- 投稿日:2020-05-23T22:46:10+09:00
java(抽象クラス)
抽象メソッドを含むクラスの宣言
abstract(アブストラクト) = 抽象メソッド
Character.javapublic abstract class Character { //抽象クラスとして宣言 String name; int hp; public void attack(Matango m) { } }抽象クラスは、newによるインスタンス化が禁止される
・newによる利用と継承(extends)による利用を区別できるattack()を抽象メソッドとして宣言
Character.javapublic abstract class Character { String name; int hp; public abstract void attack(Matango m); // {}を付けず、;(セミコロン)を書く }抽象メソッドは「現時点で何をするか確定できないメソッド」として区別
・「何もしない」と「何をするか未定」を明確にする
オーバーライドを強制できる
・オーバーライド」し忘れを解消する
- 投稿日:2020-05-23T22:00:21+09:00
Iteratorメモ
Iteratorの使い方を簡易的に残します。
今までIteratorについて触れてこなかったのですが、頻出らしいので基本的な使い方についてはまとめておこうと思った次第です。Iterator
//リスト初期化 List<String> list = new ArrayList<>(Arrays.asList("apple","banana","orange","fish")); //Iteratorの宣言 Iterator<String> iterator = list.iterator(); //IteratorのメソッドhasNext()を使用してループ処理 //hasNext():反復処理でさらに要素がある場合にtrueを返します。 while(iterator.hasNext()) { //Iteratorのメソッドnext()で要素を取り出す //next():反復処理で次の要素を返します。 String str = iterator.next(); if(str.equals("banana")) { //Iteratorのメソッドremove()で要素を削除する //ベースとなるコレクションから、このイテレータによって最後に返された要素を削除します iterator.remove(); } } System.out.println(list);[apple, orange, fish]
- 投稿日:2020-05-23T21:37:45+09:00
java(is-a原則の継承)
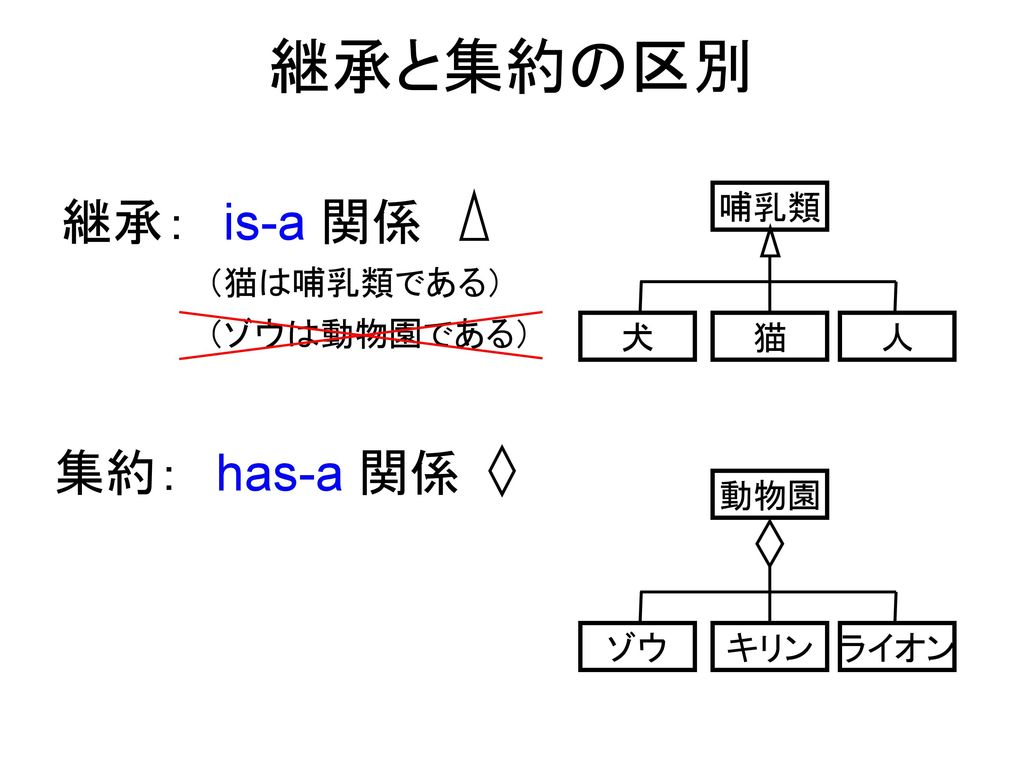
- 投稿日:2020-05-23T21:15:25+09:00
初心者によるオブジェクト指向まとめ (Java)
はじめに
研修で学んだオブジェクト指向について、自分用のメモのつもりで書きました。
詰まったり調べたりした内容を自分なりに咀嚼してまとめています。内容
・クラス
・インスタンス
・メンバ変数
・メソッド
・コンストラクタ
・クラス変数(static変数)
・継承
・オーバーライドざっくり説明
・クラス:ひな型、テンプレート(ex. 人間)
・インスタンス:クラスをもとにつくられた実体(ex. Aさん、Bさん、… )・メンバ変数:インスタンスの属性(ex. 体力、知力、年齢)
・メソッド:インスタンスのできる動作(ex. 歩く、挨拶する)
・コンストラクタ:メンバ変数の初期設定・クラス変数(static変数):クラスの属性(Aさんのデータを書き換えるとAさんのデータもBさんのデータも同じように変更される)
・継承:クラスを派生させたとき、もとのクラス(スーパークラス)の機能も使える仕組み
・オーバーライド:クラスを継承するときに、スーパークラスのメソッド(処理)を、サブクラスにおいて再定義(上書き)すること例
下の方に、クラス・インスタンス・継承などの関係がわかるようなコードを書いたので、照らし合わせながら説明を読んでみてください。
クラスとインスタンス
人間のひな型を作ったあと、人間の特徴を持った日本人というひな型を作成し、
それをもとに、太郎さんというひとりの人を生成しています。このとき、人間がスーパークラス、日本人がサブクラス、太郎さんがインスタンスです。
メンバ変数
メンバ変数は、インスタンスの持つステータスです。
今回、人間は、体力・知力・言語というステータスを持つことにします。コンストラクタ
メンバ変数の初期設定です。
今回の場合、人間の体力と知力は引数で設定することにし、言語は初期値ではnullにしています。また、日本人は日本語が母国語なので、Japaneseクラス(日本人のテンプレート)で言語を日本語に設定しています。
メソッド
人間がみんなできる動作として、歩く、挨拶する、という2つの動作を設定しています。
また、日本人特有の動作として、おじぎする、という動作をJapaneseクラスで設定しました。
さらに、挨拶は人間が共通して行う動作ですが、そのアウトプットの形は
日本人なら「こんにちは」、中国人なら「ニーハオ」などと異なります。
そのため、Japaneseクラスでgreetメソッドをオーバーロードし、「こんにちは」と挨拶するようにしています。================
Human.java// クラス(人間のテンプレート) public class Human{ // メンバ変数(インスタンスの属性) int pysicalPower; // 体力 int intellectualPower; // 知力 String langage; // 言語 // クラス変数(static変数) static int magicPower = 0; // staticなので、人間はみんな魔力0。誰かの魔力を10にすると、他の人もみんな魔力10になる。 // コンストラクタ(メンバ変数の初期設定) public Human(int pysical, int intelligence) { this.pysicalPower = pysical; this.intellectualPower = intelligence; this.langage = null; } // メソッド(動作) public void walk() { // 歩く System.out.println("テクテク"); } public void greet() { // 挨拶する System.out.println("Hello"); } // 設定確認メソッド public int getPysicalPower() { return pysicalPower; } public int getIntellectualPower() { return intellectualPower; } public String getLangage() { return langage; } }Japanese.java// クラス(日本人のテンプレート) public class Japanese extends Human { //Humanクラスを継承したサブクラス // コンストラクタ Japanese(int pysical, int intelligence) { super(pysical, intelligence); // 親コンストラクタの呼び出し super.langage = "日本語"; } // メソッド public void ojigi() { // おじぎする System.out.println("ペコリ"); } // オーバーライド @Override public void greet() { System.out.println("こんにちは"); } }Main.javapublic class Main { public static void main(String[] args) { // インスタンス(テンプレートをもとにした個人)を生成 Japanese Taro = new Japanese(50, 30); /* 日本人の 太郎(体力50、知力30) を生成 */ // 太郎のステータスを確認 System.out.println("太郎の体力は " + Taro.getPysicalPower()); System.out.println("太郎の知力は " + Taro.getIntellectualPower()); System.out.println("太郎の使用言語は " + Taro.getLangage()); System.out.println(); // 空行 // メソッド(動作)を呼び出す Taro.walk(); // Humanクラスのメソッド Taro.ojigi(); // Japaneseクラスのメソッド Taro.greet(); // Japaneseクラスでオーバーライドしたメソッド } }実行結果太郎の体力は 50 太郎の知力は 30 太郎の使用言語は 日本語 テクテク ペコリ こんにちはおわりに
実際にオブジェクト指向をつかうコードを自分で考えて書いてみると、少し理解が深まりました。
理解が浅くうまく説明できなかった部分や、複雑にならないよう盛り込まなかった内容もあるので、学習が進んだら第二弾を書くのもありかなと思っています。(気が向けば、、)参考
学習する際に参考にしたサイト
- 初心者向けに徹底解説!オブジェクト指向とは?(特に「勇者に学ぶオブジェクト指向プログラミング」の部分を一度写経してみたらかなり理解が進みました)
- メンバ変数とは|「分かりそう」で「分からない」でも「分かった」気になれるIT用語辞典
- 投稿日:2020-05-23T18:22:12+09:00
【Java】画像ファイルをバイナリで比較する方法
画像ファイルの比較
比較元ファイル
素材はPhotoACから拝借しました。
コピー元画像:PCを持つ女性
コピーしたファイルとの比較(True)
コピー元ファイルをコピーしただけのファイル。
バイナリデータに差異が無いため、比較結果はTrueになる想定。
比較元ファイルをわずかに編集して比較(False)
コピー元ファイルをコピーした後、わずかに編集したもの。
顔の右側にある、小さな黒いドットが編集箇所。
編集したため、比較結果はFalseになる想定。
別ファイルとの比較(False)
全く別のファイルのため、比較結果はFalseになる想定。
存在しないファイルの場合(False)
存在しないファイル名を指定する。
IOExceptionでキャッチされる想定。ソースコード
画像ファイルはデスクトップ上の「files」フォルダ内に格納。
Main.javapackage samples.compare; public class Main { public static void main(String...strings) { // 比較元ファイル String woman_1 = "C:\\\\Users\\user\\Desktop\\files\\woman_1.jpg"; // 比較対象ファイル String woman_1_copy = "C:\\\\Users\\user\\Desktop\\files\\woman_1_copy.jpg"; String woman_1_edit = "C:\\\\Users\\user\\Desktop\\files\\woman_1_edit.jpg"; String woman_2 = "C:\\\\Users\\user\\Desktop\\files\\woman_2.jpg"; String errer = "C:\\\\Users\\user\\Desktop\\files\\errer.jpg"; // インスタンス生成 FileCompare fc_copy = new FileCompare(woman_1, woman_1_copy); FileCompare fc_edit = new FileCompare(woman_1, woman_1_edit); FileCompare fc_2 = new FileCompare(woman_1, woman_2); FileCompare fc_errer = new FileCompare(woman_1, errer); // 比較結果を表示 System.out.println("woman_1 compare to woman_1_copy : " + fc_copy.fileCompare() ); System.out.println("woman_1 compare to woman_1_edit : " + fc_edit.fileCompare() ); System.out.println("woman_1 compare to woman_2 : " + fc_2.fileCompare() ); System.out.println("woman_1 compare to errer : " + fc_errer.fileCompare() ); } }FileCompare.javapackage samples.compare; import java.io.IOException; import java.nio.file.Files; import java.nio.file.Paths; import java.util.Arrays; public class FileCompare { private String source; private String destination; public FileCompare(String source, String destination) { this.source = source ; this.destination = destination; } public boolean fileCompare() { try { return Arrays.equals(Files.readAllBytes(Paths.get(source)), Files.readAllBytes(Paths.get(destination))); } catch (IOException e) { e.printStackTrace(); System.out.println("ファイルの読込に失敗しました。"); } return false; } }実行結果
想定通り、コピーしたファイル以外はすべてFlaseになっています。
また、存在しないファイル名を指定した場合、IOExceptionがthrowされました。
woman_1 compare to woman_1_copy : true woman_1 compare to woman_1_edit : false woman_1 compare to woman_2 : false java.nio.file.NoSuchFileException: C:\Users\user\Desktop\files\errer.jpg at sun.nio.fs.WindowsException.translateToIOException(Unknown Source) at sun.nio.fs.WindowsException.rethrowAsIOException(Unknown Source) at sun.nio.fs.WindowsException.rethrowAsIOException(Unknown Source) at sun.nio.fs.WindowsFileSystemProvider.newByteChannel(Unknown Source) at java.nio.file.Files.newByteChannel(Unknown Source) at java.nio.file.Files.newByteChannel(Unknown Source) at java.nio.file.Files.readAllBytes(Unknown Source) at samples.compare.FileCompare.fileCompare(FileCompare.java:19) at samples.compare.Main.main(Main.java:21) ファイルの読込に失敗しました。 woman_1 compare to errer : false参考




- 投稿日:2020-05-23T18:22:12+09:00
Java - 画像ファイルをバイナリで比較する方法
画像ファイルの比較
比較元ファイル
素材はPhotoACから拝借しました。
コピー元画像:PCを持つ女性
コピーしたファイルとの比較(True)
コピー元ファイルをコピーしただけのファイル。
バイナリデータに差異が無いため、比較結果はTrueになる想定。
比較元ファイルをわずかに編集して比較(False)
コピー元ファイルをコピーした後、わずかに編集したもの。
顔の右側にある、小さな黒いドットが編集箇所。
編集したため、比較結果はFalseになる想定。
別ファイルとの比較(False)
全く別のファイルのため、比較結果はFalseになる想定。
存在しないファイルの場合(False)
存在しないファイル名を指定する。
IOExceptionでキャッチされる想定。ソースコード
画像ファイルはデスクトップ上の「files」フォルダ内に格納。
Main.javapackage samples.compare; public class Main { public static void main(String...strings) { // 比較元ファイル String woman_1 = "C:\\\\Users\\user\\Desktop\\files\\woman_1.jpg"; // 比較対象ファイル String woman_1_copy = "C:\\\\Users\\user\\Desktop\\files\\woman_1_copy.jpg"; String woman_1_edit = "C:\\\\Users\\user\\Desktop\\files\\woman_1_edit.jpg"; String woman_2 = "C:\\\\Users\\user\\Desktop\\files\\woman_2.jpg"; String errer = "C:\\\\Users\\user\\Desktop\\files\\errer.jpg"; // インスタンス生成 FileCompare fc_copy = new FileCompare(woman_1, woman_1_copy); FileCompare fc_edit = new FileCompare(woman_1, woman_1_edit); FileCompare fc_2 = new FileCompare(woman_1, woman_2); FileCompare fc_errer = new FileCompare(woman_1, errer); // 比較結果を表示 System.out.println("woman_1 compare to woman_1_copy : " + fc_copy.fileCompare() ); System.out.println("woman_1 compare to woman_1_edit : " + fc_edit.fileCompare() ); System.out.println("woman_1 compare to woman_2 : " + fc_2.fileCompare() ); System.out.println("woman_1 compare to errer : " + fc_errer.fileCompare() ); } }FileCompare.javapackage samples.compare; import java.io.IOException; import java.nio.file.Files; import java.nio.file.Paths; import java.util.Arrays; public class FileCompare { private String source; private String destination; public FileCompare(String source, String destination) { this.source = source ; this.destination = destination; } public boolean fileCompare() { try { return Arrays.equals(Files.readAllBytes(Paths.get(source)), Files.readAllBytes(Paths.get(destination))); } catch (IOException e) { e.printStackTrace(); System.out.println("ファイルの読込に失敗しました。"); } return false; } }実行結果
想定通り、コピーしたファイル以外はすべてFlaseになっています。
また、存在しないファイル名を指定した場合、IOExceptionがthrowされました。
woman_1 compare to woman_1_copy : true woman_1 compare to woman_1_edit : false woman_1 compare to woman_2 : false java.nio.file.NoSuchFileException: C:\Users\user\Desktop\files\errer.jpg at sun.nio.fs.WindowsException.translateToIOException(Unknown Source) at sun.nio.fs.WindowsException.rethrowAsIOException(Unknown Source) at sun.nio.fs.WindowsException.rethrowAsIOException(Unknown Source) at sun.nio.fs.WindowsFileSystemProvider.newByteChannel(Unknown Source) at java.nio.file.Files.newByteChannel(Unknown Source) at java.nio.file.Files.newByteChannel(Unknown Source) at java.nio.file.Files.readAllBytes(Unknown Source) at samples.compare.FileCompare.fileCompare(FileCompare.java:19) at samples.compare.Main.main(Main.java:21) ファイルの読込に失敗しました。 woman_1 compare to errer : false参考
- 投稿日:2020-05-23T16:01:27+09:00
Apache DerbyをEclipse上で使う方法
はじめに
以前に書いた【Eclipse】DBViewerのインストールの続きとして、DBViewerを使ってApache Derbyを使う方法をまとめてみました。
Apache Derbyとは
- Javaで作られたRDBMS。
- OracleやMySQLのような「クライアント/サーバーモード」と、SQLiteのような「組み込みモード」の両面を併せ持つ。
Apache Derbyの用意
ダウンロード
- Apache Derbyのサイトから、JARファイルをダウンロードします。
- ダウンロードページを見ると、Javaのバージョンに応じて利用可能なApache Derbyのバージョンが異なるため、手元のJavaのバージョンを確認した上でダウンロードします。
- 私の場合は手元のJavaのバージョンがJava8だったので、Apache Derby-10.14.2.0をダウンロードしました。
インストール
- ZIPファイルを展開して、所望のフォルダに配置します。
- 今回は
C:\Program Files以下に配置しました。- 今回はPATHを通すなどの作業は特に行いませんでした。
Eclipse上での設定
DBの登録
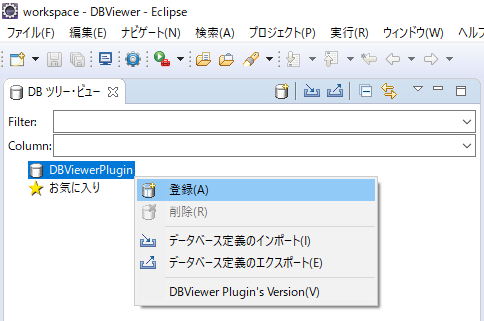
- DBViewerのパースペクティブを開いて、[DBViewerPlugin]を右クリックして[登録]を選択します。
- [データベース定義 - データベース定義の登録]という画面が開いたら、任意の定義名を入力します。
- 続けて[ファイルの追加]をクリックして、JDBCドライバーとして先程に配置したApache Derby(derby.jar)のパスを設定します。
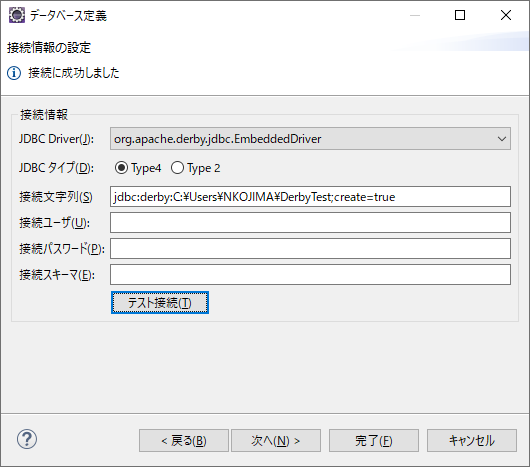
- [データベース定義 - 接続情報の設定]という画面では、JDBCドライバのタイプを選択します。
- 今回は組み込みモードで動作させるため、
org.apache.derby.jdbc.EmbeddedDriverを選択しました。- 次に接続文字列を作成しますが、ドライバタイプを選択した時に雛型が出来上がるので、あとはDB用のフォルダだけ指定します。
- 今回は
C:\Users\NKOJIMA\DerbyTestをDB用のフォルダとして指定しました。- また、スクショ上では
create=trueと書かれていますが、これは指定したフォルダが存在しない時に指定します。
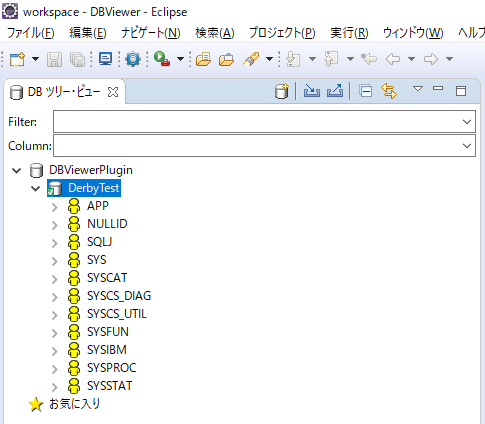
DBへの接続
- 再びDBViewerのパースペクティブに戻り、先程に作成した
DerbyTestを選択して[接続]をクリックします。
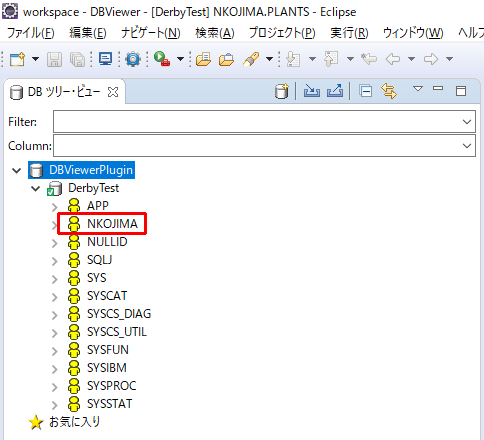
- DBへの接続が成功すると、以下の図のようにDB内のスキーマを一覧表示することが出来ます。
DBの利用
- DBViewerのパースペクティブで下側(右下)に位置する[SQL実行・ビュー]タブを開いて、スキーマを作成します。
- スキーマの作成が成功すると、以下の図のように作成したスキーマが表示されます。
- 続けてテーブルを作成します。
- なお、Apache Derbyで利用できる代表的なデータ型は以下の表のとおりです。
データ型 値の範囲 備考 INTEGER -2147483648~2147483647 DOUBLE -1.7976931348623157E+308~1.7976931348623157E+308 VARCHAR 最大32,672文字まで DATE - java.sqlで認識される任意の日付 TIME - java.sqlで認識される任意の時刻 TIMESTAMP - DATEとTIMEを合わせた値(日時)
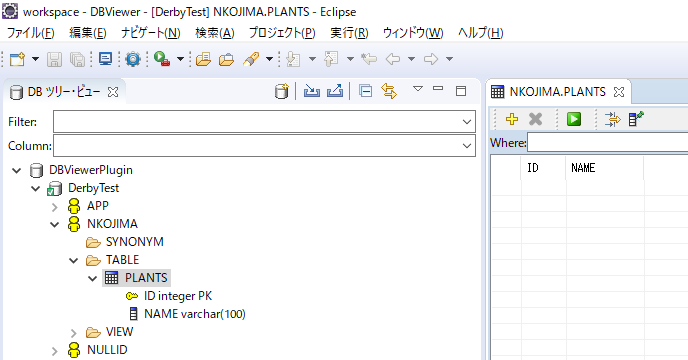
- テーブルが作成されると、以下の図のように作成したテーブルの定義を見ることが出来ます。
- 作成したテーブルを選択した状態で、DBViewerのパースペクティブの右側(右上)のパネルにある[+]をクリックすることで、手入力でレコードを追加することが出来ます。
- データが入力されるとこのように表示されます。
- 下側(右下)に位置する[SQL実行・ビュー]タブにSELECT文を書けば、入力したデータを検索することも可能です。
参考URL




- 投稿日:2020-05-23T15:26:56+09:00
Mapのメソッド
Mapのメソッドについても、復習も兼ねてまとめていこうと思います。
適宜更新予定です。put(K key, V value)
指定された値と指定されたキーをこのマップで関連付けます。
Map<String,String> map = new HashMap<String,String>() { { put("apple", "りんご"); put("orange", "オレンジ"); put("banana", "バナナ"); } }; System.out.println(map); //Mapの初期化と同時にキーと値のセットを行っているが、 //以下のように別々に実行してもOK. //map.put("apple", "りんご"); //map.put("orange", "オレンジ"); //map.put("banana", "バナナ");{orange=オレンジ, banana=バナナ, apple=りんご}get(Object key)
指定されたキーがマップされている値を返します。このマップにそのキーのマッピングが含まれていない場合はnullを返します。
Map<String,String> map = new HashMap<String,String>() { { put("apple", "りんご"); put("orange", "オレンジ"); put("banana", "バナナ"); } }; System.out.println(map.get("apple")); System.out.println(map.get("app"));りんご nullsize()
このマップ内のキー値マッピングの数を返します。
Map<String,String> map = new HashMap<String,String>() { { put("apple", "りんご"); put("orange", "オレンジ"); put("banana", "バナナ"); } }; System.out.println(map.size());3containsKey(Object key)
指定のキーのマッピングがこのマップに含まれている場合にtrueを返します。
Map<String,String> map = new HashMap<String,String>() { { put("apple", "りんご"); put("orange", "オレンジ"); put("banana", "バナナ"); } }; System.out.println(map.containsKey("orange")); System.out.println(map.containsKey("banana")); System.out.println(map.containsKey("oge"));true true falsecontainsValue(Object value)
マップが1つまたは複数のキーを指定された値にマッピングしている場合にtrueを返します。
Map<String,String> map = new HashMap<String,String>() { { put("apple", "りんご"); put("orange", "オレンジ"); put("banana", "バナナ"); } }; System.out.println(map.containsValue("りんご")); System.out.println(map.containsValue("オレンジ")); System.out.println(map.containsValue("レンジ"));true true falseclear()
マップからマッピングをすべて削除します。
Map<String,String> map = new HashMap<String,String>() { { put("apple", "りんご"); put("orange", "オレンジ"); put("banana", "バナナ"); } }; map.clear() System.out.println(map);{}entrySet()
このマップに含まれるマッピングのSetビューを返します。
Map<String,String> map = new HashMap<String,String>() { { put("apple", "りんご"); put("orange", "オレンジ"); put("banana", "バナナ"); } }; System.out.println(map.entrySet());[orange=オレンジ, banana=バナナ, apple=りんご]keySet()
このマップに含まれるキーのSetビューを返します。
Map<String,String> map = new HashMap<String,String>() { { put("apple", "りんご"); put("orange", "オレンジ"); put("banana", "バナナ"); } }; //キーをいっぺんに取得可能 System.out.println(map.keySet()); //キーをひとつずつ取得する場合は下記のように拡張for文を使用する for(String s : map.keySet()) { System.out.println(s); }[orange, banana, apple] orange banana applevalues()
このマップに含まれる値のCollectionビューを返します。
Map<String,String> map = new HashMap<String,String>() { { put("apple", "りんご"); put("orange", "オレンジ"); put("banana", "バナナ"); } }; //値をいっぺんに取得可能 System.out.println(map.values()); //値をひとつずつ取得したい場合は下記のように拡張for文を使用する for(String s : map.values()) { System.out.println(s); }[オレンジ, バナナ, りんご] オレンジ バナナ りんごremove(Object key)
このマップからキーのマッピング(ある場合)を削除します。
Map<String,String> map = new HashMap<String,String>() { { put("apple", "りんご"); put("orange", "オレンジ"); put("banana", "バナナ"); } }; map.remove("orange"); System.out.println(map);//orangeが削除されている {banana=バナナ, apple=りんご}remove(Object key, Object value)
指定された値に指定されたキーが現在マッピングされている場合にのみ、そのキーのエントリを削除します。
Map<String,String> map = new HashMap<String,String>() { { put("apple", "りんご"); put("orange", "オレンジ"); put("banana", "バナナ"); } }; //存在しない値を設定すると削除されず、そのまま map.remove("orange","オレジ"); System.out.println(map); //存在しないキーを設定すると削除されず、そのまま map.remove("oge","オレンジ"); System.out.println(map); //存在しているキーと値を設定すると削除される map.remove("orange","オレンジ"); System.out.println(map);{orange=オレンジ, banana=バナナ, apple=りんご} {orange=オレンジ, banana=バナナ, apple=りんご} {banana=バナナ, apple=りんご}replace(K key, V value)
指定されたキーがなんらかの値に現在マッピングされている場合にのみ、そのキーのエントリを置換します。
Map<String,String> map = new HashMap<String,String>() { { put("apple", "りんご"); put("orange", "オレンジ"); put("banana", "バナナ"); } }; //存在しないキーを設定するとMapはそのまま map.replace("bana", "バナナナナナ"); System.out.println(map); //存在するキーを設定するとそれに紐づく値が置換される map.replace("banana", "バナナナナナ"); System.out.println(map);{orange=オレンジ, banana=バナナ, apple=りんご} {orange=オレンジ, banana=バナナナナナ, apple=りんご}replace(K key, V oldValue, V newValue)
指定されたキーが指定された値に現在マッピングされている場合にのみ、そのキーのエントリを置換します。
Map<String,String> map = new HashMap<String,String>() { { put("apple", "りんご"); put("orange", "オレンジ"); put("banana", "バナナ"); } }; //存在しない古い値を指定すると置換されない map.replace("bana", "バナ","納豆"); System.out.println(map); //存在するキーと値を指定すると値が置換される map.replace("banana", "バナナ","納豆"); System.out.println(map);{orange=オレンジ, banana=バナナ, apple=りんご} {orange=オレンジ, banana=納豆, apple=りんご}isEmpty()
このマップがキーと値のマッピングを保持しない場合にtrueを返します。
Map<String,String> map = new HashMap<String,String>(); System.out.println(map.isEmpty());true
- 投稿日:2020-05-23T13:12:14+09:00
【Java入門】例外処理について(try-catch-finally、検査例外、非検査例外、throws、throw)
目的
Java言語を含めたプログラミングの学習を始めたばかりの方、既学習者の方は復習用に、
今回は例外処理について学ぶために書いています。【Java入門目次】
・変数と型
・型変換
・変数のスコープ
・文字列の操作(準備中)
・配列の操作(準備中)
・演算子(準備中)
・条件分岐(準備中)
・繰り返し処理(準備中)
・クラスについて(準備中)
・抽象クラス(準備中)
・インターフェース(準備中)
・カプセル化(準備中)
・モジュールについて(準備中)
・例外処理について ←今ここ例外処理とは
ソースコードに文法の間違いなどがある場合、コンパイルの時点でエラーが出力され、実行出来ないため文法のミスや間違いを修正をする事が出来る。
しかし、コンパイルの時点では分からなかったが、実行してから気づくエラーを例外(Exception)と呼ぶ。
・実行環境のトラブルやプログラムからの対処不可能な事態をエラー
・プログラムから対処可能な事態を例外上述の想定外の動作(例外)を防ぐため、対応する処理の事を例外処理という。
例外のクラス
・Throwable←エラー、例外のスーパークラス(親クラス)
Throwableクラスのサブクラス(子クラス)には、
・Errorクラス
・ExceptionExceptionクラスのサブクラス(子クラス)には、
・RuntimeExceptionクラス
・その他のクラスRuntimeExceptionクラスにはさらにサブクラス(子クラス)がある。
例外処理の方法
①try-catch-finallyブロック
try-catch
まずは、普通にコードを書いてみます。
Main.javaclass Error { public static void main(String[] args) { String[] fruits = {"りんご", "バナナ", "みかん"}; // fruits配列を一つずつ取り出すが、配列の要素外もアクセスしてみる for(int i = 0; i < 4; i++) { System.out.println(fruits[i]); } System.out.println("フルーツ全部を表示した"); } }出力結果りんご バナナ みかん Exception in thread "main" java.lang.ArrayIndexOutOfBoundsException: Index 3 out of bounds for length 3 at Main.main(Main.java:6)上記の様に表示されました。
最後の「フルーツ全部を表示した」は出力されることなく、プログラムが途中で終了しています。次にtry-catch文を用いて上記のコードを修正してみます。
tryブロックに、例外が発生しそうな箇所を記述します。
catch( 例外クラス名 変数名 )を記述して、
catchブロックに、例外が発生した時の処理を記述します。Main.javaclass Main { public static void main(String[] args) { String[] fruits = {"りんご", "バナナ", "みかん"}; try { // 例外が発生しそうな処理 for(int i = 0; i < 4; i++) { System.out.println(fruits[i]); } } catch(ArrayIndexOutOfBoundsException e) { // 例外が発生した時の処理 System.out.println("例外が発生しました"); } System.out.println("フルーツ全部を表示した"); } }実行すると、
出力結果りんご バナナ みかん 例外が発生しました フルーツ全部を表示した上記の様に出力されました。
4回目のループで例外が発生し、catchブロック内の処理が実行されています。
そして、プログラムが途中で終了することなく、最後の「フルーツ全部を表示した」まで出力されています。finally
finallyブロックには、例外が発生してもしなくても必ず実行したい処理を記述します。例外が発生しない場合(配列の要素内にアクセス)、
Main.javaclass Main { public static void main(String[] args) { String[] fruits = {"りんご", "バナナ", "みかん"}; try { // 例外が発生しそうな処理 for(int i = 0; i < 3; i++) { System.out.println(fruits[i]); } } catch(ArrayIndexOutOfBoundsException e) { // 例外が発生した時の処理 System.out.println("例外が発生しました"); } finally { // 例外の有無に関わらず必ず実行される System.out.println("必ず処理する"); } System.out.println("フルーツ全部を表示した"); } }実行すると、
出力結果りんご バナナ みかん 必ず処理する フルーツ全部を表示した上記の様にfinallyブロック内の処理が実行されています。
次に例外が発生する場合(配列の要素外にアクセス)、
Main.javaclass Main { public static void main(String[] args) { String[] fruits = {"りんご", "バナナ", "みかん"}; try { // 例外が発生しそうな処理 for(int i = 0; i < 4; i++) { System.out.println(fruits[i]); } } catch(ArrayIndexOutOfBoundsException e) { // 例外が発生した時の処理 System.out.println("例外が発生しました"); } finally { // 例外の有無に関わらず必ず実行される System.out.println("必ず処理する"); } System.out.println("フルーツ全部を表示した"); } }実行すると、
出力結果りんご バナナ みかん 例外が発生しました 必ず処理する フルーツ全部を表示した上記の様に出力されました。
例外が発生して、catchブロック内の処理が実行されます。
そして、finallyブロック内の処理が実行され、最後の「フルーツ全部を表示した」まで出力しています。try-catch-finallyの注意点
書き方の組み合わせとして、上記の通り
・try-catch
・try-finally
・try-catch-finally
はOK!以下の書き方はコンパイルエラーとなります。
・tryブロックのみ
Main.javaclass Main { public static void main(String[] args) { String[] fruits = {"りんご", "バナナ", "みかん"}; // tryブロックのみはコンパイルエラー try { for(int i = 0; i < 4; i++) { System.out.println(fruits[i]); } } System.out.println("フルーツ全部を表示した"); } }・try-finally-catch、catch-finally-try
Main.javaclass Main { public static void main(String[] args) { String[] fruits = {"りんご", "バナナ", "みかん"}; // try-finally-catchはコンパイルエラー try { for(int i = 0; i < 4; i++) { System.out.println(fruits[i]); } } finally { System.out.println("必ず処理する"); } catch(ArrayIndexOutOfBoundsException e) { System.out.println("例外が発生しました"); } // catch-finally-tryもコンパイルエラー catch(ArrayIndexOutOfBoundsException e) { System.out.println("例外が発生しました"); } try { for(int i = 0; i < 4; i++) { System.out.println(fruits[i]); } } finally { System.out.println("必ず処理する"); } } }例外の種類
例外処理の方法としてtry-catch-finallyブロックによる例外処理を学びましたが、
ここで例外の種類について触れ、実際に使用するタイミングを学びましょう。非検査例外
例外処理を記述したかどうかをコンパイラが検査しない例外のこと(例外処理の記述は任意)
RuntimeExceptionクラス以下が対象となる。例外の処理は任意なので、javaの文法自体に問題はなくコンパイルは出来てしまいます。
Main.javaclass Main { public static void main(String[] args) { int[] num = {10, 20, 30}; System.out.println(num[3]); // num配列の範囲外を出力しようとしている } }上記ファイルをコンパイルし、実行すると
Exception in thread "main" java.lang.ArrayIndexOutOfBoundsException: Index 3 out of bounds for length 3 at Main.main(Main9.java:71)RuntimeExceptionのサブクラスである、ArrayIndexOutOfBoundsExceptionの例外が発生しています。
配列のインデックス(添え字)が範囲外になった例外です。このような例外はプログラマーがコーディング時に確認をすることで防げるため、通常は例外処理を行わないです。
(一々例外が発生しそうな箇所全てに例外処理を書いていると煩雑なコードになる)でも一応、try-catch文で囲ってみます。
Main.javaclass Main { public static void main(String[] args) { String[] fruits = {"りんご", "バナナ", "みかん"}; int[] num = {10, 20, 30}; try { System.out.println(num[3]); // num配列の範囲外を出力しようとしている } catch (ArrayIndexOutOfBoundsException e) { System.out.println("例外が発生しました"); } } }コンパイルして実行すると、
例外が発生しましたcatch文内の処理が実行されています。
検査例外
例外処理を記述したかどうかをコンパイラがチェックする例外のこと(例外処理の記述が必須)
RuntimeException以外のその他のクラスが対象となる。例外処理の記述は必須となり、記述がないとコンパイル時にエラーになります。
試しに見てみましょう。例外処理の記述がない場合。
Main.javaimport java.io.File; import java.io.FileReader; import java.io.BufferedReader; import java.io.IOException; class Main { public static void main(String[] args) { // ファイルのパスを指定する File file = new File("test.text"); // ファイルの中身を1行を取得する FileReader fileReader = new FileReader(file); BufferedReader bufferedReader = new BufferedReader(fileReader); String str = bufferedReader.readLine(); // ループを回して1行ずつ表示していく while(str != null){ System.out.println(str); str = bufferedReader.readLine(); } // 最後にファイルを閉じてリソースを開放する bufferedReader.close(); } }これをコンパイルすると、
Main.java:13: エラー: 例外FileNotFoundExceptionは報告されません。スローするには、捕捉または宣言する必要があります FileReader fileReader = new FileReader(file); ^ Main.java:15: エラー: 例外IOExceptionは報告されません。スローするには、捕捉または宣言する必要があります String str = bufferedReader.readLine(); ^ Main.java:20: エラー: 例外IOExceptionは報告されません。スローするには、捕捉または宣言する必要があります str = bufferedReader.readLine(); ^ Main.java:24: エラー: 例外IOExceptionは報告されません。スローするには、捕捉または宣言する必要があります bufferedReader.close(); ^ エラー4個例外処理の記述をせずにコンパイルするとコンパイルエラーになってしまいます。
次にtry-catch文で囲ってみます。
Main.javaimport java.io.File; import java.io.FileReader; import java.io.BufferedReader; import java.io.IOException; class Main { public static void main(String[] args) { // try-catchの例外処理を記述した場合 try { // ファイルのパスを指定する File file = new File("test.text"); // ファイルの中身を1行を取得する FileReader fileReader = new FileReader(file); BufferedReader bufferedReader = new BufferedReader(fileReader); String str = bufferedReader.readLine(); // ループを回して1行ずつ表示していく while(str != null){ System.out.println(str); str = bufferedReader.readLine(); } // 最後にファイルを閉じてリソースを開放する bufferedReader.close(); } catch (IOException e) { System.out.println("例外が発生しました"); } } }コンパイルするとコンパイルエラーが出ません。
実行すると、あいうえお かきくけこ さしすせそとtest.txtファイルの中身が出力されました。
今度はファイルのパス指定部分をわざと間違えてみます。
Main.javaimport java.io.File; import java.io.FileReader; import java.io.BufferedReader; import java.io.IOException; class Main { public static void main(String[] args) { // try-catchの例外処理を記述した場合 try { // ファイルのパスを指定する File file = new File("aaaaaaaaa.text"); // 存在しないテキストファイルを指定する // ファイルの中身を1行を取得する FileReader fileReader = new FileReader(file); BufferedReader bufferedReader = new BufferedReader(fileReader); String str = bufferedReader.readLine(); // ループを回して1行ずつ表示していく while(str != null){ System.out.println(str); str = bufferedReader.readLine(); } // 最後にファイルを閉じてリソースを開放する bufferedReader.close(); } catch (IOException e) { System.out.println("例外が発生しました"); } } }コンパイルは出来ます。実行してみると、
例外が発生しましたと出力されました。
例外が発生し、catch文内の処理が実行されています。上記の様にRuntimeException以外のその他のクラスの場合、例外処理を記述していなければコンパイルエラーとなってしまうケースもあるので意識しなければいけませんね。
②throws
try-catch-blockブロックの例外処理以外に、throwsキーワードによる例外処理が出来ます。
このキーワードは、例外が発生する可能性があるメソッドを定義する時に、
throws 発生する例外クラス名と指定することで、
このメソッドの呼び出し元に例外が転送される仕組みとなっています。具体的に上述のサンプルコードを元にメソッド化して試してみます。
ファイルを読み込んで出力する動作を別クラスでメソッドとして定義します。
このメソッドを定義する時、throwsキーワードを用います。GetText.javaimport java.io.File; import java.io.FileReader; import java.io.BufferedReader; import java.io.IOException; class GetText { // throws で指定されたメソッドは呼び出し元へ例外を転送する public void getText() throws IOException { // ファイルのパスを指定する File file = new File("aaaaaaaaa.text"); // 存在しないテキストファイルを指定する // ファイルの中身を1行を取得する FileReader fileReader = new FileReader(file); BufferedReader bufferedReader = new BufferedReader(fileReader); String str = bufferedReader.readLine(); // ループを回して1行ずつ表示していく while(str != null){ System.out.println(str); str = bufferedReader.readLine(); } // 最後にファイルを閉じてリソースを開放する bufferedReader.close(); } }Main.javaにてgetTextメソッドを呼び出す時、もし例外が発生した場合はこちらで記述したcatch文の処理が実行されます。
Main.javaimport java.io.IOException; class Main { public static void main(String[] args) { // throwsの時 try { GetText gt = new GetText(); // throwsキーワードを用いた、getTextメソッドを呼ぶ gt.getText(); // 例外をキャッチする } catch (IOException e) { System.out.println("例外が発生しました"); } } }このファイルをコンパイルすると、コンパイルは出来ます。ただ実行してみると、
例外が発生しましたgetText内にて存在しないファイルにアクセスするという例外が発生しました。
ただ、処理をしているメソッド内にはtry-catch文の記述はありません。メソッドの定義時に
throws 発生する例外クラス名と宣言した事により、
このメソッドの呼び出し元にあるcatch文に例外がスローされ(投げられ)、例外処理が実行されます。ちなみに、メソッドの呼び出し元でtry-catch文を無くしてみて、
Main.javaimport java.io.IOException; class Main { public static void main(String[] args) { // throwsの時で、try-catch文を消した時 GetText gt = new GetText(); gt.getText(); } }コンパイルすると...
Main.java:16: エラー: 例外IOExceptionは報告されません。スローするには、捕捉または宣言する必要があります gt.getText(); ^ エラー1個コンパイルエラーになってしまいます。
throwsキーワードを用いたメソッドを定義した時も、メソッドの呼び出し元ではtry-catch文を用いた例外処理の記述がないとコンパイルエラーになってしまいますので、ご注意を。③throw
throwキーワードを用いて、プログラム内で明示的に例外をスローすることが出来ます。
throwsと違う点は、throwsは例外が発生した時に補足しますが、throwは明示的に例外を補足します。
ですので、自分で意図的に例外を発生させる事が出来ます。Main.javaclass Main { public static void main(String[] args) { int[] num = {10, 20, 30}; try { for(int i = 0; i < num.length; i++) { System.out.println(num[i]); if(num[i] < 20) { // 例外を明示的に投げています throw new Exception(); } } } catch (Exception e) { System.out.println("例外が発生しました"); } } }上記のコードでコンパイル、実行すると、
10 例外が発生しましたnum配列を一つずつ出力する中で、20を超えたら例外を発生させるよう明示的にしました。
結果的に2つめの20を出力しようとするときに、catch分内の処理を実行しています。throwキーワードは任意の場所で例外をスローする事ができるのが、throwsキーワードとの違いです。
終わりに
Java文法が間違えていなければコンパイル出来てしまい、
プログラムの実行途中に処理が止まってしまうことを防ぐために備えての例外処理について学びました。try-catchでの例外処理の記述が必須な検査例外というのがあるので気をつけたいですね。
まだまだ表面的な知識のみなので、もっと深掘りして実践で使えるよう理解していきたいですね。
- 投稿日:2020-05-23T12:15:29+09:00
Javaのtrueとfalse
trueとfalse
真偽値のデータ型はbooleanです。
Main.javaclass Main { public static void main(String[] args) { int number = 5; } if (isEven(number)) { System.out.println(number + "偶数"); } else { System.out.println(number + "奇数"); public static boolean isEven(int a) { return a % 2 == 0; } }上記はisEvenメソッドは引数の値が偶数かどうかを調べ、偶数であればtrue、奇数であればfalseを返します。
- 投稿日:2020-05-23T10:41:28+09:00
JVMが起動したときの Class ローディングと初期化について
概要
HotSpot Runtime Overviewにはこう書いています
The VM loads core classes such as
java.lang.Object,java.lang.Thread, etc. at JVM startup. Loading a class requires loading all superclasses and superinterfaces. And classfile verification, which is part of the linking phase, can require loading additional classes.
- JVMは起動したすぐ
java.lang.Object、java.lang.Threadなどの Class をロードする- 依頼された super と interface は自動にロードする
- その他の Class は必要なときだけにロードする
じゃ具体的にはどんな Class をいつにロードされたのか?Unified JVM Logging を利用して実際に見に行きましょう。
作業環境
前の記事との同じく Ubuntu 18.04 と OpenJDK 13 を使いています、具体的の構築方法はそちらに参照してください。
startuptimeを見てみるまずは
-Xlog:startuptimeの変数でJVMの大まかの起動時間が見てみよう$ $JAVA_HOME/bin/java -Xlog:startuptime -version [0.168s][info][startuptime] StubRoutines generation 1, 0.0257810 secs [0.229s][info][startuptime] Genesis, 0.0605841 secs [0.232s][info][startuptime] TemplateTable initialization, 0.0010887 secs [0.263s][info][startuptime] Interpreter generation, 0.0302811 secs [0.693s][info][startuptime] StubRoutines generation 2, 0.0152926 secs [0.697s][info][startuptime] MethodHandles adapters generation, 0.0017809 secs [0.703s][info][startuptime] Start VMThread, 0.0010136 secs [0.997s][info][startuptime] Initialize java.lang classes, 0.2923160 secs [1.018s][info][startuptime] Initialize java.lang.invoke classes, 0.0159241 secs [3.161s][info][startuptime] Initialize module system, 2.1431533 secs [3.173s][info][startuptime] Create VM, 3.1052374 secs openjdk version "13.0.3-internal" 2020-04-14 OpenJDK Runtime Environment (fastdebug build 13.0.3-internal+0-adhoc.root.jdk13u) OpenJDK 64-Bit Server VM (fastdebug build 13.0.3-internal+0-adhoc.root.jdk13u, mixed mode)ここでわかるのは
Start VMThreadのあどで幾つの classe と modules を初期化しました。[0.997s][info][startuptime] Initialize java.lang classes, 0.2923160 secs [1.018s][info][startuptime] Initialize java.lang.invoke classes, 0.0159241 secs [3.161s][info][startuptime] Initialize module system, 2.1431533 secsClass の
loadとinitを見る次は
-Xlog:startuptime,class+init,class+loadの変数を設定してもう一度実行しましょう。$ $JAVA_HOME/bin/java -Xlog:startuptime,class+init,class+load -version [0.096s][info][class,load] path: /vagrant/jdk/jdk13u/build/linux-x86_64-server-fastdebug/jdk/modules/java.base [0.159s][info][startuptime] StubRoutines generation 1, 0.0283598 secs [0.220s][info][startuptime] Genesis, 0.0597463 secs [0.223s][info][startuptime] TemplateTable initialization, 0.0012748 secs [0.252s][info][startuptime] Interpreter generation, 0.0291667 secs [0.284s][info][class,load ] path: /vagrant/jdk/jdk13u/build/linux-x86_64-server-fastdebug/jdk/modules/java.base [0.285s][info][class,load ] path: /vagrant/jdk/jdk13u/build/linux-x86_64-server-fastdebug/jdk/modules/java.base [0.314s][info][class,load ] java.lang.Object source: /vagrant/jdk/jdk13u/build/linux-x86_64-server-fastdebug/jdk/modules/java.base [0.321s][info][class,load ] java.io.Serializable source: /vagrant/jdk/jdk13u/build/linux-x86_64-server-fastdebug/jdk/modules/java.base ... [0.553s][info][class,load ] java.util.Iterator source: /vagrant/jdk/jdk13u/build/linux-x86_64-server-fastdebug/jdk/modules/java.base [0.578s][info][class,load ] java.lang.NullPointerException source: /vagrant/jdk/jdk13u/build/linux-x86_64-server-fastdebug/jdk/modules/java.base [0.579s][info][class,load ] java.lang.ArithmeticException source: /vagrant/jdk/jdk13u/build/linux-x86_64-server-fastdebug/jdk/modules/java.base [0.619s][info][startuptime] StubRoutines generation 2, 0.0132195 secs [0.622s][info][startuptime] MethodHandles adapters generation, 0.0018546 secs [0.627s][info][startuptime] Start VMThread, 0.0007446 secs [0.629s][info][class,init ] 0 Initializing 'java/lang/Object' (0x0000000100001080) [0.644s][info][class,init ] 1 Initializing 'java/lang/CharSequence'(no method) (0x00000001000016b8) ... [0.898s][info][class,init ] 135 Initializing 'java/lang/IllegalArgumentException'(no method) (0x000000010002b0e8) [0.898s][info][startuptime] Initialize java.lang classes, 0.2690178 secs [0.902s][info][class,init ] 136 Initializing 'java/lang/invoke/MethodHandle' (0x000000010000c560) ... [0.925s][info][class,init ] 144 Initializing 'java/lang/invoke/MethodHandleNatives' (0x000000010000d2e8) [0.925s][info][startuptime] Initialize java.lang.invoke classes, 0.0232579 secs [0.935s][info][class,load ] jdk.internal.module.ModuleBootstrap source: /vagrant/jdk/jdk13u/build/linux-x86_64-server-fastdebug/jdk/modules/java.base ... [3.112s][info][class,load ] jdk.internal.module.ModuleBootstrap$SafeModuleFinder source: /vagrant/jdk/jdk13u/build/linux-x86_64-server-fastdebug/jdk/modules/java.base [3.113s][info][class,init ] 662 Initializing 'jdk/internal/module/ModuleBootstrap$SafeModuleFinder'(no method) (0x000000010008e930) [3.113s][info][startuptime] Initialize module system, 2.1876125 secs [3.124s][info][startuptime] Create VM, 3.0688743 secs openjdk version "13.0.3-internal" 2020-04-14 OpenJDK Runtime Environment (fastdebug build 13.0.3-internal+0-adhoc.root.jdk13u) OpenJDK 64-Bit Server VM (fastdebug build 13.0.3-internal+0-adhoc.root.jdk13u, mixed mode)ここでわかったのは、実際には2つの段階があります
Interpreter generationとStubRoutines generation 2の間に幾つの Class がロードされました。Start VMThreadあどに 663 個(0-662)の Class が初期化されました
java.lang136 個 (0-135)java.lang.invoke9 個 (136-144)module system518 個 (145-622)ソースコードで確認する
上記のテキストをソースコードに検索したら、この2つの段階を触発する場所がわかります。
SystemDictionary::resolve_well_known_classes:SystemDictionaryはほぼJVMの Class 管理機能がしています。このSystemDictionaryが初期化したときにいわゆる Well Know Classes というコアな Class たちも一緒に初期化する。Well Known Classes のリストはここに記載してます、その順序は大事のようです。Threads::create_vm:Start VMThreadのあどにjava.lang classes、java.lang.invoke classesとmodule systemを一気に初期化するのはここです。具体的にはこれらの3つの関数でまとめ
JVMが起動したときにこれらのコアな Class を初期化します
- Well Know Classes (
SystemDictionaryの初期化とともに)java.langClassjava.lang.invokeClass$JAVA_HOME/modulesの Class
- 投稿日:2020-05-23T10:06:53+09:00
複数のスレッドからsynchronizedメソッドを呼び出してみる
はじめに
前回、Javaでファイルにログ出力 という記事を書いた。そこでログ出力メソッドをsyncronizedメソッドにすることでログファイルに対して排他制御できそうだと書いたので、今回はそれを検証してみたい。
検証方法
ログ出力メソッドを10000回呼び出すスレッドを10個並列に実行し、各スレッドで指示したログがもれなくログファイルに出力されているかを確認する。
検証ソース
スレッドについては、いろんなサンプルがあるから、特に解説は不要だろう。
ログ出力メソッドはいろんなスレッドから呼び出せるように、LogWriterクラスのwriteLogメソッドに移動した。LogWriterTest.javaimport java.io.File; import java.text.SimpleDateFormat; import java.util.Date; import java.util.Calendar; import java.io.*; public class LogWriterTest{ public static void main(String[] argv){ ThreadSample[] threadSamples = new ThreadSample[10]; // スレッドの準備 for (int i = 0; i < threadSamples.length; i++) { threadSamples[i] = new ThreadSample("Trhead[" + i + "]"); } // スレッドの開始 for (int i = 0; i < threadSamples.length; i++) { threadSamples[i].start(); } } } // ログ出力クラス class LogWriter { public static SimpleDateFormat sdf = new SimpleDateFormat("YYYY/MM/dd HH:mm:ss"); // ログ出力メソッド public static synchronized void writeLog(String text) { Calendar calendar = Calendar.getInstance(); String OUTPUT_DIR = "out"; int year = calendar.get(Calendar.YEAR); int month = calendar.get(Calendar.MONTH) + 1; Date date = calendar.getTime(); String yearStr = String.format("%04d", year); String monthStr = String.format("%02d", month); // ログ出力 String file_name = OUTPUT_DIR + File.separator + yearStr + "_" + monthStr + ".log"; File file = new File(file_name); FileWriter fw = null; String line = sdf.format(date) + "," + text; try { fw = new FileWriter(file, true); fw.write(line + "\n"); } catch (IOException e) { e.printStackTrace(); } finally { if (fw != null) { try { fw.close(); } catch (Exception e2) { e2.printStackTrace(); } } } } } class ThreadSample extends Thread { // スレッド名 private String name = null; public ThreadSample(String name) { this.name = name; } // ログに10000行書き込むスレッド public void run() { for (int i = 0; i < 10000; i++) { System.out.println(name + "," + i); LogWriter.writeLog(name + "," + i + ":hogehoge"); } } }検証結果
ファイルの中身
ファイルの中身はこんな感じで壊れてはなさそう。あといろんなスレッドのログが並列でファイルに出力されている様子もうかがえる。
2020/05/23 09:48:59,Trhead[2],0:hogehoge 2020/05/23 09:48:59,Trhead[5],0:hogehoge 2020/05/23 09:48:59,Trhead[6],0:hogehoge 2020/05/23 09:48:59,Trhead[9],0:hogehoge 2020/05/23 09:48:59,Trhead[0],0:hogehoge 2020/05/23 09:48:59,Trhead[7],0:hogehoge 2020/05/23 09:48:59,Trhead[8],0:hogehoge 2020/05/23 09:48:59,Trhead[3],0:hogehoge 2020/05/23 09:48:59,Trhead[1],0:hogehoge 2020/05/23 09:48:59,Trhead[4],0:hogehoge 2020/05/23 09:48:59,Trhead[1],1:hogehoge 2020/05/23 09:48:59,Trhead[3],1:hogehoge 2020/05/23 09:48:59,Trhead[8],1:hogehoge 2020/05/23 09:48:59,Trhead[7],1:hogehoge 2020/05/23 09:48:59,Trhead[0],1:hogehoge 2020/05/23 09:48:59,Trhead[9],1:hogehoge 2020/05/23 09:48:59,Trhead[6],1:hogehoge 2020/05/23 09:48:59,Trhead[5],1:hogehoge 2020/05/23 09:48:59,Trhead[2],1:hogehoge 2020/05/23 09:48:59,Trhead[5],2:hogehoge 2020/05/23 09:48:59,Trhead[6],2:hogehoge件数
件数も、各スレッドの10000件、合計100000件となっており、もれなく出力されていることが確認できた。
$ grep 'Trhead\[0\]' 2020_05.log |wc -l 10000 $ grep 'Trhead\[1\]' 2020_05.log |wc -l 10000 $ grep 'Trhead\[2\]' 2020_05.log |wc -l 10000 $ grep 'Trhead\[3\]' 2020_05.log |wc -l 10000 $ grep 'Trhead\[4\]' 2020_05.log |wc -l 10000 $ grep 'Trhead\[5\]' 2020_05.log |wc -l 10000 $ grep 'Trhead\[6\]' 2020_05.log |wc -l 10000 $ grep 'Trhead\[7\]' 2020_05.log |wc -l 10000 $ grep 'Trhead\[8\]' 2020_05.log |wc -l 10000 $ grep 'Trhead\[9\]' 2020_05.log |wc -l 10000 $ wc -l 2020_05.log 100000 2020_05.logおわりに
このメソッドを使ってガンガンログ出力するぞ!
追記
ちなみに、syncronizedをつけなくても、小職の環境ではもれなくログ出力された。処理も圧倒的に高速だった。
ただ、偶然ということもありえるので、処理時間を犠牲にしてもsyncronizedはつけた方がよいだろう。
- 投稿日:2020-05-23T10:06:53+09:00
Javaで複数のスレッドからsynchronizedメソッドを呼び出してみる
はじめに
前回、Javaでファイルにログ出力 という記事を書いた。そこでログ出力メソッドをsyncronizedメソッドにすることでログファイルに対して排他制御できそうだと書いたので、今回はそれを検証してみたい。
検証方法
ログ出力メソッドを10000回呼び出すスレッドを10個並列に実行し、各スレッドで指示したログがもれなくログファイルに出力されているかを確認する。
検証ソース
スレッドについては、いろんなサンプルがあるから、特に解説は不要だろう。
ログ出力メソッドはいろんなスレッドから呼び出せるように、LogWriterクラスのwriteLogメソッドに移動した。LogWriterTest.javaimport java.io.File; import java.text.SimpleDateFormat; import java.util.Date; import java.util.Calendar; import java.io.*; public class LogWriterTest{ public static void main(String[] argv){ ThreadSample[] threadSamples = new ThreadSample[10]; // スレッドの準備 for (int i = 0; i < threadSamples.length; i++) { threadSamples[i] = new ThreadSample("Trhead[" + i + "]"); } // スレッドの開始 for (int i = 0; i < threadSamples.length; i++) { threadSamples[i].start(); } } } // ログ出力クラス class LogWriter { public static SimpleDateFormat sdf = new SimpleDateFormat("YYYY/MM/dd HH:mm:ss"); // ログ出力メソッド public static synchronized void writeLog(String text) { Calendar calendar = Calendar.getInstance(); String OUTPUT_DIR = "out"; int year = calendar.get(Calendar.YEAR); int month = calendar.get(Calendar.MONTH) + 1; Date date = calendar.getTime(); String yearStr = String.format("%04d", year); String monthStr = String.format("%02d", month); // ログ出力 String file_name = OUTPUT_DIR + File.separator + yearStr + "_" + monthStr + ".log"; File file = new File(file_name); FileWriter fw = null; String line = sdf.format(date) + "," + text; try { fw = new FileWriter(file, true); fw.write(line + "\n"); } catch (IOException e) { e.printStackTrace(); } finally { if (fw != null) { try { fw.close(); } catch (Exception e2) { e2.printStackTrace(); } } } } } class ThreadSample extends Thread { // スレッド名 private String name = null; public ThreadSample(String name) { this.name = name; } // ログに10000行書き込むスレッド public void run() { for (int i = 0; i < 10000; i++) { System.out.println(name + "," + i); LogWriter.writeLog(name + "," + i + ":hogehoge"); } } }検証結果
ファイルの中身
ファイルの中身はこんな感じで壊れてはなさそう。あといろんなスレッドのログが並列でファイルに出力されている様子もうかがえる。
2020/05/23 09:48:59,Trhead[2],0:hogehoge 2020/05/23 09:48:59,Trhead[5],0:hogehoge 2020/05/23 09:48:59,Trhead[6],0:hogehoge 2020/05/23 09:48:59,Trhead[9],0:hogehoge 2020/05/23 09:48:59,Trhead[0],0:hogehoge 2020/05/23 09:48:59,Trhead[7],0:hogehoge 2020/05/23 09:48:59,Trhead[8],0:hogehoge 2020/05/23 09:48:59,Trhead[3],0:hogehoge 2020/05/23 09:48:59,Trhead[1],0:hogehoge 2020/05/23 09:48:59,Trhead[4],0:hogehoge 2020/05/23 09:48:59,Trhead[1],1:hogehoge 2020/05/23 09:48:59,Trhead[3],1:hogehoge 2020/05/23 09:48:59,Trhead[8],1:hogehoge 2020/05/23 09:48:59,Trhead[7],1:hogehoge 2020/05/23 09:48:59,Trhead[0],1:hogehoge 2020/05/23 09:48:59,Trhead[9],1:hogehoge 2020/05/23 09:48:59,Trhead[6],1:hogehoge 2020/05/23 09:48:59,Trhead[5],1:hogehoge 2020/05/23 09:48:59,Trhead[2],1:hogehoge 2020/05/23 09:48:59,Trhead[5],2:hogehoge 2020/05/23 09:48:59,Trhead[6],2:hogehoge件数
件数も、各スレッドの10000件、合計100000件となっており、もれなく出力されていることが確認できた。
$ grep 'Trhead\[0\]' 2020_05.log |wc -l 10000 $ grep 'Trhead\[1\]' 2020_05.log |wc -l 10000 $ grep 'Trhead\[2\]' 2020_05.log |wc -l 10000 $ grep 'Trhead\[3\]' 2020_05.log |wc -l 10000 $ grep 'Trhead\[4\]' 2020_05.log |wc -l 10000 $ grep 'Trhead\[5\]' 2020_05.log |wc -l 10000 $ grep 'Trhead\[6\]' 2020_05.log |wc -l 10000 $ grep 'Trhead\[7\]' 2020_05.log |wc -l 10000 $ grep 'Trhead\[8\]' 2020_05.log |wc -l 10000 $ grep 'Trhead\[9\]' 2020_05.log |wc -l 10000 $ wc -l 2020_05.log 100000 2020_05.logおわりに
このメソッドを使ってガンガンログ出力するぞ!
追記1
ちなみに、syncronizedをつけなくても、小職の環境ではもれなくログ出力された。処理も圧倒的に高速だった。
ただ、偶然ということもありえるので、処理時間を犠牲にしてもsyncronizedはつけた方がよいだろう。追記2
小職のプログラムでは、synchronizedメソッドの中で日付の処理やファイル名の決定を行っているが、これを呼び出し側に移動し、同期処理の時間を短くすれば、多少速くなるかもしれない(未実験)。
- 投稿日:2020-05-23T08:57:28+09:00
Javaでファイルにログ出力
はじめに
定期的に発生するJavaネタ。ある情報をログ出力することになったが、データベースに出力するか、ファイルに出力するか検討した結果、ファイルにログを出力することにしたので事前に検討した時のメモ。前提はLinux。
ファイル出力のメリット
観点は全くバラバラだが、思いつくままに列挙
- データベースに比べて格納領域のオーバヘッドが少ないため容量を食わない
- ログが大量になる場合に、データの分割を検討する必要があるが、データベースの場合はテーブルを作成する処理等の実装が面倒だが、ファイルであれば新たにファイルを作成するだけなのでプログラムが容易
- ログを参照する場合、データベースであればログインしてSQLを叩かないと見えないが、ファイルの場合はmore/lessで簡単に参照できる。
- データベースの場合、データベースのバックアップへの影響(処理時間等)を追加で検討する必要があるが、ファイルの場合はシステム全体のバックアップのみ考慮すればよい。
ファイル出力のデメリット
- 排他処理を適切に行わないと、ファイルが壊れたりする。
- 検索を行う場合、インデックスがないため性能を出すための工夫が必要
- 検索を行う場合、SQLが使えないため、自分で検索ロジックを作りこむ必要がある
ソース
ということでファイルに時間、テキストからなる1行ログを出力するプログラムを作ってみた。ファイルは月別に生成するようにした。
排他制御として、synchronizedメソッドを使う方法が簡単そうなので、この方法にした。
もちろん、このメソッド以外でログファイルの操作をしないことは大前提だ。LogWriter.javaimport java.io.File; import java.text.SimpleDateFormat; import java.util.Date; import java.util.Calendar; import java.io.*; public class LogWriterNew{ public static SimpleDateFormat sdf = new SimpleDateFormat("YYYY/MM/dd HH:mm:ss"); public static synchronized void writeLog(String text){ Calendar calendar = Calendar.getInstance(); String OUTPUT_DIR= "out"; int year = calendar.get(Calendar.YEAR); int month = calendar.get(Calendar.MONTH) + 1; Date date = calendar.getTime(); String yearStr = String.format("%04d", year); String monthStr = String.format("%02d", month); // ログ出力 String file_name = OUTPUT_DIR + File.separator + yearStr + "_" + monthStr + ".log"; File file = new File(file_name); FileWriter fw = null; String line = sdf.format(date) + "," + text; try{ fw = new FileWriter(file, true); fw.write(line + "\n"); }catch(IOException e){ e.printStackTrace(); }finally { if(fw != null) { try { fw.close(); }catch(Exception e2) { e2.printStackTrace(); } } } } public static void main(String[] argv){ for(int i=0; i<1000;i++){ System.out.println(i); writeLog(i + "aaa"); } } }出力
こんな感じ。
2020/05/23 08:25:02,0aaa 2020/05/23 08:25:02,1aaa 2020/05/23 08:25:02,2aaa 2020/05/23 08:25:02,3aaa 2020/05/23 08:25:02,4aaa 2020/05/23 08:25:02,5aaa 2020/05/23 08:25:02,6aaa 2020/05/23 08:25:02,7aaa 2020/05/23 08:25:02,8aaa 2020/05/23 08:25:02,9aaa 2020/05/23 08:25:02,10aaa ・・・・処理時間(参考)
小職のPCでは、
850件/秒のスループットが得られた。追記(2020/5/24)
FileWriterでは文字コード指定できないため、OutputStreamWriterを使って文字コード指定できるようにしてみた。
// ログ出力メソッド public static synchronized boolean writeLog(String fileName, String date, String[] items){ for(int i=0; i<items.length; i++){ items[i] = escape(items[i]); } String line = date + "," + String.join(",", items); File file = new File(fileName); PrintWriter pw = null; try { pw = new PrintWriter(new BufferedWriter(new OutputStreamWriter(new FileOutputStream(file, true), "Windows-31j"))); pw.println(line); } catch (IOException e) { e.printStackTrace(); } finally { if (pw != null) { try { pw.close(); } catch (Exception e2) { e2.printStackTrace(); return false; } } }おわりに
次回は、このsyncronizedで本当に排他制御がされるのか検証する。
- 投稿日:2020-05-23T08:35:33+09:00
java8をおさらい 〜ラムダ式〜
現場でほどんどjava8でコードを書いた事がないので、危機感を覚え学習したのでここにまとめます。
listの中身を数字に変換して出力するサンプルです。
まずはjava8以前の例。java8じゃない.javaList<String> suuzies = Arrays.asList("1", "2", null, "3"); for (String suuzi : suuzies) { if (suuzi == null) { continue; } System.out.println(Integer.parseInt(suuzi)); } // 1 2 3次はjava8。
java8.javaList<String> suuzies = Arrays.asList("1", "2", null, "3"); suuzies.stream().filter(s -> Objects.nonNull(s)).map(s -> Integer.parseInt(s)) .forEach(s -> System.out.println(s)); // 1 2 3素晴らしい!1行でおさまりましたし、可読性も上がりますね!
最初見たときは全く意味が分からず、何が可読性上がるだよ、、と思いましたが
理解するとスッキリします。stream処理の順番は
1.コレクションからstream生成
2.中間処理
3.終盤処理
になります。
なので上記コードは、
1.コレクションからstream取得
2.nullを排除
3.生き残った値を数字に変換
4.出力
ですね!
2、3が中間処理、4が終盤処理に当たります。
中間処理は満足するまで処理を書くことができ、終盤処理は1つのみ記述可能です。上記のように矢印で繋いだように処理を書けると考えると、
確かに可読性上がっているなぁと感じますね。
現場レベルだとifやforでネストがカオスになる事も多々あると思いますが、
これだと凄く読みやすくなりそうですよね。ちなみに、java8.javaのコードは下記のように記述する事も出来ます。
java8(2).javaList<String> suuzies = Arrays.asList("1", "2", null, "3"); suuzies.stream().filter(Objects::nonNull).map(Integer::parseInt) .forEach(System.out::println); // 1 2 3メソッド参照というのを使っていてさらにコードが短くなりますが、
ここでは説明を割愛させて頂きます。streamを理解した所で、ラムダ式についても少し書きます。
Stream APIには中間処理、終盤処理に使用するメソッドがいくつか用意されています。
例えば、上記に出てきたfilterメソッドはこのようになっています。Stream.classStream<T> filter(Predicate<? super T> predicate);僕は、最初見たときアレルギーを起こしました。すぐに閉じました。
filterの引数の中の(Predicate<? super T>)も覗いて見ましょう。
Predicate.class@FunctionalInterface public interface Predicate<T> { boolean test(T t); default Predicate<T> and(Predicate<? super T> other) { Objects.requireNonNull(other); return (t) -> test(t) && other.test(t); } default Predicate<T> negate() { return (t) -> !test(t); } default Predicate<T> or(Predicate<? super T> other) { Objects.requireNonNull(other); return (t) -> test(t) || other.test(t); } static <T> Predicate<T> isEqual(Object targetRef) { return (null == targetRef) ? Objects::isNull : object -> targetRef.equals(object); } }これは関数型インターフェースです。
ラムダ式とは、関数型インターフェースを短い記述で実装できる物になります。ちなみに関数型インターフェースとは、抽象メソッドが一つのみ定義されている物になります。
抽象メソッド以外のstaticやdefaultメソッドは含まれていても構いませんが、条件としては無視されます。
Predicateクラスでは'boolean test(T t)'のみが対象となり、他は無視されます。このインターフェースは見ての通り、T型の引数を受け取りboolean型の戻り値を返します。
先ほどのコード(java8.java)のfilterの部分をもう一度。java8.javafilter(s -> Objects.nonNull(s))Stream.classのfilterの引数を実装しています。
この部分がラムダ式という事になります!他にも関数型インターフェースがいくつか用意されています。
java8.classで用いたmapだと、、Stream.class<R> Stream<R> map(Function<? super T, ? extends R> mapper);引数のFunctionの中身も見てみます。
Function.class@FunctionalInterface public interface Function<T, R> { R apply(T t); // and more }T型を引数に取り、R型を返すメソッドです!
つまり、受け取った引数を処理して別の形にして返却という事です!先ほどのjava8.javaのmapの部分をもう一度。
java8.javamap(s -> Integer.parseInt(s))引数に文字を受け取り、数値に変換して返していますね!
ラムダ式の構文はこんな感じ。
( 引数 ) -> { 処理 }
抽象メソッドが一つだから出来る書き方ですね♪
他にも戻り値が無いConsumerや、引数を取らないSupplierなどがあります!ラムダ式はStreamの為に出来たのかなと思います!
勉強当初は、抽象メソッド1つのインターフェースなんて定義する事あるのかな、、
とか思ってましたが、あらかじめ用意されている物を僕達開発者がラムダ式で実装するという
使い方をすれば確かに便利だと思いました!僕もまだまだなので、これからもっと理解を深めていきます!
- 投稿日:2020-05-23T05:09:00+09:00
Google ColaboratoryでJavaを使う
はじめに
?(「Jupyter Notebookとかで共有しやすいからpython使って」と言われたけど、Jupyter NotebookでJavaって使えないのかな?)
?:Windows10のWSLでJupyterLab+Javaを使う
?(使えるな?)
?(Jupyter NotebookでJava使えるらしいけど、Google Colaboratoryでpython以外の言語使えないのかな?)
?:多分間違えてるColaboratoryの使い方(Kotlinを試す)
?(Kotlinがいけるなら同じJVM言語のJavaが使えない道理がないな?)
↓
やってみた
※Jupyter用のKernel使うとかしてないので、変則的なやり方になっている気がする(そもそもcolabでjavaを使うこと自体が変則的という話はさておき)。
Colab環境にJavaを入れる
!apt update !apt install openjdk-11-jdkJava 13とか14とか入れても良いのだが、現時点では
wgetなりtarなりで落としてくる必要があるのでちょっと面倒。
とりあえず上記のコマンドだけで11は入ってくれるので今回は11を採用。プロジェクトの作成
その場にプロジェクト作成するとゴチャッとするのでディレクトリを掘ってプロジェクトを作成する。
gradleはデフォルトで4.4.1が入っているのでinitは特にインストール必要なく使える。外部ライブラリとか全く使わないならjavaコマンドだけで完結するのでgradle無しでいける。
!mkdir Java %cd Java !gradle initColab(?)の記法詳しくないので理由は知らないけど
cdは!じゃなく%じゃないと移動した状態を維持してくれないので注意。
一時的に移動して何かコマンド打って戻りたいとかなら!cd hoge && hogehogeのように&&でつなげてもよい。これでプロジェクト自体は作成できたが、gradleのバージョンが古いので設定ファイルを書き換える必要がある。
元のgradle-wrapper.propertiesのdistributionUrlを任意のバージョンに変更するだけ。
今回はとりあえず現時点で最新の6.4.1にしておく。%%writefile gradle/wrapper/gradle-wrapper.properties distributionUrl=https\://services.gradle.org/distributions/gradle-6.4.1-bin.zip distributionBase=GRADLE_USER_HOME distributionPath=wrapper/dists zipStorePath=wrapper/dists zipStoreBase=GRADLE_USER_HOMEbuild.gradleの変更
外部のライブラリもちゃんと使えるというのを示すために
commons.math3を使うので、その辺を踏まえてbuild.gradleを変更する。
この辺順番は割とどうでも良いので、コード先に書いてからbuild.gradleを変更で良い。変更箇所は下記
- dependencies: 外部ライブラリ読み込むなら
- plugins:
id "application"- mainClassName: mainメソッドのあるクラス名
- sourceCompatibility: Javaのバージョン
pluginsとmainClassNameは実行するときにbuildしてjarを実行じゃなく、gradle runで済ませたいので設定。
なんとなく手癖でjunitも書き換えているがcolab上では使わないのでどうでも良い。入力セル:build.gradle%%writefile build.gradle plugins { id 'java' id "application" } group 'sample' sourceCompatibility = 1.11 mainClassName = "sample.Main" repositories { mavenCentral() } dependencies { // The production code uses the SLF4J logging API at compile time compile 'org.slf4j:slf4j-api:1.7.30' testCompile 'org.junit.jupiter:junit-jupiter:5.5.2' // https://mvnrepository.com/artifact/org.apache.commons/commons-math3 compile group: 'org.apache.commons', name: 'commons-math3', version: '3.6.1' }Javaプログラムの作成
ディレクトリを掘る。
!mkdir -p src/main/java/sampleサンプルコードを書く。
なお、%%writefile hogehogeでファイルを作成する形になるのでcolab上で補完は働かない。
なので基本的には手元のIDE上とかでコードを書いてcolab上にコピペするのが楽だし安全(補完なしで書くのはだいぶつらい)。入力セル:Main.java%%writefile src/main/java/sample/Main.java package sample; import org.apache.commons.math3.ml.distance.ManhattanDistance; public class Main{ public static void main(String[] args) { System.out.println("Hello Colab!!"); var d1 = new double[]{1, 1, 1, 1}; var d2 = new double[]{1, 0, 0, 1}; System.out.println(new ManhattanDistance().compute(d1,d2)); } }実際に動かす
!gradle run
やったぜ!!
完
ハマりどころとか
Javaに慣れている人だと当然複数クラス記述する場合にクラスを分けたい。
が、うまくいかなかった。入力セル:Main.java%%writefile src/main/java/sample/Main.java package sample; public class Main{ public static void main(String[] args) { Messenger sample = new Messenger("Hello Colab for Java!!"); sample.hello(); } }入力セル:Messenger.java%%writefile src/main/java/sample/Messenger.Java package sample; class Messenger{ private final String message; public Messenger(String message){ this.message = message; } public void hello(){ System.out.println(message); } }で2ファイルを作成して
gradle runを打つと下記のようにエラーが出る。
この辺、ローカル環境では普通に動くのでcolab特有の問題っぽい。
Javaではpublic classは1ファイルに1つしか記述できないがpublicではないclassならいくらでも記述できるので、以下のように全部1ファイル内にまとめてしまえば動作する。
解決策としてはあまりきれいじゃない気もしつつ、colabで動かすコード量ならこれでも問題ないかな、とも思う。入力セル:Main.java%%writefile src/main/java/sample/Main.java package sample; public class Main{ public static void main(String[] args) { Messenger sample = new Messenger("Hello Colab for Java!!"); sample.hello(); } } class Messenger{ private final String message; public Messenger(String message){ this.message = message; } public void hello(){ System.out.println(message); } }
おわりに
colabでJavaが使えて嬉しい。
とはいえpythonはpyplotで結果を簡単にグラフ表示できるのが強いので、その辺解決できるまでは結局python使うで落ち着きそう。
Javaでもpyplotみたいにcolab上でサクッと結果を可視化できるようになればJava使うの選択肢として無しではないと思うので、そんな感じのことできないか調べたい気持ちがある。というわけで、もっとpython以外の言語もデータサイエンス・機械学習系で使える環境が整ってほしいなぁ……。



- 投稿日:2020-05-23T02:19:38+09:00
マテリアルデザイン導入直後にやること
概要
Androidプロジェクトにマテリアルデザインを導入後にやることを書きます。
Androidプロジェクト作成した後のHello worldに対して行います。ライブラリ導入
マテリアルデザインを導入するために、
build.gradleを以下のように記載します。build.gradle// material design api 'com.google.android.material:material:1.2.0-alpha06'stylesの変更
res/values/styles.xmlを以下のように記載します。<!-- Base application theme. --> <style name="AppTheme" parent="Theme.MaterialComponents.Light.DarkActionBar"> <!-- Customize your theme here. --> <item name="colorPrimary">@color/colorPrimary</item> <item name="colorPrimaryDark">@color/colorPrimaryDark</item> <item name="colorAccent">@color/colorAccent</item> </style>activity_main.xmlの変更
activity_mainを変更して表示を確認します。
<?xml version="1.0" encoding="utf-8"?> <androidx.constraintlayout.widget.ConstraintLayout xmlns:android="http://schemas.android.com/apk/res/android" xmlns:app="http://schemas.android.com/apk/res-auto" xmlns:tools="http://schemas.android.com/tools" android:layout_width="match_parent" android:layout_height="match_parent" tools:context=".MainActivity"> <com.google.android.material.button.MaterialButton android:layout_width="wrap_content" android:layout_height="wrap_content" android:text="確認" app:layout_constraintTop_toTopOf="parent" app:layout_constraintBottom_toBottomOf="parent" app:layout_constraintLeft_toLeftOf="parent" app:layout_constraintRight_toRightOf="parent" /> </androidx.constraintlayout.widget.ConstraintLayout>結果
以下の表示になることを確認
余談
res/values/styles.xmlを初期値の状態のままだと以下のエラーが表示されます。Error inflating class com.google.android.material.button.MaterialButton参考
- Developer tutorials
- Getting started with Material Components for Android
