- 投稿日:2020-05-23T23:00:38+09:00
【学習メモ】AWS(基礎知識 初期設定)
1.導入
【インフラ構築の設計の考え方】
①サーバーの構成
- サーバーのOSをインストールし設定
- 必要なソフトウェアをインストールし、設定②ネットワークの構成
- 構築したサーバーをネットワークに接続する
- ネットワークで使用するIPアドレスの範囲を決める
- サーバーにIPアドレスを割り当てる
- ドメイン名とIPアドレスの対応を割り当てる【インフラとは?】
インフラ:サーバーやネットワーク(=システムやサービスの基盤となる設備)サーバー:CLTに対してサービスを提供するコンピューター
コンピューター:データベースサーバー、Webサーバーなど役割ごとに機能を提供するコンピューターのこと
ネットワーク:複数のコンピューターをつないで、データを送受信できるようにするもの
クラウド(=クラウドコンピューター):ネットワークを利用してコンピューターリソースを利用する形態
Cf.オンプレミス⇆クラウド
2.AWSの初期設定
【AWSの特徴】
①サービスが豊富
- EC2、RDSなど100以上のサービスが存在している
- 高負荷に耐えられる信頼性の高いシステムを少ない手間で運用できる
②リソースが柔軟
- リソースを必要な時に必要な分だけ使える
③従量課金初期設定
【料金アラートの設定】
・請求ダッシュボードで請求アラートを受信するよう設定・CloudWatchで料金アラートを設定する
【IAMで作業用ユーザーを作成】
・ルートユーザーでは、アドレス変更などでのみ使用することCloudTrail
<目的>
いつ誰が何をしたのか記録することで、不正アクセスや不正操作が会った時にチェックするため<設定方法>
CloudeTrailで証跡を作成し、S3にログ保存<サービスの概要>
AWSユーザーの操作を記録するサービス
いくらか料金かかるため導入は後ほど
- 投稿日:2020-05-23T22:18:37+09:00
【AWS】
マサラタウン
Managing Director & President of Amazon Web Services Japan ( 1分58秒 )
Youtube- アマゾンウェブサービス(AWS)とは?(日本語字幕) ( 36分35秒 )
アマゾンウェブサービス(AWS)とは? | AWS (日本語字幕) ( 3分11秒 )
AWS Summit Tokyo 2019 ( 1時間28分33秒 )
AWS Summit Osaka 2019 ( 36分35秒 )
AWS Summit Tokyo 2019 | AWS におけるデータベースの選択指針 ( 39分25秒 )
ここまで
AWS初期ステージの方向け
- 投稿日:2020-05-23T20:54:51+09:00
【Adjust AWS連携】AdjustのローデータをS3経由でRedshiftにエクスポートする
スタートアップで働くRailsエンジニアです。
今回、Adjustローデータをユーザーの行動分析や広告効果の検証に活用しようということで、たまたまAdjust、S3、Redshiftを触る機会があったため作業メモとして残します。Redshift、クエリの実行が早くて助かりますよね。Adjustローデータような大きなデータに対してクエリを実行して分析結果を得たいような場合、かなり良い選択肢ではないかと思います。
個人的にAdjust関連のドキュメントがとっつきにくかったため、アドテク分野そんなによくわからないけど急遽触ってみることになった、など私と同じ境遇の方の参考になれば幸いです。
やりたいこと
Adjustローデータ
↓ csv形式で毎時自動アップロード
S3
↓ csvファイルのデータを1日1回コピー
Redshift(サービス分析基盤)前提
- Redshift側は既存環境を利用(クラスタ、DBは作成済み)
- AdjustはBasicプランを契約(ローデータエクスポート機能が利用できること)
作業内容
- S3バケットを新規作成
- Adjustローデータをcsv形式でS3に自動アップロードするための設定
- Redshiftに新規テーブル作成する
- S3からRedshiftにcsvファイルの中身をコピーする
- 4.の自動化(バッチで1日1回、スクリプトを実行する)
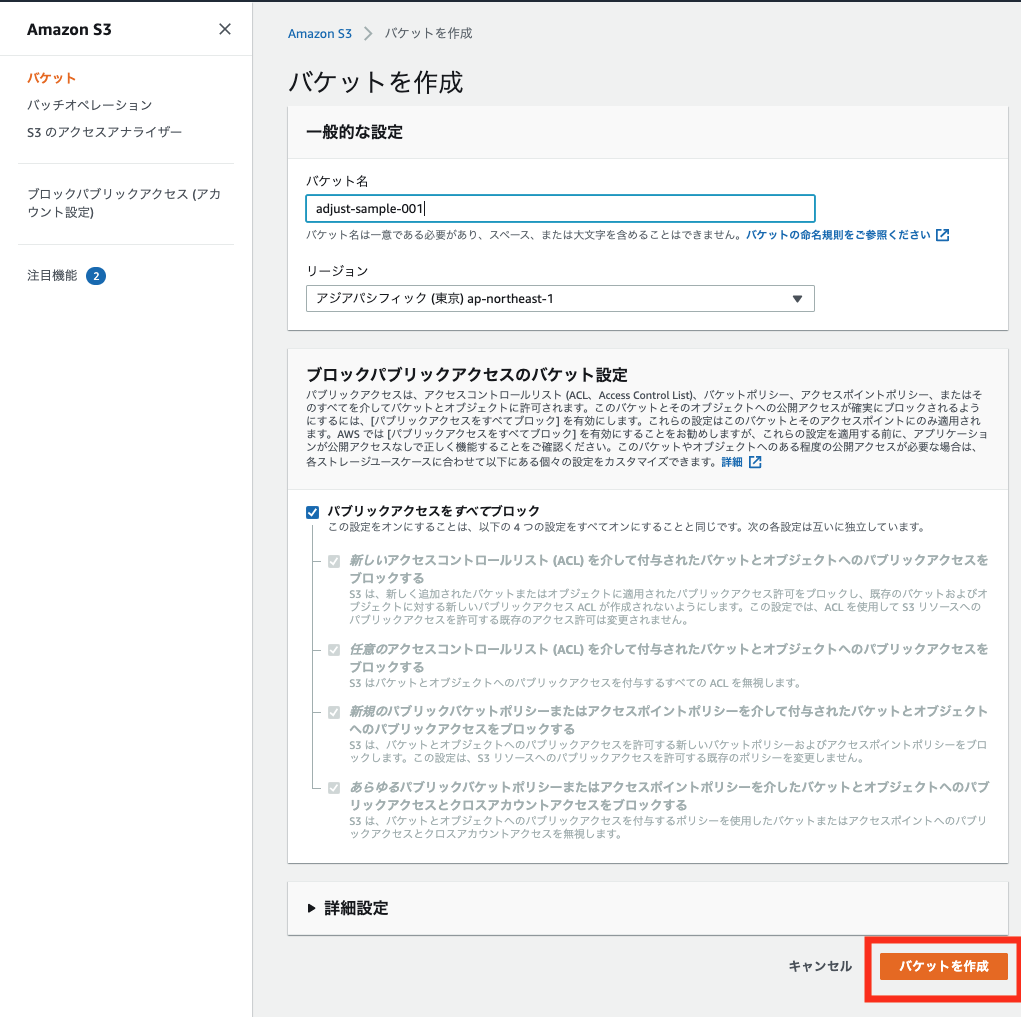
1. S3バケットを新規作成
AWSマネジメントコンソールに接続して、サービスからS3を選択します。
今回のcsvアップロード先のバケットを1つ作成していきます。
バケットを作成をクリックします。
今回はバケット名を adjust-sample-001 とします。
リージョンは東京リージョンを選択します。
ブロックパブリックアクセスの設定や詳細設定はデフォルトで問題ありません。
入力したら「バケットを作成」を実行します。これでバケットの新規作成は完了です。
2. Adjustローデータをcsv形式でS3に自動アップロードするための設定
次にAdjustからS3にローデータをエクスポートするための設定を行います。
2-1. AWS側の設定(IAMユーザーの作成)
まずはAdjustからS3にアクセスする用のIAMユーザーを1つ作成します。
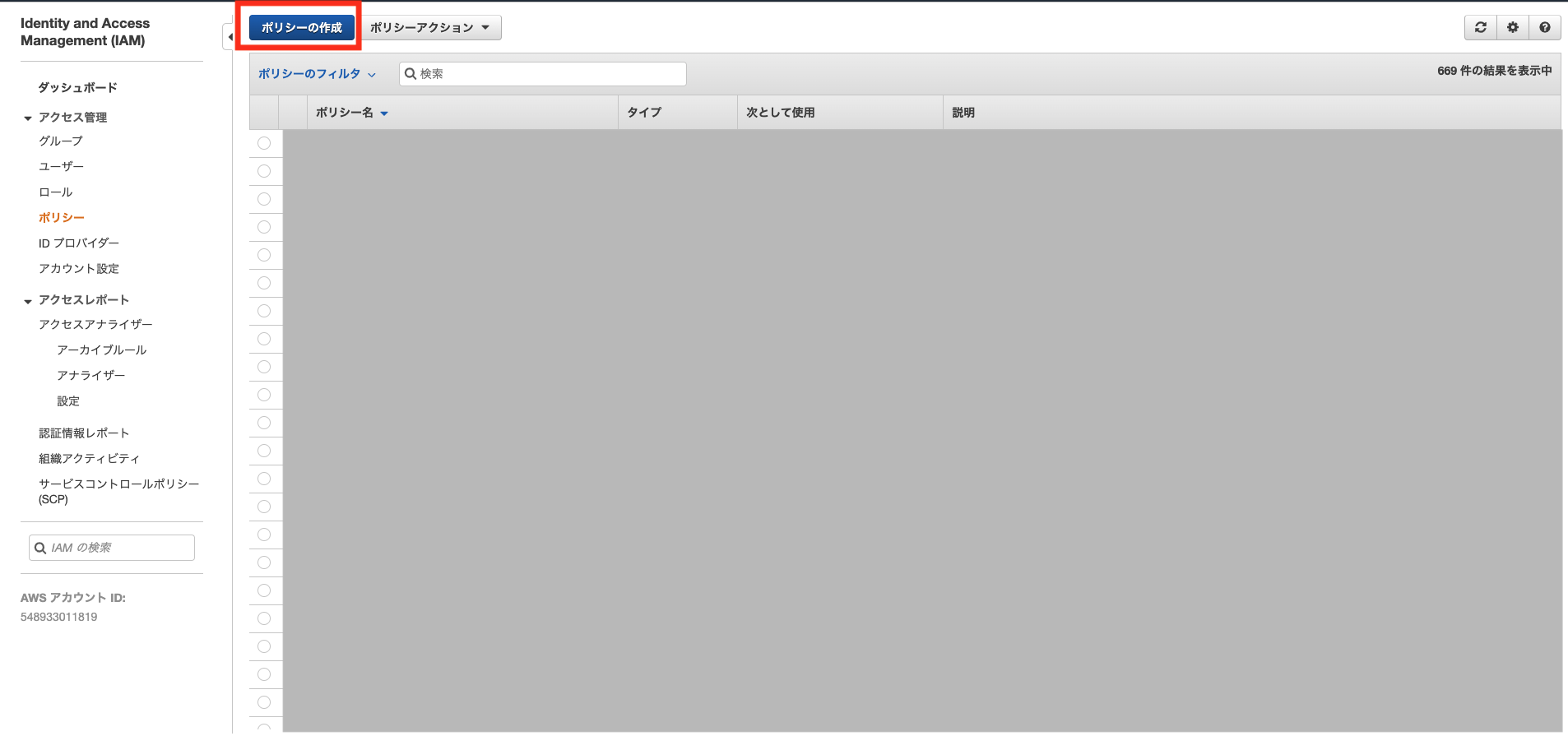
AWSマネジメントコンソール サービスからIAMを選択してIAMのコンソール画面に飛びます。IAMポリシー作成
はじめにS3からのアクセスを許可するポリシーを作成します。
ポリシータブから「ポリシーの作成」をクリックします。ポリシーの作成画面ではJSONタブを選択して、ポリシーを記述します。
下記は作成したS3バケットadjust-sample-001への読み書き権限を付与する記述です。{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": [ "s3:GetBucketLocation", "s3:ListBucket" ], "Resource": [ "arn:aws:s3:::adjust-sample-001" ] }, { "Effect": "Allow", "Action": [ "s3:PutObject" ], "Resource": [ "arn:aws:s3:::adjust-sample-001/*" ] } ] }ポリシーの作成にあたってはこちらの記事を参考にしました。
https://024minion.hatenablog.jp/entry/2018/05/02/233652
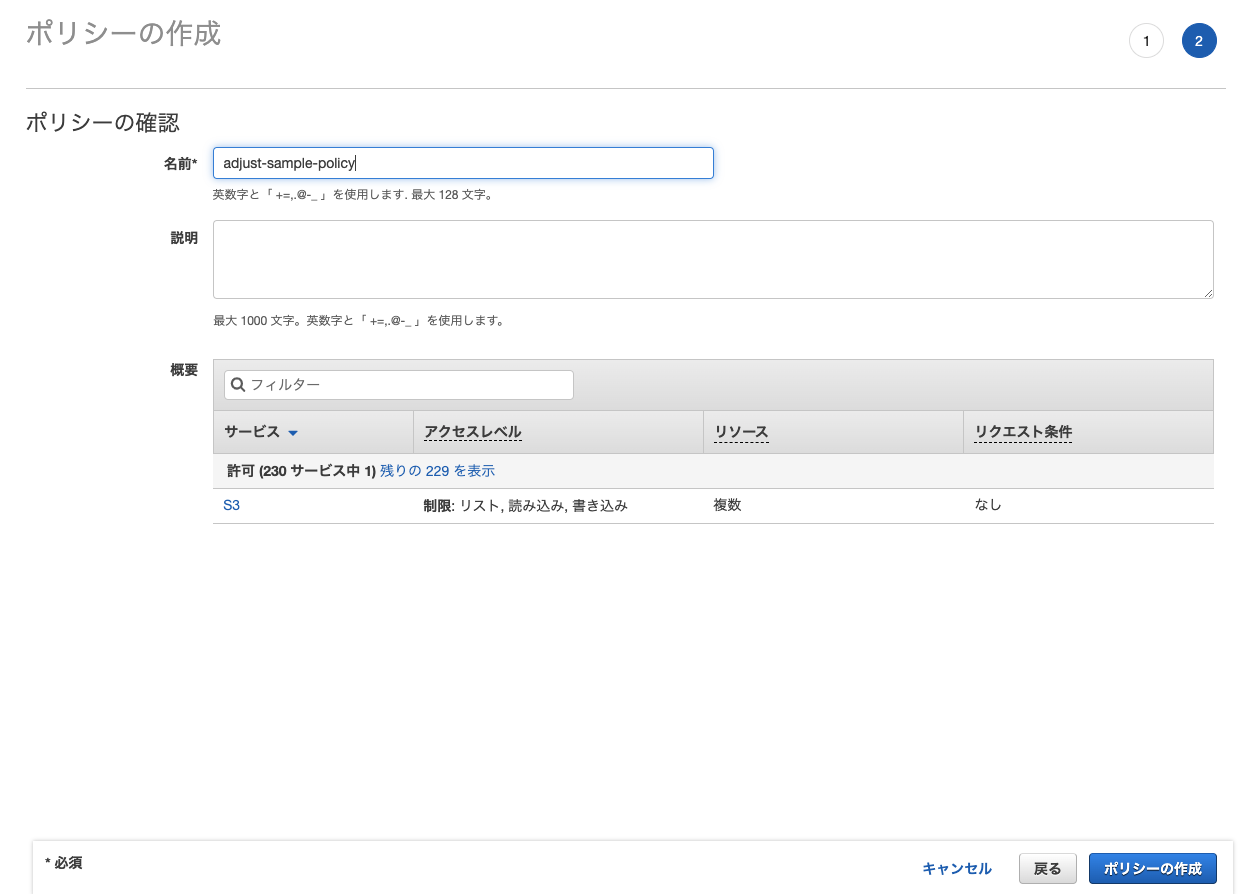
バケット名が作成したものと一致していることを確認して「ポリシーの確認」に進みます。
作成したポリシーに名前をつけます。今回は adjust-sample-policy とします。
入力後、「ポリシーの作成」を実行します。ポリシーが作成されました。
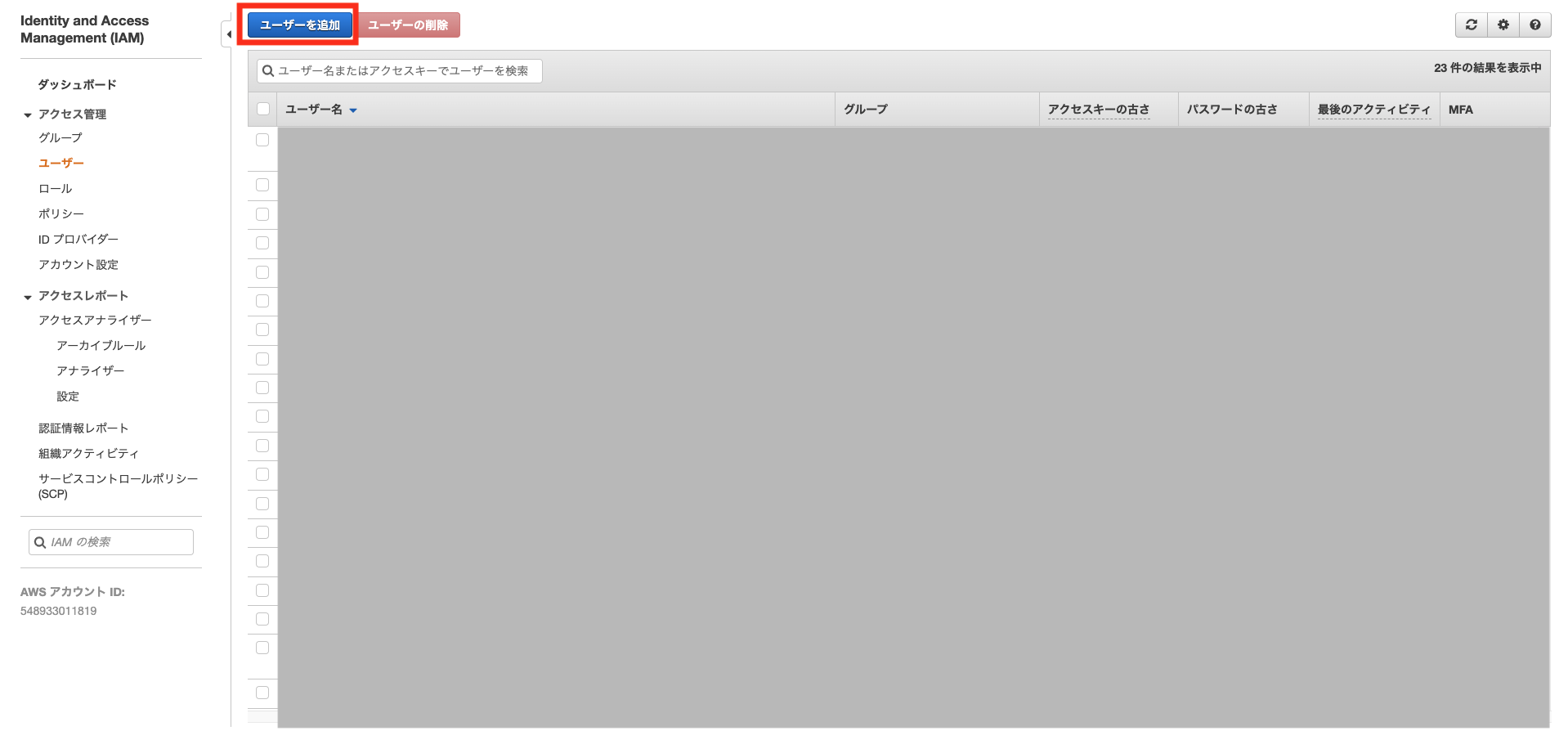
続いて、先程のポリシーを設定するIAMユーザーを作成します。IAMユーザー作成
ユーザータブから「ユーザーを作成」をクリックします。
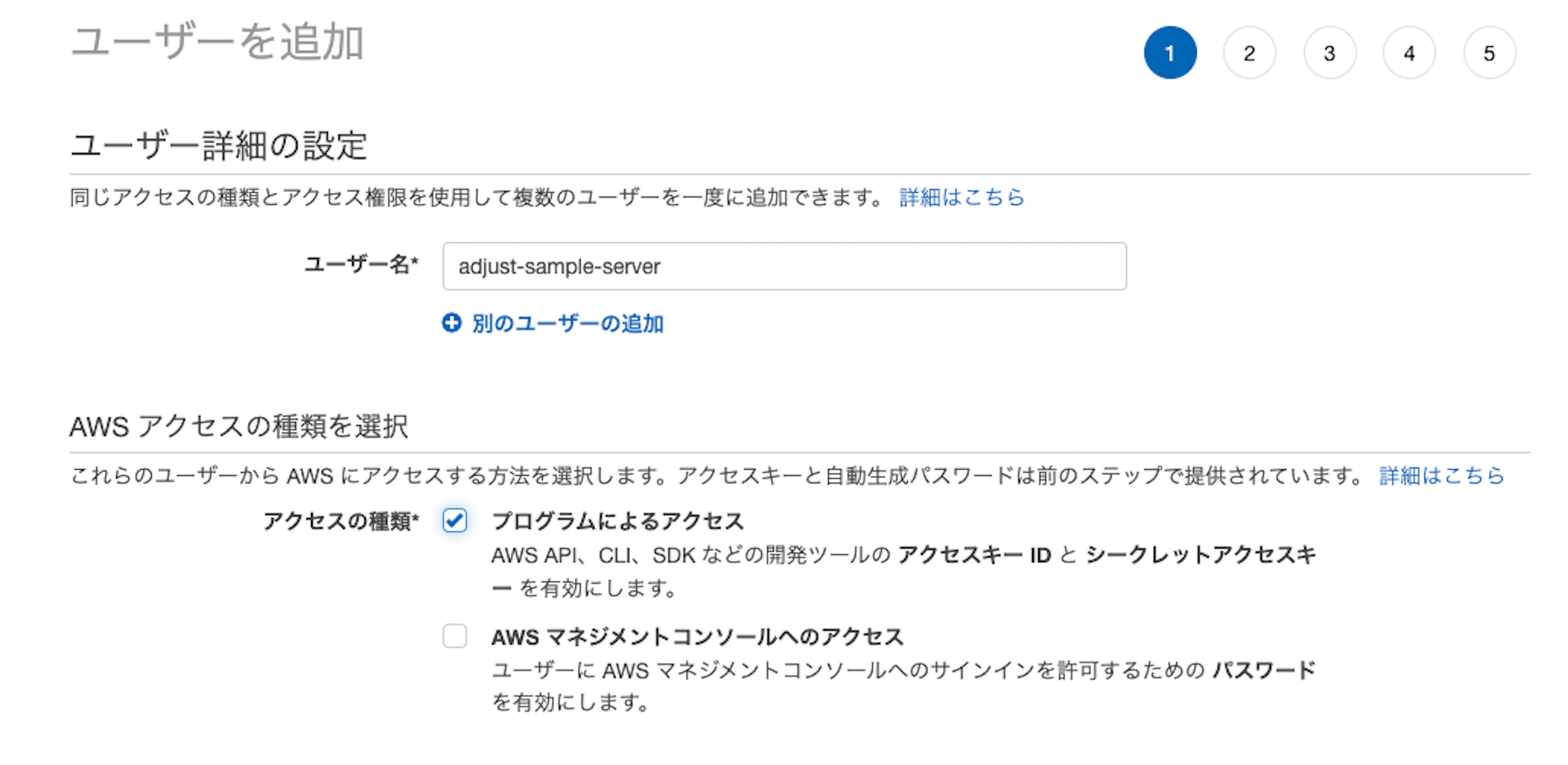
IAMユーザー名を入力します。今回は adjust-sample-server とします。
アクセスの種類は プログラムによるアクセス を選択して、次のステップに進みます。
アクセス許可の設定は 既存のポリシーを直接アタッチ を選択します。
読み込まれたポリシー一覧の中から、先ほど作成したポリシーadjust-sample-policyにチェックを入れて、次のステップに進みます。
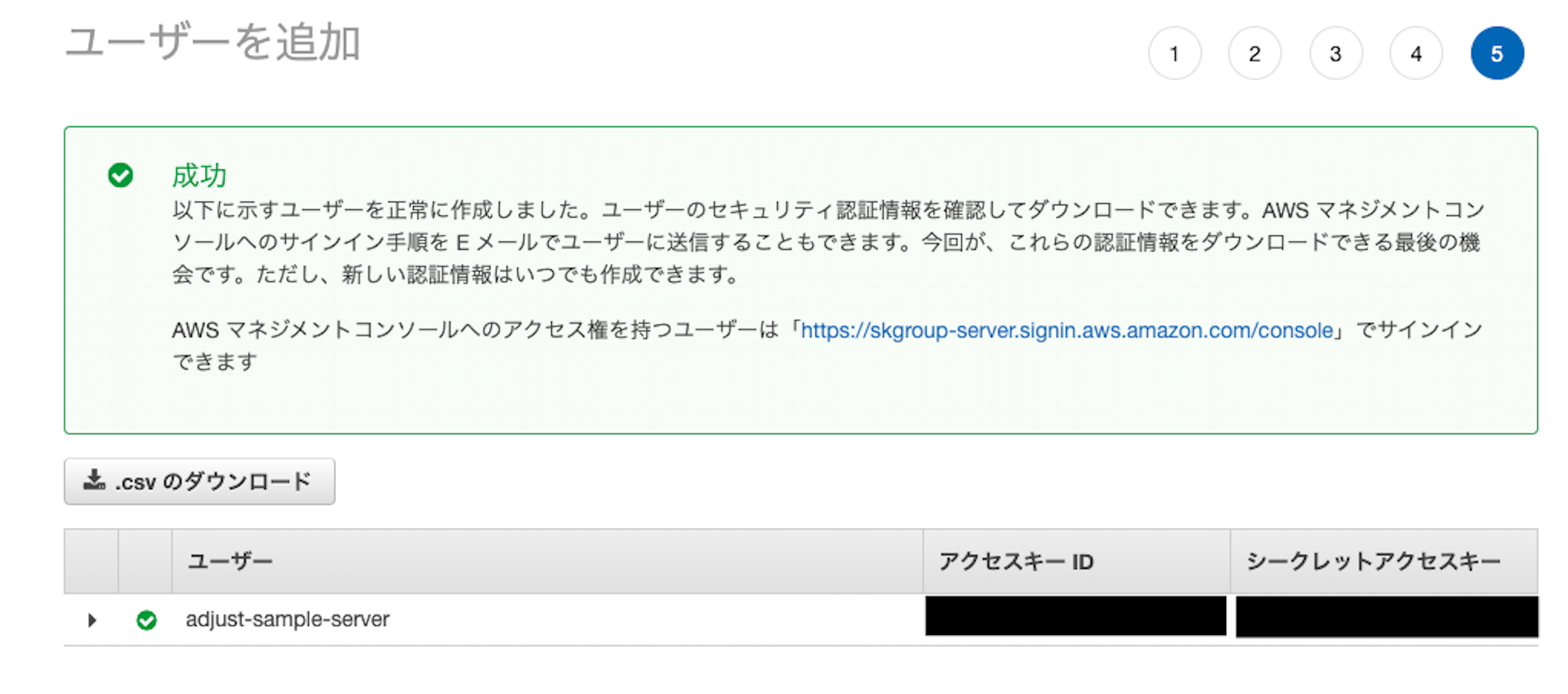
(今回、タグの追加は今回は行いませんのでさらに次のステップへ進みます)これまで作成してきたIAMユーザーの確認画面が表示されますので、「ユーザーの作成」を実行します。
これでS3バケットにプロブラム(今回はAdjsut)から接続するためのIAMユーザーが作成できました。
この画面で表示されているIAMユーザーのアクセスキーIDとシークレットアクセスキーはAdjust側の設定で必要となるため控えておく必要があります。
※ もし控え忘れてしまった場合はIAMコンソール > ユーザーから作成したIAMユーザーadjust-sample-serverを選択します。認証情報タブから「アクセスキーの作成」を実行することで新しいキーペアを作成することができます。2-2. Adjust側の設定
Adjust管理画面 ローデータエクスポート設定
次に、Adjust管理画面からアプリ>その他の設定>ローデータエクスポートと進みます。
csvアップロードを選択します。
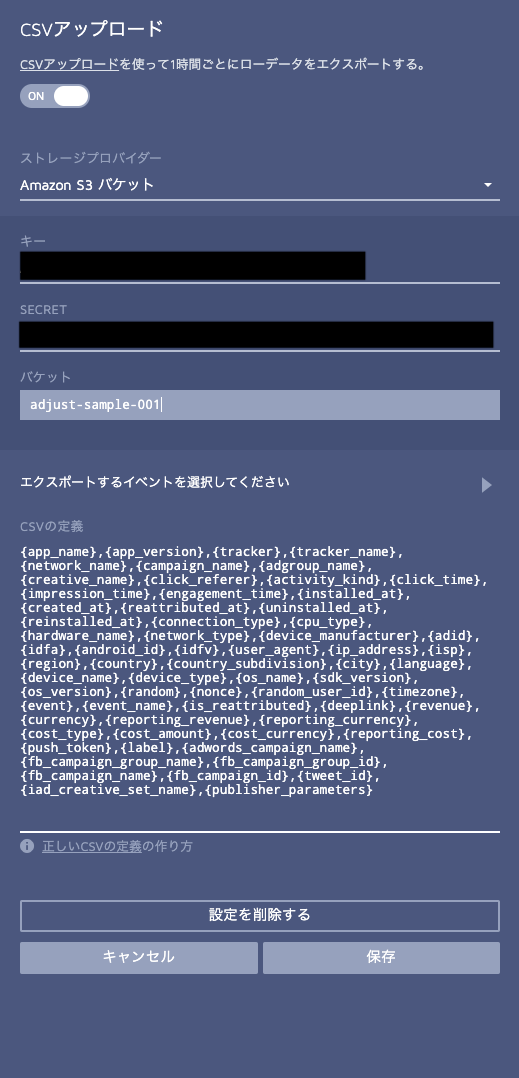
アップロード先の設定画面が表示されます。
「ストレージプロバイダー」は Amazon S3 バケット を選択します。
「キー」、「SECRET」に 先ほど作成したIAMユーザーのアクセスキーID 、シークレットアクセスキー を入力します。
「バケット」に今回作成したアップロード先のバケット名を入力します。
「エクスポートするイベント」を選択して、保存を実行します。これでAdjust側の設定は完了です。
たったこれだけの設定でAdjustからS3への自動アップロードが行われるようになります。スゴイ。
毎時0分にAdjustからローデータのcsvがS3のバケットにアップロードされます。S3にアップロードされたcsvファイル一覧
こんな感じで、gzip形式で圧縮されたcsvファイルが定時アップロードされます。お次はこのcsvファイルをRedshiftにコピーして、クエリで扱えるようにしていきます。
3. Redshiftに新規テーブル作成する
Redshiftにcsvをインポートするためのテーブルを新規作成します。
私はDBeaverというSQLクライアントツールをつかってRedshiftに接続して作業しました。
最近、Redshift側にクエリエディタというAWSコンソールから直接クエリを実行できる機能が追加されたようなので、クライアントツールをインストールしていないような場合はそちらを使っても良いかもしれません。DBeaverからテーブル作成のためのコマンドを実行
create table コマンドを実行します。
ローデータに対応するカラムを用意します。
データ型は適当ですので調整する必要がありそうです。create TABLE *table_name* ( app_name VARCHAR , app_version VARCHAR , tracker VARCHAR , tracker_name VARCHAR(512) , network_name VARCHAR , campaign_name VARCHAR , adgroup_name VARCHAR , creative_name VARCHAR , click_referer VARCHAR(4096) , activity_kind VARCHAR , click_time BIGINT , impression_time BIGINT , engagement_time BIGINT , installed_at BIGINT , created_at BIGINT , reattributed_at BIGINT , uninstalled_at BIGINT , reinstalled_at BIGINT , connection_type VARCHAR , cpu_type VARCHAR , hardware_name VARCHAR , network_type VARCHAR , device_manufacturer VARCHAR , adid VARCHAR , idfa VARCHAR , android_id VARCHAR , idfv VARCHAR , user_agent VARCHAR(512) , ip_address VARCHAR , isp VARCHAR , region VARCHAR , country VARCHAR , country_subdivision VARCHAR , city VARCHAR , language VARCHAR , device_name VARCHAR , device_type VARCHAR , os_name VARCHAR , sdk_version VARCHAR , os_version VARCHAR , random BIGINT , nonce VARCHAR , random_user_id VARCHAR , timezone VARCHAR , event VARCHAR , event_name VARCHAR , is_reattributed BOOLEAN , deeplink VARCHAR(4096) , revenue VARCHAR , currency VARCHAR , reporting_revenue VARCHAR , reporting_currency VARCHAR , cost_type VARCHAR , cost_amount FLOAT , cost_currency VARCHAR , reporting_cost FLOAT , push_token VARCHAR(512) , label VARCHAR , adwords_campaign_name VARCHAR , fb_campaign_group_name VARCHAR , fb_campaign_group_id BIGINT , fb_campaign_name VARCHAR(512) , fb_campaign_id BIGINT , tweet_id VARCHAR , iad_creative_set_name VARCHAR , publisher_parameters VARCHAR );これでRedshiftのテーブル作成は完了です。
4. S3からRedshiftにcsvファイルの中身をコピーする
先ほど作成したテーブルにS3のcsvファイルの中身をコピーしてみます。
SQLクライアントツールまたはRedshiftクエリエディタからCOPYコマンドを実行してみます。copy *table_name* FROM 's3://adjust-sample-001/3ilqwusnz62o_2020-05-19' credentials 'aws_iam_role=*Redhsiftに設定済みのS3へアクセスするためのIAMロール(既存設定)*' gzip delimiter ',' csv ignoreheader 1 region 'ap-northeast-1';S3バケット内のファイル指定ですが、前方一致で自動的にワイルドカード指定してくれるので便利です。
1日に24ファイル作られるcsvファイルを、上記の指定でまとめてコピーできます。
また、AdjustからS3にアップロードされるcsvファイルはgzip形式で圧縮されているため、gzipオプションを付ける必要があります。
また、csvファイルの1行目はヘッダ(カラム名)なので、1行目を除いてコピーするためignoreheader 1オプションをつけます。実行してみてエラーがなければ、ローデータをクエリで扱えるようになっているはずです。
RedshiftはPostgreSQLをベースに、少し独自の仕様があるので、詳しくはAWSのドキュメントをご確認ください。
https://docs.aws.amazon.com/ja_jp/redshift/latest/dg/c_redshift-and-postgres-sql.htmlここまでで、AdjustローデータをRedshiftにコピーしてクエリで扱えるようにするという当初の目的は達成しました。
最後に1日1回、自動でこのコマンドが実行されるように簡単なスクリプトを作成します。5. コピーコマンドの自動化
pythonスクリプトファイルを作成
以下のようなpythonスクリプトを用意してcrontabで1日1回実行するように設定しました。
copy_script_from_adjust.py# PostgreSQLへ接続するためにpsycopg2を利用する import psycopg2 from datetime import datetime, timedelta yesterday = (datetime.today() - timedelta(days=1)).strftime('%Y-%m-%d') # ログファイル log_file = '/home/ubuntu/project/project_analytics/copy_log/log_{}'.format(yesterday) def create_log(string): with open(log_file, 'w') as f: f.write(string + '\n') def add_log(string): with open(log_file, 'a') as f: f.write(string + '\n') # Redshift接続情報 hostName = "Redshiftのホスト名" databaseName = "RedshiftのDB名" portNo = "5439" userName = "Redshiftのユーザー名" password = "Redshiftのパスワード" # Connectionオブジェクト作成 conn = psycopg2.connect( host=hostName, database=databaseName, port=portNo, user=userName, password=password ) create_log('psycopg2 connected') # SQL文を実行するためにはConnectionオブジェクトからさらにCursorオブジェクトを作成 cur = conn.cursor() add_log('psycopg2 cursor opened.') # ファイル名が昨日の日付のcsvファイルをまとめて抽出対象とする file = 's3://adjust-sample-001/3ilqwusnz62o_{}'.format(yesterday) # copy文 copy_statement = """ COPY paters_analytics.adjust_raw_data FROM '{}' credentials 'aws_iam_role=*Redhsiftに設定済みのS3へアクセスするためのIAMロール(既存設定)*' gzip delimiter ',' csv ignoreheader 1 region 'ap-northeast-1' """.format(file) add_log(copy_statement) # Cursorオブジェクトのexecute()メソッドでSQL文を実行 add_log('COPY start.') cur.execute(copy_statement) add_log('COPY end.') # 変更をDBに保存 conn.commit() # コネクションのクローズ cur.close() add_log('psycopg2 cursor closed') conn.close() add_log('psycopg2 connection closed.')crontabで1日1回バッチを実行するように設定
cron.confファイルに毎日10:00にスクリプト実行するように設定します。
cron.conf0 10 * * * python3 /home/ubuntu/project/project_analytics/copy_script_from_adjust.pycrontabで設定ファイルを読み込んで、cronを設定します。
$ crontab cron.confこれで、今回の作業は完了です。お疲れさまでした。




- 投稿日:2020-05-23T20:02:42+09:00
コロナ時代の新常識、オンラインプロフィール交換
概要
QRコードのついたオンライン会議用の背景画像を作れるアプリを作った。
QRコードがついた背景画像のユースケース
ビジネス向けのビデオ会議でLinkedInやFacebook、Eight(sansan)などの自分のビジネス的なプロフィールを連携するQRコードを背景にビデオチャットする。
イメージ
- QRコードはサンプルとして適当に作ったプロフィールページにリンクさせていますが、LinkedIn等のプロフィールシェア用のリンクを使うと使い勝手が良さそうです。
- 背景画像は以下のツイートから拝借しました。
From the Scare Floor to Gusteau’s Kitchen, use these backgrounds to destine your next video call for fun! pic.twitter.com/CAkNEML0vJ
— Pixar (@Pixar) April 2, 2020使うメリット
ビデオ会議中に名刺交換の感覚で繋がれる。
モチベーション
コロナ時代に頑張る人たちのために何かしらの貢献ができないかと考えていて、ふと思いついたアイディアを形にしました。
嘘です。
サイト内に自分の連絡先を貼って、女性からの連絡を待っています。
下心です。コード
技術系のブログなので、コード貼っておきます。
小一時間で調べたどこかのコピペなので一切参考にならないと思います。import com.google.zxing.BarcodeFormat import com.google.zxing.client.j2se.MatrixToImageWriter import com.google.zxing.qrcode.QRCodeWriter import org.springframework.stereotype.Controller import org.springframework.ui.Model import org.springframework.web.bind.annotation.GetMapping import org.springframework.web.bind.annotation.PostMapping import org.springframework.web.bind.annotation.RequestParam import org.springframework.web.multipart.MultipartFile import java.io.ByteArrayInputStream import java.io.ByteArrayOutputStream import java.io.File import java.lang.Exception import java.util.* import javax.imageio.ImageIO ----------------------- 関係ないところ省略 ----------------------- @PostMapping("/generate") fun generate(@RequestParam("image") image: MultipartFile, @RequestParam("content") content: String, @RequestParam("xPosition") xPosition: Int?, @RequestParam("yPosition") yPosition: Int?, @RequestParam("qrSize") qrSize: Int?, model: Model): String { val bu1 = ImageIO.read(image.inputStream) val width = bu1.width val height = bu1.height val qrByteArray = QrcodeGenerator.generate(content, qrSize ?: width / 5 ) val graphics1 = bu1.graphics val x = xPosition ?: width / 20 val y = yPosition ?: height / 20 try { val bais = ByteArrayInputStream(qrByteArray) val bu2 = ImageIO.read(bais) graphics1.drawImage(bu2, x, y, null) val now: String = System.currentTimeMillis().toString() ImageIO.write(bu1, "png", File("tmp/${now}.png")) val tmpFile = File("tmp/${now}.png") val ba64 = Base64.getEncoder().encodeToString(tmpFile.readBytes()) model.addAttribute("file", "data:image/png;base64, $ba64") tmpFile.delete() } catch(e: Exception) { println(e) throw Exception() } finally { graphics1.dispose() } return "generate" } object QrcodeGenerator { fun generate(content: String, width: Int): ByteArray { val qrCodeBit = QRCodeWriter().encode(content, BarcodeFormat.QR_CODE, width, width) val output = ByteArrayOutputStream() MatrixToImageWriter.writeToStream(qrCodeBit, "png", output) return output.toByteArray() } }学び
aws ec2の無料枠で動かしています。
別件でドメイン持っていたので、使い回しました。
acmで証明書を効かせるためにec2一つでelbをたてて動かしてみたのですが、
ブラウザからリクエストしてec2に届くまで時間がかかっていました。(ec2ない方のネットワーにリクエストいっちゃってる?)
elbからcloudfrontにかえるとリクエストが早くなりました。女の子の反応はよくなかった。

- 投稿日:2020-05-23T19:09:37+09:00
Docker / ECR / ECS コンテナ入門まとめ③
前編
参考文献
- AWS CLI で Amazon ECR に docker イメージを push する
- Amazon EC2 Container Service (ECS)を試してみた
- CircleCI+ECS+ECR環境でDockerコンテナのCD(継続的デプロイ)環境を構築する -前編-
- CircleCI+ECS+ECR環境でDockerコンテナのCD(継続的デプロイ)環境を構築する -後編-
前準備
◆ Dockerインストール
$ sudo yum update -y $ sudo amazon-linux-extras install docker◆ Docker起動
$ sudo systemctl start docker◆ dockerグループにユーザ追加
$ sudo usermod -a -G docker ec2-user◆ dockerアクセス確認
$ docker infoECR編
◆ ECRログイン
$ aws ecr get-login --no-include-email ※出力される長いコマンドでログイン◆ ECRリポジトリ作成
$ aws ecr create-repository --repository-name sample ※リポジトリ名◆ 環境変数セット
$ export registryId=[出力されたレジストリId] $ export region=ap-northeast-1 ※リージョン名 $ export imagename=sample $ export tag=ver1◆ Dockerイメージ作成
$ docker build -t ${imagename}:${tag} .◆ Dockerイメージtag付け
$ docker tag ${imagename}:${tag} ${registryId}.dkr.ecr.${region}.amazonaws.com/${imagename}:${tag}◆ Dockerイメージプッシュ
$ docker push ${registryId}.dkr.ecr.${region}.amazonaws.com/${imagename}:${tag}ECS編
◆ IAMロールの作成
- 「AmazonEC2ContainerServiceforEC2Role」ポリシーの付与
ecs-role{ "Version": "2020-5-23", "Statement": [ { "Action": "ecs:*", "Effect": "Allow", "Resource": "*" } ] }◆ クラスター作成コマンド
$ export region=us-east-1 $ export cluster=sample-cluster $ aws ecs create-cluster --region ${region} --cluster-name ${cluster} $ aws ecs list-clusters --region ${region} --output json◆ ec2作成
- AMI選択:ami-34ddbe5c
- IAMロール:上記のecs-roleを使用
- ユーザデータ:下記入力
userdata#!/bin/bash echo ECS_CLUSTER=[クラスター名] >> /etc/ecs/ecs.config◆ ECS/EC2紐付け確認
$ aws ecs list-container-instances --cluster ${cluster} --output json --region ${region} $ ssh ec2-user@XX.XX.XX.XX ※ec2ログイン $ sudo docker psECSタスク登録・実行
$ vim sample.jsonsample.json[ { "environment": [], "name": "sample", "image": "sample-image", "cpu": 10, "portMappings": [], "entryPoint": [ "/bin/sh" ], "memory": 10, "command": [ "sample", "360" ], "essential": true } ]■ タスク登録コマンド
$ aws ecs register-task-definition --family sample --container-definitions file://sample.json --region ${region} --output json■ タスク確認
$ aws ecs list-task-definitions --region ${region}■ タスク実行コマンド
$ aws ecs run-task --cluster ${cluster} --task-definition sample:1 --count 1 --region ${region} --output json■ タスク実行確認
$ sudo docker ps
- 投稿日:2020-05-23T17:49:56+09:00
QuickSight の使い方 - ユーザの招待とデータ共有編
はじめに
今回は、QuickSight を用いたユーザの招待と、データの共有方法について簡単に紹介したいと思います。
■やりたいこと
・閲覧権限のみを付与した ユーザを作成したい(ユーザは、IAMユーザと紐付けたい)
・QuickSight 上の可視化してある特定の分析データを、閲覧権限を持ったユーザと共有したいユーザの招待方法
ユーザを招待する側の設定
QuickSight の閲覧ユーザの招待方法について、紹介したいと思います。
手順は以下です。
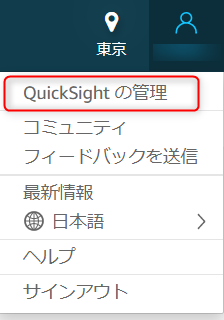
①QuickSight の画面右上のアイコンをクリックし、「QuickSIght の管理」を選択します。
②画面左の「ユーザを管理」を選択したら、「ユーザを招待」を選択
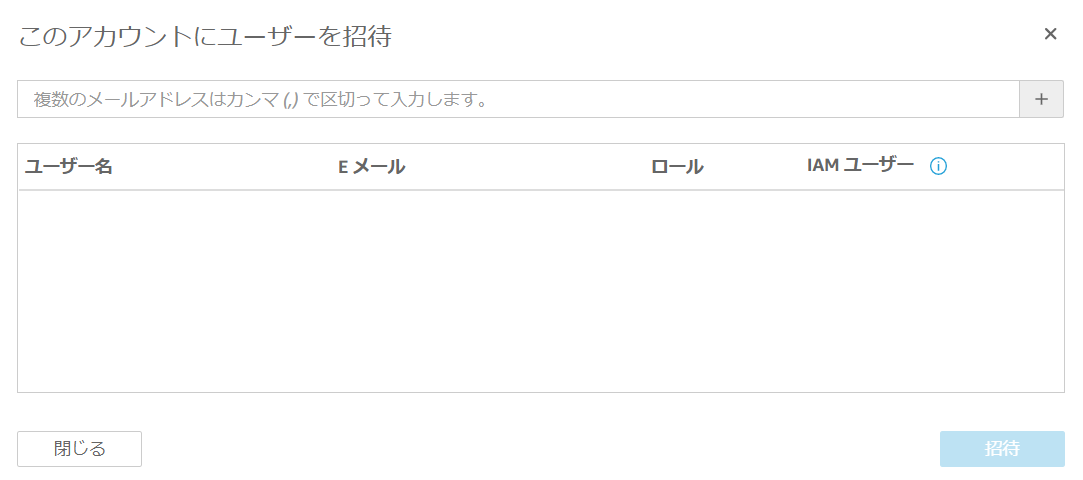
③「ユーザを招待」を選択すると、ユーザ登録となりますので、下記の情報を入力します。■情報
- ユーザ名:登録する IAM ユーザ名
- Eメール:ここ宛に QucikSight 登録のメールが届く
- ロール;閲覧・作成・管理のどこまでのロールを許可するかを選択
- IAMユーザ:作成するユーザが、既存のIAMユーザと紐付ける場合は「はい」を選択
招待された側の設定
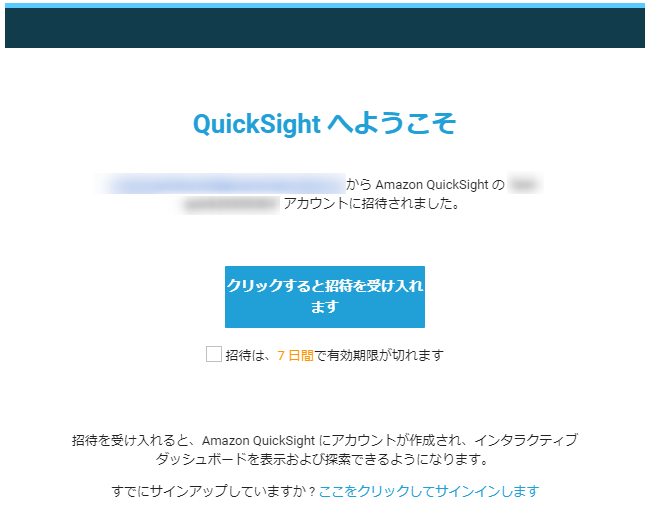
ここからは、QuickSight アカウントに招待された側の手順になります。
①上記で設定したメールアドレス宛に QuickSight からメールが届いているので確認し、クリックします
②下記の情報を入力し、無事にサインインできたら完了です。■入力情報
・QuickSight のアカウント名(これは管理者に確認)
・IAM ユーザ名
・IAM ユーザのログインパスワードデータ共有
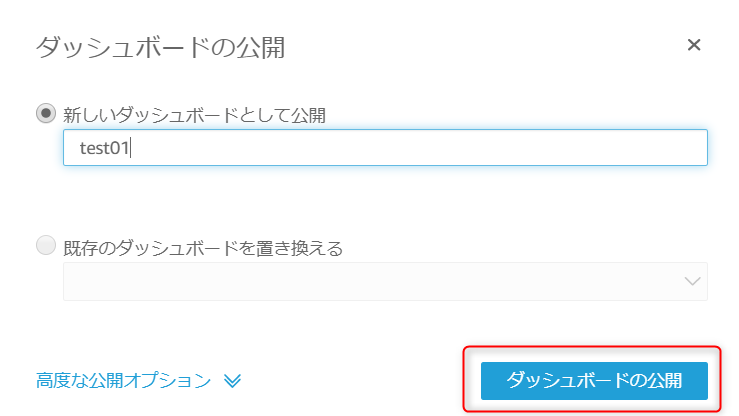
ダッシュボードの公開
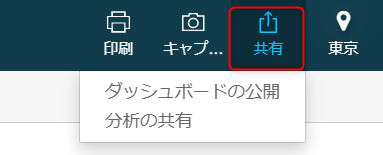
次に、閲覧権限を有した ユーザと QuickSight 上で可視化したデータを共有する手順を紹介します。
①共有したいデータのダッシュボードを開いた状態で、右上の「共有」を選択
②「ダッシュボードの公開」を選択
(※「分析の共有」は「閲覧」権限のユーザとは共有できません。)
③公開するダッシュボードの名前を決めたら、「ダッシュボードの公開」を選択以上の手順で、閲覧権限ユーザは、公開されたダッシュボードを見ることが可能となります。
データの予測などを実施する場合は、「作成」や「管理者」権限を持ったユーザを招待し、
「分析の共有」を選択する必要があります。おわりに
QuickSight にユーザの招待方法と、データ共有方法は以上となります。
上記の設定を利用することで、複数のユーザと可視化したデータを共有することができるようになります。
特定のデータのみを複数のユーザと共有したい場合など、是非、使用して下さい。


- 投稿日:2020-05-23T16:22:41+09:00
Datadog enhanced AWS Lambda metrics を試してみる
enhanced AWS Lambda metrics とは
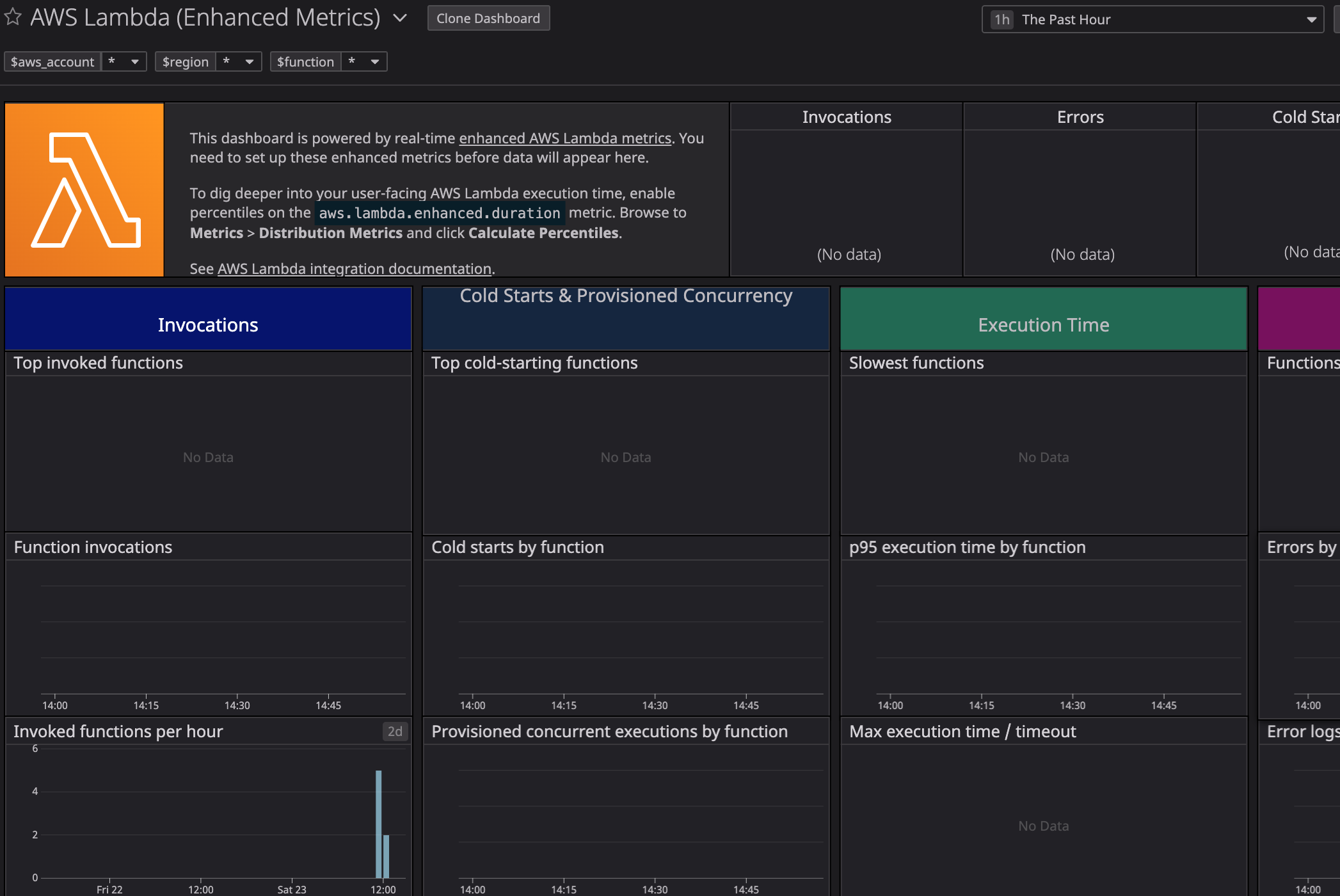
DatadogにてAWSを連携すると出てくるデフォルトダッシュボードの中に存在する謎なやつ(図の下側)
とりあえず開いてみても情報なし、下側のInvocationsの値は入ってるのに、上側のInvocationsには値が入ってない

参照元メトリクスを見てみると別物参照してますね
上側:aws.lambda.enhanced.invocations
下側:aws.lambda.invocationsenhanced はどこから取得するのか
Lambda の enhanced 情報の取得の仕方
ダッシュボードのトップに拡張Lambdaメトリクスを設定してとかかれてるので、設定方法がかかれたページへ移動します。
有効方法がかかれてますね(英語わからん)
英語わからんなりに読み解くと
1. Datadog Forwarder を設定する
2. メトリクスを取得したいLambdaのLambda LayerにDatadog Lambda Layerを入れる
3. LambdaのタグをDatadogのメトリクスに流用したければ Datadog Forwarder 側にDdFetchLambdaTags:trueの変数を付与する
4. サンプルコードのようにDatadogのLibraryでラップする(pythonだとデコレータ付与するだけで良さそう)
5. ブラウザでさっきのダッシュボードを確認するなのかな試してみます。
Datadog Forwarder を設定する
Datadog Forwarder を見に行くと、CloudFormationのテンプレート があったので利用します。
テンプレートには下記を設定(設定したもの以外はデフォルト値)
DdFetchLambdaTags:trueDdApiKey:自身のDatadogのAPIキー
IAMとかのリソース作ってよいか聞かれるので、チェックしてCreate StackDatadog Layerを使ったサンプルコード作成
何でも良いかと思い、Python3のhello-worldのBlueprintを利用します。
function名だけ指定してCreate(今回はtestって名前)
Datadog Lambda Layer を作成したコードに追加
[Datadog Lambda Layer]https://docs.datadoghq.com/integrations/amazon_lambda/?tab=awsconsole#installing-and-using-the-datadog-lambda-layer
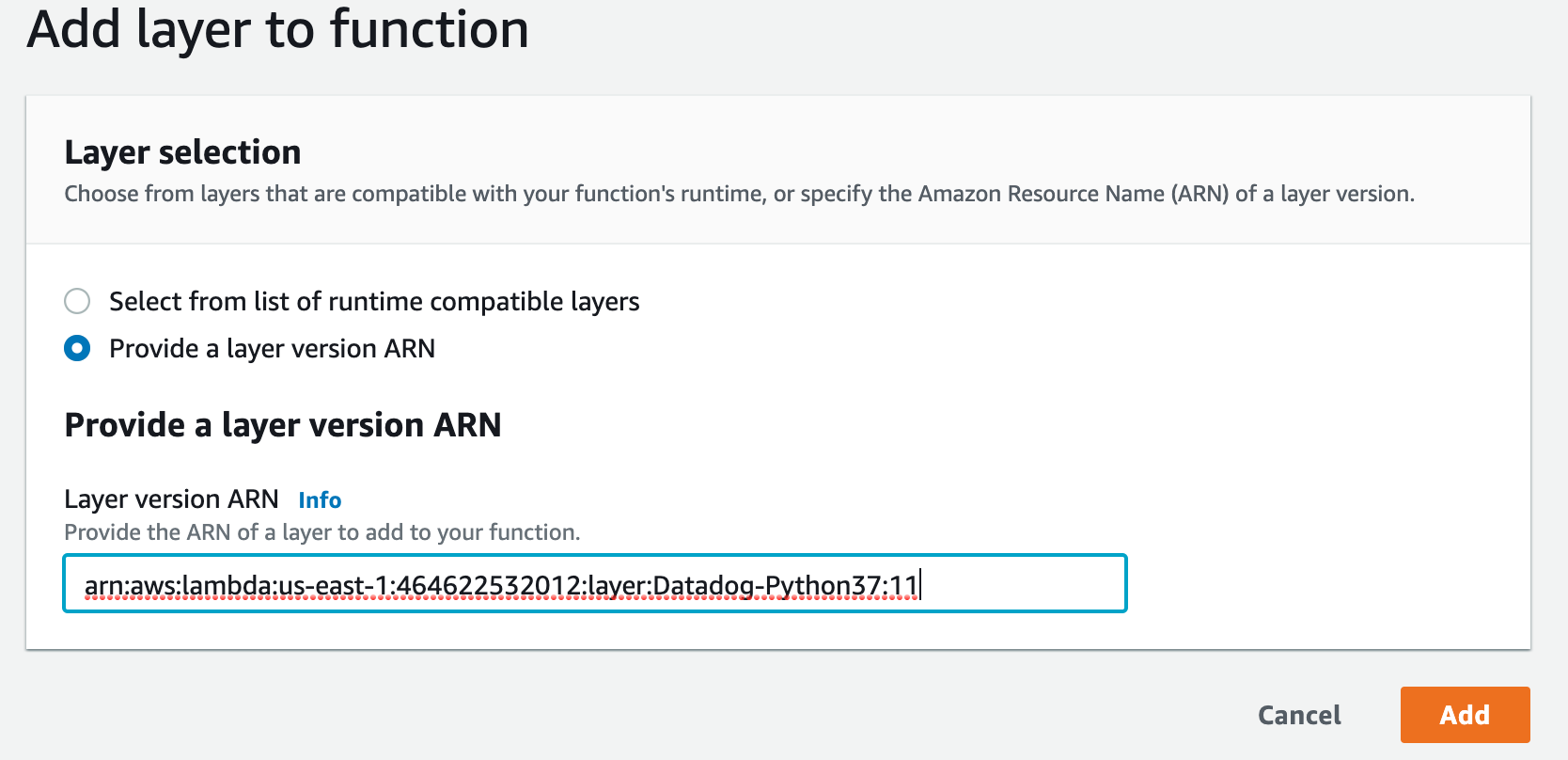
現時点のpython3.7用はarn:aws:lambda:us-east-1:464622532012:layer:Datadog-Python37:11これを使っていきます
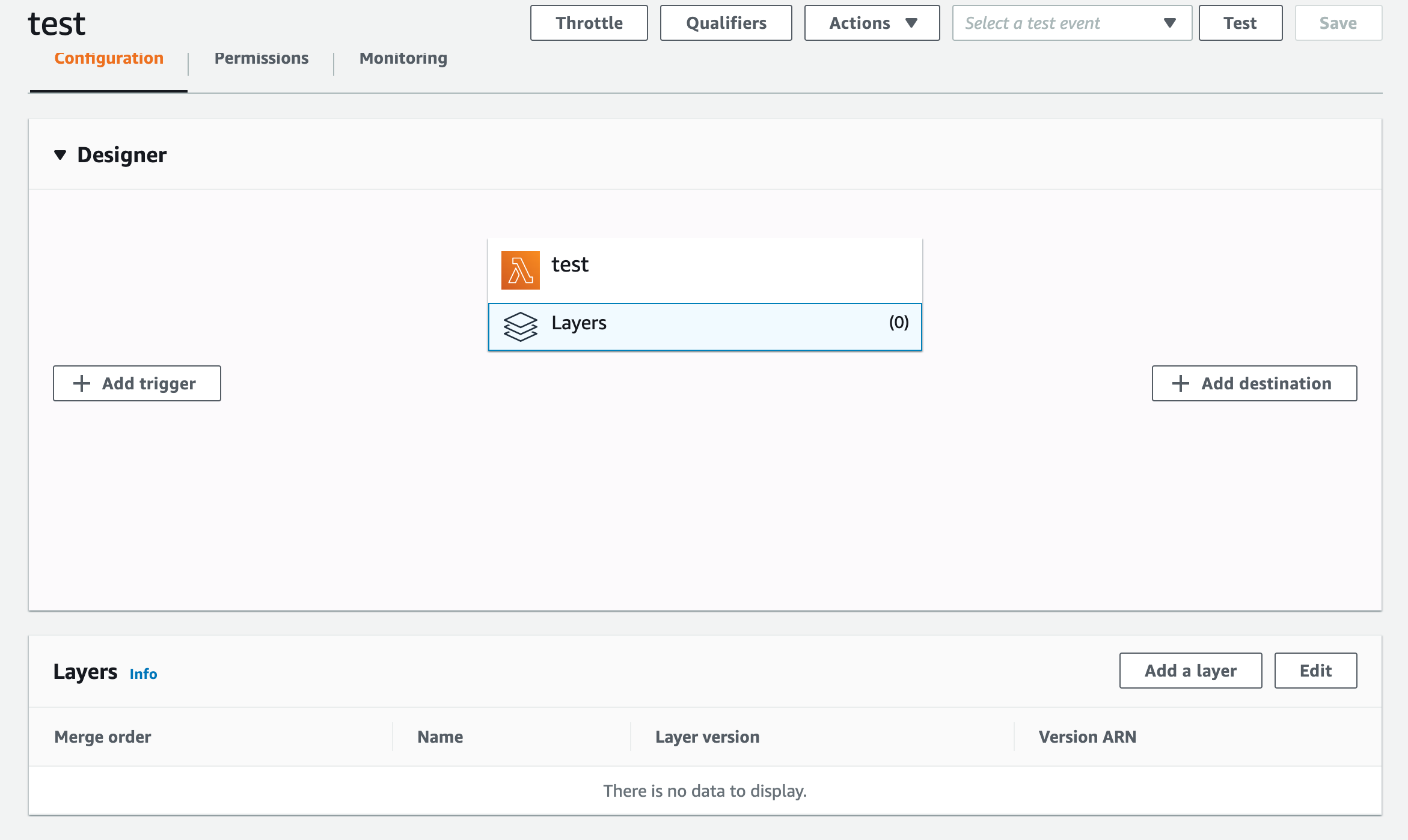
サンプルのLambdaのLayersを選択するとAdd a Layerがあるのでクリック
先程のDatadog Layerを入力する
追加されました。
Datadog ライブラリでサンプルコードをラップ
コードにこの2行を追加
from datadog_lambda.wrapper import datadog_lambda_wrapper
@datadog_lambda_wrapper全体像
lambda_function.pyimport json from datadog_lambda.wrapper import datadog_lambda_wrapper print('Loading function') @datadog_lambda_wrapper def lambda_handler(event, context): #print("Received event: " + json.dumps(event, indent=2)) print("value1 = " + event['key1']) print("value2 = " + event['key2']) print("value3 = " + event['key3']) return event['key1'] # Echo back the first key value #raise Exception('Something went wrong')サンプルコードに環境変数を追加
前段の状態でテスト実行してもエラーになるので下記環境変数を追加
DD_API_KEY:自分のDatadogのAPIキー一応これだけで動くようになるのですが、結果これだけではやりたいことに足らなかったので以下の環境変数も追加します。
DD_ENHANCED_METRICS:true
- Enhanced メトリクスを有効化
DD_FLUSH_TO_LOG:true
- 設定されていないと有効化されたEnhanced メトリクスがCloudWatch Logsにながれない
CloudWatch LogsにEnhancedメトリクス用のデータが流れる
サンプルコードの設定が終わりテスト実行すると、以下のようなログが流れるようになる。
{
"m": "aws.lambda.enhanced.invocations",
"v": 1,
"e": 1590216872,
"t": [
"region:us-east-1",
"account_id:xxxxxxxx",
"functionname:test",
"cold_start:true",
"memorysize:128",
"runtime:python3.7",
"dd_lambda_layer:datadog-python37_0.11.0"
]
}
Datadog Forwarder に サンプルコードの Logs を紐付ける
とりあえず、前段の状態でテスト実行しても、
aws.lambda.invocationsの値は増えるが
aws.lambda.enhanced.invocationsに変化は見られない。Datadog ForwarderのReadmeを見ると
Set up triggers to the installed Forwarder either automatically or manually.
って書いてあるのでサンプルコードのLogsを紐付ける
動作確認
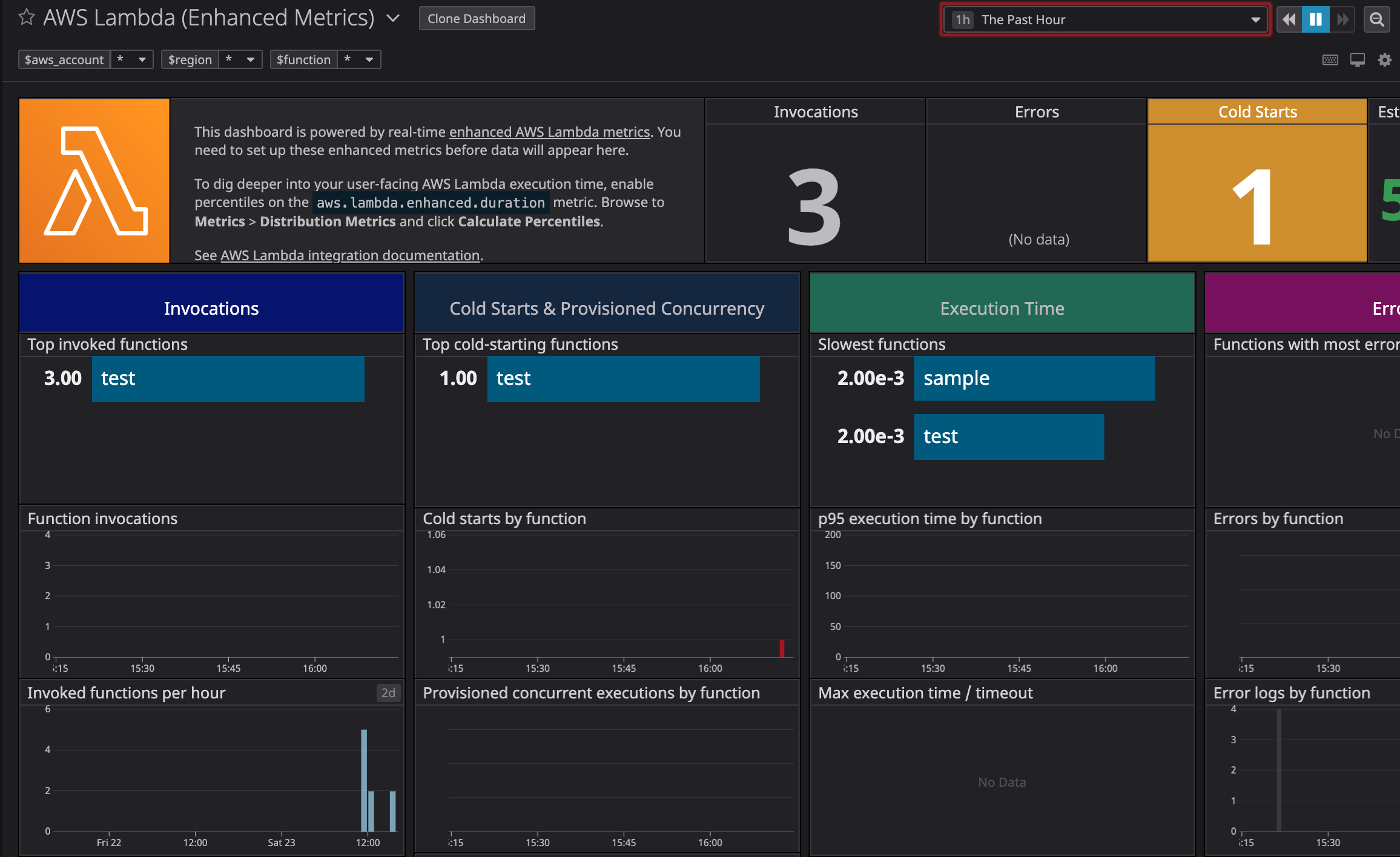
サンプルコード(test)を試しに3回連続で実行してみた
Invocations等に値が入るようになった、3連続のためか、
Invocationsは3でCold Startsが1となった。
メモリの消費状況等も見れるようだ
まとめ
Datadog の enhanced AWS Lambda metrics を利用できるようにしてみました。
通常のLambdaのダッシュボードとは異なりCold_startの状況や、メモリの消費状況などが確認できるのでLambdaのスペックなどをチューニングする際などにやくだちそうです。



- 投稿日:2020-05-23T13:08:42+09:00
【AWS】Lambda+Amazon SESでメールを送信する
前回の記事でAmazon SNSを利用してSMSを送信するlambdaを書きました。
今回はメールを送信するためにAmazon SESを利用していきます。やりたいこと
lambdaからのキックでメールを送信したいと思います。
ただし、宛先のメールアドレスはlambda内で指定したいと思います。Amazon SMSでもメールの送信は可能ですが、予め作成したサブスクリプションで認証済みのメールアドレス宛にしか送信できません。
そこで今回はAmazon SESを使用します。Amazon SESって?
システムエンジニアリングサービス…ではなく
Amazon Simple Email Serviceです。従量課金制のEメール送信サービスです。
2020年5月現在、東京リージョンではサポートされていません。
エンドユーザーへのマーケティングや、ヘルスチェック系の通知などに利用できます。コードとかより注意しておきたいこと
サンドボックスの解除
Amazon SESで送信元アドレス(ドメイン)を新たに登録すると、最初はサンドボックス環境で動作します。
サンドボックス環境においては送信数の制限があるうえ、
検証済みのメールアドレス宛にしか送信できません(SNSのような状態)。そのため本番で運用するには制限解除を申請する必要があります。
制限解除は送信数の上限引き上げ、という名目ですが、これによりサンドボックス環境の解除がされるので、
検証済み以外のアドレスにも送りたい、という場合でも制限解除を申請します。また、制限解除をする場合には、予めバウンス(送信失敗)や苦情(受信者にスパム登録される)への対策を行っておく必要があります。
バウンス率や苦情率が高いとメール送信ができなくなってしまうので、注意しましょう。登録した送信元アドレス(ドメイン)ごとに、バウンス・苦情の発生時に通知する設定をSES内でできるので、
忘れずにやっておきましょう。構成
Amazon SESに新規アドレス(ドメイン)を登録
Amazon SESコンソールを開きます。
今回はバージニア北部リージョンで利用します。左のメニューからDomainsまたはEmail Addressesを選択し、
新規の送信元アドレス(ドメイン)を登録します。今回はメールアドレスの登録をやっていきます。
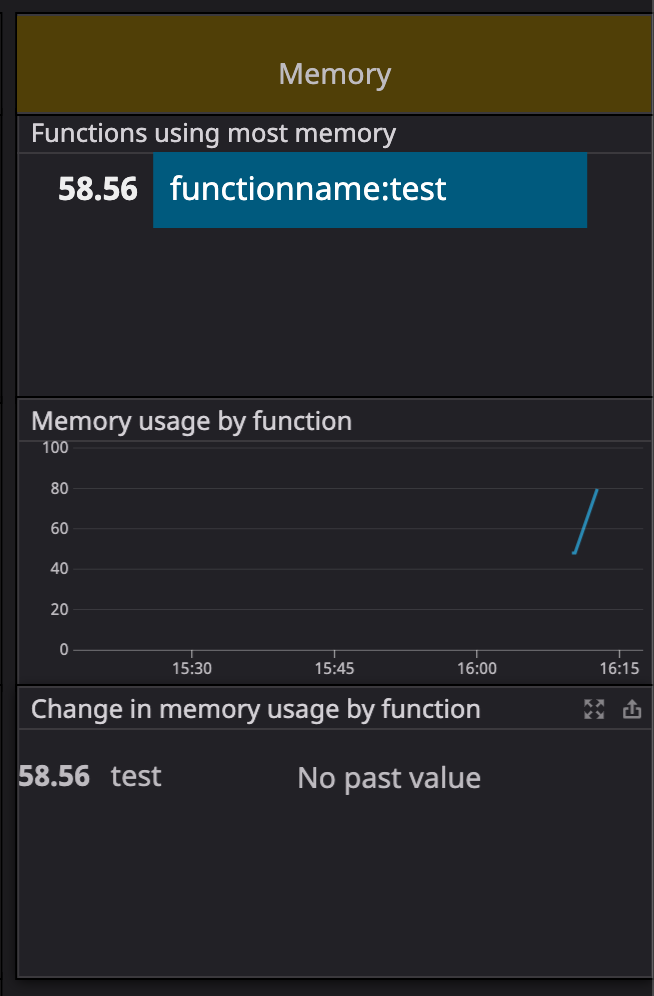
「Verify a new Email Address」を選択します。↓こんな画面です。
「Verify This Email Address」を選択すると、入力したメールアドレス宛に検証メールが届きますので、検証します。
以上です。
「Send a Test Email」からテストメールの送信ができるので一応確認しておきましょう。また、サンドボックス環境の解除については、lambdaからのテストなどが一通り完了してから行いましょう。
最悪テストでバウンス率が高まってメール停止されるかもしれないので。lambda関数
単にSESを呼び出して、指定したアドレスにメールを送信するだけのlambdaです。
ランタイムはNode.js 12.xです。test_SendEmail.jsvar aws = require('aws-sdk'); // バージニア北部リージョンを選択 var ses = new aws.SES({region: 'us-east-1'}); exports.handler = (event, context, callback) => { // メール送信設定 var params = { Destination: { ToAddresses: ['送信先メールアドレス'] }, Message: { Body: { Text: { Data: 'メッセージ' } }, Subject: { Data: '件名' } }, Source: '検証済みの送信元アドレス' }; // メール送信 ses.sendEmail(params, function (err, data) { if (err) { console.log(err); context.fail(err); } console.log(data); context.succeed(data)); }); };以上!

- 投稿日:2020-05-23T08:23:23+09:00
AWS Lambda から Cloud Firestore を使ってみる
FirestoreのデータをAlexaSkillから呼び出したかったのでLambdaに接続してみました。
そのときの手順を残しておきます。
勉強中の身ですので温かい心で読んで頂けると嬉しいです。1.環境
Windows 10
Node v11.13.02.Firebaseのプロジェクト作る
Firebaseのコンソールからプロジェクトを作成します。
プロジェクトを作るとDatabaseがサイドバーから選べるのでそこから新しいデータベースを作成します。3.ローカルフォルダにNode.jsのプロジェクトを作る
コマンドラインから任意のディレクトリに移動して
npm initを実行。
package.json が作成されます4.Firebase Admin SDK をダウンロード
Firebaseのドキュメントに従ってnode-moduleをインストールしましょう
npm install firebase-admin --save
node-modules と package-lock.json が作成されたことを確認してください5.プロジェクトの秘密鍵をダウンロード
Firebaseコンソールの「プロジェクトの設定」から「サービスアカウント」のタブ選択
Node.jsが選択された状態で「新しい秘密鍵の生成」をします。プロジェクト情報をJSONでダウンロードできますので "serviceAccount.json" にリネームして先ほどのディレクトリ内に保存します。
6.index.jsを作成
Firestoreを操作する処理を書いていきます。
詳細は公式ドキュメントに載ってますのでそちらを参照してください。
以下はデータ保存する時のサンプルです。
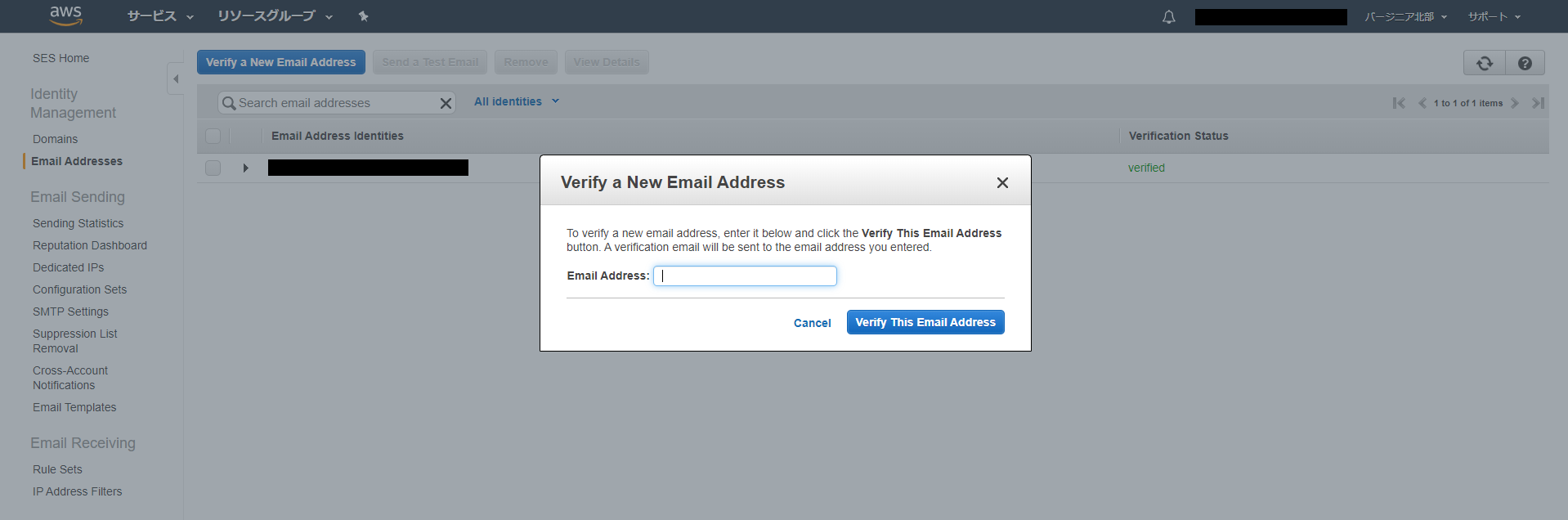
Lambdaで実行するのでhandlerの中に処理を書きますindex.jsconst admin = require('firebase-admin'); const serviceAccount = require('serviceAccount.json'); admin.initializeApp({ credential: admin.credential.cert(serviceAccount) }); const db = admin.firestore(); exports.handler = (event, context, callback) => { // Write a simple document with two fields const data = { field1: "aaa", field2: new Date() }; db.collection('lambda-docs').add(data).then((ref) => { // On a successful write, return an object // containing the new doc id. callback(null, { id: ref.id }); }).catch((err) => { // Forward errors if the write fails callback(err); }); }7.zipファイルにまとめる
ファイルがすべて揃っていることを確認してzipファイルに圧縮していきます
名前はなんでもok8.Lambdaファンクションを作成してzipをアップロード
AWSコンソールからファンクションを作成します。
Nodeのバージョンが11系を選べなかったので最新の12にしときました。
まあ大丈夫だろう、、、笑
できればここはローカル環境と合わせた方がいいかもしれませんね普通にコンソール画面からアップロードしていきましょう。
8.実行してFirestoreに書き込み
テストでもいいので実行してみます。
ログが成功となればFirestoreに書き込まれているはずです。
9.参考にしたサイト
公式のドキュメントの手順に沿ってやってみました。
Cloud Firestore を使ってみる
Lambda部分はこちらの記事がわかりやすかったです。Google翻訳にぶち込みましょう
How to use Cloud Firestore on AWS Lambda以上、誰かのお役に立てれば嬉しいです(^^)


- 投稿日:2020-05-23T06:35:12+09:00
railsチュートリアルが終わったらcloud9を削除しよう!(じゃないと毎月お金かかるよ)
①事象
awsを使用してないにも関わらず、 毎月$0.88(約100円)請求がきていた
(以下のようなメールが届いていた)
Greetings from Amazon Web Services, This e-mail confirms that your latest billing statement, for the account ending in ****, is available on the AWS web site. Your account will be charged the following: Total: $0.88 You can see a complete break down of all charges on the Billing & Cost Management page located here: https://console.aws.amazon.com/billing/home#/bill?statementTimePeriod=0000000000 To protect your privacy, we can only communicate account information to the e-mail address on file for your account. Thank you for using Amazon Web Services.②原因
railsチュートリアルを勉強していた際に、cloud9を使用していたが、railsチュートリアル完走した後にEC2を削除するのを忘れていた
EC2を使用するときに、1年後にお金かかるみたいなことを書いてあったような気がするが、そのときに「まぁ1年後だからっとすぐに消さなくていいや」ってなってしまっていた。
③類似
以下の請求書で、他に請求がかかっている項目がないか確認したがなかった。
請求書
④恒久対応
以下の資料を見ながら、Cloud9を削除すればEC2も自動的に消えます
AWS Cloud9 で環境を削除する - AWS Cloud9
⑤再発防止
何ヶ月間は無料でそのあと有料になるようなサービスは必ずリマインダやカレンダーに記載して忘れないようにする
最後に一言
何か間違っている点があれば、教えて頂けたら幸いです。
よろしくお願い致します。
