- 投稿日:2020-05-16T23:02:18+09:00
Kinx ライブラリ - DateTime
DateTime
はじめに
「見た目は JavaScript、頭脳(中身)は Ruby、(安定感は AC/DC)」 でお届けしているスクリプト言語 Kinx。言語はライブラリが命。ということでライブラリの使い方編。
今回は DateTime です。Range でも使えるようにしました。
- 参考
- 最初の動機 ... スクリプト言語 KINX(ご紹介)
- 個別記事へのリンクは全てここに集約してあります。
- リポジトリ ... https://github.com/Kray-G/kinx
- Pull Request 等お待ちしております。
使い方
using DateTime
DateTime ライブラリは標準組み込みではないため、using ディレクティブを使用して明示的に読み込む。
using DateTime;インスタンス化
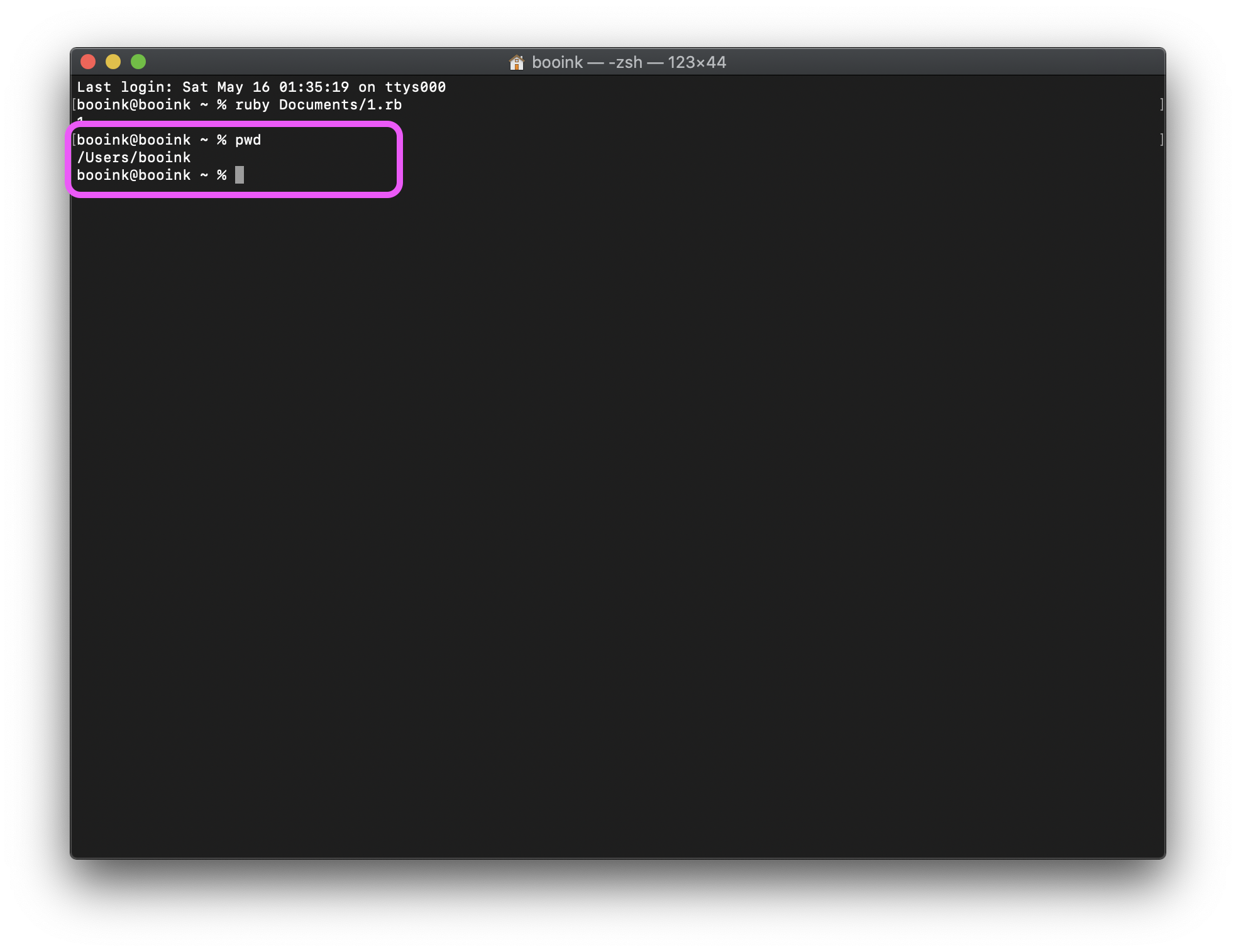
インスタンス化は基本的には DateTime オブジェクトを new する方法で行う。
new DateTime()... 現在時刻でインスタンス化new DateTime(dateString)... 文字列をパースしてインスタンス化new DateTime(Unixtime)... UNIXエポックの時刻からインスタンス化new DateTime(year, month, day[, hour, minute, second])... 日時情報を個別に指定してインスタンス化ただし、以下でも可能(内部で new して返しているだけ)。好きなものを使ってください。
DateTime.parse(...)DateTime(...)尚、
dateStringは以下のような書式を解釈する。
"2020-01-01"、"2020-1-1""2020/01/01"、"2020/1/1""2020-01-01T10:00:05"、"2020-1-01T10:0:5""2020/01/01 10:00:05"、"2020/1/01 10:0:5"メソッド
DateTime オブジェクトには以下のメソッドがある。
メソッド 動作概要 isLeapYear()うるう年であれば true を返す unixtime()現在日時の Unix エポック時間を返す datetime()現在日時を表すオブジェクトを返す year()現在日時の「年」 month()現在日時の「月」 day()現在日時の「日」 hour()現在日時の「時」 minute()現在日時の「分」 second()現在日時の「秒」 weekday()現在日時の「週」(0: 日曜, 1: 月曜, ..., 6: 土曜) isSunday()日曜日であれば true を返す isMonday()月曜日であれば true を返す isTuesday()火曜日であれば true を返す isWednesday()水曜日であれば true を返す isThursday()木曜日であれば true を返す isFriday()金曜日であれば true を返す isSaturday()土曜日であれば true を返す clone()日時オブジェクトのコピーを返す addDay(day)日時オブジェクトを day日進める(破壊的)subDay(day)日時オブジェクトを day日戻す(破壊的)addMonth(month)日時オブジェクトを monthか月進める(破壊的)subMonth(month)日時オブジェクトを monthか月戻す(破壊的)next()次の日を表す新たな日時オブジェクトを返す +(day)day日後を表す新たな日時オブジェクトを返す-(day)day日前を表す新たな日時オブジェクトを返す>>(month)monthか月後を表す新たな日時オブジェクトを返す<<(month)monthか月前を表す新たな日時オブジェクトを返す<=>(dt)0: 日時が同じ、-1: dtのほうが後の日時、1:dtのほうが以前の日時format(fmtString)fmtStringのフォーマットに従ってフォーマットする。サポートするフォーマットは以下の通り。%YYYY%:4桁の年、%YY%:2桁の年%MM%:2桁の月、%M%:月%DD%:2桁の日、%D%:日%hh%:2桁の時、%h%:時%mm%:2桁の分、%m%:分%ss%:2桁の秒、%s%:秒
月末
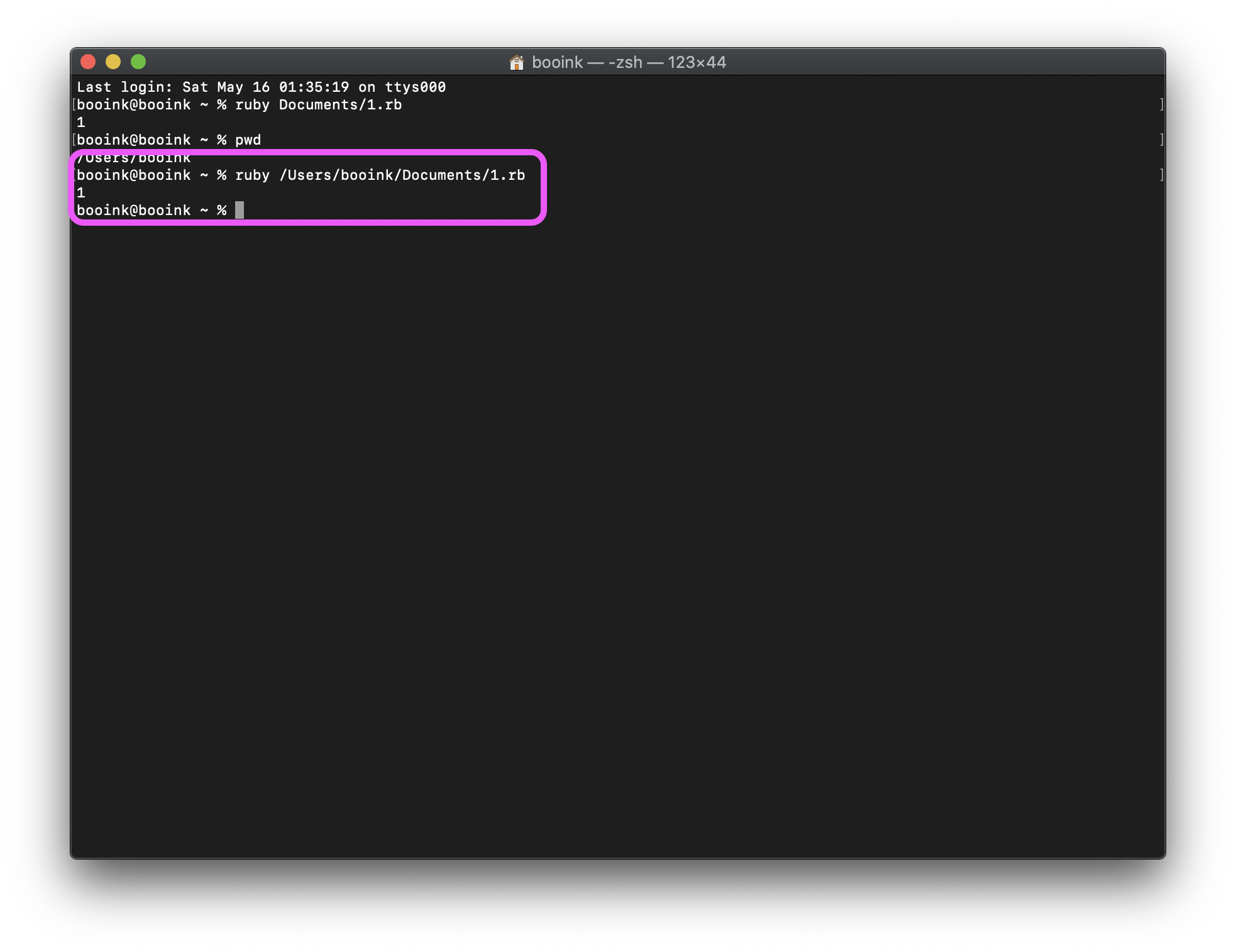
<<や>>で月を移動した場合、対応する月に同じ日が存在しない時は代わりにその月の末日が使われる。using DateTime; System.println(DateTime("2001-3-28") << 1); // 2001/02/28 00:00:00 System.println(DateTime("2001-3-31") << 1); // 2001/02/28 00:00:00このことは以下のように、もしかすると予期しない振る舞いをするかもしれない(Ruby と一緒)。
using DateTime; System.println(DateTime("2001-1-31") >> 2); // 2001/03/31 00:00:00 System.println(DateTime("2001-1-31") >> 1 >> 1); // 2001/03/28 00:00:00 System.println(DateTime("2001-1-31") >> 1 >> -1); // 2001/01/28 00:00:00Range
Range で使えるようにするには、
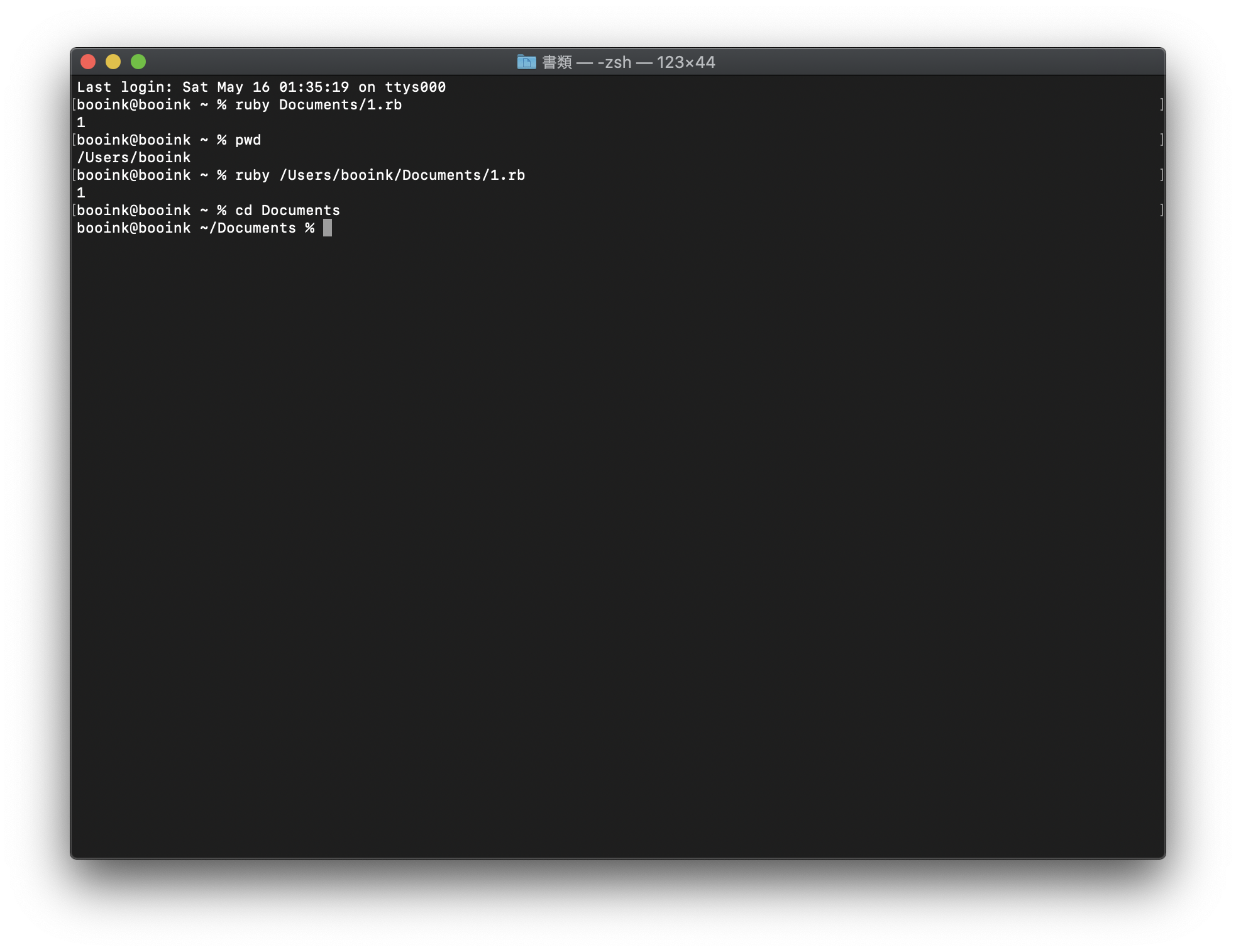
nextメソッドと<=>メソッドを定義しておけば良い。なので、DateTime オブジェクトは Range で使用できる。using DateTime; (DateTime(2020,1,1)..DateTime(2020,1,10)) .each(&(d) => System.println(d));
..なので最後の日が含まれる。...の場合は最後の日は含まれない。2020/01/01 00:00:00 2020/01/02 00:00:00 2020/01/03 00:00:00 2020/01/04 00:00:00 2020/01/05 00:00:00 2020/01/06 00:00:00 2020/01/07 00:00:00 2020/01/08 00:00:00 2020/01/09 00:00:00 2020/01/10 00:00:00Range で使えるので for-in でもそのままいける。
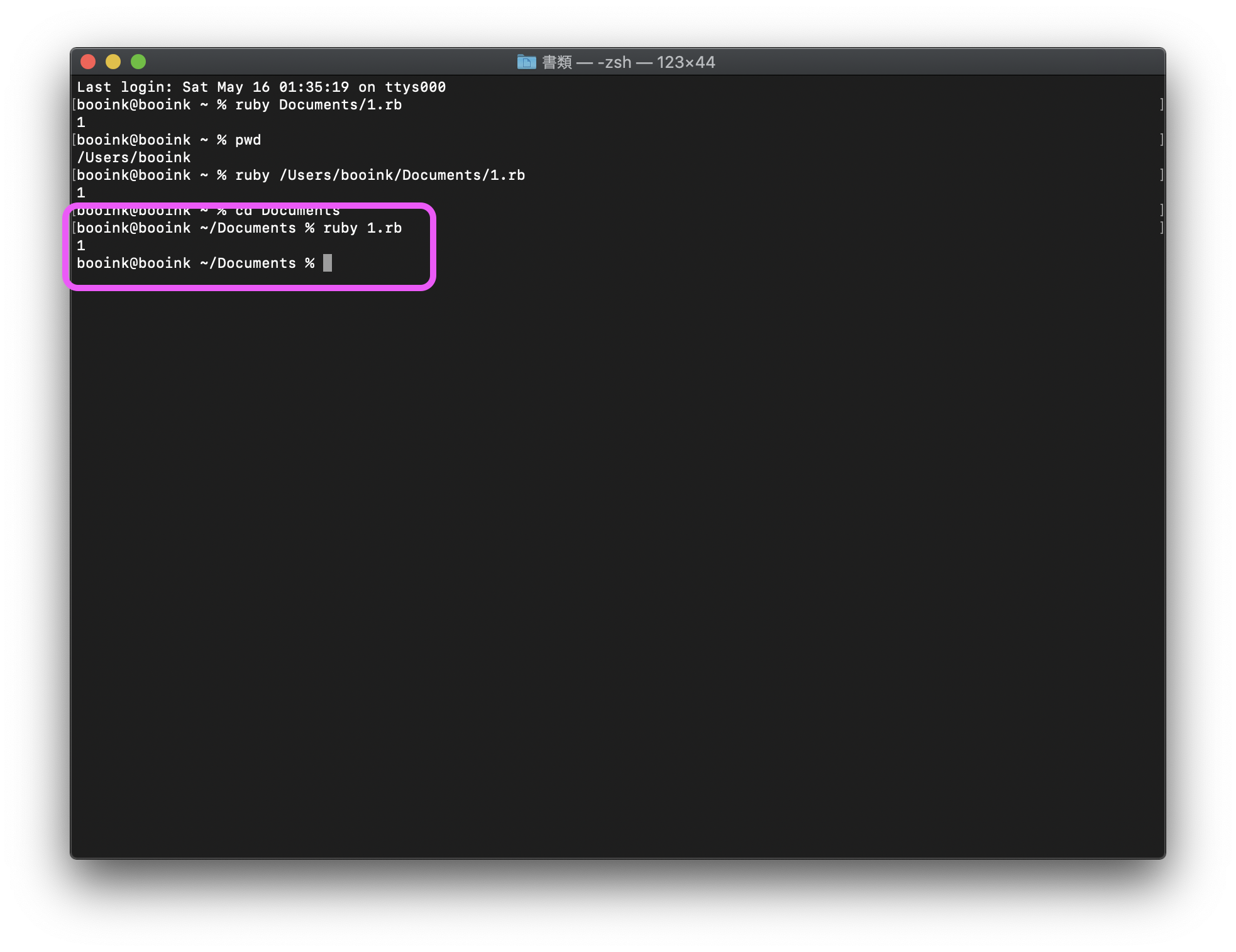
using DateTime; for (var d in DateTime(2020,1,1)...DateTime(2020,1,10)) { System.println(d); }最終日を含まないループ。
2020/01/01 00:00:00 2020/01/02 00:00:00 2020/01/03 00:00:00 2020/01/04 00:00:00 2020/01/05 00:00:00 2020/01/06 00:00:00 2020/01/07 00:00:00 2020/01/08 00:00:00 2020/01/09 00:00:00おわりに
作り始めてから約半年。色々できるようになってきましたねー。ライブラリを充実させて、何かしらのアプリを作れるようになることが次の目標ですかね。ニッチな用途でのアプリをサクッと作れる、とかできるとどこかに居場所ができるかもしれない。
ではまた次回。
- 投稿日:2020-05-16T22:37:02+09:00
Dockder + Rails Scaffoldを使用して簡単なアプリケーションを構築してみた
はじめに
書籍や動画、Qiita記事を参考にDocker-compose を使用してRuby on Railsでのアプリケーションを構築する方法について
苦戦したため、色々試してようやく動作するところまで持って行けたため、最終的なファイルと実行手順を残します。作業手順
ファイル作成
Dockerfile docker-compose.yml Gemfile Gemfile.lock# イメージ名にRuby(Ver2.6.5)の実行環境のイメージを指定 FROM ruby:2.6.5 # パッケージのリストを更新しrailsの環境構築に必要なパッケージをインストール RUN apt-get update -qq && apt-get install -y build-essential libpq-dev nodejs # プロジェクト用のディレクトリを作成 RUN mkdir /myapp # ワーキングディレクトリに設定 WORKDIR /myapp # プロジェクトのディレクトリにコピー COPY Gemfile /myapp/Gemfile COPY Gemfile.lock /myapp/Gemfile.lock # bundle install実行 RUN bundle install # ビルドコンテキストの内容を全てmyappにコピー COPY . /myappdocker-compose.ymlversion: '3' services: db: # postgresのイメージを取得 image: postgres environment: POSTGRES_USER: 'postgresql' POSTGRES_PASSWORD: 'postgresql-pass' restart: always volumes: - pgdatavol:/var/lib/postgresql/data web: # Dockerfileからイメージをビルドして使用 build: . # コンテナ起動時に実行 command: bundle exec rails s -p 3000 -b '0.0.0.0' # カレントディレクトリを/myappにバインドマウント volumes: - .:/myapp # 3000で公開して、コンテナの3000へ転送 ports: - "3000:3000" # Webサービスを起動する前にdbサービスを起動 depends_on: - db # データ永続化のためにpgdatabolのvolumeを作成し、postgresqlのデータ領域をマウント volumes: pgdatavol:source 'https://rubygems.org' gem 'rails', '5.2.4.2'Gemfile.lockrailsアプリケーション作成
docker-compose run web rails new . --force --database=postgresqlrailsプロジェクトに使用するデータベースの設定ファイルを修正
database.ymldefault: &default adapter: postgresql encoding: unicode # -------- 追加 -------- host: db username: postgresql password: postgresql-pass # -------- ここまで --------デタッチモード(バックグラウンド)で起動
docker-compose up -dbundle installが反映されない場合の対応
docker-compose build --no-cacheデータベース作成コマンド
docker-compose run web rails db:createScaffoldにて簡易的なアプリケーション作成
docker-compose run web bin/rails g scaffold User name:stringdocker-compose run web bin/rails db:migrate参考URL
いまさらだけどDockerに入門したので分かりやすくまとめてみた
Docker Compose + Railsでイメージ内でbundle installしているはずなのにgemが無いとエラーがでる。
- 投稿日:2020-05-16T21:27:29+09:00
Clound9でRailsGirlsもしくはel-trainingが試せる環境を構築する
はじめに
RailsGilrsや万葉さまの新人社員教育用カリキュラムである [el-training]など、(https://github.com/everyleaf/el-training) Rubyを勉強しようとしている方で、Macを持っていないもしくは貧弱なPCスペックの方向けの環境構築ガイドです。
RailsGirlsについては対象が参加向けではなく、コーチやってみたいなぁと思っているけど環境構築は得意じゃないよって方向け(いるのかそんな人?)ですのでご注意ください
RailsGirlsってどんな感じですすめるのだろう?とサイトに手順通り試してみようと普段使わないwindowsマシンを引っ張り出しWSL上に構築したらrailsの動作確認までに1時間かかってしまった(PCが非力なのは当然として、多分SSDじゃなくてHDDだったのが大きな原因)ので、Cloud9上で構築してみました。
ネット上で探すと同じ内容のものがいくらでも出てきますが、自分の欲しい環境とは異なっていたのでメモを兼ねて。なお、本記事公開から時間が経っても参考になるように注意しながらまとめてみました。
本構築記事のゴール
- RailsGirlsでの到達点
- 「インストールガイド」完了相当
- 違いはPostgresqlのインストール(railsgirlsでは本来不要)
- el-trainingでの到達点
- 「ステップ1: Railsの開発環境を構築しよう」完了相当
条件
- AWSアカウントの作成やIAMの設定などは事前に終わっている前提です。
- 2020/5/15~2020/5/16に試しました。
- ruby/rails環境は以下の通り
- ruby2.6.6
- railsgirlsだと最新(いまだと2.7系)なので読み替えてください
- rails6.0.3
- postgresqlを利用する(Cloud9環境にはmysqlが導入済みなので置き換えます)
- webpackerを利用する
- Clound9の設定
- Platformでは
Ubuntu Server 18.04 LTSを選択構築手順
Cloud9の起動とターミナルの起動まで
まずは起動させてください。
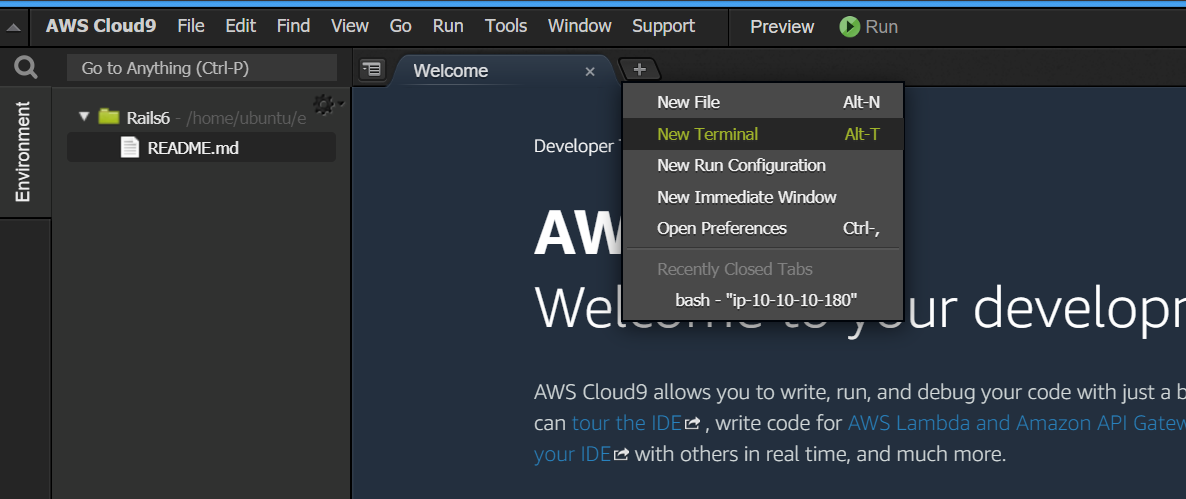
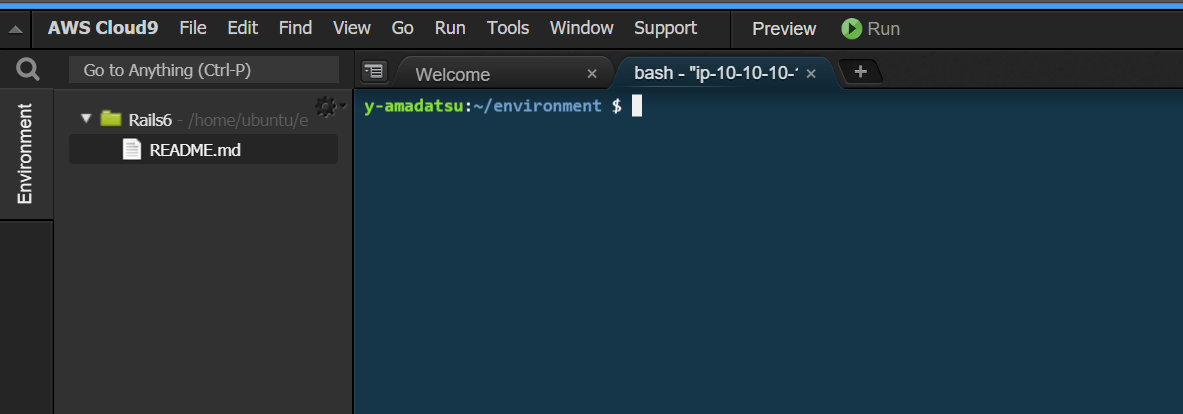
NewTerminalを開きます。
開くと
~/environmentディレクトリをカレントディレクトリとしてターミナルが起動します。どうやら、Cloud9ではプロジェクトファイルなどはこのディレクトリ配下に置くのがお作法のようです。
タイムゾーンの変更
日付が日本時間となっていない(UTC)ですね。
日付の確認y-amadatsu:~/environment $ date Sat May 16 02:29:10 UTC 2020先にタイムゾーンを変更しておきましょう。
タイムゾーンの確認y-amadatsu:~/environment $ timedatectl list-timezones | grep -i tokyo Asia/Tokyo設定するタイムゾーンを確認すると
Asia/Tokyoのようですね。タイムゾーンの設定y-amadatsu:~/environment $ sudo timedatectl set-timezone Asia/Tokyo y-amadatsu:~/environment $ date Sat May 16 11:33:46 JST 2020
dateコマンドで、日本時間に変更されたことが確認できました。Rubyのインストールまで
Rubyのバージョンを確認。ちょっと古いので新しいバージョンをインストールする準備を行います。
rubyのインストール状況の確認y-amadatsu:~/environment $ ruby -v ruby 2.6.3p62 (2019-04-16 revision 67580) [x86_64-linux] y-amadatsu:~/environment $ which ruby /home/ubuntu/.rvm/rubies/ruby-2.6.3/bin/rubyデフォルトではrvmがインストールされていたのですが、普段rbenvを使っているのでインストールしなおします。
まずはrvmさま、さようなら
rvmのアンインストールy-amadatsu:~/environment $ rvm implode Are you SURE you wish for rvm to implode? This will recursively remove /home/ubuntu/.rvm and other rvm traces? (anything other than 'yes' will cancel) > yes Removing rvm-shipped binaries (rvm-prompt, rvm, rvm-sudo rvm-shell and rvm-auto-ruby) Removing rvm wrappers in /home/ubuntu/.rvm/bin Hai! Removing /home/ubuntu/.rvm /home/ubuntu/.rvm has been removed. Note you may need to manually remove /etc/rvmrc and ~/.rvmrc if they exist still. Please check all .bashrc .bash_profile .profile and .zshrc for RVM source lines and delete or comment out if this was a Per-User installation. Also make sure to remove `rvm` group if this was a system installation. Finally it might help to relogin / restart if you want to have fresh environment (like for installing RVM again).最後に不要なファイルなどを削除するように指示がありますが、初めてのenvironment1として起動した私の環境では単にrailsを動かすだけなら不都合なさそうなのでこのまま進めます。もし後でrubyのコマンドが見つからない、実行しているrubyのバージョンが異なるなどの不都合が発生した場合は上記の設定を見直すこととしましょう。
ではrbenvをインストールします。
本家サイトのインストール手順を見ながら進めます。rbenvのインストールy-amadatsu:~/environment $ sudo apt-get update y-amadatsu:~/environment $ git clone https://github.com/sstephenson/rbenv.git ~/.rbenv y-amadatsu:~/environment $ cd ~/.rbenv && src/configure && make -C src make: Entering directory '/home/ubuntu/.rbenv/src' gcc -fPIC -c -o realpath.o realpath.c gcc -shared -Wl,-soname,../libexec/rbenv-realpath.dylib -o ../libexec/rbenv-realpath.dylib realpath.o make: Leaving directory '/home/ubuntu/.rbenv/src'今回はインストール手順のとおり試しましたが、これからは
sudo apt-get updateはsudo apt updateに置き換えて慣れたほうが良いと思います2。あと、Bashなんでついでに
cd ~/.rbenv && src/configure && make -C srcを試してみました。コンパイルしているので速度向上となると思いますが、通常は不要です3。
カレントディレクトリ~/.rbenvに変わりましたが気にせずに続けます…rbenvの設定(1)y-amadatsu:~/.rbenv (master) $ echo 'export PATH="$HOME/.rbenv/bin:$PATH"' >> ~/.bash_profile y-amadatsu:~/.rbenv (master) $ ~/.rbenv/bin/rbenv init # Load rbenv automatically by appending # the following to ~/.bash_profile: eval "$(rbenv init -)"指示の通り
.bash_profileに追加します。rbenvの設定(2)y-amadatsu:~/.rbenv (master) $ echo eval "$(rbenv init -)" >> ~/.bash_profile指示通りターミナルをいったん閉じて開きなおして4続きを。
brew dockerみたいな診断プログラムですね。rbenvの設定(3)y-amadatsu:~/environment $ curl -fsSL https://github.com/rbenv/rbenv-installer/raw/master/bin/rbenv-doctor | bash Checking for `rbenv' in PATH: /home/ubuntu/.rbenv/bin/rbenv Checking for rbenv shims in PATH: OK Checking `rbenv install' support: not found Unless you plan to add Ruby versions manually, you should install ruby-build. Please refer to https://github.com/rbenv/ruby-build#installation Counting installed Ruby versions: none There aren't any Ruby versions installed under `/home/ubuntu/.rbenv/versions'. You can install Ruby versions like so: rbenv install 2.2.4 Checking RubyGems settings: OK Auditing installed plugins: OK
ruby-buildは入れてないから当然Checking `rbenv install' support: not found
なのですが、rbenvのインストール手順ではすでに導入済みの状態でサンプルが示されているのでちょっと混乱しそうなポイント。
とはいえ、指示通り https://github.com/rbenv/ruby-build#installation を見ながらすすめましょう。今回は一般的と思われるrbenvのプラグインとしてインストールを進めます。
rbenvの設定(4)y-amadatsu:~/environment $ mkdir -p "$(rbenv root)"/plugins y-amadatsu:~/environment $ git clone https://github.com/rbenv/ruby-build.git "$(rbenv root)"/plugins/ruby-build Cloning into '/home/ubuntu/.rbenv/plugins/ruby-build'... remote: Enumerating objects: 9, done. remote: Counting objects: 100% (9/9), done. remote: Compressing objects: 100% (8/8), done. remote: Total 10844 (delta 1), reused 3 (delta 0), pack-reused 10835 Receiving objects: 100% (10844/10844), 2.28 MiB | 16.79 MiB/s, done. Resolving deltas: 100% (7158/7158), done. y-amadatsu:~/environment $ curl -fsSL https://github.com/rbenv/rbenv-installer/raw/master/bin/rbenv-doctor | bash Checking for `rbenv' in PATH: /home/ubuntu/.rbenv/bin/rbenv Checking for rbenv shims in PATH: OK Checking `rbenv install' support: /home/ubuntu/.rbenv/plugins/ruby-build/bin/rbenv-install (ruby-build 20200401-11-g12af1c3) Counting installed Ruby versions: none There aren't any Ruby versions installed under `/home/ubuntu/.rbenv/versions'. You can install Ruby versions like so: rbenv install 2.2.4 Checking RubyGems settings: OK Auditing installed plugins: OKこれでよし。それではrubyをインストールします。今回はruby2.6系の最新版である2.6.6をインストールしました。
EC2がt2.microだと時間がそれなりにかかります
私の時には10分くらいかかった…かも(記憶が飛んでいる)
rubyのインストールy-amadatsu:~/environment $ rbenv install 2.6.6 Downloading ruby-2.6.6.tar.bz2... -> https://cache.ruby-lang.org/pub/ruby/2.6/ruby-2.6.6.tar.bz2 Installing ruby-2.6.6... Installed ruby-2.6.6 to /home/ubuntu/.rbenv/versions/2.6.6 y-amadatsu:~/environment $ rbenv global 2.6.6 y-amadatsu:~/environment $ ruby -v ruby 2.6.6p146 (2020-03-31 revision 67876) [x86_64-linux]よし、インストールまで完了しました!
必要なパッケージのインストールと不要なパッケージ(mysql)への対応
今回はrails6を動かすので、必要なパッケージをインストールします。
- postgresql
- redis
- yarn
事前準備として、yarnをapt経由でインストールできるようにします。 公式サイト を参考にまずはDebian package repository用の公開鍵を登録&aptの設定をしてからインストールしましょう。
yarnのレポジトリの登録y-amadatsu:~/environment $ curl -sS https://dl.yarnpkg.com/debian/pubkey.gpg | sudo apt-key add - OK y-amadatsu:~/environment $ echo "deb https://dl.yarnpkg.com/debian/ stable main" | sudo tee /etc/apt/sources.list.d/yarn.list deb https://dl.yarnpkg.com/debian/ stable mainリポジトリを追加した場合は必ず
sudo apt updateしてください。aptのパッケージリストの更新y-amadatsu:~/environment $ sudo apt update Hit:1 https://download.docker.com/linux/ubuntu bionic InRelease Get:2 https://dl.yarnpkg.com/debian stable InRelease [17.1 kB] Hit:3 http://us-east-1.ec2.archive.ubuntu.com/ubuntu bionic InRelease Get:4 http://us-east-1.ec2.archive.ubuntu.com/ubuntu bionic-updates InRelease [88.7 kB] Get:5 http://us-east-1.ec2.archive.ubuntu.com/ubuntu bionic-backports InRelease [74.6 kB] Get:6 http://security.ubuntu.com/ubuntu bionic-security InRelease [88.7 kB] Get:7 https://dl.yarnpkg.com/debian stable/main amd64 Packages [9953 B] Get:8 https://dl.yarnpkg.com/debian stable/main all Packages [9953 B] Fetched 289 kB in 1s (499 kB/s) Reading package lists... Done Building dependency tree Reading state information... Done 30 packages can be upgraded. Run 'apt list --upgradable' to see them.最新のパッケージリストを取り込んだところ、更新できるパッケージがたくさんありそうなのでこのタイミングで更新しておきます。
更新パッケージの適用(upgrade)y-amadatsu:~/environment $ sudo apt upgrade -y Reading package lists... Done Building dependency tree Reading state information... Done Calculating upgrade... Done The following NEW packages will be installed: ...省略... mysql.time_zone_name OK mysql.time_zone_transition OK mysql.time_zone_transition_type OK mysql.user OK The sys schema is already up to date (version 1.5.2). Checking databases. sys.sys_config OK Upgrade process completed successfully. Checking if update is needed. Setting up mysql-server (5.7.30-0ubuntu0.18.04.1) ... Processing triggers for initramfs-tools (0.130ubuntu3.9) ... update-initramfs: Generating /boot/initrd.img-5.3.0-1017-aws Processing triggers for libc-bin (2.27-3ubuntu1) ... Processing triggers for systemd (237-3ubuntu10.40) ... Processing triggers for man-db (2.8.3-2ubuntu0.1) ... Processing triggers for dbus (1.12.2-1ubuntu1.1) ... Processing triggers for ureadahead (0.100.0-21) ...更新完了です…と
のログで気づいたのですがmysqlはすでにいそうですね…
mysqlプロセスの確認y-amadatsu:~/environment $ ps aux | grep [m]ysql mysql 27099 0.1 17.7 1161948 178088 ? Sl 12:36 0:00 /usr/sbin/mysqld --daemonize --pid-file=/run/mysqld/mysqld.pidやはり、入っていました。
宗教上の理由により今回は不要なので先に対応しておきます。
まずはサービスを止めてからパッケージをサービスを無効化しておきます。サービスを止めてから…
mysqlの停止y-amadatsu:~/environment $ sudo systemctl stop mysql動いていないことを確認して…
mysqlの停止(確認)y-amadatsu:~/environment $ sudo systemctl status mysql ● mysql.service - MySQL Community Server Loaded: loaded (/lib/systemd/system/mysql.service; enabled; vendor preset: enabled) Active: inactive (dead) since Fri 2020-05-15 12:47:38 UTC; 11s ago Main PID: 27099 (code=exited, status=0/SUCCESS) May 15 12:36:21 ip-10-10-10-180 systemd[1]: Starting MySQL Community Server... May 15 12:36:22 ip-10-10-10-180 systemd[1]: Started MySQL Community Server. May 15 12:47:36 ip-10-10-10-180 systemd[1]: Stopping MySQL Community Server... May 15 12:47:38 ip-10-10-10-180 systemd[1]: Stopped MySQL Community Server. y-amadatsu:~/environment $ ps aux | grep [m]ysqlサービスを無効化(起動時の自動起動設定をOFF)します。
mysqlサービスの無効化y-amadatsu:~/environment $ sudo systemctl disable mysql.service Synchronizing state of mysql.service with SysV service script with /lib/systemd/systemd-sysv-install. Executing: /lib/systemd/systemd-sysv-install disable mysql y-amadatsu:~/environment $ sudo systemctl list-unit-files mysql.service UNIT FILE STATE mysql.service disabled 1 unit files listed.それでは必要なパッケージインストールします。
rails6に必要なサービスのインストールy-amadatsu:~/environment $ sudo apt install postgresql libpq-dev redis yarn -y Reading package lists... Done Building dependency tree Reading state information... Done The following additional packages will be installed: ...省略... Adding user postgres to group ssl-cert Creating config file /etc/postgresql-common/createcluster.conf with new version Building PostgreSQL dictionaries from installed myspell/hunspell packages... Removing obsolete dictionary files: Created symlink /etc/systemd/system/multi-user.target.wants/postgresql.service → /lib/systemd/system/postgresql.service. Setting up libsensors4:amd64 (1:3.4.0-4) ... Setting up postgresql-client-10 (10.12-0ubuntu0.18.04.1) ... update-alternatives: using /usr/share/postgresql/10/man/man1/psql.1.gz to provide /usr/share/man/man1/psql.1.gz (psql.1.gz) in auto mode Setting up redis-tools (5:4.0.9-1ubuntu0.2) ... Setting up libpq-dev (10.12-0ubuntu0.18.04.1) ... Setting up sysstat (11.6.1-1ubuntu0.1) ... Creating config file /etc/default/sysstat with new version update-alternatives: using /usr/bin/sar.sysstat to provide /usr/bin/sar (sar) in auto mode Created symlink /etc/systemd/system/multi-user.target.wants/sysstat.service → /lib/systemd/system/sysstat.service. Setting up postgresql-10 (10.12-0ubuntu0.18.04.1) ... Creating new PostgreSQL cluster 10/main ... /usr/lib/postgresql/10/bin/initdb -D /var/lib/postgresql/10/main --auth-local peer --auth-host md5 The files belonging to this database system will be owned by user "postgres". This user must also own the server process. The database cluster will be initialized with locale "C.UTF-8". The default database encoding has accordingly been set to "UTF8". The default text search configuration will be set to "english". Data page checksums are disabled. fixing permissions on existing directory /var/lib/postgresql/10/main ... ok creating subdirectories ... ok selecting default max_connections ... 100 selecting default shared_buffers ... 128MB selecting default timezone ... Etc/UTC selecting dynamic shared memory implementation ... posix creating configuration files ... ok running bootstrap script ... ok performing post-bootstrap initialization ... ok syncing data to disk ... ok Success. You can now start the database server using: /usr/lib/postgresql/10/bin/pg_ctl -D /var/lib/postgresql/10/main -l logfile start Ver Cluster Port Status Owner Data directory Log file 10 main 5432 down postgres /var/lib/postgresql/10/main /var/log/postgresql/postgresql-10-main.log update-alternatives: using /usr/share/postgresql/10/man/man1/postmaster.1.gz to provide /usr/share/man/man1/postmaster.1.gz (postmaster.1.gz) in auto mode Setting up postgresql (10+190ubuntu0.1) ... Setting up redis-server (5:4.0.9-1ubuntu0.2) ... Created symlink /etc/systemd/system/redis.service → /lib/systemd/system/redis-server.service. Created symlink /etc/systemd/system/multi-user.target.wants/redis-server.service → /lib/systemd/system/redis-server.service. Setting up redis (5:4.0.9-1ubuntu0.2) ... Processing triggers for libc-bin (2.27-3ubuntu1) ... Processing triggers for systemd (237-3ubuntu10.40) ... Processing triggers for man-db (2.8.3-2ubuntu0.1) ... Processing triggers for ureadahead (0.100.0-21) ...postgresはただしくpostgresユーザが作られていることが確認できます。あと
Creating new PostgreSQL cluster 10/main ...とか気になる記載も。今のpostgresはデフォルトでクラスタ作るんですかねpostgresはあとで動作確認しますので、それ以外が正しくインストールできているか確認しましょう。
インストールの確認y-amadatsu:~/environment $ redis-cli --version redis-cli 4.0.9 y-amadatsu:~/environment $ redis-server --version Redis server v=4.0.9 sha=00000000:0 malloc=jemalloc-3.6.0 bits=64 build=9435c3c2879311f3 y-amadatsu:~/environment $ yarn --version 1.22.4redisはクライアントとサーバのどちらも4系が入っていますね。sidekiq6だと4以上が要求されるのでこれで安心
また、postgresとredisはサーバとして動作させますのでサービスとして有効化されているか確認します。
redisの確認y-amadatsu:~/environment $ sudo systemctl list-unit-files redis*.service UNIT FILE STATE redis-server.service enabled redis-server@.service disabled redis.service enabled 3 unit files listed.PostgreSQLの確認y-amadatsu:~/environment $ sudo systemctl list-unit-files postgres*.service UNIT FILE STATE postgresql.service enabled postgresql@.service indirect 2 unit files listed.問題なさそうですね!
postgresとredisを起動しておきましょう。
起動状態を確認します。redisの確認y-amadatsu:~/environment $ sudo systemctl status redis-server ● redis-server.service - Advanced key-value store Loaded: loaded (/lib/systemd/system/redis-server.service; enabled; vendor preset: enabled) Active: active (running) since Sat 2020-05-16 01:34:28 UTC; 32min ago Docs: http://redis.io/documentation, man:redis-server(1) Main PID: 962 (redis-server) Tasks: 4 (limit: 1121) CGroup: /system.slice/redis-server.service └─962 /usr/bin/redis-server 127.0.0.1:6379 May 16 01:34:27 ip-10-10-10-180 systemd[1]: Starting Advanced key-value store... May 16 01:34:28 ip-10-10-10-180 systemd[1]: redis-server.service: Can't open PID file /var/run/redis/redis-server.pid (yet?) after start: No such file or directory May 16 01:34:28 ip-10-10-10-180 systemd[1]: Started Advanced key-value store.postgresの確認y-amadatsu:~/environment $ sudo systemctl status postgresql.service ● postgresql.service - PostgreSQL RDBMS Loaded: loaded (/lib/systemd/system/postgresql.service; enabled; vendor preset: enabled) Active: active (exited) since Sat 2020-05-16 01:34:31 UTC; 33min ago Main PID: 1386 (code=exited, status=0/SUCCESS) Tasks: 0 (limit: 1121) CGroup: /system.slice/postgresql.service May 16 01:34:31 ip-10-10-10-180 systemd[1]: Starting PostgreSQL RDBMS... May 16 01:34:31 ip-10-10-10-180 systemd[1]: Started PostgreSQL RDBMS.
各サービスの起動y-amadatsu:~/environment $ sudo systemctl start redis-server.service y-amadatsu:~/environment $ sudo systemctl start postgresql.serviceきちんと動作しているか、
sudo systemctl status ...コマンドで確認すれば完璧です!なお、postgresqlについては、インストール時のログで
Success. You can now start the database server using:
/usr/lib/postgresql/10/bin/pg_ctl -D /var/lib/postgresql/10/main -l logfile start
とありましたがUbuntu環境では
systemctlを経由して起動・停止したほうが便利ですのでこちらを利用しました。必要なパッケージは(ひとまず 5 )これで揃いました。
テストでrails6を動かしてみる
railsgarlsを参考にサンプルのrails6アプリを作りながら動作確認してみましょう。動作確認ですので詳細の説明は省きます
Railsのインストール
railsのインストールy-amadatsu:~/environment $ gem install rails --no-document -v "6.0.3"サンプルのrailsアプリの作成
railsアプリの作成y-amadatsu:~/environment $ rails new sampleちなみに
rails new sampleは私の環境では約5分くらいかかりました。動作確認
railsアプリの作成~サーバ起動までy-amadatsu:~/environment $ cd sample/ y-amadatsu:~/environment/sample (master) $ rails g scaffold book y-amadatsu:~/environment/sample (master) $ rails db:migrate y-amadatsu:~/environment/sample (master) $ rails server => Booting Puma => Rails 6.0.3 application starting in development => Run `rails server --help` for more startup options Puma starting in single mode... * Version 4.3.3 (ruby 2.6.6-p146), codename: Mysterious Traveller * Min threads: 5, max threads: 5 * Environment: development * Listening on tcp://127.0.0.1:8080 * Listening on tcp://[::1]:8080 Use Ctrl-C to stopブラウザで確認してみましょう。上部メニューの
PreviewからPreview Running Applicationをクリックしてください。
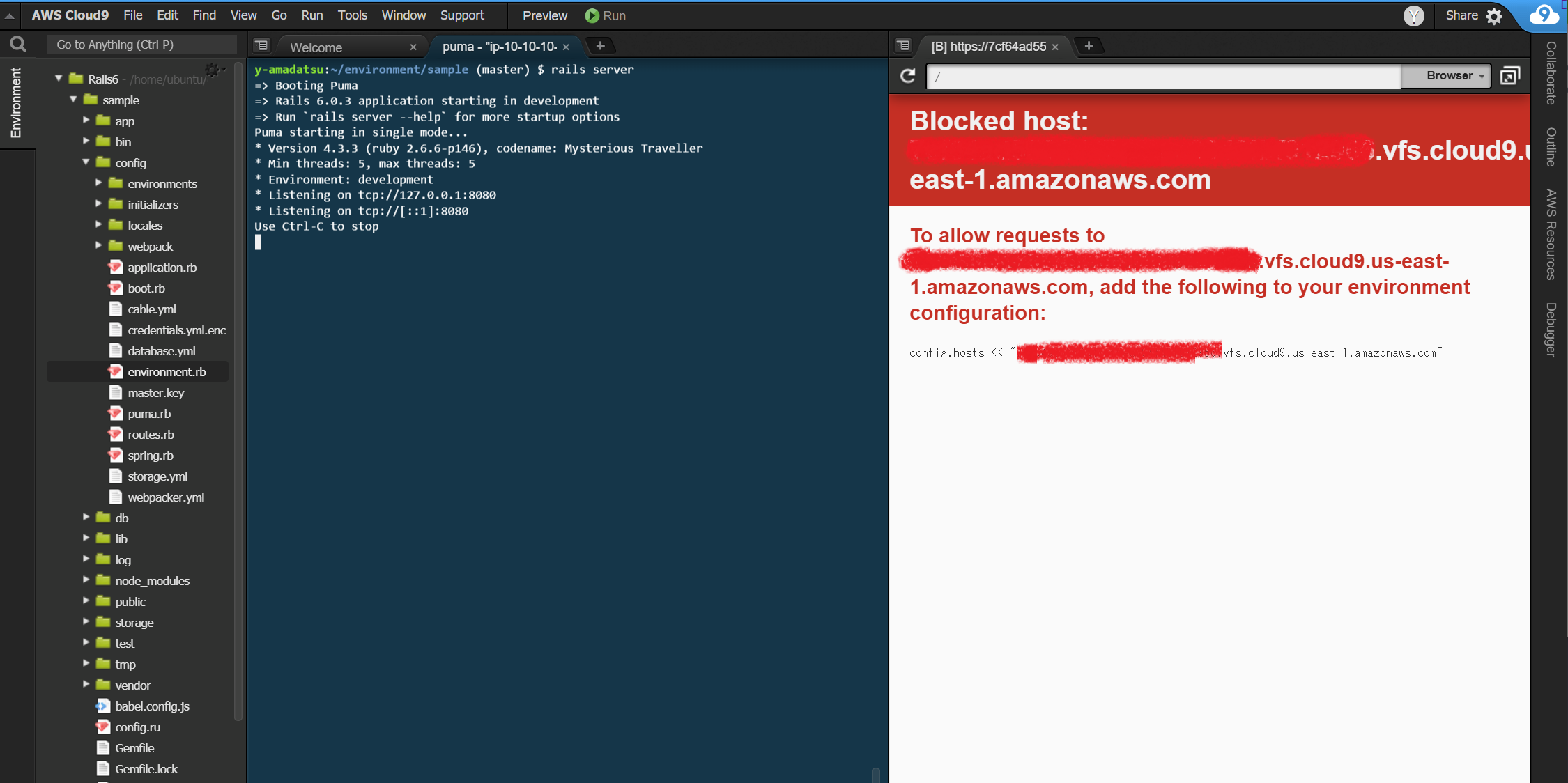
クリックすると以下のエラー画面が表示されます(一部塗りつぶしで消してます)
これはRails6の新しいセキュリティ機構によって表示されるエラーです。詳しくは下記を参照してください。
Rails6 のちょい足しな新機能を試す78(Guard DNS rebiding attacks編)
エラー画面で表示された
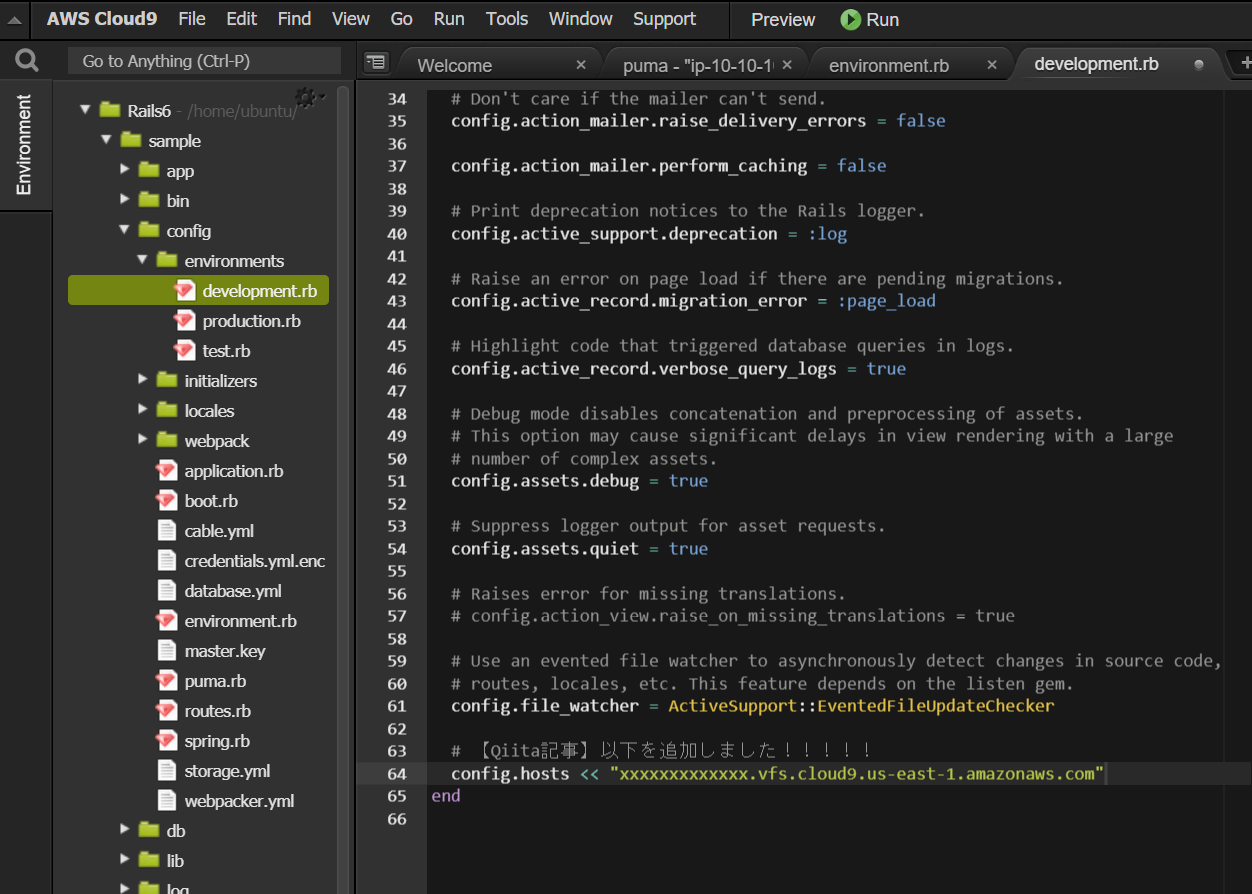
config.hosts << "xxxxxxxxxxxxxx.vfs.cloud9.us-east-1.amazonaws.com"をコピーして/sample/config/environments/development.rbに以下のように追記して保存してください。
今立ち上がっているサーバを
Ctrl-Cで停止します。railsサーバの停止y-amadatsu:~/environment/sample (master) $ rails server => Booting Puma => Rails 6.0.3 application starting in development => Run `rails server --help` for more startup options Puma starting in single mode... * Version 4.3.3 (ruby 2.6.6-p146), codename: Mysterious Traveller * Min threads: 5, max threads: 5 * Environment: development * Listening on tcp://127.0.0.1:8080 * Listening on tcp://[::1]:8080 Use Ctrl-C to stop ^C- Gracefully stopping, waiting for requests to finish === puma shutdown: 2020-05-16 17:31:18 +0900 === - Goodbye! Exitingそして再度
rails serverで起動してpreviewを再確認してください。なお、Cloud9上のブラウザではなぜか接続できません…これはググってみても誰も解決できていなさそう。間違いなくネットワークの設定なんだけどな…なので、接続できていない画面のURLの右に「矢印と重なったウィンドウのボタン」(マウスオーバーで「Pop Out Into New Window」と表示される)がありますのでクリックしてください。下記の画像右端のボタンです。
するとお使いのブラウザのタブで表示できると思います。
ここまででrailsgirlsのインストール作業としては完了です!
以下postgresqlへの接続を試す
現時点ではDBがsqliteとなっていますので、postgresqlに置き換えます。
まず
database.ymlファイルは下記の内容でまるっと置き換えてください6/config/database.ymldefault: &default adapter: postgresql encoding: utf8 pool: <%= ENV.fetch("RAILS_MAX_THREADS") { 5 } %> username: postgres password: postgres host: localhost timeout: 5000 development: <<: *default database: sample_development test: <<: *default database: sample_test production: <<: *default database: sample_productionGemfileは
sqlite3の行を見つけてコメントアウトし、gem 'pg'を追加して下さい。Gemfile#gem 'sqlite3', '~> 1.4' gem 'pg'Gemfileを修正したので
bundle installしなおしましょう7。railsに必要なパッケージをインストールするy-amadatsu:~/environment/sample (master) $ bundle install今回は開発環境なのでDBのユーザはpostgresのままでパスワードも簡易的に設定します。
postgresユーザのパスワードを設定y-amadatsu:~/environment/sample (master) $ sudo -u postgres psql psql (10.12 (Ubuntu 10.12-0ubuntu0.18.04.1)) Type "help" for help. postgres=# alter role postgres with password 'postgres'; ALTER ROLE postgres=# \q y-amadatsu:~/environ
\qでコンソールに戻ります。なお、他のサイトでは
pg_hba.confの修正が必要と書いてありますが、今回インストールされたPostgreSQL 10系だとインストール時に最低限の設定をしてくれていたのでスキップします。下記がインストール時のログの抜粋です。Creating new PostgreSQL cluster 10/main ...
/usr/lib/postgresql/10/bin/initdb -D /var/lib/postgresql/10/main --auth-local peer --auth-host md5
The files belonging to this database system will be owned by user "postgres".
This user must also own the server process.これでDBの設定も問題ないはずです8。一気に行きます。
DBの作成から起動確認までy-amadatsu:~/environment/sample (master) $ rake db:create y-amadatsu:~/environment/sample (master) $ rake db:migrate y-amadatsu:~/environment/sample (master) $ rails server簡素な画面ですが、きちんと
/booksも一覧表示できることを確認しました。
お疲れさまでした!
Cloud9の動作環境(environment)のことです。 ↩
https://linuxfan.info/package-management-ubuntu を参照。aptが推奨されるようになってかなり立つのですが、このようにネット上では最新でない記載も多々あります。 ↩
そのままでも十分早いので問題ないと思います。むしろ、今後rbenv自体をアップデートするときにも再度コンパイルが必要だと思われますが、たぶんその時には忘れていると思います
ネットで探すと
source ~/.bash_profileを実行する手順での説明が多いと思います。間違いではないのですが、ソフト提供元のインストールの指示(一次情報とも言います)どおりやったほうが未知の問題への遭遇確率が減るので慣れるまでは愚直に指示通りする方法をお勧めします。あと、ここではディレクトリ移動の説明を省きたかったのもあります。 ↩Gemfileのbundle install時にnativeコンパイルが走る場合、別途ライブラリのインストールが必要になる場合があります ↩
本来は同じrailsバージョンで
rails new appname --database=postgresqlした結果のdatabase.ymlをベースに修正したほうが無難です。 ↩ここは
bundle updateでも同じです。個人的にはbundle updateは個別パッケージのみバージョンを上げるときに利用しています。 ↩インストール時に作られた
postgresユーザはいわゆるなんでもできるスーパーユーザなので、ローカルでの開発以外ではこのような使い方はNGです。別途アプリ用のユーザを作成してください。 ↩



- 投稿日:2020-05-16T20:44:45+09:00
Rails セキュリティー
前提
本日学んだセキュリティーについて書いていきます。
本題
リダイレクトとファイル
セキュリティ上の脆弱性として検討したいのは、Webアプリケーションにおける「リダイレクトとファイル」。
リダイレクト
Webアプリケーションにおけるリダイレクトは、過小評価されがちなクラッキングツール。
攻撃者はこれを使ってユーザーを危険なWebサイトに送り込んだり、Webサイト自体に罠を仕掛けたりすることもできる。リダイレクト用のURL (の一部) を渡すことをユーザーに許すと、潜在的な脆弱性となる。
最もあからさまな攻撃方法としては、ユーザーを本物そっくりの偽Webサイトにリダイレクトすることが考えられる。
これは俗に「フィッシング(phishing)」や「釣り」などと呼ばれる攻撃手法。
具体的には、無害を装ったリンクを含むメールをユーザーに送りつけ、XSSを使ってそのリンクをWebアプリケーションに注入するか、リンクを外部サイトに配置する。
このリンクの冒頭部分はそのWebアプリケーションのURLなので、一見無害に見える。ファイルアップロード
ファイルがアップロードされたときに重要なファイルが上書きされることのないようにする。
また、メディアファイルの処理は非同期で行なう。多くのWebアプリケーションでは、ユーザーがファイルをアップロードできるようになっている。
ユーザーが選択/入力できるファイル名 (またはその一部) は必ずフィルタする。
攻撃者が危険なファイル名をわざと使ってサーバーのファイルを上書きしようとする可能性があるため。
ファイルが /var/www/uploads ディレクトリにアップロードされ、そのときにファイル名が「../../../etc/passwd」と入力されていると、重要なファイルが上書きされてしまう可能性がある。
言うまでもなく、Rubyインタプリタにそれだけの実行権限が与えられていなければ、そのような上書きは実行できない。
Webサーバー、データベースサーバーなどのプログラムは、比較的低い権限を持つUnixユーザーとして実行されているのが普通。さらにもう一つ注意。
ユーザーが入力したファイル名をフィルタするときに、ファイル名から危険な部分を取り除くアプローチを使わないこと。
Webアプリケーションがファイル名から「../」という文字を取り除くことができるとしても、今度は攻撃者が「....//」のようなその裏をかくパターンを使えば、やはり「../」という相対パスが通ってしまい、きりがない。
最も良いのは「ホワイトリスト」によるアプローチ。
これはファイル名が有効であるかどうか (指定された文字だけが使われているかどうか) をチェックするもの。
これは「ブラックリスト」アプローチと逆の手法であり、利用が許されてない文字を除去する。
ファイル名が無効の場合は、拒否するか、無効な文字を置き換えますが、取り除くわけではない。ファイルアップロードで実行可能なコードを送り込む
アップロードされたファイルに含まれるソースコードが特定のディレクトリに置かれると、ソースコードが実行可能になってしまう可能性がある。
Railsの/publicディレクトリがApacheのホームディレクトリになっている場合は、ここにアップロードファイルを置いてはいけない。広く使われているApache WebサーバーにはDocumentRootというオプションがある。
これはWebサイトのホームディレクトリであり、このディレクトリツリーに置かれているものはすべてWebサーバーによって取り扱われる。
そこに置かれているファイルの名前に特定の拡張子が与えられていると、それに対してリクエストが送信された時に実行されてしまうことがある。
実行される可能性のある拡張子は、たとえばPHPやCGIなど。
攻撃者が「file.cgi」というファイルをアップロードし、その中に危険なコードが仕込まれているとする。
このファイルを誰かがダウンロードすると、このコードが実行される。ApacheのDocumentRootがRailsの/publicディレクトリを指している場合、アップロードファイルをここに置かない。
少なくとも1階層上に保存する必要がある。ファイルのダウンロード
ユーザーが任意のファイルをダウンロードできる状態を作らないこと。
ファイルアップロード時にファイル名のフィルタが必要になるのと同様、ファイルのダウンロード時にもファイル名をフィルタする必要がある。
以下のsend_file()メソッドは、サーバーからクライアントにファイルを送信します。フィルタ処理されていないファイル名を使うと、ユーザーが任意のファイルをダウンロードできるようになってしまう。send_file('/var/www/uploads/' + params[:filename])「../../../etc/passwd」のようなファイル名を渡せば、サーバーのログイン情報をダウンロードできてしまう。
これに対するシンプルな対応策は、リクエストされたファイル名が、想定されているディレクトリの下にあるかどうかをチェックすること。その他に、ファイル名をデータベースに保存しておき、データベースのidをサーバーのディスク上に置く実際のファイル名の代りに使う方法も併用できる。
この方法も、アップロードファイルが実行される可能性を回避する方法として優れている。
attachment_fuプラグインでも同様の手法が採用されている。イントラネットAdminのセキュリティ
イントラネットおよび管理画面インターフェイスは、強い権限が許されているため、何かと攻撃の目標にされがち。
イントラネットおよび管理画面インターフェイスには、他よりも手厚いセキュリティ対策が必要ですが、現実には逆にむしろこれらの方がセキュリティ対策が薄いということがしばしばある。イントラネットや管理アプリケーションにとって最も脅威なのはXSSとCSRF。
XSS: 悪意のあるユーザーがイントラネットの外から入力したデータがWebアプリケーションで再表示されると、WebアプリケーションがXSS攻撃に対して脆弱になる。
ユーザー名、コメント、スパムレポート、注文フォームの住所のような情報すらXSS攻撃に使われることがある。管理画面やイントラネットで1箇所でもサニタイズ漏れがあれば、アプリケーション全体が脆弱になる。
想定される攻撃としては、管理者のcookieの盗み出し、管理者パスワードを盗み出すためのiframe注入、管理者権限奪取のためにブラウザのセキュリティホールを経由して邪悪なソフトウェアをインストールする、などが考えられる。CSRF: クロスサイトリクエストフォージェリ (Cross-Site Request Forgery) はクロスサイトリファレンスフォージェリ (XSRF: Cross-Site Reference Forgery) とも呼ばれ、非常に強力な攻撃手法。
この攻撃を受けると、管理者やイントラネットユーザーができることをすべて行えるようになってしまう。RailsのURLはかなり構造が素直であるため、オープンソースの管理画面を使っていると構造を容易に推測できてしまう。
攻撃者は、ありそうなIDとパスワードの組み合わせを総当りで試す危険なImageタグを送り込むだけで、数千件ものまぐれ当たりを獲得することもある。その他予防策
管理画面は、多くの場合次のような作りになっている。www.example.com/admin のようなURLに置かれ、Userモデルのadminフラグがセットされている場合に限り、ここにアクセスできる。
ユーザー入力が管理画面で再表示されると、管理者の権限でどんなデータでも削除/追加/編集できてしまう。常に最悪の事態を想定することは極めて重要。
「誰かが自分のcookieやユーザー情報を盗み出すことができたらどうなるか」。
管理画面にロール (role)を導入することで、攻撃者が行える操作の範囲を狭めることができる。
1人の管理者に全権を与えるのではなく、権限を複数管理者で分散する方法や、管理画面用に特別なログイン情報を別途設置するという方法もある。
一般ユーザーが登録されているUserモデルに管理者も登録し、管理者フラグで分類していると攻撃されやすいことから、これを避けるため。
極めて重要な操作では別途特殊なパスワードを要求する方法もある。管理者は、必ずしも世界中どこからでもそのWebアプリケーションにアクセスできる必要性はないはず。
送信元IPアドレスを一定の範囲に制限するという方法。request.remote_ipメソッドを使えばユーザーのIPアドレスをチェックできる。
この方法は攻撃に対する直接の防御にはならないが、検問としては非常に有効。
ただし、プロキシを用いて送信元IPアドレスを偽る方法がある。管理画面を特別なサブドメインに置き ( admin.application.com など)、さらに管理アプリケーションを独立させてユーザー管理を独自に行えるようにする。
このような構成にすることで、通常の www.application.com ドメインからの管理者cookieを盗み出すことは不可能。
ブラウザには同一生成元ポリシーがあるので www.application.com に注入されたXSSスクリプトからはadmin.application.comのcookieは読み出せず、逆についても同様に読み出し不可となる。ユーザー管理
認証 (authentication) と認可 (authorization) はほぼすべてのWebアプリケーションにおいて不可欠。
認証システムは自前で作るよりも、広く使われているプラグイン (訳注: 現在ならgem) を使うべき。
ただし、常に最新の状態にアップデートするようにする。Railsでは多数の認証用プラグインを利用できる。
人気の高いdeviseやauthlogicなどの優れたプラグインは、パスワードを平文ではなく常に暗号化した状態で保存する。
Rails 3.1では、同様の機能を持つビルトインのhas_secure_passwordメソッドを使える。新規ユーザーは必ずメール経由でアクティベーションコードを受け取り、メール内のリンク先でアカウントを有効にするようになっている。
アカウントが有効になると、データベース上のアクティベーションコードのカラムはNULLに設定される。
以下のようなURLをリクエストするユーザーは、データベースで見つかる最初に有効になったユーザーとしてWebサイトにログインできてしまう可能性がある。そしてそれがたまたま管理者である可能性もありえる。http://localhost:3006/user/activate http://localhost:3006/user/activate?id=一部のサーバーでは、params[:id]で参照されるパラメータidがnilになってしまっていることがあるため、上のURLが通用してしまう可能性がある。アクティベーション操作中にこのことが敵に突き止められるまでの流れは以下のとおり。
User.find_by_activation_code(params[:id])パラメータがnilの場合、以下のSQLが生成される。
SELECT * FROM users WHERE (users.activation_code IS NULL) LIMIT 1この結果、データベースに実在する最初のユーザーが検索で見つかり、結果が返されてログインされてしまう。
アカウントに対する総当たり攻撃
アカウントに対する総当たり攻撃 (Brute-force attack) とは、ログイン情報に対して試行錯誤を繰り返す攻撃。
エラーメッセージを具体的でない、より一般的なものにすることで回避可能 だが、CAPTCHA (相手がコンピュータでないことを確認するためのテスト) への情報入力の義務付けも必要。Webアプリケーション用のユーザー名リスト (名簿) は、パスワードへの総当たり攻撃に悪用される可能性がある。
パスワードがユーザー名と同じなど、単純極まりないパスワードを使っている人が驚くほど多いため、総当たり攻撃にこうした名簿が利用されやすい。
辞書に載っている言葉に数字を混ぜた程度の弱いパスワードが使われていることもよくある。
従って、名簿と辞書を使って総当り攻撃を行なう自動化プログラムがあれば、ものの数分でパスワードを見破られている。このような総当たり攻撃を少しでもかわすため、多くのWebアプリケーションではわざと具体的な情報を出さずに「ユーザー名またはパスワードが違います」という一般的なエラーメッセージを表示するようにしている。
ユーザー名とパスワードどちらが違っているのかという情報を表示しないことで、総当たり攻撃による推測を少しでも遅らせる。
「入力されたユーザー名は登録されていません」などという絶好の手がかりとなるメッセージを表示したら最後、攻撃者はすぐさまユーザー名リストを大量にかき集めて自動で巨大名簿を作成する。しかし、Webアプリケーションのデザイナーがおろそかにしがちなのは、いわゆる「パスワードを忘れた場合」ページ。
こうしたページではよく「入力されたユーザー名またはメールアドレスは登録されていません」という情報が表示される。
こうした情報を表示してしまうと、攻撃者がアカウントへの総当り攻撃に使う有効なユーザー名一覧を作成するのに利用されてしまう。これを少しでも緩和するには、「パスワードを忘れた場合」ページでも一般的なエラーメッセージを表示するようにする。
さらに特定のIPアドレスからのログインが一定回数以上失敗した場合には、CAPTCHAの入力をユーザーに義務付けるようにする。
もちろん、この程度では自動化された総当たり攻撃プログラムからの攻撃から完全に逃れることはできない。
こうしたプログラムは送信元IPアドレスを頻繁に変更するぐらいのことはやってのけるから。
しかしこの対策は攻撃に対するある程度の防御になることも確か。アカウントのハイジャック
多くのWebアプリケーションでは、ユーザーアカウントを簡単にハイジャックできてしまう。
パスワード
攻撃者が、盗み出されたユーザーセッションcookieを手に入れ、それによってWebアプリケーションが標的ユーザーとの間で共用可能になった状態を考えてみる場合。
パスワードが簡単に変更できる画面設計(古いパスワードの入力が不要)であれば、攻撃者は数クリックするだけでアカウントをハイジャックできてしまう。
あるいは、パスワード変更画面がCSRF攻撃に対して脆弱な作りになっている場合、攻撃者は標的ユーザーを別のWebページに誘い込み、CSRFを実行するように仕込まれたimgタグを踏ませて、標的ユーザーのWebパスワードを変更する。
対応策としては、パスワード変更フォームがCSRF攻撃に対して脆弱にならないようにすること。
同時に、ユーザーにパスワードを変更させる場合は、古いパスワードを必ず入力させること。メール
しかし攻撃者は、登録されているメールアドレスを変更することでアカウントを乗っ取ろうとする可能性もある。
攻撃者は、メールアドレス変更に成功すると「パスワードを忘れた場合」ページに移動し、攻撃者の新しいメールアドレスに変更通知メールを送信する。
システムによってはこのメールに新しいパスワードが記載されていることもある。
対応策は、メールアドレスを変更する場合にもパスワード入力を必須にすること。その他
Webアプリケーションの構成によっては、ユーザーアカウントをハイジャックする方法が他にも潜んでいる可能性がある。
多くの場合、CSRFとXSSが原因となる。
GMailのCSRF脆弱性で紹介されている例をとりあげる。
同記事の概念実証によると、この攻撃を受けた場合、標的ユーザーは攻撃者が支配するWebサイトに誘い込まれる。
そのサイトのImgタグには仕掛けがあり、GMailのフィルタ設定を変更するHTTP GETリクエストがそこから送信される。
この標的ユーザーがGMailにログインしていた場合、フィルタ設定が攻撃者によって変更され、この場合はすべてのメールが攻撃者に転送されるようになる。
この状態は、アカウント全体がハイジャックされたのと同じぐらいに有害。
対応策は、アプリケーションのロジックを見なおしてXSSやCSRF脆弱性を完全に排除すること。CAPTCHA
CAPTCHAとは、コンピュータによる自動応答でないことを確認するためのチャレンジ-レスポンス式テスト。
コメント入力欄などで、歪んだ画像に表示されている文字を入力させることで、入力者が自動スパムボットでないことを確認する場合によく使われる。
ネガティブCAPTCHAという手法を使えば、入力者に自分が人間であることを証明させるかわりに、ボットを罠にはめて正体を暴くことができる。CAPTCHAのAPIとしてはreCAPTCHAが有名。
これは古書から引用した単語を歪んだ画像として表示する。
初期のCAPTCHAでは背景を歪めたり文字を曲げたりしていましたが、後者は突破されたため、現在では文字の上に曲線も書き加えて強化している。
なお、reCAPTCHAは古書のデジタル化にも使える。
ReCAPTCHAはRailsのプラグインにもなっており、APIとして同じ名前が使われている。このAPIからは公開鍵と秘密鍵の2つの鍵を受け取る。
これらはRailsの環境に置く必要がある。
それにより、ビューでrecaptcha_tagsメソッドを、コントローラではverify_recaptchaメソッドをそれぞれ利用できる。
検証に失敗するとverify_recaptchaからfalseが返される。CAPTCHAの問題は、ユーザーエクスペリエンスを多少損ねること。
さらに、弱視など視力に問題のあるユーザーはCAPTCHAの歪んだ画像をうまく読めないこともある。
なおポジティブCAPTCHAは、ボットによるあらゆるフォーム自動送信を防ぐ優れた方法のひとつ。ほとんどのボットは、単にWebページをクロールしてフォームを見つけてはスパム文を入力するだけのお粗末なもの。
ネガティブCAPTCHAではこれを逆手に取り、フォームに「ハニーポット」フィールドを置いておく。
これは、CSSやJavaScriptを用いて人間には表示されないように設定されたダミーのフィールド。ネガティブCAPTCHAが効果を発揮するのはWebをクロールする自動ボットからの保護のみであり、重要なサイトに狙いを定めるボットを防ぐのには不向き。
しかしネガティブCAPTCHAとポジティブCAPTCHAをうまく組み合わせればパフォーマンスを改善できることがある。
たとえば「ハニーポット」フィールドに何か入力された(=ボットが検出された)場合はポジティブCAPTCHAの検証は不要になり、レスポンス処理の前にGoogle ReCapchaにHTTPSリクエストを送信せずに済む。JavaScriptやCSSを用いてハニーポットフィールドを人間から隠す方法。
ハニーポットフィールドを画面の外に追いやってユーザーから見えないようにする
フィールドを目に見えないくらい小さくしたり、背景と同じ色にしたりする
ハニーポットフィールドをあえて隠さず、「このフィールドには何も入力しないでください」と表示する
最もシンプルなネガティブCAPTCHAは、「ハニーポット」フィールドを1つ使う。
このフィールドはサーバー側でチェックする。
フィールドに何か書き込まれていれば、入力者はボットであると判定できる。
後はフォームの内容を無視するなり、通常通りメッセージを表示する(データベースには保存しない)などすればよい。
通常のメッセージをもっともらしく表示しておけば、ボットは書き込み失敗に気が付かないまま満足して次の獲物を探す。Ned Batchelderのブログ記事には、さらに洗練されたネガティブCAPTCHA手法がいくつか紹介されている。
現在のUTCタイムスタンプを含めたフィールドをフォームに含めておき、サーバー側でこのフィールドをチェックする。
フィールドの時刻が遠い過去や未来の時刻であれば、そのフォームは無効。
フィールド名をランダムに変更します
送信ボタンを含むあらゆる型の数だけハニーポットフィールドを複数用意。
この方法で防御できるのは自動ボットだけであり、狙いを定めて特別に仕立てられたボットは防げない。
つまり、ネガティブキャプチャはログインフォームの保護には必ずしも向いているとは限らない。ログ出力
パスワードをRailsのログに出力しないこと。
デフォルトでは、RailsのログにはWebアプリケーションへのリクエストがすべて出力される。
しかしログファイルにはログイン情報、クレジットカード番号などの情報が含まれていることがあるため、重大なセキュリティ問題の原因になることがある。
Webアプリケーションのセキュリティコンセプトを設計するときには、攻撃者がWebサーバーへのフルアクセスに成功してしまった場合のことも必ず考慮に含めておく必要がある。
パスワードや機密情報をログファイルに平文のまま出力してしまうと、データベース上でこれらの情報を暗号化する意味がなくなってしまう。
Railsアプリケーションの設定ファイル config.filter_parameters に特定のリクエストパラメータをログ出力時にフィルタする設定を追加できる。
フィルタされたパラメータはログ内で[FILTERED]という文字に置き換えられる。config.filter_parameters << :password指定したパラメータは正規表現の「部分マッチ」によって除外される。
Railsはデフォルトで:passwordを適切なイニシャライザ(initializers/filter_parameter_logging.rb)に追加し、アプリケーションの典型的なpasswordパラメータやpassword_confirmationパラメータに配慮する。正規表現
Rubyの正規表現で落とし穴になりやすいのは、より安全な\Aや\zがあることを知らずに危険な^や$を使ってしまうこと。
Rubyの正規表現では、文字列の冒頭や末尾にマッチさせる方法が他の言語と若干異なる。
このため、多くのRuby本やRails本でもこの点について間違った記載がある。
たとえば、URL形式になっているかどうかをざっくりと検証するために、以下のような単純な正規表現を使ったとする。/^https?:\/\/[^\n]+$/iこれは一部の言語では正常に動作する。
しかし、Rubyでは^や$は、入力全体の冒頭と末尾ではなく、「 行の」冒頭と末尾にマッチしてしまう。
従って、この場合以下のような毒入りURLはフィルタを通過してしまう。javascript:exploit_code();/* http://hi.com */上のURLがフィルタに引っかからないのは、入力の2行目にマッチしてしまうため。
従って、1行目と3行目にどんな文字列があってもフィルタを通過してしまう。
フィルタをすり抜けてしまったURLが、今度はビューの以下の箇所で表示されたとする。link_to "Homepage", @user.homepage表示されるリンクは一見無害に見えますが、クリックすると、攻撃者が送り込んだ邪悪なJavaScript関数を初めとするJavaScriptコードが実行されてしまう。
これらの正規表現に含まれる危険な^や$は、安全な\Aや\zに置き換える必要がある。
/\Ahttps?:\/\/[^\n]+\z/i^や$をうっかり使ってしまうミスが頻発したため、Railsのフォーマットバリデータ(validates_format_of) では、正規表現の冒頭の^や末尾の$に対して例外を発生するようになった。
めったにないと思われるが、\Aや\zの代りに^や$をどうしても使いたい場合は、:multilineオプションをtrueに設定することもできる。# この文字列のどの行にも"Meanwhile"という文字が含まれている必要がある validates :content, format: { with: /^Meanwhile$/, multiline: true }この機能は、フォーマットバリデータ利用時に起きがちなミスから保護するだけのものであり、それ以上のものではない点にご注意。
^や$はRubyでは 1つの行 に対してマッチし、文字列全体にはマッチしないということを開発者が十分理解しておくことが重要。権限昇格
パラメータが1つ変更されただけでも、ユーザーが不正な権限でアクセスできるようになってしまうことがある。
パラメータは、たとえどれほど難読化し、隠蔽したとしても、変更される可能性が常にあることを肝に銘じる。改ざんされる可能性が高いパラメータといえばid。http://www.domain.com/project/1の1がid。
このidはコントローラのparamsを経由して取得できる。
コントローラ内では多くの場合、次のようなコードが使われている可能性がある。@project = Project.find(params[:id])このコードで問題がないWebアプリケーションもあるにはあるが、そのユーザーがすべてのビューを参照する権限を持っていない場合には問題となる。
このユーザーがURLのidを42に変更し、本来のidでは表示できないページを表示できてしまうため。
このようなことにならないよう、ユーザーのアクセス権も必ずクエリに含める。@project = @current_user.projects.find(params[:id])Webアプリケーションによっては、ユーザーが改ざん可能なパラメータが他にも潜んでいる可能性がある。
要するに、安全確認が終わっていないユーザー入力が安全である可能性はゼロであり、ユーザーから送信されるいかなるパラメータであっても、何らかの操作が加えられている可能性が常にあるということ。難読化とJavaScriptによる検証のセキュリティだけでお茶を濁してはいけない。
ブラウザのWeb Developer Toolbarを使えば、フォームの隠しフィールドを見つけて変更することもできる。
JavaScriptを使ってユーザーの入力データを検証することはできても、攻撃者が想定外の値を与えて邪悪なリクエストを送信することは阻止しようがない。
Mozilla Firefox用のFirebugアドオンを使えば、すべてのリクエストをログに記録して、リクエストを繰り返し送信することも、リクエストを変更することもできてしまう。
さらに、JavaScriptによる検証はブラウザのJavaScriptをオフにするだけで簡単にバイパスできてしまう。
さらに、クライアントやインターネットのあらゆるリクエストやレスポンスを密かに傍受するプロキシがクライアント側に潜んでいる可能性すらある。インジェクション
インジェクション (注入) とは、Webアプリケーションに邪悪なコードやパラメータを導入して、そのときのセキュリティ権限で実行させること。
XSS (クロスサイトスクリプティング) やSQLインジェクションはインジェクションの顕著な例。インジェクションによって注入されるコードやパラメータは、あるコンテキストではきわめて有害であっても、それ以外のほとんどのコンテキストでは無害。
その意味で、インジェクションは非常にトリッキーであると言える。
ここでいうコンテキストとは、スクリプティング、クエリ、プログラミング言語、シェル、RubyやRailsのメソッドなどがある。ホワイトリスト方式とブラックブラックリスト方式
通常、サニタイズや保護や検証では、ブラックリスト方式よりもホワイトリスト方式が望ましい方法。
ブラックリストに使われるのは、有害なメールアドレス、publicでないアクション、邪悪なHTMLタグなど。
ホワイトリストはこれと真逆で、有害ではないメールアドレス、publicなアクション、無害なHTMLタグなどがホワイトリストになる。
スパムフィルタなど、対象によってはホワイトリストを作成しようがないこともあるが、基本的にホワイトリスト方式を使う。セキュリティに関連するbefore_actionでは、except: [...]ではなくonly: [...]を使う。
なぜなら将来コントローラにアクションを追加するときにセキュリティチェックを忘れずに済むため。
クロスサイトスクリプティング (XSS) 対策として」という文字列の攻撃能力は失われていない。
だからこそ、ホワイトリストを用いるフィルタリングをおすすめする。
ホワイトリストによるフィルタは、Rails 2でアップデートされたsanitize()メソッドで使われている。tags = %w(a acronym b strong i em li ul ol h1 h2 h3 h4 h5 h6 blockquote br cite sub sup ins p) s = sanitize(user_input, tags: tags, attributes: %w(href title))この方法なら指定されたタグのみが許可されるため、あらゆる攻撃方法や邪悪なタグに対してフィルタが健全に機能する。
第2段階として、Webアプリケーションからの出力をもれなくエスケープすることが優れた対策。これは特に、ユーザー入力の段階でフィルタされなかった文字列がWeb画面に再表示されてしまうようなことがあった場合に有効。escapeHTML() (または別名のh()) メソッドを用いて、HTML入力文字「&」「"」「<」「>」を、無害なHTML表現形式(&、"、<、>) に置き換える。
攻撃の難読化とエンコーディングインジェクション
従来のネットワークトラフィックは西欧文化圏のアルファベットがほとんどであったが、それ以外の言語を伝えるためにUnicodeなどの新しいエンコード方式が使われるようになってきた。
しかしこれはWebアプリケーションにとっては新たな脅威となるかもしれない。
異なるコードでエンコードされた中に、ブラウザでは処理可能だがサーバーでは処理されないような悪意のあるコードが潜んでいるかもしれないため。UTF-8による攻撃方法の例。<IMG SRC=javascript:a lert('XSS')>上の例を実行するとメッセージボックスが表示される。
なお、これは上のsanitize()フィルタで認識される。
Hackvertorは文字列の難読化とエンコードを行なう優れたツールであり、「敵を知る」のに最適。
Railsのsanitize()メソッドは、このようなエンコーディング攻撃をかわす。CSSインジェクション
CSSインジェクションは実際にはJavaScriptのインジェクション。
MySpace Samyワームは、攻撃者であるSamyのプロファイルページを開くだけで自動的にSamyに友達リクエストを送信するというもの。
MySpaceでは多くのタグをブロックしていたが、CSSについては禁止していなかったため、ワームの作者はCSSに以下のようなJavaScriptを仕込んだ。
<div style="background:url('javascript:alert(1)')">ここでスクリプトの正味の部分(ペイロード)はstyle属性に置かれる。
一重引用符と二重引用符が既に両方使われているので、このペイロードでは引用符を使えない。
しかしJavaScriptにはどんな文字列もコードとして実行できてしまう便利なeval()関数がある。
この関数は強力だが危険。<div id="mycode" expr="alert('hah!')" style="background:url('javascript:eval(document.all.mycode.expr)')">eval()関数はブラックリスト方式の入力フィルタを実装した開発者にとってはまさに悪夢。
この関数を使われてしまうと、たとえば以下のように「innerHTML」という単語をstyle属性に隠しておくことができてしまうため。alert(eval('document.body.inne' + 'rHTML'));次は、MySpaceは"javascript"という単語をフィルタしていたにもかかわらず、「javascript」と書くことでこのフィルタを突破された。
<div id="mycode" expr="alert('hah!')" style="background:url('java script:eval(document.all.mycode.expr)')">さらに次は、ワームの作者がCSRFセキュリティトークンを利用していた。
ワームの作者は、ユーザーが追加される直前にページに送信されたGETリクエストの結果を解析してCSRFトークンを手に入れていた。最終的に4KBサイズのワームができあがり、作者は自分のプロファイルページにこれを注入。
moz-bindingというCSSプロパティは、FirefoxなどのGeckoベースのブラウザではCSS経由でJavaScriptを注入する手段に使われる可能性があることが判明。
対応策
ブラックリストによる完璧なフィルタは決して作れません。
しかしWebアプリケーションでカスタムCSSを使える機能はめったにないため、これを効果的にフィルタできるホワイトリストCSSフィルタを見つけるのは難しい。
Webアプリケーションの色や画像をカスタマイズできるようにしたいのであれば、ユーザーに色や画像を選ばせ、Webアプリケーションの側でCSSをビルドするようにする。
ユーザーがCSSを直接カスタマイズできるような作りにはしない。
どうしても必要であれば、ホワイトリストベースのCSSフィルタとしてRailsのsanitize()メソッドを使う。テキスタイルインジェクション(Textile Injection)
セキュリティ上の理由からHTML以外のテキストフォーマット機能を提供するのであれば、何らかのマークアップ言語を採用し、それをサーバー側でHTMLに変換するようにする。
RedClothはRuby用に開発されたマークアップ言語の一種だが、注意して使わないとXSSに対しても脆弱になる。対応策
RedClothは必ずホワイトリストフィルタと組み合わせて使う。
Ajaxインクジェクション
Ajaxでも、通常のWebアプリケーション開発上で必要となるセキュリティ上の注意と同様の注意が必要。
1つ例外がある。
ページヘの出力は、アクションがビューをレンダリングしない場合であってもエスケープが必要。in_place_editorプラグインや、ビューをレンダリングする代りに文字列を返すようなアクションを使う場合は、アクションで返される値を確実にエスケープする必要がある。
もしXSSで汚染された文字列が戻り値に含まれていると、ブラウザで表示されたときに悪意のあるコードが実行されてしまう。
入力値はすべてh()メソッドでエスケープする。コマンドラインインクジェクション
ユーザーが入力したデータをコマンドラインのオプションに使う場合は十分に注意が必要。
Webアプリケーションが背後のOSコマンドを実行しなければならない場合、Rubyにはexec(コマンド)、syscall(コマンド)、system(コマンド)、そしてバッククォート記法という方法が用意されている。
特に、これらのコマンド全体または一部を入力できる可能性に注意が必要。
ほとんどのシェルでは、コマンドにセミコロン;や垂直バー|を追加して別のコマンドを簡単に結合できてしまう。対応策は、コマンドラインのパラメータを安全に渡せるsystem(コマンド, パラメータ)メソッドを使うこと。
system("/bin/echo","hello; rm *") # "hello; rm *"を実行してもファイルは削除されないヘッダーインクジェクション
HTTPヘッダは動的に生成されるものであり、特定の状況ではヘッダにユーザー入力が注入されることがある。
これを使って、にせのリダイレクト、XSS、HTTPレスポンス分割攻撃が行われる可能性がある。HTTPリクエストヘッダで使われているフィールドの中にはReferer、User-Agent (クライアント側ソフトウェア)、Cookieフィールドがありまる。
Responseヘッダーには、たとえばステータスコード、Cookieフィールド、Locationフィールド (リダイレクト先を表す) がある。
これらのフィールド情報はユーザー側から提供されるものであり、さほど手間をかけずに操作できてしまう。
これらのフィールドもエスケープする。
エスケープが必要になるのは、管理画面でUser-Agentヘッダを表示する場合などが考えられる。さらに、ユーザー入力の一部を取り入れたレスポンスヘッダを生成する場合は、何が行われているのかを正確に把握することが重要。
たとえば、ユーザーを特定のページにリダイレクトしてから元のページに戻したいとする。
このとき、refererフィールドをフォームに導入して、指定のアドレスにリダイレクトしたとする。redirect_to params[:referer]このとき、Railsはその文字列をLocationヘッダフィールドに入れて302(リダイレクト)ステータスをブラウザに送信する。
悪意のあるユーザーがこのとき最初に行なうのは、以下のような操作。http://www.yourapplication.com/controller/action?referer=http://www.malicious.tldRails 2.1.2より前のバージョン(およびRuby)に含まれるバグが原因で、ハッカーが以下のように任意のヘッダを注入できてしまう可能性がある。
http://www.yourapplication.com/controller/action?referer=http://www.malicious.tld%0d%0aX-Header:+Hi! http://www.yourapplication.com/controller/action?referer=path/at/your/app%0d%0aLocation:+http://www.malicious.tld上のURLにおける%0d%0aは\r\nがURLエンコードされたものであり、RubyにおけるCRLF文字。
2番目の例では2つ目のLocationヘッダーフィールドが1つ目のものを上書きするため、以下のようなHTTPヘッダーが生成される。HTTP/1.1 302 Moved Temporarily (...) Location: http://www.malicious.tldヘッダーインジェクションにおける攻撃方法とは、ヘッダーにCRLF文字を注入すること。
攻撃者は偽のリダイレクトでどんなことができてしまうのか。
攻撃者は、ユーザーをフィッシングサイトにリダイレクトし(フィッシングサイトの見た目は本物そっくりに作っておきます)、ユーザーを再度ログインさせてそのログイン情報を攻撃者に送信する可能性がある。
あるいは、フィッシングサイトからブラウザのセキュリティホールを経由して邪悪なソフトウェアを注入するかもしれない。
Rails 2.1.2ではredirect_toメソッドのLocationフィールドからこれらの文字をエスケープするようになった。
ユーザー入力を用いて通常以外のヘッダーフィールドを作成する場合には、CRLFのエスケープを必ず自分で実装する。レスポンス分割
ヘッダーインジェクションが実行可能になってしまっている場合、レスポンス分割(response splitting)攻撃も同様に実行可能になっている可能性がある。
HTTPのヘッダーブロックの後ろには2つのCRLFが置かれてヘッダーブロックの終了を示し、その後ろに実際のデータ(通常はHTML)が置かれる。
レスポンス分割とは、ヘッダーフィールドに2つのCRLFを注入し、その後ろに邪悪なHTMLを配置するという手法。
このときのレスポンスは以下のようになります。HTTP/1.1 302 Found [最初は通常の302レスポンス] Date: Tue, 12 Apr 2005 22:09:07 GMT Location: Content-Type: text/html HTTP/1.1 200 OK [ここより下は攻撃者によって作成された次の新しいレスポンス] Content-Type: text/html <html><font color=red>hey</font></html> [任意の邪悪な入力が Keep-Alive: timeout=15, max=100 リダイレクト先のページとして表示される] Connection: Keep-Alive Transfer-Encoding: chunked Content-Type: text/html特定の条件下で、この邪悪なHTMLが標的ユーザーのブラウザで表示されることがある。
ただし、おそらくKeep-Alive接続が有効になっていないとこの攻撃は効かない。
多くのブラウザはワンタイム接続を使っているため。
かといって、Keep-Aliveが無効になっていることを当てにするわけにはいかない。
これはいずれにしろ重大なバグであり、ヘッダーインジェクションとレスポンス分割の可能性を排除するため、Railsを2.0.5または2.1.2にアップグレードする必要がある。安全ではないクエリ生成
Rackがクエリパラメータを解析(parse)する方法とActive Recordがパラメータを解釈する方法の組み合わせに問題があり、where句がIS NULLのデータベースクエリを本来の意図に反して生成することが可能になってしまう。
(CVE-2012-2660、CVE-2012-2694 および CVE-2013-0155) のセキュリティ問題への対応として、Railsの動作をデフォルトでセキュアにするためにdeep_mungeメソッドが導入された。以下は、deep_mungeが実行されなかった場合に攻撃者に利用される可能性のある脆弱なコードの例。
unless params[:token].nil? user = User.find_by_token(params[:token]) user.reset_password! endparams[:token]が[nil]、[nil, nil, ...]、['foo', nil]のいずれかの場合、nilチェックをパスするにもかかわらず、where句がIS NULLまたはIN ('foo', NULL)になってSQLクエリに追加されてしまう。
Railsをデフォルトでセキュアにするために、deep_mungeメソッドは一部の値をnilに置き換える。
リクエストで送信されたJSONベースのパラメータがどのように見えるかを以下に表示。JSON Parameters { "person": null } { :person => nil } { "person": [] } { :person => [] } { "person": [null] } { :person => [] } { "person": [null, null, ...] } { :person => [] } { "person": ["foo", null] } { :person => ["foo"] }リスクと取扱い上の注意を十分理解している場合に限り、deep_mungeをオフにしてアプリケーションを従来の動作に戻すことができる。
config.action_dispatch.perform_deep_munge = falseデフォルトのヘッダー
Railsアプリケーションから受け取るすべてのHTTPレスポンスには、以下のセキュリティヘッダーがデフォルトで含まれている。
config.action_dispatch.default_headers = { 'X-Frame-Options' => 'SAMEORIGIN', 'X-XSS-Protection' => '1; mode=block', 'X-Content-Type-Options' => 'nosniff', 'X-Download-Options' => 'noopen', 'X-Permitted-Cross-Domain-Policies' => 'none', 'Referrer-Policy' => 'strict-origin-when-cross-origin' }デフォルトのヘッダー設定はconfig/application.rbで変更できる。
config.action_dispatch.default_headers = { 'Header-Name' => 'Header-Value', 'X-Frame-Options' => 'DENY' }以下のようにヘッダーを除去することもできる。
config.action_dispatch.default_headers.clearよく使われるヘッダーのリストを以下に示す。
X-Frame-Options: Railsではデフォルトで'SAMEORIGIN'が指定される。
このヘッダーは、同一ドメインでのフレーミングを許可。
'DENY'を指定するとすべてのフレーミングが不許可になる。
すべてのWebサイトについてフレーミングを許可するには'ALLOWALL'を指定。
X-XSS-Protection: Railsではデフォルトで'1; mode=block'が指定される。
XSS攻撃が検出された場合は、XSS Auditorとブロックページを使う。
XSS Auditorをオフにしたい場合は'0;'を指定します(レスポンスがリクエストパラメータからのスクリプトを含んでいる場合に便利)。
X-Content-Type-Options: 'nosniff'はRailsではデフォルト。
このヘッダーは、ブラウザがファイルのMIMEタイプを推測しないようにする。
X-Content-Security-Policy: このヘッダーは、コンテンツタイプを読み込む元のサイトを制御するための強力なメカニズム。
Access-Control-Allow-Origin: このヘッダーは、同一生成元ポリシーのバイパスとクロスオリジン(cross-origin)リクエストをサイトごとに許可する。
Strict-Transport-Security: このヘッダーは、ブラウザからサイトへの接続をセキュアなものに限って許可するかどうかを指定。Content Security Policy(CSP)
Railsでは、アプリケーションでContent Security Policy(CSP)を設定するためのDSLが提供されている。
グローバルなデフォルトポリシーを設定し、それをリソースごとにオーバーライドすることも、lambdaを用いてリクエストごとに値をヘッダーに注入することもできる(マルチテナントのアプリケーションにおけるアカウントのサブドメインなど)。以下はグローバルなポリシーの例。
# config/initializers/content_security_policy.rb Rails.application.config.content_security_policy do |policy| policy.default_src :self, :https policy.font_src :self, :https, :data policy.img_src :self, :https, :data policy.object_src :none policy.script_src :self, :https policy.style_src :self, :https # 違反レポートの対象URIを指定する policy.report_uri "/csp-violation-report-endpoint" end以下はコントローラでオーバーライドするコード例。
# ポリシーをインラインでオーバーライドする場合 class PostsController < ApplicationController content_security_policy do |p| p.upgrade_insecure_requests true end end # リテラル値を使う場合 class PostsController < ApplicationController content_security_policy do |p| p.base_uri "https://www.example.com" end end # 静的値と動的値を両方使う場合 class PostsController < ApplicationController content_security_policy do |p| p.base_uri :self, -> { "https://#{current_user.domain}.example.com" } end end # グローバルCSPをオフにする場合 class LegacyPagesController < ApplicationController content_security_policy false, only: :index endレガシーなコンテンツを移行するときにコンテンツの違反だけをレポートしたい場合は、設定でcontent_security_policy_report_only属性を用いてContent-Security-Policy-Report-Onlyを設定。
# config/initializers/content_security_policy.rb Rails.application.config.content_security_policy_report_only = true # コントローラでオーバーライドする場合 class PostsController < ApplicationController content_security_policy_report_only only: :index end以下の方法でnonceの自動生成を有効にできる。
# config/initializers/content_security_policy.rb Rails.application.config.content_security_policy do |policy| policy.script_src :self, :https end Rails.application.config.content_security_policy_nonce_generator = -> request { SecureRandom.base64(16) }後は以下のようにhtml_optionsの中でnonce: trueを渡せばnonce値が自動的に追加される。
<%= javascript_tag nonce: true do -%> alert('Hello, World!'); <% end -%>javascript_include_tagでも同じことができる。
<%= javascript_include_tag "script", nonce: true %>セッションごとにインライン
- 投稿日:2020-05-16T19:11:34+09:00
Ruby と Python と Java で解く AtCoder ABC141 D 優先度付きキュー
はじめに
AtCoder Problems の Recommendation を利用して、過去の問題を解いています。
AtCoder さん、AtCoder Problems さん、ありがとうございます。今回のお題
AtCoder Beginner Contest D - Powerful Discount Tickets
Difficulty: 826今回のテーマ、優先度付きキュー
Ruby
操作自体はシンプルで、一番値段の高い品物をキューから取り出し、割引券を一枚適用してキューに戻します。その都度、一番値段の高い品物ついて同様の操作を割引券がなくなるまで行います。
但し、次の様に単にソートするだけの実装では、TLEになります。ruby_tle.rbn, m = gets.split.map(&:to_i) a = gets.split.map(&:to_i) a.sort_by!{|x| -x} m.times do b = a.shift b /= 2 a << b a.sort_by!{|x| -x} end puts a.inject(:+)優先度付きキューは、ソートに比べて少ない計算量で一番値段の高い品物を調べることができます。
Python ですとheapq、Java ですとPriorityQueueになりますが、Ruby には無いので、Ruby で Priority Queue を実装してみたい のコードをお借りして、少々修正して通しました。ruby.rbclass PriorityQueue def initialize(array = []) @data = [] array.each{|a| push(a)} end def push(element) @data.push(element) bottom_up end def pop if size == 0 return nil elsif size == 1 return @data.pop else min = @data[0] @data[0] = @data.pop top_down return min end end def size @data.size end private def swap(i, j) @data[i], @data[j] = @data[j], @data[i] end def parent_idx(target_idx) (target_idx - (target_idx.even? ? 2 : 1)) / 2 end def bottom_up target_idx = size - 1 return if target_idx == 0 parent_idx = parent_idx(target_idx) while (@data[parent_idx] > @data[target_idx]) swap(parent_idx, target_idx) target_idx = parent_idx break if target_idx == 0 parent_idx = parent_idx(target_idx) end end def top_down target_idx = 0 while (has_child?(target_idx)) a = left_child_idx(target_idx) b = right_child_idx(target_idx) if @data[b].nil? c = a else c = @data[a] <= @data[b] ? a : b end if @data[target_idx] > @data[c] swap(target_idx, c) target_idx = c else return end end end # @param Integer # @return Integer def left_child_idx(idx) (idx * 2) + 1 end # @param Integer # @return Integer def right_child_idx(idx) (idx * 2) + 2 end # @param Integer # @return Boolent def has_child?(idx) ((idx * 2) + 1) < @data.size end end n, m = gets.split.map(&:to_i) a = gets.split.map(&:to_i) e = a.map{|x| -x} b = PriorityQueue.new(e) m.times do c = b.pop b.push(-(-c / 2)) end ans = 0 while b.size > 0 ans -= b.pop end puts ansこれでもギリギリです。
Python
python.pyimport heapq import math n, m = map(int, input().split()) a = [-1 * int(i) for i in input().split()] heapq.heapify(a) for _ in range(m): b = heapq.heappop(a) heapq.heappush(a, math.ceil(b / 2)) print(-1 * sum(a))Pythonの
heapqは最小値を取るものですので、マイナスの符号を付けて入れる必要があります。
また、//によるマイナスの割り算は絶対値の大きい方の値を返すので、ここではceilを使用しています。Java
java.javaimport java.util.*; class Main { public static void main(String[] args) { Scanner sc = new Scanner(System.in); int N = Integer.parseInt(sc.next()); int M = Integer.parseInt(sc.next()); PriorityQueue<Long> A = new PriorityQueue<>(Collections.reverseOrder()); for (int i=0; i<N; i++) { A.add(Long.parseLong(sc.next())); } sc.close(); for (int i=0; i<M; i++) { long new_price = (long)A.poll()/2; A.add(new_price); } long sum = 0; for (long a : A) { sum += a; } System.out.println(sum); } }PriorityQueue<Long> A = new PriorityQueue<>(Collections.reverseOrder());Java は
reverseOrder()で最大値に対応しています。
Ruby Python Java コード長 (Byte) 1933 230 673 実行時間 (ms) 1981 163 476 メモリ (KB) 14004 14536 50024 まとめ
- ABC 141 D を解いた
- Ruby に詳しくなった
- Python に詳しくなった
- Java に詳しくなった
参照したサイト
Ruby で Priority Queue を実装してみたい
[ruby] Priority Queueの実装
- 投稿日:2020-05-16T18:17:34+09:00
Heroku + Sinatra でオウム返しのLINE Botを作るときに詰まったことメモ
LINE Botの開発に初めて挑戦してみました。
まずは簡単なモノから、ということでおうむ返しのLINE Botです。
「認識が違う」などの指摘がございましたら、教えていただけますと幸いです。Sinatraを使って LINE Botを作ってみる
Heroku+Ruby+SinatraでReplyにオウム返しするLineBotを作った
大枠はこちらの記事に沿ってやっていきました.
最後までいったものの、「返事が返ってこない」という状況になったのでその解決方法をメモとして残しておきます.
「返事が返ってこない」ことに対しての原因/やったこと
原因1:コード内に直接、トークンやチャンネルシークレットを入力していた
https://github.com/line/line-bot-sdk-ruby
LINE BotのSDKの中にこういった↓コードがあるのですが、僕は直接控えたTOKENなどを入力してしまっていました。
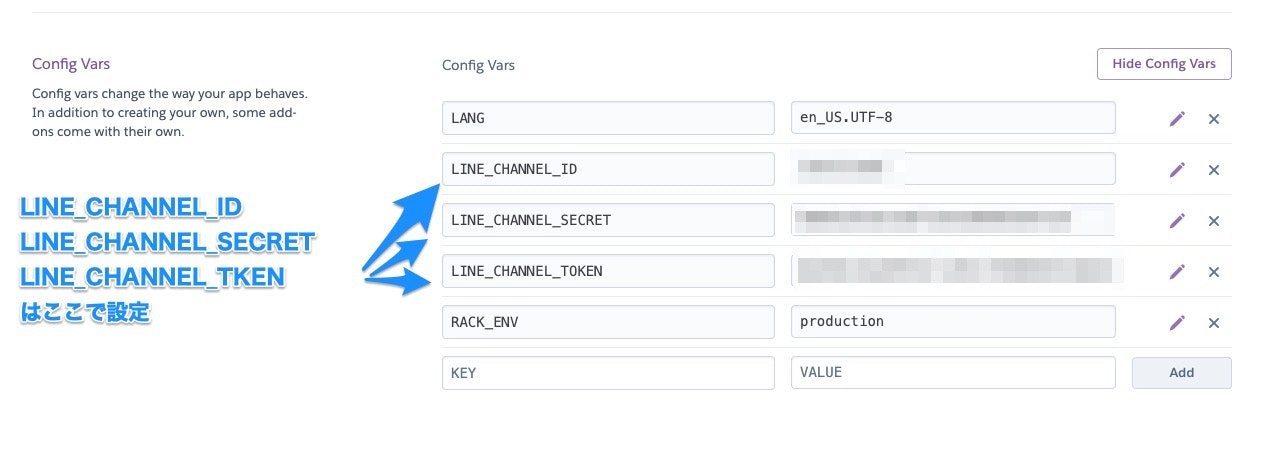
これは間違いで、Herokuの[Config Vars]で環境変数として設定するので、これはこのままで大丈夫でした。app.rb# app.rb require 'sinatra' require 'line/bot' def client @client ||= Line::Bot::Client.new { |config| # 以下3つに控えたID,SECRET,TOKENを入力していた.これはこのままでOK! config.channel_id = ENV["LINE_CHANNEL_ID"] config.channel_secret = ENV["LINE_CHANNEL_SECRET"] config.channel_token = ENV["LINE_CHANNEL_TOKEN"] } end↓↓Herokuの設定画面↓↓
ここでID, SECRET, TOKENを設定します
原因2:ローカルの変更をHerokuにpush(反映)していなかった
原因1を修正するために、ローカルでコードを変更しました。
その変更はローカルで変更しただけなので、Herokuにはその変更が反映されていませんでした。
よくみたらHerokunにもこんな記述がありました。
以下のコマンドを実行してHerokuにpushDeploy your changes
Make some changes to the code you just cloned and deploy them to Heroku using Git.$ git add .
$ git commit -am "make it better"
$ git push heroku masterこの2つを試すと、無事に返ってくるようになりました。
無事、完成
完成したけど、まだわからないこと
Herokuのadd onであるFixieは必要なのか??
試行錯誤する中で、以下の記事を見つけました。
記事を見てFixieを入れてみたものの、削除しても動いてるのでもうちょっと調べて行こうと思います。

- 投稿日:2020-05-16T17:26:03+09:00
fields_forはこうやって使う
手順
1.モデルの編集
item.rbhas_many :images accepts_nested_attributes_for :imagesimage.rbbelongs_to :item, optional: true #外部キーのnilを許可する mount_uploader :image, ImageUploader2.コントローラーの編集
item_controller.rbdef new @item = Item.new @item.images.build end def create @item = Item.new(item_params) redirect_to root_path end def edit @item = Item.find(params[:id]) end def update @item = Item.find(params[:id]) @item.update(update_item_params) redirect_to root_path end def item_params params.require(:item).permit(:name, :infomation, :price, images_attributes: [:image] ) end def update_item_params params.require(:item).permit(:name, :infomation, :price, images_attributes: [:image, :_destroy, :id] ) #編集時はdestroyとidを配列に入れておく必要がある end3.ビューの編集
<%= form_for @item do |f| %> <%= f.text.field :name %> <%= f.text.field :infomation %> <%= f.text.field :price %> <%= f.fields_for :image do |i| %> # 画像があれば表示する <%= image_tag(i.object.content) %> <%= i.file_field :image %> <%= f.submit %> <% end %>以上
- 投稿日:2020-05-16T17:19:30+09:00
Kernelモジュールについて
普段何気なく使っているputsは、なんでどういった仕組みで使えるんだろうと気になったので、調べてみました。
結論としては、Kernelモジュールが1枚噛んでいました。
Kernelモジュールが提供するメソッドputs p print require gets上記のようなメソッドは、Kernelモジュールで定義されているらしい。
String、Numeric、Array、Hashなどのクラスは、全てObjectクラスを継承しているみたいです。
親クラスの確認$ rails c >> String.superclass => Object >> Numeric.superclass => Object >> Array.superclass => Object >> Hash.superclass => Objectもともと、ほぼ全ての親クラスであるObjectクラス(superclassは、BasicObject)は、Kernelモジュールをincludeしているので、
putsメソッドを平然と何も考えなくとも、デフォルトでどのクラスでも使えるみたいです。以下に具体的に、Kernelモジュールで定義されているメソッドの一覧が載ってます。
- 投稿日:2020-05-16T16:41:41+09:00
Railsで7つの基本アクション以外の定義
基本アクションのおさらい
以下がRailsの標準アクションです
自分でアクションを定義する
上記の基本アクション以外の処理を行いたい場合は自身で定義することができます。
その際のルーティングの定義方法にはcollectionとmemberが使えます
Rails.application.routes.draw do resources :hoges do collection do HTTPメソッド 'オリジナルのメソッド名' end end endRails.application.routes.draw do resources :hoges do member do HTTPメソッド 'オリジナルのメソッド名' end end end違いとしては、生成されるルーティングにidが付くか、付か無いかです。
・collection → :idなし
・member → :idあり特定のページへ遷移する必要がある場合などは、memberを使うといった感じです。
そして、重要なのは、どこにメソッドの内容を記述するかです。
一般的に、開発現場などでも、テーブル(DB)とのやりとりに関するメソッドはモデルに記載するのが通例らしいです。
例えば、検索機能を実装したい時なんかはその処理を行うメソッドをモデルに書き、コントローラーで呼び出します(viewの検索フォームなどの記述は省略します)
使用例
routes.rbresources :tweets do collection do get 'search' end endtweet.rbclass Tweet < ApplicationRecord #省略 def self.search(search) return Tweet.all unless search Tweet.where('text LIKE(?)', "%#{search}%") end endtweets_controller.rbclass TweetsController < ApplicationController #省略 def search @tweets = Tweet.search(params[:keyword]) end endそれぞれを説明すると、
まず、searchアクションのルーティングを設定します。検索結果を表示するには、詳細ページに行く必要がなく、そのため、collectionを使っています。
formでユーザーが検索を行うと、controllerでsearchアクションからモデルに記述したsearchメソッドを呼び出します。その際、引数として検索結果を渡しています(params[:keyword])
検索結果はモデルのsearchメソッドの中で変数searchに代入されメソッド内で使用できるようになります。
処理の内容は、searchの中身が空なら全ての投稿を取得し、値が入っているならwhereメソッドの中身の条件式に一致した投稿を取得します。

- 投稿日:2020-05-16T16:21:10+09:00
�RubyのTime.parseに空文字列が指定された時に現時刻を返すようにモンキーパッチする
経緯
rubyを1.8.7から1.9.3にバージョン上げる時にTime.parseの引数に空文字列を指定すると例外が発生するようになっていました。
[EXCEPTION] ArgumentError:
dateに空文字列を与えた場合、発生します。 なお、1.9.2より前は例外は発生せず、現在時刻を表す Time のインスタンスを返していました。Ruby 1.9.2 リファレンスマニュアル Time.parse
Time.parseで空文字を指定している箇所が多すぎて修正が大変であったため、Time.parseにモンキーパッチを当てて解決することにしました。
結論
空文字列が指定されたらTime.nowを返して、それ以外は組み込みクラスのparseメソッドを呼ぶようなオーバライド的な処理にしました。
class Time class << self alias_method :__parse__, :parse private :__parse__ def parse(time) if time.empty? # 現時刻を返す Time.now else # 組み込みクラスTime.parseを呼ぶ __parse__(time) end end end endself.parseで定義しても可能です。
class Time class << self alias_method :__parse__, :parse private :__parse__ end def self.parse(time) if time.empty? # 現時刻を返す Time.now else # 組み込みクラスTime.parseを呼ぶ __parse__(time) end end end結論に至るまで
Timeのオーバライド
組み込みクラスのTimeを活かしつつ空文字列のチェックをしたかったので、Timeを継承してオーバライドすれば良いかなと思いました。
ですが、継承する時にクラス名を別名にして、Time.parse(arg)が使われている箇所をすべて新しいクラス名に変更する必要があります。
これでは本末転倒なので断念しました。Time.parseのモンキーパッチ
次にモンキーパッチを検討しました。
クックパッドさんでもモンキーパッチの対応があったため、こちらを参考にさせていただきました。(なるべくやるなと書いてありましたが。。)
Ruby on Rails アプリケーションにおけるモンキーパッチの当て方Timeの拡張クラスを用意して以下の様に定義しました。
※拡張クラスの作り方についてはクラスの拡張の記事を参照させていただきました。class Time def self.parse(time) if time.empty? Time.now else Time.parse(time) end end endですが、これではエラー。
拡張クラスのTime.parseがずっと呼ばれ無限ループ状況になってしまったので、これもNG。irb(main):002:0> Time.parse('2020-01-01 12:34:56') SystemStackError: stack level too deep from /usr/local/lib/ruby/1.9.1/irb/workspace.rb:80 Maybe IRB bug!Time.parseのモンキーパッチ & alias_methodの適用
先程のコードから拡張クラスのTime.parseを呼ぶ方法がないか調べて以下記事を参考にさせていだきました。
既存メソッドのオーバーライド
alias_methodを使って拡張クラスTimeのparseのメソッド名を__parse__に変更することで、先程の無限ループを回避できそうでした。
念の為、外部から呼ばれないようにprivateで定義します。class Time alias_method :__parse__, :parse private :__parse__ def self.parse(time) if time.empty? Time.now else Time.parse(time) end end endすると今度は
parseメソッドがないとエラーが出ます。
parseはクラスメソッドであるため、alias_medhodが適用できませんでした。bundle exec rails c `alias_method': undefined method `parse' for class `Time' (NameError)Time.parseのモンキーパッチ & alias_methodの適用(クラスメソッド)
クラスメソッドをalias_methodする方法について以下参考にさせていただきました。
クラスメソッドに alias を付ける
class << self内で
alias_methodを定義すれば適用できました。
最終形はこちらです。class Time class << self alias_method :__parse__, :parse private :__parse__ end def self.parse(time) if time.empty? Time.now else __parse__(time) end end end以下の様にparseメソッドをclass << self内で定義しても可能です。
その際はselfは不要です。class Time class << self alias_method :__parse__, :parse private :__parse__ def parse(time) if time.empty? Time.now else __parse__(time) end end end end最後に
いまさらrubyを1.8.7を使っている環境は少ないと思いますが、レガシーコードのバージョンアップ等で役に立てていただければと思います。
また、組み込みクラスのモンキーパッチの方法について参考にはなるかと思いますので、お役に立てたら幸いです。参考
Ruby 1.9.2 リファレンスマニュアル Time.parse
- 投稿日:2020-05-16T15:44:40+09:00
桁数は Math.log10(x).floor + 1 でいいのか
この記事は Ruby を前提とするが,多くの言語で似たようなことが言えると思う。
何の話?
正の整数
xが 10 進法で何桁になるか,を求めるやり方はいくつもある。
そのうちの一つがMath.log10(x).floor + 1なのだが,本当にこれで正しい答えが得られるのだろうか,という話。
数学が苦手でも,Ruby をあまり知らなくても分かるよう,なるべく丁寧に見ていく。しかし,結論だけを知りたい方は それでいいのか? の節にどうぞ。
桁数を求めるいろいろなやり方
この節では,ローカル変数
xに正の整数が代入されているとする。
Ruby はメモリーなどの条件が許せばどんな大きな整数も扱うことができる。文字列化
Ruby の整数(Integer クラス)には,N 進法で表した数字列を生成する Integer#to_s というメソッドがある。
引数を省略すると,10 進法の数字列が得られる。
p (36 + 72).to_s # => "108"一方,String クラスには,長さ(文字数)を数える String#length というメソッドがある。
p "Ruby".length # => 4これを組み合わせれば
x.to_s.lengthで桁数が得られる。
極めて簡単だ。しかし,ちょっとした不安がよぎる。桁数が知りたいだけなのに,10 万桁の整数に対し長さ 10 万の巨大文字列を作るのは,もしかして遅いのでは?
実はかなり高速なのだが,その話は置いておこう。桁ごとの数の配列を得る
Ruby には,非負整数(0 以上の整数)を N 進法で表したときの各桁の数を並べた配列を返す Integer#digits というメソッドがある。
引数を省略すると 10 進法となる。
p 1234.digits # => [4, 3, 2, 1]下の位から順に並べるので,見た目の順序は逆転している。
これと,配列の長さを返す Array#length を使えば
x.digits.lengthで桁数が得られる。
私なぞは,素人考えで「なんとなく文字列より整数のほうが処理が速そうだから,
x.to_s.lengthより速いんでは?」と思ってしまったが,そんなことはなかった。そりゃそうか。巨大が配列が作られるわけだしね。そして Math.log10(x).floor + 1
他にもやり方はあるが,本題の
Math.log10(x).floor + 1に行こう。なぜこれで
xの桁数が得られるのか?Math.log10 は,与えられた引数の常用対数の値を返すメソッド。
常用対数関数
y = \log_{10}xは 10 を底とする指数関数
x = 10^yの逆関数だったね。
この指数関数は,$y$ が整数のときは意味が分かりやすいけれど,任意の実数に対しても定義されている。$y$ が 0 以上の整数のときを見てみよう
$y = \log_{10}x$ $x = 10^y$ $0$ $1$ $1$ $10$ $2$ $100$ $3$ $1000$ $4$ $10000$ これを見れば,$y$ が 0 以上の整数のときは,$y + 1$ つまり $\log_{10}(x) + 1$ が桁数になることが分かる。
しかし,$y$ が整数になる $x$ は限られている。もっと一般の正の整数 $x$ についてはどうなるだろう?
ためしに,$x = 999$ を考えてみる。これは $1000$ よりちょっと小さい。
対数関数は単調増加($x$ が増えれば $y$ も増える)なので,$\log_{10}999$ は $3$ よりもちょっと小さいはずだ。
したがって,切り捨てで整数化すれば,$2$ が得られる。切り捨てに床関数というものを使おう。これは,半端を数直線の左(負の無限大)に向かって切り捨てる。
今の場合,負数は出てこないから「小数部の切り捨て」と考えても差し支えない1。さて,数学記号では,床関数を $\lfloor a \rfloor$ のように書くらしいが,以上の考察から,$x$ が $100$ 以上 $999$ 以下であるとき,
\lfloor \log_{10}x \rfloorは全て $2$ であることが分かる。
つまり,こんなふうになるんである。
$x$ $\lfloor \log_{10}x \rfloor$ $1$〜$9$ $0$ $10$〜$99$ $1$ $100$〜$999$ $2$ $1000$〜$9999$ $3$ $10000$〜$99999$ $4$ だから 1 を足した $\lfloor \log_{10}x \rfloor + 1$ で桁数が得られるというわけだ。数学的には,ね。
それでいいのか?
やっと核心に。
$\lfloor \log_{10}x \rfloor + 1$ を Ruby のコードで書けば
Math.log10(x).floor + 1となるわけだが,一抹の不安がよぎる。それがこの記事の主旨であった。
というのは,
Math.log10は Float クラスの浮動小数点演算だ。浮動小数点演算にはふつう誤差が伴う。
微妙な誤差に起因して結果の桁が狂うことはありえないのか?どう考えればいいのだろう?
正の整数
xを 1,2,3,… と順に見ていって,桁が変わるのはどこか。それは,もちろん 9→10 とか 99→100 とか 999→1000 といったところだよね。
浮動小数点数演算の誤差によって誤った結果が出るとすれば,この境目のあたりだろう。
10000000 のようなのが誤って一つ少ない桁にされたり,9999999999 のようなのが誤って一つ多い桁にされたり,といったことがありそう。
このうち,1000000 のような数はもともと $10^k$ の形なので,誤差が出にくい気がする。
ならば,9 が並ぶ数で実験してみようではないか。はい,こんなコードを書きました。
1.upto(100) do |k| puts "%3d %3d" % [k, Math.log10(10 ** k - 1).floor + 1] end$k$ を 1 から 100 まで変えて,$10^k - 1$(つまり 9 を $k$ 個並べた数)の桁を計算させる。これを $k$ と並べて表示させる。数学的には一致するハズなので,同じ数が並んでいるかどうかを見る。
結果は以下の通り
1 1 2 2 3 3 4 4 5 5 6 6 7 7 8 8 9 9 10 10 11 11 12 12 13 13 14 14 15 16 16 17 17 18 18 19 19 20 20 21 21 22 22 23 23 24 24 25 25 26 26 27 27 28 28 29 29 30 30 31 31 32 32 33 33 34 34 35 35 36 36 37 37 38 38 39 39 40 40 41 41 42 42 43 43 44 44 45 45 46 46 47 47 48 48 49 49 50 50 51 51 52 52 53 53 54 54 55 55 56 56 57 57 58 58 59 59 60 60 61 61 62 62 63 63 64 64 65 65 66 66 67 67 68 68 69 69 70 70 71 71 72 72 73 73 74 74 75 75 76 76 77 77 78 78 79 79 80 80 81 81 82 82 83 83 84 84 85 85 86 86 87 87 88 88 89 89 90 90 91 91 92 92 93 93 94 94 95 95 96 96 97 97 98 98 99 99 100 100 101途中からずれている。抜粋するとココ。
14 14 15 16$10^{14} - 1$ までは正しく計算できているが,$10^{15} - 1$ では案の定,正しい答えより一つ大きい数になってしまっている。
ここでふと思い当たることがあった。「浮動小数点数の精度は 10 進にして 15 桁程度」という話。
Ruby の Float は実は環境依存なので,精度は一概に言えないのだが,非常に多くの環境で IEEE 754 の「倍精度」というものが使われるらしい。これの場合,精度は 10 進で 15 桁くらいになるとのこと。だから,9 を 15 個並べた整数で
Math.log10(x).floor + 1の結果が正しい桁数にならなかった,というのはいかにもありそうな話なわけだ。結論
小さな整数に対しては
Math.log10(x).floor + 1でよいが,大きな整数では誤差が生じる。
負数の場合,
-1.1.floorは-2であって,小数部を切り捨てた-1ではないことに注意。 ↩
- 投稿日:2020-05-16T15:44:40+09:00
桁数は Math.log10(x).floor + 1 でいいのか問題
この記事は Ruby を前提とするが,多くの言語で似たようなことが言えると思う。
何の話?
正の整数
xが 10 進法で何桁になるか,を求めるやり方はいくつもある。
そのうちの一つがMath.log10(x).floor + 1なのだが,本当にこれで正しい答えが得られるのだろうか,という話。
数学が苦手でも,Ruby をあまり知らなくても分かるよう,なるべく丁寧に見ていく。しかし,結論だけを知りたい方は それでいいのか? の節にどうぞ。
桁数を求めるいろいろなやり方
この節では,ローカル変数
xに正の整数が代入されているとする。
Ruby はメモリーなどの条件が許せばどんな大きな整数も扱うことができる。文字列化
Ruby の整数(Integer クラス)には,N 進法で表した数字列を生成する Integer#to_s というメソッドがある。
引数を省略すると,10 進法の数字列が得られる。
p (36 + 72).to_s # => "108"一方,String クラスには,長さ(文字数)を数える String#length というメソッドがある。
p "Ruby".length # => 4これを組み合わせれば
x.to_s.lengthで桁数が得られる。
極めて簡単だ。しかし,ちょっとした不安がよぎる。桁数が知りたいだけなのに,10 万桁の整数に対し長さ 10 万の巨大文字列を作るのは,もしかして遅いのでは?
実はかなり高速なのだが,その話は置いておこう。桁ごとの数の配列を得る
Ruby には,非負整数(0 以上の整数)を N 進法で表したときの各桁の数を並べた配列を返す Integer#digits というメソッドがある。
引数を省略すると 10 進法となる。
p 1234.digits # => [4, 3, 2, 1]下の位から順に並べるので,見た目の順序は逆転している。
これと,配列の長さを返す Array#length を使えば
x.digits.lengthで桁数が得られる。
私なぞは,素人考えで「なんとなく文字列より整数のほうが処理が速そうだから,
x.to_s.lengthより速いんでは?」と思ってしまったが,そんなことはなかった。そりゃそうか。巨大が配列が作られるわけだしね。そして Math.log10(x).floor + 1
他にもやり方はあるが,本題の
Math.log10(x).floor + 1に行こう。なぜこれで
xの桁数が得られるのか?Math.log10 は,与えられた引数の常用対数の値を返すメソッド。
常用対数関数
y = \log_{10}xは 10 を底とする指数関数
x = 10^yの逆関数だったね。
この指数関数は,$y$ が整数のときは意味が分かりやすいけれど,任意の実数に対しても定義されている。$y$ が 0 以上の整数のときを見てみよう
$y = \log_{10}x$ $x = 10^y$ $0$ $1$ $1$ $10$ $2$ $100$ $3$ $1000$ $4$ $10000$ これを見れば,$y$ が 0 以上の整数のときは,$y + 1$ つまり $\log_{10}(x) + 1$ が桁数になることが分かる。
しかし,$y$ が整数になる $x$ は限られている。もっと一般の正の整数 $x$ についてはどうなるだろう?
ためしに,$x = 999$ を考えてみる。これは $1000$ よりちょっと小さい。
対数関数は単調増加($x$ が増えれば $y$ も増える)なので,$\log_{10}999$ は $3$ よりもちょっと小さいはずだ。
したがって,切り捨てで整数化すれば,$2$ が得られる。切り捨てに床関数というものを使おう。これは,半端を数直線の左(負の無限大)に向かって切り捨てる。
今の場合,負数は出てこないから「小数部の切り捨て」と考えても差し支えない1。さて,数学記号では,床関数を $\lfloor a \rfloor$ のように書くらしいが,以上の考察から,$x$ が $100$ 以上 $999$ 以下であるとき,
\lfloor \log_{10}x \rfloorは全て $2$ であることが分かる。
つまり,こんなふうになるんである。
$x$ $\lfloor \log_{10}x \rfloor$ $1$〜$9$ $0$ $10$〜$99$ $1$ $100$〜$999$ $2$ $1000$〜$9999$ $3$ $10000$〜$99999$ $4$ だから 1 を足した $\lfloor \log_{10}x \rfloor + 1$ で桁数が得られるというわけだ。数学的には,ね。
それでいいのか?
やっと核心に。
$\lfloor \log_{10}x \rfloor + 1$ を Ruby のコードで書けば
Math.log10(x).floor + 1となるわけだが,一抹の不安がよぎる。それがこの記事の主旨であった。
というのは,
Math.log10にせよfloorにせよ,これは Float クラスの浮動小数点演算だ。浮動小数点演算にはふつう誤差が伴う。
微妙な誤差に起因して結果の桁が狂うことはありえないのか?どう考えればいいのだろう?
正の整数
xを 1,2,3,… と順に見ていって,桁が変わるのはどこか。それは,もちろん 9→10 とか 99→100 とか 999→1000 といったところだよね。
浮動小数点数演算の誤差によって誤った結果が出るとすれば,この境目のあたりだろう。
10000000 のようなのが誤って一つ少ない桁にされたり,9999999999 のようなのが誤って一つ多い桁にされたり,といったことがありそう。
このうち,1000000 のような数はもともと $10^k$ の形なので,誤差が出にくい気がする。
ならば,9 が並ぶ数で実験してみようではないか。はい,こんなコードを書きました。
1.upto(100) do |k| puts "%3d %3d" % [k, Math.log10(10 ** k - 1).floor + 1] end$k$ を 1 から 100 まで変えて,$10^k - 1$(つまり 9 を $k$ 個並べた数)の桁を計算させる。これを $k$ と並べて表示させる。数学的には一致するハズなので,同じ数が並んでいるかどうかを見る。
結果は以下の通り
1 1 2 2 3 3 4 4 5 5 6 6 7 7 8 8 9 9 10 10 11 11 12 12 13 13 14 14 15 16 16 17 17 18 18 19 19 20 20 21 21 22 22 23 23 24 24 25 25 26 26 27 27 28 28 29 29 30 30 31 31 32 32 33 33 34 34 35 35 36 36 37 37 38 38 39 39 40 40 41 41 42 42 43 43 44 44 45 45 46 46 47 47 48 48 49 49 50 50 51 51 52 52 53 53 54 54 55 55 56 56 57 57 58 58 59 59 60 60 61 61 62 62 63 63 64 64 65 65 66 66 67 67 68 68 69 69 70 70 71 71 72 72 73 73 74 74 75 75 76 76 77 77 78 78 79 79 80 80 81 81 82 82 83 83 84 84 85 85 86 86 87 87 88 88 89 89 90 90 91 91 92 92 93 93 94 94 95 95 96 96 97 97 98 98 99 99 100 100 101途中からずれている。抜粋するとココ。
14 14 15 16$10^{14} - 1$ までは正しく計算できているが,$10^{15} - 1$ では案の定,正しい答えより一つ大きい数になってしまっている。
ここでふと思い当たることがあった。「浮動小数点数の精度は 10 進にして 15 桁程度」という話。
Ruby の Float は実は環境依存なので,精度は一概に言えないのだが,非常に多くの環境で IEEE 754 の「倍精度」というものが使われるらしい。これの場合,精度は 10 進で 15 桁くらいになるとのこと。だから,9 を 15 個並べた整数で
Math.log10(x).floor + 1の結果が正しい桁数にならなかった,というのはいかにもありそうな話なわけだ。結論
小さな整数に対しては
Math.log10(x).floor + 1でよいが,大きな整数では誤差が生じる。
負数の場合,
-1.1.floorは-2であって,小数部を切り捨てた-1ではないことに注意。 ↩
- 投稿日:2020-05-16T15:44:40+09:00
桁数は Math.log10(x).floor + 1 でいいのか問
この記事は Ruby を前提とするが,多くの言語で似たようなことが言えると思う。
何の話?
正の整数
xが 10 進法で何桁になるか,を求めるやり方はいくつもある。
そのうちの一つがMath.log10(x).floor + 1なのだが,本当にこれで正しい答えが得られるのだろうか,という話。
数学が苦手でも,Ruby をあまり知らなくても分かるよう,なるべく丁寧に見ていく。しかし,結論だけを知りたい方は それでいいのか? の節にどうぞ。
桁数を求めるいろいろなやり方
この節では,ローカル変数
xに正の整数が代入されているとする。
Ruby はメモリーなどの条件が許せばどんな大きな整数も扱うことができる。文字列化
Ruby の整数(Integer クラス)には,N 進法で表した数字列を生成する Integer#to_s というメソッドがある。
引数を省略すると,10 進法の数字列が得られる。
p (36 + 72).to_s # => "108"一方,String クラスには,長さ(文字数)を数える String#length というメソッドがある。
p "Ruby".length # => 4これを組み合わせれば
x.to_s.lengthで桁数が得られる。
極めて簡単だ。しかし,ちょっとした不安がよぎる。桁数が知りたいだけなのに,10 万桁の整数に対し長さ 10 万の巨大文字列を作るのは,もしかして遅いのでは?
実はかなり高速なのだが,その話は置いておこう。桁ごとの数の配列を得る
Ruby には,非負整数(0 以上の整数)を N 進法で表したときの各桁の数を並べた配列を返す Integer#digits というメソッドがある。
引数を省略すると 10 進法となる。
p 1234.digits # => [4, 3, 2, 1]下の位から順に並べるので,見た目の順序は逆転している。
これと,配列の長さを返す Array#length を使えば
x.digits.lengthで桁数が得られる。
私なぞは,素人考えで「なんとなく文字列より整数のほうが処理が速そうだから,
x.to_s.lengthより速いんでは?」と思ってしまったが,そんなことはなかった。そりゃそうか。巨大が配列が作られるわけだしね。そして Math.log10(x).floor + 1
他にもやり方はあるが,本題の
Math.log10(x).floor + 1に行こう。なぜこれで
xの桁数が得られるのか?Math.log10 は,与えられた引数の常用対数の値を返すメソッド。
常用対数関数
y = \log_{10}xは 10 を底とする指数関数
x = 10^yの逆関数だったね。
この指数関数は,$y$ が整数のときは意味が分かりやすいけれど,任意の実数に対しても定義されている。$y$ が 0 以上の整数のときを見てみよう
$y = \log_{10}x$ $x = 10^y$ $0$ $1$ $1$ $10$ $2$ $100$ $3$ $1000$ $4$ $10000$ これを見れば,$y$ が 0 以上の整数のときは,$y + 1$ つまり $\log_{10}(x) + 1$ が桁数になることが分かる。
しかし,$y$ が整数になる $x$ は限られている。もっと一般の正の整数 $x$ についてはどうなるだろう?
ためしに,$x = 999$ を考えてみる。これは $1000$ よりちょっと小さい。
対数関数は単調増加($x$ が増えれば $y$ も増える)なので,$\log_{10}999$ は $3$ よりもちょっと小さいはずだ。
したがって,切り捨てで整数化すれば,$2$ が得られる。切り捨てに床関数というものを使おう。これは,半端を数直線の左(負の無限大)に向かって切り捨てる。
今の場合,負数は出てこないから「小数部の切り捨て」と考えても差し支えない1。さて,数学記号では,床関数を $\lfloor a \rfloor$ のように書くらしいが,以上の考察から,$x$ が $100$ 以上 $999$ 以下であるとき,
\lfloor \log_{10}x \rfloorは全て $2$ であることが分かる。
つまり,こんなふうになるんである。
$x$ $\lfloor \log_{10}x \rfloor$ $1$〜$9$ $0$ $10$〜$99$ $1$ $100$〜$999$ $2$ $1000$〜$9999$ $3$ $10000$〜$99999$ $4$ だから 1 を足した $\lfloor \log_{10}x \rfloor + 1$ で桁数が得られるというわけだ。数学的には,ね。
それでいいのか?
やっと核心に。
$\lfloor \log_{10}x \rfloor + 1$ を Ruby のコードで書けば
Math.log10(x).floor + 1となるわけだが,一抹の不安がよぎる。それがこの記事の主旨であった。
というのは,
Math.log10にせよfloorにせよ,これは Float クラスの浮動小数点演算だ。浮動小数点演算にはふつう誤差が伴う。
微妙な誤差に起因して結果の桁が狂うことはありえないのか?どう考えればいいのだろう?
正の整数
xを 1,2,3,… と順に見ていって,桁が変わるのはどこか。それは,もちろん 9→10 とか 99→100 とか 999→1000 といったところだよね。
浮動小数点数演算の誤差によって誤った結果が出るとすれば,この境目のあたりだろう。
10000000 のようなのが誤って一つ少ない桁にされたり,9999999999 のようなのが誤って一つ多い桁にされたり,といったことがありそう。
このうち,1000000 のような数はもともと $10^k$ の形なので,誤差が出にくい気がする。
ならば,9 が並ぶ数で実験してみようではないか。はい,こんなコードを書きました。
1.upto(100) do |k| puts "%3d %3d" % [k, Math.log10(10 ** k - 1).floor + 1] end$k$ を 1 から 100 まで変えて,$10^k - 1$(つまり 9 を $k$ 個並べた数)の桁を計算させる。これを $k$ と並べて表示させる。数学的には一致するハズなので,同じ数が並んでいるかどうかを見る。
結果は以下の通り
1 1 2 2 3 3 4 4 5 5 6 6 7 7 8 8 9 9 10 10 11 11 12 12 13 13 14 14 15 16 16 17 17 18 18 19 19 20 20 21 21 22 22 23 23 24 24 25 25 26 26 27 27 28 28 29 29 30 30 31 31 32 32 33 33 34 34 35 35 36 36 37 37 38 38 39 39 40 40 41 41 42 42 43 43 44 44 45 45 46 46 47 47 48 48 49 49 50 50 51 51 52 52 53 53 54 54 55 55 56 56 57 57 58 58 59 59 60 60 61 61 62 62 63 63 64 64 65 65 66 66 67 67 68 68 69 69 70 70 71 71 72 72 73 73 74 74 75 75 76 76 77 77 78 78 79 79 80 80 81 81 82 82 83 83 84 84 85 85 86 86 87 87 88 88 89 89 90 90 91 91 92 92 93 93 94 94 95 95 96 96 97 97 98 98 99 99 100 100 101途中からずれている。抜粋するとココ。
14 14 15 16$10^{14} - 1$ までは正しく計算できているが,$10^{15} - 1$ では案の定,正しい答えより一つ大きい数になってしまっている。
ここでふと思い当たることがあった。「浮動小数点数の精度は 10 進にして 15 桁程度」という話。
Ruby の Float は実は環境依存なので,精度は一概に言えないのだが,非常に多くの環境で IEEE 754 の「倍精度」というものが使われるらしい。これの場合,精度は 10 進で 15 桁くらいになるとのこと。だから,9 を 15 個並べた整数で
Math.log10(x).floor + 1の結果が正しい桁数にならなかった,というのはいかにもありそうな話なわけだ。結論
小さな整数に対しては
Math.log10(x).floor + 1でよいが,大きな整数では誤差が生じる。
負数の場合,
-1.1.floorは-2であって,小数部を切り捨てた-1ではないことに注意。 ↩
- 投稿日:2020-05-16T15:40:00+09:00
CarrierWaveを使って、ユーザーのプロフィール画像を設定する
手順
1.Gemfileの追加
gem 'carrierwave'$ bundle install2.Uploaderの生成
uploaders/image_uploader.rbが生成される。
$ rails g uploader image3.モデルの編集
user.rbでuploaderを使う設定をする。
models/user.rbclass User < ApplicationRecord mount_uploader :image, ImageUploader end4.ビューの編集
new.html<%= form_with(model: user, local: true) do |form| %> <%= form.text_field :name %> <%= form.email_field :email %> <%= form.password_field :password %> <%= form.file_field :image %> # 画像ファイルの情報をimage_cacheに一時保存するために下記の一文も追記しよう! <%= form.hidden_field :image_cache %> <%= form.submit %> <% end %>index.html// 下記記述でimage画像を表示できる // <%= image_tag @user.image.url %> // if文で条件分岐する場合 // <% if @user.image? %> <%= image_tag @user.image.url %> <% else %> # デフォルトで表示したい場合 <%= image_tag "/assets/default.jpg" %> <% end %>5.minimagic導入
gem 'mini_magick'$ bundle install6.image_uploader.rbファイルを編集
image_uploader.rbclass AvaterUploader < CarrierWave::Uploader::Base include CarrierWave::MiniMagick # 画像をリサイズ process resize_to_fit: [100, 100] end以上
- 投稿日:2020-05-16T15:30:23+09:00
情報セキュリティについてのまとめ
情報セキュリティ
情報セキュリティとは、WEBサービスにおいてのセキュリティのことを指します。
情報漏洩や不正なアクセスを防ぎつつ権限のあるユーザーの利便性を高めるのが理想です。下記の3つを保持することがWEBサービスの使命です。
1.機密性
-権限のない人が情報資産を見たり使用したりできないようにする
2.完全性
-権限のない人が情報を消したり書き換えたりできないようにする
3.可用性
-権限のある人(ユーザー)がサービスをいつでも利用できるようにする全てにおいてのセキュリティをおびやかす欠陥や問題点のことを脆弱性と言います。
また、脆弱性は開発者のチェック不足やバグによって生まれます。脆弱性の具体例は以下です
-個人情報を勝手に閲覧される(機密性の侵害)
-WEBページの内容が改ざんされる(完全性の侵害)
-WEBページの利用ができなくなる(可用性の侵害)ユーザーへの金銭的補填、開発者の信頼の失墜、機会損失などの被害が生まれてしまうため、脆弱性への対策はしっかり行わなければいけません。
- 投稿日:2020-05-16T14:49:30+09:00
Rubyとは?Railsとは?
記事の概要
Ruby/Ruby on Railsとは何か分からない人が少し理解できるようになります。
Rubyとは
Rubyとはプログラミング言語の一つです。
小さいプログラムから大きいWebアプリケーションまでを実用的に作成することができます。Rubyの特徴
・簡潔な文法で記述することができる
・コードが読みやすい
・プログラムを記述してすぐに実行することができるRubyを使用しているサイト
・hulu
・クックパッド
・食べログ
・楽天市場
・AirbnbRailsとは
Railsとは、Ruby on Railsの略称です。Railsと言われることが多いです。
RailsはWebアプリケーションフレームワークの1つで、最も多く使われています。
Rubyという言語を使ってWebアプリケーションを作っていきます。Webアプリケーションフレームワークとは?
Webアプリケーションフレームワークとは、Webアプリケーションを簡単に作るための骨組みのことです。
これを使うことによってより少ない労力で開発することができます。この記事を読んでいただきありがとうございました。
- 投稿日:2020-05-16T14:49:13+09:00
ルーティングのネスト
ルーティングのネストとは
通常のルーティングの記述は
Rails.application.routes.draw do resources :親となるコントローラー resources :親となるコントローラー resources :親となるコントローラー ,,,,, endという感じでそれぞれ独立した形でコントローラーへのルーティングを生成していますが、
ルーティングのネストをすると、あるコントローラーのルーティング内に、別のコントローラーのルーティングを記述することができます
Rails.application.routes.draw do resources :親となるコントローラー do resources :子となるコントローラー ←階層を下げ、do,,,endで囲む end end使用するメリット
例えば、インスタグラムやツイッターなどにはコメント機能があります。
そして、そのコメントは、必ず投稿先が存在しています。
それでは、ネストをしないでルーティングを設定した場合と、ネストをした場合の生成されるルーティングの違いを見てみます。
ネストなし
Rails.application.routes.draw do #省略 resources :tweets resources :comments, only: :create endPrefix Verb URI Pattern Controller#Action #省略 comments POST /comments(.:format) comments#createネストあり
Rails.application.routes.draw do #省略 resources :tweets do resources :comments, only: :create end endPrefix Verb URI Pattern Controller#Action #省略 tweet_comments POST /tweets/:tweet_id/comments(.:format) comments#createURIに注目して下さい。コメントには投稿先が必ずあるのにも関わらず、ネストをしない場合のルーティングは、どの投稿先のコメントなのかを示す情報がありません。
それに対し、ネストをした場合は、tweet_idの箇所にツイートのid番号が入ります。それにより、どのツイートに対するコメントなのかというのがURIから判断できるようになります。
まとめ
・ネストをすることで関係性のあるもの(アソシエーション先)のid情報が取得できます
- 投稿日:2020-05-16T14:40:56+09:00
flashメッセージを使ってみよう
今回はflashメッセージを利用して、送信や編集、削除がうまくいってるかをより視覚的に確認できるようにしよう!
完成図
こんな感じ。
挙動がうまくいくとメッセージが出現するように設定する。
手順
1.application.html.erbを以下のように編集
flashが存在する場合のみ、flashメッセージが出現するようにif文で記述します。
application.html<!DOCTYPE html> <html> <head> <title>PracticeApp</title> <%= csrf_meta_tags %> <%= stylesheet_link_tag 'application', media: 'all', 'data-turbolinks-track': 'reload' %> <%= javascript_include_tag 'application', 'data-turbolinks-track': 'reload' %> </head> <body> <% if flash[:notice] %> <%= flash[:notice] %> <% end %> <%= yield %> </body> </html>2.コントローラーでメッセージの内容を設定
practices_controller.rbdef create # 省略 if @practice.save # 変数flash[:notice]に表示したいメッセージを代入する flash[:notice]="送信しました" redirect_to root_path else render :new end end def update # 省略 if @post.save # 変数flash[:notice]に表示したいメッセージを代入する flash[:notice]="編集しました" redirect_to root_path else render :edit end end以上
- 投稿日:2020-05-16T14:03:45+09:00
非同期通信の初回挙動不良の対処方法
なんで動かないの!?
アプリ作成をしていてjavaScriptで非同期やインクリメンタルサーチをしたけど、なぜか初回の挙動だけがうまくいってくれない、、!なんてなことないですか??
今回は同じ事象で困っている人のために解消方法を紹介します。
turbolinksを停止しよう
turbolinksとはgemとしてRailsアプリケーションに導入されている機能です。
今回の挙動の動作不良は手作業で作成したAjaxとturbolinksが競合してしまい、うまく作動しない可能性が考えられます。1.Gemfileからturbolinksの部分をコメントアウトする
gem 'turbolinks', '~> 5' < --- コメントアウトしましょう --- > # gem 'turbolinks', '~> 5'bundleinstallも忘れず実行する
$ bundle install2.application.html.hamlからturbolinksの関連部分を削除する
application.html.haml!!! %html %head %meta{:content => "text/html; charset=UTF-8", "http-equiv" => "Content-Type"}/ %title PracticeApp = csrf_meta_tags / 修正前 = stylesheet_link_tag 'application', media: 'all', 'data-turbolinks-track': 'reload' ← このオプションを消す = javascript_include_tag 'application', 'data-turbolinks-track': 'reload' ← このオプションを消す / 修正後 = stylesheet_link_tag 'application', media: 'all' = javascript_include_tag 'application' %body = render "layouts/notifications" = yield3.application.jsからturbolinksの関連部分を削除する
//= require jquery //= require jquery_ujs //= require turbolinks <--- こいつを消してあげる //= require_tree .以上
- 投稿日:2020-05-16T13:42:02+09:00
日時表示を日本時間にする方法
- 投稿日:2020-05-16T13:34:32+09:00
テンプレートリテラル記法を用いるとデプロイ時にエラーが出る
背景
個人アプリをデプロイしようとしたが、エラーが出てうまくいかない。。。
javaScriptでテンプレートリテラル記法を用いた記述をするとどうやらエラーが出るみたい。解決策
修正前
config/environments/production.rbconfig.assets.js_compressor = :uglifier修正後
config/environments/production.rb# config.assets.js_compressor = :uglifierUglifierというgemがあり、これはJavaScriptを軽量化するためのものです。
今回のアプリ中では、JavaScriptで使用しているテンプレートリテラル記法(`)に対応していません。
そのため、デプロイ時にエラーの原因となります。
上記部分をコメントアウトすることで解決します。以上
- 投稿日:2020-05-16T11:31:50+09:00
Rubyのオブジェクト指向を意識して簡易的なtodoアプリを作ってみた
アプリ仕様の概要
CSVを読み込んで、TODOリストを出力するアプリを作る。
CSV仕様
フォーマットは次の通り
タスク実行予定日,タスク内容,完了フラグ(1: 完了, 0: 未完了) 2020-04-27,街でたまねぎを買う,1 2020-04-27,保険料を支払う,0 2020-04-28,手紙をポストに投函する,0 2020-04-29,友人に電話する,1 2020-04-29,空港に迎えにいく,0仕様例1
下記のフォーマットで、すべてのタスクを標準出力に表示する。
[*] 2020-04-27 街でたまねぎを買う [ ] 2020-04-27 保険料を支払う [ ] 2020-04-28 手紙をポストに投函する [*] 2020-04-29 友人に電話する [ ] 2020-04-29 空港に迎えにいく[*] は完了タスク
仕様例2
下記のフォーマットで、未完了のタスクを標準出力に表示する。
[ ] 2020-04-27 保険料を支払う [ ] 2020-04-28 手紙をポストに投函する [ ] 2020-04-29 空港に迎えにいく仕様例3
下記のフォーマットで、任意の日付のタスクを標準出力に表示する。
[*] 2020-04-29 友人に電話する [ ] 2020-04-29 空港に迎えにいくコードのパターンについて3パターン書いてみた。一番保守性も高く、可読性、品質の高いコードから紹介する。
オブジェクト指向型の実装コード
アプリに必要な責務をかなり細かく分けて、オブジェクト指向に忠実にコードを書くパターンがこれ。
責務をそれぞれ以下のように分けた。
・CsvImporterクラス
文字通り、csvを読み込むためのクラス・Taskクラス
タスクごとにインスタンス化するためのクラス・TaskManagerクラス
タスク全体を管理するためのクラス・StdoutPresenterクラス
標準出力するためのクラスかなり細かく分けているが、オブジェクト指向の理解がきちんと出来ていないと書けない書き方で、初学者はこの書き方が理解できると良いと思う。
では、実装コードの説明をしていく。今回は、コード量もそれほど多くないので、クラスごとにファイルは分けず、一つのファイルに全てのクラスを書く。ターミナルで、
$ ruby 〇〇.rbで実行できるようにする。クラスごとに説明をしていく。
まずは、CsvImporterクラス。
require 'csv' class CsvImporter # csvを読み込むためのクラス # モジュールで定数を定義 module CSV_DEFINITION DATE = 0 TITLE = 1 DONE = 2 end # 引数にCSVデータを入れてインスタンス生成 def initialize(location) @csv_data = CSV.read(location) end # インスタンスメソッド # CSVをTaskインスタンスの配列に変換して返す def load @csv_data.map { |data| Task.new(date: data[CSV_DEFINITION::DATE], title: data[CSV_DEFINITION::TITLE], done: data[CSV_DEFINITION::DONE]) } end end【実装のポイント】
csvファイルが読み込めるように
require 'csv'を定義する。モジュールで定数を定義しているのは、CSVの各要素の配列を呼び出す時に、番号だけで呼び出すと、何を呼び 出しているのかわかりづらいので、定数として、呼び出す配列の添字(index)を定義している。
initializeメソッドを定義して、csvデータそのものをインスタンス化する。引数にcsvファイルを指定できるように設計
インスタンスメソッドとして、loadメソッドを定義。CSVをTaskインスタンスの配列に変換して返す。[Taskインスタンス, Taskインスタンス,..... ]と言う配列が返る。Taskインスタンスの解説は後ほど。
次に、Taskクラス
class Task # タスクごとにインスタンス化するクラス attr_accessor :date, :title, :done # 初期化 def initialize(date: , title: , done: ) @date = date @title = title @done = done end # インスタンスメソッド # 未完了のタスクかどうか、true or falseを返す def task_undone? done == '0' end # インスタンスメソッド # 引数に日付を入れてマッチしているかどうか、true or falseを返す def date_match?(condition) date == condition end end【実装のポイント】
attr_accessorでゲッター、セッターを定義
初期化で、一つのタスクを各項目ごとに、インスタンス変数に入れてインスタンス化する。引数には、呼び出し時に何の要素かわかりやすいように、キーワード引数を使用。
インスタンスメソッドとして、各タスクオブジェクトが、どう言う状態かを判別し、true or falseを返すメソッドを定義。
次に、TaskManagerクラス
class TaskManager # タスク全体を管理するためのクラス attr_accessor :tasks # 初期化 # 引数にTaskインスタンスの配列が入る def initialize(tasks) @tasks = tasks end # インスタンスメソッド # 全てのTaskインスタンスの配列をそのまま返す def all_tasks tasks end # インスタンスメソッド # 未完了のTaskインスタンスを配列にして返す def undone_tasks tasks.select(&:task_undone?) end # インスタンスメソッド # 引数に実行予定日を入れ、条件にマッチするTaskインスタンスを配列にしてを返す def tasks_at(condition) tasks.select { |task| task.date_match?(condition) } end end【実装のポイント】
アクセサーメソッドを定義
インスタンスの要素としては、Taskインスタンスの配列が入るように設計
インスタンスメソッドとして、各条件に合う、Taskインスタンスの配列を返すメソッドを定義。
最後に、StdoutPresenterクラス。
class StdoutPresenter # 標準出力するためのクラス # インスタンスメソッド # 標準出力する # tmにTaskManagerのインスタンスの配列を条件でソートした配列が入る def show(tm) tm.each do |output| puts "#{ status_label(output.done) } #{ output.title } #{output.date }" end end private # インスタンスメソッド # タスクのステータスの表示を変える def status_label(status) status_label = if status == '0' '[ ]' elsif status == '1' '[*]' end status_label end end【実装のポイント】
標準出力するためのインスタンスメソッドだけを定義している。
status_labelメソッドはクラス内部でしか参照しないので、privateに定義している。
最後に実行コード
importer = CsvImporter.new('todo.csv') tasks = importer.load # <= Arrayを返す(要素はTaskクラスのインスタンス) tm = TaskManager.new(tasks) presenter = StdoutPresenter.new presenter.show(tm.all_tasks) presenter.show(tm.undone_tasks) presenter.show(tm.tasks_at('2020-04-29'))完成!
オブジェクト指向だが、クラスを分けずにシンプルに書く実装
一つのクラスに全てをまとめて、TaskManagerオブジェクトをレシーバーとして、メソッドを実行していく。
require 'csv' class TaskManager module CSV_DEFINITION DATE = 0 NAME = 1 STATUS = 2 end # 引数にCSVデータを入れてインスタンス生成 def initialize(location) @csv_data = CSV.read(location) end # インスタンスメソッド # csvデータを全て出力する def output_all @csv_data.map { |data| output(data) } end # インスタンスメソッド # 未完了のcsvデータのみ出力する def output_undone @csv_data.select { |data| data[CSV_DEFINITION::STATUS] == '0' }.map { |data| output(data) } end # インスタンスメソッド # 特定の実行予定日のタスクを出力する def output_filtered_by(condition) @csv_data.select { |data| data[CSV_DEFINITION::DATE] == condition }.map { |data| output(data) } end private # タスクのステータスの表示を変える def status_label(status) status_label = if status == '0' '[ ]' elsif status == '1' '[*]' end status_label end # 標準出力する def output(data) p "#{status_label(data[CSV_DEFINITION::STATUS])} #{data[CSV_DEFINITION::DATE]} #{data[CSV_DEFINITION::NAME]} \n" end end tm = TaskManager.new('todo.csv') tm.output_all tm.output_undone tm.output_filtered_by('2020-04-29')完成!
データをカプセル化せずに作る場合
こちらはあまり良くない例で、外からデータを引数に入れないといけないため、保守性も低い。メソッドがまとまっているので、その点はシンプルなコード。
mainオブジェクトや、トップレベル、selfなどの概念がわかっていないと、実装出来ないコードなので、mainオブジェクト、トップレベルがわからない方は、チェリー本のモジュールの章を見ると良いと思う。(p300あたり)
csvデータはヘッダーを使わないとうまく動かない。実装コードは以下。
require "csv" class TaskTodo # 全てクラスメソッド # csvデータを全て出力する def self.output_all(csv_data) csv_data.map do |data| "#{status_label(data["完了フラグ"])} #{data["タスク実行予定日"]} #{data["タスク内容"]} \n" end end # 引数のheaderにselectしたい項目、conditionにselectしたい項目の状態を入れると、条件に応じたタスクを出力 # 条件の引数を省略すると、デフォルト値の未完了のタスクをソートして出力 def self.output_select(csv_data, header: '完了フラグ', condition: '0') csv_data.select { |data| data[header] == condition }.map do |data| "#{status_label(data["完了フラグ"])} #{data["タスク実行予定日"]} #{data["タスク内容"]} \n" end end private # タスクのステータスの表示を変える # 書き方をtask_managerクラスのパターンと変えているがどちらが良いのか。 def self.status_label(status) if status == '1' "[*]" elsif status == '0' "[ ]" else 'CSVに存在しないステータスが入っています' end end csv_data = CSV.read('todo1.csv', headers: true) puts "全てのCSV" puts self.output_all(csv_data) puts "条件で絞ってCSV出力" puts "引数省略でデフォルト値を出力" puts self.output_select(csv_data) puts "引数を入れると条件に応じて出力" puts self.output_select(csv_data, header: 'タスク実行予定日', condition: '2020-04-29') end csv_data = CSV.read('todo1.csv', headers: true) puts "全てのCSV" puts TaskTodo.output_all(csv_data) puts "条件で絞ってCSV出力" puts TaskTodo.output_select(csv_data, header: 'タスク実行予定日', condition: '2020-04-29') puts "引数省略でデフォルト値を出力" puts TaskTodo.output_select(csv_data)【実装のポイント】
全てクラスメソッドとして定義している。インスタンスを生成しないので、全てTaskTodoクラスオブジェクト(クラス自身,self)に対して実行している。
ポイントとしては、クラス内部で、実行しているコードと、クラスの外で実行しているコードで、少し記述が違っている。『self』に対してメソッドを実行するか、『TaskTodo』に対して実行するか、が違っている。
これは簡単に言うと、クラス内部では、selfがTaskTodoクラスオブジェクト(クラス自身)を表すことができるので、selfで実行出来る。対して、クラス外部は、トップレベルと呼ばれているエリアで、TaskTodoクラスのスーパークラスのゾーン(継承の上位階層のゾーン)になっている。なので、selfを使うことができず、TaskTodoを明示的に指定する必要がある。完成!
以上です!
次は、標準出力ではなく、ファイルに書き出すケースを考えていますので、また、追記します。
追記
標準出力ではなく、ファイルに結果を書き出す場合の実装もやってみました。以下になります。
class FileWriteRead < StdoutPresenter # ファイルの読み書きを担うクラス # StdoutPresenterクラス継承 # インスタンスメソッド # 引数に条件でソートしたTaskオブジェクトの配列を想定 # 引数のfile_nameはファイル名、typeは読み書きなど、tmは対象のタスクオブジェクト def write_read(file_name, type, tm) File.open(file_name, type) do |file| tm.each do |t| file.puts "#{status_label(t.done)} #{t.title} #{t.date}" end end end end【実装のポイント】
特に捻りはなく、一般的な実装。書き出しファイル名、読み書き、対象のオブジェクトを引数にとり、柔軟に対応できるようにしています。
StdoutPresenterクラスのstatus_labelメソッドを使うため、StdoutPresenterクラスを継承しています。privateメソッドも継承すれば使えます。
- 投稿日:2020-05-16T11:22:27+09:00
【Rails】remote:true形式でAjax通信を行う(ブックマーク機能のajax化)
Ajaxとは
Ajaxとは、Webブラウザ上で
非同期通信を行い、ページ全体の再読み込み無しにページを更新する方法のことです。同期通信について
同期通信では、クライアントはwebページ全体の情報(HTMLとそれに紐づくcss,js,imageなどのアセット)をサーバーから受け取って、ページを一から作り直します。
例えばページの一部を変更するだけなのに、他の部分も組み立て直すってことはその分ページの表示に時間がかかっちゃいます。(サーバー側の処理を待つことになる)しかも、このリクエスト〜レスポンスの処理を行っている間は、他の処理を行わずにサーバーからレスポンスが返ってくるのを待ち続ける必要があります(よくあるのが画面が真っ白になって何もできない状態)。
そこでAjaxのような非同期通信を使用すれば、ページ遷移無しに、高速で更新処理を行い、尚且つ、リクエスト〜レスポンスの処理を行っている間も他の処理が行えます。
非同期通信の方法は2種類
この便利なAjaxによる非同期通信を行う方法としては、
①remote:true形式
②ajax関数を使った形式
の2パターンが存在しますが、今回はremote:true形式について以下に記していきます。仕組みだけ知りたいよって方は、コードの説明は読み飛ばしちゃっても大丈夫です。
コードの説明
今回作るもの
掲示板のブックマーク(いいね)ボタンを押した時に、ブックマークの登録、解除を行うという仕組みをajax化させていきます。
ルーティングの設定
ブックマークの登録、削除を行うために必要なルーティングの設定を行う。
config/routes.rbresources :boards do resources :bookmarks, only: %i[create destroy], shallow: true endモデルの設定
モデルでUsersテーブル、Boardsテーブル、Bookmarksテーブルの関連付を行う。
簡素なER図を書くとこんな感じ。
app/models/user.rbclass User < ApplicationRecord has_many :boards, dependent: :destroy has_many :bookmarks, dependent: :destroy has_many :bookmark_boards, through: :bookmarks, source: :board # ブックマーク関連のインスタンスメソッド # ブックマークをする def bookmark(board) bookmark_boards << board end # ブックマークを解除する def unbookmark(board) bookmark_boards.destroy(board) end # ブックマークをしているかどうかを判定する def bookmark?(board) bookmarks.where(board_id: board.id).exists? end endapp/models/board.rbclass Board < ApplicationRecord belongs_to :user has_many :bookmarks, dependent: :destroy endapp/models/bookmark.rbclass Bookmark < ApplicationRecord belongs_to :user belongs_to :board validates :user_id, uniqueness: { scope: :board_id } endコントローラの設定
AjaxによるHTTP通信を行うには、formに
remote:trueオプションを設定する必要がある。
form_withメソッドでAjax通信を利用しない場合(
local: trueオプション)
bookmarksコントローラのcreateアクション実行の際に、bookmarks/create.html.erbというファイルをレンダリングしようとするため、別のページへリダイレクトさせていた。Ajax通信を利用する場合(
remote: trueオプション)
remote: trueの記述によって、AjaxでHTTPリクエストを送信するように設定される。
更に、html.erbファイルではなくjs.erbファイルをレンダリングしてくれる。そして、このjs.erbファイルをjsのコードに変換した文字列が、レスポンスボディとしてブラウザに返される(詳細は後述)。app/controllers/bookmarks_controller.rbclass BookmarksController < ApplicationController # js.erbファイルで変数を使用するため、インスタンス変数を設定 def create @board = Board.find(params[:board_id]) current_user.bookmark(@board) end def destroy @board = current_user.bookmark_boards.find(params[:id]) current_user.unbookmark(@board) end endブックマークボタンを切り替えるためのビュー
bookmarks/_bookmark_area.html.erbファイルで、ログイン中のユーザーが掲示板をブックマークしているかどうかによって呼び出すテンプレートを分ける。
- ブックマークしていない場合は
_bookmark.html.erbを呼び出す。
- ブックマークボタンは色無しの状態
- ブックマークする機能
- ブックマークしている場合は
_unbookmark.html.erbを呼び出す。
- ブックマークボタンは色付きの状態
- ブックマークを削除する機能
app/views/bookmarks/_bookmark_area.html.erb<% if current_user.bookmark?(board) %> <%= render 'bookmarks/unbookmark', { board: board } %> <% else %> <%= render 'bookmarks/bookmark', { board: board } %> <% end %>ブックマークしていない場合のボタンを実装
_bookmark.html.erbファイルを作成
- ブックマークするので、HTTPメソッドはpost。対応するコントローラがcreate.js.erbを呼び出す。
- id属性を付与(どのボタンをクリックしたか判別するため、各レコードのidを使用し、一意性を保つ)
-remote: trueオプションを付与。app/views/bookmarks/_bookmark.html.erb<%= link_to board_bookmarks_path(board), id: "js-bookmark-button-for-board-#{board.id}", method: :post, remote: true do %> <%= icon 'far', 'star' %> <% end %>ブックマークしている場合のボタンを実装
_unbookmark.html.erbファイルを作成
- ブックマークを削除するので、HTTPメソッドはdelete。destroy.js.erbを呼び出す。
- id属性を付与。
-remote: trueオプションを付与。app/views/bookmarks/_unbookmark.html.erb<%= link_to bookmark_path(board), id: "js-bookmark-button-for-board-#{board.id}", method: :delete, remote: true do %> <%= icon 'fas', 'star' %> <% end %>js.erbファイルを作成
js.erbファイルは以下2つの記述が可能。
1. jsの処理
2. rubyの記述(erbファイルだから)以下のjs.erbファイルによって、画面上に表示するブックマークボタンをAjax通信で切り替えられるようにします。
【
create.js.erbファイルを作成】
create.js.erbでhtml()メソッドを用い、指定したセレクタのhtml部分(指定したid属性を持つ部分)を置き換える。_unbookmark.html.erbに置き換えるよう記述。app/views/bookmarks/create.js.erb$("#btn-bookmark-<%= @board.id %>").html("<%= j(render('boards/unbookmark', board: @board)) %>");【
destroy.js.erbファイルを作成】
create.js.erbと逆の内容を記述する。app/views/bookmarks/destroy.js.erb$("#btn-bookmark-<%= @board.id %>").html("<%= j(render('boards/bookmark', board: @board)) %>");ここまでがコードの細かい話!!
ブックマークボタンを押した時のHTTPレスポンスについて
上記の実装によって、なぜブックマークボタンをAjax通信で切り替えられるのか、その仕組みについて以下で説明します。
先に結論を述べると、それはサーバーからレスポンスボディとしてJavaScriptのコードを返し、そのコードに対する処理をクライアント側が実行してくれているからです。HTTPレスポンスの中身とクライアントの処理は?
- ブックマークボタンを押した時のHTTPレスポンスの中身はどうなっているのか?
- それに対してクライアント(ブラウザ)側はどのような処理を行うのか?
の2点を押さえれば、ブックマークボタンをAjax通信で切り替えられる仕組みを理解できるはずです。ブックマークボタンを押した時のHTTPレスポンスの中身は?
erbファイルをJS形式のコード(この段階ではただの文字列!)に変換したものが、レスポンスボディとしてクライアントに返されます。
つまり、erbファイルをそのままクライアントに返すのではなく、サーバー側でjs.erbファイルのrubyの記述(
j renderとか@boardとか)を事前に実行し、HTMLのコードとして展開した結果を、クライアント側に返しているのです。
一言で表すなら、クライアント側が読める内容に変換してから返している、ということです。レスポンスに対するクライアント側の処理
これに対し、クライアントはサーバーから返ってきたレスポンスボディを見て、「これはjs形式のものだな」と判断し、そこでようやくレスポンスボディの文字列に対してJavaScriptを実行してくれる、といった感じです。
検証ツールのネットワークタブを確認
- HTTPレスポンスのContent-Type(どういうコンテンツの種類か)が text/javascriptになっている。
→ajax通信に設定しているから、RailsがJS形式でレスポンスを送ってくれている。
→クライアント側はContent-typeを見て「JSで処理するんだな」と判断している。
レスポンスボディにjs形式のコードが入っている。
レスポンスボディの詳細
$("#js-bookmark-button-for-board-152").replaceWith("<a id=\"js-bookmark-button-for-bo ard-152\" data-remote=\"true\" rel=\"nofollow\" data-method=\"delete\" href=\"/bookma rks/152\">\n <i class=\"fas fa-star\"><\/i>\n<\/a>");おわりに
以上でremote:true形式でAjax通信を行う方法の説明を追えます。
なにか説明部分について誤りがございましたら、ご指摘頂きたく思います。

- 投稿日:2020-05-16T11:13:13+09:00
(初学者向け)Rubyの変数について網羅的に確認しよう
Rubyの変数についてごっちゃになっていたので網羅的にまとめました。
記事の対象
Rubyを触ったことがある
クラスや継承、インスタンスについてなんとなくでもいいので理解している
Rubyの変数についてなんとなくわかるが曖昧な方この記事で解説すること
各変数の各スコープについて
- ローカル変数
- ブロック変数
- インスタンス変数
- クラスインスタンス変数
- クラス変数
- グローバル変数
用語
スコープ・・・変数が参照できる範囲のこと(変数の有効範囲)
スーパークラス・・・継承元のクラス(親クラス)
サブクラス・・・継承先のクラス(子クラス)
ブロック・・・ doとendまたは{ }で囲まれた範囲のこと検証方法
クラス内・クラス外・インスタンスメソッド内・クラスメソッド内、継承先でpメソッドを用いて各変数の返り値を見ていきます。
クラス等の説明は本記事では省きます。(機会があれば別で書こうと思います。)
また、同じような処理をあえてまとめずに繰り返して書いております。
これはひとかたまりの情報量を少なくすることでコード一つひとつの動きがわかりやすいようにあえてしております。
コードもひとかたまりが少ないので動きがわからなかったらコピペして自分で値を変えたりして動かしてみると理解が深まるかもしれません。もし見づらい、わかりづらいと感じましたらコメントで教えていただけると嬉しいです。
Rubyの変数
ローカル変数
変数といえばイメージするのはこれ。定義場所によってスコープが異なる。
- 書き方 変数名(小文字) = 値
クラスの外で定義しているのでclassからendまでの間(クラス内)では参照できない。
クラス外で定義、クラス内から呼び出しx = 10 p x #=> 10 class Sample p x #=> undefined local variable or method `x' for Sample:Class endブロック内で定義、ブロック外から呼び出しx = 10 p x #=> 10 class Sample p x #=> undefined local variable or method `x' for Sample:Class endもちろんクラス内で定義すればクラス内がスコープになる(同じ変数名でもスコープが違うので上書きはされない、ブロック内でも同様)
クラス内外両方で定義x = 10 p x #=> 10 class Sample x = 20 p x #=> 20 end p x #=> 10defからendまでの間(インスタンスメソッド内)でも同様に参照できない。
インスタンスメソッド内での呼び出しx = 10 p x #=> 10 class Sample def hoge #インスタンスメソッドの定義 p x #=> undefined local variable or method `x' for #<Sample:0x00007fd44313c7b0> end end sample = Sample.new #インスタンスの生成 sample.hoge #インスタンスメソッドの呼び出しクラスメソッド内でも同様
クラスメソッド内での呼び出しx = 10 p x #=> 10 class Sample def self.hoge #クラスメソッドの定義 p x #=> undefined local variable or method `x' for Sample:Class end end Sample.hoge #クラスメソッドの呼び出しブロック変数
スコープがブロック内のみの変数
- 書き方 do |変数名| endもしくは {|変数名|}
doからendの間以外では参照できない。
ブロック外からの呼び出しnumbers = [10, 20, 30] numbers.each do |num| #numというブロック変数を定義 p num end #=> 10 #=> 20 #=> 30 p num #=> undefined local variable or method `num' for main:Objectインスタンス変数
インスタンスメソッド内と継承先のインスタンスメソッド内で使える
- 書き方 @変数名 = 値
インスタンスメソッド内から参照できます。
インスタンスメソッド内での呼び出しclass Sample def hoge #インスタンスメソッドの定義 @x = 10 p @x end def fuga #インスタンスメソッドの定義 p @x end end sample = Sample.new sample.hoge #=> 10 sample.fuga #=> 10クラスメソッド内からは参照できません。ただしインスタンス変数はエラーにならずnilが返ります!
クラスメソッド内での呼び出しclass Sample def self.hoge #クラスメソッドの定義 p @x end def fuga #インスタンスメソッドの定義 @x = 10 p @x end end Sample.hoge #=> nil sample = Sample.new sample.fuga #=> 10クラス内でもクラス外でも参照できません。同様にnilが返ります。
クラス内での呼び出しclass Sample p @x #=> nil def hoge #インスタンスメソッドの定義 @x = 10 p @x end p @x #=> nil end sample = Sample.new sample.hoge #=> 10クラス外での呼び出しclass Sample def hoge #インスタンスメソッドの定義 @x = 10 p @x end end sample = Sample.new sample.hoge #=> 10 p @x #=> nil継承先のインスタンスメソッド内からは参照できます。
継承先インスタンスメソッドからの呼び出しclass Sample def hoge @x = 10 #これはインスタンス変数 p @x end end class SubSample < Sample #クラスの継承 def fuga p @x end end sample = Sample.new sample.hoge #=> 10 sub_sample = SubSample.new sub_sample.hoge #Sampleクラスを継承しているためインスタンスメソッドが使える #=> 10 sub_sample.fuga #fugaメソッドからでもhogeメソッド内のインスタンス変数が参照できている #=> 10あくまでもインスタンス変数なのでサブクラス直下では参照できません。(上記のようにサブクラス内のインスタンスメソッドからは参照できる)
継承先クラス内での呼び出しclass Sample def hoge @x = 10 #これはインスタンス変数 p @x end end class SubSample < Sample #クラスの継承 p @x #=> nil endクラスインスタンス変数
- 書き方 @変数名 = 値
まさかのインスタンス変数と同じ書き方でものすごく紛らわしい(泣)
ではインスタンス変数と何が違うのか
@scivolaさんからコメントいただいたので修正いたします。
クラスもオブジェクトのためインスタンス変数を持てます。そのためclass直下で定義したインスタンス変数はhogeメソッド内で出力しようとしているインスタンス変数とは別物になります。
これはobject_idを確認することでわかります。
クラスが持つインスタンス変数を特にクラスインスタンス変数と呼びます。
(@scivolaさんありがとうございました!)インスタンスメソッド内での呼び出しclass Sample @class_instance_var = "class_instance_var" #これはクラスのインスタンス変数 p @class_instance_var.object_id #=> 70139563271980 def hoge #インスタンスメソッドの定義 p @class_instance_var p @class_instance_var.object_id #=> 8 end end sample = Sample.new sample.hoge #=> nil変数名はなんでも良いのですが、ここでは
@class_instance_varと名前を付けました。
クラス直下で@を付けて定義するとクラスのインスタンス変数(クラスインスタンス変数)になります。返り値を見てみると
@class_instance_varはnilになってしまっていることがわかります。クラス内での呼び出しclass Sample @class_instance_var = 10 #これはクラスのインスタンス変数なので p @class_instance_var # 参照できる #=> 10 endクラスメソッド内での呼び出しclass Sample @class_instance_var = 10 def self.hoge p @class_instance_var end end Sample.hoge #これもOK #=> 10継承先ではオブジェクトが違うためnilになります。
継承先での呼び出しclass Sample @class_instance_var = "class_instance_var" #これはクラスインスタンス変数 p @class_instance_var #=> "class_instance_var" p @class_instance_var.object_id #=> 70266520708580 end class SubSample < Sample #クラスの継承 p @class_instance_var #=> nil p @class_instance_var.object_id #=> 8 endこれは
@class_instance_varはSampleクラスのインスタンス変数(クラスインスタンス変数)なのでSubSampleクラスでは参照できないことを表しています。(Sampleクラスの@class_instance_varとSubSampleクラスの@class_instance_varはオブジェクトが違うため参照できない)クラス変数
- 書き方 @@変数名 = 値
また変なのが出てきました(笑)
変数の前に@を2つ付けます。小さなプログラムではあまり必要とされませんが、ライブラリの設定情報等で使われることがあります。
クラス内、クラスメソッド、インスタンスメソッド、継承先のクラスから参照することができます。クラス内での呼び出しclass Sample @@x = 10 p @@x #=> 10 endクラスメソッド内での呼び出しclass Sample @@x = 10 def self.hoge p @@x end end Sample.hoge #=> 10インスタンスメソッド内での呼び出しclass Sample @@x = 10 def hoge p @@x end end sample = Sample.new sample.hoge #=> 10継承先クラスから呼び出しclass Sample @@x = 10 end class SubSample < Sample p @@x #=> 10 end継承先クラスメソッドからの呼び出しclass Sample @@x = 10 end class SubSample < Sample def self.hoge p @@x end end SubSample.hoge #=> 10継承先インスタンスメソッドからの呼び出しclass Sample @@x = 10 end class SubSample < Sample def hoge p @@x end end subsample = SubSample.new subsample.hoge #=> 10以下はエラーになる
クラス外での呼び出しclass Sample @@x = 10 end p @@x #=> uninitialized class variable @@x in Objectグローバル変数
どこからでも参照できる変数、スコープが広いものはあまり良くないので基本的に使わないと思う。
- 書き方 $変数名 = 値
クラス内での呼び出し$x = 10 p $x #=> 10 class Hoge p $x #=>10 endインスタンスメソッド内での呼び出し$x = 10 class Sample def hoge p $x end end sample = Sample.new sample.hoge #=> 10クラスメソッド内での呼び出し$x = 10 class Sample def self.hoge p $x end end Sample.hoge #=> 10以下の場合は上から順次実行されていくので最後の$xは20に書き変わってしまいますね。
クラス外での呼び出し$x = 10 p $x #=> 10 class Sample $x = 20 end p $x #=> 20組込変数・特殊変数
$で始まるrubyが持っている変数
本記事では割愛
気になる方は以下を参照してください。
https://gist.github.com/kwatch/2814940最後に
実際のところローカル変数とインスタンス変数以外はあまり使う機会がないかもしれません。
ただ、こういった動きは理解しておきたいですね!またスコープの大きさとしては
グローバル変数 > クラス変数 > クラスインスタンス変数 ≒ インスタンス変数 > ローカル変数 >ブロック変数
といったところでしょうか。(もちろん定義場所によって異なります!)
スコープが大きい変数を使うと知らぬ間に上書きされる可能性がありバグの発生につながるので、スコープはなるべく小さくするのが良いとされてます。
眠い頭を動かして書いたので間違っているところがあれば是非教えていただけると助かります!
- 投稿日:2020-05-16T10:55:36+09:00
[初心者向け]5分でできるrubocopの導入
はじめに
rubocopとは簡潔にいうとコーディング規約をチェックしてくれるgemです。
参考記事: rubocopとは導入のプロセスなどもできるだけ詳しく記述したので最後までご覧いただけましたら幸いです。
説明はいいから導入だけしたいという方向けに初めに.rubocop.ymlファイルの最終形も記述しています。対象読者
- rubocopを導入したことがないがどのように導入したらいいかわからない方
- 少しきれいなコードを書くことを意識してみたい方
環境
$ rails -v Rails 6.0.2.2 $ ruby -v ruby 2.7.0手順
- Gemfileにrubocopを記述してbundle install
- rubocop.ymlファイルに何をチェックする、しないを記述する
1. Gemfileにrubocopを記述してbundle install
GemFileに記述します
group :development do gem 'rubocop', require: false gem 'rubocop-rails', require: false end$ bundle install $ rubocop The following cops were added to RuboCop, but are not configured. Please set Enabled to either `true` or `false` in your `.rubocop.yml` file: - Layout/EmptyLinesAroundAttributeAccessor (0.83) - Layout/SpaceAroundMethodCallOperator (0.82) - Lint/RaiseException (0.81) : 48 files inspected, 223 offenses detectedひとまず導入完了です。
2. rubocop.ymlファイルに何をチェックするかを記述する
48ファイル223箇所規約違反があると指摘されました。
これを全て修正するのは途方もない時間がかかる、、、ので
規約違反の内容を記述して通るようにしてくれるコマンドがあるのでそのコマンドを実行します。$ bundle exec rubocop --auto-gen-config # 規約違反が記録された.rubocop_todo.ymlファイルが作成されるrubocop.ymlinherit_from: .rubocop_todo.yml #上記コマンドで自動で記述されるrubocop_todo.yml# This configuration was generated by # `rubocop --auto-gen-config` # on 2020-05-16 08:08:30 +0900 using RuboCop version 0.83.0. # The point is for the user to remove these configuration records # one by one as the offenses are removed from the code base. # Note that changes in the inspected code, or installation of new # versions of RuboCop, may require this file to be generated again. # Offense count: 2 # Cop supports --auto-correct. # Configuration parameters: TreatCommentsAsGroupSeparators, Include. # Include: **/*.gemfile, **/Gemfile, **/gems.rb Bundler/OrderedGems: Exclude: - 'Gemfile' # Offense count: 2 # Cop supports --auto-correct. # Configuration parameters: EnforcedStyle, IndentationWidth. # SupportedStyles: with_first_argument, with_fixed_indentation Layout/ArgumentAlignment: Exclude: - 'bin/webpack' - 'bin/webpack-dev-server' ・ ・ ・ # Offense count: 2 # Cop supports --auto-correct. # Configuration parameters: MinSize. # SupportedStyles: percent, brackets Style/SymbolArray: EnforcedStyle: brackets # Offense count: 45 # Cop supports --auto-correct. # Configuration parameters: AutoCorrect, AllowHeredoc, AllowURI, URISchemes, IgnoreCopDirectives, IgnoredPatterns. # URISchemes: http, https Layout/LineLength: Max: 198規約違反箇所が通るように自動でファイルが作成されたので再度rubocopを実行してみます。
$ rubocop The following cops were added to RuboCop, but are not configured. Please set Enabled to either `true` or `false` in your `.rubocop.yml` file: - Layout/EmptyLinesAroundAttributeAccessor (0.83) - Layout/SpaceAroundMethodCallOperator (0.82) - Lint/RaiseException (0.81) - Lint/StructNewOverride (0.81) - Style/ExponentialNotation (0.82) - Style/HashEachMethods (0.80) - Style/HashTransformKeys (0.80) - Style/HashTransformValues (0.80) - Style/SlicingWithRange (0.83) For more information: https://docs.rubocop.org/en/latest/versioning/ Inspecting 48 files ................................................ 48 files inspected, no offenses detected規約違反なし!(当たり前、、、)
rubocop_todo.ymlに規約違反の箇所が通るように記述されているので
最終的にrubocop_todo.ymlが空になるようにしていきます!まず、自動生成されたファイルはrubocopのチェックの対象外にしたいと思うのでrubocop.ymlファイルを修正していきます。
rubocop.yml# 自動生成されたファイルを対象外にする AllCops: Exclude: - 'Gemfile' - 'node_modules/**/*' - 'bin/*' - 'db/**/*' - 'config/**/*' - 'test/**/*' - 'spec/**/*'$ rubocop The following cops were added to RuboCop, but are not configured. Please set Enabled to either `true` or `false` in your `.rubocop.yml` file: - Layout/EmptyLinesAroundAttributeAccessor (0.83) - Layout/SpaceAroundMethodCallOperator (0.82) - Lint/RaiseException (0.81) - Lint/StructNewOverride (0.81) - Style/ExponentialNotation (0.82) - Style/HashEachMethods (0.80) - Style/HashTransformKeys (0.80) - Style/HashTransformValues (0.80) - Style/SlicingWithRange (0.83) For more information: https://docs.rubocop.org/en/latest/versioning/ Inspecting 12 files ............ 12 files inspected, no offenses detectedチェックするファイルが12個に減りました。
この量ならおそらく自分でチェックできると思うので.rubocop_todo.ymlファイルと下記のコードを削除します。rubocop.ymlinherit_from: .rubocop_todo.yml # 削除$ rubocop Offenses: Rakefile:1:1: C: Style/FrozenStringLiteralComment: Missing frozen string literal comment. # Add your own tasks in files placed in lib/tasks ending in .rake, ^ Rakefile:2:81: C: Layout/LineLength: Line is too long. [90/80] # for example lib/tasks/capistrano.rake, and they will automatically be available to Rake. ^^^^^^^^^^ app/channels/application_cable/channel.rb:1:1: C: Style/FrozenStringLiteralComment: Missing frozen string literal comment. module ApplicationCable ^ app/channels/application_cable/connection.rb:1:1: C: Style/FrozenStringLiteralComment: Missing frozen string literal comment. module ApplicationCable ^ app/controllers/application_controller.rb:1:1: C: Style/FrozenStringLiteralComment: Missing frozen string literal comment. class ApplicationController < ActionController::Base ^ app/helpers/application_helper.rb:1:1: C: Style/Documentation: Missing top-level module documentation comment. module ApplicationHelper ^^^^^^ app/helpers/application_helper.rb:1:1: C: Style/FrozenStringLiteralComment: Missing frozen string literal comment. module ApplicationHelper ^ app/jobs/application_job.rb:1:1: C: Style/FrozenStringLiteralComment: Missing frozen string literal comment. class ApplicationJob < ActiveJob::Base ^ app/jobs/application_job.rb:5:81: C: Layout/LineLength: Line is too long. [82/80] # Most jobs are safe to ignore if the underlying records are no longer available ^^ app/mailers/application_mailer.rb:1:1: C: Style/Documentation: Missing top-level class documentation comment. class ApplicationMailer < ActionMailer::Base ^^^^^ app/mailers/application_mailer.rb:1:1: C: Style/FrozenStringLiteralComment: Missing frozen string literal comment. class ApplicationMailer < ActionMailer::Base ^ app/models/application_record.rb:1:1: C: Style/Documentation: Missing top-level class documentation comment. class ApplicationRecord < ActiveRecord::Base ^^^^^ app/models/application_record.rb:1:1: C: Style/FrozenStringLiteralComment: Missing frozen string literal comment. class ApplicationRecord < ActiveRecord::Base ^ app/models/like.rb:1:1: C: Style/FrozenStringLiteralComment: Missing frozen string literal comment. class Like < ApplicationRecord ^ app/models/post.rb:1:1: C: Style/FrozenStringLiteralComment: Missing frozen string literal comment. class Post < ApplicationRecord ^ app/models/user.rb:1:1: C: Style/FrozenStringLiteralComment: Missing frozen string literal comment. class User < ApplicationRecord ^ config.ru:1:1: C: Style/FrozenStringLiteralComment: Missing frozen string literal comment. # This file is used by Rack-based servers to start the application. ^ 12 files inspected, 17 offenses detected17箇所規約違反していますがよく見ると似たような規約違反(下記)が存在するのでこの警告は回避します。(警告の詳細はこの記事では省略します)
Style/FrozenStringLiteralComment: Missing frozen string literal comment.rubocop.yml# 以下を追記 Style/FrozenStringLiteralComment: Enabled: false$ rubocop Offenses: Rakefile:2:81: C: Layout/LineLength: Line is too long. [90/80] # for example lib/tasks/capistrano.rake, and they will automatically be available to Rake. ^^^^^^^^^^ app/helpers/application_helper.rb:1:1: C: Style/Documentation: Missing top-level module documentation comment. module ApplicationHelper ^^^^^^ app/jobs/application_job.rb:5:81: C: Layout/LineLength: Line is too long. [82/80] # Most jobs are safe to ignore if the underlying records are no longer available ^^ app/mailers/application_mailer.rb:1:1: C: Style/Documentation: Missing top-level class documentation comment. class ApplicationMailer < ActionMailer::Base ^^^^^ app/models/application_record.rb:1:1: C: Style/Documentation: Missing top-level class documentation comment. class ApplicationRecord < ActiveRecord::Base ^^^^^ 12 files inspected, 5 offenses detected5箇所まで減りました。
Layout/LineLength: Line is too long. [90/80]これは1行あたりの文字数がで80文字という規約です。
80文字は厳しいので150文字にしたいと思います。rubocop.yml# 1行の最大文字数を150字にする LineLength: Max: 150$ rubocop Offenses: app/helpers/application_helper.rb:1:1: C: Style/Documentation: Missing top-level module documentation comment. module ApplicationHelper ^^^^^^ app/mailers/application_mailer.rb:1:1: C: Style/Documentation: Missing top-level class documentation comment. class ApplicationMailer < ActionMailer::Base ^^^^^ app/models/application_record.rb:1:1: C: Style/Documentation: Missing top-level class documentation comment. class ApplicationRecord < ActiveRecord::Base ^^^^^ 12 files inspected, 3 offenses detected残り3箇所。ラストスパート!
Style/Documentation: Missing top-level module documentation comment.これはクラスやモジュールを書くまえにドキュメントがないという指摘です。
クラスやモジュールの前にドキュメントを書けばいいのですが今回は回避します。rubocop.yml# ドキュメントのないclass, moduleを許可する Style/Documentation: Enabled: false$ rubocop The following cops were added to RuboCop, but are not configured. Please set Enabled to either `true` or `false` in your `.rubocop.yml` file: - Layout/EmptyLinesAroundAttributeAccessor (0.83) - Layout/SpaceAroundMethodCallOperator (0.82) - Lint/RaiseException (0.81) - Lint/StructNewOverride (0.81) - Style/ExponentialNotation (0.82) - Style/HashEachMethods (0.80) - Style/HashTransformKeys (0.80) - Style/HashTransformValues (0.80) - Style/SlicingWithRange (0.83) For more information: https://docs.rubocop.org/en/latest/versioning/ Inspecting 12 files ............ 12 files inspected, no offenses detected無事に指摘箇所の修正は終わりました。
The following cops were added to RuboCop, but are not configured. Please set Enabled to either `true` or `false` in your `.rubocop.yml` file:最後にrubocop.ymlにtrueかfalseを書いてとあるので記述します。
$ rubocop Inspecting 12 files ............ 12 files inspected, no offenses detectedきれいになりました!!
完成形
rubocop.yml# 自動生成したファイルはRubocopでチェックしない AllCops: Exclude: - 'Gemfile' - 'node_modules/**/*' - 'bin/*' - 'db/**/*' - 'config/**/*' - 'test/**/*' - 'spec/**/*' Style/FrozenStringLiteralComment: Enabled: false # 1行の最大文字数を150字にする LineLength: Max: 150 # ドキュメントのないclassを許可する Style/Documentation: Enabled: false # rubocopをかけたときに警告が出たのでtrue or falseの選択 Layout/EmptyLinesAroundAttributeAccessor: Enabled: true Layout/SpaceAroundMethodCallOperator: Enabled: true Lint/RaiseException: Enabled: true Lint/StructNewOverride: Enabled: true Style/ExponentialNotation: Enabled: true Style/HashEachMethods: Enabled: true Style/HashTransformKeys: Enabled: true Style/HashTransformValues: Enabled: true Style/SlicingWithRange: Enabled: trueおわりに
rubocopを導入するときれいなコードを書くという意識が生まれるのでぜひ導入してみてください。
最後までご覧いただきありがとうございます。
- 投稿日:2020-05-16T10:39:06+09:00
deviseのバリデーション設定をするとエラーが起きます。
前提・実現したいこと
rails deviseによるバリテーションについて
バリデーションを設定するとノーメソッドエラーが発生します。
エラー解決のためご教授下さい。
プログラミング始めて1ヶ月目の初学者です。発生している問題・エラーメッセージ
バリテーションが設定できない。
設定すると、createやupdate等のアクション後エラー画面になります。
``NoMethodError in Devise::RegistrationsController#createtitle' for #User:0x00007f4ebc195048
undefined method
Extracted source (around line #430):
428
429
430
431
432
433else match = matched_attribute_method(method.to_s) match ? attribute_missing(match, *args, &block) : super end endエラーメッセージ
```該当のソースコード
Ruby on rails
class ApplicationRecord < ActiveRecord::Base
ソースコード
self.abstract_class = true
validates :name, presence: true, uniqueness: true, length: {minimum: 2, maximum: 20}
validates :introduction,length: { maximum: 50}
validates :title, presence: true
validates :body, presence: true, length: {maximum: 200}
end試したこと
Deviseの再インストール
新規ファイルを作って、デバイズの初期状態を確認、routesファイル等、変更補足情報(FW/ツールのバージョンなど)
Ruby 2.6.0, devise 4.7.1, Rails 5.2.4.2
deviseの不具合だと推測してます。
バージョン変更のやり方が分からないでの教えていただけると助かります。
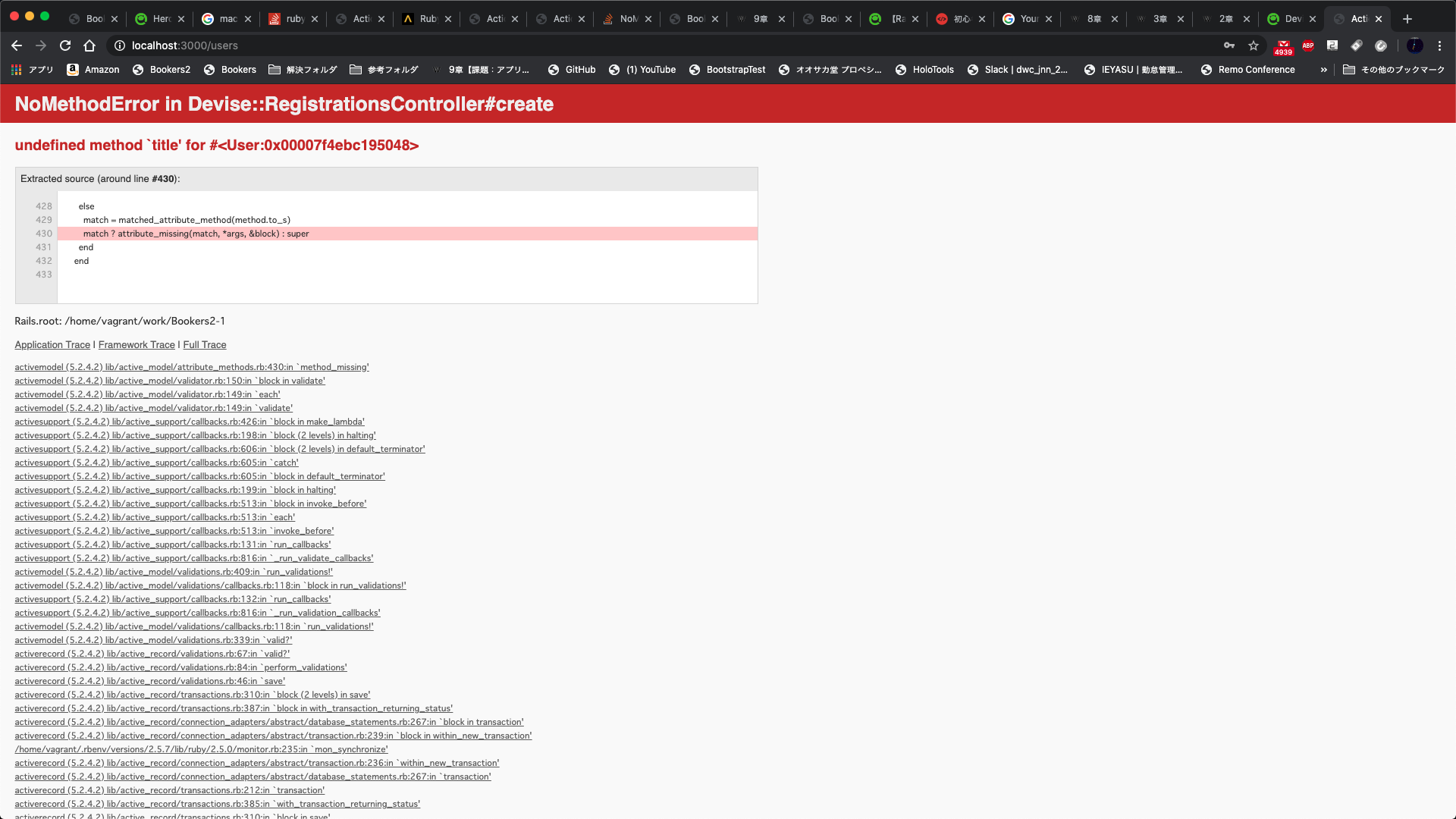
- 投稿日:2020-05-16T05:09:57+09:00
Rubyでチンチロゲームを作る 第3回 賭け金の移動
1.はじめに
今回は勝敗結果と役に基づいて賭け金を移動させるメソッドを書きます。カイジのチンチロは役とその倍率は以下のようになっています。
役 倍率 ピンゾロ (1,1,1) 5倍づけ ゾロ目 (2~6) 3倍づけ シゴロ (4,5,6) 2倍づけ 通常の目 (3個中2個がおなじ目) 1倍づけ 目なし 1倍払い ヒフミ(1,2,3) 2倍払い 〜づけというのは買った場合に賭け金の◯倍で返ってくるという意味です。〜払いというのは負けた場合にマイナスになります。
2. メソッドの作成
メソッドを作成します。引数は相手と自分の役、賭け金、勝敗結果となります。前回の記事と同様に、クラスのなかにメソッドを作成します。そのため引数は以下のようになります。
def transfer_money(opponent,win_or_lose) # 相手の役 : opponent.hand # 相手の賭け金 : opponent.bet_money # 自分の役 : @hand # 自分の賭け金 : @bet_money # 勝敗結果 : win_or_lose以下、とりあえず作ってみます。
def transfer_money(opponent,win_or_lose) strength_relationship = [ 'ヒフミ','目なし', '通常の目(1)','通常の目(2)','通常の目(3)', '通常の目(4)','通常の目(5)','通常の目(6)', 'シゴロ','ゾロ目','ピンゾロ' ] dividend_table = [ -2,-1, 1,1,1, 1,1,1, 2,3,5 ] my_hand_rank = strength_relationship.index(@hand) opponent_hand_rank = strength_relationship.index(opponent.hand) my_dividend_ratio = dividend_table[my_hand_rank] opponent_dividend_ratio = dividend_table[opponent_hand_rank] move_money = 0 case win_or_lose when '勝ち' move_money = my_dividend_ratio * bet_money when '引き分け' move_money = 0 when '負け' move_money = - opponent_dividend_ratio * opponent.bet_money end puts <<~TEXT 自分: #{@hand} / 相手: #{opponent.hand} / #{win_or_lose} ... #{move_money}ペリカ TEXT move_money end自分と相手の役を調べて、それぞれを
dividend_tableから持ってきます。勝敗結果に基づいてmove_moneyの値を計算します。 負けた場合はマイナスになります。ちょっとメソッドを使ってみましょう。クラスの外に以下の内容を書きます。
player_A = Player.new(money:1000,bet_money:100,hand:'ピンゾロ',name:'カイジ') player_B = Player.new(money:3000,bet_money:300,hand:'目なし',name:'班長') player_A.transfer_money(player_B,'勝ち')実行します。実行結果は以下のようになります。
自分: ピンゾロ / 相手: 目なし / 勝ち ... 500ペリカ賭け金100ペリカに対して5倍付の500ペリカ。問題ありませんね。それではこれはどうでしょうか。
player_A = Player.new(money:1000,bet_money:100,hand:'ヒフミ',name:'カイジ') player_B = Player.new(money:3000,bet_money:300,hand:'通常の目(2)',name:'班長') player_A.transfer_money(player_B,'負け')自分: ヒフミ / 相手: 通常の目(2) / 負け ... -300ペリカあれ?2倍払いではなく、3倍払いになっていますね。 さらにこれはどうでしょうか。
player_A = Player.new(money:1000,bet_money:100,hand:'ヒフミ',name:'カイジ') player_B = Player.new(money:3000,bet_money:300,hand:'目なし',name:'班長') player_A.transfer_money(player_B,'負け')自分: ヒフミ / 相手: 目なし / 負け ... 300ペリカむ? ヒフミで負けたのにペリカがプラスになってしまいますね。
3. メソッドの修正(例外処理)
ヒフミと目なしはちょっと特殊な役なので、相手の役によっては賭け金の計算がふつうのものと異なります。以下に表を書きます。
自分 相手 勝敗 オッズ ヒフミ 目なし 負け 2倍払い ヒフミ シゴロ 負け 2倍払い ヒフミ ゾロ目 負け 3倍払い ヒフミ ピンゾロ 負け 5倍払い 目なし ヒフミ 勝ち 2倍づけ シゴロ ヒフミ 勝ち 2倍づけ ゾロ目 ヒフミ 勝ち 3倍づけ ピンゾロ ヒフミ 勝ち 5倍づけ これを踏まえて例外をメソッドに加えます。
# ....略 move_money = 0 if @hand == 'ヒフミ' || opponent.hand == 'ヒフミ' then if @hand == 'ヒフミ' && (opponent.hand != 'シゴロ' && opponent.hand != 'ゾロ目' && opponent.hand != 'ピンゾロ') then opponent_dividend_ratio = 2 end if @hand == '目なし' && (opponent.hand == 'ヒフミ') then my_dividend_ratio = 2 end if (@hand != 'シゴロ' && @hand != 'ゾロ目' && @hand != 'ピンゾロ') && opponent.hand == 'ヒフミ' then opponent_dividend_ratio = 2 my_dividend_ratio = 2 end end case win_or_lose # ....略これでOK。次にテストをしてみましょう。
4.テスト
テストコードを書きます。
require 'minitest/autorun' require './lib/transfer_money' class DiceTest < Minitest::Test def test_transfer_money roll_map = [ 'ヒフミ','目なし', '通常の目(1)','通常の目(2)','通常の目(3)', '通常の目(4)','通常の目(5)','通常の目(6)', 'シゴロ','ゾロ目','ピンゾロ' ] win_lose_map = [ ['引き分け','負け','負け','負け','負け','負け','負け','負け','負け','負け','負け'], ['勝ち','引き分け','負け','負け','負け','負け','負け','負け','負け','負け','負け'], ['勝ち','勝ち','引き分け','負け','負け','負け','負け','負け','負け','負け','負け'], ['勝ち','勝ち','勝ち','引き分け','負け','負け','負け','負け','負け','負け','負け'], ['勝ち','勝ち','勝ち','勝ち','引き分け','負け','負け','負け','負け','負け','負け'], ['勝ち','勝ち','勝ち','勝ち','勝ち','引き分け','負け','負け','負け','負け','負け'], ['勝ち','勝ち','勝ち','勝ち','勝ち','勝ち','引き分け','負け','負け','負け','負け'], ['勝ち','勝ち','勝ち','勝ち','勝ち','勝ち','勝ち','引き分け','負け','負け','負け'], ['勝ち','勝ち','勝ち','勝ち','勝ち','勝ち','勝ち','勝ち','引き分け','負け','負け'], ['勝ち','勝ち','勝ち','勝ち','勝ち','勝ち','勝ち','勝ち','勝ち','引き分け','負け'], ['勝ち','勝ち','勝ち','勝ち','勝ち','勝ち','勝ち','勝ち','勝ち','勝ち','引き分け'] ] bet_map = [ [0,-2,-2,-2,-2,-2,-2,-2,-2,-3,-5], [2,0,-1,-1,-1,-1,-1,-1,-2,-3,-5], [2,1,0,-1,-1,-1,-1,-1,-2,-3,-5], [2,1,1,0,-1,-1,-1,-1,-2,-3,-5], [2,1,1,1,0,-1,-1,-1,-2,-3,-5], [2,1,1,1,1,0,-1,-1,-2,-3,-5], [2,1,1,1,1,1,0,-1,-2,-3,-5], [2,1,1,1,1,1,1,0,-2,-3,-5], [2,2,2,2,2,2,2,2,0,-3,-5], [3,3,3,3,3,3,3,3,3,0,-5], [5,5,5,5,5,5,5,5,5,5,0] ] player_A = Player.new(money:1000,bet_money:100,hand:'目なし',name:'カイジ') player_B = Player.new(money:1000,bet_money:300,hand:'目なし',name:'班長') new_bet_map = bet_map.map { |x| x.map { |y| if y > 0 y * player_A.bet_money elsif y < 0 y * player_B.bet_money else y = 0 end } } roll_map.each_with_index do |value_1,i| player_A.hand = value_1 roll_map.each_with_index do |value_2,j| player_B.hand = value_2 assert_equal new_bet_map[i][j], player_A.transfer_money(player_B,win_lose_map[i][j]) end end end end
each_with_indexを二回重ねることでfor文を二回回すのと同じ構造にしています。また、mapを二回重ねて二次元配列に賭け金をかけています。これでテストが通りました。
5. おわりに
これでチンチロのおおまかな機能をつくることができました。次回はゲーム進行にかかわる諸々の処理をつくります。あと記事2つくらいで終わりそうです!
コードは以下に追記していきます。
- 投稿日:2020-05-16T03:19:06+09:00
MiniMagick(imagemagick)で複数のフォントファイルを使って絵文字に対応する
ちょっと前にimagemagickで絵文字を含むテキストを合成する時に結構ハマったのでなんとなく備忘録を。
imagemagickはフォントが1つしか指定できないので、大抵の場合絵文字があると文字化けしてしまいます。
そこで、pangoを使って複数フォントに対応します。(以下、dockerでrailsを動かす前提で進めます。)
フォントを置く
まずは使いたいフォントをDLしてコンテナのfontsに置きます。
(apt-getで手に入るならそっちのほうがいいと思います)
今回はNoto Sans CJK JPとNoto Color EmojiをDLして/assets/fontsに置きました。# Dockerfile COPY /assets/fonts /usr/share/fontsmemo: Noto Color Emojiについて
Noto Color Emojiは定番のフォントだと思いますが、入手先が3つあってそれぞれ対応しているUnicodeのバージョンが違います。
- 公式サイト → Unicode10
- apt-get → Unicode11
- Github → Unicode12(最新)
Github以外は更新が止まってるようなので、Unicodeが更新される度にGithubからDLして上書きする必要があります。フォントの設定を変える
Noto Color Emojiはビットマップフォントですが、設定によってはこれがデフォルトで無効になってることがあるので書き換えます。
# Dockerfile RUN rm /etc/fonts/conf.d/70-no-bitmaps.conf RUN ln -s /etc/fonts/conf.avail/70-yes-bitmaps.conf /etc/fonts/conf.d/ビットマップフォントを無効にする設定ファイルを消して、conf.availから有効にする設定をコピーしてます。
次にNoto Color Emojiの優先度を上げるため、設定ファイルを作って/etc/fonts/に置きます。(/usr/share/fontsではないので注意)
local.conf<?xml version='1.0'?> <!DOCTYPE fontconfig SYSTEM 'fonts.dtd'> <fontconfig> <alias> <family>sans-serif</family> <prefer> <family>Noto Color Emoji</family> </prefer> </alias> <alias> <family>serif</family> <prefer> <family>Noto Color Emoji</family> </prefer> </alias> <alias> <family>monospace</family> <prefer> <family>Noto Color Emoji</family> </prefer> </alias> </fontconfig># Dockerfile COPY /config/local.conf /etc/fonts/ RUN fc-cache -f最後に念の為fc-cache -fでキャッシュを消して設定を読み込ませます。
これで、フォントの設定は完了です。pangoで画像を生成する
image.rbMiniMagick::Tool::Convert.new do |convert| convert.size "600x200" convert.pango("<span font='Noto Sans CJK JP' size='36864'>#{title}</span>") convert << "image.png" end2行目で指定したサイズに合わせてよしなに改行してくれます。
pangoはフォールバックフォントに対応しているので、Noto Sans CJK JPで表示できない文字が来た場合は先程設定したfontconfigに基づいてNoto Color Emojiで表示されるという仕組みです。
sizeはフォントサイズに1024掛けた数値を指定します。pangoは他にも色々リッチなテキストを生成できるので、興味ある方は公式のdocを御覧ください。
https://www.imagemagick.org/Usage/text/#pango絵文字がモノクロになる
出力された画像を見たら絵文字がモノクロだった…なんて時はOSのバージョンが古いかもです。
linuxの場合はUbuntu 18.04以降でないとカラーになりません。
自分はdebianのdockerコンテナ使ってたので、バージョンをbusterに変えて無事カラーになりました。# Dockerfile FROM ruby:2.6.5-busterおわりに
こうしてまとめると大したことやってないですが、これに辿り着くまでにえらい時間かかりました…
あと例えば画像サイズに収まるように文字数をカウントしてトリミングしたい時は絵文字の扱いに注意が必要です。
サロゲートペアとか、肌の色を表す文字とか、複数の絵文字を合成してたりとか、ややこしい仕様が色々あります…
その辺の仕組みは↓の記事に詳しく書かれてます。
https://qiita.com/_sobataro/items/47989ee4b573e0c2adfc
https://tech.drecom.co.jp/count-length-of-string-including-pictogram/絵文字、知れば知るほど難しい……
- 投稿日:2020-05-16T03:00:06+09:00
`Enumerable#uniq?` を実装
raise if ary.dup.uniq!なんて書かれていたら、どんな動作をするのかすぐにはわからない。動機
配列の要素に重複があるかどうか判定したい。
Array#uniq!というメソッドがある
- レシーバーの配列から重複する要素を削除する
- 重複する要素を削除しなかった場合は
nilを返す = 戻り値で「重複の有無」を判定できる- これをそのまま条件式に使うのは気が引ける
- 破壊的メソッドのため、事前に配列を複製しないといけない
- また実際に重複を全排除するのは計算の無駄
- 「重複の有無」と「戻り値の真偽」の関係がややこしい
- ⇒ 真偽判定に特化したメソッド
#uniq?を作ろう- さらに言えば Array でなくてもいい
- ⇒ Enumerable に作ろう
- ちなみに破壊的でないメソッド
#uniqは Enumerable などにもある実装
#uniq系はObject#eql?の等価判定に基づいている。ということは重複の検知には Hash のキー部分を使えばいい。 Set なら更に分かりやすいけれども、ライブラリをrequireしなければいけないので却下。module Enumerable def uniq?(&block) block ||= :itself.to_proc hash = Hash.new each do |item| key = block.call(item) return false if hash.key?(key) hash[key] = nil # register a new key end true end endやっていて気付いたが、 BasicObject には
#eql?や#hashが無いので、 Hash のキーにできないなど制約がある。組み込みの#uniq系もエラーを起こすので、上の実装でも BasicObject を無視してObject#itselfを使っている。実験
# `Array#uniq!` と同じ結果になること chars = [*"a".."z"] 1000.times do ary = Array.new(6) { chars.sample } # 5割前後の確率で重複あり expected_result = !ary.dup.uniq! raise "wrong implementation!" if ary.uniq? != expected_result endなお、今回実装した
#uniq?は重複を検知した段階で処理を終えるので、ブロックが副作用を伴う場合は#uniq!と異なる動作になりうる。ary = [3, 1, 4, 1, 5, 9, 2, 6, 5, 3] proc = method(:p).to_proc p !ary.dup.uniq!(&proc) p ary.uniq?(&proc)
- 投稿日:2020-05-16T02:23:55+09:00
MacでRubyのファイルを実行する方法
Macを使っているプログラミング初心者向けの説明です。
Macは MacBook、MacBook Pro、iMac のどれでも内容は一緒です。準備
Mac で Rubyのファイルを書くために、まずは テキストエディター をインストールする必要があります。
テキストエディター とは、実行したいプログラミング言語の処理を書いて保存するために必要な アプリ です。おすすめは Visual Studio Code です。
インストールの方法については MacOSでVisual Studio Codeをインストールする手順 を読んでいただければわかりやすいと思います。
インストールが終わって Visual Studio Code のアプリを起動できたら、次の章に移ります。
新規ファイルに Ruby のコードを書く
Visual Studio Code のアプリを起動したら、アプリの左上が↑のような見た目になっていると思います。
ピンクの枠で囲った、Start の下にある New File をクリックしてください。
そうすると Untitled-1 というタブが開きました。
この状態で、
1と書かれたスペースの右側にカーソルが点滅していると思いますので、
半角英語でputs 1と入力してください。
↑のように
puts 1と入力が済んだら、ファイル メニューから Save を選択してください。
Saveを選択すると、↓のように 名前 を入力する欄が表示されます。
ピンクの枠で囲った部分の 名前 の欄に
1.rbと入力してください。
もしかすると、↑の緑の枠で囲った部分のような見た目になっているかもしれません。
どちらの場合も、ファイルを保存する場所を指定するための画面です。
今回は 書類 フォルダに保存します。書類 フォルダを選択して、保存 ボタンをクリックしてください。
Visual Studio Code の緑の枠で囲ったあたりに、
Users > {自分の名前} > Documents > 1.rb
と表示されると思います。この
Users > {自分の名前} > Documents > 1.rbにファイルが保存されました。
書類に保存したはずなのに、Documentsになっているのはなぜ?Macの Finder のアプリでは、日本語で
書類フォルダがありますが、内部ではDocumentsフォルダと同じ扱いになります。
詳しい説明は省きますが、Mac では 名前が違うけど同じ になるフォルダがいくつかあります。今は気にせず 書類 フォルダにファイルを保存したら、Documents フォルダにも同じファイルが保存されている、とだけ覚えて、次の章に進みます。
ターミナルで
1.rbを実行する保存した
1.rbファイルを実行するために、ターミナルアプリを起動します。
アプリケーションフォルダ内のユーティリティフォルダ内にターミナルアプリがあるので、
ターミナルアプリをダブルクリックしてください。
ターミナルアプリをダブルクリックで起動したら、ruby Documents/1.rbと入力してエンターキーを押してください。
初めて実行する場合は、↓のような確認画面が出るかもしれません。
書類またはDocumentsフォルダ以下のファイルにアクセスするために OK ボタンをクリックします。
ruby Documents/1.rbの下に、1の数字が表示されたと思います。これで Ruby のファイルを実行できました。
何が起こったの?
前の章で
ターミナルに入力したruby Documents/1.rbは、コマンド と言います。
コマンド とは、簡単に言うと アプリを文字で実行する ようなものだと覚えておいてください。いつもは使いたいアプリのアイコンをダブルクリックで起動していると思いますが、似たようなことを 文字の入力だけ で実現しています。
ruby Documents/1.rbというコマンドは、
Documents/1.rbというファイルをrubyというアプリで開くというようなことをしています。
(厳密に言うとrubyはアプリではありませんが、説明のためにアプリと言い表しています。)ちょっとだけ蛇足
ターミナルのアプリにpwdと入力してエンターキーを押して実行してください。
/Users/{自分の名前}と表示されたと思います。
pwdというコマンドは 今いるフォルダの場所を表示する というコマンドです。次に
ターミナルのアプリにruby /Users/{自分の名前}/Documents/1.rbと入力してエンターキーを押して実行してください。
さっきと同じように
1が表示されたと思います。これは、
自分の今いるフォルダ の下の 書類 フォルダにある
1.rbというファイルをrubyコマンドで実行するよ。ということをしています。
最後にもう一つ。
ターミナルのアプリにcd Documentsと入力してエンターキーを押して実行してください。
次に
ターミナルのアプリにruby 1.rbと入力してエンターキーを押して実行してください。
またさっきと同じように
1が表示されました。この2つのコマンドは、
Documents (書類) フォルダに 移動 するよ。
と
1.rbというファイルをrubyコマンドで実行するよ。ということをしました。
1つめの
cdが、フォルダを 移動 するためのコマンドです。
どこに移動するかを Documents (書類) フォルダに指定しました。
↑この状態になったのと同じ意味です。
そして、今までは
1.rbというファイルがある場所を、フォルダ名と一緒にターミナルアプリで入力していましたが、2つめのコマンドruby 1.rbでは、ファイル名を入力するだけで、同じ1という表示が出せました。書類 フォルダに移動したので、書類 フォルダという場所を入力しなくてもよくなりました。
まとめ
- プログラミング言語の処理を書いてファイルに保存するための Visual Studio Code を使いました。
- Visual Studio Code で
puts 1という文字を入力して、1.rbというファイル名で、書類 (Documents) フォルダの下に保存しました。ターミナルアプリでコマンドを実行しました。ターミナルアプリで、今いるフォルダを表示しました。ターミナルアプリで、Documents (書類) フォルダに移動しました。ターミナルアプリで、1.rbというファイルをrubyコマンドで実行しました。動作環境
Mac: バージョン 10.15.4
Visual Studio Code: Version: 1.45.0
Ruby: 2.6.3p62