- 投稿日:2020-05-16T23:38:17+09:00
機械学習を用いた因果推論
機械学習を用いた因果推論
近年盛んにおこなわれている機械学習の手法を用いた因果推論についていつ利用するかの大まかな理解とメモ(備忘録)
基本的には現在の因果推論手法のフローチャート的まとめはじめに
因果推論とは、結果に対する原因を答えることを目的とした一連の統計的手法である。一般に回帰分析などの統計的アプローチでは、Xの変化がYの変化とどのように関連しているかを定量化することに重きをおいている。一方で統計的因果推論は、Xの変化がYの変化を引き起こすかどうかを判断し、この因果関係を定量化することに重きをおいている。近年盛んである機械学習と因果推論の融合分野は、このうち特定の条件下における因果効果の推定に用いられる。今回は既存の因果推論の手法と機械学習を用いた手法の使い分けを大まかに整理した。
当然だが有するデータに対して「何を、なぜ知りたいか?」を明確にしてから分析していく。
でないと、取るべき戦術が見えてこない。因果推論の一般的戦術
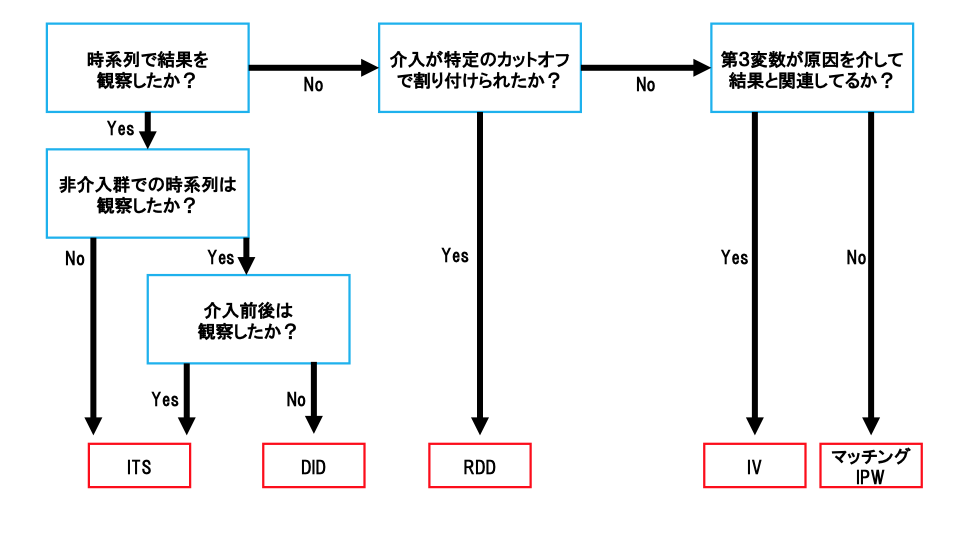
因果推論は様々な方針が取られている。そのため自身が有するデータから因果推論をおこなうには様々な方法が考えられる。まずは因果推論を構造的に理解するために、2つのカテゴリーに分ける。今回は有するデータが実験データか、または観測データかを識別し、それぞれで代表的なアプローチをみていく。
方針
- 実験データか観測データかの識別
- 実験データでの因果推論
- 観測データでの因果推論
実験データでの因果推論
実験データの場合、因果効果の検証のために実験がデザインされているため、推定は観測データに比べて明確でわかりやすい。多くの場合はRCT(Randomized Controlled Trial)条件に近づけるように解析をしていく。ただし、あくまでもデザインされた実験中の平均的な因果効果の推定では、古典的な統計的因果推論の手法を用いることで推定をすることができる。しかしながら、平均的な因果効果だけでなく、特定の状況や条件下での因果効果について推定したい場合がある。そこで、近年では機械学習の手法を織り交ぜた因果推論によりそれを可能にしている。
実験データでは大きく4つのカテゴリーに分けて考えていく。
- 介入と非介入との共変量の差異
- 介入グループの一部が非介入
- 介入グループの中でサブグループごとに効果が異なる
- 因果関係の構造的把握
有するデータが実験データと判断されたら、上から順に考えていく。そして目的の分析を実行する。
介入と非介入との共変量の差異
一般的な因果推論である。基本的には介入グループと非介入グループ間での因果効果を推定したい場合を想定している。その時、処置(原因)と応答(結果)以外の共変量がグループ間で異なってしまう。すると正しい効果を推定することができなくなってしまう。そこで、この共変量をグループ間で出来るだけ等しくなるように調整して、その上で推定していく。主な方針としてDIDやマッチング、IPWなどが挙げられる。
→ DID・マッチング・IPW etc.
介入グループの一部が非介入
実験研究において介入効果に偏りのない推定のため、介入をランダムに割り付けたとしても、この介入が必ずしもその通りに実行されるとは限らない(ノンコンプライアンス)。介入の割り付けと実際に受けた介入とが等しければ、個体は割り付けられた介入を遵守したことになる。一方、等しくないときはノンコンプライアンスとなる。つまり、ノンコンプライアンス条件下では介入グループは、遵守グループと非遵守グループとで異なるグループが混在することになる。よって、遵守グループに限定した平均因果効果を推定する必要がある(LATE)。
→ 操作変数(IV)
介入グループの中でサブグループごとに効果が異なる
介入グループの中でもサンプルごとにそれぞれ異なる共変量を取っている。そして、特定のサンプルごとに介入効果を求めるとき、介入グループの中でも特定の条件でPersonalizeされた介入効果を計算する必要がある。いわゆる機械学習を用いた因果推論。
→ HTE(Heterogeneous Treatment Effects)、Uplift Modeling
→ GRF(Generalized Random Forest)、ORF(Orthogonal Random Forest)は傾向スコアを算出せず介入効果を推定
→ Meta-Learnerはグループごとにモデリング&効果推定後、傾向スコアを用いてその推定値から介入効果を推定
因果関係の構造的把握
ある変数が別の変数に影響を与える場合、直接作用する場合と媒介変数を通じて間接的に作用する場合とがある。このとき、変数間で影響する効果のうち、どの程度直接的で、どの程度間接的であるかを分析することは重要である。この原因と結果の関係だけでなく結果の原因となったメカニズムを理解することによって、どの媒介変数を変化させれば高い効果が見込めるかを分析することが可能になる。
→ 媒介分析
観察データでの因果推論
観察データの場合、定期的に観測されるものが多い。その際、時系列データとして利用することになる。一方、時系列データでない場合は原因および結果となる変数以外の変数を定義することになる。このとき、特定の状況に関する十分な知識が必要となる。これを基に因果構造を決定していく必要がある。
観察データでは以下のように場合分けする。
Heterogeneous Treatment Effects (HTE)
個人は、バックグラウンドの特徴だけでなく、特定の治療、介入、または刺激に対する反応も異なる。特に、治療効果は治療の傾向によって系統的に変化する可能性がある(Xie et al., 2012)。そしてこの影響の不均一性が存在する場合、主な影響を用いた古典的な因果推論のアプローチであるAverage Treatment Effect(ATE)の推定では、必ずしも十分な推定がおこなえなかった。そこでバックグラウンドといったPersonalなレベルでの影響を加味した介入効果の推定としてHeterogeneous Treatment Effects(HTE)を考えることで、このそれぞれの影響を加味した推定が可能になる。その際、機械学習を用いて因果推論を実行していく。
HTEでの分析
RやPythonにライブラリやパッケージが存在する。代表的なものは以下。
R
・grf
・uplift
・rlearnerPython
・EconML
・CausalML
・pylift参照
・ノーベル経済学賞でも注目の因果推論を俯瞰する
https://note.com/tak1/n/nf35b48502339
・Using Causal Inference to Improve the Uber User Experience
https://eng.uber.com/causal-inference-at-uber/
・X-Learnerについて調べた内容のまとめ
https://dev.classmethod.jp/articles/causal-metalearner-xlearner/
・EconMLパッケージの紹介 (meta-learners編)
https://usaito.hatenablog.com/entry/2019/04/07/205756
・Yu Xie, Jennie E. Brand, and Ben Jann. (2012) Estimating Heterogeneous Treatment Effects with Observational Data. Sociol Methodol 42(1): 314-347.
- 投稿日:2020-05-16T23:38:17+09:00
機械学習を用いた因果推論(因果推論手法の整理)
機械学習を用いた因果推論
近年盛んにおこなわれている機械学習の手法を用いた因果推論についていつ利用するかの大まかな理解とメモ(備忘録)
基本的には現在の因果推論手法のフローチャート的まとめはじめに
因果推論とは、結果に対する原因を答えることを目的とした一連の統計的手法である。一般に回帰分析などの統計的アプローチでは、Xの変化がYの変化とどのように関連しているかを定量化することに重きをおいている。一方で統計的因果推論は、Xの変化がYの変化を引き起こすかどうかを判断し、この因果関係を定量化することに重きをおいている。近年盛んである機械学習と因果推論の融合分野は、このうち特定の条件下における因果効果の推定に用いられる。今回は既存の因果推論の手法と機械学習を用いた手法の使い分けを大まかに整理した。
当然だが有するデータに対して「何を、なぜ知りたいか?」を明確にしてから分析していく。
でないと、取るべき戦術が見えてこない。因果推論の一般的戦術
因果推論は様々な方針が取られている。そのため自身が有するデータから因果推論をおこなうには様々な方法が考えられる。まずは因果推論を構造的に理解するために、2つのカテゴリーに分ける。今回は有するデータが実験データか、または観測データかを識別し、それぞれで代表的なアプローチをみていく。
方針
- 実験データか観測データかの識別
- 実験データでの因果推論
- 観測データでの因果推論
実験データでの因果推論
実験データの場合、因果効果の検証のために実験がデザインされているため、推定は観測データに比べて明確でわかりやすい。多くの場合はRCT(Randomized Controlled Trial)条件に近づけるように解析をしていく。ただし、あくまでもデザインされた実験中の平均的な因果効果の推定では、古典的な統計的因果推論の手法を用いることで推定をすることができる。しかしながら、平均的な因果効果だけでなく、特定の状況や条件下での因果効果について推定したい場合がある。そこで、近年では機械学習の手法を織り交ぜた因果推論によりそれを可能にしている。
実験データでは大きく4つのカテゴリーに分けて考えていく。
- 介入と非介入との共変量の差異
- 介入グループの一部が非介入
- 介入グループの中でサブグループごとに効果が異なる
- 因果関係の構造的把握
有するデータが実験データと判断されたら、上から順に考えていく。そして目的の分析を実行する。
介入と非介入との共変量の差異
一般的な因果推論である。基本的には介入グループと非介入グループ間での因果効果を推定したい場合を想定している。その時、処置(原因)と応答(結果)以外の共変量がグループ間で異なってしまう。すると正しい効果を推定することができなくなってしまう。そこで、この共変量をグループ間で出来るだけ等しくなるように調整して、その上で推定していく。主な方針としてDIDやマッチング、IPWなどが挙げられる。
→ DID・マッチング・IPW etc.
介入グループの一部が非介入
実験研究において介入効果に偏りのない推定のため、介入をランダムに割り付けたとしても、この介入が必ずしもその通りに実行されるとは限らない(ノンコンプライアンス)。介入の割り付けと実際に受けた介入とが等しければ、個体は割り付けられた介入を遵守したことになる。一方、等しくないときはノンコンプライアンスとなる。つまり、ノンコンプライアンス条件下では介入グループは、遵守グループと非遵守グループとで異なるグループが混在することになる。よって、遵守グループに限定した平均因果効果を推定する必要がある(LATE)。
→ 操作変数(IV)
介入グループの中でサブグループごとに効果が異なる
介入グループの中でもサンプルごとにそれぞれ異なる共変量を取っている。そして、特定のサンプルごとに介入効果を求めるとき、介入グループの中でも特定の条件でPersonalizeされた介入効果を計算する必要がある。いわゆる機械学習を用いた因果推論。
→ HTE(Heterogeneous Treatment Effects)、Uplift Modeling
→ GRF(Generalized Random Forest)、ORF(Orthogonal Random Forest)は傾向スコアを算出せず介入効果を推定
→ Meta-Learnerはグループごとにモデリング&効果推定後、傾向スコアを用いてその推定値から介入効果を推定
因果関係の構造的把握
ある変数が別の変数に影響を与える場合、直接作用する場合と媒介変数を通じて間接的に作用する場合とがある。このとき、変数間で影響する効果のうち、どの程度直接的で、どの程度間接的であるかを分析することは重要である。この原因と結果の関係だけでなく結果の原因となったメカニズムを理解することによって、どの媒介変数を変化させれば高い効果が見込めるかを分析することが可能になる。
→ 媒介分析
観察データでの因果推論
観察データの場合、定期的に観測されるものが多い。その際、時系列データとして利用することになる。一方、時系列データでない場合は原因および結果となる変数以外の変数を定義することになる。このとき、特定の状況に関する十分な知識が必要となる。これを基に因果構造を決定していく必要がある。
観察データでは以下のように場合分けする。
Heterogeneous Treatment Effects (HTE)
個人は、バックグラウンドの特徴だけでなく、特定の治療、介入、または刺激に対する反応も異なる。特に、治療効果は治療の傾向によって系統的に変化する可能性がある(Xie et al., 2012)。そしてこの影響の不均一性が存在する場合、主な影響を用いた古典的な因果推論のアプローチであるAverage Treatment Effect(ATE)の推定では、必ずしも十分な推定がおこなえなかった。そこでバックグラウンドといったPersonalなレベルでの影響を加味した介入効果の推定としてHeterogeneous Treatment Effects(HTE)を考えることで、このそれぞれの影響を加味した推定が可能になる。その際、機械学習を用いて因果推論を実行していく。
HTEでの分析
RやPythonにライブラリやパッケージが存在する。代表的なものは以下。
R
・grf
・uplift
・rlearnerPython
・EconML
・CausalML
・pylift参照
・ノーベル経済学賞でも注目の因果推論を俯瞰する
https://note.com/tak1/n/nf35b48502339
・Using Causal Inference to Improve the Uber User Experience
https://eng.uber.com/causal-inference-at-uber/
・X-Learnerについて調べた内容のまとめ
https://dev.classmethod.jp/articles/causal-metalearner-xlearner/
・EconMLパッケージの紹介 (meta-learners編)
https://usaito.hatenablog.com/entry/2019/04/07/205756
・Yu Xie, Jennie E. Brand, and Ben Jann. (2012) Estimating Heterogeneous Treatment Effects with Observational Data. Sociol Methodol 42(1): 314-347.
- 投稿日:2020-05-16T23:37:15+09:00
Python: 自然言語処理
自然言語処理の基本
自然言語処理の概要
自然言語(NL, Natural Language)とは、日本語や英語のような 自然発生的に生まれた言語 のことを指し
プログラミング言語のような人工言語(Artificial Language)とは対比の存在です。自然言語処理(NLP, Natural Language Processing)とは人間が日常的に使っている 自然言語をコンピュータに処理させる技術 のことです。
自然言語処理を用いたタスクには、文書分類・機械翻訳・文書要約・質疑応答・対話などがあります。自然言語処理でよく使われるワードとして、以下のようなものがあげられます。
トークン:自然言語を解析する際、文章の最小単位として扱われる文字や文字列のこと。 タイプ:単語の種類を表す用語。 文章:まとまった内容を表す文のこと。自然言語処理では一文を指すことが多い。 文書:複数の文章から成るデータ一件分を指すことが多い。 コーパス:文書または音声データにある種の情報を与えたデータ。 シソーラス:単語の上位/下位関係、部分/全体関係、同義関係、類義関係などによって単語を分類し 体系づけた類語辞典・辞書。 形態素:意味を持つ最小の単位。「食べた」という単語は、2つの形態素「食べ」と「た」に分解できる。 単語:単一または複数の形態素から構成される小さな単位。 表層:原文の記述のこと。 原形:活用する前の記述のこと。 特徴:文章や文書から抽出された情報のこと。 辞書:自然言語処理では、単語のリストを指す。言語による違い
文章の意味を機械に理解させるためには、単語分割を行う必要があります。 例えば、「私はアイデミーで勉強します。」という文は
私 | は | 学校 | で | 勉強し | ます | 名詞 副助詞 名詞 格助詞 動詞 助動詞のように単語の区切りを同定し、その品詞と基本形を上記のように求めることができます。日本語は単語の区切りを同定することが難しいですが、一方で複数の解釈を持つ単語が少ないので品詞や、基本形を求めることは容易です。
中国語やタイ語も単語分割が必要な言語です。
英語の場合は、
I | study | at | aidemy. 名詞 動詞 前置詞 名詞のように単語の区切りは空白やピリオド等の記号により同定できますが、多くの語が複数の品詞をもつため品詞を同定することは難しいです。
以上からわかるように言語ごとに問題の所在、難しさが異なるのが自然言語処理の特徴です。以下のようにひらがな表記の時は特に難しいです。
くるま | で | まつ くる | まで | まつ文章の単語分割
形態素解析とNgram
文章の単語分割の手法は大きく二つ存在し、
①形態素解析(辞書による解析) ②Ngram(文字数による機械的な解析) があります。形態素とは 意味を持つ最小の言語単位 のことであり、単語は一つ以上の形態素を持ちます。
形態素解析とは、辞書を利用して形態素に分割し、さらに形態素ごとに品詞などのタグ付け(情報の付与)を行うことを指します。一方で Ngramとは、 N文字ごとに単語を切り分ける 、または N単語ごとに文章を切り分ける 解析手法のことです。
1文字、あるいは1単語ごとに切り出したものを モノグラム 、2文字(単語)ごとに切り出したものを バイグラム 、3文字(単語)ごとに切り出したものを トリグラム と呼びます。
例えば「あいうえお」という文の文字のモノグラム・バイグラム・トリグラムを考えてみると以下のようになります。
モノグラム:{あ, い, う, え, お} バイグラム:{あい, いう, うえ, えお} トリグラム:{あいう, いうえ, うえお}Ngram は形態素解析のように辞書や文法的な解釈が不要であるため
言語に関係なく 用いることができます。
また Ngram は特徴抽出の漏れが発生しにくいメリットがありますが
ノイズが大きくなるデメリットがあります。 逆に形態素解析は辞書の性能差が
生じてしまう代わりにノイズが少ないです。例えば、「東京都の世界一有名なIT企業」という少し長い文字列について検索する際、バイグラムによって文字列を分割し検索すると「京都」の企業がヒットする可能性が出てしまいます。 なぜなら「東京都」の文字バイグラムを列挙すると{東京, 京都}となるからです。
形態素解析を適切に用いるとこのようなことは起こりませんが、性能の高い辞書を用意する必要があります。<用語> 単語分割:文章を単語に分割すること 品詞タグ付け:単語を品詞に分類して、タグ付けをする処理のこと 形態素解析:形態素への分割と品詞タグ付けの作業をまとめたものMeCab
形態素解析を行うにあたりあらかじめ形態素解析ツールが用意されており
日本語の形態素解析器として代表的なものにMeCabやjanomeなどがあります。MeCabやjanomeは辞書を参考に形態素解析を行います。
ここではMecabの使い方を学習します。以下のMecabを使った形態素解析の実行例を見てください。import MeCab mecab = MeCab.Tagger("-Owakati") print(mecab.parse("明日は晴れるでしょう。")) # 出力結果 # 明日 は 晴れる でしょ う 。mecab = MeCab.Tagger("-Ochasen") print(mecab.parse("明日は晴れるでしょう。")) """ # 出力結果 明日 アシタ 明日 名詞-副詞可能 は ハ は 助詞-係助詞 晴れる ハレル 晴れる 動詞-自立 一段 基本形 でしょ デショ です 助動詞 特殊・デス 未然形 う ウ う 助動詞 不変化型 基本形 。 。 。 記号-句点 EOS """MeCabでは
MeCab.Tagger()の引数を変更することによりデータの出力形式を変更することができます。
例のように"-Owakati"を引数とすると単語ごとに分ける分かち書き "-Ochasen"を引数とすると形態素解析を行います。 .parse("文章")とすることにより引数の文章を指定された形式で出力させることができます。janome (1)
janomeも有名な日本語の形態素解析器の一つです。
janomeの利点としては、MeCabのインストールが面倒なことに対して
パッケージのインストールが容易な点です。
janomeは初めにTokenizerをインポートし
Tokenizer オブジェクトを Tokenizer() によって作成します。from janome.tokenizer import Tokenizer t = Tokenizer()Tokenizerのtokenizeメソッドに解析したい文字列渡すことで形態素解析できます。
tokenizeメソッドの返り値はタグ付けされたトークン(Tokenオブジェクト)のリストです。
#形態素解析 from janome.tokenizer import Tokenizer tokenizer = Tokenizer() # Tokenizerオブジェクトの作成 tokens = tokenizer.tokenize("pythonの本を読んだ") for token in tokens: print(token) """ # 出力結果 python 名詞,固有名詞,組織,*,*,*,python,*,* の 助詞,連体化,*,*,*,*,の,ノ,ノ 本 名詞,一般,*,*,*,*,本,ホン,ホン を 助詞,格助詞,一般,*,*,*,を,ヲ,ヲ 読ん 動詞,自立,*,*,五段・マ行,連用タ接続,読む,ヨン,ヨン だ 助動詞,*,*,*,特殊・タ,基本形,だ,ダ,ダ """janome (2)
janome(1)では、形態素解析を行いましたが
tokenizeメソッドの引数にwakati=True を指定することにより分かち書きをさせることができます。wakati=Trueにした時の返り値は 分かち書きのリスト となります。
from janome.tokenizer import Tokenizer # 分かち書き t = Tokenizer() tokens = t.tokenize("pythonの本を読んだ", wakati=True) print(tokens) # 出力結果 ["python", "の", "本", "を", "読ん", "だ"]split関数
自然言語処理にあたって文書データ等をダウンロードした際
"banana, apple, strawberry" のように単語と単語が特殊な文字で区切られていることがよくあります。そのようなときにPythonの組み込み関数である split関数関数をよく用いるのでここで説明します。
split関数は、数字・アルファベット・記号などが入り混じった 文字列を
ある規則に従って切り分けてリスト化 してくれる関数です。文字列がスペースや区切り文字(「,」, 「.」, 「_」など)によって区切られている時に
文字列.split("区切り文字") とすることで空白や区切り文字で区切られたリストを得ることができます。fruits = "banana, apple, strawberry" print(fruits) # str print(fruits.split(",")) # list # 出力結果 banana, apple, strawberry ["banana", " apple", " strawberry"] fruits = "banana apple srawberry" print(fruits) # str print(fruits.split()) # list # 出力結果 banana apple srawberry ["banana", "apple", "srawberry"]janome (3)
各トークン(Tokenオブジェクト)に対して
Token.surfaceで表層形を取り出すことができToken.part_of_speechで品詞を取り出すことができます。表層形とは、文中において文字列として実際に出現する形式のことです。
tokens = t.tokenize("pythonの本を読んだ") #表層形 for token in tokens: print(token.surface) """ # 出力結果 python の 本 を 読ん だ """ # 品詞 for token in tokens: print(token.part_of_speech) """ # 出力結果 名詞,固有名詞,組織,* 助詞,連体化,*,* 名詞,一般,*,* 助詞,格助詞,一般,* 動詞,自立,*,* 助動詞,*,*,*例としてはこちら
from janome.tokenizer import Tokenizer t = Tokenizer() tokens = t.tokenize("鹿の肉を食べた") word = [] # 以下が例です。 for token in tokens: part_of_speech = token.part_of_speech.split(",")[0] if part_of_speech == "名詞" or part_of_speech == "動詞": word.append(token.surface) print(word) # 出力結果 # ['鹿', '肉', '食べ']Ngram
Ngramとは、 先ほど述べたようにN文字ごとに単語を切り分ける
または N単語ごとに文章を切り分ける 解析手法のことです。Ngramのアルゴリズムは以下のgen_Ngramように書くことができます。
単語のNgramを求めたい場合は、引数に単語と切り出したい数を入れます。
文章のNgramを求めたい場合は、janomeのtokenize関数を用いて分かち書きのリストを作成し
その分かち書きのリストと切り出したい数を引数に入れます。"pythonの本を読んだ"、という文章を3単語ごと(N=3)に分割する場合を考えます。
janomeを用いると["python", "の", "本", "を", "読ん", "だ"]と分割されます。
連続した3単語は、6 - 3 + 1 (品詞を元に分割された数 - N + 1) = 4個取ることができます。
結果は["pythonの本", "の本を", "本を読ん", "を読んだ"]となります。from janome.tokenizer import Tokenizer tokenizer = Tokenizer() tokens = tokenizer.tokenize("pythonの本を読んだ", wakati=True) # tokens = ["python", "の", "本", "を", "読ん", "だ"] def gen_Ngram(words,N): ngram = [] # ここに切り出した単語を追加していきます。 for i in range(len(words)-N+1): # 連続したN個の単語が取れるまでfor文で繰り返します。 cw = "".join(words[i:i+N]) # N個分の単語をつなげてcwに代入します。 ngram.append(cw) return ngram print(gen_Ngram(tokens, 2)) print(gen_Ngram(tokens, 3)) # 文章のトリグラムの場合 gen_Ngram(tokens, 3) # 出力結果 ["pythonの本", "の本を", "本を読ん", "を読んだ"] # 単語のバイグラムの場合 gen_Ngram("bird", 2) # 出力結果 ["bi", "ir", "rd"]from janome.tokenizer import Tokenizer t = Tokenizer() tokens = t.tokenize("1郎はこの本を2郎を見た女性に渡した。", wakati=True) def gen_Ngram(words,N): # Ngramを生成してください ngram = [] for i in range(len(words)-N+1): cw = "".join(words[i:i+N]) ngram.append(cw) return ngram print(gen_Ngram(tokens, 2)) print(gen_Ngram(tokens, 3))正規化
正規化 (1)
自然言語処理では、複数の文書から特徴を抽出する場合
入力ルールが統一されておらず表記揺れが発生している場合があります。(例 iPhoneとiphone)同じはずの単語を別のものとして解析してしまい、意図しない解析結果がもたらされてしまいます。
全角を半角に統一や大文字を小文字に統一等、ルールベースで文字を変換することを正規化と言います。正規化を行い過ぎると本来区別すべき内容も区別できなくなるため注意しましょう。<用語> 表記揺れ:同じ文書の中で、同音・同義で使われるべき語句が異なって表記されていること 正規化:表記揺れを防ぐためルールベースで文字や数字を変換すること文字列の正規化において、ライブラリの
NEologdを用いると容易に正規化を行うことができます。neologdn.normalize("正規化したい文字列") # と表記すると、正規化された文字列が返り値として渡されます。neologdn で行うことができる正規化は以下のものとなります。
全角英数字を半角に統一 ai -> ai 半角カタカナを全角に統一 カタカナ -> カタカナ 長音短縮 ワーーーーーーーーイ -> ワーイ 似た文字種の統一 "− ー - "-> "-" 不必要なスペースの削除 "ス ペ ース "-> "スペース" 繰り返しの制限 (問題で確認)正規化 (2)
正規化(1)では、ライブラリを用いた正規化について見てきました。
次は、自分のデータに合わせて正規化したいときのために
自分自身で正規化をするための方法 について説明します。文書中に「iphone」「iPhone」の2種類の単語があった時に
これらを同一のものとして扱うために表記を統一する必要があります。大文字を小文字に揃えたいときは、 .lower() を文字列につけることにより揃えることができます。
以下の例のようにコード内で何度も用いるようなものは関数にすることが多いです。def lower_text(text): return text.lower() lower_letters = lower_text("iPhone") print(lower_letters) # 出力結果 # iphone正規化 (3)
また正規化では、数字の置き換えを行うことがあります。
数字の置き換えを行う理由としては、 数値表現が多様で出現頻度が高い割には
自然言語処理のタスクに役に立たない場合があるからです。たとえば、ニュース記事を「スポーツ」や「政治」のようなカテゴリに分類するタスクを考えます。
この時、記事中には多様な数字表現が出現すると思いますが
カテゴリの分類にはほとんど役に立たないと考えられます。そのため数字を別の記号に置き換えて語彙数を減らしてしまいます。ここでは正規表現という特殊な表現方法を使って文字列を変換します。
正規表現について詳しくは正規化(4)にて説明します。正規表現操作には
Pythonの標準ライブラリ reを使います。文字列を別の文字列に置き換えるには、
re.sub(正規表現, 置換する文字列, 置換される文字列全体 [, 置換回数]) # 第一引数に置き換えたいものを正規表現で指定 # 第二引数に置き換える文字列を示す。 # 第三引数に置換する文字列全体を指定します。 # 第四引数の回数を指定しないと、全て置換されることになります。以下の例を見てみましょう。"昨日は6時に起きて11時に寝た。"という文章があるとします。
normalize_numberは文章から数字を削除する関数です。re.subの
第一引数\dは数字列を表す正規表現です。これを用いることで任意の数字列を指定することができます。
第二引数は""となっており、第一引数で指定された文字列をに書き換える操作になります。
第三引数で文章を指定しており、第四引数が指定されていないので、文章中の数字列を全て変更する操作を行います。import re def normalize_number(text): replaced_text = re.sub("\d", "<NUM>", text) return replaced_text replaced_text = normalize_number("昨日は6時に起きて11時に寝た。") print(replaced_text) # 出力結果 # 昨日は<NUM>時に起きて<NUM>時に寝た。正規表現
正規表現とは、文字列の集合を一つの文字や別の文字列で置き換える表現法のことです。
文字列の検索機能などで広く使われています。12A3B -> \d\dA\dB上記の例では、半角数字を全て正規表現\dで表しています。
正規表現(3)のように自然言語処理では、解析に必要ないと思われる文字列の集合を
置き換えることによりデータ量を減らします。正規表現はそのような文字列の集合を置換するときに用いられます。
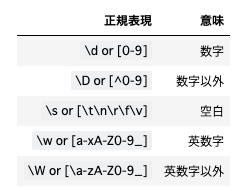
自然言語処理でよく用いられる正規表現は以下の表の通りです。
- 投稿日:2020-05-16T23:20:32+09:00
QTableWidget の指定列をReadOnly にするStyledItemDelegate
備忘録かつ添削をお願いしたく投稿します。
C++の例を書き換えたStyledItemDelegateを書いてみました。
ReadOnlyStyledItemDelegateです。ReadOnlyStyledItemDelegate.pyfrom PySide2.QtWidgets import QStyledItemDelegate class ReadOnlyStyledItemDelegate(QStyledItemDelegate): def __init__(self, parent=None): super().__init__(parent) def createEditor(self, parent, option, index): return None特定列更新不可は実務的には必要な機能だろうと思います。
C++の例がnull返しなのだから、Noneで良いのでは?という程度の理解で書いてます。
createできないのだからdelegateが実装すべき後の機能は親任せで良いだろうということで、createEditorのみです。
- 投稿日:2020-05-16T23:11:58+09:00
ゼロから始めるLeetCode Day27「101. Symmetric Tree」
概要
海外ではエンジニアの面接においてコーディングテストというものが行われるらしく、多くの場合、特定の関数やクラスをお題に沿って実装するという物がメインである。
その対策としてLeetCodeなるサイトで対策を行うようだ。
早い話が本場でも行われているようなコーディングテストに耐えうるようなアルゴリズム力を鍛えるサイト。
せっかくだし人並みのアルゴリズム力くらいは持っておいた方がいいだろうということで不定期に問題を解いてその時に考えたやり方をメモ的に書いていこうかと思います。
前回
ゼロから始めるLeetCode Day26「94. Binary Tree Inorder Traversal」基本的にeasyのacceptanceが高い順から解いていこうかと思います。
Twitterやってます。
問題
101. Symmetric Tree
難易度はeasy。
Top 100 Liked Questionsからの抜粋です。問題としては二分木が与えられるので左右対称であるかを確認してください、というお題です。
For example, this binary tree [1,2,2,3,4,4,3] is symmetric: 1 / \ 2 2 / \ / \ 3 4 4 3 But the following [1,2,2,null,3,null,3] is not: 1 / \ 2 2 \ \ 3 3解法
# Definition for a binary tree node. # class TreeNode: # def __init__(self, val=0, left=None, right=None): # self.val = val # self.left = left # self.right = right class Solution: def isSymmetric(self, root: TreeNode) -> bool: if not root: return True return self.dfs(root,root) def dfs(self,left,right): if left and right: return left.val == right.val and self.dfs(left.left,right.right) and self.dfs(left.right,right.left) else: return left == right # Runtime: 32 ms, faster than 71.25% of Python3 online submissions for Symmetric Tree. # Memory Usage: 13.9 MB, less than 5.17% of Python3 online submissions for Symmetric Tree.深さ優先探索で解きました。
きちんと左右対象のシンメトリーかを判定しなければならない点に注意しましょう。
あんまり書くことないですね・・・良さげな解答があれば追記します。
- 投稿日:2020-05-16T23:07:27+09:00
pythonでシステム環境変数を読み込む-その1
概要・目的
os.environを使ってシステム環境変数を取得する。
アプリケーション内で使用する設定情報は設定ファイル等に書いてDIできるようになっているが、
設定ファイルの数が多い、または開発状況(develop-staging-release)が複雑な場合は
メンテナンスコストが増大し、ミスする可能性がアップする。
システム環境変数に設定情報を保持することで、設定ファイルのメンテナンスコストを下げることはできないかと考え、
システム環境変数を利用するプログラムを調べてみた。os.environについて深掘り
os.environはシステム環境変数を辞書型で保持している。
pythonが実行されるまでのシステム環境変数を参照できる。
osライブラリシステム環境変数を取得するには
システム環境変数を取得するには、
os.environにシステム環境変数名を指定する。
コマンドプロンプト上で実行したSET %システム環境変数名%と同じ結果となる。$ python Python 3.8.1 (tags/v3.8.1:1b293b6, Dec 18 2019, 23:11:46) [MSC v.1916 64 bit (AMD64)] on win32 Type "help", "copyright", "credits" or "license" for more information. >>> import os >>> print(os.environ['HOMEDRIVE']) C: >>>存在しないシステム環境変数名を指定するとKeyErrorが発生する。
$ python Python 3.8.1 (tags/v3.8.1:1b293b6, Dec 18 2019, 23:11:46) [MSC v.1916 64 bit (AMD64)] on win32 Type "help", "copyright", "credits" or "license" for more information. >>> import os >>> os.environ['TEST'] Traceback (most recent call last): File "<stdin>", line 1, in <module> File "C:\Program Files\Python38\lib\os.py", line 673, in __getitem__ raise KeyError(key) from None KeyError: 'TEST' >>>存在しないシステム環境変数名に例外が発生させたくない場合は、
os.getenv(key, default=value)を使用する。
keyが存在しない場合は、defaultの指定値が返される。defaultを指定しない場合はNoneとなる。
os.environ.get(key)も同様となる。os.getenv(key, default=value)はos.environ.get(key)のエイリアスである。$ python Python 3.8.1 (tags/v3.8.1:1b293b6, Dec 18 2019, 23:11:46) [MSC v.1916 64 bit (AMD64)] on win32 Type "help", "copyright", "credits" or "license" for more information. >>> import os >>> value = os.getenv("TEST", "defaultvalue") >>> print(f"TEST={value}") TEST=defaultvalue >>>システム環境変数を更新するには
os.environが辞書型なのでシステム環境変数と値をセットするだけ
システム環境変数名が存在しない場合は追加され、存在する場合は上書きされる。
削除する場合はdel文を使って削除する。del os.environ[システム環境変数名]$ python Python 3.8.1 (tags/v3.8.1:1b293b6, Dec 18 2019, 23:11:46) [MSC v.1916 64 bit (AMD64)] on win32 Type "help", "copyright", "credits" or "license" for more information. >>> import os >>> value = os.environ["TEST"] Traceback (most recent call last): File "<stdin>", line 1, in <module> File "C:\Program Files\Python38\lib\os.py", line 673, in __getitem__ raise KeyError(key) from None KeyError: 'TEST' >>> os.environ["TEST"] = "PYTHON" >>> value = os.environ["TEST"] >>> print(f"TEST={value}") TEST=PYTHON >>> os.environ["TEST"] = "PYTHON3" >>> value = os.environ["TEST"] >>> print(f"TEST={value}") TEST=PYTHON3 >>> del os.environ["TEST"] >>> value = os.environ["TEST"] Traceback (most recent call last): File "<stdin>", line 1, in <module> File "C:\Program Files\Python38\lib\os.py", line 673, in __getitem__ raise KeyError(key) from None KeyError: 'TEST' >>>
os.environを直接変更せずにシステム環境変数をセットする関数もある。
getenvと対になるputenv(key, value)でシステム環境変数に追加や更新ができるが、公式ドキュメントにはこのような注意書きがある。putenv() がサポートされている場合、 os.environ のアイテムに対する代入を行うと、自動的に putenv() の対応する呼び出しに変換されます。直接 putenv() を呼び出した場合 os.environ は更新されないため、実際には os.environ のアイテムに代入する方が望ましい操作です。
引数 key, value を指定して 監査イベント os.putenv を送出します。
putenv()で更新したシステム環境変数がos.environに反映されないなんてバグとしか思えないのだが、辞書型のデータをして扱えばよい。
- 投稿日:2020-05-16T22:57:33+09:00
2. Pythonで綴る多変量解析 1-2. 単回帰分析(アルゴリズム)
基本的な数値計算に必要なNumpyとPandasだけを使って、単回帰式を求めていきます。
⑴ ライブラリをインポートする
import pandas as pd import numpy as np import matplotlib.pyplot as plt⑵ データを取り込み、中身を確認する
df = pd.read_csv("https://raw.githubusercontent.com/karaage0703/machine-learning-study/master/data/karaage_data.csv") print(df.head())
最小二乗法
単回帰分析は、回帰式に含まれる2つの定数、すなわち回帰係数$a$と切片$b$を求めることが目標でした。
その際、より精度の高い単回帰式を得るためには、全体としての誤差、すなわち残差 $y - \hat{y}$ ができるだけ小さくなるように定数$a$、$b$が決定されねばなりません。
このの残差の定義を考えます。
$e_{1}+e_{2}+e_{3}…+e_{n}$
となりそうですが、これは誤りです。
実測値は、回帰直線に対し、正負それぞれの側に偏在しています。つまりプラスとマイナスとが互いに打ち消し合ってしまい、合計すると 0 になってしまうのです。
そこで、個体ごとの残差を二乗することで正負をなくし、単に隔たりの大きさ(距離)として扱えるようにします。
$Q = {e_{1}}^{2}+{e_{2}}^{2}+{e_{3}}^{2}…+{e_{n}}^{2}$
回帰直線からの距離の総量として$Q$が定義されました。
この $Q$ が最も小さくなることが、回帰直線の傾き$a$の決め手となり、それが得られれば$y$軸との交点$b$もおのずと求まります。
この方法を最小二乗法といいます。最小二乗法にもとづいて、単回帰式を解いていきます。
⑶ 変数x, yそれぞれの平均値を算出する
mean_x = df['x'].mean() mean_y = df['y'].mean()
⑷ 変数x, yそれぞれの偏差を算出する
偏差とは、各個体の数値と平均値との差です。変数$x$については$x_{i}-\bar{x}$、変数$y$については$y-\bar{y}$を算出します。各変数ともデータの個数分を計算することになります。
# xの偏差 dev_x = [] for i in df['x']: dx = i - mean_x dev_x.append(dx) # yの偏差 dev_y = [] for j in df['y']: dy = j - mean_y dev_y.append(dy)
⑸ 変数xの分散を算出する
⑷で求めた偏差をつかって分散を計算します。分散とは、偏差の二乗の平均をとったもの、すなわち偏差ごとに二乗して、その総和を (データの個数-1) の数値で除算します。
# 偏差平方和 ssdev_x = 0 for i in dev_x: d = i ** 2 ssdev_x += d # 分散 var_x = ssdev_x / (len(df) - 1)
⑹ 共分散を算出する
共分散$s_{xy}$とは、2変数の関係の強さを表わす指標の一つで、次式で定義されます。
$s_{xy} = \frac{1}{n - 1} \displaystyle \sum_{i = 1}^n
{(x_i - \overline{x})(y_{i} - \overline{y})}$
データの個体ごとの組を考えます。$(x_{1}, y_{1}), (x_{2}, y_{2}), ..., (x_{n}, y_{n})$という$n$組があるとき、組ごとに$x$の偏差と$y$の偏差を乗算し、それらの総和を (データ個数-1) の数値で除算します。# 偏差積和 spdev = 0 for i,j in zip(df['x'], df['y']): spdev += (i - mean_x) * (j - mean_y) # 共分散 cov = spdev / (len(df) - 1)
⑺ 回帰係数aを算出する
最小二乗法によって回帰係数を求める公式を示します。
$a = \frac{S_{xy}}{Sx^2}$
⑹で求めた共分散$S_{xy}$を、⑸で求めた変数$x$の分散$Sx^2$で除算することで回帰係数$a$が求められます。a = cov / var_x
⑻ 切片bを算出する
単回帰式 $y = ax + b$ を変形し、$b = y -ax$として、⑶で求めた平均値$\bar{x}, \bar{y}$と、⑺で求めた回帰係数$a$を代入します。
b = mean_y - (a * mean_x)
以上、最小二乗法の公式により単回帰式が求められました。
先に、機械学習ライブラリ scikit-learn を利用して得られた計算結果と一致しています。そこで、決定係数の確認もまた自前で計算してみます。⑼ 決定係数を算出し、回帰式の精度を確認する
回帰式をつかって予測値のデータを作成し、その分散を求めます。
それが、実測値$y$の分散に対して何割を占めるか、すなわちどの程度もとの変量$y$を説明できているか。# 予測値zのデータ作成 df['z'] = (a * df['x']) + b print(df) # 予測値zの分散 ssdev_z = 0 for i in df['z']: j = (i - df['z'].mean())**2 ssdev_z += j var_z = ssdev_z / (len(df) - 1) print("予測値の分散:", var_z) # 実測値yの分散 ssdev_y = 0 for i in dev_y: j = i ** 2 ssdev_y += j var_y = ssdev_y / (len(df) - 1) print("実測値yの分散:", var_y) # 決定係数 R = var_z / var_y print("決定係数R:", R)
決定係数もまた先の scikit-learn による計算結果と一致することが確認できました。⑽ 散布図に回帰直線を合わせて図示する
plt.plot(x, y, "o") # 散布図 plt.plot(x, z, "r") # 回帰直線 plt.show()
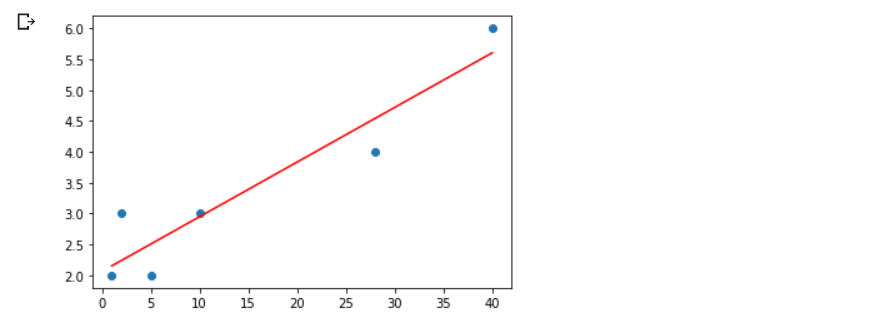
ここまで、単回帰分析のアルゴリズムを学びました。
しかし、現実の社会では、ある現象をただ1つの要因で説明できるようなケースはまずありません。ある現象の背景には、さまざまな要因が大なり小なり同時にからみ合っているものです。
次に、3つ以上の変数をあつかう重回帰分析を学びます。








- 投稿日:2020-05-16T22:56:37+09:00
2. Pythonで綴る多変量解析 1-1. 単回帰分析(scikit-learn)
ここ数年来 AI やビッグデータへの関心の高まりに伴い、機械学習のためのアプローチ法として、例えばk-meansといった分析手法を耳目にするようになりました。それらは、いずれも昭和の昔から何十年とビジネスや学術分野で活用されてきた多変量解析の手法です。
その中でも特にポピュラーな手法の一つが回帰分析です。
そこで、まず機械学習ライブラリの scikit-learn(サイキット・ラーン)を利用して単回帰分析を実装してみます。
(原則として Google Colaboratory 上でコードの記述や結果の確認をおこないます)単回帰分析
回帰分析は、2つの変量を対象とする単回帰分析と、3つ以上の変量を対象とする重回帰分析に分けられます。
まず、単回帰分析を考えます。
単回帰分析とは、データ(現象)の中に線形ないし非線形の法則性を導くもの・・・・・・、平たく言えば、$x$が増えると$y$も一定の比率で増える/減るというような法則性を明らかにするものです。
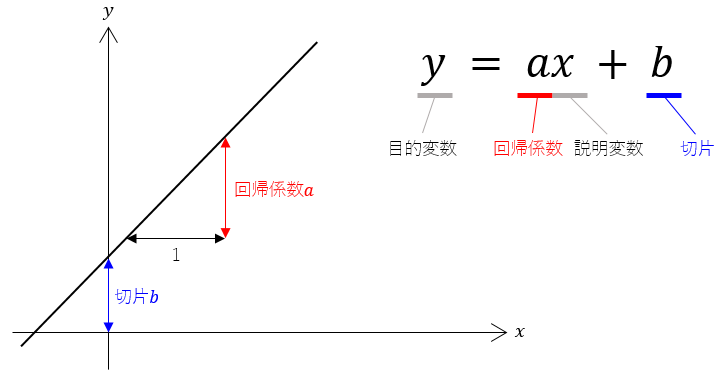
ごくシンプルな線形の単回帰分析は、次の式で表わされます。
この方程式を回帰式(単回帰式)といいます。
この$a$と$b$さえ決まってしまえば自ずと直線は引けます。すると、$x$で$y$を説明することができる、あるいは$x$から$y$を予測することができる。
変数$y$ を変数$x$ によって説明するということから、ターゲットとなる $y$ を目的変数(従属変数)、これを説明する $x$ を説明変数(独立変数)と呼びます。
また、回帰直線の傾きを示す$a$を回帰係数、$y$軸との交点を示す$b$を切片といいます。
すなわち回帰係数aと切片bを求めることが、単回帰分析の目標です。⑴ ライブラリをインポートする
# 数値計算に必要なライブラリ import numpy as np import pandas as pd # グラフを描画するパッケージ import matplotlib.pyplot as plt # scikit-learnの線形モデル from sklearn import linear_model⑵ データを読み込み、中身を確認する
df = pd.read_csv("https://raw.githubusercontent.com/karaage0703/machine-learning-study/master/data/karaage_data.csv") df
⑶ 変量x, yをNumpyのArray型に変換する
データが格納された変数dfは、Pandasのデータフレームの形式になっています。これを後々の計算のために、NumpyのArray型に変換するなどして変数x, yにそれぞれ格納します。
x = df.loc[:, ['x']].values y = df['y'].values
変量$x$は、pandasのloc関数で [全行, x列] の要素を切り出してvaluesでNumpy配列に変換し、2次元データとして格納しました。また変量$y$は、列名$y$を指定して1次元データとして取り出し、同様にNumpy配列に変換しています。⑷ 散布図にデータをプロットしてみる
描画パッケージ matplotlib を利用して、
plot関数の引数に(変数x, 変数y, ''マーカーの種類'')を指定します。plt.plot(x, y, "o")
ここから機械学習ライブラリscikit-learn の線形回帰モデルを利用して、回帰係数$a$ と切片$b$ を計算していきます。
⑸ 線形回帰モデルに変量x, yを適用する
# 線形回帰モデルを読み込み、関数clfとする clf = linear_model.LinearRegression() # 関数clfに対して変量x, yをあてはめる clf.fit(x, y)⑹ 回帰係数・切片を算出する
回帰係数は
coef_、切片はintercept_で取得できます。# 回帰係数 a = clf.coef_ # 切片 b = clf.intercept_
⑺ 決定係数を算出する
次いで、決定係数を
score(変数x, 変数y)として取得します。# 決定係数 r = clf.score(x, y)
決定係数
決定係数は、得られた回帰式の精度をあらわす指標です。
精度とはこの場合、「回帰式がデータの分布をどの程度よく説明できているか」ということです。
決定係数は、次のように定義されます。
実際に観測されたデータのことを実測値と呼びます。散布図を見て明らかなように実測値は座標上に散らばっています。
これを一本の直線に要約するわけですから、もとの分散の持っている情報をいくらか棄却することになります。
この棄却した部分、すなわち回帰式に伴う誤差のことを残差といい、次のような分数の形に表わすことができます。
分母は実測値である目的変数$y$の分散で、分子は回帰式による予測値$\hat{y}$の分散と、残差という目減り分を置いて上下は均衡します。
つまり決定係数とは、実測値の分散のうち予測値の分散が何割を占めるかということです。
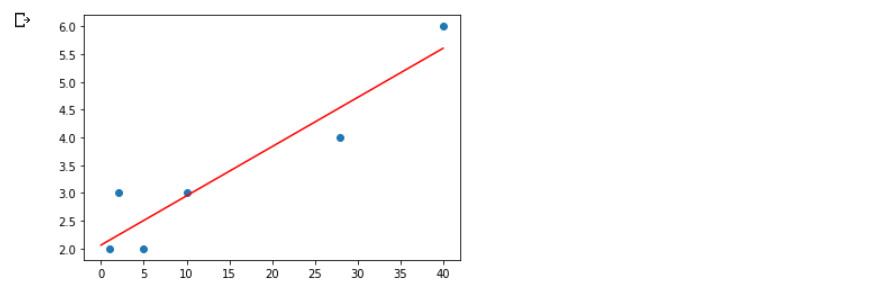
割合ですから、決定係数$R^2$は必ず0以上1以下の値をとり、1に近いほど回帰式の精度がよいと解釈されます。⑻ 回帰直線を描くためのx値を設定する
まず回帰直線の元となる$x$値を、Numpyの
linspace関数をつかって生成します。
引数には(始点, 終点, 区切る数)を指定します。fig_x = np.linspace(0, 40, 40)
⑼ 回帰係数、切片、x値の形状を確認する
print(a.shape) # 回帰係数 print(b.shape) # 切片 print(fig_x.shape) # x値
Tips
このまま $y = ax + b$ に代入するとエラーになってしまいます。
なぜなら、回帰係数$a$ は1行×1列のarray型、$x$値は40行×1列のarray型なので、配列同士を乗算するときのルールに合っていないからです。
そこで、回帰係数$a$ を単一の値に変換し、$x$値のすべてに等しく乗算されるようにしておく必要があります。⑽ 変量yを定義する
y値すなわち変数 fig_y の計算式を定義するに際し、Numpyの
reshape関数をつかって回帰係数$a$ の形状を変換します。fig_y = a.reshape(1)*fig_x + b
⑾ 回帰直線を描画する
# 散布図 plt.plot(x, y, "o") # 回帰直線 plt.plot(fig_x, fig_y, "r") # 第3引数で線の色を"r"に指定 plt.show()
以上のように、機械学習ライブラリを利用することで、複雑な計算をしなくとも分析結果を得ることはできます。
しかし、回帰分析に限ったことではありませんが、計算結果に対していかにそれを適切に解釈するか、あるいは手法を運用する上で微妙なチューニングを行なうとなると、やはり計算の仕組み(アルゴリズム)を知っておくことが望ましいといえます。
そこで次は、scikit-learn を利用しないで、すべて自前で単回帰分析を学びます。




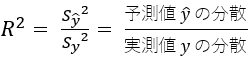




- 投稿日:2020-05-16T22:48:48+09:00
算数教具「ジャマイカ」を再現しよう❗️ vol.03 「ジャマイカの解探索を目指して 〜第1戦目〜」
はじめに
このシリーズは、とある算数教具「ジャマイカ」について、
以下の目的を達成するべく奮闘する記録です。✔︎ 1. 「ジャマイカ」のゲームを画像表示などを用いたプログラムで動かせるようになる。
▶︎ 2. 「ジャマイカ」におけるサイコロの任意の組み合わせについて、解の存在とその内容を探索・提示するプログラムを作る。前回までのおさらい
前回までは、以下の内容を扱いました。
§1. 「ジャマイカ」を再現する
Task.001 「サイコロの出目」を画像で表示する
Task.002 「ランダムな数字に合わせてサイコロ出目画像を表示する」
Task.003 「サイコロ出目画像表示のための関数を作る」これにより、
- サイコロをランダムに振る
- 振った結果に対応するサイコロの出目画像を並べて表示する
というジャマイカの基本動作を、数行のコードで実行できるようになりました。
_____【 参考記事 】_____
1 Recollection|算数教具「ジャマイカ」を再現しよう❗️の前々回記事(vol.01)
2 Recollection|算数教具「ジャマイカ」を再現しよう❗️の前回記事(vol.02)task003_jmcdisplay### function trial START ### libimports() figPlace = figplace() jmcDice = jmc_diceroll(printOption=True) jmc_display(figPlace, jmcDice, sizeRatio=1.4) ### function trial END ###> Drive already mounted at /content/drive; to attempt to forcibly remount, call drive.mount("/content/drive", force_remount=True). > ジャマイカのダイスロール結果: [ 1 5 6 5 5 30 2]
§2. 「ジャマイカ」の解を探索する
■ ジャマイカでは白サイコロの数字をそれぞれ1回ずつ用いて、四則演算(加減乗除)を行い、黒サイコロの和を作り上げることが目的です。
■ 白サイコロの数字はどの順番で四則演算しても構いません。
例) 白サイコロ: 2, 2, 3, 3, 4 黒サイコロ: 40, 5 の場合 [1] 白サイコロを1回ずつ → 2*2*3*4 - 3 = 48 - 3 = 45 [2] 黒サイコロの和 → 40 + 5 = 45 と計算できるので、この四則演算の組は解となる。Task.004 「ジャマイカルールに基づく四則演算関数を準備する」
■ 引き算や割り算で不可能な計算結果は、それ以降続かないようにしなければなりません。
例) 白サイコロ: 2, 2, 4, 5, 6 黒サイコロ: 40, 5 の場合
引き算: 2 - 6 = -4
割り算: 6 / 4 = 3/2
については、途中計算で用いることはできない。
※既約分数も許すルールがあります。■ 以上のことから、次の四則演算の関数を作ります。
2数の和を計算する関数: add() 2数の差を計算する関数: substract() ※小さい方から大きい方を引いた結果はnanとする 2数の積を計算する関数: multiply() 2数の商を計算する関数: divide() ※結果が整数でない場合について、よしとするかどうかのオプションが必要_____【 参考記事 】_____
3 Task004|【NANって何だ?】意味と用法
➡︎ 出力不能を表すために、np.nanを使えば良さそうであることに気づいた。
(後に結果判定する際に、意図しない外れ値がなくなることを期待している。)task004_calcfunctionsdef add(var1, var2): return var1 + var2 def substract(var1, var2): if var1 >= var2: #第1引数が第2引数以上であれば、引き算を実行する return var1 - var2 else: #第1引数が第2引数より小さければ、計算をそれ以降進行しないようにnanを出力する return np.nan def multiply(var1, var2): return var1 * var2 def divide(var1, var2, fracOption): #第3引数 fracOption は Trueのときに限り既約分数を許可するオプション if var2 == 0: #0で割る場合は、計算をそれ以降進行しないようにnanを出力する return np.nan elif isinstance(var1, int) and isinstance(var1, int): #2数がどちらも整数のとき if not fracOption == True: #分数を許可しない場合 if var1 >= var2 and var1 % var2 ==0: #さらに1番目の数が2番目以上であり、割り切れる場合は、商を出力する return var1 // var2 else: #1番目の数が2番目より小さいか、割り切れない場合は、計算をそれ以降進行しないようにnanを出力する return np.nan else: #分数を許可する場合は、そのまま割り算を実行する return var1 / var2 else: #2数のいずれかが整数でないとき if not fracOption ==True: #分数を許可しない場合は、計算をそれ以降進行しないようにnanを出力する return np.nan else: #分数を許可する場合は、そのまま割り算を実行する return var1 / var2task004_calcdisplay### function trial START ### # substractの計算結果をnanで出すかどうか? print('___substractのチェック___') for num in range(8): print('6-',num,' = ',substract(6,num)) # divideの計算結果をfracOption=Trueでチェック print('___divideのチェック1: fracOption=True & varA is int___') for num in range(8): print('6/',num,' = ',divide(6,num,fracOption=True)) # divideの計算結果をfracOption=Falseでチェック print('___divideのチェック2: fracOption=False & varA is int___') for num in range(8): print('6/',num,' = ',divide(6,num,fracOption=False)) # divideの計算結果をfracOption=True & 割られる数がfloatでチェック print('___divideのチェック3: fracOption=True & varA is float___') for num in range(8): print('6.5/',num,' = ',divide(6.5,num,fracOption=True)) # divideの計算結果をfracOption=False & 割られる数がfloatでチェック print('___divideのチェック4: fracOption=False & varA is float___') for num in range(8): print('6.5/',num,' = ',divide(6.5,num,fracOption=False)) ### function trial END ###___substractのチェック___ 6- 0 = 6 6- 1 = 5 6- 2 = 4 6- 3 = 3 6- 4 = 2 6- 5 = 1 6- 6 = 0 6- 7 = nan ___divideのチェック1: fracOption=True___ 6/ 0 = nan 6/ 1 = 6.0 6/ 2 = 3.0 6/ 3 = 2.0 6/ 4 = 1.5 6/ 5 = 1.2 6/ 6 = 1.0 6/ 7 = 0.8571428571428571 ___divideのチェック2: fracOption=False___ 6/ 0 = nan 6/ 1 = 6 6/ 2 = 3 6/ 3 = 2 6/ 4 = nan 6/ 5 = nan 6/ 6 = 1 6/ 7 = nan ___divideのチェック3: fracOption=True & varA is float___ 6.5/ 0 = nan 6.5/ 1 = 6.5 6.5/ 2 = 3.25 6.5/ 3 = 2.1666666666666665 6.5/ 4 = 1.625 6.5/ 5 = 1.3 6.5/ 6 = 1.0833333333333333 6.5/ 7 = 0.9285714285714286 ___divideのチェック4: fracOption=False & varA is float___ 6.5/ 0 = nan 6.5/ 1 = nan 6.5/ 2 = nan 6.5/ 3 = nan 6.5/ 4 = nan 6.5/ 5 = nan 6.5/ 6 = nan 6.5/ 7 = nanTask.005 「ジャマイカの解を探索するための関数を考える」
■ 白サイコロを用いて、ジャマイカで解候補となる計算を進める関数として、次の発想が考えられます。
[手順1] 白サイコロ5個の出目、つまり5個の整数値(1以上6以下)のうち、任意の2個を選んで並べ(5P2=20通りの組み合わせ)、四則演算(加減乗除で4種類)を行う。 [手順2] 上記[1]で生じた数1個と残りの3個の整数値(1以上6以下)のうち、任意の2個を選んで並べ(4P2=12通りの組み合わせ)、四則演算(加減乗除で4種類)を行う。 [手順3] 上記[1][2]と同様の流れで、1個の数字を出力するまで続ける。■ 上記の関数は次のような入力の条件に応じて出力を変化させなければならないでしょう。
(1) 入力される出目や計算結果のセット(np.array形式) (2) (1)の内包値の個数(=配列の長さ)がもし1なら計算をやめて、合致判定を行う (3) 分数を許可するか否か(fracOption == True or False)■ また、四則演算をどの数にどの順で適用したのかどうか、記録を出力する必要がありますから、次のような出力も残していかなければならないでしょう。
(4) 2数を計算した四則演算について「(_varA_ _演算記号_ _varB_)」 を記録する 例) 2 * 5 の場合は、「(2 * 5)」を記録する■ 以上を考えて、まずは次の関数を定義していきます。
■ 計算要素を演算可能な数値として格納する calcDice と、それを文字列化した calcDNames を出力します。
[関数1] transForClac() ___入力:サイコロ7個の結果を格納した配列 jmcDice ___出力:白サイコロ5個と黒サイコロの2個の和を格納した配列 calcDice [関数2] makeCalcName() ___入力:白サイコロ5個と黒サイコロの2個の和を格納した配列 calcDice ___出力:数字を文字列化した(任意の長さの文字列に更新できる型の)配列 calcDNamestask005_calcfunctions_1&2# [関数1] transForClac() # ___入力:サイコロ7個の結果を格納した配列 jmcDice # ___出力:白サイコロ5個と黒サイコロの2個の和を格納した配列 calcDice ################################################### def transForCalc(jmcDice, printOption): calcDice = jmcDice.astype(np.float64) #あとで計算要素を更新する際に、np.nan(float64形式)で上書きできるように、最初からfloat64の配列で再定義した calcDice を作る。 calcDice[5] = calcDice[5] + calcDice[6] #黒サイコロの値の和を計算して、index=5(つまり6番目)のサイコロの値に更新する calcDice = np.delete(calcDice, 6) #不要になった、index=6(つまり7番目)のサイコロの値を削除する if printOption == True: print('計算要素の一覧: ', calcDice) return calcDice # [関数2] makeCalcName() # ___入力:白サイコロ5個と黒サイコロの2個の和を格納した配列 calcDice # ___出力:数字を文字列化した(任意の長さの文字列に更新できる型の)配列 calcDNames ################################################### def makeCalcName(calcDice, printOption): calcDNames = np.empty(calcDice.shape[0],dtype=object) #長さの異なる文字列を格納できるようにobject形式のnp.arrayを定義する(長さはcalcDiceの配列の長さと同じ) for i in range(calcDNames.shape[0]): calcDNames[i] = str(int(calcDice[i])) #文字化した calcDice の各要素を順次格納していく if printOption == True: print('文字化配列の一覧: ', calcDNames) return calcDNames ### fanction trial START ### jmcDice = jmc_diceroll(printOption=True) calcDice = transForCalc(jmcDice, printOption=True) calcDNames = makeCalcName(calcDice, printOption=True) ### fanction trial END ###> ジャマイカのダイスロール結果: [ 2 3 1 4 4 50 5] > 計算要素の一覧: [ 2. 3. 1. 4. 4. 55.] > 文字化配列の一覧: ['2' '3' '1' '4' '4' '55']_________________________________________
■ 計算要素のみの配列 calcDice と、それを文字列化した calcDNames を作ることができました。
■ 今度は、この中で好きな2数を選択し、四則演算のうちの1つを実践することが必要になります。
■ そこで、どの四則演算を行うかを指定する arithOpeNo を入力として、選んだ2数を四則演算するような、以下の関数を定義していきます。
[関数3] arithOperator() ___入力1:演算したい2数のうちの1番目 var1 ___入力2:演算したい2数のうちの2番目 var2 ___入力3:四則演算のうち何を使うかについて、指定する番号 arithOpeNo ___入力4:分数を許可するかどうかの選択オプション fracOption ___出力:2数の四則演算の結果 [関数4] arithMarker() ___入力:四則演算のうち何を使うかについて、指定する番号 arithOpeNo ___出力:2数を計算した演算記録に使うマークtask005_calcfunctions_3&4# [関数3] arithOperator() # ___入力1:演算したい2数のうちの1番目 var1 # ___入力2:演算したい2数のうちの2番目 var2 # ___入力3:四則演算のうち何を使うかについて、指定する番号 arithOpeNo # ___入力4:分数を許可するかどうかの選択オプション fracOption # ___出力:2数の四則演算の結果 ################################################### def arithOperator(var1, var2, arithOpeNo, fracOption): if arithOpeNo == 0: #arithOpeNoで0を指定すると足し算 return add(var1, var2) elif arithOpeNo == 1: #arithOpeNoで1を指定すると引き算 return substract(var1, var2) elif arithOpeNo == 2: #arithOpeNoで2を指定すると掛け算 return multiply(var1, var2) elif arithOpeNo == 3: #arithOpeNoで3を指定すると割り算 return divide(var1, var2, fracOption) else: #arithOpeNoが0,1,2,3ではない場合は、それ以降演算結果が出ないようにnp.nanを出力する return np.nan # [関数4] arithMarker() # ___入力:四則演算のうち何を使うかについて、指定する番号 arithOpeNo # ___出力:2数を計算した演算記録に使うマーク ################################################### def arithMarker(arithOpeNo): if arithOpeNo == 0: #arithOpeNoで0を指定すると足し算 return ' + ' elif arithOpeNo == 1: #arithOpeNoで1を指定すると引き算 return ' - ' elif arithOpeNo == 2: #arithOpeNoで2を指定すると掛け算 return ' * ' elif arithOpeNo == 3: #arithOpeNoで3を指定すると割り算 return ' / ' else: #arithOpeNoが0,1,2,3ではない場合は、計算できなかったとして|???|を表示する return ' |???| ' ### fanction trial START ### var1 = 19 var2 = 4 print('___四則演算の結果___ for ', var1, ' & ', var2) for i in range(6): print(arithOperator(var1, var2, arithOpeNo=i, fracOption=True)) print('___四則演算のマーク___') for i in range(6): print(arithMarker(arithOpeNo=i)) ### fanction trial END ###___四則演算の結果___ for 19 & 4 23 15 76 4.75 nan nan ___四則演算のマーク___ + - * / |???| |???|_________________________________________
■ 指定した四則演算のキーを入力として、好きな2数を計算し、どのような四則演算を行ったかを出力できるようになりました。
■ 今度は、calcDice 配列の好きな2数を index で指定し、好きな四則演算のキー arithOpeNo に応じて、2数を計算した結果を格納した配列を出力する関数 renewDice() を定義していきます。
■ また、上記と同時に、calcDNames 配列の好きな2数を index で指定し、好きな四則演算のキー arithOpeNo に応じて、2数をどのように計算したかの記録を格納した配列を出力する関数 renewDNames() を定義していきます。
_____【 参考記事 】_____
4 Task005|Pythonのif文による条件分岐の書き方
➡︎ if文の書き方の中でも、特に条件式の改行について参考にした。task005_calcfunctions_5&6# [関数5] renewDice() # ___入力1:サイコロ出目結果を計算要素として保存した配列 calcDices # ___入力2:演算したい2数のインデックスのうちの1番目 ind1 # ___入力3:演算したい2数のインデックスのうちの2番目 ind2 # ___入力4:四則演算のうち何を使うかについて、指定する番号 arithOpeNo # ___入力5:分数を許可するかどうかの選択オプション fracOption # ___出力:2数を計算した結果を新たに格納した配列 ################################################### def renewDice(calcDice, ind1, ind2, arithOpeNo, fracOption): newDice = np.copy(calcDice) #配列を上書きしないように calcDice のコピーを取得する if newDice.shape[0] -1 > ind1 \ and newDice.shape[0] -1 > ind2 \ and ind1 != ind2: #ind1,ind2がいずれもが白サイコロを示す範囲(0以上newDiceの長さ-2以下)にあり、ind1とind2が異なるとき newDice[ind1] = arithOperator(newDice[ind1], newDice[ind2], arithOpeNo, fracOption) #arithOpeNoで指定された四則演算を指定のインデックスの値に行う else: for i in range(newDice.shape[0] - 1): newDice[i] = np.nan #すべての計算要素をnp.nanに置き換える newDice = np.delete(newDice, ind2) #共通して、ind2の値を削除し、サイコロ計算要素配列の長さを-1する return newDice # [関数6] renewDNames() # ___入力1:サイコロ出目結果を文字化した配列 calcDNames # ___入力2:演算したい2数のインデックスのうちの1番目 ind1 # ___入力3:演算したい2数のインデックスのうちの2番目 ind2 # ___入力4:四則演算のうち何を使うかについて、指定する番号 arithOpeNo # ___入力5:分数を許可するかどうかの選択オプション fracOption # ___出力:2数を計算した演算記録を残した配列 ################################################### def renewDNames(calcDNames, ind1, ind2, arithOpeNo, fracOption): newDNames = np.copy(calcDNames) #配列を上書きしないように calcDNames のコピーを取得する if newDNames.shape[0] - 1 > ind1 \ and newDNames.shape[0] -1 > ind2 \ and ind1 != ind2: #ind1,ind2がいずれもが白サイコロを示す範囲(0以上newDiceの長さ-2以下)にあり、ind1とind2が異なるとき newDNames[ind1] = '(' + newDNames[ind1] + arithMarker(arithOpeNo) + newDNames[ind2] + ')' #arithOpeNoで指定された四則演算の記録を残す else: for i in range(newDNames.shape[0] - 1): newDNames[i] = '|???|' #すべての計算要素の記録を|???|に置き換える newDNames = np.delete(newDNames, ind2) #共通して、ind2の値を削除し、サイコロ計算要素配列の長さを-1する return newDNames ### fanction trial START ### calcDice = transForCalc(jmcDice, printOption=True) calcDNames = makeCalcName(calcDice, printOption=True) print('\n___index=1, 4番目を掛け算で更新した計算要素の一覧___\n', renewDice(calcDice, 1, 4, arithOpeNo=2, fracOption=False)) print('___index=1, 4番目を掛け算で更新した文字化配列の一覧___\n', renewDNames(calcDNames, ind1=1, ind2=4, arithOpeNo=2, fracOption=False)) ### fanction trial END ###> 計算要素の一覧: [ 2. 3. 1. 4. 4. 55.] > 文字化配列の一覧: ['2' '3' '1' '4' '4' '55'] > > ___index=1, 4番目を掛け算で更新した計算要素の一覧___ > [ 2. 12. 1. 4. 55.] > ___index=1, 4番目を掛け算で更新した文字化配列の一覧___ > ['2' '(3 * 4)' '1' '4' '55']_________________________________________
■ 計算したい配列の index を2つ指定して、好きな四則演算を行い、計算要素の配列と計算記録の文字化配列を更新することができるようになりました。
■ そこで、いよいよジャマイカの解を全探索する関数を定義していきます。
■ 解探索では次のコンセプトを運用します。
[手順1] 白サイコロ5個の出目、つまり5個の整数値(1以上6以下)のうち、任意の2個を選んで並べ(5P2=20通りの組み合わせ)、四則演算(加減乗除で4種類)を行う。 [手順2] 上記[1]で生じた数1個と残りの3個の整数値(1以上6以下)のうち、任意の2個を選んで並べ(4P2=12通りの組み合わせ)、四則演算(加減乗除で4種類)を行う。 [手順3] 上記[1][2]と同様の流れで、1個の数字を出力するまで続ける。■ したがって、解探索を行うために「再帰的に」配列を更新していく以下の関数を定義します。
[解探索する関数] jmcReduce() ___入力1:サイコロ出目結果を計算要素として保存した配列 calcDice ___入力2:サイコロ出目結果を文字化した配列 calcDNames ___入力3:分数を許可するかどうかの選択オプション fracOption ___出力:指定したインデックスの2数の四則演算結果で更新した calcDice と calcDNames を引数にもつ jmcReduce() ___反復:白サイコロに該当するインデックスのみを全探索する(2数のインデックスを i , j (i ≠ j)で走査) ___反復:2数を用いた四則演算のキーは 加・減・乗・除 を表す 0, 1, 2, 3 で全探索する(kで走査)_____【 参考記事 】_____
5 Task005|再帰関数を理解するための最もシンプルな例
➡︎ 探索関数を再帰的に定義する際に、再帰関数の基本的な性質について理解し直すために参照した。task005_jmcReduce# [解探索する関数] jmcReduce() # ___入力1:サイコロ出目結果を計算要素として保存した配列 calcDice # ___入力2:サイコロ出目結果を文字化した配列 calcDNames # ___入力3:分数を許可するかどうかの選択オプション fracOption # ___出力:指定したインデックスの2数の四則演算結果で更新した calcDice と calcDNames を引数にもつ jmcReduce() # ___反復:白サイコロに該当するインデックスのみを全探索する(2数のインデックスを i , j (i ≠ j)で走査) # ___反復:2数を用いた四則演算のキーは 加・減・乗・除 を表す 0, 1, 2, 3 で全探索する(kで走査) ################################################### def jmcReduce(calcDice, calcDNames, fracOption): newDice = np.copy(calcDice) #入力1を改変しないために複製 newDNames = np.copy(calcDNames) #入力2を改変しないために複製 for i in range(newDice.shape[0] - 1): #インデックス1つ目を白サイコロの範囲(0以上newDiceの配列の長さ-2以下)でループ処理 for j in range(newDice.shape[0] - 1): #インデックス2つ目を白サイコロの範囲(0以上newDiceの配列の長さ-2以下)でループ処理 if i != j: #もしも ind1=i, ind2=j が等しくない場合 for k in range(4): #四則演算のキー番号 arithOpeNo = 0,1,2,3 を走査する反復変数 k if arithOperator(newDice[i],newDice[j],k, fracOption) != np.nan: #演算結果が np.nan にならない場合のみ、配列を更新したい if newDice.shape[0] == 3 \ and renewDice(newDice,i,j,k,fracOption)[0] == renewDice(newDice,i,j,k,fracOption)[1]: #もし配列の長さが3、つまり白サイコロの計算要素の残り2つ、黒サイコロの和1つで構成されていて #計算要素の四則演算の結果が、黒サイコロの和と一致するとき print(renewDNames(newDNames,i,j,k,fracOption)[0], ' = ', renewDNames(newDNames,i,j,k,fracOption)[1],' ______!!!!! This pattern is OK !!!!!______') #計算要素の計算記録(文字配列の値)を出力し、黒サイコロの値と一致したことを示す!(これが解のリスト) break elif newDice.shape[0] == 3 \ and renewDice(newDice,i,j,k,fracOption)[0] != renewDice(newDice,i,j,k,fracOption)[1]: #もし配列の長さが3、つまり白サイコロの計算要素の残り2つ、黒サイコロの和1つで構成されていて #計算要素の四則演算の結果が、黒サイコロの和と一致しないとき #print(renewDNames(calcDNames,i,j,k,fracOption),' ___This pattern is NG xxx___') #計算要素の計算記録(文字配列の値)を出力し、黒サイコロの値と一致しなかったことを示す!(見辛いので普通はコメントアウトする) break else: #まだ配列の長さが3より大きい場合 jmcReduce(renewDice(newDice,i,j,k,fracOption),renewDNames(newDNames,i,j,k,fracOption),fracOption) #再帰的に、もう一度短い配列に更新してやり直す else: #演算結果が np.nan になった場合は何もせずに k を更新する continue else: #もしも ind1=i, ind2=j が等しい場合は何もせずに j を更新する continue ### fanction trial START ### print('\n______START______') jmcReduce(calcDice, calcDNames, fracOption=False) ### fanction trial END ###______START______ (((2 + (4 * 4)) * 3) + 1) = 55 ______!!!!! This pattern is OK !!!!!______ (1 + ((2 + (4 * 4)) * 3)) = 55 ______!!!!! This pattern is OK !!!!!______ ((3 * (2 + (4 * 4))) + 1) = 55 ______!!!!! This pattern is OK !!!!!______ (1 + (3 * (2 + (4 * 4)))) = 55 ______!!!!! This pattern is OK !!!!!______ ((3 * ((4 * 4) + 2)) + 1) = 55 ______!!!!! This pattern is OK !!!!!______ (1 + (3 * ((4 * 4) + 2))) = 55 ______!!!!! This pattern is OK !!!!!______ (1 + (((4 * 4) + 2) * 3)) = 55 ______!!!!! This pattern is OK !!!!!______ ((((4 * 4) + 2) * 3) + 1) = 55 ______!!!!! This pattern is OK !!!!!______ (((2 + (4 * 4)) * 3) + 1) = 55 ______!!!!! This pattern is OK !!!!!______ (1 + ((2 + (4 * 4)) * 3)) = 55 ______!!!!! This pattern is OK !!!!!______ ((3 * (2 + (4 * 4))) + 1) = 55 ______!!!!! This pattern is OK !!!!!______ (1 + (3 * (2 + (4 * 4)))) = 55 ______!!!!! This pattern is OK !!!!!______ ((3 * ((4 * 4) + 2)) + 1) = 55 ______!!!!! This pattern is OK !!!!!______ (1 + (3 * ((4 * 4) + 2))) = 55 ______!!!!! This pattern is OK !!!!!______ (1 + (((4 * 4) + 2) * 3)) = 55 ______!!!!! This pattern is OK !!!!!______ ((((4 * 4) + 2) * 3) + 1) = 55 ______!!!!! This pattern is OK !!!!!______ _______END_______第1戦目における考察
結果
■ 今回は再帰的に関数定義した jmcReduce()関数によって、徐々に配列を短く更新しながら、解を探索しました。
■ 結果としては、出力された解はどれも正しく、成り立つべきジャマイカの解を少なくともいくつかは提示できていると思います。
問題点
____[1] 複数の解が数式の意味として重複している____
■ 特に加算や乗算を用いた解の場合、数式的には同じ意味なのに、四則演算の順番を変更した解グループを複数表示してしまっていました。
例) (((2 + (4 * 4)) * 3) + 1) = 55 という解と
((((4 * 4) + 2) * 3) + 1) = 55 という解は、数式的には同じ意味です。
■ これを改善するには、加算(和,add()関数)や乗算(積,multiply())の扱いを変更しなければなりません。
____[2] 全く同一の解を複数提示してしまっている____
■ 今回の計算例では2グループの全く同一の解を提示してしまっていることがわかります。
例) ((((4 * 4) + 2) * 3) + 1) = 55 という解と
((((4 * 4) + 2) * 3) + 1) = 55 という解は、見た目も数式的意味も全く同一です。
■ おそらく、白サイコロの中に同じ数字が存在すると、再帰しているうちに何度も重複して演算結果を出してしまうのではないかと考えています。
____[3] すべての解を探索できているのか?____
■ ジャマイカの解は一般に、あるサイコロの組においてかなりの種類存在することが多いです。
■ その中に減算や除算を用いた解も、いくつか含まれているでしょう。
■ 今回のjmcReduceを何種類かのダイスロール結果で試していくうちに、「どうやら減算や除算を用いた解を探索できていないのではないか?」という疑念が湧いてきました。(特に除算)
■ そこで、以下の参考記事におけるジャマイカのダイスロール結果と解の例を用いて、jmcReduceを行ってみました。
例) 白サイコロ 2 4 2 4 5 黒サイコロ 20 3
に対して、解は例えば次の4通りが考えられる。
(加減乗除を満遍なく使えているパターンです。)
(2 × 6) + 2 + 4 + 5 = 23
((6 + 4) × 2) + 5 - 2 = 23
4 × (6 + (2 ÷ 2)) - 5 = 23
5 × (6 ÷ 2) + (4 × 2) = 23
_____【 参考記事 】_____
6 Check|ジャマイカの解探索の先行実装サイト
➡︎ ジャマイカの解探索を1つだけやってくれるサイト。(分数の利用オプション付き)計算要素の一覧: [ 2. 6. 2. 4. 5. 23.] 文字化配列の一覧: ['2' '6' '2' '4' '5' '23'] ______START______ ((((2 * 6) + 2) + 4) + 5) = 23 ______!!!!! This pattern is OK !!!!!______ (5 + (((2 * 6) + 2) + 4)) = 23 ______!!!!! This pattern is OK !!!!!______ ((((2 * 6) + 2) + 5) + 4) = 23 ______!!!!! This pattern is OK !!!!!______ (4 + (((2 * 6) + 2) + 5)) = 23 ______!!!!! This pattern is OK !!!!!______ ((4 + ((2 * 6) + 2)) + 5) = 23 ______!!!!! This pattern is OK !!!!!______ ===== 中略 中略 中略 ===== (5 + (2 + ((2 * 6) + 4))) = 23 ______!!!!! This pattern is OK !!!!!______ (((2 * 6) + 4) + (2 + 5)) = 23 ______!!!!! This pattern is OK !!!!!______ ((2 + 5) + ((2 * 6) + 4)) = 23 ______!!!!! This pattern is OK !!!!!______ (2 + (5 + ((2 * 6) + 4))) = 23 ______!!!!! This pattern is OK !!!!!______ ((5 + ((2 * 6) + 4)) + 2) = 23 ______!!!!! This pattern is OK !!!!!______ (((2 * 6) + 4) + (5 + 2)) = 23 ______!!!!! This pattern is OK !!!!!______ ((5 + 2) + ((2 * 6) + 4)) = 23 ______!!!!! This pattern is OK !!!!!______ ((((2 * 6) + 5) + 2) + 4) = 23 ______!!!!! This pattern is OK !!!!!______ (4 + (((2 * 6) + 5) + 2)) = 23 ______!!!!! This pattern is OK !!!!!______ ((((2 * 6) + 5) + 4) + 2) = 23 ______!!!!! This pattern is OK !!!!!______ (2 + (((2 * 6) + 5) + 4)) = 23 ______!!!!! This pattern is OK !!!!!______ ((2 + ((2 * 6) + 5)) + 4) = 23 ______!!!!! This pattern is OK !!!!!______ (4 + (2 + ((2 * 6) + 5))) = 23 ______!!!!! This pattern is OK !!!!!______ ===== 中略 中略 中略 ===== (((5 + 4) + (2 * 6)) + 2) = 23 ______!!!!! This pattern is OK !!!!!______ ((2 * 6) + ((5 + 4) + 2)) = 23 ______!!!!! This pattern is OK !!!!!______ (((5 + 4) + 2) + (2 * 6)) = 23 ______!!!!! This pattern is OK !!!!!______ ((((2 + 2) * 6) - 5) + 4) = 23 ______!!!!! This pattern is OK !!!!!______ (4 + (((2 + 2) * 6) - 5)) = 23 ______!!!!! This pattern is OK !!!!!______ (((6 * (2 + 2)) - 5) + 4) = 23 ______!!!!! This pattern is OK !!!!!______ (4 + ((6 * (2 + 2)) - 5)) = 23 ______!!!!! This pattern is OK !!!!!______ ((2 + 2) + ((6 * 4) - 5)) = 23 ______!!!!! This pattern is OK !!!!!______ (((6 * 4) - 5) + (2 + 2)) = 23 ______!!!!! This pattern is OK !!!!!______ ((2 + 2) + ((4 * 6) - 5)) = 23 ______!!!!! This pattern is OK !!!!!______ (((4 * 6) - 5) + (2 + 2)) = 23 ______!!!!! This pattern is OK !!!!!______ ((((2 * 2) * 6) - 5) + 4) = 23 ______!!!!! This pattern is OK !!!!!______ (4 + (((2 * 2) * 6) - 5)) = 23 ______!!!!! This pattern is OK !!!!!______ (((6 * (2 * 2)) - 5) + 4) = 23 ______!!!!! This pattern is OK !!!!!______ (4 + ((6 * (2 * 2)) - 5)) = 23 ______!!!!! This pattern is OK !!!!!______ ((2 * 2) + ((6 * 4) - 5)) = 23 ______!!!!! This pattern is OK !!!!!______ (((6 * 4) - 5) + (2 * 2)) = 23 ______!!!!! This pattern is OK !!!!!______ ((2 * 2) + ((4 * 6) - 5)) = 23 ______!!!!! This pattern is OK !!!!!______ (((4 * 6) - 5) + (2 * 2)) = 23 ______!!!!! This pattern is OK !!!!!______ ((((2 + 4) * 2) + 6) + 5) = 23 ______!!!!! This pattern is OK !!!!!______ ===== 中略 中略 中略 ===== ((6 * 2) + (4 + (2 + 5))) = 23 ______!!!!! This pattern is OK !!!!!______ ((4 + (2 + 5)) + (6 * 2)) = 23 ______!!!!! This pattern is OK !!!!!______ ((2 * 6) + (4 + (2 + 5))) = 23 ______!!!!! This pattern is OK !!!!!______ ((4 + (2 + 5)) + (2 * 6)) = 23 ______!!!!! This pattern is OK !!!!!______ ((((6 - 2) * 4) + 2) + 5) = 23 ______!!!!! This pattern is OK !!!!!______ (5 + (((6 - 2) * 4) + 2)) = 23 ______!!!!! This pattern is OK !!!!!______ ((((6 - 2) * 4) + 5) + 2) = 23 ______!!!!! This pattern is OK !!!!!______ (2 + (((6 - 2) * 4) + 5)) = 23 ______!!!!! This pattern is OK !!!!!______ ((2 + ((6 - 2) * 4)) + 5) = 23 ______!!!!! This pattern is OK !!!!!______ (5 + (2 + ((6 - 2) * 4))) = 23 ______!!!!! This pattern is OK !!!!!______ (((6 - 2) * 4) + (2 + 5)) = 23 ______!!!!! This pattern is OK !!!!!______ ((2 + 5) + ((6 - 2) * 4)) = 23 ______!!!!! This pattern is OK !!!!!______ (2 + (5 + ((6 - 2) * 4))) = 23 ______!!!!! This pattern is OK !!!!!______ ((5 + ((6 - 2) * 4)) + 2) = 23 ______!!!!! This pattern is OK !!!!!______ (((6 - 2) * 4) + (5 + 2)) = 23 ______!!!!! This pattern is OK !!!!!______ ((5 + 2) + ((6 - 2) * 4)) = 23 ______!!!!! This pattern is OK !!!!!______ (((6 - 2) * 4) + (2 + 5)) = 23 ______!!!!! This pattern is OK !!!!!______ ((2 + 5) + ((6 - 2) * 4)) = 23 ______!!!!! This pattern is OK !!!!!______ ((2 + 5) + (4 * (6 - 2))) = 23 ______!!!!! This pattern is OK !!!!!______ ((4 * (6 - 2)) + (2 + 5)) = 23 ______!!!!! This pattern is OK !!!!!______ ((2 + (4 * (6 - 2))) + 5) = 23 ______!!!!! This pattern is OK !!!!!______ ===== 中略 中略 中略 ===== (((5 + 4) + 2) + (2 * 6)) = 23 ______!!!!! This pattern is OK !!!!!______ ((6 * 2) + ((5 + 4) + 2)) = 23 ______!!!!! This pattern is OK !!!!!______ (((5 + 4) + 2) + (6 * 2)) = 23 ______!!!!! This pattern is OK !!!!!______ _______END_______検証結果
■ 問題点[1][2]のために、非常に長い出力結果のため、途中を省略しました。
■ 結果として、減算を利用した解の出力はできていましたが、除算を利用した解の出力ができていませんでした。
■ 考えられる原因として、fracOptionの動作不良か、arithOperatorの定義のミスが考えられますが、Task.004にて四則演算の結果を出す際には、6/6も1と出力できていたので、正確な原因究明はできていません。
次回までの挑戦
____[1] 加算・乗算の場合に、結果が同じものを予めマージする____
■ 特に加算や乗算を用いた解の場合、数式的には同じ意味なのに、四則演算の順番を変更した解グループを複数表示してしまっていました。
■ add()関数やmultiply()関数、arithOprerator()関数の定義時、あるいはjmcReduce()関数のループ時に加算や乗算の結果が同一のi,jの組を予め排除する工夫を施せないでしょうか?
■ これについては、再帰的な関数定義によって求解するのが厳しいかもしれません。
■ 事前に考えられうる2数と四則演算の組み合わせの個数とその結果を出力した上で、探索しなければならない配列のセットをスタティック(静的)に格納したアレイを用意して、求解する方策も有効かと思いました。
____[2] 除算のエラーを改善する____
■ 正確な原因はわかりませんが、除算を利用した解の出力ができていませんでした。。
■ 四則演算関連の定義や、求解のあたりのアルゴリズムを見直しながら、正確な原因の究明から始めていきたいと思います。
次回予告
今回は、四則演算の関数定義と計算要素配列への再帰的走査関数を実装し、ジャマイカの求解に挑戦しました。
次回は、今回発生した問題を改善した上で、
再帰的探索を行わずに、スタティックに解候補を補完・生成・処理して、求解探索する関数を定義
することにも挑戦したいと思います。。題して、vol.04 「ジャマイカの解探索を目指して〜第2戦目〜」 です。
REF. ジャマイカ関連の基本情報
Q1. 算数教具「ジャマイカ」って何?
A1. 「ジャマイカ / Jamaica」とは、サイコロを用いた"数遊び"を題材とする算数教具として販売されているものです。
■ AmazonやYahoo!ショッピングなどの通販サイトでも販売されている一般的な商品です。
➡︎ Amazon販売ページはこちらからどうぞ。
➡︎ 画像は下図を参照ください(上記ページからの引用)
■ サイコロは白と黒の2種類で、それぞれ5個と2個付属しています。
➡︎ 円環部分に白サイコロ×5個と黒サイコロ×1個、中央部分に黒サイコロ×1個が付属しています。
色 / Color 数量 / amount 記載されている数字 / Numbers 白 / white 5 個 / 5 dice 1, 2, 3, 4, 5, 6 黒 / black 1 個 / 1 dice 1, 2, 3, 4, 5, 6 黒 / black 1 個 / 1 dice 10, 20, 30, 40, 50, 60 Q2. ジャマイカの遊び方は?
A2. 白サイコロ×5個の数字をそれぞれ1回ずつ使って四則演算を行い、黒サイコロ×2個の数字の和を作ります。
例えば、白サイコロの出目が(1,2,3,5,5)であり、黒サイコロの出目が(10,6)の場合は、
白サイコロの出目を全て足し合わせて 1+2+3+5+5=10+6 という等式を作ることができます。
■ 白サイコロ×5個の数字は、それぞれ1回ずつしか使えません。
➡︎ 例えば、白サイコロの出目が(2,4,5,3,3)だった場合、計算に使えるのは
2 が1回、3 が2回、4 が1回、5 が1回です。それ以上使ってはいけません。
(2 を2回使ったり、3 を3回使ったりしてはダメです。)
➡︎ もちろん、「指定回数分使わない」ことも御法度です。
(上の例では、3 を1回しか使わないなどもダメです。)■ 四則演算とは、加減乗除のことです。
➡︎ 「加」とは、「加法」すなわち「足し算」です。
例えば、2+3=5 のような和(足し算の結果)を計算します。
➡︎ 「減」とは、「減法」すなわち「引き算」です。
例えば、5-2=3 のような差(引き算の結果)を計算します。
➡︎ 「乗」とは、「乗法」すなわち「掛け算」です。
例えば、3×4=12 のような積(掛け算の結果)を計算します。
➡︎ 「除」とは、「除法」すなわち「割り算」です。
例えば、4÷2=2 のような商(割り算の結果※)を計算します。
※ 割り切れる演算のみを許す、すなわち既約分数形を許さないルールと、既約分数も許すルールがあります。
[1] 既約分数になるものは許さないルールの場合
白サイコロの出目(2,4,6,3,5)のとき、6÷3=2 という演算はできますが、
6÷4=3/2 という結果は利用不可能です。
[2] 既約分数になるものも許すルールの場合
白サイコロの出目(2,4,6,3,5)のとき、6÷3=2 という演算もできるだけでなく、
6÷4=3/2 という結果も利用可能です。
※ 既約分数を利用しないと解けないサイコロの出目の組もあります。
例) 白サイコロの出目(2,2,4,4,6)に対して、黒サイコロの出目(30,3)のとき
{(2- 2/4) + 4} × 6 = 30 + 3 という等式が成り立ちます。■ 四則演算はどのような順番で行っても構いません。
➡︎ 先に2つの数字を足しておいて、別の数字と掛ける、といった演算の順序は自由です。
つまり、いつ・どこでも括弧を何回使ってもよいということです。
例) 白サイコロの出目(3,6,4,4,1)に対して、黒サイコロの出目(20,6)のとき
{(3 + 6) + (4 × 4)} + 1 = 20 + 6 という等式が成り立ちます。参考記事まとめ
Recollection|算数教具「ジャマイカ」を再現しよう❗️の前々回記事(vol.01) ↩
Recollection|算数教具「ジャマイカ」を再現しよう❗️の前回記事(vol.02) ↩
Task004|【NANって何だ?】意味と用法 ↩
Task005|Pythonのif文による条件分岐の書き方 ↩
Task005|再帰関数を理解するための最もシンプルな例 ↩
Check|ジャマイカの解探索の先行実装サイト ↩



- 投稿日:2020-05-16T21:49:16+09:00
Pythonで脳波解析:Python MNEのチュートリアル
Python MNEはオープンソースの脳磁図(MEG),脳波(EEG)の解析や可視化のツールです.多くのデバイスのデータフォーマットに適用できるため,汎用性が高いと言えるでしょう.この記事では,最もベーシックなチュートリアルに沿って,MEGとEEGのMNEによる解析手順を説明します.
実行環境
- Mac OS 10.15.3
- Python 3.6.5
- mne 0.20.4
インストール
Anacondaでもpipでもインストールできます.公式ページではAnacondaの方がおすすめだそうです.
- Anacondaの場合
conda install -c conda-forge mne
- pipの場合
pip install -U mneまた,GPUの設定もできるようなので,フィルタリングやサンプリングで時間がかかるようであれば設定すると良いかもしれません.
$ conda install cupy $ MNE_USE_CUDA=true python -c "import mne; mne.cuda.init_cuda(verbose=True)" Enabling CUDA with 1.55 GB available memory >>> mne.utils.set_config('MNE_USE_CUDA', 'true') # mne.io.Raw.filter()などにn_jobs='cuda'を渡すMEG/EEG解析のチュートリアル
こちらのチュートリアルに沿って,脳波解析の典型的な処理とMNEの基本的なデータ構造について説明します.適当に簡潔にかいつまんで説明するので,英語と脳波解析の知識がある方は元のページを読んでもらったほうがよろしいかと思います.
解析手順
モジュールのインポート
import os import numpy as np import mneデータのロード
mneにサンプルとして用意されているデータをロードします(全データセットの一覧).ちなみに,MEGやEEGにはデバイスごとにいくつかファイルフォーマットがあるのですが,それらのデータをロードする関数が用意されています(サポートされているデータフォーマット)
sample_data_folder = mne.datasets.sample.data_path() sample_data_raw_file = os.path.join(sample_data_folder, 'MEG', 'sample', 'sample_audvis_filt-0-40_raw.fif') raw = mne.io.read_raw_fif(sample_data_raw_file)今回は
sample_audvis_filt-0-40_raw.fifという40Hzでローパスフィルタ済みのデータを使用しています.データ(1.54GB)のダウンロードには1分ほど要しました.
mne.io.read_raw_fif()という関数により,fifフォーマットのファイルからRawオブジェクトと呼ばれるMNEのデータ構造のデータを読み込んでいます.ちなみにこのデータの実験では,被験者が視覚刺激と聴覚刺激を左右ランダムに750msごとに呈示されます.また時々画面に笑った顔が表示され,被験者はそれを見たときにボタンを押すというものだそうです.これらの刺激の呈示のことをイベントと呼びます.
ロードしたオブジェクトについて表示します.
print(raw) print(raw.info) # output <Raw | sample_audvis_filt-0-40_raw.fif, 376 x 41700 (277.7 s), ~3.6 MB, data not loaded> <Info | 15 non-empty values bads: 2 items (MEG 2443, EEG 053) ch_names: MEG 0113, MEG 0112, MEG 0111, MEG 0122, MEG 0123, MEG 0121, MEG ... chs: 204 GRAD, 102 MAG, 9 STIM, 60 EEG, 1 EOG custom_ref_applied: False dev_head_t: MEG device -> head transform dig: 146 items (3 Cardinal, 4 HPI, 61 EEG, 78 Extra) file_id: 4 items (dict) highpass: 0.1 Hz hpi_meas: 1 item (list) hpi_results: 1 item (list) lowpass: 40.0 Hz meas_date: 2002-12-03 19:01:10 UTC meas_id: 4 items (dict) nchan: 376 projs: PCA-v1: off, PCA-v2: off, PCA-v3: off, Average EEG reference: off sfreq: 150.2 Hz >MNEには,Raw, Epochs, Evokedオブジェクトと呼ばれるオブジェクトによってデータが管理されています.データの時間的な区切られ方によってこれらは区別されており,Rawでは脳波の収録開始から停止までのすべての時間のデータを含んでおり,イベントにより区切られる前の状態だと考えてもらうと良いと思います.
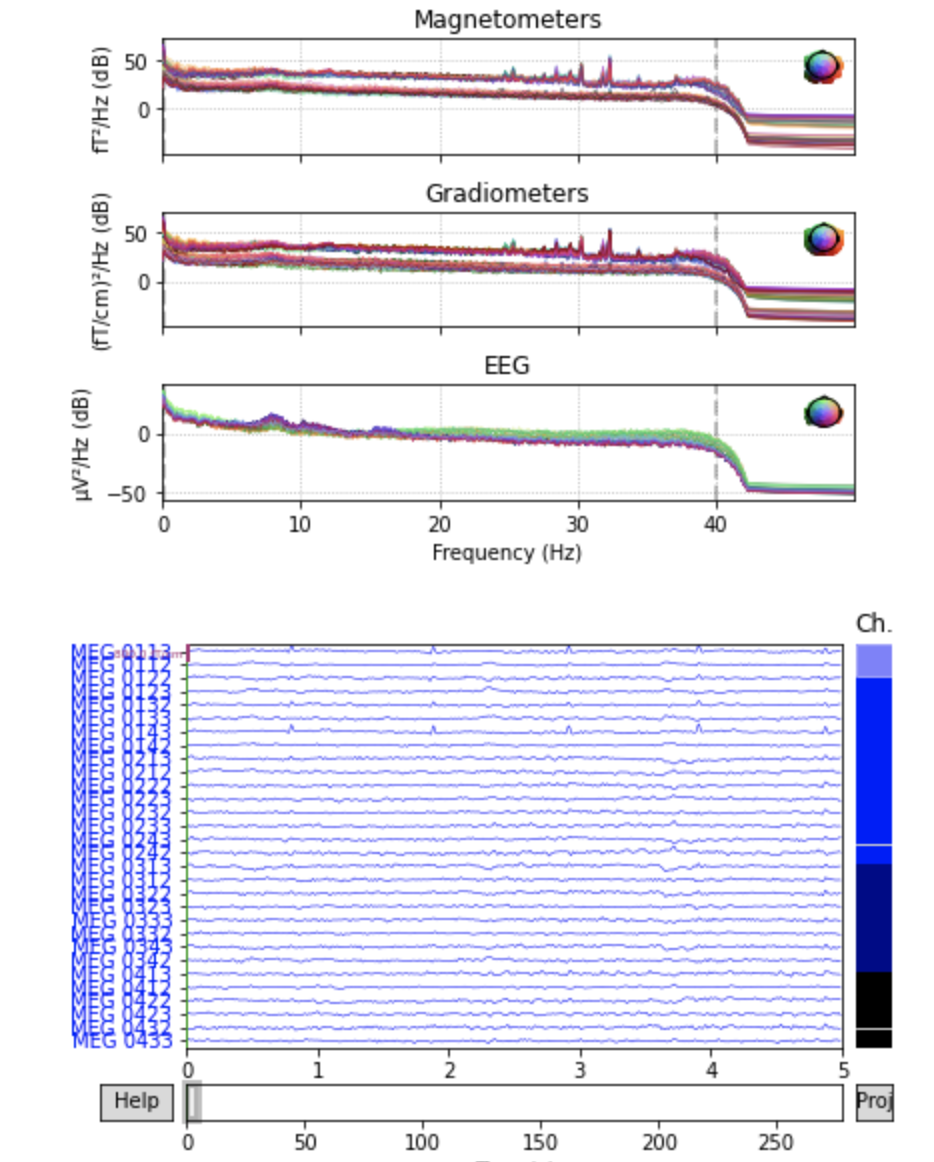
raw.infoではrawのチャンネル数や名前,サンプリングレートなどの情報が保持されています.このRawオブジェクトのpower spectral density(PSD)とセンサーごとの波形を表示します.
plot()はインタラクティブシェルではスクロールやスケーリングが可能です.raw.plot_psd(fmax=50) raw.plot(duration=5, n_channels=30)
前処理
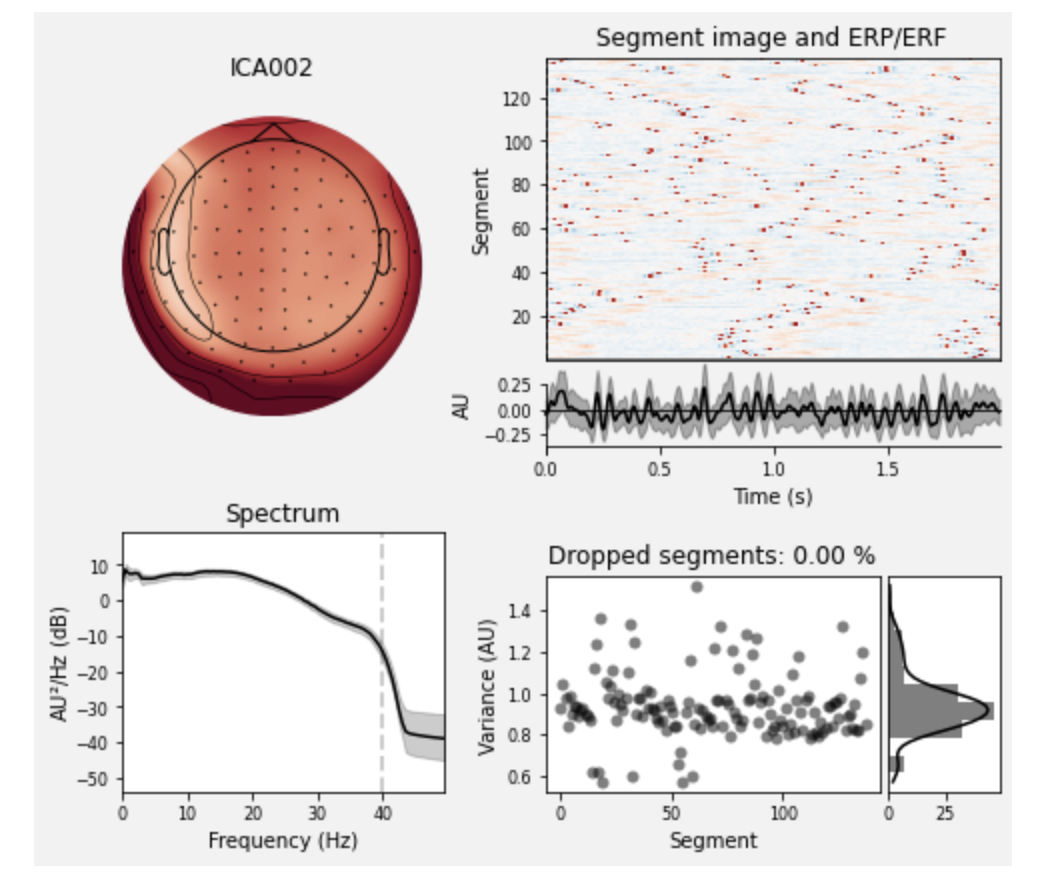
EEG/MEG解析のノイズ処理などでは定番の独立成分分析(ICA)を行います.簡単に言うと,多チャンネルの信号を独立した成分に分解することで,電源ノイズや瞬きなど脳活動に独立なものを取り除く処理を行います.
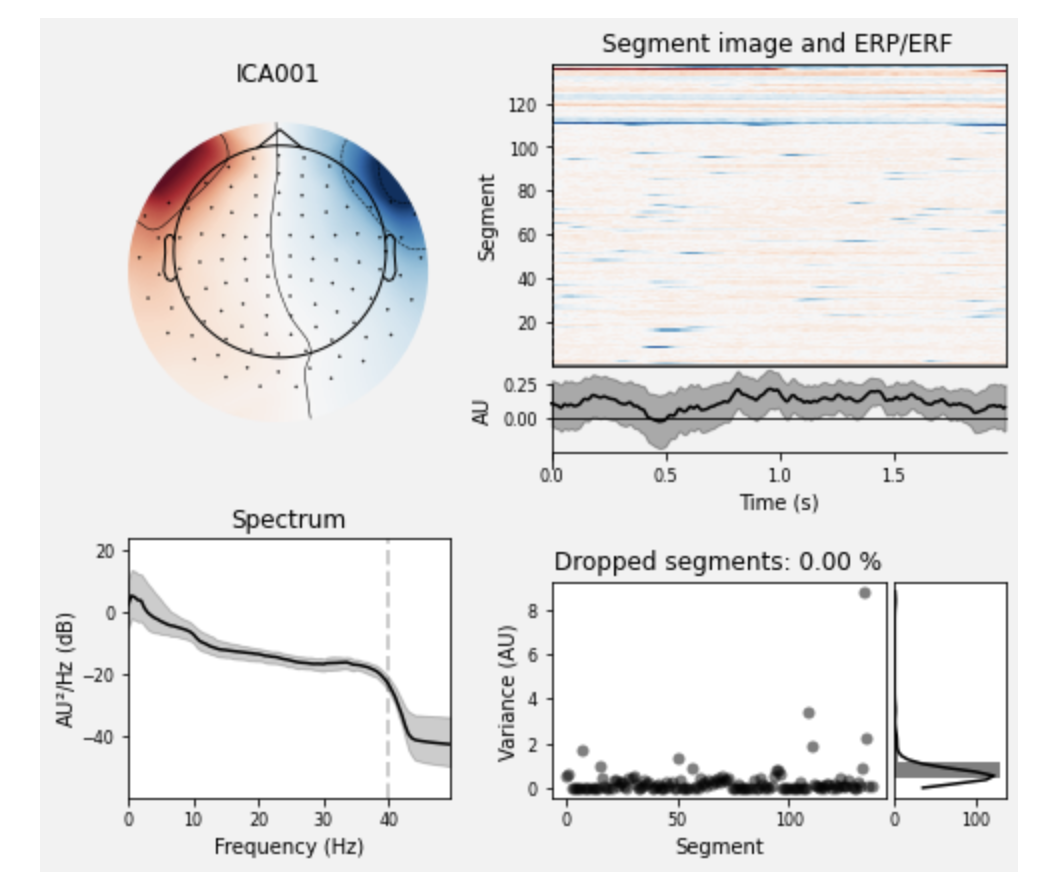
ここでは,364チャンネルの信号に対して,20個の独立成分に分解した後,
[1, 2]と取り除く成分のインデックスを指定しています(実際の除去は,次のica.apply(raw)によって行われます).ica_properties()で,独立成分の情報を表示します.# set up and fit the ICA ica = mne.preprocessing.ICA(n_components=20, random_state=97, max_iter=800) ica.fit(raw) ica.exclude = [1, 2] # details on how we picked these are omitted here ica.plot_properties(raw, picks=ica.exclude) # output Fitting ICA to data using 364 channels (please be patient, this may take a while) Inferring max_pca_components from picks Selecting by number: 20 components Fitting ICA took 2.4s. Using multitaper spectrum estimation with 7 DPSS windows 138 matching events found No baseline correction applied Not setting metadata 0 projection items activated 0 bad epochs dropped 138 matching events found No baseline correction applied Not setting metadata 0 projection items activated 0 bad epochs dropped
指定した独立成分を除去した信号を手に入れるため,先ほどのICAオブジェクトをRawオブジェクトに適用します.
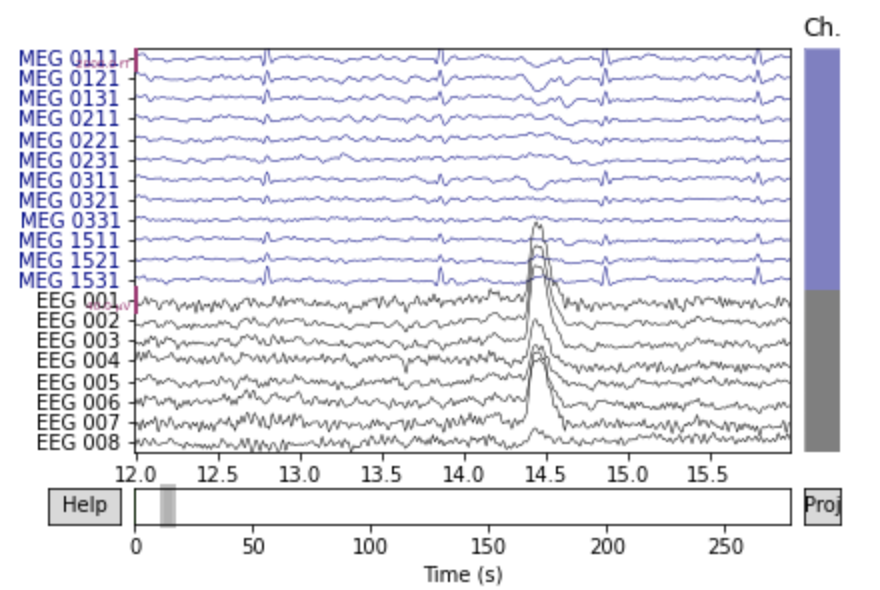
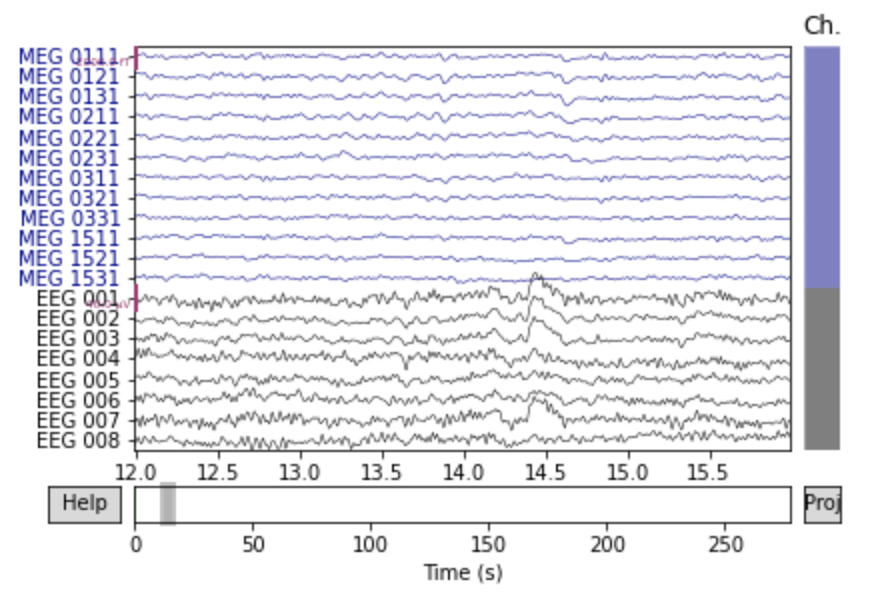
orig_raw = raw.copy() raw.load_data() ica.apply(raw)前頭のチャンネルを表示してみると次の2つの図のようにノイズが除去されています.
# show some frontal channels to clearly illustrate the artifact removal chs = ['MEG 0111', 'MEG 0121', 'MEG 0131', 'MEG 0211', 'MEG 0221', 'MEG 0231', 'MEG 0311', 'MEG 0321', 'MEG 0331', 'MEG 1511', 'MEG 1521', 'MEG 1531', 'EEG 001', 'EEG 002', 'EEG 003', 'EEG 004', 'EEG 005', 'EEG 006', 'EEG 007', 'EEG 008'] chan_idxs = [raw.ch_names.index(ch) for ch in chs] orig_raw.plot(order=chan_idxs, start=12, duration=4) raw.plot(order=chan_idxs, start=12, duration=4) # output Reading 0 ... 41699 = 0.000 ... 277.709 secs... Transforming to ICA space (20 components) Zeroing out 2 ICA components
イベント検出
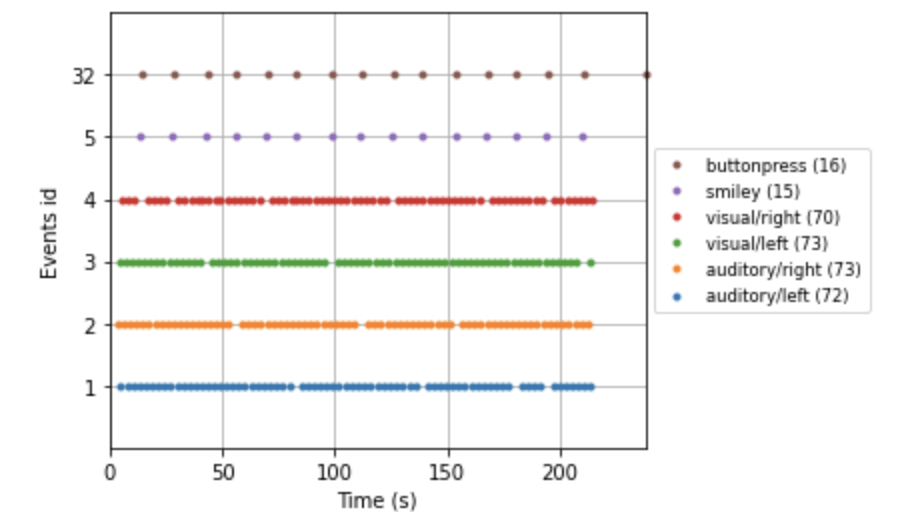
このサンプルデータにはSTIMチャンネルと呼ばれるものが含まれており,そのチャンネルにイベント種類とその時刻のデータがあります.今回は
STI 014という名前のチャンネルが該当するため,それを指定して実験のイベントを取り出します.events = mne.find_events(raw, stim_channel='STI 014') print(events[:5]) # show the first 5 # output 319 events found Event IDs: [ 1 2 3 4 5 32] [[6994 0 2] [7086 0 3] [7192 0 1] [7304 0 4] [7413 0 2]]
eventsはnumpy arrayであり,最初の列がサンプリングの時刻,最後の列がイベントの種類(ID)を表しています(真ん中の0は無視して良いです).ここでは,IDが[ 1 2 3 4 5 32]のイベントがあるそうです.
Event ID Condition 1 auditory stimulus (tone) to the left ear 2 auditory stimulus (tone) to the right ear 3 visual stimulus (checkerboard) to the left visual field 4 visual stimulus (checkerboard) to the right visual field 5 smiley face (catch trial) 32 subject button press Event IDとそのイベントの説明を辞書型で格納します.ちなみにここでのkeyは任意の文字列で構いません.
event_dict = {'auditory/left': 1, 'auditory/right': 2, 'visual/left': 3, 'visual/right': 4, 'smiley': 5, 'buttonpress': 32}時間軸上にそれぞれのイベントの呈示タイミングをプロットしてみます.
event_id=evend_dictによって先ほど定義したIDとイベントの名前がプロット上で対応づいています.fig = mne.viz.plot_events(events, event_id=event_dict, sfreq=raw.info['sfreq'], first_samp=raw.first_samp)
エポックに切り出す
MEG/EEG解析で,特にある刺激に対する反応について調べる際に,信号をエポックと呼ばれる単位に分けて,一つのデータとして扱います.刺激に対して前後の一定の区間を切り出すことで,それを一つのデータ単位とします.この切り出し処理のことをエポッキングと呼びます.Rawオブジェクトは収録中の全時間がつながっているものですが,これらを刺激に対する反応の部分のみ切り出したものが,Epochsオブジェクトというデータ型で保持されます.
エポッキングにおいて,しばしばスレッショルドリジェクションと呼ばれる処理が行われます.これは該当の時間中に大きすぎる信号が含まれている場合,その部分は大きなノイズが入り込んでしまったであろうということで,データから除外するというものです.その除外の基準を決めます.
reject_criteria = dict(mag=4000e-15, # 4000 fT grad=4000e-13, # 4000 fT/cm eeg=150e-6, # 150 µV eog=250e-6) # 250 µV次に,RawオブジェクトからEpochsオブジェクトを作成します.ここでの
mne.Epochsの引数は以下の通りです.
raw:信号のデータを含んだRawオブジェクトevents:時間とイベントIDの情報を持ったnumpy arrayevent_id:イベントIDとその名称を対応付ける辞書型tmin:刺激呈示の何秒からのデータを切り出すか(刺激呈示前の場合マイナスを付ける)tmax:刺激呈示後何秒までのデータを切り出すかreject:データ除外の基準epochs = mne.Epochs(raw, events, event_id=event_dict, tmin=-0.2, tmax=0.5, reject=reject_criteria, preload=True) # output 319 matching events found Applying baseline correction (mode: mean) Not setting metadata Created an SSP operator (subspace dimension = 4) 4 projection items activated Loading data for 319 events and 106 original time points ... Rejecting epoch based on EOG : ['EOG 061'] Rejecting epoch based on EOG : ['EOG 061'] Rejecting epoch based on MAG : ['MEG 1711'] Rejecting epoch based on EOG : ['EOG 061'] Rejecting epoch based on EOG : ['EOG 061'] Rejecting epoch based on MAG : ['MEG 1711'] Rejecting epoch based on EEG : ['EEG 008'] Rejecting epoch based on EOG : ['EOG 061'] Rejecting epoch based on EOG : ['EOG 061'] Rejecting epoch based on EOG : ['EOG 061'] 10 bad epochs dropped今回は10個のエポックが除外されたようです.
被験者のボタンを押したタイミングは今回扱わないので,視聴覚刺激イベントのみを対象にします.また,条件間でのデータ数に偏りが生じることを防ぐため,
epochs.equalize_event_counts()で,数が多い条件のイベントを消すことで,各条件の数を揃えています.conds_we_care_about = ['auditory/left', 'auditory/right', 'visual/left', 'visual/right'] epochs.equalize_event_counts(conds_we_care_about) # this operates in-place
event_dictで'auditory/left'とauditory/rightのように指定していましたが,Epochsオブジェクトに渡すことで,auditoryを指定するとこれら両方を指すことになります.ここで聴覚刺激に対するデータと視覚刺激データに分けます.aud_epochs = epochs['auditory'] vis_epochs = epochs['visual'] del raw, epochs # free up memory聴覚データでチャンネルを指定して,刺激呈示時間を揃えた加算平均波形を表示します.
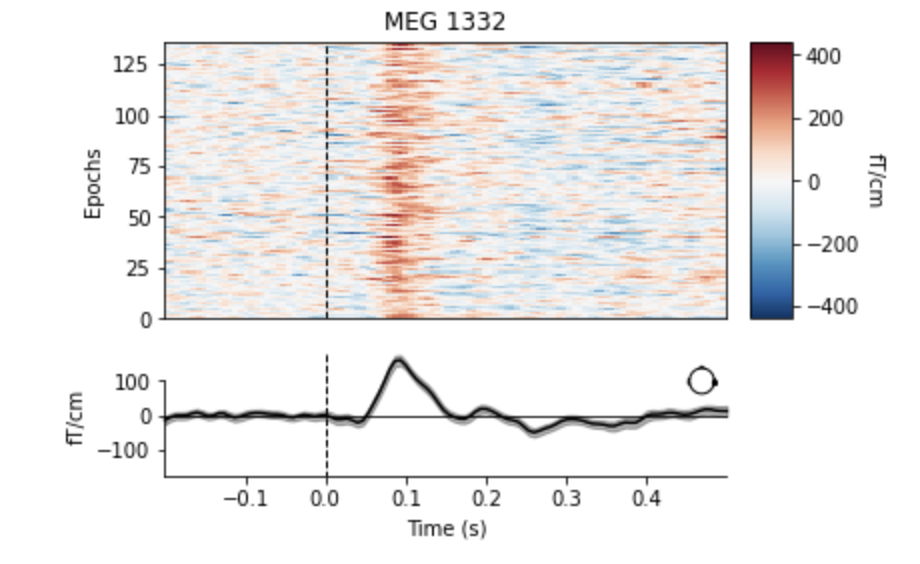
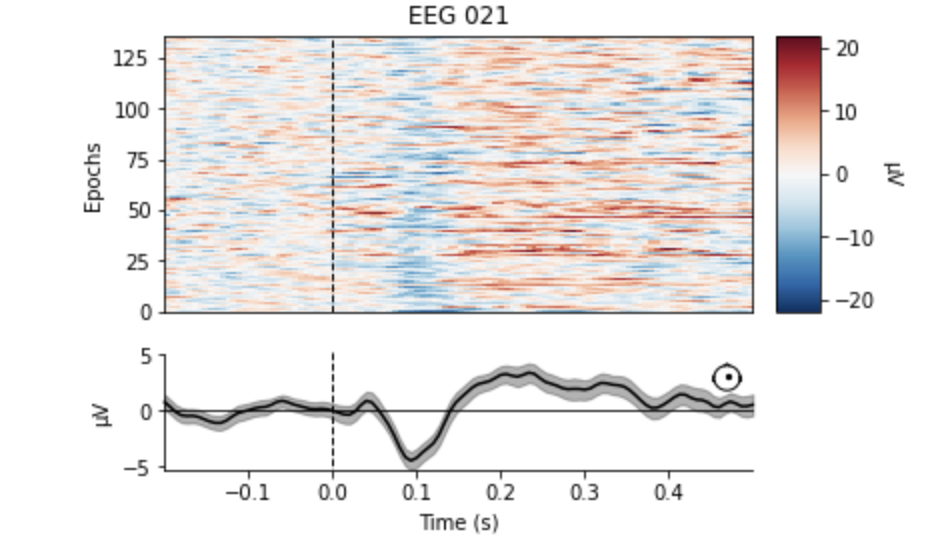
aud_epochs.plot_image(picks=['MEG 1332', 'EEG 021']) # output 136 matching events found No baseline correction applied Not setting metadata 0 projection items activated 0 bad epochs dropped 136 matching events found No baseline correction applied Not setting metadata 0 projection items activated 0 bad epochs dropped
補足ですが,Epochsオブジェクトの
get_data()メソッドによって,numpy arrayの形で時系列波形データを取得できるので,条件ごとにarrayを取ることで,機械学習のモデルに入力することなどが可能です.aud_epochs.get_data().shape (136, 376, 106) # (エポック,チャンネル,時刻)以下の周波数処理などもnumpy arrayを返すものも同様です.
時間周波数解析
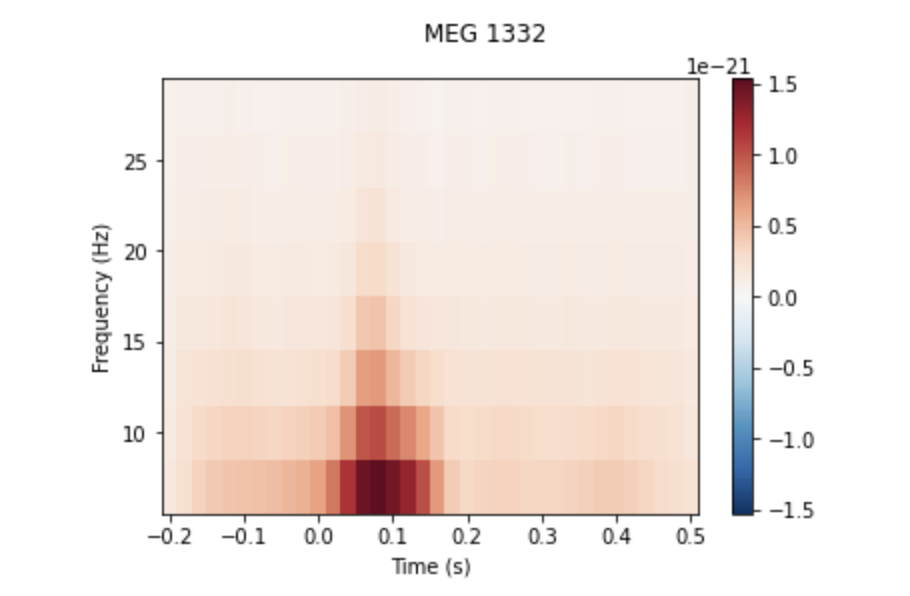
MEG/EEG波形における,刺激呈示前後の時間と周波数の関係について調べるために,時間周波数解析を行います.ここでは,聴覚刺激に対する反応を,wavelet解析によって計算し,それをプロットします.カラーバーに表示されているように,赤が濃くなるほど,その時間のその周波数の振幅が大きいということを示しています.(もっと詳しいExample)
frequencies = np.arange(7, 30, 3) power = mne.time_frequency.tfr_morlet(aud_epochs, n_cycles=2, return_itc=False, freqs=frequencies, decim=3) power.plot(['MEG 1332']) # output No baseline correction applied
誘発反応の推定
MNEのデータ型として,Epochsオブジェクトの加算平均を行ったものがEvokedオブジェクトになります.MEG/EEGデータは脳活動以外のノイズが多く,加算平均を行うことで条件間の差を調べることが多くあります.
ここでは,聴覚データと視覚データの加算波形の違いをプロットします.
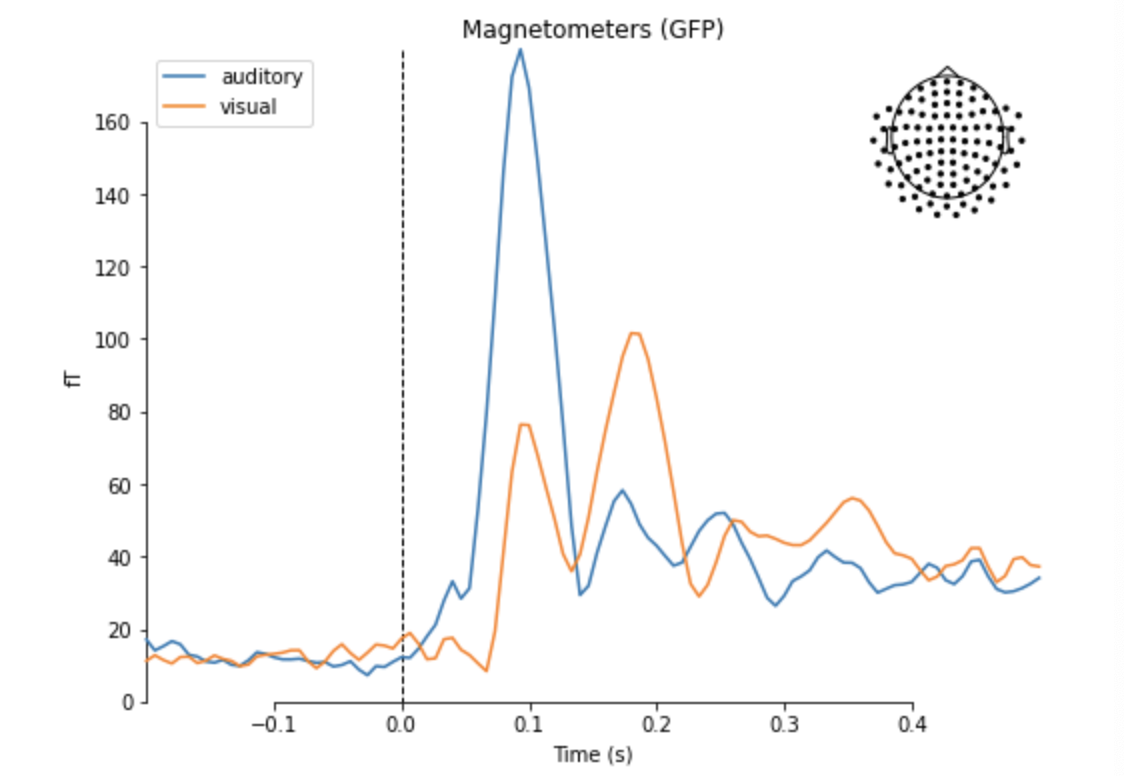
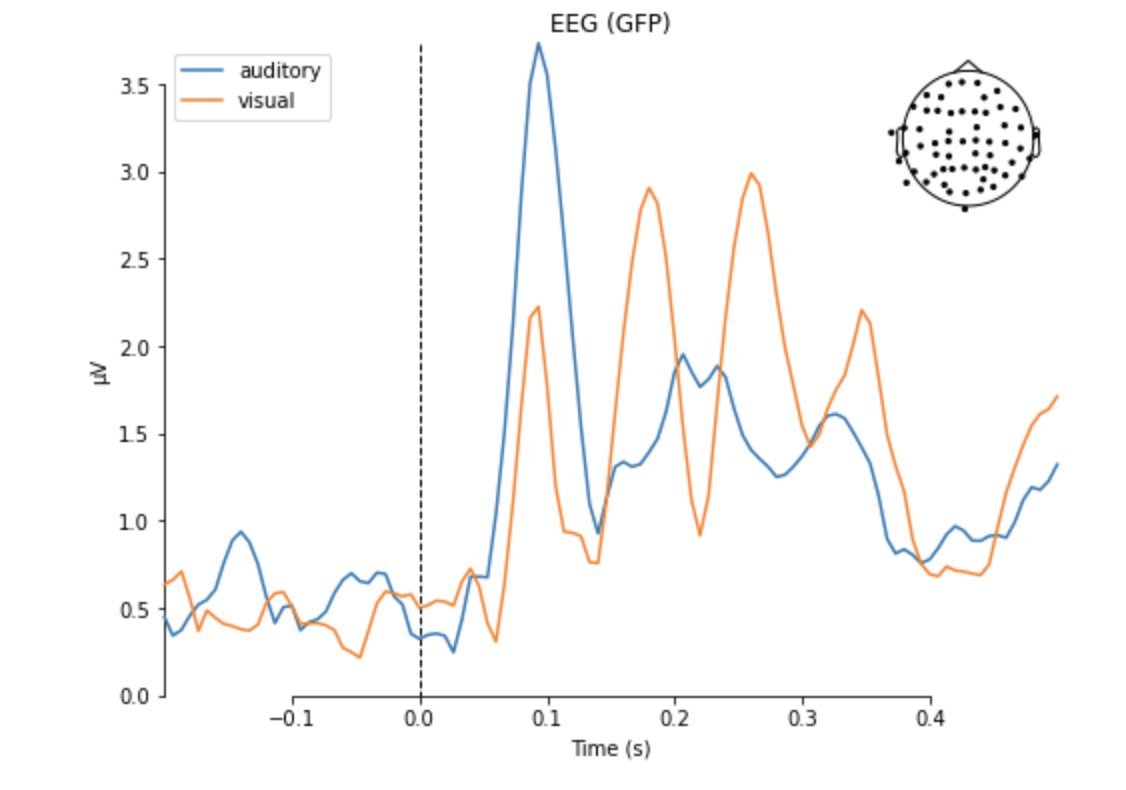
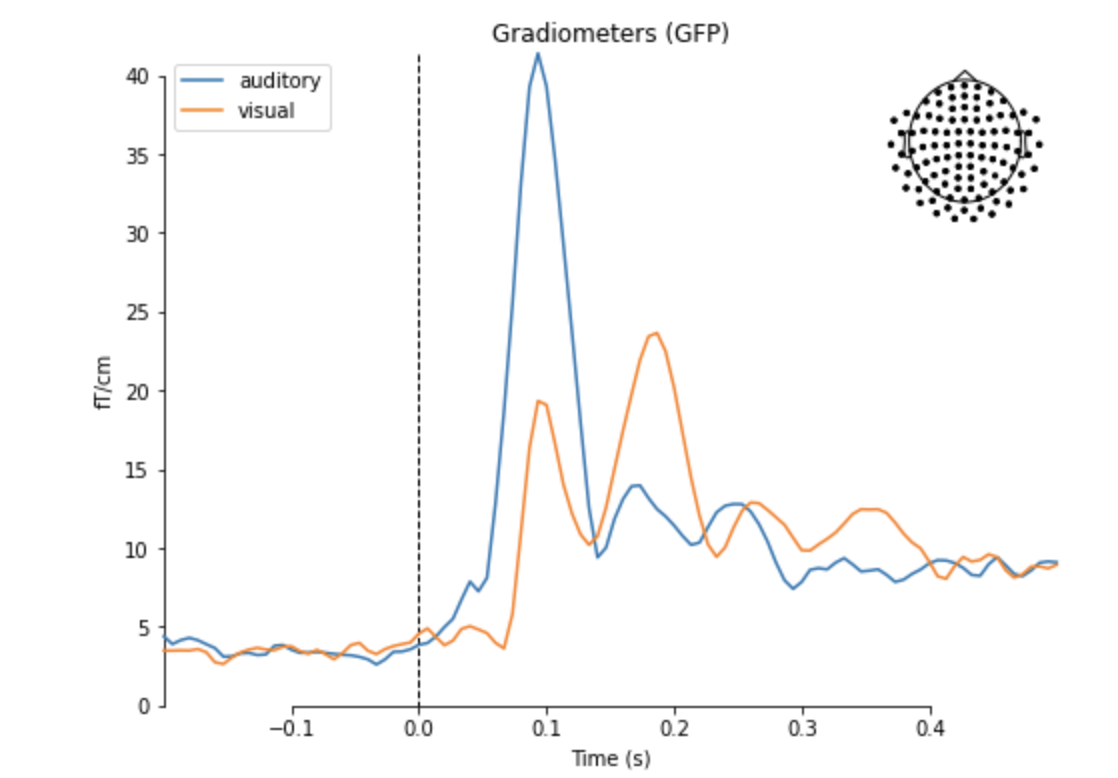
aud_evoked = aud_epochs.average() vis_evoked = vis_epochs.average() mne.viz.plot_compare_evokeds(dict(auditory=aud_evoked, visual=vis_evoked), legend='upper left', show_sensors='upper right')
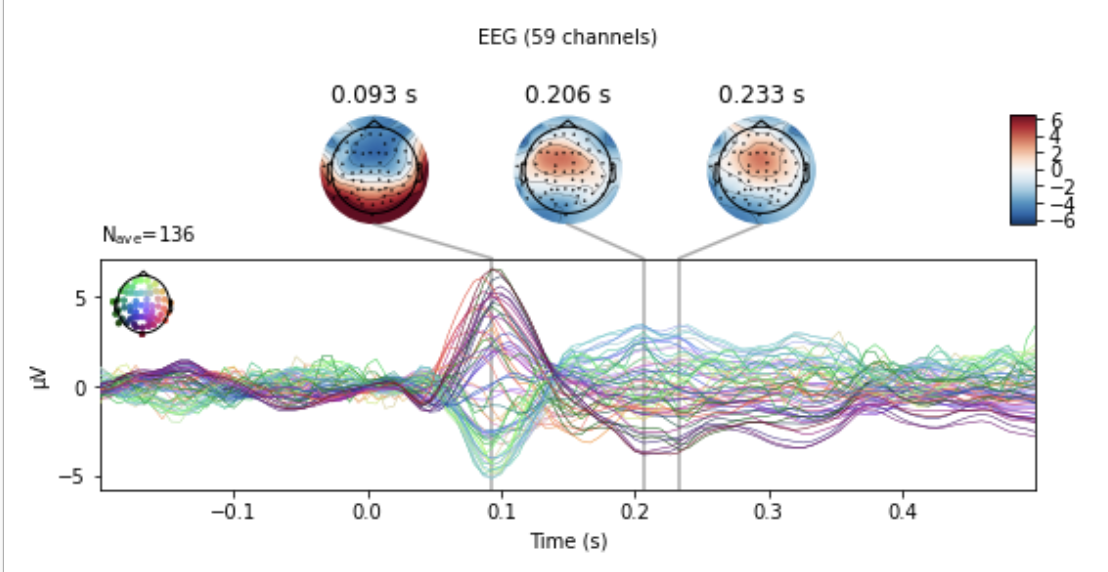
Evokedオブジェクトはさらに詳しい解析を行うメソッドを備えています.各チャンネルごとの波形を表示すると,前頭のチャンネルで100msで負になり(N100),そこから200msあたりで正のピークを持つ振れ(P200)を確認できます.
aud_evoked.plot_joint(picks='eeg')
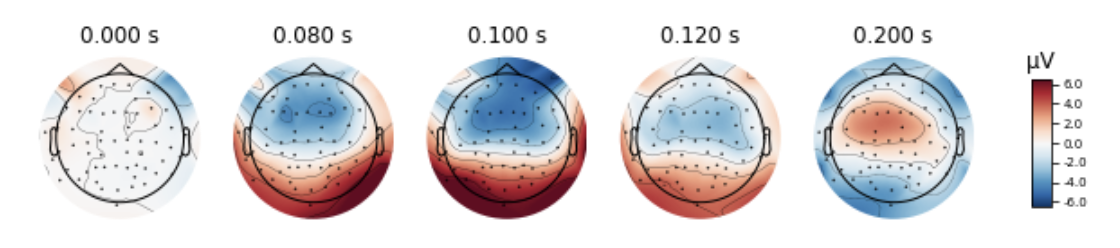
また,トポグラフィーと呼ばれる頭皮上の分布を表示することもできます.ここでは,赤いほど正の,青いほど負の電位を持った脳波が以下のように頭皮上で観測されていることが分かります.
aud_evoked.plot_topomap(times=[0., 0.08, 0.1, 0.12, 0.2], ch_type='eeg')
また,条件間の差を見るために
mne.combine_evoked()によって,2つの条件差のデータを持ったEvokedオブジェクトが生成されます(このとき片方のオブジェクトにマイナス符号をつけます).このオブジェクトの波形を表示すると,2つの条件間の差の波形を見ることができます.evoked_diff = mne.combine_evoked([aud_evoked, -vis_evoked], weights='equal') evoked_diff.pick_types('mag').plot_topo(color='r', legend=False)
おわりに
ここでは基礎的な機能のみ紹介しましたが,MNE公式ページには多くのTutorialとExampleが用意されているので,さらに詳しい分析を行うための最初のステップとして参考にしていただけたらと思います.
また,Pythonには統計や機械学習のライブラリが多くあるので,MEG/EEGの機械学習などによる分析が容易になると思います.

- 投稿日:2020-05-16T21:43:03+09:00
基底クラスのgetterプロパティに派生クラスでsetterとdeleterを追加する場合の注意点
次の例は、基底クラス
Fooのgetterプロパティxに派生クラスでsetterを追加する方法です。class Foo: def __init__(self): self._x = "I'm Foo.x" @property def x(self): return self._x class Bar(Foo): @Foo.x.setter def x(self, value): self._x = value実行すると、次のようになります。
>>> b = Bar() >>> b.x "I'm Foo.x" >>> b.x = "I'm Bar.x" >>> b.x "I'm Bar.x"さらに、deleterを追加する場合は、次のように書きます。
class Foo: def __init__(self): self._x = "I'm Foo.x" @property def x(self): return self._x class Bar(Foo): @Foo.x.setter def x(self, value): self._x = value @x.deleter def x(self): self._x = "Nothing"実行すると下記のようになります。
>>> b = Bar() >>> b.x "I'm Foo.x" >>> b.x = "I'm Bar.x" >>> b.x "I'm Bar.x" >>> del b.x 'Nothing'最後のデコレータは、
@Foo.x.deleterではなく、@x.deleterである点が注意です。
@Foo.x.deleterとすると、setterが無いプロパティが生成されてしまいます。
propertyオブジェクトの、deleterメソッドは、引数の関数をdeleterに追加した新たなpropertyオブジェクトを返します。Foo.xは、getterしかないプロパティオブジェクトで、
Barの@Foo.x.setterデコレータで始まる定義で、Bar.xにはgetterとsetterを持つproperty
オブジェクトが生成され代入されているので、@x.deleterとすると、getterとsetterに加え、deleterが追加されます。参考
- 投稿日:2020-05-16T21:41:44+09:00
OpenCVで日本語フォントを描写する を関数化する を汎用的にする
はじめに
前回の記事「OpenCVで日本語フォントを描写する を関数化する」でコメントをいただいた。大変ありがたいことだ。
しかも私がサボったところがしっかりと見抜かれている。これは頑張らねばいけません。改善
RGBとBGRについて
目指すものは
cv2.imshow()と同等の使い方で日本語を描写できる関数なので、指定する色はOpenCVの並び(BGR)。
前回の記事では関数内でPILで仕事をするにあたり、PILの色の並び(RGB)に変換した。画像もBGRからRGBに変換し、PILの機能で日本語を描写し、BGRに戻した上でOpenCVに再変換した。色順の反転をもっとエレガントに
色順の反転について上では各要素を取り出して順序変更するというエレガントでない実装の仕方をしたが、普通にスライスが使えるらしい。
>>> (255, 0, 128)[::-1] (128, 0, 255)あっれー? いろいろ試行錯誤して、これも試してみたはずなんだけどなー。
というか、色順の反転は不要
で。BGRとRGBの関係を理解した上で、という条件付きではあるが。
画像をPILにとって正しい色に変換せず、文字色もRGBであるべき並びをBGRのままでPILで描写し、それをそのままOpenCVに戻せば、それは結果としてOpenCVとして正しい色になるしそっちのほうが速いよね。というのがコメントしてくださった方の主旨だ。
学校の先生に課題として提出したら「OpenCVとPILは色の並びが逆になってると教えたじゃないか。これでは答えは合っていても途中の計算式が間違っているようなものだ」と言われてしまいそうなテクニックだが、プログラミングにはこういう発想が必要だ。
いやね、私も思いついたんですよ。だけど、せっかく作ったOpenCVとPILを変換する関数が使えなくなってしまうのでそこまでは織り込まなかったのです。言い訳ですけど。ということで投稿してくださった第3の関数を我が第2関数と比較してみよう。
# 元の関数 def cv2_putText_2(img, text, org, fontFace, fontScale, color): x, y = org b, g, r = color # 色はBGRのままでいくのでこの文は不要 colorRGB = (r, g, b) # 色はBGRのままでいくのでこの文は不要。スライスすら使わない imgPIL = cv2pil(img) # 色を変換した上でPILにする という独自関数を単にPILにするという処理にする draw = ImageDraw.Draw(imgPIL) fontPIL = ImageFont.truetype(font = fontFace, size = fontScale) w, h = draw.textsize(text, font = fontPIL) draw.text(xy = (x,y-h), text = text, fill = colorRGB, font = fontPIL) # 色は関数の引数そのまま imgCV = pil2cv(imgPIL) # 色の再変換もなく、 return imgCV # 単にOpenCVに変換したものを戻り値とする # ↓↓↓↓↓↓ # 投稿してくださった関数 def cv2_putText_3(img, text, org, fontFace, fontScale, color): x, y = org imgPIL = Image.fromarray(img) draw = ImageDraw.Draw(imgPIL) fontPIL = ImageFont.truetype(font = fontFace, size = fontScale) w, h = draw.textsize(text, font = fontPIL) draw.text(xy = (x,y-h), text = text, fill = color, font = fontPIL) return np.array(imgPIL, dtype = np.uint8)うーん、素晴らしくシンプルになったな。
ROIについて
ROI(Region of Interest)は関心領域と訳され、画像全体の中で処理のために注目するエリアを意味する。こちらの記事でも使っている。
描写されるテキストのサイズをあらかじめ取得しておいて元画像のうち文字が描写される部分のみPIL化すれば、元画像全体をPIL化するよりもっともっと速いよねというのがその次のコメントだ。頭のいい人は違うなあ…。
ただし、PILのImageDraw.textsize()を使うにはImageDraw.Drawオブジェクトが必要だ。サイズがわからなければベースとなる単色画像が作れない? そんなことはない。サイズが小さくて描写されるテキストがはみ出していようとも、ImageDraw.Drawオブジェクトが準備されてさえいればいいのだ。そこを踏まえて投稿してくださった第4の関数を読み解いてみよう。
def cv2_putText_4(img, text, org, fontFace, fontScale, color): x, y = org fontPIL = ImageFont.truetype(font = fontFace, size = fontScale) # サイズ(0,0)のベタ画像を作りそのDrawオブジェクトを作る dummy_draw = ImageDraw.Draw(Image.new("RGB", (0,0))) # 指定したフォント・サイズで指定した文を描写した際の矩形の幅と高さを取得する w, h = dummy_draw.textsize(text, font = fontPIL) """ 後でここに追加する """ # 元画像の一部を今得たサイズでトリミングし、そこのみPIL画像とする imgPIL = Image.fromarray(img[y-h:y,x:x+w,:]) # それのDrawオブジェクトを作る draw = ImageDraw.Draw(imgPIL) # それにあらためて文字を描写する トリミング済なので基準は(0,0) draw.text(xy = (0,0), text = text, fill = color, font = fontPIL) # トリミングの逆 元画像の該当部分を文字描写済画像に置き換える img[y-h:y,x:x+w,:] = np.array(imgPIL, dtype = np.uint8) return imgほお~なるほどねえ。
ただしImageDraw.textsize()のバグにより、取得した高さをそのまま使うと下が少し切れてしまう。
だったらどうするか。そんなのROIをテキトーに拡大してやればいいんですよ。
こんな感じで。b = int(0.1 * h) # ベースラインより下に確保する高さを適当に定めて、 # imgPIL = Image.fromarray(img[y-h:y,x:x+w,:]) # を imgPIL = Image.fromarray(img[y-h:y+b,x:x+w,:]) # にする画像外への描写への対応
OpenCVの画像はnumpy.ndarrayのかたちでデータ格納されているのでトリミングで一部分を取り出すのは
img[y:y+h, x:x+w]と書けばよい。これは私がOpenCVを勉強してもっとも感動した事実のひとつで、何度も何度も書いている。
だが、これには欠点がある。配列なので当然といえば当然だが、画像外を指定することができないのだ。
もちろんOpenCVが用意しているcv2.putText()や図形描写関数は元画像の外にはみ出ても問題ないよう作られているが、我が関数は現時点ではエラーになってしまう。うまくトリミングさせなくては。PILのトリミングは自分の記事としては書いていないのだが、OpenCVとは違い画像範囲外を指定することができる。
https://note.nkmk.me/python-pillow-image-crop-trimming/
だが、せっかくコメントでROIを指定する方法を示してくださったし、トリミングするために画像全部をPILにするのもこれまでの考えから逆行しているようだし、そもそも私はOpenCVの勉強をしているのであってPILのトリミングは使いたくない。こんな考え方でどうだろう。
1. テキスト描写サイズをあらかじめ取得し、その大きさの単色画像を作る ①
2. それを元画像の指定した位置に置いたときにはみ出るかどうかを確認する
テキスト描写域が完全に画像外なら何もしない
3. 単色画像の全部もしくは一部を元画像に置き換える ②
4. PILでテキストを描写する Rの輝度とBの輝度が入れ替わった状態だが見せなければ問題ない ③
5. OpenCVに戻す ④
6. 元画像があったエリアのみトリミングする ⑤
7. 元画像の該当エリアを、文字が描写されたものに更新する ⑥
① ② ③ ④ ⑤
⑥ さらに機能追加
左下に限らず右上や中央の座標を指定して描写できるようにする
cv2.putText()と同等の使い方で日本語フォントを扱えるようにするというのが当初からの目的だが、もうひとつ機能追加したくなった。
cv2.putText()のorgで指定する座標は文字の左下。前回も書いたが、これ、使いにくいと思うのよね。
そこで、orgで指定する座標をcv2.putText()と同じく左下とするか、PILと同じく左上とするか、はたまた中央とするかを指定できるようにした。下の画像は、独自関数の中で同じy座標を指定している(
cv2.MARKER_STARのy座標が同じ)が、設定の違いによって異なる高さに描写されているということを示している。
左からcv2.putText()と同じ左下基準、PILのImageDraw.text()と同等の右上基準、そして中央基準だ。
文字を傾けて描写する
勘弁してください。
以上を織り込んだ関数
サンプルプログラム付き。
import numpy as np import cv2 from PIL import Image, ImageDraw, ImageFont def cv2_putText_5(img, text, org, fontFace, fontScale, color, mode=0): # cv2.putText()にないオリジナル引数「mode」 orgで指定した座標の基準 # 0(デフォ)=cv2.putText()と同じく左下 1=左上 2=中央 # テキスト描写域を取得 fontPIL = ImageFont.truetype(font = fontFace, size = fontScale) dummy_draw = ImageDraw.Draw(Image.new("RGB", (0,0))) text_w, text_h = dummy_draw.textsize(text, font=fontPIL) text_b = int(0.1 * text_h) # バグにより下にはみ出る分の対策 # テキスト描写域の左上座標を取得(元画像の左上を原点とする) x, y = org offset_x = [0, 0, text_w//2] offset_y = [text_h, 0, (text_h+text_b)//2] x0 = x - offset_x[mode] y0 = y - offset_y[mode] img_h, img_w = img.shape[:2] # 画面外なら何もしない if not ((-text_w < x0 < img_w) and (-text_b-text_h < y0 < img_h)) : print ("out of bounds") return img # テキスト描写域の中で元画像がある領域の左上と右下(元画像の左上を原点とする) x1, y1 = max(x0, 0), max(y0, 0) x2, y2 = min(x0+text_w, img_w), min(y0+text_h+text_b, img_h) # テキスト描写域と同サイズの黒画像を作り、それの全部もしくは一部に元画像を貼る text_area = np.full((text_h+text_b,text_w,3), (0,0,0), dtype=np.uint8) text_area[y1-y0:y2-y0, x1-x0:x2-x0] = img[y1:y2, x1:x2] # それをPIL化し、フォントを指定してテキストを描写する(色変換なし) imgPIL = Image.fromarray(text_area) draw = ImageDraw.Draw(imgPIL) draw.text(xy = (0, 0), text = text, fill = color, font = fontPIL) # PIL画像をOpenCV画像に戻す(色変換なし) text_area = np.array(imgPIL, dtype = np.uint8) # 元画像の該当エリアを、文字が描写されたものに更新する img[y1:y2, x1:x2] = text_area[y1-y0:y2-y0, x1-x0:x2-x0] return img def main(): img = np.full((200,400,3), (160,160,160), dtype=np.uint8) imgH, imgW = img.shape[:2] fontPIL = "Dflgs9.TTC" # DF麗雅宋 size = 30 text = "日本語も\n可能なり" color = (255,0,0) positions = [(-imgW,-imgH), # これは画像外にあり描写されない (0,0), (0,imgH//2), (0,imgH), (imgW//2,0), (imgW//2,imgH//2), (imgW//2,imgH), (imgW,0), (imgW,imgH//2), (imgW,imgH)] for pos in positions: img = cv2.circle(img, pos, 60, (0,0,255), 3) img = cv2_putText_5(img = img, text = text, org = pos, # 円の中心と同じ座標を指定した fontFace = fontPIL, fontScale = size, color = color, mode = 2) # 今指定した座標は文字描写域の中心だぞ cv2.imshow("", img) cv2.waitKey(0) cv2.destroyAllWindows() if __name__ == "__main__": main()自分で作っておいて何だが、中央基準は
cv2.circle()と相性がよく、使いでがありそうだ。
終わりに
前回の記事でコメントをいただいたkounoikeさんおよびこの場を提供してくださったQiitaにお礼申し上げます。









- 投稿日:2020-05-16T21:35:59+09:00
メトロポリタン・ヘイスティング法(マルコフ連鎖モンテカルロ法における手法の一つ)を実装を交えて理解する
はじめに
前回はマルコフ連鎖とモンテカルロ法をそれぞれ解説し、マルコフ連鎖モンテカルロ法(通称:MCMC法)の概要をまとめました。
MCMC法は複数アルゴリズムがありますが、今回はメトロポリタンヘイスティング方法(通称:MH法)をまとめたいと思います。今回も下記記事及び、本を参考にして学びました。
マルコフ連鎖モンテカルロ法の振り返り
マルコフ連鎖モンテカルロ法(通称:MCMC法)は、多次元空間の確率分布等複雑な分布を確率分布に基づくサンプリングから求める方法です。
関数の期待値$θ_{eap}$を求めるうえで、データ分析を対象にすると高次元の関数になりがちです。その場合、計算が非常に複雑で解けない場合も多いため、その対象とする分布をランダムにサンプリング(モンテカルロ法)することを考えます。
そのサンプリングした値を集めた分布を所望の分布となるようマルコフ連鎖で調整していくのです。
このMCMC法は下記大きく4つの手法、アルゴリズムがあります。
- メトロポリス・ヘイスティング法(今回説明)
- ハミルトニアン・モンテカルロ法
- ギブズサンプリング
- スライスサンプリング
今回は、このメトロポリス・ヘイスティング法についてまとめます。
メトロポリス・ヘイスティング法とは
MCMC法では、任意の確率変数$θ,θ'$について下記に示す詳細釣り合い条件を考えます。
f(θ'|θ)f(θ) = f(θ|θ')f(θ') \hspace{1cm} 式1この時、$f(θ'|θ)$及び$f(θ|θ')$が遷移核と呼ばれる分布です。通常、既知である事後分布$f(θ)$に対して式1を満たすような遷移核をいきなり見つけることは非常に困難です。
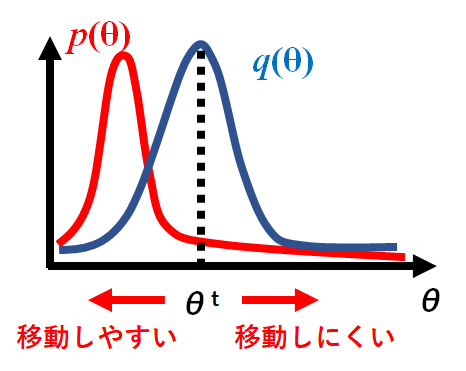
そこでこの遷移核$f(|)$の代わりに分析者が適当な遷移核$q(|)$を提案分布として利用します。この適当に選ぶことが実は難しさを表していることが後の実装で分かります。
提案分布とは、目標分布からのサンプルとして適当である候補を提案する確率分布です。この提案分布は適当に選ぶことから、必ずしも等号を満たすわけではありません。例えば、
q(θ|θ')f(θ') > q(θ'|θ)f(θ)\hspace{1cm} 式2\\こちらの式2のようになります。この式について、詳細釣り合い条件として満たすために確率補正を行う方法をメトロポリス・ヘイスティング(Metropolis-Hastings algorithm)法(通称MH法)と呼びます。
元々は、物理化学の領域で提案されたアルゴリズムです。それをベイズ統計に応用されたのです。
式2は$θ$への移動確率が、$θ'$への移動確率よりも大きくなっている状態です。但し、遷移確率との補正を行うために、符号が正の補正係数$c$と$c'$を導入します。f(θ|θ') = cq(θ|θ')\\ f(θ'|θ) = c'q(θ'|θ)となるため、補正後は、
cq(θ|θ')f(θ')=c'q(θ'|θ)f(θ)となって統合が成り立ちました。ただこの場合でも、
- 補正の係数が[tex:c,c']の二つあり冗長
- 補正係数が0以上1以下に収まっていないため、確率的行動をとりにくい
等の課題があります。従って、
r = \frac{c}{c'} = \frac{q(θ'|θ)f(θ)}{q(θ|θ')f(θ')}\\ r' =\frac{c'}{c'} = 1となります。これを代入すると
rq(θ|θ')f(θ')=r'q(θ'|θ)f(θ)となるため、$rq(θ|θ')$と$r'q(θ'|θ)$を遷移核とすれば、詳細釣り合い条件を満たすこととなります。
MHアルゴリズム
さて、MHアルゴリズムは下記です。
1) 提案分布 $q( | θ^{t})$を利用して、乱数$a$を発生させる。
2) 以下の命題を判定する。q(a|θ^{t})f(θ^{t}) > q(θ^{t}|a)f(a)
- 真:式1 不等号条件より、$θ =a$,$θ' =θ^{t}$の状態と判定されます。この場合、提案分布は$q(θ|θ')$なので、式2の左辺の係数$r$を使って確率的補正をする必要があります。
r =\frac {q(θ^{t}|a)f(a) }{q(a|θ^{t})f(θ^{t})}を計算し、確率$r$で$a$を受容し、$θ^{t+1}=a$とします。確率$1-r$で$a$を破棄し、$θ^{t+1}=θ^t$とします。
- 偽:式1 不等号条件より、$θ' =a$,$θ =θ^{t}$の状態と判定されます。この場合、提案分布は$q(θ'|θ)$なのですから、式2の右辺の係数$r'$を使って確率的補正をする必要があります。確率$1(=r')$で必ず$a$を受容し、$θ^{t+1}=a$とします。
3)$ t = t + 1$として、1へ戻る。
要約すると、提案された候補点$a$を確率$min(1,r)$で受容$(θ^{t+1}=a)$し、さもなくばその場に留まる$θ^{t+1}=θ^{t}$ことを任意回数繰り返すとなります。
移動の概要を下記図としました。目標分布$f(θ)$に向かって$θ$は移動しやすい状態を作っています。
実装して確認する(独立MH法)
それでは実際にこのMH法を実装していきたいと思います。MH法には細かく独立MH法と、ランダムウォークMH法があります。まずは独立MH法についてです。
お題は下記です。母数$θ$の事後分布を$f(θ|α=11, λ=13)$のガンマ分布と仮定する。そして、提案分布は平均1,分散0.5の正規分布$q(θ)$とする。
ここで、補正係数はr =\frac {q(θ^{t})f(a) }{q(a)f(θ^{t})}とする。プログラムは下記です(ライブラリのインポート等は書いておりません。後ほど全文リンクを御覧ください)。
theta = [] # Initial value current = 3 theta.append(current) n_itr = 100000 for i in range(n_itr): # 提案分布からの乱数生成 a = rand_prop() if a < 0: theta.append(theta[-1]) continue r = (q(current)*f_gamma(a)) / (q(a)*f_gamma(current)) assert r > 0 if r < 0: #reject theta.append(theta[-1]) continue if r >= 1 or r > st.uniform.rvs():#乱数を発生させて、rよりも大きい場合に受容させる # Accept theta.append(a) current = a else: #Reject theta.append(theta[-1])ポイントとしては、確率$r$で受容するかどうかを決める表し方です。
if r >= 1 or r > st.uniform.rvs()
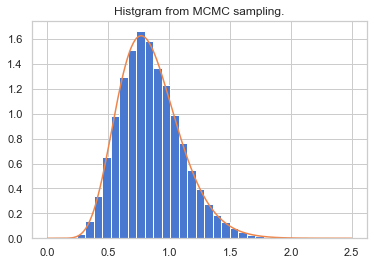
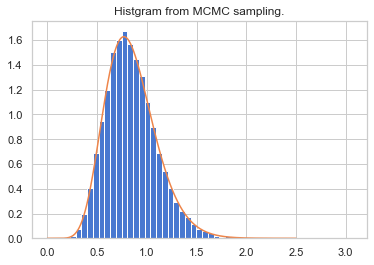
st.uniform.rvs()メソッドにより$0~1$の一様分布における乱数を発生させてやり、それより大きいと受容させると決めています。このプログラムの結果、事後分布を再現できているか確認します。
plt.title("Histgram from MCMC sampling.") plt.hist(theta[n_burn_in:], bins=30, normed=True) xx = np.linspace(0, 2.5,501) plt.plot(xx, st.gamma(11, 0, 1/13.).pdf(xx)) plt.show()
ヒストグラムとして青で表しているデータがMH法により移動した$θ$の頻度分布です。正規化して和が1となるように補正しています。
オレンジ色が元々再現したかった事後分布ですので、再現できていることが確認できます。さて、問題なくできたように見えますが先ほど提案分布では平均1、分散0.5としました。これは恣意的であり、実は上手くいかない場合があります。
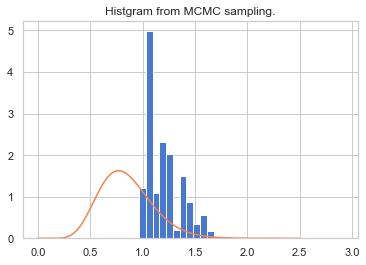
例えば、平均を3、分散を0.5の正規分布が提案分布とすると、
このようにずれてしまいます。実は、独立MH法においては目標分布に近い分布を定常分布としないと上手く収束してくれない課題があります。つまり、独立MH法は提案分布の良し悪しによって、収束までの成績に大きな違いが現れます。
今回は、簡単のために事後分布が明らかになっていますが、実際のデータ解析では分布が不明場合が多くあります。
従い、この課題を解決する方法を考える必要があります。ランダムウォークMH法
この課題を解決する方法として、ランダムウォークMH法呼ばれるアルゴリズムが提案されています。
提案の候補を
a =θ^{t} + eとします。$e$は平均0の正規分布や一様分布などが用いられます。
提案分布に正規分布や一様分布などの対称な分布を選ぶと、
q(a|θ^{t}) = q(θ^{t}|a)と提案分布がかけます。
従い、ランダムウォークMH法における補正係数rは、r = \frac {f(a)}{f(θ^{t})}となり、提案分布が常に消えます。
実装して確認する(ランダムウォークMH法)
さて、先ほどと同じ問題について実装して確認してみましょう。
# MCMC sampling theta = [] current = 5 theta.append(current) n_itr = 100000 prop_m = 5 prop_sd = np.sqrt(0.10) x = np.linspace(-1,5,501) def rand_prop1(prop_m): return st.norm.rvs(prop_m, prop_sd) for i in range(n_itr): a = rand_prop1(current) # 提案分布からの乱数生成 r = f_gamma(a) / f_gamma(current) if a < 0 or r < 0: #reject theta.append(theta[-1]) pass elif r >= 1 or r > st.uniform.rvs(): # Accept theta.append(a) current = a status = "acc" col = "r" else: #Reject theta.append(theta[-1]) passグラフ描写が下記です。
plt.title("Histgram from MCMC sampling.") n, b, p = plt.hist(theta[n_burn_in:], bins=50, density=True) xx = np.linspace(0, 2.5,501) plt.plot(xx, st.gamma(11, 0, 1/13.).pdf(xx)) plt.show() kk = 11. tt = 13. print ("sample mean:{0:.5f}, sample std:{1:.5f}".format(np.mean(theta), np.std(theta))) # 理論期待値・分散 print("mean:{0:.5f}, std:{1:.5f}".format( kk/tt, np.sqrt(kk*((1/tt)**2))) )
きれいに分布が再現できていることが分かりました。
先ほどの独立MH法と比較しても、こちらのランダムウォークMH法のアルゴリズムが安心して使えそうであることが分かりました。と言いつつもMH法の問題点
これで一安心、と言いたいところですが実はまだまだ課題が残っています。結局、$e$の値を適切に指定する必要であるため、これもハイパーパラメータ的な考え方が必要になっています。
分散が小さければ受理される遷移の割合は高いものの、状態空間での前進はゆっくりとしたランダムウォークであるため、長い収束時間が必要になります。一方、分散が多きければ棄却率が高くなります。
これを解決する方法にハミルトニアンモンテカルロ法があります。それについては次回まとめられればと思います。終わりに
今回、メトロポリス・ヘイスティング法をまとめました。事後分布の平均に向かって収束させていく方法を考えることは、さながらニューラルネットワークにおける重みパラメータの最適化に似ています。
結局アルゴリズムは異なるものの、行いたい目的は似ているのでそこが掴めると統計・機械学習の面白さや広がりが見えてくるように思いました。
プログラ全文はこちらに格納しております。
https://github.com/Fumio-eisan/Montecarlo20200516

- 投稿日:2020-05-16T21:34:32+09:00
pandas_datareaderインストール時のエラー
1.この記事について
米国株式の実データを取得するPythonライブラリ「pandasa_datareader」をインストールすると下記のエラーが出力された。
root@2a1627805ea9:/home# pip3 install pandas_datareader (途中略) src/lxml/includes/etree_defs.h:14:10: fatal error: libxml/xmlversion.h: No such file or directory #include "libxml/xmlversion.h" ^~~~~~~~~~~~~~~~~~~~~ compilation terminated. Compile failed: command 'arm-linux-gnueabihf-gcc' failed with exit status 1 cc -I/usr/include/libxml2 -c /tmp/xmlXPathInit_w7iprr1.c -o tmp/xmlXPathInit_w7iprr1.o /tmp/xmlXPathInit_w7iprr1.c:2:1: warning: return type defaults to 'int' [-Wimplicit-int] main (int argc, char **argv) { ^~~~ cc tmp/xmlXPathInit_w7iprr1.o -lxml2 -o a.out error: command 'arm-linux-gnueabihf-gcc' failed with exit status 1 ---------------------------------------- Command "/usr/bin/python3 -u -c "import setuptools, tokenize;__file__='/tmp/pip-build-6l7hbylz/lxml/setup.py';f=getattr(tokenize, 'open', open)(__file__);code=f.read().replace('\r\n', '\n');f.close();exec(compile(code, __file__, 'exec'))" install --record /tmp/pip-ex8h4yqx-record/install-record.txt --single-version-externally-managed --compile" failed with error code 1 in /tmp/pip-build-6l7hbylz/lxml/ In file included from src/lxml/etree.c:692:0: src/lxml/includes/etree_defs.h:14:10: fatal error: libxml/xmlversion.h: No such file or directory #include "libxml/xmlversion.h" ^~~~~~~~~~~~~~~~~~~~~ compilation terminated. Compile failed: command 'arm-linux-gnueabihf-gcc' failed with exit status 1 cc -I/usr/include/libxml2 -c /tmp/xmlXPathInitnltnxexy.c -o tmp/xmlXPathInitnltnxexy.o /tmp/xmlXPathInitnltnxexy.c:1:10: fatal error: libxml/xpath.h: No such file or directory #include "libxml/xpath.h" ^~~~~~~~~~~~~~~~ compilation terminated. ********************************************************************************* Could not find function xmlCheckVersion in library libxml2. Is libxml2 installed? ********************************************************************************* error: command 'arm-linux-gnueabihf-gcc' failed with exit status 1対策
libxml2-dev libxslt1-devをインストールする。
libxml2-dev libxslt1-devインストール後、pandas_datareaderが無事にインストールできました。root@2a1627805ea9:/home# apt-get install libxml2-dev libxslt1-dev
- 投稿日:2020-05-16T20:15:37+09:00
DjangoでMySQLを利用する
はじめに
ここでは、djangoのデータベースとして、標準搭載されているsqliteではなく、MySQLを利用するための設定について解説します。
なお、MySQLは、MAMPでインストールしたものとします。使用するデータベースの宣言
まず、
manage.pyで、MySQLを利用する旨を以下のように明記します。manage.pyimport pymysql pymysql.install_as_MySQLdb()使用するデータベース情報の記述
そして、
settings.pyでデータベースの詳細情報を記述します。settings.pyDATABASES = { 'default': { 'ENGINE': 'django.db.backends.mysql', 'NAME': データベース名, 'USER': (使用するデータベースの)ユーザー名, 'PASSWORD': (使用するデータベースの)パスワード, 'HOST': '/Applications/MAMP/tmp/mysql/mysql.sock', 'PORT': '8889' # MAMPの場合, } }
- 投稿日:2020-05-16T19:46:13+09:00
担当は予測できるのか? ~THE IDOL M@STER 担当推薦器作成記~
概要
本ブログは、アイドルマスター4シリーズ(本家はミリオンに含むものとする。理由は後述)において、ある特定1つのシリーズの担当をほかのシリーズの担当から推測し、プロデューサーに対してアイドルを推薦するシステムを考案・データ収集・実装した記録です。
結論から申し上げると、各シリーズの推薦システムの正答率は以下のようになりました。
- シャイニーカラーズ:80%
- SideM:49%
- ミリオンライブ:55%
- シンデレラ:37%
本ブログにて、データの構造、用いた手法、結果に対する考察を述べていきます。よろしくお願いします。
また、本ブログでは各シリーズを以下のように略記しております。
- シャイニーカラーズ:シャニ
- シンデレラガールズ:デレ
- ミリオンライブ :ミリ
正直もうちょっと精度の良いものができると思ってた目次
背景
そもそもなんでこんなこと考えたのか
twitterで同じ担当のPや絵師の方をフォローしていますが、その人たちがリツイートする他のシリーズでの絵・漫画に傾向があると思ったのがきっかけですね。自分はデレでは高森藍子、シャニでは桑山千雪を担当しております。同じ担当のPをフォローしていると、ミリオンの歌織の絵や漫画がよく流れてきたり。
なので、各シリーズでの担当傾向は似かよるんじゃないか? という仮説が自分の中にありました。
ゆくゆくは他シリーズのPを引き込むきっかけに
僕は元々シンデレラのプロデューサーだったんですが、最近他のシリーズにも手をだすようになりました。その時に、どのキャラをとっかかりとするか知れたら嬉しいなあ、と思ったので、このようなシステムを作ってみようかと。大々的にデータ集めて分析すれば、ミリオンの担当情報だけからシャニの担当をレコメンドできるんじゃないかと。そのキャラきっかけで他シリーズに触り始められるんじゃないかと。自分の好きなものを布教したい方々にとって、布教のきっかけができるのは心強いのではないかと。
そんな風に思って、本案件に取り組み始めました。
前提
アンケート集計数 7,425件
データは google フォームのアンケートで集計しました。
告知方法はtwitterのみでしたが、計 7,425件もの回答をいただきました。
ご協力いただいた皆様、誠にありがとうございました。現在も集計はしてるので、まだ答えていなければぜひご協力ください。
https://docs.google.com/forms/d/e/1FAIpQLSfPuQskKK6y1QGH8rgA1TzjVy6nQApgwC_JM3E5OBfNxJWKJQ/viewform?usp=sf_link各シリーズごとに、担当アイドル全員とそのうち一人を選ぶならだれか、担当するきっかけになったのは何かを質問
質問項目は以下の通りです。
- あなたの性別を教えてください。
- あなたの年代を教えてください。
以下、各シリーズごとに、
- 本シリーズにおいて、自身が担当するアイドルはいらっしゃいますか?
- あなたが初めて本シリーズのアイドルを担当してから、どのくらい経ちましたか?
- 本シリーズのアイドルのうち、あなたの担当アイドルは誰ですか?(複数選択可能)
- 3.で選択したアイドルのうち、一人だけ担当を選ぶとしたら、誰ですか?
- 4.で選択した担当アイドルについてお聞きします。その担当アイドルを担当するにいたった、一番のきっかけはなんでしたか?
大事なのは 3,4 ですね。
「担当」という言葉の定義は人それぞれなので、「1人しか担当しません」という方もいれば「たくさん担当います」という方もいらっしゃいます。
なので、特に制約は定めず複数選択可能にし、その中でも1人選ぶならだれか、という質問形式にしました。また、以下で3.で選択した担当アイドルと4.で選択した担当アイドルを区別するため、3.で選択された担当アイドルを「複数担当」、4.で選択された担当アイドルを「単一担当」と呼ぶことにします。
きっかけについても、同じきっかけでキャラを好きになったのならば類似性が生まれると思い追加しました。
きっかけに関する項目は以下の通りです。
- (キャラクターの)声
- (キャラクターの)容姿
- (キャラクターの)性格
- (声優さんの)ライブパフォーマンス
- (声優さんの)演技
- 好きな声優さんだった
- 持ち歌
- 二次創作
- よくわからない
- 覚えていない
- その他(自由記述)
対象は音ゲー版に出演済のアイドルのみ(シャニは原作、ストレイライトまで)
今回は、デレの韓国組、876プロのアイドル、およびシャニのノクチルは選択肢から外させていただきました。担当プロデューサーの方にはご不快な思いをさせてしまいます、申し訳ありません。理由は以下の通りです。
韓国組
『スターライトステージ』に未出演のため、サンプルに偏りが出る可能性を含む。876プロ
3人のうち1人が担当だとわかったとして、そこから最低46人(SideM の315プロメンバー)のうちの1人を予測することは不可能に近いと考えたため。ノクチル
アンケートを集計開始したのが2019年9月のため、対象とすることができなかった。
(初出から1年未満のストレイライトやデレ新規7人はサンプルに偏り出るんじゃないか、という話はややグレーな気がしますが...)本家のアイドルはミリオンのメンバーとしてカウント
本家やミリオンについてあまり詳しくないのですが、本家の765メンバーとミリでのASメンバーとではおそらく異なるものだと判断しました。
本家での「如月千早」と、ミリでの「如月千早」ではおそらく性質が異なるのではないかと。
結果、本家から担当してきたPとミリオンから入って担当し始めたPとで、同じ千早の担当なのに性質が異なることが考えられました。
ならば一つにまとめてしまったほうが賢明かと判断し、上記のように扱いました。データ
本当に傾向はあるのか調べてみた
上でレコメンドできそうとか語っていますが、本当にできるのでしょうか。
そもそも本当に他シリーズの担当に傾向がなければ難しいです。
という訳で、データを確認してみます。まずはシリーズ単体。
人数の少ないシャニで、きっかけの分布の違いなどを見ていきます。
ちなみに、アンケート7,000件超のうち、シャニに担当がいると答えた方が66%, 約4,900人でした。
十分な数字が取れていると思います。
次にシリーズごとの組み合わせ。
こちらは人数の少ないシャニと、私が一番最初に触れたデレの組み合わせで、票数の分布を確認します。
シャニ単体での傾向:実際ありそう
単一担当Pの数
4.で選択されたアイドルの数が以下の通りです。
誰が何票なのかについてはセンシティブなので、特記事項が無ければ明記いたしません。
一番表を集めたのが三峰でした。その数450程度。2位と100票ほど切り離しての1位ですね。
複数担当Pの数
3.で選択されたアイドルの数が以下の通りです。
単一担当同様、上位3人についてのみ明記します。
一番人気だったのが三峰、次いで甜花、凛世でした。票数にして800程度。
こちらは単一担当ほどぶっちぎってはいませんでした。
正直、票数を確認するだけでも結構面白いですね。担当になったきっかけ
こちらは、きっかけごとの各アイドルの票数分布を表示しております。
縦軸は、各アイドルが集めた単一担当の票のうち、何%がそのきっかけで担当になったか、を表しています。
かなり分布に違いがあることが見てとれるかと思います。
中でも、以下が特徴的に感じられました。
- 真乃の「声」がきっかけで担当になるPがぶっちぎりで多い
- 「性格」で担当になったPが多いのは夏葉と冬優子
- 果穂は「演技」「ライブパフォーマンス」で惹かれた人が他に比べ多い
- 「ライブパフォーマンス」についてはあさひも同様
- 愛依に「好きな声優」で惹かれた人が他に比べぶっちぎり(北原紗弥香さん、元ハロプロメンバー)
ユニットごとの担当
どのユニットの担当ですか、という質問は集計しませんでしたが、せっかくなので疑似的に算出したいと思います。
ユニットメンバーの過半数を複数担当に選んだP(イルミネ、ストレイ、アルストロメリアは2人以上、放クラ、アンティーカは3人以上を複数担当として選んだP)をユニットへの1票として、票数を集計した結果が以下になります。
横軸のアルファベットは各ユニットの頭文字からとっています。アルストロメリア(A)がぶっちぎりで高いですね。算出方法的に双子の両方に投票すればユニットへの投票になるので、双子への投票が多いんですかね。と思って、また調べてみました。
票の各要素がユニットへの票数です。「全体」行の値が上記のグラフの元になってます。
注目していただきたいのが「A」列(アルストロメリアへの票)です。「千雪含む」が桑山千雪を含めてアルストロメリアのメンバーの2人以上を複数担当にしたPの数、「千雪含む(双子含まない)」が千雪と双子の片方を複数担当として選んだ結果、アルストロメリアへの票になったPの数、「千雪含まない(双子のみ)」が、双子のみを複数担当として選んだ結果、アルストロメリアへの票になったPの数を表しています。アルストロメリアへの387票のうち、249票が千雪を含めたアルストロメリアへの票、138票が双子両方への票なので、双子「だけ」への投票が多い結果アルストロメリアへの票が多くなった、というわけではなさそうですね。
以上から、きっかけだけでもある程度傾向が出ているんじゃないかと思われます。
シャニとデレの組み合わせ:こちらも傾向はありそう。
次に組み合わせ。デレとシャニで、単一担当の票数、きっかけの票数の分布を比較します。
とは言え、シャニの19人ならまだしも、デレは190人以上いますので、1:1の傾向なんて見ようとしていたら日が暮れてしまいます。
なので、関係性をみるアイドルを以下の3人に厳選しました。
- 速水奏
- 大槻唯
- 小日向美穂
丁度3属性そろい、かつ傾向が異なるアイドルかなと思います。
あと知り合いの担当だったので若干ひいきしました。
複数担当同士の傾向
デレの3人を縦軸、シャニの19人を横軸にとり、両方を複数担当に選んだPの数が上記のヒートマップで表されています。
色が黒から白へ明るくなっているほど、票数が多いといえます。
名前が隠れてしまって見えづらいですが、以下の傾向が読み取れます。
- 奏と一緒に担当されている傾向にあるシャニアイドル :凛世、夏葉
- 唯と一緒に担当されている傾向にあるシャニアイドル :甘奈、甜花、三峰
- 美穂と一緒に担当されている傾向にあるシャニアイドル:甘奈、甜花
こっひと唯では双子が被りましたが、奏と唯で比較すると違いがあることが見て取れるかと思います。
きっかけと複数担当の関係
デレの3人と主要な3つのきっかけを縦軸、シャニの19人を横軸にとり、両方を複数担当に選んだPの数が上記のヒートマップで表されています。
読み取れるのは以下の通りです。
- 奏の容姿をきっかけに担当したPが担当傾向にあるシャニアイドル :咲耶、凛世
- 唯の性格をきっかけに担当したPが担当傾向にあるシャニアイドル :甘奈
- 美穂の容姿をきっかけに担当したPが担当傾向にあるシャニアイドル:甜花
- 美穂の性格をきっかけに担当したPが担当傾向にあるシャニアイドル:真乃、恋鐘
以上から、傾向が異なると言っていいのではないでしょうか。
手法
データを眺めるだけでも面白いので長くなってしまいましたが、「担当アイドルに傾向はある」ということがわかりましたので、ようやく本題に入ります。
どのようにレコメンドを実装するかについてです。
用いたのはベーシックな協調フィルタリング
今回用いたのは以下の2つの協調フィルタリング(以下 CFと略します)です。
- ユーザーベースCF
- アイテムベースCF
以下、各手法の簡単な説明を入れておきます。ご存知の方は実験結果まで飛んで大丈夫です。
ユーザーベースCF
ユーザーベースCFは簡単に言うと、「同じアイドルを好きなPならば似ているだろう」という考えによるレコメンドです。
上記の例で言えば、「蘭子を担当しているA,Bは似ているから、Aが担当しているアスランをBも担当するのではないか」ということで、Bにアスランをレコメンドします。
学習とテストの計算方法については上記の画像の通りです。テストを行う際は、テストの対象となるシリーズ以外のデータを取ってきて学習データとの類似度を計算し、類似度から得られたテスト対象シリーズの推定値を実際の値と比較します。
アイテムベースCF
アイテムベースCFは簡単に言うと、「同じPから好かれているアイドルならば似ているだろう」という考えによるレコメンドです。
上記の例で言えば、「蘭子とアスランは同じAに担当されているので、蘭子とアスランは似ているはず。Bは蘭子を担当しているから、Bは蘭子と似ているアスランも担当するのではないか」ということで、Bにアスランをレコメンドします。
学習とテストの計算方法については上記の画像の通りです。ユーザーベースと大きく異なるのは、学習データから既に類似度が算出されているので、新しくテストを行う際に類似度を計算する必要がなく、計算時間が少なく済む点です。
実験結果
ではお待ちかね、実験結果について...の前に、評価の方法について言及いたします。
順位3位以内にレコメンドされていれば正解とする
レコメンドの結果は「お勧め度合い」といった数値で返されるので、その数値が上位3位以内に担当アイドルが存在すれば正解としました。
上記の例では、デレでの担当が未央、SideMでの担当が翼、シャニでの担当がめぐるのPに対して、「デレでは未央、SideMでは翼が担当だよ」という情報をレコメンドシステムに与えてシャニのアイドルをレコメンドしてもらった結果、上位3位までのレコメンドにめぐるが入っていれば正解、そうでなければ不正解、ということになります。自分の担当データでやると、上位3人には入らないが、上位5人には入る
では、一番卑近な例として自分のデータでテストしてみます。
上記の画像に自分の担当データをまとめました。
ここで注意していただきたいのは、私のデータでシャニの担当をレコメンドしてもらう場合、デレの担当情報のみから予測するということです。「千雪が担当」という答えを知っていたらわざわざレコメンドしてもらう必要がないためです。同様に、デレの担当をレコメンドしてもらう場合、シャニの担当情報のみから予測します。千雪を性格きっかけで担当している、という情報だけで190人超の中から担当を予測するので難しそうであることがわかるかと思います。以下、結果です。
当たりませんでしたね...。
興味深いのは、「シャニでの担当が千雪のみで、性格きっかけ」の場合はユーザーベースでもアイテムベースでも三船さんが一番担当すると思うよ、とレコメンドすることですね。
個人的には納得感がありました。
一応、5位までを確認した結果だと、当たっていることがわかりました。
自分の担当がいないシリーズでやると、1位にレコメンドされる
では、担当はいないけれど他のシリーズでテストしてみたらどうだろうか、ということで、ミリ、SideMでも計算してみました。
上記の通り、担当がいない他シリーズで気になっているアイドルを暫定の正解として設定しました。
先ほどとは異なり、入力としてデレとシャニの担当情報を入れることができています。
結果は以下の通りです。
ユーザー、アイテム両方で1位に正解が来ました。
「気になる」程度なのであまり正確な結果ではありませんが、入力情報が多いと精度もあがりますね。テストデータによる精度は概要通り
では、実際のデータを用いて精度を評価してみます。
上記のようにアンケートデータを分割し、30%のテストデータで正解率を判定しました。
その結果が以下の通りです。
概要に載せた結果はユーザーベースのものです。
母数が大きくなるほど正解率が下がっているのは当然としても、デレで40%満たないかぁ...というのが第一印象でした。考察
うまくいかなかったのは、人気に引っ張られる、手法が単純、データが足りないから?
以上の結果を踏まえて、もっと精度を上げるにはどうしたらいいか(特にデレ)を考えてみます。
原因は大きく3つあると思います。
- 人気に引っ張られてしまう
- 手法が単純
- データが足りない
以下、それぞれ解説していきます。
人気に引っ張られる
データを確認した際にも見ましたが、シャニでさえ担当数に差があるんですよね。本ブログでは説明しなかったんですが、デレでの担当数は顕著で、複数担当で一番多い投票数が496人だったのに対して、一番少ない投票数が3人でした(ちなみに一番多く複数担当に投票されたのは志希でした)。
担当数に差があると何が問題かというと、投票数の多かったアイドルをレコメンドしておけば大体当たるだろうとシステムが考えてしまうんですよね。結果、レコメンドから多様性が失われてしまいます。
デレの担当は多様性に富んでいるので、デレでのレコメンドの正解率が低いのも、その多様性を考慮できなかったことが原因の一つかと考えられます。手法が単純
今回はベーシックな協調フィルタリングのみ実装したので、正直単純すぎると思います。
ただ、この件に関しては弁明がありまして。lightfm という、python のレコメンドシステム用のパッケージがあります。
https://making.lyst.com/lightfm/docs/home.html
こちら、一応使ってみたのですが、今回紹介した計算結果ほどの精度を出せませんでした。おそらく lightfm が扱うデータの意味合いが問題で、「担当でない」0を考慮すると、0に意味があると判断して、「同じレートつけてるから似てるやろ!」となってしまうようです。結果、大体みな同じ類似度になり、レコメンドも皆同じアイドルになってしまいます。
かといって0のデータを入れなければ、正しい類似度を測れなくなります。(0のデータを入れないと担当でないアイドルは「未観測のデータ」と扱われてしまうため、1人だけ担当のPと複数人担当がいてそのうちの1人がかぶったPが類似度1になる)担当でない情報も加味しつつ、担当である情報をもとに推薦したかったので、それが可能だったのが協調フィルタリングでした。
ただ、それでも単純すぎるとは思います。データが足りない
知り合いのPに計算結果を伝えたところ、「楽曲の好みも学習に含めたらいいんじゃない?」とアドバイスをいただきました。
確かにデータをいくらでも取れればそれも可能なのですが、「アンケート」という体裁でデータを集めるには、なるべく「答えやすく数分で終わる」ようにしなければならない、と思っていました。正確なデータが取れても、答えるのが面倒くさくなればデータ数が集まらなくなります。精度評価の観点で見ればデータ数が減ることは避けたかったので、今回は担当についてだけアンケートを取りました。ただ、知り合いが言っていることももっともで、さらにデータがあれば精度を上げられると思います。公式でもなんでもない一介のPが収集できる情報としては、以下が挙げられるでしょうか。
- アイドルの画像
- アイドルのテキスト
これは...データ集めがとんでもなく
面倒くさい大変だ...。
アイマスのテキストを集めるのに適したサイトやwebクローラーはないものでしょうか。まとめ
アンケートにご協力いただいた皆様、本当にありがとうございました
レコメンドシステムに関する
研究結果は以上となります。
冗長な文章にお付き合いいただきありがとうございました。
そして、アンケートにご協力くださった全Pの皆さまに、改めて格別の感謝を。本当にありがとうございました。せっかく集計したデータですので、より精度を上げられたらまた報告させてください。
ご意見・ご感想あれば、本記事か以下のtwitterアカウントまでお願いします。



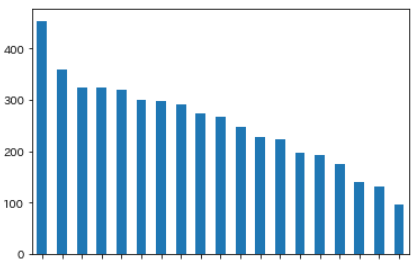

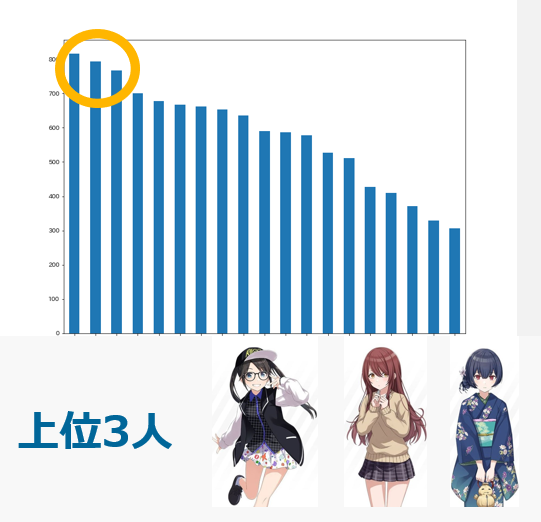
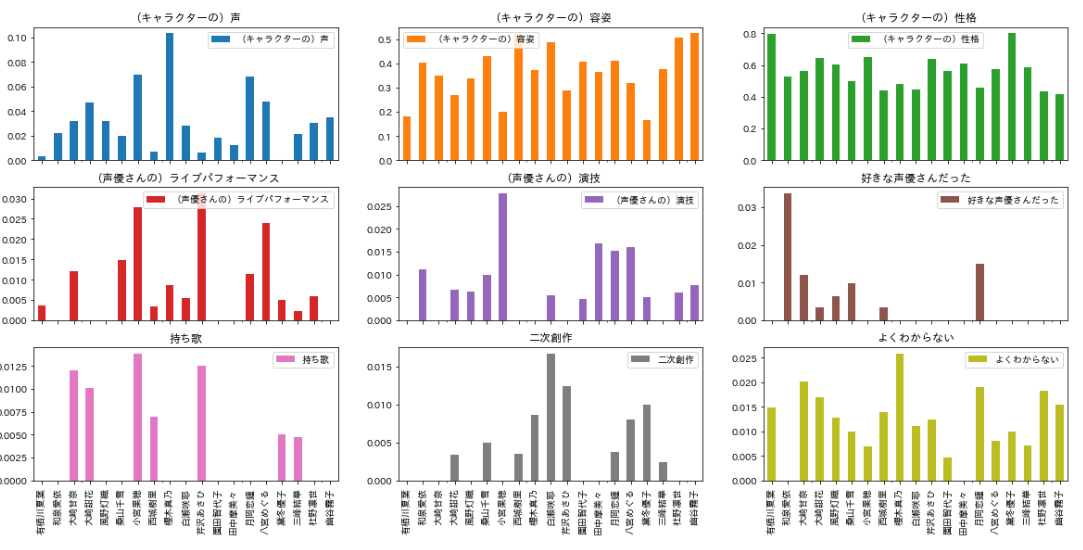
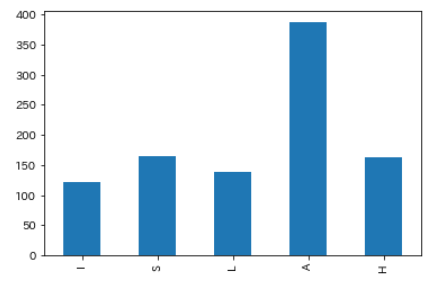
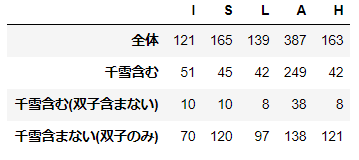

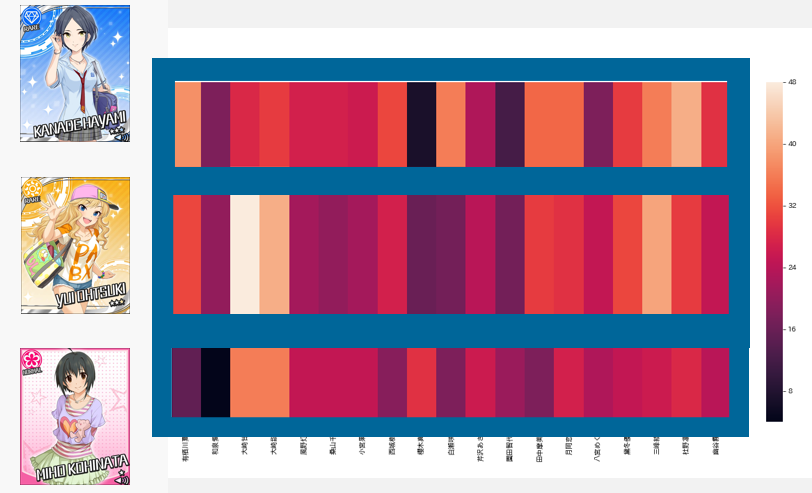
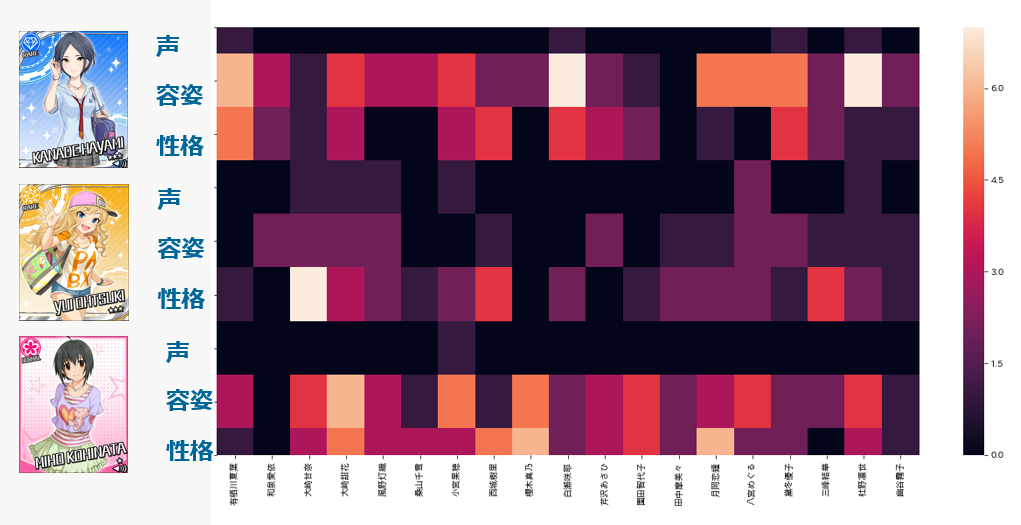
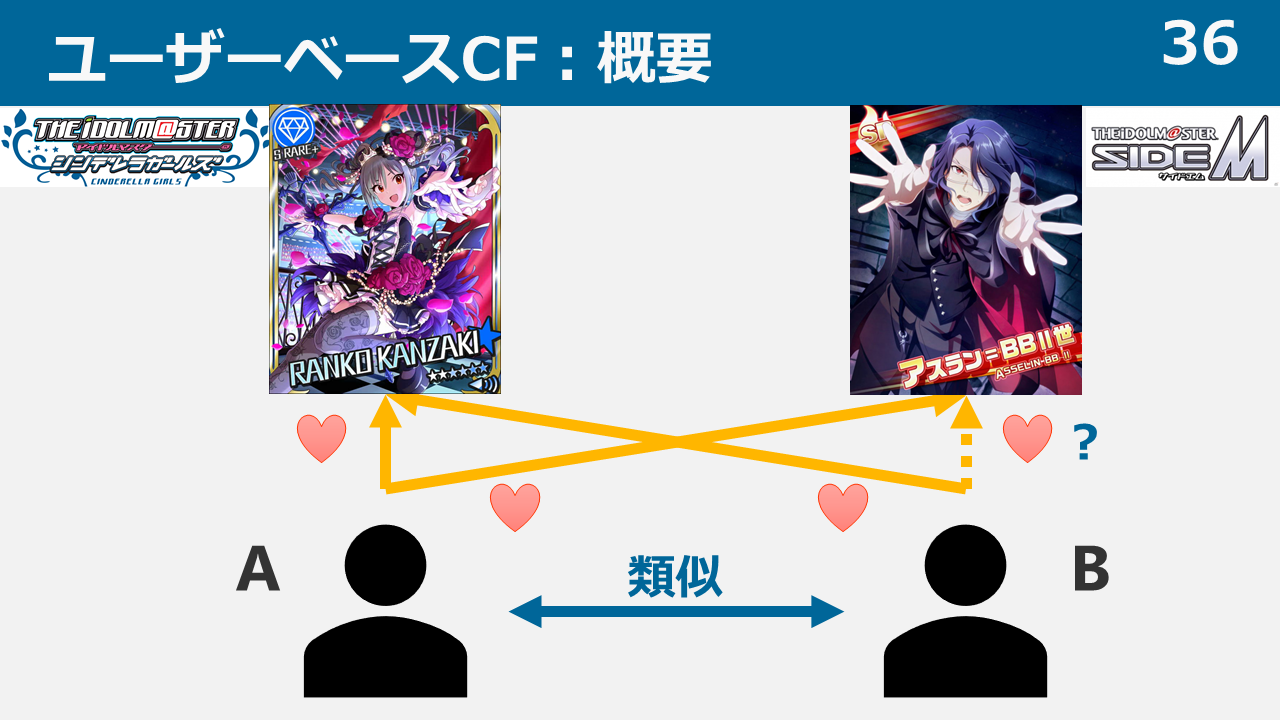
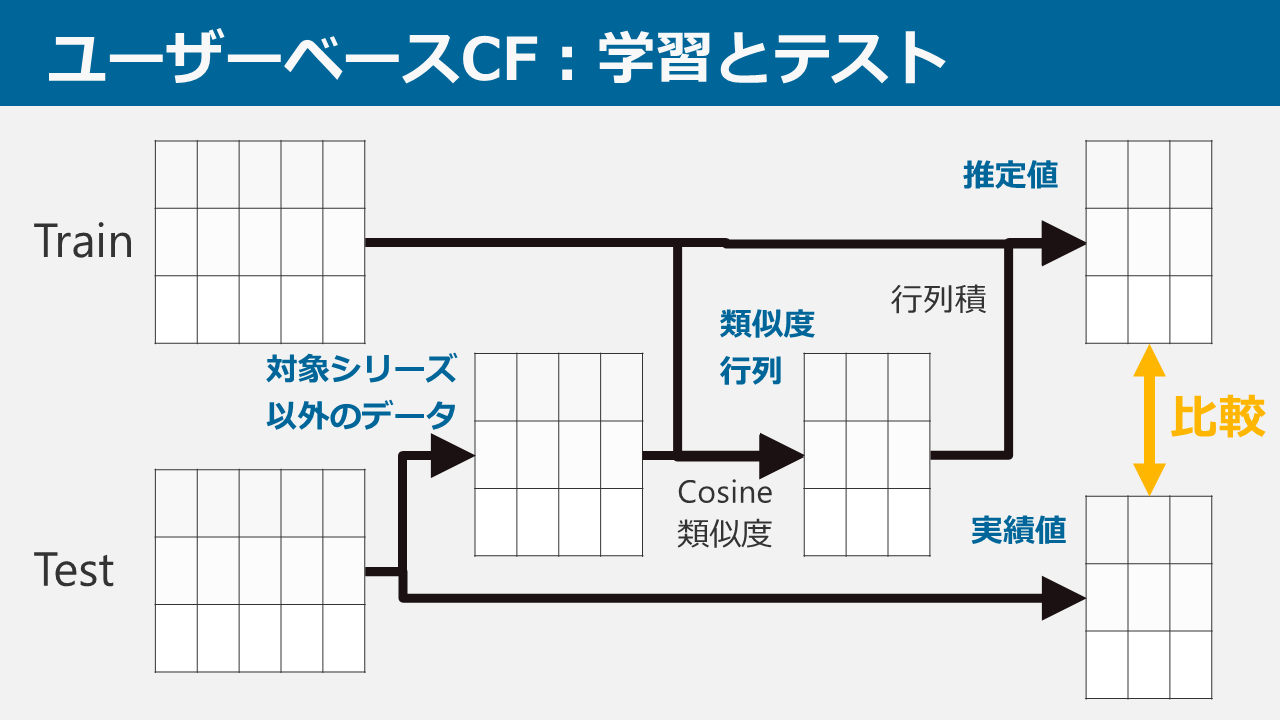
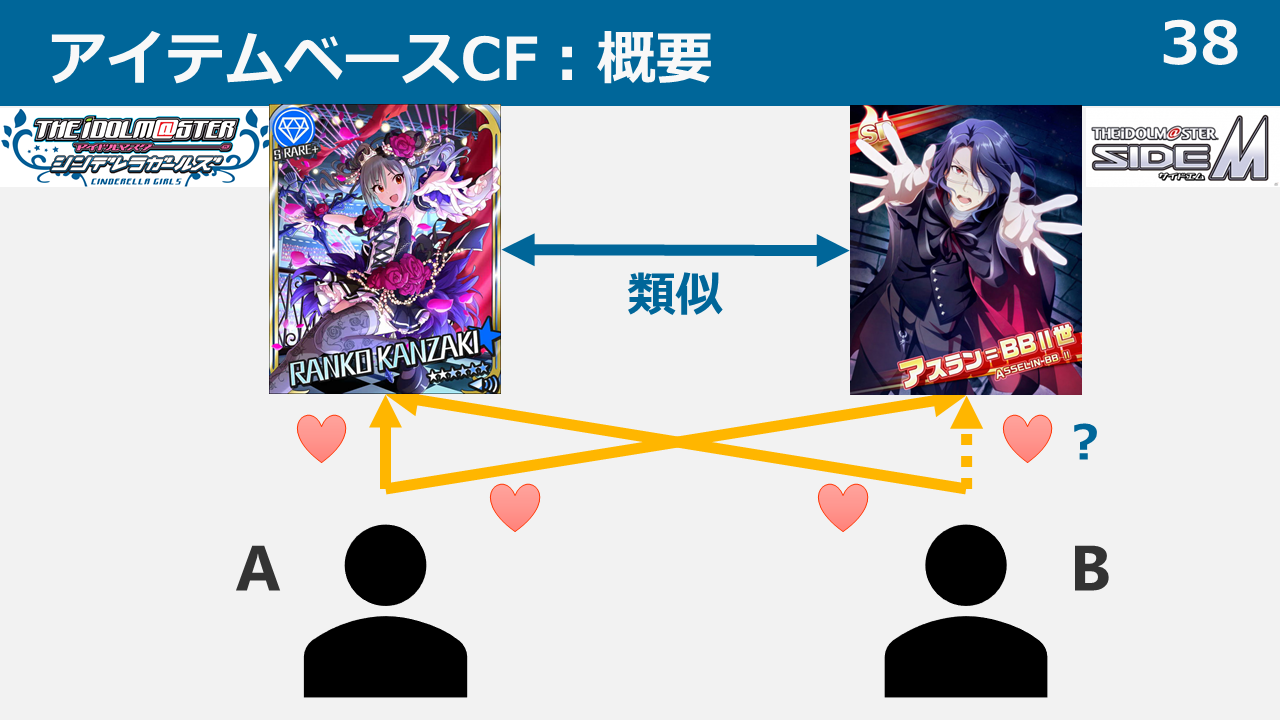
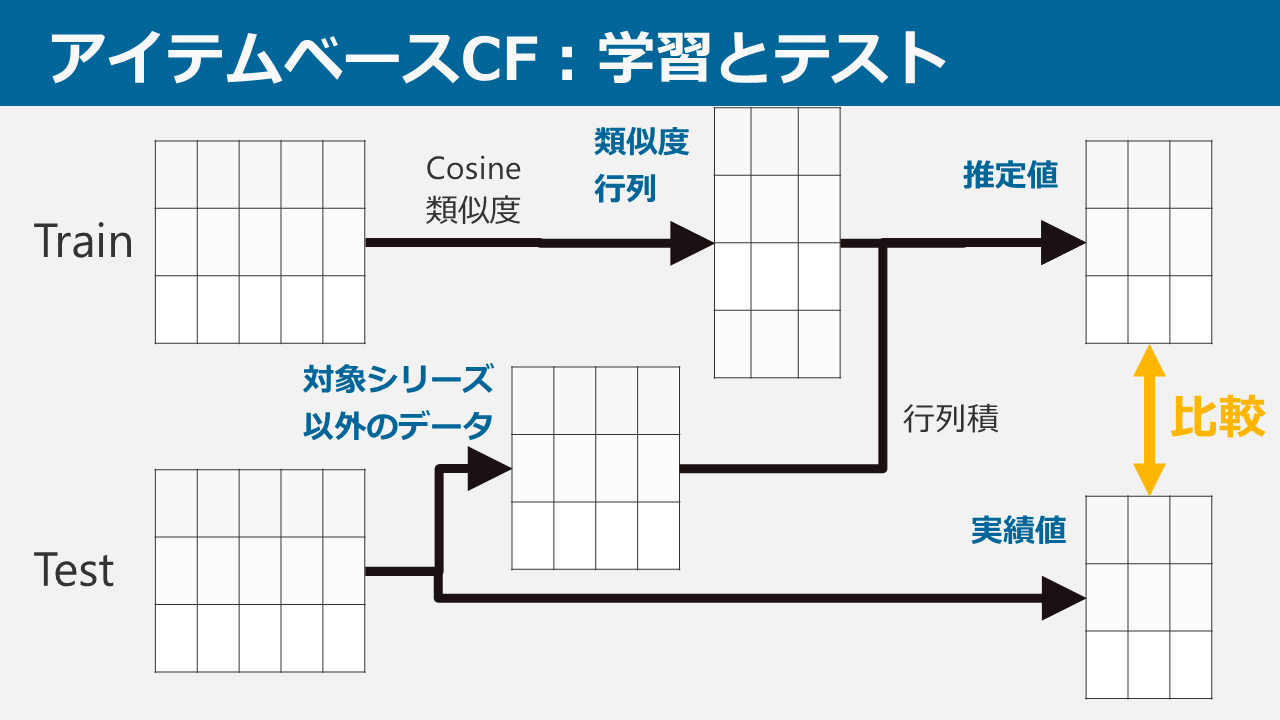


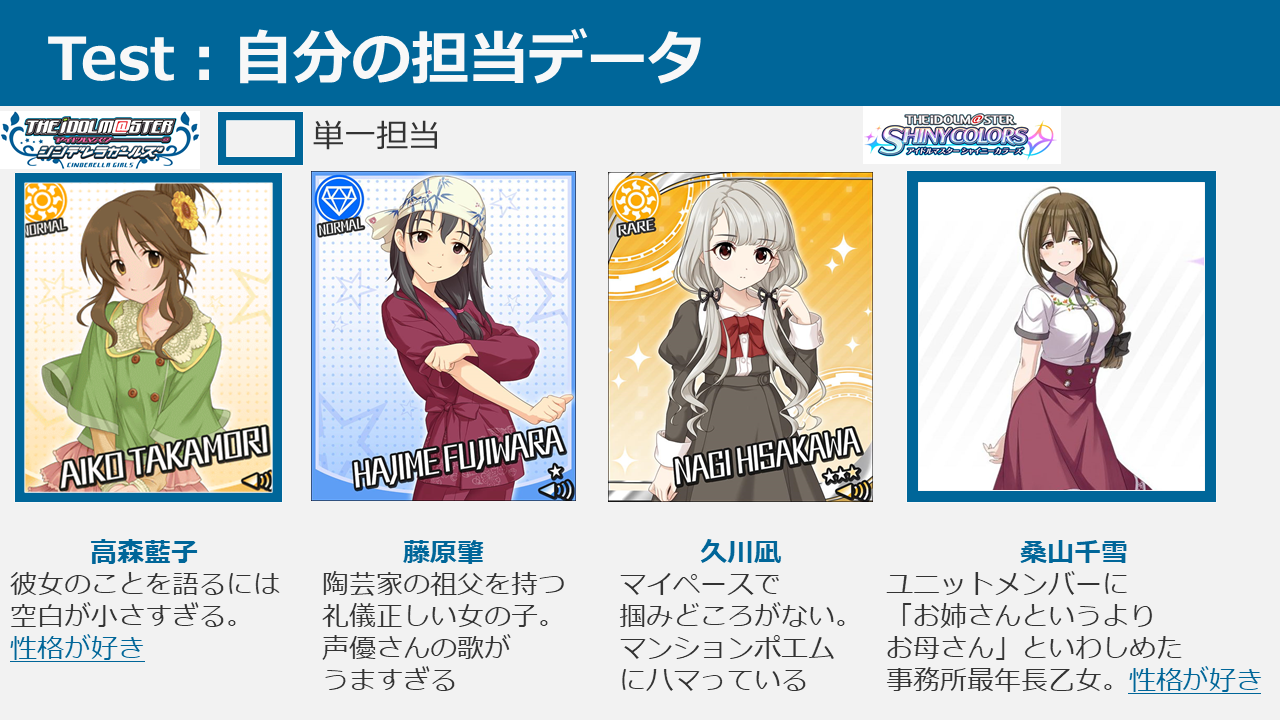



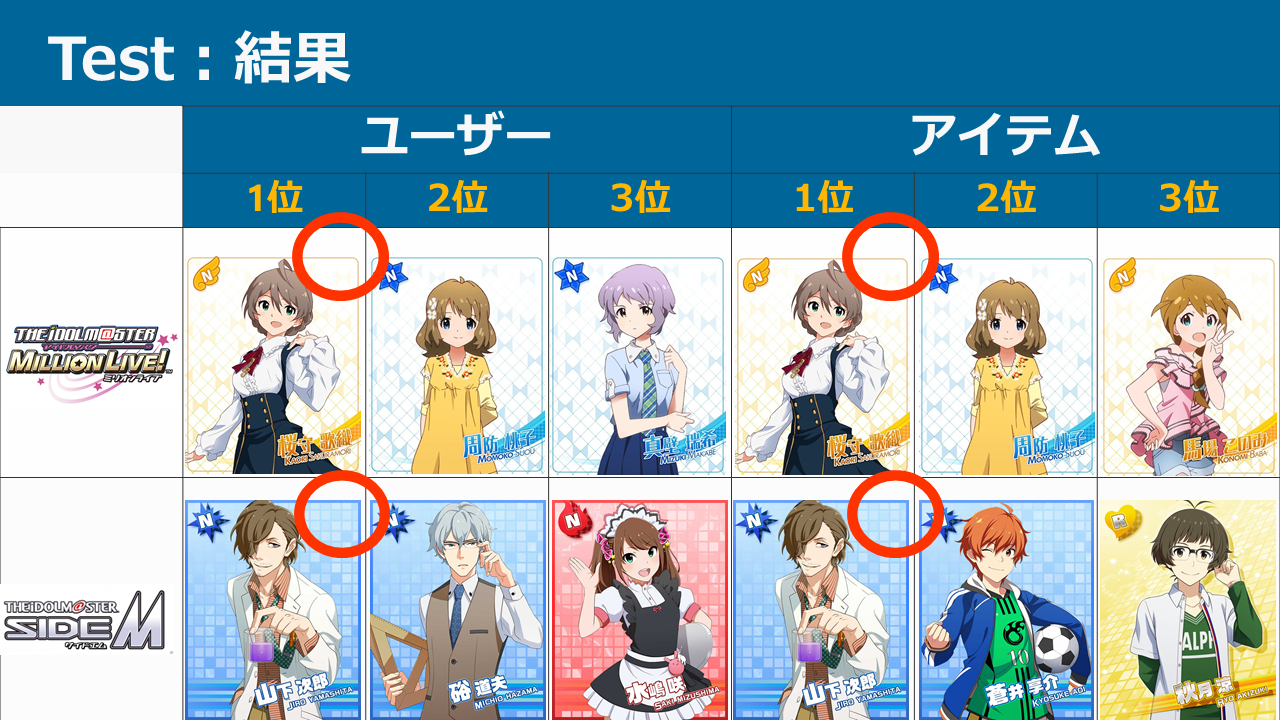
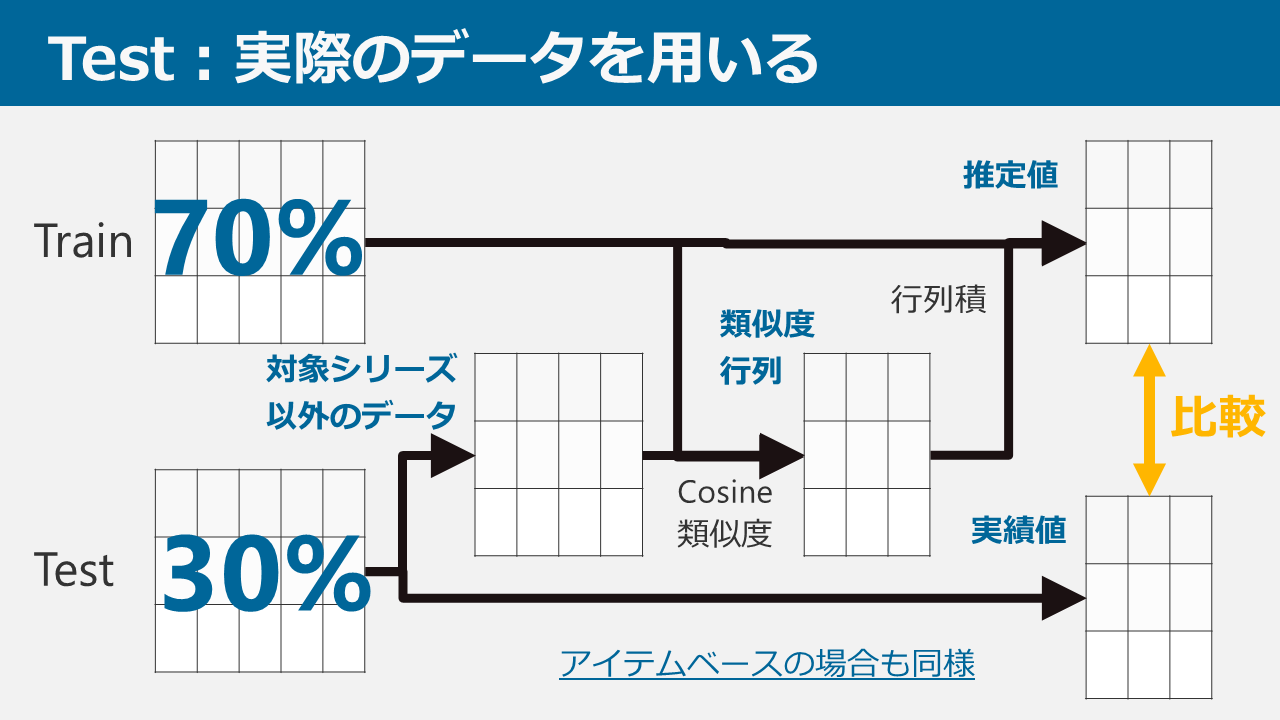
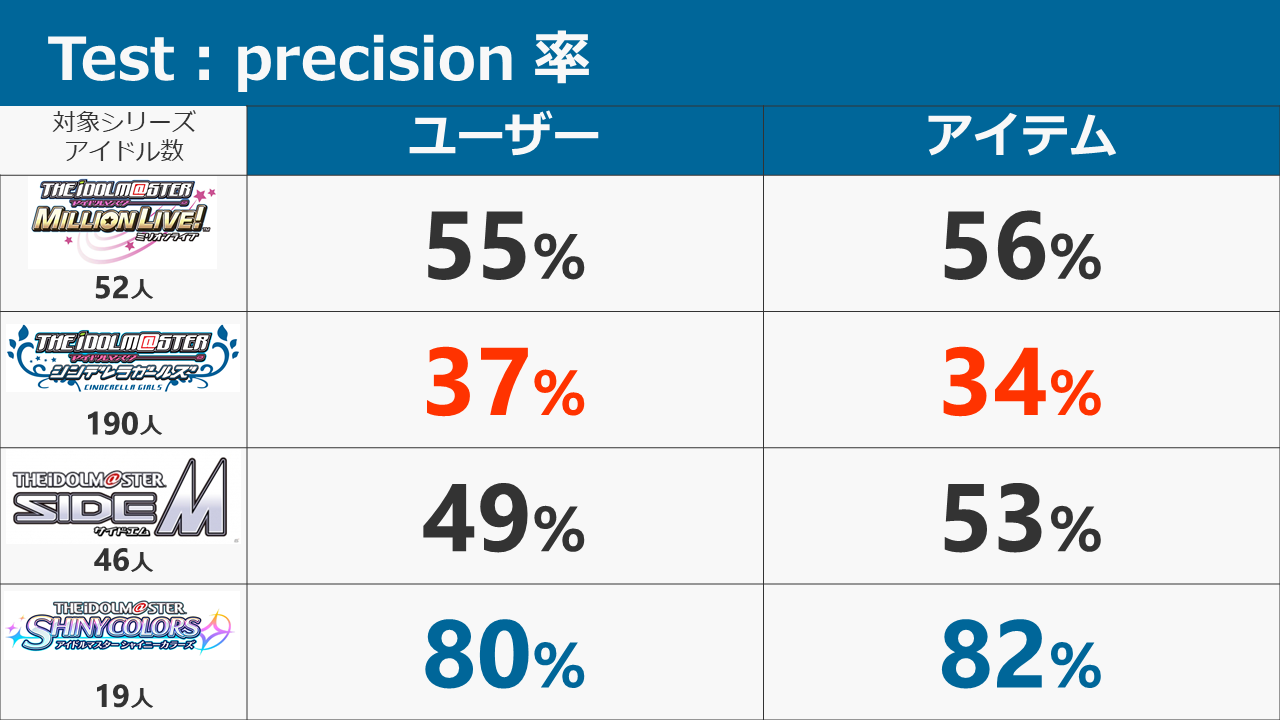
- 投稿日:2020-05-16T19:20:58+09:00
pipするとインストール済みなのに、importできない場合
pipするとインストール済みなのに、importできない場合です。
単純な話ですが、例えば、>>> import django Traceback (most recent call last): File "<stdin>", line 1, in <module> ModuleNotFoundError: No module named 'django'djangoをimportしようとするとエラーになります。
エラーの内容はそのままですが、モジュールが見つかってません。そもそもdjangoがないのかなと思って、pipしてみると、
C:\Users\aaa>pip install django Requirement already satisfied: django in c:\users\aaa\anaconda3\lib\site-packages (3.0) Requirement already satisfied: sqlparse>=0.2.2 in c:\users\aaa\anaconda3\lib\site-packages (from django) (0.3.0) Requirement already satisfied: asgiref~=3.2 in c:\users\aaa\anaconda3\lib\site-packages (from django) (3.2.3) Requirement already satisfied: pytz in c:\users\aaa\anaconda3\lib\site-packages (from django) (2019.3)already satisfiedなので、「既にあるよ」と言われています。
ということは、単純にパスが通ってないということです。パスはsys.pathで確認できます
>>> import sys >>> import path >>> pprint.pprint(sys.path) ['', 'C:\\Users\\aaa\\Anaconda3\\python37.zip', 'C:\\Users\\aaa\\Anaconda3\\DLLs', 'C:\\Users\\aaa\\Anaconda3\\lib', 'C:\\Users\\aaa\\Anaconda3', 'C:\\Users\\aaa\\Anaconda3\\lib\\site-packages', 'C:\\Users\\aaa\\Anaconda3\\lib\\site-packages\\win32', 'C:\\Users\\aaa\\Anaconda3\\lib\\site-packages\\win32\\lib', 'C:\\Users\\aaa\\Anaconda3\\lib\\site-packages\\Pythonwin',確かに、djangoのパス「django in c:\users\aaa\anaconda3\lib\site-packages (3.0)」がありません。
ここまでわかれば、あとは環境変数にパスを追加してあげるだけです。
sys.path.appendで環境変数に追加できるので、sys.path.append("c:/users/aaa/anaconda3/lib/site-packages (3.0)")突っ込めたら再度確認で
>>> pprint.pprint(sys.path) 'c:/users/daiki/anaconda3/lib/site-packages (3.0)'が追加されていればOKです。
>>> import django >>> print(django.get_version()) 3.0djangoが使えるようになったことが確認できました。
誤りパターン
ちなみに、コピペして環境変数に突っ込もうとすると、こんなエラーがでます。
>>> sys.path.append("c:\users\aaa\anaconda3\lib\site-packages (3.0)") File "<stdin>", line 1 SyntaxError: (unicode error) 'unicodeescape' codec can't decode bytes in position 2-3: truncated \uXXXX escape >>> sys.path.append("c:/users/aaa/anaconda3/lib/site-packages (3.0)")これは\マークがエスケープなので、\uでエスケープシーケンスと認識されているからです。
sys.path.append("c:\users\aaa\anaconda3\lib\site-packages (3.0)")を
sys.path.append("c:/users/aaa/anaconda3/lib/site-packages (3.0)")にすればOKです。
- 投稿日:2020-05-16T19:16:34+09:00
seleniumで自動取得してみた際の備忘録
説明
あるサイトの情報を自動で取得するためのアプリケーションを作成してみました。
https://github.com/jajaja12345-code
その際に調べたことの備忘録として書きます。備忘録
複数のclass名がある
クラス名とクラス名の間にスペースがある時、
<p class = "servings_for yield">
のような物の時、
find_element_by_css_selector("servings_for yield")
ではエラーが出てしまう。
そのため次のように記述する
find_element_by_css_selector(".servings_for.yield")参照
seleniumでby_class_nameでスペースが入った要素が取得できずエラーになる時の対処法複数の要素を取得
find_elementsで行う。
elementではなくて、elements参照
seleniumでWebElement object is not iterableが出るときの対処方法NoSuchElementExceptionのキャッチ
try文で存在するかを確かめ、exceptでNoSuchElementExceptionをキャッチする
(exceptは複数記述可能)参照
Python、Seleniumの基本
Pythonの例外処理(try, except, else, finally)何もしない処理の定義
pass文を使う
要素を見つけるまでの待ち時間を一括設定する
driver.implicitly_wait(10)
driverの各要素を見つけるために10秒まつ。参照
【Python】implicitly_wait・・・指定したドライバの要素が見つかるまでの待ち時間を設定する感想
スマホからも入力できるようにしたいなぁ。
- 投稿日:2020-05-16T19:11:34+09:00
Ruby と Python と Java で解く AtCoder ABC141 D 優先度付きキュー
はじめに
AtCoder Problems の Recommendation を利用して、過去の問題を解いています。
AtCoder さん、AtCoder Problems さん、ありがとうございます。今回のお題
AtCoder Beginner Contest D - Powerful Discount Tickets
Difficulty: 826今回のテーマ、優先度付きキュー
Ruby
操作自体はシンプルで、一番値段の高い品物をキューから取り出し、割引券を一枚適用してキューに戻します。その都度、一番値段の高い品物ついて同様の操作を割引券がなくなるまで行います。
但し、次の様に単にソートするだけの実装では、TLEになります。ruby_tle.rbn, m = gets.split.map(&:to_i) a = gets.split.map(&:to_i) a.sort_by!{|x| -x} m.times do b = a.shift b /= 2 a << b a.sort_by!{|x| -x} end puts a.inject(:+)優先度付きキューは、ソートに比べて少ない計算量で一番値段の高い品物を調べることができます。
Python ですとheapq、Java ですとPriorityQueueになりますが、Ruby には無いので、Ruby で Priority Queue を実装してみたい のコードをお借りして、少々修正して通しました。ruby.rbclass PriorityQueue def initialize(array = []) @data = [] array.each{|a| push(a)} end def push(element) @data.push(element) bottom_up end def pop if size == 0 return nil elsif size == 1 return @data.pop else min = @data[0] @data[0] = @data.pop top_down return min end end def size @data.size end private def swap(i, j) @data[i], @data[j] = @data[j], @data[i] end def parent_idx(target_idx) (target_idx - (target_idx.even? ? 2 : 1)) / 2 end def bottom_up target_idx = size - 1 return if target_idx == 0 parent_idx = parent_idx(target_idx) while (@data[parent_idx] > @data[target_idx]) swap(parent_idx, target_idx) target_idx = parent_idx break if target_idx == 0 parent_idx = parent_idx(target_idx) end end def top_down target_idx = 0 while (has_child?(target_idx)) a = left_child_idx(target_idx) b = right_child_idx(target_idx) if @data[b].nil? c = a else c = @data[a] <= @data[b] ? a : b end if @data[target_idx] > @data[c] swap(target_idx, c) target_idx = c else return end end end # @param Integer # @return Integer def left_child_idx(idx) (idx * 2) + 1 end # @param Integer # @return Integer def right_child_idx(idx) (idx * 2) + 2 end # @param Integer # @return Boolent def has_child?(idx) ((idx * 2) + 1) < @data.size end end n, m = gets.split.map(&:to_i) a = gets.split.map(&:to_i) e = a.map{|x| -x} b = PriorityQueue.new(e) m.times do c = b.pop b.push(-(-c / 2)) end ans = 0 while b.size > 0 ans -= b.pop end puts ansこれでもギリギリです。
Python
python.pyimport heapq import math n, m = map(int, input().split()) a = [-1 * int(i) for i in input().split()] heapq.heapify(a) for _ in range(m): b = heapq.heappop(a) heapq.heappush(a, math.ceil(b / 2)) print(-1 * sum(a))Pythonの
heapqは最小値を取るものですので、マイナスの符号を付けて入れる必要があります。
また、//によるマイナスの割り算は絶対値の大きい方の値を返すので、ここではceilを使用しています。Java
java.javaimport java.util.*; class Main { public static void main(String[] args) { Scanner sc = new Scanner(System.in); int N = Integer.parseInt(sc.next()); int M = Integer.parseInt(sc.next()); PriorityQueue<Long> A = new PriorityQueue<>(Collections.reverseOrder()); for (int i=0; i<N; i++) { A.add(Long.parseLong(sc.next())); } sc.close(); for (int i=0; i<M; i++) { long new_price = (long)A.poll()/2; A.add(new_price); } long sum = 0; for (long a : A) { sum += a; } System.out.println(sum); } }PriorityQueue<Long> A = new PriorityQueue<>(Collections.reverseOrder());Java は
reverseOrder()で最大値に対応しています。
Ruby Python Java コード長 (Byte) 1933 230 673 実行時間 (ms) 1981 163 476 メモリ (KB) 14004 14536 50024 まとめ
- ABC 141 D を解いた
- Ruby に詳しくなった
- Python に詳しくなった
- Java に詳しくなった
参照したサイト
Ruby で Priority Queue を実装してみたい
[ruby] Priority Queueの実装
- 投稿日:2020-05-16T18:25:52+09:00
金融予測ラベリング応用編: コールオプション戦略
イントロダクション
どうも、KOです。最近のマイブームがボラティリティで、ボラティリティが一番活用できる金融商品って先物オプションだと思うんですよね。
なので、今回はコールオプションによるラベル付けを行いたいと思います。ついでに、ブラックショールズモデルからヒストリカルのオプションの価格の乖離も見ていきたいと思います。コールオプションのペイオフ
ここでのコールオプションはヨーロピアンオプションとします。
現在時刻と$t=0$,満期を$t=T$とします。コールオプションの価値を$C(S_t, t)$とします。コールオプションの満期における価値は定義より以下の通りです。
$$C(S_T, T) = (S_T-K, 0)^{+}$$
ただし、$S_t$は時刻$t$の株価、$K$は権利行使価格とします。
時刻$t$におけるブラックショールズモデルによるコールオプションの価値は
$$C(S_t, t) = S_t N(d_1) - K e^{-r(T-t)}N(d_2)$$
ただし、
$$\displaystyle N(x) = \frac{1}{\sqrt{2\pi}}\int_{-\infty}^{x}e^{\frac{-y^2}{2}}dy$$
$$d_1 = \frac{\log{\frac{S_t}{K}}+(r+\frac{\sigma^2}{2})(T-t)}{\sigma \sqrt{T-t}}$$
$$d_1 = \frac{\log{\frac{S_t}{K}}+(r-\frac{\sigma^2}{2})(T-t)}{\sigma \sqrt{T-t}}$$データセット
今回は皆さんもお馴染みの日経平均株価の終値を使用したいと思います。1949年から2020年のデータを用います。現在との価格差があまりにも大きすぎるので、絶対差分ではなく$S_t$との変化率を見ます。
close DATE 1949-05-16 176.210007 1949-05-17 174.800003 1949-05-18 172.529999 1949-05-19 171.339996 1949-05-20 169.199997 1949-05-23 171.850006 1949-05-24 172.750000 1949-05-25 171.529999 1949-05-26 170.429993 1949-05-27 172.759995 ATMのコールオプションのラベリング
ATMはAt the moneyで現在価格と同じと意味します。銀行のATMとは特に関係はありません。そのほかの用語に、ITM(In the money)、OTM(Out of the money)もあります。
T = 20 #残存期間 labels["price diff"] = labels["close"].shift(-T)/labels["close"]-1 labels["ATM"] = 0 labels["bin"] = labels[["price diff", "ATM"]].max(axis=1) labels = labels[["bin"]] labels分析
ATMのコールオプションが実際に権利を行使出来た確率が57.9%になります。戦後からずっと価格が上がり続けているので、こういった偏った結果になっているのでしょう。
また、歴史的には平均利益(0を含む)は2.5507%になっております。つまり、現在の日経平均株価が20000円だとするなら、20000円のコールオプションはヒストリカル平均は510円ってことになります。理論値
from scipy.stats import norm def get_BS_call(S0, sigma ,r,q,T,K): ''' S0 : 現在価格 sigma : ボラティリティ r : 金利 q : 配当 T : 残存期間 K : 権利行使価格 ''' d1 = (np.log(S0 / K) + (r - q ) * T) / (sigma * np.sqrt(T))+sigma*np.sqrt(T)/ 2 d2 = (np.log(S0 / K) + (r - q ) * T) / (sigma * np.sqrt(T))-sigma*np.sqrt(T)/ 2 return S0 * np.exp(-q * T)* norm.cdf(x=d1, loc=0, scale=1) -K * np.exp(-r * T) * norm.cdf(x=d2, loc=0, scale=1)では、理論価格出していきましょう。
sample_df = df.copy() sample_df["HV"] = np.log(sample_df["close"]).diff().rolling(T).std() sample_df["r"] = 0 sample_df["q"] = 0 sample_df["T"] = T sample_df["K"] = sample_df["close"] sample_df.dropna(inplace=True) sample_df.head()#コールオプションを計算する。 sample_df["BS_Call"] = BS_Call(sample_df["close"], sample_df["HV"], sample_df["r"], sample_df["q"], sample_df["T"], sample_df["K"]) sample_df.head()
close HV r q T K BS_Call DATE 1949-06-15 153.809998 0.014752 0 0 20 153.809998 4.047386 1949-06-16 157.800003 0.016427 0 0 20 157.800003 4.623628 1949-06-17 160.130005 0.016884 0 0 20 160.130005 4.822376 1949-06-20 155.449997 0.017848 0 0 20 155.449997 4.948716 1949-06-21 152.990005 0.017941 0 0 20 152.990005 4.895667 これによると、5月8日時点での残存期間20日の20179円のコールオプションは678円ですね。ただ、実際のマーケットは権利行使価格が125円刻みであったり、マーケット価格も離散的なので、実務で応用する場合にはもう少し工夫する必要はある。
ATMのコールオプションを買い続けていたら?
本来のマーケット価格はヒストリカルボラティリティを用いておらず、かなりズレます。しかし、マーケットデータを持っていないので、これを理論価格だとして計算してみます。
今回の計算は%なので、最初の資産が1だと仮定しても単利でも100倍以上になっていた計算になります。
仮にマーケットで理論価格よりも安く購入できるのであれば、もっと有利になります。逆に高く購入することになると不利になるので、ちゃんと価格と理論価格を見て投資判断したほうが良いでしょう。結論
オプションは男の浪漫です(笑)
- 投稿日:2020-05-16T18:20:47+09:00
pandasでグループごとに標準化する
はじめに
pandasで機械学習用のデータの処理を行っていたが、
全体で標準化するよりも何かの列のグループごとに標準化したくなった。
メモ程度です。実行環境
pandas = 0.25.3
numpy = 1.18.0pandasでグループごとに標準化するコード
以下のような表をclassの名前ごとに列を標準化する
class a b c a 1.0 2.0 3.0 a 4.0 5.0 6.0 b 7.0 8.0 9.0 b 10.0 11.0 12.0 import pandas as pd import numpy as np # make data set df = pd.DataFrame(np.arange(12).reshape(4, 3), columns=['col_0', 'col_1', 'col_2'], index=['row_0', 'row_1', 'row_2','row_3']) df["class"] = ["a", "a", "b", "b"] # Standardization for each group class_ = df[["class"]] class_names = df.groupby("class").groups.keys() for name in class_names: df_tmp = df[(df['class'] == name)].drop(columns=['class']) df[(df['class'] == name)] = (df_tmp - df_tmp.mean()) /df_tmp.std() df["class"] = class_
初投稿。。メモ程度です。もっと最適な方法があったら教えてください。
- 投稿日:2020-05-16T18:16:01+09:00
AtCoder Problems の Boot camp for Beginners (Medium 100) を pythonで解く
この記事で書いている内容について(前提)
この記事は、競プロ初心者が自分の勉強記録を残すために書いています。
今日のまとめ(結論)
- 二次元リストの初期化
二次元リストを初期化するときは、
[[None]*n]*mではなく、
[[None]*n for x in range(m)]をつかう
(ABC057 B Checkpoints)
- set(集合)の積
<set> & <set>で簡単に取れる
(ABC098 B Cut and Count)- groupbyは便利
groupby(<list>)を使うと各要素とその要素が
連続している数が簡単に取れる
(ABC072 C Together)- listのindex
<list>.index(<num>)で取得
(ABC057 B Checkpoints)- listの出力
*<list>という風にリストの先頭に*をつけることで
リストの要素を展開して個別に引数として渡せる
(カンマ区切りじゃない出力をするときなどに使う)
(ABC107 B Grid Compression)- 二次元リストの転置
二次元リストの転置にはzip(*<list>)を使う
ただし、zipのreturnはiteraterなので、↓のように内包表記で書く
[list(x) for x in zip(*<list>)]
(zipは複数のイテラブルオブジェクトを引数にとって要素をまとめて取得する関数)
(ABC107 B Grid Compression)今日解いた問題(本題)
- ABC098 B Cut and Count
- ABC064 C Colorful Leaderboard
- ABC060 B Choose Integers
- ABC072 C Together
- ABC057 B Checkpoints
- ABC107 B Grid Compression ※覚書有
- ABC086 C Traveling
- ABC154 D Dice in Line ※覚書有
ABC098 B Cut and Count
# ABC098 # B # Cut and Count n = int(input()) s = input() ans = 0 for i in range(n): s_f = set(s[:i]) s_b = set(s[i:]) _l =len(s_f & s_b) if ans < _l: ans = _l print(ans)ABC064 C Colorful Leaderboard
# ABC064 # C # Colorful Leaderboard n = int(input()) a_list = list(map(int, input().split())) color_list = [0]*8 over = 0 for i in range(n): _ = a_list[i] // 400 if _ < 8: color_list[_] = 1 else: over += 1 _tmp = sum(color_list) if _tmp == 0: print("1 %d"%over) else: print("%d %d"%(_tmp, _tmp+over))ABC060 B Choose Integers
# ABC060 # B # Choose Integers a, b, c = map(int, input().split()) n = b flag = False for i in range(n): if (i * a) % b == c: flag = True break if flag: print("YES") else: print("NO")ABC072 C Together
# ABC072 # C # Together import itertools n = int(input()) a = [int(i) for i in input().split()] a.sort() gr = itertools.groupby(a) hoge_list = [0]*100001 ans = 0 for key, group in gr: hoge_list[key] = len(list(group)) for i in range(1,100000,1): _tmp = hoge_list[i-1] + hoge_list[i] + hoge_list[i+1] if ans < _tmp: ans = _tmp print(ans)ABC057 B Checkpoints
# ABC057 # B # Checkpoints n, m = map(int, input().split()) ax = [None]*n by = [None]*n cx = [None]*m dy = [None]*m d_list = [[None]*m for i in range(n)] for i in range(n): ax[i],by[i] = map(int, input().split()) for i in range(m): cx[i],dy[i] = map(int, input().split()) for i in range(n): for j in range(m): d_list[i][j] = abs(ax[i]-cx[j]) + abs(by[i]-dy[j]) for i in range(n): print(d_list[i].index(min(d_list[i]))+1)ABC107 B Grid Compression
覚書
集合(set)の重要さを学んだ。
<set>.issuperset(<set>)(親集合)
<set>.issubset(<set>)(部分集合)
の二つを使うと要素比較が簡単にできる。# ABC107 # B # Grid Compression h, w = map(int, input().split()) a_list = [] for i in range(h): _tmp = input() if set(_tmp).issuperset({"#"}): a_list.append(_tmp) a_list_T = [list(x) for x in zip(*a_list)] tmp_list = [] for i in range(w): _tmp = a_list_T[i] if set(_tmp).issuperset({"#"}): tmp_list.append(_tmp) ans = [list(x) for x in zip(*tmp_list)] for _l in ans: print(*_l,sep="")ABC086 C Traveling
# ABC086 C Traveling n = int(input()) t, x, y = 0, 0, 0 flag = True for i in range(n): _t,_x,_y = map(int, input().split()) _d = abs(x - _x) + abs(y - _y) _dt = abs(t - _t) if _d > _dt or ((_d - _dt)%2) == 1: flag = False t,x,y = _t,_x,_y if flag: print("Yes") else: print("No")ABC154 D Dice in Line
覚書
期待値の最大値を出すときに、初めは安直に
sum(e_list[i:i+k])でやってみたが、TLEになったのでitertoolsの累積和を使う方法に変更した。# ABC154 D Dice in Line import itertools n, k = map(int, input().split()) p_list = [int(x) for x in input().split()] e_list = [None]*n for i in range(n): e_list[i] = (1 + p_list[i])/2 cumsum = list(itertools.accumulate(e_list)) ans = cumsum[k-1] for i in range(k,n): _ = cumsum[i] - cumsum[i-k] if ans < _: ans = _ print(ans)
- 投稿日:2020-05-16T18:15:42+09:00
ResNetを実装してみた!
この記事を読者層について
DeepLearningの畳み込みニューラルネットワーク(以下CNN)の基礎知識があり、以下のような言葉の意味がわかる方
例)
- 畳み込み
- MaxPooling
- フィルターResNetとは
CNNの手法の1つであり、他のCNNよりも多くの層を追加する事ができる。
特徴としては、モジュールの最後に、モジュールのインプットデータをモジュール内で処理したデータに加算する(ショートカットコネクション)。
詳しくは、こちらです。動作環境
GoogleColaboratory
サンプルプログラム
# 必要なライブラリーのインストール import tensorflow.keras as keras from tensorflow.keras.models import Sequential from tensorflow.keras.layers import Conv2D from tensorflow.keras.layers import MaxPooling2D from tensorflow.keras.layers import Flatten from tensorflow.keras.layers import Dense from tensorflow.keras.datasets import cifar10 # CIFAR10のデータを取得して、ベクトルに変換するクラス class CIFAR10Dataset(): def __init__(self): self.image_shape = (32, 32, 3) self.num_classes = 10 # 学習データとテストデータを取得する。 def get_batch(self): (x_train, y_train), (x_test, y_test) = cifar10.load_data() x_train, x_test = [self.change_vec(img_data) for img_data in [x_train, x_test]] y_train, y_test = [self.change_vec(img_data, label_data=True) for img_data in [y_train, y_test]] return x_train, y_train, x_test, y_test # 目的変数の場合は、クラスベクトルに変更する。説明変数は標準化する。 def change_vec(self, img_data, label=False): if label: data = keras.utils.to_categorical(img_data, self.num_classes) else: img_data = img_data.astype("float32") img_data /= 255 shape = (img_data.shape[0],) + self.image_shape img_data = img_data.reshape(shape) return img_data # ディープラーニングのモデルを設定して返す関数 def network(input_shape, num_classes, count): filter_count = 32 inputs = Input(shape=input_shape) x = Conv2D(32, kernel_size=3, padding="same", activation="relu")(inputs) x = BatchNormalization()(x) for i in range(count): shutcut = x #ショートカットコネクション用にモジュールの入力データを取得する。 x = Conv2D(filter_count, kernel_size=3, padding="same")(x) x = BatchNormalization()(x) x = Activation('relu')(x) x = Dropout(rate=0.3)(x) x = Conv2D(filter_count, kernel_size=3, padding="same")(x) x = BatchNormalization()(x) x = Concatenate()([x, shutcut]) #ショートカットコネクション if i != count - 1: x = MaxPooling2D(pool_size=2)(x) filter_count = filter_count * 2 x = Flatten()(x) x = BatchNormalization()(x) x = Dense(1024, activation="relu")(x) x = Dropout(rate=0.3)(x) x = BatchNormalization()(x) x = Dense(1024, activation="relu")(x) x = Dropout(rate=0.3)(x) x = BatchNormalization()(x) x = Dense(num_classes, activation="softmax")(x) model = Model(inputs=inputs, outputs=x) print(model.summary()) return model # モデルを学習させるクラス class Trainer(): # モデルをコンパイルして、学習するための設定をプライベートプロパティに設定する。 def __init__(self, model, loss, optimizer): self._model = model self._model.compile( loss=loss, optimizer=optimizer, metrics=["accuracy"] ) self._verbose = 1 self._batch_size = 128 self._epochs = 30 # 実際の学習 def fit(self, x_train, y_train, x_test, y_test): self._model.fit( x_train, y_train, batch_size=self._batch_size, epochs=self._epochs, verbose=self._verbose, validation_data=(x_test, y_test) ) return self._model dataset = CIFAR10Dataset() # データを取得するためのCIFAR10Datasetのインスタンス化 model = network(dataset.image_shape, dataset.num_classes, 4) #モデルの取得 x_train, y_train, x_test, y_test = dataset.get_batch() # 学習データとテストデータの取得 trainer = Trainer(model, loss="categorical_crossentropy", optimizer="adam") # モデルとロス関数、最適化アルゴリズムを引数にして、Trainerのインスタンス化 model = trainer.fit(x_train, y_train, x_test, y_test) # モデルの学習 # モデルの評価 score = model.evaluate(x_test, y_test, verbose=0) print('Test loss: ', score[0]) print('Test accuracy: ', score[1])参考文献
- 投稿日:2020-05-16T18:07:10+09:00
(備忘録)TensorFlowを使ってオススメの楽曲名を類推するWebアプリ【docker-composeで実行環境作り】
はじめに
本記事は(備忘録)TensorFlowを使ってオススメの楽曲名を類推するWebアプリの続きです。
docker-composeでローカル環境にTensorFlow+Kerasの環境作り、
WEB API叩くところまで整理したいと思います。
自分用に作った記事なので、分かりにくい点や情報、技術が古いかもしれませんがご了承ください
また何かしらのWebアプリを独りで作りたい方のご参考になれば嬉しいです。Webアプリ実物は以下のGIFのようになります。
検索ボックスに文章で入力すると、ハンバード・ハンバードさんの「同じ話」と言う回答頂きました
$\tiny{※学習データが少ないため、一部の曲しかヒットしません。。しょぼいです}$
$\tiny{※楽譜リンクをクリックすると楽譜の一部が表示されていますが、記事の対象外です}$参考文献
この記事を作るにあたって参考にさせて頂きました
- docker-composeでgunicorn+nginx+flaskを動かしてみた話
- [イメージ図付]Nginx+gunicorn+FlaskをDocker化[後編]
- DockerでDjangoの開発環境を再構築!!!!
- すぐに使える! 業務で実践できる! Pythonによる AI・機械学習・深層学習アプリのつくり方
TODO マップ
(備忘録)TensorFlowを使ってオススメの楽曲名を類推するWebアプリの続きで、
今回はWeb API側の環境構築(実行環境)です。
章 区分 状況 内容 言語、FW、環境等 序 章 共通 済 アプリの概要 Python
TensorFlow
Keras
Google Colaboratory第一章 Web API 済 (今回)環境構築(実行環境) docker-compose
Flask
Nginx
gunicorn第二章 Web API 未着手 機械学習 Python
TensorFlow
Keras
Flask第三章 画面 未着手 環境構築 Python
Django
Nginx
gunicorn
PostgreSQL
virtualenv第四章 画面 未着手 表示、Web API呼出し部分 Python
Django第五章 AWS 未着手 AWS自動デプロイ Github
EC2
CodeDeploy
CodePipeline※まだ記事は全然整理できていないので時間ある時につくります。
未着手のまま命尽きるかも
またマップは書いてるうちに変わる可能性ありますのでご了承下さい。。環境 ※以下のVerでなくても動くと思いますが、古いのでご注意下さい
 Ubuntuバージョン$ cat /etc/os-release NAME="Ubuntu" VERSION="18.04.4 LTS (Bionic Beaver)" ID=ubuntu ID_LIKE=debian PRETTY_NAME="Ubuntu 18.04.4 LTS" VERSION_ID="18.04" HOME_URL="https://www.ubuntu.com/" SUPPORT_URL="https://help.ubuntu.com/" BUG_REPORT_URL="https://bugs.launchpad.net/ubuntu/" PRIVACY_POLICY_URL="https://www.ubuntu.com/legal/terms-and-policies/privacy-policy" VERSION_CODENAME=bionic UBUNTU_CODENAME=bionicDockerバージョン$ docker version Client: Docker Engine - Community Version: 19.03.8 API version: 1.40 Go version: go1.12.17 Git commit: afacb8b7f0 Built: Wed Mar 11 01:25:46 2020 OS/Arch: linux/amd64 Experimental: false Server: Docker Engine - Community Engine: Version: 19.03.8 API version: 1.40 (minimum version 1.12) Go version: go1.12.17 Git commit: afacb8b7f0 Built: Wed Mar 11 01:24:19 2020 OS/Arch: linux/amd64 Experimental: false containerd: Version: 1.2.13 GitCommit: 7ad184331fa3e55e52b890ea95e65ba581ae3429 runc: Version: 1.0.0-rc10 GitCommit: dc9208a3303feef5b3839f4323d9beb36df0a9dd docker-init: Version: 0.18.0 GitCommit: fec3683Docker-Composeバージョン$ docker-compose version docker-compose version 1.25.5, build unknown docker-py version: 4.2.0 CPython version: 3.7.4 OpenSSL version: OpenSSL 1.1.1c 28 May 2019
Ubuntuバージョン$ cat /etc/os-release NAME="Ubuntu" VERSION="18.04.4 LTS (Bionic Beaver)" ID=ubuntu ID_LIKE=debian PRETTY_NAME="Ubuntu 18.04.4 LTS" VERSION_ID="18.04" HOME_URL="https://www.ubuntu.com/" SUPPORT_URL="https://help.ubuntu.com/" BUG_REPORT_URL="https://bugs.launchpad.net/ubuntu/" PRIVACY_POLICY_URL="https://www.ubuntu.com/legal/terms-and-policies/privacy-policy" VERSION_CODENAME=bionic UBUNTU_CODENAME=bionicDockerバージョン$ docker version Client: Docker Engine - Community Version: 19.03.8 API version: 1.40 Go version: go1.12.17 Git commit: afacb8b7f0 Built: Wed Mar 11 01:25:46 2020 OS/Arch: linux/amd64 Experimental: false Server: Docker Engine - Community Engine: Version: 19.03.8 API version: 1.40 (minimum version 1.12) Go version: go1.12.17 Git commit: afacb8b7f0 Built: Wed Mar 11 01:24:19 2020 OS/Arch: linux/amd64 Experimental: false containerd: Version: 1.2.13 GitCommit: 7ad184331fa3e55e52b890ea95e65ba581ae3429 runc: Version: 1.0.0-rc10 GitCommit: dc9208a3303feef5b3839f4323d9beb36df0a9dd docker-init: Version: 0.18.0 GitCommit: fec3683Docker-Composeバージョン$ docker-compose version docker-compose version 1.25.5, build unknown docker-py version: 4.2.0 CPython version: 3.7.4 OpenSSL version: OpenSSL 1.1.1c 28 May 2019※なぜかbuild unknown。時間掛かりそうだったので諦めました
実行環境の作り方
端的に書くと、ちゃんとdocker-composeがインストールされていて、
以降記載のディレクトリ構成通りに必要ファイルを配置すれば、
以下のコマンドを実行するだけです。ビルド&backgroundで起動docker-compose up -d --build初回はビルドに時間かかりますが、コンテナできた後、Web API叩くと以下GIFのようになります。
Web_API実行例http://localhost:7020/recommend/api/what-music/切なくて誰かの幸せ願う歌Web API実行例
ツールは色々あるので何でも良いと思いますが、GIFのようにJSONで返ってきます。ディレクトリ構成
適当に作っています$\tiny{※凝視したらダメです}$
ゴミファイルが多いですが、Githubに置いてあります。
ソースディレクトリ構成dk_tensor_fw ├── app_tensor │ ├── Dockerfile │ ├── exeWhatMusic.py │ ├── inputFile │ │ └── ans_studyInput_fork.txt │ ├── mkdbAndStudy.py │ ├── requirements.txt │ ├── studyModel │ │ ├── genre-model.hdf5 │ │ ├── genre-tdidf.dic │ │ ├── genre.pickle │ ├── tfidfWithIni.py │ └── webQueApiRunServer.py ├── docker-compose.yml ├── web_nginx ├── Dockerfile └── nginx.confdocker-composeでローカル環境作るのに必要なファイル
docker-compose.ymlversion: '3' services: ########### Appサーバ設定 ########### app_tensor: container_name: app_tensor # サービス再起動ポリシー restart: always # ビルドするdockerファイルが格納されたディレクトリ build: ./app_tensor volumes: # マウントするディレクトリ - ./app_tensor:/dk_tensor_fw/app_tensor ports: # ホスト側のポート:コンテナ側のポート - 7010:7010 networks: - nginx_network ########### Appサーバ設定 ########### ########### Webサーバ設定 ########### web-nginx: container_name: web-nginx build: ./web_nginx volumes: # マウントするディレクトリ - ./web_nginx:/dk_tensor_fw/web_nginx ports: # ホストPCの7020番をコンテナの7020番にポートフォワーディング - 7020:7020 depends_on: # 依存関係を指定。web-serverの起動より前にapp-serverを起動するようになる - app_tensor networks: - nginx_network ########### Webサーバ設定 ########### networks: nginx_network: driver: bridge※ (参考)上記でポート番号を指定していますが、以下のコマンドで確認してます。
(参考)空いているポートの調べ方# 空いているポート調べる(何も表示されなければ空いてる) netstat -an | grep 7010Dockerfile←Apサーバ側(Gunicorn)FROM ubuntu:18.04 WORKDIR /dk_tensor_fw/app_tensor COPY requirements.txt /dk_tensor_fw/app_tensor RUN apt-get -y update \ && apt-get -y upgrade \ && apt-get install -y --no-install-recommends locales curl python3-distutils vim ca-certificates \ && curl https://bootstrap.pypa.io/get-pip.py -o get-pip.py \ && python3 get-pip.py \ && pip install -U pip \ && localedef -i en_US -c -f UTF-8 -A /usr/share/locale/locale.alias en_US.UTF-8 \ && apt-get clean \ && rm -rf /var/lib/apt/lists/* \ && pip install -r requirements.txt --no-cache-dir ENV LANG en_US.utf8 CMD ["gunicorn", "webQueApiRunServer:app", "-b", "0.0.0.0:7010"]requirements.txtFlask==1.1.0 gunicorn==19.9.0 Keras>=2.2.5 numpy==1.16.4 pandas==0.24.2 pillow>=6.2.0 python-dateutil==2.8.0 pytz==2019.1 PyYAML==5.1.1 requests==2.22.0 scikit-learn==0.21.2 sklearn==0.0 matplotlib==3.1.1 tensorboard>=1.14.0 tensorflow>=1.14.0 mecab-python3==0.996.2Dockerfile←Webサーバ側(Nginx)FROM nginx:latest RUN rm /etc/nginx/conf.d/default.conf COPY nginx.conf /etc/nginx/conf.dnginx.confupstream app_tensor_config { # コンテナのサービス名を指定すると名前解決してくれる server app_tensor:7010; } server { listen 7020; root /dk_tensor_fw/app_tensor/; server_name localhost; location / { try_files $uri @flask; } location @flask { proxy_set_header Host $host; proxy_set_header X-Real-IP $remote_addr; proxy_redirect off; proxy_pass http://app_tensor_config; } # redirect server error pages to the static page /50x.html error_page 500 502 503 504 /50x.html; location = /50x.html { root /usr/share/nginx/html; } # 静的ファイルの要求をstaticにルーティング ←使ってませんので不要です。 location /static/ { alias /dk_tensor_fw/app_tensor/satic/; } }出来上がった環境の確認
ビルド&backgroundで起動
$ docker-compose up -d --builddocker-compose イメージ情報を表示
$ docker-compose images Container Repository Tag Image Id Size ----------------------------------------------------------------------- app_tensor dk_tensor_fw_app_tensor latest 3b916ea797e0 2.104 GB web-nginx dk_tensor_fw_web-nginx latest 175c2596bb8b 126.8 MB作り方が悪いのか結構容量大きいような
コンテナの一覧表示
$ docker-compose ps Name Command State Ports ------------------------------------------------------------------------------------ app_tensor gunicorn webQueApiRunServe ... Up 0.0.0.0:7010->7010/tcp web-nginx nginx -g daemon off; Up 0.0.0.0:7020->7020/tcp, 80/tcpコンテナに接続(Apサーバ側)
$ docker-compose exec app_tensor /bin/bash root@ba0ce565430c:/dk_tensor_fw/app_tensor#Apサーバ側のコンテナに入れました。。。
TensorFlowとかKeras入っているか中身を確認
出力結果の表示が長いのでいくつか省きました
root@ba0ce565430c:/dk_tensor_fw/app_tensor# pip3 list Package Version ---------------------- ----------- absl-py 0.9.0 Flask 1.1.0 gunicorn 19.9.0 Keras 2.3.1 Keras-Applications 1.0.8 Keras-Preprocessing 1.1.2 matplotlib 3.1.1 mecab-python3 0.996.2 numpy 1.16.4 pandas 0.24.2 Pillow 7.1.2 pip 20.1 python-dateutil 2.8.0 pytz 2019.1 PyYAML 5.1.1 requests 2.22.0 requests-oauthlib 1.3.0 rsa 4.0 scikit-learn 0.21.2 six 1.14.0 sklearn 0.0 tensorboard 2.2.1 tensorboard-plugin-wit 1.6.0.post3 tensorflow 2.2.0 tensorflow-estimator 2.2.0 (省略)TensorFlow、Kerasなど一通り入っているようです。。。
Webサーバ側のコンテナに接続
$ docker-compose exec web-nginx /bin/bash root@d6971e4dc05c:/#Webサーバ側のコンテナにも入れました。
一応、Webサーバ(Nginx)が起動しているか確認します。
root@d6971e4dc05c:/# /etc/init.d/nginx status [ ok ] nginx is running.Nginxも起動しているようです。
一旦ここまでで実行環境の確認しました。
上記Web APIの実行例のようにWEB APIが叩ければWEB API側の実行環境できてると思います。。。今後について
今回はWEB API側の実行環境まで少し整理できました。
また、時間のある時に少しづつブラッシュアップ、整理できればと思います
未定ですが、次回は機械学習部分を整理できればと思います。
章 区分 状況 内容 言語、FW、環境等 序 章 共通 済 アプリの概要 Python
TensorFlow
Keras
Google Colaboratory第一章 Web API 済 環境構築(実行環境) docker-compose
Flask
Nginx
gunicorn第二章 Web API 未着手 (次回)機械学習 Python
TensorFlow
Keras
Flask第三章 画面 未着手 環境構築 Python
Django
Nginx
gunicorn
PostgreSQL
virtualenv第四章 画面 未着手 表示、Web API呼出し部分 Python
Django第五章 AWS 未着手 AWS自動デプロイ Github
EC2
CodeDeploy
CodePipeline
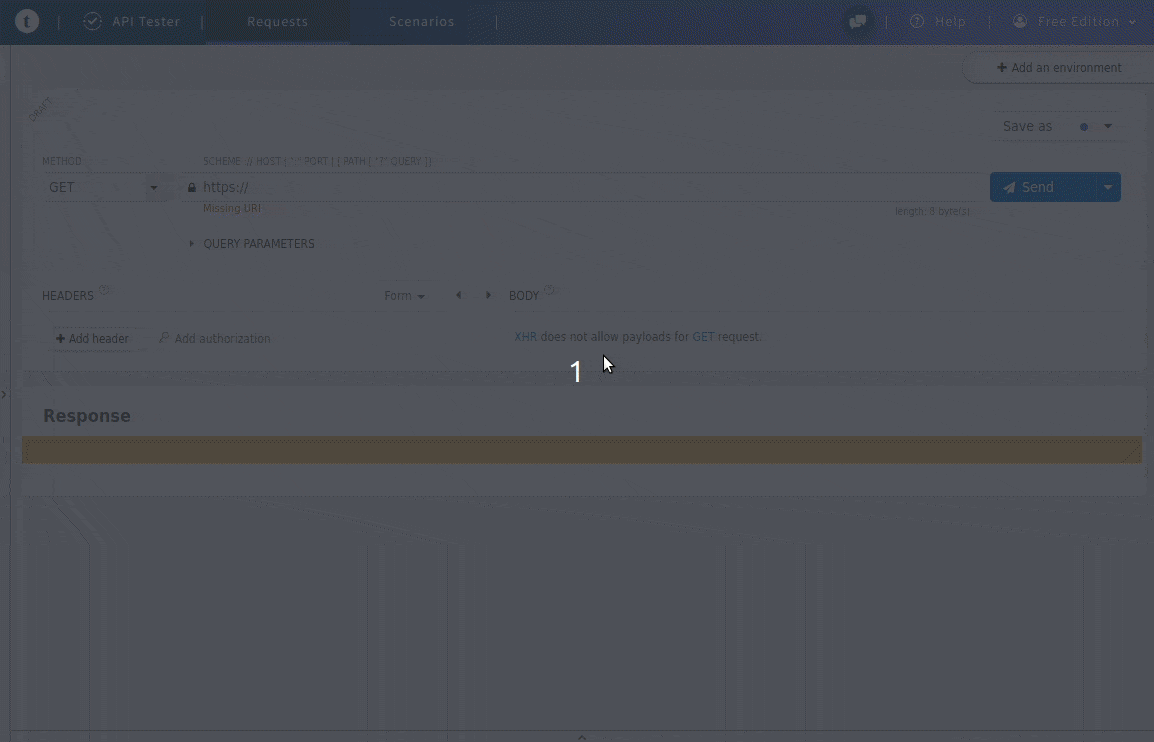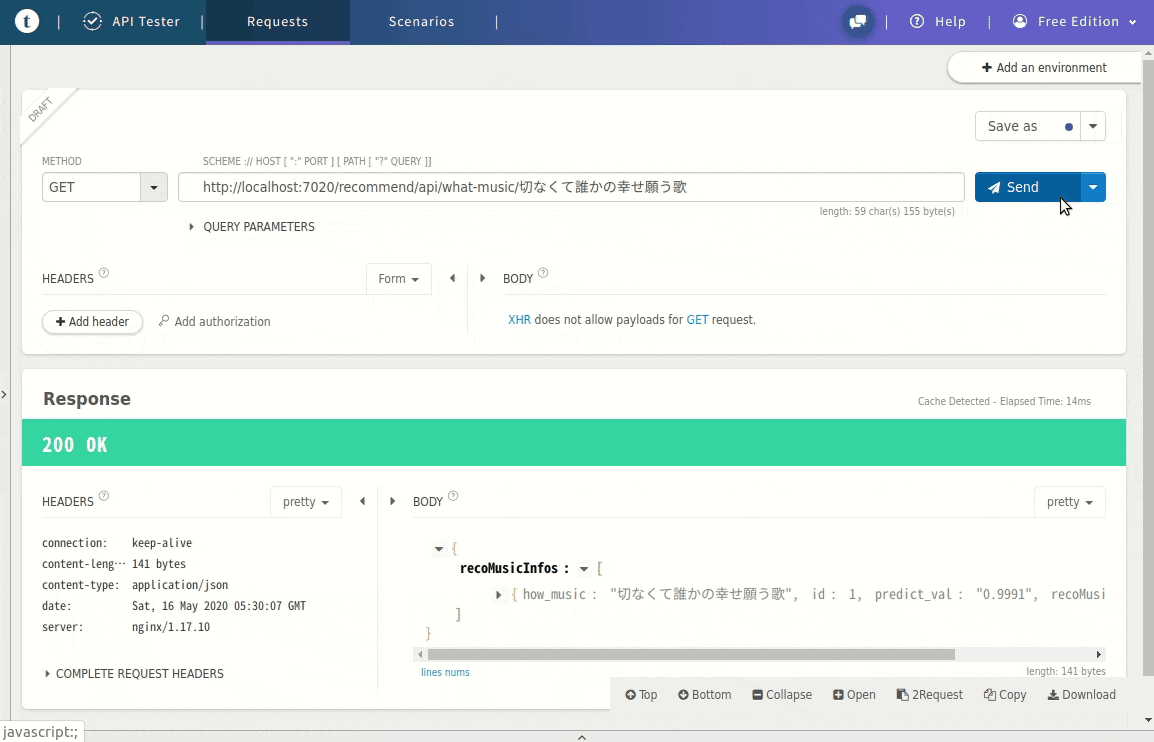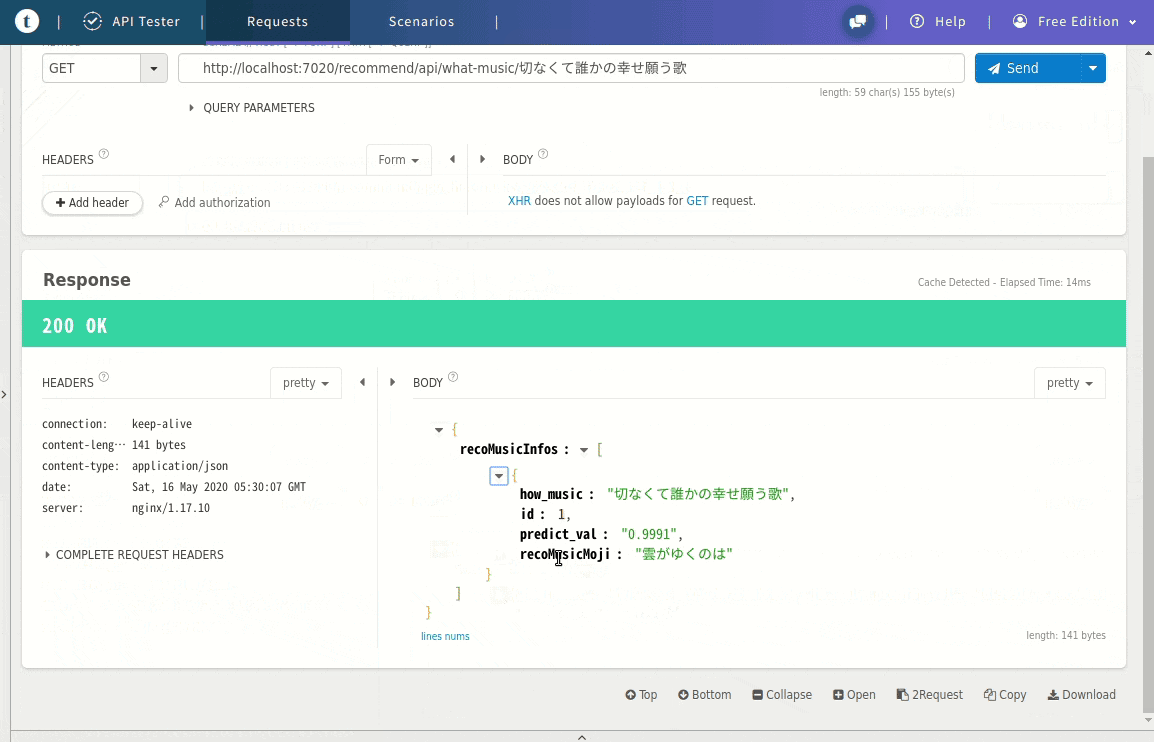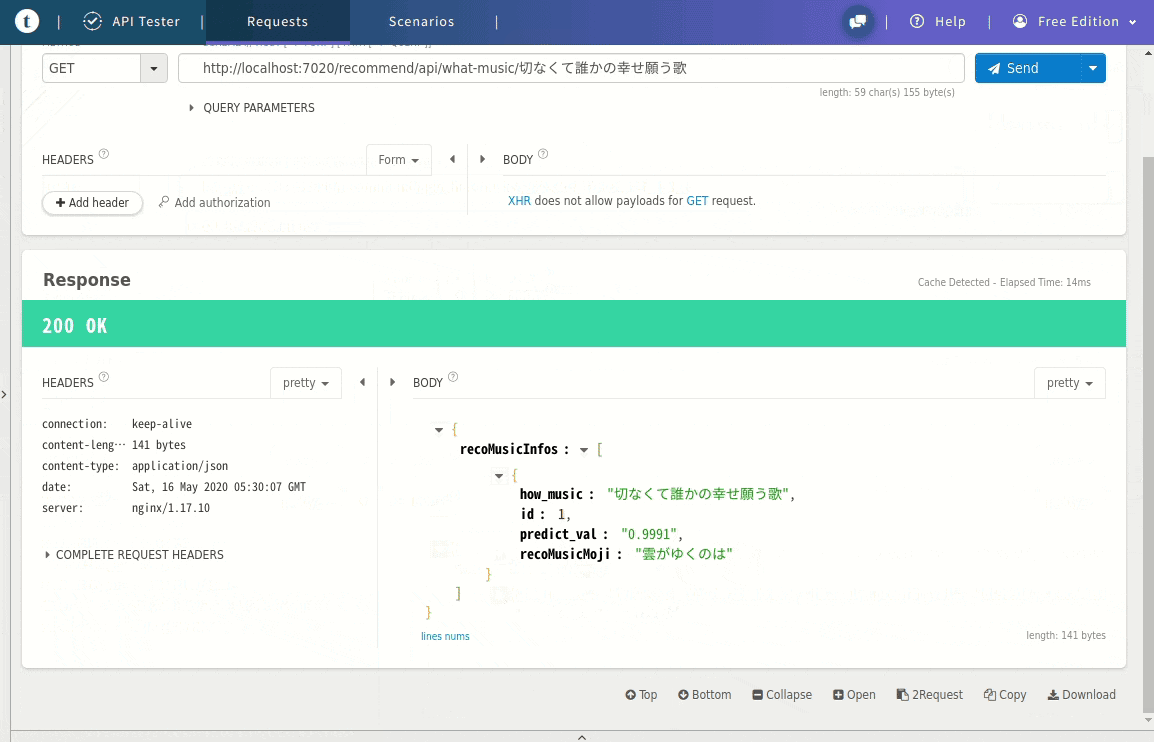
- 投稿日:2020-05-16T18:00:03+09:00
競技プログラミングの日程を教えてくれる Line Bot を作った話
競技プログラミングの日程を通知する Line Bot をアップデートしました。
DB 等も使ったので少しまとめていこうと思います。作ったもの
コンテストという文字を含んだ文章を Bot 本体または Bot が入っているグループに送ると、
Codeforces や AtCoder のコンテスト日程を送ってくれます。ちなみに下記の QR コードから友達登録ができます。
ぜひ使ってください。
使ったもの
Python
メイン言語として使用PostgreSQL
データベースとして使用ngrok
ローカル環境での Bot のテストに使用heroku
本番環境に使用
アドオンは PostgreSQL と Scheduler を利用しています。Line Bot SDK
Line 公式から提供されている Bot 開発キットです仕組み
AtCoder のコンテスト日程の取得
AtCoder には公式のコンテスト日程の API が存在しないため、
公式のページをスクレイピングして Rated なコンテストの日程を取ってきています。
スクレイピングには Python の BeautifulSoup を使用しています。
はじめに URL の情報を取得して、スクレイピングをします。
その後必要なデータのみを取り出して整形しています。utils.pydef get_upcoming_at_contests(): r = get_data(AT_URL, True) soup = BeautifulSoup(r, 'html.parser') texts = soup.get_text() words = [line.strip() for line in texts.splitlines()] upcoming = False text = [] for word in words: if word == '◉' or word == '': continue if word == 'Upcoming Contests': upcoming = True continue if word == 'Recent Contests': upcoming = False if upcoming: text.append(word) res = [] for i in range(len(text)): if i < 4: continue if i % 4 == 0: text[i], text[i + 1] = text[i + 1], text[i] if i % 4 == 1: s = '' if i == 1: pass else: for t in text[i]: if t == '+': break s += t start = datetime.datetime.strptime(s, '%Y-%m-%d %H:%M:%S') dur = datetime.datetime.strptime(text[i + 1], '%H:%M') end = start + datetime.timedelta(hours=int(dur.strftime('%H')), minutes=int(dur.strftime('%M'))) s += ' - ' s += end.strftime('%Y-%m-%d %H:%M:%S') text[i] = s if i % 4 != 2: res.append(text[i]) return resCodeforces の日程取得
Codeforces には公式 API が存在するため、API を叩いてそれを整形しています。
utils.pydef get_upcoming_cf_contests(): JST = datetime.timezone(datetime.timedelta(hours=+9), 'JST') contents = get_data(CF_URL) if contents['status'] == 'FAILED': print('Failed to call CF API') return res = [] for i in range(len(contents['result'])): if (contents['result'][i]['phase'] == 'FINISHED'): break res.insert(0, contents['result'][i]['name']) start = contents['result'][i]['startTimeSeconds'] s = '' start_jst = datetime.datetime.fromtimestamp(start, JST) start_time = datetime.datetime.strftime(start_jst, '%Y-%m-%d %H:%M:%S') s += start_time dur_sec = contents['result'][i]['durationSeconds'] dur = datetime.timedelta(seconds=dur_sec) end_time = start_jst + dur s += ' - ' s += end_time.strftime('%Y-%m-%d %H:%M:%S') res.insert(1, s) return resDB
heroku にて公式アドオンが提供されている PostgreSQL を使用しています。
レコードの挿入や取得の際は、あらかじめ関数で SQL 文を生成し、それを実行させています。
Psycopg2 というパッケージを使用しています。db.pyimport psycopg2 def update_at_table(): query = '' query += 'DELETE FROM {};'.format(AT_TABLE) data = utils.format_at_info() for i in range(len(data)): query += 'INSERT INTO {0} (name, time, range) VALUES (\'{1}\', \'{2}\', \'{3}\');'.format(AT_TABLE, data[i]['name'], data[i]['time'], data[i]['range']) execute(query) def update_cf_table(): query = '' query += 'DELETE FROM {};'.format(CF_TABLE) data = utils.format_cf_info() for i in range(len(data)): query += 'INSERT INTO {0} (name, time) VALUES (\'{1}\', \'{2}\');'.format(CF_TABLE, data[i]['name'], data[i]['time']) execute(query) def get_records(table_name, range=True): query = '' if range: query += 'SELECT name, time, range FROM {};'.format(table_name) else: query += 'SELECT name, time FROM {};'.format(table_name) res = execute(query, False) return res def execute(query, Insert=True): with get_connection() as conn: if Insert: with conn.cursor() as cur: cur.execute(query) conn.commit() else: with conn.cursor(cursor_factory=psycopg2.extras.DictCursor) as cur: cur.execute(query) res = cur.fetchall() return resまた、heroku のスケジューラで 1 時間に 1 回 DB の内容をアップデートしています。
Line へのデータの送信
公式の SDK で提供されているように、Flask を使用して Web アプリケーションを作成しました。
アプリケーションが起動するとはじめに callback 関数が呼ばれます。
callback 関数内で handle_message 関数が呼ばれメッセージを送信します。
メッセージ送信には Flex Message を利用しています。
Flex Message は Json 形式で生成するため、あらかじめ Json テンプレートをストックしておき、それを利用してメッセージを送信します。main.py@app.route("/callback", methods=['POST']) def callback(): signature = request.headers['X-Line-Signature'] body = request.get_data(as_text=True) app.logger.info('Request body: ' + body) try: handler.handle(body, signature) except InvalidSignatureError: print('Invalid signature. Please check your channel access token/channel secret.') abort(400) return 'OK' @handler.add(MessageEvent, message=TextMessage) def handle_message(event): user_id = event.source.user_id to = user_id if hasattr(event.source, "group_id"): to = event.source.group_id TARGET = 'コンテスト' if not TARGET in event.message.text: return cf_data = utils.send_cf_info() cf_message = FlexSendMessage( alt_text='hello', contents=cf_data ) at_data = utils.send_at_info() at_message = FlexSendMessage( alt_text='hello', contents=at_data ) try: line_bot_api.push_message( to, messages=cf_message) line_bot_api.push_message( to, messages=at_message) except LineBotApiError as e: print('Failed to Send Contests Information')heroku へのデプロイ
はじめにプロジェクト内に Procfile を作成します。
これは heroku にプロジェクトのタイプや動かし方を伝えるものです。
以下を記述します。web: python /app/src/main.pyheroku にプロセスタイプを Web であること、また実際に動かすプログラムを教えています。
また、デプロイには heroku CLI を使用しました。
これにより$ git push heroku masterで heroku へのデプロイができるようになります。
終わり
何か疑問点やわからないこと、改善要求や間違っている点などありましたら Twitter などからぜひ教えてください。
また、GitHub に全てのソースコードが乗っています。
ソースコード
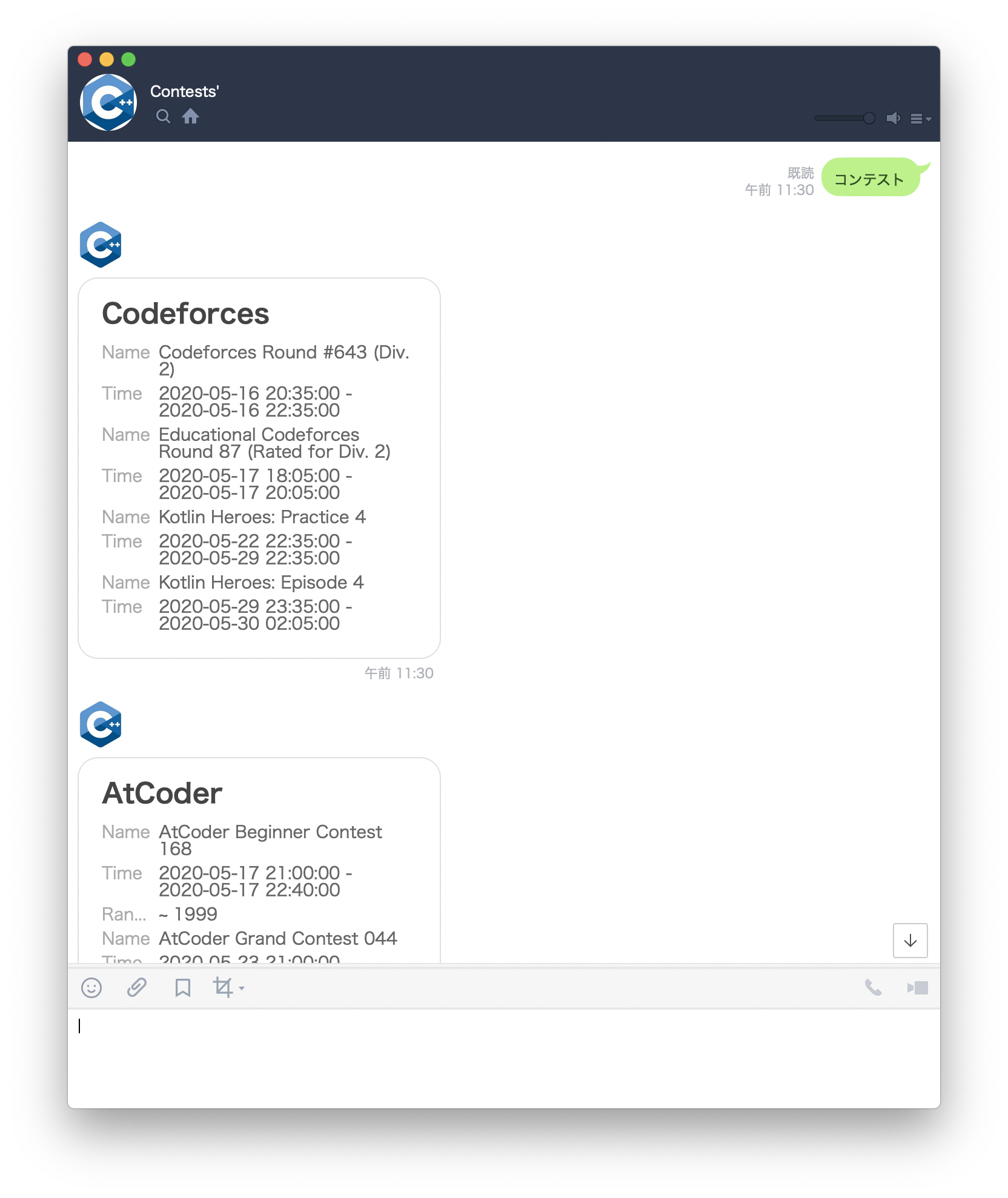

- 投稿日:2020-05-16T17:45:34+09:00
可能な限り簡単にPythonベースで量子アニーリングで最適化問題をとく
なに?
量子コンピュータとかヨクワカラナイし、イジングモデルとかよくわからない、数式もΣとか苦手、でもPythonなら読める。
数式よりもソースコードの方が直感的で何といっても動かして理解できるので「量子コンピュータ」の1方式である「量子アニーリング」のお勉強をPythonでしてみるのもいいかな、と、メモとしてまとめました。
量子コンピュータと量子アニーリング
「量子コンピュータ」と言うとそこそこ広い範囲の言葉で色々なものをさします。
そんな「量子コンピュータ」と呼ばれるものの1つに「量子アニーリング」と言われる方式があります。
ざっくり言うと「量子アニーリング」は「組み合わせ問題」を解くものです。今のパソコンに取って代わるようなものではなくシンプルに組み合わせ問題を解けるだけのものです。
組み合わせ問題といってもパッとこないかもしれませんが、たくさんの物の中からBetterな組み合わせを選ぶタイプの問題です。世の中意外とそういう問題は多くて、、、お洋服を選んだり、最適な交通経路を選んだり、300円で駄菓子を選んだり、意外とよくあるタイプの問題です。
今のコンピュータも十分に高速とは言え、数が多い組み合わせの問題を解くのには時間がかかってしまいます。「量子アニーリング」はその組み合わせ問題をより効率的に解ける可能性がある技術です。
・・・ということで前置き長くなりましたがさっそくソースコードでいきます。
環境準備
まずPythonが動く環境を用意してください。
pip で必要なライブラリをインストールします。pip install pyquboさくっと簡単なサンプルを作ってみます。
from pyqubo import Binary, solve_qubo # 今あるスキマ時間 sukima_jikan = 45 a = Binary("アニメ") # 30分 b = Binary("おもしろ動画 A") # 5分 c = Binary("おもしろ動画 B") # 4分 d = Binary("おもしろ動画 C") # 3分 e = Binary("ドラマ") # 60分 H = (sukima_jikan - a*30 - b*5 - c*4 - d*3 - e*60)**2 qubo, offset = H.compile().to_qubo() solution = solve_qubo(qubo) print(solution) # 実行結果: # {'おもしろ動画 A': 1, 'おもしろ動画 B': 1, 'おもしろ動画 C': 1, 'アニメ': 1, 'ドラマ': 0}今回の例題は、「表のような5つの動画」があって、今スキマ時間としてぽっかり「45分」時間があいたとします。その時にどういう組み合わせの動画を見ればスキマ時間を過ごせるか?という問題です。
変数 動画 時間 a アニメ 30分 b おもしろ動画 A 5分 c おもしろ動画 B 4分 d おもしろ動画 C 3分 e ドラマ 60分 それでは順番にコードを説明していきます。
まず各動画を表す変数を準備します。
Binaryとは0または1になってくれる型です。a = Binary("アニメ") b = Binary("おもしろ動画 A") c = Binary("おもしろ動画 B") d = Binary("おもしろ動画 C") e = Binary("ドラマ")そして次に、いわゆる評価関数みたいなものを作ります。
H = (sukima_jikan - a*30 - b*5 - c*4 - d*3 - e*60)**2この評価関数
Hの値が最小になるようにabcdeの組み合わせをイイ感じに考えようと思います。式
Hの意味について説明します。
abcdeはBinaryで0または1の値になってくれる。- その
Binaryの意味を 「1は動画を見る」「0は動画は見ない」とする。- 「『スキマ時間』から『見る動画の時間』を引いた数」が小さくなるほど高評価とします(つまりヒマな時間つぶせる方を良しとする)
- 小さい方がいいとはいえマイナス、つまり、スキマ時間以上に動画を見られた場合に高評価になっても困るので二乗することでマイナスをかき消す
では実際の例を見てみます。
例えば、「スキマ時間 45分」で「変数 a のアニメ」だけを見る場合、変数
aが1になって他は0になるので、H=225になります。H = (sukima_jikan - a*30 - b*5 - c*4 - d*3 - e*60)**2 ↓ H = ( 45 - 1*30 - 0*5 - 0*4 - 0*3 - 0*60 )**2 = ( 45 - 30 - 0 - 0 - 0 - 0 )**2 = ( 15 )**2 = 225別のパターンで、「変数 b のおもしろ動画」と「変数 c のおもしろ動画」を見る場合、変数
bcが1になって他は0なるので、H=1296になります。H = (sukima_jikan - a*30 - b*5 - c*4 - d*3 - e*60)**2 ↓ H = ( 45 - 0*30 - 1*5 - 1*4 - 0*3 - 0*60 )**2 = ( 45 - 0 - 5 - 4 - 0 - 0)**2 = ( 36 )**2 = 1296つまり、「変数 b のおもしろ動画 + 変数 c のおもしろ動画」の
H=1296より「変数 a のアニメ」のH=225の方がHが小さいので高い評価=時間をつぶせた、と言えます。という感じで、
abcdeの組み合わせとHの値を見ていくとこんな感じになります。
a b c d e H 0 0 0 0 0 2025 1 0 0 0 0 225 0 1 0 0 0 1600 0 0 1 0 0 1681 0 0 0 1 0 1764 0 0 0 0 1 225 1 1 0 0 0 100 1 0 1 0 0 121 1 0 0 1 0 144 : : : : : : 1 1 1 1 0 9 : : : : : : 1 1 1 1 1 3249 : : : : : : という感じでこの中から一番
Hが小さい組み合わせを選びたいのですが、普通なら1つ1つ解いていくしかありません。これをなんとなくイイ感じに解いてくれている部分がここです。
H = (sukima_jikan - a*30 - b*5 - c*4 - d*3 - e*60)**2 qubo, offset = H.compile().to_qubo() solution = solve_qubo(qubo) print(solution)評価式
H(本当は評価式ではなくハミルトニアンと呼びます)を作って、それを元に QUBO というものを作って(to_qubo())、それを解く(solve_qubo())ことで解を得ています。 このハミルトニアン(≒評価式)から解となる組み合わせを「量子」の特性を借りて選び出すのが「量子アニーリング」と言われるものです。ということで実行して見ると答えとして以下が得られます。
{'おもしろ動画 A': 1, 'おもしろ動画 B': 1, 'おもしろ動画 C': 1, 'アニメ': 1, 'ドラマ': 0}つまり、45分のスキマ時間があったら、
変数 動画 時間 視聴 a アニメ 30分 見る b おもしろ動画 A 5分 見る c おもしろ動画 B 4分 見る d おもしろ動画 C 3分 見る e ドラマ 60分 見ない 30分 + 5分 + 4分 + 3分 の 合計42分 見ると良いという組み合わせが得られます。
めでたしめでたし
まとめると、細かいことは抜きにして解きたい問題に対して
Hの式を作れるかが大事ってことです。この後にやること
例えば、スキマ時間を変えてみる、動画の数を増やしてみる、とかして色々試すと面白いです。 他にも、動画に★の数とかつけてなるべくたくさん★の高い動画を見れるようにする(そんな H の評価式を作る)とかもおススメです。
まとめ
あれ? 自分のパソコンは「量子コンピュータ」だっけ? なんでこのコード動いたの? と思ったかもしれませんが、今回使わせていただいた
PyQUBOはシミュレータが入っているので普通のPCでも動いてくれます(感謝!)。もしD-WAVEやなんとかアニーラみたいな本物の量子アニーリングマシン(とか量子ではないけど高速なアニーリングマシン)を使える方がいたら上のコードのsolve_quboあたりを差し替えることで実際の量子アニーリングも実行できます。本来はイジングモデルやQUBOとかハミルトンとかきちんと説明しないといけないのでしょうが、、、私のようなプログラマ/エンジニアのとっかかりとしては「プログラム」で理解できる方が早いのでPythonベースでまとめてみました。
識者からのツッコミ大歓迎ですのでコメント欄でぜひ何卒です。
- 投稿日:2020-05-16T17:32:05+09:00
【初心者向け】ねこでも分かるニューラルネットワーク超入門
書いてあること
1.ニューラルネットワークって?
2.ユニット?重み?バイアス?
3.活性化関数
4.NNの全体像
5.まとめニューラルネットワークの全体像をふわっと理解することを目標にしています。数式とかは使ってないので数学アレルギーの人も是非見てください。
1.ニューラルネットワークって?
ニューラルネットワークとは下のようなやつのことです。英語で書くとNeuralNetworkなので、よくNNって略します。なので今回はNNで説明していこうと思います
丸いのを「ユニット」といい、ユニット同士を結んでる線を「シナプス」と呼びます。シナプスって呼ぶのが面倒いので今回は「線」って呼んで説明させてください。
NNは層の構造をしています。だいたい、左から1層目、2層目、、って数えていきます。最初の層を「入力層」、最後の層を「出力層」、間をまとめて「中間層(隠れ層)」と呼びます。下は4層のNNの図です。
2.ユニット?重み?バイアス?
もう少し細かく見ていきます。
丸いのを「ユニット」と呼びます。ユニットは数字を1つ持っています。
ユニットの事を「ニューロン」と言ったりします。そーゆーのは全部「丸いやつ」って認識でOKです。
ユニットの数字は「線」(シナプス)を通って次のユニットに進んでいきます。数字は次のユニットに足されていきます。
線を通るときに値が変わります。たとえば下のように、前ユニットの数字「3」が線を通るとき、「×2」の計算がされ、次ユニットに「6」が足されます。
この「×2」のことを「重み」と呼びます。線が×2という数字を持っているイメージです。
線によってそれぞれ「重み」の値は違います。たとえば下のように、1つのユニットが3つの次ユニットに繋がっている場合、3本の線を数字が進んでいくことになります。
3本の線が、それぞれ×2、×-4、×3という「重み」を持っている場合を考えます。前ユニットの「3」はそれぞれの「重み」が掛け算され、次ユニットに足されてます。
また、3つの前ユニットが1つの次ユニットに繋がっている時が下の図です。この場合も同じ感じで、「13*2」「-2*-4」「-9*3」の結果がどんどん足されていき、次ユニットの値は「7」となります。
そしてまた、その「7」が次のユニットへ進んでいく感じです。
以上のようにNNの計算がされていきます。全体的にいうと、NNの「入力層」に数字を入れると、NNを通っていろいろな計算がされ、結果が「出力層」に出てくる、という流れです。
入力層には、人工知能に学習させたい「データ」を入れますが、NNには「データ以外の数字」も入れます。これを「バイアス」と呼びます。
バイアスは下の画像のように、それぞれの層に付いているイメージです。正確には、1つのユニットに1つずつ別のバイアスが付いています。
前ユニットの数字が次ユニットにどんどん足されていくタイミングで、この「バイアス」の数字も足します。
バイアスの線には重みはありません。
3.活性化関数(かっせいかかんすう)
さらにルールがもう1つあります。ユニットの数字は線に進む直前に、値が変わります。イメージ的には下の画像のような感じです。
これは「活性化関数(かっせいかかんすう)」というルールに従って、値が変化します。活性化関数には多くの種類がありますが、一番有名なのが「ReLU関数」という活性化関数です。
ReLU関数は、ユニットの値が「0以下なら0に変えて、0を超えたらそのまま通す」というルールです。
このようにして変化したユニットの値が、線へと進みます。
整理します。
流れとしては、
ユニットの値が活性化関数のルールに従って変化→その数字がシナプス(線)を通るときにまた変化→その数字とバイアスが次ユニットにどんどん足されていく、って感じです。
ちなみに活性化関数によって値が変わることを「活性化する」と言います。
4.NNの全体像
NNの「入力層」に数字を入れると、NNを通っていろいろな計算がされ、結果が「出力層」に出てくる、という流れです。
細かく言うと、
ユニットの値が活性化関数のルールに従って変化→その数字がシナプス(線)を通るときにまた変化→その数字とバイアスが次ユニットにどんどん足されていく、って感じです。
また、シナプスの「重み(×何倍にするか)」と「バイアス」は、最初テキトーな値がランダムに設定されています。
この数字をどんどん更新していく事を、「学習」といいます。
「重み」と「バイアス」を更新していくとこで、いい感じの出力にすることが、NNのゴールとなります。
5.まとめ
NNの基本的な流れについて説明しました。基本の基本の基本なので、イメージをざっくり掴んで貰えるだけでOKです。
※説明の都合上、実際の動きとは少し異なる部分があります。ご了承下さい。
以上です!素敵なNNライフを!
人工知能/AI/機械学習をもっと詳しく
「ねこアレルギーのAI」
https://t.co/4ltE8gzBVv?amp=1
YouTubeで機械学習について発信しています。
お時間ある方は覗いていただけると喜びます。created by NekoAllergy


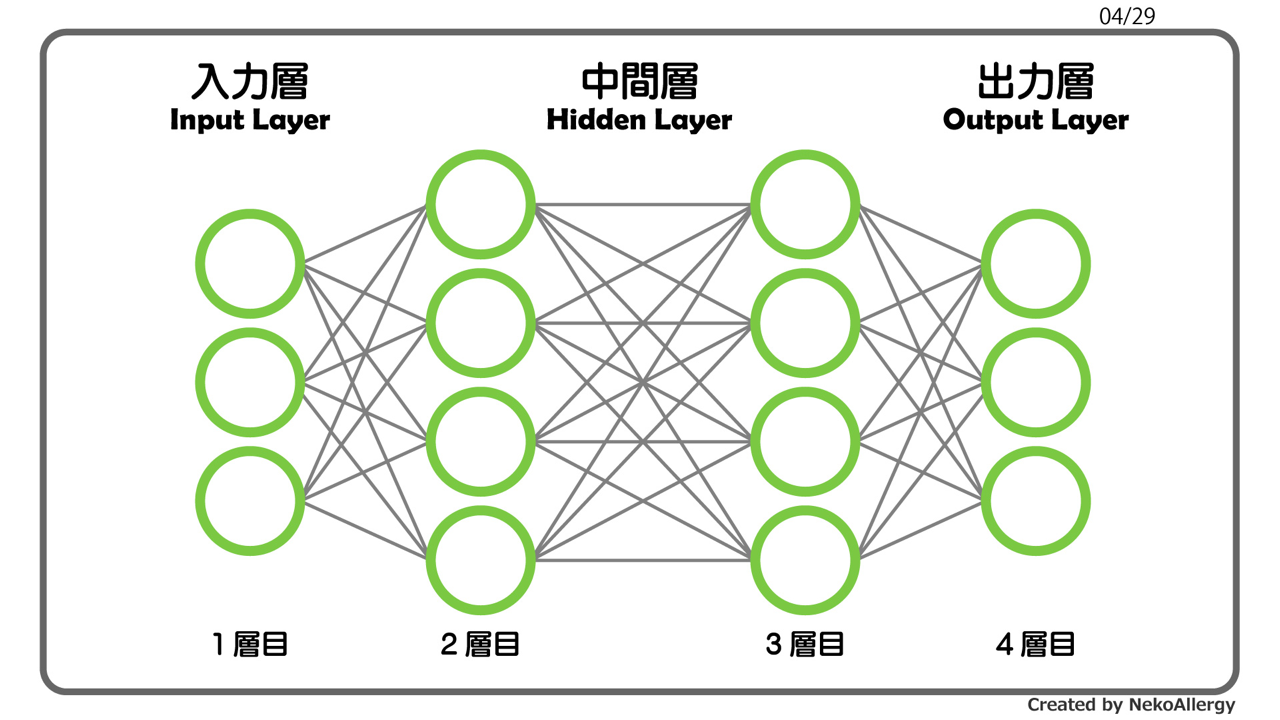


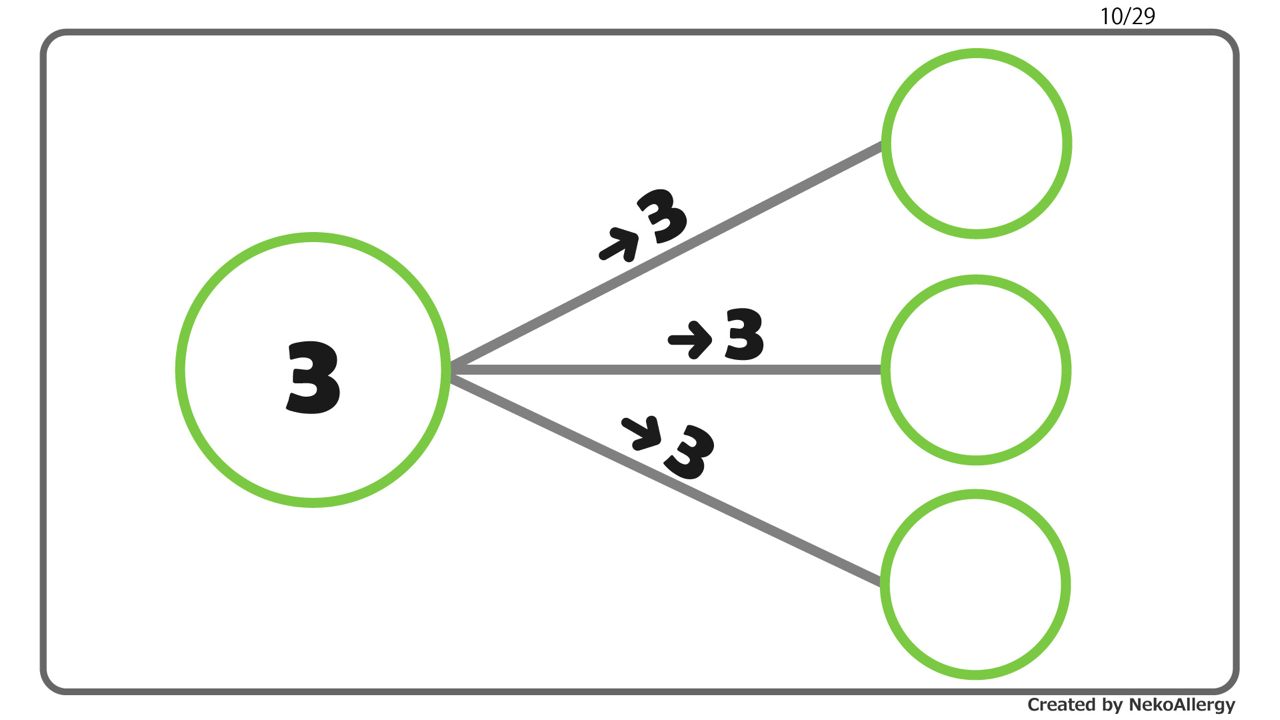
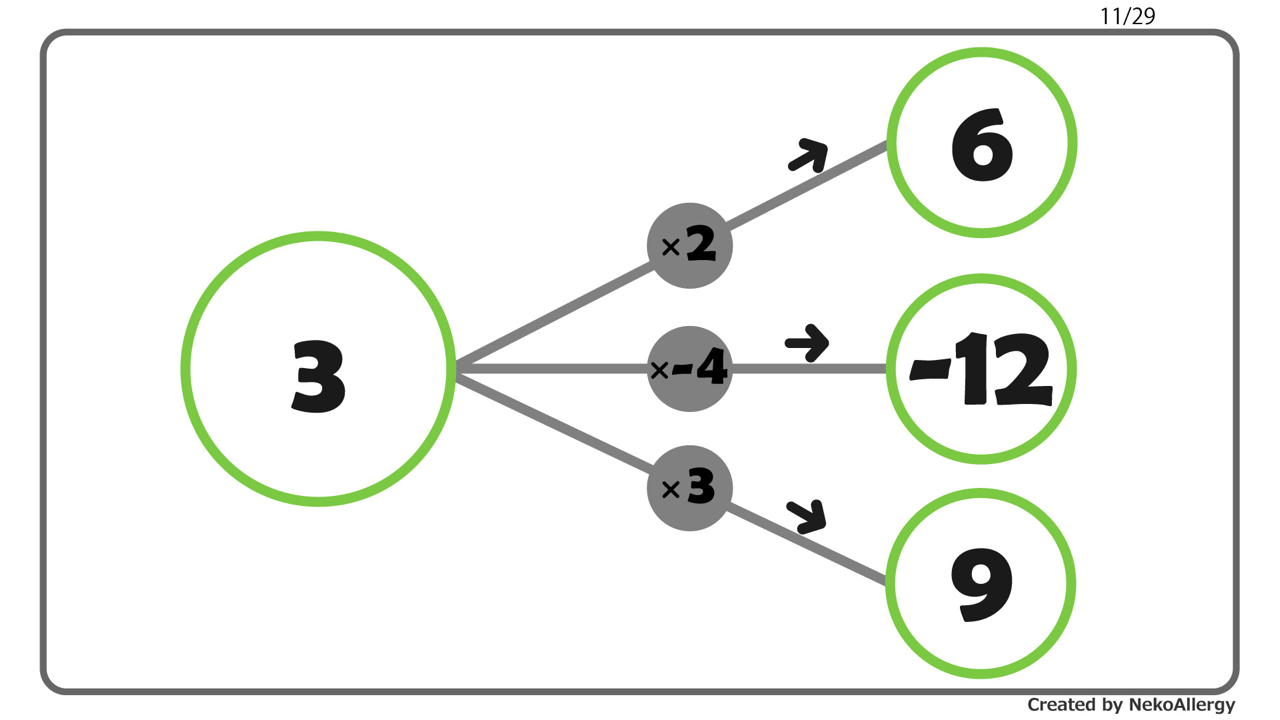
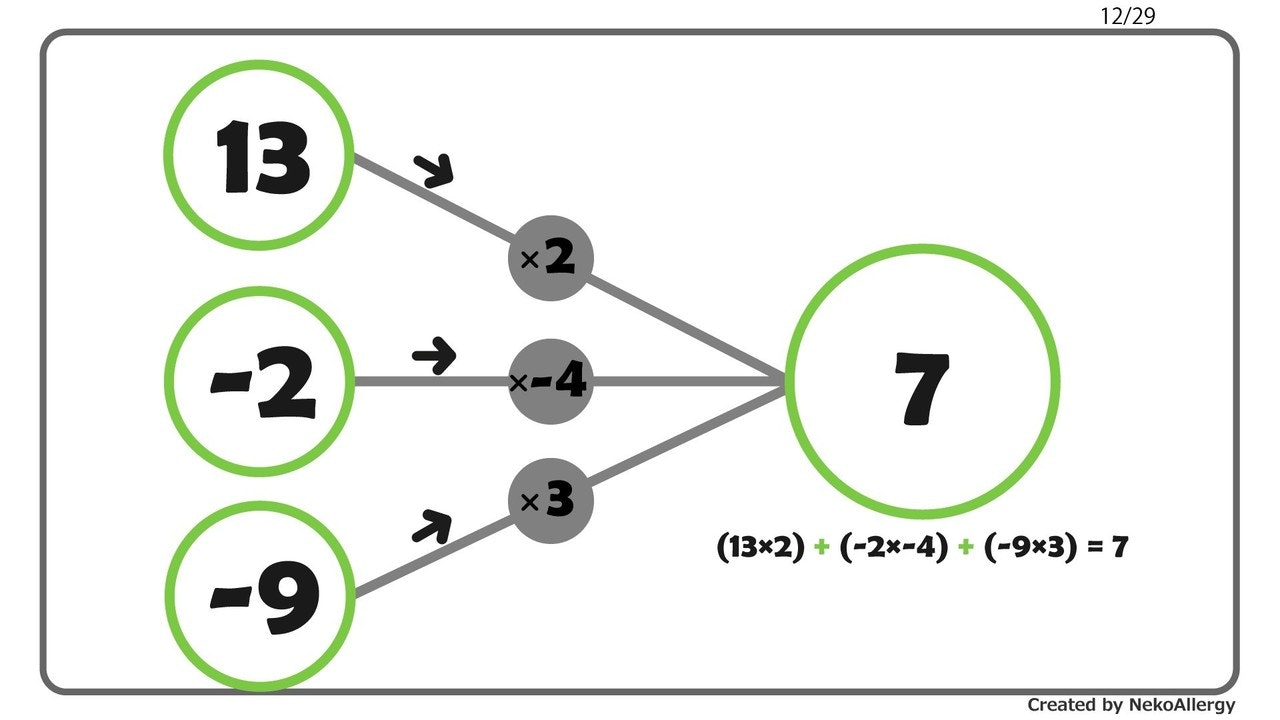


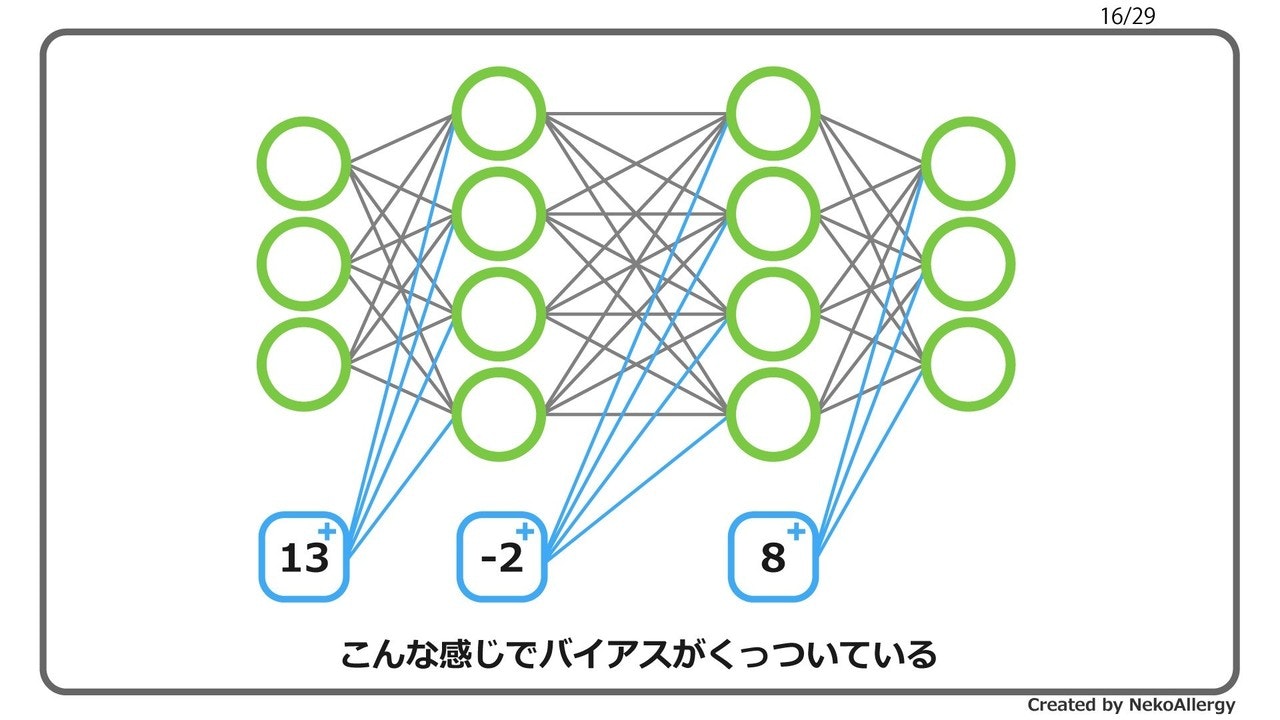


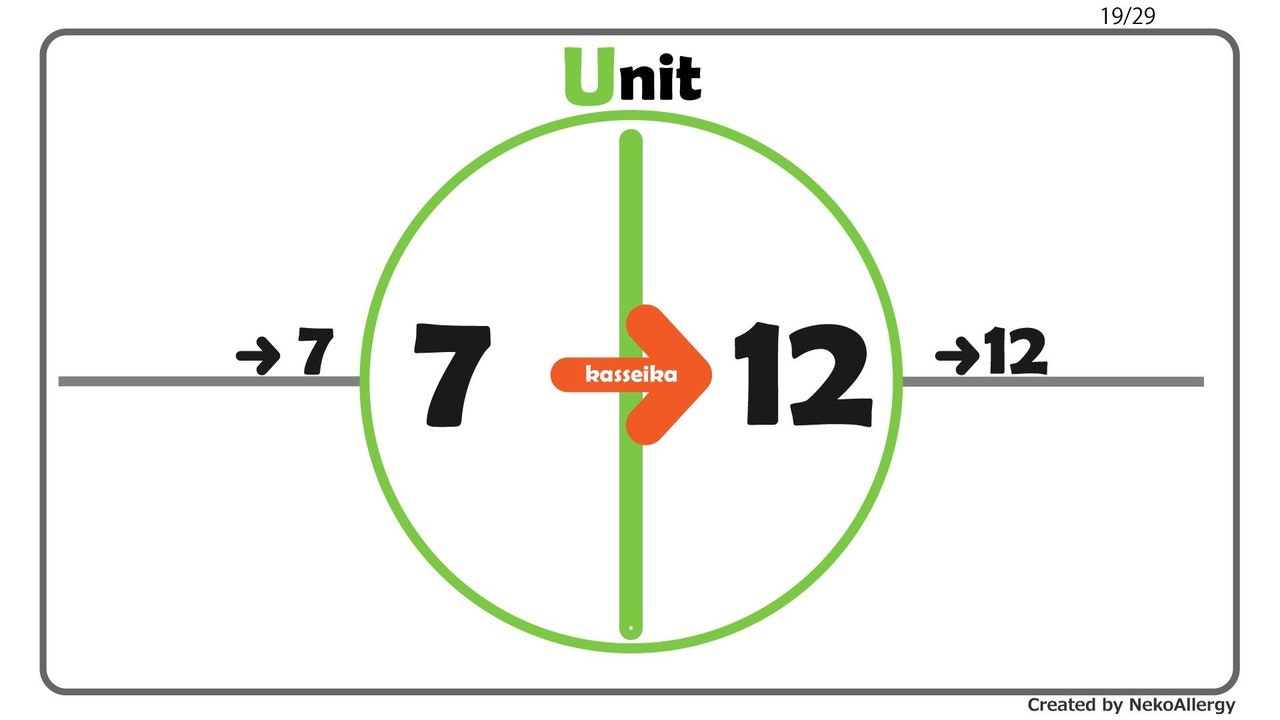
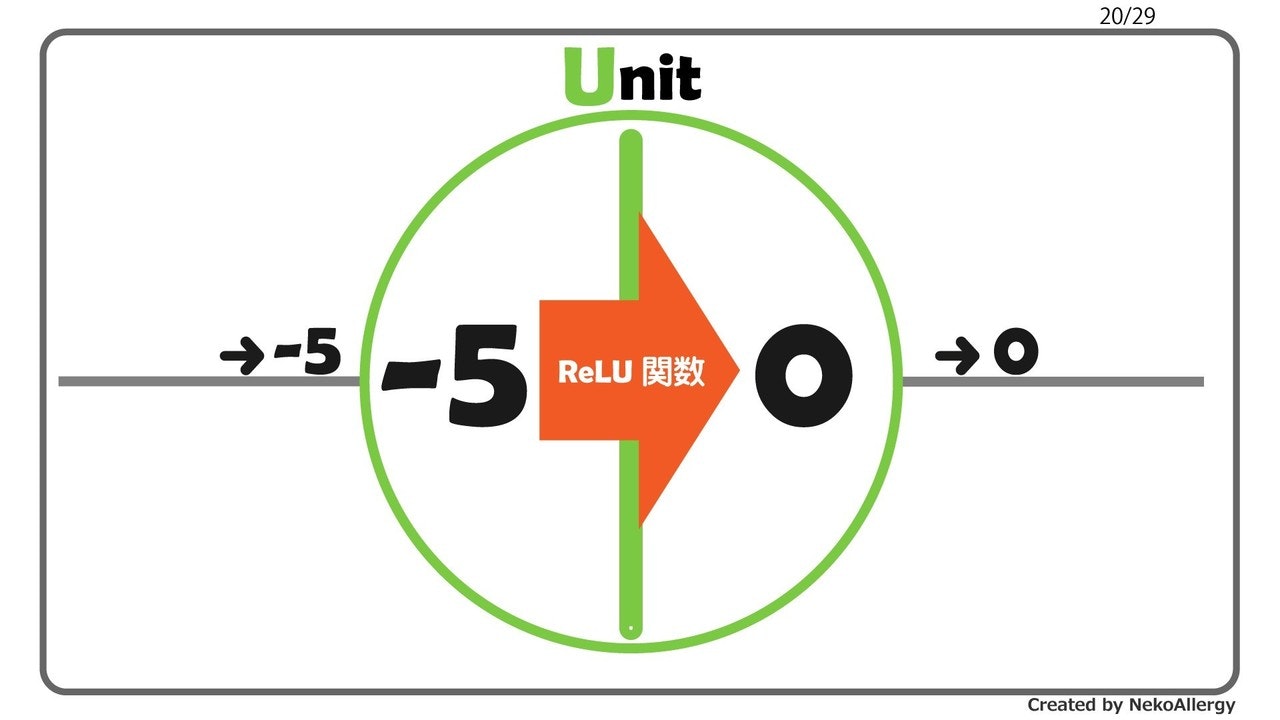
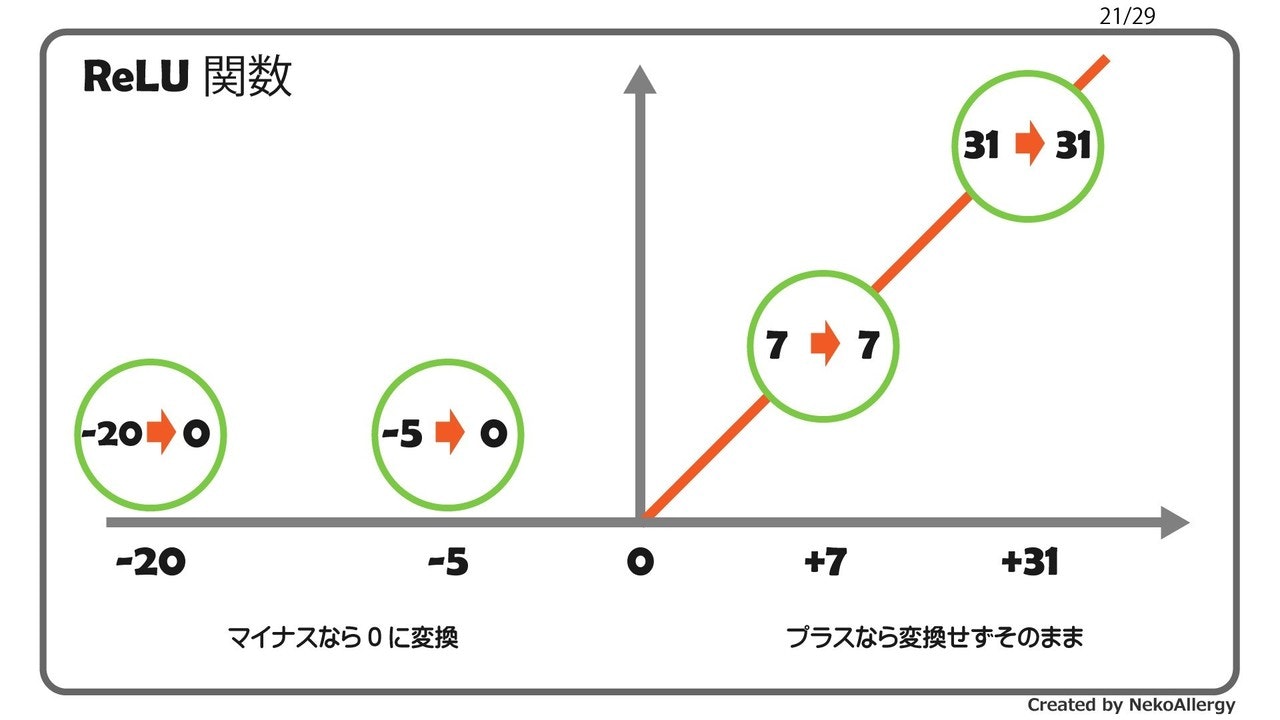
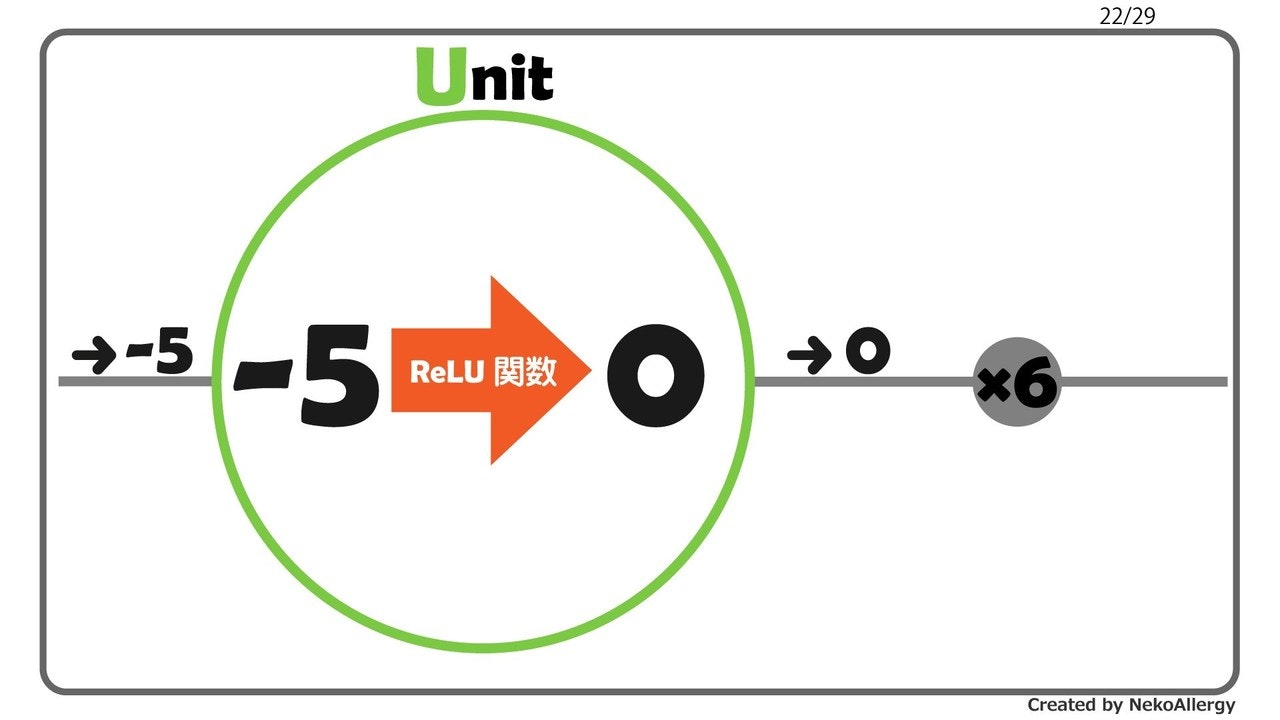
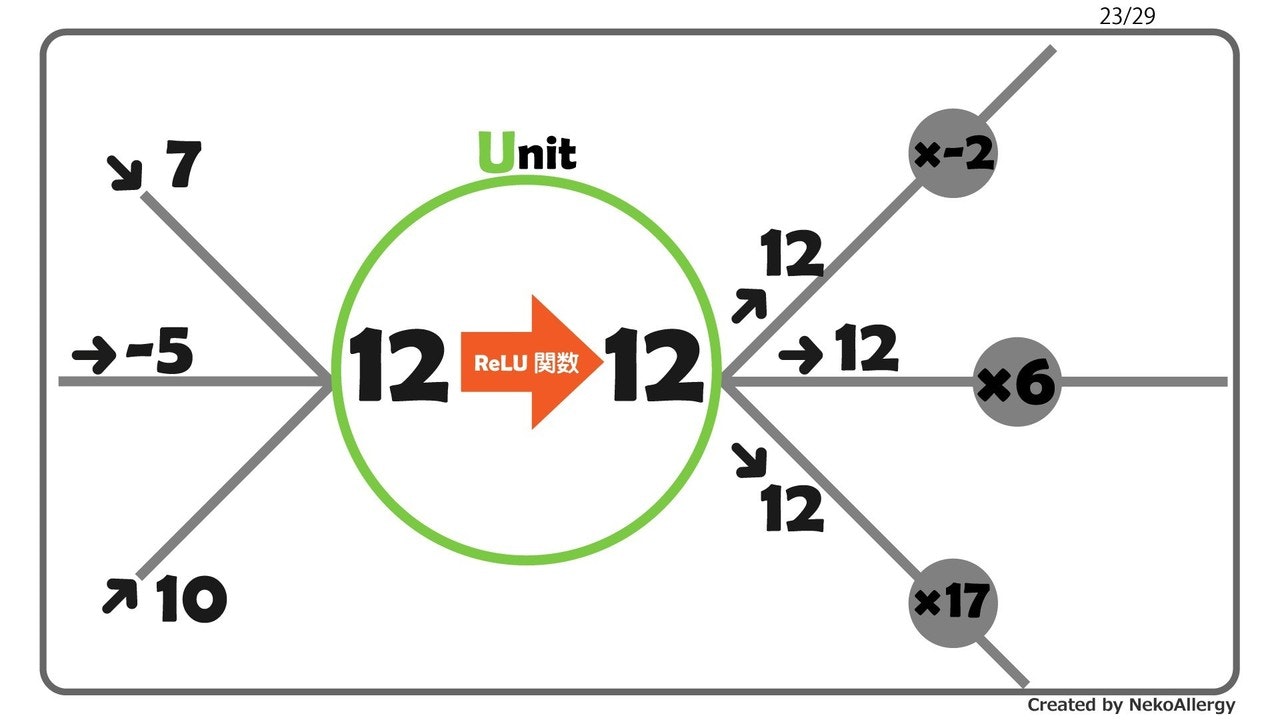

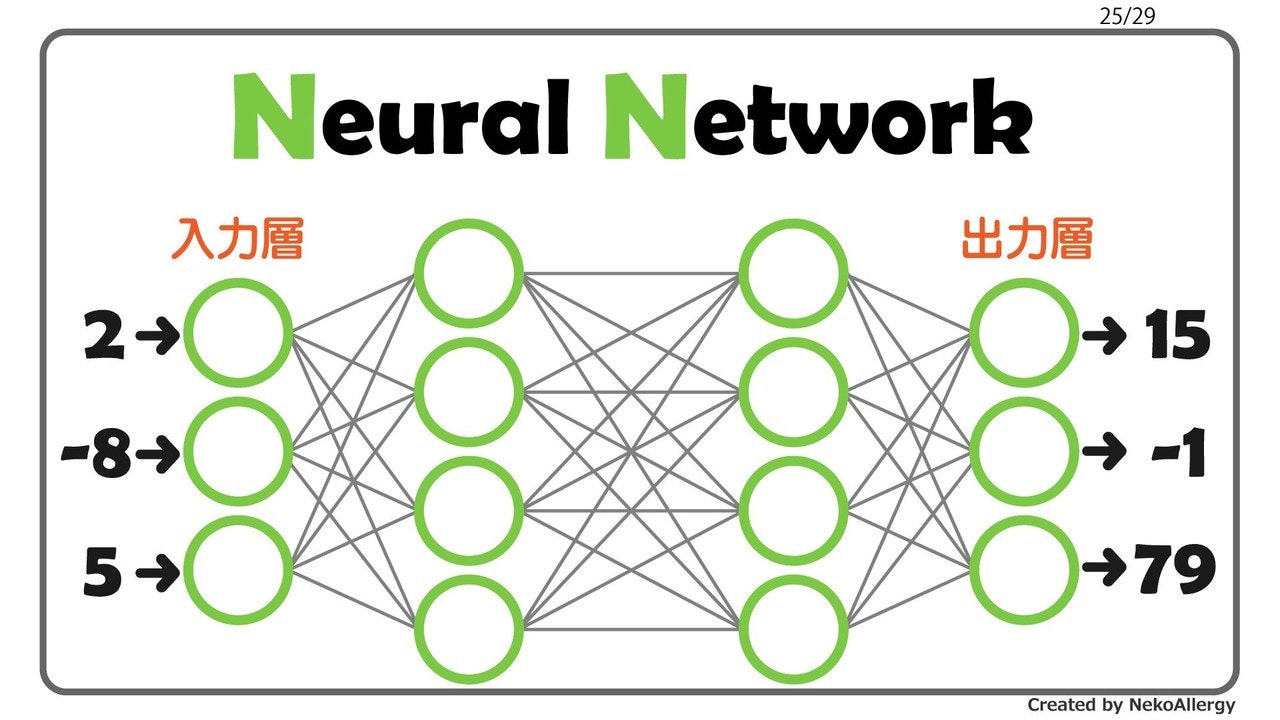
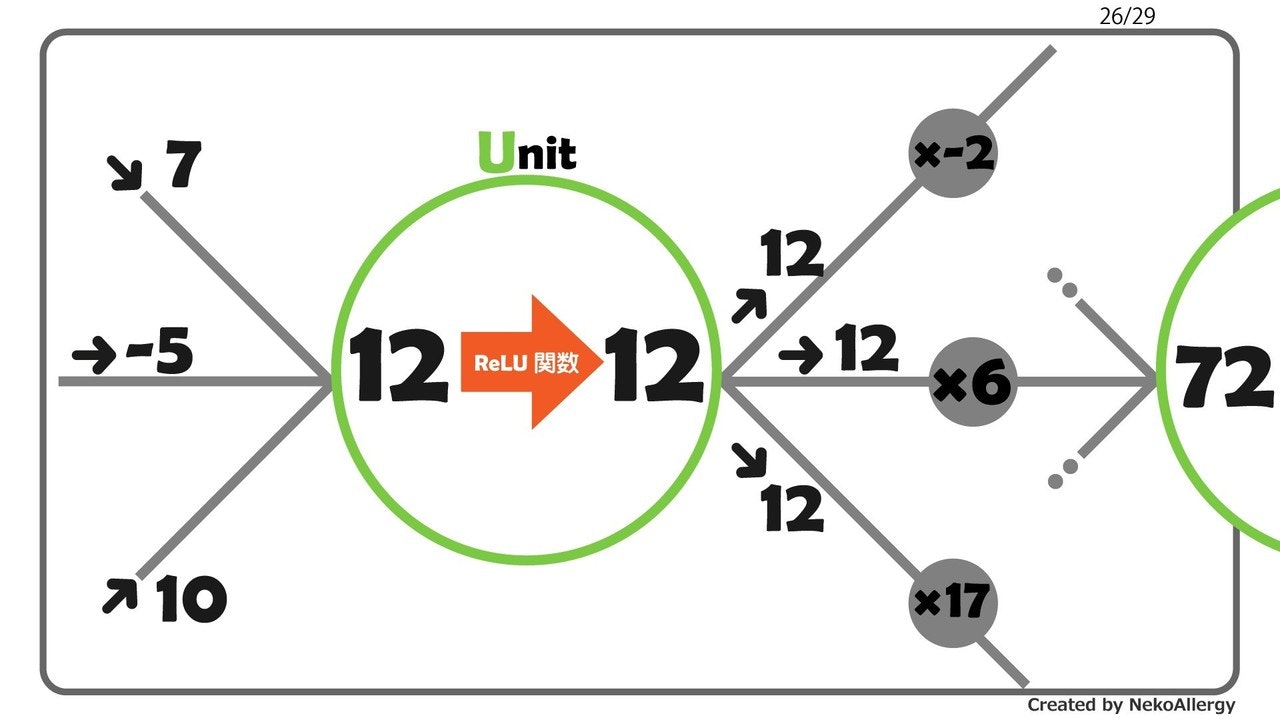



- 投稿日:2020-05-16T16:31:34+09:00
【超基礎】PythonとJavaとJavaScriptを比較します(変数, if文, while文, for文)
目的
- 今週から本配属だった
- 結局Javaを勉強することになった
- 記憶が新しいうちにJavaとPythonでちがったことまとめておこう
- ついでに少し勉強したことがあるJavaScriptも引っ張り出して比較しよう
この記事で比較する内容
- 変数
- if文
- while文
- for文
変数
Python
- データ型を宣言する必要はありません
- 変数の中身によって勝手に型を指定してくれます
- セミコロンもいりません
asobi.pypy_str = "Python" py_int = 23 py_float = 23.5 # データ型確認 print(type(py_str)) print(type(py_int)) print(type(py_float))コンソール<class 'str'> <class 'int'> <class 'float'>
- 変数のデータ型を書きかえることもできます
asobi.pypy_str = "Python" py_int = 23 print(type(py_str)) py_str = 10 print(type(py_str)) py_cal = py_str * py_int print(py_cal)コンソール<class 'str'> <class 'int'> 230Java
- データ型を宣言しなければなりません
- float型もありますが、主にdouble型を使うようです
- 直接的にデータ型を確認する方法は見つかりませんでした(instanceofというメソッドがあるようですが、intやdoubleには使えません)
- Javaのデータ型についてはこちらのサイトがわかりやすいです
- セミコロンを忘れずに
asobi.javapublic class asobi { public static void main(String[] args) { String javaStr = "Java"; int javaInt = 23; double javaFloat = 23.5; } }JavaScript
- データ型の宣言は必要ありませんが、変数名の前にvarをつける必要があります
- int型やfloat型ではなくどちらもnumber型になるんですね…
- セミコロンもいります
asobi.html<html> <script> var jsStr = "JavaScript"; var jsInt = 23; var jsFloat = 23.5; // データ型確認 console.log(typeof(jsStr)); console.log(typeof(jsInt)); console.log(typeof(jsFloat)); </script> </html>コンソールstring number numberif文
Python
- if, elif, elseが使われます
- 条件の末尾に:を付けます
- 実行する文のインデントは必須です
asobi.pyage = 23 if age >= 65: print("定年です") elif age >= 20: print("成人です") else: print("未成年です")Java
- if, else if, elseが使われます
- それぞれの条件を(), 実行する文を{}で囲います
asobi.javapublic class asobi { public static void main(String[] args) { int age = 23; if (age >= 65) { System.out.println("定年です"); }else if (age >= 20) { System.out.println("成人です"); }else{ System.out.println("未成年です"); } } }JavaScript
- if, else if, elseが使われます
- それぞれの条件を(), 実行する文を{}で囲います
- if文の形自体はJavaと同じですね
asobi.html<html> <script> var age = 23; if (age >= 65) { console.log("定年です"); }else if (age >= 20){ console.log("成人です"); }else{ console.log("未成年です"); } </script> </html>while文
- それぞれの言語で以下のようにコンソール表示させてみましょう
コンソール0です 1です 2です 3です 4ですPython
- int型であるiと文字列をそのままつなげることができないので、iをstr型にします
asobi.pyi = 0 while i < 5: print(str(i) + "です") i += 1Java
- 例によって条件を()、実行文を{}で囲います
- インクリメントでi++という形を使うことができます
asobi.javapublic class asobi { public static void main(String[] args) { int i = 0; while (i < 5){ System.out.println(i + "です"); i++; } } }JavaScript
- 例によってwhile文の形自体はJavaと同じです
asobi.html<html> <script> var i = 0; while (i < 5){ console.log(i + "です"); i++; } </script> </html>for文
- それぞれの言語で以下のようにコンソール表示させてみましょう
コンソール0です 1です 2です 3です 4ですPython
- iが0から4までの5回の範囲で繰り返されます
asobi.pyfor i in range(5): print(str(i) + "です")Java
- for文の繰り返し条件が(初期値; 範囲; 増減)で表されます
- 初期値を格納する変数はデータ型を宣言する必要があります
asobi.javapublic class asobi { public static void main(String[] args) { for (int i = 0; i < 5; i++){ System.out.println(i + "です"); } } }JavaScript
- 例によってfor文の形自体はJavaと同じです
- 初期値を格納する変数名の前にはvarを付ける必要があります
asobi.html<html> <script> for (var i = 0; i < 5; i++){ console.log(i + "です"); } </script> </html>感想
- 複数言語を勉強するとき、比較しながら勉強すると覚えやすい
- JavaとJavaScript、インドとインドネシア並にちがうといいつつ、書き方結構似てるんだな
- やっぱりPythonがいちばん書きやすい!
- 投稿日:2020-05-16T16:27:23+09:00
[Python]02章-06【任意】 Pythonプログラムの基礎(数値の取り扱い)
[Python]02章-06 数値の取り扱い
ここでは数値の取り扱いについて少し掘り下げてみていきたいと思います。
なお、ここの節は実務ではあまり取り扱いすることはなく、【任意】としていますので、本節は飛ばしても構いません。少し理論的なお話が中心となると思われます。
ただし、ITパスポート試験や基本情報技術者試験の受験を考えている方は基礎理論で取り扱われる内容ですので、目を通しておきましょう。
数値について
「02章-01」で説明しましたが、数値には以下のように分けられます。
- 整数
例)10, -7, 321 など- 浮動小数点数(実数)
例)3.14, -2.718, 6.02×1023 などこの中で、「整数」について少し掘り下げてみたいと思います。
基数(N進数)
我々が普段扱っている数値は10進数(Decimal number)となります。
実際に「0」「1」「2」「3」「4」「5」「6」「7」「8」「9」という10種類の数字を使って数値を表現しています。しかしコンピュータは「0」か「1」の2つしか扱いません。これを2進数(
Binary number)と言います。例えば、10進数の45は、2進数では101101と表記します。
2進数、10進数だけでなく、よく使われるN進数として、8進数(Octal number)、16進数(Hexadecimal)もあります。
基数の変換
まずは2進数と10進数の変換について述べていきたいと思います。(わかる方は飛ばしても構いません)
2進数→10進数への変換
先ほどの2進数、101101を変換することを考えてみます。この2進数を以下の表にしてまとめてみました。
番号 5 4 3 2 1 0 2進数 1 0 1 1 0 1 上記の表を見ると、それぞれの数字に番号を割り当てています。
しかもあえて、右から0, 1, 2, 3, 4, 5と割り当てました。この番号が後から重要になりますので覚えておいてください。さて、上記の表でそれぞれの桁に重みをつけていきます。重みとは、N進数であればNmといった、Nに各桁の番号の累乗したものものです。
以下の表にどういうことかをまとめましたので、確認してください。
番号 5 4 3 2 1 0 2進数 1 0 1 1 0 1 重み 25 24 23 22 21 20 そして、これら重みを2進数の各桁と掛け合わせたものを以下のように足していきます。
\begin{align} &(2^{5}×1)+(2^{4}×0)+(2^{3}×1)+(2^{2}×1)+(2^{1}×0)+(2^{0}×1)\\ &=32 + 0 + 8 + 4 + 0 + 1\\ &=45 \end{align}上記のように、10進数を求めることができました。
10進数→2進数への変換
では反対に10進数から2進数への変換を見ていきます。先ほどの10進数の45を2進数にしてみましょう。
一般的には10進数の数値をN進数のNで割っていき、それぞれの余りを求めていきます。
今回は2進数へ変換なので、以下のように2で割ります。
45を2で割ると商が22となり、1余るので、それを右に書いていきます。45÷2=22 ・・・1さらに、22を2で割ると商が11となり割り切れますが、この場合、以下のように0余ると考えてください。
22÷2=11 ・・・0これを繰り返していくと以下のようになります。よく、2進数を求めるには割り算のひっ算の逆を描いて計算することが多いです。
最後に右に書かれているあまりの「0」「1」ですが、これを下か順に並べていきます。
すると、「101101」となり、10進数45の2進数を求めることができました。
16進数、8進数の取り扱い
前述した通り10進数では「0」「1」「2」「3」「4」「5」「6」「7」「8」「9」という10種類の数字を使って数値を表現しています。
8進数は「0」「1」「2」「3」「4」「5」「6」「7」という8種類の数字を使って数値を表現するのは予測できると思いますが、16進数はどうなるのでしょうか?
「9」の次は「10」「11」「12」「13」「14」「15」と続くのですが、そうすると「15」が本当に「15」なのか、「1」と「5」がくっついているのかわかりません。
そこで、16進数は以下の表のようにa~fを使って表記します。
2進数 8進数 10進数 16進数 0000 0 0 0 0001 1 1 1 0010 2 2 2 0011 3 3 3 0100 4 4 4 0101 5 5 5 0110 6 6 6 0111 7 7 7 1000 10 8 8 1001 11 9 9 1010 12 10 a 1011 13 11 b 1100 14 12 c 1101 15 13 d 1110 16 14 e 1111 17 15 f 2進数は表記するとどうしても長くなるため、16進数で表現すれば長さを圧縮でき見やすくなるという利点があります。
16進数から10進数への変換
例えば、16進数の「5c2」を10進数で表すことを考えます。これも表を使って考えます。
なお、cは上記の表より12なので、以下のように12で計算します。
番号 2 1 0 16進数 5 c
(12)2 重み 162 161 160 これを先ほどの2進数の時と同じように重みをかけて足していきます。
\begin{align} &(16^{2}×5)+(16^{1}×12)+(16^{0}×2)\\ &=1280 + 192 + 2 \\ &=1474 \end{align}また、逆に10進数から16進数の変換も、以下のように今度は16で割っていった余りを並べていき求めていきます。
すると、「5c2」となり、10進数1474の16進数を求めることができました。
8進数の場合も同じように、8で割っていき、その余りを並べていきます。
そのほかのN進数
今まで、2進数、8進数、10進数、16進数と扱ってきましたが、では、ほかの3進数や5進数などは扱わないのでしょうか?
実は3進数も5進数も存在はしますが、ほとんど使用されることはありません。
求め方は10進数を3で割っていき求めていく方法は変わらないです。実は2進数は、8進数や16進数と相性が良く、先ほどの表のようにすぐに求めることができます。
前述した通り、2進数ですと表記が長くなるため、16進数を用いて変換して圧縮して見やすくするといったことがよく用いられます。例えば2進数「00101101」をそのまま16進数に変えたいときは、2進数を4つ区切りで表現し、それを上の表から16進数を求めればすぐに変換可能です。
0010 1101 = 2dPythonにおける基数の変換
では、これをPythonを使って変換していきたいと思います。
今回は、Python Consoleを使用して、説明していきます。先ほどの例の数値を用いて説明します。まずは、2進数、8進数、16進数から10進数への変換を考えます。以下のようにコードを入力してください。
上から、2進数、8進数、16進数の順で10進数に変換しています。>>>bin(45) '0b101101' >>>oct(45) '0o55' >>>hex(1474) '0x5c2'2進数へはbin関数で、8進数へはoct関数で、16進数へはhex関数で変換できます。
また出力結果について、0b(ゼロ・ビー)はBinary(2進数)を表し、0o(ゼロ・オー)はOctalを表し、0x(ゼロ・エックス)はHexadecimal(16進数)を表します。では、反対に2進数、8進数、16進数はどのように10進数に変換できるかを見ていきます。
以下のようにコードを入力してください。>>>0b101101 45 >>>0o55 45 >>>0x5c2 1474変換したい数値の前にそれぞれ「0b」「0o」「0x」と付与するのみです。
浮動小数点数について
最後に、補足として浮動小数点数について述べていきます。
例えば、以下の実数2.718は通常通りの表記となります。
他に、大きな数値や逆に小さな数値を指数を使って表記することもあります。例えば以下のものです。
3.14 × 10^{3}\\ \\ 5.1×10^{-2}(※)上記の10-2は以下の通りです。
10^{-2}=\frac{1}{10^{2}}これをPythonで実装すると以下の通りになります。
>>>3.14e3 3140.0 >>>5.1e-2 0.051ここで、e3は103、e-2は10-2を意味します。
上記のような指数を使った浮動小数点数の表記については、よく科学技術計算などで使われることが多いです。
演習問題
【1-1】以下の2進数を10進数に変換してください。(手計算で行ってください)
・10001010
・11111111
・10100100111010
【1-2】【1-1】の結果をPython Consoleにて確認してください。
【2-1】以下の16進数を10進数に変換してください。(手計算で行ってください)
・c3
・ff
・475
【2-2】【2-1】の結果をPython Consoleにて確認してください。
【3-1】以下の10進数を、2進数、8進数、16進数に変換してください。(手計算で行ってください
・31
・123
【3-2】【3-1】の結果をPython Consoleにて確認してください。

- 投稿日:2020-05-16T16:25:53+09:00
[Python]02章-05 Pythonプログラムの基礎(文字列の操作・メソッド)
[Python]02章-05 文字列の操作
「02章-02」で文字列について基本的な部分を扱いました。
今回はそれら文字列から一部を取り出したり、メソッドと呼ばれる命令を用いて操作をしてみたいと思います。
文字列の取り出し(単一文字の取り出し)
文字列に対して、一部を取り出して表示することができます。
今回はPythonコンソールからプログラムを動かしていきたいと思います。まずは、以下のコードを入力してください。
>>>str = 'ABCDEFGHIJKLMNOPQRSTUVWXYZ' >>>print(str) ABCDEFGHIJKLMNOPQRSTUVWXYZ内容はstrという変数に「ABCDEFGHIJKLMNOPQRSTUVWXYZ」という文字列を代入しています。それをprint関数で画面表示しています。
なお、アルファベットは知っての通り、26種類あります。本当に26種類あるかを確認するには、len関数を用いて、文字列の長さ(length)を知ることもできます。
>>>len(str) 26str変数に格納されている文字列を以下の表にまとめてみました。また番号は0から始めています。
番号 0 1 2 3 4 5 … 22 23 24 25 文字列 A B C D E F … W X Y Z 上記の表を把握した状態で、文字を取り出してみたいと思います。
文字を取り出すには、[]内に取り出す位置の番号を記載します。
Pythonコンソールに以下のコードを入力してください。>>>str[0] 'A' >>>str[1] 'B' >>>str[9] 'J'なんとなく気づいた方も多いと思いますが、Pythonの場合、先頭は0になります。
なお、先頭はプログラミング言語によっては1から開始するものもありますのでご注意ください。上記の表を見るとわかる通り、番号は25までしかありません。そのため、文字列の長さを超える数を指定するとエラーとなります。
>>>str[26] Traceback (most recent call last): File "<input>", line 1, in <module> IndexError: string index out of rangeまた、[]内には負の数も指定できます。負の数を指定すると、文字列の末尾からの取り出しとなります。
Pythonコンソールに以下のコードを入力してください。>>>str[-1] 'Z' >>>str[-2] 'Y' >>>str[-9] 'R'文字列の取り出し(複数の文字列取り出し)
文字列は、範囲を指定して取り出すこともできます。これをスライスと言ったりします。
範囲を指定するには「:」(コロン)を指定します。実際にPythonコンソールで確認してみましょう。以下のコードを入力してください。使用する文字列は先ほどと同じ以下の通りです。
str = 'ABCDEFGHIJKLMNOPQRSTUVWXYZ'>>>str[5:] 'FGHIJKLMNOPQRSTUVWXYZ' >>>str[:24] 'ABCDEFGHIJKLMNOPQRSTUVWX' >>>str[5:24] 'FGHIJKLMNOPQRSTUVWX'まず、str[5:]についてですが、先ほども提示した以下の表、
番号 0 1 2 3 4 5 … 22 23 24 25 文字列 A B C D E F … W X Y Z にもある通り、5番目以降の文字列('F'以降)の範囲が取り出されています。
少しこれを数学的に表現してみます。(xは番号と考えてください)5≦xとなり、5番目も含んだ範囲が取り出されています。
次に、str[:24]についてです。表と照らし合わせてみると、24番目の'Y'が含まれていません。これは24番目の手前まで取り出されることに注意してください。
数学的に表現すると、x<24となり、24番目は含まないことに注意して下さい。
最後に、str[5:24]ですが、これは上記2つを組み合わせたものでとなります。先頭と末尾を指定した範囲を取り出しています。
ただし、前述した通り、末尾の手前まで取り出されることに注意してください。
数学的に表現すると、5≦x<24となります。
範囲を指定しての取り出しについて補足ですが、何文字間隔で文字を取り出すこともできます。以下の例では2文字間隔で取り出しています。
>>>str[::2] 'ACEGIKMOQSUWY'文字列に関するメソッド
メソッド(method)とは何かに対する処理命令を行うという認識で構いません。
今回は文字列を扱ってますので、文字列に対して、「アルファベット文字列をすべて小文字にする」「最後に文字を追加する」といった処理命令です。メソッドに関する詳細な内容は、後述します。
メソッドの利用方法は、
対象.メソッド()というように、「.」(ドット)で区切ります。
メソッドにも多種あります。基本的なものをいくつか紹介していきたいと思います。文字列を小文字または先頭のみ大文字にする。
lower():文字列を小文字にできます。
>>>str.lower() 'abcdefghijklmnopqrstuvwxyz'capitalize():先頭のみ大文字にできます。
>>>str.capitalize() 'Abcdefghijklmnopqrstuvwxyz'ちなみに、str変数を使用しないでも、以下のように直接メソッドを適用できます。
>>>'ABCDEFGHIJKLMNOPQRSTUVWXYZ'.capitalize() 'Abcdefghijklmnopqrstuvwxyz'文字列のカウントに関するメソッド
今回は異なる文字列を指定します。以下のように入力してください。
>>>str1 = 'tomorrow'count(検索したい文字):検索したい文字をカウントします。
>>>str1.count('o') 3上記例では、'o'という文字がstr1内に何文字入っているかをカウントしています。
countメソッドはもっと細かく指定することもでき、以下のように範囲指定もできます。
以下の例では、3番目以上、5番目より手前までに限定した範囲で'o'という文字をカウントしています。(もちろん、0からのカウントです。)str1.count('o',3,5) 1分割や挿入
今回も異なる文字列を指定します。以下のように入力してください。
>>>str2 = 'Tanjiro,Nezuko,Zenitsu,Inosuke'split(分割文字):文字列を指定した文字列で分割したリストを作成する。
リストについての詳細は4章以降で取り上げますが、上記例では4つの要素に分けることができるという認識で構いません。
以下のように使用します。
>>>str2.split(',') ['Tanjiro', 'Nezuko', 'Zenitsu', 'Inosuke']str2変数内に格納されている1つの文字列について、「,」(カンマ)の部分で分割しています。
出力結果が、[]で囲まれており、これがリストと言われる構造です。4つの文字列に分けることができました。リストの詳細は後述します。なお、後ほど、このリストを使用するため、いったんls(エル・エス)という変数に代入します。
ls=str2.split(',') print(ls) ['Tanjiro', 'Nezuko', 'Zenitsu', 'Inosuke']join(結合対象):リストでバラバラになったものを1つの文字列にする。
先ほどのsplitメソッドと逆のことを行います。つまり4つに分けた文字列を1つにするというものです。
以下のように入力して、動作を確認してみてください。
>>>'%'.join(L) 'Tanjiro%Nezuko%Zenitsu%Inosuke'このように、4つに分かれたリストを'%'を用いて、1つの文字列にできました。
様々なメソッド
上記で紹介した例はほんの一例です。
メソッドは限りない数が存在し、実際にはメソッドをWeb上で調べてそれを適用するという形が多くなると思います。以下に今回の範囲である、文字列に関するメソッドのリンクを張っておきます。
それ以外にも、数値の取り扱いに関するメソッドなど、様々なメソッドが存在しますので、確認してみてください。
リンク先に書いてある、これらの用語は最初は読みづらいかもしれないですが、少しずつ進めていくうえで、慣れていくかと思われます。
最後に
今回は文字列の処理やメソッドについて触れました。
メソッドは多種あるため、メソッドを暗記するというよりかは、必要に応じて上記のリンク先から調べて適用していくという形になっていくと思われます。
実際に実務上でもそうなります。ぜひいろいろなメソッドを試してください。
【目次リンク】へ戻る