== '' ? req.body.text.trim().split(' ')[0] : '' switch (mode) { case '': case 'help': { await client.chat.postMessage({ channel: req.body.channel_id, text: '', blocks: [ { type: 'section', text: { type: 'mrkdwn', text: "Hello? I will explain how to use RedTicket. The first step is to initialize the user data. The command is `/redticket init` ?\n\nThe next step is to register your redmine account! You will need redmine's API token to register your account. The command is `/redticket verify [API Token]`. Let's sign up for an account right away ? You can check your registered user data at any time at `/redticket check` ?\n\nIf you need help, try send the `/redticket` or `/redticket help` ?", }, }, { type: 'divider', }, ], }) break } case 'init': { await client.chat.postMessage({ channel: req.body.channel_id, text: `?: Checking the existence of the user data`, }) const userInfo = await usersCollection.doc(`${req.body.team_id}${req.body.user_id}`).get() const setDocument = async () => { const data = { team_id: req.body.team_id, team_domain: req.body.team_domain, user_id: req.body.user_id, channel_id: req.body.channel_id, user_name: req.body.user_name, } await client.chat.postMessage({ channel: req.body.channel_id, text: `?: Creating your user data.`, }) return await usersCollection .doc(`${req.body.team_id}${req.body.user_id}`) .set(data) .then(async () => { const userInfo = await usersCollection .doc(`${req.body.team_id}${req.body.user_id}`) .get() return userInfo.data() }) } const docRef = userInfo.data() === undefined ? await setDocument() : userInfo.data() await client.chat.postMessage({ channel: req.body.channel_id, text: `?: Your user data.\n\n${JSON.stringify(docRef, null, '\t')}`, }) break } case 'check': { await client.chat.postMessage({ channel: req.body.channel_id, text: `?: Reading your user data`, }) const userInfo = await usersCollection.doc(`${req.body.team_id}${req.body.user_id}`).get() const docRef = userInfo.data() await client.chat.postMessage({ channel: req.body.channel_id, text: `?: Your user data.\n\n${JSON.stringify(docRef, null, '\t')}`, }) break } case 'verify': { if (req.body.text.trim().split(' ').length <= 1) { await client.chat.postMessage({ channel: req.body.channel_id, text: `?: Need Redmine API Token.`, }) break } await client.chat.postMessage({ channel: req.body.channel_id, text: `?: Verify the Redmine API Token.`, }) const redmineUserInfo = await axios.get(`${redmineBaseURL}/my/account.json`, { params: { key: req.body.text.trim().split(' ')[1], }, }) await client.chat.postMessage({ channel: req.body.channel_id, text: `?: Your user data in Redmine.\n\n${JSON.stringify( redmineUserInfo.data.user, null, '\t' )}`, }) const userInfo = await usersCollection.doc(`${req.body.team_id}${req.body.user_id}`).get() const docRef = userInfo.data() if (!userInfo.exists) { throw new Error('No such your data') } docRef.redmine_login = redmineUserInfo.data.user.login docRef.redmine_mail = redmineUserInfo.data.user.mail const updatedUserData = await usersCollection .doc(`${req.body.team_id}${req.body.user_id}`) .update(docRef) .then(async () => { const userInfo = await usersCollection .doc(`${req.body.team_id}${req.body.user_id}`) .get() return userInfo.data() }) await client.chat.postMessage({ channel: req.body.channel_id, text: `?: Your user data.\n\n${JSON.stringify(updatedUserData, null, '\t')}`, }) break } case 'project': { await client.chat.postMessage({ channel: req.body.channel_id, text: `?: Verify the Redmine API Token.`, }) break } default: throw new Error('Invalid parameters.') } } catch (error) { await client.chat.postMessage({ channel: req.body.channel_id, text: `?: ${error}` }) } finally { await client.chat.postMessage({ channel: req.body.channel_id, text: `?: Done /redticket ${req.body.text}`, }) } }) exports.api = functions.https.onRequest(api)リファクタしないと。
- 投稿日:2020-05-25T00:34:30+09:00
[AtCoder]問題の入力と期待値を自動取得してみた
はじめに
言語の勉強としてAtCoderのABC(AtCoder Beginners Contest)の問題を解いていました。
しかし問題ページにある複数の入力サンプルと出力サンプルをコピペして目視であってるかどうかを確認するのは面倒だなと思いました。
そこでpuppeteerによるスクレイピングで入力サンプルと出力サンプルを自動で取ってきて、自動でテストするスクリプトを書いてみました。
今回はpuppeteer部分でやったことなどを残しておきます。調査
問題ページのURLは、例えば第88回目のABCのB問題はhttps://atcoder.jp/contests/abc088/tasks/abc088_b
第160回目のABCのD問題はhttps://atcoder.jp/contests/abc160/tasks/abc160_b
となってます。
問題ページのURLは、https://atcoder.jp/contests/<コンテスト名>/tasks/<コンテスト名>_<問題名>で取れることがわかりました。
次に各問題ページ入力と出力例のDOM情報を調べてみます。
幸いどの問題でも例えば入力1では、html > body > div#main-div.float-container > div#main-container.container > \ div.row > div.col-sm-12 > div#task-statement > span.lang > span.lang-ja > \ div.part > section > pre#pre-sample0ここに配置されていることが確認できました。
pre#pre-sample<数字>の部分に関しては
入力1->pre#pre-sample0
出力1->pre#pre-sample1
入力2->pre#pre-sample2
出力2->pre#pre-sample3
入力3->pre#pre-sample4
出力3->pre#pre-sample5
...
となっていました。
これだけの情報で十分です。コード例
第xxx回目ABC->abc<xxx>
A問題->a
として例えば第160回目ABCのA問題のサンプルを全部取得したい時は、node get_sample.js abc160 aとコマンドライン引数を与えることを前提として以下のようにコードが書けます。
#!/usr/bin/env node const puppeteer = require('puppeteer'); const fs = require('fs') //ex; abc161 const contest_number=process.argv[2] //ex; a,b,c..,f const question=process.argv[3] const atcoder_url="https://atcoder.jp/contests/" + contest_number + "/tasks/" + contest_number + "_" + question (async () => { const browser = await puppeteer.launch(); const page = await browser.newPage(); await page.goto(atcoder_url); const common_selector = 'html > body > div#main-div.float-container > div#main-container.container > div.row > div.col-sm-12 > div#task-statement > span.lang > span.lang-ja > div.part > section > ' for(i = 0; ;i += 2){ const in_selector=common_selector + `pre#pre-sample${i}`; const exp_selector=common_selector + `pre#pre-sample${i+1}`; //取得する前にそもそもデータが存在するかのチェックを行う const in_data = await page.$(in_selector) != null? await page.$eval(in_selector, item => {return item.textContent;}) : null const exp_data = await page.$(exp_selector) != null? await page.$eval(exp_selector, item => {return item.textContent;}) : null if(in_data != null){ const filepath = `./test/in${i/2 + 1}` fs.writeFile(filepath, in_data, (err, data) => { if(err) console.log(err); }); }else{ break; } if(exp_data != null){ const filepath = `./test/exp${i/2 + 1}` fs.writeFile(filepath, exp_data, (err, data) => { if(err) console.log(err); }); }else{ break; } } await browser.close(); })();これでカレントディレクトリの
testというディレクトリに入力例(in〇)と出力例(exp〇)を保存できます。
このjsにshebangを記載しパスの通ったディレクトリに置いておくことでいつでも呼び出せるようにしておきます。
自動テストスクリプトの実装は省きますが、このjsにshebangを記載することで自動テストスクリプトをshellスクリプトで書いた場合、呼び出しも簡単になります。get_sample.js <コンテスト名> <問題名>自動テストスクリプトではカレントディレクトリの
test/にin1,in2,in3があることを確認し
あれば、プログラムのビルドし、これらを入力とし、実行。
それぞれの結果とexp1,exp2,exp3が一致するかはdiffコマンドで確認できます。最後に
最近アルゴリズムの勉強もした方がいいのかなと思う今日この頃、、、AtCoderまずは緑色頑張ります!